




使用 lightFM 通过推荐系统解决业务用例
对 LightFM、推荐系统和代码重用食谱概念的简单介绍。
在这篇帖子中,我将写一些关于推荐系统的内容,它们是如何在许多电子商务网站中使用的。这篇文章还将涉及使用矩阵分解算法,使用 lightFM 软件包和我的推荐系统食谱来构建简单的推荐系统模型。这篇文章将关注业务用例以及简单的实现。这篇文章只涉及算法的基本直觉,如果你想理解算法背后的数学,还会提供资源链接。
动机
我是一个狂热的读者和开源教育的信徒,并通过使用在线课程、博客、Github 存储库和参加数据科学竞赛,不断扩展我在数据科学和计算机科学方面的知识。在互联网上搜索优质内容时,我遇到了各种学习链接,这些链接要么关注使用 ABC 语言的特定数据/建模技术实现算法,要么关注使用一系列算法(如分类、预测、推荐系统等)的广义概念的业务影响/结果。)但具体怎么做就不细说了。因此,我的想法是写一些博客,将业务用例与代码和算法直觉结合起来,以提供数据科学如何在业务场景中使用的整体视图。
随着世界变得越来越数字化,我们已经习惯了大量的个性化体验,而帮助我们实现这一点的算法属于推荐系统家族。几乎每个基于网络的平台都使用一些推荐系统来提供定制内容。以下是我最钦佩的公司。

什么是个性化?
个性化是一种根据每个用户的需求动态定制内容的技术。个性化的简单例子可以是网飞上的电影推荐、电子商务平台的个性化电子邮件定向/重新定向、亚马逊上的商品推荐等。个性化帮助我们实现这四个 r-
- **认识:**了解客户和潜在客户的概况,包括人口统计、地理位置以及表达和分享的兴趣。
- 记住:回忆顾客的历史,主要是他们浏览和购买的商品所表达的行为
- **接触:**根据行动、偏好和兴趣为客户提供合适的促销、内容和推荐
- **相关性:**在数字体验的背景下,根据客户是谁、他们在哪里以及现在是一年中的什么时候来提供个性化服务

4 R’s of personalization
为什么要个性化?
个性化对用户和公司都有很多好处。对于用户来说,这让他们的生活变得轻松,因为他们只能看到与他们更相关的东西(除非是广告,即使它们是个性化的)。因为商业利益数不胜数,但这里我想提几个-
- **增强客户体验:**个性化通过显示相关内容来减少混乱并增强客户体验
- **交叉销售/追加销售机会:**根据客户偏好提供相关产品可以提高产品知名度,最终销售更多产品
- **增加购物篮的容量:**个性化的体验和针对性最终会增加购物篮的容量和购买频率
- **提高客户忠诚度:**在数字世界中,客户保留/忠诚度是许多公司面临的最突出的问题,因为找到特定服务的替代品相当容易。根据《福布斯》的一篇文章,44%的消费者表示他们可能会在个性化体验后再次光顾

Benefits of personalization
矩阵分解导论
矩阵分解是推荐系统家族中的算法之一,顾名思义,它分解一个矩阵,即将一个矩阵分解成两个(或更多)矩阵,这样一旦你将它们相乘,你就可以得到你的原始矩阵。在推荐系统的情况下,我们通常会从用户和项目之间的交互/评级矩阵开始,矩阵分解算法会将该矩阵分解为用户和项目特征矩阵,这也称为嵌入。交互矩阵例子可以是电影推荐者的用户电影评级、交易数据的用户产品购买标志等。

典型地,用户/项目嵌入分别捕获关于用户和项目属性的潜在特征。本质上,潜在特征是用户/项目在任意空间中的表示,其表示用户如何评价电影。在电影推荐器的例子中,用户嵌入的例子可以表示当潜在特征的值高时用户喜欢观看严肃类型的电影,当潜在特征的值低时喜欢观看喜剧类型的电影。类似地,当电影更多地由男性驱动时,电影潜在特征可能具有高价值,而当电影更多地由女性驱动时,该价值通常较低。

有关矩阵分解和因式分解机器的更多信息,您可以阅读这些文章—
矩阵分解:Python 中的简单教程和实现
入门指南—因式分解机器&它们在巨大数据集上的应用(用 Python 编写代码)
HandOn:用 Python 中的 LightFM 包构建推荐系统
在动手操作部分,我们将为不同的场景构建推荐系统,这些场景我们通常会在许多使用 LightFM 包和 MovieLens 数据的公司中看到。我们使用的是小型数据,其中包含 700 名用户对 9000 部电影的 100,000 个评分和 1,300 个标签应用
数据
让我们从导入数据、推荐系统指南和预处理指南文件开始,这是实际操作部分。我编写了这些可重用的通用食谱代码来提高生产率和编写干净/模块化的代码;你将会看到,通过使用这些食谱,我们可以用 10-15 行代码构建一个推荐系统(事半功倍!).
# Importing Libraries and cookbooks
from recsys import * ## recommender system cookbook
from generic_preprocessing import * ## pre-processing code
from IPython.display import HTML ## Setting display options for Ipython Notebook# Importing rating data and having a look
ratings = pd.read_csv('./ml-latest-small/ratings.csv')
ratings.head()

Ratings data
正如我们所看到的,评级数据包含用户 id、电影 id 和 0.5 到 5 之间的评级,时间戳表示给出评级的时间。
# Importing movie data and having a look at first five columns
movies = pd.read_csv('./ml-latest-small/movies.csv')
movies.head()

Movies data
电影数据由电影 id、标题和所属类型组成。
预处理
正如我之前提到的,要创建一个推荐系统,我们需要从创建一个交互矩阵开始。对于这个任务,我们将使用 recsys cookbook 中的create _ interaction _ matrix函数。该函数要求您输入一个 pandas 数据框架和必要的信息,如用户 id、项目 id 和评级的列名。如果 norm=True,它还需要一个额外的参数阈值,这意味着任何高于上述阈值的评级都被视为正面评级。在我们的例子中,我们不需要标准化我们的数据,但是在零售数据的情况下,任何特定类型的商品的购买都可以被认为是积极的评价,数量并不重要。
# Creating interaction matrix using rating data
interactions = create_interaction_matrix(df = ratings,
user_col = 'userId',
item_col = 'movieId',
rating_col = 'rating')
interactions.head()

Interaction data
正如我们所看到的,数据是以交互格式创建的,其中行代表每个用户,列代表每个电影 id,评级作为值。
我们还将创建用户和项目字典,以便稍后通过使用 create_user_dict 和 create_item dict 函数将 user_id 转换为 user_name 或将 movie_id 转换为 movie_name。
# Create User Dict
user_dict = create_user_dict(interactions=interactions)
# Create Item dict
movies_dict = create_item_dict(df = movies,
id_col = 'movieId',
name_col = 'title')
构建矩阵分解模型
为了构建一个矩阵分解模型,我们将使用 runMF 函数,它将接受以下输入-
- **互动矩阵:**上一节创建的互动矩阵
- n_components: 为每个用户和项目生成的嵌入数
- **损失:**我们需要定义一个损失函数,在这种情况下,我们使用扭曲损失,因为我们最关心的是数据的排序,即我们应该首先显示哪些项目
- epoch: 运行的次数
- n_jobs: 并行处理中使用的内核数量
mf_model = runMF(interactions = interactions,
n_components = 30,
loss = 'warp',
epoch = 30,
n_jobs = 4)
现在我们已经建立了矩阵分解模型,我们现在可以做一些有趣的事情。有各种各样的用例可以通过在 web 平台上使用这个模型来解决,让我们来研究一下。
用例 1:向用户推荐商品
在这个用例中,我们希望向用户展示,根据他/她过去的互动,他/她可能有兴趣购买/查看的商品。典型的行业例子是亚马逊上的“推荐给你的交易”或网飞上的“用户最佳照片”或个性化电子邮件活动。

对于这种情况,我们可以使用sample _ re commendation _ user函数。该函数将矩阵分解模型、交互矩阵、用户字典、项目字典、user_id 和项目数量作为输入,并返回用户可能有兴趣交互的项目 id 列表。
## Calling 10 movie recommendation for user id 11
rec_list = sample_recommendation_user(model = mf_model,
interactions = interactions,
user_id = 11,
user_dict = user_dict,
item_dict = movies_dict,
threshold = 4,
nrec_items = 10,
show = True)Known Likes:
1- The Hunger Games: Catching Fire (2013)
2- Gravity (2013)
3- Dark Knight Rises, The (2012)
4- The Hunger Games (2012)
5- Town, The (2010)
6- Exit Through the Gift Shop (2010)
7- Bank Job, The (2008)
8- Departed, The (2006)
9- Bourne Identity, The (1988)
10- Step Into Liquid (2002)
11- SLC Punk! (1998)
12- Last of the Mohicans, The (1992)
13- Good, the Bad and the Ugly, The (Buono, il brutto, il cattivo, Il) (1966)
14- Robin Hood: Prince of Thieves (1991)
15- Citizen Kane (1941)
16- Trainspotting (1996)
17- Pulp Fiction (1994)
18- Usual Suspects, The (1995) Recommended Items:
1- Dark Knight, The (2008)
2- Inception (2010)
3- Iron Man (2008)
4- Shutter Island (2010)
5- Fight Club (1999)
6- Avatar (2009)
7- Forrest Gump (1994)
8- District 9 (2009)
9- WALL·E (2008)
10- Matrix, The (1999)print(rec_list)[593L, 260L, 110L, 480L, 47L, 527L, 344L, 858L, 231L, 780L]
正如我们在这种情况下看到的,用户对*《黑暗骑士崛起(2012)》感兴趣,所以第一个推荐是《黑暗骑士(2008)》*。该用户似乎也非常喜欢戏剧、科幻和惊悚类型的电影,并且有许多相同类型的电影推荐,如《黑暗骑士》(戏剧/犯罪)、《盗梦空间》(科幻、惊悚)、《钢铁侠》(科幻惊悚)、《禁闭岛》(德拉姆/惊悚)、《搏击俱乐部》(戏剧)、《阿凡达》(科幻)、《阿甘正传》(戏剧)、《第九区》(惊悚)、《瓦力》(科幻)、《黑客帝国》(科幻)
类似的模型也可以用于构建类似“基于您最近的浏览历史”推荐的部分,只需改变评级矩阵,以包含最近的和基于特定项目的浏览历史访问的交互。
用例 2:用户对商品的推荐
在这个用例中,我们将讨论如何推荐针对某个特定项目的用户列表。这种情况的一个例子是,当您正在对某个项目进行促销,并希望围绕该促销项目向可能对该项目感兴趣的 10,000 名用户发送电子邮件时。

对于这种情况,我们可以使用sample _ re commendation _ item函数。该函数将矩阵分解模型、交互矩阵、用户字典、项目字典、item_id 和用户数量作为输入,并返回更可能对项目感兴趣的用户 id 列表。
## Calling 15 user recommendation for item id 1
sample_recommendation_item(model = mf_model,
interactions = interactions,
item_id = 1,
user_dict = user_dict,
item_dict = movies_dict,
number_of_user = 15)[116, 410, 449, 657, 448, 633, 172, 109, 513, 44, 498, 459, 317, 415, 495]
正如您所看到,函数返回了一个可能对项目 ID 1 感兴趣的用户 id 列表。另一个你可能需要这种模型的例子是,当你的仓库里有一个旧库存需要清理,否则你可能不得不注销它,你想通过给可能有兴趣购买的用户一些折扣来清理它。
用例 3:商品推荐
在这个用例中,我们将讨论如何推荐针对某个特定项目的项目列表。这种模型将帮助您找到相似/相关的项目或可以捆绑在一起的项目。此类模型的典型行业用例是产品页面上的交叉销售和向上销售机会,如“与此商品相关的产品”、“经常一起购买”、“购买此商品的客户也购买此商品”和“查看此商品的客户也查看过”。
“买了这个的顾客也买了这个”“查看了这个商品的顾客也查看了”也可以通过购物篮分析解决。

为了实现这个用例,我们将使用由矩阵分解模型生成的项目嵌入来创建余弦距离矩阵。这将帮助我们计算相似性 b/w 项目,然后我们可以向感兴趣的项目推荐前 N 个相似的项目。第一步是使用create _ item _ emdedding _ distance _ matrix函数创建一个物品-物品距离矩阵。该函数将矩阵分解模型和交互矩阵作为输入,并返回一个 item_embedding_distance_matrix。
## Creating item-item distance matrix
item_item_dist = create_item_emdedding_distance_matrix(model = mf_model,
interactions = interactions)## Checking item embedding distance matrix
item_item_dist.head()

Item-Item distance
正如我们所看到的,矩阵的行和列都有电影,值代表它们之间的余弦距离。下一步是使用 item_item_recommendation 函数获得关于 item_id 的前 N 个项目。该函数将项目嵌入距离矩阵、项目 id、项目字典和要推荐的项目数作为输入,并将相似项目列表作为输出返回。
## Calling 10 recommended items for item id
rec_list = item_item_recommendation(item_emdedding_distance_matrix = item_item_dist,
item_id = 5378,
item_dict = movies_dict,
n_items = 10)Item of interest :Star Wars: Episode II - Attack of the Clones (2002)
Item similar to the above item:
1- Star Wars: Episode III - Revenge of the Sith (2005)
2- Lord of the Rings: The Two Towers, The (2002)
3- Lord of the Rings: The Fellowship of the Ring, The (2001)
4- Lord of the Rings: The Return of the King, The (2003)
5- Matrix Reloaded, The (2003)
6- Harry Potter and the Sorcerer's Stone (a.k.a. Harry Potter and the Philosopher's Stone) (2001)
7- Gladiator (2000)
8- Spider-Man (2002)
9- Minority Report (2002)
10- Mission: Impossible II (2000)
正如我们看到的“星球大战:第二集-克隆人的进攻(2002)”电影,我们得到了它的下一部上映的电影是“星球大战:第三集-西斯的复仇(2005)”作为第一推荐。
摘要
像任何其他博客一样,这种方法并不是对每个应用程序都完美,但是如果我们有效地使用它,同样的想法也可以起作用。随着深度学习的出现,推荐系统有了很大的进步。虽然还有改进的空间,但我对目前为止它对我的作用感到满意。以后我可能会写一些基于深度学习的推荐系统。
与此同时,我希望您喜欢阅读,并随时使用我的代码为您的目的进行尝试。此外,如果对代码或博客帖子有任何反馈,请随时联系 LinkedIn 或给我发电子邮件,地址是 aayushmnit@gmail.com。
用交互代码解决深度学习中链接神经元的内部同变移位[TF 中的手动反推]

GIF from this website
所以我仍然在写我的期末论文,但是我真的很想写这篇论文。“ 用链接的神经元解决深度学习中的内部同变量移位 ”和往常一样,让我们执行手动反向传播,看看我们是否能胜过自动微分。
激活功能


我喜欢这篇论文的原因之一是因为它在介绍各种激活函数方面做了一件令人惊奇的工作。我从来不知道唰激活功能的存在,所以这是一个很好的发现。
链接神经元/实现

红框→ 链接神经元的数学公式。
本文的主要贡献是链接神经元,这意味着梯度的导数中至少有一个非零,这将解决神经元死亡的问题。这是一个非常有趣的提议。此外,这种“链接神经元”的实现也非常简单。

Implementation from here
所以基本上,我们连接每个激活函数的输出,并传递到下一层,很简单!现在让我们来看看实际情况。

当我们给这一层一个形状张量[?,28,28,32]输出为[?28,28,64],因为它在信道维度中被连接。
网络架构(图形/ OOP 形式)


红圈 →卷积运算
蓝/白圈 →不同输入的激活功能
黑圈 →串接输出层
所以以上是我们网络的基本积木,每一层都是由卷积,2 激活,最后是均值池运算组成。现在让我们看看 OOP 表单。

使用上述架构,我们将创建 5 个完全卷积网络,并在 MNIST 数据集上进行测试。

结果(自动微分)




右上 →训练图像的平均时间成本
左上 →训练图像的平均时间精度
左下 →测试图像的平均时间成本
右下 →测试图像的平均时间精度
使用自动微分,我能够在 100 个历元内获得 85%的准确度。学习率是 0.0003,但是我做了额外的实验,将学习率设置为 0.003,并且能够在相同的时间内达到+92%。
结果(扩张反向传播)




右上 →训练图像的平均时间成本
左上 →训练图像的平均时间精度
左下 →测试图像的平均时间成本
右下 →测试图像的平均时间精度
对于这个案例,我得到了一个非常令人失望的结果。该模型甚至无法达到 20%的准确率,而且随着时间的推移,成本实际上还在增加!我再三检查了我是否正确地进行了求导,结果似乎是正确的。这绝对是我想要深入研究的案例。
互动代码\透明度

对于 Google Colab,您需要一个 Google 帐户来查看代码,而且您不能在 Google Colab 中运行只读脚本,因此请在您的操场上创建一个副本。最后,我永远不会请求允许访问你在 Google Drive 上的文件,仅供参考。编码快乐!
为了使这个实验更加透明,我已经将我的命令窗口的所有输出上传到我的 github,要访问自动微分模型的输出,请单击此处,要访问手动反向传播,请单击此处。
最后的话
我不确定这种方法是否能完全取代批量标准化,但是这种方法确实很有趣。
如果发现任何错误,请发电子邮件到 jae.duk.seo@gmail.com 给我,如果你想看我所有写作的列表,请在这里查看我的网站。
同时,在我的 twitter 上关注我这里,访问我的网站,或者我的 Youtube 频道了解更多内容。如果你感兴趣的话,我还做了解耦神经网络的比较。
参考
- Molina,C. R. R .,& Vila,O. P. (2017)。用链接神经元解决深度学习中的内部协变量移位。 arXiv 预印本 arXiv:1712.02609 。
- 适合 ML 初学者的 MNIST。(2018).张量流。检索于 2018 年 4 月 18 日,来自https://www . tensor flow . org/versions/r 1.1/get _ started/mnist/初学者
- 梯度下降优化算法综述。(2016).塞巴斯蒂安·鲁德。检索于 2018 年 4 月 18 日,来自http://ruder.io/optimizing-gradient-descent/index.html#adam
- 用交互式代码实现英伟达用于自动驾驶汽车的神经网络。(2018).走向数据科学。检索于 2018 年 4 月 18 日,来自https://towards data science . com/implementing-neural-network-used-for-driving-cars-from-NVIDIA-with-interactive-code-manual-aa 6780 BC 70 f 4
- CIFAR-10 和 CIFAR-100 数据集。(2018).Cs.toronto.edu。检索于 2018 年 4 月 18 日,来自https://www.cs.toronto.edu/~kriz/cifar.html
- JaeDukSeo/个人 _ 日常 _ 神经网络 _ 实践。(2018).GitHub。检索于 2018 年 4 月 18 日,来自https://github . com/JaeDukSeo/Personal _ Daily _ neural network _ Practice/blob/master/y _ ndi via/d _ upload . py
- 欢迎阅读链接神经元的文档!—链接神经元 0.1.0 文档。(2018).linked-neurons . readthedocs . io . 2018 年 4 月 19 日检索,来自https://linked-neurons.readthedocs.io/en/latest/
- JaeDukSeo/个人 _ 日常 _ 神经网络 _ 实践。(2018).GitHub。检索于 2018 年 4 月 19 日,来自https://github . com/JaeDukSeo/Personal _ Daily _ neural network _ Practice/blob/dd6f 52 b 24 f 45 CDB 73 b 46 de 5 eeca 07 B3 be 1b 7 a 195/3 _ tensor flow/archieve/7 _ auto _ CNN . py
- TensorFlow 等同于 numpy .重复问题#8246 tensorflow/tensorflow。(2018).GitHub。检索于 2018 年 4 月 19 日,来自 https://github.com/tensorflow/tensorflow/issues/8246
- Ramachandran,p .,Zoph,b .,& Le,Q. V. (2018 年)。搜索激活功能。
用 Python 和 OpenCV 解拼图
2018 年初,我收到了一个很棒的星球大战 5000 块拼图(你可以在亚马逊这里找到它)。完成这个拼图花了我大约 2 个月的耐心和毅力,但现在我可以满意和高兴地看着我的杰作。

然而,我仍然记得当我必须完成拼图的中心部分时,它是由一个巨大的达斯·维德和卢克·天行者组成的(剧透警告:达斯·维德的儿子!!).我基本上发现自己坐在一千件黑色和深蓝色的衣服前,寻找匹配的衣服成了一件真正的痛苦。

