







Python 在网络上
在没有任何服务器的情况下展示 Python 应用


·发表于 Towards Data Science ·阅读时间 9 分钟·2023 年 10 月 11 日
–

图片由 Ales Nesetril 提供,来自 Unsplash
介绍
使用 流行的 Python 可视化库 可以相对简单地在本地创建各种形式的图表和仪表板。然而,将你的结果分享给其他人则可能复杂得多。
实现这一目标的一种可能方法是使用诸如 Streamlit、Flask、Plotly Dash 等库,并支付网络托管服务费用以覆盖服务器端,并运行你的 Python 脚本在网页上显示。另一种选择是,一些提供商如 Plotly Chart 或 Datapane 也提供免费的云支持,你可以将 Python 可视化图上传并嵌入到网页上。在这两种情况下,如果你的项目预算较小,你都能实现你所需要的功能,但是否有可能免费实现类似的结果呢?
作为本文的一部分,我们将探索三种可能的方法:
为了展示这三种方法,我们将创建一个简单的应用程序,以探索来自全球的历史通货膨胀数据。为此,我们将使用 世界银行全球通货膨胀数据库,有关数据许可的所有信息可以在 此链接 [1] 中找到。
数据下载后,我们可以使用以下预处理函数,以更好地调整数据集以进行可视化,并仅导入我们将用于分析的 3 个 Excel 表格(总体通胀数据、食品和能源价格的通胀数据)。
import pandas as pd
def import_data(name):
df = pd.read_excel("Inflation-data.xlsx", sheet_name=name)
df = df.drop(["Country Code", "IMF Country Code", "Indicator Type", "Series Name", "Unnamed: 58"], axis=1)
df = (df.melt(id_vars = ['Country', 'Note'],
var_name = 'Date', value_name = 'Inflation'))
df = df.pivot_table(index='Date', columns='Country',
values='Inflation', aggfunc='sum')
return df
inf_df = import_data("hcpi_a")
food_df = import_data("fcpi_a")
energy_df = import_data("ecpi_a")
每个数据集将会有一个日期索引,每年一行,每个国家的通胀百分比值一列(图 1)。

图 1:总体通胀数据集(图像由作者提供)。
本项目中使用的所有代码可以在我的 GitHub 个人资料上自由访问,本项目生成的在线仪表板可以通过 这个链接访问。
面板
Panel 是 HoloViz 生态系统中的一个开源 Python 库。可以使用以下命令简单安装:
pip install panel
数据导入后,我们可以继续开发我们的应用程序:
-
我们首先导入必要的库。
-
指定一个模板来样式化应用程序及其标题。
-
创建一个下拉小部件,用户可以选择一个国家进行检查。在此情况下,瑞士被提供为应用程序加载时的默认选择。
-
3 个辅助函数旨在将所选国家作为输入,然后返回系列的不同时间部分,以便向用户清晰地显示原始通胀数据。
-
最终,3 个辅助函数与下拉小部件绑定,并一起添加到界面上的一列中。
import pandas as pd
import matplotlib.pyplot as plt
import panel as pn
from holoviews import opts
import hvplot.pandas
pn.config.template = 'fast'
pn.config.template.title="Panel Inflation Monitoring Application"
country_widget = pn.widgets.Select(name="Country", value="Switzerland", options=list(inf_df.columns))
def pivot_series(inf_df, country):
df = pd.DataFrame({'Date':inf_df[country].index, 'Inflation':[round(i, 3) for i in inf_df[country].values]})
df = df.pivot_table(values='Inflation', columns='Date')
return df
def make_df_plot(country):
df = pivot_series(inf_df, country)
return pn.pane.DataFrame(df.iloc[:, : 17])
def make_df_plot2(country):
df = pivot_series(inf_df, country)
return pn.pane.DataFrame(df.iloc[:, 17:34])
def make_df_plot3(country):
df = pivot_series(inf_df, country)
return pn.pane.DataFrame(df.iloc[:, 34:])
bound_plot = pn.bind(make_df_plot, country=country_widget)
bound_plot2 = pn.bind(make_df_plot2, country=country_widget)
bound_plot3 = pn.bind(make_df_plot2, country=country_widget)
panel_app = pn.Column(country_widget, bound_plot, bound_plot2, bound_plot3)
panel_app.servable()
结果是,我们应得到如下输出(图 2):

