







人工智能是小孩子的游戏
或者增量收益如何让你迈出小步

我想澄清一个关于人工智能的误解。
我告诉人们我的职业,他们认为我有博士学位。他们认为我可以凭记忆证明所有支撑算法的数学。他们认为他们永远做不了我的工作。
事实上,我是一名软件工程师,无意中发现自己在做机器学习。我并没有打算去找这份工作,但它非常适合我,我想要挑战。这是一个陡峭的学习曲线,但如果你愿意投入工作,那么你就能够建立人工智能。
有些事情你只有深入到一个真实的项目中才会知道。
确实有拥有数百名博士的公司在研究像自动驾驶汽车这样的难题。但是对于每一个 Waymo 来说,都有一些小公司刚刚涉足机器学习领域。
花一分钟时间想一想你的业务中哪一部分会从自动化中受益。现在考虑完全自动化任务所涉及的工作。令人畏惧,对吧?但是你已经知道你一步一步地爬山。试着把问题分成更小的里程碑。
我参与的第一个机器学习项目是一个客户服务聊天机器人。我并没有打算通过图灵测试——测试机器表现出与人类无异的智能行为的能力。我看了看我们的数据集,发现我可以对大约 20%的问题给出固定的回答。那是我的目标。
目标:通过提供常见问题解答,处理 20%的客户服务查询。
实现这一目标仍然代表着真正的商业利益。五分之一的查询在到达客户服务团队之前得到处理。这减少了他们 20%的工作量。我每周给他们额外的一天时间来完成其他任务。即使一个适度的目标也会降低成本。
如果你有一个现实的目标,你会用不同的心态来处理问题。不是压倒性的。你不要试图改变世界。你解放自己去尝试事情,没有对失败的极度恐惧。
一旦你实现了你的小目标,你也为自己争取了时间去实现下一个目标。很难说服你的老板你需要一年的时间来完全自动化一个过程。要求用 6 周时间自动化 20%的流程要容易得多,如果证明对业务有价值,可以考虑在下一年继续进行。
有信心看看你的业务,看看机器学习是否适合。你不需要成为数字天才,你不需要能够从第一原理证明算法。如果你能学到足够多的关于 numpy 或 T2 的知识来解决这个问题,那就去做吧。没有利益相关者会问你是如何取得成果的。他们不关心机械。他们关心结果。
不要让被认为的无能阻碍你。相信你可以投入到一个项目中并产生结果。你不必用你的第一个项目来改变世界。选择一个目标,努力工作直到实现它。然后选择一个更大的目标,朝着这个目标努力。
如果你已经读到这里,那么我希望你选择一些自动化的东西。它需要一些重复性的东西,产生大量的数据。然后检查问题,找出你能做的最简单的事情来改变现状。最后,向你的利益相关者推销这种好处。比起神经网络和矩阵,他们更关心百分比。
我是一名软件开发人员,总部位于英国伯明翰,致力于解决大数据和机器学习问题。我在工作中学习。我没有所有的答案,但我正在获得许多经验。关注我的 Twitter 查看我的最新帖子。
人工智能不是产品差异化,而是可负担性
本着开放的精神,大型和专门的人工智能(AI)社区将他们的见解公开,每个人都可以访问。这种开放性对 AI 产品化的影响将产生这样的效果,即 AI 不会成为一种产品差异化,而是一种可负担性。
人工智能研究是开放的
目前,人工智能(AI)和机器学习(ML)社区是最活跃的两个研究社区。理论家和实践者一起工作,推动可能性的边界,在过去的十年里,他们一起极大地推进了最先进的技术。
开放的科研出版平台是传播人工智能研究成果的重要基石。开放科学模式缩短了传统的同行评议的出版过程,使研究材料一准备好就可以访问。这极大地加快了正在进行的研究工作,因为研究人员可以立即从其他小组获得结果,并在他们的研究中做出回应。此外,研究博客和教程帮助新进入者爬上人工智能的陡峭学习曲线。网络研讨会和在线课程使人们很容易从社区中一些最聪明的人的教导中受益。
人工智能平台的商业产品旨在消除人工智能的存储和计算障碍。它们提供了接口和后端系统,极大地促进了人工智能在系统中的实现和集成。因此,每个对人工智能有很好理解的人都可以在他们的原型和产品中利用人工智能。
人工智能成功案例
有用的产品解决现实世界的挑战,从而创造价值。解决人工智能固有的挑战有其自身的优点,但研究的成功并不直接转化为产品领域。产品的成功是由客户推动的。这可以通过它的采用率来衡量。自然,一个成功的产品很快就会有模仿者,他们正在争夺客户的注意力和市场份额。产品差异化为产品销售者创造了竞争优势,因为顾客认为这些产品是独一无二的或优越的。
在一个产品中添加人工智能组件既不会使它变得更好,也不会改变它的默认设置。失败的创业公司认为他们在产品中“高估了机器学习”。事实上,ML & AI 通常只是拼图的一部分。让我们来看一些使用 ML 的成功应用的例子和它们的促成因素:视频流服务基于偏好和观看历史向他们的客户推荐电影。他们的先决条件是一个能按需向用户提供电影的系统。网络搜索和社交网络会自动对图片进行分类。这需要在查询时存储和检索相关图像的能力。信用卡公司分析客户的消费行为,以识别欺诈交易。这只能在启用某些交易的红色标记的活动处理系统中完成。
人工智能提高效率
这些例子的共同主题是有一个 system。ML 补充了这个系统,例如,通过增加和控制用户交互。这些系统本身已经在创造价值。即使这些公司取消了 ML 部分,他们的系统仍然可以提供很好的服务。在这些例子中,ML & AI 是一种渐进的改进。这种推理的关键要点是,人工智能不是构建伟大系统的捷径。更直白的说,AI 并不是把一个平庸的系统在一个顶级产品里。
此外,使用人工智能的产品的竞争优势很小。即使一个市场参与者可能会因为集成人工智能技术而领先,领先优势也会减少,因为竞争对手会很快赶上来。原因是人工智能研究的开放性和人工智能工具和框架的广泛可用性。鉴于技术的快速进步,阻止竞争对手迎头赶上是很困难的。人工智能社区很快发现了人工智能的新应用,并将其复制到研究领域。例如,这是 OpenAI 的目标之一。
具有讽刺意味的是,使我们能够构建高级人工智能产品的同一件事情却使人工智能无法成为产品的区分器。为了建立一个真正的基于人工智能的产品,人工智能必须超越增量改进。想想骑一辆没有方向盘的车。显然,没有人工智能算法的控制是不可能的。
人工智能作为可提供性
在产品设计中,启示定义了产品可能的使用方式。更正式的,启示决定了对象的属性和使用它的代理的能力之间的关系。例如,方向盘提供转向,手柄提供抓握,旋钮转动等。
人工智能增加了一个新的交互维度:它能够放置没有人工智能就不会存在的手柄和旋钮。一个说明性的例子是自动驾驶汽车:移除人工智能部分,汽车将无法运行。人类驾驶员不可能使用这样的汽车。它缺乏基本的启示,如人类操作所需的方向盘和油门。AI 从自动驾驶车辆中移除了这些部件的启示。这些是你想要制造的人工智能产品,它们是真正的差异化优势。
通过启用新的技术使用和交互方式,人工智能促进了全新的用户体验。例如,通过自动驾驶汽车实现的生活方式只是冰山一角。语音控制和能够解释人类行为的机器人将是展示人工智能如何渗透并颠覆我们生活的其他例子。
AI 可以将用户体验提升到感知智能和真实智能交融的程度。这就是图灵测试发挥作用的地方:人类用户不能根据他/她的交互来区分。人工智能算法的预测能力可以预测——在受限制的环境和时间范围内——用户可能会采取什么行动,或者某些行动会产生什么结果。例如,高级驾驶辅助系统(ADAS)就是为了过滤掉可能导致撞车的不良驾驶决策而构建的。
在启示的经典定义中,启示是被动的。启示体现了产品可能的使用方式。利用 AI,一个产品可以主动拒绝某些行为。例如,ADAS 系统和自动驾驶汽车就是为了避免撞车而制造的。换句话说,这些汽车承受不起碰撞:通过使用定义的交互方式来碰撞汽车几乎是不可能的。因此,主动拒绝减少了虚假和隐藏的启示,并引导用户使用。主动拒绝是互动新维度的一个例子。更多的有待发现。
外卖食品
人工智能的真正力量在于创造新的启示。用人工智能增强系统可以提高效率,但添加全新的交互维度将使人工智能技术处于领先地位。
参考
人工智能很可能是安全的
尽管我们最终都会被宇宙[10^100]年后的的热寂所杀死,但还有更多迫在眉睫的问题需要思考。还有太阳的死亡(从现在起 50 亿年),以及行星的加热(参见模型中的 2100 年)。这是一个好主意优先考虑将杀死我们所有人的事情,并避免所说的坏事情。我们不知道人工智能的威胁在时间线中的确切位置,但看起来人工智能更像是在 100 年或更短的时间内杀死我们所有人。肯定不会太快。不要在你的 2018 日历上标注 AI 末日。
让我告诉你为什么我认为我们现在是安全的。

I love Futurama.
先说AI 为什么危险。超智能 AI 的默认状态是强优化。大多数强优化过程都是“杀死所有人类”的特例(例如集邮者、回形针机)。这就是为什么 AI 安全是一个重要的问题,有时被称为控制问题。更多此处。
超级智能也被称为“强人工智能”和人工通用智能(AGI)等。它开始是一个聪明的过程,变得越来越聪明,直到达到并超过人类水平的机器智能(HLMI)。这个点通常被称为奇点。这种人工智能不是通过已知的过程实现的。这是人类目前还没有实现的东西,我们也不知道如何制造我们给它贴上标签的东西。我们可以称暗物质和暗能量为“弗雷德和威尔玛”,因为除了它们的名字,我们所知甚少。同样,除了知道它有多危险和强大,我们对 AGI 知之甚少。人工智能(不是 AGI)的力量在短期内是帮助人类的。当你读到这些文字的时候,这是一股自动化和效率的力量,它正迅速在经济和文化中荡漾。

Fusion is hard. Really hard.
与来源不明的 AGI 相反,聚变是一个已知的过程。核聚变对人类来说是令人敬畏的,但也可能导致人类的终结(核聚变意味着每个人都拥有核武器,以及发动战争的无限能量)。所以,就大的上升空间和大的风险而言,这听起来类似于人工智能,但至少我们有了融合的蓝图。我们每天都看到太阳在进行核聚变,即使我们知道核聚变是如何在太阳中进行的,我们在地球上也没有运行的核聚变反应堆。是工程问题让核聚变遥不可及。很难在实验室里建造太阳(等离子体密封)。更容易制造太阳能电池板。
如果融合很难,而且我们知道融合是如何工作的,那么做《AGI:危险的人工智能》就格外困难。我们不知道 AGI 是如何工作的,除了人类如何进化出我们的智慧之外,我们没有其他例子,我们也不知道产生 HLMI 或超级智慧有多难。因此,比起核聚变或全球变暖,不要更担心 AGI。
通过理论上证明大过滤器在我们身后,费米悖论正在被解答/解决。比如,也许线粒体+细胞=非常稀少。比起另一个选择,我更喜欢那个。我不相信 AGI 需要如此稀有的东西来生产,因为人工智能比生物生命需要更少的进化时间。但是……我们不要自欺欺人了。深度学习任重道远,融合也是如此。杀手机器人是真实的,但由强人工智能建造的机器人还很遥远。我认为这一领域的研究应该作为国家安全的重中之重来资助,就像核聚变一样,但是让我们正视威胁。全球气候变化,在我看来,比想要杀死所有人类的 AI 更有杀伤力,更立竿见影。我们知道气候正在变化。海平面上升=洪水=糟糕。
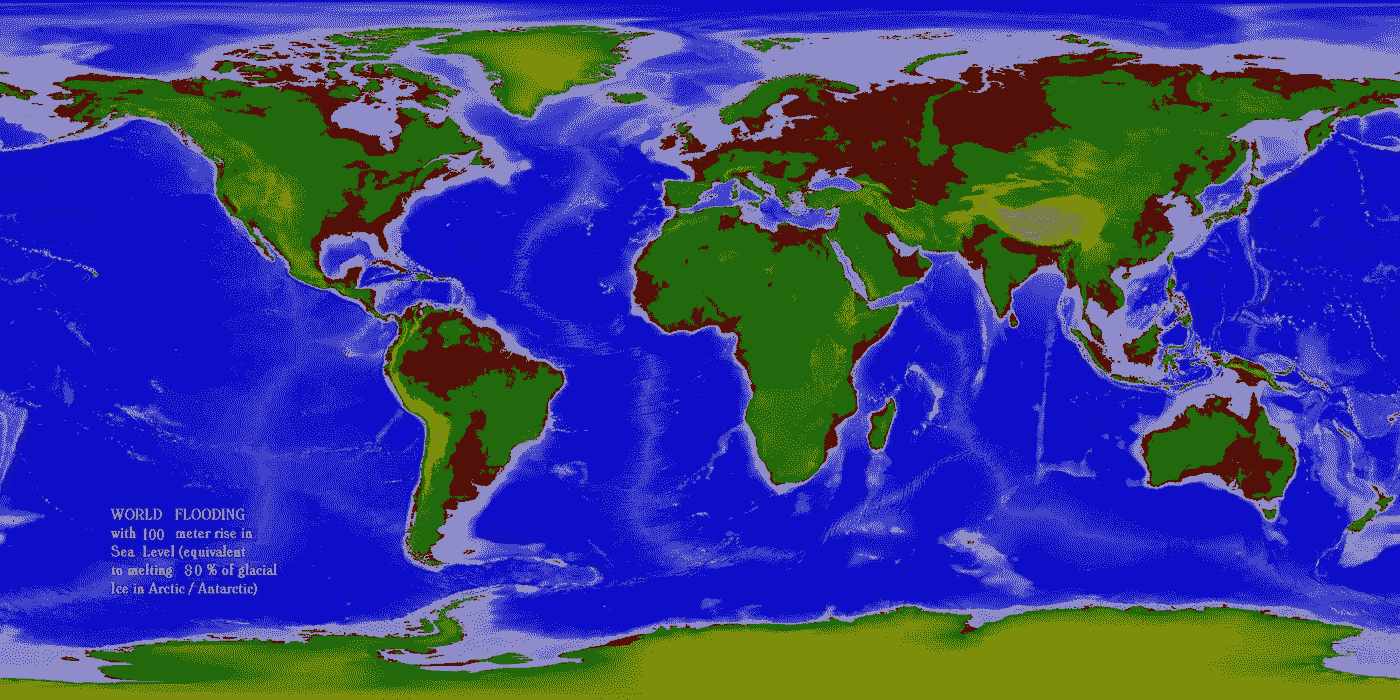
The world after a 100 meter sea level rise, caused by melting 80% of the ice on the planet. This should bother you if you live bascially anywhere near open water.
对人工智能来说,更直接的担忧应该是失业、假新闻和其他社会弊病。基本上,美国 30 万卡车司机中的 90%将被取代。所有的优步车手也是如此。如果我们现在就为这些影响做准备,这是一个好主意。也许用通用基本收入(UBI) ?一些其他的解决方案?
我在工作中制造人工智能系统,我并不害怕它。你不应该害怕。
人工智能研究的进展速度令人印象深刻。我想说的是,就目前而言,人工智能可能是安全的,但应该继续研究人工智能的安全和控制问题。我怀疑我们能否将人类价值观灌输到超级智能中,但是值得一试去思考这些问题。
在我花了很多精力准备的上一篇文章之后,这是一篇非常有趣的高水平文章。如果你喜欢这篇关于人工智能安全的文章,请告诉我。在收到关于上一篇文章的一些不错的电子邮件反馈后,我确实计划写更多带有代码示例的研究内容。我也很高兴在评论中或通过电子邮件听到你对我的想法的反馈。你怎么想呢?
试用拍手工具。轻点那个。跟着我们走。分享这篇文章的链接。去吧。
编码快乐!
——丹尼尔
丹尼尔@lemay.ai ←打个招呼。
LEMAY . AI
1(855)LEMAY-AI
您可能喜欢的其他文章:
附注:尼克·博斯特罗姆很棒:https://www.fhi.ox.ac.uk/
花絮:甜甜圈来源于面结,切一个洞有助于它们煮得更均匀。
人工智能是应对当今营销挑战的灵丹妙药

我对理解的尝试,更重要的是,将人工智能(AI)应用于当前的商业实践,迫使我将我所知道的一切都扔出窗外。经验、最佳实践、先入为主的观念、屡试不爽的真理——所有这些规则都变得过时和不相关,因为世界已经变了。媒体消费已经改变。企业已经失去了对客户的控制,正在努力获得并保持他们的注意力。
展示广告已经风光不再
目前形式的展示广告模式是不可持续的。全球数字表现的当前统计数据显示了以下广告形式:
在所有广告形式和位置中,广告点击率仅为 0.05%
富媒体广告点击率为 0.1%
脸书和谷歌继续占据主导地位……但他们只是讲述了故事的一部分
相比之下,Wordstream 最近的一项研究表明:脸书的广告似乎正在蓬勃发展:
…各个行业的点击率(CTR)从大约 0.5%到 1.6%不等。
对于截至 2016 年 3 月的谷歌 Adwords,拉里·金报道:
…平均而言,Google AdWords 广告客户在搜索网络上的转化率为 2.70%,在展示网络上的转化率为 0.89%。
很明显,脸书和谷歌从数字广告支出中获得了最大的利益。去年,超过 175 亿美元花在了数字广告上。但 FB 和谷歌获得了超过 65%的估计收入,谷歌获得了 300 亿美元,而脸书的广告收入为 80 亿美元。
尽管如此,这些平台也不是没有障碍。今年 3 月,像联合利华这样的品牌和哈瓦斯这样的机构选择冻结谷歌和 Youtube 的支出,因为除了“不受欢迎或不安全的内容”之外,还有广告投放。这一点,再加上关于可视度的可疑报道,以及不断上升的广告欺诈事件,都使得品牌和代理商对他们的支出变得更加谨慎。
消费者对广告越来越免疫:
像 Ghostery 这样检测和阻止跟踪技术的应用程序的兴起,让出版商和广告商面临更大的挑战。关于广告拦截的最新报道如下:
- 现在有 6.15 亿台设备使用 adblock
- 11%的全球人口在屏蔽网络广告,这一数字在 2016 年上升了 30%
- 移动广告拦截设备增长至 3.8 亿台,增幅达 250%
- 根据这份报告,广告拦截现在是各年龄组的主流
对出版业的影响是惊人的:假设采用率持续下去,到 2020 年,收入损失估计为 350 亿美元。
当广告拦截器、不断变化的媒体消费和广告表现阻碍我们达到目标客户时,我们如何有效地达到目标客户?
事情是这样的:顾客之旅从感兴趣的那一刻开始。我们如何与客户接触,在他们最有可能做出回应的时候,将最相关的信息放在他们面前,这是一个圣杯。过去的十年见证了这个年轻的数字领域的从业者测试、实施和成功应用技术以最大化性能。凭借这些在线行为,我们已经发展到真正理解消费者的兴趣和意图:印象、点击、访问、重复访问、内容和格式参与。大多数时候我们都是对的。直到现在。
然而,真正大规模实现个性化——并持续这样做——并不容易。除非你完成了从收购到为终身客户提供价值的完整旅程,否则你的努力充其量是支离破碎的。
谷歌知道分数:“谷歌计划如何杀死最后点击归属”
谷歌最近宣布了这一点。这位巨头已经意识到,要知道什么样的广告有效,不能通过衡量整体表现来完成。他们转向转化率指标(CV)的原因是点击率(CTR)是一个误称。它不再是衡量真实意图的标准。你如何衡量意图,并不是通过广告形式的行为聚合(是的,我在简化)。更确切地说,是通过理解购买漏斗中归因于购买行为的事件。这里是我们对人工智能的介绍,以及为什么它将是 CMO 旅程中的下一次进化。
如果你想提高绩效,你需要改变你的思维模式,去接受这个领域的新事物:
1)商业智能不具备人工智能的速度和能力:
开发适用于业务的正确算法所需的时间可能是一件苦差事。需要多次测试和不断迭代来提高结果的准确性。人类为此付出的努力可能需要数月时间。机器学习所做的是自动化预测分析,并允许模型比传统的商业智能(BI)模型更快地投入生产。随着新数据的吸收,模型会“学习”和调整。这种连续的反馈环路允许在更短的时间内以更高的精度获得更好的性能。

2)抵制做出假设的冲动:
我们所知道的有用的东西可以被扔出门外。理解消费者意图意味着消除 KPI 和已知的绩效指标变量。我一次又一次地被告知要放弃我所知道的真理。人工智能没有预先设想的偏见,因此模型将在与预期业务结果相关的事件中找到模式。它要么验证我们已经知道的,要么展现出通过人类分析无法发现的全新结果。
传统的商业智能有其优点。但是在一个竞争日益激烈、速度越来越快、对准确性的要求越来越高的环境中,随着新规范的引入,这种做法的灵活性和可扩展性也受到了限制。更重要的是,我们可能会被自己的盲点所阻碍,让(传统 BI 中)行之有效的东西继续成为首选解决方案。正因为如此,我们倾向于错过在人工智能框架下显而易见的关键见解。
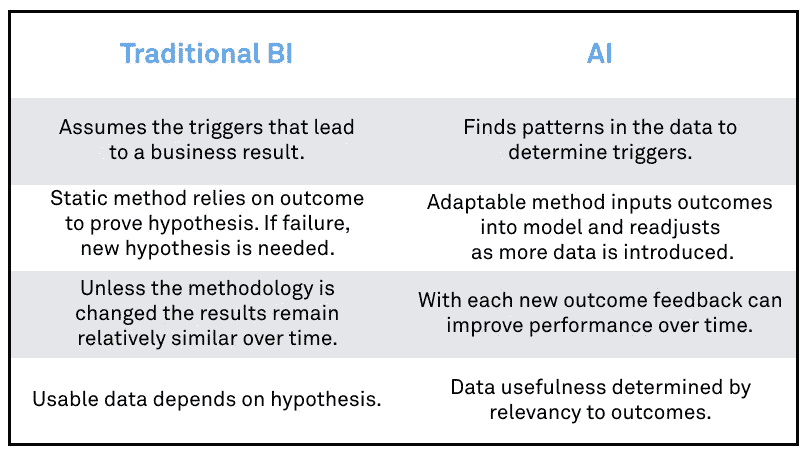
3)对客户的整体看法意味着超越孤立的广告行为:
大多数营销人员都知道这一点:点击已经今非昔比。喜欢和追随者的虚荣心指标并不直接表示意图或亲和力。我们已经看到了这些指标是如何容易地被游戏化的。除非你能把这些事件归因于客户转化,否则它们本身不太可能有任何真正的价值。
收购和保留计划也相互冲突。企业不再能够控制当前客户或潜在潜在客户可以看到哪些信息。
然而,通过利用人工智能,在社交渠道上关注一个品牌的数百万客户中,我们可以确定脸书广告或帖子的价值,因为它与单个客户有关,以及这对潜在客户有何不同。但是仅仅这一点可能还不足以让顾客改变信仰。也许,这也是一个朋友通过电子邮件或客服电话的推荐。
当在一个有序的旅程中进行分析时,这些事件在个人旅程中的个人贡献才能得到真正的重视。
4)行为是情绪的衍生物:
不开心的顾客不一定会抛弃一个品牌。就忠诚度而言,价格敏感度可能是购买机票的决定性因素,因为积分有好处,不管他/她最近可能经历过的糟糕的客户服务电话。然而,所有这些事件加在一起,将使营销人员对客户流失的风险有一个更清晰的认识。
人工智能能够从人类意图的复杂性中提取模式,并确定可能(在不同程度上)影响数百万客户决策的多种驱动因素。它可能因不同的产品或服务、一年中的不同时间、不同的地理位置和人口统计数据而异。
5)数据为王:
在这个新世界中,我们有能力将人类的倾向联系起来,并越来越擅长预测行为的可能性。内容刚刚被取消!人工智能的方法论试图揭示的是,通过轶事般地理解新消费者重视什么或他/她需要什么来提升内容的原则。内容现在是一种功能或事件,它可能有助于业务转换,与成千上万的其他事件结合在一起,在每个单独的客户旅程中。企业现在可以分析其营销工作以及客户的个性化旅程,并不断优化整体活动绩效。
人工智能使 1:1 的真正定义完全成为可能
我们兜了一圈。对于我们这些实行一对一营销的人来说,计算能力以及近年来成倍增长的数据财富为我们提供了实现这一圣杯的途径。对于传统的营销人员来说,现在的可能性是无限的。
原载于 2017 年 5 月 31 日【marketinginsidergroup.com】。
人工智能遇见艺术:神经传递风格

