







本周数据新闻集锦

这是一个短暂的星期,因为银行放假,但我们仍然很忙。哦,公司现在叫 Reach 而不是 Trinity Mirror,如果你看了我的简介,想知道我是否换了工作。
欧洲电视网:他们是讨厌我们,还是只讨厌我们的烂歌?
周六是欧洲歌唱大赛决赛。如果这意味着什么的话,这意味着第一次投票后几秒钟内英国获胜的所有希望都消失了,而格雷姆·诺顿几乎毫不掩饰地暗示,陪审团制度可能不完全客观,一些国家可能,你知道,倾向于投票给他们喜欢的国家,而不是他们喜欢的歌曲的国家。
这可能是真的吗?我们决定分析自 2000 年以来每个国家在现场决赛中的每一次投票。剧透:格雷姆是对的。
最亲密的关系?嗯,土耳其和阿塞拜疆总是给对方最多 12 分。每次都是。没有失败。摩尔多瓦和罗马尼亚平均各交换 11.5 分,塞浦路斯和希腊 11.6 分。
至于英国?每个人都讨厌我们。可能除了爱尔兰,他们平均给我们 5.3 分。和马耳他,他们给我们的平均分是 4.3。
匈牙利平均给我们 0.2 分。他们真的恨我们。
无论如何,我们建立了一个互动,让你可以看到自己的全部可怕的真相。在这里尝试我们的预览,或者在明天决赛的预备阶段在 Reach 网站上寻找它。


被剥夺了受教育的权利:贫穷和逃学是如何同时发生的
旷课水平与贫困有关吗?又到了什么程度?
为了找到答案,Rob Grant 决定调查全国每所学校未经许可的缺课情况,并与这些学校所在社区的贫困水平进行比较。
结果相当明显。例如,在伯明翰,该市最贫困地区的学校的逃课率是最富裕地区的三倍。
同样的模式到处都出现了。
形成恶性循环的风险是显而易见的:如果贫困地区的儿童无法接受教育,因此无法获得体面的资格,那么摆脱贫困就变得更加困难。
你可以在这里阅读更多关于 Rob 的调查。
只有七分之一的儿童性犯罪最终被送上法庭
2017 年,英格兰和威尔士警方记录了 43,284 起儿童性犯罪。
有多少是以嫌疑人出庭告终的?才 6519。
我知道这个相当令人不安的事实,因为 Deb Aru 一直在梳理当地儿童性犯罪的犯罪结果数据。全国各地的情况略有不同,但总的主题是相同的:绝大多数记录在案的犯罪不会导致起诉。

这是为什么呢?嗯,在大约一半的案件中有“证据困难”,而在许多其他案件中,受害者选择不继续进行。
一些警察部门对 Deb 的数据做出了回应,指出他们正在努力提高这一比例,同时也承认儿童性犯罪永远是最难证明的犯罪之一。(通常很少或没有确凿的证据。)
你如何提高利率?正如 NSPCC 对 Deb 说的那样:“在整个访谈和证据收集过程中,儿童得到适当专家的充分支持是至关重要的。”
你可以在例如布里斯托尔(这里的数字接近十分之一)利兹格里姆斯比和伯明翰读到她的发现和当地势力的反应。
准妈妈世卫组织继续吸烟
这么多人。这么多。我意识到我是 a)一个男人,和 b)一个不吸烟的人(或者说是曾经吸烟的人)。但是:这看起来很疯狂。
正如你可能预料的那样,在这个国家更贫困的地区,这些数字要糟糕得多。在大曼彻斯特地区,八分之一的准妈妈在怀孕期间都在吸烟。
在默西塞德郡是七分之一,而在德比郡大致相同。全国平均水平接近九分之一。
怀孕期间吸烟的风险众所周知。它限制了胎儿的氧气供应,阻止其正常发育,并可能导致流产、死产和婴儿猝死的更高风险。
反吸烟慈善机构 ASH 表示,尽管很大一部分女性在怀孕时会尝试戒烟,但仍有一些失败的关键标志:主要是缺乏健康服务的支持,以及与继续吸烟的伴侣生活在一起。
印刷中的数据单元
我们本周的头版主要来自我之前提到的公告,包括我们对当地犯罪数字的分析和 Deb 关于袭击护理人员的信息自由请求。



哦,我和新闻公报聊了聊数据单位,我对 2018 年数据新闻的想法,“机器人”的角色,以及类似的事情。

Click here to read
祝你周末愉快。
用 N 皇后进行数据操作
H 我们如何感知,进而如何解决问题,在很大程度上取决于给定数据的格式。事实上,通常可以将给定数据重构为一种形式,这种形式比最初呈现或收集数据的方式更有助于解决问题。在计算和数学中有一个流行的问题,它很好地证明了面向问题的数据重构的概念,它如下:
你有多少种方法可以将 n 个*(团队不可知)皇后放在一个维度为 nxn 的棋盘上,这样就没有皇后可以攻击其他的了?*
我考虑的第一种方法是将可能的解决方案表示为一个实际的棋盘,在不同的方格中放置一些皇后。一种利用这种数据格式的算法(后来证明与所提出的解决方案非常相似)包括在棋盘上的每个空间放置一个皇后。从这里开始,你可以试着把另一个皇后放在别的地方,确保第一个和第二个皇后不能互相攻击。然后对第三个皇后重复这个过程,然后是第四个,依此类推,直到你在棋盘上有了 n 个皇后。在这一点上,数数你想出了多少独特的董事会。该过程看起来像这样,为了简单起见,省略了一些内容:

你可能已经注意到了这个算法的一个或几个问题。首先,如果你严格按照流程图去做,你将会产生大量的非独特的解决方案。必须验证板是否是唯一的将浪费大量时间。第二个(也是更成问题的)问题是,每增加一个皇后,所需步骤的数量将呈指数增长。特别是,当你没有尝试每一个自由空间,并且你还没有足够的皇后,你将不得不对同一个棋盘以及一个有额外皇后的新棋盘再次执行该过程。按照这种逻辑,每次迭代都需要流程图的n * n — k个新实例,其中 k 是棋盘上已有的皇后数。问题在于,整个棋盘包含了大量的信息,我们根本不需要回答这个问题。让我们考虑提出的问题,并尝试将数据归结为一种格式,只表达我们真正需要产生解决方案的内容。
T 这里有一些方法可以让我们避免在我们知道行不通的解决方案上浪费太多时间。首先,我们知道女王可以攻击她们行中的任何东西。考虑到这一点,如果一行已经包含一个皇后,我们可以忽略整个行。添加这个简单的功能将极大地减少我们必须验证为解决方案的板的数量,以及我们需要检查唯一性的板的数量。
“但是等等!”我听到你说,“女王也可以攻击他们队伍中的任何东西,所以我们也只使用独特的队伍吧!”当我们这样做的时候,我们可能会认为只在空对角线上放置皇后是明智的。我们会到达那里;请容忍我一会儿。在这一点上,我开始怀疑摆弄整个棋盘是否真的是解决问题的最佳方式。如果我们可以轻松地表示每个皇后的行和列,并保证每个皇后的唯一性,而不需要我们管理一大块空白空间,这不是很好吗?的确会,而且碰巧有一种方法不仅能解决笨拙的棋盘问题,同时还能让我内心的组合学博士(我做梦都能拿到博士学位)高兴:输入我喜欢称之为“棋盘地图”的东西
让我们跳回到独特的行。如果每行只能容纳一个女王(它们的个人空间非常大),那么这很适合于每行只记录一个位置:女王所在的列。类似地,既然我们知道每列只能容纳一个皇后,并且我们需要一个完整的 n 皇后在我们的小战区中,我们可以说每列必须在我们的行集合中的某个地方被表示。实际电路板图的一个示例如下:

Map: 2–5–7–1–3–0–6–4
地图2-5-7-1-3-0-6-4与显示的棋盘完全对应,如下所示。映射中的第一个位置(位置 0)表示第一行,其中的值(本例中为 2)声明该行的 queen 存在于该行的第三列中。类似地,第五个位置(位置四)确定在其第四列(或第三列,因为我们从零开始)中存在皇后。把这个逻辑应用到整个地图上,你就会得到上面的板子。使用这种地图结构,很明显问题的任何解决方案都将是一种排列,即地图中数字的重新排序,平凡地图0-1-2-3-4-5-6-7\. 的重新排序。然而,我们仍然需要担心对角线。
事实证明,我们的新地图结构也恰好给了我们一个非常简单的方法来检查是否存在对角线冲突。在国际象棋棋盘上,如果一个皇后与另一个棋子相隔的行数和列数一样多,就有可能进行对角线攻击。根据这种推理,如果位置的差异与地图中任意两个项目的数量差异相同或相反(例如,3 是 3 的倒数),我们可以丢弃该地图,因为它不是问题的有效解决方案。考虑到这一点,我们的新算法变成:

请注意,这个操作没有分支,需要在当前迭代之后进行多个新的迭代。此外,平凡地图的每个排列保证代表一个独特的棋盘,因此我们可以完全消除测试是否已经计算了一个解决方案。我们的地图结构也先发制人地消除了大量有问题的棋盘,因为我们已经保证没有水平或垂直的攻击是可能的。因此,通过放弃原始的数据格式,转而采用针对问题定制的数据格式,我们能够显著降低解决方案的复杂性。
到总结,在开发一个问题的解决方案时,考虑数据和数据呈现的格式是非常有益的。操纵传达比回答给定问题所需更多信息的数据是对资源(在计算的情况下是时间和内存)的浪费。在 N 皇后的例子中,我提出的第一个解决方案花了一分多钟来计算从 0 到 8 的值的答案,而第二个只花了不到 30 毫秒。对于技术上更倾向于,原始解决方案在***【o(nᴺ】*处操作,其中 N 是板的尺寸(因此 n ),而第二个更简洁的数据集允许在 O(n!)。
数据市场:信息时代的圣杯

这是数据深度挖掘系列的第 2 部分。 第 1 部分 描述了数据如何改变我们经济和社会的几乎所有方面,但数据经济的真正希望在很大程度上仍未实现,因为我们仍然缺乏允许标准、安全和高效的数据交换的技术。
进入数据市场
首先,什么是数据市场?就像任何市场一样,它是一个平台,可以方便地购买和销售资源(在本例中为数据)。实际上,数据市场是一种软件,数据提供者和数据消费者通过图形或后端接口连接到该软件,以从彼此购买和出售数据。
正如股票和货币在不同类型的交易所交易一样,不同类型的数据和使用情形需要不同类型的市场。举例来说,一个个人数据市场可以让个人选择向谁出售他们的个人数据,并直接将所得收入囊中;而一个商业数据市场可以让两家公司相互买卖行业数据,比如本地化的产品价格、保险理赔统计数据或某个行业最近的投资交易数据。
数据市场的关键属性
为了理解数据市场为何会成为缺失的数据经济支柱,让我们来看看 数据深度挖掘第 1 部分 中列出的阻碍其充分发挥潜力的 3 个基本障碍。
- 大多数数据都以未精炼(或非结构化)的形式存在,将它们转换为结构化数据(软件使用所需的格式)并非易事。
- 数据所有者使用不兼容的数据模型来构建他们的数据,这些数据保存在孤立的孤岛中,尽管通常会受到其他人的追捧。
- 目前还没有人知道如何高效地定价和交换数据。
尽管不同的数据市场根据其特定使用情形具有不同的属性,但一般而言,数据市场范例允许:
- **众包:**通过实现自助数据销售,他们提供了摆脱不准确/昂贵的单一来源数据的解决方案。
- **一致激励:**数据所有者/收集者将数据保持在结构化形式并提供给其他人会直接受益。
- 标准化:按照设计,市场为买卖双方定义了一个通用的数据模型和数据交换界面。
- 公平:供应商可以设定自己的价格,而消费者可以选择向谁购买,而不是拥有一个中央定价数据。
更好的知识共享模式
最终,数据市场可以被认为是一个知识共享平台,它比当前的数据源方法更好地协调了数据消费者和数据所有者的动机。
例如,手动数据收集对于数据消费者来说是一个单调乏味的过程,对数据所有者来说没有任何价值。同样,网络搜集对消费者来说是缓慢和/或昂贵的,有时甚至是非法的,对所有者来说也没有任何价值。另一方面,数据消费者和孤立的数据提供者之间的临时数据交易往往将大量权力掌握在提供者手中,使他们没有动力提供负担得起的高质量数据。
因此,矛盾的是,在我们所谓的信息时代,数据流被打破了。这使得数据获取成为一项不必要的高成本任务,同时对于经常坐拥大量未利用或未充分利用的数据的数据所有者来说,这是一个巨大的错失机会——双输。

The reality of working with data today: data scientists spend over half their time collecting, cleaning and organizing data before they can use it [Figure Eight].
然而,在市场环境中,购买者只为他们消费的数据付费,这有效地激励了数据提供商提供最高质量、最受欢迎的数据,因为这可以最大化他们的收入。同样,市场创建的基础设施和固有的数据交换标准消除了数据买方和卖方之间的摩擦,从而降低了获取数据的成本,为数据经济实现其真正潜力提供了前两个障碍的解决方案。
反过来,对消费者更好的价值可能会增加需求,从而为数据提供商提供更多的潜在收入。这最终使它成为一个比现状(想想 Airbnb)对双方都更好的交易,并形成一个正反馈循环。
最后,通过允许数据提供商设定自己的数据价格,并允许数据消费者选择向谁购买数据,数据市场不仅允许消费者表明哪些数据/卖方提供价值,而且还通过采取自由市场方法解决了数据定价难题。
由于许多组织已经将收集数据作为其正常运作的一部分,
在不久的将来,数据市场将会把现有数据的广度和深度至少扩大一个数量级,就像维基百科对百科知识所做的那样。
最后一部《大英百科全书》于 2010 年出版,涵盖了 50 万个主题。今天,维基百科有超过 500 万篇文章,每天有 600 篇新文章,每秒钟有 10 次以上的编辑。
区块链:缺失的一环
既然我们已经解决了理论问题,让我们转向实践吧。为了创建实现上述承诺的数据市场,我们需要:
- 一种让数据市场尽可能开放的方法——众包尽可能多的数据——同时保护买家和卖家免受坏人的影响。
- 一种保证数据销售者每次购买数据时都能获得报酬(并获得正确金额)的方式。
- 一个快速、安全和可扩展的微支付基础设施,允许自由使用:购买者只需支付他们消费的数据。
- 一种保证数据来源的方法,以确保购买的数据没有被篡改,并且实际上来自所谓的卖家。
区块链智能合约的出现最终创造了一种强制执行这些属性的方式,这种方式不需要数据提供者和数据消费者相互信任或市场。在处理市场参与者、数据和支付的认证时,信任是一个关键因素。事实上,信任的集中化可能是之前创建数据市场的尝试失败的主要原因之一——最明显的是微软 Azure DataMarket,它在 7 年后于 2017 年 3 月关闭。
我们现在来看看新一代的企业,它们利用区块链的技术让数据成为可交易的资产。
区块链驱动的数据市场即将到来!
数据市场就像交通工具。自行车、汽车、飞机等。每一种都构成了一种独特的技术,这使得它们在不同的使用情况下都是理想的,但是似乎不太可能存在一种通用的解决方案,可以无一例外地胜过所有其他的解决方案。
因为数据利益相关者如此多样,数据的使用案例无穷无尽,所以对数据市场进行分类的直观方法是根据它们允许参与者交换的数据类型:个人、商业和传感器数据。

