







我会选择点数,而不是小节
Aaron Carroll 在结果/NYT 中写道尼文等人 2015 年的研究发表在 JAMA Internal Medicine 上,该研究表明,在一项研究表明严格控制血糖是一个好主意后,医疗实践如何增加,但在第二项更大规模的研究推翻了指导方针后,没有减少。卡罗尔的观点是,唯一比说服医生开始做某事更难的事情可能是说服他们停止。
但是让我们开始真正有趣的东西:情节!

原始图在左边,NYT/Upshot 版本在右边。按照典型的 NYT 风格,他们剥离情节,揭示一些更令人愉悦的东西。
他们坚持使用条形图——也许是为了尽可能忠实于原文——但我认为点数在这里最有效。这部分是个人偏好,部分是 Tufte 启发的关于数据-油墨比率的智慧。基本原理是这样的:所有的数据都存在于棒线的尖端,那么为什么不仅仅绘制尖端呢?

我使用ggplot2()包在 R 中创建了这个图。JAMA 的作者可能在某处共享了底层数据,但是我什么也没找到。所以我用 WebPlotDigitizer 从公布的图中提取近似值。如果你想修改的话,下面是代码。
通过患者相似性的拓扑数据分析识别二型糖尿病亚组
这篇原创的博客于 2015 年首次出现在 Ayasdi 网站上。
Ayasdi 的合作者昨天取得了另一项重大胜利,如 Fast Company 所述,西奈山的 Ichan 医学院在超负盛名的期刊Science:Translational Medicine上发表了论文,表彰他们利用拓扑数据分析识别先前未知的糖尿病亚型的工作。
这篇论文包含了突破性的研究,是对精准医疗超越癌症的验证。西奈山伊坎医学院的生物医学信息学主任 Joel Dudley 博士使用 Ayasdi Core 来确定新的患者亚组,这将最终实现对这种广泛传播、昂贵和毁灭性疾病的更精确的诊断和治疗。
对科学、医学和病人来说都是惊人的。在全球范围内,糖尿病是一种发病率很高的流行疾病,我们中的许多人都有家人受其影响。
医生知道,T2D 诊断患者有多种表现型,对糖尿病相关并发症具有易感性。
西奈山的伊坎医学院有一个大型数据库,将 30,000 多名患者的遗传、临床和医疗记录数据配对。西奈山的数据集不仅庞大,而且复杂,因为它包含许多不同的数据类型。除了基因组测序数据,它还包括每个患者的年龄、性别、身高、体重、种族、过敏、血液测试、诊断和家族史等信息。Joel 和他的团队使用精准医学方法,基于高维电子病历(EMRs)和来自 11,210 个个体的基因型数据(遗传标记和临床数据,如血液水平和症状),来表征 T2D 患者群体的复杂性。
使用拓扑数据分析,西奈山在患者-患者网络中发现了三个不同的 T2D 亚组。
- 亚型 1 以 T2D 并发症糖尿病肾病和糖尿病视网膜病变为特征;
- 亚型 2 富含癌症恶性肿瘤和心血管疾病;
- 亚型 3 与心血管疾病、神经系统疾病、过敏和 HIV 感染密切相关。

他们的网络登上了杂志的封面,并且可以在 STM 网站上找到。
因此,使用 Ayasdi Core,他们能够发现大型复杂数据集中的隐藏模式,使创新研究机构和制药公司(如 Mount Sinai)能够加快生物标志物发现、疾病类型细分和目标药物发现。
因为 Ayasdi 的方法不需要开发广泛的临床假设,并且可以根据数百种先进的数学算法自动绘制相关的患者亚组,所以 Dudley 博士的初步研究结果表明,二型糖尿病不是一种单一的疾病。
相反,它由几个小组组成,每个小组都有自己独特的复杂因素。
这一新的见解可能会为所有二型糖尿病患者带来更有效的治疗方案和更好的患者结果,并推进精准医疗的实践。
“通过使用 Ayasdi,我们看到目前二型糖尿病的临床定义太不精确,”Dudley 博士说。“我们的数据表明,根据患者人群的亚组,可能存在 3 型、4 型、5 型或更多型糖尿病,每个患者都可以从不同的治疗方法中受益。这些是令人兴奋的发现,有可能改变我们治疗这种主要疾病的方法。”
这是大医院的医生使用我们的软件改善患者护理并在顶级期刊上发表文章的第三个例子。
除了在糖尿病方面的工作,西奈山团队还利用 Ayasdi 研究了其他主要疾病。例如,在精神分裂症研究中,研究人员整合了从数百个病例中收集的 MRI 数据,并将其与分子途径数据配对。他们生成了大脑形状的数据模型,揭示了精神分裂症患者与对照组相比有显著差异的一小块区域。在未来,这一发现可能允许医生通过查明精神分裂症患者大脑中哪些分子路径被破坏来更有效地识别和治疗精神分裂症。
随着我们的合作者继续使用我们的软件改变世界,敬请关注下一季度的更多新闻。
要成为合作者,请发电子邮件给我们,姓名为collaborations@ayasdi.com。
识别 Quora 上的重复问题| ka ggle 上的前 12%!

如果你像我一样是一个普通的 Quoran 人,你很可能会无意中发现重复的问题,问同样的基本问题。
这对于作者和搜索者来说都是一个糟糕的用户体验,因为答案在同一问题的不同版本中变得支离破碎。其实这是一个在 StackOverflow 等其他社交问答平台上非常明显的问题。一个现实世界的问题,求人工智能解决:)

在过去的一个月左右的时间里,我和其他 3000 名卡格勒人一起,整夜都在为这个问题绞尽脑汁。这是我连续第二次参加严肃的比赛,有时会有压力,但总体来说我学到了很多——获得了前 12%的位置,一枚讨论金牌和几枚核心铜牌:)
一个 关于问题——Quora 已经给出了一个(几乎)真实世界的问题对数据集,每个问题对都带有 is_duplicate 的标签。目标是最小化测试数据集中重复预测的对数损失。训练集中大约有 40 万个问题对,而测试集中大约有 250 万个问题对。对,250 万!这些问题中的大部分是计算机生成的问题,以防止作弊,但有 250 万,天啊!我每隔一个小时就把我那可怜的 8GB 机器用到了极限

我的方法——我从@anokas 的 xgboost starter 开始,并逐渐在它的基础上构建。我的特征集包含了大约 70 个特征,与顶级 Kagglers 的方法相比,这是一个相当低的范围。我的特征可以大致分为基于 NLP 的特征、基于单词嵌入的距离和基于图形的特征。让我详细说明一下:

N 我尝试继续使用 tfidf 分数,但这既没什么用,又计算量大。相反,最重要的特征之一是加权单词匹配份额,其中每个单词的权重是该单词在语料库中的频率的倒数(基本上是 IDF)——如果我在两个问题中都有一个罕见的单词,他们可能会讨论类似的话题。我还有余弦距离、jaccard 距离、jarowinkler 距离、hamming 距离和 n-gram 匹配(shingling)等特性。
我在 NLP 任务中广泛使用的一个库是 Spacy,它最近开发了一些很棒的功能——Spacy 相似性也是一个很好的特性。我想到的一些有创意的问题与问题的类型有关——无论是“如何”的问题还是“为什么”的问题——取决于句子的第一个单词。奇怪的是,在建模的时候,我本应该想到建立“最后一个单词的相似度”,但是完全没有想到!命名实体是理解问题上下文的关键——因此 common_named_entity 得分和 common_noun_chunk 得分是显而易见的选择。我推出了一个关于通过 wordnet 语料库计算相似度的内核,但是 wordnet 在易用性、速度和词汇量方面都有所欠缺。
字嵌入基础距离 :
做 NLP 比赛的时候,Word2Vec 能不能留下!我觉得 word2vec 可能是我读过的最酷的计算机科学概念,我总是被它的有效性所震撼。每时每刻。

Word2Vec Magic!
总之,我将问题映射到 Sent2Vec 格式的 300 维向量中,结果每个问题都有一个向量。自然地,基于距离的矢量特征被建立起来——余弦、城市街区、jacard、堪培拉、欧几里得和布雷柯蒂斯。必须提到@abhishek 的脚本作为这些功能的灵感来源。不幸的是,我不能构建真正的嵌入层,我可以在 keras 中传递到 lstm 层——我的 RAM 不允许我这样做。我很快就会有真正的硬件了!
G 图形特征:在 NLP 比赛中,这些图形特征玩得相当扫兴!然而,这很好地提醒了我们,社交网络的理论可能如何应用于像 Quora 的问题对这样的数据集。

A typical graph structure in social media
这里,每个问题都是图中的一个节点,数据集中的一个问题对表示两个节点之间的一条边。我们也可以使用测试数据的图结构,因为我们没有在任何地方考虑 is_duplicate 标签——这 200 万条边对图贡献了很多!卡格勒夫妇就基于图表的功能是否应该是“神奇的功能”展开了激烈的讨论,这些功能应该被释放出来以创造公平的竞争环境。总之,所有这些特性都极大地提升了大多数模型:
- 一个节点的度:本质上,问题的频率,这个问题在数据集中出现多少次,就有多少条边。这个特性带来了巨大的收益,因为 Quora 所做的问题抽样(对重复项进行上抽样)很可能依赖于这个频率。
- 邻居交集:问题对的一级邻居的百分比,例如,Q1 的邻居是 Q2,Q3,Q4,Q2 的邻居是 Q1,Q3。(Q2 Q1)的共同邻居是 Q3,占所有一级邻居的一半。
- 分离度:这是我通过广度优先搜索想到并实现的一个特性,但并没有带来很大的改进。
- PageRank:我实现了这个功能,甚至在 kaggle 上发布了一个内核——page rank 较高的问题链接到重要的(page rank 较高的)问题,而垃圾问题链接到垃圾问题。
- kcore/kclique: K-core 基本上是最大的子图,其中每个节点都连接到至少“K”个节点,但没有给我太多的收获。我曾经想过 kclique,但是因为时间不够而没有实现:(结果证明这是一个相当重要的想法!
- 加权图:在比赛的后期,kagglers 的同事分享了一个加权图的想法,其中每个节点的权重是 weighted_word_share(我们之前讨论过)。这个加权图中的邻居交集是有用的。
传递性魔法——继续图结构,对问题之间的传递性建模是一种显而易见的方法。例如,如果 Q1 与 Q2 相似,Q2 与 Q3 相似,这意味着 Q1 与 Q3 更相似(根据我们的数据集)。这是我开始构建的功能之一,但中途放弃了,这是一个代价高昂的错误。许多顶级解决方案以某种形式使用了这一功能,一个更简单的版本是平均每个问题与其对应的邻居之间的重复概率。
我的白板会议

Part 1 of 2

Part 2 of 2
一些混蛋

当一个像我这样的菜鸟一头扎进一个大圈子时,肯定会有麻烦。尽管我有意识地努力保持管道的模块化和版本控制,但由于管道中的一个严重错误,我损失了几乎一个周末的工作。经过艰苦的学习,我在 ipython 笔记本上恢复并改造了管道。我在构建特性时面临的一个主要挑战是编写内存高效的代码,而不是重新构建以前的特性,模块化是关键。这导致了另一个混乱——因为我无法在我的 RAM 中处理我的整个测试数据集,我将它分成六个子集,并迭代地构建特性。这意味着我在旧的数据框架和新的特性之间做一个 pandas concat,我很少关注索引:(花了几天时间对所有 NaN 特性挠头。没有错。
QID 难题:
训练数据集的每个问题都有一个 ID,因此每行都有一个 QID1 和 QID2。然而,测试数据集的情况并非如此,这意味着“QID”不能直接用作一个功能。一位 kaggler 的同事发布了一个令人难以置信的创造性的观察,随着 QID 的增加,平均重复率(滚动平均值)下降——很可能是 Quora 随着时间的推移改进算法的迹象,从而随着 ID 的增加减少重复问题的数量。这一推断基于这样的假设,即 QID 值没有被屏蔽,并且真正代表了发布问题的时间。为了在我们的测试数据集中对 qid 建模,我有一个将问题文本映射到 qid 的哈希表。现在迭代 test_df 中的所有问题——如果我遇到一个存在的问题,相应的 QID 被分配给它。否则,我们假设这是一个新问题,按照发布的时间顺序,将 QID 加 1。这导致了各种各样的特征,如 QID 差异、平均 QID、最小 QID,以期模拟随着时间的推移重复率的下降。
阶层失衡:
讨论的主要部分集中在猜测测试数据框架中的类别划分,这与测试划分并不明显相似。数学专家通过几个恒定值的提交,这里的和这里的,计算出一个狭窄的分割范围。训练集中大约有 34%的正重复,而测试集中估计有 16%-17%的正重复——这可能是改进的 Quora 算法的结果,或者是计算机生成的问题对的结果。无论如何,一个错误的训练数据集不会有所帮助——人们想出了过采样的解决方案(复制训练中的负行),或者通过适当的因子重新调整他们的预测。
我的模特——XGBoost 是爱情,XG boost 是生活

承认这一点非常尴尬,但我提交的只是一个单一模型解决方案,一个 2000 轮的 xgboost。公平地说,我没有在参数调整或构建多样化模型上花太多时间,因为太晚了。我尝试了默认的随机森林和 GBM,效果并不比 XGB 好。堆叠和集成也在路线图中,但只是停留在那里:(
相反,我花了一个很长的周末来学习 Keras 和建立密集的神经网络——这是我的第一次!通过了解各种超参数和理想的架构,激活函数,辍学层和优化背后的理论!非常有趣的东西!我用我的两层 sigmoid 神经网络和我的 70 个特性来完善它,但它从未接近 xgboost。正如我前面提到的,我无法用我的硬件构建嵌入层或 LSTMs,那肯定会有帮助。很快。
我为自己的建模管道感到自豪,不必为每个模型都创建一个函数而烦恼——当我构建数百个模型进行堆叠时,这会很有帮助。很快。
顶级解决方案:
金牌得主的赛后评论让我觉得自己完全是个菜鸟!我必须真正提高我的比赛水平,更加努力地去达到那个高度,铜牌离我不远了!从赢家解决方案中获得的一些主要经验:
- 大多数团队根据加权图的边或节点的频率来重新调整他们的最终预测
- 每个顶级团队都建造了一个有数百个模型的堆垛机,并有一个可重复使用的模型构建管道。
- 使用了最先进的神经网络架构(Siamese/Attention NNs)、LightGBMs,但甚至像 ExtraTrees 或 Random Forests 这样的低性能模型也有帮助!
- 图形特性是许多解决方案的核心,因为团队使用各种技术从中获取价值。一些去除了虚假的(不太频繁的)节点,一些使用邻居权重的平均值/中值,而大多数模拟了传递性。
- 显然,问题 1 或问题 2 也很重要。令人惊讶!
- NLP:以多种不同的方式处理文本——小写和不变,以不同的方式替换标点,包含和排除停用词,词干化和不词干化,等等。
- 堆叠很重要,但人们也用单个 xgb 型号实现了 0.14 倍。
- 第一名后。真令人羞愧。
结论:
我应该更好地管理我的时间,为探索、特征工程、模型构建和堆叠分配适当的时间。上周我确实感到了压力,因为我提交的材料不够了。
- 我的建模管道很适合测试,但是我需要在不同的超参数/数据子集上建立更多的模型。
- 不要中途放弃构建特性,有些特性会导致代价高昂的失误。
- 不要仅仅因为你花了时间在一个功能上,就过于沉迷于它。这有点好笑,哈哈!
- 花大量时间在 Kaggle 内核和讨论上。他们太酷了:)
所以是的,就是这样。一场比赛结束,另一场比赛开始。Kaggle 会上瘾!

It’s true!
这篇文章最初发表在我的 博客 上。每周一篇博客
在背景噪音中识别希格斯玻色子

Large Hadron Collider
背景
在这篇简短的博客中,解释什么是希格斯玻色子是非常困难的。然而,为了保持它的基本性,根据一个大爆炸理论,在一个叫做玻色子的导火索导致它爆炸之前,整个宇宙曾经是一个单一的粒子。希格斯玻色子是以物理学家彼得·希格斯的名字命名的,他在 1964 年和其他六位科学家一起提出了这种机制,这表明了这种粒子的存在。这种亚原子粒子是在大型强子对撞机的一次实验中产生的。彼得·希格斯将因此发现获得 2013 年的诺贝尔奖。
历史说够了。现在进行一些有趣的机器学习!这是一个分类问题,以区分产生希格斯玻色子的信号过程和不产生希格斯玻色子的背景过程。
资料组
网址:http://archive.ics.uci.edu/ml/datasets/HIGGS#
这些数据是使用蒙特卡罗模拟产生的。前 21 个特征(第 2-22 列)是由加速器中的粒子探测器测量的运动特性。后 7 个特征是前 21 个特征的函数;这些是由物理学家得出的高级特征,有助于区分这两个类别。人们有兴趣使用深度学习方法来消除物理学家手动开发这些特征的需要。基准测试结果使用贝叶斯决策树从一个标准的物理包和 5 层神经网络提出了在原来的文件。最后 500,000 个示例用作测试集。
导入库
希格斯数据集是巨大的!因此,我们需要使用 Spark 来运行它。对于本文,我使用 Python 包装器 for Spark,或 PySpark。
**from** **time** **import** time
**from** **string** **import** split,strip
**from** **plot_utils** **import** ***from** **pyspark.mllib.linalg** **import** Vectors
**from** **pyspark.mllib.regression** **import** LabeledPoint
**from** **pyspark.mllib.tree** **import** GradientBoostedTrees
**from pyspark.mllib.tree** **import** GradientBoostedTreesModel
**from** **pyspark.mllib.tree** **import** RandomForest, RandomForestModel
**from** **pyspark.mllib.util** **import** MLUtils
准备数据
接下来,我们对数据集中感兴趣的要素列表进行硬编码
feature_text='lepton pT, lepton eta, lepton phi, missing energy magnitude, missing energy phi, jet 1 pt, jet 1 eta, jet 1 phi, jet 1 b-tag, jet 2 pt, jet 2 eta, jet 2 phi, jet 2 b-tag, jet 3 pt, jet 3 eta, jet 3 phi, jet 3 b-tag, jet 4 pt, jet 4 eta, jet 4 phi, jet 4 b-tag, m_jj, m_jjj, m_lv, m_jlv, m_bb, m_wbb, m_wwbb'features=[strip(a) **for** a **in** split(feature_text,',')]
接下来,我们把数据转换成火花 RDD
inputRDD=sc.textFile(path_to_data) #Replace with actual pathinputRDD.first()

如果每行都是一个字符串,那么数据就没有用。因此,为了使用 PySpark 的机器学习库,我们需要用逗号将它分开,并将每个单元格分配给一个 LabeledPoint。第一列是目标,因此需要从模型特征中分离出来。
Data=(inputRDD.map(**lambda** line: [float(strip(x)) **for** x **in** line.split(',')]).map(**lambda** line: LabeledPoint(line[0], line[1:])))Data.first()

为了更清楚地看到过度拟合的影响,我们将数据的大小减少了 100 倍。然后,我们将 70%–30%分成培训和测试。
Data1=Data.sample(False,0.01).cache()(trainingData,testData)=Data1.randomSplit([0.7,0.3])
**print (**'Sizes: Data1=**%d**, trainingData=**%d**, testData=**%d**'%(Data1.count(),trainingData.cache().count(),testData.cache().count()))

梯度增强树
第一个分类器将使用梯度增强树来构建。
errors={} **for** depth **in** [1,3,6,10]:
start=time()
model=GradientBoostedTrees.trainClassifier(Data1,
categoricalFeaturesInfo={}, numIterations=3)
errors[depth]={}
dataSets={'train':trainingData,'test':testData}
**for** name **in** dataSets.keys():
*# Calculate errors on train and test sets*
data=dataSets[name]
Predicted=model.predict(data.map(**lambda** x: x.features))
LabelsAndPredictions=(data.map(**lambda** lp:
lp.label).zip(Predicted))
Err=(LabelsAndPredictions.filter(**lambda** (v,p):v !=
p).count()/float(data.count()))
errors[depth][name]=Err
**print** depth,errors[depth],int(time()-start),'seconds'
**print** errors

B10=errors
make_figure([B10],['10Trees'],Title='Boosting using 10**% o**f data')

随机森林
接下来,我们尝试随机森林分类器进行比较。
errors={}
**for** depth **in** [1,3,6,10,15,20]:
start=time()
model = RandomForest.trainClassifier(Data1, numClasses=2,
categoricalFeaturesInfo={}, numTrees=3,
featureSubsetStrategy="auto", impurity='gini',
maxDepth=4, maxBins=32)
errors[depth]={}
dataSets={'train':trainingData,'test':testData}
**for** name **in** dataSets.keys():
*# Calculate errors on train and test sets*
data=dataSets[name]
Predicted=model.predict(data.map(**lambda** x: x.features))
LabelsAndPredictions=(data.map(**lambda** lp:
lp.label).zip(Predicted))
Err=(LabelsAndPredictions.filter(**lambda** (v,p):v !=
p).count()/float(data.count()))
errors[depth][name]=Err
**print** depth,errors[depth],int(time()-start),'seconds'
**print** errors

RF_10trees = errors
*# Plot Train/test accuracy vs Depth of trees graph*
make_figure([RF_10trees],['10Trees'],Title='Random Forests using 10**% o**f data')

一起想象
make_figure([B10,RF_10trees],['B10','RF_10Trees'],Title='Random Forests using 10**% o**f data')

利用深度学习识别交通标志
交通标志的成功检测和分类是自动驾驶汽车需要解决的重要问题之一。想法是让汽车足够智能,以达到成功自动化最少人类互动。在图像识别、自然语言处理、自动驾驶汽车等相关领域,深度学习相对于经典机器学习方法的优势迅速上升,并辅之以 GPU(图形处理单元)的进步,这令人震惊。
深度学习

Attendance at the Annual Conference on Neural Information Processing Systems (NIPS)
图表只显示了 2015 年和 2016 年 NIPS 有超过 6000 人参加。图表显示对深度学习和相关技术的兴趣激增。
深度学习是一种机器学习技术,其中人工神经网络使用多个隐藏层。这要归功于两位著名的神经生理学家大卫·胡贝尔和托尔斯滕·威塞尔,他们展示了视觉皮层中的神经元是如何工作的。他们的工作确定了具有相似功能的神经元如何组织成列,这些列是微小的计算机器,将信息传递到大脑的更高区域,在那里视觉图像逐渐形成。
通俗地说大脑结合低级特征,如基本形状、曲线,并从中构建更复杂的形状。深度卷积神经网络也类似。它首先识别低级特征,然后学习识别和组合这些特征,以学习更复杂的模式。这些不同级别的功能来自网络的不同层。

Feature Visualization of Convnet trained on ImageNet from [Zeiler & Fergus 2013]
我们不会进一步深入深度学习和反向传播如何工作的数学解释。跟随 cs231n 和本博客深入了解。让我们看看简单的深度卷积神经网络如何在交通标志数据集上执行。

Traffic Sign Images and Classification Probabilities
模型架构和超级参数
Tensorflow 用于实现交通标志分类的深度 conv 网。RELU 用于激活以引入非线性,不同百分比的退出用于避免不同阶段的过拟合。很难相信简单的深度网络能够在训练数据上达到高精度。以下是用于交通标志分类的架构。这里是链接到我的源代码。架构灵感来自 LeNet ,也被视为深度学习中的“Hello World”。