They are all black!!!
这时候,我决定给计算机视觉一个机会,尝试编写一个程序,能够通过查看它们的形状来找到匹配的碎片。
在这第一部分,我将解释我是如何从每一件作品中提取出四个边的,以便在将来匹配形状。在这里,我将展示一个输出图像,以明确我在这里试图实现的目标:

1.创建数据集
首先要做的是在最佳光线条件下(用我的手机)拍摄 200 多张照片。请注意,我拍了拼图背面的照片,因为我不需要拼图内容,只需要它的形状。我还固定了相机和拼图的位置,这样从整个图像中裁剪出碎片就成了一件小事:
img = cv2.imread(join('images', filename))
img = img[1750:2500, 1000:2000]

Example of picture of puzzle piece and cropping
2.分段
由于数据集内的光线条件和块颜色都不会改变,因此使用简单的二进制阈值分割来实现分割。
在应用二值化之前,对灰度图像应用中值滤波器,以去除拼图块上的白噪声。然后使用均值滤波器平滑二值化图像:
gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
gray = cv2.medianBlur(gray, ksize=5)
thresh = cv2.threshold(gray, 130, 255, cv2.THRESH_BINARY)[1]
thresh = cv2.blur(thresh, ksize=(3, 3))
一旦获得了阈值图像,我通过使用cv2.connectedComponents OpenCV 函数并采用具有最大面积的连通分量(即拼图块本身)来清除潜在的假阳性区域(标记为拼图块像素的背景像素)。最后,我进一步把它裁剪成一个正方形的图像,这样可以在不丢失部分图像的情况下进行旋转。以下是此阶段的输出图像示例:

Puzzle piece segmentation and post-processing
3.找出 4 块的角
为了分开拼图的每一面,我们需要正确地找到拼图的四个主要角。这是最关键的部分,因为如果角是正确的,所有接下来的步骤将完美地工作。
在第一步中,我找到了角点的大概位置,而在第四节中,我将解释如何改进角点检测以获得准确的位置。
3a。[不成功] Canny、Hough 变换和 KMeans
在我的第一次尝试中,我使用霍夫变换找到拼图块的主线,并试图将它们分成 4 个不同的子集(每边一个)。在这里,我将简要解释算法步骤:
- 通过应用
cv2.Canny功能对二值化图像进行边缘检测。 - 应用霍夫变换进行直线检测:
cv2.HoughLines。对于该函数返回的每一行,我们以参数形式获得其系数。 - 通过估计棋子的方向来移除不需要的线:因为我们期望通过棋子的四个角的四条线形成一个矩形,所以我将具有相同方向的线组合在一起,以便修剪不属于这个组的线。
- 用 KMeans 对线进行聚类:我们可以根据它们的系数,将所有的线分成 4 个不同的聚类,每条线代表一面。
- 计算每个聚类的平均线。
- 计算四条平均线之间的交点,最终获得四个角。

Blue lines are all the hough lines after the pruning phase. Green lines are the mean lines for each cluster of lines.
尽管简单明了,但这种算法并没有被证明是健壮的:这种情况尤其发生在拼图的一边只有几条线或者没有线的时候,使得聚类结果变得不可预测。此外,这些线并不总是足够接近真实的边线,使得它们的交点离真实的角太远。
3b。哈里斯角点检测器和最大矩形估计
在第二次尝试中,我应用了 Harris 角点检测,以找到最佳候选角点,并使用一种能够始终检测到正确角点的算法来改进这种估计,该尝试被证明是准确和稳健的。
- 我首先应用了
cv2.Harris函数,它返回一个新的浮点图像,在这里计算每个像素的‘角度’值(越高,越健壮 - 然后,我发现哈里斯图像的局部最大值高于某个阈值。在这一段之后,我有了离散的点,这些点代表了拼图块的候选角。好的一面是,对于我的数据集中的每个拼图块,该算法都返回一个候选角点,其中存在一个真实角点。请看这里的例子:

Candidate corners obtained by finding local maxima of the Harris corner detection function
3.给定所有候选角点,找出最大化一个函数的四个角点集合:
-由四个点形成的形状的“矩形度”:四个角越接近 90°,越好
-形状的面积:形状越大越好(这是因为我们期望我们能找到的最远的点就是真正的角点本身)
这个算法被证明对我所有的数据集图像都是成功的。耶!
4.改进角点检测
在进入下一个阶段之前,我旋转拼图块,使其水平(或垂直,取决于你的观点…)并使用 Canny 边缘检测器计算其边缘。
然后,我通过选择一个以检测到的角为中心的窗口,并从穿过拼图块中心的 45°或 135°方向的直线中找到最远的点,来优化检测到的角的位置。如您所见,结果相当准确:

Refinement of the 4 puzzle corners. The small circles are centered on the refined corner.
5.分开四边
现在我们有了一些好的拼图角落,我们需要将拼图块的周边分成四个边。每条边都是一条相连的曲线,从一个角开始,到另一个角结束。
最简单的想法非常有效:计算通过四个角的四条线,并根据最接近该点的线对每个周界点进行分类。
然而,在某些情况下,一侧有一个很大的突起,并且它的一部分被归类为属于错误的一侧,因为它最接近错误的线!
为了解决这个问题,我将这个简单的方法修改成了一个更健壮的方法:
- 应用“最近线”的想法,直到一个最大阈值:如果一个点远离所有四条线,它就不会被分类
- 对所有未分类的点应用滞后算法:对于每个未分类的点,检查其邻域中的周界点是否已被分类;如果这是真的,设置同一个“侧类”的要点,并继续。当所有的点都被分类后,算法结束。
最后的结果是惊人的!这里有一个例子:

In the final classification step each perimeter pixel gets assigned a different ‘side class’. In this image the four classes are shown with different colors.
我们需要的最后一个信息是每一面的方向:我们需要知道这一面是向内还是向外!(如果算法告诉我们连接两个都要出去的边,那就糟了…)
这一步非常简单,因为我们只需要检查每个边的平均点(通过平均属于同一边的所有点坐标获得)和拼图块的重心是否位于由连接其两个角的边缘线确定的同一半平面上;如果这个条件为真,那么侧面是进去的,否则是出来的。
结论
虽然我决定用蛮力的方法来完成我的星球大战拼图,但我真的很喜欢将计算机视觉算法应用到拼图中。即使这个任务乍一看似乎很简单,但需要使用大量的算法(二值化、均值滤波、边缘检测、角点检测、连通分量,……以及大量的几何图形!).
请分享你对这项工作的看法和可能的改进,也许我们可以一起建造一个完全自主的解谜机器人:)
用 sequence 2 序列模型求解 NLP 任务:从零到英雄

今天我想解决一个非常流行的 NLP 任务,叫做命名实体识别 (NER)。简而言之,NER 是一项从一系列单词(一个句子)中提取命名实体的任务。例如,给出这样一句话:
“吉姆在 2006 年购买了 300 股 Acme 公司的股票.”
我们想说“Jim”是一个人,“Acme”是一个组织,“2006”是时间。
为此,我将使用这个公开可用的 Kaggle 数据集。这里我将跳过所有的数据处理代码,把重点放在实际的问题和解决方案上。你可以在这个笔记本里看到完整的代码。在这个数据集中,有许多实体类型,如 Person (PER)、organization(ORG)和其他,对于每个实体类型,有两种类型的标签:“B-SOMETAG”和“I-SOMETAG”。b 代表实体名称的开始,I-代表该实体的延续。因此,如果我们有一个像“世界卫生组织”这样的实体,相应的标签将是[B-ORG, I-ORG, I-ORG]
以下是数据集中的一个示例:
import pandas as pd
ner_df = pd.read_csv('ner_dataset.csv')
ner_df.head(30)

所以我们得到一些序列(句子),我们想预测每个单词的“类”。这不是像分类或回归这样简单的机器学习任务。我们得到一个序列,我们的输出应该是一个大小相同的序列。
有很多方法可以解决这个问题。在这里,我将执行以下操作:
- 建立一个非常简单的模型,将这项任务视为每个句子中每个单词的分类,并将其作为基准。
- 使用 Keras 建立序列对序列模型。
- 讨论衡量和比较我们结果的正确方法。
- 在 Seq2Seq 模型中使用预先训练的手套嵌入。
请随意跳到任何部分。
词汇包和多类分类
正如我之前提到的,我们的输出应该是一系列的类,但是首先,我想探索一种有点幼稚的方法——一个简单的多类分类模型。我希望将每个句子中的每个单词视为一个单独的实例,并且对于每个实例(单词),我希望能够预测其类别,即 O、B-ORG、I-ORG、B-PER 等中的一个。这当然不是建模这个问题的最佳方式,但是我想这样做有两个原因。我想在尽可能保持简单的同时创建一个基准,我想展示当我们处理序列时,序列到序列模型工作得更好。很多时候,当我们试图模拟现实生活中的问题时,并不总是清楚我们正在处理的是什么类型的问题。有时我们试图将这些问题建模为简单的分类任务,而实际上,序列模型可能会好得多。
正如我所说的,我将这种方法作为基准,并尽可能保持简单,因此对于每个单词(实例),我的特征将只是单词向量(单词包)和同一句子中的所有其他单词。我的目标变量将是 17 个类中的一个。
def sentence_to_instances(words, tags, bow, count_vectorizer):
X = []
y = []
for w, t in zip(words, tags):
v = count_vectorizer.transform([w])[0]
v = scipy.sparse.hstack([v, bow])
X.append(v)
y.append(t)
return scipy.sparse.vstack(X), y
所以给出这样一句话:
“世界卫生组织称已有 227 人死于禽流感”
我们将得到每个单词的 12 个实例。
the O
world B-org
health I-org
organization I-org
says O
227 O
people O
have O
died O
from O
bird O
flu O
现在我们的任务是,给定句子中的一个单词,预测它的类别。
我们的数据集中有 47958 个句子,我们将它们分为“训练”和“测试”集:
train_size = int(len(sentences_words) * 0.8)train_sentences_words = sentences_words[:train_size]
train_sentences_tags = sentences_tags[:train_size]
test_sentences_words = sentences_words[train_size:]
test_sentences_tags = sentences_tags[train_size:]# ============== Output ==============================Train: 38366
Test: 9592
我们将使用上面的方法将所有的句子转换成许多单词的实例。在train数据集中,我们有 839,214 个单词实例。
train_X, train_y = sentences_to_instances(train_sentences_words,
train_sentences_tags,
count_vectorizer)print 'Train X shape:', train_X.shape
print 'Train Y shape:', train_y.shape# ============== Output ==============================
Train X shape: (839214, 50892)
Train Y shape: (839214,)
在我们的X中,我们有 50892 个维度:一个是当前单词的热点向量,一个是同一句子中所有其他单词的单词包向量。
我们将使用梯度推进分类器作为我们的预测器:
clf = GradientBoostingClassifier().fit(train_X, train_y)
predicted = clf.predict(test_X)
print classification_report(test_y, predicted)
我们得到:
precision recall f1-score support
B-art 0.57 0.05 0.09 82
B-eve 0.68 0.28 0.40 46
B-geo 0.91 0.40 0.56 7553
B-gpe 0.96 0.84 0.90 3242
B-nat 0.52 0.27 0.36 48
B-org 0.93 0.31 0.46 4082
B-per 0.80 0.52 0.63 3321
B-tim 0.91 0.66 0.76 4107
I-art 0.09 0.02 0.04 43
I-eve 0.33 0.02 0.04 44
I-geo 0.82 0.55 0.66 1408
I-gpe 0.86 0.62 0.72 40
I-nat 0.20 0.08 0.12 12
I-org 0.88 0.24 0.38 3470
I-per 0.93 0.25 0.40 3332
I-tim 0.67 0.15 0.25 1308
O 0.91 1.00 0.95 177215
avg / total 0.91 0.91 0.89 209353
好吃吗?很难说,但看起来没那么糟。我们可能会考虑几种方法来改进我们的模型,但这不是本文的目标,正如我所说,我希望保持它是一个非常简单的基准。
但是我们有一个问题。这不是衡量我们模型的正确方法。我们获得了每个单词的精确度/召回率,但是它没有告诉我们任何关于真实实体的事情。这里有一个简单的例子,给定同一个句子:
世界卫生组织称已有 227 人死于禽流感
我们有 3 个带有 ORG 类的类,如果我们只正确预测了其中的两个,我们将获得 66%的单词准确率,但是我们没有正确提取“世界卫生组织”实体,所以我们对实体的准确率将是 0!
稍后我将在这里讨论一种更好的方法来度量我们的命名实体识别模型,但是首先,让我们构建我们的“序列对序列”模型。
序列对序列模型
先前方法的一个主要缺点是我们丢失了依赖信息。给定一个句子中的单词,知道左边(或右边)的单词是一个实体可能是有益的。不仅当我们为每个单词构建实例时很难做到这一点,而且我们在预测时也无法获得这些信息。这是使用整个序列作为实例的一个原因。
有许多不同的模型可以用来做这件事。像隐马尔可夫模型(HMM)或条件随机场(CRF)这样的算法可能工作得很好,但在这里,我想使用 Keras 实现一个递归神经网络。
要使用 Keras,我们需要将句子转换成数字序列,其中每个数字代表一个单词,并且,我们需要使所有的序列长度相同。我们可以使用 Keras util 方法来实现。
首先,我们拟合一个Tokenizer,它将帮助我们将文字转化为数字。仅将其安装在train装置上非常重要。
words_tokenizer = Tokenizer(num_words=VOCAB_SIZE,
filters=[],
oov_token='__UNKNOWN__')
words_tokenizer.fit_on_texts(map(lambda s: ' '.join(s),
train_sentences_words))word_index = words_tokenizer.word_index
word_index['__PADDING__'] = 0
index_word = {i:w for w, i in word_index.iteritems()}# ============== Output ==============================
print 'Unique tokens:', len(word_index)
接下来,我们将使用Tokenizer创建序列,并填充它们以获得相同长度的序列:
train_sequences = words_tokenizer.texts_to_sequences(map(lambda s: ' '.join(s), train_sentences_words))
test_sequences = words_tokenizer.texts_to_sequences(map(lambda s: ' '.join(s), test_sentences_words))train_sequences_padded = pad_sequences(train_sequences, maxlen=MAX_LEN)
test_sequences_padded = pad_sequences(test_sequences, maxlen=MAX_LEN)print train_sequences_padded.shape, test_sequences_padded.shape
# ============== Output ==============================
(38366, 75) (9592, 75)
我们可以看到在train集合中有 38,366 个序列,在test中有 9,592 个序列,每个序列中有 75 个标记。
我们也想做一些类似于我们的标签的事情,我在这里跳过代码,和以前一样,你可以在这里找到它。
print train_tags_padded.shape, test_tags_padded.shape# ============== Output ==============================
(38366, 75, 1) (9592, 75, 1)
我们在train集合中有 38366 个序列,在test中有 9592 个序列,每个序列中有 17 个标签。
现在我们已经准备好构建我们的模型了。我们将使用双向长短期记忆 ( LSTM )层,因为它们被证明对此类任务非常有效:
input = Input(shape=(75,), dtype='int32')emb = Embedding(V_SIZE, 300, max_len=75)(input)x = Bidirectional(LSTM(64, return_sequences=True))(emb)preds = Dense(len(tag_index), activation='softmax')(x)model = Model(sequence_input, preds)
model.compile(loss='sparse_categorical_crossentropy',
optimizer='adam',
metrics=['sparse_categorical_accuracy'])
让我们看看这里有什么:
我们的第一层是Input,它接受形状向量(75,)并匹配我们的X变量(在训练和测试中,我们的每个序列中有 75 个标记)。
接下来,我们有了Embedding层。这一层将把我们的每一个符号/单词转换成一个 300 大小的密集向量。可以把它想象成一个巨大的查找表(或字典),用标记(单词 id)作为关键字,用实际的向量作为值。该查找表是可训练的,即,在模型训练期间的每个时期,我们更新那些向量以匹配输入。
在Embedding层之后,我们的输入从长度为 75 的向量变成了大小为(75,300)的矩阵。75 个标记中的每一个现在都有一个大小为 300 的向量。
一旦我们有了这个,我们可以使用Bidirectional LSTM层,对于每个单词,它将在句子中双向查看,并返回一个状态,这将有助于我们稍后对单词进行分类。默认情况下,LSTM层将返回一个向量(最后一个),但是在我们的例子中,我们希望每个令牌都有一个向量,所以我们使用return_sequences=True
它看起来像这样:

这一层的输出是一个大小为(75,128)的矩阵— 75 个记号,一个方向 64 个数字,另一个方向 64 个数字。
最后,我们有一个Time Distributed Dense层(当我们使用return_sequences=True时,它变成了Time Distributed
它获取LSTM层输出的(75,128)矩阵,并返回所需的(75,18)矩阵——75 个标记,每个标记的 17 个标记概率和一个__PADDING__的标记概率。
使用model.summary()方法很容易看出发生了什么:
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
input_1 (InputLayer) (None, 75) 0
_________________________________________________________________
embedding_1 (Embedding) (None, 75, 300) 8646600
_________________________________________________________________
bidirectional_1 (Bidirection (None, 75, 128) 186880
_________________________________________________________________
dense_2 (Dense) (None, 75, 18) 627
=================================================================
Total params: 8,838,235
Trainable params: 8,838,235
Non-trainable params: 0
_________________________________________________________________
您可以看到我们所有的层及其输入和输出形状。此外,我们可以看到模型中的参数数量。你可能注意到我们的嵌入层有最多的参数。原因是我们有很多单词,我们需要为每个单词学习 300 个数字。在这篇文章的后面,我们将使用预先训练的嵌入来改进我们的模型。
让我们训练我们的模型:
model.fit(train_sequences_padded, train_tags_padded,
batch_size=32,
epochs=10,
validation_data=(test_sequences_padded, test_tags_padded))# ============== Output ==============================
Train on 38366 samples, validate on 9592 samples
Epoch 1/10
38366/38366 [==============================] - 274s 7ms/step - loss: 0.1307 - sparse_categorical_accuracy: 0.9701 - val_loss: 0.0465 - val_sparse_categorical_accuracy: 0.9869
Epoch 2/10
38366/38366 [==============================] - 276s 7ms/step - loss: 0.0365 - sparse_categorical_accuracy: 0.9892 - val_loss: 0.0438 - val_sparse_categorical_accuracy: 0.9879
Epoch 3/10
38366/38366 [==============================] - 264s 7ms/step - loss: 0.0280 - sparse_categorical_accuracy: 0.9914 - val_loss: 0.0470 - val_sparse_categorical_accuracy: 0.9880
Epoch 4/10
38366/38366 [==============================] - 261s 7ms/step - loss: 0.0229 - sparse_categorical_accuracy: 0.9928 - val_loss: 0.0480 - val_sparse_categorical_accuracy: 0.9878
Epoch 5/10
38366/38366 [==============================] - 263s 7ms/step - loss: 0.0189 - sparse_categorical_accuracy: 0.9939 - val_loss: 0.0531 - val_sparse_categorical_accuracy: 0.9878
Epoch 6/10
38366/38366 [==============================] - 294s 8ms/step - loss: 0.0156 - sparse_categorical_accuracy: 0.9949 - val_loss: 0.0625 - val_sparse_categorical_accuracy: 0.9874
Epoch 7/10
38366/38366 [==============================] - 318s 8ms/step - loss: 0.0129 - sparse_categorical_accuracy: 0.9958 - val_loss: 0.0668 - val_sparse_categorical_accuracy: 0.9872
Epoch 8/10
38366/38366 [==============================] - 275s 7ms/step - loss: 0.0107 - sparse_categorical_accuracy: 0.9965 - val_loss: 0.0685 - val_sparse_categorical_accuracy: 0.9869
Epoch 9/10
38366/38366 [==============================] - 270s 7ms/step - loss: 0.0089 - sparse_categorical_accuracy: 0.9971 - val_loss: 0.0757 - val_sparse_categorical_accuracy: 0.9870
Epoch 10/10
38366/38366 [==============================] - 266s 7ms/step - loss: 0.0076 - sparse_categorical_accuracy: 0.9975 - val_loss: 0.0801 - val_sparse_categorical_accuracy: 0.9867
我们在测试集上获得了 98.6%的准确率。这个准确度并不能告诉我们太多,因为我们的大多数标签都是“0”(其他)。我们希望像以前一样看到每个类的精度/召回率,但是正如我在上一节中提到的,这也不是评估我们模型的最佳方式。我们想要的是一种方法,看看有多少不同类型的实体我们能够正确预测。
序列对序列模型的评估
当我们处理序列时,我们的标签/实体也可能是序列。正如我之前所展示的,如果我们有“世界卫生组织”作为真正的实体,预测“世界卫生组织”或“世界卫生”可能会给我们 66%的准确性,但两者都是错误的预测。我们希望将每个句子中的所有实体包装起来,并与预测的实体进行比较。
为此,我们可以使用优秀的 seqeval 库。对于每个句子,它寻找所有不同的标签并构造实体。通过对真实标签和预测标签进行操作,我们可以比较真实的实体值,而不仅仅是单词。在这种情况下,没有“B-”或“I-”标签,我们比较的是实体的实际类型,而不是词类。
使用我们的预测值,这是一个概率矩阵,我们希望为每个句子构建一个具有原始长度(而不是我们所做的 75)的标签序列,以便我们可以将它们与真实值进行比较。我们将对我们的LSTM模型和我们的单词包模型都这样做:
lstm_predicted = model.predict(test_sequences_padded)lstm_predicted_tags = []
bow_predicted_tags = []
for s, s_pred in zip(test_sentences_words, lstm_predicted):
tags = np.argmax(s_pred, axis=1)
tags = map(index_tag_wo_padding.get,tags)[-len(s):]
lstm_predicted_tags.append(tags)
bow_vector, _ = sentences_to_instances([s],
[['x']*len(s)],
count_vectorizer)
bow_predicted = clf.predict(bow_vector)[0]
bow_predicted_tags.append(bow_predicted)
现在我们准备使用seqeval库来评估我们的两个模型:
from seqeval.metrics import classification_report, f1_scoreprint 'LSTM'
print '='*15
print classification_report(test_sentences_tags,
lstm_predicted_tags)
print
print 'BOW'
print '='*15
print classification_report(test_sentences_tags, bow_predicted_tags)
我们得到:
LSTM
===============
precision recall f1-score support
art 0.11 0.10 0.10 82
gpe 0.94 0.96 0.95 3242
eve 0.21 0.33 0.26 46
per 0.66 0.58 0.62 3321
tim 0.84 0.83 0.84 4107
nat 0.00 0.00 0.00 48
org 0.58 0.55 0.57 4082
geo 0.83 0.83 0.83 7553
avg / total 0.77 0.75 0.76 22481
BOW
===============
precision recall f1-score support
art 0.00 0.00 0.00 82
gpe 0.01 0.00 0.00 3242
eve 0.00 0.00 0.00 46
per 0.00 0.00 0.00 3321
tim 0.00 0.00 0.00 4107
nat 0.00 0.00 0.00 48
org 0.01 0.00 0.00 4082
geo 0.03 0.00 0.00 7553
avg / total 0.01 0.00 0.00 22481
差别很大。你可以看到,弓模型几乎不能预测任何正确的事情,而 LSTM 模型做得更好。
当然,我们可以在 BOW 模型上做更多的工作,并获得更好的结果,但总体情况是清楚的,序列到序列模型在这种情况下更合适。
预训练单词嵌入
正如我们之前看到的,我们的大多数模型参数都是针对Embedding层的。训练这一层非常困难,因为有许多单词,而训练数据有限。使用预先训练好的嵌入层是很常见的。大多数当前的嵌入模型使用所谓的“分布假设”,该假设认为相似上下文中的单词具有相似的含义。通过建立一个模型来预测给定上下文中的单词(或者反过来),他们可以产生单词向量,这些向量很好地代表了单词的含义。虽然这与我们的任务没有直接关系,但使用这些嵌入可以帮助我们的模型更好地表示单词,以实现其目标。
从简单的共现矩阵到复杂得多的语言模型,还有其他方法来构建单词嵌入。在这篇的帖子中,我试图使用图像来构建单词嵌入。
这里我们将使用流行的手套嵌入。Word2Vec 或任何其他实现也可以工作。
我们需要下载它,加载单词向量并创建嵌入矩阵。我们将使用这个矩阵作为嵌入层的不可训练权重:
embeddings = {}
with open(os.path.join(GLOVE_DIR, 'glove.6B.300d.txt')) as f:
for line in f:
values = line.split()
word = values[0]
coefs = np.asarray(values[1:], dtype='float32')
embeddings[word] = coefsnum_words = min(VOCAB_SIZE, len(word_index) + 1)
embedding_matrix = np.zeros((num_words, 300))
for word, i in word_index.items():
if i >= VOCAB_SIZE:
continue
embedding_vector = embeddings.get(word)
if embedding_vector is not None:
embedding_matrix[i] = embedding_vector
现在来看看我们的模型:
input = Input(shape=(75,), dtype='int32')emb = Embedding(VOCAB_SIZE, 300,
embeddings_initializer=Constant(embedding_matrix),
input_length=MAX_LEN,
trainable=False)(input)x = Bidirectional(LSTM(64, return_sequences=True))(emb)preds = Dense(len(tag_index), activation='softmax')(x)model = Model(sequence_input, preds)
model.compile(loss='sparse_categorical_crossentropy',
optimizer='adam',
metrics=['sparse_categorical_accuracy'])model.summary()# ============== Output ==============================
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
input_2 (InputLayer) (None, 75) 0
_________________________________________________________________
embedding_2 (Embedding) (None, 75, 300) 8646600
_________________________________________________________________
bidirectional_2 (Bidirection (None, 75, 128) 186880
_________________________________________________________________
dropout_2 (Dropout) (None, 75, 128) 0
_________________________________________________________________
dense_4 (Dense) (None, 75, 18) 627
=================================================================
Total params: 8,838,235
Trainable params: 191,635
Non-trainable params: 8,646,600
_________________________________________________________________
一切都和以前一样。唯一的区别是,现在我们的嵌入层有恒定的不可训练的权重。您可以看到,总参数的数量没有变化,而可训练参数的数量要少得多。
让我们来拟合模型:
Train on 38366 samples, validate on 9592 samples
Epoch 1/10
38366/38366 [==============================] - 143s 4ms/step - loss: 0.1401 - sparse_categorical_accuracy: 0.9676 - val_loss: 0.0514 - val_sparse_categorical_accuracy: 0.9853
Epoch 2/10
38366/38366 [==============================] - 143s 4ms/step - loss: 0.0488 - sparse_categorical_accuracy: 0.9859 - val_loss: 0.0429 - val_sparse_categorical_accuracy: 0.9875
Epoch 3/10
38366/38366 [==============================] - 138s 4ms/step - loss: 0.0417 - sparse_categorical_accuracy: 0.9876 - val_loss: 0.0401 - val_sparse_categorical_accuracy: 0.9881
Epoch 4/10
38366/38366 [==============================] - 132s 3ms/step - loss: 0.0381 - sparse_categorical_accuracy: 0.9885 - val_loss: 0.0391 - val_sparse_categorical_accuracy: 0.9887
Epoch 5/10
38366/38366 [==============================] - 146s 4ms/step - loss: 0.0355 - sparse_categorical_accuracy: 0.9891 - val_loss: 0.0367 - val_sparse_categorical_accuracy: 0.9891
Epoch 6/10
38366/38366 [==============================] - 143s 4ms/step - loss: 0.0333 - sparse_categorical_accuracy: 0.9896 - val_loss: 0.0373 - val_sparse_categorical_accuracy: 0.9891
Epoch 7/10
38366/38366 [==============================] - 145s 4ms/step - loss: 0.0318 - sparse_categorical_accuracy: 0.9900 - val_loss: 0.0355 - val_sparse_categorical_accuracy: 0.9894
Epoch 8/10
38366/38366 [==============================] - 142s 4ms/step - loss: 0.0303 - sparse_categorical_accuracy: 0.9904 - val_loss: 0.0352 - val_sparse_categorical_accuracy: 0.9895
Epoch 9/10
38366/38366 [==============================] - 138s 4ms/step - loss: 0.0289 - sparse_categorical_accuracy: 0.9907 - val_loss: 0.0362 - val_sparse_categorical_accuracy: 0.9894
Epoch 10/10
38366/38366 [==============================] - 137s 4ms/step - loss: 0.0278 - sparse_categorical_accuracy: 0.9910 - val_loss: 0.0358 - val_sparse_categorical_accuracy: 0.9895
准确度变化不大,但正如我们之前看到的,准确度不是正确的衡量标准。让我们以正确的方式对其进行评估,并与我们之前的模型进行比较:
lstm_predicted_tags = []
for s, s_pred in zip(test_sentences_words, lstm_predicted):
tags = np.argmax(s_pred, axis=1)
tags = map(index_tag_wo_padding.get,tags)[-len(s):]
lstm_predicted_tags.append(tags)print 'LSTM + Pretrained Embbeddings'
print '='*15
print classification_report(test_sentences_tags, lstm_predicted_tags)# ============== Output ==============================LSTM + Pretrained Embbeddings
===============
precision recall f1-score support
art 0.45 0.06 0.11 82
gpe 0.97 0.95 0.96 3242
eve 0.56 0.33 0.41 46
per 0.72 0.71 0.72 3321
tim 0.87 0.84 0.85 4107
nat 0.00 0.00 0.00 48
org 0.62 0.56 0.59 4082
geo 0.83 0.88 0.86 7553
avg / total 0.80 0.80 0.80 22481
好多了,我们的 F1 成绩从 76 分提高到了 80 分!
结论
序列到序列模型是许多任务的非常强大的模型,如命名实体识别(NER)、词性(POS)标记、解析等等。有许多技术和选项来训练它们,但最重要的是知道何时使用它们以及如何正确地建模我们的问题。
用动态编程解决问题
此内容最初出现在 好奇洞察 上
动态编程是一种非常有用的解决问题的通用技术,它涉及到将问题分解成更小的重叠子问题,存储从子问题计算出的结果,并在问题的更大块上重用这些结果。动态编程解决方案总是比简单的暴力解决方案更有效。对于包含 最优子结构 的问题特别有效。
动态编程以有趣的方式与计算机科学中的许多其他基本概念相关联。例如,递归类似于(但不等同于)动态编程。关键的区别在于,在简单的递归解决方案中,子问题的答案可能会被计算很多次。缓存已经计算过的子问题的答案的递归解决方案被称为 记忆化 ,这基本上是动态编程的逆过程。另一种变化是当子问题实际上根本没有重叠时,在这种情况下,这种技术被称为 分治 。最后,动态编程与 数学归纳法 的概念联系在一起,可以认为是归纳推理在实践中的具体应用。
虽然动态编程背后的核心思想实际上非常简单,但事实证明,在非平凡的问题上使用它相当具有挑战性,因为如何根据重叠的子问题来构建一个困难的问题通常并不明显。这就是经验和实践派上用场的地方,这也是这篇博文的想法。我们将为几个众所周知的问题构建简单的和“智能的”解决方案,并看看如何使用动态编程解决方案来分解问题。代码是用基本的 python 编写的,没有特殊的依赖性。
斐波那契数
首先我们来看一下 斐波那契数列 中的数字计算问题。问题的定义非常简单——序列中的每个数字都是序列中前两个数字的和。或者,更正式地说:
F _ n = F _ n1+F _ N2,以 F_0=0 和 F_1=1 作为种子值。
(注意:Medium 没有能力正确地呈现方程,所以我使用了一个相当简单的解决方案,用斜体显示数学符号……如果真正的意思没有很好地表达出来,我道歉。)
我们的解决方案将负责计算每个斐波纳契数,直到某个定义的限制。我们将首先实现一个简单的解决方案,从头开始重新计算序列中的每个数字。
**def** **fib**(n):
**if** n **==** 0:
**return** 0
**if** n **==** 1:
**return** 1 **return** fib(n **-** 1) **+** fib(n **-** 2)**def** **all_fib**(n):
fibs **=** []
**for** i **in** range(n):
fibs.append(fib(i)) **return** fibs
让我们先在一个相当小的数字上试一试。
%time print(all_fib(10))[0, 1, 1, 2, 3, 5, 8, 13, 21, 34]
Wall time: 0 ns
好吧,可能太琐碎了。让我们试试大一点的…
%time print(all_fib(20))[0, 1, 1, 2, 3, 5, 8, 13, 21, 34, 55, 89, 144, 233, 377, 610, 987, 1597, 2584, 4181]
Wall time: 5 ms
运行时间现在至少是可测量的,但仍然相当快。让我们再试一次…
%time print(all_fib(40))[0, 1, 1, 2, 3, 5, 8, 13, 21, 34, 55, 89, 144, 233, 377, 610, 987, 1597, 2584, 4181, 6765, 10946, 17711, 28657, 46368, 75025, 121393, 196418, 317811, 514229, 832040, 1346269, 2178309, 3524578, 5702887, 9227465, 14930352, 24157817, 39088169, 63245986]
Wall time: 1min 9s
升级得很快!显然,这是一个非常糟糕的解决方案。让我们看看应用动态编程时是什么样子的。
**def** **all_fib_dp**(n):
fibs **=** []
**for** i **in** range(n):
**if** i **<** 2:
fibs.append(i)
**else**:
fibs.append(fibs[i **-** 2] **+** fibs[i **-** 1]) **return** fibs
这一次,我们保存每次迭代的结果,并计算新的数字,作为先前保存的结果的总和。让我们看看这对函数的性能有什么影响。
%time print(all_fib_dp(40))[0, 1, 1, 2, 3, 5, 8, 13, 21, 34, 55, 89, 144, 233, 377, 610, 987, 1597, 2584, 4181, 6765, 10946, 17711, 28657, 46368, 75025, 121393, 196418, 317811, 514229, 832040, 1346269, 2178309, 3524578, 5702887, 9227465, 14930352, 24157817, 39088169, 63245986]
Wall time: 0 ns
通过不在每次迭代中计算完整的 recusrive 树,我们基本上已经将前 40 个数字的运行时间从大约 75 秒减少到几乎即时。这也恰好是幼稚递归函数的危险的一个很好的例子。我们新的斐波那契数函数可以计算第一个版本的线性时间与指数时间的附加值。
%time print(all_fib_dp(100))[0, 1, 1, 2, 3, 5, 8, 13, 21, 34, 55, 89, 144, 233, 377, 610, 987, 1597, 2584, 4181, 6765, 10946, 17711, 28657, 46368, 75025, 121393, 196418, 317811, 514229, 832040, 1346269, 2178309, 3524578, 5702887, 9227465, 14930352, 24157817, 39088169, 63245986, 102334155, 165580141, 267914296, 433494437, 701408733, 1134903170, 1836311903, 2971215073L, 4807526976L, 7778742049L, 12586269025L, 20365011074L, 32951280099L, 53316291173L, 86267571272L, 139583862445L, 225851433717L, 365435296162L, 591286729879L, 956722026041L, 1548008755920L, 2504730781961L, 4052739537881L, 6557470319842L, 10610209857723L, 17167680177565L, 27777890035288L, 44945570212853L, 72723460248141L, 117669030460994L, 190392490709135L, 308061521170129L, 498454011879264L, 806515533049393L, 1304969544928657L, 2111485077978050L, 3416454622906707L, 5527939700884757L, 8944394323791464L, 14472334024676221L, 23416728348467685L, 37889062373143906L, 61305790721611591L, 99194853094755497L, 160500643816367088L, 259695496911122585L, 420196140727489673L, 679891637638612258L, 1100087778366101931L, 1779979416004714189L, 2880067194370816120L, 4660046610375530309L, 7540113804746346429L, 12200160415121876738L, 19740274219868223167L, 31940434634990099905L, 51680708854858323072L, 83621143489848422977L, 135301852344706746049L, 218922995834555169026L]
Wall time: 0 ns
最长增长子序列
Fibonacci 问题是一个很好的开始例子,但并没有真正抓住用最优子问题来表示问题的挑战,因为对于 Fibonacci 数来说,答案是非常明显的。让我们在难度上更上一层楼,来看一个叫做 最长增长子序列 的问题。目标是找到给定序列中最长的子序列,使得子序列中的所有元素按升序排序。请注意,元素不需要连续;也就是说,它们不需要彼此相邻出现。例如,在序列[10,22,9,33,21,50,41,60,80]中,最长的递增子序列(LIS)是[10,22,33,50,60,80]。
事实证明,很难用“蛮力”解决这个问题。动态编程解决方案更简洁,也更适合问题定义,所以我们将跳过创建不必要的复杂的简单解决方案,直接跳到 DP 解决方案。
**def** **find_lis**(seq):
n **=** len(seq)
max_length **=** 1
best_seq_end **=** **-**1 # keep a chain of the values of the lis
prev **=** [0 **for** i **in** range(n)]
prev[0] **=** **-**1 # the length of the lis at each position
length **=** [0 **for** i **in** range(n)]
length[0] **=** 1 **for** i **in** range(1, n):
length[i] **=** 0
prev[i] **=** **-**1 # start from index i-1 and work back to 0
**for** j **in** range(i **-** 1, **-**1, **-**1):
**if** (length[j] **+** 1) **>** length[i] **and** seq[j] **<** seq[i]:
# there's a number before position i that increases the lis at i
length[i] **=** length[j] **+** 1
prev[i] **=** j **if** length[i] **>** max_length:
max_length **=** length[i]
best_seq_end **=** i # recover the subsequence
lis **=** []
element **=** best_seq_end
**while** element **!=** **-**1:
lis.append(seq[element])
element **=** prev[element] **return** lis[::**-**1]
这里的直觉是,对于给定的索引 i ,我们可以通过查看所有索引 j < i 和 if length(j)+1 > i 和 seq[j] < seq[i] 来计算最长递增子序列的长度 length(i) (意味着在 jj 位置有一个数字增加了该索引处的最长子序列,使得它现在比最长记录子序列更长乍一看,这有点令人困惑,但是请仔细阅读,并说服自己这个解决方案找到了最佳子序列。“prev”列表保存构成子序列中实际值的元素的索引。
让我们生成一些测试数据并进行测试。
**import** numpy **as** np
seq_small **=** list(np.random.randint(0, 20, 20))
seq_small[16, 10, 17, 18, 9, 0, 2, 19, 4, 3, 1, 14, 12, 6, 2, 4, 11, 5, 19, 4]
现在,我们可以运行一个快速测试,看看它是否适用于一个小序列。
%time print(find_lis(seq_small))[0, 1, 2, 4, 5, 19]
Wall time: 0 ns
仅根据目测,输出看起来是正确的。让我们看看它在更大的序列上表现如何。
seq **=** list(np.random.randint(0, 10000, 10000))
%time print(find_lis(seq))[29, 94, 125, 159, 262, 271, 274, 345, 375, 421, 524, 536, 668, 689, 694, 755, 763, 774, 788, 854, 916, 1018, 1022, 1098, 1136, 1154, 1172, 1237, 1325, 1361, 1400, 1401, 1406, 1450, 1498, 1633, 1693, 1745, 1765, 1793, 1835, 1949, 1997, 2069, 2072, 2096, 2157, 2336, 2345, 2468, 2519, 2529, 2624, 2630, 2924, 3103, 3291, 3321, 3380, 3546, 3635, 3657, 3668, 3703, 3775, 3836, 3850, 3961, 4002, 4004, 4039, 4060, 4128, 4361, 4377, 4424, 4432, 4460, 4465, 4493, 4540, 4595, 4693, 4732, 4735, 4766, 4831, 4850, 4873, 4908, 4940, 4969, 5013, 5073, 5087, 5139, 5144, 5271, 5280, 5299, 5300, 5355, 5393, 5430, 5536, 5538, 5559, 5565, 5822, 5891, 5895, 5906, 6157, 6199, 6286, 6369, 6431, 6450, 6510, 6533, 6577, 6585, 6683, 6701, 6740, 6745, 6829, 6853, 6863, 6872, 6884, 6923, 6925, 7009, 7019, 7028, 7040, 7170, 7235, 7304, 7356, 7377, 7416, 7490, 7495, 7662, 7676, 7703, 7808, 7925, 7971, 8036, 8073, 8282, 8295, 8332, 8342, 8360, 8429, 8454, 8499, 8557, 8585, 8639, 8649, 8725, 8759, 8831, 8860, 8899, 8969, 9046, 9146, 9161, 9245, 9270, 9374, 9451, 9465, 9515, 9522, 9525, 9527, 9664, 9770, 9781, 9787, 9914, 9993]
Wall time: 4.94 s
所以它仍然很快,但是差别是明显的。对于序列中的 10,000 个整数,我们的算法已经需要几秒钟才能完成。事实上,即使这个解决方案使用了动态编程,它的运行时仍然是 O(n2) 。这里的教训是,动态编程并不总是能产生快如闪电的解决方案。同样的问题,应用 DP 也有不同的方法。事实上,这个问题有一个解决方案,它使用二分搜索法树,运行时间为 O(nlogn) 时间,比我们刚刚提出的解决方案要好得多。
背包问题
背包问题 是另一个经典的动态规划练习。这个问题的一般化由来已久,并且有许多变体,除了动态编程之外,实际上还有多种方法可以解决这个问题。尽管如此,这仍然是 DP 练习的一个常见例子。
其核心问题是一个组合优化问题。给定一组项目,每个项目都有一个质量和一个值,确定在不超过总重量限制的情况下产生最高可能值的项目集合。我们将看到的变化通常被称为 0–1 背包问题,它将每种物品的副本数量限制为 0 或 1。更正式地说,给定一组 n 个项目,每个项目都有重量 w_i 和值 v_i 以及最大总重量 W ,我们的目标是:
maxσv _ IX _ I,其中σW _ IX _ I≤W
让我们看看实现是什么样子,然后讨论它为什么工作。
**def** **knapsack**(W, w, v):
# create a W x n solution matrix to store the sub-problem results
n **=** len(v)
S **=** [[0 **for** x **in** range(W)] **for** k **in** range(n)] **for** x **in** range(1, W):
**for** k **in** range(1, n):
# using this notation k is the number of items in the solution and x is the max weight of the solution,
# so the initial assumption is that the optimal solution with k items at weight x is at least as good
# as the optimal solution with k-1 items for the same max weight
S[k][x] **=** S[k**-**1][x] # if the current item weighs less than the max weight and the optimal solution including this item is
# better than the current optimum, the new optimum is the one resulting from including the current item
**if** w[k] **<** x **and** S[k**-**1][x**-**w[k]] **+** v[k] **>** S[k][x]:
S[k][x] **=** S[k**-**1][x**-**w[k]] **+** v[k] **return** S
这种算法背后的直觉是,一旦你已经解决了在某个重量 x < W 和某个数量的物品 k < n 的物品的最佳组合,那么就很容易解决多一个物品或一个更高的最大重量的问题,因为你可以检查通过合并该物品获得的解决方案是否比你已经找到的最佳解决方案更好。那么如何得到初始解呢?继续沿着兔子洞往下走,直到到达 0(在这种情况下,答案是 0)。乍一看,这很难理解,但这正是动态编程的魅力所在。让我们运行一个例子来看看它是什么样子的。我们将从一些随机生成的权重和值开始。
w **=** list(np.random.randint(0, 10, 5))
v **=** list(np.random.randint(0, 100, 5))
w, v([3, 9, 3, 6, 5], [40, 45, 72, 77, 16])
现在,我们可以在一个约束条件下运行该算法,该约束条件是项目的权重之和不能超过 15。
knapsack(15, w, v)[[0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0],
[0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 45, 45, 45, 45, 45],
[0, 0, 0, 0, 72, 72, 72, 72, 72, 72, 72, 72, 72, 117, 117],
[0, 0, 0, 0, 72, 72, 72, 77, 77, 77, 149, 149, 149, 149, 149],
[0, 0, 0, 0, 72, 72, 72, 77, 77, 88, 149, 149, 149, 149, 149]]
这里的输出是给定的最大权重(将其视为列索引)和最大项目数(行索引)的最佳值数组。注意输出是如何遵循看起来有点像波前图案的。这似乎是动态编程解决方案中经常出现的现象。右下角的值是我们在给定约束条件下寻找的最大值,也是问题的答案。
我们对动态编程的介绍到此结束!在现实世界中使用这种技术肯定需要大量的练习;动态编程的大多数应用都不是很明显,需要一些技巧才能发现。就我个人而言,这对我来说一点都不自然,甚至学习这些相对简单的例子也需要花很多心思。看起来这类问题在实践中并不经常出现,这可能有一定的道理。然而,我发现,简单地了解动态编程以及它如何适应更一般的问题解决框架,已经使我成为一名更好的工程师,这本身就使得花时间去理解它是值得的。

