







数据网格的前奏
我个人对数据网格存在性的理由的看法


·
关注 发表在 Towards Data Science · 4 分钟阅读 · 2023 年 12 月 3 日
–
我在一个项目中的一位高级利益相关者提到,他们希望去中心化他们的数据平台架构,并在组织内实现数据民主化。
当我听到“去中心化数据架构”这个词时,我最初感到非常困惑!在我当时有限的数据工程经验中,我只接触过中心化的数据架构,而且它们似乎运行得非常好。因此,我不禁思考,我们想要通过去中心化的数据架构解决什么问题?还是说我们正在创造一个根本不存在的新问题?
我在哪里寻找?
显而易见的答案 — 由 Zhamak Dehghani 提出的数据网格。
一本伟大的书,带你了解一个实施这一概念并克服一些独特挑战的组织。强烈推荐给那些希望深入了解的人。
但为了说明这个概念为何出现,我认为回顾一下历史并理解数据景观的演变会很有帮助。以下是我过于简化的看法。
数据景观的演变
1980 年代——起源
-
关系型数据库诞生了。
-
组织开始将关系型数据库用于“一切”。
-
数据库被事务性和分析性负载压垮了。
结果:
- 数据仓库诞生了。

作者提供的图片
1990 年代早期——规模
-
分析工作负载开始变得复杂。
-
数据量开始增长。
-
性能需要改进。
结果:
- 引入了大规模并行处理(MPP)概念——数据在集群之间分布。

作者提供的图片
1990 年代末到 2000 年代初——产品化
-
对报告的需求不断增长。
-
架构变得复杂。
-
业务部门需要与其分析相关的数据。
结果:
-
公司开始将预配置的数据仓库作为产品出售。
-
引入了
数据集市的概念。

作者提供的图片
2004 年至 2010 年——大象进入房间
-
新一波的应用出现了——社交媒体、软件可观察性等。
-
新的数据格式出现了——JSON、Avro、Parquet、XML 等。
结果:
-
Hadoop 和 NoSQL 框架出现了。
-
引入了数据湖以存储新数据格式。

作者提供的图片
2010 年至 2020 年——云数据仓库
- 企业现在希望快速的数据分析,而不受昨天灵活性、处理能力和规模的限制。
结果:
-
云数据仓库解决方案作为关系型和半结构化数据的首选解决方案出现了。
-
示例包括:Amazon Redshift、Google BigQuery、Snowflake、Azure Synapse Analytics、Databricks 等。
那么缺少了什么?

作者提供的图片
如果我们查看一个组织中使用集中式数据架构的数据通用流程,我们会意识到数据有 3 个接触点:
-
数据生产者
-
中央数据团队
-
数据消费者
现在让我们先问自己几个问题:
-
谁管理数据仓库?
-
哪个团队响应数据请求?
-
哪个团队负责确保数据质量?
-
哪个团队被期望成为数据的 SME?
当我向一群人提问这些问题时,我得到的一个共同答案是(与其他答案结合)——选项 B,中央数据团队。
所以我们可以推断中央数据团队需要:
-
管理数据仓库
-
服务数据请求
-
确保数据质量
-
成为数据仓库中数据的 SME
还有更多问题待解决。
那么,缺少了什么?
随着企业的持续增长,中央数据团队往往成为从数据中获得可操作见解的瓶颈。
中央数据团队最终会承担大量的知识负担,并面临越来越大的交付压力。
这为我提供了支持去证明去中心化数据架构——通常被称为数据网(Data Mesh)——存在的合理性。
数据网是一种分析架构,但更重要的是,它是一种将分析数据的所有权转移给最了解和拥有数据的团队——即数据生产者和消费者——的运营模型。
该图展示了数据网架构的高层次视图:
martinfowler.com/articles/data-monolith-to-mesh/data-mesh.png
我不会详细讨论数据网的原则或逻辑架构,因为有很多文章对此做了详细解释。以下是我最喜欢的一些:
参考文献:
进行统计测试所需的基础概念简介
定量研究设计、显著性测试和不同类别的统计测试。


·发表于 Towards Data Science ·8 分钟阅读·2023 年 9 月 9 日
–

图片来源:Szabo Viktor 于 Unsplash
我写这篇文章的过程是通过一系列可预测但依然意外的事件实现的。我最近完成了一门关于统计测试和报告的课程,并着手撰写一系列文章,解释我所学到的最有用的统计测试的细节。我希望这样做既能巩固我自己的知识,也能帮助其他数据科学家学习一个我发现极为有用的主题。
第一篇文章将讨论t 检验,这是一种常见的统计测试,用于确定来自不同数据集的两个均值(平均值)是否在统计上有所不同。我开始撰写这篇文章,但意识到我首先需要解释 t 检验有两种不同的类型。然后,我意识到为了说明这一点,我需要解释一个独立但相关的基础概念。在我规划文章时,这种循环不断进行。
此外,我意识到我需要对每一篇新文章都这样做,因为每个统计测试都需要相同的基础知识。与其在每篇文章中重复这些信息,不如引用一个统一的信息来源要好得多。
因此,这篇文章诞生了。在接下来的文字中,我将尝试简明有效地介绍你在进行和报告统计测试时需要熟悉的基本概念。为了你的方便,我将这些概念按照你从开始到结束进行研究的顺序进行划分。废话不多说,让我们开始吧。
定量研究设计
在设计研究时,有几个重要的细节需要考虑。本文并不涉及研究设计的细节,也不会讨论最佳实践及其背后的理由。不过,研究的设计对最终所需的统计检验有很大影响,因此对以下概念有基本的了解是至关重要的:
-
因素和测量
-
水平和处理
-
被试间与被试内
因素和测量虽然你可能以前没有听过“因素”和“测量”这些术语,但很可能你在高中科学课上遇到过它们的不同名称:“自变量”和“因变量”。
在科学实验中,因素是你主动操控或改变的变量/条件,以观察其对另一变量的影响。你观察其效果的变量是测量。
通过一个例子更容易理解。假设我们正在进行一个有趣的实验,目的是确定一个人早晨吃的肉类是否会影响他们当天稍后的 100 米跑步时间。我们有两组参与者:第一组的每个人都吃鸡胸肉,第二组的每个人都吃牛排。下午,每组的成员都进行 100 米跑步,并记录各自的时间。
在这个实验中,因素是肉类类型,因为这是我们主动改变的内容,而测量是 100 米跑步时间,因为这是我们试图观察其效果的变量。
水平和处理
这两个术语与实验中的因素有关。因素的水平指的是它在研究中具有的不同条件的数量。每个水平上的因素的实际值或表现就是处理。
例如,在上述实验中,有两个水平,因为我们测试了两种不同类型的肉。两种处理是鸡肉和牛肉。如果我们把鸭肉也放进来,那么我们将有三个水平,其中第三种处理是鸭肉。
被试间设计和被试内设计这最后两个概念稍微复杂一些,但非常重要——研究使用被试间设计还是被试内设计直接影响可以用于分析的统计检验类型。
从根本上讲,研究设计的这一方面涉及如何将参与者分配到研究中因素的不同处理上。
在被试间设计中,每个参与者只接触一个处理,而在被试内设计中,每个参与者都接触所有处理。换句话说,被试间设计使用不同的参与者组来处理独立变量的每个水平,而被试内设计则重复使用同一组参与者。
例如,考虑一个研究,我们想看看一种新型隐形眼镜是否能提高视力测试的表现。我们可以将一个参与者组给予初始镜片,另一个组给予新镜片,并比较他们在视力测试中的表现(被试间设计)。或者,我们可以让同一组参与者尝试两种镜片,并比较同一参与者在不同镜片下的视力测试表现(被试内设计)。
请注意,并非总是可能进行被试内设计。在上面的肉类和跑步例子中,假设实验必须在一天内完成(由于资源限制,这可能确实是情况),一个人只能在早餐时选择一种肉类,而不能同时选择两种。
最后,涉及多个因素的实验可以结合被试间和被试内的元素。这种方法被称为分割实验设计。例如,假设我们想评估在心理健康评估中的表现,并且我们有两个因素:1)大学年份和 2)每日屏幕时间量。我们决定在一年内进行这个实验,让每年的参与者(大一、大二等)前六个月没有屏幕时间限制,最后六个月有每天 30 分钟的屏幕时间限制。心理健康评估在每次实验结束时进行。
在这个实验中,屏幕时间以被试内设计的方式进行测试(相同的参与者接受两种处理),但大学年份以被试间设计的方式进行测试(一个人不能同时处于两个年级)。请注意,这个实验并不是一个要遵循的模型(细致的读者会注意到许多可能的混杂因素),而只是一个简化的例子,用来解释分割实验设计可能是什么样的。
既然如此,让我们继续前进。
显著性检验
如果你曾经处理过统计检验,很可能你听过“统计学上显著差异”这一说法。现代统计检验(至少在频率主义范式中,但我们暂时不讨论这一点)大多在于尝试确定实验中不同处理组之间是否存在有意义的差异。
本节中的术语对于理解这个概念都是必不可少的。我们将以与上面不同的方式逐一讲解这些术语。首先,我将定义所有的术语。然后,由于它们在一个实验中相互关联,我们将通过一个假设实验,强调每个术语的作用。
首先:假设检验。在传统的统计实验中,我们从两个假设开始:
-
原假设:该假设表示处理组之间没有统计学上显著的差异。
-
替代假设:这一假设指出处理组之间存在统计学上显著的差异。它可以是单侧的(假设在某个特定方向上存在差异,即更大或更小),也可以是双侧的(仅仅假设存在差异)。
在所有统计测试中,我们首先假设零假设为真。然后,在这一假设下,我们计算看到实际数据的可能性。如果这种可能性非常低(低于某个特定阈值——见下文),我们就确定零假设实际上是错误的,因此我们拒绝它。
正式来说,这个阈值被称为p 值。p 值是指在假设零假设为真的情况下,我们看到的数据由于随机机会的概率。因此,如果 p 值非常低(通常低于 .05,虽然这在不同领域和实验中可能有所不同),我们就拒绝零假设,声称我们的结果具有统计学意义。这是合乎逻辑的,因为低 p 值表明在零假设下看到这些数据的概率非常低。
这就足以让你入门——如果你对了解更多细节感兴趣,我推荐这篇关于 p 值的入门文章 [2]。
两类检验
最后,当你处理统计检验时,你需要知道应该使用参数检验还是非参数检验。
参数检验是更广为人知的一类统计检验,主要是因为更流行的检验通常是参数检验。参数检验有一套关于数据各种统计参数的要求。例如,所有参数检验都要求数据来自随机样本。其他要求因检验而异,如要求特定类型的分布。
不幸的是,在处理实际数据时,这些要求并不总是能得到满足。偶尔,入门课程会教导只需随便使用检验以满足课程要求,并简要提及超出课程范围的替代技术的存在。
然而,在数据参数不符合必要要求的实际应用中,随便使用检验并不合适。非参数检验正是为了这个原因而设计的。这些统计检验不要求数据有任何特殊性质,因此应该在数据行为不符合要求的情况下使用 [3]。
对于几乎每一个参数统计检验,都有一个对应的非参数检验。因此,一旦考虑到实验中的所有要素(因素数量、每个因素的处理等),最终确定使用什么检验的问题涉及到是否应该使用参数检验还是非参数检验。
此时,自然会有人想知道为什么要使用参数检验。虽然对此的详细讨论超出了本文的范围,但高层次的原因很简单:参数检验提供了更高的统计能力,因此应尽可能使用。
回顾与最终思考
这里是一个关于你在学习统计测试时应该理解的基础概念的快速回顾:
-
定量研究设计。了解实验的组成,包括因素、测量、处理和不同的参与者设计(被试间设计和被试内设计)。
-
显著性测试。了解如何制定零假设和备择假设,以及如何使用 p 值。
-
统计测试的类型。了解何时使用参数检验与非参数检验。
当你进入研究的分析阶段时,清楚地记录上述所有元素与你的实验相关是非常有帮助的。你需要使用的统计测试将直接与这些元素相关。不过,在应用之前理解概念总是好的,希望这篇文章对你有帮助。
祝你测试愉快!
想在 Python 中表现出色? 点击这里获取我简单易读的指南的独家免费访问权限。想在 Medium 上阅读无限故事?通过我的推荐链接注册!
[## 通过我的推荐链接加入 Medium - Murtaza Ali
作为一个 Medium 会员,你的部分会员费会分给你阅读的作者,你可以获得所有故事的完全访问权限……
medium.com](https://medium.com/@murtaza5152-ali/membership?source=post_page-----ae6b6c79e9a4--------------------------------)
参考文献
[1] Lazar, J., Feng, J.H. 和 Hochheiser, H. (2017). 人机交互研究方法(第 2 版)。剑桥,MA。
[2] towardsdatascience.com/how-to-understand-p-value-in-layman-terms-80a5cc206ec2
[3] Vaughan, L. (2001). 信息专业人员的统计方法。美福德,NJ:ASIS&T Press,第 139–155 页。
《线性代数入门》
对数据科学的关键概念和操作的温和回顾


·
关注 发表在 Towards Data Science ·9 分钟阅读·2023 年 1 月 12 日
–

照片由 Vashishtha Jogi 提供,来自 Unsplash
介绍
无论你是在拟合一个简单的回归模型还是卷积神经网络,线性代数在使这些计算高效方面都起着重要作用。虽然大多数人可能对其在几何学中的应用比较熟悉——例如用来定义线条、平面及其变换(如旋转和位移)——但线性代数在科学和工程领域中都是基础性的。鉴于它对科学计算的重要性,每个数据科学家都应该对其有所了解。
所以,如果你的线性代数有些生疏,或者你只是想初步了解一下,这个入门介绍了一些基本概念,希望能温和地引导你进入线性代数的世界。
向量
一个向量包含一组有序的值,这些值告诉我们如何在n维空间中从一个点移动到另一个点。例如,在二维空间中,向量表示两个离散的(x, y)点之间的有向线段——它告诉你一个点相对于另一个点的位置。然而,向量空间可以有超过两个维度;因此,向量包含的分量数量对应于其空间的维度:

一个 n 维列向量(图片由作者提供)。
其中 ℝ 表示所有维度为n的实值向量的集合。这里,v 是一个列向量,但也可以表示为行向量:

行向量是通过转置列向量创建的(图片由作者提供)。
其中T 是转置运算符。通常,向量以列形式用小写粗体字母表示,但将向量以行形式显示也很方便。
向量运算
对向量应用运算和函数通常很有用,其中一种运算是向量加法。这个操作没有什么神秘之处,它的作用就像名字所示那样。假设我们有两个2维向量u和v,我们想将它们相加。这些向量的和就是它们分量的和:

向量加法(图片由作者提供)。
我们也可以对向量进行乘法运算,其中最简单的称为标量乘法。这涉及到将每个向量分量乘以一个实数常量c,这个常量称为标量倍数,或简称为标量。例如,向量cv 为:

向量的标量乘法(图片由作者提供)。
这会产生一个缩放后的向量,这个向量的效果是拉伸或收缩,缩放后的版本长度是原始向量的 |c| 倍。此外,如果c < 0,则向量的方向会反转。如果我们想减去向量而不是加上向量,这会非常有用,因为向量v的负数就是(-1)v = -v,所以在这种情况下c = -1。然后,向量u和v之间的差异可以表示为:

向量减法(图片由作者提供)。
标量还用于创建线性组合的向量;不过,在这种情况下,标量通常称为系数。例如,我们可以用向量u和v以及系数a和b来创建一个向量w,如下所示:

向量的线性组合(作者提供的图片)。
这只是两个缩放向量的和。
点积
点积(或数量积)取两个维度相同的向量,并产生每个对应分量的乘积的和的标量。这是相当冗长的描述,所以为了说明,在下面显示了两个n维向量u和v的点积:

点积(作者提供的图片)。
这表明,因为每个向量的大小相同,乘法是分量对应相乘–向量u中的第i个分量乘以向量v中的第i个分量–然后所有乘积相加。请注意,哪个向量乘以哪个向量都没有关系,因为点积是可交换的,意思是u x v = v x u.
点积还用于测量向量的长度,称为范数。范数是一个非负标量,等于其平方分量的和的平方根,用来衡量原点O=[0, 0]和n维空间中的向量点之间的距离。例如,具有维度n的向量v的范数计算如下:

范数是向量的长度(作者提供的图片)。
在二维空间中,这不仅测量直角三角形的斜边长度,并且与毕达哥拉斯定理完全相同。我们还可以测量两个向量之间的距离,这只是上述的一般化。如果我们想要测量向量u和v之间的距离,那么这只是两个向量之间差异的范数:

两个向量之间的距离(作者提供的图片)。
最后,点积还用于测量两个非零向量之间的角度。具体来说,向量u和v之间的角度的余弦是:

两个向量之间夹角的余弦(作者提供的图片)。
因此,角度等于:

求角度(作者提供的图片)。
在结束向量之前,一个重要的条件要认识到是正交性。如果两个向量之间的夹角为 90 度(或垂直),则说这些向量是正交的。在这种情况下,向量形成直角,因此:

