







原文:
zh.annas-archive.org/md5/86EBDE91266D2750084E0C4C5C494FF7译者:飞龙
第二部分:理解和使用内核
许多人在内核开发中挣扎的一个关键原因是对其内部机制的理解不足。这里涵盖了一些内核架构、内存管理和调度的基本要点。
本节包括以下章节:
-
第六章,内核内部要点-进程和线程
-
第七章,内存管理内部要点-基础知识
-
第八章,模块作者的内核内存分配,第一部分
-
第九章,模块作者的内核内存分配,第二部分
第六章:内核内部基础知识-进程和线程
内核内部,特别是与内存管理有关的部分,是一个广阔而复杂的主题。在本书中,我们并不打算深入研究内核和内存内部的细节。同时,我希望为像你这样的新手内核或设备驱动程序开发人员提供足够的,绝对必要的背景知识,以成功地解决理解内核架构的关键主题,包括进程、线程及其堆栈的管理。您还将能够正确高效地管理动态内核内存(重点是使用可加载内核模块(LKM)框架编写内核或驱动程序代码)。作为一个附带的好处,掌握了这些知识,你会发现自己在调试用户空间和内核空间代码方面变得更加熟练。
我将基本内部讨论分为两章,这一章和下一章。本章涵盖了 Linux 内核内部架构的关键方面,特别是关于内核内部如何管理进程和线程。下一章将专注于内存管理内部,这是理解和使用 Linux 内核的另一个关键方面。当然,事实上,所有这些事情并不真正在一两章中涵盖,而是分布在本书中(例如,有关进程/线程的 CPU 调度的详细信息将在后面的章节中找到;内存内部,硬件中断,同步等等也是如此)。
简而言之,本章涵盖了以下主题:
-
理解进程和中断上下文
-
理解进程 VAS 的基础知识(虚拟地址空间)
-
组织进程、线程及其堆栈-用户空间和内核空间
-
理解和访问内核任务结构
-
通过当前任务结构进行工作
-
遍历内核的任务列表
技术要求
我假设你已经阅读了第一章,“内核工作空间设置”,并已经适当地准备了运行 Ubuntu 18.04 LTS(或更高版本)的虚拟机,并安装了所有必需的软件包。如果没有,我建议你先这样做。
为了充分利用本书,我强烈建议你首先设置好工作环境,包括克隆本书的 GitHub 代码库(在这里找到:github.com/PacktPublishing/Linux-Kernel-Programming),并且动手实践。
我假设你已经熟悉基本的虚拟内存概念,用户模式进程的虚拟地址空间(VAS)布局,堆栈等。尽管如此,我们会在接下来的“理解进程 VAS 的基础知识”部分中花几页来解释这些基础知识。
理解进程和中断上下文
在第四章,“编写你的第一个内核模块-LKMs,第一部分”,我们介绍了一个简短的名为“内核架构 I”的部分(如果你还没有阅读,我建议你在继续之前先阅读)。我们现在将扩展这个讨论。
重要的是要理解,大多数现代操作系统都是单片式设计。单片式字面上意味着单一的大块石头。我们稍后会详细讨论这如何适用于我们喜爱的操作系统!现在,我们将单片式理解为这样:当一个进程或线程发出系统调用时,它切换到(特权)内核模式并执行内核代码,并可能处理内核数据。是的,没有内核或内核线程代表它执行代码;进程(或线程)本身执行内核代码。因此,我们说内核代码在用户空间进程或线程的上下文中执行 - 我们称之为进程上下文。想想看,内核的重要部分正是以这种方式执行的,包括设备驱动程序的大部分代码。
好吧,你可能会问,既然你理解了这一点,除了进程上下文之外,内核代码还可以以什么其他方式执行?还有另一种方式:当硬件中断(来自外围设备 - 键盘、网络卡、磁盘等)触发时,CPU 的控制单元保存当前上下文,并立即重新定位 CPU 以运行中断处理程序的代码(中断服务例程—ISR)。现在,这段代码也在内核(特权)模式下运行 - 实际上,这是另一种异步切换到内核模式的方式!许多设备驱动程序的中断代码路径就是这样执行的;我们说以这种方式执行的内核代码处于中断上下文中。
因此,任何一段内核代码都是在两种上下文中的一种中进入并执行的:
-
进程上下文:内核从系统调用或处理器异常(如页面错误)中进入,并执行内核代码,处理内核数据;这是同步的(自上而下)。
-
中断上下文:内核从外围芯片的硬件中断进入,并执行内核代码,处理内核数据;这是异步的(自下而上)。
图 6.1显示了概念视图:用户模式进程和线程在非特权用户上下文中执行;用户模式线程可以通过发出系统调用切换到特权内核模式。该图还显示了纯内核线程也存在于 Linux 中;它们与用户模式线程非常相似,关键区别在于它们只在内核空间中执行;它们甚至不能看到用户 VAS。通过系统调用(或处理器异常)同步切换到内核模式后,任务现在在进程上下文中运行内核代码。(内核线程也在进程上下文中运行内核代码。)然而,硬件中断是另一回事 - 它们导致执行异步进入内核;它们执行的代码(通常是设备驱动程序的中断处理程序)运行在所谓的中断上下文中。
图 6.1显示了更多细节 - 中断上下文的上半部分、下半部分、内核线程和工作队列;我们请求您耐心等待,我们将在后面的章节中涵盖所有这些内容以及更多内容:

图 6.1 - 概念图显示了非特权用户模式执行和特权内核模式执行,同时具有进程和中断上下文
在本书的后面,我们将向您展示如何准确检查您的内核代码当前正在运行的上下文。继续阅读!
理解进程虚拟地址空间的基础
虚拟内存的一个基本“规则”是:所有可寻址的内存都在一个盒子里;也就是说,它是沙盒的。我们把这个“盒子”看作进程镜像或进程VAS。禁止看盒子外面的东西。
在这里,我们只提供了进程用户虚拟地址空间的快速概述。有关详细信息,请参阅本章末尾的进一步阅读部分。
用户虚拟地址空间被划分为称为段或更专业的映射的同质内存区域。每个 Linux 进程至少有这些映射(或段):

图 6.2 - 进程 VAS
让我们快速了解一下这些段或映射的简要情况:
-
文本段:这是存储机器代码的地方;静态(模式:
r-x)。 -
数据段:全局和静态数据变量存储在这里(模式:
rw-)。它内部分为三个不同的段: -
初始化数据段:预初始化的变量存储在这里;静态。
-
未初始化数据段:未初始化的变量存储在这里(在运行时自动初始化为
0;这个区域有时被称为bss);静态。 -
堆段:内存分配和释放的库 API(熟悉的
malloc(3)系列例程)从这里获取内存。这也不完全正确。在现代系统上,只有低于MMAP_THRESHOLD(默认为 128 KB)的malloc()实例从堆中获取内存。任何更高的内存都将作为进程 VAS 中的一个单独的“映射”分配(通过强大的mmap(2)系统调用)。它是一个动态段(可以增长/缩小)。堆上的最后一个合法引用位置被称为程序断点。 -
库(文本,数据):所有进程动态链接的共享库都被映射到进程 VAS 中(在运行时,通过加载器)(模式:
r-x/rw-)。 -
堆栈:使用后进先出(LIFO)语义的内存区域;堆栈用于实现高级语言的函数调用机制。它包括参数传递、局部变量实例化(和销毁)以及返回值传播。它是一个动态段。在所有现代处理器上(包括 x86 和 ARM 系列),堆栈向较低地址“增长”(称为完全降序堆栈)。每次调用函数时,都会分配并初始化一个堆栈帧;堆栈帧的精确布局非常依赖于 CPU(你必须参考相应的 CPU应用程序二进制接口(ABI)文档;参见进一步阅读部分的参考资料)。SP 寄存器(或等效寄存器)始终指向当前帧,堆栈的顶部;由于堆栈向较低(虚拟)地址增长,堆栈的顶部实际上是最低(虚拟)地址!这是不直观但却是真实的(模式:
rw-)。
当然,你会理解进程必须包含至少一个执行线程(线程是进程内的执行路径);那个线程通常是main()函数。在图 6.2中,我们举例展示了三个执行线程 - main,thrd2和thrd3。此外,如预期的那样,每个线程在 VAS 中共享一切,*除了堆栈;正如你所知,每个线程都有自己的私有堆栈。main的堆栈显示在进程(用户)VAS 的顶部;thrd2和thrd3线程的堆栈显示在库映射和main的堆栈之间,并用两个(蓝色)方块表示。
我设计并实现了一个我认为非常有用的学习/教学和调试实用程序,名为procmap(github.com/kaiwan/procmap);它是一个基于控制台的进程 VAS 可视化实用程序。它实际上可以向你展示进程 VAS(非常详细);我们将在下一章开始使用它。不过,这并不妨碍你立即尝试它;在你的 Linux 系统上克隆它并试用一下。
现在你已经了解了进程 VAS 的基础知识,是时候深入了解有关进程 VAS、用户和内核地址空间以及它们的线程和堆栈的内核内部了。
组织进程、线程及其堆栈 - 用户和内核空间
传统的UNIX 进程模型 - 一切都是进程;如果不是进程,就是文件 - 有很多优点。事实上,它仍然是在近五十年的时间跨度之后操作系统遵循的模型,这充分证明了这一点。当然,现在线程很重要;线程只是进程内的执行路径。线程共享所有*进程资源,包括用户 VAS,*除了堆栈。*每个线程都有自己的私有堆栈区域(这是完全合理的;否则,线程如何能够真正并行运行,因为堆栈保存了执行上下文)。
我们关注线程而不是进程的另一个原因在第十章中更清楚地阐明,CPU 调度器,第一部分*。现在,我们只能说:线程而不是进程是内核可调度实体(也称为 KSE)。这实际上是 Linux 操作系统架构的一个关键方面的结果。在 Linux 操作系统上,每个线程 - 包括内核线程 - 都映射到一个称为任务结构的内核元数据结构。任务结构(也称为进程描述符)本质上是一个大型的内核数据结构,内核将其用作属性结构。对于每个线程,内核维护一个相应的任务结构(见图 6.3,不用担心,我们将在接下来的部分中更多地介绍任务结构)。
下一个真正关键的要点是:*每个特权级别受 CPU 支持的线程都需要一个堆栈。*在现代操作系统(如 Linux)中,我们支持两个特权级别 - 非特权用户模式(或用户空间)和特权内核模式(或内核空间)。因此,在 Linux 上,每个用户空间线程都有两个堆栈:
-
用户空间堆栈:当线程执行用户模式代码路径时,此堆栈处于活动状态。
-
内核空间堆栈:当线程切换到内核模式(通过系统调用或处理器异常)并执行内核代码路径(在进程上下文中)时,此堆栈处于活动状态。
当然,每个好的规则都有例外:内核线程是纯粹存在于内核中的线程,因此只能“看到”内核(虚拟)地址空间;它们无法“看到”用户空间。因此,它们只会执行内核空间代码路径,因此它们只有一个堆栈 - 内核空间堆栈。
图 6.3将地址空间分为两部分 - 用户空间和内核空间。在图的上半部分 - 用户空间 - 您可以看到几个进程及其用户 VASes。在图的底部 - 内核空间 - 您可以看到,对于每个用户模式线程,都有一个内核元数据结构(struct task_struct,我们稍后将详细介绍)和该线程的内核模式堆栈。此外,我们还看到(在底部)三个内核线程(标记为kthrd1,kthrd2和kthrdn);如预期的那样,它们也有一个表示其内部(属性)的task_struct元数据结构和一个内核模式堆栈:

图 6.3 - 进程、线程、堆栈和任务结构 - 用户和内核 VAS
为了帮助使这个讨论更具实际意义,让我们执行一个简单的 Bash 脚本(ch6/countem.sh),它会计算当前存活的进程和线程的数量。我在我的本机 x86_64 Ubuntu 18.04 LTS 上执行了这个操作;请参阅以下结果输出:
$ cd <booksrc>/ch6
$ ./countem.sh
System release info:
Distributor ID: Ubuntu
Description: Ubuntu 18.04.4 LTS
Release: 18.04
Codename: bionic
Total # of processes alive = 362
Total # of threads alive = 1234
Total # of kernel threads alive = 181
Thus, total # of user-mode threads alive = 1053
$
我将让您查看此简单脚本的代码:ch6/countem.sh。研究前面的输出并理解它。当然,您会意识到这是某个时间点的快照。它可能会发生变化。
在接下来的部分中,我们将讨论分成两部分(对应于两个地址空间) - 用户空间中图 6.3 中所见的内容和内核空间中图 6.3 中所见的内容。让我们从用户空间组件开始。
用户空间组织
关于我们在前面部分运行的countem.sh Bash 脚本,我们现在将对其进行分解并讨论一些关键点,目前我们只限于 VAS 的用户空间部分。请注意仔细阅读和理解这一点(我们在下面的讨论中提到的数字是指我们在前面部分运行countem.sh脚本的示例)。为了更好地理解,我在这里放置了图表的用户空间部分:

图 6.4 - 图 6.3 中整体图片的用户空间部分
在这里(图 6.4)你可以看到三个单独的进程。每个进程至少有一个执行线程(main()线程)。在前面的示例中,我们展示了三个进程P1,P2和Pn,分别包含一个,三个和两个线程,包括main()。从我们之前在countem.sh脚本的示例运行中,Pn将有n=362。
请注意,这些图表纯粹是概念性的。实际上,具有 PID 2 的“进程”通常是一个名为kthreadd的单线程内核线程。
每个进程由几个段(技术上是映射)组成。广义上,用户模式段(映射)如下:
-
文本:代码;
r-x -
数据段:
rw-;包括三个不同的映射 - 初始化数据段,未初始化数据段(或bss),以及一个“向上增长”的heap -
库映射:对于进程动态链接到的每个共享库的文本和数据
-
向下增长的堆栈
关于这些堆栈,我们从之前的示例运行中看到系统上目前有 1,053 个用户模式线程。这意味着也有 1,053 个用户空间堆栈,因为每个用户模式线程都会存在一个用户模式堆栈。关于这些用户空间线程堆栈,我们可以说以下内容:
-
每个用户空间堆栈始终存在于
main()线程,它将位于用户 VAS 的顶部 - 高端附近; 如果进程是单线程的(只有一个main()线程),那么它将只有一个用户模式堆栈; 图 6.4中的P1进程显示了这种情况。 -
如果进程是多线程的,它将对每个活动的线程(包括
main())有一个用户模式线程堆栈;图 6.4中的进程P2和Pn说明了这种情况。这些堆栈要么在调用fork(2)(对于main())时分配,要么在进程内的pthread_create(3)(对于进程内的其他线程)时分配,这将导致内核中的进程上下文中执行这段代码路径:
sys_fork() --> do_fork() --> _do_fork()
-
顺便说一下,在 Linux 上,
pthread_create(3)库 API 调用(非常特定于 Linux)clone(2)系统调用;这个系统调用最终调用_do_fork();传递的clone_flags参数告诉内核如何创建“自定义进程”;换句话说,一个线程! -
这些用户空间堆栈当然是动态的;它们可以增长/缩小到堆栈大小资源限制(
RLIMIT_STACK,通常为 8 MB;您可以使用prlimit(1)实用程序查找它)。
在看到并理解了用户空间部分之后,现在让我们深入了解内核空间的情况。
内核空间组织
继续我们关于在前面部分运行的countem.sh Bash 脚本的讨论,我们现在将对其进行分解并讨论一些关键点,目前我们只限于 VAS 的内核空间部分。请注意仔细阅读和理解这一点(在阅读我们在前面部分运行的countem.sh脚本时输出的数字)。为了更好地理解,我在这里放置了图表的内核空间部分(图 6.5):

