







使用 Ultralytics YOLO 导出模型
简介
训练模型的最终目标是在实际应用中部署它。Ultralytics YOLOv8 的导出模式提供了多种选项,可将训练好的模型导出至不同格式,从而使其能够在各种平台和设备上部署。本详尽指南旨在引导您了解模型导出的细节,展示如何实现最大的兼容性和性能。
www.youtube.com/embed/WbomGeoOT_k?si=aGmuyooWftA0ue9X
观看: 如何导出自定义训练的 Ultralytics YOLOv8 模型,并在网络摄像头上进行实时推理。
为什么选择 YOLOv8 的导出模式?
-
多功能性: 导出至包括 ONNX、TensorRT、CoreML 等多种格式。
-
性能: 使用 TensorRT 可获得最多 5 倍的 GPU 加速,使用 ONNX 或 OpenVINO 可获得最多 3 倍的 CPU 加速。
-
兼容性: 使您的模型能够普遍适用于多种硬件和软件环境。
-
易用性: 简单的命令行界面和 Python API,便于快速和直接的模型导出。
导出模式的关键特性
下面是一些突出的功能:
-
一键导出: 简单命令,可导出至不同格式。
-
批量导出: 导出支持批处理推理的模型。
-
优化推理速度: 导出模型经过优化,推理速度更快。
-
教程视频: 深入指南和教程,帮助您顺利进行导出操作。
提示
-
导出至 ONNX 或 OpenVINO,CPU 速度提升最多 3 倍。
-
导出至 TensorRT,GPU 速度提升最多 5 倍。
使用示例
将 YOLOv8n 模型导出至 ONNX 或 TensorRT 等不同格式。查看下面的参数部分,了解所有导出参数的完整列表。
示例
from ultralytics import YOLO
# Load a model
model = YOLO("yolov8n.pt") # load an official model
model = YOLO("path/to/best.pt") # load a custom trained model
# Export the model
model.export(format="onnx")
yolo export model=yolov8n.pt format=onnx # export official model
yolo export model=path/to/best.pt format=onnx # export custom trained model
参数
此表详细描述了将 YOLO 模型导出至不同格式的配置和选项。这些设置对优化导出模型的性能、大小和在各种平台和环境中的兼容性至关重要。适当的配置确保模型能够在预期应用中以最佳效率部署。
| 参数 | 类型 | 默认值 | 描述 |
|---|---|---|---|
format | str | 'torchscript' | 导出模型的目标格式,如 'onnx'、'torchscript'、'tensorflow' 等,定义与各种部署环境的兼容性。 |
imgsz | int 或 tuple | 640 | 模型输入的期望图像尺寸。可以是整数表示正方形图像,也可以是元组 (height, width) 表示具体尺寸。 |
keras | bool | False | 启用导出至 TensorFlow SavedModel 的 Keras 格式,提供与 TensorFlow Serving 和 API 的兼容性。 |
optimize | bool | False | 在导出 TorchScript 到移动设备时应用优化,可能减小模型大小并提高性能。 |
half | bool | False | 启用 FP16(半精度)量化,减小模型大小并在支持的硬件上加快推断速度。 |
int8 | bool | False | 激活 INT8 量化,进一步压缩模型并在几乎不损失精度的情况下加快推断速度,主要用于边缘设备。 |
dynamic | bool | False | 允许 ONNX、TensorRT 和 OpenVINO 导出使用动态输入尺寸,增强处理不同图像尺寸的灵活性。 |
simplify | bool | False | 使用 onnxslim 简化 ONNX 导出的模型图,可能提高性能和兼容性。 |
opset | int | None | 指定 ONNX opset 版本,以便与不同的 ONNX 解析器和运行时兼容。如果未设置,将使用支持的最新版本。 |
workspace | float | 4.0 | 设置 TensorRT 优化的最大工作空间大小(单位:GiB),平衡内存使用和性能。 |
nms | bool | False | 在 CoreML 导出中添加非最大抑制(NMS),用于精确和高效的检测后处理。 |
batch | int | 1 | 指定导出模型的批量推断大小,或者导出模型在 predict 模式下并发处理的最大图像数量。 |
调整这些参数允许定制导出过程,以适应特定的需求,如部署环境、硬件约束和性能目标。选择合适的格式和设置对于实现模型大小、速度和精度的最佳平衡至关重要。
导出格式
下面的表格列出了可用的 YOLOv8 导出格式。您可以使用 format 参数导出到任何格式,例如 format='onnx' 或 format='engine'。导出完成后,您可以直接预测或验证导出的模型,例如 yolo predict model=yolov8n.onnx。下面展示了导出后您模型的使用示例。
| 格式 | format 参数 | 模型 | 元数据 | 参数 |
|---|---|---|---|---|
| PyTorch | - | yolov8n.pt | ✅ | - |
| TorchScript | torchscript | yolov8n.torchscript | ✅ | imgsz, optimize, batch |
| ONNX | onnx | yolov8n.onnx | ✅ | imgsz, half, dynamic, simplify, opset, batch |
| OpenVINO | openvino | yolov8n_openvino_model/ | ✅ | imgsz, half, int8, batch, dynamic |
| TensorRT | engine | yolov8n.engine | ✅ | imgsz, half, dynamic, simplify, workspace, int8, batch |
| CoreML | coreml | yolov8n.mlpackage | ✅ | imgsz, half, int8, nms, batch |
| TF SavedModel | saved_model | yolov8n_saved_model/ | ✅ | imgsz, keras, int8, batch |
| TF GraphDef | pb | yolov8n.pb | ❌ | imgsz, batch |
| TF Lite | tflite | yolov8n.tflite | ✅ | imgsz, half, int8, batch |
| TF Edge TPU | edgetpu | yolov8n_edgetpu.tflite | ✅ | imgsz |
| TF.js | tfjs | yolov8n_web_model/ | ✅ | imgsz, half, int8, batch |
| PaddlePaddle | paddle | yolov8n_paddle_model/ | ✅ | imgsz, batch |
| NCNN | ncnn | yolov8n_ncnn_model/ | ✅ | imgsz, half, batch |
常见问题解答
如何将 YOLOv8 模型导出为 ONNX 格式?
使用 Ultralytics 导出 YOLOv8 模型到 ONNX 格式非常简单,提供了 Python 和 CLI 方法来导出模型。
示例
from ultralytics import YOLO
# Load a model
model = YOLO("yolov8n.pt") # load an official model
model = YOLO("path/to/best.pt") # load a custom trained model
# Export the model
model.export(format="onnx")
yolo export model=yolov8n.pt format=onnx # export official model
yolo export model=path/to/best.pt format=onnx # export custom trained model
关于包括处理不同输入尺寸在内的高级选项,更多详细流程请参考 ONNX 部分。
使用 TensorRT 进行模型导出的好处是什么?
使用 TensorRT 进行模型导出能显著提升性能。导出到 TensorRT 的 YOLOv8 模型可以实现多达 5 倍的 GPU 加速,非常适合实时推理应用。
-
通用性: 为特定硬件设置优化模型。
-
速度: 通过先进优化实现更快推理速度。
-
兼容性: 与 NVIDIA 硬件无缝集成。
要了解更多有关集成 TensorRT 的信息,请参阅 TensorRT 集成指南。
如何在导出 YOLOv8 模型时启用 INT8 量化?
INT8 量化是压缩模型并加速推理的优秀方式,尤其适用于边缘设备。以下是如何启用 INT8 量化的方法:
示例
from ultralytics import YOLO
model = YOLO("yolov8n.pt") # Load a model
model.export(format="onnx", int8=True)
yolo export model=yolov8n.pt format=onnx int8=True # export model with INT8 quantization
INT8 量化可以应用于多种格式,如 TensorRT 和 CoreML。更多详细信息请参考导出部分。
在导出模型时,为什么动态输入尺寸很重要?
动态输入尺寸允许导出的模型处理不同的图像尺寸,为不同用例提供灵活性并优化处理效率。当导出到 ONNX 或 TensorRT 等格式时,启用动态输入尺寸可以确保模型能够无缝适应不同的输入形状。
要启用此功能,在导出时使用dynamic=True标志:
示例
from ultralytics import YOLO
model = YOLO("yolov8n.pt")
model.export(format="onnx", dynamic=True)
yolo export model=yolov8n.pt format=onnx dynamic=True
关于动态输入尺寸配置的更多上下文,请参考。
如何优化模型性能的关键导出参数是什么?
理解和配置导出参数对优化模型性能至关重要:
-
format:导出模型的目标格式(例如onnx、torchscript、tensorflow)。 -
imgsz:模型输入的期望图像尺寸(例如640或(height, width))。 -
half:启用 FP16 量化,减小模型大小并可能加快推理速度。 -
optimize:为移动或受限环境应用特定优化。 -
int8:启用 INT8 量化,对边缘部署极为有益。
想了解所有导出参数的详细列表和解释,请访问导出参数部分。
多目标跟踪与 Ultralytics YOLO

在视频分析领域中进行对象跟踪是一个关键任务,不仅可以确定帧内对象的位置和类别,还可以在视频进展中为每个检测到的对象维护唯一的 ID。应用广泛,从监控和安全到实时体育分析。
为什么选择 Ultralytics YOLO 进行对象跟踪?
