







2022 年 NLP 初创公司融资情况


·
关注 发表在 Towards Data Science ·32 分钟阅读·2023 年 1 月 9 日
–

照片由 Jason Leung 提供,发布在 Unsplash
NLP 技术的商业应用近年来急剧增长已不是什么秘密。从聊天机器人和虚拟助手到机器翻译和情感分析,NLP 技术现在被广泛应用于各种行业。随着对能够处理人类语言的技术需求的增加,投资者也迫不及待地想要参与其中。本文将回顾过去一年 NLP 初创公司的融资情况,识别出获得投资的应用和领域。
这篇文章的一个版本将会在 《自然语言工程杂志》 于 2023 年初刊登。
1. 引言
在策划 This Week in NLP 的内容过程中,这是一份关于 NLP 工具和技术商业应用的通讯(免费订阅请 点击这里!),我跟踪了自然语言处理领域的公司融资和收购情况。在 2022 年,我发现了 340 多个相关的融资事件,从种子轮融资到晚期的 E 轮和 F 轮融资。本文重点关注早期公司:具体而言,是那些报告了种子轮融资、种子轮融资或 A 轮融资的公司。这些公司尚未在市场上建立他们的产品或服务,可以明确地被描述为初创公司;它们对投资者构成了最高风险,同时我们也期望它们能成为创新思想的优秀来源。在我所掌握的数据中,略超过 50%的融资事件发生在种子轮、种子轮或 A 轮阶段;在本文中,我试图对这 173 家公司提供的产品进行一定的组织和结构化,以突显过去十二个月中被认为值得投资的技术和应用领域。
2. 这里的内容
一份包含 170 多家公司的平面列表以及它们的业务内容将会非常难以阅读且缺乏洞察力。因此,本文围绕 NLP 初创公司的分类组织,旨在为对这一领域感兴趣的读者提供帮助。这样一个领域可以有多种结构方式,我并不声称这里使用的分类是唯一的方式;这只是一个对我而言有意义的领域地图,也可能使你更容易确定哪些部分的文章对你最相关。
在理想的世界里,我们可能会选择通过应用类型或应用领域来组织技术产品,将这两者视为两个正交的详尽解决方案。但正如在 我对 2021 年 NLP 初创公司融资的回顾 中所述,我认为采用一种略显不舒服的混合方法更具信息量和实用性,这种方法提取了一种技术类型的层级,但保留了一部分我们审查的公司在应用领域方面的更好组织。因此,本文结构如下:
-
在第三部分中,我们关注那些主要处理文本而非语音的产品和服务:这包括搜索、信息提取、内容审核、文本生成和机器翻译等子类别。
-
在第四部分中,我们关注那些以某种方式涉及对话的应用程序:这里识别的子类别包括开发平台、定制开发提供商、对话智能、沟通技能反馈、销售支持和会议生产力工具。
-
在第五部分中,我们讨论了视听处理,子类别包括语音处理、语音合成和视频合成。
-
在第六部分中,我们考察了领域特定的解决方案,涵盖了法律科技、健康科技、教育科技以及一些只有一两个参与者的松散领域。
-
最后,在第七部分中,我们对该领域的发展方向进行了总结性结论。
如果上面列出的类别都是相互排斥的,那就好了,但实际上并非如此;在各个地方都有交叉和边界模糊,因此你可能不同意我选择将某些公司放在特定类别的位置。特别是,第 3、4 和 5 节中讨论的一些公司本可以被视为领域特定应用,但为了识别活动集群,我认为将它们归类于技术类型下更为有用。
还需要进一步说明一些方法学的评论和一些警告事项。
-
这里呈现的信息来自对约 150 个相关新闻来源的手动和自动处理的综合搜寻。我不太可能捕捉到每一个相关的融资事件,但我相信这些结果是比较全面的;如果你认为我遗漏了一个在 2022 年获得种子轮或 A 轮融资的 NLP 初创公司,请给我发邮件,以便我可以调查遗漏的原因。
-
我认为一家公司的产品或服务提供 NLP 功能,如果语言处理技术在该产品或服务中扮演了重要角色。不可避免地,有些情况处于边缘地带;例如,许多基于网络的产品现在都集成了简单的聊天机器人功能,但我仅在聊天机器人是一个重要功能或具有有趣和创新的功能时,才将其纳入范围。
-
我对公司业务的描述基于写作时对每个公司网站的简要审查。但情况可能迅速变化,公司也可能会显著转型,因此根据你阅读本文的时间,任何给定公司的网站现在可能讲述了不同的故事。此外,我尽量在短时间内提供尽可能多的信息,通常不超过一句话;但也有几个例子,我花了过多的时间和精力在一个网站上,试图明确公司提供的内容,结果未能成功,导致描述不够清晰。
-
对于每家公司,我都标明了公司的成立年份,以及该公司获得了哪些轮次的融资、何时获得融资以及融资金额。所有金额均以美元计,尽管应注意到许多公司位于美国以外,并且获得了其他货币的融资;这里显示的美元等值金额基于撰写时的汇率,因此可能与融资时报告的金额略有不同。
不管怎样,废话不多说。我们开始吧。
3. 文档处理
在行业中使用的术语“文档 AI”通常指的是需要处理文档中的物理格式问题的方法(例如,从表格中提取信息),而“文本处理”通常更关注文档的语言内容,与其物理呈现方式抽象开来。然而,我的印象是,越来越多的解决方案正在将这两种范式结合在一起,因此我在这里将它们视为一个综合类别。
3.1 搜索
许多初创公司提供面向开发者的搜索引擎,这些开发者希望将搜索功能添加到他们的项目中。ZincSearch(成立于 2022 年;种子轮,360 万美元,2022 年 3 月)和Meilisearch(成立于 2018 年;A 轮,1500 万美元,2022 年 10 月)提供可下载的搜索引擎,Meilisearch 还提供完全托管的云版本。SeMI Technologies(成立于 2019 年;A 轮,1650 万美元,2022 年 2 月),Hebbia(成立于 2020 年;A 轮,3000 万美元,2022 年 6 月)和Vectara(成立于 2020 年;种子轮,2000 万美元,2022 年 10 月)强调他们使用向量搜索,也称为神经搜索或语义搜索,这与基于术语索引的旧方法形成对比;Pinecone Systems(成立于 2019 年;A 轮,2800 万美元,2022 年 3 月)提供一种可以作为搜索基础设施的向量数据库产品,Nuclia(成立于 2019 年;种子轮,540 万美元,2022 年 4 月)是一个端到端的 API,允许团队使用他们自己的向量化和标准化算法,同时提供存储、索引和查询功能。Deepset(成立于 2018 年;A 轮,1400 万美元,2022 年 4 月)提供一个开源 NLP 框架 Haystack,帮助开发者为各种搜索用例构建管道,而Opster(成立于 2019 年;A 轮,500 万美元,2022 年 7 月)提供一个自动化和管理企业搜索引擎及数据库的平台。
更大胆的策略是将你的搜索技术定位为对现有技术的替代方案:You.com(成立于 2020 年;A 轮,2500 万美元,2022 年 7 月),旨在成为一个开放的搜索平台,允许其他人基于其搜索技术进行开发,包括 AI 驱动的功能,如 YouCode,可以根据搜索查询生成代码,类似于 GitHub 的 Copilot,以及 YouWrite,由 OpenAI 的 GPT-3 驱动,可以生成文章、博客帖子和模板信件。但更常见的是针对特定用例:Ocean.io(成立于 2017 年;风险轮,630 万美元,2022 年 1 月)和Grata(成立于 2016 年;A 轮,2500 万美元,2022 年 2 月)都旨在帮助企业找到合适的业务目标;Vetted(成立于 2019 年;A 轮,1400 万美元,2022 年 8 月)是一个产品搜索引擎,旨在帮助消费者发现最符合需求的品牌和产品;Outmind(成立于 2019 年;种子轮,210 万美元,2022 年 9 月)专注于在各种工作场所应用中跨相关数据的聚合搜索;Mem(成立于 2021 年;A 轮,2350 万美元,2022 年 11 月)是一个生产力应用程序,能够在用户的笔记中进行搜索;Hypertype(成立于 2021 年;前种子轮,130 万美元,2022 年 5 月)搜索电子邮件档案,以自动化新邮件的撰写。
在文本搜索领域之外,Twelve Labs(成立于 2021 年;种子轮,500 万美元,2022 年 3 月)提供了一个视频搜索和理解平台,利用语义搜索在大规模视频档案中定位相关场景。
3.2 信息提取
提取和汇总信息是许多初创公司的关键关注点:KnowledgeNet.ai(成立于 2021 年;A 轮,940 万美元,2022 年 2 月)旨在通过整合电子邮件、客户关系管理系统、文件存储、职业网络和行业新闻源中的分散对话和数据,来支持交易者和高管;Ask-AI(成立于 2021 年;种子轮,900 万美元,2022 年 10 月)汇总了大量文本公司知识来源和客户沟通,通过问答界面使数据变得易于访问。
现在,通用工作流自动化产品中包含某种程度的文档 AI 能力已相当普遍。NanoNets(成立于 2017 年;A 轮融资,1000 万美元,2022 年 2 月)允许开发者创建可以从文档中提取数据并自动填充数据库的机器学习模型;Krista(成立于 2016 年;A 轮融资,1500 万美元,2022 年 2 月)强调其低代码自动化平台的对话性质;而Alkymi(成立于 2017 年;A 轮融资,2100 万美元,2022 年 10 月)提供一个统一的平台,从各种不同的非结构化数据源中提取数据,并提供大量“蓝图”用于常见文档类型。
一些信息提取产品的关注点更为狭窄:Neuron7.ai(成立于 2020 年;A 轮融资,1000 万美元,2022 年 6 月)将自己定位为服务智能平台,利用技术从组织中的数据和人员中提取信息,并利用这种“集体智能”帮助人们诊断和解决客户问题;Sensible(成立于 2020 年;种子轮融资,650 万美元,2022 年 11 月)提供一个文档编排平台,提供预先构建的模板,用于从 150 多种保险文档类型中提取数据;Stimulus(成立于 2017 年;种子轮融资,250 万美元,2022 年 8 月)是一个关系智能平台,利用数据和分析通过专有的评分机制帮助公司做出更好的采购决策;Prophia(成立于 2018 年;A 轮融资,1020 万美元,2022 年 12 月)的平台搜寻商业房地产合同,并提取关键条款,如平方英尺和租赁日期;以及theGist(成立于 2022 年;前种子轮融资,700 万美元,2022 年 11 月)的首款产品 theGist for Slack,提供 Slack 讨论的结构化、个性化摘要,过滤噪音,以免员工错过重要信息。
3.3 情感分析
情感分析仍然吸引着新的初创公司,通常是在评估和衡量消费者或用户反馈的背景下。一个常见的焦点是通过多渠道或来源聚合和分类反馈,现在使用 AI 模型:Viable(成立于 2020 年;种子轮,500 万美元,2022 年 5 月)在后台使用 GPT-3,提供综合反馈的书面分析服务,以及对反馈的自然语言查询;Idiomatic(成立于 2016 年;种子轮,400 万美元,2022 年 5 月)使用为每个特定业务案例量身定制的模型来分类反馈;Spiral(成立于 2018 年;种子轮,130 万美元,2022 年 11 月)将其反馈技术出售给中大型公司,涉及银行、金融科技、连接设备和保险行业。Lang(成立于 2018 年;A 轮,1050 万美元,2022 年 5 月)、Unwrap(成立于 2021 年;种子轮,320 万美元,2022 年 7 月)和Sturdy AI(成立于 2019 年;种子轮,310 万美元,2022 年 6 月)也类似地对检测到的问题和关注点进行分类,并提供各种形式的分析。
一个相关的重点是品牌管理:My Telescope(成立于 2018 年;前种子轮,260 万美元,2022 年 3 月)是一个市场情报和搜索平台,为营销人员和品牌提供市场趋势、品牌强度和活动效果的长期影响预测,Knit(成立于 2015 年;种子轮,360 万美元,2022 年 6 月)通过年轻消费者网络提供基于视频反馈和定量调查的详细消费者洞察;该公司的视频分析 AI 声称能在几分钟内分析数小时的视频反馈。
3.4 内容审核
尽管以上讨论的技术类别在一定程度上是传统和长期存在的,但“内容审核”是一个近年来才出现的类别,并且随着对虚假信息和有害语言使用问题的关注增加,预计将会增长。
Fairwords(成立于 2014 年;A 轮融资,530 万美元,2022 年 2 月)使用类似拼写检查的界面,提醒用户在输入时有害语言,并提供该语言可能被解释的信息;该软件还可以检测贿赂和腐败、串通及歧视的迹象;mpathic(成立于 2021 年;种子轮融资,400 万美元,2022 年 6 月)类似地帮助员工识别沟通中的潜在误解或曲解,并实时调整;Checkstep(成立于 2020 年;种子轮融资,500 万美元,2022 年 5 月)专注于虚假信息、仇恨言论、儿童性虐待材料(CSAM)、欺凌和垃圾邮件,同时具有版权侵权管理功能;Areto Labs(成立于 2020 年;前种子轮融资,73 万美元,2022 年 6 月)帮助公司识别和监控在线滥用,并通过自动化反制措施,如静音、封锁和举报负责的账户,处理这些问题;Modulate(成立于 2017 年;A 轮融资,3000 万美元,2022 年 8 月)是 ToxMod 的开发者,这是一种用于实时视频游戏语音聊天中检测和处理暴力或其他冒犯性言论的工具。Diversio(成立于 2018 年;A 轮融资,600 万美元,2022 年 1 月)衡量和跟踪关于多样性、公平性和包容性的语言,识别员工编写文本中的“包容性痛点”。
VineSight(成立于 2018 年;种子轮融资,400 万美元,2022 年 9 月)跟踪、分析并减轻针对品牌、活动和事业的在线虚假信息和毒性;Alethea(成立于 2019 年;A 轮融资,1000 万美元,2022 年 11 月)检测和减轻虚假信息和社交媒体操控的实例;Logically(成立于 2017 年;A 轮融资,2400 万美元,2022 年 3 月)将人工智能与专家分析师结合,发现、筛选和应对信息威胁;Pendulum(成立于 2021 年;种子轮融资,590 万美元,2022 年 1 月)的平台利用“叙事跟踪”在多种媒体中揭示叙事形成初期的威胁和机会,并跟踪其在网上传播的情况。
相关领域之一是隐私管理:Redactable(成立于 2018 年;种子轮,120 万美元,2022 年 5 月)和Private AI(成立于 2019 年;A 轮,800 万美元,2022 年 11 月)自动检测文档中的个人可识别信息(PII)并进行删除;Lightbeam.ai(成立于 2020 年;种子轮,450 万美元,2022 年 4 月)尝试识别信息所属的具体客户或身份,以便安全团队可以更有效地自动化保护这些数据;Protopia AI(成立于 2020 年;种子轮,200 万美元,2022 年 12 月)专注于数据在机器学习推理过程中使用时的风险,通过模糊化个人信息来避免信息被识别或泄露给未经授权的第三方。
另一个相关领域是风险管理。Shield(成立于 2018 年;A 轮,1500 万美元,2022 年 1 月)为合规团队提供了一个工作场所智能平台:其技术利用 NLP 来检测员工沟通渠道中的行为违规,如市场操控;Concentric AI(成立于 2018 年;A 轮,1450 万美元,2022 年 5 月)识别并分类敏感信息,通过一种叫做‘风险距离’的度量来评估风险并解决安全问题;VISO Trust(成立于 2020 年;A 轮,1100 万美元,2022 年 3 月)是一个安全尽职调查平台,通过使用文档启发式方法、NLP 和 ML 自动化编制第三方网络风险数据的过程。这些是公司内部关注的解决方案;另一方面,KYP(成立于 2021 年;种子轮,96 万美元,2022 年 10 月)是一个第三方风险情报平台,旨在提供业务所依赖的合作伙伴的完整情况。
3.5 文本生成
如果你错过了最近对生成性 AI 的强烈关注,尤其是大语言模型在文本预测中的应用,那你真是与世隔绝了。今年在这一领域最引人注目的初创公司是内容平台Jasper(成立于 2021 年;A 轮,1.25 亿美元,2022 年 10 月);这是我所知 2022 年最大的一次单笔 NLP 初创公司融资事件。此外,还有Regie.ai(成立于 2020 年;种子轮,480 万美元,2022 年 6 月),其 GPT-3 驱动的文案写作平台专注于销售和营销团队。
仍在吸引资金的解决方案中,有些似乎基于较旧的文本生成方法:Linguix(成立于 2018 年;Pre-seed 轮融资,100 万美元,2022 年 2 月)是一个写作助手,提供拼写和语法检查以及文本重写和各种评分指标;Magical(成立于 2020 年;A 轮融资,3500 万美元,2022 年 6 月)是一个类似文本扩展器的生产力工具,软件可以检测网页上的元素,并允许创建自定义缩写以移动相应的文本。QorusDocs(成立于 2012 年;风险投资轮融资,1000 万美元,2022 年 10 月)是一个基于云的提案管理软件,简化 RFP 响应并自动生成提案;该软件利用 NLP 技术通过从公司文档档案中选择最重要和相关的内容来简化 RFP 响应过程。
相关的还有Mintlify(成立于 2020 年;种子轮融资,280 万美元,2022 年 5 月),其平台读取代码并创建文档以解释代码,并检测用户如何与文档互动以提高其可读性;以及Findable(成立于 2020 年;种子轮融资,210 万美元,2022 年 6 月),其技术通过分析标题、图片和图纸来自动化建筑文档的组织。
3.6 机器翻译
Language I/O(成立于 2011 年;A 轮融资,650 万美元,2022 年 1 月)提供一个翻译平台,允许客户用超过 100 种语言提供实时客户支持;Viva Translate(成立于 2020 年;种子轮融资,400 万美元,2022 年 2 月)是一个跨语言翻译工具,专注于自由职业者与客户沟通中的翻译;Weglot(成立于 2016 年;A 轮融资,4800 万美元,2022 年 3 月)是一个无代码网站本地化技术提供商,其平台支持通过后期编辑功能进行人工优化;XL8(成立于 2019 年;Pre-Series A 轮融资,300 万美元,2022 年 7 月)提供优化的媒体内容机器翻译技术,包括合成配音或语音覆盖;以及WritePath(成立于 2009 年;种子轮融资,34 万美元,2022 年 12 月),是一个基于云的 B2B 翻译平台,针对商业、ESG 和投资者关系披露。
3.7 其他杂项应用
还有一些公司以不同方式处理自然语言文本输入,但这些公司并不完全符合上述已经扩展的类别。在文本到图像领域,有视觉艺术初创公司 Stability AI(成立于 2019 年;种子轮,1.07 亿美元,2022 年 10 月),该公司是 Stable Diffusion 的背后团队。Spiritt(成立于 2020 年;前种子轮,550 万美元,2022 年 7 月)将文本描述转化为应用,通过与聊天机器人的对话获取所需的信息。Zenlytic(成立于 2018 年;种子轮,540 万美元,2022 年 11 月)是一款无代码商业智能工具,提供自然语言界面。还有 Unlikely AI(成立于 2018 年;种子轮,2000 万美元,2022 年 9 月),他们以追求大型神经网络的替代方案为噱头,推出了他们的第一个产品——一个解决和解释隐晦填字谜的应用。
4. 对话 AI
4.1 开发平台
市场上似乎仍然有空间容纳新的自助式对话 AI 开发平台。其中一些平台专注于基于文本的聊天机器人开发:Druid(成立于 2018 年;A 轮,1500 万美元,2022 年 5 月)和 OpenDialog AI(成立于 2019 年;种子轮,480 万美元,2022 年 5 月)提供无代码聊天机器人创建平台;Zowie(成立于 2019 年;种子轮,500 万美元,2022 年 1 月)针对在线销售的企业,将无代码自动化能力与一套工具结合,允许客服人员提供个性化服务和产品推荐。
其他公司增加了语音功能:NLX(成立于 2018 年;种子轮,500 万美元,2022 年 1 月)和 Parloa(成立于 2017 年;种子轮,425 万美元,2022 年 5 月)提供无代码/低代码平台,用于自动化包括电话和聊天在内的全渠道客户服务,Flip CX(最初为 RedRoute;成立于 2017 年;种子轮,650 万美元,2022 年 2 月)强调能够处理语音电话的重要性,提供易于使用的配置工具,利用已经设计好的呼叫流程模式。
4.2 定制开发
也有不少新兴公司会利用他们自己的平台和工具集为你构建对话应用程序。Futr(成立于 2017 年;种子轮融资,250 万美元,2022 年 4 月)强调其平台支持所有社交渠道的多语言实时聊天;Tenyx(成立于 2021 年;种子轮融资,1500 万美元,2022 年 5 月)利用所谓的‘神经科学启发’人工智能构建基于语音的虚拟客服代理;Curious Thing(成立于 2018 年;种子轮融资,470 万美元,2022 年 5 月),其技术之前专注于人力资源相关的互动,现在转向提供更广泛的语音驱动对话人工智能解决方案,包括入站和出站电话;而Tymely(成立于 2020 年;种子轮融资,700 万美元,2022 年 9 月)则使用 AI-人类混合技术来自动化客户服务能力,每个机器生成的响应都由人工代理进行验证。
Chatdesk(成立于 2016 年;A 轮融资,700 万美元,2022 年 1 月)有一个有趣的模式:完全摒弃聊天机器人,它寻找、招聘和培训品牌的‘超级粉丝’成为‘Chatdesk 专家’,并在后台使用机器学习分析之前的支持消息,创建一个符合品牌的知识库,使这些超级粉丝能够以品牌的声音和政策回应客户问题。
4.3 对话智能
继续几年来一直可见的趋势,一些公司提供技术,对对话互动进行某种形式的分析,无论这些互动涉及虚拟代理还是人工代理。
Wiz.ai(成立于 2019 年;A 轮,2000 万美元,2022 年 1 月),专注于东南亚语言的对话 AI,使用前端对话机器人鼓励客户参与对话,同时后端实时筛选数据并将对话中的洞察存储到公司的现有 CRM 系统中以供后续分析;Talkmap(成立于 2017 年;A 轮,800 万美元,2022 年 2 月)对与客户的互动进行标记、结构化和分析,旨在提供接近实时的对话洞察;Affogata(成立于 2018 年;种子轮,950 万美元,2022 年 3 月)提供一个语音分析平台,允许企业识别异常模式,以简化实时响应并采取预防措施;Winn.AI(成立于 2021 年;种子轮,1700 万美元,2022 年 9 月)监控销售通话,自动跟踪、捕获和更新 CRM 条目,减少销售人员自行记笔记的需求;Operative Intelligence(成立于 2021 年;种子轮,350 万美元,2022 年 12 月)提供旨在帮助呼叫中心操作员克服对客户联系原因的误解的技术,通过识别真实原因来减少等待时间并改善问题解决。Jiminny(成立于 2016 年;A 轮,1700 万美元,2022 年 8 月)是一个对话智能平台,分析视频中的情绪,自动评分通话互动并生成实时洞察。
4.4 沟通技巧反馈
对人类代理对话贡献的分析,以提供关于沟通技巧的反馈,可以被视为一种特定形式的对话智能。
Abstrakt(成立于 2020 年;前种子轮,12 万美元,2022 年 3 月)提供实时电话辅导,监听通话并提出有用的建议;Klaus(成立于 2017 年;A 轮,1200 万美元,2022 年 9 月)通过跟踪各种沟通 KPI 来辅导代理,识别辅导机会并衡量支持质量。
Call Simulator(成立于 2021 年;种子轮,57.5 万美元,2022 年 1 月)是一个对话模拟平台,旨在为呼叫中心代理准备现实场景;Second Nature(成立于 2018 年;A 轮,1250 万美元,2022 年 1 月)提供一个模拟器,通过与销售代表对话的虚拟角色来测量代表们对关键话题的覆盖深度。
更广泛地说,Yoodli(成立于 2021 年;种子轮,600 万美元,2022 年 8 月)分析语音以提供改进沟通技能的建议:该平台为用户提供文字记录,并分析填充词的使用、非包容性语言、节奏、肢体语言和其他可操作的见解。该公司最近与 Toastmasters International 达成协议,为其提供演讲辅导,这是一个知名的公众演讲和领导力培训组织。
4.5 销售支持
还有许多公司提供各种形式的我们在这里称之为销售支持的服务。Tactic(成立于 2020 年;种子轮,450 万美元,2022 年 3 月)通过允许销售和营销人员用普通语言询问客户和市场数据,并应用过滤器以优先排序和排名结果来自动化客户和市场研究;Connectly.ai(成立于 2020 年;种子轮,金额未公开,2022 年 7 月)是一个无需编码的工具,允许企业通过 AI 驱动的“小型机器人”创建和发送互动和个性化的营销活动;Demoleap(成立于 2020 年;种子轮,440 万美元,2022 年 8 月)是一个现场演示助手和销售发现平台,指导销售人员在现场演示过程中遵循销售流程;Heyday(成立于 2021 年;种子轮,650 万美元,2022 年 6 月)是一个用于零售商的对话 AI 平台,自动化 FAQ;AdTonos(成立于 2016 年;种子轮,210 万美元,2022 年 8 月)通过其 YoursTruly 平台通过智能音响和移动设备播放互动广告来货币化音频流。
4.6 会议生产力工具
由于 Covid 驱动的虚拟会议平台(如 Zoom 和 Teams)的使用增加,出现了一个相对较新的工具类别市场,这些工具旨在支持会议生产力;在许多方面,这些工具是对在对话智能背景下开发的工具和技术的重新利用。
Sembly AI(成立于 2019 年;种子轮,金额未公开,2022 年 3 月)、Headroom(成立于 2020 年;种子轮,900 万美元,2022 年 8 月)、Xembly(成立于 2020 年;A 轮,1500 万美元,2022 年 10 月)、Fathom(成立于 2020 年;种子轮,470 万美元,2022 年 11 月)和 tl;dv(成立于 2020 年;种子轮,460 万美元,2022 年 6 月)都提供一些功能组合,用于转录和分析会议,提取主题和行动项目,以及生成摘要和会议记录。
Airgram(成立于 2020 年;A 轮融资,1000 万美元,2022 年 8 月)是一款音视频录制工具,可以设置为自动加入预定的 Zoom、Google Meet 或 Microsoft Teams 会议,在用户不在场时进行录制;该工具提供灵活的播放选项,并配有转录、话题检测和行动项识别功能;Amy(成立于 2019 年;种子轮融资,600 万美元,2022 年 6 月)是一个销售智能平台,旨在通过利用公开的潜在客户信息来简化会议准备,将这些数据转化为会议简报,提供对潜在客户的有价值洞察。
5.2 音视频处理
我们引入这一类别以涵盖语音技术除支持对话式人工智能之外的应用,同时也包括与视频结合使用的情况。
5.1 语音处理
NeuralSpace(成立于 2019 年;种子轮融资,170 万美元,2022 年 2 月)专注于低资源语言的语音技术开发,提供覆盖 90 多种语言的自助工具包,并包括自动语言检测;Ava(成立于 2014 年;A 轮融资,1000 万美元,2022 年 3 月)是一款实时字幕平台,能够在会议或视频中听取音频,为听障人士提供字幕,并标记每条字幕的发言者;Sounder(成立于 2019 年;A 轮融资,770 万美元,2022 年 2 月)是一款端到端的播客管理平台,涵盖品牌安全和品牌适宜性分析、话题分析、内容总结和动态分段;AssemblyAI(成立于 2017 年;A 轮融资,2800 万美元,2022 年 3 月)提供一组基于 LLM 的“音频智能”API,用于转录和理解音频数据,应用包括内容审核、情感检测、总结和个人信息遮盖。
Sanas(成立于 2020 年;A 轮融资,3200 万美元,2022 年 6 月)提供实时口音翻译,帮助多语言用户通过口音矫正实现清晰沟通;Namecoach(成立于 2014 年;A 轮融资,800 万美元,2022 年 11 月)提供嵌入上下文感知音频姓名发音按钮的软件,使用户能够自信地发音。
5.3 语音合成
Murf AI(成立于 2020 年;A 轮融资,1000 万美元,2022 年 9 月)是一家合成语音技术初创公司,开发逼真的 AI 语音用于播客、幻灯片演示和专业演讲,拥有 120 多种语言的精选语音库。在具体应用层面,ping(成立于 2016 年;种子轮融资,500 万美元,2022 年 6 月)允许商业司机听到他们的智能手机消息和电子邮件以超过 105 种语言朗读。
语音合成的一大用途是在其他语言中进行音频配音。Dubverse(成立于 2021 年;种子轮,80 万美元,2022 年 6 月)是一个自动化配音平台,允许用户几乎实时地将视频配音成多种语言,目前支持 10 种印度语言和 20 种“全球”语言;Dubdub(成立于 2021 年;种子轮,100 万美元,2022 年 9 月)使用人工智能和机器学习为企业创建多语言视频内容,覆盖 40 种语言;Deepdub(成立于 2019 年;A 轮,2000 万美元,2022 年 2 月)提供娱乐内容的配音服务,使用合成的原演员声音版本,使配音版本听起来更像原版;Papercup(成立于 2017 年;A 轮,2000 万美元,2022 年 6 月)类似地通过生成听起来像原讲者的声音来翻译视频。这些应用通常提供一个人工环节功能,专业翻译人员可以执行质量检查,编辑和修订翻译及语音,以提高质量。
5.3 视频合成
我们在此包含了那些专注于视频输出创作的公司,因为这些公司通常也涉及语音合成。
Pictory(成立于 2019 年;种子轮,210 万美元,2022 年 1 月)将长形式内容如网络研讨会、博客和白皮书转换为短社交视频;ShortTok(成立于 2021 年;前种子轮,未披露金额,2022 年 10 月)开发自动化视觉讲故事技术,从客户的视频和多模态内容库中创建短视频;Peech(成立于 2020 年;种子轮,830 万美元,2022 年 8 月)提供一个视频编辑工具,专为内容营销团队设计,可以自动合成与内容匹配的品牌视觉,并去除填充词;Rephrase.ai(成立于 2019 年;A 轮,1060 万美元,2022 年 9 月)也为营销和内容团队构建生成式人工智能工具,用于合成视频制作。
一种特定形式的视频合成是虚拟角色的生成。Metaphysic(成立于 2021 年;种子轮,750 万美元,2022 年 1 月),这家公司以其汤姆·克鲁斯深度伪造而闻名,开发用于创建可以融入元宇宙的数字头像的工具;Inworld AI(成立于 2021 年;种子轮,1250 万美元,2022 年 3 月)是另一个创建人工智能驱动的虚拟角色、沉浸式现实和元宇宙空间的平台,使非技术用户能够通过自然语言描述来创建角色个性;Deep Voodoo(成立于 2020 年;种子轮,2000 万美元,2022 年 12 月)是由《南方公园》创作者特雷·帕克和马特·斯通创办的深度伪造初创公司。
Speech Graphics(成立于 2010 年;A 轮,700 万美元,2022 年 2 月)提供基于音频的面部动画技术,使游戏和其他应用中的动画角色在讲话时能够正确地移动嘴巴;Hour One(成立于 2019 年;A 轮,2000 万美元,2022 年 4 月)的技术将人类转化为虚拟人类角色,这些角色可以以逼真的表现力被激活。Carter(成立于 2022 年;种子轮,200 万美元,2022 年 12 月)正在研发对话式 AI,以帮助游戏开发者使计算机化的游戏角色更具生动性。NeuralGarage(成立于 2021 年;种子轮,150 万美元,2022 年 11 月)是一个视频配音平台:给定音频输入和人脸,它会将人的唇部和下巴动作转化为匹配的语言,无论语言是什么。
6. 领域特定解决方案
6.1 法律技术
法律与语言密切相关,因此法律技术长期以来一直是语言处理技术应用的重要领域。
一个受欢迎的领域是文档分析和审查,其中 AI 支持的分析可以减少传统手动处理所需的大量时间。TermScout(成立于 2018 年;种子轮,500 万美元,2022 年 5 月)从合同中提取关键信息,以便于审查、评级和与行业标准的比较;Terzo(成立于 2020 年;A 轮,1630 万美元,2022 年 11 月)从合同中提取关键数据,帮助组织优化其供应商和客户关系中的支出和收入;Nammu21(成立于 2017 年;A 轮,1580 万美元,2022 年 10 月)将贷款文件拆解成结构化数据;Summize(成立于 2018 年;A 轮,600 万美元,2022 年 10 月)是一种合同审查解决方案,旨在通过与 Teams、MS Word 和 Slack 的集成来改善内部法律部门与业务用户之间的协作;以及 Della(成立于 2018 年;种子轮,250 万美元,2022 年 3 月)专注于复杂的单一文档,而不是大型文档审查项目。Zero(成立于 2014 年;A 轮,1200 万美元,2022 年 3 月)是基于 iOS 移动设备的生产力工具,集成了电子邮件收件箱和文档管理系统,提取关键信息,如可计费的交互,并自动将电子邮件归档到文件夹中。
另一个热门领域是提供法律文件起草支持。Henchman(成立于 2020 年;种子轮,320 万美元,2022 年 2 月)是一个合同起草初创公司,提供一个 Microsoft Word 插件,在你工作时从公司的数据库中建议条款;LexCheck(成立于 2015 年;种子轮,500 万美元,2022 年 3 月)提供一个合同谈判解决方案,分析合同以建立问题清单和合同语言修订;Harvey(成立于 2022 年;种子轮,500 万美元,2022 年 11 月)使用 GPT-3 根据任务描述为律师起草文档;该应用还可以回答法律问题。
许多公司将这些审查和起草功能与其他活动结合起来,以提供更全面的法律自动化平台。Uhura Solutions(成立于 2018 年;种子轮,180 万美元,2022 年 4 月)是一个低代码合同智能平台,使用 NLP 来简化合同和协议的分析及起草过程;Goodlegal(成立于 2021 年;前种子轮,130 万美元,2022 年 11 月)提供一套自动化工具,包括一个用于构建法律文本的拖放编辑器,并能够检查每个法律文本是否符合合法标准;PocketLaw(成立于 2018 年;A 轮,1060 万美元,2022 年 5 月)是一个主要面向中小企业的合同自动化 SaaS 法律技术平台;Klarity(成立于 2017 年;A 轮,1800 万美元,2022 年 1 月)为财务和会计团队提供自动化文档处理和管理平台;Josef(成立于 2017 年;种子轮,520 万美元,2022 年 11 月)是一个无代码软件平台,允许法律专业人士自动化重复任务,包括文档起草、提供法律指导和建议,并构建客户访谈的机器人。Legal OS(成立于 2018 年;种子轮,700 万美元,2022 年 1 月)是一个无代码法律自动化平台,将专家知识转化为数字知识图谱,之后可以用来构建各种法律产品和流程。
还有一些法律科技解决方案不完全符合上述类别。Alchemy Machines(成立于 2021 年;种子轮,40 万美元,2022 年 3 月)使用 NLP 和语音识别转录、分析和总结法律特定的网络会议和电话;Neur.on(成立于 2022 年;种子轮,170 万美元,2022 年 8 月)为法律专业人士提供定制的机器翻译解决方案;Ex Parte(成立于 2017 年;A 轮,750 万美元,2022 年 2 月)使用机器学习预测诉讼结果,推荐客户可以采取的行动以优化胜诉机会;而Proof Technology(成立于 2017 年;A 轮,550 万美元,2022 年 3 月)是一个相当独特的端到端解决方案,分析法院文件以提取案件标题信息,确定离被告或证人地址最近的送达人员,远程打印相关材料,并捕捉有关送达尝试的照片和描述数据。
6.2 健康科技
另一个与 NLP 有长期关系的领域是健康科技。这里的两个关键领域是医疗环境中对话式 AI 的使用以及医疗记录的处理。
在对话式 AI 方面,HeyRenee(成立于 2021 年;种子轮,440 万美元,2022 年 1 月)是一个以患者为中心的个人健康助理,可以提醒用户需要服用的药物,监测健康指标,处理处方续药,并安排与医生的虚拟或面对面访谈;Apowiser(成立于 2021 年;种子轮,150 万美元,2022 年 6 月)制作了 PharmAssist,一个基于聊天机器人的系统,用于支持客户在线购买非处方药,识别需要升级到医疗服务提供者的问题,以及检查对 OTC 药物成分的过敏和潜在敏感性;BirchAI(成立于 2020 年;种子轮,310 万美元,2022 年 1 月)旨在通过总结和分析客户与代表之间电话交谈的内容,简化医疗公司的客户支持;WhizAI(成立于 2017 年;A 轮,800 万美元,2022 年 9 月)提供了一个面向生命科学和医疗行业的分析平台的对话接口;而Kahun(成立于 2018 年;种子轮,800 万美元,2022 年 9 月)开发了一个临床评估聊天机器人,基于公司超过 3000 万条证据基础的医学见解地图。
关于医疗记录处理,DigitalOwl(成立于 2017 年;A 轮融资,2000 万美元,2022 年 1 月)提供一个医疗记录分析平台,能够从大量文档中提取相关信息;Dyania Health(成立于 2019 年;种子轮融资,530 万美元,2022 年 9 月)提供一个 NLP 平台,执行疾病专用的临床文本提取;Wisedocs(成立于 2018 年;种子轮融资,300 万美元,2022 年 3 月)使用智能字符识别技术读取和分析各种医疗记录审查相关文档;XpertDox(成立于 2015 年;种子轮融资,150 万美元,2022 年 8 月)开发了 XpertCoding 工具,该工具利用 AI 自动编码医疗索赔。DeepScribe(成立于 2017 年;A 轮融资,3000 万美元,2022 年 1 月)是一种环境医疗抄写员,记录医生与患者的对话,汇总并将其整合到健康记录系统中;Abridge(成立于 2018 年;A 轮融资,1250 万美元,2022 年 8 月)是一家对话 AI 初创公司,结构化并总结医生和患者的医疗对话,帮助填充健康记录中的相关信息;Eleos Health(成立于 2019 年;A 轮融资,2000 万美元,2022 年 4 月)构建了在行为健康临床医师与患者对话背景中环境运行的临床应用,生成会后临床进展记录和保险编码。
最后,一些不符合上述类别的健康科技初创公司:Kintsugi(成立于 2019 年;A 轮融资,2000 万美元,2022 年 2 月)利用机器学习和声音生物标志物检测临床抑郁症和焦虑的迹象;Marigold Health(成立于 2016 年;种子轮融资,600 万美元,2022 年 2 月)通过聊天支持小组帮助从物质使用或心理健康状况中恢复的个人,NLP 辅助同行管理他们的在线社区;以及 WeWalk(成立于 2019 年;资助,200 万美元,2022 年 7 月)是一家为视障人士开发智能手杖的初创公司:其语音助手可以回答有关用户位置、附近公共交通、识别附近建筑物和地标、预约 Uber,并提供适合视力有限或无视力者的实时步行导航。
6.3 其他领域
第三个领域是教育技术。FoondaMate(成立于 2020 年;种子轮融资,200 万美元,2022 年 5 月)是一个聊天机器人,通过 Facebook 和 WhatsApp 让发展中国家的学生可以提问,从而使教育变得更加可及; Prof Jim(成立于 2020 年;种子轮融资,110 万美元,2022 年 1 月)与教科书出版商和教育提供商合作,将教科书和其他文本学习材料转化为在线课程,包括自动生成的评估和头像讲师; Language Confidence(成立于 2016 年;种子轮融资,150 万美元,2022 年 3 月)提供一个 API,监听学生并评估和纠正他们的英语发音,提供视觉反馈; Copyleaks(成立于 2015 年;A 轮融资,600 万美元,2022 年 5 月)是一个抄袭检测解决方案,能够识别和跟踪 100 多种语言的在线抄袭内容。
还有一系列其他针对不同领域的应用:
-
金融服务: Aviva(成立于 2022 年;种子轮融资,220 万美元,2022 年 12 月)使用自然语言处理将客户的口语与实时信用申请中的字段匹配; Webio(成立于 2016 年;A 轮融资,400 万美元,2022 年 6 月)为信用、催收和支付业务提供无代码对话式人工智能平台,允许客户提问、改变付款日期或安排新的还款计划。
-
房地产:DOSS(成立于 2015 年;种子轮融资,金额未公开,2022 年 10 月)提供一个对话助手,允许客户咨询房地产建议和提示,搜索房源,并获取邻里信息和近期销售数据。
-
DevOps: Kubiya(成立于 2022 年;种子轮融资,600 万美元,2022 年 10 月)为 DevOps 团队提供对话式人工智能解决方案,允许用户用自然语言表达意图,并让虚拟助手自动化简单和繁琐的任务。
-
无桌面工作环境: Datch(成立于 2018 年;A 轮融资,1000 万美元,2022 年 7 月)在工业环境中作为智能语音接口运作。
-
零售:Evabot(成立于 2016 年;A 轮融资,830 万美元,2022 年 7 月)为企业礼品提供创意,通过聊天机器人管理的问卷建议最适合用户客户的礼物;它还利用 GPT-3 为每个礼物撰写个性化的‘手写’笔记。
-
餐馆:Valyant AI(成立于 2017 年;种子轮,400 万美元,2022 年 4 月)开发了一个用于餐馆、零售和服务行业的专有对话 AI 平台;ConverseNow(成立于 2018 年;A 轮融资,1000 万美元,2022 年 8 月)提供了一个对话平台,用于餐馆自动化从高容量语音渠道中接单的过程。
-
儿童:Snorble(成立于 2019 年;种子轮,1000 万美元,2022 年 4 月)制造了一款儿童就寝机器人,配备了可以讲故事、带孩子进行呼吸练习,并播放伴有灯光秀的舒缓音乐的语音驱动助手。
7. 总结
所以你可以看到:2022 年有 173 家公司获得了用于利用 NLP 技术的工具和应用程序的启动资金,总投资额刚刚超过 18 亿美元。表 1 展示了根据这里用来结构化领域的类别进行的投资细分,但请记住第二部分中关于覆盖范围和分类的各种警告。最好的情况是,我们可以将这一区分视为大致指示活动所在的地方。