图 6.5 - 图 6.3 中整体图片的内核空间部分
再次,从我们之前的样本运行中,您可以看到系统上目前有 1,053 个用户模式线程和 181 个内核线程。这导致了总共 1,234 个内核空间堆栈。为什么?如前所述,每个用户模式线程都有两个堆栈-一个用户模式堆栈和一个内核模式堆栈。因此,我们将为每个用户模式线程有 1,053 个内核模式堆栈,以及为(纯粹的)内核线程有 181 个内核模式堆栈(请记住,内核线程只有一个内核模式堆栈;它们根本无法“看到”用户空间)。让我们列出内核模式堆栈的一些特征:
-
每个应用程序(用户模式)线程都将有一个内核模式堆栈,包括
main()。 -
内核模式堆栈的大小是固定的(静态的)且非常小。从实际角度来看,它们在 32 位操作系统上的大小为 2 页,在 64 位操作系统上的大小为 4 页(每页通常为 4 KB)。
-
它们在线程创建时分配(通常归结为
_do_fork())。
再次,让我们对此非常清楚:每个用户模式线程都有两个堆栈-一个用户模式堆栈和一个内核模式堆栈。这一规则的例外是内核线程;它们只有一个内核模式堆栈(因为它们没有用户映射,因此没有用户空间“段”)。在图 6.5的下部,我们展示了三个内核线程- kthrd1,kthrd2和kthrdn(在我们之前的样本运行中,kthrdn将为n=181)。此外,每个内核线程在创建时都有一个任务结构和一个内核模式堆栈分配给它。
内核模式堆栈在大多数方面与用户模式堆栈相似-每次调用函数时,都会设置一个堆栈帧(帧布局特定于体系结构,并且是 CPU ABI 文档的一部分;有关这些细节的更多信息,请参见进一步阅读部分);CPU 有一个寄存器来跟踪堆栈的当前位置(通常称为堆栈指针(SP)),堆栈“向较低虚拟地址增长”。但是,与动态用户模式堆栈不同,内核模式堆栈的大小是固定的且较小。
对于内核/驱动程序开发人员来说,非常重要的一个含义是内核模式堆栈的大小相当小(两页或四页),因此要非常小心,不要通过执行堆栈密集型工作(如递归)来溢出内核堆栈。
存在一个内核可配置项,可以在编译时警告您关于高(内核)堆栈使用情况;以下是来自lib/Kconfig.debug文件的文本:
CONFIG_FRAME_WARN:
“告诉 gcc 在构建时警告堆栈帧大于此值。”
“设置得太低会导致很多警告。”
“将其设置为 0 会禁用警告。”
“需要 gcc 4.4”
总结当前情况
好的,现在让我们总结一下我们从countem.sh脚本的先前样本运行中学到的内容和发现的内容:
-
任务结构:
-
每个活动的线程(用户或内核)在内核中都有一个相应的任务结构(
struct task_struct);这是内核跟踪它的方式,所有属性都存储在这里(您将在理解和访问内核任务结构部分中了解更多)。 -
关于我们
ch6/countem.sh脚本的样本运行: -
由于系统上有总共 1,234 个线程(用户和内核),这意味着内核内存中有 1,234 个任务(元数据)结构(在代码中为
struct task_struct),我们可以说以下内容: -
1,053 个这些任务结构代表用户线程。
-
剩下的 181 个任务结构代表内核线程。
-
堆栈:
-
每个用户空间线程都有两个堆栈:
-
当线程执行用户模式代码路径时,会有一个用户模式堆栈。
-
内核模式堆栈(在线程执行内核模式代码路径时发挥作用)
-
纯内核线程只有一个堆栈-内核模式堆栈
-
关于我们
ch6/countem.sh脚本的样本运行: -
1,053 个用户空间堆栈(在用户空间)。
-
1,053 个内核空间堆栈(在内核内存中)。
-
181 个内核空间堆栈(对应活动的 181 个内核线程)。
-
这总共有 1053+1053+181 = 2,287 个堆栈!
在讨论用户和内核模式堆栈时,我们还应该简要提到这一点:许多体系结构(包括 x86 和 ARM64)支持为中断处理支持单独的每 CPU 堆栈。当外部硬件中断发生时,CPU 的控制单元立即将控制重新定向到最终的中断处理代码(可能在设备驱动程序内)。单独的每 CPU 中断堆栈用于保存中断代码路径的堆栈帧;这有助于避免对被中断的进程/线程的现有(小)内核模式堆栈施加太大压力。
好的,现在你了解了进程/线程及其堆栈的用户空间和内核空间的整体组织,让我们继续看看你如何实际“查看”内核和用户空间堆栈的内容。除了用于学习目的外,这些知识还可以在调试情况下极大地帮助你。
查看用户和内核堆栈
堆栈通常是调试会话的关键。当然,堆栈保存了进程或线程的当前执行上下文 – 它现在在哪里 – 这使我们能够推断它在做什么。更重要的是,能够看到和解释线程的*调用堆栈(或调用链/回溯)*至关重要,这使我们能够准确理解我们是如何到达这里的。所有这些宝贵的信息都驻留在堆栈中。但等等,每个线程都有两个堆栈 – 用户空间和内核空间堆栈。我们如何查看它们呢?
在这里,我们将展示查看给定进程或线程的内核和用户模式堆栈的两种广泛方法,首先是通过“传统”方法,然后是更近代的方法(通过[e]BPF)。请继续阅读。
查看堆栈的传统方法
让我们首先学习使用我们将称之为“传统”方法来查看给定进程或线程的内核和用户模式堆栈。让我们从内核模式堆栈开始。
查看给定线程或进程的内核空间堆栈
好消息;这真的很容易。Linux 内核通过通常的机制使堆栈可见,以将内核内部暴露给用户空间 – 强大的 proc 文件系统接口。只需查看 /proc/<pid>/stack。
所以,好吧,让我们查看一下我们 Bash 进程的内核模式堆栈。假设在我们的 x86_64 Ubuntu 客户机上(运行 5.4 内核),我们的 Bash 进程的 PID 是 3085:
在现代内核上,为了避免信息泄漏,查看进程或线程的内核模式堆栈需要root访问权限作为安全要求。
$ sudo cat /proc/3085/stack
[<0>] do_wait+0x1cb/0x230
[<0>] kernel_wait4+0x89/0x130
[<0>] __do_sys_wait4+0x95/0xa0
[<0>] __x64_sys_wait4+0x1e/0x20
[<0>] do_syscall_64+0x5a/0x120
[<0>] entry_SYSCALL_64_after_hwframe+0x44/0xa9
$
在前面的输出中,每行代表堆栈上的一个调用帧。为了帮助解释内核堆栈回溯,了解以下几点是值得的:
-
应该以自下而上的方式阅读(从底部到顶部)。
-
每行输出代表一个 调用帧;实际上是调用链中的一个函数。
-
出现为
??的函数名意味着内核无法可靠地解释堆栈。忽略它,这是内核说这是一个无效的堆栈帧(留下的“闪烁”);内核回溯代码通常是正确的! -
在 Linux 上,任何
foo()系统调用通常会成为内核中的SyS_foo()函数。而且,很多时候但并非总是,SyS_foo()是一个调用“真正”代码do_foo()的包装器。一个细节:在内核代码中,你可能会看到SYSCALL_DEFINEn(foo, ...)这种类型的宏;这个宏会变成SyS_foo()例程;附加的数字n在 [0, 6] 范围内;它是从用户空间传递给内核的系统调用的参数数量。
现在再看一下前面的输出;应该很清楚:我们的 Bash 进程目前正在执行 do_wait() 函数;它是通过系统调用 wait4() 这个系统调用到达那里的!这是完全正确的;shell 通过 fork 出一个子进程,然后通过 wait4(2) 系统调用等待其终止。
好奇的读者(您!)应该注意,在前面片段中显示的每个堆栈帧的最左列中的[<0>]是该函数的文本(代码)地址的占位符。出于安全原因(防止信息泄漏),它在现代内核上被清零。 (与内核和进程布局相关的另一个安全措施在第七章中讨论,内存管理内部-基本知识,在KASLR和用户模式 ASLR部分中讨论了随机化内存布局)。
查看给定线程或进程的用户空间堆栈
具有讽刺意味的是,在典型的 Linux 发行版上查看进程或线程的用户空间堆栈似乎更难(与我们刚刚在前一节中看到的查看内核模式堆栈相反)。有一个实用程序可以做到这一点:gstack(1)。实际上,它只是一个简单的包装器,通过批处理模式调用gdb(1),让gdb调用它的backtrace命令。
很遗憾,在 Ubuntu(至少是 18.04 LTS)上似乎存在一个问题;在任何本地软件包中都找不到gstack程序。(Ubuntu 确实有一个pstack(1)实用程序,但至少在我的测试 VM 上,它无法正常工作。)一个解决方法是直接使用gdb(您可以始终attach <PID>并发出[thread apply all] bt命令来查看用户模式堆栈)。
然而,在我的 x86_64 Fedora 29 客户系统上,gstack(1)实用程序安装和运行良好;一个示例如下(我们的 Bash 进程的 PID 恰好是12696):
$ gstack 12696
#0 0x00007fa6f60754eb in waitpid () from /lib64/libc.so.6
#1 0x0000556f26c03629 in ?? ()
#2 0x0000556f26c04cc3 in wait_for ()
#3 0x0000556f26bf375c in execute_command_internal ()
#4 0x0000556f26bf39b6 in execute_command ()
#5 0x0000556f26bdb389 in reader_loop ()
#6 0x0000556f26bd9b69 in main ()
$
同样,每行代表一个调用帧。从下到上阅读。显然,Bash执行一个命令,最终调用waitpid()系统调用(实际上,在现代 Linux 系统上,waitpid()只是对实际wait4(2)系统调用的glibc包装器!再次,简单地忽略任何标记为??的调用帧)。
能够窥视内核和用户空间堆栈(如前面的片段所示),并使用包括strace(1)和ltrace(1)在内的实用程序分别跟踪进程/线程的系统和库调用,可以在调试时提供巨大的帮助!不要忽视它们。
现在,对于这个问题的“现代”方法。
[e]BPF-查看两个堆栈的现代方法
现在-更加令人兴奋!-让我们学习(基本知识)使用一种强大的现代方法,利用(在撰写本文时)非常新的技术-称为扩展伯克利数据包过滤器(eBPF;或简称 BPF。我们在第一章中提到过[e]BPF 项目,内核工作空间设置,在其他有用的项目部分下。)旧的 BPF 已经存在很长时间,并且已经用于网络数据包跟踪;[e]BPF 是一个最近的创新,仅在 4.x Linux 内核中可用(这当然意味着您需要在 4.x 或更近的 Linux 系统上使用这种方法)。
直接使用底层内核级 BPF 字节码技术(极其)难以做到;因此,好消息是有几个易于使用的前端(工具和脚本)可以使用这项技术。(显示当前 BCC 性能分析工具的图表可以在www.brendangregg.com/BPF/bcc_tracing_tools_early2019.png找到;[e]BPF 前端的列表可以在www.brendangregg.com/ebpf.html#frontends找到;这些链接来自Brendan Gregg的博客。)在前端中,BCC和bpftrace被认为非常有用。在这里,我们将简单地使用一个名为stackcount的 BCC 工具进行快速演示(至少在 Ubuntu 上它的名称是stackcount-bpfcc(8))。另一个优势是使用这个工具可以同时看到内核和用户模式堆栈;不需要单独的工具。
您可以通过阅读此处的安装说明在主机Linux 发行版上安装 BCC 工具:github.com/iovisor/bcc/blob/master/INSTALL.md。为什么不能在我们的 Linux 虚拟机上安装?您可以在运行发行版内核(例如 Ubuntu 或 Fedora 提供的内核)时安装。原因是:BCC 工具集的安装包括linux-headers-$(uname -r)包的安装;后者仅适用于发行版内核(而不适用于我们在虚拟机上运行的自定义 5.4 内核)。
在以下示例中,我们使用stackcount BCC 工具(在我的 x86_64 Ubuntu 18.04 LTS 主机系统上)来查找我们的 VirtualBox Fedora31 客户机进程的堆栈(毕竟,虚拟机是主机系统上的一个进程!)。对于这个工具,您必须指定一个感兴趣的函数(或函数)(有趣的是,您可以在这样做时指定用户空间或内核空间函数,并且还可以使用“通配符”或正则表达式!);只有在调用这些函数时,堆栈才会被跟踪和报告。例如,我们选择包含名称malloc的任何函数:
$ sudo stackcount-bpfcc -p 29819 -r ".*malloc.*" -v -d
Tracing 73 functions for ".*malloc.*"... Hit Ctrl-C to end.
^C
ffffffff99a56811 __kmalloc_reserve.isra.43
ffffffff99a59436 alloc_skb_with_frags
ffffffff99a51f72 sock_alloc_send_pskb
ffffffff99b2e986 unix_stream_sendmsg
ffffffff99a4d43e sock_sendmsg
ffffffff99a4d4e3 sock_write_iter
ffffffff9947f59a do_iter_readv_writev
ffffffff99480cf6 do_iter_write
ffffffff99480ed8 vfs_writev
ffffffff99480fb8 do_writev
ffffffff99482810 sys_writev
ffffffff99203bb3 do_syscall_64
ffffffff99c00081 entry_SYSCALL_64_after_hwframe
--
7fd0cc31b6e7 __GI___writev
12bc [unknown]
600000195 [unknown]
1
[...]
[e]BPF 程序可能由于合并到主线 5.4 内核的新内核锁定功能而失败(尽管默认情况下已禁用)。这是一个Linux 安全模块(LSM),它在 Linux 系统上启用了额外的“硬”安全级别。当然,安全性是一把双刃剑;拥有一个非常安全的系统意味着某些事情将无法按预期工作,其中包括一些 BPF 程序。有关内核锁定的更多信息,请参阅进一步阅读部分。
传递的-d选项开关打印分隔符--;它表示进程的内核模式和用户模式堆栈之间的边界。(不幸的是,由于大多数生产用户模式应用程序将剥离其符号信息,因此大多数用户模式堆栈帧只会显示为“[unknown]”。)至少在这个系统上,内核堆栈帧非常清晰;甚至打印了所讨论的文本(代码)函数的虚拟地址。 (为了帮助您更好地理解堆栈跟踪:首先,从下到上阅读它;其次,如前所述,在 Linux 上,任何foo()系统调用通常会成为内核中的SyS_foo()函数,并且通常SyS_foo()是do_foo()的包装函数。)
请注意,stackcount-bpfcc工具仅适用于 Linux 4.6+,并且需要 root 访问权限。有关详细信息,请参阅其手册页。
作为第二个更简单的示例,我们编写一个简单的Hello, world程序(有一个无限循环的警告,以便我们可以捕获发生的write(2)系统调用),启用符号信息构建它(也就是说,使用gcc -g ...),并使用一个简单的 Bash 脚本执行与以前相同的工作:跟踪内核和用户模式堆栈的执行过程。(您将在ch6/ebpf_stacktrace_eg/中找到代码。)显示示例运行的屏幕截图(好吧,这里有一个例外:我在 x86_64 Ubuntu 20.04 LTS 主机上运行了脚本)如下:

图 6.6 - 使用 stackcount-bpfcc BCC 工具对我们的 Hello, world 进程的内核和用户模式堆栈进行跟踪的示例运行
我们在这里只是浅尝辄止;BPF 工具,如 BCC 和bpftrace,确实是在 Linux 操作系统上进行系统、应用程序跟踪和性能分析的现代、强大方法。确实要花时间学习如何使用这些强大的工具!(每个 BCC 工具都有专门的手册带有示例。)我们建议您参考进一步阅读部分,了解有关 BPF、BCC 和bpftrace的链接。
让我们通过放大镜来总结本节,看看到目前为止您学到了什么!
进程 VAS 的一览无余
在我们结束本节之前,重要的是退后一步,看看每个进程的完整 VAS,以及它对整个系统的外观;换句话说,放大并查看完整系统地址空间的“一览无余”。这就是我们尝试用以下相当大而详细的图表(图 6.7)来做的。
对于那些阅读本书的纸质副本的人,我强烈建议您从此 PDF 文档中以全彩色查看本书的图表static.packt-cdn.com/downloads/9781789953435_ColorImages.pdf。
除了您刚刚了解和看到的内容 - 进程用户空间段、(用户和内核)线程和内核模式堆栈 - 不要忘记内核中还有许多其他元数据:任务结构、内核线程、内存描述符元数据结构等等。它们都是内核 VAS的一部分,通常被称为内核段。内核段中除了任务和堆栈之外还有更多内容。它还包含(显然!)静态内核(核心)代码和数据,实际上,内核的所有主要(和次要)子系统,特定于架构的代码等等(我们在第四章*,编写您的第一个内核模块 - LKMs 第一部分*中讨论过)。
正如刚才提到的,以下图表试图总结并展示所有(或大部分)这些信息:

图 6.7 - 用户和内核 VAS 的进程、线程、堆栈和任务结构的一览无余
哇,这是相当复杂的事情,不是吗?在前面图表中的红色框圈出了核心内核代码和数据 - 主要的内核子系统,并显示了任务结构和内核模式堆栈。其余部分被认为是非核心内容;这包括设备驱动程序。(特定于架构的代码可以被认为是核心代码;我们只是在这里单独显示它。)此外,不要让前面的信息使您感到不知所措;只需专注于我们现在关注的内容 - 进程、线程、它们的任务结构和堆栈。如果您仍然不清楚,请务必重新阅读前面的材料。
现在,让我们继续真正理解并学习如何引用每个活动线程的关键或“根”元数据结构 - 任务结构。
理解和访问内核任务结构
正如您现在所了解的,每个用户空间和内核空间线程在 Linux 内核中都由一个包含其所有属性的元数据结构表示 - 任务结构。任务结构在内核代码中表示为include/linux/sched.h:struct task_struct。
不幸的是,它经常被称为“进程描述符”,导致了无尽的混乱!幸运的是,短语任务结构要好得多;它代表了一个可运行的任务,实际上是一个线程。
因此,在 Linux 设计中,每个进程由一个或多个线程组成,每个线程映射到一个称为任务结构的内核数据结构(struct task_struct)。
任务结构是线程的“根”元数据结构 - 它封装了操作系统为该线程所需的所有信息。这包括关于其内存(段、分页表、使用信息等)、CPU 调度详细信息、当前打开的任何文件、凭据、能力位掩码、定时器、锁定、异步 I/O(AIO)上下文、硬件上下文、信令、IPC 对象、资源限制、(可选)审计、安全和分析信息等等。
图 6.8是 Linux 内核任务结构的概念表示,以及它包含的大部分信息(元数据)。

图 6.8 - Linux 内核任务结构:struct task_struct
从图 6.8可以看出,任务结构包含有关系统上每个单个任务(进程/线程)的大量信息(再次强调:这也包括内核线程)。我们以图 6.8 中的分隔概念格式显示了此数据结构中封装的不同类型的属性。此外,可以看到,某些属性将被继承给子进程或线程在fork(2)(或pthread_create(3))时;某些属性将不会被继承,而将仅仅被重置。(内核模式堆栈为
至少目前,可以说内核“了解”任务是进程还是线程。我们稍后将演示一个内核模块(ch6/foreach/thrd_showall),它将准确展示我们如何确定这一点(稍等,我们会到那里的!)。
现在让我们开始更详细地了解任务结构中一些更重要的成员;继续阅读!
在这里,我只打算让你对内核任务结构有一个“感觉”;我们现在不需要深入细节。在本书的后面部分,我们将根据需要深入研究特定领域。
查看任务结构
首先,回想一下任务结构本质上是进程或线程的“根”数据结构 - 它包含任务的所有属性(正如我们之前所见)。因此,它相当庞大;强大的crash(8)实用程序(用于分析 Linux 崩溃转储数据或调查活动系统)报告其在 x86_64 上的大小为 9,088 字节,sizeof操作符也是如此。
任务结构在include/linux/sched.h内核头文件中定义(这是一个相当关键的头文件)。在以下代码中,我们显示了它的定义,并且要注意我们只显示了其中的一些成员。(另外,像这样的<<尖括号注释>>用于非常简要地解释成员):
// include/linux/sched.h
struct task_struct {
#ifdef CONFIG_THREAD_INFO_IN_TASK
/*
* For reasons of header soup (see current_thread_info()), this
* must be the first element of task_struct.
*/
struct thread_info thread_info; << important flags and status bits >>
#endif
/* -1 unrunnable, 0 runnable, >0 stopped: */
volatile long state;
[...]
void *stack; << the location of the kernel-mode stack >>
[...]
/* Current CPU: */
unsigned int cpu;
[...]
<< the members that follow are to do with CPU scheduling; some of them are discussed in Ch 9 & 10 on CPU Scheduling >>
int on_rq;
int prio;
int static_prio;
int normal_prio;
unsigned int rt_priority;
const struct sched_class *sched_class;
struct sched_entity se;
struct sched_rt_entity rt;
[...]
在以下代码块中继续查看任务结构,查看与内存管理(mm)、PID 和 TGID 值、凭据结构、打开文件、信号处理等相关的成员。再次强调,不打算(全部)详细研究它们;在本章的后续部分以及可能在本书的其他章节中,我们将重新讨论它们:
[...]
struct mm_struct *mm; << memory management info >>
struct mm_struct *active_mm;
[...]
pid_t pid; << task PID and TGID values; explained below >>
pid_t tgid;
[...]
/* Context switch counts: */
unsigned long nvcsw;
unsigned long nivcsw;
[...]
/* Effective (overridable) subjective task credentials (COW): */
const struct cred __rcu *cred;
[...]
char comm[TASK_COMM_LEN]; << task name >>
[...]
/* Open file information: */
struct files_struct *files; << pointer to the 'open files' ds >>
[...]
/* Signal handlers: */
struct signal_struct *signal;
struct sighand_struct *sighand;
sigset_t blocked;
sigset_t real_blocked;
[...]
#ifdef CONFIG_VMAP_STACK
struct vm_struct *stack_vm_area;
#endif
[...]
#ifdef CONFIG_SECURITY
/* Used by LSM modules for access restriction: */
void *security;
#endif
[...]
/* CPU-specific state of this task: */
struct thread_struct thread; << task hardware context detail >>
[...]
};
请注意,前述代码中的struct task_struct成员是根据 5.4.0 内核源代码显示的;在其他内核版本中,成员可能会发生变化!当然,毋庸置疑,整本书都是如此 - 所有代码/数据都是基于 5.4.0 LTS Linux 内核呈现的(将在 2025 年 12 月之前维护)。
好了,现在你对任务结构内的成员有了更好的了解,那么你如何访问它及其各个成员呢?继续阅读。
使用 current 访问任务结构
你会回忆,在前述countem.sh脚本的示例运行中(在组织进程、线程及其堆栈 - 用户空间和内核空间部分),我们发现系统上有总共 1,234 个线程(用户和内核)是活跃的。这意味着内核内存中将有 1,234 个任务结构对象。
它们需要以内核可以在需要时轻松访问它们的方式进行组织。因此,内核内存中的所有任务结构对象都被链接到一个称为任务列表的循环双向链表上。这种组织方式是为了使各种内核代码路径可以对它们进行迭代(通常是procfs代码等)。即使如此,请考虑这一点:当一个进程或线程在运行内核代码(在进程上下文中)时,它如何找出在内核内存中存在的数百或数千个task_struct中属于它的那个?这事实上是一个非平凡的任务。内核开发人员已经发展出一种方法来保证您可以找到代表当前运行内核代码的线程的特定任务结构。这是通过一个名为current的宏实现的。可以这样理解:
-
查找
current会返回正在运行内核代码的线程的task_struct指针,换句话说,当前在某个特定处理器核心上运行的进程上下文。 -
current类似(但当然不完全相同)于面向对象语言中称为this指针的东西。
current宏的实现非常特定于体系结构。在这里,我们不深入研究这些令人讨厌的细节。可以说,实现经过精心设计,以便快速(通常通过*O(1)*算法)。例如,在一些具有许多通用寄存器的精简指令集计算机(RISC)体系结构上(例如 PowerPC 和 Aarch64 处理器),有一个寄存器专门用于保存current的值!
我建议您浏览内核源树并查看current的实现细节(在arch/<arch>/asm/current.h下)。在 ARM32 上,*O(1)*计算会产生结果;在 AArch64 和 PowerPC 上,它存储在寄存器中(因此查找速度非常快)。在 x86_64 架构中,实现使用per-cpu 变量来保存current(避免使用昂贵的锁定)。在您的代码中包含<linux/sched.h>头文件是必需的,以包含current的定义。
我们可以使用current来解引用任务结构并从中获取信息;例如,可以按以下方式查找进程(或线程)PID 和名称:
#include <linux/sched.h>
current->pid, current->comm
在下一节中,您将看到一个完整的内核模块,它会遍历任务列表,并打印出它遇到的每个任务结构的一些细节。
确定上下文
正如您现在所知,内核代码在两种上下文中运行之一:
-
进程(或任务)上下文
-
中断(或原子)上下文
它们是互斥的-内核代码在任何给定时间点都在进程或原子/中断上下文中运行。
在编写内核或驱动程序代码时,通常需要首先弄清楚您正在处理的代码运行在什么上下文中。了解这一点的一种方法是使用以下宏:
#include <linux/preempt.h>
in_task()
它返回一个布尔值:如果您的代码在进程(或任务)上下文中运行,则返回True,在这种情况下通常可以安全休眠;返回False意味着您处于某种原子或中断上下文中,这种情况下永远不安全休眠。
您可能已经遇到了in_interrupt()宏的用法;如果它返回True,则您的代码在中断上下文中,如果返回False,则不在。然而,对于现代代码的建议是不依赖于这个宏(因为Bottom Half(BH)禁用可能会干扰这一点)。因此,我们建议使用in_task()代替。
但是要注意!这可能会有点棘手:虽然in_task()返回True意味着您的代码处于进程上下文中,但这个事实本身并不保证当前安全休眠。休眠实际上意味着调用调度程序代码和随后的上下文切换(我们在第十章 CPU 调度程序-第一部分和第十一章 CPU 调度程序-第二部分中详细介绍了这一点)。例如,您可能处于进程上下文,但持有自旋锁(内核中非常常用的锁);在锁定和解锁之间的代码-所谓的临界区 -必须以原子方式运行!这意味着尽管您的代码可能处于进程(或任务)上下文中,但如果尝试发出任何阻塞(休眠)API,仍会导致错误!
还要注意:只有在进程上下文中运行时,current才被认为是有效的。
是的;到目前为止,您已经学到了有关任务结构的有用背景信息,以及如何通过current宏访问它,以及这样做的注意事项-例如弄清楚您的内核或驱动程序代码当前运行的上下文。因此,现在,让我们实际编写一些内核模块代码来检查内核任务结构的一部分。
通过当前使用任务结构
在这里,我们将编写一个简单的内核模块,以显示任务结构的一些成员,并揭示其进程上下文以及其初始化和清理代码路径运行的情况。为此,我们编写一个show_ctx()函数,它使用current来访问任务结构的一些成员并显示它们的值。它被从init和cleanup方法中调用,如下所示:
出于可读性和空间限制的原因,这里只显示了源代码的关键部分。本书的整个源代码树都可以在其 GitHub 存储库中找到;我们希望您克隆并使用它:git clone https://github.com/PacktPublishing/Linux-Kernel-Programming.git。
/* code: ch6/current_affairs/current_affairs.c */[ ... ]
#include <linux/sched.h> /* current */
#include <linux/cred.h> /* current_{e}{u,g}id() */
#include <linux/uidgid.h> /* {from,make}_kuid() */
[...]
#define OURMODNAME "current_affairs"
[ ... ]
static void show_ctx(char *nm)
{
/* Extract the task UID and EUID using helper methods provided */
unsigned int uid = from_kuid(&init_user_ns, current_uid());
unsigned int euid = from_kuid(&init_user_ns, current_euid());
pr_info("%s:%s():%d ", nm, __func__, __LINE__);
if (likely(in_task())) {
pr_info(
"%s: in process context ::\n"
" PID : %6d\n"
" TGID : %6d\n"
" UID : %6u\n"
" EUID : %6u (%s root)\n"
" name : %s\n"
" current (ptr to our process context's task_struct) :\n"
" 0x%pK (0x%px)\n"
" stack start : 0x%pK (0x%px)\n",
nm,
/* always better to use the helper methods provided */
task_pid_nr(current), task_tgid_nr(current),
/* ... rather than the 'usual' direct lookups:
current->pid, current->tgid, */
uid, euid,
(euid == 0?"have":"don't have"),
current->comm,
current, current,
current->stack, current->stack);
} else
pr_alert("%s: in interrupt context [Should NOT Happen here!]\n", nm);
}
正如前面的代码中所用粗体标出的那样,您可以看到(对于某些成员),我们可以简单地对current指针进行解引用,以访问各种task_struct成员并显示它们(通过内核日志缓冲区)。
太好了!前面的代码片段确实向您展示了如何通过current直接访问一些task_struct成员;但并非所有成员都可以或应该直接访问。相反,内核提供了一些辅助方法来访问它们;让我们接下来深入了解一下。
内置内核辅助方法和优化
在前面的代码中,我们使用了内核的一些内置辅助方法来提取任务结构的各个成员。这是推荐的方法;例如,我们使用task_pid_nr()来查看 PID 成员,而不是直接通过current->pid。同样,任务结构中的进程凭据(例如我们在前面的代码中显示的EUID成员)在struct cred中进行了抽象,并且通过辅助例程提供对它们的访问,就像我们在前面的代码中使用的from_kuid()一样。类似地,还有其他几种辅助方法;在include/linux/sched.h中的struct task_struct定义的下方查找它们。
为什么会这样?为什么不直接通过current-><member-name>访问任务结构成员?嗯,有各种真正的原因;也许访问需要获取锁(我们在本书的最后两章中详细介绍了锁定和同步的关键主题)。也许有更优化的访问方式;继续阅读以了解更多…
此外,正如前面的代码所示,我们可以通过使用in_task()宏轻松地确定内核代码(我们的内核模块)是在进程还是中断上下文中运行-如果在进程(或任务)上下文中,则返回True,否则返回False。
有趣的是,我们还使用likely()宏(它变成了一个编译器__built-in_expect属性)来给编译器的分支预测设置一个提示,并优化被送入 CPU 流水线的指令序列,从而保持我们的代码在“快速路径”上(关于likely()/unlikely()宏的微优化,可以在本章的进一步阅读部分找到更多信息)。您会经常看到内核代码在开发者“知道”代码路径是可能还是不太可能的情况下使用likely()/unlikely()宏。
前面的[un]likely()宏是微优化的一个很好的例子,展示了 Linux 内核如何利用gcc(1)编译器。事实上,直到最近,Linux 内核只能使用gcc进行编译;最近的补丁正在慢慢地使得使用clang(1)进行编译成为现实。(值得一提的是,现代的Android 开源项目(AOSP)是使用clang进行编译的。)
好了,现在我们已经了解了我们的内核模块的show_ctx()函数的工作原理,让我们试一试。
尝试使用内核模块打印进程上下文信息
我们构建我们的current_affair.ko内核模块(这里不显示构建输出),然后将其插入到内核空间(通常使用insmod(8))。现在让我们使用dmesg(1)查看内核日志,然后使用rmmod(8)卸载它并再次使用dmesg(1)。以下截图显示了这一过程:

图 6.9 - current_affairs.ko 内核模块的输出
显然,从前面的截图中可以看出,进程上下文 - 运行current_affairs.ko:current_affairs_init()内核代码的进程(或线程) - 是insmod进程(查看输出:‘name : insmod’),而执行清理代码的current_affairs.ko:current_affairs_exit()进程上下文是rmmod进程!
请注意前面图中左列的时间戳([sec.usec]),它们帮助我们理解rmmod在insmod后约 11 秒被调用。
这个小型演示内核模块的内涵远不止表面看到的那么简单。它实际上对于理解 Linux 内核架构非常有帮助。接下来的部分将解释为什么如此。
看到 Linux 操作系统是单片式的
除了使用current宏的练习之外,这个内核模块(ch6/current_affairs)的一个关键点是清楚地向您展示了 Linux 操作系统的单片式特性。在前面的代码中,我们看到当我们对我们的内核模块文件(current_affairs.ko)执行insmod(8)进程时,它被插入到内核中并且其init代码路径运行了;谁运行了它? 啊,这个问题通过检查输出得到了答案:insmod进程本身在进程上下文中运行它,从而证明了 Linux 内核的单片式特性!(rmmod(8)进程和cleanup代码路径也是如此;它是由rmmod进程在进程上下文中运行的。)
请注意并清楚地注意:没有一个“内核”(或内核线程)执行内核模块的代码,而是用户空间进程(或线程)本身通过发出系统调用(回想一下insmod(8)和rmmod(8)工具都发出系统调用)切换到内核空间并执行内核模块的代码。这就是单片式内核的工作原理。
当然,这种内核代码的执行方式就是我们所说的在进程上下文中运行,与在中断上下文中运行相对。然而,Linux 内核并不被认为是纯粹的单片式;如果是这样的话,它将是一个硬编码的内存块。相反,像所有现代操作系统一样,Linux 支持模块化(通过 LKM 框架)。
顺便提一下,您可以在内核空间内创建和运行内核线程;当调度时,它们仍然在进程上下文中执行内核代码。
使用 printk 进行安全编码
在我们之前的内核模块演示(ch6/current_affairs/current_affairs.c)中,你可能已经注意到了printk与’特殊’%pK格式说明符的使用。我们在这里重复相关的代码片段:
pr_info(
[...]
" current (ptr to our process context's task_struct) :\n"
" 0x%pK (0x%px)\n"
" stack start : 0x%pK (0x%px)\n",
[...]
current, (long unsigned)current,
current->stack, (long unsigned)current->stack); [...]
回想一下我们在第五章中的讨论,编写你的第一个内核模块 - LKMs 第二部分,在影响系统日志的 Proc 文件系统可调参数部分,当打印地址时(首先,在生产中你真的不应该打印地址),我敦促你不要使用通常的 %p(或 %px),而是使用**%pK**格式说明符。这就是我们在前面的代码中所做的;这是为了安全,以防止内核信息泄漏。在一个经过良好调整(为安全)的系统中,%pK 会产生一个简单的哈希值,而不是显示实际地址。为了证明这一点,我们还通过 0x%px 格式说明符显示实际的内核地址,以进行对比。
有趣的是,%pK 在默认桌面版的 Ubuntu 18.04 LTS 系统上似乎没有效果。两种格式——%pK 和 0x%px——打印出来的值是相同的(如图 6.9 所示);这不是预期的结果。然而,在我的 x86_64 Fedora 31 VM 上,它确实按预期工作,使用 %pK 会产生一个简单的哈希(不正确)值,而使用 0x%px 会产生正确的内核地址。以下是我在 Fedora 31 VM 上的相关输出:
$ sudo insmod ./current_affairs.ko
[...]
$ dmesg
[...]
name : insmod
current (ptr to our process context's task_struct) :
0x0000000049ee4bd2 (0xffff9bd6770fa700)
stack start : 0x00000000c3f1cd84 (0xffffb42280c68000)
[...]
在前面的输出中,我们可以清楚地看到区别。
在生产系统(嵌入式或其他)中要保持安全:将kernel.kptr_restrict设置为1(或者更好的是2),从而对指针进行清理,并将kernel.dmesg_restrict设置为1(只允许特权用户读取内核日志)。
现在,让我们转向更有趣的事情:在接下来的部分,你将学习如何迭代 Linux 内核的任务列表,从而实际上学习如何获取系统中每个进程和/或线程的内核级信息。
迭代内核的任务列表
正如前面提到的,所有的任务结构都以一个称为任务列表的链表形式组织在内核内存中(允许对它们进行迭代)。这个列表数据结构已经发展成为非常常用的循环双向链表。事实上,用于处理这些列表的核心内核代码已经被分解到一个名为list.h的头文件中;它是众所周知的,也被期望用于任何基于列表的工作。
include/linux/types.h:list_head数据结构形成了基本的双向循环链表;正如预期的那样,它由两个指针组成,一个指向列表上的prev成员,另一个指向next成员。
你可以通过include/linux/sched/signal.h头文件中方便提供的宏来方便地迭代与任务相关的各种列表,适用于版本>= 4.11;请注意,对于 4.10 及更早版本的内核,这些宏在include/linux/sched.h中。
现在,让我们把这个讨论变得实证和实践。在接下来的几节中,我们将编写内核模块以两种方式迭代内核任务列表:
-
一:迭代内核任务列表并显示所有活动的进程。
-
二:迭代内核任务列表并显示所有活动的线程。
我们展示了后一种情况的详细代码视图。继续阅读,并确保自己尝试一下!
迭代任务列表 I - 显示所有进程
内核提供了一个方便的例程,即for_each_process()宏,它让你可以轻松地迭代任务列表中的每个进程:
// include/linux/sched/signal.h:
#define for_each_process(p) \
for (p = &init_task ; (p = next_task(p)) != &init_task ; )
显然,这个宏扩展成一个for循环,允许我们在循环列表上进行循环。init_task是一个方便的“头”或起始指针 - 它指向第一个用户空间进程的任务结构,传统上是init(1),现在是systemd(1)。
请注意,for_each_process()宏专门设计为只迭代每个进程的main()线程,而不是('子’或对等)线程。
我们的ch6/foreach/prcs_showall内核模块的简短片段输出如下(在我们的 x86_64 Ubuntu 18.04 LTS 客户机系统上运行时):
$ cd ch6/foreach/prcs_showall; ../../../lkm prcs_showall
[...]
[ 111.657574] prcs_showall: inserted
[ 111.658820] Name | TGID | PID | RUID | EUID
[ 111.659619] systemd | 1| 1| 0| 0
[ 111.660330] kthreadd | 2| 2| 0| 0
[...]
[ 111.778937] kworker/0:5 | 1123| 1123| 0| 0
[ 111.779833] lkm | 1143| 1143| 1000| 1000
[ 111.780835] sudo | 1536| 1536| 0| 0
[ 111.781819] insmod | 1537| 1537| 0| 0
请注意,在前面的片段中,每个进程的 TGID 和 PID 始终相等,'证明’for_each_process()宏只迭代每个进程的主线程(而不是每个线程)。我们将在下一节中解释详细信息。
我们将留给你作为练习的是,研究和尝试运行示例内核模块ch6/foreach/prcs_showall。
迭代任务列表 II-显示所有线程
为了迭代系统上每个活动正常的线程,我们可以使用do_each_thread() { ... } while_each_thread() 宏对;我们编写一个示例内核模块来执行此操作(这里:ch6/foreach/thrd_showall/)。
在深入代码之前,让我们先构建它,insmod它(在我们的 x86_64 Ubuntu 18.04 LTS 客户机上),并查看它通过dmesg(1)发出的输出的底部部分。由于在这里显示完整的输出并不是真正可能的-它太大了-我只显示了以下截图中输出的底部部分。此外,我们已经复制了标题(图 6.9),以便您可以理解每列代表什么:

图 6.10-来自我们的 thrd_showall.ko 内核模块的输出
在图 6.9 中,注意所有(内核模式)栈的起始地址(第五列)都以零结尾:
0xffff .... .... .000,这意味着栈区域始终对齐在页面边界上(因为0x1000在十进制中是4096)。这是因为内核模式栈始终是固定大小的,并且是系统页面大小的倍数(通常为 4 KB)。
按照惯例,在我们的内核模块中,如果线程是内核线程,则其名称将显示在方括号内。
在继续编码之前,我们首先需要稍微详细地检查任务结构的 TGID 和 PID 成员。
区分进程和线程- TGID 和 PID
想一想:由于 Linux 内核使用一个唯一的任务结构(struct task_struct)来表示每个线程,并且其中的唯一成员具有 PID,这意味着在 Linux 内核中,每个线程都有一个唯一的 PID。这带来了一个问题:同一个进程的多个线程如何共享一个公共 PID?这违反了 POSIX.1b 标准(pthreads;事实上,有一段时间 Linux 不符合标准,造成了移植问题等)。
为了解决这个令人讨厌的用户空间标准问题,Red Hat 的 Ingo Molnar 在 2.5 内核系列中提出并主线了一个补丁。任务结构中滑入了一个新成员称为线程组标识符或 TGID。它的工作原理是:如果进程是单线程的,tgid和pid的值相等。如果是多线程进程,则主线程的tgid值等于其pid值;进程的其他线程将继承主线程的tgid值,但将保留自己独特的pid值。
为了更好地理解这一点,让我们从前面的截图中取一个实际的例子。在图 6.9 中,注意右侧最后一列出现正整数时,表示多线程进程中的线程数。
因此,查看图 6.9 中看到的VBoxService进程;为了方便起见,我们将该片段复制如下(注意:我们:消除了第一列,dmesg时间戳,并添加了标题行,以便更好地可读性):它具有 PID 和 TGID 值为938,表示其主线程(称为VBoxService;为了清晰起见,我们已用粗体字显示),以及总共九个线程:
PID TGID current stack-start Thread Name MT?#
938 938 0xffff9b09e99edb00 0xffffbaffc0b0c000 VBoxService 9
938 940 0xffff9b09e98496c0 0xffffbaffc0b14000 RTThrdPP
938 941 0xffff9b09fc30c440 0xffffbaffc0ad4000 control
938 942 0xffff9b09fcc596c0 0xffffbaffc0a8c000 timesync
938 943 0xffff9b09fcc5ad80 0xffffbaffc0b1c000 vminfo
938 944 0xffff9b09e99e4440 0xffffbaffc0b24000 cpuhotplug
938 945 0xffff9b09e99e16c0 0xffffbaffc0b2c000 memballoon
938 946 0xffff9b09b65fad80 0xffffbaffc0b34000 vmstats
938 947 0xffff9b09b6ae2d80 0xffffbaffc0b3c000 automount
这九个线程是什么?首先,当然,主线程是VBoxService,下面显示的八个分别是:RTThrdPP,control,timesync,vminfo,cpuhotplug,memballoon,vmstats和automount。我们怎么知道这一点呢?很简单:仔细看前面代码块中代表 TGID 和 PID 的第一列和第二列:如果它们相同,那么它就是进程的主线程;如果 TGID 重复,那么进程是多线程的,PID 值代表“子”线程的唯一 ID。
事实上,完全可以通过普遍存在的 GNU ps(1)命令在用户空间看到内核的 TGID/PID 表示,方法是使用它的-LA选项(还有其他方法):
$ ps -LA
PID LWP TTY TIME CMD
1 1 ? 00:00:02 systemd
2 2 ? 00:00:00 kthreadd
3 3 ? 00:00:00 rcu_gp
[...]
938 938 ? 00:00:00 VBoxService
938 940 ? 00:00:00 RTThrdPP
938 941 ? 00:00:00 control
938 942 ? 00:00:00 timesync
938 943 ? 00:00:03 vminfo
938 944 ? 00:00:00 cpuhotplug
938 945 ? 00:00:00 memballoon
938 946 ? 00:00:00 vmstats
938 947 ? 00:00:00 automount
[...]
ps(1)的标签如下:
-
第一列是
PID- 这实际上代表了内核中此任务的任务结构的tgid成员。 -
第二列是
LWP(轻量级进程或线程!) - 这实际上代表了内核中此任务的任务结构的pid成员。
请注意,只有使用 GNU 的ps(1)才能传递参数(如-LA)并查看线程;这在像busybox这样的轻量级ps实现中是不可能的。不过这并不是问题:你总是可以通过查看 procfs 来查找相同的信息;在这个例子中,在/proc/938/task下,你会看到代表子线程的子文件夹。猜猜:GNU 的ps实际上也是这样工作的!
好的,现在进入代码部分…
迭代任务列表 III - 代码
现在让我们看看我们的thrd_showall内核模块的(相关)代码:
// ch6/foreach/thrd_showall/thrd_showall.c */
[...]
#include <linux/sched.h> /* current */
#include <linux/version.h>
#if LINUX_VERSION_CODE > KERNEL_VERSION(4, 10, 0)
#include <linux/sched/signal.h>
#endif
[...]
static int showthrds(void)
{
struct task_struct *g, *t; // 'g' : process ptr; 't': thread ptr
[...]
#if 0
/* the tasklist_lock reader-writer spinlock for the task list 'should'
* be used here, but, it's not exported, hence unavailable to our
* kernel module */
read_lock(&tasklist_lock);
#endif
disp_idle_thread();
关于前面的代码,有几点需要注意:
-
我们使用
LINUX_VERSION_CODE()宏来有条件地包含一个头文件。 -
现在请暂时忽略锁定工作 - 使用(或不使用)
tasklist_lock()和task_[un]lock()API。 -
不要忘记 CPU 空闲线程!每个 CPU 核心都有一个专用的空闲线程(名为
swapper/n),当没有其他线程想要运行时它就运行(n 是核心编号,从 0 开始)。我们运行的do .. while循环不从这个线程开始(ps(1)也从不显示它)。我们包括一个小例程来显示它,利用了空闲线程的硬编码任务结构在init_task处可用并导出的事实(一个细节:init_task总是指第一个 CPU 的 - 核心#0 - 空闲线程)。
让我们继续:为了迭代每个活动的线程,我们需要使用一对宏形成一个循环:do_each_thread() { ... } while_each_thread()这一对宏正是这样做的,允许我们迭代系统上的每个线程。以下代码显示了这一点:
do_each_thread(g, t) {
task_lock(t);
snprintf(buf, BUFMAX-1, "%6d %6d ", g->tgid, t->pid);
/* task_struct addr and kernel-mode stack addr */
snprintf(tmp, TMPMAX-1, " 0x%px", t);
strncat(buf, tmp, TMPMAX);
snprintf(tmp, TMPMAX-1, " 0x%px", t->stack);
strncat(buf, tmp, TMPMAX);
[...] *<< see notes below >>*
total++;
memset(buf, 0, sizeof(buf)); *<< cleanup >>*
memset(tmp, 0, sizeof(tmp));
task_unlock(t);
} while_each_thread(g, t); #if 0
/* <same as above, reg the reader-writer spinlock for the task list> */
read_unlock(&tasklist_lock);
#endif
return total;
}
参考前面的代码,do_each_thread() { ... } while_each_thread()这一对宏形成一个循环,允许我们迭代系统上的每个线程:
-
我们遵循一种策略,使用一个临时变量(名为
tmp)来获取一个数据项,然后将其附加到一个“结果”缓冲区buf中,我们在每次循环迭代时打印一次。 -
获取
TGID,PID,task_struct和stack的起始地址是微不足道的 - 在这里,保持简单,我们只是使用current来解引用它们(当然,你也可以使用我们在本章前面看到的更复杂的内核辅助方法来做到这一点;在这里,我们希望保持简单)。还要注意的是,这里我们故意不使用(更安全的)%pKprintk 格式说明符,而是使用通用的%px说明符来显示任务结构和内核模式堆栈的实际内核虚拟地址。 -
根据需要进行清理(增加总线程计数器,将临时缓冲区
memset()为NULL等)。 -
完成后,我们返回我们迭代过的总线程数。
在下面的代码块中,我们覆盖了在前面的代码块中故意省略的代码部分。我们获取线程的名称,并在它是一个内核线程时在方括号内打印它。我们还查询进程中线程的数量。解释在代码之后。
if (!g->mm) { // kernel thread
/* One might question why we don't use the get_task_comm() to
* obtain the task's name here; the short reason: it causes a
* deadlock! We shall explore this (and how to avoid it) in
* some detail in the chapters on Synchronization. For now, we
* just do it the simple way ...
*/
snprintf(tmp, TMPMAX-1, " [%16s]", t->comm);
} else {
snprintf(tmp, TMPMAX-1, " %16s ", t->comm);
}
strncat(buf, tmp, TMPMAX);
/* Is this the "main" thread of a multithreaded process?
* We check by seeing if (a) it's a user space thread,
* (b) its TGID == its PID, and (c), there are >1 threads in
* the process.
* If so, display the number of threads in the overall process
* to the right..
*/
nr_thrds = get_nr_threads(g);
if (g->mm && (g->tgid == t->pid) && (nr_thrds > 1)) {
snprintf(tmp, TMPMAX-1, " %3d", nr_thrds);
strncat(buf, tmp, TMPMAX);
}
在前面的代码中,我们可以说以下内容:
-
内核线程没有用户空间映射。
main()线程的current->mm是指向mm_struct类型结构的指针,并表示整个进程的用户空间映射;如果为NULL,那么这是一个内核线程(因为内核线程没有用户空间映射);我们检查并相应地打印名称。 -
我们也打印线程的名称(通过查找任务结构的
comm成员)。您可能会问为什么我们不在这里使用get_task_comm()例程来获取任务的名称;简短的原因是:它会导致死锁!我们将在后面关于内核同步的章节中详细探讨这一点(以及如何避免它)。目前,我们只是用简单的方式做。 -
我们通过
get_nr_threads()宏方便地获取给定进程中线程的数量;在前面的代码块中的宏上面的代码注释中已经清楚解释了其余部分。
很好!通过这样,我们(暂时)完成了对 Linux 内核内部和架构的讨论,重点是进程、线程及其堆栈。
总结
在本章中,我们涵盖了内核内部的关键方面,这将帮助您作为内核模块或设备驱动程序的作者更好地理解操作系统的内部工作。您详细研究了进程及其线程和堆栈之间的组织和关系(无论是用户空间还是内核空间)。我们研究了内核的task_struct数据结构,并学习了如何通过内核模块以不同的方式迭代任务列表。
尽管这可能不明显,但事实是,理解这些内核内部细节是成为经验丰富的内核(和/或设备驱动程序)开发人员的必要和必需步骤。本章的内容将帮助您调试许多系统编程场景,并为我们更深入地探索 Linux 内核,特别是内存管理方面奠定基础。
接下来的章节以及随后的几章确实非常关键:我们将涵盖您需要了解的关于内存管理内部的深层和复杂主题。我建议您先消化本章的内容,浏览感兴趣的进一步阅读链接,完成练习(问题部分),然后继续下一章!
问题
最后,这里是一些问题供您测试对本章材料的了解:github.com/PacktPublishing/Linux-Kernel-Programming/tree/master/questions。您会发现一些问题的答案在书的 GitHub 存储库中:github.com/PacktPublishing/Linux-Kernel-Programming/tree/master/solutions_to_assgn。
进一步阅读
为了帮助您深入了解有用的材料,我们在本书的 GitHub 存储库中提供了一个相当详细的在线参考和链接列表(有时甚至包括书籍)。进一步阅读文档在这里可用:github.com/PacktPublishing/Linux-Kernel-Programming/blob/master/Further_Reading.md。
第七章:内存管理内部 - 基本要点
内核内部,特别是关于内存管理的部分,是一个广阔而复杂的主题。在本书中,我不打算深入研究内核内存的细节。与此同时,我希望为像您这样的新兴内核或设备驱动程序开发人员提供足够的背景知识,以成功地解决这一关键主题。
因此,本章将帮助您充分了解 Linux 操作系统上内存管理是如何执行的;这包括深入研究虚拟内存(VM)分割,以及对进程的用户模式和内核段进行深入的检查,以及覆盖内核如何管理物理内存的基础知识。实际上,您将了解进程和系统的内存映射 - 虚拟和物理。
这些背景知识将在帮助您正确和高效地管理动态内核内存方面发挥重要作用(重点是使用可加载内核模块(LKM)框架编写内核或驱动程序代码;这方面 - 动态内存管理 - 在本书的接下来的两章中是重点)。作为一个重要的附带好处,掌握了这些知识,您将发现自己在调试用户和内核空间代码方面变得更加熟练。(这一点的重要性不言而喻!调试代码既是一门艺术,也是一门科学,也是一种现实。)
在本章中,我们将涵盖以下内容:
-
理解虚拟内存分割
-
检查进程 VAS
-
检查内核段
-
随机化内存布局 - [K]ASLR
-
物理内存
技术要求
我假设您已经阅读了第一章,内核工作空间设置,并已经适当地准备了运行 Ubuntu 18.04 LTS(或更高版本)的虚拟机,并安装了所有必需的软件包。如果没有,我建议您先这样做。为了充分利用本书,我强烈建议您首先设置工作环境,包括克隆本书的 GitHub 代码库(github.com/PacktPublishing/Linux-Kernel-Programming),并以实际操作的方式进行工作。
我假设您熟悉基本的虚拟内存概念,用户模式进程虚拟地址空间(VAS)段的布局,用户和内核模式的堆栈,任务结构等。如果您对此不确定,我强烈建议您先阅读前一章。
理解虚拟内存分割
在本章中,我们将广泛地研究 Linux 内核以两种方式管理内存:
-
基于虚拟内存的方法,其中内存是虚拟化的(通常情况)
-
查看内核实际如何组织物理内存(RAM 页面)
首先,让我们从虚拟内存视图开始,然后在本章后面讨论物理内存组织。
正如我们在前一章中所看到的,在理解进程虚拟地址空间(VAS)的基础部分,进程 VAS 的一个关键属性是它是完全自包含的,一个沙盒。你不能看到盒子外面。在第六章,内核内部基本要点 - 进程和线程,图 6.2 中,我们看到进程 VAS 范围从虚拟地址0到我们简单地称为高地址。这个高地址的实际值是多少?显然,这是 VAS 的最高范围,因此取决于用于寻址的位数:
-
在运行在 32 位处理器上的 Linux 操作系统(或为 32 位编译)上,最高虚拟地址将是2³² = 4 GB。
-
在运行在(并为)64 位处理器编译的 Linux 操作系统上,最高虚拟地址将是2⁶⁴=16 EB。(EB 是 exabyte 的缩写。相信我,这是一个巨大的数量。16 EB 相当于数字*16 x 10¹⁸。)
为了简单起见,为了使数字易于管理,让我们现在专注于 32 位地址空间(我们肯定也会涵盖 64 位寻址)。因此,根据我们的讨论,在 32 位系统上,进程 VAS 从 0 到 4 GB-这个区域包括空白空间(未使用的区域,称为稀疏区域或空洞)和通常称为段(或更正确地说是映射)的内存有效区域-文本、数据、库和堆栈(所有这些在第六章中已经有了详细的介绍,内核内部要点-进程和线程)。
在我们理解虚拟内存的旅程中,拿出众所周知的Hello, world C 程序,并在 Linux 系统上理解它的内部工作是很有用的;这就是下一节要讨论的内容!
深入了解-Hello, world C 程序
对了,这里有谁知道如何编写经典的Hello, world C 程序吗?好的,非常有趣,让我们来看看其中有意义的一行:
printf("Hello, world.\n");
该进程正在调用printf(3)函数。你写过printf()的代码吗?“当然没有”,你说,“它在标准的libc C 库中,通常是 Linux 上的glibc(GNU libc)。”但是等等,除非printf(以及所有其他库 API)的代码和数据实际上在进程 VAS 中,我们怎么能访问它呢?(记住,你不能看盒子外!)为此,printf(3)的代码(和数据)(实际上是glibc库的)必须在进程盒子内——进程 VAS 内被映射。它确实被映射到了进程 VAS 中,在库段或映射中(正如我们在第六章中看到的,内核内部要点-进程和线程,图 6.1)。这是怎么发生的?
事实上,在应用程序启动时,作为 C 运行时环境设置的一部分,有一个小的可执行和可链接格式(ELF)二进制文件(嵌入到你的a.out二进制可执行文件中)称为加载器(ld.so或ld-linux.so)。它很早就获得了控制权。它检测所有需要的共享库,并通过打开库文件并发出mmap(2)系统调用将它们全部内存映射到进程 VAS 中-库文本(代码)和数据段。因此,一旦库的代码和数据被映射到进程 VAS 中,进程就可以访问它,因此-等待它-printf() API 可以成功调用!(我们在这里跳过了内存映射和链接的血腥细节)。
进一步验证这一点,ldd(1)脚本(以下输出来自 x86_64 系统)显示确实如此:
$ gcc helloworld.c -o helloworld
$ ./helloworld
Hello, world
$ ldd ./helloworld
linux-vdso.so.1 (0x00007fffcfce3000)
libc.so.6 => /lib/x86_64-linux-gnu/libc.so.6 (0x00007feb7b85b000)
/lib64/ld-linux-x86-64.so.2 (0x00007feb7be4e000)
$
需要注意的一些要点:
-
每个 Linux 进程-自动且默认-链接到至少两个对象:
glibc共享库和程序加载器(不需要显式的链接器开关)。 -
加载程序的名称因架构而异。在我们的 x86_64 系统上,它是
ld-linux-x86-64.so.2。 -
在前面的
ldd输出中,括号中的地址是映射位置的虚拟地址。例如,在前面的输出中,glibc被映射到我们的进程 VAS 的用户虚拟地址(UVA),等于0x00007feb7b85b000。请注意,这是运行时相关的(也因为地址空间布局随机化(ASLR)语义而变化(稍后会看到))。 -
出于安全原因(以及在除 x86 之外的架构上),最好使用
objdump(1)实用程序来查找这类细节。
尝试对Hello, world二进制可执行文件执行strace(1),你会看到大量的mmap()系统调用,映射glibc(和其他)段!
让我们更深入地研究我们简单的Hello, world应用程序。
超越 printf() API
正如你所知,printf(3) API 转换为 write(2) 系统调用,这当然会将 "Hello, world" 字符串写入 stdout(默认情况下是终端窗口或控制台设备)。
我们也明白,由于write(2)是一个系统调用,这意味着运行此代码的当前进程-进程上下文-现在必须切换到内核模式并运行write(2)的内核代码(单内核架构)!确实如此。但等一下:write(2)的内核代码在内核 VAS 中(参见第六章,内核内部要点-进程和线程,图 6.1)。关键在于,如果内核 VAS 在盒子外面,那么我们怎么调用它呢?
嗯,可以通过将内核放在单独的 4GB VAS 中来完成,但这种方法会导致非常缓慢的上下文切换,所以不会这样做。
它的工程方式是这样的:用户和内核 VAS 都存在于同一个’盒子’中-可用 VAS。具体是如何实现的呢?通过分割可用地址空间,将用户和内核分配在某个User:Kernel :: u:k比例中。这被称为VM 分割(比例u:k通常以 GB、TB 甚至 PB 表示)。
以下图表代表了运行 Linux 操作系统的 ARM-32 系统上具有2:2 VM 分割(以 GB 为单位)的 32 位 Linux 进程;即,总共 4GB 的进程 VAS 被分割为 2GB 的用户空间和 2GB 的内核空间。这通常是运行 Linux 操作系统的 ARM-32 系统上的典型 VM 分割。

图 7.1- User:Kernel :: 2:2 GB VM split on an ARM-32 system running Linux
所以,现在内核 VAS 在盒子内,突然清楚并且至关重要的是要理解这一点:当用户模式进程或线程发出系统调用时,会发生上下文切换到内核的 2GB VAS(包括各种 CPU 寄存器,包括堆栈指针在内的寄存器会得到更新),在同一个进程的 VAS 内。发出系统调用的线程现在以特权内核模式在进程上下文中运行其内核代码(并且处理内核空间数据)。完成后,它从系统调用返回,上下文切换回非特权用户模式,并且现在在第一个 2GB VAS 内运行用户模式代码。
内核 VAS 的确切虚拟地址-也称为内核段-通常通过内核中的PAGE_OFFSET宏表示。我们将在描述内核段布局的宏和变量部分中进一步研究这一点,以及其他一些关键的宏。
关于 VM 分割的确切位置和大小的决定是在哪里做出的呢?啊,在 32 位 Linux 上,这是一个内核构建时可配置的。它是在内核构建中作为make [ARCH=xxx] menuconfig过程的一部分完成的-例如,当为 Broadcom BCM2835(或 BCM2837)SoC(Raspberry Pi 是一个搭载这个 SoC 的热门开发板)配置内核时。以下是来自官方内核配置文件的片段(输出来自 Raspberry Pi 控制台):
$ uname -r
5.4.51-v7+
$ sudo modprobe configs *<< gain access to /proc/config.gz via this LKM >>* $ zcat /proc/config.gz | grep -C3 VMSPLIT
[...]
# CONFIG_BIG_LITTLE is not set
# CONFIG_VMSPLIT_3G is not set
# CONFIG_VMSPLIT_3G_OPT is not set
CONFIG_VMSPLIT_2G=y
# CONFIG_VMSPLIT_1G is not set
CONFIG_PAGE_OFFSET=0x80000000
CONFIG_NR_CPUS=4
[...]
如前面的片段所示,CONFIG_VMSPLIT_2G内核配置选项设置为y,意味着默认的 VM 分割是user:kernel :: 2:2。对于 32 位架构,VM 分割位置是可调整的(如前面的片段中所示,CONFIG_VMSPLIT_[1|2|3]G;CONFIG_PAGE_OFFSET相应地设置)。对于 2:2 的 VM 分割,PAGE_OFFSET实际上是在虚拟地址0x8000 0000(2GB)的中间位置!
IA-32 处理器(Intel x86-32)的默认 VM 分割是 3:1(GB)。有趣的是,运行在 IA-32 上的(古老的)Windows 3.x 操作系统具有相同的 VM 分割,这表明这些概念基本上与操作系统无关。在本章的后面,我们将涵盖几种更多的架构及其 VM 分割,以及其他细节。
无法直接为 64 位架构配置 VM 分割。因此,现在我们了解了 32 位系统上的 VM 分割,让我们继续研究如何在 64 位系统上进行 VM 分割。
64 位 Linux 系统上的 VM 分割
首先值得注意的是,在 64 位系统上,并非所有 64 位都用于寻址。在标准或典型的 x86_64 Linux OS 配置中,使用(最低有效位(LSB))48 位进行寻址。为什么不使用全部 64 位?因为太多了!没有现有的计算机接近拥有甚至一半的完整2⁶⁴ = 18,446,744,073,709,551,616 字节,相当于 16 EB(即 16,384 PB)的 RAM!
“为什么”,您可能会想,“我们为什么将其等同于 RAM?”。请继续阅读 - 在此变得清晰之前,需要涵盖更多内容。在检查内核段部分,您将完全理解这一点。
虚拟寻址和地址转换
在进一步深入了解这些细节之前,非常重要的是清楚地理解一些关键点。
考虑来自 C 程序的一个小而典型的代码片段:
int i = 5;
printf("address of i is 0x%x\n", &i);
您看到printf()发出的地址是虚拟地址而不是物理地址。我们区分两种虚拟地址:
-
如果在用户空间进程中运行此代码,您将看到变量
i的地址是 UVA。 -
如果在内核中运行此代码,或者在内核模块中运行此代码(当然,您将使用
printk()API),您将看到变量i的地址是内核虚拟地址(KVA)。
接下来,虚拟地址不是绝对值(相对于0的偏移量);它实际上是位掩码:
-
在 32 位 Linux 操作系统上,32 个可用位被分为页全局目录(PGD)值,页表(PT)值和偏移量。
-
这些成为MMU(现代微处理器硅片内部的内存管理单元)进行地址转换的索引。
我们不打算在这里详细介绍 MMU 级别的地址转换。这也非常与架构相关。请参考进一步阅读部分,了解有关此主题的有用链接。
- 如预期的那样,在 64 位系统上,即使使用 48 位寻址,虚拟地址位掩码中将有更多字段。
好吧,如果这种 48 位寻址是 x86_64 处理器上的典型情况,那么 64 位虚拟地址中的位是如何布局的?未使用的 16 位 MSB 会发生什么?以下图解答了这个问题;这是 x86_64 Linux 系统上虚拟地址的分解表示:

图 7.2 - 在具有 4 KB 页面的 Intel x86_64 处理器上分解 64 位虚拟地址
基本上,使用 48 位寻址,我们使用 0 到 47 位(LSB 48 位)并忽略最高有效位(MSB)的 16 位,将其视为符号扩展。不过,未使用的符号扩展 MSB 16 位的值随着您所在的地址空间而变化:
-
内核 VAS:MSB 16 位始终设置为
1。 -
用户 VAS:MSB 16 位始终设置为
0。
这是有用的信息!知道这一点,仅通过查看(完整的 64 位)虚拟地址,您因此可以判断它是 KVA 还是 UVA:
-
64 位 Linux 系统上的 KVA 始终遵循格式
0xffff .... .... ....。 -
UVA 始终具有格式
0x0000 .... .... ....。
警告:前面的格式仅适用于将虚拟地址自定义为 KVA 或 UVA 的处理器(实际上是 MMU); x86 和 ARM 系列处理器属于这一范畴。
现在可以看到(我在这里重申),事实是虚拟地址不是绝对地址(绝对偏移量从零开始,正如你可能错误地想象的那样),而是实际上是位掩码。事实上,内存管理是一个复杂的领域,工作是共享的:操作系统负责创建和操作每个进程的分页表,工具链(编译器)生成虚拟地址,而处理器 MMU 实际上执行运行时地址转换,将给定的(用户或内核)虚拟地址转换为物理(RAM)地址!
我们不会在本书中深入讨论硬件分页(以及各种硬件加速技术,如转换旁路缓冲(TLB)和 CPU 缓存)。这个特定的主题已经被其他一些优秀的书籍和参考网站很好地涵盖,这些书籍和网站在本章的进一步阅读部分中提到。
回到 64 位处理器上的 VAS。64 位系统上可用的 VAS 是一个巨大的2*⁶⁴ = 16 EB(*16 x 10¹⁸字节!)。故事是这样的,当 AMD 工程师首次将 Linux 内核移植到 x86_64(或 AMD64)64 位处理器时,他们必须决定如何在这个巨大的 VAS 中布置进程和内核段。即使在今天的 x86_64 Linux 操作系统上,这个巨大的 64 位 VAS 的划分基本上保持不变。这个巨大的 64 位 VAS 划分如下。在这里,我们假设 48 位寻址和 4 KB 页面大小:
-
规范的下半部分,128 TB:用户 VAS 和虚拟地址范围从
0x0到0x0000 7fff ffff ffff -
规范的上半部分,128 TB:内核 VAS 和虚拟地址范围从
0xffff 8000 0000 0000到0xffff ffff ffff ffff
规范这个词实际上意味着根据法律或根据共同惯例。
在 x86_64 平台上可以看到这个 64 位 VM 分割,如下图所示:

图 7.3 - Intel x86_64(或 AMD64)16 EB VAS 布局(48 位寻址);VM 分割是用户:内核:: 128 TB:128 TB
在上图中,中间未使用的区域 - 空洞或稀疏区域 - 也称为非规范地址区域。有趣的是,使用 48 位寻址方案,绝大多数 VAS 都未被使用。这就是为什么我们称 VAS 非常稀疏。
上图显然不是按比例绘制的!请记住,这一切都是虚拟内存空间,而不是物理内存。
为了结束我们对 VM 分割的讨论,以下图表显示了不同 CPU 架构的一些常见用户:内核VM 分割比例(我们假设 MMU 页面大小为 4 KB):