Ultralytics 跟踪器的输出与标准对象检测一致,但增加了对象 ID 的价值。这使得在视频流中跟踪对象并进行后续分析变得更加容易。以下是您考虑使用 Ultralytics YOLO 进行对象跟踪的原因:
-
效率: 实时处理视频流,而不影响准确性。
-
灵活性: 支持多个跟踪算法和配置。
-
易于使用: 简单的 Python API 和 CLI 选项,快速集成和部署。
-
可定制性: 使用自定义训练的 YOLO 模型易于使用,可集成到特定领域的应用程序中。
www.youtube.com/embed/hHyHmOtmEgs?si=VNZtXmm45Nb9s-N-
观看: 使用 Ultralytics YOLOv8 进行对象检测和跟踪。
现实世界的应用
| 交通运输 | 零售 | 水产养殖 |
|---|---|---|
 |  |  |
| 车辆跟踪 | 人员跟踪 | 鱼类跟踪 |
特点一览
Ultralytics YOLO 通过扩展其对象检测功能来提供强大而多功能的对象跟踪:
-
实时跟踪: 在高帧率视频中无缝跟踪对象。
-
多跟踪器支持: 可选择多种成熟的跟踪算法。
-
可定制的跟踪器配置: 通过调整各种参数来定制跟踪算法,以满足特定需求。
可用的跟踪器
Ultralytics YOLO 支持以下跟踪算法。可以通过传递相关的 YAML 配置文件如tracker=tracker_type.yaml来启用它们:
默认跟踪器是 BoT-SORT。
跟踪
跟踪器阈值信息
如果对象置信度得分低于track_high_thresh,则将不会成功返回和更新跟踪。
要在视频流上运行跟踪器,请使用训练有素的 Detect、Segment 或 Pose 模型,例如 YOLOv8n、YOLOv8n-seg 和 YOLOv8n-pose。
示例
from ultralytics import YOLO
# Load an official or custom model
model = YOLO("yolov8n.pt") # Load an official Detect model
model = YOLO("yolov8n-seg.pt") # Load an official Segment model
model = YOLO("yolov8n-pose.pt") # Load an official Pose model
model = YOLO("path/to/best.pt") # Load a custom trained model
# Perform tracking with the model
results = model.track("https://youtu.be/LNwODJXcvt4", show=True) # Tracking with default tracker
results = model.track("https://youtu.be/LNwODJXcvt4", show=True, tracker="bytetrack.yaml") # with ByteTrack
# Perform tracking with various models using the command line interface
yolo track model=yolov8n.pt source="https://youtu.be/LNwODJXcvt4" # Official Detect model
yolo track model=yolov8n-seg.pt source="https://youtu.be/LNwODJXcvt4" # Official Segment model
yolo track model=yolov8n-pose.pt source="https://youtu.be/LNwODJXcvt4" # Official Pose model
yolo track model=path/to/best.pt source="https://youtu.be/LNwODJXcvt4" # Custom trained model
# Track using ByteTrack tracker
yolo track model=path/to/best.pt tracker="bytetrack.yaml"
如上使用中所示,跟踪适用于在视频或流媒体源上运行的所有检测、分割和姿态模型。
配置
跟踪器阈值信息
如果对象的置信度得分低,即低于 track_high_thresh,则不会成功返回和更新任何轨迹。
跟踪参数
跟踪配置与预测模式相似,例如 conf、iou 和 show。有关进一步的配置,请参阅预测模型页面。
示例
from ultralytics import YOLO
# Configure the tracking parameters and run the tracker
model = YOLO("yolov8n.pt")
results = model.track(source="https://youtu.be/LNwODJXcvt4", conf=0.3, iou=0.5, show=True)
# Configure tracking parameters and run the tracker using the command line interface
yolo track model=yolov8n.pt source="https://youtu.be/LNwODJXcvt4" conf=0.3, iou=0.5 show
跟踪器选择
Ultralytics 还允许您使用修改后的跟踪器配置文件。要做到这一点,只需从 ultralytics/cfg/trackers 复制跟踪器配置文件(例如 custom_tracker.yaml),并根据需要修改任何配置(除了 tracker_type)。
示例
from ultralytics import YOLO
# Load the model and run the tracker with a custom configuration file
model = YOLO("yolov8n.pt")
results = model.track(source="https://youtu.be/LNwODJXcvt4", tracker="custom_tracker.yaml")
# Load the model and run the tracker with a custom configuration file using the command line interface
yolo track model=yolov8n.pt source="https://youtu.be/LNwODJXcvt4" tracker='custom_tracker.yaml'
有关跟踪参数的全面列表,请参阅 ultralytics/cfg/trackers 页面。
Python 示例
持续跟踪循环
这是一个使用 OpenCV (cv2) 和 YOLOv8 在视频帧上运行对象跟踪的 Python 脚本。此脚本假定您已经安装了必要的软件包 (opencv-python 和 ultralytics)。persist=True 参数告诉跟踪器当前图像或帧是序列中的下一帧,并且在当前图像中期望来自上一帧的轨迹。
使用跟踪的流式循环
import cv2
from ultralytics import YOLO
# Load the YOLOv8 model
model = YOLO("yolov8n.pt")
# Open the video file
video_path = "path/to/video.mp4"
cap = cv2.VideoCapture(video_path)
# Loop through the video frames
while cap.isOpened():
# Read a frame from the video
success, frame = cap.read()
if success:
# Run YOLOv8 tracking on the frame, persisting tracks between frames
results = model.track(frame, persist=True)
# Visualize the results on the frame
annotated_frame = results[0].plot()
# Display the annotated frame
cv2.imshow("YOLOv8 Tracking", annotated_frame)
# Break the loop if 'q' is pressed
if cv2.waitKey(1) & 0xFF == ord("q"):
break
else:
# Break the loop if the end of the video is reached
break
# Release the video capture object and close the display window
cap.release()
cv2.destroyAllWindows()
请注意从 model(frame) 更改为 model.track(frame),这将启用对象跟踪而不是简单的检测。这个修改后的脚本将在视频的每一帧上运行跟踪器,可视化结果,并在窗口中显示它们。可以通过按下 ‘q’ 键来退出循环。
随时间绘制轨迹
在连续帧上可视化对象轨迹可以为视频中检测到的对象的移动模式和行为提供宝贵的见解。通过 Ultralytics YOLOv8,绘制这些轨迹是一个无缝且高效的过程。
在以下示例中,我们演示如何利用 YOLOv8 的跟踪能力在多个视频帧上绘制检测到的对象的移动。该脚本涉及打开视频文件,逐帧读取并利用 YOLO 模型识别和跟踪各种对象。通过保留检测到的边界框的中心点并连接它们,我们可以绘制代表被跟踪对象路径的线条。
在多个视频帧上绘制轨迹
from collections import defaultdict
import cv2
import numpy as np
from ultralytics import YOLO
# Load the YOLOv8 model
model = YOLO("yolov8n.pt")
# Open the video file
video_path = "path/to/video.mp4"
cap = cv2.VideoCapture(video_path)
# Store the track history
track_history = defaultdict(lambda: [])
# Loop through the video frames
while cap.isOpened():
# Read a frame from the video
success, frame = cap.read()
if success:
# Run YOLOv8 tracking on the frame, persisting tracks between frames
results = model.track(frame, persist=True)
# Get the boxes and track IDs
boxes = results[0].boxes.xywh.cpu()
track_ids = results[0].boxes.id.int().cpu().tolist()
# Visualize the results on the frame
annotated_frame = results[0].plot()
# Plot the tracks
for box, track_id in zip(boxes, track_ids):
x, y, w, h = box
track = track_history[track_id]
track.append((float(x), float(y))) # x, y center point
if len(track) > 30: # retain 90 tracks for 90 frames
track.pop(0)
# Draw the tracking lines
points = np.hstack(track).astype(np.int32).reshape((-1, 1, 2))
cv2.polylines(annotated_frame, [points], isClosed=False, color=(230, 230, 230), thickness=10)
# Display the annotated frame
cv2.imshow("YOLOv8 Tracking", annotated_frame)
# Break the loop if 'q' is pressed
if cv2.waitKey(1) & 0xFF == ord("q"):
break
else:
# Break the loop if the end of the video is reached
break
# Release the video capture object and close the display window
cap.release()
cv2.destroyAllWindows()
多线程跟踪
多线程跟踪提供了同时在多个视频流上运行对象跟踪的能力。这在处理多个视频输入时特别有用,例如来自多个监控摄像头的视频,其中并行处理可以极大地提高效率和性能。
在提供的 Python 脚本中,我们利用 Python 的 threading 模块同时运行多个跟踪器实例。每个线程负责在一个视频文件上运行跟踪器,所有线程在后台同时运行。
为确保每个线程接收到正确的参数(视频文件、要使用的模型和文件索引),我们定义了一个函数 run_tracker_in_thread,接受这些参数并包含主要的跟踪循环。此函数逐帧读取视频,运行跟踪器并显示结果。
此示例中使用了两种不同的模型:yolov8n.pt 和 yolov8n-seg.pt,分别在不同的视频文件中跟踪对象。视频文件由 video_file1 和 video_file2 指定。
threading.Thread 中的 daemon=True 参数意味着这些线程会在主程序完成后立即关闭。然后我们使用 start() 启动线程,并使用 join() 让主线程等待两个追踪线程都完成。
最后,在所有线程完成任务后,使用 cv2.destroyAllWindows() 关闭显示结果的窗口。
带跟踪的流式循环
import threading
import cv2
from ultralytics import YOLO
def run_tracker_in_thread(filename, model, file_index):
"""
Runs a video file or webcam stream concurrently with the YOLOv8 model using threading.
This function captures video frames from a given file or camera source and utilizes the YOLOv8 model for object
tracking. The function runs in its own thread for concurrent processing.
Args:
filename (str): The path to the video file or the identifier for the webcam/external camera source.
model (obj): The YOLOv8 model object.
file_index (int): An index to uniquely identify the file being processed, used for display purposes.
Note:
Press 'q' to quit the video display window.
"""
video = cv2.VideoCapture(filename) # Read the video file
while True:
ret, frame = video.read() # Read the video frames
# Exit the loop if no more frames in either video
if not ret:
break
# Track objects in frames if available
results = model.track(frame, persist=True)
res_plotted = results[0].plot()
cv2.imshow(f"Tracking_Stream_{file_index}", res_plotted)
key = cv2.waitKey(1)
if key == ord("q"):
break
# Release video sources
video.release()
# Load the models
model1 = YOLO("yolov8n.pt")
model2 = YOLO("yolov8n-seg.pt")
# Define the video files for the trackers
video_file1 = "path/to/video1.mp4" # Path to video file, 0 for webcam
video_file2 = 0 # Path to video file, 0 for webcam, 1 for external camera
# Create the tracker threads
tracker_thread1 = threading.Thread(target=run_tracker_in_thread, args=(video_file1, model1, 1), daemon=True)
tracker_thread2 = threading.Thread(target=run_tracker_in_thread, args=(video_file2, model2, 2), daemon=True)
# Start the tracker threads
tracker_thread1.start()
tracker_thread2.start()
# Wait for the tracker threads to finish
tracker_thread1.join()
tracker_thread2.join()
# Clean up and close windows
cv2.destroyAllWindows()
可以通过创建更多线程并应用相同的方法轻松扩展此示例以处理更多视频文件和模型。
贡献新的跟踪器
您精通多对象跟踪,并成功地使用 Ultralytics YOLO 实现或调整了跟踪算法吗?我们邀请您贡献到我们的 Trackers 部分,位于 ultralytics/cfg/trackers!您的真实应用和解决方案可能对正在处理跟踪任务的用户非常宝贵。
通过贡献到这一部分,您将帮助扩展 Ultralytics YOLO 框架中可用的跟踪解决方案范围,为社区增加功能和效用的另一层。
要开始您的贡献,请参考我们的贡献指南,详细了解提交 Pull Request(PR)的说明 🛠️。我们期待看到您能为这个项目带来什么!
让我们共同增强 Ultralytics YOLO 生态系统的跟踪能力 🙏!
常见问题解答
什么是多对象跟踪,以及 Ultralytics YOLO 如何支持它?
视频分析中的多对象跟踪涉及识别对象并在视频帧之间维护每个检测到的对象的唯一 ID。Ultralytics YOLO 通过提供实时跟踪和对象 ID 支持此功能,方便进行安全监控和体育分析等任务。系统使用诸如 BoT-SORT 和 ByteTrack 的跟踪器,可以通过 YAML 文件进行配置。
如何为 Ultralytics YOLO 配置自定义跟踪器?
您可以通过从Ultralytics 跟踪器配置目录复制一个现有的跟踪器配置文件(例如custom_tracker.yaml)并根据需要修改参数来配置自定义跟踪器,但是tracker_type除外。像这样在您的跟踪模型中使用此文件:
示例
from ultralytics import YOLO
model = YOLO("yolov8n.pt")
results = model.track(source="https://youtu.be/LNwODJXcvt4", tracker="custom_tracker.yaml")
yolo track model=yolov8n.pt source="https://youtu.be/LNwODJXcvt4" tracker='custom_tracker.yaml'
如何同时在多个视频流上运行对象跟踪?