Hokusai in Boston
介绍
神经转移风格是人工智能在创造性背景下最令人惊叹的应用之一。在这个项目中,我们将看到如何将艺术绘画风格转移到选定的图像上,创造出令人惊叹的效果。Leon A. Gatys 等人在 2015 年的论文 中构思了神经传递风格的概念,一种艺术风格 的神经算法。在那之后,许多研究人员应用并改进了这种方法,增加了损失的元素,尝试了不同的优化器,并试验了用于此目的的不同神经网络。
尽管如此,原始论文仍然是理解这一概念的最佳来源,VGG16 和 VGG19 网络是这方面最常用的模型。这种选择是不寻常的,考虑到两者都被最近的网络超越,在风格转移中实现的最高性能证明了这一点。
完整代码可以查看这个 GitHub 库 。
它是如何工作的?
这种技术的目标是将图像的样式(我们称之为“样式图像”)应用到目标图像,保留后者的内容。让我们定义这两个术语:
- 风格是图像中的纹理和视觉模式。一个例子是艺术家的笔触。
- 内容是一幅图像的宏观结构。人、建筑物、物体都是图像内容的例子。
令人惊叹的效果如下所示:

你想看到更多的效果吗?在文章的最后检查他们!
让我们看看高级步骤:
- 选择要样式化的图像
- 选择样式参考图像。通常,这是一幅风格奇特且易于辨认的画。
- 初始化预训练的深度神经网络,并获得中间层的特征表示。完成该步骤是为了实现内容图像和样式图像的表示。在内容图像中,最好的选择是获得最高层的特征表示,因为它们包含关于图像宏观结构的信息。对于样式参考影像,从不同比例的多个图层中获取要素制图表达。
- 将最小化的损失函数定义为内容损失、风格损失和变化损失之和。每次迭代,优化器都会生成一幅图像。内容损失是生成图像和内容图像之间的差异(l2 归一化),而样式损失是生成图像和样式之间的差异。我们稍后会看到这些变量是如何被数学定义的。
- 重复最小化损失
处理和取消处理图像
首先,我们需要格式化我们的图像以供我们的网络使用。我们要用的 CNN 是预先训练好的 VGG19 convnet。当我们将图像处理成兼容的数组时,我们还需要对生成的图像进行解处理,从 BGR 格式切换到 RGB 格式。让我们构建两个辅助函数来实现这一点:
# Preprocessing image to make it compatible with the VGG19 model
**def** **preprocess_image**(image_path):
img = load_img(image_path, target_size=(resized_width, resized_height))
img = img_to_array(img)
img = np.expand_dims(img, axis=**0**)
img = vgg19.preprocess_input(img)
**return** img
# Function to convert a tensor into an image
**def** **deprocess_image**(x):
x = x.reshape((resized_width, resized_height, **3**))
# Remove zero-center by mean pixel. Necessary when working with VGG model
x[:, :, **0**] += **103.939**
x[:, :, **1**] += **116.779**
x[:, :, **2**] += **123.68**
# Format BGR->RGB
x = x[:, :, ::-**1**]
x = np.clip(x, **0**, **255**).astype('uint8')
**return** x
内容损失
内容损失将主输入图像的内容保留到样式中。由于卷积神经网络的较高层包含图像宏观结构的信息,我们将内容损失计算为输入图像的最高层的输出和生成图像的相同层之间的差异(l2 归一化)。
内容损失定义为:
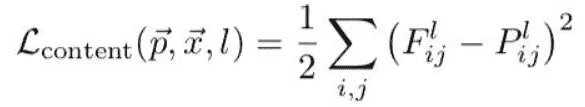
Content loss
在等式中, F 是内容图像的特征表示(当我们运行我们的输入图像时,网络输出的内容),而 P 是在特定隐藏层 l 生成的图像的特征表示。
实现如下:
# The content loss maintains the features of the content image in the generated image.
**def** **content_loss**(layer_features):
base_image_features = layer_features[**0**, :, :, :]
combination_features = layer_features[**2**, :, :, :]
**return** K.sum(K.square(combination_features - base_image_features))
风格丧失
理解风格损失不像理解内容损失那么简单。目标是在新生成的图像中保留图像的样式(即,作为笔触的视觉图案)。在前一个例子中,我们比较了中间层的原始输出。这里,我们比较样式参考图像和生成图像的特定层的 Gram 矩阵之间的差异。 Gram 矩阵被定义为给定层的矢量化特征图之间的内积。矩阵的意义在于捕捉层特征之间的相关性。计算多个层的损失允许在样式图像和生成的图像之间保留不同层中内部相关的相似特征。
单层的风格损失计算如下:

Style loss per layer
在等式中, A 是样式图像的 Gram 矩阵, G 是生成的图像的 Gram 矩阵,两者都与给定的层有关。 N 和 M 为样式图像的宽度和高度。
在等式中, A 是风格图像的克矩阵, G 是生成的图像的克矩阵,两者都与给定的层有关。 N 和 M 为样式图像的宽度和高度。
首先为每个单独的层计算样式损失,然后将其应用于被认为是对样式建模的每个层。让我们来实现它:
# The gram matrix of an image tensor is the inner product between the vectorized feature map in a layer.
# It is used to compute the style loss, minimizing the mean squared distance between the feature correlation map of the style image
# and the input image
**def** **gram_matrix**(x):
features = K.batch_flatten(K.permute_dimensions(x, (**2**, **0**, **1**)))
gram = K.dot(features, K.transpose(features))
**return** gram
# The style_loss_per_layer represents the loss between the style of the style reference image and the generated image.
# It depends on the gram matrices of feature maps from the style reference image and from the generated image.
**def** **style_loss_per_layer**(style, combination):
S = gram_matrix(style)
C = gram_matrix(combination)
channels = **3**
size = resized_width * resized_height
**return** K.sum(K.square(S - C)) / (**4.** * (channels ** **2**) * (size ** **2**))
# The total_style_loss represents the total loss between the style of the style reference image and the generated image,
# taking into account all the layers considered for the style transfer, related to the style reference image.
**def** **total_style_loss**(feature_layers):
loss = K.variable(**0.**)
**for** layer_name **in** feature_layers:
layer_features = outputs_dict[layer_name]
style_reference_features = layer_features[**1**, :, :, :]
combination_features = layer_features[**2**, :, :, :]
sl = style_loss_per_layer(style_reference_features, combination_features)
loss += (style_weight / len(feature_layers)) * sl
**return** loss
变异损失
最后,损失的最后一部分是变异损失。原始论文中没有包括这一要素,严格来说,它对于项目的成功并不是必要的。尽管如此,经验证明,添加该元素会产生更好的结果,因为它平滑了相邻像素之间的颜色变化。让我们把这个包括进去:
# The total variation loss mantains the generated image loclaly coherent,
# smoothing the pixel variations among neighbour pixels.
**def** **total_variation_loss**(x):
a = K.square(x[:, :resized_width - **1**, :resized_height - **1**, :] - x[:, **1**:, :resized_height - **1**, :])
b = K.square(x[:, :resized_width - **1**, :resized_height - **1**, :] - x[:, :resized_width - **1**, **1**:, :])
**return** K.sum(K.pow(a + b, **1.25**))
全损
最后,将所有这些因素考虑在内,计算总损失。首先,我们需要提取我们选择的特定层的输出。为此,我们定义一个字典为<层名,层输出 >:
# Get the outputs of each key layer, through unique names.
outputs_dict = dict([(layer.name, layer.output) **for** layer **in** model.layers])
然后,我们通过调用先前编码的函数来计算损失。每个分量都乘以特定的权重,我们可以调整权重以产生强烈或较轻的效果:
**def** **total_loss**():
loss = K.variable(**0.**)
# contribution of content_loss
feature_layers_content = outputs_dict['block5_conv2']
loss += content_weight * content_loss(feature_layers_content)
# contribution of style_loss
feature_layers_style = ['block1_conv1', 'block2_conv1',
'block3_conv1', 'block4_conv1',
'block5_conv1']
loss += total_style_loss(feature_layers_style) * style_weight
# contribution of variation_loss
loss += total_variation_weight * total_variation_loss(combination_image)
**return** loss
设置神经网络
VGG19 网络将一批三个图像作为输入:输入内容图像、样式参考图像和包含生成图像的符号张量。前两个是常量变量,使用 keras.backend 包定义为变量。第三个变量定义为占位符,因为它会随着优化器更新结果的时间而变化。
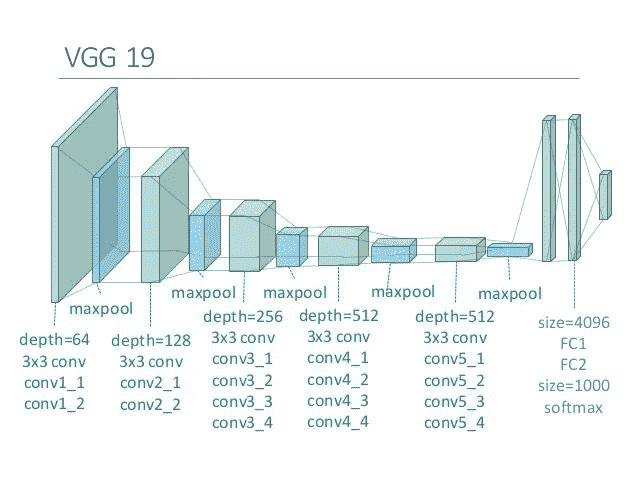
一旦变量被初始化,我们就把它们加入一个张量,这个张量将在以后提供给网络。
# Get tensor representations of our images
base_image = K.variable(preprocess_image(base_image_path))
style_reference_image = K.variable(preprocess_image(style_reference_image_path))
# Placeholder for generated image
combination_image = K.placeholder((**1**, resized_width, resized_height, **3**))
# Combine the 3 images into a single Keras tensor
input_tensor = K.concatenate([base_image,
style_reference_image,
combination_image], axis=**0**)
完成后,我们需要定义损耗、梯度和输出。原始论文使用算法 L-BFGS 作为优化器。这种算法的一个限制是它要求损失和梯度分别通过。因为单独计算它们效率极低,所以我们将实现一个赋值器类,它可以同时计算损失和梯度值,但分别返回它们。让我们这样做:
loss = total_loss()
# Get the gradients of the generated image
grads = K.gradients(loss, combination_image)
outputs = [loss]
outputs += grads
f_outputs = K.function([combination_image], outputs)
# Evaluate the loss and the gradients respect to the generated image. It is called in the Evaluator, necessary to
# compute the gradients and the loss as two different functions (limitation of the L-BFGS algorithm) without
# excessive losses in performance
**def** **eval_loss_and_grads**(x):
x = x.reshape((**1**, resized_width, resized_height, **3**))
outs = f_outputs([x])
loss_value = outs[**0**]
**if** len(outs[**1**:]) == **1**:
grad_values = outs[**1**].flatten().astype('float64')
**else**:
grad_values = np.array(outs[**1**:]).flatten().astype('float64')
**return** loss_value, grad_values
# Evaluator returns the loss and the gradient in two separate functions, but the calculation of the two variables
# are dependent. This reduces the computation time, since otherwise it would be calculated separately.
**class** **Evaluator**(object):
**def** **__init__**(self):
self.loss_value = **None**
self.grads_values = **None**
**def** **loss**(self, x):
**assert** self.loss_value **is** **None**
loss_value, grad_values = eval_loss_and_grads(x)
self.loss_value = loss_value
self.grad_values = grad_values
**return** self.loss_value
**def** **grads**(self, x):
**assert** self.loss_value **is** **not** **None**
grad_values = np.copy(self.grad_values)
self.loss_value = **None**
self.grad_values = **None**
**return** grad_values
evaluator = Evaluator()
最后一档
终于万事俱备了!最后一步是多次迭代优化器,直到我们达到期望的损失或期望的结果。我们将保存迭代的结果,以检查算法是否按预期工作。如果结果不令人满意,我们可以调整权重以改善生成的图像。
# The oprimizer is fmin_l_bfgs
**for** i **in** range(iterations):
print('Iteration: ', i)
x, min_val, info = fmin_l_bfgs_b(evaluator.loss,
x.flatten(),
fprime=evaluator.grads,
maxfun=**15**)
print('Current loss value:', min_val)
# Save current generated image
img = deprocess_image(x.copy())
fname = 'img/new' + np.str(i) + '.png'
save(fname, img)
要查看完整代码,请参考页面开头提供的 GitHub 链接。
惊人的结果



如果你想尝试特定的效果,绘画,或者你有任何建议,请留下评论!
如果你喜欢这篇文章,我希望你能点击鼓掌按钮👏因此其他人可能会偶然发现它。对于任何意见或建议,不要犹豫留下评论!
我是一名数据科学专业的学生,热爱机器学习及其无尽的应用。你可以在 maurocomi.com找到更多关于我和我的项目的信息。你也可以在 Linkedin 上找到我,或者直接给我发邮件。我总是乐于聊天,或者合作新的令人惊奇的项目。
人工智能需要重置

DepositPhotos
我有机会采访我在 ArCompany 的同事 Karen Bennet,她是平台技术、开源和闭源系统以及人工智能技术领域经验丰富的工程主管。雅虎前工程主管。作为带领 Red Hat 取得成功的原始团队的一员,Karen 随着技术革命而发展,在 IBM 早期的专家系统中利用人工智能,目前正在见证机器学习和深度学习的快速实验。我们对人工智能现状的讨论最终形成了这篇文章。
在所有的炒作中,很难驾驭人工智能。在很大程度上,人工智能的承诺还没有实现。人工智能仍在出现,并没有成为承诺的无孔不入的力量。考虑一下令人信服的数据,这些数据证实了人工智能炒作中的兴奋:
- 自 2000 年以来,活跃的人工智能初创公司数量增加了 14 倍
- 自 2000 年以来,风投对人工智能初创企业的投资增加了 6 倍
- 自 2013 年以来,需要人工智能技能的工作份额增长了 4.5 倍
截至 2017 年,统计局公布了这些调查结果:
截至去年,全球只有 5%的企业将人工智能广泛纳入了他们的流程和产品,32%尚未采用,22%没有计划采用。
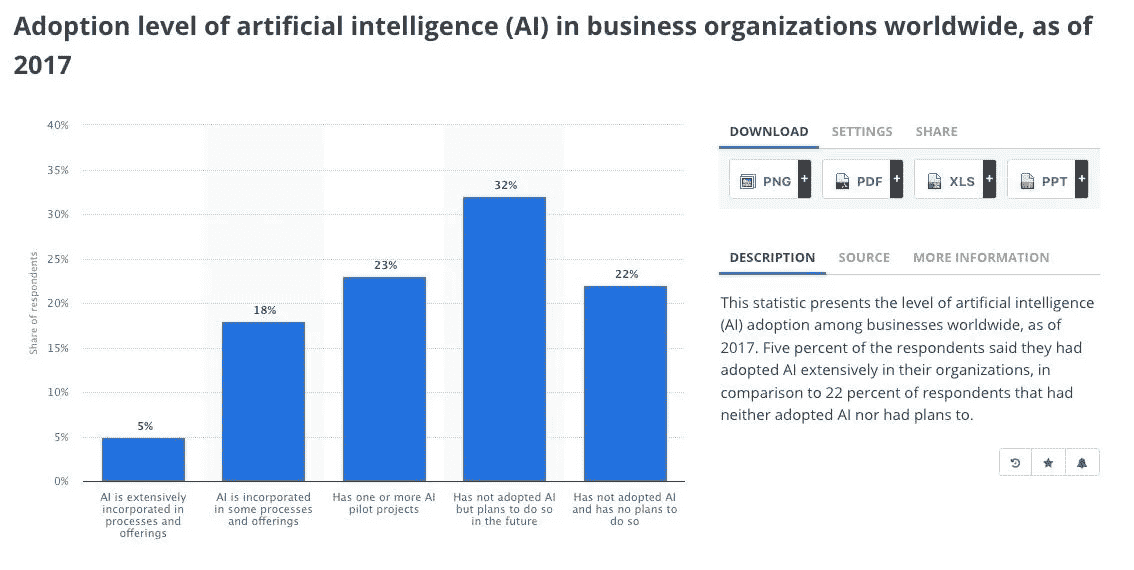
Statista: Adoption level of artificial intelligence (AI) in business organizations worldwide, as of 2017STATISTA
菲利普·皮涅夫斯基(Filip Pieniewski)最近在 VentureBeat 上的帖子中证实:“人工智能的冬天即将到来”:
我们现在处于 2018 年中期,事情已经发生了变化。还没有浮出水面 NIPS 会议仍然被过度销售,企业公关仍然在其新闻稿中到处都是人工智能,埃隆·马斯克仍然保持着对自动驾驶汽车的承诺,谷歌继续推动吴恩达的路线,即人工智能大于电力。但这种说法开始出现裂痕。
我们吹捧自动驾驶汽车的说法。今年春天早些时候,一名行人死于自动驾驶汽车引发了超出技术范畴的警报,并引发了对自动化系统决策背后的道德或缺乏道德的质疑。电车问题不是在一个人的生命和拯救 5 个人之间的简单二元选择,而是演变成一场良心、情感和感知的辩论,现在使机器做出合理决定的道路变得复杂。这篇文章的结论是:
但是,完全自动驾驶汽车的梦想可能比我们意识到的更远。人工智能专家越来越担心,自动驾驶系统可能需要几年甚至几十年才能可靠地避免事故。
使用历史作为预测,云和点网行业都花了大约 5 年时间才开始以一种显著的方式影响人们,而这些行业在影响市场的重大转变之前花了将近 10 年时间。我们正在为人工智能设想一个类似的时间表。正如凯伦解释的那样,
为了让每个人都能够采用,需要有一个产品,一个可扩展的产品,一个每个人都可以使用的产品,而不仅仅是数据科学家。该产品将需要考虑到捕获数据、准备数据、训练模型和预测的数据生命周期。随着数据存储在云中,数据管道可以不断地提取和准备它们,以训练将做出预测的模型。模型需要根据新的训练数据不断改进,这反过来将保持模型的相关性和透明性。这是目标,也是承诺。
构建没有重要用例的人工智能概念证明
凯伦和我都来自科技和人工智能初创公司。在与人工智能社区同行的讨论中,我们所目睹和意识到的是对大量商业问题的广泛实验,这些实验往往停留在实验室中。
这篇最近的文章证实了如今更加普遍的广泛人工智能试点:
人工智能技术的供应商经常受到激励,让他们的技术听起来比实际更有能力——但暗示比他们实际拥有的更多真实世界的牵引力……企业中的大多数人工智能应用程序只不过是“试点”首先,销售人工智能营销解决方案、医疗保健解决方案和金融解决方案的供应商公司只是在测试这项技术。在任何给定的行业中,我们发现,在数百家销售人工智能软件和技术的供应商公司中,只有大约三分之一的公司真正具备从事人工智能的必要技能。
风投们意识到,他们可能在一段时间内看不到投资回报。然而,无处不在的实验中很少有模型能看到日光,这只是人工智能还没有准备好迎接黄金时代的原因之一。
算法可以问责吗?
我们听说过人工智能“黑匣子”,这是一种当前的方法,无法了解决策是如何做出的。这种做法与银行和大型机构背道而驰,它们有强制问责的合规标准和政策。当系统作为黑盒运行时,只要这些算法的创建已经被关键的利益相关者审查并满足一些标准,就可能存在对这些算法的固有信任。鉴于生产中有大量错误算法的证据,以及由此产生的意想不到的有害后果,这一观点很快遭到了质疑。我们许多简单的系统像黑匣子一样运作,超出了任何有意义的审查范围,因为有意的公司保密,缺乏足够的教育和理解如何批判地检查输入,结果,最重要的是,为什么会出现这些结果。凯伦表示赞同,
今天的人工智能行业正处于企业就绪的非常早期的阶段。人工智能非常有用,可以用于发现和帮助解析大量数据,但是,它仍然需要人工干预来指导评估和处理数据及其结果。
Karen 澄清说,今天的机器学习技术使数据能够被标记以识别洞察力。然而,作为这个过程的一部分,如果一些数据被错误地标记,或者如果没有足够的数据表示,或者如果有问题的数据表示偏差,则很可能出现糟糕的决策结果。她还证实,当前的流程仍在不断完善:
目前,人工智能完全是关于决策支持,以提供对业务可以得出结论的形式的见解。在人工智能的下一个阶段,自动根据数据采取行动,还有其他问题需要解决,如偏见、可解释性、隐私、多样性、道德和持续的模型学习。
Karen 举例说明了一个人工智能模型犯错误的例子,当图像字幕暴露了通过对标记有它们包含的对象的图像进行训练而学到的知识时。这表明,人工智能产品需要有一个对物体和人的常识世界模型才能真正理解。仅暴露于训练集中有限数量的标记对象和有限种类的模型将限制这种常识世界模型的功效。企业需要研究确定一个模型如何以人类可以理解的方式处理其输入并得出其结论。亚马逊发布的 Rekognition,其面部识别技术是目前正在生产和许可使用的技术的一个例子,但其有效性存在明显的差距。根据美国公民自由联盟发布的一项研究:
这项技术成功地将 28 名国会议员的照片与公开的面部照片混淆起来。鉴于亚马逊积极向美国执法机构推销认知,这还不够好。
Joy Buolamwini,麻省理工学院毕业生和算法正义联盟的创始人,在最近的采访中呼吁暂停这项技术,称其无效,需要更多的监管,并呼吁在公开发布之前为这些类型的系统制定更多的政府标准。
艾的主要障碍:心态、文化和遗产
不得不从遗留系统转型是当今许多组织实施人工智能的最大障碍。心态和文化是这些遗留系统的元素,它们提供了对既定流程、价值观和业务规则的系统视图,这些流程、价值观和业务规则不仅决定了组织如何运营,还决定了为什么这些根深蒂固的元素会给业务带来重大障碍,尤其是在当前形势良好的情况下。因此,目前没有拆除基础设施的真正动机。
人工智能是业务转型的一个组成部分,尽管这个主题已经获得了与人工智能宣传一样多的关注,但做出重大改变所需的投资和承诺却遇到了犹豫。我们听说一些公司愿意在特定的用例上进行实验,但是对于培训、重新设计流程以及修改治理和公司政策的要求却没有做好准备。对于被迫进行这些重大投资的大型组织来说,问题不应该是投资回报,而是可持续的竞争优势。
数据完整性的问题
今天的人工智能需要大量的数据才能产生有意义的结果,但无法利用其他应用程序的经验。虽然 Karen 认为克服这些限制的工作正在进行中,但在模型能够以可扩展的方式应用之前,需要学习的转移。然而,现在有一些场景可以有效地使用人工智能,例如揭示图像,语音,视频的洞察力,以及能够翻译语言。
公司开始意识到应该关注:
1)数据的多样性,包括不同人群的适当代表性
2)确保创作算法中包含不同的经验、观点和想法
3)优先考虑数据的质量而不是数量
这一点非常重要,尤其是在引入偏见、降低对数据的信任和信心的情况下。例如,土耳其语是一种中性语言,但谷歌翻译工具中的 AI 模型在翻译成英语时错误地预测了性别。同样,癌症识别人工智能图像识别只在皮肤白皙的人身上进行训练。从上面的计算机视觉例子中,Joy Buolamwini 测试了这些人工智能技术,并意识到它们在男性和女性以及浅色和深色皮肤上更有效。男性的“”错误率低至 1%,而深色皮肤的女性高达 35%。“出现这些问题是因为未能使用多样化的培训数据。凯伦承认,
人工智能的概念很简单,但通过吸收越来越多的真实世界数据,算法变得越来越智能,然而,能够解释决策变得极其困难。数据可能会不断变化,人工智能模型需要过滤器来防止错误的标记,例如一个黑人被标记为大猩猩,或者一只熊猫被标记为长臂猿。企业依靠错误的数据做出决策将导致错误的结果。
幸运的是,鉴于人工智能的恶劣,今天很少有组织根据这些数据做出重大的商业决策。据我们所见,大多数解决方案主要产生产品推荐和个性化营销传播。由此得出的任何错误结论对社会的影响都较小……至少目前如此。
使用数据进行业务决策并不新鲜,但发生变化的是所使用的结构化和非结构化数据的数量和组合呈指数级增长。人工智能使我们能够持续使用来自其来源的数据,并更快地获得洞察力。对于有能力和结构来处理来自不同来源的数据量的企业来说,这是一个机会。然而,对于其他组织来说,大量数据可能会带来风险,因为不同的来源和格式使信息转换更加困难:电子邮件、系统日志、网页、客户记录、文档、幻灯片、非正式聊天、社交网络和爆炸式增长的富媒体,如图像和视频。数据转换仍然是开发干净的数据集和有效模型的绊脚石。
偏见比我们意识到的更加普遍
在许多商业模式中存在偏见,以最大限度地减少风险评估,优化目标机会,虽然它们可能产生有利可图的商业结果,但已知它们会导致意想不到的后果,造成个人伤害并加深经济差距。保险公司可能会利用位置信息或信用评分数据向贫困客户发放更高的保费。银行可能会批准信用评分较低的潜在客户,他们已经负债累累,但可能无法承受更高的贷款利率。
围绕偏见有一种高度的谨慎,因为人工智能的引入不仅会延续现有的偏见,这些学习模型的结果可能会概括到加深经济和社会鸿沟的地步。像 COMPAS 一样,偏差出现在当前算法中以确定再犯的可能性(重新犯罪的可能性)。替代制裁罪犯管理概况(COMPAS)是由一家名为 Northpointe 的公司创建的。COMPAS 的目标是在审前听证中评估被告的犯罪风险和预测。在最初的 COMPAS 研究中使用的问题类型揭示了足够多的人类偏见,以至于该系统使无意中对待黑人的建议永久化,这些黑人永远不会再犯,法律对他们的惩罚比白人被告更严厉,而白人被告会再犯,在判决时会得到更宽大的对待。在没有公共标准可用的情况下,Northpointe 能够创建自己的公平定义,并在没有第三方评估的情况下开发一种算法……直到最近。这篇文章证实,“一个流行的算法在预测犯罪方面并不比随机的人好” …
如果这个软件只是像未受过训练的人回答在线调查一样准确,我认为法院在试图决定在决策中给他们多少权重时应该考虑这一点
凯伦规定,
虽然我们试图修复现有系统以尽量减少这种偏见,但关键是模型要根据不同的数据集进行训练,以防止未来的伤害。
考虑到商业和社会中普遍存在的错误模型的潜在风险,企业没有治理机制来监管会无意中影响最终消费者的不公平或不道德的决策。这在伦理学下讨论。
对隐私日益增长的需求
凯伦和我来自雅虎!我们与强大的研究和数据团队合作,这些团队能够将用户在我们平台上的行为联系起来。我们不断研究用户行为,了解他们在我们众多酒店中的倾向,从音乐、主页、生活方式、新闻等等。当时,数据使用没有严格的标准或规定。隐私被归入用户对平台条款和条件的被动协议,类似于今天。
最近的剑桥分析/脸书丑闻将个人数据隐私推到了前沿和中心。主要信贷机构频繁发生数据泄露事件,如 Equifax 以及最近的脸书和 Google + 继续加剧这一问题。所有权、同意和错误语境化的问题使得这成为一个成熟的话题,因为 AI 继续解决它的问题。已于 2018 年 5 月 25 日生效的欧洲通用数据保护法规(GDPR)将改变组织的游戏,特别是那些收集、存储和分析个人用户信息的组织。它将改变多年来商业运作的规则。个人信息的无节制使用已经到了紧要关头,因为企业现在将会意识到数据使用将会有重大限制,更重要的是所有权。
在基于位置的广告中,我们看到了这一点的早期影响。这个价值 750 亿美元的行业预计到 2021 年将以 5 年 21%的 CAGR 增长,继续受到脸书和谷歌寡头垄断的阻碍,确保了大部分收入。现在, GDPR 加大赌注,让这些广告技术公司更加负责任:
Hessie Jones Twitter
风险如此之大,以至于(广告商)必须有高度的信心,相信你被告知的内容实际上是合规的。关于什么将最终构成违规,似乎存在足够多的普遍困惑,以至于人们对此采取了宽泛的方法,直到您能够精确地了解合规性是什么样子。
虽然监管最终会削弱收入,但至少在目前,移动和广告平台行业也面临着来自消费者的越来越多的审查,这些审查正是他们多年来一直在赚钱的对象。这一点,再加上对既定实践的检查,将迫使行业改变他们在收集、汇总、分析和共享用户信息方面的实践。
实施隐私需要时间、大量投资(这是一个需要给予更多关注的话题),以及影响组织政策、流程和文化的思维方式的改变。
人工智能与伦理学的必然耦合
人工智能的主要因素确保了社会效益,包括简化流程,提高便利性,改善产品和服务,以及通过自动化检测潜在的危害。放弃后者意味着随时根据更新的制造流程、服务和评估解决方案、生产以及产品质量的结果来衡量投入/产出。
随着关于人工智能的讨论和新闻持续不断,这个术语“人工智能”加上“伦理”揭示了越来越严重的担忧,即人工智能技术可能造成社会损害,这将考验人类的良知和价值观。
CB Insights: Tech Cos Confront Ethics of AI
除了个人隐私问题,今天我们看到了一些近乎不合理的创新例子。如前所述,Rekognition 和 Face++被用于执法和公民监控,而该技术被认为是有缺陷的。员工罢工抗议谷歌决定向国防部提供人工智能来分析无人机镜头,目标是在一个名为 Project Maven 的项目中创建一个复杂的系统来监视城市。同一家科技巨头还在为中国建设项目蜻蜓,这是一个经过审查的搜索引擎,也有能力将个人搜索映射到身份。
决策者和监管者需要注入新的流程和政策,以正确评估人工智能技术的使用方式、目的以及在此过程中是否可能有意想不到的后果。Karen 指出了在确定人工智能算法中使用数据时需要考虑的新问题:
我们如何检测敏感数据字段并匿名化它们,同时保留数据集的重要特征?我们能在短期内用合成数据作为替代进行训练吗?在创建算法时,我们需要问自己的问题是:我们需要哪些领域来交付我们想要的结果?此外,我们应该创建什么参数来定义模型中的“公平”,也就是说这是否对两个个体有所不同?如果是,为什么?我们如何在系统中持续监控这一点?
人工智能冬天是一个让人工智能做好准备的偶然机会
AI 已经走过了很长的路,但仍需要更多的时间来成熟。在一个自动化程度越来越高、认知计算能力不断提高的世界,即将到来的人工智能冬天给了企业必要的时间来确定人工智能如何融入他们的组织以及它想要解决的问题。需要在政策、治理及其对个人和社会的影响中解决即将到来的人工智能伤亡。
在下一次工业革命中,它的影响要大得多,因为它在我们生活中的无处不在将变得更加微妙。来自杰夫·辛顿、李菲菲和吴恩达的人工智能领军人物呼吁人工智能重置,因为深度学习尚未被证明可以规模化。人工智能的前景并没有减弱,相反,对它真正到来的预期被推得更远了——也许是 5-10 年。我们有时间在深度学习、其他人工智能方法以及从数据中有效提取价值的过程上解决这些问题。这种业务准备、监管、教育和研究的高潮是必要的,以使企业和消费者跟上速度,并确保监管系统到位,以适当地限制技术,并让人类更长时间地掌舵。
Karen Bennet , Arcompany ,的首席顾问,是一位经验丰富的高级工程领导者,在开源和闭源解决方案的软件开发领域拥有超过 25 年的经验。最近,卡伦的努力集中在人工智能上,使企业,特别是银行和汽车行业的企业,能够试验人工智能/人工智能。她在 Cerebri AI、IBM、Yahoo!他是早期的领导者,帮助天鹅座和红帽成长为可持续发展的企业。
这篇文章最初出现在福布斯上。
要订阅的人工智能时事通讯

