







深拉链:一个打开的拉链探测器
用你手机的磁强计来探测一个打开的传单。

Photo by Alex Holyoake on Unsplash
拉链:1851 年获得专利,从 20 年代开始被广泛采用,直到今天仍然让我们失望。在这个飞行汽车的时代,科技能帮助我们吗?当你的传单被打开而不应该被打开的时候,除了一个被逗乐的同事之外,我们能得到一个提醒吗?
金属
我们信任的智能手机上布满了传感器,其中一个就是磁力计。如果你的拉链是由金属制成的,当拉链形成的金属环在打开和关闭状态之间改变形状时,其附近(如你的口袋中)的磁力计捕捉到的磁场应该受到干扰。
很可能,磁场的绝对值无法追溯到一个国家。然而,动态变化,如行走时捕捉到的变化(触发拉链两侧之间的距离变化),应该会给你一个可识别的信号。
在这篇文章中,我用这个想法描述了我的实验。从捕捉和处理信号到拟合和优化 3 种不同的模型:梯度推进机、卷积神经网络(ZipNet)和 RNN。
捕捉信号
一个小的 iOS 应用程序将捕获磁力计和加速计数据,并将其导出到 csv 进行分析。这里可以找到。
为了验证最初的假设,我在打开和关闭拉链时取样。我也做了同样的手势,但没有碰到拉链,以确保这不是我扭曲了磁场。乍一看,好像有信号(见下文)。


Left moving the hands only not the zipper. Right opening and closing the zipper and corresponding x axis signal
生成真实生活数据是一件令人兴奋的事情。我会掩饰这一点,但我为 4 个象限生成了 60 集,分别是行走时或不行走时,以及开放时或不开放时,总共 95K 长的时间序列。
以下是 4 象限信号的一个例子(笔记本)。行走(左)与不行走(右)应该很容易察觉。如果磁信号上的频率模式差异(分别为 x、y 和 z 轴的橙色、蓝色和绿色线条)是一致的,则行走时的打开与关闭(左)看起来似乎是合理的。特别是在不同的样品上,mz 在峰值后出现小的隆起,闭合时比打开时更明显。

mx (orange), my(blue), mz(green). More high frequency in mz when closed?
机器学习拯救世界
在检测磁信号形状变化的前提下,我们希望连续检测用户是静止还是运动——然后,只有在运动的情况下,才评估拉链打开时磁信号是否像一个信号。

model serialization

raw data from the app
为培训准备时间序列
除了设置验证集和规范化数据之外,还有一个额外的预处理步骤来为时间序列分类准备数据。我们使用一个滑动时间窗口来分块数据,该窗口涉及两个超参数:窗口大小和每个训练样本之间的步长增量。
直觉上,我们希望窗口大小足够大以捕捉几个周期,但又足够小以使检测器快速反应。根据这些数据,我测试了各种窗口,在 128 个样本之外,没有发现太大的差异。对于步骤,我选择了 10。
*数据扩充:*让我们添加“窗口扭曲”来挤压或扩展时间序列(人工创建样本,其中你会走得更快或更慢)。让我们也添加噪声到输入信号(高斯),帮助模型区分噪声和信号。


Left: window slicing Xn and Xn+1 input training tensors. Right: window warping
特征工程:为了帮助我们的分类器,让我们用傅立叶变换处理输入数据,并将其添加到输入中。我们去除 0 频率,这是已经在原始数据中捕获的平均值。

Left, ‘mx’ normalized signal. Right, FFT of normalized ‘mx’. 0 freq is indeed removed on the right.
如果我们考虑加速度计和磁信号,这将为我们提供总共 12 个维度的输入特征。
避免验证数据污染:对于经过上述预处理的数据,我们不能按照 80%,20%的规则在训练和验证之间随意分割。如果其中一个采样片段被分割,由于窗口重叠,训练将会看到一些验证数据。因此,训练和验证首先按集分开,试图保持类的平衡,然后进行处理。
梯度推进
我们先测试一下现在流行的 LGBM 算法(笔记本)。为此,我们需要用形状的训练张量(样本数、特征数)来整形。
行走还是静止
如前所述,我们可以观察行走和站立发作之间的差异,我们的分类器也是如此。使用默认分类器,我们获得了接近 100%的准确率(下图的标题显示了准确率、f1 分数和召回率)。

Confusion matrices, Left: training, Right validation (with accuracy, f1 and recall scores in the title)
行走时,打开还是关闭
这更具挑战性,在这种情况下,对时间序列进行仔细的预处理对于获得良好的结果至关重要。使用默认的 LGBM 设置,并根据剧集的采样,我们通常可以获得 80%的准确率(见下面的 dist)。

accuracy and recall distribution over different sampling of the episodes
下面是一个相当典型的性能样本,分类器预测 86%的拉链是打开的(回忆),准确率为 82%。

Confusion matrices: Left training, Right validation (accuracy 82%, recall 86%)
这是在添加了加速度和磁场之后,磁场似乎提高了性能,可能允许模型区分行走和拉链的磁场变化。
数据增强似乎也有所帮助,下面是在标准化信号上添加 5%的时间变量和 2%的高斯噪声。

After data augmentation: 2% boost on scores
另一个 1-2%的增量改进来自超参数优化(请查看 Will Koerhsen 关于该主题的精彩文章,我在笔记本中大量复制了该文章)。

With hyper-parameters optimization, getting to 90% recall, 85% accuracy
ZipNet
让我们尝试一个卷积神经网络作为分类器。我将使用 PyTorch 和非常棒的 fast.ai 库进行训练(笔记本)。该自定义 convnet 仅对时序输入使用卷积,并将 fft 输入直接旁路至密集层。
对于与 LGBM(和增强版)相同的剧集样本,这里是比较性能。准确率低,召回率高。

Zipnet overfit: validation accuracy 73%, recall 95%
虽然我在创建 ZipNet 时很开心,但 LGBM 在大多数情况下表现得更好。让我们检查一个香草 LSTM。
LSTM

This vanilla LSTM performed worst than LGBM
香草 LSTM 也一样,LGBM 在这个小数据集上胜出,尽管可以说我没有花太多时间优化它。
组装三个模型没有帮助。你可以在附带的笔记本中找到尝试。
最后
你的手机变得更私人了。在(笔记本)纸上,在我测试的环境中,用我的手机,用我的牛仔裤,用你手机的磁力计来检测一个打开的传单似乎工作得不错(80%的准确率)。我怀疑它会用我收集的少量数据来概括,所以这里是一个新的众包数据集和 Kaggle 竞争。
感谢阅读。
通过 Spotify 的 airy、Tensorflow 和 Pytorch 更深入地寻找相似的面孔
在我之前的帖子中,我开玩笑说我跳进了一个兔子洞,试图改善我的命运大阶面部相似度管道,我在那里使用了 Tensorflow 对象检测器、Pytorch 特征提取器和 Spotify 的近似最近邻居库(惹恼了)。我的总体想法是,我想对角色面部特征(寻找相似的角色)和背景信息(返回具有相似颜色/感觉的图像)进行编码。
我想我能做的就是把从预训练的 Resnet101 中提取的特征向量连接起来,用于基础图像和头像。然而,这种方法证明是相当令人失望的。
作为一个快速回顾,这里是一个示例图像和使用版本 1 模型的类似配对,该模型使用整个图像。
版本 1 模型输出

V1 full image sample output: Left image is the original and the next four are the four most similar
输出正常,但是 4 个相似图像中的 2 个具有不同的字符。
接下来回顾一下第二版基于头像的管道,我使用了一个定制的 Tensorflow 对象检测器来裁剪图像中的人物头像,并使用它们来建立烦人的索引和查找相似的图像。
版本 2 头像模型

V2 headshot model output
这条管道似乎相当成功,在所有图像中返回相同角色的图像,但我想看看我是否能得到更接近原始的“感觉”。这就是为什么我试图结合 Resnet 101 输出向量,并将其输入到 annoy 中,以制作一个新的模型版本 3。
版本 3:结合前两个
我的下一个测试是从头像和基本图像中提取特征向量,并将它们组合在一起,并将新的长度为 2000 的数组输入到 aroy 中。希望向量的第一部分可以帮助找到相似的人脸,第二部分可以对图像整体的相似信息进行编码。
第 3 版组合头像和基本图像

V3 combined feature array sample output
所以这个管道的第三个版本不是我所希望的…虽然这些字符有相似的面孔,但 4 个输出中的 2 个与基础图像中的字符不同。
这对我来说很有趣,因为我的第一个想法是,这是我根据图像构建的要素表示的质量问题。我甚至用更大的 Resnet 152 进行了测试,但结果基本相同。
下一步是检查我是否认为我在管道的其余部分做错了什么……就像我在从原始稀疏 3D 像素表示构建图像的 1D 表示时做错了什么。然而,这是非常可靠和真实的…

这一次,我意识到重新阅读恼人的 git 回购页面,并看到了这一说明。
如果您没有太多的维度(比如< 100),效果会更好,但即使达到 1000 个维度,效果似乎也令人惊讶
对于该管道的基础图像和头部特写版本,特征向量是来自 Resnet 101 的标准 1000 个特征。并且将这两个向量连接在一起会将其推到长度为 2000 的向量,这大大超出了推荐的维数。
版本 4:哑吧?
虽然选择使用功能较弱的网络进行深度学习并不常见,但任何事情都有时间和地点。
考虑到这一点,我实际上将该管道版本 4 的特征提取器 Resnet 从 101 降级为 Resnet 34。这是因为在 Resnet 101 中最后 1000 个完全连接的层之前的层的大小是 2048,而 Resnet 34 只有 512。我的想法是,通过使用这个较小的层,我可以连接两个 512 层,以获得长度为 1024 而不是 2000 的最终向量。希望这能减少维度的数量,让 annoy 更好地发挥作用。
我认为这一改变提高了我的产出质量。
版本 4 Resnet 34

V4 Resnet34 headshot and base image model output
因此,运行我之前展示的相同示例图像,这个 Resnet 34 模型看起来比使用更大的 Resnet 101 的初始头像+基础图像模型更好。四个图像中的两个与角色匹配。第三个图像只是原始角色的邪恶版本,所以我认为它很重要。然而,最终的图像似乎很不相关…所以有进步要做。
这里是另一个显示 Resnet 34 模型输出与前三个版本的比较的例子。我对图像标题中的输出进行评论。
版本 1 基础映像

V1 Original full image model. no correct characters, similarly colored (sort of)
版本 2 头像

V2 model based on just the headshot. 3 similar characters but images arn’t that similar to the base image.
第 3 版结合了头像和基本图像

v3 headshot + base image Resnet 101 length 2000 vector. This version of the pipeline seems to just combine the first two versions
版本 4 Resnet 34

V4 Resnet 34 length 1024 vectors. It produces decent looking output, but in looking through the outputs I usually find odd images included like the second image in this list
因此,尽管 Resnet 34 相对于该管道的 Resnet 101 版本是一个改进,但它仍然表现不佳…我仍然相信我可以改进它,问题只是,如何改进?
版本 5:从 1024 维减少到 52 维
在思考了如何获得比 Resnet 34 的 512 输出更小的最终特征表示并绘制了一段时间的空白之后…我感觉自己像个白痴,因为在我起草的另一个帖子中,我一直在这个相同的数据集上训练基于 Pytorch 的多任务模型,以执行跨 5 个类别和 26 个不同目标变量的多标签分类。
这个网络是 Pytorch Resnet 50,其中我修改了最后几层来处理 5 个任务,我试图同时优化它们。我有一个草稿模式的帖子,但我太懒了,没有完成它…但在这种情况下,这个网络非常方便,因为它给了我一个微调网络,它已经成为区分命运大订单图像的技能。这里的好处是,不必使用 512 或 1000 个输出节点,这个特定的网络在这个问题空间中是熟练的,并且只有 26 个输出节点,这意味着我可以用 52 维而不是 1024 或 2000 维的向量来表示人脸和基础图像。这些图像的这种更密集的表示应该允许更好地区分这些图像。
因此,在交换后端特征提取器并测试输出后,使用我的多任务模型进行特征提取的 V5 模型表现得相当好。
请看下面我在这篇文章中强调的两个例子。其他型号在某些方面表现不错,但在其他方面有所欠缺。我认为这个第 5 版模型确实获得了我在上一篇文章中提到的两个世界的最佳效果。
第 5 版微调多任务模型