在探索了 LeNet 之后,我决定从简单的架构开始。想法是从简单开始,如果需要,增加更多的复杂性。架构与上面张贴的图表相同。将图像转换为灰度确实有助于获得更好的准确性。使用 【亚当】 优化器为 256 批量 训练模型 40 个历元 ,学习率最初设置为 0.0001,后来进一步增加到 0.001 以收敛到目标精度。我发现这个博客真的很有助于理解不同的梯度下降优化算法。这是我在 tensorflow 上面的第一个模型。下面是这个模型的一个小片段。
**def** deepnn_model(x,train=**True**):
*# Arguments used for tf.truncated_normal, randomly defines variables for the weights and biases for each layer*
x = tf.nn.conv2d(x, layer1_weight, strides=[1, 1, 1, 1], padding='VALID')
x = tf.nn.bias_add(x, layer1_bias)
x = tf.nn.relu(x)
x = tf.nn.max_pool(x,ksize=[1, 2, 2, 1],strides=[1, 2, 2, 1],padding='SAME')
**if**(train):
x = tf.nn.dropout(x, dropout1)
x = tf.nn.conv2d(x, layer2_weight, strides=[1, 1, 1, 1], padding='VALID')
x = tf.nn.bias_add(x, layer2_bias)
x = tf.nn.relu(x)
conv2 = tf.nn.max_pool(x,ksize=[1, 2, 2, 1],strides=[1, 2, 2, 1],padding='SAME')
**if**(train):
conv2 = tf.nn.dropout(conv2, dropout2)
fc0 = flatten(conv2)
fc1 = tf.add(tf.matmul(fc0, flat_weight),bias_flat)
fc1 = tf.nn.relu(fc1)
**if**(train):
fc1 = tf.nn.dropout(fc1, dropout3)
fc1 = tf.add(tf.matmul(fc1, flat_weight2),bias_flat2)
fc1 = tf.nn.relu(fc1)
**if**(train):
fc1 = tf.nn.dropout(fc1, dropout4)
fc1 = tf.add(tf.matmul(fc1, flat_weight3),bias_flat3)
logits = tf.nn.relu(fc1)
**return** logits
结果
我的目标是从简单的架构开始,达到 90%的准确性,我惊讶地发现在第一次运行中,它接近 94%的准确性。进一步向模型中添加更多的层和复杂性,并辅以数据扩充,可以实现高达 98%的准确性。
讨论
深度学习真的令人印象深刻,它带来的结果看起来很有前途。从图像识别到自然语言处理,可能性是无穷无尽的。在了解了反向传播和卷积神经网络等相关概念后,我个人很难相信它完全是这篇文章中提到的黑箱。请随时提问,评论和建议。迫不及待地想在这个领域探索更多。
参考
Udacity 自动驾驶汽车工程师纳米学位。
G ithub 回购源代码。
CS231n 课程和 Andrej Karpathy 关于卷积神经网络的视频讲座。
交通标志 d 数据来源
这首诗是什么时候写的?我的电脑可以告诉你

用数据科学来理解诗歌中的动作
我最近的项目真的很令人兴奋。我热爱诗歌已经有一段时间了,所以我选择它作为我第一次涉足自然语言处理(NLP)的主要领域。
数据科学最酷的事情之一是它的普遍性和多功能性。你可以“数据科学”几乎任何东西。所以我用这个项目来拓展我的数据科学经验,并用一种非常酷的方式来阐述这个想法。

To be or not to be?
你也许能分辨出莎士比亚的诗和艾米莉·狄金森的作品。莎士比亚死于 1616 年,狄金森死于 1886 年,在这 270 年里,英语的使用方式发生了相当大的变化。但是狄金森和罗伯特·弗罗斯特之间的区别呢?罗伯特·弗罗斯特一直活到 1963 年。他们两人都用今天仍可理解的语言写作,没有“thous”和“thys”。在他们所处的时代,英语发生了多大的变化?毕竟,1886 年并不算太久。那是可口可乐被发明的那一年。
但也许你是诗歌专家。也许你对弗罗斯特的风格超级熟悉。如果是这样的话,你也许能分辨出其中的区别,但这远不像对莎士比亚那样容易。但是你,专家先生,如果我给你 1500 首诗,然后问你哪些是 18、19 和 20 世纪的呢?你现在有多自信?
对我们大多数人来说,这是相当困难的。风格和用词的差异并不明显。
这个项目旨在发现这些差异是否实际上是可以区分的。机器学习模型可以学习几个世纪之间的风格和单词选择的差异吗?如果有,准确度如何?剧透警告:可以。也很好。
获取数据:
我的第一个挑战是获得足够大的诗歌语料库来训练模型。起初,我期望这在互联网的某个地方很容易得到。我是说,互联网什么都有,对吧?不对。如果有,我没找到。
下一个可能性是网络抓取。有很多网站上有大量的诗歌。问题是他们中的一些人喝太多了。我指的是用户提交的内容。让任何一个汤姆、迪克或哈利出版他们杰作的网站。伟大的家伙,汤姆,迪克和哈利。但是为了这个项目,我没有要他们的大作。
经过一番搜索,我找到了一个合适的网站,但不幸的是,这个网站做得不是很好。一个完全不合逻辑的 URL 方案和一个过时的 HTML 结构使它成为一个挑战。但是我刮了。我想出了大约 30,000 首诗,并对其进行删减以创建我的最终数据集。
数据清理:
下一步是清洗和预处理。有几个步骤。
由于数据来自一个网站,我必须在不丢失任何内容的情况下删除所有的 HTML 标签。我还去掉了所有的标点符号和数字,把所有的字母都改成了小写。这很重要,因为计算机将大写和小写字母视为不同的字母,即使它们代表相同的字符。
在这个过程的最后,我留下了大约 4000 首诗,每一首都只是一滴原始文本,没有标点符号或大写字母。看起来像这样:

If you can figure out what ‘bughts’ are, you get ten points.
建模:
下一步是建模。我决定使用计数矢量器来分析这些诗歌。计数矢量器是 NLP 任务中常用的一种相对简单的方法。它基本上从整个语料库中的每个单词创建一个特征,然后为每首诗中的每个特征分配一个频率计数。它通常被称为“单词包”,因为它只是简单地统计每个单词在每次观察中的出现次数。还有更复杂的文本分析方法,但我选择这种方法主要是因为它简单。大多数自然语言处理任务集中在分析文本的内容,但是在这个任务中,我关注的是 T2 风格。
关于这一点,我在这个项目中做了另一个有趣的决定。NLP 项目中的一个标准步骤是去除“停用词”。停用词是像“the”这样的词,它们在所有文本中如此普遍,以至于不能提供任何见解。如果你看词频的话,几乎总是最常见的一个,但它并不能真正告诉我们什么。这个项目是不同的。因为我寻找的是风格,而不是内容,所以我可以从“the”中学到很多。也许 20 世纪的诗人比 18 世纪的诗人更经常使用特定的连词。所以我决定留下停用词。这被证明是一个好的决定,因为去掉它们会损害模型的性能。
预处理之后是模型构建阶段。scikit-learn 和 nltk 中有许多现成的建模技术,适用于文本分类项目。在尝试了许多方法并试验了它们的不同参数后,我选定了一个多项式朴素贝叶斯分类器。
朴素贝叶斯模型之所以被称为朴素贝叶斯模型,是因为它们假设所有特征都是独立的,即使这并不完全正确。通过这样做,他们可以查看每个特征属于每个类的概率。然后,他们将每个观察值分配给其组合特征具有最高概率的类。尽管有天真的假设,但它们通常在文本数据上表现得非常好。
朴素贝叶斯模型获得了 82%的总准确率。不同班级的分数有一个有趣的分类。下面是一个混乱矩阵,显示了正确和错误分类的诗歌。

It’s appropriately called a confusion matrix because it can be confusing. A more detailed description below.
看这个矩阵,看起来 18 世纪和其他阶级最有区别。该模型正确预测了 91%的 18 世纪诗歌。有趣的是,虽然它确实将一些 18 世纪的诗歌误归类为 19 世纪和 20 世纪,但它没有将任何 20 世纪的诗歌误归类为属于 18 世纪。
这个模型在 19 世纪和 20 世纪遇到了更多的麻烦。你可以看到它只正确识别了 72%的 19 世纪诗歌,和 81%的 20 世纪诗歌。夹在另外两个阶级中间的 19 世纪,给这一模式造成了最大的混乱。时间上更远的几个世纪比中间的几个世纪更容易区分,这肯定是有道理的。
下面是一些最有可能属于每个世纪的特征。许多单词可能会出现在不止一个类中,这似乎有悖常理。但它确实有意义,因为为了识别类别,模型结合了这首诗中所有单词的概率。但是每个单词对于每个类别都有一个可能性。通过观察某些单词在不同类别中的概率差异,你仍然可以获得一些有趣的见解。当停用词被实际取出时,下面的单词属于每一类的概率最高。即使我把它们留在我的最具预测性的模型中,我还是把它们拿出来放在一个模型中,以便对特定的单词有所了解。看一看:

Looks like God went out of style!
如果你注意到其他有趣的东西,请在下面留言。
后续步骤:
这个项目让我着迷,我会继续探索和发展它。
下一步是动态主题建模,这是一种提取数据中正在谈论的主题,并观察它们如何随时间变化的方法。请继续关注这方面的新闻。
在那之后,我计划收集更多的数据,创建额外的功能,并在分类上做出一些深思熟虑的决定。
Jupyter 笔记本和原始诗歌数据可以在我的 Github 这里找到。如果你对这些数据有任何创造性的使用,我很乐意听到并贡献出来。
有问题吗?评论?喜欢吗?讨厌?在下面留言。
意识形态 Vs 现实?特朗普总统会见约旦国王后的讲话
本周中期,特朗普总统在白宫会见约旦国王的消息铺天盖地。这通常表明,正如媒体广泛指出的那样,在处理中东问题时,国家之间的联盟越来越重要。
这篇文章的目的是分享一种更深层次的政治洞察力,这种洞察力可以通过应用于政治演讲文稿的认知分析技术获得。总统讲话的会议记录可以在白宫发布的公共领域找到。
该分析和方法基于我在认知和社会心理学领域的研究,包括从公开可用的数据中研究数百种认知取向,以及我在非结构化政治数据上应用高级分析工具和技术的经验。
认知文本分析
在对总统讲话的分析中,有三个重要的基于心理取向的洞察力维度,它们可能会阐明这种会议的重要性,如下所示。,
- **政治信任:**观察到一种积极的倾向,表明通过伙伴关系和合作与约旦建立了更密切的关系。
- **对外关系:态度上取向是有可能定位在左边(左翼政治支持社会平衡方面和 平均主义 )。此外,在从属关系的驱动下,对外关系的倾向于和平(而非战争)。我们在合作中的角色可能是调停者/整合者,而不是影响者或积极独立的角色扮演者(基于参考文献。数据来自赫尔曼 1987 年 b)
3.订婚的方法?(对外交易):这种定位是关于一个人如何在外部世界交易/参与,并表明特朗普可能会谨慎(相对于雄心勃勃)*,但在处理合作目标中的实际问题时,他的方法是自信和正式的。*
动机分析(回答为什么?)
人类的动机表现为寻求改变的愿望或挫折,关注自我、物质或社会/人际世界。在我对总统讲话的分析中发现的主要动机如下。
- 成就 (76%) —这种动机情绪有寻求结果的愿望(获得胜利),关注物质或任务导向的世界(而不是关注自我或社会世界)
- 精通(70%)——这是另一个动机,人们渴望或寻求的变化变得不同寻常(以精通),以便川普能够更好地同化和处理中东局势(通过约旦合作)。掌握动机关注自我(与物质或社会世界相对的内在自我)
- 归属感(68%)——这种动机表示与对未来的期望相关的愿望,关注社会或人际关系世界。这就像是在说,在实现目标的过程中,我们将是值得信赖和可靠的(真诚的)伙伴。这也暗示了约旦对美国的支持。
- 养成 (52%) —有与体验关怀和支持相关的愿望。(养育和被养育的概念)。这个动机的重点在社交/人际世界。我相信在给定的环境下,这更多的是关于培养约旦和约旦在中东目标上对美国的回报。这一动机也表明了美国邀请约旦国王访问白宫的重要性。
来自文本分析的线索
- 上下文发现
为了从总统的会议讲话中分析上下文,我把讲话记录分成三个部分,即。a)基于过去 b)现在和 c)将来时态。因为我很想知道这次会议可能会产生什么,所以我把分析的重点放在了文本中与未来相关的线索上,我的发现列举如下。
摘录 演讲正文 传达将来时方面
**一个非常特别的地方,我可以告诉你。我已经很了解它了。就此而言,美国与我们在全球的盟友一起谴责这一恐怖袭击和所有其他恐怖袭击。
*陛下,约旦人素以热情好客著称,我们将尽最大努力成为同样热情的东道主。
*然而,我不得不说,他们也因他们的战斗能力而闻名。*通过所有这些,美国将约旦视为一个宝贵的伙伴,一个文明价值观的倡导者,以及稳定和希望的源泉。
*我坚定地致力于维护我们牢固的关系——我会的——并加强美国对约旦的长期支持。
通过这一切,美国将约旦视为一个重要的合作伙伴,一个文明价值观的倡导者,以及稳定和希望的源泉。我坚定地致力于维护我们牢固的关系——我将这样做——并加强美国对约旦的长期支持。我可以告诉你,在我们国家,你确实拥有巨大的支持。约旦军人在这场与文明敌人的战斗中做出了巨大牺牲,我要感谢他们所有人,感谢他们令人难以置信的勇气。国王是呼吁一劳永逸地击败 ISIS 的领导者。
上下文发现—动作词(将来时文本)
上面引用的文本中的单词及其含义暗示了一种谨慎、合作和防御的姿态,而不是任何进攻的姿态。积极词汇与消极词汇的比率表明了一种预期的/积极的合作。

上下文发现—唯一&重要术语 术语—词语和短语
这些是从上述文本中提取的重要关键词。如果你看到,无论是意义,然后积极的比率与消极的话是倾向于积极的方面有关方面的合作和联盟与约旦。文本“约旦服务成员”是一个有趣和独特的观察,因为合作可能与军事方面有关。(编辑注:我认为 AMN 在这篇文章发表两天后发布的这条 特别新闻与这意味着什么有关,并暗示了新兴合作的性质)

Unique & Important terms from the speech (with future orientation)
2。语言风格&语气分析(将来时文本)
a.人们发现这种语言风格反映了自信和希望。
b .情绪基调表明存在喜悦(在 0-100%的范围内为 56 ),表示没有任何重大负面情绪的伙伴关系方面。
在上下文中,术语“恐怖袭击”与恐惧情绪有关,而恐惧情绪与战斗或逃跑反应有关。因此,很明显,在恶劣天气下,任何应对措施都可能以战斗(军国主义)姿态出现。(打架)。“谴责”这个词与愤怒的情绪有关。(对情况做出反应)。根据 CMU 的一项研究,尤其是愤怒的情绪可能会让人愿意冒更大的风险。
总结
总体分析主要指向“关系”因素,这意味着美国与约旦的政治伙伴关系的持续和日益增长的重要性。这种关系如何体现和出现将是一件有趣的事情,这取决于中东正在发生的变化。
虽然这种分析具有预测性,但考虑到问题的复杂性、人类思维和文本数据的较小/有限大小,最好将分析结果视为可能有助于准备工作的线索,而不是真正预测确定性的东西。
免责声明:
这里提到的观点是我自己的。
本文使用的数据来自公共领域的可用信息。但对其准确性、完整性、及时性或正确性不做任何明示或暗示的陈述或保证。我不对任何错误或不准确负责,不管是什么原因造成的。(读者)。
如果数据是新的黑金,那么医疗数据就是新的黄金!

Paper based Medical Records
作为一名热情的计算科学家和未来学家,我监视、跟踪和预测即将到来的、正在快速融合的重大趋势。根据学术界和工业界专家的说法,我们已经进入了大数据时代,并正在向人工智能(AI)时代过渡,人工智能有可能改变所有主要的行业和部门。这尤其与搜索引擎(谷歌)、电子商务(亚马逊、Flipkart)、社交网络(脸书、LinkedIn)等领域相关。
我们在brain pan Innovations,正在大力分析发展中国家的医疗保健领域。我们倾向于顺应潮流,认为我们正处于一个*‘少数据、旧数据、无数据’*的时代,因为作为一个社会,我们仍然停留在一项 5000 年的技术上,那就是纸。
令我们困惑的是,大多数印度医生都在“新金矿”的顶端,但并不完全了解他们所拥有的资产的潜力和价值。根据我们在二线城市(HRA 分类中的 Y 级)的调查,私人诊所每天的患者数量从 10 到 25 不等,医院从 50 到 200 不等,每年产生几千个医疗数据记录。但是,这些数据存在于纸质处方和医疗报告中,而不是电子形式,即 EHR。
在我国,电子医疗数据的价值被惊人地低估和利用不足。从作为药物开发项目的催化剂到定制的私人护理,它们的效用是无穷的。例如,理解 EHR 系统的数千个数据点中保存的医疗数据的结构可以快速找到相关的模式,从而帮助我们揭示定义治疗方案的最有利方式,同时确定哪些药物、测试和其他程序有助于获得最佳结果。以下是一些支持事实,供参考。
在 2011 年,赛诺菲安万特成功地证明了 EHR 使许多二型糖尿病和心脏病患者得到了改善。这是一个为期 12 个月的项目,在两个试点跟踪 119 名患者,为期 6 个月。
2016 年,辉瑞使用匿名的 EHR 数据开发了 Xalkori 作为第一种专门针对 ALK 基因突变的肺癌患者的美国 FDA 药物。
为了能够改变人们的生活,解决未满足的患者需求,医疗保健公司需要访问健康数据,以便实施机器学习算法等人工智能技术来改善他们的医疗诊断。
在人口超过 12.5 亿的印度,非传染性疾病呈上升趋势,心血管疾病(24%)、慢性呼吸道疾病(11%)、癌症(6%)和糖尿病(2%)是导致死亡的主要原因。
问我们所有人一个问题——为什么印度的医生不利用这个巨大的数据库来加速人工智能、机器学习或更准确地说是计算机辅助诊断(CAD)?如果有一种算法可以分析胸部 CT,检测肺部的肺气肿区域,或者在有肺动脉高压迹象时发出警报,岂不是更好?从妇科角度来看,在心脏病、中风的急性病例中的其他可能用途,或量化高危妊娠、纤维瘤将是突破性的。
我们的初创公司brain pan Innovations(隐形模式)正在不断开发和改进数据驱动预防性 EHR 平台’医生日记,该平台旨在通过弥合生命科学和计算之间的差距来应对所有这些科学挑战。
如果机器学习不能帮你省钱,那你就做错了
注来自《走向数据科学》的编辑: 虽然我们允许独立作者根据我们的 规则和指导方针 发表文章,但我们不认可每个作者的贡献。你不应该在没有寻求专业建议的情况下依赖一个作者的作品。详见我们的 读者术语 。
我们都同意,机器学习是新的热点。或许你读过的每一个标题都很吸引人的故事,比如“ 7 种将主导 2018 年的技术趋势”,都会以这样或那样的方式提到机器学习或人工智能。
事实是,机器学习是伟大的,但如果你没有以正确的方式进行,它真的很容易很快被剥夺。我从亲身经历中了解到这一点。

Photo by NeONBRAND on Unsplash
以一个问题开始
首先,也可能是最重要的,机器学习仍然只是触及了可能的表面。令人沮丧的是,你绝对不会听到有人试图向你出售机器学习能力或服务。即使是你雇佣的热门数据科学家和 ML 工程师(可以理解)可能也不会立即鹦鹉学舌当前技术水平的局限性。
我无法告诉你我从大大小小的企业那里听到了多少根本不可能的使用案例和请求。我可能听到过同样多的请求,这些请求实际上并不需要机器学习来完成。
把机器学习扔给任何老问题都不会奏效。你最终会浪费很多时间和金钱。
相反,仔细考虑你试图解决的问题。你能把问题变得越简单,机器学习就越有可能奏效。不要想象你认为只有计算机会擅长的问题。先看看手动解决这个问题需要多少努力,然后评估计算机系统是否可以独立完成这项任务。
训练就是一切
从零开始学习机器仍然非常非常困难。我认为最难的部分是训练。当我试图训练一个机器学习模型来检测电影和视频中的吸烟时,我学到了这一点。我最初认为,我只需要向它展示数百张香烟的图片,然后它就会知道香烟的样子。
失败了。
然后我发现我需要给它两个标签;吸烟和不吸烟。所以我找了一堆随机的不是香烟的东西的图片,然后把它们放了进去。
那也失败了。
然后我尝试了一种不同的方法。我决定从人们吸烟的电影中截取定格画面。因为这是模型运行的环境,我想我有更好的机会让它工作。为了我的不吸烟标签,我使用了不同电影中对话场景的定格画面。

差点就成功了。问题是,事实证明,我所做的是训练模型检测我用来训练的电影。所以它本质上是一个是不是这 5 部电影中的一部模型。
One of my favorite scenes from Silicon Valley
我在这上面花的时间和精力都白费了。我也从其他顾客那里听到过类似的趣闻。他们雇佣了 ML 工程师和专家来建造定制模型,这花了一年的时间,结果却是一些不太好的东西。
这个问题的解决方案与上面的部分相同。首先考虑问题,并确保一个好的训练集是你可以得到的。
我最终使用机器盒中的标签盒解决了这个问题,但我仍然必须考虑我的训练数据,并决定边缘情况发生的可能性有多大。
不要花的钱比你存的多
这似乎是显而易见的,但值得重复。谷歌、微软、IBM 等公司有一些非常棒的机器学习 API。但在实践中,这些工具的成本会迅速增加。我曾见过有人仅仅为了一个月的开发工作就得到 45,000 美元的账单。我采访过的一家主要广播公司告诉我,通过这些云 API 运行他的所有内容比付钱给高中生手动标记所有内容要昂贵得多。
这是一个巨大的投资回报率问题。(这也是我加入机器盒子的原因,因为我们解决了这个问题,不管使用与否,所有东西都要支付统一的订阅费)。在 GPU 和其他地方训练机器学习模型的成本已经下降,但仍然需要一些成本。在许多情况下,有些东西可能比它的价值更高。
你从特定的机器学习模型中提取的价值将取决于你的用例。确保它经过深思熟虑和验证。
不要期待奇迹
Alexa 有没有理解过你说的话?真的很让人沮丧吗?我仍然看到这些语音助手有很多准确性问题。语音识别非常非常难实现。在机器学习中,当我们谈到一个特定的模型时,我们经常会引用一个百分比的准确率。如果准确率在 80%以上,我们会觉得我们得到了有用的东西。开车到 90%以上通常只是稍微调整一下。但我们真正做的是讨论我们的模型如何从我们搁置的训练数据子集预测一些东西,我们称之为验证集。当您的模型与不在训练集中的东西运行时,可能会出现问题。在很多情况下,不可能考虑到所有可能的边缘情况。当 Alexa 被激活时,它处于数百万种不同的听觉情况中。背景噪音、口音、回声和许多其他东西会干扰语音识别系统。

A lot of false positives from an implementation of OpenCV face recognition: https://goo.gl/m9jpwR
当机器学习模型错过一些东西时,很容易认为这是一个错误,或者可能是模型中的缺陷。非常重要的是,你要明白事实并非如此。误报和漏报是机器学习的一部分。它有时也会犯错,就像我们一样。每个企业都必须为机器学习中偶尔出现的误报和漏报做好准备。这就是生活的现实。作为企业执行任务的人类总是会犯错误。
我们在机器盒子帮助缓解这些问题的方法之一是让我们的盒子可教。也就是说,您可以简单地对模型进行修改或添加,而不需要进行任何类型的再培训。就像人类一样,机器学习模型需要随着时间的推移不断改进,以考虑所有可能的边缘情况。
但是你的业务和对机器学习的理解需要考虑偶尔的误报和漏报。仅仅因为你的系统漏掉了一些文本中的关键词,或者图片中的一张脸,并不意味着整个系统应该崩溃。如果你曾经在电视上看过隐藏式字幕,你就会知道人类总是会犯错。是否意味着隐藏式字幕没有用?当然不是。它仍然提供重要的服务。你的机器学习实现也应该如此。
我该不该用?
尽管如此,我想重申,机器学习是一种奇妙、强大的计算类型,可以给大大小小的企业带来很多价值。我已经看到了很多非常好的机器学习用例,用机器盒和其他工具廉价而有效地解决了这些问题。从提高安全性和合规性到改进搜索和发现,无所不包。使用得当,它可以节省人们大量的时间。它还可以帮助创造新的收入来源,识别威胁,找到丢失的数据,等等。
所有这些成功的实现都是如此,因为它们都是定义明确的问题,可以通过当前或以前最先进的机器学习来解决。投入的精力没有超过创造的价值。
如果你不确定你的用例是否能被机器学习解决,你能做的最好的事情就是实验。但是很明显,以一种不会破产的方式。你可以用机器盒或者一些云工具轻松做到这一点。
在你开始一个耗时的数据科学项目之前,尽你所能评估这个问题,并确保它是用例最简单的迭代。
什么是机器盒子?

