




原文:
zh.annas-archive.org/md5/14CAB13674AB79FC040D2749FA52D757译者:飞龙
第五章:范畴论
托马斯·沃森曾经著名地说过:“我认为世界市场上可能只需要五台计算机。”那是在 1948 年。当时,每个人都知道计算机只会用于两件事:数学和工程。甚至科技界最伟大的头脑也无法预测,有一天,计算机将能够将西班牙语翻译成英语,或者模拟整个天气系统。当时,最快的机器是 IBM 的 SSEC,每秒进行 50 次乘法运算,显示终端要等 15 年才会出现,多处理意味着多个用户终端共享一个处理器。晶体管改变了一切,但科技的远见者仍然未能抓住要点。肯·奥尔森在 1977 年又做了一个著名的愚蠢预测,他说:“没有理由让任何人在家里放一台计算机。”
现在对我们来说很明显,计算机不仅仅是为科学家和工程师准备的,但这是事后诸葛亮。70 年前,机器不仅仅能做数学这个想法一点都不直观。沃森不仅没有意识到计算机如何改变社会,他也没有意识到数学的变革和发展力量。
但是,计算机和数学的潜力并没有被所有人忽视。约翰·麦卡锡在 1958 年发明了Lisp,这是一种革命性的基于算法的语言,开启了计算机发展的新时代。自诞生以来,Lisp 在使用抽象层(编译器、解释器、虚拟化)推动计算机从严格的数学机器发展到今天的样子方面发挥了重要作用。
从 Lisp 出现了Scheme,它是 JavaScript 的直接祖先。现在我们又回到了原点。如果计算机在本质上只是做数学,那么基于数学的编程范式就会表现出色是理所当然的。
这里使用的“数学”一词并不是用来描述计算机显然可以做的“数字计算”,而是用来描述离散数学:研究离散数学结构的学科,比如逻辑陈述或计算机语言的指令。通过将代码视为离散数学结构,我们可以将数学中的概念和思想应用到其中。这就是为什么函数式编程在人工智能、图搜索、模式识别和计算机科学中的其他重大挑战中如此重要。
在本章中,我们将尝试一些这些概念及其在日常编程挑战中的应用。它们将包括:
-
范畴论
-
态射
-
函子
-
可能性
-
承诺
-
镜头
-
函数组合
有了这些概念,我们将能够非常轻松和安全地编写整个库和 API。我们将从解释范畴论到在 JavaScript 中正式实现它。
范畴论
范畴论是赋予函数组合力量的理论概念。范畴论和函数组合就像发动机排量和马力,像 NASA 和航天飞机,像好啤酒和杯子一样紧密相连。基本上,一个离不开另一个。
范畴论简介
范畴论实际上并不是一个太难的概念。它在数学中的地位足以填满整个研究生课程,但它在计算机编程中的地位可以很容易地总结起来。
爱因斯坦曾说过:“如果你不能向一个 6 岁的孩子解释清楚,那么你自己也不懂。”因此,在向一个 6 岁的孩子解释的精神下,范畴论就是连接点。虽然这可能严重简化了范畴论,但它确实很好地以直接的方式解释了我们需要知道的内容。
首先,您需要了解一些术语。范畴只是具有相同类型的集合。在 JavaScript 中,它们是包含明确定义为数字、字符串、布尔值、日期、节点等的变量的数组或对象。态射是纯函数,当给定特定的输入集时,总是返回相同的输出。同态操作限于单个范畴,而多态操作可以在多个范畴上操作。例如,同态函数乘法只对数字起作用,但多态函数加法也可以对字符串起作用。
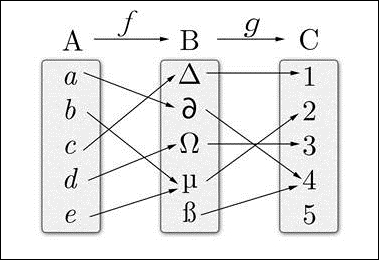
下图显示了三个范畴——A、B 和 C——和两个态射——ƒ和ɡ。
范畴论告诉我们,当我们有两个态射,其中第一个的范畴是另一个的预期输入时,它们可以组合成以下内容:
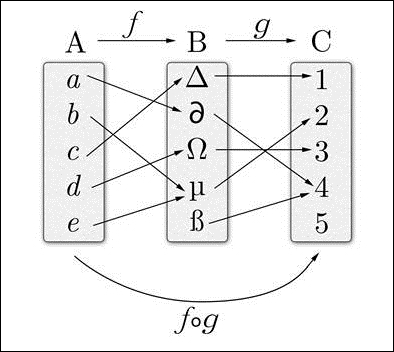
ƒ o g符号是态射ƒ和g的组合。现在我们可以连接点了。

这就是它的全部内容,只是连接点。
类型安全
让我们连接一些点。范畴包含两个东西:
-
对象(在 JavaScript 中,类型)。
-
态射(在 JavaScript 中,只对类型起作用的纯函数)。
这些是数学家给范畴论的术语,所以我们的 JavaScript 术语中存在一些不幸的命名重载。范畴论中的对象更像是具有显式数据类型的变量,而不是 JavaScript 对象定义中的属性和值的集合。态射只是使用这些类型的纯函数。
因此,将范畴论的思想应用到 JavaScript 中非常容易。在 JavaScript 中使用范畴论意味着每个范畴都使用一种特定的数据类型。数据类型包括数字、字符串、数组、日期、对象、布尔值等。但是,在 JavaScript 中没有严格的类型系统,事情可能会出错。因此,我们将不得不实现自己的方法来确保数据是正确的。
JavaScript 中有四种原始数据类型:数字、字符串、布尔值和函数。我们可以创建类型安全函数,它们要么返回变量,要么抛出错误。这满足了范畴的对象公理。
var str = function(s) {
if (typeof s === "string") {
return s;
}
else {
throw new TypeError("Error: String expected, " + typeof s + " given.");
}
}
var num = function(n) {
if (typeof n === "number") {
return n;
}
else {
throw new TypeError("Error: Number expected, " + typeof n + " given.");
}
}
var bool = function(b) {
if (typeof b === "boolean") {
return b;
}
else {
throw new TypeError("Error: Boolean expected, " + typeof b + " given.");
}
}
var func = function(f) {
if (typeof f === "function") {
return f;
}
else {
throw new TypeError("Error: Function expected, " + typeof f + " given.");
}
}
然而,这里有很多重复的代码,这并不是很实用。相反,我们可以创建一个返回另一个函数的函数,这个函数是类型安全函数。
var typeOf = function(type) {
return function(x) {
if (typeof x === type) {
return x;
}
else {
throw new TypeError("Error: "+type+" expected, "+typeof x+" given.");
}
}
}
var str = typeOf('string'),
num = typeOf('number'),
func = typeOf('function'),
bool = typeOf('boolean');
现在,我们可以使用它们来确保我们的函数表现如预期。
// unprotected method:
var x = '24';
x + 1; // will return '241', not 25
// protected method
// plusplus :: Int -> Int
function plusplus(n) {
return num(n) + 1;
}
plusplus(x); // throws error, preferred over unexpected output
让我们看一个更有意思的例子。如果我们想要检查由 JavaScript 函数Date.parse()返回的 Unix 时间戳的长度,而不是作为字符串而是作为数字,那么我们将不得不使用我们的str()函数。
// timestampLength :: String -> Int
function timestampLength(t) { return num(**str(t)**.length); }
timestampLength(Date.parse('12/31/1999')); // throws error
timestampLength(Date.parse('12/31/1999')
.toString()); // returns 12
像这样明确地将一种类型转换为另一种类型(或相同类型)的函数被称为态射。这满足了范畴论的态射公理。通过类型安全函数和使用它们的态射强制类型声明,这些都是我们在 JavaScript 中表示范畴概念所需要的一切。
对象标识
还有一个重要的数据类型:对象。
var obj = typeOf('object');
obj(123); // throws error
obj({x:'a'}); // returns {x:'a'}
然而,对象是不同的。它们可以被继承。除了原始的数字、字符串、布尔值和函数之外,一切都是对象,包括数组、日期、元素等。
没有办法知道某个对象是什么类型,比如从typeof关键字知道 JavaScript 的一个子类型是什么,所以我们将不得不 improvisation。对象有一个toString()函数,我们可以利用它来实现这个目的。
var obj = function(o) {
if (Object.prototype.toString.call(o)==="[object Object]") {
return o;
}
else {
throw new TypeError("Error: Object expected, something else given.");
}
}
再次,有了所有这些对象,我们应该实现一些代码重用。
var objectTypeOf = function(name) {
return function(o) {
if (Object.prototype.toString.call(o) === "[object "+name+"]") {
return o;
}
else {
throw new TypeError("Error: '+name+' expected, something else given.");
}
}
}
var obj = objectTypeOf('Object');
var arr = objectTypeOf('Array');
var date = objectTypeOf('Date');
var div = objectTypeOf('HTMLDivElement');
这些将对我们接下来的主题非常有用:函子。
函子
虽然态射是类型之间的映射,函数器是范畴之间的映射。它们可以被看作是将值从容器中提取出来,对其进行态射,然后将其放入新的容器中的函数。第一个输入是类型的态射,第二个输入是容器。
注意
函数器的类型签名如下:
// myFunctor :: (a -> b) -> f a -> f b
这意味着,“给我一个接受a并返回b的函数和一个包含a的盒子,我会返回一个包含b的盒子”。
创建函数器
事实证明,我们已经有一个函数器:map()。它从容器中(数组)获取值,并对其应用函数。
[1, 4, 9].map(Math.sqrt); // Returns: [1, 2, 3]
但是,我们需要将其编写为全局函数,而不是数组对象的方法。这将使我们能够以后编写更清洁、更安全的代码。
// map :: (a -> b) -> [a] -> [b]
var map = function(f, a) {
return arr(a).map(func(f));
}
这个例子看起来像一个人为的包装,因为我们只是依赖map()函数。但它有一个目的。它为其他类型的映射提供了一个模板。
// strmap :: (str -> str) -> str -> str
var strmap = function(f, s) {
return str(s).split('').map(func(f)).join('');
}
// MyObject#map :: (myValue -> a) -> a
MyObject.prototype.map(f{
return func(f)(this.myValue);
}
数组和函数器
在函数式 JavaScript 中,数组是处理数据的首选方式。
有没有一种更简单的方法来创建已经分配给态射的函数器?是的,它被称为arrayOf。当你传入一个期望整数并返回一个数组的态射时,你会得到一个期望整数数组并返回一个数组的态射。
它本身不是一个函数器,但它允许我们从态射创建函数器。
// arrayOf :: (a -> b) -> ([a] -> [b])
var arrayOf = function(f) {
return function(a) {
return map(func(f), arr(a));
}
}
以下是如何使用态射创建函数器:
var plusplusall = arrayOf(plusplus); // plusplus is our morphism
console.log( plusplusall([1,2,3]) ); // returns [2,3,4]
console.log( plusplusall([1,'2',3]) ); // error is thrown
arrayOf函数器的有趣属性是它也适用于类型安全。当你传入字符串的类型安全函数时,你会得到一个字符串数组的类型安全函数。类型安全被视为恒等函数态射。这对于确保数组包含所有正确的类型非常有用。
var strs = arrayOf(str);
console.log( strs(['a','b','c']) ); // returns ['a','b','c']
console.log( strs(['a',2,'c']) ); // throws error
重新审视函数组合
函数是我们可以为其创建一个函数器的另一种原始类型。这个函数器被称为fcompose。我们将函数器定义为从容器中取出一个值并对其应用函数的东西。当容器是一个函数时,我们只需调用它以获取其内部值。
我们已经知道函数组合是什么,但让我们看看它们在范畴论驱动的环境中能做什么。
函数组合是可结合的。如果你的高中代数老师像我的一样,她教你这个性质是什么,但没有教你它能做什么。在实践中,组合是可结合性能做的事情。