对我来说,有几个点特别引人注目。以下是我从这次活动中总结出的十大要点。
-
尽管谷歌在搜索领域几乎垄断——通常报道显示其占有超过 80%的搜索引擎使用率——投资者仍然认为搜索领域值得投入资金。这里的大部分活动并不直接与谷歌竞争,而是更多地面向企业搜索和其他特定用途,但正当这篇文章撰写时,据报道谷歌的管理层已宣布‘红色警戒’,以应对 OpenAI 的 ChatGPT 问答聊天机器人的出现,以及担心这种方法可能会重新发明或取代传统的互联网搜索引擎。值得注意的是,You.com 迅速将类似 ChatGPT 的模型和界面集成到其搜索引擎中,Perplexity.ai和Neeva也在尝试将传统搜索与 LLM 结合起来。
-
文档 AI 似乎因深度学习技术的应用而经历了近期的复兴;越来越多的应用表明,文档处理领域的实际解决方案不能仅限于无实体的文本,而必须采取“整体文档”立场,以产生价值。我怀疑我们会看到智能字符识别与基于大型语言模型的文本处理的进一步进展,尽管目前还处于初期阶段:我今年早些时候有机会尝试了多种文档 AI 产品,但对它们在从被认为相当简单的表格中可靠提取信息的困难感到失望。
-
广义上的情感分析关注的是语言使用的实用方面。我们已经从早期仅仅确定电影评论或产品推荐的极性中走了很远,情感分析技术的变体在两个关键领域引起了显著关注,这两个领域在十年前无人察觉:沟通效果分析(无论是在销售电话还是会议场合中),以及内容审核。特别是后者在面对社交媒体平台的分裂性和恶意性,以及像欧洲数字服务法这样的法规影响时,似乎充满了增长的潜力。
-
文本生成的商业应用正处于剧烈的范式转变的边缘,过去十年中以模板为基础的技术相比于最近在大型语言模型基础上的文本生成技术显得如此平凡,以至于它们现在难以被认为是 AI 的一部分。这些早期的方法在可预见的未来仍将发挥作用,但它们正越来越远离前沿。当然,我们仍然需要克服大型语言模型不是可靠真相来源的问题。
-
机器翻译感觉上像是一个基本解决的问题,或者至少是一个在投资前值得再三考虑的问题。总是有改进的空间,但这些改进可能来自于谷歌和微软等大型公司之间的竞争;从投资者的角度来看,未来在于与其他技术的有趣配置功能的打包,或者解决有趣且创新的用例。
-
对话 AI 通常是一个令我困惑的领域:这是一个非常密集的空间,往往很难看出任何给定公司的独特卖点。我不愿意在这个领域寻找开发工具或应用程序开发人员,我也很难理解这里的投资决策动机。也许像 ChatGPT 这样的技术会在这个领域带来变化,尽管再次提到的关于需要说实话的棘手警告仍然存在。就目前而言,我认为这里的创新发展空间在于对话分析,以服务于目标,比如识别问题、沟通技能培训以及我们尚未想到的其他用途。
-
关于 Covid 没有什么积极的说法,但它确实推动了在线会议技术应用程序的发展,如 Zoom、Microsoft Teams 和 Google Meet;这反过来又开辟了一个全新的技术领域,即会议生产力工具。如上所述,这些工具通常是为对话智能开发的多方变体,但鉴于其处理的内容性质——我们可能称之为“长篇对话”——它提供了利用几乎所有类型的 NLP 技术的机会。我认为这是一个值得密切关注的领域。
-
与几年前相比,语音合成现在达到了非常高的标准,我认为这是一个我们只能期待逐步改进的领域。现在语音配音已经成为了一个重点,尤其是在与视频中的合成唇动相结合时;例如 Netflix 的整个目录中逼真的视听翻译潜力巨大。
-
法律科技和健康科技一直是 NLP 的关键应用领域,并且可能会继续如此。值得注意的是——从我来看,这有点令人担忧——LLMs 正在进入法律科技领域,健康科技也肯定会跟随。我不想听起来像是老生常谈,但如果要出现问题,这就是问题显现的地方:疲惫或不专注的人类编辑可能会在 LLM 起草的合同中漏掉严重的不实信息,导致昂贵的修正,或者——更糟糕——在健康报告中,导致伤害甚至生命丧失。我们可能会看到支持者争辩,类似于自动驾驶汽车的主张,这些 LLMs 的使用在这些背景下总体上减少了错误和损害。
-
教育部门将如何应对大型语言模型?ChatGPT 引发了关于“大学论文终结”的媒体广泛报道,担心代写服务将变得对即使是最贫困的学生也极为容易获得;就在这篇文章撰写时,媒体纷纷报道了一位南卡罗来纳州教授发现一名学生使用该应用写哲学论文的事件。这将值得关注:技术要么朝着解决传统教育关切的方向发展,要么传统教育评估实践将不得不进行根本性的改变。
总体而言,2022 年引入了一些引人入胜的技术和解决方案。随着 GPT-4 的到来,2023 年有望成为更有趣的一年。
如果你想跟上商业 NLP 世界的最新动态,可以考虑订阅免费的This Week in NLP 新闻通讯,网址是 www.languagetechnology.com/twin。
使用 Python 进行 NLP:知识图谱
原文:
towardsdatascience.com/nlp-with-python-knowledge-graph-12b93146a458

作者提供的图片
SpaCy、句子分割、词性标注、Dependency parsing、命名实体识别等……
 [外链图片转存中…(img-5ceeDXkQ-1726872521027)] Mauro Di Pietro
[外链图片转存中…(img-5ceeDXkQ-1726872521027)] Mauro Di Pietro
·发表于Towards Data Science ·14 分钟阅读·2023 年 4 月 19 日
–
摘要
在这篇文章中,我将展示如何使用 Python 和自然语言处理构建知识图谱。

照片由Moritz Kindler提供,Unsplash
网络图是一种数学结构,用于展示点之间的关系,可以通过无向图/有向图结构进行可视化。这是一种映射连接节点的数据库形式。
知识库是来自不同来源的信息的统一存储库,如维基百科。
知识图谱是一种使用图结构数据模型的知识库。简单来说,它是一种网络图,展示了现实世界实体、事实、概念和事件之间的定性关系。“知识图谱”一词首次由谷歌在 2012 年使用,以介绍他们的模型。
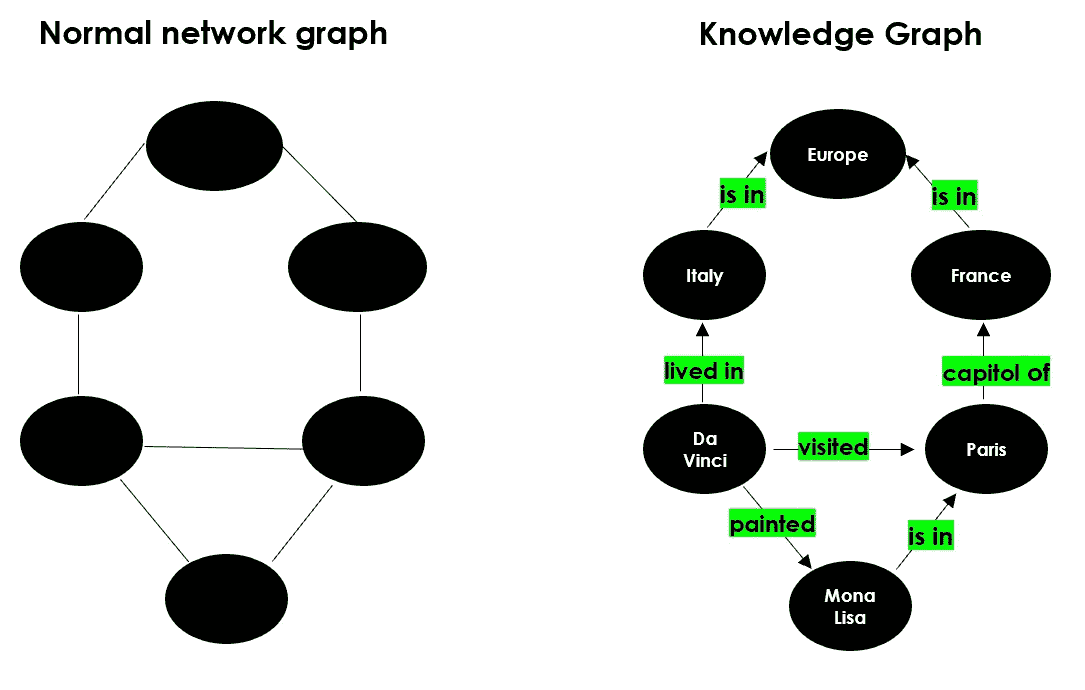
作者提供的图片
目前,大多数公司正在构建数据湖,这是一个中央数据库,用于存储从不同来源获取的各种原始数据(即结构化和非结构化数据)。因此,人们需要工具来理解这些不同信息片段。知识图谱变得越来越流行,因为它们可以简化对大型数据集的探索和洞察发现。换句话说,知识图谱将数据和相关的元数据连接起来,因此可以用来构建组织信息资产的全面表示。例如,知识图谱可以替代你需要浏览的所有文档堆,以便找到某一特定信息。
知识图谱被认为是自然语言处理领域的一部分,因为为了构建“知识”,必须经过一个叫做“语义丰富化”的过程。由于没有人愿意手动执行这个过程,我们需要机器和 NLP 算法来为我们完成这项任务。
我将展示一些有用的 Python 代码,这些代码可以轻松地应用于其他类似的情况(只需复制、粘贴、运行),并逐行讲解代码的注释,以便你可以复制这个示例(完整代码的链接如下)。
## DataScience_ArtificialIntelligence_Utils/example_knowledge_graph.ipynb at master ·…
你现在无法执行该操作。你在另一个标签页或窗口中登录了。在另一个标签页中注销了…
我将解析维基百科并提取一个页面,该页面将用作本教程的数据集(链接如下)。
俄乌战争是俄罗斯及其支持的分裂主义者之间正在进行的国际冲突…
具体来说,我将介绍:
-
设置:通过Wikipedia-API读取数据和数据包。
-
使用SpaCy进行 NLP:句子分割、词性标注、依存句法分析、命名实体识别。
-
使用Textacy提取实体及其关系。
-
带有NetworkX的网络图构建。
-
带有DateParser的时间线图。
设置
首先,我需要导入以下库:
## for data
import pandas as pd #1.1.5
import numpy as np #1.21.0
## for plotting
import matplotlib.pyplot as plt #3.3.2
## for text
import wikipediaapi #0.5.8
import nltk #3.8.1
import re
## for nlp
import spacy #3.5.0
from spacy import displacy
import textacy #0.12.0
## for graph
import networkx as nx #3.0 (also pygraphviz==1.10)
## for timeline
import dateparser #1.1.7
Wikipedia-api 是一个 Python 包装器,可以轻松解析 Wikipedia 页面。我将提取我需要的页面,排除页面底部的所有“注释”和“参考书目”:

来源于 Wikipedia
我们可以简单地写出页面的名称:
topic = "Russo-Ukrainian War"
wiki = wikipediaapi.Wikipedia('en')
page = wiki.page(topic)
txt = page.text[:page.text.find("See also")]
txt[0:500] + " ..."

