







使用 Mlflow 和 Amazon Sagemaker 将模型部署到生产环境中
2019 年 8 月 21 日更新:更改了参数和一些硬编码变量,以便与 mlflow 1.2.0 一起使用
随着数据科学在 2019 年继续成熟,对数据科学家超越笔记本电脑的需求越来越多。一些绩效指标不再足以交付商业价值。模型需要以可伸缩的方式部署和使用,实时模型推理应该是容错和高效的。

Is Naruto in Sage Mode too nerdy even for this post? Probably…the SageMaker pun is weak as hell too but whatever — Source
传统上,模型部署是由工程团队处理的。数据科学家将模型交给工程师进行代码重构和部署。然而,数据科学家缺乏标准化和良好的开发/运营会在两个团队之间产生摩擦,使部署变得繁琐和低效。作为对这一趋势的回应,Databricks 公司(由 Apache Spark 的创始人创立)一直致力于 ml flow——一个用于模型跟踪、评估和部署的开源机器学习平台。参见介绍发布帖。
Mlflow 与 Amazon SageMaker 或 AzureML 等托管部署服务配合得很好。你甚至可以用它来构建定制的开源部署管道,比如 Comcast 的这个。鉴于最近发布的 mlflow 1.0.0,我想为数据科学家提供一些关于部署和管理他们自己的模型的最低限度的指导。
设置
对于本教程,您需要:
- AWS 帐户
- 安装在本地机器上的 Docker
- 安装了
mlflow>=1.0.0的 Python 3.6
让我们开始吧。
配置亚马逊
您需要做的第一件事是在您的本地机器上配置 AWS CLI,以便您可以通过编程方式与您的帐户进行交互。如果你还没有,在这里创建一个账户然后从终端运行下面的命令。
pip install awscli --upgrade --user
aws configure
第二个命令将提示您输入您的密钥和区域,您可以在登录到控制台时从您的帐户获得。在此处查看完整指南。如果您愿意,您还可以创建具有更具体和有限权限的 IAM 用户,如果您有多组凭证,请确保将AWS_DEFAULT_PROFILE环境变量设置为正确的帐户。

View of the AWS Console
最后,您需要一个能够访问 SageMaker 的角色。在 AWS 上,转到 IAM 管理控制台并创建一个新角色。然后,将“AmazonSageMakerFullAccess”策略附加到角色,稍后您将需要它来与 SageMaker 进行交互。
其他安装
按照正确的步骤在你的操作系统上安装 Docker 。然后确保你启动了 Docker 守护进程(在你的菜单栏里查看有趣的小鲸鱼)。
不打算解释如何安装 Python——我们必须超越这个权利?只要确保你已经用pip install mlflow安装了最新的 mlflow。如果您与团队合作,您也可以运行远程 mlflow 服务器,只需确保您指定了 mlflow 记录模型的位置(S3 存储桶)。请参见下面的服务器命令:
mlflow server --default-artifact-root s3://bucket --host 0.0.0.0
该服务应该在端口 5000 上启动。只需确保启动 mlflow 的主机和您的本地机器都具有对 S3 存储桶的写访问权限。如果只是在本地工作,不需要启动 mlflow。
使用 Mlflow 进行模型跟踪
酷,现在我们准备好开始实际建模了。Mlflow 允许您记录参数和指标,这对于模型比较来说非常方便。在您的代码中创建一个实验将会创建一个名为“mlruns”的目录,其中存储了您的实验的所有信息。
不要恨我,但我将使用 iris 数据集,因为它非常简单,这里的目的是说明 mlflow 如何与 SageMaker 一起使用。下面,我们可以看到一个记录我们的超参数、模型性能度量和实际模型本身的例子。
现在还不清楚发生了什么,但是如果你打开另一个终端,在你当前的工作目录中输入mlflow ui,你可以在一个方便的应用程序中检查我们刚刚登录的所有内容。Mlflow 允许您通过参数和指标进行过滤,并查看您可能已经记录的任何工件,如模型、环境、元数据等…

Look at the Mlflow UI (not our models) — Source
当 mlflow 记录模型时,它还会生成一个conda.yaml文件。这是您的模型需要运行的环境,它可以根据您的需要进行大量定制。使用 mlflow 模型可以做更多的事情,包括自定义预处理和深度学习。这个库有各种各样的模型“风格”,所以你不会被 sklearn 束缚住,还可以使用 Pytorch 或 TF。点击查看文件。
亚马逊 ECR 图像
既然我们已经保存了我们的模型工件,我们需要开始考虑部署。第一步是向 Amazon 的弹性容器注册中心提供一个 Docker 映像,我们可以用它来服务我们的模型。如果你对 Docker 不熟悉,请查看文档。

Amazon ECR — Source
mlflow Python 库有用于这一部分的函数,但我在编写时遇到了一些问题,所以我使用了 CLI。打开一个新终端,并在命令行中键入以下内容:
mlflow sagemaker build-and-push-container
如果您已经使用适当的权限正确地设置了 AWS,这将在本地构建一个映像,并将其推送到 AWS 上的映像注册表中。要检查它是否正常工作,请转到 AWS 控制台,并单击“服务”下拉菜单中“计算”下面列出的“ECR”服务。您应该看到一个名为mlflow-pyfunc的存储库,其中应该列出了一个图像。
部署到 Sagemaker
现在,在部署供消费的模型端点之前,我们只剩下有限的事情要做了。基本上,我们所要做的就是向 mlflow 提供我们的图像 url 和所需的模型,然后我们可以将这些模型部署到 SageMaker。

Amazon SageMaker Workflow — Source
您需要的是您的 AWS ID,您可以从控制台或通过在终端中键入aws sts get-caller-identity --query Account --output text来获得它。此外,您将需要在设置 Amazon 时创建的 SageMakerFullAccess 角色的 ARN。转到 IAM 管理控制台,单击角色并复制 ARN。如果您的模型托管在本地系统之外的其他地方,您还必须编辑模型路径。
如果您的 AWS 凭证设置正确,这应该会连接到 SageMaker 并部署一个模型!可能需要一点时间才能达到“使用中”状态。一旦完成,您就可以使用boto3库或通过进入控制台,以编程方式检查您的模型是否已经启动并运行。这段代码改编自这里的数据块教程。
输出应该如下所示:
Application status is: InService
Received response: [2.0]
现在您正在调用您的端点,您可以通过 AWS 控制台查看使用情况的统计数据,方法是转到 SageMaker 服务。使用 SageMaker 还可以做更多的事情,但是我将把这些留给大量其他可用的教程。一旦你玩完了新的机器学习模型,你就可以删除端点了。
mfs.delete(app_name=app_name, region_name=region)
就是这样!这是一个非常简单的教程,但希望这能让你一窥生产级机器学习的各种可能性。请记住,永远不要将 AWS 密钥发布或上传到 Github 这样的地方——有人会偷走它们,并在你的硬币上挖掘一堆比特币。玩得开心!
用 JavaScript 部署您的数据科学项目
一小时内将 React 客户端、Python JSON API 和 SSL 证书从 Let’s Encrypt 推送到 DigitalOcean

Photo by Daniel Mayovskiy on Unsplash
对于我最新的项目,我决定使用 React 进行大部分探索性数据分析(EDA ),并需要一个非常简单的 JSON API 来提供必要的数据,以避免加载+70 MB 的页面。在本教程中,我将带你在 DigitalOcean 上使用 create-react-app 、 fastapi 和 Nginx 部署一个示例应用的过程。您可以探索真正的应用程序,因为它目前位于 https://ecce.rcd.ai 。这种产品部署过程有点手动,但是如果需要的话,当然可以自动化。
以下是实现这一目标的顶级步骤:
- 用 fastapi 创建 Python API
- 使用 create-react-app 创建客户端应用程序(并将请求传递给 API)
- 创建 DigitalOcean droplet 并安装依赖项
- 配置 Nginx(将 React 和 Python 统一为一个 web 服务)
- 构建客户端应用程序并拷贝到 droplet
- 克隆客户端 API 并作为 cronjob 安装
- 设置域并从 Let’s Encrypt 获取 SSL 证书
- 为出色完成的工作拿一杯咖啡☕!🎉
Python API 和 fastapi
据我所知, fastapi 是创建 Python API 最简单、最快的方法。这是一个单一文件服务器,可以根据需要轻松扩展和配置。对于这个例子,我们将提供来自 ESV 的诗句(法律允许,因为这是一个非商业项目)。我们将使用这些命令从头开始项目:
*# Create directory and jump into it* mkdir -p fastapi-react-demo/app cd fastapi-react-demo *# Download data source* curl -LO [https://github.com/honza/bibles/raw/master/ESV/ESV.json](https://github.com/honza/bibles/raw/master/ESV/ESV.json)
mv ESV.json app/esv.json *# Install dependencies* pip install fastapi uvicorn toolz *# Save dependencies for later use* pip freeze | grep "fastapi\|uvicorn\|toolz" > requirements.txt*# Create server file* touch app/server.py
在app/server.py中:
from fastapi import FastAPI
from starlette.middleware.cors import CORSMiddleware
import json
import os
from toolz import memoizeapp = FastAPI() *# TODO: Change origin to real domain to reject Ajax requests from elsewhere* app.add_middleware(CORSMiddleware, allow_origins=['*'])@memoize
def data():
with open(os.path.join(os.path.dirname(__file__), 'esv.json')) as f:
return json.load(f) @app.get('/api/verse/{book}/{chapter}/{verse}')
def load_text(book: str, chapter: int, verse: int):
try:
return {'text': data()[book][str(chapter)][str(verse)]}
except KeyError as e:
return {'error': str(e), 'type': 'KeyError'}
从这个简单的文件中,我们有了 JSON API、CORS、参数验证等等。让我们继续在开发模式下运行它来检查一下:
# Start app
uvicorn app.server:app --reload# Send API request (in separate window)
curl [http://localhost:8000/api/verse/Genesis/1/1](http://localhost:8000/api/verse/Genesis/1/1)
# => {"text":"In the beginning, God created the heavens and the earth."}
随着服务器的运行,我们不仅在开发中拥有完全可操作的 JSON API,而且如果我们改变了文件中的任何内容,它甚至会实时重新加载。让我们谈谈客户。
具有创建-反应-应用的客户端应用
API 在开发模式下运行,让我们继续创建一个客户端应用程序。如果你在 React 中做数据科学可视化,我假设你熟悉 JavaScript 生态系统。
npx create-react-app client
在添加我们的 ajax 代码之前,我们需要为create-react-app配置代理,以将它不能处理的请求转发给运行在端口 8000 上的 API 服务器。
在client/package.json
...
},
"proxy": "http://localhost:8000",
"scripts": ...
我们将继续从客户端进行一个简单的 API 调用:
在client/src/App.js
import React, { Component } from 'react';class App extends Component {
constructor(props) {
super(props);
this.state = { verse: 'Loading...' };
} componentDidMount() {
fetch('/api/verse/Genesis/1/1')
.then(r => r.json())
.then(data => this.setState({ text: data.text }));
} render() {
return (
<div>
<h1>fastapi-react-demo</h1>
<p>Result of API call: {this.state.text}</p>
</div>
);
}
}export default App;
有了更新的文件,我们就可以开始启动服务器了。
cd client && yarn start

万岁!它肯定不会赢得任何设计奖项,但我们现在有两个应用程序互相交谈。我们来谈谈如何实际部署这些应用程序。
请确保您已经将它上传到一个 Git 存储库,以便我们稍后可以轻松地克隆它。(如果没有,不要担心——你可以只使用 https://github.com/rcdilorenzo/fastapi-react-demo 的样本库)。
随着应用程序的启动和运行,我们现在必须为世界部署我们的代码!我们将从创建一个数字海洋水滴开始。在这种情况下,我将选择 Ubuntu 18 的最小磁盘大小来为应用程序服务。

有了 SSH 键,我们就可以进入设置中描述的 droplet 了。

ssh root@<DROPLET_IP xxx.xxx.xxx.128># (on server)
apt-get update apt-get install -y nginx-full
配置 Nginx
我们现在需要设置 Nginx 来完成三项任务。
- 每当路线以
/api开始时提供 Python 应用 - 对于任何特定资产或未找到路线,可退回到 React 应用程序
- 强制 SSL 并使用来自“让我们加密”的证书
我不会跳过此配置的所有细节,但它应该可以实现我们的目标,稍后您将了解更多细节。对于编辑,继续使用您最喜欢的命令行编辑器。(我的是 vim,用于快速编辑;最简单的是纳米。)确保用您的自定义域替换demo.rcd.ai。
在/etc/nginx/sites-available/demo.rcd.ai.conf
server {
listen [::]:80;
listen 80;
server_name demo.rcd.ai;
location / {
return 301 [https://$host$request_uri](/$host$request_uri);
}
}server {
listen [::]:443 ssl http2;
listen 443 ssl http2;
server_name demo.rcd.ai;
access_log /var/log/nginx/access.log;
error_log /var/log/nginx/error.log; ssl_certificate /etc/letsencrypt/live/demo.rcd.ai/fullchain.pem;
ssl_certificate_key /etc/letsencrypt/live/demo.rcd.ai/privkey.pem; root /var/www/demo/; index index.html; location / {
try_files $uri $uri/ /index.html;
} location /api {
proxy_pass [http://localhost:1234](http://localhost:1234); # Port of Python server
} # JavaScript/CSS
location ~* \.(?:css|js)$ {
try_files $uri =404;
expires 1y;
access_log off;
add_header Cache-Control "public";
} # Any file route
location ~ ^.+\..+$ {
try_files $uri =404;
}
}
让我们将这个文件符号链接到sites-enabled文件夹中,这样 Nginx 在收到来自域demo.rcd.ai的请求时就会知道要服务它。
ln -s /etc/nginx/sites-available/demo.rcd.ai.conf /etc/nginx/sites-enabled/demo.rcd.ai
虽然我们可以让 Nginx 重新加载,但是在它正常工作之前,我们还有一些事情要做。
- 用我们的域名注册商添加
demo.rcd.ai来指向这个 IP 地址 - 将客户端的生产版本复制到
/var/www/demo - 克隆 Python 服务器,并在端口 1234 上启动它
- 请求让我们加密证书
我不会过多讨论设置子域记录的细节,因为这取决于你的提供商。这是我添加到 NameCheap 的内容,因为那是我的注册商。

请注意,这可能需要一段时间才能将变化反映到“互联网”上您总是可以通过简单的 ping 命令来检查它:
❯ ping demo.rcd.ai
# PING demo.rcd.ai (159.89.130.128) 56(84) bytes of data.
# 64 bytes from 159.89.130.128 (159.89.130.128): icmp_seq=1 ttl=48 time=88.4 ms
# 64 bytes from 159.89.130.128 (159.89.130.128): icmp_seq=2 ttl=48 time=85.4 ms
# ^C
# --- demo.rcd.ai ping statistics ---
# 2 packets transmitted, 2 received, 0% packet loss, time 1000ms
# rtt min/avg/max/mdev = 85.411/86.921/88.432/1.539 ms
构建和部署客户端
回到开发机器上的client/文件夹,创建一个产品版本就像发出一个命令一样简单。然后我们将它打包并发送到/var/www/demo目录中的 DigitalOcean droplet。
# Build production-optimized assets
yarn build# Zip contents
zip -r build.zip build/# Upload with scp
scp build.zip root@<DROPLET_IP>:/var/www/
然后在水滴上:
# Unzip and rename folder
apt-get install -y unzip
cd /var/www && unzip build.zip
mv build demo
此时,Nginx 应该适当地服务于资产。然而,因为证书还没有到位,它甚至不允许我们加载配置。
来自“让我们加密”的 SSL 证书
虽然我们可以设置 Python 服务器,但最好能得到一些反馈,以确保至少我们的客户端得到了正确的服务。本着快速迭代的精神,让我们首先设置证书。从 https://certbot.eff.org很容易获得说明。在 droplet 上,继续安装 certbot。
apt-get update
apt-get install software-properties-common
add-apt-repository universe
add-apt-repository ppa:certbot/certbot
apt-get update apt-get install certbot python-certbot-nginx
在这里,可以通过一个命令获得证书。
certbot certonly --standalone \
--pre-hook "service nginx stop" \
--post-hook "service nginx start" \
--preferred-challenges http -d demo.rcd.ai
# ...
# Running pre-hook command: service nginx stop
# Obtaining a new certificate
# Performing the following challenges:
# http-01 challenge for demo.rcd.ai
# Waiting for verification...
# Cleaning up challenges
# Running post-hook command: service nginx start
# # IMPORTANT NOTES:
# - Congratulations! Your certificate and chain have been saved at:
# /etc/letsencrypt/live/demo.rcd.ai/fullchain.pem
# Your key file has been saved at:
# /etc/letsencrypt/live/demo.rcd.ai/privkey.pem
# Your cert will expire on 2019-06-26\. To obtain a new or tweaked
# version of this certificate in the future, simply run certbot
# again. To non-interactively renew *all* of your certificates, run
# "certbot renew"
# - Your account credentials have been saved in your Certbot
# configuration directory at /etc/letsencrypt. You should make a
# secure backup of this folder now. This configuration directory will
# also contain certificates and private keys obtained by Certbot so
# making regular backups of this folder is ideal.
# ...
因为这个命令停止并重启 Nginx,所以我们应该可以直接进入应用程序,看到一些东西( https://demo.rcd.ai )。我们还可以特别请求 Nginx 重新加载配置。
nginx -s reload

部署 API
Nginx 配置需要一个内部服务器监听端口 1234,剩下的就是在 droplet 上运行 Python 服务器。因为我们将代码推送到 GitHub,所以剩余的命令可以从 droplet 运行。
# Clone code to folder
cd /var/www
git clone https://github.com/rcdilorenzo/fastapi-react-demo.git demo-server# Install Python-3.6 based virtualenv (to avoid version conflicts)
apt-get install -y python3.6-venv python3-venv python3.6-dev# Jump into server folder
cd demo-server# Create virtual environment in /var/www/demo-server/demo_3.6
python3.6 -m venv demo_3.6# Install a couple of prerequisites for compiling some dependencies
./demo_3.6/bin/pip install wheel
apt-get install -y gcc# Install dependencies
./demo_3.6/bin/pip install -r requirements.txt
安装完依赖项后,可以内联启动服务器进行测试。
./demo_3.6/bin/uvicorn app.server:app --port 1234
INFO:uvicorn:Started server process [9357]
INFO:uvicorn:Waiting for application startup.
INFO:uvicorn:Uvicorn running on http://127.0.0.1:1234 (Press CTRL+C to quit)
重新访问页面,我们可以看到诗句现在正确加载。

然而,只有当我们打开 SSH 会话时,这个 Python 服务器才会运行。为了让它在重启后仍然存在,我们可以添加到crontab中。我们必须运行的唯一命令是切换到服务器根目录并运行uvicorn。用CTRL-c杀死服务器,用crontab -e打开 crontab。
@reboot cd /var/www/demo-server && ./demo_3.6/bin/uvicorn app.server:app --port 1234
保存并关闭该文件。用reboot重启服务器。一旦 droplet 重新启动,应用程序应该会自动启动。
如果你已经走到这一步,那么恭喜你。🎉去喝杯咖啡吧!这个过程可能看起来有点乏味,但它表明,只需每月$ 5美元,您就可以拥有一个生产级的、交互式的数据项目 web 应用程序,而无需通过一组更狭窄的可视化工具来强制数据科学过程。这种程度的灵活性在很多情况下肯定是不必要的,但是现在你知道如何为自己设置一切了。
关于这些步骤中的每一步,还有很多可以说的,但是我想把重点放在主要的工作流程上。当然,更新客户机或服务器需要几个命令,但这很容易实现自动化。如果你真的想要一个长期的、生产就绪的系统,和一个团队一起部署一个 CI/CD 过程当然是值得花时间投资的。
部署您的第一个深度学习模型:生产环境中的 MNIST
让你的深度学习模型飞起来
如何在生产环境中部署您的 MNIST 模型