Machine Box 将最先进的机器学习功能放入 Docker 容器中,以便像您这样的开发人员可以轻松整合自然语言处理、面部检测、对象识别等功能。到您自己的应用程序中。
这些盒子是为扩展而建造的,所以当你的应用真正起飞时,只需水平地添加更多的盒子,直到无限甚至更远。哦,它比任何云服务都要便宜得多(而且可能更好)……而且你的数据不会离开你的基础设施。
有戏让我们知道你的想法。
如果出租车旅行是萤火虫:13 亿次纽约出租车旅行

NYC Metro Area Taxi Dropoffs, 1.3 Billion points plotted. Click for full resolution
纽约市出租车和豪华轿车委员会(TLC)公开发布了一个从 2009 年 1 月到 2016 年 6 月的出租车出行数据集,其中包含起点和终点的 GPS 坐标。最初,Chris Whong 向 TLC 发送了一个 FOIA 请求,让他们发布数据,并制作了一个著名的可视化图像,纽约市出租车:生活中的一天。 Mark Litwintschik 使用这个 400GB 大小的数据集对各种关系数据库和大数据技术进行了基准测试。值得注意的是, Todd W. Schneider 制作了一些非常好的数据集摘要,其中一些与我在这里展示的作品相似。实际上,我是在这篇文章写出来之后才知道 Todd 在这个话题上的工作的,所以尽管有一些重叠,这篇文章和其中的图片都是原创的。
我从 TLC 网站下载了数据文件,并且使用 Python、Dask 和 Spark(非常 痛苦地)生成了一个清晰的 Parquet 格式的数据集,我在这篇文章的最后将它提供给 AWS 用户。
所以我很好奇,出租车在哪里接客,或者更准确地说,出租车接客地点的分布是什么样的?由于有 13 亿辆出租车,以不忽略细节的方式绘制分布图非常具有挑战性。由于过度绘制,散点图是无用的,2D 直方图是一种核密度估计形式,必然会模糊或像素化许多细节。此外,对于完整的数据集,仅拾取位置就有 21GB,这比我的 16GB 笔记本电脑的内存还多。核心外的工具可以很容易地解决这个技术问题(子采样比这更容易),但是视觉问题呢?人眼无法在一个情节中吸收 21GB 的信息。
这个问题的解决方案来自一个叫做 Datashader 的有趣的库。它会以您的显示器(或指定的画布)的分辨率动态生成 2D 直方图。显示器上的每个像素对应于数据中的特定直方图边界。该库为每个像素计算落入这些边界内的数据点的数量,该数量用于给像素的亮度着色。利用 Dask,直方图的创建可以扩展到万亿字节的数据,并分布在整个集群中。利用散景,最终的情节可以缩放和平移。使用来自高动态范围摄影的技术,强度范围被映射,使得最大动态对比度出现在任何变焦水平和任何给定的视窗中。
出租车接送位置
这是曼哈顿上空出租车上客点(13 亿个点)的地图,使用 Viridis 感知均匀色图绘制。

NYC Taxi pickups map for Manhattan Click for full resolution
我注意到的第一件事是我能多么清楚地看到街道图案。在布鲁克林和皇后区的部分地区,街道格局非常鲜明。在曼哈顿,这种模式是“模糊的”,尤其是在曼哈顿南端附近和中央公园以南的中城。根据全球定位系统的坐标,有相当多的货车掉在哈德逊河或东河,也有相当多的货车掉在中央公园没有道路的地方。显然,并没有很多出租车从曼哈顿周围的河流出发,但这个图显示的是 GPS 误差有多重要。这种模糊性来自于高层建筑,这使得很难获得良好的 GPS 定位,而且建筑物越高,街道看起来就越模糊。更广泛地说,中央公园以南的市中心区非常明亮,表明许多出租车旅行都是从那里开始的。

Taxi pickups map for NYC Metro Area Click for full resolution
第二个图像也是出租车皮卡,但在一个更广泛的规模。缩小后,曼哈顿的大部分地区像灯塔一样亮着,表明曼哈顿的皮卡数量远远超过周围地区。但是机场,特别是 JFK 和拉瓜迪亚机场,也亮起来了,显示出几乎和市中心区一样的视觉强度(从那里开始的单位面积的旅行次数)。
出租车下车地点
现在让我们使用地狱色图来检查衰减位置。

NYC Taxi dropoffs map for Manhattan Click for full resolution
乍一看,交货地点很像曼哈顿的交货地点。同样的地区,中央公园以南的中城和曼哈顿的南端展示了最明亮(也是最模糊)的街道。

Taxi dropoffs map for NYC Metro Area Click for full resolution
缩小到更广阔的都会区,布鲁克林和皇后区的街道更清晰、更明亮,这表明外围区的落客比皮卡多得多,也表明这些地区的 GPS 误差往往更低,这可能是因为高层建筑更少。事实上,在一些地方,它看起来足够好,可以用作街道地图,表明布鲁克林和皇后区的出租车乘客分布相对均匀。这与皮卡地图截然不同,表明在外区有相对较少的皮卡,但有很多落客。许多人从曼哈顿乘出租车去郊区,但很少有人从郊区乘出租车去曼哈顿。
出租车上下车地点
最后两个图逐个像素地比较了拾取和衰减。在拾取高于衰减的地方,像素用绿色和黄色色图着色。在衰减高于拾取的地方,像素用紫色和橙色的地狱色图着色。

Pickups (Yellow-Green) and Dropoffs (Orange) for Manhattan Click for full resolution
在曼哈顿,街道(南北向的街道)两旁都是绿色,这表明接送的人比下车的人多。十字路口(东-西)是橙色的,表示更多的下降。实际上,如果我想搭出租车,走到最近的大街上搭一辆可能更容易。

Pickups (Yellow-Green) and Dropoffs (Orange) for NYC Metro Area Click for full resolution
缩小到更广阔的区域,布鲁克林和皇后区的几条主要街道是绿色的,表明这些街道上有大量的皮卡,而其他街道仍然是橙色的,显示从曼哈顿开始的旅行有所减少。在 JFK 和拉瓜迪亚机场,机场内的上客区和下客区被突出显示,部分区域用绿色阴影表示(上客区),其他区域用橙色阴影表示(下客区)。
GPS 呢?
使用 Datashader 和 Bokeh 绘制出租车上客和下客位置表明,有时 GPS 坐标数据相当不准确,表明上客和下客位置在东河或哈德逊河。我们从曼哈顿的接送地图上看到,GPS 受到高楼的强烈影响。特别是下降显示了一个令人惊讶的均匀分布在外围行政区,每条道路,每座桥梁都被突出。我觉得这很令人惊讶,因为我不希望在桥上或其他不鼓励停车让乘客下车的地方出现很多下车现象,比如通往 JFK 的范威克高速公路。然而,这样的桥梁和道路被突出显示,这让我想知道这是不是 GPS 的一个怪癖?这都是我的推测,但是如果 GPS 设备只是以固定的时间间隔更新,比如每两分钟,或者只要它可以获得位置锁定,会怎么样呢?在这种情况下,出租车行程将在一个合理的位置结束,但数据将被记录为行程在沿途某处结束。这可以解释为什么大量的接送发生在看似不可能的地点。
鉴于数据集可以追溯到 2009 年,智能手机中的 GPS 接收器从那时起已经走过了很长的路,我非常好奇是否有可能在出租车数据集中看到 GPS 精度的提高。作为 GPS 误差的一个替代,我检查了在物理上不可能的位置上的上下车地点的数量,例如在哈德逊河和东河的中间。然后我把这种不可能的旅行的比例标绘成总旅行次数的比率。鉴于优步和 Lyft 等打车服务和拼车服务的增长,费率调整是必要的。

Rate of Pickups and Dropoffs outside of the Taxi Zones, but within the local NYC area
果不其然,自 2009 年以来,不可能的地点的接送率下降了 4 到 5 倍。我不清楚是什么导致了 2009-2012 年的年度周期,错误率在夏季月份增加。自 2011 年以来,错误率大幅下降,这可能是由于整个出租车车队的出租车计价器发生了变化,或者 GPS 报告方式发生了变化。掉线率高于接站率的事实表明,我的理论可能有一些支持,即 GPS 设备只在固定的时间间隔更新,或者每当它们可以锁定位置时更新。
值得一提的是,0.5% — 0.1%的误差率不一定代表特定位置的实际 GPS 误差。例如,中央公园以南中城的模糊街道表明,那里的位置误差远高于 0.5%。此外,全球定位系统的位置可能是错误的,在某种程度上不是把它放在水面上,而是放在不正确的陆地位置上,这不会被我的 GPS 误差的原始代理检测到。
摘要
我获取、清理并绘制了纽约出租车数据集。我制作了一些有趣的接送地点的可视化图像,显示大多数接送发生在曼哈顿、JFK 和拉瓜迪亚机场,但是从曼哈顿到布鲁克林和皇后区有大量的出租车行程。很少有旅行是从郊区开始,在曼哈顿结束的。我逐点比较了出租车的上客和下客情况,显示出曼哈顿的大街上出租车上客的数量比十字路口多,十字路口上客的数量比十字路口多。
我还展示了 GPS 位置的准确性如何有问题。在市中心区,这可以通过“模糊”的街道和相当数量的点看到,这些点显示了在像哈德逊或东河这样不可能的位置的皮卡。在不方便让乘客下车的地方,比如范怀克高速公路,也有大量的上下车点,这表明上下车点地图上对这些街道的清晰定义是 GPS 设备不经常更新的一个怪癖。对恰好在水中的上下车地点的数量进行分析显示,自 2009 年以来,4 5X 的数量显著下降,这可能要归功于出租车计价器中 GPS 技术的改进。尽管如此,GPS 定位的误差表明应该有所保留。
在接下来的几周里,我将发布更多关于这个数据集的数据分析。
数据可用性
我把代码放在我的 NYC-transport github 库中。你可以在 Github 或 NBViewer 上查看用于制作这篇文章情节的笔记本。
我已经将亚马逊 S3 上包含出租车数据和优步数据(不是本文的主题)的原始拼花格式数据帧放在一个请求者付费桶中。如果您在美国东部地区使用正确配置的s3cmd启动 EC2 实例,您可以如下复制文件。一定要在美国东部地区,否则你可能会招致巨额带宽费用。
s3cmd sync --requester-pays s3://transit-project/parquet/all_trips_spark.parquet .
数据大约为 33GB,采用快速压缩的柱状拼花格式。如果用 Dask 读取,需要使用 PyArrow 后端。
如果您想联系我,请通过 LinkedIn 联系我。
如果你不能衡量它,你就不能改善它!!!
如何用 python 中的 LightFM 为一个电商搭建一个可扩展的推荐系统?

photo credit: pixabay
在过去的几年里,网上购物发生了很大的变化。像亚马逊这样的在线商店,在更个人化的层面上对待他们的顾客。他们根据您的网上购物活动(查看商品、将商品添加到购物车并最终购买)了解您对某些商品的兴趣。例如,你在亚马逊上搜索一件商品,然后点击一些搜索结果。下次你访问亚马逊时,你可以看到有一个特定的部分,根据你上次搜索的内容为你推荐类似的产品。故事并未就此结束,随着你与在线商店的互动越来越多,你会收到更多个性化的推荐,包括“购买该商品的顾客也购买了”,它会向你显示经常一起购买的商品列表。此外,一些商店发送促销电子邮件,提供针对更有可能购买这些产品的客户的产品。
推荐系统是机器学习最常用的应用之一。由于这里的目标是关注如何使用 LightFM 软件包构建推荐系统,并提供清晰的度量标准来衡量模型性能,所以我将只简要提及不同类型的推荐系统。关于推荐系统的更多细节,我建议观看 Siraj Raval 的这个简短的视频,并查看 Chhavi Aluja 的这篇文章。有三种类型的推荐系统:
- 基于内容
- 协作过滤(基于项目、基于用户和基于模型)
- 混合方法(将基于内容的方法添加到协同过滤中)
我最初的目标是建立一个混合模型,因为它可以将基于内容的推荐整合到协同过滤中,并且能够解决纯协同过滤推荐系统的冷启动问题。然而,没有多少公开可用的好数据集既有项目或用户的元数据,又有评级交互。所以我决定首先研究一个协同过滤模型,理解推荐系统的不同方面,在我的下一篇文章中,我将建立一个混合模型。
方法:
为什么选择 LightFM???
在研究推荐系统时,我遇到了许多相关的伟大项目,但是缺少一件事是缺乏一个明确的指标来评估模型的性能。我相信,如果你不能通过提供清晰的指标来评估你的模型的性能,你可能很难让你的读者相信这个模型(推荐系统)工作得足够好。因此,我选择了 LightFM ,因为它提供了清晰的指标,如 AUC 得分和 Precision@K,可以帮助评估训练模型的性能。这对于构建更好的模型和实现更高的准确性非常有用。
根据我们要解决的用例或问题类型,在 Precision@K 和 AUC score 之间做出选择可能会很棘手。在这种情况下,我们将使用 AUC 评分,因为它衡量整体排名的质量,并可以解释为随机选择的正面项目排名高于随机选择的负面项目的概率。
“LightFM 是许多流行的隐式和显式反馈推荐算法的 Python 实现,包括 BPR 和 WARP 排名损失的高效实现。它易于使用,快速(通过多线程模型估计),并产生高质量的结果。” LightFm 文档。

photo credit:pixabay
数据
对于这个项目,我们将使用图书交叉数据集实现一个基于矩阵分解方法的纯协作过滤模型。我们将利用 Chhavi Aluja 在她关于 towardsdatascience.com 的帖子中对这个数据集进行的惊人的数据清理和预处理。让我们来看看数据:
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
from datetime import datetime, timedelta
from sklearn import preprocessing
from lightfm import LightFM
from scipy.sparse import csr_matrix
from scipy.sparse import coo_matrix
from sklearn.metrics import roc_auc_score
import time
from lightfm.evaluation import auc_score
import pickle
import re
import seaborn as snsbooks = pd.read_csv('BX-Books.csv', sep=';', error_bad_lines=False, encoding="latin-1")
books.columns = ['ISBN', 'bookTitle', 'bookAuthor', 'yearOfPublication', 'publisher', 'imageUrlS', 'imageUrlM', 'imageUrlL']
users = pd.read_csv('BX-Users.csv', sep=';', error_bad_lines=False, encoding="latin-1")
users.columns = ['userID', 'Location', 'Age']
ratings = pd.read_csv('BX-Book-Ratings.csv', sep=';', error_bad_lines=False, encoding="latin-1")
ratings.columns = ['userID', 'ISBN', 'bookRating']

size of each dataframe


books.drop(['imageUrlS', 'imageUrlM', 'imageUrlL'],axis=1,inplace=True)
books.loc[books.ISBN == '0789466953','yearOfPublication'] = 2000
books.loc[books.ISBN == '0789466953','bookAuthor'] = "James Buckley"
books.loc[books.ISBN == '0789466953','publisher'] = "DK Publishing Inc"
books.loc[books.ISBN == '0789466953','bookTitle'] = "DK Readers: Creating the X-Men, How Comic Books Come to Life (Level 4: Proficient Readers)"
books.loc[books.ISBN == '078946697X','yearOfPublication'] = 2000
books.loc[books.ISBN == '078946697X','bookAuthor'] = "Michael Teitelbaum"
books.loc[books.ISBN == '078946697X','publisher'] = "DK Publishing Inc"
books.loc[books.ISBN == '078946697X','bookTitle'] = "DK Readers: Creating the X-Men, How It All Began (Level 4: Proficient Readers)"
books.loc[books.ISBN == '2070426769','yearOfPublication'] = 2003
books.loc[books.ISBN == '2070426769','bookAuthor'] = "Jean-Marie Gustave Le Cl�©zio"
books.loc[books.ISBN == '2070426769','publisher'] = "Gallimard"
books.loc[books.ISBN == '2070426769','bookTitle'] = "Peuple du ciel, suivi de 'Les Bergers"
books.yearOfPublication=pd.to_numeric(books.yearOfPublication, errors='coerce')
books.loc[(books.yearOfPublication > 2006) | (books.yearOfPublication == 0),'yearOfPublication'] = np.NAN
books.yearOfPublication.fillna(round(books.yearOfPublication.mean()), inplace=True)
books.loc[(books.ISBN == '193169656X'),'publisher'] = 'other'
books.loc[(books.ISBN == '1931696993'),'publisher'] = 'other'
users.loc[(users.Age > 90) | (users.Age < 5), 'Age'] = np.nan
users.Age = users.Age.fillna(users.Age.mean())
users.Age = users.Age.astype(np.int32)
上面的代码块是常规的数据清理,以确保在将数据用于模型输入之前,数据的格式是正确的。此外,我们需要确保 ratings 数据框架中的所有行都代表来自用户和图书数据框架的数据。接下来,评级必须只包括有效的评级分数(1-10),我们应该去掉评级值为零的所有行。
ratings_new = ratings[ratings.ISBN.isin(books.ISBN)]
ratings = ratings[ratings.userID.isin(users.userID)]
ratings_explicit = ratings_new[ratings_new.bookRating != 0]
这是评分值的分布:

为了完成我们的数据预处理,我们可以做的最后一件事是为已经对图书进行评级的用户数量以及已经被用户评级的图书数量分配一个阈值。换句话说,我们必须有一个用户和书籍的最低评级计数。我认为,如果只有至少评价了 20 本书的用户和至少被 20 个用户评价过的书就好了。
counts1 = ratings_explicit['userID'].value_counts()
ratings_explicit = ratings_explicit[ratings_explicit['userID'].isin(counts1[counts1 >= 20].index)]
counts = ratings_explicit['bookRating'].value_counts()
ratings_explicit = ratings_explicit[ratings_explicit['bookRating'].isin(counts[counts >= 20].index)]**ratings_explicit.shape
(217729, 3)**

训练我们的模型:
在这一步,我们将训练我们的模型。但这个问题不一样。在协作过滤模型中,我们基于用户-项目交互来寻找表征每个项目(书)的潜在特征,并且我们寻找每个用户与所发现的每个潜在特征的相似性。这个过程是通过矩阵分解完成的。首先,我们需要将数据(ratings_explicit)分成训练集和测试集。这就是事情变得棘手的地方。很明显,纯粹的协同过滤方法不能解决冷启动问题。因此,必须进行训练和测试拆分,以便测试集中的用户或书籍的实例必须具有训练集中的剩余实例:
**def informed_train_test(rating_df, train_ratio):**
split_cut = np.int(np.round(rating_df.shape[0] * train_ratio))
train_df = rating_df.iloc[0:split_cut]
test_df = rating_df.iloc[split_cut::]
test_df = test_df[(test_df['userID'].isin(train_df['userID'])) & (test_df['ISBN'].isin(train_df['ISBN']))]
id_cols = ['userID', 'ISBN']
trans_cat_train = dict()
trans_cat_test = dict()
for k in id_cols:
cate_enc = preprocessing.LabelEncoder()
trans_cat_train[k] = cate_enc.fit_transform(train_df[k].values)
trans_cat_test[k] = cate_enc.transform(test_df[k].values)# --- Encode ratings:
cate_enc = preprocessing.LabelEncoder()
ratings = dict()
ratings['train'] = cate_enc.fit_transform(train_df.bookRating)
ratings['test'] = cate_enc.transform(test_df.bookRating)n_users = len(np.unique(trans_cat_train['userID']))
n_items = len(np.unique(trans_cat_train['ISBN']))train = coo_matrix((ratings['train'], (trans_cat_train['userID'], \
trans_cat_train['ISBN'])) \
, shape=(n_users, n_items))
test = coo_matrix((ratings['test'], (trans_cat_test['userID'], \
trans_cat_test['ISBN'])) \
, shape=(n_users, n_items))
return train, test, train_df
函数 informed_train_test()返回训练集和测试集的 coo 矩阵以及原始训练数据帧,以便稍后对模型进行评估。让我们看看如何拟合我们的模型并评估其性能:
train, test, raw_train_df = informed_train_test(ratings_explicit, 0.8)start_time = time.time()
model=LightFM(no_components=110,learning_rate=0.027,loss='warp')
model.fit(train,epochs=12,num_threads=4)
# with open('saved_model','wb') as f:
# saved_model={'model':model}
# pickle.dump(saved_model, f)
auc_train = auc_score(model, train).mean()
auc_test = auc_score(model, test).mean()print("--- Run time: {} mins ---".format((time.time() - start_time)/60))
print("Train AUC Score: {}".format(auc_train))
print("Test AUC Score: {}".format(auc_test))**--- Run time: 4.7663776795069377 mins ---
Train AUC Score: 0.9801499843597412
Test AUC Score: 0.853681743144989**
正如所料,训练集的 AUC 分数接近 1,我们在测试集中得到了 0.853 的 AUC 分数,不算太差。使用随机搜索来调整用于训练 LightFm 模型的参数。GridSearh 运行起来太昂贵了,所以我决定使用 scikit-optimize 包中的 forest_minimize()来调优参数。关于调整参数的函数的更多细节在本文的 github 页面中。
我知道我之前提到过,对于向没有与项目进行任何交互的新用户推荐项目来说,纯协作过滤预计表现不佳(冷启动问题)。在 LightFM 文档页面中展示的示例中,他们还表明,在使用 movielens 数据集向新客户推荐电影时,纯粹的协作方法无法获得令人满意的结果,但是,我很好奇自己是否会针对图书交叉数据集进行测试。令人惊讶的是,结果显示该数据集对冷启动问题反应良好,AUC 得分相对较高!!!为了在这种情况下训练模型,唯一的区别是我们将数据集随机分为训练集和测试集。这意味着在训练集和测试集中出现常见用户-项目交互的概率是完全随机的:
import scipy.sparse as spdef _shuffle(uids, iids, data, random_state):shuffle_indices = np.arange(len(uids))
random_state.shuffle(shuffle_indices)return (uids[shuffle_indices],
iids[shuffle_indices],
data[shuffle_indices])**def random_train_test_split(interactions_df,
test_percentage=0.25,
random_state=None):**
"""
Randomly split interactions between training and testing.This function takes an interaction set and splits it into
two disjoint sets, a training set and a test set. Note that
no effort is made to make sure that all items and users with
interactions in the test set also have interactions in the
training set; this may lead to a partial cold-start problem
in the test set.Parameters
----------interactions: a scipy sparse matrix containing interactions
The interactions to split.
test_percentage: float, optional
The fraction of interactions to place in the test set.
random_state: np.random.RandomState, optional
The random state used for the shuffle.Returns
-------(train, test): (scipy.sparse.COOMatrix,
scipy.sparse.COOMatrix)
A tuple of (train data, test data)
"""
interactions = csr_matrix(interactions_df.values)
if random_state is None:
random_state = np.random.RandomState()interactions = interactions.tocoo()shape = interactions.shape
uids, iids, data = (interactions.row,
interactions.col,
interactions.data)uids, iids, data = _shuffle(uids, iids, data, random_state)cutoff = int((1.0 - test_percentage) * len(uids))train_idx = slice(None, cutoff)
test_idx = slice(cutoff, None)train = coo_matrix((data[train_idx],
(uids[train_idx],
iids[train_idx])),
shape=shape,
dtype=interactions.dtype)
test = coo_matrix((data[test_idx],
(uids[test_idx],
iids[test_idx])),
shape=shape,
dtype=interactions.dtype)return train, test
现在让我们来看看 AUC 分数在随机训练测试分割中是如何不同的:
train, test = random_train_test_split(ratings_matrix)start_time = time.time()
model=LightFM(no_components=115,learning_rate=0.027,loss='warp')
model.fit(train,epochs=12,num_threads=4)
# with open('saved_model','wb') as f:
# saved_model={'model':model}
# pickle.dump(saved_model, f)
auc_train = auc_score(model, train).mean()
auc_test = auc_score(model, test).mean()print("--- Run time: {} mins ---".format((time.time() - start_time)/60))
print("Train AUC Score: {}".format(auc_train))
print("Test AUC Score: {}".format(auc_test))**--- Run time: 8.281255984306336 mins ---
Train AUC Score: 0.9871253967285156
Test AUC Score: 0.6499683856964111**
随机分割数据预计会得到 0.5 左右的 AUC 分数,但我们可以看到,我们做得比扔硬币向新用户推荐商品或向当前用户推荐新商品好得多,因为我们的 AUC 分数为 0.649。我把对这种行为的进一步分析留给了本文的读者。
应用:
让我们假设数据集中的书籍是我们正在销售的商品,数据集中的用户实际上是目标客户。为了使案例更接近电子商务在线商店,我们可以改变评分值的一个方面是将值的范围从(1–10)减少到(7–10)。顾客的交互可以总结为: **A-查看商品,B-点击商品,C-将商品添加到他们的购物车,以及 D-进行交易以购买商品。**因此,在这种情况下,通过将评分值减少到前 4 名(7、8、9、10),我们可以更接近地模拟上述商品与顾客的互动。

photo credit: unsplash
**在电子商务应用中,推荐系统主要有三种应用场景。**我不打算包含为本文接下来的部分提供结果的函数的实际代码,但它们会在 github repo 的主 jupyter 笔记本中。
- 最常见的场景是根据特定客户的互动(查看和点击商品)向其进行典型推荐:

User-Item interaction matrix
user_dikt, item_dikt = user_item_dikts(user_item_matrix, books)similar_recommendation(model, user_item_matrix, 254, user_dikt, item_dikt,threshold = 7)**Items that were liked (selected) by the User:**
1- The Devil You Know
2- Harlequin Valentine
3- Shout!: The Beatles in Their Generation
4- Sandman: The Dream Hunters
5- Dream Country (Sandman, Book 3)
6- Assata: An Autobiography (Lawrence Hill & Co.)
7- The Golden Compass (His Dark Materials, Book 1)
8- The Fellowship of the Ring (The Lord of the Rings, Part 1)
9- The Hobbit: or There and Back Again
10- Harry Potter and the Sorcerer's Stone (Book 1)
11- Something Wicked This Way Comes
12- Martian Chronicles
13- Animal Farm
14- 1984
15- The Dark Half
16- Harry Potter and the Goblet of Fire (Book 4)
17- Harry Potter and the Prisoner of Azkaban (Book 3)
18- Harry Potter and the Prisoner of Azkaban (Book 3)
19- Harry Potter and the Chamber of Secrets (Book 2)
20- Harry Potter and the Chamber of Secrets (Book 2)
21- The Bonesetter's Daughter
22- The Wolves in the Walls
23- Stardust
24- Martian Chronicles
25- American Gods: A Novel
**Recommended Items:**
1- The Lovely Bones: A Novel
2- Harry Potter and the Order of the Phoenix (Book 5)
3- The Catcher in the Rye
4- The Da Vinci Code
5- Harry Potter and the Sorcerer's Stone (Harry Potter (Paperback))
6- Red Dragon
7- Interview with the Vampire
8- Divine Secrets of the Ya-Ya Sisterhood: A Novel
9- Sphere
10- The Pelican Brief
11- Little Altars Everywhere: A Novel
12- To Kill a Mockingbird
13- Coraline
14- The Queen of the Damned (Vampire Chronicles (Paperback))
15- The Hours: A Novel
基于相似的用户-项目交互,我们向 ID#为 254 的用户推荐了 15 个项目(书籍)。
- 第二种最常见的情况是,您计划告知客户有关追加销售(销售补充已购商品的额外商品)和交叉销售(销售客户可能感兴趣的其他独立类别的商品)**的选项。明确的例子有:“经常一起购买”、“查看了该商品的顾客也查看了……”。**对于这个任务,我必须将用户和图书评分的阈值从 20 增加到 200,这样我就可以得到一个更小的评分数据框架。查找相似的项目需要为数据集中的所有项目创建项目嵌入,这可能会占用大量内存(RAM)。我试着运行了几次,但我得到了低内存错误,所以如果您的机器上有足够的 RAM,您可以尝试使用较低的阈值:
item_embedings = item_emdedding_distance_matrix(model,user_item_matrix)
also_bought_recommendation(item_embedings,'B0000T6KHI' ,item_dikt)**Item of interest :Three Fates (ISBN:** B0000T6KHI**)**
**Items that are frequently bought together:**
1- Surrender to Love (Avon Historical Romance)
2- Landower Legacy
3- Ranch Wife
4- Sara's Song
- 这种推荐系统的第三个应用可以帮助改善客户体验并增加销售额,当您拥有一家商店,并且您决定通过向更有可能购买该商品的特定用户推荐商品来开展促销活动时:
users_for_item(model, user_item_matrix, '0195153448', 10)**[98391, 5499, 136735, 156214, 96473, 83443, 67775, 28666, 115929, 42323]**
我们推荐了 10 个更有可能对 ISBN #为 0195153448 的物品(书)感兴趣的用户(id)。下一步可能是向这些用户发送促销电子邮件,看看他们是否对提到的商品感兴趣。
最终想法:
值得注意的是,一般来说,协同过滤方法需要足够的数据(用户-项目交互)才能获得好的结果。非常感谢您的提问和评论。
以下是该项目的 github repo 的链接:
使用 python-nxs 5899/Recommender-System-LightFM 中的 light FM 包的可扩展电子商务推荐系统
github.com](https://github.com/nxs5899/Recommender-System-LightFM)
参考资料:
https://github . com/aayushmnit/cookbook/blob/master/rec sys . py
https://towards data science . com/my-journey-to-building-book-recommendation-system-5ec 959 c 41847
如果你想增加枪支致死的风险,就不要管制枪支。哦,等等,那很糟糕…

2015 年,如果你的孩子住在阿拉斯加,他们死于子弹的可能性是住在马萨诸塞州的 24 倍。就我个人而言,我不希望我的孩子去上图左上角的任何一个州处理他们的日常事务或参加电影或音乐会或大学课程,因为我希望他们健康长寿,为我生孙子,这样我就可以有孩子一起玩了。我跑题了。
为了制作这个图表,我按照美国各州和年份过滤了疾病预防控制中心的数据库中的死亡原因。根据以下死亡原因代码,任何火器造成的死亡都包括在内,无论是合法死亡还是意外死亡:
U01.4(涉及火器的恐怖主义)
W32(手枪发射)
W33(步枪、猎枪和大型火器发射)
W34(从其他和未指明的火器发射)
X72(手枪走火造成的故意自残)
X73(用步枪、猎枪和更大的火器发射故意自残)
X74(其他未具体说明的火器发射造成的故意自伤)
X93(手枪发射攻击)
X94(步枪、猎枪和大型火器攻击)
X95(用其他未具体说明的火器发射攻击)
Y22(手枪射击,未确定意图)
Y23(步枪、猎枪和大型火器发射,未确定意图)
Y24(其他和未指明的火器发射,未确定的意图)
Y35.0(涉及火器发射的法律干预)
我将这些数据与总部位于波士顿大学的州枪支法律项目的州级枪支限制法规数据结合起来(嘿,我儿子在波士顿大学读的研究生——耶!).我刚刚被指向 2013 年 J AMA 内科学的一篇文章,该文章使用类似的数据(CDC 枪支死亡数据+各州枪支法律数据)得出类似的结论。它在付费墙后面,但是你可以阅读摘要。
我没有在这个情节上花太多时间。这并不好看,不仅仅是因为这个话题。我故意省略了州名和红蓝标签,因为我想专注于两个指标:被子弹打死的可能性&买枪有多难。如果你对你所在州的法律感到关注或好奇,请查看页面,了解更多。
用于数据操作和数据可视化的代码可以在我的 GitHub 中找到。
感谢您的阅读。
我欢迎反馈——您可以“鼓掌”表示赞同,或者如果您有具体的回应或问题,请在此给我发消息。我也有兴趣听听你想在未来的帖子中涉及哪些主题。
阅读更多关于我的作品jenny-listman.netlify.com。欢迎随时通过 Twitter@ jblistman或LinkedIn联系我。
注意事项:
- 枪支法律数据:美国各州从 1991 年到 2017 年的枪支法律可从https://www.kaggle.com/jboysen/state-firearms获得
- 疾控中心 1999 年至 2015 年火器致死原因数据:https://wonder.cdc.gov/ucd-icd10.html
- 使用 R 中的工具处理和绘制数据
如果你的文件只保存在你的笔记本电脑上,它们就像不存在一样!

如何避免计算机灾难
上周,当我在做三个研究生课程项目中的一个时,我的笔记本电脑决定是时候放弃了。我花了 15 分钟徒劳地重置电池,并按住电源按钮试图得到回应,但无济于事:我的笔记本电脑永远完了。
一年前的这个时候,我会无法控制地哭泣,我的学期在最后一周结束了。然而,这一次,我放下我的笔记本电脑,走到学校图书馆,登录到一台电脑上,从 Google Drive 下载我的文件,这些文件一直同步到我的笔记本电脑变暗的那一分钟,并在 30 分钟内完成我的最终项目。总而言之,多亏了自动备份,我没有损失一整个学期,而是损失了一份报告的两行内容。
这个近乎悲剧的例子说明了任何在电脑上工作的人都必须记住的两点:
- 不久的某个时候,你的电脑会彻底失灵
- 这可能是致命的损失,也可能没什么大不了的,这取决于你的安全措施
亲眼目睹了电脑故障对同学们造成的破坏,几个月前,我终于安装了谷歌硬盘备份和同步。这是将在你的电脑后台运行的服务之一,将所有文件(或你选择的文件)保存到云端,你可以从世界上任何一台电脑上访问它们。
有一句话我很喜欢,叫做二的法则:“二等于一,一等于零。”(我第一次在 Cortex 播客上从 CGPGrey 那里听到这个。这意味着,如果你只有一件必需品,它还不如不存在,因为你可能会不可避免地失去它。说到文件存储,如果你的文件只存在你的笔记本电脑上,它们可能根本不会被保存,因为你是如此的脆弱。
注册备份服务往往是每个人都说他们会抽时间去做,但从来没有真正实施的事情之一(我在这个群体中呆了很长时间)。然而,在你开始做任何你不想失去的工作之前,有适当的备份应该是必要的!
在今天这个存储便宜得离谱的世界里,没有任何理由不在云中提供文件的多个副本。对于学生来说,你可能会通过 Google Drive 获得免费的无限存储空间,这意味着你可以存储任何你想要的东西(我没有测试过无限的限制,但有朋友节省了数 TB)。对于其他人来说, 100 GB 的存储空间在 Google Drive 上只需每月 2 美元,其他选项也同样合理。我知道当我的屏幕变成一片空白时,我会很乐意每年支付 100 美元来确保我的文件是安全的。
您选择的确切备份路径并不重要,但重要的是确保您的文件位于多个位置(u 盘总比没有好,但云备份是最佳选择)。我更喜欢自动同步,因为人类会犯错。有了自动同步文件的服务,你就没有什么风险会受到技术的阻碍!这是一个你应该满足于让计算机替你思考的领域。(同样,如果一个程序提供了自动保存文件的选项,一定要让它尽可能频繁地保存!)
每当我在笔记本电脑上看到 Google Drive sync 的小图标呼呼转动时,我都会花一点时间来欣赏自动文件备份的奇迹。下次我的笔记本电脑不可避免地出现故障时,我知道这只是一个小的、可恢复的不便。你能说同样的话吗?
我欢迎反馈和讨论,可以通过 Twitter @koehrsen_will 联系到我。
如果你不关注分析和归因,那么你就没有抓住重点

所有网站都有某种目标或一组目标。你想要一定数量的读者,或者一定数量的新闻订阅,或者(很常见)一定数量的销售额。但是当你试图实现这些目标时,除非你有某种盲目的运气,否则你需要一条通往那里的道路。如果你想一个月卖 50 个小部件,而你只卖了 20 个,你如何得到另外 30 个呢?
这很容易成为任何电子商务新手最常见的第一个问题。对于一个不具备所需各种技能的专业人士来说,尤其是在数字营销领域,提高转化率的途径很容易变得模糊不清。你需要尽你所能让它尽可能的清晰。怎么会?通过学习如何解读网络分析。
维基百科给出了定义:“分析是数据中有意义模式的发现、解释和交流。”
首先,你有责任对你正在吸引的流量类型、这些用户来自哪里以及他们在你的网站上做什么有一个非常坚实的概念。因为营销预算不是无限的,即使是很大的预算也必须有效利用,所以有必要(也很明显)吸引最有可能帮助你以经济高效的方式实现目标的流量。
我个人在过去看到过许多公司对整个问题采取极不科学的方法的例子——尤其是当忽视适当的分析设置时。然后,他们会想为什么他们的目标甚至没有接近实现,吸引流量或增加转化率的整个概念对他们来说就像是巫术。
当看着你的战略不断完善时,在你开始“建立更多”之前,通常更好地利用时间来完善你已经拥有的。你想知道网站的哪些部分已经吸引了最多的流量,用户在哪里停留的时间最长,最高价值的用户来自哪里,等等。
能够访问这么多数据的好处在于,你可以对网站上的所有流量和行为有一个非常细致的了解。这种数据供应是可以利用的。你需要收集尽可能多的数据,并学会热爱、生活和呼吸数据。需要从第一个访客那里收集。即使在一开始,当流量水平较低时,你仍然可以获得有价值的见解,这将使你受益,并在早期阶段给你动力。
例如,一个主要的数据是桌面和移动用户的细分。如今,随着越来越多的流量是移动的,这是一个需要考虑的非常重要的问题(许多网站的绝大多数流量细分都倾向于移动)。另一方面,许多设计师和开发人员倾向于以桌面优先的方式来考虑网站的设计和可用性——我认为这在很大程度上是因为桌面是一个更大的“画布”,当你有很多页面元素想要融入设计时,桌面会更加宽容。这种方法的结果并不理想。如果你看了你的分类,发现 90%的流量是移动的,那么你可能会重新考虑这种方法。
即使对那些没有预算的人来说, Google Analytics 也是一项非常强大的分析服务,被全球数百万网站所使用。对于那些害怕的人,谷歌甚至提供免费培训,所以没有借口。这是一个比你的网络主机可能提供的内置分析好得多的解决方案。
一旦你开始有一个更具体的想法,你的典型流量来自哪里,他们如何与你的网站互动,以及其余的基础知识,这是很重要的,看看到底是什么样的流量给你想要的结果,所以你可以专注于它们。你需要了解是什么样的流量在推动转化。这叫归因。
维基百科给出了定义:“营销归因提供了一种理解,即以何种特定顺序发生的事件的何种组合会影响个人从事所需的行为,通常被称为转化。”
一旦你有了一些转化数据,和大量的流量数据,你就可以看看是什么来源和平台给你带来了最好的结果。例如,通常你会看到移动电子商务的转换率(和其他数据,如会话时间)低于桌面电子商务。在这种情况下,你可能想增加桌面流量的广告支出,以提高你的整体转化率。此外,你可以根据页面速度优化优先处理移动网站,重新考虑用户结账流程,并测试不同的登录页面。
如果你发现你所有的转化率对搜索流量更有利(这是我见过的典型情况),那么你需要更多地关注 SEO 来吸引更多的这类流量。如果你发现来自 Instagram 的流量比来自脸书的流量表现更好,那么你可以重新考虑你的社交媒体策略。
你明白了。
然而,要当心“虚荣尺度”。这意味着这些数字实际上并不意味着什么。总会话数是一个虚荣心指标,关注者也是。你可以针对某个东南亚国家开展一场极其廉价的页面点击活动,让成千上万的用户点击你的网站,但我保证没有人(或很少人)会采取任何有意义的转化行动。就追随者而言,那些总是可以买到的。主要数字是转化率,是百分比。垃圾流量太多,这个比例就会下降。
一旦数字变得更加清晰,那么增加转化率的途径也会变得更加清晰。自然,理解这一切是一个学习的过程。无论如何,这是创建一个盈利网站或电子商务业务最重要的第一步。现在投入的时间会让你的生活更轻松,你的目标更接近,从长远来看,你的网站会更赚钱。祝你好运。
注册我的时事通讯,了解更多类似的故事和其他有趣的事情。
我是住在纽约市的数码战略家和偶尔的摄影师。在 Instagram 上的 @andreikorchagin 关注我,或者在 andreikorchagin.com拜访我。
IGLOO:一种不使用递归神经网络处理序列的不同范例

在 ReDNA labs,我们最近发表了一篇研究论文,虽然其中充满了技术细节、基准和实验,但我们希望对这种新的神经网络结构给出更直观的解释。原文在此。
在本文中,我们介绍了一种新的神经网络架构,它是特别擅长处理长序列,并且与主要教条相反,没有利用任何形式的递归神经网络。虽然这不是第一次对序列进行卷积处理,但我们的结构 IGLOO 利用了输入片段之间的一些特殊关系。这种新颖的方法在各种常见的基准测试中产生了良好的结果;值得注意的是,我们表明,在一些常见的任务上,它可以处理多达 25000 个时间步,而历史递归神经网络则难以处理超过 1000 个时间步。该方法可应用于各种研究领域,本文特别将其应用于医学数据和情感分析。
使用神经网络处理序列
直到最近,一旦在机器学习任务中有了顺序的概念,神经网络一直是首选结构。众所周知,鉴于递归神经网络(RNN)的递归性质,存在消失梯度的问题。历史上,长短期记忆(LSTM)和门控循环单位(GRU)细胞是最常用的 RNN 结构,但最近出现了新的改进细胞,如独立循环神经网络(IndRNN)、准循环神经网络(QRNN)、循环加权平均(RWA)和其他一些细胞。它们在速度和对历史单元的收敛方面有所改进。
所有这些单元的主要思想是数据被顺序处理。
除此之外,一种称为时间卷积网络(TCN)的新结构可用于分析顺序数据。TCN 使用 1D 卷积和扩张卷积来寻找序列的表示。(Bai 等人,2018) [3]的论文-用于序列建模的一般卷积和递归网络的经验评估,给出了更多细节。
自从最初尝试使用卷积来处理序列,就为新方法的出现开辟了道路。
爱斯基摩人圆顶小屋

Basic IGLOO cell
我们知道,应用于序列的 1D 卷积返回特征图,指示序列如何对各种过滤器作出反应。给定核大小 K*,K 个滤波器,并使用因果 1D 卷积(以便在时间 T,只有直到时间 T 的数据是可用的),每个时间步长找到具有向量的表示。该向量中的每一项代表该时间步中每个过滤器的激活。完整特征图 F1 的大小为(T,K)。
然后,通常的卷积网络将另一个卷积应用于该初始卷积,并返回第二个更深(在某种意义上,它离输入更远)的特征图。该第二卷积可以被视为学习特征图的邻接片之间的关系。通常的 Convnets 继续以这种方式堆叠层。例如,时间卷积网络(TCN)结构使用扩展卷积来减少网络的总深度,同时旨在使较深层具有尽可能大的感受域,即,使较高层具有关于初始输入的尽可能全局的视野。由于更高层连接到所有的输入,然后由训练过程使信息向上流动。
冰屋结构的工作方式不同。在初始卷积之后,不是将第二卷积层应用于 F1,而是我们在第一轴上从可用的 T(p 的典型值为 4)中收集 p 个切片,然后我们将这些切片连接起来以获得大小为(p,K)的矩阵 H。这些 p 切片可以来自附近地区,也可以来自遥远的地区,因此汇集了来自特征地图不同部分的信息。因此,可以说冰屋在初始特征地图 F1 中利用了非本地关系。收集数量为 L 的这些大块以产生大小为(L,p,K)的矩阵。然后,该矩阵逐点乘以相同大小的可训练滤波器。看待这种操作的一种方式是,过滤器学习 F1 的非连续切片之间的关系。然后,我们将最后一个和倒数第二个轴上的逐点乘法产生的每个元素加在一起,以找到大小为 l 的向量 U。我们还将偏差添加到该输出。因此会有 L 偏差。应用诸如 ReLU 的非线性(该步骤不是必需的)。结果,我们获得了一个向量 U,它将代表序列,然后可以输入到一个密集层,用于分类或回归。总之,我们训练(L . k . p+1)个参数(不包括初始卷积 C1)。
一些评论:
U 的每个元素可以被视为特征图 F1 的 p 个不一定连续的随机选择的切片之间的关系的表示。这种关系的本质是由为该补丁训练的唯一过滤器给出的。
给定足够大的 L,U 具有完整的感受野,并且连接到输入向量的每个元素,因此它可以用作该序列的表示向量。这对于收敛不是绝对必要的,因为一些输入点可能对有效的表示没有贡献。CNN 架构并不总是具有这种特性。
传统的 CNN 依靠网络深度来汇集来自输入的遥远部分的信息,而 IGLOO 直接从输入的遥远部分采样补丁,因此它不需要深度。在某些情况下,一层就足够了。然而,由于 CNN 在每一层深度提供了不同的粒度级别,所以使用不同级别的补丁也是很有趣的,这是我们实现的。
虽然卷积网络都是以金字塔的方式利用本地信息,但 IGLOO 试图从整个输入空间收集信息。直观上,convnets 将连续的卷积层应用于输入序列或图像,并且每一层以不同的粒度水平表示信息,因为离输入数据越远的每一层具有越大的感受域。IGLOO 可以直接访问不同区域的输入数据,所以不需要完全依赖这种金字塔结构。本质上,它试图利用输入空间的不同部分之间的相似性来找到可用于回归或分类的表示。
思想实验
例如,让我们想象下面的思维实验。给定我们具有 100 个时间步长和 10 个特征的序列,即大小为(100,10)的矩阵。一些序列在前 50 个时间步长和后 50 个时间步长中包含大小为 10 的相同向量。其他一些序列没有任何重复的向量。该机器学习任务的目标是在大量的例子上进行训练(在训练集上),然后能够在给定测试集的情况下正确地识别那些具有重复元素的序列(类 1)和那些没有重复元素的序列(类 0)。如果随机选择,我们有 50%的几率是正确的。
RNN 将如何处理这项任务?RNN 有一个内部存储器,用于记录将误差降至最低所需的重要信息。因此,RNN 将一个接一个地处理序列中的每个元素,并跟踪是否存在重复。
冰屋将如何处理这项任务?想象在训练集中,对于第一个样本,在索引 1 和 51 处有相同的向量。然后,在收集随机补丁时,IGLOO 将处理向量(0,1,10,25),(20,40,60,80)或(1,51,10,3)(它可以设置为处理 1000 个这样的补丁)。在后一种情况下,应用于该小块的可训练滤波器将通过输出一个大的正数而做出强烈的反应,因此网络将了解到如果在第 1 个索引处的向量和在第 51 个索引处的向量是相同的,那么为该序列找到的表示应该是第 1 类。然后在测试时,如果索引 1 和 51 处的向量相同,网络现在知道它应该被分类为类别 1。
虽然这项任务相当简单,但研究文档中介绍了一些稍微复杂一些的任务。
使用复制记忆任务延长记忆时间
这项任务最初是在(Hochreiter 和 J. Schmidhuber,1997 年)[1]中介绍的。我们给定一个大小为 T+20 的向量,其中前 10 个元素 G=[G0,G1,…,G9]是 1 到 8 之间的随机整数,接下来的 T-1 个元素是 0,接下来的元素是 9(作为标记),接下来的 10 个元素又是 0。任务是生成一个序列,该序列除了最后 10 个项目之外在任何地方都是零,该序列应该能够再现 g。任务 A 可以被认为是一个分类问题,并且所使用的损失将是分类交叉熵(跨 8 个类别)。该模型将输出 8 个类别,这些类别将与实际类别进行比较。
实验表明,对于超过 1000 个时间步长,rnn 在这个任务上很难实现收敛,部分原因是梯度消失的问题。因为冰屋把一个序列看作一个整体,所以它没有同样的缺点。
复制记忆——冰屋模型。达到精度> 0.99 秒的时间。
t 大小(补丁数量)—时间—参数
T=100 (300) — 12s — 80K
T=1000 (500) — 21s — 145K
T=5000 (2500) — 52s — 370K
T=10000 (7000) — 61s — 1520K
T=20000 (10000) — 84s — 2180K
T=25000 (15000) — 325s — 3270K
对于超过 25000 个时间步的序列,IGLOO 似乎可以实现收敛。文献中没有 RNN 能够做到这一点。
虽然 NLP 任务通常使用少于 1000 步的序列,但在某些领域长序列是常见的。例如 EEG 数据和声波。这篇论文包括一个用脑电图数据做的实验。
更快地收敛语法任务