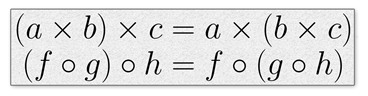
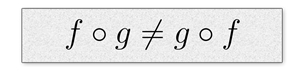
我们可以进行任何内部组合,不管它是如何分组的。这与交换律属性不同。ƒ o g并不总是等于g o ƒ。换句话说,字符串的第一个单词的反向不同于字符串反向的第一个单词。
这一切意味着,不管应用了哪些函数以及顺序如何,只要每个函数的输入来自前一个函数的输出,就没有关系。但是,等等,如果右边的函数依赖于左边的函数,那么难道只能有一种评估顺序吗?从左到右?是的,但如果它被封装起来,那么我们可以根据自己的意愿来控制它。这就是 JavaScript 中懒惰评估的强大之处。
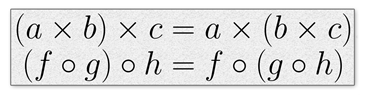
让我们重新编写函数组合,不是作为函数原型的扩展,而是作为一个独立的函数,这将允许我们更充分地利用它。基本形式如下:
var fcompose = function(f, g) {
return function() {
return f.call(this, g.apply(this, arguments));
};
};
但是我们需要它能够处理任意数量的输入。
var fcompose = function() {
// first make sure all arguments are functions
var funcs = arrayOf(func)(arguments);
// return a function that applies all the functions
return function() {
var argsOfFuncs = arguments;
for (var i = funcs.length; i > 0; i -= 1) {
argsOfFuncs = [funcs[i].apply(this, args)];
}
return args[0];
};
};
// example:
var f = fcompose(negate, square, mult2, add1);
f(2); // Returns: -36
现在我们已经封装了这些函数,我们对它们有了控制。我们可以重写 compose 函数,使得每个函数都接受另一个函数作为输入,存储它,并返回一个做同样事情的对象。我们可以接受一个单一数组作为输入,对源中的每个元素执行所有操作(每个map()、filter()等等,组合在一起),最后将结果存储在一个新数组中。这是通过函数组合实现的惰性评估。这里没有理由重新发明轮子。许多库都有这个概念的很好的实现,包括Lazy.js、Bacon.js和wu.js库。
这种不同的模式使我们能够做更多的事情:异步迭代,异步事件处理,惰性评估,甚至自动并行化。
注意
自动并行化?在计算机科学行业中有一个词:不可能。但它真的不可能吗?摩尔定律的下一个进化飞跃可能是一个为我们的代码并行化的编译器,而函数组合可能就是这样的编译器?
不,事情并不完全是这样的。JavaScript 引擎才是真正进行并行化的,不是自动的,而是通过深思熟虑的代码。Compose 只是给引擎一个机会将其拆分成并行进程。但这本身就很酷。
单子
单子是帮助您组合函数的工具。
像原始类型一样,单子是可以用作函子“触及”的容器的结构。函子抓取数据,对其进行处理,将其放入一个新的单子中,并返回它。
我们将专注于三个单子:
-
Maybes
-
承诺
-
Lenses
所以除了数组(map)和函数(compose)之外,我们还有五个函子(map、compose、maybe、promise 和 lens)。这些只是许多其他函子和单子中的一些。
Maybes
Maybes 允许我们优雅地处理可能为空的数据,并设置默认值。也就是说,maybe 是一个变量,它要么有一些值,要么没有。而对调用者来说这并不重要。
单独看起来,这似乎并不是什么大不了的事。每个人都知道,使用if-else语句很容易实现空检查:
if (getUsername() == null ) {
username = 'Anonymous') {
else {
username = getUsername();
}
但是通过函数式编程,我们正在摆脱逐行进行程序的程序化方式,而是使用函数和数据的管道。如果我们必须在中间打断链条来检查值是否存在,我们将不得不创建临时变量并编写更多的代码。Maybes 只是帮助我们保持逻辑在管道中流动的工具。
为了实现 maybes,我们首先需要创建一些构造函数。
// the Maybe monad constructor, empty for now
var Maybe = function(){};
// the None instance, a wrapper for an object with no value
var None = function(){};
None.prototype = Object.create(Maybe.prototype);
None.prototype.toString = function(){return 'None';};
// now we can write the `none` function
// saves us from having to write `new None()` all the time
var none = function(){return new None()};
// and the Just instance, a wrapper for an object with a value
var Just = function(x){return this.x = x;};
Just.prototype = Object.create(Maybe.prototype);
Just.prototype.toString = function(){return "Just "+this.x;};
var just = function(x) {return new Just(x)};
最后,我们可以编写maybe函数。它返回一个新的函数,要么返回空,要么返回一个 maybe。它是一个函子。
var maybe = function(m){
if (m instanceof None) {
return m;
}
else if (m instanceof Just) {
return just(m.x);
}
else {
throw new TypeError("Error: Just or None expected, " + m.toString() + " given.");
}
}
我们也可以创建一个与数组类似的函子生成器。
var maybeOf = function(f){
return function(m) {
if (m instanceof None) {
return m;
}
else if (m instanceof Just) {
return just(f(m.x));
}
else {
throw new TypeError("Error: Just or None expected, " + m.toString() + " given.");
}
}
}
所以Maybe是一个单子,maybe是一个函子,maybeOf返回一个已经分配给一个态射的函子。
在我们继续之前,我们还需要一件事。我们需要为Maybe单子对象添加一个帮助我们更直观地使用它的方法。
Maybe.prototype.orElse = function(y) {
if (this instanceof Just) {
return this.x;
}
else {
return y;
}
}
在其原始形式中,maybes 可以直接使用。
maybe(just(123)).x; // Returns 123
maybeOf(plusplus)(just(123)).x; // Returns 124
maybe(plusplus)(none()).orElse('none'); // returns 'none'
任何返回一个然后执行的方法都足够复杂,以至于容易出问题。所以我们可以通过调用我们的curry()函数来使它更加简洁。
maybePlusPlus = maybeOf.curry()(plusplus);
maybePlusPlus(just(123)).x; // returns 123
maybePlusPlus(none()).orElse('none'); // returns none
但是当直接调用none()和just()函数的肮脏业务被抽象化时,maybes 的真正力量将变得清晰。我们将通过一个使用 maybes 的示例对象User来做到这一点。
var User = function(){
this.username = none(); // initially set to `none`
};
User.prototype.setUsername = function(name) {
this.username = just(str(name)); // it's now a `just
};
User.prototype.getUsernameMaybe = function() {
var usernameMaybe = maybeOf.curry()(str);
return usernameMaybe(this.username).orElse('anonymous');
};
var user = new User();
user.getUsernameMaybe(); // Returns 'anonymous'
user.setUsername('Laura');
user.getUsernameMaybe(); // Returns 'Laura'
现在我们有了一个强大而安全的方法来定义默认值。记住这个User对象,因为我们将在本章后面使用它。
承诺
承诺的本质是它们对变化的情况保持免疫。
- 弗兰克·安德伍德,《纸牌屋》
在函数式编程中,我们经常使用管道和数据流:一系列函数,其中每个函数产生一个数据类型,由下一个函数消耗。然而,许多这些函数是异步的:readFile、事件、AJAX 等。我们如何修改这些函数的返回类型来指示结果,而不是使用延续传递风格和深度嵌套的回调?通过将它们包装在promises中。
Promises 就像回调的函数式等价物。显然,回调并不都是函数式的,因为如果有多个函数对同一数据进行变异,就会出现竞争条件和错误。Promises 解决了这个问题。
你应该使用 promises 来完成这个:
fs.readFile("file.json", function(err, val) {
if( err ) {
console.error("unable to read file");
}
else {
try {
val = JSON.parse(val);
console.log(val.success);
}
catch( e ) {
console.error("invalid json in file");
}
}
});
进入以下代码片段:
fs.readFileAsync("file.json").then(JSON.parse)
.then(function(val) {
console.log(val.success);
})
.catch(SyntaxError, function(e) {
console.error("invalid json in file");
})
.catch(function(e){
console.error("unable to read file")
});
上述代码来自bluebird的 README:一个功能齐全的*Promises/A+*实现,性能异常出色。*Promises/A+是 JavaScript 中实现 promises 的规范。鉴于它在 JavaScript 社区内的当前辩论,我们将把实现留给Promises/A+*团队,因为它比可能更复杂得多。
但这是一个部分实现:
// the Promise monad
var Promise = require('bluebird');
// the promise functor
var promise = function(fn, receiver) {
return function() {
var slice = Array.prototype.slice,
args = slice.call(arguments, 0, fn.length - 1),
promise = new Promise();
args.push(function() {
var results = slice.call(arguments),
error = results.shift();
if (error) promise.reject(error);
else promise.resolve.apply(promise, results);
});
fn.apply(receiver, args);
return promise;
};
};
现在我们可以使用promise()函子将接受回调的函数转换为返回 promises 的函数。
var files = ['a.json', 'b.json', 'c.json'];
readFileAsync = promise(fs.readFile);
var data = files
.map(function(f){
readFileAsync(f).then(JSON.parse)
})
.reduce(function(a,b){
return $.extend({}, a, b)
});
镜头
程序员真正喜欢单子的另一个原因是,它们使编写库变得非常容易。为了探索这一点,让我们扩展我们的User对象,增加更多用于获取和设置值的函数,但是,我们将使用lenses而不是使用 getter 和 setter。
镜头是一流的获取器和设置器。它们不仅允许我们获取和设置变量,还允许我们在其上运行函数。但是,它们不是对数据进行变异,而是克隆并返回由函数修改的新数据。它们强制数据是不可变的,这对于安全性和一致性以及库来说非常好。无论应用程序如何,它们都非常适合优雅的代码,只要引入额外的数组副本不会对性能造成重大影响。
