







用对立的例子打破机器学习
机器学习是人工智能的前沿。随着对计算机视觉、自然语言处理等的应用,ML 对技术的未来有着巨大的影响!然而,随着我们对 ML 依赖的增加,我们对 ML 安全性的担忧也在增加。
我不是在谈论机器人起义,而是更现实的东西——敌对例子的威胁。
什么是对立的例子?
简而言之,对立的例子是专门设计来欺骗 ML 模型(例如神经网络)的模型输入。可怕的是,对立的例子与它们在现实生活中的对应部分几乎完全相同——通过向源图像添加少量的“对立噪声”,对立的例子可以与未改变的图像区分开来!

*一只熊猫(右)被误归类为长臂猿的反面例子
那么我们如何产生对立的例子呢?
虽然可以使用许多不同的方法来生成对立的例子,但在本文中,我将重点关注一种叫做快速梯度符号方法 (FGSM)的方法。此外,为了简单起见,我将介绍如何使用这种方法为图像分类任务生成一个对立的示例。

FGSM Equation
让我们花点时间将 FGSM 方程分解成几个步骤。
- 设置损失函数,使得预期标签 y_target 将是我的模型将我的输入图像错误分类到的标签。
- 一个输入图像被输入到我的模型中,模型的损失用上面提到的损失函数来计算。
- 计算我的损失函数相对于我的输入图像的梯度。
- 为了限制我改变图像的程度,我将把我的渐变的符号(我的渐变中每个值的符号(与输入图像的形状相同))乘以超参数/常数ε(通常是一个很小的数字,以限制图像的改变)。
- 从我的输入图像中减去上面的表达式——因为损失函数的梯度总是将我指向一个会增加损失的方向,所以我减去来做相反的事情。
然后,FGSM 被重复多次,直到最终生成期望的对立示例。

Code snippet for the FGSM equation (keras backend)
使用这种技术,我能够创建一个狗的对立例子,在这里我成功地欺骗了 MobiNet 图像分类器,将我的图像错误地分类为一只青蛙!

Admittedly, the generative example in this case has more visible differences, but can be improved with additional fine tuning.
对抗性攻击及其影响
虽然我主要关注对立例子对图像分类器的影响,但对立例子可以在许多不同的场景中造成巨大的破坏。以自动驾驶汽车为例。如果停车标志以某种方式(贴纸、油漆等)被修改。)被错误地识别,那么自动驾驶汽车不会停下来——导致严重的后果。

此外,对立的例子在计算机视觉之外工作。如果将它应用于自然语言处理等领域,输入的句子可能会被识别为完全不同的东西(想象一下后果吧!).
简而言之,对抗性攻击对人工智能安全构成了非常现实的威胁。在这个领域一直有持续的研究(例如,生成防御网络、输入转换),但仍然没有单一的解决方案来对抗对抗性攻击。最终,尽管展望人工智能发展的未来很重要,但我们始终需要意识到它带来的潜在问题。
在你离开之前:
- 鼓掌这个故事!
- 将此分享给你的网络!
- 在 Linkedin 上联系我!
打破机器学习中小数据集的魔咒:第 1 部分
为什么数据的大小很重要,以及如何处理小数据?

Source: Movie Scene from Pirates of the Caribbean: The Curse of the Black Pearl
这是打破机器学习中小数据集的诅咒的第一部分。在这一部分,我将讨论数据集的大小如何影响传统的机器学习算法,以及缓解这些问题的几种方法。 在第二部分 中,我将讨论深度学习模型性能如何依赖于数据大小,以及如何与更小的数据集合作以获得类似的性能。
介绍
我们都知道机器学习近年来如何彻底改变了我们的世界,并使各种复杂的任务变得更容易执行。最近在实现深度学习技术方面的突破表明,高级算法和复杂架构可以赋予机器类似人类的能力来完成特定任务。但我们也可以观察到,大量的训练数据在使深度学习模型成功方面发挥了关键作用。 ResNet 是一种流行的图像分类架构,在 ILSVRC 2015 分类竞赛中获得第一名,比之前的技术水平提高了约 50%。

Figure 1: ILSVRC top model performance across years
ResNet 不仅拥有非常复杂和深入的架构,而且还在 1.2 Mn 图像上进行了训练。*工业界和学术界都公认,对于一个给定的问题,如果数据足够多,不同的算法实际上执行起来是一样的。*需要注意的是,大数据应该包含有意义的信息,而不仅仅是噪音,以便模型可以从中学习。这也是谷歌、脸书、亚马逊、推特、百度等公司在人工智能研究和产品开发领域占据主导地位的主要原因之一。尽管与深度学习相比,传统的机器学习需要较少的数据,但大数据以非常相似的方式影响性能。下图清楚地描绘了传统机器学习和深度学习模型的性能如何随着大数据而提高。

Figure 2: Model performance as a function of the amount of data
我们为什么需要机器学习?

Figure 3: Projectile Motion formula
让我们用一个例子来回答这个问题。假设我们有一个以速度 v 和一定角度 θ 抛出的球,我们希望预测球会落地多远。从高中物理中,我们知道球将遵循抛体运动,我们可以使用图中所示的公式找到范围。上述等式可视为任务的模型/表示,等式中涉及的各项可视为重要特征,即 v ,θ和 g (重力加速度)。在上面这样的情况下,我们的功能更少,并且我们很好地理解了它们对我们任务的影响。因此,我们能够想出一个好的数学模型。让我们考虑另一种情况,我们想预测 2018 年 12 月 30 日苹果的股价。在这样的任务中,我们对各种因素如何影响股票价格没有充分的了解。在没有真实模型的情况下,我们利用历史股票价格和各种特征,如标准普尔 500 指数、其他股票价格、市场情绪等。用机器学习算法找出潜在的关系。这是一个例子,说明人类很难理解大量特征之间的复杂关系,但机器可以通过探索大量数据轻松捕捉到这种关系。另一个类似的复杂任务是将电子邮件标记为垃圾邮件。作为一个人,我们可能不得不提出许多难以编写和维护的规则和启发。另一方面,机器学习算法可以轻松地获取这些关系,并且可以做得更好,易于维护和扩展。由于我们不必明确制定大量这些规则,但数据有助于我们了解这种关系,机器学习已经彻底改变了不同的领域和行业。
大型数据集如何帮助建立更好的机器学习模型?
在我们跳到更多数据如何提高模型性能之前,我们需要理解偏差和方差。
偏差:让我们考虑一个因变量和自变量之间存在二次关系的数据集。但是,我们不知道真实的关系,近似为线性。在这种情况下,我们将观察到我们的预测和实际观测数据之间的显著差异。观察值和预测值之间的差异称为偏差。这种模型据说功率较小,代表不适合。
**方差:**在同一个例子中,如果我们将关系近似为三次或任何更高次幂,我们就有了高方差的情况。方差被定义为训练集和测试集的性能差异。高方差的主要问题是模型非常适合训练数据,但它不能很好地概括训练数据集之外的数据。这是验证和测试集在模型构建过程中非常重要的主要原因之一。

Figure 4: Bias vs Variance (Source)
我们通常希望最小化偏差和方差,即建立一个模型,它不仅能很好地拟合训练数据,还能很好地概括测试/验证数据。有很多技术可以实现这一点,但用更多数据进行训练是实现这一点的最佳方式之一。让我们通过下图来理解这一点:

Figure 5: Large data results in better generalization(Source)
假设我们有一个类似正弦波的数据分布。图(5a) 描绘了多个模型在拟合数据点方面同样出色。这些模型中有很多过度拟合,不能很好地概括整个数据集。随着我们增加数据,图(5b) 说明了符合数据的模型数量的减少。随着我们进一步增加数据点的数量,我们成功地捕捉到了数据的真实分布,如图图(5c) 所示。这个例子帮助我们清楚地理解更多的数据如何帮助模型揭示真实的关系。接下来,我们将尝试理解一些机器学习算法的这种现象,并弄清楚模型参数如何受到数据大小的影响。
(一)线性回归: 在线性回归中,我们假设预测变量(特征)和因变量(目标)之间存在线性关系,关系式为:

其中 y 为因变量, x(i)的 为自变量。***β(I)***为真实系数,ϵ为模型未解释的误差。对于单变量情况,基于观察数据的估计系数由下式给出:


上述等式给出了斜率和截距项的点估计值,但这些估计值总是存在一些不确定性,这些不确定性可以通过方差等式量化:


因此,随着数据点数量的增加,分母值会变大,从而降低我们点估计的方差。因此,我们的模型对潜在的关系变得更有信心,并给出稳健的系数估计。借助下面的代码,我们可以看到上面的现象:

Fig 6: Improvement in point estimates with more data in Linear regression
我们模拟了一个线性回归模型,斜率(b)=5,截距(a)=10。当我们用较少的数据图 6(a) 和较多的数据图 6(b) 建立回归模型时,我们可以清楚地看到斜率和截距之间的差异。在图 6(a) 中,我们有一个线性回归模型,斜率为 4.65,截距为 8.2,而图 6(b) 中的斜率为 5.1,截距为 10.2,更接近真实值。
(b)k-最近邻(k-NN): k-NN 是一种最简单但非常强大的算法,用于回归和分类。k-NN 不需要任何特定的训练阶段,顾名思义,预测是基于测试点的 k-最近邻进行的。由于 k-NN 是非参数模型,模型性能取决于数据的分布。在下面的例子中,我们正在研究虹膜数据集以了解数据点的数量如何影响 k-NN 性能。为了便于可视化,我们只考虑了四个特征中的两个,即萼片长度和萼片宽度。

Fig 7: Change in predicted class in k-NN with data size
让我们从类别 1 中随机选择一个点作为测试数据*(用红星表示)*,并使用 k=3 来使用多数投票预测测试数据的类别。图 7(a) 表示数据较少的情况,我们观察到模型将测试点误分类为类别 2。对于较大的数据点,模型会正确地将类别预测为 1。从上面的图中,我们可以注意到 k-NN 受可用数据的影响很大,更多的数据可能有助于使模型更加一致和准确。
©决策树: 与线性回归和 k-NN 类似,决策树性能也受到数据量的影响。

Fig 8: Difference in tree splitting due to the size of the data
决策树也是一个非参数模型,它试图最好地拟合数据的底层分布。对特征值执行分割,目的是在子级创建不同的类。由于模型试图最好地拟合可用的训练数据,所以数据的数量直接决定了拆分级别和最终类别。从上图中,我们可以清楚地观察到,分割点和最终类别预测受数据集大小的影响很大。更多的数据有助于找到最佳分割点,避免过度拟合。
如何解决数据少的问题?

Fig 9: Basic implications of fewer data and possible approaches and techniques to solve it
上图试图捕捉处理小数据集时面临的核心问题,以及解决这些问题的可能方法和技术。在这一部分,我们将只关注传统机器学习中使用的技术,其余的将在博客的第二部分讨论。
a)改变损失函数: 对于分类问题,我们经常使用交叉熵损失,很少使用平均绝对误差或均方误差来训练和优化我们的模型。在不平衡数据的情况下,模型变得更偏向于多数类,因为它对最终损失值有更大的影响,我们的模型变得不那么有用。在这种情况下,我们可以为不同类别对应的损失增加权重,以消除这种数据偏差。例如,如果我们有两个数据比率为 4:1 的类,我们可以将比率为 1:4 的权重应用于损失函数计算,以使数据平衡。这种技术可以帮助我们轻松缓解不平衡数据的问题,并提高不同类之间的模型泛化能力。我们可以很容易地找到 R 和 Python 中的库,它们有助于在损失计算和优化过程中为类分配权重。Scikit-learn 有一个方便的实用函数,可以根据课程频率计算权重:
我们可以通过使用 class_weight=balanced 来避免上述计算,它执行相同的计算来找到 class_weights。我们还可以根据自己的需求提供显式的类权重。更多详情请参考 Scikit-learn 的文档
b)异常/变化检测: 在欺诈或机器故障等高度不平衡数据集的情况下,是否可以将此类例子视为异常值得深思。如果给定的问题满足异常的标准,我们可以使用模型如 OneClassSVM 、聚类方法或高斯异常检测方法。这些技术要求我们转变思维,将次要类视为离群类,这可能有助于我们找到新的分离和分类方法。变化检测类似于异常检测,只是我们寻找的是变化或差异,而不是异常。这些可能是通过使用模式或银行交易观察到的用户行为的变化。请参考以下文档以了解如何使用 Scikit-Learn 实现异常检测。

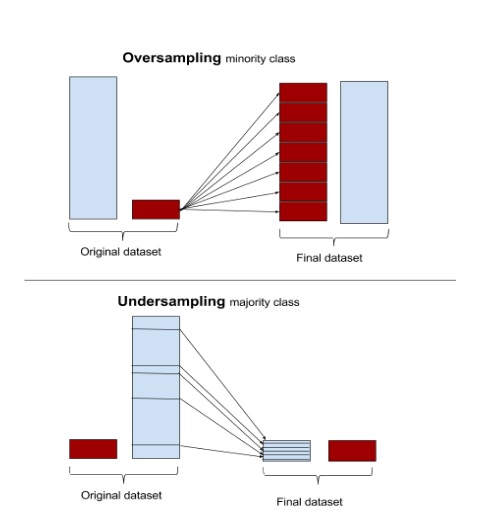
Fig 10: Over and Undersampling depiction (Source)
c)上采样或下采样: 由于与少数类相比,不平衡的数据固有地以不同的权重惩罚多数类,所以该问题的一个解决方案是使数据平衡。这可以通过增加少数类的频率或通过随机或聚类抽样技术减少多数类的频率来实现。过采样与欠采样以及随机与聚类的选择取决于业务环境和数据大小。通常,当整体数据量很小时,首选上采样,而当数据量很大时,下采样很有用。同样,随机抽样与整群抽样取决于数据分布的好坏。详细了解请参考下面的博客。借助如下所示的imb learn包,可以轻松完成重采样:
d)生成合成数据: 虽然上采样或下采样有助于使数据平衡,但重复数据会增加过拟合的机会。解决这个问题的另一种方法是在少数类数据的帮助下生成合成数据。合成少数过采样技术(SMOTE)和改进的 SMOTE 是产生合成数据的两种这样的技术。简而言之,SMOTE 获取少数类数据点,并创建位于由直线连接的任意两个最近数据点之间的新数据点。为了做到这一点,该算法计算特征空间中两个数据点之间的距离,将该距离乘以 0 到 1 之间的随机数,并将新数据点放置在距离用于距离计算的数据点之一的这个新距离处。请注意,考虑用于数据生成的最近邻的数量也是一个超参数,可以根据需要进行更改。

Fig 11: SMOTE in action with k=3 (Source)
M-SMOTE 是 SMOTE 的修改版本,它也考虑了少数类的基本分布。该算法将少数类样本分为 3 个不同的组——安全/安全样本、边界样本和潜在噪声样本。这是通过计算少数类样本和训练数据样本之间的距离来完成的。与 SMOTE 不同,该算法从安全样本的 k 个最近邻中随机选择一个数据点,从边界样本中选择最近邻,并且对潜在噪声不做任何事情。如需详细了解,请参考博客。
e)集成技术: 聚合多个弱学习者/不同模型的思想在处理不平衡数据集时表现出了很好的效果。装袋和增压技术在各种问题上都取得了很好的效果,应该与上面讨论的方法一起探索,以获得更好的结果。为了限制这篇博客的篇幅,我将不讨论这些技术,但是要详细了解各种集成技术以及如何将它们用于不平衡数据,请参考下面的博客。
结论:
在这一部分中,我们看到数据的大小可能表现出与泛化、数据不平衡和难以达到全局最优有关的问题。我们已经介绍了一些最常用的技术来解决传统机器学习算法的这些问题。根据手头的业务问题,上述一种或多种技术可能是一个很好的起点。为了保持博客简短,我没有详细介绍这些技术,但是网上有很多很好的资源详细介绍了上述技术。在第 2 部分中,我们将讨论小数据集如何阻碍深度学习模型中的学习过程,以及克服这一点的各种方法。
****关于我:研究生,旧金山大学数据科学硕士
****LinkedIn:https://www . LinkedIn . com/in/jyoti-pra kash-maheswari-940 ab 766/
GitHub:https://github.com/jyotipmahes
参考
- 如何处理机器学习中的不平衡分类问题?
- 如何处理“小”数据?
- 如何处理机器学习中的不平衡类
- 小数据&深度学习(AI)——一个数据约简框架
- 基于 DTE-SBD 的非均衡企业信用评估:基于 SMOTE 和 bagging 的差别采样率决策树集成
乳腺癌细胞类型分类器