Grammar rules
紧随其后(Ostemeyer et al .,2017)[2],我们使用这个任务来确保 IGLOO 可以高效地表示序列,而不仅仅是集合。为了成功完成这项任务,任何神经网络都需要能够提取序列元素出现顺序的信息。基于人工语法生成器,我们生成训练集,该训练集包括遵循所有预定义语法规则并且被分类为正确的序列,并且我们生成具有错误的序列,该错误应该被识别为无效。作为语法生成器的结果,诸如 BPVVE、BTSSSXSE 和 BPTVPXVVE 的序列将被分类为有效,而诸如 BTSXXSE、TXXTTVVE 和 BTSSSE 的序列将被分类为无效。
在这种情况下,序列只有 50 倍步长,有 7 个特征。实验记录了在使用不同模型的测试集上达到 95%的准确率需要多长时间。

Results on the Grammar task from the original paper
在这个实验中,IGLOO 似乎比测试的其他 RNN 细胞更快,尤其是比 CuDNNGRU 细胞更快,CuDNNGRU 细胞是普通 GRU 的优化版本
结论
我们引入了一种新型的神经网络,通过利用非局部相似性来处理序列。从基准测试来看,它在处理非常长的序列时似乎比普通的 RNNs 更好,同时也更快。
虽然基准可以很好地确保一个想法在原则上是有意义的,但在野外尝试冰屋将有助于了解它在某些情况下是否可以作为替代方案。
提供了该结构的 Keras/tensorflow 代码,所以这实际上是将 RNN 细胞换成冰屋细胞的问题,看看是否会发生奇迹。我们鼓励读者报告他们的发现。
此处提供了一个 Keras 实现

我们确实帮助公司将机器学习添加到他们的业务流程中,也许我们也可以帮助你。取得联系!【ai@rednalabs.com 号
参考文献
1-S. Hochreiter 和 J. Schmidhuber。长短期记忆。神经计算,9(8):1735–1780,1997。
2-J .奥斯特迈耶和 l .科威尔。基于递归加权平均的序列数据机器学习。arXiv:1703.01253v5,2018。
3-S .白、j .济科-科尔特尔和 v .科尔通。用于序列建模的一般卷积和递归网络的经验评估。在 arXiv:1803.01271v2,2018。
原载于 2018 年 7 月 19 日www.rednalabs.com。
用排列测试阐明我们的灯泡数据
几乎每天我都会遇到一种新的“环境统计”(是的,现在有了一个新的名称)。卫生纸每天杀死 27000 棵树。三分之二的大堡礁正在消失。虽然我确信这些有趣的事实是相关的,但我经常发现它们不相关,不可思议,也不那么有趣。此外,随着我对统计的了解越来越多,我开始质疑这些数字背后隐藏的过程。所以我决定自己做一个关于伯克利学生和灯泡的环境统计。

Photo by Luis Tosta on Unsplash
这学期,我有机会在加州大学伯克利分校的能源和资源组领导一门课程的教学——ERG 98:为了更绿色的明天的可持续能源。在这个标题乐观的课堂上,我和我的同事伊丽莎白给 30 名学生讲授能源和环境的基础知识——从千瓦与千瓦时到气候变化的社会不公。然后,我们邀请来自可持续发展公司的演讲嘉宾,如特斯拉和 Volta Charging,以及学术界人士,如可持续交通行为的研究人员。
我们的一个固定的演讲嘉宾,克里斯托弗·琼斯,在加州大学伯克利分校运行凉爽气候网络。他创造了第一个综合碳足迹计算器,它询问用户的生活方式并输出他们估计的碳排放量。利用这些数据,Chris 绘制了美国各县的估计排放量。

Average Household Carbon Footprint — Eastern United States. Credit: CoolClimate Network
你看到了什么?
在看到这张图之前,我就在期待类似的图。随着我们接近更发达的地区,每户平均排放量通常会增加。但是一个奇怪的现象引起了我的注意——城市中心的那些绿色斑点。城市真的比周围的郊区更有效率吗?2010 年,Edward Glaeser 和 Matthew Kahn 在为城市经济学杂志撰写的题为 城市的绿色:二氧化碳排放和城市发展 的论文中讨论了这一趋势。 Glaeser 和 Kahn 观察了 48 个大都市的城市和郊区的交通、家庭取暖和电力使用的排放。在这项研究中,他们得出结论:
“如果城市人口居住在更靠近城市中心的高密度地区,这些地区的冬天更温暖,夏天更凉爽,电力公司使用更少的煤来发电,那么家庭温室气体排放量就会更低。”
从本质上讲,人口密度的增加通常意味着碳强度的降低,尤其是在煤炭不太受欢迎的地区。
看到这种趋势,我决定以 ERG 98 的学生为对象进行自己的统计测试。不幸的是,个人的总排放量很难计算,所以用一个不完美的替代物来代替:灯泡数。下课时,我顺手在考勤表上加了两个额外的问题。以下是我问他们的问题:
- 你会把你的家分为农村、郊区还是城市?
- 你家大约有多少个灯泡?
这些是我收到的分发内容:

Histograms of survey answers for number of lightbulbs, split by area type
很明显,城市和郊区的灯泡数量有所不同,大约有 11 个灯泡!这可能支持这样的观点,即大都市地区的能源使用通常在城市中心较低。但是在我做太多宽泛的陈述之前,我必须认识到我的假设。这绝不是对大都市居民的随机抽样。此外,这种手段上的差异可能完全是随机发生的。
让我们把重点放在后一种说法上。如果我的特定城市学生只是碰巧因为未知原因少了灯泡怎么办?见鬼,我住在伯克利市,但是我的室友(也住在这个城市)比我多了 3 个灯泡!在比较两种分布时,应该有一种方法来解释这种随机变化。
一种越来越流行的比较两种分布的方法是排列测试。置换检验的前提是假设两组数字来自相同的基础分布(科学家称此为零假设 ) *。*在这种假设下,我们通过改变“城市”和“郊区”标签来模拟新的学生调查。然后,经过多次模拟,我们可以确定我们观察的近似可能性——11 个灯泡的平均差异。
这个过程从随机地将标签“郊区”和“市区”重新分配给调查中给出的各种灯泡数量开始。我们有 13 名郊区学生和 14 名城市学生,所以我们打乱了数据表,将前 13 行分配给“郊区”,其余的分配给“城市”这给了我们两个新的分布来比较。
然后,我们计算两个随机生成的分布的平均值之间的新差异。称之为 D1。我们可以将 D1 解释为城市和郊区灯泡数量之间的一个可能差异,假设它们是从相同的基础分布中选择的。然后,我们重复这个过程很多次(我做了 10,000 次),每次都得到一个新的“随机”差异。

Two instances of shuffling the labels and calculating a new difference in means.
现在,假设城市和郊区学生的答案来自相同的分布,我们通过 10,000 来近似所有可能的均值差异来观察 D1。

正如我们从这个直方图中看到的,最有可能的差异在-10 到 10 个灯泡之间。右侧中突出显示的空间表示大于或等于 11 个差异灯泡的区域。因此,我们可以将这个区域中的蓝条视为满足该差异的所有“随机”时间。这相当于整个分布的 3.48%——意味着至少 11 个灯泡的差异有 3.48%的可能性是由于随机性造成的。
因此,我们可以有 96%的把握说,由于某种潜在的原因,我的城市学生比我的郊区学生拥有的灯泡少。正如研究表明的那样,人口密度和每户能源使用量之间似乎存在某种联系。Glaeser 和 Kahn 认为公共交通的便利和房子的大小是可能的原因。显然,城市化进程的加快是气候变化之谜的一部分。
要了解更多关于排列测试的知识,我推荐阅读托马斯·斯莫尔的概念性文章这里和切斯特·伊茨的编程文章这里。你也可以在我的 github 上查看我的博客代码。
我希望你喜欢这个小小的社会和环境问题的统计之旅。如果您对此分析有任何问题或意见,请发表评论,我将确保做出回应。你也可以在johnleyden.com找到我的联系方式。
LSTM 和 GRU 的图解指南:一步一步的解释

嗨,欢迎来到长短期记忆(LSTM)和门控循环单位(GRU)的图解指南。我是迈克尔,我是人工智能语音助手领域的机器学习工程师。
在这篇文章中,我们将从 LSTM 和 GRU 背后的直觉开始。然后我会解释让 LSTM 和 GRU 表现如此出色的内部机制。如果你想了解这两个网络的内幕,那么这篇文章就是为你准备的。
如果你愿意,你也可以在 youtube 上观看这篇文章的视频版本。
问题是,短期记忆
递归神经网络存在短期记忆的问题。如果一个序列足够长,它们将很难将信息从较早的时间步骤传递到较晚的时间步骤。因此,如果你试图处理一段文字来做预测,RNN 氏症可能会从一开始就遗漏重要信息。
在反向传播期间,递归神经网络遭受消失梯度问题。梯度是用于更新神经网络权重的值。消失梯度问题是当梯度随着时间向后传播而收缩时。如果一个梯度值变得极小,它不会贡献太多的学习。

Gradient Update Rule
所以在递归神经网络中,获得小梯度更新的层停止学习。这些通常是早期的层。因此,因为这些层不学习,RNN 氏症可以忘记它在更长的序列中看到的东西,因此有短期记忆。如果你想知道更多关于递归神经网络的一般机制,你可以在这里阅读我以前的帖子。
嗨,欢迎来到循环神经网络图解指南。我是迈克尔,也被称为学习矢量。我是一个…
towardsdatascience.com](/illustrated-guide-to-recurrent-neural-networks-79e5eb8049c9)
LSTM 的和 GRU 的作为解决方案
LSTM 和 GRU 的发明是为了解决短期记忆问题。它们有称为“门”的内部机制,可以调节信息的流动。

这些门可以了解序列中哪些数据是重要的,应该保留或丢弃。通过这样做,它可以将相关信息传递到长长的序列链中进行预测。几乎所有基于递归神经网络的现有技术结果都是用这两个网络实现的。LSTM 和 GRU 氏症可以在语音识别、语音合成和文本生成中找到。你甚至可以用它们来为视频生成字幕。
好了,到这篇文章结束的时候,你应该对为什么 LSTM 和 GRU 擅长处理长序列有了一个坚实的理解。我将用直观的解释和插图来处理这个问题,并尽可能避免使用数学。
直觉
好了,先来一个思维实验。假设你正在网上看评论,以决定是否要买生活麦片(不要问我为什么)。你将首先阅读评论,然后决定是否有人认为它是好的还是坏的。

当你阅读评论时,你的大脑下意识地只记住重要的关键词。你会听到像“惊人的”和“完美平衡的早餐”这样的词。你不太在意“这个”、“给了”、“所有”、“应该”之类的词。如果一个朋友第二天问你这篇评论说了什么,你可能不会一字不差地记住它。你可能还记得要点,比如“肯定会再次购买”。如果你和我很像,其他的词会从记忆中消失。

这基本上就是 LSTM 或 GRU 所做的。它可以学习只保留相关信息来进行预测,而忘记不相关的数据。在这种情况下,你记住的单词让你判断它是好的。
递归神经网络综述
为了理解 LSTM 和 GRU 是如何做到这一点的,让我们回顾一下递归神经网络。一个 RNN 是这样工作的;第一个单词被转换成机器可读的向量。然后,RNN 逐一处理向量序列。

Processing sequence one by one
在处理时,它将前一个隐藏状态传递给序列的下一步。隐藏状态充当神经网络的记忆。它保存网络以前看到的以前数据的信息。

Passing hidden state to next time step
让我们看看 RNN 的一个单元,看看如何计算隐藏态。首先,将输入和先前的隐藏状态组合起来形成一个向量。该向量现在具有关于当前输入和先前输入的信息。向量经过 tanh 激活,输出是新的隐藏状态,或者网络的记忆。

RNN Cell
Tanh 激活
tanh 激活用于帮助调节流经网络的值。tanh 函数将值压缩为总是在-1 和 1 之间。

Tanh squishes values to be between -1 and 1
当向量流经神经网络时,由于各种数学运算,它会经历许多转换。所以想象一个值继续乘以比如说 3 。你可以看到一些价值如何爆炸,成为天文数字,导致其他价值似乎微不足道。

vector transformations without tanh
双曲正切函数确保值保持在-1 和 1 之间,从而调节神经网络的输出。您可以看到上面的相同值是如何保持在 tanh 函数允许的边界之间的。

vector transformations with tanh
这是 RNN 的作品。它的内部操作很少,但是在适当的情况下(比如短序列)可以很好地工作。RNN 算法使用的计算资源比它的变种 LSTM 算法和 GRU 算法少得多。
LSTM
LSTM 具有与递归神经网络相似的控制流。当信息向前传播时,它处理传递信息的数据。不同之处在于 LSTM 细胞内的操作。

LSTM Cell and It’s Operations
这些操作用于允许 LSTM 保存或忘记信息。现在,查看这些操作可能会有点让人不知所措,因此我们将一步一步地讲解。
核心概念
LSTM 的核心概念是细胞状态,以及它的各种门。细胞状态就像一条传输高速公路,沿着序列链一路传输相关信息。你可以把它想象成网络的“记忆”。理论上,细胞状态可以在整个序列处理过程中携带相关信息。因此,即使是来自较早时间步骤的信息也可以传递到较晚的时间步骤,从而减少短期记忆的影响。当细胞状态继续它的旅程时,信息通过门被添加到细胞状态或从细胞状态移除。这些门是不同的神经网络,决定细胞状态允许哪些信息。盖茨夫妇可以在训练中了解哪些信息是应该保留或忘记的。
乙状结肠的
门包含乙状结肠激活。乙状结肠活化类似于双曲结肠活化。它不是挤压-1 和 1 之间的值,而是挤压 0 和 1 之间的值。这有助于更新或忘记数据,因为任何乘以 0 的数字都是 0,导致值消失或被“忘记”任何数字乘以 1 都是相同的值,因此该值保持不变或“保持不变”网络可以了解哪些数据不重要,因此可以忘记,或者哪些数据重要,需要保留。

Sigmoid squishes values to be between 0 and 1
让我们更深入地了解一下各个门在做什么,好吗?所以我们有三个不同的门来调节 LSTM 细胞中的信息流动。遗忘门、输入门和输出门。
忘记大门
首先,我们有遗忘之门。这个门决定哪些信息应该被丢弃或保留。来自先前隐藏状态的信息和来自当前输入的信息通过 sigmoid 函数传递。值介于 0 和 1 之间。越接近 0 表示忘记,越接近 1 表示保留。

Forget gate operations
输入门
为了更新单元状态,我们有输入门。首先,我们将先前的隐藏状态和当前输入传递给一个 sigmoid 函数。它通过将值转换为 0 和 1 之间的值来决定哪些值将被更新。0 表示不重要,1 表示重要。您还可以将隐藏状态和当前输入传递给 tanh 函数,以挤压-1 和 1 之间的值,从而帮助调节网络。然后将双曲正切输出乘以 sigmoid 输出。sigmoid 输出将决定哪些信息对 tanh 输出很重要。

Input gate operations
细胞状态
现在我们应该有足够的信息来计算细胞状态。首先,单元格状态逐点乘以遗忘向量。如果乘以接近 0 的值,这有可能会丢失单元状态中的值。然后,我们从输入门获取输出,进行逐点加法,将细胞状态更新为神经网络认为相关的新值。这给了我们新的细胞状态。

Calculating cell state
输出门
最后,我们有输出门。输出门决定下一个隐藏状态应该是什么。请记住,隐藏状态包含以前输入的信息。隐藏状态也用于预测。首先,我们将先前的隐藏状态和当前输入传递给一个 sigmoid 函数。然后,我们将新修改的单元格状态传递给 tanh 函数。我们将双曲正切输出乘以 sigmoid 输出来决定隐藏状态应该携带什么信息。输出是隐藏状态。然后,新的单元状态和新的隐藏被带入下一个时间步骤。

output gate operations
回顾一下,“遗忘之门”决定了哪些内容与之前的步骤相关。输入门决定从当前步骤添加哪些相关信息。输出门决定下一个隐藏状态应该是什么。
代码演示
对于那些通过查看代码更好理解的人,这里有一个使用 python 伪代码的例子。

python pseudo code
1.首先,前一个隐藏状态和当前输入被连接起来。我们就叫它组合。
2。合并把得到的输入到遗忘层。该层移除不相关的数据。
4。使用组合创建一个候选层。候选包含可能添加到单元格状态的值。
3。 Combine 也把 get 的馈入输入层。这一层决定来自候选的什么数据应该被添加到新的单元状态。
5。在计算了遗忘层、候选层和输入层之后,使用这些向量和先前的像元状态来计算像元状态。
6。然后计算输出。
7。逐点乘以输出和新的单元状态得到新的隐藏状态。
就是这样!LSTM 网络的控制流是一些张量运算和一个 for 循环。您可以使用隐藏状态进行预测。结合所有这些机制,LSTM 可以选择在序列处理过程中记住或忘记哪些相关信息。
苏军总参谋部情报总局
现在我们知道了 LSTM 是如何工作的,让我们简单看看 gru。GRU 是新一代的递归神经网络,与 LSTM 非常相似。GRU 摆脱了细胞状态,用隐藏状态来传递信息。它也只有两个门,一个复位门和更新门。

GRU cell and it’s gates
更新门
更新门的作用类似于 LSTM 的遗忘和输入门。它决定丢弃什么信息和添加什么新信息。
复位门
重置门是另一个用来决定忘记多少过去信息的门。
这是一个 gru。GRU 的张量运算较少;因此,他们比 LSTM 的训练速度要快一些。没有明显的赢家哪一个更好。研究人员和工程师通常尝试两者来确定哪一个更适合他们的用例。
原来如此
综上所述,RNN 氏综合症对于处理序列数据进行预测是很好的,但是会受到短期记忆的影响。LSTM 氏症和 GRU 氏症是作为一种利用被称为“门”的机制来减轻短期记忆的方法而产生的。门只是调节流经序列链的信息流的神经网络。LSTM 和 GRU 的被用于先进的深度学习应用,如语音识别、语音合成、自然语言理解等。
如果你有兴趣深入了解,这里有一些很棒的资源链接,可以让你从不同的角度理解 LSTM 和 GRU。这篇文章深受他们的启发。
http://colah.github.io/posts/2015-08-Understanding-LSTMs/
【https://www.youtube.com/watch?v=WCUNPb-5EYI
我写这篇文章很开心,所以请在评论中告诉我这是否有帮助,或者你想在下一篇文章中看到什么。一如既往,感谢您的阅读!
查看michaelphi.com了解更多类似的内容。
✍🏽想要更多内容?查看我的博客https://www.michaelphi.com
📺喜欢看基于项目的视频?来看看我的 Youtube !
🥇注册我的 电子邮件简讯 ,了解最新的文章和视频!
递归神经网络图解指南
理解直觉

嗨,欢迎来到循环神经网络图解指南。我是迈克尔,也被称为学习矢量。我是人工智能语音助手领域的机器学习工程师。如果你刚刚开始学习 ML,并且想获得递归神经网络背后的一些直觉,这篇文章是为你准备的。
如果你愿意,你也可以观看这篇文章的视频版本。
如果你想进入机器学习,递归神经网络是一种强大的技术,理解这一点很重要。如果你使用智能手机或经常上网,奇怪的是你已经使用了利用 RNN 的应用程序。递归神经网络用于语音识别、语言翻译、股票预测;它甚至被用于图像识别来描述图片中的内容。
所以我知道有很多关于循环神经网络的指南,但我想分享一些插图和解释,关于我是如何理解它的。我将避免所有的数学,而是专注于 RNNs 背后的直觉。在这篇文章结束时,你应该对 RNN 有了很好的理解,并希望有一个灯泡的时刻。
序列数据
好的,RNN 的神经网络擅长对序列数据建模。为了理解这意味着什么,让我们做一个思维实验。假设你拍了一张球随时间运动的静态快照。

假设你想预测球的运动方向。那么,只有你在屏幕上看到的信息,你会怎么做呢?好吧,你可以猜一猜,但是你能想到的任何答案都是,一个随机的猜测。如果不知道球去了哪里,你就没有足够的数据来预测它要去哪里。
如果你连续记录球的位置的许多快照,你将有足够的信息来做出更好的预测。

所以这是一个序列,一个事物跟随另一个事物的特殊顺序。有了这些信息,你现在可以看到球正在向右移动。
序列数据有多种形式。音频是一个自然的序列。你可以把一个音频声谱图分割成块,然后输入 RNN 的大脑。

Audio spectrogram chopped into chunks
文本是序列的另一种形式。您可以将文本分成一系列字符或一系列单词。
顺序记忆
好的,RNN 擅长处理序列数据进行预测。但是怎么做呢??
他们通过一个我称之为顺序记忆的概念做到了这一点。为了更好地理解顺序记忆的含义…
我想邀请你说出你脑中的字母表。

那很简单,对吧。如果你被教导这个特定的顺序,它应该很快就会出现在你面前。
现在试着倒着说字母表。

我打赌这要困难得多。除非你以前练习过这个特定的顺序,否则你可能会有一段艰难的时间。
这里有一个有趣的,从字母 f 开始。

起初,你会纠结于前几个字母,但当你的大脑掌握了这个模式后,剩下的就会自然而然了。
所以这很难做到是有逻辑原因的。你按顺序学习字母表。顺序记忆是一种让你的大脑更容易识别顺序模式的机制。
递归神经网络
好的,RNN 有顺序记忆的抽象概念,但是 RNN 是怎么复制这个概念的呢?让我们来看看传统的神经网络,也称为前馈神经网络。它有输入层、隐藏层和输出层。

Feed Forward Neural Network
我们如何让一个前馈神经网络能够利用以前的信息来影响以后的信息?如果我们在神经网络中添加一个可以向前传递先验信息的回路会怎么样?