对本文的评论,请查看原贴 好奇洞察
关注我的Twitter获取新帖子更新
使用数据科学解决现实世界的问题

Source: Betsol
数据科学的世界每天都在发展。这个领域的每一个专业人士都需要更新,不断学习,否则就有落伍的风险。你必须有解决问题的欲望。所以我决定研究并解决一个现实世界中的问题,这个问题是我们大多数人在职业生涯中都面临过的。面试中的技术回合!

有多少次你经历了一场技术面试,你觉得自己表现得很好,然后一个问题出现了,把你难住了?从那以后,整个面试就走下坡路了,因为现在你已经失去了信心,招聘人员也失去了兴趣。
但是完全根据 3 个小时的面试来判断一个应聘者的技术能力公平吗?这是两端的损失,因为现在公司失去了一个潜在的候选人,候选人也失去了一个机会。
要是有一种方法能让招聘人员在面试大厅之外了解候选人的技术能力就好了。各种各样的评分系统——给出理想的分数来衡量候选人的技术知识,从而帮助招聘人员做出明智、公正的决定。听起来像梦里的场景,对吧?
因此,我决定启动一个名为“Scorey”的项目,旨在破解这一挑战。
Scorey 根据公开来源帮助搜集、汇总和评估候选人的技术能力。
设置问题陈述
当前的面试场景偏向于“候选人在 3 小时面试中的表现”,而没有考虑其他因素,例如候选人的竞争性编码能力,对开发人员社区的贡献,等等。
我们将采取的方法
Scorey 试图通过汇总各种网站的公开数据来解决这个问题,例如:
- 开源代码库
- StackOverflow
- 厨师长
- Codebuddy
- 代码力
- 黑客地球
- SPOJ
- git 奖
一旦收集到数据,算法就会定义一个综合评分系统,根据以下因素对候选人的技术能力进行评级:
- 等级
- 解决的问题数量
- 活动
- 名声
- 贡献
- 追随者
然后给候选人打分,满分为 100 分。这有助于面试官全面了解候选人的能力,从而做出公正、明智的决定。
设置项目
对于这个项目的整个范围,我们将使用 Python,一个 Jupyter 笔记本&抓取库。因此,如果你是一个喜欢笔记本的人,那么这一部分就是为你准备的。如果没有,请随意跳过这一部分,继续下一部分。
**def color_negative_red(val):
*"""*
*Takes a scalar and returns a string with*
*the css property `'color: red'` for negative*
*strings, black otherwise.*
*"""*
color = 'red' if val > 0 else 'black'
return 'color: %s' % color*****( Set CSS properties for th elements in dataframe)*
th_props = [
('font-size', '15px'),
('text-align', 'center'),
('font-weight', 'bold'),
('color', '#00c936'),
('background-color', '##f7f7f7')
]
*# Set CSS properties for td elements in dataframe*
td_props = [
('font-size', '15px'),
('font-weight', 'bold')
]
*# Set table styles*
styles = [
dict(selector="th", props=th_props),
dict(selector="td", props=td_props)
]**
这将使您的 dataframe 输出看起来整洁,干净,真的很好!
现在我们已经有了我们要解决的问题的要点以及我们将如何去做,让我们开始编码吧!
第一步:抓取个人网站
我们需要汇总一个人在互联网上的整个*编码存在。但是我们从哪里开始呢?咄!他/她的个人网站。当然,前提是我们有权访问候选人的个人网站。我们可以从那里解析所有必要的链接。*
**from** **bs4** **import** BeautifulSoup
**import** **urllib**
**import** **urllib.parse**
**import** **urllib.request**
**from** **urllib.request** **import** urlopen
url = input('Enter your personal website - ')
html = urlopen(url).read()
soup = BeautifulSoup(html, "lxml")
tags = soup('a')
**for** tag **in** tags:
print (tag.get('href',**None**))
当我们运行这段代码时,我们得到下面的输出:

这里我们使用的是 BeautifulSoup ,这是一个流行的抓取库。使用这段代码,我们可以直接链接到候选人的在线个人资料。
现在,如果你必须在一个更精细的层次上评估一个程序员,你会从哪里开始呢?
- Github
首先,让我们使用 Github API 来获取我们需要的特定用户的所有信息。
对于我们的用例,我们只需要电子邮件、存储库数量、追随者、可雇佣者(对或错)、当前公司和最后记录的活动。

- StackOverflow
啊。Devs 可能不相信上帝,但 StackOverflow 绝对是他们的圣殿。你可能已经知道,在 StackOverflow 上获得声誉是非常困难的。对于这一步,您可以使用 StackExchange 的 API——它为您提供用户数据,如信誉、回答数量等。
然后,我们将这些新属性添加到现有的数据帧中。

现在,我们将瞄准并收集全球竞争性编程平台,如 CodeChef、SPOJ、Codebuddy、Hackerearth、CodeForces & GitAwards(以深入了解他们的项目)。
如你所见,所有这些刮擦给了我们很多信息。代码是很容易解释的。我还使用注释进行了记录,以便于理解。
在不深入代码本质的情况下,我想把重点放在过程上。但是如果你在执行代码时遇到任何问题,你可以大声告诉我。:)现在我们已经有了所有的数据,我们将继续创建一个评分算法。
第二步:评分系统
下一步是根据以下参数对候选人进行评分:
- 排名(25 分)
- 解决的问题数量(25 分)
- 声誉(25 分)
- 关注者(15 分)
- 活动(5 分)
- 贡献(5 分)
所以如果你仔细阅读这段代码,你就会明白我们如何创建一个评分系统。虽然在这一点上它非常基础,但我们可以使用机器学习来创建一个强大的动态评分系统。
最终得分
基于我们上面看到的分数系统,算法现在将为候选人的技术能力分配一个最终分数。
所以用户 poke19962008 的分是 100 分中的 64 分!这会让招聘人员在面试室外了解候选人的技术能力。
步骤 3:预测建模
当你试图解决一个现实世界中的问题并"有效化解决方案时,考虑最终用户的需求是很重要的。
在这种情况下,是招聘人员。
我们如何利用机器学习的力量为招聘人员增加价值?
经过头脑风暴,我发现了以下用例—
1。预测候选人的技能组合是否能满足管理层需求的模型
2。预测招聘后候选人流失概率的模型
3。使用遗传算法将候选人链接分配到各自的团队
让我们试着编写第一个用例——预测公司的满意度
,假设招聘人员使用 Scorey 筛选候选人已经有一段时间了,现在有一个 100 名候选人的数据库。
招聘后,根据候选人的表现,招聘人员使用新的二进制属性“满意度”更新数据库,该属性的值为 0 或 1。
现在让我们创建一个虚拟数据库,并尝试使用 Scikit-Learn、Pandas、Numpy 创建一个模型,并构建一个预测模型。
- 导入数据和库
- 清理数据-移除重复项和空值
- 使用标签编码器处理分类数据
- 将数据集分为训练和测试
- 使用 kNN 分类器进行预测
- 检查准确性
使用这些步骤,你将得到一个利基模型,它将能够根据潜在趋势预测候选人是否适合该公司。
对于 eg——拥有更高声誉并对开源做出贡献的候选人更有可能保留更长时间。
第四步:仪表板
我做了一个仪表板。这仍然是一项正在进行中的工作,我很乐意分享一些界面截图。

这就是了。您自己的端到端产品。
总结一下——
1。我们发现了一个问题
2。有条不紊地思考如何解决这个问题。使用网络搜集收集数据
4。建立一个算法评分系统。机器学习建立预测模型
5。传达结果的仪表板
我们使用的技术栈— Python: BeautifulSoup,Urllib,Pandas,Sklearn
所以这篇文章到此为止。我们拿了一个现实生活中的问题,尝试用数据和算法去解决!
下次你去面试时,你可以向招聘人员推销这个系统。😃
那么下一步是什么?
整个项目的代码可以在 Github 上找到——这里是
- 集成用于规则生成的机器学习组件
- 动态处理缺失数据异常
如果你认为这个项目很酷,并且愿意贡献自己的一份力量,我们非常欢迎你!让我们为社区建造一些令人兴奋的东西。
您可以通过LinkedIn 或**Twitter与我联系,以获取数据科学&机器学习的每日更新。**
用数据解决员工流失

时不时地,我喜欢跳到 Kaggle 上,看看是否有我可能想玩的有趣的数据集。本周早些时候,我偶然发现了一个关于员工流失的虚构数据集。
您可以使用下面的链接找到数据集:
为什么我们最优秀、最有经验的员工会过早离开?
www.kaggle.com](https://www.kaggle.com/ludobenistant/hr-analytics)
一位名叫卢多维克·贝尼斯坦特的先生分享了这个数据集,他提出了这样一个问题:“为什么我们最优秀、最有经验的员工都过早地离开了?”
他还提出了一个挑战,那就是“享受这个数据库,并尝试预测哪些有价值的员工将会在下一个离开”,这是我肯定会做的。
然而,我必须承认,尽管他的问题很有趣,我却没有兴趣回答。我还有其他问题要问:
- 我能预测下一个离开的员工是谁吗?
- 我能否创建一个有助于留住员工的系统?
我承认,问题 1 离 Ludovic 想知道的并不是很远,但是我在这个实验中真正的目标是想出一个解决问题 2 的系统。
描述数据集
数据集是模拟的,包含以下字段:
- 员工满意度
- 上次评估
- 项目数量
- 平均每月小时数
- 在公司度过的时间
- 他们是否发生过工伤事故
- 他们在过去 5 年中是否有过晋升
- 部门
- 薪水
- 员工是否已经离职
制定方法
为了解决这个问题,我决定结合使用三种分析方法:
- **描述性分析:**哪些观察有助于我们形成关于员工流失的各种假设?
- **预测分析:**哪些员工将要离开?
- **规定性分析:**对于那些可能离职的员工,你有什么见解或建议?
预测员工流失
只是为了好玩,我想我会先把简单的东西拿出来:建立一个机器学习模型来预测哪些员工会离开或不会离开。
我想我应该指出这种东西什么时候会在现实世界中使用。如果我在现实世界中应用这个算法,我可能会在绩效评估之后或者在“上次评估”被填充的时候运行这个算法。我认为这样做会使模型无缝地融入组织的工作流程。
对于那些可能对我的设置感到好奇的人,我正在使用一个名为 Anaconda 的 Python 环境,我用它来管理我所有的包,并且我正在使用带有和后端的 Keras api 来开发我的模型。然而,我打算很快学习张量流。
对于这个任务,我创建了一个有 1 个输入层,4 个隐藏层和一个输出层的模型。准确度分数是(我很确定这里发生了一些过度拟合)。代码如下:
Neural Network Architecture for Predicting Staff Attrition
这个模型产生了 97%的准确率。
发展一个假设
有了创建的模型,我可以预测谁将离开组织,接下来我需要找出原因。为此,我决定使用相关性分析来确定哪些因素对员工流失影响最大。
我发现与流失最相关的变量是工作满意度,得分为 -0.39 。负相关意味着离职的可能性随着工作满意度的下降而增加(有道理吧?)。我还观察到,离开的员工比留下的员工对工作的满意度低 34%。
我有了一个良好的开端,但我还没有完全完成。

最大的问题是:什么因素有助于工作满意度?
在得知员工因为对工作不满意而离职后,我需要知道为什么会这样,以及如何提高工作满意度。为了找到解决员工工作满意度的方法,我对影响工作满意度的因素做了更深入的调查。
我做了另一个关于工作满意度的相关性分析,我发现在公司花费的时间和参与的项目数量对工作满意度的影响最大。其他因素如员工的平均月工作时间和他们最近的评估也有影响。
创造洞察力
现在我有了一个机器学习模型,可以预测一名员工是否会离开,我也知道什么有助于工作满意度,我需要建立一个系统,为可能很快离开的员工提供提高工作满意度的建议。我认为创建一个“保留概况”是有用的,它总结了没有离开组织的工作人员的特点。这样做将使我能够将可能离职的工作人员的概况与这一"保留概况"进行比较,并容易产生可操作的见解。
我要补充的是,如果这个系统在野外使用,我们也会考虑员工对组织的价值(这就需要回答 Ludovic 的问题)。
以下是我为创建保留配置文件而编写的代码:
现在我已经有了一个保留配置文件,下一步是创建一个系统,该系统将结合我之前创建的模型,为用户提供关于如何对待可能离开公司的员工的建议。
我想到的逻辑相当简单:
- 使用机器学习模型来寻找可能离开组织的员工
- 将此人的分数与之前创建的保留档案进行比较
- 根据分数和属性与工作满意度的相关性…
- 提出可行的建议,以提高留住人才的可能性
我得到的输出如下所示:
This member of staff will leave.I’ve noticed that this member of staff’s ‘number_project’ is below the norm. You may want to consider increasing his/her ‘number_project’ by 2.8155514094640495
我承认这不是最好看的,但我认为这是一个很好的开始。最终产品是一个可操作的洞察。
最后的想法
说明性分析有助于增强刚担任管理职位的员工的决策能力,这些员工可能正在担任此类职位或正在接受此类职位的培训。我想在某些情况下,它甚至可以用来评估这些职位的潜在候选人。
我个人认为,对于这种类型的场景,说明性分析对于找到员工不满的根本原因并找到加强员工和管理层之间关系的方法是有用的。检验这个系统是否真的能够传递价值的最好方法是在现实生活中进行尝试。
我们无法从数据中确定的一件事是组织中项目的质量,我确实相信相关性本身可能不足以确定提高工作满意度的最佳方式。也许有了更多的数据,我们可以更好地理解影响工作满意度的因素。
*更新: 我的一个朋友提到,这种类型的项目对于组织内各部门制定战略目标会很有用。之前没想到,但我绝对同意她的说法(感谢 Shades)。
我希望这个实验是有用的,我希望你学到了一些东西。我在这方面很新,我会喜欢你的反馈。请尽可能诚实,建设性的批评总是受欢迎的。
这个实验的代码可以在 这里 找到。
如果你想知道其他人是如何处理这些数据的,请点击以下链接:
为什么我们最优秀、最有经验的员工会过早离开?
www.kaggle.com](https://www.kaggle.com/ludobenistant/hr-analytics/kernels)
其他人的想法给我留下了深刻的印象。
下一步是什么?
既然我已经克服了这个挑战,我将使用一个类似的数据集来测试这个方法:IBM 员工流失数据集。我想这一次我会真正回答这个问题。😃
预测你有价值的员工的流失
www.kaggle.com](https://www.kaggle.com/pavansubhasht/ibm-hr-analytics-attrition-dataset)
回头见。
将猎人-猎物问题作为单智能体问题求解
在本文中,我们讨论如何使用猎人相对于猎物的相对坐标将(N,N)网格上的双代理猎人-猎物问题简化为(2N-1,2N-1)网格上的单代理网格世界问题。

The hunter agent (blue) capturing its constantly spawning prey (red)
虽然我们在这里描述的方法是解决猎人-猎物问题的许多独特方法之一,但它最大的效用是简单地重复利用以前在 解决单智能体网格世界问题 (我们以前的帖子)中使用的经典强化学习技术,而不需要引入任何新技术!当然,我们不能将这个解决方案扩展到更复杂的多智能体问题,但它确实是一个强化学习的例子,在这个例子中,添加额外的物理或几何约束可以绕过对更高级方法的需求。
使用相对坐标实现猎人-猎物的 Python 代码可以在我的 Github 中找到:
***** ***当前代码实现正在重新完成(我现在正在升级我的许多 repos) * *
- 完成后将使用链接更新这篇博文****
更多我关于深度学习和强化学习的博客、教程、项目,请查看我的 中 和我的 Github 。
如何将猎人-猎物问题格式化为固定环境下的单代理问题
尽管广义的猎人-猎物问题确实需要一个动态的第二智能体,在捕获猎物后在网格周围产卵的最简单版本可以简化为单智能体在猎人相对于猎物的相对网格坐标中找到原点(0,0)的静态环境。这种将参考系固定在运动物体上的方法,是二体经典力学物理问题中非常常用的一种方法,用来获得更简单的运动方程。
为了说明相对坐标是如何工作的,考虑一个位于全局笛卡尔坐标(2,4)的猎人和一个位于全局笛卡尔坐标(1,1)的猎物。用猎物坐标减去猎人坐标,我们得到(2,4) - (1,1) = (+1,+3)作为在笛卡尔坐标中猎人相对于猎物的相对位置。如果猎人能够以某种方式学会在这个坐标系中导航并到达(0,0),那么我们将使猎人与猎物在同一个网格方块上重合(也称为猎人捕获猎物!).