如果满足这个条件,两个向量是正交的(作者提供的图片)。
由此可见:

正交性的另一个影响(作者提供的图片)。
矩阵
一个矩阵是一个按列和行排列的值的表格。矩阵中的每个值称为元素或条目,矩阵的大小描述了它有多少行和列。例如,一个m x n(读作“m 乘 n”)矩阵有m 行和n 列。如果一个矩阵只有一行,那么它与上面介绍的行向量相同,但也可以称为行矩阵。类似地,只有一列的矩阵是列向量或列矩阵。
一般来说,大小为n x m 的矩阵的形式为:

一个m x n 矩阵(作者插图)。
在引用特定矩阵元素时,通常使用双下标符号,其中i 为条目的行下标,j 为列下标。对于上述矩阵A,一个条目可以引用为:

矩阵 A 中元素的定义(作者插图)。
对于任何矩阵,我们可以将对角元素定义为那些具有相同下标的元素:

矩阵的对角元素具有相同的下标(作者插图)。
如果条件m = n 成立,那么矩阵被称为方阵,并且沿主对角线的元素数量等于行或列的数量。此外,对于任何n x n 方阵,迹定义为沿主对角线元素的总和:

方阵的迹(作者插图)。
现在,如果一个矩阵只有非零的对角线元素——这意味着所有其他元素都是零——那么这个矩阵被称为对角矩阵:

对角矩阵沿主对角线只有非零元素(作者插图)。
然而,如果对角矩阵的值都是相同的——也就是说,对角线上的值是一个标量——那么这个矩阵被称为标量矩阵:

标量矩阵沿主对角线只有非零标量(作者插图)。
但如果标量恰好是c = 1,那么这个矩阵被称为单位矩阵:

单位矩阵沿主对角线只有 1(作者插图)。
请注意,对于任何标量c,标量矩阵可以作为单位矩阵的标量倍数来推导:B = c I。
矩阵运算
之前讨论的向量运算也可以推广到矩阵。例如,如果两个矩阵A和B大小相等,则可以按元素相加,如下所示:

矩阵加法(作者插图)。
类似地,矩阵可以使用任何实值常数c进行缩放:

矩阵的标量乘法(作者插图)。
我们还讨论了如何使用转置运算符将列向量转换为行向量。这个运算符也可以推广到矩阵,并通过交换行和列来实现。具体来说,矩阵A的转置结果是:

矩阵的转置(图像作者提供)。
这表明转置矩阵的第i列是原始矩阵A的第i行。换句话说,转置矩阵中第i行和第j列的元素与矩阵A中第j行和第i列的元素相同。
转置也用于评估一个方阵是否是对称的。如果满足以下条件,则为对称矩阵:

对称方阵的条件(图像作者提供)。
这表明A等于它的转置。
矩阵乘法
与上面讨论的向量和矩阵操作不同,矩阵乘法不是逐元素的。例如,如果A是一个m x n的矩阵,B是一个n x p的矩阵,那么积C = AB 是一个m x p的矩阵,其中第i行和第j列的条目计算为:

对于第i行和第j列的逐元素计算(图像作者提供)。
这看起来与之前讨论的点积非常相似,实际上它就是一个点积!具体来说,矩阵C中第i行和第j列的元素是矩阵A的第i行与矩阵B的第j列的点积。请注意,矩阵的大小不必相等;然而,矩阵乘法要求A的列数与B的行数匹配。
最后的备注
本文涉及了一些线性代数中的基础概念和操作,所以有很多内容无法挤进一篇文章中。其他一些值得注意的内容包括可逆矩阵和矩阵求逆、线性方程组的解法,以及特征值和特征向量。我将在未来的文章中详细讲解这些内容,同时希望你觉得这篇简短的入门文章有用。
感谢阅读!
如果你喜欢这篇文章并希望保持更新,请考虑关注我在 Medium 上。这样可以确保你不会错过任何新内容。
要获取所有内容的无限访问权限,请考虑注册 Medium 会员。
你还可以在 Twitter 上关注我、在 LinkedIn 上关注我,或者查看我的GitHub,如果你更喜欢这样😉
线性代数入门:第二部分
数据科学必备的基本概念和操作的温故知新


·
关注 发表在 Towards Data Science · 6 分钟阅读 · 2023 年 4 月 25 日
–

图片由Viktor Forgacs在Unsplash提供
介绍
在我之前的文章中,我介绍了一些线性代数的基本操作和概念。这包括向量和矩阵,以及转置、点积和矩阵乘法运算符。在这篇文章中,我将介绍一些补充之前讨论过的概念。如果你还没有阅读我的线性代数入门文章,可以在这里查看。
线性独立性
在定义线性独立性之前,我们首先需要定义线性依赖性。简单来说,向量序列是线性依赖的,如果至少有一个可以表示为其他向量的线性组合。具体来说,假设我们有一个由 n 个向量 v₁、v₂、⋯、vₙ 组成的矩阵 V 的列。线性依赖成立当且仅当存在 n 个标量 a₁、a₂、⋯、aₙ,使得:

线性依赖性的条件(作者提供的图片)。
其中 0 表示零向量,且至少有一个 aᵢ 不等于零。
这个要求很重要,因为没有它,你可以将所有 a 设置为零并得到结果*。* 那么线性独立性的定义就是相反的情况;即,向量序列不是线性依赖的情况。这意味着以下条件成立:

线性独立性的条件(作者提供的图片)。
因此需要所有标量都为零。在这些条件下,序列中的任何向量都不能表示为其他剩余向量的线性组合。
例如,假设我们有两个向量v₁和v₂,每个向量都是ℝ²。为了保持线性独立性,我们需要一组系数,使得:

展示 2 x 2 矩阵线性独立性的示例(作者提供的图片)。
其中 a₁ 和 a₂ 都等于零。
行列式
行列式 是一个标量值,它是方阵中元素的函数。如果矩阵的维度较小,手动计算行列式相对简单。例如,设 A 为一个 2 × 2 的矩阵;在这种情况下,行列式就是:

2 x 2 矩阵的行列式(作者提供的图片)。
我们还可以计算一个 3 × 3 矩阵的行列式,虽然这个过程稍微复杂一些。我不会在这里详细说明,但这个情况的解是:

3 x 3 矩阵的行列式(作者提供的图片)。
这个解被称为莱布尼茨公式,并且可以推广到更高维度。同样,我不会在这里深入细节,但会提供通用公式:

3 x 3 矩阵的行列式(作者提供的图片)。
其中sgn是群 Sₙ 中排列的符号函数,σ表示一个重新排序——或排列——整数集合的函数。
虽然行列式的公式并不是特别直观,但它提供的信息却是直观的。行列式本质上是几何的,告诉我们图像在变换下如何变化。再次考虑一个简单的 2 × 2 矩阵,行列式实际上是平行四边形的面积,这个平行四边形代表了单位正方形在矩阵给定的变换下的图像。
这同样适用于更高维度,虽然此时行列式对应的是体积,而不是面积。例如,一个 3 × 3矩阵的行列式是一个平行六面体的体积,而任何n × n矩阵的行列式是一个n维平行六面体的超体积。
秩
从定义上讲,矩阵的秩决定了线性独立列的最大数量;虽然更正式地,它对应于由其列张成的向量空间的维度。通常,我们希望矩阵具有满秩,因为这一条件意味着列向量之间没有冗余。任何存在列间线性相关的矩阵都不会具有满秩,被称为秩亏损。
举个例子,考虑一个方阵n × n的矩阵A。如果这个矩阵中的所有列都是线性独立的,那么这个矩阵被称为具有满列秩,它将等于n。由于矩阵是方阵,我们也可以考虑其行是否线性独立。如果是,那么矩阵也具有满行秩,这也将等于n。因为这些是等价的,一个方阵被认为具有满秩,如果所有的行和列都是线性独立的,这表示 rank(A) = n。
实际上,对于方阵,只有当其行列式非零时,满秩才是可能的。因此,我们实际上可以使用行列式来测试方阵中的线性独立性。
但,如果矩阵不是方阵怎么办?在这种情况下,满秩的定义略有不同。假设我们有一个非方阵B,它有m行和n列,那么满秩定义为给定矩阵形状下可能的最高行或列秩。违反直觉的是,这将等于较小的维度。
例如,如果B的行数相对于列数更多(即,m > n),则满秩要求B具有满列秩,因此 rank(B) = n。相反,如果行数少于列数(即,m < n),则B必须具有满行秩,因此 rank(B) = m。这是因为如果矩阵不是方阵,那么它的行或列必定线性相关。
矩阵求逆
从定义上讲,一个n × n的方阵A 被认为是可逆的,如果存在另一个n × n的方阵B,使得以下条件成立:

矩阵可逆性的条件(作者提供的图像)。
这表明,如果矩阵A和B的矩阵乘积是单位矩阵,那么矩阵的可逆性成立。如果这确实正确,那么B由A唯一确定,我们称矩阵B是A的乘法逆矩阵,记作A⁻¹。矩阵求逆的任务是尝试找到一个满足可逆性条件的矩阵B。不过,我这里不会深入讨论矩阵求逆中使用的数值方法。
请注意,只有在矩阵具有满秩的情况下,矩阵才可以被求逆,这意味着A的列是线性独立的。任何不能被求逆的矩阵都被称为退化或奇异。
最后的备注
本文轻描淡写地介绍了线性代数中的一些基本概念。像任何话题一样,你可以深入探讨细节,因此这篇文章并不是完全详尽的,只是触及了表面。不过,本文讨论的概念在构建数学模型时至关重要,因此数据科学家需要了解。在后续文章中,我们将看到这些概念以及我早期入门文章中介绍的那些概念是如何应用于线性回归模型的。敬请期待!
相关文章
感谢阅读!
如果你喜欢这篇文章并希望保持更新,请考虑 在 Medium 上关注我。这将确保你不会错过任何新内容。
若想无限访问所有内容,请考虑注册 Medium 订阅。
你也可以在 Twitter、LinkedIn 上关注我,或者查看我的 GitHub,如果你更喜欢这个😉
统计估计与推断基础
大数法则和扎实的统计推理是数据科学中有效统计推断的基础


·
关注 发表在 Towards Data Science · 17 分钟阅读 · 2023 年 10 月 31 日
–

图片来源:Gabriel Ghnassia 在 Unsplash
大数法则和扎实的统计推理是数据科学中有效统计推断的基础。
以下内容大部分取自我的书籍,《数据科学——统计与机器学习导论》([Plaue 2023]),由 Springer Nature* 最近出版。*
引言
通过我们的日常经验,我们对人群的典型身高有一个直观的理解。在世界大部分地区,成年人通常身高在 1.60 m 到 1.80 m 之间,而身高超过两米的人则很少见。通过提供身高的频率分布,这一直观事实可以用数值证据来支持。

表 1:人类身高频率。图像由作者提供。
这些数据基于美国疾病控制与预防中心(CDC)收集的数据集,其中列出了包括身高在内的 340,000 多人的各种属性[CDC 2018]。对这个频率表的检查表明,实际上,超过一半的受访者报告他们的身高在
1.60 m 和 1.80 m。
尽管样本的规模有限,我们仍然相信我们的调查使我们能够对整体人群得出结论。例如,仅基于数据,我们可以相对有把握地得出结论,人类不可能长到三米高。
随机过程的一个重要目标是严谨而数学地证明这些结论。该领域可以分为两个子领域:
-
概率论处理概率概念的数学定义和研究。此类研究的一个中心对象是随机变量:这些变量的值并未被精确指定或知道,而是存在不确定性。换句话说,只能给出一个概率,即随机变量取值在某个范围内。
-
推断统计学基于这样的假设,即统计观察和测量(例如频率、均值等)是随机变量的值或实现。相反,该领域研究了随机变量的特征在多大程度上可以从样本数据中估计出来。特别地,在某些简化假设下,可以量化这种估计的准确性或误差。
让我们来看看一个简单的统计推断示例:通过观察一系列掷币结果来确定一枚硬币是否公平或有偏。我们可以假设掷硬币的结果由一个离散随机变量 *X_*1 决定,该变量取值为零(代表反面)或一(代表正面)。如果我们再次掷同一枚硬币,我们可以假设结果可以用第二个随机变量 *X_*2 来描述,该变量与第一个变量独立但遵循相同的分布。
如果我们没有任何证据支持硬币有偏的假设,我们可以假设硬币是公平的。换句话说,我们期望正面和反面的出现概率相同。在这种被称为零假设的假设下,如果我们重复多次实验,我们期望正面出现的频率与反面大致相同。
相反,这些数据使我们能够对潜在的真实分布得出结论。例如,如果我们观察到正反面出现的频率差异很大,比如正面出现的频率为 70%,而反面为 30%,那么——如果样本量足够大——我们会相信需要修正我们最初关于等概率的假设。换句话说,我们可能需要放弃我们认为硬币是公平的假设。
在上述例子中,数据中正面出现的频率作为“硬币出现正面”这一随机事件的概率的估计量。常识表明,我们对这些估计的信心随着样本量的增加而增加。例如,如果之前提到的不平衡只出现在十次掷硬币中(七次正面和三次反面),我们可能还不会确信我们有一个偏倚的硬币。零假设,即公平的硬币,仍然有可能成立。在日常术语中,实验结果也可能归因于“纯粹的运气”。然而,如果我们观察到在一百次掷硬币中出现了七十次正面,那将是更有力的证据支持硬币是偏倚的替代理论!
中心极限定理:从点估计到置信区间
点估计是统计学家和数据科学家工具包中最基本的工具之一。例如,从大量样本中得到的算术平均值提供了对给定变量可能取值的洞察。在机器学习中,我们从训练数据中估计模型参数,这些数据应涵盖足够数量的标记示例。
通过经验和直觉,我们相信较大的样本和更多的训练数据可以提供更准确的统计程序和更好的预测模型。推断统计提供了更稳健的基础来支持这种直觉,这通常被称为大数法则。此外,通过计算置信区间,我们对什么是“足够大的样本”有了更深刻的理解,而不是仅仅依赖点估计。置信区间为我们提供了一些范围值,在这些范围内,我们可以合理地断言我们试图估计的真实参数存在。
在接下来的部分中,我们将以自包含的方式展示计算置信区间的数学框架,其核心在于中心极限定理。
切比雪夫大数法则
正如我们期望相对频率是事件或二元变量结果概率的良好估计器一样,我们也期望算术均值是产生我们观察到的数值数据的随机变量期望值的良好估计器。
需要注意的是,这个估计值本身也是一个随机变量。如果我们掷骰子 50 次并记录平均数,然后重复实验,我们可能会得到略有不同的值。如果我们多次重复实验,我们记录的算术均值将遵循某种分布。然而,对于大样本,我们期望它们仅显示出小的离散度,并围绕真实的期望值集中。这是切比雪夫大数法则的核心信息,我们将在下面详细说明。
在此之前,我们引入一个概率理论中的重要工具— 切比雪夫不等式。假设我们有一个随机变量 X,其均值为 μ,方差为 σ²。那么,对于任何 ε > 0,下述关系成立,其中 Pr( · ) 表示“概率”:

这一结果与我们对离散度量的直观理解是一致的:方差越小,随机变量取值接近均值的可能性越大。
例如,随机变量在其期望值的六个标准差范围内的观察值的概率非常高,至少为 97%。换句话说,随机变量取值偏离均值超过六个标准差的概率非常低,小于 3%。这一结果适用于任何形状的分布,只要期望值和方差是有限值。
现在假设我们在样本中观察到数值,这些数值是随机变量 *X_*1, …, *X_*N 的实现。我们假设这些随机变量彼此独立,并且遵循相同的分布,这一属性通常被称为独立同分布,简称i.i.d.。当观察结果是由独立设立和相同准备的实验所得,或代表从总体中随机选择的样本时,这一假设是合理的。然而,需要注意的是,这一假设可能并不总是成立。
此外,我们假设每个随机变量的期望值 μ 和方差 σ² 存在且有限。由于这些变量遵循相同的分布,这些值对每个变量都是相同的。接下来,我们考虑以下产生算术平均值的随机变量:

首先,我们展示算术均值估计量 x̄是无偏估计量:其值围绕真实均值μ分布。这是直接从期望值E[ · ]的线性性质中得出的结果。

接下来,我们希望展示对于大样本,算术均值估计量的值不会过于偏离真实均值。由于*X_*1, …, *X_*N 被假定为相互独立,它们是成对不相关的。检查成对不相关的随机变量的方差可以按如下方式表示,因为所有交叉项都消失了,并不困难:

因此,算术均值估计量的方差如下:

既然我们知道了算术均值估计量的均值和方差,我们可以应用切比雪夫不等式:

这一结果表明算术均值是一致估计量:它在概率上收敛于真实均值。换句话说,对于大样本,底层分布的期望值μ与样本的算术均值之间不太可能有显著差异。
林德伯格–列维中心极限定理
切比雪夫大数法则指出,在相当一般的条件下,大样本的算术均值很可能接近于底层分布的真实均值。或许令人惊讶的是,我们可以相当具体地说明大样本的均值围绕真实期望值的分布情况。这是林德伯格–列维中心极限定理的核心信息。对于任意数字a,b且a < b:

方程右侧的被积函数是标准正态分布的概率密度函数:正态分布——其具有著名的钟形曲线——均值为零,方差为一。
通常,若一序列随机变量对某随机变量收敛于分布,则其累计分布函数点对点地收敛于该随机变量的分布*。* 从数学上讲,中心极限定理表明,无论*X_*1, … *X_*N 如何分布(只要它们是独立同分布的),以下随机变量序列总是收敛于标准正态分布的随机变量:

从统计学角度讲,中心极限定理暗示,如果我们重复收集一组
对于来自同一总体的足够大样本,这些样本的均值将呈正态分布。这个定理具有实际意义,因为它允许我们对统计估计的准确性做出精确的陈述。一个常见的误解是,这个定理是为什么许多经验分布在实践中可以近似为正态分布的原因。然而,事实并非如此。
尽管定理的证明需要高级分析工具,我们在这里不讨论(参见,例如,[Durrett 2019,定理 3.4.1]),但我们可以通过一个数值例子理解它的实际意义。我们来考虑以下概率密度函数,我们假设它生成了正在研究的数据:

图 1:任意概率密度函数。图片来源于作者。
为了强调定理适用于任何形状的底层分布,请注意密度函数如何与钟形曲线不相似。我们可以通过数值模拟检查从分布中重复抽取的样本大小 N 的大量均值的直方图。对于仅由单一实例组成的样本,N = 1,我们不能期望极限定理适用——我们只是重复底层分布:

图 2:从任意分布中采样得到的直方图(N = 1 的情况)。图片来源于作者。
然而,即使对于相对较小的样本大小 N = 5,算术均值的分布——即,重复采样并计算 (*x_*1 + … + *x_*5) / 5——仍然显示出正态分布的典型钟形曲线:

图 3:样本均值的分布,样本大小为 N = 5。图片来源于作者。
Grant Sanderson 在他的 YouTube 频道 3Blue1Brown 上制作了一个视频,提供了关于中心极限定理的额外直观见解,非常值得观看。
区间估计和假设检验
中心极限定理很重要,因为它允许我们指定置信区间而不仅仅是点估计来估计某些总体的均值:我们指定一个区间,我们可以相当确定地认为这个区间包含真实均值,而不是一个单一的估计值。例如,假设我们希望在样本足够大的情况下,以 95%的置信度确保我们的估计是正确的。我们可以通过设置置信区间,并将置信水平设为γ = 0.95 来实现:

我们做出以下假设,数值 z > 0 尚待确定:

中心极限定理允许我们得出以下结论:

因此,z = z(γ) 是由在标准正态分布曲线下产生面积 γ 的积分界限决定的。例如,z(0.95) = 1.96 或 z(0.99) = 2.58。
总结来说,基于足够大样本的均值的区间估计(常用的经验法则是 N > 30 或 N > 50)在置信水平 γ 下为:

为了得出上述公式,我们用经验估计值 x̄ 和 s(x) 替代了均值 μ 和标准差 σ。这对于足够大的样本是一个合理的近似,并可以通过 斯卢茨基定理 证明,该定理基本上说明了只要其中一个加数/因子收敛到常数,基本算术运算与分布极限的操作是可以交换的。
而不是置信水平 γ,显著性水平,或 **概率
error,**α = 1 − γ 可以指定。
让我们计算一个实际的例子。CDC 调查中男性受访者的 99.9% 置信区间为 [177.98 cm, 178.10 cm]。这种高统计准确性得益于超过 190,000 名男性受访者的大样本量。我们想展示如何对较小样本量进行区间估计。为此,我们反复抽取 N = 50 的随机样本体高值,并计算相应的 95% 置信区间。结果见下图:

图 5:从样本大小 N = 50 的体高区间估计。图像来源于作者。
注意,大多数置信区间(以垂直误差条表示)也包含了 178 cm 的真实值(以水平虚线表示)。然而,有些则不包含,大约百分之一 — 这是按照构造预期的,并与指定的误差概率 α = 5% 一致。总是有可能区间估计会错过总体的真实均值,特别是在低置信水平下。
中心极限定理的另一个重要应用,与区间估计密切相关,是假设检验。假设我们有理由相信随机变量 X 的期望值 不 等于某个值 μ。在这种情况下,我们想要驳斥原假设 E[X] = μ。如果观察到的均值不包含在以下区间内,我们可以说这个原假设与数据不一致:

让我们回顾一下引言中的可能有偏的硬币的例子。我们记录每次抛硬币的结果,得到一个二进制值序列,其中值为 1 表示正面,值为 0 表示反面。该序列的算术平均值等于正面的相对频率,我们可以应用迄今为止学到的知识。假设我们有理由相信这枚硬币是不公平的。零假设声称硬币是公平的,即 E[X] = 0.5。在第一次实验中,我们观察到经过十次抛掷后,硬币正面朝上的次数为七次。在置信水平 γ = 0.95 下,此实验的零假设区间为:[0.24, 0.76]。实际观察到的 0.7 比例仍在此区间内。因此,在给定的置信水平下,不能拒绝公平硬币的零假设。
样本量相对较小,实际上建议使用学生的 t-检验。t-检验会将临界标准分数 z(0.95) = 1.96 调整为 2.26,从而得到更宽的置信区间。
如果我们观察到一百次抛硬币中有七十次结果为正面,那么在假设零假设为真的情况下,得到的置信区间将是[0.41, 0.59]。在这种情况下,实际观察到的 0.7 比例不包含在置信区间内。因此,应该拒绝零假设,我们可以在给定的置信水平下得出结论——硬币是有偏的。
我们还可以基于每个样本调查两个总体的均值是否相等。双侧的双样本 Z-检验 如果满足以下条件则意味着拒绝均值相等的零假设:

从数据中得出结论:统计推断的陷阱
进行统计测试和计算置信区间并不能替代适当的统计推理:统计上显著的效果可能仍然具有很小的实际相关性,或者可能只是虚假的关系。
统计显著性与实际显著性:效应量
特别是对于非常大的样本,检测到统计上显著的均值差异或其他类型的效应是相当常见的,这些效应在统计检验中被认为是显著的。然而,这些效应的实际大小可能仍然很小。
例如:CDC 数据集允许比较不同的美国州。我们可以将罗德岛的男性受访者的平均身高与纽约的进行比较。应用Z检验,我们得到 95%置信水平下的检验分数为 0.33 cm。这个值低于观察到的 0.44 cm 的差异。因此,该差异在统计上是显著的。然而,其大小非常小,因此我们可以预期其实际相关性很小。
在许多情况下,可以通过指定效应来很好地衡量效应大小。
自然单位。在上述示例中,我们选择了长度的公制单位。另一种可能性是以标准差的倍数单位来指定。Cohen’s d 是衡量统计效应实际相关性的一个指标。它被定义为均值差异除以合并方差[Cohen 1988, p.67]:

上述示例中观察到的 0.44 cm 的差异对应于 Cohen’s d 为 0.05。当我们比较波多黎各的受访者与纽约的受访者的平均身高时,我们得到 Cohen’s d 为 0.50,对应于 4.1 cm 的度量单位差异。
解释 Cohen’s d 值的经验法则见下表[Sawiloswky 2009]:

表 2:根据 Cohen’s d 的效应大小。图片由作者提供。
统计推断与因果解释:辛普森悖论
当然,统计推断中最常被引用的陷阱之一就是“相关性不等于因果关系”的格言。这一概念通常通过明显虚假且有时滑稽的 例子来说明,例如将海盗短缺归因于全球变暖。
然而,在实际应用中,统计关联是否确实是虚假的或指示因果关系通常并不明显。一个不易察觉的虚假相关来源是未知的混杂变量。事实上,未知混杂因素的存在可能导致在检查特定子群体时关联方向的逆转,这种现象被称为辛普森悖论。
下面的例子可以说明辛普森悖论(参见[Blyth 1972]、[Bickel et al. 1975] 和 [Freedman et al. 2007,第二章,第四部分]):在一所大学的六个最大部门中,p_x = 30%的 1835 名女性申请者被录取,而p_y = 45%的 2691 名男性申请者被录取。我们可以使用Z检验来得出这一录取率差异在 99%的置信水平下是显著的结论。
这些是按大学部门划分的数字:

表 3:按部门划分的大学招生率。图片来源:作者。
对于每个部门,我们可以计算双侧检验分数,并将该分数与观察到的招生率差异的绝对值| p_y − p_x |进行比较。根据可用数据,我们还可以计算每个部门的录取率p,不论性别:

表 4:大学招生率分析。图片来源:作者。
只有部门A在招生率上显示出显著差异。与所有部门的比较相反,这一差异对女性申请者更为有利。部门A和B是申请者最有可能被录取的部门,差距很大。51%的男性申请者选择这两个部门申请,但所有女性申请者中只有 7%这样做。因此,这些数据与女性申请者更可能申请竞争性较强的课程的假设是一致的,这意味着她们更可能被拒绝。
结论
大数法则为统计估计过程提供了坚实的基础,其有效性得到了中心极限定理的严格支持。随着数据的增加,统计估计变得越来越准确,在许多情况下,我们可以计算出量化结果准确性和我们信心的指标。
然而,重要的是强调,采用“闭嘴并计算”的方法不足以进行稳健的统计推理和有效的数据科学。首先,即使随机误差被最小化,统计结果仍可能受到各种系统性误差的影响。这些误差可能源于反应偏差、测量设备故障或引入抽样偏差的缺陷研究设计。因此,对潜在偏差源的全面检查对于可靠的统计分析至关重要。
其次,在解释结果时,重要的是要认识到,仅凭统计显著性和相关性不足以评估实际意义或观察到的效应背后的潜在原因。统计结果必须放在背景中进行解读,以确定其现实世界的重要性并提供对观察到现象的解释。
参考文献
[普劳 2023] 马蒂亚斯 普劳. “数据科学 — 统计学与机器学习导论”。施普林格 柏林,海德堡。2023 年。
[CDC 2018] 美国疾病控制与预防中心 (CDC). 行为风险因素监测系统调查数据。亚特兰大,乔治亚州:美国卫生与公共服务部,疾病控制与预防中心。2018 年。
CDC 数据 属于公共领域,可以在无需许可的情况下复制*。
[杜雷特 2019] 里克 杜雷特. 概率:理论与示例。第 5 版。剑桥大学出版社,2019 年 5 月。
[科恩 1988] 雅各布 科恩. 行为科学的统计功效分析。第 2 版。新泽西州,美国:劳伦斯·厄尔鲍姆协会,1988 年。
[萨维洛斯基 2009] 什洛莫 S. 萨维洛斯基. “新的效应大小规则”。发表于《现代应用统计方法杂志》8.2(2009 年 11 月),第 597–599 页。
[布莱斯 1972] 科林 R. 布莱斯. “关于辛普森悖论和确定性原则”。发表于《美国统计协会杂志》67.338(1972 年 6 月),第 364–366 页。
[比克尔等 1975] P. J. 比克尔、E. A. 汉梅尔 和 J. W. 奥康奈尔. “研究生录取中的性别偏见:来自伯克利的数据”。发表于《科学》187.4175(1975 年 2 月),第 398–404 页。
[弗里德曼等 2007] 大卫 弗里德曼、罗伯特 皮萨尼 和 罗杰 普维斯. 统计学。第 4 版。W. W. 诺顿公司,2007 年 2 月。
一种经过验证的方法,用以记住数据科学概念,直到你需要的时候
以及在人工智能时代将方法付诸实践的工具


·发表于 Towards Data Science ·8 分钟阅读·2023 年 4 月 18 日
–

图片由我提供。通过我的好朋友 Midjourney
自学数据科学的问题
每当我想用 Anaconda 安装一个库时,命令中的-c部分总是会变动。因此,像大多数人一样,我谷歌搜索,有时一天 3-4 次:
conda install -c conda-forge library_name
听起来很熟悉?
这个小例子揭示了我们今天学习数据科学和机器学习方式的一个根本性缺陷:数据科学知识比空气便宜,因此我们没有像应有的那样认真对待学习它。
我们看到大学生为了记住大量信息以通过考试和测试而绞尽脑汁。如果他们做得不好,他们将被赶出他们花了很多钱的学校。
作为自学的数据科学家,我们没有那种压力。我们只有自律,它不断说服我们,在沙发上看 YouTube 课程时我们做得很好。
我们的学习过程是零散的。我们学到一些新东西就跳到下一个闪亮的事物,而第一个东西尚未深入我们的大脑。
我们把信息保留的事情交给了运气。
当我们真正坐下来实践我们“学到”的东西(用空气引号),我们会发现我们在打开电脑的时间里已经忘记了 80%的新知识。
所以,我们开始用谷歌搜索。当这种行为成为常态后,我们会在小推文中炫耀我们在谷歌搜索方面的卓越。我们实际上是在向他人微妙地暗示,我们没有可靠的系统来学习和记住数据科学中大量的信息。
由于我们的过失,我们变成了最差劲的学习者。
解决方案
没有有效的方法和工具来学习和保持新知识,成为数据科学家是很困难的。
需要学习的内容实在太多了:数学、统计学、机器学习理论、数十个 Python 库中的函数和方法等等。跟踪所有这些信息确实很困难。

图片来自于维基百科。维基媒体共享资源。
上面的艾宾浩斯遗忘曲线展示了新信息从记忆中流失的速度。
从图表中可以清楚地看到,完全失去新信息只需要六天。而当信息是以我们随意和粗心的方式学习的,这个时间会更短。
但一旦你认真努力将新知识投入到一个可靠的重复系统中,你就有意识地选择将其记住终生或至少在需要的时候记住。
我可能在谈论死记硬背(🤒)吗?当然不是。我在谈论间隔重复!
间隔重复是一种强大的记忆技巧,它充分利用了艾宾浩斯遗忘曲线:

图片来自于维基百科。维基媒体共享资源。
间隔重复会在逐渐增加的最佳间隔时间内重新暴露你于新信息,每个间隔正好在记忆即将流失时出现。
这将重置你的记忆,并增加下一次复习材料的间隔时间。
SR 的好处是什么?
也许,间隔重复最有益的地方在于它将知识从短期记忆转移到长期记忆的方式。
除了高效利用时间和提高记忆保持外,研究显示该系统的以下好处:
-
个性化:可以根据你的独特偏好进行自定义,因为它适应你的学习节奏和对材料的掌握程度。
-
改善理解:通过不断强化概念和联系,随着时间的推移,你可以更容易地建立知识网络,更深入地理解复杂的主题。
-
动力增加:随着我的重复间隔变得更长,间隔重复给了我很大的进步和成就感。
这可能是为什么许多医学生把他们的生命托付于这种方法,因为他们用它来记住骨骼、血管、神经分支以及人体的所有疲惫细节。
数据科学可能并不像看上去那样复杂,但我们仍然需要记住相当多的东西。
间隔重复算法
实际上有许多算法实现间隔重复,其中最受欢迎的是SuperMemo。
SuperMemo 是一系列间隔重复算法,自 1982 年开始不断推出。作者皮奥特·沃兹尼亚克博士在 2008 年被《连线》杂志评选为“将人们变成天才的技巧发明者”。
那么,你如何通过这种方法变成天才呢?
在充分学习了基础概念和事实后,你首先使用闪卡将材料分解成块(是的,我知道这是一个大问题,但请耐心等待到最后)。
创建卡片数据库后,你开始在会话中复习它们。第一次会话按照添加顺序或洗牌(根据你的偏好)显示卡片。然后,你根据记忆情况对卡片进行评分。
在 SuperMemo-2 中,有六个选项:
-
0: 我完全没有头绪。
-
1: 错误,但看到答案后,记忆犹新。
-
2: 错误,但看到答案后,我迅速想起来了。
-
3: 正确回应,但我不得不深入挖掘并努力记住。
-
4: 正确回应,但我犹豫不决。
-
5: 我记得就像刚刚发生的事情一样。
然后,选择的评分会被输入到复杂的计算中,这些计算涉及卡片之前成功回忆的次数、卡片的易记因素(别问),以及重复间隔。最终结果将决定何时再次显示卡片。
对于评分低于 4 的卡片,SuperMemo 会要求你在当前会话中重复查看卡片,直到评分超过 4。
每张正确回忆的卡片将在越来越长的间隔后显示。例如,如果你记住了将时间戳转换为日期时间的函数是 datatime.datetime.fromtimestamp,你只需在一个月内复习这张卡片 4-5 次,就能在接下来的六个月内记住它。
正如你想象的那样,这比死记硬背、固定间隔重复或最糟糕的随心情重复要好得多。
间隔重复工具。
有许多由类似 SuperMemo 算法驱动的 SR 工具。
第一个(也是最重要的)是 Anki。它是开源的,实现了 SuperMemo-2 的修改版。它显示四个记忆评分:

用 Anki 记忆俄语词汇。图片来自维基百科。维基共享资源。
由于是开源的,它有一种非常古老的外观,但它是一个跨平台的免费应用(iOS 版本除外)。软件的 GitHub 仓库 有超过 13k 的星标,这表明社区的广泛支持。
他们已经在 Anki 上工作了十多年,目前的版本具有以下功能:
-
随处可用:Windows、macOS、Linux、Android 和 iOS(iOS 版本需要付费)。
-
完全可定制:创建你自己的闪卡,将它们组织成卡组,并设置你自己的间隔重复算法参数。
-
跨设备同步:Anki 的电脑版本是主要应用,移动和网页版只是伴随应用,但会同步。
-
多媒体支持:添加图片、音频、视频、文本格式和 LaTeX,以使闪卡更具记忆性和吸引力。还支持图像遮挡来记忆视觉信息。
-
附加功能:类似于 Python 扩展,你可以为软件创建并添加自己的功能,如自定义快捷键、主题和高级统计信息。
-
预制卡组:社区不断分享包含预制卡片的卡组,涵盖了热门话题。这包括数以万计的语言学习卡片,或者几乎所有大学考试的学科,以及许多其他有趣/酷炫/奇怪的主题。
一个显而易见的痛点是我们没有强调的,就是创建社区中没有的闪卡。
我知道数据科学在间隔重复方面是一个相对年轻的领域。任何人都有大量的信息需要转换成闪卡,这听起来既繁琐又令人厌烦。但这是一个必要的恶习。
我坚信,用间隔重复法创建一个主题的闪卡并完全掌握它所需的整体时间,将远少于数小时的谷歌搜索或数十次恶性循环的遗忘与再学习。
此外,我们很幸运生活在 AI 的黄金时代(我们确实是,对吧?)。已经有像Monic.ai这样的便宜的 AI 驱动闪卡软件了。
我已经尝试过 Monic.ai,它看起来非常棒。你只需上传截图或 PDF 文件,它就会在几秒钟内自动将其中的文字转换成闪卡。它还支持间隔重复技术。
如果你决定尝试,你应该考虑下载GoFullPage Chrome 扩展以捕捉全页截图,或者了解如何将网页保存为 PDF,这样你就可以将任何在线文章、教程或 Python 框架的文档页面转换为 Monic.ai 闪卡。
结束
是时候改变我们学习数据科学的方法了。我们应该抛弃那种为了观看而观看的随意方式,或者连续参加课程寻找新的无用电子证书的做法。
我们应该停止一次学习某个东西,然后希望它能保持在那里。我们应该停止一厢情愿。
我们应该停止把记忆留给偶然。
相反,我们应该采取有意识的行动,记住每一个必要的事实、理论、概念、终端命令、Python 函数或函数参数,直到我们不再需要它们。
是的,这需要一些适应,但一旦我们适应了,就可以显著缩短从“在线学习数据科学”到“在一个高薪工作中做数据科学”的时间。
感谢阅读!
喜欢这篇文章吗?说实话,它那奇特的写作风格?想象一下,能访问到更多这样的文章,全由一位才华横溢、迷人、有趣的作者(顺便说一下就是我 😃)创作。
只需 4.99$ 的会员费用,你不仅能访问我的故事,还能获取 Medium 上最聪明、最优秀的头脑带来的知识宝库。如果你使用我的推荐链接,你将获得我超新星般的感激和对我工作的虚拟击掌。
[## 通过我的推荐链接加入 Medium — Bex T.
获得对所有我的⚡高级⚡内容以及 Medium 上的无限访问权限。通过为我购买一份…来支持我的工作。

图片由我制作。通过 Midjourney。
参考文献
[1] Anki,强大的智能闪卡,Anki 网站
[2] 维基百科,SuperMemo,wikipedia.org
[3] E-student,间隔重复:技巧指南,e-student.org
[4] 维基百科,间隔重复,wikipedia.org
从 Google Maps 空气质量 API 获取空气污染数据的 Python 工具
了解如何从全球各地获取丰富的实时空气质量数据


·
关注 发表在 Towards Data Science ·16 分钟阅读·2023 年 10 月 16 日
–
本文详细说明了如何在 Python 中使用 Google Maps 空气质量 API 获取和探索实时空气污染数据、时间序列和地图。查看完整代码 这里
1. 背景
2023 年 8 月,Google 宣布将空气质量服务添加到其映射 API 列表中。你可以在这里阅读更多关于此的信息。看来这些信息现在也可以通过 Google Maps 应用获得,不过通过 API 获得的数据要丰富得多。
根据公告,Google 正在结合来自不同分辨率的多种来源的信息——地面污染传感器、卫星数据、实时交通信息和来自数值模型的预测——以生成一个动态更新的空气质量数据集,涵盖 100 个国家,分辨率高达 500 米。这听起来像是一个非常有趣且潜在有用的数据集,适用于各种映射、医疗和规划应用!
当第一次读到这个消息时,我计划在一个“与数据对话”的应用中尝试它,利用从构建这个旅行规划器工具中学到的一些东西。也许是一个可以绘制你最喜欢城市空气污染浓度时间序列的系统,或者一个帮助人们规划本地徒步旅行以避免空气质量差的工具?
这里有三个 API 工具可以提供帮助——一个“当前条件”服务,它提供给定位置的当前空气质量指数值和污染物浓度;一个“历史条件”服务,它提供相同的信息,但以小时为间隔,覆盖最多 30 天的历史数据;以及一个“热图”服务,它提供给定区域的当前条件的图像。
以前,我使用过优秀的[googlemaps](https://github.com/googlemaps/google-maps-services-python)包来调用 Python 中的 Google Maps API,但这些新 API 尚未得到支持。令人惊讶的是,除了官方文档,我几乎找不到使用这些新工具的人的示例,也没有预先存在的 Python 包来调用它们。如果有人知道其他信息,我会很高兴地接受纠正!
因此,我自己构建了一些快速工具,在这篇文章中,我们将详细介绍它们的工作原理及使用方法。我希望这对那些希望在 Python 中尝试这些新 API 并寻找起点的人有所帮助。这个项目的所有代码可以在这里找到,我可能会随着时间的推移扩展这个仓库,增加更多功能,并使用空气质量数据构建某种映射应用。
2. 获取给定位置的当前空气质量
让我们开始吧!在本节中,我们将介绍如何使用 Google Maps 获取给定位置的空气质量数据。你首先需要一个 API 密钥,你可以通过你的 Google Cloud 账户生成。它们有一个90 天的免费试用期,之后你将为你使用的 API 服务付费。在开始进行大量调用之前,请确保启用“空气质量 API”,并了解定价政策!

Google Cloud API 库的截图,你可以从中激活空气质量 API。图片由作者生成。
我通常将 API 密钥存储在 .env 文件中,并通过类似下面的函数使用 dotenv 加载它。
from dotenv import load_dotenv
from pathlib import Path
def load_secets():
load_dotenv()
env_path = Path(".") / ".env"
load_dotenv(dotenv_path=env_path)
google_maps_key = os.getenv("GOOGLE_MAPS_API_KEY")
return {
"GOOGLE_MAPS_API_KEY": google_maps_key,
}
获取当前条件需要进行 POST 请求,详细信息请参见此处。我们将借鉴googlemaps包的设计,以一种可以概括的方法来实现这一点。首先,我们构建一个使用 requests 进行调用的客户端类。目标非常简单——我们想构建一个类似下面的 URL,并包含所有特定于用户查询的请求选项。
https://airquality.googleapis.com/v1/currentConditions:lookup?key=YOUR_API_KEY
Client 类将我们的 API 密钥作为 key 传入,然后构建查询的 request_url。它接受作为 params 字典的请求选项,然后将它们放入 JSON 请求体中,这由 self.session.post() 调用处理。
import requests
import io
class Client(object):
DEFAULT_BASE_URL = "https://airquality.googleapis.com"
def __init__(self, key):
self.session = requests.Session()
self.key = key
def request_post(self, url, params):
request_url = self.compose_url(url)
request_header = self.compose_header()
request_body = params
response = self.session.post(
request_url,
headers=request_header,
json=request_body,
)
return self.get_body(response)
def compose_url(self, path):
return self.DEFAULT_BASE_URL + path + "?" + "key=" + self.key
@staticmethod
def get_body(response):
body = response.json()
if "error" in body:
return body["error"]
return body
@staticmethod
def compose_header():
return {
"Content-Type": "application/json",
}
现在我们可以创建一个函数,帮助用户为当前条件 API 组装有效的请求选项,然后使用这个 Client 类来发起请求。这也受到 googlemaps 包设计的启发。
def current_conditions(
client,
location,
include_local_AQI=True,
include_health_suggestion=False,
include_all_pollutants=True,
include_additional_pollutant_info=False,
include_dominent_pollutant_conc=True,
language=None,
):
"""
See documentation for this API here
https://developers.google.com/maps/documentation/air-quality/reference/rest/v1/currentConditions/lookup
"""
params = {}
if isinstance(location, dict):
params["location"] = location
else:
raise ValueError(
"Location argument must be a dictionary containing latitude and longitude"
)
extra_computations = []
if include_local_AQI:
extra_computations.append("LOCAL_AQI")
if include_health_suggestion:
extra_computations.append("HEALTH_RECOMMENDATIONS")
if include_additional_pollutant_info:
extra_computations.append("POLLUTANT_ADDITIONAL_INFO")
if include_all_pollutants:
extra_computations.append("POLLUTANT_CONCENTRATION")
if include_dominent_pollutant_conc:
extra_computations.append("DOMINANT_POLLUTANT_CONCENTRATION")
if language:
params["language"] = language
params["extraComputations"] = extra_computations
return client.request_post("/v1/currentConditions:lookup", params)
这个 API 的选项相对简单。它需要一个包含你想要调查的点的经纬度的字典,并可以选择接受其他各种控制返回信息量的参数。让我们来看一下所有参数都设置为True时的效果。
# set up client
client = Client(key=GOOGLE_MAPS_API_KEY)
# a location in Los Angeles, CA
location = {"longitude":-118.3,"latitude":34.1}
# a JSON response
current_conditions_data = current_conditions(
client,
location,
include_health_suggestion=True,
include_additional_pollutant_info=True
)
返回了很多有趣的信息!不仅有来自通用和美国 AQI 指数的空气质量指数值,还有主要污染物的浓度、每种污染物的描述,以及针对当前空气质量的整体健康建议。
{'dateTime': '2023-10-12T05:00:00Z',
'regionCode': 'us',
'indexes': [{'code': 'uaqi',
'displayName': 'Universal AQI',
'aqi': 60,
'aqiDisplay': '60',
'color': {'red': 0.75686276, 'green': 0.90588236, 'blue': 0.09803922},
'category': 'Good air quality',
'dominantPollutant': 'pm10'},
{'code': 'usa_epa',
'displayName': 'AQI (US)',
'aqi': 39,
'aqiDisplay': '39',
'color': {'green': 0.89411765},
'category': 'Good air quality',
'dominantPollutant': 'pm10'}],
'pollutants': [{'code': 'co',
'displayName': 'CO',
'fullName': 'Carbon monoxide',
'concentration': {'value': 292.61, 'units': 'PARTS_PER_BILLION'},
'additionalInfo': {'sources': 'Typically originates from incomplete combustion of carbon fuels, such as that which occurs in car engines and power plants.',
'effects': 'When inhaled, carbon monoxide can prevent the blood from carrying oxygen. Exposure may cause dizziness, nausea and headaches. Exposure to extreme concentrations can lead to loss of consciousness.'}},
{'code': 'no2',
'displayName': 'NO2',
'fullName': 'Nitrogen dioxide',
'concentration': {'value': 22.3, 'units': 'PARTS_PER_BILLION'},
'additionalInfo': {'sources': 'Main sources are fuel burning processes, such as those used in industry and transportation.',
'effects': 'Exposure may cause increased bronchial reactivity in patients with asthma, lung function decline in patients with Chronic Obstructive Pulmonary Disease (COPD), and increased risk of respiratory infections, especially in young children.'}},
{'code': 'o3',
'displayName': 'O3',
'fullName': 'Ozone',
'concentration': {'value': 24.17, 'units': 'PARTS_PER_BILLION'},
'additionalInfo': {'sources': 'Ozone is created in a chemical reaction between atmospheric oxygen, nitrogen oxides, carbon monoxide and organic compounds, in the presence of sunlight.',
'effects': 'Ozone can irritate the airways and cause coughing, a burning sensation, wheezing and shortness of breath. Additionally, ozone is one of the major components of photochemical smog.'}},
{'code': 'pm10',
'displayName': 'PM10',
'fullName': 'Inhalable particulate matter (<10µm)',
'concentration': {'value': 44.48, 'units': 'MICROGRAMS_PER_CUBIC_METER'},
'additionalInfo': {'sources': 'Main sources are combustion processes (e.g. indoor heating, wildfires), mechanical processes (e.g. construction, mineral dust, agriculture) and biological particles (e.g. pollen, bacteria, mold).',
'effects': 'Inhalable particles can penetrate into the lungs. Short term exposure can cause irritation of the airways, coughing, and aggravation of heart and lung diseases, expressed as difficulty breathing, heart attacks and even premature death.'}},
{'code': 'pm25',
'displayName': 'PM2.5',
'fullName': 'Fine particulate matter (<2.5µm)',
'concentration': {'value': 11.38, 'units': 'MICROGRAMS_PER_CUBIC_METER'},
'additionalInfo': {'sources': 'Main sources are combustion processes (e.g. power plants, indoor heating, car exhausts, wildfires), mechanical processes (e.g. construction, mineral dust) and biological particles (e.g. bacteria, viruses).',
'effects': 'Fine particles can penetrate into the lungs and bloodstream. Short term exposure can cause irritation of the airways, coughing and aggravation of heart and lung diseases, expressed as difficulty breathing, heart attacks and even premature death.'}},
{'code': 'so2',
'displayName': 'SO2',
'fullName': 'Sulfur dioxide',
'concentration': {'value': 0, 'units': 'PARTS_PER_BILLION'},
'additionalInfo': {'sources': 'Main sources are burning processes of sulfur-containing fuel in industry, transportation and power plants.',
'effects': 'Exposure causes irritation of the respiratory tract, coughing and generates local inflammatory reactions. These in turn, may cause aggravation of lung diseases, even with short term exposure.'}}],
'healthRecommendations': {'generalPopulation': 'With this level of air quality, you have no limitations. Enjoy the outdoors!',
'elderly': 'If you start to feel respiratory discomfort such as coughing or breathing difficulties, consider reducing the intensity of your outdoor activities. Try to limit the time you spend near busy roads, construction sites, open fires and other sources of smoke.',
'lungDiseasePopulation': 'If you start to feel respiratory discomfort such as coughing or breathing difficulties, consider reducing the intensity of your outdoor activities. Try to limit the time you spend near busy roads, industrial emission stacks, open fires and other sources of smoke.',
'heartDiseasePopulation': 'If you start to feel respiratory discomfort such as coughing or breathing difficulties, consider reducing the intensity of your outdoor activities. Try to limit the time you spend near busy roads, construction sites, industrial emission stacks, open fires and other sources of smoke.',
'athletes': 'If you start to feel respiratory discomfort such as coughing or breathing difficulties, consider reducing the intensity of your outdoor activities. Try to limit the time you spend near busy roads, construction sites, industrial emission stacks, open fires and other sources of smoke.',
'pregnantWomen': 'To keep you and your baby healthy, consider reducing the intensity of your outdoor activities. Try to limit the time you spend near busy roads, construction sites, open fires and other sources of smoke.',
'children': 'If you start to feel respiratory discomfort such as coughing or breathing difficulties, consider reducing the intensity of your outdoor activities. Try to limit the time you spend near busy roads, construction sites, open fires and other sources of smoke.'}}
3. 获取给定位置的空气质量时间序列
能够获取给定位置的这些 AQI 和污染物值的时间序列不是很好吗?这可能会揭示有趣的模式,例如污染物之间的相关性或由交通或天气因素引起的每日波动。
我们可以通过另一个 POST 请求到historical conditions API,获取小时历史记录。这个过程与当前条件非常相似,唯一的主要区别是,由于结果可能很长,它们作为多个pages返回,需要一些额外的逻辑来处理。
修改Client的request_post方法以处理这个问题。
def request_post(self,url,params):
request_url = self.compose_url(url)
request_header = self.compose_header()
request_body = params
response = self.session.post(
request_url,
headers=request_header,
json=request_body,
)
response_body = self.get_body(response)
# put the first page in the response dictionary
page = 1
final_response = {
"page_{}".format(page) : response_body
}
# fetch all the pages if needed
while "nextPageToken" in response_body:
# call again with the next page's token
request_body.update({
"pageToken":response_body["nextPageToken"]
})
response = self.session.post(
request_url,
headers=request_header,
json=request_body,
)
response_body = self.get_body(response)
page += 1
final_response["page_{}".format(page)] = response_body
return final_response
这处理了response_body包含一个名为nextPageToken的字段的情况,该字段是已生成并准备好提取的下一页数据的 ID。如果存在该信息,我们只需使用一个名为pageToken的新参数再次调用 API,该参数指示到相关页面。我们在 while 循环中重复执行此操作,直到没有更多页面为止。因此,我们的final_response字典现在包含了由页码表示的另一层。对于调用current_conditions,将只有一页,但对于调用historical_conditions,可能会有多个页面。
处理完这些事项后,我们可以以与current_conditions非常相似的风格编写historical_conditions函数。
def historical_conditions(
client,
location,
specific_time=None,
lag_time=None,
specific_period=None,
include_local_AQI=True,
include_health_suggestion=False,
include_all_pollutants=True,
include_additional_pollutant_info=False,
include_dominant_pollutant_conc=True,
language=None,
):
"""
See documentation for this API here https://developers.google.com/maps/documentation/air-quality/reference/rest/v1/history/lookup
"""
params = {}
if isinstance(location, dict):
params["location"] = location
else:
raise ValueError(
"Location argument must be a dictionary containing latitude and longitude"
)
if isinstance(specific_period, dict) and not specific_time and not lag_time:
assert "startTime" in specific_period
assert "endTime" in specific_period
params["period"] = specific_period
elif specific_time and not lag_time and not isinstance(specific_period, dict):
# note that time must be in the "Zulu" format
# e.g. datetime.datetime.strftime(datetime.datetime.now(),"%Y-%m-%dT%H:%M:%SZ")
params["dateTime"] = specific_time
# lag periods in hours
elif lag_time and not specific_time and not isinstance(specific_period, dict):
params["hours"] = lag_time
else:
raise ValueError(
"Must provide specific_time, specific_period or lag_time arguments"
)
extra_computations = []
if include_local_AQI:
extra_computations.append("LOCAL_AQI")
if include_health_suggestion:
extra_computations.append("HEALTH_RECOMMENDATIONS")
if include_additional_pollutant_info:
extra_computations.append("POLLUTANT_ADDITIONAL_INFO")
if include_all_pollutants:
extra_computations.append("POLLUTANT_CONCENTRATION")
if include_dominant_pollutant_conc:
extra_computations.append("DOMINANT_POLLUTANT_CONCENTRATION")
if language:
params["language"] = language
params["extraComputations"] = extra_computations
# page size default set to 100 here
params["pageSize"] = 100
# page token will get filled in if needed by the request_post method
params["pageToken"] = ""
return client.request_post("/v1/history:lookup", params)
为了定义历史时期,API 可以接受一个lag_time(以小时为单位,最多 720 小时(30 天))。它也可以接受一个specific_period字典,其中定义了开始和结束时间,格式如上面的注释所述。最后,要获取单个小时的数据,可以提供由specific_time提供的时间戳。还要注意pageSize参数的使用,它控制每次调用 API 返回的时间点数量。这里的默认值是 100。
让我们试一下。
# set up client
client = Client(key=GOOGLE_MAPS_API_KEY)
# a location in Los Angeles, CA
location = {"longitude":-118.3,"latitude":34.1}
# a JSON response
history_conditions_data = historical_conditions(
client,
location,
lag_time=720
)
我们应该得到一个长而嵌套的 JSON 响应,其中包含过去 720 小时内每小时增量的 AQI 指数值和特定污染物值。有许多方法可以将其格式化为更适合可视化和分析的结构,下面的函数将把它转换为“长”格式的 pandas 数据框,这种格式与seaborn绘图非常匹配。
from itertools import chain
import pandas as pd
def historical_conditions_to_df(response_dict):
chained_pages = list(chain(*[response_dict[p]["hoursInfo"] for p in [*response_dict]]))
all_indexes = []
all_pollutants = []
for i in range(len(chained_pages)):
# need this check in case one of the timestamps is missing data, which can sometimes happen
if "indexes" in chained_pages[i]:
this_element = chained_pages[i]
# fetch the time
time = this_element["dateTime"]
# fetch all the index values and add metadata
all_indexes += [(time , x["code"],x["displayName"],"index",x["aqi"],None) for x in this_element['indexes']]
# fetch all the pollutant values and add metadata
all_pollutants += [(time , x["code"],x["fullName"],"pollutant",x["concentration"]["value"],x["concentration"]["units"]) for x in this_element['pollutants']]
all_results = all_indexes + all_pollutants
# generate "long format" dataframe
res = pd.DataFrame(all_results,columns=["time","code","name","type","value","unit"])
res["time"]=pd.to_datetime(res["time"])
return res
在historical_conditions的输出上运行这个操作将生成一个数据框,其列格式化以便进行易于分析。
df = historical_conditions_to_df(history_conditions_data)

