







我如何学习深度学习——第三部分
我已经答应了太多的隐藏单位
在我们进入细节之前,这篇文章有很多细节,这里有一个 10 秒钟的总结:
- 📈通过 Udacity 深度学习基础纳米学位
- 🤓使用特雷罗板来跟踪我的学习
- 📚在树屋和学习 Python《艰难之路》教材
- ➗Learning 数学与汗学院
- 📝在这个媒体系列中每天写我的学习心得
- 每天⌚️studying 3-4 小时,使用番茄工作法并用 Toggl 追踪时间
- 📽每周发布 1 条 VLOG总结我的日常学习
- 👀在 YouTube 上观看 Siraj 的所有视频
现在,让我们深入一下。
今年二月,我还没有写过一行 Python 代码。我一生都在接触科技,但从来没有接触过创造,只是把它用于消费。我想改变这一切。所以我决定开始学习编程,我在这个领域的短暂研究让我找到了 Udacity ,从这里我看了无数他们各种纳米学位项目的预告片,但最让我印象深刻的是深度学习基金会纳米学位(DLFND) 。
在开始询问退款政策之前的几天,我向 Udacity support 发送了一封电子邮件,现在我已经进入了该计划的最后一个模块(参见第 1 部分)。我很高兴我没有继续写那封邮件。
距离我上次更新只有两个月了,我已经学到了很多。我写这些更新主要是作为我自己反思的一种方法。过去,反思我所学到的东西是我的一个弱点。学习全新的东西是困难的,我发现回头回顾你做过的事情是提醒自己实际上已经走了多远的好方法。
与其他帖子一样,这不会完全是关于深度学习的,但 DLFND 已经成为我过去几个月研究的基础,从这一点上,我开始提升自己在其他领域的技能(Python、统计、代数)。
在这篇文章中,我将回顾一些事情,包括我目前的学习日程和自第 2 部分以来我所学内容的简要概述。
我目前的学习日程是怎样的?
正如在之前的帖子中提到的,我使用了一个 Trello 板作为我的主要规划工具。我把 DLFND 需要的所有东西以及我在纳米学位之外做的任何补充研究都写在了板上。

What the board looks like as of July 14 2017.
如果你愿意,你可以看看公告板,我已经公开发布了。
即使我已经完成了 DLFND,我也将保持 Trello 板的最新状态,我计划参加下一个课程(在未来的帖子中会有更多关于这方面的内容)。
每天早上,我起床后在白板上写下一系列目标。

My personal assistant.
你可以把这块板子想象成有组织的混乱。上面散落着随机的激励性引语,我的“是和不是清单”,每天要做的事情(左手边黑色的),有一天要做的事情(蓝色的复选框),当然,我目前的幸福方程在顶部。
右下角的“是和不是”列表不断提醒我,哪些事情我想说是,哪些事情我想说不。DL 是深度学习,ML 是机器学习, AnyGym 是我和一些朋友正在做的一个项目(稍后会详细介绍),其余的应该不言自明。
经过几年的研究,我发现番茄工作法最适合我。每天我的目标是完成至少 6 个 Pomodoro(25 分钟一组)的给定主题。例如,如果是以 Python 为主题的一天,我的目标是完成 6 个 Pomodoro(150 分钟)的无分心 Python 学习。这段时间的大部分将在午饭前完成(我在早上学得最好)。
我通常做三个 25 分钟的街区,然后有 30-45 分钟的休息时间,我会吃早餐或者出去散散步。休息过后,在我完成一天的学习之前,我将继续接下来的三个街区。
这种套路是在读了卡尔·纽波特的深度作品后产生的。我发现,在 3 到 4 个小时集中精力、不受干扰的工作中,我能比在 6 到 8 个小时的持续干扰中完成更多的工作。
你可以说我在遵循达尔文式的常规。
晨间散步和早餐后,达尔文 8 点钟就在书房里,持续工作一个半小时。九点半,他会阅读早班邮件并写信。10:30,达尔文回到更严肃的工作中,有时搬到他的鸟舍、温室或其他几个进行实验的建筑中的一个。到了中午,他会宣布,“我完成了一天的工作,”然后开始在沙滩漫步,这是他在买下房子后不久铺设的一条路。(部分沙滩漫步穿过卢伯克家族租给达尔文的土地。)
当他一个多小时后回来时,达尔文吃了午饭,回复了更多的信。三点钟时,他会去睡觉小睡一会儿;一个小时后,他会起床,绕着沙滩散步,然后回到书房,直到 5:30,他会和他的妻子艾玛以及他们的家人一起吃晚饭。在这个时间表上,他写了 19 本书,包括关于攀缘植物、藤壶和其他主题的技术书籍;有争议的人类起源;《物种起源》可能是科学史上最著名的一本书,这本书仍然影响着我们对自然和自身的看法。
我学到了什么?
这个系列的最后一部分在 DLND 的第 6 周结束,我现在已经到第 16 周了。以下是我所学内容的简要总结。
第 7–10 周
我花了一段时间,但我终于明白了一个事实,即深度学习需要大量的计算能力。我还了解到 GPU(图形处理单元)特别擅长进行深度学习的计算类型(大规模矩阵乘法等)。我用的是带 Touch Bar 的 2016 款 13 寸 MacBook Pro,它没有专用 GPU。正因为如此,在我的本地机器上训练深度学习模型需要非常长的时间,不理想。

My work station of choice and a nice view from one of my city’s libraries.
大约就在这个时候,我发现了云计算的力量。我过去听说过,但从未完全体验过。如果你几个月前问我什么是 AWS(亚马逊网络服务),我可能一点都不知道。
我仍然没有完全理解云计算,但没关系,你不需要完全理解它来利用它。简而言之,AWS 是一台你可以通过互联网访问的巨型计算机(至少,我是这么告诉自己的)。
第一次浏览 AWS 控制台令人生畏,但在几次失败的尝试后,我设法启动了我的第一个实例。一个实例实际上激活了 AWS 上您可以访问的少量计算能力。我很惊讶。我现在可以通过互联网访问 GPU 的全部功能,在那里我可以训练我的深度学习模型。
第一次体验这种感觉就像开着一辆比你的车快得多的车。突然间,我开始了训练,而不是在本地机器上等待相当于五分钟的微波时间(很长时间)。

Thanks to the internet, my patience with computers has been beaten down to practically zero.
我还发现了 FloydHub 。对我来说,FloydHub 是设计更精美的 AWS 版本(更不用说更便宜了)。我更喜欢使用 Floydhub,因为它很容易安装和运行。通过命令行中的几行代码,您可以开始训练您的深度学习模型。

How quickly you can start training a model using FloydHub.
我喜欢 FloydHub 的另一个原因是他们的网站。布置得太漂亮了。在页面上的几秒钟内,我立即知道它能做什么以及如何使用他们的服务。而 AWS 是一个更陡峭的学习曲线。
还有人对网页设计着迷吗,还是只有我?
有了这些新发现的云计算知识,我能够为 DLFND 进行我的第二个项目。我的任务是使用卷积神经网络对来自 CIFAR-10 数据集的图像进行分类。
在论坛和专门的 Slack 频道的帮助下(谢谢大家!),我设法提交了一个工作的 CNN。当你在 Udacity 上提交一个项目时,会出现一条消息说它将在 24 小时内被审核。我过去认为(现在仍然认为)在 24 小时内对一个项目进行全面的评审是令人惊奇的。在我大学的五年里,我从来没有这么快得到反馈。
令我惊讶的是,24 小时实际上是一个夸大的时间。我在提交后的两个小时内完成了一个完整的项目评审。虽然我没有看它,但我需要在那天剩下的时间里从我的电脑上休息一下。
我的第一次提交远非完美,该项目需要改进,我才能获得及格分数。在重新提交之前,我花了大约 8 个小时(和一个 Udacity 支持成员进行了 3 个小时的实时聊天)来调整超参数、训练模型和改进各种功能。我把第二次提交的材料传了过去。
*我的模型还能进一步改进吗?*当然。但我并没有追求完美。我本来可以再花一周时间努力让模型变得更好,但我的目标是学习深度学习的首要原则,而不是完善我的项目提交,这可以稍后进行。
我的完整提交可以在我的 GitHub 上获得,但是如果没有正确上传请原谅,我正在努力学习如何使用 Git 和 GitHub(稍后会有更多)。
大约在 DLFND 开始 9 周后,我看到吴恩达的 机器学习课程的一个新班级正在 Coursera 上开课。我觉得报名参加这个课程会很棒,可以更深入地了解机器学习,以及深度学习的专业知识。再一次,我没有阅读先决条件就开始了课程。我能学会吗?

A photo of me after starting Machine Learning Course on Coursera without reading the prerequisites.
哦,是的,本着签约的精神,我决定挑战自己,承诺 100 天的代码。我开始了每日媒体系列和每周视频博客记录我的学习。我会更有规律地更新这些内容,每 4-6 周左右写一篇更长的文章。
VLOG 10 of my 100 Days of Code.
第 11–14 周
DLFND 课程的第 3 部分是关于递归神经网络(RNN 氏)。我还不完全理解 RNN 的作品,但我正在慢慢理解这个概念。 Andrej Karpathy 有一篇非常深入的文章关于 RNN 的有效性,我自己正在读。
我认为 RNN 的方法是,他们接受一系列输入,并能够产生单一输出或一系列输出。
来自一系列输入的单个输出在哪里可以派上用场?
比方说,你有一堆电影评论(作为输入的单词序列),你想知道哪些是好的和坏的评论(单个输出)。RNN 可用于对评论进行情感分析,并输出评论是好是坏。
输入序列中的输出序列在哪里使用更好?
以翻译为例。如果你有一个英语句子(作为输入的单词序列)并想将其翻译成法语(作为输出的单词序列),可以使用 RNN 来执行翻译。
当然,现在 RNN 还可以产生其他输出(单输入到多输出),但是我现在让专家来解释这些。我的定义是基本的,但这是我学得最好的方法。我从事物如何工作的总体概念开始,然后慢慢地在此基础上构建。
Siraj 的这个视频展示了一个如何使用 RNN 创作音乐的很酷的例子。
使用长短期记忆(LSTM)网络,Siraj 将采用一系列乐器数字接口(MIDI)并训练 RNN 产生全新的声音。
什么是 LSTM?
我把 LSTM 想象成一系列阀门。如果你把整个 RNN 想象成一个管道系统,水就是流经网络的信息。LSTM 决定有多少水应该流过网络。将这些因素结合起来将有助于微调输出。
再说一次,这是我对他们的看法,还有更多内幕。为了更深入的理解,我推荐这篇阎石的文章。
什么是迷笛?
MIDI 相当于音乐设备的字母表。就像在单词序列是输入(例如,英语)和输出(例如,法语)的机器翻译模型中一样,MIDI 输入序列(例如,旧钢琴歌曲)可以用于生成输出序列(例如,新钢琴歌曲)。
项目 3
使用我们在之前的课程中学到的知识,下一个项目涉及创建我们自己的 RNN,目标是生成一个电视脚本。
网络的输入将是一个数据集,其中包含 27 季《辛普森一家》的剧本,特别是在莫酒馆的场景。使用这个输入序列(文本串),RNN 将被用于产生一个全新的场景(输出序列)。
我不会深入研究这个项目的细节(有机会的话,我会把我的代码上传到 GitHub ),但是在准备好数据和几个小时的构建和训练网络之后,下面是我得到的一些输出。
1)
最低工资和小费。(意味深长地)当然有,但是,嗯,有两个。
荷马·辛普森:你知道什么在搅拌吗?
moe_szyslak:好吧,为什么我有的只是如果这是或者女人的方式他死了。
嘿。抱歉。
韦伦史密瑟斯:嗷。
荷马辛普森:(大笑着,朋友)现在是荷马,我在做一个比我还猪的人(一个热情得可以的家伙)在这种紧张的时候,又有什么好寂寞的。现在,考虑把一个可怕的。
moe_szyslak:(笑)他会?让我赢!答(很荷马)
荷马 _ 辛普森:(对簿)程序。
荷马·辛普森:(笑)现在如果你想上游戏,我就和我的新生活一样”。
homer_simpson:让我们看看什么是玛吉。
少年巴特:(说唱,莫伊)这个角色太好了,哪里是真正的你。
听着,荷马,这是我记得的时间,我一直在用它?
荷马·辛普森:(暂定)
2)
moe_szyslak:喝酒会帮助我们计划。
荷马·辛普森:这个情人节的垃圾必须是一个酒吧。(下车)新健康检查员:除了一个白痴。
(自言自语)对不起,我需要我在你的脚后面。
moe_szyslak:但是我想我有 200 个孩子,所有人都可以用这些孩子。
荷马·辛普森:成为最好的东西?
因为我以为你只说了一个。
(对自己)有人做了一个小的,我能要一个免费的吗?拿着这个!(荷马的声音)
荷马·辛普森:有一个,但我没打算去找出来。
moe_szyslak:(唱)我只想告诉我的生活,直到他们走了!
男人们在女人的绅士世界里游荡。
哦,你不让我呆在这里?不,莫伊。
你知道,是你,莫伊。饮料算你的。
西摩·斯金纳:(叹气)不再是眼睛了。
荷马·辛普森:(笑)好吧。
这些脚本完全由网络生成,我觉得不可思议。它们也很有可能是完全独一无二的,没有人曾经创造过这样的场景。
迁移学习
DLFND 的下一个主题是迁移学习。我认为迁移学习就是把你在一个领域中的知识应用到另一个领域中,而不需要明显地改变它。
所以对我来说,一个真实的例子就是我把我在运动中学到的知识应用到学习中。在过去的七年里,我发现对我来说最好的锻炼方式是设定一个目标,并设定一段时间来实现这个目标。如果我把这些知识应用到学习中,我认为这是迁移学习。
在机器学习/深度学习的情况下,你可以将一个已经在一个数据集上训练过的模型应用于另一个类似的数据集,而不必完全重新训练该模型。能够做到这一点,可以节省大量的时间。
可以使用迁移学习的一个例子是在虚拟模拟中训练机器人,然后使用它在虚拟世界中学到的知识,并将其应用到现实世界的场景中。类似于 OpenAI 用他们的积木堆叠机器人所做的。
如果你想了解更多关于转移学习的信息,我强烈建议你看看来自 Sebastian Ruder 的这篇博文。
项目 4
DLFND 中的第四个项目涉及使用从一种语言到另一种语言的神经网络。
这个项目将利用我们对 RNN 氏症的了解来建立一个能够将一小串英语单词翻译成法语的网络。
如果你在几个月前问我该怎么做,我不会告诉你。现在,我仍然不能完全解释这一过程,但我对谷歌翻译等应用程序如何完成大部分翻译有一个大致的了解。
我发现课程和项目的一个趋势是,我花了大约 50%(有时更多)的时间来完成它们,比预期的工作时间要多。例如,这个项目在最初的描述中有 2 个小时的工作时间,然而,我花了 6 个多小时才完全完成它,如果你包括模型训练时间,那就更多了。我通过 Toggl 跟踪我所有的在线学习,这有助于我了解我的时间被分配到哪里,并帮助我调整/计划我的学习时间表。

A screenshot of the time I spent working on Project 4 from Toggl.
我花了三次提交来为这个项目获得及格分数,主要是因为如果我诚实的话,我的第一次提交有点仓促。这一模式行之有效,但还可以做得更好。
Udacity 评论者的反馈总是很迅速,充满了洞察力和进一步学习的机会。

An example of feedback from a Udacity reviewer.
最后,我的模型仍然不完美,但在将英语单词的一个小句子翻译成法语方面,它做得还不错。我本可以在这个项目上花更多的时间来使它变得更好,但是在花了 6 个多小时试图提高一点点的精确度后,我发现最好是继续前进,继续学习。
我发现的一个重要细节是超参数的多样性。我在 Udacity 论坛上看了看,发现一些学生使用了非常不同的参数,仍然得到了很好的结果。我的直觉告诉我,超参数只是最后一步。如果您的模型一开始就没有正确构建,那么再多的超参数调整也不会有助于它的改进(或者只能有很小的改进)。

An example of my model translating English to French.
我正式创造了一个比我懂法语的模特。
第 15 周—2017 年 7 月 14 日
很难相信我在没有正确使用 GitHub 的情况下坚持到了第 15 周。当我开始学习这门课程时,我使用 git clone 下载了所有的 Udacity 深度学习文件,并从那时起一直使用相同的文件。
这导致了项目 4 的问题。我最终完成了这个项目的一个老版本,当我完成了 80%的时候才意识到这一点。正是因为如此,我决定是时候开始正确使用 GitHub 了。在课程的大部分时间里,我一直忽略它,因为我对它了解得不够,我的工作方式也很好,直到项目 4 事件。
如果还能更好,那就跟坏了一样。—格雷格·普利特
这句话与我完全相关。我的工作流程可以更好。它坏了。
这让我开始在树屋上了解 Git 和 GitHub 。很快,我开始对使用它更有信心了。我还没有完全弄明白,但它现在在我的清单上。我保证在我写下一篇文章的时候,你会在 GitHub 上看到我所有的文件。
第四部分
DLFND 的第 4 部分是关于生成性敌对网络(GANs)的。这就是我现在的情况。
我说我对课程的每一个新部分都感到兴奋,但这一部分已经让我大吃一惊。
2014 年,Ian good fellow在酒吧与朋友交谈后想到了 GANs 这个概念(多么不可思议的创始故事)。
我认为 GANs 是两个相互竞争以产生更好输出的网络。

An overview of GANs.
有一个网络叫做生成器(G ),它接收随机的噪声样本。发生器的目标是从噪声中产生新的样本,这些样本与进入另一个网络(鉴别器(D))的真实样本输入具有相同的概率分布。D 的作用是破译哪个输入是真实的。
随着 G 越来越擅长制作假样本,D 也越来越擅长检测假样本。这两个网络相互竞争,并随着时间的推移在各自的特定角色上变得更好。
如果你在寻找更深入的描述,我建议你看看亚瑟·朱利安尼的这篇文章。朱利安尼用海绵宝宝来比喻甘斯。
由于 GANs 仍然是深度学习领域相对较新的突破,它们的大多数用例可能还没有被发明出来。GANs 目前的一些用途包括生成人脸图像、将草图转换成全尺寸图片( edges2cats )以及将马变成斑马。

Turning a bunch of random lines into pictures of cats. (Source)
CycleGAN turning a horse into a Zebra using styling transfer at 60 fps.

Using GANS to generate and change the direction a face is looking. (Source)
DLFND 即将到来的最终项目包括构建一个 GAN 来生成人脸。我有点害怕又有点兴奋。
到目前为止,我仍然不明白它们到底是如何工作的。在最终截止日期(2017 年 8 月 3 日)之前,我还有几周的课程。
额外学习
当我报名参加 DLFND 时,我几乎没有任何 Python 或机器学习的经验,而且从高中起就没有接触过微积分。
因此,我一直在使用许多其他资源来帮助我学习深度学习所需的技能。
对于 Python,我一直使用的是结合了 Treehouse 和艰难地学习 Python的教材。在撰写本文时,我几乎已经完成了这两篇文章,在写作过程中,我实际上已经学会了所需的 Python 技能。
为了获得一些机器学习的基础知识,我一直在使用 Coursera 上吴恩达的机器学习课程。这是我上过的最好的课程之一。我上周完成了课程(没有正式证书)。

可汗学院的各种课程让我的数学技能达到了标准。我一直在断断续续地学习诸如线性代数、多元微积分、矩阵和向量之类的课程。
我还没有掌握 Git 或 GitHub 的使用,但是 Treehouse 是一个快速提升我在这两个工具上的技能的好方法。我保证,我的 GitHub 在接下来的几周内会有点像样。
我还每隔一天早上使用 Anki 来帮助巩固我的 Python 语法知识。
侧项目
我不知道这是否适合这篇文章,但我想我最好把它放在这里,因为它是我每周投入一部分时间的地方。
5 月底,我终于掌握了几周前开始的 Coursera 的 DLFND 和机器学习课程。这给了我一些时间开始做一些我已经计划了一段时间的副业。
利用我所学的 AWS 和云计算知识。我在免费的 AWS 微层上构建了一个 LEMP 堆栈服务器来托管我一直在计划的一个网站。我花了相当多的时间在谷歌上寻找一些可靠的指南,但我设法用 WordPress 前端安装并运行了它。几天后,我有了一个功能齐全的网站,并开始运行,只需为域名付费。
我的背景是健身和营养,我计划将我从这些不同的课程中学到的技能与我过去学到的知识结合起来,为这个世界带来价值。
我和我的团队有一个目标,那就是帮助世界前进。所以我们搭建了一个平台,连接全世界的健身设施和用户。目前,它在我们的家乡布里斯班发挥作用,但我们计划在未来的某个时候扩展。它可能永远不会起飞,我知道这一点,但这不是重点。旅程就是一切,我宁愿尝试,也不愿根本没有尝试过。
你可以在 useanygym.com 查看我们的进展。更新 2019: 我们失败了。
到目前为止,我还不知道我所学的东西是如何与这个项目联系在一起的,但是我确信我会想出办法的。另外,做自己的项目总是很有趣。
下一步是什么?
如果你要求我,我仍然无法编写一个完整的深度学习模型,但我正在慢慢理解基本概念,并从零开始更好地构建网络。
我还有几周的深度学习纳米学位,所以这是我目前优先学习的内容。
我将继续使用各种在线资源学习 Python,并在未来通过构建一些项目来实践(我将尽我所能来写这些)。
Trello 板块会每隔几天更新一次我学到的东西,所以如果你感兴趣的话,一定要去看看。
我还将在我的中型系列中记录我剩余的 100 天代码,并制作一个关于我一直在做什么的每周 VLOG。
这篇文章是一个系列的一部分,这里是其余的。
- 第一部分:新的开始。
- 第二部分:动态学习 Python。
- 第三部分:广度太多,深度不够。
- 第四部分: AI(营养)对 AI(智能)。
- 第五部分:回归基础。
- 号外:我自创的 AI 硕士学位
我是如何学习深度学习的——第四部分
大量数据是最终的前沿吗?