Some of the key properties of blockchain-powered data marketplaces categorized by data type [The DX Network]
个人数据市场的使命是通过允许消费者根据自己的条件直接利用他们的数据赚钱来赋予他们权力。例子包括 数据 、 数据钱包 和 数据钱包 允许用户出售任何东西,从他们的电子邮件地址到社交媒体流或他们的位置。
个人数据市场的主要特征是它们具有面向消费者的组件,例如移动应用程序,其目的是收集数据,确保数据被安全地存储/交付(本地或第三方分散存储),并为用户提供管理数据购买请求的界面。在买方方面,使用 API 从目标用户处购买个体数据集,以集成到内部产品、线索生成流程、营销活动等中。
业务数据市场旨在实现高效的企业对企业数据交换,重点关注结构化数据和大型数据提供商/消费者。 海洋协议 和我们自己的 DX 网络就是这种情况,这些为交易企业知识如特定行业的数据或科学实验结果提供平台。****
商业数据市场的独特之处在于,提供商提供的数据通常与提供商本身无关。这对他们的底层技术有着根本性的影响,底层技术必须具有共享数据库的许多属性,而个人和传感器数据市场更接近于数据目录。这导致数据在市场内被聚集,从而可以立即使用。提供商和消费者都通过面向商业智能、研究、机器学习等的 API 与市场进行交互。
传感器数据市场允许从远程设备购买实时数据。例如, IOTA Data Market , DataBroker DAO 和stream提供污染、电网和车辆远程信息处理数据馈送。
传感器数据市场的特性是待售数据的实时性。目前,卖家在市场界面上列出他们的传感器,以及每期或每次读数的价格,买家使用相同的界面订阅数据流。在未来,物联网设备可以使用 marketplace APIs 自动列出自己并将其数据流货币化,和/或自主从其他设备购买数据流,以改善城市生活、交通、制造等。
**如果你知道另一个应该在上面提到的数据市场,请在下面留下评论或联系@twitter.com/itsJeremiahS
智能合同是关键
区块链驱动的数据市场是推动新兴数据经济的创新。下一次数据深度探讨将给出智能合约如何用于在数据市场中分散信任的实际细节。
数据挖掘
1.数据挖掘和工具简介
一个小序言
数据挖掘有时被称为从数据中发现知识(KDD ),就是在数据中发现模式。这个领域已经发展成为一门科学,而不仅仅是信息技术中的一个模块,因为它在所有领域都有越来越多的用例。本文是我准备发表的关于数据挖掘的系列文章的第一篇,从简单的步骤开始,向更深层次的概念发展。
为什么和如何?
在现代社会中,随着社交网络的发展,数据以非常快的速度产生。数据本身没有任何意义,除非它们被识别为以某种方式(模式)相关。这种模式的发现是 KDD,它已经成为信息技术的自然演变。数据就是金钱!所有的购物建议,生物学、医学的新发现,甚至是微小的板球预测都是一些相关数据 KDD 的结果。
如何做是最有趣的部分。数据科学已经成为一个完整的研究领域,数学、计算机科学和数据所属的所有其他科学都在其中发挥主要作用。如今,这与程序员几乎没有任何关系。这是一个非常快速的烤箱加热介绍。
弄脏手
对于本系列,我们将使用 Python,我们认为数据主要是结构化数据。这意味着数据遵循表格格式,其中属性是表格标题,数据以行的方式存在。
为什么是 python? Python 是一种解释型语言,其中大部分数据挖掘和预处理库都是 C++扩展,使得用户执行起来既快速又简单。
为什么不是 python?
Python 按照它的解释可能需要更多的 CPU 时间,在移动计算中它不是首选。节省程序员时间,代价是 cpu 时间。python 语言的并发性不是很有效,因为它是一种解释型语言,而 C/C++包装器的使用在一定程度上解决了这个问题。
基本 python 库
普通 Python 无法独自完成很多工作。我们需要一堆图书馆。让我们看看如何在我们的机器上安装和运行它们。
- Numpy —数值 Python,基本上用于线性代数目的,执行向量运算。
- 熊猫——用于操纵和执行数据结构上的操作
- Matplot 库——用于绘制和可视化输出工作
- IPython——交互式 Python,将一切整合在一起,我们将拭目以待。这是更好的安装使用 Anaconda 官方网站和使用 Spyder 从 Navigator(尝试一下,完全值得努力)。
- 科学 python,基本上是 Python 的科学计算器
这些库的安装可以通过访问我链接的官方页面来完成。最简单的方法是使用
pip或pip3包安装程序,它可以在所有平台上运行。
文章系列的工具
我将使用 IPython Spyder。从 Navigator 安装 Anaconda 执行 Spyder。你会看到这样的东西。

Spyder 3.1.4, The Scientific Python Development Environment
几个重要的概念
属性类型
正如我所提到的,属性与表列同义,并且种类很少。
- 被识别为分类属性的名词性名称或类别不涉及数学运算,但涉及决策运算
- 二进制
属性,即取 为真(1) 为假(0) - 序数
对排名数据有意义的属性,例如 GPA 某学生的图。 - 数字
数量属性,例如:测试案例、受害者、死亡等等,这些是大多数情况下最有趣的数字。
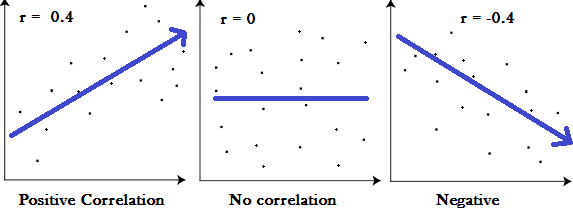
相关

From: http://www.statisticshowto.com/wp-content/uploads/2012/10/pearson-2-small.png
正相关是成正比的关系,负相关是成反比的关系,无相关意味着属性是正交的。相关性的识别证明了数据挖掘中的一个重要步骤。我们将在接下来的主题中看到。
页(page 的缩写)在数据挖掘的方法识别中,统计分布有着重要的表现。我们会用相关的话题来讨论它们。
下一步:数据清理、转换、合并和整形
数据挖掘
2.熊猫数据结构和基本操作介绍

Pandas Logo
我已经在我的 上一篇文章 中讨论了如何设置工具和数据挖掘的基本介绍。Pandas 基本上是作为一个库来管理数据结构的。该库还提供了一些对数据进行预处理和清理的重要操作。
将熊猫导入工作区
import pandas as pd导入为 pd 使其更简单,手更短。
导入特定功能
from pandas import Series, DataFrame
我们将主要使用这两种数据结构
熊猫数据结构
系列
数组形式的数据结构,让标签从 0 开始,一直递增。举个例子。
In [1]: from pandas import Series
In [2]: obj = Series([1, 2, 3, 4, 5, 6])
In [3]: obj
Out[3]:
0 1
1 2
2 3
3 4
4 5
5 6
dtype: int64
您也可以使用自定义标签。
In [1]: from pandas import DataFrame, Series
In [2]: obj = Series([4, 7, -5, 3], index=['d', 'b', 'a', 'c'])
In [3]: obj
Out[4]:
d 4
b 7
a -5
c 3
dtype: int64
一些有用的特性
*将字典转换为序列,s = Series({'age':23, 'name': 'anuradha'}),
*直接分配索引obj.index = ['attr 1', '*attr 2*', '*attr 3*'],
*索引可以有属性名obj.name = 'Population'
数据帧
这些是表格数据的数据结构,非常类似于电子表格,可以包含大量数据。
In [1]: data = {'state': ['Ohio', 'Ohio', 'Ohio', 'Nevada', 'Nevada'], 'year': [2000, 2001, 2002, 2001, 2002], 'pop': [1.5, 1.7, 3.6, 2.4, 2.9]}In [2]: data
Out[2]:
{'pop': [1.5, 1.7, 3.6, 2.4, 2.9],
'state': ['Ohio', 'Ohio', 'Ohio', 'Nevada', 'Nevada'],
'year': [2000, 2001, 2002, 2001, 2002]}In [3]: frame = DataFrame(data)
In [4]: frame
Out[4]:
pop state year
0 1.5 Ohio 2000
1 1.7 Ohio 2001
2 3.6 Ohio 2002
3 2.4 Nevada 2001
4 2.9 Nevada 2002
在不深入研究上述数据结构的情况下,让我们继续研究一些功能,并在以后探索更深的领域。😃
过滤
对于这个例子,让我们考虑下面这段代码。
In [1]: from pandas import DataFrame, Series
In [2]: import numpy as npIn [3]: data = DataFrame(np.arange(16).reshape(4,4), index=['Ohio', 'Colorado', 'Utah', 'New York'], columns=['one', 'two', 'three', 'four'])
In [4]: data
Out[4]: one two three fourOhio 0 1 2 3
Colorado 4 5 6 7
Utah 8 9 10 11
New York 12 13 14 15
我们使用np.arange(16)创建一个从 0 到 15 的元素数组,并使用reshape(4, 4)使其成为一个 4x4 的矩阵。只是一组虚拟数据。
布尔比较
In [6]: data > 5Out[6]: one two three fourOhio False False False False
Colorado False False True True
Utah True True True True
New York True True True True
代替
我们提供了一个查询函数data < 5和一个替换操作= -1来用-1 替换小于 5 的值。
In [7]: data[data < 5] = -1
In [8]: data
Out[8]: one two three four
Ohio -1 -1 -1 -1
Colorado -1 5 6 7
Utah 8 9 10 11
New York 12 13 14 15
真实场景中的应用
熊猫的一个直接应用是处理缺失值。大多数时候我们进行数据挖掘得到的数据并不是干净纯粹的数据。它们包含不一致数字的缺失数字。因此,我们需要把它们过滤掉,或者用一个替代的数字来代替。
过滤掉丢失的值
创建带有缺失值(NaN 值或非数字值)的样本数组。
In [9]: a = np.array([1,2,3,np.nan,4])
In [10]: a
Out[10]: array([ 1., 2., 3., nan, 4.])
In [11]: df = DataFrame(a)
In [12]: df
Out[12]: 00 1.0
1 2.0
2 3.0
3 NaN
4 4.0
一旦我们有了缺失值/nan 的数据框,我们可以使用以下方式填充它们。这里我用-1 填充它。
In [13]: df.fillna(-1)
Out[13]: 00 1.0
1 2.0
2 3.0
3 -1.0
4 4.0
我们可以在不同的柱子上使用不同的填充物。例如,第一列为 0.5,第三列为-1。注意:列编号从 0 开始。
df.fillna({1: 0.5, 3: -1})
可以用更聪明的方式比如填充使用 mean,其中 也许 在某些情况下更有意义。
data = Series([1., NA, 3.5, NA, 7])
data.fillna(data.mean())
这是对熊猫及其常用功能的简单介绍。随着我们继续前进,我们会发现更多。感谢阅读。
娱乐和盈利的数据挖掘朋友*
Python 网页抓取、NLP(情感分析)、IBM Watson API & Max/MSP 音频编程

- 形象地说
最近我又一次被说服去做一些音乐/艺术方面的事情,这一次是在一个好朋友的磁带发行 &生日庆祝会上。我又一次利用这个机会做了些无聊的电脑工作。
下面是 python 代码和输出示例,我使用它们来收集公共(ish)数据,执行基本的 NLP /情感分析,并将结果输出馈送到 IBM Watson 以返回 600 个合成语音文件,然后我通过一个定制的 Max 程序处理和操作这些文件。一些代号被更改以保护无辜者😬).
用 Python 刮网,硒&美汤
(注:本节内容是欠 本 Udemy 课程 我几个月前闲着没事完成的)
作为对上述朋友生日的一种敬意,我想我应该挖掘一些他们的公共网络活动&然后… 用它做些事情。
首先,我启动了以下 python 库:
为了避免被起诉而被遗忘,代码示例使用了一个假设的社交网络,姑且称之为……faceplace.com。(任何与真实的社交网络巨擘的相似之处,无论是活着的还是死去的,纯属巧合。让我们假设真实的 faceplace.com 不是……不管它实际上是什么。
一些调查显示,由于其流线型的布局,append face place . com 的移动网站(faceplace.com)是最容易抓取的。此外,给定年份的所有帖子都可以通过 url 结构https://m.faceplace.com/daniels_friend/year/2017/隔离。
但是最初只加载了有限数量的帖子,然后当用户滚动到当前页面的底部时,更多的帖子就会显示出来。由于这个原因(一些讨厌的登录要求),我们不能简单地抓取页面源代码。相反,我们必须在收集页面代码之前模拟浏览器和用户动作。我不会详细解释这些步骤,但是前面提到的 Udemy 课程会详细解释。
它最终看起来像这样:
…这会给你一堆无意义的标记,开头是:
在这些混乱中的某个地方会有这样的东西:
正如你可能注意到的,唯一感兴趣的人类语言发生在<p></p>标签之间,所以我想只提取那些位,丢弃其余的&继续我的生活。美丽的汤让这变得微不足道,&被称为正则表达式的神秘魔法允许我们移除封闭标签&任何(大部分)剩余的 html:
this left some stray html & long hashes in the data for some reason, but was adequate for my weird purposes so I didn’t attempt to improve
然后,我收到了一组来自我朋友时间线的纯文本帖子。
是时候做些事情了。

使用文本块进行自然语言处理/情感分析
几个知名的库为自然语言处理提供 pythonic 工具,功能多样,易于使用。我使用 TextBlob 是因为它的开箱即用特性集非常全面,非常适合我的快速原型需求(阅读:到处乱搞)。
在将一些文本分配给一个TextBlob()对象后,对.sentiment属性的简单调用返回两个值:
polarity-浮动 x 使得 -1 ≤ x ≤ 1 ,表示积极或消极情绪subjectivity——一个浮点数 y 使得 0 ≤ y ≤ 1 ,表示主观程度— 0 最客观&1 最主观
示例:
好吧,当然,足够近了。
现在,我可以将每个纯文本帖子输入到函数中&返回两个算法确定的浮点数。
然后呢?
IBM Watson 开发者云文本到语音合成
我知道我想最终以某种方式对我的数据采集进行声音处理。与其只是将自然语言翻译成数字用于算法组合,我想我应该直接对语言进行发音,在这个过程中使用任何定量推导作为调制参数。显而易见的解决方案是文本到语音引擎(TTS)。
经过一番探索,我选定了 IBM Watson 开发人员云 TTS 引擎,因为每月的前一百万个字符是免费的,它接受几个参数来以各种方式调制声音。我必须创建一个 IBM Bluemix 账户(免费 30 天),这很简单,然后搜罗他们的实质性文档来了解我的方位。
我不会在这里重复这些文档,但长话短说:该服务提供了几种不同的基本语音模型,其中一些接受额外的语音合成标记语言 (SSML)参数来转换&影响语音的表现力。这在他们的互动演示中得到了很好的展示。我选择了通用的沃森声音(来自 Jeopardy ),因为它允许最大的“转变”。
我编写了一个小循环来遍历帖子列表,检索 TextBlob 情感分析分数,然后将它们输入 Watson TTS api:
如上面的代码所示,有几个 SSML 变换参数(我用polarity & subjectivity情感分析分数的各种组合填充了这些参数):
breathinesspitchpitch rangerateglottal tensiontimbre
相关文件见此处。
下面是一个输出文件示例:
在遍历了我的数据集中的所有文本帖子后,我最终得到了大约 600 个这样的帖子——每一个都是我朋友的独特表达,每一个都通过几个算法过程进行了独特的合成和调制。
很好。
现在让它们发挥作用。
Max/MSP 中的随机回放和实时音频处理
我打算在这篇文章的所有部分都留在 Python 环境中,但是没有任何一个的几个包&接近从 Python 控制台进行音频回放&操作。所以表演/作曲部分我把退进 Max 。
我改编了 Abby Aresty 的这些 教程视频的大部分内容。我不太明白她为什么做一些事情,所以我也做了一些自由处理,&然后用一些参数来修饰它,以操纵音频播放:

我基本上创建了三个频道/播放列表,每个都连续播放从各自的播放列表中随机选择的文件&通过相同的信号处理链传递它们。我希望通过一些随机过程来编程控制这些参数,但没有时间编程,所以最终只能手动实时操纵信号。还有一些单独的文件(沿着右边界),我希望能够在调用时触发和循环。
我不会在这里花时间详细解释补丁;在上面链接的教程和[sfplay~](https://docs.cycling74.com/max7/maxobject/sfplay~)(回放对象)& [comb~](https://docs.cycling74.com/max7/maxobject/comb~)(梳状滤波器对象)Max 参考文档之间,没有太多其他的了。我把它上传到了 github repo 上,还有上面剩下的代码片段,供感兴趣的人参考。
有点不幸的是,在实际演出中,当我完成了计划持续时间的 3/4 时,马克斯崩溃了。但我很高兴事情发展到这一步,寿星和我们其他古怪的朋友似乎也很喜欢。我们还策划了一些模糊的计划,为可能的磁带发行重新审视素材和算法过程。敬请关注。
与此同时,这是表演中流产的部分:
—
在推特上关注:@ dnlmcLinkedIn:【linkedin.com/in/dnlmc】T4Github:https://github.com/dnlmc
数据挖掘简介

数据挖掘是当今非常热门的话题。与几年前不同,现在一切都与数据绑定,我们有能力很好地处理这些类型的大数据。
通过收集和检查这些数据,人们能够发现一些模式。即使整个数据集是一个垃圾,也有一些隐藏的模式可以通过组合多个数据源来提取,以提供有价值的见解。这被称为数据挖掘。
数据挖掘通常与各种数据源相结合,包括受组织保护且存在隐私问题的企业数据,有时还会集成多个数据源,包括第三方数据、客户人口统计数据和财务数据等。这里可用的数据量是一个关键因素。因为我们要发现顺序或非顺序数据中的模式、相关性,以确定获得的数据量是否是高质量的,以及可用的数据是否是好的。
先说个例子。假设我们获得了一些与 web 应用程序的登录日志相关的数据。整体来看,这组数据没有任何价值。它可能包含用户的用户名、登录时间戳、注销时间、已完成的活动等。
如果我们纵观全局,这是一个整体混乱。但是我们可以通过分析来提取一些有用的信息。
例如,该数据可用于找出特定用户的常规习惯。此外,这将有助于找出系统的高峰时间。该提取的信息可用于提高系统的效率,并使用户更加友好。
然而,数据挖掘并不是一项简单的任务。这需要一定的时间,也需要特殊的程序。
数据挖掘步骤
数据挖掘的基本步骤如下
- 数据收集
- 数据清理
- 数据分析
- 解读

