







协议:CC BY-NC-SA 4.0
四、IPv4
第三章讲述了 ICMP 协议在 IPv4 和 IPv6 中的实现。本章涉及 IPv4 协议,展示了在某些情况下如何使用 ICMP 消息来报告互联网协议错误。IPv4 协议(互联网协议版本 4)是当今基于标准的互联网的核心协议之一,并且路由互联网上的大部分流量。基本定义在 1981 年的 RFC 791“互联网协议”中。IPv4 协议提供任意两台主机之间的端到端连接。IP 层的另一个重要功能是转发数据包(也称为路由)和管理存储路由信息的表。第五章和第六章讨论 IPv4 路由。本章描述了 IPv4 Linux 实现:接收和发送 IPv4 数据包,包括多播数据包、IPv4 转发和处理 IPv4 选项。有些情况下,要发送的数据包大于传出接口的 MTU 在这种情况下,应该将数据包分割成更小的片段。当收到分段的数据包时,应该将它们组合成一个大的数据包,该数据包应该与分段前发送的数据包相同。这些也是本章讨论的 IPv4 协议的重要任务。
每个 IPv4 数据包都以至少 20 字节长的 IP 报头开始。如果使用 IP 选项,IPv4 报头最多可以有 60 个字节。在 IP 报头之后是传输报头(例如,TCP 报头或 UDP 报头),在它之后是有效载荷数据。要理解 IPv4 协议,您必须首先了解 IPv4 报头是如何构建的。在图 4-1 中,您可以看到 IPv4 报头,它由两部分组成:第一部分 20 个字节(直到 IPv4 报头中 options 字段的开头)是基本的 IPv4 报头,其后是 IP options 部分,其长度可以是 0 到 40 个字节。
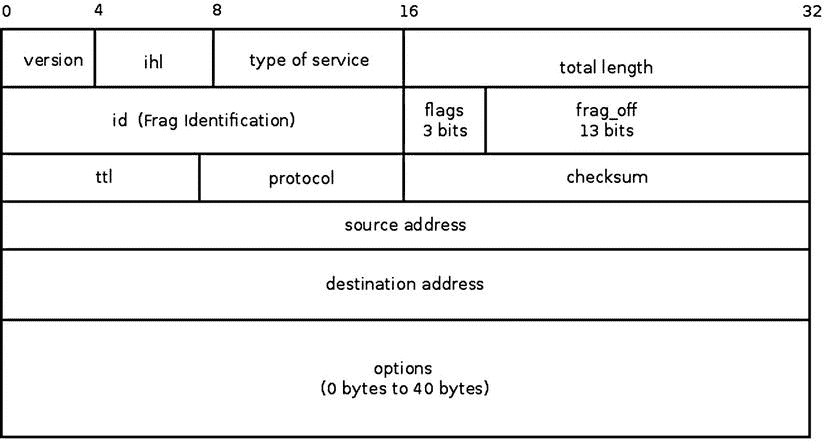
图 4-1 。IPv4 标头
IPv4 报头
IPv4 报头包含定义内核网络堆栈应该如何处理数据包的信息:正在使用的协议、源地址和目的地址、校验和、分段所需的数据包标识(id)、ttl有助于避免数据包因某些错误而被无休止地转发,等等。该信息存储在 IPv4 报头的 13 个成员中(第 14 个成员 IP Options 是 IPv4 报头的扩展,是可选的)。接下来描述 IPv4 的各种成员和各种 IP 选项。IPv4 报头由iphdr结构表示。其成员出现在图 4-1 中,将在下一节描述。本章后面的“IP 选项”一节将介绍 IP 选项及其用法。
图 4-1 显示了 IPv4 报头。所有成员始终存在,除了最后一个成员,即可选的 IP 选项。IPv4 成员的内容决定了它在 IPv4 网络堆栈中的处理方式:当出现问题时(例如,如果第一个成员的版本不是 4,或者校验和不正确),数据包将被丢弃。每个 IPv4 数据包都以 IPv4 报头开始,其后是有效载荷:
struct iphdr {
#if defined(__LITTLE_ENDIAN_BITFIELD)
__u8 ihl:4,
version:4;
#elif defined (__BIG_ENDIAN_BITFIELD)
__u8 version:4,
ihl:4;
#else
#error "Please fix <asm/byteorder.h>"
#endif
__u8 tos;
__be16 tot_len;
__be16 id;
__be16 frag_off;
__u8 ttl;
__u8 protocol;
__sum16 check;
__be32 saddr;
__be32 daddr;
/*The options start here. */
};
(include/uapi/linux/ip.h)
以下是对 IPv4 标头成员的描述:
-
ihl:表示互联网头长度。IP v4 报头的长度,以 4 字节的倍数度量。IPv4 报头的长度是不固定的,而 IPv6 报头的长度是固定的(40 字节)。原因是 IPv4 报头可以包括可选的可变长度选项。当没有选项时,IPv4 报头的最小大小为 20 字节,最大大小为 60 字节。对应的ihl值对于最小 IPv4 报头大小是 5,对于最大大小是 15。IPv4 标头必须与 4 字节边界对齐。 -
version:应该是 4。 -
tos:IP v4 报头的tos字段最初用于服务质量(QoS)服务;tos代表服务类型。多年来,该字段具有不同的含义,如下所示:RFC 2474 定义了 IPv4 和 IPv6 报头中的区分服务字段(DS 字段),即tos的 0–5 位。它也被称为区分服务码点(DSCP)。2001 年的 RFC 3168 定义了 IP 报头的显式拥塞通知(ECN );它是tos字段的第 6 位和第 7 位。 -
tot_len:总长度,包括表头,以字节计量。因为tot_len是 16 位字段,最大可达 64KB。根据 RFC 791,最小大小为 576 字节。 -
id:IP v4 报头的标识。id字段对于分段很重要:当分段一个 SKB 时,该 SKB 的所有片段的id值应该是相同的。根据碎片的id重组碎片数据包。 -
frag_off:片段偏移量,16 位字段。低 13 位是片段的偏移量。在第一个片段中,偏移量为 0。偏移量以 8 字节为单位进行测量。高 3 位是标志: -
001 是 MF(碎片多)。它是为所有片段设置的,除了最后一个片段。
-
010 是 DF(不要碎片化)。
-
100 is CE (Congestion).
参见
include/net/ip.h中的 IP_MF、IP_DF 和 IP_CE 标志声明。 -
生存时间:这是一个跳数计数器。每个转发节点将
ttl减 1。当它达到 0 时,该数据包被丢弃,并且发送回超时 ICMPv4 消息;这样可以避免数据包因为这样或那样的原因被无休止地转发。 -
protocol:数据包的 L4 协议,例如, IPPROTO_TCP 用于 TCP 流量,IPPROTO_UDP 用于 UDP 流量(有关所有可用协议的列表,请参见include/linux/in.h)。 -
check:校验和(16 位字段)。校验和仅在 IPv4 报头字节上计算。 -
saddr:源 IPv4 地址,32 位。 -
daddr:目的 IPv4 地址,32 位。
在本节中,您已经了解了各种 IPv4 头成员及其用途。下一节将讨论 IPv4 协议的初始化,它设置在接收 IPv4 报头时调用的回调。
IPv4 初始化
IPv4 数据包是以太网类型为 0x0800 的数据包(以太网类型存储在 14 字节以太网报头的前两个字节中)。每个协议都应该定义一个协议处理程序,并且每个协议都应该初始化,以便网络堆栈可以处理属于该协议的数据包。为了让您了解是什么原因导致接收到的 IPv4 数据包被 IPv4 方法处理,本节描述了 IPv4 协议处理程序的注册:
static struct packet _type ip_packet_type __read_mostly = {
.type = cpu_to_be16(ETH_P_IP),
.func = ip_rcv,
};
static int __init inet_init(void)
{
...
dev_add_pack(&ip_packet_type);
...
}
(net/ipv4/af_inet.c)
dev_add_pack()方法添加了ip_rcv()方法作为 IPv4 数据包的协议处理程序。这些数据包的以太网类型为 0x0800 (ETH_P_IP,在include/uapi/linux/if_ether.h中定义)。inet_init()方法执行各种 IPv4 初始化,并在引导阶段被调用。
IPv4 协议的主要功能分为 Rx(接收)路径和 Tx(发送)路径。现在您已经了解了 IPv4 协议处理程序的注册,您知道哪个协议处理程序管理 IPv4 数据包(ip_rcv回调)以及这个协议处理程序是如何注册的。现在,您可以开始了解 IPv4 Rx 路径以及如何处理接收到的 IPv4 数据包。Tx 路径将在后面的章节“发送 IPv4 数据包”中介绍
接收 IPv4 数据包
主要的 IPv4 接收方法是ip_rcv()方法,,它是所有 IPv4 数据包(包括多播和广播)的处理程序。事实上,这种方法主要由健全性检查组成。真正的工作是在它调用的ip_rcv_finish()方法中完成的。在ip_rcv()方法和ip_rcv_finish()方法之间是 NF_INET_PRE_ROUTING netfilter 钩子,通过调用 NF_HOOK 宏来调用(参见本节后面的代码片段)。在这一章中,你会遇到很多 NF_HOOK 宏的调用——这些是 netfilter 钩子。netfilter 子系统允许您在数据包在网络堆栈中的行程中的五个点注册回调。这些点将很快被提到他们的名字。添加 netfilter 挂钩的原因是为了能够在运行时加载 netfilter 内核模块。NF_HOOK 宏调用指定点的回调,如果这样的回调被注册的话。你也可能遇到 NF_HOOK 宏,叫做 NF_HOOK_COND,它是 NF_HOOK 宏的一个变种。在网络堆栈的某些地方,NF_HOOK_COND 宏包含一个布尔参数(最后一个参数),这个参数必须是true,钩子才能被执行(第九章讨论 netfilter 钩子)。请注意,netfilter 挂钩可以丢弃数据包,在这种情况下,它将不会继续沿其普通路径前进。图 4-2 显示了网络驱动程序接收到的数据包的接收路径(Rx) 。此数据包可以被传送到本地机器,也可以被转发到另一台主机。正是在路由表中的查找决定了这两个选项中的哪一个会发生。
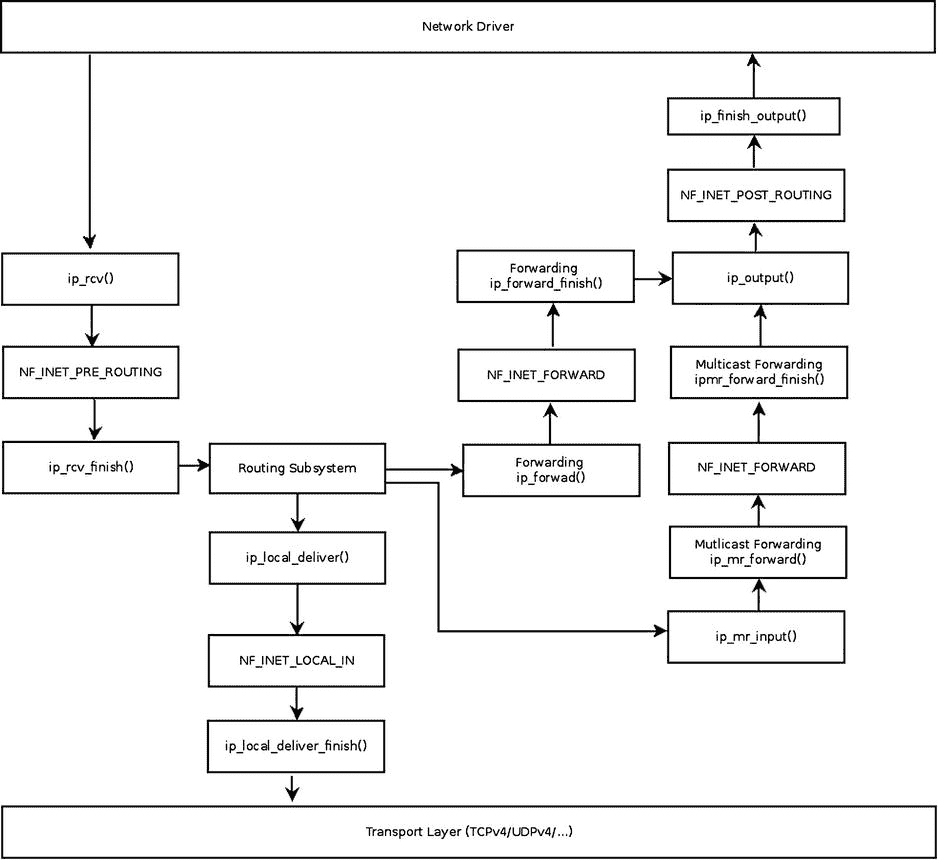
图 4-2 。接收 IPv4 数据包。为简单起见,该图不包括碎片/碎片整理/选项/IPsec 方法
图 4-2 显示了接收到的 IPv4 数据包的路径。IPv4 协议处理器ip_rcv()方法接收数据包(见图的左上侧)。首先,在调用ip_rcv_finish()方法之后,应该立即在路由子系统中执行查找。路由查找的结果决定了数据包是本地传送到本地主机还是被转发(路由查找在第五章的中解释)。如果数据包的目的地是本地主机,它将首先到达ip_local_deliver()方法,然后到达ip_local_deliver_finish()方法。当数据包要被转发时,将通过ip_forward()方法进行处理。图中出现了一些 netfilter 钩子,比如 NF_INET_PRE_ROUTING 和 NF_INET_LOCAL_IN。请注意,多播流量由ip_mr_input()方法处理,这将在本章后面的“接收 IPv4 多播数据包”一节中讨论。NF_INET_PRE_ROUTING、NF_INET_LOCAL_IN、NF_INET_FORWARD 和 NF_INET_POST_ROUTING 是 netfilter 挂钩的五个入口点中的四个。第五个是 NF_INET_LOCAL_OUT,在本章后面的“发送 IPv4 数据包”一节中会提到。这五个入口点在include/uapi/linux/netfilter.h中定义。注意,这五个钩子的相同的enum也在 IPv6 中使用;例如,在ipv6_rcv()方法中,一个钩子正在 NF_INET_PRE_ROUTING ( net/ipv6/ip6_input.c)上注册。我们来看看ip_rcv()方法:
int ip_rcv(struct sk_buff *skb, struct net_device *dev, struct packet_type *pt, struct net_device *orig_dev)
{
首先执行一些健全性检查,我在本节中提到了其中的一些。IPv4 报头(ihl)的长度以 4 字节的倍数来度量。IP v4 报头的大小必须至少为 20 个字节,这意味着ihl的大小必须至少为 5。version应该是 4(对于 IPv4)。如果其中一个条件不满足,数据包将被丢弃,统计信息(IPSTATS _ MIB _ INHDRERRORS)将被更新。
if (iph->ihl < 5 || iph->version != 4)
goto inhdr_error;
根据 RFC 1122 的 3.2.1.2 部分,主机必须验证每个收到的数据报的 IPv4 报头校验和,并自动丢弃每个校验和不正确的数据报。这是通过调用ip_fast_csum()方法完成的,如果成功,该方法将返回 0。IPv4 报头校验和仅在 IPv4 报头字节上计算:
if (unlikely(ip_fast_csum((u8 *)iph, iph->ihl)))
goto inhdr_error;
然后调用 NF_HOOK 宏:
return NF_HOOK(NFPROTO_IPV4, NF_INET_PRE_ROUTING, skb, dev, NULL,
ip_rcv_finish);
当注册的 netfilter hook 方法返回 NF_DROP 时,表示应该丢弃数据包,数据包遍历不继续。当注册的 netfilter 挂钩返回 NF _ stopped 时,意味着该数据包被 netfilter 子系统接管,数据包遍历不再继续。当注册的 netfilter 钩子返回 NF_ACCEPT 时,数据包继续遍历。netfilter 钩子还有其他返回值(也称为判断),比如 NF_QUEUE、NF_REPEAT 和 NF_STOP,这在本章中没有讨论。(如前所述,netfilter 钩子在第九章中讨论过。)让我们暂时假设在 NF_INET_PRE_ROUTING 入口点中没有注册 netfilter 回调,因此 NF_HOOK 宏不会调用任何 netfilter 回调,而会调用ip_rcv_finish()方法。我们来看看ip_rcv_finish()的方法:
static int ip_rcv_finish(struct sk_buff *skb)
{
const struct iphdr *iph = ip_hdr(skb);
struct rtable *rt;
skb_dst()方法检查是否有dst对象附着在 SKB 上;dst是dst_entry ( include/net/dst.h)的实例,代表路由子系统中的查找结果。查找是根据路由表和数据包报头完成的。路由子系统中的查找还设置了dst的input和/或output回调。例如,如果要转发数据包,路由子系统中的查找会将input回调设置为ip_forward()。当数据包的目的地是本地机器时,路由子系统中的查找会将input回调设置为ip_local_deliver()。对于多播包,在某些情况下可以是ip_mr_input()(我将在下一节讨论多播包)。dst对象的内容决定了数据包将如何继续它的旅程;例如,在转发数据包时,根据dst决定在调用dst_input()时应该调用哪个input回调,或者应该在哪个接口上传输。(我将在下一章深入讨论路由子系统)。
如果没有dst连接到 SKB,则通过ip_route_input_noref()方法在路由子系统中执行查找。如果查找失败,数据包将被丢弃。请注意,处理多播数据包不同于处理单播数据包(将在本章后面的“接收 IPv4 多播数据包”一节中讨论)。
...
if (!skb_dst(skb)) {
在路由子系统中执行查找:
int err = ip_route_input_noref(skb, iph->daddr, iph->saddr,
iph->tos, skb->dev);
if (unlikely(err)) {
if (err == -EXDEV)
NET_INC_STATS_BH(dev_net(skb->dev),
LINUX_MIB_IPRPFILTER);
goto drop;
}
}
 注意当设置了反向路径滤波器(RPF) 时,在某些情况下
注意当设置了反向路径滤波器(RPF) 时,在某些情况下__fib_validate_source()方法会返回-EXDEV(“跨设备链接”)错误。可以通过procfs中的一个条目设置 RPF。在这种情况下,数据包被丢弃,统计信息(LINUX_MIB_IPRPFILTER)被更新,该方法返回 NET_RX_DROP。注意,您可以通过查看cat /proc/net/netstat输出中的IPReversePathFilter列来显示 LINUX_MIB_IPRPFILTER 计数器。
现在执行检查以查看 IPv4 报头是否包括选项。因为 IPv4 报头的长度(ihl)是以 4 字节的倍数来度量的,如果它大于 5,这意味着它包括选项,所以应该调用ip_rcv_options()方法来处理这些选项。处理 IP 选项将在本章后面的“IP 选项”部分进行深入讨论。请注意,ip_rcv_options()方法可能会失败,您很快就会看到。如果是多播条目或广播条目,则分别更新 IPSTATS_MIB_INMCAST 统计信息或 IP stats _ MIB _ INM cast 统计信息。然后调用dst_input()方法。这个方法反过来简单地通过调用skb_dst(skb)->input(skb)来调用input回调方法:
if (iph->ihl > 5 && ip_rcv_options(skb))
goto drop;
rt = skb_rtable(skb);
if (rt->rt_type == RTN_MULTICAST) {
IP_UPD_PO_STATS_BH(dev_net(rt->dst.dev), IPSTATS_MIB_INMCAST,
skb->len);
} else if (rt->rt_type == RTN_BROADCAST)
IP_UPD_PO_STATS_BH(dev_net(rt->dst.dev), IPSTATS_MIB_INBCAST,
skb->len);
return dst_input(skb);
在本节中,您了解了接收 IPv4 数据包的各个阶段:执行的完整性检查、路由子系统中的查找、执行实际工作的ip_rcv_finish()方法。您还了解了当应该转发数据包时调用哪个方法,以及当数据包用于本地传递时调用哪个方法。IPv4 多播是一个特例。处理 IPv4 多播数据包的接收将在下一节讨论。
接收 IPv4 组播数据包
ip_rcv()方法也是多播数据包的处理程序。如前所述,在一些完整性检查之后,它调用ip_rcv_finish()方法,该方法通过调用ip_route_input_noref()在路由子系统中执行查找。在ip_route_input_noref()方法中,首先通过调用ip_check_mc_rcu()方法,检查本地机器是否属于目的多播地址的多播组。如果是,或者如果本地机器是多播路由器(CONFIG_IP_MROUTE被设置),则调用ip_route_input_mc()方法;让我们看一下代码:
int ip_route_input_noref(struct sk_buff *skb, __be32 daddr, __be32 saddr,
u8 tos, struct net_device *dev)
{
int res;
rcu_read_lock();
. . .
if (ipv4_is_multicast(daddr)) {
struct in_device *in_dev = __in_dev_get_rcu(dev);
if (in_dev) {
int our = ip_check_mc_rcu(in_dev, daddr, saddr,
ip_hdr(skb)->protocol);
if (our
#ifdef CONFIG_IP_MROUTE
||
(!ipv4_is_local_multicast(daddr) &&
IN_DEV_MFORWARD(in_dev))
#endif
) {
int res = ip_route_input_mc(skb, daddr, saddr,
tos, dev, our);
rcu_read_unlock();
return res;
}
}
. . .