要同时在多个视频流上运行对象跟踪,您可以使用 Python 的threading模块。每个线程将处理一个单独的视频流。以下是如何设置的示例:
多线程跟踪
import threading
import cv2
from ultralytics import YOLO
def run_tracker_in_thread(filename, model, file_index):
video = cv2.VideoCapture(filename)
while True:
ret, frame = video.read()
if not ret:
break
results = model.track(frame, persist=True)
res_plotted = results[0].plot()
cv2.imshow(f"Tracking_Stream_{file_index}", res_plotted)
if cv2.waitKey(1) & 0xFF == ord("q"):
break
video.release()
model1 = YOLO("yolov8n.pt")
model2 = YOLO("yolov8n-seg.pt")
video_file1 = "path/to/video1.mp4"
video_file2 = 0 # Path to a second video file, or 0 for a webcam
tracker_thread1 = threading.Thread(target=run_tracker_in_thread, args=(video_file1, model1, 1), daemon=True)
tracker_thread2 = threading.Thread(target=run_tracker_in_thread, args=(video_file2, model2, 2), daemon=True)
tracker_thread1.start()
tracker_thread2.start()
tracker_thread1.join()
tracker_thread2.join()
cv2.destroyAllWindows()
利用 Ultralytics YOLO 进行多目标跟踪的实际应用是什么?
使用 Ultralytics YOLO 进行多目标跟踪有许多应用,包括:
-
交通: 用于交通管理和自动驾驶的车辆跟踪。
-
零售: 用于店内分析和安全的人员跟踪。
-
水产养殖: 用于监测水生环境的鱼类跟踪。
这些应用程序受益于 Ultralytics YOLO 在实时处理高帧率视频的能力。
如何使用 Ultralytics YOLO 在多个视频帧上可视化对象轨迹?
要在多个视频帧上可视化对象轨迹,您可以使用 YOLO 模型的跟踪功能以及 OpenCV 来绘制检测到的对象的路径。以下是演示此操作的示例脚本:
绘制多个视频帧上的轨迹
from collections import defaultdict
import cv2
import numpy as np
from ultralytics import YOLO
model = YOLO("yolov8n.pt")
video_path = "path/to/video.mp4"
cap = cv2.VideoCapture(video_path)
track_history = defaultdict(lambda: [])
while cap.isOpened():
success, frame = cap.read()
if success:
results = model.track(frame, persist=True)
boxes = results[0].boxes.xywh.cpu()
track_ids = results[0].boxes.id.int().cpu().tolist()
annotated_frame = results[0].plot()
for box, track_id in zip(boxes, track_ids):
x, y, w, h = box
track = track_history[track_id]
track.append((float(x), float(y)))
if len(track) > 30:
track.pop(0)
points = np.hstack(track).astype(np.int32).reshape((-1, 1, 2))
cv2.polylines(annotated_frame, [points], isClosed=False, color=(230, 230, 230), thickness=10)
cv2.imshow("YOLOv8 Tracking", annotated_frame)
if cv2.waitKey(1) & 0xFF == ord("q"):
break
else:
break
cap.release()
cv2.destroyAllWindows()
此脚本将绘制跟踪线,显示跟踪对象随时间的移动路径。
使用 Ultralytics YOLO 进行模型基准测试
介绍
一旦您的模型经过训练和验证,下一个合乎逻辑的步骤就是在各种真实场景中评估其性能。Ultralytics YOLOv8 的基准模式通过提供一个强大的框架,为您的模型在一系列导出格式中评估速度和准确性提供了一个坚实的基础。
www.youtube.com/embed/j8uQc0qB91s?start=105
观看: Ultralytics 模式教程:基准测试
为什么基准测试至关重要?
-
明智的决策: 深入了解速度和准确性之间的权衡。
-
资源分配: 了解不同导出格式在不同硬件上的性能表现。
-
优化: 了解哪种导出格式对于您特定的用例提供最佳性能。
-
成本效率: 根据基准测试结果更有效地利用硬件资源。
基准模式中的关键指标
-
mAP50-95: 用于目标检测、分割和姿态估计。
-
accuracy_top5: 用于图像分类。
-
推理时间: 每张图像所需的时间(毫秒)。
支持的导出格式
-
ONNX: 用于最佳的 CPU 性能
-
TensorRT: 实现最大的 GPU 效率
-
OpenVINO: 适用于英特尔硬件优化
-
CoreML、TensorFlow SavedModel 等等: 适用于多样化的部署需求。
提示
-
导出到 ONNX 或 OpenVINO 可以实现高达 3 倍的 CPU 加速。
-
导出到 TensorRT 可以实现高达 5 倍的 GPU 加速。
使用示例
在所有支持的导出格式上运行 YOLOv8n 基准测试,包括 ONNX、TensorRT 等。请查看下面的参数部分,了解完整的导出参数列表。
示例
from ultralytics.utils.benchmarks import benchmark
# Benchmark on GPU
benchmark(model="yolov8n.pt", data="coco8.yaml", imgsz=640, half=False, device=0)
yolo benchmark model=yolov8n.pt data='coco8.yaml' imgsz=640 half=False device=0
参数
参数如 model、data、imgsz、half、device 和 verbose 为用户提供了灵活性,可以根据其特定需求微调基准测试,并轻松比较不同导出格式的性能。
| 键 | 默认值 | 描述 |
|---|---|---|
model | None | 指定模型文件的路径。接受 .pt 和 .yaml 格式,例如,"yolov8n.pt" 用于预训练模型或配置文件。 |
data | None | 定义用于基准测试的数据集的 YAML 文件路径,通常包括验证数据的路径和设置。示例:“coco8.yaml”。 |
imgsz | 640 | 模型的输入图像大小。可以是一个整数用于方形图像,或者是一个元组 (width, height) 用于非方形图像,例如 (640, 480)。 |
half | False | 启用 FP16(半精度)推理,减少内存使用量,并可能在兼容硬件上增加速度。使用 half=True 来启用。 |
int8 | False | 激活 INT8 量化,以进一步优化支持设备上的性能,特别适用于边缘设备。设置 int8=True 来使用。 |
device | None | 定义基准测试的计算设备,如 "cpu"、"cuda:0",或像 "cuda:0,1" 这样的多 GPU 设置。 |
verbose | False | 控制日志输出的详细级别。布尔值;设置 verbose=True 可获取详细日志,或设置浮点数以进行错误阈值设定。 |
导出格式
基准测试将尝试自动运行所有可能的导出格式。
| 格式 | format 参数 | 模型 | 元数据 | 参数 |
|---|---|---|---|---|
| PyTorch | - | yolov8n.pt | ✅ | - |
| TorchScript | torchscript | yolov8n.torchscript | ✅ | imgsz, optimize, batch |
| ONNX | onnx | yolov8n.onnx | ✅ | imgsz, half, dynamic, simplify, opset, batch |
| OpenVINO | openvino | yolov8n_openvino_model/ | ✅ | imgsz, half, int8, batch, dynamic |
| TensorRT | engine | yolov8n.engine | ✅ | imgsz, half, dynamic, simplify, workspace, int8, batch |
| CoreML | coreml | yolov8n.mlpackage | ✅ | imgsz, half, int8, nms, batch |
| TF SavedModel | saved_model | yolov8n_saved_model/ | ✅ | imgsz, keras, int8, batch |
| TF GraphDef | pb | yolov8n.pb | ❌ | imgsz, batch |
| TF Lite | tflite | yolov8n.tflite | ✅ | imgsz, half, int8, batch |
| TF Edge TPU | edgetpu | yolov8n_edgetpu.tflite | ✅ | imgsz |
| TF.js | tfjs | yolov8n_web_model/ | ✅ | imgsz, half, int8, batch |
| PaddlePaddle | paddle | yolov8n_paddle_model/ | ✅ | imgsz, batch |
| NCNN | ncnn | yolov8n_ncnn_model/ | ✅ | imgsz, half, batch |
查看导出页面的完整导出详情。
常见问题
如何使用 Ultralytics 对我的 YOLOv8 模型进行基准测试?
Ultralytics YOLOv8 提供了一个基准模式,可以评估模型在不同导出格式下的性能。该模式提供关键指标,如平均精度(mAP50-95)、准确性以及推断时间(毫秒)。要运行基准测试,可以使用 Python 或 CLI 命令。例如,在 GPU 上运行基准测试:
示例
from ultralytics.utils.benchmarks import benchmark
# Benchmark on GPU
benchmark(model="yolov8n.pt", data="coco8.yaml", imgsz=640, half=False, device=0)
yolo benchmark model=yolov8n.pt data='coco8.yaml' imgsz=640 half=False device=0
有关基准参数的更多详情,请访问参数部分。
导出 YOLOv8 模型到不同格式有哪些好处?
将 YOLOv8 模型导出到不同格式,如 ONNX、TensorRT 和 OpenVINO,可以根据部署环境优化性能。例如:
-
**ONNX:**提供最多 3 倍的 CPU 加速。
-
**TensorRT:**提供最多 5 倍的 GPU 加速。
-
**OpenVINO:**专为 Intel 硬件优化。这些格式提升了模型的速度和准确性,使其在各种实际应用中更加高效。访问导出页面获取完整详情。
为什么基准测试在评估 YOLOv8 模型时至关重要?
对您的 YOLOv8 模型进行基准测试至关重要,理由如下:
-
**明智决策:**理解速度和准确性之间的权衡。
-
资源分配: 评估在不同硬件选项上的性能。
-
优化: 确定哪种导出格式针对特定用例提供最佳性能。
-
成本效率: 根据基准测试结果优化硬件使用。关键指标如 mAP50-95、Top-5 准确性和推理时间有助于进行这些评估。有关更多信息,请参阅关键指标部分。
YOLOv8 支持哪些导出格式,它们各自有什么优势?
YOLOv8 支持多种导出格式,每种都针对特定的硬件和用例进行了定制:
-
ONNX: 最适合 CPU 性能。
-
TensorRT: 理想的 GPU 效率。
-
OpenVINO: 针对 Intel 硬件优化。
-
CoreML & TensorFlow: 适用于 iOS 和一般 ML 应用程序。有关支持的所有格式及其各自优势的完整列表,请查看支持的导出格式部分。
我可以使用哪些参数来优化我的 YOLOv8 基准测试?