准备好绘图的历史 AQI 数据的示例数据框。
现在我们可以在seaborn或其他可视化工具中绘制结果。
import seaborn as sns
g = sns.relplot(
x="time",
y="value",
data=df[df["code"].isin(["uaqi","usa_epa","pm25","pm10"])],
kind="line",
col="name",
col_wrap=4,
hue="type",
height=4,
facet_kws={'sharey': False, 'sharex': False}
)
g.set_xticklabels(rotation=90)

该位置在 LA 的 30 天期间的通用 AQI,美国 AQI,pm25 和 pm10 值。由作者生成的图像。
这已经非常有趣了!显然,污染物时间序列中存在几个周期性现象,并且美国 AQI 与 pm25 和 pm10 浓度密切相关,这是预期中的结果。我对 Google 提供的 Universal AQI 并不太熟悉,所以无法解释为什么它与 pm25 和 pm10 显示出反相关。较小的 UAQI 是否意味着更好的空气质量?尽管进行了搜索,我仍未找到一个好的答案。
4. 获取空气质量热图瓦片
现在是 Google Maps 空气质量 API 的最终使用案例——生成热图瓦片。关于这一点的文档较为稀疏,这很遗憾,因为这些瓦片是可视化当前空气质量的强大工具,尤其是与Folium地图结合使用时。
我们通过 GET 请求获取这些瓦片,这涉及到构建以下格式的 URL,其中瓦片的位置由 zoom、x 和 y 指定。
GET https://airquality.googleapis.com/v1/mapTypes/{mapType}/heatmapTiles/{zoom}/{x}/{y}
zoom、x 和 y 的含义是什么?我们可以通过了解 Google Maps 如何将纬度和经度坐标转换为“瓦片坐标”来回答这个问题,这在这里有详细描述。本质上,Google Maps 将图像存储在每个单元格为 256 x 256 像素的网格中,而单元格的实际尺寸是缩放级别的函数。当我们调用 API 时,需要指定要从哪个网格中绘制——这是由缩放级别决定的——以及在网格上的哪个位置绘制——这是由x 和 y 瓦片坐标决定的。返回的是一个字节数组,可以由 Python Imaging Library (PIL) 或类似的图像处理包读取。
在上述格式中形成 url 后,我们可以向 Client 类添加一些方法,以便获取相应的图像。
def request_get(self,url):
request_url = self.compose_url(url)
response = self.session.get(request_url)
# for images coming from the heatmap tiles service
return self.get_image(response)
@staticmethod
def get_image(response):
if response.status_code == 200:
image_content = response.content
# note use of Image from PIL here
# needs from PIL import Image
image = Image.open(io.BytesIO(image_content))
return image
else:
print("GET request for image returned an error")
return None
这很好,但我们真正需要的是将一组经纬度坐标转换为瓦片坐标的能力。文档解释了如何做——我们首先将坐标转换为墨卡托投影,然后使用指定的缩放级别将其转换为“像素坐标”。最后,我们将其转换为瓦片坐标。为了处理所有这些转换,我们可以使用下面的 TileHelper 类。
import math
import numpy as np
class TileHelper(object):
def __init__(self, tile_size=256):
self.tile_size = tile_size
def location_to_tile_xy(self,location,zoom_level=4):
# Based on function here
# https://developers.google.com/maps/documentation/javascript/examples/map-coordinates#maps_map_coordinates-javascript
lat = location["latitude"]
lon = location["longitude"]
world_coordinate = self._project(lat,lon)
scale = 1 << zoom_level
pixel_coord = (math.floor(world_coordinate[0]*scale), math.floor(world_coordinate[1]*scale))
tile_coord = (math.floor(world_coordinate[0]*scale/self.tile_size),math.floor(world_coordinate[1]*scale/self.tile_size))
return world_coordinate, pixel_coord, tile_coord
def tile_to_bounding_box(self,tx,ty,zoom_level):
# see https://developers.google.com/maps/documentation/javascript/coordinates
# for details
box_north = self._tiletolat(ty,zoom_level)
# tile numbers advance towards the south
box_south = self._tiletolat(ty+1,zoom_level)
box_west = self._tiletolon(tx,zoom_level)
# time numbers advance towards the east
box_east = self._tiletolon(tx+1,zoom_level)
# (latmin, latmax, lonmin, lonmax)
return (box_south, box_north, box_west, box_east)
@staticmethod
def _tiletolon(x,zoom):
return x / math.pow(2.0,zoom) * 360.0 - 180.0
@staticmethod
def _tiletolat(y,zoom):
n = math.pi - (2.0 * math.pi * y)/math.pow(2.0,zoom)
return math.atan(math.sinh(n))*(180.0/math.pi)
def _project(self,lat,lon):
siny = math.sin(lat*math.pi/180.0)
siny = min(max(siny,-0.9999), 0.9999)
return (self.tile_size*(0.5 + lon/360), self.tile_size*(0.5 - math.log((1 + siny) / (1 - siny)) / (4 * math.pi)))
@staticmethod
def find_nearest_corner(location,bounds):
corner_lat_idx = np.argmin([
np.abs(bounds[0]-location["latitude"]),
np.abs(bounds[1]-location["latitude"])
])
corner_lon_idx = np.argmin([
np.abs(bounds[2]-location["longitude"]),
np.abs(bounds[3]-location["longitude"])
])
if (corner_lat_idx == 0) and (corner_lon_idx == 0):
# closests is latmin, lonmin
direction = "southwest"
elif (corner_lat_idx == 0) and (corner_lon_idx == 1):
direction = "southeast"
elif (corner_lat_idx == 1) and (corner_lon_idx == 0):
direction = "northwest"
else:
direction = "northeast"
corner_coords = (bounds[corner_lat_idx],bounds[corner_lon_idx+2])
return corner_coords, direction
@staticmethod
def get_ajoining_tiles(tx,ty,direction):
if direction == "southwest":
return [(tx-1,ty),(tx-1,ty+1),(tx,ty+1)]
elif direction == "southeast":
return [(tx+1,ty),(tx+1,ty-1),(tx,ty-1)]
elif direction == "northwest":
return [(tx-1,ty-1),(tx-1,ty),(tx,ty-1)]
else:
return [(tx+1,ty-1),(tx+1,ty),(tx,ty-1)]
我们可以看到 location_to_tile_xy 函数接收一个位置字典和缩放级别,并返回可以找到该点的瓦片。另一个有用的函数是 tile_to_bounding_box,它会找到指定网格单元的边界坐标。如果我们要对单元格进行地理定位并将其绘制在地图上,我们需要这个函数。
让我们看看air_quality_tile函数如何工作,该函数将接收我们的client、location和一个表示我们要提取的瓦片类型的字符串。我们还需要指定一个缩放级别,这在开始时可能很难选择,需要一些试验和错误。我们稍后将讨论get_adjoining_tiles参数。
def air_quality_tile(
client,
location,
pollutant="UAQI_INDIGO_PERSIAN",
zoom=4,
get_adjoining_tiles = True
):
# see https://developers.google.com/maps/documentation/air-quality/reference/rest/v1/mapTypes.heatmapTiles/lookupHeatmapTile
assert pollutant in [
"UAQI_INDIGO_PERSIAN",
"UAQI_RED_GREEN",
"PM25_INDIGO_PERSIAN",
"GBR_DEFRA",
"DEU_UBA",
"CAN_EC",
"FRA_ATMO",
"US_AQI"
]
# contains useful methods for dealing the tile coordinates
helper = TileHelper()
# get the tile that the location is in
world_coordinate, pixel_coord, tile_coord = helper.location_to_tile_xy(location,zoom_level=zoom)
# get the bounding box of the tile
bounding_box = helper.tile_to_bounding_box(tx=tile_coord[0],ty=tile_coord[1],zoom_level=zoom)
if get_adjoining_tiles:
nearest_corner, nearest_corner_direction = helper.find_nearest_corner(location, bounding_box)
adjoining_tiles = helper.get_ajoining_tiles(tile_coord[0],tile_coord[1],nearest_corner_direction)
else:
adjoining_tiles = []
tiles = []
#get all the adjoining tiles, plus the one in question
for tile in adjoining_tiles + [tile_coord]:
bounding_box = helper.tile_to_bounding_box(tx=tile[0],ty=tile[1],zoom_level=zoom)
image_response = client.request_get(
"/v1/mapTypes/" + pollutant + "/heatmapTiles/" + str(zoom) + '/' + str(tile[0]) + '/' + str(tile[1])
)
# convert the PIL image to numpy
try:
image_response = np.array(image_response)
except:
image_response = None
tiles.append({
"bounds":bounding_box,
"image":image_response
})
return tiles
从阅读代码中,我们可以看出工作流程如下:首先,找到感兴趣位置的瓦片坐标。这指定了我们要提取的网格单元。然后,找到该网格单元的边界坐标。如果我们要提取周围的瓦片,找到边界框的最近角落,然后使用该角落计算三个相邻网格单元的瓦片坐标。然后调用 API,并将每个瓦片返回为带有相应边界框的图像。
我们可以按标准方式运行,如下所示:
client = Client(key=GOOGLE_MAPS_API_KEY)
location = {"longitude":-118.3,"latitude":34.1}
zoom = 7
tiles = air_quality_tile(
client,
location,
pollutant="UAQI_INDIGO_PERSIAN",
zoom=zoom,
get_adjoining_tiles=False)
然后用 folium 绘制一个可缩放的地图!请注意,我在这里使用的是 leafmap,因为此包可以生成与 gradio 兼容的 Folium 地图,gradio 是一个强大的工具,用于生成 Python 应用程序的简单用户界面。有关示例,请查看这篇文章。
import leafmap.foliumap as leafmap
import folium
lat = location["latitude"]
lon = location["longitude"]
map = leafmap.Map(location=[lat, lon], tiles="OpenStreetMap", zoom_start=zoom)
for tile in tiles:
latmin, latmax, lonmin, lonmax = tile["bounds"]
AQ_image = tile["image"]
folium.raster_layers.ImageOverlay(
image=AQ_image,
bounds=[[latmin, lonmin], [latmax, lonmax]],
opacity=0.7
).add_to(map)
也许令人失望的是,在此缩放级别下包含我们位置的瓦片大部分是海洋,尽管看到空气污染绘制在详细地图上仍然不错。如果你放大,可以看到道路交通信息被用来指示城市区域的空气质量信号。

在 Folium 地图上绘制空气质量热力图瓦片。图像由作者生成。
设置get_adjoining_tiles=True为我们提供了一个更漂亮的地图,因为它在该缩放级别下提取了三个最近的、不重叠的瓦片。在我们的情况下,这有助于使地图更加美观。

当我们还提取相邻瓦片时,会产生更有趣的结果。请注意,这里的颜色显示的是通用 AQI 指数。图像由作者生成。
我个人更喜欢当pollutant=US_AQI时生成的图像,但还有几种不同的选项。不幸的是,API 未返回颜色尺度,尽管可以使用图像中的像素值和对颜色含义的了解生成一个。

上面的相同瓦片根据美国 AQI 着色。此地图生成于 2023 年 10 月 12 日,根据此工具www.frontlinewildfire.com/california-wildfire-map/的描述,中央加州的亮红色区域似乎是位于科阿林加附近山丘的处方火。图像由作者生成。
结论
感谢你阅读到最后!在这里,我们探讨了如何使用 Google Maps 空气质量 API 来在 Python 中提供结果,这些结果可以用于各种有趣的应用程序。未来,我希望能继续更新关于 air_quality_mapper 工具的文章,因为它还在不断发展,但我希望这里讨论的脚本本身能对你有用。像往常一样,任何进一步发展的建议都将受到非常欢迎!
《Pythonista 的语义内核入门》


·
关注 发表在 Towards Data Science ·30 分钟阅读·2023 年 9 月 2 日
–
自从发布了ChatGPT以来,大型语言模型(LLMs)在行业和媒体中受到了极大的关注;导致了几乎在所有可以想到的背景下利用 LLMs 的前所未有的需求。
语义内核是一个开源 SDK,最初由微软开发,用于支持 Microsoft 365 Copilot 和 Bing 等产品,旨在简化将 LLM 集成到应用程序中的过程。它使用户能够利用 LLM 根据自然语言查询和命令来编排工作流程,通过将这些模型与提供附加功能的外部服务连接,使模型能够利用这些服务完成任务。
由于它是针对 Microsoft 生态系统创建的,因此目前可用的许多复杂示例都是用 C# 编写的,关注 Python SDK 的资源较少。在这篇博客文章中,我将展示如何使用 Python 入门 Semantic Kernel,介绍关键组件,并探索如何利用这些组件执行各种任务。
在这篇文章中,我们将涵盖以下内容:
-
内核
-
连接器
-
提示函数
- 创建自定义连接器
-
使用聊天服务
- 制作一个简单的聊天机器人
-
内存
-
使用文本嵌入服务
-
将内存集成到上下文中
-
-
插件
-
使用现成插件
-
创建自定义插件
-
链式调用多个插件
-
-
使用规划器编排工作流
免责声明: 由于 Semantic Kernel 和所有与 LLM 相关的内容一样,发展非常迅速。因此,接口可能会随着时间的推移稍有变化;我会尽量保持这篇文章的更新。
尽管我在 Microsoft 工作,但我并没有被要求或获得任何补偿来推广 Semantic Kernel。在 行业解决方案工程 (ISE) 中,我们以根据情况和所服务的客户选择我们认为最佳的工具为荣。在我们选择不使用 Microsoft 产品的情况下,我们会向产品团队提供详细的反馈,说明原因以及我们认为缺失或可以改进的地方;这种反馈循环通常会导致 Microsoft 产品更好地满足我们的需求。
在这里,我选择推广 Semantic Kernel,因为尽管有一些小瑕疵,我相信它显示了很大的潜力,并且我更喜欢 Semantic Kernel 在设计选择上的表现,相比于我所探索的其他一些解决方案。
撰写时使用的软件包包括:
dependencies:
- python=3.10.1.0
- pip:
- semantic-kernel==0.9.3b1
- timm==0.9.5
- transformers==4.38.2
- sentence-transformers==2.2.2
- curated-transformers==1.1.0
简而言之: 如果你只是想看看一些可以直接使用的工作代码,所有复制此文章所需的代码都可以在这里的笔记本中找到 这里。
致谢
我想感谢我的同事 Karol Zak,感谢他与我合作探索如何在我们的用例中充分利用 Semantic Kernel,并提供了一些启发本文中示例的代码!