通过将参照系固定在猎物上,我们不再需要关心全球地球参照系——我们可以单独在猎物参照系中工作。这意味着我们可以关注 S_{hunter,relative}的相对状态空间,而不是更令人生畏的直积 S_{hunter} x S_{prey}全局状态空间。这样做不仅缩小了我们的状态搜索空间,以更快地训练我们的代理,而且还消除了在翻译等价的物理情况下训练代理的许多冗余*,即,现在教(2,4)处的猎人在(1,1)处捕捉猎物也教(3,5)处的猎人在(2,2)处捕捉猎物,因为猎人与猎物的相对位置(+1,+3)是等价的。*
为了确切地了解我们如何建立单代理框架,让我们从一个大小为(N,N)的全局网格开始。作为与单个智能体合作的交换,我们将不得不扩展我们的相对位置状态空间网格,以容纳所有可能的相对位置。具体来说,这个数字是一个大小为(2N-1,2N-1)的放大的状态空间网格,其整数值为[-N+1,N-1] x [-N+1,N-1]。这背后的推理是给定 x 或 y 的特定笛卡尔方向,全局网格上任意 2 个网格点之间的最大位移是 N 个网格正方形。因此,通过考虑正位移和负位移,我们有 2*N-1 个可能的网格平方位移的完整范围(这里的-1 来自共享的零网格平方距离)。一旦我们确定了这个扩大的(但固定的)网格状态空间,我们就可以简单地将我们看似双智能体的猎人-猎物问题解决为在[-N+1,N-1] x [-N+1,N-1]网格上搜索(0,0)的单智能体网格世界问题!
使用 AuDaS 在几分钟内解决 Kaggle Telco 客户流失挑战
【更新:我开了一家科技公司。你可以在这里找到更多
A uDaS 是由 Mind Foundry 开发的自动化数据科学家,旨在让任何人,无论有没有数据科学背景,都可以轻松构建和部署质量受控的机器学习管道。AuDaS 通过允许业务分析师和数据科学家在模型构建过程中轻松插入他们的领域专业知识,并提取可操作的见解,为他们提供支持。
在本教程中,我们将看到如何使用 AuDaS 在几分钟内建立一个分类管道。目标是使用来自 Kaggle 的数据预测电信客户流失。在这种情况下,当客户决定取消订阅或不续订时,他们会感到不安。这对电信公司来说代价很高,因为获得新客户比留住现有客户更昂贵。通过预测模型,电信公司可以预测哪些客户最有可能流失,并采取适当的决策来留住他们。
在本教程中,我们将遵循标准的数据科学流程:
- 数据准备
- 管道施工和调整
- 解释和部署
数据准备
首先,我们将数据加载到 AuDaS 中,在本例中,它是一个简单的 csv,有 21 列和 3333 行:

每行代表一个客户,每列代表一个属性,包括语音邮件数量、总分钟数(日/夜)、总呼叫数(日/夜)等。
AuDaS 自动扫描数据,检测每个列的类型,并提供灯泡突出显示的数据准备建议。在这里,数据科学家的业务分析师可以根据相关建议和适当的答案来介绍他们的领域知识。

在这种情况下,我们知道“语音邮件消息数”列中缺少的值实际上应该用 0 来填充,只需单击:

一旦我们做到了这一点,并删除了不包含任何预测功能的客户 id 和电话号码,我们就能够获得所有数据准备步骤的完整审计跟踪。如果我们愿意,我们也可以很容易地恢复到预先准备好的数据版本。

AuDaS 还会自动为您生成漂亮的数据可视化效果。

您还可以通过加入其他数据集来丰富数据集(如果适用)。AuDaS 支持您通常会做的所有其他数据准备步骤。现在,我们对数据感到满意,我们将建立我们的分类管道。
处理数据
AuDaS 允许您快速设置分类过程,为此您只需选择目标列并指定模型验证框架和评分标准。

然后,AuDaS 使用我们的贝叶斯优化器 OPTaaS 启动并搜索可能的管道(特征工程和机器学习模型)及其相关超参数的解决方案空间。AuDaS 还对其评估的所有管道进行审计跟踪,如果需要,您可以查询这些跟踪。

我以前写过使用贝叶斯优化的直觉和优势。OPTaaS 也可以作为一个 API 获得,你可以联系我要一个密钥。
部署解决方案
一旦 AuDaS 找到了最好的管道,它将对从一开始就展示出来并且从未在任何模型训练中使用过的 10%的数据进行最终质量检查。这 10%的性能指标在最后给出,AuDaS 提供了其选择的最终管道的完全透明性(特征工程、模型、超参数值)。


然后,该模型可以通过自动生成的 RESTful API 集成到您的网站、产品或业务流程中。功能相关性由 LIME 提供,对于我们的最终模型,预测客户流失的主要功能是每日总费用。

更完整的教程可以在这里找到。如果你有兴趣尝试奥达斯,请不要犹豫,联系 out !
团队和资源
Mind Foundry 是牛津大学的一个分支机构,由斯蒂芬·罗伯茨(Stephen Roberts)和迈克尔·奥斯本(Michael Osborne)教授创建,他们在数据分析领域已经工作了 35 年。Mind Foundry 团队由 30 多名世界级的机器学习研究人员和精英软件工程师组成,其中许多人曾是牛津大学的博士后。此外,Mind Foundry 通过其分拆地位,拥有超过 30 名牛津大学机器学习博士的特权。Mind Foundry 是牛津大学的投资组合公司,其投资者包括牛津科学创新、牛津技术与创新基金、、牛津大学创新基金和 Parkwalk Advisors 。
用数据科学解决“X 先生转移问题”
在现代足球世界中,我们能够衡量每个球员和球队的表现。这给了我们一堆数据,可以用作机器学习和统计的有价值的信息来源。现代足球比赛建立在统计数据的基础上,遵循既定的规则。每个赛季,俱乐部都必须接受寻找新球员的挑战,这些新球员要么应该提高他们的比赛水平,要么支持另一名离开俱乐部的球员。

All credits and rights to Mitch Rosen https://unsplash.com/photos/g9SNY0aLMF0
对于这篇文章,让我们假设我们有一个球员 x 在夏天离开了俱乐部,现在我们必须找到一个合适的替代者。找到一名球员替代另一名球员的最简单的方法是分析老球员的给定统计数据,并找到一些进球和助攻数量几乎相同的球员。这种方法给我们带来了一个大问题:这种假设让我们完全忽略了球员在哪个球队踢球,以及他的球队在一个赛季中表现出了什么样的踢球风格,这对我们的指标也有很大的影响。对于本文,我们将使用不同的方法。让我们假设我们可以用数字来定义离开的玩家的优势和劣势。通过这样做,我们将能够专注于个人指标,而不是仅仅关注目标和助攻。这将使我们能够寻找与老球员相比在特定领域具有相同天赋的球员——这也可以理解为潜力。这意味着我们将寻找有潜力的新球员来取代老球员。
在这篇文章中,我们将使用 FIFA 19 球员属性,因为它们使我们能够使用超过 14000 名球员的个人优势和技能,并且它们也是球员个人数字素质和技能的良好指标。您可以在此处找到数据集:
https://www . ka ggle . com/aishwarya 1992/FIFA-19-player-database
定义指标
在我们开始之前,我们必须看看我们想要替换的球员:
- 向前
- 左脚和右脚
- 年龄:33 岁
- 联赛:西甲
现在让我们来看看前锋位置的 10 大参数以及球员的这些属性:
- 步速:90
- 加速度:89
- 冲刺:91
- 敏捷:87
- 控球:94
- 拍摄:93
- 完成:94
- 标题:89
- 定位:95°
- 沉着:95
如果我们将这个玩家的个人资料可视化,我们会得到这样的结果:

这个球员的参数形象告诉我们,我们必须更换一个“世界级球员”。上面列出的所有参数都接近或高于 90。现在我们知道了我们想要取代什么,我们必须寻找有潜力取代这种“世界级球员”的球员。
**听起来是个有趣的任务。**😎
定义配置文件
在我们开始寻找有潜力取代老球员的球员之前,我们必须指定我们希望球员所处的重要条件:球员不应超过 26 岁,因为我们希望有人能够从一开始就表现出高水平,但也有改进和适应的空间。除此之外,球员应该在欧洲顶级联赛之一踢球,因为这意味着球员习惯于在一个赛季踢很多比赛,也习惯于在最高水平上竞争。
个人资料:
- 我们如何处理和评定这类参数?
- 对于这个问题,我想具体说明我们的参数以及如何划分这些参数。考虑一个足球运动员的表现,我们有两个非常重要的因素:身体素质和技术。如果我们现在看一下我们选择的参数,我们可以将它们分成两个新的参数:
body_gene =配速+速度+加速度+敏捷
前锋 _ 基因=控球+射门+射门+头球+定位+沉着
对于这种方法,我们将使用算术平均值。算术平均值的公式如下:
对于我们的老玩家,指标如下:
- 身体基因= 89.25
- striker_gene = 93.2
这允许我们使用平均值作为球员身体和射手能力的指标。如果我们现在应用这两个参数,并为数据集中的所有玩家计算它们,我们将得到下面的图:

Formula arithmetic mean
该图包含我们数据集中的所有玩家。现在我们不得不减去那些没有在五个联赛中比赛的和/或年龄超过 26 岁的球员。在这一步之后,我们得到相同的图,但是只有相关和合适的样本。
仔细观察我们的图会发现,它可以很容易地分为两类。第一个从左下角区域开始,在(50,30) (x,y)处停止。第二个从(50,40)开始。对于我们的任务——找到一个与我们的老玩家潜力相当的玩家——我们只能关注第二个集群,因为那里有真正优秀的玩家。我们要考虑的下一件事是,如果我们今天签下他们,我们想要那些有潜力表现出色的球员。正因为如此,我们关注所有身体基因和前锋基因至少有 70 分的球员。这导致了下面的图:
既然我们已经选择了球员,我们可以用 k-means 把他们分成不同的类别。K-means 是一种将选择的点分成多个聚类的算法。对于我们的例子,我们将把样本分成十个组。这使我们对我们的球员进行了如下划分:
显而易见,最适合我们任务的星团是星团‘8’。如果我们仔细观察聚类 8 中的点,我们可以看到这些点是我们定义的两个参数之间的最佳连接。此外,我们还有一个“离群值”,它独立于集群中其他真正优秀的参与者…聚类 2 和聚类 5 包含部分合适的玩家,因为它们在参数中的一个方面都非常好,但在两个方面都不好。我们寻找的球员需要在这两方面都很优秀或者很有潜力。

x = body_gene , y = striker_gene (over 14000 players)
我们选择了哪些球员?

x = body_gene , y = striker_gene (1426 players)
在集群 8 中,我们找到了八名符合我们要求的玩家,现在我们必须仔细查看他们的个人资料。通过分析分离的参数,我们看到我们有优秀的球员,但他们都有一些斗争考虑一个或两个参数相比,我们的原始球员的参数。但是在我们旅程的这一点上,我们可以说我们已经发现了八个非常有趣的球员。

x = body_gene , y = striker_gene (168 players)
上面所有的球员都很年轻,但就他们的职业生涯阶段而言,他们的发展还很远。如果我们现在想选择一名球员来代替我们的老队员,我们当然应该考虑比球员参数更多的因素,因为每支球队都踢得不同,阵容中有不同的球员。这让我们有了一个不可或缺的信念:如果某个球员在 A 队表现很好,不一定在 B 队也很好,因为 B 队对球员的表现也有很大的影响。但是在这篇文章中,我们关注于相似的玩家类型和属性,认为这是一个有趣的任务。

x = body_gene , y = striker_gene
结果
现在是时候看看我们选择的球员了,当然还有我们想要选择的球员。我想对你们大多数人来说,很明显,我们想在这个夏天寻找一个替代者:克里斯蒂亚诺罗纳尔多。众所周知,取代像罗纳尔多这样的球员是一项不可能的任务,但对于这项有趣的任务,我想发现那些有潜力成为前锋位置真正替代者的球员。我敢肯定,如果我们看看我们发现的八名球员的名字,你们大多数人都会在 2019 年夏天的下一次转会中至少将两名球员作为皇家马德里的转会目标。如果我们记得我们必须替换一个身体基因为 89.25,前锋基因为 93.2 的球员,我们会发现我们没有这样的球员,但是如果我们看一下我们选择的所有球员的年龄以及他们的身体和前锋基因,我们就知道我们选择了最有潜力的球员,有一天可能成为像罗纳尔多一样的球员。
这些是我们通过数据分析和聚类算法选出的球员。我个人认为这些球员是伟大的、有天赋的、年轻的,但也是昂贵的选择。我希望你喜欢这篇文章,并从中得到一点乐趣。⚽️

All of the players above are very young but also very far in their development in reference to their career-stage. If we now want to select one player to replace our the old one we should definteley consider more factors than the player’s parameters because every team plays differently and has different players in the squad. That leads us to the indispensable conviction that if a certain player plays really well in team A — does not have to bee immediately good in team B since the team has a big impact on a player’s performance as well. But for this article we focused on similar player-types and attributes considering this to be a fun task.
The results
Now it’s time to look at the players we have selected and of course which player we want to choose. I think for the most of you it’s clear that we wanted to search an alternative for the transfer of the summer: Cristiano Ronaldo. As we all know it’s an impossible task to replace a player like Ronaldo but for this fun task I wanted to discover the players with the potential to become a real alternative considering their skillset for the forward position. I’m sure that if we take a look at the names of our discovered eight players most of you would minimum take two players as an real transfer target for Real Madrid in the next transfer summer 2019. If we remember that we have to replace a player with a body_gene of 89.25 and a striker_gene of 93.2 we see that we don’t have a player that is in the direct space of this quality but if we take a look at the age of all our selected players and their body and striker_genes then we know that we have selected the players with the highest potential to maybe become one day a player like Ronaldo.

selection with body and striker mean
So these are the players we selected with our data analysis and cluster-algorithm. Personally I would evaluate those players as a great, talented, young but also expensive choice. I hope you enjoyed this article and had a little bit of fun. ⚽️
解决多臂强盗问题
多臂土匪问题是一个经典的强化学习例子,我们有一个带 n 个臂(土匪)的老虎机,每个臂都有自己操纵的成功概率分布。拉任何一只手臂都会给你一个随机奖励,成功的话 R=+1,失败的话 R=0。我们的目标是按顺序一个接一个地拉动手臂,这样从长远来看,我们可以获得最大的总回报。

多臂土匪问题的重要性在于我们(代理人)无法获得真正的土匪概率分布——所有的学习都是通过试错法和价值估计的方式进行的。所以问题是:
我们如何设计一个系统的策略来适应这些随机的回报?
这是我们针对多兵种土匪问题的目标,拥有这样的策略将在许多现实世界的情况下证明非常有用,在这些情况下,人们希望从一群土匪中选出“最好的”土匪,即 A/B 测试、阵容优化、评估社交媒体影响力。
在本文中,我们使用一种经典的强化学习技术来解决多臂强盗问题,这种技术由一个ε-贪婪代理和一个学习框架报酬-平均抽样来计算行动值 Q(a)以帮助代理改进其未来行动决策,从而实现长期报酬最大化。这个多臂 bandit 算法解决方案的 Python 代码实现可以在我的 Github 中找到,网址是:
https://github . com/ankonzoid/learning x/tree/master/classical _ RL/multi armed _ bandit
请参考我们的附录,了解关于ε贪婪代理的更多细节,以及如何使用平均回报采样方法迭代更新 Q(a)。在下一节中,我们将解释在 multi-armed bandit 环境中部署这样一个代理的结果。
我关于深度学习和强化学习的更多博客、教程和项目可以在我的和我的 Github 找到。
结果:代理选择了哪些土匪?
考虑我们的 Python 代码示例,其中有 10 个硬编码的盗匪,每个盗匪都有自己的成功概率(请记住,我们的代理对这些数字视而不见,它只能通过对盗匪进行单独采样来实现这些数字):
**Bandit #1 = 10% success rate
Bandit #2 = 50% success rate
Bandit #3 = 60% success rate
**Bandit #4 = 80% success rate (best)**
Bandit #5 = 10% success rate
Bandit #6 = 25% success rate
Bandit #7 = 60% success rate
Bandit #8 = 45% success rate
**Bandit #9 = 75% success rate (2nd best)**
**Bandit #10 = 65% success rate (3rd best)****
通过检查,我们将期待我们的代理长期挑选出 Bandit #4 作为最强的信号,Bandit #9 紧随其后,Bandit #10 紧随其后,以此类推。
现在来看结果。我们以 10%的 epsilon 探索概率对 agent 进行了 2000 次从头开始的实验,每次实验对 agent 进行 10000 集的训练。代理选择的强盗的平均比例作为集数的函数如图 1 所示。

Fig 1) Bandit choices by the epsilon-greedy agent (epsilon = 10%) throughout its training
在图 1 中,我们可以看到,在训练开始(< 10 episodes) as it is in its exploratory phase of not knowing which bandits to take advantage of yet. It is until we reach later episodes (> 100 集)时,强盗的选择均匀地分布在所有强盗中约 10%。我们是否看到一个明显的贪婪机制优先于决定哪个强盗应该获得更高的优先级,因为到目前为止所采样的奖励。不出所料,在训练的中后期阶段,4 号、9 号和 10 号强盗是被代理人选中的。最后,几乎不可避免的是,在训练结束时,代理人倾向于几乎总是选择 Bandit #4 作为“最佳”Bandit,其平台期约为 90%(由于固定的 epsilon exploration 参数,应始终保持约 10%)。
尽管在这个问题中,最佳策略是选择强盗 4,但是你会注意到,这并不意味着拉强盗 4 就一定会在给定的拉中击败任何其他强盗,因为奖励是随机的;在长期平均回报中,你会发现土匪#4 占优势。此外,使用我们的代理来解决这个问题并没有什么特别之处——这只是可以适应性地最大化长期回报集合的许多方法之一。绝对存在这样的情况,完全探索性的(ε= 100%),或完全贪婪的代理人(ε= 0%),或介于两者之间的任何人,可能最终在有限的几集里获得比我们的ε= 10%贪婪的代理人更多的奖励。在我看来,部署这样一个代理的主要吸引力在于,可以自动最小化重新选择已经显示出一些失败迹象的强盗。从商业和实践的角度来看,这可以节省大量的时间和资源,否则会浪费在寻找“最佳”强盗的优化过程中。
附录:ε-贪婪代理“个性”和报酬平均抽样“学习规则”
简而言之,ε-贪婪代理是(1)完全探索代理和(2)完全贪婪代理的混合体。在多臂土匪问题中,一个完全探索性的代理将以统一的速率对所有土匪进行采样,并随着时间的推移获得关于每个土匪的知识;这种代理的警告是,这种知识从来没有被用来帮助自己做出更好的未来决策!在另一个极端,一个完全贪婪的代理人会选择一个强盗,并永远坚持自己的选择;它不会努力尝试系统中的其他强盗,看看他们是否有更好的成功率来帮助它实现长期回报的最大化,因此它是非常狭隘的!
为了得到一个拥有两个世界的最好的有点令人满意的代理,ε贪婪代理被设计为在任何状态下给ε机会(例如 10%)来随机地探索土匪,并且在所有其他时间贪婪地对其当前的“最佳”土匪值估计采取行动。围绕这一点的直觉是,贪婪机制可以帮助代理专注于其当前最“成功”的盗匪,而探索机制让代理探索可能存在的更好的盗匪。
剩下的唯一问题是:我们如何给代理定义一个强盗的“价值”概念,以便它可以贪婪地选择?借鉴强化学习,我们可以定义行动价值函数 Q(s,a)来表示从状态 s 采取行动 a 的预期长期回报。在我们的多臂强盗的例子中,每一个动作都将代理带入一个终结状态,因此长期回报就是直接回报,我们将动作价值的定义简化为

其中 k 是一个(强盗)在过去被选择的次数的计数器,而 r 是每次选择强盗的随机奖励。通过一些额外的算术操作,这个定义可以递归地重写为

由于我们不知道从知道 Q(a)的“真实”值开始,我们可以使用这个递归定义作为迭代工具,在每集结束时近似 Q(a)。
为了将ε-贪婪代理与我们的动作值 Q(a)估计配对,我们让ε-贪婪代理在时间的随机ε-概率上选择一个强盗,并让代理在其余时间从我们的 Q(a)估计中贪婪地选择一个动作