SOURCE: HIROSHI WATANABE VIA GETTY IMAGES
这里是 Josh.ai 我们正在为家庭开发一个相当令人兴奋的人工智能代理。这是一个令人兴奋的领域,我们试图跟踪该领域的一些时事通讯。我们没有跟上所有这些,但这里有一个精选的列表,列出了我们在那里发现的一些最好的
AI Weekly —订阅人工智能和机器学习方面的最佳新闻和资源的每周集合。免费的。
Deep Hunt —由 Avinash Hindupur 精心策划的人工智能最热门事物的每周简讯!
热门机器人 —我们在网上搜寻关于机器人&人工智能的最新内容。
奥莱利人工智能简讯 —接收每周人工智能新闻、业内人士的见解以及独家交易和优惠。
机器学习周刊 —机器学习与深度学习博客(7.1k 订阅用户)。
数据科学每周简讯 —免费的每周简讯,提供与数据科学相关的新闻、文章和工作。
机器学习—ML&AI 新闻每周综述。机器学习和人工智能正在对我们的生活产生巨大影响。
人工智能新闻——AI&深度学习快讯。****
当树倒了……—机器学习与人工智能博客。****
WildML——AI、深度学习、NLP Bl og
C olah 的博客 —神经网络聚焦博客。
我是特拉斯克——一个机器学习的手艺博客作者@iamtrask
人工智能内部——带给你人工智能、机器人和神经技术的最新进展
阿齐姆·阿兹哈尔:指数观点 —指数变化:技术、商业模式、政治经济&社会。
库兹韦尔人工智能——库兹韦尔加速智能简讯通过电子邮件简明扼要地报道相关的重大科技突破(每日或每周)。
导入 AI —导入 AI 是一份关于人工智能的每周简讯,有成千上万的专家阅读。
AI 中的野周—AI 中的野周是由@ dennybritz 策划的每周一期 AI &深度学习简讯。
——通过阅读每个工作日直接发送到你收件箱的顶级文章,了解人工智能&数据科学的最新动态。****
订阅获取智能家居、语音控制和人工智能的最新信息。
自动驾驶汽车:监管还是自由市场?

Photo Credit Patrick Curtet
人工智能将成为我们作为个人和社会的最终反映。考虑到这一点,应该如何管理呢?
- 在一个法律结构中应该有政府监督吗?
- 行业自律行得通吗?
- 自由市场应该决定这项技术的界限吗?
虽然没有简单的答案,或放之四海而皆准的答案,但这个问题现在需要各方广泛讨论,以保持领先地位。
构建和实现这项技术时需要做出的决策部分取决于我们希望这项技术如何发挥作用。虽然不可能对软件的使用方式下禁令,但我们确实有集体力量来影响决策的方式和成本。
当提供人工智能解决方案时,我们应该总是问可能性的范围是什么,这样我们就可以考虑如何使任何结果更加人性化。如果这种方法被认为是重要的,人性可以被嵌入到任何软件中。在危急或影响生活的情况下,我认为这很重要。
目前建造的东西几乎完全取决于两个输入。
1。软件的最终目标是什么,它应该实现什么,最终导致那个结果的决策是什么?
2。用于支持软件的数据或信息是什么?在收集这些数据或信息时做出了哪些决策?
这些决定通常被认为是最终结果的主要驱动因素或影响因素,比任何法律、道德或人文因素都重要。
毕竟人工智能是由工程师而不是律师构建的。
以自动驾驶汽车为例,在只有两种可能结果的碰撞类型场景中,可以问一个简单的问题。
结果 A. 自动驾驶汽车撞向路边的一群人,导致那群人死亡,但对车上的乘客没有持久的影响。
结果 B. 自动驾驶汽车在路边错过一群现在导致乘员死亡的人。
对任何一种结果做出的决定都将被设计到 car 软件中。至于哪种结果更好,这将是一个人为的决定。从这个意义上说,从实际角度来看,结果是二元的,应该从总体影响的角度来考虑。由于汽车现在也是司机,在什么情况下所有的责任都让给了软件?
虽然这种行驶数十万英里的事件很少发生,但随着路上自动驾驶汽车数量的增加,这种事件将会发生。应该采取什么行动?结果 A 还是 B 更好?
政府监管自然会在自动驾驶汽车中发挥作用,汽车制造商的自身利益也是如此。目前,美国政府强制实施了现代汽车安全标准。总的来说,安全标准弱于加拿大和欧洲,但强于发展中国家。美国汽车工业努力游说降低安全标准的限制性。这只是导致美国 10.6/10 万居民死亡率的因素之一。(2015 年世卫组织报告)
自由市场方法不鼓励对贸易或商业的限制。举一个例子,合法出售给 SUV 车主以保护他们的汽车免受损坏的金属球棒具有对任何被撞行人造成更大伤害或死亡的副作用。然而,SUV 司机现在得到了更好的保护,不太可能受到伤害。这种自由市场方式将公司利益置于行人安全之上。如果将类似的模型用于所有自动驾驶汽车,进而用于所有人工智能软件,会有什么结果?
每个人都可以也应该围绕我们未来想要的驾驶环境类型展开对话。如果我们不参与,那么围绕安全的决策将继续主要由汽车制造商做出。
“2010 年,成年人饮酒过度,驾车次数约为 1.12 亿次。”美国疾病预防控制中心 2011 年报告
“每天,人们酒后驾车近 30 万次,但只有不到 4000 人被逮捕。”—美国联邦调查局 2010 年报告
酒后驾车是一个有着悠久法律的领域。然而,现有的酒后驾驶法律往往被无视,难以执行。很大一部分公众继续在醉酒状态下开车,而警察却没有足够的人力来执行这项法律。
这是一个自动驾驶汽车将立即减少酒驾影响的领域。然而,更广泛地说,当公众决定在既定规则或法律之外行事时,执行这些法律可能是一个挑战。
当人工智能系统出现在世界上,在普通大众的手中,它们将如何被监管?如果不进行辩论,规则、监管和法律可能会来得太晚,无法有效管理人类和机器需要共存的环境。现在是讨论我们希望人工智能如何在我们的道路上和更广阔的世界中行动的时候了。
为大家揭秘人工智能
有意识的机器人真的来了吗?外行人的指南

What does an AI brain look like? Image credit: JÉSHOOTS
“智力的概念就像舞台魔术师的戏法。比如“非洲未开发地区”的概念。我们一发现它就消失了。”
—马文·明斯基(1927–2016),数学家,人工智能先驱。
T 上面引用的一位计算机科学泰斗的话,恰如其分地营造了一种氛围,让我们得以一窥当今最热门、最具争议的技术之一的背后。对于围绕它的所有神秘,如果我们简单地说,“人工智能只不过是涡轮增压的统计推断”,我们不会离真相太远。让我们仔细看看。
每个计算机程序的核心都有一个数学函数在起作用。这可能像计算未偿还贷款的利息一样简单,也可能像自动驾驶飞机一样复杂。人工智能,或 AI ,是一个计算机程序的通称,其核心数学功能已经(几乎)自动创建;而机器学习,或 ML ,指的是提供创造人工智能方式的一系列技术。
一个 ML 技术需要两件事:第一,一个函数看起来像什么的粗略草图,第二,一组训练例子’在情况 A 中函数应该执行动作 B,在情况 X 中函数应该执行动作 Y,等等’。对于每一个例子,ML 技术都细化了草图,使得结果函数更好地符合到目前为止所看到的一切。

Our painter AI might look like a muscular version of this writer automaton by Henri Maillardet, ca. 1810. Image credit: Wikipedia
假设我们有一种 ML 技术,它知道如何将肌肉粘在骨头上,了解关节如何工作,并知道关于健康生物体肌肉平衡的限制。我们可以从一个人体骨骼(功能草图)和一大套笔触(例子集)开始,通过试错,创造一个知道如何绘画的人工智能。虽然创造一个简单地在墙上泼洒颜料的人工智能可能很容易,但创造一个具有梵高或莫奈技能的人工智能却困难得多;这是科学家的薪水支票。
从错误中学习。想象一下!
在创建画家 AI 时,ML 技术通常从创建随意的笔触开始,而不考虑训练示例。随着观察到的例子越来越多,它的目标是更好地模仿它们。如果这项技术非常适合这项任务,那么它会通过猜测给骨骼的哪个部分添加多少肌肉以及微调运动来改善,以便最好地补偿绘画错误。
尽管存在数学限制,但总的来说,更多的训练示例有助于创建更好的人工智能。这当然假设开发了适当的机器学习技术。在“训练”完成后,人工智能被释放到现实世界中,它可能会通过其核心功能处理每一个新的情况,以产生它认为最好的反应,或者就画家而言,最佳的笔触。
人工智能的每一项著名成就——从深蓝战胜加里·卡斯帕罗夫(Gary Kasparov)到自动驾驶汽车——都是科学家磨练机器学习技术并将其与正确的基本规范和训练样本结合起来的结果。但是人工智能比这些例子所暗示的更普遍。

Machine Learning is everywhere. Image credit: Giphy
我在亚马逊和猫途鹰上的搜索触发了我的谷歌搜索中的广告。脸书认出了我和我朋友的照片。LinkedIn 可以知道我什么时候在找工作。一个经常被引用的例子是,一家超市发现一个十几岁的女孩怀孕了,甚至在她的家人知道之前,因为她突然从普通化妆品转向无香水化妆品。
等等,那电影呢?
今天,当你使用网络浏览器或手机应用程序时,是人工智能决定你观看什么广告。欧洲粒子物理研究所的 T2 正在帮助科学家从噪音中辨别基本粒子的信号;这就是他们如何发现希格斯玻色子。它把一种语言的文本翻译成另一种语言。从苹果的 Siri 到亚马逊的 Alexa,语音助手都是由人工智能驱动的。它保护信用卡和借记卡免受欺诈。它预测天气,甚至写新闻文章。去年,人工智能在空战模拟中击败了王牌飞行员,在围棋比赛中击败了世界特级大师。以这样或那样的形式,人工智能正在落后于所有形式的技术。
然而,所有这些都是非常具体、非常专业的应用。如果我们的期望是由科幻小说设定的,它们可能仍然显得平淡无奇。我们应该准备好迎接一个有自我意识、有能力并倾向于统治世界的流氓人工智能吗?

In Ex Machina, the AI learns to deceive and kill in order to preserve itself. Or out of malice. Who knows!? Image credit: BagoGames
就人工智能的现代化身而言,这个领域在出生时就设定了这样的期望。现代计算机的创造者艾伦·图灵在 1950 年问道:“机器能思考吗?他提出了所谓的图灵测试,作为对机器思考能力的终极测试。测试表明,如果通过对话,一台机器可以让法官相信它是人类,那么必须假定这台机器具有与人类无法区分的思维能力。
他推测,只要有足够的内存,这样的机器是可以制造出来的,而且将会在 20 世纪初制造出来。在他 1951 年的一次演讲中,他说,“他们将能够彼此交谈,以提高他们的智慧。因此,在某个阶段,我们应该预料到机器会控制局面。”事实证明,这比想象的要难得多。
事实是,不仅一个有自我意识的计算机程序——它毕竟是一个计算机程序——很难设计,甚至不清楚这样的程序是否存在。正如图灵测试所评估的那样,创造一个与人类没有区别的人工智能是一个更小的挑战。
我们已经看到实验室里出现了许多令人瞠目结舌的技术。有人甚至可以说计算机和技术已经控制了我们生活的大部分。但是有自我意识的机器,更不用说失控的杀手机器人,还没有出现。
艺术的状态
一台机器能否通过图灵测试取决于它理解自然语言的能力,比如英语、汉语或梵语。这就是所谓的自然语言处理或者 NLP 的问题。由于历史原因,20 世纪下半叶的主要努力集中在使用数理逻辑规则设计 NLP 程序上。
这些程序发展成为 20 世纪末 21 世纪初的专家系统,旨在帮助组织基于事实和纯逻辑推理做出决策。专家系统因无法处理大量数据和复杂问题而失宠。出于类似的原因,依赖于基于规则的逻辑推理的方法被完全抛弃了。另一种思维方式流行开来:一种基于概率和统计的思维方式。
例如,像国际象棋这样的游戏的专业知识被图灵和许多后来的人工智能研究人员认为是战略思维的有力证据。然而,IBM 在 1996 年击败加里·卡斯帕罗夫的名为“深蓝”的计算机程序并非基于逻辑。这个程序根据什么最大化胜利的概率来选择它的行动— 概率是关键词。这种游戏方式与早期对机器智能的理解背道而驰。但也许它重新定义了机器智能。
事实上,在众多其他问题中,即使是图灵最初的 NLP 问题也从将统计学和概率论应用于该任务中获益匪浅。
随着时间的推移,机器学习科学家也将有线和无线通信领域的一些经典思想改编为自己使用。通信工程师非常担心在介质中传输的珍贵比特中能容纳多少“信息”,以及如何恢复传输中丢失的信息。同样,ML 的科学家们担心从他们能得到的零碎数据中收集尽可能多的“信息”。相反,如果他们不会丢失太多信息,他们会很乐意为了效率而忽略一些数据。

Using concepts from communication and information theory, data can be represented in alternative forms to make them better suited for specific applications. Image credit: Wikimedia Commons
这种概率和统计技术与人类在大脑中组织信息和知识的方式相去甚远。从这个意义上说,它们补充了人类的智力。最接近模仿人脑的东西被称为人工神经网络或安。这是一种在过去十年里变得特别流行的技术。人工神经网络是“功能草图”——我们之前描述过的一个术语——它们可以被训练来执行各种任务:从手写识别,到预测销售,到识别医学图像中的异常对象,到自然语言处理和语言翻译。
人工神经网络令人着迷,最近理所当然地受到了很多关注。但是,我们是否会很快见证一个类似人类的、有自我意识的计算机程序的到来,还没有定论。
那么接下来会发生什么呢?
可以肯定地说,人工智能的最新发展在很大程度上归功于计算机硬件的最新发展。如果没有密集封装的内存芯片和快如闪电的处理器,我们就不会产生海量的数据,也没有能力处理所有这些数据。这也解释了机器学习统计技术的兴起:一个人提供的数据越多,统计推断就越好。

Statistical inferences work because we are, after all, not much different from one another.
只要有数据,就一定会有人最终应用机器学习并获得推论,这些推论往往令人惊讶,甚至无法通过其他方式获得。然而,无论怎么强调都不为过的是,找到数据和学习技巧的正确组合绝非易事。很多事情都可能出错,也确实出错了。通常很难获得高质量的数据,这些数据公平统一地反映了手头问题的所有方面。此外,ML 技术很容易因缺乏经验或工程师的偏见而受阻。
2015 年,谷歌因其图像分类器 AI 将非裔美国人标记为大猩猩而受到批评。美国法院越来越依赖由 ML 驱动的算法来决定一名囚犯在出狱后是否有可能再次犯罪;如果是的话,那么判决会更严厉。但是这些算法中的一些被证明对某些种族的人有不公平的偏见。这是因为与学习技巧一起使用的一组例子没有统一地代表所有种族的人。在某种意义上,人工智能无意中学会了仅仅根据人的种族来预测重返犯罪生活的可能性。
我们意识到,画家艾的水平取决于用来训练他的例子和技巧。这样的例子不胜枚举,它们提醒我们,就像所有人造的东西一样,人工智能也受到天生愚蠢的束缚。
如果你喜欢这篇文章,你可能也想知道更多关于人工智能的历史。从希腊神话,到中世纪的人形机器人,再到计算机的发明。
人工智能:理解炒作
“迄今为止,人工智能最大的危险在于,人们过早地断定自己理解它。”—埃利泽·尤德科夫斯基