Basic data mining steps
- 数据收集— 第一步是收集一些数据。尽可能多的信息有助于以后的分析。我们必须确保数据的来源是可靠的。
- 数据清理— 由于我们正在获取大量数据,我们需要确保我们只有必要的数据,并删除不需要的数据。否则,它们可能会让我们得出错误的结论。
- 数据分析 —顾名思义,分析和发现模式就是在这里完成的
- 解释— 最后,对分析的数据进行解释,以得出预测等重要结论
数据挖掘模型
有不同种类的模型与数据挖掘相关联
- 描述性建模
- 预测建模
- 规范建模
在描述性建模中,它检测收集到的数据之间的相似性及其背后的原因。这对于从数据集构建最终结论非常重要。
预测建模用于分析过去的数据,预测未来的行为。过去的数据对未来给出了某种暗示。
随着 web 的飞速发展,文本挖掘作为一个相关学科加入到数据挖掘中。需要适当地处理、过滤和分析数据,以创建这样的预测模型。
数据挖掘的应用

http://slideplayer.com/6218639/20/images/21/Data+Mining+Applications.jpg
数据挖掘在许多方面都很有用。对于营销来说,可以有效应用。使用数据挖掘,我们可以分析客户的行为,我们可以通过更接近他们来做广告。
它将有助于识别市场中顾客对商品的趋势,并允许零售商了解购买者的购买行为。
在教育领域,我们可以识别学生的学习行为,学习机构可以相应地升级他们的模块和课程。
我们也可以使用数据挖掘来解决自然灾害。如果我们能收集一些信息,我们可以用它们来预测滑坡、降雨、海啸等。
如今,数据挖掘有了更多的应用。它们可以从非常简单的事情,如营销,到非常复杂的领域,如环境灾难预测等。
特殊备注
- 当特定问题有可能得到完整、准确的解决方案时,不应使用数据挖掘。当这种解决方案不可行时,我们可以使用具有大量数据的数据挖掘技术来将问题表征为输入-输出关系。
- 需要分析问题性质来确定是分类(离散输出 Ex:真或假)还是估计(连续输出Ex:0,1 之间的实数)问题。
- 输入应该有足够的信息来产生准确的输出。否则会导致不可避免的减少。
- 应该有足够的数据做出准确的结果。需要根据输入数据选择合适的算法。一些算法需要大量的数据来达到良好的精度,而另一些算法则可以快速达到。

Algorithm Comparison
感谢阅读…
干杯!
数据挖掘——注意差距
当评估您希望挖掘用于机器学习或数据分析的大量数据时,您经常会看到大量显式数据点,因此似乎很难看出您需要添加更多数据。但往往最重要的数据不是点而是点与点之间的关系。
如果我们把显式数据看作节点,那么隐式数据就变成了节点之间的连接和关系。一个简单的例子可能是一组坐标,大小,大气组成,以及更多关于我们太阳系中的物体。这组事实可能看起来很重要,也很全面,但是直观地展示它们会暴露出主要的差距。

Solar System as Nodes (Image courtesy of NASA per https://gpm.nasa.gov/image-use-policy)
虽然事实都是真实的,但最重要的事实可能是对象之间的关系。行星围绕太阳旋转,这可能会被你的快照所猜测,但不会被显示出来。冥王星可能是一颗路过的彗星。这些行星可能会撞向中心。我们不知道。

Solar System as Nodes and Connections (Image courtesy of NASA per https://gpm.nasa.gov/image-use-policy)
虽然还有更多的东西可以展示,但这张修改后的太阳系视图增加了天体之间的重要关系,即它们围绕中心太阳的轨道旋转。
在你的数据挖掘中,中心联系和关系可能不像围绕太阳运行的行星那样明显。时间可能已经过去,机构记忆也随之消逝。有些联系并不在数据本身的范围内,但需要扩展您的视野,以了解收集数据的公司(例如,2014 年的一次合并可能从根本上改变了销售的产品组合,因此合并前的数据应与合并后的数据分开处理)。
数据挖掘不仅仅是挖掘。它也是关于理解和欣赏你的数据的背景。两个独立的数据库最好被看作是相关的,而另外两个应该被看作是独立的。这些差距必须得到尊重。
实际上,定义数据的存储桶并询问存储桶之间的关系通常是很好的。谁创建了每个桶中的数据,他们如何与其他桶的创建者交互?
另一个重要的练习是询问在你的数据挖掘中需要回答什么样的问题。试着从实际问题后退一步,进入类型,尽管你可能需要头脑风暴一些具体的问题来帮助人们前进。
然后从问题中退一步,问一下遗漏了什么,假设了什么?列出假设,不管有多基本。然后,问一个机构知识为零的人会不会从数据中知道那些假设。如果没有,你已经找到了你的差距。找出如何填充或完成数据,使假设成为事实,你的数据挖掘将更加有用,不太可能掩盖重要的理解。
数据管理,透视图
如何处理,缺失值,重复值,离群值等等很多只是用 Python 和 Azure ML
我记得我的媒体帐号后,我想写一篇文章,但我没有任何虚构的内容。这是我的技术故事。抱歉,如果它没有感动你。我正在使用 Azure Machine learning learning studio,并将对数据进行一些预处理。所以,这个故事通常会带你走过这条小径,抓紧了。

Joining data [Left Outer Join]
两个数据集被获取并使用一个键连接。
记住:这个键(列)应该出现在两个数据集中

你不必处理每一个数据,排除你不需要的列。
‘额外加工就是赔钱’

当我们看到柱面数量列时,数据的分布有点倾斜。所以我们可以对它进行分类。

就像这样
编辑元数据:它包括选择“缸数”并转换成分类数据

这里,制造了 4 组,4 个或更少组,5 个和 6 个,8 个和 12 个

缺失数据,哦……!!
我现在该怎么办?

你也可以有其他清洁模式,但我们在这里选择’删除整行’

重复行也是如此

价格是成比例的
低价车比中价或高价车多得多
这是一种根据汽车的特点来预测其价格的方法
,但是价格分布的偏斜性质会使这种预测
变得困难。将更平衡的对数分布价格值拟合到
预测模型可能更容易。

这就是你怎么做的
您可以添加许多其他数学运算

所以这里有两列
价格和 ln(价格)
是的,很明显你可以把 1 扔出去。

你可以比较一下它的其他价值
在这里我比较一下价格,你猜怎么着?
对数图


这是 ln(价格)和城市英里数之间的图表
哪个比价格更平
这是价格和城市英里数之间的图表
对数运算减少了价格和城市-mpg 图中“异常值”的初始假设
人们可以使用其他变换
发现和可视化异常值
我们将根据重量、发动机尺寸和城市英里数来直观显示价格,并确定异常值



用 Python 可视化离群值

## Define plot columns
plot_cols = [“weight”, “enginesize”, “citympg”]
auto_scatter_simple(df,plot_cols)
return df
输出如下图所示

这个图类似于上面的图,
上面的 Python 代码只是迭代列的值,我们通过函数的参数,然后我们用 lnprice 绘制散点图。
当经过 3 列时,会生成 3 个散点图。
到目前为止,我们已经检查了数据中的关系,并确定了一些潜在的
异常值。

我们现在需要验证异常值是使用提到的阈值确认的,该阈值实际上是过滤异常值。
##Python code for detecting Outliersdef id_outlier(df):
## Create a vector of 0 of length equal to the number of rows
temp = [0] * df.shape[0]
## test each outlier condition and mark with a 1 as required
for i, x in enumerate(df['enginesize']):
if (x > 190): temp[i] = 1
for i, x in enumerate(df['weight']):
if (x > 3500): temp[i] = 1
for i, x in enumerate(df['citympg']):
if (x > 40): temp[i] = 1
df['outlier'] = temp # append a column to the data frame
return dfdef auto_scatter_outlier(df, plot_cols):
import matplotlib.pyplot as plt
outlier = [0,0,1,1] # Vector of outlier indicators
fuel = ['gas','diesel','gas','diesel'] # vector of fuel types
color = ['DarkBlue','DarkBlue','Red','Red'] # vector of color choices for plot
marker = ['x','o','o','x'] # vector of shape choices for plot
for col in plot_cols: # loop over the columns
fig = plt.figure(figsize=(6, 6))
ax = fig.gca()
## Loop over the zip of the four vectors an subset the data and
## create the plot using the aesthetics provided
for o, f, c, m in zip(outlier, fuel, color, marker):
temp = df.ix[(df['outlier'] == o) & (df['fueltype'] == f)]
if temp.shape[0] > 0:
temp.plot(kind = 'scatter', x = col, y = 'lnprice' ,
ax = ax, color = c, marker = m)
ax.set_title('Scatter plot of lnprice vs. ' + col)
fig.savefig('scatter_' + col + '.png')
return plot_colsdef azureml_main(df):
import matplotlib
matplotlib.use('agg')
## Define the plot columns
plot_cols = ["weight",
"enginesize",
"citympg"]
df = id_outlier(df) # mark outliers
auto_scatter_outlier(df, plot_cols) # create plots
df = df[df.outlier == 1] # filter for outliers
return df
那么我们用代码做什么呢?
检查这段代码,注意 auto_scatter_outlier 函数绘制 col 与 lnprice 的关系,点颜色由 outlier 决定,形状由 fueltype 决定。id_outlier 函数使用 Python 列表理解中的嵌套 ifelse 语句来标记离群值。使用熊猫过滤器提取异常值。
结果是:



如果你到现在还在这里,那么你很棒,你需要成为一名数据科学家。如果你只是向下滚动到这里,看看上面,一些很酷的东西已经完成了。
谢谢
人工智能创业的数据网络效应
将注意力从产品和数据收集转移到网络和数据共享

人工智能(AI)生态系统成熟,仅仅通过附加一个标签来打动客户、投资者和潜在收购者变得越来越困难。无论你在做什么。因此,从长远来看,建立一个可防御的商业模式的重要性变得显而易见。
在这篇文章中,我探索了一个人工智能初创公司如何解锁各种数据网络效应。我解释了为什么为了改进你的模型/产品,超越数据网络效应的传统定义作为一种从客户那里收集数据的方式是重要的。
数据网络效应——用它来收集更多的数据有什么错?
围绕人工智能业务建立护城河的一个被广泛引用的方法是数据网络效应,将定义为“……由于数据片段之间的紧急关系,产品的属性随着可用数据的增加而改善”。数据网络效应是一种更广泛的网络效应现象的特殊表现,当“……任何用户对产品的更多使用增加了产品对其他用户(有时是所有用户)的价值”时,就可以看到这种现象。数据网络效应与通过从用户处收集的数据来改进产品等相关联。
鉴于数据对任何人工智能初创公司的重要性,数据网络效应被视为相关的护城河也就不足为奇了。训练一个模型所需的数据很难得到,如果有偏差,你就有麻烦。因此,试图收集尽可能多的数据,并在此基础上改进产品,似乎是一个非常好的主意。在某种程度上的确如此。 然而,不应高估仅围绕数据收集和产品改进构建的数据网络效应的力量,应探索创造数据网络效应的替代方法。 为了开始区分各种类型的数据网络效应,我们先把上面描述的一种贴上数据收集网络效应的标签。
为什么拥有数据收集网络效应可能还不足以取得成功?除此之外,这是因为产品使用和产生的有用新数据之间的不对称关系。例如,只有一小部分用户在 Yelp 上写评论,也就是说,对 Yelp 的数据收集网络效果有贡献。
有时数据收集网络效应是渐近,这意味着 Yelp 上的第 5 次评论比第 30 次评论更有价值。在某个时候,新数据的价值会下降,要么是直接对用户而言(人们很难阅读关于一家咖啡馆的 50 篇评论),要么是对产品/模型开发而言(有时更好的效果来自于增加模型的复杂性,而不是注入更多的数据)。
数据收集网络效应的其他挑战与数据可用性有关。首先,数据可能被窃取/复制。其次,它的可用性越来越大。对于例,2017 年新增了 8 个公共物体检测识别数据集,而 2016 年只有 4 个。此外,还有合成数据,帮助初创公司甚至与数据丰富的巨头竞争。处理/标记数据的数据和工具的更广泛可用性使数据收集网络效应不那么有吸引力,因为它用更少的时间来破坏拥有标记数据集的人的先发优势。
尽管如此,我并不是说数据收集不是人工智能初创公司应该掌握的东西,因为专有数据仍然是一个护城河。这也是一种保险政策,帮助初创公司保持对投资者/收购者的吸引力,即使一切都不顺利。
需要强调的是,数据收集网络效应很难对所有的 AI 业务都起到很好的作用 。例如,它非常适合像 Waze 这样的人,每个用户都实时贡献有价值的数据(没有不对称性和渐进性)(如果 Waze 的数据被复制/公开,危害会更小)。但是其他类型的企业应该考虑其他类型的数据网络效应。
更广泛地了解数据网络效应——与您的网络共享更多数据
新型的数据网络效应可能来自于围绕人工智能初创公司建立更广泛的客户和合作伙伴网络,以及这些网络内的数据共享 。众所周知,有时‘……提供大部分价值的是网络,而不是应用或网站本身——这解释了为什么像易贝和 Craigslist 这样的市场产品可以在 16 年后看起来基本没有变化。
人们可能会发现大量关于数据收集网络效应(被称为“数据网络效应”,或“数据飞轮”)的文献,例如这里的、这里的、这里的、这里的和这里的。然而,网络效应在数据收集和直接用于改进模型/产品之外的应用似乎没有得到很好的涵盖。
一些作者提出了数据共享的想法 ,但没有涉及操作细节。例如,Gil Dibner 提出了网络智能系统的概念,该概念适用于“供应链中的各方”,并且“通过在客户之间共享智能来创造增值”,因此数据不仅是为了改进模型而聚合,而是在整个供应链中共享。开放数据研究所(ODI)及其五种商业模式的 框架 也在探索数据共享的思路,根据数据和算法开放程度 进行区分。例如,Nik Bostrom 在的中介绍了数据共享在人工智能生态系统发展中的基本作用。
如何建立网络?
受到上面引用的文献的启发, 人们需要从将人工智能初创公司仅视为一种产品(通过从客户/用户收集的数据来改进)转变为将它视为一个网络 ,它点燃/管理各种类型的参与者之间的各种类型的数据交换。下面,基于网络效应的文献和对各种人工智能创业公司背后的商业模式的分析,我探索如何围绕人工智能创业公司建立数据网络,以及在那里推出什么样的交易所。
人工智能创业公司网络的参与者大致可以分为两类:
1.客户/用户,直接受益于产品并产生支撑产品的数据的人;
2.通过各自的价值链/供应链与创业公司的客户互动的实体。这些实体也可以从人工智能初创公司客户产生的数据中受益。例如,如果一家人工智能初创公司为农民开发了一种自动化解决方案,那么那些制造化肥和购买农民产品的人可能会被视为其网络的参与者。
因此,一个 AI 创业公司可能会使用两个方向来构建数据网络效果,即 :
- 横向 ,通过帮助客户相互交流,创造直接网络效应,“…当一个额外的参与者使同类的其他参与者受益时”;
2.,通过将客户与其价值链/供应链的其他要素联系起来并创造间接网络效应,“…当一种类型的额外参与者增加另一种类型的参与者获得的价值时”。
三种数据交换
当理解了数据交换的方向后,问题就来了,这些交换是什么。通过探索我们投资组合内外的数百家人工智能初创公司,我可以根据它们的目的 : 重点介绍 三种类型的数据交换
1.获得洞察力;
2.支持交易。
3.整合流程。
通常以间接的方式,通过网络分享见解是数据交换的一种方式 这种方式基于从人工智能初创公司的客户那里收集的数据,并为他们各自使用的产品增加价值。
例如,移动应用营销公司 Localytics 使用机器学习来帮助客户“从被动收集应用内活动数据转向识别提高转化率的关键行为”。它还提供统计摘要和行业基准,在某种程度上帮助客户从市场中学习。Localytics 利用了直接的网络效应,因为随着越来越多的客户使用其核心产品,他们每个人都可以更好地了解更广阔的市场和竞争格局。
此外,人工智能初创公司不仅可以使用从客户那里获得的数据来改进核心产品,还可以让客户与价值链的其他参与者进行更好的交易。
例如,软件公司 Connecterra 收集并分析来自奶牛场的数据,以帮助农民。同时,它也为兽医和饲料公司打开了一个平台,他们认为这是一个与农民更好互动的平台。他们可以通过应用程序看到农场发生的事情。如果需要,兽医也可以收到警报。在没有成为兽医市场的情况下,Connecterra 通过发送预先通知来帮助价值链的两个要素(农民和兽医)进行交易。Connecterra 利用了间接的数据网络效应,因为兽医从平台上更多的农民中受益。
通常,价值链的各个要素之间需要一定程度的整合。因此, 一个 AI 创业公司可能不仅仅是直接服务于其中一个元素,而是通过数据交换可以提高这个元素与其他 的整合。
例如,TraceAair 使用无人机图像不仅帮助建筑承包商通过减少两次移动泥土来降低成本,还与土地开发商分享工地进度,使他们能够“掌握工地平衡,按时完成项目并节省应急预算”。在这种情况下,土地开发商受益于更多的承包商加入该平台,而 TraceAir 利用了间接的数据网络效应。
构建人工智能产品以改善整个价值链整合的另一个例子是 Cotrtex Health,它可以学习趋势并预测患者的负面结果,然后提醒适当的医疗保健提供商采取特定行动。Cortex 网络是围绕“…在整个护理过程中,通过与所有负责任的医疗保健提供者共享患者状态的可见性,可以改善患者结果的理念”而建立的。请注意,这种集成远远超出了为事务目的共享数据。
水平和/或垂直应用的三种类型的数据交换为 AI 初创公司提供了数据网络效应 的六个新机会(参见下面的数据网络效应矩阵)。这些新的数据网络效应的基础是通过直接/间接在网络上共享数据来使数据变得有用的能力,而更广为人知的数据网络效应(数据收集网络效应)主要基于数据的稀缺性和与收集数据相关的挑战。这些新的数据网络效应与平台的概念和的理念非常吻合,即在 21 世纪……供应链不再是商业价值的中心聚合器。一家公司拥有什么比它能连接什么更重要。
随着人工智能生态系统的成熟和数据可用性的增加,人工智能初创公司越来越有动力将自己转变为服务于复杂网络的平台,这些网络在多个价值/供应链内和跨多个价值/供应链蔓延。
非常感谢 尤里·布罗夫 和 瓦列里·科米萨洛夫 审阅本帖的早期草稿。感谢 马特·图尔克 , 吉尔·迪布纳 , 布拉德福德·克罗斯 ,NFX*,以及其他帮助我写出这篇文章的人。*
披露:文中提到的 TraceAir 和connecter ra,都是Sistema _ VC的投资组合公司,彼得是该基金的风险合伙人。
数据网络效果矩阵