A few of the resources helping me break into the world of AI. — Hinton Image Source
第三部之后发生了很多事情。虽然前两篇文章深入探讨了我到底学到了什么,但这篇文章会有所不同。我不会一周一周地分解它,我会涵盖主要的里程碑。
我是去年 8 月从 Udacity 深度学习纳米学位 (DLND)毕业的。想想我是如何在开课前给支持团队发邮件询问退款政策的,我就觉得好笑。这无疑是我参加过的最好的学习项目之一。如果你想了解更多细节,我最近在 DLND 上发布了一个深度回顾视频。
制作关于我的旅程的视频让我与同路的其他人进行了一些很棒的对话。我在加拿大遇到一个人,他和我学的课程几乎完全一样。更有趣的是,我们房间里有一张和阿诺一模一样的海报。世界真小。
最近,我有机会与来自印度的 14 岁人工智能开发者 Shaik Asad 进行了一次对话。完成作业后,他自学人工智能。从那以后,我们一直在积极地谈论生活和我们的其他兴趣。看到 Shaik 对人工智能的热情,听到他的目标是什么,灵感是一种轻描淡写的说法。
AI 硕士学位
从 DLND 毕业后,我就像车灯前的小鹿。我已经了解了深度学习(DL)的惊人力量,但仍然没有完全理解是什么让深度神经网络运转起来。我还想知道 DL 是否是人工智能的全部和终结(后面会有更多)。
我需要知道更多。好奇心促使我创建了自己的 AI 硕士。有一个粗略的课程大纲可以让我缩小如何度过我的时间。我的使命是用 AI 帮助人们多运动,吃得更好。我在健身和营养世界的游戏中有皮肤,我在人工智能方面工作。
在过去的几个月里,我已经完成了吴恩达和 deeplearning.ai 团队的 Coursera 深度学习专门化(课程 5 在撰写本文时刚刚发布)的 80%,以及 Udacity 人工智能纳米学位 (AIND)的第一学期。
对于那些从基础方法学习的人来说,deeplearning.ai 专业化是开始学习 DL 的最好地方。如果你对项目建设更感兴趣,或者想继续学习 Udacity 的高级纳米学位,可以从 DLND 开始。
AIND 的术语 1 涵盖了经典的人工智能方法。由于我缺乏编程能力和最近对 DL 的关注,我有时会迷失自己。然而,了解这个领域自诞生以来已经取得了多大的进展是令人着迷的。
我现在进入第二学期,包括使用 DL 在计算机视觉、自然语言处理和语音识别方面构建项目。回到熟悉的鱼缸里。
一旦我完成了 deeplearning.ai 和 AIND,我会发布对它们的全面深入的评论。
人工智能的未来
在了解了更多关于 DL 的工作原理后,我开始怀疑它的长寿前景。许多 DL 模型需要大量的数据来产生有用的输出。
如果你是世界上拥有足够数据让泰坦尼克号继续航行的两家公司之一,这很好,但如果你是一个年轻的人工智能希望,这就不太好了。深度学习已经带来了许多令人难以置信的见解,但其中许多是在监督学习的领域,这仍然需要大量的人力投入。
虽然我们收集和产生数据的能力正在呈指数增长,但我不相信更多的数据是解决我们所有人工智能问题的关键。
我们真的只是数据处理机器吗?上个世纪,人们认为我们的内部过程可以用蒸汽机的概念来模拟。想到了有锤子问题的人。
反向传播(一种帮助神经网络自我改进的算法)在未标记的数据上工作得不是很好,这些数据是组成宇宙的大部分。
想象一个四岁的孩子走进一个他们从未去过的房间。年幼的孩子不需要一万张贴有标签的房间图片就能知道如何导航。他们甚至不需要一个房间的标签图像,他们只是开始与它互动。
甚至深度学习的教父似乎也在沿着同样的思路思考。在去年年底的一次采访中,杰弗里·辛顿被问及他对人工智能技术现状的看法。
“我的观点是抛弃这一切,重新开始。”
“未来取决于某个对我所说的一切深感怀疑的研究生。”
听了 Monica Anderson 的讲座和演讲(尤其是关于 T2 的双过程理论的讲座和演讲)并发现她在人工直觉作为人工智能方法方面的工作提出了更多的问题。
我将在以后的文章中更深入地探讨这些话题。
后续步骤
在接下来的几个月里,我将完成我为自己设定的课程。
我刚刚提交了 AIND 第二学期的第一个主要项目,一个检测面部关键点的计算机视觉模型。
对于每个即将到来的主要项目,我将发表一篇文章,详细介绍我对这项工作的理解,以及为那些希望建立一个等效的一步一步的指导。
我也非常喜欢麻省理工学院提供的关于人工通用智能和自动驾驶汽车深度学习的免费课程。
完成 AIND 后, fast.ai 似乎很可能是我的下一个停靠站。
当我完成我的课程时,我将寻求搬到美国,加入健康和人工智能领域的创业公司(或创建我自己的公司)。如果你认识任何人,或者认为我应该关注目前在健康和人工智能十字路口的任何人,请告诉我。
对于那些考虑开始自己的自主学习之旅或了解更多人工智能的人来说,Naval Ravikant 的话完美地总结了这一点。
当前的教育体系是一种路径依赖的结果。我们现在有互联网,如果你真的有学习的欲望,一切都在互联网上。学习的能力、方法和工具是丰富的和无限的,学习的欲望是难以置信的稀缺。
第五部见。
这篇文章是一个系列的一部分,这里是其余的。
- 第一部分:新的开始。
- 第二部分:动态学习 Python。
- 第三部分:广度太多,深度不够。
- 第四部分: AI(营养)对 AI(智能)。
- 第五部分:回到基础。
- 额外:我自创的 AI 硕士学位
我如何学习深度学习——第五部分

A Day In The Life Of A Machine Learning Engineer on YouTube.
回归基础。
**重大更新:**我被聘为机器学习工程师。麦克斯·凯尔森太牛了。我们正在研究一些很酷的东西。周一是研究日。我制作了一部短片来展示我们在做什么。
从上个帖子开始,我毕业于 Udacity 的人工智能纳米学位。这是一门很棒的课程。我拍的最好的一张。
许多人伸出手来,问自己在某个地方得到一个角色是否足够。
简短回答:不完全是。
稍微长一点的回答:是的,如果你能够通过自己的项目或其他课外活动有效地交流你所学到的东西。
我认为,工作准备来自于参加吴恩达的 deeplearning.ai 或 Udacity 的 AI Nanodegree 等课程,然后利用你所获得的知识寻找自己的项目。一些让你足够感兴趣的事情,让你去做一段时间,并与世界分享你的旅程。我还没有真正做到这一点。
有一些很棒的在线课程,但是当你在解决一个问题时,没有什么能让你做好准备,你必须自己寻找答案。
回归基础
我开始用深度学习学习 Python。有点像被丢在山顶而没有爬完剩下的部分。
自从在 Max Kelsen 开始工作以来,我的大部分时间都花在清理和准备数据集上,以便在上面使用机器学习和深度学习技术。
基础可能是个错误的词。但经过一些实践经验后,我发现深度学习在数据方面只是冰山一角。如果您的数据看起来像本地转储,那么准备好史诗级深度学习模型就没有意义。
俗话说的好。
垃圾进,垃圾出。
但是,改变这种说法是一个崭露头角的机器学习工程师或数据科学家的职责。
垃圾进来,美丽出去。
为了对此有所帮助,我从 Wes McKinney 那里得到了一本关于使用 Python 进行数据分析的书。它与我们最近工作的相似之处令人震惊。
我哥哥和我正在 Coursera 上应用数据科学与 Python 专业。它补充了这本书。我甚至用了前几天在工作中的一个讲座中学到的精确函数。
未来深度学习课程
第一部是史诗级的。我喜欢杰里米的教学方式。他是一个真正的从业者。
不过,在继续第 2 部分之前,我将先浏览一下 Jeremy 的机器学习讲座和 Rachel(fast . ai 的联合创始人)关于计算线性代数的系列讲座。
在这些之后,我会寻找一些基因组学和人工智能主题的课程。健康和科技的交叉让我着迷。在 Max Kelsen,我们很快将开始一项分析全基因组的项目,试图为癌症患者找到更个性化的治疗方法。我等不及了。
在不久的将来,我计划将这些技能带到营养基因组学领域,或与你的 DNA 相匹配的营养学领域。
一如既往,这些将在我的 Trello 板上显示。

你能做什么?
如果你想学习深度学习和机器学习。太好了。你会经历一场地狱之旅。
但是要注意,并不是你在网上课程之外找到的所有数据都有一个整洁的小包装。
一定要称赞你的深度学习和机器学习能力,有能力获取数据集,操纵它,精心打扮它,并带它出去吃饭,你将拥有一套危险的(以好的方式)技能。
编程语言其实也不重要。挑一个坚持下去。我选择了 Python。我每天都努力提高一点。
这篇文章是一个系列的一部分,这里是其余的。
第一部分:新的开始。
第二部分:动态学习 Python。
第三部分:广度太多,深度不够。
第四部分: AI(ntuition)对 AI(intelligence)。
第五部分:回归基础。(你目前正在阅读这篇文章)
号外:我自创的 AI 硕士
信息技术如何影响风险管理?

Risk management process / Image Source: www.edarabia.com/229684/pmi-risk-management-professional-pmi-rmp-abu-dhabi-uae
1.介绍
风险管理是一项非常需要的核心能力,可以帮助组织随着时间的推移交付和增加利益相关者的价值。良好的风险管理需要更好的数据和信息,因此组织可以对不断变化的风险清单采取行动。
风险管理团队必须促进和鼓励当前和前瞻性风险信息的获取、分析和交付。预测风险信息可以帮助管理层做出更明智的决策,并帮助他们采取行动,产生更可靠的结果。
计算和风险技术的发展,以及利用大数据、分析、移动应用、云计算、企业资源规划(ERP)和治理、风险和合规(GRC)系统的新技术的相关发展,对风险管理也很重要。这些技术进步为风险管理者和那些参与改进现有风险管理计划的管理人员或组织外部人员提供了增强风险管理有效性的更好能力。
在这份报告中,我将试图总结信息技术和风险管理之间的关系,以及信息技术的发展如何影响风险管理领域。
2.风险管理
2.1.什么是风险管理?
风险管理是识别、评估、评价和控制对组织资本和收益的威胁的过程。这些威胁或风险可能来自各种来源,包括财务不确定性、法律责任、战略管理失误、事故和自然灾害。[18]
2.2.风险管理流程
所有的风险管理计划都遵循相同的步骤,这些步骤共同构成了整个风险管理过程:[18]
1.风险识别:公司识别并定义可能对特定公司流程或项目产生负面影响的潜在风险。
2.风险分析:一旦确定了特定类型的风险,公司就可以确定风险发生的可能性以及风险的后果。分析的目标是进一步了解风险的每个具体实例,以及它如何影响公司的项目和目标。
3.风险评估和评价:在确定风险发生的总体可能性及其总体后果后,对风险进行进一步评估。然后,公司可以根据其风险偏好来决定风险是否可接受以及公司是否愿意承担风险。
4.风险缓解:在这一步骤中,公司评估其最高级别的风险,并制定计划,使用特定的风险控制来缓解风险。这些计划包括风险缓解流程、风险预防策略和风险实现时的应急计划。
5.风险监控:缓解计划的一部分包括跟踪风险和整体计划,以持续监控和跟踪新的和现有的风险。整体风险管理流程也应进行相应的审查和更新。
2.3.风险管理策略
在确定了公司的具体风险并实施了风险管理流程后,公司可以针对不同类型的风险采取几种不同的策略:[18]
1.风险规避:虽然完全消除所有风险几乎是不可能的,但风险规避策略旨在转移尽可能多的威胁,以避免破坏性事件的高成本和破坏性后果。
2.降低风险:公司有时能够降低某些风险对公司流程的影响。这是通过调整整个项目计划或公司流程的某些方面,或通过缩小其范围来实现的。
3.风险分担:有时,风险的后果被分担,或分布在项目的几个参与者或业务部门中。风险也可以由第三方分担,如供应商或业务伙伴。
4.风险保留:有时,公司决定从商业角度来看风险是值得的,并决定保留风险和处理任何潜在的后果。公司往往会保留一定程度的风险,一个项目的预期利润大于其潜在风险的成本。
2.4.风险管理标准
自 21 世纪初以来,一些行业和政府机构扩大了监管合规性规则,以审查公司的风险管理计划、政策和程序。越来越多的行业要求董事会审查和报告企业风险管理流程的充分性。因此,风险分析、内部审计和其他风险评估手段已经成为企业战略的主要组成部分。
风险管理标准已由多个组织制定,包括美国国家标准与技术研究所和 ISO。这些标准旨在帮助组织识别特定的威胁,评估独特的漏洞以确定其风险,确定降低这些风险的方法,然后根据组织战略实施风险降低措施。
例如,《ISO 31000 原则》提供了改进风险管理流程的框架,无论公司的规模或目标部门如何,都可以使用这些框架。根据 ISO 网站[13],ISO 31000 旨在“增加实现目标的可能性,改善对机会和威胁的识别,并有效地分配和使用风险处理资源”。虽然 ISO 31000 不能用于认证目的,但它可以帮助为内部或外部风险审计提供指导,并允许组织将其风险管理实践与国际公认的基准进行比较。
ISO 建议以下目标领域或原则应成为整体风险管理流程的一部分:
- 这个过程应该为组织创造价值。
- 它应该是整个组织过程的一个组成部分。
- 它应该成为公司整体决策过程中的一个因素。
- 它必须明确解决任何不确定性。
- 它应该是系统的和结构化的。
- 它应该基于现有的最佳信息。
- 应该根据项目量身定制。
- 它必须考虑到人为因素,包括潜在的错误。
- 它应该是透明的和包罗万象的。
- 它应该能适应变化。
- 应该不断对其进行监测和改进
ISO 标准和其他类似的标准已经在世界范围内制定,以帮助组织系统地实施风险管理最佳实践。这些标准的最终目标是建立通用框架和流程,以有效实施风险管理策略。
这些标准通常得到国际监管机构或目标行业团体的认可。它们还会定期补充和更新,以反映快速变化的业务风险来源。尽管遵循这些标准通常是自愿的,但行业监管机构或商业合同可能会要求遵守这些标准。
2.5.企业风险管理
企业风险管理包括各组织用来管理风险和抓住与实现其目标相关的机会的方法和流程。机构风险管理提供了一个风险管理框架,通常涉及确定与组织目标(风险和机会)相关的特定事件或情况,从影响的可能性和程度方面对其进行评估,确定应对战略,并监测进展情况。通过识别和积极应对风险和机遇,工商企业保护并为其利益相关者创造价值,包括所有者、员工、客户、监管者和整个社会。[2]
2.6.治理、风险管理和法规遵从性(GRC)
治理、风险管理和法规遵从性(GRC)是一个涵盖组织在这三个领域的方法的总称:治理、风险管理和法规遵从性。GRC 被正式定义为“使组织能够可靠地实现目标、解决不确定性并诚信行事的能力的集成集合。”[1]
GRC 是一个旨在跨治理、风险管理和合规同步信息和活动的学科,以便更有效地运营、实现有效的信息共享、更有效地报告活动并避免浪费的重叠。尽管在不同的组织中有不同的解释,但 GRC 通常包括诸如公司治理、企业风险管理(ERM)和公司遵守适用法律法规等活动。
组织达到需要对 GRC 活动进行协调控制才能有效运营的规模。这三个学科中的每一个都为其他两个学科创造了有价值的信息,并且这三个学科都影响着相同的技术、人员、流程和信息。
当独立管理治理、风险管理和法规遵从性时,会出现大量重复任务。重叠和重复的 GRC 活动会对运营成本和 GRC 矩阵产生负面影响。[8]
3.风险信息
有效的风险计划应该为管理层提供增强的能力,以持续捕捉、评估、分析和应对因内部运营、外部市场或法规变化而产生的风险。不能有效地管理这些变化会产生财务损失、负面宣传,并影响组织目标或任务的实现。因此,有效的风险计划考虑、评估并为组织的规划、绩效衡量提供输入,并支持评估潜在的负面事件及其对组织既定风险偏好和容忍度设定流程的影响。此外,请注意,信息和沟通是基本的框架组件,但更重要的是反馈工具。
拥有及时的信息是有效的机构风险管理计划的关键。例如,立即知道一个关键供应商经历了原材料供应链的重大中断,使客户能够调用供应链弹性计划,以快速在其他地方获得替代材料。如果没有及时的信息,供应商的中断也可能会中断其客户的制造流程。管理层必须持续监控内部运营、供应商、关联方、交易对手和客户,以寻找必须解决的不断变化的情况,从而降低损失风险。
4.风险管理和信息技术
信息技术的发展已经影响到我们生活的每个领域,如学习、营销、商业、娱乐和政治。风险管理是受这种发展影响很大的领域之一,因为它主要基于数据。日复一日,信息技术促进了从风险识别到监控过程的自动化。大数据、分析、移动应用、云计算、企业资源规划(ERP)以及治理、风险和合规(GRC)系统等新技术的开发对于风险管理非常重要。这些技术进步为风险管理者和那些从事改进的管理人员或组织外的人员提供了机会。
在这一部分,我将描述不同信息技术领域在风险管理中的作用。
4.1.基本风险可视化程序
信息技术影响风险管理领域的第一个基本因素是不太复杂和不太昂贵的应用程序的基础,如 Microsoft Excel、PowerPoint 和 SharePoint 等办公自动化工具,这些工具在大、中、小型组织中广泛用于风险跟踪和报告目的。
此外,还有许多由著名服务提供商发明的基本威胁建模程序,如微软[20],以及许多其他程序,如 CORAS 威胁建模[19]。
4.2.社会化媒体
一些企业现在积极监控社交媒体内容(例如 Yelp ),以收集关于客户服务、产品质量或服务交付问题的及时见解。在这种情况下,广泛和即时可用的社交媒体内容提供了关于公众对企业产品和服务的看法的宝贵见解,这有助于企业通过提供管理工具来避免声誉受损,这些工具可以在服务和产品质量问题造成严重的品牌或特许经营损害之前快速解决它们。[9]
4.3.数据集成和分析
许多组织目前已经在生产中拥有大型和广泛的数据库,许多 IT 部门正在积极地将这些数据库与现有应用程序更好地集成,以从 IT 投资中获取更多价值。许多数据库包含风险数据点,这些数据点也可以被更强大的计算平台提取、“挖掘”或摄取,从而随着时间的推移提供更多的组织价值。组织的首席信息官(CIO)现在使用的工具包括电子数据仓库(edw)、“大数据”、商业智能(BI)应用和信息分析技术。[9]
这些工具可以辅以强大的数据提取、转换和加载(ETL)技术,这些技术为从难以定位和解析的数据文件中提取价值提供了更大的自由度。虽然风险经理最初可能不是这种数据集成投资的预期受益者,但是许多组织仍然在为此目的使用这些工具。
此外,大数据分析可以在许多与市场风险分析相关的领域提供帮助:[21]
-欺诈管理:快速识别欺诈,将损失降至最低
-信用管理:更好的预测能力,新的数据来源允许预测用户行为
-洗钱:更快发现问题,实时反应
-市场和商业贷款:允许更好地模拟和预测市场和公司
-运营风险:对与客户的互动提供更多控制和知识,提高安全性。
-综合风险管理:在出现金融风险的不同部门和领域提供全球视野
4.4.数据挖掘
此外,对于我们在上一部分中提到的数据分析的使用,组织可以从数据挖掘技术中受益,以预测组件或机器的故障,识别欺诈,甚至预测公司利润。与其他数据挖掘技术结合使用,预测包括分析趋势、分类、模式匹配和关系。通过分析过去的事件或实例,你可以对一个事件做出预测。
例如,使用信用卡授权,您可以将对单个过去交易的决策树分析与分类和历史模式匹配结合起来,以识别交易是否是欺诈性的。在购买飞往美国的航班和在美国的交易之间进行匹配,很可能交易是有效的。[6]
4.5.开放数据
开放数据是这样一种理念,一些数据应该免费提供给每个人使用和重新发布,不受版权、专利或其他控制机制的限制。[23]
如今,大多数组织都可以通过实时数据源即时获得有关不断变化的经济状况和市场的数据。商业新闻服务提供商,如 Thompson Reuters、Blackrock、彭博、道琼斯和华尔街日报,都提供有关金融资产和市场价值变化的最新信息。这种数据馈送还可以用来支持成熟的机构风险管理方案和风险监测流程,这些信息服务对股票交易和资本市场参与者的影响是显而易见的。[9]
许多全球性组织正变得越来越全球一体化,并跨境运营非常复杂的业务流程。当市场条件发生实时变化时,这样的组织在纳秒内执行交易、评估和采取行动。
许多新一代面向大数据、“基于分析”的 BI 系统已经支持智能决策、交易处理和数据可视化,这些都是监控风险和运营绩效的有用工具。
4.6.云计算
在评估 GRC 应用程序时,基于云的 IT 环境的发展也是人们可能希望或需要了解和考虑的事情。提供“按需”GRC 软件即服务(SaaS)的基于云的 IT 环境利用了基于平台的操作系统和相关基础设施及中间件软件的固有虚拟化功能,为“租户”用户提供了比购买 GRC 应用程序并在内部运行更高效、更经济的替代方案。基于云的应用程序,或“租户”,以及使用它们的组织提供并收取这些应用程序的用户所需的处理能力的费用。[9]
基于需求的使用和收费方案为用户提供了更大的灵活性,因为它要求用户只在运营业务所需的应用程序上花钱。基于云的应用程序利用了规模经济的优势,SaaS 允许多个租户用户组织使用云托管的应用程序,同时支持多种 IT 使用案例。
4.7.物联网
对于风险经理来说,物联网可以归结为在业务之上引入一层技术。运营不需要重新发明。这为依赖管理风险的组织提供了一个不可或缺的工具。通过为公司配备更多连接到互联网的传感器和设备,组织能够收集更多实时数据来推动商业价值。这对管理风险也有很大影响。
例如,使用物联网来帮助用射频识别(RFID)标签标记资产。这有助于监控从起重机等设备的维修间隔到确保发电机具有正确的燃料水平的一切。[3] [4]
物联网使决策者能够发现趋势,适应不断变化的市场条件,并改进他们的战略。此外,物联网主导的方法可以应用于任何企业,无论是零售商、医疗机构、初创公司,甚至是建筑公司。
通过利用物联网等新兴技术并实施集成系统,您可以收集和分析来自多个位置的无限数量来源的海量数据。通过这种方式,您可以改进运营流程以提高报告的及时性,并利用数据来推动预防措施,让您在潜在风险面前领先一步。
4.8.数字图象处理
图像处理是将图像转换成数字形式并对其进行某种操作,以获得增强的图像或从中提取一些有用信息的方法。[17]
从 1997 年开始,图像处理被引入作为医疗风险评估的工具。应用于高分辨率乳腺热像图的图像处理技术用于预测乳腺癌。目标是观察由于温度差异和/或观察到的泡状结构区域和其他“热点”导致的热模式的不对称性。[16]
此外,图像处理还被用于预测自然风险,如森林火灾,处理和分析由飞机或卫星平台上的传感器捕获的图像。图像衍生产品用于火灾风险的火灾前评估、火灾范围和移动的实时绘图、烧伤范围和严重程度的火灾后分析以及火灾后恢复。[14] [15]
4.9.网络安全
网络安全是旨在保护网络、计算机、程序和数据免受攻击、破坏或未经授权访问的技术、流程和实践的集合。[5]
风险管理人员必须受益于领先的网络安全公司,如赛门铁克、卡巴斯基等,这些公司定期发布最新的威胁、恶意软件和系统漏洞。这将使他们对使用技术时可能发生的风险有更多的了解,从而提高意识并选择适当的安全防御措施来防止风险。
网络安全最成问题的因素之一是安全风险的快速和不断演变的性质。传统的方法是将大部分资源集中在最关键的系统组件上,并防范已知的最大威胁,这使得一些不太重要的系统组件和一些不太危险的风险无法防范。这种方法在当前环境下是不够的
4.10.人工智能
人工智能是一种“认知技术”,它扩展了过去被认为是人类过程的东西——如思考、学习和预测——并将它们嵌入到联网的机器中。此外,由于谷歌、IBM 和微软等主要开发商如今通常可以免费获得这项技术,初创公司就像资金雄厚的大型组织一样能够颠覆行业。
例如,在风险管理中,人工智能可用于将政策、程序和控制与监管机构和监管变化相结合,以提高其组织的合规性。[24] [25]
5.挑战
正如我们在上一节中所描述的,风险管理受到信息技术兴起的极大影响。然而,我们必须考虑到每一种可以使用的技术都有其自身的风险。因此,在使用一项技术时,我们必须意识到所有潜在的漏洞。
例如,当在云上存储企业数据以便在风险评估流程中使用时,我们可能会遇到隐私问题,尤其是在使用机密数据时,例如新发明的产品或战略计划。[22]
另一方面,每个组织都必须有精通知识的 IT 专家,以便能够处理使用某项技术带来的任何风险。或者,公司必须与外部 IT 公司签订合同,这可能会导致隐私泄露
6.摘要
在本报告中,我们简要概述了风险管理,其中我们描述了流程、方法和标准。之后,我们谈到了信息收集在风险管理中的重要性。然后我们讨论了影响这个领域的信息技术,从可视化程序开始,到人工智能结束。
另一方面,我们谈到了在使用这些技术时发现的一些挑战。
未来可以做的工作之一,是研究使用信息技术来评估一个组织中的风险会带来哪些风险,以及许多技术的集成是否会有风险。
7.参考
- [1] OCEG,“GRC 能力模型”,网址:https://go.oceg.org/grc-capability-model-red-book,访问日期:2017–12–25
- [2]托马斯·h·斯坦顿,“企业风险管理”,网址:【https://www.youtube.com/watch?v=voGyHN-tWMg ,访问日期:2017–12–25
- [3] Beatrix Knopjes,“为什么物联网是集成风险管理的未来”,URL:【https://www.isometrix.com/iot-in-risk-management/ ,访问日期:2017–12–25
- [4] Hein Koen,“物联网如何有利于风险管理”,网址:http://www . riskmanagementmonitor . com/How-the-Internet-of-Things-Benefits-Risk-Management/,访问日期:2017–12–25
- [5]玛格丽特·劳斯,“什么是网络安全?”,网址:http://whatis.techtarget.com/definition/cybersecurity,访问日期:2017–12–25
- [6]马丁·布朗,《数据挖掘技术》,网址:https://www . IBM . com/developer works/library/ba-Data-mining-techniques/,访问日期:2017–12–23
- [7]约翰·史派西,“7 种风险清单”,网址:https://simplicable.com/new/inventory-risk,访问日期:2017–12–24
- [8] OCEG,“风险管理是 GRC 和原则性绩效的核心”,URL:https://www.oceg.org/about/people-like-you-risk/,访问日期:2017–12–26
- [9]汤姆·帕特森,“信息技术在风险管理中的应用”,出版日期:2015 年 9 月
- [10] Michael Thoits,“企业风险管理技术解决方案”,出版日期:2009 年
- [11] Maryam Teymouria 和 Maryam Ashoori,“信息技术对风险管理的影响”,出版日期:2010 年
- [12] Hamidi Tohidi,“风险管理在组织的 IT 系统中的作用”,出版日期:2010 年
- [13] ISO 组织,“ISO 31000 —风险管理”,网址:https://www.iso.org/iso-31000-risk-management.html,访问日期:2017–12–26
- [14] Douglas Stow,“遥感和图像处理在火灾管理中的作用”,URL:【http://map.sdsu.edu/Notes/stow-remotesensing.htm, 访问日期:2017–12–26
- [15]PRIYADARSHINI M . HANAMARADDI,“森林火灾探测图像处理的文献研究”,出版日期:2016 年 12 月
- [16] C.A. Lipari 和 J.F. Head,“用于乳腺癌风险评估的高级红外图像处理”,出版日期:1997 年 10 月 30 日
- [17] EngineersGarage,《图像处理导论》,网址:https://www . engineers garage . com/articles/image-processing-tutorial-applications,访问日期:2017–12–26
- [18]玛格丽特·劳斯,“什么是风险管理?”,网址:http://search compliance . tech target . com/definition/risk-management,访问日期:2017–12–23
- [19]“CORAS 方法”,网址:http://coras.sourceforge.net/,访问日期:2017–12–26
- [20]微软,《微软威胁建模工具 2016》,网址:https://www.microsoft.com/en-us/download/details.aspx?id=49168,访问日期:2017–12–26
- [21] ICAR,“大数据如何帮助金融风险管理?”,网址:https://www . icar vision . com/en/how-does-big-data-help-with-financial-risk-management-,访问日期:2017–12–25
- [22] CEPIS,“云计算安全与隐私问题”,网址:https://www.cepis.org/index.jsp?p=641&n = 825&a = 4758,访问日期:2017–12–26
- [23] Auer,S. R .和 Bizer,c .和 Kobilarov,g .和 Lehmann,j .和 Cyganiak,r .和 Ives,z .“DBpedia:开放数据网的核心”,出版日期:2007 年
- [24]企业风险,“人工智能与风险管理”,网址:https://enterpririsgmag . com/ARTIFICIAL-INTELLIGENCE-Risk-MANAGEMENT,访问日期:2017–12–27
- [25]彭博,“人工智能是金融风险管理的游戏规则改变者”,网址:https://www . Bloomberg . com/professional/blog/Artificial-Intelligence-game-changer-risk-management-finance,访问日期:2017–12–27
物联网将如何变革教育行业