在这个用例中,我将尝试通过识别和提取文本中的主题-动作-对象(因此动作即为关系)来映射历史事件。
NLP
为了构建知识图谱,我们首先需要识别实体及其关系。因此,我们需要使用 NLP 技术处理文本数据集。
当前,用于此类任务的最常用库是 SpaCy,这是一个用于高级 NLP 的开源软件,利用 Cython (C+Python)。SpaCy 使用预训练的语言模型将文本分词,并将其转换为一个通常称为 “document” 的对象,基本上是一个包含模型预测的所有注释的类。
#python -m spacy download en_core_web_sm
nlp = spacy.load("en_core_web_sm")
doc = nlp(txt)
NLP 模型的第一个输出是 句子分割:确定一个句子开始和结束的位置的问题。通常,通过基于标点符号拆分段落来完成。让我们看看 SpaCy 将文本拆分成了多少个句子:
# from text to a list of sentences
lst_docs = [sent for sent in doc.sents]
print("tot sentences:", len(lst_docs))

作者提供的图片
现在,对于每个句子,我们将提取实体及其关系。为此,我们首先需要理解 词性标注 (POS tagging): 将句子中的每个单词标记上适当的语法标签的过程。以下是可能的标签的完整列表(截至今天):
ADJ: 形容词,例如 big, old, green, incomprehensible, first
ADP: 介词(前置词/后置词)例如 in, to, during
ADV: 副词,例如 very, tomorrow, down, where, there
AUX: 助动词,例如 is, has (done), will (do), should (do)
CONJ: 连词,例如 and, or, but
CCONJ: 并列连词,例如 and, or, but
DET: 限定词,例如 a, an, the
INTJ: 感叹词,例如 psst, ouch, bravo, hello
NOUN: 名词,例如 girl, cat, tree, air, beauty
NUM: 数字,例如 1, 2017, one, seventy-seven, IV, MMXIV
PART: 语气词,例如 ‘s, not
PRON: 代词,例如 I, you, he, she, myself, themselves, somebody
PROPN: 专有名词,例如 Mary, John, London, NATO, HBO
PUNCT: 标点符号,例如 ., (, ), ?
SCONJ: 从属连词,例如 if, while, that
SYM: 符号,例如 $, %, §, ©, +, −, ×, ÷, =, 😃, 表情符号
VERB: 动词,例如 run, runs, running, eat, ate, eating
X: 其他,例如 sfpksdpsxmsa
SPACE: 空格,例如
仅仅进行词性标注是不够的,模型还试图理解词对之间的关系。这项任务称为 依存句法分析。以下是所有可能的标记列表(截至今天):
从句修饰名词: clausal modifier of noun
形容词补足语: adjectival complement
副词从句修饰语: adverbial clause modifier
副词修饰语: adverbial modifier
施事者: agent
形容词修饰语: adjectival modifier
同位修饰语: appositional modifier
属性: attribute
辅助词: auxiliary
辅助动词(被动): auxiliary (passive)
格标记: case marker
并列连词: coordinating conjunction
从句补足语: clausal complement
复合修饰语: compound modifier
连接词: conjunct
从句主语: clausal subject
从句主语(被动): clausal subject (passive)
与格: dative
依存词: unclassified dependent
限定词: determiner
直接宾语: direct object
虚词: expletive
感叹词: interjection
标记: marker
元修饰语: meta modifier
否定修饰语: negation modifier
名词修饰语: modifier of nominal
名词短语作为副词修饰语: noun phrase as adverbial modifier
名词主语: nominal subject
名词主语(被动): nominal subject (passive)
数量修饰语: number modifier
对象谓词: object predicate
并列语法: parataxis
介词补足语: complement of preposition
介词宾语: object of preposition
所有格修饰语: possession modifier
前关联连词: pre-correlative conjunction
前限定词: pre-determiner
介词修饰语: prepositional modifier
词素: particle
标点: punctuation
数量词修饰语: modifier of quantifier
关系从句修饰语: relative clause modifier
根: root
开放从句补足语: open clausal complement
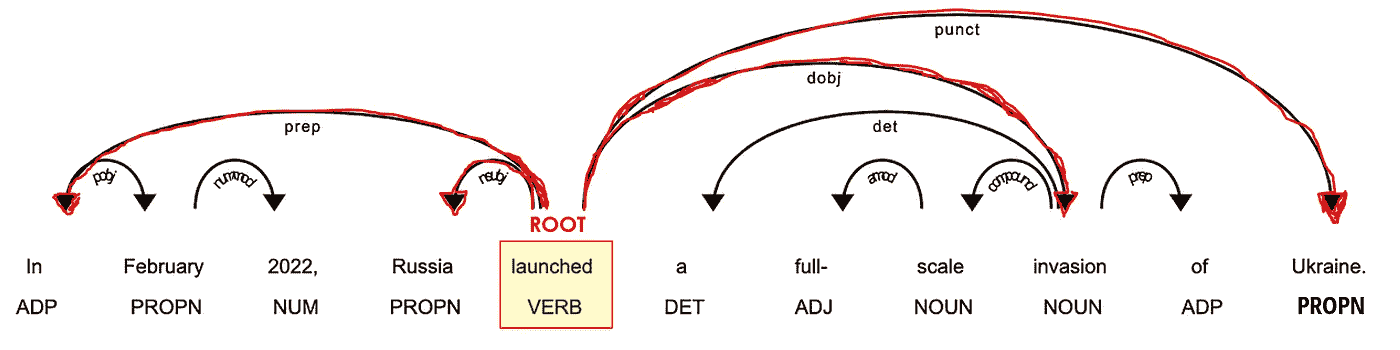
让我们举个例子来理解词性标注和依存句法分析:
# take a sentence
i = 3
lst_docs[i]

让我们检查一下 NLP 模型预测的词性和依存标记:
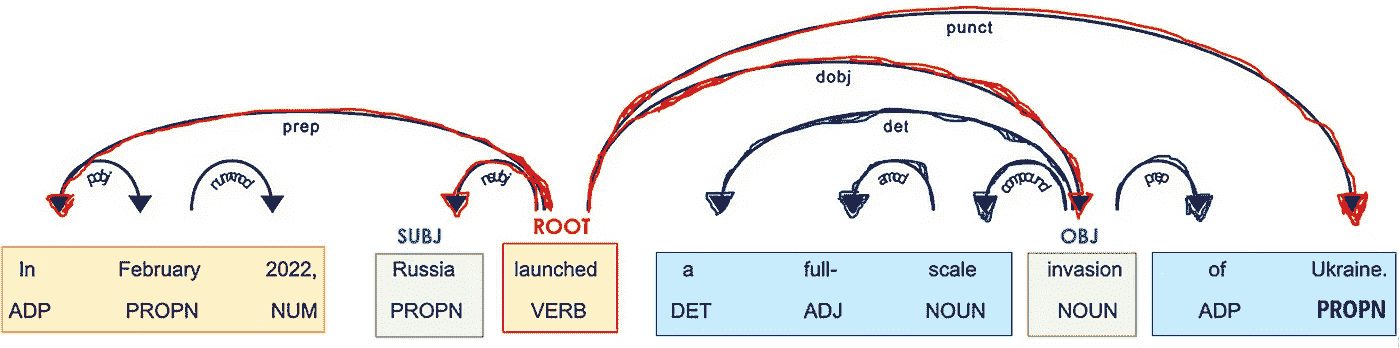
for token in lst_docs[i]:
print(token.text, "-->", "pos: "+token.pos_, "|", "dep: "+token.dep_, "")

作者提供的图片
SpaCy 还提供了一个 图形工具 来可视化这些标注:
from spacy import displacy
displacy.render(lst_docs[i], style="dep", options={"distance":100})

作者提供的图片
最重要的词素是动词(POS=VERB),因为它是句子意义的根源(DEP=ROOT)。
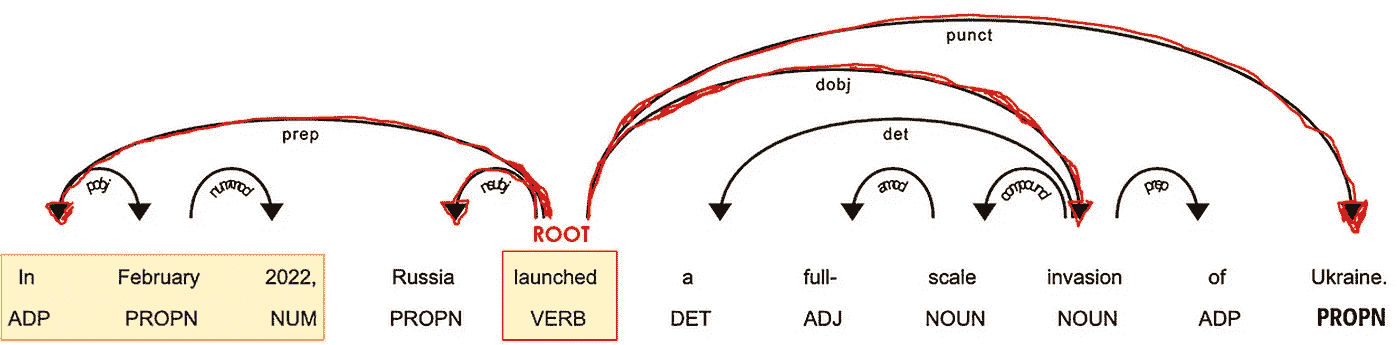
作者提供的图片
辅助粒子,例如副词和介词(POS=ADV/ADP),通常作为修饰语与动词相连(*DEP=mod),因为它们可以修饰动词的意义。例如,“travel to” 和 “travel from” 尽管根词相同(“travel”),却有不同的含义。
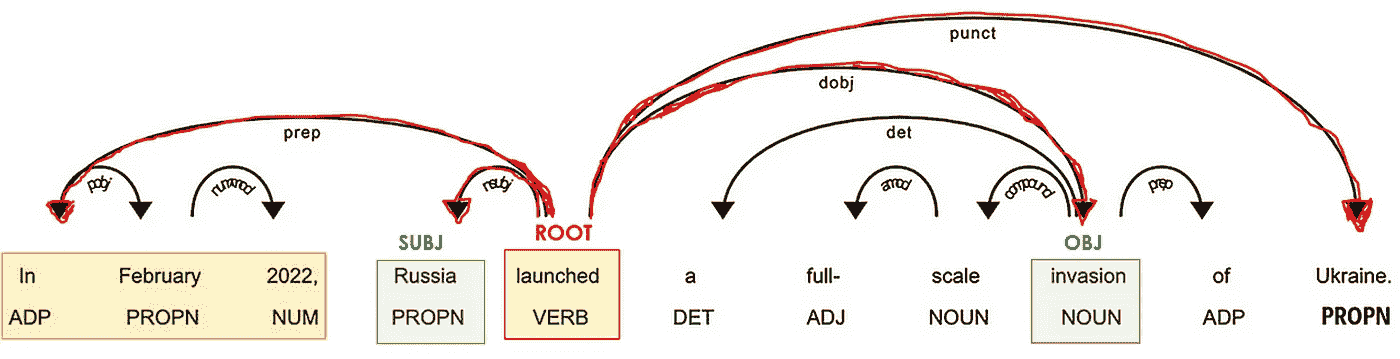
作者提供的图片
在与动词相关联的词中,必须有一些名词(POS=PROPN/NOUN),它们充当句子的主语和宾语(*DEP=nsubj/obj)。
作者提供的图片
名词通常靠近一个形容词(POS=ADJ),这个形容词充当它们意义的修饰词(DEP=amod)。例如,在“好人”和“坏人”中,形容词给名词*“人”*带来了相反的含义。
作者提供的图片
SpaCy 执行的另一个酷炫任务是 命名实体识别(NER)。命名实体是一个“现实世界的对象”(即人、国家、产品、日期),模型可以识别文档中的各种类型。以下是可能标签的完整列表(截至今日):
人物: 人,包括虚构的。
国家/宗教/政治组织: 国籍、宗教或政治团体。
设施: 建筑物、机场、公路、桥梁等。
组织: 公司、机构、组织等。
GPE: 国家、城市、州。
地点: 非 GPE 位置、山脉、水体。
产品: 物品、车辆、食品等。(不是服务。)
事件: 命名的飓风、战役、战争、体育赛事等。
艺术作品: 书籍、歌曲等的标题。
法律: 成为法律的命名文档。
语言: 任何命名的语言。
日期: 绝对或相对的日期或时期。
时间: 小于一天的时间。
百分比: 包括“%”的百分数。
货币: 包括单位的货币值。
数量: 以重量或距离为单位的测量值。
序数: “第一”、“第二”等。
基数: 不属于其他类型的数字。
让我们看看我们的例子:
for tag in lst_docs[i].ents:
print(tag.text, f"({tag.label_})")

作者提供的图片
或者使用 SpaCy 的图形工具:
displacy.render(lst_docs[i], style="ent")
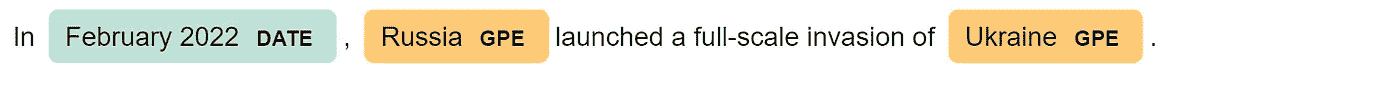
作者提供的图片
这在我们想要向知识图谱中添加几个属性时非常有用。
继续,使用 NLP 模型预测的标签,我们可以提取实体及其关系。
实体与关系提取
这个想法非常简单,但实现起来可能会很棘手。对于每个句子,我们将提取主语和宾语及其修饰词、复合词和它们之间的标点符号。
这可以通过两种方式完成:
- 手动地,你可以从基线代码开始,这些代码可能需要稍微修改和适应你的特定数据集/用例。
def extract_entities(doc):
a, b, prev_dep, prev_txt, prefix, modifier = "", "", "", "", "", ""
for token in doc:
if token.dep_ != "punct":
## prexif --> prev_compound + compound
if token.dep_ == "compound":
prefix = prev_txt +" "+ token.text if prev_dep == "compound" else token.text
## modifier --> prev_compound + %mod
if token.dep_.endswith("mod") == True:
modifier = prev_txt +" "+ token.text if prev_dep == "compound" else token.text
## subject --> modifier + prefix + %subj
if token.dep_.find("subj") == True:
a = modifier +" "+ prefix + " "+ token.text
prefix, modifier, prev_dep, prev_txt = "", "", "", ""
## if object --> modifier + prefix + %obj
if token.dep_.find("obj") == True:
b = modifier +" "+ prefix +" "+ token.text
prev_dep, prev_txt = token.dep_, token.text
# clean
a = " ".join([i for i in a.split()])
b = " ".join([i for i in b.split()])
return (a.strip(), b.strip())
# The relation extraction requires the rule-based matching tool,
# an improved version of regular expressions on raw text.
def extract_relation(doc, nlp):
matcher = spacy.matcher.Matcher(nlp.vocab)
p1 = [{'DEP':'ROOT'},
{'DEP':'prep', 'OP':"?"},
{'DEP':'agent', 'OP':"?"},
{'POS':'ADJ', 'OP':"?"}]
matcher.add(key="matching_1", patterns=[p1])
matches = matcher(doc)
k = len(matches) - 1
span = doc[matches[k][1]:matches[k][2]]
return span.text
让我们在这个数据集上试试,并查看常见的例子:
## extract entities
lst_entities = [extract_entities(i) for i in lst_docs]
## example
lst_entities[i]

## extract relations
lst_relations = [extract_relation(i,nlp) for i in lst_docs]
## example
lst_relations[i]

## extract attributes (NER)
lst_attr = []
for x in lst_docs:
attr = ""
for tag in x.ents:
attr = attr+tag.text if tag.label_=="DATE" else attr+""
lst_attr.append(attr)
## example
lst_attr[i]

2. 你也可以使用 Textacy,这是一个建立在 SpaCy 之上的库,用于扩展其核心功能。这更友好且通常更准确。
## extract entities and relations
dic = {"id":[], "text":[], "entity":[], "relation":[], "object":[]}
for n,sentence in enumerate(lst_docs):
lst_generators = list(textacy.extract.subject_verb_object_triples(sentence))
for sent in lst_generators:
subj = "_".join(map(str, sent.subject))
obj = "_".join(map(str, sent.object))
relation = "_".join(map(str, sent.verb))
dic["id"].append(n)
dic["text"].append(sentence.text)
dic["entity"].append(subj)
dic["object"].append(obj)
dic["relation"].append(relation)
## create dataframe
dtf = pd.DataFrame(dic)
## example
dtf[dtf["id"]==i]

作者提供的图片
让我们也使用 NER 标签(即日期)提取属性:
## extract attributes
attribute = "DATE"
dic = {"id":[], "text":[], attribute:[]}
for n,sentence in enumerate(lst_docs):
lst = list(textacy.extract.entities(sentence, include_types={attribute}))
if len(lst) > 0:
for attr in lst:
dic["id"].append(n)
dic["text"].append(sentence.text)
dic[attribute].append(str(attr))
else:
dic["id"].append(n)
dic["text"].append(sentence.text)
dic[attribute].append(np.nan)
dtf_att = pd.DataFrame(dic)
dtf_att = dtf_att[~dtf_att[attribute].isna()]
## example
dtf_att[dtf_att["id"]==i]

作者提供的图片
现在我们已经提取了“知识”,可以构建图谱。
网络图
标准的 Python 库用于创建和操作图网络是NetworkX。我们可以从整个数据集开始创建图,但如果节点太多,视觉效果会变得混乱:
## create full graph
G = nx.from_pandas_edgelist(dtf, source="entity", target="object",
edge_attr="relation",
create_using=nx.DiGraph())
## plot
plt.figure(figsize=(15,10))
pos = nx.spring_layout(G, k=1)
node_color = "skyblue"
edge_color = "black"
nx.draw(G, pos=pos, with_labels=True, node_color=node_color,
edge_color=edge_color, cmap=plt.cm.Dark2,
node_size=2000, connectionstyle='arc3,rad=0.1')
nx.draw_networkx_edge_labels(G, pos=pos, label_pos=0.5,
edge_labels=nx.get_edge_attributes(G,'relation'),
font_size=12, font_color='black', alpha=0.6)
plt.show()
图片由作者提供
知识图谱使得从大局上看到事物之间的关系成为可能,但像这样是相当无用的……所以最好是根据我们要寻找的信息应用一些过滤器。对于这个例子,我将只取涉及最频繁实体(基本上是最连接的节点)的图的一部分:
dtf["entity"].value_counts().head()

图片由作者提供
## filter
f = "Russia"
tmp = dtf[(dtf["entity"]==f) | (dtf["object"]==f)]
## create small graph
G = nx.from_pandas_edgelist(tmp, source="entity", target="object",
edge_attr="relation",
create_using=nx.DiGraph())
## plot
plt.figure(figsize=(15,10))
pos = nx.nx_agraph.graphviz_layout(G, prog="neato")
node_color = ["red" if node==f else "skyblue" for node in G.nodes]
edge_color = ["red" if edge[0]==f else "black" for edge in G.edges]
nx.draw(G, pos=pos, with_labels=True, node_color=node_color,
edge_color=edge_color, cmap=plt.cm.Dark2,
node_size=2000, node_shape="o", connectionstyle='arc3,rad=0.1')
nx.draw_networkx_edge_labels(G, pos=pos, label_pos=0.5,
edge_labels=nx.get_edge_attributes(G,'relation'),
font_size=12, font_color='black', alpha=0.6)
plt.show()

图片由作者提供
这样更好。如果你想将其做成 3D,使用以下代码:
from mpl_toolkits.mplot3d import Axes3D
fig = plt.figure(figsize=(15,10))
ax = fig.add_subplot(111, projection="3d")
pos = nx.spring_layout(G, k=2.5, dim=3)
nodes = np.array([pos[v] for v in sorted(G) if v!=f])
center_node = np.array([pos[v] for v in sorted(G) if v==f])
edges = np.array([(pos[u],pos[v]) for u,v in G.edges() if v!=f])
center_edges = np.array([(pos[u],pos[v]) for u,v in G.edges() if v==f])
ax.scatter(*nodes.T, s=200, ec="w", c="skyblue", alpha=0.5)
ax.scatter(*center_node.T, s=200, c="red", alpha=0.5)
for link in edges:
ax.plot(*link.T, color="grey", lw=0.5)
for link in center_edges:
ax.plot(*link.T, color="red", lw=0.5)
for v in sorted(G):
ax.text(*pos[v].T, s=v)
for u,v in G.edges():
attr = nx.get_edge_attributes(G, "relation")[(u,v)]
ax.text(*((pos[u]+pos[v])/2).T, s=attr)
ax.set(xlabel=None, ylabel=None, zlabel=None,
xticklabels=[], yticklabels=[], zticklabels=[])
ax.grid(False)
for dim in (ax.xaxis, ax.yaxis, ax.zaxis):
dim.set_ticks([])
plt.show()

图片由作者提供
请注意,图表可能很有用且可视化效果很好,但这不是本教程的主要焦点。知识图谱最重要的部分是“知识”(文本处理),然后结果可以以数据框、图形或其他图表的形式展示。例如,我可以使用 NER 识别的日期来构建一个时间轴图。
时间轴图
首先,我必须将被识别为“日期”的字符串转换为 datetime 格式。库DateParser可以解析几乎所有在网页上常见的字符串格式的日期。
def utils_parsetime(txt):
x = re.match(r'.*([1-3][0-9]{3})', txt) #<--check if there is a year
if x is not None:
try:
dt = dateparser.parse(txt)
except:
dt = np.nan
else:
dt = np.nan
return dt
让我们将其应用于属性的数据框:
dtf_att["dt"] = dtf_att["date"].apply(lambda x: utils_parsetime(x))
## example
dtf_att[dtf_att["id"]==i]

图片由作者提供
现在,我将其与主要的实体-关系数据框合并:
tmp = dtf.copy()
tmp["y"] = tmp["entity"]+" "+tmp["relation"]+" "+tmp["object"]
dtf_att = dtf_att.merge(tmp[["id","y"]], how="left", on="id")
dtf_att = dtf_att[~dtf_att["y"].isna()].sort_values("dt",
ascending=True).drop_duplicates("y", keep='first')
dtf_att.head()

图片由作者提供
最后,我可以绘制时间轴。正如我们已经知道的,完整的图表可能不会很有用:
dates = dtf_att["dt"].values
names = dtf_att["y"].values
l = [10,-10, 8,-8, 6,-6, 4,-4, 2,-2]
levels = np.tile(l, int(np.ceil(len(dates)/len(l))))[:len(dates)]
fig, ax = plt.subplots(figsize=(20,10))
ax.set(title=topic, yticks=[], yticklabels=[])
ax.vlines(dates, ymin=0, ymax=levels, color="tab:red")
ax.plot(dates, np.zeros_like(dates), "-o", color="k", markerfacecolor="w")
for d,l,r in zip(dates,levels,names):
ax.annotate(r, xy=(d,l), xytext=(-3, np.sign(l)*3),
textcoords="offset points",
horizontalalignment="center",
verticalalignment="bottom" if l>0 else "top")
plt.xticks(rotation=90)
plt.show()

