







看路——自动驾驶汽车入门
在一个奇怪的虐待狂事件中,我决定一头扎进自动驾驶汽车,把人工智能作为一个副业。有一家咨询公司,一个蹒跚学步的孩子,几乎没有空闲时间,我想,“顺便上些课程?这真是个好主意!”[1] .至少,也许我可以解开一些技术之谜
在参加自驾课程的过程中,我经常与人谈论这项技术。我在与人们谈论自动驾驶汽车时发现,大多数人要么对当前的技术水平感到惊讶,要么感到震惊。这是很自然的反应。驾驶已经成为如此明显的人类努力,以至于大多数人不可能理解计算机可以在很少或没有驾驶员错误的情况下在更高的程度上执行这项任务。或者他们认为自动驾驶汽车还很遥远,他们不必担心。
但是,低估计算机的能力并不是驾驶所独有的。在我年轻的时候,作为一个无耻的糟糕棋手,我崇拜大师们的激情和强度。用“创造性、侵略性、不屈不挠”这样的术语来说,卡斯帕罗夫确实是 1997 年在一系列电视比赛中倒下之前的最后几位大师之一。这成了国际象棋中计算机算法的转折点,他们没有回头。如今,即使是一款 20 美元的普通游戏,的等级也比的特级大师高。象棋是人类能力巅峰的时代迅速陨落,并且没有回头。
Even if you didn’t like chess you have to admire that soundtrack
同样,自动驾驶汽车将在更短的时间内超越人类的能力。这很好,因为我无法想象教我女儿开车的压力。
计算机视觉
人类司机没有太多的传感器来工作,但他们有一个出色的视觉系统。驾驶是为配合它而量身定做的。交通标志、车道标志和转向灯(甚至在宝马上)为在环境中导航提供了线索。但是看到一些东西并不等同于理解它的背景。我们可以看到道路标记,但理解它们的含义完全不同。对于计算机来说,驾驶的感知部分是复杂的(大多数司机也是如此,认真看路),大多数人认为这是人类擅长的地方。如果自动驾驶汽车要在路上行驶,他们不仅需要看到道路,还需要理解这些标记背后的背景。
自动驾驶汽车的计算机视觉技术现在反映了我们对人类视觉的了解(或猜测)。眼睛在视锥细胞中执行一系列图像转换,提取颜色、线条和图案,并将这些信息传递给大脑进行处理。它从不捕捉整个图像,而是简单地聚焦不同的区域来寻找模式。这就是为什么你可以数球的移动,却看不到大猩猩。
NVIDIA 和其他公司已经采用了这个概念,并将其集成在一个学习算法中,称为卷积神经网络 (CNN)。CNN 是机器视觉中的一个重要工具,并且已经被证明在大量的计算机视觉领域中是有效的。在驾驶中,我们希望专注于道路上的视觉指示器,CNN 可以通过简单地用驾驶视频训练它来识别道路特征。

End to End Learning for Self-Driving Cars, NVIDIA, https://arxiv.org/pdf/1604.07316v1.pdf
NVIDIAs 的实现甚至走得更远,教汽车仅使用摄像头视觉导航道路。如果你认为这种类型的技术仅限于拥有巨额研究预算的大大学或公司,这里有一个应用于模拟课程的相同技术,作为 3 个月自动驾驶课程的一小部分;
应用于自动驾驶汽车的计算机视觉领域还很遥远。与谷歌、宝马、奔驰和几乎所有其他汽车制造商在计算机视觉方面所做的工作相比,这里甚至连概念都是初级的。
也许我们需要一个人对机器车的挑战…
[1]如果你熟悉他们的话,我正在参加 Udacity 的几个纳米学位项目,专门研究人工智能和自动驾驶汽车。它们是对该领域的很好的介绍,并吸引了一些顶级的行业人员。它们涵盖了大量的信息,有时感觉就像从消防水管里喝水一样。
分割、定位和计数图像中的对象实例
当我们视觉感知世界时,可能会获得大量的数据。如果你用现代相机拍一张照片,它会有超过 400 万像素和几兆字节的数据。
但实际上,在一张照片或一个场景中,我们人类消耗的有趣数据很少。这取决于任务,但例如在一个场景中,我们寻找其他动物和人类,他们的位置,他们的行动。我们可能会通过寻找面孔来衡量情绪,或者行动的强度和严重性来了解整个场景中的情况。
开车时,我们会寻找可通行的道路、其他车辆、行人和移动物体的行为,并注意交通标志、灯光和道路标记。
在大多数情况下,我们会寻找一些物体,它们的 x,y,z 位置,并拒绝绝大多数我们称之为背景的东西。背景是我们的任务不需要注意的任何东西。如果我们在找钥匙,人们可以做背景。
有时我们也需要数数,并且能够说出一种物体有多少,它们在哪里。
在大多数情况下,我们观察一个场景,并希望获得以下信息:

Ideal segmentation, localization and instance counting in a visual scene. Segmentation gives precise boundaries of object instances, a much more refined approach that bounding boxes.
我们可能还想在第二次扫视时获得更多的细节信息,例如面部关键点、人体骨骼关键点的位置等等。一个例子:
Our facial keypoints detector neural network in action
我们现在将回顾如何通过神经网络和深度学习算法来实现这一点。
我们应该明白,人类的视觉在视觉场景中是多次传递的。这意味着我们递归地观察波形中的视觉场景,首先在最短的时间内获得最粗糙的内容,对于时间敏感的任务。然后,我们可能会一遍又一遍地扫视,以找到越来越多的细节,用于精确的任务。例如,在驾驶情况下,我们想知道我们是否在路上,是否有障碍物。为了快速响应,我们着眼于粗略的特征。我们对将要撞上的车的颜色或牌子/型号不感兴趣。我们只需要快速刹车。但如果我们在人群中寻找特定的人,我们会先找到人,然后找到他们的脸,然后用多种眼神研究他们的脸。
神经网络不需要遵循人脑的规则和方式,但通常在算法的第一次迭代中这样做是一个好主意。
现在,如果你运行一个神经网络来对一幅大图像中的物体进行分类,你会在输出端得到几幅地图。这些地图包含物体在多个位置出现的概率。但是因为分类神经网络想要将大量的像素减少到少量的数据(分类),所以它们也在某种程度上失去了精确定位对象实例的能力。请参见下面的示例:

Neural network raw output on a large image: probability of person category
请注意,您得到的输出是“免费的”,这意味着我们确实需要运行除神经网络之外的任何其他算法来找到定位概率。输出图的分辨率通常较低,并且取决于神经网络、其输入训练眼大小和输入图像大小。通常这是粗糙的,但是对于许多任务来说这已经足够了。这不能给你所有对象的精确实例分割和精确的边界。
为了获得最精确的边界,我们使用分割神经网络,例如我们的 LinkNet ,这里修改了来检测许多不同种类的图像关键点和边界框。:

Our Generative Ladder Network used to detect key-points in an image (facial, bounding boxes, body pose, etc…). This uses a special new network architecture designed for maximum efficiency.
这些类型的神经网络是生成梯形网络,它使用编码器作为分类网络和解码器,能够在输入图像平面上提供精确的定位和图像分割。
这种网络为同时识别、分类和定位任何种类的对象提供了最佳性能。
以下是我们可以用生成式梯形网络获得的结果:

Typical results obtained with LinkNet and Generative Ladder Networks — see videos [here](https://codeac29.github.io/projects/linknet/index.html)
生成梯形网络的计算量不是很大,因为编码器是一个标准的神经网络,可以设计成高效的,像 eNet 或 LinkNet 。解码器是一个上采样神经网络,它可以被制造得非常快并且计算成本低廉,例如在 eNet 中,或者使用像 LinkNet 这样的旁路层来提高精度。
旁路层用于通知每层的解码器如何在多个尺度上聚集特征,以实现更好的场景分割。由于编码器层对某些层中的图像数据进行下采样,因此编码器必须根据编码器中发现的特征对每层的神经图进行上采样。
我们多年来一直在争论和论证**像LinkNet**为分类、精确定位和切分提供了主干。分割在图像中提供了更精细的定位,也为神经网络提供了更好的训练示例。原因是精确的边界比不精确的边界(如边界框)更有效地将对象组合在一起。显而易见,一个边界框将包含许多背景或其他类别的像素。用这样的错误标签训练神经网络会降低网络的分类能力,因为背景信息会混淆其训练。我们建议不要使用边界框。
在过去,文献中充斥着使用边界框的方法,对神经网络的使用效率非常低,甚至对它们的工作方式和使用方式的理解也很差。次优方法列表在这里: Yolo , SSD 单拍多盒检测器, R-CNN 。对这些劣质方法的回顾和比较是这里是 —我们注意到 SSD 是唯一一种至少尝试使用神经网络作为尺度金字塔来回归边界框的方法。
这些方法不合格的原因列表:
- 使用低效编码器作为 VGG
- 使用边界框进行训练比使用更精确的分割标签产生更差的准确性
- 复杂的体系结构,有些不能通过端到端的反向传播来训练
- 边界框的选择性搜索、边界框的裁剪和回归并不是一种优雅的端到端方法,而是让人想起在深度神经网络之前执行计算机视觉的方式:作为不同方法的任意集合
- 需要一个单独的“客观”网络来查找区域建议
- 在多个尺度上使用低效且庞大的分类器来回归边界框
最近的工作来自:密集物体检测的焦点损失更有见地,因为它表明生成梯形网络可以被视为基本框架,该框架应该驱动未来的神经网络设计,例如分类、定位(参见注释 1)。
但是我们如何使用像 LinkNet 这样的网络来执行包围盒回归、关键点检测和实例计数呢?这可以通过在每个解码器层的输出端附加子网来实现,如这里的和这里的和所做的那样。这些子网需要最少网络和小分类器来快速有效地工作。这些网络的设计需要由有经验的神经网络架构工程师来执行。请看我们最近的工作在这里,我们展示了一个像 LinkNet 这样的单一神经网络是如何执行所有提到的任务的。
总结:
****注 1:最近的一篇关于定位、分割和实例级视觉识别方法的教程也指出,像 LinkNet 这样的模型是对象检测的通用框架。他们称生成梯形网络为:特征金字塔网络(FPN)。他们认识到生成式梯形网络具有编码器下采样内置的内在比例金字塔。他们还认识到,解码器可以对图像进行上采样,以更好地定位、分割和完成更多任务。
注 2: 试图从单一图像中识别动作并不是一个好主意。动作生活在视频空间中。图像可以让你了解一个动作,因为它可以识别一个与动作相关的关键帧,但它不能代替准确分类动作所需的序列学习。不要在单个帧上使用这些技术来分类动作。你不会得到准确的结果。使用基于视频的神经网络,如 CortexNet 或类似的。
注 3: 分割标签比包围盒更费力获得。用粗略的边界框来标记图像更容易,以便手动精确地绘制所有对象的轮廓。这是像包围盒这样的劣质技术长期存在的一个原因,这是由越来越多的具有包围盒的大型数据集的可用性决定的。但最近有一些技术可以帮助分割图像,尽管可能不如人类标记精确,但至少可以自动分割大量图像。参见本作品(通过观察物体移动学习特征)和本作为参考。
注 4:**生成式梯形网络的编码器网络需要高效设计,以实现实际应用中的真实性能。人们不能使用花费 1 秒来处理一帧的分段神经网络。然而,文献中的大多数结果只关注于获得最佳的精度。我们认为最好的度量是准确性/推理时间,正如这里所报告的。这是我们 eNet 和 LinkNet 的关键设计。一些论文仍然使用 VGG 作为输入网络,这是迄今为止效率最低的模型。**
关于作者
我在硬件和软件方面都有将近 20 年的神经网络经验(一个罕见的组合)。在这里看关于我:媒介、网页、学者、 LinkedIn 等等…
宋飞与神经网络:一个关于虚无的博客(第二部分)
继续我的科学研究所有数据的旅程,我终于进入了深度学习和人工神经网络(ANN)的世界。这个话题绝对是最吸引人的话题之一,但也是我最紧张的话题之一。我的焦虑主要源于这样一个事实,即这个故事的技术和数学方面非常吓人、复杂,对我的舒适区来说太乏味了。然而,在了解到神经网络本质上是一种组合以及通过反向传播迭代调整的权重和偏差的炼金术之后,我的焦虑水平大大降低了,我确信神经网络不仅强大,而且超级酷。

任何优秀的数据科学学生都知道,学习新概念的最佳方式是良好的实践。我决定以我之前关于宋飞的博客为基础,将新概念应用于一个老问题,并测试各种工具的组合来提高我的模型的分类准确性。迷你项目的目标是获得建立神经网络和自然语言处理的经验。
在为我的班级项目分析 OKCupid 约会简介一周后,我想做一些有趣的事情,同时仍然…
towardsdatascience.com](/seinfeld-with-tf-idf-a-blog-about-nothing-1732abcfd773)
之前的模型涉及使用 TF-IDF 对文本进行矢量化,并使用投票分类器来训练机器学习模型,以预测哪个字符说了哪一行。实验取得了 43%的准确率,不算很大。有了人工神经网络及其更好地提取特征的能力,我认为可能值得尝试一种新的模型。

Overview of dialogue distribution for each of the main characters over the 9 seasons. Jerry has significantly more dialogues than the rest of the characters, signaling a class imbalance. https://www.ceros.com/originals/breaking-down-seinfeld/
首先,考虑到 Jerry 的对话和其他演员之间的类别不平衡,我决定只运行来自 George、Elaine 和 Kramer 的对话的模型。下面列出了模型的精度结果。


The model does not perform better with increase epochs, it essentially plateaus at around epoch 2 for this particular model.
83%的训练准确率和 57.05%的低测试准确率表明,该模型对于我正在执行的特定分类来说过于笼统,并且该模型不适合该任务。使用带有计数矢量化的新矢量化,对超参数进行一些调整,并添加正则化,结果仍然暗淡无光。

考虑到我随机猜测的基线是 33.33%,之前模型的准确率是 48%,模型的测试准确率 57.83%可能不显著,但它仍然比随机猜测要好。

A slight increase in test data accuracy and epoch numbers. An increase in epoch number will increase my training accuracy, however, the tradeoff struggles with the long training time.
最后,我决定让杰瑞回来。这需要额外的调整来适应类的不平衡,结果见下文。

With Jerry added back to the mix, the accuracy is slightly lower as I expected, however, it still outperforms the previous model.
49.92%的准确率并不令人印象深刻,但这是使用浅层学习模型或 4 个类别之间随机猜测的 25%基线的 43%的改进。相对而言,我对我训练的模型并不那么失望,但是,我对它的表现也不是特别满意。
由于神经网络更擅长提取人类语言中的特征,因此它通常是用于自然语言处理的更有效的模型。然而,由于语言在与上下文相关联时是有意义的,所以我喜欢尝试的另一种方法是 Word2Vec。Word2Vec 被认为是更好的矢量化/嵌入方法,可以更好地处理语言数据。
目标是对嵌入参数(\theta)进行更新,以改进(在这种情况下,最大化)这个目标…
www.tensorflow.org](https://www.tensorflow.org/tutorials/representation/word2vec)
对于诸如语音识别之类的任务,成功执行识别任务需要编码数据,因为人类的认知能力允许我们从原始文本中识别含义,而计算机从稀疏矩阵中辨别矢量化文本的上下文具有挑战性,因为传统的自然语言处理系统将单词视为离散元素。因此,使用 TF-IDF 和 CountVectorization,正如我对我的模型所做的那样,计算机在识别语言模式和字符的区别方面面临着挑战。
我这个迷你项目的下一步是尝试不同的矢量化技术,结合不同的机器学习模型(监督或无监督),以便比较和对比每个模型的结果性能。即使我还没有完全用尽我的机器学习工具包,随着更多的时间和更多的练习,我可能能够将这些野生神经网络计算成一个足够的分类模型,以区分彼此的字符。
使用 Seinfeld 脚本帮助我了解了许多关于每个机器学习模型的细微差别以及使用自然语言处理的挑战。
资源:
完整的宋飞正传剧本和剧集细节
www.kaggle.com](https://www.kaggle.com/thec03u5/seinfeld-chronicles)
宋飞与 TF-IDF:一个什么都没有的博客
在为我的班级项目分析了 OKCupid 约会简介一周之后,我想做一些有趣的事情,同时还得到了一些急需的单词矢量化练习,TF-IDF ( 术语频率,逆文档频率)。

由于我最近没怎么看电视,探索经典情景喜剧《宋飞正传》中的这个数据集似乎是一个有趣的想法,我将尝试预测哪个角色说了哪句台词。
TF-IDF 是一种矢量化形式,它根据术语在样本中的独特程度对样本中的每个术语进行加权。基本上,这种方法有助于提取与特定来源密切相关的关键词。将 TF-IDF 的概念应用到我的《宋飞正传》挑战中:如果一个单词被角色经常使用,那么这个单词不够独特,不足以帮助指示哪个角色说了那个对话;另一方面,如果一个单词经常被其中一个角色提及,但很少被其他角色提及,这个单词就成为了一个强有力的指示器,告诉我们是哪个角色说了这句话。
为了缩小数据集的范围以优化效率,我根据每个角色说出的行数选择了主要角色,并挑选了前 5 个角色进行处理。此外,为了找出剧中哪个角色说了最多的话,下图显示了杰瑞在所有角色中拥有最多的台词和最多的单词…这个节目是以他的名字命名的,所以这并不奇怪。

number of dialogues for each of the main characters

number of words spoken by each of the characters
知道 Jerry 说了大部分台词,我意识到单词 predictor 将受到这种限制的挑战。因为大多数台词是杰瑞说的,所以数据集在他的对话上有很大权重。此外,作为该剧的编剧和制片人,他的声音可能会渗透到其他角色的对话中。如下面我们的 TF-IDF 分类模型的摘要所示,在数据集中包括 Jerry 的对话时,我们的精度是 43%,而没有 Jerry 的对话时,我们的精度是 48%。精确度比我预期的要低。

Prediction model without Jerry

Prediction model with Jerry
为了更好地理解角色之间的对话有多相似,我使用了一个名为 g ensim 的语义库,由 Kaggle Kernal 提出,它有一个相似性方法,能够确定特定文档和一组其他文档之间的相似程度。通过使用 TF-IDF 为每个角色的对话转换一个单词包,用单词计数作为每个单词的权重,我能够对 gensim 库中的文本运行相似性查询。下图显示了一个字符的对话分数,作为与每个文档进行比较的查询向量。相似性得分范围从 0 到 1,0 表示不相似,1 表示非常相似。

visualization of how similar each of the characters’ corpus in relation to another.
图表证实了我的怀疑,杰瑞、乔治、伊莱恩和克莱默非常相似。乔治和杰瑞的对话是最相似的,这也解释了为什么这两个人是最好的朋友。人物对话相似性的可视化是数据集局限性的另一个解释。因为主要角色所讲的语言非常相似,所以预测模型无法检测角色对话之间的细微差别。

我不愿意放弃享受数据集的乐趣,所以我探索了用预测工具娱乐自己的其他方式。考虑到这部剧是由杰瑞·宋飞和拉里·戴维共同编剧/制作的,我想看看这个模型是否能够预测拉里和剧中其他主要角色之间的差异。


这个结果并没有让我吃惊。由于拉里是这部剧的原创作者之一,他的声音和乔治的声音一定非常相似。为了好玩,我测试了拉里在《抑制你的热情》中最著名的几段话,看看这个模型的表现如何。拉里更像乔治还是杰瑞?