图 7.4 - 不同 CPU 架构的常见用户:内核 VM 分割比例(4 KB 页面大小)
我们用粗体红色突出显示第三行,因为它被认为是常见情况:在 x86_64(或 AMD64)架构上运行 Linux,使用用户:内核:: 128 TB:128 TB VM 分割。在阅读表格时要小心:第六列和第八列的数字,结束 vaddr,每个都是单个 64 位数量,而不是两个数字。数字可能只是简单地绕回去了。因此,例如,在 x86_64 行中,第 6 列是单个数字0x0000 7fff ffff ffff而不是两个数字。
第三列,地址位,告诉我们,在 64 位处理器上,实际上没有真正的处理器使用所有 64 位进行寻址。
在 x86_64 下,上表显示了两个 VM 分割:
-
第一个,128 TB:128 TB(4 级分页)是今天在 Linux x86_64 位系统上使用的典型 VM 分割(嵌入式笔记本电脑,个人电脑,工作站和服务器)。它将物理地址空间限制为 64 TB(RAM)。
-
第二个,64 PB:64 PB,截至目前为止,仍然纯理论;它支持所谓的 5 级分页,从 4.14 版 Linux 开始;分配的 VAS(56 位寻址;总共 128PB 的 VAS 和 4PB 的物理地址空间!)是如此巨大,以至于截至目前为止,没有实际的计算机(尚未)使用它。
请注意,运行在 Linux 上的 AArch64(ARM-64)架构的两行仅仅是代表性的。正在开发产品的 BSP 供应商或平台团队可能会使用不同的分割。有趣的是,(旧)Windows 32 位操作系统上的 VM 分割是 2:2(GB)。
实际上驻留在内核 VAS 中的是什么,或者通常所说的内核段?所有内核代码、数据结构(包括任务结构、列表、内核模式堆栈、分页表等等)、设备驱动程序、内核模块等等都在这里(正如第六章中内核内部要点 - 进程和线程的图 6.7的下半部分所显示的;我们在理解内核段部分中详细介绍了这一点)。
重要的是要意识到,在 Linux 上,作为性能优化,内核内存始终是不可交换的;也就是说,内核内存永远不会被换出到交换分区。用户空间内存页总是可以进行分页,除非被锁定(参见mlockall系统调用)。
有了这个背景,您现在可以理解完整的进程 VAS 布局。继续阅读。
进程 VAS - 完整视图
再次参考图 7.1;它显示了单个 32 位进程的实际进程 VAS 布局。当然,现实情况是 - 这是关键的 - 系统上所有活动的进程都有自己独特的用户模式 VAS,但共享相同的内核段。与图 7.1形成对比的是,它显示了 2:2(GB)的 VM 分割,下图显示了典型 IA-32 系统的实际情况,其中有 3:1(GB)的 VM 分割:

图 7.5 - 进程具有独特的用户 VAS,但共享内核段(32 位操作系统);IA-32 的 VM 分割为 3:1
请注意,在前面的图中,地址空间反映了 3:1(GB)的 VM 分割。用户地址空间从0扩展到0xbfff ffff(0xc000 0000是 3GB 标记;这是PAGE_OFFSET宏的设置),内核 VAS 从0xc000 0000(3GB)扩展到0xffff ffff(4GB)。
在本章的后面,我们将介绍一个有用的实用程序procmap的用法。它将帮助您详细可视化 VAS,包括内核和用户 VAS,类似于我们之前的图表所显示的方式。
需要注意的几点:
-
在图 7.5 中显示的示例中,
PAGE_OFFSET的值为0xc000 0000。 -
我们在这里展示的图表和数字并不是所有架构上的绝对和约束性的;它们往往是非常特定于架构的,许多高度定制的 Linux 系统可能会改变它们。
-
图 7.5详细介绍了 32 位 Linux 操作系统上的 VM 布局。在 64 位 Linux 上,概念保持不变,只是数字(显著)变化。正如前面的章节中所详细介绍的,x86_64(带 48 位寻址)Linux 系统上的 VM 分割变为
User:Kernel :: 128 TB:128 TB。
现在,一旦理解了进程的虚拟内存布局的基本原理,您会发现它在解密和在难以调试的情况下取得进展方面非常有帮助。像往常一样,还有更多内容;接下来的部分将介绍用户空间和内核空间内存映射(内核段),以及一些关于物理内存映射的内容。继续阅读!
检查进程 VAS
我们已经介绍了每个进程 VAS 由哪些段或映射组成(参见第六章中的理解进程虚拟地址空间(VAS)基础知识部分)。我们了解到进程 VAS 包括各种映射或段,其中包括文本(代码)、数据段、库映射,以及至少一个堆栈。在这里,我们将对此进行更详细的讨论。
能够深入内核并查看各种运行时值是开发人员像您这样的重要技能,以及用户、QA、系统管理员、DevOps 等。Linux 内核为我们提供了一个令人惊叹的接口来做到这一点 - 这就是,你猜对了,proc文件系统(procfs)。
这在 Linux 上始终存在(至少应该存在),并且挂载在/proc下。procfs系统有两个主要作用:
-
提供一组统一的(伪或虚拟)文件和目录,使您能够深入了解内核和硬件的内部细节。
-
提供一组统一的可写根文件,允许系统管理员修改关键的内核参数。这些文件位于
/proc/sys/下,并被称为sysctl- 它们是 Linux 内核的调整旋钮。
熟悉proc文件系统确实是必须的。我建议您查看一下,并阅读关于proc(5)的优秀手册页。例如,简单地执行cat /proc/PID/status(其中PID当然是给定进程或线程的唯一进程标识符)会产生一大堆有用的进程或线程任务结构的细节!
在概念上类似于procfs的是sysfs文件系统,它挂载在/sys下(在其下是debugfs,通常挂载在/sys/kernel/debug)。sysfs是 2.6 Linux 新设备和驱动程序模型的表示;它公开了系统上所有设备的树形结构,以及几个内核调整旋钮。
详细检查用户 VAS
让我们从检查任何给定进程的用户 VAS 开始。用户 VAS 的相当详细的映射可以通过procfs获得,特别是通过/proc/PID/maps伪文件。让我们学习如何使用这个接口来窥视进程的用户空间内存映射。我们将看到两种方法:
-
直接通过
procfs接口的/proc/PID/maps伪文件 -
使用一些有用的前端(使输出更易于理解)
让我们从第一个开始。
直接使用 procfs 查看进程内存映射
查找任意进程的内部进程细节需要root访问权限,而查找自己拥有的进程的细节(包括调用进程本身)则不需要。因此,举个简单的例子,我们将使用self关键字来查找调用进程的 VAS,而不是 PID。以下屏幕截图显示了这一点(在 x86_64 Ubuntu 18.04 LTS 客户机上):

图 7.6 - cat /proc/self/maps 命令的输出
在前面的屏幕截图中,您实际上可以看到cat进程的用户 VAS - 该进程的用户 VAS 的实际内存映射!还要注意,前面的procfs输出是按(用户)虚拟地址(UVA)升序排序的。
熟悉使用强大的mmap(2)系统调用将有助于更好地理解后续的讨论。至少要浏览一下它的手册页。
解释/proc/PID/maps 输出
要解释图 7.6 的输出,请逐行阅读。每行代表了进程的用户模式 VAS 的一个段或映射(在前面的示例中,是cat进程的)。每行包括以下字段。
为了更容易,我将只展示一行输出,我们将在接下来的注释中标记并引用这些字段:
start_uva - end_uva mode,mapping start-off mj:mn inode# image-name
555d83b65000-555d83b6d000 r-xp 00000000 08:01 524313 /bin/cat
在这里,整行表示进程(用户)VAS 中的一个段,或更正确地说,是一个映射。uva是用户虚拟地址。每个段的start_uva和end_uva显示为前两个字段(或列)。因此,映射(段)的长度可以轻松计算(end_uva-start_uva字节)。因此,在前面的行中,start_uva是0x555d83b65000,end_uva是0x555d83b6d000(长度可以计算为 32 KB);但是,这个段是什么?请继续阅读…
第三个字段r-xp实际上是两个信息的组合:
-
前三个字母表示段(通常以
rwx表示)的模式(权限)。 -
下一个字母表示映射是私有的(
p)还是共享的(s)。在内部,这是由mmap(2)系统调用的第四个参数flags设置的;实际上是**mmap(2)**系统调用在内部负责创建进程中的每个段或映射! -
因此,对于前面显示的示例段,第三个字段的值为
r-xp,我们现在可以知道它是一个文本(代码)段,并且是一个私有映射(如预期的那样)。
第四个字段start-off(这里是值0)是从已映射到进程 VAS 的文件开头的起始偏移量。显然,此值仅对文件映射有效。您可以通过查看倒数第二个(第六个)字段来判断当前段是否是文件映射。对于不是文件映射的映射 - 称为匿名映射 - 它始终为0(例如表示堆或栈段的映射)。在我们之前的示例行中,这是一个文件映射(/bin/cat),从该文件开头的偏移量为0字节(如我们在前一段中计算的映射长度为 32 KB)。
第五个字段(08:01)的格式为mj:mn,其中mj是设备文件的主编号,mn是映像所在设备文件的次编号。与第四个字段类似,它仅对文件映射有效,否则显示为00:00;在我们之前的示例行中,这是一个文件映射(/bin/cat),设备文件的主编号和次编号(文件所在的设备)分别为8和1。
第六个字段(524313)表示映像文件的索引节点号 - 正在映射到进程 VAS 的文件的内容。索引节点是**VFS(虚拟文件系统)**的关键数据结构;它保存文件对象的所有元数据,除了其名称(名称在目录文件中)。同样,此值仅对文件映射有效,否则显示为0。实际上,这是一种快速判断映射是文件映射还是匿名映射的方法!在我们之前的示例映射中,显然是文件映射(/bin/cat),索引节点号是524313。事实上,我们可以确认:
ls -i /bin/cat
524313 /bin/cat
第七个和最后一个字段表示正在映射到用户 VAS 的文件的路径名。在这里,因为我们正在查看cat(1)进程的内存映射,路径名(对于文件映射的段)当然是/bin/cat。如果映射表示文件,则文件的索引节点号(第六个字段)显示为正值;如果不是 - 意味着是没有后备存储的纯内存或匿名映射 - 索引节点号显示为0,此字段将为空。
现在应该很明显了,但我们仍然会指出这一点 - 这是一个关键点:前面看到的所有地址都是虚拟地址,而不是物理地址。此外,它们仅属于用户空间,因此被称为UVA,并且始终通过该进程的唯一分页表访问(和转换)。此外,前面的屏幕截图是在 64 位(x86_64)Linux 客户机上拍摄的。因此,在这里,我们看到 64 位虚拟地址。
虽然虚拟地址的显示方式不是完整的 64 位数字 - 例如,显示为0x555d83b65000而不是0x0000555d83b65000 - 但我希望您注意到,因为它是用户虚拟地址(UVA),最高 16 位为零!
好了,这涵盖了如何解释特定段或映射,但似乎还有一些奇怪的 - vvar,vdso和vsyscall映射。让我们看看它们的含义。
vsyscall 页面
您是否注意到图 7.6 的输出中有一些不太寻常的东西?那里的最后一行 - 所谓的vsyscall条目 - 映射了一个内核页面(到目前为止,您知道我们如何判断:其起始和结束虚拟地址的最高 16 位被设置)。在这里,我们只提到这是一个(旧的)用于执行系统调用的优化。它通过减轻对于一小部分不真正需要的系统调用而实际上不需要切换到内核模式来工作。
目前,在 x86 上,这些包括gettimeofday(2),time(2)和getcpu(2)系统调用。实际上,上面的vvar和vdso(又名 vDSO)映射是同一主题的现代变体。如果您对此感兴趣,可以访问本章的进一步阅读部分了解更多信息。
因此,您现在已经看到了如何通过直接阅读和解释/proc/PID/maps(伪)文件的输出来检查任何给定进程的用户空间内存映射。还有其他方便的前端可以这样做;我们现在将检查一些。
查看进程内存映射的前端
除了通过/proc/PID/maps(我们在上一节中看到如何解释)的原始或直接格式外,还有一些包装实用程序可以帮助我们更轻松地解释用户模式 VAS。其中包括额外的(原始)/proc/PID/smaps伪文件,pmap(1)和smem(8)实用程序,以及我自己的简单实用程序(名为procmap)。
内核通过/proc/PID/smaps伪文件在proc下提供了每个段或映射的详细信息。尝试cat /proc/self/smaps来查看这些信息。您会注意到对于每个段(映射),都提供了大量详细信息。proc(5)的 man 页面有助于解释所见到的许多字段。
对于pmap(1)和smem(8)实用程序,我建议您查阅它们的 man 页面以获取详细信息。例如,对于pmap(1),man 页面告诉我们更详细的-X和-XX选项:
-X Show even more details than the -x option. WARNING: format changes according to /proc/PID/smaps
-XX Show everything the kernel provides
关于smem(8)实用程序,事实是它不显示进程 VAS;相反,它更多地是回答一个常见问题:即确定哪个进程占用了最多的物理内存。它使用诸如Resident Set Size(RSS),Proportional Set Size(PSS)和Unique Set Size(USS)等指标来呈现更清晰的图片。我将把进一步探索这些实用程序作为一个练习留给您,亲爱的读者!
现在,让我们继续探讨如何使用一个有用的实用程序 - procmap - 以相当详细的方式查看任何给定进程的内核和用户内存映射。
procmap 进程 VAS 可视化实用程序
作为一个小型的学习和教学(以及在调试期间有帮助!)项目,我编写并托管了一个名为procmap的小型项目,可以在 GitHub 上找到:github.com/kaiwan/procmap(使用git clone进行克隆)。其README.md文件的一部分有助于解释其目的:
procmap is designed to be a console/CLI utility to visualize the complete memory map of a Linux process, in effect, to visualize the memory mappings of both the kernel and user mode Virtual Address Space (VAS). It outputs a simple visualization, in a vertically-tiled format ordered by descending virtual address, of the complete memory map of a given process (see screenshots below). The script has the intelligence to show kernel and user space mappings as well as calculate and show the sparse memory regions that will be present. Also, each segment or mapping is scaled by relative size (and color-coded for readability). On 64-bit systems, it also shows the so-called non-canonical sparse region or 'hole' (typically close to 16,384 PB on the x86_64).
顺便说一句:在撰写本材料时(2020 年 4 月/5 月),COVID-19 大流行席卷全球大部分地区。类似于早期的SETI@home项目(setiathome.berkeley.edu/),Folding@home项目(foldingathome.org/category/covid-19/)是一个分布式计算项目,利用互联网连接的家用(或任何)计算机来帮助模拟和解决与 COVID-19 治疗相关的问题(以及找到治愈我们的其他严重疾病)。您可以从foldingathome.org/start-folding/下载软件(安装它,并在系统空闲时运行)。我就是这样做的;这是在我的(本机)Ubuntu Linux 系统上运行的 FAH 查看器(一个漂亮的 GUI 显示蛋白质分子!)进程的部分截图:
$ ps -e|grep -i FAH
6190 ? 00:00:13 FAHViewer
好了,让我们使用procmap实用程序来查询它的 VAS。我们如何调用它?简单,看看接下来的内容(由于空间不足,我不会在这里显示所有信息、警告等;请自行尝试):
$ git clone https://github.com/kaiwan/procmap
$ cd procmap
$ ./procmap
Options:
--only-user : show ONLY the user mode mappings or segments
--only-kernel : show ONLY the kernel-space mappings or segments
[default is to show BOTH]
--export-maps=filename
write all map information gleaned to the file you specify in CSV
--export-kernel=filename
write kernel information gleaned to the file you specify in CSV
--verbose : verbose mode (try it! see below for details)
--debug : run in debug mode
--version|--ver : display version info.
See the config file as well.
[...]
请注意,这个procmap实用程序与 BSD Unix 提供的procmap实用程序不同。它还依赖于bc(1)和smem(8)实用程序;请确保它们已安装。
当我只使用--pid=<PID>运行procmap实用程序时,它将显示给定进程的内核和用户空间 VAS。现在,由于我们尚未涵盖有关内核 VAS(或段)的详细信息,我不会在这里显示内核空间的详细输出;让我们把它推迟到即将到来的部分,检查内核段。随着我们的进行,您将发现procmap实用程序的部分截图仅显示用户 VAS 输出。完整的输出可能会相当冗长,当然取决于所涉及的进程;请自行尝试。
正如您将看到的,它试图以垂直平铺的格式提供完整进程内存映射的基本可视化 – 包括内核和用户空间 VAS(如前所述,这里我们只显示截断的截图):

图 7.7 – 部分截图:从 procmap 实用程序的内核 VAS 输出的第一行
请注意,从前面(部分)截图中,有一些事情:
-
procmap(Bash)脚本自动检测到我们正在运行的是 x86_64 64 位系统。 -
虽然我们现在不专注于它,但内核 VAS 的输出首先出现;这是自然的,因为我们按照虚拟地址降序显示输出(图 7.1、7.3 和 7.5 重申了这一点)
-
您可以看到第一行(在
KERNEL VAS标题之后)对应于 VAS 的顶部 – 值为0xffff ffff ffff ffff(因为我们是 64 位)。
继续看 procmap 输出的下一部分,让我们看一下FAHViewer 进程的用户 VAS 的上端的截断视图:

图 7.8 – 部分截图:procmap 实用程序的用户 VAS 输出的前几行(高端)
图 7.8 是procmap输出的部分截图,显示了用户空间 VAS;在其顶部,您可以看到(高)端 UVA。
在我们的 x86_64 系统上(请记住,这是与架构相关的),(高)end_uva值是
0x0000 7fff ffff ffff 和 start_uva 当然是 0x0。procmap 如何找出精确的地址值呢?哦,它相当复杂:对于内核空间内存信息,它使用一个内核模块(一个 LKM!)来查询内核,并根据系统架构设置一个配置文件;用户空间的细节当然来自 /proc/PID/maps 直接的 procfs 伪文件。
顺便说一句,procmap的内核组件,一个内核模块,建立了一种与用户空间进行交互的方式 – 通过创建和设置一个debugfs(伪)文件的procmap脚本。
以下屏幕截图显示了进程用户模式 VAS 的低端的部分截图,直到最低的 UVA 0x0:

图 7.9 - 部分截图:进程用户 VAS 输出的最后几行(低端)来自 procmap 实用程序
最后一个映射,一个单页,如预期的那样,是空指针陷阱页(从 UVA 0x1000到0x0;我们将在即将到来的空指针陷阱页部分中解释其目的)。
然后,procmap实用程序(如果在其配置文件中启用)会计算并显示一些统计信息;这包括内核和用户模式 VAS 的大小,64 位系统上稀疏区域占用的用户空间内存量(通常是空间的绝大部分!)的绝对数量和百分比,报告的物理 RAM 量,最后,由ps(1)和smem(8)实用程序报告的此特定进程的内存使用详细信息。
通常情况下,在 64 位系统上(参见图 7.3),进程 VAS 的稀疏(空)内存区域占用了可用地址空间的接近 100%!(通常是诸如 127.99[…] TB 的 VAS 占用了 128 TB 可用空间的情况。)这意味着 99.99[…]%的内存空间是稀疏的(空的)!这就是 64 位系统上巨大的 VAS 的现实。实际上,巨大的 128 TB 的 VAS(就像在 x86_64 上一样)中只有一小部分被使用。当然,稀疏和已使用的 VAS 的实际数量取决于特定应用程序进程的大小。
能够清晰地可视化进程 VAS 在深层次调试或分析问题时可以提供很大帮助。
如果您正在阅读本书的实体版本,请务必从出版商的网站下载图表/图像的全彩 PDF:static.packt-cdn.com/downloads/9781789953435_ColorImages.pdf。
您还会看到输出末尾(如果启用)打印出的统计信息显示了目标进程设置的虚拟内存区域(VMAs)的数量。接下来的部分简要解释了 VMA 是什么。让我们开始吧!
理解 VMA 的基础知识
在/proc/PID/maps的输出中,实际上每行输出都是从一个称为 VMA 的内核元数据结构中推断出来的。这实际上非常简单:内核使用 VMA 数据结构来抽象我们所说的段或映射。因此,在用户 VAS 中的每个段都有一个由操作系统维护的 VMA 对象。请意识到,只有用户空间段或映射受到称为 VMA 的内核元数据结构的管理;内核段本身没有 VMA。
那么,给定进程会有多少个 VMA?嗯,它等于其用户 VAS 中的映射(段)数量。在我们的FAHViewer进程示例中,它恰好有 206 个段或映射,这意味着内核内存中为该进程维护了 206 个 VMA 元数据对象,代表了 206 个用户空间段或映射。
从编程的角度来看,内核通过根据current->mm->mmap的任务结构维护 VMA“链”(实际上是红黑树数据结构,出于效率原因)来进行管理。为什么指针称为mmap?这是非常有意义的:每次执行mmap(2)系统调用(即内存映射操作)时,内核都会在调用进程的(即在current实例内)VAS 中生成一个映射(或“段”)和代表它的 VMA 对象。
VMA 元数据结构类似于一个包含映射的伞,包括内核执行各种内存管理操作所需的所有信息:处理页面错误(非常常见),在 I/O 期间将文件内容缓存到(或从)内核页缓存中等等。
页面错误处理是一个非常重要的操作系统活动,其算法占用了相当大一部分内核 VMA 对象的使用;然而,在本书中,我们不深入讨论这些细节,因为对内核模块/驱动程序的作者来说,这些细节基本上是透明的。
为了让您感受一下,我们将在下面的片段中展示内核 VMA 数据结构的一些成员;旁边的注释有助于解释它们的目的:
// include/linux/mm_types.h
struct vm_area_struct {
/* The first cache line has the info for VMA tree walking. */
unsigned long vm_start; /* Our start address within vm_mm. */
unsigned long vm_end; /* The first byte after our end address
within vm_mm. */
/* linked list of VM areas per task, sorted by address */
struct vm_area_struct *vm_next, *vm_prev;
struct rb_node vm_rb;
[...]
struct mm_struct *vm_mm; /* The address space we belong to. */
pgprot_t vm_page_prot; /* Access permissions of this VMA. */
unsigned long vm_flags; /* Flags, see mm.h. */
[...]
/* Function pointers to deal with this struct. */
const struct vm_operations_struct *vm_ops;
/* Information about our backing store: */
unsigned long vm_pgoff;/* Offset (within vm_file) in PAGE_SIZE units */
struct file * vm_file; /* File we map to (can be NULL). */
[...]
} __randomize_layout
现在应该更清楚了cat /proc/PID/maps是如何在底层工作的:当用户空间执行cat /proc/self/maps时,cat发出了一个read(2)系统调用;这导致cat进程切换到内核模式,并在内核中以内核特权运行read(2)系统调用代码。在这里,内核虚拟文件系统开关(VFS)将控制权重定向到适当的procfs回调处理程序(函数)。这段代码遍历了每个 VMA 元数据结构(对于current,也就是我们的cat进程),将相关信息发送回用户空间。cat进程然后忠实地将通过读取接收到的数据转储到stdout,因此我们看到了它:进程的所有段或映射 - 实际上是用户模式 VAS 的内存映射!
好了,通过这一部分,我们总结了检查进程用户 VAS 的细节。这种知识不仅有助于理解用户模式 VAS 的精确布局,还有助于调试用户空间内存问题!
现在,让我们继续理解内存管理的另一个关键方面 - 内核 VAS 的详细布局,换句话说,内核段。
检查内核段
正如我们在前一章中讨论过的,以及在图 7.5中所见,非常重要的是要理解所有进程都有自己独特的用户 VAS,但共享内核空间 - 我们称之为内核段或内核 VAS。让我们开始这一部分,从开始检查内核段的一些常见(与架构无关)区域。
内核段的内存布局非常依赖于架构(CPU)。然而,所有架构都有一些共同点。下面的基本图表代表了用户 VAS 和内核段(以水平平铺的格式),在 x86_32 上以 3:1 的 VM 分割中看到:

图 7.10 - 在 x86_32 上以 3:1 VM 分割为焦点的用户和内核 VAS
让我们逐个地过一遍每个区域:
-
用户模式 VAS:这是用户 VAS;我们在前一章和本章的早些部分详细介绍了它;在这个特定的例子中,它占用了 3GB 的 VAS(从
0x0到0xbfff ffff)。 -
所有接下来的内容都属于内核 VAS 或内核段;在这个特定的例子中,它占用了 1GB 的 VAS(从
0xc000 0000到0xffff ffff);现在让我们逐个部分来检查它。 -
低端内存区域:这是平台(系统)RAM 直接映射到内核的地方。(我们将在直接映射 RAM 和地址转换部分更详细地介绍这个关键主题。如果有帮助的话,您可以先阅读该部分,然后再回到这里)。现在先跳过一点,让我们先了解一下内核段中平台 RAM 映射的基本位置,这个位置由一个名为
PAGE_OFFSET的内核宏指定。这个宏的精确值非常依赖于架构;我们将把这个讨论留到后面的部分。现在,我们要求您只是相信,在具有 3:1(GB)VM 分割的 IA-32 上,PAGE_OFFSET的值是0xc000 0000。
内核低内存区域的长度或大小等于系统上的 RAM 量。(至少是内核看到的 RAM 量;例如,启用 kdump 功能会让操作系统提前保留一些 RAM)。构成这个区域的虚拟地址被称为内核逻辑地址,因为它们与它们的物理对应物有固定的偏移量。核心内核和设备驱动程序可以通过各种 API(我们将在接下来的两章中详细介绍这些 API)从这个区域分配(物理连续的)内存。内核静态文本(代码)、数据和 BSS(未初始化数据)内存也驻留在这个低内存区域内。
-
内核 vmalloc 区域:这是内核 VAS 的一个完全虚拟的区域。核心内核和/或设备驱动程序代码可以使用
vmalloc()(和其他类似的)API 从这个区域分配虚拟连续的内存。同样,我们将在第八章和第九章中详细介绍这一点,即模块作者的内核内存分配第一部分和模块作者的内核内存分配第二部分。这也是所谓的ioremap空间。 -
内核模块空间:内核 VAS 的一个区域被留出来,用于存放可加载内核模块(LKMs)的静态文本和数据所占用的内存。当您执行
insmod(8)时,生成的[f]init_module(2)系统调用的底层内核代码会从这个区域分配内存(通常通过vmalloc()API),并将内核模块的(静态)代码和数据加载到那里。
前面的图(图 7.10)故意保持简单甚至有点模糊,因为确切的内核虚拟内存布局非常依赖于架构。我们将暂时抑制绘制详细图表的冲动。相反,为了使这个讨论不那么学究,更实用和有用,我们将在即将到来的一节中介绍一个内核模块,该模块查询并打印有关内核段布局的相关信息。只有在我们对特定架构的内核段的各个区域有了实际值之后,我们才会呈现详细的图表。
学究地(如图 7.10 所示),属于低内存区域的地址被称为内核逻辑地址(它们与它们的物理对应物有固定的偏移量),而内核段的其余地址被称为 KVA。尽管在这里做出了这样的区分,请意识到,实际上,这是一个相当学究的区分:我们通常会简单地将内核段内的所有地址称为 KVA。
在此之前,还有几个其他信息要涵盖。让我们从另一个特殊情况开始,这主要是由 32 位架构的限制带来的:内核段的所谓高内存区域。
32 位系统上的高内存
关于我们之前简要讨论过的内核低内存区域,有一个有趣的观察结果。在一个 32 位系统上,例如,3:1(GB)的 VM 分割(就像图 7.10 所描述的那样),拥有(例如)512 MB RAM 的系统将其 512 MB RAM 直接映射到从PAGE_OFFSET(3 GB 或 KVA 0xc000 0000)开始的内核中。这是非常清楚的。
但是想一想:如果系统有更多的 RAM,比如 2GB,会发生什么?现在很明显,我们无法将整个 RAM 直接映射到 lowmem 区域。它根本就放不下(例如,在这个例子中,整个可用的内核 VAS 只有 1GB,而 RAM 是 2GB)!因此,在 32 位 Linux 操作系统上,允许将一定数量的内存(通常是 IA-32 上的 768MB)直接映射,因此落入 lowmem 区域。剩下的 RAM 则间接映射到另一个内存区域,称为ZONE_HIGHMEM(我们认为它是一个高内存区域或区域,与 lowmem 相对;关于内存区域的更多信息将在后面的部分区域中介绍)。更准确地说,由于内核现在发现不可能一次性直接映射所有物理内存,它设置了一个(虚拟)区域,可以在其中设置和使用该 RAM 的临时虚拟映射。这就是所谓的高内存区域。
不要被“高内存”这个词所迷惑;首先,它不一定放在内核段的“高”位置,其次,这并不是high_memory全局变量所代表的 - 它(high_memory)代表了内核的 lowmem 区域的上限。关于这一点,后面的部分会有更多介绍,描述内核段布局的宏和变量。
然而,现在(特别是 32 位系统越来越少使用),这些问题在 64 位 Linux 上完全消失了。想想看:在 64 位 Linux 上,x86_64 的内核段大小达到了 128 TB(!)。目前没有任何系统的 RAM 接近这么多。因此,所有平台的 RAM 确实(轻松地)可以直接映射到内核段,而ZONE_HIGHMEM(或等效)的需求也消失了。
再次,内核文档提供了有关这个“高内存”区域的详细信息。如果感兴趣,请查看:www.kernel.org/doc/Documentation/vm/highmem.txt。
好的,现在让我们来做我们一直在等待的事情 - 编写一个内核模块(LKM)来深入了解内核段的一些细节。
编写一个内核模块来显示有关内核段的信息
正如我们所了解的,内核段由各种区域组成。有些是所有架构(与架构无关)共有的:它们包括 lowmem 区域(其中包含未压缩的内核映像 - 其代码、数据、BSS 等)、内核模块区域、vmalloc/ioremap区域等。
这些区域在内核段中的精确位置,以及可能存在的区域,都与特定的架构(CPU)有关。为了帮助理解并针对任何给定的系统进行固定,让我们开发一个内核模块,查询并打印有关内核段的各种细节(实际上,如果需要,它还会打印一些有用的用户空间内存细节)。
通过 dmesg 查看树莓派上的内核段
在跳入并分析这样一个内核模块的代码之前,事实上,类似于我们在这里尝试的事情 - 打印内核段/VAS 中各种有趣区域的位置和大小 - 已经在流行的树莓派(ARM)Linux 内核的早期引导时执行。在下面的片段中,我们展示了树莓派 3 B+(运行默认的 32 位树莓派 OS)启动时内核日志的相关输出:
rpi $ uname -r 4.19.97-v7+ rpi $ journalctl -b -k
[...]
Apr 02 14:32:48 raspberrypi kernel: Virtual kernel memory layout:
vector : 0xffff0000 - 0xffff1000 ( 4 kB)
fixmap : 0xffc00000 - 0xfff00000 (3072 kB)
vmalloc : 0xbb800000 - 0xff800000 (1088 MB)
lowmem : 0x80000000 - 0xbb400000 ( 948 MB)
modules : 0x7f000000 - 0x80000000 ( 16 MB)
.text : 0x(ptrval) - 0x(ptrval) (9184 kB)
.init : 0x(ptrval) - 0x(ptrval) (1024 kB)
.data : 0x(ptrval) - 0x(ptrval) ( 654 kB)
.bss : 0x(ptrval) - 0x(ptrval) ( 823 kB)
[...]
需要注意的是,前面的打印非常特定于操作系统和设备。默认的树莓派 32 位操作系统会打印这些信息,而其他操作系统可能不会:YMMV(你的情况可能有所不同!)。例如,我在设备上构建和运行的标准的树莓派 5.4 内核中,这些信息性的打印是不存在的。在最近的内核版本中(如在 4.19.97-v7+树莓派操作系统内核的前面日志中所见),出于安全原因 - 防止内核信息泄漏 - 许多早期的printk函数不会显示“真实”的内核地址(指针)值;你可能只会看到它打印了0x(ptrval)字符串。
这个**0x(ptrval)**输出意味着内核故意不显示甚至是散列的 printk(回想一下第五章,编写你的第一个内核模块 - LKMs 第二部分中的%pK格式说明符),因为系统熵还不够高。如果你坚持要看到一个(弱)散列的 printk,你可以在启动时传递debug_boot_weak_hash内核参数(在这里查找内核启动参数的详细信息:www.kernel.org/doc/html/latest/admin-guide/kernel-parameters.html)。
有趣的是,(如前面信息框中提到的),打印这个Virtual kernel memory layout :信息的代码非常特定于树莓派内核补丁!它可以在树莓派内核源代码树中找到:github.com/raspberrypi/linux/blob/rpi-5.4.y/arch/arm/mm/init.c。
现在,为了查询和打印类似的信息,你必须首先熟悉一些关键的内核宏和全局变量;我们将在下一节中这样做。
描述内核段布局的宏和变量
要编写一个显示相关内核段信息的内核模块,我们需要知道如何询问内核这些细节。在本节中,我们将简要描述内核中表示内核段内存的一些关键宏和变量(在大多数架构上,按 KVA 降序排列):
- 向量表 是一个常见的操作系统数据结构 - 它是一个函数指针数组(也称为切换表或跳转表)。它是特定于架构的:ARM-32 使用它来初始化它的向量,以便当处理器发生异常或模式更改(如中断,系统调用,页错误,MMU 中止等)时,处理器知道要运行的代码:
| 宏或变量 | 解释 |
|---|---|
VECTORS_BASE | 通常仅适用于 ARM-32;内核向量表的起始 KVA,跨越 1 页 |
- fix map 区域 是一系列编译时的特殊或保留的虚拟地址;它们在启动时被用来修复内核段中必须为其提供内存的必需内核元素。典型的例子包括初始化内核页表,早期的
ioremap和vmalloc区域等。同样,它是一个与架构相关的区域,因此在不同的 CPU 上使用方式不同:
| 宏或变量 | 解释 |
|---|---|
FIXADDR_START | 内核 fixmap 区域的起始 KVA,跨越FIXADDR_SIZE字节 |
- 内核模块 在内核段中的特定范围内分配内存 - 用于它们的静态文本和数据。内核模块区域的精确位置因架构而异。在 ARM 32 位系统上,实际上是放在用户 VAS 的正上方;而在 64 位系统上,通常放在内核段的更高位置:
| 内核模块(LKMs)区域 | 从这里分配内存用于 LKMs 的静态代码+数据 |
|---|---|
MODULES_VADDR | 内核模块区域的起始 KVA |
MODULES_END | 内核模块区域的结束 KVA;大小为MODULES_END - MODULES_VADDR |
- KASAN*😗 现代内核(从 x86_64 的 4.0 版本开始,ARM64 的 4.4 版本开始)采用了一种强大的机制来检测和报告内存问题。它基于用户空间地址 SANitizer(ASAN)代码库,因此被称为内核地址 SANitizer(KASAN)。它的强大之处在于能够(通过编译时的插装)检测内存问题,如释放后使用(UAF)和越界(OOB)访问(包括缓冲区溢出/溢出)。但是,它仅在 64 位 Linux 上工作,并且需要一个相当大的阴影内存区域(大小为内核 VAS 的八分之一,如果启用则显示其范围)。它是一个内核配置功能(
CONFIG_KASAN),通常仅用于调试目的(但在调试和测试期间保持启用非常关键!):
| KASAN 阴影内存区域(仅适用于 64 位) | [可选](仅在 64 位且仅在 CONFIG_KASAN 定义的情况下;请参见以下更多信息) |
|---|---|
KASAN_SHADOW_START | KASAN 区域的 KVA 起始 |
KASAN_SHADOW_END | KASAN 区域的 KVA 结束;大小为KASAN_SHADOW_END - KASAN_SHADOW_START |
- vmalloc 区域是为
vmalloc()(及其相关函数)分配内存的空间;我们将在接下来的两章节中详细介绍各种内存分配 API:
| vmalloc 区域 | 用于通过 vmalloc()和相关函数分配的内存 |
|---|---|
VMALLOC_START | vmalloc区域的 KVA 起始 |
VMALLOC_END | vmalloc区域的结束 KVA;大小为VMALLOC_END - VMALLOC_START |
- 低内存区域 - 根据
1:1 ::物理页框:内核页的基础,直接映射到内核段的 RAM 区域 - 实际上是 Linux 内核映射和管理(通常)所有 RAM 的区域。此外,它通常在内核中设置为ZONE_NORMAL(稍后我们还将介绍区域):
| 低内存区域 | 直接映射内存区域 |
|---|---|
PAGE_OFFSET | 低内存区域的 KVA 起始;也代表某些架构上内核段的起始,并且(通常)是 32 位上的 VM 分割值。 |
high_memory | 低内存区域的结束 KVA,直接映射内存的上限;实际上,这个值减去PAGE_OFFSET就是系统上 RAM 的数量(注意,这并不一定适用于所有架构);不要与ZONE_HIGHMEM混淆。 |
- 高内存区域或区域是一个可选区域。它可能存在于一些 32 位系统上(通常是当 RAM 的数量大于内核段本身的大小时)。在这种情况下,它通常设置为
ZONE_HIGHMEM(稍后我们将介绍区域)。此外,您可以在之前的标题为32 位系统上的高内存的部分中了解更多关于这个高内存区域的信息:
| 高内存区域(仅适用于 32 位) | [可选] 在一些 32 位系统上可能存在 HIGHMEM |
|---|---|
PKMAP_BASE | 高内存区域的 KVA 起始,直到LAST_PKMAP页;表示所谓的高内存页的内核映射(较旧,仅适用于 32 位) |
- 内核镜像本身(未压缩)- 其代码、
init和数据区域 - 是私有符号,因此对内核模块不可用;我们不尝试打印它们:
| 内核(静态)镜像 | 未压缩内核镜像的内容(请参见以下);不导出,因此对模块不可用 |
|---|---|
_text, _etext | 内核文本(代码)区域的起始和结束 KVA(分别) |
__init_begin, __init_end | 内核init部分区域的起始和结束 KVA(分别) |
_sdata, _edata | 内核静态数据区域的起始和结束 KVA(分别) |
__bss_start, __bss_stop | 内核 BSS(未初始化数据)区域的起始和结束 KVA(分别) |
- 用户 VAS:最后一项当然是进程用户 VAS。它位于内核段的下方(按虚拟地址降序排列),大小为
TASK_SIZE字节。在本章的前面部分已经详细讨论过:
| 用户 VAS | 用户虚拟地址空间(VAS) |
|---|---|
(用户模式 VAS 如下)TASK_SIZE | (通过procfs或我们的procmap实用程序脚本之前详细检查过);内核宏TASK_SIZE表示用户 VAS 的大小(字节)。 |
好了,我们已经看到了几个内核宏和变量,实际上描述了内核 VAS。
继续我们的内核模块的代码,很快您将看到它的init方法调用了两个重要的函数:
-
show_kernelseg_info(),打印相关的内核段细节 -
show_userspace_info(),打印相关的用户 VAS 细节(这是可选的,通过内核参数决定)
我们将从描述内核段函数并查看其输出开始。此外,Makefile 的设置方式是,它链接到我们的内核库代码的对象文件klib_llkd.c*,并生成一个名为show_kernel_seg.ko的内核模块对象。
试一下 - 查看内核段细节
为了清晰起见,我们将在本节中仅显示源代码的相关部分。 请从本书的 GitHub 存储库中克隆并使用完整的代码。 还要记住之前提到的procmap实用程序; 它有一个内核组件,一个 LKM,它确实与此类似 - 使内核级信息可用于用户空间。 由于它更复杂,我们不会在这里深入研究它的代码; 看到以下演示内核模块show_kernel_seg的代码在这里已经足够了:
// ch7/show_kernel_seg/kernel_seg.c
[...]
static void show_kernelseg_info(void)
{
pr_info("\nSome Kernel Details [by decreasing address]\n"
"+-------------------------------------------------------------+\n");
#ifdef CONFIG_ARM
/* On ARM, the definition of VECTORS_BASE turns up only in kernels >= 4.11 */
#if LINUX_VERSION_CODE > KERNEL_VERSION(4, 11, 0)
pr_info("|vector table: "
" %px - %px | [%4ld KB]\n",
SHOW_DELTA_K(VECTORS_BASE, VECTORS_BASE + PAGE_SIZE));
#endif
#endif
前面的代码片段显示了 ARM 向量表的范围。 当然,这是有条件的。 输出仅在 ARM-32 上发生 - 因此有#ifdef CONFIG_ARM预处理指令。(此外,我们使用%px printk 格式说明符确保代码是可移植的。)
在这个演示内核模块中使用的SHOW_DELTA_*()宏在我们的convenient.h头文件中定义,并且是帮助程序,使我们能够轻松显示传递给它的低值和高值,计算两个数量之间的差异,并显示它; 这是相关的代码:
// convenient.h
[...]
/* SHOW_DELTA_*(low, hi) :
* Show the low val, high val and the delta (hi-low) in either bytes/KB/MB/GB, as required.
* Inspired from raspberry pi kernel src: arch/arm/mm/init.c:MLM()
*/
#define SHOW_DELTA_b(low, hi) (low), (hi), ((hi) - (low))
#define SHOW_DELTA_K(low, hi) (low), (hi), (((hi) - (low)) >> 10)
#define SHOW_DELTA_M(low, hi) (low), (hi), (((hi) - (low)) >> 20)
#define SHOW_DELTA_G(low, hi) (low), (hi), (((hi) - (low)) >> 30)
#define SHOW_DELTA_MG(low, hi) (low), (hi), (((hi) - (low)) >> 20), (((hi) - (low)) >> 30)
在以下代码中,我们展示了发出printk函数描述以下区域范围的代码片段:
-
内核模块区域
-
(可选)KASAN 区域
-
vmalloc 区域
-
低内存和可能的高内存区域
关于内核模块区域,如下面源代码中的详细注释所解释的那样,我们尝试保持按降序 KVAs 的顺序:
// ch7/show_kernel_seg/kernel_seg.c
[...]
/* kernel module region
* For the modules region, it's high in the kernel segment on typical 64-
* bit systems, but the other way around on many 32-bit systems
* (particularly ARM-32); so we rearrange the order in which it's shown
* depending on the arch, thus trying to maintain a 'by descending address' ordering. */
#if (BITS_PER_LONG == 64)
pr_info("|module region: "
" %px - %px | [%4ld MB]\n",
SHOW_DELTA_M(MODULES_VADDR, MODULES_END));
#endif
#ifdef CONFIG_KASAN // KASAN region: Kernel Address SANitizer
pr_info("|KASAN shadow: "
" %px - %px | [%2ld GB]\n",
SHOW_DELTA_G(KASAN_SHADOW_START, KASAN_SHADOW_END));
#endif
/* vmalloc region */
pr_info("|vmalloc region: "
" %px - %px | [%4ld MB = %2ld GB]\n",
SHOW_DELTA_MG(VMALLOC_START, VMALLOC_END));
/* lowmem region */
pr_info("|lowmem region: "
" %px - %px | [%4ld MB = %2ld GB]\n"
#if (BITS_PER_LONG == 32)
"| (above:PAGE_OFFSET - highmem) |\n",
#else
"| (above:PAGE_OFFSET - highmem) |\n",
#endif
SHOW_DELTA_MG((unsigned long)PAGE_OFFSET, (unsigned long)high_memory));
/* (possible) highmem region; may be present on some 32-bit systems */
#ifdef CONFIG_HIGHMEM
pr_info("|HIGHMEM region: "
" %px - %px | [%4ld MB]\n",
SHOW_DELTA_M(PKMAP_BASE, (PKMAP_BASE) + (LAST_PKMAP * PAGE_SIZE)));
#endif
[ ... ]
#if (BITS_PER_LONG == 32) /* modules region: see the comment above reg this */
pr_info("|module region: "
" %px - %px | [%4ld MB]\n",
SHOW_DELTA_M(MODULES_VADDR, MODULES_END));
#endif
pr_info(ELLPS);
}
让我们在 ARM-32 Raspberry Pi 3 B+上构建和插入我们的 LKM; 以下屏幕截图显示了它的设置,然后是内核日志:

图 7.11 - 在运行标准 Raspberry Pi 32 位 Linux 的 Raspberry Pi 3B+上显示 show_kernel_seg.ko LKM 的输出
正如预期的那样,我们收到的关于内核段的输出完全匹配标准 Raspberry Pi 内核在启动时打印的内容(您可以参考通过 dmesg 查看 Raspberry Pi 上的内核段部分来验证这一点)。 从PAGE_OFFSET的值(图 7.11 中的 KVA 0x8000 0000)可以解释出来,我们的 Raspberry Pi 的内核的 VM 分割配置为 2:2(GB)(因为十六进制值0x8000 0000在十进制基数中为 2 GB。有趣的是,更近期的 Raspberry Pi 4 Model B 设备上的默认 Raspberry Pi 32 位操作系统配置为 3:1(GB)VM 分割)。
从技术上讲,在 ARM-32 系统上,至少用户空间略低于 2 GB(2 GB - 16 MB = 2,032 MB),因为这 16 MB 被视为内核模块区域,就在PAGE_OFFSET下面;确实,这可以在图 7.11 中看到(这里的内核模块区域跨越了0x7f00 0000到0x8000 0000的 16 MB)。 此外,正如您很快将看到的,TASK_SIZE宏的值 - 用户 VAS 的大小 - 也反映了这一事实。
我们在以下图表中展示了大部分这些信息:

图 7.12 - Raspberry Pi 3B+上 ARM-32 进程的完整 VAS,具有 2:2 GB VM 分割
请注意,由于不同型号之间的差异、可用 RAM 的数量,甚至设备树的不同,图 7.12 中显示的布局可能与您拥有的树莓派上的布局并不完全匹配。
好了,现在您知道如何在内核模块中打印相关的内核段宏和变量,帮助您了解任何 Linux 系统上的内核 VM 布局!在接下来的部分中,我们将尝试通过我们的procmap实用程序“看”(可视化)内核 VAS。
通过 procmap 的内核 VAS
好了,这很有趣:在前面的图中以某些细节看到的内存映射布局的视图正是我们前面提到的procmap实用程序提供的!正如之前承诺的,现在让我们看一下运行procmap时内核 VAS 的截图(之前,我们展示了用户 VAS 的截图)。
为了与即时讨论保持同步,我们现在将展示procmap在同一台树莓派 3B+系统上提供内核 VAS 的“视觉”视图的截图(我们可以指定--only-kernel开关来仅显示内核 VAS;尽管我们在这里没有这样做)。由于我们必须在某个进程上运行procmap,我们任意选择systemd PID 1;我们还使用--verbose选项开关。然而,似乎失败了:

图 7.13 - 显示 procmap 内核模块构建失败的截图
为什么构建内核模块失败了(这是procmap项目的一部分)?我在项目的README.md文件中提到了这一点(github.com/kaiwan/procmap/blob/master/README.md#procmap):
[...]to build a kernel module on the target system, you will require it to have a kernel development environment setup; this boils down to having the compiler, make and - key here - the 'kernel headers' package installed for the kernel version it's currently running upon. [...]
我们的自定义5.4 内核(用于树莓派)的内核头文件包不可用,因此失败了。虽然您可以想象地将整个 5.4 树莓派内核源树复制到设备上,并设置/lib/module/<kver>/build符号链接,但这并不被认为是正确的做法。那么,正确的做法是什么?当然是从主机上交叉编译树莓派的procmap内核模块!我们在这里的第三章中涵盖了有关从源代码构建树莓派内核的交叉编译的详细信息,构建 5.x Linux 内核的第二部分,在树莓派的内核构建部分;当然,这也适用于交叉编译内核模块。
我想强调一点:树莓派上的procmap内核模块构建仅因为在运行自定义内核时缺少树莓派提供的内核头文件包而失败。如果您愿意使用默认的树莓派内核(之前称为 Raspbian OS),那么内核头文件包肯定是可安装的(或已安装),一切都将正常工作。同样,在您典型的 x86_64 Linux 发行版上,procmap.ko内核模块可以在运行时得到干净地构建和插入。请仔细阅读procmap项目的README.md文件;其中,标有IMPORTANT: Running procmap on systems other than x86_64的部分详细说明了如何交叉编译procmap内核模块。
一旦您成功在主机系统上交叉编译了procmap内核模块,通过scp(1)将procmap.ko内核模块复制到设备上,并将其放置在procmap/procmap_kernel目录下;现在您已经准备好了!
这是复制到树莓派上的内核模块:
cd <...>/procmap/procmap_kernel
ls -l procmap.ko
-rw-r--r-- 1 pi pi 7909 Jul 31 07:45 procmap.ko
(您也可以在其上运行modinfo(8)实用程序,以验证它是否为 ARM 构建。)
有了这个,让我们重试一下我们的procmap运行,以显示内核 VAS 的详细信息:

图 7.14 - 显示 procmap 内核模块成功插入和各种系统详细信息的截图
现在它确实起作用了!由于我们已经将verbose选项指定给procmap,因此您可以看到它的详细进展,以及非常有用的各种感兴趣的内核变量/宏及其当前值。
好的,让我们继续查看我们真正想要的内容-树莓派 3B+上内核 VAS 的“可视地图”,按 KVA 降序排列;以下截图捕获了procmap的输出:

图 7.15-我们的 procmap 实用程序输出的部分截图,显示了树莓派 3B+上完整的内核 VAS(32 位 Linux)
完整的内核 VAS-从end_kva(值为0xffff ffff)右到内核的开始,start_kva(0x7f00 0000,正如你所看到的,是内核模块区域)-被显示出来。请注意(绿色)标签右侧的某些关键地址的标注!为了完整起见,我们还在前面的截图中包括了内核-用户边界(以及用户 VAS 的上部分,就像我们一直在说的那样!)。由于前面的输出是在 32 位系统上,用户 VAS 紧随内核段。然而,在 64 位系统上,内核段和用户 VAS 之间有一个(巨大的!)“非规范”稀疏区域。在 x86_64 上(正如我们已经讨论过的),它跨越了 VAS 的绝大部分:16,383.75 拍字节(总 VAS 为 16,384 拍字节)!
我将把运行这个procmap项目的练习留给你,仔细研究你的 x86_64 或其他盒子或虚拟机上的输出。它在带有 3:1 虚拟机分割的 BeagleBone Black 嵌入式板上也能正常工作,显示了预期的详细信息。顺便说一句,这构成了一个作业。
我还提供了一个解决方案,以三个(大的、拼接在一起的)procmap输出的截图形式,分别是在本机 x86_64 系统、BeagleBone Black(AArch32)板和运行 64 位操作系统(AArch64)的树莓派上:solutions_to_assgn/ch7。研究procmap的代码*,*特别是它的内核模块组件,肯定会有所帮助。毕竟它是开源的!
让我们通过查看我们之前的演示内核模块ch7/show_kernel_seg提供的用户段视图来完成本节。
尝试一下-用户段
现在,让我们回到我们的ch7/show_kernel_segLKM 演示程序。我们提供了一个名为show_uservas的内核模块参数(默认值为0);当设置为1时,还会显示有关进程上下文的用户空间的一些详细信息。以下是模块参数的定义:
static int show_uservas;
module_param(show_uservas, int, 0660);
MODULE_PARM_DESC(show_uservas,
"Show some user space VAS details; 0 = no (default), 1 = show");
好了,在同一设备上(我们的树莓派 3 B+),让我们再次运行我们的show_kernel_seg内核模块,这次请求它也显示用户空间的详细信息(通过前面提到的参数)。以下截图显示了完整的输出:

图 7.16-我们的 show_kernel_seg.ko LKM 的输出截图,显示了在树莓派 3B+上运行时内核和用户 VAS 的详细信息,带有树莓派 32 位 Linux 操作系统
这很有用;我们现在可以看到进程的(或多或少)完整的内存映射-所谓的“上(规范)半”内核空间以及“下(规范)半”用户空间-一次性看清楚(是的,没错,尽管procmap项目显示得更好,更详细)。
我将把运行这个内核模块的练习留给你,仔细研究你的 x86_64 或其他盒子或虚拟机上的输出。也要仔细阅读代码。我们通过从current中解引用mm_struct结构(名为mm的任务结构成员)打印了你在前面截图中看到的用户空间详细信息的代码段。回想一下,mm是进程用户映射的抽象。执行此操作的代码片段如下:
// ch7/show_kernel_seg/kernel_seg.c
[ ... ]
static void show_userspace_info(void)
{
pr_info (
"+------------ Above is kernel-seg; below, user VAS ----------+\n"
ELLPS
"|Process environment "
" %px - %px | [ %4zd bytes]\n"
"| arguments "
" %px - %px | [ %4zd bytes]\n"
"| stack start %px\n"
[...],
SHOW_DELTA_b(current->mm->env_start, current->mm->env_end),
SHOW_DELTA_b(current->mm->arg_start, current->mm->arg_end),
current->mm->start_stack,
[...]
还记得用户 VAS 开头的所谓空陷阱页面吗?(再次,procmap的输出-参见图 7.9显示了空陷阱页面。)让我们在下一节中看看它是用来做什么的。
空陷阱页面
您是否注意到前面的图表(图 7.9)和图 7.12 中,极左边(尽管非常小!)用户空间开头的单个页面,名为null trap页面?这是什么?很简单:虚拟页面0在硬件 MMU/PTE 级别上没有权限。因此,对该页面的任何访问,无论是r,w还是x(读/写/执行),都将导致 MMU 引发所谓的故障或异常。这将使处理器跳转到 OS 处理程序(故障处理程序)。它运行,杀死试图访问没有权限的内存区域的罪犯!
非常有趣:先前提到的 OS 处理程序实际上在进程上下文中运行,猜猜current是什么:哦,它是启动这个坏NULL指针查找的进程(或线程)!在故障处理程序代码中,SIGSEGV信号被传递给故障进程(current),导致其死亡(通过段错误)。简而言之,这就是 OS 如何捕获众所周知的NULL指针解引用错误的方式。
查看内核文档中的内存布局
回到内核段;显然,对于 64 位 VAS,内核段比 32 位的要大得多。正如我们之前看到的,对于 x86_64,它通常是 128 TB。再次研究先前显示的 VM 分割表(图 7.4 中的64 位 Linux 系统上的 VM 分割部分);在那里,第四列是不同架构的 VM 分割。您可以看到在 64 位 Intel/AMD 和 AArch64(ARM64)上,这些数字比 32 位的大得多。有关特定于架构的详细信息,我们建议您参考此处有关进程虚拟内存布局的“官方”内核文档:
| 架构 | 内核源树中的文档位置 |
|---|---|
| ARM-32 | Documentation/arm/memory.txt。 |
| AArch64 | Documentation/arm64/memory.txt。 |
| x86_64 | Documentation/x86/x86_64/mm.txt 注意:此文档的可读性最近得到了极大改善(截至撰写时)Linux 4.20 的提交32b8976:github.com/torvalds/linux/commit/32b89760ddf4477da436c272be2abc016e169031。我建议您浏览此文件:www.kernel.org/doc/Documentation/x86/x86_64/mm.txt。 |
冒着重复的风险,我敦促您尝试这个show_kernel_seg内核模块 - 更好的是,procmap项目(github.com/kaiwan/procmap)- 在不同的 Linux 系统上并研究输出。然后,您可以直接看到任何给定进程的“内存映射” - 完整的进程 VAS - 包括内核段!在处理和/或调试系统层问题时,这种理解至关重要。
再次冒着过度陈述的风险,前两节 - 涵盖对用户和内核 VASes进行详细检查 - 确实非常重要。确保花费足够的时间来研究它们并处理示例代码和作业。做得好!
在我们通过 Linux 内核内存管理的旅程中继续前进,现在让我们来看看另一个有趣的主题 - [K]ASLR 通过内存布局随机化功能的保护。继续阅读!
随机化内存布局 - KASLR
在信息安全圈中,众所周知的事实是,利用proc 文件系统(procfs)和各种强大的工具,恶意用户可以预先知道进程 VAS 中各种函数和/或全局变量的精确位置(虚拟地址),从而设计攻击并最终 compromise 给定系统。因此,为了安全起见,为了使攻击者无法依赖于“已知”虚拟地址,用户空间以及内核空间支持**ASLR(地址空间布局随机化)和KASLR(内核 ASLR)**技术(通常发音为*Ass-*ler / Kass-ler)。
这里的关键词是随机化: 当启用此功能时,它会改变进程(和内核)内存布局的部分位置,以绝对数字来说,它会通过随机(页面对齐)数量偏移内存的部分从给定的基址。我们到底在谈论哪些“内存部分”?关于用户空间映射(稍后我们将讨论 KASLR),共享库的起始地址(它们的加载地址),mmap(2)-based 分配(记住,任何malloc()函数(/calloc/realloc*)*超过 128 KB 都会成为mmap-based 分配,而不是堆外分配),堆栈起始位置,堆和 vDSO 页面;所有这些都可以在进程运行(启动)时被随机化。
因此,攻击者不能依赖于,比如说,glibc函数(比如system(3))在任何给定进程中被映射到特定的固定 UVA;不仅如此,位置每次进程运行时都会变化!在 ASLR 之前,以及在不支持或关闭 ASLR 的系统上,可以提前确定给定架构和软件版本的符号位置(procfs 加上诸如objdump、readelf、nm等实用程序使这变得非常容易)。
关键在于要意识到[K]ASLR 只是一种统计保护。事实上,通常情况下,并没有太多比特可用于随机化,因此熵并不是很好。这意味着即使在 64 位系统上,页面大小的偏移量也不是很多,因此可能导致实现受到削弱。
现在让我们简要地看一下关于用户模式和内核模式 ASLR(后者被称为 KASLR)的更多细节;以下各节分别涵盖了这些领域。
用户模式 ASLR
通常所说的 ASLR 指的是用户模式 ASLR。它的启用意味着这种保护在每个进程的用户空间映射上都是可用的。实际上,ASLR 的启用意味着用户模式进程的绝对内存映射每次运行时都会有所变化。
ASLR 在 Linux 上已经得到支持很长时间了(自 2.6.12 以来)。内核在 procfs 中有一个可调的伪文件,可以查询和设置(作为 root)ASLR 的状态;在这里:/proc/sys/kernel/randomize_va_space。
它可以有三个可能的值;这三个值及其含义如下表所示:
| 可调值 | 在/proc/sys/kernel/randomize_va_space中对该值的解释 |
|---|---|
0 | (用户模式)ASLR 已关闭;或者可以通过在启动时传递内核参数norandmaps来关闭。 |
1 | (用户模式)ASLR 已开启:基于mmap(2)的分配,堆栈和 vDSO 页面被随机化。这也意味着共享库加载位置和共享内存段被随机化。 |
2 | (用户模式)ASLR 已开启:所有前述(值1)加上堆位置被随机化(自 2.6.25 起);这是默认的操作系统值。 |
(正如前面的一节中所指出的,vsyscall 页面,vDSO 页面是一种系统调用优化,允许一些频繁发出的系统调用(gettimeofday(2)是一个典型的例子)以更少的开销来调用。如果感兴趣,您可以在这里查看有关 vDSO(7)的 man 页面的更多详细信息:man7.org/linux/man-pages/man7/vdso.7.html。)
用户模式 ASLR 可以通过在启动时通过引导加载程序向内核传递norandmaps参数来关闭。
KASLR
类似于(用户)ASLR - 而且,更近期的是从 3.14 内核开始 - 甚至内核VAS 也可以通过启用 KASLR 来随机化(在某种程度上)。在这里,内核和内核段内的模块代码的基本位置将通过与 RAM 基址的页面对齐随机偏移量而被随机化。这将在该会话中保持有效;也就是说,直到重新上电或重启。
存在多个内核配置变量,使平台开发人员能够启用或禁用这些随机化选项。作为 x86 特定的一个例子,以下是直接从Documentation/x86/x86_64/mm.txt中引用的:
“请注意,如果启用了 CONFIG_RANDOMIZE_MEMORY,所有物理内存的直接映射,vmalloc/ioremap 空间和虚拟内存映射都将被随机化。它们的顺序被保留,但它们的基址将在引导时提前偏移。”
KASLR 可以通过向内核传递参数(通过引导加载程序)在引导时进行控制:
-
通过传递
nokaslr参数明确关闭 -
通过传递
kaslr参数明确打开
那么,您的 Linux 系统当前的设置是什么?我们可以更改它吗?当然可以(只要我们有root访问权限);下一节将向您展示如何通过 Bash 脚本进行操作。
使用脚本查询/设置 KASLR 状态
我们在<book-source>/ch7/ASLR_check.sh提供了一个简单的 Bash 脚本。它检查(用户模式)ASLR 和 KASLR 的存在,并打印(彩色编码!)有关它们的状态信息。它还允许您更改 ASLR 值。
让我们在我们的 x86_64 Ubuntu 18.04 客户端上试一试。由于我们的脚本被编程为彩色编码,我们在这里展示它的输出截图:

图 7.17 - 当我们的 ch7/ASLR_check.sh Bash 脚本在 x86_64 Ubuntu 客户端上运行时显示的输出截图
它运行,向您显示(至少在此框上)用户模式和 KASLR 确实已打开。不仅如此,我们编写了一个小的“测试”例程来查看 ASLR 的功能。它非常简单:运行以下命令两次:
grep -E "heap|stack" /proc/self/maps
根据您在早期章节中学到的内容,解释/proc/PID/maps 输出,您现在可以在图 7.17 中看到,堆和栈段的 UVAs 在每次运行中都是不同的,从而证明 ASLR 功能确实有效!例如,看一下起始堆 UVA:在第一次运行中,它是0x5609 15f8 2000,在第二次运行中,它是0x5585 2f9f 1000。
接下来,我们将进行一个示例运行,其中我们向脚本传递参数0,从而关闭 ASLR;以下截图显示了(预期的)输出:

图 7.18 - 展示了如何通过我们的 ch7/ASLR_check.sh 脚本在 x86_64 Ubuntu 客户端上关闭 ASLR 的截图
这一次,我们可以看到 ASLR 默认是打开的,但我们关闭了它。这在上面的截图中以粗体和红色清楚地突出显示。(请记住再次打开它。)此外,正如预期的那样,由于它已关闭,堆和栈的 UVAs(分别)在两次测试运行中保持不变,这是不安全的。我将让您浏览并理解脚本的源代码。
要利用 ASLR,应用程序必须使用-fPIE和-pieGCC 标志进行编译(PIE代表Position Independent Executable)。
ASLR 和 KASLR 都可以防御一些攻击向量,典型情况下是返回到 libc,Return-Oriented Programming(ROP)。然而,不幸的是,白帽和黑帽安全是一场猫鼠游戏,[K]ASLR 和类似的方法被击败是一些高级攻击确实做得很好。有关更多详细信息,请参阅本章的进一步阅读部分(在Linux 内核安全标题下)。
谈到安全性,存在许多有用的工具来对系统进行漏洞检查。查看以下内容:
-
checksec.sh脚本(www.trapkit.de/tools/checksec.html)显示各种“硬化”措施及其当前状态(对于单个文件和进程):RELRO,堆栈 canary,启用 NX,PIE,RPATH,RUNPATH,符号的存在和编译器强化。 -
grsecurity 的 PaX 套件。
-
hardening-check脚本(checksec 的替代品)。 -
kconfig-hardened-checkPerl 脚本(github.com/a13xp0p0v/kconfig-hardened-check)检查(并建议)内核配置选项,以防止一些预定义的检查清单中的安全问题。 -
其他几个:Lynis,
linuxprivchecker.py,内存等等。
因此,下次你在多次运行或会话中看到不同的内核或用户虚拟地址时,你会知道这可能是由于[K]ASLR 保护功能。现在,让我们通过继续探索 Linux 内核如何组织和处理物理内存来完成本章。
物理内存
现在我们已经详细研究了虚拟内存视图,包括用户和内核 VASes,让我们转向 Linux 操作系统上物理内存组织的主题。
物理 RAM 组织
Linux 内核在启动时将物理 RAM 组织和分区为一个类似树状的层次结构,包括节点、区域和页框(页框是物理 RAM 页面)(参见图 7.19 和图 7.20)。节点被划分为区域,区域由页框组成。节点抽象了一个物理的 RAM“bank”,它将与一个或多个处理器(CPU)核心相关联。在硬件级别上,微处理器连接到 RAM 控制器芯片;任何内存控制器芯片,因此任何 RAM,也可以从任何 CPU 访问,通过一个互连。显然,能够物理上接近线程正在分配(内核)内存的核心的 RAM 将会提高性能。这个想法被支持所谓的 NUMA 模型的硬件和操作系统所利用(这个含义很快就会解释)。
节点
基本上,节点是用于表示系统主板上的物理 RAM 模块及其相关控制器芯片的数据结构。是的,我们在这里谈论的是实际的硬件通过软件元数据进行抽象。它总是与系统主板上的物理插座(或处理器核心集合)相关联。存在两种类型的层次结构:
-
**非统一内存访问(NUMA)**系统:核心对内核分配请求的位置很重要(内存被非统一地处理),从而提高性能。
-
**统一内存访问(UMA)**系统:核心对内核分配请求的位置并不重要(内存被统一处理)
真正的 NUMA 系统是那些硬件是多核(两个或更多 CPU 核心,SMP)并且有两个或更多物理 RAM“bank”,每个与一个 CPU(或多个 CPU)相关联。换句话说,NUMA 系统将始终具有两个或更多节点,而 UMA 系统将具有一个节点(FYI,抽象节点的数据结构称为pg_data_t,在这里定义:include/linux/mmzone.h:pg_data_t)。
你可能会想为什么会有这么复杂的结构?嗯,这就是——还有什么——都是关于性能! NUMA 系统(它们通常倾向于是相当昂贵的服务器级机器)和它们运行的操作系统(通常是 Linux/Unix/Windows)都是设计成这样的方式,当一个特定 CPU 核心上的进程(或线程)想要执行内核内存分配时,软件会保证通过从最接近核心的节点获取所需的内存(RAM)来实现高性能(因此有了 NUMA 的名字!)。UMA 系统(典型的嵌入式系统、智能手机、笔记本电脑和台式电脑)不会获得这样的好处,也不会有影响。现在的企业级服务器系统可以拥有数百个处理器和数 TB,甚至数 PB 的 RAM!这些几乎总是作为 NUMA 系统进行架构。
然而,由于 Linux 的设计方式,这是一个关键点,即使是常规的 UMA 系统也被内核视为 NUMA(好吧,伪 NUMA)。它们将有恰好一个节点;所以这是一个快速检查系统是否是 NUMA 还是 UMA 的方法 - 如果有两个或更多节点,它是一个真正的 NUMA 系统;只有一个,它就是一个“伪 NUMA”或伪 NUMA 盒子。你怎么检查?numactl(8)实用程序是一种方法(尝试执行numactl --hardware)。还有其他方法(通过procfs本身)。稍等一下,你会到达那里的……
因此,一个更简单的可视化方法是:在 NUMA 盒子上,一个或多个 CPU 核心与一块(硬件模块)物理 RAM 相关联。因此,NUMA 系统总是一个对称多处理器(SMP)系统。
为了使这个讨论更实际,让我们简要地想象一下实际服务器系统的微体系结构——一个运行 AMD Epyc/Ryzen/Threadripper(以及旧的 Bulldozer)CPU 的系统。它有以下内容:
-
在主板上有两个物理插槽(P#0 和 P#1)内的 32 个 CPU 核心(由操作系统看到)。每个插槽包含一个 8x2 CPU 核心的包(8x2,因为实际上每个核心都是超线程的;操作系统甚至将超线程核心视为可用核心)。
-
总共 32GB 的 RAM 分成四个物理内存条,每个 8GB。
因此,Linux 内存管理代码在引导时检测到这种拓扑结构后,将设置四个节点来表示它。(我们不会在这里深入讨论处理器的各种(L1/L2/L3 等)缓存;在下图后的提示框中有一种方法可以查看所有这些。)
以下概念图显示了在运行 Linux OS 的一些 AMD 服务器系统上形成的四个树状层次结构的近似情况 - 每个节点一个。图 7.19 在系统上显示了每个物理 RAM 条的节点/区域/页框:

图 7.19 - Linux 上物理内存层次结构的(近似概念视图)
使用强大的lstopo(1)实用程序(及其相关的hwloc-* - 硬件位置 - 实用程序)来图形化查看系统的硬件(CPU)拓扑结构!(在 Ubuntu 上,使用sudo apt install hwloc进行安装)。值得一提的是,由lstopo(1)生成的先前提到的 AMD 服务器系统的硬件拓扑图可以在这里看到:en.wikipedia.org/wiki/CPU_cache#/media/File:Hwloc.png。
再次强调这里的关键点:为了性能(这里是指图 7.19),在某个处理器上运行一些内核或驱动程序代码的线程在进程上下文中请求内核获取一些 RAM。内核的 MM 层,了解 NUMA,将首先从 NUMA 节点#2 上的任何区域中的任何空闲 RAM 页框中服务请求(作为第一优先级),因为它“最接近”发出请求的处理器核心。以防在 NUMA 节点#2 中的任何区域中没有可用的空闲页框,内核有一个智能的回退系统。它现在可能跨连接并从另一个节点:区域请求 RAM 页框(不用担心,我们将在下一章节中更详细地介绍这些方面)。
区域
区域可以被认为是 Linux 平滑处理和处理硬件怪癖的方式。这些在 x86 上大量存在,Linux 当然是在那里“长大”的。它们还处理一些软件困难(在现在大部分是遗留的 32 位 i386 架构上查找ZONE_HIGHMEM;我们在前面的章节中讨论了这个概念,32 位系统上的高内存)。
区域由页框组成 - 物理 RAM 页。更技术性地说,每个节点内的每个区域都分配了一系列页框号(PFN):

图 7.20 - Linux 上物理内存层次结构的另一个视图 - 节点、区域和页框
在图 7.10 中,您可以看到一个通用(示例)Linux 系统,具有N个节点(从0到N-1),每个节点包含(假设)三个区域,每个区域由 RAM 的物理页面框架组成。每个节点的区域数量(和名称)由内核在启动时动态确定。您可以通过深入procfs来检查 Linux 系统上的层次结构。在下面的代码中,我们来看一下一个具有 16GB RAM 的本机 Linux x86_64 系统:
$ cat /proc/buddyinfo
Node 0, zone DMA 3 2 4 3 3 1 0 0 1 1 3
Node 0, zone DMA32 31306 10918 1373 942 505 196 48 16 4 0 0
Node 0, zone Normal 49135 7455 1917 535 237 89 19 3 0 0 0
$
最左边的列显示我们只有一个节点 - Node 0。这告诉我们实际上我们在一个UMA 系统上,尽管 Linux 操作系统会将其视为(伪/假)NUMA 系统。这个单一的节点0分为三个区域,标记为DMA,DMA32和Normal,每个区域当然由页面框架组成。现在先忽略右边的数字;我们将在下一章中解释它们的含义。
Linux 在 UMA 系统上“伪造”NUMA 节点的另一种方法可以从内核日志中看到。我们在同一个本机 x86_64 系统上运行以下命令,该系统具有 16GB 的 RAM。为了便于阅读,我用省略号替换了显示时间戳和主机名的前几列:
$ journalctl -b -k --no-pager | grep -A7 "NUMA"
<...>: No NUMA configuration found
<...>: Faking a node at [mem 0x0000000000000000-0x00000004427fffff]
<...>: NODE_DATA(0) allocated [mem 0x4427d5000-0x4427fffff]
<...>: Zone ranges:
<...>:DMA [mem 0x0000000000001000-0x0000000000ffffff]
<...>: DMA32 [mem 0x0000000001000000-0x00000000ffffffff]
<...>: Normal [mem 0x0000000100000000-0x00000004427fffff]
<...>: Device empty
$
我们可以清楚地看到,由于系统被检测为非 NUMA(因此是 UMA),内核会伪造一个节点。节点的范围是系统上的总 RAM 量(这里是0x0-0x00000004427fffff,确实是 16GB)。我们还可以看到在这个特定系统上,内核实例化了三个区域 - DMA,DMA32和Normal - 来组织可用的物理页面框架。这与我们之前看到的/proc/buddyinfo输出相吻合。顺便说一下,在 Linux 上代表区域的数据结构在这里定义:include/linux/mmzone.h:struct zone。我们将在本书的后面有机会访问它。
为了更好地理解 Linux 内核如何组织 RAM,让我们从最开始 - 启动时间开始。
直接映射的 RAM 和地址转换
在启动时,Linux 内核将所有(可用的)系统 RAM(也称为平台 RAM)直接映射到内核段。因此,我们有以下内容:
-
物理页面框架
0映射到内核虚拟页面0。 -
物理页面框架
1映射到内核虚拟页面1。 -
物理页面框架
2映射到内核虚拟页面2,依此类推。
因此,我们称之为 1:1 或直接映射,身份映射的 RAM 或线性地址。一个关键点是所有这些内核虚拟页面都与它们的物理对应物有固定偏移(如前所述,这些内核地址被称为内核逻辑地址)。固定偏移是PAGE_OFFSET值(这里是0xc000 0000)。
所以,想象一下。在一个 32 位系统上,3:1(GB)的虚拟内存分配,物理地址0x0 = 内核逻辑地址0xc000 0000(PAGE_OFFSET)。如前所述,术语内核逻辑地址适用于与其物理对应物有固定偏移的内核地址。因此,直接映射的 RAM 映射到内核逻辑地址。这个直接映射内存区域通常被称为内核段中的低内存(或简称为lowmem)区域。
我们已经在之前展示了一个几乎相同的图表,在图 7.10 中。在下图中,稍作修改,实际上显示了前三个(物理)页面框架如何映射到内核段的前三个内核虚拟页面(在内核段的低内存区域):

图 7.21 - 直接映射的 RAM - 32 位系统,3:1(GB)虚拟内存分配
例如,图 7.21 显示了在 32 位系统上平台 RAM 直接映射到内核段的情况,VM 分割比为 3:1(GB)。物理 RAM 地址0x0映射到内核的位置是PAGE_OFFSET内核宏(在前面的图中,它是内核逻辑地址0xc000 0000)。请注意,图 7.21 还显示了左侧的用户 VAS,范围从0x0到PAGE_OFFSET-1(大小为TASK_SIZE字节)。我们已经在之前的检查内核段部分详细介绍了内核段的其余部分。
理解物理到虚拟页面的映射可能会诱使你得出这些看似合乎逻辑的结论:
- 给定一个 KVA,计算相应的物理地址(PA) - 也就是执行 KVA 到 PA 计算 - 只需这样做:
pa = kva - PAGE_OFFSET
- 相反,给定一个 PA,计算相应的 KVA - 也就是执行 PA 到 KVA 计算 - 只需这样做:
kva = pa + PAGE_OFFSET
再次参考图 7.21。RAM 直接映射到内核段(从PAGE_OFFSET开始)确实预示着这个结论。所以,这是正确的。但请注意,这里请仔细注意:这些地址转换计算仅适用于直接映射或线性地址 - 换句话说,内核低端内存区域的 KVAs(技术上来说,是内核逻辑地址) - 不适用于任何其他地方的 UVAs,以及除了低端内存区域之外的任何和所有 KVAs(包括模块地址,vmalloc/ioremap(MMIO)地址,KASAN 地址,(可能的)高端内存区域地址,DMA 内存区域等)。
正如你所预料的,内核确实提供了 API 来执行这些地址转换;当然,它们的实现是与体系结构相关的。它们如下:
| 内核 API 它的作用 |
|---|
phys_addr_t virt_to_phys(volatile void *address) |
void *phys_to_virt(phys_addr_t address) |
x86 的virt_to_phys() API 上面有一条注释,明确提倡这个 API(以及类似的 API)不应该被驱动程序作者使用;为了清晰和完整,我们在这里重现了内核源代码中的注释:
// arch/x86/include/asm/io.h
[...]
/**
* virt_to_phys - map virtual addresses to physical
* @address: address to remap
*
* The returned physical address is the physical (CPU) mapping for
* the memory address given. It is only valid to use this function on
* addresses directly mapped or allocated via kmalloc.
*
* This function does not give bus mappings for DMA transfers. In
* almost all conceivable cases a device driver should not be using
* this function
*/
static inline phys_addr_t virt_to_phys(volatile void *address)
[...]
前面的注释提到了(非常常见的)kmalloc() API。不用担心,它在接下来的两章中会有详细介绍。当然,对于phys_to_virt() API 也有类似的注释。
那么谁会(少量地)使用这些地址转换 API(以及类似的)呢?当然是内核内部的mm代码!作为演示,我们在本书中至少在两个地方使用了它们:在下一章中,在一个名为ch8/lowlevel_mem的 LKM 中(实际上,它的使用是在我们的“内核库”代码klib_llkd.c的一个函数中)。
值得一提的是,强大的crash(8)实用程序确实可以通过其vtop(虚拟到物理)命令将任何给定的虚拟地址转换为物理地址(反之亦然,通过其ptov命令也可以实现相反的转换!)。
另一个关键点是:通过将所有物理 RAM 映射到其中,不要被误导以为内核正在保留RAM 给自己。不,它没有;它只是映射了所有可用的 RAM,从而使它可以分配给任何想要的人——核心内核代码、内核线程、设备驱动程序或用户空间应用程序。这是操作系统的工作之一;毕竟,它是系统资源管理器。当然,在引导时,一定会占用(分配)一定部分 RAM——静态内核代码、数据、内核页表等,但您应该意识到这是非常小的。举个例子,在我的 1GB RAM 的虚拟机上,内核代码、数据和 BSS 通常总共占用大约 25MB 的 RAM。所有内核内存总共约 100MB,而用户空间内存使用量大约为 550MB!几乎总是用户空间占用内存最多。
您可以尝试使用smem(8)实用程序和--system -p选项开关,以查看内存使用情况的百分比摘要(还可以使用--realmem=开关传递系统上实际的 RAM 数量)。
回到重点:我们知道内核页表在引导过程中早早地设置好了。因此,当应用程序启动时,内核已经将所有 RAM 映射并可用,准备分配!因此,我们理解,虽然内核将页框直接映射到其虚拟地址空间,用户模式进程却没有这么幸运——它们只能通过操作系统在进程创建(fork(2))时在每个进程基础上设置的分页表间接映射页框。再次强调,通过强大的mmap(2)系统调用进行内存映射可以提供将文件或匿名页面“直接映射”到用户虚拟地址空间的错觉。
还有一些额外的要点需要注意:
(a) 为了性能,内核内存(内核页面)永远不会被交换,即使它们没有被使用。
(b) 有时候,你可能会认为,用户空间内存页面通过操作系统在每个进程基础上设置的分页表,映射到(物理)页框上(假设页面是常驻的),这是相当明显的。是的,但内核内存页面呢?请非常清楚地理解这一点:所有内核页面也通过内核“主”分页表映射到页框上。内核内存也是虚拟化的,就像用户空间内存一样。 在这方面,对于您这位感兴趣的读者,我在 Stack Overflow 上发起了一个问答:内核虚拟地址到物理 RAM 的确切转换是如何进行的?:stackoverflow.com/questions/36639607/how-exactly-do-kernel-virtual-addresses-get-translated-to-physical-ram。© Linux 内核中已经内置了几种内存优化技术(很多是配置选项);其中包括透明巨大页面(THPs)和对云/虚拟化工作负载至关重要的内核同页合并(KSM,也称为内存去重)。 我建议您参考本章的进一步阅读部分以获取更多信息。
好的,通过对物理 RAM 管理的一些方面进行覆盖,我们完成了本章的内容;进展非常不错!
总结
在本章中,我们深入研究了内核内存管理这一大主题,对于像您这样的内核模块或设备驱动程序作者来说,我们提供了足够详细的级别;而且还有更多内容要学习!一个关键的拼图——VM 分割以及在运行 Linux 操作系统的各种架构上如何实现它——作为一个起点。然后我们深入研究了这个分割的两个区域:首先是用户空间(进程 VAS),然后是内核 VAS(或内核段)。在这里,我们涵盖了许多细节和工具/实用程序,以及如何检查它(特别是通过相当强大的procmap实用程序)。我们构建了一个演示内核模块,可以生成内核和调用进程的相当完整的内存映射。用户和内核内存布局随机化技术([K]ASLR)也被简要讨论了一下。最后,我们看了一下 Linux 内存中 RAM 的物理组织。
本章中学到的所有信息和概念实际上都非常有用;不仅适用于设计和编写更好的内核/设备驱动程序代码,而且在遇到系统级问题和错误时也非常有用。
这一章是一个漫长而且关键的章节;完成得很好!接下来,在接下来的两章中,您将继续学习如何有效地分配(和释放)内核内存的关键和实际方面,以及这一常见活动背后的重要概念。继续前进!
问题
最后,这里有一些问题供您测试对本章材料的了解:github.com/PacktPublishing/Linux-Kernel-Programming/tree/master/questions。您会发现一些问题的答案在书的 GitHub 存储库中:github.com/PacktPublishing/Linux-Kernel-Programming/tree/master/solutions_to_assgn。
进一步阅读
为了帮助您深入研究这个主题并提供有用的材料,我们在本书的 GitHub 存储库中提供了一个相当详细的在线参考和链接列表(有时甚至包括书籍)的 Further reading 文档。Further reading文档在这里可用:github.com/PacktPublishing/Linux-Kernel-Programming/blob/master/Further_Reading.md。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言










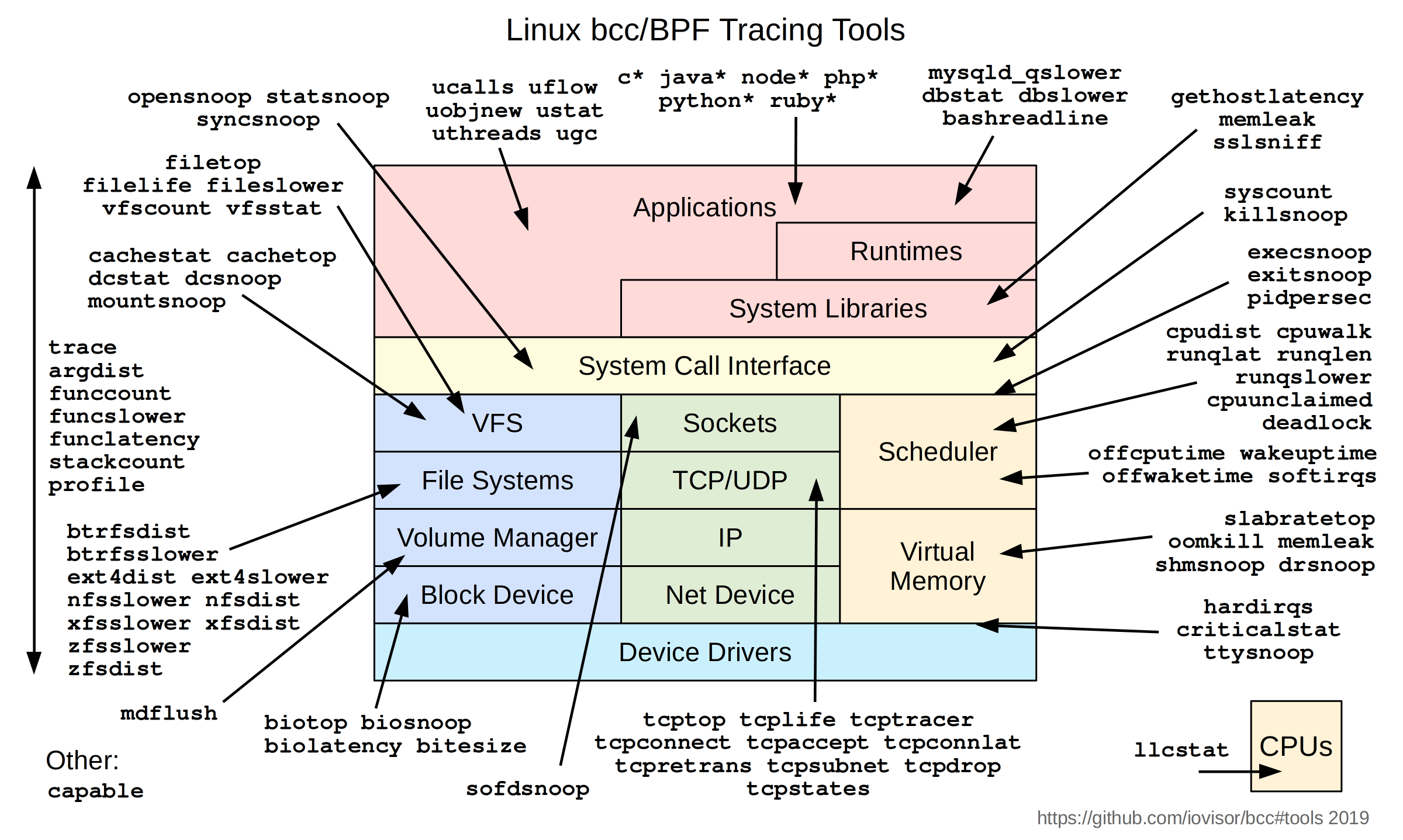{kind=link}
{kind=link}