在编写lens()函数之前,让我们看看它是如何工作的。
var first = lens(
function (a) { return arr(a)[0]; }, // get
function (a, b) { return [b].concat(arr(a).slice(1)); } // set
);
first([1, 2, 3]); // outputs 1
first.set([1, 2, 3], 5); // outputs [5, 2, 3]
function tenTimes(x) { return x * 10 }
first.modify(tenTimes, [1,2,3]); // outputs [10,2,3]
这就是lens()函数的工作原理。它返回一个具有 get、set 和 mod 定义的函数。lens()函数本身是一个函子。
var lens = fuction(get, set) {
var f = function (a) {return get(a)};
f.get = function (a) {return get(a)};
f.set = set;
f.mod = function (f, a) {return set(a, f(get(a)))};
return f;
};
让我们来试一个例子。我们将扩展我们之前例子中的User对象。
// userName :: User -> str
var userName = lens(
function (u) {return u.getUsernameMaybe()}, // get
function (u, v) { // set
u.setUsername(v);
return u.getUsernameMaybe();
}
);
var bob = new User();
bob.setUsername('Bob');
userName.get(bob); // returns 'Bob'
userName.set(bob, 'Bobby'); //return 'Bobby'
userName.get(bob); // returns 'Bobby'
userName.mod(strToUpper, bob); // returns 'BOBBY'
strToUpper.compose(userName.set)(bob, 'robert'); // returns 'ROBERT'
userName.get(bob); // returns 'robert'
jQuery 是一个单子
如果你认为所有这些关于范畴、函子和单子的抽象胡言没有真正的现实应用,那就再想想吧。流行的 JavaScript 库 jQuery 提供了一个增强的接口,用于处理 HTML,实际上是一个单子库。
jQuery对象是一个单子,它的方法是函子。实际上,它们是一种特殊类型的函子,称为endofunctors。Endofunctors是返回与输入相同类别的函子,即F :: X -> X。每个jQuery方法都接受一个jQuery对象并返回一个jQuery对象,这允许方法被链接,并且它们将具有类型签名jFunc :: jquery-obj -> jquery-obj。
$('li').add('p.me-too').css('color', 'red').attr({id:'foo'});
这也是 jQuery 的插件框架的强大之处。如果插件以jQuery对象作为输入并返回一个作为输出,则可以将其插入到链中。
让我们看看 jQuery 是如何实现这一点的。
单子是函子“触及”以获取数据的容器。通过这种方式,数据可以受到库的保护和控制。jQuery 通过其许多方法提供对底层数据的访问,这些数据是一组包装的 HTML 元素。
jQuery对象本身是作为匿名函数调用的结果编写的。
var jQuery = (function () {
var j = function (selector, context) {
var jq-obj = new j.fn.init(selector, context);
return jq-obj;
};
j.fn = j.prototype = {
init: function (selector, context) {
if (!selector) {
return this;
}
}
};
j.fn.init.prototype = j.fn;
return j;
})();
在这个高度简化的 jQuery 版本中,它返回一个定义了j对象的函数,实际上只是一个增强的init构造函数。
var $ = jQuery(); // the function is returned and assigned to `$`
var x = $('#select-me'); // jQuery object is returned
与函子将值提取出容器的方式相同,jQuery 包装了 HTML 元素并提供对它们的访问,而不是直接修改 HTML 元素。
jQuery 并不经常宣传,但它有自己的map()方法,用于将 HTML 元素对象从包装器中提取出来。就像fmap()方法一样,元素被提取出来,对它们进行处理,然后放回容器中。这就是 jQuery 的许多命令在后端工作的方式。
$('li').map(function(index, element) {
// do something to the element
return element
});
另一个用于处理 HTML 元素的库 Prototype 不是这样工作的。Prototype 通过助手直接改变 HTML 元素。因此,它在 JavaScript 社区中的表现并不好。
实施类别
是时候我们正式将范畴论定义为 JavaScript 对象了。范畴是对象(类型)和态射(仅在这些类型上工作的函数)。这是一种非常高级的、完全声明式的编程方式,但它确保代码非常安全可靠——非常适合担心并发和类型安全的 API 和库。
首先,我们需要一个帮助我们创建同态的函数。我们将其称为homoMorph(),因为它们将是同态。它将返回一个函数,该函数期望传入一个函数,并根据输入生成其组合。输入是态射接受的输入和输出的类型。就像我们的类型签名一样,即// morph :: num -> num -> [num],只有最后一个是输出。
var homoMorph = function( /* input1, input2,..., inputN, output */ ) {
var before = checkTypes(arrayOf(func)(Array.prototype.slice.call(arguments, 0, arguments.length-1)));
var after = func(arguments[arguments.length-1])
return function(middle) {
return function(args) {
return after(middle.apply(this, before([].slice.apply(arguments))));
}
}
}
// now we don't need to add type signature comments
// because now they're built right into the function declaration
add = homoMorph(num, num, num)(function(a,b){return a+b})
add(12,24); // returns 36
add('a', 'b'); // throws error
homoMorph(num, num, num)(function(a,b){
return a+b;
})(18, 24); // returns 42
homoMorph()函数相当复杂。它使用闭包(参见第二章,“函数式编程基础”)返回一个接受函数并检查其输入和输出值的类型安全性的函数。为此,它依赖于一个辅助函数:checkTypes,其定义如下:
var checkTypes = function( typeSafeties ) {
arrayOf(func)(arr(typeSafeties));
var argLength = typeSafeties.length;
return function(args) {
arr(args);
if (args.length != argLength) {
throw new TypeError('Expected '+ argLength + ' arguments');
}
var results = [];
for (var i=0; i<argLength; i++) {
results[i] = typeSafetiesi;
}
return results;
}
}
现在让我们正式定义一些同态。
var lensHM = homoMorph(func, func, func)(lens);
var userNameHM = lensHM(
function (u) {return u.getUsernameMaybe()}, // get
function (u, v) { // set
u.setUsername(v);
return u.getUsernameMaybe();
}
)
var strToUpperCase = homoMorph(str, str)(function(s) {
return s.toUpperCase();
});
var morphFirstLetter = homoMorph(func, str, str)(function(f, s) {
return f(s[0]).concat(s.slice(1));
});
var capFirstLetter = homoMorph(str, str)(function(s) {
return morphFirstLetter(strToUpperCase, s)
});
最后,我们可以把它带回家。以下示例包括函数组合、镜头、同态和其他内容。
// homomorphic lenses
var bill = new User();
userNameHM.set(bill, 'William'); // Returns: 'William'
userNameHM.get(bill); // Returns: 'William'
// compose
var capatolizedUsername = fcompose(capFirstLetter,userNameHM.get);
capatolizedUsername(bill, 'bill'); // Returns: 'Bill'
// it's a good idea to use homoMorph on .set and .get too
var getUserName = homoMorph(obj, str)(userNameHM.get);
var setUserName = homoMorph(obj, str, str)(userNameHM.set);
getUserName(bill); // Returns: 'Bill'
setUserName(bill, 'Billy'); // Returns: 'Billy'
// now we can rewrite capatolizeUsername with the new setter
capatolizedUsername = fcompose(capFirstLetter, setUserName);
capatolizedUsername(bill, 'will'); // Returns: 'Will'
getUserName(bill); // Returns: 'will'
前面的代码非常声明式,安全,可靠和可信赖。
注
代码声明式是什么意思?在命令式编程中,我们编写一系列指令,告诉机器如何做我们想要的事情。在函数式编程中,我们描述值之间的关系,告诉机器我们想要它计算什么,机器会找出指令序列来实现它。函数式编程是声明式的。
整个库和 API 可以通过这种方式构建,允许程序员自由编写代码,而不必担心并发和类型安全,因为这些问题在后端处理。
总结
大约每 2000 人中就有一人患有一种称为共感觉的病症,这是一种神经现象,其中一种感官输入渗入另一种感官。最常见的形式涉及将颜色与字母相匹配。然而,还有一种更罕见的形式,即将句子和段落与味道和感觉联系起来。
对于这些人来说,他们不是逐字逐句地阅读。他们看整个页面/文档/程序,感受它的“味道”——不是口中的味道,而是“心灵”中的味道。然后他们像拼图一样把文本的部分放在一起。
这就是编写完全声明式代码的样子:描述值之间的关系,告诉机器我们想要它计算什么。程序的部分不是按照逐行指令。共感者可能自然而然地做到这一点,但只要稍加练习,任何人都可以学会如何将关系拼图一起放在一起。
在本章中,我们看了几个数学概念,这些概念适用于函数式编程,以及它们如何允许我们在数据之间建立关系。接下来,我们将探讨递归和 JavaScript 中的其他高级主题。
第六章:JavaScript 中的高级主题和陷阱
JavaScript 被称为 Web 的"汇编语言"。这个类比(它并不完美,但哪个类比是完美的?)源自于 JavaScipt 经常是编译的目标,主要来自Clojure和CoffeeScript,但也来自许多其他来源,比如pyjamas(python 到 JS)和 Google Web Kit(Java 到 JS)。
但这个类比也提到了一个愚蠢的想法,即 JavaScript 和 x86 汇编一样具有表现力和低级。也许这个想法源于 JavaScript 自从 1995 年首次与网景一起发布以来就一直因其设计缺陷和疏忽而受到抨击。它是在匆忙开发和发布的,还没有完全开发就发布了。正因为如此,一些有问题的设计选择进入了 JavaScript,这种语言很快成为了 Web 的事实脚本语言。分号是一个大错误。定义函数的模糊方法也是错误的。是var foo = function();还是function foo();?