在参加了许多数据科学和机器学习的在线课程后,现在是我着手一些项目并扩展我的技能和知识的时候了。除了这门课的实验室,这个项目将是我的第一个项目。其目的是在癌细胞特征数据集上训练分类器模型,以预测细胞是 B =良性还是 M =恶性。
该数据集由威斯康星大学创建,具有 569 个实例(行-样本)和 32 个属性(特征-列)。有关数据来源的更多信息,请访问 UCI 网站(点击此处)。然而,作为第一步,解释什么是属性信息以及它们是如何计算的是很重要的。
在本文中,我将带您经历分析数据、构建模型并最终评估它的步骤。一些读者可能对编码部分不感兴趣,所以他们可以跳过它,享受数据分析、可视化和评估部分。
步骤 1 —数据集信息和理解
如 UCI 网站所述,“特征是从乳腺肿块的细针抽吸(FNA)的数字化图像中计算出来的。它们描述了图像中出现的细胞核的特征”。此外,FNA 是一种活检程序,在 CT 扫描或超声监视器的引导下,将一根非常细的针插入异常组织或细胞区域(图 1)。然后将收集到的样本转移给病理学家,在显微镜下进行研究,并检查活检中的细胞是否正常。

figure 1
数据集属性信息:
1)身份证号码
2)诊断(M =恶性,B =良性)
3–32)
为每个细胞核计算十个实值特征:
a)半径(从中心到周边各点的平均距离)
b)纹理(灰度值的标准偏差)
c)周界
d)面积
e)平滑度(半径长度的局部变化)
f)紧密度(周长/面积-1.0)
g)凹度(轮廓凹入部分的严重程度)
h)凹点(轮廓的凹入部分的数量)
I)对称性
j)分形维数(“海岸线近似值”-1)
对每幅图像计算这些特征的平均值、标准误差和“最差”或最大值(三个最大值的平均值),得到 30 个特征。例如,字段 3 是平均半径,字段 13 是半径 SE,字段 23 是最差半径。”
步骤 2 —导入函数
我用的是 ANACODA NAVIGATOR V1.5 和 Jupyter 笔记本环境。在网络环境中,我开始了一个新的 Python 3 笔记本,将其命名为“乳腺癌分类器”,并导入了一些功能:

步骤 3 —加载数据集
下载并检查 wdbc.data 文件后,我需要将它加载到笔记本中,分配列名并检查前五个示例:

第 4 步—数据争论
在这一步中,我删除了每个属性的“ID”列、标准误差和最差值,以检查分类器如何处理主平均值。

已检查是否有任何要处理的缺失值:

太好了,看起来没有丢失值。当然,我必须确保 na _ 值在加载阶段被识别。接下来,检查数据类型并在需要时进行转换是很重要的。

一切都很好,除了标签列“诊断”,我稍后将映射它的信息。
步骤 5 —数据探索和可视化
数据集中标签列和视图 B 与 M 比率的条形图(1.7: 1)。

打印描述所有数值数据的功能和检查数据统计的摘要。但是,创建箱线图,检查数据分布,并尝试发现一些细节(如异常值)是一个好主意。

我做了一个 for 循环,为按诊断标签分组的所有数字特征创建单独的箱线图。以下是一些例子:“半径”、“面积”和“凹度”:

虽然有轻微的重叠,但我们仍然可以注意到大多数良性细胞的半径(面积)比恶性细胞小。凹度也是如此,良性细胞比恶性细胞的凹度小。此外,还有一些潜在的异常值,我们稍后可能需要处理它们。
直方图绘制,直观显示数据频率和总体数据分布的密度图。创建另一个 for 循环来绘制所有特征。以下是“半径”、“面积”和“凹度”特征:




曲线是正峰度和正偏斜的。显然,这是因为恶性细胞的可用数据较少(检查直方图)。半径和面积密度图中的第二个峰值是由于良性和恶性曲线的累积拟合,而不是由于异常值。我们可以将它们分为以下几类:


我必须记住,一些分类模型需要数据的正态分布。对于散点图,我喜欢对所有特征运行矩阵函数,这样我就可以理解并收集一些见解。此外,我用不同的颜色标记了两个类。为此,我利用了 seaborn 库的一个强大功能:


在本文中,我不会逐一查看每个图表。然而,你可以注意到一些线性关系,例如(半径对凹点),(凹度对紧密度)…等等。半径和分形维数之间似乎存在指数关系。因为面积= π(半径)&周长= 2π(半径),所以它们之间应该具有所示的关系。我们可以用相关性指标来总结所有这些:


步骤 6 —数据转换
我将特性列分配给 X,将标签列“诊断”分配给 y:

接下来,我分割 30%的数据作为我的测试输入和输出,以便稍后对分类器模型进行评分。其余的分配给训练数据集(X_train 和 y_train)

之后,我运行一个著名的无监督降维算法:主成分分析(PCA)。它通过捕捉数据的最大可变性来模拟数据的线性子空间。由于它对最易变的数据很敏感,我标准地缩放了所有的特征,并使它们的方差统一起来。



然后,建立 n _ omponents = 7 的 PCA 模型,将其拟合到训练数据,然后使用 PCA 模型转换测试和训练数据:

步骤 7 —分类建模
我在训练数据上尝试了许多分类算法,并用测试数据对模型进行评分,以了解它们的表现如何。实际上,我得到了许多好的准确率分数,其中之一是通过径向核支持向量分类器(SVC)。通过少量迭代,我设置了以下参数:C= 0.9 和 gamma = 0.063,并用测试数据对模型进行评分:

该模型的得分为:94.7%的准确率。但是我们必须转到交叉验证步骤,以验证模型的准确性,并观察它的表现。
步骤 8 —模型评估
在这里,我对训练数据运行 10 重交叉验证函数。这样,训练数据首先被切割成多个“K”组(在本例中是 10)。然后,训练模型的“K”个版本,每个版本使用“K”个可用集合中的独立的 K-1 个。每个模型都用最后一套来评估,它是一套:


10 倍交叉验证准确度的平均值为:%94.98,AUROC(接收器工作曲线下面积)= 0.99

让我们深入挖掘分类器评估,看看它是如何执行的,特别是恶性类别(映射为 1)。如你所知,假阴性非常低或为零是非常重要的,因为实际上在阳性时错过恶性细胞是非常危险和昂贵的。

利用测试数据集(原始数据的 30%),分类器能够检测所有良性细胞(真阴性),而在预测恶性细胞时,它有 9 个假阴性和 55 个真阳性。此外,让我们检查评分标准:

最后,我将提到一些可能影响模型准确性的优化想法,更重要的是减少假阴性预测。然而,我将期待着收到您的经验丰富的思想和想法,以优化模型,除了整个项目。我相信知识共享,并认为这是提高技能的最佳方式。最后但同样重要的是,这里有一些优化“乳腺癌分类器”的想法:
处理异常值并研究其影响,包括更多数据集,例如:标准误差和最大值,使模型更“偏向”恶性类别以移除假阴性事件,对其他分类模型(如决策树和朴素贝叶斯)进行更多试验,或使用 RandomizedSearchCV 函数试验更多参数…等等。
使用支持向量机(SVM)的乳腺癌分类

背景:
乳腺癌是世界上女性中最常见的癌症。它占所有癌症病例的 25%,仅在 2015 年就影响了超过 210 万人。当乳房中的细胞开始不受控制地生长时,它就开始了。这些细胞通常形成肿瘤,可以通过 X 射线看到或在乳房区域感觉到肿块。
早期诊断大大增加了存活的机会。对其检测的关键挑战是如何将肿瘤分类为恶性(癌性)或良性(非癌性)。如果肿瘤细胞可以生长到周围组织或扩散到身体的远处,则肿瘤被认为是恶性的。良性肿瘤不会侵犯附近的组织,也不会像恶性肿瘤那样扩散到身体的其他部位。但是,如果良性肿瘤压迫血管或神经等重要结构,就会很严重。
机器学习技术可以显著提高乳腺癌的诊断水平。研究表明,经验丰富的医生可以以 79%的准确率检测癌症,而使用机器学习技术可以达到 91 %(有时高达 97%)的准确率。
项目任务
在这项研究中,我的任务是使用从几个细胞图像中获得的特征将肿瘤分为恶性(癌性)或良性(非癌性)。
从乳腺肿块的细针抽吸(FNA)的数字化图像中计算特征。它们描述了图像中出现的细胞核的特征。
属性信息:
- 识别号
- 诊断(M =恶性,B =良性)
为每个细胞核计算十个实值特征:
- 半径(从中心到周边各点的平均距离)
- 纹理(灰度值的标准偏差)
- 周长
- 面积
- 平滑度(半径长度的局部变化)
- 紧凑性(周长/面积— 1.0)
- 凹度(轮廓凹入部分的严重程度)
- 凹点(轮廓凹陷部分的数量)
- 对称
- 分形维数(“海岸线近似值”-1)
加载 Python 库和乳腺癌数据集

让我们来看看数据框中的数据

功能(列)细分

想象我们特征之间的关系



让我们检查一下我们特征之间的相关性


There is a strong correlation between mean radius and mean perimeter, as well as mean area and mean perimeter
先说数据科学中的建模。
我们说“建模”是什么意思?
根据我们在一个特定的地方住了多长时间和去了一个地方,我们可能对我们所在地区的通勤时间有很好的了解。例如,我们通过地铁、公交车、火车、优步、出租车、拼车、步行、骑自行车等方式去上班/上学。
所有人类都自然地模仿他们周围的世界。
随着时间的推移,我们对交通的观察建立了一个心理数据集和心理模型,帮助我们预测不同时间和地点的交通状况。我们可能使用这种思维模式来帮助计划我们的一天,预测到达时间和许多其他任务。
- 作为数据科学家,我们试图通过使用数据和数学/统计结构,使我们对不同量之间关系的理解更加精确。
- 这个过程叫做建模。
- 模型是对现实的简化,帮助我们更好地理解我们观察到的事物。
- 在数据科学环境中,模型通常由感兴趣的独立变量(或输出)和一个或多个被认为会影响独立变量的因变量(或输入)组成。
基于模型的推理
- 我们可以使用模型进行推理。
- 给定一个模型,我们可以更好地理解自变量和因变量之间或多个自变量之间的关系。
一个心智模型的推理很有价值的例子是:
决定一天中什么时候我们工作得最好或者最累。
预言;预测;预告
- 我们可以使用模型进行预测,或者在给定至少一个自变量的值的情况下估计因变量的值。
- 即使预测不完全正确,它们也是有价值的。
- 好的预测对于各种各样的目的来说都是非常有价值的。
心智模型预测有价值的一个例子:
预测从 A 点到 b 点需要多长时间。
模型预测和推断有什么区别?
- 推断是判断数据和输出之间的关系,如果有的话。
- 预测是基于数据和基于该数据构建的模型对未来情景进行猜测。
在这个项目中,我们将讨论一种叫做支持向量机(SVM)的机器学习模型
分类建模简介:支持向量机(SVM)
什么是支持向量机(SVM)?
支持向量机(SVM)是一种二元线性分类,其决策边界被显式构造以最小化泛化误差。它是一个非常强大和通用的机器学习模型,能够执行线性或非线性分类、回归甚至异常值检测。
SVM 非常适合对复杂的中小型数据集进行分类。
SVM 如何分类?
对于 SVM 的特殊线性可分分类案例,从直觉开始很重要。
如果观察值的分类是**“线性可分”,那么 SVM 符合“决策边界”,它是由每类最近点之间的最大差值定义的。这就是通常所说的“最大边缘超平面(MMH)”**。

支持向量机的优势在于:
- 在高维空间有效。
- 在维数大于样本数的情况下仍然有效。
- 在决策函数中使用训练点的子集(称为支持向量),因此它也是内存高效的。
- 通用:可以为决策函数指定不同的内核函数。提供了通用内核,但是也可以指定定制内核。
支持向量机的缺点包括:
现在我们对建模和支持向量机(SVM)有了更好的理解,让我们开始训练我们的预测模型。
模特培训
从我们的数据集中,让我们创建目标和预测矩阵
- “y”=是我们试图预测的特征(输出)。在这种情况下,我们试图预测我们的“目标”是癌性的(恶性)还是非良性的(良性)。也就是说,我们将在这里使用“目标”功能。
- “X”=剩余列(平均半径、平均纹理、平均周长、平均面积、平均平滑度等)的预测值。)


创建培训和测试数据
既然我们已经为“X”和“y”赋值,下一步就是导入 python 库,它将帮助我们将数据集分成训练和测试数据。
- 训练数据=用于训练模型的数据子集。
- 测试数据=模型以前没有见过的数据子集(我们将使用这个数据集来测试模型的性能)。

让我们将数据分成两部分,80%用于训练,剩下的 20%用于测试。

导入支持向量机(SVM)模型

现在,让我们用“训练”数据集来训练我们的 SVM 模型。

让我们使用训练好的模型,利用我们的测试数据进行预测

下一步是通过与我们已有的输出(y_test)进行比较来检查我们预测的准确性。我们将使用混淆矩阵进行比较。

让我们为分类器在测试数据集上的性能创建一个混淆矩阵。

让我们在热图上可视化我们的混淆矩阵



如我们所见,我们的模型在预测方面做得并不好。它预测有 48 名健康患者患有癌症。我们只达到了 34%的准确率!
让我们探索提高模型性能的方法。
改进我们的模型
我们将尝试的第一个过程是通过标准化我们的数据
数据标准化是一个将所有值纳入范围[0,1]的特征缩放过程
X ’ =(X-X _ min)/(X _ max-X _ min)
规范化培训数据




规范化培训数据

现在,让我们用我们的缩放(标准化)数据集来训练我们的 SVM 模型。

利用缩放数据集进行预测

缩放数据集上的混淆矩阵



我们的预测好了很多,只有一个错误预测(预测癌症而不是健康)。我们达到了 98%的准确率!
总结:
本文带我们经历了解释“建模”在数据科学中的含义、模型预测和推理之间的差异、支持向量机(SVM)介绍、SVM 的优点和缺点、训练 SVM 模型以进行准确的乳腺癌分类、提高 SVM 模型的性能以及使用混淆矩阵测试模型准确性的旅程。
如果你想要一个 Jupyter 笔记本格式的这个项目的所有代码,你可以从我的 GitHub 仓库 下载它们。
来源:
- http://scikit-learn.org/stable/modules/svm.html
- http://www.robots.ox.ac.uk/~az/lectures/ml/lect2.pdf
- http://pyml.sourceforge.net/doc/howto.pdf
- https://www.bcrf.org/breast-cancer-statistics
- https://www . cancer . org/cancer/breast-cancer/about/what-is-breast-cancer . html
和 TPOT 一起酝酿一批机器学习

当处理一个新的数据集时,我经常会考虑以迭代的方式可视化、分析和构建模型的最佳工具。也许我很难理解数据的某些方面。我可能会研究一些致力于类似问题集可视化的 Kaggle 内核,以便收集一些新的想法。我也可能会向一些朋友和同事请教。我继续尝试新的方法来找到一个充分的解决方案。
如果我的模型管道没有产生期望的结果,我可能会做出大量的特征选择、缩放和算法选择。这些选择有些是基于经验,有些是凭直觉。然而,大多数时候我最终做了很多工作,尝试了一系列不同的模型和超参数、特征工程等。

近年来,像 h2o.ai 和 AutoML 这样的工具通过自动化这些更繁琐的任务变得越来越流行。虽然出于教学目的,我偶尔喜欢尝试不同的模型架构,但是在其他情况下,我希望自动化其中的一些选择。虽然这些工具令人印象深刻,但我最近了解到一个开源项目,它将几乎完整的机器学习管道直接送到您的手中:。
TPOT 使用进化框架来优化超参数、选择特性,甚至为您选择算法。方便的是,它利用了几乎所有数据科学家都熟悉和使用的 sklearn 算法。乍一看,TPOT 看起来太强大了,令人难以置信,所以我知道我必须尝试一下。
此外,我最近对进化系统及其在机器学习方面的持续成功非常着迷。这篇博文启发我甚至构建了自己的进化算法来扮演太空入侵者。《走向数据科学》也有一些非常好的文章。当我听说 TPOT 使用 ES 时,我受到了进一步的启发,开始着手一个试验项目。
正如我前面提到的,通常我手头有一项任务,我会为这项工作选择一套工具。在这篇文章中,我打破了这个模式:TPOT 是我唯一的工具,我将收集一个数据集来测试它!我想要一些相对简单的、由开放数据组成的、我热爱的东西。一个辅助目标是让数据足够小,任何人都可以将其加载到笔记本电脑上或在 Kaggle 上使用(如果你感兴趣,这就是我最终存储数据集的地方)。

我对可再生能源和环境感到非常兴奋。在之前的博客帖子中,我使用了来自三藩市的建筑能效公开数据来描述这些数据的趋势。对于这个练习,我想我会利用来自国家可再生能源实验室(NREL)的关于太阳能的邮政编码级别的数据集。我将这些数据与 catalog.data.gov/dataset/zip-code-data 的邮政编码信息结合在一起。