修正 & 放大
*在本帖的最初版本中,r4 Technologies 被用来举例说明洞察驱动的数据网络效应。因为这个例子不完全正确,所以在这个版本中使用了另一个例子。
好莱坞还有女人问题吗?
电影中的性别表现数据

来自维基百科的好莱坞数据
维基百科是电影数据的宝库。不幸的是,这很难大规模实现。幸运的是,python wptools 库允许我们获取所有这些有趣的维基百科信息框。
我写了一些脚本来收集和清理 2000 年至 2018 年好莱坞电影的所有维基百科数据。然后,我使用 python“ntlk”男性和女性姓名语料库,按性别对所有演员、制片人和导演进行分类。当然,这个过程中存在一些误差。电影中的许多人不在这些名单中(如“雷德利”斯科特)。此外,一些男女通用的名字如“Leslie”会导致分类错误。我花了很多时间尽可能地手工清理东西。我设法得到的数据表明,不到 10%的好莱坞演员/作家/制片人不能被归类为男性或女性。
通过对 90%的数据进行分类和修正,很容易就能了解好莱坞电影中性别表现的状况。正如你在下面看到的,这个行业还有很多工作要做。
2018 年的不平等
下表显示了 2018 年参与制作好莱坞电影的男女比例。在所有情况下(演员、导演、制片人、编剧和音乐),男性都远远多于女性。

即使我们慷慨地假设大部分未分类的名字都是女性,这种不平等仍然是明显的。
下面我绘制了 2018 年好莱坞电影中表现最佳的演员的条形图,以及所有演员的整体性别代表。从蓝色的海洋来看,很明显女性的代表性远远不足。这一点在编剧、导演、配乐领域尤为明显。
演员


董事


生产者


作家


音乐


趋势
回顾 2000 年的数据,可以看出女性在电影中的惨淡表现是否有所好转。下面我画出了电影中女性比例的趋势。
演员


董事


生产者


作家


音乐家


虽然女性在表演、导演、制作和写作方面的代表性正在缓慢提高,但在女性为电影评分方面似乎没有进展。
结论
从以上数据可以明显看出,好莱坞的性别代表性仍然是一个主要问题。我个人认为,这一事实是美国国内票房收入增长乏力的部分原因。不到 15%的电影由女性编剧或导演。当这些电影不能代表一半的观众时,它们不赚钱有什么奇怪的吗?
笔记
本项目使用的所有代码和数据都可以在 https://github.com/taubergm/HollywoodGenderData的 github 上获得
1—https://pypi.org/project/wptools/
2—【http://www.nltk.org/howto/corpus.html
3—【https://www.boxofficemojo.com/yearly/
有关这一趋势的其他确认,请参见:—https://www . the guardian . com/film/2018/Jan/04/Hollywood-diversity-sees-no-improvement-in-2017-report-finds
面向高数据可用性的数据管道工程

从数据中提取见解并做出预测是我的主要目标,然而,在我从数据中获取价值之前,我首先需要从数据仓库中获取数据。通常我需要的数据并不容易获得,也没有工程师有资源来支持我,因此我沉浸在数据仓库的荒野中来建立我自己的数据管道,这也被称为 ETL(提取、转换和加载)。
真正的数据科学工作很难在必要的数据可用之前开始,因此建立数据管道以有效地提供可供分析的数据具有重要意义。根据我在工作中构建和使用数据管道的经验,我看到了支撑管道效率的三个要素,它们随后创建了一个高数据可用性的环境。
1.由分析单元定义的数据管道
有一天,我收到一个紧急数据请求。在听到请求细节之前,我不确定这种紧迫性是否会暂停我的其他项目。在我了解到这一需求后,我知道现有的数据管道可以满足大部分需求。我所需要的只是找到一些额外的数据元素。果然,我很快解决了这个请求。这一经历是好的数据管道带给我的众多好处之一。一个好的数据管道可能会在我的新项目到达时完成 80%,让我专注于剩下的 20%。既节省时间又让人安心(当然这里的 80%和 20%只是想象中的尺度)。
运气并不总是在身边。在一个项目中,我不得不构建一个很长的数据管道,通过从多个来源提取大量原始数据,将业务运营的全局但详细的视图放在一起。这个项目花了我很长时间才完成。即使完工,这条管道的一次通过也需要 20 多个小时。通常,我会启动管道,并在第二天收集结果。后来,我发现我们的数据工程团队已经建立了一个类似的数据管道。我决定利用他们的来缩短我的。现在,我的管道只需不到 6 个小时。在一个管道上铺设另一个管道对我来说非常有效。除了节省时间之外,还节省了大量的计算、存储和维护。
数据管道显然会带来价值。那么,如何打造有价值的数据管道呢?我认为,当管道将独立的信息汇集在一起,创建一个高度感兴趣的分析单元的丰富图片时,它往往是有价值的。例如,在信用卡支付业务中,交易是一个非常有趣的分析单元,因此一个好的数据管道是创建每个交易的端到端生命周期图的管道。使用这个管道,用户可以很容易地找到想要的细节,无论他们对交易授权还是交易争议感兴趣。在医疗保健中,患者是一个高度感兴趣的分析单位,因此一个良好的数据管道是一个包含每个患者的整个医疗保健旅程的管道,包括诊断、治疗、保险范围和再入院。人们以后可以很容易地放大到整个医疗保健过程中的一个特定部分。考虑到原始数据是如此孤立、混乱和庞大,这种方法减轻了数据科学家的负担,并使数据更容易用于分析和建模。
2.晚上睡觉时在管道中处理数据
当我的数据管道持续很多小时时,我遇到了“意大利面条”式的管理挑战。我无法断开我的笔记本电脑与互联网的连接,我运行的管道分散了我对其他工作的注意力,我忘记了我已经完成了哪些步骤。因此,我想让我的管道在服务器集群中运行,这样我就可以忘记它们,让我的笔记本电脑离线回家。Apache Oozie 是我发现的帮助我在 Hadoop 集群中管理管道的工具。
Oozie 采用了我的脚本和工作流设计,然后根据集群中的工作流执行我的脚本。Oozie 是 Apache 开源工具,详情请访问http://oozie.apache.org/。后来,我想安排我完成的管道,向我的管道添加通知并参数化我的管道,Oozie 也能够帮助满足这些需求。Oozie 几乎成了我的生产基地。使用 Oozie 让我相信,工作流管理工具(现成的或内部构建的)是数据工程师和数据科学家的必备工具,尤其是在大型项目中。除了 Oozie 之外,Airflow 是另一个非常流行的工作流管理工具,在许多公司中经常使用。
我的数据管道是 Hive、Impala、Python 和 Spark 的混合体。大多数是在蜂巢和黑斑羚。Oozie 能够促进所有这些批处理,并根据工作流规范运行它们。日志和错误会自动保存,并可用于调试和跟踪目的。当数据管道得到管理时,我可以更快、更容易地获得数据。我可以“一边睡觉一边啃大数据”。
3.挤压管道的一百种方法

数据管道工作似乎有一个缓慢的时钟。根据我的经验,一遍数据管道需要几个小时(数据大小以 TBs 为单位)。为了从数小时的流水线工作中挤出额外的效率,我们必须使用许多优化技术。在我的 Hive、Impala 和 Spark 管道中,我使用了一系列个人最喜欢的优化技巧,尽管可能有上百种技巧。
首先,我使用试错法来确定查询复杂性中的最佳点。复杂的查询对分布式文件系统来说是一个挑战,因此我试图避免不必要的复杂性。然而,将复杂的查询分解成较小的查询可能会导致太多的小步骤。通过反复试验,我可以找到一个既快速又易于维护的最佳点。第二,我努力更新元数据统计数据,并选择正确的连接来最小化文件移动。例如,由于系统内部工作方式的不同,当涉及到连接表排序时,我确保大表在 Hive 中排在后面,但是在 Impala 中最大的表排在前面。这样的安排让小桌子搬到大桌子,而不是相反。第三,我操纵设置来动态地将资源分配到需要的地方。在一个 Spark 步骤中,尽管集群中的内存和内核使用率较低,但我看到了缓慢的性能,我增加了该步骤的内存设置和内核设置,并很快完成了 Spark 任务。
好的优化技巧的列表非常长。当我需要额外的效率时,我会参考技术手册。这些技巧的使用还取决于集群环境和情况。一个单独的戏法在它能做的事情上是有限的,然而,将许多戏法结合在一起肯定会很有意义。
在学习环境中,我们被提供数据来建立模型和进行分析。在数据可用性的另一方面,我们必须自己搜索数据、获取数据和清理数据。我发现后一种情况更现实,因此我渴望磨练我的数据工程技能,并希望与感兴趣的读者分享我的数据管道经验。除了上面提到的技术性更强的因素,项目规划、进度文档等软性因素对数据管道的成功也有重要影响。我个人认为,每个数据科学家都部分是数据工程师,我们都应该不仅为创建模型对象而自豪,而且为创建数据管道而自豪。
数据管道、Luigi、气流:你需要知道的一切

Photo by Gerrie van der Walt on Unsplash
这篇文章是基于我最近给同事们做的关于气流的演讲。
特别是,演讲的重点是:什么是气流,你可以用它做什么,它与 Luigi 有什么不同。
你为什么需要 WMS
在公司中,移动和转换数据是很常见的事情。
例如,您在 S3 的某个地方存储了大量日志,您希望定期获取这些数据,提取和聚合有意义的信息,然后将它们存储在分析数据库中(例如,Redshift)。
通常,这种任务首先是手动执行的,然后,随着规模的扩大,这个过程是自动化的,例如,用 cron 触发。最终,您会发现原来的 cron 已经无法保证稳定和健壮的性能。这已经远远不够了。
这时候你就需要一个工作流管理系统(WMS)。
气流
Airflow 是 Airbnb 在 2014 年开发的,后来开源了。2016 年,它加入了阿帕奇软件基金会的孵化计划。
当被问及“是什么让 WMS 的气流与众不同?”,Maxime Beauchemin(创造者或气流)回答:
一个关键的区别是气流管道被定义为代码,任务是动态实例化的。
希望在这篇文章结束时,你能够理解,更重要的是,同意(或不同意)这种说法。
我们先来定义一下主要概念。
工作流作为 Dag
在 Airflow 中,工作流被定义为具有方向依赖性的任务的集合,基本上是有向无环图(DAG)。图中的每个节点是一个任务,边定义了任务之间的依赖关系。
任务属于两类:
- 操作员:他们执行一些操作
- 传感器:它们检查进程或数据结构的状态
现实生活中的工作流可以从每个工作流只有一个任务(你不必总是很花哨)到非常复杂的 Dag,几乎不可能可视化。
主要组件
气流的主要组成部分有:
- 一个元数据库
- 一个调度器
- 一个执行者

Airflow architecture
元数据数据库存储任务和工作流的状态。调度器使用 DAGs 定义以及元数据数据库中的任务状态,并决定需要执行什么。
执行器是一个消息队列进程(通常是芹菜,它决定哪个工人将执行每个任务。
使用 Celery executor,可以管理任务的分布式执行。另一种方法是在同一台机器上运行调度器和执行器。在这种情况下,将使用多个进程来管理并行性。
气流也提供了一个非常强大的用户界面。用户能够监控 Dag 和任务的执行,并通过 web UI 与它们直接交互。
气流遵循*“设置好就忘了”*的方法是很常见的,但这意味着什么呢?
表示一旦设置了 DAG,调度器将自动调度它按照指定的调度间隔运行。
路易吉
理解气流最简单的方法大概就是把它比作 Luigi。
Luigi 是一个用于构建复杂管道的 python 包,由 Spotify 开发。
在 Luigi 中,与在 Airflow 中一样,您可以将工作流指定为任务以及它们之间的依赖关系。
Luigi 的两个积木是任务和目标。目标通常是任务输出的文件,任务执行计算并消耗其他任务生成的目标。

Luigi pipeline structure
你可以把它想象成一条真正的管道。一个任务完成它的工作并生成一个目标。结果,第二个任务接受目标文件作为输入,执行一些操作并输出第二个目标文件,依此类推。

Coffee break (Photo by rawpixel on Unsplash)
简单的工作流程
让我们看看如何实现由两个任务组成的简单管道。
第一个任务用一个单词生成一个. txt 文件(在本例中是“pipeline”),第二个任务读取该文件并添加“My”修饰该行。新的一行写在一个新的文件上。
Luigi simple pipeline
每个任务被指定为从luigi.Task派生的类,方法output()指定输出,因此目标,run()指定任务执行的实际计算。
方法requires()指定了任务之间的依赖关系。
从代码中,很容易看出一个任务的输入是另一个任务的输出,依此类推。
让我们看看如何在气流中做同样的事情。
Airflow simple DAG
首先,我们定义并初始化 DAG,然后向 DAG 添加两个操作符。
第一个是BashOperator,它基本上可以运行所有的 bash 命令或脚本,第二个是执行 python 代码的PythonOperator(为了演示,我在这里使用了两个不同的操作符)。
如你所见,没有输入和输出的概念。两个运营商之间没有信息共享。有很多方法可以在操作符之间共享信息(你基本上共享一个字符串),但是作为一个通用的规则:如果两个操作符需要共享信息,那么它们可能应该合并成一个。
更复杂的工作流程
现在让我们考虑一下我们想要同时处理更多文件的情况。
在 Luigi,我们可以用多种方式做到这一点,但没有一种是真正简单的。
Luigi a pipeline managing multiple files
在这种情况下,我们有两个任务,每个任务处理所有的文件。从属任务(t2)必须等到t1处理完所有文件。
我们使用一个空文件作为目标来标记每个任务完成的时间。
我们可以为循环增加一些并行化。
这种解决方案的问题是t1开始产生输出后,t2就可以开始逐渐处理文件,实际上t2不必等到t1创建完所有文件。
Luigi 中的一个常见模式是创建一个包装器任务并使用多个 workers。
这是代码。
Luigi a pipeline using multiple workers
要使用多个工作线程运行任务,我们可以在运行任务时指定— workers number_of_workers。
现实生活中常见的一种方法是委托并行化。基本上,你使用第一种方法,例如在run()函数中使用 Spark,来进行实际的处理。
让我们用气流来做
您还记得在最初的引用中,dag 是用代码动态实例化的吗?
但是这到底是什么意思呢?
这意味着借助气流,你可以做到这一点
Airflow a parallel DAG with multiple files
任务(和依赖项)可以以编程方式添加(例如,在 for 循环中)。相应的 DAG 如下所示。

Parallel DAG
此时,您不必担心并行化。气流执行器从 DAG 定义中知道,每个分支可以并行运行,这就是它所做的!
最终考虑
我们在这篇文章中谈到了很多点,我们谈到了工作流程、Luigi、气流以及它们之间的区别。
让我们快速回顾一下。
路易吉
- 它通常基于管道,任务输入和输出共享信息并连接在一起
- 基于目标的方法
- UI 是最小的,没有用户与正在运行的进程的交互
- 没有自己的触发
- Luigi 不支持分布式执行
气流
- 基于 DAGs 表示
- 一般来说,任务之间没有信息共享,我们希望尽可能地并行
- 没有功能强大的任务间通信机制
- 它有一个执行器,管理分布式执行(您需要设置它)
- 方法是“设置它,然后忘记它”,因为它有自己的调度程序
- 强大的用户界面,你可以看到执行和互动运行的任务。
结论:在本文中,我们了解了 Airflow 和 Luigi,以及这两者在工作流管理系统中的不同之处。我们看了一些非常简单的管道示例,以及它们如何使用这两种工具来实现。最后我们总结了 Luigi 和 Airflow 的主要区别。
如果您喜欢这篇文章,并且觉得它很有用,请随意👏或者分享。
干杯
数据污染——沉默的黑仔