参与这项挑战给了我一些使用 TF-IDF 作为语言预测工具的实践,同时,我也有机会学习 gensim 的功能,并从预测模型中获得一些乐趣。我很想知道如果我用《抑制你的热情》中的对话训练模型,该模型是否能够区分宋飞和拉里的声音。此外,我很好奇这个模型在真实的文本样本中是否会有更好的性能,在真实的文本样本中,声音的作者不是由房间中真正有趣的作者创建的。
测绘世界各地的地震活动
自 1965 年以来,全球平均每年发生 441 次 5.5 级以上地震。5.5-6.0 的震级可能会造成轻微的破坏,而 6.1 或更高的震级可能会在人口密集的地区造成重大破坏。

Magnitude 6.1 or over
来自国家地震信息中心(NEIC)的数据集包含地震的日期时间、坐标、震级和类型(并非所有地震都是由自然引起的,少数是由 20 世纪 60-90 年代的核弹引起的地震活动)。)
当观察重大地震时,我们可以看到东亚和东南亚的高度集中,尤其是印度尼西亚。

Magnitude 5.5–6.0
可视化这些不太重要的地震给了我们一个“火环”的清晰视图,这是一个位于太平洋盆地的地震带。
除了自然灾害之外,研究由核弹引起的地震也是值得的。

seismic activity from nuclear bombs in 1960s-1990s. Icon from http://www.flaticon.com/free-icon/radiation_195741#term=radioactivity&page=1&position=20
试验的可怕核弹的数量简直让我吃惊。由于数据只涵盖到 1965 年,那些早期的活动,如广岛不包括在内。
我今天学到的:
- 传单地图很酷,但fleet . extras包只是增加了这种酷炫感,有像 addWebGLHeatmap 和 addDrawToolBar 这样的功能。
- 有几种方法可以将地理坐标映射到国家。但是,对于该数据集,许多数据点位于海洋中,不会映射到国家。
这是我第 100 天项目的第 11 天。我的 github 上的全部代码。感谢阅读。
不要害怕人工智能的孩子:人工智能面临的紧迫挑战的优先列表
最近,我在 LinkedIn 上目睹了两位从事人工智能工作的专业人士之间的对话——尽管他们都不是技术人员。这次对话是关于谷歌的 AutoML ,这是一个可以自动优化自身以在给定任务中实现更好性能的系统。悲剧源于谷歌研究博客使用的措辞:文章称两个网络控制器和一个孩子。然后文章继续解释人工智能设计可以超越人类制造的。
不用说,孩子这个词已经引起了轻微的恐慌,因为它已经被几家主流 媒体媒体报道,如太阳报和类似的。这种恐慌源于“人工智能创造出超越人类的孩子”的框架,但这种不准确往往是因为人工智能研究人员和人工智能实践者不参与这些辩论。使用“孩子”这样的术语,并将这个网络的输出描述为比人类设计的更聪明,肯定会成为一些头条新闻。然而,将所发生的描述为“算法使用一组预定义的规则来实现稍好的性能”并不可怕,但可能更准确。
上面的例子比其他任何事情都有趣,但我认为它展示了一个更深层次的观点,即人工智能的讨论可能会偏离未来几年真正关注的问题。
尽管我很欣赏公众对人工智能安全的兴趣,但对人工智能技术经验和理解有限的人的兴趣最终导致了对辩论的重新构建,我认为这对最终目标毫无帮助,甚至是有害的。
作为一名人工智能从业者,即将在生成对抗网络上发布一个教育资源,我觉得有必要以我所看到的方式来框定这场讨论。毫无疑问,会有主观的判断,但鉴于讨论的状态,我觉得这仍然是一个重要的贡献。
我将从最有争议的部分开始:与谷歌的员工研究员、最受欢迎的深度学习框架之一的作者 Francois Chollet 一致,我认为人工通用智能仍然非常遥远。因此,对超级智能的担忧也许并非无关紧要,但绝对不紧迫。
应用历史学家和人工智能研究人员长期以来一直在谈论这种智能爆炸的想法。我不完全确定这种推理应该归功于谁,但我第一次从在牛津马丁学院讲课的乔安娜·布赖森博士那里听说了这一点。这个讲座很棒,你绝对应该听一听,但要点是:最终担心人工智能爆炸是没有意义的。人工智能将通过增加恶意的人类行为者并帮助他们达到规模来造成更多的破坏。
直觉上这是有道理的:和核武器一样,人工智能最终只是一项技术,它取决于人类将如何使用它。这再加上事实上大多数人工智能是一些人所谓的“白痴学者”,因此在偏离原始任务的微小情况下都会灾难性地失败,这让我们得出一个不可避免的结论,即摧毁人类的超级智能不太可能成为“未来几十年”的担忧。
那么,在我看来,有什么值得担心的呢?
- 俄罗斯或其他民族国家被 AI 增强
这个列表中的第一个是我们已经见过的。除非在未来,仅仅通过应用现有的企业技术,这可以变得更加可扩展,因此也更加危险。更不用说中国将投资 1500 亿美元到 AI 。(不过,公平地说,与俄罗斯相比,中国对参与经合组织成员国政治的兴趣要小得多。)
在混合战争、对民族国家的网络攻击和对核计划的网络破坏的时代,我们面临着世界上许多理论上完全无法追踪的问题。越来越多的关于俄罗斯干预美国选举结果的指控当然于事无补。更糟糕的是,对世界上最强大的民主国家进行这样一次根本性的攻击据称花费了一架 F-35 战斗机花费的四分之一。
如果你在世界上的任何地方,认为美国的衰落对你没有任何意义,请三思。不仅有证据表明俄罗斯通过使用大型复杂的 Twitter 机器人网络试图在英国社会制造不和来干涉英国退出欧盟的投票,还有证据表明俄罗斯干涉了荷兰、德国、法国和英国的选举。
现在,如果这没有吓到你,还有大量证据表明,剑桥分析公司(Cambridge analytic a)——罗伯特·默瑟和其他影子人物资助的组织——正在提升其使用数据分析和人工智能影响美国和英国人口的能力。
最后,如果你研究这些人工智能增强的试图挑起不和的动态,它们会跨越围栏两边每个预先存在的社会鸿沟。例如,外国机器人在美国被检测到既支持 NFL 球员又反对他们,批评特朗普又支持他,还利用性别、性和身份问题进一步分裂美国社会。
不要误解我的意思,所有这些在原则上都是可以解决的,主要还是由人工智能来解决,但目前无论是科技公司还是政府都没有付出足够的努力来真正解决这些问题。即使你相信这些关于的段落只是一些疯狂的阴谋论,你也必须承认这至少是可信的,而且我们目前没有任何适当的监控来防止这种情况。
2。人工智能破坏社会结构
记住,平均每个人每天查看手机 150 次,想想这对社交能力有什么影响。此外,对于我们的孩子来说,完美的顺从技术在如何与世界尤其是其他人互动方面是一个非常糟糕的心理模型。毫无疑问:你今天购买的软件和硬件产品都装载了人工智能,它不断学习如何抓住你的注意力。
这还没提到在脸书上花太多时间会让我们不那么快乐;愤怒和愤慨推动了脸书的大部分互动,因为那些非法的高回复率;对自动化日益逼近的恐惧让许多人更加焦虑,也让他们的工作变得更加公平。这甚至还没有深入到在线回音室的问题中,这是一个巨大的问题,正如链接的文章所描述的。
此外,当你想到人类巨人及其最先进的智能产品:企业时,我们陷入了另一个泥潭。这条推文总结得很好:“非常令人惊讶的是,人们立即看到了“如果人工智能被设计成不惜一切代价制造曲别针会怎么样”的问题,但没有看到“我们将围绕一个机械的社会过程来设计我们的整个社会,以最大化短期资本增长”的危险信号。公司是原始的超级智能,因为它们聚合了几十个人的知识来追求一个目标。
目前的解决方案肯定是思考你花在技术上的所有时间是否都是值得的,从长远来看,开始考虑自动化和普遍基本收入的心理影响。
3。人工智能增强的非国家行为者
第三个角度与民族国家或公司的关系要小得多,与独立的个人或个人团体如何行动的关系要大得多。我将只给你一瞥我的意思,因为我相信这一个是不紧急的,我们将继续缩短与降低重要性。
另外,我已经解释过了,很多熊都有一个类似于民族国家的例子,除了现在,或者用更少的资源处理更分散的群体。但是人们只是在考虑安全后果和自主武器。
我普遍认为,各国将能够通过联合国或其他方式进行协调,或许禁止发展,但最有可能的是使用自主武器技术。然而,我不相信非国家行为者会在涉及到笑机器人和类似的问题时坚持同样的标准。
这已经在小范围内发生了;像“匿名者”这样的组织和像“丝绸之路”这样的平台已经证明了政府没有能力处理超出其范围的行为者。尤其是如果他们的东道国政府不合作的话。因此,我们可能不得不应对网络恐怖主义、规模空前的黑客以及来自非国家行为者的自动化政治宣传。
4。超级智能
最初,我想把超级智能放在第五位,但后来我的几个朋友在谷歌 Deepmind 安全团队的影响下说服了我。我不会争论超级智能的时机;关于这个话题,其他人已经写了很多。
我只想说,有许多研究人员认为,即使我们很快实现奇点,对世界的影响也是有限的。说来有趣,想想你高中班上最聪明的孩子。他们走了多远?他们的智力帮了他们这么大的忙吗?事实上,当我们考虑到在优化中没有免费的午餐时,是否有可能构建一个一致的更智能的方法?
也许这里的论点是,人工智能的增长是指数级的,因此进化的人工智能对于人类来说就像人对于马一样。马永远不会成为发明家。所以它在数量上要好得多,在质量上也不同。然而,这一点我也有异议,因为人们通常在没有太多正当理由的情况下将生物系统作为人工智能的明显类比。AI 的成长不像一个人从孩童到成人的成长。人工智能可以以超人的表现解决许多问题,但看似类似的问题实际上是不可能的。
此外,尽管有理由认为超级智能可能有能力伤害人类,但请记住,尽管投资了数十亿美元,Siri 仍然几乎不明白你的意思。比方说,我们必须在明年(非常乐观)完成语音合成中的语音识别,并在两年后实现量产。在接下来的五年里,我们解决了感知问题,在那之后的五年里,我们解决了无监督理解问题,在那之后的十年里,我们解决了常识推理问题。但是以上所有(1-3)都是现在有可能发生的事情。看起来还那么紧急吗?
但总的来说,我很乐意向任何人提出这个挑战:你怎么能想象超级智能会毁灭人类?为什么它会在乎呢?
5。AI 只是犯错或者偷工减料
这两个问题是紧密相通的,因为我不相信有人想写会出错的 AI。但是正如我所说,这一点非常接近第五名。最终我相信,即使我们到达奇点,我们也不知道这是否完全有目的,这种可能性是 50%。事实上,我们仍然没有真正理解为什么深度学习完全有效。
最终,人工智能研究人员和实践者将受到来自他们的经理、赞助商或其他利益相关者的压力,因此被迫走捷径。公平地说,对于公众辩论,我认为这是传播意识——无论多么初级——极其有用的一点。
因此,总的来说,尽管人工智能安全看起来像是一个有趣的问题,许多哲学家已经等待了很长时间,但我们应该避免通过它的叙述来判断这项技术。至少目前是这样。
写这篇文章花了我大约 2 天的时间。在这个时候,最初的故事又发生了,在我看来,这只是表明那些流行的误解是多么频繁。
想加入对话吗?查看更多 at或tweet at meat @ langrjakub!我也正在写一本关于 生成对抗网络 (人工智能新的最令人兴奋的领域之一)的书,你可以 查看这里 。如果您速度很快,在结账时使用促销代码“mllangr”仍然可以享受 50%的折扣(持续到 7 月 26 日)。
(我为标题的变化道歉,但文章的原名称是“选自丹吉·desc 的 ai_threats ORDER ”,尽管我无法想象还有比 SQL 查询更令人兴奋的事情,但我认为这恰恰分散了我最想吸引的读者群。)
为您的回归问题选择最佳的机器学习算法

想获得灵感?快来加入我的 超级行情快讯 。😎
当处理任何类型的机器学习(ML)问题时,有许多不同的算法可供选择。在机器学习中,有一个叫做“没有免费的午餐”的定理,它基本上说明了没有一种最大似然算法对所有问题都是最好的。不同 ML 算法的性能很大程度上取决于数据的大小和结构。因此,除非我们通过简单的试错法直接测试我们的算法,否则算法的正确选择通常是不清楚的。
但是,每个 ML 算法都有一些优点和缺点,我们可以用它们作为指导。虽然一种算法并不总是比另一种算法更好,但是每种算法都有一些特性,我们可以用它们来指导快速选择正确的算法和调整超参数。我们将看看一些用于回归问题的著名的最大似然算法,并根据它们的优缺点设定何时使用它们的准则。这篇文章将有助于为你的回归问题选择最好的 ML 算法!
在我们开始之前,请查看 人工智能快讯 以阅读人工智能、机器学习和数据科学方面的最新和最棒的信息!
线性和多项式回归

Linear Regression
从简单的例子开始,单变量线性回归是一种使用线性模型(即直线)对单个输入自变量(特征变量)和输出因变量之间的关系进行建模的技术。更一般的情况是多变量线性回归,其中为多个独立输入变量(特征变量)和一个输出因变量之间的关系创建模型。该模型保持线性,因为输出是输入变量的线性组合。
还有第三种最常见的情况,称为多项式回归,其中模型现在变成特征变量的非线性组合,即可能有指数变量、正弦和余弦等。然而,这需要了解数据与输出之间的关系。可以使用随机梯度下降(SGD)来训练回归模型。
优点:
- 建模速度快,并且当要建模的关系不是非常复杂并且您没有大量数据时特别有用。
- 线性回归很容易理解,对商业决策非常有价值。
缺点:
- 对于非线性数据,多项式回归的设计可能相当具有挑战性,因为必须有一些关于数据结构和特征变量之间关系的信息。
- 由于上述原因,当涉及到高度复杂的数据时,这些模型不如其他模型好。
神经网络

Neural Network
神经网络由称为神经元的一组相互连接的节点组成。来自数据的输入特征变量作为多变量线性组合传递给这些神经元,其中乘以每个特征变量的值称为权重。然后将非线性应用于该线性组合,这赋予神经网络模拟复杂非线性关系的能力。神经网络可以有多层,其中一层的输出以相同的方式传递到下一层。在输出端,通常没有应用非线性。使用随机梯度下降(SGD)和反向传播算法(都显示在上面的 GIF 中)来训练神经网络。
优点:
- 由于神经网络可以有许多非线性层(和参数),它们在模拟高度复杂的非线性关系时非常有效。
- 我们一般不用担心数据的结构,神经网络在学习几乎任何一种特征变量关系时都非常灵活。
- 研究一直表明,简单地给网络提供更多的训练数据,无论是全新的还是增加原始数据集,都有利于网络性能。
缺点:
- 由于这些模型的复杂性,它们不容易解释和理解。
- 它们的训练可能非常具有挑战性和计算强度,需要仔细的超参数调整和学习率时间表的设置。
- 它们需要大量数据来实现高性能,并且在“小数据”情况下通常优于其他 ML 算法。
回归树和随机森林

Random Forest
从基本情况开始,决策树是一种直观的模型,通过它可以遍历树的分支,并根据节点上的决策选择下一个分支。树归纳的任务是将一组训练实例作为输入,决定哪些属性最适合拆分,拆分数据集,并在生成的拆分数据集上重复,直到所有训练实例都被分类。在构建树时,目标是在属性上进行分割,以创建尽可能最纯粹的子节点,这将使分类数据集中的所有实例所需的分割数量保持最小。纯度是通过信息增益的概念来衡量的,信息增益与需要知道多少关于一个以前未见过的实例的信息以便对其进行正确分类有关。实际上,这是通过将熵(或对当前数据集分区的单个实例进行分类所需的信息量)与对单个实例进行分类所需的信息量(如果当前数据集分区将在给定属性上进一步分区)进行比较来测量的。
随机森林只是决策树的集合。输入向量在多个决策树中运行。对于回归,所有树的输出值被平均;对于分类,使用投票方案来确定最终类别。
优点:
- 擅长学习复杂、高度非线性的关系。它们通常可以实现相当高的性能,比多项式回归更好,通常与神经网络不相上下。
- 非常容易解释和理解。虽然最终训练的模型可以学习复杂的关系,但在训练期间建立的决策界限易于理解且实用。
缺点:
- 由于训练决策树的性质,它们很容易过度拟合。完整的决策树模型可能过于复杂,并且包含不必要的结构。虽然这有时可以通过适当的树木修剪和更大的随机森林集合来缓解。
- 使用更大的随机森林集合来实现更高的性能会带来速度更慢和需要更多内存的缺点。
结论
嘣!有你的利弊!在下一篇文章中,我们将看看不同分类模型的优缺点。我希望你喜欢这篇文章,并学到一些新的有用的东西。如果你看到了,请随意鼓掌。
自动驾驶汽车——我们应该因为黑客而扣上安全带吗?
保护 CAN 总线和避开传感器欺骗是迈向 5 级自治的一部分。

Freakout level as a new technology navigates the hype cycle
自从第一个网络摄像头出现以来,我们已经看到了大量联网设备出错的轶事。消费和工业物联网的滚雪球扩大了可能被恶意攻击的设备的数量。黑客已经控制了设备,监视人们,扰乱企业和政府,将数以千计的设备涌入 T2 僵尸网络。这样的例子不胜枚举。
每一项新技术都驱使坏人花费时间和精力去寻找利用他人的方法。物联网技术是一个大目标:智能助理、联网家庭、医疗保健设备、交通系统、制造传感器等。
物联网安全是一个热门话题,大玩家都知道。最近,芯片制造商 ARM 宣布了平台安全架构(PSA) ,这是一项针对开发者、硬件和芯片提供商的行业标准提案。Standard schmstandard ,但是微软、谷歌、思科、Sprint 和其他公司都支持它,所以谁知道呢?
汽车黑客和自动驾驶技术
对物联网安全的普遍担忧促使技术和主流媒体产生点击诱饵和耸人听闻的新闻。毫不奇怪,自动驾驶技术现在也出现了同样的情况。

CAN 总线和汽车黑客
控制器局域网(CAN)总线是由博世和英特尔于 1983 年开发的标准,其当前版本于 20 世纪 90 年代发布。CAN 是一种串行通信协议,允许在车辆部件(如制动器)之间进行分布式实时通信和控制👀,动力转向🙀、窗户、空调、安全气囊、巡航控制、信息娱乐系统、车门、电动汽车的电池和充电系统等。
通过对 CAN 总线进行逆向工程,我们能够通过软件向车辆发出命令。所以控制一辆车就是访问 CAN 总线。因为它的主要焦点是安全性和可靠性,所以它从未提供任何加强安全性的方法——例如,通过认证或加密。

汽车黑客手册是向任何人介绍这些部件的“圣经”。这本书研究脆弱性;详细解释了 CAN 总线上以及设备和系统之间的通信。
自动驾驶
自动驾驶车辆将给我们的生活带来实质性的转变。人工智能、计算机视觉和传感器技术的进步正在将我们推向第五级场景(汽车方向盘是“可选”的,不需要任何人为干预的状态。)
这一切都是由摩尔定律和数十亿美元的资本促成的。
就这样,我们的老朋友 CAN 总线突然变得流行起来。原因是大多数自动驾驶汽车公司不是从零开始设计或制造自己的车辆。他们正在开发控制汽车的软件——更具体地说是控制转向、加速和刹车。查看这里来自 Voyage (一种自动驾驶出租车服务)的工程师如何使用福特嘉年华的 CAN 总线来控制其温度。
根据自动驾驶技术传感器捕获的大量数据,制动、加速或改变转向角度的命令被发送到 CAN 总线。安装的摄像头、雷达和激光雷达是汽车的眼睛和耳朵。粗略地说,十几个传感器混合数据(称为传感器融合)来跟踪车辆环境,本地软件实时做出所有决定。
但是汽车是物联网的一部分吗?
对于自动驾驶技术来说,好消息是每辆车都像一个封闭的系统。不需要持续的云连接到汽车。它们最终将连接到外部世界来发送和接收信息,例如交通报告。仍然存在这样的风险,即与自动驾驶功能无关的另一个系统——如 wi-fi——可能会为黑客提供一个入口。这种黑客行为促使克莱斯勒在 2015 年召回 140 万辆汽车。
传感器欺骗
外部因素可以影响汽车传感器的行为,或者欺骗它的人工智能“认为”它“看到”不同的东西。
许多关于对抗性扰动的论文表明,深度神经网络可以被愚弄来错误分类对象。例如,通过在交通标志上添加伪装成涂鸦艺术的贴纸,软件会将其解释为不同的东西。看下面的视频。
现在有项研究正在进行中,用机器学习模型来对抗这些扰动,这些模型通过训练具有更高抵抗力的网络来保证鲁棒性。
除了摄像头,还有其他已知类型的传感器欺骗。一组中国研究人员成功发起攻击,使用现成的无线电、声音和光工具来欺骗特斯拉的超声波传感器和毫米波雷达,影响其自动驾驶系统。
韩国的另一个小组想出了一种方法( PDF )在路上创造假的物体,这些物体被激光雷达检测到,使汽车锁住刹车以避免撞车。
前方的路
因为我们处理的是乘客和行人的生命,所以安全必须始终是首要考虑的问题。不幸的是,在没有尖端技术的情况下,车辆武器化已经成为现实。大多数黑客攻击相当于临时攻击,比如有人从天桥上向汽车投掷重物。或者类似于将激光指示器瞄准驾驶员的眼睛。
你上一次从高层建筑的顶层乘电梯时担心黑客会让电梯坠落 30 层以上是什么时候?嗯,有人认为自动驾驶汽车就像电梯。
变革即将到来,现在的问题是什么时候,而不是如何。所以让我们系好安全带上路吧!
使用深度学习的自动驾驶汽车
无人驾驶汽车无疑将成为未来的标准交通方式。从优步和谷歌到丰田和通用汽车的大公司都愿意花费数百万美元来实现它们,因为未来的市场预计价值数万亿美元。在过去的几年里,我们看到了这一领域的巨大发展,优步、特斯拉和 Waymo 的汽车记录中总共有 800 万英里。
当然,由于硬件和软件方面的许多不同技术进步,自动驾驶汽车现在已经成为现实。激光雷达传感器、照相机、全球定位系统、超声波传感器协同工作,从每一个可能的来源接收数据。这些数据使用先进的算法进行实时分析,使自动驾驶功能成为可能。

https://www.technologyreview.com/s/609674/whats-driving-autonomous-vehicles/
形成自动驾驶管道有 5 个基本步骤,顺序如下:
- 本地化
- 感觉
- 预言;预测;预告
- 规划
- 控制
定位基本上是自动驾驶车辆如何准确地知道它在世界上的位置。在这一步中,他们从所有上述传感器(传感器融合)获得数据,并使用一种称为卡尔曼滤波器的技术以最高的精度找到他们的位置。卡尔曼滤波器是一种概率方法,使用随时间变化的测量值来估计物体的位置状态。另一种广泛使用的技术是粒子过滤器。
感知是汽车感知和理解周围环境的方式。这就是计算机视觉和神经网络发挥作用的地方。但稍后会详细介绍。
在预测步骤中,汽车预测周围每个物体(车辆或人)的行为。它们将如何运动,朝哪个方向,以什么速度,沿着什么轨迹运动。这里最常用的模式之一是递归神经网络,因为它可以从过去的行为中学习并预测未来。
路径规划是不言自明的。它是汽车规划路线的地方,或者说是产生轨迹的地方。这是通过搜索算法(如 A* )、点阵规划和强化学习来完成的。
最后,控制工程师从这里接手。他们使用上一步生成的轨迹来相应地改变汽车的转向、加速和刹车。最常见的方法是 PID 控制,但也有一些其他方法,如线性二次调节器(LQR) 和模型预测控制(MPC)
顺便说一句,如果你想了解更多,请查看 Udacity 免费提供的两门精彩课程:
嗯,我认为现在是我们自己制造自动驾驶汽车的时候了。好吧,不全是。但我们能做的是使用驾驶模拟器,记录下摄像头看到的东西。然后,我们可以将这些帧输入神经网络,希望汽车能够学会如何自己驾驶。让我想想…
我们将使用 Udacity 开源的自动驾驶汽车模拟器。要使用它,你需要安装 Unity 游戏引擎。现在有趣的部分来了:

不言而喻,我花了大约一个小时记录帧。是一些认真工作的人。我不是在鬼混。
无论如何,现在模拟器已经从 3 个不同的角度产生了 1551 帧,还记录了 517 个不同状态下的转向角、速度、油门和刹车。
在 keras 中构建模型之前,我们必须读取数据,并将它们分成训练集和测试集。
之后,我们将建立我们的模型,该模型具有 5 个卷积层、1 个漏失层和 4 个密集层。
网络将只输出一个值,即转向角。
在我们传递模型的输入之前,我们应该做一些预处理。请注意,这是通过 OpenCV 完成的,OpenCV 是一个为图像和视频操作而构建的开源库。
首先,我们必须产生更多数据,我们将通过扩充现有数据来做到这一点。例如,我们可以翻转现有的图像,翻译它们,添加随机阴影或改变它们的亮度。
接下来,我们必须确保裁剪和调整图像大小,以适应我们的网络。
培训时间:
现在我们有了经过训练的模型。它本质上克隆了我们的驾驶行为。让我们看看我们是怎么做的。为此,我们需要一个简单的服务器(socketio server)将模型预测实时发送给模拟器。我不打算谈论太多关于服务器的细节。重要的是我们利用模拟器实时生成的帧和日志来预测转向角度的部分。
结果是:

还不错。一点也不差。
我们真的做到了。我认为 Udacity 的模拟器是开始学习自动驾驶车辆的最简单的方法。
总而言之,自动驾驶汽车已经开始成为主流,毫无疑问,它们比我们大多数人想象的更快变得司空见惯。建造一个非常复杂,因为它需要从传感器到软件的许多不同的组件。但是这里我们只是迈出了非常非常小的第一步。
重要的是未来就在眼前。令人兴奋的是…
如果您有任何想法、评论、问题或者您只想了解我的最新内容,请随时在Linkedin,Twitter,insta gram,Github或在我的
原载于 2018 年 9 月 4 日sergioskar . github . io。
无人驾驶(非常小)汽车——第一部分
在野外用 Python,蓝牙汽车和多米尼克·托雷托做人工智能。
人工智能与物理世界相遇(在预算之内)
“我是那种欣赏好身材的男孩,不管身材如何。”——多米尼克·托雷托
A 自动驾驶汽车初创公司现在在非常火:即使不考虑通常的嫌疑人(、 Waymo 、 Cruise 等)。),有一大堆不太知名、资金相对较少的初创公司正在攻击这个领域(甚至还有一个 Udacity 课程!).这里的关键词是相对:你如何做并不重要,与你的标准 SaaS 公司相比,这只是一个很高的价格(因为像激光雷达这样的酷工具非常昂贵+收集训练/测试数据是一件痛苦的事情)。
为什么这些人要享受所有的乐趣?在我们破烂不堪的车库里,我们就不能做点什么来开始玩耍吗?事实证明,行业中一个常见的举动是使用模拟器,从特设的物理引擎到现成的视频游戏(你也可以在你的浏览器中尝试!).然而,我们在周末的黑客活动中尝试了一些别的东西:我们没有用现实世界来换取对现实世界的模拟,而是选择缩小问题的规模,用一个玩具宇宙来工作。
以前已经强调过玩具的教育(甚至研究)价值:如果你年纪足够大,还记得人工智能时代的美好时光,你可能会想起一只昂贵的索尼狗是机器人世界杯球队之类的天堂(有趣的事实:我写的第一个程序运行在一只白蓝相间的艾博上,它现在在好机器狗的天堂里自由自在地游荡)。具体来说,在谈到移动玩具时,荣誉奖当然要归功于车辆,这是由瓦伦蒂诺·布莱滕贝格撰写的一本聪明的书,在书中,简单的车辆展现出越来越复杂的“合成心理学”特征。
在这篇由两部分组成的文章中,我们将建立一个基于 Python 的开发环境来发送/接收赛车上的蓝牙小汽车的信息。由于我们缺钱,但不缺款式,我们将从著名的 Anki Overdrive 赛车套装的速度与激情版开始。
如果你像我们一样生活,一次一个 Git commit,跟随我们一起踏上从零到无人驾驶(非常小)汽车的疯狂旅程。
写这篇文章时,还没有好莱坞名人受到伤害。
免责声明:这是一个有趣的周末项目,绝不是经过深思熟虑的研究声明或生产就绪代码;事实证明,在选定的环境中,有许多真实的汽车无法再现(稍后将详细介绍)。也就是说,我们开始学习蓝牙的东西,更有趣的是,如何在不同的约束下构建人工智能和学习问题,而不是我们习惯的 API 开发的稀薄世界。
请注意,这个帖子的所有代码都免费 在 Github 上提供。
设置
“你刚刚赢得了与魔鬼共舞的机会,孩子。”—卢克·霍布斯
为了开始与卢克和多姆一起玩,我们只需要一条装有蓝牙汽车的赛道和一台可以与它们对话的计算机,这样我们就可以教它如何自动驾驶:
- 正如预期的那样,我们选择了 Anki Overdrive 作为我们的小尺度物理宇宙。Overdrive 被宣传为“智能战斗赛车系统”,它基本上是你的旧polis til/scale xtric赛道的蓝牙版本。让 Overdrive 对书呆子友好的是,包含与汽车交互的蓝牙协议的 Drive SDK 是开源的(然而,弄清楚汽车通信的具体细节花了我们一段时间:见下文);
- 就“具有蓝牙功能的计算机”而言,我们选择 Python+node 来通过 noble 实现跨平台兼容性,因此几乎任何东西都应该只需很小的修改,甚至不需要修改。具体来说,我们使用我们的 Rasp Pi 3B+ 在 Linux 上编译和运行原始 C 库,并在大多数实验中使用我们的 2017 MacBook Pro。
没有一个车库项目可以说是完整的,如果没有一张低分辨率的粒状照片——所以这是我们的(这里是原件):

The difference between man and boy is apparently the price of their toys.
愤怒但不要太快:去试驾
首先,让我们测试一下设置:在深入研究 Anki Drive 协议之前,我们检查一下我们是否可以使用现成的库从我们的蓝牙汽车中读取/向我们的蓝牙汽车发送消息。我们将运行两个测试:为您自己的设置选择一个您最喜欢的。
Anki 官方 C 工具上的一个树莓派
- 按照此处的说明编译并安装示例 Anki 应用程序(不要忘记首先安装所有依赖项);
- 启动
vehicle-scanapp 扫描车辆(记下 id!); - 使用上面获取的 id 启动
vehicle-tool连接到车辆; - 测试一堆命令(截屏 +笨拙的我开车通过码头的视频)。
2017 款 Mac Book Pro 上的 Chrome 68+web app+ 蓝牙 API
任务开始!
使用 Python 实现实时汽车通信
“我们做我们最擅长的事情。我们随机应变,好吗?”—布莱恩·奥康纳
既然我们知道一切正常,现在是 Python 时间了!我们只能找到一个非官方的 Python 包装器用于驱动 SDK:代码实际上看起来很惊人,我们在 Raspberry 上测试成功example.py;但是依赖于 bluepy ,所以只是在 Linux 上运行。
我们最终开发的 hack-y 解决方案是来自上面的 Python 包装器(的简化版本)、一个不错的 Java 包装器和这个节点项目的想法的混合:

特别是,所有的“决定”都将在 Python 层做出,正如预期的那样,但 Python 不会直接与汽车通信,因为一个小节点网关(用 noble 构建)将从蓝牙传感器提供所需的跨平台抽象;在内部,Python 和 node 将利用套接字连接的速度来读/写信息。
如果你想了解更多关于包装器本身的信息,回购协议是有点自我说明的,结尾的附录会给你一个很好的高层次概述。如果您只是想开始驾驶,您需要:
- 记下目标车辆的蓝牙设备 id
- 克隆回购
- cd 放入节点文件夹,用
npm install下载依赖项 - cd 放入 python 文件夹,并下载您最喜欢的 Python env
pip install -r requirements.txt的依赖项(如果有的话) - 启动节点网关
node node_server.js PORT UUID - 从你最喜欢的 Python env,运行
python constant_speed_example.py —-car=UUID并看到车辆移动!
(这是我 在一分钟内完成所有这些步骤 ,为了方便起见,重用了一个 Python virtualenv)
我们已经准备好开始我们的第一个四分之一英里!
我们的第一个四分之一英里
“要么骑要么死,记得吗?”—多米尼克·托雷托
我们要做的第一件事就是绕着我们的椭圆形轨道匀速跑,比如说,400 毫米/秒(我知道,那是太慢了)。

Oval track with piece identifiers (IDs from our kit).
(可以用回购中的constant_speed_example.py来做同样的事情;轨迹图像取自此处。
我们的 Python 应用程序将开始实时打印汽车位置通知,例如:
{'location': 17, 'piece': 36, 'offset': 67.5, 'speed': 390, 'self_speed': 400, 'clockwise': 7, 'notification_time': datetime.datetime(2018, 8, 25, 21, 9, 33, 359248), 'is_clockwise': False}{'location': 23, 'piece': 57, 'offset': 67.5, 'speed': 422, 'self_speed': 400, 'clockwise': 71, 'notification_time': datetime.datetime(2018, 8, 25, 21, 9, 32, 229689), 'is_clockwise': True}...
piece和speed都很琐碎(speed是车辆记录的速度,self_speed是我们命令设定的“理论”速度),offset标识“车道”(见此处的一个直观解释,位置是一个增量整数(见此处的一个很好的直观解释)。
我们现在可以走快了吗?我们当然可以,但是在踩油门之前,我们需要解决一个基本问题:我们如何测量跑完一圈需要的时间?当我们梦想改进我们的机器辅助驾驶策略时,我们需要一种方法来衡量我们一圈接一圈的速度。
即使位置更新没有那么频繁(因为我们每秒收到 3/4 次通知),我们也将简单地以 33 分段(起跑线)上两次连续通过之间的时间作为圈速。这是在我们的椭圆形跑道上以 400 毫米/秒的速度运行lap_time_example.py的输出:
time lap in seconds was 9.046201
...
time lap in seconds was 9.029405
...
time lap in seconds was 9.045055
...
time lap in seconds was 9.044495
...
虽然有一些差异,但看起来没那么糟糕(SD 0.007)!作为进一步的测试,这是在 800 毫米/秒下的相同程序:
time lap in seconds was 4.497926
...
time lap in seconds was 4.502276
...
time lap in seconds was 4.497534
...
还是合理的!作为第一近似值,这就足够了。
正如我们刚刚看到的(惊喜惊喜!),通过提高车辆速度,我们获得了更好的性能(在 800 毫米/秒时,时间几乎正好是 400 毫米/秒时的 1/2)。为什么我们不越走越快呢?嗯,这不是那么微不足道,因为我们的宇宙很小,但仍然是物理现实的。为了理解我的意思,如果我们以 1000 毫米/秒的速度初始化汽车,会发生这样的情况:
Oooops
即使是多米尼克·托雷托也不可能转过那个弯(嗯,也许他可能有)!
让我们从专业飞行员手册(或者实际上只是常识)中获取一些技巧:我们将写下稍微复杂一点的驾驶政策(参见custom_policy_example.py),如下所示:
- 在每个直线段开始时,我们将速度增加到 1000 毫米/秒;
- 就在掉头之前,我们将刹车并将速度降低到 800 毫米/秒。

Pretty basic, but we need to start somewhere, don’t we?
结果在数量上(更快的单圈时间)和质量上都更好:车辆行为现在更加真实:
We’re drifting baby!
当然,许多其他改进会立即浮现在脑海中,例如以更智能的方式使用车道。
由于可能的优化是无止境的,如果计算机能解决这个问题,那该多好? 是的,它会(也就是说,最终,玩具车如此有趣的全部科学借口)。
在我们的玩具世界里,确实有很多有趣的数据问题可以尝试和提问:
- 给定赛道配置,车辆如何学习最佳“驾驶策略”?这实际上是两个挑战合二为一:学习一项政策并将其推广——如果在一个领域学到的东西可以立即用于另一个看不见的领域,那不是很酷吗?
- 当我们将其他车辆引入组合时,会有什么变化?例如,我们可以让他们相互竞争,或者我们可以使用第二个工具来学习合作行为(例如避免碰撞)。
- 除了赛道配置之外,我们能否以其他变量作为学习过程的条件?例如,我们可以想象通过一个以不同方式实现它们的汽车接口,从当前库中抽象出转向和制动命令。会有什么变化?
- 使用当前的传感器,车辆能有多智能?正如我们已经看到的位置,传感器是非常基本的,不允许细粒度的控制:我们可以做些什么来更智能地利用我们所拥有的(例如,插值位置?)我们可以轻松添加哪些东西,让我们有更多的玩法(例如带物体识别功能的网络摄像头)?
- …当然还有更多我们没有想到的!
重要的是,我们现在有一个基本的,但功能性的设置来运行实验,并从我们的小型汽车中收集数据。在第二部中,我们将开始将所有这些工程材料投入使用,并帮助我们为无人驾驶汽车设计越来越智能的行为(剧透:我们将从使用 Mac 键盘手动驾驶开始)。
附录:回购结构
本教程使用的代码是开源的,拥有 Apache 许可证。请注意,当前的master是作为 alpha 发布的,因为它只包含了最基本的东西:没有单元测试,没有花哨的东西,几乎没有对错误的保护,等等…随着实验的进展,我们希望对代码库进行一些改进:非常欢迎反馈和贡献!
项目结构非常简单,两个主要文件夹包含 node 和 Python 代码:
node_app
node_socket-app
node_server.js
package-lock.json
python_app
py_overdrive_sdk
py_overdrive.py
track_images/
create_track_image.py
constant_speed_example.py
track_discovery_example.py
custom_policy_example.py
requirements.txt
.gitignore
node_server.js是一个服务器扫描和与蓝牙设备聊天的简单节点实现(受这个包装器的启发)。当服务器启动时, noble 等待蓝牙设备可用,并开始使用 Anki 特征 UUIDs 进行扫描。剩下的代码只是服务器监听来自 Python 的事件并执行蓝牙相关的逻辑:“元命令”带有语法 COMMAND|PARAM (例如CONNECT | ba 0 d6a 19–1bf 6–4681–93da-e 9c 28 F2 b 6743**),而 car 命令是十六进制字符串,直接发送给车辆(例如 03900101 启用 SDK 模式)。仅供参考,这也是我在 node 中编写的第一个应用程序(所以如果它不工作,那就是我的借口!).**
py_overdrive.py包含Overdrive类,该类封装了车辆相关逻辑和来自/去往节点网关的通信。我们利用 Python 线程和队列来处理并发进程,以非阻塞的方式写入、读取和处理位置事件。在初始化时,如果一个函数被提供给构造器,系统将采取定制的动作(“驱动策略”)来响应位置事件(简单的用例见custom_policy_example.py)。track_discovery_example.py和配套的脚本create_track_image.py将让你开始绘制轨道的不同部分,并打印出布局(附注:代码只是一个快速而肮脏的存根,它做出了许多简化的假设)。
如果你愿意帮忙,repo README包含了一个正在进行的改进和实验清单。随时寻求评论、反馈和想法。
再见,太空牛仔

*请继续关注,因为我们将很快带着*第二部分回来。如果您有问题、反馈或评论,请将您的故事分享到jacopo . taglia bue @ tooso . ai。
别忘了在 Linkedin 、 Twitter 和 Instagram 上获取 Tooso 的最新消息。
感谢
这将是一个月的项目,而不是一个周末的项目,没有互联网和互联网上的出色的人分享他们的代码和想法(具体的学分见回购内的链接):就复制+粘贴而言,这个项目确实是首屈一指的。
当然,如果没有 Anki 让机器人民主化的愿景,这一切都不可能实现。我们第一次发现 Anki 是通过 Cozmo,一个瓦力般可爱的小机器人和一个奇妙的 Python SDK (Cozmo 的可能性使它成为各种周末项目的令人难以置信的游乐场)。虽然我们当然与 Anki blah blah 法律事务没有任何关系,但我懒得复制+粘贴 blah blah blah,我们非常喜欢他们的产品。
自学习人工智能代理 IV:随机策略梯度
在连续的动作空间中控制人工智能:从自动驾驶汽车到机器人。

自学习人工智能代理系列—目录
- 第一部分:马尔可夫决策过程
- 第二部分:深度 Q 学习
- 第三部分:深度(双)Q 学习
- 第四部分:随机政策梯度(本文)
- 第五部分:确定性政策梯度
0.介绍
使用 深度 Q 学习 和 深度(双)Q 学习 我们能够在离散的动作空间中控制 AI,其中可能的动作可能简单到向左或向右、向上或向下。尽管有这些简单的可能性,人工智能代理仍然能够完成令人惊讶的任务,例如以超人的表现玩雅达利游戏,或者在棋盘游戏中击败世界上最好的人类选手 T21。
然而,强化学习的许多现实应用,如训练机器人或无人驾驶汽车需要代理从连续空间中选择最佳行动。让我们用一个例子来讨论连续作用空间这个术语。

当你开车转动方向盘时,你可以控制方向盘转动的幅度。这就产生了一个连续的动作空间:例如,对于某个范围内的每一个正实数 x ,“向右转动轮子 x 度”。或者你踩油门到什么程度?这也是一个持续的输入。
记住:连续的动作空间意味着(理论上)有无限量的可能动作。
事实上,我们在现实生活中会遇到的大多数动作都来自连续动作空间。这就是为什么理解我们如何训练一个在有无限可能性的情况下选择行动的人工智能是如此重要。
这就是随机政策梯度算法显示其优势的地方。
你如何实践随机政策梯度?

OpenAI 健身房“连续登山”问题的这个例子是用随机政策梯度解决的,如下所示。有据可查的源代码可以在我的 GitHub 资源库 中找到。我选择 MountainCarContinuous 作为一个例子,因为这个问题的训练时间非常短,你可以很快地自己重现它。如果你看完这篇文章想练习一下,克隆库,执行src/policy gradients/random/random _ pg . py启动算法。
1.随机政策
在马尔可夫决策过程中,我引入了人工智能代理作为一个神经网络,它与环境(电脑游戏、棋盘、现实生活等)相互作用。)通过观察它的状态 s (屏幕像素、板配置等。)并根据当前可观测状态采取**动作 a、**

Fig. 1 Schematic depiction of deep reinforcement learning
对于处于**状态s的每一个**动作at**,AI 代理接收一个奖励。奖励的数量告诉代理他的动作在这个特定的状态中关于解决给定目标的质量,例如学习如何走路或赢得一个计算机游戏。任何给定的状态下的动作由策略π 决定。**
在马尔可夫决策过程中,我引入了策略作为 AI 的策略,该策略决定了他从一个状态 s 到下一个状态**s’**的移动,跨越所有可能状态 s_1 的整个序列,…,环境中的 s_n 。
在深度 Q 学习中,代理遵循策略 π ,该策略告知在状态 s 中采取动作,这对应于最高动作值 Q(s,a) 。行动价值函数是我们从状态 s 开始,采取行动 a ,然后遵循政策 π 所获得的预期回报(所有状态的回报总和)(比较马尔可夫决策过程 ) 。
在随机策略的情况下,基本思想是通过参数概率分布来表示策略:

Eq. 1 Stochastic policy as a probability distribution.