图 2:显示表格数据(图像由作者提供)。
按照类似的结构,我们可以继续制作一个滑块,用户可以选择要检查的年份范围,并创建一个图表以可视化国家历史趋势(图 3)。
years_widget = pn.widgets.RangeSlider(name='Years Range', start=1970, end=2022, value=(1970, 2022), step=1)
def make_inf_plot(country, years):
df = inf_df[country].loc[inf_df[country].index.isin(range(years[0], years[1]))]
return df.hvplot(height=300, width=400, label=country + ' Overall Inflation')
bound_plot = pn.bind(make_inf_plot, country=country_widget, years=years_widget)
panel_app = pn.Column(years_widget, bound_plot)
panel_app.servable()
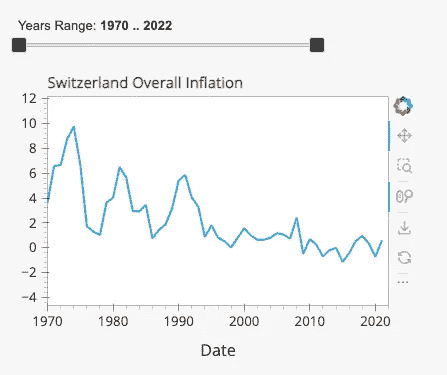
图 3:总体通胀趋势(图像由作者提供)。
现在我们已经能够可视化总体通胀数据,我们可以添加第二个图表,用户可以选择检查食品或能源价格的通胀趋势(图 4)。
type_plot_widget = pn.widgets.Select(name="Inflation Type", value="Food", options=["Food", "Energy"])
def make_type_plot(plt_type, country, years):
if plt_type == "Food":
df = food_df[country].loc[inf_df[country].index.isin(range(years[0], years[1]))]
return df.hvplot(height=300, width=400, label=country + ' Food Inflation')
else:
df = energy_df[country].loc[inf_df[country].index.isin(range(years[0], years[1]))]
return df.hvplot(height=300, width=400, label=country + ' Energy Inflation')
bound_plot = pn.bind(make_type_plot, plt_type=type_plot_widget, country=country_widget, years=years_widget)
panel_app = pn.Column(type_plot_widget, bound_plot)
panel_app.servable()
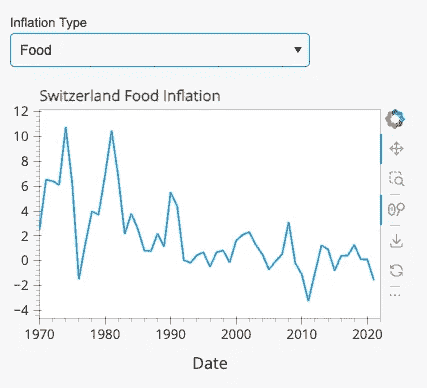
图 4:食品/能源通胀趋势(图像由作者提供)。
最后,我们还可以在仪表板上添加一个探索器小部件,以便用户能够创建自己的图表(图 5)。
hvexplorer = hvplot.explorer(inf_df)
pn.Column(
'## Feel free to explore the entire dataset!', hvexplorer
).servable()
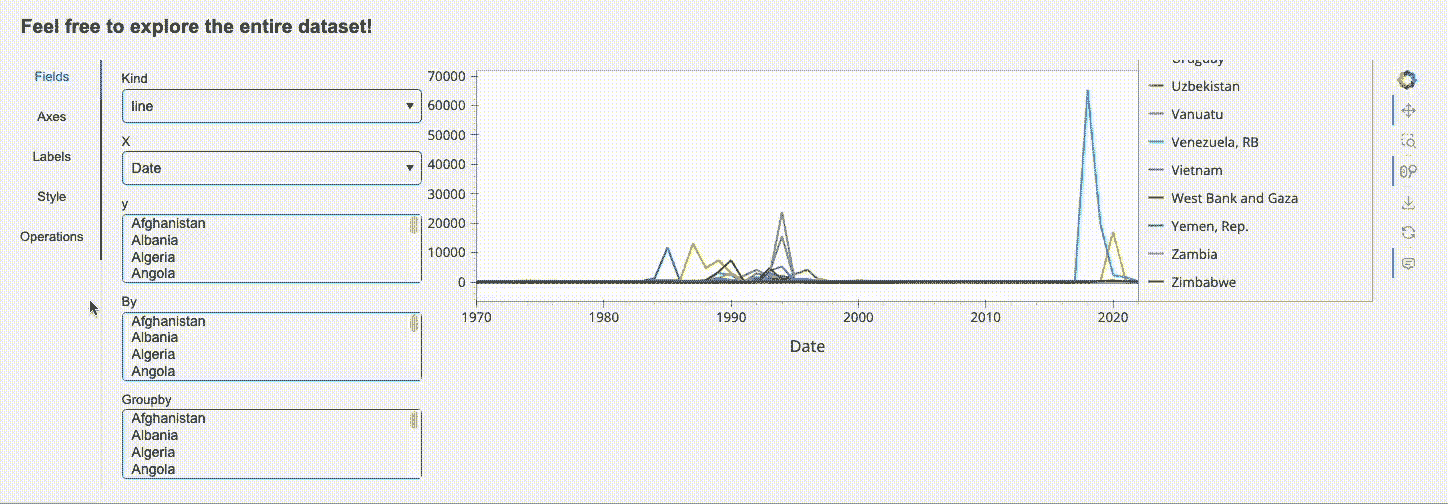
图 5:探索器小部件(图像由作者提供)。
一旦创建了完整的应用程序并将其存储在 pane_example.py 文件中,我们可以运行以下命令以可视化结果。
panel serve panel_example.py --autoreload --show
然后,可以使用以下命令将应用程序转换为 HTML 格式:
panel convert panel_example.py --to pyodide-worker --out docs
转换后,应该可以使用 HTTP 服务器启动它。网页应该可以通过以下链接访问:http://localhost:8000/docs/panel_example.html
python3 -m http.server
Shiny for Python
Shiny 是一个最初为 R 开发的开源库,现在也可供 Python 用户使用。可以使用以下命令轻松安装:
pip install shiny
导入数据后,我们可以继续工作,首先导入必要的依赖项,然后构建应用程序的布局。具体采用以下步骤:
-
首先为应用程序创建一个标题。
-
设计一个包含下拉菜单和滑块的侧边栏(用于作为输入填充以下图表)。
-
在侧边栏旁输出 2 个图表(展示一个国家的整体通胀趋势及其年度通胀变化)。
-
在应用程序末尾添加一个最终下拉菜单和图表(用户可以检查食品/能源价格的通胀趋势)。
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
from shiny import ui, render, reactive, App
app_ui = ui.page_fluid(
ui.h2("Python Shiny Inflation Monitoring Application"),
ui.layout_sidebar(
ui.panel_sidebar(
ui.input_selectize("country", "Country",
list(inf_df.columns)
),
ui.input_slider("range", "Years", 1970, 2022, value=(1970, 2022), step=1),
),
ui.panel_main(
ui.output_plot("overall_inflation"),
ui.output_plot("annual_change")
)
),
ui.input_selectize("type", "Inflation Type",
["Food", "Energy"]
),
ui.output_plot("inflation_type")
)
定义布局后,我们可以继续创建不同的图表:
def server(input, output, session):
@output
@render.plot
def overall_inflation():
df = inf_df[input.country()].loc[inf_df[input.country()].index.isin(range(input.range()[0], input.range()[1]))]
plt.title("Overall Inflation")
return df.plot()
@output
@render.plot
def annual_change():
annual_change = inf_df[input.country()].diff().loc[inf_df[input.country()].index.isin(range(input.range()[0], input.range()[1]))]
plt.title("Annual Change in Inflation")
return plt.bar(annual_change.index, annual_change.values, color=np.where(annual_change>0,"Green", "Red"))
@output
@render.plot
def inflation_type():
if input.type() == "Food":
df = food_df[input.country()].loc[inf_df[input.country()].index.isin(range(input.range()[0], input.range()[1]))]
plt.title(input.country() + ' Food Inflation')
return df.plot()
else:
df = energy_df[input.country()].loc[inf_df[input.country()].index.isin(range(input.range()[0], input.range()[1]))]
plt.title(input.country() + ' Energy Inflation')
return df.plot()
app = App(app_ui, server)
然后可以使用以下命令在本地启动应用程序(见图 6):
shiny run --reload app.py
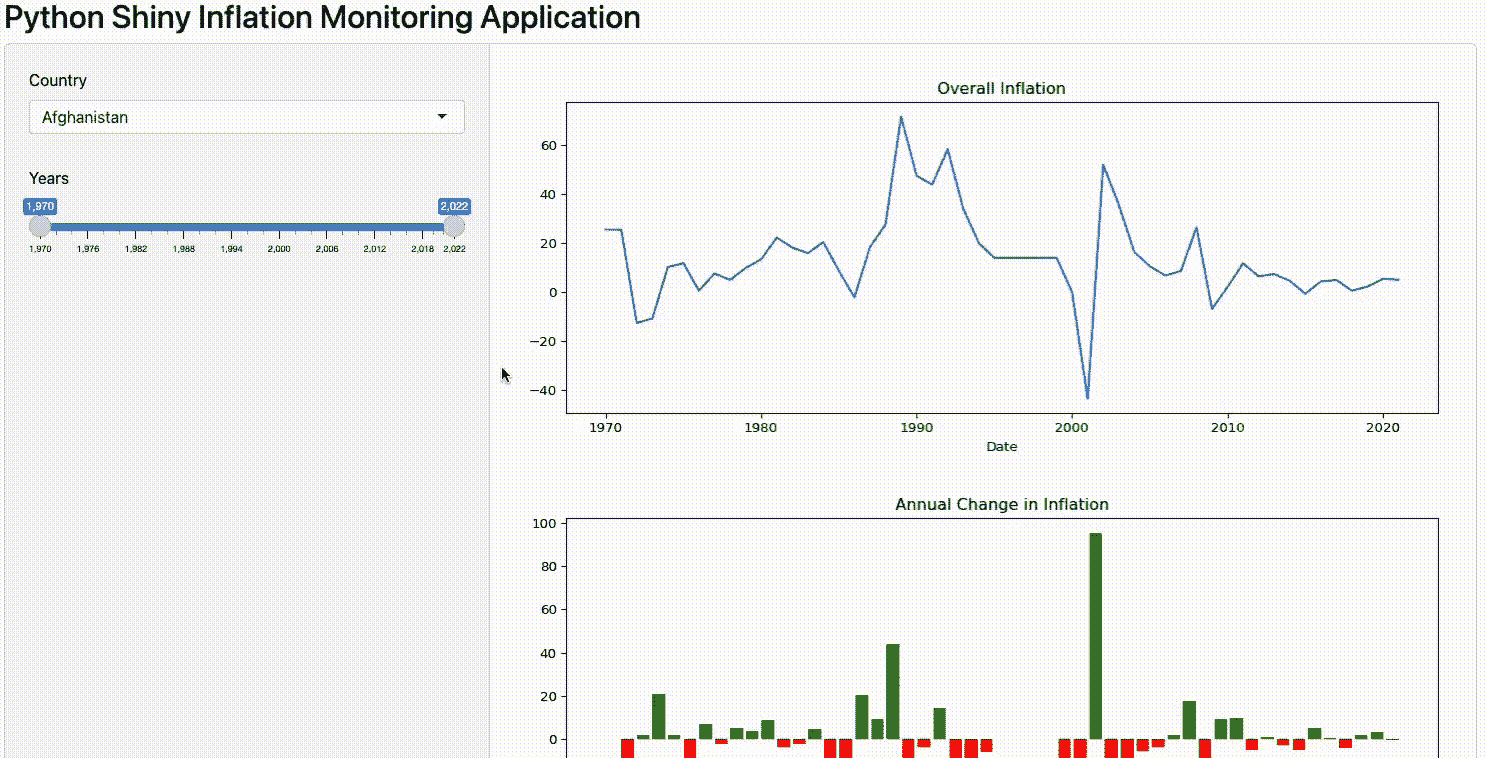
图 6:Shiny 应用程序示例(图片来源于作者)。
如果有兴趣将代码转换为 HTML 以便在网页上共享,我们需要首先安装 shinylive,然后使用以下命令(确保将应用程序命名为 app.py!)。
pip install shinylive
shinylive export . docs
转换后,应该可以使用 HTTP 服务器启动应用程序。网页应该可以通过以下链接访问:http://[::1]:8008/
python3 -m http.server --directory docs --bind localhost 8008
PyScript
PyScript 是 Anaconda 开发的一个框架,用于直接在 HTML 文件中编写 Python 代码。导入 pyscript.js 脚本后,Python 代码将会自动执行并处理,从而在应用程序中呈现结果。
为运行我们的应用程序所需的所有 HTML 代码如下所示。然后,Python 代码可以直接粘贴在 命令之间。在 命令之后,还添加了一个 div 元素,以便为应用程序添加标题,并获取图表的不同输入参数(与我们在 Panel 和 Shiny 仪表板中所用的输入参数方式相同)。
<html>
<head>
<title>Inflation Monitoring</title>
<meta charset="utf-8">
<link rel="stylesheet" href="https://pyscript.net/latest/pyscript.css" />
<script defer src="https://pyscript.net/latest/pyscript.js"></script>
</head>
<body>
<py-config>
packages = ["pandas", "matplotlib", "numpy"]
</py-config>
<py-script>
# TODO: Your Python Code Here
</py-script>
<div id="input" style="margin: 20px;">
<h1> Pyscript Inflation Monitoring Application</h1>
Choose the paramters to use: <br/>
<input type="number" id="s_year" name="params" value=1970 min="1970" max="2022"> <br>
<label for="s_year">Starting Year</label>
<input type="number" id="e_year" name="params" value=2022 min="1970" max="2022"> <br>
<label for="e_year">Ending Year</label>
<select class="form-control" name="params" id="country">
<option value="Switzerland">Switzerland</option>
<option value="Italy">Italy</option>
<option value="France">France</option>
<option value="United Kingdom">United Kingdom</option>
</select>
<label for="country">Country</label>
</div>
<div id="graph-area"></div>
</body>
</html>
在这种情况下,我们首先导入库并定义一个绘图函数,用于创建整体通胀趋势图和年度变化图。使用 js 库,我们可以获取 HTML 文件中指定的输入参数,并调用我们的绘图函数。
最后,创建一个代理,以便检查最终用户是否随时间更改了任何参数,如果是的话,自动更新其在 Python 中存储的值和相应的图表。
import js
import pandas as pd
import numpy as np
from io import StringIO
import matplotlib.pyplot as plt
from pyodide.ffi import create_proxy
def plot(country, s_year, e_year):
df = inf_df[country].loc[inf_df[country].index.isin(range(s_year, e_year))]
annual_change = inf_df[country].diff().loc[inf_df[country].index.isin(range(s_year, e_year))]
fig, (ax1, ax2) = plt.subplots(2)
fig.suptitle('Overall inflation and annual change in ' + country)
ax1.set_ylabel("Inflation Rate")
ax2.set_ylabel("Annual Change")
ax1.plot(df.index, df.values)
ax2.bar(annual_change.index, annual_change.values, color=np.where(annual_change>0,"Green", "Red"))
display(plt, target="graph-area", append=False)
s_year, e_year = js.document.getElementById("s_year").value, js.document.getElementById("e_year").value
country = js.document.getElementById("country").value
plot(str(country), int(s_year), int(e_year))
def get_params(event):
s_year, e_year = js.document.getElementById("s_year").value, js.document.getElementById("e_year").value
country = js.document.getElementById("country").value
plot(str(country), int(s_year), int(e_year))
ele_proxy = create_proxy(get_params)
params = js.document.getElementsByName("params")
for ele in params:
ele.addEventListener("change", ele_proxy)
一旦开发完成应用程序并将其存储在***.html***文件中,我们可以通过使用网页浏览器打开文件来立即启动它(图 7)。
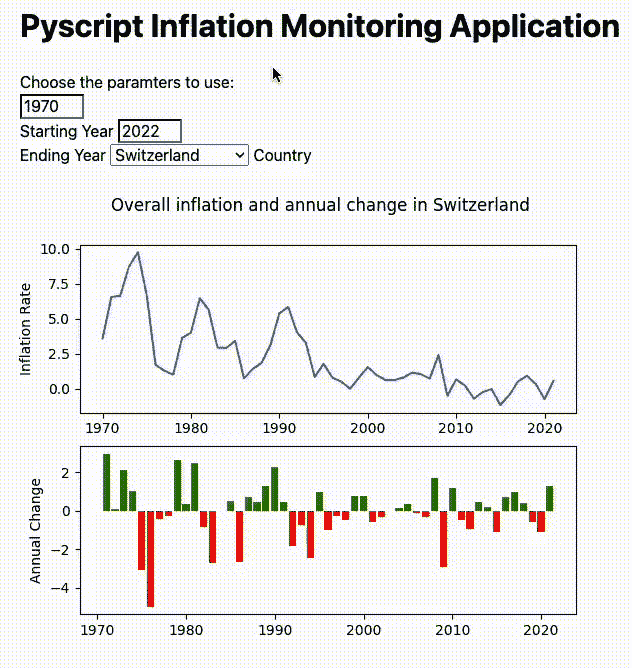
图 7:PyScript 示例应用程序(图片由作者提供)。
部署
为了将我们的应用程序部署到网上,可能需要将我们的输入数据与应用程序一起存储在一个文件中(例如,Python 转换为 HTML 后,可能不再能够从 XLSX 中加载数据)。一种可能的方法是:
-
将最初导入的 3 个数据帧导出为 CSV 文件。
-
一次打开一个 CSV 文件,并将全部内容粘贴到一个变量中(如下所示)。
-
在与应用程序其余部分相同的文件中使用此设置(而不是import_data函数)。
from io import StringIO
inf_df = """TODO: PASTE YOUR CSV FILE HERE"""
csvStringIO = StringIO(inf_df)
inf_df = pd.read_csv(csvStringIO, sep=",").set_index('Date')
使用上述设置并将 Panel 和 Python Shiny 应用程序转换为 HTML 代码后,便可以在不需要支付任何服务器费用的情况下将应用程序托管到网上。
一种简单的方法是使用 GitHub Pages 并将我们的项目文件添加到在线仓库中。有关 GitHub Pages 的更多信息,请参见此处。
结论
在本文中,我们探讨了三种不同的选项,这些选项可以用来在不支付任何服务管理费用的情况下共享你的 Python 应用程序。虽然我们也看到这种方法存在一些固有的局限性,因此在设计更复杂的应用程序或处理大量数据时,可能不是最佳选择。
如果你对在线展示你的机器学习项目感兴趣(无需服务器架构),Tensorflow.js 和 ONNX 可能是你需求的两个优秀解决方案。
联系方式
如果你想跟进我最新的文章和项目,请在 Medium 上关注我(follow me on Medium)并订阅我的邮件列表。以下是我的一些联系方式:
参考文献
[1] 世界银行,全球通货膨胀数据库。访问网址:www.worldbank.org/en/research/brief/inflation-database。许可:知识共享署名 4.0 国际许可协议 (CC-BY 4.0)。
Python OOP 教程:如何创建类和对象
原文:
towardsdatascience.com/python-oop-tutorial-how-to-create-classes-and-objects-c36a92b01552
关于在面向对象编程(OOP)中使用类和对象的简单指南
 [外链图片转存中…(img-hHWttMhL-1726872405597)] Yasmine Hejazi
[外链图片转存中…(img-hHWttMhL-1726872405597)] Yasmine Hejazi
·发表于 Towards Data Science ·阅读时间 6 分钟·2023 年 1 月 4 日
–
由 Taylor Heery 提供的照片,来源于 Unsplash
介绍
在 Python 编程中,一切都是对象。变量甚至函数都是对象。类是一个模具,用于创建对象。
想象一个冰棒托盘。 首先,你制造冰棒托盘以创建你所需的大小、形状和深度;这就是类。然后,你可以决定向冰棒托盘中倒入什么来冻结——也许你加入水并简单制作冰块,或者你加入不同种类的水果和果汁制作冰棒。你创建的每个冰棒都是一个对象,对象可以有不同的“数据”或口味。
本文将通过代码演示如何创建自己的类并在 Python 代码中使用它。类的不同组件可以分解为以下内容:构造函数、获取器和设置器、属性、装饰器、私有命名、类方法、属性和继承。
何时使用类/对象与模块:
-
当你需要多个具有类似行为但数据不同的独立实例时使用类
-
当你需要支持继承时使用类;模块不支持继承
-
如果你只需要一个东西,就使用模块
-
使用最简单的解决方案;模块通常比类更简单
类的介绍示例
以下是一个简单类的示例。在这个类中,我们看到三个组件:__init__ 方法,它是初始化方法或构造函数,一个称为 toss 的设置方法,以及一个称为 get_sideup 的获取方法。
class Coin():
def __init__(self): # Constructor
self.sideup = "Heads"
def toss(self): # Method
if(random.randint(0, 1) == 0):
self.sideup = "Heads"
else:
self.sideup = "Tails"
def get_sideup(self): # Method
return self.sideup
如何在你的主 Python 脚本中使用它?在你的脚本中,你只需调用对象并将其设置为一个新变量。然后你可以开始使用它的组件。
my_coin = Coin() # Creates the object
my_coin.toss()
print("This side is up: ", my_coin.get_sideup())
让我们来分解一下。
类组件
对象初始化方法
当你看到一个方法具有特殊名称__init__时,你会知道这是对象初始化方法。这被称为构造函数,因为它在内存中构造了对象。当你创建类的对象时,这个方法会自动运行。
class Person():
def __init__(self, name):
self.name = name
我们上面的 __init__ 方法需要一个名为name的参数。当我们使用 Person 类创建对象时,我们应该像这样传入一个名字:Person("Bob")。
self 参数指定它指的是对象本身。记住,类是一个模板,我们可以使用这个模板来初始化(然后稍后修改)多个对象。例如,我们可以用 Person 类创建两个对象:
me = Person("Author")
me.name # --> "Author"
you = Person("Reader")
you.name # --> "Reader"
Getter 和 Setter
一些面向对象语言支持私有对象属性,这些属性不能从外部直接访问。因此,你需要getter和setter方法来读取和写入私有属性的值。
在 Python 中,所有属性和方法都是公开的。我们不需要 getter 和 setter。为了做到“Pythonic”,使用属性。
class Duck():
def __init__(self, input_name):
self.hidden_name = input_name # The user won't know to try duck.hidden_name
def get_name(self): # Getter
print("inside the getter")
return self.hidden_name
def set_name(self, input_name): # Setter
print("inside the setter")
self.hidden_name = input_name
name = property(get_name, set_name)
最后一行将 getter 和 setter 方法定义为name属性的属性。现在它会在以下情况下调用 getter 和 setter 方法:
pet = Duck("Donald")
pet.name
# --> inside the getter
# --> "Harold"
pet.name = "Daffy"
# --> inside the setter
装饰器
装饰器是另一种定义属性的方法(即我们上面做的事情)。
class Duck():
def __init__(self, input_name):
self.hidden_name = input_name # The user won't know to try duck.hidden_name
@property
def name(self): # Getter
print("inside the getter")
return self.hidden_name
@name.setter
def name(self, input_name): # Setter
print("inside the setter")
self.hidden_name = input_name
name = property(get_name, set_name)
隐私命名
首先在名称中使用两个下划线。这使得一旦你创建了对象,属性就无法在类定义外部访问。这也有助于防止子类意外覆盖属性。
在我们的 Duck 类中,代替使用 hidden_name,使用 __name。
self.hidden_name = input_name → self.__name = input_name
类方法
到目前为止,我们演示的都是实例方法。我们怎么知道?实例方法的第一个参数是self。当你调用实例方法时,调用只会影响你正在使用的对象的副本。
类方法影响整个类(因此影响所有对象副本)。类方法使用cls参数,而不是self参数。类方法可以通过使用类装饰器@classmethod来定义。
@classmethod
def count_objects(cls):
print("The class has", cls.count, "objects")
静态方法是第三种类型的方法,它既不影响类也不影响其对象。它不使用 self 或 cls 参数。它只是为了方便而存在。
@staticmethod
def commercial():
print("This product is brought to you by Medium.")
属性
实例属性是我们希望对象实例共享的外部行为。一个学生类可能具有以下属性:
-
方法:student.get_gpa(),student.add_class(),student.get_schedule()
-
数据:student.first_name,student.last_name,student.class_list
dir(object_instance) 给你提供该对象的属性列表。
object_instance.__dict__ 为你提供特定于该实例的所有实例属性(及其值)
类属性是类的属性,而不是类的 实例 的属性。这是类的所有对象共享的属性。假设我们想跟踪每个学生都是人类:
class Student():
isHuman = True # --> class attribute
def __init__(self, ...):
...
如果你想了解更多,可以查看这个关于 Python 类属性的详尽指南。
继承
继承允许你创建一个类的层次结构,其中一个类继承了父类的所有属性和行为。然后,你可以在子类上进行自己的规格定义,这些定义不同于父类。
例如,我们有一个父类 Animal,它具有吃和睡的能力。然后我们创建一个子类 Cat,它继承了 Animal 的属性,并增加了自己特有的属性。
class Animal():
def eat(self):
print("Munch munch")
def sleep(self):
print("Zzz...")
class Cat(Animal):
def meow(self):
print("Meow!")
你需要做的就是将 Animal 类传递给 Cat。现在 Cat 类有了 eat() 和 sleep() 方法。你可以通过在 Cat 中定义方法来覆盖 eat 或 sleep 方法。你也可以通过 __init__() 方法覆盖任何方法。
子类可以添加父类中没有的方法(例如 meow())。父类将不包含此方法。
当子类自己做某些事情但仍需要从父类中获取某些内容时,使用 super():
class Person():
def __init__(self, name):
self.name = name
class EmailPerson(Person):
def __init__(self, name, email):
super().__init__(name)
self.email = email
继承的好处:
-
允许子类重用父类的代码
-
不必从头开始创建类,你可以专门化或扩展一个类
-
父类可以定义一个接口,以允许子类与程序进行交互
-
允许程序员组织相关对象
总结
-
类是一个模具(冰棒托),对象是从该类中创建的(冰棒)
-
对象可以调用其类的实例方法(使用 self)来接收和更改数据
-
隐私命名有助于防止子类意外覆盖属性
-
类本身具有方法(使用 cls),你可以跟踪和操作该类的所有对象实例
-
继承允许我们扩展相似的类
Python OPP 以及为何 repr() 和 str() 重要
原文:
towardsdatascience.com/python-opp-and-why-repr-and-str-matter-1cff584328f4
PYTHON 编程
这篇文章探讨了使用 repr() 和 str() 为 Python 类提供的各种面貌