}
. . .
让我们进一步研究一下ip_route_input_mc()方法。如果本机属于目的组播地址的组播组(变量our的值为 1),那么dst的input回调被设置为ip_local_deliver。如果本地主机是组播路由器并且IN_DEV_MFORWARD(in_dev)被设置,那么dst的input回调被设置为ip_mr_input。调用dst_input(skb)的ip_rcv_finish()方法因此根据dst的input回调调用ip_local_deliver()方法或ip_mr_input()方法。IN_DEV_MFORWARD 宏检查procfs组播转发条目。请注意,procfs多播转发条目/proc/sys/net/ipv4/conf/all/mc_forwarding是一个只读条目(与 IPv4 单播procfs转发条目相反),因此您不能简单地通过从命令行运行来设置它:echo 1 > /proc/sys/net/ipv4/conf/all/mc_forwarding。例如,启动pimd守护进程会将其设置为 1,停止守护进程会将其设置为 0。pimd是一个轻量级的独立 PIM-SM v2 多播路由守护程序。如果您对学习多播路由守护进程的实现感兴趣,您可能想看看https://github.com/troglobit/pimd/中的pimd源代码:
static int ip_route_input_mc(struct sk_buff *skb, __be32 daddr, __be32 saddr,
u8 tos, struct net_device *dev, int our)
{
struct rtable *rth;
struct in_device *in_dev = __in_dev_get_rcu(dev);
. . .
if (our) {
rth->dst.input= ip_local_deliver;
rth->rt_flags |= RTCF_LOCAL;
}
#ifdef CONFIG_IP_MROUTE
if (!ipv4_is_local_multicast(daddr) && IN_DEV_MFORWARD(in_dev))
rth->dst.input = ip_mr_input;
#endif
. . .
多播层保存一种称为多播转发缓存(MFC)的数据结构。我在这里不讨论 MFC 或ip_mr_input()方法的细节(我在第六章中讨论它们)。在这种情况下重要的是,如果在 MFC 中找到一个有效的条目,就调用ip_mr_forward()方法。ip_mr_forward()方法执行一些检查并最终调用ipmr_queue_xmit()方法。在ipmr_queue_xmit()方法中,ttl减少,通过调用ip_decrease_ttl()方法更新校验和(在ip_forward()方法中也是如此,您将在本章后面看到)。然后通过调用 NF_INET_FORWARD NF_HOOK 宏来调用ipmr_forward_finish()方法(假设 NF_INET_FORWARD 上没有注册的 IPv4 netfilter 钩子):
static void ipmr_queue_xmit(struct net *net, struct mr_table *mrt,
struct sk_buff *skb, struct mfc_cache *c, int vifi)
{
. . .
ip_decrease_ttl(ip_hdr(skb));
...
NF_HOOK(NFPROTO_IPV4, NF_INET_FORWARD, skb, skb->dev, dev,
ipmr_forward_finish);
return;
}
ipmr_forward_finish()方法非常简短,在此完整展示。它所做的只是更新统计数据,如果 IPv4 报头中有选项,就调用ip_forward_options()方法(IP 选项将在下一节描述),并调用dst_output()方法:
static inline int ipmr_forward_finish(struct sk_buff *skb)
{
struct ip_options *opt = &(IPCB(skb)->opt);
IP_INC_STATS_BH(dev_net(skb_dst(skb)->dev), IPSTATS_MIB_OUTFORWDATAGRAMS);
IP_ADD_STATS_BH(dev_net(skb_dst(skb)->dev), IPSTATS_MIB_OUTOCTETS, skb->len);
if (unlikely(opt->optlen))
ip_forward_options(skb);
return dst_output(skb);
}
本节讨论了如何处理接收 IPv4 多播数据包。pimd是作为多播路由守护进程的一个例子提到的,它在多播数据包转发中与内核交互。下一节将描述各种 IP 选项,这些选项支持使用网络堆栈的特殊功能,例如跟踪数据包的路由、跟踪数据包的时间戳、指定数据包应该经过的网络节点。我还讨论了如何在网络堆栈中处理这些 IP 选项。
IP 选项
IPv4 报头的 IP 选项字段是可选的,并且由于安全原因和处理开销,不经常使用。哪些选项可能有帮助?例如,假设您的数据包被某个防火墙丢弃。您可以使用严格或宽松的源路由选项来指定不同的路由。或者如果你想找出数据包到一些目的地址的路径,你可以使用记录路由选项。
IPv4 标头可以包含零个、一个或多个选项。没有选项时,IPv4 报头大小为 20 字节。IP 选项字段的长度最多为 40 个字节。IPv4 最大长度为 60 字节的原因是因为 IPv4 报头长度是一个 4 位字段,它以 4 字节的倍数来表示长度。因此,该字段的最大值是 15,这给出了 60 字节的 IPv4 最大报头长度。当使用多个选项时,选项只是一个接一个地连接起来。IPv4 报头必须与 4 字节边界对齐,因此有时需要填充。以下 RFC 讨论了 IP 选项:781(时间戳选项)、791、1063、1108、1393(使用 IP 选项的 Traceroute)和 2113 (IP 路由器警报选项)。有两种形式的 IP 选项:
-
单字节选项(选项类型) : T “选项列表结束”和“无操作”是仅有的单字节选项。
-
多字节选项:当在选项类型 byte 后使用多字节选项时,有以下三个字段:
-
长度(1 字节):选项的长度,以字节为单位。
-
指针(1 字节):从选项开始的偏移量。
-
选项数据:这是一个中间主机可以存储数据的空间,例如时间戳或 IP 地址。
在图 4-3 中显示了选项类型。

图 4-3 。选项类型
置位时,copied标志表示该选项应在所有片段中复制。如果未设置该选项,则只应在第一个片段中复制该选项。IPOPT_COPIED 宏检查是否设置了指定 IP 选项的copied标志。它在ip_options_fragment()方法中用于检测不可复制的选项,并插入 IPOPT_NOOP。本节稍后将讨论ip_options_fragment()方法。
选项类可以是以下 4 个值之一:
- 00:控制类(IPOPT_CONTROL)
- 01:预留 1 (IPOPT_RESERVED1)
- 10:调试和测量(IPOPT_MEASUREMENT)
- 11: reserved2 (IPOPT_RESERVED2)
在 Linux 网络栈中,只有 IPOPT_TIMESTAMP 选项属于调试和测量类。所有其他选项都是控件类。
选项编号通过唯一编号指定一个选项;可能的值是 0–31,但不是所有的值都被 Linux 内核使用。
表 4-1 根据 Linux 符号、选项号、选项类别和copied标志显示了所有选项。
表 4-1 。选项表
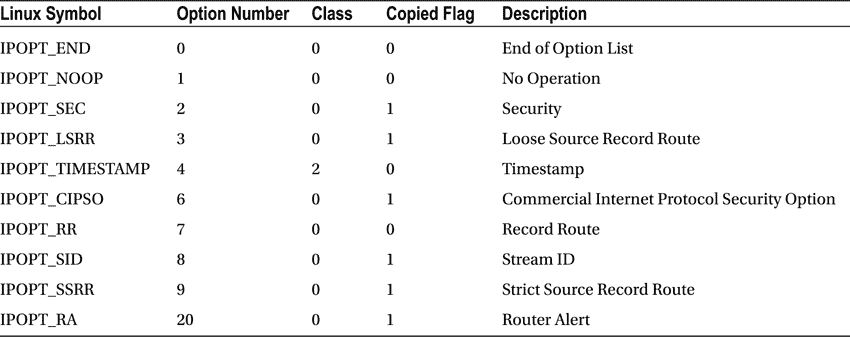
选项名(IPOPT_*)声明在include/uapi/linux/ip.h中。
Linux 网络堆栈不包括所有的 IP 选项。完整列表见www.iana.org/assignments/ip-parameters/ip-parameters.xml。
我将简要描述这五个选项,然后深入描述时间戳选项和记录路径选项:
- 选项列表结束(IPOPT_END) : 1 字节选项,用于表示选项字段的结束。这是一个单一的零字节选项(它的所有位都是“0”)。其后不能有 IP 选项。
- 无操作(IPOPT_NOOP) : 1 字节选项用于内部填充,用于对齐。
- Security (IPOPT_SEC) : 该选项为主机提供了一种发送安全性、处理限制和 TCC(封闭用户组)参数的方式。参见 RFC 791 和 RFC 1108。最初打算用于军事应用。
- 松散源记录路由(IPOPT_LSRR) : 此选项指定数据包应该经过的路由器列表。在列表中的每两个相邻节点之间,可以有没有出现在列表中的中间路由器,但是应该保持顺序。
- 商业互联网协议安全选项(IPOPT_CIPSO) : CIPSO 是 IETF 的草案,已经被多家厂商采用。它涉及网络标签标准。套接字的 CIPSO 标记意味着将 CIPSO IP 选项添加到通过该套接字离开系统的所有数据包中。该选项在收到数据包时生效。有关 CIPSO 选项的更多信息,请参见
Documentation/netlabel/draft-ietf-cipso-ipsecurity-01.txt和Documentation/netlabel/cipso_ipv4.txt。
时间戳选项
Timestamp (IPOPT_TIMESTAMP):时间戳选项在 RFC 781“互联网协议(IP)时间戳选项的规范”中指定此选项存储数据包路由上主机的时间戳。存储的时间戳是一个 32 位的时间戳,从 UTC 当天午夜开始,以毫秒为单位。此外,它还可以存储数据包路由中所有主机的地址,或者只存储沿路由选择的主机的时间戳。时间戳选项的最大长度是 40。不为片段复制时间戳选项;它只出现在第一个片段中。时间戳选项以三个字节的选项类型、长度和指针(偏移量)开始。第四个字节的高 4 位是溢出计数器,它在没有可用空间存储所需数据的每一跳中递增。当溢出计数器超过 15 时,返回一个参数问题的 ICMP 消息。低 4 位是标志。标志的值可以是下列值之一:
- 0 :仅时间戳(IPOPT _ TS _ TSONLY)
- 1 :时间戳和地址(IPOPT_TS_TSANDADDR)
- 3 :仅指定跳数的时间戳(IPOPT_TS_PRESPEC)
 注意您可以使用带有时间戳选项和前面提到的三个子类型的命令行
注意您可以使用带有时间戳选项和前面提到的三个子类型的命令行ping实用程序:
ping -T tsonly (IPOPT_TS_TSONLY)
ping -T tsandaddr (IPOPT_TS_TSANDADDR)
ping -T tsprespec (IPOPT_TS_PRESPEC)
图 4-4 显示了仅带有时间戳的时间戳选项(设置了 IPOPT_TS_TSONLY 标志)。路径上的每台路由器都会添加其 IPv4 地址。当没有更多空间时,溢出计数器递增。
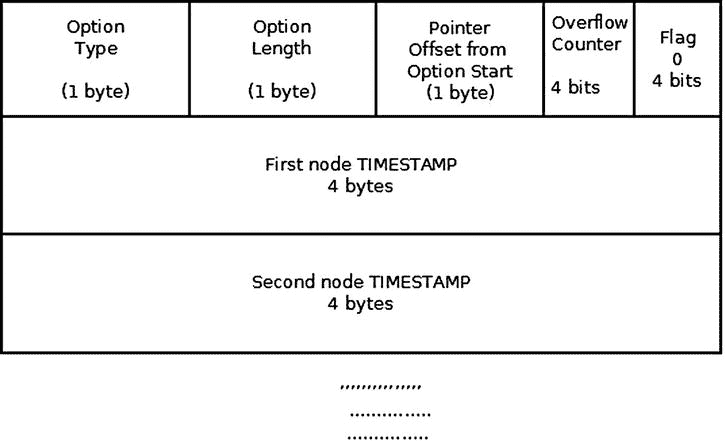
图 4-4 。时间戳选项(只有时间戳,标志= 0)
图 4-5 显示了带有时间戳和地址的时间戳选项(设置了 IPOPT_TS_TSANDADDR 标志)。路径上的每台路由器都会添加其 IPv4 地址和时间戳。同样,当没有更多空间时,溢出计数器递增。
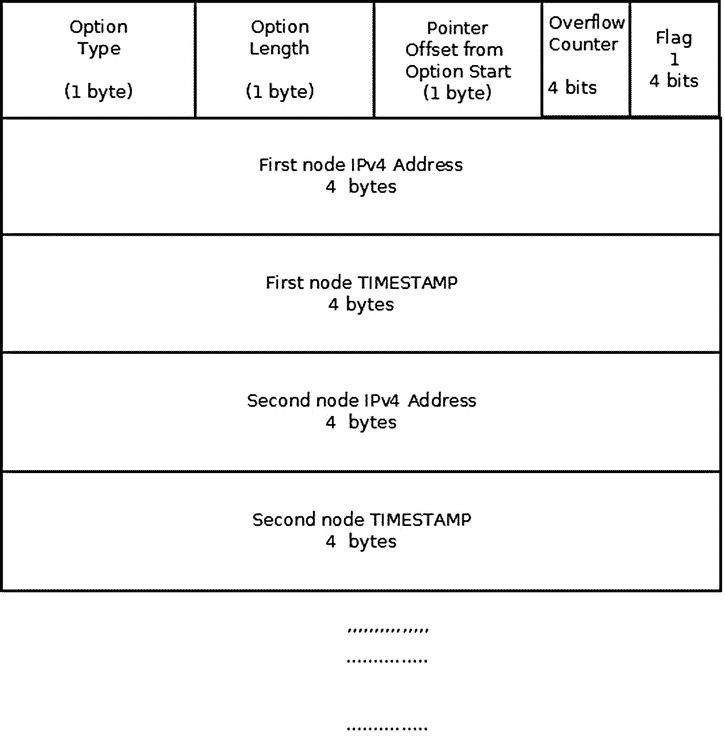
图 4-5 。时间戳选项(带时间戳和地址,标志= 1)
图 4-6 显示了带有时间戳的时间戳选项(设置了 IPOPT_TS_PRESPEC 标志)。路径上的每个路由器只有在预先指定的列表中才会添加其时间戳。同样,当没有更多空间时,溢出计数器递增。
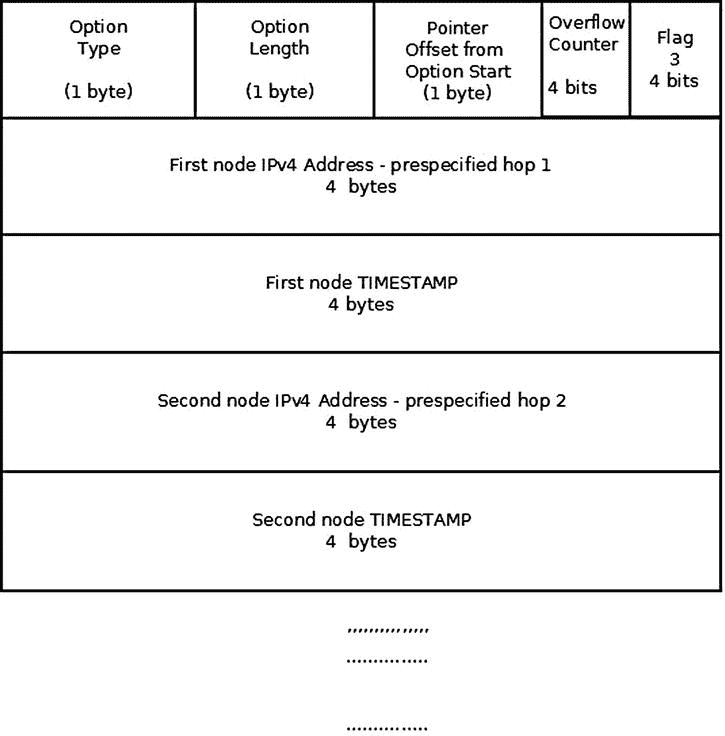
图 4-6 。时间戳选项(仅带有指定跳数的时间戳,标志= 3)
记录路线选项
记录路由(IPOPT_RR):记录一个数据包的路由。途中的每个路由器都会添加它的地址(见图 4-7 )。长度由发送设备设置。命令行实用程序ping –R使用记录路由 IP 选项。请注意,IPv4 报头仅够九个这样的路由使用(如果使用更多选项,甚至更少)。当报头已满并且没有空间插入额外的地址时,数据报被转发,而不将地址插入 IP 选项。参见 RFC 791 第 3.1 节。
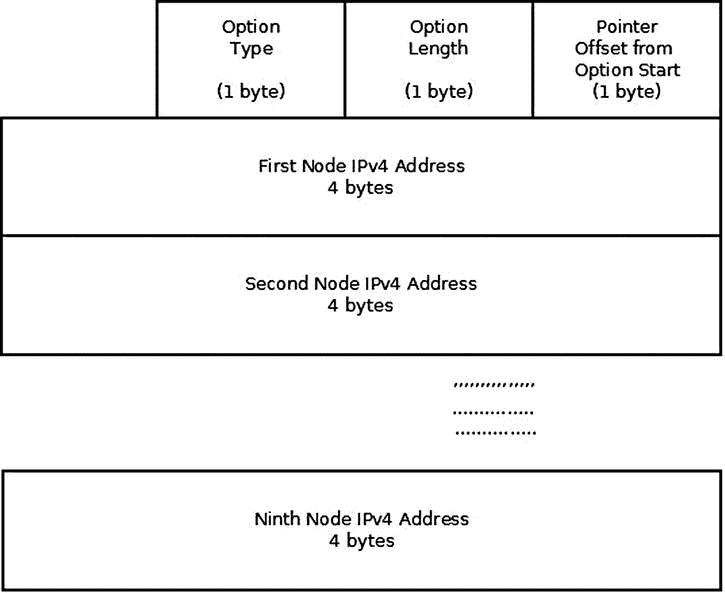
图 4-7 。记录路线选项
虽然ping –R使用记录路由 IP 选项,但在许多情况下,如果您尝试它,您将不会得到沿途所有网络节点的预期结果,因为出于安全原因,许多网络节点会忽略此 IP 选项。ping的manpage明确提到了这一点。从man ping开始:
. . .
-R
Includes the RECORD_ROUTE option in the ECHO_REQUEST packet and displays the route buffer on returned packets.
. . .
Many hosts ignore or discard this option.
. . .
- 流 ID (IPOPT_SID) : 该选项提供了一种通过不支持流概念的网络携带 16 位 SATNET 流标识符的方式。
- 严格源记录路由 【伊波特 _ SSRR】:该选项指定数据包应该经过的路由器列表。应该保持顺序,并且不允许在遍历中进行任何更改。出于安全原因,许多路由器会阻止宽松源记录路由(LSRR)和严格源记录路由(SSRR)选项。
- 路由器警报(IPOPT _ RA):IP 路由器警报选项可用于通知中转路由器更仔细地检查 IP 数据包的内容。例如,这对于新协议是有用的,但是需要在路径上的路由器中进行相对复杂的处理。在 RFC 2113“IP 路由器警报选项”中指定
IP 选项在 Linux 中由ip_options结构表示:
struct ip_options {
__be32 faddr;
__be32 nexthop;
unsigned char optlen;
unsigned char srr;
unsigned char rr;
unsigned char ts;
unsigned char is_strictroute:1,
srr_is_hit:1,
is_changed:1,
rr_needaddr:1,
ts_needtime:1,
ts_needaddr:1;
unsigned char router_alert;
unsigned char cipso;
unsigned char __pad2;
unsigned char __data[0];
};
(include/net/inet_sock.h)
以下是 IP 期权结构成员的简短描述:
faddr:保存的第一跳地址。当处理松散和严格路由时,在ip_options_compile()中设置,此时方法不是从 Rx 路径调用的(SKB 为空)。nexthop:保存了 LSRR 和 SSRR 的 nexthop 地址。optlen:选项长度,以字节为单位。不能超过 40 个字节。is_strictroute:指定使用严格源路由的标志。解析严格路由选项类型(IPOPT_SSRR)时在ip_options_compile()方法中设置标志;请注意,它不是为松散路由(IPOPT_LSRR)设置的。srr_is_hit:指定数据包目的地addr是本地主机的标志srr_is_hit标志在ip_options_rcv_srr()中设置。is_changed:IP 校验和不再有效(当其中一个 IP 选项改变时,该标志被置位)。rr_needaddr:需要记录传出设备的 IPv4 地址。为记录路由选项(IPOPT_RR)设置标志。ts_needtime:需要记录时间戳。该标志是为时间戳 IP 选项的这些标志设置的:IPOPT_TS_TSONLY、IPOPT_TS_TSANDADDR 和 IPOPT_TS_PRESPEC(参见本节后面关于这些标志之间的差异的详细解释)。ts_needaddr:需要记录传出设备的 IPv4 地址。仅当 IPOPT_TS_TSANDADDR 标志被置位时,该标志才被置位,并且它指示应该添加沿着分组路由的每个节点的 IPv4 地址。router_alert:在ip_options_compile()方法中设置解析路由器时的报警选项(IPOPT_RR)。__data[0]:一个缓冲区,用于存储由setsockopt()从用户空间接收的选项。
参见ip_options_get_from_user()和ip_options_get_finish() ( net/ipv4/ip_options.c)。
我们来看看ip_rcv_options()方法:
static inline bool ip_rcv_options(struct sk_buff *skb)
{
struct ip_options *opt;
const struct iphdr *iph;
struct net_device *dev = skb->dev;
. . .