解决炒作问题
人工智能到处都是头条新闻。如果你没有生活在岩石下,你肯定会遇到人工智能、机器学习、自然语言处理等术语。任何对科技行业略知一二的人都知道,它对流行语、时尚、流行语和炒作并不陌生。
AI、ML 等成了流行语。围绕人工智能的炒作在世界其他地方已经减少,但印度仍然是炒作周期的一部分。学生们甚至在拥有计算机科学基础之前就想学习人工智能。求职者希望找到允许他们使用人工智能的工作,公司希望在他们的产品中实现人工智能。创业公司正在将人工智能作为其平台的核心技术,因为他们充分意识到投资者对人工智能感兴趣。球场甲板上充满了人工智能参考和空洞的承诺。公司在计划如何在产品中使用人工智能之前,会聘请人工智能专家。任何以如此迅猛的速度发展的技术都很难被任何人忽视。谷歌首席执行官桑德尔·皮帅表示,世界正在从移动第一世界过渡到 T2 人工智能第一世界。
每个人都想搭上人工智能的顺风车。但是人们了解 AI 吗?你会惊讶地发现有多少人不知道人工智能究竟是什么。我打算用这篇文章来帮助解释人工智能。
理解人工智能
简单地说,人工智能是计算机科学的一个分支,目标是让机器或程序思考和学习。
**机器学习:**当你在谷歌上搜索某个东西时,它使用一种叫做 RankBrain 的机器学习算法,根据各种参数过滤结果。它是人工智能的一个子集。它允许机器获取数据并自我学习。
深度学习: Google Now 也称为 Android 智能手机上的 Google Assistant,使用深度学习来执行使用大量数据的任务。当你提出一个问题时,谷歌助手会在大量数据中搜索,给你一个答案。它是机器学习的一个子集。它通过使用神经网络模拟人类决策来解决现实世界的问题。机器知道如何通过在大量数据上训练自己来模仿人类的决策。
**自然语言处理:**你安卓智能手机上的谷歌助手也使用 NLP。当你提问时,它会翻译人类语言,然后执行动作给你答复。也是 AI 的子集。它允许机器理解人类语言。NLP 可以使用基于 ML 的模型来帮助它解释语言。

Photo: Neota Logic
人工智能的其他领域如上图所示。希望以上信息能让你对 AI 有一个基本的了解。我建议你在读完这篇文章后深入挖掘。我个人喜欢 Udacity 上的这个课程,如果你想了解更多关于 AI 的知识: 人工智能简介 **。**如果你想学习机器学习,吴恩达 Coursera 上的 这个课程 是一个很好的开始。
当今人工智能的一些流行应用:
- 苹果设备上的 Siri。使用 NLP 和 ML。
- Amazon.com 使用 ML 向用户推荐产品。
- 网飞通过分析大量数据,使用 ML 和深度学习向用户推荐电影和电视节目。
- 谷歌搜索使用 ML 对搜索结果进行排名。Google 还使用 ML 根据用户的浏览器历史和其他参数向用户显示有针对性的广告。
做出明智的决定
跟上技术的发展是很重要的,但是在我们了解技术将如何帮助我们之前学习或实现某些东西是一个坏主意。人工智能在正确使用的情况下是非常强大的。不要因为别人在用就用 AI,当你觉得它会比其他技术更快更好的帮助你解决一个问题的时候就用它。做出明智的决定很重要。在没有想法的情况下使用引人注目的技术只不过是一种实验。
如果你喜欢这篇文章,请点击底部的♥按钮。另外,请订阅我下面的时事通讯:
线下/数字营销中的人工智能用例/应用领域
在推出 appliedAI.com 时,我们采访了企业领导人和各种规模的人工智能供应商,搜索了新闻文章、专利、风险投资融资等,以确定现有和新兴的人工智能用例。我们已经确定了大约十几个营销中的基本人工智能用例。我们专注于核心营销活动,例如优化定价和投放、优化广告/营销、个性化推荐、收集和利用客户反馈。我们一直在改进我们的结构,希望听到您的意见和建议。
下面列出了主要的营销活动和这些活动中的人工智能用例。要了解更多信息,请访问相关页面,查看参考资料、视频和详细解释:
1-优化定价&投放
**定价优化:**优化降价以最小化自相残杀,同时最大化收益。
**商品销售优化:**利用机器学习和大数据来优化您的在线或离线商品销售
**货架审计/分析:**在零售区使用视频、图像或机器人来审计和分析您对货架空间的使用。识别和管理缺货或货架空间的次优使用。
**视觉搜索功能:**利用机器视觉,让您的客户能够通过图像或视频搜索您的产品,从而立即找到他们想要的产品。
**图像标记以改进产品发现:**利用机器视觉来标记图像,同时考虑用户的偏好和产品的相关背景。
2-优化广告
**神经营销:**利用神经科学和生物传感器来了解你的内容如何影响你的观众的情绪和记忆。私下测试你的内容,直到达到预期效果。
**分析:**自动连接你所有的营销数据和 KPI。根据您的数据管理营销活动、触发警报并提高您的营销效率
个性化营销:在正确的时间,通过正确的设备和渠道,将正确的信息传达给正确的客户。用您的个性化营销提高客户满意度,让您的客户大吃一惊。
**情境感知广告:**利用机器视觉和自然语言处理来理解广告投放的情境。通过确保您的信息与共享信息的网页或应用程序的上下文一致,保护您的品牌并提高营销效率
3-个性化推荐
**个性化推荐:**利用客户数据,通过电子邮件、网站搜索或其他渠道向客户提供个性化推荐。
4-联系&利用客户反馈
**社交媒体监控:**利用机器学习优化你的社交媒体帖子的渠道、目标受众、信息和时机。
**社交分析&自动化:**利用自然语言处理和机器视觉来分析和处理你的实际或潜在客户在社交媒体、调查和评论上生成的所有内容。
**社交媒体优化:**利用机器学习来优化你的社交媒体帖子的渠道、目标受众、信息和时机
**公关分析:**学习、分析和衡量你的公关工作。这些解决方案跟踪媒体活动,并提供对公关工作的见解,以突出推动参与度、流量和收入的因素。
你可以在下面这张相当复杂的图表中看到所有这些用例。
要获得更多关于这些用例的信息,包括参考资料、案例研究、客户视频和关于在该领域运营的供应商的信息,请访问我们的https://appliedai.com或查看我们关于人工智能在营销中的用例的扩展博客文章。

保持乐观!
杰姆·迪尔梅加尼
人工智能:你成功的关键:)

人工智能(AI)带来的潜在问题与疯狂的机器人或理智的机器人接管工作无关。这与人和产品变得“过时”有关。好消息是,这可以通过理解什么是人工智能以及它将影响哪些领域来补救,以期创造一种与这种短期必然性相一致的思维模式。
鉴于我在人工智能方面的背景,同事和朋友们一直在问我,人工智能是否意味着我们所知道的世界末日。他们询问关于软件编写软件、奇点、斯蒂芬·霍金说过的话等等。大多数人在阅读或讨论 Al 时都表示感觉过时了。到目前为止,在职业上,他们已经掌握了各种新技术,比如电子邮件、学习谷歌、在易贝购物、在脸书上传个人资料供所有人观看、Snapchatting 等等。
但是人工智能呢?你是怎么处理的?是时候看看退休选择了吗?号码
AI 会留在这里。人工智能本质上是知识的科学。都是知识和学习的问题。技术是知识,在某种程度上,存在的一切都是技术,包括人类。
那么,什么是 AI?
长话短说,AI 可以分解成各个重点领域,其中最重要的是机器学习和自然语言处理。下面是对这些问题的快速而简单的解释。
1。机器学习(ML)
机器学习基于模拟生物大脑功能的神经网络。神经网络是一个由神经元(脑细胞)组成的网络,这些神经元通过称为突触的连接相互连接(想象一下渔网)。这些连接具有一定的强度(正的或负的),这些连接的组合将根据某个阈值导致神经元被打开(放电),或不被打开(想象一个连接了一些电源线的灯泡:如果累积的功率足够大,灯泡就会打开)。人类的思维是神经元放电(或不放电)的结果(尽管这可能是一种保守的说法)。
现在,拿一个神经网络的一边,打开一些神经元。然后拿另一边,再次打开一些神经元。你已经给了网络一个给定输入和预期输出的例子(想象一个 1 加 1 的输入和一个 2 的输出,以便教它加法)。接下来,给它许多例子,然后使用一种特定的标准化学习算法,通过这种算法,它可以通过调整其连接的能力以及神经元何时激活来学习。一旦它通过多次迭代稳定下来,让它添加你没有教过它的数字:它会根据它所学到的东西以很高的概率做出准确的响应。这样,给定输入数据集(例如图像)和输出数据集(例如这些图像的描述),基于它“看到”的模式,它可以非常准确地回答新图片包含什么,即使它以前从未见过它。
这方面的一个实际例子是谷歌视觉 API,它在一个巨大的图像数据集上进行训练,可以理解图像的内容。
**2。**自然语言处理
本质上,我们对世界的认识是一种内在的本体论。本体是概念和类别以及它们的属性和它们之间的关系的分层集合。婴儿在他们在地球上的职业生涯的第一天就开始建立这个本体,从“饥饿”的概念和相关的“牛奶”的子概念开始(属性:颜色:白色,味道:非常好)。
然后引入一种叫做“语言”的交流媒介,这种媒介很快被所有相关方认为非常有用。语言与不断扩展的内部本体(知识库)直接相关。起初,基于范例的学习模式被用来教授这种新的交流技术,但最终在学校引入了一套正式的语法规则。
自然语言处理对上述内容进行建模,以便在句法/语义上(如语言所定义的)和上下文上(如与环境和本体知识相关的)理解文本。
长话短说,人工智能在实践中使用 NLP 的一个实际例子是 Thinkfor.me Email ,它通过使用 NLP 总结每封电子邮件,并可选地以摘要、要点或单页模式展示它们,从而长话短说。
如何留在比赛中
伸出双手和双腿站在河中央,你无法阻止河水流动。根据你的职业,与人工智能打交道的最好也是唯一的方式是考虑它如何帮助你增加你所做事情的价值、准确性和效率。如果你是一名企业主,你应该看看嵌入式人工智能如何帮助你变得更具竞争力,并防止你的产品迅速过时。。
下面不是提供一个“十大途径”的列表,而是一个在不久的将来人工智能潜在影响领域的职业参考。
生产力中的人工智能
创造一个包罗万象的人工智能助手
金融中的人工智能
决策支持通过对经常性股票图表模式的分析使用 ML 来评估潜在的价格变动
基于神经网络的应用程序,可根据案例历史数据集做出更明智的贷款决策
教育中的人工智能
使用 NLP 作为学习工具学习工具从语法和概念上分析和总结文本
在给定历史数据集的情况下使用 ML 预测学习结果
使用自然语言处理评估和评分论文
艾在法
基于历史案例数据和结果预测法院判决
基于上下文级别智能搜索案例和决策文本
销售中的人工智能
使用 NLP 和 ML 管理电子邮件活动,以阅读和理解电子邮件回复,从而确定要追求的目标
智能广告:如何赢得买家并影响销售(请留意这一条)
艾未未
使用 ML 支持慢性疾病患者
使用 ML 作为治疗计划选择的决策支持
艾在新闻(假的还是假的)
在给定历史数据集的情况下,使用 ML 结合 NLP 来区分假新闻和真实新闻
人工神经网络:人对机器?

Photo Credits — Äkta människor SVT1
本文是探索 10 种基本机器学习算法的 BAI 系列文章的一部分*
这些机器人是人类还是某种机器?如果人类智能能够快速区分这两者,那么机器学习就必须依靠像人工神经网络这样的算法来做出预测。人工神经网络模仿人类大脑的结构,允许机器像人类一样思考吗?到底什么是 ann,它们是如何工作的,它们与其他机器学习算法有什么不同,它们在数据科学中的使用场景是什么?
计算机最初是围绕由预定步骤组成的算法设计的,以计算给定情况下的正确答案。这种对“绝对确定性”的信念使组织能够优化业务流程,加快会计程序,并改善他们的供应链。然而,图像分类、对象检测和语音转文本的挑战超出了传统算法的能力范围,因为它们需要能够基于不完全信息预测概率的算法。
1943 年,麦卡洛克和皮茨利用基于概率论的计算模型,结合阈值逻辑,创建了第一个人工神经网络。人工神经网络由三层相连的神经元组成:输入层将数据输入系统进行处理,隐藏层依靠一组加权输入通过激活函数产生结果,输出层产生程序的结果。因此,人工神经网络是基于概率的算法,它们不像人脑那样“思考”,而是采用数学函数来应对随机学习环境的挑战。
神经元或节点是一个数学函数,它接收输入并给出代表输入计算结果的单一输出。人工神经网络是通过例子和经验逐步学习的,而不是通过一系列命令。深度神经网络由数千个这样的神经元组成。深度神经网络为数据科学家提供了一种处理模糊性和复杂性的方法,因为它们将问题分解为微小的子问题,从而允许构建输入如何呈现的精确表示。
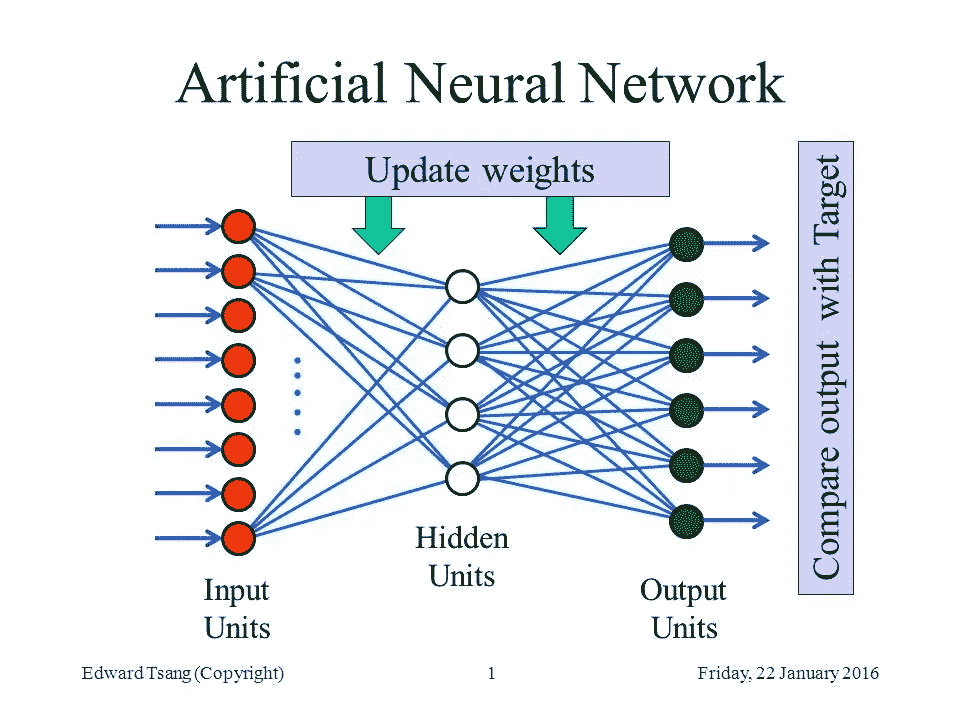
人工神经网络的每一层都以特定的权重处理其输入,从而产生操作值。然后,该值乘以生成的阈值,并发送至激活函数以计算输出。给定一组输入,二元、线性和非线性激活函数用于定义每个神经元的输出。然后,该函数的输出作为另一层的输入发送,或者如果该层是最后一层,则作为网络的最终响应发送。【1】
通过使用被称为前向传播和反向传播的技术来标准化“权重”,进行人工神经网络的训练。人工神经网络的一个关键特征是这些迭代学习过程,其中数据一次一个地呈现给网络,并且与输入值相关联的权重以同样的方式进行调整。因此,训练人工神经网络在计算上是昂贵的,并且经常会导致过度拟合。
在前向传播中,样本权重通过输入被输入到人工神经网络,相应的样本输出被记录。更准确地说,前向传播是这样一个过程:向人工神经网络输入一组输入,以获得它们的分量乘积(即它们的点积)与它们的权重之和,然后将后者输入到激活函数,并将其数值与实际输出(地面真实值)进行比较。
反向传播是一种用于计算梯度的方法,该方法需要校准网络中使用的权重。在反向传播数据中,科学家从输出单元通过隐藏单元到输入单元,考虑每层输出的误差范围。然后调整输入,使误差幅度最小。
最后,人工神经网络有几种形式。最初,感知器被设计为用于二元预测的线性分类器。这种模型的主要限制是数据必须是线性可分的,这导致了多层人工神经网络能够解决复杂的分类和回归任务。目前使用的神经网络有六种基本形式,它们集成了不同的数学运算和不同的参数集。前馈主要用于语音和声音识别,径向基函数已用于预测电网短缺,Kohonen 自组织是模式识别的逻辑选择,递归神经网络已用于语音到文本,卷积用于信号处理,模块化神经网络作为多模块决策策略的一部分。【2】

Kohonen Neural Networks
回到我们从瑞典电视连续剧《真实人类》中拍摄的 hubots 照片,让我们假设我们的神经网络中有三个神经元(A、B、C)。【3】在对数据进行训练并将神经元 A、B 和 C 分配给区分人和机器的重要特征之后,可以训练算法,当激活 A & C 时,图像属于人类,但如果 A & B 被激活,则图像属于机器。可以开发神经网络来破译与人类相关的一系列特征:同理心、自然智力、想象力、信仰、情感等。这些特征的定义本身就是人类的构造,超出了当前人工智能应用的范围。尽管如此,由数千个,甚至数百万个神经元组成的深度神经网络可以帮助我们更精确地描述这些特征,从而建立更好的预测模型来探索这种复杂性和模糊性。
李施伦克博士,商业分析研究所,2018 年 10 月 5 日
*之前在白系列中发表的关于基本机器学习算法的文章包括 k-NN —了解最近的邻居、 贝叶斯定理—熟能生巧 和 鲨鱼攻击—解释泊松回归的使用
Lee Schlenker 是商业分析和社区管理教授,也是 http://baieurope.com 商业分析研究所的负责人。在可以看到他的 LinkedIn 个人资料在可以在的 Twitter 上关注白
【1】Gnanasegaram,t .(2018),人工神经网络——简介
【2】(2018)马拉德哈尔,k .,目前在机器学习中使用的 6 种人工神经网络,印度分析
【3】这个例子的灵感来自约翰·奥拉芬瓦(John Olafenwa),(2018),神经网络简介
人工神经网络和神经科学
TL;博士
众所周知,人工神经网络受到不同学科的影响,如数学、物理和神经科学(顾名思义)。
人工神经网络能提供任何线索回到神经科学去理解一些大脑结构吗?
长版
人工神经网络是数学、物理(如统计力学)和神经科学交叉领域的结果。
人工神经网络最初的神经科学灵感可以追溯到 40 年代,因为它收到了上述领域的大量贡献:
- 从数学的角度来看,让我们考虑一下函数优化和误差反向传播(梯度计算等)的所有影响
- 从物理的角度,我们来思考一下受限玻尔兹曼机和自旋玻璃之间的联系
- 从神经科学的角度来看,让我们想想最近生物启发的卷积神经网络(CNN)的成功
所以问题是安能给这些领域什么回报?
许多臭名昭著的深度神经网络应用于数据密集型领域,如应用数学、物理和显然的工程,目前已经开发并正在开发中,但神经科学呢?
人工神经网络的最新发展是否有助于提高我们对大脑的了解,反之亦然,从而引发良性循环?
似乎是这样的:计算神经科学领域的一些最新推测可以被定义为“人工神经网络启发的”,事实也的确如此
- 动态学习相当于大脑中发生的成本函数优化
- 对于架构和成本函数来说,任务特异性对于实现足够好的性能水平是必要的
- 计算专用结构存在:不同种类的存储器(例如,内容可寻址、缓冲区等),不同种类的信息路由系统(例如,注意力、高级门控系统等)
大脑神经元和人工神经元的区别
首先,重要的是观察到,即使一些 ANN / DL 架构具有某种生物灵感,但人工神经元和生物神经元之间仍然存在很大差异。
最臭名昭著的差异之一是关于网络上的物理时间效应:虽然目前最常用的人工神经网络没有物理时间的概念(因为推理和训练计算发生在离散的计算时间内),但生物网络深受物理时间的影响,因为神经元通过发送尖峰信号工作,网络状态取决于时间。
这就是说,如果 ANN / DL 体系结构和生物学体系结构在某些方面看起来相似,它们在许多其他方面,甚至是基本方面仍然非常不同。
大脑中的成本函数优化
在当前的人工神经网络中,典型的优化算法类是依赖于成本函数局部梯度计算的梯度下降类。由于一系列的原因,大脑不太可能利用这样的机制,因此已经形成了其他的假说,如 1) 赫布边可塑性和 2) 系列扰动。
Hebbian 可塑性基本上是一个基于成对神经元尖峰活动相关性的神经元权重学习规则:神经元对连接越强,其尖峰活动相关性越强,减弱越弱。

Fig.1. Hebbian Plasticity: the connection between 2 neurons is strenghtened the more their spiking activity is correlated and weakened the less their spiking activity is correlated.
串行扰动是一种基于噪声的策略,旨在探索神经元参数状态空间:对神经元连接权值随机执行扰动,并根据假设使用的参考成本函数评估其效果。
任务特定成本函数
第二个假设是关于大脑中存在任务特定的架构和成本函数,根据特定的算法进行优化(即学习),其中一些算法在前一点中已经介绍过。
这种假设是基于“一刀切”的成本函数和架构无法提供足够好的性能水平,因此需要某种程度的专业化。
根据这种假设,理解如何定义任务特定的成本函数也是有趣的,从而执行一种“元学习”(即,决定哪个成本函数是最佳优化的,以便在特定任务中实现良好的性能)。
这些话题将在一个专门的文章系列中讨论。
计算专用结构
类似于前一点,一些“计算启发”的结构也被认为存在于大脑中,如:记忆和信息路由。
众所周知,记忆是大脑中发生的复杂现象,存在不同种类的记忆,如:内隐记忆(即,不可明确恢复的记忆)、内容可寻址记忆和短期记忆。
对于这些类型的现象,存在一些 DNN 模型,如通过脉冲网络实现的内容可寻址存储器的 Hopfield 网络。
信息路由机制允许高效和有效的信息处理:注意机制导致效率,使得处理系统聚焦于最相关的信息,而门控系统允许在处理系统的不同区域之间提供远程连接的效率(在没有完全连接的拓扑的情况下)。
这些话题也将在专门的文章系列中讨论。
Matplotlib 中的“艺术家”——这是我在花大量时间在谷歌上搜索如何做之前想知道的。