·发表于 Towards Data Science ·14 分钟阅读·2023 年 11 月 3 日
–

Python 类需要字符串表示,以便向用户和开发者提供比一堆字母更多的信息。图片由 Surendran MP 在 Unsplash 提供
Python 类有许多面貌。例如,你可以创建一个空类:
class MyClass:
pass
它仍然可以有所用处,例如作为 哨兵值。你可以添加一个 __init__() 方法:
class MyClass:
def __init__(self, value):
self.value = value
这仍然会是一个非常简单的类,但这次它将保持一个特定的值。
Python 类的一个极佳功能是它们可以被用作类型,如下所示:
def foo(x: MyClass, n: int) -> list[MyClass]:
return [x] * n
记住,不实现 __init__() 方法并不意味着它不存在。实际上,我们上面重载了 __init__() 方法,而不仅仅是实现了它。这是 Python 类的另一个重要方面,你应该知道:你可以重载许多其他方法,如 __new__()、__eq__() 和 __setattr__()。如果你不重载这些方法,有些方法会有默认实现(如 __init__()、__new__()、__setattr__() 和 __eq__()),而其他方法则没有(如 __lt__() 和所有其他比较方法,除了 __eq__()、__getitem__()、__setitem__() 和 __len__())。
一个类可以继承另一个类,如下所示:
class MyClass(dict):
@staticmethod
def say_hello(self):
print("Hello!")
同样如上所述,它可以使用静态方法,也可以使用类方法。你可以创建混合类和抽象基类、单例模式,还可以做许多其他事情,有时非常有用。
Python 类有很多面向不同的特性,详细讨论每一种特性需要几年时间,我们将在未来的文章中进行探讨。在这篇文章中,我们将重点关注一个特定方面:__repr__() 和 __str__() 方法的区别和作用。
初看起来,你可能认为这是一个小话题,但实际上它非常重要。实现一个 Python 类很容易,但实现一个 好的 Python 类则需要更多的努力。正是这些小细节使得一个熟练的 Python 开发者与普通开发者有所区别。
注意:为了运行 doctests,我使用了 Python 3.11。不要惊讶于较旧版本的 Python 可能会提供稍微不同的结果。如果你想了解更多关于 Python doctest 的内容,请阅读以下文章:
Python 文档测试与 doctest:简单方法
doctest 允许进行文档测试、单元测试、集成测试以及测试驱动开发。
towardsdatascience.com
repr 与 str
理论上,repr() 应该返回一个明确的对象字符串表示,从中你应该能够重建对象。另一方面,str() 应该返回一个人类可读的对象字符串表示。
因此,理论上,repr() 应该提供有关其所用对象的详细信息,而 str() 应该提供一个可读的字符串来解释对象是什么以及可能包含什么。例如,我们使用 str() 来查看交互式会话中的对象或用于日志记录。但当我们调试并需要更多细节时,repr() 是更好的选择。正如我们将在下一部分看到的,我们通常会间接调用这些函数,甚至可能不知道这一点——或者至少没有想到这一点。
我们在上面比较了 repr() 和 str() 函数。要在类中实现或重载它们,我们需要使用相应的方法,分别是 __repr__() 和 __str__()。如果一个类定义了 __repr__() 方法,当你调用 repr() 时,它会用于生成该类对象的字符串表示。str() 和 __str__() 也是如此。
我们很快就会看到这一点——首先让我们了解一下我提到的间接调用 repr() 和 str() 的含义。
间接调用 repr() 和 str()
有一个与这两个函数相关的秘密,了解它是很有帮助的。请考虑以下代码:
>>> class StrAndRepr:
... def __repr__(self): return f"I am __repr__"
... def __str__(self): return "I am __str__"
>>> str_and_repr = StrAndRepr()
>>> str_and_repr
I am __repr__
>>> print(str_and_repr)
I am __str__
注意最后两个调用。正如你所看到的,在 Python 会话中使用 print() 打印对象与仅使用对象名称之间可能会有所不同。