函数式编程是规避一些这些错误的绝佳方式。通过专注于 JavaScript 实际上是一种函数式语言这一事实,可以清楚地看到,在前面关于不同声明函数的方式的示例中,最好将函数声明为变量。分号大多只是为了使 JavaScript 看起来更像 C 而已。
但是,始终记住你正在使用的语言。JavaScript,像任何其他语言一样,都有其缺陷。而且,在编写通常会绕过可能的边缘的风格时,这些小失误可能会变成不可恢复的陷阱。其中一些陷阱包括:
-
递归
-
变量作用域和闭包
-
函数声明与函数表达式
然而,这些问题可以通过一点注意来克服。
递归
在任何语言中,递归对于函数式编程非常重要。许多函数式语言甚至要求通过不提供for和while循环语句来进行迭代,这只有在语言保证尾调用消除时才可能,而 JavaScript 并非如此。在第二章函数式编程基础中简要介绍了递归。但在本节中,我们将深入探讨递归在 JavaScript 中的工作原理。
尾递归
JavaScript 处理递归的例程被称为尾递归,这是一种基于堆栈的递归实现。这意味着,对于每次递归调用,堆栈中都会有一个新的帧。
为了说明这种方法可能出现的问题,让我们使用经典的递归算法来计算阶乘。
var factorial = function(n) {
if (n == 0) {
// base case
return 1;
}
else {
// recursive case
return n * factorial(n-1);
}
}
该算法将自己调用n次以获得答案。它实际上计算了(1 x 1 x 2 x 3 x … x N)。这意味着时间复杂度是O(n)。
注意
O(n),读作"大 O 到 n",意味着算法的复杂度将随着输入规模的增长而增长,这是更精简的增长。O(n2)是指数增长,O(log(n))是对数增长,等等。这种表示法既可以用于时间复杂度,也可以用于空间复杂度。
但是,由于每次迭代都会为内存堆栈分配一个新的帧,因此空间复杂度也是O(n)。这是一个问题。这意味着内存将以这样的速度被消耗,以至于很容易超出内存限制。在我的笔记本电脑上,factorial(23456)返回Uncaught Error: RangeError: Maximum call stack size exceeded。
虽然计算 23456 的阶乘是一种不必要的努力,但可以肯定的是,许多使用递归解决的问题将很容易增长到这样的规模。考虑数据树的情况。树可以是任何东西:搜索应用程序、文件系统、路由表等。下面是树遍历函数的一个非常简单的实现:
var traverse = function(node) {
node.doSomething(); // whatever work needs to be done
node.childern.forEach(traverse); // many recursive calls
}
每个节点只有两个子节点时,时间复杂度和空间复杂度(在最坏的情况下,整个树必须被遍历以找到答案)都将是O(n2),因为每次都会有两个递归调用。如果每个节点有许多子节点,复杂度将是O(nm),其中m是子节点的数量。递归是树遍历的首选算法;while循环会更加复杂,并且需要维护一个堆栈。
指数增长意味着不需要一个非常大的树就能抛出RangeError异常。必须有更好的方法。
尾调用消除
我们需要一种方法来消除每次递归调用都分配新的堆栈帧。这就是所谓的尾调用消除。
通过尾调用消除,当一个函数返回调用自身的结果时,语言实际上不执行另一个函数调用。它为您将整个过程转换为循环。
好的,我们该怎么做呢?使用惰性求值。如果我们可以将其重写为对惰性序列进行折叠,使得函数返回一个值或者返回调用另一个函数的结果而不对该结果进行任何操作,那么就不需要分配新的堆栈帧。
为了将其转换为“尾递归形式”,阶乘函数必须被重写,使得内部过程fact在控制流中最后调用自身,如下面的代码片段所示:
var factorial = function(n) {
var _fact = function(x, n) {
if (n == 0) {
// base case
return x;
}
else {
// recursive case
return _fact(n*x, n-1);
}
}
return fact(1, n);
}
注意
与其让递归尾部产生结果(比如n * factorial(n-1)),不如让结果在递归尾部进行计算(通过调用_fact(r*n, n-1)),并由该尾部中的最后一个函数产生结果(通过return r;)。计算只朝一个方向进行,而不是向上。对解释器来说,将其处理为迭代相对容易。
然而,尾调用消除在 JavaScript 中不起作用。将上述代码放入您喜欢的 JavaScript 引擎中,factorial(24567)仍然会返回Uncaught Error: RangeError: Maximum call stack size exceeded异常。尾调用消除被列为要包含在下一个 ECMAScript 版本中的新功能,但在所有浏览器实现它之前还需要一些时间。
JavaScript 无法优化转换为尾递归形式的函数。这是语言规范和运行时解释器的特性,简单明了。这与解释器如何获取堆栈帧的资源有关。有些语言在不需要记住任何新信息时会重用相同的堆栈帧,就像在前面的函数中一样。这就是尾调用消除如何减少时间和空间复杂度。
不幸的是,JavaScript 不会这样做。但如果它这样做了,它将重新组织堆栈帧,从这样:
call factorial (3)
call fact (3 1)
call fact (2 3)
call fact (1 6)
call fact (0 6)
return 6
return 6
return 6
return 6
return 6
转换为以下形式:
call factorial (3)
call fact (3 1)
call fact (2 3)
call fact (1 6)
call fact (0 6)
return 6
return 6
trampolining
解决方案?一种称为trampolining的过程。这是一种通过使用thunks来“黑客”尾调用消除概念的方法。
注意
为此,thunks 是带有参数的表达式,用于包装没有自己参数的匿名函数。例如:function(str){return function(){console.log(str)}}。这可以防止表达式在接收函数调用匿名函数之前被评估。
trampoline 是一个接受函数作为输入并重复执行其返回值直到返回的不再是函数的函数。以下是一个简单的实现代码片段:
var trampoline = function(f) {
while (f && f instanceof Function) {
f = f.apply(f.context, f.args);
}
return f;
}
要实际实现尾调用消除,我们需要使用 thunks。为此,我们可以使用bind()函数,它允许我们将一个方法应用于具有分配给另一个对象的this关键字的对象。在内部,它与call关键字相同,但它链接到方法并返回一个新的绑定函数。bind()函数实际上进行了部分应用,尽管方式非常有限。
var factorial = function(n) {
var _fact = function(x, n) {
if (n == 0) {
// base case
return x;
}
else {
// recursive case
return _fact.bind(null, n*x, n-1);
}
}
return trampoline(_fact.bind(null, 1, n));
}
但是编写 fact.bind(null, ...) 方法很麻烦,会让任何阅读代码的人感到困惑。相反,让我们编写自己的函数来创建 thunks。thunk() 函数必须做一些事情:
-
thunk()函数必须模拟_fact.bind(null, n*x, n-1)方法,返回一个未评估的函数 -
thunk()函数应该包含另外两个函数: -
用于处理给定函数,以及
-
用于处理函数参数,这些参数将在调用给定函数时使用
有了这些,我们就可以开始编写函数了。我们只需要几行代码就可以写出来。
var thunk = function (fn) {
return function() {
var args = Array.prototype.slice.apply(arguments);
return function() { return fn.apply(this, args); };
};
};
现在我们可以在阶乘算法中使用 thunk() 函数,就像这样:
var factorial = function(n) {
var fact = function(x, n) {
if (n == 0) {
return x;
}
else {
return thunk(fact)(n * x, n - 1);
}
}
return trampoline(thunk(fact)(1, n));
}
但是,我们可以通过将 _fact() 函数定义为 thunk() 函数来进一步简化。通过将内部函数定义为 thunk() 函数,我们无需在内部函数定义中和返回语句中都使用 thunk() 函数。
var factorial = function(n) {
var _fact = thunk(function(x, n) {
if (n == 0) {
// base case
return x;
}
else {
// recursive case
return _fact(n * x, n - 1);
}
});
return trampoline(_fact(1, n));
}
结果是美丽的。看起来像 _fact() 函数被递归调用以实现无尾递归,实际上几乎透明地被处理为迭代!
最后,让我们看看 trampoline() 和 thunk() 函数如何与我们更有意义的树遍历示例一起工作。以下是使用 trampolining 和 thunks 遍历数据树的一个简单示例:
var treeTraverse = function(trunk) {
var _traverse = thunk(function(node) {
node.doSomething();
node.children.forEach(_traverse);
}
trampoline(_traverse(trunk));
}
我们已经解决了尾递归的问题。但是有没有更好的方法?如果我们能够简单地将递归函数转换为非递归函数呢?接下来,我们将看看如何做到这一点。
Y 组合子
Y 组合子是计算机科学中令人惊叹的事物之一,即使是最熟练的编程大师也会感到惊讶。它自动将递归函数转换为非递归函数的能力是为什么 Douglas Crockford 称其为 “计算机科学中最奇怪和奇妙的产物”,而 Sussman 和 Steele 曾经说过,“这个方法能够工作真是了不起”。
因此,一个真正令人惊叹的、奇妙的计算机科学产物,能够让递归函数屈服,一定是庞大而复杂的,对吗?不完全是这样。它在 JavaScript 中的实现只有九行非常奇怪的代码。它们如下:
var Y = function(F) {
return (function (f) {
return f(f);
} (function (f) {
return F(function (x) {
return f(f)(x);
});
}));
}
它的工作原理是:找到作为参数传入的函数的 “不动点”。不动点提供了另一种思考函数的方式,而不是在计算机编程理论中的递归和迭代。它只使用匿名函数表达式、函数应用和变量引用来实现。请注意,Y 并没有引用自身。事实上,所有这些函数都是匿名的。
正如你可能已经猜到的,Y 组合子源自 λ 演算。它实际上是借助另一个称为 U 组合子的组合子推导出来的。组合子是特殊的高阶函数,它们只使用函数应用和早期定义的组合子来从输入中定义结果。
为了演示 Y 组合子,我们将再次转向阶乘问题,但我们需要以稍微不同的方式定义阶乘函数。我们不再写一个递归函数,而是写一个返回数学定义阶乘的函数。然后我们可以将这个函数传递给 Y 组合子。
var FactorialGen = function(factorial) {
return (function(n) {
if (n == 0) {
// base case
return 1;
}
else {
// recursive case
return n * factorial(n – 1);
}
});
};
Factorial = Y(FactorialGen);
Factorial(10); // 3628800
然而,当我们给它一个非常大的数字时,堆栈会溢出,就像使用尾递归而没有 trampolining 一样。
Factorial(23456); // RangeError: Maximum call stack size exceeded
但是我们可以像下面这样在 Y 组合子中使用 trampolining:
var FactorialGen2 = function (factorial) {
return function(n) {
var factorial = thunk(function (x, n) {
if (n == 0) {
return x;
}
else {
return factorial(n * x, n - 1);
}
});
return trampoline(factorial(1, n));
}
};
var Factorial2 = Y(FactorialGen2)
Factorial2(10); // 3628800
Factorial2(23456); // Infinity
我们还可以重新排列 Y 组合子以执行称为 memoization 的操作。
Memoization
Memoization 是一种存储昂贵函数调用结果的技术。当以相同的参数再次调用函数时,将返回存储的结果,而不是重新计算结果。
尽管 Y 组合子比递归快得多,但它仍然相对较慢。为了加快速度,我们可以创建一个记忆化的不动点组合子:一个类似 Y 的组合子,它缓存中间函数调用的结果。
var Ymem = function(F, cache) {
if (!cache) {
cache = {} ; // Create a new cache.