Cover Photo by Caleb Salomons on Unsplash
最初发表于 dev.to 并稍作修改以适应 Medium 的编辑系统。
matplotlib 确实是 Python 中一个非常棒的可视化工具。但是在 matplotlib 中调整细节确实是一件痛苦的事情。你可能很容易失去几个小时来找出如何改变你的一小部分情节。有时你甚至不知道零件的名称,这使得谷歌搜索变得更加困难。即使您发现了关于堆栈溢出的提示,您可能还需要花费几个小时来使它适合您的情况。通过了解 matplotlib 中的图形由什么组成以及可以用它们做什么,可以避免这些没有回报的任务。我想,和你们大多数人一样,我已经通过阅读 matplotlib 大师关于堆栈溢出的大量回答克服了我的绘图问题。最近,我注意到一个关于 [Artist](https://matplotlib.org/tutorials/index.html) 对象的官方教程非常有用,有助于理解我们使用 matplotlib 绘图时发生的事情,并减少调整所花费的大量时间。在这篇文章中,我想分享一些关于 matplotlib 中的Artist对象的基本知识,这将避免你花费数小时进行调整。
这个职位的目的
我不打算写像“当你想这样做时就这样做”这样的操作方法,而是 matplotlib 中Artist的一个基本概念,它可以帮助你选择合适的搜索查询,并为类似的问题安排一个解决方案。读完这篇文章后,你可能会更清楚地理解网上那些海量的食谱。这也适用于那些使用 seaborn 和熊猫绘图特性的人,这些特性是 matplotlib 的包装。
内容
这个帖子基本上是我用日语写的原文的英文版,大部分基于艺术家教程和使用指南(原文发表时为 2.1.1)
这是给谁的?
Matplotlib 用户
- 如果需要的话,他们能够制作情节,但通常很难使其适合出版或展示(并且对“最后一英里”是你真正想要的感到恼火)。
- 已经成功地找到了堆栈溢出的精确解决方案,但仍然不清楚它是如何工作的,也不能将其应用于其他问题。
- 找到了一个问题的多个提示,但不确定应该遵循哪一个。
环境
- Python 3.6
- matplotlib 2.2
%matplotlib inline
import matplotlib.pyplot as plt
import numpy as np
plt.show()在本文中省略,因为我用的是 Jupyter notebook 的内联情节。
你应该知道的两种绘图风格
在研究Artist对象之前,我想提一下plt.plot和ax.plot的区别,或者 Pyplot 和面向对象的 API。虽然官方推荐使用面向对象的 API 风格,但是仍然有很多例子和代码片段使用 Pyplot 风格,包括官方文档。有些人甚至毫无意义地混合了两种风格,这给初学者造成了不必要的困惑。由于官方文档对它们有很好的注释,如关于面向对象 API vs Pyplot 的注释和编码风格,这里我只对它们做一些评论。如果你要找他们的介绍,我推荐官方教程。
面向对象的 API 接口
这是推荐的风格,通常以fig, ax = plt.subplots()或其他类似的开头,后面是ax.plot、ax.imshow等。fig和ax其实就是Artist s,下面是一些最简单的例子。
# example 1
fig, ax = plt.subplots()
ax.plot(x,y) # example 2
fig = plt.figure()
ax = fig.add_subplot(1,1,1)
ax.plot(x, y)
有些教程使用fig = plt.gcf()和ax = plt.gca()。当你从 Pyplot 接口切换到 OO 接口时应该使用这些,但是一些基于 Pyplot 的代码包括,例如,无意义的ax = plt.gca(),它显然是在没有理解的情况下从基于 OO 的代码中复制的。如果有人有意切换界面,使用plt.gcf()或plt.gca()并不是一件坏事。考虑到隐式切换可能会给初学者带来困惑,如果plt.subplots或fig.add_subplot是公开可用的,那么从一开始就使用它们将是大多数情况下的最佳实践。
Pyplot 界面
这是一种 MATLAB 用户友好的风格,所有的事情都用plt.***来完成。
# [https://matplotlib.org/tutorials/introductory/pyplot.html](https://matplotlib.org/tutorials/introductory/pyplot.html)def f(t):
return np.exp(-t) * np.cos(2*np.pi*t)t1 = np.arange(0.0, 5.0, 0.1)
t2 = np.arange(0.0, 5.0, 0.02)
plt.figure(1)
plt.subplot(211)
plt.plot(t1, f(t1), 'bo', t2, f(t2), 'k')
plt.subplot(212)
plt.plot(t2, np.cos(2*np.pi*t2), 'r--')
plt.show()
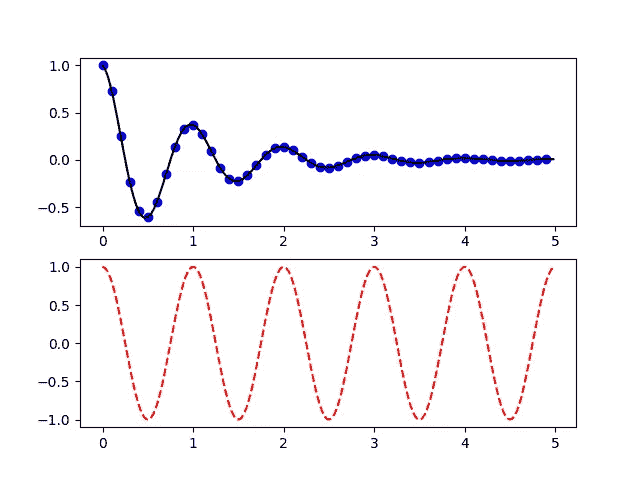
起初,它看起来非常简单,因为不需要考虑您正在处理哪些对象。你只需要知道你处于哪种“状态”,这也是为什么这种风格也被称为“有状态接口”。这里的“状态”指的是你当前所处的人物和支线剧情。正如你在 Pyplot 教程中看到的,如果你的情节不是那么复杂,它会给出一个不错的数字。虽然 Pyplot 界面提供了很多改变绘图设置的功能,但你可能会在几个小时、几天、几个月内达到它的极限(如果你足够幸运的话,可能永远也不会),这取决于你想做什么。这个阶段需要切换到 OO 界面。这也是我一开始就推荐使用 OO 接口的原因。但 Pyplot 对于快速检查或任何需要粗略绘图的场合仍然有用。
matplotlib 中的层次结构
谷歌几次后,你会注意到 matplotlib 有一个层次结构,由通常被称为fig和ax的东西组成。matplotlib 1.5 的旧文档有一个很好的图像来解释这一点。
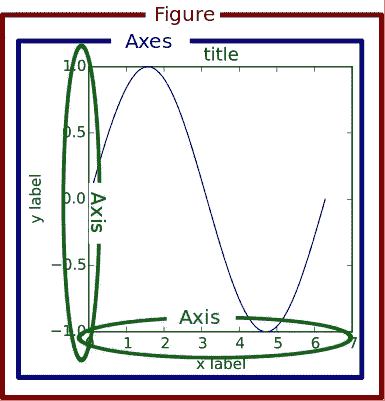
实际上,这三个组件是被称为“容器”的特殊Artist(还有第四个容器Tick,我们稍后会看到。这种层次结构使得上面的简单例子更加清晰。
# example 1
fig, ax = plt.subplots()
# make Figure and Axes which belongs to 'fig'# example 2
fig = plt.figure()
# make Figure
ax = fig.add_subplot(1,1,1)
# make Axes belonging to fig
进一步查看fig和ax的属性有助于您更好地理解层次结构。
fig = plt.figure()
ax = fig.add_subplot(1,1,1) # make a blank plotting area
print('fig.axes:', fig.axes)
print('ax.figure:', ax.figure)
print('ax.xaxis:', ax.xaxis)
print('ax.yaxis:', ax.yaxis)
print('ax.xaxis.axes:', ax.xaxis.axes)
print('ax.yaxis.axes:', ax.yaxis.axes)
print('ax.xaxis.figure:', ax.xaxis.figure)
print('ax.yaxis.figure:', ax.yaxis.figure)
print('fig.xaxis:', fig.xaxis)
输出:
fig.axes: [<matplotlib.axes._subplots.AxesSubplot object at 0x1167b0630>]
ax.figure: Figure(432x288)
ax.xaxis: XAxis(54.000000,36.000000)
ax.yaxis: YAxis(54.000000,36.000000)
ax.xaxis.axes: AxesSubplot(0.125,0.125;0.775x0.755)
ax.yaxis.axes: AxesSubplot(0.125,0.125;0.775x0.755)
ax.xaxis.figure: Figure(432x288)
ax.yaxis.figure: Figure(432x288)
---------------------------------------------------------------------------
AttributeError Traceback (most recent call last)
<ipython-input-21-b9f2d5d9fe09> in <module>()
9 print('ax.xaxis.figure:', ax.xaxis.figure)
10 print('ax.yaxis.figure:', ax.yaxis.figure)
---> 11 print('fig.xaxis:', fig.xaxis)
AttributeError: 'Figure' object has no attribute 'xaxis'
从这些结果中,我们可以预期关于Figure、Axes和Axis的层级的以下规则。
Figure知道Axes但不知道Axis。Axes知道Figure和Axis两者。Axis知道Axes和Figure两者。Figure可以包含多个Axes,因为fig.axes是Axes的列表。Axes可以只属于单个Figure因为ax.figure不是列表。- 出于类似的原因,
Axes可以分别有一个XAxis和YAxis。 XAxis和YAxis可以属于单个Axes,相应地也可以属于单个Figure。
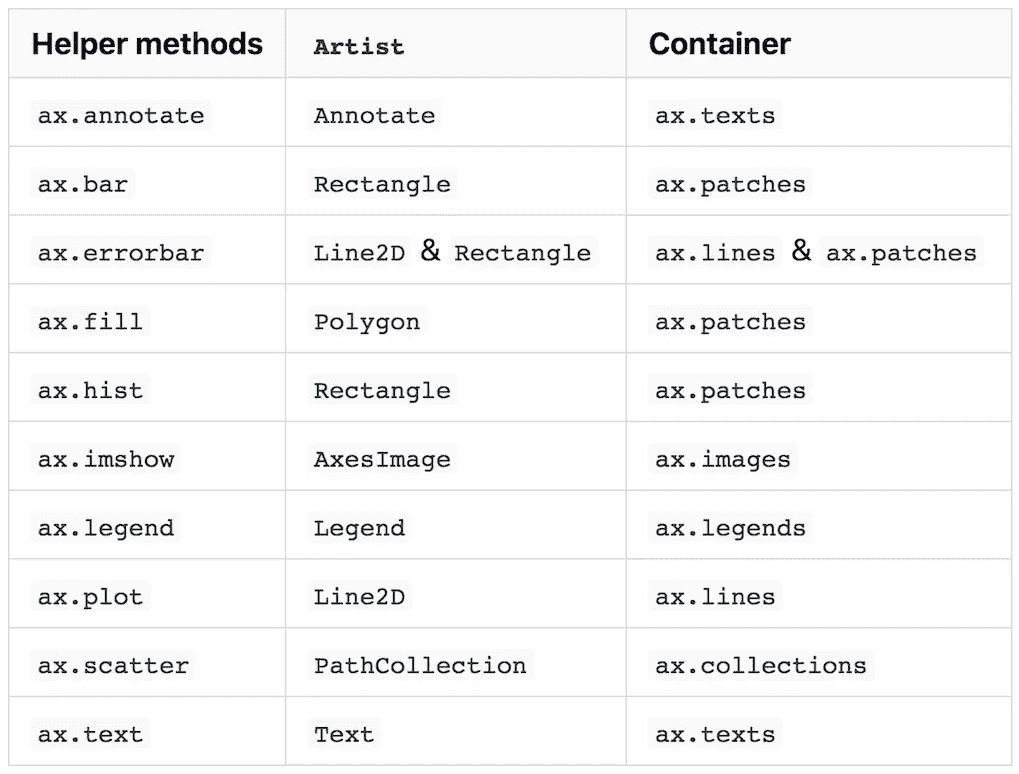
你情节中的一切都是一个Artist
当前文档中的使用指南没有使用图来解释层次结构,而是使用“图的剖析”来解释图中的所有组件,这也是一种信息。

从代表数据的线和点,到 x 轴上的小记号和文本标签,图形中的每一个组件都是一个Artist object⁴.Artist有两种类型,容器和原语。正如我在上一节中所写的,matplotlib 的层次结构中的三个组件,Figure、Axes和Axis是容器,它们可以包含更低的容器和多个原语,例如由ax.plot生成的Line2D、ax.scatter生成的PathCollection或由ax.annotate生成的Text。甚至刻度线和标签实际上都是属于第四个容器Tick的Line2D和Text。
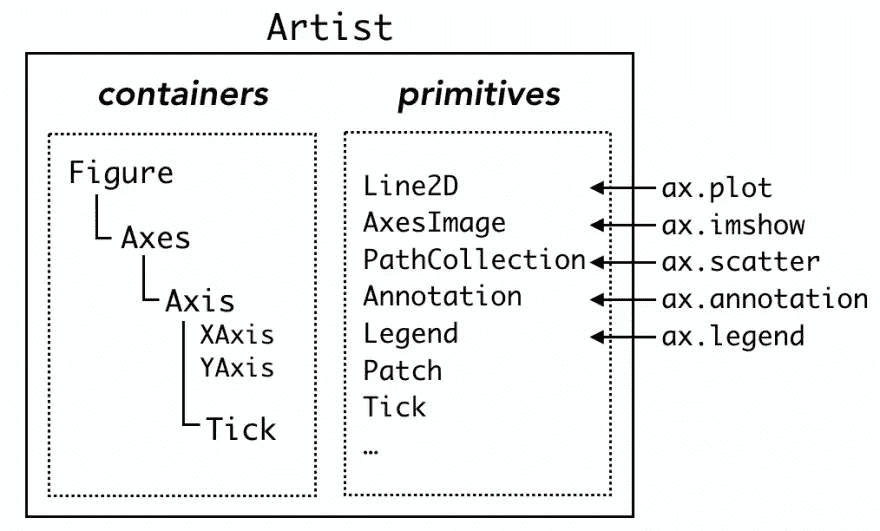
对于每种类型的原语,容器都有许多“盒子”(Python 列表,技术上来说)。例如,一个Axes对象ax,在实例化之后有一个空列表ax.lines。常用命令ax.plot在列表中添加一个Line2D对象,并静默进行其他伴随设置。
x = np.linspace(0, 2*np.pi, 100)
fig = plt.figure()
ax = fig.add_subplot(1,1,1)
print('ax.lines before plot:\n', ax.lines) # empty list# add Line2D in ax.lines
line1, = ax.plot(x, np.sin(x), label='1st plot')
print('ax.lines after 1st plot:\n', ax.lines)# add another Line2D
line2, = ax.plot(x, np.sin(x+np.pi/8), label='2nd plot')
print('ax.lines after 2nd plot:\n', ax.lines)ax.legend()
print('line1:', line1)
print('line2:', line2)
输出:
ax.lines before plot:
[]
ax.lines after 1st plot:
[<matplotlib.lines.Line2D object at 0x1171ca748>]
ax.lines after 2nd plot:
[<matplotlib.lines.Line2D object at 0x1171ca748>, <matplotlib.lines.Line2D object at 0x117430550>]
line1: Line2D(1st plot)
line2: Line2D(2nd plot)

w
以下部分总结了四种容器。表格复制自艺人教程。
Figure

具有复数名称的属性是列表,具有单数名称的属性表示单个对象。值得注意的是,属于Figure的Artist默认使用Figure坐标。这可以用 [Transforms](https://matplotlib.org/users/transforms_tutorial.html)转换成Axes或者数据坐标,不在本帖讨论范围内。
fig.legend和ax.legend
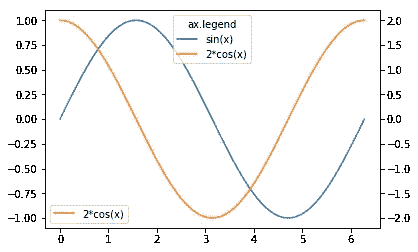
fig.legends是通过[fig.lenged](https://matplotlib.org/api/_as_gen/matplotlib.figure.Figure.html#matplotlib.figure.Figure.legend) 方法添加的图例的“框”。你可能会想“那是干什么的?我们有ax.legend。”不同之处在于每种方法的范围。ax.legend只收集属于ax的Artist的标签,fig.legend收集fig下所有Axes的标签。这很有用,例如,当你使用ax.twinx绘图时。简单的用两次ax.legend就做了两个图例,一般不可取。
x = np.linspace(0, 2*np.pi, 100)
fig = plt.figure()
ax = fig.add_subplot(111)
ax.plot(x, np.sin(x), label='sin(x)')
ax1 = ax.twinx()
ax1.plot(x, 2*np.cos(x), c='C1', label='2*cos(x)')
# cf. 'CN' notation
# https://matplotlib.org/tutorials/colors/colors.html#cn-color-selection
ax.legend()
ax1.legend()
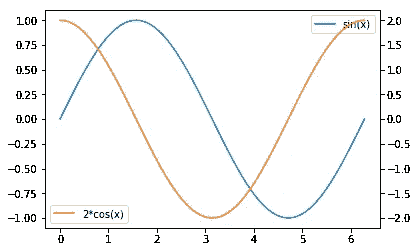
将它们放在一起的一个著名方法是将两者的图例处理程序和标签结合起来。
# Executing this part in a different notebook cell shows an updated figure.
handler, label = ax.get_legend_handles_labels()
handler1, label1 = ax1.get_legend_handles_labels()
ax.legend(handler+handler1, label+label1, loc='upper center', title='ax.legend')
# Legend made by ax1.legend remains
fig
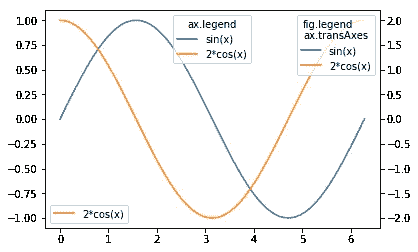
这可以通过fig.legend轻松完成,而无需在版本 2.1 ⁵.中引入的参数默认情况下,位置由Figure坐标指定,当您想将其放在绘图框中时,该坐标没有用。你可以用bbox_transform关键字把它改成Axes坐标。
fig.legend(loc='upper right', bbox_to_anchor=(1,1), bbox_transform=ax.transAxes, title='fig.legend\nax.transAxes')
fig
Axes
matplotlib . axes . axes 是 matplotlib 宇宙的中心
这是引用自艺人教程的话。这是非常正确的,因为 matplotlib 中数据可视化的重要部分都来自于Axes方法。

经常使用的命令如ax.plot和ax.scatter被称为“助手方法”,它们在适当的容器中添加相应的Artist,并做其他杂七杂八的工作。
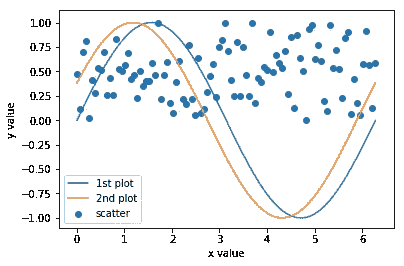
这个例子显示了ax.plot和ax.scatter在相应的列表中添加Line2D和PathCollection对象。
x = np.linspace(0, 2*np.pi, 100)
fig = plt.figure()
ax = fig.add_subplot(1,1,1)
# empty Axes.lines
print('ax.lines before plot:\n', ax.lines) # add Line2D in Axes.lines
line1, = ax.plot(x, np.sin(x), label='1st plot')
print('ax.lines after 1st plot:\n', ax.lines)# add another Line2D
line2, = ax.plot(x, np.sin(x+np.pi/8), label='2nd plot')
print('ax.lines after 2nd plot:\n', ax.lines)
print('ax.collections before scatter:\n', ax.collections)
scat = ax.scatter(x, np.random.rand(len(x)), label='scatter') # add PathCollection in Axes.collections
print('ax.collections after scatter:\n', ax.collections)
ax.legend()
print('line1:', line1)
print('line2:', line2)
print('scat:', scat)
ax.set_xlabel('x value')
ax.set_ylabel('y value')
输出:
ax.lines before plot:
[]
ax.lines after 1st plot:
[<matplotlib.lines.Line2D object at 0x1181d16d8>]
ax.lines after 2nd plot:
[<matplotlib.lines.Line2D object at 0x1181d16d8>, <matplotlib.lines.Line2D object at 0x1181d1e10>]
ax.collections before scatter:
[]
ax.collections after scatter:
[<matplotlib.collections.PathCollection object at 0x1181d74a8>]
line1: Line2D(1st plot)
line2: Line2D(2nd plot)
scat: <matplotlib.collections.PathCollection object at 0x1181d74a8>
不建议重复使用打印对象
在知道列表中包含绘制的对象后,您可能会想到通过将这些对象附加到另一个Axes.lines列表中来重用这些对象,以加快绘制速度。艺术家教程明确指出不推荐这样做,因为助手方法除了创建Artist还能做很多事情。一个快速测试告诉我们这不是一个好主意。
x = np.linspace(0, 2*np.pi, 100)
fig = plt.figure()
# upper subplot
ax1 = fig.add_subplot(2,1,1)
# create a Line2D object
line, = ax1.plot(x, np.sin(x), label='ax1 line')
ax1.legend()
# lower subplot
ax2 = fig.add_subplot(2,1,2)
# try to reuse same `Line2D` object in another `Axes`
ax2.lines.append(line)

甚至add_line方法也不管用。
ax2.add_line(line)
输出:
ValueError: Can not reset the axes. You are probably trying to re-use an artist in more than one Axes which is not supported
这个错误消息表明一个Artist,容器或者原语,不能包含在多个容器中,这与每个Artist将父容器作为一个空对象而不是在一个列表中的事实是一致的
print('fig:', id(fig))
print('ax1:', id(ax1))
print('line.fig:', id(line.figure))
print('line.axes:', id(line.axes))
输出:
fig: 4707121584
ax1: 4707121136
line.fig: 4707121584
line.axes: 4707121136
如果你以适当的方式做了所有必要的事情,这也许是可能的,但是这远不是仅仅把一个对象附加到一个列表中的第一想法,并且是不这样做的足够的理由。
Axis
虽然Axis以XAxis或YAxis出现,只包含与记号和标签相关的Artist,但它经常需要一些谷歌搜索进行细微调整,偶尔需要一个小时。我希望这一部分能帮助你快速完成工作。
由于美工教程不像其他容器一样有表,所以我做了一个类似的表。

我们在示例中使用ax.set_xlabel和ax.set_ylabel来表示Axes容器。你可能认为这些方法改变了Axes实例(ax)的 X 和 Y 标签,但实际上它们分别改变了XAxis和YAxis、ax.xaxis.label和ax.yaxis.label的label属性。
xax = ax.xaxis
print('xax.label:', xax.label)# seven major ticks (from 0 to 6) and
# two invisible ticks locating outside of the figure
print('xax.majorTicks:\n', xax.majorTicks) # two ticks outside the figure
print('xax.minorTicks:\n', xax.minorTicks)
输出:
xax.label: Text(0.5,17.2,'x value')
xax.majorTicks:
[<matplotlib.axis.XTick object at 0x117ae4400>, <matplotlib.axis.XTick object at 0x117941128>, <matplotlib.axis.XTick object at 0x11732c940>, <matplotlib.axis.XTick object at 0x1177d0470>, <matplotlib.axis.XTick object at 0x1177d0390>, <matplotlib.axis.XTick object at 0x1175058d0>, <matplotlib.axis.XTick object at 0x1175050b8>, <matplotlib.axis.XTick object at 0x117bf65c0>, <matplotlib.axis.XTick object at 0x117bf6b00>]
xax.minorTicks:
[<matplotlib.axis.XTick object at 0x117ab5940>, <matplotlib.axis.XTick object at 0x117b540f0>]
ax.set_***方法是临时的
Axes有许多“set_”辅助方法来修改Axis和Tick实例的属性和值。它们非常方便,matplotlib 初学者遇到的大部分问题都可以用它们来解决。值得注意的是,这些“set_”方法是静态的。当某些内容发生变化时,对它们所做的更改不会更新。例如,如果您使用ax.set_xticks更改 X 刻度以使它们在第一个图中看起来更好,而第二个图超出了第一个图的 X 范围,结果看起来不像它应该的样子。
x = np.linspace(0, 2*np.pi, 100)
fig = plt.figure()
ax = fig.add_subplot(1,1,1)# X range: 0 to 2pi
line1, = ax.plot(x, np.sin(x), label='')
ax.set_xticks([0, 0.5*np.pi, np.pi, 1.5*np.pi, 2*np.pi])# X range: 0 to 3p
iline2, = ax.plot(1.5*x, np.sin(x), label='')

Ticker那你呢
如果不使用“set_***”方法更改与记号相关的设置,则记号和记号标签会相应地为每个新绘图自动更新。这是由Ticker完成的,更具体地说,是由格式化程序和定位器完成的。尽管它们对于与 tick 相关的设置非常重要,但是如果您已经通过复制和粘贴堆栈溢出 answers⁶.解决了问题,那么您可能对它们知之甚少让我们看看前面的例子中发生了什么。
xax = ax.xaxis
yax = ax.yaxis
print('xax.get_major_formatter()', xax.get_major_formatter())
print('yax.get_major_formatter()', yax.get_major_formatter())
print('xax.get_major_locator():', xax.get_major_locator())
print('yax.get_major_locator():', yax.get_major_locator())
输出:
xax.get_major_formatter() <matplotlib.ticker.ScalarFormatter object at 0x118af4d68>
yax.get_major_formatter() <matplotlib.ticker.ScalarFormatter object at 0x118862be0>
xax.get_major_locator(): <matplotlib.ticker.FixedLocator object at 0x1188d5908>
yax.get_major_locator(): <matplotlib.ticker.AutoLocator object at 0x118aed1d0>
ScalarFormatter是为 X 轴和 Y 轴设置的,因为它是默认的格式化程序,我们没有改变它。另一方面,当默认AutoLocator被设置为 Y 轴时,FixedLocator被设置为 X 轴,我们使用ax.set_xticks方法改变了刻度位置。从它的名字可以想象,FixedLocator固定刻度位置,即使绘图范围改变也不更新。
让我们把前面例子中的Ticker换成ax.set_xticks。
# this is required to used `Ticker`
import matplotlib.ticker as ticker # locate ticks at every 0.5*piax.xaxis.set_major_locator(ticker.MultipleLocator(0.5*np.pi))# display the figure again with new locator.
fig

格式化程序怎么样?
# FuncFormatter can be used as a decorator
@ticker.FuncFormatter
def major_formatter_radian(x, pos):
# probably not the best way to show radian tick labels
return '{}$\pi$'.format(x/np.pi)
ax.xaxis.set_major_formatter(major_formatter_radian)
fig