从 SKB 获取 IPv4 报头:
iph = ip_hdr(skb);
从与 SKB 关联的inet_skb_parm对象中获取ip_options对象:
opt = &(IPCB(skb)->opt);
计算预期期权长度:
opt->optlen = iph->ihl*4 - sizeof(struct iphdr);
调用ip_options_compile()方法从 SKB 中构建一个ip_options对象:
if (ip_options_compile(dev_net(dev), opt, skb)) {
IP_INC_STATS_BH(dev_net(dev), IPSTATS_MIB_INHDRERRORS);
goto drop;
}
当在 Rx 路径中调用ip_options_compile()方法(从ip_rcv_options()方法)时,它解析指定 SKB 的 IPv4 报头,并在验证选项的有效性后,根据 IPv4 报头内容,用它构建一个ip_options对象。当通过带有 IPPROTO_IP 和 IP_OPTIONS 的setsockopt()系统调用从用户空间获取选项时,也可以从ip_options_get_finish()方法调用ip_options_compile()方法。在这种情况下,数据从用户空间复制到opt->data,并且ip_options_compile()的第三个参数,即 SKB,为空;在这种情况下,ip_options_compile()方法从opt->__data构建ip_options对象。如果在解析选项时发现一些错误,并且是在 Rx 路径中(从ip_rcv_options()调用了ip_options_compile()方法),则发送回“参数问题”ICMPv4 消息(ICMP_PARAMETERPROB)。无论该方法是如何被调用的,如果出现错误,将返回代码为–EINVAL的错误。自然,使用ip_options对象比使用原始 IPv4 头更方便,因为这样访问 IP 选项字段要简单得多。在 Rx 路径中,ip_options_compile()方法构建的ip_options对象存储在 SKB 的控制缓冲区(cb)中;这通过将opt对象设置为&(IPCB(skb)->opt)来完成。IPCB(skb)宏是这样定义的:
#define IPCB(skb) ((struct inet_skb_parm*)((skb)->cb))
并且inet_skb_parm结构(包括一个ip_options对象)是这样定义的:
struct inet_skb_parm {
struct ip_options opt; /* Compiled IP options */
unsigned char flags;
u16 frag_max_size;
};
(include/net/ip.h)
所以&(IPCB(skb)->opt指向inet_skb_parm对象内部的ip_options对象。在本书中,我不会深入研究在ip_options_compile()方法中解析 IPv4 报头的所有小而繁琐的技术细节,因为有大量这样的细节,而且它们是不言自明的。我将简要讨论ip_options_compile()如何解析 Rx 路径中的一些单字节选项,如 IPOPT_END 和 IPOPT_NOOP,以及一些更复杂的选项,如 IPOPT_RR 和 IPOPT_TIMESTAMP,并展示一些在此方法中完成检查的示例,以及如何在下面的代码片段中实现它:
int ip_options_compile(struct net *net, struct ip_options *opt, struct sk_buff *skb)
{
...
unsigned char *pp_ptr = NULL;
struct rtable *rt = NULL;
unsigned char *optptr;
unsigned char *iph;
int optlen, l;
为了开始解析过程,optptr指针应该指向 IP options 对象的开始,并在一个循环中迭代所有选项。对于 Rx 路径(当从ip_rcv_options()方法调用ip_options_compile()方法时),在ip_rcv()方法中接收到的 SKB 作为参数传递给ip_options_compile(),不用说,不能为空。在这种情况下,IP 选项在 IPv4 报头的初始固定大小(20 字节)之后立即开始。当从ip_options_get_finish()调用ip_options_compile()时,optptr指针被设置为opt->__data,因为ip_options_get_from_user()方法复制了从用户空间发送到opt->__data的选项。为了准确起见,我应该提到,如果需要对齐,ip_options_get_finish()方法也会写入opt->__data(它会在适当的位置写入 IPOPT_END)。
if (skb != NULL) {
rt = skb_rtable(skb);
optptr = (unsigned char *)&(ip_hdr(skb)[1]);
} else
optptr = opt->__data;
在这种情况下,不能改为使用iph = ip_hdr(skb),因为要考虑 SKB 为空的情况。以下分配对于非 Rx 路径也是正确的:
iph = optptr - sizeof(struct iphdr);
变量l初始化为选项长度(最多 40 字节)。在接下来的for循环的每次迭代中,它会减少当前选项的长度:
for (l = opt->optlen; l > 0; ) {
switch (*optptr) {
如果遇到一个 IPOPT_END 选项,则表明这是选项列表的结尾,后面不能有其他选项。在这种情况下,您为每个不同于 IPOPT_END 的字节写入 IPOPT_END,直到选项列表结束。还应设置is_changed布尔标志,因为它指示 IPv4 报头已更改(因此,校验和的重新计算待定—现在或在for循环内没有理由计算校验和,因为在循环期间 IPv4 报头可能有其他更改):
case IPOPT_END:
for (optptr++, l--; l>0; optptr++, l--) {
if (*optptr != IPOPT_END) {
*optptr = IPOPT_END;
opt->is_changed = 1;
}
}
goto eol;
如果遇到单字节选项的无操作(IPOPT_NOOP)选项类型,只需将l减 1,将optptr增 1,然后前进到下一个选项类型:
case IPOPT_NOOP:
l--;
optptr++;
continue;
}
Optlen被设置为被读取的选项的长度(因为optptr[1]保存选项长度):
optlen = optptr[1];
无操作(IPOPT_NOOP)选项和选项列表结束(IPOPT_END)选项是仅有的单字节选项。所有其他选项都是多字节选项,必须至少有两个字节(选项类型和选项长度)。现在检查至少有两个选项字节,并且没有超过选项列表长度。如果有一些错误,pp_ptr指针被设置为指向问题的根源并退出循环。如果是在 Rx 路径,则回送一个“参数问题”的 ICMPv4 消息,将出现问题的偏移量作为参数传递,以便对方分析问题:
if (optlen<2 || optlen>l) {
pp_ptr = optptr;
goto error;
}
switch (*optptr) {
case IPOPT_SSRR:
case IPOPT_LSRR:
...
case IPOPT_RR:
记录路由选项的选项长度必须至少为 3 个字节:选项类型、选项长度和指针(偏移量):
if (optlen < 3) {
pp_ptr = optptr + 1;
goto error;
}
记录路由选项的选项指针偏移量必须至少为 4 个字节,因为为地址列表保留的空间必须在三个初始字节(选项类型、选项长度和指针)之后开始:
if (optptr[2] < 4) {
pp_ptr = optptr + 2;
goto error;
}
if (optptr[2] <= optlen) {
如果偏移量(optptr[2])加上三个初始字节超过了选项长度,则出现错误:
if (optptr[2]+3 > optlen) {
pp_ptr = optptr + 2;
goto error;
}
if (rt) {
spec_dst_fill(&spec_dst, skb);
将 IPv4 地址复制到记录路由缓冲区:
memcpy(&optptr[optptr[2]-1], &spec_dst, 4);
设置is_changed布尔标志,表示 IPv4 报头已更改(校验和的重新计算待定):
opt->is_changed = 1;
}
对于记录路由缓冲区中的下一个地址,将指针(偏移量)增加 4(每个 IPv4 地址为 4 个字节):
optptr[2] += 4;
设置rr_needaddr标志(该标志在ip_forward_options()方法中检查):
opt->rr_needaddr = 1;
}
opt->rr = optptr - iph;
break;
case IPOPT_TIMESTAMP:
...
时间戳选项的选项长度必须至少为 4 个字节:选项类型、选项长度、指针(偏移量),第四个字节分为两个字段:较高的 4 位是溢出计数器,它在没有可用空间来存储所需数据的每一跳中递增,较低的 4 位是标志:仅时间戳、时间戳和地址以及指定跳的时间戳:
if (optlen < 4) {
pp_ptr = optptr + 1;
goto error;
}
optptr[2]是指针(偏移量)。因为,如前所述,每个时间戳选项以 4 个字节开始,这意味着指针(偏移量)必须至少为 5:
if (optptr[2] < 5) {
pp_ptr = optptr + 2;
goto error;
}
if (optptr[2] <= optlen) {
unsigned char *timeptr = NULL;
if (optptr[2]+3 > optptr[1]) {
pp_ptr = optptr + 2;
goto error;
}
在切换命令中,检查optptr[3]&0xF的值。它是时间戳选项的标志(第四个字节的 4 个低位):
switch (optptr[3]&0xF) {
case IPOPT_TS_TSONLY:
if (skb)
timeptr = &optptr[optptr[2]-1];
opt->ts_needtime = 1;
对于带有仅时间戳标志(IPOPT_TS_TSONLY)的时间戳选项,需要 4 个字节;因此指针(偏移量)增加 4:
optptr[2] += 4;
break;
case IPOPT_TS_TSANDADDR:
if (optptr[2]+7 > optptr[1]) {
pp_ptr = optptr + 2;
goto error;
}
if (rt) {
spec_dst_fill(&spec_dst, skb);
memcpy(&optptr[optptr[2]-1],
&spec_dst, 4);
timeptr = &optptr[optptr[2]+3];
}
opt->ts_needaddr = 1;
opt->ts_needtime = 1;
对于带有时间戳和地址标志的时间戳选项(IPOPT_TS_TSANDADDR),需要 8 个字节;因此指针(偏移量)增加了 8:
optptr[2] += 8;
break;
case IPOPT_TS_PRESPEC:
if (optptr[2]+7 > optptr[1]) {
pp_ptr = optptr + 2;
goto error;
}
{
__be32 addr;
memcpy(&addr, &optptr[optptr[2]-1], 4);
if (inet_addr_type(net,addr) == RTN_UNICAST)
break;
if (skb)
timeptr = &optptr[optptr[2]+3];
}
opt->ts_needtime = 1;
对于带有时间戳和预先指定的跳数标志(IPOPT_TS_PRESPEC)的时间戳选项,需要 8 个字节,因此指针(偏移量)增加 8:
optptr[2] += 8;
break;
default:
...
}
...
在ip_options_compile()方法构建了ip_options对象之后,严格的路由被处理。首先,检查设备是否支持源路由。这意味着/proc/sys/net/ipv4/conf/all/accept_source_route被设置,并且/proc/sys/net/ipv4/conf/<deviceName>/accept_source_route被设置。如果不满足这些条件,数据包将被丢弃:
. . .
if (unlikely(opt->srr)) {
struct in_device *in_dev = __in_dev_get_rcu(dev);
if (in_dev) {
if (!IN_DEV_SOURCE_ROUTE(in_dev)) {
. . .
goto drop;
}
}
if (ip_options_rcv_srr(skb))
goto drop;
}
我们来看看ip_options_rcv_srr()方法(还是那句话,我会把重点放在重要的点上,而不是小细节)。源路由地址列表被迭代。在解析过程中,会在循环中进行一些完整性检查,以查看是否有错误。当遇到第一个非本地地址时,循环退出,并执行以下操作:
- 设置 IP 选项对象的
srr_is_hit标志(opt->srr_is_hit = 1)。 - 将
opt->nexthop设置为找到的下一跳地址。 - 将
opt->is_changed标志设置为 1。
应该转发该数据包。当到达方法ip_forward_finish()时,调用ip_forward_options()方法。在此方法中,如果设置了 IP 选项对象的srr_is_hit标志,则 ipv4 报头的daddr被更改为opt->nexthop,偏移量增加 4(指向源路由地址列表中的下一个地址),并且—因为 IPv4 报头被更改—通过调用ip_send_check()方法重新计算校验和。
IP 选项和碎片化
在本节开始描述选项类型时,我提到了选项类型字节中的一个copied标志,它指示在转发分段数据包时是否复制选项。碎片中 IP 选项的处理由ip_options_fragment()方法完成,该方法从准备碎片的方法ip_fragment()中调用。只为第一个片段调用它。我们来看看ip_options_fragment()的方法,很简单:
void ip_options_fragment(struct sk_buff *skb)
{
unsigned char *optptr = skb_network_header(skb) + sizeof(struct iphdr);
struct ip_options *opt = &(IPCB(skb)->opt);
int l = opt->optlen;
int optlen;
e 循环简单地遍历选项,读取每个选项类型。optptr是指向选项列表的指针(从 IPv4 报头的前 20 个字节的末尾开始)。l是选项列表的大小,在每次循环迭代中递减 1:
while (l > 0) {
switch (*optptr) {
当选项类型为 IPOPT_END 时,它终止选项字符串,这意味着读取选项已完成:
case IPOPT_END:
return;
case IPOPT_NOOP:
当option type为 IPOPT_NOOP,用于选项之间的填充时,optptr指针加 1,l递减,处理下一个选项:
l--;
optptr++;
continue;
}
对选项长度执行健全性检查:
optlen = optptr[1];
if (optlen<2 || optlen>l)
return;
检查是否应复制该选项;如果没有,只需用memset()函数放一个或几个 IPOPT_NOOP 选项来代替它。memset()写入的 IPOPT_NOOP 字节数是被读取的选项的大小,即optlen:
if (!IPOPT_COPIED(*optptr))
memset(optptr, IPOPT_NOOP, optlen);
现在进入下一个选项:
l -= optlen;
optptr += optlen; }
IPOPT_TIMESTAMP 和 IPOPT_RR 是copied标志为 0 的选项(见表 4-1 )。在您之前看到的循环中,它们被替换为 IPOPT_NOOP,并且它们在 IP option 对象中的相关字段被重置为 0:
opt->ts = 0;
opt->rr = 0;
opt->rr_needaddr = 0;
opt->ts_needaddr = 0;
opt->ts_needtime = 0;
}
(net/ipv4/ip_options.c)
在本节中,您已经了解了ip_rcv_options()如何处理带有 IP 选项的数据包的接收,以及ip_options_compile()方法如何解析 IP 选项。还讨论了知识产权方案的不成体系问题。下一节将介绍构建 IPv4 选项的过程,包括根据指定的ip_options对象设置 IPv4 报头的 IP 选项。
构建 IP 选项
ip_options_build()方法可以被认为是你在本章前面看到的ip_options_compile()方法的反向。它将一个ip_options对象作为参数,并将其内容写入 IPv4 报头。让我们来看看:
void ip_options_build(struct sk_buff *skb, struct ip_options *opt,
__be32 daddr, struct rtable *rt, int is_frag)
{
unsigned char *iph = skb_network_header(skb);
memcpy(&(IPCB(skb)->opt), opt, sizeof(struct ip_options));
memcpy(iph+sizeof(struct iphdr), opt->__data, opt->optlen);
opt = &(IPCB(skb)->opt);
if (opt->srr)
memcpy(iph+opt->srr+iph[opt->srr+1]-4, &daddr, 4);
if (!is_frag) {
if (opt->rr_needaddr)
ip_rt_get_source(iph+opt->rr+iph[opt->rr+2]-5, skb, rt);
if (opt->ts_needaddr)
ip_rt_get_source(iph+opt->ts+iph[opt->ts+2]-9, skb, rt);
if (opt->ts_needtime) {
struct timespec tv;
__be32 midtime;
getnstimeofday(&tv);
midtime = htonl((tv.tv_sec % 86400) *
MSEC_PER_SEC + tv.tv_nsec / NSEC_PER_MSEC);
memcpy(iph+opt->ts+iph[opt->ts+2]-5, &midtime, 4);
}
return;
}
if (opt->rr) {
memset(iph+opt->rr, IPOPT_NOP, iph[opt->rr+1]);
opt->rr = 0;
opt->rr_needaddr = 0;
}
if (opt->ts) {
memset(iph+opt->ts, IPOPT_NOP, iph[opt->ts+1]);
opt->ts = 0;
opt->ts_needaddr = opt->ts_needtime = 0;
}
}
ip_forward_options()方法处理转发分片包(net/ipv4/ip_options.c)。在该方法中,记录路由和严格记录路由选项被处理,并且ip_send_check()方法被调用以计算其 IPv4 报头被改变的分组的校验和(opt->is_changed标志被设置)并将opt->is_changed标志重置为 0。下一节将讨论 IPv4 Tx 路径,即数据包的发送方式。
我关于 Rx 路径的讨论到此结束。下一节将讨论 Tx 路径——发送 IPv4 数据包时会发生什么。
发送 IPv4 数据包
IPv4 层为其上一层(传输层(L4 ))提供了通过将数据包传递给链路层(L2)来发送数据包的方法。我将在本节中讨论这是如何实现的,您将看到在 IPv4 中处理 TCPv4 数据包传输和在 IPv4 中处理 UDPv4 数据包传输之间的一些差异。从第 4 层(传输层)发送 IPv4 数据包有两种主要方法:第一种是ip_queue_xmit()方法,由传输协议使用,它们自己处理碎片,如 TCPv4。ip_queue_xmit()方法并不是 TCPv4 使用的唯一传输方法,例如,它还使用ip_build_and_send_pkt()方法来发送 SYN ACK 消息(参见net/ipv4/tcp_ipv4.c)中的tcp_v4_send_synack()方法实现)。第二种方法是ip_append_data()方法,由不处理碎片的传输协议使用,如 UDPv4 协议或 ICMPv4 协议。ip_append_data()方法不发送任何包——它只准备包。ip_push_pending_frames()方法用于实际发送数据包,例如,它由 ICMPv4 或原始套接字使用。调用ip_push_pending_frames()实际上是通过调用ip_send_skb()方法启动传输过程,最终调用ip_local_out()方法。在内核 2.6.39 之前的 UDPv4 中使用了ip_push_pending_frames()方法进行传输;对于 2.6.39 中新的ip_finish_skb API,使用的是ip_send_skb()方法。两种方法都在net/ipv4/ip_output.c中实现。
有直接调用dst_output()方法的情况,没有使用ip_queue_xmit()方法或者ip_append_data()方法;例如,当使用使用 IP_HDRINCL 套接字选项的原始套接字发送时,不需要准备 IPv4 报头。自行构建 IPv4 的用户空间应用使用 IPv4 IP_HDRINCL 套接字选项。例如,众所周知的iputils的ping和nmap的nping都允许用户这样设置 IPv4 报头的ttl:
ping –ttl ipDestAddress
或者:
nping –ttl ipDestAddress
通过设置了 IP_HDRINCL socket 选项的原始套接字发送数据包的过程如下:
static int raw_send_hdrinc(struct sock *sk, struct flowi4 *fl4,
void *from, size_t length,
struct rtable **rtp,
unsigned int flags)
{
...
err = NF_HOOK(NFPROTO_IPV4, NF_INET_LOCAL_OUT, skb, NULL,
rt->dst.dev, dst_output);
...