Photo by Ravi Roshan on Unsplash
数据集对于像我们这样的大多数 ML 爱好者来说是一个 hello world 数据集。在某个时候,每个已经开始这个领域的旅程或愿意开始的人都会遇到这个数据集,并肯定会得到它。
对于那些希望在真实世界数据上尝试学习技术和模式识别方法,同时花费最少精力进行预处理和格式化的人来说,这是一个很好的数据集。——扬·勒昆

我们在建造什么?
在这篇文章中,我将讲述每个完成 MNIST 的人如何在生产环境中使用 Django 和 Heroku 将训练好的模型部署为漂亮的 web 应用程序。

MNIST Web App Demo
先决条件
您应该具备以下基本知识:
并且你应该有一个基于 Keras 的 MNIST 的模型文件;或者你可以马上开始用的小本子整理文件。****
准备好您的后端
首先,让我们使用 CMD 或 bash 终端安装 Django 如果你还没有这样做。
如果你以前没有 Django 的经验,网上有很多免费的资源。请考虑看看。对于使用 Python 构建 Web 应用程序来说,这是一个非常棒的框架。没什么可失去的。
启动项目

****pip install django****
这将为您安装 Django,您将可以访问 Django CLI 来创建您的项目文件夹。
****django-admin startproject digitrecognizer****
我将把我的项目命名为 digitrecognizer 你可以随意命名。一旦你这样做了,你会看到一个文件夹,里面有一些文件。
让我们使用 mange.py cli 在该文件夹中创建我们的新应用程序 main 。
**python manage.py startapp main**
这将为您创建一个名为 main 的新应用程序。现在我们可以在 views.py 文件中编写我们的主要代码了。
代码部分
让我们在 views.py 文件中编写一些代码:
**## Views.pyfrom django.shortcuts import render
from scipy.misc.pilutil import imread, imresize
import numpy as np
import re
import sys
import os
sys.path.append(os.path.abspath("./model"))
from .utils import *
from django.http import JsonResponse
from django.views.decorators.csrf import csrf_exempt
global model, graph
model, graph = init()
import base64OUTPUT = os.path.join(os.path.dirname(__file__), 'output.png')from PIL import Image
from io import BytesIOdef getI420FromBase64(codec):
base64_data = re.sub('^data:image/.+;base64,', '', codec)
byte_data = base64.b64decode(base64_data)
image_data = BytesIO(byte_data)
img = Image.open(image_data)
img.save(OUTPUT)def convertImage(imgData):
getI420FromBase64(imgData)[@csrf_exempt](http://twitter.com/csrf_exempt)
def predict(request):imgData = request.POST.get('img')convertImage(imgData)
x = imread(OUTPUT, mode='L')
x = np.invert(x)
x = imresize(x, (28, 28))
x = x.reshape(1, 28, 28, 1)
with graph.as_default():
out = model.predict(x)
print(out)
print(np.argmax(out, axis=1))
response = np.array_str(np.argmax(out, axis=1))
return JsonResponse({"output": response})**

看起来很多,其实不是!😂相信我。
我们来分解一下
在代码的最开始,我们导入每个需要的库和模块。
进口
每一个导入都是不言自明的,我也评论了重要的部分,考虑看看它。
**from django.shortcuts import render
from scipy.misc.pilutil import imread, imresize
import numpy as np
import re
import sys## Apending MNIST model path
import os
sys.path.append(os.path.abspath("./model"))## custom utils file create for writing some helper func
from .utils import *from django.http import JsonResponse
from django.views.decorators.csrf import csrf_exempt## Declaring global variable
global model, graph## initializing MNIST model file (It comes from utils.py file)
model, graph = init()import base64
from PIL import Image
from io import BytesIO## Declaring output path to save our imageOUTPUT = os.path.join(os.path.dirname(__file__), 'output.png')**
什么是 utils.py 文件?
导入所需的库之后,让我们编写一些助手函数来处理一个 utils.py 文件中的 MNIST 模型。
**## utils.pyfrom keras.models import model_from_json
from scipy.misc.pilutil import imread, imresize, imshow
import tensorflow as tf
import osJSONpath = os.path.join(os.path.dirname(__file__), 'models', 'model.json')
MODELpath = os.path.join(os.path.dirname(__file__), 'models', 'mnist.h5')def init():
json_file = open(JSONpath, 'r')
loaded_model_json = json_file.read()
json_file.close()
loaded_model = model_from_json(loaded_model_json)
loaded_model.load_weights(MODELpath)
print("Loaded Model from disk")
loaded_model.compile(loss='categorical_crossentropy',
optimizer='adam', metrics=['accuracy']) graph = tf.get_default_graph() return loaded_model, graph**
这个文件包含了 init 函数,它基本上初始化了我们使用 Keras 保存的 MNIST 模型文件。它抓取或模型文件加载它们,并使用 adam optimizer 编译它们,使它们为预测做好准备。
这里,我们使用分类交叉熵作为我们的损失函数, adam 作为我们的优化器,而准确性作为我们的性能测量指标。
你可以从 这里 学习如何使用 Keras 保存模型。
继续查看. py
这里我们有另一个帮助函数来帮助我们转换我们的 BASE64 图像文件;它是从客户端抓取到一个 PNG 文件;并保存为输出变量中的任何内容;即在当前目录下保存为 output.png 文件。
**def getI420FromBase64(codec):
base64_data = re.sub('^data:image/.+;base64,', '', codec)
byte_data = base64.b64decode(base64_data)
image_data = BytesIO(byte_data)
img = Image.open(image_data)
img.save(OUTPUT)def convertImage(imgData):
getI420FromBase64(imgData)**
编写我们的 API
现在让我们把主要的 API 写到:
- 获取客户端提交的 base64 图像文件
- 将其转换成 png 文件
- 处理它以适应我们的训练模型文件
- 使用我们之前的帮助函数预测图像,并获得相应的性能指标
- 将其作为 JSON 响应返回
**[@csrf_exempt](http://twitter.com/csrf_exempt)
def predict(request):imgData = request.POST.get('img')convertImage(imgData)
x = imread(OUTPUT, mode='L')
x = np.invert(x)
x = imresize(x, (28, 28))
x = x.reshape(1, 28, 28, 1)
with graph.as_default():
out = model.predict(x)
print(out)
print(np.argmax(out, axis=1))
response = np.array_str(np.argmax(out, axis=1))
return JsonResponse({"output": response})**
它使用 csrf_exempt decorator,因为 Django 对安全性非常严格。通过使用它,我们只是禁用 CSRF 验证。
现在,我们已经完成了应用程序后端代码的编写,可以对给定图像的标签进行分类。
提供路线
现在,让我们为我们的主要功能提供一条路线。
转到 settings.py 和 urls.py 文件所在的项目文件夹。
在 INSTALLED_APPS 数组下的 settings.py 文件中,安装我们之前创建的用于编写函数的主应用程序。
**INSTALLED_APPS = [
'django.contrib.admin',
'django.contrib.auth',
'django.contrib.contenttypes',
'django.contrib.sessions',
'django.contrib.messages',
'django.contrib.staticfiles', ## our main application
'main'
]**
之后,返回 urls.py 文件,编写一条到达我们的 predict 函数的路径。
**from django.contrib import admin
from django.urls import path, include
from main.views import predicturlpatterns = [
path('', include('main.urls')),
path('api/predict/', predict)
]**
保存所有东西,现在我们的后端 API 已经准备好了。
前端部分
现在是时候写我们的前端代码,使我们能够与我们的后端 API 进行交互。
我们使用 Django 的模板来编写我们的前端。
让我们在主文件夹中创建一个模板文件夹,然后在里面创建一个index.html文件。
在 HTML 文件中,让我们编写一些代码来创建一个画布,并提交用户在该画布中绘制的图像。
**<canvas
id="canvas"
width="280"
height="280"
style="border:2px solid; float: left; border-radius: 5px; cursor: crosshair;"
></canvas><p id="result" class="text-center text-success"></p>
<a href="#" class="btn btn-success btn-block p-2" id="predictButton">
Predict
</a>
<input
type="button"
class="btn btn-block btn-secondary p-2"
id="clearButton"
value="Clear"
/>**
你可以随心所欲地设计你的前端,并在里面创建画布。
显示画布后,让我们用一些 JS(Jquery)使它变得难以处理。
**(function()
{
var canvas = document.querySelector( "#canvas" );
canvas.width = 280;
canvas.height = 280;
var context = canvas.getContext( "2d" );
var canvastop = canvas.offsetTopvar lastx;
var lasty;context.strokeStyle = "#000000";
context.lineCap = 'round';
context.lineJoin = 'round';
context.lineWidth = 5;function dot(x,y) {
context.beginPath();
context.fillStyle = "#000000";
context.arc(x,y,1,0,Math.PI*2,true);
context.fill();
context.stroke();
context.closePath();
}function line(fromx,fromy, tox,toy) {
context.beginPath();
context.moveTo(fromx, fromy);
context.lineTo(tox, toy);
context.stroke();
context.closePath();
}canvas.ontouchstart = function(event){
event.preventDefault();lastx = event.touches[0].clientX;
lasty = event.touches[0].clientY - canvastop;dot(lastx,lasty);
}canvas.ontouchmove = function(event){
event.preventDefault();var newx = event.touches[0].clientX;
var newy = event.touches[0].clientY - canvastop;line(lastx,lasty, newx,newy);lastx = newx;
lasty = newy;
}var Mouse = { x: 0, y: 0 };
var lastMouse = { x: 0, y: 0 };
context.fillStyle="white";
context.fillRect(0,0,canvas.width,canvas.height);
context.color = "black";
context.lineWidth = 10;
context.lineJoin = context.lineCap = 'round';debug();canvas.addEventListener( "mousemove", function( e )
{
lastMouse.x = Mouse.x;
lastMouse.y = Mouse.y;Mouse.x = e.pageX - this.offsetLeft;
Mouse.y = e.pageY - this.offsetTop;}, false );canvas.addEventListener( "mousedown", function( e )
{
canvas.addEventListener( "mousemove", onPaint, false );}, false );canvas.addEventListener( "mouseup", function()
{
canvas.removeEventListener( "mousemove", onPaint, false );}, false );var onPaint = function()
{
context.lineWidth = context.lineWidth;
context.lineJoin = "round";
context.lineCap = "round";
context.strokeStyle = context.color;context.beginPath();
context.moveTo( lastMouse.x, lastMouse.y );
context.lineTo( Mouse.x, Mouse.y );
context.closePath();
context.stroke();
};function debug()
{
/* CLEAR BUTTON */
var clearButton = $( "#clearButton" );clearButton.on( "click", function()
{context.clearRect( 0, 0, 280, 280 );
context.fillStyle="white";
context.fillRect(0,0,canvas.width,canvas.height);});/* COLOR SELECTOR */$( "#colors" ).change(function()
{
var color = $( "#colors" ).val();
context.color = color;
});/* LINE WIDTH */$( "#lineWidth" ).change(function()
{
context.lineWidth = $( this ).val();
});
}
}());**
这基本上是我们的 JS 函数,允许用户在我们的画布内绘图。它抓住用户的鼠标+触摸笔划,并根据他们的绘图在画布内绘制线条。
之后,让我们编写一个代码,将这些绘制的线条作为 base64 图像文件提交到后端。
**<script type="text/javascript">
$("#predictButton").click(function() {
var $SCRIPT_ROOT = "/api/predict/";
var canvasObj = document.getElementById("canvas");
var context = canvas.getContext( "2d" );
var img = canvasObj.toDataURL();
$.ajax({
type: "POST",
url: $SCRIPT_ROOT,
data: { img: img },
success: function(data) {
$("#result").text("Predicted Output is: " + data.output);context.clearRect( 0, 0, 280, 280 );
context.fillStyle="white";
context.fillRect(0,0,canvas.width,canvas.height);}
});
});
</script>**
这里我们使用 jquery 来:
- 收听我们的按钮点击事件
- 定义我们的 API 路由路径
- 抓住我们的画布元素
- 以 base64 图像的形式获取画布的上下文
- 使用 ajax 请求将其提交到我们的后端
- 从我们的后端获得一个响应,并显示在我们的输出部分。
现在最后,让我们添加一个路由到我们的前端,并编写一个函数来服务我们的主应用程序中的 HTML 文件。
**# views.pydef index(request):
return render(request, 'index.html', {})# urls.py
from django.urls import path
from .views import indexurlpatterns = [
path('', index, name="index")
]**
就是这样!我们已经成功地完成了我们的后端+前端开发,以识别手写数字。
现在让我们部署它。
部署

我们将使用 Heroku 来部署我们的 Django 项目,因为它很棒而且免费!
你可以从 heroku 的官方文档页面了解更多。它很漂亮,一切都有据可查。
在你的笔记本电脑上安装 Heroku CLI,让我们开始吧。
为了准备好我们的 Django 项目 Heroku,让我们在根目录中编写一个 Procfile 。
**# Procfileweb: gunicorn digitrecognizer.wsgi --log-file - --log-level debug**
现在让我们在 Heroku 中创建新的应用程序存储库,并获取该应用程序的远程 URL。

之后,git 初始化我们的项目目录,将 git 远程 URL 添加到 Heroku url,并将我们的项目文件夹推送到 Heroku,其中包含 requirements.txt 文件。
这就是部署😊。我们已经成功地在云中部署了我们的应用程序,现在它已经上线了。您可以使用 Heroku 在您的应用仪表板中提供的 URL 来访问该应用。
最后的想法
在真实环境中部署您的项目以展示您的项目是非常重要的。这对你的项目组合很有帮助。
我希望您已经学到了一些东西,尝试构建自己的手写数字分类器,并将其部署到生产环境中。你可以从 这里 查看我的演示 app。
参考
**[1] 熊伟·弗莱塔斯,如何在 Heroku 上部署 Django 应用,2016 年 8 月 9 日[ 在线 ]
[2] 扬·勒库恩, MNIST 数据库,1998 [ 在线 ]
揭秘机器学习模型的部署(第 1 部分)
如何设计预测贷款违约率的算法

source: https://blogs.oracle.com/r/data-science-maturity-model-deployment-part-11
这是由两部分组成的系列文章的第一部分。你可以读一下 第二部分在这 之后
想象一下,建立一个受监督的机器学习(ML)模型来决定是否应该批准贷款申请。有了模型在成功应用中的置信水平(概率),我们就可以计算无风险可贷金额。部署这样的 ML 模型是这个项目的目标。
请和我一起经历我在尼日利亚数据科学公司的实习项目,在那里我有幸与数据科学家、软件工程师和人工智能研究人员中的精英一起工作。我们的目标是在 10 年内培养 100 万人工智能人才,我很自豪能成为其中的一员。
数据科学家在 jupyter lab、google colab 等公司建立机器学习模型,而机器学习工程师将建立的模型投入生产。
ML 模型的部署简单地意味着将模型集成到现有的生产环境中,该环境可以接收输入并返回输出,该输出可用于做出实际的业务决策。
为了揭开部署过程的神秘面纱,我写了这篇文章,分为四章。在第一章中,我们介绍了构建基线模型的过程,在第二章中,我们将这个模型引入生产就绪代码。第 3 章和第 4 章包含在本系列的第 2 部分中。
第一章:建立基线模型
在这种情况下,基线模型指的是具有最小可能数量的特征但具有良好评估测量的 ML 模型。当构建用于部署目的的 ML 模型时,您必须始终考虑您的最终用户。一个拥有数千个特征的模型要达到 90%以上的评估准确率可能不够好,因为以下几个原因:
- 可移植性:软件从一台机器或系统转移到另一台机器或系统的能力。一个可移植的模型减少了代码的响应时间,并且当你的目标发生变化时,你必须重写的代码量将是最小的。
- 可伸缩性:是一个程序伸缩的能力。当一个模型不需要被重新设计来保持有效的性能时,它就被认为是可伸缩的。
- 可操作化:业务应用使用的模型的部署,用于预测分类/回归问题的目标值。
- 测试:对过程输出和输入的验证。健壮的模型将不必要地难以测试。
点击下载将用于本项目的数据集、笔记本和独家摘要,其中包含探索性数据分析、数据预处理、特征工程、特征选择、训练 ML 模型和模型评估。
作为第一步,我们使用 pandas 导入我们的测试和训练数据。
train = pd.read_csv("train.csv")
test = pd.read_csv("test.csv")
**数据预处理:**这包括将原始数据转换成适合训练模型的可理解格式。它需要处理缺失值、异常值、编码分类变量。
出于部署的目的,您希望始终保留您用来填充缺失值的值的记录,并且该方法必须是可复制的。具有缺失值的特性可以通过下面的代码片段一目了然

The horizontal white stripes indicate the locations of missing values.
有许多方法可以处理数字特征中的缺失值,但为了简单起见,我将尝试平均值和中值。
对于每个具有缺失值的数值特征,计算平均值和中值,估算该值并拟合数据模型,以查看每种情况对验证集的影响。例如,在试验 applicant_income 功能时,我们可以定义一个简单的 python 函数,它接受数据帧、感兴趣的变量、平均值和中值,并用平均值和中值填充功能的缺失部分。

split into training and testing sets and defined a function to fill in missing values
在填充缺失值时,可以执行一个简单的要素工程,即创建一个表示缺失(0 或 1)的二元要素,您可以判断缺失是否具有正面的预测效果。
#addition missingness features# create variable indicating missingness in applicant_income
X_train['applicant_income_NA'] = np.where(X_train.applicant_income.isnull(),1,0)
X_test['applicant_income_NA'] = np.where(X_test.applicant_income.isnull(),1,0)
现在,我们可以使用一个简单的逻辑回归模型来确定填充缺失值的最佳方法。
kindly download the notebook to see the full code snippets

the output of the code snippet above
对所有具有缺失值的要素重复此方法,并根据模型结果做出最佳决策。
特征工程 : 这是使用数据的领域知识来创建使机器算法工作的特征的过程。我将创建的唯一特性是 income_loan_ratio,以避免部署过程中的复杂性。
特征选择:自动或手动选择对预测变量贡献最大的特征的过程。数据中包含不相关的要素会降低模型的准确性。
有几种为最终模型选择特征的方法,包括
过滤方法如恒定特征消除、准恒定特征消除、重复特征消除、fisher 评分、单变量法、互信息、相关性等。
包装方法如向前一步选择、向后一步选择和穷举搜索等。
嵌入方法如 LASSO、决策树导出重要性、回归系数等。
**训练 ML 模型:**这个项目的机器学习算法的类型是监督的,它是一个分类模型。在训练模型之前,我们需要从目标变量中分离出特征。
我选择使用 sklearn 的 GradientBoostingClassifier 进行部署,但在实验过程中也探索了其他算法,如 xgboost、Microsoft LGBM。
kindly check the notebook for the output
车型评测
从上述训练模型的输出来看,测试数据的准确率为 70.3%,ROC-AUC 为 77.2%。由于这个项目的目标是预测抵押贷款申请的接受状态,以及预测接受的贷款申请的安全金额,70%的准确性对于问题案例场景来说已经足够好了。该模型可以在以后进行改进,但我们不会专注于此,因为我们现在希望尽可能简单地部署。
第 2 章:采用 ML 系统架构并编写生产就绪代码
根据 ISO/IEC 42010 和我的解释,架构可以被定义为软件组件的排列方式以及它们之间的交互。
ML 系统架构是指组成系统的软件组件的排列方式,以及它们之间在实现预定目标时的交互方式。ML 模型的开发和部署相对快速和便宜,但是随着时间的推移有效地维护它们是困难和昂贵的。根据贵公司的能力和目标,选择最佳架构可能有点困难,因为它需要业务、数据科学、工程和开发运维的同步。
这是两部分系列的第一部分。你可以在此 之后阅读 第二部分
设计 ML 系统架构时,应牢记以下几点。
- 模块性:预处理/特征工程中使用的代码要安排在综合流水线中。
- 再现性:每一个组件的输出必须能在任何时间版本上再现。
- 可伸缩性:模型必须能够以最短的响应时间服务于大量的客户。
- 可扩展性:应该很容易为将来的任务修改。
- 测试:测试模型版本之间差异的能力。
- 自动化:尽可能消除手动步骤,减少出错几率。
ML 架构概述
- 批量训练,动态预测,通过 REST API 服务:离线训练和持续,实时预测。
- 分批训练,分批预测,通过共享数据库服务:训练和持续离线完成,而预测在分布式队列中完成,几乎类似于实时预测
- 通过流进行训练和预测:训练和预测都是在不同但相连的流上进行的。
- 批量训练,在移动(或其他客户端)上预测:类似于类型 1,但预测是在客户小工具上进行的。
架构对比