在过去的两天里,我在三个客户网站上工作——它们都表现出相似的概念问题。这个问题并不新,也不特别深奥——只是影响如此严重,让我担心。
这是我在过去 4 年里研究的将近 200 个谷歌分析配置的积累。一篇关于我从所有这些工作中学到的元水平的文章将是有用的——但我想提出的关键点之一是这一点。
我开始称之为数据污染,但在最简单的层面上,它是关于在你的计算或度量中没有测量意图或“可转换的”流量。这就是为什么“平均”网站指标在有数据污染的网站上更糟糕——因为它们默默地掩盖了数据是有偏差的。
让我们举一个最简单的例子:
假设您经营一家在线宠物用品店,您的开发团队使用与您的实时网站相同的分析标签。他们运行一个测试工具,检查网站在世界各地的直播,所以你得到所有这些访问到你的网站,他们不购买东西,但通过你的漏斗到最后。
你能想象这对你的漏斗数据会有什么影响吗?
让我们尝试一些其他的例子:
你经营着一家将工作外包到菲律宾的机构。当他们使用你网站外的网络界面时,你的团队通过你的主页登录,现在你主页超过 30%的流量来自菲律宾,直接从你的网站弹出(当他们登录管理系统时)。
你的竞争对手正在你的网站上使用机器人网络进行价格抓取。它们都显示为 Chrome 浏览器,但来自不同的 IP 地址——你的许多访问者统计数据都被抓取活动带来的大量和持续的流量注入所扭曲。
那么每个使用你网站的管理界面登录的人呢——有人让分析标签在上面运行。现在,你所有的内部员工流量都被发送到你的谷歌分析视图。
你有一堆域名或子域,但它们在谷歌分析上设置不正确——所以当人们在域名间移动时,所有的营销跟踪都会重置。因此,你不知道转换的来源,或者他们只是被标记为“直接”访问。
你的开发者、QA 团队、代理、合作伙伴或员工污染了你的现场数据。你没有过滤或寻找任何这些东西,所以你不知道它在那里,默默地与所有有用的东西混合在一起。
为什么这是一个问题?
嗯,在最简单的例子中,当您的“员工”或“第三方”污染数据时,您的所有转换指标都会降低。根据数据污染的实际位置,您的站点中的一些或所有关键站点范围或本地指标现在包含来自“无意做您想要测量的事情”的人的数据。
我见过一些网站,潜在客户的数据才是客户真正想要的。然而,他们的网站将被客户、合作伙伴、供应商使用,为整个企业服务,而不会考虑这会如何污染数据。
这就像我站在百货商店外面,用遥控器数顾客。如果送货员使用同一个入口呢?员工呢?如果我把所有人都算上,那意味着什么?
嗯——这取决于商店有多忙或者有多少外卖。在有很多快递的安静日子里,我对“真正的员工”的统计可能是可疑的,而在其他日子里,它更接近事实。
问题是,这些数据是垃圾——更重要的是,质量是可变的,很大程度上在我的控制之外,报告系统很难区分,除非它在收集层被剔除!
一个处理过的例子:
这是一个来自假想客户的完美场景(但基于真实客户):
清洁工喂!
客户提供一次性或定期清洁服务。您可以下载应用程序或访问网站来开始使用。
客户有几个人们要经历的状态。当你下载应用程序或注册时,你还没有交易。你处于数据收集和行动之间的中间状态。姑且称之为‘挂号’吧。
然后,一旦你预定了一份一次性的或固定的工作,你就提供了支付细节,安排了约会,并挑选了一个看起来不错的更干净的个人资料。让我们称之为“客户”
基于粗略的 RFM 计算和对当前 LTV 的了解,“客户”还有其他状态——基于客户保留模型。让我们称这些为“低”“中”和“高”价值界限。
我们这里还有其他演员。“干净”用户通过网站登录,使用其他人使用的相同主页。
这家“清洁用品”公司通过网站登录,再次使用其他人使用的同一主页的链接。
那么,我们的主页上有哪些用户呢?
顾客:40%
供应商:10%
前景:30%
清洁工:20%
由于这个主页是转化路径的主要部分,我现在有 60%的数据完全没有用在我营销活动的投资回报率建模上。我的跳出率完全扭曲了,我的水平漏斗模型完全被污染了,网站中有各种路径有对我没用的流量。
当然,我们可以重新设计所有的网站,以符合我们在精神上的期望——但这是不可能的,不是吗(笑)。我们正在做的是通过设计“标志”来支持他们,让我们能够识别流量。
例如,我们现在将记录一个“潜在客户”的标志,如果我们不能预测你是其他类型之一。如果我们以前见过你(使用 cookie)或者你执行了一个动作(身份验证或登录)来识别你,我们就会知道你是其他类型之一。所以,如果你让我走到这一步——如果我们不能预测你是谁,你就在潜在客户中。
现在,如果我将它扩展到这里的其他用户类型,这并不难,我得到的是一组像这样的标志:
潜在客户、已注册客户、低、中、高
(我也看到了清洁工人和供应商的旗帜)
现在,我可以用这些标志(设置为自定义维度)来创建一个 Google Analytics 视图,它整齐地围绕其中一个标志。
我可以创建一个“潜在客户”视图,在数据中没有供应商、客户或清洁工——并将我的进站流量优化工作集中在“真正重要”的东西上。当我在这个视图中查看数据时,它允许我查看、理解和模拟关于着陆、反弹、参与深度、渠道和设备混合的数据。如果我试图优化我的有机搜索或付费营销活动,当数据被污染时,我该如何做?
现在,您可以扩展该模型,以获得所有状态的视图,甚至可以包围其中的几个状态。在某些情况下,我们可能希望关注低价值客户的行为,但我们可能希望只围绕新客户——等等。最重要的是,绘制污染地图让我们能够绘制正确的东西——并为创建数据足迹的行为者的正确状态建模。
回到问题上来!
我们看到谷歌分析配置经常出现问题,设置、过滤和数据污染问题扭曲了数据。
在许多情况下,客户承认,似乎没有什么工作,他们已经变得不信任数据。对他们来说,这就像是在风中撒尿,所以他们退回到“只是猜测”作为明智的后备选择(笑)。
不是每个人都能解决所有的问题——但是我们在客户做重要的事情上取得了很大的成功。可能需要几分钟或几周的时间来找出并修复你的收集污染——但在你这么做之前,你不会知道。我们与每个人合作,最重要的是与技术和开发团队合作——快速完成工作,不会给数据带来风险。几个月后,清晰性改变了每个相关人员的工作。
想象一下,如果百货商店的收银机是可信的。从来没有人检查过抽屉里的现金是否与收银机显示的相符?从来没有人数过——他们只是把它倒在一个大箱子里。你在开玩笑吗?你会因为犯了这个基本错误而在零售业被解雇——那么为什么要在你的网站上犯这个错误呢?你实际上要检查这个——看它是否匹配,看你是否被盲目抢劫。
收集和数据污染很简单。在钱柜的例子中,让我们想象一下,我们给员工发放午餐费,这笔钱来自钱柜。我们也给顾客退款。我们卖礼券。我们从收银台向供应商付款。
所有这些都必须记录在零售中。所有这些都必须匹配。
然后——也只有到那时——它才会以原子粒子的形式组合成钱柜、部门、楼层、商店和业务级别的指标。如果你把废话推到钱柜数据和指标中,这些废话会在整个组织中流畅地向上流动,一直到董事会层面。
分析也是如此,如果你有污染,如果你不知道那里有什么或在哪里,如果你在数据中有几个用户状态,那么你就是在玩忽职守,让废话流入今年将在你公司打开的每个分析屏幕。
从零售商店拿一片树叶,校准你的数据——只要检查一下那里没有污染。几乎每个人都有一些,所以了解你的是值得的。
如果您需要审核配置方面的帮助或想要自己做,请联系。如果你只是需要有人来验证它是否工作正常,或者你有一些非常复杂的东西——一定要联系!
再见皮普。
C.
你应该知道的数据预处理技术

嗨伙计们!欢迎回来。今天,我们将讨论可以帮助您获得更高准确度的特征工程技术。
如您所知,对于数据科学家来说,数据可能非常令人生畏。如果你手里有一个数据集,如果你是一个数据科学家,那么你会开始考虑对你手里的原始数据集做些什么。这是数据科学家的天性。所以我还在成为数据科学家的学习过程中。我试图用各种数据预处理技术来充实我的头脑,因为这些技术对于了解你是否想处理数据是非常必要的。
对于这个分析,我将使用 Kaggle 提供的信用卡交易数据集。我已经写了一篇关于使用自动编码器检测信用卡欺诈的文章。链接在这里:https://medium . com/@ manisharajarathna/credit-card-fraud-detection-using-auto 编码器-in-h2o-399cbb7ae4f1
什么是数据预处理?
它是一种将原始数据转换成可理解格式的数据挖掘技术。原始数据(真实世界的数据)总是不完整的,并且这些数据不能通过模型发送。这将导致某些错误。这就是为什么我们需要在通过模型发送之前预处理数据。
数据预处理的步骤
以下是我遵循的步骤;
1。导入库
2。读取数据
3。检查缺失值
4。检查分类数据
5。标准化数据
6。PCA 变换
7。数据分割
1.输入数据
作为主库,我使用熊猫、Numpy 和 time
熊猫:用于数据操作和数据分析。
Numpy :用 Python 进行科学计算的基础包。
至于可视化,我用的是 Matplotlib 和 Seaborn。
对于数据预处理技术和算法,我使用了 Scikit-learn 库。
# main libraries
import pandas as pd
import numpy as np
import time# visual libraries
from matplotlib import pyplot as plt
import seaborn as sns
from mpl_toolkits.mplot3d import Axes3D
plt.style.use('ggplot')# sklearn libraries
from sklearn.neighbors import KNeighborsClassifier
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import normalize
from sklearn.metrics import confusion_matrix,accuracy_score,precision_score,recall_score,f1_score,matthews_corrcoef,classification_report,roc_curve
from sklearn.externals import joblib
from sklearn.preprocessing import StandardScaler
from sklearn.decomposition import PCA
2.读出数据
你可以在这里找到更多关于数据集的细节:https://www.kaggle.com/mlg-ulb/creditcardfraud
*# Read the data in the CSV file using pandas*
df = pd.read_csv('../input/creditcard.csv')
df.head()

Fig 1 : Dataset
df.shape
> (284807, 31)
3.检查缺少的值
df.isnull().any().sum()
> 0
因为在数据集中没有发现缺失值,所以我没有使用任何缺失值处理技术。
让我们看看数据
因此数据集被标记为 0 和 1。
- 0 =非欺诈
- 1 =欺诈
All = df.shape[0]
fraud = df[df['Class'] == 1]
nonFraud = df[df['Class'] == 0]
x = len(fraud)/All
y = len(nonFraud)/All
print('frauds :',x*100,'%')
print('non frauds :',y*100,'%')

*# Let's plot the Transaction class against the Frequency* labels = ['non frauds','fraud']
classes = pd.value_counts(df['Class'], sort = True)
classes.plot(kind = 'bar', rot=0)
plt.title("Transaction class distribution")
plt.xticks(range(2), labels)
plt.xlabel("Class")
plt.ylabel("Frequency")

Fig 2 : Class vs Frequency
4.检查分类数据
我们在这个数据集中唯一的分类变量是目标变量。其他要素已经是数字格式,所以不需要转换成分类数据。
让我们画出特征的分布
我使用 seaborn distplot()来可视化数据集中的要素分布。数据集中有 30 个特征和目标变量。
*# distribution of Amount*
amount = [df['Amount'].values]
sns.distplot(amount)

Fig 3 : Distribution of Amount
*# distribution of Time*
time = df['Time'].values
sns.distplot(time)

Fig 4 : Distribution of Time
*# distribution of anomalous features*
anomalous_features = df.iloc[:,1:29].columns
plt.figure(figsize=(12,28*4))
gs = gridspec.GridSpec(28, 1)
for i, cn **in** enumerate(df[anomalous_features]):
ax = plt.subplot(gs[i])
sns.distplot(df[cn][df.Class == 1], bins=50)
sns.distplot(df[cn][df.Class == 0], bins=50)
ax.set_xlabel('')
ax.set_title('histogram of feature: ' + str(cn))
plt.show()

Fig 5 : Distribution of anomalous features
在这个分析中,我不会放弃任何查看特征分布的特征,因为我仍处于以多种方式处理数据预处理的学习过程中。所以我想一步一步地实验数据。
相反,所有的特征将被转换成比例变量。
*# heat map of correlation of features*
correlation_matrix = df.corr()
fig = plt.figure(figsize=(12,9))
sns.heatmap(correlation_matrix,vmax=0.8,square = True)
plt.show()

Fig 6 : Heatmap of features
5.使数据标准化
数据集仅包含作为 PCA 变换结果的数字输入变量。V1、V2……v 28 是通过五氯苯甲醚获得的主要成分,唯一没有通过五氯苯甲醚转化的特征是“时间”和“数量”。因此,主成分分析受比例的影响,所以我们需要在应用主成分分析之前对数据中的特征进行比例缩放。对于缩放,我使用 Scikit-learn 的 StandardScaler()。为了适合定标器,数据应该在-1 和 1 之间整形。
*# Standardizing the features*
df['Vamount'] = StandardScaler().fit_transform(df['Amount'].values.reshape(-1,1))
df['Vtime'] = StandardScaler().fit_transform(df['Time'].values.reshape(-1,1))
df = df.drop(['Time','Amount'], axis = 1)
df.head()

Fig 7 : Standardized dataset
现在,所有特征都被标准化为单位尺度(平均值= 0,方差= 1)
6.PCA 变换
PCA(主成分分析)主要用于减少特征空间的大小,同时保留尽可能多的信息。在这里,所有的特征使用 PCA 转换成 2 个特征。
X = df.drop(['Class'], axis = 1)
y = df['Class']
pca = PCA(n_components=2)
principalComponents = pca.fit_transform(X.values)
principalDf = pd.DataFrame(data = principalComponents
, columns = ['principal component 1', 'principal component 2'])finalDf = pd.concat([principalDf, y], axis = 1)
finalDf.head()

Fig 8 : Dimensional reduction
*# 2D visualization*
fig = plt.figure(figsize = (8,8))
ax = fig.add_subplot(1,1,1)
ax.set_xlabel('Principal Component 1', fontsize = 15)
ax.set_ylabel('Principal Component 2', fontsize = 15)
ax.set_title('2 component PCA', fontsize = 20)
targets = [0, 1]
colors = ['r', 'g']
for target, color **in** zip(targets,colors):
indicesToKeep = finalDf['Class'] == target
ax.scatter(finalDf.loc[indicesToKeep, 'principal component 1']
, finalDf.loc[indicesToKeep, 'principal component 2']
, c = color
, s = 50)
ax.legend(targets)
ax.grid()

Fig 9 : Scatter plot of PCA transformation
由于数据非常不平衡,我只从非欺诈交易中提取了 492 行。
*# Lets shuffle the data before creating the subsamples*
df = df.sample(frac=1)
frauds = df[df['Class'] == 1]
non_frauds = df[df['Class'] == 0][:492]
new_df = pd.concat([non_frauds, frauds])
*# Shuffle dataframe rows*
new_df = new_df.sample(frac=1, random_state=42) *# Let's plot the Transaction class against the Frequency*
labels = ['non frauds','fraud']
classes = pd.value_counts(new_df['Class'], sort = True)
classes.plot(kind = 'bar', rot=0)
plt.title("Transaction class distribution")
plt.xticks(range(2), labels)
plt.xlabel("Class")
plt.ylabel("Frequency")

Fig 10 : Distribution of classes
*# prepare the data*
features = new_df.drop(['Class'], axis = 1)
labels = pd.DataFrame(new_df['Class'])
feature_array = features.values
label_array = labels.values
7.数据分割
*# splitting the faeture array and label array keeping 80% for the trainnig sets*
X_train,X_test,y_train,y_test = train_test_split(feature_array,label_array,test_size=0.20)
*# normalize: Scale input vectors individually to unit norm (vector length).*
X_train = normalize(X_train)
X_test=normalize(X_test)
对于模型建筑,我使用 K 个最近邻。因此,我们需要找到一个最佳的 K 来获得最佳效果。
k-最近邻
来自维基百科;
在模式识别中,k-最近邻算法 ( k -NN )是一种用于分类和回归的非参数方法。在这两种情况下,输入由特征空间中的 k 个最接近的训练样本组成。输出取决于 k -NN 是用于分类还是回归。
KNN 算法假设相似的事物存在于附近。换句话说,相似的事物彼此靠近。
“物以类聚,人以群分。”
训练算法只存储数据,计算由预测算法完成。
neighbours = np.arange(1,25)
train_accuracy =np.empty(len(neighbours))
test_accuracy = np.empty(len(neighbours))
for i,k **in** enumerate(neighbours):
*#Setup a knn classifier with k neighbors*
knn=KNeighborsClassifier(n_neighbors=k,algorithm="kd_tree",n_jobs=-1)
*#Fit the model*
knn.fit(X_train,y_train.ravel())
*#Compute accuracy on the training set*
train_accuracy[i] = knn.score(X_train, y_train.ravel())
*#Compute accuracy on the test set*
test_accuracy[i] = knn.score(X_test, y_test.ravel())
我们可以通过将测试集的准确性与训练集的准确性进行绘图来找到最佳 K 值。k 的最佳值是给出最大测试精度的点。
*#Generate plot*
plt.title('k-NN Varying number of neighbors')
plt.plot(neighbours, test_accuracy, label='Testing Accuracy')
plt.plot(neighbours, train_accuracy, label='Training accuracy')
plt.legend()
plt.xlabel('Number of neighbors')
plt.ylabel('Accuracy')
plt.show()