}
return function(arg) {
if (cache[arg]) {
// Answer in cache
return cache[arg] ;
}
// else compute the answer
var answer = (F(function(n){
return (Ymem(F,cache))(n);
}))(arg); // Compute the answer.
cache[arg] = answer; // Cache the answer.
return answer;
};
}
那么它有多快呢?通过使用jsperf.com/,我们可以比较性能。
以下结果是使用 1 到 100 之间的随机数。我们可以看到,记忆化的 Y 组合子要快得多。而且加上 trampolining 并不会使它变慢太多。您可以在此 URL 查看结果并运行测试:jsperf.com/memoizing-y-combinator-vs-tail-call-optimization/7。
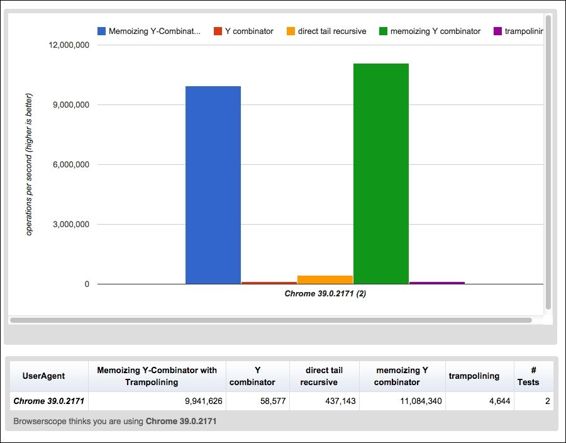
最重要的是:在 JavaScript 中执行递归的最有效和最安全的方法是使用记忆化的 Y 组合子,通过 trampolining 和 thunks 进行尾调用消除。
变量作用域
JavaScript 中变量的作用域并不是自然的。事实上,有时它甚至是违反直觉的。他们说 JavaScript 程序员可以通过他们对作用域的理解程度来判断。
作用域解析
首先,让我们来看一下 JavaScript 中不同的作用域解析。
JavaScript 使用作用域链来确定变量的作用域。在解析变量时,它从最内部的作用域开始,向外搜索。
全局作用域
在这个级别定义的变量、函数和对象对整个程序中的任何代码都是可用的。这是最外层的作用域。
var x = 'hi';
function a() {
console.log(x);
}
a(); // 'hi'
局部作用域
每个描述的函数都有自己的局部作用域。在另一个函数内定义的任何函数都有一个与外部函数相关联的嵌套局部作用域。几乎总是源代码中的位置定义了作用域。
var x = 'hi';
function a() {
console.log(x);
}
function b() {
var x = 'hello';
console.log(x);
}
b(); // hello
a(); // hi
局部作用域仅适用于函数,而不适用于任何表达式语句(if、for、while等),这与大多数语言处理作用域的方式不同。
function c() {
var y = 'greetings';
if (true) {
var y = 'guten tag';
}
console.log(y);
}
function d() {
var y = 'greetings';
function e() {
var y = 'guten tag';
}
console.log(y)
}
c(); // 'guten tag'
d(); // 'greetings'
在函数式编程中,这不是太大的问题,因为函数更常用,表达式语句不太常用。例如:
function e(){
var z = 'namaste';
[1,2,3].foreach(function(n) {
var z = 'aloha';
}
isTrue(function(){
var z = 'good morning';
});
console.log(z);
}
e(); // 'namaste'
对象属性
对象属性也有它们自己的作用域链。
var x = 'hi';
var obj = function(){
this.x = 'hola';
};
var foo = new obj();
console.log(foo.x); // 'hola'
foo.x = 'bonjour';
console.log(foo.x); // 'bonjour'
对象的原型在作用域链中更靠下。
obj.prototype.x = 'greetings';
obj.prototype.y = 'konnichi ha';
var bar = new obj();
console.log(bar.x); // still prints 'hola'
console.log(bar.y); // 'konnichi ha'
这甚至不能算是全面的,但这三种作用域类型足以让我们开始。
闭包
这种作用域结构的一个问题是它不留下私有变量的空间。考虑以下代码片段:
var name = 'Ford Focus';
var year = '2006';
var millage = 123456;
function getMillage(){
return millage;
}
function updateMillage(n) {
millage = n;
}
这些变量和函数是全局的,这意味着程序后面的代码很容易意外地覆盖它们。一个解决方法是将它们封装到一个函数中,并在定义后立即调用该函数。
var car = function(){
var name = 'Ford Focus';
var year = '2006';
var millage = 123456;
function getMillage(){
return Millage;
}
function updateMillage(n) {
millage = n;
}
}();
在函数外部没有发生任何事情,所以我们应该通过使其匿名来丢弃函数名。
(function(){
var name = 'Ford Focus';
var year = '2006';
var millage = 123456;
function getMillage(){
return millage;
}
function updateMillage(n) {
millage = n;
}
})();
为了使函数getValue()和updateMillage()在匿名函数外部可用,我们需要在对象字面量中返回它们,如下面的代码片段所示:
var car = function(){
var name = 'Ford Focus';
var year = '2006';
var millage = 123456;
return {
getMillage: function(){
return millage;
},
updateMillage: function(n) {
millage = n;
}
}
}();
console.log( car.getMillage() ); // works
console.log( car.updateMillage(n) ); // also works
console.log( car.millage ); // undefined
这给我们伪私有变量,但问题并不止于此。下一节将探讨 JavaScript 中变量作用域的更多问题。
陷阱
在 JavaScript 中可以找到许多变量作用域的微妙之处。以下绝不是一个全面的列表,但它涵盖了最常见的情况:
- 以下将输出 4,而不是人们所期望的’undefined’:
for (var n = 4; false; ) { } console.log(n);
这是因为在 JavaScript 中,变量的定义发生在相应作用域的开头,而不仅仅是在声明时。
- 如果你在外部作用域中定义一个变量,然后在函数内部用相同的名称定义一个变量,即使那个
if分支没有被执行,它也会被重新定义。例如:
var x = 1;
function foo() {
if (false) {
var x = 2;
}
return x;
}
foo(); // Return value: 'undefined', expected return value:
2
同样,这是由于将变量定义移动到作用域的开头,使用undefined值引起的。
- 在浏览器中,全局变量实际上是存储在
window对象中的。
window.a = 19;
console.log(a); // Output: 19
全局作用域中的a表示当前上下文的属性,因此a===this.a,在浏览器中的window对象充当全局作用域中this关键字的等价物。
前两个示例是 JavaScript 的一个特性导致的,这个特性被称为提升,在下一节关于编写函数的内容中将是一个关键概念。
函数声明与函数表达式与函数构造函数
这三种声明之间有什么区别?
function foo(n){ return n; }
var foo = function(n){ return n; };
var foo = new Function('n', 'return n');
乍一看,它们只是编写相同函数的不同方式。但这里还有更多的事情。如果我们要充分利用 JavaScript 中的函数以便将它们操纵成函数式编程风格,那么我们最好能够搞清楚这一点。如果在计算机编程中有更好的方法,那么那一种方法应该是唯一的方法。
函数声明
函数声明,有时称为函数语句,使用function关键字定义函数。
function foo(n) {
return n;
}
使用这种语法声明的函数会被提升到当前作用域的顶部。这实际上意味着,即使函数在几行下面定义,JavaScript 也知道它并且可以在作用域中较早地使用它。例如,以下内容将正确地将 6 打印到控制台:
foo(2,3);
function foo(n, m) {
console.log(n*m);
}
函数表达式
命名函数也可以通过定义匿名函数并将其赋值给变量来定义为表达式。
var bar = function(n, m) {
console.log(n*m);
};
它们不像函数声明那样被提升。这是因为,虽然函数声明被提升,但变量声明却没有。例如,这将无法工作并抛出错误:
bar(2,3);
var bar = function(n, m) {
console.log(n*m);
};
在函数式编程中,我们希望使用函数表达式,这样我们可以将函数视为变量,使它们可以用作回调和高阶函数的参数,例如map()函数。将函数定义为表达式使得它们更像是分配给函数的变量。此外,如果我们要以一种风格编写函数,那么为了一致性和清晰度,我们应该以该风格编写所有函数。
函数构造函数
JavaScript 实际上有第三种创建函数的方式:使用Function()构造函数。与函数表达式一样,使用Function()构造函数定义的函数也不会被提升。
var func = new Function('n','m','return n+m');
func(2,3); // returns 5
但Function()构造函数不仅令人困惑,而且非常危险。无法进行语法纠正,也无法进行优化。以以下方式编写相同函数要容易得多、更安全、更清晰:
var func = function(n,m){return n+m};
func(2,3); // returns 5
不可预测的行为
所以区别在于函数声明会被提升,而函数表达式不会。这可能会导致意想不到的事情发生。考虑以下情况:
function foo() {
return 'hi';
}
console.log(foo());
function foo() {
return 'hello';
}
实际打印到控制台的是hello。这是因为foo()函数的第二个定义被提升到顶部,成为 JavaScript 解释器实际使用的定义。
虽然乍一看这可能不是一个关键的区别,在函数式编程中这可能会引起混乱。考虑以下代码片段:
if (true) {
function foo(){console.log('one')};
}
else {
function foo(){console.log('two')};
}
foo();
当调用foo()函数时,控制台会打印two,而不是one!