运行基准测试时,可以自定义多个参数以满足特定需求:
-
模型: 模型文件的路径(例如,“yolov8n.pt”)。
-
数据: 定义数据集的 YAML 文件路径(例如,“coco8.yaml”)。
-
imgsz: 输入图像大小,可以是单个整数或元组。
-
half: 启用 FP16 推理以获得更好的性能。
-
int8: 为边缘设备激活 INT8 量化。
-
设备: 指定计算设备(例如,“cpu”,“cuda:0”)。
-
详细模式: 控制日志详细程度。有关所有参数的完整列表,请参阅参数部分。
Ultralytics YOLOv8 任务

YOLOv8 是一个支持多个计算机视觉任务的 AI 框架。该框架可用于执行检测、分割、obb、分类和姿态估计。每个任务都有不同的目标和用例。
www.youtube.com/embed/NAs-cfq9BDw
Watch: 探索 Ultralytics YOLO 任务:对象检测、分割、OBB、跟踪和姿态估计。
检测
检测是 YOLOv8 支持的主要任务。它涉及在图像或视频帧中检测物体,并在它们周围绘制边界框。检测到的对象根据其特征被分类为不同类别。YOLOv8 可以以高精度和速度在单个图像或视频帧中检测多个物体。
检测示例
分割
分割是一项任务,涉及根据图像内容将图像分割成不同区域。每个区域根据其内容被赋予一个标签。这项任务在图像分割和医学成像等应用中非常有用。YOLOv8 使用改进的 U-Net 架构执行分割。
分割示例
分类
分类是一项任务,涉及将图像分类为不同的类别。YOLOv8 可以基于图像内容对图像进行分类。它使用改进的 EfficientNet 架构进行分类。
分类示例
姿态
姿态/关键点检测是一项任务,涉及在图像或视频帧中检测特定点。这些点称为关键点,用于跟踪运动或姿态估计。YOLOv8 可以以高精度和速度检测图像或视频帧中的关键点。
姿态示例
OBB
定向目标检测比常规物体检测更进一步,引入额外的角度来更精确地定位图像中的对象。YOLOv8 可以以高精度和速度检测图像或视频帧中的旋转对象。
定向检测
结论
YOLOv8 支持多个任务,包括检测、分割、分类、定向物体检测和关键点检测。每个任务都有不同的目标和用例。通过理解这些任务之间的差异,您可以选择适合您的计算机视觉应用的任务。
常见问题
Ultralytics YOLOv8 能执行哪些任务?
Ultralytics YOLOv8 是一个多才多艺的 AI 框架,能够以高精度和速度执行各种计算机视觉任务。这些任务包括:
-
检测: 通过在图像或视频帧中绘制边界框来识别和定位物体。
-
分割: 将图像根据其内容分割成不同区域,适用于医学成像等应用。
-
分类: 基于其内容对整个图像进行分类,利用 EfficientNet 架构的变体。
-
姿态估计: 在图像或视频帧中检测特定的关键点,以跟踪动作或姿势。
-
定向目标检测(OBB): 通过增加方向角度参数检测旋转对象,实现更高精度。
如何使用 Ultralytics YOLOv8 进行目标检测?
要使用 Ultralytics YOLOv8 进行目标检测,请按以下步骤操作:
-
准备适当格式的数据集。
-
训练 YOLOv8 模型使用检测任务。
-
使用模型通过输入新图像或视频帧进行预测。
示例
from ultralytics import YOLO
model = YOLO("yolov8n.pt") # Load pre-trained model
results = model.predict(source="image.jpg") # Perform object detection
results[0].show()
yolo detect model=yolov8n.pt source='image.jpg'
获取更详细的说明,请查看我们的检测示例。
使用 YOLOv8 进行分割任务有哪些好处?
使用 YOLOv8 进行分割任务具有多个优势:
-
高精度: 分割任务利用 U-Net 架构的变体实现精准的分割。
-
速度: YOLOv8 针对实时应用进行了优化,即使处理高分辨率图像也能快速处理。
-
多应用场景: 适用于医学成像、自动驾驶等需要详细图像分割的应用。
了解有关分割部分中 YOLOv8 的优势和用例。
Ultralytics YOLOv8 能够处理姿态估计和关键点检测吗?
是的,Ultralytics YOLOv8 能够以高精度和速度有效执行姿态估计和关键点检测。这一功能在运动分析、医疗保健和人机交互应用中特别有用。YOLOv8 能够检测图像或视频帧中的关键点,实现精准的姿态估计。
获取更多关于姿态估计示例的详细信息和实施提示。
为什么我应该选择 Ultralytics YOLOv8 进行定向目标检测(OBB)?
使用 YOLOv8 进行定向目标检测(OBB)通过检测具有额外角度参数的对象,提供了增强的精度。这一特性对需要精确定位旋转对象的应用尤为有益,例如航空影像分析和仓库自动化。
-
增加精度: 角度组件减少了旋转对象的误报。
-
多功能应用: 适用于地理空间分析、机器人技术等任务。
查看定向目标检测部分以获取更多详细信息和示例。
目标检测

目标检测是一项任务,涉及在图像或视频流中识别对象的位置和类别。
目标检测器的输出是一组边界框,这些边界框围绕图像中的对象,以及每个框的类别标签和置信度分数。当您需要识别场景中感兴趣的对象,但不需要知道对象的确切位置或确切形状时,目标检测是一个不错的选择。
www.youtube.com/embed/5ku7npMrW40?si=6HQO1dDXunV8gekh
观看: 使用预训练的 Ultralytics YOLOv8 模型进行目标检测。
提示
YOLOv8 Detect 模型是默认的 YOLOv8 模型,即 yolov8n.pt,并在 COCO 上进行了预训练。
模型
YOLOv8 预训练 Detect 模型显示在此处。Detect、Segment 和 Pose 模型在 COCO 数据集上进行了预训练,而 Classify 模型在 ImageNet 数据集上进行了预训练。
模型 在首次使用时会自动从最新的 Ultralytics 发布 中下载。
| 模型 | 尺寸 ^((像素)) | mAP^(val 50-95) | 速度 ^(CPU ONNX
(ms)) | 速度 ^(A100 TensorRT
(ms)) | 参数 ^((M)) | FLOPs ^((B)) |
| — | — | — | — | — | — | — |
|---|---|---|---|---|---|---|
| YOLOv8n | 640 | 37.3 | 80.4 | 0.99 | 3.2 | 8.7 |
| YOLOv8s | 640 | 44.9 | 128.4 | 1.20 | 11.2 | 28.6 |
| YOLOv8m | 640 | 50.2 | 234.7 | 1.83 | 25.9 | 78.9 |
| YOLOv8l | 640 | 52.9 | 375.2 | 2.39 | 43.7 | 165.2 |
| YOLOv8x | 640 | 53.9 | 479.1 | 3.53 | 68.2 | 257.8 |
-
mAP^(val) 值是在 COCO val2017 数据集上进行单模型单尺度测试的结果。
通过
yolo val detect data=coco.yaml device=0复现 -
速度 是在使用 Amazon EC2 P4d 实例对 COCO val 图像进行平均处理的。
通过
yolo val detect data=coco8.yaml batch=1 device=0|cpu复现
训练
在尺寸为 640 的图像上使用 COCO8 数据集对 YOLOv8n 进行 100 个 epochs 的训练。有关可用参数的完整列表,请参阅配置页面。
示例
from ultralytics import YOLO
# Load a model
model = YOLO("yolov8n.yaml") # build a new model from YAML
model = YOLO("yolov8n.pt") # load a pretrained model (recommended for training)
model = YOLO("yolov8n.yaml").load("yolov8n.pt") # build from YAML and transfer weights
# Train the model
results = model.train(data="coco8.yaml", epochs=100, imgsz=640)
# Build a new model from YAML and start training from scratch
yolo detect train data=coco8.yaml model=yolov8n.yaml epochs=100 imgsz=640
# Start training from a pretrained *.pt model
yolo detect train data=coco8.yaml model=yolov8n.pt epochs=100 imgsz=640
# Build a new model from YAML, transfer pretrained weights to it and start training
yolo detect train data=coco8.yaml model=yolov8n.yaml pretrained=yolov8n.pt epochs=100 imgsz=640
数据集格式
YOLO 检测数据集格式的详细信息可以在数据集指南中找到。要将现有数据集从其他格式(如 COCO 等)转换为 YOLO 格式,请使用 Ultralytics 的JSON2YOLO工具。
Val
在 COCO8 数据集上验证训练好的 YOLOv8n 模型的准确性。不需要传递任何参数,因为model保留了其训练data和参数作为模型属性。
示例
from ultralytics import YOLO
# Load a model
model = YOLO("yolov8n.pt") # load an official model
model = YOLO("path/to/best.pt") # load a custom model
# Validate the model
metrics = model.val() # no arguments needed, dataset and settings remembered
metrics.box.map # map50-95
metrics.box.map50 # map50
metrics.box.map75 # map75
metrics.box.maps # a list contains map50-95 of each category
yolo detect val model=yolov8n.pt # val official model
yolo detect val model=path/to/best.pt # val custom model
预测
使用训练好的 YOLOv8n 模型对图像进行预测。
示例
from ultralytics import YOLO
# Load a model
model = YOLO("yolov8n.pt") # load an official model
model = YOLO("path/to/best.pt") # load a custom model
# Predict with the model
results = model("https://ultralytics.com/images/bus.jpg") # predict on an image
yolo detect predict model=yolov8n.pt source='https://ultralytics.com/images/bus.jpg' # predict with official model
yolo detect predict model=path/to/best.pt source='https://ultralytics.com/images/bus.jpg' # predict with custom model
查看预测模式详细信息,请参阅预测页面。
导出
将 YOLOv8n 模型导出到 ONNX、CoreML 等不同格式。
示例
from ultralytics import YOLO
# Load a model
model = YOLO("yolov8n.pt") # load an official model
model = YOLO("path/to/best.pt") # load a custom trained model
# Export the model
model.export(format="onnx")
yolo export model=yolov8n.pt format=onnx # export official model
yolo export model=path/to/best.pt format=onnx # export custom trained model
可用的 YOLOv8 导出格式在下表中列出。您可以使用format参数导出到任何格式,例如format='onnx'或format='engine'。您可以直接在导出的模型上进行预测或验证,例如yolo predict model=yolov8n.onnx。导出完成后,显示了您的模型的使用示例。
| Format | format Argument | Model | Metadata | Arguments |
|---|---|---|---|---|
| PyTorch | - | yolov8n.pt | ✅ | - |
| TorchScript | torchscript | yolov8n.torchscript | ✅ | imgsz, optimize, batch |
| ONNX | onnx | yolov8n.onnx | ✅ | imgsz, half, dynamic, simplify, opset, batch |
| OpenVINO | openvino | yolov8n_openvino_model/ | ✅ | imgsz, half, int8, batch, dynamic |
| TensorRT | engine | yolov8n.engine | ✅ | imgsz, half, dynamic, simplify, workspace, int8, batch |
| CoreML | coreml | yolov8n.mlpackage | ✅ | imgsz, half, int8, nms, batch |
| TF SavedModel | saved_model | yolov8n_saved_model/ | ✅ | imgsz, keras, int8, batch |
| TF GraphDef | pb | yolov8n.pb | ❌ | imgsz, batch |
| TF Lite | tflite | yolov8n.tflite | ✅ | imgsz, half, int8, batch |
| TF Edge TPU | edgetpu | yolov8n_edgetpu.tflite | ✅ | imgsz |
| TF.js | tfjs | yolov8n_web_model/ | ✅ | imgsz, half, int8, batch |
| PaddlePaddle | paddle | yolov8n_paddle_model/ | ✅ | imgsz, batch |
| NCNN | ncnn | yolov8n_ncnn_model/ | ✅ | imgsz, half, batch |
查看完整的导出详细信息,请参阅导出页面。
常见问题解答
如何在自定义数据集上训练 YOLOv8 模型?