}
图 4-8 显示了从传输层发送 IPv4 数据包的路径。
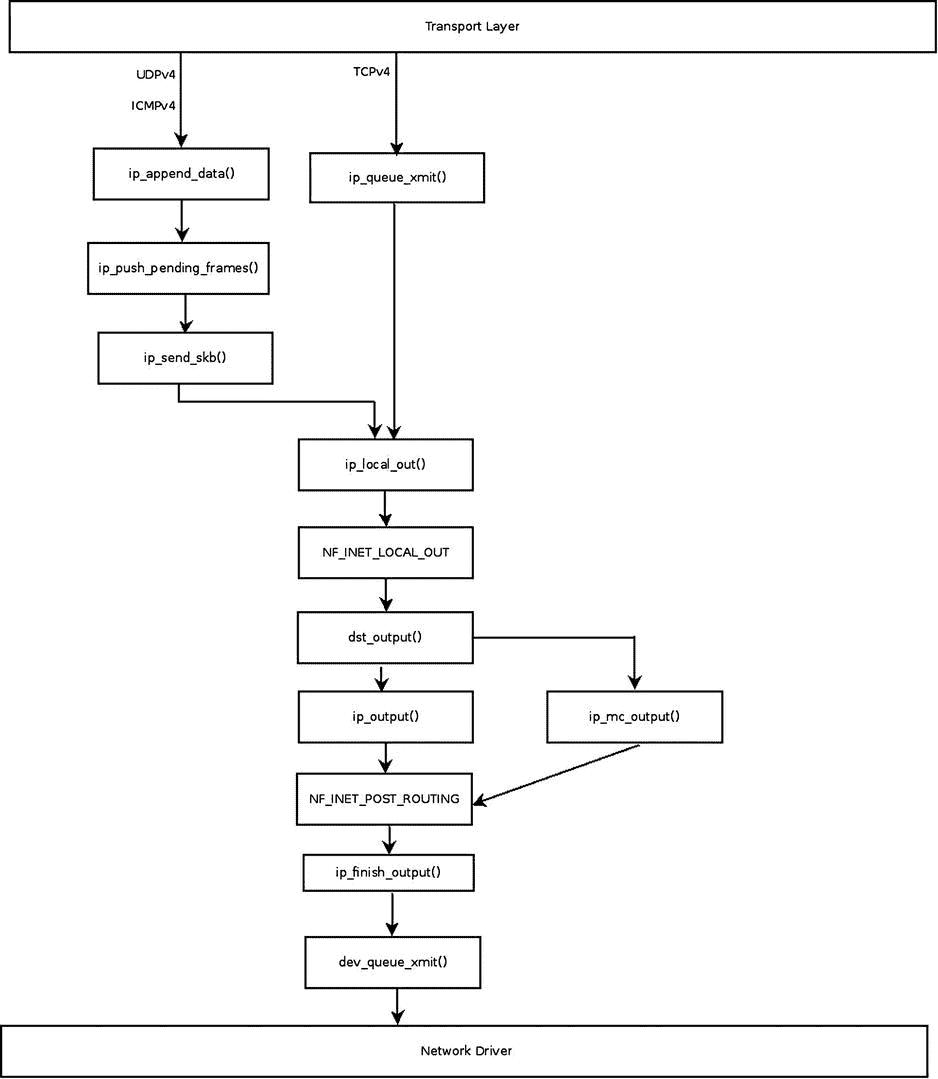
图 4-8 。发送 IPv4 数据包
在图 4-8 中,你可以看到来自传输层(L4)的传输数据包的不同路径;这些数据包由ip_queue_xmit()方法或ip_append_data()方法处理。
让我们从ip_queue_xmit()方法开始,这是两种方法中比较简单的一种:
int ip_queue_xmit(struct sk_buff *skb, struct flowi *fl)
. . .
/* Make sure we can route this packet. */
rt = (struct rtable *)__sk_dst_check(sk, 0);
rtable对象是在路由子系统中查找的结果。首先,我讨论了rtable实例为空的情况,您需要在路由子系统中执行查找。如果设置了严格路由选项标志,则目的地址被设置为 IP 选项的第一个地址:
if (rt == NULL) {
__be32 daddr;
/* Use correct destination address if we have options. */
daddr = inet->inet_daddr;
if (inet_opt && inet_opt->opt.srr)
daddr = inet_opt->opt.faddr;
现在,在路由子系统中使用ip_route_output_ports()方法执行查找:如果查找失败,数据包将被丢弃,并返回错误–EHOSTUNREACH:
/* If this fails, retransmit mechanism of transport layer will
* keep trying until route appears or the connection times
* itself out.
*/
rt = ip_route_output_ports(sock_net(sk), fl4, sk,
daddr, inet->inet_saddr,
inet->inet_dport,
inet->inet_sport,
sk->sk_protocol,
RT_CONN_FLAGS(sk),
sk->sk_bound_dev_if);
if (IS_ERR(rt))
goto no_route;
sk_setup_caps(sk, &rt->dst);
}
skb_dst_set_noref(skb, &rt->dst);
. . .
如果查找成功,但设置了选项中的is_strictroute标志和路由条目中的rt_uses_gateway标志,则数据包被丢弃,并返回错误–EHOSTUNREACH:
if (inet_opt && inet_opt->opt.is_strictroute && rt->rt_uses_gateway)
goto no_route;
现在正在构建 IPv4 报头。您应该记得数据包来自第 4 层,这里的skb->data指向传输头。通过skb_push()方法将skb->data指针向后移动;将其移回所需的偏移量是 IPv4 报头的大小加上 IP 选项列表的大小(optlen),如果使用了 IP 选项:
/* OK, we know where to send it, allocate and build IP header. */
skb_push(skb, sizeof(struct iphdr) + (inet_opt ? inet_opt->opt.optlen : 0));
将 L3 标题(skb->network_header)设置为指向skb->data:
skb_reset_network_header(skb);
iph = ip_hdr(skb);
*((__be16 *)iph) = htons((4 << 12) | (5 << 8) | (inet->tos & 0xff));
if (ip_dont_fragment(sk, &rt->dst) && !skb->local_df)
iph->frag_off = htons(IP_DF);
else
iph->frag_off = 0;
iph->ttl = ip_select_ttl(inet, &rt->dst);
iph->protocol = sk->sk_protocol;
ip_copy_addrs(iph, fl4);
选项长度(optlen)除以 4,并且结果被添加到 IPv4 报头长度(iph->ihl),因为 IPv4 报头是以 4 字节的倍数来测量的。然后调用ip_options_build()方法,根据指定 IP 选项的内容构建 IPv4 报头中的选项。ip_options_build()方法的最后一个参数is_frag指定没有碎片。本章前面的“IP 选项”部分讨论了ip_options_build()方法。
if (inet_opt && inet_opt->opt.optlen) {
iph->ihl += inet_opt->opt.optlen >> 2;
ip_options_build(skb, &inet_opt->opt, inet->inet_daddr, rt, 0);
}
设置 IPv4 报头中的id:
ip_select_ident_more(iph, &rt->dst, sk,
(skb_shinfo(skb)->gso_segs ?: 1) - 1);
skb->priority = sk->sk_priority;
skb->mark = sk->sk_mark;
发送数据包:
res = ip_local_out(skb);
在讨论ip_append_data()方法之前,我想提到一个回调,它是ip_append_data()方法的参数:getfrag()回调。getfrag()方法是将实际数据从用户空间复制到 SKB 的回调。在 UDPv4 中,getfrag()回调被设置为通用方法ip_generic_getfrag()。在 ICMPv4 中,getfrag()回调被设置为特定于协议的方法icmp_glue_bits()。这里我应该提到的另一个问题是 UDPv4 的软木塞特性。在内核 2.5.44 中增加了 UDP_CORK socket 选项;当启用此选项时,此套接字上的所有数据输出都累积到一个数据报中,该数据报在禁用此选项时传输。您可以通过setsockopt()系统调用来启用和禁用该套接字选项;参见man 7 udp。在内核 2.6.39 中,无锁传输快速路径被添加到 UDPv4 实现中。通过这种添加,当不使用软木塞功能时,不使用套接字锁。所以当 UDP_CORK socket 选项被设置时(通过setsockopt()系统调用),或者 MSG_MORE 标志被设置时,就会调用ip_append_data()方法。当 UDP_CORK socket 选项未设置时,使用udp_sendmsg()方法中的另一个路径,该路径不持有套接字锁,因此速度更快,并调用ip_make_skb()方法。调用ip_make_skb()方法类似于将ip_append_data()和ip_push_pending_frames()方法合二为一,除了它不发送产生的 SKB。通过ip_send_skb()方法发送 SKB。
现在让我们来看看ip_append_data()方法:
int ip_append_data(struct sock *sk, struct flowi4 *fl4,
int getfrag(void *from, char *to, int offset, int len,
int odd, struct sk_buff *skb),
void *from, int length, int transhdrlen,
struct ipcm_cookie *ipc, struct rtable **rtp,
unsigned int flags)
{
struct inet_sock *inet = inet_sk(sk);
int err;
如果 MSG_PROBE 标志 us used,则表示调用者只对某些信息感兴趣(通常是 MTU,用于 PMTU 发现),所以不需要实际发送数据包,方法返回 0:
if (flags&MSG_PROBE)
return 0;
transhdrlen的值用于指示它是否是第一片段。ip_setup_cork()方法创建一个不存在的 cork IP options 对象,并将指定的ipc ( ipcm_cookie对象)的 IP 选项复制到 cork IP options:
if (skb_queue_empty(&sk->sk_write_queue)) {
err = ip_setup_cork(sk, &inet->cork.base, ipc, rtp);
if (err)
return err;
} else {
transhdrlen = 0;
}
真正的工作是由 __ ip_append_data()方法完成的;这是一个漫长而复杂的方法,我无法深入研究它的所有细节。我会提到,在这个方法中,根据网络设备是否支持分散/聚集(NETIF_F_SG),有两种不同的处理碎片的方式。当 NETIF_F_SG 标志置位时,使用skb_shinfo(skb)->frags,而当 NETIF_F_SG 标志未置位时,使用skb_shinfo(skb)->frag_list。当 MSG_MORE 标志被置位时,也有不同的内存分配。MSG_MORE 标志表示很快将发送另一个数据包。从 Linux 2.6 开始,UDP 套接字也支持这个标志。
return __ip_append_data(sk, fl4, &sk->sk_write_queue, &inet->cork.base,
sk_page_frag(sk), getfrag,
from, length, transhdrlen, flags);
}
在本节中,您已经了解了 Tx 路径,即如何发送 IPv4 数据包。当数据包长度高于网络设备 MTU 时,数据包无法按原样发送。下一节将介绍 Tx 路径中的碎片以及如何处理碎片。
碎片化
网络接口对数据包的大小有限制。通常在 10/100/1000 Mb/s 以太网中,它是 1500 字节,尽管有网络接口允许使用高达 9K 的 MTU(称为巨型帧)。当发送的数据包大于传出网卡的 MTU 时,应该将其分成更小的片段。这在ip_fragment()方法 ( net/ipv4/ip_output.c)中完成。收到的分段数据包应重新组装成一个数据包。这是通过ip_defrag()方法(net/ipv4/ip_fragment.c)完成的,在下一节“碎片整理”中讨论
我们先来看看ip_fragment()方法。这是它的原型:
int ip_fragment(struct sk_buff *skb, int (*output)(struct sk_buff *))
output回调是要使用的传输方法。当从ip_finish_output()调用ip_fragment()方法时,output回调就是ip_finish_output2()方法。ip_fragment()方法中有两条路径:快速路径和慢速路径。快速路径用于 SKB 的frag_list不为空的数据包,慢速路径用于不满足该条件的数据包。
首先执行检查以查看是否允许分段,如果不允许,则将带有所需分段代码的“Destination Unreachable”icmp v4 消息发送回发送方,更新统计信息(IPSTATS_MIB_FRAGFAILS ),丢弃数据包,并返回错误代码–EMSGSIZE:
int ip_fragment(struct sk_buff *skb, int (*output)(struct sk_buff *))
{
unsigned int mtu, hlen, left, len, ll_rs;
. . .
struct rtable *rt = skb_rtable(skb);
int err = 0;
dev = rt->dst.dev;
. . .
iph = ip_hdr(skb);
if (unlikely(((iph->frag_off & htons(IP_DF)) && !skb->local_df) ||
(IPCB(skb)->frag_max_size &&
IPCB(skb)->frag_max_size > dst_mtu(&rt->dst)))) {
IP_INC_STATS(dev_net(dev), IPSTATS_MIB_FRAGFAILS);
icmp_send(skb, ICMP_DEST_UNREACH, ICMP_FRAG_NEEDED,
htonl(ip_skb_dst_mtu(skb)));
kfree_skb(skb);
return -EMSGSIZE;
}
. . .
. . .
下一节将讨论分段中的快速路径及其实现。
快速路径
现在让我们来看看捷径。首先,通过调用skb_has_frag_list()方法,检查是否应该在快速路径中处理数据包,该方法简单地检查skb_shinfo(skb)->frag_list不为空;如果为空,则进行一些健全性检查,如果无效,则激活慢路径机制的回退(只需调用goto slow_path)。然后为第一个片段构建 IPv4 报头。该 IPv4 报头的frag_off被设置为htons(IP_MF),表示前面还有更多碎片。IPv4 报头的frag_off字段是 16 位字段;低 13 位是片段偏移量,高 3 位是标志。对于第一个片段,偏移量应该为 0,标志应该为 IP_MF(更多片段)。对于除最后一个片段之外的所有其他片段,应设置 IP_MF 标志,低 13 位应为片段偏移量(以 8 字节为单位测量)。对于最后一个片段,不应设置 IP_MF 标志,但低 13 位仍将保存片段偏移量。
以下是如何将hlen设置为以字节为单位的 IPv4 报头大小:
hlen = iph->ihl * 4;
. . .
if (skb_has_frag_list(skb)) {
struct sk_buff *frag, *frag2;
int first_len = skb_pagelen(skb);
. . .
err = 0;
offset = 0;
frag = skb_shinfo(skb)->frag_list;
通过skb_frag_list_init(skb)将skb_shinfo(skb)->frag_list设置为空:
skb_frag_list_init(skb);
skb->data_len = first_len - skb_headlen(skb);
skb->len = first_len;
iph->tot_len = htons(first_len);
为第一个片段设置 IP_MF(更多片段)标志:
iph->frag_off = htons(IP_MF);
因为某些 IPv4 报头字段的值已更改,所以需要重新计算校验和:
ip_send_check(iph);
现在看看遍历frag_list并构建片段的循环:
for (;;) {
/* Prepare header of the next frame,
* before previous one went down. */
if (frag) {
frag->ip_summed = CHECKSUM_NONE;
skb_reset_transport_header(frag);
ip_fragment()是从传输层(L4)调用的,所以skb->data指向传输头。skb->data指针应该向后移动hlen字节,这样它将指向 IPv4 报头(hlen是 IPv4 报头的大小,以字节为单位):
__skb_push(frag, hlen);
将 L3 标头(skb->network _header)设置为指向skb->data:
skb_reset_network_header(frag);
将创建的 IPv4 报头复制到 L3 网络报头中;在这个for循环的第一次迭代中,它是在循环之外为第一个片段创建的头:
memcpy(skb_network_header(frag), iph, hlen);
现在,下一个片段的 IPv4 报头及其tot_len被初始化:
iph = ip_hdr(frag);
iph->tot_len = htons(frag->len);
将 SKB 的各种 SKB 字段(如pkt_type、priority、protocol)复制到frag:
ip_copy_metadata(frag, skb);
只有对于第一个片段(偏移量为 0 ),才应该调用ip_options_fragment()方法:
if (offset == 0)
ip_options_fragment(frag);
offset += skb->len - hlen;
IPv4 报头的frag_off字段是以 8 字节的倍数来测量的,因此将偏移量除以 8:
iph->frag_off = htons(offset>>3);
除了最后一个片段,每个片段都应该设置 IP_MF 标志:
if (frag->next != NULL)
iph->frag_off |= htons(IP_MF);
某些 IPv4 标头字段的值已更改,因此应重新计算校验和:
/* Ready, complete checksum */
ip_send_check(iph);
}
现在发送带有output回调的片段。如果发送成功,递增 IPSTATS_MIB_FRAGCREATES。如果有错误,退出循环:
err = output(skb);
if (!err)
IP_INC_STATS(dev_net(dev), IPSTATS_MIB_FRAGCREATES);
if (err || !frag)
break;
获取下一个 SKB:
skb = frag;
frag = skb->next;
skb->next = NULL;
下面的右括号是for循环的结尾:
}
for循环终止,应该检查最后一次调用output(skb)的返回值。如果成功,则更新统计信息(IPSTATS_MIB_FRAGOKS ),该方法返回 0:
if (err == 0) {
IP_INC_STATS(dev_net(dev), IPSTATS_MIB_FRAGOKS);
return 0;
}
如果对output(skb)的最后一次调用在一次循环迭代中失败,包括最后一次,skb 被释放,统计数据(IPSTATS_MIB_FRAGFAILS)被更新,并且返回错误代码(err):
while (frag) {
skb = frag->next;
kfree_skb(frag);
frag = skb;
}
IP_INC_STATS(dev_net(dev), IPSTATS_MIB_FRAGFAILS);
return err;
您现在应该对碎片化中的快速路径以及它是如何实现的有了很好的理解。
慢速路径
现在让我们来看看如何在碎片化中实现慢速路径:
. . .
iph = ip_hdr(skb);
left = skb->len - hlen; /* Space per frame */
. . .
while (left > 0) {
len = left;
/* IF: it doesn't fit, use 'mtu' - the data space left */
if (len > mtu)
len = mtu;
每个片段(除了最后一个)应该在一个 8 字节的边界上对齐:
if (len < left) {
len &= ∼7;
}
分配一个 SKB:
if ((skb2 = alloc_skb(len+hlen+ll_rs, GFP_ATOMIC)) == NULL) {
NETDEBUG(KERN_INFO "IP: frag: no memory for new fragment!\n");
err = -ENOMEM;
goto fail;
}
/*
* Set up data on packet
*/
将各种 SKB 字段(如pkt_type、priority、protocol)从skb复制到skb2:
ip_copy_metadata(skb2, skb);
skb_reserve(skb2, ll_rs);
skb_put(skb2, len + hlen);
skb_reset_network_header(skb2);
skb2->transport_header = skb2->network_header + hlen;
/*
* Charge the memory for the fragment to any owner
* it might possess
*/
if (skb->sk)
skb_set_owner_w(skb2, skb->sk);
/*
* Copy the packet header into the new buffer.
*/
skb_copy_from_linear_data(skb, skb_network_header(skb2), hlen);
/*
* Copy a block of the IP datagram.
*/
if (skb_copy_bits(skb, ptr, skb_transport_header(skb2), len))
BUG();
left -= len;
/*
* Fill in the new header fields.
*/
iph = ip_hdr(skb2);
frag_off是 8 字节的倍数,因此将偏移量除以 8:
iph->frag_off = htons((offset >> 3));
. . .
对于第一个片段,仅处理选项一次:
if (offset == 0)
ip_options_fragment(skb);
MF 标志(更多片段)应设置在除最后一个片段之外的任何片段上:
if (left > 0 || not_last_frag)
iph->frag_off |= htons(IP_MF);
ptr += len;
offset += len;
/*
* Put this fragment into the sending queue.
*/
iph->tot_len = htons(len + hlen);
因为某些 IPv4 报头字段的值已更改,所以应该重新计算校验和:
ip_send_check(iph);
现在发送带有output回调的片段。如果发送成功,递增 IPSTATS_MIB_FRAGCREATES。如果有错误,则释放数据包,更新统计信息(IPSTATS_MIB_FRAGFAILS),并返回错误代码:
err = output(skb2);
if (err)
goto fail;
IP_INC_STATS(dev_net(dev), IPSTATS_MIB_FRAGCREATES);
}
现在while (left > 0)循环已经终止,调用consume_skb()方法释放 SKB,统计信息(IPSTATS_MIB_FRAGOKS)被更新,返回err的值:
consume_skb(skb);
IP_INC_STATS(dev_net(dev), IPSTATS_MIB_FRAGOKS);
return err;
本节讨论了分段中慢速路径的实现,Tx 路径中分段的讨论到此结束。请记住,在主机上收到的分段数据包应该重新构建,以便应用可以处理原始数据包。下一节讨论碎片整理——碎片整理的反义词。
碎片整理
碎片整理是将数据包的所有碎片重新组合到一个缓冲区中的过程,这些碎片在 IPv4 报头中都具有相同的id。Rx 路径中处理碎片整理的主要方法是ip_defrag() ( net/ipv4/ip_fragment.c,从ip_local_deliver()调用。还有一些地方可能需要碎片整理,比如在防火墙中,为了能够检查数据包,应该知道数据包的内容。在ip_local_deliver()方法中,调用ip_is_fragment()方法检查数据包是否有碎片;如果是,则调用ip_defrag()方法。ip_defrag()方法有两个参数:第一个是 SKB,第二个是一个 32 位字段,表示方法被调用的点。它的值可以是以下值:
- 调用
from ip_local_deliver()时的 IP_DEFRAG_LOCAL_DELIVER。 - 从
ip_call_ra_chain()调用时的 IP_DEFRAG_CALL_RA_CHAIN。 - 从 IPVS 调用时的 IP_DEFRAG_VS_IN 或 IP_DEFRAG_VS_FWD 或 IP_DEFRAG_VS_OUT。
关于第二个参数ip_defrag()的可能值的完整列表,请查看include/net/ip.h中的ip_defrag_users enum定义。
让我们看看ip_local_deliver()中的ip_defrag()调用:
int ip_local_deliver(struct sk_buff *skb)
{
/*
* Reassemble IP fragments.