好吧,也许你还想做些调整,但我想这已经足够清楚了。
可以在 matplotlib 图库了解更多。
图库>记号格式化器
图库>记号定位器
xunits关键字为ax.plot
供您参考,ax.plot有xunits关键词,是文档中暂时没有描述的。我从未尝试过使用这个选项,但是你可以在图库>弧度刻度中看到一个例子,并在这里了解更多关于matplotlib.units.ConversionInterface的信息。
import numpy as np
from basic_units import radians, degrees, cos
from matplotlib.pyplot import figure, show
x = [val*radians for val in np.arange(0, 15, 0.01)]
fig = figure()
fig.subplots_adjust(hspace=0.3)
ax = fig.add_subplot(211)
line1, = ax.plot(x, cos(x), xunits=radians)
ax = fig.add_subplot(212)
line2, = ax.plot(x, cos(x), xunits=degrees)

Tick
最后,我们到达了 matplotlib 层次结构的底部。Tick是一个小容器,主要存放刻度本身的短线和刻度标签的文本。
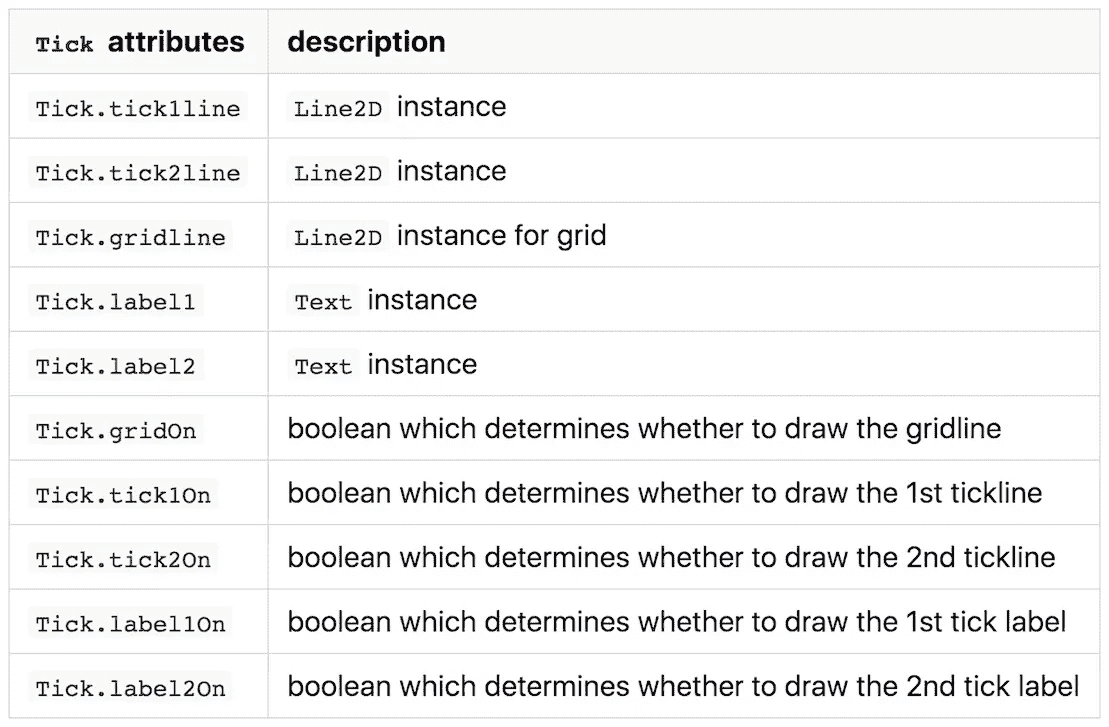
正如我们在Axis中看到的,Tick也作为XTick或YTick出现。第一个和第二个表示XTick上下两侧的刻度,而第二个表示YTick左右两侧的刻度。默认情况下,后面的记号不可见。
# tick at 0.5 pi in the previous figure
xmajortick = ax.xaxis.get_major_ticks()[2]
print('xmajortick', xmajortick)
print('xmajortick.tick1line', xmajortick.tick1line)
print('xmajortick.tick2line', xmajortick.tick2line)
print('xmajortick.gridline', xmajortick.gridline)
print('xmajortick.label1', xmajortick.label1)
print('xmajortick.label2', xmajortick.label2)
print('xmajortick.gridOn', xmajortick.gridOn)
print('xmajortick.tick1On', xmajortick.tick1On)
print('xmajortick.tick2On', xmajortick.tick2On)
print('xmajortick.label1On', xmajortick.label1On)
print('xmajortick.label2On', xmajortick.label2On)
输出:
xmajortick <matplotlib.axis.XTick object at 0x11eec0710>
xmajortick.tick1line Line2D((1.5708,0))
xmajortick.tick2line Line2D()
xmajortick.gridline Line2D((0,0),(0,1))
xmajortick.label1 Text(1.5708,0,'0.5$\\pi$')
xmajortick.label2 Text(0,1,'0.5$\\pi$')
xmajortick.gridOn False
xmajortick.tick1On True
xmajortick.tick2On False
xmajortick.label1On True
xmajortick.label2On False
由于有许多助手方法、Ticker和[Axes.tick_params](https://matplotlib.org/api/_as_gen/matplotlib.axes.Axes.tick_params.html),我们几乎不需要直接处理Tick。
是时候定制你的默认风格了
看一下默认样式的参数列表。
教程>定制 matplotlib >一个示例 matplotlibrc 文件
我想现在你不仅能弄清楚一个参数是干什么的,还能弄清楚一个参数实际上对哪个Artist有影响,这让你为 googling⁷.节省时间您还可以自定义默认样式,而不需要生成 matplotlibrc 文件,只需在代码的开头键入如下内容。
plt.rcParams['lines.linewidth'] = 2
(再次)去看医生
你们中的一些人可能对 matplotlib 的文档有负面的印象。我同意很难从一长串列表中找到适合你的问题的例子。但是自从 2.1⁸.版本以来,它已经有了很大改进如果您比较改进前后的相应页面,这一点很明显。
感谢阅读。享受用 matplotlib 绘图(和谷歌搜索) 📈🤗📊
脚注:
- 是的,如果你没有懒到在使用之前阅读教程的话,教程总是有帮助的。事实上,当我几年前开始用 matplotlib 绘图时,我可能曾经试图阅读过一次关于 Artist 的文档,但我很确定当时我认为“好吧,这不适合我”。(可能不是现在的教程。)
- 下面是这个图的示例代码https://matplotlib.org/gallery/showcase/anatomy.html
- 当然还有其他的
Artist这一页对于那些想要大图的人来说是一个很好的入口。您可以点击Artist名称获得进一步解释。 - 从技术上来说,
Artist让我们在 matplotlib 的画布上绘制你漂亮的数据。多么可爱的说辞。 fig.legend没有当前版本有用,因为根据版本的文档,它需要图例手柄和标签。2.0.2- 当你从“set_***”方法进一步谷歌 tick 相关设置,并放弃为你自己的问题安排它们时,你会经常遇到使用它们的食谱。(没错,就是几个月前的我。)
- 或者你可以像我一样,利用节省下来的时间深入挖掘。
- 这里是一个很好的阅读,以了解如何困难,以改善文件。 Matplotlib 引导 Dev 解释为什么他不能修复 Docs | NumFOCUS
原载于 dev.to 。
作为 2019 年的管理者,你将真正需要了解 AI 的哪些方面?

Photo Credits — Tech Crunch
试图预测未来就像试图在没有灯的夜晚开车行驶在乡间小路上,同时从后窗往外看一样——彼得·德鲁克
彼得·德鲁克的漫长职业生涯早于人工智能。在他的一生中,领导力都与人有关,而数据科学则局限于编码机器。他关于管理的开创性论文本质上是关于应用过去的经验来开发当前的市场机会。人工智能可能改变了一切:模糊了人类和机械流程之间的界限,并将管理重点从研究最佳实践转移到影响消费者行为。作为 2019 年的管理者,你真正需要了解的人工智能知识有哪些?
人工智能的商业价值与其降低组织变化成本和/或市场预测成本的潜力相关。今天,“狭义”人工智能应用程序可以比经理更快、更准确地执行计划、组织和预算任务。明天,“广泛的”人工智能应用将提供多任务、多领域的服务,这些服务将动摇公司和市场的基础。在可预见的未来,“通用”人工智能将整合感知和推理的认知能力,这可能会有效地改变我们思考工作的方式。
试图忽视这些简单事实的经理们正有效地行驶在黑暗的道路上,他们的眼睛紧紧盯着过去。普华永道预测,人工智能的实施将消除目前 20%至 40%的就业机会。【1】通过将强化学习、机器人、计算机视觉和自然语言处理交给独立承包商和跨国公司,人工智能应用已经在平整管理领域。无论你是否敢于展望未来,管理都不会是一成不变的。
一个事实仍然可以掩盖另一个事实。客户和股东不是根据事实思考、决定或行动,而是根据对数据的感知。建立愿景、建设社区和激励员工的基本管理活动是人类固有的活动。未来的竞争优势不会来自人工智能的数据或算法,而是来自经理们获得和培养他们商业社区的信任。
管理人员需要发展哪些技能才能利用人工智能?管理人员将不会编写代码,而是定义和评估人工智能在其业务中的方向和采用率。他们需要思考可能会发生什么,并问自己如何用实验来检验这是不是真的。管理人才将越来越多地被定义为与判断相关的技能:指导、激励和采取道德立场。管理层将专注于开发运营流程,以优化专注于判断的员工团队和专注于预测的人工智能代理。
当我们抓住机会在数据科学平台上投入时间和金钱时,我们很可能错过了更大的图景。数据只不过是一组等待管理者提出正确问题的答案。算法可以发现数据中的模式,但无法解释它们的意义。归纳、演绎和绑架仍将是管理决策的核心。如果机器学习旨在寻找数据集中的相似性,有才华的经理将继续关注运营流程中例外(异常值)的重要性。
最后,管理者和数据科学家都不是在真空中运作,而是与他们的同事和客户协同工作。为了让人工智能产生巨大影响,管理者必须创建人工智能数据就绪生态系统。招募具有分析思维的合作者是必须的——正如野田友男教授最近建议的那样,“只有好人才能创造出好的人工智能”【2】一个经理的面包和黄油将来自于创造一个工作环境,在这个环境中,他的同事、商业伙伴和员工使用数据来应对他们的商业挑战。由于最有价值的数据往往在自己组织的边界之外,鼓励负责任地使用客户数据将是他们的首要任务。在可预见的未来,和过去一样,管理人员的表现将不会根据他或她在电脑前做了什么来评估,而是根据他们在同事和客户面前能做出什么来评估。
在我们关于“人工智能管理”的免费网络研讨会上,我们将探讨这些论点,并提供每个论点的真实例子商业分析实践是商业分析学院的核心和灵魂。在我们在巴约纳和波士顿的暑期学校,以及我们在欧洲各地的硕士班中,商业分析研究所专注于数字经济学、管理决策、机器学习和数据故事,将使分析为您和您的组织工作。
Lee Schlenker 是商业分析和社区管理教授,也是 http://baieurope.com 商业分析学院的负责人。他的 LinkedIn 个人资料可以在 www.linkedin.com/in/leeschlenker 的查看。你可以在 https://twitter.com/DSign4Analytics的推特上关注我们
【1】普华永道,(2018),人工智能和相关技术对工作岗位的净影响会是什么 …
【2】IESE,人工智能改变管理的 10 种方式
当我开始学习数据科学时
分享我在开始学习数据分析和机器学习时参加的课程的经验。
- Coursera 的吴恩达 ML 课程 —当我搜索可用的 ML 课程时,我发现这个课程是最受推荐和报名的。课程大纲相当广泛,涵盖了大多数的 ML 技术。我发现这门课有点太详细了,讲座幻灯片比动手操作还多。这导致我退学,重新注册,多次退学。所以我把它放在一边,一旦我对事情有了一个可行的理解,我就会重新审视它。
- 数据分析简介 Udacity — 这是 Udacity 提供的免费课程,也是他们纳米学位项目的一部分。本课程包括使用 Numpy 和 Pandas 进行数据分析。课程内容涵盖了 Numpy 和 Pandas 入门所需的主题。然而,它没有太多的实践例子,也可以感觉到课程运行非常快。
- 机器学习 Udacity 简介——本课程由 Udacity 的巴斯蒂安·特龙教授。这也是 Udacity 纳米学位项目的一部分。这包括算法,如朴素贝叶斯,SVM,决策树,回归。好的一面是,在进入任何算法的详细工作之前,它给出了一个简单易懂的例子,说明算法到底解决了什么问题。我发现这非常有用,而不是深入理论。然而,它又缺乏足够的练习集。我也觉得课程应该更深入算法,而不是简单地让你学习如何调用某些 sklearn 方法。
4.创建一个精选的课程列表—medium 中有一本好书https://medium . com/@ David venturi/I-dropped-out-of-school-to-create-my-own-data-science-master-s-here-s-my-course-1b 400 DCE 412。我试着跟着课程走。这个列表有非常好的课程,包括数据分析部分和 ML 部分。
- DataQuest —我在 DataQuest(dataquest.io)数据科学赛道注册,从 Numpy 和熊猫开始。这种通过编码学习的风格让我着迷,它还提供了一个路线图,而不是在不同的课程之间切换。它提供一些免费课程,然后要求基本/高级订阅。首先,我订阅了每月 29 美元的基本服务。大量的实践和细节是我喜欢的东西,最后我为 ML 订阅了高级订阅(49 美元/月)。订阅还附带项目,提供良好的实践经验。还有一个 slack 社区可以讨论这些话题。
除了上述任何课程,使用 kaggle 数据集真的帮助我理解了如何处理更大的数据。
我学的课程除了吴恩达的 ML 都是用 Python 作为语言的。因为我熟悉这门语言,所以我选择了 Python,这样可以节省我学习语言结构的时间。
希望我的两分钱能帮助别人。
问我任何事——与卡格勒大师弗拉基米尔·伊格洛维科夫的对话

你好,我叫弗拉基米尔。
从大学毕业并获得理论物理学位后,我搬到了硅谷,在行业中寻找数据科学的角色。这让我在 Lyft 的自动驾驶汽车部门找到了目前的职位,从事计算机视觉相关应用的工作。
在过去的几年里,我在机器学习竞赛上投入了大量的时间。一方面,这很有趣,但另一方面,这也是提高数据科学技能的非常有效的方式。我不会说所有的比赛都很容易,我也不会说我在所有的比赛中都取得了好成绩。但时不时我还是能接近巅峰,最终有了 Kaggle 特级大师的称号。
感谢 @Lasteg 提出了这个 AMA(向我提问环节)的想法,并在 Reddit 、 Kaggle 和 science.d3.ru(俄语)上收集问题。有很多问题。我会尽我所能回答这个问题,但是我不可能在这篇博文中回答所有的问题。如果有你问的问题,但在下面的文字中没有提到,就写在评论中,我会尽力回答。
以下是我(或我的团队)有幸在排行榜上名列前茅的深度学习挑战列表。:
- 第十名:超声波神经分割
- 第三名: Dstl 卫星影像特征检测
- 第二名:安全通道:对航拍图像中的车辆进行检测和分类
- 第 7 名: Kaggle:星球:从太空了解亚马逊
- 第 1 名: MICCAI 2017:胃肠图像分析(GIANA)
- 第一名: MICCAI 2017:机器人器械分割
- 第一名:卡格尔:卡瓦纳图像掩蔽挑战
- 第 9 名: Kaggle: IEEE 的信号处理学会——相机型号识别
- 第二名:CVPR 2018 深度地球。道路提取。
- 第二名:CVPR 2018 深度地球。建筑检测。
- 第三名:CVPR 2018 深度地球。土地覆盖分类。
- 第 3 名:MICCAI 2018:胃肠图像分析(GIANA)
问:你有数据之外的生活吗?
是的,我愿意:)
我喜欢背包旅行和攀岩。如果你早上在使命悬崖攀岩馆攀岩,下次见到我的时候,你可以打个招呼。
我也喜欢伙伴舞蹈,尤其是蓝调融合。旧金山的使命融合和南湾融合舞蹈场馆是我通常去的地方。
旅行对我来说也很重要。今年春天,我去了白俄罗斯、摩洛哥和约旦。九月,我在芬兰、德国和奥地利呆了三周。当然,燃烧的人 2018 是今年最好的体验:)
问:身高/体重?
6 英尺,185 磅
我想这个问题可能与锻炼有关,所以让我在《力量举重》中展示一些我在研究生院时的结果:)
- 最大钳工 225 lb ( 102 kg)
- 最大下蹲 315 lb ( 142 kg)
- 最大硬拉 405 lb ( 183 kg)
问:怎样才能既有事业又全职做 kaggle?

为 Kaggle 比赛工作是第二份无薪全职工作。你应该有一个很好的理由这样做。对于积极的 Kaggle 参与者来说,寻求改变领域是很常见的。我也不例外。当我从学术界过渡到工业界时,我开始从事竞赛工作。我需要一种有效的方式来适应 ML 可能解决的问题,掌握工具,并将我的思维方式扩展到机器学习的新世界。
后来,我在biggely找到第一份工作后,我更加沉迷于 Kaggle。白天我从事信号处理工作,几乎所有晚上都在与表格数据的竞赛中度过。我的工作与生活的平衡不是很好,但我在单位时间内获得的知识量是值得的。
在某个时候,我准备好了,换了工作,加入了 TrueAccord,在那里我做了很多传统的 ML 工作。但是停止我的工作是不明智的。所以白天是传统的机器学习,晚上和周末是深度学习。工作与生活的平衡甚至更糟,但我学到了很多东西,并且作为获得的技能的一个很好的补充,成为了 Kaggle Master 。当我能够在 Lyft 获得一份 Level5 的工作时,所有这些努力都得到了回报,这是一份将深度学习技术应用于自动驾驶问题的工作。
最后,我没有全职在 Kaggle 上工作。但我还是在积极学习。工作中有很多令人兴奋的计算机视觉问题,我正试图在 Kaggle 没有涉及的领域获得更多的知识。我仍然不时地向各种比赛提交材料,但这主要是为了更好地了解参与者面临的问题和挑战,这反过来有助于从论坛上分享的信息中获得最多的信息。
问:帮助你提高效率的日常惯例是什么?你如何安排你的一天?
首先,我不确定我是否很有效率。:)我一直在寻找新的方法来优化我的日常工作。
总是有更多的问题需要解决,有更多的活动需要去做。并不是所有的都同样有用和令人愉快。这意味着我总是需要为每一个行动设定优先级。有几本书对这个话题进行了精彩的讨论。我推荐每个想变得更有效率的人去阅读它们:
好到他们无法忽视你:为什么在寻找你热爱的工作时,技能胜过激情深度工作:在纷乱的世界中专注成功的法则。
在工作日,我早上 6 点起床,去攀岩馆。这有助于我保持身材,让我在接下来的一天里保持清醒。在这之后,我开车去上班。我们的自动驾驶工程中心位于帕洛阿尔托,这让我有点难过。我更喜欢住在城市。开车很有趣,但通勤就不是了。为了更有效率地度过通勤时间,我在车里听有声读物。我不会说我可以在通勤时非常专注于这本书,但有大量的文学作品,大多是软技能或商业导向的,这对开车很好。
我想说我有一个很好的工作生活平衡,但这不是真的。当然,相当多的时间是和朋友一起度过的,而且是在不同的场合。幸运的是,旧金山一直在发生一些事情。同时,我还需要学习;关于机器学习,我仍然需要保持身材。不仅仅是我在办公室的问题,而是更广泛的问题。这意味着晚上要花一些时间阅读技术文献,为竞赛、兼职项目或开源项目编写代码。
说到开源项目,我将借此机会推广一个图像增强库,它是由 Alexander Buslaev 、 Alex Parinov 、 Eugene Khvedchenia 和 I 基于我们在计算机视觉挑战工作中获得的见解而创建的。
如果不提供具体的技巧,我想我无法完成这个问题:)
- 比起 MacBook 我更喜欢 Ubuntu + i3 ,主观上对我的性能+ 10%。
- 我很少使用 Jupyter 笔记本。仅用于 EDA 和可视化。我写的几乎所有代码都是用 PyCharm 写的,用 flake8 检查,然后提交给 GitHub。很多 ML 的问题都很相似。投资于更好的代码库,尽量不重复自己,思考如何最好地重构可能会在开始时减慢进度,但在后来会加快速度。
- 我尽可能地编写单元测试。每个人都在谈论单元测试在数据科学中的重要性,但是并不是每个人都花时间去写它们。Alex Parinov 写了一篇很好的文档,指导你如何从简单到复杂。你可以试着跟随它,给你的学术界或 Kaggle ML 管道增加更多的测试。我想你已经在工作中这样做了。
- 目前,我正在试验模型版本控制工具 DVC ,我希望它能让我的 ML 管道生成的结果更具可复制性,代码更具可重用性。
- 我尽量少用鼠标。有时候这意味着我需要把热键写在纸上,放在我面前,尽可能多地使用它们。
- 我不使用社交网络。
- 我一天只检查几次电子邮件。
- 每天早上我都会列出今天要完成的任务,并努力完成这些任务。我用特雷罗来做这个。
- 我试着不把我的一天分割得太多。许多任务需要集中注意力,一直转换焦点是没有帮助的。
所有这些想法都很标准,但我想不起口袋里有什么魔术。😃
问:你如何跟上该领域的最新研究?
我不会说我知道。如今的 ML 领域是如此的活跃,论文、竞赛、博客文章和书籍的数量是如此的巨大,以至于浏览它们都是不可能的。在实践中,当我面临一些问题时,我会专注于浏览最近的结果,并深入挖掘。做完这个问题后,我会切换到下一个问题。因此,我只对自己没有实践经验的领域有高水平的了解,而且我对此没有意见。与此同时,我所处理过的问题清单,也就是我所精通的问题清单,相对来说是很大的,而且这个清单还在继续增长。这个事实让我确信,我已经编写并保存在私有存储库中的经验和代码的组合将帮助我快速开始任何新的 ML 相关任务。
此外,这意味着对于许多问题,我已经实现了非常强大的管道,这给了我一个温暖的开始,当我下次面临类似的问题时。
我也参加像 NIPS,CVPR 和其他会议。那里展示的结果很好地代表了在目前的研究阶段我们能做什么和不能做什么。
问:回到过去(比如 4-5 年前),在非 ML 特定领域(物理、力学等)拥有博士学位。)对雇主非常有利。目前,我觉得情况发生了变化,如果比较非 ML 领域的博士和 ML 领域的硕士,IT/ML 行业似乎更喜欢 ML 工程/开发人员的角色,但我不确定研究角色。既然你也是物理学博士,然后转到 ML,我想以你现在的经历你可能知道问题的答案。
如果一个人想在获得非 ML 博士学位后转入 ML 行业,你对此有什么看法?在公司获得研究职位会有帮助吗?与相关的理学硕士相比,在传销行业找工作有帮助吗?
这是一个很难回答的问题,我不知道答案,所以我只能自言自语。
物理是一个很棒的专业。即使我可以回到过去,在物理和计算机科学之间做出选择,即使我知道最终我会转到计算机科学,我还是会选择物理。
当然,主要原因是我对物理学和一般的自然科学感到兴奋。ML 教你我们周围这个巨大的、丰富多彩的、令人兴奋的宇宙是如何工作的吗?不完全是。但是物理有。而且不仅仅是这个。从物理学转到 ML 相对顺利的原因之一是,作为一个专业,物理学不仅给了我量子力学、相对论、量子场论和其他高度专业化主题的知识,还给了我数学、统计、编码方面的关键技能,所有这些都可以很容易地转移到其他领域。
物理学教你如何以结构化的方式在严格的理论和实验之间周旋;任何 ML 从业者的必备技能。而且不上大学,靠自学,学物理或高等数学几乎是不可能的。在这方面,我坚信,当我们找到如何将为物理、化学和其他高级领域开发的高级数学应用于机器学习时,深度学习的下一个重大突破将会发生。现在,在大学一年级的水平上了解数学就足以解决计算机视觉中的问题。
所有这一切意味着,目前数学不是一个阻碍因素,这就是为什么一个人在数学/物理/化学和其他 STEM 部门获得的额外知识对于解决大多数商业问题几乎毫无用处,这就是为什么这些部门的许多毕业生感到被背叛了。他们有很多专业知识;他们有博士学位,他们在学术界呆了很多年。他们不能得到一份有趣的高薪工作。互联网上充斥着这种类型的博客帖子。
另一方面,能够编写代码在任何地方都是必不可少的,这就是为什么当潜在雇主在一个精通数学的人和一个擅长编写代码的人之间进行选择时,后者几乎总是会胜出。
但我相信会改变的。不是现在,而是将来的某个时候。
值得注意的是,你在大学里阅读的论文和参加的课程可能与你在这个行业需要的技能没有直接关系。这是真的,但我不认为这有什么大不了的。
通常情况下,作为一名数据科学家或软件开发人员,你需要知道的事情,你可以自学,或者你无论如何都无法在大学里学习。人们在这个行业学到的大部分东西只有在你在某个公司的全职工作中才能获得。
与此同时,在研究数据科学的同时,我一边写理论物理论文,一边试图在行业中找到一份工作,这让我感到压力很大。
我不具备所有必需的知识;我不明白硅谷是怎么做事的,也不知道对我有什么期望。我有接近零的网络,我唯一尝试做的事情就是向不同的公司发送我的简历,一次又一次,一次又一次地面试失败,从每一次失败中学习,并重复它,直到它以某种方式工作。
我记得有一次有人问我在做什么论文?我在做量子蒙特卡罗,我告诉面试官这个。之后,我试图解释这意味着什么,为什么我们需要它。面试官看着我问道:“这项技术如何帮助我们提高顾客的参与度?”
我认为对于那些非计算机科学专业的学生来说,最有希望的方法是参加计算机科学系的 DS 相关课程。空闲时间学习 DS / ML。幸运的是,这方面有很多很好的资源。我会说,在你的系里找一个对应用 ML 解决他或她的问题感兴趣的教授是个好主意。在科技公司申请与 ML 相关的实习,并以研究生身份获得实习机会比获得全职工作更容易。
实习结束后找一份全职工作非常简单。例如,我的朋友胡(T1)就是这样做的,他也在我们的研究小组学习物理,他在人工智能研究所获得了一个研究科学家的职位。
一般来说,过高估计你的专业、大学等的影响力是不明智的。为了在行业内找工作。当一家公司雇佣你时,他们打算付给你钱来解决他们面临的问题。你的学位和专业只是评估你能力的一个代理。当然,如果简历中没有他们希望看到的内容,通过简历筛选阶段是很难的,你的人际关系网(这对于求职来说是必不可少的)也会变弱,但同样,这不应该影响你选择专业的决定。
我可能听起来很天真,但一个人应该选择专业,不是因为他/她相信它会带来好的薪水,而是因为你对它充满热情。
问:你认为目前数据科学/ML 中有趣的问题在哪里?我已经完成了大约 50%的硕士课程,但不确定我想在 ML 的哪个部门工作。我和一个人谈过,他断言两个最好的领域是算法创建和扩展(与 DS/ML 应用相反,后者可能更多的是库插入和突突)。你对此有什么想法?/职业弹性方面有什么推荐。
我要说的是,DS/ML 中有趣的问题与当今的主流相去甚远。主流问题拥挤。将 ML 应用于信用评分、推荐系统、零售和其他我们知道如何将数据转化为金钱的学科是很无聊的。但是,如果你将 DS/ML 应用于数学、物理、生物、化学、历史、考古、地质或任何其他人们没有那么尝试应用 ML 的领域中未解决的问题,你可能会找到你的下一个紫牛。
关于职业选择。与生物学或物理学不同,你在 DS/ML 中学到的技能更容易从一个领域转移到另一个领域。当然,在一些银行或对冲基金开发交易算法与在无人驾驶汽车上工作是不同的,但区别并不是那么大,只要你的基本面良好,你就能很快掌握必要的技能。
问:30 岁加入有背景的 ML 社区,而不是数学/CS,是不是太晚了?或者有可能赶上末班车?如果是,你认为最低要求是什么?
当然,现在还不算太晚。90%的 ML 需要理工大学大一水平的数学知识,所以不需要超深的数学知识。而且 DS 中使用最广泛的语言是 a python 和 R,级别很高,可以开始使用,不会死在技术细节上。
我建议参加一些 DS 的在线课程,并开始在 Kaggle 上解决问题。当然,许多概念听起来会很新,但你只需要有一些纪律和奉献精神,一切都会到来。
还有两个与年龄有关的例子:
- Kaggle 大师 Evgeny Patekha 在四十岁时开始了他的数据科学之旅。
- Kaggle 特级大师亚历山大·拉科在 55 岁时加入了 Kaggle。
问:您认为技术领域的正规基础教育对于在数据科学和 Kaggle 竞赛中取得成功至关重要吗?在你的工作经历中有相反的例子吗?
有帮助是的。基本没有。在 Kaggle,有很多取得巨大成就的人没有接受过技术领域的基础教育。最典型的例子是米克尔·波贝尔-伊里扎尔,他是卡格尔特级大师,但仍在高中学习。
另一件事是,你需要记住,你在 Kaggle 学到的技能只是你在工业界或学术界从事 ML 工作时所需技能的一小部分。对于那些卡格尔没有开发的技能,技术领域的基础教育可能是至关重要的。
但是还是那句话。没有高中文凭也能擅长 Kaggle。
问:你花了多长时间学习数据科学/ML,以达到在 Kaggle 中有竞争力的水平?
2015 年 1 月决定转行数据科学。在这之后,我开始在 Coursera 上在线课程。2 月底,我了解了 Kaggle,并在那里注册了。两个月后,我获得了我的第一枚银牌。
问:在没有云的情况下,用一台简单的家用电脑能获得很高的 kaggle 结果吗?
我不在比赛中使用云。但是我家里有两台比较强大的电脑。一个有四个 GPU,另一个有两个。在 kaggle 上,没有一台非常强大的机器,你也可以得到很好的结果,但是缺乏计算能力会限制你在单位时间内可以检查多少个想法。你检查的这些想法的数量与你的结果密切相关。所以,如果你正在全天候训练模特,你应该投资一台好的台式机。
经过几次迭代,我最终得到了下面的 dev box,它有四个 GPU 用于繁重的工作,一个桌面有两个 GPU 用于原型开发。