技术无处不在,它正在改变我们的生活、学习和工作方式!从汽车到洗碗机,日常用品正在成为互联设备,智能手机正在成为生活的完全遥控器。根据 Statista 的数据,预计全球“物联网”设备的安装数量将增长至近 310 亿台。如今,物联网正在改变各行各业,教育领域也不例外。传统上,学习的起源仅限于教室、会议、在线教程等,但随着物联网的出现,这开始缓慢而稳步地转向更好的方向。
那么,物联网到底能如何颠覆这个行业呢?让我们仔细看看!
将世界各地的人们联系起来
想象一个场景,学生坐在他们的舒适区,与世界各地的教育者和同龄人互动,所有人都可以模仿个人互动。嗯,很有可能。智能板和数字荧光笔允许将印刷文本传输到手机或任何其他设备,然后,交互式板可以接收、确认和回复信息(我们做的一个这样的试点项目的快速演示在这里),使学习互动和有趣,并且人人都可以使用。

教材增强
还记得翻遍图书馆书架寻找参考资料和辅助材料吗?随着技术的进步,这已经成为过去。如今,几乎所有的教科书都有一个二维码,可以扫描该二维码,以便在他/她的设备上获取教科书。他们可以轻松下载或将书保存到 iBooks,并在任何地方开始阅读。更重要的是,在电子书的情况下,如果你正在寻找一些特定的东西,你可以直接搜索并立即找到它,而不是花很长时间翻阅页面来找到它。
残疾人的援助之手
除非你听力不好,或者你与听力好的人关系密切,否则你根本不知道什么是手语,这对依赖手语的人来说是令人沮丧的。在物联网的帮助下,手语现在可以被翻译成文本和语音。这也是确保听障人士能够获得尽可能最好的手语教育的一个很好的方式。每当戴着手套的学习者做手势时,传感器就会获取信号,进行分析,并提供关于他/她的准确性的反馈。

提高效率
使用物联网简化日常运营有助于更加专注于实际的教学活动,例如,自动检测学生在学校的设备可以消除考勤需求,还允许学校官员向家长发送电子消息。他们可以与物联网传感器合作,并使用它来为经过验证的进入者开门,并在出现任何不速之客的情况下向管理层发送警报。

安全
一所学校里有成千上万的学生,监视他们每个人的行踪和活动是一项不可能完成的任务。射频识别(RFID)芯片使用无线电波来读取和捕获数据,这些数据作为标签存储在物体上,可以在几英尺外读取,不需要在数据收集器的直接视线范围内。
这有助于当局和家长在任何给定的时间点监控学生,在增强安全性方面增加了巨大的价值。启用 GPS 的公共汽车系统意味着可以跟踪路线和公共汽车的运动。此外,学生可以在公交车到达时得到通知,从而缩短不必要的等待时间。
根据皮尤研究中心的数据,95%的青少年有智能手机,45%的人说他们“几乎经常”在线。那么,有了这样的统计数据,在采用“智能学校”的学校和大学的帮助下,有什么更好的办法来尝试和引导他们持续的网瘾变得更好呢?物联网确实正在改变教育领域,让学习变得更简单、更快速、更安全。在这些技术的帮助下,地理、语言、残疾等常见的教育障碍将不复存在。然而,这仅仅是一个开始,我们才刚刚开始触及未来基于技术的教育的表面。
最初发布于:binary 乡亲
大型企业如何利用人工智能/机器学习

我们在新闻中听到了很多关于机器学习的消息,并且开始变得很难将双曲线和令人兴奋的未来主义预测与务实的现实世界商业应用分开。我热爱人工智能领域,它每天都激励着我,但人工智能往往看起来像是发生在一个遥远的先进技术领域,或者只有谷歌、脸书和亚马逊的企业在实施它。认为这是错过了一个相当大的机会,其他企业已经在利用这个机会。实际上,我认为大企业比更常见的“小”、“灵活”和“颠覆性”的创业部门有独特的优势。大型企业在实施改变游戏规则的机器学习产品或利用机器学习来获得更高的运营效率方面具有优势。这是因为大企业有两个巨大的优势。1)您有一个现有的客户分销网络。但最重要的是在机器学习的背景下,2)你有方式更多的专有数据来训练机器学习算法,而初创公司根本无法获得这些数据。
首先,在谈论这个话题时,你会经常听到三个常见的短语:“人工智能”、“机器学习”和“深度学习”是最常见的。把它们放在一个概念层次中考虑。“人工智能”或“AI”处于顶端,它是计算机科学的整个学科,试图使用机器/软件复制智能推理和行为。人工智能的一个特别强大的策略是所谓的“机器学习”,本质上是指通过给计算机大量数据来学习,教它做一些事情。机器学习算法实际上是非常强大的模式识别过程。在大量数据示例中查看模式是机器学习的目的。最后,“深度学习”是机器学习策略中的一个特殊算法家族,它被发现非常擅长解决以前我们无法解决的人工智能问题(对象识别、理解文本和语音)。出于本文的目的,我经常将机器学习和人工智能作为同义词,但现在你知道了,它们不是。
想想机器学习和人工智能,因为它可以应用到您的业务中,就像高级模式识别一样! 如果你是一名企业领导者,正在阅读这篇文章,最好的办法是不要陷入技术实现或炒作,而是为自己建立一个概念镜头,这样你就可以审视你组织的各个领域,并开始注意到自己应用机器学习的机会。然后就可以更深入的看技术实现了。这里有一些问题要问你自己:
- **数据在哪里?**您在组织的哪个部门收集或利用大量数字数据?(这里的很多是指 10 万到 100,000,000 以上的记录。这些数据可能是客户交易、销售记录或支持票据。与应用程序的一些交互。不可能先验地说你所拥有的数据是否足够。机器学习算法需要大量高质量的数据来开始形成可靠的预测和假设。根据数据的质量,你可能需要更多。高质量的数据越多越好。在这些数据密集的领域,您可以开始利用机器学习来发现复杂的模式并加以利用。重要的是,这些数据需要是机器可读的。如果你有数百万份客户记录,但它们都在纸质文件夹中,你首先需要考虑数字化,然后才能梦想利用机器学习。一个常见的例子是使用机器学习来阐明销售线索列表中的模式,这些模式基于哪些销售线索关闭和哪些未关闭,以便您可以根据关闭概率对销售线索列表进行排序/优先排序,从而提高内部销售团队的转化率,因为他们首先将时间花在关闭销售线索的最高概率上。
- 你在哪里做预测?您在公司的哪个部门使用数据进行预测?这通常包括财务预测、需求预测、营销预测等。预测越大,从越多的数据中进行预测,机器学习就越适用于提高这些预测的准确性。您的业务分析师可能已经使用了一种称为无监督聚类的机器学习技术来创建客户细分,但您还可以开始做更多的事情。例如,使用历史需求数据、所有 CRM 数据,甚至天气数据,实时进行高度准确的需求预测。
- **重复的流程在哪里?**哪些重复过程可能需要人的判断,但仍在可预测的参数或界限内。您试图使用结构良好的数据(即贷款或保险申请)评估欺诈风险或可能性,或浏览陈旧流程(大多数支持渠道请求、数据输入)的任何地方。通常,我们认为需要人类判断的独特洞察力的事情都落在某些具有非常可预测的约束和参数的老路之中。当然,总会有例外情况,比如如何评估贷款申请,但大多数都可以像人类一样准确地自动化,而将例外情况留给人类来评估。机器学习正在迅速自动化这些传统的人类活动。
现在,这些问题应该让你开始用你自己的模式识别镜头来审视你的公司,并开始想象你可以在你的公司中利用机器学习的方法。然而,一旦你看了,我可以预测你将最常看到三个直接用途中的一个。还有许多其他方法来利用机器学习,但这些通常都是唾手可得的成果。
- 销售优化 —销售通常是我们拥有一些机器学习最佳数据的领域。这也是实施机器学习可以获得最直接的财务影响的地方。请记住,机器学习可以识别模式,因此它可以注意到:当某些客户群最适合追加销售时,哪种类型的客户线索最有可能关闭,以及潜在客户关闭的概率,以及基于您的历史销售数据和客户档案中的模式的产品推荐系统。如果有足够的数据,所有这些实施都会对转化率产生直接影响,因为你开始将销售人员的时间优先安排在最有可能赢得销售的事情上。无论你是想雇人来定制实现这一点,还是试图使用大多数 CRM 现在提供或正在争相开发的许多交钥匙 SaaS 人工智能支持的销售优化产品,都没有关系,公司在这一领域已经获得的回报是真实而显著的。
- 流程自动化 —这是机器学习的一种不同用途。从自动化手动数据输入,到自动化保险风险应用评估。这是在你的公司中寻找大量使用人工决策的地方,但这些地方通常属于共同的模式、界限或约束。我已经给出了评估应用程序的示例,但我还想在这一领域中包括支持渠道自动化。如果你正在阅读这方面的内容,你肯定听说过“聊天机器人”或“对话界面”,如果实现得好,它们可以大大减轻你的支持团队的负担。这里的数据不是销售数据,而是支持票评论和客户档案。它通常不是定量数据,而是定性数据,但仍然有方法来自动化这些经典的人类判断过程。
- 支持人工智能的产品/功能 —这是机器学习/人工智能的一种更加无定形和创造性的应用。这就是你利用你的优势,作为一个现有的企业,可以访问所有这些专有数据和现有的客户分销网络,来部署其价值来自他们对人工智能的使用的产品。在这里,你开始审视你的客户数据和客户需求,并开始问自己,现在你可以使用人工智能/机器学习而不是人工劳动(作为一种产品/服务,这可能不具成本效益),为客户大规模完成哪些看似类似人类的模式识别任务。这不是取代工作,这是做一些你的公司从一开始就做不到的事情,因为用人力做这件事的成本很高。
我的最后一条建议是,开始阅读大公司中人工智能的不同应用。它将开始激发你的想象力,让你有可能在自己的企业中有所建树。首先,这里有两个资源,但我发现简单地在谷歌上搜索“在[在此插入企业功能]中的人工智能应用”,往往会让你找到许多有趣的文章。这里有几个让你开始。
德勤人工智能创新报告 2016
人工智能在销售:10 家公司看
真正的商家是如何使用机器学习的
最后,一旦你准备好继续前进,组建/雇佣一个小团队,开始探索潜在的应用。这种价值很大程度上取决于数据的质量、相关性和数量,因此在开始试验数据、阐明有趣的模式并进行试点以测试其影响之前,你无法确切知道其影响。
学习神经网络是如何给我带来生存危机的
此刻没有人能忽视的一件事是 AI 在我们日常生活中的盛行。我们在日常使用的所有应用程序中都可以看到人工智能的雏形。脸书最近一直用我和我的朋友们的旧记忆困扰着我。他们很好地使用了他们的图像识别算法,与我建立了另一个层次的情感联系,提醒我我已经没有朋友了。
因此,就像所有其他对人工智能感兴趣的产品开发人员一样,我最近开始想办法在我的平台上使用机器学习、神经网络和其他预测算法。我想知道如何让它变得更智能,并显著减少由于数千个基于开关/案例规则的系统而导致的处理过载。所以我开始了解什么是神经网络以及如何实现它的一些基础知识。
开发人工神经网络的方法包括松散地复制我们自己的大脑如何工作。开始时,我没有注意太多的逻辑——但我越是试图理解神经网络如何实现背后的逻辑,它就越让我起鸡皮疙瘩。我知道这听起来很荒谬。我过度使用它,直到我的大脑自动关闭,我在周末剩下的时间里狂看黑白电影 Strangelove 博士,North x northwestern 和 Clerks。

这是两个神经元之间连接的非常精确的细胞表达。人工神经网络也基于非常相似的概念工作——有不同的节点&连接节点的突触。每个节点都被编程为对其输入执行特定的处理。你在神经网络的开始传递某些输入,它经过不同的处理层产生一个输出。Siraj Raval 在他的一个视频中很好地解释了这个概念——他是我此刻的英雄。

此图中的圆圈显示了一个三层神经网络,每层都有不同的节点集。尽管该图看起来非常简单,但是每个节点都内置了许多抽象概念。然而,神经网络如何工作背后的简单思想是,传入的每组输入根据其对输出的贡献大小而被赋予一定的权重。
例如,如果我要选择一家餐馆或酒吧进行约会,我会注意某个地方的以下特征——食物质量、饮料质量、等级、离家距离、音乐类型、屋顶或其他。接下来,我会使用上述所有特征以及约会质量对我以前的约会地点进行手动分类。然后,我会将这些分类数据传入我的神经网络进行训练。这里的输入是一家餐馆的所有特色,输出是约会的质量。在对训练集进行多次迭代之后,神经网络将知道每个特征在产生期望输出中的重要性。然后,它将根据每个要素对输出的影响程度为其分配相关权重。节点之间的每个突触都有自己的逻辑程序,为不同的特征分配相应的权重。
我的神经网络的目的是根据我选择的地点来预测我的约会是令人惊奇还是不那么棒。当然,这是一个非常愚蠢的例子,因为约会的地点与约会的质量关系不大。和你的人际交往能力有很大关系。所以请不要真的设计一个神经网络来预测你约会的质量。然而,这将有助于确定你约会的最佳地点。
好了,这是我将偏离技术细节的时刻,因为这真的让我反思我们的大脑是如何工作的。我们一生都在接受所谓的“训练数据”,以规划我们当前的行为模式。无论我们一天中做什么,都只是我们体内的神经元根据周围环境传递给我们的输入进行计算。我们的突触被训练来分配传递到我们系统的不同输入的权重,这就是我们的个性。
这让我质疑我生活和存在的基础。我是不是一辈子都在无意识地训练自己的神经元,才真正塑造了我现在的人格?我一直是 A 型人格,总是努力不断改进,这真的让我很失望,因为这需要我完全重新编程我的神经元,以改善我人格的某些方面。这一开始听起来确实令人难以置信,但并非完全不可能。
这个训练我们的神经元来改变它们的连接并影响我们行为的过程也被称为神经可塑性。临床心理学家经常使用这一过程来帮助大脑适应新的环境或适应任何类型的伤害或疾病。这个模型给了我们希望,通过有意识地训练我们的大脑,我们有可能从任何对我们心灵造成的严重伤害中恢复过来,事实证明我们的大脑非常灵活——这与传统的观点相反,传统观点认为人类的大脑是僵化的,人类的行为在一定年龄后无法改变。
这怎么可能呢?神经网络中使用的感知器模型意味着,如果我们简单地改变我们每天从周围环境中接收的训练数据,那么我们就可以显著地改变我们提供的输出。现在的困境是——如何准确地过滤训练数据,以便给你的个性塑造理想的形象?这要求我们完全意识到我们是如何度过我们的时间和我们所接触的一切的。一些无意识决策的时刻,我们的神经元以某种方式被编程,以影响我们的决策能力。
这个想法是首先要注意我们是如何做决定的(即使是冲动的决定),并理解我们的神经元是如何权衡每个输入的。一旦我们对我们的神经元如何被编程有了想法,我们就可以开始有意识地权衡传入我们系统的不同输入,以提供符合我们真正想要成为的人的期望输出。
我怀疑没有人读到这里。点击下面的绿色心脏,让我知道你是否做了:)
Python 的列表理解:用途和优点

The eyes of an interpreter, the scales of robust code. Source: Pixabay
无论您是数据科学家、从事 API 工作的 Web 开发人员,还是一长串角色中的任何一个,您都有可能在某个时候偶然发现 Python。
我们中的一些人喜欢它的简单、流畅和易读。其他人讨厌它,因为它不像 C 或纯汇编那样高性能,具有鸭式类型,或者是单线程的(ish)。
不管你属于哪一类,如果你处于想要/必须写 Python 代码的位置,你会希望它尽可能的易读。或者你可能在野外偶然发现了一个列表理解,并对如何驯服它感到困惑。如果这些都是真的,那么这篇文章是给你的。
什么是列表理解?
首先,我们来定义一下我们的术语。列表理解是替代以下模式的一种句法糖:
用这个,相当于,一个:
为什么我们应该使用它们
使用列表理解有什么好处?首先,你将三行代码减少为一行,这对于任何理解列表理解的人来说都是显而易见的。其次,第二段代码更快,因为 Python 会先分配列表的内存,然后再添加元素,而不是在运行时调整大小。它还可以避免调用“append ”,这可能很便宜,但会增加成本。最后,使用理解的代码被认为更“Python 化”——更符合 Python 的风格准则。
重构代码的味道
另一个更微妙的优势是嗅觉检测。没有理解的代码可能如下所示:
如果’ some_function '中前面或后面的代码足够长,那么关于列表的那部分可能会丢失。但是在这 6 行中直接使用列表理解看起来并不漂亮:
试图用你的眼睛来解析它会让你头疼。你们座位下面有一些纸袋,以防你们需要用。这里发生了什么事?很明显,一点逻辑应该被抽象成一个新的函数,就像这样:
refactoring with two levels of abstraction
然后,前六行代码最终只是
another_list = [new_function(i) for i in range(k)]
如果你知道发生了什么,它会更清晰(如果我没有为我们的函数取这么糟糕的名字)并且读起来更快。有些人可能会说,为了达到这个目的,我最终添加了 6 行开销代码。确实如此,但是如果这种行为在代码中至少出现了一次,那么即使这样也不算是一种损失。即使不是这种情况,我们在代码大小上的损失,我们在可维护性和易读性上的收益,这是应该追求的。
优秀的程序员编写人类能够理解的代码。
——马丁·福勒。
使用列表理解很容易做的其他事情有
将矩阵展开成向量:
vector_version = [1,0,0,0,1,0,0,0,1]
过滤列表:
生成一个类的许多实例(在这种情况下用一个简单的字典建模,比如 JSON 对象):
将某种类型的对象列表转换为另一种类型的列表:
We generate a list of the first 100 numbers turned into strings, or just a string joining them with commas. All in one smooth line!
性能提升
为了验证性能是否真的有所提升,我决定运行一些测试。我运行了相同代码的 for 循环版本和 list comprehension 版本,过滤和不过滤都可以。下面是测试的片段:
list_a 方法以通常的方式生成列表,带有 for 循环和追加。 list_b 方法使用列表理解。
我的结果如下:
- 列表 a 为 5.84 秒
- 名单 b 为 4.07 秒
- 过滤列表 a 为 4.85 秒
- 过滤列表 b 为 4.13 秒
我鼓励您在自己的计算机上运行同样的脚本,亲自看看性能的提升,甚至可以改变输入大小。
在未过滤的情况下,我们看到从切换到列表理解的速度提高了 33%,而过滤的算法只提高了 15%。这证实了我们的理论,即主要的性能优势来自于不必在每次迭代时调用 append 方法,在过滤的情况下,每隔一次迭代就跳过一次。
最后,我应该补充一点,我刚刚教你的关于列表理解的所有内容都可以用 Python 字典来完成。
字典理解:
这是我的列表理解速成班,我希望你喜欢它!如果有任何你觉得我应该提到而没有提到的功能,或者对 gists 有任何抱怨,请让我知道。
最后,有一本我喜欢的 O’Reilly 的书,当我开始我的数据科学之旅时,我发现它非常有用。实际上,我就是从这本书上学会理解列表的。用 Python 从零开始叫 数据科学,大概也是我得到这份工作的一半原因。如果你读到这里,你可能会喜欢它!
P.S:如果你想在这个话题上展开,建议你看我的文章 Python 的生成器表达式 。我也鼓励您关注我,获取更多的 Python 教程、技巧和诀窍。
机器学习和人工智能如何给软件测试带来新的维度

看起来,软件测试行业从未停止,并且一直在发展。根据 2017 年测试调查的状态,未来是自动化测试,因为 62%的受访者认为未来几年将会增加。根据同一份报告,我们还可以预计测试人员将花费更多的时间和资源来测试移动和混合应用程序,而花费在实际开发上的时间将会减少。
虽然这些因素很大,但没有一个因素(测试自动化、更短的开发周期或专注于移动和混合应用程序)像新兴的机器学习技术一样真正改变了测试游戏。
机器学习现在正在各行各业成功应用,那么问题来了,机器学习和人工智能会如何影响软件测试?他们真的会增强它吗?
阅读这篇文章,了解软件测试和质量保证在机器学习和人工智能时代是如何发展的。
传统测试方法的头号挑战
软件测试曾经是一项简单直接的任务。只要我们知道系统在用例中是如何表现的,输入一个输入并比较结果和期望就相对容易了。匹配意味着测试通过。如果有不匹配,警报就会响起,因为我们有一个潜在的错误,需要重新开始来修复它。
在这样一个传统的场景中,测试人员会仔细检查清单,以确保潜在用户的步骤和行为都被覆盖,问题得到解决。然而,由于消费者在某种意义上变得越来越苛刻,越来越缺乏耐心,传统的测试方法往往跟不上他们的步伐。
主要问题在于测试人员需要在他们目前通常拥有的有限时间内处理大量的数据。仅仅这一点就将传统的测试方法排除在外,需要一种更相关的方法。也就是说,由人工智能、机器学习和预测分析驱动的那个。
交给机器:不再有人工干预(和错误)
传统的测试技术仍然依赖于人类来获取和分析数据。但是我们只能说,人类并不是一贯正确的,并且很容易做出错误的假设。
处理数据的时间越少,测试产生错误结果的机会就越大,软件中的错误就被忽略了。在你知道之前,消费者会发现这些缺陷,这通常会导致沮丧和破坏品牌的声誉。
这就是为什么机器学习,它教会系统在未来学习和应用这些知识,使软件测试人员得出比传统测试更准确的结果。更不用说出错的概率并不是唯一降低的。执行软件测试和发现可能的错误所需的时间也缩短了,而需要处理的数据量仍然可以增加,而不会给测试团队带来任何压力。
使用预测分析来预测客户需求
随着市场需求的增长,企业需要找到比竞争对手领先一步的方法,并能够预测消费者的需求。预测分析在质量保证和软件测试中发挥着关键作用,因为它允许企业分析客户数据,以更好地了解(和预测)他们想要什么样的新产品和功能。
在这一点上,机器学习和预测分析在今天的软件测试和 QA 中齐头并进。它们对于一个不间断的、更短的测试过程都是必要的,最终会带来更好的用户体验。
机器学习在 QA 和软件测试中的位置?
人工智能和机器学习无疑也正在成为质量保证和软件测试的重要组成部分。
专家们对这一切可能带来的前景感到兴奋。例如,埃森哲欧洲、非洲和拉丁美洲的董事总经理兼测试服务负责人 Shalini Chaudhari 在接受 QA Financial 采访时表示,人工智能起飞的原因是物联网突破带来的巨大数据可用性,以及不再仅限于专业研究机构的不断增长的计算能力。
结论
机器学习让测试人员有机会更好地了解他们客户的需求,并对他们不断变化的期望做出比以往更快的反应。此外,测试人员现在还需要分析越来越多的数据,而给他们的时间却越来越少,同时他们的误差幅度也在不断减小。机器学习和预测分析等工具提供了一种解决这些挑战的方法,要么通过精通测试的内部团队,要么如果情况不是这样,转向 QA 外包。无论如何,这种方法将填补传统测试方法的空白,并使整个过程更有效,更符合用户的需求。
机器学习和人工智能如何改善旅行服务

这篇关于机器学习和 AI 在旅游行业的文章最初发表在 Django Stars 博客上。
克里斯托弗·哥伦布是历史上最著名的旅行家之一,他一生只进行了 4 次旅行。其中一次旅行花了他将近 6 年的时间来准备、计划和预算。幸运的是,现代旅行者可以在仅仅一年甚至一个月甚至一周内轻松打破那个终身记录(一些铁杆)。
廉价的航班,实惠的酒店价格,以及大量帮助旅行者计划和导航旅行的旅行应用程序,使人们能够更多地旅行。难怪数字旅游销售额预计到 2020 年将突破 8000 亿美元。像 Kayak、、Booking.com和 Expedia 这样的应用颠覆了旅行社行业,现在正通过使用机器学习为的旅游服务开发重新创造全方位服务体验。

尽管看起来很痛苦,但人们实际上喜欢计划他们的旅行,可以花 2 / 4 /(你可以选择)个小时粘在屏幕上寻找最佳地点、最佳行程和最佳价格。这就是机器学习和人工智能发挥作用的时候:通过分析大型数据集,人工智能融合的旅行系统可以为旅行者提供超级个性化的建议。

AI & ML 的螺母和螺栓
越来越难找到一个成功的故事,说明旅游公司 X 如何进行技术改进,使销售额增加 Z%,而没有发现“机器学习”或“人工智能”的字眼。有时互换使用,这两个概念实际上有不同的含义。
人工智能是计算机科学的一个广阔领域,它研究如何教会计算机像人一样思考和行动。
机器学习是 AI 的子集,重要,但不是唯一。简而言之,机器学习就是建立模型,在输入数据的基础上以高精度预测结果。使用统计方法,随着更多的数据被输入系统,它使机器能够提高它们的准确性。
机器学习模型的最终输出取决于:
**1)数据的质量。**数据越多样、越丰富,机器就越能发现模式,结果也就越精确。例如,以下是旅游业提供商获取数据的一些方式和方法:

Image source: Markrs.co
高质量的数据集通常需求量很大,公司有时不得不寻找合适的数据集。
2)特征是现有数据包含的有意义的输入,如用户性别/位置/浏览器扩展等。通常数据有更多的信息需要建立模型,因此有必要选择重要的特征。在此过程中,分析师或建模工具根据属性对分析的有用程度来选择或丢弃属性。

众多的特征使得算法工作得更慢,所以通常数据准备和 having 的过程是整洁的。xlsx 和。csv 文件最终比整个培训过程花费更多的时间。
3)分析数据的算法寻找模式或趋势,然后找到创建模型的最佳参数。选择最佳算法来解决特定任务是一项相当具有挑战性的任务,因为每种算法都可能产生不同的结果,其中一些算法会产生不止一种结果。
以下是机器学习驱动的模型是如何构建的:

机器学习模型可以胜过传统的僵化的商业智能,在传统的商业智能中,商业规则无法捕捉隐藏的模式。
旅游公司正在积极实施 AI & ML,以深入挖掘可用数据,优化其网站和应用程序的流程,并提供真正卓越的体验。
您可能还喜欢:
[## 如何开发旅游预订服务:来自 PADI 开发团队的 5 条经验
易于使用,顺利交易,快速获取信息和交易-热情的旅行者通常使用这些…
pxlme.me](https://pxlme.me/CxAiPOj-)
你随时想要的任何东西的世界。旅游公司如何使用人工智能和机器学习解决方案来取悦客户
旅行是一种高度情绪化的体验,有无数的选择来满足不同预算和类型的旅行者。独自旅行、公司旅行或家庭度假——心中有不同目标的旅行者希望应用程序从一开始就建议正确的套餐。证据如下: 88%的休闲旅行者会换一个不同的应用或网站,如果你的不能满足他们的需求。
Booking.com 在其调查中发现,几乎三分之一(29%)的全球旅行者表示,他们愿意让计算机根据他们之前的旅行历史数据来计划即将到来的旅行,一半(50%)的人不介意与真人或计算机打交道,只要任何问题都能得到回答。
目前,预订机票、酒店和租车已经完全变成了一种在线体验。因此,我们所有的旅行习惯都有大量的数据,这允许人工智能算法提取大量的见解,并将它们转化为定制的产品和一种新的体验。
谷歌首席执行官桑德尔·皮帅已经讲述了人工智能如何引领世界:
“随着时间的推移,计算机本身——无论其外形如何——都将成为帮助你度过一天的智能助手。我们将从移动优先转向人工智能优先的世界”。
人工智能是一个强大的工具,可以促进客户与旅游提供商之间的关系,即时丰富体验,并提供无摩擦的体验。以下是人工智能和人工智能在旅游业中最成功的应用:
- 聊天机器人
根据 HubSpot 的研究报告,71%的人使用聊天机器人快速解决他们的问题。截至目前,我们在酒店领域看到人工智能的最大地方是用于客户服务的聊天机器人。客户服务在旅游业中占有非常重要的位置,聊天机器人可以提供全天候的全面客户支持,从而减轻工作人员的负担。
聊天机器人有两种类型:
第一种由一组预先设定的答案驱动,这些答案是预先编程的,由一组规则驱动。这些需要手动编程,并且往往代表一大组常见问题,例如:
- “明天布鲁克林的天气怎么样?”
- “下一趟去巴黎的航班是什么时候?”
阅读如何创建电报机器人的教程
[## 如何开发旅游预订服务:来自 PADI 开发团队的 5 条经验
易于使用,顺利交易,快速获取信息和交易-热情的旅行者通常使用这些…
pxlme.me](https://pxlme.me/CxAiPOj-)
第二种更复杂,由人工智能驱动,它理解语言和命令,并在交互过程中学习。它可以回答一些更复杂的问题,比如:
- “150 美元能带我去哪里?”
- “纽约发生了什么事?”