*/
if (ip_is_fragment(ip_hdr(skb))) {
if (ip_defrag(skb, IP_DEFRAG_LOCAL_DELIVER))
return 0;
}
return NF_HOOK(NFPROTO_IPV4, NF_INET_LOCAL_IN, skb, skb->dev, NULL,
ip_local_deliver_finish);
}
(net/ipv4/ip_input.c)
ip_is_fragment()是一个简单的 helper 方法,它将 IPv4 报头作为唯一的参数,并在它是一个片段时返回true,如下所示:
static inline bool ip_is_fragment(const struct iphdr *iph)
{
return (iph->frag_off & htons(IP_MF | IP_OFFSET)) != 0;
}
(include/net/ip.h)
在以下两种情况下,ip_is_fragment()方法返回true:
- IP_MF 标志被设置。
- 片段偏移量不为 0。
因此,它将在所有片段上返回true:
- 在第一个片段上,其中
frag_off为 0,但设置了 IP_MF 标志。 - 在最后一个片段上,其中
frag_off不是 0,但是 IP_MF 标志没有被设置。 - 在所有其他片段上,其中
frag_off不为 0 并且设置了 IP_MF 标志。
碎片整理的实现基于ipq对象的哈希表。哈希函数 ( ipqhashfn)有四个参数:片段 id、源地址、目的地址和协议:
struct ipq {
struct inet_frag_queue q;
u32 user;
__be32 saddr;
__be32 daddr;
__be16 id;
u8 protocol;
u8 ecn; /* RFC3168 support */
int iif;
unsigned int rid;
struct inet_peer *peer;
};
请注意,IPv4 碎片整理的逻辑是与其 IPv6 副本共享的。因此,举例来说,inet_frag_queue结构和像inet_frag_find()方法和inet_frag_evictor()方法这样的方法并不特定于 IPv4 它们也用于 IPv6(参见net/ipv6/reassembly.c和net/ipv6/nf_conntrack_reasm.c)。
ip_defrag()方法很短。首先,它通过调用ip_evictor()方法来确保有足够的内存。然后它试图通过调用ip_find()方法为 SKB 找到一个ipq;如果没有找到,它就创建一个ipq对象。ip_find()方法返回的ipq对象被分配给一个名为qp的变量(一个指向ipq对象的指针)。然后它调用ip_frag_queue()方法将片段添加到片段链表中(qp->q.fragments)。对列表的添加是根据片段偏移量完成的,因为列表是按片段偏移量排序的。在添加了 SKB 的所有片段后,ip_frag_queue() 方法调用ip_frag_reasm()方法从其所有片段构建一个新的包。ip_frag_reasm()方法还通过调用ipq_kill()方法来停止ip_expire()的定时器。如果有错误,并且新数据包的大小超过了最大允许大小(65535),ip_frag_reasm()方法更新统计信息(IPSTATS_MIB_REASMFAILS)并返回-E2BIG。如果调用ip_frag_reasm()中的skb_clone()方法失败,则返回–ENOMEM。在这种情况下,IPSTATS_MIB_REASMFAILS 统计信息也会更新。应该在指定的时间间隔内从其所有片段构造分组。如果未在该时间间隔内完成,方法ip_expire()将发送一条“超时”的 ICMPv4 消息,并带有“片段重组时间超时”代码。碎片整理时间间隔可以通过以下procfs条目设置:/proc/sys/net/ipv4/ipfrag_time。默认情况下是 30 秒。
我们来看看ip_defrag()方法:
int ip_defrag(struct sk_buff *skb, u32 user)
{
struct ipq *qp;
struct net *net;
net = skb->dev ? dev_net(skb->dev) : dev_net(skb_dst(skb)->dev);
IP_INC_STATS_BH(net, IPSTATS_MIB_REASMREQDS);
/* Start by cleaning up the memory. */
ip_evictor(net);
/* Lookup (or create) queue header */
if ((qp = ip_find(net, ip_hdr(skb), user)) != NULL) {
int ret;
spin_lock(&qp->q.lock);
ret = ip_frag_queue(qp, skb);
spin_unlock(&qp->q.lock);
ipq_put(qp);
return ret;
}
IP_INC_STATS_BH(net, IPSTATS_MIB_REASMFAILS);
kfree_skb(skb);
return -ENOMEM;
}
在查看ip_frag_queue()方法之前,考虑下面的宏,它只是返回与指定的 SKB 相关联的ipfrag_skb_cb对象:
#define FRAG_CB(skb) ((struct ipfrag_skb_cb *)((skb)->cb))
现在我们来看一下ip_frag_queue()方法。我不会描述所有的细节,因为该方法非常复杂,并且考虑了可能由重叠引起的问题(由于重传可能出现重叠片段)。在下面的代码片段中,qp->q.len被设置为包的总长度,包括它的所有片段;当未设置 IP_MF 标志时,这意味着这是最后一个片段:
static int ip_frag_queue(struct ipq *qp, struct sk_buff *skb)
{
struct sk_buff *prev, *next;
. . .
/* Determine the position of this fragment. */
end = offset + skb->len - ihl;
err = -EINVAL;
/* Is this the final fragment? */
if ((flags & IP_MF) == 0) {
/* If we already have some bits beyond end
* or have different end, the segment is corrupted.
*/
if (end < qp->q.len ||
((qp->q.last_in & INET_FRAG_LAST_IN) && end != qp->q.len))
goto err;
qp->q.last_in |= INET_FRAG_LAST_IN;
qp->q.len = end;
} else {
. . .
}
现在,通过查找片段偏移量之后的第一个位置,找到了添加片段的位置(片段的链表是按偏移量排序的):
. . .
prev = NULL;
for (next = qp->q.fragments; next != NULL; next = next->next) {
if (FRAG_CB(next)->offset >= offset)
break; /* bingo! */
prev = next;
}
现在,prev指向新片段的添加位置,如果它不为空。跳过处理重叠和其他一些检查,让我们继续将片段插入到列表中:
FRAG_CB(skb)->offset = offset;
/* Insert this fragment in the chain of fragments. */
skb->next = next;
if (!next)
qp->q.fragments_tail = skb;
if (prev)
prev->next = skb;
else
qp->q.fragments = skb;
. . .
qp->q.meat += skb->len;
注意,对于每个片段,qp->q.meat增加了skb->len。如前所述,qp->q.len是所有片段的总长度,当它等于qp->q.meat时,意味着所有的片段都被添加,应该用ip_frag_reasm()的方法重新组装成一个包。
现在您可以看到重组是如何发生的以及在哪里发生的:(重组是通过调用ip_frag_reasm()方法来完成的):
if (qp->q.last_in == (INET_FRAG_FIRST_IN | INET_FRAG_LAST_IN) &&
qp->q.meat == qp->q.len) {
unsigned long orefdst = skb->_skb_refdst;
skb->_skb_refdst = 0UL;
err = ip_frag_reasm(qp, prev, dev);
skb->_skb_refdst = orefdst;
return err;
}
我们来看看ip_frag_reasm()方法:
static int ip_frag_reasm(struct ipq *qp, struct sk_buff *prev,
struct net_device *dev)
{
struct net *net = container_of(qp->q.net, struct net, ipv4.frags);
struct iphdr *iph;
struct sk_buff *fp, *head = qp->q.fragments;
int len;
...
/* Allocate a new buffer for the datagram. */
ihlen = ip_hdrlen(head);
len = ihlen + qp->q.len;
err = -E2BIG;
if (len > 65535)
goto out_oversize;
...
skb_push(head, head->data - skb_network_header(head));
促进
转发数据包的主要处理程序是ip_forward()方法:
int ip_forward(struct sk_buff *skb)
{
struct iphdr *iph; /* Our header */
struct rtable *rt; /* Route we use */
struct ip_options *opt = &(IPCB(skb)->opt);
我应该描述一下为什么大的接收卸载(LRO)数据包在转发中被丢弃。LRO 是一种性能优化技术,它将数据包合并在一起,创建一个大型 SKB,然后将它们传递到更高的网络层。这减少了 CPU 开销,从而提高了性能。转发由 LRO 建造的大型 SKB 是不可接受的,因为它将比传出的 MTU 更大。因此,当启用 LRO 时,SKB 被释放,并且该方法返回 NET_RX_DROP。通用接收卸载(GRO) 设计包括转发能力,但 LRO 没有:
if (skb_warn_if_lro(skb))
goto drop;
如果设置了router_alert选项,应该调用ip_call_ra_chain()方法来处理数据包。当在原始套接字上用 IP_ROUTER_ALERT 调用setsockopt()时,该套接字被添加到名为ip_ra_chain的全局列表中(参见include/net/ip.h)。ip_call_ra_chain()方法将数据包传递给所有的原始套接字。您可能想知道为什么数据包被发送到所有的原始套接字,而不是单个原始套接字?与 TCP 或 UDP 相反,在原始套接字中没有套接字侦听的端口。
如果pkt_type——由eth_type_trans()方法确定,应该从网络驱动程序调用,并在附录 A 中讨论——不是 PACKET_HOST,则数据包被丢弃:
if (IPCB(skb)->opt.router_alert && ip_call_ra_chain(skb))
return NET_RX_SUCCESS;
if (skb->pkt_type != PACKET_HOST)
goto drop;
IPv4 报头的ttl(生存时间)字段是在每个转发设备中减 1 的计数器。如果ttl达到 0,则表明应该丢弃该数据包,并且应该发送带有“超过 TTL 计数”代码的相应超时 ICMPv4 消息:
if (ip_hdr(skb)->ttl <= 1)
goto too_many_hops;. . .
. . .
too_many_hops:
/* Tell the sender its packet died... */
IP_INC_STATS_BH(dev_net(skb_dst(skb)->dev), IPSTATS_MIB_INHDRERRORS);
icmp_send(skb, ICMP_TIME_EXCEEDED, ICMP_EXC_TTL, 0);
. . .
现在,检查严格路线标志(is_strictroute)和rt_uses_gateway标志是否都被设置;在这种情况下,严格路由不能被应用,并且带有“严格路由失败”代码的“目的地不可达”ICMPv4 消息被发回:
rt = skb_rtable(skb);
if (opt->is_strictroute && rt->rt_uses_gateway)
goto sr_failed;
. . .
sr_failed:
icmp_send(skb, ICMP_DEST_UNREACH, ICMP_SR_FAILED, 0);
goto drop;
. . .
现在,执行检查以查看分组的长度是否大于输出设备 MTU。如果是,这意味着不允许按原样发送该数据包。执行另一个检查以查看 IPv4 报头中的 DF(不分段)字段是否被设置,以及 SKB 中的local_df标志是否未被设置。如果满足这些条件,这意味着当数据包到达ip_output()方法时,它不会被ip_fragment()方法分段。这意味着数据包不能按原样发送,也不能被分段;因此,带有“需要分段”代码的目的地不可达 ICMPv4 消息被发回,数据包被丢弃,统计信息(IPSTATS_MIB_FRAGFAILS)被更新:
if (unlikely(skb->len > dst_mtu(&rt->dst) &&
!skb_is_gso(skb) && (ip_hdr(skb)->frag_off & htons(IP_DF)))
&& !skb->local_df) {
IP_INC_STATS(dev_net(rt->dst.dev), IPSTATS_MIB_FRAGFAILS);
icmp_send(skb, ICMP_DEST_UNREACH, ICMP_FRAG_NEEDED,
htonl(dst_mtu(&rt->dst)));
goto drop; }
因为 IPv4 报头的ttl和校验和将要被改变,所以应该保留 SKB 的副本:
/* We are about to mangle packet. Copy it! */
if (skb_cow(skb, LL_RESERVED_SPACE(rt->dst.dev)+rt->dst.header_len))
goto drop;
iph = ip_hdr(skb);
如前所述,转发数据包的每个节点都应该减少ttl。由于ttl的改变,校验和也在ip_decrease_ttl()方法中相应更新:
/* Decrease ttl after skb cow done */
ip_decrease_ttl(iph);
现在,重定向 ICMPv4 消息被发回。如果路由条目的 RTCF _ 多尔直接标志被设置,那么“重定向到主机”代码被用于该消息(我在第五章的中讨论 ICMPv4 重定向消息)。
/*
* We now generate an ICMP HOST REDIRECT giving the route
* we calculated.
*/
if (rt->rt_flags&RTCF_DOREDIRECT && !opt->srr && !skb_sec_path(skb))
ip_rt_send_redirect(skb);
Tx 路径中的skb->priority被设置为套接字优先级(sk->sk_priority)—例如,参见ip_queue_xmit()方法。接下来,可以通过调用带有 SOL_SOCKET 和 SO_PRIORITY 的setsockopt()系统调用来设置套接字优先级。但是,在转发数据包时,没有套接字连接到 SKB。因此,在ip_forward()方法中,skb->priority是根据一个名为ip_tos2prio的特殊表格设置的。该表有 16 个条目(见include/net/route.h)。
skb->priority = rt_tos2priority(iph->tos);
现在,假设没有 netfilter NF_INET_FORWARD 钩子,调用ip_forward_finish()方法:
return NF_HOOK(NFPROTO_IPV4, NF_INET_FORWARD, skb, skb->dev,
rt->dst.dev, ip_forward_finish);
在ip_forward_finish()中,统计数据被更新,我们检查 IPv4 包是否包含 IP 选项。如果是,就调用ip_forward_options()方法来处理选项。如果它没有选项,就调用dst_output()方法。这个方法唯一做的事情就是调用skb_dst(skb)->output(skb):
static int ip_forward_finish(struct sk_buff *skb)
{
struct ip_options *opt = &(IPCB(skb)->opt);
IP_INC_STATS_BH(dev_net(skb_dst(skb)->dev), IPSTATS_MIB_OUTFORWDATAGRAMS);
IP_ADD_STATS_BH(dev_net(skb_dst(skb)->dev), IPSTATS_MIB_OUTOCTETS, skb->len);
if (unlikely(opt->optlen))
ip_forward_options(skb);
return dst_output(skb);
}
在本节中,您了解了转发数据包的方法(ip_forward()和ip_forward_finish()))、数据包在转发过程中被丢弃的情况、发送 ICMP 重定向的情况等等。
摘要
本章讨论了 IPv4 协议——如何构建 IPv4 数据包、IPv4 报头结构和 IP 选项,以及如何处理它们。您了解了 IPv4 协议处理程序是如何注册的。您还了解了 IPv4 中的 Rx 路径(如何处理 IPv4 数据包的接收)和 Tx 路径(如何处理 IPv4 数据包的传输)。有些情况下,数据包大于网络接口 MTU,因此如果不在发送方进行分段,然后在接收方进行碎片整理,就无法发送数据包。您了解了 IPv4 中碎片的实现(包括慢速路径和快速路径如何实现以及何时使用)以及 IPv4 中碎片整理的实现。本章还讲述了 IPv4 转发——在不同的网络接口上发送传入的数据包,而不将其传递到上层。您还看到了一些在转发过程中丢弃数据包和发送 ICMP 重定向的例子。下一章将讨论 IPv4 路由子系统。接下来的“快速参考”部分涵盖了与本章中讨论的主题相关的主要方法,按其上下文排序。
快速参考
我以本章中提到的 IPv4 子系统的重要方法和宏的简短列表来结束本章。
方法
以下是本章中提到的 IPv4 层的重要方法的简短列表。
int IP _ queue _ xmit(struct sk _ buf * skb,struct flow * fl);
这种方法将数据包从 L4(传输层)移动到 L3(网络层),例如从 TCPv4 调用。
int IP _ append _ data(struct sock * sk,struct flowi4 *fl4,int getfrag(void *from,char *to,int offset,int len,int odd,struct sk_buff *skb),void *from,int length,int transhdrlen,struct ipcm_cookie *ipc,struct rtable **rtp,unsigned int flags);
这种方法将数据包从 L4(传输层)移动到 L3(网络层);例如,在使用 corked UDP 套接字时从 UDPv4 调用,以及从 ICMPv4 调用。
struct sk _ buff * IP _ make _ skb(struct sock * sk,struct flowi4 *fl4,int getfrag(void *from,char *to,int offset,int len,int odd,struct sk_buff *skb),void *from,int length,int transhdrlen,struct ipcm_cookie *ipc,struct rtable **rtp,unsigned int flags);
这个方法是在内核 2.6.39 中添加的,用于启用 UDPv4 实现的无锁传输快速路径;不使用 UDP_CORK 套接字选项时调用。
int IP _ generic _ get frag(void * from,char *to,int offset,int len,int odd,struct sk _ buff * skb);
这个方法是将数据从用户空间复制到指定的skb的通用方法。
static int icmp _ glue _ bits(void * from,char *to,int offset,int len,int odd,struct sk _ buff * skb);
这个方法就是 ICMPv4 getfrag回调。ICMPv4 模块用icmp_glue_bits()作为getfrag回调来调用ip_append_data()方法。
int IP _ options _ compile(struct net * net,struct ip_options *opt,struct sk _ buff * skb);
该方法通过解析 IP 选项构建一个ip_options对象。
void IP _ options _ fragment(struct sk _ buff * skb);
此方法使用 NOOPs 填充其复制标志未设置的选项,并重置这些 IP 选项的相应字段。仅针对第一个片段调用。
void IP _ options _ build(struct sk _ buff * skb,struct ip_options *opt,__be32 daddr,struct rtable *rt,int is _ frag);
该方法获取指定的ip_options对象,并将其内容写入 IPv4 头。最后一个参数is_frag,在所有对ip_options_build()方法的调用中实际上都是 0。
void IP _ forward _ options(struct sk _ buff * skb);
此方法处理 IP 选项转发。
int ip_rcv(struct sk_buff *skb,struct net_device *dev,struct packet_type *pt,struct net _ device * orig _ dev);
此方法是 IPv4 数据包的主要接收处理程序。
IP _ rcv _ options(struct sk _ buf * skb):
此方法是处理接收带有选项的数据包的主要方法。
int IP _ options _ rcv _ SRR(struct sk _ buf * skb):
此方法使用严格路由选项处理数据包的接收。
int IP _ forward(struct sk _ buff * skb);
此方法是转发 IPv4 数据包的主要处理程序。
静态 void ipmr _ queue _ xmit(struct net * net,struct mr_table *mrt,struct sk_buff *skb,struct mfc_cache *c,int vifi);
这种方法是多播传输方法。
static int raw _ send _ HDR Inc(struct sock * sk,struct flowi4 *fl4,void *from,size_t length,struct rtable **rtp,unsigned int flags);
当设置了 IPHDRINC 套接字选项时,原始套接字使用此方法进行传输。它直接调用dst_output()方法。
int IP _ fragment(struct sk _ buff * skb,int(* output)(struct sk _ buff *));
这种方法是主要的分段方法。
int ip_defrag(struct sk_buff *skb,u32 user);
这种方法是主要的碎片整理方法。它处理传入的 IP 片段。第二个参数user表示从哪里调用这个方法。关于第二个参数可能值的完整列表,请查看include/net/ip.h中的ip_defrag_users enum定义。
bool skb _ has _ frag _ list(const struct sk _ buff * skb);
如果skb_shinfo(skb)->frag_list不为空,该方法返回true。方法skb_has_frag_list()过去被命名为skb_has_frags(),在内核 2.6.37 中被重命名为skb_has_frag_list()。(原因是这个名字令人困惑。)skb 可以以两种方式分段:通过页面数组(称为skb_shinfo(skb)->frags[])和通过 skb 列表(称为skb_shinfo(skb)->frag_list)。因为skb_has_frags()测试的是后者,所以它的名字很混乱,因为听起来更像是在测试前者。
int IP _ local _ deliver(struct sk _ buff * skb);
此方法处理向第 4 层传送数据包。
int IP _ options _ get _ from _ user(struct net * net,struct ip_options_rcu **optp,unsigned char __user *data,int optlen);
该方法通过使用 IP_OPTIONS 的setsockopt()系统调用处理来自用户空间的设置选项。
bool IP _ is _ fragment(const struct ipdr * IPF):
如果包是一个片段,这个方法返回true。
int IP _ decrease _ TTL(struct iphdr * iph);
此方法将指定 IPv4 标头的ttl减 1,并且由于其中一个 IPv4 标头字段(ttl)已更改,因此会重新计算 IPv4 标头校验和。
int IP _ build _ and _ send _ PKT(struct sk _ buff * skb,struct sock *sk,__be32 saddr,__be32 daddr,struct IP _ options _ rcu * opt);
TCPv4 使用此方法发送 SYN ACK。参见net/ipv4/tcp_ipv4.c中的tcp_v4_send_synack()方法。
int IP _ Mr _ input(struct sk _ buff * skb);
此方法处理传入的多播数据包。
int ip_mr_forward(struct net *net,struct mr_table *mrt,struct sk_buff *skb,struct mfc_cache *cache,int local);
此方法转发多播数据包。
bool IP _ call _ ra _ chain(struct sk _ buff * skb);
此方法处理路由器警报 IP 选项。
宏指令
本节提到了本章中的一些宏,它们处理 IPv4 堆栈中遇到的机制,如分段、netfilter 挂钩和 IP 选项。
断续器
这个宏返回skb->cb指向的inet_skb_parm对象。它用于访问存储在inet_skb_parm对象(include/net/ip.h)中的ip_options对象。
问 _CB(skb)
这个宏返回skb->cb指向的ipfrag_skb_cb对象(net/ipv4/ip_fragment.c)。
int NF_HOOK(uint8_t pf,unsigned int hook,struct sk_buff *skb,struct net_device *in,struct net_device *out,int (*okfn)(struct sk_buff *))