All of the output is of the correct character, and the images style/background seem more similar than just the v2 headshot model

Once again all the output is of the correct character
总体而言,这一变化显著提高了管道输出的质量。我想这凸显了获得良好要素制图表达的重要性,并且使它们更密集通常会更好。

V5 sample output, same character in all images
结束语
这两篇文章很好地提醒了我们降低数据维度以获得更好结果的重要性。
每个图像都以 150,528 像素(224x224x3 宽、高、rgb 颜色)开始,然后使用标准的预训练 imagenet 网络可以压缩到只有 1000 个特征。我认为这本身就很酷。
然而,对于这个特定的问题,当我添加第二个图像时,我的最终特征向量是 2000 个特征。这又一次是太稀疏的信息,使我无法产生好的结果,所以我不得不去寻找一种方法来进一步减少我的数据的维度。

V5 output, 3 out of 4 images have the correct character and decent style matches. hair color in the odd image is a close match
为了进一步减少我的图像表示的维数,我使用了一个较小的 Resnet 34,并看到了一些改进,但该模型会输出奇怪的相似图像。由于这不起作用,我想我可以尝试制作更密集的数据表示,最终我能够使用我在类似问题空间中微调的网络,将原始的 150,528 像素原始表示降低到 26 像素。
这是一个类似于特征选择或主成分分析的过程,其目标是将一些原始水平的输入降低到一组有意义的特征。这对于我自己来说也是一个有用的注释,当我使用对象检测器或其他输入来添加更多额外的上下文时,我会尝试进一步关注特定网络学习的细节。
请随意查看 github repo 中的代码示例。
因为我很兴奋,这似乎是工作得很好,这里有一堆更多的图像示例如下。







深入到 DCGANs
我上一篇关于 DCGANs 的文章主要集中在用卷积替换全连接层和用 Keras 实现上采样卷积的想法上。本文将进一步解释 Raford 等人[1]提到的架构指南,以及论文中提到的其他主题,如使用 GAN 的无监督特征学习、GAN 过拟合和潜在空间插值。

DCGAN architecture used by Radford et al. [1] to generate 64x64 RGB bedroom images from the LSUN dataset
与 LAPGAN 或渐进增长 GAN 等多尺度架构相比,或者与最新的 BigGAN 相比,BigGAN 使用了许多辅助技术,如自我关注、频谱归一化和鉴别器投影等 DCGAN 是一个更容易完全理解的系统。
DCGAN 无法实现与 BigGAN 模型相当的图像质量,也不具备与 StyleGAN 几乎相同的潜在空间控制能力。然而,仍然值得考虑将 DCGAN 作为 GAN 研究的基础支柱。DCGAN 模型的基本组件是用这些上采样卷积层替换生成器中的全连接层。在设计这个架构时,作者引用了三个灵感来源。
- 全卷积网络→用空间下采样卷积代替汇集操作
- 消除卷积后的完全连接层
- 批量标准化→标准化激活以帮助梯度流动
考虑到这些进步,作者寻找了一种稳定的 DC-GAN 架构,并采用了以下架构准则:
- 用鉴别器中的步长卷积和生成器中的分数步长卷积替换任何池层
- 在生成器和鉴别器中使用批处理规范化
- 为更深层次的架构移除完全连接的隐藏层
- 在发生器中对除 Tanh 外的所有层使用 ReLU 激活输出*(这些图像在[-1,1]而不是[0,1]之间标准化,因此 Tanh 在 sigmoid 上)*
- 在所有层的鉴别器中使用 LeakyReLU 激活
这些建筑方针后来在现代甘文学中得到了扩展。例如,创成式模型中的批处理规范化有新出现的表亲,如虚拟批处理规范化、实例规范化和自适应实例规范化。Salimans 等人[2]提出了进一步的架构指导方针,并且在这篇文章中做了很好的解释。
除了模型架构,本文还讨论了许多与 GAN 相关的有趣想法,如无监督学习、GAN 过拟合、GAN 特征可视化和潜在空间插值。
基于 GANs 的无监督学习
已经探索了 GANs 的许多应用,并且大部分研究试图实现更高质量的图像合成。许多实现高质量图像合成的方法实际上是监督学习技术,因为它们需要类别标签进行调节。
这里的主要思想是使用由鉴别器学习的特征作为分类模型的特征提取器。具体来说,拉德福德等人探索了结合 L2 + SVM 分类模型的无监督 GAN 特征提取器的使用。SVM 模型使用损失函数和高维超平面,该损失函数旨在基于每个类中最近点之间的差值来最大化类间距离。SVM 模型是一个很好的分类器,然而,它不是一个特征提取器,将 SVM 应用于图像会导致大量的局部极小值,本质上使问题变得难以处理。因此,DC-甘充当特征提取器,其以语义保留的方式减少图像的维度,使得 SVM 可以学习辨别模型。
甘过拟合
重读这篇论文,我觉得甘过度拟合的想法特别有趣。监督学习环境中的过拟合非常直观:

Common picture showing overfitting on a supervised learning task
上图是回归任务中过度拟合的常见图示。过度参数化模型会自我调整,使其与训练数据完全匹配,并且没有错误。抛开偏差-方差权衡的统计数据,我们可以直观地将过度拟合想象为模型的泛化能力,即与测试数据相比,它在训练数据上的表现如何。
在 GANs 的背景下,这是一个非常有趣的想法。生成器的任务是产生鉴别器预测为“真实”的数据,这意味着它非常类似于训练数据集。看起来,如果生成器放弃任何向数据点添加随机变化的尝试,而只是精确模拟训练数据,那么它将是最成功的。拉德福德等人讨论了三种有趣的方法来证明他们的 DC-甘模型没有做到这一点。
- 启发式近似:快速学习的模型概括得很好
- 自动编码器哈希冲突(训练 a 3072–128–3072 自动编码器对生成数据和原始数据进行编码,并查看生成数据和原始数据之间的低维(128)表示有多少相似之处。
- 潜在空间的平滑度(急剧过渡=过度拟合)
本文中没有使用的另一种探索 GANs 过度拟合的有趣技术是使用 L1 或 L2 距离(甚至可能是 VGG-19 特征距离)进行最近邻搜索,从训练数据集中抓取与给定生成图像最相似的图像。
甘特征可视化
CNN 中的特征可视化如下实现。通过梯度下降来训练生成器网络,以产生导致给定特征的最大激活的图像。拉德福德等人在 LSUN bedroom 数据集上使用他们的鉴别器模型对此进行了测试,并展示了下图:

有趣的是,这些是鉴别器用来辨别图像真假的特征。
潜在空间插值
潜在空间插值是 GAN 研究中最有趣的课题之一,因为它能够控制发生器。例如,GANs 最终可能被用于设计网站。您希望能够控制设计的特征或在设计之间进行插值。除了这个轶事,潜在空间插值在 Word2Vec 中有非常普遍的描述,其中向量“国王”-“男人”+“女人”=“女王”。拉德福德等人用他们生成的图像探索了这种插值方法。


本文中讨论的潜在空间插值的一个有趣的细节是,它们不使用单个点的 Z 向量,这是我最初没有注意到的。例如,他们不只是用一个微笑的女人的 Z 向量减去一个中性女人的 Z 向量,然后加上一个中性男人的 Z 向量来获得一个微笑的男人图像。相反,它们取一系列显示外部特征(如“微笑的女人”)的生成图像的平均 Z 向量。
感谢您阅读本文!我发现这篇论文对我研究 GANs 非常有用。每次我回到这篇论文,我都会对论文的细节有所欣赏。这篇文章是关于 GANs 的基础工作之一,我强烈推荐你去看看,特别是如果你对图像生成感兴趣的话。
参考
[1]亚历克·拉德福德,卢克·梅斯,苏密特·钦塔拉。深度卷积生成对抗网络的无监督表示学习。2015.
[2]蒂姆·萨利曼斯、伊恩·古德菲勒、沃伊切赫·扎伦巴、张维基、亚历克·拉德福德、陈曦。训练 GANs 的改良技术。2016.
深度造假——今日新闻热门话题
是时候质疑你看到的每一张照片和视频了!

Photo of a woman (Photo by Andrey Zvyagintsev on Unsplash)
“亚马逊联合脸书和微软打击 deep fakes”—2019 年 10 月 22 日的下一个网络
“对 deepfakes 的战争:亚马逊用 100 万美元的云信用支持微软和脸书”—ZDNet,2019 年 10 月 22 日
“什么是‘深度假货’,它们有多危险”—《美国消费者新闻与商业频道》2019 年 10 月 13 日报道
“人工智能无法保护我们免受 deepfakes 的影响,新报告认为” — The Verge 于 2019 年 9 月 18 日
我注意到“ DeepFake ”这个词一次又一次地出现在我的新闻提要中,在我第六次或第七次遇到它之后,我开始想这是不是我应该知道的事情。我的意思是,如果像亚马逊、脸书和微软这样的大型科技公司正在共同努力打击 DeepFake,而美国消费者新闻与商业频道正在报告其危险,那一定是很严重的事情。
事实证明,使用 DeepFake ,你可以创建一个甚至不存在的人的面部图像,操纵视频来交换人们的面部,并使用某人的声音编造演讲,甚至无需他们同意。试试这个 hispersonedoesnotexist.com 网站,你会大吃一惊。这个网站生成一个甘想象的人的形象(根据网站左下角的注释)。下面是该网站生成的一些人脸图像。我打赌你不会猜到这些图像是假的,我也不会。