在 Python 会话中调用 print(obj) 和仅调用对象名之间的区别。图片由作者提供
下图总结了这一点:print(obj)调用str(obj),而obj调用repr(obj)。
repr与str
上面,我解释了repr()和__repr__()以及str()和__str__()的概念。前一对应该提供比后一对更多的信息。
然而,实践中往往显示出不同的情况:
>>> class MyClass: ...
>>> inst = MyClass()
>>> inst.__repr__()
'<__main__.MyClass object at 0x7f...>'
>>> inst.__str__()
'<__main__.MyClass object at 0x7f...>'
>>> inst.__repr__() == repr(inst)
True
>>> inst.__str__() == str(inst)
True
如你所见,这两个方法的默认实现是相同的:
>>> str(inst) == repr(inst)
True
因此,即使是默认实现的__str__()和__repr__(),当你在 Python 类中没有重载这两个方法时,也违反了上述规则。此外,开发者可以重载这两个方法中的一个或两个,而在实际应用中,这也可能意味着违反这一规则。
当仅实现其中一个方法时会发生什么?为了展示这一点,我将实现以下四个类:
>>> class StrAndRepr:
... def __repr__(self): return "I am repr of StrAndRepr"
... def __str__(self): return "I am str of StrAndRepr"
>>> class OnlyStr:
... def __str__(self): return "I am str of OnlyStr"
>>> class OnlyRepr:
... def __repr__(self): return "I am repr of OnlyRepr"
>>> class NeietherStrNorRepr: ...
因此,我们定义了四个类:一个既没有__str__()也没有__repr__(),两个有其中一个,和一个两个都有。让我们看看如果我们对它们的实例调用str()和repr()会发生什么:
>>> str_and_repr = StrAndRepr()
>>> str(str_and_repr)
'I am str of StrAndRepr'
>>> repr(str_and_repr)
'I am repr of StrAndRepr'
>>> only_str = OnlyStr()
>>> str(only_str)
'I am str of OnlyStr'
>>> repr(only_str)
'<__main__.OnlyStr object at 0x7f...>'
>>> only_repr = OnlyRepr()
>>> str(only_repr)
'I am repr of OnlyRepr'
>>> repr(only_repr)
'I am repr of OnlyRepr'
>>> neither_str_nor_repr = NeietherStrNorRepr()
>>> str(neither_str_nor_repr)
'<__main__.NeietherStrNorRepr object at 0x7...>'
>>> repr(neither_str_nor_repr)
'<__main__.NeietherStrNorRepr object at 0x7f...>'
以下是上述doctest的结论:
-
实现既没有
__str__()也没有__repr__():对于两者,都会使用默认实现;它们是一样的,都提供类的名称和实例的地址。 -
实现
__str__()和__repr__():通常,这是一种推荐的方法。它使你的代码更具可读性和可维护性——尽管同时也更长。 -
仅实现
__str__():Python 会在str()中使用它,但对于repr()将使用默认实现。 -
仅实现
__repr__():Python 会将其用于str()和repr()。
那么,我应该实现什么呢?
这要看情况。最明显的结论是,如果你实现了一个复杂的类,你应该定义两个这些方法。这将给你更多的调试代码和更好的日志记录的机会。
然而,当你没有太多时间编程而截止日期临近时,你至少应该实现其中一个方法。不实现任何方法意味着类的字符串表示将包含很少的有用信息,因为它将包含类的名称和实例的地址。因此,只有在你确定类的名称是你需要的全部信息时才这样做。例如,在原型设计中,这通常是你需要的全部信息。
对于小类,实现其中一个方法可能就足够了,但一定要确保这确实足够。此外,你有多久会没有时间来实现像__str__()或__repr__()这样简单的方法?我知道这种情况可能会发生——但我认为这种情况不会比偶尔发生的多。说实话,在我超过五年的 Python 开发中,这种情况甚至没有发生过一次。
因此,我认为时间很少是一个问题。而空间,另一方面,可能是。当你的模块包含多个小类,每个类占用几行时,为所有这些类实现__repr__()和__str__()可能会使模块的长度增加一倍。这可能会带来很大差异,因此值得考虑是否需要这两个方法,如果不需要,应该实现哪个方法。
许多内置类使用相同的实现来处理__repr__()和__str__(),包括dict和list。许多来自知名附加包的类也是如此,一个来自数据科学领域的完美例子是pandas.DataFrame。
让我们总结一下我们的讨论,形成一套规则。说实话,尽管我已经使用它们很多年了,这还是我第一次想到将它们写下来。我希望你能在编码实践中找到它们的用处,以决定是否实现__repr__()和__str__()这两个方法中的一个或两个,或者都不实现。
-
当你编写一个原型类且不打算使用它的字符串表示时,可以忽略
__repr__()和__str__()。然而,对于生产代码,最好再三考虑。在开发过程中,除非需要通过类的实例调试代码,否则我通常会跳过这些方法。 -
当你的类生成具有多个属性的复杂实例时,我通常会考虑同时实现
__repr__()和__str__()。然后:(i)__str__()方法应提供一个简单的人类可读的字符串表示,这可以通过使用print()和str()函数打印实例来获得。(ii)__repr__()方法应提供尽可能多的信息,包括重建类实例所需的所有信息;这可以通过repr()函数或在交互式会话中输入实例名称来获得。 -
如果你的类需要用于调试,无论是否实现
__str__(),都要使其__repr__()方法尽可能详细。这并不意味着__repr__()的输出必须异常长;而是,在这种情况下,包含调试所需的任何信息。 -
当一个类需要一个人类可读的字符串表示,并且同时你需要实现详细的
__repr__()方法时,实现__str__()。 -
如果一个类需要一个人类可读的字符串表示,但你不需要详细的
__repr__(),则仅实现__repr__()。这将使用户从两个方法中获得一个不错的人类可读字符串表示,并避免看到默认的__repr__()表示,通常这没有太大价值。在仅实现__repr__()时,保持返回字符串格式的一致性很重要,这将使用户更容易阅读和理解str()和repr()的输出。
实现__repr__()和__str__()
现在我们知道了何时实现这两种方法,值得考虑如何实现它们。只有两个规则是你必须遵守的,而且幸运的是,这两个规则都很简单。
第一个处理方法的参数,另一个处理其返回值的类型。因此,我们可以使用这两种方法的预期签名来展示它们,即:
def __repr__(self) -> str:
...
def __str__(self) -> str:
...
这就全部了吗?
基本上,是的——但是……我写这些是预期的签名,但实际上,你应该将它们视为必需的签名。下面你会明白为什么。
为了了解原因,你应该知道一个有趣的事情,我猜很多 Python 用户可能不知道。就我而言,我在很长一段时间内也不知情。
这个规则适用于当你希望类的__str__()与str()和print()配合使用,而__repr__()与repr()以及在会话中使用实例名称时。为此,让我们实现一个具有非可选参数的__str__()的类:
>>> class StrWithParams:
... def __str__(self, value):
... return f"StrWithParams with value of {value}"
这个方法会工作吗?
>>> inst = StrWithParams()
>>> inst.__str__(10)
'StrWithParams with value of 10'
嘿,它确实适用!那我怎么刚才写了__str__()应该不接受参数呢?
理论上不会——尽管它是可能的。这在一个不切实际的条件下才会发生,即唯一调用该方法的方式是inst.__str__(10)(值本身并不重要)。如上所述,我们看到过这样的调用,它确实有效。但接下来我们将看到三个痛苦的失败:
>>> str(inst, value=10)
Traceback (most recent call last):
...
TypeError: 'value' is an invalid keyword argument for str()
>>> print(inst)
Traceback (most recent call last):
...
TypeError: StrWithParams.__str__() missing 1 required positional argument: 'value'
>>> print(inst, value=10)
Traceback (most recent call last):
...
TypeError: 'value' is an invalid keyword argument for print()
因此,使用参数的__str__()不是语法错误,但它绝对是一个静态错误。
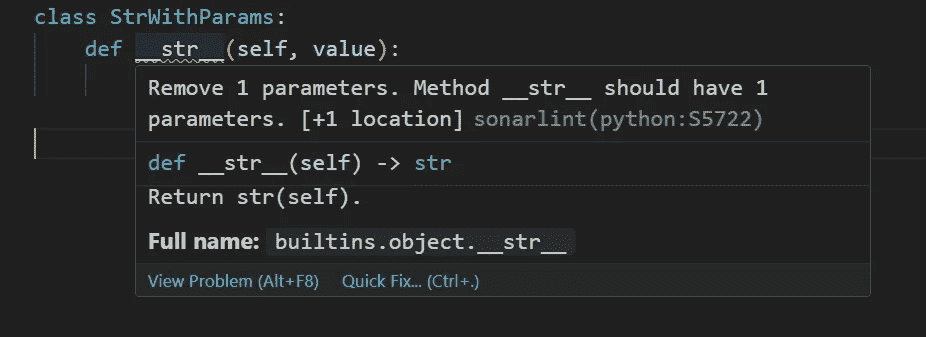
来自 Visual Studio Code 的截图。Sonarlint 显示__str__()不应该接受参数。图片由作者提供
这绝对是一个静态错误,但如上所示,一个更大的问题是,使用参数的__str__()很可能会在运行时引发TypeError异常,如上所示。
在会话中直接键入inst会调用repr(),由于我们没有实现它,使用了默认实现:
>>> inst
<__main__.StrWithParams object at 0x7f...>
但如前所示,调用print(inst)失败了,原因很简单,因为没有直接提供非可选参数value的方式。
现在,让我们转到另一个问题,即返回一个非字符串类型的对象。这似乎是一个静态错误。我们考虑两种版本:未类型化和类型化的类定义:
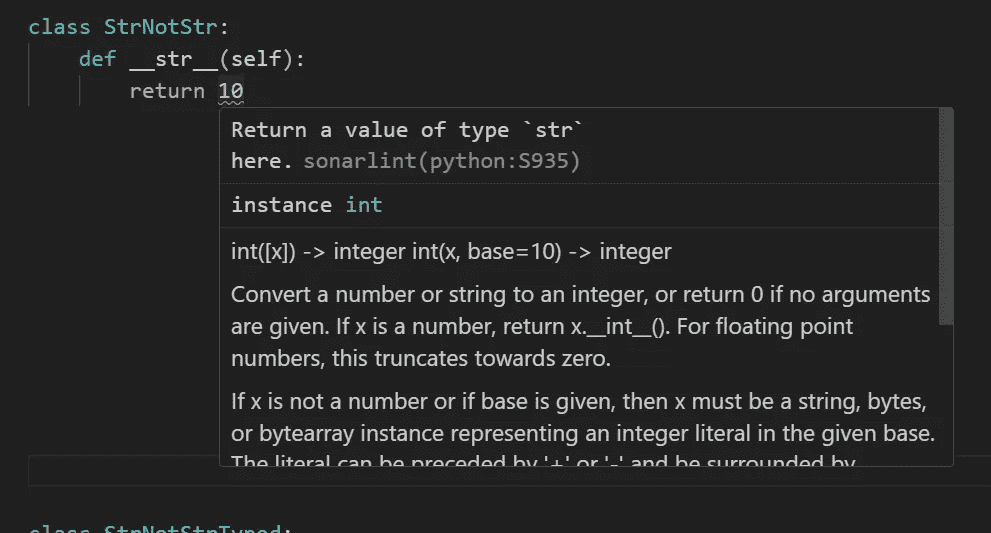
来自 Visual Studio Code 的截图。基于未类型化的类定义,Sonarlint 显示__str__()应该返回一个字符串。图片由作者提供
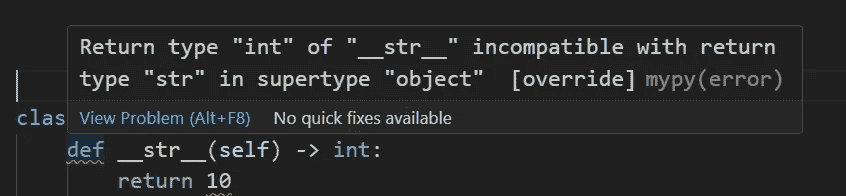
来自 Visual Studio Code 的截图。基于类型化的类定义,Mypy 显示__str__()应该返回一个字符串。图片由作者提供
因此,从__str__()方法返回非字符串对象绝对是一个静态错误——但这是否也会导致在运行时引发TypeError异常呢?
是的,会的:
>>> class StrNotStr:
... def __str__(self):
... return 10
>>> inst = StrNotStr()
>>> inst.__str__()
10
>>> str(inst)
Traceback (most recent call last):
...
TypeError: __str__ returned non-string (type int)
__repr__() 的规则是一样的:
>>> class ReprWithParams:
... def __repr__(self, value):
... return f"ReprWithParams with value of {value}"
>>> inst = ReprWithParams()
>>> inst.__repr__(10)
'ReprWithParams with value of 10'
>>> repr(inst, value=10)
Traceback (most recent call last):
...
TypeError: repr() takes no keyword arguments
>>> inst
Traceback (most recent call last):
...
TypeError: ReprWithParams.__repr__() missing 1 required positional argument: 'value'
>>> class ReprNotStr:
... def __repr__(self):
... return 10
>>> inst = ReprNotStr()
>>> inst.__repr__()
10
>>> repr(inst)
Traceback (most recent call last):
...
TypeError: __repr__ returned non-string (type int)
因此,请记住不要为 __repr__() 和 __str__() 使用参数,并记住它们都应返回字符串。但也值得记住,当你违反这两个规则中的任何一个时会发生什么。
自定义类示例
如上所述,当你实现一个复杂的自定义类时,通常应实现 __str__() 和 __repr__(),并且它们应有所不同。
在这个上下文中,“复杂”是什么意思?它可能意味着不同的东西,但在下面的例子中,它意味着类包含一些不需要在常规字符串表示中包含的属性,但我们可能希望在调试或日志记录时包含它们。
我们将实现一个流行的 Point 类,但我们会使它更复杂一些:
-
它的主要属性是
x和y,定义点的坐标。 -
它还有一个可选的
group属性,用于定义实例的组成员身份;它可以是像著名的 Iris 数据集中的物种这样的组。 -
你还可以给类的实例添加评论。它可以是任何评论,例如“纠正组”,“双重检查坐标”或“可能的错误”。评论不会用于比较—只是作为关于特定点的信息来源;我们将在下面的代码中看到这一点。
这是 Point 类的实现:
from typing import Optional
class Point:
def __init__(
self,
x: float,
y: float,
group: Optional[str] = None,
comment: Optional[str] = None) -> None:
self.x = x
self.y = y
self.group = group
self.comment = comment
def distance(self, other: "Point") -> float:
"""Calculates the Euclidean distance between two Point instances.
Args:
other: Another Point instance.
Returns:
The distance between two Point instances, as a float.
>>> p1 = Point(1, 2)
>>> p2 = Point(3, 4)
>>> p1.distance(p2)
2.8284271247461903
>>> p1.distance(Point(0, 0))
2.23606797749979
"""
dx = self.x - other.x
dy = self.y - other.y
return (dx**2 + dy**2)**.5
def __str__(self) -> str:
"""String representation of self.
>>> p1 = Point(1, 2, "c", "Needs checking")
>>> p1
Point(x=1, y=2, group=c)
Comment: Needs checking
>>> print(p1)
Point(1, 2, c)
When group is None, __str__() and __repr__() will
provide different representations:
>>> p2 = Point(1, 2, None)
>>> p2
Point(x=1, y=2, group=None)
>>> print(p2)
Point(1, 2)
"""
if self.group is not None:
return f"Point({self.x}, {self.y}, {self.group})"
return f"Point({self.x}, {self.y})"
def __repr__(self) -> str:
msg = (
f"Point(x={self.x}, y={self.y}, "
f"group={self.group})"
)
if self.comment is not None:
msg += (
"\n"
f"Comment: {self.comment}"
)
return msg
def __eq__(self, other) -> bool:
"""Compare self with another object.
Group must be provided for comparisons.
Comment is not used.
>>> Point(1, 2, "g") == 1
False
>>> Point(1, 2, "c") == Point(1, 2, "c")
True
>>> Point(1, 2) == Point(1, 2)
False
>>> Point(1, 2) == Point(1, 3, "s")
False
"""
if not isinstance(other, Point):
return False
if self.group is None:
return False
return (
self.group == other.group
and self.x == other.x
and self.y == other.y
)
if __name__ == "__main__":
import doctest
doctest.testmod()
让我们分析一下 __repr__() 和 __str__() 之间的区别:
细节的层次
如上所述,这种评论通常在类实例的常规字符串表示中不是必需的。因此,我们不需要在 __str__() 中包含它们。然而,当我们进行调试时,评论可以非常有用,尤其是当它们提供有关特定类实例的重要信息时。
这就是为什么我们应该在 __repr__() 中包含评论,但在 __str__() 中不包含评论的原因。请考虑这个例子:
>>> p1 = Point(1, 2, "c", "Needs checking")
>>> p1
Point(x=1, y=2, group=c)
Comment: Needs checking
>>> print(p1)
Point(1, 2, c)
更详细的图片
在我们的实现中,这两个方法提供了类实例的不同视图。比较
Point(x=1, y=2, group=c)
Comment: Needs checking
通过
'Point(1, 2, c)'
除了提供评论外,__repr__() 通过提供属性名称,提供比 __str__() 更详细的图片。在这个特定的类中,这可能差别不大,但当一个类有更多的属性需要包括在字符串表示中,并且它们的名称比这里更长时,差异可能会更加明显。即使在这里,__str__() 提供的信息也比 __repr__() 更简洁。
从 __repr__() 重建实例
我们也提到过这一点。如果可能的话,提供在 __repr__() 中所需的所有信息以重建实例是一个好的实践。在这里,__str__() 对我们来说还不够:
>>> str(p1)
'Point(1, 2, c)'
>>> p1_recreated_from_str = Point(1, 2, "c")
>>> p1
Point(x=1, y=2, group=c)
Comment: Needs checking
>>> p1_recreated_from_str
Point(x=1, y=2, group=c)
在这里,评论没有用于比较实例,因此 p1 == p1_recreated_from_str 返回 True 这并不重要:
>>> p1 == p1_recreated_from_str
True
这只是说明从用户的角度来看这两个实例是相等的。然而,从开发者的角度来看,它们并不相同:p1 不 等于 p1_recreated_from_str。如果我们想要完全重建p1,我们需要使用其__repr__()表示形式:
>>> p1
Point(x=1, y=2, group=c)
Comment: Needs checking
>>> p1_recreated_from_repr = Point(
... 1, 2, "c", comment="Needs checking")
>>> p1_recreated_from_repr
Point(x=1, y=2, group=c)
Comment: Needs checking
结论
我希望阅读这篇文章能帮助你理解repr()和str()之间,以及__repr__()和__str__()之间的微妙差异。这样的细微差别可能对中级 Python 用户不是必需的,但如果你想成为高级 Python 用户或开发者,这正是你需要在日常编码中了解并使用的。
这只是冰山一角,但我不会仅仅停留在这里。我们之前讨论过 Python 的这些细微之处,未来的文章中我们会进一步探讨。
感谢阅读。如果你喜欢这篇文章,你可能也会喜欢我写的其他文章;你可以在这里看到它们。如果你想加入 Medium,请使用下面的推荐链接:
## 使用我的推荐链接加入 Medium - Marcin Kozak
作为一个 Medium 会员,你的一部分会费会分配给你阅读的作者,并且你可以完全访问每一个故事……
解释 Python ord() 和 chr() 函数
原文:
towardsdatascience.com/python-ord-and-chr-functions-explained-dcb39944c480
在这篇文章中,我们将探讨如何使用 Python ord() 和 chr() 函数。
 [外链图片转存中…(img-ckXIgbwK-1726872405600)] Misha Sv
[外链图片转存中…(img-ckXIgbwK-1726872405600)] Misha Sv
·发布于 Towards Data Science ·阅读时长 3 分钟·2023 年 1 月 12 日
–