训练 YOLOv8 模型的自定义数据集涉及几个步骤:
-
准备数据集:确保您的数据集采用 YOLO 格式。有关指导,请参阅我们的数据集指南。
-
加载模型:使用 Ultralytics YOLO 库加载预训练模型或从 YAML 文件创建新模型。
-
训练模型:在 Python 中执行
train方法或在 CLI 中执行yolo detect train命令。
示例
from ultralytics import YOLO
# Load a pretrained model
model = YOLO("yolov8n.pt")
# Train the model on your custom dataset
model.train(data="my_custom_dataset.yaml", epochs=100, imgsz=640)
yolo detect train data=my_custom_dataset.yaml model=yolov8n.pt epochs=100 imgsz=640
欲了解详细的配置选项,请访问配置页面。
YOLOv8 中有哪些预训练模型可用?
Ultralytics YOLOv8 提供多个预训练模型,用于目标检测、分割和姿态估计。这些模型在 COCO 数据集或 ImageNet 上进行了预训练,用于分类任务。以下是一些可用的模型:
如需详细列表和性能指标,请参阅模型部分。
如何验证我训练的 YOLOv8 模型的准确性?
要验证您训练的 YOLOv8 模型的准确性,可以在 Python 中使用.val()方法或在 CLI 中使用yolo detect val命令。这将提供诸如 mAP50-95、mAP50 等指标。
示例
from ultralytics import YOLO
# Load the model
model = YOLO("path/to/best.pt")
# Validate the model
metrics = model.val()
print(metrics.box.map) # mAP50-95
yolo detect val model=path/to/best.pt
更多验证细节,请访问 Val 页面。
YOLOv8 模型可以导出到哪些格式?
Ultralytics YOLOv8 支持将模型导出到各种格式,如 ONNX、TensorRT、CoreML 等,以确保在不同平台和设备上的兼容性。
示例
from ultralytics import YOLO
# Load the model
model = YOLO("yolov8n.pt")
# Export the model to ONNX format
model.export(format="onnx")
yolo export model=yolov8n.pt format=onnx
查看支持的格式列表和导出页面的说明。
为什么应该使用 Ultralytics YOLOv8 进行目标检测?
Ultralytics YOLOv8 旨在提供优越的目标检测、分割和姿态估计性能。以下是一些关键优势:
-
预训练模型:利用在流行数据集如 COCO 和 ImageNet 上预训练的模型,加快开发速度。
-
高准确性:实现了令人印象深刻的 mAP 分数,确保可靠的目标检测。
-
速度:优化用于实时推理,非常适合需要快速处理的应用。
-
灵活性:将模型导出到 ONNX 和 TensorRT 等多种格式,用于在多平台部署。
浏览我们的博客,查看使用案例和展示 YOLOv8 效果的成功故事。
实例分割

实例分割比目标检测更进一步,涉及识别图像中的单个对象并将其从图像的其余部分分割出来。
实例分割模型的输出是一组掩膜或轮廓,勾勒出图像中每个对象的轮廓,以及每个对象的类别标签和置信度分数。当你需要知道图像中对象的位置以及它们的确切形状时,实例分割非常有用。
www.youtube.com/embed/o4Zd-IeMlSY?si=37nusCzDTd74Obsp
观看: 在 Python 中使用预训练的 Ultralytics YOLOv8 模型运行分割。
提示
YOLOv8 分割模型使用 -seg 后缀,例如 yolov8n-seg.pt,并在 COCO 数据集上进行预训练。
模型
这里展示了 YOLOv8 预训练的分割模型。检测、分割和姿态模型在 COCO 数据集上进行预训练,而分类模型在 ImageNet 数据集上进行预训练。
模型 在首次使用时会自动从最新的 Ultralytics 发布 下载。
| 模型 | 大小 ^((像素)) | mAP^(框 50-95) | mAP^(掩膜 50-95) | 速度 ^(CPU ONNX
(毫秒)) | 速度 ^(A100 TensorRT
(毫秒)) | 参数 ^((M)) | FLOPs ^((B)) |
| — | — | — | — | — | — | — | — |
|---|---|---|---|---|---|---|---|
| YOLOv8n-seg | 640 | 36.7 | 30.5 | 96.1 | 1.21 | 3.4 | 12.6 |
| YOLOv8s-seg | 640 | 44.6 | 36.8 | 155.7 | 1.47 | 11.8 | 42.6 |
| YOLOv8m-seg | 640 | 49.9 | 40.8 | 317.0 | 2.18 | 27.3 | 110.2 |
| YOLOv8l-seg | 640 | 52.3 | 42.6 | 572.4 | 2.79 | 46.0 | 220.5 |
| YOLOv8x-seg | 640 | 53.4 | 43.4 | 712.1 | 4.02 | 71.8 | 344.1 |
-
mAP^(val) 值是针对 COCO val2017 数据集的单模型单尺度。
通过
yolo val segment data=coco.yaml device=0重现 -
速度 是在使用 Amazon EC2 P4d 实例的 COCO val 图像上平均计算得出的。
通过
yolo val segment data=coco8-seg.yaml batch=1 device=0|cpu来复现
训练
在图像大小为 640 的情况下,在 COCO128-seg 数据集上训练 YOLOv8n-seg 100 个 epoch。有关可用参数的完整列表,请参见配置页面。
例子
from ultralytics import YOLO
# Load a model
model = YOLO("yolov8n-seg.yaml") # build a new model from YAML
model = YOLO("yolov8n-seg.pt") # load a pretrained model (recommended for training)
model = YOLO("yolov8n-seg.yaml").load("yolov8n.pt") # build from YAML and transfer weights
# Train the model
results = model.train(data="coco8-seg.yaml", epochs=100, imgsz=640)
# Build a new model from YAML and start training from scratch
yolo segment train data=coco8-seg.yaml model=yolov8n-seg.yaml epochs=100 imgsz=640
# Start training from a pretrained *.pt model
yolo segment train data=coco8-seg.yaml model=yolov8n-seg.pt epochs=100 imgsz=640
# Build a new model from YAML, transfer pretrained weights to it and start training
yolo segment train data=coco8-seg.yaml model=yolov8n-seg.yaml pretrained=yolov8n-seg.pt epochs=100 imgsz=640
数据集格式
YOLO 分割数据集格式的详细信息可以在数据集指南中找到。要将现有数据集从其他格式(如 COCO 等)转换为 YOLO 格式,请使用 Ultralytics 的 JSON2YOLO 工具。
验证
在 COCO128-seg 数据集上验证训练好的 YOLOv8n-seg 模型准确性。不需要传递任何参数,因为model保留其训练data和参数作为模型属性。
例子
from ultralytics import YOLO
# Load a model
model = YOLO("yolov8n-seg.pt") # load an official model
model = YOLO("path/to/best.pt") # load a custom model
# Validate the model
metrics = model.val() # no arguments needed, dataset and settings remembered
metrics.box.map # map50-95(B)
metrics.box.map50 # map50(B)
metrics.box.map75 # map75(B)
metrics.box.maps # a list contains map50-95(B) of each category
metrics.seg.map # map50-95(M)
metrics.seg.map50 # map50(M)
metrics.seg.map75 # map75(M)
metrics.seg.maps # a list contains map50-95(M) of each category
yolo segment val model=yolov8n-seg.pt # val official model
yolo segment val model=path/to/best.pt # val custom model
预测
使用训练好的 YOLOv8n-seg 模型对图像进行预测。
例子
from ultralytics import YOLO
# Load a model
model = YOLO("yolov8n-seg.pt") # load an official model
model = YOLO("path/to/best.pt") # load a custom model
# Predict with the model
results = model("https://ultralytics.com/images/bus.jpg") # predict on an image
yolo segment predict model=yolov8n-seg.pt source='https://ultralytics.com/images/bus.jpg' # predict with official model
yolo segment predict model=path/to/best.pt source='https://ultralytics.com/images/bus.jpg' # predict with custom model
查看预测页面中的全部predict模式细节。
导出
将 YOLOv8n-seg 模型导出到 ONNX、CoreML 等不同格式。
例子
from ultralytics import YOLO
# Load a model
model = YOLO("yolov8n-seg.pt") # load an official model
model = YOLO("path/to/best.pt") # load a custom trained model
# Export the model
model.export(format="onnx")
yolo export model=yolov8n-seg.pt format=onnx # export official model
yolo export model=path/to/best.pt format=onnx # export custom trained model
可用的 YOLOv8-seg 导出格式列在下表中。您可以使用format参数导出到任何格式,例如format='onnx'或format='engine'。您可以直接在导出模型上预测或验证,例如yolo predict model=yolov8n-seg.onnx。导出完成后,您的模型示例将显示使用示例。
| Format | format 参数 | 模型 | 元数据 | 参数 |
|---|---|---|---|---|
| PyTorch | - | yolov8n-seg.pt | ✅ | - |
| TorchScript | torchscript | yolov8n-seg.torchscript | ✅ | imgsz, optimize, batch |
| ONNX | onnx | yolov8n-seg.onnx | ✅ | imgsz, half, dynamic, simplify, opset, batch |
| OpenVINO | openvino | yolov8n-seg_openvino_model/ | ✅ | imgsz, half, int8, batch, dynamic |
| TensorRT | engine | yolov8n-seg.engine | ✅ | imgsz, half, dynamic, simplify, workspace, int8, batch |
| CoreML | coreml | yolov8n-seg.mlpackage | ✅ | imgsz, half, int8, nms, batch |
| TF SavedModel | saved_model | yolov8n-seg_saved_model/ | ✅ | imgsz, keras, int8, batch |
| TF GraphDef | pb | yolov8n-seg.pb | ❌ | imgsz, batch |
| TF Lite | tflite | yolov8n-seg.tflite | ✅ | imgsz, half, int8, batch |
| TF Edge TPU | edgetpu | yolov8n-seg_edgetpu.tflite | ✅ | imgsz |
| TF.js | tfjs | yolov8n-seg_web_model/ | ✅ | imgsz, half, int8, batch |
| PaddlePaddle | paddle | yolov8n-seg_paddle_model/ | ✅ | imgsz, batch |
| NCNN | ncnn | yolov8n-seg_ncnn_model/ | ✅ | imgsz, half, batch |
查看导出页面中的全部export细节。
常见问题
如何在自定义数据集上训练 YOLOv8 分割模型?
要在自定义数据集上训练 YOLOv8 分割模型,您首先需要将数据集准备成 YOLO 分割格式。您可以使用 JSON2YOLO 等工具将其他格式的数据集转换为 YOLO 格式。准备好数据集后,可以使用 Python 或 CLI 命令来训练模型:
例子
from ultralytics import YOLO
# Load a pretrained YOLOv8 segment model
model = YOLO("yolov8n-seg.pt")
# Train the model
results = model.train(data="path/to/your_dataset.yaml", epochs=100, imgsz=640)
yolo segment train data=path/to/your_dataset.yaml model=yolov8n-seg.pt epochs=100 imgsz=640
检查配置页面以获取更多可用参数信息。
YOLOv8 中对象检测和实例分割的区别是什么?
