







原文:
zh.annas-archive.org/md5/92E2CBA50423C2D275EEE8125598FF8B译者:飞龙
前言
成为科技行业的数据科学家是当今地球上最有价值的职业之一。我去研究了科技公司数据科学家职位的实际工作描述,并将这些要求归纳为您将在本课程中看到的主题。
《动手做数据科学和 Python 机器学习》真的非常全面。我们将从 Python 的速成课程开始,然后回顾一些基本的统计和概率知识,但接着我们将直接涉及超过 60 个数据挖掘和机器学习的主题。其中包括贝叶斯定理、聚类、决策树、回归分析、实验设计;我们将全面研究它们。其中一些主题真的非常有趣。
我们将开发一个实际的电影推荐系统,使用实际的用户电影评分数据。我们将创建一个真正适用于维基百科数据的搜索引擎。我们将构建一个可以正确分类垃圾邮件和非垃圾邮件的垃圾邮件分类器,并且我们还有一个关于将这项工作扩展到在大数据上运行的集群的整个部分,使用 Apache Spark。
如果您是一名软件开发人员或程序员,希望转向数据科学职业,这门课程将教会您最热门的技能,而不需要所有这些数学符号和伪装,这些都是与这些主题相关的。我们只会解释这些概念,并向您展示一些真正有效的 Python 代码,您可以深入研究并进行操作,以使这些概念深入人心,如果您在金融行业担任数据分析师,这门课程也可以教会您转向科技行业。您只需要一些编程或脚本编写的经验,就可以开始了。
这本书的一般格式是我将从每个概念开始,用一堆部分和图形示例来解释它。我会向您介绍一些数据科学家喜欢使用的符号和花哨的术语,这样您就可以用相同的语言交流,但这些概念本身通常非常简单。之后,我会让您实际运行一些真正有效的 Python 代码,让我们可以运行并进行一些操作,并且这将向您展示如何将这些想法应用到实际数据中。这些将被呈现为 IPython Notebook 文件,这是一种我可以在其中混合代码和解释代码周围的笔记的格式,解释概念中发生的事情。在阅读完本书后,您可以将这些笔记本文件带走,并在以后的职业生涯中使用它作为方便的快速参考,而在每个概念的结尾,我会鼓励您实际深入研究 Python 代码,进行一些修改,进行一些操作,并通过实际进行一些修改,看到它们产生的效果,从而更加熟悉。
这本书是为谁准备的
如果您是一名新兴的数据科学家或数据分析师,希望使用 Python 分析数据并获得可操作的见解,那么这本书适合您。有一些 Python 经验的程序员,希望进入数据科学这个利润丰厚的领域,也会发现这本书非常有用。
约定
在这本书中,您将找到许多文本样式,用于区分不同类型的信息。以下是这些样式的一些示例以及它们的含义解释。
文本中的代码词、数据库表名、文件夹名、文件名、文件扩展名、路径名、虚拟 URL、用户输入和 Twitter 用户名显示如下:“我们可以使用sklearn.metrics中的r2_score()函数来衡量这个。”
代码块设置如下:
import numpy as np
import pandas as pd
from sklearn import tree
input_file = "c:/spark/DataScience/PastHires.csv"
df = pd.read_csv(input_file, header = 0)
当我们希望引起您对代码块的特定部分的注意时,相关行或项目将以粗体显示:
import numpy as np
import pandas as pd
from sklearn import tree
input_file = "c:/spark/DataScience/PastHires.csv"
df = pd.read_csv(input_file, header = 0)
任何命令行输入或输出都将按以下方式书写:
spark-submit SparkKMeans.py
新术语和重要单词以粗体显示。例如,屏幕上显示的单词,例如菜单或对话框中的单词,会以这种方式出现在文本中:“在 Windows 10 上,您需要打开“开始”菜单,然后转到“Windows 系统”|“控制面板”以打开“控制面板”。”
警告或重要提示会显示为这样。
提示和技巧会显示为这样。
第一章:入门
由于这本书将涉及与代码相关的内容和您需要获取的示例数据,让我先向您展示在哪里获取这些内容,然后我们就可以开始了。我们首先需要做一些设置。首先,让我们获取本书所需的代码和数据,这样您就可以跟着操作,并且有一些代码可以进行实际操作。最简单的方法是直接转到 入门。
在本章中,我们将首先安装并准备好一个可用的 Python 环境:
-
安装 Enthought Canopy
-
安装 Python 库
-
如何使用 IPython/Jupyter Notebook
-
如何使用、阅读和运行本书的代码文件
-
然后我们将进行一个快速课程,了解 Python 代码:
-
Python 基础知识 - 第一部分
-
理解 Python 代码
-
导入模块
-
尝试使用列表
-
元组
-
Python 基础知识 - 第二部分
-
运行 Python 脚本
一旦我们设置好您的环境并在本章中让您熟悉 Python,您就会拥有一切进行 Python 数据科学的绝妙旅程所需的一切。
安装 Enthought Canopy
让我们立即开始,安装您在桌面上实际开发 Python 数据科学所需的内容。我将带您完成安装一个名为 Enthought Canopy 的软件包,它已经预先安装了开发环境和所有 Python 软件包。这将使生活变得非常容易,但如果您已经了解 Python,可能已经在您的 PC 上有现有的 Python 环境,如果您想继续使用它,也许您可以。
最重要的是,您的 Python 环境必须具有 Python 3.5 或更新版本,支持 Jupyter Notebook(因为这是我们在本课程中要使用的),并且您的环境中已安装了本书所需的关键软件包。我将详细解释如何通过几个简单的步骤实现完整安装 - 这将非常容易。
让我们首先概述这些关键软件包,其中大部分 Canopy 将自动为我们安装。Canopy 将为我们安装 Python 3.5,以及我们需要的一些其他软件包,包括:scikit_learn、xlrd 和 statsmodels。我们需要手动使用 pip 命令来安装一个名为 pydot2plus 的软件包。就是这样 - 使用 Canopy 非常容易!
一旦完成以下安装步骤,我们将拥有一切需要的内容来真正开始运行,然后我们将打开一个小样本文件,进行一些真正的数据科学。现在让我们尽快为您设置好一切所需的内容:
- 您首先需要的是一个称为 IDE 的 Python 代码开发环境。我们将在本书中使用的是 Enthought Canopy。这是一个科学计算环境,将与本书很好地配合使用:

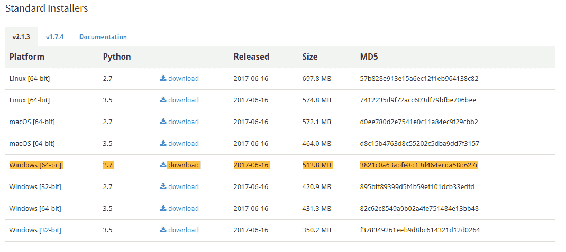
- 要安装 Canopy,只需转到 www.enthought.com,然后点击下载:Canopy:

- Enthought Canopy 是免费的,适用于 Canopy Express 版本 - 这是您在本书中需要的版本。然后您必须选择您的操作系统和架构。对我来说,这是 Windows 64 位,但您需要点击相应的下载按钮,选择适用于您操作系统的 Python 3.5 选项:
- 在这一步我们不需要提供任何个人信息。这是一个相当标准的 Windows 安装程序,所以只需让它下载:
-
下载完成后,我们继续打开 Canopy 安装程序,并运行它!您可能想在同意之前阅读许可协议,这取决于您,然后只需等待安装完成。
-
一旦您在安装过程的最后点击完成按钮,允许它自动启动 Canopy。您会看到 Canopy 自动设置 Python 环境,这很好,但这将需要一两分钟的时间。
-
安装程序设置完成您的 Python 环境后,您应该会看到下面的屏幕。它会显示欢迎来到 Canopy 和一堆友好的大按钮:

-
美妙的事情是,几乎您在本书中所需的一切都已经预先安装在 Enthought Canopy 中,这就是为什么我建议使用它!
-
我们只需要设置最后一件事,所以请点击 Canopy 欢迎屏幕上的编辑器按钮。然后您会看到编辑器屏幕出现,如果您在底部的窗口中点击,我希望您只是输入:
!pip install pydotplus
- 当您在 Canopy 编辑器窗口底部输入上述行时,屏幕会显示如下;当然不要忘记按回车键:

-
按下回车键后,这将安装我们在本书后面需要的一个额外模块,当我们开始讨论决策树和渲染决策树时。
-
一旦安装完成pydotplus,它应该会回来并说它已成功安装,您现在已经拥有了开始的一切!此时安装已经完成-但让我们再走几步来确认我们的安装是否正常运行。
对安装进行测试
-
现在让我们对您的安装进行测试。首先要做的事情是完全关闭 Canopy 窗口!这是因为我们实际上不会在这个 Canopy 编辑器中编辑和使用我们的代码。相反,我们将使用一个称为 IPython 笔记本的东西,现在也被称为 Jupyter 笔记本。
-
让我向您展示一下它是如何工作的。如果您现在在操作系统中打开一个窗口,查看您下载的附带书籍文件,就像本书的前言中描述的那样。它应该看起来像这样,带有您为本书下载的一组
.ipynb代码文件:

现在在列表中找到异常值文件,即Outliers.ipynb文件,双击它,应该会启动 Canopy,然后启动您的网络浏览器!这是因为 IPython/Jupyter 笔记本实际上存在于您的网络浏览器中。一开始可能会有一小段暂停,第一次可能会有点混乱,但您很快就会习惯的。
您很快就会看到 Canopy 出现,对我来说,我的默认网络浏览器 Chrome 会出现。您应该会看到以下 Jupyter 笔记本页面,因为我们双击了Outliers.ipynb文件:
如果您看到这个屏幕,这意味着您的安装工作得很好,您已经准备好继续阅读本书的其余部分了!
如果您偶尔遇到打开 IPNYB 文件的问题
偶尔,我注意到当您双击.ipynb文件时,有时会出现一些小问题。不要惊慌!有时,Canopy 可能会有点不稳定,您可能会看到一个寻找密码或令牌的屏幕,或者偶尔会看到一个完全无法连接的屏幕。
如果您遇到这些情况,不要惊慌,它们只是偶然的怪癖,有时事情就是不按正确的顺序启动,或者它们在您的 PC 上没有及时启动,没关系。
您只需返回并尝试第二次打开该文件。有时需要两三次尝试才能正确加载它,但如果您多试几次,最终它应该会弹出,并且您应该会看到一个 Jupyter 笔记本屏幕,就像我们之前看到的关于处理异常值的那个。
使用和理解 IPython(Jupyter)笔记本
恭喜您的安装!现在让我们探索使用 Jupyter 笔记本,也称为 IPython 笔记本。如今,更现代的名称是 Jupyter 笔记本,但很多人仍然称其为 IPython 笔记本,因此我认为这两个名称对于工作开发人员来说是可以互换的。我也发现 IPython 笔记本这个名称有助于我记住笔记本文件的后缀名是.ipynb,在本书中您将非常熟悉这个后缀名!
好的,现在让我们从头开始 - 首先探索 IPython/Jupyter 笔记本。如果您还没有这样做,请导航到我们为本书下载的DataScience文件夹。对我来说,那是E:DataScience,如果您在前面的安装部分中没有这样做,请现在双击并打开Outliers.ipynb文件。
现在,当我们双击此 IPython .**ipynb**文件时,首先会启动 Canopy,然后会启动一个 Web 浏览器。这是完整的Outliers笔记本网页在我的浏览器中的样子:
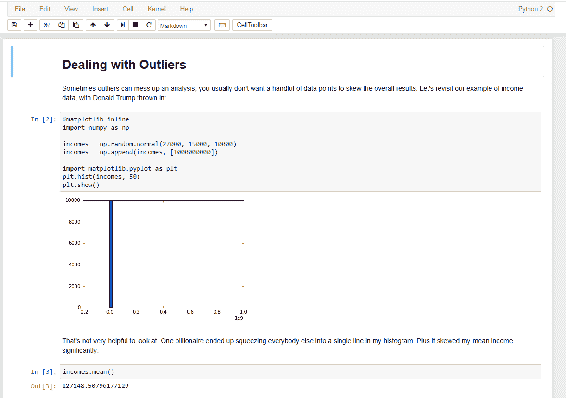
正如您在这里看到的,笔记本的结构使我可以在实际代码中穿插一些关于您在这里看到的内容的小注释和评论,您实际上可以在 Web 浏览器中运行此代码!因此,对我来说,这是一个非常方便的格式,可以为您提供一些参考,以便以后在生活中去回顾这些我们将要讨论的算法是如何工作的,并且实际上可以自己尝试和玩耍。
IPython/Jupyter 笔记本文件的工作方式是它们实际上是在您的浏览器中运行的,就像一个网页,但它们由您安装的 Python 引擎支持。因此,您应该看到与前一个屏幕截图中显示的类似的屏幕。
当您在浏览器中向下滚动笔记本时,您会注意到有代码块。它们很容易识别,因为它们包含我们的实际代码。请在异常值笔记本中找到此代码的代码框,它就在顶部附近:
%matplotlib inline
import numpy as np
incomes = np.random.normal(27000, 15000, 10000)
incomes = np.append(incomes, [1000000000])
import matplotlib.pyplot as plt
plt.hist(incomes, 50)
plt.show()
让我们在这里快速看一下这段代码。在这段代码中,我们设置了一些收入分布。我们模拟了人口中的收入分布,并且为了说明异常值对该分布的影响,我们模拟了唐纳德·特朗普加入并扰乱了收入分布的平均值。顺便说一句,我并不是在发表政治言论,这都是在特朗普成为政治人物之前完成的。所以,您知道,完全披露在这里。
我们可以通过单击来选择笔记本中的任何代码块。因此,如果您现在点击包含我们刚才查看的代码的代码块,然后点击顶部的运行按钮来运行它。这是屏幕顶部的区域,您将在其中找到运行按钮:

选择代码块并点击运行按钮,将导致重新生成此图:

同样,我们可以点击稍微向下的下一个代码块,您会看到其中有以下一行代码:
incomes.mean()
如果您选择包含此行的代码块,并点击运行按钮运行代码,您将在其下看到输出,由于异常值的影响,输出将是一个非常大的值,类似于这样:
127148.50796177129
让我们继续并且玩得开心。在下面的下一个代码块中,您将看到以下代码,它尝试检测像唐纳德·特朗普这样的异常值,并将它们从数据集中删除:
def reject_outliers(data):
u = np.median(data)
s = np.std(data)
filtered = [e for e in data if (u - 2 * s < e < u + 2 * s)]
return filtered
filtered = reject_outliers(incomes)
plt.hist(filtered, 50)
plt.show()
因此,请在笔记本中选择相应的代码块,然后再次按运行按钮。当您这样做时,您将看到这张图:

现在我们看到了一个更好的直方图,代表了更典型的美国人-现在我们已经去掉了混乱的异常值。
所以,此时,您已经具备了开始本课程所需的一切。我们拥有您需要的所有数据,所有脚本,以及 Python 和 Python 笔记本的开发环境。所以,让我们开始吧。接下来,我们将进行一些关于 Python 本身的速成课程,即使您熟悉 Python,这也可能是一个不错的温习,所以您可能还是想观看一下。让我们深入学习 Python。
Python 基础-第一部分
如果您已经了解 Python,您可能可以跳过接下来的两个部分。但是,如果您需要温习,或者以前没有接触过 Python,您可能需要浏览一下。关于 Python 脚本语言有一些古怪的地方,您需要知道,所以让我们深入学习一下,通过编写一些实际代码来学习一些 Python。
就像我之前说的,在本书的要求中,您应该具备某种编程背景才能成功。您已经在某种语言中编写过代码,即使是脚本语言,JavaScript,我不在乎它是 C++,Java,还是其他什么,但如果您是 Python 的新手,我将在这里给您一个速成课程。我将直接开始并在本节中给出一些示例。
Python 有一些与您可能见过的其他语言有些不同的地方;所以我只是想通过查看一些真实的例子来介绍 Python 与其他脚本语言的不同之处。让我们直接开始,看一些 Python 代码:
如果您打开了在之前部分中下载的DataScience文件夹,您应该会找到一个Python101.ipynb文件;请双击打开。如果您已经正确安装了所有内容,它应该会在 Canopy 中立即打开,并且应该看起来有点像以下的截图:

新版本的 Canopy 将在您的网络浏览器中打开代码,而不是 Canopy 编辑器!这没问题!
Python 的一个很酷的地方是,有几种运行 Python 代码的方式。您可以将其作为脚本运行,就像您使用普通编程语言一样。您还可以在这个叫做IPython Notebook的东西中编写代码,这就是我们在这里使用的东西。因此,这是一种格式,您实际上可以在其中以类似网络浏览器的视图中编写一些小注释和 HTML 标记的笔记,还可以嵌入实际使用 Python 解释器运行的代码。
理解 Python 代码
我想给您展示一些 Python 代码的第一个例子就在这里。以下代码块代表了一些真正的 Python 代码,我们实际上可以在整个笔记本页面的视图中运行,但现在让我们放大一下,看看那段代码:

让我们看看发生了什么。我们有一个数字列表和 Python 中的一个列表,类似于其他语言中的数组。它由这些方括号指定:

我们有一个包含 1 到 6 的数字列表的数据结构,然后要遍历该列表中的每个数字,我们将说for number in listOfNumbers:,这是 Python 遍历一系列东西的语法,后面跟着一个冒号。
在 Python 中,制表符和空格是有实际意义的,所以您不能随意格式化。您必须注意它们。
我想要表达的观点是,在其他语言中,通常会有括号或大括号来表示我在for循环、if块或某种代码块中,但在 Python 中,这一切都是由空格来指定的。制表符实际上在告诉 Python 哪些代码块中有什么:
for number in listOfNumbers:
print number,
if (number % 2 == 0):
print ("is even")
else:
print ("is odd")
print ("Hooray! We're all done.")
你会注意到,在这个for块中,我们有一个制表符,对于listOfNumbers中的每个number,我们将执行所有这些代码,这些代码都是通过一个Tab进行缩进的。我们将打印出这个数字,逗号只是表示我们不会在后面换行。我们将在后面打印其他东西,如果(number % 2 = 0),我们将说它是even。否则,我们将说它是odd,当我们完成时,我们将打印出All done:
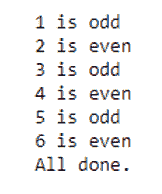
你可以在代码下方看到输出。我之前已经运行了输出,因为我已经将它保存在我的笔记本中,但如果你想自己运行它,你只需点击该块并点击播放按钮,我们将实际执行它并再次运行。为了让自己确信它确实做了一些事情,让我们把print语句改成其他的,比如说,Hooray! We're all done. Let's party!如果我现在运行这个,你会看到,我的消息确实改变了:
所以,我想要表达的观点是空格很重要。你会使用缩进或制表符来指定一起运行的代码块,比如for循环或if then语句,所以记住这一点。还要注意冒号。你会注意到很多从句都是以冒号开始的。
导入模块
Python 本身,就像任何语言一样,其功能是相当有限的。使用 Python 进行机器学习、数据挖掘和数据科学的真正力量在于为此目的提供的所有外部库的强大功能。其中一个库叫做NumPy,或者叫做数值 Python,例如,我们可以import Numpy包,它包含在 Canopy 中,名称为np。
这意味着我将把NumPy包称为np,我可以随意更改它的名称。我可以称它为Fred或Tim,但最好还是使用有意义的名称;现在我把NumPy包称为np,我可以使用np来引用它了:
import numpy as np
在这个例子中,我将调用NumPy包提供的random函数,并调用其正态函数来生成一组随机数的正态分布,并将其打印出来。由于它是随机的,每次我应该得到不同的结果:
import numpy as np
A = np.random.normal(25.0, 5.0, 10)
print (A)
输出应该是这样的:
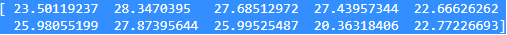
果然,我得到了不同的结果。这很酷。
数据结构
让我们继续讨论数据结构。如果你需要暂停一下,让事情沉淀一下,或者你想更多地玩弄一下这些,随时都可以这样做。学习这些东西的最好方法就是投入其中,实际进行实验,所以我绝对鼓励这样做,这也是为什么我给你们提供了可工作的 IPython/Jupyter 笔记本,这样你们就可以真正进入其中,改变代码,做不同的事情。
举个例子,这里我们有一个围绕25.0的分布,但让我们把它围绕55.0:
import numpy as np
A = np.random.normal(55.0, 5.0, 10)
print (A)
嘿,我的所有数字都变了,它们现在更接近 55 了,怎么样?
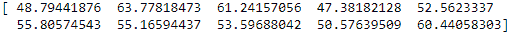
好的,让我们来谈谈数据结构。就像我们在第一个例子中看到的那样,你可以有一个列表,语法看起来是这样的。
列表实验
x = [1, 2, 3, 4, 5, 6]
print (len(x))
你可以说,比如,调用一个名为x的列表,并将其赋值为数字1到6,这些方括号表示我们使用的是 Python 列表,它们是不可变的对象,我可以随意添加和重新排列。有一个用于确定列表长度的内置函数叫做len,如果我输入len(x),那么会返回数字6,因为我的列表中有 6 个数字。
只是为了确保,再次强调这实际上是在运行真正的代码,让我们在那里再添加一个数字,比如4545。如果你运行这个,你会得到7,因为现在列表中有 7 个数字:
x = [1, 2, 3, 4, 5, 6, 4545]
print (len(x))
前面代码示例的输出如下:
7
回到原来的例子。现在你也可以对列表进行切片。如果你想要取列表的一个子集,有一个非常简单的语法可以做到:
x[3:]
上面代码示例的输出如下:
[1, 2, 3]
冒号之前
例如,如果你想要取列表的前三个元素,即第 3 个元素之前的所有东西,我们可以说:3来获取前三个元素,1,2和3,如果你想想那里发生了什么,就是索引方面的事情,就像大多数语言一样,我们从 0 开始计数。所以第 0 个元素是1,第 1 个元素是2,第 2 个元素是3。因为我们说我们想要在第 3 个元素之前的所有东西,这就是我们得到的。
所以,你知道,在大多数语言中,你从 0 开始计数,而不是 1。
现在这可能会让事情变得混乱,但在这种情况下,它确实是直观的。你可以把冒号理解为我想要所有东西,我想要前三个元素,我可以再次将其更改为四,以再次说明我们实际上正在做一些真实的事情:
x[:4]
上面代码示例的输出如下:
[1, 2, 3, 4]
冒号之后
现在如果我把冒号放在3的另一侧,那就表示我想要3之后的所有东西,所以3和之后的。如果我说x[3:],那就是给我第三个元素,0,1,2,3,以及之后的所有东西。所以在这个例子中会返回 4,5 和 6,明白吗?
x[3:]
输出如下:
[4, 5, 6]
你可能想要保留这个 IPython/Jupyter Notebook 文件。这是一个很好的参考,因为有时候会让人困惑,不知道切片操作符是否包括该元素,或者是到或包括它,还是不包括。所以最好的方法就是在这里玩一下,提醒自己。
负数语法
你还可以使用这种负数语法:
x[-2:]
上面代码的输出如下:
[5, 6]
通过说x[-2:],这意味着我想要列表中的最后两个元素。这意味着从末尾向后退两个,这将给我5和6,因为这些是列表中的最后两个元素。
添加列表到列表
你还可以改变列表。比如说我想要把一个列表添加到另一个列表中。我可以使用extend函数来做到这一点,如下面的代码块所示:
x.extend([7,8])
x
上面代码的输出如下:
[1, 2, 3, 4, 5, 6, 7, 8]
我有一个列表1,2,3,4,5,6。如果我想要扩展它,我可以说我有一个新列表在这里,[7, 8],那个方括号表示这本身就是一个新列表。这可能是一个隐式的列表,在那里,它可以被另一个变量引用。你可以看到,一旦我这样做了,我得到的新列表实际上是在原来的列表上附加了7,8的列表。所以我通过扩展另一个列表来得到一个新列表。
添加函数
如果你只想在列表中再添加一些东西,你可以使用append函数。所以我只想在末尾加上数字9,就这样:
x.append(9)
x
上面代码的输出如下:
[1, 2, 3, 4, 5, 6, 7, 8, 9]
复杂的数据结构
你还可以使用列表创建复杂的数据结构。所以你不只是可以把数字放进去;你实际上可以把字符串放进去。你可以把数字放进去。你可以把其他列表放进去。都没关系。Python 是一种弱类型语言,所以你基本上可以把任何类型的数据放到任何地方,通常都是可以的:
y = [10, 11, 12]
listOfLists = [x, y]
listOfLists
在上面的例子中,我有一个包含10,11,12的第二个列表,我称之为y。我将创建一个包含两个列表的新列表。这对你来说是不是很惊人?我们的listofLists列表将包含x列表和y列表,这是完全有效的。你可以看到这里有一个括号表示listofLists列表,而在其中,我们有另一组括号表示该列表中的每个单独的列表:
[[ 1, 2, 3, 4, 5, 6, 7, 8, 9 ], [10, 11, 12]]
所以,有时这样的东西会派上用场。
取消引用单个元素
如果你想取消引用列表的单个元素,你可以像这样使用括号:
y[1]
上面代码的输出如下:
11
所以y[1]将返回元素1。记住y中有10,11,12 - 观察上面的例子,我们从 0 开始计数,所以元素 1 实际上是列表中的第二个元素,或者在这种情况下是数字11,好吗?
排序函数
最后,让我们来看一个内置的排序函数,你可以使用它:
z = [3, 2, 1]
z.sort()
z
所以如果我从列表z开始,它是3,2和1,我可以在该列表上调用排序,然后z现在将按顺序排序。上面代码的输出如下:
[1, 2, 3]
反向排序
z.sort(reverse=True)
z
上面代码的输出如下:
[3, 2, 1]
如果你需要进行反向排序,你可以在sort函数中添加一个参数reverse=True,这将使它恢复到3,2,1。
如果你需要让这个概念沉淀一下,可以随意回去再读一下。
元组
元组就像列表一样,只是它们是不可变的,所以你实际上不能扩展、追加或排序它们。它们就是它们,除了你不能改变它们,并且你用括号而不是方括号表示它们是不可变的元组,它们的行为就像列表一样。所以你可以看到它们在其他方面基本上是一样的:
#Tuples are just immutable lists. Use () instead of []
x = (1, 2, 3)
len(x)
上面代码的输出如下:
3
我们可以说x=(1,2,3)。我仍然可以在上面使用length - len来说这个元组中有三个元素,即使,如果你不熟悉术语元组,一个元组实际上可以包含任意多个元素。尽管它听起来像是基于数字三的拉丁语,但这并不意味着你在其中有三个东西。通常,它只有两个东西。它们可以有任意多个,真的。
取消引用一个元素
我们还可以对元组的元素进行取消引用,所以第 2 个元素再次是第三个元素,因为我们从 0 开始计数,这将在下面的截图中给我返回数字6:
y = (4, 5, 6)
y[2]
上面代码的输出如下:
6
元组列表
我们也可以像对待列表一样,使用元组作为列表的元素。
listOfTuples = [x, y]
listOfTuples
上面代码的输出如下:
[(1, 2, 3), (4, 5, 6)]
我们可以创建一个包含两个元组的新列表。所以在上面的例子中,我们有我们的x元组(1,2,3)和我们的y元组(4,5,6);然后我们将这两个元组放入一个列表中,我们得到了这样的结构,其中我们有方括号表示包含两个由括号表示的元组的列表,元组在我们进行数据科学或任何数据管理或处理时通常用于将变量分配给输入数据。我想向你解释一下下面例子中发生了什么:
(age, income) = "32,120000".split(',')
print (age)
print (income)
上面代码的输出如下:
32
120000
假设我们有一行输入数据进来,它是一个逗号分隔的值文件,其中包含年龄,比如32,用逗号分隔的收入,比如120000,只是为了举个例子。当每行数据进来时,我可以调用split函数来将其分隔成由逗号分隔的一对值,并将split的结果元组一次性分配给两个变量-age和income,通过定义一个年龄、收入的元组,并说我想将其设置为split函数的结果元组。
所以这基本上是你会看到的一种常见的简写,用于一次性为多个变量分配多个字段。如果我运行它,你会看到age变量实际上被分配为32,income被分配为120,000,因为有这个小技巧。当你这样做的时候,你需要小心,因为如果你没有预期的字段数量或者结果元组中的预期元素数量,如果你尝试分配更多或更少的东西,你会得到一个异常。
字典
最后,我们将在 Python 中经常看到的最后一个数据结构是字典,你可以把它看作是其他语言中的映射或哈希表。这基本上是一种在 Python 中内置的一种方式,可以有一种类似于键/值数据存储的迷你数据库。所以假设我想建立一个小小的星际迷航飞船和他们的船长的字典:

我可以设置captains = {},花括号表示一个空字典。现在我可以使用这种语法来为字典中的条目赋值,所以我可以说captains为Enterprise是Kirk,为Enterprise D是Picard,为Deep Space Nine是Sisko,为Voyager是Janeway。现在我基本上有了这个查找表,它将船名与船长关联起来,例如,我可以说print captains["Voyager"],我会得到Janeway。
这基本上是一种非常有用的工具,可以用来做某种查找。假设你在数据集中有某种标识符,它映射到一些可读的名称。当你打印出来时,你可能会使用字典来进行实际的查找。
我们还可以看看如果尝试查找不存在的东西会发生什么。嗯,我们可以在字典上使用get函数来安全地返回一个条目。所以在这种情况下,Enterprise在我的字典中有一个条目,它只是给我Kirk,但如果我在字典上调用NX-01船,我从来没有定义过那个船的船长,所以在这个例子中它会返回一个None值,这比抛出异常要好,但你需要意识到这是可能的:
print (captains.get("NX-01"))
上面代码的输出如下:
None
船长是乔纳森·阿彻,但你知道,我现在有点太迷恋了。
遍历条目
for ship in captains:
print (ship + ": " + captains[ship])
上面代码的输出如下:

让我们来看一个遍历字典条目的小例子。如果我想要遍历我字典中的每艘船,并打印出captains,我可以输入for ship in captains,这将遍历字典中的每个键。然后我可以打印出每艘船船长的查找值,这就是我得到的输出。
就是这样。这基本上是你在 Python 中会遇到的主要数据结构。还有其他一些,比如集合,但我们在这本书中不会真正使用它们,所以我认为这已经足够让你开始了。让我们在下一节中深入了解一些 Python 的细微差别。
Python 基础-第二部分
除了Python 基础-第一部分,现在让我们试着更详细地掌握更多 Python 概念。
Python 中的函数
让我们谈谈 Python 中的函数。与其他语言一样,你可以有函数让你重复一组操作,只是参数不同。在 Python 中,做到这一点的语法看起来像这样:
def SquareIt(x):
return x * x
print (SquareIt(2))
上面代码的输出如下:
4
你使用def关键字声明一个函数。它只是说这是一个函数,我们将称这个函数为SquareIt,然后在括号内跟着参数列表。这个特定的函数只接受一个我们将称为x的参数。再次记住,在 Python 中空白很重要。这个函数不会有任何花括号或者其他东西来包围它。它完全由空白定义。所以我们有一个冒号,它表示这个函数声明行结束了,但是它是通过一个或多个制表符来告诉解释器我们实际上在SquareIt函数内部。
所以def SquareIt(x): tab 返回x * x,这将返回这个函数中x的平方。我们可以试一下。print squareIt(2)就是我们调用这个函数的方式。它看起来就像在任何其他语言中一样。这应该返回数字4;我们运行代码,事实上确实是这样的。太棒了!这很简单,这就是函数的全部。显然,如果我愿意,我可以有多个参数,甚至需要多少个参数都可以。
现在在 Python 中有一些奇怪的事情你可以做,这些事情有点酷。你可以像传递参数一样传递函数。让我们仔细看看这个例子:
#You can pass functions around as parameters
def DoSomething(f, x):
return f(x)
print (DoSomething(SquareIt, 3))
前面代码的输出如下:
9
现在我有一个名为DoSomething的函数,def DoSomething,它将接受两个参数,一个我将称为f,另一个我将称为x,如果我愿意,我实际上可以为其中一个参数传递一个函数。所以,请思考一分钟。看看这个例子,更有意义。在这里,DoSomething(f,x):将返回f的x;它基本上会调用 f 函数并将 x 作为参数传递进去,Python 中没有强类型,所以我们必须确保我们为第一个参数传递的是一个函数,这样才能正常工作。
例如,我们将打印DoSomething,并且对于第一个参数,我们将传入SquareIt,这实际上是另一个函数,以及数字3。这应该做的是使用SquareIt函数和3参数做一些事情,这将返回(SquareIt, 3),我上次检查的时候,3 的平方是 9,确实是这样的。
这可能对你来说是一个新概念,将函数作为参数传递,所以如果你需要停下来一分钟,等一下,让它沉淀下来,玩弄一下,请随意这样做。再次,我鼓励你停下来,按照自己的步调学习。
Lambda 函数 - 函数式编程
还有一件事,这是一种 Python 式的做法,你可能在其他语言中看不到,那就是 lambda 函数的概念,它有点叫做函数式编程。这个想法是你可以在一个函数中包含一个简单的函数。通过一个例子来解释会更有意义:
#Lambda functions let you inline simple functions
print (DoSomething(lambda x: x * x * x, 3))
上面代码的输出如下:
27
我们将打印DoSomething,记住我们的第一个参数是一个函数,所以我们可以使用lambda关键字内联声明这个函数,而不是传递一个命名函数。Lambda 基本上意味着我正在定义一个暂时存在的未命名函数。它是瞬时的,并且它接受一个参数x。在这里的语法中,lambda意味着我正在定义某种内联函数,后面跟着它的参数列表。它有一个参数x,然后是冒号,然后是这个函数实际上要做的事情。我将取x参数并将其自身乘以三次,基本上得到参数的立方。
在这个例子中,DoSomething将这个 lambda 函数作为第一个参数传递进去,它计算x的立方和3参数。那么在幕后这实际上是在做什么呢?这个lambda函数本身是一个函数,在前面的例子中被传递到DoSomething中的f,而这里的x将是3。这将返回x的f,最终执行我们的 lambda 函数在值3上。所以这个3进入我们的x参数,我们的 lambda 函数将其转换为3乘以3乘以3,当然是27。
当我们开始做 MapReduce 和 Spark 等工作时,这种情况经常出现。因此,如果以后要处理 Hadoop 等技术,这是一个非常重要的概念。再次,我鼓励您花点时间让它沉淀下来,理解发生了什么,如果需要的话。
理解布尔表达式
布尔表达式语法有点奇怪或不寻常,至少在 Python 中是这样:
print (1 == 3)
上面代码的输出如下:
False
像往常一样,我们有双等号符号,可以测试两个值之间的相等性。所以1等于3吗,不,因此False。值False是由 F 指定的特殊值。请记住,在测试时,当您在进行布尔运算时,相关的关键字是True和False。这与我之前使用过的其他语言有点不同,所以请记住这一点。
print (True or False)
上面代码的输出如下:
True
嗯,True或False是True,因为其中一个是True,你运行它,它会返回True。
if 语句
print (1 is 3)
上面代码的输出如下:
False
我们还可以使用is,它与等号的作用类似。这是一种更 Python 风格的相等表示,所以1 == 3和1 is 3是一样的,但这被认为是更 Pythonic 的方式。因此1 is 3返回False,因为1不是3。
if-else 循环
if 1 is 3:
print "How did that happen?"
elif 1 > 3:
print ("Yikes")
else:
print ("All is well with the world")
上面代码的输出如下:
All is well with the world
我们还可以在这里使用if-else和else-if块。让我们在这里做一些更复杂的事情。如果1 是 3,我会打印怎么会发生这种事?但当然1不是3,所以我们将回到else-if块,否则,如果1不是3,我们将测试1>3。好吧,那也不对,但如果是的话,我们打印天哪,最后我们将进入这个万能的else子句,它将打印世界一切安好。
实际上,1不是3,1也不大于3,确实,世界一切安好。所以,你知道,其他语言有非常相似的语法,但这些是 Python 的特点,以及如何做if-else或else-if块。所以,随时保留这个笔记本。以后可能会成为一个很好的参考。
循环
我想在我们的 Python 基础知识中涵盖的最后一个概念是循环,我们已经看到了一些例子,但让我们再做一个:
for x in range(10):
print (x),
上面代码的输出如下:
0 1 2 3 4 5 6 7 8 9
例如,我们可以使用这个范围运算符自动定义一个数字范围的列表。所以如果我们说for x in range(10),range 10将产生一个0到9的列表,通过在该列表中说for x,我们将遍历该列表中的每个条目并打印出来。再次强调,print语句后的逗号表示不要给我一个新行,继续进行。因此,这样的输出最终是该列表的所有元素打印在一起。
要做一些更复杂的事情,我们将做类似的事情,但这次我们将展示continue和break的工作原理。与其他语言一样,您实际上可以选择跳过循环迭代的其余处理,或者提前停止循环的迭代:
for x in range(10):
if (x is 1):
continue
if (x > 5):
break
print (x),
上面代码的输出如下:
0 2 3 4 5
在这个例子中,我们将遍历 0 到 9 的值,如果我们遇到数字 1,我们将在打印它之前继续。我们将跳过数字 1,基本上,如果数字大于5,我们将中断循环并完全停止处理。我们期望的输出是,我们将打印出数字0到5,除非是1,在这种情况下,我们将跳过数字1,确实,这就是它的作用。
while 循环
另一种语法是 while 循环。这是大多数语言中都能看到的一种标准循环语法:
x = 0
while (x < 10):
print (x),
x += 1
上述代码的输出如下:
0 1 2 3 4 5 6 7 8 9
我们还可以说,从x = 0开始,然后while (x < 10):,打印它,然后将x增加1。这将一遍又一遍地进行,递增 x 直到小于 10 为止,此时我们跳出while循环并完成。所以它和这里的第一个例子做的事情是一样的,只是以不同的风格。它使用while循环打印出数字0到9。只是一些例子,没有太复杂的东西。再次,如果你之前做过任何编程或脚本,这应该很简单。
现在为了让这个概念真正深入人心,我一直在整个章节中说,去尝试,动手去做,玩一下。所以我要让你这样做。
探索活动
这里有一个活动,对你来说有点挑战:

这是一个很好的代码块,你可以开始编写你自己的 Python 代码,运行它,并玩耍,所以请这样做。你的挑战是编写一些代码,创建一个整数列表,循环遍历该列表的每个元素,到目前为止都很容易,然后只打印出偶数。
现在这不应该太难。这本笔记本中有做所有这些事情的例子;你所要做的就是把它们放在一起并让它们运行起来。所以,重点不是给你一些难的东西。我只是想让你真的对编写自己的 Python 代码并实际运行它并看到它运行有信心,所以请这样做。我绝对鼓励你在这里进行互动。所以加油,祝你好运,欢迎来到 Python。
所以这就是你的 Python 速成课程,显然,只是一些非常基本的东西。随着我们在整本书中越来越多的例子,它会变得越来越有意义,因为你有更多的例子可以参考,但如果你现在感到有点害怕,也许你对编程或脚本有点太新了,那么在继续之前可能最好先进行一次 Python 复习,但如果你对到目前为止看到的东西感到相当满意,让我们继续前进,我们将继续前进。
运行 Python 脚本
在整本书中,我们将使用 IPython/Jupyter 笔记本格式(即.ipynb文件),这是一个很好的格式,因为它让我可以在里面放一些代码块,并加一些文字和解释它在做什么,你可以实时尝试一些东西。
当然,从这个角度来看,这很棒,但在现实世界中,你可能不会真的使用 IPython/Jupyter 笔记本来在生产中运行你的 Python 脚本,所以让我简要地介绍一下你可以运行 Python 代码的其他方式,以及其他交互式运行 Python 代码的方式。所以这是一个相当灵活的系统。让我们来看看。
不仅仅是 IPython/Jupyter 笔记本
我想确保你知道有多种运行 Python 代码的方式。现在,在整本书中,我们将使用 IPython/Jupyter 笔记本格式,但在现实世界中,你不会将你的代码作为笔记本来运行。你将把它作为一个独立的 Python 脚本来运行。所以我只是想确保你知道如何做到这一点并看看它是如何工作的。

所以让我们回到我们在书中运行的第一个例子,只是为了说明空格的重要性。我们可以从笔记本格式中选择并复制代码,然后粘贴到一个新文件中。
这可以通过点击最左边的“新建”按钮来完成。所以让我们创建一个新文件,粘贴进去,然后保存这个文件,命名为test.py,其中py是我们给 Python 脚本通常使用的扩展名。现在,我可以以几种不同的方式运行它。
在命令提示符中运行 Python 脚本
我实际上可以在命令提示符中运行脚本。如果我去工具,我可以选择 Canopy 命令提示符,这将打开一个命令窗口,其中已经设置好了运行 Python 所需的所有必要的环境变量。我只需输入python test.py并运行脚本,结果就出来了:

所以在现实世界中,你可能会做类似的事情。可能是在 Crontab 上或其他地方,谁知道呢?但在生产中运行一个真正的脚本就是这么简单。现在你可以关闭命令提示符。
使用 Canopy IDE
回到 IDE,我也可以在 IDE 中运行脚本。所以在 Canopy 中,我可以去运行菜单。我可以选择运行文件,或者点击小播放图标,这也会执行我的脚本,并在输出窗口底部看到结果,如下图所示:
这是另一种方法,最后,你也可以在底部的交互式提示符中运行脚本。我实际上可以逐个输入 Python 命令,并让它们在环境中执行并保留在那里:
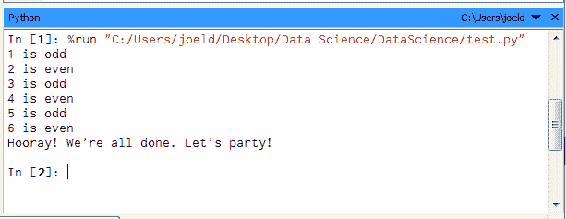
例如,我可以说stuff,将其作为list调用,并有1,2,3,4,现在我可以说len(stuff),这将给我4:

我可以说,for x in stuff:print x,我们得到的输出是1 2 3 4:

所以你可以看到,你可以在底部的交互式提示符中逐步制作脚本并逐个执行。在这个例子中,stuff是我们创建的一个变量,一个保留在内存中的列表,它有点像其他语言中的全局变量在这个环境中。
现在如果我想要重置这个环境,如果我想要摆脱stuff并重新开始,你可以这样做,你可以在这里点击运行菜单,然后选择重新启动内核,这将给你一个空白的状态:
所以现在我有一个新的 Python 环境,是一个干净的状态,这种情况下,我叫它什么来着?输入stuff,stuff还不存在,因为我有一个新的环境,但我可以把它变成其他东西,比如[4, 5, 6];运行它,就是这样:
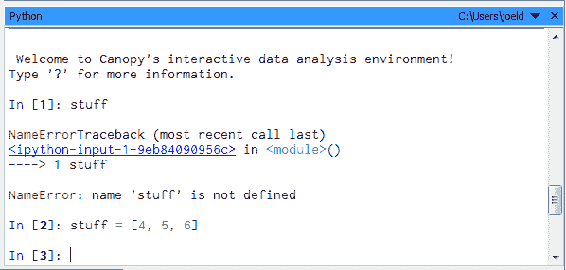
所以你看到了,有三种运行 Python 代码的方式:IPython/Jupyter Notebook,我们将在本书中使用它,因为它是一个很好的学习工具,你也可以作为独立的脚本文件运行脚本,也可以在交互式命令提示符中执行 Python 代码。
所以你看到了,你有三种不同的方式来运行 Python 代码和在生产中进行实验和运行。记住这一点。在本书的其余部分中,我们将使用笔记本,但当时机到来时,你还有其他选择。
总结
在本章中,我们开始了我们的旅程,建立了本书最重要的基石 - 安装 Enthought Canopy。然后我们继续安装其他库和不同类型的软件包。我们还借助各种 Python 代码掌握了一些 Python 的基础知识。我们涵盖了模块、列表以及元组等基本概念,最终更深入地了解了 Python 的基础知识,包括函数和循环。最后,我们开始运行一些简单的 Python 脚本。
在下一章中,我们将继续了解统计和概率的概念。
第二章:统计和概率复习,以及 Python 实践
在本章中,我们将介绍一些统计和概率的概念,这对于一些人来说可能是复习。如果您想成为一名数据科学家,这些概念很重要。我们将看到一些示例,以更好地理解这些概念。我们还将看看如何使用实际的 Python 代码来实现这些示例。
本章我们将涵盖以下主题:
-
您可能会遇到的数据类型以及如何相应处理它们
-
统计概念的均值、中位数、众数、标准差和方差
-
概率密度函数和概率质量函数
-
数据分布类型及如何绘制它们
-
理解百分位数和矩
数据类型
好了,如果您想成为一名数据科学家,我们需要讨论您可能会遇到的数据类型,如何对其进行分类以及如何可能以不同方式对待它们。让我们深入了解您可能会遇到的不同类型的数据:

这似乎很基础,但我们必须从简单的东西开始,然后逐步深入研究更复杂的数据挖掘和机器学习内容。了解您正在处理的数据类型非常重要,因为不同的技术可能会根据您处理的数据类型有不同的细微差别。因此,可以说数据有几种不同的类型,我们将主要关注其中的三种。它们是:
-
数值数据
-
分类数据
-
有序数据
同样,对于不同类型的数据,可能会使用不同的技术变体,因此在分析数据时,您始终需要牢记您正在处理的数据类型。
数值数据
让我们从数值数据开始。这可能是最常见的数据类型。基本上,它代表一些可以测量的可量化的东西。一些例子是人的身高、页面加载时间、股票价格等。变化的东西,您可以测量的东西,具有广泛可能性的东西。现在基本上有两种数值数据,所以可以说是一种变体的变体。
离散数据
有离散数据,基于整数,例如某种事件的计数。一些例子是客户一年内购买了多少次。这只能是离散值。他们买了一件东西,或者他们买了两件东西,或者他们买了三件东西。他们不可能买了 2.25 件或三个四分之三的东西。这是一个具有整数限制的离散值。
连续数据
另一种数值数据是连续数据,这是一种具有无限可能性范围的数据,可以进入分数。例如,回到人的身高,有无限可能的身高。您可能身高五英尺十点三七六二五英寸,或者做某事的时间,例如在网站上结账可能有任意巨大范围的可能性,可能是 10.7625 秒,或者一天内的降雨量。同样,这里有无限的精度。这就是连续数据的一个例子。
总之,数值数据是您可以用数字量化地测量的东西,它可以是离散的,例如基于事件计数的整数,也可以是连续的,其中您可以对该数据有无限范围的精度。
分类数据
我们将讨论的第二种数据类型是分类数据,这是没有固有数值含义的数据。
大多数时候,您实际上无法直接比较一个类别和另一个类别。例如性别、是/否问题、种族、居住州、产品类别、政党;您可以为这些类别分配数字,通常您会这样做,但这些数字没有固有含义。
所以,例如,我可以说德克萨斯的面积大于佛罗里达的面积,但我不能只是说德克萨斯大于佛罗里达,它们只是类别。它们没有真正的数值可量化的意义,只是我们根据类别对不同的事物进行分类的方式。
再次,我可能对每个州有某种数值的指定。我的意思是,我可以说佛罗里达是第 3 州,德克萨斯是第 4 州,但 3 和 4 之间没有真正的关系,对吧,这只是更紧凑地表示这些类别的一种简便方法。所以,分类数据没有任何固有的数值意义;它只是一种你选择根据类别来分割数据集的方式。
有序数据
你通常听到的最后一种数据类型是有序数据,它是数值和分类数据的一种混合。一个常见的例子是电影或音乐的星级评价,或其他什么的。

在这种情况下,我们有分类数据,可以是 1 到 5 颗星,其中 1 可能代表差,5 可能代表优秀,但它们确实有数学意义。我们知道 5 意味着比 1 好,所以这是一种数据,其中不同的类别之间有数值关系。所以,我可以说 1 颗星小于 5 颗星,我可以说 2 颗星小于 3 颗星,我可以说 4 颗星在质量上大于 2 颗星。现在你也可以把实际的星数看作是离散数值数据。所以,这些类别之间的界限确实很微妙,在很多情况下你实际上可以互换对待它们。
所以,这就是三种不同类型。有数值、分类和有序数据。让我们看看它是否已经深入人心。别担心,我不会让你交作业或者什么的。
**快速测验:**对于这些例子中的每一个,数据是数值的、分类的还是有序的?
-
让我们从你的油箱里有多少汽油开始。你觉得呢?嗯,正确的答案是数字。这是一个连续的数值,因为你的油箱里可能有无限的汽油可能性。我的意思是,是的,你可能有多少汽油可以装进去,但是你有多少汽油的可能值是没有尽头的。它可能是油箱的四分之三,可能是油箱的十六分之七,可能是油箱的1/π,谁知道呢?
-
如果你在 1 到 4 的范围内评估你的整体健康状况,其中这些选择对应于差、中等、良好和优秀的类别,你觉得呢?这是有序数据的一个很好的例子。这非常类似于我们的电影评分数据,再次取决于你如何对待它,你可能也可以把它当作离散数值数据,但从技术上讲,我们将把它称为有序数据。
-
你的同学的种族呢?这是一个很明显的分类数据的例子。你不能真正比较紫色的人和绿色的人,对吧,他们只是紫色和绿色,但它们是你可能想要研究和了解在某些其他维度上的差异的类别。
-
你的同学的年龄呢?这有点是个陷阱问题;如果我说它必须是整数年龄,比如 40、50 或 55 岁,那就是离散数值数据,但如果我有更多的精度,比如 40 年 3 个月 2.67 天,那就是连续数值数据,但无论如何,它都是数值数据类型。
-
最后,商店里花费的钱。同样,这可能是连续数值数据的一个例子。所以,这只是重要的原因是你可能会对不同类型的数据应用不同的技术。
也许有一些概念,我们对分类数据和数值数据采用不同类型的实现,例如。
这就是你需要了解的关于你通常会发现的不同类型的数据,以及我们在本书中将重点关注的内容。它们都是非常简单的概念:你有数值、分类和顺序数据,数值数据可以是连续的或离散的。根据你处理的数据类型,可能会有不同的技术应用到数据中,我们将在本书中看到这一点。让我们继续。
均值、中位数和众数
让我们来进行一次统计学 101 的复习。这就像小学的东西,但是再次经历一遍并看看这些不同的技术是如何使用的是很好的:均值、中位数和众数。我相信你以前听过这些术语,但看看它们是如何不同地使用是很好的,所以让我们深入研究一下。
这对大多数人来说应该是一个复习,一个快速的复习,现在我们开始真正地深入一些实际的统计数据。让我们看看一些实际的数据,然后找出如何测量这些数据。
均值
均值,你可能知道,只是平均值的另一个名称。要计算数据集的均值,你所要做的就是把所有值加起来,然后除以你拥有的值的数量。
样本总和/样本数量
让我们以同样的数据集来计算我社区每个房子的平均孩子数量。
假设我在我的社区挨家挨户地问每个人,他们家有多少孩子。 (顺便说一句,这是离散数值数据的一个很好的例子;还记得前一节吗?)假设我四处走动,发现第一家没有孩子,第二家有两个孩子,第三家有三个孩子,依此类推。我积累了这些离散数值数据的小数据集,为了计算均值,我所要做的就是把它们全部加起来,然后除以我去过的房子的数量。
我街上每个房子的孩子数量:
0, 2, 3, 2, 1, 0, 0, 2, 0
均值是*(0+2+3+2+1+0+0+2+0)/9 = 1.11*
结果是 0 加 2 加 3 加所有其他数字除以我看过的房子的总数,即 9,我样本中每个房子的平均孩子数量是 1.11。所以,这就是均值。
中位数
中位数有点不同。计算数据集的中位数的方法是通过对所有值进行排序(无论是升序还是降序),并取中间的那个值。
因此,例如,让我们使用我社区孩子的相同数据集
0, 2, 3, 2, 1, 0, 0, 2, 0
我会按数字顺序排列,然后取出数据中间的数字,结果是 1。
0, 0, 0, 0, 1, 2, 2, 2, 3
同样,我所要做的就是取数据,按数字顺序排列,然后取中间的点。
如果数据点的数量是偶数,那么中位数可能会落在两个数据点之间。不清楚哪一个实际上是中间的。在这种情况下,你所要做的就是取两个中间的数的平均值,并将该数字视为中位数。
异常值的因素
现在,在前面的例子中,每个家庭的孩子数量,中位数和均值非常接近,因为没有太多的异常值。我们有 0、1、2 或 3 个孩子,但我们没有一些有 100 个孩子的疯狂家庭。那会使均值受到很大的影响,但可能不会太大地改变中位数。这就是为什么中位数通常是一个非常有用的东西,经常被忽视。
中位数比均值更不容易受到异常值的影响。
有时人们倾向于用统计数据误导人。我会在整本书中尽可能地指出这一点。
例如,你可以谈论美国的平均家庭收入,去年我查到的实际数字大约是 72000 美元,但这并不能真正准确地反映出典型的美国人的收入。这是因为,如果你看中位数收入,它要低得多,只有 51939 美元。为什么呢?因为收入不平等。美国有一些非常富有的人,其他很多国家也是如此。美国甚至不是最糟糕的,但你知道那些亿万富翁,那些住在华尔街或硅谷或其他一些非常富有的地方的超级富人,他们会使平均值偏离。但他们数量很少,所以他们并不会对中位数产生太大影响。
这是一个很好的例子,中位数比平均数更好地反映了这个例子中典型的人或数据点的情况。每当有人谈论平均数时,你必须考虑数据分布是什么样子。是否有可能会使平均数偏离的异常值?如果答案可能是肯定的,你也应该要求中位数,因为通常情况下,中位数提供的洞察力比平均数更多。
众数
最后,我们将讨论众数。实际上在实践中这并不经常出现,但你不能谈论均值和中位数而不谈论众数。众数的意思就是数据集中最常见的值。
让我们回到我关于每个房子中孩子数量的例子。
0、2、3、2、1、0、0、2、0
每个值有多少个:
0: 4, 1: 1, 2: 3, 3: 1
众数是 0
如果我只看最频繁出现的数字,结果是 0,因此这组数据的众数是 0。在这个社区中,一个房子里孩子的最常见数量是没有孩子,这就是它的含义。
现在这实际上是一个很好的连续与离散数据的例子,因为这只适用于离散数据。如果我有一系列连续的数据,那么我就无法谈论最常出现的值,除非我以某种方式将其量化为离散值。所以我们已经遇到了一个数据类型很重要的例子。
众数通常只与离散数值数据相关,而不与连续数据相关。
很多现实世界的数据往往是连续的,所以也许这就是为什么我不太听到关于众数的事情,但我们在这里看到了它的完整性。
就是这样:均值、中位数和众数的概要。这可能是你能做的最基本的统计工作,但我希望你在选择中位数和均值的重要性上得到了一点复习。它们可以讲述非常不同的故事,但人们往往在头脑中将它们等同起来,所以确保你是一个负责任的数据科学家,并以传达你试图代表的含义的方式代表数据。如果你试图显示一个典型值,通常中位数比平均数更好,因为异常值,所以记住这一点。让我们继续。
在 Python 中使用均值、中位数和众数
让我们开始在 Python 中进行一些真正的编码,看看如何使用 Python 在 IPython Notebook 文件中计算均值、中位数和众数。
所以,如果你想跟着做的话,可以打开本节数据文件中的MeanMedianMode.ipynb文件,我绝对鼓励你这样做。如果你需要回到之前关于从哪里下载这些材料的部分,请去做,因为你将需要这些文件来完成本节。让我们开始吧!
使用 NumPy 包计算均值
我们要做的是创建一些虚假的收入数据,回到上一节的例子。在这个例子中,我们将创建一些虚假数据,其中典型的美国人在这个例子中每年赚大约$27,000,我们将说这是以正态分布和标准差为 15,000 分布的。所有的数字都是完全虚构的,如果你还不知道正态分布和标准差是什么意思,不用担心。我会在本章稍后介绍,但我只是想让你知道这个例子中这些不同参数代表什么。以后会有意义的。
在我们的 Python 笔记本中,记得将 NumPy 包导入 Python,这样计算平均值、中位数和众数就变得非常容易。我们将使用import numpy as np指令,这意味着我们可以使用np作为调用numpy的简写。
然后我们将使用np.random.normal函数创建一个名为incomes的数字列表。
import numpy as np
incomes = np.random.normal(27000, 15000, 10000)
np.mean(incomes)
np.random.normal函数的三个参数表示我希望数据以27000为中心,标准差为15000,并且我希望 Python 在这个列表中生成10000个数据点。
一旦我这样做了,我就可以通过在incomes上调用np.mean来计算这些数据点的平均值,或者说是平均值。就是这么简单。
让我们继续运行。确保你选择了那个代码块,然后你可以点击播放按钮来执行它,由于这些收入数字有一个随机成分,每次我运行它,我都会得到一个略微不同的结果,但它应该总是接近27000。
Out[1]: 27173.098561362742
好的,这就是在 Python 中计算平均值的全部内容,只需使用 NumPy(np.mean)就可以轻松搞定。你不必写一堆代码,或者实际上把所有东西加起来,计算出你有多少项,然后做除法。NumPy mean,为你做了所有这些。
使用 matplotlib 可视化数据
让我们可视化这些数据,以使它更加有意义。还有另一个叫做matplotlib的包,我们以后也会更多地谈论它,但它是一个让我在 IPython 笔记本中制作漂亮图形的包,所以这是一种简单的方式来可视化你的数据并了解发生了什么。
在这个例子中,我们使用matplotlib创建了一个包含50个不同桶的收入数据的直方图。所以基本上,我们将我们的连续数据离散化,然后我们可以在matplotlib.pyplot上调用 show 来实际显示这个直方图。参考以下代码:
%matplotlib inline
import matplotlib.pyplot as plt
plt.hist(incomes, 50)
plt.show()
继续选择代码块并点击播放。它将为我们创建一个新的图表。