由 Brett Jordan 提供的照片,刊登在 Unsplash
目录
-
介绍
-
使用 ord() 将字符转换为 Unicode 代码点
-
使用 ord() 将字符串转换为 Unicode 代码点
-
使用 chr() 将整数转换为 Unicode 字符
-
结论
介绍
Python ord() 函数是一个内置函数,它返回指定字符的 Unicode 代码点。
Unicode 代码点是一个整数,用于表示 Unicode 标准 中的字符。
ord() 函数的处理定义如下:
ord(character) -> Unicode code
其中 character 是一个 Unicode 字符。
Python chr() 函数是一个内置函数,它返回指定字符的 Unicode 代码点。
chr() 函数的处理定义如下:
chr(integer) -> Unicode character
使用 ord() 将字符转换为 Unicode 代码点
让我们尝试使用 ord() 函数来查找字母 A、B 和 C 的 Unicode 代码点:
#UCP of letter A
a = ord('A')
#UCP of letter B
b = ord('B')
#UCP of letter C
c = ord('C')
#Print values
print(a)
print(b)
print(c)
你应该得到:
65
66
67
每个整数代表一个 Unicode 字符。
你可以使用 ord() 函数查找其他字符的 Unicode 代码点,包括特殊字符。
使用 ord() 将字符串转换为 Unicode 代码点
注意 ord() 函数只能接受一个字符作为参数,如 介绍 中提到的:
ord(character) -> Unicode code
如果你尝试将其用于一个包含多个字符的字符串,你会得到一个 TypeError:
#UCP of string
x = ord('Python')
你应该得到:
TypeError: ord() expected a character, but string of length 6 found
那么我们如何将整个字符串转换为 Unicode 代码点呢?
我们需要逐个字符地处理它,有几种方法可以解决这个任务:
-
使用 Python 的map()函数
-
使用列表推导式
使用 ord() 和 map() 将字符串转换为 Unicode 代码点
使用Python map() 函数我们可以对字符串的每个元素应用 Python ord() 函数:
#Define a string
py_str = 'Python'
#UCP of string
ucp_vals = list(map(ord, py_str)
#Print UCP values
print(ucp_vals)
你应该得到:
[80, 121, 116, 104, 111, 110]
使用 ord() 和列表推导式将字符串转换为 Unicode 代码点
解决这个任务的另一种方法是使用 Python 中带有列表推导式的**ord()**函数:
#Define a string
py_str = 'Python'
#UCP of string
ucp_vals = [ord(char) for char in py_str]
#Print UCP values
print(ucp_vals)
你应该得到:
[80, 121, 116, 104, 111, 110]
使用 chr() 将整数转换为 Unicode 字符
你也可以通过使用**chr()函数来逆转ord()**函数的操作,它将一个 Unicode 代码点(以整数格式)转换为一个 Unicode 字符。
例如,让我们看看 97、98 和 99 的 Unicode 代码点代表了哪些字符:
#UCP of letter A
c1 = chr(97)
#UCP of letter B
c2 = chr(98)
#UCP of letter C
c3 = chr(99)
#Print values
print(c1)
print(c2)
print(c3)
你应该得到:
a
b
c
结论
在这篇文章中,我们探讨了如何使用 Python 的**ord()和chr()**函数。
现在你知道了基本功能,你可以通过与其他可迭代的数据结构一起练习,以应对更复杂的用例。
如果你有任何问题或对某些编辑有建议,请随时在下方留言,并查看更多我的Python 函数教程。
原文发布于 https://pyshark.com 于 2023 年 1 月 12 日。
Python Pandas 到 Polars:数据过滤
原文:
towardsdatascience.com/python-pandas-to-polars-data-filtering-a67ccb70a8b3
你可能需要尽快做出转变


·发布在 Towards Data Science ·5 分钟阅读·2023 年 4 月 18 日
–
照片由 Daphné Be Frenchie 拍摄,发布在 Unsplash
我非常欣赏 Pandas。我从开始学习数据科学的第一天起就一直在使用它。Pandas 在数据清洗、预处理和分析的大多数任务中已经绰绰有余。
我对 pandas 唯一的不满是在处理大数据集时。Pandas 进行内存分析,所以当数据量变得非常大时,它的性能开始下降。
另一个与数据大小相关的缺点是某些操作会产生中间副本。因此,为了能够高效地工作,数据集应相对较小于内存。
对于如此大的数据集,存在不同的替代方案。最近获得显著人气的替代方案之一是 Polars。
有大量文章关注 Polars 与 pandas 的速度比较,但很少有从实际角度解释如何使用 Polars 执行常见的数据清洗和处理操作的文章。
在这一系列文章中,我将向你展示一些常用 Pandas 函数的 Polars 版本。第一个主题是数据过滤操作。在开始示例之前,让我们简要提及一下 Polars 的优势。
Polars 提供了什么?
Polars 是一个用于 Rust 和 Python 的 DataFrame 库。
-
Polars 利用你计算机上的所有可用核心,而 pandas 仅使用单个 CPU 核心来执行操作。
-
Polars 相较于 pandas 更加轻量,并且没有依赖项,这使得导入 polars 的速度非常快。导入 polars 只需 70 毫秒,而导入 pandas 需要 520 毫秒。
-
Polars 进行查询优化,以减少不必要的内存分配。它还能够以流式方式部分或完全处理查询。因此,polars 可以处理比机器上可用 RAM 更大的数据集。
使用 pandas 和 polars 进行数据过滤
我们将通过几个示例来学习如何过滤 polars DataFrames。我们还将看到相同操作的 pandas 版本,以便于从 pandas 过渡到 polars。
首先,我们将创建一个 DataFrame 来进行操作。我们将使用我准备的示例数据集。你可以从我的 数据集 仓库下载。
# pandas
import pandas as pd
# read csv
df_pd = pd.read_csv("datasets/sales_data_with_stores.csv")
# display the first 5 rows
df_pd.head()