Fig. 1 Sample an action a from the policy, which is a normal distribution in this case.
该分布根据一个参数向量 θ 随机选择状态 s 中的动作 a 。作为概率分布的策略的一个例子是高斯分布,其中我们随机选择一个动作,作为这个分布的样本(图 1)。这就产生了动作是一个连续变量。**
记住 :与深度 Q 学习相反,策略现在是从状态到动作的直接映射/函数。******
一步法
但是我们如何确定当前的政策π是一个好政策呢?为此我们必须为π定义一个性能函数,我们称之为 J(θ) 。
我们来讨论一个简单的案例,这里我们要衡量的是 π 的质量/性能只针对代理的一个步骤(从状态 s 到下一个状态s’)。在这种情况下,我们可以将质量函数定义如下:****

Eq. 2
等式中的第二行无非是期望操作符 E 对期望动作的执行——值 r(s,a) 对于动作 a 处于状态s是从环境中选择的,而 a 是根据策略选择的 R_a_s 是状态 s 中动作 a 的奖励。
请注意 : r(s,a) 与 Q(s,a) 或 q(s,a) 含义相同,但仅针对一步流程。****
必须考虑到,在深度强化学习中,环境是随机的,这意味着采取行动并不能保证代理人最终会处于他想要的状态。环境在一定程度上决定了代理的最终位置。因为动作值【s,a】依赖于也依赖于下一个状态【s’(参见等式。17 在 马尔可夫决策过程中 )我们必须平均报酬 R_a_s 整体转移概率p(s):= p(s→s’)从状态 s 到下一个状态s’。*** 再者因为 R_a_s 也取决于行动,我们必须将所有可能的 π(a,s)上的报酬平均化。*****
2.随机政策梯度定理
策略梯度算法通常通过对这种随机策略进行采样并朝着更大的累积回报的方向调整策略参数来进行。
现在我们已经定义了策略 π、 的性能,我们可以更进一步,讨论如何学习最优策略。由于 π(θ) 取决于一些参数 θ ( 这些参数在大多数情况下是神经网络的权重和偏差)我们必须找到使性能最大化的最优 θ 。
政策梯度法背后的基本思想是在绩效梯度的方向上调整政策的这些参数【θ】。******
如果我们计算 J(θ) 的梯度,我们得到下面的表达式:

Eq. 3 The gradient of the performance function for the one-step process.
因为我们想要找到使性能最大化的,所以我们必须更新进行梯度上升——与梯度下降相反,我们想要找到使预定义损失函数最小化的参数。******

多步骤过程
既然我们知道了如何改进一步式流程的策略,我们可以继续这个案例,在这里我们考虑 AI 智能体在整个状态序列中的移动过程。
实际上,这种情况并没有那么困难,如果我们记住,在遵循一个政策从一个状态到另一个状态的运动过程中,我们将获得的(折扣)奖励的总和,就是行动-价值函数 Q(s,a) 的准确定义。这产生了多步骤过程的策略梯度的以下定义,其中单个预期回报【r(s,a)】与预期累积回报(回报总和) Q(s,a) 交换。

Eq. 4 The gradient of the performance function for the multi-step process.
3.演员-评论家算法
根据等式使用更新规则的算法。4 被称为演员评论家算法。策略 π(a|s) 被称为参与者,因为参与者决定了在 s 状态下必须采取的动作。与此同时,评论家 Q(s,a), 通过赋予演员的行为一个质量值来达到批评的目的。
可以看到J【θ】的渐变与这个的质量值成比例。高质量值表明在状态中采取的动作 a 实际上是一个好的选择,并且可以增加性能方向上的 θ 的更新。反之适用于小质量值。**
现实中,我们无法预先知道【Q(s,a)】T3。因此我们必须用一个函数 Q_w(s,a) 来近似它,这个函数依赖于参数 w 。一般来说 Q_w(s,a) 可以通过神经网络来估计。******

Eq. 5 Estimation of the action-value function.
这产生了性能梯度的新定义:

E6. A new definition of the performance gradient.
总之,随机策略梯度算法试图完成以下两件事:
- 更新演员 π 的参数 θ 朝向表演的渐变 J(θ)
- 用常规的时间差异学习算法更新评论家的参数 w ,这是我在深度 Q 学习中介绍的。
整个 Actor-Critic 算法可以用下面的伪代码来表示:

算法的关键部分发生在代表人工智能代理生命周期的循环中。让我们更深入地讨论每一步:
- 通过在状态中采取动作从环境中获得奖励 R ,并观察新状态【s’********
- **给定这个新状态s’***样本一个动作 *一个’随机地从分布 π
- 使用旧的, a 和新的s’**,a’计算时间差异目标δ
- 根据时间差异学习更新规则更新参数 w 。(更好的替代:用常规的梯度下降算法最小化r+γQ(s’,a’)和【s,a】*之间的距离来更新w****。)*******
- 通过向性能梯度 J(θ) 执行梯度上升步骤,更新策略的参数 θ**
- 将新状态 s’ 设为旧状态 s ,并将新动作 a’ 设为旧动作 a
- 如果进程没有终止,从头开始循环
4.减少方差
众所周知,Actor-Critic-Algorithm 的普通实现具有很高的方差。减小这种方差的一种可能性是从动作值【Q(s,a)】中减去状态值 V(s) (等式 1)。7) 。 状态值在马尔可夫决策过程中被定义为预期的总奖励,如果它在状态 、 中开始它的进程而不考虑动作,AI 代理将会收到该奖励。**

Eq. 7 Definition of the advantage.
这个新术语被定义为 优势 并且可以被插入到性能的梯度中。利用这一优势在减少算法的方差方面显示了有希望的结果。

Eq. 8 Advantages is inserted into the policy gradient.
在具有优势的另一方面,我们引入了要求具有第三函数逼近器(如神经网络)来估计的问题。然而,可以看出预期的时间差误差为**【V(s)】(等式。9) 无非是优点。****

Eq. 9 Temporal difference error of V(s).
这可以用 Q(s,a) 的一个定义来表示,就是r+γV(s’)的期望值。通过减去剩余的项 V(s) 我们获得优势 A (等式 1)的先前定义。10) 。**

Eq. 10 Advantage equals the expected TD-Error of V(s).
最后,我们可以将【V(s)的时差误差插入到【J(s)的梯度中。这样做我们一举两得:
- 我们减少了整个算法的方差
- 同时,我们去掉了三次函数近似

Eq. 11
自学习人工智能代理第一部分:马尔可夫决策过程
深度强化学习理论的数学指南
这是关于自我学习人工智能代理的多部分系列的第一篇文章,或者更准确地说,是深度强化学习。本系列的目的不仅仅是让你对这些话题有一个直觉。相反,我想为您提供对最流行和最有效的深度强化学习方法背后的理论、数学和实现的更深入的理解。
自学习人工智能代理系列—目录
- 第一部分:马尔可夫决策过程(本文)
- 第二部分:深度 Q 学习
- 第三部分:深度(双)Q 学习
- 第四部分:持续行动空间的政策梯度
- 第五部分:决斗网络
- 第六部分:异步演员-评论家代理
- …

Fig. 1. AI agent learned how to run and overcome obstacles.
马尔可夫决策过程—目录
- 0。简介
- 1。简而言之强化学习
- 2。马尔可夫决策过程
- 2.1 马尔可夫过程
- 2.2 马尔可夫奖励过程
- 2.3 价值函数
- 3。贝尔曼方程
- 3.1 马尔可夫报酬过程的贝尔曼方程
- 3.2 马尔可夫决策过程— 定义
- 3.3 政策
- 3.4 动作值函数
- 3.5 最佳政策
- 3.6 贝尔曼最优方程
如果你喜欢这篇文章,想分享你的想法,问问题或保持联系,请随时通过 LinkedIn 与我联系。
0.介绍
深度强化学习正在兴起。近年来,深度学习的其他子领域没有被研究人员和全球大众媒体谈论得更多。深度学习中的大多数杰出成就都是由于深度强化学习而取得的。从谷歌的阿尔法围棋(Alpha Go)击败了世界上最好的人类棋手(这一成就在几年前被认为是不可能的),到 DeepMind 的人工智能智能代理(AI agents ),它们可以自学行走、奔跑和克服障碍(图 1-3)。

Fig. 2. AI agent learned how to run and overcome obstacles.

Fig. 3. AI agent learned how to run and overcome obstacles.
自 2014 年以来,其他人工智能代理在玩老派雅达利游戏如突破(图 4)时超过了人类水平。在我看来,所有这些最令人惊讶的事情是,这些人工智能代理中没有一个是由人类明确编程或教会如何解决这些任务的。他们是靠深度学习和强化学习的力量自己学会的。这个多部分系列的第一篇文章的目标是为您提供必要的数学基础,以便在接下来的文章中处理这个人工智能子领域中最有前途的领域。

Fig. 4 AI agent learned how to play Atari’s Breakthrough.
1.简而言之,深度强化学习
深度强化学习可以概括为构建一个直接从与环境的交互中学习的算法(或 AI agent)(图 5)。环境可以是真实的世界、计算机游戏、模拟甚至是棋盘游戏,如围棋或象棋。像人类一样,人工智能代理从其动作的结果中学习,而不是从被明确教导中学习。

Fig. 5 Schematic depiction of deep reinforcement learning
在深度强化学习中,代理由神经网络表示。神经网络直接与环境互动。它观察环境的当前状态并决定采取哪个动作(例如向左、向右移动等。)基于当前状态和过去的经验。基于所采取的动作,AI 代理接收奖励。奖励的数量决定了所采取的行动在解决给定问题方面的质量(例如学习如何走路)。一个代理的目标是学习在任何给定的情况下采取行动,使累积的回报随着时间的推移而最大化。
2.马尔可夫决策过程
一个马尔可夫决策过程 ( MDP )是一个离散时间随机控制过程。MDP 是迄今为止我们为人工智能代理的复杂环境建模的最好方法。代理旨在解决的每个问题都可以被认为是一系列状态 S1、S2、S3……Sn(例如,一个状态可以是围棋/国际象棋棋盘配置)。代理采取行动并从一种状态转移到另一种状态。在接下来的内容中,你将学习在任何给定的情况下,决定代理人必须采取何种行动的数学方法。
2.1 马尔可夫过程
马尔可夫过程是描述一系列可能状态的随机模型,其中当前状态仅依赖于先前状态。这也称为马尔可夫性质(等式)。1).对于强化学习,这意味着人工智能主体的下一个状态只依赖于上一个状态,而不是之前的所有状态。

Eq. 1 Markov Property
马尔可夫过程是一个随机过程。意味着从当前状态 s 到下一个状态s’的过渡只能以一定的概率发生Pss’(等式。2).在马尔可夫过程中,被告知向左的代理只会以某个概率(例如 0.998)向左。在小概率情况下,由环境来决定代理的最终位置。

Eq. 2 Transition probability from state s to state s’.
Pss’可以被认为是状态转移矩阵 P 中的一个条目,该矩阵定义了从所有状态 s 到所有后继状态’s**的转移概率。3).

Eq. 3. Transition probability matrix.
记住:一个马尔可夫过程(或马尔可夫链)是一个元组 < S , P > 。 S 是状态的(有限)集合。 P 是状态转移概率矩阵。
2.2 马尔可夫奖励过程
一个马氏奖励过程是一个元组 < S,P,R > 。这里 R 是代理人在状态 s (Eq。4).这一过程的动机是,对于一个旨在实现某个目标(例如赢得一场国际象棋比赛)的人工智能主体来说,某些状态(比赛配置)在策略和赢得比赛的潜力方面比其他状态更有希望。

Eq. 4. Expected reward in a state s.
兴趣的首要话题是总奖励 Gt (Eq。5)这是代理将在所有状态序列中收到的预期累积奖励。每个奖励由所谓的折扣因子γ ∈ [0,1]加权。贴现回报在数学上是方便的,因为它避免了循环马尔可夫过程中的无限回报。此外,贴现因子意味着我们越是在未来,回报就变得越不重要,因为未来往往是不确定的。如果奖励是经济上的,即时奖励可能比延迟奖励获得更多的利息。此外,动物/人类的行为显示出对即时回报的偏好。

Eq. 5. Total reward across all states.
2.3 价值函数
另一个重要的概念是价值函数 v(s) 的概念。value 函数将一个值映射到每个状态 s 。状态 s 的值被定义为如果 AI 代理在状态 s 中开始其进程,它将接收的预期总奖励(等式。6).

Eq. 6. Value function, the expected return starting in state s.
价值函数可以分解为两部分:
- 代理人在状态****【s .**下收到的即时报酬 R(t+1)
- 状态之后的下一个状态的贴现值 v(s(t+1))**

Eq. 7 Decomposition of the value function.

3.贝尔曼方程
3.1马尔可夫奖励过程的贝尔曼方程
分解的值函数(等式。8)也称为马尔可夫奖励过程的贝尔曼方程。该功能可以在节点图中可视化(图 6)。从状态 s 开始导致值 v(s) 。处于状态 s 我们有一定的概率*【Pss’结束于下一个状态s’。在这个特例中,我们有两个可能的下一个状态。为了获得值 v(s) ,我们必须对可能的下一个状态的值s v(s)求和,该值由概率【Pss’*加权,并加上从处于状态 s 中得到的直接奖励。这产生了等式。如果我们在等式中执行期望操作符 E ,这就是等式 8。

Eq. 8 Decomposed value function.

Fig. 6 Stochastic transition from s to s’.

Eq. 9 Bellman Equation after execution of the expectation operator E.
3.2 马尔可夫决策过程—定义
马尔可夫决策过程是一个带有决策的马尔可夫回报过程。马尔可夫决策过程由一组元组 < S,A,P,R >来描述,A 是代理在状态 s 中可以采取的有限的可能动作集合。因此,处于状态 s 的直接回报现在也取决于代理在这种状态下采取的动作(等式。10).**

Eq. 10 Expected reward depending on the action in a state s.
3.3 政策
在这一点上,我们将讨论代理如何决定在一个特定的状态下必须采取的行动。这是由所谓的策略【π】(等式。11).从数学上来说,策略是给定状态 s 下所有动作的分布。该策略确定从状态到代理必须采取的动作的映射。****

Eq. 11 Policy as a mapping from s to a.
记住:直观地说,策略π可以描述为代理根据当前状态 s 选择某些动作的策略。
该政策导致了国家价值函数的新定义 v(s) (等式。我们现在把它定义为从状态 s 开始,然后遵循一个策略 π的期望收益。

Eq. 12 State-value function.
3.4 动作值函数
**除了状态值函数之外,另一个重要的函数是所谓的动作值函数 q(s,a) (等式。13) **。行动值函数是我们从状态 s 开始,采取行动 a ,然后遵循策略 π 所获得的预期收益。注意,对于状态 s , q(s,a) 可以取几个值,因为在状态 s 中代理可以采取几个动作。 Q(s,a) 的计算由神经网络实现。给定一个状态 s 作为输入,网络以标量形式计算该状态下每个可能动作的质量(图 7)。更高的质量意味着对于给定的目标更好的行动。

Fig. 7 Illustration of the action-value function.
****记住:行动价值函数告诉我们,在特定状态下采取特定行动有多好。

Eq. 13 Action-value function.
之前,状态值函数 v(s) 可以分解为以下形式:

Eq. 14 Decomposed state-value function.
同样的分解可以应用于动作值函数:

Eq. 15 Decomposed action-value function.
此时,让我们讨论一下*【v(s)*和 q(s,a) 是如何相互关联的。这些函数之间的关系可以在图表中再次可视化:

Fig. 8 Visualization of the relation between v(s) and q(s,a).
在这个例子中,处于状态 s 允许我们采取两种可能的动作 a 。根据定义,在特定的状态下采取特定的动作给了我们动作值 q(s,a) 。价值函数*【v(s)是在状态【s】(Eq)中采取行动的概率(非策略 π )加权的可能*【q(s,a)*** 之和。16) 。***

Eq. 16 State-value function as weighted sum of action-values.

现在让我们考虑图 9 中相反的情况。二叉树的根现在是一种状态,在这种状态下我们选择采取一个特定的动作。记住马尔可夫过程是随机的。采取行动并不意味着你会百分百确定地到达你想去的地方。严格地说,你必须考虑采取行动后在其他州结束的可能性。在这种特殊情况下,在采取行动之后,你可能会以两种不同的下一个状态结束:****

Fig. 9 Visualization of the relation between v(s) and q(s,a).
要获得行动值,您必须获得由概率Pss’加权的贴现状态值,以结束所有可能的状态(在本例中只有 2 个),并添加即时奖励:

Eq. 17 Relation between q(s,a) and v(s).
现在我们知道了这些函数之间的关系,我们可以从等式中插入【v(s)】。16 从 Eq 变成 q(s,a) 。17.我们得到等式。18,可以注意到,当前 q(s,a) 和下一个动作值q(s’,a’)之间存在递归关系。

Eq. 18 Recursive nature of the action-value function.
这种递归关系可以在二叉树中再次可视化(图 10)。我们从 q(s,a) 开始,以某个概率在下一个状态 s’ 中结束 Pss’ 从那里我们可以以概率*【π采取行动’ a '并以行动值结束为了获得 q(s,a)* ,我们必须沿着树向上,对所有概率进行积分,如等式 1 所示。18.**

Fig. 10 Visualization of the recursive behavior of q(s,a).
3.5 最佳政策
深度强化学习中最重要的感兴趣的主题是找到最佳动作值函数 q 。寻找 q 意味着代理人确切地知道在任何给定状态下动作的质量。此外,代理可以根据质量决定必须采取的行动。让我们定义一下 q* 的意思。最可能的行动价值函数是遵循最大化行动价值的政策的函数:**

Eq. 19 Definition of the best action-value function.
为了找到可能的最佳策略,我们必须在q(s,a)上最大化。最大化意味着我们只从所有可能的动作中选择动作,其中 q(s,a) 具有最高值。这就产生了最优策略π的如下定义:**

Eq. 20 Optimal policy. Take actions that maximize q(s,a).
3.6 贝尔曼最优方程
最优策略的条件可以代入方程。18.从而为我们提供了贝尔曼最优性方程:

Eq. 21 Bellman Optimality Equation
如果人工智能代理可以解决这个方程,那么它基本上意味着给定环境中的问题得到了解决。代理人知道在任何给定的状态或情况下任何可能的行动的质量,并能相应地行动。
解决贝尔曼最优方程将是接下来文章的主题。在接下来的文章中,我将向你展示第一种叫做深度 Q 学习的技术。
自学习人工智能代理第二部分:深度 Q 学习
深度 Q 学习的数学指南。在这个关于深度强化学习的多部分系列的第二部分中,我将向您展示一种有效的方法,来说明 AI 智能体如何在具有离散动作空间的环境中学习行为。

自学习人工智能代理系列—目录
- 第一部分:马尔可夫决策过程
- 第二部分:深度 Q-Learning ( 本文)
- 第三部分:深度(双)Q 学习
- 第四部分:持续行动空间的政策梯度
- 第五部分:决斗网络
- 第六部分:异步演员-评论家代理
- …
深度 Q-学习-目录
- 0。简介
- 1。时间差异学习
- 2。q-学习
- 2.1 开启和关闭策略
- 2.2 贪婪政策
- 3。深度 Q 学习
- 3.1 目标网络和 Q 网络
- 3.2ε-贪婪政策
- 3.3 勘探/开采困境
- 3.4 体验回放
- 4。具有经验重放伪算法的深度 Q 学习
如果你喜欢这篇文章,想分享你的想法,问问题或保持联系,请随时通过 LinkedIn 与我联系。
0.介绍
在本系列的第一篇文章中,我向您介绍了马尔可夫决策过程的概念,这是深度强化学习的基础。为了完全理解下面的主题,我建议你重温一下第一篇文章。
通过深度 Q 学习,我们可以编写能够在具有离散动作空间的环境中运行的人工智能代理。离散动作空间是指定义明确的动作,例如向左或向右、向上或向下移动。

FIg. 1. Atari’s Breakthrough as an example for discrete action spaces.
雅达利的突破是一个具有离散行动空间的环境的典型例子。人工智能代理可以向左或向右移动。每个方向的运动都有一定的速度。
如果代理可以决定速度,那么我们将有一个连续的动作空间,有无限多的可能动作(不同速度的运动)。这一案件将在今后审议。
1.动作值函数
在上一篇文章中,我介绍了动作值函数的概念 ***Q(s,a)***由 Eq 给出。1. 提醒一下,动作值函数被定义为 AI 智能体通过从状态 s 开始,采取动作 a 然后遵循策略 π而获得的预期回报。
记住:直观地说,策略π可以描述为代理根据当前状态 s 选择某些动作的策略。

Eq. 1 Action-Value function.
***【s,a】***告诉代理人一个可能动作的值(或质量)s。给定一个状态 s ,动作值函数计算该状态下每个可能动作 a_i 的质量/值,作为标量值(图 1)。更高的质量意味着对于给定的目标更好的行动。

Fig. 1 Given a state s, there are many actions and appropriate values of Q(s,a)
如果我们执行等式中的期望运算符 E 。1 我们获得了一种新形式的行动价值函数,在这里我们处理概率。*【Pss’是从一个状态到下一个状态【s’的转移概率,由环境决定。【π(a ')*是政策或从数学上讲是给定状态下所有行动的分配

Eq. 2 Another form of Q(s,a) incorporates probabilities.
1.时间差异学习
我们在深度 Q-Learning 中的目标是求解动作值函数 Q(s,a) 。我们为什么想要这个?如果 AI 智能体知道 Q(s,a) ,那么给定的目标(比如赢得一场与人类玩家的象棋比赛或者玩 Atari 的突破)可以被认为是已解决的。这样做的原因是这样一个事实,即 Q(s,a) 的知识将使代理人能够确定在任何给定状态下任何可能行动的质量。因此,代理可以相应地行动。

情商。2 还给出了一个递归解,可以用来计算 Q(s,a) 。但是因为我们在考虑递归,而且用这个方程来处理概率是不实际的。而是必须使用所谓的时间差分 ( TD )学习算法来迭代求解 Q(s,a) 。**
在 TD 学习中我们更新 Q(s,a) 对于每一个动作 a 处于一种状态 s 朝向估计返回 R(t+1)+γQ(s(t+1),a(t+1)) ( Eq。3 )。估计回报也称为 TD 目标。对每个状态和动作多次迭代地执行该更新规则,对于环境中的任何状态-动作对,产生正确的动作值*【Q(s,a)。*