Face images created using thispersonedoesnotexist.com

Note on thispersonedoesnotexist.com
DeepFakes 是由一种被称为生成对抗网络(GANs)的深度学习技术创建的,其中使用了两种机器学习模型来使假货更加可信。通过研究一个人的图像和视频,以训练数据的形式,第一个模型创建一个视频,而第二个模型试图检测它的缺陷。这两个模型携手合作,直到他们创造出一个可信的视频。
当谈到无监督学习时,DeepFake 打开了一个全新的世界,这是机器学习的一个子领域,机器可以学习自学,并且有人认为,当谈到自动驾驶汽车检测和识别道路上的障碍以及 Siri、Cortana 和 Alexa 等虚拟助手学习更具对话性时,它有很大的前景。
真正的问题是,像其他技术一样,它有可能被滥用。利用 DeepFake 作为报复的一种形式,通过在色情中使用它,操纵政治家的照片和影响政治运动只是冰山一角。
它引发了一个严重的问题,即我们是否可以信任以图像、视频或声音形式呈现给我们的任何数字信息。
据 BBC 新闻, DeepFake 视频在短短九个月内翻了一番,其中 96%是色情性质的。这对 DeepFake 的受害者意味着什么?谁应该为创建和分享这种虚假媒体并诽谤另一个人负责?
科技巨头们意识到了 DeepFake 的危害,已经主动站出来反对 DeepFake 的滥用。脸书和微软在 9 月份宣布了一项竞赛deep face Detection Challenge(DFDC),以帮助检测 DeepFakes 和被操纵的媒体,脸书正在通过创建一个大型的 DeepFake 视频数据集来提供帮助,亚马逊正在为这项价值 100 万美元的挑战提供云资源。这项比赛将于 12 月启动,总奖金为 1000 万美元。
另一方面,谷歌也在创建一个 DeepFake 视频数据集,以便 Munchin 技术大学、那不勒斯大学 Federico II 和埃尔兰根-纽伦堡大学的研究人员可以将其用于 FaceForensics 项目,这是一个检测被操纵的面部图像的项目。
总而言之,技术正一天天变得越来越聪明,DeepFake 的创造证明了机器已经发展到这样一个水平,它们可以合成照片、视频和语音,甚至我们都无法将它们与真的区分开来。DeepFake 有一定的好处,其中之一是为自动驾驶汽车的改进创造更多的训练数据。但是,就像所有其他技术一样,人们正在滥用它来制作虚假视频,并在社交媒体上分享错误信息。科技巨头们已经加紧对付这一问题,希望在不久的将来,我们将拥有一个可以检测深度造假的系统。
我们能做些什么来帮助防止 DeepFake 被滥用,并确保它以安全的方式使用? 在下面留下你的想法作为评论。
点击这里 阅读我其他关于 AI/机器学习的帖子。
来源:
* [## 100,000 张人工智能生成的免费头像让股票照片公司受到关注
使用人工智能来生成看起来令人信服,但完全虚假的人的照片变得越来越容易。现在…
www.theverge.com](https://www.theverge.com/2019/9/20/20875362/100000-fake-ai-photos-stock-photography-royalty-free) [## ThisPersonDoesNotExist.com 利用人工智能生成无尽的假脸
人工智能产生虚假视觉效果的能力还不是主流知识,但一个新的网站…
www.theverge.com](https://www.theverge.com/tldr/2019/2/15/18226005/ai-generated-fake-people-portraits-thispersondoesnotexist-stylegan) [## 新报告称,人工智能无法保护我们免受深度欺诈
来自数据和社会的一份新报告对欺骗性修改视频的自动化解决方案提出了质疑,包括…
www.theverge.com](https://www.theverge.com/2019/9/18/20872084/ai-deepfakes-solution-report-data-society-video-altered) [## Deepfakes:目前,女性,而不是民主,是主要的受害者
虽然 2020 年美国总统选举让立法者对人工智能生成的假视频感到紧张,但一项由…
www.zdnet.com](https://www.zdnet.com/article/deepfakes-for-now-women-are-the-main-victim-not-democracy/) [## 忘掉假新闻吧,Deepfake 视频其实都是关于未经同意的色情内容
“深度造假”对公平选举,特别是 2020 年美国总统大选的威胁越来越大…
www.forbes.com](https://www.forbes.com/sites/daveywinder/2019/10/08/forget-2020-election-fake-news-deepfake-videos-are-all-about-the-porn/#7ea9952563f9) [## Deepfakes 可能会打破互联网
我们可能已经在一个深度造假的世界里游泳了,而公众甚至不会知道。毕竟,我们要怎么做呢?那些…
www.cpomagazine.com](https://www.cpomagazine.com/cyber-security/deepfakes-could-break-the-internet/) [## 向假货宣战:亚马逊用 100 万美元的云信用支持微软和脸书
AWS 全力支持即将到来的 Deepfake 检测挑战赛,这是一项奖金高达 1000 万美元的比赛…
www.zdnet.com](https://www.zdnet.com/article/war-on-deepfakes-amazon-backs-microsoft-and-facebook-with-1m-in-cloud-credits/) [## 什么是“深度假货”,它们有多危险
“Deepfakes”被用来在虚假视频中描绘他们实际上并没有出现的人,并可能潜在地影响…
www.cnbc.com](https://www.cnbc.com/2019/10/14/what-is-deepfake-and-how-it-might-be-dangerous.html) [## 亚马逊联合脸书和微软打击 deepfakes
Deepfakes 今年遇到了严重的问题,大公司现在开始关注。亚马逊宣布…
thenextweb.com](https://thenextweb.com/artificial-intelligence/2019/10/22/amazon-joins-facebook-and-microsoft-to-fight-deepfakes/) [## Deepfake 视频:它们是如何工作的,为什么工作,以及有什么风险
Deepfakes 是假的视频或音频记录,看起来和听起来就像真的一样。曾经是…的辖区
www.csoonline.com](https://www.csoonline.com/article/3293002/deepfake-videos-how-and-why-they-work.html) [## Deepfake 视频’九个月翻倍’
新的研究显示,所谓的深度假视频创作激增,在线数量几乎…
www.bbc.com](https://www.bbc.com/news/technology-49961089)*
Deepfakes:一个未知和未知的法律景观

https://m.wsj.net/video/20181012/1012-deepfakes-finalcut/1012-deepfakes-finalcut_960x540.jpg
2017 年标志着“深度造假”的到来,随之而来的是另一个由技术引发的法律模糊的新领域。术语“ deepfake ”指的是使用深度学习篡改的图像、视频或音频片段,以描述并未真正发生的事情。起初,这听起来可能很普通,也没什么坏处——Adobe 的 Photoshop 已经有几十年的历史了,像詹姆斯·卡梅隆的阿凡达这样的电影完全依赖于计算机生成图像(CGI)技术。然而,让 deepfakes 与众不同的是它们的范围、规模和复杂程度。虽然先进的数字更改技术已经存在多年,但它们在获取方面受到成本和技能的限制。逼真地修改视频和图像曾经需要高性能和昂贵的软件以及广泛的培训,而创建一个深度假几乎任何人都可以用电脑。这种便利带来了新的和前所未有的法律和道德挑战。
什么是 Deepfake?
这些令人信服的伪造视频的第一次出现是在 2017 年 12 月的,当时 reddit 上的一名匿名用户以“Deepfakes”的笔名将名人的面孔叠加到色情视频上。Deepfakes 在这种背景下蓬勃发展,刺激了诸如 DeepNude 这样的应用程序的建立,这些应用程序提供免费和付费的服务来改变女性的图像,使其看起来完全裸体。其他应用如 FakeApp 将这种体验推广到更广泛的背景,如欺凌、勒索、假新闻和政治破坏。与这些视频的创作同样令人震惊的是它们的泛滥——在它们短暂的历史中,deepfakes 在主流媒体上掀起了波澜。尤其是当唐纳德·特朗普总统转发众议院议长南希·佩洛西(D-CA)的视频时,显然是含糊不清的话,或者当一个巨魔发布马克·扎克伯格发表威胁性演讲的 deepfake。
deep fakes 是如何工作的?
在分析 deepfakes 的法律和社会后果之前,理解它们是如何工作的以及它们为什么如此有效是很重要的。Deepfakes 需要一种特定类型的人工智能(AI)和机器学习,称为深度学习,它利用人工神经网络变得更聪明,更善于检测和适应数据中的模式。Deepfakes 依赖于一种特殊形式的深度学习,称为生成对抗网络(GANS),由蒙特利尔大学的研究人员在 2014 年推出。GANS 将自己与其他深度学习算法区分开来,因为它们利用了两种相互竞争的神经网络架构。这种竞争发生在数据训练过程中,其中一种算法生成数据(生成器),另一种算法同时对生成的数据进行鉴别或分类(鉴别器)。神经网络在这种情况下是有效的,因为它们可以自己识别和学习模式,最终模仿和执行。正如凯伦·郝在麻省理工学院技术评论中所引用的那样,“(甘)的过程‘模仿了一个伪造者和一个艺术侦探之间的反复较量,他们不断试图智取对方。’“虽然这种算法听起来可能相当先进,但它的可用性和可访问性被开源平台如谷歌的 TensorFlow 或通过 GitHub(deep nude 在被关闭前存放其代码的地方)提供的公共存储库放大了。这项技术正变得越来越易于使用,因此也越来越危险,尤其是当它的情报迅速积累,变得越来越有说服力的时候。

https://www.edureka.co/blog/wp-content/uploads/2018/03/AI-vs-ML-vs-Deep-Learning.png
deep fakes 的含义:
deepfake 视频的后果可能是显而易见的:参与者的公开羞辱,错误信息,以及新的和脆弱的真理概念化。一个更难回答的问题是,如何保护个人,进而保护美国社会,免受 deepfakes 的严重影响。某些州已经采取了措施,例如弗吉尼亚州更新了其报复色情法以包括 deepfakes,或者得克萨斯州的 deepfake 法将于 2019 年 9 月 1 日生效,以规范选举操纵。虽然事后追究个人责任可以对其他人起到威慑作用,但一旦这些视频被发布到网上,往往已经造成了严重的损害。因此,在社交媒体和互联网病毒式传播的时代,保护第一修正案权利和最大限度地减少诽谤传播之间的平衡变得不那么明显,特别是随着社交媒体平台成为政治和社会话语的论坛。
除了更新或制定法律,还值得考虑将审查的负担转移到社交媒体平台上,让这些视频获得牵引力和传播。例如,如果脸书在南希·佩洛西的深层假货被认定为假货时将其移除,许多伤害本可以避免。虽然该公司提醒用户视频被篡改,但他们选择不删除视频,以保护宪法第一修正案的权利。然而,在上述扎克伯格 deepfake 发布之后,在 2019 年阿斯彭创意节上,马克·扎克伯格承认脸书可能会在未来对他们的 deepfake 政策进行修改。但是到目前为止,1996 年《通信行为规范法》第 230 条保护脸书或任何其他社交媒体平台免于为其用户发布的内容承担任何责任。这实际上给了这些平台更多的自由裁量权来决定宪法权利的范围。随着 deepfakes 变得更加普遍和有害,政府必须找到一种方法来监管大型科技公司,并调和它们已经成为民主平台的事实。
另一个需要记住的法律问题是法庭上的深度假证。多年来,数字图像和视频镜头已经为沉默证人理论下的可验证和可靠的证据创造了条件。然而,如果 deepfakes 持续生产,这些图像的可验证性将变得更加模糊和难以证明,从而根据美国联邦证据规则的规则 901(b) (9)加强对所有数字证据的审查。对数字证据全面丧失信心的后果将是增加对目击者证词的依赖,从而让法院在已经有偏见的系统中做出更有偏见的裁决。无论在何种背景下,法律体系都必须预测和调整 deepfakes 崛起带来的巨大变化,特别是因为它们的传播和影响难以遏制。
打击深度假货:
除了考虑社交媒体网站的潜在监管变化和预测法律困境,重要的是要考虑替代方法来规避 deepfakes 造成的潜在损害。罗伯特·切斯尼和丹妮尔·香橼提出了一种解决方案,即“认证不在场证明服务”。理论上,这些服务将创建跟踪个人的数字生活日志,以便他们最终可以推翻 deepfakes 提出的说法。这种解决方案很有意思,因为它损害了个人隐私,可能会遭到错误信息的拒绝。也许这表明了社会对隐私的冷漠,或者我们对假货的恐惧程度——或者两者兼而有之。无论如何,经过认证的不在场证明看起来像是一种绝望的防御措施,揭示了个人为了保护自己愿意牺牲多少。
Deepfakes 对美国社会构成严重威胁。虽然政治极化和假新闻已经玷污了事实,因此,我们的民主基础,我们必须制定战略,以防止信任和真理的进一步崩溃。因此,预测法律问题并相应调整法律,对于确保利用创新技术改善社会和抑制恶意工具的传播至关重要。
Deepfakes:丑陋与美好
我们的工作是确保我们开发的技术被善用。
昨天,我的朋友让我玩这个游戏,它叫做哪张脸是真实的。是的,我知道这听起来很扯,但是我每次都猜错了😐。