对象检测通过在图像中绘制边界框来识别和定位对象,而实例分割不仅能识别边界框,还能勾画出每个对象的精确形状。YOLOv8 实例分割模型提供了每个检测到的对象的掩码或轮廓,这对于需要知道对象精确形状的任务非常有用,如医学成像或自动驾驶。
为什么使用 YOLOv8 进行实例分割?
Ultralytics YOLOv8 是一种现代化的模型,以其高精度和实时性能而闻名,非常适合实例分割任务。YOLOv8 Segment 模型在COCO 数据集上预训练,确保在各种对象上表现稳健。此外,YOLOv8 支持训练、验证、预测和导出功能,与 Python 和 CLI 无缝集成,非常适用于研究和工业应用。
如何加载和验证预训练的 YOLOv8 分割模型?
加载和验证预训练的 YOLOv8 分割模型非常简单。以下是使用 Python 和 CLI 的操作方法:
示例
from ultralytics import YOLO
# Load a pretrained model
model = YOLO("yolov8n-seg.pt")
# Validate the model
metrics = model.val()
print("Mean Average Precision for boxes:", metrics.box.map)
print("Mean Average Precision for masks:", metrics.seg.map)
yolo segment val model=yolov8n-seg.pt
这些步骤将为您提供像平均精度(mAP)这样的验证指标,对评估模型性能至关重要。
如何将 YOLOv8 分割模型导出为 ONNX 格式?
将 YOLOv8 分割模型导出为 ONNX 格式非常简单,可以使用 Python 或 CLI 命令完成:
示例
from ultralytics import YOLO
# Load a pretrained model
model = YOLO("yolov8n-seg.pt")
# Export the model to ONNX format
model.export(format="onnx")
yolo export model=yolov8n-seg.pt format=onnx
有关导出到各种格式的更多详细信息,请参阅导出页面。
图像分类

图像分类是三项任务中最简单的,它涉及将整个图像分类为预定义类别集中的一类。
图像分类器的输出是一个类标签和置信度分数。当你只需知道图像属于哪个类别,而不需要知道该类别的对象在何处或其确切形状时,图像分类非常有用。
www.youtube.com/embed/5BO0Il_YYAg
观看: 探索 Ultralytics YOLO 任务:使用 Ultralytics HUB 进行图像分类
提示
YOLOv8 分类模型使用-cls后缀,例如yolov8n-cls.pt,并且在ImageNet上进行了预训练。
模型
YOLOv8 预训练分类模型显示在此处。检测、分割和姿态模型是在COCO数据集上预训练的,而分类模型是在ImageNet数据集上预训练的。
模型在第一次使用时会从最新的 Ultralytics 发布自动下载。
| 模型 | 尺寸 ^(像素) | 准确率 ^(top1) | 准确率 ^(top5) | 速度 ^(CPU ONNX
(毫秒)) | 速度 ^(A100 TensorRT
(毫秒)) | 参数 ^((百万)) | FLOPs ^((十亿,以 640 为单位)) |
| — | — | — | — | — | — | — | — |
|---|---|---|---|---|---|---|---|
| YOLOv8n-cls | 224 | 69.0 | 88.3 | 12.9 | 0.31 | 2.7 | 4.3 |
| YOLOv8s-cls | 224 | 73.8 | 91.7 | 23.4 | 0.35 | 6.4 | 13.5 |
| YOLOv8m-cls | 224 | 76.8 | 93.5 | 85.4 | 0.62 | 17.0 | 42.7 |
| YOLOv8l-cls | 224 | 76.8 | 93.5 | 163.0 | 0.87 | 37.5 | 99.7 |
| YOLOv8x-cls | 224 | 79.0 | 94.6 | 232.0 | 1.01 | 57.4 | 154.8 |
-
准确度值是模型在ImageNet数据集验证集上的准确性。
重现命令
yolo val classify data=path/to/ImageNet device=0 -
速度是通过 ImageNet 验证图像在Amazon EC2 P4d实例上平均得出的。
重现命令
yolo val classify data=path/to/ImageNet batch=1 device=0|cpu
训练
在图像大小为 64 的 MNIST160 数据集上训练 YOLOv8n-cls 100 个周期。有关所有可用参数的完整列表,请参阅配置页面。
示例
from ultralytics import YOLO
# Load a model
model = YOLO("yolov8n-cls.yaml") # build a new model from YAML
model = YOLO("yolov8n-cls.pt") # load a pretrained model (recommended for training)
model = YOLO("yolov8n-cls.yaml").load("yolov8n-cls.pt") # build from YAML and transfer weights
# Train the model
results = model.train(data="mnist160", epochs=100, imgsz=64)
# Build a new model from YAML and start training from scratch
yolo classify train data=mnist160 model=yolov8n-cls.yaml epochs=100 imgsz=64
# Start training from a pretrained *.pt model
yolo classify train data=mnist160 model=yolov8n-cls.pt epochs=100 imgsz=64
# Build a new model from YAML, transfer pretrained weights to it and start training
yolo classify train data=mnist160 model=yolov8n-cls.yaml pretrained=yolov8n-cls.pt epochs=100 imgsz=64
数据集格式
YOLO 分类数据集格式的详细信息可在数据集指南中找到。
验证
在 MNIST160 数据集上验证训练好的 YOLOv8n-cls 模型准确性。作为模型保留其训练数据和参数属性,无需传递任何参数。
示例
from ultralytics import YOLO
# Load a model
model = YOLO("yolov8n-cls.pt") # load an official model
model = YOLO("path/to/best.pt") # load a custom model
# Validate the model
metrics = model.val() # no arguments needed, dataset and settings remembered
metrics.top1 # top1 accuracy
metrics.top5 # top5 accuracy
yolo classify val model=yolov8n-cls.pt # val official model
yolo classify val model=path/to/best.pt # val custom model
预测
使用训练好的 YOLOv8n-cls 模型对图像进行预测。
示例
from ultralytics import YOLO
# Load a model
model = YOLO("yolov8n-cls.pt") # load an official model
model = YOLO("path/to/best.pt") # load a custom model
# Predict with the model
results = model("https://ultralytics.com/images/bus.jpg") # predict on an image
yolo classify predict model=yolov8n-cls.pt source='https://ultralytics.com/images/bus.jpg' # predict with official model
yolo classify predict model=path/to/best.pt source='https://ultralytics.com/images/bus.jpg' # predict with custom model
查看完整的预测模式细节,请参阅预测页面。
导出
将 YOLOv8n-cls 模型导出为 ONNX、CoreML 等其他格式。
示例
from ultralytics import YOLO
# Load a model
model = YOLO("yolov8n-cls.pt") # load an official model
model = YOLO("path/to/best.pt") # load a custom trained model
# Export the model
model.export(format="onnx")
yolo export model=yolov8n-cls.pt format=onnx # export official model
yolo export model=path/to/best.pt format=onnx # export custom trained model
可用的 YOLOv8-cls 导出格式如下表所示。您可以使用format参数导出到任何格式,例如format='onnx'或format='engine'。您可以直接在导出的模型上进行预测或验证,例如yolo predict model=yolov8n-cls.onnx。导出完成后,示例中将显示您模型的用法。
| 格式 | format 参数 | 模型 | 元数据 | 参数 |
|---|---|---|---|---|
| PyTorch | - | yolov8n-cls.pt | ✅ | - |
| TorchScript | torchscript | yolov8n-cls.torchscript | ✅ | imgsz, optimize, batch |
| ONNX | onnx | yolov8n-cls.onnx | ✅ | imgsz, half, dynamic, simplify, opset, batch |
| OpenVINO | openvino | yolov8n-cls_openvino_model/ | ✅ | imgsz, half, int8, batch, dynamic |
| TensorRT | engine | yolov8n-cls.engine | ✅ | imgsz, half, dynamic, simplify, workspace, int8, batch |
| CoreML | coreml | yolov8n-cls.mlpackage | ✅ | imgsz, half, int8, nms, batch |
| TF SavedModel | saved_model | yolov8n-cls_saved_model/ | ✅ | imgsz, keras, int8, batch |
| TF GraphDef | pb | yolov8n-cls.pb | ❌ | imgsz, batch |
| TF Lite | tflite | yolov8n-cls.tflite | ✅ | imgsz, half, int8, batch |
| TF Edge TPU | edgetpu | yolov8n-cls_edgetpu.tflite | ✅ | imgsz |
| TF.js | tfjs | yolov8n-cls_web_model/ | ✅ | imgsz, half, int8, batch |
| PaddlePaddle | paddle | yolov8n-cls_paddle_model/ | ✅ | imgsz, batch |
| NCNN | ncnn | yolov8n-cls_ncnn_model/ | ✅ | imgsz, half, batch |
查看完整的导出细节,请参阅导出页面。
常见问题解答
YOLOv8 在图像分类中的目的是什么?
YOLOv8 模型(例如yolov8n-cls.pt)专为高效的图像分类而设计。它们为整个图像分配单一类别标签,并提供置信度分数。对于仅需知道图像具体类别而无需识别其位置或形状的应用程序,这非常有用。
如何训练 YOLOv8 模型进行图像分类?
您可以使用 Python 或 CLI 命令训练 YOLOv8 模型。例如,对于图像大小为 64 的 MNIST160 数据集,可以在 100 个周期内训练yolov8n-cls模型:
示例
from ultralytics import YOLO
# Load a model
model = YOLO("yolov8n-cls.pt") # load a pretrained model (recommended for training)
# Train the model
results = model.train(data="mnist160", epochs=100, imgsz=64)
yolo classify train data=mnist160 model=yolov8n-cls.pt epochs=100 imgsz=64
欲了解更多配置选项,请访问配置页面。
我可以在哪里找到预训练的 YOLOv8 分类模型?
预训练的 YOLOv8 分类模型可以在模型部分找到。像yolov8n-cls.pt、yolov8s-cls.pt、yolov8m-cls.pt等模型,都是在ImageNet数据集上进行了预训练,可以轻松下载并用于各种图像分类任务。
如何将训练好的 YOLOv8 模型导出到不同的格式?
你可以使用 Python 或 CLI 命令将训练好的 YOLOv8 模型导出到各种格式。例如,要将模型导出为 ONNX 格式:
示例
from ultralytics import YOLO
# Load a model
model = YOLO("yolov8n-cls.pt") # load the trained model
# Export the model to ONNX
model.export(format="onnx")
yolo export model=yolov8n-cls.pt format=onnx # export the trained model to ONNX format
欲了解详细的导出选项,请参考导出页面。
我如何验证训练好的 YOLOv8 分类模型?