Eq. 3 Update rule for Q(s,a)
TD-Learning 算法可以总结为以下步骤:
- 对于状态 s_t 中的动作 a_t 计算 Q(s_t,a_t)
- 转到下一个状态*【t+1】,在那里采取一个动作【t+1】*并计算值 Q( s_(t+1),a(t+1))
- 使用 Q( s_(t+1),a(t+1)) 和即时奖励 R(t+1) 进行动作 a_t 最后状态 s_t 计算 TD-Target
- 通过将*【Q(s _ t,a _ t)】添加到 TD-Target 和【Q(s _ t,a _ t)】α之间的差值来更新先前的【s _ t,a _ t】*。
1.1 时间差异
让我们更详细地讨论 TD 算法的概念。在 TD- learning 中我们考虑了 Q(s,a) — 两个“版本”之间的差异【a】Q(s,】一旦在之前我们采取行动处于状态
采取行动前:
请看图 2。假设 AI 代理处于状态 s (蓝色箭头)。在状态下,他可以采取两种不同的动作**【a _ 1】【a _ 2】。基于来自一些先前时间步骤的计算,代理知道该状态下两个可能动作的动作值【s,a _ 1】和 Q(s,a_2) 。**

Fig. 2 Agent in state s knows every possible Q(s,a).
采取行动后:
基于这个知识,代理决定采取行动 a_1 。采取此操作后,代理处于下一个状态*‘s’。因为采取了行动 a_1 他获得了直接奖励 R 。处于状态s’时,代理可以再次采取两种可能的动作a’_ 1和a’_ 2***,他从先前的一些计算中再次知道了这些动作的值。**
如果从方程 Eq 中 Q(s,a) 的定义上看。1 你会发现,在状态*s’中,我们现在有了新的信息,可以用来计算 Q(s,a_1) 的新值。该信息是针对上一个状态中的上一个动作而接收到的即时奖励 R 以及针对动作a’而接收到的Q(s’,a’)代理将在这个新状态中获取。根据图 3 中的等式可以计算出 Q(s,a_1) 的新值。等式的右边也是我们所说的 TD 目标。TD-target 与旧值或【s,a _ 1】*的’时态版本之差称为时态差。
记住:在 TD-learning 期间,我们为任何可能的动作值Q(s,a)【s,a】计算时间差,并同时使用它们来更新*【Q(s,a)*** ,直到 Q(s,a) 收敛到其真实值。****

Fig, 3 Agent in state s’ after taking action a_1.
2.萨尔萨
应用于*【S,A】*的 TD-Learning 算法俗称 SARSA 算法(State—Aaction—Reward—State—Aaction)。 SARSA 是被称为 on-policy 算法的特殊学习算法的一个很好的例子。
前面我介绍了策略 π(a|s) 作为从状态 s 到动作 a 的映射。此时需要记住的一点是, on-policy 算法使用与相同的策略来获取 TD-Target 中*【s _ t,a _ t】以及 Q(s(t+1),a_(t+1)) 的动作。这意味着我们正在跟随和同时改进同样的政策。*

3.q 学习
我们最终到达文章的核心,在这里我们将讨论 Q-Learning 的概念。但在此之前,我们必须先看看第二种特殊类型的算法,称为非策略算法。正如你可能已经想到的,Q-Learning 属于这种算法,这是一个区别到 on-policy 算法,如 SARSA 。
为了理解非策略算法,我们必须引入另一个策略 (a|s) ,并将其称为行为策略。行为策略决定行动*a _ t ~(a | s)forQ(s _ t,a _ t)*for all在 SARSA、的情况下,行为策略将是我们同时遵循并试图优化的策略。
在 非策略 算法中,我们有两种不同的策略(a | s)***和 π(a|s) 、 (a|s) 是行为,而π(a|s) 是所谓的目标策略。*行为策略用于计算 Q(s_t,a _ t)目标策略用于计算 Q(s_t,a_t) 只有中的TD-Target。(这一概念将在下一节进行实际计算时更加全面)
记住:行为策略为所有 Q(s,a) 挑选动作。相比之下,目标策略只为 TD 目标的计算确定行动。
*我们实际上称之为 Q 学习算法的算法是一个特例,其中目标策略【π(a | s)***是一个贪婪的 w.r.t. **Q(s,a)这意味着我们的策略正在采取导致最高值 Q 的行动。这产生了以下目标策略:

Eq. 4 Greedy target policy w.r.t Q(s,a).
在这种情况下,目标策略被称为贪婪策略。贪婪策略意味着我们只选择产生最高**【s,a】值的行为。这个贪婪的目标策略可以被插入到行动等式中-值【Q(s,a)】其中我们之前已经遵循了随机策略【π(a | s):

Eq. 5 Insertion of greedy policy into Q(s,a).
贪婪策略为我们提供了最优动作值 Q(s,a) ,因为根据定义 Q(s,a)* 是 Q(s,a) 遵循最大化动作值的策略:***

Eq. 6 Definition of optimal Q(s,a).
Eq 中的最后一行。5 就是我们在上一篇文章中推导出的贝尔曼最优方程。这个方程作为递归更新规则,用来估计最优动作值函数 Q(s,a)。*
然而,TD-learning 仍然是找到 Q(s,a) 的最佳方法。利用贪婪目标策略,对等式中的 Q(s,a) 的 TD 学习更新步骤。3 变得更加简单,如下所示:*

Eq. 7 TD-learning update rule with greedy policy.
用于具有贪婪目标策略的【Q(s,a)】的 TD-学习算法可以概括为以下步骤:
- 对于状态 s_t 中的动作 a_t 计算 Q(s_t,a_t)
- 转到下一个状态【s (t+1),采取动作‘a’***,产生最高值 Q ,并计算 ***Q( s(t+1),a’)******
- ***使用 ***Q( s_(t+1),a’)和即时奖励 R 进行动作 a_t 最后状态 s_t 计算 TD-Target
- 更新先前的 Q(s_t,a_t) ,将 Q(s_t,a_t) 添加到 TD-Target 和 Q(s_t,a_t)之间的差值,α 为学习率。
考虑前面的图(图 3),其中代理处于状态【s’,并且知道该状态下可能动作的动作值。遵循贪婪目标策略,代理将采取具有最高动作值的动作(图 4 中的蓝色路径)。这个策略还为我们提供了一个新的值 Q(s,a_1) (图中的等式),这就是定义的 TD 目标。

Eq. 8 Calculation of Q(s,a_1) following the greedy policy.
3.深度 Q 学习
*我们终于到达了这篇文章的标题得到其序言深度的地方— 我们终于利用了深度学习。如果您查看 Q(s,a) 的更新规则,您可能会认识到,如果 TD-Target 和 Q(s,a) 具有相同的值,我们不会得到任何更新。在这种情况下 ***Q(s,a)收敛到真实的动作值,目标达到。
这意味着我们的目标是最小化 TD-Target 和【Q(s,a)】之间的距离,这可以通过平方误差损失函数(等式 1)来表示。10).这种损失函数的最小化可以通过通常的梯度下降算法来实现。

Eq. 10 Squared error loss function.
3.1 目标网络和 Q 网络
在深度 Q 学习中,TD-Targety _ I和 Q(s,a) 分别由两个不同的神经网络估计,这两个网络通常称为 Target-和 Q-网络(图 4)。目标网络的参数 θ(i-1) (权重、偏差)对应于 Q 网络在较早时间点的参数【θ(I)。意味着目标网络参数在时间上被冻结。在用 Q 网络的参数进行了 n 次迭代之后,它们被更新。
记住 :给定当前状态 s ,Q 网络计算动作值 Q(s,a) 。同时,目标网络使用下一个状态s’来计算 TD 目标的Q(s’,a)* 。***

Fig. 4 Target,- and Q-Network. s being the current and s’ the next state.
研究表明,对 TD-Target 和 Q(s,a) 计算采用两种不同的神经网络,模型的稳定性更好。
3.2ε-贪婪政策
虽然目标策略【π(a | s)仍然是贪婪策略,但是行为策略 (a|s) 决定了 AI 代理采取的动作 a_i ,因此必须将哪个 Q(s,a_i) (由 Q-网络计算)插入到平方误差中
行为方针通常选择ε-贪婪。使用ε-贪婪策略,代理在每个时间步选择一个具有固定概率ε的随机动作。如果ε具有比随机生成的数 p ,0 ≤ p ≤ 1 更高的值,则 AI 代理从动作空间中选取一个随机动作。否则,根据学习的动作值 Q(s,a): 贪婪地选择动作**

Eq. 11 Definition of the ε-Greedy policy.
选择ε-贪婪策略作为行为策略解决了探索/剥削权衡的困境。
3.3 勘探/开采

关于采取何种行动的决策涉及一个基本选择:
- 利用:根据当前信息做出最佳决策
- 探索:收集更多信息,探索可能的新路径
就利用而言,代理根据行为策略采取可能的最佳行动。但是这可能会导致一个问题。也许有时可以采取另一种(替代的)行动,在状态序列中产生(长期)更好的路径,但是如果我们遵循行为策略,这种替代行动可能不会被采取。在这种情况下,我们利用当前政策,但不探索其他替代行动。
ε-贪婪策略通过允许 AI 代理以一定的概率从动作空间中采取随机动作来解决这个问题。这叫探索**。通常,根据等式,ε的值随着时间而减小。12.这里 n 是迭代次数。减小ε意味着在训练开始时,我们试图探索更多的可选路径,而在最后,我们让政策决定采取何种行动。**

Eq. 12 Decreasing of ε over time.
3.4 体验回放
过去,可以表明,如果 Deep-Q 学习模型实现经验重放**,则估计 TD-Target 和 Q(s,a) 的神经网络方法变得更加稳定。经验回放无非是存储 < s,s’,a’,r>元组的记忆,其中
- s:AI 代理的状态
- a’:代理在 s 状态下采取的动作
- r :在 s 状态下行动*a’*获得即时奖励
- s’ :状态 s 后代理的下一个状态
在训练神经网络时,我们通常不使用最近的 < s,s’,a’,r > 元组。而是我们从经验回放中随机取一批 < s,s’,a’,r > 来计算 TD-Target, Q(s,a) 最后应用梯度下降。
3.5 具有经验重放伪算法的深度 Q 学习
下面的伪算法实现了具有经验重放的深度 Q 学习。我们之前讨论的所有主题都以正确的顺序包含在这个算法中,就像它在代码中是如何实现的一样。

Pseudo-Algorithm for Deep-Q Learning with Experience Replay.
带有交互代码的 Tensroflow 中的自组织地图/图层[带 TF 的手动后道具]

GIF from this website
Teuvo Kohonen 是一位传奇的研究者,他发明了自组织地图。(能读到他 1990 年发表的原创论文,我感到荣幸和感谢)。有不同类型的自组织映射,如递归 Som 和无参数 Som 。它们还与神经气体密切相关。
Paper from this website
附加阅读和帮助实现

Image from this website
对于任何有兴趣阅读更多这方面内容的人,请查看这个链接(ai-junkie),它在更深入地解释这个问题方面做了令人惊讶的工作。我在网上找到了两种实现方式,这篇博文通过在线训练的方式实现,而这篇博文通过批量训练实现。
自组织地图作为图层

通过使用这里完成的实现,我修改了这里和那里的代码,以便我使用 SOM 作为神经网络中的典型层。如果你想看完整的代码,请看下面。
颜色数据结果

如上所述,当我们将一些颜色数据(如下所示)应用到 SOM 时,我们可以清楚地看到它在颜色聚类方面做得很好。

MNIST 数据结果

上图是对 30 * 30 * 784 维的 SOM 进行无监督学习的结果,值得一提的是,这个 SOM 的总维数相当大。现在,我们可以做一些有趣的事情,因为我们已经将 SOM 修改为一个层,我们可以在 SOM 之前连接任何类型的神经网络,希望聚类将更加清晰,并减少维数。


蓝色矩形 →全连通层
红色立方体 →自组织地图
如上所述,在将我们的 MNIST 向量(784*1)传递到 SOM 之前,我们可以有几个完全连接的层来处理数据。同时也降低了向量的维数。结果可以在下面看到。

关于上面的 SOM 需要注意的一件重要事情是,它只有(3030256)维,所以现在我们使用 256 而不是 784 的向量大小。但是我们仍然能够在这里和那里得到一些好的结果。但我真的相信我们可以做得比上述结果更好。
结果于 CIFAR 10 数据

上图显示了矢量化 CIFAR 10 上的聚类结果,我们可以直接观察到聚类有多糟糕。对自然图像进行聚类实际上是一项相当具有挑战性的任务,即使它们的维数仅为 3072 的向量。(32323).


绿色矩形 →卷积层
蓝色矩形 →全连通层
红色立方体 →自组织图
现在对于 CIFAR 10,让我们使用完全连接层和卷积层的组合来(希望)有效地减少维度和集群数据。

与直接使用 SOM 的情况相比,它做得更好。但总的来说,这是可怕的集群。(再次注意,上述 SOM 具有(3030256)的维数,这比直接使用 SOM 小 12 倍。(230400 个参数用于带网络的 SOM,2764800 个参数用于直接使用 SOM,不计算网络参数。)
然而,我对结果很失望。
交互代码

对于 Google Colab,你需要一个 Google 帐户来查看代码,而且你不能在 Google Colab 中运行只读脚本,所以在你的操场上做一个副本。最后,我永远不会请求允许访问你在 Google Drive 上的文件,仅供参考。编码快乐!
要访问带颜色的 SOM 代码,请点击此处。
要访问与 MNIST、的 SOM 代码,请点击此处。
要访问 for SOM 网络的代码,请点击此处。
要访问带有 CIFAR 的 SOM 代码,请点击此处。
要使用 CIFAR 访问 SOM 网络代码,请点击此处。
最后的话
现在,下一个任务是设计一个好的成本函数,我不认为直接从差值的幂减少平均值中取成本是一个好主意。我认为还有另一种方法。
如果发现任何错误,请发电子邮件到 jae.duk.seo@gmail.com 给我,如果你想看我所有写作的列表,请点击这里查看我的网站。
同时,在我的推特这里关注我,访问我的网站,或者我的 Youtube 频道了解更多内容。我还实现了广残网,请点击这里查看博文 pos t。
参考
- NumPy . histogram—NumPy 1.14 版手册。(2018).Docs.scipy.org。检索于 2018 年 5 月 10 日,来自https://docs . scipy . org/doc/numpy-1 . 14 . 0/reference/generated/numpy . histogram . html
- pylab_examples 示例代码:histogram _ demo . py—Matplotlib 1 . 2 . 1 文档。(2018).Matplotlib.org。检索于 2018 年 5 月 10 日,来自https://matplotlib . org/1 . 2 . 1/examples/pylab _ examples/histogram _ demo . html
- (2018).Cis.hut.fi 于 2018 年 5 月 10 日检索,来自http://www.cis.hut.fi/research/som-research/teuvo.html
- t .科霍宁(1998 年)。自组织地图。神经计算,21(1–3),1–6。
- 自组织地图——IEEE 期刊和杂志。(2018).Ieeexplore.ieee.org。检索于 2018 年 5 月 11 日,来自https://ieeexplore.ieee.org/document/58325/
- SOM 教程第 1 部分。(2018).Ai-junkie.com。检索于 2018 年 5 月 11 日,来自http://www.ai-junkie.com/ann/som/som1.html
- CPU,H. (2018)。如何在 CPU 上运行 Tensorflow?堆栈溢出。检索于 2018 年 5 月 11 日,来自https://stack overflow . com/questions/37660312/how-to-run-tensor flow-on-CPU
- tensorflow,C. (2018)。改变张量流中张量的比例。堆栈溢出。检索于 2018 年 7 月 19 日,来自https://stack overflow . com/questions/38376478/changing-a-scale-of-a-tensor-in-tensor flow
- tf.random_uniform | TensorFlow。(2018).张量流。检索于 2018 年 7 月 19 日,来自https://www . tensor flow . org/API _ docs/python/TF/random _ uniform
- 使用 Google 的 TensorFlow 进行自组织地图。(2015).Sachin Joglekar 的博客。检索于 2018 年 7 月 19 日,来自https://codesachin . WordPress . com/2015/11/28/self-organizing-maps-with-Google-tensor flow/
- cgorman/tensorflow-som。(2018).GitHub。检索于 2018 年 7 月 19 日,来自https://github.com/cgorman/tensorflow-som
- t,V. (2018)。递归自组织映射。公共医学——NCBI。Ncbi.nlm.nih.gov。检索于 2018 年 7 月 19 日,来自https://www.ncbi.nlm.nih.gov/pubmed/12416688
- JaeDukSeo/忧郁。(2018).GitHub。检索于 2018 年 7 月 19 日,来自https://github.com/JaeDukSeo/somber
- [复本],H. (2018)。如何在 Matplotlib (python)中隐藏轴和网格线?堆栈溢出。检索于 2018 年 7 月 19 日,来自https://stack overflow . com/questions/45148704/how-to-hide-axes-and-gridlines-in-matplotlib-python
- 数据,S. (2017)。MNIST 数据的自组织映射。SurfingMLDL。检索于 2018 年 7 月 19 日,来自https://wonikjang . github . io/deep learning _ unsupervised _ som/2017/06/30/som . html
- 数据,S. (2017)。MNIST 数据的自组织映射。SurfingMLDL。检索于 2018 年 7 月 19 日,来自https://wonikjang . github . io/deep learning _ unsupervised _ som/2017/06/30/som . html
自助本地新闻
在不稳定的媒体景观中提升同理心
眼前的危机
在互联网和唐纳德·特朗普(Donald Trump)总统任期的双重拐点上,美国新闻业陷入了危机。社交媒体和在线注意力经济扰乱了曾经支撑良好报道的经济模式和读者模式,导致印刷媒体大量解雇有才华的记者,并在数字媒体中转向愤怒、点击诱饵和企业赞助。与此同时——也许是同样的潜在技术文化转变的结果——至少自理查德·尼克松(如果不是更早的话)以来最公开反对新闻的总统的当选重新点燃了对媒体机构的普遍怀疑,并打破了对自由、独立新闻业的共识支持的假设。
但是,尽管在这个动荡的时代,全国的时报和邮报吸引了人们的注意力,但首当其冲的冲击还是来自地方层面。皮尤研究中心最近的一项研究发现美国新闻编辑室的就业人数在 2008 年至 2017 年间下降了近四分之一,下降了 45 %,这对报纸来说损失更大。但中型报纸似乎失血最多;虽然自 2016 年以来,全国范围内的报道(具有讽刺意味的是)重新焕发了活力,超级地方报纸得到了其紧密联系的社区的支持,但许多城市和地区媒体既缺乏读者支持,也缺乏经济偿付能力,无法跟上互联网出现前的标准。

不用说,这是一场民主危机。在第一修正案中,媒体的名字不仅是为了保证记者写作的权利,也是为了保证公民阅读的权利。毕竟,只有在知情的情况下,投票才是真正的民主。
这个问题的答案之一是通过新的经济模式和报道方法来振兴城市和地区报纸。一种可行的方法?通过将文案制作部分外包给外部合作伙伴,新闻编辑室的时间和精力支出可以削减,新闻编辑室之间的冗余(如多家城市报纸委托记者报道同一篇报道时的 T2)可以消除。当然,这已经是某些类型报道的标准,如联合通讯社(美联社)、多功能数据工具(ProPublica)或公共文档库(The Intercept)。但是,在创造独特的本地体验时,这些选择会遇到问题。例如,每份刊登路透社关于最新枪支管制措施的报道的城市报纸都会刊登相同的路透社报道,即使国家趋势或细节与那些对特定地方读者更有意义的报道不一致。
考虑一下 2015 年皮尤的一份报告,其中发现“每个城市大约十分之九的居民说他们至少在一定程度上密切关注当地的新闻,而大约十分之八的人说他们关注附近的新闻。”这些读者显然有兴趣了解这些问题——然而,如果没有经济上可行的渠道来满足他们的需求,这很可能得不到满足。通过重新思考记者如何在地区性和全国性报道之间斡旋,以及他们的雇主如何在两种报道之间分配资源,这一差距可以被填补。
地方报道的问题也是新闻效率的问题。通过将原本是全国性的故事地方化,抽象的问题变成了读者切实关心的问题。《纽约时报》的一篇关于美国毒品战争的文章可能会引起读者的兴趣,比如说,坦帕市的读者,但是对他们来说,改编成包含坦帕市具体细节的同一篇文章更有切身利益。如果新闻在很大程度上是政治教育的工具,而地方政治对读者有最明显的影响(至少在短期内),那么对于记者来说,在可能的情况下,通过本地化的镜头来探索大局问题是有意义的。
因此,自助式本地新闻的主张是:通过创建技术基础设施和报道流程,利用国家规模的资源进行本地规模的报道,有可能同时满足经济现实和现代本地新闻的内容需求。
新闻本地化
作为这一理论概念的证明,我们的团队选择了 Maimuna Majumder 年发表的一篇名为“仇恨犯罪率上升与收入不平等有关”的文章 Majumder 的文章使用数据分析在全国范围内探索了人均仇恨犯罪和经济不平等(以及在较小程度上的教育不平等)之间的联系。