Which face is real? Well, I actually don’t know. ❓
这让我意识到一件事。我意识到人类只是一个非常愚蠢的物种,我不是指冒犯的方式,无论如何都是冒犯的(抱歉!)😅。
“我们首先应该假设自己很笨。我们绝对可以让东西比我们自己更聪明。”—埃隆·马斯克😶
这不是人工智能是否会比人类聪明的问题,它已经在几个领域聪明了,但真正的问题是我们如何才能善用这种智能?
在过去的几年里,人工智能的进步已经走上了指数曲线。

That’s right, AI is disrupting almost every single field. 💪
仅仅 10 年前,像 Siri 和 Alexa 这样的东西甚至还不存在。

Siri vs Alexa Rap Battle, that’s how good AI has become! 😂
今天,我们能够利用人工智能从医学图像中检测癌症,谷歌助手可以通过模仿人的声音在电话上为你预约,开发与真实图像几乎完美相似的假图像从未像现在这样简单。
对隐私和错误信息的广泛关注避开了对 deepfakes 的关注,deep fakes 是使用自动编码器和生成对抗网络等算法制作的虚假媒体。
在错误的人手中,这种技术可以用于诈骗。例如,最近,一个伪造的声音被用来诈骗一家英国公司的首席执行官 244,000 美元🤯**。**
Deepfakes 背后的技术:生成对抗模型
生成对抗网络(GANs) 的出现,打乱了假像的发展。
以前,我们一直使用像 photoshop 这样的手动方法,但有了生成式对抗网络,这一过程正在自动化,结果通常明显更好。
生成对抗网络是一种相对较新的神经网络,由 Ian Goodfellow 在 2014 年首次介绍。GANs 的目标是制作尽可能真实的假图像。
GAN 包含两个组件:
- 生成器 —生成图像
- 鉴别器 —对生成的图像是假图像还是真图像进行分类
发生器接受一个潜在样本,一个随机噪声向量作为输入。通过利用解卷积层,其本质上是卷积层的逆,产生图像。

De-convolutional layers
卷积层负责从输入中提取特征,解卷积层执行相反的操作,将特征作为输入,并产生图像作为输出。
假设你在和朋友玩猜字谜游戏。表演这个短语的人在表演“去卷积”,而其他猜这个短语的人在表演“卷积”。“表演”类似于形象,“猜测”类似于形象的特征。

Charades — reminds me of the fun times
本质上,卷积层识别图像的特征,而去卷积层根据图像的特征构建图像。

Convolutional layers
另一方面,鉴别器利用卷积层进行图像分类,因为它的工作是预测生成器生成的图像是真实(1) 还是虚假(0) 。生成器的目标是生成尽可能真实的图像,并成功地欺骗鉴别器,使其认为生成的图像是真实的。

鉴别器的工作对生成器的成功至关重要。为了帮助生成器生成更真实的图像,鉴别器必须非常擅长区分真实图像和虚假图像。鉴别器越好,发生器就越好。
每次迭代后,生成器的可学习参数、权重和偏差都根据鉴别器给出的建议进行调整。
网络通过反向传播关于生成图像的鉴别器输出梯度来更新可学习参数。本质上,鉴别器告诉生成器应该如何调整每个像素,以使图像更加真实。
假设生成器创建了一个图像,鉴别器认为该图像有 0.29 (29%)的概率是真实图像。生成器的工作是更新其可学习的参数,以便在计算反向传播后,概率增加到例如 30%。
然而,生成器依赖于鉴别器才能成功。
一种更直观的思考方式是,想象发生器类似于学生,鉴别器类似于老师。

Does this spark any memories from grade school? 📝
还记得你写测试的时候,你对自己的结果感到非常紧张,因为你不知道自己做得有多好。
学生不知道他们犯了什么错误,直到老师给他们打分并给他们反馈。学生的工作是从老师给他们的反馈中学习,以提高他们的考试成绩。
老师教得越好,学生的学习成绩就越好。
从理论上讲,生成器在创建几乎完美无缺的真实图像方面做得越好,鉴别器在区分真实图像和虚假图像方面就做得越好。反之亦然,鉴别器对图像分类越好,生成器就越好。
利用 MobileNetV2 检测伪造图像
为了对真假图像进行分类,我使用了一个预先训练好的卷积神经网络,称为 MobileNetV2 ,它是在 1400 万图像数据集 ImageNet 上训练的。
我利用 MobileNet 2.0 版本 MobileNetV2 而不是构建自己的卷积神经网络的主要原因是,MobileNetV2 旨在对移动设备友好,这意味着它需要明显更少的计算能力。
通过在 MobileNetV2 上添加几个额外的层,并根据真实与虚假图像数据集 t 对其进行训练,我的模型能够以 75%的准确率区分虚假图像和真实图像。
我的神经网络结构看起来像这样:
1。MobileNetV2
2。平均池层 —该层负责通过执行向下采样来降低数据的维度。例如,假设我们有一个 4x4 的输入矩阵,并且应用了一个 2x2 的平均池层。实际上,对于输入矩阵中的每个 2×2 块,取这些值的平均值**,从而降低维数。**

Average pooling layer
3。密集层 —密集层只是一个常规的全连接层,其中每层中的每个节点都连接到下一层中的每个节点。激活函数 ReLU ( R(z) = max (0,z) )应用于该层,主要负责将范围限制为正值。

ReLU function
4。 批量标准化层 —该层负责标准化通过该层的输入,以增强神经网络的稳定性。
5。丢弃层 —该层负责通过将某些随机节点的激活设置为 0 来防止过拟合。在辍学层,没有可学习的参数(即。这不是像其他层那样的训练层)。
6。输出层 —这实际上是一个应用了 softmax 激活功能的规则密集层。softmax 函数产生 0-1 之间的输出,表示最终预测输出类的概率分布。

Softmax function
这个模型的准确性可以通过拥有更大的数据集来容易地增强。我在 2041 张图像的数据集上训练了模型,但想象一下,如果我们在 100 万张图像上训练它,模型的准确性可以明显更高!
氮化镓的应用
GANs 的应用不仅仅局限于负面目的,比如制造错误信息,它实际上可以以积极的方式应用于许多行业!
甘的一些非常有趣的用法:
- 生成艺术😍—是的,谁说机器不能做创造性的事情,我想它可以!
- 创作音乐🎵—人们实际上喜欢人工智能音乐!
- 创造虚假的人类形象
- 生成虚假的动漫图像——我不是一个超级动漫爱好者,但如果你是,那就太棒了!

Fake images generated by GANs
更多实际应用:🚀
通过利用 GANs,我们有可能加速机器学习本身的进步!
我们可以利用 GANs 来解决小数据集的问题,通过生成与数据集中的真实数据相似的新数据,这是机器学习的主要瓶颈之一。
拥有更大的数据集是增强基于分类的机器学习程序的性能的最可靠的方法之一。
🖼️潜在的应用之一可能是利用 GANs 生成合成的大脑 MRI 图像,以提高对神经胶质瘤(一种脑癌)的检测。
💊最令人兴奋的应用是利用 GANs 合成新的分子或候选药物,这些分子或候选药物针对引起疾病的特定蛋白质或生物标志物。
为了做到这一点,生成器负责生成新的分子,然后鉴别器预测分子的作用,看它是否可以抑制或兴奋某种蛋白质。我们可以用 gan 来推进和加速药物发现的进程。
🎥在电影和漫画行业,GANs 可用于文本到图像的合成。
GANs 的实际应用多了去了!这项技术有可能颠覆许多行业,从医疗保健到电影!我们有责任确保这项技术用于正确的目的,并补充人类。
关键要点:
- GANs 是一种用于创建合成数据的技术,包括两个组件:生成器和鉴别器。
- 通过利用卷积神经网络,我的机器学习程序能够以 75%的准确率检测出 GANs 生成的假图像。****
- GANs 的应用有好有坏。虽然 GANs 可以制造假介质,但是它也可以用于合成新药研发的新分子。
不要忘记:
- 在 LinkedIn 上与我联系
- 访问我的网站来一窥我的全部作品集!
Deep fool——欺骗深度神经网络的简单而准确的方法。
敌对的攻击

Fig 1. Its not a fish, its a bird 😃 [Confidences shown are the values of logits and not passed through softmax]
论文摘要 DeepFool:一种简单准确的愚弄深度神经网络的方法 由 赛义德-穆赫森·穆沙维-德兹夫利、阿尔侯赛因·法齐、帕斯卡尔·弗罗萨德 论文链接:https://arxiv.org/pdf/1511.04599.pdf
概观
深度神经网络在许多任务中实现了最先进的性能,但在轻微扰动的图像上惨败,以有意义的方式(而不是随机地)扰动。
DeepFool 论文有以下主要贡献:
- 计算不同分类器对敌对扰动的鲁棒性的简单而精确的方法。
- 实验表明
- DeepFool 计算出更优的对抗性扰动
-对抗性训练显著增加了鲁棒性。
- DeepFool 计算出更优的对抗性扰动
二元分类器的 DeepFool

FIg 2. Simple Image with Linear model to explain what DeepFool does.
使用线性二进制分类器可以容易地看出,对于输入x_{0}的模型的鲁棒性(f)等于x_{0}到超参数平面的距离(其将两个类别分开)。
改变分类器决策的最小扰动对应于x_{0}在超参数平面上的正交投影。给出者:

Fig 3. Equation to calculate the minimal perturbation.
以下是 DeepFool 针对二元分类器的算法:

Fig 4. Algorithm to calculate the Adversarial Image for Binary Classifiers.
我们来过一遍算法:
1。该算法采用一个输入x和一个分类器f。
2。输出对图像进行微分类所需的最小扰动。
3。用原始输入初始化对立图像。并将循环变量设置为 1。
4。开始并继续循环,而真实标签和对抗扰动图像的标签是相同的。
5。计算输入到最近超平面的投影。
(最小扰动)6。将扰动添加到图像中并进行测试。
7–8。增量循环变量;结束循环
9。返回最小扰动
多类分类器的 DeepFool
对于多类分类器,假设输入是x,每个类都有一个超平面(将一个类与其他类分开的直平面),并根据x在空间中的位置将其分类到一个类中。现在,这种算法所做的就是,找到最近的超平面,然后将x投影到该超平面上,并将其推得更远一点,从而尽可能以最小的扰动将其错误分类。就是这样。(浏览论文中的第 3 节以深入了解)
让我们来看看算法

Fig 5. Algorithm to calculate the Adversarial Image for Multiclass Classifiers.
让我们快速预排一下算法的每一步:
1。输入是一个图像x和模型分类器f。
2。扰动
3 的输出。【空白】
4。我们用原始图像和循环变量初始化扰动的图像。
5。我们开始迭代并继续进行,直到原始标签和扰动标签不相等。
6–9。我们考虑在原始类之后具有最大概率的n类,并且我们存储原始梯度和这些类中的每一个的梯度之间的最小差异(w_{k})以及标签中的差异(f_{k})。10。内部循环存储最小值 w_{k}和 f_{k},并使用它计算输入x的最近超平面(见图 6)。对于最近超平面的计算公式)
11。我们计算将x投影到我们在 10 中计算的最近超平面上的最小向量。12。我们将最小扰动添加到图像中,并检查它是否被微分类。13 至 14 岁。循环变量增加;端环
15。返回总扰动,它是所有计算扰动的总和。
下面是计算最近超平面的公式:

Fig 6. Equation to calculate the closest hyperplane.
其中,以f开头的
变量为类别标签
以w开头的变量为梯度
其中,以k为下标的变量为真实类别之后概率最大的类别,以\hat{k}(x+{0})为下标的变量为真实类别。
下面是计算最小扰动(将输入投影到最近超平面的向量)的等式

Fig 7. Equation to calculate the minimal perturbation for multiclass classifiers.
模型的对抗性稳健性
DeepFool 算法还提供了一种度量算法的对抗性鲁棒性的方法。它由提供
# For images with a batch size of 1
num_images = len(tloader))
adversarial_robustness = (1 / num_images) * ((torch.norm(rt.flatten()) / (torch.norm(x.flatten()))
实验

Fig 8. Table demonstrating the test error rates and robustness of the models using each attack and the time to generate one adversarial example with each attack.
其中,
4 —是快速梯度符号法。
18 —攻击来自 Szegedy 等人题为《神经网络的有趣特性》的论文。

使用通过快速梯度符号方法和 DeepFool 生成的对抗图像显示对抗训练效果的图表。这些图表证明了用最小扰动(而不是像快速梯度符号方法那样过度扰动)的对立例子进行训练的重要性。)

该图证明用过度扰动的图像进行训练降低了模型的稳健性。在这个实验中,作者仅使用α值逐渐增加的 DeepFool(其中α是与产生的扰动相乘的值)

该表显示了使用不同方法微调网络后的测试错误率。该表显示,用过度扰动的图像调整网络导致更高的测试错误率(由快速梯度符号方法产生的对立图像)。)

图表显示了使用精确指标计算模型的对抗性稳健性的重要性。在这个实验中,他们使用 FGM 攻击和 DeepFool 攻击的p_adv来计算 NIN(网络中的网络)模型的鲁棒性。该图显示了使用 FGM 攻击计算的鲁棒性如何给出错误的度量,因为它实际上并不像前面的示例所示的那样鲁棒(以及使用 DeepFool 攻击计算的鲁棒性的蓝线)。此外,请注意,在第一个额外时期(在用正常图像进行原始训练后,用相反扰动的图像对网络进行 5 个额外时期的训练),红线(FGM)不够敏感,不足以证明鲁棒性的损失。
参考
- 赛义德-穆赫辛-穆沙维-德兹夫利、阿尔侯赛因-法齐、帕斯卡尔-弗罗萨德;IEEE 计算机视觉和模式识别会议(CVPR),2016 年,第 2574–2582 页
希望这篇文章足够清晰,能让你很好地理解 DeepFool 算法是什么以及它是如何工作的。如果我发现更直观的解释或需要更多关注的地方,我希望将来更新这篇文章。请务必阅读这篇论文,以便更好地理解。感谢阅读!
DeepLabv3:语义图像分割
来自谷歌的作者扩展了先前的研究,使用最先进的卷积方法来处理不同尺度图像中的对象[1],在语义分割基准上击败了最先进的模型。

From Chen, L.-C., Papandreou, G., Schroff, F., & Adam, H., 2017 [1]
介绍
使用深度卷积神经网络(DCNNs)分割图像中的对象的一个挑战是,随着输入特征图通过网络变得越来越小,关于更小尺度的对象的信息可能会丢失。

Figure 1. The repeated combination of pooling and striding reduces the spatial resolution of the feature maps as the input traverses through the DCNN.
DeepLab 的贡献在于引入了 *atrous 卷积、*或 expanded 卷积,以提取更密集的特征,从而更好地保留给定不同尺度对象的信息【2–3】。Atruos 卷积还有一个额外的参数 r ,称为 ATR uos 速率,它对应于输入信号的采样步幅。在图 2 中,这相当于沿着每个空间维度在两个连续的滤波器值之间插入 r -1 个零。在这种情况下, r=2 ,因此每个滤波器值之间的零值数量为 1。这种方法的目的是灵活地修改滤波器的视野,并修改计算特征的密度,所有这些都通过改变 r 来实现,而不是学习额外的参数。

Equation 1. The formulation for the location i in the output feature map y, or in other words, one of the squares in the green matrix in Figure 2. x is the input signal, r is the atrous rate, w is the filter and k is the kernel.

Figure 2. A atruous 2D convolution using a 3 kernel with a atrous rate of 2 and no padding. From “An Introduction to Different Types of Convolutions in Deep Learning” by Paul-Louis Pröve
作者调整了一个名为 output_stride,的值,它是输入图像分辨率和输出分辨率之间的比率。他们比较并结合了三种方法来创建他们的最终方法:阿特鲁空间金字塔池(ASPP) 。第一种是级联卷积,它是简单的相互进行的卷积。当这些卷积为 r =1 时,这是现成的卷积,详细信息被抽取,使分割变得困难。作者发现,使用 atrous 卷积通过允许在 DCNN 的更深块中捕获远程信息来改善这一点。图 3 示出了“普通”DCNN 与级联 DCNN 的比较,级联 DCNN 具有r1 个卷积。

Figure 3. The top (a) is a regular CNN while the second uses atrous convolutions with r>1 in a cascading manner and with an output_stride of 16.
第二种是多重网格方法,不同大小的网格层次结构(见图 4)。他们将多网格参数定义为一组 atrous rates ( r₁,r ₂, r ₃),按顺序应用于三个区块。最终速率等于单位速率和相应速率的乘积。例如,在 output_stride 为 16,multi_grid 为(1,2,4)的情况下,块 4(见图 3)将有三个速率为 2 ⋅ (1,2,4) = (2,4,8)的卷积,

Figure 4. A multi-grid CNN architecture. From Ke, T., Maire, M., & Yu, S.X., 2016 [4]
作者的主要贡献是从[5]修改阿特鲁空间金字塔池(ASPP),它在空间“金字塔”池方法中使用 Atrous 卷积,以包括批量归一化和包括图像级特征。如图 5 (b)所示,他们通过在最后一个特征图上应用全局平均池来实现这一点。然后,它们将结果馈送到具有 256 个滤波器的 1x1 卷积。他们最终将该特征双线性上采样到期望的空间维度。图 5 中的例子提供了两个输出。输出(a)是具有 multi_grid rates = (6,12,18)的 3×3 卷积。输出(b)是图像级特征。然后,网络连接这些输出,并在生成 logit 类输出的最终 1x1 卷积之前,通过 1x1 卷积传递它们。

Figure 5. Parallel modules with atrous convolutions. From Chen, L.-C., Papandreou, G., Schroff, F., & Adam, H., 2017 [1].
实验
为了给他们的方法提供支持,他们将级联和多重网格网络与 ASPP 进行了比较。结果是:
- **输出步幅:**他们发现,较大的分辨率,或较小的 output_stride,比没有 atrous 卷积或较大的 Output _ Stride 表现明显更好。他们还发现,当在比较 output_stride 为 8(更大的分辨率)和 output_stride 为 16 的验证集上测试这些网络时,output_stride 为 8 的网络性能更好。
- 级联:与常规卷积相比,级联 atrous 卷积的结果提高了性能。然而,他们发现添加的块越多,改善的幅度就越小。
- 多网格:相对于“普通”网络,他们的多网格架构结果确实有所改善,并且在第 7 块的( r₁,r ₂, r ₃) = (1,2,1)处表现最佳。
- ASPP +多重网格+图像池:多重网格速率为( r₁,r ₂, r ₃) = (1,2,4),使得 ASPP (6,12,18)模型在 7721 万时表现最佳。在具有多尺度输入的 COCO 数据集上,当 output_stride = 8 时,模型在 82.70 处测试,显示通过将 output_stride 从 16 改变为 8 而进一步改善。
结论
作者提出了一种方法,通过向空间“金字塔”池 atrous 卷积层添加批处理和图像特征来更新 DeepLab 以前的版本。结果是,网络可以提取密集的特征图来捕捉长范围的上下文,从而提高分割任务的性能。他们提出的模型的结果在 PASCAL VOC 2012 语义图像分割基准上优于最先进的模型。

From Chen, L.-C., Papandreou, G., Schroff, F., & Adam, H., 2017 [1].
更多信息请访问他们的 GitHub:https://GitHub . com/tensor flow/models/tree/master/research/deep lab
参考
[1]陈,L.-C .,帕潘德里欧,g .,施罗夫,f .,&亚当,H. (2017)。语义图像分割中阿特鲁卷积的再思考。从http://arxiv.org/abs/1706.05587取回
[2] Holschneider,Matthias & Kronland-Martinet,Richard & Morlet,j .和 Tchamitchian,Ph. (1989 年)。一种基于小波变换的实时信号分析算法。小波、时频方法和相空间。-1.286.10.1007/978–3–642–75988–8_28.
[3] Giusti,a .,Cireş an,D. C .,Masci,j .,Gambardella,L. M .,& Schmidhuber,J. (2013 年 9 月)。深度最大池卷积神经网络的快速图像扫描。在 2013 IEEE 国际图像处理会议(第 4034–4038 页)。IEEE。
[4]柯,t .梅尔,m .,,余,S.X. (2016)。多重网格神经结构。 2017 年 IEEE 计算机视觉与模式识别大会(CVPR) ,4067–4075。
[5]陈、帕潘德里欧、科基诺斯、墨菲和尤耶。Deeplab:使用深度卷积网络、atrous 卷积和全连接 CRF 的语义图像分割。arXiv:1606.00915,2016。
DeepMind 联合创始人的休假

Photo by @heysupersimi
为什么会发生,有什么信息?
我决定调查 DeepMind 的联合创始人穆斯塔法·苏莱曼的休假,并浏览一下 DeepMind 的历史。
深度思维简介
DeepMind Technologies 是一家成立于 2010 年 9 月的英国公司,目前归 Alphabet 所有,公司总部位于伦敦,在加拿大、法国和美国设有研究中心。该公司由戴密斯·哈萨比斯、穆斯塔法·苏莱曼和沙恩·莱格于 2010 年创立。它在 2014 年以 4 亿英镑或当时的 6.5 亿美元购得。
谷歌收购该公司后,他们建立了一个人工智能道德委员会,但人工智能研究的道德委员会仍然是一个谜,我们真的不知道谁在委员会中。DeepMind 与亚马逊、谷歌、脸书、IBM 和微软一起,是致力于*“社会-人工智能界面”*的组织 Partnership on AI 的创始成员。
DeepMind 有一个名为 DeepMind 伦理与社会的部门,专注于伦理和社会问题。2017 年 10 月,DeepMind 启动了一个新的研究团队,调查 AI 伦理。
最近提交给英国公司注册处的文件显示,2018 年 DeepMind 的税前亏损增长至 5.7 亿美元,收入为 1.25 亿美元。据说这是由于它努力获得最好的人工智能人才。
新闻说什么?
来自不同新闻出版物的一些标题或关键论点:
- “穆斯塔法·苏莱曼的撤退表明艾集团的自主权已被其母公司剥夺” —英国《金融时报》2019 年 8 月 23 日
- 一位发言人向《福布斯》证实,谷歌广受好评的人工智能实验室 DeepMind 的联合创始人穆斯塔法·苏莱曼正在休假。该公司说,在忙碌了十年之后,穆斯塔法现在要休假一段时间,并称休假是双方的决定,并补充说该公司预计他将在年底前回来。——《福布斯》特约撰稿人 吉利安·德昂弗罗,在 2019 年 8 月 21 日的一篇文章中
- 谷歌旗下备受瞩目的人工智能实验室 DeepMind 的联合创始人因其领导的一些项目引发争议而被停职。穆斯塔法·苏莱曼管理着 DeepMind 的“应用”部门,该部门为实验室在健康、能源和其他领域的研究寻求实际用途。苏莱曼也是 DeepMind 的一个关键公众形象,他在官员和活动中谈论人工智能的承诺以及限制恶意使用该技术所需的道德护栏。”–彭博,2019 年 8 月 21 日
穆斯塔法·苏莱曼
然而,在这件事上我们必须考虑穆斯塔法本人。8 月 22 日,穆斯塔法在推特上写道:

这位伊斯灵顿本地人 19 岁从牛津大学辍学,帮助建立了一个名为穆斯林青年帮助热线的电话咨询服务,这是英国同类服务中最大的心理健康服务之一。他在 22 岁时离开该组织,共同创立了 DeepMind。
在 DeepMind,他最近领导了一个专注于人工智能和健康的项目。
7 月,DeepMind 宣布,其技术现在可以在急性肾损伤发生前两天进行预测。
穆斯塔法在 2018 年的 a Wired 专栏中写道:“我们需要做艰苦、实际和混乱的工作,找出伦理人工智能的真正含义。”他预测人工智能的安全和社会影响的研究将是“最紧迫的调查领域之一。”
穆斯塔法和哈萨比斯要求,作为谷歌收购 DeepMind 的一部分,该公司需要建立一个内部道德委员会,以监督所有部门的人工智能工作。2019 年初,谷歌试图创建一个外部人工智能伦理委员会,但在内部和外部对其成员的抗议之后,很快解散了该项目。
名为 Streams 的应用程序
苏莱曼一直在运营该集团的“应用人工智能”部门,该部门旨在为其科学研究找到现实世界的用途,并在此前领导了该集团的健康工作,包括与英国国家医疗服务系统的广泛批评的 2016 年合作。这项合作让 DeepMind 获得了一款名为 Streams 的肾脏监测应用程序的 160 万份患者记录,其数据共享做法最终在 2017 年被视为非法,促使苏莱曼和该公司道歉。去年年底,谷歌宣布 Streams 及其团队将并入谷歌旗下,实质上解散了 DeepMind Health group。
我从英国广播公司找到了几个报道这一过程的链接:
从那以后,这款应用受到了医院管理者的高度赞扬,被认为大大加快了诊断速度。皇家自由医院的玛丽·埃默森在本月早些时候接受英国广播公司采访时说:“能够在医院的任何地方接收病人的警报,这是一个巨大的变化。”。
2019 年 7 月 31 日的一篇博文
我决定回过头来看看由穆斯塔法·苏莱曼和多米尼克·金写的一篇关于使用人工智能让医生在危及生命的疾病面前领先 48 小时的博文。
“人工智能现在可以在可避免的患者伤害发生前两天预测其主要原因之一,正如我们在《自然》 上发表的最新研究 所证明的那样。我们与美国退伍军人事务部(VA)的专家一起工作,开发了一种技术,在未来,这种技术可以让医生在治疗急性肾损伤(AKI)时提前 48 小时开始,这种疾病与英国每年超过 10 万人有关。这些发现与我们针对临床医生的移动助手 Streams 的同行评审服务评估相一致,该评估表明,通过使用数字工具,可以改善患者护理,降低医疗保健成本。它们共同构成了医学变革性进步的基础,有助于从反应性护理模式转向预防性护理模式。”

Screenshot of post from DeepMind blog published the 31st of July and retrieved on the 26th of August
后来在博文中说:
“这对 DeepMind 健康团队来说是一个重要的里程碑,他们将在大卫·范伯格博士的领导下,作为谷歌健康的一部分推进这项工作。正如我们在 2018 年 11 月 宣布的 一样,Streams 团队和从事医疗转化研究的同事将加入谷歌,以便在全球范围内产生积极影响。DeepMind Health 团队与谷歌团队的经验、基础设施和专业知识相结合,将帮助我们继续开发移动工具,为更多临床医生提供支持,解决关键的患者安全问题,我们希望能够拯救全球成千上万人的生命。”
最后
由于我妻子的父亲患有肾病,这是他早逝的一个主要原因,在这种情况下,我很难保持中立。然而,我能说的是,我们必须阅读眼前的新闻之外的东西,试图更好地理解穆斯塔法·苏莱曼暂时离开的情况是很有趣的。
这是#500daysofAI 每天写关于人工智能的第 83 天。
DeepPiCar 第 1 部分:如何在预算有限的情况下建造深度学习、自动驾驶的机器人汽车
DeepPiCar 系列
概述如何建立一个树莓 Pi 和 TensorFlow 供电的自动驾驶机器人汽车

介绍
今天,特斯拉、谷歌、优步和通用汽车都在试图创造自己的自动驾驶汽车,可以在现实世界的道路上行驶。许多分析师预测,在未来 5 年内,我们将开始有完全自动驾驶的汽车在我们的城市中行驶,在 30 年内,几乎所有的汽车都将是完全自动驾驶的。使用一些大公司使用的相同技术来建造你自己的无人驾驶汽车不是很酷吗?在这篇文章和接下来的几篇文章中,我将指导您如何从头开始构建自己的物理、深度学习、自动驾驶的机器人汽车。在一周之内,你将能够让你的汽车检测并跟随车道,识别并回应交通标志和路上的人。这里先睹为快,看看你的最终产品。


Lane Following (left) and Traffic Sign and People Detection (right) from DeepPiCar’s DashCam
我们的路线图
第 2 部分:我将列出需要购买的硬件以及如何设置它们。简而言之,你将需要一个树莓 Pi 板(50 美元) SunFounder PiCar 套件(115 美元)谷歌的 Edge TPU(75 美元)加上一些配件,以及在后面的文章中每个部分是如何重要的。这些材料的总成本约为 250-300 美元。我们还会安装树莓派和 PiCar 需要的所有软件驱动。



Raspberry Pi 3 B+ (left), SunFounder PiCar-V (middle), Google Edge TPU (right)
第三部分:我们将设置所有需要的计算机视觉和深度学习软件。我们使用的主要软件工具有 Python (机器学习/AI 任务的事实上的编程语言) OpenCV (强大的计算机视觉包) Tensorflow (谷歌流行的深度学习框架)。注意,我们在这里使用的所有软件都是免费和开源的!



第 4 部分:随着(乏味的)硬件和软件设置的结束,我们将直接进入有趣的部分!我们的第一个项目是使用 python 和 OpenCV 来教会 DeepPiCar 通过检测车道线在蜿蜒的单车道上自主导航,并相应地转向。

Step-by-Step Lane Detection
第 5 部分:我们将训练 DeepPiCar 自动导航车道,而不必像在我们的第一个项目中那样显式地编写逻辑来控制它。这是通过使用“行为克隆”来实现的,我们只使用道路的视频和每个视频帧的正确转向角度来训练 DeepPiCar 自动驾驶。实现的灵感来自于 NVIDIA 的 DAVE-2 全尺寸自动驾驶汽车,它使用深度卷积神经网络来检测道路特征,并做出正确的转向决策。
Lane Following in Action
最后,在第 6 部分中:我们将使用深度学习技术,如单次多框对象检测和转移学习,来教会 DeepPiCar 检测道路上的各种(微型)交通标志和行人。然后我们会教它在红灯和停车标志时停下来,在绿灯时继续,停下来等待行人过马路,根据张贴的速度标志改变它的速度限制,等等。

Traffic Signs and People Detection Model Training in TensorFlow
先决条件
以下是这些文章的先决条件:
- 首先也是最重要的是愿意修补和破坏东西。与汽车模拟器不同,在汽车模拟器中,一切都是确定的,完全可重复的,真实世界的模型汽车可能是不可预测的,您必须愿意弄脏自己的手,并开始修补硬件和软件。
- 基本 Python 编程技能。我将假设您知道如何阅读 python 代码和编写函数,以及 python 中的 if 语句和循环。我的大部分代码都有很好的文档记录,特别是较难理解的部分。
- 基础 Linux 操作系统知识。我将假设您知道如何在 Linux 的 Bash shell 中运行命令,这是 Raspberry Pi 的操作系统。我的文章将告诉您运行哪些命令,我们为什么运行它们,以及期望输出什么。
- 最后,你需要大约 250-300 美元来购买所有的硬件和工作电脑(Windows/Mac 或 Linux)。同样,所有使用的软件都是免费的。
进一步的想法[可选]
这是可选阅读,因为我试图在我的文章中涵盖你需要知道的一切。然而,如果你想更深入地研究深度学习,(一语双关),除了我在整篇文章中提供的链接之外,这里还有一些资源可供查阅。
吴恩达在 Coursera 上的机器学习和深度学习课程。正是这些课程点燃了我对机器学习和 AI 的热情,给了我创作 DeepPiCar 的灵感。
- 机器学习(免费):本课程涵盖传统的机器学习技术,如线性回归、逻辑回归、支持向量机等,以及神经网络。它是在 2012 年创建的,所以它使用的一些工具,即 Matlab/Octave,已经过时了,而且它没有长篇大论地谈论深度学习。但是它教给你的概念是无价的。你只需要高中水平的数学和一些基本的编程技能就可以学习这门课程,ng 博士非常好地解释了像反向传播这样的困难概念。完成本课程大约需要 3 个月的时间。

- 深度学习 5 门课程专业化(免费或 50 美元/月,如果你想获得证书):这门课程于 2018 年初推出。因此它涵盖了到那时为止所有最新的人工智能研究,如全连接神经网络、卷积神经网络(CNN)和序列模型(RNN/LSTM)。这门课对我来说是一种享受。作为一名工程师,我总是想知道一些很酷的小工具是如何工作的,比如 Siri 如何回应你的问题,以及汽车如何识别路上的物体等。现在我知道了。完成这 5 门课程的专业化大约需要 3-4 个月。

下一步是什么
第一条到此为止。我们将在第 2 部分见面,我们将动手制作一辆机器人汽车!
以下是整个指南的链接:
第 1 部分:概述(本文)
第 2 部分: Raspberry Pi 设置和 PiCar 装配
第 3 部分:让 PiCar 看到并思考
第 4 部分:通过 OpenCV 的自主车道导航
第五部分:自主 通过深度学习进行车道导航
第六部分:交通标志和行人检测处理
DeepPiCar —第 2 部分:Raspberry Pi 设置和 PiCar 装配
DeepPiCar 系列
组装 PiCar 硬件并安装所有软件驱动程序。让它在客厅里运行
行动纲要
欢迎回来!在本指南中,我们将首先介绍要购买的硬件以及我们为什么需要它们。接下来,我们将设置它们,以便在本文结束时,我们将有一个 PiCar 在我们的客厅中运行。
硬件供应清单

- 1 个树莓 Pi 3 型号 B+套件,带 2.5A 电源 ($50)这是你 DeepPiCar 的大脑。这款最新型号的 Raspberry Pi 具有 1.4Ghz 64 位四核处理器、双频 wifi、蓝牙、4 个 USB 端口和一个 HDMI 端口。我推荐这个套件(不仅仅是 Raspberry Pi 板),因为它配有一个电源适配器,你需要在进行非驱动编码和测试时插入,还有两个芯片散热器,这将防止你的 Raspberry Pi CPU 过热。
- 1 个 64 GB 微型 SD 卡 ($8)这是你的树莓派的操作系统和我们所有软件的存储位置。任何品牌的 micro SD 卡应该都可以。你家里可能就有一个。32GB 应该也可以。我选择 64 GB 是因为我计划在我的汽车行驶时录制大量视频,以便我可以在以后分析它的行为,并在以后的项目中使用这些视频进行深度学习训练。