这个宏是 netilter 钩子;第一个参数pf是协议族;对于 IPv4,它是 NFPROTO_IPV4,对于 IPv6,它是 NFPROTO_IPV6。第二个参数是网络堆栈中五个 netfilter 挂钩点之一;这五点在include/uapi/linux/netfilter.h中定义,IPv4 和 IPv6 都可以使用。如果没有注册钩子或者如果注册的 netfilter 钩子没有丢弃或拒绝数据包,将调用okfn回调。
int NF_HOOK_COND(uint8_t pf,unsigned int hook,struct sk_buff *skb,struct net_device *in,struct net_device *out,int (*okfn)(struct sk_buff *),bool cond)
这个宏与NF_HOOK()宏相同,但是增加了一个布尔参数cond,它必须是true,以便调用 netfilter 钩子。
IPOPT_COPIED()
该宏返回选项类型的复制标志。
五、IPv4 路由子系统
第四章讨论了 IPv4 子系统。在本章和下一章,我将讨论最重要的 Linux 子系统之一,路由子系统,以及它在 Linux 中的实现。Linux 路由子系统被广泛用于路由器——从家庭和小型办公室路由器,到企业路由器(连接组织或 ISP)和互联网主干网上的核心高速路由器。无法想象没有这些设备的现代世界。这两章中的讨论仅限于 IPv4 路由子系统,它与 IPv6 的实现非常相似。本章主要介绍 IPv4 路由子系统使用的主要数据结构,如路由表、转发信息库(FIB)信息和 FIB 别名、FIB TRIE 等。(顺便说一下,TRIE 不是首字母缩略词,但它来源于单词 retrieval )。TRIE 是一种数据结构,一种取代 FIB 哈希表的特殊树。您将了解如何在路由子系统中执行查找,如何以及何时生成 ICMP 重定向消息,以及如何删除路由缓存代码。请注意,本章中的讨论和代码示例都与内核 3.9 相关,只有两个部分明确提到了不同的内核版本。
转发和 FIB
Linux 网络栈的一个重要目标是转发流量。这一点在讨论在互联网主干网上运行的核心路由器时尤为重要。负责转发数据包和维护转发数据库的 Linux IP 堆栈层称为路由子系统。对于小型网络,FIB 的管理可以由系统管理员完成,因为大多数网络拓扑是静态的。当讨论核心路由器时,情况有点不同,因为拓扑是动态的,并且有大量不断变化的信息。在这种情况下,FIB 的管理通常由用户空间路由守护进程来完成,有时与特殊的硬件增强功能一起完成。这些用户空间守护进程通常维护自己的路由表,有时会与内核路由表交互。
让我们从基础开始:什么是路由?看一个非常简单的转发例子:你有两个以太局域网,LAN1 和 LAN2。在 LAN1 上有一个子网 192.168.1.0/24,在 LAN2 上有一个子网 192.168.2.0/24。这两个局域网之间有一台机器,将被称为“转发路由器”转发路由器中有两个以太网网卡(NIC)。连接到 LAN1 的网络接口是eth0,IP 地址为 192.168.1.200,连接到 LAN2 的网络接口是eth1,IP 地址为 192.168.2.200,如图图 5-1 所示。为了简单起见,我们假设转发路由器上没有运行防火墙守护程序。您开始从 LAN1 发送流量,目的地是 LAN2。根据称为路由表的数据结构,转发从 LAN1 发送到 LAN2(反之亦然)的输入数据包的过程称为路由。我将在本章和下一章讨论这个过程和路由表数据结构。

图 5-1 。在两个局域网之间转发数据包
在图 5-1 中,从 LAN1 在eth0到达目的地为 LAN2 的数据包通过eth1作为输出设备转发。在此过程中,传入的数据包从内核网络堆栈的第 2 层(链路层)移动到转发路由器的第 3 层(网络层)。然而,与流量被指定到转发路由器机器(“流量到我”)的情况相反,不需要将分组移动到第 4 层(传输层),因为该流量不打算由任何第 4 层传输套接字处理。应该转发该流量。移动到第 4 层有性能成本,最好尽可能避免。该流量在第 3 层处理,根据转发路由器上配置的路由表,数据包在作为输出接口的eth1上转发(或被拒绝)。
图 5-2 显示了前面提到的内核处理的三个网络层。
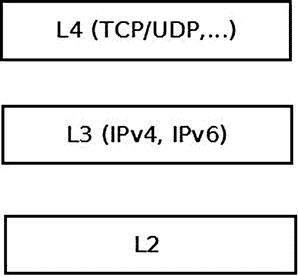
图 5-2 。由网络内核堆栈处理的三层
我在这里应该提到的另外两个术语是路由中常用的默认网关和默认路由。当您在路由表中定义默认网关条目时,其它路由条目(如果有)未处理的每个数据包都必须转发给它,而不管该数据包 IP 报头中的目的地址。在无类域间路由(CIDR)表示法中,默认路由被指定为 0.0.0.0/0。举个简单的例子,您可以添加一台 IPv4 地址为 192.168.2.1 的机器作为默认网关,如下所示:
ip route add default via 192.168.2.1
或者,当使用route命令时,像这样:
route add default gateway 192.168.2.1
在本节中,您学习了什么是转发,并看到了一个简单的示例,说明了数据包如何在两个局域网之间转发。您还学习了什么是默认网关,什么是默认路由,以及如何添加它们。现在您已经知道了基本术语和转发是什么,让我们继续看一看路由子系统中的查找是如何执行的。
在路由子系统中执行查找
对于 Rx 路径和 Tx 路径中的每个分组,在路由子系统中进行查找。在 3.6 之前的内核中,Rx 路径和 Tx 路径中的每次查找都包括两个阶段:在路由缓存中查找,以及在缓存未命中的情况下,在路由表中查找(我将在本章末尾的“IPv4 路由缓存”一节中讨论路由缓存)。通过fib_lookup()方法进行查找。当fib_lookup()方法在路由子系统中找到合适的条目时,它构建一个由各种路由参数组成的fib_result对象,并返回 0。我将在本节和本章的其他部分讨论fib_result对象。这里是fib_lookup()的原型:
int fib_lookup(struct net *net, const struct flowi4 *flp, struct fib_result *res)
flowi4对象由对 IPv4 路由查找过程很重要的字段组成,包括目的地址、源地址、服务类型(TOS)等等。事实上,flowi4对象定义了路由表中查找的关键字,应该在用fib_lookup()方法执行查找之前初始化。对于 IPv6,有一个名为flowi6的并行对象;两者都在include/net/flow.h中定义。fib_result对象构建在 IPv4 查找过程中。fib_lookup()方法首先搜索本地 FIB 表。如果查找失败,它将在主 FIB 表中执行查找(我将在下一节“FIB 表”中描述这两个表)。成功完成查找后,在 Rx 路径或 Tx 路径中,构建一个dst对象(在include/net/dst.h中定义的dst_entry结构的一个实例,目的缓存)。dst对象嵌入在一个名为rtable的结构中,您很快就会看到。实际上,rtable对象代表一个可以与 SKB 相关联的路由条目。dst_entry对象最重要的成员是两个名为input和output的回调。在路由查找过程中,根据路由查找结果,这些回调被分配为适当的处理程序。这两个回调只得到一个 SKB 作为参数:
struct dst_entry {
...
int (*input)(struct sk_buff *);
int (*output)(struct sk_buff *);
...
}
下面是rtable结构;如您所见,dst对象是这个结构中的第一个对象:
struct rtable {
struct dst_entry dst;
int rt_genid;
unsigned int rt_flags;
__u16 rt_type;
__u8 rt_is_input;
__u8 rt_uses_gateway;
int rt_iif;
/* Info on neighbour */
__be32 rt_gateway;
/* Miscellaneous cached information */
u32 rt_pmtu;
struct list_head rt_uncached;
};
(include/net/route.h)
以下是对rtable结构成员的描述:
-
rt_flags:rtable对象标志;这里提到了一些重要的标志: -
RTCF _ 广播:该位置位时,目的地址是一个广播地址。该标志在
__mkroute_output()方法和ip_route_input_slow()方法中设置。 -
RTCF 多播:当该位置位时,目的地址是一个多播地址。该标志在
ip_route_input_mc()方法和__mkroute_output()方法中设置。 -
RTCF _ 多尔直接:当设置时,应该发送一个 ICMPv4 重定向消息作为对传入数据包的响应。设置该标志需要满足几个条件,包括输入设备和输出设备相同,并且设置了相应的
procfs send_redirects条目。还有更多条件,你将在本章后面看到。该标志在__mkroute_input()方法中设置。 -
RTCF _ 本地:该位置位时,目的地址是本地的。该标志有以下几种设置方法:
ip_route_input_slow()、__mkroute_output()、ip_route_input_mc()和__ip_route_output_key()。一些 RTCF_XXX 标志可以同时设置。例如,当设置了 RTCF 广播或 RTCF 多播时,可以设置 RTCF 本地。关于 RTCF_ XXX 旗帜的完整列表,请查阅include/uapi/linux/in_route.h。注意,其中有一些是未使用的。 -
rt_is_input:当这是输入路径时被设置为 1 的标志。 -
rt_uses_gateway:根据下式得到一个值: -
当下一跳是网关时,
rt_uses_gateway为 1。 -
当下一跳是直接路由时,
rt_uses_gateway为 0。 -
rt_iif:呼入接口的ifindex。(注意在内核 3.6 中,rt_oif成员被从rtable结构中移除;它被设置为指定流键的oif,但实际上只在一个方法中使用过)。 -
rt_pmtu: The Path MTU (the smallest MTU along the route).请注意,在内核 3.6 中,添加了
fib_compute_spec_dst()方法,它获取 SKB 作为参数。这个方法使得rtable结构中的rt_spec_dst成员变得不需要,结果rt_spec_dst从rtable结构中被移除。在特殊情况下需要使用fib_compute_spec_dst()方法,例如在icmp_reply()方法中,当使用发送方的源地址作为回复目的地来回复发送方时。
对于目的地为本地主机的输入单播包,dst对象的input回调被设置为ip_local_deliver(),对于应该被转发的输入单播包,这个input回调被设置为ip_forward()。对于在本地机器上生成并发送出去的数据包,output回调被设置为ip_output()。对于一个组播包,input回调可以设置为ip_mr_input()(在本章没有详细描述的一些条件下)。有些情况下input回调被设置为ip_error(),你将在本章后面的禁止规则示例中看到。让我们看看fib_result对象:
struct fib_result {
unsigned char prefixlen;
unsigned char nh_sel;
unsigned char type;
unsigned char scope;
u32 tclassid;
struct fib_info *fi;
struct fib_table *table;
struct list_head *fa_head;
};
(include/net/ip_fib.h)
prefixlen:前缀长度,代表网络掩码。其值在 0 到 32 的范围内。使用默认路由时为 0。例如,当通过ip route add 192.168.2.0/24 dev eth0添加路由条目时,根据添加条目时指定的网络掩码,prefixlen是 24。在check_leaf()方法(net/ipv4/fib_trie.c)中设置prefixlen。nh_sel:下一跳号。当只使用一个下一跳时,它是 0。使用多路径路由时,可以有多个下一跳。nexthop 对象存储在路由条目的数组中(在fib_info对象中),这将在下一节中讨论。type:fib_result对象的type是最重要的字段,因为它实际上决定了如何处理数据包:是否将它转发到不同的机器,本地传送,无声地丢弃它,用 ICMPv4 消息回复丢弃它,等等。fib_result对象的类型是根据数据包内容(尤其是目的地址)和管理员设置的路由规则、路由守护程序或重定向消息来确定的。在本章后面和下一章中,你将看到fib_result对象的type是如何在查找过程中确定的。两种最常见的类型的fib_result对象是 RTN_UNICAST 类型和 RTN_LOCAL 类型,前者在数据包通过网关或直接路由转发时设置,后者在数据包发往本地主机时设置。您将在本书中遇到的其他类型是 RTN_BROADCAST 类型,用于应该作为广播在本地接受的数据包 RTN _ MULTICAST 类型,用于多播路由 RTN _ UNREACHABLE 类型,用于触发发送回 icmp v4“Destination UNREACHABLE”消息的数据包,等等。总共有 12 种路线类型。有关所有可用路线类型的完整列表,请参见include/uapi/linux/rtnetlink.h。fi:指向fib_info对象的指针,表示一个路由条目。fib_info对象保存了对下一跳(fib_nh)的引用。我将在本章后面的“FIB 信息”一节中讨论 FIB 信息结构。table:指向在其上进行查找的 FIB 表的指针。在check_leaf()方法(net/ipv4/fib_trie.c)中设置。fa_head:指向fib_alias列表的指针(与该路线相关联的fib_alias对象的列表);路由条目的优化是在使用fib_alias对象时完成的,这避免了为每个路由条目创建一个单独的fib_info对象,尽管事实上还有其他fib_info对象非常相似。所有 FIB 别名按fa_tos降序和fib_priority(公制)升序排序。fa_tos为 0 的别名是最后一个,可以匹配任何 TOS。我将在本章后面的“FIB 别名”一节中讨论fib_alias结构。
在本节中,您学习了如何在路由子系统中执行查找。您还了解了与路由查找过程相关的重要数据结构,如fib_result和rtable。下一节讨论 FIB 表是如何组织的。
纤维表
路由子系统的主要数据结构是路由表,用fib_table结构表示。路由表可以以某种简化的方式描述为条目表,其中每个条目确定应该为去往子网(或特定 IPv4 目的地地址)的流量选择哪个下一跳。当然,这个条目还有其他参数,将在本章后面讨论。每个路由条目包含一个fib_info对象(include/net/ip_fib.h,它存储最重要的路由条目参数(但不是全部,您将在本章后面看到)。fib_info对象由fib_create_info()方法(net/ipv4/fib_semantics.c)创建,并存储在一个名为fib_info_hash的散列表中。当路由使用prefsrc时,fib_info对象也被添加到一个名为fib_info_laddrhash的散列表中。
有一个名为fib_info_cnt的fib_info对象的全局计数器,它在通过fib_create_info()方法创建一个fib_info对象时递增,在通过free_fib_info()方法释放一个fib_info对象时递减。当哈希表增长超过某个阈值时,它会动态调整大小。在fib_info_hash散列表中的查找由fib_find_info()方法完成(当没有找到条目时返回 NULL)。序列化对fib_info成员的访问是由名为fib_info_lock的自旋锁完成的。下面是fib_table的结构:
struct fib_table {
struct hlist_node tb_hlist;
u32 tb_id;
int tb_default;
int tb_num_default;
unsigned long tb_data[0];
};
(include/net/ip_fib.h)
tb_id:表格标识符。对于主表,tb_id是 254 (RT_TABLE_MAIN),对于本地表,tb_id是 255 (RT_TABLE_LOCAL)。我很快就会谈到主表和本地表——现在,只需注意在没有策略路由的情况下工作时,只有这两个 FIB 表,即主表和本地表,是在 boot 中创建的。tb_num_default:表中默认路线的数量。创建表格的fib_trie_table()方法将tb_num_default初始化为 0。通过fib_table_insert()方法,添加默认路由会使tb_num_default增加 1。通过fib_table_delete()方法,删除默认路由会使tb_num_default递减 1。tb_data[0]:路由条目(trie)对象的占位符。
本节讲述了 FIB 表是如何实现的。接下来,您将了解 FIB 信息,它表示单个路由条目。
纤维信息
路由条目由一个fib_info结构表示。它由重要的路由条目参数组成,例如传出网络设备(fib_dev)、优先级(fib_priority)、该路由的路由协议标识符(fib_protocol)等等。我们来看看fib_info的结构:
struct fib_info {
struct hlist_node fib_hash;
struct hlist_node fib_lhash;
struct net *fib_net;
int fib_treeref;
atomic_t fib_clntref;
unsigned int fib_flags;
unsigned char fib_dead;
unsigned char fib_protocol;
unsigned char fib_scope;
unsigned char fib_type;
__be32 fib_prefsrc;
u32 fib_priority;
u32 *fib_metrics;
#define fib_mtu fib_metrics[RTAX_MTU-1]
#define fib_window fib_metrics[RTAX_WINDOW-1]
#define fib_rtt fib_metrics[RTAX_RTT-1]
#define fib_advmss fib_metrics[RTAX_ADVMSS-1]
int fib_nhs;
#ifdef CONFIG_IP_ROUTE_MULTIPATH
int fib_power;
#endif
struct rcu_head rcu;
struct fib_nh fib_nh[0];
#define fib_dev fib_nh[0].nh_dev
};
(include/net/ip_fib.h)
-
fib_net:fib_info对象所属的网络名称空间。 -
fib_treeref:一个引用计数器,表示保存对这个fib_info对象的引用的fib_alias对象的数量。该参考计数器在fib_create_info()方法中递增,在fib_release_info()方法中递减。两种方法都在net/ipv4/fib_semantics.c。 -
fib_clntref:参考计数器,通过fib_create_info()方法(net/ipv4/fib_semantics.c)递增,通过fib_info_put()方法(include/net/ip_fib.h)递减。如果在fib_info_put()方法中将它减 1 后,它达到零,那么相关联的fib_info对象被free_fib_info()方法释放。 -
fib_dead:表示是否允许用free_fib_info()方法释放fib_info对象的标志;在调用free_fib_info()方法之前,必须将fib_dead设置为 1。如果没有设置fib_dead标志(其值为 0),那么它被认为是活动的,并且试图用free_fib_info()方法释放它将会失败。 -
fib_protocol:该路由的路由协议标识。当在没有指定路由协议 ID 的情况下从用户空间添加路由规则时,fib_protocol被指定为 RTPROT_BOOT。管理员可以添加带有“proto static”修饰符的路由,这表示该路由是由管理员添加的;这可以这样做,例如,像这样:ip route add proto static 192.168.5.3 via 192.168.2.1。可以给fib_protocol分配这些标志中的一个: -
RTPROT_UNSPEC:一个错误值。
-
RTPROT_REDIRECT:设置时,路由条目是由于接收到 ICMP 重定向消息而创建的。RTPROT_REDIRECT 协议标识符仅在 IPv6 中使用。
-
RTPROT_KERNEL:该位置位时,路由条目由内核创建(例如,在创建本地 IPv4 路由表时,简要说明)。
-
RTPROT_BOOT:设置时,管理员添加了一个路由,但没有指定“proto static”修饰符。
-
RTPROT_STATIC:系统管理员安装的路由。
-
RTPROT_RA:不要误读这个——这个协议标识符不是用于路由器告警的;它用于 RDISC/ND 路由器广告,并且仅由 IPv6 子系统在内核中使用;参见:
net/ipv6/route.c。我在第八章中讨论了它。
路由条目也可以由用户空间路由守护进程添加,比如 ZEBRA、XORP、MROUTED 等等。然后,将从协议标识符列表中为其分配相应的值(参见include/uapi/linux/rtnetlink.h中的 RTPROT_XXX 定义)。例如,对于 XORP 守护进程,它将是 RTPROT_XORP。注意,这些标志(如 RTPROT_KERNEL 或 RTPROT_STATIC)也被 IPv6 用于并行字段(rt6_info结构中的rt6i_protocol字段);rt6_info对象是与rtable对象平行的 IPv6。
-
fib_scope:目的地址的范围。简而言之,作用域被分配给地址和路由。Scope 表示主机与其他节点之间的距离。ip address show命令显示主机上所有已配置 IP 地址的范围。ip route show命令显示主表所有路由表项的范围。范围可以是下列之一: -
主机(RT_SCOPE_HOST):该节点无法与其他网络节点通信。环回地址的作用域是主机。
-
global (RT_SCOPE_UNIVERSE):地址可以在任何地方使用。这是最常见的情况。
-
link (RT_SCOPE_LINK):该地址只能从直接连接的主机访问。
-
site (RT_SCOPE_SITE):这个只在 IPv6 中使用(我在第八章中讨论)。
-
nowhere (RT_SCOPE_NOWHERE):目的地不存在。
当管理员在未指定范围的情况下添加路由时,会根据以下规则为fib_scope字段分配一个值:
-
全局范围(RT_SCOPE_UNIVERSE):用于所有网关单播路由。
-
scope link (RT_SCOPE_LINK):用于直接单播和广播路由。
-
scope host (RT_SCOPE_HOST):用于本地路由。
-
fib_type:路线的类型。fib_type字段被添加到了fib_info结构中,作为一个键来确保fib_info对象的类型是不同的。在内核 3.7 中,fib_type字段被添加到了fib_info struct中。最初,这个类型只存储在 FIB alias 对象(fib_alias)的fa_type字段中。您可以根据指定的类别添加规则来阻止流量,例如通过:ip route add prohibit 192.168.1.17 from 192.168.2.103. -
生成的
fib_info对象的fib_type为 RTN_PROHIBIT。 -
从 192.168.2.103 向 192.168.1.17 发送流量会导致 ICMPv4 消息“数据包过滤”(ICMP_PKT_FILTERED)。
-
fib_prefsrc:有时候你想给查找键提供一个特定的源地址。这是通过设置fib_prefsrc.来完成的 -
fib_priority:该路径的优先级默认为 0,优先级最高。优先级值越高,优先级越低。例如,优先级 3 低于优先级 0,优先级 0 是最高优先级。例如,您可以通过以下方式之一使用ip命令对其进行配置: -
ip route add 192.168.1.10 via 192.168.2.1 metric 5 -
ip route add 192.168.1.10 via 192.168.2.1 priority 5 -
ip route add 192.168.1.10 via 192.168.2.1 preference 5
这三个命令中的每一个都将fib_priority设置为 5;他们之间没有任何区别。此外,ip route命令的metric参数与fib_info结构的fib_metrics字段没有任何关系。
-
fib_mtu,fib_window,fib_rtt, andfib_advmsssimply give more convenient names to commonly used elements of thefib_metricsarray.fib_metrics是由各种度量组成的 15 (RTAX_MAX)个元素的数组。它在net/core/dst.c中被初始化为dst_default_metrics。很多指标都与 TCP 协议有关,比如初始拥塞窗口(initcwnd)指标。本章末尾的表 5-1 显示了所有可用的度量,并显示每个度量是否是 TCP 相关的度量。从用户空间,可以这样设置 TCPv4
initcwnd指标,例如:ip route add 192.168.1.0/24 initcwnd 35有些指标不是特定于 TCP 的——例如,
mtu指标,可以从用户空间像这样设置:ip route add 192.168.1.0/24 mtu 800或者像这样:
ip route add 192.168.1.0/24 mtu lock 800这两个命令的区别在于,当指定修饰符
lock时,不会尝试任何路径 MTU 发现。当没有指定修饰符lock时,由于路径 MTU 发现,MTU 可能被内核更新。有关如何实现的更多信息,请参见net/ipv4/route.c中的__ip_rt_update_pmtu()方法:static void __ip_rt_update_pmtu(struct rtable *rt, struct flowi4 *fl4, u32 mtu) {指定
mtu lock修饰符时避免路径 MTU 更新是通过调用dst_metric_locked()方法实现的:. . . if (dst_metric_locked(dst, RTAX_MTU)) return; . . . } -
fib_nhs:下一跳的次数。当未设置多路径路由(CONFIG_IP_ROUTE_MULTIPATH)时,它不能大于 1。多路径路由功能为一条路由设置多条备选路径,可能会为这些路径分配不同的权重。这个特性提供了一些好处,比如容错、增加带宽或提高安全性(我将在第六章中讨论)。 -
fib_dev:将数据包传输到下一跳的网络设备。 -
fib_nh[0]:fib_nh[0]成员代表下一跳。使用多路径路由时,您可以在一个路由中定义多个下一跳,在这种情况下,有一个下一跳数组。定义两个 nexthop 节点可以这样做,例如:ip route add default scope global nexthop dev eth0 nexthop dev eth1。
如前所述,当fib_type为 RTN_PROHIBIT 时,发送一条“包过滤”(ICMP_PKT_FILTERED)的 ICMPv4 消息。是如何实现的?名为fib_props的数组由 12 (RTN_MAX)个元素组成(在net/ipv4/fib_semantics.c中定义)。这个数组的索引是路由类型。可用的路由类型,如 RTN_PROHIBIT 或 RTN_UNICAST,可在include/uapi/linux/rtnetlink.h中找到。数组中的每个元素都是struct fib_prop的一个实例;fib_prop结构是一个非常简单的结构:
struct fib_prop {
int error;
u8 scope;
};
(net/ipv4/fib_lookup.h)
对于每个路线类型,对应的fib_prop对象包含该路线的error和scope。例如,对于 RTN_UNICAST 路由类型(网关或直接路由),这是一种非常常见的路由,错误值为 0,表示没有错误,范围为 RT_SCOPE_UNIVERSE。对于 RTN_PROHIBIT 路由类型(系统管理员为阻止流量而配置的规则),错误为–EACCES,范围为 RT_SCOPE_UNIVERSE:
const struct fib_prop fib_props[RTN_MAX + 1] = {
. . .