Fig 11 : Number of Neighbors vs Accuracy
idx = np.where(test_accuracy == max(test_accuracy))
x = neighbours[idx]
我使用 Scikit-learnKNeighborsClassifier()来构建模型。
*#k_nearest_neighbours_classification*
knn=KNeighborsClassifier(n_neighbors=x[0],algorithm="kd_tree",n_jobs=-1)
knn.fit(X_train,y_train.ravel())

*# save the model to disk*
filename = 'finalized_model.sav'
joblib.dump(knn, filename)*# load the model from disk*
knn = joblib.load(filename)
在我们建立模型之后,我们可以使用 predict()来预测测试集的标签。
*# predicting labels for testing set*
knn_predicted_test_labels=knn.predict(X_test)
模型评估
from pylab import rcParams
*#plt.figure(figsize=(12, 12))*
rcParams['figure.figsize'] = 14, 8
plt.subplot(222)
plt.scatter(X_test[:, 0], X_test[:, 1], c=knn_predicted_test_labels)
plt.title(" Number of Blobs")

Fig 12 : Number of Blobs
*#scoring knn*
knn_accuracy_score = accuracy_score(y_test,knn_predicted_test_labels)
knn_precison_score = precision_score(y_test,knn_predicted_test_labels)
knn_recall_score = recall_score(y_test,knn_predicted_test_labels)
knn_f1_score = f1_score(y_test,knn_predicted_test_labels)
knn_MCC = matthews_corrcoef(y_test,knn_predicted_test_labels)

混淆矩阵
混淆矩阵是一个表格,通常用于描述一个分类模型(或“分类器”)对一组真实值已知的测试数据的性能。Scikit-learn 提供了使用混淆矩阵方法计算混淆矩阵的工具。
import seaborn as sns
LABELS = ['Normal', 'Fraud']
conf_matrix = confusion_matrix(y_test, knn_predicted_test_labels)
plt.figure(figsize=(12, 12))
sns.heatmap(conf_matrix, xticklabels=LABELS, yticklabels=LABELS, annot=True, fmt="d");
plt.title("Confusion matrix")
plt.ylabel('True class')
plt.xlabel('Predicted class')
plt.show()

Fig 13 : Confusion Matrix
结论
我试图不标准化数据,以获得更好的准确性。但是在我学会并应用这个方法后,它给出了一个有希望的结果。我还在做实验,还在学习数据预处理技术。对于这个数据集,我只使用了 KNN 算法。如果你觉得这个内核有帮助,请随意评论并投赞成票。
参考
你可以在这里找到更多关于 PCA 转换的信息:https://towardsdatascience . com/PCA-using-python-scikit-learn-e653 f 8989 e 60
数据准备和预处理与在数据科学中创建实际模型同样重要——第 1 部分
我最近报名参加了 Kaggle 上的房价:高级回归技术挑战。这个问题要求参与者在超过 75 个基本预测值的基础上预测每栋房屋的最终价格。显然,这是一个回归问题。顾名思义,它测试用户对高级回归技术的使用。
我花了近 2 周时间在工作、几门课程、几个其他项目和生活中周旋,并学到了一些关于 EDA(探索性数据分析)、特征工程和数据准备的技巧。在我带您完成以下步骤的同时,我还将分享我从挑战中的其他参与者那里学到的东西。当前版本的笔记本没有太多的建模技术。我仍在研究模型,稍后将发表另一篇关于模型选择及其基本概念的文章。
本文重点介绍数据理解和预处理的几个步骤,即基于相关矩阵、异常值处理和目标变量转换的初步特征选择。在相应的文章中,我还会谈到像缺失值处理和特征工程这样的步骤。
了解数据集
竞赛的数据部分包含一个详细的数据描述文件,解释了所有变量的定义和内容。人们应该知道的一些重要变量是:
- “销售价格”——这是目标变量,包含以美元为单位的房产销售价格。虽然此变量是为训练数据集中的所有记录填充的,但必须为 test.csv 文件中的数据预测相同的列
- “总体质量”——这一指标对房屋的整体材料和装修质量进行评级。它有从 1 到 10 的等级,1 对应“非常差”,10 对应“非常好”。这个分类变量实际上是一个变量。我们将不得不相应地对待它。
- “总体状况”——这一指标对酒店的整体状况进行评级。就像,总的来说,它对相同的类有 1 到 10 的排名。
- ’ year build '-这个变量给出了房产最初建造的年份。
- yearremodaddd '-这个变量表示房产的改造日期。如果没有进行改造或添加,则该列的值应该与建造日期(建造年份)相同
- YrSold’-这包含房子出售的年份(YYYY 格式)。
- 这是房产出售的月份(MM 格式)。
- GarageYrBlt’-这是房子的车库建造的年份。
- GrLivArea’-这是许多可用的区域相关参数之一。这一项特别指出了房屋中可利用的地上(等级)居住面积(平方英尺)。
- TotalBsmtSF’-顾名思义,这个指标包含了地下室的总面积,以平方英尺为单位。
- “1stFlrSF”和“2 ndflrsf”-这些变量分别代表一楼和二楼的面积(平方英尺)
- ’ GarageArea’-这个变量代表车库的平方英尺大小。
- GarageCars 这一栏包含车库的大小,以汽车容量表示。因此,该指标中的所有值都应该是整数。
- TotRmsAbvGrd’-该参数包含地面以上的房间总数。数据描述文件清楚地表明,这没有考虑到浴室。
- ’ LotFrontage’-该列包含与物业相连的街道的线性英尺数。
还有一些其他指标,如“PoolQC”、“Utilities”、“Alley”、“CentralAir”等,这些指标表明酒店中某些功能的存在和质量。人们可以参考数据字典并了解如何研究和使用它。
train.csv 文件有 1461 行和 81 列(包括列标题)。另一方面,test.csv 文件有 1460 行和 80 列(不包括目标变量,即“销售价格”)。
数据探索(EDA)
相关性和主要特征选择
我在这个问题上的第一步是理解变量,评估它们,做一些基本的 EDA。我从绘制训练数据集的相关矩阵开始。

Correlation Matrix
相关矩阵的一些基本要点如下:
- 如果我们看上面的热图,所有的白色方块表示相应变量之间的高度相关性
- “GarageCars”和“GarageArea”显示出高度的相关性,也符合我们的直觉思维。车库的面积越大,车的数量就越多。此外,两者似乎都与“销售价格”有着相似(且相对较高)的相关性。这清楚地表明了多重共线性的情况。因此,我们可以删除其中一个,保留另一个。
- 此外,“TotalBsmtSF”和“1stFlrSF”再次显示高度相关性,表明多重共线性。因此,我们应该删除其中一个。
- 如果我们查看“TotalBsmtSF”和“SalePrice”之间的相关性,我们会看到一个白色方块,即高相关性。这表明应该保留 TotalBsmtSF,因为它有助于销售价格预测
- 另一组显示高相关性的变量是“YearBuilt”和“GarageYrBlt”。如果我们比较“GarageYrBlt”中缺失值的百分比,我们会看到它有超过 5%的缺失值(我们将在后面查看相同的详细分析)。此外,“YearBuilt”似乎与“SalePrice”有相当好的相关性(大约 0.5)。看来我们应该保留‘year build’而放弃‘GarageYrBlt’。
- 此外,除了‘year build’、‘GarageCars’或‘GarageArea’中的一个)和‘TotalBsmtSF’之外,我们还应该记住其他四个似乎与‘销售价格’有很好相关性的变量:‘总体质量’、‘GrLivArea’、‘全浴’和‘TotRmsAbvGrd’
- 然而,如果我们观察’ TotRmsAbvGrd ‘与其他变量的相关性,我们会发现与’ GrLivArea '的相关性很高。为了能够决定删除哪个变量,让我们再看一些分析。
然后,我绘制了一个散点图,它会给出一些列相对于其他列的数据分布的详细信息。我们选择了上面提到的列。

scatter plot of selected variables
从上面的情节我们可以推断:
- ‘GrLivArea’和‘TotRmsAbvGrd’表现出高度的线性关系。
- 当我们关注“GrLivArea”和“TotalBsmtSF”时,显示出一种线性关系,几乎有一个边界定义了该图。这基本上表明“GrLivArea”定义了“TotalBsmtSF”(地下室面积)的上限。没有多少房子会有比底层居住面积更大的地下室。
- “销售价格”显示“一年建成”几乎急剧上升,基本上表明价格随着房屋年限的减少而上升(几乎呈指数增长)。大多数最近的房子价格都很高。
为了最终决定保留上面的哪些变量,放弃哪些变量,我们将进行最后的分析。让我们放大几个具体变量的相关矩阵。

Zoomed in correlation matrix for top 10 variables
从上面的相关矩阵快照中,我决定了最终要明确考虑的变量列表和要排除的变量列表:
- 与“销售价格”相关性最高的变量是“总体质量”——保留“总体质量”
- “GarageCars”和“GarageArea”之间的高相关性+“GarageCars”和“SalePrice”之间的高相关性— 保留“GarageCars”;移除‘车库区域’
- ’ TotalBsmtSF ‘和’ 1stFlrSF ‘相关性高,与’ SalePrice '相关性相等——保留’ TotalBsmtSF ‘,删除’ 1stFlrSF’
- 在“GarageYrBlt”和“year build”中,“year build”的缺失值较低,与“销售价格”的相关性较高— 保留“year build”,删除“GarageYrBlt”
- “TotRmsAbvGrd”和“GrLivArea”之间的相关性很强+“GrLivArea”和“SalePrice”之间的相关性更高— 保留“GrLivArea”;删除’ TotRmsAbvGrd’
- 保留“全浴”,因为我们没有看到与任何其他变量的相关性,但它与“销售价格”有显著关联
在我们进入下一步之前,让我们试着理解为什么我删除了可能导致多重共线性的变量。为此,我们将不得不钻研一些简单的数学。
回归分析分离出每个预测值或自变量(x)和目标/因变量(y)之间的关系。在最后的方程中,回归系数表示在所有其他自变量都不变的情况下,相应自变量的单位变化在目标变量中引起的平均变化。
现在,在一种情况下,当独立变量相关时(这种情况是多重共线性),它表明一个变量的变化也会导致另一个变量的变化。这种相关性越强,改变一个变量而不改变另一个变量的难度就越高。这使得回归模型难以独立估计每个自变量和因变量之间的关系。这基本上导致了 3 个相互关联的主要问题:
由于预测因素导致的解释方差不可靠
系数变得对模型中的微小变化和其他独立预测因子的存在高度敏感。
它会降低方程系数的精度,从而降低回归模型的性能(用于确定独立变量统计显著性的不可靠 p 值)。
异常值处理
既然我们已经关注了导致目标变量“销售价格”最大方差的变量,让我们从这些变量中移除异常值。为什么这很重要?回归作为一种算法,试图通过数据点拟合最佳直线。为了找到最佳拟合函数,它试图适应所有点,这使得它对异常值非常敏感。虽然线性回归比其他稳健算法更敏感,但在任何回归练习之前的最佳实践是处理异常值,而不管使用什么算法。
我采用了一种启发式方法来处理异常值,这样我就可以看到和控制我正在处理的数据点。我在处理异常值时注意的一些变量是
- 格里瓦雷亚
首先,我使用散点图比较了变量“GrLivArea”和“SalePrice”。

“之前”图表中大约 4600 平方英尺和 5600 平方英尺的两个点看起来像是异常值。我通过在大于 4000 平方英尺的‘GrLivArea’应用降点条件来移除它们。制成’销售价格’低于 30 万美元。
2.总计 BsmtSF
对地下室总面积(TotalBsmtSF)也做了类似的工作。移除异常值([’ TotalBsmtSF ']>3000)前后的散点图如下所示:

3.总体平等
总体质量度量是一个顺序变量。“总体质量”相对于“销售价格”的散点图有望为我们提供价格范围,以及相应的物业质量。使用散点图,我删除了 2 个数据点,看起来像离群值。使用条件( [‘总体质量’] > 9) & ([‘销售价格’] > 700000) ),我获得了“总体质量”散点图之前和之后的以下内容:

上述练习从训练数据集中移除了 7 个数据点(或总共记录)。使用上述数据集,我继续进行下一个练习:调查目标变量,即“销售价格”
目标变量的调查和转换
在我深入研究这一步的复杂性之前,让我解释一下我们通过这一步想要达到的目的。我们正在调查问题中目标或响应变量的行为和趋势,即“销售价格”。这一步的发现还将帮助我们转换变量,以尽可能最好的方式适应我们的模型。
这对于确保模型预测更加准确非常重要。在回归算法中,残差必须服从正态分布。只是修改一下残差的定义,它被定义为因变量/目标变量的观测值( y )和预测值( ŷ )之差。
现在出现的一个明显的问题是关于正态残差的需要。为了回答这个问题,让我们试着简化这个练习背后的数学逻辑:
残差和异方差的非正态性(一个变量的可变性在用于预测它的另一个变量的值的范围内不相等的性质。)提出了一个主要问题。它基本上是说,模型中的误差量在观察或训练数据的整个范围内是不一致的。就独立变量或预测变量而言,这意味着它们所具有的解释方差(或预测能力)的数量(按β权重计算)在目标变量的整个范围内并不相同。本质上,预测因子可以解释不同水平的响应变量的不同趋势和差异。换句话说,当残差不是正态分布时,则假设它们是随机数据集,取值为“否”。这意味着模型不能解释数据集中的所有趋势(低 R 平方值)。这无疑降低了试验预测的可靠性。
我们可以通过转换因变量来纠正这一点。现在,如果预测值是正态分布的,那么残差也是正态分布的,反之亦然。一些常见的转换变量是:1。对数,2。平方根,3。反向(1/x)。根据观察到的响应变量趋势,还可以使用其他几个函数或转换。
更详细的解释也可以参考这个链接这里。
因此,我从绘制直方图开始,研究“销售价格”的分布:

Plots for original ‘SalePrice’ values
我们可以从直方图中观察到正偏度。这不完全是正态分布。此外,在概率图中,“销售价格”列的有序值不遵循线性趋势。这基本上都代表了数据的右偏度。
现在,如果我们观察到正或右偏斜,对数变换是一个很好的选择。对这些值应用对数函数应给出线性趋势,并将这组值转换为“正态分布”值。我们将看到如何。
您可以参考下面的代码片段来查看我执行了什么转换:
观察到的 mu 和 sigma 值为:均值= 12.02 和标准差。戴夫。= 0.39。我获得的图是:

Plots for log-transformed ‘SalePrice’ values
正如我们在这里看到的,分布现在看起来是正常的,并且在概率图中是线性趋势。
在这一步之后,我添加了经过处理的训练和测试数据集,以形成一个数据集:“total_df”。接下来的步骤包括缺失值处理和特征工程。我将在下一篇文章中讨论这些内容。
上述步骤的要点
正如你在上面看到的,每一步都有其背后的基本原理。分析相关矩阵以减少多重共线性。进行异常值处理是为了优化回归模型的性能。对目标变量进行分析和转换,以获得推理和直观的误差趋势。
您的用例可能需要也可能不需要这些步骤。但是,在开始构建模型之前,最好先检查一下这些情况。缺乏这些可能会错误地摆动你的模型而没有解释,或者可能会给你完全不可靠的测试预测。
我将在相应的文章中介绍其余的步骤。请留意这个空间的链接。
编辑:
链接到本系列的下一篇文章: 数据准备和预处理与创建数据科学中的实际模型同样重要——第 2 部分
Python 中的数据预处理

我在我的文本摘要工具中执行了数据预处理,现在,这里是详细内容。
数据预处理不过是为实验准备数据——转换原始数据以供进一步处理。
正在使用的 Python 库— NLTK 、beautiful soup、 re 。

考虑以下保存为 sample_text.txt 的文本-
这只是我用 HTML 标签、额外空格和特殊字符加上的一组随机的句子。
****目标是通过移除多余的空格、换行符、标签、特殊字符和小写单词来清理这段文本。

让我们对上述数据进行预处理-
我已经开始编写一些函数,即*【get _ text()*clean _ html()和remove _ string _ special _ characters()-

让我们在 sample_text.txt. 上使用这些函数
首先我们从 get_text() 函数获取文本,使用 clean_html() 移除 HTML 标签,然后使用 sent_tokenize 将文本分成句子。
这些句子然后被传入remove _ string _ special _ characters()。**
然后,将几乎清理干净的句子连接起来,再次给出全文。

最后一步是使用 word_tokenize 将文本标记成单词。
单词小写并且停止单词从最终单词列表 text_words 中移除。****

所以现在我们有了一个文本中的单词语料库。
这部文集能告诉我们什么?使用一些基本方法探索内容,典型的方法是数单词。我们可以找出哪些词在语料库中出现频率最高,通过按语料库频率对词进行排序,我们可以研究语料库的词汇分布。NLP 有很多!
可以实现更多的函数来满足特定类型的文本,但以上是清理数据以供进一步处理的最常见方法。
编码快乐!