最后,有一种方法可以结合函数表达式和声明。它的工作方式如下:
var foo = function bar(){ console.log('hi'); };
foo(); // 'hi'
bar(); // Error: bar is not defined
使用这种方法几乎没有意义,因为在声明中使用的名称(在前面的示例中的bar()函数)在函数外部不可用,会引起混乱。只有在递归的情况下才适用,例如:
var foo = function factorial(n) {
if (n == 0) {
return 1;
}
else {
return n * factorial(n-1);
}
};
foo(5);
总结
JavaScript 被称为“Web 的汇编语言”,因为它像 x86 汇编语言一样无处不在且不可避免。它是唯一在所有浏览器上运行的语言。它也有缺陷,但将其称为低级语言却不准确。
相反,把 JavaScript 看作是网络的生咖啡豆。当然,有些豆子是受损的,有些是腐烂的。但是如果选择好豆子,由熟练的咖啡师烘焙和冲泡,这些豆子就可以变成一杯绝妙的摩卡咖啡,一次就无法忘怀。它的消费变成了日常习惯,没有它的生活会变得单调,更难以进行,也不那么令人兴奋。一些人甚至喜欢用插件和附加组件来增强这种咖啡,比如奶油、糖和可可,这些都很好地补充了它。
JavaScript 最大的批评者之一道格拉斯·克劳福德曾说过:“肯定有很多人拒绝考虑 JavaScript 可能做对了什么。我曾经也是那些人之一。但现在我对其中的才华仍然感到惊讶。”
JavaScript 最终变得非常棒。
第七章:JavaScript 中的函数式和面向对象编程
你经常会听到 JavaScript 是一种空白语言,其中空白可以是面向对象的、函数式的或通用的。本书将 JavaScript 作为一种函数式语言进行了重点研究,并且已经付出了很大的努力来证明它是这样的。但事实上,JavaScript 是一种通用语言,意味着它完全能够支持多种编程风格。与 Python 和 F#不同,JavaScript 是多范式的。但与这些语言不同,JavaScript 的 OOP 方面是基于原型的,而大多数其他通用语言是基于类的。
在本章中,我们将把函数式和面向对象编程与 JavaScript 联系起来,看看这两种范式如何相辅相成,共存。本章将涵盖以下主题:
-
JavaScript 如何既是函数式的又是面向对象的?
-
JavaScript 的 OOP - 使用原型
-
如何在 JavaScript 中混合函数式和面向对象编程
-
函数继承
-
函数式混入
更好的代码是目标。函数式和面向对象编程只是实现这一目标的手段。
JavaScript - 多范式语言
如果面向对象编程意味着将所有变量视为对象,而函数式编程意味着将所有函数视为变量,那么函数不能被视为对象吗?在 JavaScript 中,它们可以。
但说函数式编程意味着将函数视为变量有些不准确。更好的说法是:函数式编程意味着将一切都视为值,尤其是函数。
描述函数式编程的更好方式可能是将其称为声明式。与命令式编程风格无关,声明式编程表达了解决问题所需的计算逻辑。计算机被告知问题是什么,而不是如何解决它的过程。
与此同时,面向对象编程源自命令式编程风格:计算机会得到解决问题的逐步说明。OOP 要求计算的说明(方法)和它们操作的数据(成员变量)被组织成称为对象的单元。访问数据的唯一方式是通过对象的方法。
那么这两种风格如何集成在一起呢?
-
对象方法中的代码通常以命令式风格编写。但如果以函数式风格呢?毕竟,OOP 并不排斥不可变数据和高阶函数。
-
也许更纯粹的混合方式是同时将对象视为函数和传统的基于类的对象。
-
也许我们可以简单地在面向对象的应用程序中包含一些函数式编程的思想,比如承诺和递归。
-
OOP 涵盖了封装、多态和抽象等主题。函数式编程也涵盖了这些主题,只是它采用了不同的方式。也许我们可以在面向函数的应用程序中包含一些面向对象编程的思想。
重点是:OOP 和 FP 可以混合在一起,有几种方法可以做到这一点。它们并不互斥。
JavaScript 的面向对象实现 - 使用原型
JavaScript 是一种无类语言。这并不意味着它比其他计算机语言更时尚或更蓝领;无类意味着它没有类结构,就像面向对象的语言那样。相反,它使用原型进行继承。
尽管这可能让有 C++和 Java 背景的程序员感到困惑,基于原型的继承比传统继承更具表现力。以下是 C++和 JavaScript 之间差异的简要比较:
| C++ | JavaScript |
|---|---|
| 强类型 | 弱类型 |
| 静态 | 动态 |
| 基于类 | 基于原型 |
| 类 | 函数 |
| 构造函数 | 函数 |
| 方法 | 函数 |
继承
在我们进一步讨论之前,让我们确保我们充分理解面向对象编程中的继承概念。基于类的继承在以下伪代码中得到了展示:
class Polygon {
int numSides;
function init(n) {
numSides = n;
}
}
class Rectangle inherits Polygon {
int width;
int length;
function init(w, l) {
numSides = 4;
width = w;
length = l;
}
function getArea() {
return w * l;
}
}
class Square inherits Rectangle {
function init(s) {
numSides = 4;
width = s;
length = s;
}
}
Polygon类是其他类继承的父类。它只定义了一个成员变量,即边数,该变量在init()函数中设置。Rectangle子类继承自Polygon类,并添加了两个成员变量length和width,以及一个方法getArea()。它不需要定义numSides变量,因为它已经被继承的类定义了,并且它还覆盖了init()函数。Square类通过从Rectangle类继承其getArea()方法进一步延续了这种继承链。通过简单地再次覆盖init()函数,使长度和宽度相同,getArea()函数可以保持不变,从而需要编写的代码更少。
在传统的面向对象编程语言中,这就是继承的全部含义。如果我们想要向所有对象添加一个颜色属性,我们只需将其添加到Polygon对象中,而无需修改任何继承自它的对象。
JavaScript 的原型链
JavaScript 中的继承归结为原型。每个对象都有一个名为其原型的内部属性,它是指向另一个对象的链接。该对象本身也有自己的原型。这种模式可以重复,直到达到一个具有undefined作为其原型的对象。这就是原型链,这就是 JavaScript 中继承的工作原理。以下图解释了 JavaScript 中的继承:
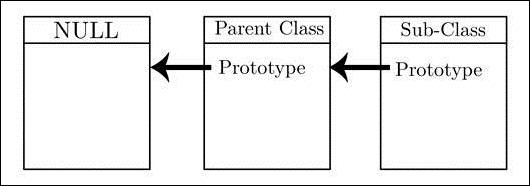
在搜索对象的函数定义时,JavaScript 会“遍历”原型链,直到找到具有正确名称的函数的第一个定义。因此,覆盖它就像在子类的原型上提供一个新定义一样简单。
JavaScript 中的继承和Object.create()方法
就像有许多方法可以在 JavaScript 中创建对象一样,也有许多方法可以复制基于类的经典继承。但做这件事的首选方法是使用Object.create()方法。
var Polygon = function(n) {
this.numSides = n;
}
var Rectangle = function(w, l) {
this.width = w;
this.length = l;
}
// the Rectangle's prototype is redefined with Object.create
Rectangle.prototype = Object.create(Polygon.prototype);
// it's important to now restore the constructor attribute
// otherwise it stays linked to the Polygon
Rectangle.prototype.constructor = Rectangle;
// now we can continue to define the Rectangle class
Rectangle.prototype.numSides = 4;
Rectangle.prototype.getArea = function() {
return this.width * this.length;
}
var Square = function(w) {
this.width = w;
this.length = w;
}
Square.prototype = Object.create(Rectangle.prototype);
Square.prototype.constructor = Square;
var s = new Square(5);
console.log( s.getArea() ); // 25
这种语法对许多人来说可能看起来不寻常,但经过一点练习,它将变得熟悉。必须使用prototype关键字来访问所有对象都具有的内部属性[[Prototype]]。Object.create()方法声明一个新对象,该对象继承自指定的对象原型。通过这种方式,可以在 JavaScript 中实现经典继承。
注意
Object.create()方法在 2011 年的 ECMAScript 5.1 中引入,并被宣传为创建对象的新方法。这只是 JavaScript 整合继承的众多尝试之一。幸运的是,这种方法运行得相当好。
在构建第五章范畴论中的Maybe类时,我们看到了这种继承结构,Maybe、None和Just类,它们彼此之间也是继承关系。
var Maybe = function(){};
var None = function(){};
None.prototype = Object.create(Maybe.prototype);
None.prototype.constructor = None;
None.prototype.toString = function(){return 'None';};
var Just = function(x){this.x = x;};
Just.prototype = Object.create(Maybe.prototype);
Just.prototype.constructor = Just;
Just.prototype.toString = function(){return "Just "+this.x;};
这表明 JavaScript 中的类继承可以成为函数式编程的一种实现方式。
一个常见的错误是将构造函数传递给Object.create()而不是prototype对象。这个问题的复杂性在于,直到子类尝试使用继承的成员函数时才会抛出错误。
Foo.prototype = Object.create(Parent.prototype); // correct
Bar.prototype = Object.create(Parent); // incorrect
Bar.inheritedMethod(); // Error: function is undefined
如果inheritedMethod()方法已经附加到Foo.prototype类,则无法找到该函数。如果inheritedMethod()方法直接附加到实例上,即在Bar构造函数中使用this.inheritedMethod = function(){...},那么Object.create()中使用Parent作为参数可能是正确的。
在 JavaScript 中混合函数式和面向对象编程
面向对象编程已经是主导的编程范式数十年了。它在世界各地的计算机科学 101 课程中被教授,而函数式编程则没有。软件架构师用它来设计应用程序,而函数式编程则没有。这也是有道理的:面向对象编程使得抽象思想更容易理解。它使编写代码更容易。
所以,除非你能说服你的老板应用程序需要全部是函数式的,否则我们将在面向对象的世界中使用函数式编程。本节将探讨如何做到这一点。
函数式继承
将函数式编程应用于 JavaScript 应用程序的最直接方式可能是在面向对象编程原则内使用大部分函数式风格,比如继承。
为了探索这可能如何工作,让我们构建一个简单的应用程序来计算产品的价格。首先,我们需要一些产品类:
var Shirt = function(size) {
this.size = size;
};
var TShirt = function(size) {
this.size = size;
};
TShirt.prototype = Object.create(Shirt.prototype);
TShirt.prototype.constructor = TShirt;
TShirt.prototype.getPrice = function(){
if (this.size == 'small') {
return 5;
}
else {
return 10;
}
}
var ExpensiveShirt = function(size) {
this.size = size;
}
ExpensiveShirt.prototype = Object.create(Shirt.prototype);
ExpensiveShirt.prototype.constructor = ExpensiveShirt;
ExpensiveShirt.prototype.getPrice = function() {
if (this.size == 'small') {
return 20;
}
else {
return 30;
}
}
然后我们可以在Store类中组织它们如下:
var Store = function(products) {
this.products = products;
}
Store.prototype.calculateTotal = function(){
return this.products.reduce(function(sum,product) {
return sum + product.getPrice();