Image source: JWT Intelligence
无论白天还是晚上,随时提供即时回答,提供全面的支持,尽管听起来可能很奇怪,但以友好的方式管理与人类的关系。通过适当的预编程,聊天机器人可以增强整个旅行体验,从到达前的自动提醒到建议目的地附近的娱乐场所和交通设施。
如果游客到达一个新的目的地,在游客信息中心撞上了“关闭”的标牌,不用担心——只需轻点几下,他们就可以启动一个机器人,询问他们需要什么。事实上,客户对人工智能聊天机器人的期望很高——他们希望聊天机器人以友好的方式解决他们的问题,而且在紧急情况下提供帮助。下面是用户请求的表达方式:

Kayak 因将机器人融入旅行体验而闻名。这个机器人会为你提供完整的信息,包括航班、租车、行程选择,还会告诉你一些活动。此外,它还通过 messenger 向客户发送未来旅行计划的更新信息。
Kayak 首席执行官史蒂夫·哈夫纳说,
“整整一代人更熟悉通过 Siri 发送短信和语音,他们在寻找与在线旅行社不同的互动方式。我们有与 Alexa 的语音交互,你可以对 Kayak 说,‘嘿 Kayak,我今天晚些时候飞往丹佛的航班情况如何?’‘这个周末我可以花 300 美元去哪里?’”

到目前为止,旅游行业出现了一些很棒的聊天机器人,如 Lola,它使用人工智能增强功能来授权旅游顾问,以便他们可以提供完美的旅行。由人工智能驱动的 Mezi,一个可以帮助所有旅行安排的聊天机器人,人工智能由旅行专家训练和改进,或者 Sam,一个帮助提高旅行顾问专业知识的聊天机器人。沃森驱动的“康妮”机器人是为连锁酒店希尔顿开发的,它使用沃森的大脑来帮助客人办理登机手续并推荐当地景点。

Image source: theverge.com
- 推荐系统
Youtube、Spotify、网飞、Booking.com——这些领先的公司有一个共同点。这个东西让他们的客户在网站上保持很长时间,对历史和实时数据进行操作,并生成大量的相关命题。
通常,旅行者一旦进入旅游网站或应用程序,就会被信息淹没。另一方面,以正确的方式响应客户日益复杂的期望是一个相当大的挑战。将人工智能和人工智能纳入其业务的酒店和旅游提供商有一张王牌——通过利用大量数据,公司可以更密切地调查客户的行为,并最终提供定制产品。
旅游平台上每个客户的数字足迹使系统能够了解每个客户的需求、预算和偏好,并建议合适的交易。在正确的时间提供正确的建议将有助于增强客户的忠诚度,让他们一次又一次地回来。

人工智能支持的推荐系统可以输入历史数据,如旅行者以前的预订、行为或实时数据。例如,当这个人打开电子邮件时事通讯时,它会向数据科学家发回一个信号,以便在下一次触摸时合并该信号。
经过处理并与旅行者的背景保持一致后,人工智能支持的推荐系统可以提供卓越的体验。比较这两种情况:

这种量身定制的推荐无疑会提升整体体验。
- 预测:从机票价格到酒店客房供应
“航空公司什么时候降价?”、“周二的航班真的便宜吗?”而且一堆类似的问题,每天都要多次输入谷歌搜索栏。难道它们不是人们渴望找到脑海中出现的最佳价格的最好证据吗?似乎每个人都有这样的情况:你刚刚找到一个好的航班交易,然后过一会儿回到网站,哇!—票价上涨(或者如果你幸运的话,下跌)。
航班价格生成引擎根据特定规则工作,可能会考虑以下一些参数:

众所周知,机器学习可以发现隐藏的模式,而人类的眼睛甚至可能看不到这些模式。例如,ML 算法可以在票价大幅上涨后检测到异常情况,并考虑导致这种上涨的特征组合。
旅游提供商可以通过利用机器学习来帮助旅行者找到预订酒店或购买廉价机票的最佳时间。当交易变得可用时,应用程序可能会向用户发送通知。
例如,以帮助客户跟踪最佳航班交易而闻名的 Hopper 应用,最近加入了选择酒店的功能;应用程序中实现的 ML 算法将推荐是否预订酒店或等待价格下降,类似于机票的工作方式。人工智能和预测分析是这一驱动力的核心。使用彩色编码的日历,用红色标记昂贵的日期,用黄色标记适中的日期,用绿色标记最便宜的日期,Hopper 允许用户查看哪些日期会比其他日期更昂贵:

Image source: theverge.com
- 内容监管
对于品牌与顾客的互动来说,内容才是王道,旅游和酒店业也不例外。网站上的一张照片,移动应用程序中的推送通知,新收到的电子邮件,这些只是为旅行者提供所有所需信息的整个内容机器的几个触摸。告知、启发、互动、推动对话——一流的内容总是会引发用户在网站上的活动。
通常,内容监管是一个依赖于人的过程;然而,AI & ML 可能有助于提供个性化和自动化一些日常任务。
Trip Advisor 在重新设计网站时,注意到他们的网站上有很多很棒的照片(超过 1.1 亿张);然而,你永远不知道哪张照片会先出现。这就是为什么工程团队决定改进照片在不同背景下的显示方式。
该团队可以要求业主对照片进行评级,为他们的列表选择主要照片,并根据场景类型标记照片。在那之后,他们不得不雇佣一大群照片版主来标记、排列和选择照片,但是这又慢又贵。
工程团队从深度学习的角度来完成这项任务。深度学习是机器学习的一个子集,专门用于神经网络架构开发和训练。该团队开发了一个模型,选择有吸引力的相关照片,然后在网站上优先显示它们。只需对比一下他们在实现深度学习模型前后的英雄照片:

Image source: tripadvisor.com
内容优化中人工智能应用的另一个变革性例子是 Booking.com 的翻译管理。他们是迄今为止最大的旅游运营商,通过神经机器翻译(NMT)提供相关的交流——酒店描述、房间描述和酒店名称被翻译成 43 种语言:

也请阅读我们的案例研究

用户体验管理
对于旅游行业的企业来说,你的网站/应用程序的客户之旅对公司的成功至关重要。一些统计数据证明:事实上, 38%的人会停止使用内容或布局不吸引人的网站。
ML 可以在不同的点上注入客户的旅程:从灵感、研究、体验到与家人和朋友分享印象。就 UX 而言,旅游提供商面临两大挑战:
- 优化用户交互界面的方式,从点击式模式到更具对话性的模式
- 让选择选项的过程变得简单快捷
人工智能可以从网站上的每一次互动中主动学习,从而优化用户流量。接触点是否过多?在客户旅程的每一点,会有什么建议?每个阶段应该弹出哪些上下文提示?
将人工智能和人工智能应用于 UX 将有助于理解如何设计客户体验。
大量的数据允许追踪:
- 客户最关心的事情是什么?
- 客户的细分是什么?
- 人们在旅途中会从哪里掉下来,最重要的是,为什么?
- 客户生命周期是怎样的?
- 用户能多快找到东西?
Booking.com公司的全球客户服务总监詹姆斯·沃特斯说
“由于我们在一个极其个人化、情绪化和复杂的行业中运营,在真正的人际互动和高效的自动化之间保持适当的平衡是我们在消费者旅程的每个阶段一直努力微调和优化的事情。”
Skyscanner 分析了用户在使用该应用程序时经历的客户旅程,发现为了获得他想要的东西,用户必须在应用程序中至少进行 9 步操作和 17 次点击。在那之后,该公司转向用基于人工智能的聊天机器人建立对话界面。

旅游公司将通过跟踪元数据提供更相关的体验,例如:
- 意味着你更愿意离开机场
- 和你一起旅行的同伴
- 不管是出差
- 个人/团体
- 该地点的天气如何
旅游业中的机器学习和数据分析:转变商业运作
让我们把话题从客户利益转到业务利益上,因为人工智能和人工智能可以在许多情况下应用于调整业务流程:
销售优化
人工智能模型可以在销售漏斗的所有阶段增强销售经理的能力:
- 发现阶段帮助客户找到目的地
- 参与阶段,找出最适合每个客户的选项
- 通过处理众包数据的转化和保留阶段
旅行历史、以前的行为模式、购买历史和加入忠诚度计划——如果这些数据被输入基于人工智能的系统,它可以帮助销售团队生成个性化的旅行套餐。
人工智能和人工智能模型也可以通过应用程序帮助追加销售/交叉销售产品。例如,如果客户更喜欢在商务旅行中开车,并且正在寻找一些酒店报价,则该算法将从整个建议池中获得租车报价。

Image source: http://gearmark.blogs.com
价格优化
人工智能注入的动态定价技术可以帮助精确定位购买模式,使航空公司可以实时同步其定价策略,并在正确的时间提供正确的价格。
让我们以 Hopper 为例:它鼓励旅行者利用他们的数据驱动技术进行智能购物,这是他们应用的核心。每个用户都有特定的特征,例如更喜欢的飞行日期和时间、购买机票的时间、便利性等。该系统自动检测价格和产品特性之间的正确权衡,并在正确的时间以最优的价格提供相关优惠。
Hopper 在他们的博客中写道,他们 90%的销售额直接依赖于应用程序通知:

当公司的大部分收入来自特定数量的客户时(就像帕累托法则),为什么不为公司的忠实客户优化价格呢?
例如,当系统有一个新客户的一天需求和一个忠实客户的五天需求时,系统可以为这两种不同类型的客户生成价格。
营销机会

在理想的价值链中,来自营销工作和人工智能及人工智能技术的销售收益激励营销人员根据上下文和信息在所有客户的设备上开展所有营销活动。
通过分析 cookies 和设备 id,人工智能系统将允许营销人员通过精确定位,在正确的时间通过正确的设备精准地接触到用户,因此该公司的所有客户都不会被“一刀切”的广告吓倒。
欺诈检测
使用自然语言处理、计算机视觉和机器学习的人工智能工具可以实时分析大量数据集和各种数据源。在这些数据的基础上,人工智能系统可以识别异常行为,并创建风险评分,以全面了解每笔支付交易。
AI & ML 可以帮助旅游公司跟踪不同类型的欺诈行为:
- 信用卡信息被盗时的支付欺诈
- 创建假账户
- 内容滥用(如果它们包含评论和其他用户生成的内容)
- 账户接管(忠诚度欺诈)
通过整合人工智能工具,旅游公司将能够识别可信的付款人和不可信的付款人,以高精度和高速度检测异常,从而确保在线交易的安全。
结果
有了人工智能和机器学习所建议的各种各样酷而闪亮的东西,很容易捕捉到火花,并陷入“我想要全部”的想法。请记住,技术只有在正确实施时才能发挥作用。考虑以下事项,并在您的企业中推广这些技术:
- 收集质量数据。他们说“垃圾进——垃圾出”,这很刺耳,但却是事实。数据的丰富程度、是否可连接以及如何标记数据都非常重要。数据质量直接影响模型的输出。数据科学家可能会帮助你整理这些数据集,并建立整个系统。
- *了解你的产品。*是的,这听起来像是“谢谢,显而易见的队长”,但实际上这是任何技术实施的起点。我们 Django Stars 告诉我们的客户,我们可以构建任何复杂的算法,但产品负责人必须清楚地了解如何插入这些算法,商业目标是什么,以及它应该如何工作。
- 考虑你业务的成熟度。引入人工智能是一项艰巨的任务,需要非常好的领域知识、高级技能和法律限制知识(例如数据捕获法规)。这就是为什么你可以考虑聘请工程师来协助,因为在公司内部很难找到并留住工程师。
- 关注最重要的事情。“吃到饱”的方法有一点成功的机会。一些模型只给出了 5%的改进,但在大范围内,这是一个实质性的进步,带来了更好的体验和收入。另一方面,专注于人工智能聊天机器人可能会解放你的员工,并将客户体验带到新的水平。

如果你觉得这篇文章有用,请点击👏下面的按钮:)
机器学习如何为你构建应用

© 2013 Les Stone
或者说用户架构师和机器学习有什么关系?
用户架构师是系统的用户。甚至在这个系统存在之前,它们就以一种模糊不清的方式进入我们的大脑。我们想象这些角色将会是系统的使用者。我们想象和虚构的用户然后形成用户档案。我们向这些用户授予特性。我们赋予他们人格,然后用黑魔法让他们复活。或者,如果不能让他们活起来,至少要清除和洗掉一些模糊我们对他们的看法的因素。
对我们来说,黑魔法只不过是构建一个满足用户需求的应用程序。提供我们认为有用甚至是必要的功能。关于这些需求是什么,我们有大量以前的信息。我们也有足够的证据表明我们将整合哪些功能并赋予其价值。然而,这些证据并不能保证这个系统是一个完美的,甚至是好的解决方案。
为了尝试和设计更完美的解决方案,我们回到用户身边,收集他们的行为。在这个过程开始时,我们进行了调查和采访,但是,这只是我们的第一反应。它没有提供打造良好用户体验所需的深度信息。为突破性特征或前沿功能提供一个计划是不够的。尽管如此,这是一个起点,让我们能够生产出最低限度的可行产品。一个成熟的应用程序将从中成长和发展的产品。
从这个意义上说,它让我们进入了下一个阶段,是不断改进系统的关键一步。让用户告诉我们应用程序的第一步是提供词汇表。通过这种方式,他们开始在系统的架构中发挥作用。他们已经告诉我们他们对应用程序中使用的语言的理解。如果一个应用程序提供了处理数据的方法,那么我们必须知道用户所说的“数据”是什么意思。这个阶段的设计可能有点像泥巴,但我们能够从中找到真理。
让应用程序告诉我们用户想要什么
提供软件的悠久历史让我们看到了用户经历的痛苦和问题。我们的灵感是缓解这些痛苦和问题。询问用户他们遇到了什么样的痛苦和挫折使这一点成为焦点。他们面临的问题反复出现,使得简单的任务变得艰巨。寻求减轻负担的系统往往过于复杂。
所有的工程师,包括软件工程师,都倾向于过度工程化。用户可以,也确实要求太多琐碎的功能,这些功能极大地扰乱了他们的生活。我们如何发现什么是本质的,什么是杂乱的?我们如何沿着持续改进的道路前进?是的,我们要求我们的用户,但是以不同的方式,我们要求他们向我们展示。
一个处理数据并提供分析的应用程序应该知道用户如何对数据提出问题。它应该观察并记录他们是如何做的,以及他们收集了什么结果集。为了使应用程序更容易使用,它应该能够预测用户提出的问题。它应该能够建议他们将需要数据的哪些部分,以及如何最好地呈现。
机器学习是实现这一目标的理想工具。这可以手动完成,但需要观察以多种不同方式询问的大量查询。手动这一过程将需要亿万年。在计算上,我们可以编写一个程序,查看所有选项,并有规则来决定输出应该是什么。这将花费大量的时间和精力来设计和编写。我们没有时间做这个,应用程序需要更快地响应。使用机器学习,我们可以实现一个网络来承担这项任务,这将大大缩短时间。它还需要到达一个能快速适应的位置。它需要在描述它正在响应的时间长度内做出响应。

© 2013 Les Stone
过去,我们会让用户参加研讨会,捕捉并观察他们的行为。我们观看并记录他们做了什么以及如何做的实验环节。这种收集数据的方法提供了定性信息,但缺乏定量信息。没有足够的数据来支持从小样本中收集的观点。即使对焦点小组进行了最仔细的选择,还是会出现观点偏颇的风险。监督学习算法可以取代这种类型的实验室会议,并产生更好的结果。
通过反复做来学习。
观察和记录用户的质量是明确的。然而,没有定量数据,就无法确保所需的平衡。获得洞察力需要适度测量定量和定性数据输入。
从观察用户中获取数据所需的人力和精力是昂贵且耗时的。然而,重复性和耗时的任务是软件非常适合的。机器学习,特别是深度学习和神经网络,由大量数据滋养*。*
深度学习也擅长从少量数据中归纳,最近关于使用深度学习逼近函数的工作指出;“深度学习的成功不仅取决于数学,也取决于物理:尽管众所周知的数学定理保证神经网络可以很好地逼近任意函数,但实际感兴趣的函数类可以通过“廉价学习”来逼近,其参数比一般函数少得多,因为它们具有可追溯到物理定律的简化属性。”
深度学习(DL)是机器学习(ML)的一种类型,深度学习中有子集。深度神经网络(DNNs);通常用于表格数据集。卷积神经网络(CNNs 通常用于图像数据。递归神经网络;通常用于时态数据。下图显示了由神经元和相互连接的突触组成的神经网络中的多个层。

当软件能够参与自己的设计时,它就变得自省,变得有用。捕捉用户与系统的交互收集了新的数据语料库。能够对数据的各个部分进行分类将数据暴露给分析,使用户能够通过使用系统的简单过程来设计应用程序。让我们考虑一下这在实践中是如何运作的。我们将通过检查提供数据分析系统的软件应用的可能性来做到这一点。

© 2013 Les Stone
在一个旨在捕捉数据、混合数据、分类数据和探索数据的系统中,各个步骤可以相互分离。捕获数据需要用户将文件上传到系统或将系统插入源。对于此图,让我们看看机器学习如何帮助优化捕获过程。
上传文件需要找到它们,而且通常需要添加一些描述性信息。这同样适用于插入式数据源,一个 API 很可能有一个描述性名称或者一个名称和一个描述。
查找正确的文件和具有正确内容的文件时可能会出现问题。在上传时添加的描述性信息可以提供密钥。如果用户上传一系列电子表格并添加描述(例如“每周销售额”),系统就能够执行特定的任务。
在上传时,应用程序可以检查文档的结构,并计算单词或模式的实例。它可以检测样式和布局的属性。它可以查看数学或公式的类型。它可以计算数据类型的出现次数,例如:字符串或文本、整数或数字。

格式可以揭示其他数据特征,如:浮点数、小数、文本、运算符。然后,一系列模式和子模式可以与描述中的摘录相结合。一旦这些组合暴露在分类过程中,系统就学到了一些东西。它已经自学了“销售”文档可能是什么样子。然后,它可以用“每周”、“每月”、“每季度”或“每年”做同样的事情。

这同样适用于诸如“销售”、“采购”、“订单”或“发票”等标签。一旦它学会了这一点,而不是要求分类,它将能够预测描述符合什么。应用程序可以问用户“你想处理月度数据吗?”。然后,系统能够查找包含以月为间隔构建的数据的文档或数据源。

系统对数据检查得越多,它学到的东西就越多,也就越确定自己学到了什么。问题是谁在教谁?机器是自动学习的吗?是的,但是是用户在教它这些描述适用于什么数据的限制和范围。用户是分类过程所利用的语言的原始来源。
收集用户输入、描述和后续查询的摘录作为元数据。该元数据、上传的数据集、查询和查询结果集是学习过程的来源。标签是从这些描述中提取出来的,算法是为了对不同的部分进行加权而编写的。数据集的结构与查询传递的结果集和输出一样分类。
说到做到——来自机器学习
机器,或深度学习,接受用户输入并预测行动。这些预测改进了界面,这是系统架构变化的起源。这就是从用户动作中获取的数据如何构建应用程序。它类似于一个进化过程,因为它提供持续的改进。应用越来越好。
随着应用程序理解自然语言查询能力的提高,部分界面可能会被替换。“月”、“季度”、“年”的选择功能可能会被弃用。应用程序将学习提供相关的摘要报告和可视化,以响应:“给我欧洲最近 4 个月的销售数据.”,“在接下来的 12 周内,我们需要开始订购什么?”,“如果这个价位提高. 5%会怎么样?”。该系统将学习期望它提供什么报告,并在请求它们之前产生它们。
对许多软件工程师来说,这似乎是对系统架构应该如何设计的彻底背离。很长一段时间以来,计算机科学似乎更乐于忽视用户。许多人认为从采购软件的人那里获取规范,然后构建功能来交付规范是正确的途径。然后出现了一个更开明的观点,即观察用户交互有一定的价值。现在,将用户交互的结果融入到设计中似乎势在必行。
可以收集和存储通过详细日志记录存储的用户交互。监督机器学习从例子和经验中学习,而不是从硬编码规则中学习。处理大量用户输入的可能性打开了新的大门。随着大量不断增长的数据,机器学习将有所借鉴。
软件编写软件,每一种编译语言在编译时都是这样做的。软件创造本身已经被抑制了,人工智能暗示这种选择在某种程度上现在是可能的。现在,软件能够提供一些工具来改进自己。其中最明显的是自动化测试。另一个是跟踪用户如何使用应用程序。
机器学习将应用程序的用户转变为应用程序的架构师,这导致他们成为 用户架构师 。真正构建应用程序的是用户使用应用程序所获得的用户数据。从这个意义上说,更好的做法是将他们视为 数据架构师 ,因为我们正在考虑一个主要任务是处理数据的应用程序。
深度学习能够在编写软件应用程序中发挥重要作用,并揭示新的方法。这将使编写软件的整个概念从一个主要的工程学科向一个自然科学学科靠拢。下面给出了机器学习和深度学习如何帮助这种转变的简单说明。
机器和深度学习如何设计自己。
使用网格搜索并通过学习算法的超参数空间来精炼应用的模型,并在训练集上交叉验证它,这是使用机器学习来微调算法并发现新算法的方式。通过优化算法的性能来优化学习算法的超参数,是模型变得自省的一种方式。
最近的一篇论文指出,现代计算机视觉的最大突破是学习如何直接从数据中优化算法,从循环中去除人工工程。由长短期记忆网络 ( LSTMs)执行的学习算法,在它们被训练完成的任务上胜过一般的、手工设计的竞争对手
鉴于深度信任网络、卷积网络和基于特征提取的分类器通常包含十到五十个超参数,因此毫不奇怪,诸如超参数优化的强力随机搜索等策略是所有学习算法中有趣且重要的组成部分。在模型选择中使用机器学习也是一项有趣的工作,它与程序合成和归纳编程并行。
也已经完成了使用递归网络来生成卷积架构的架构的工作。它基于这样的观察,即神经网络的结构和连通性通常可以由可变长度的字符串来指定。

发现’神经架构搜索可以从零开始设计好的模型。像设计算法的例子一样,网络正在创建神经网络的架构超参数。在许多方面,人工设计神经网络的架构比设计算法更具挑战性。
机器和深度学习如何编写函数
举个简单的例子,机器学习可以通过看例子来定义函数。标准编程遵循以下过程:为一个函数设置规范,然后实现该函数以满足规范。

机器学习允许给出( x,y )对的例子,从这些例子中我们可以猜出函数 y = f(x) 。

对于任何函数,对于 x 的每个输入都有一个神经网络,值(x)从该网络输出。我们可以从 x=1 和 f(x ) =1 开始,这与我们的训练数据相匹配,但是当我们输入 x = 2 和 f(x) =5 时,它会失败,因为训练数据显示 x = 3。单个输入和层将不能预测我们正在寻找的功能。如果我们的训练数据非常干净,比如 2,3,5,8,13,21,34,那就不一样了