Source: https://www.udemy.com/course/deployment-of-machine-learning-models/
对于这个项目,将使用模式 1,预测可以是单个的,也可以是批量的,也就是说,我们将在本地训练模型,并通过 flask 公开预测功能,我们可以在 flask 中上传我们的测试批量进行预测。

Source: Building a Reproducible Machine Learning Pipeline, Surgimura and Hart

Source: https://www.udemy.com/course/deployment-of-machine-learning-models/
上图可以看出,整个系统分为开发和生产。在开发中,训练数据、特征提取器和模型构建器部分是离线完成的,而生产是在线的。

Training Phase
训练数据:该单元处理用于将模型训练到训练环境中的数据集的提取和用于训练的格式化。这个单元可以是复杂的,也可以是简单的,这取决于你正在处理的 ML 架构。这可能包括从多个续集、Hadoop 分布式文件系统中提取数据或进行 API 调用,出于本项目的目的,将编写一个简单的 python 脚本,以将已经下载到文件夹/目录中的数据集提取到训练环境中,然后通过数据管道传递,在训练前将在该管道中进行若干预处理。
特征提取器:选择/生成训练模型所需的基本特征的单元。注意,这是管道使用 sklearn 的一部分。除了 sklearn 库之外,另一个可以用来完成相同任务的流行库是 TensorFlow Extended(TFX ),这超出了本文的范围。
**模型构建器:**这是对已训练模型进行序列化和持久化、版本化和格式化以进行部署的单元。在 python 上下文中,这可能是使用 setuptools 构建包或简单地将模型保存为 pickle 格式的单元,这取决于您采用的架构。这些方法之间有很大的不同,但本文不会讨论。虽然我尝试了这两种方法,但是为了简单起见,我将和你分享后一种方法。
训练模型:这是上面讨论的三个子主题的输出,可以通过 REST API 轻松部署。

Prediction Phase
这是两部分系列的第一部分。你可以读一下 第二部分在此之后
在生产中,通过 REST API 批量发送请求,由特征提取器进行清理和预处理,然后使用加载的训练模型预测贷款申请是否被接受。然后,在通过我们的端点返回预测之前,接受的贷款将进一步分析无风险可贷金额。
在第 2 部分(第 3 章和第 4 章),我将讨论如何将笔记本转换为生产就绪代码,以及如何创建可复制的管道、API 端点、通过 Postman 测试端点、CI/CD 在 ML 系统架构中的意义和使用、部署到 Pass、Docker 容器、部署到 Lass、无服务器部署等。
这是两部分系列的第一部分。你可以在此 之后阅读 第二部分
你可以通过下面的链接克隆 Github 库:
[## opeyemibami/机器学习-抵押部署-批准-状态-模型
有助于 opeyemibami/machine _ learning-Deployment-of-mortgage-Approval-Status-Model 的开发
github.com](https://github.com/opeyemibami/machine_learning-Deployment-of-Mortage-Approval-Status-Model)
包扎
有许多方法可以将 ML 模型部署到生产中,有许多方法可以存储它们,还有不同的方法可以在部署后管理预测模型。为用例选择最佳方法可能具有挑战性,但随着团队技术和分析的成熟,整体组织结构及其交互可以帮助选择正确的方法来将预测模型部署到生产中。
一定要抽出时间来看看我的其他文章和参考资料部分的进一步阅读。请记得关注我,以便获得我的出版物的通知。
具有无风险可贷金额的贷款接受状态预测
medium.com](https://medium.com/@opeyemibami/deployment-of-machine-learning-models-demystified-part-2-63eadaca1571) [## 用 NLTK 和 TensorFlow 构建对话聊天机器人(第 1 部分)
用卷积神经网络构建的网球聊天机器人
heartbeat.fritz.ai](https://heartbeat.fritz.ai/building-a-conversational-chatbot-with-nltk-and-tensorflow-part-1-f452ce1756e5) [## 用 NLTK 和 TensorFlow 构建对话聊天机器人(第 2 部分)
用卷积神经网络构建的网球聊天机器人
heartbeat.fritz.ai](https://heartbeat.fritz.ai/building-a-conversational-chatbot-with-nltk-and-tensorflow-part-2-c67b67d8ebb) [## 将机器学习模型部署为 Web 应用程序(第 1 部分)
具有 Streamlit 的机器学习支持的 Web 应用程序
heartbeat.fritz.ai](https://heartbeat.fritz.ai/deploy-a-machine-learning-model-as-a-web-application-part-1-a1c1ff624f7a) [## 将机器学习模型部署为 Web 应用程序(第 2 部分)
具有 Streamlit 的机器学习支持的 Web 应用程序
heartbeat.fritz.ai](https://heartbeat.fritz.ai/deploy-a-machine-learning-model-as-a-web-application-part-2-2f590342b390) [## 在谷歌云平台上部署机器学习模型(GCP)
在 Kaggle 上训练;部署在谷歌云上
heartbeat.fritz.ai](https://heartbeat.fritz.ai/deploying-machine-learning-models-on-google-cloud-platform-gcp-7b1ff8140144) [## 主题建模开源工具
使用 python 和 streamlit 构建的主题建模工具
medium.com](https://medium.com/towards-artificial-intelligence/topic-modeling-open-source-tool-fbdcc06f43f6)
对于建模部署策略的其他方法,您可以通过下面的链接查看 NeptuneAi 帖子:
海王星部署策略:https://neptune.ai/blog/model-deployment-strategies
参考文献
- [1] Julien Kervizic ,将机器学习(ML)模型投入生产的不同方法概述。
- [2] Mark Hornick ,数据科学成熟度模型—部署(第 11 部分)
- [3] 索莱达·加利 & 克里斯托弗·萨米乌拉,部署机器学习模型
*特别感谢我的导师(Olubayo Adekanmbi 博士、James alling ham)*Wu raola oye wus 和尼日利亚数据科学公司的全体员工。
# 100 万年
干杯!
基于 DenseNets 的相机图像深度估计
用数据做很酷的事情!
介绍
当观看二维场景时,人脑具有推断深度的非凡能力,即使是单点测量,就像观看照片一样。然而,从单幅图像进行精确的深度映射仍然是计算机视觉中的一个挑战。来自场景的深度信息对于增强现实、机器人、自动驾驶汽车等许多任务都很有价值。在这篇博客中,我们探索如何在 NYU 深度数据集上训练深度估计模型。该模型在该数据集上获得了最先进的结果。我们还添加了代码,以在用户收集的图像+视频上测试该模型。
经过训练的模型在来自野外的数据上表现非常好,如下面的视频所示。

Actual Image on left and predicted depth map on the right
完整代码在我的 Github repo 上开源。
深度信息是什么样的?深度可以存储为图像帧中每个像素到相机的距离,单位为米。下图显示了单一 RGB 图像的深度图。深度图在右边,实际深度已经用这个房间的最大深度转换成了相对深度。

RGB Image and its corresponding depth map
数据集
为了建立深度估计模型,我们需要 RGB 图像和相应的深度信息。深度信息可以通过像 Kinect 这样的低成本传感器来收集。对于这个练习,我使用了流行的 NYU v2 深度数据集来建立一个模型。该数据集由超过 400,000 幅图像及其相应的深度图组成。我在训练任务中使用了全部数据集中的 50,000 幅图像的子集。
模型概述
我阅读了几篇执行深度估计任务的论文,其中许多论文使用了编码器解码器类型的神经网络。对于深度估计任务,模型的输入是 RGB 图像,输出是深度图像,该深度图像或者是与输入图像相同的维度,或者有时是具有相同纵横比的输入图像的缩小版本。用于该任务的标准损失函数考虑了实际深度图和预测深度图之间的差异。这可能是 L1 或 L2 的损失。
我决定使用来自 Alhashim 和 Wonka 的密集深度模型。这个模型的简单性和准确性令人印象深刻。很容易理解,训练起来也比较快。它使用图像增强和自定义损失函数来获得比更复杂的架构更好的结果。该型号使用功能强大的 DenseNet 型号,带有预先调整的砝码,为编码器提供动力。
密集深度模型
本文介绍的编码器是一个预训练的 DenseNet 169。
编码器由 4 个密集块组成,出现在 DenseNet 169 模型中完全连接的层之前。它不同于其他深度模型,因为它使用非常简单的解码器。每个解码器模块由单个 bi-
线性上采样层和两个卷积层组成。遵循编码器解码器架构中的另一标准实践,上采样层与编码器中的相应层连接。下图更详细地解释了该架构。关于层的更多细节,请阅读原文。写得非常好!

Encoder Decoder model from Dense Depth Paper
训练和测试深度估计模型
在 NYU-v2 数据集的 50K 样本上训练密集深度。输入是 640×480 分辨率 RGB 图像,输出是 320×240 分辨率的深度图。使用 Adam optimizer 在 Keras 中训练该模型。我利用密集深度作者的回购开始。
训练了三种不同的模型架构:
- 原代码提供了 DensetNet 169 en-
编码器的实现。这个模型被训练了 8 个纪元(9 个小时在
NVIDIA 1080 Ti 上) - 原始代码被修改以实现 DenseNet 121 编码器,其具有比 DenseNet 169 更少的参数。该模型被训练了 6 个时期(在 GPU 上 5 个小时),因为验证损失在此
点已经稳定 - 修改了原始代码以实现 Resnet
50 编码器,该编码器具有比 DenseNet 169 更多的参数。
我试验了连接编码器和解码器的不同方式。这个模型被训练了
5 个时期(在 GPU 上 8 个小时),并且训练是不连续的,因为模型已经开始过度拟合。
所有这些代码修改都被推送到 github repo 上,并附有如何进行培训、评估和测试的解释。
评估不同的模型
我们使用三种不同的指标来比较模型性能——预测深度和实际深度的平均相对误差(rel)、RMSE (rms) —实际深度和预测深度的均方根误差以及两个深度之间的平均对数误差(log)。所有这些指标的值越低,表示模型越强。

Model Comparison
如上表所示,DenseNet 169 型号的性能优于 DenseNet121 和 ResNet 50。此外,我训练的 DenseNet 169 在性能上与原作者(Alhashim 和 Wonka)的非常接近。
结论
我们希望这篇博客能成为理解深度估计工作原理的一个好的起点。我们提供了一个管道来使用一个强大的、简单的和易于训练的深度估计模型。我们还分享了代码,可用于从您收集的室内图像或视频中获取深度图像。希望您自己尝试一下这些代码。
我有自己的深度学习咨询公司,喜欢研究有趣的问题。我已经帮助许多初创公司部署了基于人工智能的创新解决方案。请到 http://deeplearninganalytics.org/来看看我们吧。如果你有一个我们可以合作的项目,那么请通过我的网站或在 info@deeplearninganalytics.org联系我
你也可以在 https://medium.com/@priya.dwivedi的看到我的其他作品
参考文献:
自动驾驶中的深度识别
本文将介绍一些在车辆捕获的图像序列中进行深度预测的先进方法,这些方法有助于在不使用额外摄像头或传感器的情况下开发新的自动驾驶模型。
正如我在之前的文章《中提到的,自动驾驶是如何工作的?SLAM 介绍,有许多传感器用于在车辆行驶时捕捉信息。捕获的各种测量值包括速度、位置、深度、热量等。这些测量值被输入到一个反馈系统中,该反馈系统训练并利用车辆要遵守的运动模型。本文主要关注深度预测,这通常是由激光雷达传感器捕获的。激光雷达传感器使用激光捕捉与物体的距离,并使用传感器测量反射光。然而,激光雷达传感器对于日常司机来说是负担不起的,那么我们还能如何测量深度呢?我将描述的最先进的方法是无监督的深度学习方法,它使用一帧到下一帧的像素差异来测量深度。
- 请注意图片说明,因为大部分图片取自引用的原始论文,而不是我自己的产品或创作。
单深度 2
[1]中的作者开发了一种方法,该方法使用深度和姿态网络的组合来预测单个帧中的深度。他们通过在一系列帧和几个损失函数上训练他们的结构来训练两个网络。这种方法不需要地面真实数据集进行训练。相反,它们使用图像序列中的连续时间帧来提供训练信号。为了帮助约束学习,他们使用了一个姿势估计网络。根据输入图像和从姿态网络和深度网络的输出重建的图像之间的差异来训练该模型。稍后将更详细地描述重建过程。[1]的主要贡献是:
- 去除不重要像素焦点的自动遮罩技术
- 用深度图修正光度重建误差
- 多尺度深度估计
体系结构
本文的方法使用了深度网络和姿态网络。深度网络是一个经典的 U-Net [2]编码器-解码器架构。编码器是预训练的 ResNet 模型。深度解码器与之前的工作类似,将 sigmoid 输出转换为深度值。

Sample image of U-Net [2].

6-DoF. Image from Wikipedia.
作者使用 ResNet18 中的姿势网络,该网络经过修改,可以将两幅彩色图像作为输入来预测单个 6 自由度相对姿势,或者旋转和平移。姿态网络使用时间帧作为图像对,而不是典型的立体图像对。它从序列中另一个图像的视点预测目标图像的外观,无论是前一帧还是后一帧。
培养
下图说明了该架构的培训过程。

Images taken from KITTI and [1].
光度重建误差
目标图像位于第 0 帧,用于我们预测过程的图像可以是前一帧或后一帧,因此是第+1 帧或第-1 帧。该损失基于目标图像和重建的目标图像之间的相似性。重建过程从使用姿态网络从源帧(帧+1 或帧-1)计算变换矩阵开始。这意味着我们正在使用关于旋转和平移的信息来计算从源帧到目标帧的映射。然后,我们使用从目标图像的深度网络预测的深度图和来自姿态网络的变换矩阵投影到具有固有矩阵 K 的相机中,以获得重建的目标图像。该过程需要首先将深度图转换成 3D 点云,然后使用相机固有特性将 3D 位置转换成 2D 点。产生的点被用作采样网格,从目标图像对进行双线性插值。
这种损失的目的是减少目标图像和重建的目标图像之间的差异,其中姿态和深度都是需要的。

Photometric Loss function from [1].

Benefit of using minimum photometric error. Pixel area circled are occluded. Image from [1].
典型地,类似的方法将重新投影误差一起平均到每个源图像中,例如帧+1 和帧-1。然而,如果一个像素在这些帧之一中不可见,但是因为它靠近图像边界或被遮挡而在目标帧中,则光度误差损失将不公平地高。为了解决与此相关的问题,他们在所有源图像上取最小光度误差。
自动遮罩
最终的光度损失乘以一个遮罩,该遮罩解决了与相机在静态场景中移动的假设中的变化相关的问题,例如,一个对象以与相机相似的速度移动,或者当其他对象正在移动时相机已经停止。这种情况的问题是深度图预测无限的深度。作者用一种自动蒙版方法解决了这个问题,这种方法可以过滤掉从一帧到下一帧外观不变的像素。它们使用二进制生成它们的掩模,其中如果目标图像和重建的目标图像之间的最小光度误差小于目标图像和源图像的最小光度误差,则为 1,否则为 0。

Auto-masking generation in [1] where Iverson bracket returns 1 if true and 0 if false.
当相机静止时,结果是图像中的所有像素都被遮蔽。当物体以与相机相同的速度移动时,会导致图像中静止物体的像素被遮蔽。
多尺度估计
作者结合了每个尺度下的个体损失。它们将较低分辨率的深度图上采样到较高的输入图像分辨率,然后以较高的输入分辨率重新投影、重新采样并计算光度误差。作者声称,这限制了每个比例的深度图朝着同一目标工作,即目标图像的精确高分辨率重建。
其他损失
作者还使用平均归一化的逆深度图值和输入/目标图像之间的边缘感知平滑度损失。这鼓励模型学习尖锐的边缘并平滑掉噪声。
最终损失函数变为:

The final loss function in [1] which is averaged over each pixel, scale and batch.
结果
作者在包含驾驶序列的三个数据集上比较了他们的模型。在所有的实验中,他们的方法胜过了几乎所有其他的方法。下图显示了它们的性能示例:

Image from [1] GitHub repository: https://github.com/nianticlabs/monodepth2/
有关他们的结果的更多细节,请参见原始论文“深入研究自监督单目深度估计
Monodepth2 扩展:Struct2Depth
物体运动建模
Google brain 的作者发表了进一步扩展 Monodepth2 的文章[3]。他们通过预测单个物体的运动来改进之前的姿态网络,而不是将整个图像作为一个整体。因此,重建的图像不再是单一的投影,而是一系列的投影,然后被组合起来。他们通过两个模型来做到这一点,一个对象运动模型和一个自我运动网络(类似于前面章节中描述的姿态网络)。步骤如下:

Sample output for Mask R-CNN [2]. Image from [2].
- 应用预训练的掩模 R-CNN [2]来捕获潜在移动对象的分割。
- 二进制掩模用于从静态图像(帧-1、帧 0 和帧+1)中去除这些潜在的运动物体
- 掩蔽的图像被发送到自运动网络,并且输出帧-1 和 0 以及帧 0 和+1 之间的变换矩阵。

The masking process to extract the static background followed by the ego-motion transformation matrix without objects that move. Equation from [3].
- 使用步骤 3 中得到的自我运动变换矩阵,并将其应用于第 1 帧和第+1 帧,以获得扭曲的第 0 帧。
- 使用从步骤 3 得到的自运动变换矩阵,并将其应用于潜在移动对象到帧-1 和帧+1 的分割蒙版,以获得帧 0 的扭曲分割蒙版,所有都针对每个对象。
- 使用二进制掩模来保持与扭曲的分割掩模相关联的像素。
- 屏蔽的图像与扭曲的图像相结合,并被传递到输出预测的对象运动的对象运动模型。

The object motion model for one object. Equation from [3].
结果是为了“解释”物体外观的变化,照相机必须如何移动的表示。然后,我们希望根据从对象运动建模过程的步骤 4 得到的运动模型来移动对象。最后,我们将扭曲的对象运动与扭曲的静态背景相结合,以获得最终的扭曲:

Equation from [3].