}, 10) * TAX; // start with $10 markup, times global TAX var
};
var TAX = 1.08;
var p1 = new TShirt('small');
var p2 = new ExpensiveShirt('large');
var s = new Store([p1,p2]);
console.log(s.calculateTotal()); // Output: 35
calculateTotal()方法使用数组的reduce()函数来干净地将产品的价格相加。
这样做完全没问题,但如果我们需要一种动态计算标记值的方法呢?为此,我们可以转向一个称为策略模式的概念。
策略模式
策略模式是一种定义一组可互换算法的方法。它被面向对象编程程序员用于在运行时操纵行为,但它基于一些函数式编程原则。
-
逻辑和数据的分离
-
函数的组合
-
函数作为一等对象
还有一些面向对象编程的原则:
-
封装
-
继承
在我们之前解释的用于计算产品成本的示例应用中,假设我们想要给予某些客户优惠待遇,并且需要调整标记来反映这一点。
所以让我们创建一些客户类:
var Customer = function(){};
Customer.prototype.calculateTotal = function(products) {
return products.reduce(function(total, product) {
return total + product.getPrice();
}, 10) * TAX;
};
var RepeatCustomer = function(){};
RepeatCustomer.prototype = Object.create(Customer.prototype);
RepeatCustomer.prototype.constructor = RepeatCustomer;
RepeatCustomer.prototype.calculateTotal = function(products) {
return products.reduce(function(total, product) {
return total + product.getPrice();
}, 5) * TAX;
};
var TaxExemptCustomer = function(){};
TaxExemptCustomer.prototype = Object.create(Customer.prototype);
TaxExemptCustomer.prototype.constructor = TaxExemptCustomer;
TaxExemptCustomer.prototype.calculateTotal = function(products) {
return products.reduce(function(total, product) {
return total + product.getPrice();
}, 10);
};
每个Customer类封装了算法。现在我们只需要Store类调用Customer类的calculateTotal()方法。
var Store = function(products) {
this.products = products;
this.customer = new Customer();
// bonus exercise: use Maybes from Chapter 5 instead of a default customer instance
}
Store.prototype.setCustomer = function(customer) {
this.customer = customer;
}
Store.prototype.getTotal = function(){
return this.customer.calculateTotal(this.products);
};
var p1 = new TShirt('small');
var p2 = new ExpensiveShirt('large');
var s = new Store([p1,p2]);
var c = new TaxExemptCustomer();
s.setCustomer(c);
s.getTotal(); // Output: 45
Customer类进行计算,Product类保存数据(价格),Store类维护上下文。这实现了非常高的内聚性和面向对象编程与函数式编程的很好的混合。JavaScript 的高表现力使这成为可能,而且相当容易。
Mixins
简而言之,mixins 是允许其他类使用它们的方法的类。这些方法仅供其他类使用,而mixin类本身永远不会被实例化。这有助于避免继承的模糊性。它们是将函数式编程与面向对象编程混合的绝佳手段。
每种语言中的 mixin 实现方式都不同。由于 JavaScript 的灵活性和表现力,mixins 被实现为只有方法的对象。虽然它们可以被定义为函数对象(即var mixin = function(){...};),但最好将它们定义为对象字面量(即var mixin = {...};)以保持代码的结构纪律。这将帮助我们区分类和 mixins。毕竟,mixins 应该被视为过程,而不是对象。
让我们从声明一些 mixins 开始。我们将扩展我们之前部分的Store应用程序,使用 mixins 来扩展类。
var small = {
getPrice: function() {
return this.basePrice + 6;
},
getDimensions: function() {
return [44,63]
}
}
var large = {
getPrice: function() {
return this.basePrice + 10;
},
getDimensions: function() {
return [64,83]
}
};
我们不仅仅局限于这些。还可以添加许多其他的 mixins,比如颜色或面料材质。我们需要稍微修改我们的Shirt类,如下面的代码片段所示:
var Shirt = function() {
this.basePrice = 1;
};
Shirt.getPrice = function(){
return this.basePrice;
}
var TShirt = function() {
this.basePrice = 5;
};
TShirt.prototype = Object.create(Shirt.prototype);
TShirt..prototype.constructor = TShirt;
现在我们准备使用 mixins 了。
经典 mixin
你可能想知道这些 mixin 是如何与类混合在一起的。这样做的经典方式是将 mixin 的函数复制到接收对象中。可以通过以下方式扩展Shirt原型来实现:
Shirt.prototype.addMixin = function (mixin) {
for (var prop in mixin) {
if (mixin.hasOwnProperty(prop)) {
this.prototype[prop] = mixin[prop];
}
}
};
现在可以添加 mixins 如下:
TShirt.addMixin(small);
var p1 = new TShirt();
console.log( p1.getPrice() ); // Output: 11
TShirt.addMixin(large);
var p2 = new TShirt();
console.log( p2.getPrice() ); // Output: 15
然而,存在一个主要问题。当再次计算p1的价格时,结果是15,即大件物品的价格。它应该是小件物品的价格!
console.log( p1.getPrice() ); // Output: 15
问题在于Shirt对象的prototype.getPrice()方法每次添加混入时都会被重写;这根本不是我们想要的函数式编程。
函数式混入
还有另一种使用混入的方法,更符合函数式编程。
我们不是将混入的方法复制到目标对象,而是需要创建一个新对象,该对象是目标对象的克隆,并添加了混入的方法。首先必须克隆对象,这可以通过创建一个继承自它的新对象来实现。我们将这个变体称为plusMixin。
Shirt.prototype.plusMixin = function(mixin) {
// create a new object that inherits from the old
var newObj = this;
newObj.prototype = Object.create(this.prototype);
for (var prop in mixin) {
if (mixin.hasOwnProperty(prop)) {
newObj.prototype[prop] = mixin[prop];
}
}
return newObj;
};
var SmallTShirt = Tshirt.plusMixin(small); // creates a new class
var smallT = new SmallTShirt();
console.log( smallT.getPrice() ); // Output: 11
var LargeTShirt = Tshirt.plusMixin(large);
var largeT = new LargeTShirt();
console.log( largeT.getPrice() ); // Output: 15
console.log( smallT.getPrice() ); // Output: 11 (not effected by 2nd mixin call)
现在就来玩乐趣部分!现在我们可以真正地使用混入进行函数式编程。我们可以创建产品和混入的每种可能的组合。
// in the real world there would be way more products and mixins!
var productClasses = [ExpensiveShirt, Tshirt];
var mixins = [small, medium, large];
// mix them all together
products = productClasses.reduce(function(previous, current) {
var newProduct = mixins.map(function(mxn) {
var mixedClass = current.plusMixin(mxn);
var temp = new mixedClass();
return temp;
});
return previous.concat(newProduct);
},[]);
products.forEach(function(o){console.log(o.getPrice())});
为了使其更加面向对象,我们可以重写Store对象以具有此功能。我们还将在Store对象而不是产品中添加一个显示函数,以保持接口逻辑和数据的分离。
// the store
var Store = function() {
productClasses = [ExpensiveShirt, TShirt];
productMixins = [small, medium, large];
this.products = productClasses.reduce(function(previous, current) {
var newObjs = productMixins.map(function(mxn) {
var mixedClass = current.plusMixin(mxn);
var temp = new mixedClass();
return temp;
});
return previous.concat(newObjs);
},[]);
}
Store.prototype.displayProducts = function(){
this.products.forEach(function(p) {
$('ul#products').append('<li>'+p.getTitle()+': $'+p.getPrice()+'</li>');
});
}
我们所要做的就是创建一个Store对象并调用它的displayProducts()方法来生成产品和价格的列表!
<ul id="products">
<li>small premium shirt: $16</li>
<li>medium premium shirt: $18</li>
<li>large premium shirt: $20</li>
<li>small t-shirt: $11</li>
<li>medium t-shirt: $13</li>
<li>large t-shirt: $15</li>
</ul>
这些行需要添加到product类和混入中,以使前面的输出正常工作:
Shirt.prototype.title = 'shirt';
TShirt.prototype.title = 't-shirt';
ExpensiveShirt.prototype.title = 'premium shirt';
// then the mixins got the extra 'getTitle' function:
var small = {
...
getTitle: function() {
return 'small ' + this.title; // small or medium or large
}
}
就这样,我们拥有了一个高度模块化和可扩展的电子商务应用。新的衬衫款式可以非常容易地添加——只需定义一个新的Shirt子类,并将其添加到Store类的数组product类中。混入的添加方式也是一样的。所以现在当我们的老板说:“嘿,我们有一种新类型的衬衫和外套,每种都有标准颜色,我们需要在你今天下班前将它们添加到网站上”,我们可以放心地说我们不会加班了!