要验证训练好的模型在类似 MNIST160 的数据集上的准确性,可以使用以下 Python 或 CLI 命令:
示例
from ultralytics import YOLO
# Load a model
model = YOLO("yolov8n-cls.pt") # load the trained model
# Validate the model
metrics = model.val() # no arguments needed, uses the dataset and settings from training
metrics.top1 # top1 accuracy
metrics.top5 # top5 accuracy
yolo classify val model=yolov8n-cls.pt # validate the trained model
欲了解更多信息,请访问验证部分。
姿势估计
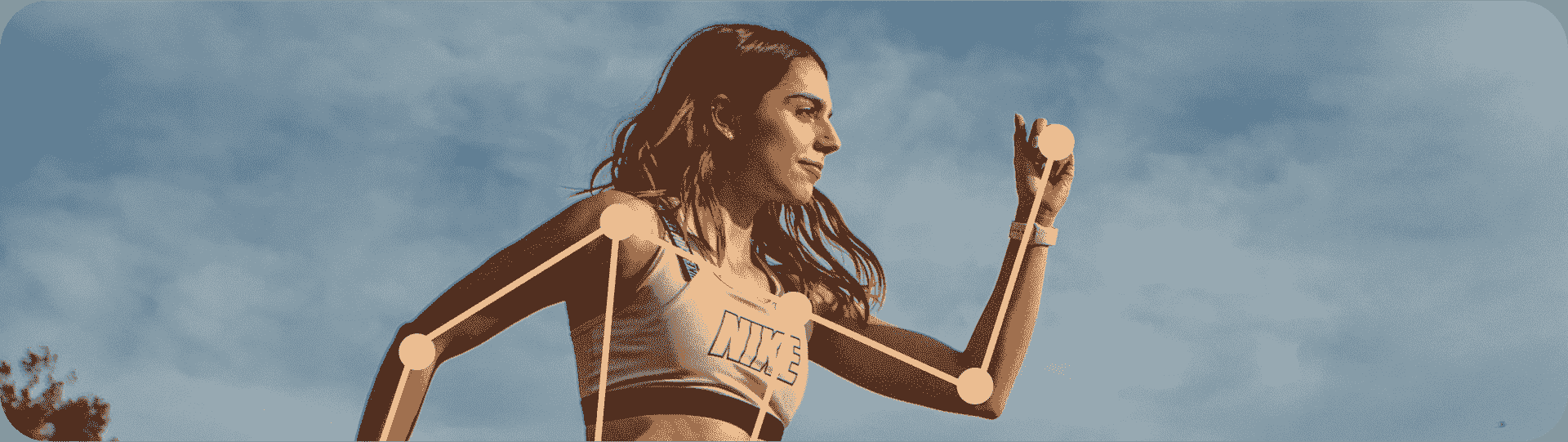
姿势估计是一项任务,涉及在图像中识别特定点的位置,通常称为关键点。关键点可以代表对象的各种部位,如关节、地标或其他显著特征。关键点的位置通常表示为一组 2D [x, y] 或 3D [x, y, visible]坐标。
姿势估计模型的输出是一组点,表示图像中对象的关键点,通常还包括每个点的置信度分数。当您需要识别场景中对象特定部分及其相互位置时,姿势估计是一个不错的选择。
|
www.youtube.com/embed/Y28xXQmju64?si=pCY4ZwejZFu6Z4kZ
观看: 与 Ultralytics YOLOv8 一起的姿势估计。
www.youtube.com/embed/aeAX6vWpfR0
观看: 与 Ultralytics HUB 一起的姿势估计。
提示
YOLOv8 pose模型使用-pose后缀,例如yolov8n-pose.pt。这些模型是在COCO 关键点数据集上训练的,适用于各种姿势估计任务。
在默认的 YOLOv8 姿势模型中,有 17 个关键点,每个代表人体不同部位。以下是每个索引与其对应身体关节的映射:
0: 鼻子 1: 左眼 2: 右眼 3: 左耳 4: 右耳 5: 左肩 6: 右肩 7: 左肘 8: 右肘 9: 左腕 10: 右腕 11: 左髋 12: 右髋 13: 左膝 14: 右膝 15: 左踝 16: 右踝
模型
YOLOv8 预训练的姿势模型显示在这里。检测、分割和姿势模型在COCO数据集上进行了预训练,而分类模型则在ImageNet数据集上进行了预训练。
模型将在首次使用时自动从最新的 Ultralytics 发布中下载。
| 模型 | 大小 ^((像素)) | mAP^(姿势 50-95) | mAP^(姿势 50) | 速度 ^(CPU ONNX
(ms)) | 速度 ^(A100 TensorRT
(ms)) | 参数 ^((M)) | FLOPs ^((B)) |
| — | — | — | — | — | — | — | — |
|---|---|---|---|---|---|---|---|
| YOLOv8n-pose | 640 | 50.4 | 80.1 | 131.8 | 1.18 | 3.3 | 9.2 |
| YOLOv8s-pose | 640 | 60.0 | 86.2 | 233.2 | 1.42 | 11.6 | 30.2 |
| YOLOv8m-pose | 640 | 65.0 | 88.8 | 456.3 | 2.00 | 26.4 | 81.0 |
| YOLOv8l-pose | 640 | 67.6 | 90.0 | 784.5 | 2.59 | 44.4 | 168.6 |
| YOLOv8x-pose | 640 | 69.2 | 90.2 | 1607.1 | 3.73 | 69.4 | 263.2 |
| YOLOv8x-pose-p6 | 1280 | 71.6 | 91.2 | 4088.7 | 10.04 | 99.1 | 1066.4 |
-
**mAP^(val)**值适用于COCO 关键点 val2017数据集上的单一模型单一尺度。
通过
yolo val pose data=coco-pose.yaml device=0重现 -
速度是使用Amazon EC2 P4d实例对 COCO 验证图像进行平均化。
通过
yolo val pose data=coco8-pose.yaml batch=1 device=0|cpu重现
训练
在 COCO128-pose 数据集上训练 YOLOv8-pose 模型。
示例
from ultralytics import YOLO
# Load a model
model = YOLO("yolov8n-pose.yaml") # build a new model from YAML
model = YOLO("yolov8n-pose.pt") # load a pretrained model (recommended for training)
model = YOLO("yolov8n-pose.yaml").load("yolov8n-pose.pt") # build from YAML and transfer weights
# Train the model
results = model.train(data="coco8-pose.yaml", epochs=100, imgsz=640)
# Build a new model from YAML and start training from scratch
yolo pose train data=coco8-pose.yaml model=yolov8n-pose.yaml epochs=100 imgsz=640
# Start training from a pretrained *.pt model
yolo pose train data=coco8-pose.yaml model=yolov8n-pose.pt epochs=100 imgsz=640
# Build a new model from YAML, transfer pretrained weights to it and start training
yolo pose train data=coco8-pose.yaml model=yolov8n-pose.yaml pretrained=yolov8n-pose.pt epochs=100 imgsz=640
数据集格式
YOLO 姿势数据集格式详见数据集指南。要将现有数据集(如 COCO 等)转换为 YOLO 格式,请使用Ultralytics 的 JSON2YOLO工具。
验证
在 COCO128-pose 数据集上验证训练的 YOLOv8n-pose 模型准确性。作为模型属性,不需要传递任何参数。
示例
from ultralytics import YOLO
# Load a model
model = YOLO("yolov8n-pose.pt") # load an official model
model = YOLO("path/to/best.pt") # load a custom model
# Validate the model
metrics = model.val() # no arguments needed, dataset and settings remembered
metrics.box.map # map50-95
metrics.box.map50 # map50
metrics.box.map75 # map75
metrics.box.maps # a list contains map50-95 of each category
yolo pose val model=yolov8n-pose.pt # val official model
yolo pose val model=path/to/best.pt # val custom model
预测
使用训练的 YOLOv8n-pose 模型对图像进行预测。
示例
from ultralytics import YOLO
# Load a model
model = YOLO("yolov8n-pose.pt") # load an official model
model = YOLO("path/to/best.pt") # load a custom model
# Predict with the model
results = model("https://ultralytics.com/images/bus.jpg") # predict on an image
yolo pose predict model=yolov8n-pose.pt source='https://ultralytics.com/images/bus.jpg' # predict with official model
yolo pose predict model=path/to/best.pt source='https://ultralytics.com/images/bus.jpg' # predict with custom model
在预测页面查看完整的predict模式详细信息。
导出
将 YOLOv8n Pose 模型导出到 ONNX、CoreML 等不同格式。
示例
from ultralytics import YOLO
# Load a model
model = YOLO("yolov8n-pose.pt") # load an official model
model = YOLO("path/to/best.pt") # load a custom trained model
# Export the model
model.export(format="onnx")
yolo export model=yolov8n-pose.pt format=onnx # export official model
yolo export model=path/to/best.pt format=onnx # export custom trained model
可用的 YOLOv8-pose 导出格式如下表所示。您可以使用format参数导出到任何格式,例如format='onnx'或format='engine'。导出完成后,您可以直接在导出的模型上进行预测或验证,例如yolo predict model=yolov8n-pose.onnx。使用示例在导出模型后显示您的模型。
| 格式 | format参数 | 模型 | 元数据 | 参数 |
|---|---|---|---|---|
| PyTorch | - | yolov8n-pose.pt | ✅ | - |
| TorchScript | torchscript | yolov8n-pose.torchscript | ✅ | imgsz, optimize, batch |
| ONNX | onnx | yolov8n-pose.onnx | ✅ | imgsz, half, dynamic, simplify, opset, batch |
| OpenVINO | openvino | yolov8n-pose_openvino_model/ | ✅ | imgsz, half, int8, batch, dynamic |
| TensorRT | engine | yolov8n-pose.engine | ✅ | imgsz, half, dynamic, simplify, workspace, int8, batch |
| CoreML | coreml | yolov8n-pose.mlpackage | ✅ | imgsz, half, int8, nms, batch |
| TF SavedModel | saved_model | yolov8n-pose_saved_model/ | ✅ | imgsz, keras, int8, batch |
| TF GraphDef | pb | yolov8n-pose.pb | ❌ | imgsz, batch |
| TF Lite | tflite | yolov8n-pose.tflite | ✅ | imgsz, half, int8, batch |
| TF Edge TPU | edgetpu | yolov8n-pose_edgetpu.tflite | ✅ | imgsz |
| TF.js | tfjs | yolov8n-pose_web_model/ | ✅ | imgsz, half, int8, batch |
| PaddlePaddle | paddle | yolov8n-pose_paddle_model/ | ✅ | imgsz, batch |
| NCNN | ncnn | yolov8n-pose_ncnn_model/ | ✅ | imgsz, half, batch |
请参阅导出页面以查看完整的导出细节。
常见问题解答
什么是使用 Ultralytics YOLOv8 进行姿势估计,它是如何工作的?
使用 Ultralytics YOLOv8 进行姿势估计涉及在图像中识别特定点,称为关键点。这些关键点通常代表对象的关节或其他重要特征。输出包括每个点的[x, y]坐标和置信度分数。YOLOv8-pose 模型专门设计用于此任务,并使用-pose后缀,如yolov8n-pose.pt。这些模型预先在数据集(如COCO 关键点)上进行了训练,并可用于各种姿势估计任务。欲了解更多信息,请访问姿势估计页面。
如何在自定义数据集上训练 YOLOv8-pose 模型?
在自定义数据集上训练 YOLOv8-pose 模型涉及加载模型,可以是由 YAML 文件定义的新模型或预训练模型。然后,您可以使用指定的数据集和参数开始训练过程。
from ultralytics import YOLO
# Load a model
model = YOLO("yolov8n-pose.yaml") # build a new model from YAML
model = YOLO("yolov8n-pose.pt") # load a pretrained model (recommended for training)
# Train the model
results = model.train(data="your-dataset.yaml", epochs=100, imgsz=640)
欲了解有关训练的详细信息,请参阅训练部分。
如何验证已训练的 YOLOv8-pose 模型?