我很快在这个数据集中为我的目标变量寻找一个重要的特征。我决定让 TPOT 决定预测太阳能装置每瓦成本的最佳模型。有几个主要原因:
- 作为一个社会,我们需要从化石燃料快速过渡到碳中性能源。
- 不幸的是,这一切发生得还不够快,尽管与气候变化有着难以置信的代价(人类痛苦、环境等)。
- 幸运的是,可再生能源的成本正在下降。在美国,只有当一项行动与金钱利益相关联时,这种行动才会发生。

Median cost_per_watt at the state level
如果我(或者更确切地说是 TPOT)能够有效地从数据中学习一些能够预测某些地区低每瓦成本的驱动特征,也许这个结果可以在该国的其他地区进一步探索。

我故意不帮 TPOT 提什么东西。我的实验试图确定系统的开箱即用效率。该算法声称可以处理数据科学管道中的几乎每一部分。我写了一个快速的 Kaggle 内核,它加载数据,加入数据,删除一些 nan,释放 TPOT 的愤怒。我们可以期待什么?来自 TPOT 的文件:
- 对于默认的 TPOT 参数,100 个“基因样本”将在您的数据集上运行 100 代,每代都由各种算法和超参数组成
- 每个样本(在这种情况下是 10,000 个独特的样本)将进行 10 次交叉验证。如果你愿意,你甚至可以使用一个自定义的损失函数!
- 如果找到了最佳管道,将输出 CV 分数和管道参数。
API 调用非常简单,看起来很像您在 Python 中使用的任何 ML 算法:

Pretty simple!
我肯定会建议在多个 CPU 上运行这个程序( n_jobs=-1 ),然后去做午饭,因为这可能需要很长时间。在免费的 Kaggle 机器上,我保持了较小的世代和群体规模,并且仍然需要将我的特征空间减少到只有 5-10 个相关特征。TPOT 的文档警告用户可能需要一整天的时间来实现融合模型!在会话结束时,我收到了如下输出:

Best negative Mean Squared Error: -0.137
现在我可以去 sklearn ,做一点功能工程,然后使用相对简单的 ExtraTreesRegressor 来构建这个模型。上述模型仅使用了 OpenPV 数据集中的要素样本。后来的一个测试,仅使用邮政编码数据,表现不尽如人意。
然而,这篇文章的目的并不是深入这个特殊的数据问题,所以我们不会进一步讨论它。这应该都是关于 TPOT 的!总的结论是,TPOT 值得进一步探索。积极的一面是:
- 它容易使用,非常危险。它与您日常的 Python 数据工作流相集成。一个完全的初学者可以加载并使用它。
- 它探讨了多项式特性、大量超参数和各种组合的算法。
- 一旦管道决定了一个模型,你可以稍后在 sklearn 中构建它,而不用再使用 TPOT。
- 文档是以简单明了的方式编写的。
- 您可以轻松地提供自定义损失函数。
我发现的唯一真正的缺点是我在使用 Kaggle 内核时遇到的速度和内存问题。但是,这真的是一个问题吗?在一个装备更加完善的数据科学平台上,TPOT 真的可以大放异彩。
在过去的几年里,随着 AutoML 变得越来越强大,我已经听到了数据科学职业生涯的厄运。有一些令人信服的反驳观点没有得到太多的关注。数据科学家的工作流程中有哪一块没有包括在 TPOT 管道中?*数据清洗。*在我的日常工作中,这一项就能消耗我 80%的时间和精神能量。
如何制定正确的问题?在类似 Kaggle 的竞赛中,问题集和数据都是为数据科学家精心准备的,这很少被考虑。在商业环境中工作时,简单地问正确的问题是成功项目的重要组成部分。你在优化什么?企业需要什么?你如何向决策者解释这一点?TPOT 对此没有帮助。
总的来说,TPOT 和 AutoML 将使数据科学家更有效率。计算是廉价的,但我们的时间是宝贵的。使用这些工具来改进您的工作流程,花时间问正确的问题,有效地清理/分析数据,并交流您的结果。网格搜索超参数不是对你时间的有效利用。我肯定会再次使用 TPOT,我希望你也能尝试一下。如果你喜欢这篇文章,请看看我的其他帖子!我感谢你的读者。
在 AWS SageMaker 上酝酿定制 ML 模型

最近爱上了 SageMaker。仅仅是因为它太方便了!我真的很喜欢他们的方法,向客户隐藏所有的基础设施需求,让他们专注于解决方案中更重要的 ML 方面。只需在这里或那里点击几下并输入,瞧,您就有了一个准备好生产的模型,每天可以处理 1000 个(如果不是数百万个)请求。如果你需要一个关于 SageMaker 的好的介绍,看看下面这个非亚马逊公司的视频吧!
那么可能会出什么问题呢?
但是当您试图在自己的 docker 容器中设置和创建自己的模型来执行定制操作时,麻烦就来了!这不像一开始就用 SageMaker 构建一切那样简单流畅。
为什么您需要定制模型?
您需要自己的定制模型的原因有很多。你可能是:
- 使用一些特定的 python 库版本,而不是最新的版本(例如 TensorFlow)
- 使用 SageMaker 上不可用的库
继续之前…
在继续之前,请确保您具备以下条件。
- Docker 安装并运行在您的操作系统中
- Docker 工作原理的基本知识
我们如何做到这一点?
现在有了一个好的背景,让我们深入了解为 SageMaker 做准备的细节。教程将有三个不同的部分。
- 用你的代码创建一个 docker 图像
- 在本地测试 docker 容器
- 在 Amazon ECR(弹性容器存储库)上部署映像
让我在这里把这些观点具体化。首先,您创建一个 docker 映像,其中包含库和代码以及其他需求(例如对端口的访问)。然后,从该映像创建一个容器并运行该容器。然后,您用容器中的一小块数据测试代码/模型。成功测试后,您将 docker 映像上传到 ECR。然后,您可以将该图像指定为 ML 模型,并通过 Amazon SageMaker 将其用于训练/预测。
此外,我将使用这个教程/指南作为这个博客的参考框架。真的是很好的教程。我想重新创作这篇博文的原因很少:
- 如果你只依赖 scikit-learn,这是一个很好的教程。我想到用 XGBoost 创建一个容器,所以我们必须对 Docker 容器做一些修改。
- 我想要 Python 3 而不是 Python 2,原因显而易见。
- 我还觉得这里和那里缺少一些细节(尤其是在本地测试时)。
为了演示这个过程,我将在虹膜数据集上训练一个 XGBoost 分类器。你可以在这里 找到所有代码 的 Github 库。
Docker 概述
你知道还有什么比 SageMaker 更神奇吗?码头工人。Docker 极其强大,便携,快速。但这不是讨论原因的地方。所以让我们直接开始设置吧。使用 Docker 时,您有一套清晰的步骤:
- 创建一个包含代码/模型的文件夹和一个名为
Dockerfile的特殊文件,该文件包含用于创建 docker 图像的配方 - 运行
docker build -t <image-tag>创建一个 docker 映像 - 通过运行
docker run <image>来运行图像 - 使用
docker push <image-tag>将 docker 映像推送到将存储该映像的某个存储库(例如 dockerhub 或 AWS ECR 存储库)
SageMaker 兼容 Docker 容器概述
注意,SageMaker 要求图像有一个特定的文件夹结构。SageMaker 寻找的文件夹结构如下。主要有两个父文件夹/opt/program存放代码,和/opt/ml存放工件。请注意,我已经模糊掉了一些您可能不需要编辑的文件(至少对于本练习来说是这样),它们超出了本教程的范围。

Adapted from of awslabs/ amazon-sagemaker-examples Github

Program structure in the Docker container
现在让我们详细讨论一下这些实体中的每一个。首先,opt/ml是所有人工制品将要存放的地方。现在让我们来谈谈每个子目录。
目录:/opt/ml
input/data是存储模型数据的目录。它可以是任何与数据相关的文件(假设您的 python 代码可以读取数据,并且容器具有这样做所需的库)。这里的<channel_name>是模型将要使用的一些消耗性输入源的名称。
model是模型将要驻留的地方。您可以将模型放在它自己的容器中,您可以指定一个 URL (S3 桶位置),模型工件以一个tar.gz文件的形式保存在那里。例如,如果您有亚马逊 S3 桶中的模型工件,您可以在 SageMaker 上的模型设置期间指向那个 S3 桶。然后,当您的模型启动并运行时,这些模型工件将被复制到model目录中。
最后,output是控制器,如果失败,它将存储请求/任务失败的原因。
目录:/opt/program
现在让我们深入研究我们模型的精华部分;算法。这应该可以在我们 Docker 容器的/opt/program目录中找到。关于train、serve和predictor.py,我们需要小心的主要有三个文件。
train保存用于训练模型和存储训练模型的逻辑。如果train文件运行无故障,它将保存一个模型(即 pickle 文件)到/opt/ml/model目录。
serve essential 使用 Flask 将predictor.py中编写的逻辑作为 web 服务运行,它将监听任何传入的请求,调用模型,做出预测,并返回带有预测的响应。
Dockerfile 文件
这是支持 Docker 容器中可用内容的文件。这意味着这个文件极其重要。所以让我们来看看里面。如果您已经熟悉如何编写 Dockerfile 文件,这是非常简单的。不过,还是让我带你简单参观一下吧。
FROM指令指定一个基本图像。所以这里我们使用一个已经构建好的 Ubuntu 映像作为我们的基础映像。- 接下来使用
RUN命令,我们使用apt-get install安装几个包(包括 Python 3.5) - 然后再次使用
RUN命令,我们安装 pip,接着是numpy、scipy、scikit-learn、pandas、flask等。 - 随后,我们使用
ENV命令在 Docker 容器中设置了几个环境变量。我们需要将我们的/opt/program目录添加到path变量中,这样,当我们调用容器时,它会知道我们的算法相关文件在哪里。 - 最后但同样重要的是,我们将包含算法相关文件的文件夹
COPY到/opt/program目录,然后将其设置为WORKDIR
创建我们自己的 Docker 容器
首先,我将使用aw slaps Github 库提供的惊人包的修改版本(链接此处为)。这个原始存储库包含了我们运行 SageMaker 模型所需的所有文件,因此只需编辑这些文件,使其符合我们的需求。将原始链接中的内容下载到一个名为xgboost-aws-container的文件夹中,如果你想从头开始,或者,你可以摆弄我的版本。
注意:如果你是 Windows 用户,并且你是那些运行过时的 Docker 工具箱的不幸者之一,确保你使用了
C:\Users目录中的某个目录作为你的项目主文件夹。否则,将文件夹挂载到容器时,您会遇到非常糟糕的体验。
对现有文件的更改
- 将
decision-trees文件夹重命名为xgboost - 编辑存储库中提供的
train文件。我本质上所做的是,我导入了xgboost并将决策树模型替换为XGBClassifier模型。注意,一旦出现异常,就会被写入*/opt/ml/output*文件夹中的故障文件。因此,您可以自由地包含尽可能多的描述性异常,以确保您知道程序失败时哪里出错了。 - 编辑存储库中提供的
predictor.py文件。本质上,我所做的类似于在train上所做的改变。我导入了xgboost,把分类器改成了XGBClassifier。 - 打开你的
Dockerfile进行以下编辑。
我们使用python3.5而不是python,并根据 xgboost 的要求添加了libgcc-5-dev。
RUN apt-get -y update && apt-get install -y — no-install-recommends \
wget \
python3.5 \
nginx \
ca-certificates \
libgcc-5-dev \
&& rm -rf /var/lib/apt/lists/*
我们将询问numpy、scikit-learn、pandas、xgboost的具体版本,以确保它们相互兼容。指定您想要使用的库的版本的另一个好处是,您知道它不会仅仅因为某个库的新版本与您的代码不兼容而中断。
RUN wget [https://bootstrap.pypa.io/3.3/get-pip.py](https://bootstrap.pypa.io/3.3/get-pip.py) && python3.5 get-pip.py && \
pip3 install numpy==1.14.3 scipy scikit-learn==0.19.1 xgboost==0.72.1 pandas==0.22.0 flask gevent gunicorn && \
(cd /usr/local/lib/python3.5/dist-packages/scipy/.libs; rm *; ln ../../numpy/.libs/* .) && \
rm -rf /root/.cache
然后,我们将拷贝命令更改为以下内容
COPY xgboost /opt/program
建立码头工人形象
现在打开您的 Docker 终端(如果在 Windows 上,否则是 OS 终端)并转到包的父目录。然后运行以下命令。
docker build -t xgboost-tut .
这应该建立我们需要的一切形象。确保映像是通过运行,
docker images
您应该会看到如下所示的内容。

运行 Docker 容器来训练模型
现在是运行容器的时候了,开始执行下面的命令。
docker run --rm -v $(pwd)/local_test/test_dir:/opt/ml xgboost-tut train
让我们来分解这个命令。
--rm:表示当你离开集装箱时,集装箱将被销毁
-v <host location>:<container location>:将卷安装到容器中的所需位置。警告 : Windows 用户,如果你选择C:\Users之外的任何东西,你都会有麻烦。
xgboost-tut:图像的名称
train:随着容器的启动,将自动开始运行/opt/program目录下的火车文件。这就是为什么指定/opt/program作为PATH变量的一部分很重要。
事情应该运行良好,您应该会看到类似下面的输出。
Starting the training.
Training complete.
您还应该在您的<project_home>/local_test/test_dir/model目录中看到xgboost-model.pkl文件。这是因为我们将local_test/test_dir目录挂载到了容器的/opt/ml中,所以无论/opt/ml发生什么都将反映在test_dir中。
在本地测试容器以供食用
接下来,我们要看看服务(推理)逻辑是否正常工作。现在让我在这里再次警告,如果你错过了以上!如果您是 Windows 用户,请注意正确安装宗卷。为了避免任何不必要的问题,确保您在C:\Users文件夹中选择一个文件夹,作为您的项目主目录。
docker run --rm --network=host -v $(pwd)/local_test/test_dir:/opt/ml xgboost-tut serve
让我指出我们在 Docker run 命令中指定的一个特殊选项。
--network=host:表示主机的网络栈将被复制到容器中。所以这就像在本地机器上运行一些东西。这是检查 API 调用是否正常工作所必需的。
注意:我用的是
--network=host,因为-p <host_ip>:<host_port>:<container_port>不工作(至少在 Windows 上)。我推荐使用-p 选项(如果有效的话),如下所示。警告:仅使用其中一个命令,不要同时使用两个。但我将假设--network=host选项继续前进。
docker run --rm -p 127.0.0.1:8080:8080 -v $(pwd)/local_test/test_dir:/opt/ml xgboost-tut serve
serve:这是调用推理逻辑的文件
这将向您显示类似下面的输出。

现在,为了测试我们是否能成功 ping 通服务,运行以下命令(在单独的终端窗口中)。
curl http://<docker_ip>:8080/ping
您可以通过以下方式找到 Docker 机器的 IP
docker-machine ip default
这个 ping 命令应该在主机端和服务器端产生两条消息。类似下面的东西。

如果这一切进展顺利(我非常希望如此),直到这一点。恭喜你!您几乎已经建立了一个 SageMaker 兼容的 Docker 映像。直播前我们还需要做一件事。
现在让我们试试更刺激的东西。让我们试着通过我们的 web 服务做一个预测。为此,我们将使用位于local_test文件夹中的predict.sh文件。请注意,我已经对它进行了修改,以适应我的需求,这意味着它不同于原始 awslabs 存储库中提供的那个。确切地说,我引入了一个新的用户提示参数,除了原始文件中的 IP 地址和端口之外,它还会接受这些参数。我们使用下面的命令调用修改后的[predict.sh](https://github.com/thushv89/xgboost-aws-container/blob/master/local_test/predict.sh)文件。
./predict.sh [<container_ip>:<](http://192.168.99.100:8080)port> payload.csv text/csv
这里我们使用payload.csv中的数据调用推理 web 服务,并说它是一个 csv 文件。它应该会返回以下内容。它将其中的数据点标识为属于类setosa。
* timeout on name lookup is not supported
* Trying <container_ip>…
* TCP_NODELAY set
* Connected to <container_ip> (<container_ip>) port <port> (#0)
> POST /invocations HTTP/1.1
> Host: <container_ip>:<port>
> User-Agent: curl/7.55.0
> Accept: */*
> Content-Type: text/csv
> Content-Length: 23
>
* upload completely sent off: 23 out of 23 bytes
< HTTP/1.1 200 OK
< Server: nginx/1.10.3 (Ubuntu)
< Date: <date and time> GMT
< Content-Type: text/csv; charset=utf-8
< Content-Length: 7
< Connection: keep-alive
<
setosa
* Connection #0 to host <container_ip> left intact
把它推到控制室
好吧。所以努力终于有了回报。是时候将我们的图像推送到亚马逊弹性容器库(ECR)了。在此之前,请确保您在 ECR 中创建了一个存储库,以便将图像推送到其中。如果你有一个 AWS 账户,这很简单。
从 AWS 仪表板转到 ECR 服务,然后单击“创建存储库”