总结
JavaScript 具有很高的表现力。这使得将函数式编程和面向对象编程混合使用成为可能。现代 JavaScript 不仅仅是面向对象编程或函数式编程,它是两者的混合体。诸如策略模式和混入之类的概念非常适合 JavaScript 的原型结构,并且它们有助于证明当今 JavaScript 最佳实践中函数式编程和面向对象编程的使用量是相等的。
如果你从这本书中只学到了一件事,我希望是如何将函数式编程技术应用到现实应用中。本章向你展示了如何做到这一点。
附录 A. JavaScript 中函数式编程的常见函数
这个附录涵盖了 JavaScript 中函数式编程的常见函数:
- 数组函数:
var flatten = function(arrays) {
return arrays.reduce( function(p,n){
return p.concat(n);
});
};
var invert = function(arr) {
return arr.map(function(x, i, a) {
return a[a.length - (i+1)];
});
};
- 绑定函数:
var bind = Function.prototype.call.bind(Function.prototype.bind);
var call = bind(Function.prototype.call, Function.prototype.call);
var apply = bind(Function.prototype.call, Function.prototype.apply);
- 范畴论:
var checkTypes = function( typeSafeties ) {
arrayOf(func)(arr(typeSafeties));
var argLength = typeSafeties.length;
return function(args) {
arr(args);
if (args.length != argLength) {
throw new TypeError('Expected '+ argLength + ' arguments');
}
var results = [];
for (var i=0; i<argLength; i++) {
results[i] = typeSafetiesi;
}
return results;
};
};
var homoMorph = function( /* arg1, arg2, ..., argN, output */ ) {
var before = checkTypes(arrayOf(func)(Array.prototype.slice.call(arguments, 0, arguments.length-1)));
var after = func(arguments[arguments.length-1])
return function(middle) {
return function(args) {
return after(middle.apply(this, before([].slice.apply(arguments))));
};
};
};
- 组合:
Function.prototype.compose = function(prevFunc) {
var nextFunc = this;
return function() {
return nextFunc.call(this,prevFunc.apply(this,arguments));
};
};
Function.prototype.sequence = function(prevFunc) {
var nextFunc = this;
return function() {
return prevFunc.call(this,nextFunc.apply(this,arguments));
};
};
- 柯里化:
Function.prototype.curry = function (numArgs) {
var func = this;
numArgs = numArgs || func.length;
// recursively acquire the arguments
function subCurry(prev) {
return function (arg) {
var args = prev.concat(arg);
if (args.length < numArgs) {
// recursive case: we still need more args
return subCurry(args);
}
else {
// base case: apply the function
return func.apply(this, args);
}
};
};
return subCurry([]);
};
- 函子:
// map :: (a -> b) -> [a] -> [b]
var map = function(f, a) {
return arr(a).map(func(f));
}
// strmap :: (str -> str) -> str -> str
var strmap = function(f, s) {
return str(s).split('').map(func(f)).join('');
}
// fcompose :: (a -> b)* -> (a -> b)
var fcompose = function() {
var funcs = arrayOf(func)(arguments);
return function() {
var argsOfFuncs = arguments;
for (var i = funcs.length; i > 0; i -= 1) {
argsOfFuncs = [funcs[i].apply(this, args)];
}
return args[0];
};
};
- 镜头:
var lens = function(get, set) {
var f = function (a) {return get(a)};
f.get = function (a) {return get(a)};
f.set = set;
f.mod = function (f, a) {return set(a, f(get(a)))};
return f;
};
// usage:
var first = lens(
function (a) { return arr(a)[0]; }, // get
function (a, b) { return [b].concat(arr(a).slice(1)); } // set
);
- Maybes:
var Maybe = function(){};
Maybe.prototype.orElse = function(y) {
if (this instanceof Just) {
return this.x;
}
else {
return y;
}
};
var None = function(){};
None.prototype = Object.create(Maybe.prototype);
None.prototype.toString = function(){return 'None';};
var none = function(){return new None()};
// and the Just instance, a wrapper for an object with a value
var Just = function(x){return this.x = x;};
Just.prototype = Object.create(Maybe.prototype);
Just.prototype.toString = function(){return "Just "+this.x;};
var just = function(x) {return new Just(x)};
var maybe = function(m){
if (m instanceof None) {
return m;
}
else if (m instanceof Just) {
return just(m.x);
}
else {
throw new TypeError("Error: Just or None expected, " + m.toString() + " given.");
}
};
var maybeOf = function(f){
return function(m) {
if (m instanceof None) {
return m;
}
else if (m instanceof Just) {
return just(f(m.x));
}
else {
throw new TypeError("Error: Just or None expected, " + m.toString() + " given.");
}
};
};
- 混入:
Object.prototype.plusMixin = function(mixin) {
var newObj = this;
newObj.prototype = Object.create(this.prototype);
newObj.prototype.constructor = newObj;
for (var prop in mixin) {
if (mixin.hasOwnProperty(prop)) {
newObj.prototype[prop] = mixin[prop];
}
}
return newObj;
};
- 部分应用:
function bindFirstArg(func, a) {
return function(b) {
return func(a, b);
};
};
Function.prototype.partialApply = function(){
var func = this;
args = Array.prototype.slice.call(arguments);
return function(){
return func.apply(this, args.concat(
Array.prototype.slice.call(arguments)
));
};
};
Function.prototype.partialApplyRight = function(){
var func = this;
args = Array.prototype.slice.call(arguments);
return function(){
return func.apply(
this,
Array.protype.slice.call(arguments, 0)
.concat(args));
};
};
- Trampolining:
var trampoline = function(f) {
while (f && f instanceof Function) {
f = f.apply(f.context, f.args);
}
return f;
};
var thunk = function (fn) {
return function() {
var args = Array.prototype.slice.apply(arguments);
return function() { return fn.apply(this, args); };
};
};
- 类型安全:
var typeOf = function(type) {
return function(x) {
if (typeof x === type) {
return x;
}
else {
throw new TypeError("Error: "+type+" expected, "+typeof x+" given.");
}
};
};
var str = typeOf('string'),
num = typeOf('number'),
func = typeOf('function'),
bool = typeOf('boolean');
var objectTypeOf = function(name) {
return function(o) {
if (Object.prototype.toString.call(o) === "[object "+name+"]") {
return o;
}
else {
throw new TypeError("Error: '+name+' expected, something else given.");
}
};
};
var obj = objectTypeOf('Object');
var arr = objectTypeOf('Array');
var date = objectTypeOf('Date');
var div = objectTypeOf('HTMLDivElement');
// arrayOf :: (a -> b) -> ([a] -> [b])
var arrayOf = function(f) {
return function(a) {
return map(func(f), arr(a));
}
};
- Y 组合子:
var Y = function(F) {
return (function (f) {
return f(f);
}(function (f) {
return F(function (x) {
return f(f)(x);
});
}));
};
// Memoizing Y-Combinator:
var Ymem = function(F, cache) {
if (!cache) {
cache = {} ; // Create a new cache.
}
return function(arg) {
if (cache[arg]) {
// Answer in cache
return cache[arg] ;
}
// else compute the answer
var answer = (F(function(n){
return (Ymem(F,cache))(n);
}))(arg); // Compute the answer.
cache[arg] = answer; // Cache the answer.
return answer;
};
};
附录 B. 术语表
这个附录涵盖了本书中使用的一些重要术语:
-
匿名函数:没有名称且未绑定到任何变量的函数。也称为 Lambda 表达式。
-
回调:可以传递给另一个函数以在以后的事件中使用的函数。
-
范畴:在范畴论中,范畴是相同类型的对象集合。在 JavaScript 中,范畴可以是包含明确定义为数字、字符串、布尔值、日期、对象等的对象的数组或对象。
-
范畴论:一种将数学结构组织成对象集合和对这些对象的操作的概念。本书中使用的计算机程序中的数据类型和函数形成了这些范畴。
-
闭包:一种环境,使得其中定义的函数可以访问外部不可用的局部变量。
-
耦合:每个程序模块依赖于其他模块的程度。函数式编程减少了程序内部的耦合程度。
-
Currying:将具有多个参数的函数转换为一个参数的函数的过程,返回另一个可以根据需要接受更多参数的函数。形式上,具有N个参数的函数可以转换为N个函数的函数链,每个函数只有一个参数。
-
Declarative programming:一种表达解决问题所需的计算逻辑的编程风格。计算机被告知问题是什么,而不是解决问题所需的过程。
-
Endofunctor:将一个范畴映射到自身的函子。
-
Function composition:将许多函数组合成一个函数的过程。每个函数的结果作为下一个参数传递,最后一个函数的结果是整个组合的结果。
-
Functional language:促进函数式编程的计算机语言。
-
Functional programming:一种声明式编程范式,侧重于将函数视为数学表达式,并避免可变数据和状态变化。
-
Functional reactive programming:一种侧重于响应式元素和随时间变化的变量的函数式编程风格。
-
Functor:范畴之间的映射。
-
Higher-order function:以一个或多个函数作为输入,并返回一个函数作为输出的函数。
-
Inheritance:一种面向对象编程的能力,允许一个类从另一个类继承成员变量和方法。
-
Lambda expressions:参见匿名函数。
-
Lazy evaluation:一种计算机语言的评估策略,延迟对表达式的评估,直到需要其值。这种策略的相反称为急切评估或贪婪评估。惰性评估也被称为按需调用。
-
Library:一组具有明确定义接口的对象和函数,允许第三方程序调用它们的行为。
-
Memoization:存储昂贵函数调用的结果的技术。当以相同参数再次调用函数时,返回存储的结果,而不是重新计算结果。
-
Method chain:一种模式,其中许多方法并排调用,直接将一个方法的输出传递给下一个方法的输入。这避免了将中间值分配给临时变量的需要。
-
Mixin:一个对象,可以让其他对象使用它的方法。这些方法只能被其他对象使用,而 mixin 对象本身永远不会被实例化。
-
Modularity:程序可以被分解为独立的代码模块的程度。函数式编程增加了程序的模块化。
-
Monad:提供函子所需的封装的结构。
-
Morphism:仅在特定范畴上工作并在给定特定输入集时始终返回相同输出的纯函数。同态操作受限于单一范畴,而多态操作可以在多个范畴上操作。
-
Partial application:将一个或多个参数的值绑定到函数的过程。它返回一个部分应用的函数,该函数反过来接受剩余的未绑定参数。
-
Polyfill:用于用新函数增强原型的函数。它允许我们将新函数作为先前函数的方法来调用。
-
Pure function:其输出值仅取决于作为函数输入的参数的函数。因此,用相同值的参数x两次调用函数f,每次都会产生相同的结果f(x)。
-
递归函数:调用自身的函数。这样的函数依赖于解决同一问题的较小实例来计算较大问题的解决方案。与迭代类似,递归是重复调用相同代码块的另一种方式。但是,与迭代不同,递归要求代码块定义重复调用应该终止的情况,即基本情况。
-
可重用性:通常是指代码块(通常是 JavaScript 中的函数)可以在同一程序的其他部分或其他程序中被重复使用的程度。
-
自执行函数:在定义后立即被调用的匿名函数。在 JavaScript 中,通过在函数表达式后放置一对括号来实现这一点。
-
策略模式:用于定义一组可互换算法的方法。
-
尾递归:基于堆栈的递归实现。对于每个递归调用,堆栈中都有一个新的帧。
-
工具包:一个小型软件库,提供一组函数供程序员使用。与库相比,工具包更简单,需要与调用它的程序耦合更少。
-
蹦床编程:一种递归策略,可以在不提供尾调用消除功能的编程语言中实现,比如 JavaScript。
-
Y 组合子:Lambda 演算中的固定点组合子,消除了显式递归。当它作为返回递归函数的输入时,Y 组合子返回该函数的不动点,即将递归函数转换为非递归函数的转换。

















 7488
7488

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