我们可以有多个输入,并试图创建一个单一的输出,我们正在寻找的输出是一个函数,以预测当 x =n 时,y 会是什么。从我们的例子对(其中我们知道什么是 x 和 y)X1[2, 3, 1.5],X2[3, 5, 1.66],X3[n,n,n]


输出(x)可以由以下函数表示

在 Clojure 这样的函数式语言中,这可以写成:

深度学习采用示例 x,y 对,并在几个抽象层次上形成它们的表示,以产生对小说 x 很好概括的函数
使用深度学习来产生一个函数的众多优势之一是,如果该函数有许多输入,Ǭ=Ǭ(x1,…,x m )和许多输出,它也可以工作。

虽然这是一个非常简单的例子,并且有许多方法可以生成斐波纳契数列,但是从数据中导出函数的过程有许多可能性。
我们想要生成的程序是一个相当简单的数学运算序列,比如使用上一个运算的输出和上一个运算的输出。使用递归神经网络,其中控制器输出下一个操作应该是什么的概率分布。它会执行所有可能的操作(例如乘、加、除、减),然后对输出进行平均。因为我们能够定义导数,只要问题的结果是已知的,程序的输出是可微的,损失是可以计算的。因此,网络能够被训练成诱导程序提供正确的答案。
编写源代码
设计算法和架构离用 AI 写程序只有一步之遥。中间步骤可以包括使用神经网络来预测函数出现在源代码中的概率,而不是预测整个源代码。 DeepCoder 是一个提出使用神经网络来“指导搜索与一组输入输出示例一致的程序”的项目。
而对程序综合的初步研究将集中在特定领域语言上。使用受限语言(如 SQL)进行搜索比使用全功能语言(如 python)更容易。查询日志还将提供输入源。网络公司的目标是创造模型,将程序表现为简单、自然的源代码,即人们编写的那种源代码。
学习如何编写新程序的机器已经使用学习表示和解释程序的架构开发出来。
动态程序
语音识别方面的进步,但更重要的是序列到序列学习和允许神经网络相互通信的技术将影响程序的构建方式。对世界的推理是有序的,这些序列中有一些潜在的随机结构。递归神经网络(RNNs)和随机状态空间模型(SSMs)被广泛用于建模序列数据,随机递归神经网络结合了这两种模型。
设想一个将自然语言查询与程序合成结合起来的应用程序并不太困难。通过提供语音驱动指令集,合成程序将通过搜索可能的功能来匹配这些输入,并设计新的输出。这样,它将创建一个程序来动态地交付所需要的东西。
要做到这一点,网络需要自己的工作记忆。信息的短期存储及其以简单子程序形式进行的基于规则的操作将在运行中创建功能和算法,并设计自我修改的体系结构。而短期存储器将用于保存变量,长期和可重写存储器将用于存储将通过自我学习而改变的例程。
向神经网络添加内存是一个相当明显的步骤可微分神经计算机就是这样做的,使网络能够利用知识进行思考或推理。除了使学习过程更有效和计算要求更低之外,它将允许核心程序的持续修改。这将使基于经验的改进成为可能。

神经网络和深度学习被 Michael A. Nielsen 描述为“有史以来发明的最美丽的编程范例之一”*
首次发布【2016 年 4 月 14 日
致谢。
本文中的所有图片均由摄影师 Les Stone 在 2013 海地伏都教仪式 20 年间拍摄。它们发表在互联网上的其他地方,我在这里分享它们(至今未经作者许可),以反映我个人对他的工作的钦佩。溴
- 迈克尔·a·尼尔森《神经网络与深度学习》,决心出版社,2015 年
参考
为什么深度廉价学习效果这么好?https://arxiv.org/pdf/1608.08225v2.pdf
通过梯度下降学习
通过梯度下降学习https://arxiv.org/pdf/1606.04474v2.pdf
超参数优化算法https://papers . nips . cc/paper/4443-algorithms-for-Hyper-Parameter-Optimization . pdf
基于序列模型的集成优化http://auai.org/uai2014/proceedings/individuals/229.pdf
用【https://arxiv.org/pdf/1611.01578v1.pdf 强化学习
搜索神经架构
DEEPCODER:学习写程序https://arxiv.org/pdf/1611.01989v1.pdf
TERPRET:一种概率编程语言
用于程序归纳https://arxiv.org/pdf/1612.00817.pdf
神经程序员-解释器https://arxiv.org/pdf/1511.06279.pdf
神经程序员:用梯度下降诱导潜在程序https://arxiv.org/pdf/1511.04834v3.pdf
用神经网络进行序列对序列学习https://arxiv.org/pdf/1409.3215v3.pdf
使用合成梯度解耦神经接口https://deep mind . com/blog/decoupled-Neural-networks-Using-Synthetic-Gradients/
具有随机层的序列神经模型https://arxiv.org/pdf/1605.07571v2.pdf
可微分神经计算机https://deepmind.com/blog/differentiable-neural-computers/
机器学习可能如何帮助千禧一代买房子和继承未来

如今,似乎你必须成为顶尖的计算机专家才能获得成功,尤其是在机器学习和人工智能被大肆宣传的情况下。但我认为你真正需要做的是跳出框框思考。当然,机器学习现在正在让人们赚钱,但是有一场革命正在进行,我认为它可能会影响硅谷技术魔法之外的事情。我相信每个千禧一代都会受益。那么这和买房有什么关系呢?
千禧一代不买房,主要是因为买不起入门级的房子。千禧一代倾向于住在市区,需要住得离他们工作的地方近一些(尽管他们更愿意住在郊区),所以今天他们租房住,希望有一天他们能负担得起美国梦。这种情况似乎充满了绝望和灾难,但我知道千禧一代可能会如何利用人工智能革命,在这个新世界住房市场中比你想象的更富裕。
重大技术进步可以改变整个行业,或者创造全新的赚钱方式。喷气发动机让整整一代企业可以在一天之内穿越全国或海外,无论是运送货物还是举行面对面的会议。航空业会变成我们今天所知道的样子,这在当时似乎并不明显。想一想所有全新的市场、经济和商业类型,它们今天因为互联网而蓬勃发展;音乐流媒体、快递服务、加密货币、社交媒体……太疯狂了。
我相信我们正处于另一场机器学习的技术革命中。我知道这么说很流行,但我每天都生活在其中,感受着它,我看到了它对商业经济的影响。但是住房呢?
在旧金山湾区,交通绝对是一场噩梦。糟糕的是,离我们工作地点更近的住房需求非常高,这反过来推动了价格上涨。如果你出门离城市足够远,房价会大幅下跌。我认为这将会改变,因为有一项非常有前途的技术;自动驾驶汽车。

http://static6.businessinsider.com/image/57d84375077dcc21008b5865-1200/uber-self-driving-car.jpg
2027 年,的交通可能会因为特斯拉而消失。那栋远离以前不受欢迎的位置的房子现在更受欢迎,因为住在城市附近的压力已经消失了。我们现在可以分散开来,知道上班的通勤时间(假设由于增强现实,我们真的需要在办公室工作)不再是距离的反函数。
因此,千禧一代可能会在今天对通勤来说是噩梦的地方购买这些更便宜的房子,但在其他方面却非常令人向往,并收回他们承诺继承的美国梦。
机器学习(ML)如何改变制造业

对于没有合适的工具来开发产品的公司来说,制造过程既耗时又昂贵。近年来,机器学习(ML)在建造和组装物品方面变得更加流行,使用先进的技术来减少制造的长度和成本。在组装过程中使用ML有助于创造所谓的智能制造,在智能制造中,机器人以外科手术般的精度将物品组装在一起,同时该技术实时调整任何误差,以减少溢出。
使用 ML 算法、应用程序和平台可以通过监控其组装过程的质量来彻底变革商业模式,同时优化运营。TrendForce 估计,智能制造将在未来三年内快速增长。该公司预测,到今年年底,智能制造市场的价值将超过 2000 亿美元,到 2020 年将增长到 3200 亿美元,预计复合年增长率为 12.5%。 WorkFusion 正通过一系列智能解决方案帮助企业满足其制造需求。
以下是 ML 改变制造业游戏的一些方式。
1)优化半导体制造

McKinsey & Company 看到了使用 ML 将半导体制造产量提高 30%的巨大价值。该公司认为,该公司可以通过降低废品率和优化与 ML 的业务。该技术可以使用根本原因分析,并通过简化制造工作流程来降低测试成本。此外,在 ML 上运行的制造设备的年维护成本预计将降低 10%,同时停机时间减少 20%,检测成本减少 25%。
2)质量控制和 OEE

术语 OEE 指的是总体设备效率,ML 在提高设备效率方面起着关键作用。这个指标衡量组装设备的可用性、性能和质量,这些都是通过集成深度学习神经网络来提高的,深度学习神经网络可以快速学习这些机器的弱点,并帮助将其最小化。德国企业集团西门子几十年来一直在使用神经网络监控其钢铁厂并提高效率。该公司表示,在过去十年中,它已投资约 100 亿美元收购美国软件公司,包括加入 IBM 的 Watson Analytics,以提高其运营的质量水平。
3)完善供应链

ML 还通过改善物流解决方案,包括资产管理、供应链管理和库存管理流程,在实现公司价值最大化方面发挥着重要作用。人工智能(AI)和物联网的成功结合对于现代公司来说是必要的,以确保其供应链在最高水平上运行。世界经济论坛(WEF)和 A.T. Kearny 的一项研究发现,制造商正在寻找将 ML、AI 和物联网等新兴技术与提高资产跟踪准确性、库存优化和供应链可见性相结合的方法。通用电气推出了一套出色的制造套件,它监控制造、包装和交付过程的每一步,是该公司供应链管理的重要组成部分。
4)更多统计数据

普华永道预测,更多的制造商将采用机器学习和分析来改善预测性维护,预计未来五年将增长 38%。在此期间,流程可视化和自动化预计将增长 34%,而分析、API 和大数据的集成将使互联工厂增长 31%。麦肯锡补充说,ML 将减少 50%的供应链预测误差,同时也减少 65%的销售损失。
互联的未来
制造业中的 ML 有很多值得期待的地方,因为该技术有助于组装厂建立一系列互联的物联网设备,这些设备协调工作,以改善工作流程。从质量控制到资产管理、供应链解决方案和降低开支,ML 正在以多种方式改变制造业的未来。
WorkFusion 提供了 RPA 解决方案来帮助希望改善制造流程的公司。
机器如何理解我们的语言:自然语言处理导论

Photo by Tatyana Dobreva on Unsplash
对我来说,自然语言处理是数据科学中最迷人的领域之一。机器能够以一定的准确度理解文本内容的事实令人着迷,有时甚至令人害怕。
自然语言处理的应用是无穷无尽的。这是机器如何分类一封电子邮件是否是垃圾邮件,如果评论是正面或负面的,以及搜索引擎如何根据您的查询内容识别您是什么类型的人,以相应地定制响应。
但是这在实践中是如何运作的呢?这篇文章介绍了自然语言处理的基础概念,并重点介绍了在 Python 中使用的nltk包。
注意:要运行下面的例子,您需要安装
nltk库。如果没有的话,开机前在你的 shell 中运行pip install nltk,在你的笔记本中运行nltk.download()即可。
无论输入机器的是什么文本或句子,都需要首先进行简化,这可以通过标记化和词条化来完成。这些复杂的单词意味着一些非常简单的事情:标记化意味着我们将文本分解成标记,根据具体情况分解成单个或成组的单词。词汇化意味着我们将一些单词转换成它们的词根,即复数变成单数,共轭动词变成基本动词等等。在这些操作之间,我们还从文本中清除所有不携带实际信息的单词,即所谓的停用词。
让我们看看下面的句子,用一个例子来理解这一切意味着什么。

Example of tokenization and lemmatization for ngrams = 1.
对文本进行分词时,相应地选择 ngram 很重要。它是指定我们希望每个令牌包含多少单词的数字,在大多数情况下(就像上面的例子),这个数字等于 1。但是,如果你在一个商业评论网站上进行情绪分析,你的文本可能会包含“不高兴”或“不喜欢”这样的语句,你不希望这些词相互抵消,以传达评论背后的负面情绪。在这种情况下,您可能需要考虑增加 ngram,看看它对您的分析有何影响。
在进行标记化时,还需要考虑其他因素,例如标点符号。大多数时候你想去掉任何标点符号,因为它不包含任何信息,除非文本中有有意义的数字。在这种情况下,您可能需要考虑保留标点符号,否则文本中包含的数字将在出现.或,的地方被拆分。
在下面的代码中,我使用了RegexpTokenizer,一个正则表达式标记器。对于那些不熟悉正则表达式的人来说,在形式语言理论中,它是一个定义模式的字符序列,根据您在RegexpTokenizer函数中传递的参数,它将根据该参数分割文本。在一个正则表达式中,\w+字面意思是将所有长度大于或等于 1 的单词字符分组,丢弃空格(从而标记单个单词)和所有非单词字符,即标点符号。
Tokenizing with RegexpTokenizer.
这段代码生成的令牌列表如下:
tokens = ['Rome', 'was', 'founded', 'in', '753BC', 'by', 'its', 'first', 'king', 'Romulus']
这是一个不错的开始,我们有了由单个单词组成的令牌,标点符号不见了!现在我们必须从令牌中删除停用词:幸运的是,对于许多不同的语言,nltk中包含了停用词列表。但是当然,根据具体情况,您可能需要定制这个单词列表。例如,文章默认包含在此列表中,但是如果您正在分析一个电影或音乐数据库,您可能希望保留它,因为在这种情况下,它确实有所不同(有趣的事实:帮助和帮助!是两部不同的电影!).
Discarding the stop words from a text.
新令牌列表是:
*clean_tokens = ['Rome', 'founded', '753BC', 'first', 'king', 'Romulus']*
我们从 10 个单词增加到 6 个单词,现在终于到了词汇化的时候了!到目前为止,我已经测试了两个具有相同目的的物体:WordNetLemmatizer和PorterStemmer,后者肯定比前者更残忍,如下例所示。
Lemmatization example with WordNetLemmatizer.
最后一个列表理解的输出是:
*['Rome', 'founded', '753BC', 'first', 'king', 'Romulus']*
什么都没变!这是因为WordNetLemmatizer只作用于复数单词和一些其他的东西,在这个特殊的例子中,没有单词真正被词条化。另一方面,PorterStemmer转换复数和衍生词、动词,并使所有术语小写,如下所示:
Lemmatization example with PorterStemmer.
列表理解的输出是:
*['rome', 'found', '753bc', 'first', 'king', 'romulu']*
在这种情况下,没有大写字母的单词了,这对我们来说是没问题的,因为仅仅因为一个是小写字母而另一个不是,区分相同的单词是没有意义的,它们有相同的意思!动词 founded 已经改成了 found 甚至 Romulus 都把自己名字的最后一个字母弄丢了,可能是因为PorterStemmer以为是复数词。
这些引理化函数非常不同,根据具体情况,一个会比另一个更合适。
在建模之前,有许多不同的方法来收集和组织文本中的单词,这些只是可用选项的一小部分。在将文本输入机器学习模型以尽可能简化它之前,所有这些清理都是必要的。当你在预测模型中分析大量词汇时,在完成上述步骤后,你将很可能依靠[CountVectorizer](http://scikit-learn.org/stable/modules/generated/sklearn.feature_extraction.text.CountVectorizer.html)、[TfidfVectorizer](http://scikit-learn.org/stable/modules/generated/sklearn.feature_extraction.text.TfidfVectorizer.html#sklearn.feature_extraction.text.TfidfVectorizer)或[HashingVectorizer](http://scikit-learn.org/stable/modules/generated/sklearn.feature_extraction.text.HashingVectorizer.html#sklearn.feature_extraction.text.HashingVectorizer)等sklearn方法,将原始文本转换成一个令牌计数的矩阵来训练你的预测模型。
管理者应该如何为深度学习做准备:新范式

Exploring the unique challenges for managing analytic systems enabled by Deep Learning [photo by Charlie Wild on [Unsplash]](https://unsplash.com/@charles_the1st)
本文是关于深度学习 的管理视角系列文章的第一篇,该系列文章面向参与或负责由使用人工神经网络技术的深度学习** (DL)实现的分析系统的管理人员。在处理这些系统时,他们面临混乱的概念和独特的挑战。这篇文章关注的是新范例,这些范例引导这些管理者思考 DL 的基本性质。[1]**
作为一名大学教授、软件企业家和行业分析师,我的职业生涯一直在大型信息技术(IT)系统中探索。在过去的五年里,这一焦点已经集中在商业分析上,特别是在由神经网络技术驱动的深度学习(DL)上。我最近完成了深度学习领域的 Coursera 专门化课程和反思其含义。[2]
注意:我不喜欢这些文章中的术语深度学习*,尤其是人工智能,因为它们有令人困惑的含义和分散注意力的包袱。正确的技术术语是*人工神经网络 (ANN)。所以,想象下面 DL = ANN。
DL 与传统的机器学习有独特的区别,尤其是在企业系统的环境中。此外,DL 有潜力以今天无法想象的方式增强这些系统,无论是好的还是不好的。
IT-DL 断开
在企业系统中正确采用 DL 的一个主要障碍是 IT 专业人员和 DL 实践者之间概念上的脱节。这两个群体对基本原则有不同的想法——问题陈述、数据的性质、结果的交付、性能准确性、数据治理以及对业务的价值。
在这个 IT-DL 脱节的中间,是大型 IT 生态系统中与 DL 支持的分析系统有关的经理(和高管)。这些经理了解组织的优先事项和 IT 资源,经常与 IT 和数据科学团队进行跨职能互动。他们也意识到 DL 的非凡成就,这要归功于 Google。他们对面部识别、自动驾驶、文本分析和聊天机器人的新兴应用感到惊讶。此外,他们还担心媒体对人工智能(AI)的神奇好处和悲剧性影响的神秘炒作。
这些文章的读者是这些经理。他们将负责指导使用 DL 的分析应用程序。当这些应用程序成功时,他们将获得荣誉,当#失败时,他们将承担责任。他们很难处理发展迅速的数字鸿沟问题。此外,他们必须解决IT-DL 脱节的问题,并需要弥合这一差距。
这个问题
本系列文章的问题是…
对于负责支持 DL 的系统的经理来说,DL 有哪些新的不同之处?

Business Intelligence — Machine Learning — Deep Learning
通过这个系列,这个问题会有几种形式。本文将讨论新范例,管理者需要这些范例来理解 DL 的独特性质,与一般的商业智能(BI ),特别是传统的机器学习(ML)相比较。这种理解对于实现与 DL 实践者的流畅对话以及与 IT 团队的协作至关重要,从而使 DL 项目取得成功。
接下来的部分研究了这些新的范例,将它们与旧的(但仍然相关的)IT 范例进行了对比。对于每一个,从这种范式转变中吸取的教训都被记录下来。
TL;dr —选择几个看起来有趣的。以后再看别人。
超越已知数据的概括
旧的 IT 分析范式是生成洞察,让各级经理能够基于数据做出更好的决策。这种模式出现在 20 世纪 70 年代,由 Peter Keen 等人开发的决策支持系统。从那时起,IT 的一个关键角色就是以报告和仪表板的形式提供有组织的数据,最初是在厚厚的纸张上,到 CRT 屏幕,再到移动设备。这一趋势导致了视觉分析领域的繁荣,出现了 Tableau 和 Qlik 等灵活的仪表盘产品。向管理人员直观地描述已知数据是必不可少的。
新的 DL 分析范式将支持超越已知数据的概括方法。组织的竞争优势将是推断(聪明地猜测)复杂业务系统的动态。这意味着预测未来事件,就像在预测分析中一样。更重要的是,这意味着能够理解为什么过去的事件在这些复杂的系统中以独特和令人惊讶的方式展开。DL 生成的模型有潜力提取和捕捉这些超出人类能力的复杂性。这既令人欣慰又令人不安。
要点 : DL 是关于……获取关于你的组织的具体已知事实,并创建其行为的通用模型。要知道在商业环境中,一个决策需要超越可用数据的概括…这几乎是每一个决策!这个决定是主观(凭直觉)做出的吗?)基于一个人漫长的经历?或者,它是基于具体的数据吗?如果是,数据是什么,这些数据是如何分析的?当管理 DL 驱动的系统时,质疑决策的基础变得更加重要。
耕种农场
软件项目的旧 IT 范式就像盖房子一样。第一,设计它;聚集资源;建造它;移动到下一个房子,以及对以前的房子进行一些维护。几十年来,软件开发方法有了很大的改进。敏捷方法目前允许在设计和实现中有更多的灵活性。然而,剩下的是完成项目的概念,以便资源可以应用于新的项目。

“A farmer in a tractor, clearing wheat during sunset in Lincoln” by Noah Buscher on Unsplash
新的 DL 范式更像是一个农民在耕地。这是一个持续的过程。农民不会在地里播种后就离开。在收获和为即将到来的季节做计划的过程中,人们一直在努力。DL 项目不是正常意义上的项目!这是一个不断完善 DL 模型以更好地支持用例的过程。
收获:对 DL“项目”进行缓慢而谨慎的长期投资。评估每一步的商业利益是否超过商业成本和风险。不要指望从“低洼的水果”中获得巨大或快速的回报。只期待适度和持续的收益。另一方面,不惜早杀,勤杀 DL 项目。避免认为“项目”已经完成,可以在无人看管的情况下继续运行。
应对黑盒
IT 范例是应用程序系统应该(并且可以)被清晰地指定,从而易于维护和管理。事实是,新的 DL 范式是一个邪恶的黑盒!
DL 模型由一组矩阵组成,通过神经网络层传播以产生准确的预测。在数以千计的矩阵中,结果是人类无法解释和说明的。例如,回答 DL 模型拒绝特定贷款申请的原因。这是一个 DL 结果可解释性的巨大问题,对于一个可操作的 DL 系统来说必须解决。
然而,这个硬币有两面。管理者不应该被血淋淋的细节所吸引,成为房间里的焦点人物。作为管理者应对黑箱!下图说明了这种情况。神奇的是数据科学团队的责任。

The DL Blackbox where the Magic Happens
导读:你正在和技术人员讨论新的支持 DL 的系统,慢慢陷入黑暗。去白板上画一个简单的方框。询问产出;然后是投入。质疑输出是否促进了特定的业务目标。质疑我们是否能够恰当地将数据作为训练示例的输入。询问如何从模型中解释影响客户的结果。在所有人(尤其是你)都理解并同意之前,不要离开房间!设法拿到黑匣子。
举例教学
IT 范例是将预定义的过程编程到硬代码中。首先,必须指定过程,然后编码,最后调试。
DL 范例与过去典型的 IT 软件项目有着本质的区别。第一个区别是,您通过用示例训练 DL 模型来编程,这些示例标有每个示例的预期结果。这叫做监督学习。
我不喜欢在这种情况下使用“学习”甚至“训练”这样的术语。第一个暗示学习是模型的责任。第二个意味着模型应该遵循严格的协议来执行任务。两者都暗示责任在于 DL 模型。事实上,真正的责任在于经理和数据科学团队,通过清楚地将示例标记为“好”或“坏”来教授DL 模型。

Photo by NeONBRAND on Unsplash
经理的比喻就像一年级老师给全班同学讲解动物园,而你们班没有人见过。你的责任就像为他们下周的动物园之旅做准备。所以,你准备一套他们将会看到的动物的例子,详细描述它们。
从技术上讲,DL 中的这个过程被称为“训练模型”,但它更像是教授甚至指导模型。和一年级学生一样,模型一开始知道的很少。不像一年级学生,模型只会通过你的例子来学习。如果你的例子选择不当或标记不当,预计一年级学生和你的模型会有不好的结果。有足够的数量吗?它们是否足够多样化以涵盖未来的情况?诸如此类。
外带:负责将数据整理成有标签的例子,教授DL 模型。这将是你讨论黑盒输入的主要部分。您会发现,这一职责将严重依赖于您现有的 IT 生态系统来存储和集成跨数据仓库和可能的数据湖的数据。感谢这个生态系统遗产。如果没有这样的生态系统,那就另谋高就。
保存信息
数据监管的 IT 范式是清理和组织数据,以满足人们的消费需求,让人们赏心悦目。相比之下,DL 范式是为机器消费保留数据中的信息(类似于 T4 的香农信息熵),以最精细的粒度进行处理。DL 模特都爱丑位!

Photo by kevin laminto on Unsplash
这类似于艺术博物馆中的策展。策展人保存艺术作品,同时用背景和历史增强其本质。似乎数据湖的人们可以通过内化这种类比回到正轨。此外,数据仓库通过提供上下文(即示例数据的补充功能)发挥着关键作用。
许多 DL 项目从与数据仓库隔离的应用程序开始,只是意识到为组织做任何有用的事情都必须小心地与数据仓库联系起来。为自己节省额外的精力,从数据仓库开始,向外构建。数据仓库作为包含上下文和关系的官方结构化数据的存储库,反映了被认为对组织的运作很重要的信息。
原始数据(对人类来说是杂乱的)是好的,如果它准确地传达了关于组织及其环境的准确信息。因此,如果设计得当,数据湖工作可以很好地评估有效性和纠正准确性/有效性。
外卖:DL 的动力开始和结束于数据。所以,不要为了让它们看起来漂亮而丢弃它们!丑陋是现实的真实面目。
将数据视为现实照片
IT 范式将数据可视化为由行和列组成的表格电子表格。当我学习 DL 的时候,这是影响我个人的范式转变。我会经常回到我旧的表格思维,好像这就是地面真相。然而,当我放开这根拐杖,开始思考矩阵,然后是张量(更高维度的矩阵)作为基础真理时,DL 变得容易多了。以一种微妙的方式,思考表格(行-列,实例-特征)过度简化了现实。我们的眼睛和耳朵无法在电子表格中捕捉每一分钟的真实情况!