创建存储库后,在存储库中,您应该能够看到完成推送 ECR 的指令。
注意:您也可以使用存储库中提供的 build_and_push.sh。但是我个人觉得自己做事情更舒服。推动存储库其实没有那么多步骤。
首先,您需要获得登录 ECR 的凭证
aws ecr get-login — no-include-email — region <region>
它应该会返回一个输出,
docker login …
复制粘贴该命令,现在您应该登录到 ECR。接下来,您需要重新标记您的图像,以便能够正确地推送至 ECR。
docker tag xgboost-tut:latest <account>.dkr.ecr.<region>.amazonaws.com/xgboost-tut:latest
现在是时候将图像推送到您的存储库了。
docker push <account>.dkr.ecr.<region>.amazonaws.com/xgboost-tut:latest
现在图像应该出现在您的 ECR 存储库中,标签为latest。困难的部分已经完成,接下来您需要创建一个 SageMaker 模型并指向图像,这就像用 SageMaker 本身创建一个模型一样简单。所以我不会在博文中详述这些细节。
你可以在这里 找到所有代码 的 Github 库。
结论
这是一次漫长的旅行,但(在我看来)很有收获。所以我们在本教程中做了以下工作。
- 首先,我们理解了为什么我们可能需要制作我们自己的定制模型
- 然后我们检查了 SageMaker 运行容器所需的 Docker 容器的结构。
- 然后,我们讨论了如何创建容器的 Docker 映像
- 接下来是如何构建映像和运行容器
- 接下来,我们讨论了在推出之前,如何在本地计算机上测试容器
- 最后,我们讨论了如何将图像推送到 ECR,以便通过 SageMaker 使用。
特别感谢做出原始 Github 库的贡献者给了我一个令人敬畏的起点!最后但重要的是,如果你喜欢这篇文章,请留下一些掌声:)
想在深度网络和 TensorFlow 上做得更好?
检查我在这个课题上的工作。

[2] (视频教程)Python 中的机器翻译 — DataCamp
[3] (书)TensorFlow 中的自然语言处理 1 — Packt
新的!加入我的新 YouTube 频道

如果你渴望看到我关于各种机器学习/深度学习主题的视频,请确保加入 DeepLearningHero 。
医学图像分析和深度学习简介

我最近开始从事一个与医学图像分析相关的项目,在寻找关于图像分析及其医学应用的资源时,我觉得我们通常没有一些关于这些信息的合适文章。在本文中,我们将简要介绍过去如何分析医学图像,以及自从引入深度学习以来发生了什么变化。对于图像分析,我们通常使用 CNN (卷积神经网络),虽然在这里解释它会使整篇文章变得繁琐,但我将提供一些链接来正确解释CNN。
一旦有可能扫描医学图像并将其加载到计算机中,研究人员就试图建立系统来自动分析这些图像。最初,从20 世纪 70 年代到20 世纪 90 年代,医学图像分析是通过顺序应用低级像素处理(边缘和线检测器过滤器)和数学建模来构建一个基于规则的系统,该系统只能解决特定的任务。同时还有一些基于 if-else 规则的代理,在人工智能领域很流行,通常被称为 GOFAI (老式人工智能)代理。
*20 世纪 90 年代末,*监督技术开始流行,其中训练数据用于训练模型,并且它们在医学图像分析领域变得越来越流行。例子可能包括活动形状模型、图谱方法。这种模式识别和机器学习仍然流行,但引入了一些新的想法。因此,我们可以看到从人类设计的系统到计算机基于示例数据训练的系统的转变。计算机算法现在有足够的能力来确定边缘和重要特征,以分析图像并给出最佳结果。
迄今为止,最成功的图像分析模型是卷积神经网络(CNN)。单个 CNN 模型包含许多不同的层,这些层在较浅的层上识别边缘和简单特征,在较深的层上识别更深的特征。用滤波器(有人称之为核)对图像进行卷积,然后应用池化,这个过程可以在一些层上继续,最后获得可识别的特征。CNN 的工作从80 年代就开始了,在 1995 年就已经应用于医学图像分析。CNN 的第一个真实应用出现在LeNetT11【1998】中,用于手写数字识别。尽管早期取得了一些小的成功,但 CNN 获得了动力,直到引入了深度学习中的改进训练算法。GPU的引入有利于该领域的研究,自 ImageNet 挑战赛引入以来,可以看到此类模型的快速发展。

Illustration of CNN (Convolutional Neural Network)
在计算机视觉领域,CNN 已经成为首选。医学图像分析社区已经注意到这些关键的发展。然而,从使用手工特征的系统到从数据本身学习特征的系统的过渡是渐进的。深度学习在医学图像分析中的应用首先开始出现在研讨会和会议上,然后出现在期刊上。如图所示,论文数量在 2015 和 2016 有所增长。

- 分类:这是医学图像分析中最早使用深度学习的领域之一。诊断图像分类包括诊断图像的分类,在这种设置下,每个诊断检查都是样本,数据量小于计算机视觉的数据量。对象或病变分类通常集中于将医学图像的一部分分类成两个或多个类别。对于这些任务中的许多,精确分类需要关于病变外观和位置的局部和全局信息。
- 检测:器官/病变等解剖对象定位是分割任务的重要预处理部分。图像中对象的定位需要图像的 3D 解析,已经提出了几种算法来将 3D 空间转换为 2D 正交平面的组合。使用计算机辅助技术检测医学图像中的病变,提高检测精度或减少人类的检测时间,已经成为一种长期的研究趋势。有趣的是,第一个这样的系统是在 1995 年开发的,它使用一个有 4 层的 CNN 来检测 x 光图像中的结节。
- 分割:医学图像中器官和其他子结构的分割允许与形状、大小和体积相关的定量分析。分割的任务通常被定义为识别定义感兴趣的轮廓或对象的一组像素。病灶的分割结合了在深度学习算法的应用中对象检测以及器官和子结构分割的挑战。肿瘤分割与对象检测共有的一个问题是类别不平衡,因为图像中的大多数像素来自非患病类别。
- 配准:有时也称为空间对准,是一种常见的图像分析任务,其中计算从一幅图像到另一幅图像的坐标变换。这通常是在迭代框架中执行的,其中假设了特定类型的转换,并且优化了预先训练的度量。尽管病变检测和对象分割被视为深度学习算法的主要用途,但研究人员发现,深度网络有利于获得最佳的配准性能。
- 医学成像中的其他任务:深度学习在医学成像中还有一些其他用途。基于内容的图像检索 ( CBIR )是一种在大型数据库中进行知识发现的技术,为病历和理解罕见疾病提供类似的数据检索。图像生成和增强是另一项使用深度学习来提高图像质量、标准化图像、数据完善和模式发现的任务。将图像数据与报告结合起来是另一项任务,在现实世界中似乎有非常大的应用规模。这导致了两个不同的研究领域(1)利用报告来提高图像分类的准确性。(2)从图像生成文本报告。

Number of papers in different application areas of Deep Learning in medical imaging
很明显,深度学习在医学图像分析中的应用存在许多挑战,大数据集的不可用性经常被提到。然而,这种观点只是部分正确。在放射科使用 PACS 系统已经成为大多数西方医院的惯例,它们装满了数百万张图像。我们还可以看到大型公共数据集是由组织提供的。因此,主要的挑战不是图像数据本身的可用性,而是这些图像的标记。传统上 PACS 系统存储放射科医生描述他们发现的自由文本报告。以自动化的方式将这些报告转换成准确的注释或适当的标签,这本身就是一个需要复杂的文本挖掘技术的研究课题。
在医学成像中,分类或分割通常表现为二元任务:正常对异常,对象对背景。然而,这通常是一种粗略的简化,因为两个类都是高度异构的。例如,正常类别通常包括完全正常的组织,但也包括几种良性发现,这可能是罕见的。这导致了一个系统非常善于排除最常见的正常子类,但在几个罕见的子类上却失败得很惨。一个直接的解决方案是通过为系统提供所有可能子类的详细注释,将系统变成多类系统。再次,这是另一个问题,专业地标记所有的类,这似乎不实际。
在医学图像分析中,有用的信息不仅仅包含在图像本身中。医生通常会查看患者的病史、年龄和其他属性,以做出更好的决定。已经进行了一些研究,以在深度学习中包括除图像之外的这些特征,但结果显示,这并不那么有效。挑战之一是平衡深度学习网络中的成像特征与临床特征的数量,以防止临床特征被忽略。
原载于 2018 年 10 月 16 日medium.com。
将计算机视觉数据集纳入单一格式:迈向一致性

当你有一个好的工作算法,并且你想在一些数据集上测试你的杰作时,几乎总是要在数据的实际加载和预处理上花费相当多的时间。如果我们能够以一种单一的格式和一致的方式访问数据(例如,总是将训练图像存储在关键字“train/image”下),那就太好了。
在这里,我将分享一个由我编写的 github repo ,它将几个流行的数据集转换为 HDF5 格式。当前支持以下数据集。
这段代码是做什么的?
所以这个仓库做了很多事情。首先让我告诉你组织。代码库非常简单。每个数据集都有一个文件来预处理数据并另存为 HDF5(例如,对于 Imagenet,我们有preprocess_imagenet.py、CIFAR-10 和 CIFAR-100,我们有preprocess_cifar.py,对于 SVHN,我们有preprocess_svhn.py)。实际上,每个文件都执行以下操作:
- 将原始数据载入内存
- 执行所需的任何整形,以使数据达到适当的维度(例如,cifar 数据集将图像作为向量给出,因此需要将其转换为三维矩阵)
- 创建一个 HDF5 文件来保存数据
- 使用 Python 多重处理库,并根据用户规范处理每个图像
下面我将告诉 ImageNet 文件是做什么的。这是最复杂的文件,其他的都很简单。
这里我讨论一下preprocess_imagenet.py文件的作用。这基本上将 ImageNet 数据的子集保存为 HDF5 文件。该子集是属于许多自然类别(例如植物、猫)和人工类别(例如椅子、桌子)的数据。此外,您可以在保存数据时规范化数据。
一旦运行脚本,save_imagenet_as_hdf5(...)函数就会接管。该函数首先在有效的数据集文件名和标签之间创建一个映射(即build_or_retrieve_valid_filename_to_synset_id_mapping(...))。接下来,它用write_art_nat_ordered_class_descriptions(...)或retrieve_art_nat_ordered_class_descriptions(...)隔离与 ImageNet 数据集(1000 个类)的分类问题相关的类。然后我们使用write_selected_art_nat_synset_ids_and_descriptions(...)方法将选择的人工和自然类信息写入一个 xml 文件。
接下来,我们扫描训练数据中的所有子目录,并将所有相关数据点放入内存。接下来,我们创建 HDF 文件来保存数据。这是通过save_train_data_in_filenames(...)功能完成的。数据将保存在以下注册表项下:
/train/images//train/images//valid/images//valid/images/
稍后访问和加载数据
您以后可以通过以下方式访问这些保存的数据:
dataset_file = h5py.File(“data” + os.sep + “filename.hdf5”, “r”)train_dataset, train_labels = dataset_file[‘/train/images’], dataset_file[‘/train/labels’]test_dataset, test_labels = dataset_file[‘/test/images’], dataset_file[‘/test/labels’]
编码和进一步阅读
代码可以在这里获得,你可以在我的博客文章中查看关于代码做什么以及如何运行的完整描述。
**注意:**如果您在运行代码时看到任何问题或错误,请通过评论或在 Github 页面上打开问题让我知道。这将有助于我改进代码,消除任何讨厌的错误。
干杯!
为数据科学带来 Jupyter 笔记本电脑的最佳性能
使用这些提示和技巧提高 Jupyter 笔记本的工作效率。

Photo by Aaron Burden on Unsplash
重新想象 Jupyter 笔记本可以是什么,可以用它做什么。
旨在为其 1.3 亿观众提供个性化内容。网飞的数据科学家和工程师与他们的数据交互的重要方式之一是通过 Jupyter 笔记本。笔记本电脑利用协作、可扩展、可扩展和可复制的数据科学。对于我们中的许多人来说,Jupyter 笔记本电脑是快速原型制作和探索性分析的事实平台。然而,这并不像看上去那样简单。Jupyter 的许多功能有时隐藏在幕后,没有得到充分开发。让我们尝试探索 Jupyter 笔记本电脑的功能,这些功能可以提高我们的工作效率。
目录
- 执行 Shell 命令
- Jupyter 主题
- 笔记本扩展
- Jupyter 小工具
- Qgrid
- 幻灯片
- 嵌入 URL、pdf 和 Youtube 视频
1.执行 Shell 命令
笔记本是新壳
外壳是一种与计算机进行文本交互的方式。最流行的 Unix shell 是 Bash(Bourne Again SHell)。Bash 是大多数现代 Unix 实现和大多数为 Windows 提供类 Unix 工具的包中的默认 shell。
现在,当我们使用任何 Python 解释器时,我们需要定期在 shell 和 IDLE 之间切换,以防我们需要使用命令行工具。然而,Jupyter 笔记本通过在命令前添加一个额外的**!**,让我们可以轻松地从笔记本中执行 shell 命令。任何在命令行运行的命令都可以在 IPython 中使用,只需在前面加上**!**字符。
In [1]: !ls
example.jpeg list tmpIn [2]: !pwd
/home/Parul/Desktop/Hello World Folder'In [3]: !echo "Hello World"
Hello World
我们甚至可以像下面这样在 shell 之间传递值:
In [4]: files= !lsIn [5]: **print**(files)
['example.jpeg', 'list', 'tmp']In [6]: directory = !pwdIn [7]: **print**(directory)
['/Users/Parul/Desktop/Hello World Folder']In [8]: type(directory)
IPython.utils.text.SList
注意,返回结果的数据类型不是列表。
2.Jupyter 主题
将你的 Jupyter 笔记本主题化!
如果你是一个盯着 Jupyter 笔记本的白色背景会感到厌烦的人,那么主题就是为你准备的。主题也增强了代码的表现形式。你可以在这里找到更多关于 Jupyter 主题的信息。让我们开始工作吧。
安装
pip install jupyterthemes
可用主题列表
jt -l
目前,可用的主题有 chesterish,3 年级,gruvboxd,gruvboxl monokai,oceans16,onedork,solarizedd,solarizedl。
# **selecting a particular theme**jt -t <name of the theme># **reverting to original Theme**jt -r
- 每次更改主题时,您都必须重新加载 jupyter 笔记本,才能看到效果。
- 通过在命令前放置“
*!*”,也可以从 Jupyter 笔记本中运行相同的命令。



Left: original | Middle: Chesterish Theme | Right: solarizedl theme

3.笔记本扩展
扩展可能性
笔记本扩展功能让您超越 Jupyter 笔记本的常规使用方式。笔记本扩展(或 nbextensions)是 JavaScript 模块,您可以将其加载到笔记本前端的大多数视图中。这些扩展修改了用户体验和界面。
安装
安装 conda:
conda install -c conda-forge jupyter_nbextensions_configurator
或使用画中画:
pip install jupyter_contrib_nbextensions && jupyter contrib nbextension install#incase you get permission errors on MacOS,pip install jupyter_contrib_nbextensions && jupyter contrib nbextension install --user
现在启动一个 Jupyter 笔记本,你应该能看到一个有很多选项的 NBextensions 标签。点击你想要的,看看奇迹发生。

如果你找不到标签,可以在菜单**Edit** 下找到第二个小的 nbextension。

让我们讨论一些有用的扩展。
1.内地
****腹地为代码单元格中的每一次按键启用代码自动完成菜单,而不仅仅是用 tab 调用它。这使得 Jupyter notebook 的自动补全像其他流行的 ide 一样,比如 PyCharm。

2.片段
该扩展向笔记本工具栏添加了一个下拉菜单,允许将代码片段单元格轻松插入到当前笔记本中。

3.分裂细胞笔记本
这个扩展将笔记本的单元格分开,然后彼此相邻放置。

4.目录
这个扩展使得能够收集所有正在运行的标题,并在一个浮动窗口中显示它们,作为一个侧边栏或一个导航菜单。该扩展也是可拖动、可调整大小、可折叠和可停靠的。

5.可折叠标题
可折叠标题 a 允许笔记本拥有可折叠的部分,由标题分隔。因此,如果你的笔记本中有很多脏代码,你可以简单地折叠它,以避免反复滚动。

6.Autopep8
只需点击一下,Autopep8 就可以帮助重新格式化/修饰代码单元格的内容。如果你厌倦了一次又一次地敲空格键来格式化代码,autopep8 就是你的救星。