验证 YOLOv8-pose 模型涉及使用在训练期间保留的相同数据集参数来评估其准确性。以下是一个示例:
from ultralytics import YOLO
# Load a model
model = YOLO("yolov8n-pose.pt") # load an official model
model = YOLO("path/to/best.pt") # load a custom model
# Validate the model
metrics = model.val() # no arguments needed, dataset and settings remembered
欲了解更多信息,请访问验证部分。
我可以将 YOLOv8-pose 模型导出为其他格式吗?如何操作?
是的,您可以将 YOLOv8-pose 模型导出为 ONNX、CoreML、TensorRT 等各种格式。可以使用 Python 或命令行界面(CLI)来完成此操作。
from ultralytics import YOLO
# Load a model
model = YOLO("yolov8n-pose.pt") # load an official model
model = YOLO("path/to/best.pt") # load a custom trained model
# Export the model
model.export(format="onnx")
欲了解更多详细信息,请参阅导出部分。
可用的 Ultralytics YOLOv8-pose 模型及其性能指标是什么?
Ultralytics YOLOv8 提供各种预训练姿势模型,如 YOLOv8n-pose、YOLOv8s-pose、YOLOv8m-pose 等。这些模型在尺寸、准确性(mAP)和速度上有所不同。例如,YOLOv8n-pose 模型实现了 mAP^(pose)50-95 为 50.4 和 mAP^(pose)50 为 80.1。有关完整列表和性能详细信息,请访问模型部分。
定向边界框目标检测
定向目标检测比普通目标检测更进一步,引入额外的角度以在图像中更准确地定位对象。
定向目标检测器的输出是一组旋转的边界框,精确包围图像中的对象,并附带每个框的类别标签和置信度分数。当您需要识别场景中感兴趣的对象但不需要精确知道对象在哪里或其精确形状时,目标检测是一个不错的选择。
提示
YOLOv8 OBB 模型使用 -obb 后缀,例如 yolov8n-obb.pt 并在DOTAv1 数据集上预训练。
|
www.youtube.com/embed/Z7Z9pHF8wJc
观看: 使用 Ultralytics YOLOv8 定向边界框(YOLOv8-OBB)进行目标检测 |
www.youtube.com/embed/uZ7SymQfqKI
观看: 使用 Ultralytics HUB 的 YOLOv8-OBB 进行目标检测 |
视觉样本
| 使用 OBB 进行船只检测 | 使用 OBB 进行车辆检测 |
|---|---|
 |  |
模型
YOLOv8 预训练的 OBB 模型显示在此处,这些模型是在DOTAv1 数据集上预训练的。
模型在首次使用时会自动从最新的 Ultralytics 发布版下载。
| 模型 | 尺寸 ^((像素)) | mAP^(测试 50) | 速度 ^(CPU ONNX
(ms)) | 速度 ^(A100 TensorRT
(ms)) | 参数 ^((M)) | FLOPs ^((B)) |
| — | — | — | — | — | — | — |
|---|---|---|---|---|---|---|
| YOLOv8n-obb | 1024 | 78.0 | 204.77 | 3.57 | 3.1 | 23.3 |
| YOLOv8s-obb | 1024 | 79.5 | 424.88 | 4.07 | 11.4 | 76.3 |
| YOLOv8m-obb | 1024 | 80.5 | 763.48 | 7.61 | 26.4 | 208.6 |
| YOLOv8l-obb | 1024 | 80.7 | 1278.42 | 11.83 | 44.5 | 433.8 |
| YOLOv8x-obb | 1024 | 81.36 | 1759.10 | 13.23 | 69.5 | 676.7 |
-
mAP^(测试) 值是在DOTAv1 测试 数据集上的单模型多尺度结果。
通过
yolo val obb data=DOTAv1.yaml device=0 split=test复现,并将合并结果提交到 DOTA evaluation。 -
Speed 使用 Amazon EC2 P4d 实例在 DOTAv1 val 图像上平均。
通过
yolo val obb data=DOTAv1.yaml batch=1 device=0|cpu复现
训练
在图像尺寸为 640 的情况下,在 dota8.yaml 数据集上对 YOLOv8n-obb 进行 100 个 epochs 的训练。查看 Configuration 页面获取所有可用参数的完整列表。
示例
from ultralytics import YOLO
# Load a model
model = YOLO("yolov8n-obb.yaml") # build a new model from YAML
model = YOLO("yolov8n-obb.pt") # load a pretrained model (recommended for training)
model = YOLO("yolov8n-obb.yaml").load("yolov8n.pt") # build from YAML and transfer weights
# Train the model
results = model.train(data="dota8.yaml", epochs=100, imgsz=640)
# Build a new model from YAML and start training from scratch
yolo obb train data=dota8.yaml model=yolov8n-obb.yaml epochs=100 imgsz=640
# Start training from a pretrained *.pt model
yolo obb train data=dota8.yaml model=yolov8n-obb.pt epochs=100 imgsz=640
# Build a new model from YAML, transfer pretrained weights to it and start training
yolo obb train data=dota8.yaml model=yolov8n-obb.yaml pretrained=yolov8n-obb.pt epochs=100 imgsz=640
数据集格式
OBB 数据集格式详细信息可在 Dataset Guide 中找到。
Val
在 DOTA8 数据集上验证训练好的 YOLOv8n-obb 模型的准确性。不需要传递任何参数,因为model保留其训练data和参数作为模型属性。
示例
from ultralytics import YOLO
# Load a model
model = YOLO("yolov8n-obb.pt") # load an official model
model = YOLO("path/to/best.pt") # load a custom model
# Validate the model
metrics = model.val(data="dota8.yaml") # no arguments needed, dataset and settings remembered
metrics.box.map # map50-95(B)
metrics.box.map50 # map50(B)
metrics.box.map75 # map75(B)
metrics.box.maps # a list contains map50-95(B) of each category
yolo obb val model=yolov8n-obb.pt data=dota8.yaml # val official model
yolo obb val model=path/to/best.pt data=path/to/data.yaml # val custom model
预测
使用训练好的 YOLOv8n-obb 模型对图像进行预测。
示例
from ultralytics import YOLO
# Load a model
model = YOLO("yolov8n-obb.pt") # load an official model
model = YOLO("path/to/best.pt") # load a custom model
# Predict with the model
results = model("https://ultralytics.com/images/bus.jpg") # predict on an image
yolo obb predict model=yolov8n-obb.pt source='https://ultralytics.com/images/bus.jpg' # predict with official model
yolo obb predict model=path/to/best.pt source='https://ultralytics.com/images/bus.jpg' # predict with custom model
查看 Predict 页面中的完整predict模式详细信息。
导出
将 YOLOv8n-obb 模型导出为 ONNX、CoreML 等不同格式。
示例
from ultralytics import YOLO
# Load a model
model = YOLO("yolov8n-obb.pt") # load an official model
model = YOLO("path/to/best.pt") # load a custom trained model
# Export the model
model.export(format="onnx")
yolo export model=yolov8n-obb.pt format=onnx # export official model
yolo export model=path/to/best.pt format=onnx # export custom trained model
可用的 YOLOv8-obb 导出格式列在下表中。您可以使用format参数导出任何格式,例如format='onnx'或format='engine'。您可以直接在导出的模型上进行预测或验证,例如yolo predict model=yolov8n-obb.onnx。导出完成后,模型的使用示例将显示在您的模型中。
| Format | format 参数 | 模型 | 元数据 | 参数 |
|---|---|---|---|---|
| PyTorch | - | yolov8n-obb.pt | ✅ | - |
| TorchScript | torchscript | yolov8n-obb.torchscript | ✅ | imgsz, optimize, batch |
| ONNX | onnx | yolov8n-obb.onnx | ✅ | imgsz, half, dynamic, simplify, opset, batch |
| OpenVINO | openvino | yolov8n-obb_openvino_model/ | ✅ | imgsz, half, int8, batch, dynamic |
| TensorRT | engine | yolov8n-obb.engine | ✅ | imgsz, half, dynamic, simplify, workspace, int8, batch |
| CoreML | coreml | yolov8n-obb.mlpackage | ✅ | imgsz, half, int8, nms, batch |
| TF SavedModel | saved_model | yolov8n-obb_saved_model/ | ✅ | imgsz, keras, int8, batch |
| TF GraphDef | pb | yolov8n-obb.pb | ❌ | imgsz, batch |
| TF Lite | tflite | yolov8n-obb.tflite | ✅ | imgsz, half, int8, batch |
| TF Edge TPU | edgetpu | yolov8n-obb_edgetpu.tflite | ✅ | imgsz |
| TF.js | tfjs | yolov8n-obb_web_model/ | ✅ | imgsz, half, int8, batch |
| PaddlePaddle | paddle | yolov8n-obb_paddle_model/ | ✅ | imgsz, batch |
| NCNN | ncnn | yolov8n-obb_ncnn_model/ | ✅ | imgsz, half, batch |
查看 Export 页面中的完整export详细信息。
FAQ
什么是有向边界框(OBB),它们与常规边界框有何不同?
定向边界框(OBB)在图像中增加了一个额外的角度,以提高对象定位的准确性。与常规的轴对齐矩形边界框不同,OBB 可以旋转以更好地适应对象的方向。这在需要精确对象放置的应用中特别有用,比如航空或卫星图像(数据集指南)。
如何使用自定义数据集训练 YOLOv8n-obb 模型?
要使用自定义数据集训练 YOLOv8n-obb 模型,请按照下面的示例使用 Python 或 CLI:
示例
from ultralytics import YOLO
# Load a pretrained model
model = YOLO("yolov8n-obb.pt")
# Train the model
results = model.train(data="path/to/custom_dataset.yaml", epochs=100, imgsz=640)
yolo obb train data=path/to/custom_dataset.yaml model=yolov8n-obb.pt epochs=100 imgsz=640
要了解更多训练参数,请检查配置部分。
我可以用什么数据集训练 YOLOv8-OBB 模型?
YOLOv8-OBB 模型预先训练在像 DOTAv1 这样的数据集上,但您可以使用任何格式化为 OBB 的数据集。有关 OBB 数据集格式的详细信息,请参阅数据集指南。
如何将 YOLOv8-OBB 模型导出为 ONNX 格式?
使用 Python 或 CLI 可以轻松将 YOLOv8-OBB 模型导出为 ONNX 格式:
示例
from ultralytics import YOLO
# Load a model
model = YOLO("yolov8n-obb.pt")
# Export the model
model.export(format="onnx")
yolo export model=yolov8n-obb.pt format=onnx
若要了解更多导出格式和详细信息,请参阅导出页面。
如何验证 YOLOv8n-obb 模型的准确性?
要验证 YOLOv8n-obb 模型,您可以使用下面显示的 Python 或 CLI 命令:
示例
from ultralytics import YOLO
# Load a model
model = YOLO("yolov8n-obb.pt")
# Validate the model
metrics = model.val(data="dota8.yaml")
yolo obb val model=yolov8n-obb.pt data=dota8.yaml
在 Val 部分查看完整的验证细节。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