Photo of Business Reality by Charlize Birdsinger on Unsplash
DL 范式以两种方式转向图像和其他非结构化数据格式。首先,用于物体检测和识别的 DL 图像处理已经非常成功,这意味着利用了照片中嵌入的空间信息。其次,一个新的 DL 技巧是将表格数据视为实际(但杂乱)图像中的像素,然后利用相同的有效 DL 技术。使用这种技巧的早期结果是惊人的。[3]
外卖:不要再把数据当成表格了!相反,请将数据视为商业现实的照片。此外,把商业行为想象成现实的视频。得到的 DL 模型可能执行得更好。
超越人类水平的性能
IT 范例是通过将组织任务的过程编程到硬代码中来使这些任务计算机化。动机是与同等的人的表现相比,更便宜和更快地完成任务。例如,由于这种更便宜更快的目标,自动化制造装配线(在关键点有几个人)已经取代了人工。
DL 的新范式是教会 DL 模型执行这些相同的任务,并期望超越人类水平的表现(HLP)。为什么?
我们人类已经创造了足够聪明的工具来超越我们自己!
计算机在国际象棋和围棋比赛中击败世界冠军的消息,以及 IBM Watson 在 2011 年的 Jeopardy,似乎证明了这种说法是正确的。然而,许多人对这些成就不屑一顾,因为这些例子仅仅是游戏,而不是混乱商业环境中的真实用例。
也许不是这样的……吴恩达经常说,在任何需要人类几秒钟思考才能完成的智力任务上,人工智能技术都可以超越人类。为了证明他的观点,他已经建立了一个风险基金。[4]
每个月,DL 都在进化,将这 5 秒钟增加到更深思熟虑的任务上。这在图像识别任务中尤其明显,从半导体制造缺陷到癌症的 CT 扫描。智力任务的范围正在逐渐扩大,侵入了以前专为受过大学教育的白领工人保留的领域。
对于管理人员来说,这一 DL 成就的意义在于,它使人类能够创建在挑战智力任务方面超过 HLP 的算法。此外,它揭示了思考和学习这些任务的本质,以便可以实现超越 HLP 的一致的增量改进。
这不是通常的超级智能机器人因为我们的自卑而决定消灭人类的科幻故事。真正的问题是在大型系统中嵌入 DL 应用程序的意想不到的后果,如脸书、亚马逊、谷歌和其他影响许多人生活的公司。
要点:大胆地(负责任地)考虑将 DL 应用到重要的用例中。鉴于 HLP 由来已久的限制,现在可以实现不可想象的任务。DL 赋予了我们巨大的力量,同时也赋予了我们巨大的责任,为了人类的利益,我们应该明智地使用它。有人将 DL 与人类的其他重大发明相提并论,比如核能。如果这种比较是正确的,那么它是一个发人深省的想法。
数据驱动性能
IT 范式是,有了更多的数据,人们就能够在数据中产生更多的关系和更多的跨职能比较,从而产生更多有用的见解。这一假设在过去几十年中推动了数据仓库和商业智能的发展。
新的数字图书馆范例是相似的和协同的。有了更多的数据,DL 模型就能够在概括(即预测)的准确性方面表现得更好。下面是吴恩达在他的 Coursera DL 专业中的一张简单而深刻的幻灯片,标题是“规模推动 DL 进步”。

Model Performance vs Labeled Data
对于任何预测算法来说,模型预测的准确性都受到精选的标记样本数据量的影响。在左边,这些数量可能是几千个例子,不到十亿字节。在右侧,这些数量可能是数百万或数十亿个示例,超过数百万亿字节。左下角表示在没有数据和经验的基础上做出预测,就像掷硬币一样。
这里有几点需要注意…
- 在低量的情况下,任何预测算法都和其他算法一样好。DL 没有优势;因此,使用传统的机器学习算法(如随机森林),因为它们更容易,更快,并提供更好的可解释性。
- 在较高的数量下,具有较多数据的 DL 模型总是胜过那些具有较少数据的模型。然而,DL 模型必须在其结构上变得更加复杂(即,更多的隐藏层,每层具有更多的权重),以吸收数据中的附加信息。而且,这种结构的复杂性意味着训练和解释模型的工作量增加。
- 右上角是机器算法能够超过 HLP 的最佳点。认识到并非所有用例都需要 HLP,因此更少的数据和更简单的算法可能就足够了。
外卖:简单来说,谁拥有数据谁就赢了。控制最多数据的公司最终会战胜所有其他公司!同样,DL 的力量始于数据,也止于数据,不管模型结构有多奇特和复杂。标签化的训练数据集是 DL 的“阿喀琉斯之踵”。
作为打包应用的训练模型
交付解决特定用例的软件工具的常见 IT 范例是通过打包的应用程序,通常由专门处理该用例的专有软件供应商提供。例如,Salesforce.com 推出了一个客户关系管理包,为大公司跟踪从最初的合同到购买的整个销售活动。
新的 DL 范式是软件 2.0……Andrej Karpathy,Testa 的 AI 主管,在他最近的文章中明确了这个概念,然后在推特上对所有的程序员朋友说,“梯度下降可以比你写得更好。对不起。”【5】哎哟!
你能想象吗……数百万程序员因为 DL 而失去工作,涌向华盛顿要求立法限制 DL 的使用并禁止支持 GPU 的设备。同样的事情也可能发生在套装软件供应商身上!
对于 DL 系统的经理来说,这意味着您在过去几年中一直在小心翼翼地成熟的 DL 模型…那是您定制的打包应用程序!打包应用程序供应商的下一代将销售基于大量示例数据集的预训练 DL 模型。通过迁移学习,这些预先训练的模型可以帮助您的 DL 项目节省数月的努力,以达到所需的绩效水平。
外卖:非常尊重地对待你训练过的 DL 模特。这些是您公司的 IT 珠宝,就像一个成熟的数据仓库一样。精通迁移学习,无论是在你的行业内,还是在有类似信息对象的其他行业。
增强,而不是自动化!
信息技术范式是计算机化,以减少日常任务,增加执行任务的一致性。
DL 范式更像是一种伦理主张,包含了大量的常识… 使用 DL 来增加人工任务,而不是使这些任务自动化。
这里的挑战是创造性地将人重新插入到工作流程中。术语 人在回路 (HITL)已经在快速系统的界面设计中使用了几十年(决策时间要求亚秒级响应),就像驾驶战斗机一样。HITL 的典型模式是:监视异常情况,批准高度不确定的情况,调查预测错误的情况,否决感觉不正确的情况,等等。
著名的数字图书馆研究者 Francois Chollet 认为数字图书馆工具不应该被用来操纵人。相反,DL 应该让人们控制那些工具,去追求他们自己的目标和激情。[6]
DL 扩充挑战不受时间限制;它受到思想(或信息)的限制。在 DL 模型中,知识包含在数百万个数字中,这对于张量粉碎来说完全有意义,但对于人脑来说意义不大。我们需要新一代的沉浸式分析(就像下一代视觉分析)来创建虚拟空间,利用所有人类感官来表现这些数字的全部复杂性。我认为人类能够胜任这项任务,并将让他们与计算能力更强的人工同事平起平坐。[7]
要点:设计 DL 系统时,你的 HITL 临界点在哪里?将如何增加,扩大和人性化的人的任务?在模糊的情况下,人类的判断将如何应用?这些人将如何得到适当的装备来执行这些 HITL 任务?
承担责任!
总之,DL 在企业系统中有潜在的好处和坏处。在所有级别,负责支持 DL 的系统的经理必须负责监控和平衡组织和社会的收益和成本。
这篇文章描述了这些经理应该理解并传达给他们的同事的十个范式转变,减轻 IT-DL 脱节的问题,并成功利用 DL。
感谢博尔德数据侦探的 DL 研究小组在过去几个月里与我们进行的讨论,这有助于澄清这些想法。
最后… 如果你从这些文章中受益,请支持 my Patreon 创建并指导小型经理同行小组,以探索由深度学习实现的分析系统的关键管理问题。如果同事对该计划感兴趣,请分享链接或推文。谢谢,理查德
笔记
[1]文章系列概述。惊讶于这个问题是如何爆炸成几十个话题的。这应该够我忙一阵子了!
https://medium . com/@ Hackathorn/series-on-how-managers-should-prepare-for-deep-learning-f5b 795 b 36148
【2】我在完成深度学习 Coursera 专业化后对 DL 的反思。第一部分对课程的逻辑进行了评论,而第二部分则更深入地探讨了创造出比我们更聪明的工具所引发的问题。结论:权力越大,责任越大。
https://towards data science . com/deep-issues-pending-within-deep-learning-f923a 96564 c 7
[3]用像素表示表格数据。一个新兴的 DL 技巧,对举例教学有着更深的含义。与此相关的是由 Rutger Ruizendaal 撰写的文章,该文章基于 de Brébisson 等人在 2015 年发表的论文,强调了实体嵌入用于分类特征。【更新于 2018 年 7 月 4 日。还没有找到表格到图像技巧的参考资料!救命?】
https://towards data science . com/deep-learning-structured-data-8d6a 278 f 3088
[4]五年前的文章,仍然总结了深度学习即将产生的影响,以及吴恩达的背景。经常被引用。
https://www . wired . com/2013/05/neuro-artificial-intelligence/
[5]Karpathy 关于软件 2.0 的文章。对 DL 软件如何不同于我们过去几十年对软件的传统想法的极好描述。他可爱的推文总结了他的观点!
https://medium.com/@karpathy/software-2-0-a64152b37c35
[6]Fran ois Chollet 关于他对人工智能的社会和伦理关注的个人观点。思路清晰,考虑周到。强化增强,而不是自动化点。
https://medium . com/@ Francois . chollet/what-worries-me-about-ai-ed 9df 072 b 704
[7]沉浸式分析(IA),我的长期爱好!别让我开始!然而,我现在看到了通过由 DL 模型集群驱动的沉浸式虚拟世界(大规模的和协作的), DL 和 IA 之间的紧密耦合,所有这些都集中在一个特定的问题领域。感兴趣吗?更多详情请见…
https://www.immersiveanalytics.com/
管理者应该如何为深度学习做准备:新价值观

Exploring the unique challenges for managing analytic systems enabled by Deep Learning [photo by Charlie Wild on [Unsplash]](https://unsplash.com/@charles_the1st)
TL;DR —请参见末尾的摘要以快速了解概况。
本文是关于深度学习 的管理视角系列文章中的第二篇,面向负责或参与由深度学习** (DL)使用人工神经网络技术实现的分析系统的管理人员。在处理这些系统时,他们面临混乱的概念和独特的挑战。本文重点关注新价值,这些新价值建议了不同的方法来评估组织从支持 DL 的分析中实现的价值。在每一部分的结尾,都有一份外卖为经理们提供了实用的建议。**
走向智能有效性
大型 IT 系统为组织和整个社会创造的价值正在从成本效率转移到智能效率。
正如彼得·德鲁克所说,“效率就是把事情做对;有效性就是做正确的事情。[01]利用这句话,成本效率是指更快、更便宜、更可靠地执行特定任务,而智能效率是指定制任务以满足特定情况的需求。
这两者都很重要,但当任务的目的不能完全明确或随各种情况而有很大变化时,更应注重有效性。对于大规模的系统来说尤其如此。
自从计算的早期以来,计算机系统的价值主要在于以降低成本为目标的效率。手动程序在数据采集和报告方面容易出错。早期的计算机应用是简单地在纸上打印工资支票,这比手工写支票有了巨大的效率提高。生成工资单的任务已被精确地定义,因此计算机化的时机已经成熟。
今天,电子商务系统正在帮助成千上万的客户从成千上万的选择中选择正确的产品,这些选择基于各种因素的组合,如价格、畅销、最低成本、最近更新、关联购买和评论星级。没有预先指定的程序,因为功能会根据产品的可用性和客户的独特性不断变化。在这种大规模的情况下,聪明有效是创造价值的关键。
**收获:**作为一名与分析系统相关的经理,要意识到为特殊情况定制标准程序的机会。评估潜在的业务价值,并向 LOB 同事强调这些机会。请技术同事思考如何利用分析,以便以每小时超过 1000 次的速度独特地处理每种情况。在你的组织中培养一个提高智能效率的机会列表。
超越已知数据的概括
这些系统的智能有效性取决于对大规模生态系统行为的理解,但也取决于小规模的独特互动。促成因素是对已知数据的概括,这与描述已知数据形成对比。[02]
的定义概括意味着通过从较小(但有代表性的)样本中进行推断,做出一个适用于(有效)广泛情况的陈述(假设)。
这是分析的本质——获取关于一组示例案例的数据,并创建适用于类似案例的模型。在对已知数据进行归纳的分析背后有两个关键假设。首先,训练模型的范例案例必须代表模型将预测的所有案例。第二,训练好的模型必须在一个随机的(有约束的)样本子集上进行验证,以获得准确的预测。
在正常生活中,自文明出现以来,人类凭借直觉一直在超越已知数据进行归纳。事实上,我们作为一个物种的生存依赖于这种能力。最近,我们使用我们的 IT 系统以巧妙的方式描述已知数据,使用常规报告、交互式仪表盘和可视化分析。因此,人类的直觉擅长创造洞见,从而归纳因果关系并预测商业未来。
**要点:**作为一名与分析系统相关的经理,您是否意识到您的组织中有哪些领域超出了人类直觉的能力范围而无法得到正确管理?你能举出这个失败的具体例子吗?导致这个问题的因素是什么?你的企业是否涉足新领域,而多年的业务经验与当前的业务问题并不相关?是否有数据可以充分描述当前问题的例子?
一百万个独特的东西
当处理智能有效性情况时,人类直觉的一致性和可靠性是有限的,即使使用描述性分析工具来增强。随着系统复杂性的增加,研究表明直觉本质上是非理性的,因此是次优的。[03]
从管理的角度来看,衡量复杂性的一个标准是经理要负责百万件独特的事情(简称 MUT)。[04]让我们考虑三个例子来说明这一点。
假设你是一家小型零售店的老板。您已经在您的社区开展业务多年,并且亲自了解大多数光顾您商店的顾客。你本能地以定制服务独特地对待这些客户,同时保持社区作为一个整体的感觉。当一个陌生人进入你的商店,你热情地迎接他们,并了解他们的独特需求。你的智能效率可能会得 A。那么,你有多少独特的客户?可能有几百个。四舍五入到 10 的幂,对于一个小型零售店来说,独立客户的数量大约是 10 到 10。
假设你成功了,并在你的区域内建立了多个大型商店。现在你的独特客户可能已经增加到 10⁵.你个人是否认识今天光顾你的商店的大多数顾客?大概不会。你为客户服务的智能效率如何?
想象一下,你取得了巨大的成功,将自己的企业发展成为一家全球零售连锁企业,在几十个国家拥有数千家门店。现在这个数字已经轻松超过了 10⁶.为了服务您的客户,您现在在智能有效性方面遇到了一个真正的大问题!你必须处理好你的 MUT!
结论是,在一百万个独特的事物周围,人类直觉去归纳超越已知数据变得不可靠。[05]
我们世界的复杂性现在已经超出了我们人类直觉的能力,无法进行大规模的可靠概括,尤其是在经济、社会和政治领域。
分析(能够大规模归纳已知数据以外的信息)变得必不可少。支持这些分析的技术已经从描述性统计(过去一百年)发展到机器学习(过去二十年)和人工神经网络(过去五年)。
请注意,从人类历史的大角度来看,这项技术的发展是最近才出现的!古希腊人没有 MUT 问题。
作为人类,我们必须明智地接受分析,以使我们能够智能有效地应对我们世界日益增长的复杂性。
正如一篇相关文章中所指出的,分析应该用来增强人类的直觉,而不是用自动化流程来取代它。[增强直觉]挑战在于用客观数据驱动的支持来增强人类的直觉,以便超越已知数据进行归纳。
**收获:**作为一名分析系统经理,调查你的组织中必须处理 mut 的关键领域。在集成数据仓库的主要主题领域中寻找线索。您的组织在这些方面表现得足够好吗?如果您的组织能够在这些领域显著提高其智能效率,会带来显著的好处吗?
体积—速度—变化
你不必成为一家拥有 1000 家店铺的全球性公司,也能理解和管理一个 MUT。术语大数据经常被滥用来兜售你的成功业务和所有人的更好生活的承诺。然而,来自大数据的 3V 概念有助于解释为什么分析可以实现智能有效性。这完全取决于是否有足够的数据来描述这些 mut。
真正的问题是处理需要管理 MUT 情况的信息内容。[06]换句话说,充分描述一个 MUT 需要多少位数据?1gb 还是 1pb?[06]
以在您的商店购物的 100 万客户为例,MUT 对收集的这些客户的数据意味着什么?
考虑 3V 的维度— 体积 速度 变化 —来解释数据的信息内容,从而解释其支持超出已知数据的概括的潜力。
体积… 客户的例子将事物的体积视为独特事物的数量——它的基数。然而,这可能很棘手,取决于如何定义客户。客户是个人、家庭还是大公司?进一步说,这个东西是顾客与商店的互动吗?而且,这种互动是对商店的实际访问,还是对网站的浏览,还是对邮件优惠券的回应,还是对电子邮件报价的回复?因此,您可能认为您的组织只与几百个客户打交道,但是您将被迫处理数百万件事情来理解这些客户。
速度… 客户互动的例子涉及事物的速度——单位时间内独特的事物。每当时间维度相关时(通常如此),数据速度就成为一个重要因素。所有客户关系管理(CRM)系统都是对客户互动进行分析,而不是对客户进行分析。分析结果可能会汇总到单个客户的邮件活动中,但这些结果是基于对这些交互的概括。
多样性… 作为个人、家庭或公司的客户的例子处理事物的多样性——单一事物的信息丰富性。充分描述一个人、一个家庭或一个公司所需要的信息是非常不同的。如果你的客户是 IBM 或 Apple,你将需要大量的数据来理解如何正确地为公司客户服务。此外,数据现在因图像、文本、音频、传感器等固有的丰富种类而变得丰富。
因此,MUT 的信息内容是体积、速度和这些东西的变化的乘积。例如,100 件事情(比如管理公司客户,而不是个人)可能足以超过人类直觉碰壁的 IC 水平。作为人类,我们不是被设计(也不是进化)来超越这个水平的。[07]
**要点:**作为一名与分析系统相关的经理,3V 如何影响您在关键的百万独特事物领域的信息内容?
特征示例(加标签)
从传统的机器学习到较新的神经网络,一个共同的特征是输入数据的格式,即示例(或行、实例)特征(列、属性),加上一个标签(或目标)作为特征之一。这就是所谓的示例 - 特征 - 标签(简称 EFL)数据格式。[08]
大多数人认为 EFL 数据是表格形式的,因为它通常以类似 Excel 的电子表格形式显示。然而,这是一种误导,因为支持 DL 的模型的特征可能是图像、音乐或其他非结构化数据。神经网络的当前实现将张量(多维矩阵)作为数据的基本单位。
其中一个特征可以是一个标签(或目标),该标签表示该示例的一个重要特征。例如,一个客户可以用一个包含各种特征的例子来表示,比如年龄、性别等等。标签可能是他们过去一个月的购买总额。标签特征是“监督”(引导)算法向有效泛化方向优化的目标。
总之,数据分析以感兴趣事物的示例开始(并结束),由一组特征描述,其中一个可以是重要特征的标签。标签通常是分类值,例如“非常重要客户”,这通常由主观判断决定。
**要点:**作为一名分析系统经理,专注于 EFL 数据中标签的管理。如果数据与其他特征相似,这是模型预期结果的关键陈述。它的值可能是由专家主观设定的,这是昂贵的、容易出错的,并且规模不灵活。
EFL 数据作为价值驱动因素
在关于新范例的文章中,解释了这个数字。[09]横轴对应于 EFL 数据量,右侧是 MUT 区域。纵轴对应于分析生成模型的良好程度,该模型可以超越已知数据进行归纳。

因此,该图(右上方)表明神经网络是目前处理 MUT 问题的最佳技术。此外,这项技术在某些任务上可以超越人类水平的表现。然而,关键的要求是我们能够收集和整理足够的关于我们 mut 的 EFL 数据。
**要点:**作为一名与分析系统相关的经理,评估可用于解决 MUT 问题的 EFL 数据量。如果数据不足,传统的机器学习技术是否足够?如果有足够的数据,潜在的商业价值是否激励你的组织开发神经网络?你有这样做的资源吗?
分析成熟度阶段
分析的价值通常被描述为一系列成熟阶段,对于这些阶段,可以回答某些问题。[10]注意,后面的阶段是超越已知数据的各种形式的概括。
- 描述性——发生了什么?…描述已知数据
- 诊断 —为什么会这样?…从相关性中推断因果关系
- 预测性的 —会发生什么?…推断未来事件的各个方面
- 规定性 —应该发生什么?…朝着理想目标优化计划
这个框架意味着……一个公司通过将分析能力从阶段 1 发展到阶段 4 来达到更高的分析成熟度。由于能够解决更广泛的问题,更高的分析成熟度增加了产生更大商业价值的潜力。然而,努力(以及成本、技能、资源、风险)也会增加。
成熟度阶段对于评估分析能力是很有用的,因为它支持问题的类型。它严重依赖于从洞察力中主观得出的人类直觉,如前所述,这可能不足以处理 MUT 问题。
**要点:**作为一名与分析系统相关的经理,评估 IT 系统支持跨各种职能领域的分析成熟度阶段的能力。您的分析是否足以处理当前运营和未来增长的 MUT 问题?
分析价值链
在组织研究中,称为“价值链”的框架将价值定义为向消费者交付产品或服务所需的一系列活动。这个概念最早是由迈克尔·波特在他 1985 年的著作 【竞争优势】 中描述的,用来解释一个典型公司在为股东创造价值方面的功能。
让我们从分析价值链的角度将这一范式应用于分析。

Analytic Value Chain as pipeline from data to action
分析价值链是从数据到行动的管道,以智能有效的组织行为的形式产生不断增加的价值。序列从左向右流动(实际操作中有相当大的循环)。原材料是数据,而成品是行动,意在改变公司的行为。
如果您的组织必须处理管理 mut,那么它必须支持所有五个阶段的功能,端到端的结果是数据到行动。其含义是:当分析使业务流程能够智能有效地积极影响客户、产品等时,就创造了商业价值。如果没有通过行动对业务流程产生积极的影响,那么组织就不会受益。有了这些输入,所有的分析系统都是昂贵的开销!
**要点:**作为一名与分析系统相关的经理,经理应该采用端到端的关注点,因为这个框架代表了一个价值流,在任何阶段都可能被打断。此外,中间三个阶段是数据科学团队的重点。因此,管理者应该特别注意第一阶段和最后阶段。第一个——Acquire&Curate——处理前面部分讨论的问题,如 MUT 和 EFL。最后一个——操作化&治理——是下一节的主题。
分析最后一英里
与大型电气、通信和运输系统一样,众所周知的“最后一英里”通常是这些复杂系统中最昂贵、最慢、最容易出错的环节。从端到端价值链的角度来看,分析也是如此。
分析的最后一英里强调价值链的最后阶段——操作化和治理——处理操作化分析,以及治理其应用。此时,初始 EFL 数据用于训练和验证神经网络模型。该模型以智能有效的方式增强了特定的业务流程,并根据一组策略监控和治理其行为。
当前的实践通常被称为分析开发,以表明开发模型的团队和执行其生产应用程序的团队之间的紧密协作。神经网络模型出现了一系列独特的问题:
- 所需的软件能在生产环境中执行吗?做模型预测需要什么?
- 在大型流系统中实施实时模型预测,而不是对数据仓库进行批量预测更新
- 检测到当前模型不再有效,因为操作数据已经偏离了训练数据
- 模型是否需要再培训:再培训可以在生产环境中同时进行吗?在什么时间周期—每天、每小时?
- 检测训练数据中的非预期偏见,如性别/种族偏见。
- 链接到数据治理,将模型作为学习逻辑而非静态逻辑来管理
- 通过冠军挑战者动态不断改进模型性能
- 经理和受影响的消费者对模型结果的可解释性
- 整个端到端分析工作流的管理和可审核性
**要点:**作为一名分析系统经理,分析的最后一英里是你最大的挑战。尽早并经常分配足够的资源,并给予你高度的关注。
作为价值维系者的学习
最后一个主题是,通过分析系统学习成为价值的长期维持者。一旦这种学习停止,系统的价值就会下降,因为模型概括新例子的能力会减弱。
Testa 人工智能总监 Andrej Karpathy 在他 2017 年的文章 Software 2.0 中最好地捕捉了这种范式转变。他写道…
因为现在很容易收集关于许多业务问题的数据,所以与编写显式静态代码相比,可以使用这些数据更快、更有效地训练神经网络模型。这些模型实际上是数据驱动的,而不是像前 50 年的商业计算那样是代码驱动的。
Karpathy 区分了静态逻辑(硬编码)和学习逻辑(示例训练),并假设这些示例有足够的数据。
让我们再进一步学习逻辑,不断对新的示例数据进行再训练。
通常的情况是……一个模型在一组原始的例子上被训练和验证。创建这样的范例集是一项困难、昂贵和劳动密集型的工作。该模型在生产系统中投入运行后,表现符合预期。而且,由于创建这些新示例的工作量很大,该模型不会在新示例上重新验证。
请注意潜在的假设…新的示例被认为与旧的示例相似(具有代表性),因为业务没有发生重大变化。因此,重新训练是不值得的。
然而,对于大多数组织来说,当前环境的变化超出了人们的想象。此外,数据基础设施正在走向成熟,因此可以收集新的示例作为正常操作的一部分,如果该功能作为模型操作化的一部分实现的话。
**要点:**作为一名分析系统经理,将您的分析系统从静态逻辑转移到学习逻辑和学习逻辑的商业价值是什么?你有实现这一价值的资源吗?
摘要
本文为定义和确定大型分析系统的价值构建了一个循序渐进的论证。该论点用基本概念解释了这些步骤,这些基本概念可以在所有管理级别上讨论,并为评估和协作提供了一个共同的基础。