4.Jupyter 小工具
让笔记本互动
小部件是多事件的 python 对象,在浏览器中有一个表示,通常是像滑块、文本框等控件。小部件可以用来为笔记本电脑构建交互式图形用户界面**。**
装置
# **pip**
pip install ipywidgets
jupyter nbextension enable --py widgetsnbextension# **Conda** conda install -c conda-forge ipywidgets#Installing **ipywidgets** with conda automatically enables the extension
让我们来看看一些小部件。完整的细节,你可以访问他们的 Github 库。
交互
interact函数(ipywidgets.interact)自动创建一个用户界面(UI)控件,用于交互式地浏览代码和数据。这是开始使用 IPython 小部件的最简单的方法。
# Start with some imports!from ipywidgets import interact
import ipywidgets as widgets
1.基本部件
def f(x):
return x# Generate a slider
interact(f, x=10,);

# Booleans generate check-boxes
interact(f, x=True);

# Strings generate text areas
interact(f, x='Hi there!');

2.高级小部件
这里列出了一些有用的高级小部件。
播放小工具
Play 小部件有助于通过以一定速度迭代整数序列来执行动画。下面滑块的值与播放器相关联。
play = widgets.Play(
# interval=10,
value=50,
min=0,
max=100,
step=1,
description="Press play",
disabled=False
)
slider = widgets.IntSlider()
widgets.jslink((play, 'value'), (slider, 'value'))
widgets.HBox([play, slider])

日期选择器
日期选择器小部件可以在 Chrome 和 IE Edge 中工作,但目前不能在 Firefox 或 Safari 中工作,因为它们不支持 HTML 日期输入字段。
widgets.DatePicker(
description='Pick a Date',
disabled=False
)

颜色选择器
widgets.ColorPicker(
concise=False,
description='Pick a color',
value='blue',
disabled=False
)

标签页
tab_contents = ['P0', 'P1', 'P2', 'P3', 'P4']
children = [widgets.Text(description=name) for name in tab_contents]
tab = widgets.Tab()
tab.children = children
for i in range(len(children)):
tab.set_title(i, str(i))
tab

5.Qgrid
使数据帧直观
Qgrid 也是一个 Jupyter 笔记本小部件,但主要集中在数据帧上。它使用 SlickGrid 在 Jupyter 笔记本中呈现熊猫数据帧。这使您可以通过直观的滚动、排序和过滤控件来浏览数据框,并通过双击单元格来编辑数据框。Github 库包含了更多的细节和例子。
装置
使用 pip 安装:
pip install qgrid
jupyter nbextension enable --py --sys-prefix qgrid# only required if you have not enabled the ipywidgets nbextension yet
jupyter nbextension enable --py --sys-prefix widgetsnbextension
使用 conda 安装:
# only required if you have not added conda-forge to your channels yet
conda config --add channels conda-forgeconda install qgrid

6.幻灯片
沟通时代码是伟大的。
笔记本是教授和编写可解释代码的有效工具。然而,当我们想要展示我们的作品时,我们要么展示整个笔记本(包括所有代码),要么借助 powerpoint。不再是了。Jupyter 笔记本可以轻松转换成幻灯片,我们可以轻松选择在笔记本上显示什么和隐藏什么。
有两种方法可以将笔记本转换成幻灯片:
1.Jupyter 笔记本的内置滑动选项
打开一个新笔记本,导航到视图→单元格工具栏→幻灯片。每个单元格顶部会出现一个浅灰色条,您可以自定义幻灯片。

现在转到笔记本所在的目录,输入以下代码:
jupyter nbconvert *.ipynb --to slides --post serve
*# insert your notebook name instead of* **.ipynb*
幻灯片在端口 8000 显示。另外,目录中会生成一个.html文件,您也可以从那里访问幻灯片。

如果有主题背景,看起来会更有格调。让我们将主题’ onedork '应用到笔记本上,然后将其转换为幻灯片。

这些幻灯片有一个缺点,即你可以看到代码,但不能编辑它。RISE plugin 提供了一个解决方案。
2.使用 RISE 插件
RISE 是 Reveal.js 的缩写——Jupyter/IPython 幻灯片扩展。它利用 reveal.js 来运行幻灯片。这非常有用,因为它还提供了无需退出幻灯片就能运行代码的能力。
安装
1 —使用 conda(推荐):
conda install -c damianavila82 rise
2 —使用画中画(不太推荐):
pip install RISE
然后再分两步将 JS 和 CSS 安装到正确的位置:
jupyter-nbextension install rise --py --sys-prefix**#enable the nbextension:** jupyter-nbextension enable rise --py --sys-prefix
现在让我们使用 RISE 进行交互式幻灯片演示。我们将重新打开之前创建的 Jupyter 笔记本。现在我们注意到一个新的扩展,上面写着“进入/退出上升幻灯片”

点击它,你就可以开始了。欢迎来到互动幻灯片的世界。

更多信息请参考文件。
6.嵌入 URL、pdf 和 Youtube 视频
就显示在那里!
当你可以使用 IPython 的显示模块轻松地将 URL、pdf 和视频嵌入到你的 Jupyter 笔记本中时,为什么还要选择链接呢?
资源定位符
#Note that http urls will not be displayed. Only https are allowed inside the Iframefrom IPython.display import IFrame
IFrame('[https://en.wikipedia.org/wiki/HTTPS'](https://en.wikipedia.org/wiki/HTTPS'), width=800, height=450)

from IPython.display import IFrame
IFrame('[https://arxiv.org/pdf/1406.2661.pdf'](https://arxiv.org/pdf/1406.2661.pdf'), width=800, height=450)

Youtube 视频
from IPython.display import YouTubeVideoYouTubeVideo('mJeNghZXtMo', width=800, height=300)

结论
以上是 Jupyter 笔记本的一些功能,我觉得很有用,值得分享。有些对你来说是显而易见的,而有些可能是新的。所以,继续用它们做实验吧。希望他们能够节省你一些时间,给你一个更好的 UI 体验。也可以在评论中提出其他有用的功能。
顾客幸福吗?为他们建造一个聊天机器人。
人工智能(AI)以聊天机器人的形式首次亮相主流商业。各种规模的组织都在构建简单的信使机器人,以便更容易被他们的客户访问,特别是在支持场景中。聊天机器人使用逻辑来帮助人们更快地回答问题,而不是将人们指引到通用的电子邮件地址或服务台。这就像和一个人交谈——只不过你是在和一个机器人交谈。
聊天机器人对于规模较小、资源匮乏的组织尤其有价值。众所周知,各种规模的公司在向客户展示自己时,都会建立更牢固、更有同理心的关系。组织可以通过自动化往往是多余的对话来节省员工的宝贵时间。公司节省资金,提高客户成功的结果,引导人们通过销售周期,并提供支持。
对于不经意的观察者来说,聊天机器人可能看起来很复杂,但它们并不像看起来那么复杂。
简单而有效的聊天机器人在没有编码知识的情况下也是可以构建的。遵循这个框架,用更少的资源在几个小时内构建您的。

#研究您的聊天机器人的具体使用案例,并据此制定您的计划
Kore.ai 是一个允许人们在没有编程专业知识的情况下构建聊天机器人的工具。这家总部位于美国的公司由设计师、技术专家和学者组成,从用户体验的角度来看,它将自己描述为类似于苹果 Siri 这样的软件。该平台提供的是一种简单的方式来构建满足特定目的的聊天机器人应用程序。
“聊天机器人需要激发对话,”Kore.ai 的创始人拉杰·科内鲁(Raj Koneru)说,“它需要帮助处理自然语言是最佳沟通选择的那部分互动,它在这方面做得很好。一家在全球拥有超过 4.5 万名员工的 10 亿美元公司在内部使用 Kore.ai 的聊天机器人,为每位员工提供轻松的信息访问,以及即时请求创建和警报。该公司还消除了人为错误带来的风险,转而标准化和简化他们的成功方法”
Kore.ai Bot platform 使您能够构建对话机器人,这些机器人可以回答用户的查询,推动用户通过对话来执行业务功能或交易。Kore.ai 使用一种称为自然语言处理双重模式(NLP)的技术,实时适应对话。

在 Kore.ai 中建立对话
该平台结合了两种不同的 NLP 方法(机器学习+基本含义),可以即时构建对高达 70%的对话有用的对话机器人——无需语言培训即可开始。使用同义词、模式和完整的话语可以非常快速地完成额外的训练,这减少了开发人员提供的手动训练输入的数量,从而减少了启动和运行聊天机器人的时间。如果一开始就有大量的训练数据,也可以从一开始就应用 ML 模型,或者随着时间的推移使用 ML 模型来继续训练机器人以实现更好的意图识别。
“所有这些都是可以定制的,可以由机器人的制造者来训练。因为在 Kore.ai 平台中,所有的服务都是集成的。上下文信息(对话如何展开)被输入到神经网络,使其能够做出更明智的决定。Kore.ai 的首席技术官 Prasanna Arikala 说:“通过这种方式,该引擎允许用户模拟更复杂的对话流,如聊天期间转换对话主题,或从网站浏览行为中获取上下文信息。”
聊天机器人构建者需要采取以下步骤:
- 确定使用案例和渠道
- 设计您的流程、撰写文案并添加多媒体
- 训练你的机器人
- 集成服务
- 确定 KPI 并与测试对象一起评估
- 重复
#战略性地使用自动化,永远不要取代组织中人的一面
聊天机器人 AI 可能足够智能,可以做出简单的判断,但你构建的东西不会有取代人类同情心的情商。
“如果一家公司主要想降低成本,投资人工智能机器人是一个明智的商业举措,”Kore.ai 的 CMO 赛拉姆·维达姆说
然而,如果目标是客户满意,事情看起来就完全不同了。机器人还不能给出口头暗示,比如偶尔的“mhm”,来保证有人在听。他们也不能在棘手的情况下运用同情心和道德观。这些缺陷阻碍了机器人解决复杂的、个体的问题,而这些问题顾客可能连自己都无法识别。
如今,这种移交可以通过两种方式设计到 Kore.ai 平台上构建的机器人中:开发人员设计一个对话框,其中包含一个节点,在用户提出特定问题或采取其他行动后,可以移交给一个实时代理。这基于 Kore.ai 客户选择的预定义规则和业务逻辑。例如,对于特定类型的问题,您希望人工代理接管对话,或者对于特定类型的客户群或级别,您可能也希望人工代理介入。利用平台的情绪分析工具,开发人员可以设计情绪阈值(例如:如果用户情绪低于 3.0,则为负),以触发机器人移交给实时代理。一旦移交给代理,当用户在他们使用的任何通道中键入或说话时,消息将进入实时代理已经使用的软件中的聊天线程,允许他们无缝地响应用户,反之亦然。Kore.ai 的平台已经测试了与 Live Chat Inc,Genesys 等的集成。,并且可以轻松地与其他呼叫中心解决方案集成,作为我们客户的定制功能。
自 90 年代中期以来,美国客户满意度指数的最大跌幅发生在 2013 年至 2015 年间。在这一时期,许多技术变革正在发生,包括互联网接入的增加、市场和独立电子商务商店的增长,以及客户对更快服务的期望的改变。市场上需要企业提供更有同情心和更有知识的客户服务代理。尽管有这个令人清醒的统计数据,32%的组织计划将客户服务从现场协助转变为自动化服务,剥夺了客户与品牌进行更有效对话和互动的机会。
“在创建聊天机器人时,用户体验需要放在第一位,其次才是技术。Tech Republic 说:“聊天机器人就像一个婴儿,需要培养和教导,你不能只建立一个聊天机器人就让它走了。”
“当企业考虑在联络中心实施人工智能和机器学习时,请记住,技术不应该取代人类,”赛拉姆说。“相反,它应该提高他们的生产力,让人们参与并培养与客户的关系,让你的品牌与众不同。确保你的组织不会变成一个不知名的实体。”
聊天机器人不是人,所以避免用它们来代替人。相反,把聊天机器人看作是一种让生活变得更好的工具。

#必须优先考虑安全性,而不是事后才想到
聊天机器人是新的数字通信媒介,这意味着它们给企业带来了新的漏洞。任何负责构建聊天机器人的人都需要在计划中采取措施来防止潜在的安全漏洞。每一次对话都为一个坏演员打开了新的通道。
安全性对一切数字化事物的影响程度无需赘述。要了解安全性正在成为一个多么重要的考虑因素——对于即使是最小的企业也必须做出的每一个微决策——看看来自加州大学圣地亚哥分校、萨尔兰大学和特温特大学的这份报告,看看攻击的范围有多广。
“即使是非技术人员也可以通过 DDoS 即服务提供商(即 Booters) 发起重大攻击,”该研究的第一作者 Mattijs Jonker 说。“人们可以向他人支付订阅费,只需几美元。”
为了应对潜在的不良行为者——可能看起来像自动化或机器人的聊天机器人用户——了解在哪里采取预防措施很重要。关键是关注客户参与聊天机器人对话的原因,以便您可以实施贵公司特有的安全协议作为预防措施。
这里有一些数据可以帮助聊天机器人的开发者理解聊天机器人的用例,并将其吸收到他们的策略中。
- 超过一半的搜索该类别的人在社交媒体上寻求与客户互动的帮助(55%)
- 最具前瞻性的聊天机器人平台,脸书,已经取得了明显的收益,超过三分之二的受访者称其拥有聊天机器人参与的理想平台。
- 买家寻求帮助的其他领域包括客户服务(27%)、购物和下订单(24%)以及收集线索信息(39%)。
- 一家最大的零售商很好地利用了这一点,通过聊天机器人提供实时时尚推荐。通过询问顾客本季的流行风格,这款应用“游戏化”了销售过程的各个方面,让那些可能不确定自己想要什么的顾客在网上购物变得有趣。
- 一家领先的旅游服务提供商利用聊天机器人作为 24/7 自助客户支持平台,不仅可以解决客户关于航班的查询,还可以帮助客户预订酒店。因此,简化了客户支持流程,从而带来了总体收入
- 一家最大的投资银行最近推出了一款聊天机器人,能够更快、更有效地分析复杂的法律合同。自推出以来,该机器人仅在 6 个月内就帮助了公司超过 360,000 小时的人力
谢谢你
法尼·马鲁帕卡,
产品营销和解决方案布道者—聊天机器人|AL、NLP、ML | https://www.linkedin.com/in/phani-marupaka-02646b33/ |区块链|
用 R 构建一个加密货币交易机器人

Photo by Branko Stancevic on Unsplash
**请注意,本教程中使用的 API 已经不再使用。考虑到这一点,这篇文章应该作为示例来阅读。
交易者的思想是任何交易策略或计划中的薄弱环节。有效的交易执行需要与我们的本能背道而驰的人类输入。我们应该在我们爬行动物的大脑想卖的时候买。当我们的直觉希望我们买更多的时候,我们应该卖出。
如果加密货币的构成非常关键,那么交易加密货币就更加困难。年轻和新兴市场充斥着“泵组”,它们助长了强烈的 FOMO(害怕错过),将价格推高,然后再将价格推回地面。许多新手投资者也在这些市场交易,这些投资者可能从未在纽约证券交易所交易过。在每笔交易中,都有一个创造者和一个接受者,精明的加密投资者发现利用充斥这个领域的新手很容易。
为了将我的情绪从加密交易中分离出来,并利用 24/7 开放的市场,我决定建立一个简单的交易机器人,它将遵循简单的策略,并在我睡觉时执行交易。
许多被称为“机器人交易员”的人使用 Python 编程语言来执行这些交易。如果你在谷歌上搜索“加密交易机器人”,你会在各种 Github 存储库中找到 Python 代码的链接。
我是数据科学家,R 是我的主要工具。我搜索了一个关于使用 R 语言构建交易机器人的教程,但是一无所获。当我发现包 rgdax 时,我开始构建自己的包来与 GDAX API 接口,它是 GDAX API 的 R 包装器。下面是一个拼凑交易机器人的指南,你可以用它来建立自己的策略。
战略
简而言之,我们将通过 rgdax 包装器通过他们的 API 在 GDAX 交易所交易以太币-美元对。我喜欢交易这一对,因为以太坊(ETH) 通常处于看涨立场,这使得这一策略大放异彩。
注意:这是一个超级简单的策略,在牛市中只会赚几个钱。对于所有的意图和目的,使用它作为建立你自己的策略的基础。
当相对强弱指数(RSI) 指标组合指向暂时超卖市场时,我们将买入,假设多头将再次推高价格,我们可以获利。
一旦我们买入,机器人将输入三个限价卖单:一个是 1%的利润,另一个是 4%的利润,最后一个是 7%的利润。这使我们能够快速释放资金,进入前两个订单的另一个交易,7%的订单提高了我们的整体盈利能力。
软件
我们将使用 Rstudio 和 Windows 任务调度器定期(每 10 分钟)执行我们的 R 代码。你需要一个 GDAX 账户来发送订单,还需要一个 Gmail 账户来接收交易通知。