我们选择对本文进行本地化试验有几个原因:
- 这个想法很有趣;特别是在特朗普意外赢得选举以及随后仇恨犯罪激增的背景下,Majumder 的论文激起了我们的兴趣。
- 它有明确定义的主张——仇恨犯罪和经济不平等是相关的;仇恨犯罪和教育水平是相关的——这可以用数量来检验。
- Majumder 在 GitHub 存储库中提供了她的所有数据,消除了许多来源挑战。
- 关于仇恨犯罪、经济不平等和教育不平等的数据是固有的地理,因此我们本地化文章的中心任务是有意义的。
为了开始开发一个系统来本地化 Majumder 的文章,我们首先创建了一个中性的文章“模板”版本,可以根据它修改版本。这包括从模板中删除任何特定日期的内容(因为这篇文章已经发表一年多了),并删除大部分解释 Majumder 统计分析方法的内容。这给我们留下了我们称之为的基础层。

然后,我们必须收集所有必要的数据,以获取 Majumder 的故事,并放大到地方一级。这些本地数据来自各种来源。我们从美国人口普查局的年度美国社区调查中获取给定城市或州的人口统计数据,如经济不平等的基尼指数或高中毕业率。与此同时,仇恨犯罪的数据来自联邦调查局的统一犯罪报告计划,该计划汇编了当地机构的犯罪数据。最后,我们询问了南方贫困法律中心(SPLC ),寻找活跃在各州的仇恨组织。
除了 SPLC 的数据,我们利用了预计算的汇总统计数据。例如,对于毕业率,人口普查局已经收集了某个城市每个居民的教育程度的详细资料,并计算了至少获得高中学位的人的百分比。因此,获取数据意味着下载这些预先计算的百分比,而不是下载每个居民的教育记录。
然后,我们用编程语言 R 创建了一个数据框架,这将允许我们测试仇恨犯罪与经济不平等和教育率之间的相关性。将来自联邦调查局(仇恨犯罪)、SPLC(仇恨团体)和美国人口普查局(经济不平等和高中毕业率的基尼指数)的数据结合在一起,我们得到了一个强大的数据集,可以探索不同因素之间的关系,例如,在任何给定的城市或州,仇恨犯罪率和经济不平等在几年内的密切相关程度。为了计算相关性,我们只研究了拥有至少六年数据的城市和州。
从地区数据的特殊性转移到记者可能想告诉的关于地区数据的故事的大概情况,我们决定了可能有必要发表的八种一般类型的文章,这取决于记者为哪个城市或州写文章。这些文章基于三个二元价值观:
- 仇恨犯罪和经济不平等之间是否有统计学上的显著关系。
- 仇恨犯罪和教育水平之间是否有统计学上的显著关系。
- 给定区域是城市还是州。
因此我们有 222 个因素在起作用,或者总共八个可能的文章。我们将文章本地化的这一阶段概念化为一个决策树,由此利用关于数据的相关细节(在我们的数据集中识别的相关性)和用户输入(文章将被本地化的地理位置)来识别多个预先编写的文章框架中的哪个将被加载到系统中。

生成的树上的八个“叶子”中的每一个都用这些骨架中的一个来标识,这些骨架是通过修改基础层文章来组装的。我们有两种主要的方法来进行这种修改。
一种类型的修改是通过基于它们在文章中的相对重要性上下移动某些文本块来重新组织文章,基于这些重要性,趋势被识别为与给定位置相关。例如,一篇关于经济不平等和仇恨犯罪之间存在关联的城市的文章可能会强调这种关系,而一篇关于教育水平和仇恨犯罪之间存在关联的州的文章可能会强调这种关系。这植根于倒金字塔的新闻实践,即一篇文章中最重要的信息放在顶部。

另一种类型的修改是在文章框架中标识出内容中立的站点,在这里可以插入额外的特定位置信息。我们将文章本地化的这个阶段概念化为一个疯狂的 Libs 游戏。在 Mad Libs 中,提供了一个短篇故事的框架,但是为某些单词留出了空间。然而,为了在文章的上下文中有意义——并且模仿自然语言——这些插入的单词必须满足某些参数;最常见的是词类。类似地,我们的文章框架确定了什么类型的数据或其他信息可以自动插入给定框架的特定部分。但是,在一个疯狂的 Libs 游戏可能需要一个动词或名词的地方,文章骨架可能需要 X 国仇恨犯罪的最常见原因或 y 国的基尼指数。
首先,我们确定了近 70 种可以插入文章的数据特征:

然后,我们将这些数据点合并到我们的骨架中,根据这些数据点,在讲述一个属于决策树上八个分类之一的地方的故事时,哪一个最相关。这产生了八个最终骨骼,其中一个开始于:

带括号的紫色元素是插入的数据点,而绿色文本标识添加到基础层的任何副本。与此同时,括号中的橙色特性是 Mad Libs 风格插件的第二种类型,它需要更多的叙述性(而不是数字)细节。因为人们可能希望包含在文章中的某些特定于地点的“价值”——如轶事或引语——在有组织的数据库或电子表格中(还)不存在,这些地点向当地记者标识他们仍然需要出去做他们自己的报道的地方。然后,该系统的最终输出将使用相关值填充紫色要素,但不修改橙色要素。
本土化实践
如果一名记者正在为洛杉矶的一家报纸写作,这种两部分本地化方法将导致以下决策树…

…这将导致下面的文章框架…

…当系统插入相关数据点时,会输出最终文章…

八个可能的文章框架与 3020 个城市、44 个州和哥伦比亚特区的数据相结合,结果是一个灵活的系统,用于自动生成独特的定制文章,这些文章可以以相对较小的开销整合到全国各地的本地媒体。虽然不是这个过程的每个方面都是自动化的,也就是说,编写文章框架和填充橙色文本特征,但是这个过程确实提出了一种大规模生产本地化文章的可能方法。
使用 JavaScript libraries Mapbox 进行绘图,使用 D3.js 进行数据可视化,我们的团队开发了一个 web 应用程序,使得这个系统易于使用,并且对于没有计算机或数据科学背景的人来说也是可访问的:

通过点击他们的城市或州,一个资源稀缺的新闻编辑室不仅可以调出一篇充实的文章…

…而且还有有用的汇总统计数据…

…特定于地点的数据可视化…


…甚至还有一份简洁的提示表,如果文章内容本身没有必要,它会指出哪些内容仍然值得研究…

扩大范围
为了进一步发展这种概念验证,我们的团队决定将同样的方法应用于另一篇文章:本·卡塞尔曼的《2015 年警察杀死美国人的地方》,另一篇 538 文章。Casselman 的文章使用了美国人口普查局的数据和《卫报》关于警察杀人的数据项目,探讨了贫困、种族和该国警察杀害最多平民的地方之间的关系。
本地化这一叙述基本上遵循与以前相同的过程:
- 从初始副本创建一个中性的“基础层”。
- 聚合数据,并在数据框架中将它们连接在一起。
- 创建一个考虑规模(州或城市)和统计趋势(人均警察杀人事件和平均家庭收入是高于还是低于全国平均水平)的决策树。
- 识别可以插入的 Mad Libs 风格的特征(定量和定性),可以从数据集插入,也可以由本地记者插入。
- 修改基础层以考虑决策树结果(又是八种可能性)和 Mad Libs 特征。
- 将这个过程嵌入到基于地图的 web 应用中。
- 整合额外的数据可视化、汇总统计、提示表等。如有可能。
- 让记者了解结果。


主要依赖汇总统计回避了这种产品是否能扩展到大规模数据集的问题。例如,在处理警察杀人的文章时,我们遇到了一个数据集,它包含了几年来美国每一次警察杀人的记录。当用户点击一个特定的地点来查看自动生成的填充了相关数据的文章时,一种简单的方法是查询发生在特定城市的所有警察杀人事件的数据集,然后计算适当的信息。然而,这种方法在计算上是昂贵的和低效的,因为相同的查询和计算可能被执行多次。一个更健壮的解决方案将涉及预计算每个城市的必要信息,并将这些信息存储在一个数据库中,该数据库将城市映射到它们的特定数据,这样每当用户点击一个特定的城市时,我们的系统将直接返回信息,而无需进行额外的计算。
例如,下图说明了当用户单击德克萨斯州的城市韦科时会发生什么。每一行都包含一个警察杀害受害者的信息。在前面提到的简单解决方案中,程序将搜索整个表,选择城市与 Waco 匹配的每一行。然而,在健壮的解决方案中,程序将搜索 Waco 并返回与之相关的数据块。因此,我们看到我们的程序对于大型数据集在计算上是可伸缩的。

大局
对于一个资金紧张、遭受多轮裁员、在一个适得其反的环境中努力维持读者信任的新闻编辑室来说,这种系统可以——在 AP 或 ProPublica 等组织的基础设施和报道支持下——将标准报道流程中涉及的大量体力劳动外包出去。目前,像数据采集、数据清理、统计分析、文章写作、源编辑、文案编辑、图形开发等工作对新闻编辑室来说是一个巨大的压力,并且还可能在报道类似问题的多个新闻编辑室之间造成劳动力冗余。如果这项工作被集中起来,它将为已经承受巨大压力的媒体机构减轻一个重大负担,即利用有限的资源制作大量高质量的内容。
与任何自动化一样,新闻编辑室可能会将此视为裁员的机会。但至少聪明的人会看到它的本来面目:让有才华的记者腾出手来从事更重要的工作的机会,比如激发同情心的人类兴趣报道或让当权者承担责任的深度调查报道。明智而充满激情地去做,最终的结果将是美国自由媒体的各个层面都变得更强大、更聪明、更有效。
笔记
这个项目是为斯坦福大学 2018 年秋季的课程“探索计算新闻学”(CS206/COMM281)创建的,与布朗媒体创新研究所合作。
两个网络应用都可以在这里访问:http://web.stanford.edu/~sharon19/.
特别感谢:
教授们。Krishna Bharat、Maneesh Agrawala 和 R.B. Brenner 在本项目过程中提供了真知灼见、指导和专家建议;
Maimuna Majumder、Ben Casselman 和 FiveThirtyEight 深刻的报告和可获得的数据;
Cheryl Phillips 教授、Dan Jenson 和斯坦福开放警务项目,感谢他们对本项目早期迭代的帮助;
以及所有参与实现这项工作的人。
图像引用:
图 1:皮尤研究中心(链接
图 5:萨姆·斯普林,中等(林克)
数据来源包括:
联邦调查局
《卫报》
南方贫困法律中心
美国人口普查局
华盛顿邮报
如果您有兴趣了解这项工作的更多信息,可以通过以下方式联系相关人员:
陈莎伦(sharon19@stanford.edu)
布莱恩·孔特雷拉斯(brianc42@stanford.edu,@ _ 布莱恩 _ 孔特雷拉斯 _)
黄志鹏(dhuang7@stanford.edu)
向利益相关者销售分析
你不会想到你不得不卖掉这么值钱的东西。你错了。
我们刚刚完成了一个大规模数据收集和分析项目中最雄心勃勃的阶段。我们的一个关键项目发起人提出了一个关键问题:如果人们在内部截止日期后向我们提交,这对他们成功的机会有多大影响?因此,我们深入到新创建的工作流模式中,找出了答案。
这并没有伤害他们。事实上,这帮助了他们。这对他们帮助很大!他们给我们的时间越少,我们做得越好。*看,这里是曲线,*我们说。看看这个置信区间。让我们从时间的角度来看——哇,我们比以往任何时候都更擅长处理最后一分钟的提交。
我们的赞助商回复了。
“我不想再听了。我估计这个数据没用。”
什么?!
经过近两年的艰苦工作,从一个晦涩的供应商系统的噩梦般的事务模式中映射和提取数千个数据元素,我们能够将工作流里程碑和一些真正有趣的维度联系起来。
与此同时,我们的项目发起人已经为他们的内部客户忽略最后期限而奋斗了多年,让发起人的团队来收拾残局。这导致了高流动率、低工作满意度、高压力和低绩效。其中一个赞助者有一个想法:如果我们能让我们的客户看到,忽视截止日期会损害他们的成果,那么他们将不得不开始尊重我们!他在寻找一个数据大头棒来敲碎一些脑袋。

I think his plan went something like this
因此,我们尽职尽责地处理这些数字,自豪地展示我们现在能够提供的各种见解,这要归功于我们的 SQL 团队和数据分析师的不懈努力。正如你现在已经知道的,我们提供了一个非常有趣的见解。
这当然立刻开启了各种后续问题。我们的零假设:忽略截止日期的人和遵守截止日期的人在成功率上没有区别。我们的结果让这一切变得不可思议。但它做错了!分析师们接下来会有一大堆有趣的后续问题——我们会优先考虑这些迟交的问题吗?迟到的提交者是不是在骚扰我们的员工,只是成为吱吱作响的轮子?我们从哪里获得这些数据,电子邮件服务器日志和 PBX 日志?或者这只是一种关联,因为我们最成功的提交者也确实很忙,所以他们通常会延迟提交?
所以我们来参加会议,介绍我们的发现以及我们提出的所有有趣的后续问题。为了更好地了解我们的组织,我们制定了一个战略来追踪这一激动人心的线索。我们直接撞到了墙上。
我们不仅要学会做分析师,还要学会做分析理念和流程的销售人员。我们的项目发起人对我们正在做的事情感到非常兴奋,因为他们听说了其他人在“大数据”方面取得的成就他们思考了他们最大的问题,并将数据和分析视为解决问题的灵丹妙药,因为数据最终会证明他们是对的。我们谁都没有想到,他们给我们的第一个假设会是完全错误的。
事后看来,我们本可以做得更好,也应该做得更好的是,告诉他们数据可以帮助你提出正确的问题。然后它会帮助你找到答案!在这个框架中,一个不正确的假设并不是一件坏事——它真的很有趣!
但我们被赋予了一个特定的使命,我们傲慢地攻击了这些数据,认为其他人也会因为我们的结论而同样兴奋。所以我们走进一个会议,基本上是说,“嘿,你错了,但是看看我们发现的这些很酷的东西!”在“你错了”之后,我们强大的赞助商停止了倾听,并停止了讨论。
我们的项目发起人对他的业务线没有错,他对违法行为对他的办公室造成的不良影响也没有错,但 hr 错在只有一个假设,并把所有鸡蛋都放在那个篮子里。
我们将很快为不同的系统和不同的赞助商启动另一个数据提取项目。在我们进行这一旅程时,我打算记住以下几点,如果您有利益相关者赞助您自己的计划,这对您也可能有用:
- 确认偏差是真实的。我们的利益相关者都是有才华的人,他们在职业生涯中已经升到了管理链的顶端。很可能你们中的一些人也是。而且,像我们一样,很可能你们的一些利益相关者在没有任何数据分析来支持他们的管理决策的情况下已经这样做了几十年。他们习惯于相信自己的直觉,并期望数据能完全支持他们的想法。
- 公开表扬,私下批评。如果我们的发起人(或项目中的任何人)有一个未被证实的假设,公共项目会议不是揭开它的地方。提前与他们会面,填写表格,并在后续调查中获得他们的认可。这让他们认同这些努力,并让他们在公开会议上显得聪明,而不是错误。
- 教授分析的过程,而不仅仅是结果。我们过于关注我们的潜在“胜利”对我们的数据来说有多么令人兴奋。我们的赞助商只有从同事和会议上获得的信息,这些信息是“管理层”的总结信息。对这一过程的更广泛的理解会导致更多好奇的利益相关者,他们会更支持有机调查。
- “做点什么”数据。我们不会只是等待我们的利益相关者告诉我们他们想知道什么。当我们把新的数据集放到网上时,我们会主动挖掘它们以获得有趣的(也许是令人愉快的)见解。如果我们需要捍卫一个不受欢迎的观点,这将给我们一些政治信用。这也意味着我们的利益相关者将被介绍给对我们有利的数据,而不是根据他们自己想法的价值来掷骰子。
乔纳森是加州大学洛杉矶分校研究信息系统的助理主任。在获得斯坦福大学的物理学学位后,他在信息系统架构、数据驱动的业务流程改进和组织管理领域工作了 10 多年。他还是Peach Pie Apps Workshop的创始人,这是一家专注于为非营利和小型企业构建数据解决方案的公司。
销售您的数据科学项目

无论你的数据科学项目有多伟大,如果没有人想要,它都是徒劳的。如果我们不能让其他人相信我们的工作会改善他们的生活,或者至少有这种潜力,它就会一直呆在某个服务器上,直到它坏掉停止工作。
但是,告诉顾客为什么我们的工作会让他们的生活变得更好,正确的方法是什么呢?创建销售文档或演示文稿,列出我们的数据科学应用程序可以做的所有闪亮的新东西是非常诱人的。我们努力开发这些功能,每个人都会喜欢的,对吗?
不完全是。首先,很有可能你的目标受众不具备理解你所推销的东西的技术能力。毕竟,如果他们有你的技术技能,他们就不会考虑雇佣数据科学,他们只会自己做。当你创建一份销售文件时,你首先要做的是尽量减少对最新工具的引用,让他们知道你知道你在做什么。
下一个问题是,你不能相信客户意识到你的解决方案是如何帮助他们走出目前的困境的。此外,让他们替你做事是不尊重你的。因此,你需要确保你的推销在你打算为客户做什么和如何让他们的生活变得更轻松之间加入了点。
在销售行话中,这被称为“销售好处”,也就是说,让潜在客户清楚购买你的产品将如何改善他们的生活,这被概括为一句话“没有人想买床,他们想睡个好觉”。困难在于,在大多数数据科学场景中,与潜在利益相对应的问题是业务问题,如库存减少或销售成本下降,而不是人的问题,如睡个好觉。
因此,要想完成从功能到益处的旅程,需要对客户的业务有所了解(尽管每个人都知道睡个好觉的好处——以及睡不好觉的可怕之处——但在床垫弹性和床结构的细节方面,了解的人要少得多),还需要能够解释其中的联系。最后一点至关重要,因为你的工作带来的好处太重要了,不能让你的客户错过。
所有这一切最终意味着,希望找到“洞见”的检查数据集的方法往往会失败,甚至可能是危险的。相反,您需要从您的客户想要实现什么、他们面临什么问题开始,然后才能看到哪些问题与可用于构建工具来解决问题的数据相对应。在这方面,古老的格言“你生来就有两只耳朵和一张嘴,所以多听少说”开始发挥作用。
如果你成为一名数据科学家,部分原因是你的气质更适合安静地分析数据,而不是高兴地接待客户,那么销售的整个概念可能听起来令人生畏。不过,这听起来不应该太令人畏惧。上面的建议同样适用于内部销售——向公司的其他部门销售——也适用于外部销售。如果你想在内部销售,应该有很多机会去发现是什么让你公司的其他人感到痛苦。人们喜欢谈论自己,世界上许多人都不会错过抱怨的机会。
如果涉及外部销售,很有可能正在使用或可能会使用团队销售方法。在这种情况下,您将作为首席销售人员的技术支持。让你的首席销售人员做他们最擅长的事情——培养关系,获得领导地位,介绍你的业务,让客户兴奋起来。
利用这段时间尽可能多地学习,找出客户生活中不尽如人意的地方,并搭配您的分析解决方案,使其变得简单。如果一个客户的生活已经够痛苦了,那么只要有人能解决这个问题,他们就会立刻掏出自己的支票簿。
这篇文章的早期版本也出现在我的博客上,名为“销售和数据科学”。详见本页同系列后续文章。
SELU——让 FNNs 再次伟大(SNN)
上个月,我看到了一篇最近的文章(发表于 2017 年 6 月 22 日),文章提出了一个新概念,叫做自归一化网络(SNN)。在这篇文章中,我将回顾它们的不同之处,并展示一些对比。
文章链接——Klambauer 等人
本帖代码摘自bio info-jku 的 github 。
这个想法
在我们进入什么是 SNN 之前,让我们谈谈创建它们的动机。作者在文章的摘要中提到了一个很好的观点;虽然神经网络在许多领域获得了成功,但似乎主要阶段属于卷积网络和递归网络(LSTM,GRU),而前馈神经网络(FNNs)被留在初学者教程部分。
还要注意的是,在 Kaggle 取得胜利结果的 FNN 最多只有 4 层。
当使用非常深的架构时,网络变得容易出现梯度问题,这正是批量归一化成为标准的原因——这是作者将 FNNs 的薄弱环节放在训练中对归一化的敏感性上的地方。
snn 是一种替代使用外部标准化技术(如 batch norm)的方法,标准化发生在激活函数内的**。
为了清楚起见,激活函数建议(SELU-比例指数线性单位)输出归一化值,而不是归一化激活函数的输出。
为了使 SNNs 工作,它们需要两样东西,一个定制的权重初始化方法和 SELU 激活函数。**
认识 SELU
在我们解释它之前,让我们看一下它是关于什么的。

Figure 1 The scaled exponential linear unit, taken from the article
SELU 是某种 ELU,但有一点扭曲。
α和λ是两个固定的参数,这意味着我们不会通过它们进行反向传播,它们也不是需要做出决策的超参数。
α和λ是从输入中得到的——我不会深入讨论这个,但是你可以在文章中看到你自己的数学计算(有 93 页附录:O,数学计算)。
对于标准比例输入(平均值为 0,标准偏差为 1),值为α=1.6732,λ=1.0507。
让我们绘制图表,看看这些值是什么样子。