pandas DataFrame 的前 5 行 (图片由作者提供)
# polars
import polars as pl
# read_csv
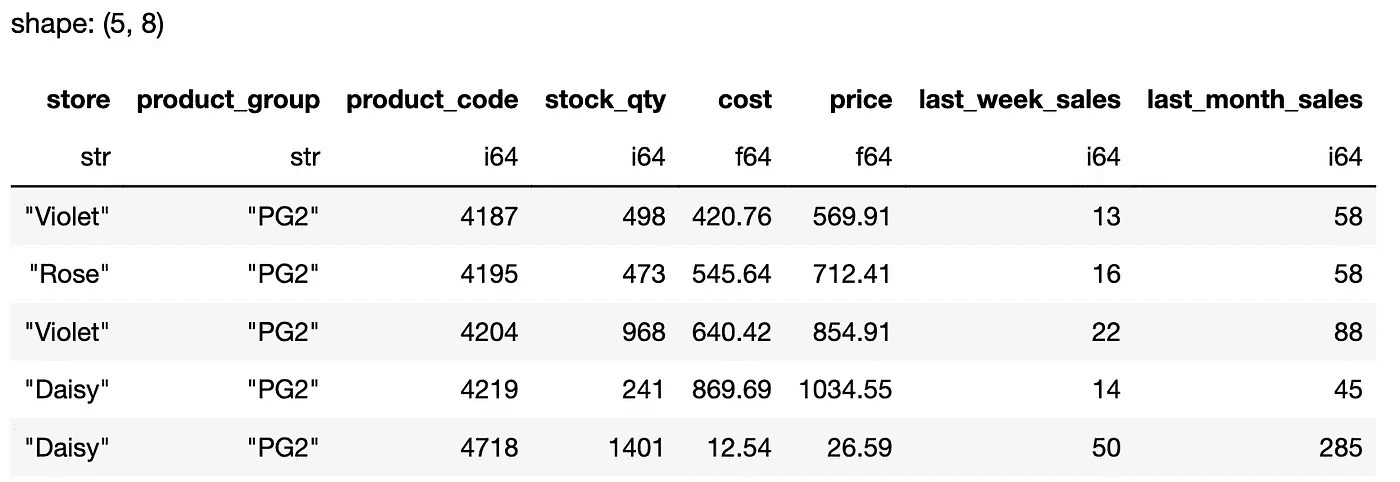
df_pl = pl.read_csv("datasets/sales_data_with_stores.csv")
# display the first 5 rows
df_pl.head()
polars DataFrame 的前 5 行 (图片由作者提供)
pandas 和 polars 都有相同的函数来读取 csv 文件并显示 DataFrame 的前 5 行。Polars 还显示了列的数据类型和输出的形状,我认为这是一个很有用的附加功能。
示例 1:按数值过滤
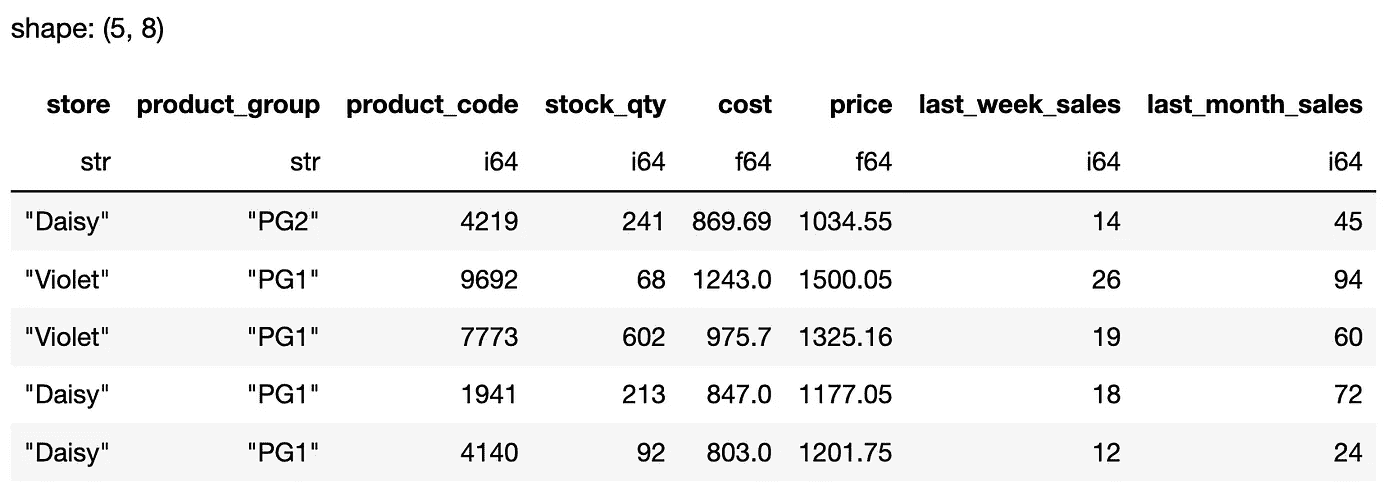
让我们过滤价格高于 750 的行。
# pandas
df_pd[df_pd["cost"] > 750]
# polars
df_pl.filter(pl.col("cost") > 750)
我将仅展示 pandas 或 polars 版本的输出,因为它们是相同的。
(图片由作者提供)
示例 2:多个条件
pandas 和 polars 都支持按多个条件过滤。我们可以使用“and”和“or”逻辑来组合这些条件。
让我们过滤价格大于 750 且商店值为 Violet 的行。
# pandas
df_pd[(df_pd["cost"] > 750) & (df_pd["store"] == "Violet")]
# polars
df_pl.filter((pl.col("cost") > 750) & (pl.col("store") == "Violet"))

(图片由作者提供)
示例 3:isin 方法
pandas 的 isin 方法可以用来将行值与一组值进行比较。当条件由多个值组成时,它非常有用。polars 版本的方法是“is_in”。
我们可以按照如下方式选择 PG1、PG2 和 PG3 的行:
# pandas
df_pd[df_pd["product_group"].isin(["PG1", "PG2", "PG5"])]
# polars
df_pl.filter(pl.col("product_group").is_in(["PG1", "PG2", "PG5"]))
输出的前 5 行:
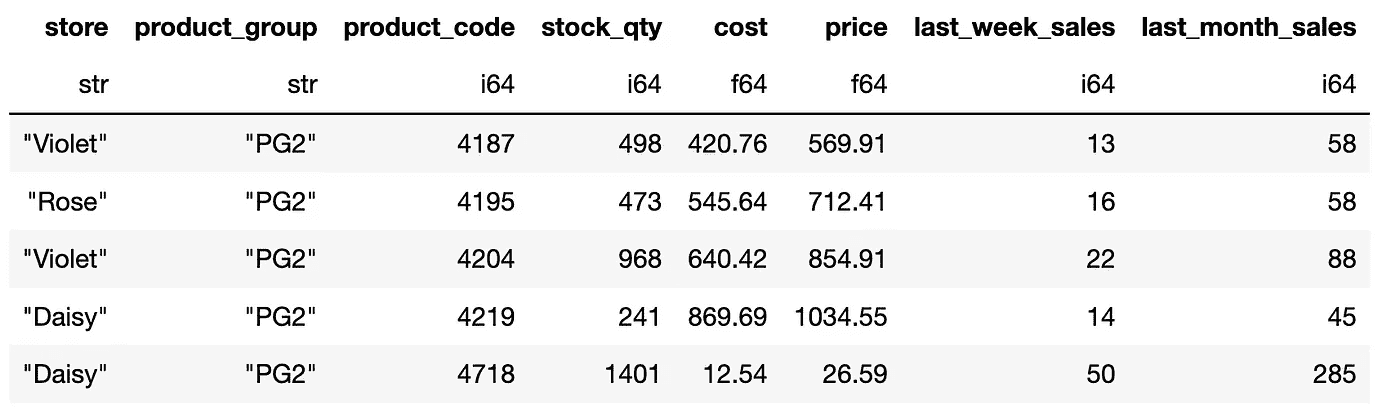
(图片由作者提供)
示例 4:选择部分列
要选择一部分列,我们可以将列名列表传递给 pandas 和 polars DataFrames,如下所示:
cols = ["product_code", "cost", "price"]
# pandas (both of the following do the job)
df_pd[cols]
df_pd.loc[:, cols]
# polars
df_pl.select(pl.col(cols))
输出的前 5 行:
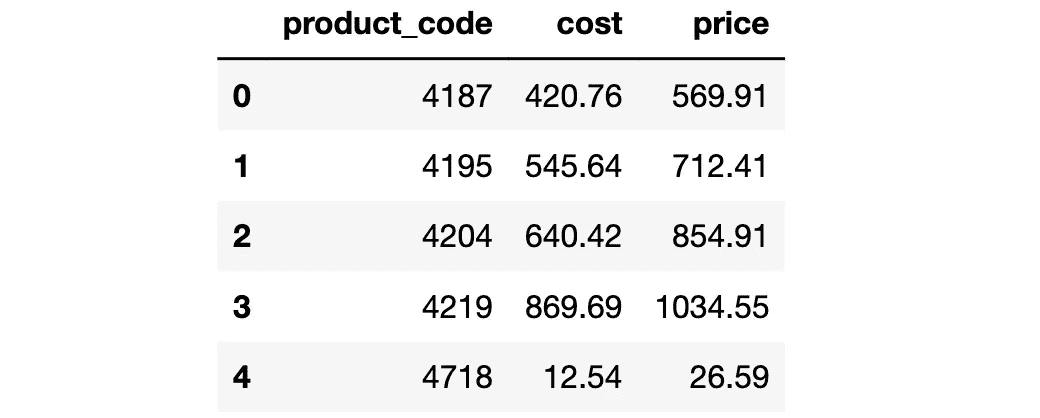
(图片由作者提供)
示例 5:选择部分行
我们可以使用 loc 或 iloc 方法来选择 pandas 的部分行。在 polars 中,我们使用非常类似的方法。
这是一个简单的示例,选择第 10 行到第 20 行之间的行:
# pandas
df_pd.iloc[10:20]
# polars
df_pl[10:20]
要选择相同的行但仅选择前三列:
# pandas
df_pd.iloc[10:20, :3]
# polars
df_pl[10:20, :3]
如果我们想通过名称选择列,可以使用 pandas 中的 loc 方法。
# pandas
df_pd.loc[10:20, ["store", "product_group", "price"]]
# polars
df_pl[10:20, ["store", "product_group", "price"]]
示例 6:按数据类型选择列
我们还可以选择特定数据类型的列。让我们做一个选择具有 64 位整数(即 int64)数据类型的列的示例。
# pandas
df_pd.select_dtypes(include="int64")
# polars
df_pl.select(pl.col(pl.Int64))
输出的前 5 行:
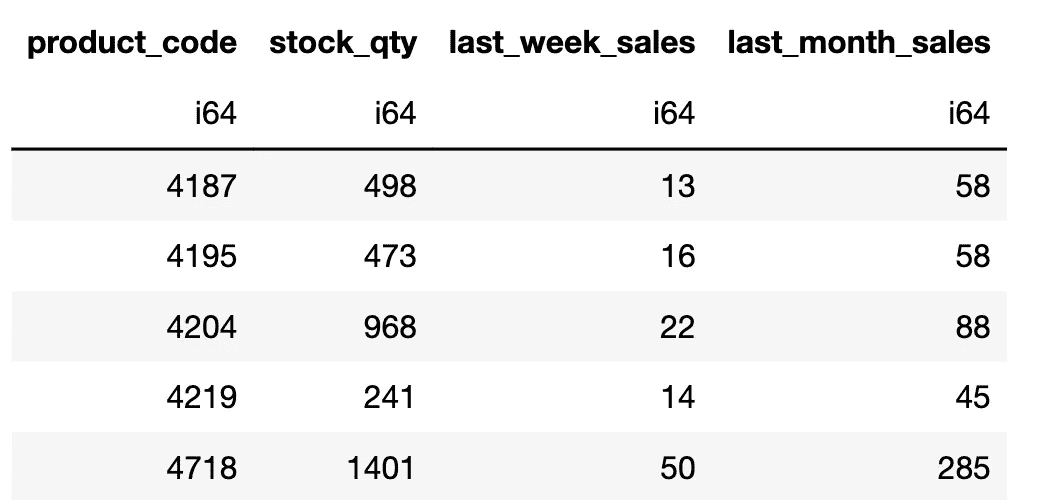
(图片由作者提供)
我们做了几个示例来比较Pandas和Polars之间的过滤操作。总体而言,Polars与Pandas非常相似,但在某些情况下采用了类似于Spark SQL的方法。如果你对使用Spark SQL进行数据清洗和操作很熟悉,你会发现这些相似之处。
话虽如此,考虑到在处理大型数据集时Polar的效率,它可能很快成为取代Pandas进行数据清洗和操作任务的有力候选者。
你可以成为 Medium 会员 以解锁我所有的写作内容,以及 Medium 的其他内容。如果你已经是会员了,请不要忘记 订阅 ,以便在我发布新文章时收到电子邮件。
感谢阅读。如果你有任何反馈,请告诉我。
Python 怪癖:了解如何通过一个不返回任何东西的函数来修改变量
深入了解 Python 如何传递参数和可变性,以防止意外错误
 [外链图片转存中…(img-8tSu8vBD-1726872405602)] Mike Huls
[外链图片转存中…(img-8tSu8vBD-1726872405602)] Mike Huls
·发布于 Towards Data Science ·8 分钟阅读·2023 年 4 月 13 日
–