Recurrent Neural Network
这就是递归神经网络的本质。RNN 有一个循环机制,充当高速公路,允许信息从一个步骤流向下一个步骤。

Passing Hidden State to next time step
这个信息是隐藏状态,它是先前输入的表示。让我们通过一个 RNN 用例来更好地理解它是如何工作的。
假设我们想要建立一个聊天机器人。它们现在很受欢迎。假设聊天机器人可以从用户输入的文本中对意图进行分类。

Classifying intents from users inputs
来解决这个问题。首先,我们将使用 RNN 对文本序列进行编码。然后,我们将把 RNN 的输出输入一个前馈神经网络,这个网络将对意图进行分类。
好的,那么一个用户输入… 现在是几点? 。首先,我们把句子分解成单个的单词。RNN 的作品是按顺序排列的,所以我们一次输入一个单词。

Breaking up a sentence into word sequences
第一步是将“什么”输入 RNN。RNN 对“什么”进行编码并产生输出。

对于下一步,我们输入单词“时间”和上一步的隐藏状态。RNN 现在有了关于“什么”和“时间”的信息

我们重复这个过程,直到最后一步。你可以看到,在最后一步,RNN 已经对前面步骤中所有单词的信息进行了编码。

因为最终输出是从序列的其余部分创建的,所以我们应该能够获得最终输出,并将其传递给前馈层以对意图进行分类。

对于那些喜欢看代码的人来说,这里有一些 python 展示了控制流。

Pseudo code for RNN control flow
首先,初始化网络层和初始隐藏状态。隐藏状态的形状和维度将取决于你的递归神经网络的形状和维度。然后循环输入,将单词和隐藏状态传递给 RNN。RNN 返回输出和修改后的隐藏状态。你继续循环,直到你没有词了。最后,将输出传递给前馈层,它会返回一个预测。就是这样!递归神经网络正向传递的控制流是 for 循环。
消失渐变
你可能已经注意到隐藏状态中奇怪的颜色分布。这说明了 RNN 所谓的短期记忆的问题。

Final hidden state of the RNN
短期记忆是由臭名昭著的消失梯度问题引起的,这在其他神经网络架构中也很普遍。随着 RNN 处理更多的步骤,它很难保留以前步骤的信息。如你所见,来自单词“什么”和“时间”的信息在最后的时间步几乎不存在。短期记忆和消失梯度是由于反向传播的性质;一种用于训练和优化神经网络的算法。为了理解这是为什么,让我们看看反向传播对深度前馈神经网络的影响。
训练神经网络有三个主要步骤。首先,它向前传递并进行预测。其次,它使用损失函数将预测与地面实况进行比较。损失函数输出一个误差值,该误差值是对网络性能有多差的估计。最后,它使用该误差值进行反向传播,计算网络中每个节点的梯度。

梯度是用于调整网络内部权重的值,允许网络学习。梯度越大,调整越大,反之亦然。这就是问题所在。当进行反向传播时,一个层中的每个节点计算它的梯度相对于它之前的层中的梯度的效果。因此,如果对之前图层的调整很小,那么对当前图层的调整会更小。
这导致梯度向下反向传播时呈指数级收缩。早期的层无法进行任何学习,因为内部权重由于极小的梯度而几乎没有被调整。这就是消失梯度问题。

Gradients shrink as it back-propagates down
让我们看看这是如何应用于递归神经网络的。您可以将递归神经网络中的每个时间步视为一层。为了训练一个递归神经网络,可以使用一种称为时间反向传播的反向传播应用程序。随着梯度值在每个时间步长中传播,梯度值将按指数规律收缩。

Gradients shrink as it back-propagates through time
再次,梯度用于调整神经网络的权重,从而允许它学习。小梯度意味着小调整。这导致早期层不学习。
由于渐变消失,RNN 不会学习跨时间步长的长程相关性。这意味着当试图预测用户的意图时,有可能不考虑单词“什么”和“时间”。然后,网络必须用“是吗?”做出最好的猜测。这相当模糊,即使对人类来说也很困难。所以不能学习更早的时间步骤会导致网络有短期记忆。
LSTM 和 GRU 的
好了,RNN 氏症患者患有短期记忆障碍,我们该如何克服呢?为了减轻短期记忆,创建了两个专门的递归神经网络。一种叫做长短期记忆,简称 LSTM 氏症。另一种是门控循环单元或 GRU 氏症。LSTM 和 GRU 的功能本质上和 RNN 的一样,但是他们能够使用被称为“门”的机制来学习长期的依赖性这些门是不同的张量运算,可以学习向隐藏状态添加或删除什么信息。因为这种能力,短期记忆对他们来说不是问题。如果你想了解更多关于 LSTM 和 GRU 的情况,你可以看看我关于他们的帖子。
嗨,欢迎来到 LSTM 和 GRU 的图解指南。我是迈克尔,我是人工智能领域的机器学习工程师…
towardsdatascience.com](/illustrated-guide-to-lstms-and-gru-s-a-step-by-step-explanation-44e9eb85bf21)
那还不算太糟
综上所述,RNN 氏综合症对于处理序列数据进行预测是很好的,但是会受到短期记忆的影响。香草 RNN 氏症的短期记忆问题并不意味着完全跳过它们,使用更进化的版本,如 LSTM 或 GRU 氏症。RNN 的优势在于训练速度更快,使用的计算资源更少。这是因为需要计算的张量运算较少。当你期望对具有长期相关性的较长序列建模时,你应该使用 LSTM 或 GRU 的方法。
如果你有兴趣深入了解,这里有一些解释 RNN 氏症及其变体的链接。
[## 任何人都可以学习用 Python 编写 LSTM-RNN 代码(第 1 部分:RNN)——我是特拉斯克
机器学习技术博客。
iamtrask.github.io](https://iamtrask.github.io/2015/11/15/anyone-can-code-lstm/) [## 了解 LSTM 网络——colah 的博客
这些循环使得循环神经网络看起来有点神秘。然而,如果你想得更多一点,事实证明…
colah.github.io](https://colah.github.io/posts/2015-08-Understanding-LSTMs/)
我写这篇文章很开心,所以请在评论中告诉我这是否有帮助,或者你想在下一篇文章中看到什么。感谢阅读!
查看michaelphi.com了解更多类似的内容。
✍🏽想要更多内容?在 https://www.michaelphi.com 查看我的博客
📺喜欢看基于项目的视频?看看我的 Youtube !
🥇注册我的 电子邮件简讯 ,了解最新文章和视频!
我是一名数据科学家,我为什么要使用云?
人们通常认为云只是一种租赁电脑的服务,由像 AWS (亚马逊网络服务)或 GCP (谷歌云平台)这样的公司提供。有人让我用他们的电脑,而不是我自己的?那又怎样!?!我的机器拥有我构建和开发机器学习算法所需的所有能力,我为什么要使用云呢?让我来解释一下云是如何让你的生活变得更加轻松的。
如果你想尝试一些新的、令人惊叹的开源技术(例如 Apache Spark ),但不知道在你的机器上设置它时从哪里开始,该怎么办?为什么不直接让云提供商给你一台已经预装了这个的机器(例如 AWS EMR 或 GCP DataProc )?简单。
另一个场景可能是您有一个在本地运行的数据库(即不在云中)。您不断遇到升级问题(永远无法完成)、查询永远无法返回任何数据,以及存储空间耗尽的持续威胁。一种选择是继续打这场败仗,花掉你(和你的数据/软件工程师)所有的时间试图阻止数据库在任何时候冻结。为什么不直接让云提供商立即让你访问一个数据库(运行在完全由他们管理的机器上),这个数据库可以处理你扔给它的所有数据,而不会增加查询返回的时间(例如 AWS DynamoDB 或 GCP BigQuery )?简单。
也许您想定期运行一个流程,比如每日报告。在本地,您需要在一台机器上安装一个应用程序,该应用程序将触发每个进程在正确的时间运行。您选择的机器现在是单点故障。它会崩溃,需要更新,会变旧,你会错误地运行一个耗尽所有计算资源的应用程序。为什么不直接让云提供商 100%保证地管理时间表呢?如果出现错误,他们甚至会重试单个流程(例如,如果您的每日报告流程在完成前崩溃),或者在重试 3 次后创建一个失败通知系统(例如, AWS 数据管道)。太美了。
你刚刚构建了一个惊人的数据科学算法。您已经将代码包装在一个 Docker 容器中,现在想要部署它。将它托管在单台机器上意味着您将会遇到上一段提到的单点故障噩梦。当需求增加时,您也无法轻松扩展。您的另一个选择是创建一些集群架构,将您的机器变成一个计算实体。如果一台机器停机,没问题,您的模型将自动移动到集群的不同部分。试图设置这将是一个非常痛苦和缓慢的练习。为什么不要求云提供商立即创建一个集群来托管你的模型(例如 AWS EC2 容器服务或 GCP 容器引擎)?太神奇了。
在云中工作的便利性是无与伦比的。它甚至真的很棒。云提供商现在提供一种叫做无服务器计算的服务(例如 AWS Lambda 或 GCP 云功能)。它让您无需供应或管理任何服务器就可以运行代码。您只需提供要运行的代码,仅此而已。它仅在需要时执行您的代码,并自动伸缩。改变游戏规则。
所以云很神奇,一定很贵。事实恰恰相反。首先,AWS 和 GCP(举例来说)都提供广泛的自由层。越来越多的云提供商之间的竞争也保持了低价。但最重要的是,它是随用随付。您只需为您的云数据库中的数据量或您使用的计算能力付费。没有必要过度购买你可能一天只使用 8 小时的昂贵硬件。您可以在云中快速轻松地扩展,无需前期成本。你还能要求什么?
云让你的生活更轻松。作为一名数据科学家,您的目标是使用最先进的技术运行最佳算法,最可靠,所需维护最少,使用所有可用数据,尽可能缩短设置时间,只为您使用的数据付费,并且能够在需要时快速轻松地扩展。云让你到达那里,而本地工作却不能。结案了。
IMA 杂志时代
吴恩达卷积神经网络课程回顾
通过这篇文章,我将尝试诚实地回顾我在 Coursera 上学习的最新课程:吴恩达的“卷积神经网络”。
我第一次跟随来自吴恩达的“机器学习课程是在 2014 年。我真的很喜欢他的授课速度,以及他积累知识让你跟上进度的方式。因此,当他关于深度学习的新纳米学位在今年 8 月发布时,我是第一批加入的人之一,我很快完成了三门课程。几周前,五门课程中的第四门课程发布了。我立即上了“卷积神经网络”课程,继续我的旅程。
正如预期的那样,该课程结构合理,进度恰当。内容分为四周。第一周建立卷积神经网络(CNN)的基础,并解释这些卷积是如何计算的,机制。它解释了它在计算机视觉中的基础,然后将详细说明与填充、步幅和池层(最大池、平均池)的卷积。
第二周着眼于几个“经典”的 CNN,并解释如何通过在已有概念的基础上添加新的概念来构建架构。然后,它继续解释 ResNets(这个概念可以应用于其他网络,而不仅仅是 CNN),然后建立盗梦空间网络(是的,盗梦空间就像电影中一样)
第三周介绍了两个新的实用概念,目标定位和目标检测。计算出一个物体在照片中的位置,其次,我们可以在照片中检测到多少个物体,以及它们各自的位置。它很好地展示了如何使用锚定框来预测和评估边界框。
最后,在第四周你会学到一些关于 CNN 最酷最有趣的事情:人脸识别和神经类型转移。这里介绍了一些重要的概念,如一次性学习(这也适用于 CNN 以外的其他网络)和连体网络。
总而言之,这是一门很好的课程。一路上有些小故障。一些视频没有尽可能地完美,即一些“漏洞”需要删除,幻灯片上有一些错误需要纠正,但非常轻微。我最大的不满是关于编程作业。首先,它们不是独立的。他们从一开始就提到了在纳米学位第二个课程的第三周对 Tensorflow 的介绍:“改进深度神经网络”。当你每天不使用 Tensorflow(通常我对 Keras 没问题)并且课程之间有 2-3 个月的间隔时,这就有点尴尬了…
第二,与纳米学位的其他课程相比,作业的指导性稍差,也就是说,你将需要花更多的时间来解决编程中的小问题,而这些问题不像以前的课程那样需要大量的手工处理。这与其说是一个问题,不如说是一个声明,然而,当它与有问题的 Coursera 作业提交引擎结合起来时,就成了一个问题(嗯,老实说,我不知道这是 Coursera 的错还是课程的错,但结果是一样的)。有时,它会拒绝正确地给你的作业评分,甚至不会给你错误的东西评分,或者会引入人为的界限,而不告诉你这些界限已经存在……我希望这些问题能尽快得到解决,因为它不会阻止像我这样的早期采用者,但很可能会阻止未来出现更多的人。
最后,网站上使用的 jupyter 内核很麻烦。服务器可用性有时似乎很粗略。即使保存了您的工作,也经常会丢失(您应该定期保存/导出到您的本地机器以缓解这些问题)。简而言之,距离 Kaggle 内核的处理还有很长的路要走。我的一个同事在参加另一个 Coursera 课程后也报告了同样的问题,所以这不是 CNN 课程独有的。此外,由于 Coursera 的访问现在是基于订阅的,如果您在课程结束后不续订,您将无法访问您的内核。因此,如果你不想丢失你的作品(因为它和课程视频一样具有参考价值),你必须将它们存储在你的本地机器或首选云存储中。
尽管如此,这是一门很好的课程,教会了我很多我以前不知道的东西,所以总共 4/5!但是要做好准备,尤其是在编程作业中。我特别喜欢一次性学习,我打算将它应用于我工作中的一个深层神经网络问题(与 CNN 无关)和神经类型转移。在最后一个编程练习中,您完成了一个神经类型转换算法代码。在我的好朋友 Marc-Olivier 的推动下,我更进一步,实现了一个多风格的传输算法。这些是我最小的孩子,他们从爱德华·蒙克、巴勃罗·毕加索、文森特·梵高和乔治·布拉克都有不同程度的风格转变。

My youngest kids with style transferred left to right, top to bottom: Edvard Munch, Pablo Picasso, Vincent Van Gogh and Georges Braques.
本网站上的帖子是我个人的,不一定代表爱立信的立场、策略或观点。
自定义图像增强
图象生成
图像增强
图像增强是一种技术,用于人为扩展数据集。当我们得到一个只有很少数据样本的数据集时,这是很有帮助的。在深度学习的情况下,这种情况很糟糕,因为当我们在有限数量的数据样本上训练它时,模型往往会过度拟合。
通常用于增加数据样本计数的图像增强参数是缩放、剪切、旋转、预处理 _ 函数等。这些参数的使用导致在深度学习模型的训练期间生成具有这些属性的图像。使用图像增强生成的图像样本通常会导致现有数据样本集增加近 3 到 4 倍。

在 Keras 中,我们借助一个名为 ImageDataGenerator 的函数来实现图像增强。函数定义的基本概要如下:

Function to Initialize Data Augmentation Parameters
自定义图像增强
自定义图像增强我们可能希望在 Keras 中为 ImageDataGenerator 定义我们自己的预处理参数,以便使它成为一个更强大的图像生成 API。我们可以通过更改 Keras image.py 文件来实现这一点。
为了便于理解,最好创建 image.py 的副本,并在副本中进行更改。这是在运行于 Anaconda 环境的 Windows 机器上通过以下步骤实现的:

Steps to Create Custom Image Augmentation File — image_dev.py
现在,按照以下步骤添加您希望在 ImageDataGenerator 中看到的自定义参数:




实验结果


Augmented Images Obtained Using - datagen_1

Augmented Images Obtained Using — datagen_2
源代码
深度学习——这个知识库由 Shreenidhi Sudhakar 实施的深度学习项目组成。
github.com](https://github.com/shree6791/Deep-Learning/tree/master/CNN/Cats%20and%20Dogs/keras/src)
Python 中的图像增强示例
我目前正在进行一项研究,审查图像数据增强的深度和有效性。这项研究的目标是了解如何增加我们的数据集大小,以训练具有有限或少量数据的稳健卷积网络模型。
这项研究需要列出我们能想到的所有图像增强,并列举所有这些组合,以尝试和提高图像分类模型的性能。想到的一些最简单的增强是翻转、平移、旋转、缩放、隔离单独的 r、g、b 颜色通道和添加噪声。更令人兴奋的扩展集中在使用生成对抗网络模型,有时用遗传算法交换生成网络。还提出了一些创造性的方法,例如对图像应用 Instagram 风格的照明过滤器,应用随机区域锐化过滤器,以及基于聚类技术添加平均图像。本文将向您展示如何使用 NumPy 对图像进行放大。
以下是一些增强技术的列表和说明,如果您能想到任何其他方法来增强图像,以提高图像分类器的质量,请留下评论。

Original Image, (Pre-Augmentation)
增加
所有的扩充都是在没有 OpenCV 库的情况下使用 Numpy 完成的
# Image Loading Code used for these examples
from PIL import Image
import numpy as np
import matplotlib.pyplot as pltimg = Image.open('./NIKE.png')
img = np.array(img)
plt.imshow(img)
plt.show()
轻弹
翻转图像是最流行的图像数据增强方法之一。这主要是由于翻转代码的简单性,以及对于大多数问题来说,翻转图像将为模型增加价值是多么直观。下面的模型可以被认为是看到了一只左脚的鞋子而不是右脚的鞋子,因此,随着数据的增加,该模型对于看到鞋子的潜在变化变得更加稳健。

# Flipping images with Numpy
flipped_img = np.fliplr(img)
plt.imshow(flipped_img)
plt.show()
翻译
很容易想象以检测为目的的分类器的翻译增强的价值。好像这个分类模型试图检测鞋子何时在图像中,何时不在图像中。这些平移将帮助它拾取鞋子,而不用在框架中看到整个鞋子。

# Shifting Left
for i in range(HEIGHT, 1, -1):
for j in range(WIDTH):
if (i < HEIGHT-20):
img[j][i] = img[j][i-20]
elif (i < HEIGHT-1):
img[j][i] = 0plt.imshow(img)
plt.show()

# Shifting Right
for j in range(WIDTH):
for i in range(HEIGHT):
if (i < HEIGHT-20):
img[j][i] = img[j][i+20]plt.imshow(img)
plt.show()

# Shifting Up
for j in range(WIDTH):
for i in range(HEIGHT):
if (j < WIDTH - 20 and j > 20):
img[j][i] = img[j+20][i]
else:
img[j][i] = 0plt.imshow(img)
plt.show()

#Shifting Down
for j in range(WIDTH, 1, -1):
for i in range(278):
if (j < 144 and j > 20):
img[j][i] = img[j-20][i]plt.imshow(img)
plt.show()
噪音
噪声是一种有趣的增强技术,我开始越来越熟悉它。我看过很多关于对抗性训练的有趣论文,在这些论文中,你可以向一幅图像中加入一些噪声,结果模型将无法对其进行正确分类。我仍然在寻找产生比下图更好的噪音的方法。添加噪波可能有助于消除光照失真,并使模型总体上更加健壮。

# ADDING NOISE
noise = np.random.randint(5, size = (164, 278, 4), dtype = 'uint8')
for i in range(WIDTH):
for j in range(HEIGHT):
for k in range(DEPTH):
if (img[i][j][k] != 255):
img[i][j][k] += noise[i][j][k]
plt.imshow(img)
plt.show()
甘斯:
我对使用生成性对抗网络进行数据增强的研究产生了浓厚的兴趣,下面是我使用 MNIST 数据集制作的一些图像。

从上面的图像中我们可以看出,它们看起来确实像 3、7 和 9。我目前在扩展网络架构以支持运动鞋的 300x300x3 尺寸输出(相比于 28x28x1 MNIST 数字)时遇到了一些问题。然而,我对这项研究感到非常兴奋,并期待着继续下去!
感谢您阅读本文,希望您现在知道如何实现基本的数据扩充来改进您的分类模型!
用于深度学习的图像增强
深度网络需要大量的训练数据来实现良好的性能。为了使用非常少的训练数据建立强大的图像分类器,通常需要图像增强来提高深度网络的性能。图像增强通过不同的处理方式或多种处理方式的组合,如随机旋转、平移、剪切、翻转等,人工创建训练图像。
图像数据发生器
使用 Keras 中的 ImageDataGenerator API 可以轻松创建一个增强图像生成器。ImageDataGenerator通过实时数据增强生成批量图像数据。创建和配置ImageDataGenerator以及用增强图像训练深度神经网络的最基本代码如下。
datagen = ImageDataGenerator()
datagen.fit(train)
X_batch, y_batch = datagen.flow(X_train, y_train, batch_size=batch_size)
model.fit_generator(datagen, samples_per_epoch=len(train), epochs=epochs)
我们可以用下面的代码来创建具有所需属性的增强图像。在我们的例子中,下面的数据生成器生成一批 9 个增强图像,旋转 30 度,水平移动 0.5。
datagen = ImageDataGenerator(rotation_range=30, horizontal_flip=0.5)
datagen.fit(img)i=0
for img_batch in datagen.flow(img, batch_size=9):
for img in img_batch:
plt.subplot(330 + 1 + i)
plt.imshow(img)
i=i+1
if i >= batch_size:
break


Original Image and Augmented Images
直方图均衡
除了 Keras 中的ImageDataGenerator类提供的标准数据扩充技术,我们还可以使用自定义函数来生成扩充图像。例如,您可能想要使用对比度拉伸来调整图像的对比度。对比度拉伸是一种简单的图像处理技术,通过将图像的亮度值范围重新缩放(“拉伸”)到所需的值范围来增强对比度。
直方图均衡是另一种图像处理技术,使用图像强度直方图增加图像的整体对比度。均衡图像具有线性累积分布函数。这种方法不需要参数,但有时会产生看起来不自然的图像。
另一种方法是自适应直方图均衡化 (AHE),它通过计算对应于图像不同部分的几个直方图来提高图像的局部对比度(不同于仅使用一个直方图来调整全局对比度的普通直方图均衡化),并将它们用于局部对比度调整。然而,AHE 倾向于过度放大图像中相对均匀区域的噪声。
对比度受限的自适应直方图均衡 (CLAHE)是为了防止 AHE 导致的噪声过度放大而开发的。简言之,它通过在计算累积分布函数之前将直方图限幅在预定值来限制 AHE 的对比度增强。
为了在 Keras 中实现用于增强的定制预处理函数,我们首先定义我们的定制函数,并将其作为参数传递给ImageDataGenerator。例如,我们可以使用下面的代码实现 AHE。
def AHE(img):
img_adapteq = exposure.equalize_adapthist(img, clip_limit=0.03)
return img_adapteqdatagen = ImageDataGenerator(rotation_range=30, horizontal_flip=0.5, preprocessing_function=AHE)