图片由作者提供
所以最好是过滤出特定时间段:
yyyy = "2022"
dates = dtf_att[dtf_att["dt"]>yyyy]["dt"].values
names = dtf_att[dtf_att["dt"]>yyyy]["y"].values
l = [10,-10, 8,-8, 6,-6, 4,-4, 2,-2]
levels = np.tile(l, int(np.ceil(len(dates)/len(l))))[:len(dates)]
fig, ax = plt.subplots(figsize=(20,10))
ax.set(title=topic, yticks=[], yticklabels=[])
ax.vlines(dates, ymin=0, ymax=levels, color="tab:red")
ax.plot(dates, np.zeros_like(dates), "-o", color="k", markerfacecolor="w")
for d,l,r in zip(dates,levels,names):
ax.annotate(r, xy=(d,l), xytext=(-3, np.sign(l)*3),
textcoords="offset points",
horizontalalignment="center",
verticalalignment="bottom" if l>0 else "top")
plt.xticks(rotation=90)
plt.show()
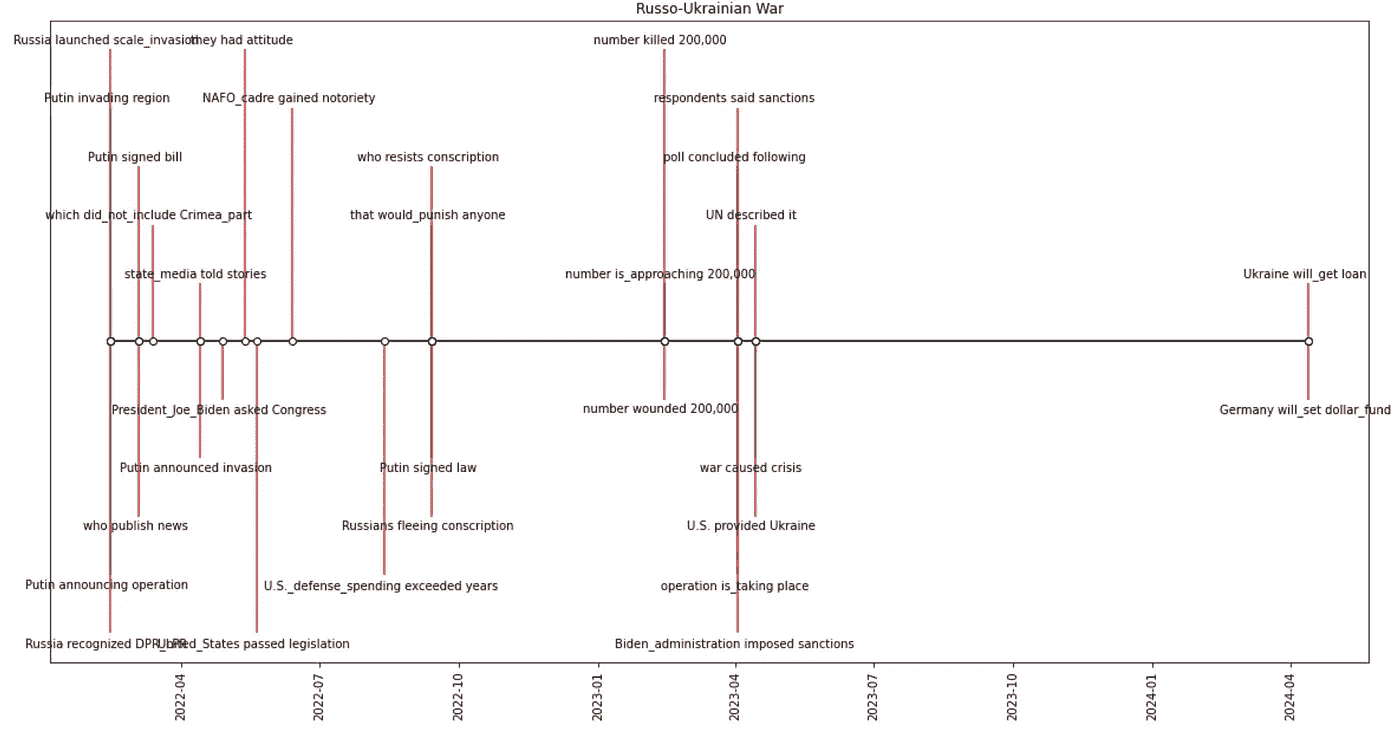
图片由作者提供
正如你所见,一旦“知识”被提取出来,你可以用任何方式绘制它。
结论
本文是关于如何用 Python 构建知识图谱的教程。我使用了几种 NLP 技术处理从维基百科解析的数据,以提取“知识”(即实体和关系),并将其存储在一个网络图对象中。
现在你明白了为什么公司正在利用 NLP 和知识图谱来映射来自多个来源的相关数据,并找到对业务有用的洞察。试想一下,通过在与单一实体(例如 Apple Inc)相关的所有文档(例如财报、新闻、推文)上应用这种模型,可以提取出多少价值。你可以快速了解所有与该实体直接相关的事实、人物和公司。然后,通过扩展网络,甚至可以获取与起始实体(A — > B — > C)不直接相关的信息。
希望你喜欢这个!如有任何问题或反馈,或想分享你的有趣项目,欢迎随时联系我。
👉 让我们联系 👈
本文是使用 Python 进行 NLP系列的一部分,还可以查看:
## 使用 NLP 进行文本总结:TextRank 与 Seq2Seq 与 BART
使用 Python 进行自然语言处理、Gensim、Tensorflow、Transformers
[towardsdatascience.com ## NLP 的文本分类:Tf-Idf 与 Word2Vec 与 BERT
预处理、模型设计、评估、Bag-of-Words、词嵌入、语言模型的可解释性
[towardsdatascience.com ## NLP 的文本分析与特征工程
语言检测、文本清理、长度、情感、命名实体识别、N-gram 频率、词向量、主题……
[towardsdatascience.com ## BERT 用于无模型训练的文本分类
当你没有标记训练集时,使用 BERT、词嵌入和向量相似性
[towardsdatascience.com ## 使用 NLP 构建 AI 聊天机器人:语音识别+Transformers
使用 Python 构建一个会话聊天机器人,与 AI 进行对话
[towardsdatascience.com
无代码机器学习平台:福音还是祸根?
原文:
towardsdatascience.com/no-code-ml-platforms-boon-or-bane-eee27290245d
深入了解无代码平台如何促进加速的机器学习应用


·发表在Towards Data Science ·9 分钟阅读·2023 年 1 月 13 日
–

Scott Graham的照片,来源于Unsplash
近年来,我们看到一些大型企业和蓬勃发展的初创公司推出了多种无代码机器学习和数据科学平台。如今,大多数领先的云服务提供商至少提供一种无代码/低代码机器学习平台。微软的Azure ML Studio、亚马逊的Sagemaker Canvas和谷歌的AutoML是其中的一些例子。如果你更深入地观察它们,会发现它们的共同使命是民主化 AI/ML/DS。很长一段时间,我坚信无代码/低代码不会有效地民主化机器学习。然而,最近我改变了看法,原因可能不是你所猜测的。让我解释一下。
简短回顾
回到 2015 年,当我探索 Azure ML 工作室时,我确实感到很惊讶。那个时候的平台已经成熟,提供了丰富的功能来解决机器学习问题。数据导入、探索性数据分析、模型构建、超参数调优和部署的整个过程都可以通过拖放工具完成。这是我在这个类别中使用的第一个工具之一,我感到了一种完整感。这个工具让我实现了当时测试的目标——将一个模型部署到生产环境中,而不需要写一行代码(尽管是一个用于测试的简单模型)。然后,到 2016 年底,我确信这一类别的服务有巨大的市场,而且无代码工具很快会在机器学习问题上得到广泛采用。
然而,随着时间的推移,我几乎没有注意到这些工具在我主要参与的社区中的采用情况。这些工具确实有一些很炫的演示,但在大多数情况下,它们对我而言意义不大。渐渐地,我开始倾向于认为这些工具对于使人工智能普及来说是多余的。我的理由很简单;对于商业上重要的并最终部署到生产环境中的严肃机器学习用例而言,从不适合使用将控制权锁定在基于 UI 的工具中的工具构建。此外,对于严肃的机器学习用例,数据工程和数据处理是一个庞大的工作量。工程的庞大体量和复杂性永远无法适合过于简化的无代码工具。对我而言,无代码/低代码平台突然变成了一个被美化的工具,仅仅用于做出优秀的营销。
回到今天
最近,我开始从不同的角度看待这些工具。我觉得我可能对这些工具的看法存在偏见。这个可能性很大,因为我大多与已经熟悉某种形式的编码的数据显示科学家或在该领域经验丰富的专业人士互动。此外,我大多数时候在一个与软件工程师紧密合作的环境中工作,这些工程师帮助将研究原型转化为生产管道。因此,我们必须建立一个研究工作流程实践,以确保将研究原型和生产工件之间的转化努力降到最低。因此,我们通常选择了大数据工具支持的 Python 生态系统,这些工具运行在成熟的云平台上。在这种情况下,排除无代码解决方案是非常自然的。
为了用更广泛的视角和不同的用户群体理解现状,我开始联系我现有网络之外的人,以了解他们技术栈的变化以及无代码工具的采用情况。总体来说,在接触了相当多样化的受众后,我有了一些学习体会,这些体会最终改变了我的看法。
从新的视角看待问题
首先,我重新审视了组织在科学实践中的结构。尽管机器学习领域已经成熟,但在很多组织中仍然很少有科学职能。大多数组织在起步时都很艰难,通常团队人数也很不足。尽管这些组织中的科学问题潜力可能很大,但从一开始就很难明确大方向。从机器学习问题中发现价值并实现其业务影响的过程是缓慢且迭代的,需要有面对重大失败的心理准备。没有一种完美的科学路径能够帮助人们从识别问题到生成业务价值,像过于简化的从 A 点到 B 点的过程一样。这个过程通常是艰难且迭代的。这让我思考——不同成熟度的组织采用了什么工具?
事实上,并非所有组织都能负担得起或愿意从一开始就大规模投资于昂贵的科学技能。这个过程通常是一个未定义的路径。下图展示了从问题发现到解决以产品为驱动的科学解决方案的简化路径。[当然,每一步都有其自己的迭代,但你可以看到更大的图景。]
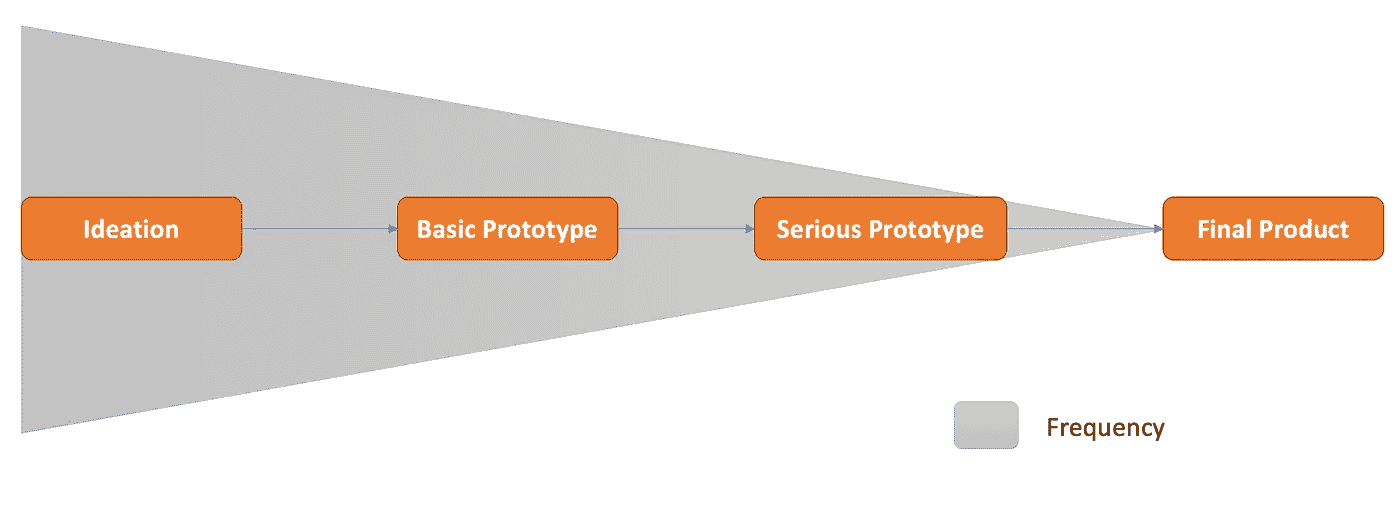
[作者提供的图像] - 机器学习使用案例的产品化路径示意图。
灰色区域表示给定里程碑的迭代频率。自然地,我们会有大量的想法在实现基本原型之前被淘汰,而这些原型在正式投入到严肃的原型之前还会进一步修剪,最后收窄为用于最终产品的关键优化版本。
长时间以来,我一直从不同的视角看待这些产品,并且不合理地批评了无代码平台的价值。我关键的问题是——这个解决方案对严肃的业务有多大价值? 在某些地方,这看起来对重要的用例来说有些多余。但后来我意识到,我是在从一个不缺乏机器学习技能和工程资源的工作环境的角度来进行比较。然而,并非所有地方都是这样。大多数组织没有足够的资源和团队来大规模支持科学用例验证,也可能没有成熟的科学职能来支持这一点。
下图展示了无代码平台在业务问题生命周期中的有效性的思考过程。

[作者提供的图像] — 无代码工具在问题生命周期阶段的有效性示意图
我的偏见是由于对问题更成熟阶段的倾斜。然而,这只是一个具体而狭窄的视角。每个组织根据其科学成熟度的位置,将拥有不同的工具。如果我们对大多数组织的解决问题过程进行概括,我们需要理解并非所有的想法都会变成生产产品。想法、原型、MVP 和最终产品的比例看起来像是多米诺骨牌倒退的顺序。因此,需要用不同的工具以不同的方式支持问题的每个生命周期阶段。下表将更深入地探讨上述问题生命周期阶段。
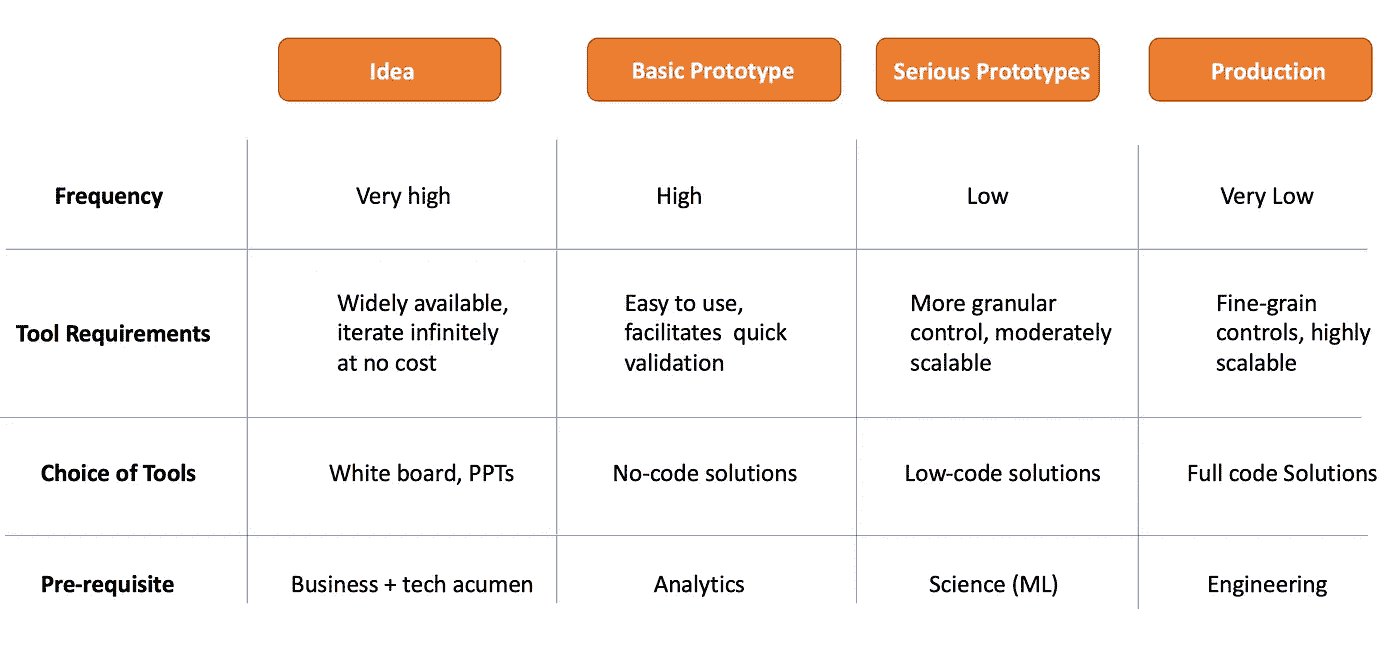
[图片来自作者]
如上所示,如果我们将问题的生命周期拆解成更小的里程碑,我们可以看到不同阶段对技能和资源的不同需求。专门的科学团队绝不是节省资源的团队,他们的成本通常与工程团队相当或更高。因此,小型组织中通常没有太多这样的团队。那么,那些可能没有专门科学团队的人员如何在不进行重大妥协的情况下更快地完成这个过程呢?
这时我开始看到无代码平台的新价值。
重新考虑无代码平台
在解决方案旅程中使用一刀切的解决方案是否合理?当然不!随着问题的进展会发生什么变化?在理想的世界中,为了使数据科学和机器学习变得普及,确实需要一个生态系统来促进在迭代频率非常高且失败率高的领域中更快地移动。为了支持创意阶段,我们已经拥有了最好的工具,比如白板、PPT、文档、写作等。对于基础和严肃的原型,我们是否有能够更快推进的工具?有人认为 Python 已经被充分普及,可以促进这一过程。这可能只是部分正确;不是所有分析师都精通 Python 和 SQL。因此,存在可以填补这一空白的东西。
这就是为什么我强烈认为无代码解决方案可以蓬勃发展的原因。
无代码解决方案提供了什么?
本质上,无代码机器学习平台显著降低了普通人接受数据科学的门槛。通过用模块化构建块整洁地抽象出关键复杂科学组件,这些平台支持从构思到实验和验证的过程,并留有额外的自定义空间。这些工具提供了稳健的默认设置,确保大多数任务可以在用户几乎不需自定义输入的情况下顺利进行。因此,这些工具通过简化数据工程和模型构建任务的过程,加快了验证创意的进程。此外,这些工具还简化了结果(成果)的消费过程,并支持更广泛的 go/no-go 决策,适用于大规模实验。对于首次接触机器学习的小型组织或新团队,这些工具以实惠且有效的价格点提供了巨大的价值,可以自信地加快初步步伐。
无代码机器学习平台不提供什么?
无代码工具绝不是大型严肃解决方案的替代品。它不是一个永久的工具集,无法应对从原型到生产的整个过程。当业务问题经过充分验证并开始扩展时,无代码工具的价值将开始减小,提示需要更精细的控制。无代码工具缺乏使大规模生产问题运行的复杂性。
那么它适合什么场景呢?
机器学习和数据科学用例的迭代和实验性特征确实使其成为一个资源密集型的倡议。不断增长的科技企业和/或最近刚刚采用机器学习进行业务的企业需要时间来验证创意,然后再做进一步投入。我们目前拥有的工具集可能并不是新团队开始数据科学工作的最友好和易于上手的手段。虽然它肯定是一个稳健的工具,但对于初学者来说可能不太理想。这正是民主化 AI/ML 工具开始发挥关键作用的地方。一个组织能否以仅一名员工和没有前期成本的低数据科学投资开始新的旅程?创意能否在没有严重工程努力和有限科学成熟度的情况下得到验证?一个有前途的创意能否逐步扩展,直到团队对大规模投资有信心?所有这些问题的明确答案并不总是容易获得,尤其是在现有的 Python 机器学习宇宙中;需要有更多的工具来提供支持。对于那些需要快速验证并有效地迭代到成熟的规模问题,无代码机器学习解决方案恰到好处。
当我们民主化 AI 和 ML 工具时,我们开始为生态系统提供合适的工具,以像抚养新生儿直到上幼儿园一样培养创意。一旦进入幼儿园,或许是时候寻求更好的工具了。但在此之前,无代码平台是你最好的朋友。
总结思考
一般来说,高质量的生产材料不建议通过过于简化的工具进行交付。但科学用例的迭代和实验性特征使得从一开始就进行资源密集型工程并不合适。问题的不同阶段以及组织的科学成熟度需要不同的工具来导航科学之旅。无代码/低代码解决方案提供了一个很好的起点,并有效降低了组织探索该领域是否对其业务有价值的门槛。当组织认真起来时,才有可能需要迁移到提供更多细化控制的工具和服务。在那之前,无代码工具将是您团队探索的好伙伴。
你好,感谢阅读!如果你想获取我即将发布的博客更新,请在 Twitter 上关注我,以便第一时间收到新帖通知。再次感谢!
TensorFlow 中不再出现 OOM 异常
使用包装函数来避免 OOM 异常
 [外链图片转存中…(img-D9YW2pdF-1726872521034)] Pascal Janetzky
[外链图片转存中…(img-D9YW2pdF-1726872521034)] Pascal Janetzky
·发表于 Towards Data Science ·阅读时间 8 分钟·2023 年 4 月 1 日
–
现在是 2023 年。机器学习不再是炒作,而是日常产品的核心。越来越快的硬件使得训练更大规模的机器学习模型成为可能——而且时间更短。每天在 arXiv 提交的关于机器学习或相关领域的论文约有 100 篇,至少三分之一的论文利用了硬件的能力进行超参数搜索以优化其使用的模型。这不是很简单吗?只需选择一个框架——Optuna, wandb,随便哪个——接入你的常规训练循环,然后…
OOM 错误。
至少,这种情况在 TensorFlow 中经常发生。

图片由 İsmail Enes Ayhan 提供,来源于 Unsplash
当前状态
缺乏适当释放 GPU 内存的功能引发了许多讨论和问题,特别是在 StackOverflow 或 GitHub 等问答论坛中 (1, 2, 3, 4, 5, 6)。对于每个问题,都提出了一组类似的解决方法:
-
限制 GPU 内存增长
-
使用 numba 库清除 GPU
-
使用本地 TF 函数,它们应该可以做到这一点
-
切换到 PyTorch
本博文提出了我对这一长期存在且烦人的 OOM 异常问题的解决方案。在过去几年中进行了一些超参数优化运行后,我最近遇到了编程中最令人生畏的问题之一:
不易重复的异常,通常发生在百次运行中的某一次。在我的情况下,它偶尔发生在优化运行中选择了特别具有挑战性的参数组合时。比如,较大的批量大小和较多的卷积滤波器,这两者都对 GPU 内存造成压力。
有趣但更令人恼火的是,当我从新系统本地初始化这样的模型时——即之前没有运行其他 TF 代码——我可以成功运行模型。在检查了其他影响因素,如 GPU 大小、CUDA 版本和其他要求后,我没有发现此部分的错误。因此,必须是同一程序内神经网络的重复初始化导致了 OOM 错误。
在继续之前,我想澄清:OOM 错误可能有其他原因,迄今为止这些原因尚未明确指出。特别是,显然不可能将一个内存占用过大的模型放到一个内存过小的 GPU 上。
当模型在物理上过大时,解决方案是修改模型——相关关键词包括 混合精度训练、逐层训练、蒸馏 和 剪枝——以及在多个加速器上运行训练——关键词:分布式训练,模型并行——或者切换到具有更多可用内存的计算设备。但这超出了本文的范围。
问题
返回到在超参数优化期间遇到的可怕 OOM 异常,我认为首先从概念上展示导致这种错误的原因是至关重要的。因此,请考虑以下可视化,其中我绘制了一个 GPU 及其内存块:
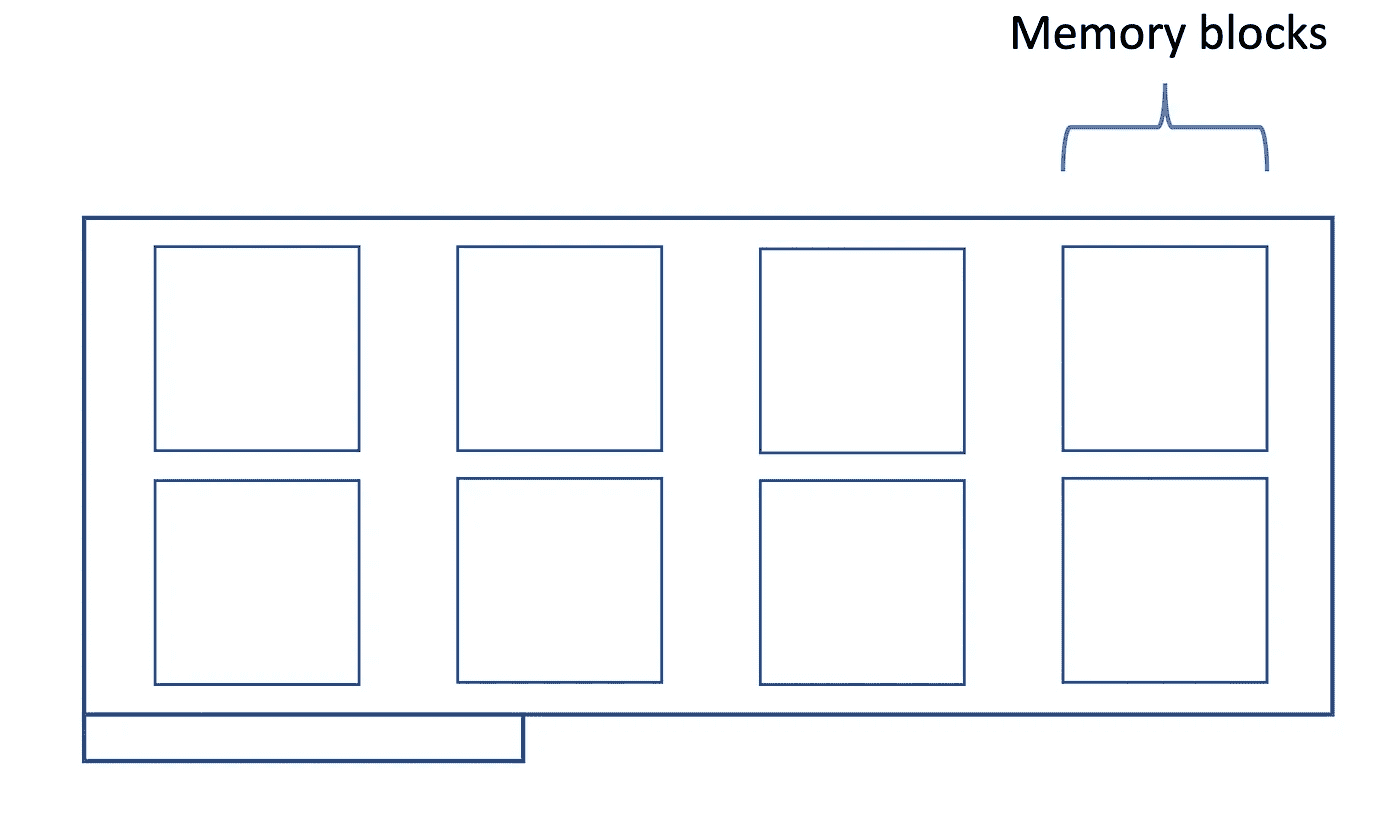
GPU 及其内存块的草图。图片由作者提供。
虽然这是一个简化的描述,但每次初始化新模型时,都会消耗另一块内存。