同时,拥有强大的机器是不够的。您需要能够编写能够利用它的代码。
- 我从 Keras 转到 Pytorch 的原因之一是因为当时 PyTorch 中的 DataLoader 要优越得多。
- 我们写albuminations是因为 imgaug 太慢了,我们得到了 100%的 CPU 利用率,而 GPU 没有得到充分利用。
- **为了加速来自磁盘的 jpeg 图像 I/O,不应该使用 PIL 、 skimage、甚至 OpenCV ,而应该寻找 libjpeg-turbo 或 PyVips 。
等等。

问:他能就从哪里开始与 Kaggle 合作向刚起步的数据科学家志向者提供一些建议吗?给第一次参加比赛的新手的最好建议?
有很多方法可以进入 Kaggle,但根据我的观察,获得所需知识的最有效方法之一是使用黑客的方法。
- 观看一些涵盖 python 编程和机器学习基础的在线课程。
- 在卡格尔选一场比赛。如果您可以编写一个 end2end 管道,将数据映射到提交,那就太好了。如果你是新人,可能会比较难。在这种情况下,去论坛复制粘贴别人分享的内核。
- 在您的电脑上运行,生成提交内容,并出现在排行榜上。在这一步,你很可能会感受到操作系统、驱动程序、库版本、I/O 问题等带来的痛苦。尽早开始习惯它是很重要的。如果您不知道内核中发生了什么,那也没关系。
- 调整一些参数,盲目地做是可以的,重新训练你的模型,提交你的预测。希望你的一些修改能让你在排行榜上有所上升。不要担心,你周围成百上千的人也在做同样的事情。他们正在调整不同的旋钮,这些旋钮是他们在没有深入的知识或直觉的情况下也能触及的。
- 为了超越那些盲目调整参数的人,你需要开始发展直觉,获得关于什么可行什么不可行的基本知识,这样你就可以更智能、更有效地探索可能方法的相空间。在这一步,你需要在你的实验中加入学习。你需要从两个方向学习。第一—基础,像 mlcourse.ai 、 CS231n 这样的课,看书,学习数学,统计,如何写出更好的代码等等。通常,很难让自己做到这一点,但从长远来看,这是至关重要的。其次,你会在论坛上看到大量与你试图解决的问题相关的新术语。关注他们。试着把你在排行榜上变得更好的渴望作为学习新事物的额外动力。但是不要在研究和试验管道之间选择——两者同时进行。机器学习是一门应用学科,你不希望你的知识变成纯粹的书本知识。没有实践的理论是愚蠢的。没有理论的实践是盲目的。
- 比赛结束后,尽管你尽了最大努力,你很可能会发现自己在排行榜上排名很低。这是意料之中的。仔细阅读论坛,阅读获胜者分享的解决方案,尝试了解您可以做得更好的地方。下次你再看到类似问题的时候,你的起点会高很多。
- 在许多比赛中重复这个过程,你就会到达顶峰。更重要的是,你将拥有处理许多问题的良好渠道,以及如何处理你在竞争、工作或学术界面临的机器学习挑战的良好直觉。
问:作为一个物理学出身的人,当竞赛更多地是一种过度适应的练习,而不是特定任务的实际概括时,你是否有时会感到沮丧?假设如此,你如何应对?
通常,您需要对数据和指标进行过度拟合,以获得良好的结果。这很好,这是意料之中的。人们在 ImageNet 数据集上过度适应了这么多年,新的知识仍在这个过程中产生。但是要做到这一点,你需要理解指标和数据的细微差别。这就是知识的来源。只要新知识是在挑战期间创造出来的,我就不介意过度适应。正如你可能注意到的,在一个问题上擅长的管道和想法成为下一个问题的可靠基线,这说明了一些普遍性。
问:你对 Kaggle,例如桑坦德银行、飞艇预测和谷歌分析的数据泄露有什么看法?在 Kaggle 比赛中使用数据泄露是否道德?
我承认组织比赛是非常困难的,所以当漏洞被发现时,我不会责怪组织者。当人们利用漏洞时,我也没事。我必须承认,泄密使我不愿意参加挑战,但这主要是因为我不能那么容易地将获得的知识推广给其他被挑战的人。我仍然认为 Kaggle 管理员需要创建一个可能的数据泄漏清单,并在挑战前检查数据,以防止同样的问题一再发生,但我相信他们正在努力。
问:作为一名设计工程师,Kaggle 竞赛对商业/工作有多大用处??
很难说。Kaggle 在一些关键但非常狭窄的领域提升你的技能。这是一项重要的技能,对一些职位来说,它可能非常有益,而对另一些职位来说则不然。对于我从事的所有工作,尤其是现在我从事自动驾驶工作时,Kaggle 技能是我从学术界和其他知识来源获得的一套技能的强大补充。
但同样,拥有 Kaggle 技能,即使他们是坚实的也是不够的。很多东西只有在行业里才能学到。
成为一名 Kaggle 大师并不必要,也不足以胜任你的工作,但同时,我相信,如果一个人是 Kaggle 大师,那么通过 HR 的简历筛选阶段并邀请一个人到技术屏幕上就足够了。
问:成为特级大师后,参加卡格尔比赛有多大用处?当你已经是一名有成就的数据科学家时,你做 Kaggle 的动机是什么?
正如我提到的,我已经不怎么参加 Kaggle 比赛了,但我开始关注与不同会议相关的比赛。我的团队在 2017 年 MICCAI、2018 年 CVPR 和 2018 年 MICCAI 取得了好成绩。竞争通常包括漂亮、干净的数据集,只需要最少的数据清理,并允许您更少地关注数据,而更多地关注数字技术。这是您在工作中通常没有的奢侈,在工作中,数据选择过程通常是创建有用管道的最重要的组成部分。
问:从你的学习和竞争经历中,你对本科生和研究生有什么建议?要掌握数据科学,必须树立哪些里程碑?
我甚至不知道数据科学中的精通是什么。有很多方法可以回答这个问题。但是在这次 AMA 中,我是以一个卡格大师的身份说的,所以让我们说你的第一个里程碑应该是成为卡格大师。这相对来说比较简单,但是当你在做的时候,你会对你在这个领域想要什么有一个更好的认识。
问:如果没有数学/计算机科学或其他一些高度计算学科的教育背景,你能在 Kaggle(以及更广泛的数据科学领域)上走多远?相反,激情和学习的欲望能让你走多远?
如果你有目标并且愿意学习,你可以在 Kaggle 或任何其他数据科学领域达到顶峰。最难的一步是第一步。去做吧。最好的时间就是现在,今天,因为明天,通常意味着永远不会。
没有人问我,你如何找到能帮助你在特定比赛中取得更好成绩的人?我认为这是一个我没有在博客文章中看到过的重要话题。
最常见的方法是:一些朋友或同事对比赛感到兴奋,他们谈论比赛,开会,讨论问题,组成一个团队。有些人试图做某事;其他人忙于其他活动。这个团队取得了一些进展,但通常不会那么远。
对我和其他参与者都有效的更好的方法是:
- 你写你的管道或者重构在论坛上分享的管道。
- 这个管道应该以适当的格式将输入数据映射到提交,并生成交叉验证分数。
- 您验证了您的交叉验证分数的提高与排行榜上的提高相关。
- 你进行探索性的数据分析,你通过论坛仔细阅读,你阅读与你所做的类似的论文、书籍、以前比赛的解决方案。你完全靠自己工作。
- 在某个时候,比如说在结束前的 2-4 周,你会被卡住。这些想法都不会提高你的地位。你什么都试过了。你需要一个新的想法来源。
- 此时,你看着你周围的排行榜,并与具有类似地位的积极参与者交流。
- 首先,你的预测的纯平均值会给你一个很小但很重要的推动。第二,很有可能你的方法有点不同,分享一系列尝试过或没尝试过的想法是有益的。第三,因为比赛最初是为每个人单独进行的,所以你们所有人都查看了数据,所有人都写了管道,所有人都将比赛置于其他活动之上,所有人都被实时排行榜创造的游戏化效果所激励。

但更重要的是,人们往往会高估他们愿意花在挑战上的空闲时间,并低估他们在拥有稳定的端到端管道之前将面临的问题数量。通过排行榜创建团队可以作为一个过滤器,确保你的潜在队友和你在同一页上。
在一些比赛中,领域知识对于取得好成绩非常重要。例如,表格数据和相应的特征工程或医学成像,在这种情况下,您可以考虑与具有深厚领域知识的人组成一个团队,即使他/她没有强大的 DS 背景,但这种情况相当罕见。
同时,行业内团队组建的方式也完全不同。使用 Kaggle 的方法在工业环境中组建团队是不明智的。
我要感谢我有幸成为队友的所有人,他们在我参加的所有比赛中教会了我很多东西:
阿尔特姆·萨纳克乌,亚历山大·布斯拉耶夫,谢尔盖·穆辛斯基,叶夫根尼·日比茨基,康斯坦丁·洛普欣,阿列克谢·诺斯科夫,阿图尔·库津,鲁斯兰·拜库洛夫,帕维尔·内斯特罗夫,阿尔谢尼·克拉夫琴科
这些人我大多是通过 ODS 认识的。AI 。混乱办。AI 是一个精英管理的俄语数据科学社区。如果你会说俄语,并且想在 Kaggle 做得更好,加入它是一个好主意。
全球 Kaggle 评级前 100 名中的 20+已经在那里了!
如果你的问题没有得到答案:请随意写在评论里,我保证你会得到答案的。
下次 Kaggle 比赛再见!
在家里组装一台惊人的深度学习机器,价格不到 1500 美元

在过去的一年半时间里,我一直在为各种客户探索深度学习和机器学习的应用。当我们使用云计算资源建立这些解决方案时,我觉得有必要在企业环境之外实践我的技能。当然,只要我想学习,我可以继续使用亚马逊来构建一些 GPU 驱动的 EC2 实例……但要真正深入到深度学习的世界中,我觉得我必须做两件事 1)给自己一条探索的道路,以自己的速度和自己的设备。2)通过投资一些迫使我使其工作的设备或失去我对自己的大投资,在游戏中加入一些皮肤。
简而言之,我渴望建造自己的高性能机器,我可以在任何需要的时候使用它,此外,它还可以作为一台非常好的家用电脑,用于偶尔的家庭计算任务。(至少,这是我的辩解。)
这篇博文证明了你也可以建造一台深度学习机器,它非常能够处理各种深度学习任务。我将介绍从组件到组装和设置的所有内容。
让我们开始吧。
挑选组件
我不得不承认,我被所有的选择吓到了。令人欣慰的是,对于为深度学习计算机选择正确的组件,有一些非常有用的资源。PC Part Picker 帮助我了解需要什么,以及是否有任何兼容性问题。
注意:如果你不喜欢修改,请不要选择我的版本。我不得不对散热器做一些特殊的修改,以适应它的位置。这包括在我的圆锯上用金属切割刀片切割散热片。谢天谢地,我准备了工具来进行调整。
这是我完整的零件清单:【https://pcpartpicker.com/list/ZKPxqk
主板——125 美元
对于主板,我需要的只是支持一个 GPU,并确保它可以支持英特尔的最新芯片(Kaby Lake-i5–7600k。)Gigabyte-GA-B250N-Phoenix WIFI 迷你 ITX LGA1151 主板符合要求,它内置了 WIFI 和一个非常酷的 LED 功能——所以你仍然可以给你的游戏朋友留下深刻印象。

案例——90 美元
机箱不贵,但大小很重要,因为我们要添加一些非常大的组件。请确保您选择的机箱能够适合您的所有组件,并且能够容纳迷你 ITX 外形。我去的案例,Corsair-Air 240 MicroATX Mid Tower Case,有很多粉丝,布局对我的身材来说相当不错。

中央处理器——230 美元
我们的神经网络将使用 GPU 来完成大部分繁重的计算。事实上,CPU 可能是事后才想到的。不幸的是,我是一个非常“保守”的人,想要一个非常重要的处理器。英特尔酷睿 i5 7600k 3.8 GHz 四核处理器符合我的要求。首先,它超频了,所以我觉得自己像个坏蛋。你可以随意降级,但是如果你降级的话…确保你的主板支持你选择的任何处理器。到目前为止,这款处理器的表现符合预期。令人惊讶的是。

拉姆——155 美元
RAM 很便宜。得到很多。尽可能多的获取。我从未对我为电脑购买的任何 RAM 升级失望过。在我的例子中,我购买了一个巨大的 16GB 内存**。**我的选择,海盗船—复仇 LED 16GB(2 x 8GB)DDR 4–3200 内存还附带了额外的 LED……因为你永远无法获得足够的灯光表演!

散热器——45 美元
这是我最大的遗憾。我买的散热片,冷却器大师——双子座 M4 58.4 CFM 套筒轴承 CPU 冷却器棒极了。就是不合适。我不得不切掉边缘的鱼鳍,为我巨大的公羊腾出空间。如果我必须再做一次,我可能会找到一个更好的散热器,完全适合我的身材。我所做的修改是最新的,风扇非常安静。所以我不会抱怨太多。

存储——50 美元
好吧,说实话,1TB 太大了。但是 Imagenet 也很庞大。如果你能负担得起更多的存储空间,那就去吧,因为当你开始下载数据集时,你就会开始耗尽空间。我选择了西部数据——蓝色 1TB 3.5”5400 rpm 内置硬盘。它在 SATA 接口中提供了 1TB 的存储空间——这对于深度学习来说很好。如果你想升级,考虑更大的 SATA 硬盘或更快的固态硬盘。事后看来,我可能会添加第二个 SATA 硬盘。我建议您从一开始就升级存储空间。我在考虑最终得到 2-3 TB。

电源——85 美元
我用我的电源走了极端,但它相对便宜,我真的不希望它成为一个问题。我的Cooler Master——650 w 80+青铜认证的半模块化 ATX 电源可以为一艘小型潜艇供电,我的 PC 不会有任何问题。

GPU——700 美元
这是你系统中最大的投资,所以为什么要节省。GPU 将为你所有的深度学习处理提供动力。在选择 GPU 时,有许多事情需要考虑,我们一会儿就会谈到这些,但你需要做的一件事是购买 Nvidia 卡。英伟达在支持深度学习加速计算上投入了大量的时间和投资。他们的并行计算平台 CUDA 几乎得到了包括 Tensorflow、Pytorch、Caffe 等所有深度学习框架的支持。
我们知道我们正在选择 Nvidia 卡,我们还应该考虑什么…
预算:我卡上的预算不到 1000 美元。有许多符合要求的卡片,包括 GTX 1080 Ti,GTX 1080,GTX 1070 等等。所以我有很多潜在的卡片可以选择。唯一的牌是泰坦 X 和即将发布的 Volta。
**一个与多个 GPU:**由于我选择的 PC 的外形因素,我只使用了一个 GPU。我还打算用这台机器在表面层面探索深度学习。对于我的大多数用例,我实际上不需要一个以上的 GPU。另外,围绕两张卡片设计一个模型似乎是一件痛苦的事情。我现在就保持简单。
内存: Tim Dettmers 建议 8GB 的 RAM 对于大多数家庭深度学习项目来说已经足够了。我听起来也很合理。由于大多数 10 系列卡将工作。对我来说,11GB 的 GTX 1080 Ti 已经足够了。
总而言之,我选择了亚马逊上售价 699 美元的 Nvidia 1080 Ti。有点贵,但值得在单个 GPU 设置中获得我想要的功能。

电脑总成本为 1,475 美元。
当然,你需要一台显示器、键盘和鼠标来使用这台机器。
电脑版本
如果你真的对计算机构建感到不舒服,把这个部分外包给专业人士!我觉得自己很勤奋,所以我去了。除了一个修改(见上面零件列表的散热器部分),构建非常简单。我花了几个小时,按照主板和其他组件附带的手册进行操作。我还咨询了各种各样的留言板,以解决我在这个过程中犯的一些人为错误。
根据我的经验,最好的办法是把机器放在机箱外面,然后测试各个部件。一旦经过测试,一切正常,就可以安装到机箱中了。
软件设置
现在我们的电脑已经准备好了,是时候设置我们的软件了,这样我们就可以深入学习了。对于我们的系统,我选择了 Ubuntu 16.04——它有很好的文档记录;我们使用的许多库都在 Linux 环境下工作。
1。安装 Ubuntu 16.04 —桌面
我选择的 Linux 版本是 Ubuntu,16.04 版本是迄今为止最新的稳定版本。你可以在这里下载 Ubuntu 16.04 桌面:https://www.ubuntu.com/download/desktop
我从 USB 驱动器安装了操作系统。我把它设置成直接引导到 GUI 中;但是启动到终端来安装 CUDA 和 GPU 驱动程序可能会更好。安装完成后,继续使用 apt-get 更新您的操作系统。
sudo add-apt-repository PPA:graphics-drivers/PPA #安装图形存储库以启用 nvidia-381
sudo apt-get 更新
sudo apt-get-assume-yes 升级
sudo apt-get-assume-yes 安装 tmux build-essential gcc g++ make binutils
sudo apt-get-assume-yes 安装软件-properties-common 【T36
2。安装 CUDA(不带驱动程序)
现在是时候安装一些技术来帮助利用我们的 GPU 进行深度学习了。我们的第一步是安装 CUDA。你可以用驱动程序安装它,但我遇到了与 1080Ti 兼容的问题——因为 CUDA 没有配备最新的驱动程序。就我而言,我是从*安装的。通过直接从 Nvidia 下载来运行文件。
https://developer.nvidia.com/cuda-downloads
运行 sudo 服务灯 dm 停止
关闭 lightdm 并运行 CUDA *。在终端中运行文件。记住,不要安装 CUDA 自带的 Nvidia 驱动。
安装之后,您需要将下面几行代码添加到 PATH 中。您可以简单地运行以下代码:
猫> > ~ ~/。tmp << ‘EOF’
导出路径=/usr/local/cuda-8.0/bin $ { PATH:+:$ { PATH } }
导出 LD _ LIBRARY _ PATH =/usr/local/cuda-8.0/lib 64
$ { LD _ LIBRARY _ PATH:+:$ { LD _ LIBRARY _ PATH } }
EOF
source ~/。bashrc
3。安装支持您的 GPU 的 Nvidia 驱动程序。
在我的例子中,它是 Nvidia 381.22 驱动程序——发布时 1080Ti 的最新驱动程序。
wgethttp://us . download . NVIDIA . com/XFree86/Linux-x86 _ 64/381.22/NVIDIA-Linux-x86 _ 64-381.22 . run
sudo sh NVIDIA-Linux-x86 _ 64–381.22 . run
sudo 重新启动
或者,你可以通过 apt-get 下载并安装 nvidia-381(见下文。)
sudo apt-get 安装 nvidia-381
4。可选:登录循环
如果您遇到可怕的登录循环,您可以通过运行以下代码清除 nvidia 驱动程序并重新安装。我不得不这样做了几次,安装最终坚持。
sudo apt-get remove-purge NVIDIA *
sudo apt-get auto remove
sudo reboot
5。检查 CUDA 和 Nvidia 驱动程序安装
运行下面几行代码来检查您当前的安装。
nvcc 版本# CUDA 检查
nvidia-smi #驱动程序检查
6。一切都好吗?很好,该安装 CuDNN 了。
要安装 CuDNN,你需要是一个搭载 Nvidia 开发者的卡。别担心,报名很容易,而且是免费的。对我来说,转机是瞬间的;但是您的帐户可能需要 48 小时才能得到确认。YMMV。一旦你有了一个帐号,下载并安装 CuDNN 到你的 CUDA 目录中。我的例子如下:
tar tar-xzf cud nn-8.0-Linux-x64-v 5.1 . tgz
CD cuda
sudo CP lib 64//usr/local/cuda/lib 64/
sudo CP include//usr/local/cuda/include/
7。你的深度学习环境和工具。
安装的其余部分涉及 Tensorflow、Pytorch、Keras、Python、Conda 以及您想要用于深度学习实验的任何其他工具。我将把这个设置留给你,但只要记住如果你使用 Tensorflow 下载该软件的 GPU 版本。我的机器运行以下程序:
python 2.7(Ubuntu 自带)
面向 Python 2.7 和 GPU 的 tensor flow—https://www.tensorflow.org/install/install_linux
py torch—http://pytorch.org/
OpenCV—http://opencv.org/
让我们看看它的实际效果吧!
好吧,我花了 1500 美元在一台 PC 上做深度学习问题的实验。这台机器能做什么?这里有一些有趣的例子,我可以在我的新电脑上演示。
MNIST 解决方案在几秒钟内。
我想通过培训 PyTorch 的一个已知的 MNIST 解决方案来尝试一下。https://github.com/pytorch/examples/tree/master/mnist这里有一个在我的个人电脑上训练的视频,大约 45 秒,准确率 98%。
IMAGENET 培训。
我想尝试另一个 CNN 来解决 Tensorflow 上的 Imagenet 问题。我训练了来自https://github . com/tensor flow/models/tree/master/tutorials/image/Imagenet的 Imagenet 分类器,训练结束后,我对我的好友乔纳森(Jonathan)在佛罗里达群岛的一个沉船地点潜水的图像进行了分类。