Figure 2 SELU plotted for α=1.6732~, λ=1.0507~
看起来很像 leaky ReLU,但等着看它的魔力吧。
重量初始化
SELU 不能让它单独工作,所以一个定制的权重初始化技术正在使用。
SNNs 用零均值初始化权重,并使用 1/(输入大小)的平方根的标准偏差。
代码如下所示(摘自开篇提到的 github)
# Standard layer
tf.Variable(tf.random_normal([n_input, n_hidden_1], stddev=np.sqrt(
1 / n_input))# Convolution layer
tf.Variable(tf.random_normal([5, 5, 1, 32], stddev=np.sqrt(1/25)))
现在我们已经了解了初始化和激活方法,让我们开始工作吧。
表演
让我们看看 SNNs 如何使用指定的初始化和 SELU 激活函数在 MNIST 和 CIFAR-10 数据集上运行。
首先,让我们看看在 2 层 SNN(两个隐藏层都是 784 个节点,MNIST)上使用 TensorBoard 是否真的保持了输出的标准化。
绘制第 1 层的激活函数输出和第 2 层的权重。
github 代码中没有layer1_act的绘图,我是为了这个直方图才添加的。

Figure 3 SELU’s output after the first layer in the MLP from the github

Figure 4 Second layer’s weights on the second layer.
不出所料,第一层的激活和第二层产生的权重几乎都是完美的零均值(我在运行中得到 0.000201)。
相信我,直方图在第一层权重上几乎是一样的。

更重要的是,snn 似乎能够表现得更好,正如你从提到的 github 的图中看到的那样,比较了 3 个具有相同架构的卷积网络,只是它们的激活功能和初始化不同。
SELU vs ELU vs 雷鲁。
似乎 SELU 收敛得更好,在测试集上得到更好的精度。
请注意,使用 SELU +上述初始化,我们在 CNN 网络上获得了更高的精度和更快的收敛速度,因此不要犹豫,在非纯 FNN 的架构上尝试它,因为它似乎也能够提高其他架构的性能。
结论和进一步阅读
看起来 snn 确实可以在神经网络的世界中找到自己的位置,也许可以在更短的时间内提高一点额外的准确性——但我们必须等待,看看它们自己会产生什么结果,更重要的是整合到联合架构中(就像上面的 conv-snn)。也许我们会在竞赛获奖的建筑中遇到他们,谁知道呢。
有些东西我没有在这里讨论,但在这篇文章中提到了,比如提议的“alpha dropout ”,这是一种符合 SNNs 概念的 dropout 技术,也在提到的 github 中实现,所以非常欢迎您深入研究。
SNNs 是不是一个东西,我真的不知道,但他们是另一个工具添加到您的工具包。希望你喜欢这篇文章并学到一些新东西:)
如何用深度学习创建任意对象的自然语言语义搜索
这是一个端到端的例子,展示了如何构建一个可以在语义上搜索对象的系统。由哈默尔侯赛因 & 吴和祥

A picture of Hubot.
动机:
现代搜索引擎的力量是不可否认的:你可以随时从互联网上获取知识。不幸的是,这种超级力量并非无处不在。在许多情况下,搜索被归为严格的关键字搜索,或者当对象不是文本时,搜索可能不可用。此外,严格的关键字搜索不允许用户进行语义上的搜索,这意味着信息不容易被发现。
今天,我们分享一个可复制的、最低限度可行的产品,它展示了如何为任意对象启用语义搜索!具体来说,我们将向您展示如何创建一个从语义上搜索 python 代码的系统——但是这种方法可以推广到其他实体(比如图片或声音剪辑)。
语义搜索为什么这么激动人心?考虑下面的例子:

Semantic search at work on python code. *See Disclaimer section below.
呈现的搜索查询是“ Ping REST api 并返回结果”。然而,即使找到的代码&注释不包含单词 Ping、REST 或 api,搜索也会返回合理的结果。
这说明了 语义搜索 的威力:除了关键词之外,我们还可以搜索内容的含义,最大限度地提高用户找到所需信息的几率。语义搜索的含义是深远的——例如,这样一个过程将允许开发人员在存储库中搜索代码,即使他们不熟悉语法或者没有预料到正确的关键字。更重要的是,你可以将这种方法推广到图片、音频和其他我们还没有想到的东西。
如果这还不够令人兴奋的话,这里有一个现场演示,展示在本教程结束时你能够构建的东西:

Sometimes I use Jupyter notebooks and custom magic functions to create demonstrations when I cannot build a pretty website. it can be a quick way to interactively demonstrate your work!
直觉:构建一个共享的向量空间
在深入研究技术细节之前,向您提供一个关于我们将如何完成语义搜索的高层次直觉是很有用的。中心思想是在一个共享的向量空间中表示文本和我们想要搜索的对象(代码),如下所示:

Example: Text 2 and the code should be represented by similar vectors since they are directly related.
目标是将代码映射到自然语言的向量空间中,使得描述相同概念的(文本,代码)对是近邻,而不相关的(文本,代码)对则相距更远,通过余弦相似度来测量。
有许多方法可以实现这一目标,但是,我们将展示一种方法,即采用一个预先训练好的模型从代码中提取特征,然后微调这个模型,将潜在的代码特征投射到自然语言的向量空间中。一个警告:在本教程中,我们交替使用术语 向量 和 嵌入*。*
{ 2020 年 1 月 1 日更新}:代码搜索网
这篇博文中介绍的技术是旧的,并且在随后的一个名为 CodeSearchNet 的项目中得到了显著的改进,并附有一篇相关的论文。
我建议看看前面提到的项目,寻找一种更现代的方法来解决这个问题,因为回想起来这篇博文有点丑陋。
先决条件
我们建议在阅读本教程之前熟悉以下内容:
- **序列对序列模型:回顾一下之前教程中的信息会很有帮助。
- 从高层次阅读本文,理解所介绍方法的直觉。我们利用类似的概念在这里介绍。
概述:
本教程将分为 5 个具体步骤。这些步骤如下所示,在您学习本教程的过程中,它们将成为有用的参考。完成本教程后,重新查看此图以强调所有步骤是如何结合在一起的,这将非常有用。

A mind map of this tutorial. Hi-res version available here.
每一步 1-5 对应一个 Jupyter 笔记本这里。我们将在下面更详细地探讨每个步骤。
第 1 部分—获取和解析数据:
谷歌的人从开源的 GitHub 仓库收集数据并存储在 BigQuery 上。这是一个非常棒的开放数据集,适合各种有趣的数据科学项目,包括这个!当你注册一个谷歌云账户时,他们会给你 300 美元,这足够你查询这个练习的数据了。获取这些数据非常方便,因为您可以使用 SQL 查询来选择您要查找的文件类型以及关于 repos 的其他元数据,如 commits、stars 等。
本笔记本中概述了获取这些数据的步骤。幸运的是,Google的 Kubeflow 团队中一些出色的人已经经历了这些步骤,并慷慨地为这个练习托管了数据,这也在本笔记本中有所描述。
收集完这些数据后,我们需要将这些文件解析成(code, docstring )对。对于本教程,一个代码单元要么是一个顶级函数,要么是一个方法。我们希望收集这些对作为模型的训练数据,该模型将总结代码(稍后将详细介绍)。我们还希望剥离所有注释的代码,只保留代码。这似乎是一项艰巨的任务,然而,在 Python 的标准库中有一个名为 ast 的惊人的库,可用于提取函数、方法和文档字符串。我们可以通过使用 Astor 包将代码转换成一个 AST ,然后再从该表示转换回代码,从而从代码中删除注释。本教程不要求理解 ASTs 或这些工具是如何工作的,但这是非常有趣的话题!
For more context of how this code is used, see this notebook.
为了准备用于建模的数据,我们将数据分为训练集、验证集和测试集。我们还维护文件(我们称之为“沿袭”)来跟踪每个(code,docstring)对的原始来源。最后,我们对不包含 docstring 的代码应用相同的转换,并单独保存,因为我们也希望能够搜索这些代码!
第 2 部分——使用 Seq2Seq 模型构建代码摘要:
从概念上讲,构建一个序列到序列的模型来汇总代码与我们之前介绍的 GitHub 问题汇总器是相同的——我们使用 python 代码代替问题主体,使用文档字符串代替问题标题。
然而,与 GitHub 问题文本不同,代码不是自然语言。为了充分利用代码中的信息,我们可以引入特定于域的优化,比如基于树的 LSTMs 和语法感知标记化。对于本教程,我们将保持简单,像对待自然语言一样对待代码(并且仍然得到合理的结果)。
构建一个函数摘要器本身是一个非常酷的项目,但是我们不会花太多时间在这上面(但是我们鼓励你这么做!).本笔记本中的描述了该模型的整个端到端培训流程。我们不讨论该模型的预处理或架构,因为它与问题汇总器相同。
我们训练这个模型的动机不是将它用于总结代码的任务,而是作为代码的通用特征提取器。从技术上讲,这一步是可选的,因为我们只是通过这些步骤来初始化相关下游任务的模型权重。在后面的步骤中,我们将从这个模型中提取编码器,并为另一个任务微调。下面是该模型的一些示例输出的屏幕截图:

Sample results from function summarizer on a test set. See notebook here.
我们可以看到,虽然结果并不完美,但有强有力的证据表明,该模型已经学会了从代码中提取一些语义,这是我们这项任务的主要目标。我们可以使用 BLEU metric 对这些模型进行量化评估,在本笔记本中也有讨论。
应该注意的是,训练 seq2seq 模型来总结代码并不是构建代码特征提取器的唯一方法。例如,你也可以训练一个 GAN 和使用鉴别器作为特征提取器。然而,这些其他方法超出了本教程的范围。
第 3 部分—训练一个语言模型来编码自然语言短语
现在我们已经建立了一个将代码表示为向量的机制,我们需要一个类似的机制来编码自然语言短语,就像在文档字符串和搜索查询中找到的那些一样。
有太多的通用预训练模型可以生成高质量的短语嵌入(也称为句子嵌入)。这篇文章提供了一个很好的景观概述。例如,谷歌的通用句子编码器在许多情况下都工作得很好,并且在 Tensorflow Hub 上有售。
尽管这些预先训练的模型很方便,但是训练一个捕捉特定领域词汇和文档字符串语义的模型可能是有利的。有许多技术可以用来创建句子嵌入。这些方法从简单的方法,如平均单词向量到更复杂的技术,如用于构建通用句子编码器的技术。
对于本教程,我们将利用一个神经语言模型,使用一个 AWD LSTM 来生成句子的嵌入。我知道这听起来可能有点吓人,但是精彩的 fast.ai 库提供了一些抽象概念,允许您利用这项技术,而不必担心太多的细节。下面是我们用来构建这个模型的一段代码。有关该代码如何工作的更多内容,请参见本笔记本。
Part of the train_lang_model function called in this notebook. Uses fast.ai.
在构建语言模型时,仔细考虑用于训练的语料库非常重要。理想情况下,您希望使用与下游问题领域相似的语料库,这样您就可以充分捕获相关的语义和词汇。例如,这个问题的一个很好的语料库是栈溢出数据,因为这是一个包含非常丰富的代码讨论的论坛。然而,为了保持本教程的简单性,我们重用了一组文档字符串作为我们的语料库。这是次优的,因为关于堆栈溢出的讨论通常包含比单行 docstring 更丰富的语义信息。我们把它作为一个练习,让读者通过使用替代语料库来检查对最终结果的影响。
在我们训练语言模型之后,我们的下一个任务是使用这个模型为每个句子生成一个嵌入。这样做的一个常见方法是总结语言模型的隐藏状态,例如本文中的 concat 池方法。然而,为了简单起见,我们将简单地计算所有隐藏状态的平均值。我们可以用这行代码从 fast.ai 语言模型中提取隐藏状态的平均值:

How to extract a sentence embedding from a fast.ai language model. This pattern is used here.
评估句子嵌入的一个好方法是测量这些嵌入对下游任务的有效性,如情感分析、文本相似性等。你可以经常使用通用基准测试,比如这里列出的例子来测量你的嵌入的质量。然而,这些通用的基准可能不适合这个问题,因为我们的数据是非常具体的领域。不幸的是,我们还没有为这个领域设计一套可以开源的下游任务。在没有这种下游任务的情况下,我们至少可以通过检查我们知道应该相似的短语之间的相似性来检查这些嵌入是否包含语义信息。下面的屏幕截图展示了一些例子,在这些例子中,我们根据用户提供的短语(摘自本笔记本)来搜索矢量化文档字符串的相似性:

Manual inspection of text similarity as a sanity check. More examples in this notebook.
应该注意的是,这只是一个健全性检查——更严格的方法是测量这些嵌入对各种下游任务的影响,并使用它来形成关于您的嵌入质量的更客观的意见。关于这个话题的更多讨论可以在这本笔记本中找到。
第 4 部分—将代码向量映射到与自然语言相同的向量空间的训练模型
在这一点上,重温一下本教程开始时介绍的图表可能会有所帮助。在该图中,您可以找到第 4 部分的图示:

A visual representation of the tasks we will perform in Part 4
这一步的大部分内容来自本教程前面的步骤。在这一步中,我们将对第 2 部分中的 seq2seq 模型进行微调,以预测文档字符串嵌入,而不是文档字符串。下面是我们用来从 seq2seq 模型中提取编码器并添加密集层进行微调的代码:
Build a model that maps code to natural language vector space. For more context, see this notebook.
在我们训练该模型的冻结版本之后,我们解冻所有层,并训练该模型几个时期。这有助于对模型进行微调,使其更接近这个任务。你可以在这本笔记本中看到完整的训练程序。
最后,我们希望对代码进行矢量化,以便构建搜索索引。出于评估的目的,我们还将对不包含 docstring 的代码进行矢量化,以查看该过程对我们尚未看到的数据的推广情况。下面是完成这项任务的代码片段(摘自本笔记本)。请注意,我们使用 ktext 库将我们在训练集上学到的相同预处理步骤应用于该数据。
Map code to the vector space of natural language with the code2emb model. For more context, see this notebook.
收集了矢量化代码后,我们就可以开始最后一步了!
第 5 部分—创建语义搜索工具
在这一步中,我们将使用我们在前面步骤中创建的工件构建一个搜索索引,如下图所示:

Diagram of Part 5 (extracted from the main diagram presented at the beginning)
在第 4 部分中,我们对不包含任何文档字符串的所有代码进行了矢量化。下一步是将这些向量放入搜索索引中,这样可以快速检索最近的邻居。一个很好的用于快速最近邻查找的 python 库是 nmslib 。要享受使用 nmslib 的快速查找,您必须预先计算搜索索引,如下所示:
How to create a search index with nmslib.
现在您已经构建了代码向量的搜索索引,您需要一种将字符串(查询)转换成向量的方法。为此,您将使用第 3 部分中的语言模型。为了简化这个过程,我们在 lang_model_utils.py 中提供了一个名为 Query2Emb 的助手类,在本笔记本中的中演示了这个类。
最后,一旦我们能够将字符串转换成查询向量,我们就可以检索该向量的最近邻居,如下所示:
*idxs, dists = self.search_index.knnQuery(query_vector, k=k)*
搜索索引将返回两个项目(1)索引列表,这些索引是数据集中最近邻居的整数位置(2)这些邻居与您的查询向量的距离(在这种情况下,我们将索引定义为使用余弦距离)。一旦有了这些信息,构建语义搜索就简单了。下面的代码概述了如何实现这一点的示例:
A class that glues together all the parts we need to build semantic search.
最后,这个笔记本向你展示了如何使用上面的 search_engine 对象来创建一个交互式演示,如下所示:

This is the same gif that was presented at the beginning of this tutorial.
恭喜你!您刚刚学习了如何创建语义搜索。我希望这次旅行是值得的。
等等,你说搜查任意的东西?
尽管本教程描述了如何为代码创建语义搜索,但是您可以使用类似的技术来搜索视频、音频和其他对象。与使用从代码中提取特性的模型(第 2 部分)不同,您需要训练或找到一个预先训练好的模型,从您选择的对象中提取特性。唯一的先决条件是,您需要一个足够大的带有自然语言注释的数据集(比如音频的文字记录,或者照片的标题)。
我们相信您可以使用在本教程中学到的想法来创建自己的搜索,并希望收到您的来信,看看您创建了什么(参见下面的联系部分)。
限制和遗漏
- {Update 1/1/20202}:这篇博文中讨论的技术已经过时,尤其是关于模型架构和技术。对于同一项目的更新版本,请参见 CodeSearchNet 项目和相关论文。
- 这篇博文中讨论的技术是经过简化的,并且仅仅触及了可能的表面。我们提供的是一个非常简单的语义搜索—但是,为了使这种搜索有效,您可能需要使用关键字搜索和其他过滤器或规则来增强这种搜索(例如,搜索特定回购、用户或组织的能力以及通知相关性的其他机制)。
- 有机会使用利用代码结构的特定领域架构,例如树-lstms 。此外,还有其他标准技巧,如利用注意力和随机教师强迫,为了简单起见,我们省略了这些技巧。
- 我们忽略的一部分是如何评估搜索。这是一个复杂的主题,值得在自己的博客上发表。为了有效地迭代这个问题,你需要一个客观的方法来衡量你的搜索结果的质量。这将是未来博客文章的主题。
取得联系!
我们希望你喜欢这篇博文。请随时与我们联系:
资源
- GitHub 回购本文供图。
- 为了让那些试图重现这个例子的人更容易,我们已经将所有依赖项打包到一个 Nvidia-Docker 容器中。对于那些不熟悉 Docker 的人来说,你可能会发现这篇文章很有帮助。这里有一个链接,链接到 Dockerhub 上本教程的 docker 图片。
- 对于任何试图获得深度学习技能的人,我的首要建议是尽快掌握。艾乘杰瑞米·霍华德。我在那里学到了写这篇博文所需的许多技能。此外,本教程利用了 fastai 库。
- 请关注这本书,它仍处于早期发行阶段,但已经深入到这个主题的有用细节。
- Avneesh Saluja 的演讲强调了 Airbnb 如何研究使用共享向量空间来支持对房源和其他数据产品的语义搜索。
谢谢
实体模型搜索界面是由贾斯汀·帕尔默设计的(你可以在这里看到他的其他作品)。也感谢以下人员的评论和投入:艾克·奥康科沃、大卫·希恩、金梁。
放弃
本文中提出的任何想法或观点都是我们自己的。提出的任何想法或技术不一定预示 GitHub 的未来产品。这个博客的目的只是为了教育。
基于深度学习的语义分割
指南和代码

Semantic Segmentation
想获得灵感?快来加入我的 超级行情快讯 。😎
什么是语义切分?
深度学习和计算机视觉社区的大多数人都明白什么是图像分类:我们希望我们的模型告诉我们图像中存在什么单个对象或场景。分类很粗,层次很高。
许多人也熟悉对象检测,我们试图通过在它们周围绘制边界框,然后对框中的内容进行分类,来对图像中的多个对象进行定位和分类。检测是中级的,我们有一些非常有用和详细的信息,但仍然有点粗糙,因为我们只画了边界框,并没有真正得到对象形状的准确想法。
语义分割是这三者中信息量最大的,我们希望对图像中的每一个像素进行分类,就像你在上面的 gif 中看到的那样!在过去的几年里,这完全是通过深度学习来完成的。
在本指南中,您将了解语义分割模型的基本结构和工作原理,以及所有最新、最棒的最先进方法。
如果您想亲自尝试这些模型,您可以查看我的语义分割套件,其中包含 TensorFlow 培训和本指南中许多模型的测试代码!
TensorFlow 中的语义切分套件。轻松实现、训练和测试新的语义分割模型!…
github.com](https://github.com/GeorgeSeif/Semantic-Segmentation-Suite)
基本结构
我将要向您展示的语义分割模型的基本结构存在于所有最先进的方法中!这使得实现不同的应用程序变得非常容易,因为几乎所有的应用程序都有相同的底层主干、设置和流程。
U-Net 模型很好地说明了这种结构。模型的左侧代表**为图像分类而训练的任何特征提取网络。**这包括像 VGGNet、ResNets、DenseNets、MobileNets 和 NASNets 这样的网络!在那里你真的可以使用任何你想要的东西。
选择用于特征提取的分类网络时,最重要的是要记住权衡。使用一个非常深的 ResNet152 会让你非常准确,但不会像 MobileNet 那样快。将这些网络应用于分类时出现的权衡也出现在将它们用于分割时。需要记住的重要一点是在设计/选择您的细分网络时,这些主干将是主要驱动因素,这一点我再强调也不为过。

U-Net model for segmentation
一旦这些特征被提取出来,它们将在不同的尺度下被进一步处理。原因有两个。首先,你的模型很可能会遇到许多不同大小的物体;以不同的比例处理要素将赋予网络处理不同规模要素的能力。
第二,当执行分段时,有一个折衷。如果你想要好的分类准确度,那么你肯定会想要在网络的后期处理那些高级特征,因为它们更有鉴别能力,包含更多有用的语义信息。另一方面,如果你只处理那些深度特征,由于分辨率低,你不会得到好的定位!
最近最先进的方法都遵循上面的特征提取结构,然后是多尺度处理。因此,许多都非常易于端到端的实施和培训。您选择使用哪一个将取决于您对准确性与速度/内存的需求,因为所有人都在尝试提出新的方法来解决这一权衡,同时保持效率。
在接下来的最新进展中,我将把重点放在最新的方法上,因为在理解了上面的基本结构之后,这些方法对大多数读者来说是最有用的。我们将按照大致的时间顺序进行演练,这也大致对应于最新技术的发展。
最先进的漫游
全分辨率残差网络(FRRN)
FRRN 模型是多尺度处理技术的一个非常明显的例子。它使用两个独立的流来实现这一点:剩余流和池流。
我们希望处理这些语义特征以获得更高的分类精度,因此 FRRN 逐步处理和缩减采样池流中的特征映射。同时,它在残差流中以全分辨率处理特征图。所以池流处理高级语义信息(为了高分类精度),残差流处理低级像素信息(为了高定位精度)!
现在,由于我们正在训练一个端到端网络,我们不希望这两个流完全断开。因此,在每次最大池化后,FRRN 对来自两个流的特征地图进行一些联合处理,以组合它们的信息。