Image from [5]
学习目标量表
虽然 Monodepth2 通过其自动遮罩技术解决了静态对象或以与相机相同的速度移动的对象的问题,但这些作者建议实际训练模型来识别对象比例,以改善对象运动的建模。

Image from Struct2Depth. Middle column shows the problem of infinite depth being assigned to objects moving at the same speed of the camera. The third column shows their method improving this.
他们根据对象的类别(如房屋)来定义每个对象的比例损失。其目的是基于对物体尺度的了解来约束深度。损失是图像中对象的输出深度图与通过使用相机的焦距、基于对象类别的高度先验以及图像中被分割对象的实际高度计算的近似深度图之间的差,两者都由目标图像的平均深度来缩放:

The formulation for the loss that helps the model learn object scale. Equations from [3].
结果
[3]中描述的扩展直接与 Monodepth2 模型进行比较,显示出显著的改进。

The middle row shows the results from [3] while the ground truth is shown in the third row. Image from [5].
摘要
自动驾驶中深度估计的常用方法是使用一对立体图像,需要两个摄像头或一个激光雷达深度传感器。然而,这些都是昂贵的,并不总是可用的。这里描述的方法能够训练深度学习模型,该深度学习模型在一幅图像上预测深度,并且仅在一系列图像上训练。它们表现出良好的性能,在自动驾驶研究方面有着广阔的前景。
为了亲自尝试这些模型,这两份报纸都有位于下面的存储库:
单部门 2:https://github.com/nianticlabs/monodepth2
struct 2 depth:https://github . com/tensor flow/models/tree/master/research/struct 2 depth
参考
[1]戈达尔,c .,麦克奥德哈,o .,菲尔曼,m .,&布罗斯托,G. (2018)。深入研究自我监督的单目深度估计。 arXiv 预印本 arXiv:1806.01260 。
[2]奥拉夫·龙内贝格、菲利普·费舍尔和托马斯·布罗克斯。U-Net:生物医学图像分割的卷积网络。InMICCAI,2015。
[3] 文森特·卡塞尔、苏伦·皮尔克、礼萨·马赫茹里安、阿内莉亚·安杰洛娃:没有传感器的深度预测:利用结构从单目视频进行无监督学习。第三十三届 AAAI 人工智能会议(AAAI’19)。
[4] He,k .,Gkioxari,g .,Dollár,p .,& Girshick,R. (2017 年)。屏蔽 r-cnn。IEEE 计算机视觉国际会议论文集(第 2961–2969 页)。
[5] Vincent Casser , Soeren Pirk , Reza Mahjourian , Anelia Angelova :无监督单目深度和自我运动学习,具有结构和语义。CVPR 视觉里程计研讨会&基于位置线索的计算机视觉应用(VOCVALC),2019
描述人工智能

公司正在投资数百万英镑开发人工智能(AI)技术。许多人每天都在使用人工智能技术,让他们的生活变得更加轻松。但是在谷歌上搜索“人工智能”的图片,你会看到一片发光的、亮蓝色的、相互连接的大脑的海洋。用来说明人工智能的图像与人工智能在用户眼中的更平凡的现实相去甚远,在用户眼中,人工智能为导航、语音助手和人脸识别等服务提供支持。这种脱节让人们很难把握人工智能的现实。

用来描述人工智能的语言可能和使用的图像一样有问题。随着人工智能越来越多地影响如此多的人的日常生活,准确地描述它,而不是模糊设计系统的人的责任是非常重要的。
“人工智能自学”
大部分关于 AI 的文章都在说机器学习(ML)。那是一套从数据中训练模型的算法。训练后,模型对训练数据中存在的模式进行编码。机器学习是我们所知的让计算机执行复杂任务的最佳方式,比如理解语音,这是我们无法明确编程让它们去做的。
我们谈论 ML 模型学习,所以写“AI 教自己……”做一些事情是很有诱惑力的。例如,AI 已经自学了偏好男性候选人、玩游戏、、解魔方等等。短语“自学是有问题的,因为它暗示计算机和机器学习模型有代理。它隐藏了机器学习的现实,即科学家或工程师仔细构建数据集和模型,然后花大量时间构建和调整模型,直到它们表现良好。该模型仅从训练数据中学习,训练数据通常以某种方式受到约束。也许只有有限数量的数据可用,或者有限的时间和计算能力来运行训练。无论约束条件如何,模型最终学到的东西都受到其创造者的设计选择的强烈影响。
“人工智能作弊”
机器人还教自己作弊,可能通过隐藏数据或利用电脑游戏中的漏洞。然而,欺骗是一个情绪化的词,也暗示了欺骗背后的意图。
欺骗(动词):“为了获得利益而不诚实或不公平地行事”
ML 模型被训练完成的任务是由它的创建者很好地定义的。通常,不完美的模拟或视频游戏被用来模仿现实世界,因为在外面太昂贵或太危险。在这些模拟中,计算机可以比人重复相同的动作更多次,并且行动更快,因此它们可以发现和利用人无法发现的错误。他们不会因为点击鼠标或按下按钮的物理行为而慢下来。发现和利用任务中的错误是机器学习模型的完美合理的预期结果。我们有一个默契,利用模拟或电脑游戏中的漏洞是作弊。然而,计算机不知道这不符合游戏的精神。他们看不到游戏规则和执行过程中的错误之间的区别。
“这个机器人无视物理定律!”
在现实世界中,没有什么能违背物理定律。当一个模拟违反物理定律时,就有问题了。机器学习模型可以利用模拟中的错误来发明行为,我们直观地知道这些行为是错误的,但这些行为满足任务的约束。尽管如此,结果可能很有趣,并告诉我们一些关于机器学习如何工作的事情:
“当他们对算法没有任何限制,并要求它穿过一个充满障碍的路线时,人工智能建造了一个极高的两足动物,它只需摔倒就可以到达出口。”
“人工智能可以判断你是不是罪犯”
已发表的研究表明,人工智能可以从你的脸部照片判断你是罪犯还是你的性取向,从你的声音判断你是否在撒谎,或者从你的步态识别你的情绪。但是,即使是表现最好的人工智能也不能完成不可能的事情。
用于训练机器学习模型的数据集必须被准确标记。如果人们不能准确地标记数据集,那么机器就不太可能学习这项任务。有时需要专家来标记数据集——几乎任何人都可以转录音频,但很少有人有专业知识来标记 MRI 扫描——但准确的数据标签对机器学习任务来说是必不可少的。对任何人来说,正确标记性取向,你是否在说谎,你是否是一个罪犯,或者你处于什么样的情绪状态都是一项不可能的工作。
有一些场景,机器学习可以揭示人们看不到的模式。例如,可以使用来自活检的附加信息来标记 MRI 扫描。也许做标记的医生不能从图像中确定肿块是否是癌性的,但是来自活检的额外信息可以帮助标记图像。然而,在这种情况下,您必须额外注意设置和评估,以确保模型确实在学习新的和新奇的东西。
关于用于训练 ML 模型的数据集,需要注意的另一点是,它们是由在约束内工作的人构建的。这些限制可能与时间、金钱、标签工作或其他事情完全相关。例如,在对性取向的研究中,研究人员从约会网站上搜集了个人资料照片。用户从他们自己的许多照片中选择约会简档照片,以向世界传达特定的图像。从这些照片中预测性取向告诉我们的更多的是性别表述的文化规范,而不是你是否可以从一个人的面部预测他的性取向。有时,在实验室环境中完成一项任务的令人印象深刻的结果并不能转移到现实世界中。
机器学习和人工智能最近显示了一些令人印象深刻的结果——包括语言之间的翻译,过滤掉你的垃圾邮件,回答问题,检测欺诈,驾驶汽车等等。去掉夸张并不会减损它的成功,最终会让每个人更容易理解。
** NB:不能,也不应该。关于性取向研究的更深入的探讨,请看这篇* 文章
原载于 2019 年 9 月 18 日http://mycomputerdoesntlisten.wordpress.com。你可以雇用我!如果我能帮助你的组织使用 AI &机器学习,请 取得联系 。
时间序列建模中的描述统计学

有各种统计测试可以用来描述时间序列数据。时间序列建模要求数据以某种方式存在,这些要求因模型而异。这些模型一旦符合数据,就需要通过统计测试进行某种验证。
但最常见的是,我们在时间序列中寻找的是平稳性、因果性、相关性、季节性等属性。ARMA、ARIMA、SARIMA、Holt Winters 等模型处理不同类型的时间序列数据。需要检查数据的底层属性,statsmodels 有各种测试来探索和处理这些属性。以下是这些属性的简要概述。
平稳性
如果时间序列不随时间线性或指数增加或减少(无趋势),并且不显示任何类型的重复模式(无季节性),则称其为平稳的。在数学上,这被描述为随着时间的推移具有恒定的平均值和恒定的方差。同样,对于方差,自协方差也不应该是时间的函数。如果你已经忘记了什么是均值和方差:均值是数据的平均值,方差是距离均值的平均平方距离。

Stationary data: Total number of daily female births

Non- stationary data: Number of airlines passengers over the years
一些模型对时间序列的平稳性做了一般性的假设,但大多数模型如 ARMA、ARIMA、SARIMA、VARMA 等。,需要数据是平稳的。但是,我们如何确定给定的数据是否是平稳的呢?
理解这一点的最基本的方法是绘制数据,并检查是否有任何潜在趋势或季节性的迹象。这种视觉练习很少有帮助,而且通常人眼很难分辨出来。因此,我们可以将滚动统计(如移动平均)添加到具有固定窗口大小的数据中,以检查平稳性。

Rolling mean with a window size of 12
有时,甚至很难直观地解释滚动平均值,因此我们借助统计测试来确定这一点,一个这样的增强 Dickey Fuller 测试。ADCF 检验是使用 python 中的 statsmodels 实现的,它执行经典的零假设检验并返回 p 值。
*原假设检验的解释:*如果 p 值小于 0.05 (p 值:低),我们拒绝原假设,假设数据是平稳的。但是,如果 p 值大于 0.05 (p 值:高),那么我们无法拒绝零假设,并确定数据是非平稳的。
一旦确定了数据集的稳定性,我们就根据需求执行转换。如果发现数据是稳定的,我们继续对其进行建模,但是如果发现数据不是稳定的,那么我们必须在拟合模型之前对其进行转换。“差分”是一种将数据转换为静态数据的常用方法,它只不过是找到连续数据项之间的差异,并将它们移动 1。首先,我们尝试对数据进行一阶差分,然后是二阶、三阶等等,直到数据变得稳定。但是每一步的差异都是以丢失一行数据为代价的。(因为我们每一步都将行/数据点移动 1)如果数据显示季节性,则差异是按季节进行的。例如,如果我们有具有年度季节性的月度数据,那么我们用时间单位 12 来区别数据。
因果关系
因果关系与因果现象有关:如果一个时间序列可以用来预测另一个时间序列,那么这两个时间序列被认为有某种因果关系。如何检验因果关系?格兰杰因果关系检验无疑是检验它的最佳方法。也可以使用 python 中的 statsmodels 来实现。
从视觉上看,确定数据中是否存在因果关系变得很困难。正如我们在下面的例子中看到的,我们很难理解因果关系。

The two time series ‘a’ and ‘d’ have causality
在上图中,两个时间序列有某种因果关系;如果你把 a 向前移动两个单位,就会得到 d 值。
格兰杰因果关系检验的解释:当 p 值大于 0.05 时,没有因果关系,当 p 值较低,即小于 0.05 时,数据中有因果关系的迹象。
评估预测
时间序列建模包括通过绘制数据与某些时间单位的滞后版本来查看数据中的相关性。当我们将时间序列与其自身的滞后版本进行比较时,很难看出任何与时间显著增加的相关性。为了评估模型拟合度和预测质量,我们使用了 MAE、MSE、RMSE、AIC 和 BIC 等指标。
平均绝对误差、均方误差和均方根误差是我们用于回归问题的几种误差,因此也用于基于回归的时间序列模型。
我们想了解的是 AIC 和 BIC 指标。
AIC:1971 年开发的 Akaike 信息标准评估了一组模型——它评估了每个模型相对于其他模型的质量,并将这些模型相互比较。
AIC 专门用于基于 ARIMA 的模型,以确定 p、d、q 参数。所以,如果你要用不同的 p,d 和 q 阶来运行 ARIMA 模型,你需要一个指标来比较这些模型。AIC 是做这项工作的最佳人选。这种度量的优点是,它提供了用于努力阻止过拟合的多个参数的惩罚。假设您有一个性能相对较好的简单模型和一个性能略好于前一个模型的复杂模型。如果这两个模型之间有微小的性能改进,那么 AIC 会考虑这一点,并告诉你选择简单的模型,而不是复杂的模型。在这种情况下,复杂模型将比简单模型具有更低的信息标准值。在某种程度上,AIC 惩罚了使用太多参数的模型。
感谢您阅读文章!
带 Spotifyr 的荒岛光盘()
使用 R 中的 Spotify API 来可视化我们的朋友和家人最喜爱的音乐

介绍
一年多前,我最好的朋友、室友兼音乐势利者“山姆”突发奇想。我可能稍微夸大了这个概念,但考虑到他有限的认知能力,我认为他的提议非常简洁。两人都是 BBC 荒岛唱片系列的狂热粉丝,他指出,他认为知道他所爱的人最喜欢的音乐会比知道名人更多。对我来说,这非常有意义。我们对我们的朋友和家人有一种实际的亲近感,一种崇拜和理解,这是我们永远无法与在电视上见过但从未见过面的人联系在一起的。假设是,通过了解我们所爱的人最喜欢的音乐,我们可能会明白是什么让他们这样做。
首先,山姆让我们所有的朋友和家人给他发送他们各自的荒岛光盘,他将这些光盘整理成单独的 Spotify 播放列表。在听完每个播放列表后,萨姆来找我,问我是否可以帮助他拼凑一个片段——书面的或其他形式的——可以显示他收到的关于荒岛光盘的所有信息;既相互比较,又确定汇编之间是否存在共性。我同意帮忙,在 Spotify API 和他们的开发者文档的大力帮助下,我们能够收集到一些关于朋友和家人的播放列表的真正有趣的信息。
这篇文章将展示在我们的发现中获得信息的步骤,同时也讨论我们合成的实际结果。虽然你可能不知道我们为这首曲子所用的人,但它向你展示了 Spotify API 的一些功能,以及如何用它来比较你喜欢的人的音乐品味。
享受吧。
仅供参考: 这篇文章的一部分涉及技术设置和用于计算这项研究结果的代码。对于那些不太关心这些技术方面并且对分析结果感兴趣的人(尽管这首先是一个数据科学博客),您可以跳到“发现”部分。
方法
Spotify API
进行这种分析所需的几乎所有繁重工作都由 Spotify API 完成,我发现它具有惊人的可塑性。你不仅可以用很多有趣又酷的方式来操作和组织数据,Spotify 对你可以访问的元数据也相当开放,每个音轨都有各种各样的性能指标(见下面的“指标”)。
这一节将分解为我们朋友的所有汇编创建一个数据框架的步骤,以便进行探索性分析,这可以很容易地复制和开发。
软件包安装/帐户创建
首先,你需要安装所有用于从 Spotify API 中提取、格式化、排列和绘制数据的软件包。
要访问 Spotify Web API,您首先需要 设置一个开发帐户 。这将给你你的客户 ID 和客户秘密。一旦你有了这些,你就可以用*get _ Spotify _ access _ token()把你的访问令牌拉入 R。最简单的认证方式是将您的凭证设置为sys . setenv:*SPOTIFY _ CLIENT _ ID 和 SPOTIFY_CLIENT_SECRET 中的输入。get _ Spotify _ access _ token()(以及这个包中的所有其他函数)的默认参数将与这些相关。用您唯一的客户 ID 和 Spotify 生成的密码填充散列值:
# Install packages/load librariesinstall.packages('spotifyr')
install.packages('ggstatsplot')
library(spotifyr)
library(ggjoy)
library(lubridate)
library(tidyr)
library(dplyr)
library(ggplot2)
library(ggstatsplot)
library(yarrr)# Create access tokenSys.setenv(SPOTIFY_CLIENT_ID = ‘####’)
Sys.setenv(SPOTIFY_CLIENT_SECRET = ‘####’)
access_token <- get_spotify_access_token()
access_token
数据格式编排
如前所述,Spotify API 提供了多个有用的功能,我强烈建议您去看看。但是这篇文章是关于荒岛唱片的,所以会涉及到多个播放列表的组织和绑定。如前所述,我们让朋友和家人把他们的歌曲发过来,我们在 Spotify 上把它们组合成单独的播放列表。然后我们使用了*get _ playlist _ audio _ features()*函数,使用 playlist_uri(可以在任何公共播放列表中找到)。最佳实践是将每个 API 调用分配给一个新的向量,并创建一个名为“$curator”的新列,这将允许您按照每个单独的播放列表及其创建者来划分搜索结果。然后,您可以 rbind() 所有播放列表创建一个新的数据框(DID_project ),您可以稍后使用它来浏览数据:
# Frank Musicfrank_playlist <- get_playlist_audio_features(playlist_uris = '5s9tAnjcHVagUHtN9YXoC0')
frank_play$curator <- paste("Frank")# Joe Musicjoe_playlist <- get_playlist_audio_features(playlist_uris = '6mvg2kNHyxZ6Jgr11TuQv8')
joe_play$curator <- paste("Joe")# Sam Musicsimon_playlist <- get_playlist_audio_features(playlist_uris = '3UNv39UZ29o7dCpdXzHdUw')
simon_play$curator <- paste("Sam")DID_project <- rbind(frank_playlist, joe_playlist, sam)
韵律学
现在,这就是酷的地方。Spotify 会在每首曲目上附上大量元数据,包括:曲目时长、曲目受欢迎程度、曲目和专辑的发布日期、节奏以及歌曲创作的基调。除此之外,Spotify 还提供了许多与每首歌曲相关的指标,用于后续分析。你可以在他们的 开发者文档 中查看 Spotify 如何计算他们所有的指标。
这是我们的新数据帧,包含所有相关的音频功能和指标:

排列数据
现在,我们可以根据这些指标排列数据,并开始查看每个曲目和播放列表的表现。你必须通过曲目名称、指标,然后是馆长(这样我们可以评估每张荒岛唱片相对于其他播放列表的“性能”)。您可以将 arrange() 参数换成任何感兴趣的指标,并相应地进行选择。因为我们总共收到了 129 首曲目,所以我将范围缩小到每个音频功能的前 25 首表演曲目:
top_25_loudness <- DID_project %>%
arrange(-loudness) %>%
select(track.name, loudness, curator) %>%
head(25)
可视化数据
下面是在下面讨论的发现中使用的许多有用图的语法。
分别绘制所有策展人与曲目流行度(使用密度脊)和 pirateplot() 的关系图:
# Density plotggplot(DID_project, aes(x = DID_project$track.popularity, y = DID_project$curator, fill = DID_project$curator)) +
geom_joy() +
xlab("Track Popularity (0-100)")+
ylab("Curator")+
ggtitle("Desert Island Disc Popularity by Curator")# Pirate plotpirateplot(DID_project$track.popularity ~ DID_project$curator, DID_project,
xlab = "Curator", ylab = "Track Popularity",
theme = 0, point.o = 0.7, avg.line.o = 1, jitter.val = .05,
bty = "n", cex.axis = 0.6)# Pirate plot to calculate "DID Score"pirateplot(DID_project$track.popularity + DID_project$energy + DID_project$valence + DID_project$danceability ~ DID_project$curator, DID_project,
xlab = "Curator", ylab = "DID Score",
theme = 0, point.o = 0.7, avg.line.o = 1, jitter.val = .05,
bty = "n", cex.axis = 0.6)
根据轨道持续时间绘制所有策展人:
ggplot(DID_project, aes(x = DID_project$track.duration_ms, y = DID_project$curator, fill = DID_project$curator)) +
geom_joy() +
xlab("Track Duration (ms)")+
ylab("Curator")+
ggtitle("Desert Island Disc Track Duration by Curator")
绘制与这些音频特征相关的指标和前 25 首曲目:
ggplot(top_25_loudness, aes(x = loudness, y = track.name, col = curator, size = loudness)) +
geom_point()+
geom_joy() +
theme_joy()+
ggtitle("Top 25 - Loud Songs")
使用 ggstatsplot() 绘制相关图,以评估指标/音频特征之间的统计关系:
ggstatsplot::ggcorrmat(
data = DID_project,
corr.method = “robust”,
sig.level = 0.001,
p.adjust.method = “holm”,
cor.vars = c(energy, danceability, liveness, acousticness, loudness, instrumentalness, track.popularity),
matrix.type = “upper”,
colors = c(“mediumpurple3”, “violet”, “blue”),
title = “Correlalogram for all Spotify Performance Metrics”
)
调查的结果
追踪受欢迎程度
Spotify 是这样对他们文档中的歌曲流行度进行分类的:
曲目的受欢迎程度是一个介于 0 和 100 之间的值,100 是最受欢迎的。流行度是通过算法计算的,并且在很大程度上基于该曲目的总播放次数以及这些播放的最近时间。一般来说,现在经常播放的歌曲会比过去经常播放的歌曲更受欢迎。重复曲目(例如单曲和专辑中的同一首曲目)被独立评级。艺术家和专辑的受欢迎程度是从曲目的受欢迎程度中数学推导出来的。请注意,流行度值可能会滞后实际流行度几天:该值不会实时更新
由于播放次数似乎是评估曲目受欢迎程度的主要指标,可以说每个人在这一指标上的得分越高,他们的品味相对于 Spotify 的其他部分就越受欢迎。根据这一理论,分数越低,他们的品味就越小众。(我可以向你保证,作为本次分析中大多数策展人的密友,Spotify 在评估曲目受欢迎程度方面做得很好)。总的来说,最受欢迎的歌曲来自瑞秋、海伦和喷火战机乐队。不出所料,特里斯坦最没有流行音乐品味(或者说最小众,取决于你怎么看)。如果你认识特里斯坦,这就说得通了。他得分最低的歌曲包括:阿兹特克摄像机的《在我心中的某个地方》、恐惧之泪的《给心中的年轻人的忠告》和新秩序的《奇异的三角恋》。看起来,尽管这些 80 年代后期的新浪潮流行歌曲在特里斯坦心中有着特殊的地位,但在 Spotify 的眼中,它们仍然是一首未雨绸缪的歌曲(或肖尔迪奇的家庭聚会)。
有趣的是, Joe 就其受欢迎程度而言拥有最多样的音乐品味,歌曲从 11 首到 72 首不等;这可能意味着乔愿意听流行音乐的两端。这很有趣,因为我们家一直流传着一个笑话“乔只听摩城”。(虽然应该提到的是,这一指标的方差是衡量歌曲在 Spotify-universe 中的受欢迎程度,而不是歌曲选择的多样性,因此这一假设仍有待否定)。
这可以通过一些巧妙的方式来可视化(方法中引用的代码):

Figure 1. Desert island disc popularity (0–100) by curator

Figure 2. Track popularity (0–100) by curator
持续时间
这是一个有趣的问题。每个人的荒岛光盘似乎落在平均 3-6 分钟的区域,这是可以预期的。如果不是因为西蒙在他的播放列表中包含了两首导致数据倾斜的歌曲,这些数据会被认为是正态分布的。西蒙收录了我们收到的所有荒岛唱片中最长的两首歌曲:Yes 的《谵妄之门》(约 22 分钟)和米勒·戴维斯的《嘘/和平——LP 混音》(约 18 分钟)。两首歌加起来足足有 40 分钟,有人可能会说这对于它自己的播放列表来说已经足够了(如果你喜欢 40 分钟的摇滚和爵士乐的话!).