最后一个例子:YOLO 实时物体识别
最后,我想通过让 GPU 从我的网络摄像头实时识别对象来真正测试 GPU 的能力。这是我对我的机器的能力感到非常兴奋的视频。
接下来是什么?
现在我家里有了相当惊人的深度学习能力,我计划了很多实验。我的下一个项目涉及更多的计算机视觉应用。我甚至会为我妈妈的生日做一个分类器。她正在寻找一个应用程序来帮助她对院子里的植物进行分类。没问题,妈妈。我掩护你。

组装入门级高频交易(HFT)系统
在过去的几个月里,我花了很多时间来构建和组装自己的加密货币入门级 HFT 系统。由于我已经研究机器学习应用于金融很长一段时间了,并试图找出在现实世界中如何工作,我决定真正进入兔子洞。我这样做是为了提供信息,因为互联网上没有太多的资源。我希望告诉你一些你在尝试类似的事情时可能会遇到的陷阱。我将努力使它变得有趣(和富有哲理),同时深入研究。希望你喜欢。

介绍
让我们从这个问题开始:
高频交易系统的基本原理是什么?
要建立一个 HFT 系统,你必须假设“市场无效率”是正确的。因为每个人都在同时关注市场,所以会有一群人发现这些低效之处(例如使用统计数据)并试图弥补它们。这意味着你等待的时间越长,你在效率低下被纠正之前发现的可能性就越低。不同的时间窗口有不同类型的低效率,也就是说,你看到的时间范围越小,低效率就越容易预测,你将面临更多的竞争(假设你无法发现没有人看到的低效率,因为我从未实现过这一点,所以我不能谈论它)。
为什么要为加密货币建立一个 HFT 系统?
在我看来,标准资产市场相当糟糕。为什么?如果你试图作为一个单独的个体获得市场数据的原始实时访问,你会发现这很难(没有人会免费给你,如果他们这样做,我可以向你保证,你将与比你有更好访问权限的人竞争)。大多数加密货币货币交易所“借用”了标准资产市场已经建立的基础设施,其 FIX API 的结构与标准资产市场上的完全相同。此外,由于加密货币交易所竞争激烈,你会发现你为交易这些工具支付的佣金比普通市场更具竞争力。例如,你可以找到为市场带来流动性的经纪人(这对于常规资产行业的个人来说是不可想象的)。
为什么你需要直接进入市场?这个问题用一个机器学习座右铭来回答:
垃圾进,垃圾出
此外,如果您想要执行任何类型的定量分析,您必须控制系统上的一切,也就是说,您希望您所做的分析在您将要使用的同一数据聚合平台上完成。当你建立一个机器学习模型时,你假设他们的预测在一组边界条件内是有效的,你违反这些条件越多,你的预测就越无效。因此,你最好的选择是让经纪人尽可能快地将每笔交易(或订单簿变更)传输给你。
系统的简化概述
出于我稍后将解释的原因,HFT 系统必须对错误有巨大的容忍度。当我发现这一点时,我采用了微服务架构,因为对我来说,这是确保多组件系统容错和可伸缩的最佳方式。我可以向你保证,当你进行实时交易时,你的系统会出现不可预见的故障(其中一些会与第三方有关,例如对经纪人的分布式拒绝服务 (DDOS)攻击。是的,会出现这种情况)。当你使用微服务架构时,当一个服务失败时,你有调度程序试图立即重启服务,这是一个非常优雅的解决方案,当试图单独构建这样的系统时。

Simplified diagram of an entry level HFT architecture
组件的简要说明:
- **数据库:**高密度时间序列数据库,需要能够在一天内处理成千上万的数据插入。(提示:选择一个 IOT 数据库奇迹)。还需要可扩展,以便它能够以不可变和分布式的方式执行非常高速的重新采样。
- Scrapper: 将新传输的数据插入到数据库中
- **定量模型:**当α存在时发出信号的定量模型
- **订单执行器:**拾取量化模型的信号,与市场进行交互。有时候市场是不流动的,或者你的策略必须满足某种类型的滑点要求。因此,为了使您的系统不变,最好有一个微系统,它试图以最好的方式执行您的头寸,这允许您节省佣金,例如,您现在可以执行限价单,而不是使用市价单,这将需要一些时间来消耗,并可能需要根据市场流动性进行调整。
- **定量分析:**你必须开发的制作模型的一套工具。由于这些数据来自基础设施,因此您有更好的方法来确保系统的边界条件。例如,你不能保证在高度波动的市场条件下拥有完全的市场准入,因此,通过建设你的基础设施,你有办法准确地衡量发生了什么,什么时候发生,并记录下来。
为什么要采用这样的微服务架构?嗯,有时你的废品回收器会由于经纪人中断而失败(在高度不稳定的情况下,有恶意代理开始 DDOS,使其他人更难进入市场)。我推断这是一个 DDOS 攻击,但为了更正确,让我们称之为代理不可用。这是市场有效时的样子(注意,这些图不是重新采样的,实际上,这个时间窗口内的每笔交易都被绘制出来):
Efficient Market with nice spreads
经纪人不在时,市场效率非常低(请注意,在下一张图中,y 轴的刻度要大一个数量级):

Inefficient Market
你可以在最后一张图中看到,在一个小的时间窗口中,价差出现了巨大的缺口。这是由于代理不可用而导致的。由于算法无法发出常规的限价订单,为市场带来稳定性和流动性,因此出现了一些高市价订单(不管市场状况如何,这些订单都被接受,但不保证你会得到什么价格),通过消耗现有的限价订单来扩大价差。
更详细的架构概述
我将尝试对这个系统做一个更详细的概述,并解释一些设计选择。我建议使用 Docker 来开发服务。Docker 提供了非常好的管理工具,如果您想使用像 Kubernetes 这样的集群,它可以让您更容易地进行部署。
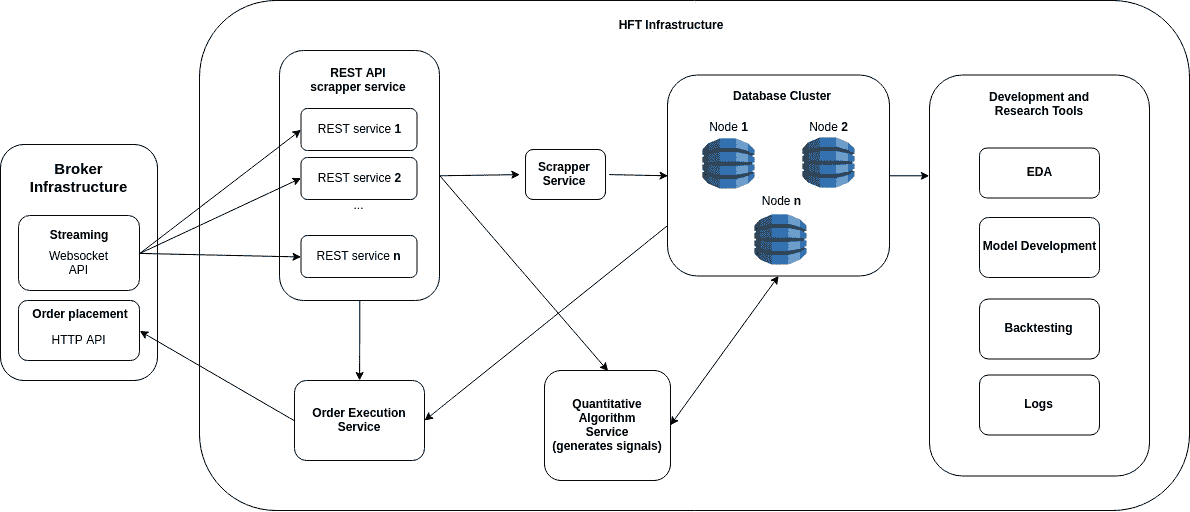
Detailed architectural design of an entry level HFT system
- **REST API scraper 服务:**这个服务有一个缓冲区,缓冲经纪人的 Websocket API 通过流提供的最近的市场交易、报价和订单。它拥有多个工作器的原因是为了减轻代理基础设施的中断(如果代理服务器开始堵塞,这种情况经常发生,拥有多个冗余工作器会增加所有消息通过的机会)。例如,代理服务器可能会开始丢弃一些连接,以保持其工作负载运行,如果您有更多的工作线程,则在已经丢弃的工作线程重新启动时,您有更高的可能性保持至少一个连接。您还有机会让多个服务在多个 IP 上运行,这将为您带来更多冗余。
- **scraper 服务:**scraper 服务收集发布在 REST API 上的信息,并将其插入数据库。它能够在多个 REST 服务之间跳转,如果检测到错误的行为,就触发重启。
- **订单执行服务:**从数据库的表格中获取信号以执行动作,并通过执行市价订单或限价订单(取决于模型的规格)来启动其执行。它还能够在多个 REST 服务中跳转。
- **量化算法服务:**有模型实现,使用数据库上收集的数据生成交易信号。
- **数据库集群:**从市场接收原始数据需要高带宽的数据传输。对这些数据进行重新采样可能是相当密集的,因为您希望将相同的数据库用于开发和生产,所以您需要有高吞吐量。
- **开发和研究工具:**通过在相同的系统上开发您的模型,您可以确保在满足必要的边界条件时有更好的质量。毕竟,现在它是你的数据,你确切地知道你花了多长时间来接收和处理它。
为什么 REST API 和 scrapper 服务是分开的?
这一决定是为了提高系统的速度并确保 24/7 系统的可靠性,例如,当您决定要开仓或平仓时,您不希望不断地查询数据库,通过查询将信息直接存储在 RAM 上的 REST API(降低硬盘开销),您能够实现更高的池化频率(这也在很大程度上取决于您离交易所和所选编程语言的距离)。如果 REST 服务由于某种未知原因失败,您可以重启,不会丢失任何正在进行的数据流,同时有足够的时间安全地重启它。触发交易信号和试图执行交易是有区别的。你确实想尽快完成交易。
结论
我可以持续几个小时(特别是谈论我在试图对时间序列实现 ML 时的糟糕经历,让我们把它留给另一篇博文),但今天就足够了。我在实现这样一个架构的时候遇到了很多瓶颈,同时试图为我的模型所做的预测获得最佳的边界条件。这是一次在实现 24/7 可靠性的同时尽可能获得最佳数据的旅程。如果你想给我建议,讨论想法,给我上关于非平稳过程的课(这是我绝对需要的),或者只是聊天,你可以联系我
abriosipublic@gmail.com
评估 Python 中注释者的分歧以构建用于机器学习的健壮数据集

Tea vs. Coffee: the perfect example of decisions and disagreements!
正如 Matthew Honnibal 在他的 2018 PyData Berlin talk [1]中指出的那样,开发一个可靠的注释模式并拥有专注的注释者是成功的机器学习模型的基石之一,也是工作流不可或缺的一部分。下面的金字塔——摘自他的幻灯片——显示这些是模型开发之前的基本阶段。

我最近完成了数据分析硕士学位,然后与一家机器学习慈善机构密切合作,直到现在,我才意识到正规教育的状况令人担忧的是,对底部三个组成部分的关注明显不足,而对顶部两个组成部分的关注过度。尽管这很麻烦,但原因很明显:学生们对粗糙的机器学习前阶段不感兴趣。但事实仍然是,如果不了解如何处理可能不太令人兴奋的东西,就根本不可能构建一个健壮、强大和可靠的机器学习产品。
我注意到注释不一致评估方法的解释并不局限于网上的一篇文章,用 Python 来做这件事的方法也不局限于单个库。因此,在本文中,我们将讨论注释者协议领域的一些重要主题:
- 用于评估协议质量的著名统计分数的定义。(数学也可以在维基百科的相关页面上找到。)
- 这些统计分数的 Python 实现使用了我写的新库,名为 disagree。
- 如何使用同一个库评估哪些标签值得进一步关注,引入双向同意的概念。
什么是注释模式?
在我们开始任何形式的计算学习之前,我们需要一个数据集。在监督学习中,为了让计算机学习,我们数据的每个实例都必须有一些标签。为了获得标签,我们可能需要一组人坐下来手工标记每个数据实例——这些人就是注释者。为了允许人们这样做,我们必须开发并编写一个注释模式,建议他们如何正确标记数据实例。
当多个注释者标记同一个数据实例时(情况总是如此),可能会对标记应该是什么产生分歧。注释者之间的分歧是不好的,因为这意味着我们不能有效地分配带有标签的实例。如果我们开始用存在重大分歧的标签分配数据实例,那么我们的机器学习模型就处于严重危险之中。这是因为数据无法依赖,我们开发的任何模型也无法依赖。
因此,一旦所有数据都被标记,就必须调查这些不一致的情况,这样我们就可以了解和理解不一致的来源。
- 删除有重大分歧的数据:这给我们留下的只有那些有把握标记的可靠数据。
- 修改注释模式以备将来使用:可能是写得不清楚,我们可以改进未来的协议。
- 改变或合并标签类型:也许我们在有用的标签类型上根本就错了。有时我们需要修改标签来适应注释器的功能。
为了介绍一些定量评估注释者间分歧的最有用(和不太有用)的方法,我将首先向您展示如何设置 Python‘disagree’库。然后,我将研究各种统计数据,结合数学理论和 Python 实现。
“不同意”库
它旨在做几件事:
- 为定量评估注释者的分歧提供统计能力。
2。提供不同注释者之间的可视化。
3。提供可视化效果,以查看哪些标签的分歧最大。
在分别观察了这三点之后,如果有必要,可以考虑上面提到的三种解决方案。首先,您需要导入库。以下是所有可用的模块,我将在此进行演示:
from disagree.agreements import BiDisagreements
from disagree import Metrics, Krippendorff
不同意有两个基本的细微差别。首先,您需要以特定的方式将注释存储在 pandas 数据帧中。行由数据实例进行索引,列是该数据实例的每个注释者的标签。列标题是注释者的字符串名称。标签的类型可以是字符串、整数、浮点或缺失值(即 nan 或 None)。以下是一个数据集示例:
example_annotations = {"a": [None, None, None, None, None, "dog", "ant", "cat", "dog", "cat", "cat", "cow", "cow", None, "cow"],
"b": ["cat", None, "dog", "cat", "cow", "cow", "ant", "cow", None, None, None, None, None, None, None],
"c": [None, None, "dog", "cat", "cow", "ant", "ant", None, "dog", "cat", "cat", "cow", "cow", None, "ant"]}df = pd.DataFrame(example_annotations)
因此,在我们的例子中,我们有 3 个标注者,名为“a”、“b”和“c”,他们共同标记了 15 个数据实例。(数据的第一个实例没有被“a”和“c”标注,被“b”标注为 0。)
现在,我们准备探索用于评估注释者协议的可能的度量标准。从从指标模块设置指标实例开始:
mets = metrics.Metrics(df)
联合概率
联合概率是评估注释者协议的最简单、最天真的方法。它可以用来查看一个注释者与另一个注释者的一致程度。
本质上,它将注释者 1 和 2 同意的次数相加,然后除以他们都标记的数据点的总数。
对于我们的示例数据集,我们可以在我们选择的两个注释器之间进行计算:
joint_prob = mets.joint_probability("a", "b")print("Joint probability between annotator a and b: {:.3f}".format(joint_prob))**Out:** Joint probability between annotator a and b: 0.333
科恩的卡帕
这是一种比联合概率更先进的统计方法,因为它考虑了偶然同意的概率。它还比较了两个注释器。
使用 Python 库:
cohens = mets.cohens_kappa("a", "b")print("Cohens kappa between annotator a and b: {:.3f}".format(cohens))**Out:** Cohens kappa between annotator a and b: 0.330
关联
关联也是显而易见的选择!如果注释者 1 和注释者 2 有很高的相关性,那么他们很可能在标签上达成一致。相反,低相关性意味着他们不太可能同意。
spearman = mets.correlation("a", "b", measure="spearman")
pearson = mets.correlation("a", "b", measure="pearson")
kendall = mets.correlation("a", "b", measure="kendall")print("Spearman's correlation between a and b: {:.3f}".format(spearman[0]))
print("Pearson's correlation between a and b: {:.3f}".format(pearson[0]))
print("Kendall's correlation between a and b: {:.3f}".format(kendall[0]))**Out:** Spearman's correlation between a and b: 0.866
**Out:** Pearson's correlation between a and b: 0.945
**Out:** Kendall's correlation between a and b: 0.816
请注意,对于相关性测量,会返回一个相关性和 p 值的元组,因此在打印结果时会进行零索引。(这使用了 scipy 库。)
此时,您可能会这样想:“但是如果我们有两个以上的注释者呢?这些方法不是挺没用的吗?”答案既可以是“是”,也可以是“不是”。是的,它们对于评估全局注释者在使数据集更加健壮方面的分歧是没有用的。但是,在许多情况下,您可能希望这样做:
- 假设您有 10 个注释者,其中 2 个一起坐在一个房间里,而另外 8 个分开坐。(可能是办公场地的原因。)根据注释,您可能想看看坐在一起的两个人之间是否有更大的一致性,因为他们可能一直在讨论标签。
- 也许您希望看到具有相同教育背景的注释者之间的一致,相对于来自另一种教育背景的群体。
现在,我将介绍一些更高级的——也可以说是最流行的——方法,用于评估任意数量的注释者之间的注释者协议统计数据。这些在现代机器学习文献中更常见。
弗莱斯卡帕
弗莱斯的卡帕是科恩的卡帕的延伸。它通过考虑注释者协议的一致性来扩展它,与 Cohen 的 kappa 所关注的绝对协议相反。这是一种统计上可靠的方法,通常在文献中用于证明数据质量。
在 Python 中:
fleiss = mets.fleiss_kappa()
克里彭多夫的阿尔法值
最后,也是计算量最大的,是 Krippendorff 的 alpha。这和 Fleiss 的 kappa 一起,被认为是最有用的统计数据之一(如果不是最有用的话)。这里有一个 Krippendorff 自己的出版物的链接,概述了数学并给出了一些手工计算的例子:
在 disagree 库中,这与任何其他统计一样简单:
kripp = Krippendorff(df)
alpha = kripp.alpha(data_type="nominal")print("Krippendorff's alpha: {:.3f}".format(alpha))**Out:** Krippendorff's alpha: 0.647
我将 Krippendorff 的 alpha 保留在单独的类中的原因是因为在初始化中有一些计算量非常大的过程。如果有大量的注释(比如说 50,000 到 100,000 个),当人们对使用 Krippendorff alpha 数据结构不感兴趣时,必须对其进行初始化是令人沮丧的。
这就是——在一个易于使用的紧凑 Python 库中计算一组有用的注释不一致统计数据。
双方同意
另一个值得考虑的有用的东西是我喜欢称之为**的双向协议。**这是两个不同的标注器对一个数据实例进行不同标注的次数。之所以有用,是因为它们允许您检查所使用的标签系统或者提供给注释者的注释模式中可能存在的缺陷。
例如,在数据集的给定实例中,标签[0,0,1]或[1,1,1,2]或[1,3,1,3]将被视为单个 bidisagreement。(第 8 行和第 15 行是上述数据帧中的双向协议示例。)这可以扩展到三不同意、四不同意、五不同意等等。
使用不同意库,我们可以用上面导入的双向同意模块来检查这些情况。
首先,设置实例:
bidis = BiDisagreements(df)
下面是一个有用的属性:
bidis.agreements_summary()Number of instances with:
=========================
No disagreement: 9
Bidisagreement: 2
Tridisagreement: 1
More disagreements: 0
Out[14]: (9, 2, 1, 0)
输出显示,从我们的示例注释来看,有 9 个数据实例没有不一致之处;存在 bidisagreement 的 2 个数据实例;和 1 个数据实例,其中有一个 tridisagreement。(注意,这将元组作为输出返回。)这些加起来是 12 而不是 15 的原因是因为在我们的示例数据集中,有 3 个实例,其中最多有 1 个标注器标记了实例。这些不包括在计算中,因为由 1 个注释器标记的任何数据实例都应该被认为是无效的。
我们还可以看到哪些标签导致了双向重复:
mat = bidis.agreements_matrix(normalise=False)
print(mat)[[0\. 0\. 1\. 0.]
[0\. 0\. 0\. 0.]
[1\. 0\. 0\. 1.]
[0\. 0\. 1\. 0.]]
当然,对于没有从 0 到某个数字进行索引的标签,我们需要能够看到矩阵中的哪个索引对应于哪个标签,这可以通过 bidis.labels_to_index()在字典形式中看到。
从这个矩阵中,我们可以看到一个 bidisagreement 源于标签 0 vs 标签 2,另一个源于标签 2 vs 标签 3。使用这个矩阵,你可以创建一个你选择的可视化——比如使用 matplotlib 的混乱矩阵形式的东西:https://www.kaggle.com/grfiv4/plot-a-confusion-matrix.
当您有非常大的数据集时,这最后一个功能特别有用。最近,我对 6,000 个数据实例中的 25,000 个注释使用了这种方法,能够非常快速地识别出几乎 650 个 bidisagreements 来自两个标签。这使我能够处理这两个标签,以及如何在机器学习模型中使用它们,以及何时修改注释模式以供注释者将来使用。
未来考虑
使用 bidisagreements,您会注意到库只能显示频率。这有一个相当重要的底线。想象以下两组标签用于两个数据实例:
- [0, 0, 0, 0, 1]
- [2, 1, 1, 2, 2]
显然,第一个比第二个有更好的一致性,然而不一致认为他们是平等的。致力于一种 bidisagreement 方法将是有趣的,该方法在统计上将第二个加权为比第一个更重要的 bidisagreement,然后相应地归一化 bidisagreement 矩阵。
关于“不同意”的最终注释
这个库是最近的,也是我第一次实现它。(出于这个原因,我请你原谅混乱的版本和提交历史。)完整的 GitHub 回购可以在这里找到:【https://github.com/o-P-o/disagree。
回购包括所有的代码,以及 Jupyter 笔记本与上述例子类似。自述文件中也有完整的文档。
请随时提出问题,并对其他功能提出建议。我将立即处理这些问题。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言










{kind=link}
{kind=link}