- 1 x SunFounder PiCar-V 套件 ($115)这是 DeepPiCar 的主体。确保你得到的是如上图所示的 V 型车(又名 2.0 版)。它配备了机器人汽车所需的一切,除了树莓派和电池。市场上有许多 Raspberry Pi 车载套件,我选择了这个车载套件,因为它带有开源 python API 来控制汽车,而其他供应商有其专有的 API 或基于 C 的 API。我们知道,python 现在是机器学习和深度学习的首选语言。此外,开源很重要,因为如果我们发现 API 中的错误,我们可以自己修补汽车 API 的内部,而不必等待制造商提供软件更新。
- 4 节 18650 电池和 1 节电池充电器 ($20)您可以获得任何 18650 电池和兼容充电器。这些电池用于高消耗应用,例如驱动 Raspberry Pi 板和 PiCar。PiCar 只需要两节电池,但你总是希望身边有另一节刚刚充电的电池,这样你就可以让你的车一直在赛道上行驶。我建议在晚上给两套充电,这样你就不用担心测试时电池没电了。

- 1 x 谷歌边缘 TPU USB 加速器 ($75)每个英雄都需要一个助手。谷歌的 Edge TPU (Edge 意味着它用于移动和嵌入式设备,TPU 代表张量处理单元)是 Raspberry Pi 板的一个很好的附加组件。虽然 Pi CPU 将大量计算能力打包在一个微小的包中,但它不是为深度学习而设计的。另一方面,谷歌新发布的 Edge TPU(2019 年 3 月)是专门为运行用 TensorFlow 编写的深度学习模型而设计的。在本系列的第 6 部分中,我们将在 TensorFlow 中构建一个实时交通标志检测模型。这个模型有 200+层深!仅在 Raspberry Pi 的 CPU 上运行该模型只能处理每秒 1 帧(FPS),这几乎不是实时的。此外,它消耗 100%的 CPU,使所有其他程序无响应。但是在 Edge TPU 的帮助下,我们现在可以处理 12 FPS,这对于实时工作来说已经足够了。我们的 CPU 保持凉爽,可以用来做其他处理任务,如控制汽车。


- 1 套微型交通标志(15 美元)和一些乐高玩具。如果你的小宝宝在游戏室里有这些玩具标志和乐高玩具,你可能就不需要买了。你可以使用你找到的任何标志来训练模型,只要确保它们不要太大!

- (可选)1 个 170 度广角 USB 摄像头(40 美元)。这是一个可选配件。我买它是为了取代 SunFounder PiCar 附带的库存相机,以便汽车可以拥有广阔的视野。库存相机很棒,但没有我喜欢的广角,它看不到前轮前 3-4 英寸的车道线。最初,我在第 4 部分中用库存相机编写了车道跟踪代码。在尝试了几个镜头后,我发现这个广角相机大大提高了车道跟踪的准确性和稳定性。控制你的硬件和软件是很好的(相对于在汽车模拟器中驾驶一辆汽车),因为如果一个问题不能简单地通过软件解决,你可以求助于硬件修复。
- 接受 HDMI 输入的 USB 键盘/鼠标和显示器。您只需要在 Pi 的初始设置阶段使用它们。之后,我们可以通过 VNC 或 Putty 远程控制 Pi。
- 一台运行 Windows/Mac 或 Linux 的台式机或笔记本电脑,从这里开始我将称之为“PC”。我们将使用这台 PC 远程访问 Pi 计算机并将代码部署到 Pi 计算机。
有时候,让我惊讶的是,我们汽车的大脑树莓派仅售 30 美元,比我们的许多其他配件都便宜。事实上,随着时间的推移,硬件越来越便宜,功能越来越强大,而软件则完全免费且丰富。我们不是生活在一个伟大的时代吗?!
组装完成后,这就是最终产品。我这里用的是广角相机。

树莓 Pi 设置
Raspberry Pi 操作系统设置(1 小时)
- 按照这个优秀的一步一步的指导将 NOOBS Raspbian 操作系统(Linux 的一个变种)安装到一个微型 SD 卡上。这大约需要 20 分钟和 4GB 的磁盘空间。安装和重启后,您应该会看到一个完整的 GUI 桌面,如下所示。这感觉就像你在一个 Windows 或者 Mac 的 GUI 环境中,不是吗?

- 在安装过程中,Pi 会要求您更改默认用户
pi的密码。比如我们把密码设为rasp。 - 初次安装后,Pi 可能需要升级到最新的软件。这可能还需要 10-15 分钟。
设置远程访问
设置远程访问允许 Pi 计算机无头运行(即没有显示器/键盘/鼠标),这使我们不必一直连接显示器和键盘/鼠标。这个视频给出了一个非常好的关于如何设置 SSH 和 VNC 远程访问的教程。不管怎样,这是步骤。
- 打开终端应用程序,如下所示。终端应用程序是一个非常重要的程序,因为我们在后面文章中的大多数命令都将从终端输入。

- 通过运行
ifconfig找到 Pi 的 IP 地址。在这个例子中,我的 Pi 的 IP 地址是192.168.1.120。
pi@raspberrypi:~ $ **ifconfig | grep wlan0 -A1**
wlan0: flags=4163<UP,BROADCAST,RUNNING,MULTICAST> mtu 1500
inet **192.168.1.120** netmask 255.255.255.0 broadcast 192.168.1.255
- 在终端运行
sudo raspi-config,启动“树莓 Pi 软件配置工具”。可能会提示您输入用户pi的密码

- 启用 SSH 服务器:选择
5\. Interface Options->-SSH->-Enable - 启用 VNC 服务器:选择
5\. Interface Options->-VNC->-Enable - 下载并安装 RealVNC 浏览器到你的电脑上。
- 连接到 Pi 的 IP 地址使用真正的 VNC 浏览器。您将看到与 Pi 正在运行的桌面相同的桌面。
- 此时,您可以安全地断开显示器/键盘/鼠标与 Pi 计算机的连接,只保留电源适配器。

设置远程文件访问
由于我们的 Pi 将无头运行,我们希望能够从远程计算机访问 Pi 的文件系统,以便我们可以轻松地将文件传输到 Pi 计算机或从 Pi 计算机传输文件。我们将在 Pi 上安装 Samba 文件服务器。
pi@raspberrypi:~ $ **sudo apt-get update && sudo apt-get upgrade -y**
Get:1 [http://archive.raspberrypi.org/debian](http://archive.raspberrypi.org/debian) stretch InRelease [25.4 kB]
Packages [45.0 kB]
[omitted...]
Unpacking lxplug-ptbatt (0.5) over (0.4) ...
Setting up lxplug-ptbatt (0.5) ...pi@raspberrypi:~ $ **sudo apt-get install samba samba-common-bin -y**
Reading package lists... Done
Building dependency tree
[omitted...]
Processing triggers for libc-bin (2.24-11+deb9u4) ...
Processing triggers for systemd (232-25+deb9u11) ...pi@raspberrypi:~ $ **sudo rm /etc/samba/smb.conf**pi@raspberrypi:~ $ **sudo nano /etc/samba/smb.conf**
然后将下面几行粘贴到 nano 编辑器中
[global]
netbios name = Pi
server string = The PiCar File System
workgroup = WORKGROUP
[HOMEPI]
path = /home/pi
comment = No comment
browsable = yes
writable = Yes
create mask = 0777
directory mask = 0777
public = no
按 Ctrl-X 保存并退出 nano,按 Yes 保存更改。
然后设置一个 Samba 服务器密码。为了简单起见,我们将使用相同的rasp作为 Samba 服务器密码。设置密码后,重启 Samba 服务器。
# create samba password
pi@raspberrypi:~ $ **sudo smbpasswd -a pi**
New SMB password:
Retype new SMB password:
Added user pi.# restart samba server
pi@raspberrypi:~ $ **sudo service smbd restart**
此时,您应该能够通过 Pi 的 IP 地址(我的 Pi 的 IP 是 192.168.1.120)从 PC 连接到 Pi 计算机。转到您的 PC (Windows),打开命令提示符(cmd.exe)并键入:
# mount the Pi home directory to R: drive on PC
C:\>**net use r: \\192.168.1.120\homepi**
The command completed successfully.
C:\Users\dctia>r:C:\>**dir r:**
Volume in drive R is HOMEPI
Volume Serial Number is 61E3-70FFDirectory of R:\05/02/2019 03:57 PM <DIR> .
04/08/2019 04:48 AM <DIR> ..
04/08/2019 05:43 AM <DIR> Desktop
04/08/2019 05:43 AM <DIR> Documents
04/08/2019 05:43 AM <DIR> Downloads
04/08/2019 05:15 AM <DIR> MagPi
04/08/2019 05:43 AM <DIR> Music
05/02/2019 03:43 PM <DIR> Pictures
04/08/2019 05:43 AM <DIR> Public
04/08/2019 05:43 AM <DIR> Templates
04/08/2019 05:43 AM <DIR> Videos
0 File(s) 0 bytes
11 Dir(s) 22,864,379,904 bytes free
事实上,这是我们的 Pi 计算机的文件系统,我们可以从它的文件管理器中看到。这将是非常有用的,因为我们可以直接从我们的 PC 编辑驻留在 Pi 上的文件。例如,我们可以先使用 PyCharm IDE 在 Pi 上编辑 Python 程序,然后只需使用 Pi 的终端(通过 VNC)运行这些程序。

如果你有一台 Mac,这里是如何连接到 Pi 的文件服务器。点击 Command-K 调出“连接到服务器”窗口。输入网络驱动器路径(替换为您的 Pi 的 IP 地址),即 smb://192.168.1.120/homepi,然后单击连接。输入登录/密码,即 pi/rasp,然后单击 OK 以安装网络驱动器。然后,该驱动器将出现在您的桌面上和 Finder 窗口的边栏中。关于 Mac 更深入的网络连接指导,请查看这篇优秀的文章。