跟踪意外的错误(图片来自 cottonbro studio on Pexels)
在这篇文章中,我们将戴上侦探帽,解开一个“Python 神秘”。在这一集里,我们将了解一个不返回值的函数如何改变一个变量。(下面有示例)。不仅如此:它只对某些类型的变量‘有效’。此外,这种行为很容易让人陷入陷阱,因此了解其原因非常重要。
我们将重点理解神秘背后的机制。更好地理解 Python 不仅会让你成为更优秀的开发者,还会节省你解决难以理解的错误的沮丧。让我们开始编程吧!
神秘——一个例子
首先让我们更深入地分析一下我们的“Python 神秘”:假设我们有两个函数:
-
接受 一个变量
-
修改 该变量
-
不要返回 该变量
def change_string(input_string:str) -> None:
""" Notice that this functions doesn't return anything! """
input_string += 'a'
def change_list(input_list:list) -> None:
""" Notice that this functions doesn't return anything! """
input_list.append('a')
对于这两个函数,我们定义一个变量,打印出来,调用函数并传递变量,然后再次打印出来
my_str = 'hello'
print(my_str) # 'hello'
change_string(input_string=my_str)
print(my_str) # 'hello'
my_list = ['hello']
print(my_list) # ['hello']
change_list(input_list=my_list)
print(my_list) # ['hello', 'a'] !?
发生了什么?为什么my_list变量改变了,而my_str变量没有?尽管这些函数没有返回任何东西!我们有三个问题,将在三个相应的章节中解答:
-
函数如何“访问”变量?
-
为什么列表被修改而字符串没有改变?
-
我们如何防止这种行为?
通过同时做多件事来加快你的程序
towardsdatascience.com
1. 函数如何访问变量
为了弄清楚这一点,我们需要理解变量是如何进入函数的:我们需要了解 Python 是如何将变量传递给函数的。有很多种方法可以做到这一点。为了理解 Python 如何将变量传递给函数,我们首先需要了解 Python 如何在内存中存储值。
1.1 Python 如何存储变量
你可能会认为当我们定义一个变量时,比如:person = 'mike',内存中有一个名为 ‘person’ 的对象,其值为 ‘mike’(参见下面的图片)。这只是部分正确。
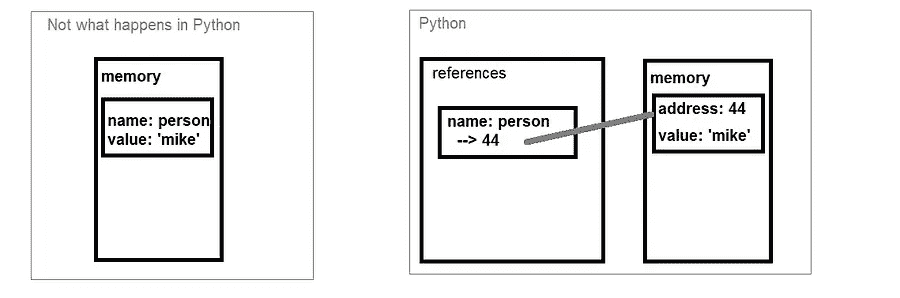
变量在 Python 和其他语言(例如 C)的内存存储方式(由作者专业绘制)
Python 使用 引用。它在内存中创建一个对象,然后创建一个名为 ‘person’ 的引用,指向内存中的对象,具体的内存地址和值是 ‘mike’。可以把它看作是在对象上挂一个标签,这个标签上写着变量的名字。
如果我们做类似这样的操作:person2 = person,我们不会在内存中创建一个新对象,只是创建了一个名为‘person2’的新引用,指向已经存在的内存中的对象:
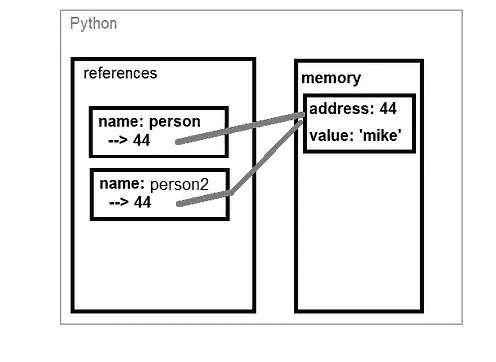
创建一个新的引用,指向相同的对象(图片由作者提供)
重新定义 person2 = ‘bert' 将导致 Python 在内存中创建一个新对象,并将名为“person2”的引用指向那里:
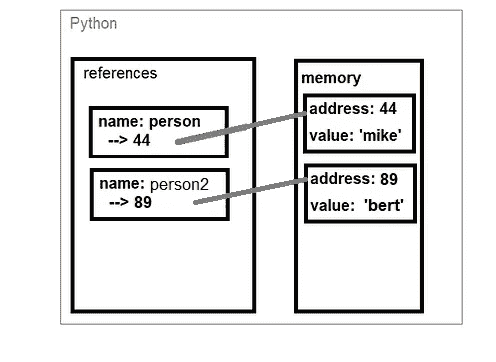
1.2 Python 是传递对象还是引用给函数?
理解一个关键点是,当我们调用 somefunction(person) 时 我们并没有给函数一个内存中的对象,而只是该对象的引用。
Python 变量是 “按引用” 传递的,而不是 “按值” 传递的。
这是解决谜团的第一个答案:我们给函数提供了一个内存中值的引用,而不是给函数提供一个 对象的副本。这就是为什么我们可以修改值 而不需要函数返回 任何东西。
现在让我们来看解决方案的另一部分:为什么有些变量可以被修改而有些不能。
## 参数与关键字参数:哪种方式在 Python 中调用函数最快?
timeit 模块的清晰演示
[towardsdatascience.com
2. 为什么有些值可以被改变而有些不能? — 可变性
可变性是对象在创建后改变其值的能力。让我们首先了解一下可变变量:
IMMUTABLE MUTABLE
int, float, decimal, complex (numbers) list
bool set
str dict
tuple
frozenset
正如你所见,str是不可变的;这意味着它在初始化后不能改变。那么我们之前如何“修改”了我们的字符串(例如:input_string += ‘a')。接下来的部分解释了当我们尝试更改和覆盖可变和不可变值时会发生什么。
看一看背后的机制,了解 Python 的瓶颈所在
[towardsdatascience.com
2.1 当我们尝试更改不可变值时会发生什么?
我们创建了一个名为my_str的变量,值为'a'。接下来,我们使用id函数打印变量的内存地址。这是引用指向的内存位置。
重申一下:在下面的例子中,我们创建了一个引用,名为my_str,它指向一个内存中的对象,该对象的值为'a',并位于内存地址 1988650365763。
my_str = 'a'
print(id(my_str)) # 1988650365763
my_str += 'b'
print(id(my_str)) # 1988650363313
接下来,在第 3 行,我们将'b'添加到my_str中,并再次打印内存位置。如你所见,通过内存位置的变化,my_str在添加了'b'后变得不同。这意味着在内存中创建了一个新对象。
看起来 Python 似乎在更改字符串,但实际上它只是创建了一个新的内存对象,并将名为my_str的引用指向那个新对象。值为'a'的旧对象将被移除。查看这篇文章了解更多关于为什么 Python 不直接覆盖内存中的对象以及旧值如何被移除的内容。
2.2 当我们尝试更改可变值时会发生什么?
让我们用一个可变变量做同样的实验:
my_list= ['a']
print(id(my_list)) # 1988503659344
my_list.append('b')
print(id(my_list)) # 1988503659344
所以名为my_list的引用仍然指向内存中对象所在的同一位置。这证明了内存中的对象已经改变!还要注意,列表中的元素可以包含不可变类型。如果我们尝试更改这些变量,情况与之前所述相同。
2.3 当我们尝试覆盖变量时会发生什么?
正如我们在前面的部分所看到的,Python 不会覆盖内存中的对象。让我们看看实际效果:
# Immutable var: string
my_str = 'a'
print(id(my_str)) # 1988650365936
my_str = 'b'
print(id(my_str)) # 1988650350704
# Mutable var: list
my_lst = ['a', 'list']
print(id(my_lst)) # 1988659494080
my_lst = ['other', 'list']
print(id(my_lst)) # 1988659420608
如你所见,所有内存位置都发生了变化,包括可变和不可变的变量。这是 Python 处理变量的默认方式。注意我们并没有尝试改变可变列表的内容:我们定义了一个新的列表;我们并不是在改变它,而是将完全新的数据分配给my_lst。
2.4 为什么有些值是可变的而有些不是?
可变性通常是设计选择;一些变量保证内容保持不变并且有序。
## 入门 Cython:如何在 Python 中每秒进行超过 1.7 亿次计算
将 Python 的简便性与 C 的速度结合
towardsdatascience.com
解决方案:按引用传递和可变性的实际操作
在这一部分,我们将运用新学到的知识来解决谜题。在下面的代码中,我们声明了一个(可变的)列表,并将其(通过引用)传递给一个函数。然后函数能够更改列表的内容。我们可以通过以下事实看到这一点:内存地址在第 3 行和最后一行是相同的,而内容已经改变:
# 1\. Define list and check out the memory-address and content
my_list = ['a', 'list']
print(id(my_list), my_list) # 2309673102336 ['a', 'list']
def change_list(input_list:list):
""" Adds value to the list but don't return the list """
print(id(input_list), input_list) # 2309673102336 ['a', 'list']
input_list.append('b')
print(id(input_list)) # 2309673102336 ['a', 'list', 'b']
# 2\. Pass the list into our function (function doesn't return anything)
change_list(input_list=my_list)
# 3\. Notice that the memory location is the same and the list has changed
print(id(my_list), my_list) # 2309673102336 ['a', 'list', 'b']
这如何与不可变值一起工作?
好问题。让我们用一个不可变的元组来检查一下:
# 1\. Define a tuple, check out memory address and content
my_tup = {'a', 'tup'}
print(id(immutable_string), my_tup) # 2560317441984, {'a', 'tup'}
def change_tuple(input_tuple:tuple):
""" 'overwrites' the tuple we received, don't return anything """
print(id(input_tuple)) # 2560317441984, {'a', 'tup'}
input_tuple = ('other', 'tuple')
print(id(input_tuple)) # 2560317400064, {'other', 'tup'}
# 2\. Pass the list into our function (nothing is returned from function)
change_tuple(input_tuple=immutable_tuple)
# 3\. Print out memory location and content again
print(id(my_tup), my_tup) # 2560317441984, {'a', 'tup'}
由于我们不能改变值,我们必须在change_tuple函数中“覆盖”input_tuple。这并不意味着内存中的对象被覆盖,而是创建了一个新的对象。
然后我们修改在change_tuple函数作用域内存在的引用input_tuple,使其现在指向这个新对象。当我们退出函数时,这个引用会被清理,在外部作用域中,my_tup引用仍然指向旧对象的内存地址。
简而言之:“新”元组仅存在于函数的作用域中。
## 使用 OpenCV 毁灭《鸭子猎人》——初学者的图像分析
编写能打破所有《鸭子猎人》高分的代码
towardsdatascience.com
3. 如何防止不希望出现的行为
你可以通过给函数一个my_list.copy()来防止这种行为。这会先创建列表的副本,并将该副本的引用提供给函数,从而使所有更改都作用于副本而不是my_list:
# 2\. Pass the list into our function (nothing is returned from function)
change_list(input_list=my_list.copy())
## 完整指南:使用 Docker 和 Compose 的环境变量和文件
通过这个简单的教程,让你的容器既安全又灵活。
towardsdatascience.com
结论
我们讨论了可变性以及 Python 如何将变量传递给函数;这两个概念在设计 Python 代码时非常重要。通过这篇文章,我希望你避免难以理解的错误和大量的调试时间。
我希望这篇文章能像我期望的那样清晰,如果不是这样,请告诉我我可以做些什么来进一步澄清。同时,查看我在其他文章中讨论的各种编程相关主题:
编程愉快!
— Mike
附注:喜欢我在做的事吗? 关注我!
[## 通过我的推荐链接加入 Medium - Mike Huls
阅读 Mike Huls 的每个故事(以及 Medium 上的其他成千上万的作者)。你的会员费直接支持 Mike…
mikehuls.medium.com](https://mikehuls.medium.com/membership?source=post_page-----343a40cc6923--------------------------------)
Python sorted() 函数解析
原文:
towardsdatascience.com/python-sorted-function-explained-8e46bc002147
本文将探讨如何使用 Python 的 sorted() 函数
 [外链图片转存中…(img-pn73uArf-1726872405603)] Misha Sv
[外链图片转存中…(img-pn73uArf-1726872405603)] Misha Sv
·发表于 Towards Data Science ·4 分钟阅读·2023 年 1 月 16 日
–