Figure 3. Desert island disc track duration (ms) by curator.
拍子
似乎威尔在他的播放列表中拥有最大范围的节奏——以每分钟的节拍来衡量。这可能很好地反映了他在早上举重到他最喜欢的北方摇滚乐队的能力,同时能够在作为一名工料测量师的艰难一天后放松下来。(或者更有可能的是,由于本分析中使用的名义样本量,这是一种统计上的巧合)。
似乎卡哈尔更喜欢快节奏的歌曲。也许这就是他在房子里跺着脚听的音乐,而没有考虑到他沉重的脚步对周围环境的影响?
海伦的播放列表在 120 bpm 左右形成了一个几乎完美的分布。鉴于这是“流行歌曲”的典型节奏,这些发现得到了如上所述的曲目流行度数据的支持,其中海伦的歌曲是 Spotify 上最受欢迎的歌曲之一。
Emily 的数据也形成了一个很好的钟形曲线,但是在 110 bpm 左右。也许她对慢节奏歌曲的偏好决定了她在为 M 和 s 设计典型的英国桌布时总是镇定自若,举止放松。

Figure 4. Desert island disc track tempo (bpm) by curator.
25 首充满活力的歌曲
Spotify 是这样确定活力音乐的:
能量是一种从 0.0 到 1.0 的度量,代表强度和活动的感知度量。通常,高能轨道感觉起来很快,很响,很嘈杂。例如,死亡金属具有高能量,而巴赫前奏曲在音阶上得分较低。对该属性有贡献的感知特征包括动态范围、感知响度、音色、开始速率和一般熵。该特性的值分布如下所示:

Figure 5. How Spotify determine energetic music
下面展示了策展人在这次荒岛唱片分析中选出的 25 首最响亮的歌曲:

Figure 6. Top 25 most energetic songs by curator
前 25 首响亮的歌曲
Spotify 是这样确定活力音乐的:
轨道的整体响度,以分贝(dB)为单位。响度值是整个轨道的平均值,可用于比较轨道的相对响度。响度是声音的质量,是与体力(振幅)相关的主要心理因素。值的典型范围在-60 和 0 db 之间。该特性的值分布如下所示:

Figure 7. How Spotify determine loud music
下面展示了策展人在这次荒岛唱片分析中选出的 25 首最响亮的歌曲。Spotify 是如何确定这一指标的:

Figure 8. Top 25 most loud songs by curator
统计分析
尽管这个项目使用了名义上的样本量,我还是忍不住尝试了一些统计分析。本节将简要讨论我对我们收集的所有播放列表数据进行的两项分析。
“得分了”
我在 yarrr() 包的 pirateplot() 函数中发现了一个非常酷的功能,您可以在其中创建一个包含多个其他指标的组合效果的自定义变量。考虑到荒岛唱片是指当你被困在荒岛上时你会听的实际音乐,我创建了一个名为“DID Score”的变量,我觉得它最能反映如果你真的独处了很长一段时间你可能会选择听的音乐类型。此输出是从 Spotify API 中提取的以下变量的综合得分:
**人气:**先前定义(见上图)
**能量:**先前定义的(见上文)
效价:从 0.0 到 1.0 的量度,描述一首曲目所传达的音乐积极性。高价曲目听起来更积极(例如,快乐、愉快、欣快),而低价曲目听起来更消极(例如,悲伤、沮丧、愤怒)。该特性的值分布如下所示:

Figure 9. How Spotify determine valence
**可跳舞性:**根据音乐元素的组合,包括速度、节奏稳定性、节拍强度和整体规律性,描述一首曲目适合跳舞的程度。值 0.0 最不适合跳舞,1.0 最适合跳舞。该特性的值分布如下所示:

Figure 10. How Spotify determine danceability
下面反映了所有策展人如何为他们的 DID 评分(对不起特里斯坦!):

Figure 11. DID Score for all curators
相关分析
我尝试了一下,看看从 Spotify API 中提取的任何音频功能/指标之间是否有任何相关的关联。有趣的是,没有独立变量与跟踪受欢迎程度相关。响度和能量显著相关(0.74)。精力和跳舞能力也是如此(0.36)。毫不奇怪,能量和声音(-0.71)以及响度和声音(-0.54)之间存在负相关。这比什么都重要,是一个相当好的指标,表明 Spotify 对这些音频功能的分类相当严格。然而,值得一提的是,这种分析只在我们收到的荒岛光盘播放列表中使用的 129 个数据点上进行。很有可能通过增加样本量,Spotify 的音频功能——无论是独立的还是作为多元线性模型的一部分——能够预测歌曲的受欢迎程度。然而,这仍有待阐明。

结论
音乐是我们生活中极其重要的一个方面。我们可能与电车上邻座的男人、地铁上的女人品味不同,当然也不会与在合作社花很长时间结账的老太太品味相同,但我们确实有一个共同的理解,那就是音乐能够带我们去某个地方。一些音乐激励我们在周六踢足球,一些音乐让我们反思我们希望能够收回的时间,一些音乐带我们回到我们最喜欢的海滩,在任何酷玩唱片的情况下,一些音乐让我们真诚地沮丧或想睡觉。
为了了解我们的朋友和家人喜爱的音乐,Sam 和我不仅能够实际聆听我们收到的播放列表,解读它们与馆长的相关性,还能想象它们对更广泛的音乐社区以及与其他人的播放列表的关系的重要性。在 Spotify 和他们的公共 API 的帮助下,以及这与 R 的良好集成,我能够对我们收到的播放列表所附的数据进行一些真正有趣的探索性分析,如果你对音乐或数据的热爱甚至只有我的一半,我真诚地推荐这个练习。
为您的变革管理设计实验
实验设计的逐步指南

数据科学专业人员,您是否曾经面临过以下任何挑战?
故事一:机器学习不等于实验设计
由于你的统计专业知识,你被要求设计一个实验,但是你意识到你的机器学习工具不能帮助你设计一个实验。
故事二:观测数据不可重复
你的团队观察到了与几个因素相关的销售趋势。你的团队想要提出新的商业策略。但是团队不能决定复制该过程的正确因素。
故事 3:相关性不是因果关系
你的团队发现了两个因素之间的强相关性,并提出了业务变革计划。你的团队得到了客户的认可,在一个有希望的试点测试中实现了商业提议。测试期过后,你没有得到声称的结果。
如果是这样,你可能犯了用相关性来证明因果关系的错误。在我的岗位"机器学习还是计量经济学?“我分享过很多解析题都是关于因果的。这些因果问题需要数据生成的设计,不能从大数据中导出。今天,机器学习和统计实验的分歧似乎汇聚到了大数据科学的保护伞下。然而,这两个不同的学科可以而且应该交叉融合来解决众多的业务计划。
使用实验设计是做这件事的正确方法。实验设计已经在制造业、临床试验和医院服务中实践了几十年。在这篇文章中,我将带你经历建立一个成功的 DoE 的步骤,从而引导你进行变革管理。我将用银行业的一个服务操作来介绍 DoE 的思路。
什么是实验设计(DoE)?
实验设计是对受控测试进行适当的计划、实施、分析和解释,以评估影响结果的因素。
DoE 有什么好处?
实验的设计能够真正识别因果洞见。结果使您能够为您的变更管理提出可行的策略。DoE 成本更低。它使用统计学来设计有效测试结果的最小样本量。您可以同时处理多个输入因素,并识别可能会错过的重要交互。
[## 通过我的推荐链接加入 Medium-Chris Kuo/data man 博士
阅读 Chris Kuo/data man 博士的每一个故事。你的会员费直接支持郭怡广/戴塔曼博士和其他…
dataman-ai.medium.com](https://dataman-ai.medium.com/membership)
它是如何工作的?
DoE 在以下七个步骤中有其成熟的程序。第一,目标是什么?您应确定目标的衡量标准。二、考什么?你将确定测试的因素。第三,如何进行?你将决定指导和衡量的方式。第四,如何衡量?你会选择正确的统计分析。第五,结果是否可信?您将确定所需的样本量。六、如何分析数据?应用统计分析。第七,接下来是什么?在统计分析的帮助下,你可以做出结论和可行的项目。

案例研究:银行业服务运营的 DoE
以下是美国能源部指导变革管理的成功案例。
一家零售银行需要重新设计其账户申请流程。虽然可以在线申请,但仍然需要无需预约的申请。该银行的不完整申请比例很高,需要重新处理申请。再加工工作也减缓了其他操作,导致整体效率低下。银行需要实施正确的行动改变,以消除再加工中的浪费。
步骤 1:确定目标的衡量标准
可量化的目标总是起点。项目团队决定将完成应用程序的百分比作为目标。该团队排除了其他有趣但不太相关的指标,如平均存款额。
步骤 2:确定测试的因素
项目团队怀疑有四个因素可能会影响应用程序是否完整。该团队为四个因素中的每一个设计了两个级别:(I)申请类型(贷款账户或储蓄账户),(ii)分行位置(中西部和东北部),(iii)申请表的说明(中级或高级描述),以及(iv)有无示例。
步骤 3:确定指导和衡量的方式
实验在两个分支进行了两个月。自行管理的申请表继续在前台展示,因此展示方式没有变化。每个地点只有一种类型的申请表。表(A)中列出了这些因素的不同组合。

Exhibit (A)
步骤 4:选择正确的统计分析
项目团队需要了解各种因素水平的所有可能组合的影响。图表(A)被称为全因子设计。这样的实验允许研究者研究每个因素对目标变量的影响,以及因素之间的相互作用对目标变量的影响。
步骤 5:确定所需的样本量
如何确定析因分析的最小样本量?这是一个棘手的问题,因为它不仅取决于因素的数量,还取决于每个因素的“负载”或系数。正如“探索性和验证性因子分析”( Bruce Thompson,2004 )所解释的,如果一个因子有四个以上的水平,并且每个水平的系数小于 0.60,那么 N = 60 就足够了。如果一个因子有十个以上的水平,每个水平的系数在 0.40 左右,那么样本量至少应该是 150。任何超过 300 的样本量都被认为是足够的。项目组决定在每个因素组合中收集至少 300 份申请。
步骤 6:进行统计分析
该项目的目标是确定哪个因素组合显示出具有统计显著性的最高平均值。“统计显著性”是关键,这意味着这种差异足以保证下次的可重复性。研究小组使用了一种叫做 ANOVA(方差分析)的技术来比较“平均”。%完成”来验证差异是否具有统计学意义。
图表(B)显示了五个因素之间的差异。只有“描述”和“示例”中的差异在统计上具有显著性,置信度为 95%。这意味着高水平的描述和申请表中的例子将导致高完成率。

Exhibit (B)
一个因素可以影响另一个因素。这是通过因素之间的相互作用捕捉到的。申请表中的一个“例子”预计会降低中西部的毕业率,但会提高东北部的毕业率。

步骤 7:结论和可行策略
基于这些结果,项目团队总结了几个可行的策略:
- 两种账户类型的申请表格相同
- 提供更多描述
- 在申请表中为东北地区提供了一个示例,但没有为中西部地区提供示例
新的申请表将完成率从 60%提高到 95%以上。这一改变大大缩短了申请时间,并消除了重新处理的时间。
这里值得注意的是,在“识别因果关系”系列文章中,我涵盖了旨在识别因果关系的计量经济学技术。这些文章涵盖了回归不连续性、差异中的差异、面板数据分析和因子设计的随机对照试验:
- 机器学习还是计量经济学?(见“机器学习还是经济学?
- 回归不连续(见通过回归不连续识别因果关系),
- (DiD)(见)【通过差异鉴别因果关系】
- 固定效应模型(参见通过固定效应模型识别因果关系)**、**
- 采用析因设计的随机对照试验(参见“您的变更管理实验设计”)。
您还可以将“ Dataman 学习路径——培养技能,推动职业发展”加入书签,了解更多信息。
** [## 通过我的推荐链接加入 Medium-Chris Kuo/data man 博士
阅读 Chris Kuo/data man 博士的每一个故事。你的会员费直接支持郭怡广/戴塔曼博士和其他…
dataman-ai.medium.com](https://dataman-ai.medium.com/membership)**
R 的实验设计
r 代表工业工程师
构建 2^k 析因设计

Image by Hans Reniers available at Unsplash
实验设计
实验设计是六适马方法中最重要的工具之一。这是 DMAIC 循环中改进阶段的精髓,也是稳健流程设计的基础。
实验设计被定义为应用统计学的一个分支,它处理计划、实施、分析和解释受控试验,以评估控制一个参数或一组参数值的因素。DOE 是一个强大的数据收集和分析工具,可用于各种实验情况。它允许操纵多个输入因素,确定它们对期望输出(响应)的影响。
-美国质量协会
充分利用 DOE 将导致过程的改进,但是糟糕的设计会导致错误的结论,并产生相反的效果:效率低下,成本更高,竞争力更弱。
2^ k 析因设计
2^ k 析因设计是一般析因设计的特例; k 因子正在研究中,都在 2 个级别(即高,称为“+”或“+1”,低,称为“-”或“–1”)。这种析因设计广泛用于工业实验中,并且由于筛选大量可能在实验中有意义的因素的过程,通常被称为筛选设计,目的是选择它们用于测量响应。如果试验考虑了 n 次重复,那么试验总数为 n * 2^ k 。
因子通常用大写拉丁字母(A、B、…)表示,而主效应通常用与因子的拉丁字母相对应的希腊字母(α、β、…)表示,交互作用的效应用字母组合表示,这些字母代表其效应相互作用的因子。对于具有 3 个因子和 n 次重复的 2^ k 析因实验,统计模型为

对于下面的例子,我们将考虑一个 2 次重复的 2 全因子设计实验(即 222*2 = 16 次运行)。我们将这些因素命名为 A 、 B 和 C ,它们将有两个级别,分别为“ + ”和“-”。
让我们看看 R 代码!
第一步是导入 SixSgima R 包,设计 2 因子实验,将其随机化以消除未知或不可控变量的影响,定义一组重复,并为每个因子设计指定相应的响应。
设计好实验后,接下来的步骤包括聚合不同的析因设计,并从模型的汇总表中获得结果。
查看p-值,我们可以很有把握地得出,因子 C 和 A 的影响是显著的,而因子 B 的影响则不显著。这些因素之间的相互作用既不是双向的,也不是三向的,因此它们并不重要。获得这些统计信息后,我们可以通过排除所有不显著的影响来简化模型,获得模型的系数,获得所有实验条件的估计量,并计算每个因素的置信区间。
同样,我们也可以在单个地块中可视化每个因素对模型结果的影响。让我们用下面几行代码来绘制因子 A 的对模型结果的影响。

根据前面的图,我们可以观察到,当因子 A 设置在“+”级别(即 1.0)时,结果的值大于设置在“-”级别时的值(即-1.0)。此外,我们可以通过使用 ggplot2 包中的 facet_grid 来绘制单个图中重要因素的影响。

根据上面的图,与因子 A 对模型结果的影响相比,当因子 C 设置在“+”级别时(即 1.0),结果的值低于设置在“-”级别时(即-1.0)。同样,我们可以在一个图中绘制两个因素的相互作用,以可视化它们对模型结果的影响。

如上图所示,由于两条线不相交,这两个因素之间没有相互作用。为了使结果值最大化,因子 A 应设置在“+”级,因子 C 应设置在“-”级;另一方面,为了最小化结果值,因子 A 应设置在“-”级,因子 C 应设置在“+”级。最后,我们可以绘制残差图,并使用正态性检验验证它们是否遵循正态分布。

Residuals Plots
根据上面的残差图,残差中没有清晰的模式。但是,正常的 Q-Q 图不够直。
总结想法
给出的实际案例是一个非常有代表性的例子,说明了如何在一个使用 R 软件的六适马项目中使用 DOE。从工程的角度来看,可以用来减少时间来设计/开发新产品和新工艺;提高现有流程的性能;提高产品的可靠性和性能;实现产品和流程的稳健性;并执行评估材料、设计方案、设置组件和系统公差。然而,DOE 本身并不是一种改进。工程师有责任充分利用这一工具来实现多个目标和更好的结果。
— —
如果你觉得这篇文章有用,欢迎在GitHub上下载我的个人代码。你也可以直接在 rsalaza4@binghamton.edu 给我发邮件,在LinkedIn上找到我。有兴趣了解工程领域的数据分析、数据科学和机器学习应用的更多信息吗?通过访问我的介质 简介 来探索我以前的文章。感谢阅读。
-罗伯特
设计模式:简介
最近,我在一个由 Net Objectives 提供的 3 天沉浸式课程中了解到了设计模式的概念。虽然这门课教得很好,概念也很深刻,但我一直被教室里的每个人分心,除了我和我的队友是软件开发工程师。事实上,我记得在准备数据科学面试时很少阅读关于这个问题的博客帖子,因为这是一个高级话题。因此,在这篇文章中,我想探索设计模式的概念以及它们如何与数据科学相关。
什么是设计模式?
设计模式是一组模板(或正式的最佳实践),用于解决编程世界中经常出现的问题。
想象一下,这是一个慵懒的周六下午的中午,你很渴;人类常见的问题。所以,你不情愿地从沙发上起来,抓起一个空杯子,从水龙头里倒满水,喝光,把杯子放回晾衣架上,然后回到沙发上。30 分钟后,由于你在看你最喜欢的节目的大结局时吃的咸爆米花,你又渴了。现在,你比以前更不情愿地从沙发上起来,经历和上面一样的步骤。也许你可以使用由有经验的饮水者制定的设计模式,来帮助使这个过程更有效。
如果受你妈妈设计模式的启发,你用一个过滤器装满一大罐自来水,会怎么样?这种设计模式做了几件重要的事情:
首先,它遵循了重要的“不要重复自己”(干)原则。手边有一壶水,你就不必重复这个过程中的几个步骤,比如从沙发上站起来,找到一个玻璃杯,然后装满自来水。
第二,它封装了自来水系统的脏乱和杂质,并允许您以您期望的形式获得水——无杂质且易于倾倒。
最后,它将玻璃杯(它只是水壶和嘴之间的水传送器)与水壶(它关注的是存储)和过滤器(它关注的是净化)分开。早些时候,你可能会考虑买一个更大的杯子,既能储存水,又能让你喝水,而完全忽略了净化的问题。类似地,编程中的设计模式可以帮助解决一些关于冗余、关注点分离和代码可重用性的问题。
对于这个例子,设计模式的概念深受物质世界的影响。建筑师兼设计理论家克里斯托弗·亚历山大(Christopher Alexander)在他的书《永恒的建筑之道》(The Timeless Way of Building)中谈到了建筑中的设计模式。这启发了 Gamma、Helm、Johnson 和 Vlissides(被亲切地称为四人组)在《设计模式:可重用面向对象软件的元素》一书中提出的现代软件开发中设计模式的概念。这两本书为这一领域的所有从业者形成参考材料。
概括地说,有三种被普遍接受的设计模式:
1.创造性设计模式——这些模式与新类、对象或实例的创建有关。
2.结构设计模式——这些属于类和对象的结构。
3.行为设计模式——这些模式与类的对象之间的交流有关。
随着新语言的发展,一些设计模式变得过时了。例如,由于 Python 是一种动态语言,它不需要称为“工厂”的创造性设计模式,这种模式与对象的创建有关。此外,遵循“模式不是被发明的,而是被发现的”这句格言,新的设计模式可能会从开发用例中出现。这就是数据科学和机器学习及其蓬勃发展的用例将有助于发现新的设计模式的地方。
设计模式如何对数据科学家有用?
作为一名数据科学家,我大部分时间都在用 Python (70%)、SQL (20%)或 R (10%)编写代码。我为数据收集和探索性数据分析编写简短的脚本。我也为模型原型编写更长的脚本。最后,我为我们的数据科学团队开发软件工具。这个过程有几个部分可以用设计思维来改进:
脚本 —该领域迫切需要遵循编码标准,如 PEP-8 格式指南,以确保脚本可供其他数据科学团队甚至您以后阅读和重用。我的 Python 脚本倾向于放在 Jupyter 笔记本中,这可能很难浏览。在这里, Chelsea Troy 谈论笔记本电脑的最佳实践。由于这些脚本大多很短,并且使用来自不同包的可重用命令,我看不出有必要大规模重构我的代码。
构建工具 —这是风格和设计模式都可以产生最大影响的地方,因为这类似于软件开发。在这里,我发现重构大师的插图非常有见地。
在这堂课后,我确信在每个数据科学家的工作流程中融入一定程度的设计思维是非常重要的。首先,设计将提升由数据科学家产生的代码的质量。其次,但对产品团队顺利工作非常重要的是,它将使数据科学家和软件工程师(或机器学习工程师)之间的沟通更容易,他们经常负责扩展我们的代码。
大数据性能的设计原则