每个新模型都会占用 GPU 内存。图片由作者提供。
最终,加速器上的空间将不再剩余,导致 OOM 错误。模型越大,这种情况发生得越快。理想情况下,我们应在超参数试验结束时调用清理函数,为下一个模型释放内存。即使是可能适配到干净 GPU 上的网络,在没有进行垃圾回收时也会失败,因为宝贵的内存已经被之前模型的碎片占用。
我想称之为TensorFlow 在 GPU 上的作用域的部分在之前的草图中没有显示。默认情况下,TensorFlow 保留整个资源——这很聪明,因为后续请求增加配额将导致执行瓶颈。在下图中,TensorFlow 进程被勾画为“悬停”在整个 GPU 上:

TF 进程占用 GPU 以实现快速数据访问。图片由作者提供。
在其生命周期内,悬停的 TF 进程就像是即将到来的 TF 操作的占位符,这些操作在 GPU 及其内存上运行。
然后,一旦进程终止,TF 释放内存,使其可供其他程序使用。问题是:通常,作为超参数研究的一部分,所有网络初始化都是在同一个进程中(例如,在一个 for 循环中)进行的,这个进程悬停在 GPU 上。
解决方案,我希望,很明显:为每个试验/模型配置使用不同的进程。
这种方法适用于所有 TensorFlow 版本,尤其是旧版本(这些版本自然不会收到功能更新)。新的版本可能会增加适当的内存清理功能,但旧版本将缺乏这一可能性。所以,事不宜迟,这里是解决方案。
解决方案
为了在每个超参数试验中运行自己的进程,我们需要使用本地的 python multiprocessing 库。更新代码以使用这个包所需的努力出乎意料地少。
从全局视角来看,负责运行代码的过程——即主要驱动函数——需要修改以接受一个额外的参数,即队列。我们无需进一步深入,但这个队列对象作为调用函数(即调用 main()、run()、train() 或类似函数的函数)与主函数之间的桥梁。在主函数中,我们基本上可以保持现状。正如在参数搜索中常见的做法,改进训练/评估代码的返回值是优化实践的目标。
我们之前通过return语句返回这个值,而现在我们将这个目标值放入队列对象中。然后,我们从调用函数中提取它,并将其传递给超参数框架。
从优化框架的角度来看,变化不大。最显著的变化是它不再直接与训练函数“通信”,而是通过一个中介函数进行。概念上,这种更新的设置如下所示。
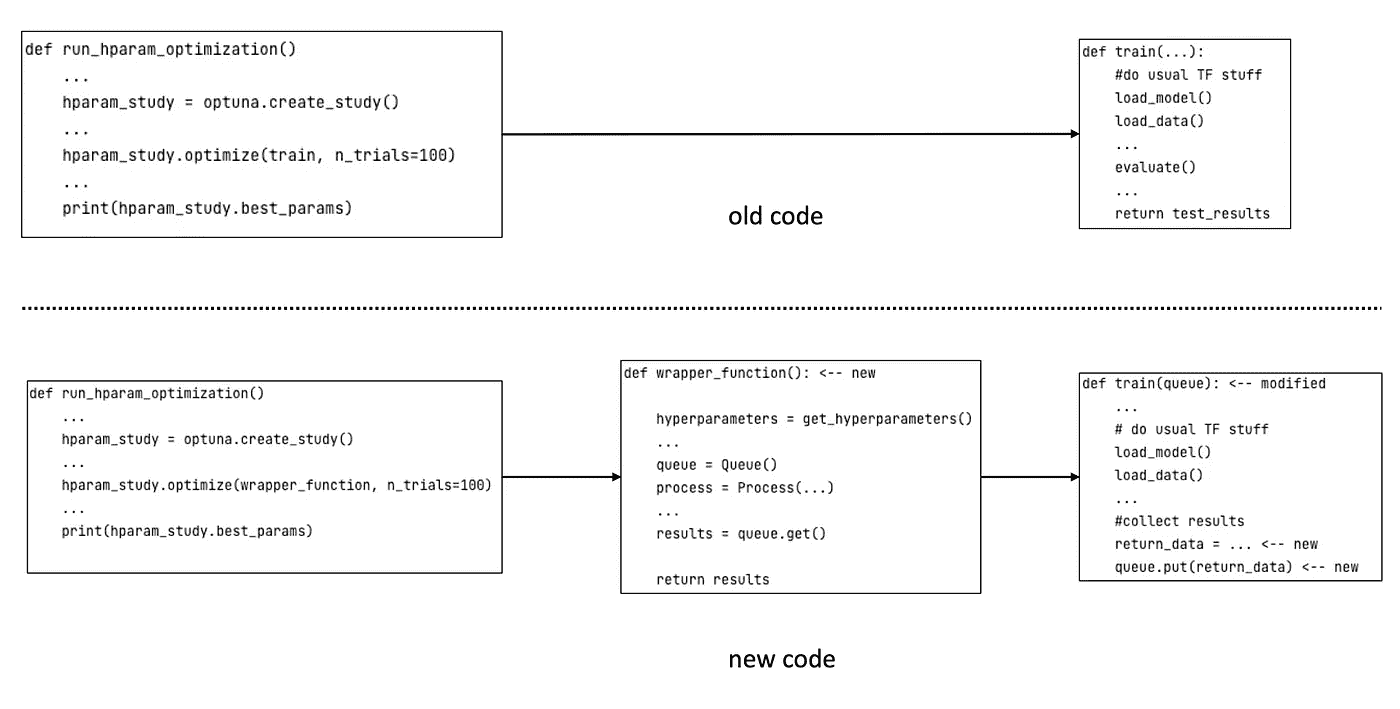
旧的默认代码(顶部)和更新后的代码(底部)的比较。在新代码中,优化框架通过包装函数与机器学习代码进行通信。
但除了这个变化之外,我们可以像往常一样进行参数搜索。从概念上讲,使用 python/伪代码的混合,让我向你展示修改后的代码的样子。
首先,我们必须将选择当前试验的参数组合的逻辑从主函数中移除(如果它曾被放在那儿)。这部分应该在我们添加进程管理之前完成。然后,我们使用多进程工具为 TF 相关代码生成一个进程,包装常用的 main()/train()/run()/等 函数:
def wrapper_function(): ← new
hyperparameters = get_hyperparameters()
…
queue = Queue()
process = Process(…)
…
results = queue.get()
return results
与 TF 的通信,特别是结果的收集,通过队列对象完成,这就是为什么我们也将其传递给函数(稍后详细说明)。然后我们开始模型训练,等待其完成,并从队列对象中获取结果,将其传递给调用函数(通常是超参数框架)。这个值 —— 或者在多目标优化的情况下,这些值 —— 是超参数框架最终看到的;它对进程的细节一无所知。
在训练代码中,我们需要包含一种将参数优化目标传递到队列对象中的方法。在这里,我假设通常会返回模型在验证集上的表现,因为该指标(在该子集上)通常被用作优化目标。
(适应你的用例;概念是相同的)。
为此:
-
查找你退出训练/评估函数并将结果返回给调用者的地方。
-
在这里,将优化框架需要知道的一切信息收集到一个列表或其他数据集合中。
-
在下一步,将此列表传递给队列。
如前面段落所述,这些值可以从队列中查询,并从那里传递回优化框架:
def train(queue): ← modified
…
# do usual TF stuff
load_model()
load_data()
…
#collect results
return_data = … ← new
queue.put(return_data) ← new
关键点是:当我们获得评估结果时,TF 进程已经完成 —— 清除 GPU 内存。因此,训练和评估过程可以在下一次调用中访问干净的(内存方面的)GPU,并且使用新的超参数集。特别是,创建待评估的模型不会争夺剩余的 GPU 内存,因为之前的模型及其痕迹已经被移除。这样,我们避免了 OOM 问题。
一个简单的例子
此时,你可能会想知道如何将这些内容转化为代码。我听到了,虽然每个人的需求不同,但我构建了以下简单的设置来给你一个如何工作的概念。我们将使用 Optuna 来优化卷积神经网络的超参数。通过这些代码,你可以加载你喜欢的数据集,并在其上优化 CNN。
这里是 Optuna 代码的部分:
在这段代码中,请注意 Optuna 调用的函数。它不是实际的训练代码,而是一个中间函数,即包装函数。如前一节所述,包装函数会使用将要评估的超参数集调用底层训练代码。
至于训练代码,这段代码基本遵循标准设置:加载数据子集、初始化模型、训练并评估模型。新颖之处在于函数的最后几行。在这里,验证子集上的结果被传递到队列中。
这就是 OOM-free 超参数优化的核心代码**。完整代码可以在 这里 找到。
*我的经验表明,应该在调用函数中选择超参数,即在进程修改生效之前。
**唯一的例外是当模型实在太大而无法适应 GPU 内存时。
总结
在这篇博客文章中,我介绍了我对 TensorFlow 中长期存在的 OOM 异常挑战的解决方案。虽然自然地,我们不能将物理上过大的模型放入 GPU 中,但这种方法适用于研究关键的超参数搜索。从概念上讲,这个解决方案很简单:为每次试验(超参数组合)启动一个新进程。使用本地 Python 库,只需添加几行新代码和对现有设置进行一些更改即可实现。最后,将优化框架指向一个中间包装函数,而不是直接指向训练代码。
数据科学中没有“科学”?
我们是在分析数据,还是在工程现实?


·
关注 发表在 Towards Data Science ·16 min read·2023 年 11 月 1 日
–

Vernagt Ferner — 提洛尔阿尔卑斯山。图片由作者提供。
引言
不用担心,我选择这个标题不是为了抱怨数据科学不是“真正的科学”(无论那意味着什么)。相反,我希望提供一些不同的视角来理解作为数据科学家的意义,希望能帮助在分析问题时考虑不同的视角。最初,我打算将这篇文章命名为“我从柏拉图和书呆子那里学到的作为数据科学家的经验”[1]。柏拉图和书呆子是爱德华·阿什福德·李最近写的一本书。我发现这本书的标题并没有真正传达书的内容。从某种程度上说,这符合李的写作风格。他走了许多有趣的旁路——他称之为“书呆子风暴”——使得书的主要信息仍然不清晰。在这篇文章中,我将专注于他书中的一个方面:科学和工程学之间的区别以及这如何与数据科学中的常见思维碰撞。虽然李写这本书是为了大众,但我发现这本书对我反思自己在计算机科学/信息技术领域的研究特别有用。
我猜这篇文章可以被看作是李描述工程学和科学之间差异的一个推论。特别是,通过李的论点,普遍的看法是*“[数据科学是一个] 统一统计学、数据分析、信息学及其相关方法的概念 [以便于]* 理解和分析实际现象 [通过数据]。”(强调是我加的)[2],目前在维基百科的数据科学页面上是第一条引用,似乎是一个误解。在这篇文章的其余部分,我将尝试解释为什么在李的论点下,这是这样。我将首先更仔细地查看我们最常指的“实际现象”是什么意思。其次,我将反思李关于工程学和科学的区分,因为既然我们谈论的是数据科学,这似乎是相关的。最后,我将对这可能意味着什么进行哲学上的思考,尤其是对数据科学家的工作。

Vernagthutte — 提罗尔阿尔卑斯山。图片作者
将现实付诸实践(以及为什么这很重要)
最近我经常听 BBC 播客《你已死于我》[3],这是一个历史喜剧播客。我特别喜欢的一集是关于时间测量的历史。在这一集中,他们讨论了我们现在理所当然的许多时间方面。尽管我经常使用时间的概念,但这集让我意识到我对这些概念的起源知之甚少(甚至现在也不多)。我只是接受一个小时包含 60 分钟,工作时间和休闲时间之间有差异,或者时间存在于一个连续体中。所有这些关于时间的概念都是人们的视角,仍然在我们的文化中回响而我们却未曾意识到。难怪李将这些称为“未知的已知”。未知的已知也被称为另一种名称:心理模型。
科学的一项重要任务是意识到这些未知的已知,并将其与现实进行对比。科学史上充满了这样的例子。在哥白尼之前,普遍的心理模型是太阳绕地球运转。在我们的历史上,放血或使用汞曾被认为是医学上合理的。统计学本身也充满了未知的已知。在 1750 年之前,结合观察以提高准确性,例如使用均值而不是选择最`可靠’的单一观察点,这种做法很少见且常常受到批评。当欧拉试图预测木星和土星的运动时,他使用了他认为最可能的数据点,而不是对所有数据进行平均以预测[4, p.p. 25–31]。另一个例子是,19 世纪的经济学家在将多个产品的价格合并成一个指数时不得不为自己辩护[4, Ch. 1],尽管当时统计方法在天文学家中已经广泛使用。
对于数据科学家来说,将心理模型与现实对比似乎是其活动的核心。这不仅适用于像 A/B 测试这样的琐碎例子,也适用于预测和优化。人们有很强的倾向将信息片段连接起来,形成一个连贯的故事,即使这些信息片段实际上是断裂的(所谓的事后偏见)。一旦这样的故事在某人的脑海中形成,就很难改变。事实上,确认偏误会暗示这个人主要会寻找支持该故事的证据。即使你可以证明预测模型更准确,或者规划算法比人类做得更好,你仍然会发现有人争辩说模型在这个或那个例外情况中不起作用。或者说,由于模型可能是一个黑箱,因此不能被信任。我个人在最近关于 ChatGPT 的发展中经历了这种情况。很难接受这种软件仅凭几句指令可能写出比我更好的博客。这只让我想到 ChatGPT 一定是不准确、不安全或不可靠的理由。你创建的模型会以开放的心态被接受的想法是一个幻想。你总是要与已有的模型竞争,无论是心理上还是实际的。
我最喜欢的关于将心理模型与现实对比的名言来自 Croll 和 Yozkovitz 在他们的书《精益分析》中[5]:
“我们都在自欺欺人——有些人比其他人更严重。企业家是最自欺欺人的。[…] 说谎甚至可能是成功的企业家的前提——毕竟,你需要说服别人相信某些事情,即使没有确凿的证据。你需要信徒和你一起冒险。你需要对自己说谎,但不能到危及你业务的地步。”
“这就是数据的作用”。
数据被用作镜子来验证思维模型与现实的一致性。因此,我们称之为数据科学。正如李所说的那样,一位科学家“选择(或发明)一个忠实于目标的模型”。Croll 和 Yozkovitz 的引言也强调了基于先前信念创建思维模型并非坏事:自我欺骗是一条细线。一方面,欺骗自己能够做某事可能是重要的。以冒名顶替综合症为例,人们觉得自己取得的成功只是运气,并且随时可能被揭穿为骗子。你需要“假装直到成功”,以克服这种认知偏差。另一方面,许多人对自己的决策过于自信(例如,达宁-克鲁格效应)。你的自我要么阻止你做该做的事,要么妨碍你意识到自己不应该做某事。
自我欺骗特别困难的一点在于,它在某种程度上并不是撒谎,因为这些认知偏差使你真的相信你的思维模型就是现实,而你不会接受任何与此不同的论点[22, p. 490–492]。这就是数据科学难的原因:有时候你可能拥有所有证据,但如果这些证据与决策者的思维模型相悖,你将很难说服那个人。正如谚语所说:*数据科学家的角色是告诉人们他们的宝宝很丑,*人们通常不喜欢听到这个。
所以,这就是我对成为数据科学家的思维模型,直到柏拉图和书呆子将其拆解。

Mt Chaberton — Claviere, Piedmont. 作者提供的图片
现实是一个思维模型的堆叠
如果你再看看前一段,你会发现我刚才称之为“现实”的东西充满了另一层思维模型。精益分析中的“精益”指的是 Eric Ries 的《精益创业》[6]中的思维模型,它提倡一种快速创业试错的方法以实现快速增长。希望这将使公司变大到可以上市。随后,企业需要快速“扩张”的想法,很可能受到硅谷指数组织[7]中成功商业模型的启发(尽管只有 0.4%的初创公司实际上扩张[8])。
进一步追溯历史,公司需要成长的观念显然是资本主义的,起源于 18 世纪亚当·斯密的思想。公众公司这一概念是 17 世纪荷兰东印度公司(VOC)的发明[9],来自一个在当时才刚刚被发明的国家,经过了四代勃艮第统治者的锤炼。或许最有趣的是货币本身的概念,李提到的塞尔(Searle)[10 p.78]认为货币是“任何人们使用并认为是货币的东西”。
就像任何曾经与六岁孩子讨论过的人可能见证的那样,我们可以通过不断地问“为什么”来不断剥离心理模型,只是为了得到新的模型。直到某一时刻,你到达了某些看似是自己思维公理的心理模型。但这里有一个问题:所有这些模型都是,嗯,模型。它们不是现实。即使是像量子力学这样的基本模型,在大尺度上考虑时也是不准确的。

Mt Chaberton — Claviere, Piedmont. 作者图片。
为什么数据科学家是工程师
你被心理模型包围着,这也是工程师进入故事的地方。李谈到科学家和工程师之间的区别:
“我们可以选择(或发明)一个忠于目标的模型,或者我们可以选择(或发明)一个忠于模型的目标。前者是科学家的本质。后者是工程师的本质。” P.197。
举个例子,李提到了晶体管。晶体管是一个开/关开关的模型。也就是说,晶体管实际上并不是开/关开关:它们是放大器。晶体管被创造得如此贴近开/关开关。目标(晶体管)忠于模型(开/关开关)。按照上述工程师和科学家的定义,晶体管的创造是一项工程工作。而且,李还表明,像法拉第定律这样的电磁学定律,虽然描述了晶体管的“真实行为”,实际上也是模型。现实只有在某些情况下遵循这些模型;在其他情况下,它们可能完全错误。事实上,科学似乎是一堆模型,每个模型都建立在之前模型的近似基础上。直到某个抽象层级,现实才会变得与模型不符。正如李在第 2–6 章所示,计算机科学中的模型堆栈,从晶体管到网站,似乎几乎是无尽的。
经济模型也不例外。下次你遇到某个人时,问问他是否可以借用他们的笔。令人惊讶的是,大多数人不会向你收取费用,甚至会坚持让你保留这支笔。在某些人际交往的情境中,一种“日常共产主义”的形式似乎是主流,而不是资本主义[11, pp. 94–102]。
但李继续争论,实际上,我们称之为科学的大部分内容是工程学。
“但更根本的是,标题[柏拉图与书呆子]将知识及技术看作是存在于人类之外的柏拉图式观念,并由人类发现的观念,与另一种观点对立,即人类创造而非发现知识和技术。[……] 标题中的书呆子是一个创造性的力量,主观且甚至古怪,而不是客观地复述现有的真理。”
读完这段话后,我有一种感觉,或许我选择了错误的职业。对我而言,数据科学的概念正是‘发现’的部分。应该作为独立观察者来分析数据,提出帮助组织增加‘价值’的‘见解’。按照这个概念,数据科学家就像阿加莎·克里斯蒂笔下的波洛探员,他寻找证据以解开谜团,但并不是谋杀计划的一部分。当然,一旦谜团解开,它会呈现给观众(对数据科学家而言,可能是稍微不那么壮观的 PowerPoint 演示),观众对解决方案的精彩表现感到惊叹。确实,这有点夸张,但解决方案应该复杂并由戴眼镜的白人发现的观念无疑是另一种思维模式的一部分[12]。根据李对科学家的定义,我们的数据科学 Poirot 确实描述了一个发明忠实于现实的模型的人,因此是一个科学家。
但现在考虑以下问题:你得到了一些历史销售数据(见下图),这些数据来自一个相对较新的产品,你和许多人几乎都确定该产品的销售在不久的将来会增长。你会做出什么预测?你会只是“让数据说话”:拟合一个线性模型,并将其外推到未来吗?还是会利用这些信息定义一个在接下来几年内具有指数增长的模型?假设你选择了后者,做出了预测,并与业务所有者分享。业务所有者随后决定启动营销机制以实现这一预测。到现在为止,你的预测已成为商业目标,销售增长甚至超出你的预测。根据李氏对工程师和科学家的讨论:这些商业结果是工程出来的?还是一些不可避免的科学?
这个例子来自 Makridakis 的《21 世纪的规划与预测》[13]。在他的书中,他描述了一个实验,要求商业人士根据一些历史销售数据做出预测。除了数据,他们还被告知产品是旧的、新的还是成熟的。正如图 1 所示,预测结果差异巨大。这些预测没有哪个本质上是错误的;它们遵循了产品生命周期的心理模型。这只是表明,即使使用相同的数据,预测也可能完全不同,这会影响到行动和结果。我们的数据科学家是解决了谋杀案,还是实施了谋杀?
现实情况是,作为数据科学家,你在‘价值’(模型)的定义中扮演着重要角色。你与业务部门讨论如何通过数据增加价值。你参与了 KPI 的定义。如果无法找到财务利益,数据分析通常还有其他方面的好处。一个成功的数据科学家,往往是一个懂得如何改变行为(例如客户的行为),以忠实于某个模型(例如优化收入)的人。当然,人们只能对现实进行有限的改变。改变人类行为可能是困难的。但是,如果没有意识到作为数据科学家,你可以,也很可能已经在改变‘现实’,那将是一个错误。数据科学家是工程师。
图 1,基于相同数据的 3 种截然不同的预测,基于 Makridakis [13,第 19 页]。作者提供的图像。
工程现实
“好吧,如果游戏规则迫使我们采取不良策略,也许我们不应该尝试改变策略。也许我们应该尝试改变游戏。”
这段引文来自《算法的生活》[14,第 240 页]。在游戏理论的一章中,作者讨论了 Vickrey 拍卖[15]。Vickrey 拍卖是一种所谓的第二价格拍卖,赢家支付的是第二高竞标的金额。在 Vickrey 拍卖中,每个参与者的主导策略是根据他/她认为物品的实际价值进行出价,而不是例如,通过虚张声势使另一方支付高价。从这个意义上讲,Vickrey 拍卖是一个如何改变行为以忠于某个偏好模型的例子。
实践中,还有许多其他的“首选模型”。一个模型的常见特征是,比如说,具有较小的随机性。无论是在制造和物流中被称为“六西格玛”的模型,还是在客户服务中的“轻松体验”[16]。如果模型能够应对随机性,那么基于它分析和做出决策会更容易。这时,数据科学家的概率背景就显得非常重要。可以通过使用统计模型来解释部分随机性,使用模拟技术来确定模型应对不确定性的能力,或指出商业所有者可能过于关注波动的日常表现,而没有看到更稳定的长期模式。正如李氏对晶体管及其后续抽象层的例子所示,减少随机性对于构建后续的抽象层至关重要。当我在用 Python 编程时,我不需要考虑程序在我的机器上是如何精确执行的,我也理所当然地认为程序可能不如在更接近机器代码的语言中编写时那样快。
但减少随机性也是有风险的。当较低层次的抽象中的某些假设被违反时,往往会发生危机。以物流供应链为例。在过去十年中,“六西格玛”理念一直是管理供应链部分的一个重要策略。但是,较长的供应链更容易引入更多的随机性。小的干扰可以通过使用缓冲区来平滑,但大规模的干扰则不然,自新冠危机以来,这种情况频繁发生[17]。因此,研究越来越多地寻求为干扰做准备的方法,而不是试图减少它们[18]。在这里,数据科学家也扮演着工程师的角色。他/她会将观察到的方差解释为需要减少的东西,还是接受它作为不可避免的东西?解释一个而非另一个,将如同在预测示例中一样,导致不同的策略:严格流程与鲁棒流程。
数据科学家作为工程师的概念也在数据和人工智能的伦理讨论中频繁出现。虽然引导客户购买/点击/消费更多在许多情况下可能是无害的,但有时情况却不那么简单。施尔[19]描述了一个令人震惊的例子。施尔研究了拉斯维加斯老虎机的成瘾性,包括老虎机的工程设计如何促成这种成瘾,许多原则也适用于其他数字设备,如手机。在一个离奇的例子中,赌场里有人心脏病发作。在急救人员尝试救她时,其他赌场访客继续玩他们的老虎机。老虎机经过优化,使得用户即使在邻居倒地的情况下也能保持在“流动”状态中。
当然,人们可以争论是否应责怪那个进行 A/B 测试的工程师,使得老虎机如此上瘾,但我希望到目前为止我已经说服读者,我认为这至少部分是事实。从积极的一面来看,尽管老虎机仍然像以往一样上瘾,但对算法失误的媒体关注已增加了对算法公平性等问题的关注[20]。重要的公共算法(如搜索引擎)更经常接受算法审计[21]。秉持“你无法管理你无法测量的事物”这一原则,如果在分析中包括了公平性度量,决策者就必须解释为什么可能忽视了这一度量。如果没有报告公平性度量,决策者可能不会意识到首先存在公平性问题。