Semantic Kernel 组件概述。图片来源:learn.microsoft.com/en-us/semantic-kernel/media/kernel-flow.png
现在,让我们从库的核心组件开始。
内核
核心: “对象或系统的核心、中心或本质。” — 维基词典
语义内核中的一个关键概念就是内核本身,它是我们用来协调基于 LLM 的工作流的主要对象。最初,内核的功能非常有限;它的所有功能主要由我们将要连接的外部组件提供。然后,内核作为一个处理引擎,通过调用适当的组件来完成给定的任务。
我们可以按照下面的示例创建一个内核:
import semantic_kernel as sk
kernel = sk.Kernel()
连接器
为了使我们的内核有用,我们需要连接一个或多个 AI 模型,这使我们能够利用内核来理解和生成自然语言;这通过连接器来完成。语义内核提供了开箱即用的连接器,使得从不同来源添加 AI 模型变得简单,例如 OpenAI、Azure OpenAI 和 Hugging Face。这些模型随后用于向内核提供服务。
在撰写本文时,支持以下服务:
-
文本生成服务:用于生成自然语言
-
聊天服务:用于创建对话体验
-
文本嵌入生成服务:用于将自然语言编码为嵌入
每种类型的服务可以同时支持来自不同来源的多个模型,这使得可以根据任务和用户的偏好在不同模型之间切换。如果没有指定特定的服务或模型,内核将默认为定义的第一个服务和模型。
我们可以使用以下属性查看所有当前注册的服务:

正如预期的那样,我们当前没有任何连接的服务!让我们来改变这一点。
在这里,我将开始访问一个 GPT3.5-turbo 模型,这是我通过 Azure OpenAI 服务 在我的 Azure 订阅 中部署的。
由于这个模型可以用于文本生成和聊天,我将同时注册这两项服务。
from semantic_kernel.connectors.ai.open_ai import (
AzureChatCompletion,
AzureTextCompletion,
)
kernel.add_service(
service=AzureTextCompletion(
service_id="azure_gpt35_text_completion",
deployment_name=OPENAI_DEPLOYMENT_NAME,
endpoint=OPENAI_ENDPOINT,
api_key=OPENAI_API_KEY
),
)
gpt35_chat_service = AzureChatCompletion(
service_id="azure_gpt35_chat_completion",
deployment_name=OPENAI_DEPLOYMENT_NAME,
endpoint=OPENAI_ENDPOINT,
api_key=OPENAI_API_KEY,
)
kernel.add_service(gpt35_chat_service)
我们现在可以看到,聊天服务已注册为文本生成和聊天生成服务。

要使用非 Azure OpenAI API,我们唯一需要更改的是使用OpenAITextCompletion和OpenAIChatCompletion连接器,而不是我们的 Azure 类。如果你没有访问 OpenAI 模型的权限,也不用担心,我们稍后会看看如何连接到开源模型;模型的选择不会影响后续步骤。
要在注册服务后检索服务,我们可以使用内核上的以下方法。

现在我们已经注册了一些服务,让我们探索一下如何与它们交互!
提示函数
通过语义内核与 LLM 交互的方式是创建一个提示函数。提示函数期望自然语言输入,并使用 LLM 来解释所要求的内容,然后采取相应的行动以返回合适的响应。例如,提示函数可用于文本生成、摘要、情感分析和问答等任务。
在语义内核中,语义功能由两个组件组成:
-
提示模板:将发送给 LLM 的自然语言查询或命令
-
执行配置:包含提示功能的设置和选项,例如应该使用的服务、期望的参数以及功能描述。
最简单的入门方法是使用内核的create_function_from_prompt方法,该方法接受提示和执行配置,以及一些标识符以帮助跟踪内核中的函数。
为了说明这一点,让我们创建一个简单的提示:
prompt = """
{{$input}} is the capital city of
"""
在这里,我们使用了{{$}}语法来表示将注入到提示中的参数。虽然我们将在整个帖子中看到更多的示例,但有关模板语法的全面指南可以在文档中找到。
接下来,我们需要创建一个执行配置。如果我们知道要使用哪种服务来执行我们的函数,可以导入相应的配置类并创建其实例,如下所示。
from semantic_kernel.connectors.ai.open_ai import OpenAITextPromptExecutionSettings
execution_config = OpenAITextPromptExecutionSettings(service_id = "azure_gpt35_text_completion",
max_tokens=100,
temperature=0,
top_p=0.0)
虽然这样做有效,但它将我们的函数与某种类型的服务耦合,限制了我们的灵活性。另一种方法是直接从我们打算使用的服务中检索相应的配置类,如下所示。

这样,我们可以在运行时选择我们希望使用的服务,并自动加载合适的配置对象。让我们使用这种方法来创建我们的执行配置。
target_service_id = "azure_gpt35_text_completion"
execution_config = kernel.get_service(target_service_id).instantiate_prompt_execution_settings(
service_id=target_service_id,
max_tokens=100,
temperature=0,
seed=42
)
现在,我们可以创建我们的函数了!
generate_capital_city_text = kernel.create_function_from_prompt(
prompt=prompt,
plugin_name="Generate_Capital_City_Completion",
function_name="generate_city_completion",
execution_settings=execution_config
)
现在,我们可以使用内核的invoke方法来调用我们的函数。由于我们连接的许多服务可能会调用外部 API,invoke是一个异步方法,基于Asyncio。这使我们能够同时执行多个外部服务调用,而无需为每个调用等待响应。
response = await kernel.invoke(generate_capital_city_text, input="Paris")
响应对象包含有关我们的函数调用的有价值信息,例如所使用的参数;如果一切按预期工作,我们可以使用对象上的str构造函数来访问结果。


在这里,我们可以看到我们的函数已经成功工作!
使用本地模型
除了使用 API 背后的模型外,我们还可以使用内核来协调对本地模型的调用。为了说明这一点,让我们注册另一个文本完成服务,并创建一个配置,使我们能够指定我们希望使用新的服务。对于我们的第二个完成服务,我们使用来自Hugging Face transformers library的模型。为此,我们使用HuggingFaceTextCompletion连接器。
在这里,由于我们将本地运行模型,我选择了OPT-350m,这是一个较旧的模型,旨在大致匹配 GPT-3 的性能,应该能够在大多数硬件上快速轻松地运行。
from semantic_kernel.connectors.ai.hugging_face import HuggingFaceTextCompletion
hf_model = HuggingFaceTextCompletion(service_id="hf_text_completion", ai_model_id="facebook/opt-350m", task="text-generation")
kernel.add_service(hf_model)
现在,让我们创建我们的配置对象。我们可以以类似的方式进行,但这次需要传递与我们 Hugging Face 服务相关的service_id。
target_service_id = "hf_text_completion"
execution_config = kernel.get_service(target_service_id).instantiate_prompt_execution_settings(
service_id=target_service_id,
max_tokens=100,
temperature=0,
seed=42
)
我们现在可以创建并执行我们的函数,就像我们之前看到的那样。
hf_complete = kernel.create_function_from_prompt(
prompt=prompt,
plugin_name="Generate_Capital_City_Completion",
function_name="generate_city_completion_opt",
execution_settings=execution_config
)
response = await kernel.invoke(hf_complete, input='Paris')

好的,生成似乎已经成功,但可以说效果不如 GPT-3.5 所提供的响应。这并不意外,因为这是一个较旧的模型!有趣的是,我们可以看到,在达到最大令牌限制之前,它开始以类似的模式回答关于柏林的问题;这种行为在处理文本完成模型时并不意外。
创建自定义连接器
现在我们已经看到如何创建语义函数并指定我们希望我们的函数使用哪个服务。然而,直到这一点为止,我们使用的所有服务都依赖于现成的连接器。在某些情况下,我们可能希望使用来自不同库的模型,而不是当前支持的模型,这时我们需要一个自定义连接器。让我们来看看如何实现这一点。
例如,我们可以使用来自curated transformers库的变换器模型。
要创建自定义连接器,我们需要继承TextCompletionClientBase,它作为我们模型的一个轻量级封装。下面提供了一个简单的示例。
from typing import Any, Dict, List, Optional, Union
import torch
from curated_transformers.generation import (AutoGenerator,
SampleGeneratorConfig)
from semantic_kernel.connectors.ai.prompt_execution_settings import \
PromptExecutionSettings
from semantic_kernel.connectors.ai.text_completion_client_base import \
TextCompletionClientBase
class CuratedTransformersPromptExecutionSettings(PromptExecutionSettings):
temperature: float = 0.0
top_p: float = 1.0
def prepare_settings_dict(self, **kwargs) -> Dict[str, Any]:
settings = {
"temperature": self.temperature,
"top_p": self.top_p,
}
settings.update(kwargs)
return settings
class CuratedTransformersCompletion(TextCompletionClientBase):
device: Any
generator: Any
def __init__(
self,
service_id: str,
model_name: str,
device: Optional[int] = -1,
) -> None:
"""
Use a curated transformer model for text completion.
Arguments:
model_name {str}
device_idx {Optional[int]} -- Device to run the model on, -1 for CPU, 0+ for GPU.
Note that this model will be downloaded from the Hugging Face model hub.
"""
device = (
"cuda:" + str(device)
if device >= 0 and torch.cuda.is_available()
else "cpu"
)
generator = AutoGenerator.from_hf_hub(
name=model_name, device=torch.device(device)
)
super().__init__(
service_id=service_id,
ai_model_id=model_name,
device=device,
generator=generator,
)
async def complete(
self, prompt: str, settings: CuratedTransformersPromptExecutionSettings
) -> Union[str, List[str]]:
generator_config = SampleGeneratorConfig(**settings.prepare_settings_dict())
try:
with torch.no_grad():
result = self.generator([prompt], generator_config)
return result[0]
except Exception as e:
raise ValueError("CuratedTransformer completion failed", e)
async def complete_stream(self, prompt: str, request_settings):
raise NotImplementedError(
"Streaming is not supported for CuratedTransformersCompletion."
)
def get_prompt_execution_settings_from_settings(
self, settings: CuratedTransformersPromptExecutionSettings
) -> CuratedTransformersPromptExecutionSettings:
return settings
现在,我们可以注册我们的连接器并创建一个语义函数,如前所示。这里,我使用了Falcon-7B 模型,这需要一个 GPU 才能在合理的时间内运行。在这里,我使用了英伟达 A100在 Azure 虚拟机上运行,因为在本地运行太慢了。
kernel.add_service(
CuratedTransformersCompletion(
service_id="custom",
model_name="tiiuae/falcon-7b",
device=-1,
)
)
complete = kernel.create_function_from_prompt(
prompt=prompt,
plugin_name="Generate_Capital_City_Completion",
function_name="generate_city_completion_curated",
prompt_execution_settings=CuratedTransformersPromptExecutionSettings(
service_id="custom", temperature=0.0, top_p=0.0
),
)
print(await kernel.invoke(complete, input="Paris"))

再次,我们可以看到生成的内容有效,但在回答了我们的问题后很快陷入了重复。
这很可能是由于我们选择的模型。通常,自回归变换器模型被训练以预测大量文本中的下一个单词;从本质上讲,使其成为强大的自动补全机器!在这里,它似乎试图‘完成’我们的问题,这导致它继续生成文本,这对我们并没有帮助。
使用聊天服务
一些 LLM 模型经过了额外的训练,使其在交互中更有用。OpenAI 的InstructGPT论文详细介绍了这一过程的一个例子。
从高层次来看,这通常涉及添加一个或多个监督微调步骤,在这些步骤中,模型不是在随机的非结构化文本上训练,而是在策划的任务示例上进行训练,例如问答和总结;这些模型通常被称为指令调优或聊天模型。
由于我们已经观察到基础 LLM 可以生成比我们需要的更多的文本,因此让我们调查聊天模型是否表现不同。要使用我们的聊天模型,我们需要更新配置以指定适当的服务并创建一个新函数;在我们的情况下,我们将使用azure_gpt35_chat_completion。

generate_capital_city_chat = kernel.create_function_from_prompt(
prompt=prompt,
plugin_name="Generate_Capital_City",
function_name="capital_city_chat_2",
prompt_execution_settings=kernel.get_service(target_service_id).instantiate_prompt_execution_settings(
service_id=target_service_id, temperature=0.0, top_p=0.0, seed=42
),
)
print(await kernel.invoke(generate_capital_city_chat, input="Paris"))

很好,我们可以看到聊天模型给出了一个更简洁的回答!
之前,由于我们使用的是文本补全模型,我们将提示格式化为模型要完成的句子。然而,经过指令调优的模型应该能够理解问题,因此我们可能能够调整提示,使其更加灵活。让我们看看如何调整我们的提示,以便与模型进行互动,就像它是一个设计来提供有关我们可能喜欢访问的地方的信息的聊天机器人。
首先,让我们调整我们的函数配置,使提示更加通用。
chatbot = kernel.create_function_from_prompt(
prompt="{{$input}}",
plugin_name="Chatbot",
function_name="chatbot",
prompt_execution_settings=kernel.get_service(target_service_id).instantiate_prompt_execution_settings(
service_id=target_service_id, temperature=0.0, top_p=0.0, seed=42
),
)
在这里,我们可以看到我们仅传递了用户输入,因此我们必须将输入表达为问题。让我们尝试一下。
async def chat(user_input):
print(await kernel.invoke(generate_capital_city_chat, input=user_input))

很好,这似乎有效。让我们尝试提出一个后续问题。

我们可以看到模型提供了一个非常通用的回答,这完全没有考虑到我们之前的问题。这是可以预期的,因为模型收到的提示是"What are some interesting things to do there?",我们没有提供“那里”指的是哪里!
让我们看看如何在接下来的部分中扩展我们的方法,制作一个简单的聊天机器人。
制作一个简单的聊天机器人
现在我们已经了解了如何使用聊天服务,让我们探索如何创建一个简单的聊天机器人。
我们的聊天机器人应该能够做三件事:
-
知道它的目的并告知我们
-
理解当前对话的上下文
-
回复我们的提问
让我们调整我们的提示以反映这一点。
chatbot_prompt = """
"You are a chatbot to provide information about different cities and countries.
For other questions not related to places, you should politely decline to answer the question, stating your purpose"
+++++
{{$history}}
User: {{$input}}
ChatBot: """
注意我们添加了变量history,它将用于向聊天机器人提供以前的上下文。虽然这是一种相当幼稚的方法,因为长时间的对话会很快导致提示达到模型的最大上下文长度,但对于我们的目的来说应该有效。
到目前为止,我们只使用了使用单个变量的提示。要使用多个变量,我们需要调整我们的配置,如下所示,通过创建一个PromptTemplateConfig;它定义了我们期望的输入。
from semantic_kernel.prompt_template.input_variable import InputVariable
execution_config = kernel.get_service(target_service_id).instantiate_prompt_execution_settings(
service_id=target_service_id,
max_tokens=500,
temperature=0,
seed=42
)
prompt_template_config = sk.PromptTemplateConfig(
template=chatbot_prompt,
name="chat",
template_format="semantic-kernel",
input_variables=[
InputVariable(name="input", description="The user input", is_required=True),
InputVariable(name="history", description="The conversation history", is_required=True),
],
execution_settings=execution_config,
)
现在,让我们使用这个更新后的配置和提示来创建我们的聊天机器人
chatbot = kernel.create_function_from_prompt(
function_name="chatbot_with_history",
plugin_name="chatPlugin",
prompt_template_config=prompt_template_config,
)
为了跟踪要包含在提示中的历史记录,我们可以使用ChatHistory对象。让我们创建一个新的实例。
from semantic_kernel.contents.chat_history import ChatHistory
chat_history = ChatHistory()
此外,为了将多个参数传递给我们的提示,我们可以使用KernelArguments,这样我们只需将一个参数传递给invoke;这个参数包含所有的参数。
我们可以通过创建一个简单的聊天功能来实现这一点,以在每次互动后更新我们的历史记录。
from pprint import pprint
async def chat(input_text, verbose=True):
# Save new message in the context variables
context = KernelArguments(user_input=input_text, history=chat_history)
if verbose:
# print the full prompt before each interaction
print("Prompt:")
print("-----")
# inject the variables into our prompt
print(await chatbot.prompt_template.render(kernel, context))
print("-----")
# Process the user message and get an answer
answer = await kernel.invoke(chatbot, context)
# Show the response
pprint(f"ChatBot: {answer}")
# Append the new interaction to the chat history
chat_history.add_user_message(input_text)
chat_history.add_assistant_message(str(answer))
让我们试试看!