过去 20 年来,大数据技术的发展呈现了一部与不断增长的数据量进行斗争的历史。大数据的挑战尚未解决,这一努力肯定会继续,未来几年数据量将继续增长。原始的关系数据库系统(RDBMS)和相关联的 OLTP(在线事务处理)使得在所有方面使用 SQL 处理数据变得如此容易,只要数据大小足够小以便管理。然而,当数据达到相当大的数量时,处理起来就变得非常困难,因为成功地读取、写入和处理数据需要很长时间,有时甚至是不可能的。
总的来说,处理大量数据是数据工程师和数据科学家的普遍问题。这个问题在许多新技术(Hadoop、NoSQL 数据库、Spark 等)中都有体现。)在过去十年中蓬勃发展,这一趋势将继续下去。本文致力于在设计和实现大数据量的数据密集型流程时要记住的主要原则,这可能是为您的机器学习应用程序准备数据,或者从多个来源提取数据并为您的客户生成报告或仪表板。
事实上,处理大数据的根本问题是资源问题。因为数据量越大,就内存、处理器和磁盘而言,所需的资源就越多。性能优化的目标是减少资源的使用,或者提高充分利用可用资源的效率,从而减少读取、写入或处理数据的时间。任何优化的最终目标应该包括:
- 最大限度地利用可用内存
- 减少了磁盘 I/O
- 最小化网络上的数据传输
- 并行处理,充分利用多处理器
因此,在处理大数据性能时,一个好的架构师不仅仅是一名程序员,还应该具备服务器架构和数据库系统方面的知识。考虑到这些目标,让我们看看设计或优化您的数据流程或应用程序的 4 个关键原则,无论您使用哪种工具、编程语言或框架。
原则 1。基于您的数据量进行设计
在开始构建任何数据流程之前,您需要知道您正在处理的数据量:从什么数据量开始,以及数据量将增长到什么程度。如果数据总是很小,那么设计和实现会更简单、更快。如果数据开始时很大,或者开始时很小但会快速增长,则设计需要考虑性能优化。对于大数据表现良好的应用程序和流程通常会给小数据带来过多的开销,并导致负面影响,从而降低流程速度。另一方面,对于大数据来说,为小数据设计的应用程序需要太长时间才能完成。换句话说,对于小数据和大数据,应用程序或流程的设计应该有所不同。下面详细列出了原因:
- 因为从端到端处理大型数据集非常耗时,所以中间需要更多的分解和检查点。目标是双重的:首先,在整个流程结束之前,允许用户检查即时结果或在流程的早期提出异常;第二,在作业失败的情况下,允许从最后一个成功的检查点重新开始,避免从头重新开始,这是更昂贵的。对于小数据,相反,由于运行时间短,通常 1 次执行所有步骤的效率更高。
- 在处理小数据时,流程中任何低效率的影响也往往很小,但同样的低效率可能会成为大数据集的主要资源问题。
- 并行处理和数据分区(见下文)不仅需要额外的设计和开发时间来实现,而且还会在运行时占用更多的资源,因此,对于小数据应该跳过这些。
- 当处理大量数据时,性能测试应该包含在单元测试中;这通常不是小数据的问题。
- 利用可用的硬件可以快速完成小数据的处理,而当处理大量数据时,由于耗尽内存或磁盘空间,相同的过程可能会失败。
底线是同一流程设计不能同时用于小数据和大数据处理。大数据处理需要不同的思维方式、以前处理大数据量的经验,以及在初始设计、实现和测试方面的额外努力。另一方面,不要对为大数据设计的流程采取“一刀切”的做法,这可能会损害小数据的性能。
原则 2:在流程的早期减少数据量。
当处理大型数据集时,在处理过程的早期减小数据大小始终是获得良好性能的最有效方法。无论投入多少资源和硬件,都没有解决大数据问题的灵丹妙药。因此,在开始真正的工作之前,一定要尽量减少数据量。根据不同的用例,有许多方法可以实现这一点。下面列出了一些常见的技术,以及其他一些技术:
- 当字段为空值时,不要占用存储空间(例如,空间或固定长度字段)。
- 经济地选择数据类型。例如,如果一个数从不为负,则使用整数类型,但不使用无符号整数;如果没有小数,就不要用浮点数。
- 使用整数中的唯一标识符对文本数据进行编码,因为文本字段会占用更多的空间,应该避免在处理中使用。
- 当不需要较低粒度的数据时,数据聚集总是减少数据量的有效方法。
- 尽可能压缩数据。
- 减少字段的数量:只阅读那些真正需要的字段。
- 利用复杂的数据结构减少数据重复。一个例子是使用数组结构将一个字段存储在同一个记录中,而不是在字段共享许多其他公共键字段时将每个字段存储在单独的记录中。
我希望上面的列表能给你一些关于如何减少数据量的想法。事实上,相同的技术已经在许多数据库软件和物联网边缘计算中使用。您对数据和业务逻辑理解得越好,在处理数据之前尝试减少数据的大小时,您就越有创造力。最终的结果是,利用可用的内存、磁盘和处理器,工作效率会高得多。
原则 3:根据处理逻辑合理划分数据
启用数据并行是快速数据处理的最有效方式。随着数据量的增长,并行进程的数量也在增长,因此,添加更多硬件将扩展整体数据处理,而无需更改代码。对于数据工程师来说,一个常用的方法是数据分区。关于数据分区技术有很多细节,这超出了本文的范围。一般来说,有效的分区应该导致以下结果:
- 允许下游数据处理步骤(如连接和聚合)在同一个分区中进行。例如,如果数据处理逻辑在一个月内是独立的,那么按时间段划分通常是一个好主意。
- 每个分区的大小应该是均匀的,以确保处理每个分区所需的时间相同。
- 随着数据量的增长,分区的数量应该增加,而处理程序和逻辑保持不变。
此外,根据需要对数据执行的操作,应该考虑在处理的不同阶段更改分区策略以提高性能。例如,在处理用户数据时,用户 ID 的散列分区是一种有效的分区方式。然后,在处理用户的事务时,按时间段(如月或周)进行划分可以使聚合过程更快、更具可伸缩性。
Hadoop 和 Spark 将数据存储到数据块中作为默认操作,这使得并行处理能够在本机进行,而不需要程序员进行自我管理。然而,因为他们的框架非常通用,以同样的方式对待所有的数据块,所以它阻止了一个有经验的数据工程师在他或她自己的程序中可以做的更好的控制。因此,了解本文中陈述的原则将有助于您基于可用的工具和您正在使用的工具或软件来优化流程性能。
原则 4:尽可能避免不必要的耗费资源的处理步骤
如原则 1 所述,为大数据设计流程与为小数据设计流程有很大不同。设计的一个重要方面是尽可能避免不必要的耗费资源的操作。这需要高技能的数据工程师,他们不仅要很好地理解软件如何与操作系统和可用的硬件资源一起工作,还要全面了解数据和业务用例。在本文中,我只关注为了提高数据处理效率,我们应该避免的前两个过程:数据排序和磁盘 I/O。
当 1)与另一个数据集连接时,通常需要将数据记录按一定顺序排列;2)聚合;3)扫描;4)重复数据删除等。但是,当输入数据集远大于可用内存时,排序是最昂贵的操作之一,需要内存和处理器以及磁盘。为了获得良好的性能,按照以下原则非常节俭地进行排序是很重要的:
- 如果数据已经在上游或源系统中排序,则不要再次排序。
- 通常,两个数据集的连接需要对两个数据集进行排序,然后合并。将大数据集与小数据集联接时,将小数据集更改为哈希查找。这可以避免对大型数据集进行排序。
- 仅在数据大小减小后(原则 2)并在一个分区内(原则 3)进行排序。
- 设计流程时,将需要相同排序的步骤放在一起,以避免重新排序。
- 使用最佳排序算法(例如,合并排序或快速排序)。
另一个普遍考虑的因素是减少磁盘 I/O。这方面有许多技术,超出了本文的范围。下面列出了这方面需要考虑的 3 个常见原因:
- 数据压缩
- 数据索引
- 在写入磁盘之前,在内存中执行多个处理步骤
在处理大数据时,数据压缩是必不可少的,因为它允许更快的读写以及更快的网络传输。快速数据访问需要数据文件索引,但代价是写入磁盘的时间更长。仅在必要时对表或文件进行索引,同时牢记它对写入性能的影响。最后,在将输出写入磁盘之前,尽可能在内存中执行多个处理步骤。这种技术不仅用于 Spark,还用于许多数据库技术。
总结
设计具有良好性能的大数据流程和系统是一项具有挑战性的任务。本文中阐述的 4 个基本原则将为您提供一个指南,让您在处理大数据和其他数据库或系统时,积极主动地和创造性地思考**。最初的设计往往不会带来最佳性能,这主要是因为开发和测试环境中的硬件和数据量有限。因此,在生产中运行流程后,需要多次反复进行性能优化。此外,优化的数据流程通常是为特定的业务用例定制的。当使用新特性增强流程以满足新用例时,某些优化可能会变得无效,需要重新考虑。总而言之,提高大数据的性能是一项永无止境的任务,它将随着数据的增长以及发现和实现数据价值的持续努力而不断发展。**
为适当的互动而设计
如果我们把机器设计成更体贴的社会角色会怎么样?

all images by author
我们的设备被设计成在社交上很笨拙。尽管如此,在过去十年里,没有什么比智能手机及其引发的二次效应对社会的影响更大了。在未来十年,随着技术变得更加亲密,同时通过传感器和人工智能的进步,我们作为设计师和技术专家有一个独特的机会来塑造技术作为社会行为者的角色。
人们经常引用迪特·拉姆斯的话说,他努力把产品设计得像“一个优秀的英国管家”。这是对拉姆斯的第五个原则“好的设计不引人注目”的一个很好的比喻。而在实体产品领域,这与他的第二个原则“好的设计让产品有用”明显不同——随着产品变得越来越相互关联,同时越来越深入我们的生活,如果它们在根本上不是为了不引人注目而设计的,它们很容易变得无用。
人们已经可以感觉到,在今天的智能手机使用中,人们对他们收到的大量通知是多么不知所措。现在,想象一下一套增强现实护目镜,它不知道什么时候适合显示信息,什么时候必须清除视野。
从更广泛的意义上来说,在现实世界中,产品是“英国管家”的理念和产品“在你需要的时候出现在你面前,但一直在后台”的要求通常被转化为审美品质。然而,数字产品在很长一段时间内都无法满足这种期望。有限的感知能力,但更重要的是电池寿命和计算能力的缺点,导致了交互设计中基于“拉”的模型,这种模型主要需要用户手动询问要采取的动作。随着智能手机的出现,以及无处不在的连接的出现,“推送通知”系统成为我们日常生活中根深蒂固的一部分,随之而来的是不断努力跟上这种新的基于“推送”的交互方式。虽然拟人化的数字管家(软件)在很长一段时间内从未预测到我们的需求,并且总是不得不被要求为我们执行一项行动,但它最近转向不断要求我们的注意,并对我们施加任何琐碎的干扰,同时不仅为他们的雇主(“我们”——用户)服务,还为任何其应用程序以某种方式出现在我们主屏幕上的公司的利益服务。
在 2006 年的论文“魔法墨水”中,Bret Victor 已经得出结论,当涉及到信息软件的人机界面设计时,“交互”将被“认为是有害的”——或者用一种更“拉姆齐”的说法——软件设计师应该努力做到“尽可能少的交互”。
Victor 提出了一个策略来减少与系统交互的需要,他建议“信息软件的设计最初应该主要作为一个图形设计项目来处理”,把任何界面设计项目首先作为图形设计的一个练习,只有在最后才使用操作。虽然这对于基于“拉”的信息软件来说是一种有效的方法,但对于通信软件(Victor 将其描述为“操纵软件和粘在一起的信息软件”)来说却是不够的,因为如今通信软件将信息强加给我们,而大多数通信软件根本没有多少图形界面。
另一种策略是通过环境、历史和用户交互来推断上下文。维克多写道,软件可以
1.推断出需要其数据的上下文,
2。筛选数据,排除不相关的和
3。生成一个直接针对当前需求的图形
12 年后,随着技术的进步,尤其是硬件和软件的集成,其推断上下文和筛选数据的能力变得更强,因此可以用于生成“图形”(或任何其他输出),以更好地满足当前用户的需求,但更重要的是在时间、空间和方式上适合用户及其环境。
但是适当对(交互)行为意味着什么呢?韦氏词典将合适定义为“特别适合或合适的品质或状态”。在这里,我认为任何行为或互动都是适当的,如果它不能通过自动化或预期来避免,并且符合特定社会的道德模式。这在不同的社会之间变化很大,但也取决于一个人与特定人群的个人关系——无论是整个文化还是一群朋友。
随着移动电话的广泛使用和铃声的出现,电影院决定制定一份合同,规定在他们提供的环境中如何恰当地使用这项技术。直到今天,每部电影都以一个通知开始,要求人们将手机设置为“静音模式”。公共交通也采取了类似的措施。智能手机的出现甚至导致了设备的家庭手工业,试图让人们更难使用智能手机,更难在演出时分心。
然而,通过计算模拟适当性并不是一件容易的事情。在我们目前的设备中解决这个问题的尝试都是非常战术性的。人机礼仪的整个领域在今天的大多数软件中仍然被忽视——有时仅仅是因为的法律要求才被考虑。
但即使是更通用的建模方法,如苹果 iOS 的“请勿打扰”功能,也需要用户在设置时非常谨慎,缺乏灵活性和流动性,因为它们都是模仿他们的祖先“飞行模式”的设计蓝图。
在交互设计或人机交互研究中,机器作为社会参与者的探索并不新鲜。传感器和计算的进步,加上更有能力的机器学习,自然导致了一场让计算机更具情境或社会意识的运动。
这篇文章是基于在情感计算和人机礼仪以及 CASA (计算机作为一个社会角色)领域所做的大量工作。
我从探索工作的未来开始了我的设计过程。办公室一直是交互设计的沃土。在“所有演示之母”中,道格拉斯·恩格尔巴特通过讲述一个发生在知识工作者(或当时的“知识分子”)办公室的场景,开始解释观众将要看到的内容:
“…如果在您的办公室里,作为一名脑力劳动者,为您提供一台由计算机支持的计算机显示器,它整天为您工作,并对您的每个动作做出即时(…)响应,您能从中获得多少价值?”
从那以后,办公室发生了很大的变化,这在很大程度上要归功于 Engelbart 和 Licklider 通过 SRI 所做的贡献。许多人再也不在办公室工作了——所有最终变成思维工具和大脑自行车的技术,真正帮助增强了我们大脑的能力、生产力和创造力,但同时也最小化了我们思维的空间——我们大脑的容量。
在以人为中心的设计过程中,我首先围绕当今的知识工作是什么样子采访人们,然后构思出超越知识工作者办公室的概念,无论是小隔间、开放式办公室还是任何地方。
最终出现的框架为其个别应用程序奠定了基础,即“API”,它建立在一个传感器和智能系统的基础上,该系统具有推断上下文和筛选数据的能力,以建立一个仅在适当时发生的最小交互模型,该模型基于用户的环境、精神状态和道德模型,该模型基于系统与用户在给定上下文中的先前交互的反馈进行训练。

Conceptual ‘API’ graph for appropriate machine behaviour
现在,我们将把这个系统应用于从目前包含“不适当”行为的研究中出现的场景,并尝试将涉及的机器想象为更体贴的社会行为者。
每一个原型都伴随着一个宽泛的‘我们怎么可能?’旨在作为一个松散原则的问题,以便其他设计师和技术人员在设计他们的产品或服务时可以问自己同样的问题——将原型视为许多可能的实施策略之一。
1 →人机礼仪
我们怎样才能设计出能够恰当对待用户的机器?
如果一个导航系统能够尊重对话会怎么样?
想象一下,开着你的车。与你的副驾驶进行深入的交谈。当你说话时,你的副驾驶会听你说话,反之亦然。这是一个引人入胜的讨论,每个懂自然语言的人都能看出来。

Prototype → a simple iOS app that doesn’t interrupt the user when it hears them speak, but uses short audio signals to make itself heard.
导航系统也是如此,它使用语音识别和自然语言处理来通知其“道德模型”。因此,只有在对话自然中断时,它才会说出下一个方向。当信息变得更紧急时,它会使用更具侵入性的信号。只有当紧急程度达到最大时,系统才会发出大声说话这样的干扰信号。在眼球追踪和其他传感设备的帮助下,它甚至可以判断你是否已经识别了指令。
使用“API”的同一个系统甚至可以与 Apple Music 或 Spotify 等应用程序集成,在你最喜欢的播客中的对话出现自然中断时,或者就在你正在听的当前歌曲中你最喜欢的部分之后,完美地定时中断。
2 →可协商的环境
我们怎样才能设计出意识到并关注周围环境的机器?
一般来说,“谈判环境”是指机器和它的主人之间的互动对周围的人产生影响的环境。这通常与公共空间相关,例如在火车上或公园里,但更重要的是在更私密的空间,由同一批人共享,如在开放式办公室、电影院甚至飞机上。
如果机器能够礼貌地对待它们影响的每一个人,会怎么样?

Prototype → A new take on the brightness slider that contains a subtle gradient to visualize how others set brightness around you to nudge you to set it similarly.
只有少数人还在使用他们的设备。当第一批人调低他们笔记本电脑的亮度进入睡眠模式时,附近设备的平均亮度开始下降,其他没有调整亮度的设备也相应地自动适应。如果他们的用户不重置它(并因此应用负面强化),他们各自的“道德模型”会接受这种行为的训练,并被他们的用户接受。
3 →一致性
我们如何设计能够在新的未知环境和情况下适应适当行为的机器?
最后一个故事带来了一个有趣的问题:设置是否应该自动适应环境?当人们来到一个不熟悉的地方,他们会观察其他人的行为,以弄清楚“这个地方是如何运作的”。只有当他们对环境有信心时,他们才会开始做出调整,或者对自己在规则之外的行为感到自信。
如果机器能够理解并动态适应不同的习俗和新环境会怎样?