Photo by delfi de la Rua on Unsplash
数据揭示:是什么让 Ted 演讲受欢迎?
你有没有想过是什么让一些 TED 演讲比其他的更受欢迎?
我分析了 2550 个 ted 演讲的数据集来寻找这个问题的答案。我研究了一个特定演讲的哪些可用变量,如评论数量、翻译语言数量、演讲时长、标签数量或在线发布日期,是其受欢迎程度的强有力预测因素,以浏览量衡量。
底线
在对数据集中其他可用变量的视图进行分析和回归后,揭示了一些有趣的关联。
一个高点击率的热门话题有什么特点?
- 评论数高(自然)。
- 多语种翻译(自然也是)。
- 许多评论的组合和许多翻译语言产生的浏览量远远高于它们单独使用时的预期。
- 它不应该太短。持续时间根本没有太大的影响,但如果有的话,它对更长的谈话是积极的。最受欢迎的演讲时间在 8-18 分钟之间。
- 标签数量更多,最好在 3-8 个之间。
- 它会在工作日上传,最好是星期五!
- 你可能会看到一些时髦的职业会因为他们的演讲而获得比平均水平高得多的评价,比如:神经解剖学家、安静的革命者、测谎仪、模特、拳击运动员、弱点研究员或禅宗牧师。这不具有代表性,但他们确实获得了最高的票数(这是一个不公平的游戏,但嘿)。
下面是实际数据分析。你可以在我的 R-Pubs 页面上看到完整的 R markdown 笔记本,以及我的 GitHub 上的所有文件和数据。

Edward Snowden’s Surprise Appearance at TED, Speaking with Chris Anderson and Tim Berners Lee on a telepresence robot, beaming in from a secret location in Russia. Source: Wikimedia Commons, originally uploaded from [Filckr](http://Uploaded from http://flickr.com/photo/44124348109@N01/13332430295).
让我们深入研究数据
首先,你应该意识到:不要把这个(或者从观察数据中得到的几乎任何其他结论)作为一个的因果推断。这不是一个实验,也不足以证明因果关系。对照组和治疗组或数据的各种亚组之间的观察结果不匹配,即使在回归之后,变量的解释力也不够严格。我手头现有的数字参数不足以得出这样的结论;我无法将真正重要的内容与苹果进行比较,即使使用多元回归进行控制,也不是所有的事情都是相同的(其他条件不变假设仍然不成立)。然而,我能够得到一个像样的预测器,并了解哪些变量与较高的视图计数最密切相关。
数据是什么样的?
该数据集包括 2550 场演讲的名称、标题、描述和 URL、主要演讲人的姓名和职业、演讲人数、演讲时长、TED 活动和拍摄日期、在线发布日期、评论数量、翻译的语言和浏览量。它还包括一个压缩形式的相关标签、评级和相关谈话的数组,但在数组内部,这些需要转换才能使用。有关完整列表,请参见 Kaggle 上的数据集页面。
1:直方图
首先,让我们看看每个变量是如何分布的直方图。
直方图 是表示该变量取值分布的一种方式;或者直观地表示:“一分钟有多少次谈话?两分钟?三分钟?等等……”。形式上,直方图是“由矩形组成的图,其面积与变量的频率成比例,宽度等于类间隔”。
看看下面我们的变量是什么样子的。

会谈持续时间更接近于正态分布,但在较长的持续时间内,一些会谈的右侧尾部较宽,平均值约为 14 分钟,中位数为 12 分钟。几乎所有的演讲都在 1-18 分钟之间(正常 Ted 演讲的最长时间)。

评论数量是泊松分布(视觉上类似于指数分布,但技术上不是,因为评论是以离散数字测量的),对于不受欢迎的视频,强烈偏向于 0 评论的最小值。

视图数量也是一个向左倾斜的泊松分布,视图数量的中位数是 1124524,视图数量的平均数是 1698297
最后,我们的变量分布的总体情况:

Histograms of each numerical variable: number of comments, duration, date filmed, number of languages translated, number of speakers presenting (almost always one), published date, view counts, month, year, whether it was published on a weekend, and number of tags.
从这些分布中我们看到:
- 标签数量也是向左倾斜的泊松分布,峰值在 4-7 个标签之间。
- 冷门演讲的翻译语言数量最高为 0,但大部分都在 20-40 种语言之间。
- 虽然 2012 年之前的电影日期很低,但它们都以更加统一的速度出版。
最常见的职业有哪些?
显然,作家是 TED 演讲者最常见的职业!其次是其他创造性职业和从事该职业的人数:
- 作者:45
- 艺术家:34 岁,设计师:34 岁
- 记者:33 岁
- 企业家:31 岁
- 建筑师:30 岁
- 发明者:27(显然那是一种职业!)
- 心理学家:26
- 摄影师:25
- 电影制作人:21

但是平均来说,导致最受欢迎的谈话的职业是什么?
这些职业差别很大!他们被最受欢迎的 ted 演讲中的离群值扭曲了(例如,# [4]漏洞研究员仅指布琳·布朗),因此不是代表性样本。总之,这里有一些令人惊讶的发现:
[1] **Neuroanatomist**
[2] Life coach; expert in leadership psychology
[3] Model *# okay, nature of man doesn't change*
**[4] Vulnerability researcher**
[5] Career analyst
**[6] Quiet revolutionary** *# great occupation*
**[7] Lie detector**
[8] Psychiatrist, psychoanalyst and **Zen priest**
[9] Director of research, Samsung Research America
[10] Author/educator
**[11] Illusionist, endurance artist #(really?)**
**[12] Gentleman thief**
[13] Health psychologist
[14] Comedian and writer
[15] Leadership expert
[16] Social activist
[17] Relationship therapist
[18] Vocalist, **beatboxer**, comedian
[19] Clinical psychologist
[20] Comedian and writer

2:参数之间的相关性
让我们看看每对数值变量之间的总体相关对散点图矩阵;

pairs scatter-plot matrix
为了补充这一点,可以看到一个相关矩阵,用颜色表示从 0(白色)到深蓝色(+1)或深色条纹红色(强负相关,-1)的相关强度,用星号(***)表示 p 值的显著性。

correlation matrix
大多数参数没有很强的相关性。
- 自然,出版数据和拍摄日期之间有很高的相关性。从数字和逻辑上看,拍摄日期似乎与观看次数没有太大关联——因为观众更受 ted 演讲发布日期的影响,而不是它是一个月前还是一年前录制的。
- 评论数和浏览量之间存在相对较高的正相关性,这是有道理的(更多的受众,更多的评论)
- 翻译语种数与浏览量(0.38)和评论数(0.32)呈正相关
- 时长和语言数量之间存在较小的负相关;讲话越短,翻译的语言就越多,大概是因为更容易翻译吧。
3:现在是有趣的部分,这些参数中的每一个与视图的数量有多大关联?
这些变量如何与视图相关联?是线性关系,非线性关系,还是非线性关系?了解这一点很重要,这样才能知道如何将它们插入回归中。
让我们从本周日开始,这篇讲话发表于。

因此,一周中的某一天似乎确实与平均观点有一些关联!周末发布的 Ted Talks 浏览量似乎少很多,周六最低,周五是 ted talks 发布日最受欢迎的一天。
下面是散点图,黄土弹性回归用白色表示,线性回归用粉色表示,看看线性形状与弹性移动平均线有什么不同。这向我们表明,通常,除了在这些变量的分布的故事中,只有几个异常值的数据,线性模型在某种程度上描述了这种关系。
让我们从持续时间和标签数量开始:

令人惊讶的是,持续时间与视图数量几乎没有一致的相关性;除了最受欢迎的演讲接近 8-18 分钟。标签数量在 3-8 之间似乎是最佳的,这也是更常见的标签数量;有一些特别受欢迎的谈话的异常值。
那么评论数量和翻译语言呢?

不出所料,显然,评论数量与浏览量有很好的相关性,语言数量也是如此——它们都来自于拥有大量的观众。因此,基于这些因素来预测观点是不“公平”的,在现实世界中,我们不能使用这些参数来预测,因为它们不是更多观点的原因,但是它们也是许多观点的结果,并且是一个加强反馈循环的原因:评论越多,社区就越参与讨论,并且更有可能传播;语种越多,观众能看的越多;而且观众越多,评论翻译的观众就越多。其余的有一个小的线性效应,没有偏离太多,虽然很小。
粉色线是线性回归,而白色线是黄土。与黄土回归相比,线性回归似乎不会丢失太多信息,黄土回归具有任意的灵活性,并且会显示明显的非线性形状。虽然它们中的一些确实具有非线性形状,但从更近的角度来看,它只是在数据稀缺的尾部,并且受到那里的几个数据点 和一些异常值的影响(如在注释相关性中)。因此,将回归变量作为线性拟合输入可能就足够说明问题了。
模型和结果
我首先对每个感兴趣的变量分别进行了视图数量的回归,这使得我们能够看到哪些变量具有解释力以及解释力有多强。后来,我加入了更好的解释,将它们一个接一个地添加到多元回归中,同时检查它们的添加是否真的提高了我们的性能。结果如下表所示,对于模型(1)到(8),每一列都是不同的模型。

选择的模型是最后一个模型,因为它在 R 平方、调整后的 R 平方、p 值和 F 统计方面具有最佳的解释能力,尽管它与模型(5)相比只有微小的改进,只有注释和翻译的语言。
出于预测的目的,我会选择包含所有变量的模型 8。出于解释的目的,我选择模型 5 来解释注释和语言是目前为止与视图最相关的,并解释了它的大部分差异。
模型 5 表明,每增加一条评论,就会增加 4,044 次浏览(p 值低于 0.01),每增加一种语言的翻译,就会增加 60,650 次浏览(p 值低于 0.01)。然而,常数是负的(-733)视图,这没有意义,但这伴随着线性模型的限制。这些共同解释了 0.33 的方差(包括 R 平方和调整的 R 平方)。
**Y(浏览量)=—733+4044 评论+60650 语言
然而,在模型 8 中加入所有其他变量后,R 平方略微提高到 0.336,调整后的 R 平方为 0.334。因此,如果我们追求预测的准确性,我会使用最后一个完整的模型:
***Y(浏览量)=—1455238+3931 *评论+68222 *语言+408 时长+26625 数量 _ 标签—41407 是 _ 周末
结果,尤其是模型 8,显示了总体意义。大多数变量都显示出显著性,虽然周末没有,但加入它仍然稍微提高了解释力,所以我保留它。f 统计量相对较低,R and R 平方分别为 0.336 和 0.334,但在这组模型中表现最好。常数下降得更多,给变量更多的权力来提高预测的视图计数。评论的系数(效果的估计)从 4044 减少到 3931,并且对于语言的数量重新分配到更高的系数,对于新增加的变量重新分配到新的系数:每增加一秒钟就有 408 个更多的视图,每增加一个标签就有 26625 个更多的视图,并且如果在周末发布,这通过将预测的视图数量减少 41407 来补偿。
最后,我用标签数量和持续时间的多项式进行了最终回归,最高达三次**,添加评论数量和语言数量之间的交互项做出了重大贡献,提高了准确性,R 平方为 0.436,调整后的 R 平方为 0.434。由于系数为正,这表明**与许多评论进行对话与 d m 任何语言的翻译加在一起比只与其中一个人进行对话产生更多的观点。然而,这种模型不太便于得出一般性结论,可能不太通用,容易过度拟合。并不是所有的多项式都有统计学意义,但是当我放弃其中一个时,它们仍然改善了结果。因此,在这里我不会过多地指望它的含义,但是对于类似的数据,它会是一个稍微好一点的预测模型。下面是它的表现(以及如何运行)😗***
Call:
lm(formula = views ~ comments + languages + num_tags + I(num_tags^2) +
I(num_tags^3) + weekend + duration + I(duration^2) + I(duration^3) +
comments * languages, data = ted)
Residuals:
Min 1Q Median 3Q Max
-26821919 -682956 -290905 234527 25305423
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) -4.548e+05 3.394e+05 -1.340 0.18035
comments -5.796e+03 4.838e+02 -11.979 < 2e-16 ***
languages 3.522e+04 4.930e+03 7.145 1.17e-12 ***
num_tags -9.210e+04 7.291e+04 -1.263 0.20668
I(num_tags^2) 9.235e+03 6.441e+03 1.434 0.15174
I(num_tags^3) -2.236e+02 1.666e+02 -1.343 0.17950
weekend 1.342e+05 1.905e+05 0.704 0.48120
duration 2.038e+03 4.664e+02 4.369 1.30e-05 ***
I(duration^2) -9.895e-01 3.355e-01 -2.949 0.00321 **
I(duration^3) 1.367e-04 5.555e-05 2.462 0.01389 *
comments:languages 2.464e+02 1.171e+01 21.052 < 2e-16 ***
---
Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
Residual standard error: 1879000 on 2539 degrees of freedom
Multiple R-squared: 0.4369, Adjusted R-squared: 0.4346
F-statistic: 197 on 10 and 2539 DF, p-value: < 2.2e-16
结论
这个有限模型传达的是相关性,而不是因果关系。它没有很好地传达因果关系,因为因果推理的基本问题没有用这些变量很好地解决,这些预测因子*不独立于 y 变量,*并且它们高度相关(主要是评论和语言数量,它们自然是最好的预测因子。我不相信通过这些可用的数值预测,我们可以得出一个因果推论。接下来的尝试可能会使用谈话的转录来分析内容,或使用音频来分析鼓掌的程度,或使用谈话中的视觉效果和说话者的服装来更好地预测谈话的内容。
含义
认识到这不是因果关系,这些相关性可以帮助你(1)在给定这些参数的情况下,更好地预测一次谈话的浏览量,以及(2)假设可能的因果方向,并进一步测试它们。
那么, 一段通俗的谈话会有什么特点呢?
- **评论数高。**看得越多,你得到的评论就越多,但因果关系也可能是双向的:评论越多→甚至更多的观点。因此,如果你想增加你的浏览量,让你所有的朋友都来评论并开始讨论可能会有所帮助。这可能会刺激你的视频的病毒式传播,增加浏览量,并可能增加 TED 展示它的可能性。实验一下,让我知道!
- 多种语言的翻译。这也很可能具有双面因果关系;浏览量越多→翻译量越多→能看的人越多,浏览量甚至更多。所以如果你想开始这个循环,让你的朋友或自由职业者翻译并宣传这个演讲,T2 可能会有所帮助。如果有很多评论和多种翻译语言——这时候你就知道要赌上更多的浏览量了。
- 不应该太短。久期非常轻微的正相关;最受欢迎的演讲时长为 8-18 分钟。这可能表明,通常来说,太短的谈话不够深刻,不够鼓舞人心。然而,如果你的演讲天生很短,我不认为延长它并冒着它很无聊的风险是一个好主意。
- 标签数量更多,最好在 3-8 个之间!回归表明,更多的标签有积极的影响,这是有意义的,因为足够广泛,并建议从更多的主题和其他谈话作为来源。最受欢迎的演讲有 3-8 个标签,所以这可能意味着演讲太宽泛或没有重点不是一个好主意。
- 它会在工作日上传,最好是周五!这有点令人惊讶,但显然,在周末上传有负面影响(除了在最后一个模型中,它可能被如此多的其他形式的其他变量所混淆);但不可否认的是,一周中的某一天与平均浏览量之间的相关性表明,在工作日上传的谈话,尤其是在周五,明显比周末更受欢迎。当人们在工作的时候,他们对 TED 新发布的内容了解多少?或者更具体地说,当他们在工作中偷懒时,在周五最常做的是什么?
最后,现在你可以和你的朋友继续你的 TED 狂欢派对,进行一些更有根据的猜测了!如果你赢了大奖,你也可以送我一些表示感谢的东西。
你可以在我的 R-Pubs 页面上看到完整的 R markdown 笔记本,以及我的 GitHub 上的所有文件和数据。
祝你这周过得愉快,一定要看看一个新的 TED 演讲,有 3-8 个标签,8-18 分钟长,有很多评论和语言,是在周五上传的!
数据科学项目管理方法

在数字化背景下,组织正在部署越来越多的数据科学项目。这篇文章揭示了一些可以指导新一代项目的项目管理方法。即使敏捷方法在 IT 中非常普遍,数据科学通常也需要更新的方法,如 Adaptive 或 Extreme。
这篇文章将快速回顾这些方法,展示每种方法的优缺点。
首先,有必要将项目方法分为两类:目标和解决方案过程。我们会选择目标是从一开始就绝对明确的(如在建筑施工中)还是不明确的(如在研究中)。第二,如果解决方案过程是明确的和预先建立的,或者如果过程是临时的和在开发项目的过程中发现的。

Project Characteristics Quadrants by Goal and Solution Uncertainty — Adapted from [1]
1 型。线性策略:
线性策略包括没有反馈回路连续阶段。项目解决方案直到最后阶段才发布。该策略的特点是明确定义的目标解决方案和要求、零或很少的范围变更要求、项目内部的常规和重复过程、使用预先建立的公式和模板。

1 型。增量策略:
这种策略类似于线性策略,但是项目的每个阶段都发布一个部分解决方案。在这个策略中,价值必须在最终阶段之前交付。

1 型或 2 型。迭代策略(例如 Scrum 或特性驱动开发)

试图对不断变化的环境进行全面规划和计划是没有效率的。因此,敏捷鼓励基于数据的迭代决策**。**例如,在 Scrum 中,主要的焦点是以小的迭代增量交付满足客户需求的产品。
类似于增量战略,但由许多重复的阶段组成。该策略包括一组阶段完成后的反馈回路。当客户满意时,循环停止,即该策略使用几个中间解决方案作为发现最终解决方案的途径。

2 型或 3 型。适应性策略(如适应性项目框架或适应性软件开发)
类似于迭代策略,但是每次迭代反馈都将调整项目的未来,以收敛到一个完整的解决方案。一次迭代可能会为客户创建一个部分的解决方案。这种策略是自适应的,因为最终的解决方案只有部分为客户所知,所以成功取决于分配频繁变化的能力。在这里,计划是以适时的方式完成的。[2]

4 型。极端战略(如研究&开发项目)
类似于适应性策略,但是每次迭代反馈,项目的目标也必须被发现,并且项目将在其上收敛。这是第 4 类策略,因为目标或解决过程都是未知的。这类项目中目标和路径的不确定性导致了高度的复杂性。通常,最终产品与最初的预期大相径庭。

Differences between traditionam project management and extreme Project Management. Figure from the book Extreme Project Manament by Doug DeCarlo [3]
从一种类型的项目管理转换到另一种类型的项目管理并不是一件简单的任务,在下面的文章中,我将解释如何从经典的方法(传统的,V-cycle)转换到本文中描述的敏捷方法。如果你想阅读它,只需点击以下链接:
项目管理过渡不一定是破坏性的,相反,我提出了一个模型来实现这一点…
medium.com](https://medium.com/agileinsider/how-can-we-facilitate-the-transformation-of-project-management-from-classic-to-agile-d0c63a20c809)
感谢阅读!!!
如果你想继续阅读这样的故事,你可以在这里订阅!
参考书目
[1] R. K. Wysocki,有效的项目管理传统的、适应性的、极端的。威利出版社,2006 年。
[2] J. A. Highsmith,适应性软件开发:管理复杂系统的协作方法,第 12 卷。2000.
[3] D. Doug,极限项目管理:在现实面前使用领导、原则和工具交付价值。,第 22 卷,第 6 号。2005.
数据科学 101:Python 比 R 好吗?