Our Process
第 1 部分:调用库和构建函数
我们将从调用几个库开始:

rgdax 包提供了 GDAX api 的接口,mailR 用于通过 Gmail 帐户向我们发送电子邮件更新,stringi 帮助我们解析来自 JSON 的数字,TTR 允许我们执行技术指标计算。
功能:curr _ bal _ USD&curr _ bal _ eth
您将在 api 部分使用从 GDAX 生成的 API 密钥、秘密和密码短语。这些函数查询您的 GDAX 帐户的最新余额,我们将在交易中重复使用这些余额:

功能:RSI
我们将使用 RSI 或相对强弱指数作为这一策略的主要指标。 Curr_rsi14_api 使用 15 分钟蜡烛线获取最近 14 个周期的 rsi 值。 RSI14_api_less_one 等等拉入之前时段的 RSI:

功能:出价&询问
接下来,我们需要当前的出价,并为我们的策略询问价格:

功能: usd_hold、eth_hold 和 cancel_orders 和
为了让我们以迭代的方式下限价单,我们需要能够拉进我们已经下的订单的当前状态,并且能够取消已经在订单簿上移动得太远而无法完成的订单。对于前者,我们将使用 rgdax 包的“holds”功能,对于后者,我们将使用“cancel_order”功能:

功能:buy _ exe
这是实际执行我们的限价单的重要功能。这个函数有几个步骤。
1.Order_size 函数计算我们可以购买多少 eth,因为我们希望每次购买尽可能多的 eth,减去 0.005 eth 以考虑舍入误差
2.我们的 WHILE 函数在我们的 ETH 仍然为零时发出限价单。
3.以 bid()价格添加一个订单,系统休眠 17 秒钟以允许订单被执行,然后检查订单是否被执行。如果不是,则重复该过程。
第 2 部分:存储变量
接下来,我们需要存储一些我们的 RSI 指标变量作为对象,以便交易循环运行得更快,并且我们不会超过 API 的速率限制:

第 3 部分:交易循环执行
到目前为止,我们一直在准备函数和变量,以便执行交易循环。以下是实际交易循环的口头演练:
如果我们账户的美元余额大于 20 美元,我们将开始循环。接下来,如果当前的 RSI 大于或等于 30,而前一期的 RSI 小于或等于 30,并且前 3 期的 RSI 至少有一次小于 30,那么我们就用当前的美元余额尽可能多地买入 ETH。
接下来,我们将购买价格保存到一个 CSV 文件中。
然后,我们给自己发一封电子邮件,提醒我们购买行动。
然后循环输出“buy ”,这样我们可以在日志文件中跟踪它。
然后系统休眠 3 秒钟。

现在,我们输入 3 层限价单来获利。
我们的第一个限价卖单获利 1%,第二个获利 4%,最后一个获利 7%。

就这样,这就是整个剧本。
第 4 部分:使用 Windows 任务计划程序自动化脚本
这个机器人的全部目的是消除交易中的人为错误,让我们不必出现在屏幕前就可以进行交易。我们将使用 Windows 任务计划程序来完成这一任务。
使用 Rstudio 插件调度脚本
使用方便的 Rstudio 插件轻松安排脚本:

使用任务计划程序修改计划的任务
导航到由 Rstudio 插件创建的任务,并调整触发器以您希望的时间间隔触发。在我的例子中,我无限期地选择每 10 分钟一次。

使用日志文件关注您的任务
每次运行脚本时,它都会在文本日志文件中创建一个条目,这允许您排除脚本中的错误:

您可以看到“开始日志条目”和“结束日志条目”打印功能如何方便地将我们的条目分开。
让它成为你自己的
您可以修改这个脚本,让它变得简单或复杂。我正在改进这个脚本,添加了来自 Tensorflow for Rstudio 的 Keras 模块的神经网络。这些神经网络为脚本增加了指数级的复杂元素,但对于发现数据中的隐藏模式来说却非常强大。
此外,TTR 包为我们提供了大量的财务函数和技术指标,可用于改进您的模型。
综上所述,不要玩你输不起的钱。市场不是一场游戏,你可能会输得精光。

花 1000 加元打造一台深度学习 PC
因为加拿大人也很便宜

Photo by: Thomas Kvistholt Copenhagen
在参与了由 Fast.ai 创始人瑞秋·托马斯和杰瑞米·霍华德创建的一个名为程序员实用深度学习的 MOOC 之后,我第一次想到要建立自己的深度学习机器。
课程本身并不要求你有自己的设置,而是使用 AWS(在我写作时,我正在学习第 1 部分的第 3 课)。不幸的是,为课程使用 p2 实例支付 0.90 美元/小时的费用很快就会增加。但对我来说,我最大的问题不是成本——我限制使用 AWS 来降低成本——而是生产率。
想象一下本地工作的周转时间——将文件传输到 AWS 来运行测试,失败,关闭 AWS,在本地重新思考问题,并重新做一遍——从生产力的角度来看,这是不合理的。
值得庆幸的是,有很多学生有类似的问题或成本问题,并在我之前铺平了道路,如 Brendan Fortuner 和 Sravya Tirukkovalur ,以及来自 fast.ai 课程论坛、Tim Dettmers 的深度学习硬件指南和 O’Reilly.com 建造一台低于 1000 美元的“超快”DL 机器的大量灵感。
伟大的建议和建议的组件列表,但他们都有一些缺失。
- 加拿大的价格(很少的电子公司和没有大的交易)
- “足够快/足够好”的版本(我真的需要 2 个 GPU 和一个英特尔酷睿 i7 处理器吗!?!?)
为什么是 1000 美元?因为最新和最棒的 NVIDIA GPU GTX 1080Ti 基本上是 1K CAD,所以我认为这是一个很好的价格目标。
假设:
花 1000 加元就可以建造一台“快速”深度学习机器
预测:
如果我使用多个在线供应商和折扣/销售,我可以将预算/初学者深度学习机器的成本降低到 1000 美元,同时仍然允许未来的扩展(更多的 RAM,更好的 GPU 等)
当然,术语“快”是相对的,我也使用了“预算/初学者”,所以让我们限定一下:我认为初学者是像我这样的人,他对 DL 感兴趣,要么正在学习 DL 课程,要么正在积极参加 Kaggle 比赛(或者两者都有)。在这种情况下,您需要一台速度足够快的机器,这样您的端到端实验/测试不会影响您的工作效率。
生产力何时开始下降并没有固定的数字,所以我将尝试用我一直使用的 AWS p2 实例来测试性能。
由于我不想重复其他人提供的所有伟大的建议,下面我给你我对每个组件的想法,以及我为什么选择它们。主要是,我有两个总是需要回答“是”的问题。
- (目前)够好了吗?
- 我可以以后再升级吗(不需要重建一个全新的盒子)?
Btw,强烈推荐 PCPartsPicker ,太牛逼了!你可以在最后找到我的组件列表的链接。






A little eye candy before we get started
中央处理器
这是一个棘手的问题。深度学习机器都是关于 GPU 的,所以理论上我可以得到最便宜的 CPU,对吗?也许,从我在网上读到的一切来看,这似乎是普遍的共识,但你仍然需要不要购买会成为你 GPU 瓶颈的组件。
英特尔 i3
国家政治保卫局。参见 OGPU
市场上最新的卡是 GTX 1080Ti,我不会说你为什么要买 NVIDIA,你只要买就行了。但是你需要最新最好的吗?在加拿大,1080Ti 基本上是 1000 美元起。
- 这是我应该花钱的地方吗?是啊!
- Cuda 内核有多重要?很多!
- 一个 1070 或者 1060 够好吗?是啊!
EVGA GTX 1070
储存;储备
让我们长话短说。我正在努力达到 1000 美元大关,所以我有非常具体的需求…
- 足够存储完成课程所需的任何数据
- 足够的存储空间,可用于 Kaggle 比赛和个人项目
固态硬盘比硬盘更贵,但从长远来看更快更好。
金士顿固态硬盘 120GB
主板和机箱
对于“mobo”(显然这是主板的简称)有一些事情要记住…
- 主板的外形会影响机箱大小,有时还会影响成本(ATX > mATX)
- 确保你的 GPU 可以放在你的箱子里(特别是如果你买的是很漂亮的那种)
- 检查内存插槽,PCIe,如果 SLI 是受支持的(你不希望主板规定你可以选择哪些组件)。
如果你使用电脑零件选择器,兼容性问题应该不是问题。我想要一个有成长空间的简约盒子。我决定在微 ATX 董事会和 ATX 的情况。
我的主板只有 1 个 PCIe x16 插槽,但我真的需要并行运行两个 GPU 吗?升级的话我就把 1070 卖了买个 1080Ti(还是 1090?1100?等等)。
微星微 ATX 和 ATX 中塔
电源装置(PSU)
回顾网上的文章,人们有一台正在运行的机器,但是东西坏了或者不能正常工作,这种情况似乎很常见。它们最终都用更强大的力量解决了。
为了避免令人讨厌的调试问题,我选择了一款合适但便宜的 PSU。再问一次,够不够好?我可以以后升级吗?是的,都是。
EVGA 450 w
记忆
散热器?我们要去的地方,不需要散热器(回到未来参考,以防你今天跑得慢)。
我们在省钱,对吧?那么大部分 RAM 就是 RAM,忽略 RAM 的散热器的市场营销…尽管它们看起来很酷。
我们要用 DDR 4(“2133”因为主板不能处理更多,即使 RAM 可以)。购买 2,4GB 而不是 1 8GB 的记忆棒。听说了一些关于双通道的伟大之处,但不知道是不是真的。
关键 4GB DDR 4–2133(2x)
最终结果

A lot of room to grow (2TB HDD salvaged from old PC)
把所有东西放在一起非常简单。为我的深度学习环境安装软件将是一个更大的挑战。
更新:用 Nvidia GPU 安装 Ubuntu 非常困难。
但在此之前,让我们先解决一些细节问题。
**不含税:**加拿大的税是个痛。他们一有机会就会毁了你的一天。一旦包括在内,账单将超过 1000 美元,但我懒得在订购零件之前手动计算,所以我们将忽略税务员。
邮寄返利:我无法抗拒一笔好交易的冲动,这笔交易帮助我将成本降低到略低于 1000 美元。我能拿回我的钱吗?大概不会。但是如果我幸运的话,在 8 到 10 周内。总之,我“节省”了大约 35 美元。
**运输+处理:**虽然 PC Parts Picker 试图将它包括在内,但它很难显示何时有额外成本。一些零件的运费+手续费约为 11 美元,而其他商店的基本价格高出 5 美元,但不含运费+手续费。做一点工作,为自己省钱。
**其他:**显示器、键盘、鼠标、机箱外风扇、CPU 冷却器等。那些都被遗漏了。我确实有几个键盘和一个显示器,但因为这是一台 DL 机器,我真的不需要它们(我将主要使用我的 mac book 上的 ssh)。同样,目前不需要额外的机箱风扇或 CPU 冷却器。
最终名单:
- GPU:EVGA GeForce GTX 1070 8GB SC 游戏 ACX 3.0
- CPU :英特尔酷睿 i3–6100 3.7 GHz 双核处理器
- 主板:微星 B150M 火箭筒加微型 ATX
- 内存:至关重要的 4GB(2x4gb)DDR 4–2133 内存
- 存储:金士顿 SSDNow UV400 120GB
- 案例:冷却器主箱 5 ATX 中塔案例
- 电源电源:EVGA 450W 80+青铜认证 ATX 电源
总价:997.43 美元
使用 TensorFlow 构建手写文本识别系统
可在 CPU 上训练的最小神经网络实现

离线手写文本识别(HTR)系统将包含在扫描图像中的文本转录成数字文本,图 1 中示出了一个例子。我们将建立一个神经网络(NN ),它是根据来自 IAM 数据集的单词图像进行训练的。由于文字图像的输入层(以及所有其他层)可以保持较小,因此 NN 训练在 CPU 上是可行的(当然,GPU 会更好)。这个实现是 HTR 使用 TF 所需的最低要求。

Fig. 1: Image of word (taken from IAM) and its transcription into digital text.
获取代码和数据
- 你需要安装 Python 3,TensorFlow 1.3,numpy 和 OpenCV
- 从 GitHub 获取实现:要么采用本文所基于的代码版本,要么采用最新的代码版本,如果你可以接受文章和代码之间的一些不一致
- 更多说明(如何获取 IAM 数据集、命令行参数等)可以在自述文件中找到
模型概述
我们使用神经网络来完成我们的任务。它由卷积神经网络(CNN)层、递归神经网络(RNN)层和最终的连接主义者时间分类(CTC)层组成。图 2 显示了我们的 HTR 系统的概况。

Fig. 2: Overview of the NN operations (green) and the data flow through the NN (pink).
我们也可以用一种更正式的方式把神经网络看作一个函数(见等式)。1)它将大小为 W×H 的图像(或矩阵)M 映射到长度在 0 和 l 之间的字符序列(c1,c2,…)。正如您所看到的,文本是在字符级别上被识别的,因此未包含在训练数据中的单词或文本也可以被识别(只要单个字符被正确分类)。

Eq. 1: The NN written as a mathematical function which maps an image M to a character sequence (c1, c2, …).
操作
CNN :输入图像被送入 CNN 层。这些层被训练以从图像中提取相关特征。每一层由三个操作组成。首先是卷积运算,它在前两层中应用大小为 5×5 的滤波器核,在后三层中应用大小为 3×3 的滤波器核。然后,应用非线性 RELU 函数。最后,汇集层汇总图像区域并输出输入的缩小版本。当图像高度在每层中缩小 2 倍时,添加特征图(通道),使得输出特征图(或序列)具有 32×256 的大小。
RNN :特征序列每个时间步包含 256 个特征,RNN 通过这个序列传播相关信息。使用流行的长短期记忆(LSTM)实现的 RNNs,因为它能够通过更长的距离传播信息,并且提供比普通 RNN 更健壮的训练特征。RNN 输出序列被映射到大小为 32×80 的矩阵。IAM 数据集由 79 个不同的字符组成,CTC 操作还需要一个额外的字符(CTC 空白标签),因此 32 个时间步长中的每一个都有 80 个条目。
CTC :在训练 NN 时,CTC 得到 RNN 输出矩阵和地面真实文本,它计算损失值。在推断时,CTC 仅获得矩阵,并将其解码为最终文本。基本事实文本和识别文本的长度最多为 32 个字符。
数据
输入:大小为 128×32 的灰度图像。通常,数据集中的图像没有这个大小,因此我们调整它的大小(没有失真),直到它的宽度为 128 或高度为 32。然后,我们将该图像复制到大小为 128×32 的(白色)目标图像中。这个过程如图 3 所示。最后,我们归一化图像的灰度值,这简化了神经网络的任务。通过将图像复制到随机位置,而不是将其向左对齐或随机调整图像大小,可以轻松集成数据扩充。

Fig. 3: Left: an image from the dataset with an arbitrary size. It is scaled to fit the target image of size 128×32, the empty part of the target image is filled with white color.
CNN 输出:图 4 示出了长度为 32 的 CNN 层的输出。每个条目包含 256 个特征。当然,这些特征由 RNN 层进一步处理,然而,一些特征已经显示出与输入图像的某些高级属性的高度相关性:存在与字符(例如“e”)或者与重复字符(例如“tt”)或者与诸如循环(包含在手写“l”或“e”中)的字符属性高度相关的特征。

Fig. 4: Top: 256 feature per time-step are computed by the CNN layers. Middle: input image. Bottom: plot of the 32nd feature, which has a high correlation with the occurrence of the character “e” in the image.
RNN 输出:图 5 示出了包含文本“little”的图像的 RNN 输出矩阵的可视化。最上面的图表中显示的矩阵包含字符的得分,包括作为其最后一个(第 80 个)条目的 CTC 空白标签。其他矩阵条目从上到下对应于以下字符:“!”# & '()*+,-。/0123456789:;?ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz”。可以看出,在大多数情况下,字符是在它们出现在图像中的位置被准确预测的(例如,比较“I”在图像和图形中的位置)。只有最后一个字符“e”没有对齐。但是这是可以的,因为 CTC 操作是无分段的,并且不关心绝对位置。从显示字符“l”、“I”、“t”、“e”和 CTC 空白标签的分数的最下面的图中,文本可以很容易地被解码:我们只是从每个时间步中取出最可能的字符,这形成了所谓的最佳路径,然后我们丢弃重复的字符,最后是所有的空白:“l-ii-t-t-l-…-e”→“l-I-t-t-…-e”→“little”。