Andre Taissin 摄影,来自 Unsplash
目录
-
介绍
-
基本排序使用 sorted()
-
使用 key 函数与 sorted()
-
使用
sorted()对自定义对象进行排序 -
结论
介绍
Python sorted() 函数是用于排序可迭代对象的内置函数。
它使用 timsort 作为排序算法,该算法源自归并排序和插入排序。
Python sorted() 函数的语法是:
sorted(iterable, key=None, reverse=False)
其中:
-
iterable — 可以是任何可迭代的 Python 对象,如字符串、元组、列表、集合、字典 等。
-
key — 可选参数,允许添加一个函数(例如 lambda 函数)作为排序的关键字。默认为 None。
-
reverse — 可选参数,允许反转可迭代对象(按降序排序),如果设置为 True。默认为 False。
sorted() 函数的过程定义为:
sorted(iterable) -> sorted list
基本排序使用 sorted()
**sorted()**函数有很多应用,下面我们来看几个基本的示例。
将数字列表按升序排序
最简单的例子是将一个 列表 的数字按升序排序:
#Create a list of numbers
nums = [3, 1, 9, 7, 5]
#Sort the list of numbers
s_nums = sorted(nums)
#Print sorted list
print(s_nums)
你应该得到:
[1, 3, 5, 7, 9]
将数字列表按降序排序
类似于之前的示例,我们将排序一个数字列表,但现在按降序排序:
#Create a list of numbers
nums = [3, 1, 9, 7, 5]
#Sort the list of numbers
s_nums = sorted(nums, reverse=True)
#Print sorted list
print(s_nums)
你应该得到:
[9, 7, 5, 3, 1]
排序一个字符串列表
Python 的 sorted() 函数也可以排序包含字符串元素的列表。
排序数字的过程非常简单直观,也可以扩展到排序字符串。
Python sorted() 函数根据每个字符串的第一个字符对字符串进行排序(例如,‘apple’ 排在 ‘orange’ 之前,因为 ‘a’ 在字母表中排在 ‘o’ 之前)。
让我们看一个例子:
#Create a list of strings
fruit = ['banana', 'pineapple', 'orange', 'apple']
#Sort the list of strings
s_fruit = sorted(fruit)
#Print sorted list
print(s_fruit)
你应该得到:
['apple', 'banana', 'orange', 'pineapple']
如你所见,字符串列表已经根据字符串的第一个字符按字母顺序(升序)排序了。
你还可以通过将可选的 reverse 参数设置为 True 来按降序对字符串列表进行排序。
注意: 你可以将上述功能扩展到其他可迭代对象,如 元组、集合,以及其他对象。
使用带有 key 函数的 sorted()
对于更复杂的排序任务,我们可以在 sorted() 中使用 key 函数,这将作为排序的关键。
使用 key 函数有两种方式:
-
使用 lambda 函数作为 key 函数
-
使用自定义函数作为 key 函数
使用 lambda 函数与 sorted()
让我们创建一个包含单词的示例列表:
['Python', 'programming', 'tutorial', 'code']
现在,在这个示例中,我们希望根据元素的长度对列表进行排序,这意味着单词将按从短到长的顺序排列。
如你所料,我们将不得不使用 len() 函数来计算每个元素的长度,使用 lambda 函数可以将其作为排序的 key 函数:
#Create a list of words
words = ['Python', 'programming', 'tutorial', 'code']
#Sort the list of words based on length of each word
s_words = sorted(words, key=lambda x: len(x))
#Print sorted list
print(s_words)
你应该得到:
['code', 'Python', 'tutorial', 'programming']
使用自定义函数与 sorted()
让我们重用前面示例中的相同单词列表:
['Python', 'programming', 'tutorial', 'code']
现在,我们希望基于列表中每个元素的长度进行相同的排序,但使用自定义函数来计算每个单词的长度。
我们可以定义一个简单的函数来计算单词的长度,并将其作为 key 函数传递给 sorted():
#Create a list of words
words = ['Python', 'programming', 'tutorial', 'code']
#Define a function to calculate length of a word
def calc_len(word):
len_w = len(word)
return len_w
#Sort the list of words based on length of each word
s_words = sorted(words, key=calc_len)
#Print sorted list
print(s_words)
你应该得到:
['code', 'Python', 'tutorial', 'programming']
这与我们使用 len() 和 lambda 函数作为 sorted() 的 key 函数时的结果是相同的。
使用 sorted() 对自定义对象进行排序
Python sorted() 函数的功能可以扩展到自定义对象(只要我们排序的是可迭代对象)。
例如,让我们创建一个具有两个属性 name 和 age 的自定义类 Person:
class Person:
def __init__(self, name, age):
self.name = name
self.age = age
def __repr__(self):
return repr((self.name, self.age))
这个类将创建一个包含每个人信息的元组列表:
#Create a list of tuples
persons = [
Person('Mike', 20),
Person('John', 35),
Person('David', 23),
]
#Print list of tuples
print(persons)
你应该得到:
[('Mike', 20), ('John', 35), ('David', 23)]
如你所见,这现在是一个元组的列表,这是一个 Python 可迭代对象,可以使用 sorted() 函数进行排序。
在这个例子中,我们希望根据每个人的 age 属性对列表进行排序:
#Sort the list of tuples based on age attribute
s_persons = sorted(persons, key=lambda person: person.age)
#Print sorted list
print(s_persons)
你应该得到:
[('Mike', 20), ('David', 23), ('John', 35)]
结论
在本文中,我们探讨了如何使用 Python sorted() 函数。
现在你了解了基本功能,你可以在其他可迭代的 数据结构 中练习使用它,以应对更复杂的用例。
如果你有任何问题或对某些修改有建议,请随时在下方留言,并查看更多我的Python 函数教程。
最初发表于 https://pyshark.com 于 2023 年 1 月 16 日。
Python 字符串数据类型解释
原文:
towardsdatascience.com/python-string-data-type-explained-ff81a363fe08
在本文中,我们将探索 Python 字符串数据类型


·发表于 Towards Data Science ·阅读时间 6 分钟·2023 年 1 月 30 日
–
照片由 Gaelle Marcel 拍摄,来自 Unsplash
在本文中,我们将探索 Python 字符串数据类型。
目录
-
介绍
-
在 Python 中创建字符串
-
在 Python 中访问字符串中的字符
-
在 Python 中查找字符串中的字符
-
在 Python 中切片字符串
-
在 Python 中迭代字符串
-
在 Python 中连接字符串
-
在 Python 中拆分字符串
-
结论
介绍
在 Python 中,字符串是不可变的字符序列,用于处理文本数据。
你应该了解关于字符串的关键点如下:
-
有序的
-
不可变的
-
可迭代的
学习每种编程语言中的数据类型对于理解代码和程序至关重要。
字符串数据类型在许多编程和机器学习解决方案中广泛使用,特别是在 Python 中用于存储一些格式化的文本数据。
在 Python 中创建字符串
在 Python 中,你可以通过 4 种不同的方式创建字符串:
-
通过用单引号括起字符
-
通过用双引号括起字符
-
通过用三重引号括起字符
-
通过使用 str() 构造函数
使用单引号创建字符串
这是在 Python 中创建字符串的最常见方式之一,非常简单:
#Single quotes
my_string1 = 'Hello World!'
print(my_string1)
你应该得到:
Hello World!
使用双引号创建字符串
这种创建字符串的方式与之前的方法相同,只是现在我们将使用双引号:
#Double quotes
my_string2 = "Hello World!"
print(my_string2)
你应该得到:
Hello World!
使用三重引号创建字符串
这种创建字符串的方式可能是最少见的,因为只有少数几种情况需要使用它。
用三重引号括起字符将产生与前两种方法相同的输出:
#Double quotes
my_string3 = '''Hello World!'''
print(my_string3)
你应该得到:
Hello World!
然而,使用三重引号的一个主要区别是,当你想创建一个多行字符串时,字符串的不同部分会在输出中显示在不同的行上。
例如:
#Double quotes
my_string4 = '''Hello
World!'''
print(my_string4)
你应该得到:
Hello
World!
使用 str() 构造函数创建一个字符串
在 Python 中,你也可以通过使用**str()**构造函数来创建字符串。
str(object) 构造函数接受任何对象并返回其字符串表示形式。
它返回:
让我们来看几个使用**str()**的不同数据类型的示例:
#String of int
str_int = str(5)
#String of float
str_float = str(1.5)
#String of complex
str_complex = str(1+3j)
#String of bool
str_bool = str(True)
#Print values
print(str_int)
print(str_float)
print(str_complex)
print(str_bool)
你应该得到:
5
1.5
(1+3j)
True
在 Python 中访问字符串中的字符
Python 列表的一个重要且非常有用的属性是它是一个带索引的序列,这意味着对于一个包含n个元素的列表,第一个元素的索引 = 0,第二个元素的索引 = 1,一直到n-1。
字符串中的字符可以通过其索引访问,索引也可以反转,这意味着第一个元素的索引 = — n,第二个元素的索引 = — n+1,一直到 -1。
为了更容易展示,请看下面的可视化图:
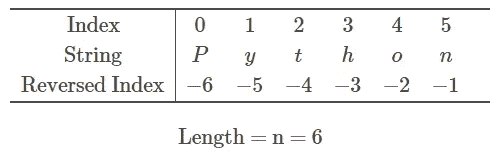
图片由作者提供
我们可以看到字符串中的‘P’字符有两个索引:0 和 -6。
让我们在 Python 中创建这个字符串,并使用上述索引打印出它的第一个字符:
#Create a string
my_string = 'Python'
#Print first character
print(my_string[0])
print(my_string[-6])
你应该得到:
P
P
在 Python 中查找字符串中的字符
使用索引,我们还可以找到字符串中字符的位置。
让我们重用之前示例中的字符串:‘Python’,并尝试找到*‘y’*字符在字符串中的位置。
使用 Python 字符串的**.index()** 方法,我们可以通过将字符作为参数传递给它来找到字符的位置:
#Create a string
my_string = 'Python'
#Find character
i = my_string.index('y')
#Print index
print(i)
你应该得到:
1
在 Python 中切片字符串
在前一节中,我们探讨了如何通过其精确索引从 Python 字符串中访问一个字符。
在本节中,我们将探讨如何访问一系列字符,例如前两个或最后两个。
记住,若要使用索引从字符串中检索字符,我们将索引放在方括号**[]**中。
切片使用相同的方法,但我们传递的是一个范围,而不是单一的索引值。
Python 中的范围是使用以下语法传递的**[from : to]**。
使用范围我们可以切片字符串以访问多个字符:
#Create a string
my_string = 'Python'
#First two characters
first_two = my_string[:2]
#Second to fourth characters
mid_chars = my_string[1:4]
#Last two characters
last_two = my_string[-2:]
#Print characters
print(first_two)
print(mid_chars)
print(last_two)
你应该得到:
Py
on
yth
注意,指定的字符在to索引处不包括在内,因为在 Python 切片算法中,它会遍历字符直到指定的to索引,并包括所有到达该索引但不包括to索引下的字符。
在 Python 中迭代字符串
Python 字符串是一个可迭代对象,这意味着我们可以遍历字符串中的字符。
可以使用 for() 循环执行简单的迭代:
#Create a string
my_string = 'Python'
#Iterate over a string
for char in my_string:
print(char)
你应该得到:
P
y
t
h
o
n
在 Python 中连接字符串
在 Python 中,我们也可以将多个字符串连接(组合)在一起以创建一个单一字符串。
在 Python 中连接字符串的两种最流行的方法是:
-
使用 ‘+’ 操作符
-
使用 .join() 方法
使用 ‘+’ 操作符
使用 ‘+’ 操作符是连接多个字符串的最常见方法之一。
让我们看一个例子:
#Create strings
s1 = 'Python'
s2 = 'Tutorial'
sep = ' '
#Concatenate strings
new_string = s1 + sep + s2
#Pring new string
print(new_string)
你应该得到:
Python Tutorial
使用 .join() 方法
Python 字符串 .join() 方法允许将一个字符串列表连接起来以创建一个新字符串。
Python 字符串 .join() 方法的语法是:
separator.join([list of strings])
让我们看一个例子:
#Create strings
s1 = 'Python'
s2 = 'Programming'
s3 = 'Tutorial'
sep = ' '
#Concatenate strings
new_string = sep.join([s1, s2, s3])
#Pring new string
print(new_string)
你应该得到:
Python Programming Tutorial
在 Python 中拆分字符串
在 Python 中,正如我们可以连接多个字符串一样,我们也可以将一个字符串拆分成多个字符串。
有多种方法可以做到这一点,但最常用的方法是使用字符串的 .split() 方法,它根据分隔符(默认分隔符是:‘ ’)将字符串拆分成一个字符串列表。
Python 字符串 .split() 方法的语法是:
string.split(separator)
让我们看一个例子:
#Create a string
long_string = 'Apple Banana Orange Pineapple'
#Concatenate strings
new_strings = long_string.split()
#Pring new string
print(new_strings)
你应该得到:
['Apple', 'Banana', 'Orange', 'Pineapple']
你还可以根据你想要拆分字符串的内容指定自定义分隔符。
例如:
#Create a string
long_string = 'Apple, Banana, Orange, Pineapple'
#Concatenate strings
new_strings = long_string.split(', ')
#Pring new string
print(new_strings)
你应该得到:
['Apple', 'Banana', 'Orange', 'Pineapple']
结论
在本文中,我们探讨了 Python 布尔数据类型,包括它在布尔表达式和控制结构中的使用。
作为学习 Python 的下一步,考虑阅读以下文章,了解 Python 数据类型和数据结构:
最初发表于 https://pyshark.com 2023 年 1 月 30 日。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