Prototype → A settings app in which the settings change based on the user’s location or context (represented through proximity to different iBeacons).
想象一下,日本的一个家庭正在当地的餐馆享用美食。一名商人(似乎是他第一次来日本)在进入餐厅时,正大声录制语音信息发送给一名同事。他的智能手机识别新的环境,查看其他手机(都切换到“请勿打扰”)并复制它们的设置,因为他已经将自己对不熟悉环境的“符合性”级别设置为“高”。一旦他离开餐厅,他就会收到同事的回复,因此可以尽情享受他的用餐。
4 →增强
当我们通过数字方式交流时,我们如何利用机器成为更好的社会参与者?
既然我们已经看了关于系统如何使机器成为更好的社会行为者的多个例子,我们可能会问自己,这个系统如何帮助我们成为更好的社会行为者——特别是在数字通信中,即使是人类也经常缺乏我们用来判断中断是受欢迎还是具有破坏性的常见社会线索。
如果我们一直都知道可以问同事一个“快速问题”会怎么样?

Prototype → iOS App that uses Face ID eye-tracking and networks with another iPhone running the same app detecting when both people pay attention (or not) and then signaling between them.
想象一下在一个开放式的办公室里。现在是上午 10 点,通常是一天中最忙的时候。马克有一个紧迫的问题,但他的同事劳拉似乎很忙。马克知道劳拉今天某个时候有一个截止日期。他不确定是否应该马上问这位同事,还是等到午餐时间,甚至是傍晚,这样才省点事。
马克使用“我的同事”应用程序,劳拉用它来表示她是否高度集中注意力或者是否为一点点分散注意力而高兴。该应用程序使用眼球追踪和其他参数来区分这两者。Laura 看起来确实很专注,所以 Mark 可以在她不再专注并且乐于聊天时请求通知。当系统检测到劳拉可能需要一点休息时,它会问她是否想和马克聊天。劳拉同意,她会感谢一点休息,并接受了邀请。马克收到通知,他们聊了一会儿。
这个系统的一个重要元素是它从头学习的能力。每一个配备了这个框架的系统都可以从一个非常基本的“道德模型”开始——一个“白板”。随着它从环境中学习,主要是从它的用户那里学习,它将根据自己的经验——根据它在现实世界中采取的行动获得的反馈——对什么是适当的行为形成独特的观点。因此,一个被一位法国时尚博主“社会化”的系统,对于它认为合适的东西,会有一个略微不同的想法,这个系统是由一位日本老年妇女通过使用训练出来的,她刚刚得到了她的第一部智能手机。只有当这些设备在相同的附近时,它们才会开始相互影响,如果博主曾经去过日本,出于对他们不熟悉的文化的尊重,他们甚至会将设备的“一致性设置”更改为更高的级别,包括人对人和设备对设备。
这种“在情境伦理中的计算方法”与如今科技公司在判断对错时采用的更像“圣经法则”的方法截然不同。如今,互联网的大量使用由脸书控制,当谈到平台上允许或不允许什么内容时,它有一种非常典型的硅谷方式。硅谷的工程师、设计师和产品经理定义了使用他们产品的整个世界的道德标准。一旦脸书(或其子公司)不断进入新的市场并超越其 20 亿用户,或者来自其他文化的网络在技术世界中占据主导地位,今天已经形成的紧张局势只会进一步加剧,必须开始开发一种更具可扩展性、动态性和包容性的解决方案。
我很想听听你对我们如何让机器成为更体贴的社会角色的想法。请在这里或在推特上告诉我 @sarahmautsch 。

释文
[1]想想通知(其设计大多由操作系统的创造者规定)或语音用户界面,如 Siri 或 Alexa。
[2]在这篇文章中,伦理一词是在狭义上使用的,基于其字面上的原始含义,来自希腊民族精神/έθος/,在牛津词典中被定义为“一种文化、时代或社会的特有精神,表现在其态度和愿望中”。当考虑到环境来对其进行伦理评价时,它被称为情境伦理。相反,圣经法律类型的方法是基于绝对的道德学说来判断。由于这个项目关注的是让机器根据它们从环境中的(交互)行动中学习到的知识做出适当的行为,所以这个作品培养了情境伦理的思想。
[3]API 代表应用程序编程接口,是‘一套规则,允许程序员为特定的操作系统开发软件,而不必完全熟悉那个操作系统’—这里我们将把它看作是系统的一个概念(包括所有的输入、输出和核心功能),在此基础上我们可以开始设计。
应用商店搜索广告系统的拍卖机制设计

The Microcosm of London (1808), an engraving of Christie’s auction room. Taken from here.
这个故事分享了我为伊朗第三方 Android market placeCafe Bazaar的搜索广告系统设计拍卖机制的经历。
在深入研究该机制的细节之前,我需要解释一下该机制所针对的搜索广告模型。
搜索广告模型
简单地说,Search-ads——app store 搜索广告系统,会在用户使用 app store 搜索系统搜索到的查询关键词***【q】的搜索结果的第一行显示安卓应用【a】***,作为广告。
如果***【u】点击广告上的安装底部,【a】将被收取从对(【q】***【u】)对进行的拍卖中确定的价格金额。
综上所述,可以推断 S earch-ads 是一个点击付费广告系统,其成功因素依赖于两个方面:
- 使用 app store 搜索系统,并希望找到自己想要的 android 应用程序的用户
- 投资他们的钱为他们的 android 应用做广告的开发者
从现在开始,我将把使用 app store 下载自己想要的安卓应用的用户称为用户,把自己的安卓应用放到 app store 的安卓开发者称为开发者。

Two different ways that an ad can be shown in the search results of a query.
Search-ads 是一个先进的广告系统,这意味着每个想要为他们的应用做广告的 android 应用开发者都应该创建一个活动,包括开始和结束日期、预算金额和其他一些标识符。在创建活动之后,他们对他们想要的搜索查询进行竞价,并可能使用额外的搜索广告功能,如查询建议、广泛竞价等。
Search-ad 对任何用户搜索的每个搜索查询进行拍卖;并且进一步选择最多一个获胜者应用作为广告显示在搜索结果的第一行中。
这个系统是针对开发商的复杂投标。他们应该准确地知道什么目标查询,并相应地管理他们的出价。
拍卖
拍卖是搜索广告的核心。思考设计拍卖机制将导致人们考虑其特点。因此,对于应用程序商店的广告目标,机制设计过程在其设计者肩上奠定了一套具体的政策。
搜索广告‘拍卖必备特征’是:
- 首先,搜索广告的广告模式高度依赖用户——广告点击是最重要的赚钱行为。
要交付像样的用户体验,搜索结果必须符合用户查询。此外,搜索广告,作为最突出的查询结果,在传递这种体验方面发挥了重要作用。如果有任何东西干扰这样做,用户对搜索结果的忠诚度就会丧失。这可能有不同的解释。有些人可能会说,获奖的应用程序应该具有高质量,其他人可能会说,它应该尽可能与查询相关,等等。然而,第一个特征告诉我们首先来自用户。 - 第二,模型需要有开发者作为不同拍卖的参与者。开发者正在投资一个出售安装点击的广告系统。因此,可以有把握地假设,他们的第一个也是最重要的动机是让新的可靠用户安装他们的 android 应用程序,从而促进他们业务的增长。考虑到这一点,拍卖机制应该是简单和健壮的,也就是说,对博弈论有幼稚理解的每个人都可以使用它。开发者对使用搜索广告的满意度将导致更多的参与和投资。因此,第二个特征告诉我们第二个来自开发者。
- 最后但同样重要的是,这种模式为应用商店创造了收入。因此,设计一个在创收方面最优或接近最优的拍卖机制是合理的。这最后一个特征告诉我们最后出现在 app store 中。
不仅这些特征的定义很重要,它们的顺序也很重要。他们的命令为设计拍卖机制强加了一套政策。
机械设计
为简单起见,固定查询关键字***【q】。让我们假设有 n 个开发者想要使用搜索广告在**【q】上为他们的 android 应用做广告。说我第八个开发者愿意支付搜索广告高达Vi*——估价,每点击***【q】***。理想情况下,该机制希望每次点击获得的最大收入是 MAXi{Vi} 。然而,问题是点击是随着用户的动作发生的。为了更好地理解这一点,记住这两个概念是有帮助的:
- 印象:
当一个应用在***【q】***的搜索结果中显示为广告时,就会产生印象。 - 点击率(CTR):app***【a】查询【q】的
点击率,是【a】在【q】***的搜索结果上显示为广告时被点击的 id 概率。
给定上面的定义,让我们假设第个开发者的应用在**【q】**上有 CTR Pi 。解释这些 CTR 的一种方法是将它们视为来自用户的直接反馈。因此,使用 CTRs 并在该机制中引入期望将使得每次印象的期望最大收入为 MAXi{Pi * Vi} 。具体来说,如果拍卖机制知道投标人的估价和 CTR,则该值是可实现的。但是,可能无法准确地拥有这两个变量。首先,开发商是在战略环境下投标。因此,他们可能不会在拍卖中使用他们的真实估价,并可能操纵他们的出价。其次,评估一个真正的点击率本质上是一项艰巨的任务,我们应该估计相关的点击分布。
在讨论提议的拍卖机制之前,让我们首先考虑一种估计点击率的有效方法。
CTR 估计
存在许多方式来考虑统计和机器学习方法,以估计点击的概率,例如用足够和可靠的数据训练模型等。
解决 CTR 估计问题的一种方法是将其视为强化学习(RL)设置。处理探索与开发的权衡是 RL 优化的独特之处之一。准确地说,多臂 bandit (MAB)算法有助于平衡 CTR 估计问题中的探索和利用。
要估算 app***【a】在【q】上的点击概率,可以把它想象成 MAB 设定中的一只手臂。每当作为广告在*【q】******【a】上显示给用户时,用户对【q】有了印象,并通过他们在【q】上的动作接收是否点击的信号,这完全取决于用户。这个点击率可以用【a】在【q】**上获得的点击数来估算,方法如下:
- P = 1——点击的概率,在开始时被初始化——假设某个常数因子 c 使得*T5【a】*已经得到 c 的印象和点击数,这导致了 c/c 的概率
- 每当在拍卖中被宣布为获胜者并作为广告显示给用户时,其在***【q】上的印象数增加 1,因此如果用户点击该广告,其在【q】*上的点击数也增加 1。 P 是利用点击次数对印象数的上限置信区间估计——转化率重新估计的。
上限置信区间估计可以被解释为好像 Search-ads 把它的信任放在开发者——arm 的 MAB 设置上,并且为每个开发者使用最高可能的点击概率。
拟议机制
我们假设用户*【u】搜索【q】。假设第 i 个开发商在【q】的那一轮拍卖中出价 Bi 。 Search-ads,估算完第 i th 开发者的 app CTR Pi,会对 BiPi 值进行降序排序。让我们假设 B1P1 是拍卖中最高的,而 B2P2 是第二高的值。具有与 B1P1 匹配的 BP 值的开发者是拍卖的获胜者。再者,他们的 app 显示为*【u】的广告。如果【u】*点击广告,拍卖的获胜者被收取价格金额,计算如下:

机理分析
关于搜索广告的拍卖机制政策,让我们来看一下提议的机制。首先,该机制使用用户的直接反馈来估计点击率,点击率在确定广告的预期收入方面起着关键作用。毫无疑问,在这种设置中存在探索的成本,然而,该机制通过用户的反馈学会准确地估计点击率,从而在未来导致更好的广告分配。第二,该机制信任开发者——投标人,估计他们的 CTR 的上界置信区间。此外,它将获胜者的出价降低到他们可能出价但仍赢得拍卖的最小金额,并在点击发生时向他们收取该价值的费用——这类似于维克瑞(第二价格)拍卖背后的哲学。最后,该机制试图获得每个广告印象的最高预期收入。这三个分析与搜索广告三大政策是一致的。我鼓励读者进一步阅读[1]中介绍的拍卖机制,并仔细分析适用于搜索广告拍卖机制的差异和相似之处。
结论
在这篇文章中,我试图说明在应用商店中为搜索广告系统设计拍卖机制时的重要因素,并介绍了基于这些因素的拍卖机制。我希望读者会觉得这段经历有用。
参考
[1] Nikhil Devanur 和 Sham M. Kakade。点击付费拍卖的真实价格。在第十届 ACM 会议上。关于电子商务,第 99–106 页,2009 年。
设计 ML 产品的用户体验
三个原则:期望、错误和信任!

之前,我谈到了管理机器学习(ML)产品的挑战,因为它涉及更多的实验、迭代,因此有更多的不确定性。作为一名项目经理,在决定前进的道路之前,您需要给工程师和数据科学家足够的空间和灵活性来探索。但是你也需要清晰地定义目标函数和鼓励团队尽早并经常进行测试,这样你就不会迷失方向。
为什么管理机器学习产品这么难?为什么你应该关心?
towardsdatascience.com](/how-to-manage-machine-learning-products-part-1-386e7011258a)
当你为你的 ML 产品设计用户体验(UX)时,同样的挑战也适用。在过去的几个月里,我一直在与我们的 UX 团队合作,收集客户意见并改进我们产品的 UX。这里是我们学到的三个最重要的教训。
设定正确的期望值
机器学习模型的性能随着它们用更多的数据训练而提高。模特会不断提升自己,这很棒。但这也意味着他们的表现从第一天起就不会完美。
帮助用户理解机器学习产品的本质至关重要。更重要的是,我们需要与用户合作,事先就一套验收标准达成一致。只有当机器学习模型符合接受标准时,我们才会推出它们。
在设定验收标准时,您可以查看系统的基准性能或替代/现有解决方案的性能,例如人工或当前软件程序的性能。
有时,你可能有不止一个用户组,他们在利益上有冲突。或者您的用例要求特定区域的零错误。您可能还需要根据您的业务案例,在精度和召回之间做出权衡。

source: Bastiane Huang
对于用户需要模型从发布的第一天起就表现良好的情况。预先训练的模型可能是有用的。但是,即使有了预先训练的模型,边缘情况仍然会发生。您需要与用户一起工作,提出风险缓解计划:如果模型不起作用,备用计划是什么?如果用户想要装载新的项目或添加新的用例,重新训练模型需要多长时间?当不允许模型更新时,用户可以设置封锁期吗?

通过设定正确的用户期望,你不仅可以避免客户失望,还可以让客户高兴。亚马逊的智能音箱 Alexa 就是一个很好的例子。我们对类人机器人有很高的期望:我们希望它们像人类一样说话和行动。因此,当 Pepper 无法与我们进行明智的对话时,我们感到沮丧。相比之下,Alexa 被定位为降低客户期望的智能扬声器。当我们了解到它不仅仅可以演奏音乐时,我们很高兴。
透明度是增进沟通和信任的另一个重要因素。ML 比软件工程更具有概率性。因此,显示每个预测的置信水平是设定正确预期的一种方式。这也有助于用户理解算法是如何工作的,从而与用户建立信任。
建立信任
ML 算法通常缺乏透明度,就像一个黑匣子,接受输入(例如图像)并输出预测(例如图像中的物体/人是什么/谁)。这就是为什么向用户解释机器学习模型如何建立信任和获得认同至关重要。
如果做不到这一点,就会疏远用户。例如,优步的司机报告说他们感觉失去了人性,他们质疑算法的公平性,尤其是当他们在没有明确解释的情况下受到处罚的时候。这些司机觉得应用程序对他们了解很多,但他们对算法如何工作和做出决策却知之甚少。
另一方面,亚马逊的网页告诉我们他们为什么推荐这些书。只是简单的一行解释。但它有助于用户理解算法是如何工作的,因此用户可以更好地信任系统。

同一个优步司机研究还发现,司机们觉得他们不断被监视,但他们不知道这些数据将被用于什么目的。除了遵守 GDPR 或其他数据保护法规之外,还要让用户容易知道他们的数据是如何被管理的。
优雅地处理错误
“…但也有未知的未知——我们不知道我们不知道的……后一类往往是困难的。”——唐纳德·拉姆斯菲尔德
当你在设计系统时,通常很难预测系统会如何出错。这就是为什么用户测试和质量保证对于识别失败状态和边缘情况是极其重要的。在实验室和现场进行广泛的测试有助于最大限度地减少这些错误。
同样重要的是对错误进行分类,并根据它们的严重程度和频率进行处理。存在需要通知用户并要求立即采取措施的致命错误。但是也有一些小错误并不会真正影响系统的整体运行。如果你把每一个小错误都通知给用户,那将会非常具有破坏性。如果不立即解决致命错误,这可能是灾难性的。
您也可以将错误视为用户期望和系统假设之间的意外交互:
用户错误一般由系统设计者在用户“误用”系统导致错误时定义。
系统错误发生在系统不能提供用户期望的正确答案的时候。它们往往是系统固有的局限性造成的。
当系统按预期工作,但用户察觉到错误时,就会发生上下文错误。这通常是因为我们设计系统的假设是错误的。
例如,如果用户一直拒绝来自某个应用程序的建议,产品团队可能想要看一看并了解原因。例如,应用程序可能会根据用户的信用卡信息错误地假设用户住在亚洲。在这种情况下,也许用户的实际位置数据将是做出这种建议的更好的数据点。
最棘手的错误是未知的未知:系统检测不到的错误。解决这个问题的一个方法是回到数据中,分析不寻常的模式,比如我们刚刚谈到的持续拒绝。
另一种方法是允许用户提供反馈:方便用户随时随地提供他们想要的反馈。让用户帮你发现未知的未知。您还可以利用用户反馈来改进您的系统。比如说。Youtube 允许用户告诉系统他们不想看到某些推荐。它还利用这一点来收集更多的数据,使他们的建议更加个性化和准确。


将你的机器学习模型预测框定为建议也是管理用户预期的一种方式。你可以给用户选项来选择,而不是命令用户应该做什么。但是请注意,如果您的用户没有足够的信息来做出正确的决定,这就不适用。
我们在之前谈到的许多一般原则在这里仍然适用。你可以在我之前的文章中找到更多的细节。
最佳实践和我一路走来学到的东西。
towardsdatascience.com](/how-to-manage-machine-learning-products-part-ii-3bdabf91eae4)
- 很好地定义问题,并尽早和经常地进行测试:如果你听到有人说“让我们构建模型,看看它能做什么”,要小心了。
- 知道什么时候应该或者不应该使用 ML。
- 从第一天开始就考虑你的数据策略。
- 构建 ML 产品是跨学科的。超越 ML 思考。
Bastiane Huang 是 OSARO 的产品经理,OSARO 是一家总部位于旧金山的初创公司,致力于开发软件定义的机器人技术。她曾在亚马逊的 Alexa 小组和哈佛商业评论以及该大学的未来工作倡议中工作。她写关于人工智能、机器人和产品管理的文章。跟着她到这里 。
本帖已在www.productschool.com社区发布。
设计你的神经网络
逐步演练

训练神经网络可能会非常混乱!
什么是好的学习率?你的网络应该有多少隐藏层?退学其实有用吗?为什么你的渐变消失了?
在这篇文章中,我们将揭开神经网络的一些更令人困惑的方面,并帮助你对你的神经网络架构做出明智的决定。
我强烈推荐分叉 这个内核 并且玩不同的积木来磨练你的直觉。
如果你有任何问题,随时给我发信息。祝你好运!
1.基本神经网络结构

输入神经元
- 这是你的神经网络用来进行预测的特征数量。
- 输入向量的每个特征需要一个输入神经元。对于表格数据,这是数据集中相关要素的数量。您需要仔细选择这些特征,并删除任何可能包含无法超出训练集(并导致过度拟合)的模式的特征。对于图像,这是你的图像的尺寸(MNIST 的尺寸是 28*28=784)。