Fig. 5: Top: output matrix of the RNN layers. Middle: input image. Bottom: Probabilities for the characters “l”, “i”, “t”, “e” and the CTC blank label.
使用 TF 实现
实施由 4 个模块组成:
- SamplePreprocessor.py:从 IAM 数据集中为 NN 准备图像
- py:读取样本,将它们放入批处理中,并提供一个迭代器接口来遍历数据
- py:如上所述创建模型,加载并保存模型,管理 TF 会话,并为训练和推理提供接口
- 将前面提到的所有模块放在一起
我们只看 Model.py,因为其他源文件涉及基本文件 IO (DataLoader.py)和图像处理(SamplePreprocessor.py)。
美国有线新闻网;卷积神经网络
对于每个 CNN 层,创建一个 k×k 大小的核,用于卷积运算。
然后,将卷积的结果输入 RELU 运算,然后再次输入大小为 px×py、步长为 sx×sy 的池层。
对 for 循环中的所有层重复这些步骤。
RNN
创建并堆叠两个 RNN 层,每层 256 个单位。
然后,从它创建一个双向 RNN,这样输入序列从前到后遍历,反之亦然。结果,我们得到大小为 32×256 的两个输出序列 fw 和 bw,我们随后沿着特征轴将它们连接起来以形成大小为 32×512 的序列。最后,它被映射到大小为 32×80 的输出序列(或矩阵),该输出序列(或矩阵)被馈送到 CTC 层。
同CITY TECHNOLOGY COLLEGE
对于损失计算,我们将基础事实文本和矩阵输入到操作中。基本事实文本被编码为稀疏张量。输入序列的长度必须传递给两个 CTC 操作。
我们现在有了创建丢失操作和解码操作的所有输入数据。
培养
批次元素损失值的平均值用于训练神经网络:它被输入到优化器中,如 RMSProp。
改进模型
如果你想输入完整的文本行,如图 6 所示,而不是文字图像,你必须增加神经网络的输入大小。

Fig. 6: A complete text-line can be fed into the NN if its input size is increased (image taken from IAM).
如果您想提高识别准确性,可以遵循以下提示之一:
- 数据扩充:通过对输入图像应用进一步的(随机)变换来增加数据集的大小
- 去除输入图像中的草书书写风格(参见去除草书风格)
- 增加输入大小(如果神经网络的输入足够大,可以使用完整的文本行)
- 添加更多 CNN 图层
- 用 2D-LSTM 取代 LSTM
- 解码器:使用令牌传递或字束搜索解码(参见 CTCWordBeamSearch )将输出限制为字典单词
- 文本更正:如果识别的单词不在字典中,则搜索最相似的单词
结论
我们讨论了一种能够识别图像中文本的神经网络。NN 由 5 个 CNN 和 2 个 RNN 层组成,输出一个字符概率矩阵。该矩阵或者用于 CTC 丢失计算,或者用于 CTC 解码。提供了一个使用 TF 的实现,并给出了部分重要的代码。最后,给出了提高识别准确率的建议。
常见问题解答
关于展示的模型有一些问题:
- 如何识别样品/数据集中的文本?
- 如何识别行/句中的文本?
- 如何计算识别文本的置信度得分?
我在的 FAQ 文章中讨论了它们。
参考资料和进一步阅读
源代码和数据可从以下网址下载:
这些文章更详细地讨论了文本识别的某些方面:
在这些出版物中可以找到更深入的介绍:
最后,概述一下我的其他媒体文章。
用自动编码器构建一个简单的图像检索系统

图像检索是近十年来非常活跃且发展迅速的研究领域。最著名的系统是谷歌图片搜索和 Pinterest 视觉大头针搜索。在本文中,我们将学习使用一种特殊类型的神经网络构建一个非常简单的图像检索系统,称为自动编码器。我们将以无人监管的方式进行,即不看图像标签。事实上,我们只能通过图像的视觉内容(纹理、形状等)来检索图像。这种类型的图像检索被称为基于内容的图像检索(CBIR) ,与基于关键词或文本的图像检索相对。
对于本文,我们将使用手写数字的图像、MNIST 数据集和 Keras 深度学习框架。

The MNIST dataset
自动编码器
简而言之,自动编码器是旨在将其输入复制到其输出的神经网络。它们的工作原理是将输入压缩成一个潜在空间表示,然后从这个表示中重建输出。这种网络由两部分组成:
- **编码器:**这是将输入压缩成潜在空间表示的网络部分。可以用编码函数 h=f(x) 来表示。
- **解码器:**该部分旨在从潜在空间表示中重建输入。可以用解码函数 r=g(h) 来表示。

如果你想了解更多关于自动编码器的知识,我建议你阅读我之前的博客文章。
这种潜在的表示或代码是我们感兴趣的,因为这是神经网络压缩每幅图像视觉内容的方式。这意味着所有相似的图像将以相似的方式编码(希望如此)。
有几种类型的自动编码器,但由于我们正在处理图像,最有效的是使用卷积自动编码器,它使用卷积层来编码和解码图像。
因此,第一步是用我们的训练集来训练我们的自动编码器,让它学习将我们的图像编码成潜在空间表示的方法。
一旦完成训练,我们只需要网络的编码部分。
这个编码器现在可以用来编码我们的查询图像。

Our query image
同样的编码必须在我们的搜索数据库中完成,我们希望在其中找到与查询图像相似的图像。然后,我们可以将查询代码与数据库代码进行比较,并尝试找到最接近的代码。为了进行这种比较,我们将使用最近邻技术。
最近邻居
我们将通过执行最近邻算法来检索最近的代码。最近邻方法背后的原理是找到距离新点最近的预定义数量的样本。距离可以是任何度量单位,但最常见的选择是欧几里得距离。对于尺寸都为 *n、*的查询图像 q 和样本 *s、*来说,该距离可以通过以下公式来计算。

在这个例子中,我们将检索与查询图像最接近的 5 个图像。
结果
这些是我们取回的图像,看起来很棒!所有检索到的图像都与我们的查询图像非常相似,并且都对应于相同的数字。这表明,即使没有显示图像的相应标签,自动编码器也找到了以非常相似的方式编码相似图像的方法。

The 5 retrieved images
摘要
在本文中,我们学习了使用自动编码器和最近邻算法创建一个非常简单的图像检索系统。我们通过在一个大数据集上训练我们的 autoencoder 来进行,让它学习如何有效地编码每个图像的视觉内容。然后,我们将查询图像的代码与搜索数据集的代码进行比较,并检索最接近的 5 个代码。我们看到,我们的系统给出了相当好的结果,因为我们的 5 个检索图像的视觉内容接近我们的查询图像,而且它们都表示相同的数字,即使在这个过程中没有使用任何标签。
我希望这篇文章对新的深度学习实践者来说是清晰和有用的,并且它让你很好地了解了使用自动编码器进行图像检索是什么样子的!如果有不清楚的地方,请随时给我反馈或问我问题。
GitHub 是人们构建软件的地方。超过 2800 万人使用 GitHub 来发现、分享和贡献超过…
github.com](https://github.com/nathanhubens/Unsupervised-Image-Retrieval)
使用 TensorFlow 对象检测 API、ML 引擎和 Swift 构建 Taylor Swift 检测器

**注意:**在撰写本文时,Swift 还没有官方的 TensorFlow 库,我使用 Swift 构建了针对我的模型的预测请求的客户端应用程序。这种情况将来可能会改变,但泰勒对此有最终决定权。
这是我们正在建造的:

TensorFlow 对象检测 API 演示可以让您识别图像中对象的位置,这可以带来一些超级酷的应用程序。但是因为我花更多的时间给人拍照,而不是给东西拍照,所以我想看看是否同样的技术可以应用于识别人脸。结果证明效果相当好!我用它建造了上图中的泰勒斯威夫特探测器。
在这篇文章中,我将概述我将从 T-Swift 图像集合中获取到一个 iOS 应用程序的步骤,该应用程序根据一个训练好的模型进行预测:
- 图像预处理:调整大小,标记,分割成训练集和测试集,转换成 Pascal VOC 格式
- 将图像转换为 TFRecords 以提供给目标检测 API
- 使用 MobileNet 在云 ML 引擎上训练模型
- 导出训练好的模型,部署到 ML 引擎服务
- 构建一个 iOS 前端,针对训练好的模型发出预测请求(显然是在 Swift 中)
这是一个架构图,展示了这一切是如何组合在一起的:

如果你想直接跳到代码,你可以在 GitHub 上找到它。
现在看起来,这一切似乎很简单
在我深入这些步骤之前,解释一下我们将使用的一些技术和术语会有所帮助: TensorFlow 对象检测 API 是一个构建在 TensorFlow 之上的框架,用于识别图像中的对象。例如,你可以用许多猫的照片来训练它,一旦训练好了,你可以传入一张猫的图像,它会返回一个矩形列表,它认为图像中有一只猫。虽然它的名字中有 API,但你可以把它看作是一套方便的迁移学习工具。
但是训练一个模型来识别图像中的物体需要时间和吨数据。对象检测最酷的部分是它支持五个预训练模型用于迁移学习。这里有一个类比来帮助你理解迁移学习是如何工作的:当一个孩子学习他们的第一语言时,他们会接触到许多例子,如果他们识别错误,就会得到纠正。例如,他们第一次学习识别一只猫时,他们会看到父母指着猫说“猫”这个词,这种重复加强了他们大脑中的路径。当他们学习如何识别一只狗时,孩子不需要从头开始。他们可以使用与对猫相似的识别过程,但应用于一个稍微不同的任务。迁移学习也是如此。
我没有时间找到并标记成千上万的 TSwift 图像,但我可以通过修改最后几层并将它们应用于我的特定分类任务(检测 TSwift)来使用从这些模型中提取的特征,这些模型是在数百万图像上训练的。
步骤 1:预处理图像
非常感谢 Dat Tran 写了这篇关于训练浣熊探测器进行物体探测的超赞帖子。我关注了他的博客文章,为图片添加标签,并将其转换为 TensorFlow 的正确格式。他的帖子有详细内容;我在这里总结一下我的步骤。
我的第一步是从谷歌图片下载 200 张泰勒·斯威夫特的照片。原来 Chrome 有一个扩展——它会下载谷歌图片搜索的所有结果。在标记我的图像之前,我把它们分成两个数据集:训练和测试。我保留了测试集,以测试我的模型在训练期间没有看到的图像上的准确性。根据 Dat 的建议,我写了一个调整脚本来确保没有图像宽于 600 像素。
因为对象检测 API 将告诉我们我们的对象在图像中的位置,所以您不能仅仅将图像和标签作为训练数据传递给它。您需要向它传递一个边界框,标识对象在图像中的位置,以及与该边界框相关联的标签(在我们的数据集中,我们只有一个标签,tswift)。
为了给我们的图像生成边界框,我使用了 Dat 的浣熊探测器博文中推荐的 LabelImg 。LabelImg 是一个 Python 程序,它允许您手工标记图像,并为每个图像返回一个带有边框和相关标签的 xml 文件(我确实花了一整个上午标记 tswift 图像,而人们带着关切的目光走过我的桌子)。它是这样工作的——我在图像上定义边界框,并给它贴上标签tswift:

然后 LabelImg 生成一个 xml 文件,如下所示:
现在我有了一个图像、一个边界框和一个标签,但是我需要将它转换成 TensorFlow 可以接受的格式——这种数据的二进制表示称为TFRecord。我基于对象检测报告中提供的指南编写了一个脚本来完成这个。要使用我的脚本,您需要在本地克隆 tensorflow/models repo 并打包对象检测 API:
# From tensorflow/models/research/
python setup.py sdist
(cd slim && python setup.py sdist)
现在您已经准备好运行TFRecord脚本了。从tensorflow/models/research目录运行下面的命令,并向其传递以下标志(运行两次:一次用于训练数据,一次用于测试数据):
python convert_labels_to_tfrecords.py \
--output_path=train.record \
--images_dir=path/to/your/training/images/ \
--labels_dir=path/to/training/label/xml/
步骤 2:在云机器学习引擎上训练 TSwift 检测器
我可以在我的笔记本电脑上训练这个模型,但这需要时间和大量的资源,如果我不得不把我的电脑放在一边做其他事情,训练工作就会突然停止。这就是云的用途!我们可以利用云在许多核心上运行我们的培训,以便在几个小时内完成整个工作。当我使用 Cloud ML Engine 时,我可以通过利用 GPU(图形处理单元)来更快地运行训练作业,GPU 是专门的硅芯片,擅长我们的模型执行的计算类型。利用这种处理能力,我可以开始一项训练工作,然后在我的模型训练时去 TSwift 玩几个小时。
设置云 ML 引擎
我所有的数据都是TFRecord格式的,我准备把它们上传到云端,开始训练。首先,我在 Google Cloud 控制台中创建了一个项目,并启用了 Cloud ML 引擎:


然后,我将创建一个云存储桶来打包我的模型的所有资源。确保为存储桶指定一个区域(不要选择多区域):

我将在这个 bucket 中创建一个/data子目录来存放训练和测试TFRecord文件:


对象检测 API 还需要一个将标签映射到整数 ID 的pbtxt文件。因为我只有一个标签,所以这将非常简短:
为迁移学习添加 MobileNet 检查点
我不是从零开始训练这个模型,所以当我运行训练时,我需要指向我将要建立的预训练模型。我选择使用一个 MobileNet 模型——MobileNet 是一系列针对移动优化的小型模型。虽然我不会直接在移动设备上提供我的模型,但 MobileNet 将快速训练并允许更快的预测请求。我下载了这个 MobileNet 检查点用于我的培训。检查点是包含张量流模型在训练过程中特定点的状态的二进制文件。下载并解压缩检查点后,您会看到它包含三个文件:

我需要它们来训练模型,所以我把它们放在我的云存储桶的同一个data/目录中。
在运行培训作业之前,还有一个文件要添加。对象检测脚本需要一种方法来找到我们的模型检查点、标签映射和训练数据。我们将通过一个配置文件来实现。TF Object Detection repo 为五种预训练模型类型中的每一种都提供了示例配置文件。我在这里使用了 MobileNet 的占位符,并用我的云存储桶中的相应路径更新了所有的PATH_TO_BE_CONFIGURED占位符。除了将我的模型连接到云存储中的数据,该文件还为我的模型配置了几个超参数,如卷积大小、激活函数和步骤。
在我开始培训之前,以下是应该放在我的/data云存储桶中的所有文件:

我还将在我的 bucket 中创建train/和eval/子目录——这是 TensorFlow 在运行训练和评估作业时写入模型检查点文件的地方。
现在我准备好运行训练了,这可以通过[gcloud](https://cloud.google.com/sdk/)命令行工具来完成。请注意,您需要在本地克隆tensor flow/models/research,并从该目录运行这个训练脚本:
在训练跑步的同时,我也拉开了评测工作的序幕。这将使用以前没有见过的数据来评估我的模型的准确性:
您可以通过导航到您的云控制台中 ML 引擎的作业部分来验证您的作业是否正常运行,并检查特定作业的日志:

步骤 3:部署模型以服务于预测
为了将模型部署到 ML 引擎,我需要将我的模型检查点转换成 ProtoBuf。在我的train/桶中,我可以看到在整个训练过程中从几个点保存的检查点文件:

checkpoint文件的第一行将告诉我最新的检查点路径——我将从该检查点本地下载 3 个文件。每个检查点应该有一个.index、.meta和.data文件。将它们保存在本地目录中,我可以利用 Objection Detection 的便利的export_inference_graph脚本将它们转换成 ProtoBuf。要运行下面的脚本,您需要定义 MobileNet 配置文件的本地路径、从培训作业下载的模型检查点的检查点编号,以及您希望将导出的图形写入的目录的名称:
在这个脚本运行之后,您应该在您的.pb输出目录中看到一个saved_model/目录。将saved_model.pb文件(不用担心其他生成的文件)上传到您的云存储桶中的/data目录。
现在,您已经准备好将模型部署到 ML 引擎进行服务了。首先,使用gcloud创建您的模型:
gcloud ml-engine models create tswift_detector
然后,创建您的模型的第一个版本,将它指向您刚刚上传到云存储的保存的模型 ProtoBuf:
gcloud ml-engine versions create v1 --model=tswift_detector --origin=gs://${YOUR_GCS_BUCKET}/data --runtime-version=1.4
一旦模型部署,我准备使用 ML 引擎的在线预测 API 来生成对新图像的预测。
步骤 4:使用 Firebase 函数和 Swift 构建预测客户端
我用 Swift 编写了一个 iOS 客户端,用于对我的模型进行预测请求(因为为什么要用其他语言编写 TSwift 检测器呢?).Swift 客户端将图像上传到云存储,这将触发 Firebase 函数,该函数在 Node.js 中发出预测请求,并将生成的预测图像和数据保存到云存储和 Firestore。
首先,在我的 Swift 客户端中,我添加了一个按钮,让用户可以访问他们设备的照片库。一旦用户选择了一张照片,就会触发一个将照片上传到云存储的操作:
接下来,我为我的项目编写了上传到云存储桶时触发的 Firebase 函数。它获取图像,对其进行 base64 编码,并将其发送到 ML 引擎进行预测。你可以在这里找到完整的功能代码。下面我包含了函数中向 ML 引擎预测 API 发出请求的部分(感谢 Bret McGowen 的专家云函数帮助我完成这项工作!):
在 ML 引擎响应中,我们得到:
- 如果在图像中检测到 Taylor,我们可以使用它来定义她周围的边界框
detection_scores返回每个检测框的置信度值。我将只包括分数高于 70%的检测detection_classes告诉我们与检测相关的标签 ID。在这种情况下,因为只有一个标签,所以它总是1
在函数中,我使用detection_boxes在图像上画一个框,如果泰勒被检测到,以及置信度得分。然后,我将新的盒装图像保存到云存储中,并将图像的文件路径写入 Cloud Firestore,这样我就可以读取路径,并在我的 iOS 应用程序中下载新图像(带矩形):
最后,在我的 iOS 应用程序中,我可以收听 Firestore 路径的图像更新。如果发现检测,我将下载图像并在我的应用程序中显示它以及检测置信度得分。该函数将替换上述第一个 Swift 片段中的注释:
呜哇!我们有一个泰勒·斯威夫特探测器。请注意,这里的重点不是准确性(在我的训练集中,我只有 140 张图像),所以该模型确实错误地识别了一些人的图像,您可能会将其误认为 tswift。但是如果我有时间手工标注更多的图片,我会更新模型并在应用商店发布应用:)
接下来是什么?
这个帖子包含了很多信息。想自己造吗?下面是这些步骤的详细说明,并附有参考资料的链接:
- 预处理数据:我跟随 Dat 的博客帖子使用 LabelImg 手工标记图像并生成带有包围盒数据的 xml 文件。然后我写了这个脚本来将标签图像转换成 TFRecords
- 训练和评估一个对象检测模型:使用这篇博文中的方法,我将训练和测试数据上传到云存储,并使用 ML 引擎运行训练和评估
- 将模型部署到 ML 引擎:我使用
gcloudCLI 来将我的模型部署到 ML 引擎 - 发出预测请求:我使用 Firebase 云函数 SDK向我的 ML 引擎模型发出在线预测请求。这个请求是由从我的 Swift 应用程序向 Firebase Storage 上传的触发的。在我的函数中,我将预测元数据写到 Firestore 。
你有什么问题或话题想让我在以后的帖子中涉及吗?留言或者在 Twitter 上找我 @SRobTweets 。
从头开始构建和设置您自己的深度学习服务器
今年早些时候,我完成了杰瑞米·霍华德的“实用深度学习—第一部分”课程。这是一门实用的课程,教你如何使用 AWS 实践各种深度学习技术。AWS 是一种快速启动和运行的方式,但成本会迅速增加。我有一个大约 0.9 美元/小时的 p2 实例,我们不要忘记 AWS 带来的所有额外的隐藏成本。我每月挣 50-100 美元。这影响了我的工作效率,因为我试图限制 AWS 的使用来降低成本。我想在深度学习方面追求更多,并决定冒险建立自己的深度学习服务器。这种东西变化很快,所以当你读到这篇文章的时候,如果内容已经过时了,我不会感到惊讶。然而,我希望这能让你对如何构建自己的服务器有所了解。
构建自己的深度学习服务器的 6 个步骤
1.选择组件
2。五金件组装
3。安装操作系统
4。安装显卡和驱动程序
5。设置深度学习环境
6。设置远程访问
1.选择组件
做大量的研究(例如阅读博客)来了解你需要购买哪些零件是很有用的。
在你购买之前,使用 pcpartpicker.com。该网站帮助你做“兼容性检查”,以确保你的所有组件都相互兼容。我的零件清单是这里的。
一般来说,您需要以下内容:
CPU—Intel—Core i5–6600k 3.5 GHz 四核处理器$ 289.50
RAM—G . Skill—rip jaws V 系列 32GB (2 x 16GB) DDR 4–2133 内存$ 330
GPU—EVGA—GeForce GTX 1070 8GB SC 游戏 ACX 3.0 显卡【589】
SSD—三星— 850 EVO 系列 500GB 2.5 英寸固态硬盘
主板 — MSI —EVGA—SuperNOVA NEX 650 w 80+金牌认证全模块化 ATX 电源120 美元
机箱 — 海盗船— 200R ATX 中塔机箱75 美元**总计:**1800 美元以下 CAD

关键要点:
- GPU 是最重要的组件!如果你预算紧张,一定要把钱花在好的显卡上。NVIDIA 拥有多年构建显卡的经验。做一些额外的研究,你就会明白我的意思。在撰写本文时,GTX1080Ti 是最新的最佳选择,不过 GTX1070 也可以。
- **想一想能让您在未来升级的组件。**考虑多付一点钱买一块可以支持多个 16e PCIe 插槽的主板。这使您能够安装一个额外的 GPU,如果你想获得性能提升以后。同样,也要确保有足够的内存插槽用于升级。
- 当有疑问时,选择顾客评论最多的零件。我发现,如果有很多评论,这意味着该零件已经过测试,你更有可能在网上找到帮助或操作指南。
- **从可信的卖家那里购买!**pcpartpicker.com 会给你不同卖家的报价。我注意到有一家经销商以略低的价格提供组件。只要有可能,省点钱总是好的。我正准备从这个不太出名的经销商那里买一些东西,直到我看到他们的评论。感谢上帝我做了,因为他们的评论是可怕的!我选择了更安全的方式,从我信任的商店如亚马逊和新蛋购买组件。
- **免运费&处理:**考虑从亚马逊等提供免运费&处理的地方购买零件。你可以给自己省点钱。
其他有用的资源:
2.硬件装配
我从高中开始就没有接触过计算机硬件,所以一开始我有点紧张。如果你真的不愿意把硬件组装在一起,你可以去加拿大计算机公司或类似的公司,他们可以为你组装,价格大约 80 美元。对我来说,我不想错过这个绝佳的学习机会。
在做任何事情之前,我建议浏览说明手册和操作视频,以熟悉各种组件。你已经花了这么多美元,你还不如花一点时间来确保你知道你在做什么!
以下是一些对我使用的组件有帮助的视频:
关键要点:
- 开始前观看所有视频。文字和手册只能交流这么多。看别人安装后你会觉得自信很多。通常有一些手册没有指出的问题。
- **确保所有的插头都插好了。**我害怕弄坏自己的零件,所以我对所有东西都很温柔。第一次插上电源线,打开电源,什么也没发生——没有灯,没有声音。我想我一定是打碎了什么东西,浪费了 1000 美元。我把它关掉,检查了所有的插头,确保所有的插头都插好了。你瞧,后来一切都正常了。
- **先不要安装你的 GPU!**等到你安装好你的操作系统。我犯了这个错误,以为我的主板坏了,因为我的显示器出现了黑屏。暂时把你的显卡放在一边。请看下面的细节——我专门为此写了一节。
3.安装操作系统
我选择用 USB 安装 ubuntu 16.04。从技术上来说,你也可以安装 Windows,但我认为目前没有这个必要。
3.1 创建一个可引导的 USB 驱动器
1.买一个 2GB 或更大的 USB。
2。从 Ubuntu 下载 ISO 文件。我用的是 16.04
3。按照这些说明创建一个可引导的 u 盘。
3.2 安装 Ubuntu
重新启动你的系统,Ubuntu 安装界面应该会弹出。按照屏幕上的指示做,应该很简单。这里有一个有用的教程。
有些人可能不会自动获得 Ubuntu 设置屏幕。如果你是这种情况,你只需要重新启动进入 BIOS(对我来说是在电脑启动时按 F11),并配置你的启动优先级,先加载 USB 驱动器,再加载硬盘驱动器(SSD)。
3.3 获取最新信息
打开您的终端并运行以下命令:
sudo apt-get update
sudo apt-get upgrade
sudo apt-get install build-essential cmake g++ gfortran git pkg-config python-dev software-properties-common wget
sudo apt-get autoremove
sudo rm -rf /var/lib/apt/lists/*
4.安装图形卡及其驱动程序
NVIDIA 显卡很难安装。有点鸡生蛋的意思因为只有安装了驱动程序才能使用显卡,但是除非主板检测到你的显卡安装了,否则是不能真正安装驱动的。如果我的主板检测到 PCI 插槽中有显卡,它也会首先自动启动显卡,但因为我还没有安装驱动程序,所以我最终只能看到一个空白屏幕。那你是做什么的?在做了大量的研究后,我发现下面的步骤是可行的。希望能给你省些麻烦。
4.1 更改 BIOS 设置
主板应该有一个集成的图形设备,这样你就可以把显示器直接连接到主板上。现在,您应该已经将显示器连接到主板显示设备上了。因为我们要安装一个图形卡,这是你需要告诉 BIOS 首先启动哪个图形设备的地方。BIOS 中有两种设置:
- **PEG — PCI Express 显卡:**如果在 PCI 插槽上检测到显卡,主板会引导显卡。如果没有,那么它会从主板启动内置的那个。
- **IGD —集成图形设备:**将始终使用主板的内置卡
默认情况下,BIOS 将设置为 PEG。在正常情况下,一旦你安装了 NVIDIA 驱动程序,这是有意义的,因为你想利用卡。然而,当你必须安装 NVIDIA 驱动程序时,它会引起问题。

通过以下方式更改 BIOS 配置:
- 重新启动计算机并引导至 BIOS (F11)。
- 转到:设置->集成图形配置->启动图形适配器
- 将设置从 PEG 更改为 IGD
- 保存并关闭您的计算机
4.2 物理插入显卡
现在系统已经关闭,将图形卡插入 PCI 插槽。有时候你必须比你想象的更努力。确保它完全进去了。

4.3 安装驱动程序
现在显卡已经连接到主板上了,打开机器安装 NVIDIA 驱动程序。
- 找到您的显卡型号
lspci | grep -i nvidia
2.确定适用于您的显卡的最新版本的 NVIDIA 驱动程序
- 访问图形驱动程序 PPA 页面并查看可用的驱动程序版本。截至 2017 年 8 月,384 是最新版本。
- 访问 NVIDIA 驱动程序下载网站以确定与您的卡和操作系统兼容的版本。
3.添加和更新图形驱动程序 PPA
sudo add-apt-repository ppa:graphics-drivers
sudo apt-get update
4.安装 NVIDIA 驱动程序。输入与您的卡兼容的版本号。例如,我安装了 384 版本
sudo apt-get install nvidia-384
5.重新启动系统并验证您的安装
lsmod | grep nvidia
如果有问题,需要从头开始,可以使用以下命令清除所有内容。我听说升级显卡的人经常遇到驱动问题。
sudo apt-get purge nvidia*
6.再次将 BIOS 图形设备优先级更改为 PEG。(参见步骤 2)
5.设置深度学习环境
在你开始安装任何东西之前,或者盲目地遵循博客上的指导,花一些时间去了解你需要什么库版本。这些东西变化如此之快,以至于当你阅读它们的时候,大多数博客都已经过时了。还有,也不要盲目下载安装最新版本。例如,Tensorflow 1.3 支持最高 python 3.6(截至 2017 年 8 月 1 日),但 Theano 仅支持最高 python 3.5。Anaconda 的最新版本运行在 python 3.6 上,但是您可以使用 python 3.5 创建 conda 环境。我在深度学习课程的第 1 部分中使用的代码是用 pythonn2.7 编写的,但课程的第 2 部分使用 python 3.5——因此我创建了 2 个 conda 环境。
我最终使用了下面的库列表及其相应的版本。
【CUDA】(V8)——一个利用 GPU 能力的并行计算平台
cud nn(V6)——位于 CUDA 之上的 CUDA 深度神经网络库。
Anaconda(v 3.6)——一个很好的包和环境管理器,自带了很多数据科学计算工具,比如 Numpy、Pands 和 Matplotlib。Anaconda 的另一个好处是它使得创建定制的 python 环境变得容易。****
tensor flow(v 1.3)——谷歌的机器学习框架
the ano(v 0.9)——一个另类的机器学习框架。****
Keras——运行在 Tensorflow、Theano 或其他机器学习框架之上的更高级的神经网络库。****
5.1 安装 CUDA
- 转到 NVIDIA 网站并找到下载 CUDA 工具包。
- 运行下面的代码来安装 CUDA。更改与您的系统兼容的软件包对应的版本。
**wget http://developer.download.nvidia.com/compute/cuda/repos/ubuntu1604/x86_64/cuda-repo-ubuntu1604_8.0.44-1_amd64.deb
sudo dpkg -i cuda-repo-ubuntu1604_8.0.44-1_amd64.deb
sudo apt-get update
sudo apt-get install cuda**
- 将路径添加到您的环境中
**echo 'export PATH=/usr/local/cuda/bin:$PATH' >> ~/.bashrc
echo 'export LD_LIBRARY_PATH=/usr/local/cuda/lib64:$LD_LIBRARY_PATH' >> ~/.bashrc
source ~/.bashrc**
- 检查您是否安装了正确的版本
**nvcc -V**
- 查看有关您的显卡的详细信息
**nvidia-smi**
5.2 安装 cuDNN
- 转到 NVIDIA 网站下载该库。你必须注册才能下载。该网站说可能需要几天时间才能批准,但对我来说周转时间是即时的。
- 将文件解压并复制到安装 CUDA 的地方(通常是/usr/local/cuda)
**cd ~/<folder you downloaded the file>
tar xvf cudnn*.tgz
cd cuda
sudo cp */*.h /usr/local/cuda/include/
sudo cp */libcudnn* /usr/local/cuda/lib64/
sudo chmod a+r /usr/local/cuda/lib64/libcudnn***
5.3 安装蟒蛇
- 转到网站下载安装程序并按照说明操作。最新的 Tensorflow 版本(撰写本文时是 1.3 版)需要 Python 3.5。所以下载 python 3.6 版本,就可以用特定的 python 版本创建 conda 环境了。
- 使用以下命令创建一个虚拟环境。关于如何管理环境的更多细节可以在这里找到。您可能希望为 Theano 和 Tensorflow 分别创建一个环境,因为它们通常支持不同版本的库。
**conda create -n tensorflowenv anaconda python=3.5**
- 激活您刚刚创建的 conda 环境
**source activate tensorflowenv**
5.4 安装 TensorFlow
- 安装 TensorFlow 库。根据您的操作系统、Python 版本和 CPU 与 GPU 支持,有不同的包。看一下这里的来决定你应该使用的 TensorFlow 二进制 URL。
**pip install --ignore-installed --upgrade <*tensorFlowBinaryURL>***
例如,如果您在具有 GPU 支持的 Ubuntu 上运行 Python 3.5,您可以使用以下命令。
**pip install --ignore-installed --upgrade \https://storage.googleapis.com/tensorflow/linux/gpu/tensorflow_gpu-1.3.0-cp35-cp35m-linux_x86_64.whl**
有关 TensorFlow 安装的更多详细信息,请参见此处的。
5.5 安装 no
你可以在找到安装细节。然而,它几乎只是一个命令。
**sudo pip install Theano**
5.6 安装 Keras
- 使用以下命令安装 Keras
**sudo pip install keras**
- 根据您使用的后端(TensorFlow 或 Theano ),您必须对其进行相应的配置。
**vi ~/.keras/keras.json**
配置文件如下所示。你只需要将“后端”改为“tensorflow”或“theano ”,这取决于你使用的后端。
**{
“image_data_format”: “channels_last”,
“epsilon”: 1e-07,
“floatx”: “float32”,
“backend”: “tensorflow”
}**
5.7 其他有用的资源:
6.设置远程访问
这一步是可选的,但是如果您计划从笔记本电脑远程工作,这里有一些选项。
6.1 团队浏览器
Teamviewer 基本上是一个屏幕共享软件。它有时有点笨重,但对于远程控制来说是个不错的选择。
6.2 SSH
大多数开发人员希望通过终端 SSH 到机器中,并不真正需要图形用户界面。可以用 OpenSSH 。
您可以使用以下命令来安装并检查其状态。默认情况下,OpenSSH 服务器将在第一次引导时开始运行。
**sudo apt-get install openssh-server
sudo service ssh status**
6.3 远程 Jupyter 笔记本
我经常使用 Jupyter 笔记本。如果你想在笔记本电脑的浏览器上运行它,这是一个非常酷的技巧。点击查看完整的教程。总之,只需在您的笔记本电脑和服务器上运行以下代码。
**$laptop: ssh -l <username>@<yourNewServerIP>
$server: jupyter notebook --no-browser --port=8888
$laptop: ssh -NL 8888:localhost:8888 <username>@<yourNewServerIP>**
然后你可以在笔记本电脑的浏览器上进入 http://localhost:8888 并远程查看/编辑你的 Jupyter 笔记本。
就是这样!我很想听听你的设置体验!


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言










{kind=link}