Augmented Images using Contrast Stretching (left), Histogram Equalization (middle) and Adaptive Histogram Equalization (right)
参考
基于 Keras 和直方图均衡的深度学习图像增强

在本帖中,我们将回顾:
- 图像增强:它是什么?为什么重要?
- Keras:如何使用它进行基本的图像增强。
- 直方图均衡化:它是什么?怎么有用?
- 实现直方图均衡化技术:修改 keras .预处理 image.py 文件的一种方法。
图像增强:它是什么?为什么重要?
深度神经网络,尤其是卷积神经网络(CNN),尤其擅长图像分类任务。最先进的 CNN 甚至被证明在图像识别方面超过了人类的表现。

https://www.eff.org/ai/metrics
然而,正如我们从杨健先生在热门电视节目*【硅谷】*(该应用程序现已在 app store 上提供)中的“热狗,不是热狗”食物识别应用中了解到的那样,收集图像作为训练数据既昂贵又耗时。
如果你不熟悉电视节目《硅谷》,请注意以下视频中的语言是 NSFW 语:
为了对抗收集成千上万训练图像的高费用,已经开发了图像增强,以便从现有数据集生成训练数据。图像增强是获取已经在训练数据集中的图像并操纵它们以创建同一图像的许多改变版本的过程。这不仅提供了更多的图像进行训练,而且还可以帮助我们的分类器暴露在更广泛的光照和颜色情况下,从而使我们的分类器更加鲁棒。下面是一些来自 imgaug 库的不同扩充的例子。

https://github.com/aleju/imgaug
使用 Keras 进行基本图像增强
有许多方法可以对图像进行预处理。在这篇文章中,我们将回顾一些最常见的开箱即用的方法,这些方法是 keras 深度学习库为增强图像提供的,然后我们将展示如何改变keras . preprocessing image . py文件,以便启用直方图均衡化方法。我们将使用 keras 附带的 cifar10 数据集。然而,我们将只使用来自数据集中的猫和狗的图像,以便保持任务足够小,可以在 CPU 上执行——如果您想继续的话。你可以从这篇文章中查看 IPython 笔记本的源代码。
加载和格式化数据
我们要做的第一件事是加载 cifar10 数据集并格式化图像,以便为 CNN 做准备。我们还将浏览一些图片,以确保数据已经正确加载。

cifar10 图像只有 32 x 32 像素,因此在这里放大时看起来有颗粒,但 CNN 不知道它有颗粒,它看到的只是数据。
从 ImageDataGenerator()创建图像生成器
用 keras 增加我们的图像数据非常简单。杰森·布朗利在这方面提供了很棒的教程。首先,我们需要通过调用ImageDataGenerator()函数创建一个图像生成器,并向它传递一个参数列表,描述我们希望它对图像执行的更改。然后,我们将调用图像生成器上的fit()函数,它将把更改一批一批地应用到图像上。默认情况下,修改将被随机应用,所以不是每个图像每次都会改变。您还可以使用keras.preprocessing将增强的图像文件导出到一个文件夹中,以便建立一个巨大的修改图像数据集。
我们将在这里看一些视觉上更有趣的增强。所有可能的ImageDataGenerator()参数的描述以及keras.preprocessing中可用的其他方法列表可在 keras 文档中找到。
随机旋转图像

垂直翻转图像

水平翻转图像也是为分类器生成更多数据的经典方法之一。这很容易做到,并且可能对这个数据集更有意义,但是,我已经省略了代码和图像,因为在没有看到原始图像的情况下,没有办法知道狗或猫的图像是否被水平翻转。
将图像垂直或水平移动 20%

直方图均衡技术
直方图均衡化是采用低对比度图像并增加图像相对高点和低点之间的对比度的过程,以便带出阴影中的细微差异并创建更高对比度的图像。结果可能是惊人的,尤其是对于灰度图像。以下是一些例子:

https://www.bruzed.com/2009/10/contrast-stretching-and-histogram-equalization/

http://www-classes.usc.edu/engr/ee-s/569/qa2/Histogram%20Equalization.htm

https://studentathome.wordpress.com/2013/03/27/local-histogram-equalization/
在本帖中,我们将探讨三种提高图像对比度的图像增强技术。这些方法有时也被称为“直方图拉伸”,因为它们采用像素强度的分布,并拉伸该分布以适应更大范围的值,从而增加图像最亮和最暗部分之间的对比度。
直方图均衡
直方图均衡化通过检测图像中像素密度的分布并将这些像素密度绘制在直方图上来增加图像的对比度。然后分析该直方图的分布,如果存在当前未被利用的像素亮度范围,则直方图被“拉伸”以覆盖这些范围,然后被“反向投影到图像上以增加图像的整体对比度。
对比度扩展
对比度拉伸采用的方法是分析图像中像素密度的分布,然后“重新缩放图像,以包含第二和第 98 个百分点内的所有强度。”
自适应均衡
自适应均衡不同于常规直方图均衡,因为计算了几个不同的直方图,每个直方图对应于图像的不同部分;然而,它有在其他不感兴趣的部分过度放大噪声的趋势。

以下代码来自于 sci-kit image library 的 docs,并已被修改以在我们的 cifar10 数据集的第一个图像上执行上述三个增强。首先,我们将从 sci-kit image (skimage)库中导入必要的模块,然后修改来自 sci-kit image 文档的代码,以查看数据集的第一个图像的增强。
以下是来自 cifar10 数据集的低对比度猫的修改图像。如您所见,结果不如低对比度灰度图像那样引人注目,但仍有助于提高图像质量。

修改 keras .预处理以启用直方图均衡化技术。
既然我们已经成功地修改了来自 cifar10 数据集的一幅图像,我们将演示如何修改 keras.preprocessing image.py 文件,以便执行这些不同的直方图修改技术,就像我们使用ImageDataGenerator()对现成的 keras 增强所做的那样。为了实现这一功能,我们将遵循以下一般步骤:
概观
- 在您自己的机器上找到 keras.preprocessing image.py 文件。
- 将 image.py 文件复制到您的文件或笔记本中。
- 将每个均衡技术的一个属性添加到 DataImageGenerator() init 函数中。
- 将 IF 语句子句添加到 random_transform 方法中,以便在我们调用
datagen.fit()时实现扩充。
对 keras.preprocessing 的image.py文件进行修改的最简单的方法之一就是简单地将其内容复制并粘贴到我们的代码中。这将消除导入它的需要。你可以在这里查看 github 上image.py文件的内容。然而,为了确保你抓取的文件版本与你之前导入的文件版本相同,最好抓取你机器上已经存在的image.py文件。运行print(keras.__file__)将打印出机器上 keras 库的路径。该路径(对于 mac 用户)可能类似于:
/usr/local/lib/python3.5/dist-packages/keras/__init__.pyc
这为我们提供了本地机器上 keras 的路径。继续导航到那里,然后进入preprocessing文件夹。在preprocessing里面你会看到image.py文件。然后,您可以将其内容复制到您的代码中。这个文件很长,但是对于初学者来说,这可能是对它进行修改的最简单的方法之一。
编辑image.py
在 image.py 的顶部,你可以注释掉这一行:from ..import backend as K,如果你已经在上面包含了它。
此时,还要仔细检查以确保您导入了必要的 scikit-image 模块,以便复制的image.py可以看到它们。
from skimage import data, img_as_float
from skimage import exposure
我们现在需要在 ImageDataGenerator 类的__init__ 方法中添加六行代码,这样它就有三个属性来表示我们将要添加的增强类型。下面的代码是从我当前的 image.py 复制过来的,旁边有#####的那几行是我添加的。
random_transform()函数(如下)响应我们传递给ImageDataGenerator()函数的参数。如果我们已经将contrast_stretching、adaptive_equalization或histogram_equalization参数设置为True,当我们调用ImageDataGenerator()(就像我们对其他图像增强所做的那样)random_transform()将应用所需的图像增强。
现在我们已经有了所有必要的代码,可以调用 ImageDataGenerator()来执行直方图修改技术。如果我们将这三个值都设置为True,下面是一些图像的样子。

对于任何给定的数据集,我不建议将它们中的一个以上设置为True。请确保使用您的特定数据集进行实验,以了解哪些内容有助于提高分类器的准确性。对于彩色图像,我发现对比度拉伸通常比直方图修改或自适应均衡获得更好的结果。
训练和验证你的 Keras CNN
最后一步是训练我们的 CNN,并使用model.fit_generator()验证模型,以便在增强图像上训练和验证我们的神经网络。

深度学习中的图像字幕
什么是图像字幕?
图像字幕是生成图像文字描述的过程。它同时使用了自然语言处理和计算机视觉来生成字幕。

Image Captioning
数据集将采用[ 图像 → 标题的形式。数据集由输入图像及其相应的输出标题组成。
网络拓扑

编码器
卷积神经网络(CNN)可以被认为是一个编码器。输入图像交给 CNN 提取特征。CNN 的最后一个隐藏状态连接到解码器。
解码器
解码器是一个递归神经网络(RNN ),它在单词级别进行语言建模。第一时间步接收编码器的编码输出和矢量。
培训
CNN(编码器)最后一个隐藏状态的输出被提供给解码器的第一个时间步长。我们设置 x1 = <开始> 向量和期望的标号 y1 = 序列中的第一个字。类似地,我们设置第一个单词的 x2 = 单词向量,并期望网络预测第二个单词。最后,在最后一步, xT = 最后一个字,目标标签yT=**token。**
在训练过程中,即使解码器之前出错,也会在每个时间步向解码器提供正确的输入。
测试
****图像表示被提供给解码器的第一时间步。设置 x1 = <开始> 向量,计算第一个字 y1 的分布。我们从分布中抽取一个单词(或者挑选 argmax),将其嵌入向量设为 x2 ,重复这个过程,直到生成 < END > token。
在测试期间,解码器在时间 t 的输出被反馈,并成为解码器在时间 t+1 的输入
数据集
- 语境中的常见对象(COCO) 。超过 120,000 张图片和描述的集合
- Flickr 8K 。从 flickr.com 收集了八千张描述过的图片。
- Flickr 30K 。收集了 3 万张来自 flickr.com 的图片。
- 探索图像字幕数据集,2016 年
使用 Keras 的图像字幕
教计算机描述图片
目录:
- 介绍
- 动机
- 先决条件
- 数据收集
- 理解数据
- 数据清理
- 加载训练集
- 数据预处理—图像
- 数据预处理—标题
- 使用生成器功能准备数据
- 单词嵌入
- 模型架构
- 推理
- 估价
- 结论和未来工作
- 参考
1。简介
在下图中你看到了什么?

Can you write a caption?
有些人可能会说“草地上的白狗”,有些人可能会说“带褐色斑点的白狗”,还有一些人可能会说“草地上的狗和一些粉红色的花”。
毫无疑问,所有这些说明都与这张图片相关,可能还有其他一些说明。但是我想说的是。对我们人类来说,只是看一眼图片,然后用合适的语言描述它是如此容易。即使是一个 5 岁的孩子也能轻而易举地做到。
但是,你能编写一个将图像作为输入并产生相关标题作为输出的计算机程序吗?

The Problem
就在深度神经网络最近发展之前,这个问题甚至是计算机视觉领域最先进的研究人员都无法想象的。但是随着深度学习的出现,如果我们有了所需的数据集,这个问题就可以很容易地解决。
Andrej Karapathy 在斯坦福大学[1]的博士论文中很好地研究了这个问题,他现在也是特斯拉的 AI 总监。
这篇博客文章的目的是解释(用尽可能简单的话)如何使用深度学习来解决为给定图像生成字幕的问题,因此得名图像字幕。
为了更好地了解这个问题,我强烈建议使用这个由微软创建的最先进的系统,名为 字幕机器人 。只需转到此链接,尝试上传您想要的任何图片;这个系统会为它生成一个标题。
2.动机
我们必须首先理解这个问题对现实世界的场景有多重要。让我们看看这个问题的解决方案非常有用的几个应用。
- 自动驾驶汽车——自动驾驶是最大的挑战之一,如果我们能够适当地描述汽车周围的场景,它可以促进自动驾驶系统的发展。
- 帮助盲人——我们可以为盲人创造一种产品,引导他们在没有他人帮助的情况下上路。我们可以先将场景转换成文本,然后将文本转换成声音。两者现在都是深度学习的著名应用。参考这个 链接 ,它展示了 Nvidia research 如何试图创造这样一个产品。
- 今天,闭路电视摄像头无处不在,但随着观看世界,如果我们也可以生成相关的字幕,那么我们就可以在某个地方发生恶意活动时发出警报。这可能有助于减少一些犯罪和/或事故。
- 自动字幕可以帮助,使谷歌图片搜索像谷歌搜索一样好,因为然后每个图像可以首先转换成标题,然后可以根据标题进行搜索。
**3。**先决条件
这篇文章假设读者熟悉基本的深度学习概念,如多层感知器、卷积神经网络、递归神经网络、迁移学习、梯度下降、反向传播、过拟合、概率、文本处理、Python 语法和数据结构、Keras 库等。
4.数据收集
这个问题有很多开源数据集可用,像 Flickr 8k(包含 8k 张图片)、Flickr 30k(包含 30k 张图片)、MS COCO(包含 180k 张图片)等。
但是出于这个案例研究的目的,我使用了 Flickr 8k 数据集,您可以通过填写伊利诺伊大学香槟分校提供的这个 表格 来下载该数据集。此外,用大量图像训练模型在不是非常高端的 PC/膝上型电脑的系统上可能是不可行的。
这个数据集包含 8000 个图像,每个图像有 5 个标题(正如我们在简介部分已经看到的,一个图像可以有多个标题,所有标题同时相关)。
这些图像分为以下两部分:
- 训练集— 6000 幅图像
- 开发集— 1000 个图像
- 测试集— 1000 幅图像
5.理解数据
如果您已经从我提供的链接下载了数据,那么,除了图像之外,您还将获得一些与图像相关的文本文件。其中一个文件是“Flickr8k.token.txt ”,它包含每张图片的名称及其 5 个标题。我们可以这样阅读这个文件:
# Below is the path for the file "Flickr8k.token.txt" on your disk
filename = "/dataset/TextFiles/Flickr8k.token.txt"
file = open(filename, 'r')
doc = file.read()
该文本文件如下所示:
Sample Text File
因此每行包含 #i ,其中 0≤i≤4
即图像的名称、标题号(0 到 4)和实际标题。
现在,我们创建一个名为“descriptions”的字典,它包含图像的名称(没有。jpg 扩展名)作为键,对应图像的 5 个标题的列表作为值。
例如,参考上面的屏幕截图,字典将如下所示:
descriptions['101654506_8eb26cfb60'] = ['A brown and white dog is running through the snow .', 'A dog is running in the snow', 'A dog running through snow .', 'a white and brown dog is running through a snow covered field .', 'The white and brown dog is running over the surface of the snow .']
6.数据清理
当我们处理文本时,我们通常会执行一些基本的清理,如将所有单词小写(否则“hello”和“Hello”将被视为两个独立的单词),删除特殊标记(如“%”、“$”、“#”等)。),删除包含数字的单词(如“hey199”等)。).
以下代码执行这些基本的清理步骤:
Code to perform Data Cleaning
创建在数据集中所有 8000*5(即 40000)个图像标题(语料库)中出现的所有唯一单词的词汇表;
vocabulary = set()
for key in descriptions.keys():
[vocabulary.update(d.split()) for d in descriptions[key]]
print('Original Vocabulary Size: %d' % len(vocabulary))
Original Vocabulary Size: 8763
这意味着在所有 40000 个图片说明中,我们有 8763 个独特的单词。我们将所有这些说明连同它们的图像名称一起写入一个新文件,即“descriptions . txt”,并将其保存在磁盘上。
然而,如果我们仔细想想,这些词中有许多会出现很少次,比如说 1 次、2 次或 3 次。由于我们正在创建一个预测模型,我们不希望所有的单词都出现在我们的词汇表中,而是更有可能出现或更常见的单词。这有助于模型变得对异常值更加稳健,并减少错误。
因此,我们只考虑那些在整个语料库中至少出现 10 次的单词。这方面的代码如下:
Code to retain only those words which occur at least 10 times in the corpus
所以现在我们的词汇中只有 1651 个独特的单词。然而,我们将附加 0(零填充将在后面解释),因此总字数= 1651+1 =1652(0 的一个索引)。
7.加载训练集
文本文件“Flickr_8k.trainImages.txt”包含属于训练集的图像的名称。所以我们把这些名字加载到一个列表“train”中。
filename = 'dataset/TextFiles/Flickr_8k.trainImages.txt'
doc = load_doc(filename)
train = list()
for line in doc.split('\n'):
identifier = line.split('.')[0]
train.append(identifier)
print('Dataset: %d' % len(train))
Dataset: 6000
因此,我们在名为“train”的列表中分离了 6000 个训练图像。
现在,我们从 Python 字典“train_descriptions”中的“descriptions.txt”(保存在硬盘上)加载这些图像的描述。
然而,当我们加载它们时,我们将在每个标题中添加两个标记,如下所示(重要性稍后解释):
startseq ’ - >这是一个开始序列标记,将被添加到每个字幕的开头。
endseq ’ - >这是一个结束序列标记,将被添加到每个标题的末尾。
8.数据预处理—图像
图像只是我们模型的输入(X)。您可能已经知道,模型的任何输入都必须以向量的形式给出。
我们需要将每张图像转换成固定大小的向量,然后将其作为神经网络的输入。为此,我们通过使用 Google Research 创建的 InceptionV3 模型(卷积神经网络)选择了迁移学习。
该模型在 Imagenet 数据集上进行训练,以对 1000 个不同类别的图像执行图像分类。然而,我们在这里的目的不是对图像进行分类,而是获得每幅图像的固定长度的信息向量。这个过程被称为自动特征工程。
因此,我们只是从模型中移除最后一个 softmax 层,并为每个图像提取 2048 长度向量(瓶颈特征),如下所示:

Feature Vector Extraction (Feature Engineering) from InceptionV3
这方面的代码如下:
# Get the InceptionV3 model trained on imagenet data
model = InceptionV3(weights='imagenet')
# Remove the last layer (output softmax layer) from the inception v3
model_new = Model(model.input, model.layers[-2].output)
现在,我们将每个图像传递给该模型,以获得相应的 2048 长度的特征向量,如下所示:
# Convert all the images to size 299x299 as expected by the
# inception v3 model
img = image.load_img(image_path, target_size=(299, 299))
# Convert PIL image to numpy array of 3-dimensions
x = image.img_to_array(img)
# Add one more dimension
x = np.expand_dims(x, axis=0)
# preprocess images using preprocess_input() from inception module
x = preprocess_input(x)
# reshape from (1, 2048) to (2048, )
x = np.reshape(x, x.shape[1])
我们将所有的瓶颈训练特征保存在一个 Python 字典中,并使用 Pickle 文件保存在磁盘上,即“ encoded_train_images.pkl ”,其关键字是图像名,值是对应的 2048 长度特征向量。
**注意:**如果您没有高端 PC/笔记本电脑,这个过程可能需要一两个小时。
类似地,我们对所有的测试图像进行编码,并将它们保存在文件“ encoded_test_images.pkl ”中。
9.数据预处理—标题
我们必须注意,字幕是我们想要预测的东西。因此在训练期间,字幕将是模型正在学习预测的目标变量(Y)。
但是对给定图像的整个字幕的预测不会立即发生。我们将逐字预测字幕**。因此,我们需要将每个单词编码成一个固定大小的向量。然而,这一部分将在我们稍后查看模型设计时看到,但现在我们将创建两个 Python 字典,即“wordtoix”(发音—单词到索引)和“ixtoword”(发音—单词到索引)。**
简单地说,我们将用一个整数(索引)来表示词汇表中的每个唯一的单词。如上所述,我们在语料库中有 1652 个唯一的单词,因此每个单词将由 1 到 1652 之间的整数索引来表示。
这两个 Python 字典的用法如下:
wordtoix[’ abc ‘]–>返回单词’ ABC '的索引
ixtoword[k] ->返回索引为“k”的单词
使用的代码如下:
ixtoword = {}
wordtoix = {}ix = 1
for w in vocab:
wordtoix[w] = ix
ixtoword[ix] = w
ix += 1
我们还需要计算一个参数,即字幕的最大长度,我们的计算如下:
# convert a dictionary of clean descriptions to a list of descriptions
def to_lines(descriptions):
all_desc = list()
for key in descriptions.keys():
[all_desc.append(d) for d in descriptions[key]]
return all_desc# calculate the length of the description with the most words
def max_length(descriptions):
lines = to_lines(descriptions)
return max(len(d.split()) for d in lines)# determine the maximum sequence length
max_length = max_length(train_descriptions)
print('Max Description Length: %d' % max_length)
Max Description Length: 34
所以任何标题的最大长度是 34。
****10。使用生成器功能准备数据
这是本案例研究中最重要的步骤之一。在这里,我们将了解如何以一种方便的方式准备数据,以作为深度学习模型的输入。
在下文中,我将尝试通过以下示例来解释剩余的步骤:
假设我们有 3 张图片和 3 个相应的标题,如下所示:

(Train image 1) Caption -> The black cat sat on grass

(Train image 2) Caption -> The white cat is walking on road

(Test image) Caption -> The black cat is walking on grass
现在,假设我们使用前两幅图像和它们的标题来训练模型,使用第三幅图像来测试我们的模型。
现在将要回答的问题是:我们如何将这一问题框定为监督学习问题?,数据矩阵是什么样子的?我们有多少数据点?等。
首先,我们需要将两个图像转换成它们相应的 2048 长度的特征向量,如上所述。设“图像 _1 ”和“图像 _2 ”分别为前两幅图像的特征向量
其次,让我们为前两个(train)标题构建词汇表,在这两个标题中添加两个标记“startseq”和“endseq”:(假设我们已经执行了基本的清理步骤)
caption _ 1–> “黑猫坐在草地上”
caption _ 2–> " start seq 白猫走在路上 endseq "
vocab = {black,cat,endseq,grass,is,on,road,sat,startseq,the,walking,white}
让我们给词汇表中的每个单词编个索引:
黑色-1,猫-2,结束序列-3,草-4,是-5,on -6,道路-7,sat -8,开始序列-9,the -10,步行-11,白色-12
现在让我们试着把它框定为一个监督学习问题其中我们有一组数据点 D = {Xi,易},其中 Xi 是数据点‘我’的特征向量,易是相应的目标变量。
让我们取第一个图像向量 Image_1 和它对应的标题“ startseq the 黑猫坐在草地上 endseq ”。回想一下,图像向量是输入,标题是我们需要预测的。但是我们预测标题的方式如下:
第一次,我们提供图像向量和第一个单词作为输入,并尝试预测第二个单词,即:
input = Image _ 1+’ start seq ';Output = 'the ’
然后,我们提供图像向量和前两个单词作为输入,并尝试预测第三个单词,即:
input = Image _ 1+’ start seq the ';输出= ‘猫’
诸如此类…
因此,我们可以将一幅图像的数据矩阵及其相应的标题总结如下:

Data points corresponding to one image and its caption
必须注意,一个图像+字幕不是单个数据点**,而是取决于字幕长度的多个数据点。**
类似地,如果我们考虑图像及其标题,我们的数据矩阵将如下所示:

Data Matrix for both the images and captions
我们现在必须明白,在每一个数据点中,不仅仅是图像作为系统的输入,还有部分标题帮助预测序列中的下一个单词。****
由于我们正在处理序列**,我们将使用递归神经网络来读取这些部分字幕(稍后将详细介绍)。**
然而,我们已经讨论过,我们不会传递标题的实际英文文本,而是传递索引序列,其中每个索引代表一个唯一的单词。
因为我们已经为每个单词创建了一个索引,现在让我们用它们的索引来替换单词,并理解数据矩阵将会是什么样子:

Data matrix after replacing the words by their indices
由于我们将进行批处理**(稍后解释),我们需要确保每个序列的长度相等。因此,我们需要在每个序列的末尾添加 0 的(零填充)。但是我们应该在每个序列中添加多少个零呢?**
这就是我们计算标题最大长度的原因,它是 34(如果你记得的话)。因此,我们将添加这些数量的零,这将导致每个序列的长度为 34。
数据矩阵将如下所示:

Appending zeros to each sequence to make them all of same length 34
需要数据生成器:
我希望这能给你一个好的感觉,关于我们如何为这个问题准备数据集。然而,这里面有一个很大的陷阱。
在上面的例子中,我只考虑了导致 15 个数据点的 2 个图像和标题。
然而,在我们实际的训练数据集中,我们有 6000 张图片,每张图片有 5 个标题。这使得总共有 30000 张图片和说明文字。
即使我们假设每个字幕平均只有 7 个单词长,也将导致总共 30000*7,即 210000 个数据点。
计算数据矩阵的大小:

Data Matrix
数据矩阵的大小= n*m
其中 n->数据点的数量(假设为 210000)
和 m->每个数据点的长度
显然 m=图像向量的长度(2048) +部分字幕的长度(x)。
m = 2048 + x
但是 x 的值是多少呢?
你可能认为是 34,但是不对,等等,这是错的。
每个单词(或索引)将通过一种单词嵌入技术被映射(嵌入)到更高维度的空间。
稍后,在模型构建阶段,我们将看到使用预训练的手套单词嵌入模型将每个单词/索引映射到 200 长的向量。
现在每个序列包含 34 个索引,其中每个索引是长度为 200 的向量。因此 x = 34*200 = 6800
因此,m = 2048 + 6800 = 8848。
最后,数据矩阵的大小= 210000 * 8848= 1858080000 块。
现在,即使我们假设一个块占用 2 个字节,那么,为了存储这个数据矩阵,我们将需要超过 3 GB 的主存储器。
这是一个相当大的需求,即使我们能够将这么多数据加载到 RAM 中,也会使系统非常慢。
由于这个原因,我们在深度学习中大量使用数据生成器。数据生成器是一种在 Python 中本地实现的功能。Keras API 提供的 ImageDataGenerator 类只不过是 Python 中生成器函数的一个实现。
那么使用生成器函数如何解决这个问题呢?
如果你知道深度学习的基础,那么你必须知道,为了在特定的数据集上训练模型,我们使用一些版本的随机梯度下降(SGD),如 Adam,Rmsprop,Adagrad 等。
使用 SGD ,我们不用计算整个数据集的损失来更新梯度。相反,在每次迭代中,我们计算一批数据点(通常是 64、128、256 等)的损失。)来更新梯度。****
这意味着我们不需要一次将整个数据集存储在内存中。即使我们在内存中有当前的一批点,它也足以满足我们的目的。
Python 中的生成器函数正好用于此目的。它就像一个迭代器,从上次被调用的地方恢复功能。
数据生成器的代码如下:
Code to load data in batches
11。单词嵌入
如上所述,我们将把每个单词(索引)映射到 200 长的向量,为此,我们将使用预先训练的手套模型:
**# Load Glove vectors
glove_dir = 'dataset/glove'
embeddings_index = {} # empty dictionary
f = open(os.path.join(glove_dir, 'glove.6B.200d.txt'), encoding="utf-8")for line in f:
values = line.split()
word = values[0]
coefs = np.asarray(values[1:], dtype='float32')
embeddings_index[word] = coefs
f.close()**
现在,对于我们词汇表中的所有 1652 个唯一单词,我们创建一个嵌入矩阵,该矩阵将在训练之前加载到模型中。
**embedding_dim = 200# Get 200-dim dense vector for each of the 10000 words in out vocabulary
embedding_matrix = np.zeros((vocab_size, embedding_dim))for word, i in wordtoix.items():
#if i < max_words:
embedding_vector = embeddings_index.get(word)
if embedding_vector is not None:
# Words not found in the embedding index will be all zeros
embedding_matrix[i] = embedding_vector**
要了解更多关于单词嵌入的信息,请参考此 链接
12.模型架构
由于输入由两部分组成,一个图像向量和一个部分标题,我们不能使用 Keras 库提供的顺序 API。出于这个原因,我们使用函数式 API 来创建合并模型。
首先,让我们看看包含高级子模块的简要架构:

High level architecture
我们将模型定义如下:
Code to define the Model
让我们来看看模型总结:

Summary of the parameters in the model
下图有助于形象化网络结构,并更好地理解两个输入流:

Flowchart of the architecture
右侧的红色文本是为您提供的注释,用于将您对数据准备的理解映射到模型架构。
****LSTM(长短期记忆)层只不过是一个专门的递归神经网络来处理序列输入(在我们的例子中是部分字幕)。要了解更多关于 LSTM 的信息,点击 这里 。
如果您已经阅读了前面的部分,我认为阅读这些评论应该有助于您以一种直接的方式理解模型架构。
回想一下,我们已经从预训练的手套模型中创建了一个嵌入矩阵,我们需要在开始训练之前将它包含在模型中:
**model.layers[2].set_weights([embedding_matrix])
model.layers[2].trainable = False**
请注意,由于我们使用的是预训练的嵌入层,所以在训练模型之前,我们需要冻结它(可训练=假),这样它就不会在反向传播过程中更新。
最后,我们使用 adam 优化器编译模型
**model.compile(loss=’categorical_crossentropy’, optimizer=’adam’)**
最后,通过反向传播算法更新模型的权重,并且给定图像特征向量和部分字幕,模型将学习输出单词。总而言之,我们有:
Input_1 ->部分字幕
Input_2 ->图像特征向量
Output ->一个适当的单词,在 input_1 中提供的部分字幕序列中的下一个(或者用概率术语我们说以图像向量和部分字幕为条件)
训练期间的高参数:
然后用 0.001 的初始学习率和每批 3 张图片(批量大小)训练该模型 30 个时期。然而,在 20 个时期之后,学习率降低到 0.0001,并且每批在 6 张图片上训练模型。
这通常是有意义的,因为在训练的后期阶段,由于模型正在走向收敛,我们必须降低学习率,以便我们朝着最小值迈出更小的步伐。此外,随着时间的推移增加批量大小有助于您的渐变更新更加强大。
****耗时:我在www.paperspace.com上使用了 GPU+ Gradient 笔记本,因此我花了大约一个小时来训练模型。然而,如果你在没有 GPU 的 PC 上训练它,它可能需要 8 到 16 个小时,这取决于你的系统配置。
13.推理
到目前为止,我们已经了解了如何准备数据和构建模型。在本系列的最后一步,我们将了解如何通过传入新图像来测试(推断)我们的模型,也就是说,我们如何为新的测试图像生成标题。
回想一下,在我们看到如何准备数据的例子中,我们只使用了前两个图像及其标题。现在,让我们使用第三个图像,并尝试理解我们希望标题如何生成。
第三个图像向量和标题如下:

Test image
描述->黑猫在草地上行走
示例中的词汇还有:
vocab = {black,cat,endseq,grass,is,on,road,sat,startseq,the,walking,white}
我们将迭代生成标题,一次一个单词,如下所示:
迭代 1:
输入:图像向量+“startseq”(作为部分字幕)
预期输出字:“the”
(现在您应该理解标记“startseq”的重要性,它在推断过程中用作任何图像的初始部分标题)。
但是等等,模型生成了一个 12 长的向量(在示例中是 1652 长的向量,而在原始示例中是 1652 长的向量),这是词汇表中所有单词的概率分布。由于这个原因,我们贪婪地选择具有最大概率的单词,给定特征向量和部分标题。
如果模型训练良好,我们必须期望单词“the”的概率最大:

Iteration 1
这被称为最大似然估计(MLE) ,即我们根据给定输入的模型选择最有可能的单词。有时这种方法也被称为贪婪搜索,因为我们贪婪地选择具有最大概率的单词。
迭代 2:
输入:图像向量+ "startseq the "
预期输出字:“黑色”

Iteration 2
迭代 3:
输入:图像向量+ "startseq the black "
预期输出字:“猫”

Iteration 3
迭代 4:
输入:图像向量+ "startseq the black cat "
预期的输出字:“是”

Iteration 4
迭代 5:
输入:图像向量+ “startseq 黑猫是”
预期输出字:“行走”

Iteration 5
迭代 6:
输入:图像向量+ “startseq 黑猫在走”
预期输出字:“开”

Iteration 6
迭代 7:
输入:图像向量+“黑猫正在行走的起始序列”
预期输出字:“草”

Iteration 7
迭代 8:
输入:图像向量+“startseq 黑猫在草地上走”
预期输出字:“endseq”

Iteration 8
这是我们停止迭代的地方。
因此,当满足以下两个条件之一时,我们停止:
- 我们遇到了一个“ endseq ”标记,这意味着模型认为这是标题的结尾。(您现在应该明白’ endseq '标记的重要性了)
- 我们达到由模型生成的单词数量的最大阈值。****
如果满足以上任何一个条件,我们就中断循环,并将生成的标题报告为给定图像的模型输出。用于推理的代码如下:
Inference with greedy search
14.估价
为了了解模型有多好,让我们尝试在测试数据集的图像上生成标题(即模型在训练期间没有看到的图像)。

Output — 1
注意:我们必须理解模型是如何精确地识别颜色的。

Output — 2

Output — 3

Output — 4

Output — 5
当然,如果我只给你看适当的说明,我是在欺骗你。世界上没有一个模型是完美的,这个模型也会犯错误。让我们来看一些例子,这些例子中的标题不是很相关,有时甚至是不相关的。

Output — 6
可能衬衫的颜色和背景色混在一起了

Output — 7
为什么模型把著名的拉菲尔·纳达尔归为女性:-)?大概是因为长发的缘故吧。

Output — 7
这次模型得到的语法不正确

Output — 9
很明显,这个模型尽了最大努力去理解这个场景,但是标题仍然不太好。

Output — 10
这又是一个模型失败,标题不相关的例子。
所以总而言之,我必须说,我天真的第一次切割模型,没有任何严格的超参数调整,在生成图像字幕方面做得很好。
重点:
我们必须理解,用于测试的图像必须与用于训练模型的图像在语义上相关。例如,如果我们在猫、狗等的图像上训练我们的模型。我们不能在飞机、瀑布等图像上测试它。这是一个训练集和测试集的分布将非常不同的例子,在这种情况下,世界上没有机器学习模型会提供良好的性能。
15.结论和未来工作
如果你已经到达这里,非常感谢。这是我第一次尝试写博客,所以我希望读者能慷慨一点,忽略我可能犯的小错误。
请参考我的 GitHub 链接 这里 访问 Jupyter 笔记本上写的完整代码。
请注意,由于模型的随机性,您生成的标题(如果您试图复制代码)可能与我的案例中生成的标题不完全相似。
当然,这只是一个初步的解决方案,可以进行许多修改来改进该解决方案,例如:
- 使用一个更大的数据集。
- 改变模型架构,例如包括注意模块。
- 做更多超参数调整(学习率、批量大小、层数、单位数、辍学率、批量标准化等。).
- 使用交叉验证集了解过拟合。
- 推断时使用波束搜索代替贪婪搜索。
- 使用 BLEU Score 评估和测量模型的性能。
- 以适当的面向对象的方式编写代码,以便其他人更容易复制:-)
16.参考
- https://cs.stanford.edu/people/karpathy/cvpr2015.pdf
- https://arxiv.org/abs/1411.4555
- https://arxiv.org/abs/1703.09137
- https://arxiv.org/abs/1708.02043
- https://machine learning mastery . com/develop-a-deep-learning-caption-generation-model-in-python/
- https://www.youtube.com/watch?v=yk6XDFm3J2c
- https://www.appliedaicourse.com/
PS: 如果你认为他们可以改进这个博客,请随时提供意见/批评,我一定会努力做出必要的修改。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言










{kind=link}
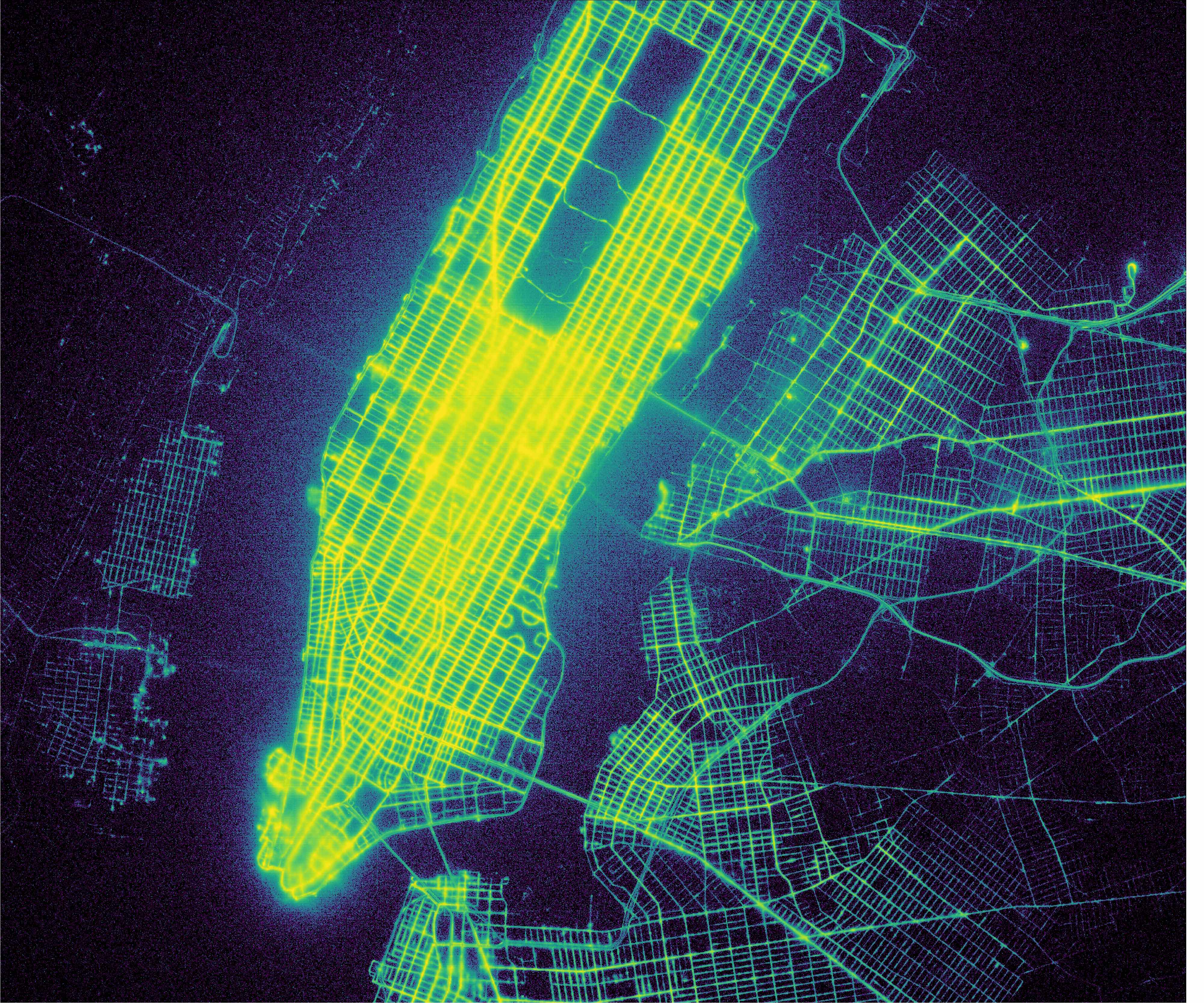{kind=link}
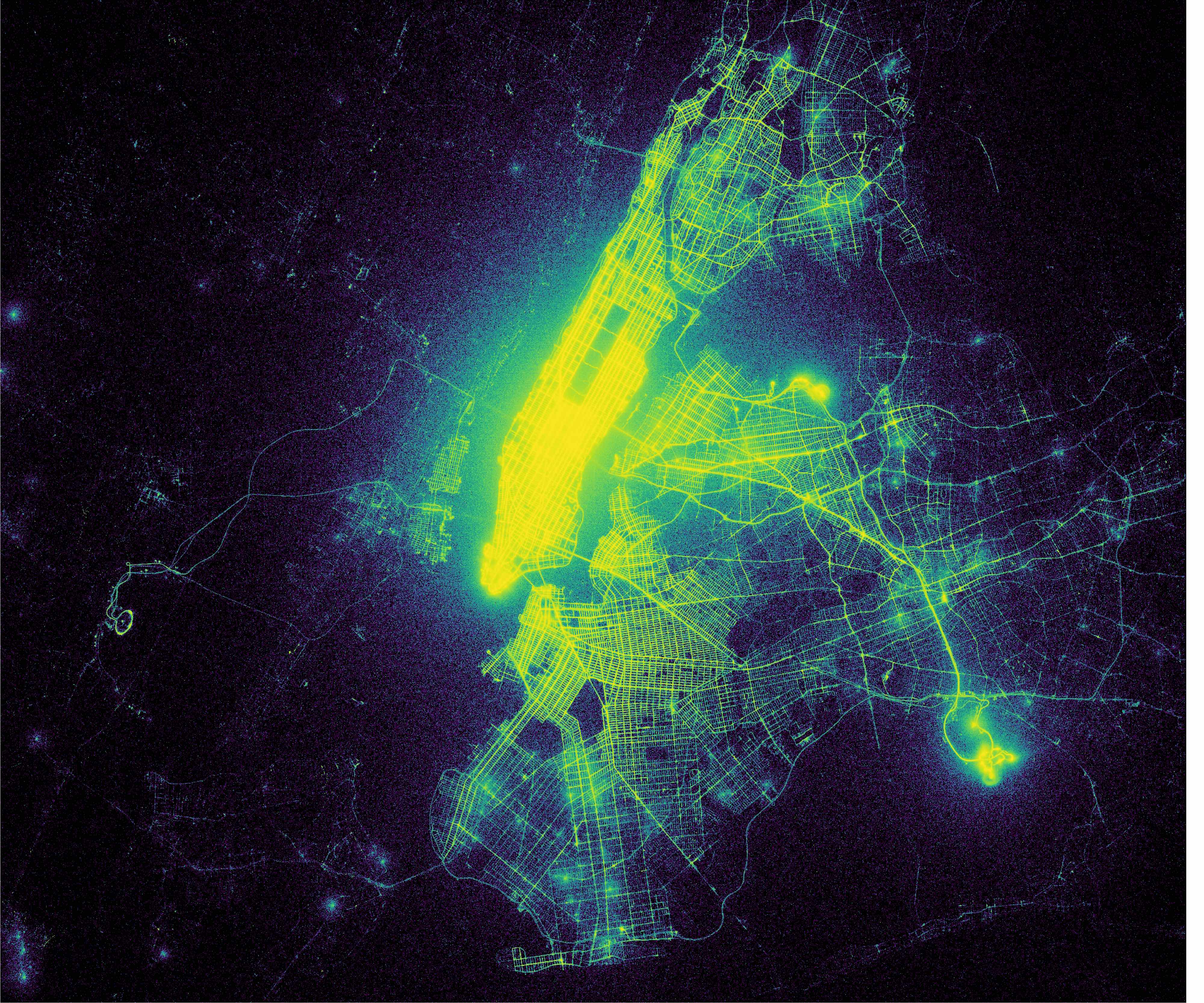{kind=link}
{kind=link}
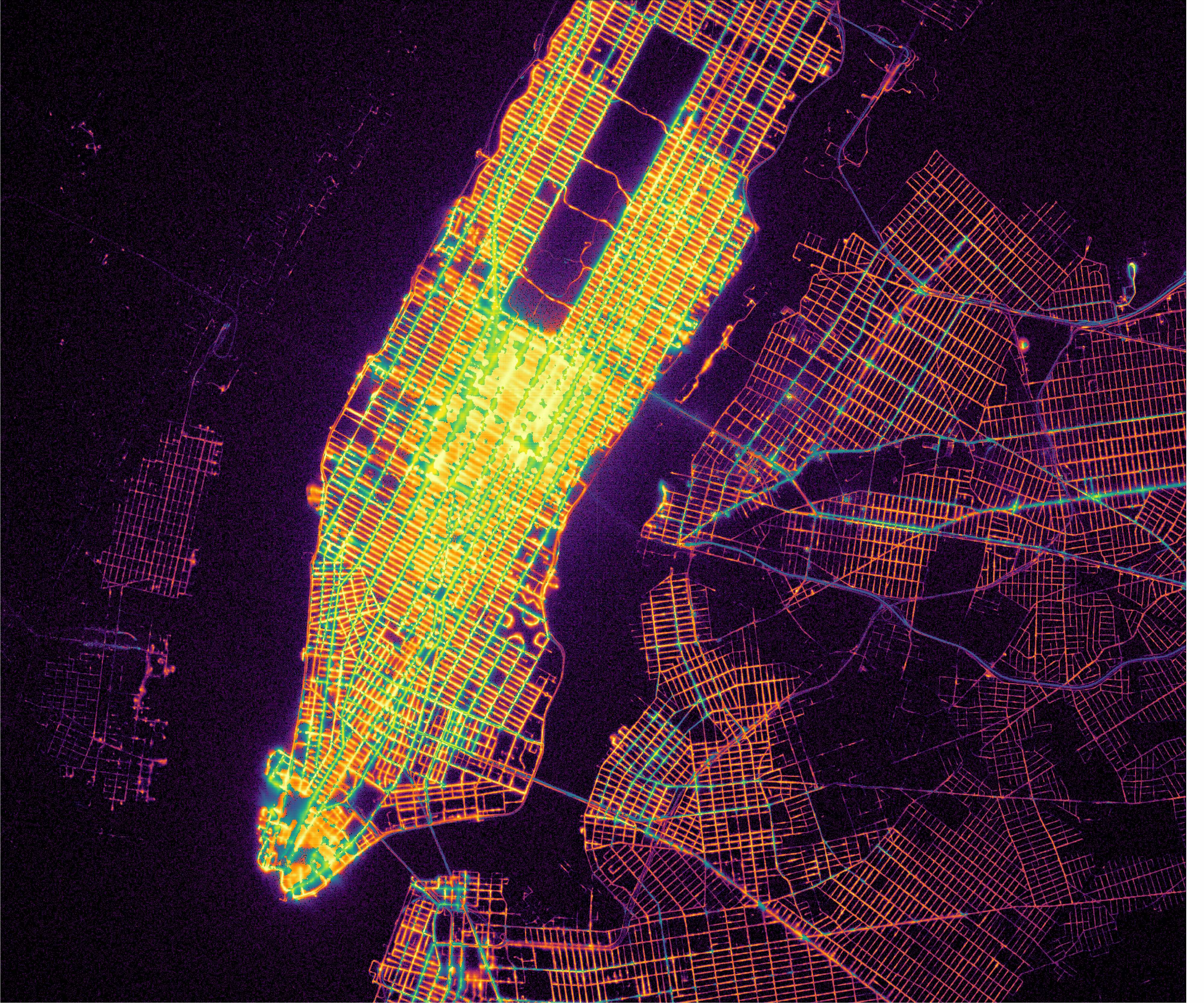{kind=link}
{kind=link}