查贝顿山 — 克拉维耶,皮埃蒙特。图像由作者提供。
结论
在数据科学和分析的描述中,对分析的强调随处可见,但是否应该更多关注发明呢?在 Gartner 的分析成熟度曲线上,只有在完成描述性和预测性分析(这些仅仅是分析现象)阶段后,才会开始‘规范性分析’。然而,在许多应用中,我们可能会发现行为(实际现象)已经根据模型(如收入、公平等)进行了调整,而不是相反。虽然一些系统和技术比其他系统更用户友好,但人们已然适应了技术,这一点不容忽视。是的,我认为谷歌是一个用户友好的搜索引擎,但我也已经训练自己寻找可能带我到正确网页的合适关键词。我学会了如何开车以及过马路时要小心,这后一点在提高交通效率上贡献不亚于汽车的发明本身。
当然,作为数据科学家,你也会遇到只是分析现象的情况。在这种情况下,你仅仅扮演了波洛的角色,仅仅是调查谋杀。然而,知道行为往往跟随技术的发展,而不是相反,对于数据科学家来说是有用的。与其分析实际现象,不如思考一个理想的现象可能是什么样的,然后据此设计模型。
参考文献
[1] 李·爱德华·阿什福德,《柏拉图与书呆子:人类与技术的创意合作》(2017),MIT 出版社
[2] 林千江,《什么是数据科学?基础概念与启发式示例》。数据科学、分类及相关方法(1998),Springer,东京,40–51. 通过维基百科:en.wikipedia.org/wiki/Data_science. 方括号中的部分来自维基百科页面,其余内容引用自原始论文。最后访问时间:2023 年 2 月 4 日。
[3] BBC,《时间测量的历史》(2022 年),你对我已经死了,BBC,检索自:www.bbc.co.uk/programmes/p07mdbhg,最后访问日期:2023 年 2 月 4 日。
[4] Stigler, Stephen M. 统计学的历史:1900 年以前的不确定性测量。哈佛大学出版社,1986 年。
[5] Croll, Alistair 和 Benjamin Yoskovitz. 精益分析:利用数据更快地打造更好的初创公司。O’Reilly Media, Inc.,2013 年。
[6] Reis, Eric. 精益创业。纽约:Crown Business,2011 年,第 27 期:2016–2020 年。
[7] Ismail, Salim. 指数型组织:为什么新的组织比你的组织好、快、便宜十倍(以及该怎么做)。Diversion Books,2014 年。
[8] ScaleUpNation. 扩展的艺术。2020 年。scaleupnation.com/wp-content/uploads/2021/02/The-Art-of-Scaling-3.1.pdf。最后访问日期:2023 年 2 月 4 日。
[9] VOC。检索自:en.wikipedia.org/wiki/Dutch_East_India_Company,最后访问日期:2023 年 2 月 4 日。
[10] Searle, J. 心智、品牌与科学。哈佛大学出版社,剑桥,MA。
[11] Graeber, David. 债务:前 5000 年。Penguin UK,2012 年。
[12] Chang, E. 男性主导的科技行业。Penguin,2019 年。
[13] Makridakis, Spyros. 21 世纪的预测、规划和战略。Free Press,1990 年。
[14] Christian, Brian 和 Tom Griffiths. 活用算法:人类决策的计算机科学。Macmillan,2016 年。
[15] Vickrey 拍卖。检索自:en.wikipedia.org/wiki/Vickrey_auction,最后访问日期:2023 年 2 月 4 日。
[16] Dixon, Matthew, Nick Toman Rick DeLisi 和 N. Toman. 轻松体验。Penguin Random House,2020 年。
[17] 国会研究服务部。供应链中断与美国经济。2022 年。检索自:crsreports.congress.gov/product/pdf/IN/IN11926,最后访问日期:2023 年 2 月 4 日。
[18] Spieske, Alexander 和 Hendrik Birkel. 通过工业 4.0 提高供应链韧性:在 COVID-19 大流行的影响下的系统文献综述。计算机与工业工程 158,2021 年。
[19] Schüll, Natasha Dow. 设计中的成瘾。普林斯顿大学出版社,2012 年。
[20] Pitoura, Evaggelia, Kostas Stefanidis 和 Georgia Koutrika. 排名和推荐中的公平性:概述。VLDB 期刊,第 1–28 页。Springer,2022 年。
[21] Bandy, Jack. 有问题的机器行为:算法审计的系统文献综述。ACM 人机交互会议录 5,CSCW1,第 1–34 页。ACM,2021 年。
[22] Pinker, Steven. 我们天性的更好天使:历史中暴力的减少及其原因。Penguin UK,2011 年。
NODE:专注于表格数据的神经树
原文:
towardsdatascience.com/node-tabular-focused-neural-trees-ee08c752fcd2
探索 NODE:一种用于表格数据的神经决策树架构


·发表于 Towards Data Science ·7 分钟阅读·2023 年 7 月 4 日
–
近年来,机器学习迅猛发展,神经深度学习模型在图像和文本处理等复杂任务中已经超越了像 XGBoost [4] 这样的浅层模型。然而,深度模型在处理表格数据时往往不如这些浅层模型有效,目前尚未有一种通用的深度学习方法能够 consistently 超越梯度提升树。
为了解决这一差距,俄罗斯互联网服务公司 Yandex 的研究人员提出了一种新的架构:神经遗忘决策集成(NODE) [1]。该网络利用轻量级且可解释的神经决策树,并将其整合到神经网络框架中。这使得模型能够在保持可解释性的同时,捕捉表格数据中的复杂交互和依赖关系。
在这篇文章中,我旨在解释 NODE 的工作原理以及使其成为一个强大而可解释的预测模型的各种属性。像往常一样,我鼓励大家阅读原始论文。如果你想使用 NODE,请查看模型的 GitHub。
本文是关于神经决策树系列中的一部分,这些高度可解释的架构提供了与传统深度网络相当的预测能力。

软/神经决策树
查看列表3 个故事
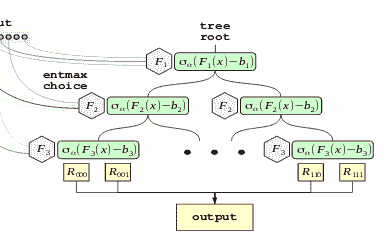
NODE 决策树结构
神经决策树
本文假设你对神经决策树有一定的了解。如果你没有,我强烈建议阅读我之前关于它们的文章以获得深入的解释。然而,总结来说:神经决策树是既柔软又倾斜的决策树。
倾斜树是指在每个节点中使用多个变量来做出决策(通常以线性组合的形式排列)。例如,为了预测汽车事故,正交树可能使用规则“car_speed — speed_limit <10”来产生分支决策。这不同于像 CART(基本决策树)这样的“正交”树,后者在任何给定的节点只使用一个变量,并且需要更多的节点来近似相同的决策边界。
柔软树是指所有分支决策都是概率性的,每个节点的计算定义了进入特定分支的概率。这与像 CART 这样的普通“硬”决策树不同,后者的每个分支决策是确定性的。
由于树不限制每个节点使用的变量数量,并且分支决策是连续的,因此整个树是可微分的。由于整个树是可微分的,它可以集成到任何神经网络框架中,如 Pytorch 或 Tensorflow,并使用传统神经优化器(例如,随机梯度下降和 Adam)进行训练。
NODE 树
NODE 使用的决策树与传统神经树略有不同。让我们逐一分析这些差异。
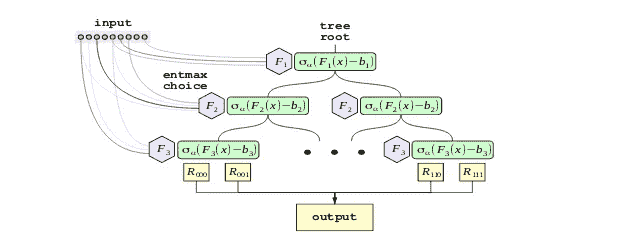
NODE 树。F(*)表示分支函数,b 表示分支阈值。Sigma 表示概率转换函数。R 是叶节点结果(图来自 Popov 等人,2019 年[1])
无意识特性
第一个重大变化是树的特性是“无意识”的。**这意味着树在相同深度的所有内部节点上使用相同的分裂权重和阈值。**因此,无意识决策树(ODTs)可以表示为一个具有 2^d个条目的决策表(d为深度)。一个好处是,ODTs 比传统决策树更具可解释性,因为决策更少,更容易可视化和理解决策路径。然而,与传统决策树相比,ODTs 的学习能力显著较弱(再次由于分裂函数的受限特性)。
那么如果我们的目标是性能,为什么要使用 ODTs 呢?正如 CATBoost 的开发者[2]所展示的,ODTs 在集成在一起时效果非常好,并且不易过拟合数据。此外,ODTs 的推理非常高效,因为所有分裂可以并行计算,迅速找到表中的合适条目。
用于特征选择和分支的 Entmax
NODE 相对于传统神经决策树的第二个改进是其架构中使用了 alpha-entmax [3]而不是 sigmoid。Alpha-entmax 是 softmax 的一个广义版本,能够产生稀疏分布,其中大部分结果为零。这种稀疏性由一个参数(因此得名 alpha)控制,alpha 值越高,分布越稀疏。
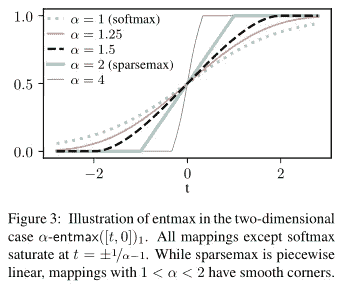
图源于 Peters 等人 2019 年[3]
这种变换在两个关键地方使用。第一个使用场景是稀疏特征选择。NODE 包括一个可训练的特征选择权重矩阵 F(大小为 d x n,其中 n 是特征数量,d 是树的深度),通过 entmax 变换。由于 entmax 变换的大多数条目都等于零,这自然会导致在每个决策节点中使用的特征数量很少。
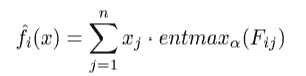
分支函数(图源于 Popov 等人 2019 年[1])
除了特征选择,entmax 还用于分支概率。这是通过传递分支函数的结果,减去一个学习的阈值,然后适当地缩放来完成的。然后将这个值与 0 串联,并传入 entmax 函数,以创建一个 2 类概率分布,这正是我们进行分支所需的。

分支方程见[1]。b_i 是分支阈值,tau_i 是缩放数据的学习值(图由作者提供)
使用这个,我们可以通过计算所有分支分布 c 的外积来定义一个“选择”张量 C。然后可以将其与叶子中的值相乘,以创建网络的结果。
集成
正如名字所示,这些神经遗忘决策树会被集成在一起。一个 NODE 层被定义为m棵单独树的串联,每棵树都有自己的分支决策和叶值。如前所述,这种集成与单个树的遗忘性质协同作用,有助于提高准确性,同时减少过拟合的可能性。
多层 NODE
NODE 是一个灵活的架构,可以单独训练(结果是单一的决策树集成)或使用复杂的多层结构,其中每组集成从前一层获取输入。
多层 NODE 架构(图源于 Popov 等人 2019 年[1])
NODE 的多层架构紧密跟随了流行的 DenseNet 架构。每个 NODE 层包含若干棵树,其输出被串联起来作为后续层的输入。最终输出是通过对所有层中所有树的输出进行平均获得的。由于每一层依赖于所有之前预测的链条,网络能够捕捉到复杂的依赖关系。
实验性能
为了测试他们的架构,Popov 等人(2019 年)将 NODE 与 CatBoost [2]、XGBoost [4]、全连接神经网络、mGBDT [5] 和 DeepForest [6]进行了比较。他们的方法涉及在六个不同的数据集上测试这些模型。具体来说,他们进行了使用每个模型默认参数的比较,以及另一项使用调整后的超参数的比较。

NODE 与其他模型的比较结果(图来源于 Popov 等人,2019 年)
NODE 的实验结果极为令人鼓舞。例如,NODE 架构在所有其他模型的默认参数下表现优于它们。即使在调整参数的情况下,NODE 在 6 个选定数据集中的 4 个数据集上仍优于大多数其他模型。
结论
通过将决策树的优势融入神经网络架构,NODE 为深度学习在结构化表格数据普遍存在的领域(如金融、医疗保健和客户分析)开辟了新的可能性。
不过,这并不是说 NODE 是完美的。例如,架构的集成意味着使用神经决策树所获得的许多局部可解释性收益被舍弃,模型中只能获得全局特征重要性。然而,这一架构确实提供了改进神经可解释性的基础构件,并且已提出了一个后续模型 (NODE-GAM [7])以弥合可解释性差距。
此外,虽然 NODE 在许多浅层模型中表现优异,但我使用它的经验表明,即使使用 GPU,训练时间也较长(这一结论得到了论文作者提供的实验结果的支持)。
总体而言,这是一种极具前景的方法,我计划在未来开发的深度学习模型中积极使用它作为一个组件。
资源与参考文献
-
NODE 论文:
arxiv.org/abs/1909.06312 -
NODE 代码:
github.com/Qwicen/node -
NODE 也可以在 Pytorch Tabular 包中找到:
github.com/manujosephv/pytorch_tabular -
如果你对可解释机器学习或时间序列预测感兴趣,可以考虑关注我:
medium.com/@upadhyan。 -
查看我关于神经决策树的其他文章:
medium.com/@upadhyan/list/3b4a9cb97b84
参考文献
[1] Popov, S., Morozov, S., & Babenko, A. (2019). Neural oblivious decision ensembles for deep learning on tabular data. 第八届国际学习表征会议.
[2] Prokhorenkova, L., Gusev, G., Vorobev, A., Dorogush, A. V., & Gulin, A. (2018). CatBoost: unbiased boosting with categorical features. 神经信息处理系统进展, 31.
[3] Peters, B., Niculae, V., & Martins, A. (2019). 稀疏序列到序列模型。发表于第 57 届计算语言学协会年会论文集(第 1504–1519 页)。计算语言学协会。
[4] Chen, T., & Guestrin, C. (2016 年 8 月). Xgboost: 一个可扩展的树提升系统。发表于第 22 届 ACM SIGKDD 国际知识发现与数据挖掘会议论文集(第 785–794 页)。
[5] Feng, J., Yu, Y., & Zhou, Z. H. (2018). 多层梯度提升决策树。神经信息处理系统进展, 31。
[6] Zhou, Z. H., & Feng, J. (2019). 深度森林。国家科学评论, 6(1), 74–86。
[7] Chang, C.H., Caruana, R., & Goldenberg, A. (2022). NODE-GAM: 神经广义加性模型用于可解释的深度学习。发表于国际学习表征会议。
非负矩阵分解(NMF)用于图像数据的降维
使用 Python 和 Scikit-learn 讨论理论和实现


·发表于 Towards Data Science ·9 分钟阅读·2023 年 5 月 6 日
–
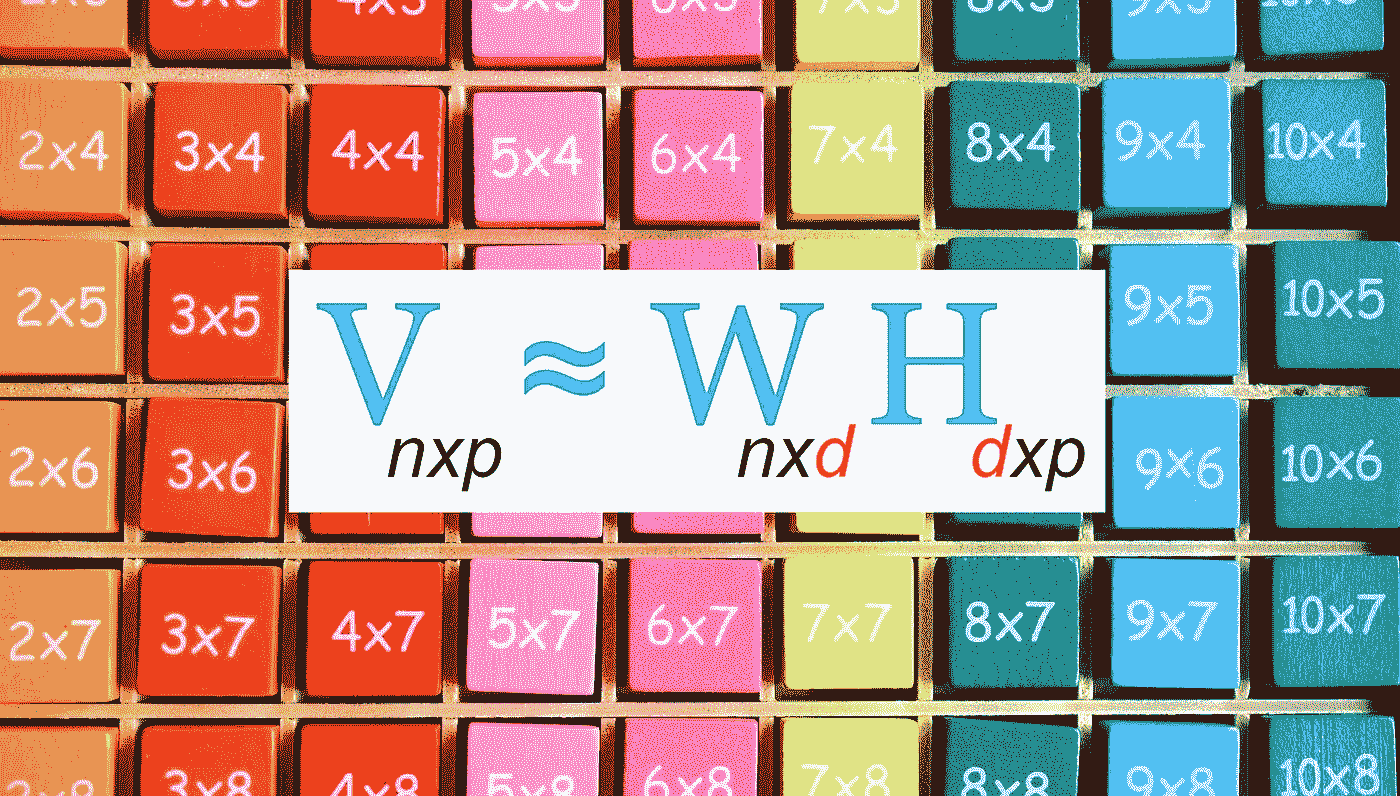
原图来自 an_photos 从 Pixabay(作者稍作编辑)
我已经详细讨论了不同类型的降维技术。
主成分分析(PCA)、因子分析(FA)、线性判别分析(LDA)、自编码器(AEs)和核主成分分析是最受欢迎的几种。
非负矩阵分解(NMF 或 NNMF)也是一种线性降维技术,可以用于减少特征矩阵的维度。
所有降维技术都属于无监督机器学习的范畴,通过这种方法,我们可以揭示数据中隐藏的模式和重要的关系,而不需要标签。
因此,降维算法处理的是无标签的数据。在训练这种算法时,fit() 方法只需要特征矩阵 X 作为输入,不需要标签列 y。
正如其名称所示,非负矩阵分解(NMF)需要特征矩阵为非负值。
由于这种非负性约束,NMF 的使用范围被限制在非负值的数据上,例如图像数据(像素值总是介于 0 和 255 之间,因此图像数据中没有负值!)。
**What you will learn:
----------------------------------------------------**
1\. Maths behind NMF
2\. NMF equation
3\. Feature matrix, V
4\. Transformed data matrix, W
5\. Factorization matrix, H
6\. Scikit-learn NMF() class
7\. Arguments, methods and attributes of NMF() class
8\. Load the MNIST with Scikit-learn
9\. Perform dimensionality reduction in image data
**Other matrix decomposition methods:
----------------------------------------------------** 1\. Eigendecomposition
2\. Singular value decomposition
非负矩阵分解(NMF)的数学原理
非负矩阵分解来源于线性代数。简单来说,它是将一个矩阵分解为两个小矩阵的乘积的过程。
更准确地说,
非负矩阵分解(NMF)是将一个非负特征矩阵 V (nxp) 分解为两个非负矩阵 W (nxd) 和 H (dxp) 的乘积的过程。这三个矩阵都应包含非负元素。

非负矩阵分解方程(作者图片)
W 和 H 矩阵的乘积仅能给出矩阵 V 的近似值。因此,在应用 NMF 时应预期会有一些信息损失。
-
V (n x p): 表示特征矩阵,其中 n 是观察(样本)的数量,p 是特征(变量)的数量。这是我们要分解的数据矩阵。
-
W (n x d): 表示应用 NMF 后的转化数据矩阵。我们可以用这个转化后的矩阵代替原始特征矩阵V。因此,W 是 NMF 的最重要输出。它通过调用 Scikit-learn NMF 的 fit_transform() 方法获得。n 是观察(样本)的数量,d 是潜在因素或组件的数量。换句话说,d 描述了我们希望保留的维度量。实际上,这是一个超参数,我们需要在 Scikit-learn NMF 的 n_components 参数中指定。这个整数值应该小于特征数量 p,且大于 0。选择合适的 d 值是执行 NMF 时的一个真正挑战。我们需要考虑信息量与我们希望保留的组件数量之间的平衡。
from sklearn.decomposition import NMF
# W = transformed data matrix, V = original feature matrix
W = NMF(n_components=d).fit_transform(V)
- H (d x p): 表示分解矩阵。d 和 p 的定义如上所述。这个矩阵不是特别重要。然而,可以通过调用 Scikit-learn NMF 的 components_ 属性来获得。
from sklearn.decomposition import NMF
# H = factorization matrix
H = NMF(n_components=d).fit(V).components_
非负矩阵分解(NMF)的 Python 实现
在 Python 中,NMF 通过使用 Scikit-learn 的 NMF() 类来实现。如你所知,Scikit-learn 是 Python 的机器学习库。
你只需导入 NMF() 类,并通过指定所需的参数来创建其实例。
# Import
from sklearn.decomposition import NMF
# Create an instance
nmf_model = NMF(n_components, init, random_state)
NMF() 类的重要参数
-
n_components: 定义组件或潜在因素的数量或我们希望保留的维度量的整数值。最重要的超参数!该值小于原始特征数量,并且大于 0。
-
init: 初始化过程的一种方法。NMF 模型返回的结果会因所选择的 init 方法而显著不同。
-
random_state: 在初始化方法为 ‘nndsvdar’ 或 ‘random’ 时使用。使用一个整数以确保不同执行之间结果的一致性。
注意: NMF() 类中有许多参数。如果我们没有指定它们,调用**NMF()**函数时将采用默认值。要了解更多关于这些参数的信息,请参阅 Scikit-learn 文档。
NMF() 类的重要方法
-
fit(V): 从特征矩阵V中学习 NMF 模型。这里不应用任何转换。
-
fit_transform(V): 从特征矩阵V中学习 NMF 模型,并返回转换后的数据矩阵W。
W = nmf_model.fit_transform(V)
- transform(V): 返回经过拟合模型后的转换数据矩阵W。
nmf_model.fit(V) # Fitted model
W = nmf_model.transform(V)
- inverse_transform(W): 将数据矩阵W转换(恢复)回原始空间。对可视化非常有用!
recovered_data = nmf_model.inverse_transform(W)
NMF() 类的重要属性
- components_: 返回分解矩阵H。这个矩阵不是非常重要。
H = nmf_model.components_
- reconstruction_err_: 返回一个浮点数表示的 beta 散度,该值衡量V与WH的乘积之间的距离。求解器在训练过程中尝试最小化此误差。通过设置不同的n_components值来分析此误差是选择正确的组件数量的一个好方法,d。
使用非负矩阵分解(NMF)减少图像数据的维度
我们将使用 MNIST 数字数据集来完成这个任务。我们将对 MNIST 数据进行 NMF 处理,通过选择不同数量的组件来降低维度,然后将每个输出与原始数据进行比较。
第 1 步:使用 Scikit-learn 加载 MNIST 数据集
MNIST 数字数据集可以使用 Scikit-learn 按如下方式加载。
from sklearn.datasets import fetch_openml
mnist = fetch_openml('mnist_784', version=1)
image_data = mnist['data']
print("Shape:", image_data.shape)
print("Type:", type(image_data))