[RTN_PROHIBIT] = {
.error = -EACCES,
.scope = RT_SCOPE_UNIVERSE,
},
. . .
本章末尾的表 5-2 显示了所有可用的路由类型、错误代码和范围。
当您通过ip route add prohibit 192.168.1.17 from 192.168.2.103配置前面提到的规则时,当数据包从 192.168.2.103 发送到 192.168.1.17 时,会发生以下情况:在 Rx 路径中执行路由表查找。当找到相应的条目时,实际上是 FIB TRIE 中的一个叶子,调用check_leaf()方法。该方法以数据包的路由类型作为索引来访问fib_props数组(fa->fa_type):
static int check_leaf(struct fib_table *tb, struct trie *t, struct leaf *l,
t_key key, const struct flowi4 *flp,
struct fib_result *res, int fib_flags)
{
. . .
fib_alias_accessed(fa);
err = fib_props[fa->fa_type].error;
if (err) {
. . .
return err;
}
. . .
最后,在 IPv4 路由子系统中启动查找的fib_lookup()方法返回一个错误–EACCES(在我们的例子中)。它从check_leaf()通过fib_table_lookup()一路传播回来,直到它返回到触发这个链的方法,即fib_lookup()方法。当fib_lookup()方法在接收路径中返回一个错误时,它由ip_error()方法处理。根据错误,采取行动。在–EACCES 的情况下,会发回一个代码为 Packet Filtered(ICMP _ PKT _ Filtered)的目的地不可达的 ICMPv4,并丢弃该数据包。
本节介绍了 FIB 信息,它代表一个路由条目。下一节讨论 IPv4 路由子系统中的缓存(不要与 IPv4 路由缓存混淆,后者已从网络堆栈中删除,将在本章末尾的“IPv4 路由缓存”一节中讨论)。
贮藏
缓存路由查找的结果是一种优化技术,可以提高路由子系统的性能。路由查找的结果通常缓存在 nexthop ( fib_nh)对象中;当数据包不是单播数据包或使用了realms(数据包itag不为 0)时,结果不会缓存在下一跳中。原因是,如果所有类型的数据包都被缓存,那么不同类型的路由可以使用相同的下一跳,这是应该避免的。有一些小的例外,我不在本章讨论。Rx 和 Tx 路径中的缓存执行如下:
- 在 Rx 路径中,缓存 nexthop (
fib_nh)对象中的fib_result对象是通过设置 nexthop (fib_nh)对象的nh_rth_input字段来完成的。 - 在 Tx 路径中,缓存 nexthop (
fib_nh)对象中的fib_result对象是通过设置 nexthop (fib_nh)对象的nh_pcpu_rth_output字段来完成的。 nh_rth_input和nh_pcpu_rth_output都是rtable结构的实例。- 缓存
fib_result是通过 Rx 和 Tx 路径中的rt_cache_route()方法完成的(net/ipv4/route.c)。 - 路径 MTU 和 ICMPv4 重定向的缓存是通过 FIB 异常完成的。
为了提高性能,nh_pcpu_rth_output是每个 CPU 的变量,这意味着每个 CPU 都有一个输出dst条目的副本。几乎总是使用缓存。少数例外情况是当发送了 ICMPv4 重定向消息,或者设置了itag ( tclassid,或者没有足够的内存。
在本节中,您已经学习了如何使用 nexthop 对象进行缓存。下一节讨论代表下一跳的fib_nh结构,以及 FIB 下一跳异常。
下一跳(fib_nh)
fib_nh结构表示下一跳。它包括诸如传出下一跳网络设备(nh_dev)、传出下一跳接口索引(nh_oif)、范围(nh_scope等信息。我们来看看:
struct fib_nh {
struct net_device *nh_dev;
struct hlist_node nh_hash;
struct fib_info *nh_parent;
unsigned int nh_flags;
unsigned char nh_scope;
#ifdef CONFIG_IP_ROUTE_MULTIPATH
int nh_weight;
int nh_power;
#endif
#ifdef CONFIG_IP_ROUTE_CLASSID
__u32 nh_tclassid;
#endif
int nh_oif;
__be32 nh_gw;
__be32 nh_saddr;
int nh_saddr_genid;
struct rtable __rcu * __percpu *nh_pcpu_rth_output;
struct rtable __rcu *nh_rth_input;
struct fnhe_hash_bucket *nh_exceptions;
};
(include/net/ip_fib.h)
nh_dev字段表示网络设备(net_device对象),去往下一跳的流量将在该网络设备上传输。当与一个或多个路由相关联的网络设备被禁用时,会发送 NETDEV_DOWN 通知。处理这个事件的 FIB 回调是fib_netdev_event()方法;它是fib_netdev_notifier通知对象的回调,通过调用register_netdevice_notifier()方法在ip_fib_init()方法中注册(通知链在第十四章中讨论)。fib_netdev_event()方法在收到 NETDEV_DOWN 通知时调用fib_disable_ip()方法。在fib_disable_ip()方法中,执行以下步骤:
- 首先调用
fib_sync_down_dev()方法(net/ipv4/fib_semantics.c)。在fib_sync_down_dev()方法中,设置下一跳标志(nh_flags)的 RTNH_F_DEAD 标志,并且设置 FIB 信息标志(fib_flags)。 - 通过
fib_flush()方法刷新路径。 - 调用
rt_cache_flush()方法和arp_ifdown()方法。arp_ifdown()方法不在任何通知链上。
FIB 下一跳异常
在内核 3.6 中添加了 FIB nexthop 异常,以处理不是由于用户空间操作而是由于 ICMPv4 重定向消息或路径 MTU 发现而导致路由条目更改的情况。哈希键是目的地址。FIB 下一跳异常基于 2048 条目哈希表;回收(释放散列条目)从链深度 5 开始。每个 nexthop 对象(fib_nh)都有一个 FIB nexthop 异常哈希表,nh_exceptions(fnhe_hash_bucket结构的一个实例)。我们来看看fib_nh_exception的结构:
struct fib_nh_exception {
struct fib_nh_exception __rcu *fnhe_next;
__be32 fnhe_daddr;
u32 fnhe_pmtu;
__be32 fnhe_gw;
unsigned long fnhe_expires;
struct rtable __rcu *fnhe_rth;
unsigned long fnhe_stamp;
};
(include/net/ip_fib.h)
通过update_or_create_fnhe()方法(net/ipv4/route.c)创建fib_nh_exception对象。FIB 下一跳异常在哪里生成?第一种情况是在__ip_do_redirect()方法中接收到 ICMPv4 重定向消息(“重定向到主机”)时。“重定向到主机”消息包括一个新网关。fib_nh_exception的fnhe_gw字段在创建 FIB nexthop 异常对象时被设置为新网关(在update_or_create_fnhe()方法中):
static void __ip_do_redirect(struct rtable *rt, struct sk_buff *skb, struct flowi4 *fl4,
bool kill_route)
{
...
__be32 new_gw = icmp_hdr(skb)->un.gateway;
...
update_or_create_fnhe(nh, fl4->daddr, new_gw, 0, 0);
...
}
生成 FIB nexthop 异常的第二种情况是在路径 MTU 已经改变时,在__ip_rt_update_pmtu()方法中。在这种情况下,当创建 FIB nexthop 异常对象(在update_or_create_fnhe()方法中)时,fib_nh_exception对象的fnhe_pmtu字段被设置为新的 MTU。如果 PMTU 值在过去 10 分钟内没有更新,则该值过期(ip_rt_mtu_expires)。通过ipv4_mtu()方法(一个dst->ops->mtu处理程序)在每次dst_mtu()调用时检查这个时间段。默认为 600 秒的ip_rt_mtu_expires可通过procfs条目/proc/sys/net/ipv4/route/mtu_expires进行配置:
static void __ip_rt_update_pmtu(struct rtable *rt, struct flowi4 *fl4, u32 mtu)
{
. . .
if (fib_lookup(dev_net(dst->dev), fl4, &res) == 0) {
struct fib_nh *nh = &FIB_RES_NH(res);
update_or_create_fnhe(nh, fl4->daddr, 0, mtu,
jiffies + ip_rt_mtu_expires);
}
. . .
}
 注意 FIB nexthop 异常用于 Tx 路径。从 Linux 3.11 开始,它们也用于 Rx 路径。结果,没有了
注意 FIB nexthop 异常用于 Tx 路径。从 Linux 3.11 开始,它们也用于 Rx 路径。结果,没有了fnhe_rth,有了fnhe_rth_input和fnhe_rth_output。
从内核 2.4 开始,支持策略路由。使用策略路由,数据包的路由不仅取决于目的地址,还取决于其他几个因素,如源地址或 TOS。系统管理员最多可以添加 255 个路由表。
策略路由
在没有策略路由的情况下工作时(未设置 CONFIG_IP_MULTIPLE_TABLES),会创建两个路由表:本地表和主表。主表 id 是 254 (RT_TABLE_MAIN),本地表 id 是 255 (RT_TABLE_LOCAL)。本地表包含本地地址的路由条目。这些路由条目只能由内核添加到本地表中。向主表(RT_TABLE_MAIN)添加路由条目由系统管理员完成(例如,通过ip route add)。这些表格是由net/ipv4/fib_frontend.c的fib4_rules_init()方法创建的。在 2.6.25 之前的内核中,这些表被称为ip_fib_local_table和ip_fib_main_table,但是它们被删除了,以便使用带有适当参数的fib_get_table()方法来统一访问路由表。通过统一访问,我的意思是,当策略路由支持启用和禁用时,对路由表的访问都是以相同的方式完成的,使用fib_get_table()方法。fib_get_table()方法只获得两个参数:网络名称空间和表 id。请注意,net/ipv4/fib_rules.c中的策略路由案例有一个不同的同名方法fib4_rules_init(),该方法在使用策略路由支持时被调用。当使用策略路由支持(设置了 CONFIG_IP_MULTIPLE_TABLES)时,有三个初始表(本地、主和默认),最多可以有 255 个路由表。我将在第六章的中详细讨论策略路由。访问主路由表的方法如下:
-
通过系统管理员命令(使用
ip route或route): -
通过
ip route add添加路由是通过从用户空间发送 RTM_NEWROUTE 消息实现的,该消息由inet_rtm_newroute()方法处理。请注意,路由不一定总是允许流量的规则。您还可以添加一个阻止流量的路由,例如通过ip route add prohibit 192.168.1.17 from 192.168.2.103.应用此规则的结果是,从 192.168.2.103 发送到 192.168.1.17 的所有数据包都将被阻止。 -
ip route del删除路由是通过从用户空间发送 RTM_DELROUTE 消息实现的,该消息由inet_rtm_delroute()方法处理。 -
ip route show转储路由表是通过从用户空间发送 RTM_GETROUTE 消息实现的,该消息由inet_dump_fib()方法处理。
注意ip route show显示主表。为了显示本地表,您应该运行ip route show table local。
- 通过
route add添加路由是通过发送 SIOCADDRT IOCTL 实现的,它由ip_rt_ioctl()方法(net/ipv4/fib_frontend.c)处理。 - 由
route del删除路由是通过发送 SIOCDELRT IOCTL 实现的,它由ip_rt_ioctl()方法(net/ipv4/fib_frontend.c)处理。 - 由用户空间路由守护进程执行路由协议,如 BGP(边界网关协议)、EGP(外部网关协议)、OSPF(开放最短路径优先)等。这些路由守护程序运行在核心路由器上,核心路由器在互联网主干上运行,可以处理成千上万的路由。
这里我应该提到,由于 ICMPv4 重定向消息或路径 MTU 发现而改变的路由缓存在下一跳异常表中,稍后将讨论。下一节描述 FIB 别名,它有助于路由优化。
光纤别名(fib_alias)
有时会创建几个指向同一目的地址或同一子网的路由条目。这些路由条目的不同之处仅在于它们的 TOS 值。不是为每个这样的路线创建一个fib_info,而是创建一个fib_alias对象。一个fib_alias更小,减少了内存消耗。下面是一个创建 3 个fib_alias对象的简单例子:
ip route add 192.168.1.10 via 192.168.2.1 tos 0x2
ip route add 192.168.1.10 via 192.168.2.1 tos 0x4
ip route add 192.168.1.10 via 192.168.2.1 tos 0x6
让我们来看看fib_alias的结构定义:
struct fib_alias {
struct list_head fa_list;
struct fib_info *fa_info;
u8 fa_tos;
u8 fa_type;
u8 fa_state;
struct rcu_head rcu;
};
(net/ipv4/fib_lookup.h)
注意在fib_alias结构(fa_scope)中也有一个作用域,但是在内核 2.6.39 中它被移到了fib_info结构中。
fib_alias对象存储到相同子网的路由,但参数不同。你可以拥有一个被许多fib_alias对象共享的fib_info对象。在这种情况下,所有这些fib_alias对象中的fa_info指针将指向同一个共享的fib_info对象。在图 5-3 中,你可以看到一个fib_info对象被三个fib_alias对象共享,每个对象有不同的fa_tos。注意,fib_info对象的参考计数器值是 3 ( fib_treeref)。
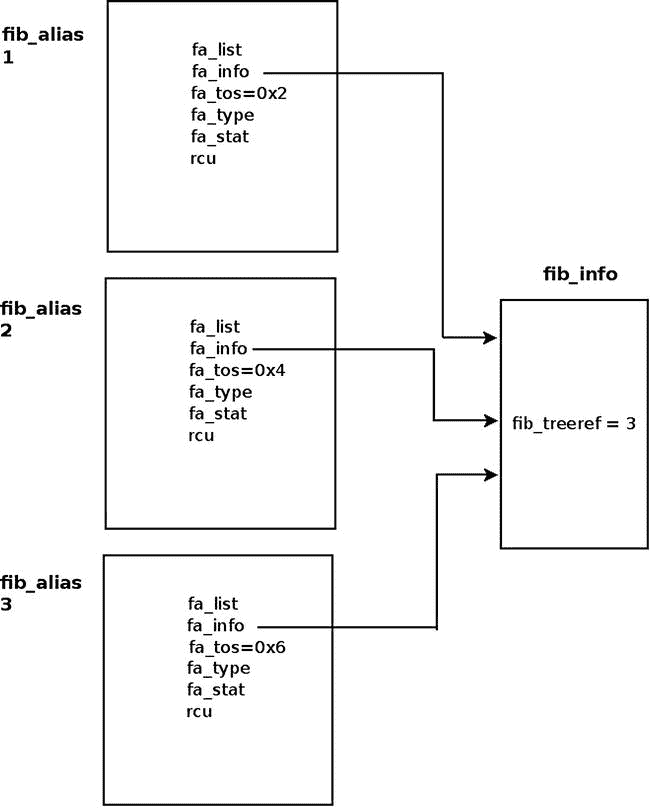
图 5-3 。由三个 fib_alias 对象共享的 fib_info。每个 fib_alias 对象都有不同的 fa_tos 值
让我们来看看当您试图添加一个之前已经添加了一个fib_node的键时会发生什么(就像前面的例子中的三个 TOS 值 0x2、0x4 和 0x 6);假设您已经创建了 TOS 为 0x2 的第一个规则,现在您创建了 TOS 为 0x4 的第二个规则。
fib_alias对象由fib_table_insert()方法创建,该方法处理添加路由条目:
int fib_table_insert(struct fib_table *tb, struct fib_config *cfg)
{
struct trie *t = (struct trie *) tb->tb_data;
struct fib_alias *fa, *new_fa;
struct list_head *fa_head = NULL;
struct fib_info *fi;
. . .