有了这两个概念,我们现在可以着手解决多臂土匪问题!
一些重要的数据科学工具,不是 Python、R、SQL 或 Math
一些你可能想熟悉的必要的、重要的或者很酷的数据科学工具
如果你问任何一位数据科学家,要想在这个领域取得成功,你需要知道什么,他们可能会告诉你以上几点的组合。每一份 DS 的工作描述都会提到 Python 或 R(有时甚至是 Java lol)、SQL 和数学,还夹杂着一些火花、AWS/cloud 体验,并以一部分流行词汇结束。

Random pic from travel. West Lake in Hangzhou, China.
虽然这些是不可否认的必备条件,但现实是大多数数据科学家并不存在于真空中——你不太可能获得完美的数据,在自己的环境中在本地机器上构建模型,然后只需保存这些权重并收工。现代数据科学家需要必要的 CS 技能,以使他们的工作成为可能,并在其他工程师的 leu 中可用。你不会把你的 jupyter 笔记本通过电子邮件发给你的老板来展示你的工作。
这些可能并不适用于所有职位,但是以我的经验和观点来看,这些工具可以像你的面包和黄油 Python 一样重要(或者一样方便)(尽管 Python 肯定是最重要的)。我不打算深入解释这些事情,但我会解释为什么你会想了解它们,以成为一个好的数据科学家——一个能够构建生产就绪的应用程序,而不是在你的本地机器上凌乱的、探索性的笔记本。
Linux
应该不用说。让我震惊的是,有多少数据科学家可能不熟悉命令行。使用 bash 脚本是计算机科学中最基本的工具之一,由于数据科学中很大一部分是编程性的,所以这项技能非常重要。

Check out my dude the Linux Penguin
几乎可以肯定,您的代码将在 linux 上开发和部署,因此我鼓励尽可能使用命令行。像数据科学一样,Python 也不存在于真空中,你几乎肯定必须通过一些命令行界面处理包/框架管理、环境变量、你的$PATH和许多其他东西。
Git
也应该不用说。大多数数据科学家知道 git,但并不真正了解 git。因为数据科学的定义非常模糊,所以我们中有很多人没有遵循良好的软件开发实践。我甚至很久都不知道什么是单元测试。

当在一个团队中编码时,知道 git 变得巨大。你需要知道当团队成员提交冲突时,或者当你需要挑选部分代码进行错误修复、更新等时,该怎么做。将代码提交给开源或私有的 repo(如 Github)也允许你使用像工作服这样的东西进行代码测试,还有其他框架可以在提交时方便地将代码部署到生产环境中。就 git 和开源回购协议提供的功能而言,偶尔承诺一个只有你使用的回购协议只是冰山一角。
REST APIs
你已经训练了一个模型——现在呢?没人想看你的 jupyter 笔记本或者某种蹩脚的交互式 shell 程序。此外,除非您在共享环境中接受培训,否则您的模型仍然只对您可用。仅仅有模型是不够的,这是大量数据科学家碰壁的地方。

为了实际服务于来自模型的预测,通过标准 API 调用或有助于应用程序开发的东西使其可用是一个好的实践。像亚马逊 SageMaker 这样的服务已经获得了巨大的欢迎,因为它能够无缝地以生产就绪的方式制作模型。你可以用 Python 中的 Flask 之类的东西自己构建一个。

最后,有许多 Python 包在后端进行 API 调用,因此理解什么是 API 以及如何在开发中使用 API 有助于成为更有能力的数据科学家。
Docker&Kubernetes
我个人最喜欢的两个——docker 允许用户拥有一个生产就绪的应用程序环境,而不必为需要在其上运行的每一项服务集中配置生产服务器。与安装完整操作系统的大型虚拟机不同,docker 容器运行在与主机相同的内核上,并且更加轻量级。

想象一下像 Python 的venv这样的 docker 容器,它有更多的功能。更高级的机器学习库,如谷歌的 Tensorflow,需要特定的配置,在某些主机上可能难以排除故障。因此,docker 经常与 Tensorflow 一起使用,以确保为训练模型提供一个开发就绪的环境。

Lil’ guy thinking about containerized, scalable applications
随着市场趋向于更微的服务和容器化的应用,docker 是一项巨大的技能,并且越来越受欢迎。Docker 不仅适用于训练模型,也适用于部署。将你的模型想象成服务,你可以将它们容器化,这样它们就有了运行它们所需的环境*,然后可以与你的应用程序的其他服务无缝交互。这使得你的模型既可扩展*又可便携。**

Kubernetes (K8s)是一个跨多个主机大规模管理和部署容器化服务的平台。本质上,这意味着您可以在一个可水平扩展的集群中轻松管理和部署 docker 容器。

I wish Kubernetes also had a fun whale
当 Google 使用 Kubernetes 来管理他们的 Tensorflow 容器(以及其他东西)时,他们更进一步,开发了 Kubeflow :一个在 Kubernetes 上训练和部署模型的开源工作流。容器化的开发和生产正越来越多地与机器学习和数据科学相结合,我相信这些技能对于 2019 年的数据科学家来说将是巨大的。

阿帕奇气流
现在我们变得更加小众,但是这个很酷。Airflow 是一个 Python 平台,使用有向无环图(Dag)以编程方式创作、调度和监控工作流。

DAG
这基本上意味着您可以轻松地将 Python 或 bash 脚本设置为在您需要的时候运行,无论您需要多频繁。与不太方便和可定制的 cron 作业相反,Airflow 让您可以在一个用户友好的 GUI 中控制您的计划作业。超级毒品。
弹性搜索
一样小众。这个有点特别,取决于你是否有搜索/NLP 用例。然而,我可以告诉你,在一家财富 50 强公司工作,我们有大量的搜索用例,这是我们堆栈中最重要的框架之一。与用 Python 从头开始构建不同,Elastic 用一个方便的 Python 客户端提供了你需要的一切。

Elasticsearch 让您能够以容错和可伸缩的方式轻松地索引和搜索文档。数据越多,运行的节点就越多,查询的执行速度就越快。Elastic 使用 Okapi BM25 算法,该算法在功能上非常类似于使用 TF-IDF(term frequency——逆文档频率,Elastic 曾使用该算法)。它有很多其他的功能,甚至支持像多语言分析器这样的定制插件。

因为它本质上是在查询和索引中的文档之间执行相似性比较,所以它也可以用于比较文档之间的相似性。我强烈建议不要从 scikit-learn 导入 TF-IDF,而是看看 Elasticsearch 是否能为您提供开箱即用的一切。
自制 (mac OS)
Ubuntu 有apt-get,Redhat 有yum,Windows 10 甚至有 OneGet ,我是从下面的一个评论得知的。这些包管理器通过 CLI 帮助安装,管理依赖关系,并自动更新您的$PATH。虽然 mac OS 开箱即用,但家酿软件可以通过终端命令轻松安装,这是本文的重点,因为它是我最喜欢的东西之一。

假设出于某种违反直觉的原因,您想在本地安装 Apache Spark。你可以去https://spark.apache.org/downloads.html,下载它,解压它,自己把spark-shell命令添加到你的$PATH中,或者在终端中键入brew install apache-spark就可以上路了(注意你还需要安装 scala 和 java 来使用 spark)。我知道这只是一个 mac OS 特有的东西,但我太喜欢它了,我不能不包括它。
还有更多…
我可能每天都会下载几个新的包或框架(这让我的电脑很懊恼)。这个领域变化如此之快,以至于很难跟上新的东西,更难分辨什么是真正有用的。然而,在我看来,以上的一切都将继续存在。希望你喜欢它,并随时通过 LinkedIn 联系我。以后再说。
关于工作板和机器学习的一些说明

找工作最难的部分之一是首先找到申请什么。用户知道自己想要什么工作、工作地点和工资范围,但招聘信息板很难搞清楚。
与其让求职者在无穷无尽的清单中寻找合适的东西,为什么不使用机器学习来做一些排序呢?至少,一个算法可以清理掉一些杂物,让用户专注于严肃的选项。充其量,它可以找到一个完美的职业发展机会。
首先,机器学习算法必须学习职位发布的样子。也就是说,它必须知道如何提取标题,位置,薪酬范围等。从一个文本块。这些信息构成了数据库,程序从中提取信息,将工作发送给用户。然后,一旦程序能够提取所有这些信息,它需要能够根据经验和偏好向求职者提供好的建议。
所有这些后端计算意味着用户只能看到系统总库存的一小部分。只有少数工作会出现在用户的提要中,应用程序在提供未来选择时会考虑这些工作的匹配程度。
这种系统最困难的部分是从用户反馈中微调推荐。随着用户数量的增加,对新回复进行再培训的需求将呈指数级增长,而快速、可靠地改善每个人的个人资料将需要大量的时间和金钱。然而,规模问题并不妨碍构建一个基本的程序架构。
和大多数事情一样,机器学习可能会彻底改变我们找工作的方式。更有针对性的推荐可以节省求职者的时间和精力,也让公司的招聘过程不那么痛苦。通过仔细减少给用户的选择,一种算法可以让漫长而艰苦的求职成为过去。
申请经济学背景的数据科学工作的几点思考
作为一名应届经济学博士毕业生,我最近申请了数据科学家的工作,并将在几周后开始我的数据科学家生涯。这整个经历对我来说是开放的和充实的。一路走来学到了很多,刷新了对行业的认识。趁着记忆犹新,我写下一些简短的想法,与和我有相似背景的人分享,他们也对转型感兴趣。
总体印象
如今,数据科学在科技界是一个非常宽泛的概念。任何与数据相关的东西都可以称为数据科学。机器学习技术和计算能力的发展大大增强了它的能力。所以,机器学习和编码方面的知识是进入这个领域的必备知识。除此之外,我认为数据科学世界非常欢迎受过经济学培训的人。有许多职位需要很好地理解因果推理,用建模的眼光来看待一些更复杂的反馈循环会有所帮助。我发现我在处理观察数据和内生性方面的经验被我采访过的团队所重视。
DS 战队的例子
下面是两个需要很好理解因果推理的例子:
1.实验平台团队
几乎所有数据驱动的公司每天都要进行数百次实验。实验平台团队提出了有助于快速实施和评估实验的方法。在科技界,人们进行随机对照试验,这听起来可能很简单,但实际上包含许多陷阱。当 RCT 不可行时,就需要对观测数据进行因果推断。如果您是估计平均治疗效果和/或边际治疗效果的专家,并且对在大数据上应用这些传统推理工具感到兴奋,那么这将是一个非常合适的选择。
例如,在优步的实验平台上有一篇关于他们所做工作的信息丰富的博文:https://eng.uber.com/xp/。
2.脸书大学的营销科学 R&D 团队
同样,这个团队专注于开发评估脸书各种产品营销活动的指标和方法。和许多其他团队一样,他们结合使用倾向评分匹配、重新加权和其他技术。这篇文章非常清晰地介绍了他们所做的项目类型。
这只是我有限的求职经历中的两个例子。肯定还有很多要探索的。当我在写这份总结的时候,我发现了这篇最新的综述论文,这篇论文全面概述了经济学博士在科技公司的工作。
如何准备
我们(传统培养的经济学博士)需要赶上的两件事是机器学习和编码(python,数据结构和算法)。有许多关于这些的在线资源。《统计学习简介(ISLR)这本书是机器学习很好的参考。如果你对以下问题感到满意,那你就对了:
1.什么是偏差-方差权衡?
2.如何处理模型过度拟合?L1 和 L2 正规化的利与弊是什么?
3.写一个 python 代码实现快速排序,说说时间复杂度。
4.编写一个 python 类来实现 K 近邻分类。
5.XGboost 和随机森林有什么区别?
6.使用 SQL 查找每个班级学生成绩的中位数。
我是如何准备的
除了自学之外,我还参加了 Insight Fellowship 计划,该计划有助于创建一个协作学习环境并加快过渡。我向任何想快速过渡到数据科学的人强烈推荐这个项目。你可以从他们的博客和特别是这篇文章中获得更全面的信息。他们在旧金山、西雅图、纽约和多伦多都有项目,而且发展很快!
关于医疗保健中机器学习的一些思考
我最近在 USSOCOM 做了一个关于医疗保健中的机器学习(ML)的演讲,我想发表它以获得反馈。在 ML 任务中,找到合适的 ML 工具来克服问题和找到合适的问题来解决是不同的挑战。跨学科团队可以最好地克服这些挑战。这个博客仅限于我自己的经历,但就我的职业生涯跨越不同领域而言(协调学术 ML 研究小组,帮助深度学习初创公司,研究医学,研究商业,并在演讲系列中采访许多 ML 先驱),我希望它带来一个广阔的视角。我可以在每个要点的基础上进行构建,并且会根据读者的反馈进行构建。
ML 在医疗保健领域的前景怎么强调都不为过。在众多承诺中,我将着重谈几个:
- 我们可以改变我们对健康的看法。被动、主动的预防医学体系让位于前瞻性预测医学和被动健康监测。
- 我们可以改变患有罕见疾病的人的生活,他们中的许多人花了十年或更长时间才得到正确的诊断,这不是因为临床医生从未听说过他们的疾病,而是因为他们在实践中从未见过它。
- 在过去的 20 年里,我们已经有了大量的临床证据,而且增长速度还在继续加快。我们正在达到一个饱和点,我们可以教人们如何遵循这些东西,即使在我离开医学的几年里,我教育的大部分领域已经过时了。ML 既可以帮助监测大量潜在信号,也可以整合最新信息,无论是来自新的临床研究还是新疾病爆发时的实时信息。
也就是说,医疗改革的步伐可能会让你失望。
- 发达国家医疗保健的激励结构是围绕下行最小化而不是上行最大化建立的。我们对临床医生的错误惩罚过度,而对他们的成功奖励过度,随着我们转向基于价值的模式,这些支出的相对规模不会发生实质性变化。因此,护理者通过尝试新的东西(尤其是新的和未经证实的)通常会获得很少或没有收获,而由于偏离护理标准而遭受重大损失。
- 我相信这就是为什么医疗保健组织倾向于不承担风险,即使给他们一些余地。以加拿大的医疗体系为例,该体系向各省提供整体拨款。这种模式的好处之一是,各省可以试验如何实施医疗保健系统,并随着时间的推移相互学习。在实践中,试验从未体现过(相反,各省实施了类似的模式,并大多通过削减资金的传统政策机制来节省资金)。即使有一些力量推动医疗保健系统进行创新,这些结构内的激励因素(医疗保健工作者的职业价值观,谁得到晋升,谁受到惩罚)和围绕这些结构的激励因素(医疗事故侵权,对糟糕的医疗保健结果的负面公众反应)导致系统向平均值收敛。
- 第二,从医学的角度来说,照顾他人是“奇怪的”,而其他关系却不是。我们将这种怪异的关系正常化,将关怀行为纳入仪式中。围绕护理者的仪式在不同的民族和不同的时间有所不同,但护理总是仪式化的。我认为这是人类的需要。目前对这些仪式性角色的广泛需求将减缓医疗保健的根本变化。
- 顺便说一下,面向病人的医疗保健技术应该专注于创造这种治愈感。在吸引用户方面,创造这种治愈感可能比拥有功效更重要。看看被揭穿的补品的持久流行就知道了。
- 对于 ML 来说,转变医疗保健存在严重的技术障碍,尽管这些障碍并不是医疗保健所独有的。一些公司已经封存了大量潜在数据。很多数据都没有结构化。这种非结构化数据的保真度不是很高——一些人可能拥有完整的信息,另一些人可能没有,并且报告的信息可能会因观察者之间的差异而受到不可接受的影响。
- 以我的经验来看,在回答问题的 ML 从业者和提出这些问题的护理者之间仍然有很大的差距。我认为这部分是由于各种类型的护理人员在培训中很少接触 ML,这反过来使得 ML 研究人员更难从该领域找到合适的合作者。
如果我是一个投资者,这些将是我的论点:
- 在医疗保健的所有领域中,ML 将在未来五年对网络安全产生最显著的影响。我们已经看到对医院的网络攻击快速增长,越来越多地涉及影响患者护理和安全的勒索软件。政府对患者数据安全的重视程度非常苛刻。我预计政府将授权医院投资更好的网络安全技术。作为前兆,联邦调查局刚刚向医院发出了另一份私人行业通知(PIN ),警告他们存在网络漏洞。如果这对于政府来说是一个足够重要的优先事项,那么这将是一个要求,同时为组织购买新系统提供资金。我怀疑基于 ML 的网络安全解决方案将最适合捕捉这一价值。
- 供应链创新将有望对医院产生重大影响。许多在医院工作的人花费他们的时间来帮助材料流向正确的位置(例如,保持手术室供应的网络,护士一天多次给所有病人分发他们的药物)。除了无人驾驶汽车,我们正在进入一个更加无人驾驶的时代。
- 发展中国家将超越发达国家。在世界上的许多地方,医疗保健有一个主要的上行最大化组件。尽管我们必须在“全新护理或当前标准护理”之间做出选择,但许多人被迫选择“全新护理或不护理”,因为他们无法用现有资源满足医疗保健需求。世界上的其他地方是风险厌恶型的,技术人才是流动的,ML 的现成实现对于解决主要的医疗保健需求来说已经足够好了。求解均衡。
关于 Coursera 深度学习专业化的几点思考
最近完成了 Coursera 上的深度学习专精。这个专业要求你参加一系列的五门课程。我想这让我有点像独角兽,因为我不仅完成了的一门 MOOC,还完成了的五门相关课程。
所以,我想分享一下我的想法。但是,我不想把这篇文章正式地当成一件事,所以把它当成一些未经修饰的思考:
- 你学习的东西的种类;
- 你做的事情的种类;而且,
- 49 美元/月,值得吗?
放弃
但是,首先:我可能不是这个专业的目标受众。因此,您的里程可能会有所不同。这门课程似乎是面向那些拥有计算机背景、希望在“深度学习”领域获得一份行业工作的人。我不是那样的。我有博士学位,并且是排名前十的计算机科学系的终身教职教师。我获得这个证书并不是为了推进我的职业生涯或者进入这个领域。相反,我参加了这一系列课程,方便地排序为“专业化”,从一个显然在吴恩达对深度学习了解很多的人那里学习更多关于深度学习的知识。
“为什么?”你可能会问。第一,能够聪明地谈论和思考似乎是一件有用的事情——几乎每个计算机科学部门都在试图雇用从事人工智能/人工智能/深度学习的人,你真的无法逃避关于它的对话。二、因为刻意练习。三,因为我也想一年被引用 12000 次,因为我写了一些关于深度学习的东西。
总之。
你学到的东西的种类
专业化的第一门课程提供了对神经网络如何工作的基本的、表层的理解,以及我们如何和为什么使它们深入。Andrew 将会谈到为什么你应该深入学习,尽管你可能已经想这么做了,因为你正在学习这门课程。他把人工智能比作电。呃…
我发现第一门课的技术内容足够深入(没有双关语的意思)。Andrew 很好地传达了深层微积分背后的直觉——他详细到足以让你思考:“是的,我明白。我可以做到。我不想这么做,但我肯定能做到。”
第二道和第三道菜更元。他们:指导你如何有效地构建机器学习项目(例如,你应该将多少数据放入训练/开发/测试集?);诊断您的模型的问题(例如,它是一个偏见问题吗?方差问题?两者都有?您需要更多数据还是不同的架构?);并且,教你可以用来解决这些问题的策略(例如,什么时候使用什么优化器,如何初始化权重矩阵)。
第四和第五门课程是最酷的:它们教你卷积神经网络和递归神经网络,并带你了解计算机视觉、人脸识别、图像字幕、自然语言处理、音乐生成、神经风格转换等方面的前沿架构。在你做这些之前,你肯定需要学第一门课,但是你可以…也许跳过第二和第三门课。我不推荐,但是如果你很急,我又不是你爸。做你想做的。
总的来说,我认为这门课程的知识性内容是学术和应用知识的完美结合。他谈到了具体学术论文背后的见解和直觉,还谈到了像矢量化这样的实际实现细节。
你做的事情
我欣赏专业化的一点是,它不仅仅是讲座和测验:有实际的编程任务,你实际上可以对深度神经网络进行编程。当然,有很多自举——他们不只是让你前进和随机梯度下降。相反,所有的作业都在 Jupyter 的笔记本上做了注释,相关的理论信息在你要写的代码上方的单元格块中被很好地格式化了。
此外,因为有五门课程,所以进度很快。这些任务开始时相当简单——用 numpy 旋转一些向量和数组来实现单个神经元向前传递的一次迭代。在课程结束时,您将使用 Keras 等更高级的深度学习编程框架来实现实际的深度神经网络,该网络可以识别面部表情并生成(糟糕的)莎士比亚十四行诗。
49 美元/月,值得吗?
这是一个复杂的问题,取决于你期望从课程中得到什么。49 美元/月已经很多了。大概有 5 个网飞会员——或者大约 50 个网飞用户。所以,是的,尽管我对这个课程总体上是积极的,但我不认为我能明确地说答案是肯定的。
首先,我个人认为:
我喜欢这种专业化,并认为这是值得的,因为信息的组织方式最大限度地增加了我搜索的可能性。仅仅通过阅读大量免费提供的公共领域知识,我可能就能更便宜、更快、更有效地学到我在那门课程中学到的一切。但是,我不得不投入更多的前期工作,这需要时间,反过来,这可能意味着我永远不会这样做,因为没有人有时间。
有了这个专业,我知道什么是我知道的,什么是我不知道的,如果我想的话,大概知道如何让后者成为前者。我还可以与比我了解深度学习的人(例如,所有 ML/AI 教员候选人)进行关于深度学习的大致可理解的对话,并非常得意地评判所有了解较少的人。这门课程也让我大致了解了该领域的最新进展,现在我对如何将它应用到我自己的研究中有了很好的理解。
所以,对我来说是值得的。
但这句话出自一个人之口,这个人很幸运,有多余的钱,而且并不渴望这门课程能让我进入一个新的领域,帮我找到一份新工作。
如果你想进入深度学习领域,并在人工智能的某个高端领域找到一份工作,我认为 49 美元/月是一种相对便宜的方式,可以让你在简历上显示出你了解深度学习。课程结束时,你会获得一份证书,可以放在你的 LinkedIn 个人资料上。我不确定那个证书是否有用。
只是为了得到一些非常不科学的实证数据,就在一个多星期前,我把证书添加到了我的 LinkedIn 个人资料中。根据提供给非 LinkedIn 专业会员的非常粗略的指标,我注意到我的 LinkedIn 个人资料每周被查看的次数略有增加(显然,比前一周增加了 25%)。此外,第二个最受欢迎的搜索是“Python +统计学+机器学习+数据科学”,第三个最受欢迎的是“计算机视觉”。不过要记住,我之前在 LinkedIn 上被推荐过“python”、“机器学习”和“数据科学”。但是,我对计算机视觉没有兴趣。所以,你想怎么做就怎么做。