输出神经元
- 这是你想做的预测的数量。
- **回归:**对于回归任务,可以是一个值(如房价)。对于多变量回归,每个预测值对应一个神经元(例如,对于边界框,可以是 4 个神经元,每个神经元对应边界框的高度、宽度、x 坐标和 y 坐标)。
- **分类:**对于二元分类(垃圾邮件-非垃圾邮件),我们对每个肯定类别使用一个输出神经元,其中输出表示肯定类别的概率。用于多类分类(例如,在对象检测中,实例可以被分类为汽车、狗、房子等。),我们每个类有一个输出神经元,并在输出层使用soft max activation函数来确保最终概率总和为 1。
隐藏层和每个隐藏层的神经元
- 隐藏层的数量高度依赖于问题和你的神经网络的结构。你实际上是在尝试进入完美的神经网络架构——不要太大,不要太小,刚刚好。
- 一般来说,1-5 个隐藏层可以很好地解决大多数问题。当处理图像或语音数据时,您可能希望您的网络有几十到几百个层,但并非所有层都是完全连接的。对于这些用例,有预先训练好的模型(【YOLO】、【ResNet】、【VGG】),允许你使用它们网络的大部分,在这些网络之上训练你的模型,只学习高阶特征。在这种情况下,您的模型仍然只有几层需要训练。
- 一般来说,对所有隐藏层使用相同数量的神经元就足够了。对于某些数据集,拥有一个较大的第一层并随后拥有较小的层将会带来更好的性能,因为第一层可以学习许多较低级别的要素,这些要素可以输入到后续层中的一些较高级别的要素中。

- 通常,添加更多的层比在每层中添加更多的神经元会获得更大的性能提升。
- 我建议从 1-5 层和 1-100 个神经元开始,慢慢增加更多的层和神经元,直到你开始适应过度。您可以在您的 权重和偏差 仪表板中跟踪您的损失和准确性,以查看哪个隐藏层+隐藏神经元组合导致最佳损失。
- 选择较小数量的层/神经元时要记住的一点是,如果这个数量太小,您的网络将无法学习数据中的潜在模式,因此是无用的。抵消这一点的方法是从大量的隐藏层+隐藏神经元开始,然后使用放弃和早期停止让神经网络为你缩小自己的规模。同样,我建议尝试一些组合,并在您的 权重和偏好 仪表板中跟踪性能,以确定针对您的问题的完美网络规模。
- 安德烈·卡帕西还推荐了 过度拟合然后正则化的方法——“首先获得一个足够大的模型,它可以过度拟合(即专注于训练损失),然后适当地正则化它(放弃一些训练损失,以改善验证损失)。”
损失函数

批量大小
- 大批量可以很好,因为它们可以利用 GPU 的能力,每次处理更多的训练实例。 OpenAI 已经发现 更大的批量(对于 图像分类 和 语言建模 为数万,对于 RL 代理 为数百万)很好地服务于缩放和并行化。
- 然而,小批量也是有道理的。根据 Masters 和 Luschi 的本文 中的 所述,通过运行大批量而增加的并行性所获得的优势被较小批量所实现的更高的性能概括和更小的内存占用所抵消。他们表明,增加批量大小会降低提供稳定收敛的学习速率的可接受范围。他们的观点是,事实上,越小越好;并且最佳性能是由 2 到 32 之间的小批量获得的。
- 如果您没有大规模操作,我建议您从较低的批量开始,慢慢增加规模,并在您的 重量和偏差 仪表板中监控性能,以确定最合适的。
历元数
- 我建议从大量的历元开始,并使用早期停止(参见第 4 节)。消失+爆炸梯度)以在表现停止改善时停止训练。
缩放您的特征

- 简要说明:在将所有特征用作神经网络的输入之前,请确保它们具有相似的比例。这确保了更快的收敛。当您的要素具有不同的比例时(例如,以千为单位的工资和以十为单位的经验年数),成本函数将看起来像左边拉长的碗。这意味着与使用归一化要素(右侧)相比,您的优化算法将需要很长时间来遍历山谷。
2.学习率

- 选择学习速度是非常重要的,你要确保你得到这个权利!理想情况下,当你调整网络的其他超参数时,你需要重新调整学习率。
- 要找到最佳学习率,从一个非常低的值(10^-6)开始,然后慢慢乘以一个常数,直到达到一个非常高的值(如 10)。在你的权重和偏差仪表盘中测量你的模型表现(相对于你的学习率的对数),以确定哪个学习率对你的问题最有效。然后,您可以使用这个最佳学习率来重新训练您的模型。
- 最佳学习速率通常是导致模型发散的学习速率的一半。在附带的代码中随意为 learn_rate 设置不同的值,并查看它如何影响模型性能,以发展您对学习率的直觉。
- 我还推荐使用莱斯利·史密斯提出的 学习率查找器 方法。对于大多数梯度优化器(SGD 的大多数变体)来说,这是找到一个好的学习率的极好方法,并且适用于大多数网络架构。
- 此外,请参见下面的学习率计划部分。
3.动力

- 梯度下降 朝着局部最小值采取微小的、一致的步骤,当梯度很小时,可能需要很长时间才能收敛。另一方面,动量考虑了先前的梯度,并通过更快地越过山谷和避免局部最小值来加速收敛。
- 一般来说,你希望你的动量值非常接近 1。对于较小的数据集,0.9 是一个很好的起点,随着数据集变得越来越大,您可能希望逐渐向 1(0.999)靠拢。(设置 nesterov=True 让 momentum 在当前点之前几个步骤考虑成本函数的梯度,这使它稍微更准确和更快。)
4.消失+爆炸渐变

- 就像人一样,不是所有的神经网络层都以相同的速度学习。因此,当反向投影算法将误差梯度从输出层传播到第一层时,梯度变得越来越小,直到它们到达第一层时几乎可以忽略不计。这意味着第一层的权重在每一步都不会显著更新。
- 这就是 消失渐变 的问题。(当某些层的梯度逐渐变大时,会出现类似的爆炸梯度问题,导致一些层的权重相对于其他层发生大规模更新。)
- 有几种方法可以抵消消失渐变。现在就让我们来看看它们吧!
激活功能
隐藏层激活 一般来说,使用不同 激活函数 的性能按此顺序提高(从最低→最高性能):逻辑→ tanh → ReLU →泄漏 ReLU → ELU → SELU。
ReLU 是最流行的激活功能,如果你不想调整你的激活功能,ReLU 是一个很好的起点。但是,请记住,与 eLU 的或葛鲁的相比,热卢的效果越来越差。
如果你更喜欢冒险,你可以尝试以下方法:
- 对抗神经网络过拟合:RReLU
- 减少运行时的延迟:泄漏 ReLU
- 对于大规模训练集:PReLU
- 对于快速推理时间:漏 ReLU
- 如果你的网络不能自我正常化:ELU
- 对于整体鲁棒的激活函数:SELU
一如既往,不要害怕尝试一些不同的激活功能,转向您的 权重和偏好 仪表盘,帮助您选择最适合您的功能!
这篇 是一篇优秀的论文,深入比较了神经网络的各种激活函数。
****输出层激活
回归:回归问题不需要针对其输出神经元的激活函数,因为我们希望输出呈现任何值。在我们希望 out 值被限制在某个范围内的情况下,我们可以对-1→1 值使用 tanh,对 0→1 值使用逻辑函数。在我们只寻求正输出的情况下,我们可以使用 softplus 激活。
****分类:使用 sigmoid 激活函数进行二进制分类,确保输出在 0 和 1 之间。使用 softmax 进行多类分类,以确保输出概率总和为 1。
权重初始化方法
- 正确的权重初始化方法可以大大加快收敛时间。初始化方法的选择取决于激活函数。一些可以尝试的事情:
- 当使用 ReLU 或漏 RELU 时,使用 He 初始化
- 当使用 SELU 或 ELU 时,使用 LeCun 初始化
- 当使用 softmax、logistic 或 tanh 时,使用 Glorot 初始化
- 大多数初始化方法都是统一的和正态分布的。
批次号
- BatchNorm 只是学习每一层输入的最佳方法和规模。它通过对其输入向量进行零居中和归一化,然后对其进行缩放和移位来实现这一点。它也像一个正则化,这意味着我们不需要辍学或 L2 注册。
- 使用 BatchNorm 可以让我们使用更大的学习速率(这将导致更快的收敛),并通过减少消失梯度问题在大多数神经网络中带来巨大的改进。唯一的缺点是它稍微增加了训练时间,因为每一层都需要额外的计算。
渐变裁剪
- 减少渐变爆炸的一个很好的方法,尤其是在训练 rnn 的时候,就是在它们超过某个值的时候简单地修剪它们。我建议尝试 clipnorm 而不是 clipvalue,这样可以保持渐变矢量的方向一致。Clipnorm 包含 l2 范数大于某个阈值的任何梯度。
- 尝试几种不同的阈值,找到最适合您的阈值。
提前停止
- 早期停止让您可以通过训练具有更多隐藏层、隐藏神经元和比您需要的更多时期的模型来体验它,并且当性能连续 n 个时期停止改善时停止训练。它还会为您保存性能最佳的型号。您可以通过在适合您的模型时设置回调并设置 save_best_only=True 来启用提前停止。
5.拒绝传统社会的人
- Dropout 是一种奇妙的正则化技术,它为您提供了一个巨大的性能提升(对于最先进的模型来说,性能提升约 2%),因为该技术实际上非常简单。dropout 所做的只是在每一层、每一步训练中随机关闭一定比例的神经元。这使得网络更加健壮,因为它不能依赖任何特定的输入神经元来进行预测。知识分布在整个网络中。在 2^n 周围(其中 n 是架构中神经元的数量),在训练过程中会生成略微独特的神经网络,并将其集合在一起进行预测。
- 好的辍学率在 0.1 到 0.5 之间;RNNs 为 0.3,CNN 为 0.5。对较大的图层使用较大的速率。增加退出率会减少过度拟合,而降低退出率有助于克服欠拟合。
- 您希望在网络的早期层中试验不同的辍学率值,并检查您的 权重和偏差 仪表板,以选择表现最佳的一个。您肯定不想在输出图层中使用 dropout。
- 在与 BatchNorm 一起使用 Dropout 之前,请先阅读 本文 。
- 在这个内核中,我使用了 AlphaDropout,这是一种香草味的 Dropout,通过保留输入的均值和标准差,它与 SELU 激活函数配合得很好。
6.优化者
- 梯度下降不是唯一的优化游戏!有几种不同的可供选择。 这篇文章 很好地描述了一些你可以选择的优化器。

- 我的一般建议是,如果你非常关心收敛的质量,并且时间不是最重要的,那么就使用随机梯度下降。
- 如果您关心收敛时间,接近最佳收敛点就足够了,请尝试 Adam、Nadam、RMSProp 和 Adamax 优化器。您的 权重和偏好 仪表盘将引导您找到最适合您的优化器!
- Adam/Nadam 通常是很好的起点,并且往往对糟糕的后期学习和其他非最佳超参数相当宽容。
- 根据安德烈·卡帕西 的说法,在 ConvNets 的情况下,“一个调优的 SGD 几乎总是略胜亚当一筹”。
- 在这个内核中,我从 Nadam 获得了最好的性能,它只是一个常规的带有内斯特罗夫技巧的 adam 优化器,因此比 Adam 收敛得更快。
7.学习率调度

- 我们已经讨论了良好学习率的重要性——我们不希望它太高,以免成本函数在最佳值附近波动并发散。我们也不希望它太低,因为这意味着收敛将需要很长时间。
- 照看学习率可能很困难,因为较高和较低的学习率都有其优势。好消息是我们不必承诺一个学习率!通过学习速率调度,我们可以从较高的速率开始,以更快的速度通过梯度斜坡,并在到达超参数空间中的梯度谷时减慢速度,这需要采取较小的步骤。
- 有许多方法可以安排学习率,包括指数降低学习率,或者使用阶跃函数,或者在性能开始下降时调整学习率,或者使用 1 周期安排。在这个内核中,我将向您展示如何使用 ReduceLROnPlateau 回调函数,在 n 个时期内性能下降时以一个常数因子降低学习率。
- 我强烈建议您也尝试一下 1 周期计划。
- 使用恒定的学习速率,直到你训练完所有其他的超参数。最后实现学习率衰减调度。
- 与大多数事情一样,我建议用不同的调度策略进行一些不同的实验,并使用你的 权重和偏好 仪表板来挑选出一个最佳模型。
8.还有几件事
- 尝试 EfficientNets 以最佳方式扩展您的网络。
- 阅读 本文 了解一些额外的学习率、批量大小、动量和重量衰减技术的概述。
- 还有 这个 上的随机加权平均(SWA)。它表明,可以通过沿 SGD 的轨迹对多个点进行平均,以循环或恒定的学习速率来实现更好的泛化。
- 阅读安德烈·卡帕西的 优秀指南 ,让你的神经网络发挥最大效用。
结果
在这篇文章中,我们已经探索了神经网络的许多不同方面!
我们已经了解了如何建立一个基本的神经网络(包括选择隐藏层数、隐藏神经元、批量大小等)。)
我们已经了解了动量和学习率在影响模型性能中的作用。
最后,我们探讨了渐变消失的问题,以及如何使用非饱和激活函数、批处理、更好的权重初始化技术和早期停止来解决这个问题。
通过访问您的 权重和偏差 仪表盘,您可以在一个图表中比较我们尝试的各种技术的准确性和损失性能。
神经网络是强大的野兽,它给你很多杠杆来调整,以获得你试图解决的问题的最佳性能!他们提供的定制的庞大规模甚至会让经验丰富的从业者不知所措。像 权重和偏差 这样的工具是你在超参数领域导航、尝试不同实验和挑选最强大模型的最好朋友。
我希望这本指南能成为你冒险的良好开端。祝你好运!我强烈推荐分叉 这个内核 并尝试不同的构建模块来磨练你的直觉。
如有任何问题或反馈,欢迎随时 推特我 !


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言










{kind=link}
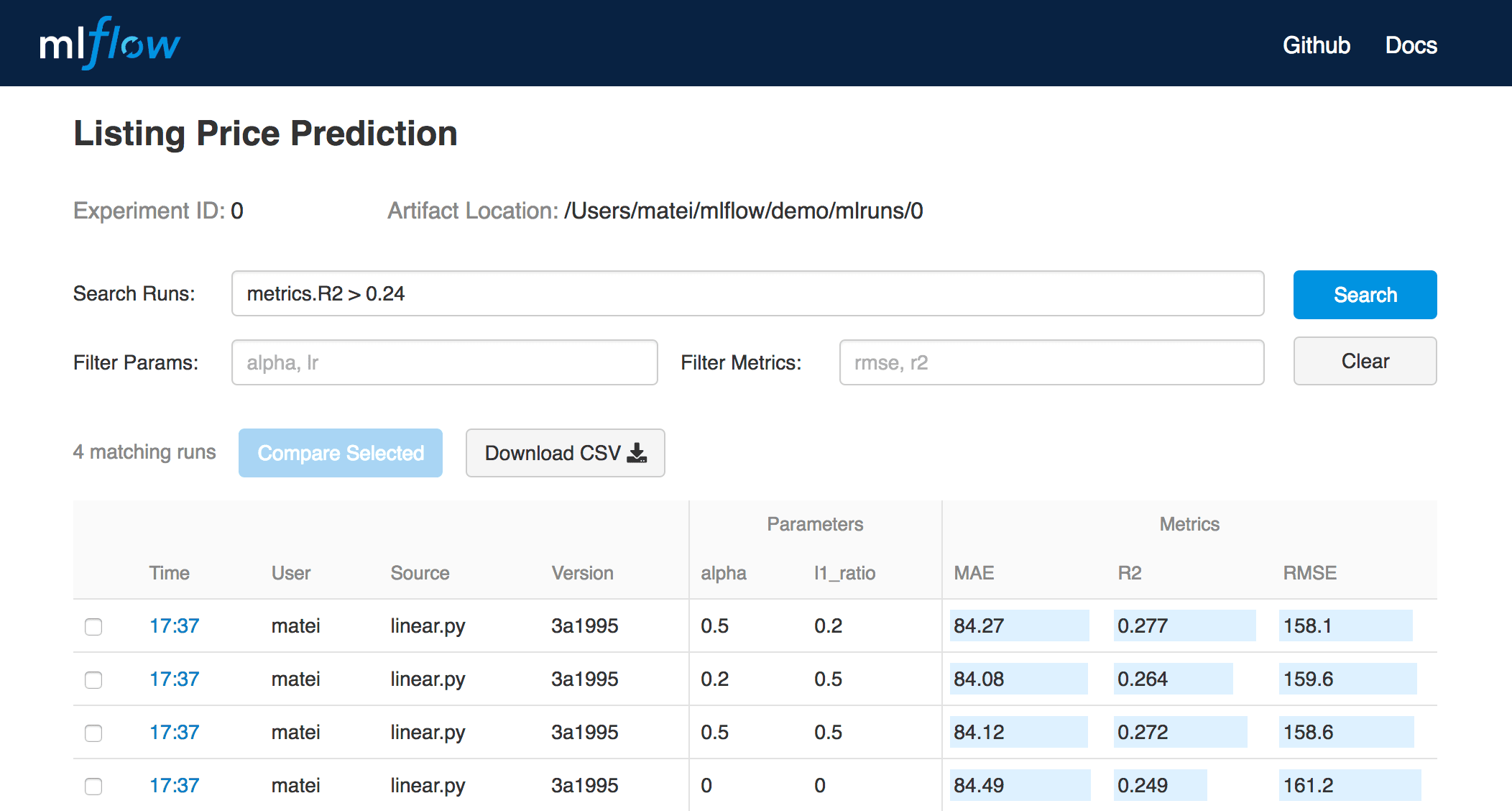{kind=link}
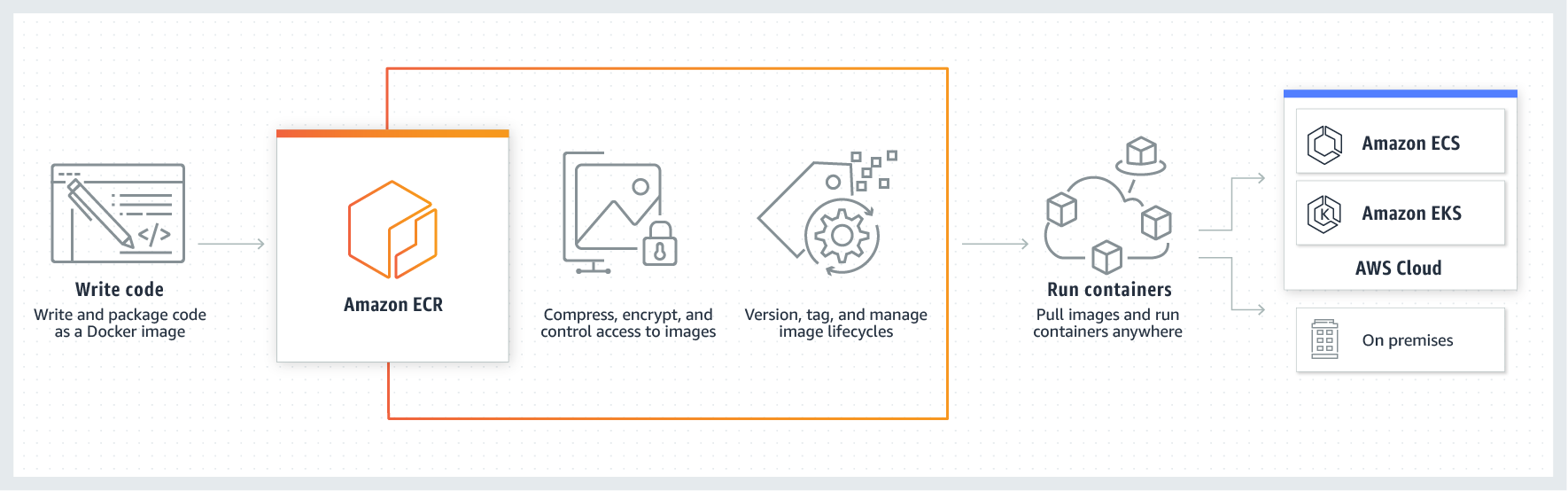{kind=link}
{kind=link}