首先,创建一个fib_info对象。注意,在fib_create_info()方法中,在分配和创建了一个fib_info对象之后,通过调用fib_find_info()方法执行查找来检查是否已经存在一个类似的对象。如果这样的对象存在,它将被释放,并且被发现的对象的引用计数器(您很快就会看到代码片段中的ofi)将增加 1:
fi = fib_create_info(cfg);
我们来看看前面提到的fib_create_info()方法中的代码片段;为了创建第二个 TOS 规则,第一个规则的fib_info对象和第二个规则的fib_info对象是相同的。你应该记得 TOS 字段存在于fib_alias对象中,而不存在于fib_info对象中:
struct fib_info *fib_create_info(struct fib_config *cfg)
{
struct fib_info *fi = NULL;
struct fib_info *ofi;
. . .
fi = kzalloc(sizeof(*fi)+nhs*sizeof(struct fib_nh), GFP_KERNEL);
if (fi == NULL)
goto failure;
. . .
link_it:
ofi = fib_find_info(fi);
如果发现类似的对象,释放fib_info对象并增加fib_treeref引用计数:
if (ofi) {
fi->fib_dead = 1;
free_fib_info(fi);
ofi->fib_treeref++;
return ofi;
}
. . .
}
现在执行一个检查来找出是否有一个fib_info对象的别名;在这种情况下,将没有别名,因为第二个规则的 TOS 不同于第一个规则的 TOS:
l = fib_find_node(t, key);
fa = NULL;
if (l) {
fa_head = get_fa_head(l, plen);
fa = fib_find_alias(fa_head, tos, fi->fib_priority);
}
if (fa && fa->fa_tos == tos &&
fa->fa_info->fib_priority == fi->fib_priority) {
. . .
}
现在一个fib_alias被创建,它的fa_info指针被指定指向被创建的第一个规则的fib_info:
new_fa = kmem_cache_alloc(fn_alias_kmem, GFP_KERNEL);
if (new_fa == NULL)
goto out;
new_fa->fa_info = fi;
. . .
现在我已经介绍了 FIB 别名,您已经准备好查看 ICMPv4 重定向消息,该消息是在存在次优路由时发送的。
ICMPv4 重定向消息
有时路由条目不是最佳的。在这种情况下,会发送一条 ICMPv4 重定向消息。次优条目的主要标准是输入设备和输出设备相同。但是,正如您将在本节中看到的,还需要满足更多的条件才能发送一个 ICMPv4 重定向消息。ICMPv4 重定向消息有四个代码:
- ICMP_REDIR_NET:重定向网络
- ICMP_REDIR_HOST:重定向主机
- ICMP_REDIR_NETTOS:为 TOS 重定向网络
- ICMP_REDIR_HOSTTOS:为 TOS 重定向主机
图 5-4 显示了一个次优路线的设置。此设置中有三台机器,都位于同一子网(192.168.2.0/24)中,并且都通过网关(192.168.2.1)连接。AMD 服务器(192.168.2.200)增加了 Windows 服务器(192.168.2.10)作为ip route add 192.168.2.7 via 192.168.2.10访问 192.168.2.7(笔记本电脑)的网关。例如,AMD 服务器通过ping 192.168.2.7向笔记本电脑发送流量。因为默认网关是192.168.2.10,流量被发送到192.168.2.10。Windows 服务器检测到这是一个次优路由,因为 AMD 服务器可以直接发送到 192.168.2.7,并向 AMD 服务器发回一个带有 ICMP_REDIR_HOST 代码的 ICMPv4 重定向消息。
图 5-4 。重定向到主机(ICMP_REDIR_HOST),一个简单的设置
现在您对重定向有了更好的理解,让我们看看 ICMPv4 消息是如何生成的。
生成 ICMPv4 重定向消息
当存在一些次优路由时,发送 ICMPv4 重定向消息。次优路由最显著的条件是输入设备和输出设备相同,但还需要满足更多条件。生成 ICMPv4 重定向消息分两个阶段完成:
-
在
__mkroute_input()方法 : 中,如果需要,这里会设置 RTCF _ 多尔直接标志。 -
In the
ip_forward()method: Here the ICMPv4 Redirect message is actually sent by calling theip_rt_send_redirect()method.static int __mkroute_input(struct sk_buff *skb, const struct fib_result *res, struct in_device *in_dev, __be32 daddr, __be32 saddr, u32 tos) { struct rtable *rth; int err; struct in_device *out_dev; unsigned int flags = 0; bool do_cache;应满足以下所有条件,以便设置 RTCF _ 多尔直接标志:
-
输入设备和输出设备是相同的。
-
设置
procfs条目/proc/sys/net/ipv4/conf/<deviceName>/send_redirects。 -
该传出设备是共享媒体,或者源地址(
saddr)和下一跳网关地址(nh_gw)在同一个子网:if (out_dev == in_dev && err && IN_DEV_TX_REDIRECTS(out_dev) && (IN_DEV_SHARED_MEDIA(out_dev) || inet_addr_onlink(out_dev, saddr, FIB_RES_GW(*res)))) { flags |= RTCF_DOREDIRECT; do_cache = false; } . . .
通过以下方式设置rtable对象标志:
rth->rt_flags = flags;
. . .
}
发送 ICMPv4 重定向消息是在第二阶段通过ip_forward()方法完成的:
int ip_forward(struct sk_buff *skb)
{
struct iphdr *iph; /* Our header */
struct rtable *rt; /* Route we use */
struct ip_options *opt = &(IPCB(skb)->opt);
接下来,执行检查以查看 RTCF _ 多尔直接标志是否被设置,严格路由的 IP 选项是否不存在(参见第四章),以及它是否不是 IPsec 分组。(对于 IPsec 隧道,隧道化分组的输入设备可以与解封装的分组输出设备相同;参见http://lists.openwall.net/netdev/2007/08/24/29):
if (rt->rt_flags&RTCF_DOREDIRECT && !opt->srr && !skb_sec_path(skb))
ip_rt_send_redirect(skb);
在ip_rt_send_redirect()方法中,实际发送 ICMPv4 重定向消息。第三个参数是建议的新网关的 IP 地址,在本例中为 192.168.2.7(笔记本电脑的地址):
void ip_rt_send_redirect(struct sk_buff *skb)
{
. . .
icmp_send(skb, ICMP_REDIRECT, ICMP_REDIR_HOST,
rt_nexthop(rt, ip_hdr(skb)->daddr))
. . .
}
(net/ipv4/route.c)
接收 ICMPv4 重定向消息
对于要处理的 ICMPv4 重定向消息,它应该通过一些健全性检查。通过__ip_do_redirect()方法 : 处理 ICMPv4 重定向消息
static void __ip_do_redirect(struct rtable *rt, struct sk_buff *skb, struct flowi4
*fl4,bool kill_route)
{
__be32 new_gw = icmp_hdr(skb)->un.gateway;
__be32 old_gw = ip_hdr(skb)->saddr;
struct net_device *dev = skb->dev;
struct in_device *in_dev;
struct fib_result res;
struct neighbour *n;
struct net *net;
. . .
执行各种检查,例如网络设备被设置为接受重定向。如有必要,重定向会被拒绝:
if (rt->rt_gateway != old_gw)
return;
in_dev = __in_dev_get_rcu(dev);
if (!in_dev)
return;
net = dev_net(dev);
if (new_gw == old_gw || !IN_DEV_RX_REDIRECTS(in_dev) ||
ipv4_is_multicast(new_gw) || ipv4_is_lbcast(new_gw) ||
ipv4_is_zeronet(new_gw))
goto reject_redirect;
if (!IN_DEV_SHARED_MEDIA(in_dev)) {
if (!inet_addr_onlink(in_dev, new_gw, old_gw))
goto reject_redirect;
if (IN_DEV_SEC_REDIRECTS(in_dev) && ip_fib_check_default(new_gw, dev))
goto reject_redirect;
} else {
if (inet_addr_type(net, new_gw) != RTN_UNICAST)
goto reject_redirect;
}
在相邻子系统中执行查找;查找的关键是建议网关的地址new_gw,它是在本方法开始时从 ICMPv4 消息中提取的:
n = ipv4_neigh_lookup(&rt->dst, NULL, &new_gw);
if (n) {
if (!(n->nud_state & NUD_VALID)) {
neigh_event_send(n, NULL);
} else {
if (fib_lookup(net, fl4, &res) == 0) {
struct fib_nh *nh = &FIB_RES_NH(res);
创建/更新 FIB 下一跳异常,指定建议网关的 IP 地址(new_gw):
update_or_create_fnhe(nh, fl4->daddr, new_gw,
0, 0);
}
if (kill_route)
rt->dst.obsolete = DST_OBSOLETE_KILL;
call_netevent_notifiers(NETEVENT_NEIGH_UPDATE, n);
}
neigh_release(n);
}
return;
reject_redirect:
. . .
(net/ipv4/route.c)
既然我们已经介绍了如何处理接收到的 ICMPv4 消息,我们接下来可以处理 IPv4 路由缓存以及删除它的原因。
IPv4 路由缓存
在 3.6 之前的内核中,有一个带有垃圾收集器的 IPv4 路由缓存。内核 3.6 中移除了 IPv4 路由缓存(大约在 2012 年 7 月)。FIB TRIE / FIB hash 是内核多年来的选择,但不是默认的。使用 FIB TRIE 可以删除 IPv4 路由缓存,因为它存在拒绝服务(DoS)问题。FIB TRIE(也称为 LC-trie)是最长的匹配前缀查找算法,对于大型路由表,其性能优于 FIB hash。它消耗更多的内存,也更复杂,但是由于它的性能更好,所以它使得删除路由缓存变得可行。FIB TRIE 代码在被合并之前在内核中存在了很长时间,但它不是默认的。移除 IPv4 路由缓存的主要原因是对其发起 DoS 攻击很容易,因为 IPv4 路由缓存为每个唯一的流创建了一个缓存条目。基本上,这意味着通过向随机目的地发送数据包,您可以生成无限数量的路由缓存条目。
合并 FIB TRIE 需要移除路由缓存、一些麻烦的 FIB 哈希表以及路由缓存垃圾收集器方法。本章简要讨论了路由缓存。因为新手读者可能不知道它有什么用,请注意,在基于 Linux 的软件行业中,在像 RedHat Enterprise 这样的商业发行版中,内核在很长一段时间内都是完全维护和完全支持的(例如,RedHat 对其发行版的支持长达 7 年)。因此,很有可能一些读者会参与基于 3.6 之前内核的项目,在那里你会找到路由缓存和基于 FIB 散列的路由表。深入研究 FIB TRIE 数据结构的理论和实现细节超出了本书的范围。要了解更多信息,我推荐 Robert Olsson 和 Stefan Nilsson 的文章“TRASH-A dynamic LC-trie and hash data structure”,
请注意,对于 IPv4 路由缓存实施,无论使用多少个路由表,都只有一个缓存(使用策略路由时,最多可以有 255 个路由表)。请注意,它也支持 IPv4 多路径路由缓存,但在 2007 年的内核 2.6.23 中被删除了。事实上,它从未很好地工作过,也从未脱离过实验状态。
对于 3.6 内核之前的内核,FIB TRIE 尚未合并,在 IPv4 路由子系统中的查找是不同的:对路由表的访问先于对路由缓存的访问,这些表以不同的方式组织,并且有一个路由缓存垃圾收集器,它既是异步的(周期性定时器)又是同步的(在特定条件下激活,例如当缓存条目的数量超过某个阈值时)。缓存基本上是一个很大的散列,以 IP 流源地址、目的地址和 TOS 作为关键字,与所有特定于流的信息相关联,如邻居条目、PMTU、重定向、TCPMSS 信息等等。这样做的好处是,缓存的条目查找起来很快,并且包含了更高层所需的所有信息。
 注以下两段(“Rx 路径”和“Tx 路径”)指的是 2.6.38 内核。
注以下两段(“Rx 路径”和“Tx 路径”)指的是 2.6.38 内核。
Rx 路径
在 Rx 路径中,首先调用ip_route_input_common()方法。此方法在 IPv4 路由缓存中执行查找,这比在 IPv4 路由表中查找要快得多。在这些路由表中的查找基于最长前缀匹配(LPM)搜索算法。使用 LPM 搜索,最具体的表条目(具有最高子网掩码的条目)称为最长前缀匹配。如果在路由缓存中查找失败(“缓存未命中”),则通过调用ip_route_input_slow()方法在路由表中进行查找。这个方法调用fib_lookup()方法来执行实际的查找。成功后,它调用ip_mkroute_input()方法,该方法通过调用rt_intern_hash()方法将路由条目插入到路由缓存中。
Tx 路径
在 Tx 路径中,首先调用ip_route_output_key()方法。该方法在 IPv4 路由缓存中执行查找。在缓存未命中的情况下,它调用ip_route_output_slow()方法,后者调用fib_lookup()方法在路由子系统中执行查找。随后,一旦成功,它就调用ip_mkroute_output()方法,该方法(以及其他动作)通过调用rt_intern_hash()方法将路由条目插入路由缓存。
摘要
本章讲述了 IPv4 路由子系统的各种主题。路由子系统对于处理传入和传出的数据包至关重要。您了解了各种主题,如转发、路由子系统中的查找、FIB 表的组织、策略路由和路由子系统以及 ICMPv4 重定向消息。您还了解了 FIB 别名带来的优化,以及路由缓存被移除的事实,以及原因。下一章将介绍 IPv4 路由子系统的高级主题。
快速参考
我用 IPv4 路由子系统的重要方法、宏和表格的简短列表,以及关于路由标志的简短解释来结束本章。
 注IP v4 路由子系统在
注IP v4 路由子系统在net/ipv4 : fib_frontend.c、fib_trie.c、fib_semantics.c、route.c下的这些模块中实现。
fib_rules.c模块实现策略路由,仅在 CONFIG_IP_MULTIPLE_TABLES 设置时编译。其中最重要的头文件是fib_lookup.h、include/net/ip_fib.h和include/net/route.h。
目标缓存(dst)的实现在net/core/dst.c和include/net/dst.h中。
应该为多路径路由支持设置 CONFIG_IP_ROUTE_MULTIPATH。
方法
本节列出了本章中提到的方法。
int fib _ table _ insert(struct fib _ table * TB,struct fib _ config * CFG);
该方法基于指定的fib_config对象将 IPv4 路由条目插入到指定的 FIB 表(fib_table对象)中。
int fib _ table _ delete(struct fib _ table * TB,struct fib _ config * CFG);
该方法基于指定的fib_config对象,从指定的 FIB 表(fib_table对象)中删除 IPv4 路由条目。
struct fib _ info * fib _ create _ info(struct fib _ config * CFG);
该方法创建一个从指定的fib_config对象派生的fib_info对象。
请参阅 free _ fib _ info(struct fib _ info * fi):
该方法释放一个处于非活动状态的fib_info对象(fib_dead标志不为 0),并递减全局fib_info对象计数器(fib_info_cnt)。
void fib _ alias _ accessed(struct fib _ alias * fa);
该方法将指定的fib_alias的fa_state标志设置为 FA _ S _ ACCESSED。注意,唯一的fa_state标志是 FA _ S _ ACCESSED。
void IP _ rt _ send _ redirect(struct sk _ buff * skb);
此方法发送 ICMPV4 重定向消息,作为对次优路径的响应。
void _ _ IP _ do _ redirect(struct rtable * rt,struct sk_buff skb,struct flowi4fl4,bool kill _ route);
此方法处理接收 ICMPv4 重定向消息。
void update _ or _ create _ fnhe(struct fib _ NH * NH,__be32 daddr,__be32 gw,u32 pmtu,unsigned long expires);
该方法在指定的下一跳对象(fib_nh)中创建 FIB 下一跳异常表(fib_nh_exception),如果它还不存在,并初始化它。当由于 ICMPv4 重定向或由于 PMTU 发现而应该有路由更新时,将调用该命令。
u32 dst _ metric(const struct dst _ entry * dst,int metric);
该方法返回指定的dst对象的度量。
struct fib _ table * fib _ trie _ table(u32 id);
该方法分配并初始化 FIB TRIE 表。
struct leaf * fib _ find _ node(struct trie * t,u32 key);
此方法使用指定的键执行 TRIE 查找。成功时返回一个leaf对象,失败时返回 NULL。
宏指令
本节列出了 IPv4 路由子系统的宏,其中一些宏在本章中提到过。
FIB_RES_GW()
这个宏返回与指定的fib_result对象相关联的nh_gw字段(下一跳网关地址)。
FIB_RES_DEV()
该宏返回与指定的fib_result对象相关的nh_dev字段(下一跳net_device对象)。
OIF 纤维网()
这个宏返回与指定的fib_result对象相关联的nh_oif字段(下一跳输出接口索引)。
FIB_RES_NH()
该宏返回指定的fib_result对象的fib_info的下一跳(fib_nh对象)。设置多路径路由时,可以有多个 nexthops 在这种情况下,考虑指定的fib_result对象的nh_sel字段的值,作为嵌入在fib_info对象中的下一跳数组的索引。
(include/net/ip_fib.h)
IN_DEV_FORWARD()
此宏检查指定的网络设备(in_device对象)是否支持 IPv4 转发。
IN _ DEV _ RX _ 重定向()
此宏检查指定的网络设备(in_device对象)是否支持接受 ICMPv4 重定向。
IN_DEV_TX_REDIRECTS()
此宏检查指定的网络设备(in_device对象)是否支持发送 ICMPv4 重定向。
IS_LEAF()
该宏检查指定的树节点是否是叶节点。
IS_TNODE()
该宏检查指定的树节点是否是内部节点(trie节点或tnode)。
change_nexthops()
该宏迭代指定的fib_info对象(net/ipv4/fib_semantics.c)的下一跳。
桌子
路由有 15 个(RTAX_MAX)度量。有些是 TCP 相关的,有些是通用的。表 5-1 显示了这些指标中哪些与 TCP 相关。
表 5-1。路线指标
|Linux 符号
|
TCP 度量(是/否)
|
| — | — |
| RTAX_UNSPEC | 普通 |
| RTAX_LOCK | 普通 |
| S7-1200 可编程控制器 | 普通 |
| RTAX _ 窗口 | Y |
| S7-1200 可编程控制器 | Y |
| rtax _ rttvar(消歧义) | Y |
| rtax _ ssthresh(消歧义) | Y |
| RTAX_CWND | Y |
| RTAX_ADVMSS | Y |
| RTAX _ 重新排序 | Y |
| RTX _ hope 限制 | 普通 |
| rtax _ initcwnd(虚拟专用网络) | Y |
| RTAX _ 功能 | 普通 |
| RTAX_RTO_MIN | Y |
| RTAX_INITRWND | Y |
(include/uapi/linux/rtnetlink.h)
表 5-2 显示了所有路线类型的误差值和范围。
表 5-2。路线类型
|Linux 符号
|
错误
|
范围
|
| — | — | — |
| RTN_UNSPEC | Zero | RT_SCOPE_NOWHERE |
| RTN _ 单播 | Zero | RT _ SCOPE _ 宇宙 |
| RTN _ 本地 | Zero | RT _ SCOPE _ 主机 |
| RTN _ 广播 | Zero | RT_SCOPE_LINK |
| RTN _ 任播 | Zero | RT_SCOPE_LINK |
| RTN _ 多播 | Zero | RT _ SCOPE _ 宇宙 |
| rtn _ 黑洞 | -埃因瓦尔 | RT _ SCOPE _ 宇宙 |
| RTN _ 不可达 | -EHOSTUNREACH | RT _ SCOPE _ 宇宙 |
| RTN _ 禁止 | -电子会议 | RT _ SCOPE _ 宇宙 |
| RTN_THROW | -伊根 | RT _ SCOPE _ 宇宙 |
| RTN_NAT | -埃因瓦尔 | RT_SCOPE_NOWHERE |
| RTN_XRESOLVE | -埃因瓦尔 | RT_SCOPE_NOWHERE |
路线标志
当运行route –n命令时,您会得到一个显示路由标志的输出。下面是标志值和一个简短的route –n输出示例:
u(航路打开)
h(目标是主机)
g(使用网关)
r(为动态路由恢复路由)
d(由守护程序或重定向动态安装)
m(从路由守护程序或重定向修改)
答(由 addrconf 安装)
!(拒绝路线)
表 5-3 显示了运行route –n的输出示例(结果组织成表格形式):
表 5-3。内核 IP 路由表


















 277
277

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