FRRN model structure
金字塔场景解析网络
FRRN 在直接执行多尺度处理方面做得很好。但是在每一个尺度上进行繁重的处理是相当计算密集的。此外,FRRN 做一些全分辨率的处理,非常慢的东西!
PSPNet 提出了一个聪明的方法来解决这个问题,通过使用*多尺度池。*它从标准特征提取网络(ResNet、DenseNet 等)开始,并对第三次下采样的特征进行进一步处理。
为了获得多尺度信息,PSPNet 使用 4 种不同的窗口大小和步长应用 4 种不同的最大池操作。这有效地从 4 个不同的尺度捕获特征信息,而不需要对每个尺度进行大量的单独处理!我们简单地对每个图做一个轻量级的卷积,然后进行上采样,这样每个特征图都有相同的分辨率,然后把它们连接起来。
瞧啊。我们已经合并了多尺度特征地图,而没有对它们应用很多卷积!
所有这些都是在较低分辨率的特征图上完成的。最后,我们使用双线性插值将输出分割图放大到期望的大小。这种仅在所有处理完成后才进行升级的技术出现在许多最新的作品中。

PSPNet model structure
一百层提拉米苏
如果深度学习带来了一种令人敬畏的趋势,那就是令人敬畏的研究论文名称!百层提拉米苏(听起来很好吃!)使用了和我们之前看到的 U-Net 架构类似的结构。主要贡献是巧妙使用了类似于 DenseNet 分类模型的密集连接。
这确实强调了计算机视觉的强大趋势,其中特征提取前端是在任何其他任务中表现良好的主要支柱。因此,寻找精度增益的第一个地方通常是您的特征提取前端。

FCDenseNet model structure
重新思考阿特鲁卷积
DeepLabV3 和是另一种进行多尺度处理的聪明方法,这次没有增加参数。
这个模型非常轻便。我们再次从特征提取前端开始,获取第四次下采样的特征用于进一步处理。这个分辨率非常低(比输入小 16 倍),因此如果我们能在这里处理就太好了!棘手的是,在如此低的分辨率下,由于像素精度差,很难获得良好的定位。
这就是 DeepLabV3 的主要贡献所在,它巧妙地使用了阿特鲁卷积。常规卷积只能处理非常局部的信息,因为权重总是彼此紧挨着。例如,在标准的 3×3 卷积中,一个权重与任何其他权重之间的距离只有一个步长/像素。
对于 atrous 卷积,我们将直接增加卷积权重之间的间距,而不会实际增加运算中权重的数量。因此,我们仍然使用一个总共有 9 个参数的 3x3,我们只是将相乘的权重间隔得更远!每个砝码之间的距离称为膨胀率。下面的模型图很好地说明了这个想法。
当我们使用低膨胀率时,我们将处理非常局部/低尺度的信息。当我们使用高膨胀率时,我们处理更多的全局/高尺度信息。因此,DeepLabV3 模型混合了具有不同膨胀率的 atrous 卷积来捕捉多尺度信息。
在 PSPNet 中解释的所有处理之后,在最后进行升级的技术也在这里完成。

DeepLabV3 model structure
多路径细化网络
我们之前已经看到 FRRN 是如何成功地将来自多个分辨率的信息直接组合在一起的。缺点是在如此高的分辨率下处理是计算密集型的,我们仍然需要处理和结合那些低分辨率的特征!
RefineNet 模型说我们不需要这样做。当我们通过特征提取网络运行输入图像时,我们自然会在每次下采样后获得多尺度特征图。
然后,RefineNet 以自下而上的方式处理这些多分辨率特征图,以组合多尺度信息。首先,独立处理每个特征图。然后,当我们放大时,我们将低分辨率的特征图与高分辨率的特征图结合起来,对它们一起做进一步的处理。因此,多尺度特征地图被独立地和一起处理。在下图中,整个过程从左向右移动。
这里也采用了 PSPNet 和 DeepLabV3 中所述的在所有处理结束后进行升级的技术。

RefineNet model structure
大内核问题(GCN)
之前,我们看到了 DeepLabV3 模型如何使用具有不同膨胀率的 atrous 卷积来捕捉多尺度信息。棘手的是,我们一次只能处理一个秤,然后必须将它们组合起来。例如,速率为 16 的 atrous 卷积不能很好地处理局部信息,必须在以后与来自速率小得多的卷积的信息相结合,以便在语义分割中表现良好。
因此,在以前的方法中,多尺度处理首先单独发生,然后将结果组合在一起。如果能一次性获得多尺度信息,那就更有意义了。
为了做到这一点,全球卷积网络(GCN) 巧妙地提出使用大型一维核,而不是方形核。对于像 3x3、7x7 等这样的平方卷积,我们不能让它们太大而不影响速度和内存消耗。另一方面,一维内核的缩放效率更高,我们可以在不降低网络速度的情况下将它们做得很大。这张纸甚至被放大到了 15 号!
你必须确保做的重要的事情是平衡水平和垂直回旋。此外,该论文确实使用了具有低滤波器数的小 3×3 卷积,以有效细化一维卷积可能遗漏的任何内容。
GCN 遵循与以前作品相同的风格,从特征提取前端处理每个尺度。由于一维卷积的效率,GCN 在所有尺度上执行处理,一直到全分辨率,而不是保持小规模,然后扩大规模。这允许在我们按比例放大时不断细化分割,而不是由于停留在较低分辨率而可能发生的瓶颈。

GCN model structure
DeepLabV3+
DeepLabV3+ 模型,顾名思义,是 DeepLabV3 的快速扩展,从它之前的进步中借用了一些概念上的想法。正如我们之前看到的,如果我们只是简单地等待在网络末端使用双线性插值来扩大规模,就会存在潜在的瓶颈。事实上,最初的 DeepLabV3 模型在结尾被 x16 升级了!
为了解决这个问题,DeepLabV3+建议在 DeepLabV3 之上添加一个中间解码器模块。通过 DeepLabV3 处理后,特征由 x4 进行上采样。然后,它们与来自特征提取前端的原始特征一起被进一步处理,然后被 x4 再次放大。这减轻了网络末端的负载,并提供了从特征提取前端到网络近端的快捷路径。

DeepLabV3+ model structure
CVPR 和 ECCV 2018
我们在上一节中讨论的网络代表了你需要知道的进行语义分割的大部分技术!今年在计算机视觉会议上发布的许多东西都是微小的更新和准确性上的小波动,对开始并不是非常关键。为了彻底起见,我在这里为任何感兴趣的人提供了他们的贡献的快速回顾!
图像级联网络(ICNet) — 使用深度监督并以不同的尺度运行输入图像,每个尺度通过其自己的子网并逐步组合结果
【DFN】**—**使用深度监督并尝试分别处理线段的平滑和边缘部分
DenseASPP**—**结合了密集连接和粗糙卷积
上下文编码**——**通过添加通道关注模块,利用全局上下文来提高准确性,该模块基于新设计的损失函数来触发对某些特征地图的关注。损失基于网络分支,该网络分支预测图像中存在哪些类别(即,更高级别的全局上下文)。
密集解码器快捷连接 — 在解码阶段使用密集连接以获得更高的精度(以前仅在特征提取/编码期间使用)
【BiSeNet】**—**有两个分支:一个是深度分支,用于获取语义信息,另一个是对输入图像进行很少/很小的处理,以保留低级像素信息
ex fuse**—**使用深度监督,在处理之前,显式组合来自特征提取前端的多尺度特征,以确保多尺度信息在各级一起处理。

ICNet model structure
TL;DR 或者如何做语义分割
- 注意分类网络权衡。您的分类网络是您处理要素的主要驱动力,您的大部分收益/损失将来自于此
- 在多个尺度上处理并将信息结合在一起
- 多尺度池、atrous convs、大型一维 conv 都适用于语义分割
- 你不需要在高分辨率下做大量的处理。为了速度,在低分辨率下完成大部分,然后升级,如果必要的话,在最后做一些轻微的处理
- 深度监督可以稍微提高你的准确性(尽管设置训练更加棘手)
喜欢学习?
在 twitter 上关注我,我会在这里发布所有最新最棒的人工智能、技术和科学!也在 LinkedIn 上和我联系吧!
半监督学习和 GANs

文森特·梵高在 1889 年画了这幅美丽的艺术作品:“星夜”,今天我的甘模型(我喜欢称之为甘·高:P)画了一些 MNIST 数字,只有 20%的标记数据!!它是如何实现这一非凡壮举的?…让我们来看看
简介
什么是半监督学习 ?
大多数深度学习分类器需要大量的标记样本才能很好地泛化,但获得这样的数据是一个昂贵而困难的过程。为了处理这种限制提出了半监督学习,这是一类利用少量已标记数据和大量未标记数据的技术。许多机器学习研究人员发现,未标记数据在与少量标记数据结合使用时,可以大大提高学习精度。GANs 在半监督学习中表现出了很大的潜力,其中分类器可以用很少的标记数据获得良好的性能。
甘斯背景
gan 是深度生成模型的成员。它们特别有趣,因为它们没有明确表示数据所在空间的概率分布。相反,它们通过从概率分布中抽取样本,提供了一些与概率分布不太直接交互的方式。

Architecture of a Vanilla GAN
甘的基本想法是在两个玩家之间建立一个游戏:
- A 发生器 G :以随机噪声 z 为输入,输出一幅图像 x 。它的参数被调整,以便在它生成的假图像上从鉴别器得到高分。
- A 鉴别器 D :取图像 x 作为输入,输出反映其为真实图像的置信度的分数。它的参数被调整为当由真实图像馈送时具有高分,当由生成器馈送假图像时具有低分。
我建议您浏览一下这个和这个,了解更多关于他们工作和优化目标的细节。现在,让我们稍微转动一下轮子,谈谈 GANs 最突出的应用之一,半监督学习。
直觉
鉴别器的标准结构只有一个输出神经元用于分类 R/F 概率。我们同时训练两个网络,并在训练后丢弃鉴别器,因为它仅用于改进生成器。

对于半监督任务,除了 R/F 神经元之外,鉴别器现在将有 10 个以上的神经元用于 MNIST 数字的分类。此外,这一次它们的角色发生了变化,我们可以在训练后丢弃生成器,它的唯一目标是生成未标记的数据以提高鉴别器的性能。
现在,鉴别器变成了 11 类分类器,其中 1 个神经元(R/F 神经元)代表假数据输出,另外 10 个神经元代表具有类的真实数据。必须谨记以下几点:
- 当来自数据集的真实无监督数据被馈送时,断言 R/F 神经元输出标签= 0
- 当来自生成器的假的无监督数据被馈送时,断言 R/F 神经元输出标签= 1
- 当输入实际监控数据时,置位 R/F 输出标签= 0,相应标签输出= 1
不同数据源的这种组合将有助于鉴别器比仅提供一部分标记数据更准确地分类。
体系结构
现在是时候用一些代码:D 弄脏我们的手了
甄别器
接下来的架构类似于 DCGAN 论文中提出的架构。我们使用步长卷积来降低特征向量的维度,而不是任何池层,并对所有层应用一系列 leaky_relu、dropout 和 BN 来稳定学习。对于输入层和最后一层,BN 被丢弃(为了特征匹配)。最后,我们执行全局平均池,以在特征向量的空间维度上取平均值。这将张量维数压缩为一个值。拼合要素后,将添加 11 个类别的密集图层,并激活 softmax 以实现多类别输出。
发电机
发生器结构被设计成反映鉴频器的空间输出。分数步长卷积用于增加表示的空间维度。噪声 z 的 4-D 张量的输入被馈送,其经历一系列转置卷积、relu、BN(除了在输出层)和丢失操作。最后,tanh 激活映射范围(-1,1)内的输出图像。
模型损失
我们首先通过将实际标签附加为零来为整批准备一个扩展标签。这样做是为了在输入标记数据时将 R/F 神经元输出置为 0。通过将假图像的 R/F 神经元输出置为 1,将真实图像置为 0,可以将未标记数据的鉴别器损失视为二进制 sigmoid 损失。
生成器损失是假图像损失和特征匹配损失的组合,假图像损失错误地将 R/F 神经元输出断言为 0,特征匹配损失惩罚训练数据上的某组特征的平均值和生成样本上的该组特征的平均值之间的平均绝对误差*。*
培养
训练图像的大小从[batch_size,28,28,1]调整到[batch_size,64,64,1]以适应生成器/鉴别器架构。计算损耗、精度和生成的样本,并观察其在每个时期的改进。
结论
由于 GPU 访问受限,训练进行了 5 个时期和 20%的标记率。为了获得更好的结果,建议使用具有更低标记率的更多训练时段。完整的代码笔记本可以在这里找到。

Training Results
无监督学习被认为是 AGI 领域的一个空白。为了弥补这一差距,GANs 被认为是学习低标记数据复杂任务的潜在解决方案。随着半监督学习领域新方法的出现,我们可以预期这种差距将会缩小。
如果我不提及我从这个美丽的博客,这个实现以及我在类似项目中工作的同事的帮助中获得的灵感,那将是我的失职。
下次见!!Kz
基于 PCA 和 PLS 的半监督回归:MATLAB、R 和 Python 代码——你所要做的只是准备数据集(非常简单、容易和实用)


我发布了基于主成分分析和偏最小二乘法的半监督回归的 MATLAB、R 和 Python 代码。它们非常容易使用。你准备数据集,然后运行代码!然后,可以获得新样本的 PCAPLS 和预测结果。非常简单容易!
你可以从下面的网址购买每一个代码。
矩阵实验室
https://gum.co/PnRna
请从下面的 URL 下载补充 zip 文件(这是免费的)来运行 PCAPLS 代码。
http://univproblog . html . xdomain . jp/code/MATLAB _ scripts _ functions . zip
稀有
https://gum.co/PXJsf
请从下面的 URL 下载补充 zip 文件(这是免费的)来运行 PCAPLS 代码。
http://univproblog . html . xdomain . jp/code/R _ scripts _ functions . zip
计算机编程语言
https://gum.co/XwnQl
http://univprovblog . html . xdomain . jp/code/supporting functions . zip
MATLAB 中的 PCAPLS 程序,R 和 Python 代码
为了执行适当的 PCAPLS,加载数据集后,MATLAB、R 和 Python 代码遵循以下程序。
1。决定 PCA 的累积贡献率的阈值
主成分数(PCs)在检查累积贡献率时确定。例如,如果给定数据集中包含 5%的噪声,则应使用累积贡献率为 95%的 PCs。其他 PC 可以作为噪声去除。
2。将带有目标变量(Y)的数据集和不带有目标变量(Y)的数据集合并(样本被合并)
3。组合数据集
的自动缩放解释变量(X)自动缩放意味着居中和缩放。通过从居中的变量中减去每个变量的平均值,每个变量的平均值变为零。通过将每个变量的标准偏差除以换算中的变量,每个变量的标准偏差变为 1。
缩放是任意的(但是推荐),但是需要居中,因为 PCA 是基于轴的旋转。
4。运行 PCA,并获得每台 PC 的得分和加载向量
5。根据 1 中的阈值决定电脑的数量。
6。仅提取 Y 样本的分数
7。自动缩放分数和 Y
缩放是任意的(但推荐)。需要对中。
8。用交叉验证(CV)估计 Y,把分量数从 1 改成 m
留一 CV 很有名,但是在训练样本数很高的时候会造成过拟合。所以,5 折或 2 折 CV 比较好。首先,将训练样本分成 5 或 2 组。第二,一组作为测试样本处理,另一组建立模型。重复 5 或 2 次,直到每组都作为测试样品处理。然后,可以得到不是计算的 Y 而是估计的 Y。
m 必须小于 X 变量的数量,但 m=30 最大值就足够了。
9。计算每个组件数量的实际 Y 和估计 Y 之间的均方根误差(RMSE)
10。用最小 RMSE 值
决定最佳元件数,用第一个局部最大 RMSE 值决定最佳元件数即可
11。用最佳组分数构建 PLS 模型,得到标准回归系数
12。计算实际 Y 和计算 Y 之间的行列式系数和 RMSE(r2C 和 RMSEC)以及实际 Y 和估计 Y 之间的行列式系数和 RMSE(r2CV 和 RMSECV)
r2C 是指 PLS 模型能够解释的 Y 信息的比值。
RMSE 表示 PLS 模型中 Y 误差的平均值。
r2CV 表示 PLS 模型对新样本可以估计的 Y 信息的可能比率。
RMSECV 表示新样本 Y 误差的可能平均值。
较好的 PLS 模型具有较高的 r2CV 值和较低的 RMSECV 值。
r2C 和 r2CV 之间以及 RMSEC 和 RMSECV 之间的巨大差异意味着 PLS 模型对训练样本的过拟合。
*小心!r2CV 和 RMSECV 不能代表 PLS 模型的真实可预测性,因为它是 CV 而不是外部验证。
13。检查实际 Y 和计算 Y 之间以及实际 Y 和估计 Y 之间的图
可以检查计算值和估计值的异常值。
14。在预测中,用 1 减去 X 的自动调用中的平均值。然后,用 X 变量除以 X 在 1 中自动调用的标准偏差。,用于新样品
15。使用 4 中的加载向量计算新样本的分数。
16。减去 7 中分数自动调用的平均值。从新分数开始,然后用新分数除以 7 中分数自动调用的标准偏差。
17。根据 11 中的标准回归系数估计 Y。
18。将 Y 的自动调用中的标准差乘以 1。通过估计的 Y,然后,在 1 中添加 Y 的自动调用中的平均值。到估计 Y
执行 PCAPLS 的方法
1.购买代码并解压文件
MATLAB:https://gum.co/PnRna的
R:https://gum.co/PXJsf
Python:https://gum.co/XwnQl
2.下载并解压缩补充 zip 文件(这是免费的)
MATLAB:http://univprovblog . html . xdomain . jp/code/MATLAB _ scripts _ functions . zip
R:http://univprovblog . html . xdomain . jp/code/R _ scripts _ functions . zip
Python:http://univproblog . html . xdomain . jp/code/supporting functions . zip
3.将补充文件放在与 PCAPLS 代码相同的目录或文件夹中。
4.准备数据集。有关数据格式,请参见下面的文章。
data.csv、data_prediction1.csv 和 data_prediction2.csv 的样本在 PCA 之前合并。
5.运行代码!
“data_prediction2.csv”的 Y 估计值保存在“PredictedY2.csv”中。
必需的设置
执行结果的示例




 ****
****


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言










{kind=link}
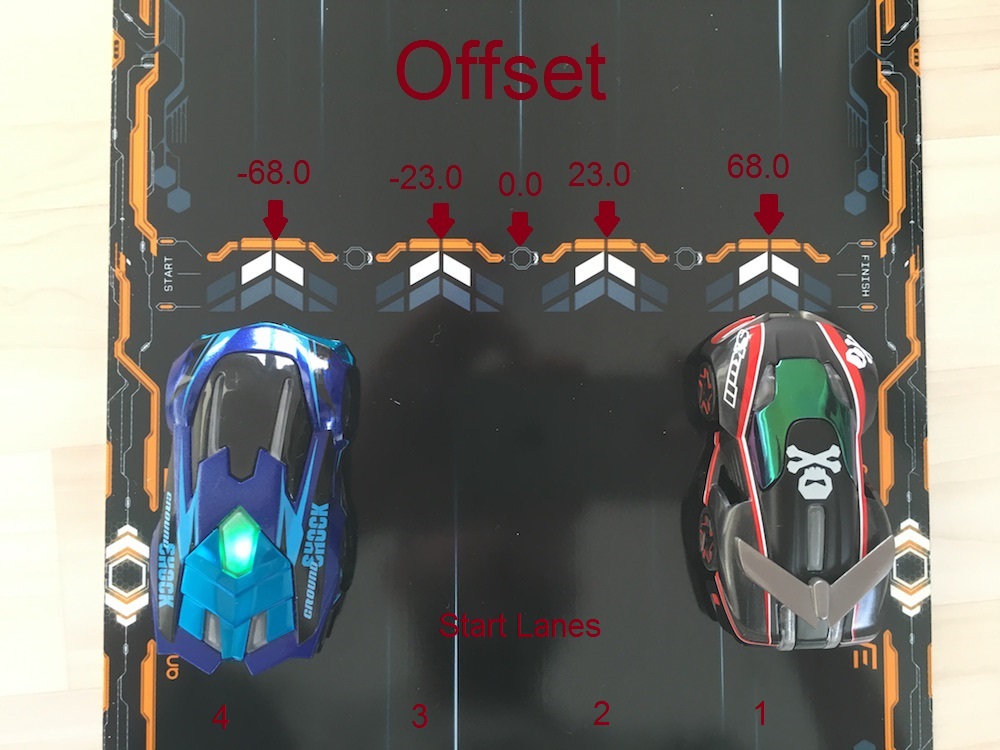{kind=link}
{kind=link}
{kind=link}