在这里,我们可以看到这满足了我们的要求!
检查我们的提示,我们可以看到历史记录被渲染成一个可以包含额外元数据的格式。虽然这可能是一个有用的实现细节,但我们很可能不希望我们的提示以这种方式格式化!
当使用如语义内核这样的库时,能够准确验证传递给模型的内容非常重要,因为提示的书写和格式化方式对结果有很大影响。
大多数语言模型,例如 OpenAI API,不接受单个提示作为输入,而是更喜欢格式化为消息列表的输入;在用户和模型之间交替。我们可以检查我们的提示将如何被拆分成消息。

在这里,我们可以看到与聊天历史相关的所有格式都已被移除,消息看起来符合我们的预期。
记忆
在与我们的聊天机器人互动时,使体验感觉像有用互动的关键因素之一是聊天机器人能够保留我们之前问题的上下文。我们通过让聊天机器人访问记忆,利用ChatHistory来处理这一点。
尽管这对于我们简单的用例效果很好,但我们所有的对话历史都存储在系统的 RAM 中,并未持久化;一旦我们关闭系统,这些数据将永远消失。对于更智能的应用程序,能够构建和持久化短期和长期记忆以供模型访问是很有用的。
此外,在我们的示例中,我们将所有之前的互动内容都输入到我们的提示中。由于模型通常具有固定大小的上下文窗口——这决定了我们的提示可以有多长——如果我们开始进行长时间的对话,这将很快崩溃。避免这种情况的一种方法是将记忆存储为独立的“块”,并仅将我们认为可能相关的信息加载到提示中。
语义内核提供了一些关于如何将记忆融入应用程序的功能,所以让我们探索一下如何利用这些功能。
例如,让我们扩展我们的聊天机器人,使其能够访问存储在记忆中的一些信息。
首先,我们需要一些可能与我们的聊天机器人相关的信息。虽然我们可以手动研究和整理相关信息,但让模型为我们生成信息会更快!让我们让模型生成一些关于伦敦市的事实。我们可以按如下方式进行:
response = chatbot(
"""Please provide a comprehensive overview of things to do in London. Structure your answer in 5 paragraphs, based on:
- overview
- landmarks
- history
- culture
- food
Each paragraph should be 100 tokens, do not add titles such as `Overview:` or `Food:` to the paragraphs in your response.
Do not acknowledge the question, with a statement like "Certainly, here's a comprehensive overview of things to do in London".
Do not provide a closing comment.
"""
)

现在我们有了一些文本,为了让模型只访问它需要的部分,让我们将其划分成几个块。语义内核提供了一些功能来实现这一点,在它的text_chunker模块中。我们可以按如下方式使用它:
from semantic_kernel.text import text_chunker as tc
chunks = tc.split_plaintext_paragraph([london_info], max_tokens=100)

我们可以看到文本被分割成了 8 个块。根据文本内容,我们需要调整每个块的最大标记数。
使用文本嵌入服务
现在我们已经对数据进行了块化处理,我们需要创建每个块的表示,以便能够计算文本之间的相关性;我们可以通过将文本表示为嵌入来实现这一点。
为了生成嵌入,我们需要将文本嵌入服务添加到我们的内核中。类似于之前的情况,根据基础模型的来源,有各种连接器可以使用。
首先,让我们使用一个[text-embedding-ada-002](https://learn.microsoft.com/en-us/azure/ai-services/openai/concepts/models#embeddings-models) 模型,该模型在 Azure OpenAI 服务中部署。这个模型由 OpenAI 训练,更多关于这个模型的信息可以在他们的发布博客文章中找到。
from semantic_kernel.connectors.ai.open_ai import AzureTextEmbedding
embedding_service = AzureTextEmbedding(
service_id="azure_openai_embedding",
deployment_name=OPENAI_EMBEDDING_DEPLOYMENT_NAME,
endpoint=OPENAI_ENDPOINT,
api_key=OPENAI_API_KEY,
)
kernel.add_service(embedding_service)
现在我们可以访问生成嵌入的模型,我们需要一个地方来存储这些嵌入。Semantic Kernel 提供了一个 MemoryStore 的概念,它是各种持久性提供程序的接口。
对于生产系统,我们可能会希望使用数据库进行持久化。为了简化我们的示例,我们将使用内存存储。让我们创建一个内存中的记忆存储实例。
memory_store = sk.memory.VolatileMemoryStore()
虽然我们使用了内存中的记忆存储来简化我们的示例,但在构建更复杂的系统时,我们可能会希望使用数据库进行持久化。Semantic Kernel 提供了与流行存储解决方案的连接器,如CosmosDB、Redis、Postgres等。由于记忆存储具有通用接口,因此唯一需要更改的只是修改使用的连接器,这使得在提供程序之间切换变得容易。
现在我们已经定义了我们的记忆存储,我们需要生成嵌入。Semantic Kernel 提供了语义记忆数据结构来帮助实现这一点;它将记忆存储与可以生成嵌入的服务关联起来。在这里,我们将使用SemanticTextMemory,它将使我们能够嵌入和检索我们的文档片段。
from semantic_kernel.memory.semantic_text_memory import SemanticTextMemory
memory = SemanticTextMemory(storage=memory_store, embeddings_generator=embedding_service)
我们现在可以按照如下方式将信息保存到我们的记忆存储中。
for i, chunk in enumerate(chunks):
await memory.save_information(
collection="London", id="chunk" + str(i), text=chunk
)
在这里,我们创建了一个新的集合,用于分组相似的文档。
我们现在可以以以下方式查询此集合:
results = await memory.search(
"London", "what food should I eat in London?", limit=2
)

查看结果,我们可以看到返回了相关信息;这反映在高相关性评分上。
然而,这其实很简单,因为我们有直接相关的信息,使用了非常相似的语言。让我们尝试一个更微妙的查询。
results = await memory.search(
"London", "Where can I eat non-british food in London?", limit=2
)

在这里,我们可以看到我们得到了完全相同的结果。然而,由于我们的第二个结果明确提到了‘来自世界各地的食物’,我认为这是更好的匹配。这突显了语义搜索方法的一些潜在局限性。
使用开源模型
出于兴趣,让我们看看开源模型在这个上下文中与我们的 OpenAI 服务的比较。我们可以注册一个Hugging Face 句子变换模型来实现这一点,如下所示:
from semantic_kernel.connectors.ai.hugging_face import HuggingFaceTextEmbedding
hf_embedding_service = HuggingFaceTextEmbedding(
service_id="hf_embedding_service",
ai_model_id="sentence-transformers/all-MiniLM-L6-v2",
device=-1
)
hf_memory = SemanticTextMemory(storage=sk.memory.VolatileMemoryStore(), embeddings_generator=hf_embedding_service)
我们现在可以以与之前相同的方式进行查询。
for i, chunk in enumerate(chunks):
await kernel.memory.save_information_async(
"hf_London", id="chunk" + str(i), text=chunk
)
hf_results = await hf_memory.search(
"hf_London", "what food should I eat in London", limit=2, min_relevance_score=0
)

hf_results = await hf_memory.search(
"hf_London",
"Where can I eat non-british food in London?",
limit=2,
min_relevance_score=0,
)

我们可以看到,我们返回了相同的片段,但相关性评分不同。我们还可以观察到不同模型生成的嵌入的维度差异。

将记忆集成到上下文中
在我们之前的示例中,我们看到虽然可以基于嵌入搜索识别大致相关的信息,但对于更细微的查询,我们没有得到最相关的结果。让我们探索是否可以改进这一点。
我们可以采取的一种方法是将相关信息提供给我们的聊天机器人,然后让模型决定哪些部分最相关。让我们创建一个提示,指示模型根据提供的上下文回答问题,并注册一个提示功能。
prompt_with_context = """
Use the following pieces of context to answer the users question.
This is the only information that you should use to answer the question, do not reference information outside of this context.
If the information required to answer the question is not provided in the context, just say that "I don't know", don't try to make up an answer.
----------------
Context: {{$context}}
----------------
User question: {{$question}}
----------------
Answer:
"""
execution_config = kernel.get_service(target_service_id).instantiate_prompt_execution_settings(
service_id=target_service_id,
max_tokens=500,
temperature=0,
seed=42
)
prompt_template_config = sk.PromptTemplateConfig(
template=prompt_with_context,
name="chat",
template_format="semantic-kernel",
input_variables=[
InputVariable(name="question", description="The user input", is_required=True),
InputVariable(name="context", description="The conversation history", is_required=True),
],
execution_settings=execution_config,
)
chatbot_with_context = kernel.create_function_from_prompt(
function_name="chatbot_with_memory_context",
plugin_name="chatPluginWithContext",
prompt_template_config=prompt_template_config,
)
现在,我们可以使用这个功能来回答我们更细微的问题。首先,我们创建一个上下文对象,并将问题添加到其中。
question = "Where can I eat non-british food in London?"
接下来,我们可以手动执行嵌入搜索,并将检索到的信息添加到我们的上下文中。
results = await hf_memory.search("hf_London", question, limit=2)
我们创建一个上下文对象,并将问题添加到其中。
context = KernelArguments(question=question, context="\n".join([result.text for result in results]))
最后,我们可以执行我们的功能。
answer = await kernel.invoke(chatbot_with_context, context)

这一次,我们看到我们的答案引用了我们寻找的信息,并提供了更好的答案!
插件
在语义内核中,插件是一组可以加载到内核中以暴露给 AI 应用程序和服务的功能。插件中的功能可以由内核协调以完成任务。
文档将插件描述为语义内核的“构建块”,可以将它们链接在一起以创建复杂的工作流程;由于插件遵循 OpenAI 插件规范,因此为 OpenAI 服务、必应和 Microsoft 365 创建的插件可以与语义内核一起使用。
语义内核 提供了几种开箱即用的插件,包括:
-
ConversationSummaryPlugin:用于总结对话
-
HttpPlugin:用于调用 API
-
TextMemoryPlugin:用于在内存中存储和检索文本
-
TimePlugin:用于获取时间和任何其他时间信息
让我们先探索如何使用预定义的插件,然后再调查如何创建自定义插件。
使用开箱即用的插件
语义内核中包含的一个插件是TextMemoryPlugin,它提供了从内存中保存和检索信息的功能。让我们看看如何使用它来简化我们之前的示例,即从内存中填充提示上下文。
首先,我们必须导入我们的插件,如下所示。

在这里,我们可以看到这个插件包含两个语义功能,recall 和 save。
现在,让我们修改我们的提示:
prompt_with_context_plugin = """
Use the following pieces of context to answer the users question.
This is the only information that you should use to answer the question, do not reference information outside of this context.
If the information required to answer the question is not provided in the context, just say that "I don't know", don't try to make up an answer.
----------------
Context: {{recall $question}}
----------------
User question: {{$question}}
----------------
Answer:
"""
我们可以看到,要使用recall功能,我们可以在提示中引用它。现在,让我们创建一个配置并注册一个功能。
execution_config = kernel.get_service(target_service_id).instantiate_prompt_execution_settings(
service_id=target_service_id,
max_tokens=500,
temperature=0,
seed=42
)
prompt_template_config = sk.PromptTemplateConfig(
template=prompt_with_context_plugin,
name="chat",
template_format="semantic-kernel",
input_variables=[
InputVariable(name="question", description="The user input", is_required=True),
InputVariable(name="context", description="The conversation history", is_required=True),
],
execution_settings=execution_config,
)
chatbot_with_context_plugin = kernel.create_function_from_prompt(
function_name="chatbot_with_context_plugin",
plugin_name="chatPluginWithContextPlugin",
prompt_template_config=prompt_template_config,
)
在我们的手动示例中,我们能够控制返回结果的数量和搜索的集合。使用TextMemoryPlugin时,我们可以通过将这些添加到KernelArguments来设置它们。让我们尝试一下我们的函数。
context = KernelArguments(question="Where can I eat non-british food in London?", collection='London', relevance=0.2, limit=2)
answer = await kernel.invoke(chatbot_with_context_plugin, context)

我们可以看到这与我们的手动方法是等效的。
创建自定义插件
现在我们了解了如何创建语义函数以及如何使用插件,我们拥有了一切所需来开始制作自己的插件!
插件可以包含两种类型的函数:
-
提示函数:使用自然语言执行操作
-
本地函数:使用 Python 代码执行操作
这些可以在一个插件中结合使用。
是否使用提示函数或本地函数取决于你所执行的任务。对于涉及理解或生成语言的任务,提示函数显然是首选。然而,对于更确定性的任务,如执行数学运算、下载数据或访问时间,本地函数更为合适。
让我们探讨如何创建每种类型。首先,让我们创建一个文件夹来存储我们的插件。
from pathlib import Path
plugins_path = Path("Plugins")
plugins_path.mkdir(exist_ok=True)
创建一个诗歌生成器插件
对于我们的示例,让我们创建一个生成诗歌的插件;为此,使用提示函数似乎是自然的选择。我们可以在目录中为此插件创建一个文件夹。
poem_gen_plugin_path = plugins_path / "PoemGeneratorPlugin"
poem_gen_plugin_path.mkdir(exist_ok=True)
回顾一下,插件只是函数的集合,而我们正在创建一个语义函数,下一部分应该很熟悉。关键的不同点在于,我们将不再在线定义提示和配置,而是为这些创建单独的文件,以便更容易加载。
让我们为我们的语义函数创建一个文件夹,命名为write_poem。
poem_sc_path = poem_gen_plugin_path / "write_poem"
poem_sc_path.mkdir(exist_ok=True)
接下来,我们创建我们的提示,保存为skprompt.txt。

现在,让我们创建我们的配置并将其存储在 json 文件中。
虽然在配置中设置有意义的描述总是一个好习惯,但当我们定义插件时,这变得更加重要;插件应提供清晰的描述,说明它们的行为、输入输出以及副作用。原因在于,这是由我们的内核呈现的接口,如果我们希望使用 LLM 来协调任务,它需要能够理解插件的功能及如何调用它,以便选择适当的函数。
config_path = poem_sc_path / "config.json"
%%writefile {config_path}
{
"schema": 1,
"description": "A poem generator, that writes a short poem based on user input",
"execution_settings": {
"azure_gpt35_chat_completion": {
"max_tokens": 512,
"temperature": 0.8,
"top_p": 0.0,
"presence_penalty": 0.0,
"frequency_penalty": 0.0,
"seed": 42
}
},
"input_variables": [
{
"name": "input",
"description": "The topic that the poem should be written about",
"default": "",
"is_required": true
}
]
}
现在,我们可以导入我们的插件:
poem_gen_plugin = kernel.import_plugin_from_prompt_directory(
plugins_path, "PoemGeneratorPlugin"
)
检查我们的插件,我们可以看到它暴露了我们的write_poem语义函数。

我们可以像以前一样使用内核调用我们的函数。
result = await kernel.invoke(poem_gen_plugin["write_poem"], KernelArguments(input="Munich"))

或者,我们可以在另一个语义函数中使用它:
prompt = """
{{PoemGeneratorPlugin.write_poem $input}}
"""
target_service_id = "azure_gpt35_chat_completion"
execution_config = kernel.get_service(target_service_id).instantiate_prompt_execution_settings(
service_id=target_service_id,
max_tokens=500,
temperature=0.8,
seed=42
)
prompt_template_config = sk.PromptTemplateConfig(
template=prompt,
name="chat",
template_format="semantic-kernel",
input_variables=[
InputVariable(name="input", description="The user input", is_required=True),
],
execution_settings=execution_config,
)
write_poem_wrapper = kernel.create_function_from_prompt(
function_name="poem_gen_wrapper",
plugin_name="poemWrapper",
prompt_template_config=prompt_template_config,
)
result = await kernel.invoke(write_poem_wrapper, KernelArguments(input="Munich"))