(图片由作者提供)
数据集被加载为 Pandas 数据框。形状为(70000, 784)。数据集中有 70000 个观测值(图像)。每个观测值有 784 个特征(像素值)。图像的大小为 28 x 28。以这种方式加载 MNIST 数据集时,每张图像被表示为一个包含 784(28 x 28)元素的一维数组。这是我们完成此任务所需的格式,数据集无需进一步修改。
或者,你也可以使用 Keras 加载 MNIST 数据集。那样的话,你将获得每张图像的 28 x 28 二维数组,而不是一维数组。你可以在这里了解更多信息。
第 2 步:可视化原始图像的样本
现在,我们将可视化 MNIST 数据集中前五张图像的样本。这个样本可以用来与 NMF 模型的输出进行比较。
import matplotlib.pyplot as plt
n = 5
plt.figure(figsize=(6.75, 1.5))
for i in range(n):
ax = plt.subplot(1, n, i+1)
plt.imshow(image_data.iloc[i].values.reshape(28, 28), cmap="binary")
ax.axis('off')
plt.show()
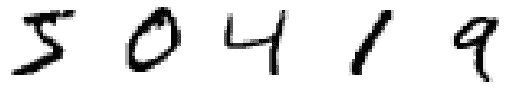
原始 MNIST 数字的样本(图片由作者提供)
第 3 步:应用具有 9 个组件的 NMF(d = 9)
from sklearn.decomposition import NMF
nmf_model = NMF(n_components=9, init='random', random_state=0)
image_data_nmf = nmf_model.fit_transform(image_data)
print("Shape:", image_data_nmf.shape)
print("Type:", type(image_data_nmf))
(图片由作者提供)
现在,新的维度是 9。原始维度为 784。因此,维度已经显著降低!
要获取V、W和H矩阵的形状,我们可以运行以下代码。
print("V_shape:", image_data.shape)
print("W_shape:", image_data_nmf.shape)
print("H_shape", nmf_model.components_.shape)

(图片由作者提供)
要获取重建误差或V与WH乘积之间的β散度,我们可以运行以下代码。
nmf_model.reconstruction_err_

(图片由作者提供)
重建误差非常高。这是因为我们只选择了 784 中的 9 个组件。我们可以通过可视化输出来验证这一点。
image_data_nmf_recovered = nmf_model.inverse_transform(image_data_nmf)
n = 5
plt.figure(figsize=(6.75, 1.5))
for i in range(n):
ax = plt.subplot(1, n, i+1)
plt.imshow(image_data_nmf_recovered[i, :].reshape(28, 28), cmap="binary")
ax.axis('off')
plt.show()
NMF 输出:9 个组件或 d = 9

NMF 输出:9 个组件或 d = 9(图片由作者提供)
数字不清晰。你可以将此输出与原始图像的样本进行比较。
我运行了 NMF 算法,选择了 100、225 和 784 个组件。以下是结果。
NMF 输出:100 个组件或 d = 100
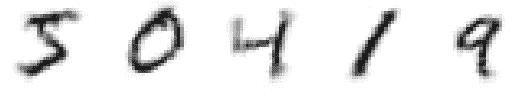
NMF 输出:100 个组件或 d = 100(图片由作者提供)
重建误差为 174524.20。
NMF 输出:225 个组件或 d = 225
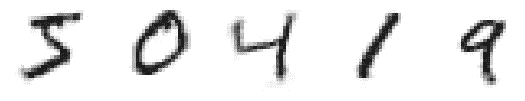
NMF 输出:225 个组件或 d = 225(图片由作者提供)
重建误差为 104024.62。
NMF 输出:784 个组件或 d = 784(所有组件)
NMF 输出:784 个组件或 d = 784(图片由作者提供)
重建误差为 23349.67。
结论
当运行非负矩阵分解(NMF)时,组件数量增加,图像变得更清晰,重建误差变得更低。
通过查看输出和重建误差,可以选择一个合适的d值。为此,你需要多次运行 NMF 算法,这可能会根据你计算机的资源而耗时。
使用 d = 784(所有组件),你仍然会得到 23349.67 的重建误差,而不是零。
显然,W 和 H 矩阵的乘积仅仅给出了特征矩阵 V 的非负矩阵近似。
我们能在负矩阵上运行 NMF 吗?
答案是不。如果你尝试使用含有负值的特征矩阵进行 NMF,你将得到以下ValueError!
import numpy as np
from sklearn.decomposition import NMF
V = np.array([[1, 1, -2, 1], [2, 1, -3, 2], [3, 1.2, -3.3, 5]])
nmf_model = NMF(n_components=2, init='random', random_state=0)
W = nmf_model.fit_transform(V)
print("V_shape:", V.shape)
print("W_shape:", W.shape)
print("Reconstruction error:", nmf_model.reconstruction_err_)

ValueError!(图片由作者提供)
在运行非负矩阵分解(NMF)时,不能打破非负性约束。特征矩阵应始终包含非负元素。
这是今天文章的结束。
如果你有任何问题或反馈,请告诉我。
你可能感兴趣的其他矩阵分解方法
-
奇异值分解
阅读下一篇(推荐)
-
RGB 与灰度图像在 NumPy 数组中的表示
来一门 AI 课程怎么样?
加入我的私人邮件列表
永远不要再错过我的精彩故事。通过 订阅我的邮件列表,你将直接收到我发布的故事。
非常感谢你们的持续支持!下篇文章见。祝大家学习愉快!
MNIST 数据集信息
-
引用: Deng, L., 2012. The mnist database of handwritten digit images for machine learning research. IEEE Signal Processing Magazine, 29(6), pp. 141–142.
-
许可证: Yann LeCun(纽约大学 Courant 研究所)和Corinna Cortes(谷歌实验室,纽约)持有 MNIST 数据集的版权,该数据集在Creative Commons Attribution-ShareAlike 4.0 International License(CC BY-SA)下提供。你可以在这里了解更多不同的数据集许可证类型。
设计与撰写:
2023–05–06
非参数检验入门(第一部分:秩和符号检验)
原文:
towardsdatascience.com/non-parametric-tests-for-beginners-part-1-rank-and-sign-tests-629704f27f2f
附有示例和 R 代码


·发表于Towards Data Science ·阅读时长 9 分钟·2023 年 6 月 1 日
–

图片由Joshua Earle提供,来源于Unsplash
非参数检验是推断统计的一个重要分支。然而,许多数据科学家和分析师对它的使用还不广泛,也没有完全理解它。它是传统 t 检验等参数检验的自然替代方法,具有一系列优点,并在现代应用如 A/B 测试中具有很大的潜力。
非参数检验基于数据点的秩或符号,或使用如自助法(bootstrap)等重采样方法构建。在这篇文章中,讨论了基于秩和符号的检验,并提供了示例和 R 代码。自助法将在系列的第二部分中讨论。我想感谢 Venkat Raman,他最近的LinkedIn 帖子激发了这篇文章的写作。
1. 参数检验与非参数检验
推断统计或假设检验的关键元素如下:
-
零假设和备择假设(H0 和 H1)
-
检验统计量
-
在 H0 下的检验统计量的采样分布
-
决策规则(p 值或临界值,在给定的显著性水平下)
参数检验
包括诸如 t 检验、F 检验和卡方检验等知名检验。参数检验的一个典型特征是
-
这需要估计未知参数,如均值和方差;以及
-
它的采样分布遵循正态分布或由正态分布衍生出的其他分布(例如,F 分布或卡方分布)。
为确保采样分布的正态性,总体应遵循正态分布。如果总体不正态,则当样本量足够大时,采样分布可以通过正态分布进行近似。这称为渐近近似,其有效性基于在一系列参数假设下的中心极限定理。
非参数检验
非参数检验以不同于其参数对等方法的方式计算检验统计量及其采样分布:
-
这些分布是通过完全依赖数据的方法获得的,例如数据点的秩和符号,而不需要估计总体参数。
-
非参数检验具有精确的采样分布,即它可以在不依赖任何近似的情况下获得。该分布要么完全通过解析获得,要么可以通过蒙特卡罗模拟计算获得。
非参数检验的优点包括以下几点:
-
它不需要强参数假设,如总体的正态性;
-
它不需要对其采样分布进行渐近近似;
-
由于采样分布是精确的,因此显著性水平(第一类错误的概率)在重复采样中始终是正确的(无规模失真);
-
它的 p 值和临界值也是精确的;
-
它的检验功效(拒绝虚假零假设的概率)通常高于其参数替代方法,尤其是在样本量较小的情况下。
它的主要缺点是当样本量较大或非常大时,计算精确的采样分布(以及精确的 p 值和临界值)可能会很耗时。然而,这在现代计算能力日益增强的情况下是一个小问题。此外,许多非参数检验采用解析公式或高效算法,当计算负担较重时,可以准确地近似其精确 p 值或临界值。
2. 简单的非参数检验
中位数的符号检验
考虑一个完全随机从其总体中生成的变量 X。使用其样本实现 (X1, …, Xn),研究者希望进行检验
H0: 中位数 = 0;H1: 中位数 ≠ 0。
在 H0 下,每个 X 值应为正(或负),概率为 0.5。或者,在 H0 下,X 的正案例的期望数为 n/2。
设测试统计量 T(X,n) 为 X > 0 的总案例数。假设 H0 下 T(X,n) 的采样分布服从一个具有 n 次试验的二项分布,每次试验的成功概率 § 等于 0.5,记作 B(n, p = 0.5)。分布 B(n=20, p = 0.5) 如下图所示:
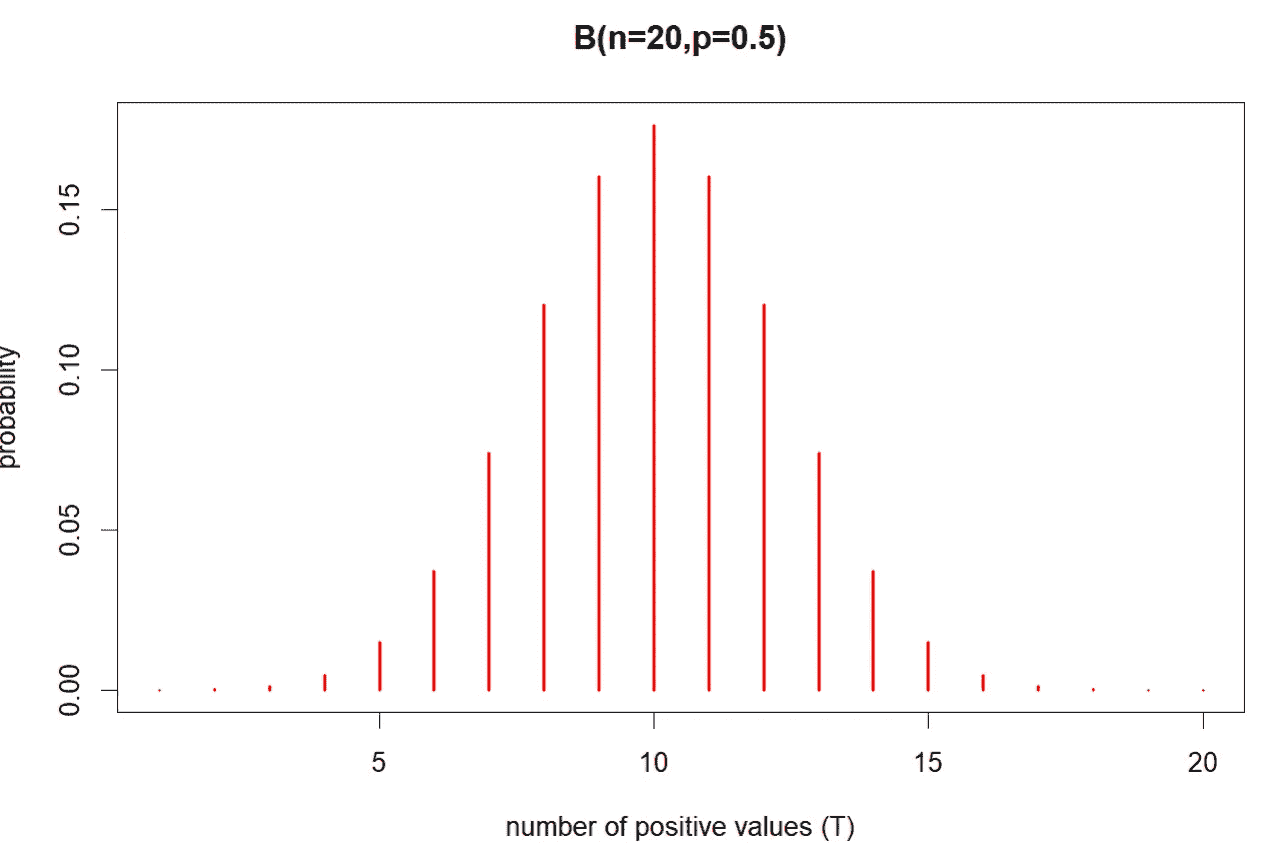
T(X, n=20) 的精确采样分布,图片由作者创建
上述是 n = 20 时在 H0 下检验统计量 T(X,n) 的精确采样分布。如果 T(X,n) 的观测值接近 10,则不能拒绝原假设。检验的精确 p 值可以使用 R 中的 binom.test 函数计算。
作为一个例子,考虑以下的 X 和 Y 值,其中 n = 20。
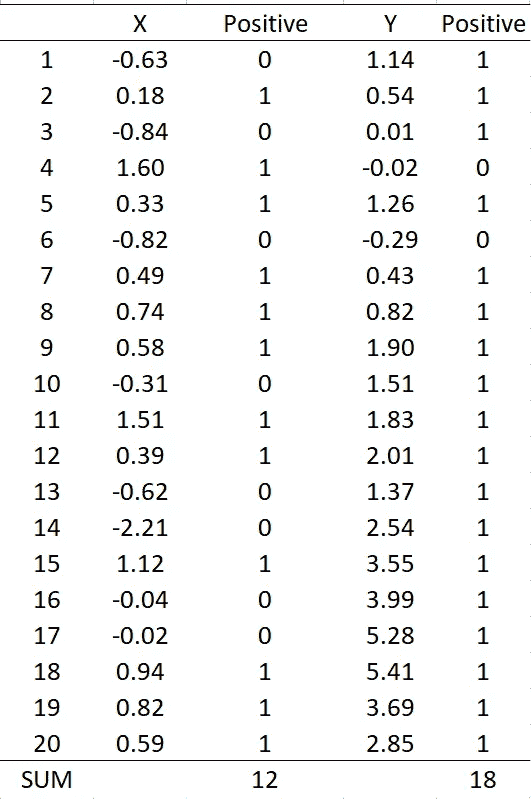
表 1(如果 X > 0 则 Positive = 1;否则 Positive = 0),图像由作者创建
从上表 1 可知,T(X) = 12 和 T(Y) = 18,X 的中位数为 0.36,Y 的中位数为 1.67。显然,X 与 H0 高度兼容,而 Y 不兼容。X 的检验精确 p 值为 0.5034,Y 的检验精确 p 值为 0.0004,这些可以使用下面的 R 函数获得:
x = c(-0.63, 0.18,-0.84,1.60,0.33, -0.82,0.49,0.74,0.58,-0.31,
1.51,0.39,-0.62,-2.21,1.12,-0.04,-0.02,0.94,0.82,0.59)
y=c(1.14,0.54,0.01,-0.02,1.26,-0.29,0.43,0.82,1.90,1.51,
1.83,2.01,1.37,2.54,3.55, 3.99,5.28,5.41,3.69,2.85)
# Test statistics
Tx=sum(0.5*(sign(x)+1)); Ty=sum(0.5*(sign(y)+1))
# Sign test
binom.test(x=Tx,n=20,p=0.5); binom.test(x=Ty,n=20,p=0.5)
当 n 较大时,采样分布仍然精确地遵循 B(n, p = 0.5)。然而,该分布接近于均值为 0.5n 和方差为 0.25n 的正态分布。因此,当 n 较大时,正态分布可以作为精确分布 B(n, p=0.5) 的近似。
2. 随机性秩检验
可以使用数据的秩对一组时间序列观测进行简单的随机性检验。秩是样本观测值(X1, …, Xn)按升序排列的排名值。即,值 1 被分配给 X 的最小值;值 2 被分配给 X 的下一个最小值;依此类推,直到值 n 被分配给最大值。
原假设是时间序列是完全随机的,而备择假设是时间序列不是完全随机的。Bartels (1982) 提出了以下形式的检验统计量:
方程 (1)
其中 Ri 是第 i 个值 (Xi) 在 n 次观测序列中的秩。在原假设下,(R1, …, Rn)以相等的概率遵循(1, …., n)的任何排列。这是因为如果时间序列观测是完全随机的,其秩也应是完全随机的。基于这一点,RV 的精确分布可以使用以下 R 代码进行模拟:
nit=50000 # number of Monte Carlo iterations
n=20 # Sample size
# Calculating RV statistic
RV=matrix(NA,ncol=1,nrow=nit)
for (i in 1:nit) {
ranking <- sample(1:n, n, replace = FALSE)
RV[i,] = sum(diff(ranking)²)/(n*(n²-1)/12)
}
# Histogram
hist(RV)
# Critical Values replicating the values in Table 2 of Bartels (1982)
quantile(RV,probs = c(0.01,0.05,0.10))
1% 5% 10%
1.013534 1.285714 1.439098
上述 R 代码生成了在 H0 下 n = 20 时的 RV 精确采样分布,绘制在下方:

RV 的精确采样分布,图像由作者创建
精确的 p 值或临界值是按照通常的方式从上述分布中获得的。请注意,临界值(用上面的 R 代码给出)与 Bartels(1982)列出的值几乎相同。
如果方程 (1) 中给出的计算 RV 统计量小于显著性水平下的临界值,则拒绝完全随机的原假设。这是因为完全随机的序列的秩值也应是完全随机的,这会导致 RV 统计量的值较大(见下面的例子)。
当样本量较大或巨大的时候,上述模拟仍然可以进行,以生成确切的采样分布,而不会带来很大的计算负担。Bartels(1982)还提供了这些确切临界值的近似公式。
例如,考虑表 1 中的 X 和 Y,如下图所示:
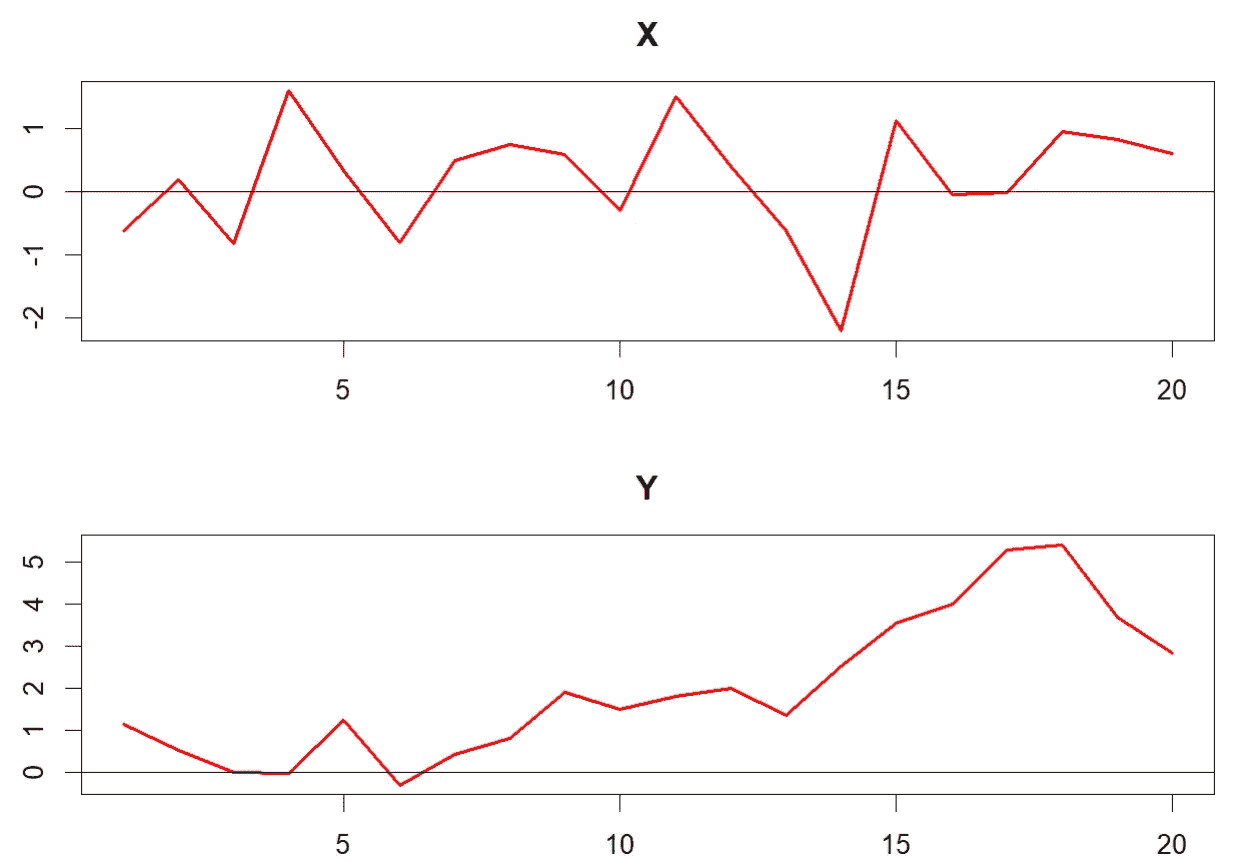
X 和 Y 的时间图(图片由作者创建)
变量 X 围绕 0 随机变化,而 Y 则显示出上升趋势,这是非纯随机时间序列的特征。以下 R 代码绘制了 X 和 Y,并计算了 RV 统计量及其 p 值:
# plots
plot.ts(x,col="red",lwd=2,main="X"); abline(h=0)
plot.ts(y,col="red",lwd=2,main="Y"); abline(h=0)
# RV statistics and p-values
library(trend)
bartels.test(x); bartels.test(y)
X 的 RV 统计量为 2.21,p 值为 0.6844;而 Y 的为 0.32,p 值为 0.0000。这意味着在常规显著性水平下,不能拒绝 X 是纯随机的零假设,但 Y 的零假设被拒绝。
计算过程也在下表中说明:
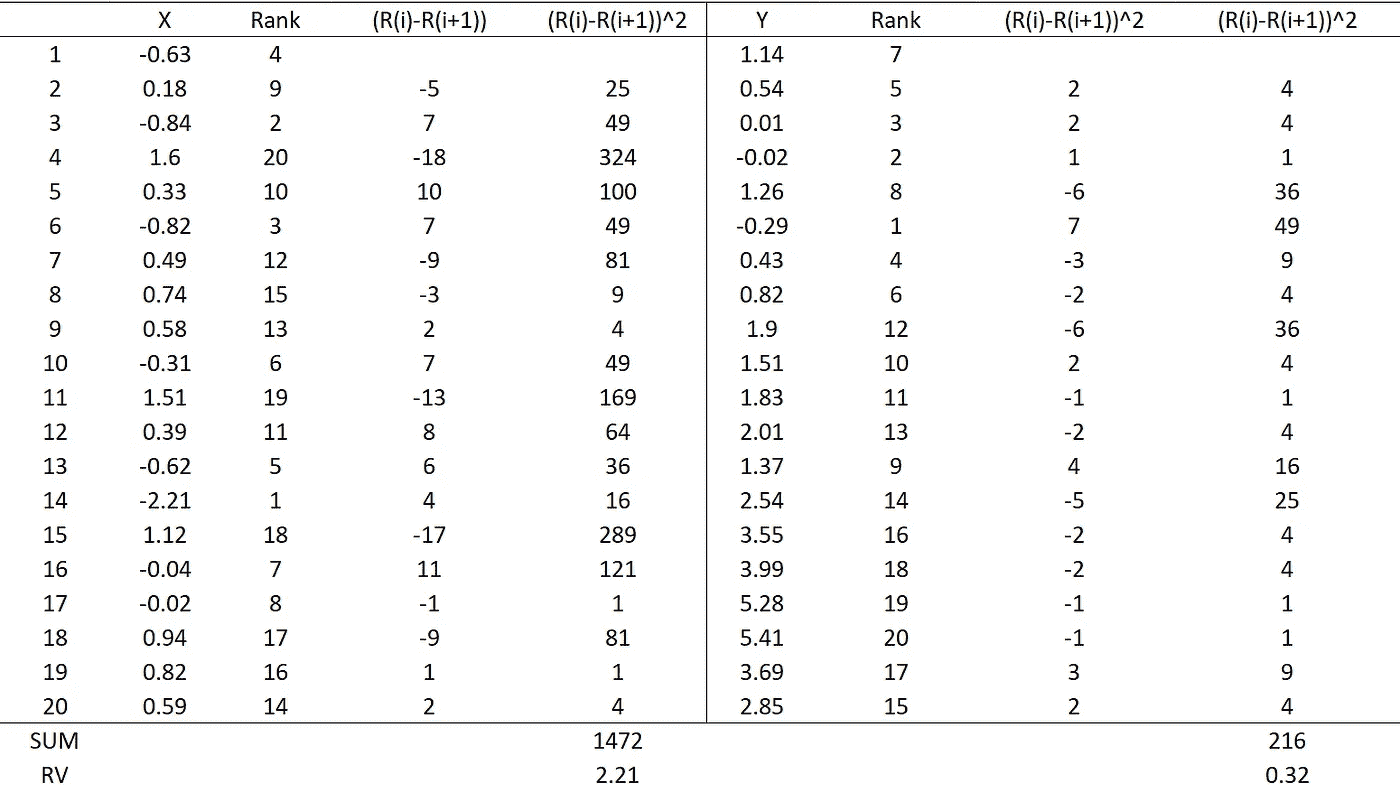
X 和 Y 的 RV 统计量的说明(图片由作者创建)
作为一个纯随机序列,X 的秩值完全随机且高度变化(导致 RV 的分子值很大)。相反,Y 不是纯随机的,其秩值变化不大。由于这一特性,X 的 RV 统计量比 Y 的要大得多。
3. 威尔科克森检验
威尔科克森检验(McDonald, 2014)是 Welch 两样本 t 检验的非参数替代方法。零假设是两个总体的中位数值相等,对立假设是它们不相等。检验有两个版本:
-
威尔科克森秩和检验(也称为 Mann–Whitney–Wilcoxon 检验),当 X 和 Y 独立时;以及
-
威尔科克森符号秩检验,当 X 和 Y 配对时。
设(X1, …, Xn)和(Y1, …, Ym)为来自各自总体的随机样本。独立样本的检验统计量(威尔科克森秩和检验)为
其中 S(X,Y) = 1,如果 X > Y;S(X,Y) = 0.5,如果 X = Y;S(X,Y) = 0,如果 X < Y。
依赖样本情况下的统计量(威尔科克森符号秩检验)计算为
其中 Zi = Xi — Yi;如果 Zi > 0,则 sgn(Zi) = 1;否则 sgn(Zi) = —1;Ri 为|Zi|(Zi 的绝对值)的秩。注意有不同版本的 T 统计量,但它们都是等效的。
对于 U 和 T 统计量,H0 下的确切采样分布可以通过蒙特卡罗模拟获得,也可以进行近似。
对于表 1 中给出的 X 和 Y,威尔科克森检验的 R 代码为
# Wilcoxon rank-sum test (U)
wilcox.test(x,y,mu=0,paired = FALSE,exact=TRUE)
# Wilcoxon signed rank test (T)
wilcox.test(x,y,mu=0,paired = TRUE,exact=TRUE)
其中 H0: μ = 0 且μ = median(X) — median(Y)。U 检验统计量为 67.5,p 值为 0.0004;T 统计量为 11,p 值为 0.0001。因此,在 5%的显著性水平下,两者均拒绝了中位数相等的零假设。
本文回顾了三种基于秩和符号的简单非参数检验。非参数检验和参数检验之间的主要区别在于检验统计量及其在 H0 下的采样分布的计算方式。也就是说,
-
非参数检验的检验统计量和采样分布是使用完全依赖数据的方法获得的,如秩和符号,而不需要估计未知的总体参数。
-
它们是在没有依赖任何参数假设或基于中心极限定理的渐近近似的情况下获得的。
-
非参数检验的采样分布是精确的。因此,检验在没有任何规模失真的情况下进行,其 p 值和临界值都是精确的。
-
非参数检验通常比其参数检验对照显示出更好的统计性质(例如,更高的统计功效和没有规模失真),尤其是当样本量较小或参数检验的假设被违反时。
强烈建议研究人员在他们的应用中(例如 A/B 测试)采用这些非参数检验作为参数检验的替代方案。在这篇文章中,介绍了几个简单的非参数检验,附有示例和 R 代码。
参考文献:
Bartels, R. (1982). 《冯·诺伊曼随机性比率检验的秩版本》。美国统计学会杂志, 77(377), 40–46。
McDonald, J. H. (2014). 生物统计学手册. 纽约。 www.biostathandbook.com/wilcoxonsignedrank.html
非线性维度降低、核 PCA(kPCA)和多维尺度分析— Python 简单教程
如何在不破坏瑞士卷的情况下将其展平!!