如果你现在就想深入学习某个特定的项目,那么这门课程对你来说可能太慢了。有许多免费的在线教程,介绍如何将带有预训练权重的高级深度学习框架用于许多开箱即用的应用(如面部识别和语音合成)。
如果你有更多的时间投资于深度学习的理论基础,并希望在完成课程后成为一名有效的深度学习者,那么…你可能会失望。还记得我说过的作业是强自举的吗?这有助于减少你不得不花在作业上的时间,但也使你很难轻松地将知识转移到课程之外。
在过去的一周左右,我个人一直在做一个兼职项目,它比我想象的要困难得多。不要误解我,很多知识肯定是可以转移的。但是,我必须阅读大量的文档并搜索大量的代码示例,然后才能做任何与我在课程中所做的相近的事情。哦,在课程结束后,他们会收回他们为作业提供的笔记本,所以你不可能回去重新学习你做过的事情。(如果您参加了本课程,您可能应该保存这些笔记本以供以后参考)。
所以:不好意思,值不值得我无法回答。这不是一个明确的“是”——这取决于你的目标、时间限制和可支配收入。不过,希望这篇评论至少给你一个权衡利弊的起点。
现在,像老板一样走下去。
机器学习/数据科学入门问答
我们讨论了一些对机器学习/数据科学“初学者”有用的建议和问答。我们涵盖了开启旅程所需的关键书籍、课程、基础知识、数学和编程工具。

在获得电子工程博士学位后,我在 R&D 做了 8 年的工程师。我在半导体设备领域工作,仅在过去一年左右的时间里,我才开始学习和实践机器学习(ML)和相关的数据科学(DS)概念和技术。
除了参加许多在线 mooc和建立我的 GitHub repos 之外,我还花时间在 Medium 上写了一些关于数据科学和机器学习主题的文章。他们中的一些人得到了很好的回应,并激发了有趣的讨论。在这段时间里,我的许多来自类似技术背景的朋友都问我是如何继续学习的,以及我专注于哪些方面来学习必不可少的 ML/DS 概念。此外,我在我参加的一些社交媒体论坛上默默地观察了数百个这样的问题。在我的个人收件箱中,我收到了来自完全陌生的人的电子邮件,他们讨论我的 Github 代码的问题,或者在作为一名机械工程师辛苦工作一整天后,寻求如何管理时间学习数据科学的技巧!
作为回应,我试着列出迄今为止在我的旅程中我所拥有并发现有价值的最重要的见解。当然,对于一个有经验的从业者来说,这些可能看起来很平常。但是,我的目标是给像我这样的初学者一些入门的思路。与此同时,我会试着写下我从朋友和陌生人的收件箱中收到的一些经常重复的问题的答案。
这将是高度偏向以我自己的经验。而且没有方差因为样本集只包含一个心智——我的:)因此,如果你继续读下去,请应用一个合适的过滤器(卷积与否),然后放上最终的分类标签:-)
初学者的一般问答
“我 是计算机科学/工程专业的学生。我如何进入机器学习/深度学习/人工智能领域?”
—你很幸运。当我还是学生的时候,这个领域仍然有点“冷”,我从来没有听说过:(不管你的主要研究领域是什么,你都可以阅读和获得关于机器学习的知识。请不要仅仅因为有人在网上滔滔不绝地谈论或者你在你朋友的 LinkedIn 个人资料上看到证书,就直接去 Coursera 注册 Ng 教授的课程。
- 从 YouTube 上一些很酷的视频开始。读几本好书或文章。例如,你读过《大师算法:对终极学习机的追求将如何重塑我们的世界》吗?而且我敢保证你会爱上这个很酷的关于机器学习的互动页面?
- 先学会明确区分流行语— 机器学习、人工智能、深度学习、数据科学、计算机视觉、机器人学。阅读或听专家们关于每一个问题的演讲。观看 Brandon Rohrer 的精彩视频,他是一位有影响力的数据科学家。或者这个关于数据科学相关的各种角色的清晰定义和区别的视频。
- 明确你想学什么的目标。然后,去上 Coursera 课程。在开始学习这门课程之前,确保你已经熟悉了 MATLAB,并且知道如何做矩阵乘法。或者考华盛顿大学的另一个也不错。请不要在学习基础课程之前学习 deeplearning.ai 课程。
- 关注一些好的博客 : KDnuggets , Mark Meloon 关于数据科学生涯的博客, Brandon Rohrer 的博客,打开 AI 关于他们研究的博客,
- 如果你已经开始学习和实践机器学习,但对自己的理解没有信心,你可以尝试 Simplilearn 的这个 12 个重要的机器学习面试问题 指南,调整你的学习指南针。
- 最重要的是,培养对它的感觉。加入一些好的社交论坛,但是抵制住诱惑,不去关注耸人听闻的标题和发布的新闻。做你自己的阅读,了解它是什么和不是什么,它可能去哪里,它可以打开什么可能性。然后坐下来思考如何应用机器学习或将数据科学原理融入日常工作。构建一个简单的回归模型来预测您下一顿午餐的成本,或者从您的能源提供商那里下载您的用电数据,并在 Excel 中绘制一个简单的时间序列图来发现一些使用模式。 如果能下到那种个人水平,那么恋情自然有保障 。当你完全迷上机器学习后,你可以看这个视频
“W有哪些关于 AI/机器学习/深度学习的好书可以看?”
—这个问题似乎有很多可靠的答案。我不会把我自己的偏见堆积起来,而是倾向于给你一些显示最有用的精选收藏的顶级链接,

- 10 本机器学习和数据科学的免费必读书籍作者马修·梅奥。
- 关于机器学习和人工智能的初学者必读书籍 —作者 AnalyticsVidhya。
- 这个牛逼的 GitHub 回购。
- 来自 machinelearningmastery.com 的各层次从业者的可靠指南。
"N 现在告诉我一些最适合初学者的在线课程"
—同样,几个链接和一些建议。首先是链接,

- 顶级机器学习 MOOCs 和在线讲座:综合调查。
- 为机器学习和数据科学选择有效课程的 15 分钟指南。
- 最好的机器学习课程——班级中央职业指导
建议是,只有你才能通过这些 MOOCs 决定正确的学习顺序和速度。有些人非常喜欢上在线课程,并能保持足够的动力去下载所有的编程材料并练习它们。有些人充满热情,但无法在网上视频讲座中保持清醒。介于两者之间的还有很多。作为一个初学者,你可以从在线课程中获得大量的知识并建立坚实的基础,但你必须掌握它们的节奏并正确地接近它们。
“OK,那么你上网络课程有什么特别的小技巧?付费课程/证书值得吗?”
- 研究最佳课程的精选列表(如上),并全部参观。应该不会花你什么钱。列出要求和难度,以及所涵盖主题的广度。
- 永远为你想学的东西保留一份个人路线图。它应该几乎像一个时间序列,即在确定的时间点要实现的明确目标。
- 戴上数据科学家的帽子,尝试用这个时间序列来适应课程。它是否与你想要在不久的将来获得的有价值的概念和工具相匹配,即教给你这些概念和工具?它是否深入到了您已经知道但想要进一步完善的框架和专业领域?根据课程的实用性和你的个人需求给课程打分。
- 列出一个季度的前 5 门课程。我发现用季度来思考很有用。
- 现在,寻找成本的影响,阅读前 5 名学生的评论。尽量快速判断哪个评论者的个人情况最像你,并给那个评论高度加权。
- 我大部分时间都参加了旁听课程/自由选择课程。我只为课程/证书付费,我认为这些课程/证书会提高我在这个领域的可信度。测验并不重要,但编程作业/笔记本很重要。大多数被审核的课程会让你免费下载笔记本。这就是你所需要的。相信我,如果你认真努力,你可以把这些笔记本做得比老师提供的版本好得多。
- 如果你有一定的开支预算,我建议你去找当地提供证书的大学或者有课堂选择的训练营课程。这也适用于职业人士,因为他们大多在晚上或周末投递。只有当你从 it 部门获得高度可信的证书时才花钱——最好是从好的大学附属夏令营或项目中获得。
- 如果你需要从头开始温习编程语言技能,Udemy 上几乎没有专注且节奏轻松的课程。一般来说,这些课程旨在用您选择的语言教授您编程的基本知识,而没有更深层次主题的负担。我发现,Coursera 或 edX 课程大多由学术研究人员提供,最适合于主题学习,而不是作为编程 101。另一方面,Udemy 课程非常适合复习基础知识。等待 Udemy 的 10 美元优惠活动(他们几乎每个月都有),然后打包购买这些课程。我特别喜欢何塞·马西亚尔·波尔蒂利亚的关于 Python、R、SQL 和 Apache Spark 的课程。
- 互联网是一所大学,图书馆也是一所大学。根据你的需要考虑和利用任何在线资源——整体的或零碎的。如果你对 Gits 一无所知,可以找一些关于 Gits 的短期课程。如果你需要了解一门特定语言的快速网页清理技术,只需观看一门更大课程的讲座。如果你真的认为基本的数据结构是神秘的,那就去参加大一计算机科学课程吧。哈瓦德的 CS50 就是一个很优秀的。或者甚至有一个为商务人士设计的版本有着不同的味道。
抄袭托尔斯泰却反其道而行之,“每一个坏的过程都是相似的,每一个伟大的过程都有其独特的伟大之处 ”。培养发现顶级课程伟大之处的眼光。
“So、开启旅程需要哪些绝对的基岩知识?”
——除了学习新事物的好奇心和为之努力的热情,什么都没有。你必须获得知识,实践,并在过程中内化概念。但即便如此,结构化学习方法还是有一些基本要点。同样,这是我个人的经验,因此需要根据你的个人情况和目标进行彻底的重新调整。

By Camelia.boban (Own work), via Wikimedia Commons
- 用数字让自己适应数据和模式。并接受数据可能来自任何类型的信号或来源的事实——电子表格财务、银行交易、广告点击、医院病历、可穿戴电子设备、亚马逊 echo、工厂装配线、客户调查。因此,它们可能是混乱的、不完整的和难以解读的,学习如何耐心和聪明地处理它们对于以后构建伟大的模型是有用的。这不是一门硬知识,而是一种才能。
- 你应该对高中水平的数学非常非常熟悉,包括基础微积分。这里有一篇关于它的文章。具体来说,关于多元函数、线性代数、导数和图形的概念应该是清楚的。

- 熟记基本统计学原理。大多数(如果不是全部的话)经典机器学习只不过是用计算机编程和优化技术的接口包装起来的合理的统计建模。深度学习是一个不同的领域,与之相关的理论仍在积极开发中。然而,如果你对基础统计学有扎实的掌握,你就离成为一名优秀的机器学习实践者还有很长的路要走。这是一本优秀的免费在线书籍。或者说,加州大学圣地亚哥分校的这门课程确实以一种有趣的方式确定了基础知识。或者,如果你喜欢看有趣的 YouTube 视频,你可以试试这个频道。

- 熟悉至少一种高级编程语言是有用的。因为,除非你是机器学习领域的博士研究员,致力于一些复杂算法的纯理论证明,否则你应该主要使用现有的机器学习算法,将它们应用于解决新问题,并基于这些技术创建酷的预测模型。这需要戴上编程的帽子。虽然没什么特别的需要。仅仅是对特定语言的语法、变量、数据结构、条件、函数和类定义的基本熟悉。关于“数据科学的最佳语言”有大量的争论和积极的讨论。当争论激烈进行时,拿起你的咖啡,阅读这篇有见地的文章来获得一个想法,看看你的选择。或者,在 KDnuggets 上查看这篇文章。

- 学习 Jupyter 基础 。对于数据科学家来说,这是一个非常棒的编程和实验工具。不仅要学习如何编码,还要学习如何使用 Jupyter 编写完整的技术文档或报告,包括图像、降价、LaTex 格式等。这是我根据 markdown 功能整理的 Github 笔记本。请记住,Jupyter 项目最初是 IPython 的一个分支,但后来发展成为一个成熟的开发平台,支持您能想到的任何数量的编程语言。


- 熟悉 Linux/命令行界面、git 和堆栈交换对于您开始实际实现非常有帮助。令人惊讶的是,这比听起来要难。特别是,对于像我一样的许多工作专业人士来说,使用基于 Windows 或 Mac 的企业级工具已经成为一种根深蒂固的天性。对于软件工具的技术帮助,我们期望弹出一个闪亮的小电子手册。注册一个账号,在 Stack 论坛上发布一个框架良好的问题,对我们来说太多了。但是尽早学习它们,并且拥抱开源文化。你会发现,甚至在你在 stack overllow:)上打完你的问题之前,整个世界都渴望解决你的问题,你还会惊喜地发现,安装一个强大的软件库并不像那些极客让你相信的那样令人生畏。就像“ pip 安装… ”一样简单
第一部分到此为止。在第二部分中,我希望涵盖另外两个方面最重要的问答,
- 一些对初学者有用的关键机器学习/统计建模概念,
- 其他非常需要的技能,如在社交/专业平台上引人注目,以及定期关注构建材料。
如果您有任何问题或想法要分享,请通过tirthajyoti【AT】Gmail . com联系作者。你也可以查看作者的 GitHub 资源库 中其他有趣的 Python、R 或 MATLAB 代码片段和机器学习资源。如果你像我一样,对机器学习/数据科学/半导体充满热情,请随时在 LinkedIn 上添加我或在 Twitter 上关注我。
从无到有:GANs 的进展如何?
克洛伊·布莱斯维特

早在 2014 年,Ian Goodfellow 就向我们介绍了生成式对抗网络,简称 GAN,这是一种可以在无人监督的情况下工作的深度机器学习。Yoshua Bengio 与 Goodfellow 一起编写了深度学习教材。
“为了让计算机变得智能,它们需要拥有知识。但问题是他们从哪里获得这些知识?”蒙特利尔大学蒙特利尔学习算法研究所(MILA)所长 Yoshua Bengio 教授问道。
“以前,研究人员试图直接传授知识。这是经典的人工智能,我们告诉计算机事实和规则,但不幸的是,我们知道的许多事情是不可传达的,它们是直觉的。”
本质上,有些事情我们知道,但不能,或者就是不解释。
“我们在过去几年取得的进展非常惊人,但这主要是基于监督学习,即人类告诉计算机如何解释图像、声音或文本。我们认为,我们现在所做的这种学习有一些局限性,人类能够应对。”
问题是如何让计算机在无人监督的情况下学习,而不是硬编码事实和数字。
“我们不想告诉计算机解释(某些)数据的基本概念是什么。”
本吉奥强调,他不确定最佳的前进方式是什么,他高兴地承认,开发自主学习人工智能可能有多种方式。这种清晰路径的缺乏导致了许多创新,GANs 在生成性学习领域处于领先地位。
“检验计算机是否理解我们输入的数据的一种方法是,让计算机生成应该来自同一分布的新示例。”
例如,也许一个程序已经看到了成千上万张不同的新面孔的图像。为了查看计算机是否理解了这组训练图像,程序员可以请求计算机根据数据集生成一张全新的、完全新奇的脸。这项任务比看起来更难,因为“自然”图像与计算机生成的图像非常不同。
多年来,机器学习中出现了许多生成模型,但生成对抗网络的成功来自于它们的对抗性。
“GANs 与传统的机器学习非常不同。我们有这两个网络,生成器和鉴别器,它们中的每一个实际上都在优化一个不同的东西,所以使一个表现良好的东西会使另一个变得更差。”
“gan 以及许多具有潜在空间和内部表示的生成网络的一个优点是,我们实际上可以玩表示,并在表示之间进行插值,或从表示中进行加减。
“我们观察到的第一件事是训练 GAN 可能不稳定。有时候,训练进行得很顺利,你可以看到生成的图像越来越好,但突然间,事情变得糟糕起来,训练目标开始以奇怪的方式前进。”
这种不稳定性的主要原因与它作为一种生成模型如此成功的原因是一样的。
研究人员已经开始面临的其他常见障碍包括模式崩溃,即图像重复多次;缺失模式,没有足够的多样性进入生成的数据集;缺乏明确的质量量化措施。
那么,既然要克服这样的挑战,为什么还要继续研究 GANs 呢?
“嗯,它与以前在机器学习方面所做的事情如此不同,你知道,它可能会在未来给我们带来更好的东西!”
注意:这篇文章是基于本吉奥在 4 月 29 日至 30 日的最佳会议上关于人工智能的演讲。他是一个主题演讲人,这是他第一次与最优秀的人交谈。
歌曲流行度预测器