增强始于对比有效性(做正确的任务)和效率(做正确的任务)。重点放在智能有效性——定制任务以满足特定情况的需求。关键的能力是根据关于过去情况的数据概括新的情况,从而实现任务的定制。人类的直觉很好地服务于这一功能,直到最近复杂性超过了它的极限。当管理超过百万个唯一事物(简称 MUT)时,这个限制就会出现。然而,事物在数量、速度和多样性方面存在差异,因此一些快速发展的复杂事物可能会非常难以管理。
捕捉这种复杂性的格式是一组示例,每个示例都有其特性,外加一个表示目标值的标签。这种“示例-特征-标签”格式的数据称为 EFL 数据,它是分析系统的价值驱动因素。随着 EFL 数据量的增加,DL 模型的表现越来越好,最终超过了人类水平的表现水平。

讨论转移到处理各种问题的四个分析成熟度阶段。这与分析价值链形成对比,后者展示了将数据转化为行动的增值渠道。突出显示的是分析的最后一英里,这是可操作的&治理步骤,通常是为组织产生价值的瓶颈。
最后一部分关注作为价值维系者的学习。对静态逻辑、习得逻辑和学习逻辑进行了区分。后者是长期保值的唯一选择。
感谢… 位于的 DL 研究小组,博尔德的数据侦探们在过去几个月里与我们进行了讨论,帮助我们理清了这些想法。
最后… 如果你从这些文章中受益,请支持 my Patreon 创建并指导小型经理同行小组,探索由深度学习支持的分析系统的关键管理问题。如果同事对该计划感兴趣,请分享链接或推文。谢谢,理查德
尾注
[01]引用自德鲁克的著作 《有效的管理者:把正确的事情做好 。这本书的 12 条经验的简明摘要似乎非常适用于管理支持 DL 的系统。此外,1993 年 5 月的文章对这种效率-效益的区别进行了详尽的阐述。
[02]概括是数百年来科学、逻辑和统计中的一个基本概念。来自维基百科的定义抓住了它的本质:通过抽象共同属性从具体实例中形成一般概念,这导致定义形成整体的相互关联的部分。术语抽象是遵循一般规则的过程的结果,就像数据分析算法一样。
[03]丹·艾瑞里 2008 年出版的《可预测的非理性:塑造我们决策的隐藏力量 是一本革命性的书,讲述了当今社会动态,无论是个人还是社会,似乎都以违背理性逻辑的方式表现。因此,基于理性的模型充其量是误导性的。2016 年,《福布斯》的乔诺·培根采访了艾瑞里,探究我们如何【能够】帮助机器更好地理解我们【人类】*。有一句话引人注目:我认为我们应该与人性合作,而不是试图违背人性,并且……看看人们犯的错误,并……想想纠正这些错误的途径是什么,以及需要什么样的系统。*
【04】术语 thing 是有意的非正式用法,用于泛指某一情况下涉及的物体或事件。正式术语是实体*,在韦氏词典中定义为独立存在的任何事物。在数据结构化中,术语实体在实体关系模型 (ER 模型)中具有正式角色,即在一种情况下相互关联的感兴趣的事物。*
【05】TBD:需要研究来支持断言人类无法超越 MUT* 进行可靠的概括。阅读大卫·温伯格 2012 年的著作《大到不知道:重新思考知识》 ,寻找灵感。*
【06】术语 信息量 (或自我信息)是分析学的一个基础性课题,涉及到 1948 年 Claude Shannon 的 信息论 ,形式化为 熵 的概念。它是从随机数据样本中获得的“惊喜”。惊喜越多,熵就越多。如果来自数据的惊奇加倍(即,提供两倍的选择)并且继续加倍(例如,乘以 2、4、8…),则信息内的比特数(即,其熵)是 1、2、3…
[07]解决方案是增强人类的直觉,而不是用自动化过程取代它。这一点——增强而不是自动化——在新范例文章中有解释。分析可以是将信息复杂性降低到人类直觉可以理解并成功执行的水平的工具。这个类比就像一架望远镜或显微镜,可以增强人类感官和直觉来观察和理解非常大或非常小的物体。在上面的注释[03]中,增强应该有助于人类直觉中的错误。
[08]这是假设模型的常规监督*(相对于非监督)训练。通过预测“真实”标签值的准确度来监督(指导、评估)训练。这组例子被分成一个较大的训练集和一个较小的测试集。所有训练示例的每个循环被称为一个时期。在每个时期之后,记录训练和测试示例的标签和预测值的不匹配,并绘制在学习曲线中。该图表显示了该模型在偏差(接近正确值)和方差(接近某个值)误差方面的泛化能力。这总结了当今大多数传统的机器学习实践。然而,深度学习实践正在以令人惊讶的方式扩展这个框架,这将在未来的文章新视野中讨论,该文章讨论了元学习研究。*
[09]此图表在新范例文章的数据驱动性能部分有更详细的解释。这是吴恩达在 Coursera DL 专业化中题为“规模推动 DL 进步”的幻灯片的简化版。
[10]大多数显示分析成熟度四个阶段的图表都是 Gartner 在 2012 年 3 月发布的。然而,有人引用了汤姆·达文波特 2007 年的一篇文章。甚至维基百科也对其起源保持沉默。也许这个图表应该被重新命名为分析能力阶段(或者级别)。
男士服装店如何利用数据科学竞赛。
写完关于男士服装店如何利用数据科学的短文后。我和我的团队继续讨论如何向顾客推荐男装店的产品。我们相信,如果男装店可以将他们的店内顾客体验和时尚知识(这很棒)转移到网上,那么他们的市值将从目前的 16.5 亿美元增长到现在的几倍。不知何故,Stitch Fix 的市盈率为 666 倍,市值为 2B 美元(高于亚马逊的市盈率)。同样,男装店也有机会创造类似或更好的服务,帮助推荐可能会增加网上购买的产品。
在创建一个推荐产品的系统时,我们的第一步是将客户分类。这可以使用像 K-最近邻或 SVM 这样的算法来完成。这也取决于客户是否已经被分类(我们假设没有)。因此,这一步首先需要一种无监督的方法,看看你是否能开发出可以解释的自然聚类。
如果这是成功的,那么接下来的几个步骤可以分开并同时完成。
其中一个重要的步骤是计算客户的可能价值。这可以通过考虑过去的购买习惯来计算,例如客户是否经常购买一种产品,或者他们是否每年购买一次价值 2000 美元的产品,这些客户是为了销售而来,还是购买全价商品。他们还可以购买第三方数据来计算顾客在商店外的其他消费习惯和可自由支配收入。这将提供更准确地向每个客户营销正确价格点的能力,以及更好地引导客户转向客户已经知道的品牌。

另一个重要的步骤是考虑每个人可能会购买哪些产品。顾客是否想购买一双绿色条纹袜子、一个领结、一条领带、一套新西装等。由于男装店已经有很多过去的购买历史,他们已经知道什么样的服装可以搭配顾客已经拥有的服装。这将是一组独立的试探法或业务逻辑,在将每个组分成不同的类别后会出现,因为这将有助于更好地拟合预测,并消除您在查看过大数据集时遇到的一些干扰(您将注意到的一件事是,我们将多次使用分解数据或步骤的概念,因为我们相信这有助于提高准确性并减少复杂问题的干扰)。
这可能是一个算法,也可能是多个算法来进一步分解问题。例如,你可以试着预测一个人会买哪种产品。然而,尝试创建一个算法来预测可能是替换购买、新购买和自发购买的购买可能更容易。这些都可能有不同的模式和功能,可能会被浏览时,试图使所有的所有产品推荐算法结束。

这需要测试,以确定哪种方法更好。一旦做出决定,那么算法可以是从决策树到神经网络的任何东西,可以用来预测该人应该购买的下一件产品是一件新的紫色条纹礼服衬衫,搭配灰色三件套西装和纯紫色领带(我实际上不确定这是否可行),这就是为什么该系统会对他们的客户有帮助!它消除了对犯错的恐惧,并提供了不思考的便利。
一旦决定了产品,就需要正确地包装广告。我们可以预见广告会出现在电子邮件中,也会出现在男士服装店的“完美合身”应用程序中。如果他们可以在应用程序上获得良好的用户基础,那将是最佳的,然后每隔几个月就会弹出一个通知,列出客户可能感兴趣的 2-5 种产品。而不是仅仅告诉顾客他们的衬衫尺寸。为更多的购买制定可行的步骤。归根结底,这才是他们真正的目标。做这件事可能会有帮助。这种类型的系统有可能消除知道穿什么的压力。也许它甚至可以推荐在特殊场合或日常商务场合穿什么。男装店越能提供服务,而不仅仅是产品,就会增加顾客的忠诚度和购买量。因此,如果男装店可以在网上衡量他们的店内感觉,我们预计会有类似的结果。我们有很多方法可以看到这种数据产品被用来提高客户满意度和销售额。

最后,一旦广告展示给你的客户,跟踪广告的成功是很重要的。这是最有价值的步骤之一,因为知道结果将允许公司在未来创建更准确的算法和产品。如果顾客在网上看到广告后立即购买,那么就很容易合理地判断广告何时成功。客户也可能在几天后亲自或在线购买产品,因此也必须考虑这一点。这可能需要某种形式的商业规则。也许如果一个产品在看到广告后不到 15-30 天内被购买,他们会认为它是成功的。在这个范围内会有假阳性,但是这需要实际的测试。
我们非常好奇,看看已经存在一段时间的男装店和其他零售商将如何开始越来越多地将他们的数字战略与他们已经拥有的所有数据整合起来。在我们看来,有很多旧的概念,如产品推荐和广告定位,仍然有很多工作可以做,以帮助增加公司的利润和整体效率。此外,将核心竞争力转移到网上,比如店内时尚建议,将大有裨益。
有兴趣阅读更多关于成为更好的数据科学家的信息吗?
男士服装店如何利用数据科学
最近,我会见了几个朋友,为将于 5 月 31 日在西雅图举行的关于电子商务的机器学习小组会议做准备。我们的目标是用数据科学和数据分析解决方案回答零售商的实际业务问题。我们开始讨论如何利用数据来改善不同的实体店和电子商务网站。
我们的一次讨论让我们谈到了男士服装店。我们最初是从讨论网上买衣服的问题开始的。主要问题是尺寸和品牌之间的差异。
最终,它让我们意识到,男装店可能正坐拥利用其客户大量数据的机会,或者……它应该抓住机会收集更多数据。老实说,我们感到惊讶的是,男装店似乎仍然没有类似下面的一些想法,因为 Stitch Fix 已经提供了一些这样的服务。

Here is an example from Stitch Fix’s Algorithm Page…it is honestly just fun to watch and think about all the different algorithms they have developed to mange each portion of their supply chain.
以前的购买历史
上次我去男装店时,销售助理查看了我上次购买的服装,帮我找到了一些与我之前购买的套装相配的衬衫和领带。
为什么不用这些信息为我下次网上购物提供时尚建议。有点像虚拟时尚顾问(有点像缝针)。而不是每天用 2-3 封电子邮件来轰炸我的销售(这是他们目前的做法)。他们可以用更个性化的方式来处理这个问题。
男装店已经知道我有一套灰色西装,搭配两件不同款式的紫色礼服衬衫、一件蓝色礼服衬衫等。也许他们发送的电子邮件会推荐另一件与顾客当前西装相配的礼服衬衫,也许是另一条与礼服衬衫相配的领带,或者是一套全新的西装。你明白了。他们可以从本质上管理顾客的衣柜,并通过消除知道什么衬衫配什么西装的不便来增加价值。归根结底,大多数成功使用数据的服务都专注于提供更多便利。网飞、亚马逊、优步等。与同类产品相比,它们都提供了更多的便利,而且……最重要的是,让花钱变得更容易。
事实上,男装店甚至可以更上一层楼。如果他们能够获得足够的数据,将他们的客户分为不同的类别,如“传统型”、“冒险型”和/或“古怪型”,那么他们就可以更好地知道向谁销售哪些产品。有时候,人们甚至不知道他们穿其他颜色好看,疯狂的袜子等。他们只是需要有人建议一个新的外观。
同样,也许男装店可以预测某个性类型的人会喜欢戴领结,然后要么推荐一款与顾客西装相配的领结,要么免费送给他们一款(这可能会令人毛骨悚然)。但最终,它可能会让顾客在未来购买三个领结,并对佩戴它们感到自信。
也许男装店还可以打造一个豪华版的 Stitch Fix 服务,专门针对西装和更精致的时装。

他们有我的尺寸
再一次,以一种奇怪的方式,男装店可能拥有的关于我们的信息量可能令人毛骨悚然。然而,事实上,他们得到我们的尺寸对所有的服装零售商来说都是非常有价值的。
我相信梅西百货会很想知道我的确切尺寸!然后,他们可以更好地向我推荐产品。此外,我相信在未来,所有的零售商都必须知道我们的尺寸和尺寸,才能与像 Stitch Fix 这样专注于让产品尽可能方便的公司竞争。
这对男式 Wearhouse 来说是一个巨大的优势。我不在网上购买衣服的一半原因是我不确定它们是否合身。然而,如果他们真的知道什么产品适合他们的客户,什么不适合,那么他们就意味着他们可以给我们发送产品,避免过多的退货。这将为他们或他们的客户节省一大笔退货费用。无论是哪种情况,都会改善他们的服务,给我留下一个满意的顾客。

结论
这是我们讨论过的两个想法。在这种情况下,Stitch Fix 确实具有先发优势,我们认为,像梅西百货、男装店和其他服装店这样的公司将不得不效仿,以便参与竞争。
否则,这些公司就有可能像百视达或巴诺一样完蛋。让服务和产品更方便往往是最成功的策略。
如果 Men’s Wearhouse 突然开始向你推荐与你目前的衣橱直接相关的衣橱,你会有什么感觉?
是不是有点太小众报道了?
加入我们关于电子商务的机器学习小组进一步讨论!
其他关于数据科学的精彩阅读:
p 值二分法会如何影响统计测试中得出的结论?
具有相似数据属性的模拟数据中显著 p 值缺乏可重复性的探索性分析

研究人员目前主要关注的一个问题是以前和现在的研究结果缺乏可重复性。在当前和未来的研究中,有一种认识认为需要采取措施来减少假阳性的估计数量。然而,对于实现这一目标的最佳战略存在分歧。战略范围从更自愿和理想主义的到更有限制性和务实的。
在获得更具可重复性的结果的过程中,一个激烈的争论是降低甚至消除单变量测试的典型 0.05 临界值(此处为争论的介绍)。典型的单变量统计分析包括对数据集每个特征的单变量测试(如病例和对照之间的学生 t 检验)中的 p 值进行计算。从几十个要素中,观察到一些具有显著 p 值的要素,因为它们低于截止值。然后,根据所分析的因素,阐述了与这些特征中发现的显著差异相一致的故事。
这种策略承认,在显著性和非显著性 p 值的这种二分法过程中,可能会产生一些假阳性和假阴性。一个 p=0.049 的特征的结果和另一个 p=0.051 的特征的结果实际上有多大差别?直观上,差异可以忽略不计。然而,我感觉有一种默契,即一定的任意限制对于删除非信息数据是必要的,这样结果(以及对这些结果的解释)就更容易被潜在的读者理解。基本上是通过分析来避免瘫痪。
我理解这种简化的需要。然而,我认为目前对于这种简化会在多大程度上改变结论缺乏理解。我发现探究由于 p 值的二分法,结果的可重复性有多低很有趣。为此,我使用了 113 个样本(57 个对照样本和 56 个病例样本)和 46 个特征的代谢组学数据集。在下一张表中,我显示了 p 值最低的 10 个要素及其相关的 t 统计量(绝对值大于 1.96 表示 p 值小于 0.05):

所以我们有 7 个显著不同的特征。有了这 7 个特征,我们就产生了一个关于这些差异是如何被所研究的因素解释的好故事,并且我们有了一篇文章。
但是,如果我们模拟与分析的数据集具有相同属性的数据,会发生什么呢?t 检验研究两组正态分布样本的均值之间的差异,考虑每组中样本的数量和标准差。如果我们模拟具有相同特征的数据,我们应该在 t 检验中观察到相似的结果。这种模拟数据应该是后来试图复制相同效果的研究中发现的数据的最佳代表。
这是在原始数据集和模拟数据集中估计的 46 个 t 统计量(每个要素一个)的比较:

当模拟具有相同分布的数据时,模拟的数据将不会与原始数据完全相同。生成的略有不同的数据集解释了观察到的略有不同的 t 统计。
然而,当我们对 p 值进行二分法处理时,原始数据集中的 t 统计量和模拟数据集中的 t 统计量之间的高度相关性会恶化。下图左图中的红线表示 1.96 的界限,它区分了显著和不显著的结果。我们可以观察到,在模拟数据集中有一些值高于 1.96,而在原始数据集中有一些值低于 1.96。因此,模拟数据集中会有几个更重要的 p 值。在下面的右图中,我们可以更好地观察二分法的效果(0 =不显著;1 =显著)。这种二分法在质量较差的模拟数据集和原始数据集之间进行比较。

这些不同的显著和非显著结果的产生帮助我们更好地理解 p-hacking 的本质,这是一组注定要使显著 p 值的数量最大化的实践。通常,我们将 p-hacking 与试图尽可能扭曲数据以生成更多重要 p 值的恶意面孔联系在一起。然而,我们需要理解的是,具有相同分布的重复数据可以产生数量大不相同的显著 p 值。这是在 1000 次模拟数据迭代中发现的显著 p 值数量的密度图:

因此,如果不扭曲数据,而只是在处理后查看“复制数据”,我们可能会发现不同数量的 p 值。提高数据质量的可能措施范围有助于意外地找到一种最大化显著 p 值生成的配置;我们发现后验关于这种最大化是如何产生的合理解释,而不是通过数据改进,而不是通过掷骰子直到得到正确的组合。最大限度地减少非自愿的 p-hacking 实践可能需要加强对数据操作的限制,对执行这种操作的必要性进行更深刻的解释,或者如果不是绝对必要的话,简单地删除 p-值二分法。
当将 p 值二分法时,我们实际上是将数值数据转化为二元分类数据。因此,我们可以通过分类性能度量标准(如 ROC 曲线下的面积 (AUROC ))来开发对假阳性和假阴性的直觉。这种度量有助于直观地了解分类模型在不产生假阳性的情况下找到真阳性的能力。
通过 AUROC,我们可以比较在原始数据集中获得的显著和非显著 p 值在模拟数据集中的统计分析中是如何复制的。如果我们对模拟数据进行 1000 次迭代,对得到的 AUROC 值进行分析,我们得到的是得到的 AUROC 值的这个密度图(是“AUROC 值”,不是“AUROC 曲线”;抱歉:)):

你真的会相信预测分类和获得分类之间的分类仅仅比 0.7 好一点的模型吗?这就是在随后的研究中用相同的数据分布获得的显著 p 值的可重复性。
当通过 Benjamini-Hochberg 调整 p 值时,没有发现有意义的改善(发现 1.00 值中的尖峰;然而,这是与非常低数量的有效 p 值的产生相关的假象)。

p 值校正有助于处理执行的测试数量,但可能无法帮助处理将数值变量转换为二进制变量时信息是如何失真的。
对模拟的 AUROC 值的分析应该是 p 值二分法对可重复研究的可能有害后果的另一个例子。
我相信,大多数研究人员至少有一些直觉,知道在这种二分法之后,信息有多糟糕,以及在未来的研究中,结果可能不会总是重现。然而,这种影响的强度可能被低估,因为 p 值和 t 统计的解释很困难。更好地理解这种恶化的可能方法是显示某个特性具有显著 p 值的模拟迭代的百分比。下表比较了 p 值、t 统计量和 1000 次模拟迭代中 p 值显著的百分比:

为什么特征 26 比特征 11 更重要,而特征 26 的显著差异在未来的研究中可能只再现了 4.8%呢?
依我看,像第三个这样的度量标准可以更好地理解每个特性的能力,以区分病例和控制。更容易检测到三个特征可以作为区分病例和对照的单一生物标记。此外,其他几个特征也显示出一定的辨别能力。然而,这种能力似乎是部分的,而是由可能通过特征工程(例如,PCA)或多变量分析来分析的高级机制来调节。试图基于几个特征来叙述一个故事是没有任何意义的,这些特征显示出在具有类似分布的未来数据中再现的能力略好于 50%。此外,故事的质量将会提高,因为需要与其他特征的部分差异保持一致。最后,这种带有部分歧视的其他特征的报告将减少参与 p-hacking 的动机。
我对这些现象背后的统计学基础缺乏了解,这让我不愿意陷入一些武断的结论。然而,我有一种直觉,可以取得一些进展,以确保为解释所取得的成果而创造的故事更加可靠。作为一种选择,我认为至少有必要帮助读者更清楚地了解关于后来研究结果可重复性的实际观点。
一个 IT 工程师需要学多少数学才能进入数据科学/机器学习?

注意:如果你正在寻找一篇关于数据科学的各种数学资源的更全面的文章,请看看这篇文章。
成为更好的数据科学家需要掌握的关键主题
towardsdatascience.com](/essential-math-for-data-science-why-and-how-e88271367fbd)
免责声明和序言
一、免责声明,我不是 IT 工程师:-)
我是一名技术开发工程师,从事半导体领域的工作,特别是高功率半导体,日常工作主要是处理半导体物理、硅制造过程的有限元模拟或电子电路理论。当然,在这一努力中有一些数学,但无论好坏,我不需要涉足一个数据科学家所必需的数学。
然而,我有许多 IT 行业的朋友,并观察到许多传统的 IT 工程师热衷于学习或为数据科学和机器学习或人工智能的激动人心的领域做出贡献。
我正在涉足这个领域,学习一些可以应用到半导体器件或工艺设计领域的技巧。但是当我开始深入这些令人兴奋的科目时(通过自学),我很快发现我不知道/只有一个初步的想法/忘记了我在本科学习的一些基本数学。在这篇 LinkedIn 文章中,我漫谈一下 …
现在,我拥有美国一所著名大学的电子工程博士学位,但如果没有复习一些基本的数学知识,我仍然觉得自己在扎实掌握机器学习或数据科学技术方面的准备不完整。
无意冒犯 IT 工程师,但我必须说,他/她的工作性质和长期培训通常会让他/她远离应用数学世界。(S)他可能每天都在处理大量的数据和信息,但可能不强调这些数据的严格建模。通常,有巨大的时间压力,重点是“将数据用于你的迫切需要,并继续前进”,而不是对其进行深入的探测和科学探索。
然而,数据科学应该永远是关于科学的(而不是数据),沿着这条线索,某些工具和技术变得不可或缺。
这些工具和技术——通过探索潜在的动态来模拟一个过程(物理的或信息的),严格估计数据源的质量,训练人们从信息流中识别隐藏模式的感觉,或清楚地理解模型的局限性——是合理的科学过程的标志。
它们通常在应用科学/工程学科的高级研究生课程中讲授。或者,你可以通过类似领域的高质量的研究生水平的研究工作来吸收它们。不幸的是,即使是十年的传统 IT 职业生涯(开发操作系统、数据库或 QA/测试)也无法严格传授这种培训。简单地说,没有必要。
它们变化的次数
直到现在。
您看,在大多数情况下,对 SQL 查询有无可挑剔的了解,对总体业务需求有清晰的认识,并对相应的 RDBMS 的一般结构有所了解,足以执行提取-转换-加载循环,从而为任何称职的 IT 工程师为公司创造价值。
但是,如果有人突然来访,并开始问一个奇怪的问题,如“你的人工合成测试数据集足够随机吗”或“你如何知道下一个数据点是否在你的数据底层分布的 3-sigma 限制内”,会发生什么呢?或者,即使隔壁隔间的计算机科学毕业生/书呆子偶尔开玩笑说任何有意义的数据表(也称为矩阵)数学运算的计算负载随着表的大小(即行数和列数)非线性增长,也会令人恼火和困惑。
这类问题越来越频繁和紧迫,因为数据是新的货币。
执行官、技术经理、决策者不再满足于仅仅通过传统 ETL 工具获得的干巴巴的表格描述。他们希望看到隐藏的模式,感受列之间的微妙交互,希望获得完整的描述性和推理性统计数据,这些统计数据可能有助于预测建模,并将数据集的投影能力扩展到远远超出其包含的值的直接范围。
今天的数据必须讲一个故事,或者,如果你愿意,唱一首歌。然而,要聆听它美妙的旋律,你必须精通音乐的基本音符,这些是数学真理。
事不宜迟,让我们来看问题的关键。如果一个普通的 IT 工程师想进入商业分析/数据科学/数据挖掘领域,他必须学习/更新的数学基本主题/子主题是什么?我将在下面的图表中展示我的想法。

基础代数、函数、集合论、绘图、几何

从根源开始总是一个好主意。现代数学的大厦是建立在一些关键基础上的——集合论、泛函分析、数论等。从应用数学学习的角度来看,我们可以通过一些简洁的模块(排名不分先后)来简化对这些主题的学习:

a)集合论基础,b)实数和复数及基本性质,c)多项式函数,指数,对数,三角恒等式,d)线性和二次方程,e)不等式,无穷级数,二项式定理,f)排列和组合,g)图形和绘图,笛卡尔和极坐标系统,圆锥曲线,h)基本几何和定理,三角形性质。
结石
伊萨克·牛顿爵士想要解释天体的行为。但是他没有足够好的数学工具来描述他的物理概念。因此,当他躲在他的乡村农场里躲避英格兰城市爆发的瘟疫时,他发明了这个(或某种现代形式的)数学分支。从那时起,它被认为是任何分析研究的高级学习的门户——纯科学或应用科学,工程学,社会科学,经济学,…

毫不奇怪,微积分的概念和应用出现在数据科学或机器学习领域的许多地方。涉及的最基本主题如下-
a)单变量函数、极限、连续性和可微性,b)中值定理、不定形式和洛必达法则,c)最大值和最小值,d)乘积和链法则,e)泰勒级数,f)积分学的基本和中值定理,g)定积分和反常积分的计算,h)β和γ函数,I)二元函数,极限、连续性、偏导数,j)常微分方程和偏微分方程的基础。
线性代数
在上得到了新朋友建议脸书?一个久违的职业联系突然在 LinkedIn 上加了你? 亚马逊 突然推荐了一本超赞的言情-惊悚小说给你下次假期阅读?还是 网飞 为你挖掘出一部纪录片中那颗鲜为人知的宝石,恰好符合你的口味和心情?