·发表于 Towards Data Science ·阅读时长 11 分钟·2023 年 12 月 11 日
–
瑞士卷数据(作者提供的图片)
在我的文章 主成分分析(PCA)— Python 简单教程 中,我讨论了如何使用 PCA 来减少数据的维度,同时尽可能保留点对点之间的距离。我用 MNIST 手写数据集举了一些例子,说明 PCA 如何将数据的维度从 784 降到 35,并且仍然能够使用高准确度的监督学习技术。
在这篇文章中,我们以一个简单的瑞士卷数据的三维示例开始,其中数据的真实流形具有 2 维,我们将从 PCA 开始。
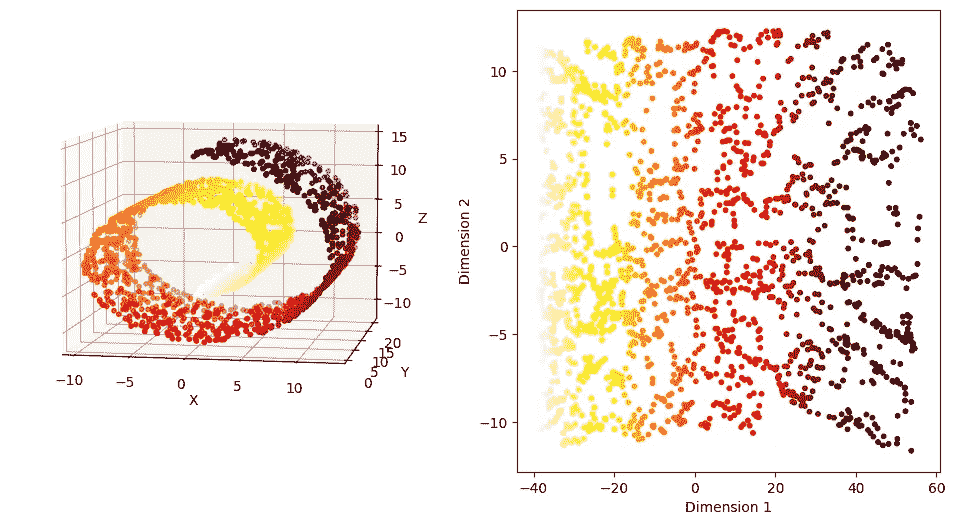
示例:瑞士卷数据集
图 1 显示了使用sklearn库模拟的瑞士卷数据,包含𝑛=2000 个点。散点图显示了不同颜色的点分布在螺旋的不同部分。
#Load the libraries
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
#Generate the Swiss Roll Dataset
from sklearn.datasets import make_swiss_roll
np.random.seed(42)
n_samples = 2000
X, t = make_swiss_roll(n_samples, noise=0.0)
fig = plt.figure(figsize=(10,8))
ax = fig.add_subplot(projection='3d')
ax.scatter(X[:,0], X[:,1], X[:,2], c=t, s=10, cmap='hot_r')
ax.set_xlabel('X')
ax.set_ylabel('Y')
ax.set_zlabel('Z')
#ax.set_zlim(-1,1)
ax.view_init( elev=7, azim=-80)
plt.show()

图 1:瑞士卷数据的三维视图(作者提供的图片)
我们首先对这个数据集应用 PCA,并在图 2 中可视化前两个主成分。我们观察到它仍然保留了数据的螺旋形状。螺旋的不同部分的点无法使用线性边界分离,大多数分类方法在降维后的数据上将会失败。
from sklearn.decomposition import PCA
pca_X = PCA(n_components=2)
prcomps_X= pca_X.fit_transform(X)
fig = plt.figure(figsize=(6,4))
plt.scatter(prcomps_X[:,0], prcomps_X[:,1],c=t, s=10, cmap='hot_r')
plt.xlabel('PCA Dimension 1')
plt.ylabel('PCA Dimension 2')
plt.show()
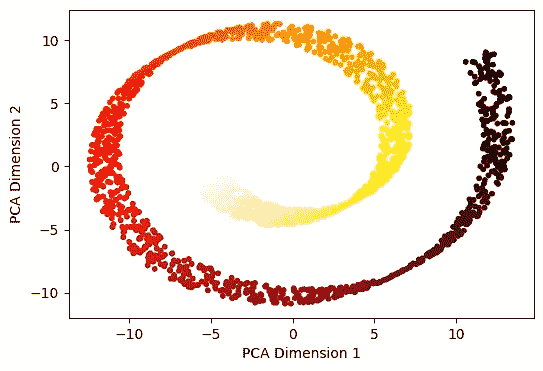
图 2:瑞士卷数据的前两个主成分维度(作者提供的图片)
它没有展开潜在的二维空间。为什么会这样?为了理解这一点,我们来看一下图 3,其中两点 A 和 B 之间的欧几里得距离用蓝色虚线表示。尽管这两点位于螺旋的完全不同部分,它们在欧几里得距离上却很接近。
u = np.linspace(0,1,100)
t1 = 1.5*np.pi*(1+2*u)
x1 = t1*np.cos(t1)
z1 = t1*np.sin(t1)
y1 = 10*np.ones((len(t1),))
fig = plt.figure(figsize=(10,8))
ax = fig.add_subplot(projection='3d')
ax.scatter(X[:,0], X[:,1], X[:,2], s=2,c='gray')
ax.plot(x1[20:90],y1[20:90],z1[20:90], c='red',linewidth=2.0)
ax.plot(x1[[20,89]],y1[[20,89]],z1[[20,89]], 'b--',linewidth=2.0)
ax.scatter(x1[[20,89]],y1[[20,89]],z1[[20,89]], 'o',s=50, alpha=1)
ax.text(x1[20], y1[20], z1[20]+1, s='A',c='k',fontweight='bold',size=12,alpha=1 )
ax.text(x1[89], y1[89], z1[89]+1, s='B',c='k',fontweight='bold',size=12,alpha=1 )
ax.set_xlabel('X')
ax.set_ylabel('Y')
ax.set_zlabel('Z')
ax.view_init(7,-80)
plt.show()

图 3:瑞士卷数据的测地距离与欧几里得距离(图片由作者提供)
在 PCA 中,欧几里得距离被保留。然而,这两点 A 和 B 沿螺旋流形的距离由红线显示,表明这两点在流形上相距较远。关键区别在于流形不是线性的。当我们处理线性流形时,欧几里得距离或 PCA 的效果非常好。但数据往往不在直线流形上,如这个示例数据集所示。其他图像数据,如手写数字数据,是高维数据中非线性流形的好例子。
我们需要以不同的方式定义距离以捕捉这种差异。但在此之前,我们先讨论一下如何利用距离构建主成分。
主成分:数学公式
给定一个 𝑛×𝑝 数据矩阵 𝐗,主成分方向 被定义为在这些方向上,𝐗 的样本方差依次被最大化的 𝑝 维正交向量。对于中心化的 𝐗,即 𝐗 的每一列之和为 0,第 𝑘 个主成分方向是
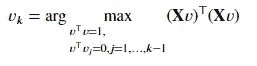
𝑛 维向量 𝐗𝑣_𝑘 称为 𝐗 的第 𝑘 个 主成分得分,且 𝑢_𝑘=(𝐗𝑣_𝑘)/𝑑_k 是归一化的第 𝑘 个主成分得分,其公式为

数量 d²_k/n 是 𝑣_𝑘 解释的方差量。
𝐗 的 奇异值分解 𝐗 = 𝑈𝐷𝑉^⊤ 描述了所有主成分得分和方差,其中 𝑈 是一个 𝑛×𝑝 维矩阵,列为 𝑢_1,𝑢_2,…,𝑢_𝑝,𝑉 是一个 𝑝×p 维矩阵,列为 𝑣_1,𝑣_2,…,𝑣_𝑝,𝐷 是一个 𝑝×𝑝 的对角矩阵,对角元素为 𝑑_1,𝑑_2,…,𝑑_𝑝。
让我们考虑前 𝑘 个主成分得分 𝐗𝑣_1=𝑑_1𝑢_1, …, 𝐗𝑣_𝑘=𝑑_𝑘𝑢_𝑘 作为新的特征向量。然后我们可以将其写成 𝐙=𝐗𝑉_𝑘=(𝑈𝐷)_𝑘,也就是矩阵 (𝑈𝐷) 的前 𝑘 列,并将 Z 视为 𝐗 的新低维表示。
𝐙 的行 𝑧_1,…,𝑧_𝑛 是这个新低维表示中的数据点。我们之前讨论过

在低维表示中,𝑖 和 𝑗 点之间的欧几里得距离大致等于这两点之间的原始欧几里得距离。
内积矩阵
𝑛×𝑛 维矩阵 𝐗𝐗^⊤ 被称为 内积矩阵,其 (𝑖,𝑗) 元素由 𝑥_i^⊤x_j 给出,即矩阵 𝐗 的第 𝑖 行和第 𝑗 行之间的内积。从上面我们可以得出
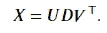
因此我们可以写道,

这称为 𝐗𝐗^⊤ 的 特征分解,因为 𝑈 的列是 𝐗𝐗^⊤ 的特征向量。从这个表示中,我们可以简单地计算特征分解或 分解 内积矩阵 𝐗𝐗^⊤,然后主成分得分由 𝑈𝐷 的列给出,即 𝑑_𝑗𝑢_𝑗,𝑗=1,…,𝑝。这表明,如果仅给出内积矩阵而不是原始数据点,则可以计算主成分得分。
仅从距离中获得的低维表示
假设我们只有数据点之间的距离,而没有原始数据。也就是说,我们有欧几里得距离。

或者所有 𝑖 和 𝑗。我们还能从这些距离中恢复主成分方向吗?
首先定义一个 𝑛×𝑛 维的距离矩阵 Δ,其中 (𝑖,𝑗) 元素由 Δ_𝑖𝑗 给出。我们可以从距离矩阵 Δ 恢复内积矩阵 𝐵=𝐗𝐗^⊤。
- 创建 𝑛×𝑛 矩阵 𝐴,其 (𝑖,𝑗) 元素由
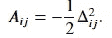
2. 对 𝐴 进行双重中心化,即同时中心化 𝐴 的列和行,通过使用变换 B = (I — M)A(I — M) 来恢复矩阵 𝐵,其中

核主成分分析
核主成分分析通过用核矩阵 𝐾=((𝐾_𝑖𝑗)) 替换内积矩阵 𝐵 来简单模拟此过程,其中 𝐾_𝑖𝑗=<𝜙(𝑥_𝑖),𝜙(𝑥_𝑗)>,即特征向量 𝜙(𝑥_𝑖) 和 𝜙(𝑥_𝑗) 之间的内积。这里 𝜙 是从 ℝ^𝑝 → 𝐹 的非线性映射,𝐹 是任意维度的特征空间。这个想法类似于用于分类问题的支持向量机(SVM)中的核函数。我们将观察值投影到一个更高维的空间中,然后在该空间中获得主成分。我们可以简单地定义 𝐾_𝑖𝑗=Φ(𝑥_𝑖,𝑥_𝑗),对于径向基核,
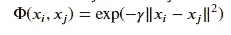
对于多项式核,
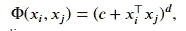
其中 𝛾、𝑐 和 𝑑 是相应核函数的参数。
算法可以描述如下:
-
将 𝑛×𝑛 核内积矩阵 𝐾 定义为 𝐾=((Φ(𝑥_𝑖,𝑥_𝑗))。
-
使用 𝐾 的特征分解来提取 𝐾 的特征值和特征向量。
-
𝐾 的特征向量将给出主成分得分。
这是一种非线性降维,我们可以通过在前面示例中讨论的 瑞士卷 数据来说明核主成分分析的使用。
from sklearn.decomposition import KernelPCA
kpca_X = KernelPCA(n_components=2, kernel='rbf', gamma=0.002)
prcomps_kX= kpca_X.fit_transform(X)
fig = plt.figure(figsize=(6,4))
plt.scatter(prcomps_kX[:,0], prcomps_kX[:,1],c=t, s=10, cmap='hot_r' )
plt.xlabel('Kernel PCA Dimension 1')
plt.ylabel('Kernel PCA Dimension 2')
plt.show()
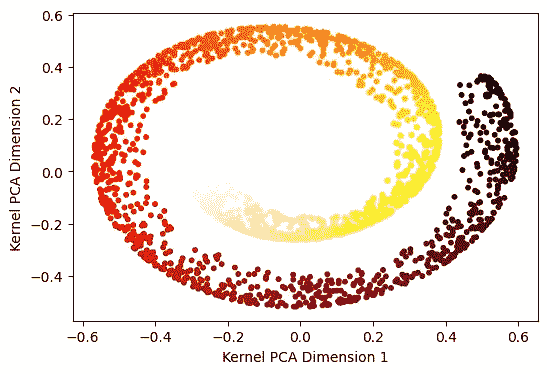
图 4:瑞士卷数据的核主成分分析维度(作者提供的图片)
在上述内容中,我们使用了一个rbf核,𝛾 = 0.002。尽管结果相比主成分分析有所改进,但它仍然没有展开瑞士卷数据,而是很好地捕捉了流形。
我们在下面用不同的模拟数据集展示了核主成分分析。

图 5:左侧模拟数据的核 PCA 维度。(作者提供的图片)
在左侧,我们有一个包含半径分别为 1.0、2.8 和 5.0 的 3 个同心圆的模拟数据,分布均匀。在右侧,我们绘制了使用rbf核和𝛾=0.3 的核 PCA 组件。我们观察到数据的三个簇之间有很好的分离。
多维缩放
我们在关于 PCA 的文章中讨论过,它试图在低维表示中保留观察之间的距离。换句话说,如果 𝑧_1,𝑧_2,…,𝑧_𝑛 是 𝑥_1,𝑥_2,…,𝑥_𝑛 的低维表示,那么 PCA 最小化

我们现在通过定义一个压力函数来推广这个想法,如下所示:
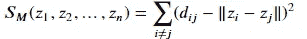
其中 𝑑_𝑖𝑗 是 𝑥_𝑖 和 𝑥_𝑗 之间的距离。通常,我们选择欧几里得距离,但也可以使用其他距离。
多维缩放寻求值 𝑧_1,𝑧_2,…,𝑧_𝑛∈ℝ^𝑘,以最小化压力函数 𝑆_𝑀(𝑧_1,𝑧_2,…,𝑧_𝑛)。
这被称为最小二乘或Kruskal–Shephard 缩放。这个想法是找到一个低维的数据表示,尽可能保留成对的距离。请注意,这种近似是基于距离而不是平方距离的。
让我们看看它在瑞士卷数据上的实现。
from sklearn.manifold import MDS
embedding = MDS(n_components=2, normalized_stress='auto')
X_MDS = embedding.fit_transform(X)
fig = plt.figure(figsize=(6,4))
plt.scatter(X_MDS[:,0], X_MDS[:,1],c=t, s=10, cmap='hot_r' )
plt.xlabel('MDS Dimension 1')
plt.ylabel('MDS Dimension 2')
plt.show()
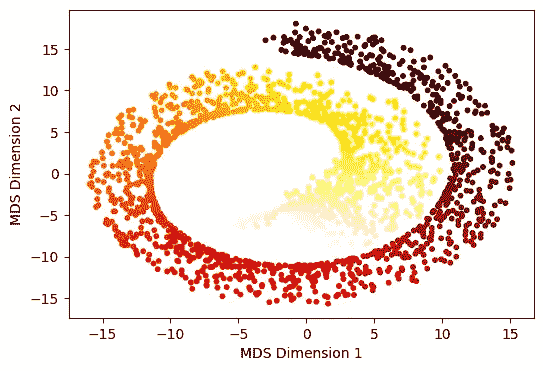
图 6:经典多维缩放的前两个维度。(作者提供的图片)
我们观察到结果与核主成分分析(kernel PCA)非常相似。
到目前为止,我们还没有超越欧几里得距离。但我们之前提到,在瑞士卷数据中,欧几里得距离并不理想。
有一类方法构造一个更复杂的距离 𝑑_𝑖𝑗 来度量高维点 𝑥_1,…,𝑥_𝑛∈ℝ^𝑝 之间的距离,然后将这些 𝑑_𝑖𝑗 通过多维缩放处理,以获得低维表示 𝑧_1,…,𝑧_𝑛∈ℝ^𝑘。这样,我们不仅得到主成分得分,我们的低维表示可能最终成为数据的非线性函数。
切向距离
切向距离是一个我们可以通过多维缩放(虽然也用于其他地方)运行的更复杂的度量。
一个激励示例是我们之前使用的 手写数字数据。这里,我们有 16 \times 16 的图像,将其视为点 𝑥_𝑖∈ℝ²⁵⁶(即,它们被展开成向量)。例如,如果我们取一个“3”并 旋转 它一个小角度,我们希望旋转后的图像被认为接近原始图像。这在欧几里得距离中不一定成立。

图 7:原始“3”和旋转后的“3”图像(图片由作者提供)
我们可以定义 Δ_𝑖𝑗^rotation 为旋转后的 𝑥_𝑖 和旋转后的 𝑥_𝑗 之间的最短欧几里得距离。然而,你可以立即发现旋转数字“6”和“9”存在问题。
我们需要一些更容易计算的东西,并且将注意力限制在 小旋转 上。可以将图像的旋转集视为定义了 ℝ^𝑝 中的曲线——一个图像 𝑥_𝑖 是 ℝ^𝑝 中的一个点,当我们在任意方向上旋转它时,我们得到一条曲线。
切线距离 Δ_𝑖𝑗^tangent 通过首先计算每条曲线在观察到的图像处的切线,然后使用切线之间的最短欧几里得距离来定义。
等距特征映射(Isomap)
等距特征映射(Isomap)在更一般的设置中学习结构以定义距离。基本思想是构造一个图 𝐺=(𝑉,𝐸),即在顶点 𝑉={1,…,𝑛} 之间构造边 𝐸,基于 𝑥_1,…,𝑥_𝑛∈ℝ^𝑝 之间的结构。然后我们定义 𝑥_𝑖 和 𝑥_𝑗 之间的图距离 Δ_𝑖𝑗^Isomap,并使用多维缩放进行低维表示。
构造图:对于每对 𝑖,𝑗,如果满足以下任一条件,我们将 𝑖,𝑗 用边连接:
-
𝑥_𝑖 是 𝑥_𝑗 的 𝑚 个最近邻之一,或者
-
𝑥_𝑗 是 𝑥_𝑖 的 𝑚 个最近邻之一。这条边 𝑒 = {𝑖,𝑗} 的权重为 𝑤_𝑒=‖𝑥_𝑖−𝑥_𝑗‖。
定义图距离:现在我们已经构建了图,即我们已经构建了边集 𝐸,我们定义图距离 Δ_𝑖𝑗^Isomap 为从 𝑖 到 𝑗 的最短路径:
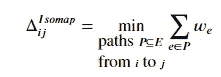
(这可以通过例如 迪杰斯特拉算法 或 弗洛伊德算法 计算)
让我们现在深入研究其在 瑞士卷 数据上的实现。
from sklearn.manifold import Isomap
embedding = Isomap(n_components=2, n_neighbors=7)
X_iso = embedding.fit_transform(X)
fig = plt.figure(figsize=(6,4))
plt.scatter(X_iso[:,0], X_iso[:,1],c=t, s=10, cmap='hot_r' )
plt.xlabel('Isomap Dimension 1')
plt.ylabel('Isomap Dimension 2')
plt.show()

图 8:瑞士卷数据的二维表示。(图片由作者提供)
在邻居数量 𝑚=7 的情况下,多维缩放与 isomap 距离现在展开了 瑞士卷 数据。
局部线性嵌入
另一种非线性维度约减方法是 局部线性嵌入(LLE),它在精神上类似但细节却大相径庭。它不使用多维缩放。
基本思想分为两个步骤:
-
学习一组局部近似来描述 𝑥_1,…,𝑥_𝑛∈ℝ^𝑝 之间的结构
-
学习一个低维表示 𝑧_1,…,𝑧_𝑛∈ℝ^𝑘,最好与这些局部近似匹配
什么是局部近似?我们只是尝试用附近点𝑥_𝑗的线性函数来预测每个𝑥_𝑖(因此得名局部线性嵌入)。
对于每个𝑥_𝑖,我们首先找到它的𝑚个最近邻,并将它们的索引收集为 N(𝑖)。然后我们构建一个权重向量𝑤_𝑖∈ℝ^𝑛,设置𝑤_𝑖𝑗=0(当𝑗∉N(𝑖)时),并通过最小化来设置𝑤_𝑖𝑗(当𝑗∈N(𝑖)时)。

最后,我们取这些权重𝑤_1,…,𝑤_𝑛∈ℝ𝑛,并通过最小化来拟合低维表示𝑧_1,…,𝑧_𝑛∈ℝ𝑘。
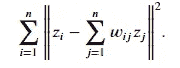
我们再次使用局部线性嵌入(Local Linear Embedding)来说明如何处理瑞士卷数据。
from sklearn.manifold import LocallyLinearEmbedding
embedding = LocallyLinearEmbedding(n_components=2, n_neighbors=25)
X_lle = embedding.fit_transform(X)
fig = plt.figure(figsize=(6,4))
plt.scatter(X_lle[:,0], X_lle[:,1],c=t, s=10, cmap='hot_r' )
plt.xlabel('LLE Dimension 1')
plt.ylabel('LLEp Dimension 2')
plt.show()
图 9:瑞士卷数据的局部线性嵌入维度。(作者提供的图像)
局部线性嵌入的降维效果优于核 PCA 或经典 MDS,尽管不如Isomap。
在这篇文章中,我们通过对 PCA 概念的推广学习了一些非线性降维技术。然而,没有一种单一的方法可以适用于所有类型的数据降维。根据数据的性质,我们应选择合适的降维技术。
希望你喜欢这篇文章!!
有关数据科学问题的咨询,请联系 biman.pph@gmail.com


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