几十年来,研究人员和开发人员一直在争论 Python 和 R 是数据科学和分析的更好语言。数据科学在包括生物技术、金融和社交媒体在内的多个行业中迅速发展。它的重要性不仅被在行业中工作的人们所认识,而且也被现在开始提供数据科学学位的学术机构所认识。随着开源技术迅速取代传统的闭源商业技术,Python 和 R 在数据科学家和分析师中变得非常流行。

“Data science job growth chart — Indeed.com
(非常)简短的介绍
Python 由吉多·范·罗苏姆发明,于 1991 年首次发布。 Python 2.0 发布于 2000 年,8 年后 Python 3.0 也发布了。 Python 3.0 有一些主要的语法修订,并且不向后兼容 Python 2.0 。然而,有一些 Python 库,比如 2to3 ,可以自动完成两个版本之间的翻译。 Python 2.0 目前计划于 2020 年退役。
r 是 1995 年由 Ross Ihaka 和 Robert Gentleman 发明的。它最初是约翰·钱伯斯在 1976 年发明的 S 编程语言的一个实现。一个稳定的测试版本 1.0.0 于 2000 年发布。目前由 R 开发核心团队维护,最新稳定版本为 3.5.1 。与 Python 不同,R 在过去没有需要语法转换的重大变化。

Guido van Rossum (left) Ross Ihaka (middle) Robert Gentleman (right)
Python 和 R 都有庞大的用户群体和支持。由 Stack Overflow 完成的 2017 年调查显示,几乎 45% 的数据科学家使用 Python 作为他们的主要编程语言。而 r 则被 11.2% 的数据科学家使用。

“Developer Survey Results 2017” — Stack Overflow
值得注意的是,Python,特别是 Jupyter Notebook ,在最近几年里获得了极大的流行。虽然 Jupyter Notebook 可以用于 Python 以外的语言,但它主要用于在数据科学竞赛的浏览器中记录和展示 Python 程序,如 Kaggle 。由 Ben Frederickson 做的一项调查显示 Jupyter Notebook 在 Github 上的月活跃用户百分比(MAU)在 2015 年后大幅上升。

“Ranking Programming Languages by GitHub Users” — Ben Frederickson
随着 Python 近年来越来越受欢迎,我们观察到用 r 编写的 Github 用户的 MAU 百分比略有下降。然而,这两种语言在数据科学家、工程师和分析师中仍然非常受欢迎。
可用性
最初用于研究和学术领域,R 已经不仅仅是一种统计语言。R 可以从 CRAN (综合 R 档案网)轻松下载。CRAN 还被用作一个包管理器,有超过 10,000 个包可供下载。许多流行的开源 ide 如 R Studio 可以用来运行 R。作为一名统计学专业的学生,我认为 R 在堆栈溢出方面有一个非常强大的用户社区。我在本科学习期间关于 R 的大多数问题都可以在 Stack Overflow 的 R 标签 Q 和 A 上找到答案。如果你刚刚开始学习 R,许多 MOOCs 如 Coursera 也提供入门 R 甚至 Python 课程。
在本地机器上设置 Python 工程环境也同样容易。事实上,最近的 MAC 电脑都内置了 Python 2.7 和几个有用的库。如果你像我一样是一个狂热的 Mac 用户,我建议查看 Brian Torres-Gil 的Mac OSX 上的 Python 权威指南以获得更好的 Python 设置。开源 Python 包管理系统,如 PyPI 和 Anaconda 可以很容易地从他们的官方网站下载。在这一点上,我可能应该提到 Anaconda 也支持 R。当然,大多数人更喜欢直接通过 CRAN 管理包。PyPI 或 Python 通常比 r 有更多的包。然而,并不是所有的 100,000+ 包都适用于统计和数据分析。
形象化
Python 和 R 都有优秀的可视化库。由 R Studio 的首席科学家 Hadley Wickham ,ggplot2创建,现在是 R 历史上最流行的数据可视化软件包之一。我完全爱上了 gg plot 2 的各种功能和定制。与 base R 图形相比,ggplot2 允许用户在更高的抽象层次上定制绘图组件。ggplot2 提供了超过 50 种适用于不同行业的地块。我最喜欢的图表包括日历热图、分层树状图和聚类图。塞尔瓦·普拉巴卡兰有一个关于如何开始使用 ggplot2 的精彩教程。

Calendar Heatmap (top left), Clusters (bottom left) and Hierarchical Dendrogram (right) in ggplot2
Python 也有很好的数据可视化库。 Matplotlib 及其 seaborn 扩展对于可视化和制作有吸引力的统计图非常有帮助。我强烈推荐你去看看 George Seif 的用 Python 编写的快速简单的数据可视化代码,以便更好地理解 matplotlib。与 R 的 ggplot2 类似,matplotlib 能够创建各种各样的图,从直方图到矢量场流图和雷达图。也许 matplotlib 最酷的特性之一是地形山体阴影,在我看来,这比 R raster 的hillShade()功能更强大。

Topographic hillshading using matplotlib
R 和 Python 都有fleet . js的包装器,这是一个用 Javascript 编写的漂亮的交互式地图模块。我之前写过一篇文章,介绍了如何使用 follow 可视化房地产价格(follow 是 fleet . js 的 Python 包装)。Leaflet.js 是我使用过的较好的开源 GIS 技术之一,因为它提供了与 OpenStreetMaps 和 Google Maps 的无缝集成。您还可以使用 fleed . js 轻松创建吸引人的气泡图、热图和 choropleth 图。我强烈建议您查看 fleed . js 的 Python 和 R wrappers,因为与底图和其他 GIS 库相比,安装要简单得多。
或者, Plotly 是两种语言共有的令人惊叹的图形库。Plotly(或 Plot.ly)是使用 Python,特别是 Django 框架构建的。它的前端是用 JavaScript 构建的,集成了 Python、R、MATLAB、Perl、Julia、Arduino 和 REST。如果你正试图建立一个 web 应用程序来展示你的可视化,我肯定会推荐你去看看 Plotly,因为他们有很棒的带有滑块和按钮的交互图。

Plotly correlation plots of the Iris dataset
预测分析
正如我之前提到的,Python 和 R 都有强大的预测分析库。很难在高层次上比较两者在预测建模方面的表现。r 是专门作为统计语言编写的,因此与 Python 相比,它更容易搜索与统计建模相关的信息。简单的谷歌搜索logistic regression in R会返回 6000 万个结果,这是搜索logistic regression in Python的 37 倍。然而,对于具有软件工程背景的数据科学家来说,使用 Python 可能更容易,因为 R 是由统计学家编写的。虽然我发现与其他编程语言相比,R 和 Python 同样容易理解。
Kaggle 用户 NanoMathias 已经做了一个非常彻底的调查关于 Python 或 R 在预测分析中是否是一个更好的工具。他总结道,在数据科学家和分析师中,Python 和 R 用户的数量相当。他的研究中有一个有趣的发现,那就是从事编码工作 12 年以上的人倾向于选择 R 而不是 Python。这说明程序员选择 R 还是 Python 进行预测分析,无非是个人喜好。

Linear Discriminant Analysis with embeded scalings, R and Python user analysis
嗯(表示踌躇等)…所以普遍的共识是两种语言在预测的能力上非常相似。这有点无聊,不是吗?让我们使用 R 和 Python 将逻辑回归模型拟合到 Iris 数据集,并计算其预测的准确性。我选择 Iris 数据集是因为它很小并且缺少缺失数据。没有进行探索性数据分析(EDA)和特征工程。我只是做了一个 80-20 的训练测试分割,并用一个预测因子拟合了一个逻辑回归模型。
library(datasets)#load data
ir_data<- iris
head(ir_data)#split data
ir_data<-ir_data[1:100,]
set.seed(100)
samp<-sample(1:100,80)
ir_train<-ir_data[samp,]
ir_test<-ir_data[-samp,]#fit model
y<-ir_train$Species; x<-ir_train$Sepal.Length
glfit<-glm(y~x, family = 'binomial')
newdata<- data.frame(x=ir_test$Sepal.Length)#prediction
predicted_val<-predict(glfit, newdata, type="response")
prediction<-data.frame(ir_test$Sepal.Length, ir_test$Species,predicted_val, ifelse(predicted_val>0.5,'versicolor','setosa'))#accuracy
sum(factor(prediction$ir_test.Species)==factor(prediction$ifelse.predicted_val...0.5...versicolor....setosa..))/length(predicted_val)

95% accuracy achieved with R’s glm model. Not bad!
import pandas as pd
from sklearn.linear_model import LogisticRegression
from sklearn.metrics import confusion_matrix#load data
traindf = pd.read_csv("~/data_directory/ir_train")
testdf = pd.read_csv("~/data_directory/ir_test")
x = traindf['Sepal.Length'].values.reshape(-1,1)
y = traindf['Species']
x_test = testdf['Sepal.Length'].values.reshape(-1,1)
y_test = testdf['Species']#fit model
classifier = LogisticRegression(random_state=0)
classifier.fit(x,y)#prediction
y_pred = classifier.predict(x_test)#confusion matrix
confusion_matrix = confusion_matrix(y_test, y_pred)
print confusion_matrix#accuracy
print classifier.score(x_test, y_test)

90% accuracy achieved with Python sklearn’s LogisticRegression model
使用 R stat 的glm函数和 Python scikit-learn 的LogisticRegression,我将两个逻辑回归模型拟合到 Iris 数据集的随机子集。在我们的模型中,我们只使用了一个预测因子sepal length来预测花的species。两个模型都达到了 90%或更高的准确率,R 给出了稍好的预测。然而,这不足以证明 R 比 Python 有更好的预测模型。逻辑回归只是你可以用 Python 和 R 构建的许多预测模型中的一种。Python 挤掉 R 的一个方面是它构建良好的深度学习模块。流行的 Python 深度学习库包括 Tensorflow 、 Theano 和 Keras 。这些库都有足够的文档,我确信 Siraj Raval 有数百个关于如何使用它们的 Youtube 教程。老实说,我宁愿花一个小时在 Keras 中编写 dCNNs(深度卷积神经网络),也不愿花半天时间弄清楚如何在 r 中实现它们。 Igor Bobriakov 制作了一个出色的信息图,描述了 Python、Scala 和 r 中流行库的提交和贡献者数量。我强烈推荐阅读他的文章(下面提供了链接)。

“Comparison of top data science libraries for Python, R and Scala [Infographic]” — Igor Bobriakov
表演
测量编程语言的速度通常被认为是一项有偏见的任务。每种语言都有针对特定任务优化的内置特性(比如 R 如何针对统计分析进行优化)。用 Python 和 R 进行性能测试可以用许多不同的方法来完成。我用 Python 和 R 编写了两个简单的脚本来比较 Yelp 的学术用户数据集的加载时间,该数据集略超过 2g。
R
require(RJSONIO)
start_time <- Sys.time()
json_file <- fromJSON("~/desktop/medium/rpycomparison/yelp-dataset/yelp_academic_dataset_user.json")
json_file <- lapply(json_file, function(x) {
x[sapply(x, is.null)] <- NA
unlist(x)
})
df<-as.data.frame(do.call("cbind", json_file))
end_time <- Sys.time()
end_time - start_time#Time difference of 37.18632 secs
Python
import time
import pandas as pd
start = time.time()
y1 = pd.read_json('~/desktop/medium/rpycomparison/yelp-dataset/yelp_academic_dataset_user.json', lines = True)
end = time.time()
print("Time difference of " + str(end - start) + " seconds"#Time difference of 169.13606596 seconds
嗯……有意思。r 加载 json 文件的速度几乎是 Python 的 5 倍。众所周知,Python 比 R 有更快的加载时间,布莱恩·雷(Brian Ray)的 T2 测试(T3)证明了这一点。让我们看看这两个程序如何处理一个大的?csv 文件为。csv 是一种常用的数据格式。我们稍微修改了上面的代码,以加载西雅图图书馆库存数据集,它几乎有 4.5 千兆字节。
R
start_time <- Sys.time()
df <- read.csv("~/desktop/medium/library-collection-inventory.csv")
end_time <- Sys.time()
end_time - start_time#Time difference of 3.317888 mins
Python
import time
import pandas as pd
start = time.time()
y1 = pd.read_csv('~/desktop/medium/library-collection-inventory.csv')
end = time.time()
print("Time difference of " + str(end - start) + " seconds")#Time difference of 92.6236419678 seconds
呀!r 花了几乎两倍的时间来加载 4.5 千兆字节。csv 文件比 Python pandas (用于数据操作和分析的 Python 编程语言)。重要的是要知道,虽然 pandas 主要是用 Python 编写的,但是库的更重要的部分是用 Cython 或 c 编写的,这可能会对加载时间产生潜在的影响,具体取决于数据格式。
现在让我们做一些更有趣的事情。 Bootstrapping 是一种从总体中随机重新取样的统计方法。我以前做过足够的引导,知道这是一个耗时的过程,因为我们必须重复地对数据进行多次迭代。以下代码分别测试了在 R 和 Python 中引导 100,000 次复制的运行时:
R
#generate data and set boostrap size
set.seed(999)
x <- 0:100
y <- 2*x + rnorm(101, 0, 10)
n <- 1e5#model definition
fit.mod <- lm(y ~ x)
errors <- resid(fit.mod)
yhat <- fitted(fit.mod)#bootstrap
boot <- function(n){
b1 <- numeric(n)
b1[1] <- coef(fit.mod)[2]
for(i in 2:n){
resid_boot <- sample(errors, replace=F)
yboot <- yhat + resid_boot
model_boot <- lm(yboot ~ x)
b1[i] <- coef(model_boot)[2]
}
return(b1)
}
start_time <- Sys.time()
boot(n)
end_time <- Sys.time()#output time
end_time - start_time#Time difference of 1.116677 mins
Python
import numpy as np
import statsmodels.api as sm
import time
#generate data and set bootstrap size
x = np.arange(0, 101)
y = 2*x + np.random.normal(0, 10, 101)
n = 100000
X = sm.add_constant(x, prepend=False)#model definition
fitmod = sm.OLS(y, X)
results = fitmod.fit()resid = results.resid
yhat = results.fittedvalues#bootstrap
b1 = np.zeros((n))
b1[0] = results.params[0]
start = time.time()
for i in np.arange(1, 100000):
resid_boot = np.random.permutation(resid)
yboot = yhat + resid_boot
model_boot = sm.OLS(yboot, X)
resultsboot = model_boot.fit()
b1[i] = resultsboot.params[0]
end = time.time()#output time
print("Time difference of " + str(end - start) + " seconds")#Time difference of 29.486082077 seconds
r 花了几乎两倍的时间来运行引导程序。这是相当令人惊讶的,因为 Python 通常被认为是一种“慢”的编程语言。我慢慢开始后悔用 R 而不是 Python 来运行我所有的本科统计学作业。
结论
本文只讨论了 Python 和 R 之间的基本区别。就个人而言,我会根据手头的任务在 Python 和 R 之间进行转换。最近,数据科学家一直在推动在结合中使用 Python 和 R。很有可能在不久的将来会出现第三种语言,并最终在流行程度上超过 Python 和 R。作为数据科学家和工程师,跟上最新技术并保持创新是我们的责任。最后,强烈推荐你阅读 Karlijn Willems 的选择 R 还是 Python 做数据分析?一张信息图。它为我们在本文中讨论的内容提供了一个很好的视觉总结,并提供了额外的信息,包括就业趋势和平均工资。在下面评论,让我知道你更喜欢哪种语言!
感谢您阅读我的文章。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言










{kind=link}
{kind=link}
{kind=link}