如果你不熟悉直方图或者需要复习一下,解释这个的方法是,我们将数据离散化为每个桶,显示了该数据的频率。
例如,大约在 27,000 左右,我们看到每个给定值范围内大约有600个数据点。在 27,000 左右有很多人,但当你到达80,000这样的异常值时,就没有那么多了,显然有一些可怜的人甚至负债**-40,000**,但是他们很少,不太可能,因为我们定义了一个正态分布,这就是正态概率曲线的样子。我们以后会更详细地谈论这个,但我只是想让你知道这个想法,如果你还不知道的话。
使用 NumPy 包计算中位数
好的,计算中位数就像计算平均值一样简单。就像我们有 NumPy 的mean一样,我们也有一个 NumPy 的median函数。
我们可以在我们的数据列表incomes上使用median函数,这将给我们中位数。在这种情况下,中位数是$26,911,与均值$26988\相差不大。同样,初始数据是随机的,所以你的值会略有不同。
np.median(incomes)
以下是前面代码的输出:
Out[4]: 26911.948365056276
我们不希望看到很多异常值,因为这是一个很好的正态分布。当你没有很多奇怪的异常值时,中位数和均值是可以比较的。
分析异常值的影响
为了证明一点,让我们加入一个异常值。我们来加入唐纳德·特朗普;我认为他算是一个异常值。让我们继续添加他的收入。所以我将手动使用np.append将这个数据添加到数据中,假设添加 10 亿美元(这显然不是唐纳德·特朗普的实际收入)到收入数据中。
incomes = np.append(incomes, [1000000000])
我们将看到的是,这个异常值并没有真正改变中位数很多,你知道,它仍然会在大约相同的值$26,911 左右,因为我们实际上并没有改变中间点在哪里,只是在下面的例子中显示了一个值:
np.median(incomes)
这将输出以下内容:
Out[5]: 26911.948365056276
这给出了一个新的输出:
np.mean(incomes)
以下是前面代码的输出:
Out[5]:127160.38252311043
啊哈,就是这样!这是一个很好的例子,说明了中位数和均值,尽管人们在日常语言中倾向于将它们等同起来,但它们可能非常不同,并讲述了一个非常不同的故事。因此,这一个异常值导致了这个数据集中的平均收入超过了每年 12.7 万美元,但更准确的情况是这个数据集中典型人的年收入接近 2.7 万美元。我们只是因为一个大的异常值而使均值偏离了。
故事的寓意是:如果你怀疑可能存在异常值,那么对于谈论均值或平均数的人要持怀疑态度,而收入分布显然就是这种情况。
使用 SciPy 包计算众数
最后,让我们来看看众数。我们将生成一堆随机整数,精确地说是 500 个,范围在18到90之间。我们将为人们创建一堆虚假的年龄。
ages = np.random.randint(18, high=90, size=500)
ages
你的输出将是随机的,但应该看起来像以下的截图:
现在,SciPy,有点像 NumPy,是一堆方便的统计函数,所以我们可以使用以下语法从 SciPy 导入stats。这与我们之前看到的有点不同。
from scipy import stats
stats.mode(ages)
这段代码的意思是,从scipy包中导入stats,我只是用stats来引用这个包,这意味着我不需要像之前使用 NumPy 那样使用别名,只是另一种做法。两种方法都可以。然后,我在ages上使用了stats.mode函数,这是我们的随机年龄列表。当我们执行上面的代码时,我们得到了以下输出:
Out[11]: ModeResult(mode=array([39]), count=array([12]))
所以在这种情况下,实际的众数是39,在数组中出现了12次。
现在,如果我真的创建一个新的分布,我会期望得到一个完全不同的答案,因为这些数据确实是完全随机的。让我们再次执行上面的代码块来创建一个新的分布。
ages = np.random.randint(18, high=90, size=500)
ages
from scipy import stats
stats.mode(ages)
随机化方程的输出如下分布:

确保你选择了那个代码块,然后你可以点击播放按钮来执行它。
在这种情况下,众数最终是数字29,出现了14次。
Out[11]: ModeResult(mode=array([29]), count=array([14]))
所以,这是一个非常简单的概念。你可以再做几次,只是为了好玩。这有点像转动轮盘。我们将再次创建一个新的分布。
就是这样,均值、中位数和众数就是这样。使用 SciPy 和 NumPy 包非常简单。
一些练习
我将在本节中给你一个小作业。如果你打开MeanMedianExercise.ipynb文件,里面有一些你可以玩的东西。我希望你能动手尝试一下。
在文件中,我们有一些随机的电子商务数据。这些数据代表的是每笔交易的总金额,就像我们之前的例子一样,这只是一组数据的正态分布。我们可以运行它,你的作业是使用 NumPy 包找出这些数据的平均值和中位数。这几乎是你能想象到的最简单的作业。你需要的所有技巧都在我们之前使用的MeanMedianMode.ipynb文件中。
这里的重点并不是真的要挑战你,而是让你真正写一些 Python 代码,并让自己相信你实际上可以得到一个结果并让事情发生。所以,继续玩吧。如果你想再玩一会儿,可以随意玩一下这里的数据分布,看看你对数字有什么影响。尝试添加一些异常值,就像我们在收入数据中所做的那样。这是学习这些东西的方法:掌握基础知识,高级知识就会随之而来。尽情享受吧。
一旦你准备好了,让我们继续前进到我们的下一个概念,标准差和方差。
标准差和方差
让我们谈谈标准差和方差。这些概念和术语你可能以前听过,但让我们更深入地了解一下它们的真正含义以及如何计算它们。这是数据分布的分散程度的一种度量,几分钟后你就会更清楚了。
标准差和方差是数据分布的两个基本量,你将在本书中一遍又一遍地看到它们。所以,如果你需要温习一下,让我们看看它们是什么。
方差
让我们来看一个直方图,因为方差和标准差都与数据的分散程度、数据集的分布形状有关。看一下下面的直方图:
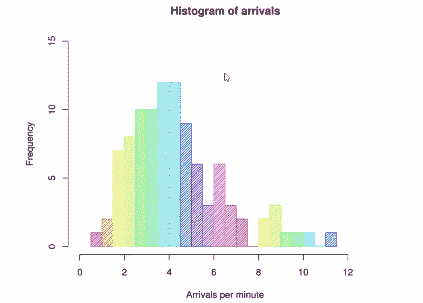
假设我们有一些关于飞机在机场到达频率的数据,例如,这个直方图表明我们大约每分钟有 4 次到达,我们观察到的数据中大约有 12 天出现了这种情况。然而,我们也有一些异常值。有一天到达速度非常慢,每分钟只有一次到达,还有一天到达速度非常快,几乎每分钟有 12 次到达。因此,读取直方图的方法是查找给定值的桶,并告诉您该值在数据中出现的频率,直方图的形状可以告诉您很多关于给定数据集的概率分布的信息。
我们从这些数据中知道,我们的机场很可能每分钟有大约 4 次到达,但很不可能有 1 次或 12 次到达,我们还可以具体讨论中间所有数字的概率。因此,不仅每分钟有 12 次到达的可能性很小,每分钟有 9 次到达的可能性也很小,但一旦我们开始接近 8 左右,事情就开始有点起色了。从直方图中可以得到很多信息。
方差衡量数据的分散程度。
测量方差
我们通常将方差称为 sigma 平方,你马上就会知道为什么,但现在,只需知道方差是平均值与平方差的差值。
-
要计算数据集的方差,首先要找出它的平均值。假设我有一些数据,可以代表任何东西。比如说某个小时排队的最大人数。在第一个小时,我观察到有 1 个人在排队,然后是 4 个,然后是 5 个,然后是 4 个,然后是 8 个。
-
计算方差的第一步就是找到这些数据的均值或平均值。我把它们全部加起来,将总和除以数据点的数量,结果是 4.4,这是排队人数的平均数*(1+4+5+4+8)/5=4.4*。
-
现在下一步是找到每个数据点与均值的差异。我知道均值是 4.4。所以对于我的第一个数据点,我有 1,所以1-4.4=-3.4,下一个数据点是 4,所以 4-4.4=-0.44-4.4=-0.4,依此类推。所以我得到这些正负数,代表每个数据点与均值的方差*(-3.4,-0.4,0.6,-0.4,3.6)*。
-
现在我需要一个单一的数字来代表整个数据集的方差。因此,我接下来要做的是找到这些差异的平方。我将逐个计算这些与均值的原始差异的平方。这是出于几个不同的原因:
-
- 首先,我要确保负方差和正方差一样重要。否则,它们将互相抵消。那就不好了。
-
其次,我还想给异常值更多的权重,因此这会放大与均值非常不同的事物的影响,同时确保负数和正数是可比较的*(11.56,0.16,0.36,0.16,12.96)*。
让我们看看那里发生了什么,所以(-3.4)²是一个正数 11.56,(-0.4)²最终是一个更小的数字,即 0.16,因为它更接近均值 4.4。同样(0.6)²结果接近均值,只有 0.36。但是当我们到达正的异常值时,(3.6)²最终是 12.96。这给了我们:(11.56,0.16,0.36,0.16,12.96)。
要找到实际的方差值,我们只需取所有这些平方差的平均值。因此,我们将所有这些平方差相加,将总和除以 5,也就是我们拥有的值的数量,最终得到方差为 5.04。

好的,这就是方差的全部内容。
标准差
通常,我们谈论标准差比方差更多,结果标准差只是方差的平方根。就是这么简单。
因此,如果我有这个方差5.04,标准差就是2.24。所以你现在明白为什么我们说方差=(σ)²。因为σ本身代表标准差。因此,如果我取(σ)²的平方根,我得到σ。在这个例子中,结果是 2.24。
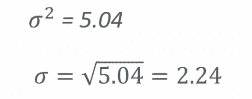
使用标准差识别异常值
这是我们在前面的示例中查看的实际数据的直方图,用于计算方差。

现在我们看到数字4在我们的数据集中出现了两次,然后我们有一个1,一个5,和一个8。
标准差通常用作一种思考如何识别数据集中的异常值的方法。如果我说如果我在均值 4.4 的标准差内,那在正态分布中被认为是一种典型值。然而,你可以看到在前面的图表中,数字1和8实际上位于该范围之外。因此,如果我取 4.4 加减 2.24,我们得到大约7和2,而1和8都落在标准差范围之外。因此我们可以数学上说,1 和 8 是异常值。我们不必猜测和凭眼测量。现在仍然需要判断一个数据点与均值相比是多少标准差的异常值。
通常可以通过一个数据点与均值相差多少标准差(有时也可以是多少西格玛)来谈论一个数据点有多少异常值。
这就是标准差在现实世界中使用的一些情况。
总体方差与样本方差
标准差和方差有一点微妙之处,就是当你谈论总体与样本方差时。如果你在处理完整的数据集,一组完整的观察数据,那么你就按照我告诉你的做。你只需取平均值,从均值开始所有平方差的平均值就是你的方差。
然而,如果你在对数据进行抽样,也就是说,如果你只是取数据的一个子集来简化计算,你就要做一些不同的事情。你不是除以样本数,而是除以样本数减 1。让我们看一个例子。
我们将使用刚刚研究的排队人员的样本数据。我们将平方差的总和除以 5,也就是我们有的数据点的数量,得到 5.04。
σ² = (11.56 + 0.16 + 0.36 + 0.16 + 12.96) / 5 = 5.04
如果我们看样本方差,用 S²表示,它是由平方差的总和除以 4 得到的,也就是*(n - 1)*。这给我们了样本方差,结果是 6.3。
S² = (11.56 + 0.16 + 0.36 + 0.16 + 12.96) / 4 = 6.3
所以,如果这是我们从一个更大的数据集中取出的样本,那就是你要做的。如果这是一个完整的数据集,你就除以实际的数量。好的,这就是我们计算总体和样本方差的方法,但背后的实际逻辑是什么呢?
数学解释
至于为什么总体和样本方差之间有差异,这涉及到概率的一些非常奇怪的东西,你可能不想太多地去思考,而且需要一些复杂的数学符号,我尽量避免在这本书中使用符号,因为我认为概念更重要,但这是非常基础的东西,你会一遍又一遍地看到它。
正如我们所见,总体方差通常被表示为 sigma squared (σ²),其中 sigma (σ)是标准差,我们可以说这是每个数据点 X 减去均值 mu 的平方的总和,这是每个样本平方的方差除以数据点的数量 N,我们可以用以下方程表示:

-
X 表示每个数据点
-
µ表示均值
-
N 表示数据点的数量
样本方差同样被表示为 S²,用以下方程表示:
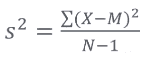
-
X 表示每个数据点
-
M 表示均值
-
N-1 表示数据点的数量减 1
就是这样。
在直方图上分析标准差和方差
让我们在这里写一些代码,玩一些标准差和方差。所以如果你打开StdDevVariance.ipynb文件的 IPython 笔记本,并跟着我一起做。请这样做,因为最后有一个我想让你尝试的活动。我们要做的就像前面的例子一样,从以下代码开始:
%matplotlib inline
import numpy as np
import matplotlib.pyplot as plt
incomes = np.random.normal(100.0, 20.0, 10000)
plt.hist(incomes, 50)
plt.show()
我们使用matplotlib来绘制一些正态分布的随机数据的直方图,并将其命名为incomes。我们说它将以100为中心(希望这是小时工资之类的,而不是年薪,或者其他奇怪的单位),标准差为20,有10,000个数据点。
让我们继续执行上面的代码块,并按照下图所示绘制出来:
我们有 10,000 个以 100 为中心的数据点。通过正态分布和标准差为 20,这是数据的扩展度量,你可以看到最常见的情况是在 100 左右,随着我们离这个点越来越远,事情变得越来越不太可能。我们指定的标准差点 20 在 80 左右和 120 左右。你可以在直方图中看到,这是事情开始急剧下降的点,所以我们可以说在那个标准差边界之外的事情是不寻常的。
使用 Python 计算标准差和方差
现在,NumPy 也使计算标准差和方差变得非常容易。如果你想计算我们生成的数据集的实际标准差,你只需在数据集本身上调用std函数。因此,当 NumPy 创建列表时,它不仅仅是一个普通的 Python 列表,它实际上附加了一些额外的东西,所以你可以在上面调用函数,比如标准差的std。现在让我们来做一下:
incomes.std()
这给我们一些类似以下输出(记住我们使用了随机数据,所以你的图形可能与我的不完全相同):
20.024538249134373
当我们执行时,得到的数字非常接近 20,因为这是我们在创建随机数据时指定的。我们想要一个标准差为 20。果然,20.02,非常接近。
方差只是一个调用var的问题。
incomes.var()
这给了我以下结果:
400.98213209104557
结果非常接近 400,这是 20²。对,世界是有道理的!标准差只是方差的平方根,或者你可以说方差是标准差的平方。果然,这是成立的,所以世界是按照应有的方式运行的。
自己试试
我希望你能深入研究并实际尝试一下,让它变得真实,尝试使用不同的参数来生成正态数据。记住,这是对数据分布形状的度量,所以如果我改变中心点会发生什么?这重要吗?它实际上会影响形状吗?为什么不试一下,找出答案呢?
尝试改变我们指定的实际标准差,看看对图形形状有什么影响。也许尝试一个标准差为 30,然后你知道,你可以看看它实际上如何影响事物。让我们更夸张一点,比如 50。试试 50。你会看到图形开始变得有点胖。尝试不同的值,感受一下这些值是如何起作用的。这是真正获得标准差和方差直观感觉的唯一方法。尝试一些不同的例子,看看它的影响。
这就是实践中的标准差和方差。你已经亲自体验了一些,我希望你能稍微玩弄一下,以便更熟悉。这些是非常重要的概念,我们将在整本书中经常谈论标准差,毫无疑问,在你的数据科学职业生涯中也会经常谈论,所以确保你已经掌握了这些。让我们继续。
概率密度函数和概率质量函数
因此,我们已经在本书的一些例子中看到了正态分布函数。这是概率密度函数的一个例子,还有其他类型的概率密度函数。所以让我们深入了解一下,看看它实际上意味着什么,还有一些其他例子。
概率密度函数和概率质量函数
我们已经在本书中看到了一些正态分布函数的例子。这是概率密度函数的一个例子,还有其他类型的概率密度函数。让我们深入了解一下,看看这实际上意味着什么,还有一些其他例子。
概率密度函数
让我们谈谈概率密度函数,我们在书中已经使用过其中之一。我们只是没有这样称呼它。让我们正式化一些我们谈论过的东西。例如,我们已经多次看到正态分布,这是概率密度函数的一个例子。以下图是正态分布曲线的一个例子

在概念上,试图将这个图形看作给定值发生的概率是很容易的,但是当你谈论连续数据时,这有点误导。因为在连续数据分布中,实际可能的数据点有无限多个。可能是 0 或 0.001 或 0.00001,所以一个非常具体的值发生的实际概率是非常非常小的,无限小。概率密度函数实际上告诉了给定值范围发生的概率。所以这就是你必须考虑的方式。
例如,在上图中显示的正态分布中,均值(0)和均值的一个标准差(1σ)之间,有 34.1%的机会出现在这个范围内。你可以收紧或扩展这个范围,找出实际值,但这就是概率密度函数的思考方式。对于给定值范围,它给出了发生该范围的概率的方法。
-
你可以看到在图中,当你接近均值(0)时,在一个标准差(-1σ和1σ)内,你很可能会落在这个范围内。我的意思是,如果你把 34.1 和 34.1 相加,等于 68.2%,你就得到了落在均值一个标准差范围内的概率。
-
然而,当你处于两个到三个标准差之间(-3σ到**-2σ和2σ到3σ**),我们只剩下略微超过 4%(确切地说是 4.2%)。
-
当你超出三个标准差(-3σ和3σ)时,概率远远小于 1%。
因此,图表只是一种可视化和讨论给定数据点发生概率的方式。再次强调,概率分布函数给出了数据点落在给定值范围内的概率,正态函数只是概率密度函数的一个例子。我们稍后会看一些更多的例子。
概率质量函数
现在,当你处理离散数据时,关于有无限多个可能值的微妙之处就消失了,我们称之为另一种东西。这就是概率质量函数。如果你处理离散数据,你可以谈论概率质量函数。这里有一个图表来帮助可视化这一点:
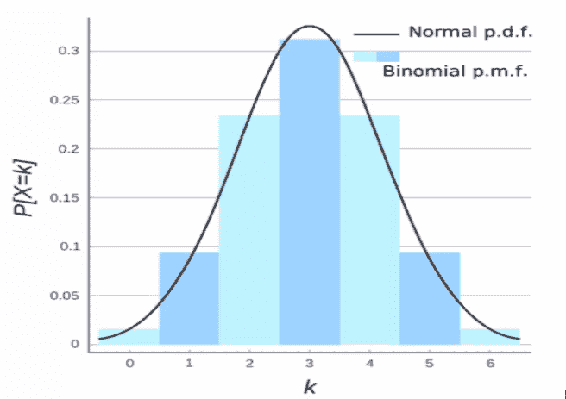
例如,你可以在图中显示连续数据的正态概率密度函数,但如果我们将其量化为离散数据集,就像我们在直方图中所做的那样,我们可以说数字 3 出现了一定次数,你实际上可以说数字 3 有超过 30%的机会出现。因此,概率质量函数是我们可视化离散数据发生概率的方式,它看起来很像直方图,因为它基本上就是一个直方图。
术语差异:概率密度函数是描述连续数据发生范围的实心曲线。概率质量函数是数据集中给定离散值发生的概率。
数据分布类型
让我们看一些概率分布函数和数据分布的真实例子,更全面地理解数据分布以及如何在 Python 中可视化和使用它们。
继续打开书中的Distributions.ipynb,如果你愿意,你可以跟着我一起学习。
均匀分布
让我们从一个非常简单的例子开始:均匀分布。均匀分布意味着在给定范围内,一个值发生的概率是平坦的常数。
import numpy as np
Import matplotlib.pyplot as plt
values = np.random.uniform(-10.0, 10.0, 100000)
plt.hist(values, 50)
plt.show()
所以我们可以使用 NumPy 的random.uniform函数创建一个均匀分布。前面的代码表示,我想要一个在-10和10之间范围的均匀分布的随机值,并且我想要100000个。如果我然后创建这些值的直方图,你会看到它看起来像下面这样。

在这些数据中,任何给定值或值范围发生的概率几乎是相等的。因此,与正态分布不同,我们在均匀分布中看到的是在你定义的范围内任何给定值都有相等的概率。
那么这个的概率分布函数会是什么样子呢?嗯,我期望在**-10或10之外基本上看不到任何东西。但当我在-10和10**之间时,我会看到一条平直的线,因为任何一个这些值范围发生的概率是恒定的。因此在均匀分布中,你会看到概率分布函数上的一条平直线,因为每个值,每个值范围出现的概率都是相等的。
正态或高斯分布
现在我们已经在本书中看到了正态分布,也称为高斯分布函数。你实际上可以在 Python 中可视化这些。scipy.stats.norm包函数中有一个名为pdf(概率密度函数)的函数。
所以,让我们看下面的例子:
from scipy.stats import norm
import matplotlib.pyplot as plt
x = np.arange(-3, 3, 0.001)
plt.plot(x, norm.pdf(x))
在上面的例子中,我们通过使用arange函数创建了一个在-3 和 3 之间以 0.001 为间隔的 x 值列表用于绘图。所以这些是图表上的 x 值,我们将使用这些值绘制x轴。y轴将是正态函数norm.pdf,即正态分布的概率密度函数,对这些 x 值。我们得到了下面的输出:

正态分布的概率密度函数看起来就像我们上一节中的样子,也就是说,对于我们提供的给定数字,0 代表均值,而数字**-3**、-2、-1、1、2和3代表标准差。
现在,我们将使用正态分布生成随机数。我们已经做过几次了;把它当作一个复习。参考下面的代码块:
import numpy as np
import matplotlib.pyplot as plt
mu = 5.0
sigma = 2.0
values = np.random.normal(mu, sigma, 10000)
plt.hist(values, 50)
plt.show()
在上面的代码中,我们使用了 NumPy 包的random.normal函数,第一个参数mu代表你想要将数据围绕其均值中心化的均值。sigma是数据的标准差,基本上是数据的扩散。然后,我们使用正态概率分布函数指定我们想要的数据点的数量,这里是10000。这是使用概率分布函数的一种方式,在这种情况下是正态分布函数,用来生成一组随机数据。然后我们可以绘制一个直方图,分成50个桶并显示出来。下面的输出就是我们得到的结果:

它看起来更像是一个正态分布,但由于有一个随机元素,它不会是一个完美的曲线。我们在谈论概率;有一些事情不太可能是我们期望的样子。
指数概率分布或幂律
你经常看到的另一个分布函数是指数概率分布函数,其中事物以指数方式下降。
当你谈论指数下降时,你期望看到一个曲线,在接近零时很可能发生某些事情,但随着你离开它越远,它会迅速下降。自然界中有很多事物都是以这种方式行为的。
在 Python 中,就像我们在scipy.stats中有一个norm.pdf函数一样,我们也有一个expon.pdf,或者指数概率分布函数来做这个。在 Python 中,我们可以使用与正态分布相同的语法来处理指数分布,如下面的代码块所示:
from scipy.stats import expon
import matplotlib.pyplot as plt
x = np.arange(0, 10, 0.001)
plt.plot(x, expon.pdf(x))
所以在上面的代码中,我们只是使用 NumPy 的arange函数创建我们的 x 值,以便在0到10之间创建一堆值,步长为0.001。然后,我们将这些 x 值绘制在 y 轴上,y 轴定义为函数expon.pdf(x)。输出看起来像是指数下降。如下截图所示:

二项概率质量函数
我们也可以可视化概率质量函数。这被称为二项概率质量函数。我们将使用与之前相同的语法,如下面的代码所示:
from scipy.stats import expon
import matplotlib.pyplot as plt
x = np.arange(0, 10, 0.001)
plt.plot(x, expon.pdf(x))
所以我们不再使用expon或norm,而是使用binom。提醒一下:概率质量函数处理离散数据。实际上,一直以来我们一直在处理离散数据,只是你要如何思考它。
回到我们的代码,我们正在创建一些在0到10之间的离散x值,间隔为0.01,并且我要绘制一个使用这些数据的二项概率质量函数。使用binom.pmf函数,我实际上可以使用两个形状参数n和p来指定数据的形状。在这种情况下,它们分别是10和0.5。输出如下图所示:

如果你想尝试不同的值来看看它的影响,这是一个直观了解这些形状参数如何影响概率质量函数的好方法。
泊松概率质量函数
最后,你可能听说的另一个分布函数是泊松概率质量函数,它有一个非常特定的应用。它看起来很像正态分布,但有点不同。
这里的想法是,如果你有关于在给定时间段内发生的事情的平均数量的一些信息,这个概率质量函数可以让你预测在未来的某一天获得其他值的几率。
举个例子,假设我有一个网站,平均每天有 500 位访客。我可以使用泊松概率质量函数来估计在特定一天看到其他数值的概率。例如,以我平均每天 500 位访客为例,看到在某一天有 550 位访客的几率是多少?这就是泊松概率质量函数可以给你的,看看下面的代码:
from scipy.stats import poisson
import matplotlib.pyplot as plt
mu = 500
x = np.arange(400, 600, 0.5)
plt.plot(x, poisson.pmf(x, mu))
在这个代码示例中,我说我的平均值是 500 mu。我将设置一些 x 值,范围在400到600之间,间隔为0.5。我将使用poisson.pmf函数来绘制图表。我可以使用该图表来查找在正态分布情况下获得任何特定值的几率:

在特定一天看到 550 位访客的几率,结果是大约 0.002 或 0.2%的概率。非常有趣。
好的,这些是你在现实世界中可能遇到的一些常见数据分布。
记住,我们使用概率分布函数处理连续数据,但当我们处理离散数据时,我们使用概率质量函数。
所以这就是概率密度函数和概率质量函数。基本上,这是一种可视化和测量数据集中出现的一定范围数值的实际机会的方法。这是非常重要的信息,也是非常重要的理解的事情。我们将一遍又一遍地使用这个概念。好的,让我们继续。
百分位数和矩
接下来,我们将讨论百分位数和矩。你经常在新闻中听到百分位数。收入排在前 1%的人:这是百分位数的一个例子。我们将解释这一点,并举一些例子。然后,我们将讨论矩,这是一个非常复杂的数学概念,但事实证明,在概念上非常容易理解。让我们深入讨论百分位数和矩,这是统计学中的一些基本概念,但是,我们正在逐步解决困难的问题,所以请耐心等待我们复习一些内容。
百分位数
让我们看看百分位数的意思。基本上,如果你要对数据集中的所有数据进行排序,给定的百分位数是数据小于你所在位置的百分比。
一个常见的例子是收入分布。当我们谈论第 99 百分位数,或者百分之一的人,想象一下,你要把这个国家,这里是美国,所有人的收入按收入排序。第 99 百分位数将是收入的金额,99%的人收入低于这个金额。这是一个非常容易理解的方法。
在数据集中,百分位数是数值小于该点的值的x%。
下图是收入分布的一个例子:

上图显示了一个收入分布数据的例子。例如,在第 99 百分位数,我们可以说 99%的数据点,代表美国人,年收入低于 50,6553 美元,而 1%的人年收入高于这个数。相反,如果你是百分之一的人,你的年收入超过 50,6553 美元。恭喜!但如果你是一个更典型的中位数人,第 50 百分位数定义了一半的人收入低于你,一半的人收入高于你,这就是中位数的定义。第 50 百分位数和中位数是一回事,在这个数据集中是 42,327 美元。所以,如果你在美国年收入 42,327 美元,你的收入正好是全国的中位数。
你可以从上面的图表中看到收入分布的问题。事物往往非常集中在图表的高端,这是目前在国家中一个非常大的政治问题。我们将看看发生了什么,但这超出了本书的范围。这就是百分位数的要点。
四分位数
百分位数也用于讨论分布中的四分位数。让我们看一个正态分布,以更好地理解这一点。
这是一个例子,说明正态分布中的百分位数:

看看上图中的正态分布,我们可以谈论四分位数。中间的四分位数 1(Q1)和四分位数 3(Q3)只是包含 50%数据的点,所以 25%在中位数的左侧,25%在中位数的右侧。
在这个例子中,中位数恰好接近平均值。例如,四分位距(IQR),当我们谈论一个分布时,是分布中包含 50%数值的中间区域。
图像的最上部是我们所谓的箱线图的一个例子。暂时不要担心箱子边缘的东西。那有点混乱,我们稍后会讨论。即使它们被称为四分位数 1(Q1)和四分位数 3(Q1),它们并不真正代表 25%的数据,但暂时不要纠结在这一点上。重点是中间的四分位数代表数据分布的 25%。
在 Python 中计算百分位数
让我们看一些使用 Python 的百分位数的更多例子,并更深入地理解它。如果你愿意跟着做,可以打开Percentiles.ipynb文件,我鼓励你这样做,因为我希望你稍后能够玩一下这个。
让我们首先生成一些随机分布的正态数据,或者说是正态分布的随机数据,请参考以下代码块:
%matplotlib inline
import numpy as np
import matplotlib.pyplot as plt
vals = np.random.normal(0, 0.5, 10000)
plt.hist(vals, 50)
plt.show()
在这个例子中,我们要做的是生成一些以零为中心的数据,也就是均值为零,标准差为0.5,我将用这个分布生成10000个数据点。然后,我们将绘制一个直方图,看看我们得到了什么。

生成的直方图看起来非常像正态分布,但由于存在随机因素,我们在这个例子中有一个偏离值接近-2。在均值处有一点点的倾斜,一点点的随机变化使事情变得有趣。
NumPy 提供了一个非常方便的百分位数函数,可以为您计算这个分布的百分位数值。因此,我们使用np.random.normal创建了我们的vals数据列表,我可以调用np.percentile函数来计算第 50 个百分位数值,使用以下代码:
np.percentile(vals, 50)
以下是前面代码的输出:
0.0053397035195310248
输出结果为 0.005。所以记住,第 50 个百分位数其实就是中位数的另一个名称,而在这个数据中,中位数非常接近零。你可以在图表中看到我们稍微向右倾斜,所以这并不太令人惊讶。
我想计算第 90 个百分位数,这将给我一个数,这个数小于它的值占总数的 90%。我们可以很容易地用以下代码来实现:
np.percentile(vals, 90)
以下是该代码的输出:
Out[4]: 0.64099069837340827
这些数据的第 90 个百分位数值是 0.64,所以大约在这里,基本上,在这个值以下的数据不到 90%。我可以相信这个结果。10%的数据大于 0.64,90%的数据小于 0.65。
让我们计算第 20 个百分位数值,这将给我一个数,这个数小于它的值占总数的 20%。同样,我们只需要对代码进行一个非常简单的修改:
np.percentile(vals, 20)
这给出了以下输出:
Out[5]:-0.41810340026619164
第 20 个百分位数值大约是-0.4,我相信这个结果。它表示 20%的数据位于-0.4 的左侧,相反,80%的数据大于-0.4。
如果你想了解数据集中的分界点在哪里,百分位数函数是一个简单的方法来计算它们。如果这是一个代表收入分布的数据集,我们可以调用np.percentile(vals, 99)来计算第 99 个百分位数。你可以找出人们一直在谈论的那些百分之一的人到底是谁,以及你是否是其中之一。
好了,现在让我们动手。我希望你能玩弄这些数据。这是一个 IPython Notebook,所以你可以随意修改它,尝试不同的标准差值,看看它对数据形状和百分位数的影响,例如。尝试使用更小的数据集大小,并在其中增加一点随机变化。只要熟悉一下,玩弄一下,你会发现你实际上可以做这些事情,并编写一些真正有效的代码。
矩
接下来,让我们谈谈矩。矩是一个花哨的数学术语,但实际上你并不需要数学学位来理解它。直观地说,它比听起来要简单得多。
这是统计学和数据科学领域的一个例子,人们喜欢使用大而花哨的术语来使自己听起来很聪明,但实际上这些概念非常容易理解,这也是你将在本书中一再听到的主题。
基本上,时刻是衡量数据分布形状的方式,概率密度函数的方式,或者任何东西的方式。从数学上讲,我们有一些非常花哨的符号来定义它们:

如果你懂微积分,实际上这并不是一个很复杂的概念。我们正在计算每个值与某个值的差的 n 次方,其中 n 是时刻数,并在整个函数从负无穷到正无穷的范围内进行积分。但直观上,它比微积分容易得多。
时刻可以被定义为概率密度函数形状的定量度量。
准备好了吗?我们开始吧!
-
第一时刻实际上就是你所看到的数据的平均值。就是这样。第一时刻就是平均值,就是平均数。就是这么简单。
-
第二时刻是方差。就是这样。数据集的第二时刻就是方差值。这些东西似乎自然而然地从数学中产生出来有点吓人,但是想一想。方差实际上是基于与平均值的差的平方,所以找到一个数学方式来说方差与平均值相关并不是那么难以理解,对吧。就是这么简单。
-
现在当我们到达第三和第四时刻时,事情变得有点棘手,但它们仍然是容易理解的概念。第三时刻被称为偏度,它基本上是一个度量分布有多倾斜的度量。
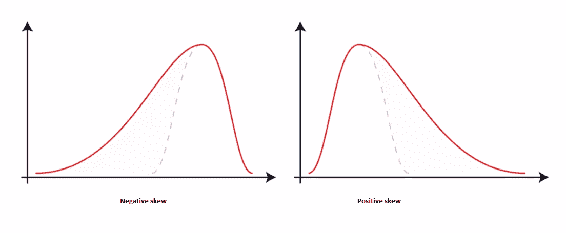
- 你可以在上面的这两个例子中看到,如果我左边有一个更长的尾部,那么这是一个负偏态,如果我右边有一个更长的尾部,那么这是一个正偏态。虚线显示了没有偏态的正态分布的形状。在左边的虚线上,我最终得到了一个负偏态,或者在另一边,这个例子中的正偏态。好的,这就是偏态。基本上就是拉长一侧的尾部,它是一个度量数据分布有多倾斜的度量。
- 第四时刻被称为峰度。哇,这是一个花哨的词!实际上,它就是尾部有多厚,峰有多尖。所以,它是数据分布形状的一种度量。这里有一个例子:

- 你可以看到更高的峰值具有更高的峰度值。最顶部的曲线比最底部的曲线具有更高的峰度。这是一个非常微妙的差异,但仍然是一个差异。它基本上衡量了你的数据有多尖。
让我们回顾一下:第一时刻是平均值,第二时刻是方差,第三时刻是偏度,第四时刻是峰度。我们已经知道平均值和方差是什么。偏度是数据有多倾斜,一个尾部有多伸展。峰度是数据分布有多尖,有多挤在一起。
在 Python 中计算时刻
让我们在 Python 中玩耍并实际计算这些时刻,看看你如何做到这一点。要玩弄这个,请打开Moments.ipynb,你可以跟着我在这里一起进行。
让我们再次创建相同的随机数据的正态分布。再次,我们将使其以零为中心,标准差为 0.5,有 10,000 个数据点,并绘制出来:
import numpy as np
import matplotlib.pyplot as plt
vals = np.random.normal(0, 0.5, 10000)
plt.hist(vals, 50)
plt.show()
所以,我们再次得到一个围绕零的正态分布的随机生成的数据集。

现在,我们找到了平均值和方差。我们以前做过这个;NumPy 只是给你一个mean和var函数来计算。所以,我们只需调用np.mean来找到第一时刻,这只是一个对平均值的花哨的说法,如下面的代码所示:
np.mean(vals)
这是我们示例中的输出:
Out [2]:-0.0012769999428169742
结果非常接近零,就像我们期望的那样,对于以零为中心的正态分布的数据。到目前为止,世界是有道理的。
现在我们找到了第二个矩,这只是方差的另一个名称。我们可以用以下代码来做到这一点,就像我们之前看到的那样:
np.var(vals)
提供以下输出:
Out[3]:0.25221246428323563
结果约为 0.25,这再次符合一个很好的检查。记住标准差是方差的平方根。如果你对 0.25 取平方根,结果是 0.5,这是我们在创建这个数据时指定的标准差,所以这也是正确的。
第三个矩是偏度,为了做到这一点,我们需要使用 SciPy 包而不是 NumPy。但这又是内置在任何科学计算包中的,比如 Enthought Canopy 或 Anaconda。一旦我们有了 SciPy,函数调用就像我们之前的两个一样简单:
import scipy.stats as sp
sp.skew(vals)
这显示了以下输出:
Out[4]: 0.020055795996111746
我们可以在vals列表上调用sp.skew,这将给我们一个偏度值。由于这是以零为中心的,它应该几乎没有偏度。结果是,随机变化确实有一点向左偏,实际上这与我们在图表中看到的形状是一致的。看起来我们确实把它拉向了负数。
第四个矩是峰度,描述了尾部的形状。同样,对于正态分布,这个值应该约为零。SciPy 为我们提供了另一个简单的函数调用
sp.kurtosis(vals)
以下是输出:
Out [5]:0.059954502386585506
事实上,结果确实是零。峰度以两种相关的方式显示我们的数据分布:尾部的形状,或者峰值有多尖。如果我把尾部压扁,峰值就会变得更尖,同样,如果我把分布压下去,你可以想象这样会把事情扩散开一点,使尾部变得更厚,峰值变得更低。这就是峰度的意思,在这个例子中,峰度接近零,因为它只是一个普通的正态分布。
如果你想玩一下,继续,再试着修改分布。使它以 0 以外的某个值为中心,看看是否真的会改变什么。应该吗?嗯,实际上不应该,因为这些都是关于分布形状的度量,它并不真的说出这个分布究竟在哪里。这是对形状的度量。这就是矩的全部意义。继续玩,尝试不同的中心值,尝试不同的标准差值,看看它对这些值有什么影响,它并没有改变。当然,你会期望像均值这样的东西会改变,因为你改变了均值,但方差、偏度,也许不会。玩一下,找出来。
这里有百分位数和矩。百分位数是一个相当简单的概念。矩听起来很难,但实际上很容易理解如何做,而且在 Python 中也很容易。现在你已经掌握了这个。是时候继续前进了。
总结
在本章中,我们看到了你可能会遇到的数据类型(数值、分类和有序数据),以及如何对它们进行分类,以及根据你处理的数据类型的不同对待它们。我们还介绍了统计概念的均值、中位数和众数,我们也看到了在中位数和均值之间进行选择的重要性,通常中位数比均值更好,因为存在离群值。
接下来,我们分析了如何在 IPython Notebook 文件中使用 Python 计算均值、中位数和众数。我们深入了解了标准差和方差的概念以及如何在 Python 中计算它们。我们看到它们是数据分布的扩展度量。我们还看到了一种可视化和测量数据集中给定范围的值发生的实际机会的方法,使用概率密度函数和概率质量函数。
我们总体上看了数据分布的类型(均匀分布、正态或高斯分布、指数概率分布、二项概率质量函数、泊松概率质量函数)以及如何使用 Python 对其进行可视化。我们分析了百分位数和矩的概念,并看到如何使用 Python 计算它们。
在下一章中,我们将更深入地研究使用matplotlib库,并深入探讨协方差和相关性等更高级的主题。
第三章:Matplotlib 和高级概率概念
在上一章中,我们已经介绍了一些统计学和概率的简单概念,现在我们将把注意力转向一些更高级的主题,这些主题是你需要熟悉的,以便充分利用本书的剩余部分。别担心,它们并不太复杂。首先,让我们来玩一玩,看看matplotlib库的一些惊人的绘图能力。
在本章中,我们将涵盖以下主题:
-
使用
matplotlib包绘制图表 -
理解协方差和相关性以确定数据之间的关系
-
理解条件概率及其示例
-
理解贝叶斯定理及其重要性
Matplotlib 的速成课程
你的数据只有你能向他人呈现得好,所以让我们谈谈如何绘制和展示你的数据,以及如何向他人呈现你的图表并使其看起来漂亮。我们将更全面地介绍 Matplotlib,并对其进行全面测试。
我会向你展示一些技巧,让你的图表尽可能漂亮。让我们用图表玩一玩。将你的工作做成漂亮的图片总是很好的。这将为你提供更多的工具,用不同类型的图表来可视化不同类型的数据,并使其看起来漂亮。我们将使用不同的颜色、不同的线条样式、不同的坐标轴等等。重要的不仅是使用图表和数据可视化来尝试在数据中找到有趣的模式,而且还要有趣地向非技术人员展示你的发现。话不多说,让我们开始学习 Matplotlib 吧。
继续打开MatPlotLib.ipynb文件,你可以和我一起玩弄这些东西。我们将从绘制一个简单的折线图开始。
%matplotlib inline
from scipy.stats import norm
import matplotlib.pyplot as plt
import numpy as np
x = np.arange(-3, 3, 0.001)
plt.plot(x, norm.pdf(x))
plt.show()
所以在这个例子中,我导入matplotlib.pyplot作为plt,然后我们可以在笔记本中从现在开始将其称为plt。然后,我使用np.arange(-3, 3, 0.001)创建一个 x 轴,其中填充了在-3和3之间以 0.001 增量的值,并使用pyplot的plot()函数来绘制x。y 函数将是norm.pdf(x)。所以我将根据x值创建一个正态分布的概率密度函数,并使用scipy.stats norm包来实现。
所以将其与上一章关于概率密度函数的内容联系起来,这里我们使用matplotlib绘制正态概率密度函数。我们只需调用pyplot的plot()方法来设置我们的图表,然后使用plt.show()显示它。当我们运行前面的代码时,我们得到以下输出:

这就是我们得到的:一个漂亮的小图表,带有所有默认格式。
在一个图表上生成多个图表
假设我想一次绘制多个图表。在调用 show 之前,你实际上可以多次调用 plot 来添加多个函数到你的图表中。让我们看看下面的代码:
plt.plot(x, norm.pdf(x))
plt.plot(x, norm.pdf(x, 1.0, 0.5))
plt.show()
在这个例子中,我调用了我的原始函数,只是一个正态分布,但我还要渲染另一个正态分布,均值约为1.0,标准差为0.5。然后,我会把这两个一起显示出来,这样你就可以看到它们彼此之间的比较。

你可以看到,默认情况下,matplotlib会自动为每个图形选择不同的颜色,这对你来说非常好和方便。
将图表保存为图像
如果我想把这个图表保存到文件中,也许我想把它包含在文档中,我可以像下面的代码一样做:
plt.plot(x, norm.pdf(x))
plt.plot(x, norm.pdf(x, 1.0, 0.5))
plt.savefig('C:\\Users\\Frank\\MyPlot.png', format='png')
不仅仅调用plt.show(),我可以调用plt.savefig()并指定我想要保存这个文件的路径以及我想要的格式。
如果你在跟着做的话,你会想把它改成你的机器上实际存在的路径。你可能没有一个Users\Frank文件夹。还要记住,如果你在 Linux 或 macOS 上,你将使用正斜杠而不是反斜杠,并且你不会有一个驱动器号。对于所有这些 Python 笔记本,每当你看到这样的路径时,确保你将它改为在你的系统上有效的路径。我在 Windows 上,我有一个Users\Frank文件夹,所以我可以继续运行。如果我在Users\Frank下检查我的文件系统,我有一个MyPlot.png文件,我可以打开并查看,并且我可以在任何我想要的文档中使用它。

这很酷。还有一件要注意的事情是,根据你的设置,当你保存文件时可能会遇到权限问题。你只需要找到适合你的文件夹。在 Windows 上,你的Users\Name文件夹通常是一个安全的选择。好了,让我们继续。
调整坐标轴
假设我不喜欢上一个图表中的轴的默认选择。它自动调整到你可以找到的最紧凑的轴值集,这通常是一个好事,但有时你希望按绝对比例来做。看看下面的代码:
axes = plt.axes()
axes.set_xlim([-5, 5])
axes.set_ylim([0, 1.0])
axes.set_xticks([-5, -4, -3, -2, -1, 0, 1, 2, 3, 4, 5])
axes.set_yticks([0, 0.1, 0.2, 0.3, 0.4, 0.5, 0.6, 0.7, 0.8, 0.9, 1.0])
plt.plot(x, norm.pdf(x))
plt.plot(x, norm.pdf(x, 1.0, 0.5))
plt.show()
在这个例子中,首先我使用plt.axes获取坐标轴。一旦我有了这些坐标轴对象,我就可以调整它们。通过调用set_xlim,我可以将 x 范围设置为-5 到 5,通过set_ylim,我将 y 范围设置为 0 到 1。你可以在下面的输出中看到,我的 x 值范围从-5到5,y 值从 0 到 1。我还可以明确控制坐标轴上的刻度标记的位置。因此,在上面的代码中,我说我希望 x 刻度在-5,-4,-3等处,y 刻度从 0 到 1,间隔为 0.1,使用set_xticks()和set_yticks()函数。现在我可以使用arange函数更紧凑地做到这一点,但关键是你可以明确控制这些刻度标记的位置,也可以跳过一些。你可以按照你想要的增量或分布来设置它们。除此之外,其他都是一样的。
一旦我调整了我的坐标轴,我只需调用plot()和我想要绘制的函数,并调用show()来显示它。确实,你可以看到结果。
添加网格
如果我想在图表中添加网格线呢?嗯,同样的道理。我只需要在从plt.axes()获取的坐标轴上调用grid()。
axes = plt.axes()
axes.set_xlim([-5, 5])
axes.set_ylim([0, 1.0])
axes.set_xticks([-5, -4, -3, -2, -1, 0, 1, 2, 3, 4, 5])
axes.set_yticks([0, 0.1, 0.2, 0.3, 0.4, 0.5, 0.6, 0.7, 0.8, 0.9, 1.0])
axes.grid()
plt.plot(x, norm.pdf(x))
plt.plot(x, norm.pdf(x, 1.0, 0.5))
plt.show()
通过执行上面的代码,我得到了漂亮的小网格线。这样可以更容易看到特定点在哪里,尽管会使事情有点凌乱。这是一个小小的风格选择。

更改线型和颜色
如果我想要玩线型和颜色的游戏呢?你也可以这样做。
axes = plt.axes()
axes.set_xlim([-5, 5])
axes.set_ylim([0, 1.0])
axes.set_xticks([-5, -4, -3, -2, -1, 0, 1, 2, 3, 4, 5])
axes.set_yticks([0, 0.1, 0.2, 0.3, 0.4, 0.5, 0.6, 0.7, 0.8, 0.9, 1.0])
axes.grid()
plt.plot(x, norm.pdf(x), 'b-')
plt.plot(x, norm.pdf(x, 1.0, 0.5), 'r:')
plt.show()
所以你可以看到在上面的代码中,plot()函数的末尾实际上有一个额外的参数,我可以传递一个描述线条样式的小字符串。在第一个例子中,b-表示我想要一个蓝色的实线。b代表蓝色,短线表示实线。对于我的第二个plot()函数,我将以红色绘制,这就是r的含义,冒号表示我将以虚线绘制。

如果我运行它,你可以在上面的图表中看到它的效果,并且你可以改变不同类型的线型。
此外,你可以做一个双虚线(--)。
axes = plt.axes()
axes.set_xlim([-5, 5])
axes.set_ylim([0, 1.0])
axes.set_xticks([-5, -4, -3, -2, -1, 0, 1, 2, 3, 4, 5])
axes.set_yticks([0, 0.1, 0.2, 0.3, 0.4, 0.5, 0.6, 0.7, 0.8, 0.9, 1.0])
axes.grid()
plt.plot(x, norm.pdf(x), 'b-')
plt.plot(x, norm.pdf(x, 1.0, 0.5), 'r--')
plt.show()
上面的代码给出了虚线红线作为线型,如下图所示:

我还可以做一个点划线组合(-.)。
axes = plt.axes()
axes.set_xlim([-5, 5])
axes.set_ylim([0, 1.0])
axes.set_xticks([-5, -4, -3, -2, -1, 0, 1, 2, 3, 4, 5])
axes.set_yticks([0, 0.1, 0.2, 0.3, 0.4, 0.5, 0.6, 0.7, 0.8, 0.9, 1.0])
axes.grid()
plt.plot(x, norm.pdf(x), 'b-')
plt.plot(x, norm.pdf(x, 1.0, 0.5), 'r-.')
plt.show()
你会得到一个看起来像下面的图表图像的输出:

所以,这些就是不同的选择。我甚至可以让它变成绿色并带有垂直斜杠(g:)。
axes = plt.axes()
axes.set_xlim([-5, 5])
axes.set_ylim([0, 1.0])
axes.set_xticks([-5, -4, -3, -2, -1, 0, 1, 2, 3, 4, 5])
axes.set_yticks([0, 0.1, 0.2, 0.3, 0.4, 0.5, 0.6, 0.7, 0.8, 0.9, 1.0])
axes.grid()
plt.plot(x, norm.pdf(x), 'b-')
plt.plot(x, norm.pdf(x, 1.0, 0.5), ' g:')
plt.show()
我将得到以下输出:

如果你愿意,可以尝试一些有趣的东西,尝试不同的值,你可以得到不同的线条样式。
给坐标轴加标签和添加图例
你经常会做的一件事是给你的坐标轴加上标签。你绝对不想孤立地呈现数据。你肯定想告诉人们它代表什么。为了做到这一点,你可以使用plt上的xlabel()和ylabel()函数来实际在你的坐标轴上放置标签。我将 x 轴标记为 Greebles,y 轴标记为 Probability。你还可以添加一个图例插图。通常情况下,这将是相同的事情,但为了显示它是独立设置的,我也在以下代码中设置了一个图例:
axes = plt.axes()
axes.set_xlim([-5, 5])
axes.set_ylim([0, 1.0])
axes.set_xticks([-5, -4, -3, -2, -1, 0, 1, 2, 3, 4, 5])
axes.set_yticks([0, 0.1, 0.2, 0.3, 0.4, 0.5, 0.6, 0.7, 0.8, 0.9, 1.0])
axes.grid()
plt.xlabel('Greebles')
plt.ylabel('Probability')
plt.plot(x, norm.pdf(x), 'b-')
plt.plot(x, norm.pdf(x, 1.0, 0.5), 'r:')
plt.legend(['Sneetches', 'Gacks'], loc=4)
plt.show()
在图例中,你基本上传入了一个你想要为每个图表命名的列表。所以,我的第一个图表将被称为 Sneetches,我的第二个图表将被称为 Gacks,而loc参数表示你想要的位置,其中4代表右下角。让我们运行一下代码,你应该会看到以下内容:

你可以看到我正在为 Sneetches 和 Gacks 绘制 Greebles 与 Probability 的图表。这是一个小的苏斯博士的参考。这就是你设置坐标轴标签和图例的方法。
一个有趣的例子
这里有一个小有趣的例子。如果你熟悉网络漫画 XKCD,Matplotlib 中有一个小彩蛋,你可以以 XKCD 风格绘制图表。以下代码显示了你可以这样做。
plt.xkcd()
fig = plt.figure()
ax = fig.add_subplot(1, 1, 1)
ax.spines['right'].set_color('none')
ax.spines['top'].set_color('none')
plt.xticks([])
plt.yticks([])
ax.set_ylim([-30, 10])
data = np.ones(100)
data[70:] -= np.arange(30)
plt.annotate(
'THE DAY I REALIZED\nI COULD COOK BACON\nWHENEVER I WANTED',
xy=(70, 1), arrowprops=dict(arrowstyle='->'), xytext=(15, -10))
plt.plot(data)
plt.xlabel('time')
plt.ylabel('my overall health')
在这个例子中,你调用了plt.xkcd(),这将 Matplotlib 置于 XKCD 模式。在这之后,事情将自动以一种漫画书字体和波浪线的风格呈现。这个简单的例子将展示一个有趣的小图表,其中我们绘制了你的健康与时间的关系,当你意识到你可以随时煮培根时,你的健康状况急剧下降。我们所做的就是使用xkcd()方法进入那种模式。你可以在下面看到结果:

这里有一点有趣的 Python,我们实际上是如何将这个图表放在一起的。我们首先制作了一个数据线,它只是在 100 个数据点上的值为 1。然后我们使用旧的 Python 列表切片运算符来取出值为 70 之后的所有内容,并从这个 30 个项目的子列表中减去 0 到 30 的范围。这样做的效果是,随着超过 70,线性地减去一个更大的值,导致该线在 70 之后向下倾斜到 0。
所以,这是 Python 列表切片的一个小例子,以及arange函数的一点创造性用法来修改你的数据。
生成饼图
现在,回到现实世界,我们可以通过在 Matplotlib 上调用rcdefaults()来移除 XKCD 模式,并在这里回到正常模式。
如果你想要一个饼图,你只需要调用plt.pie并给它一个包含你的值、颜色、标签以及是否要爆炸的数组,如果是的话,爆炸多少。以下是代码:
# Remove XKCD mode:
plt.rcdefaults()
values = [12, 55, 4, 32, 14]
colors = ['r', 'g', 'b', 'c', 'm']
explode = [0, 0, 0.2, 0, 0]
labels = ['India', 'United States', 'Russia', 'China', 'Europe']
plt.pie(values, colors= colors, labels=labels, explode = explode)
plt.title('Student Locations')
plt.show()
在这段代码中,你可以看到我正在创建一个饼图,其中包含值12、55、4、32和14。我为每个值分配了明确的颜色,并为每个值分配了明确的标签。我将饼图中的俄罗斯部分扩大了 20%,并给这个图表加上了一个标题“学生位置”并显示出来。以下是你应该看到的输出:

就是这样。
生成条形图
如果我想生成一个条形图,也是非常简单的。这是一种类似于饼图的想法。让我们看看以下代码。
values = [12, 55, 4, 32, 14]
colors = ['r', 'g', 'b', 'c', 'm']
plt.bar(range(0,5), values, color= colors)
plt.show()
我定义了一个值数组和一个颜色数组,然后绘制数据。上面的代码从 0 到 5 的范围绘制,使用values数组中的 y 值,并使用colors数组中列出的显式颜色列表。继续展示,你就会得到你的条形图:

生成散点图
散点图是我们在本书中经常看到的东西。所以,假设你有一些不同的属性,你想为同一组人或物体绘制图表。例如,也许我们正在为每个人绘制年龄与收入的散点图,其中每个点代表一个人,轴代表这些人的不同属性。
使用散点图的方法是调用plt.scatter(),使用包含你想要绘制的数据的两个轴,也就是包含你想要相互绘制的数据的两个属性。
假设我在X和Y中有一个随机分布,我把它们散点图上,然后展示出来:
from pylab import randn
X = randn(500)
Y = randn(500)
plt.scatter(X,Y)
plt.show()
你会得到以下散点图作为输出:

这就是它的样子,非常酷。你可以看到中心的一种集中,因为在两个轴上都使用了正态分布,但由于它是随机的,所以这两者之间没有真正的相关性。
生成直方图
最后,我们会回顾一下直方图是如何工作的。我们在书中已经看到了很多次。让我们看看以下代码:
incomes = np.random.normal(27000, 15000, 10000)
plt.hist(incomes, 50)
plt.show()
在这个例子中,我调用了一个以 27000 为中心,标准差为 15000 的正态分布,有 10000 个数据点。然后,我只是调用了pyplot的直方图函数,也就是hist(),并指定了输入数据和我们想要将事物分组到直方图中的桶的数量。然后我调用show(),剩下的就是魔术。

生成盒须图
最后,让我们看看盒须图。还记得在上一章中,当我们谈到百分位数时,我稍微提到了这一点。
同样,使用盒须图,盒子代表了 50%的数据所在的两个内四分位数。相反,另外 25%分布在盒子的两侧;盒须(在我们的例子中是虚线)代表了除异常值外的数据范围。
我们在盒须图中将异常值定义为超出 1.5 倍四分位距或盒子大小的任何值。因此,我们将盒子的大小乘以 1.5,然后在虚线盒须上到那一点,我们称这些部分为外四分位数。但是在外四分位数之外的任何值都被视为异常值,这就是超出外四分位数的线所代表的。这就是我们根据盒须图的定义来定义异常值的地方。
关于盒须图的一些要点:
-
它们用于可视化数据的分布和偏斜
-
盒子中间的线代表数据的中位数,盒子代表第 1 和第 3 四分位数的范围
-
数据的一半存在于盒子中
-
“盒须”表示数据的范围,异常值除外,异常值绘制在盒须之外。
-
异常值是四分位距的 1.5 倍或更多。
现在,为了给你一个例子,我们创建了一个虚假数据集。以下示例创建了在-40 和 60 之间均匀分布的随机数,再加上一些在100以上和-100以下的异常值:
uniformSkewed = np.random.rand(100) * 100 - 40
high_outliers = np.random.rand(10) * 50 + 100
low_outliers = np.random.rand(10) * -50 - 100
data = np.concatenate((uniformSkewed, high_outliers, low_outliers))
plt.boxplot(data)
plt.show()
在代码中,我们有一个均匀随机分布的数据(uniformSkewed)。然后我们在高端添加了一些异常值(high_outliers),也添加了一些负异常值(low_outliers)。然后我们将这些列表连接在一起,并使用 NumPy 从这三个不同的集合创建了一个单一的数据集。然后我们拿到了这个组合数据集,其中包括均匀数据和一些异常值,我们使用plt.boxplot()进行了绘制,这就是如何得到箱线图的。调用show()进行可视化,就完成了。
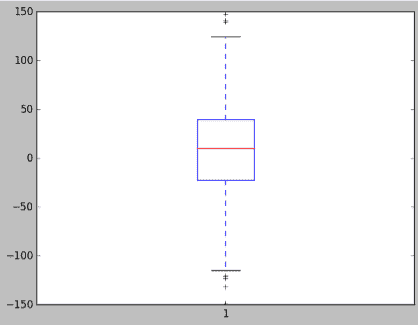
你可以看到图表显示了代表所有数据内部 50%的箱子,然后我们有这些异常值线,我们可以看到每个在该范围内的个体异常值的小叉(在你的版本中可能是圆圈)。
自己试试
好了,这就是 Matplotlib 的速成课程。是时候动手操作了,在这里实际做一些练习。
作为挑战,我希望你创建一个散点图,代表你编造的年龄与看电视时间的随机数据,你可以随意制造任何你想要的东西。如果你脑海中有一个不同的虚构数据集,你想要玩玩,那就尽情玩吧。创建一个散点图,将两组随机数据相互绘制,并标记你的坐标轴。让它看起来漂亮一些,尝试一下,玩得开心一些。你需要的所有参考和示例都应该在这个 IPython 笔记本中。这是一种速查表,如果你愿意的话,可以用来生成不同类型的图表和不同风格的图表。希望它能够有所帮助。现在是时候回到统计学了。
协方差和相关性
接下来,我们将讨论协方差和相关性。假设我有某个东西的两个不同属性,我想看看它们是否实际上与彼此相关。这一部分将为你提供你需要的数学工具,以便这样做,我们将深入一些示例,并使用 Python 实际计算协方差和相关性。这些是衡量两个不同属性在一组数据中是否相关的方法,这可能是一个非常有用的发现。
定义概念
想象我们有一个散点图,每个数据点代表我们测量的一个人,我们在一个轴上绘制他们的年龄,另一个轴上绘制他们的收入。每一个点代表一个人,例如他们的 x 值代表他们的年龄,y 值代表他们的收入。我完全是在编造,这是虚假数据。

现在,如果我有一个散点图,看起来像前面图片中的左边那个,你会发现这些值倾向于分散在各个地方,这会告诉你基于这些数据,年龄和收入之间没有真正的相关性。对于任何给定的年龄,收入可能有很大的范围,它们倾向于聚集在中间,但我们并没有真正看到年龄和收入这两个不同属性之间非常明显的关系。相比之下,在右边的散点图中,你可以看到年龄和收入之间有一个非常明显的线性关系。
因此,协方差和相关性给了我们一种衡量这些关系有多紧密的方法。我期望左边散点图中的数据具有非常低的相关性或协方差,但右边散点图中的数据具有非常高的协方差和相关性。这就是协方差和相关性的概念。它衡量了我正在测量的这两个属性似乎彼此依赖的程度。
测量协方差
数学上测量协方差有点困难,但我会尝试解释一下。以下是步骤:
-
将两个变量的数据集想象成高维向量
-
将这些转换为与均值的方差向量。
-
取两个向量的点积(它们之间的余弦值)
-
除以样本大小
更重要的是你理解如何使用它以及它的含义。实际上,想象数据的属性是高维向量。我们要做的是对每个数据点的每个属性计算均值的方差。现在我有了这些高维向量,其中每个数据点,每个人,对应不同的维度。
在这个高维空间中,我有一个向量代表了所有属性(比如年龄)的方差与均值的差值。然后我有另一个向量代表了另一个属性(比如收入)的方差与均值的差值。然后我对这些测量每个属性的方差的向量进行点积。从数学上讲,这是一种衡量这些高维向量之间角度的方法。所以如果它们非常接近,那告诉我这些方差在不同属性上几乎是同步变化的。如果我将最终的点积除以样本大小,那就是协方差的量。
现在你永远不需要自己从头计算这个。我们将看到如何在 Python 中以简单的方式做到这一点,但从概念上讲,就是这样工作的。
现在协方差的问题在于它很难解释。如果我有一个接近零的协方差,那么我知道这告诉我这些变量之间几乎没有相关性,但是一个大的协方差意味着存在关系。但大到什么程度?根据我使用的单位不同,可能有非常不同的解释方式。这是相关性解决的问题。
相关性
相关性通过每个属性的标准差进行归一化(只需将协方差除以两个变量的标准差即可实现归一化)。通过这样做,我可以非常清楚地说,相关性为-1 意味着完全的反向相关,因此一个值增加,另一个值减少,反之亦然。相关性为 0 意味着这两组属性之间根本没有相关性。相关性为 1 意味着完美的相关性,这两个属性在查看不同数据点时以完全相同的方式移动。
记住,相关性并不意味着因果关系。仅仅因为你找到了一个非常高的相关性值,并不意味着其中一个属性导致了另一个属性。它只是意味着两者之间存在关系,而这种关系可能是由完全不同的东西引起的。真正确定因果关系的唯一方法是通过控制实验,我们稍后会更多地讨论。
在 Python 中计算协方差和相关性
好了,让我们用一些实际的 Python 代码来深入了解协方差和相关性。所以你可以从概念上将协方差看作是对每个属性的均值方差的多维向量,并计算它们之间的角度作为协方差的度量。做这件事的数学比听起来简单得多。我们谈论的是高维向量。听起来像是史蒂芬·霍金的东西,但从数学的角度来看,它非常直接。
计算相关性 - 最困难的方式
我将从最困难的方式开始。NumPy 确实有一个方法可以直接为你计算协方差,我们稍后会讨论,但现在我想展示你实际上可以从头原理开始做到这一点:
%matplotlib inline
import numpy as np
from pylab import *
def de_mean(x):
xmean = mean(x)
return [xi - xmean for xi in x]
def covariance(x, y):
n = len(x)
return dot(de_mean(x), de_mean(y)) / (n-1)
协方差再次被定义为点积,这是两个向量之间的角度的度量,对于给定数据集的偏差向量和另一个给定数据集的偏差向量,我们将其除以 n-1,在这种情况下,因为我们实际上处理的是一个样本。
所以de_mean(),我们的偏差函数接收一组数据x,实际上是一个列表,并计算该数据集的平均值。return行包含一些 Python 的技巧。语法是说,我将创建一个新的列表,并遍历x中的每个元素,称之为xi,然后返回整个数据集中xi和平均值xmean之间的差异。这个函数返回一个新的数据列表,表示每个数据点相对于平均值的偏差。
我的covariance()函数将对进入的两组数据进行散点图绘制,除以数据点的数量减 1。还记得上一章关于样本与总体的事情吗?嗯,这在这里起作用。然后我们可以使用这些函数,看看会发生什么。
为了扩展这个例子,我将捏造一些数据,试图找到页面速度和人们花费的金额之间的关系。例如,在亚马逊,我们非常关心页面渲染速度和用户在体验之后实际花费的金额之间的关系。我们想知道网站速度和用户在网站上实际花费的金额之间是否存在实际关系。这是你可能会去解决这个问题的一种方式。让我们为页面速度和购买金额生成一些正态分布的随机数据,由于它是随机的,所以它们之间不会有真正的相关性。
pageSpeeds = np.random.normal(3.0, 1.0, 1000)
purchaseAmount = np.random.normal(50.0, 10.0, 1000)
scatter(pageSpeeds, purchaseAmount)
covariance (pageSpeeds, purchaseAmount)
所以,作为一个理智的检查,我们将从散点图开始:

你会看到它倾向于围绕中间聚集,因为每个属性上的正态分布,但两者之间没有真正的关系。对于任何给定的页面速度,花费的金额有很大的变化,对于任何给定的花费金额,页面速度也有很大的变化,所以除了通过随机性或正态分布的性质产生的相关性之外,没有真正的相关性。果然,如果我们计算这两组属性的协方差,我们最终得到一个非常小的值,-0.07。所以这是一个非常小的协方差值,接近于零。这意味着这两件事之间没有真正的关系。
现在让我们让生活变得更有趣一点。让我们实际上使购买金额成为页面速度的一个真实函数。
purchaseAmount = np.random.normal(50.0, 10.0, 1000) / pageSpeeds
scatter(pageSpeeds, purchaseAmount)
covariance (pageSpeeds, purchaseAmount)
在这里,我们保持事情有点随机,但我们在这两组值之间建立了一个真实的关系。对于给定的用户,他们遇到的页面速度和他们花费的金额之间存在着真实的关系。如果我们绘制出来,我们可以看到以下输出:

你可以看到实际上有一个小曲线,事物倾向于紧密排列。在底部附近会有一些混乱,只是因为随机性的工作方式。如果我们计算协方差,我们最终得到一个更大的值,-8,这个数字的大小很重要。符号,正或负,只是意味着正相关或负相关,但 8 这个值表示比零大得多。所以有一些事情发生了,但是再次很难解释 8 实际上意味着什么。
这就是相关性的作用,我们通过以下代码将一切标准化:
def correlation(x, y):
stddevx = x.std()
stddevy = y.std()
return covariance(x,y) / stddevx / stddevy #In real life you'd check for divide by zero here
correlation(pageSpeeds, purchaseAmount)
再次,从第一原则出发,我们可以计算两组属性之间的相关性,计算每个属性的标准差,然后计算这两个属性之间的协方差,并除以每个数据集的标准差。这给我们提供了归一化到-1 到 1 的相关值。我们得到了一个值为-0.4,这告诉我们这两个属性之间存在一些负相关的关系:

这不是一个完美的线性关系,那将是-1,但其中有一些有趣的东西。
-1 的相关系数意味着完美的负相关,0 表示没有相关性,1 表示完美的正相关。
计算相关性-NumPy 的方式
现在,NumPy 实际上可以使用corrcoef()函数为您计算相关性。让我们看一下以下代码:
np.corrcoef(pageseeds, purchaseAmount)
这一行代码给出了以下输出:
array([(1\. ,-046728788],
[-0.46728788], 1\. ])
所以,如果我们想简单地做到这一点,我们可以使用np.corrcoef(pageSpeeds, purchaseAmount),它会给你一个数组,其中包含了你传入的数据集的每一种可能的组合之间的相关性。输出的方式是:1 表示在比较pageSpeeds和purchaseAmount自身时有完美的相关性,这是预期的。但当你开始比较pageSpeeds和purchaseAmount或purchaseAmount和pageSpeeds时,你得到了-0.4672 的值,这大致是我们用较困难的方法得到的结果。会有一些精度误差,但这并不重要。
现在我们可以通过制造一个完全线性的关系来强制产生完美的相关性,所以让我们看一个例子:
purchaseAmount = 100 - pageSpeeds * 3
scatter(pageSpeeds, purchaseAmount)
correlation (pageSpeeds, purchaseAmount)
再次,我们期望相关性的结果为-1,表示完美的负相关,事实上,这就是我们得到的结果:

再次提醒:相关性并不意味着因果关系。只是因为人们可能会在页面速度更快时花费更多,也许这只是意味着他们能负担得起更好的互联网连接。也许这并不意味着页面渲染速度和人们花费的金额之间实际上存在因果关系,但它告诉你有一个值得进一步调查的有趣关系。你不能在没有进行实验的情况下说任何关于因果关系的事情,但相关性可以告诉你你可能想要进行的实验。
相关性活动
所以动手做,卷起袖子,我希望你使用numpy.cov()函数。这实际上是让 NumPy 为你计算协方差的一种方法。我们看到了如何使用corrcoef()函数计算相关性。所以回去重新运行这些例子,只使用numpy.cov()函数,看看你是否得到了相同的结果。它应该非常接近,所以不要用我从头开始编写的协方差函数的较困难的方法,只需使用 NumPy,看看你是否能得到相同的结果。再次强调,这个练习的目的是让你熟悉使用 NumPy 并将其应用到实际数据中。所以试试看,看看你能得到什么结果。
这就是协方差和相关性的理论和实践。这是一个非常有用的技术,所以一定要记住这一部分。让我们继续。
条件概率
接下来,我们将讨论条件概率。这是一个非常简单的概念。它试图找出在发生某事的情况下另一件事发生的概率。尽管听起来很简单,但实际上理解其中的一些细微差别可能会非常困难。所以多倒一杯咖啡,确保你的思维帽戴好了,如果你准备好接受一些更具挑战性的概念。让我们开始吧。
条件概率是衡量两件事相互发生关系的一种方法。假设我想找出在另一件事已经发生的情况下某个事件发生的概率。条件概率可以帮助你找出这个概率。
我试图通过条件概率找出的是两个事件是否相互依赖。也就是说,两者都发生的概率是多少?
在数学表示法中,我们表示这些事情的方式是 P(A,B) 表示 A 和 B 同时发生的概率,而与其他事情无关。也就是说,这两件事情发生的概率是多少,与其他一切无关。
而这种表示法 P(B|A),读作给定 A 的情况下 B 的概率。那么,在事件 A 已经发生的情况下,B 发生的概率是多少?这有点不同,但这些事情是相关的,就像这样:

给定 A 的情况下 B 的概率等于 A 和 B 同时发生的概率除以 A 单独发生的概率,这就揭示了 B 的概率依赖于 A 的概率。
这里举个例子会更容易理解,所以请耐心等待。
假设我给你们读者两个测试,60%的人都通过了两个测试。现在第一个测试比较容易,80%的人通过了。我可以利用这些信息来计算通过第一个测试的读者中有多少人也通过了第二个测试。这是一个真实的例子,说明了给定 A 的情况下 B 的概率和 A 和 B 的概率之间的差异。
我将把 A 表示为通过第一个测试的概率,B 表示通过第二个测试的概率。我要找的是在通过第一个测试的情况下通过第二个测试的概率,即 P(B|A)。

因此,给定通过第一个测试的情况下通过第二个测试的概率等于通过两个测试的概率 P(A,B)(我知道 60%的人通过了两个测试,而不考虑彼此的影响),除以通过第一个测试的概率 P(A),即 80%。计算结果是通过了两个测试的概率为 60%,通过了第一个测试的概率为 80%,因此给定通过第一个测试的情况下通过第二个测试的概率为 75%。
好的,这个概念有点难以理解。我花了一点时间才真正理解了给定某事物的概率和两件事情发生的概率之间的差异。在继续之前,请确保你理解了这个例子以及它是如何运作的。
Python 中的条件概率练习
好的,让我们继续,用一些真实的 Python 代码来做另一个更复杂的例子。然后我们可以看看如何实际使用 Python 来实现这些想法。
让我们在这里把条件概率付诸实践,并使用一些想法来找出年龄和购买商品之间是否存在关系,使用一些虚构的数据。如果你愿意,可以打开ConditionalProbabilityExercise.ipynb并跟着我一起做。
我要做的是写一些 Python 代码,创建一些虚假数据:
from numpy import random
random.seed(0)
totals = {20:0, 30:0, 40:0, 50:0, 60:0, 70:0}
purchases = {20:0, 30:0, 40:0, 50:0, 60:0, 70:0}
totalPurchases = 0
for _ in range(100000):
ageDecade = random.choice([20, 30, 40, 50, 60, 70])
purchaseProbability = float(ageDecade) / 100.0
totals[ageDecade] += 1
if (random.random() < purchaseProbability):
totalPurchases += 1
purchases[ageDecade] += 1
我要做的是取 10 万个虚拟人,随机分配到一个年龄段。他们可以是 20 多岁、30 多岁、40 多岁、50 多岁、60 多岁或 70 多岁。我还要给他们分配一些在某段时间内购买的东西的数量,并根据他们的年龄来加权购买某物的概率。
这段代码最终的作用是使用 NumPy 的random.choice()函数随机将每个人分配到一个年龄组。然后我将分配购买东西的概率,并且我已经加权,使得年轻人购买东西的可能性小于老年人。我将遍历 10 万人,并在遍历过程中将所有东西加起来,最终得到两个 Python 字典:一个给出了每个年龄组的总人数,另一个给出了每个年龄组内购买的总数。我还将跟踪总体购买的总数。让我们运行这段代码。
如果你想花点时间在脑海中思考并弄清楚代码是如何工作的,你可以使用 IPython Notebook。你以后也可以回头看。让我们看看我们最终得到了什么。

我们的totals字典告诉我们每个年龄段有多少人,这与我们预期的一样是相当均匀的。每个年龄组购买的数量实际上是随年龄增长而增加的,所以 20 岁的人只购买了大约 3000 件东西,70 岁的人购买了大约 11000 件东西,总体上整个人口购买了大约 45000 件东西。
让我们使用这些数据来玩玩条件概率的概念。首先让我们弄清楚在你 30 岁时购买东西的概率是多少。如果我们将购买表示为 E,将你 30 岁的事件表示为 F,那么表示为P(E|F)。
现在我们有了这个复杂的方程,它给出了一种计算*P(E|F)给定P(E,F)和P(E)*的方法,但我们不需要那个。你不能只是盲目地应用方程。你必须直观地思考你的数据。它告诉我们什么?我想要计算在你 30 岁时购买东西的概率。我有计算它所需的所有数据。
PEF = float(purchases[30]) / float(totals[30])
我知道 30 岁的人购买的东西在购买[30]桶中有多少,我也知道有多少 30 岁的人。所以我可以将这两个数字相除,得到 30 岁购买的比例与 30 岁人数的比率。然后我可以使用 print 命令输出这个比例:
print ("P(purchase | 30s): ", PEF)
最终我得到了在你 30 岁时购买东西的概率大约为 30%。
P(purchase | 30s): 0.2992959865211
请注意,如果你使用的是 Python 2,print 命令没有周围的括号,所以应该是:
print "p(purchase | 30s): ", PEF
如果我想找到P(F),那就是总体 30 岁的概率,我可以将 30 岁的总人数除以我的数据集中的人数,即 10 万:
PF = float(totals[30]) / 100000.0
print ("P(30's): ", PF)
如果你使用的是 Python 2,再次删除 print 语句周围的括号。这应该得到以下输出:
P(30's): 0.16619
我知道在你30 岁的概率大约是 16%。
我们现在要找出P(E),这只是代表不考虑年龄的总体购买概率:
PE = float(totalPurchases) / 100000.0
print ("P(Purchase):", PE)
P(Purchase): 0.45012
在这个例子中,这大约是 45%。我只需将所有人购买的东西的总数除以总人数,就可以得到总体购买的概率。
好了,那么我有什么?我有在你 30 岁时购买东西的概率大约为 30%,然后我有总体购买东西的概率大约为 45%。
现在如果 E 和 F 是独立的,如果年龄不重要,那么我期望P(E|F)大约等于P(E)。我期望在你 30 岁时购买东西的概率大约等于总体购买东西的概率,但事实并非如此,对吧?因为它们不同,这告诉我它们实际上是有依赖关系的。所以这是一种使用条件概率来揭示数据中这些依赖关系的方法。
让我们在这里做一些更多的符号表示。如果你看到像*P(E)P(F)*这样的东西在一起,那意味着将这些概率相乘在一起。我可以简单地取购买的总体概率乘以在你30 岁的总体概率:
print ("P(30's)P(Purchase)", PE * PF)
P(30's)P(Purchase) 0.07480544280000001
这大约是 7.5%。
仅仅从概率的工作方式来看,我知道如果我想要得到两件事情同时发生的概率,那就等同于将它们各自的概率相乘。所以结果是P(E,F)发生,就等同于P(E)P(F)。
print ("P(30's, Purchase)", float(purchases[30]) / 100000.0)
P(30's, Purchase) 0.04974
现在由于数据的随机分布,它并不完全相同。记住,我们在谈论概率,但它们大致相同,这是有道理的,大约 5%与 7%,足够接近。
现在这又不同于P(E|F),所以在你30 岁和购买某物的概率与在你30 岁的情况下购买某物的概率是不同的。
现在让我们做一个小小的检查。我们可以检查我们在之前的条件概率部分看到的方程式,即购买某物的概率,假设你是30 岁,等同于在你30 岁和购买某物的概率除以购买某物的概率。也就是说,我们检查P(E|F)=P(E,F)/P(F)。
(float(purchases[30]) / 100000.0) / PF
这给了我们:
Out []:0.29929598652145134
果然,它起作用了。如果我取购买某物的概率,假设你是30 岁,除以总体概率,我们最终得到大约 30%,这几乎就是我们最初得出的P(E|F)。所以这个方程式是有效的,耶!
好了,有些东西确实很难理解。我知道有点令人困惑,但如果需要的话,再看一遍,研究一下,确保你理解这里发生了什么。我尽量在这里放了足够的例子来说明不同的思考方式。一旦你内化了它,我要挑战你实际上在这里做一些工作。
条件概率作业
我希望你修改以下 Python 代码,这些代码在前面的部分中使用过。
from numpy import random
random.seed(0)
totals = {20:0, 30:0, 40:0, 50:0, 60:0, 70:0}
purchases = {20:0, 30:0, 40:0, 50:0, 60:0, 70:0}
totalPurchases = 0
for _ in range(100000):
ageDecade = random.choice([20, 30, 40, 50, 60, 70])
purchaseProbability = 0.4
totals[ageDecade] += 1
if (random.random() < purchaseProbability):
totalPurchases += 1
purchases[ageDecade] += 1
修改它以实际上不让购买和年龄之间存在依赖关系。同样让它成为均匀分布的机会。看看这对你的结果有什么影响。你最终得到了非常不同的在你30 岁购买东西的条件概率和总体购买东西的概率吗?这告诉了你关于你的数据和这两个不同属性之间关系的什么?继续尝试一下,确保你实际上可以从这些数据中得到一些结果并理解发生了什么,我马上就会运行我的解决方案来解决这个问题。
所以这就是条件概率,无论是在理论上还是在实践中。你可以看到它有很多微妙之处,还有很多令人困惑的符号表示。如果需要,回过头再看一遍这一节。我给了你一个作业,所以现在去做吧,看看你是否真的可以修改我的代码在那个 IPython 笔记本中为不同年龄组产生一个恒定的购买概率。然后回来,我们将看看我是如何解决这个问题以及我的结果是什么。
我的作业解决方案
你做完作业了吗?希望如此。让我们来看看我对在一个虚假数据集中如何使用条件概率来告诉我们年龄和购买概率之间是否存在关系的问题的解决方案。
提醒一下,我们试图做的是消除年龄和购买概率之间的依赖关系,并看看我们是否能够在我们的条件概率值中实际反映出来。这是我得到的:
from numpy import random
random.seed(0)
totals = {20:0, 30:0, 40:0, 50:0, 60:0, 70:0}
purchases = {20:0, 30:0, 40:0, 50:0, 60:0, 70:0}
totalPurchases = 0
for _ in range(100000):
ageDecade = random.choice([20, 30, 40, 50, 60, 70])
purchaseProbability = 0.4
totals[ageDecade] += 1
if (random.random() < purchaseProbability):
totalPurchases += 1
purchases[ageDecade] += 1
我在这里所做的是,我拿了原始的代码片段,用于创建我们的年龄组字典以及每个年龄组购买了多少,针对 10 万个随机人。我没有让购买概率依赖于年龄,而是让它成为 40%的常数概率。现在我们只是随机地将人分配到一个年龄组,他们都有相同的购买某物的概率。让我们继续运行。
现在,这一次,如果我计算P(E|F),也就是,给定你处于30 岁的情况下购买某物的概率,我得到的结果大约是 40%。
PEF = float(purchases[30]) / float(totals[30])
print ("P(purchase | 30s): ", PEF)
P(purchase | 30s): 0.398760454901
如果我将其与总体购买概率进行比较,那也是大约 40%。
PE = float(totalPurchases) / 100000.0
print ("P(Purchase):", PE)
P(Purchase): 0.4003
我可以看到,如果你处于30 岁,购买某物的概率与不考虑你的年龄而言购买某物的概率大致相同(也就是,*P(E|F)与P(E)*非常接近)。这表明这两件事之间没有真正的关系,实际上,我知道从这些数据中并没有关系。
现在在实践中,你可能只是看到了随机的机会,所以你会想要观察不止一个年龄组。你会想要观察不止一个数据点,以查看是否真的存在关系,但这表明在我们修改的这个样本数据中,年龄和购买概率之间没有关系。
所以,这就是条件概率的作用。希望你的解决方案相当接近并且有类似的结果。如果不是,回去研究我的解决方案。这就在这本书的数据文件中,ConditionalProbabilitySolution.ipynb,如果你需要打开它并研究它并进行试验。显然,数据的随机性会使你的结果有些不同,并且会取决于你对总体购买概率的选择,但这就是这个想法。
有了这个背景,让我们继续讲贝叶斯定理。
贝叶斯定理
现在你了解了条件概率,你就能理解如何应用贝叶斯定理,这是基于条件概率的。这是一个非常重要的概念,特别是如果你要进入医学领域,但它也是广泛适用的,你马上就会明白为什么。
你会经常听到这个,但并不是很多人真正理解它的意义。有时它可以非常定量地告诉你,当人们用统计数据误导你时,所以让我们看看它是如何起作用的。
首先,让我们从高层次来谈谈贝叶斯定理。贝叶斯定理就是:给定 B 的情况下 A 的概率等于 A 的概率乘以给定 A 的情况下 B 的概率除以 B 的概率。所以你可以用任何你想要的东西来替换 A 和 B。

关键的见解是,依赖于 B 的某事的概率很大程度上取决于 B 和 A 的基本概率。人们经常忽视这一点。
一个常见的例子是药物测试。我们可能会说,如果你对某种药物测试呈阳性,那么你是实际使用该药物的概率是多少。贝叶斯定理之所以重要,是因为它指出这在很大程度上取决于 A 和 B 的概率。在整个人群中,对于药物测试呈阳性的概率,实际上很大程度上取决于整体使用该药物的概率和整体测试呈阳性的概率。药物测试的准确性很大程度上取决于整体人群中使用该药物的概率,而不仅仅是测试的准确性。
这也意味着在给定 A 的情况下 B 的概率并不等同于在给定 B 的情况下 A 的概率。也就是说,在测试呈阳性的情况下成为药物用户的概率可能与在成为药物用户的情况下测试呈阳性的概率非常不同。您可以看到这是一个非常现实的问题,在医学诊断测试或药物测试中会产生很多假阳性。您仍然可以说测试检测用户的概率可能非常高,但这并不一定意味着在测试呈阳性的情况下成为用户的概率很高。这是两回事,而贝叶斯定理允许您量化这种差异。
让我们举一个例子来更好地理解。
再次,药物测试可以是应用贝叶斯定理证明观点的常见例子。即使高度准确的药物测试也可能产生比真阳性更多的假阳性。因此,在我们的例子中,我们将提出一种药物测试,该测试可以在 99%的时间内准确识别药物用户,并且对非用户有 99%的准确的阴性结果,但是实际上只有 0.3%的总体人口实际使用该药物。因此,我们实际上成为药物用户的概率非常小。看起来非常高的 99%的准确性实际上还不够高,对吧?
我们可以通过以下方式计算出概率:
-
事件 A = 使用该药物的用户
-
事件 B = 测试呈阳性
事件 A 表示您使用某种药物,事件 B 表示您使用此药物测试呈阳性。
我们需要计算总体测试呈阳性的概率。我们可以通过计算用户测试呈阳性的概率和非用户测试呈阳性的概率的总和来计算出来。因此,在这个例子中,P(B)计算为 1.3%(0.990.003+0.010.997)。因此,我们有了 B 的概率,即在不了解您的其他情况下,总体上测试呈阳性的概率。
让我们来计算一下,在测试呈阳性的情况下实际成为药物用户的概率。

因此,在实际成为药物用户的情况下测试呈阳性的概率计算为总体上成为药物用户的概率*(P(A)),即 3%(您知道 3%的人口是药物用户),乘以P(B|A)*,即在成为用户的情况下测试呈阳性的概率,除以总体上测试呈阳性的概率,即 1.3%。再次,这个测试听起来非常准确,准确率为 99%。我们有 0.3%的人口使用药物,乘以 99%的准确性,除以总体上测试呈阳性的概率,即 1.3%。因此,您在测试呈阳性的情况下实际成为该药物用户的概率只有 22.8%。因此,即使这种药物测试在 99%的时间内准确,它仍然在大多数情况下提供了错误的结果。
即使*P(B|A)很高(99%),也不意味着P(A|B)*很高。
人们经常忽视这一点,因此如果有一件事可以从贝叶斯定理中学到的,那就是始终要持怀疑态度。将贝叶斯定理应用于这些实际问题,您经常会发现,听起来高准确率实际上可能会产生非常误导性的结果,如果您处理的是某个问题的总体发生率很低的情况。我们在癌症筛查和其他类型的医学筛查中也看到了同样的情况。这是一个非常现实的问题;有很多人因为不理解贝叶斯定理而接受了非常真实且不必要的手术。如果您要从事医学行业的大数据工作,请,请,请记住这个定理。
这就是贝叶斯定理。永远记住,给定某事物的概率并不等同于反过来,它实际上很大程度上取决于你正在测量的这两件事物的基本概率。这是一件非常重要的事情要牢记,并且始终要以此为依据来查看你的结果。贝叶斯定理为你提供了量化这种影响的工具。我希望它能够证明有用。
总结
在本章中,我们讨论了如何绘制和图形化你的数据,以及如何使用 Python 中的matplotlib库使你的图形看起来漂亮。我们还介绍了协方差和相关性的概念。我们看了一些例子,并使用 Python 计算了协方差和相关性。我们分析了条件概率的概念,并看了一些例子以更好地理解它。最后,我们看到了贝叶斯定理及其重要性,特别是在医学领域。
在下一章中,我们将讨论预测模型。

















 868
868

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