如果你学习了线性代数的基础知识,那么你就拥有了关于基本数学对象的知识,这是科技行业所有这些成就的核心,这种感觉难道不好吗?
至少,你会知道控制你在 目标 上购物的数学结构的基本属性,你如何使用 谷歌地图 ,你在 潘多拉 上听哪首歌,或者你在 Airbnb 上租谁的房间。
要研究的基本主题是(无论如何不是有序或详尽的列表):
a)矩阵和向量的基本性质——标量乘法、线性变换、转置、共轭、秩、行列式,b)内积和外积,c)矩阵乘法规则和各种算法,d)矩阵求逆,e)特殊矩阵——方阵、单位矩阵、三角矩阵、关于稀疏矩阵和密集矩阵的概念、单位向量、对称矩阵、埃尔米特矩阵、斜埃尔米特矩阵和酉矩阵,f)矩阵分解概念/LU 分解、高斯/高斯-乔丹消去法、解 Ax=b 线性方程组,g)向量空间、基、跨度、正交性、正交性、线性最小二乘法
这里有一篇很好的关于线性代数的文章。
统计和概率
只有死亡和税收是确定的,其他都是正态分布。

在关于数据科学的讨论中,牢固掌握统计学和概率的基本概念的重要性怎么强调都不为过。该领域的许多从业者实际上将机器学习称为统计学习。当我在研究我的第一个机器学习 MOOC 时,我看了广为人知的“统计学习简介”,并立即意识到我在这个主题上的概念差距。为了填补这些空白,我开始参加其他侧重于基本统计和概率的 MOOCs 课程,并阅读/观看相关主题的视频。这个主题是巨大的和无止境的,因此有重点的规划是至关重要的,以涵盖最基本的概念。我试图尽我所能把它们列出来,但我担心这是我最欠缺的地方。
A)数据汇总和描述性统计,中心趋势,方差,协方差,相关性,B)概率:基本思想,期望,概率演算,贝叶斯定理,条件概率,c)概率分布函数-均匀,正态,二项式,卡方,学生 t 分布,中心极限定理,d)抽样,测量,误差,随机数,e)假设检验,A/B 检验,置信区间,p 值,f)方差分析,g)线性回归,h)功效,效应大小,测试方法,I)研究和实验设计。
这是一篇关于数据科学家统计知识的必要性的好文章。
专题:最优化理论,算法分析
这些主题与应用数学中的传统论述几乎没有什么不同,因为它们在专业研究领域(理论计算机科学、控制理论或运筹学)中最相关和最广泛使用。然而,对这些强大技术的基本理解在机器学习的实践中可以是如此富有成效,以至于它们在这里值得一提。

例如,几乎每种机器学习算法/技术都旨在最小化受到各种约束的某种估计误差。这是一个最优化问题,通常通过线性规划或类似的技术来解决。另一方面,理解计算机算法的时间复杂性总是一种非常令人满意和深刻的体验,因为当算法应用于大型数据集时,它变得极其重要。在这个大数据时代,数据科学家通常需要提取、转换和分析数十亿条记录,因此他必须非常小心地选择正确的算法,因为它可以决定惊人的性能或彻底的失败。算法的一般理论和属性最好在正式的计算机科学课程中学习,但要理解如何分析和计算它们的时间复杂性(即,对于给定大小的数据,算法运行需要多长时间),必须对数学概念有基本的了解,例如 【动态编程】 或递归方程。熟悉数学归纳法 的**证明的技巧也会非常有帮助。**
收场白
害怕吗?作为先决条件要学习的令人费解的主题列表?不要害怕,你会随时随地根据需要学习。但是目标是让你的心灵之窗和门保持敞开和欢迎。
甚至还有一门简明的 MOOC 课程让你入门。注意,这是一门初级课程,用于更新您高中或大一水平的知识。这里有一篇关于 kdnuggets 上 15 门最佳数据科学数学课程的总结文章。
但你可以放心,在刷新这些话题之后,其中许多你可能在本科时就已经学习过,甚至学习过新概念,你会感到如此有力量,你一定会开始听到数据唱出的隐藏的音乐。这被称为成为数据科学家的一大飞跃…
#数据科学,#机器学习,#信息,#技术,#数学
如果您有任何问题或想法要分享,请通过tirthajyoti【AT】Gmail . com联系作者。此外,您可以查看作者的 GitHub 资源库 中其他有趣的 Python、R 或 MATLAB 代码片段和机器学习资源。也可以在 LinkedIn 上关注我。
学数据科学应该交多少钱?

对于任何想知道他们是否应该追求 MS Analytics(又名 MS 数据科学)或只是使用在线培训的人,以下是我作为已经获得 MS Analytics 和的人使用在线资源的观点。
首先,我们来谈谈货币。你不应该只考虑金钱成本,还应该考虑那些时间、信誉和意志力的成本。你必须找到一个适合你的平衡点。
时间
是的,你需要学习的一切都可以在网上免费或低价获得。然而,它的大部分是过度技术性和迟钝的。另一个常见的问题是,许多错误的材料也被兜售。围绕数据科学的炒作正处于白热化,大量骗子已经进入这个领域。
这两种杂乱的来源——迟钝的材料和错误的材料——会浪费你很多时间。如果你处在一个你的时间很宝贵的位置,那么为一个精心策划的、精简的、可信的课程付费将会有很强的价值主张。
在线学习也有价值。尽管我已经完成了 MS Analytics,但我仍然经常使用在线资料,以(1)保持自己的敏锐,(2)扩展我的知识库,以及(3)注意不同的术语(例如,“行”≈、“记录”≈、“元组”≈、“个人”≈、“观察”≈、“对象”≈、、 … )。随着其他学科对统计技术的“重新发明”,许多新的术语不必要地产生了。一个典型的例子是将计算多元统计学重新命名为“数据科学”和“机器学习”。咳咳…“科学”和“学习”功能主要是统计数据。(除非你只是想……宣传你正在销售的东西,否则你为什么要更名呢?…嗯…)
如果你有强烈的动力,从网上学习可能是简单学习材料的一个完美可行的选择。然而,如果你追求一种纯在线的方法,你可能仍然会遇到其他人是否能验证你的自学培训的问题。
可靠性
我从我的 MS 分析程序中获得了一些东西,这是任何预先录制的在线养生法都无法提供的。(请注意,我参加了一个现场和面对面的 MS Analytics 项目。)
- **信任。**这个是大的。在我的行业中,有权势的人往往是婴儿潮一代。他们重视正规教育,尤其是来自高排名大学的教育。数十亿美元是根据他们的最佳判断进行分配的。我选择做 MS 分析,很大程度上是因为我知道这将提升他们对我的能力的满意度。任何做决策的经理都喜欢让他们的侧翼被容易辩护的论点所覆盖。相比自学成才的候选人,雇佣或提升受过正规教育的候选人要容易得多。
- 师徒。我的顶点教练在我的行业中有超过 45 年的统计经验(流行的 ISLR 文本甚至以他的名字命名了一个奖项)。在我的许多课上,我的教授们在统计学研究方面享有世界声誉(其中一位教授引用了 10,000 篇文献)。他们不只是对我说话。他们回答了问题…大量问题!他们对我的工作提供了反馈。这是我知道我可以信任的反馈。它帮助我知道统计学的指导方针有多灵活或不灵活。首先,是面对面的。与统计界的资深人士进行个人互动的价值是巨大的。
- 友情。我在团队中完成了许多项目。我了解了队友的长处,他们也了解了我的长处。他们中的许多人成了亲密的朋友。职业教练会经常反复强调人际关系网的重要性。没有比团队项目更好的人际关系网了…只要你做好自己的本分。

My Texas A&M University ring
一所被认可的大学,在一系列科目上有分级的学分,增加了可信度。在顶点项目中加入专家指导。考虑战壕里的网络。与数据科学一样,这里需要考虑多种因素。对于我的职业生涯,你可能会明白为什么我不顾代价选择这条路。
意志力
我见过非常能干的工程师为了自我激励的唯一目的而报名参加日间课程。这花了他们的钱,但节省了他们的时间,让他们走上正轨。他们花钱买了一个弹弓——这是一种刺激,可以让他们不浪费时间(加上通过导师指导节省时间),让他们更快达到目标。
在线自定进度学习的一个缺陷是没有截止日期和评分。最终期限带来的压力可能是学习过程中的一个有效组成部分。压力有助于保持一个人在正轨上,并锁定经验教训。没有一个需要遵循的时间表,很容易将困难的任务推迟到以后。即使在线课程设置了时间表并有同行评分,也存在延迟注册的问题(因为实际上无论何时入学都是有保证的)…并且不知道同行是否给你正确评分(回到可信度问题)。
当意志力减弱时,战略性地利用压力可以维持努力。然而,硬币还有另一面——需要一些意志力才能在全职工作的同时不退出兼职 MS 项目。会有艰难的时期。
σ
综上所述,不管花费多少,获得 MS Analytics 是一个最佳的决定。我的最终目标不是改变职业。我以前是领域专家(地球科学家),现在也是。首先,在我的行业中,一个有经验的地球科学家的平均工资仍然高于大多数数据科学家的工资。那么我得到了什么?我现在是一名领域专家,也牢牢掌握了多元统计。这给我的职业生涯增加了灵活性和安全性。它打开了大门,其中一些已经抵消了学位的成本(入学时为 5 万美元)。说一句统计学上的双关语,我现在有了更多的自由度。
这对你来说是正确的道路吗?这是你根据你的时间的相对价值、对可信度的需要、意志的力量、财务状况以及从曾经获得的学位中获益的能力来做出的决定。(有趣的是,在我的 MS Analytics 团队中,约 90%的人在项目期间或之后不久获得了职位提升或工作变动。)如果你有一些时间来决定,我建议现在就从在线学习开始。早点开始,帮你一把也无妨。
根据您的最终目标,其他完全有效的替代方案也同样有效。物理学、生物统计学、计算机科学、等专业的硕士或博士学位。可能是你追求目标的最佳方式。已经有了成功的事业或职位?那么,也许你只是需要一个不那么正式的方法来帮助你保持竞争优势或保持“时髦的合规性”无论你选择哪条路,祝你好运。
世界是我们创造的,它需要变得更聪明。你应该避免的一个选择是什么都不学。
我的团队如何在我们的第一次黑客马拉松中赢得人民选择奖
现在我们在争夺全球大奖。投票给余烬警戒!

From left-to-right and top-to-bottom: Eric MacEwen, Adrian Nip, Tanweer Rajwani, Paul McLaughlin, Kim Andrew, Sam MacEwen, Caroline Dikibo
在 http://www.emberalert.co/查看我们的网络应用程序
两个周末前,我参加了我的第一次黑客马拉松… **,我的团队赢得了人民选择奖!**现在我们正在角逐全球大奖,而可能需要您的投票。
我们参加了 2017 休斯敦 NASA 太空应用挑战赛。事情发生的时候,我刚刚进入休斯顿的一个编码训练营 Digital Crafts 两周。所以我花了两周时间学习 Python,以及一些非常基础的 HTML/CSS 和 Javascript,这些都是我在训练营的前期工作中学到的。而且,不知何故,我最终加入了一个我拥有最多开发经验的团队。
我学到了什么?
参加黑客马拉松时,经验水平并不重要,但快速学习的心态至关重要。
不要害怕寻求帮助。
如果你的黑客技术不是最炫的,也不用担心。现在就做你能做的,如果将来有能力扩展,那就太好了。
做好结束时精疲力尽的准备。
团队合作让梦想成真。
灰烬警报的诞生
黑客马拉松跑了两天。我认识的唯一参加的人是我的高中朋友阿德里安,他也不认识那里的其他人;所以我们直到周六早上到达那里才组队。从一开始,你就可以看到人们开始为他们的团队承担他们的角色。并不是每个人都有突破性的想法。所以“创造者”很早就显现出来了。对我们来说,那就是 Adrian,他的背景是项目管理、工程和创业。他很快就想到了使用无人机为处理野火的人们创建快速反应策略的愿景。任何对使用无人机或灭火感兴趣的人都很快加入了我们的团队。令人惊讶的是,这是我们所有人的第一次黑客马拉松除了 Sam 和 Eric,他们之前参加了 NASA 的太空应用挑战赛。
唯一的问题是……我们没有无人驾驶飞机,也不知道如何自动应对火灾。但我们的想法有一个基础:我们想用技术帮助任何人处理火灾。我们的目标消费者既是救火的紧急服务团队,也是想要逃离火灾的平民。
小组形成后,我们急忙跑到各个角落,开始设计我们的黑客。我们很快确定了每个人的优势,并相应地划分了研究。保罗和我是数据人员。阿德里安和埃里克是硬件人员。金和萨姆是设计人员。卡罗琳和我成了开发者。我们花了最初的几个小时研究我们有哪些可用的资源。由于黑客马拉松是由美国国家航空航天局赞助的,我们可以公开访问他们所有的数据集。
**我们很快就意识到,我们最初的计划很难在 48 小时内实现。所以我们开始缩小规模。**我们知道我们既想帮助紧急服务机构,也想帮助平民,但由于我们有最后期限,我们决定把重点放在平民身上。我们知道我们想帮助他们避免处理火灾时的危险情况,所以我们研究了人们在应对火灾时遇到的问题。
我们的黑客很快从无人机扩展到一个网络应用程序,当附近发生火灾时,它会向人们发出警报。我们利用了美国宇航局提供给我们的活跃火情数据。我们的目标是使用谷歌地图的 API 并利用他们的路由算法。不幸的是,我们的 48 小时的最后期限和缺乏开发经验,使我们无法钻研它谷歌地图。我们满足于使用leafle JS,一个用 javascript 生成的开源地图 API。经过一点修补和折腾,我能够在传单的地图上绘制美国宇航局的数据集。现在我们有了一个交互式地图,允许用户看到他们附近和世界各地所有活跃的火灾。

Ember Alert’s interactive map. It displays active fires happening around the world.
这听起来很简单,但是由于我们组中没有人接触过使用 javascript,我们开始的时候有点像无头鸡。我遇到的最具挑战性的问题是将 NASA 的 CSV 格式的数据转换成与传单兼容的 JSON。幸运的是,我在 github 上找到了一个项目,我能够在我们的项目中利用它。
我们项目的第二层是为人们建立一个警报系统,以防附近发生火灾。随着我对后端开发和数据库管理的了解越来越多,这一部分仍然是一个未完成的工作。但这个想法是,人们可以向我们提交他们浏览器的地理位置,以及电子邮件地址或电话号码,每当我们检测到他们附近有火灾时,我们就会提醒他们。这个特性激发了我们项目的名字……Ember Alert。

经过 48 小时的艰苦工作,提出了一个产品创意,并为其开发了一个 MVP,Ember Alert 已经准备好向世界展示了。我们有机会在各种评委面前展示我们的技术。我运用我在高中和大学时的辩论技巧,把我们的项目作为一种工具展示给消费者,让他们避免在火灾中措手不及。我们的黑客得到了评委们的积极回应。给我们的主要建议是将我们的产品定位于保险公司,他们在防止客户房屋被烧毁方面有既得利益。
一开始对我们来说有点过于雄心勃勃的东西,缩小到最终赢得人民选择奖的黑客!

下一步是什么?
我计划在我的新兵训练营中继续开发余烬警报。我的目标是在几周内让该产品完全发挥作用,这意味着该应用程序将能够存储人们的地理位置,并在附近发生新的火灾时发送短信。
一个更长期的目标是将 Ember Alert 迁移到谷歌地图的 API,这样我们就可以使用更强大的功能,例如为处于危险中的平民选择离开防火区的安全路径,以及为紧急救援人员选择进入防火区的安全路径。我还想使用气候数据来预测火灾可能蔓延的路径,让我们能够在火灾发生前提醒人们火灾的风险。最终,我希望《余烬警报》也能扩展到其他的自然灾害,但是现在我将专注于火灾。
与此同时
Ember Alert 正在角逐 2017 年美国宇航局太空应用挑战全球人民选择奖。我们需要你的帮助!
在https://2017.spaceappschallenge.org/vote?q=Ember%20Alert为余烬警报投票
你必须注册一个账户,但这个过程相当简单。你可以每天投票一次,直到 5 月 22 日。
在 http://www.emberalert.co/查看我们的网络应用
神经网络如何“学习”

Source: https://stats385.github.io/assets/img/grad_descent.png
在我的第一个故事中,我解释了神经网络如何处理你的输入。在神经网络能够像前一篇文章那样进行预测之前,它必须经过一个预处理阶段。这个阶段控制神经网络在处理输入时使用的权重和偏差值。
在神经网络生命周期中有两个阶段,一般来说,所有机器学习算法都是训练阶段和预测阶段。寻找权重和偏差值的过程发生在训练阶段。与此同时,神经网络处理我们的输入以产生预测的阶段发生在预测阶段,如在之前的中。这一次,我将讨论神经网络如何在训练阶段获得正确的权重和偏差也称为“学习”以做出准确的预测(阅读:回归或分类)。
那么,神经网络如何获得最优的权重和偏差值呢?答案是通过一个误差梯度。在固定当前权重和偏移(最初随机生成)时,我们想知道的是当前权重和偏移值是太大还是太小(我们需要减少还是增加我们的当前值吗?)关于它们的最优值?以及它偏离了多少(我们需要减少或增加当前值多少?)从它们的最优值。我们寻找的梯度是误差相对于权重和偏差的导数。

where E is an error, W is weight and b is bias
这是为什么呢?因为我们想知道我们当前的权重和偏差如何影响神经网络误差的值,作为回答上段 2 个问题(减少或增加以及增加多少)的参考。我们如何得到梯度值是通过一个众所周知的算法叫做反向传播。我们如何利用通过反向传播获得的梯度来改善权重值和偏差是通过优化算法实现的。优化算法的一个例子是梯度下降,这是最简单和最常用的优化算法。它只是用获得的梯度值乘以学习速率常数来减少最近的权重和偏差值。什么是学习率以及更多细节,我们将在本帖中立即讨论。
假设我们有一个如下的神经网络。

Our neural network has a structure 3–2–2
假设我们有一个输入向量、偏差向量、权重矩阵和真值,如下所示






为了明确起见,权重值的顺序为


让我们做一下向前传球 。流程与上一篇相同。在本演示中,我们对所有神经元使用的激活函数是 sigmoid 函数。




这里我们将 sigmoid 函数的输出值四舍五入到 4 位小数。在实际计算中,这样一轮会大大降低神经网络的精度。小数的个数对神经网络的准确性至关重要。我们这样做是为了简化计算,这样写作就不会太长。
在我们进行下一层之前,请注意下一层是最后一层。意味着下一层是输出层。在这一层,我们只做纯线性运算。

是时候计算误差了。在这种情况下,我们使用均方误差 (MSE)来计算输出神经元的误差。MSE 方程如下

在我们的例子中,N = 1,因为我们只有 1 个数据,所以等式简化为

让我们根据前面定义的真值(T)来计算输出层神经元的误差。


这就是我们当前在输出层的误差。现在是通过反向传播(也称为反向传递)在层之间的每次交互中寻找相对于权重和偏差的误差梯度,然后应用梯度下降来最小化误差的时候了。反向传播仅仅是一个链式法则,它是如何工作的将立即讨论。现在,让我们找出我们在正向传递中使用的所有方程的导数。
- E 关于 O 的导数

2.sigmoid (h)函数关于 P 的导数(纯线性运算的输出)

h 在哪里

3.关于权重(W)、偏差(b)和输入(h)的纯线性导数。



purelin 在哪里

其中 l 是从 1 到 m 的数。
这就是我们所需要的,是时候应用反向传播了。我们首先寻找隐藏层和输出层之间的权重和偏差的梯度。为了寻找梯度,我们使用链式法则。


通过应用这些,我们得到






这就是我们在隐藏层和输出层之间的渐变。现在,进入下一层。这里真正的挑战(不那么挑战)!但是不要担心,在这之后一切都会变得清晰和容易:)。
反向传播中的链式法则完全是关于神经元之间的路径。让我们收集信息吧!
- 隐含层有 2 个神经元,每个神经元在左侧(输入层和隐含层之间)用 3 个权值和 1 个偏置连接**。**
- 在右侧,隐藏层中的每个神经元都与输出层中的 2 个神经元相连**。**
这些信息对于求 W1 的梯度非常重要。从这些,我们想要找到的梯度是

在哪里

添加了从我们关注的权重到输出层的所有可能路径。这就是为什么上面的等式中有两项之和。现在,让我们计算 W1 的真实梯度。

代入 E 对 h 的偏导数,我们得到




现在谈谈偏见,又称 b1


这就是反向传播算法作用的终点。现在,让我们来看看优化算法。优化算法是关于如何利用我们已经获得的梯度来校正现有的权重和偏差。我们选择的优化算法是梯度下降法。梯度下降法通过下面的等式校正权重和偏差。

其中 W’是新的权重,W 是权重,a 是学习常数,梯度是我们从反向传播获得的梯度。学习常数是至关重要的常数,因为如果这个常数太大,结果将不会收敛,如果太小,需要更多的迭代,这意味着训练阶段将更加耗时。假设我们有一个等于 0.02 的学习常数。








依此类推,该过程将被重复(具有将被输入的相同输入)直到达到所需的迭代次数或目标误差。
这就是神经网络一般是如何“学习”的。如果我有更多的空闲时间(当然还有好心情),我会用 numpy 分享 python 中多层感知器(另一种“普通神经网络”的名称,这是我们这里的重点)的源代码。再见。
我的另一个神经网络系列:


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言










{kind=link}
{kind=link}
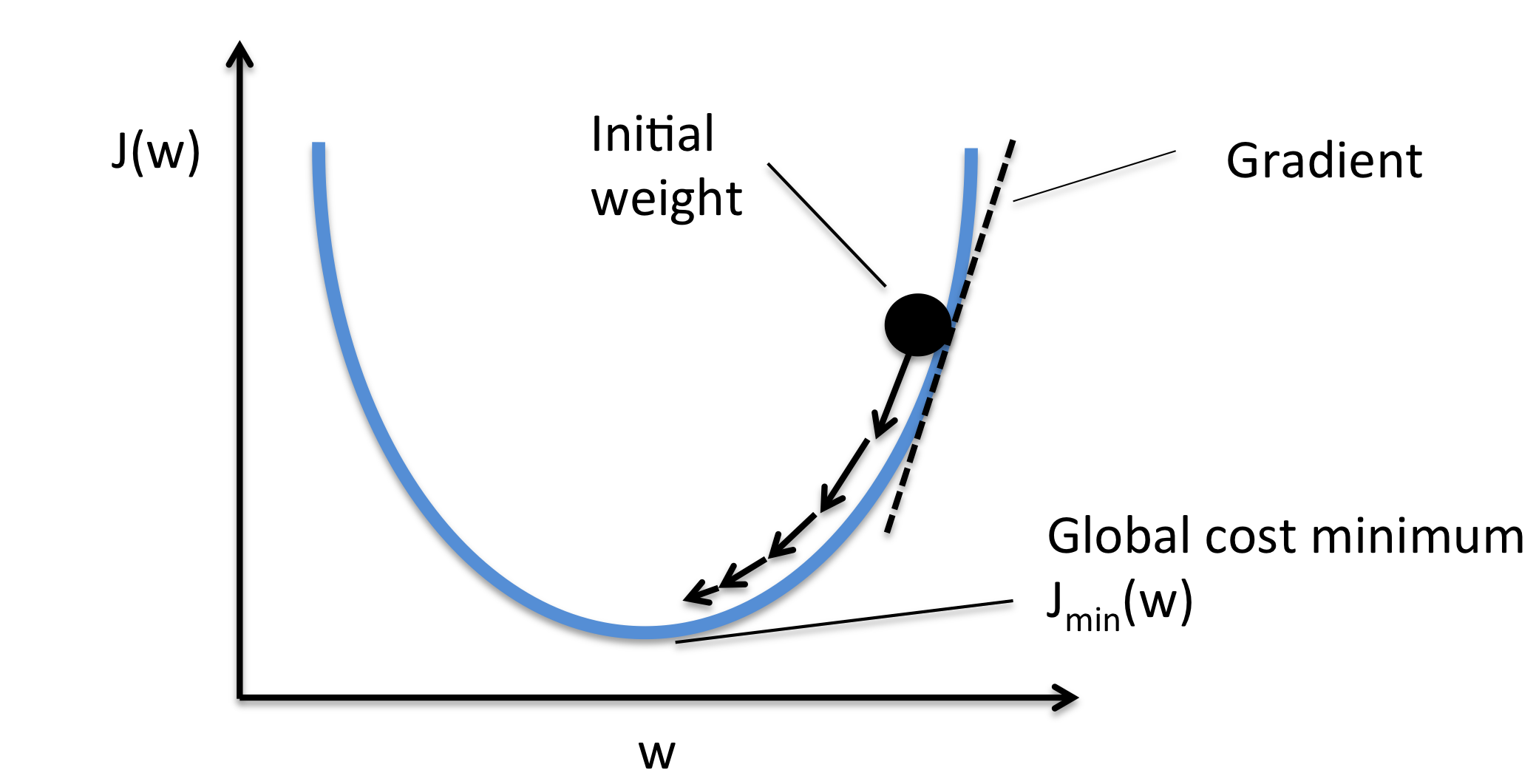{kind=link}