创建一个图像分类器插件
现在我们已经看到了如何在插件中使用提示函数,让我们来看看如何使用原生函数。
现在,让我们创建一个插件,它接受一个图片网址,然后下载并分类图片。再一次,让我们为我们的新插件创建一个文件夹。
image_classifier_plugin_path = plugins_path / "ImageClassifierPlugin"
image_classifier_plugin_path.mkdir(exist_ok=True)
download_image_sc_path = image_classifier_plugin_path / "download_image.py"
download_image_sc_path.mkdir(exist_ok=True)
现在,我们可以创建我们的 Python 模块。在模块内部,我们可以非常灵活。在这里,我们创建了一个具有两个方法的类,关键步骤是使用kernel_function装饰器来指定哪些方法应该作为插件的一部分被暴露。
对于我们的输入,我们使用了Annotated类型提示来提供我们参数的描述。更多信息可以在文档中找到。
import requests
from PIL import Image
import timm
from timm.data.imagenet_info import ImageNetInfo
from typing import Annotated
from semantic_kernel.functions.kernel_function_decorator import kernel_function
class ImageClassifierPlugin:
def __init__(self):
self.model = timm.create_model("convnext_tiny.in12k_ft_in1k", pretrained=True)
self.model.eval()
data_config = timm.data.resolve_model_data_config(self.model)
self.transforms = timm.data.create_transform(**data_config, is_training=False)
self.imagenet_info = ImageNetInfo()
@kernel_function(
description="Takes a url as an input and classifies the image",
name="classify_image"
)
def classify_image(self, input: Annotated[str, "The url of the image to classify"]) -> str:
image = self.download_image(input)
pred = self.model(self.transforms(image)[None])
return self.imagenet_info.index_to_description(pred.argmax())
def download_image(self, url):
return Image.open(requests.get(url, stream=True).raw).convert("RGB")
在这个例子中,我使用了出色的Pytorch Image Models库来提供我们的分类器。有关该库如何工作的更多信息,请查看这篇博客文章。
现在,我们可以如下面所示简单地导入我们的插件。
image_classifier = ImageClassifierPlugin()
classify_plugin = kernel.import_plugin_from_object(image_classifier, plugin_name="classify_image")
检查我们的插件,我们可以看到只有我们装饰过的函数被暴露出来。

我们可以使用来自 Pixabay 的猫的图片来验证我们的插件是否有效。

url = "https://cdn.pixabay.com/photo/2016/02/10/16/37/cat-1192026_1280.jpg"
response = await kernel.invoke(classify_plugin["classify_image"], KernelArguments(input=url))

通过手动调用我们的函数,我们可以看到我们的图片已被正确分类!和之前一样,我们也可以直接从提示中引用这个函数。然而,既然我们已经演示过了,让我们在下一部分尝试一些稍微不同的东西。
链接多个插件
现在我们已经定义了各种函数,包括内联函数和插件,让我们看看如何协调一个调用多个函数的工作流程。
如果我们希望独立执行多个函数,这很简单;我们只需将函数列表传递给invoke,如下所示。
answers = await kernel.invoke([classify_plugin["classify_image"], poem_gen_plugin["write_poem"]], arguments=KernelArguments(input=url))

在这里,我们可以看到相同的输入被用于每个函数。我们本可以在KernelArguments中定义不同命名的参数,但如果多个函数的参数具有相同的名称,这会变得困难。顺便提一下,我们的诗歌生成器似乎做得很棒,考虑到它只提供了一个网址!
更有趣的情况是,当我们希望将一个函数的输出用作另一个函数的输入时,让我们来深入探讨一下。
为了提供对函数调用方式的更精细控制,内核使我们能够定义处理程序,在其中我们可以注入自定义行为:
-
add_function_invoking_handler:用于注册在函数调用之前调用的处理程序 -
add_function_invoked_handler:用于注册在函数调用后被调用的处理程序
由于我们希望将输入更新为下一个函数的输出,可以定义一个简短的函数来完成此操作,并注册它,以便在每次函数调用后调用。让我们看看如何做到这一点。
首先,我们需要定义一个函数,该函数接受内核和FunctionInvokedEventArgs实例,并更新我们的参数。
from semantic_kernel.events.function_invoked_event_args import FunctionInvokedEventArgs
def store_results(kernel, invoked_function_info: FunctionInvokedEventArgs):
previous_step_result = str(invoked_function_info.function_result)
invoked_function_info.arguments['input'] = previous_step_result
invoked_function_info.updated_arguments = True
接下来,我们可以将其注册到我们的内核中。
kernel.add_function_invoked_handler(store_results)
现在,我们可以像之前一样调用我们的函数。
answers = await kernel.invoke([classify_plugin["classify_image"], poem_gen_plugin["write_poem"]], arguments=KernelArguments(input=url))

我们可以看到,通过顺序使用两个插件,我们已经对图像进行了分类并为其写了一首诗!
使用规划器协调工作流
到此为止,我们已经深入探讨了语义函数,理解了函数如何被分组并用作插件的一部分,并且已经看到如何手动将插件链在一起。现在,让我们探索如何使用 LLMs 创建和协调工作流。为此,Semantic Kernel 提供了Planner对象,它可以动态创建函数链以尝试实现目标。
规划器是一个类,它接受用户提示和内核,并利用内核的服务创建执行任务的计划,使用内核中可用的函数和插件。由于插件是这些计划的主要构建块,因此规划器在很大程度上依赖于提供的描述;如果插件和函数没有明确的描述,规划器将无法正确使用它们。此外,由于规划器可以以各种不同的方式组合函数,因此确保仅暴露我们希望规划器使用的函数是很重要的。
由于规划器依赖于模型来生成计划,因此可能会引入错误;这些错误通常发生在规划器未能正确理解如何使用函数时。在这些情况下,我发现提供明确的指令——如描述输入和输出,并说明输入是否为必需——可以取得更好的结果。此外,使用指令调优模型比使用基础模型效果更佳;基础文本补全模型往往会虚构不存在的函数或生成多个计划。尽管存在这些限制,当一切正常工作时,规划器可以非常强大!
让我们通过探讨是否可以创建一个基于图像 url 的诗歌计划,使用我们之前创建的插件,来探索如何做到这一点。由于我们定义了许多不再需要的函数,让我们创建一个新的内核,以便控制暴露的函数。
kernel = sk.Kernel()
为了创建我们的计划,让我们使用我们的 OpenAI 聊天服务。
service_id = "azure_gpt35_chat_completion"
kernel.add_service(
service=AzureChatCompletion(
service_id=service_id,
deployment_name=OPENAI_DEPLOYMENT_NAME,
endpoint=OPENAI_ENDPOINT,
api_key=OPENAI_API_KEY
),
)
现在,让我们导入我们的插件。
classify_plugin = kernel.import_plugin_from_object(
ImageClassifierPlugin(), plugin_name="classify_image"
)
poem_gen_plugin = kernel.import_plugin_from_prompt_directory(
plugins_path, "PoemGeneratorPlugin"
)
我们可以看到我们的内核可以访问哪些函数,如下所示。

现在,让我们导入我们的规划器对象。
from semantic_kernel.planners.basic_planner import BasicPlanner
planner = BasicPlanner(service_id)
要使用我们的规划工具,我们只需要一个提示。通常,我们需要根据生成的计划进行调整。在这里,我尽可能明确所需的输入。
ask = f"""
I would like you to write poem about what is contained in this image with this url: {url}. This url should be used as input.
"""
接下来,我们可以使用我们的规划工具来制定解决任务的计划。
plan = await planner.create_plan(ask, kernel)

检查我们的计划,我们可以看到模型已经正确识别了输入,以及正确的函数使用方法!
最后,只剩下执行我们的计划了。
poem = await planner.execute_plan(plan, kernel)

哇,成功了!对于一个被训练来预测下一个词的模型来说,这真是相当强大的!
作为一个警告,在制作这个示例时,我很幸运地第一次生成的计划就有效。然而,我们依赖于模型正确解读我们的指令,并理解可用的工具;更不用说 LLM 可能会出现虚假信息,甚至可能会梦到不存在的新功能!对我个人来说,在生产系统中,我会觉得手动创建工作流程执行会更舒服,而不是依赖 LLM!随着技术的不断进步,尤其是当前的速度,希望这个建议会变得过时!
结论
希望这为您提供了对 Semantic Kernel 的良好介绍,并激励您探索将其用于自己的用例。
*重复此帖子所需的所有代码可以在这里找到。
Chris Hughes 在 LinkedIn 上
参考资料
-
microsoft/semantic-kernel: 将最前沿的 LLM 技术快速、轻松地集成到您的应用程序中 (github.com)
-
explosion/curated-transformers: 🤖 PyTorch 精选 Transformer 模型及其可组合组件 (github.com)
-
使用 PyTorch 图像模型 (timm) 入门:实用指南 | by Chris Hughes | Towards Data Science


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言










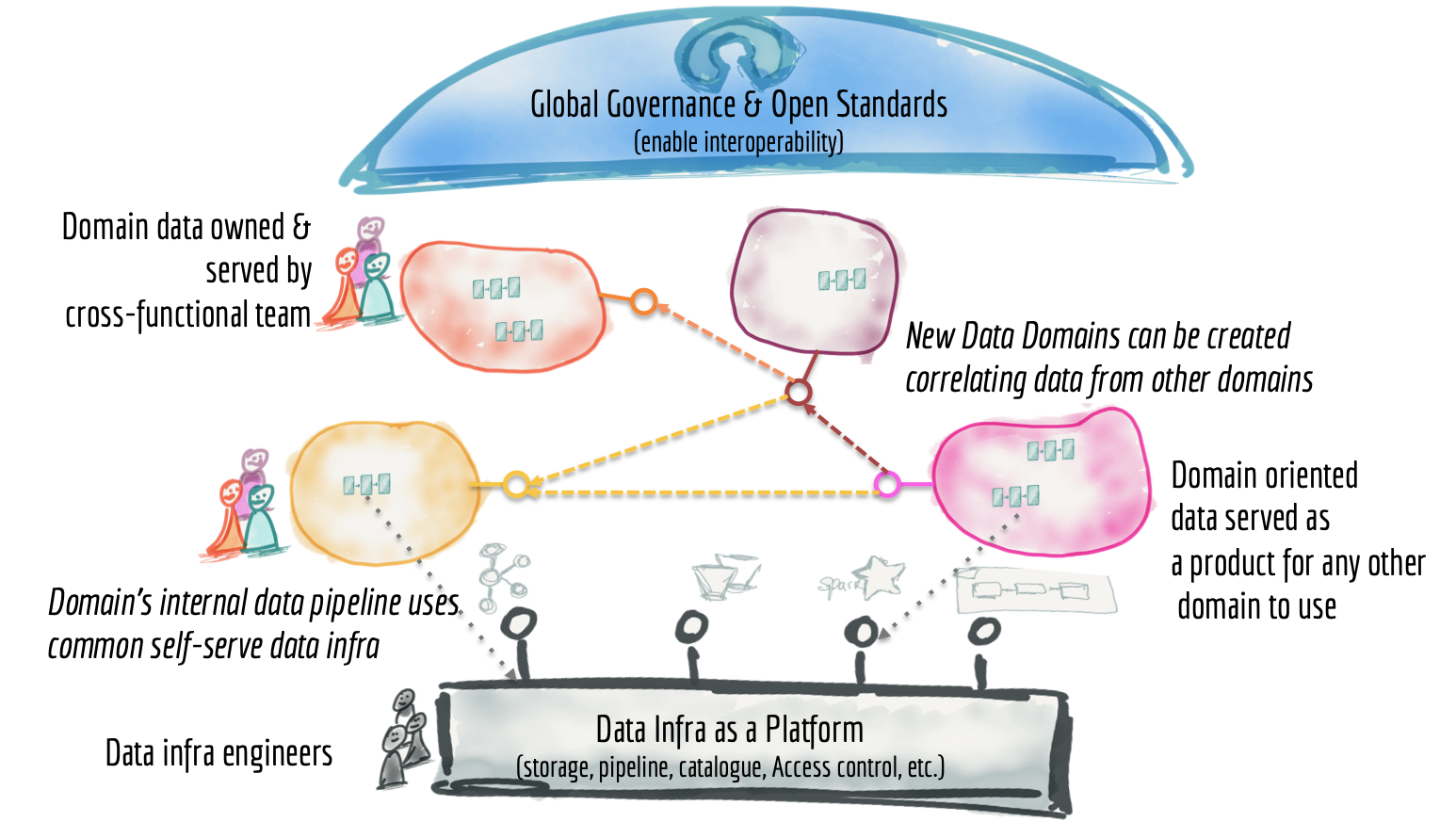{kind=link}
{kind=link}
{kind=link}
{kind=link}
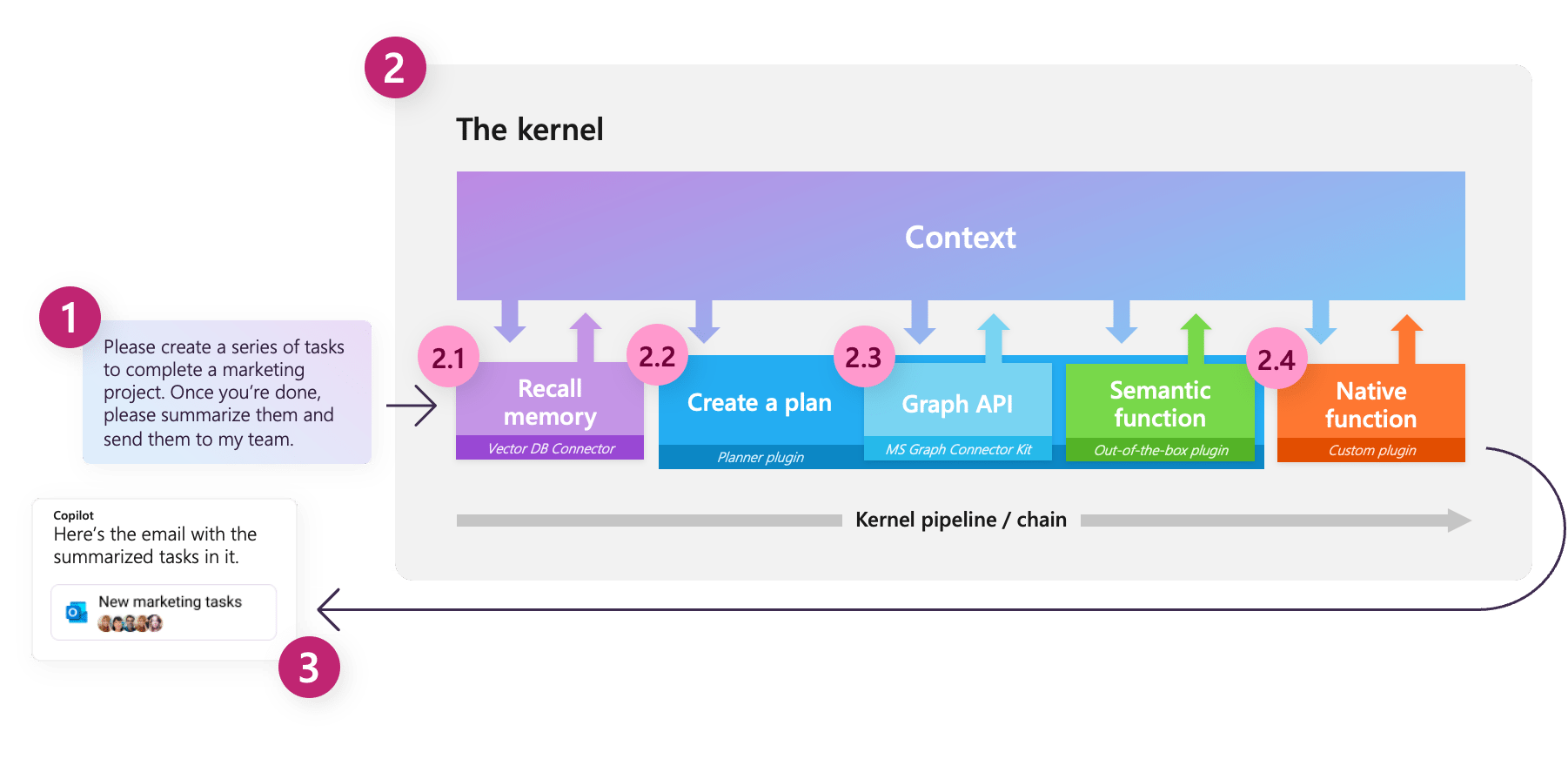{kind=link}