Mohamed Nasreldin、Stephen Ma、Eric Dailey、Phuc Dang 的项目
简介
DJ Khaled 大胆宣称总能知道一首歌什么时候会流行。我们决定通过问三个关键问题来进一步调查:热门歌曲是否有某些特征,对一首歌的成功影响最大的因素是什么,以及老歌甚至可以预测新歌的受欢迎程度吗?预测一首歌会有多流行不是一件容易的事。为了回答这些问题,我们利用了哥伦比亚提供的百万首歌曲数据集,Spotify 的 API,以及机器学习预测模型。我们提出了一个模型,可以预测一首歌有多大可能成为热门歌曲,通过将其列入 Billboard 的前 100 名来定义,准确率超过 68%。
背景
2017 年,仅在美国,音乐产业就创造了 87.2 亿美元的收入。由于流媒体服务(Spotify、Apple Music 等)的增长,这个行业继续繁荣发展。流行歌曲获得了大部分收入。2016 年前 10 名艺人总共创造了 3.625 亿美元的收入。关于是什么让一首歌流行的问题在之前已经被研究过,并取得了不同程度的成功。每首歌曲都有关键特征,包括歌词、时长、艺术家信息、温度、节拍、音量、和弦等。先前的研究认为歌词可以预测一首歌的受欢迎程度,但收效甚微。
数据采集&预处理
获取数据
选择的数据集是哥伦比亚大学提供的百万首歌曲数据集,从 Echo Nest 中拉出。我们选择这个数据集是因为它有大量的特征和大小。这个数据集的主要问题是提供的格式。为每首歌曲提供了单独的 h5 文件。提供了一个脚本来将数据集转换为 mat 文件,以便在 matlab 中使用。我们修改了脚本,以便它可以生成一个 csv,我们可以用它来训练我们的模型。数据集也太大了。所有 100 万首歌曲的容量约为 280 GB。谢天谢地,有一个随机选择的子集,只有 10,000 首歌曲。
数据集中的每首歌曲都包含 41 个特征,通过音频分析、艺术家信息和歌曲相关特征进行分类。
音频分析功能:速度,持续时间,模式,响度,关键,拍号,部分开始
艺术家相关特征:艺术家熟悉度、艺术家受欢迎程度、艺术家姓名、艺术家位置
歌曲相关特征:版本,标题,年份,歌曲热度
刮广告牌歌曲
百万首歌曲数据集中的原始数据带有歌曲热度特征。然而,大约有 4500 首歌曲没有这个功能,这几乎是我们使用的子集的一半。因此,我们想找到一种新的方法来分类一首歌是否流行。我们决定使用 BillBoard Top 100 来确定受欢迎程度。如果一首歌至少出现在 100 强排行榜上一次,那么它将被列为热门歌曲。
我们使用 BeautifulSoup 编写 python 脚本来抓取 billboard.com,得到 1958 年到 2012 年出现在排行榜上的所有歌曲。我们停在了 2012 年,因为数据集中最近的歌曲都是在 2012 年发布的。在获得 billboard 上的歌曲列表后,我们回到我们的 10,000 首歌曲数据集,并相应地对它们进行分类。在我们的数据集中的 10,000 首歌曲中,有 1192 首被归类为热门歌曲。
清洗数据集
由于旧的不推荐使用的数据,数据集中的许多字段不可用。许多数据字段丢失,并且没有 echonest API 来填充数据,因为 API 被 Spotify 修改了。因此,许多领域不得不放弃。有些要素只缺少合理的数量,我们决定用平均值来填充缺少的值。一个例子是艺术家熟悉度字段,它只有 10 个缺失值。
艺术家 ID 和模式这两个要素被修改,以更好地反映它们在数据集中的属性。数据中的每个艺术家都由一个字符串唯一标识,所以我们决定对他们进行标签编码。调式是歌曲在制作过程中使用大调还是小调。虽然这个值很简单,0 表示次要,1 表示主要,但是还有一个名为 mode_confidence 的值,它描述了所选模式准确的概率。有了这两个值,我们组合了从-1(小调)到 1(大调)的特性。值-1 表示 100%确信该键是次要的,1 表示 100%确信该键是主要的。小调的置信度范围在-1 和 0 之间,大调的置信度范围在 0 和 1 之间。这大大增加了这个值的重要性,我们将在下一节看到。
该过程可以总结如下:
- 从 labrosa Columbia 下载数据子集
- 将数据格式从 h5 转换为数据帧
- 刮掉出现在排行榜前 100 名歌曲
- 数据中的分类歌曲
- 清理数据集

数据探索
在收集数据并对其进行清理以供使用后,我们通过研究特征的重要性、数据集中的趋势以及确定这些特征的最佳值,继续进行数据探索。
特征重要性

在这里,我们可以看到最终数据集中每个要素的 f1 值。我们在这里可以看到一个有趣的趋势,即歌曲的实际音乐方面与艺术家信息合理地纠缠在一起。诸如速度、模式和响度之类的技术特征与诸如熟悉度、热度和辨识度之类的艺术家信息一样重要。
艺人熟悉度
艺人熟悉度与歌曲热度

正如我们所料,艺术家的熟悉程度与热度值相关。Y 轴是根据歌曲热度 Y,其中 0 是最低分,1 是最高分。熟悉度在 x 轴上,范围也是从 0 到 1,根据 Echo Nest 的算法描述艺术家的“熟悉”程度。当这个值接近 1 时,歌曲的热度也接近 1(谁能想到呢?).
艺人位置
艺人经度 vs 歌曲热度

我们也可以在上面的图表中看到一些有趣的趋势。虽然通常在也产生点击的区域中有更多的活动,但是我们可以看到点击集中在这些特定的区域。大多数活动来自世界的西部,在北美,我们也可以看到东海岸和西海岸之间的分界线。因此,我们可以期待模型使用这一点来预测一首歌是否是热门歌曲。
速度和持续时间


我们对热门歌曲的分布感兴趣,所以我们隔离了热度值为 1 的所有歌曲,并绘制了这些歌曲的不同特征的分布。我们可以看到,热门歌曲通常使用的节奏有一个范围,在这个范围内有两个峰值,分别为 100 bpm 和 135 bpm。热门歌曲的时长平均在 200 秒左右,一般在 3 到 4 分钟之间。

Optimal values for key selected features
对于登上 Billboard 前 100 名的歌曲,我们研究了之前使用 f1 评分检测到的一些顶级特征的平均值和标准偏差,结果相当合理。节奏约为 122 bpm,标准偏差为 33 bpm,艺术家熟悉度为 61%,标准偏差为 16%,大多数歌曲都是大调,但标准偏差相当大,响度约为-10 dB,艺术家热度约为 0.43。艺术家信息显示,这些艺术家中的大多数都是“昙花一现”,因为他们缺乏热情和熟悉度。
模式选择&调谐
我们在不同的模型上训练我们的数据来预测一首歌是否是热门歌曲。在调整之前,Xgboost 在 0.63 曲线下面积(AUC)分数处似乎是具有最高准确度的。下表显示了我们尝试的一些模型的结果。

Models considered and their AUC scores
在 XGBoost 上进行网格搜索以进一步提高 AUC 分数。每个参数都进行了调整,一些值同时被过度调整。例如,n 估计值和学习率被一起调整,因为较高的 n 估计值需要较低的学习率来产生最佳结果。调整后 AUC 值从 0.632 增加到 0.68。随机预测将产生 0.5 的 AUC 分数。
结果
这个项目展示了预测音乐热度的可能性,确定了流行音乐的趋势,并使用 Spotify 的 API 开发了特征提取工具。XGBoost 在训练模型上提供了最佳预测,AUC 得分为 0.68。
我们决定用我们的模型预测一些新歌。下面的演示展示了我们的脚本的运行。

自从 Spotify 收购 EchoNest 以来,许多不同的功能都发生了变化,包括通过 ID 查找歌曲信息的简单方法。因此,这个演示使用了一种非常迂回的方式来获取歌曲信息。首先,使用 API 上的搜索端点运行搜索,以获取 Spotify ID。使用 Spotify ID 音频功能和深入的音频分析,可以抓取歌曲。然后进行一些功能工程,以便将 Spotify 数据转换回可用于我们模型的格式。我们开发的用于将 Spotify API 数据映射到我们的训练数据的脚本可以在这里查看。
以下是我们的模型预测的其他一些歌曲的结果,以及与 Spotify hotness 结果进行比较的结果:

结论
在这项工作中,我们不确定是否有可能比随机预测更好地预测一首歌是否会流行。在对来自 Spotify 的新歌测试我们的模型后,我们观察到正确预测一首坏歌比预测一首热门歌曲简单得多。预测非热门歌曲可能更容易,因为我们的数据是倾斜的,只有 1200 首热门歌曲。接下来,我们将探讨艺术家所在地或发行日期等其他特征如何影响歌曲的受欢迎程度。此外,我们可以考虑使用完整的数据集,看看是否可以改进我们的模型。另一种选择是使用 Spotify API 来收集我们自己的数据。
虽然 DJ Khaled 没有配备强大的数据科学和机器学习工具,但他是正确的,热门歌曲中确实存在某些趋势。
你迟早会面临这个问题

source: kaggle
几天前在 kaggle 举办的梅赛德斯-奔驰比赛结束了,这场比赛是我经历过的最艰难的比赛之一(我并不孤单),在这篇文章中我将解释为什么,并分享一些我们可以从中吸取的教训。这篇文章旨在简短,我写这篇文章是为了与你分享我的团队在这场比赛中的经验,解释为什么解决呈现给我们的问题仍然被认为是一个困难的问题,并列出一些你在解决一个兼职项目或在一家公司工作的机器学习问题时可能会遇到的问题。
是什么让奔驰竞争如此艰难?
首先让我向你介绍来自戴姆勒的任务,当这个比赛开始时,它带来了这个问题:
你能减少一辆奔驰花在测试台上的时间吗?
关于这项任务,还有一点更有趣的信息:
“在这场比赛中,戴姆勒向卡格勒挑战,以解决维数灾难并减少汽车在测试台上花费的时间。竞争对手将使用代表梅赛德斯-奔驰汽车功能不同排列的数据集来预测通过测试所需的时间。获胜的算法将有助于加快测试速度,从而在不降低戴姆勒标准的情况下降低二氧化碳排放。”
解决这个问题的方法是把它当作回归问题,给定特征建立模型来预测 y(测试时间)。
在数据科学项目中,有许多事情可能会出错,但以下是许多竞争对手发现的常见问题,在就解决该问题的最佳方法展开公开讨论之前,以下是这场比赛为何具有传奇色彩的原因:
- 小数据集和许多要素
- 极端值
- 敏感指标
- CV 和 LB 不一致
(1).小数据集和许多要素
每当你想要解决任何机器学习问题时,大多数时候,最理想的做法是首先寻找将帮助你训练模型的数据(数据收集或收集)。但有时你找不到你想要的具体数据,或者你找不到足够的数据,这是一个行业直到今天仍然面临的问题。在 Mercedes Benz 数据集中,训练数据由 3209 个训练示例和 300 多个特征组成(8 个分类特征,其余为数字特征),您可能会猜测从如此少的数据中构建强大的机器学习模型具有挑战性。
但是如果我们没有足够的数据会怎么样呢?
当我们没有足够的数据时,我们的模型很可能有很高的方差,这意味着过度拟合变得更加难以避免。
过度适应的悲伤
你永远也不想吃太多。当我们的模型学习到包括噪声数据点(例如离群值)并且这最终未能概括,另一种认为过度拟合的方式是当模型过于复杂时发生,例如相对于观察值的数量有太多的参数。过度拟合的模型具有较差的预测性能,因为它对训练数据中的微小波动反应过度。提交给 kagglers 的数据集导致许多竞争对手过度适应,这就是为什么公共和私人排行榜之间有很大的变化(我不会详细说明这一点,如果你真的想了解公共和私人排行榜之间的差异,请在评论中问我)。
(2).极端值
噪声通常会成为一个问题,无论是在你的目标变量上还是在某些特性上。对于小数据集,离群值变得更加危险和难以处理。离群值很有趣。根据具体情况,它们要么值得特别关注,要么应该被完全忽略。如果数据集包含相当数量的异常值,重要的是要么使用对异常值鲁棒的建模算法,要么过滤掉异常值。谈到梅赛德斯-奔驰绿色制造大赛的比赛,目标变量(y)中有一些异常值,大多数 y 值在 70 到 120 之间,发现像 237 这样的值对我们来说是一个警告。
(3).敏感指标
模型评估用于量化预测的质量,无论何时训练机器学习模型,理想情况下,您都希望选择一个评分指标(用于模型评估),该指标将指导您了解所做的更改是否提高了模型的性能/预测能力。对于分类问题,通常使用准确度、负对数损失和 f1,对于 Kaggle 上的回归问题,通常使用 MSE(均方误差)、MAE(平均绝对误差)或这些指标的一些变体。他们有不同程度的鲁棒性,但在这场比赛中,他们选择了 R,这是一个非常有趣的选择。因为度量太简单了,所以使用传统的 Kaggle 技术,如元集成或深度学习,都是徒劳的。也许我应该写一个关于评估指标和损失函数的帖子?你告诉我。
对于梅赛德斯-奔驰绿色制造竞赛,评分标准与 RMSE 或 MAE 等 Kaggle 竞赛使用的传统标准相反。相比之下,R 是一个非常不稳定的度量,对异常值非常敏感,并且非常容易过度拟合。因为容易过度拟合,所以公排行榜的领袖在私排行榜上摔得那么惨。一个简单的几乎没有特征的模型是概括所选指标的最佳方式,但许多 Kagglers 都很虚荣,宁愿在公共排行榜上看到更高的排名。除了训练数据之外,我们的预测应该基于看不见的数据(测试集),在梅赛德斯-奔驰中也有一些异常值,所以如果对于给定的看不见的实例,我们的模型预测 y = 133,而真实值是 219,R 对我们的模型不利很多(记住,R 是一个非常敏感的度量)。虽然从训练集中移除离群值降低了公共 LB 上的分数,但这是要采取的适当行动,因为它仍然给出了相对于其他的最佳分数。
(4).不一致的 CV
CV =交叉验证。
当我们没有成功地建立一个对你的模型进行适当验证的设置时,就会出现 CV 不一致的问题,这可能会导致你认为你做得很好,而实际上并不是。交叉验证是我所知道的评估机器学习模型的最好方法之一(如果不是最好的话),但是对于小数据集,许多功能和工具甚至交叉验证都可能失败(特别是当使用 R 时)。
如果你不熟悉交叉验证,这份草案可能会帮助你。
使用 K 倍交叉验证的评估程序

5-Fold
- 将数据集分成 K 个相等的分区(或“折叠”)。
- 将褶皱 1 作为测试集,将其他褶皱的并集作为训练集。
- 计算测试精度。
- 重复步骤 2 和 3 K 次,每次使用不同的折叠作为测试设置。
- 使用平均测试精度作为样本外精度的估计。
合理的事情要做
在这里,我将尝试提出一些解决方案,如果你面临上面提到的一些问题,你可以使用。有些我的团队用过,有些我们没有。
- **坚持使用简单的模型:**在这次竞赛中,首先使用的算法是基于决策树的模型,在与 Steven 合作后,他告诉我简单的线性模型得分也很高,有时甚至超过了 Random Forest 和 xgboost 等更复杂的模型,这让我感到惊讶。
- **执行特征选择:**这可能是本次比赛中最有价值的事情,数据集包含 300 多个特征,从一些特征的相关矩阵图中(因为有许多特征,所以选择了 15 个特征),相关矩阵帮助我们认识到有许多冗余特征,这是不好的,如果我们将冗余信息添加到我们的模型中,它会一次又一次地学习相同的东西,这没有帮助,只要有可能,我们就想删除冗余特征。

correlation matrix done using seaborn (for plotting) and pandas(for data representation)
- **使用集成模型:**集成方法使用多种学习算法来获得比单独使用任何组成学习算法更好的预测性能。特别是如果你的模型在不同的事情上做得很好(例如:一个擅长分类反面例子,另一个擅长分类正面例子),将两者结合起来通常会产生更好的结果。我们最终的模型是我的模型(大部分是 xgboost)和 Steven 的模型(RF、SVR、GBM、ElasticNet、Lasso 等)的组合。无需深入细节,我可以告诉你的是,结合我们的模型,我们得到了改进。
最终注释
这篇文章并不是我们为梅赛德斯-奔驰绿色制造竞赛准备的解决方案,而是带来一些你在研究新问题或从事数据驱动项目时可能会发现的问题。寻找好的大数据是我们一直想要的,理想情况下,我们希望有至少 50K 训练样本的数据集。这篇文章没有描述完整的解决方案,还有一些细节我省略了。
关于我的团队(🏎本茨🏎)
在这次比赛中,我和史蒂文在 3835 支队伍中名列第 91 位。


Kaggle profile: Steven Nguyen
我特别感谢史蒂文·阮在梅赛德斯-奔驰比赛和我写这篇文章时给予的支持。
进一步阅读
- 进行机器学习时的 7 个常见错误
- 第二名解决方案
- 讨论:数据科学刚刚失败了吗?
让我知道你对此的想法,如果你有一个主题的建议,你会喜欢看我写的。
和往常一样,如果你喜欢这些作品,请留下你的掌声👏推荐这篇文章,让别人也能看到。
SOPR:公共关系和狙击手思维挑战

公共关系一直被认为是一种与魔鬼的交易,目的是扩大你的营销范围,维护你的声誉。这个行业总是被外人视为编造故事的大师或炒作的兜售者,但 21 世纪“假新闻”的困扰以及社论和 T2 付费媒体之间界限的模糊,对这个行业几乎没有帮助。
媒体的碎片化和公关有时对所有可用渠道发送垃圾信息的盲从,加上对其可信度的挑战,这影响了信任度,产生了一个可能难以解决的多维挑战。
与此相反,由国际公共关系协会在保加利亚索非亚举办的 SOPR 会议和颁奖典礼绝不是一件严肃的事情。我的任务是向来自 27 个国家的与会者讲述“狙击手思维”及其对现代公关专业人士的影响,我概述了当前的形势,并重点讲述了活跃在商界的每个人感受到的差异。

20 分钟很难做多少事。因此,任何演讲者所能希望的是将关键信息传达出去,并希望它能融入听众的感知和他们对问题的意识,从而引发新的思维过程。在这一点上,我并不失望。
公共关系(PR)正在发生变化,这种变化是由专业人士而不是他们的客户主导的。为了理解为什么这很重要,我需要描绘一个更广阔的图景。
一切都是数据。一直都是。当数据传到我们手中的渠道受到限制时,我们对自己认为观察到的现实的感知也受到限制。这使得一切公式化。例如,在 60 年代杰罗姆·麦卡锡(Jerome McCarthy)提出 4Ps 产品、价格和促销之前,市场营销就一直遵循同样的规定性方法。

那些 4p 今天已经被经验、无处不在(或每一个地方)、交换(价值)和传福音的 4e 所取代。

从一种营销口号到另一种营销口号的转变是市场最基本层面——消费者——转变的直接结果。
消费者因技术而赋能,通过设备而联系,比以往任何时候都更知情、更具移动性和更有发言权,他们已经打破了传统的条块分割的孤岛,这种孤岛允许他们通过一对多、自上而下的模式进行营销。他们的注意力和忠诚度要么失去了,要么被共同的价值观、赋予他们生活意义的能力以及在他们需要的时候帮助他们做一些有用的事情的方法所赢得。
所有这些都很重要,因为它是由数据驱动的,这使得一切都可以测量。如果可以衡量,就可以量化,如果可以量化,就可以改进。
在这个极具挑战性的环境中,信任和感知是一切的基础。
信任是任何关系交换发生的必要条件,信任本身由接触、感知、评估、联系这四个步骤组成。

这些步骤中的每一步本身都相对脆弱。谨慎、努力和真实性在实现这一切的过程中起着关键作用。就其本身而言,它们需要意识、明确理解的认同感、共同的价值观和同理心。
感知的出现需要五个组成部分:刺激、注意力识别、翻译、行为,每一部分都与一个特定的、直接相关的属性相关联。

所有这些都很重要,因为它是由数据驱动的,这使得一切都可以测量。如果可以衡量,就可以量化,如果可以量化,就可以改进。
大数据的问题
然而,数据本身并不是没有问题。作为大数据特征的四个向量:数量、速度、多样性和准确性在处理它们时带来了独特的挑战。它们中的每一个都以自己的方式延伸到我们现代分析和理解数据向我们揭示的确切内容的能力的极限。

碰巧的是,并非只有商界感受到了这一挑战。自上世纪 90 年代以来,美国陆军战争学院一直在教导学生,他们现在是在一个由波动性、不确定性、复杂性和模糊性所支配的 VUCA 世界中运作。

对于那些没有立即建立联系的人来说,大数据的 4v 与 VUCA 世界的组成部分完全对应。数据在每个上下文中可能有不同的标签,但它的行为是相同的,因为它响应相同的动态。
公共关系的新角色
这使我们回到 SOPR 会议。现代公共关系专业人士生活在大数据的 4V 世界和军事的 VUCA 世界中,他们被夹在面临危机、需要传播信息并迫切希望让自己的声音被听到的客户和越来越抵制自上而下的广播和宣传的观众之间。
为了适应挑战,这个行业正在发生变化。在我的主题演讲后,我与之交谈的人都非常清楚他们角色的微妙之处。需要温和地引导他们的客户远离谎言,走向真正的交流。他们都非常清楚以一种与其价值观和观念产生共鸣并创造信任的方式与观众建立联系的必要性。
简而言之,他们意识到公共关系正在从简单的传播信息和宣传形象转变为交流共同的价值观和创造客户与受众之间的共同接触点。
当一个对通信至关重要的行业认识到挑战,并开始缓慢的审慎变革过程时,商业乃至政治世界从 20 世纪向 21 世纪的转变就有了真正的希望,比预期的要快得多。
狙击思维:消除恐惧,应对不确定性,做出更好的决定可以在亚马逊或任何书店买到。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言










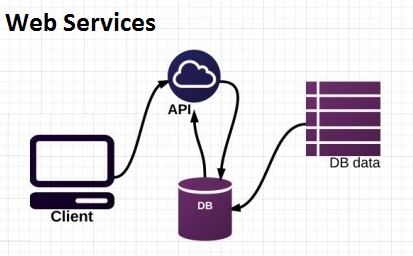{kind=link}
{kind=link}
{kind=link}