安装 USB 摄像头
USB 摄像头的设备驱动程序应该已经带有 Raspian 操作系统。我们将安装一个视频摄像头查看器,这样我们就可以看到现场视频。
- 从 PiCar 套件中取出 USB 摄像头,并将其插入 Pi 计算机的 USB 端口
- 从终端运行
sudo apt-get install cheese安装“Cheese”,相机浏览器。
pi@raspberrypi:~ $ **sudo apt-get install cheese -y**
Reading package lists... Done
Building dependency tree
Reading state information... Done
....
cheese is the newest version (3.22.1-1).
- 通过
Raspberry Pi button(Top Left Corner)->-Sound & Video->-Cheese启动奶酪应用程序,您应该会看到一个直播视频,如上图所示。
SunFounder PiCar-V 软件配置(偏离手册)
在组装 PiCar 之前,我们需要安装 PiCar 的 python API。SunFounder 发布了其 Python API 的服务器版本和客户端版本。用于远程控制 PiCar 的客户端 API 代码运行在您的 PC 上,并且使用 Python 版本 3。服务器 API 代码运行在 PiCar 上,不幸的是,它使用的是 Python 版本 2,这是一个过时的版本。由于我们编写的自动驾驶程序只能在 PiCar 上运行,PiCar 服务器 API 也必须在 Python 3 中运行。幸运的是,SunFounder 的所有 API 代码都在 Github 上开源,我做了一个 fork 并将整个 repo(包括服务器和客户端)更新到 Python 3。(我将很快向 SunFounder 提交我的更改,这样一旦 SunFounder 批准,它就可以合并回主 repo。)
目前,运行以下命令(粗体代替 SunFounder 手册中的软件命令。您不必运行手册第 20-26 页上的命令。
# route all calls to python (version 2) to python3,
# pip (version 2) to pip3, even in sudo mode
# note: `sudo abcd` runs `abcd` command in administrator mode
**alias python=python3
alias pip=pip3
alias sudo='sudo '**# Download patched PiCar-V driver API, and run its set up
pi@raspberrypi:~ $ **cd**pi@raspberrypi:~ $ **git clone** [**https://github.com/dctian/SunFounder_PiCar.git**](https://github.com/dctian/SunFounder_PiCar.git)
Cloning into 'SunFounder_PiCar'...
remote: Enumerating objects: 9, done.
remote: Counting objects: 100% (9/9), done.
remote: Compressing objects: 100% (9/9), done.
remote: Total 276 (delta 0), reused 2 (delta 0), pack-reused 267
Receiving objects: 100% (276/276), 53.33 KiB | 0 bytes/s, done.
Resolving deltas: 100% (171/171), done.
pi@raspberrypi:~ $ **cd ~/SunFounder_PiCar/picar/**
pi@raspberrypi:~/SunFounder_PiCar/picar $ **git clone** [**https://github.com/dctian/SunFounder_PCA9685.git**](https://github.com/dctian/SunFounder_PCA9685.git)
Cloning into 'SunFounder_PCA9685'...
remote: Enumerating objects: 7, done.
remote: Counting objects: 100% (7/7), done.
remote: Compressing objects: 100% (5/5), done.
remote: Total 87 (delta 2), reused 6 (delta 2), pack-reused 80
Unpacking objects: 100% (87/87), done.pi@raspberrypi:~/SunFounder_PiCar/picar $ **cd ~/SunFounder_PiCar/**
pi@raspberrypi:~/SunFounder_PiCar $ **sudo python setup.py install**
Adding SunFounder-PiCar 1.0.1 to easy-install.pth file
Installing picar script to /usr/local/bin
[omitted....]# Download patched PiCar-V applications
# and install depedent software
pi@raspberrypi:~/SunFounder_PiCar/picar $ **cd**
pi@raspberrypi:~ $ **git clone** [**https://github.com/dctian/SunFounder_PiCar-V.git**](https://github.com/dctian/SunFounder_PiCar-V.git)
Cloning into 'SunFounder_PiCar-V'...
remote: Enumerating objects: 969, done.
remote: Total 969 (delta 0), reused 0 (delta 0), pack-reused 969
Receiving objects: 100% (969/969), 9.46 MiB | 849.00 KiB/s, done.
Resolving deltas: 100% (432/432), done.pi@raspberrypi:~ $ **cd SunFounder_PiCar-V**pi@raspberrypi:~/SunFounder_PiCar-V $ **sudo ./install_dependencies**
Adding SunFounder-PiCar 1.0.1 to easy-install.pth file
Installing picar script to /usr/local/binInstalled /usr/local/lib/python2.7/dist-packages/SunFounder_PiCar-1.0.1-py2.7.egg
Processing dependencies for SunFounder-PiCar==1.0.1
Finished processing dependencies for SunFounder-PiCar==1.0.1
complete
Copy MJPG-Streamer to an Alternate Location. complete
Enalbe I2C. completeInstallation result:
django Success
python-smbus Success
python-opencv Success
libjpeg8-dev Success
The stuff you have change may need reboot to take effect.
Do you want to reboot immediately? (yes/no)**yes**
当提示重新启动时,回答是。重新启动后,应安装所有必需的硬件驱动程序。我们将在汽车组装后测试它们。
皮卡装配
组装过程紧密地重新组装一个复杂的乐高玩具,整个过程需要大约 2 个小时,大量的手眼协调,非常有趣。(在构建阶段,你甚至可以让你的年轻人参与进来。)PiCar 套件附带印刷的分步指导手册。但是我推荐这两个额外的资源。
- PDF 版本的指导手册。打印手册很小,图表可能打印不太清楚,而 PDF 版本非常清晰,可以搜索和放大以了解更多细节。在组装阶段,我发现它对我笔记本电脑上的 PDF 非常有帮助。
- SunFounder 发布的 YouTube 4 集教学视频。不幸的是,这些视频是为老版本的 PiCar,所以有些部分(如伺服电机组件)是不同的。但是大部分零件和组装技术都是一样的。因此,如果您对组装手册中的某个图感到困惑,您可能需要看一下视频的相关部分。我希望 SunFounder 能为新的 PiCar-V 套件发布一组新的视频。
Assembly Videos (4 Parts) for an Older Version of PiCar, a Useful reference
当橡胶遇到路面!
既然 PiCar 的所有基本硬件和软件都已就绪,让我们试着运行它吧!
- 从 PC 通过 VNC 连接到 PiCar
- 确保放入新电池,将开关切换到 ON 位置,并拔下 micro USB 充电电缆。请注意,您的 VNC 远程会话应该仍处于活动状态。
- 在 Pi 终端中,运行以下命令(粗体显示的**)。您应该:**
- 看到车开快了,再发出
picar.back_wheel.test()就慢下来 - 当你发出
picar.front_wheel.test()时,看到前轮转向左、中、右。要停止这些测试,请按 Ctrl-C。要退出 python 程序,请按 Ctrl-D。
pi@raspberrypi:~/SunFounder_PiCar/picar $ **python3**
Python 3.5.3 (default, Sep 27 2018, 17:25:39)
[GCC 6.3.0 20170516] on linux
Type "help", "copyright", "credits" or "license" for more information.>>> **import picar**
>>> **picar.setup()**>>> **picar.front_wheels.test()**
DEBUG "front_wheels.py": Set debug off
DEBUG "front_wheels.py": Set wheel debug off
DEBUG "Servo.py": Set debug off
turn_left
turn_straight
turn_right>>> **picar.back_wheels.test()**
DEBUG "back_wheels.py": Set debug off
DEBUG "TB6612.py": Set debug off
DEBUG "TB6612.py": Set debug off
DEBUG "PCA9685.py": Set debug off
Forward, speed = 0
Forward, speed = 1
Forward, speed = 2
Forward, speed = 3
Forward, speed = 4
Forward, speed = 5
Forward, speed = 6
Forward, speed = 7
Forward, speed = 8
Forward, speed = 9
Forward, speed = 10
Forward, speed = 11
- 如果您遇到错误或看不到轮子移动,那么要么是您的硬件连接或软件设置有问题。对于前者,请仔细检查你的电线连接,确保电池充满电。对于后者,请在评论区发布消息,详细说明您遵循的步骤和错误消息,我会尽力提供帮助。
下一步是什么
恭喜你,你现在应该有一个 PiCar 可以看到(通过 Cheese),运行(通过 python 3 代码)!这还不是一辆深度学习的汽车,但我们正在朝着它前进。当你准备好了,就开始第三部分吧,在那里我们将赋予 PiCar 计算机视觉和深度学习的超能力。
以下是整个指南的链接:
第 1 部分:概述
第 2 部分: Raspberry Pi 设置和 PiCar 装配(本文)
第 3 部分:让皮卡看到并思考
第 4 部分:通过 OpenCV 的自主车道导航
第五部分:自主 通过深度学习进行车道导航
第六部分:交通标志和行人检测与处理
DeepPiCar —第 3 部分:让 PiCar 看到并思考
DeepPiCar 系列
设置计算机视觉(OpenCV)和深度学习软件(TensorFlow)。把 PiCar 变成 DeepPiCar。
行动纲要
欢迎回来!如果你一直关注我在 DeepPiCar 上的前两篇帖子(第一部分和第二部分),你应该有一辆可以通过 Python 控制的跑步机器人汽车。在文章中,我们将赋予您的汽车计算机视觉和深度学习的超能力。在文章的结尾,它将被改造成一个真正的 DeepPiCar,能够检测和识别你房间里的物体。

用于计算机视觉的 OpenCV
请注意,我们 PiCar 的唯一感知传感器是 USB DashCam。DashCam 为我们提供了一个实时视频,它本质上是一系列图片。我们将使用 OpenCV,一个强大的开源计算机视觉库,来捕捉和转换这些图片,以便我们可以理解相机所看到的内容。运行以下命令(粗体)将其安装到您的 Pi 上。
安装打开的 CV 和相关库
# install all dependent libraries of OpenCV (yes, this is one long command)
pi@raspberrypi:~ $ **sudo apt-get install libhdf5-dev -y && sudo apt-get install libhdf5-serial-dev -y && sudo apt-get install libatlas-base-dev -y && sudo apt-get install libjasper-dev -y && sudo apt-get install libqtgui4 -y && sudo apt-get install libqt4-test -y**# install OpenCV and other libraries
pi@raspberrypi:~ $ **pip3 install opencv-python**
Collecting opencv-python
[Omitted....]
Installing collected packages: numpy, opencv-python
Successfully installed numpy-1.16.2 opencv-python-3.4.4.19pi@raspberrypi:~ $ **pip3 install matplotlib**
Collecting matplotlib
Collecting pyparsing!=2.0.4,!=2.1.2,!=2.1.6,>=2.0.1 (from matplotlib)
[Omitted...]
Successfully installed cycler-0.10.0 kiwisolver-1.1.0 matplotlib-3.0.3 numpy-1.16.3 pyparsing-2.4.0 python-dateutil-2.8.0 setuptools-41.0.1 six-1.12.0
测试 OpenCV 安装
下面是最基本的测试,看看我们的 python 库是否安装了。OpenCV 的 Python 模块名是cv2。如果您在运行以下命令时没有看到任何错误,那么模块应该安装正确。Numpy 和 Matplotlib 是两个非常有用的 python 模块,我们将结合 OpenCV 使用它们进行图像处理和渲染。
pi@raspberrypi:~ $ **python3 -c "import cv2"** pi@raspberrypi:~ $ **python3 -c "import numpy"** pi@raspberrypi:~ $ **python3 -c "import matplotlib"**
好了,让我们来尝试一些现场视频处理吧!
pi@raspberrypi:~ $ **cd**
pi@raspberrypi:~ $ **git clone** [**https://github.com/dctian/DeepPiCar.git**](https://github.com/dctian/DeepPiCar.git)
Cloning into 'DeepPiCar'...
remote: Enumerating objects: 482, done.
[Omitted...]
Resolving deltas: 100% (185/185), done.pi@raspberrypi:~ $ **cd DeepPiCar/driver/code**
pi@raspberrypi:~ $ **python3 opencv_test.py**

如果您看到两个实时视频屏幕,一个是彩色的,一个是黑白的,那么您的 OpenCV 正在工作!按下q退出测试。本质上,该程序获取从相机捕获的图像并按原样显示它(原始窗口),然后将图像转换为黑白图像(黑白窗口)。这非常重要,因为在第 4 部分:自动车道导航中,我们将调出多达 9-10 个屏幕,因为原始视频图像将经过许多阶段处理,如下所示。

为 CPU 和 EdgeTPU 安装 TensorFlow
谷歌的 TensorFlow 是目前最流行的深度学习 python 库。它可以用于图像识别、人脸检测、自然语言处理和许多其他应用。在 Raspberry Pi 上安装 TensorFlow 有两种方法:
- CPU 的张量流
- 面向 Edge TPU 协处理器的 TensorFlow(售价 75 美元的 Coral 品牌 u 盘)
为 CPU 安装 TensorFlow
第一种方法安装 TensorFlow 的 CPU 版本。我们不会使用 Pi 来执行任何深度学习(即模型训练),因为它的 CPU 远远不足以进行反向传播,这是学习过程中需要的非常慢的操作。然而,我们可以使用 CPU 根据预先训练的模型进行推理。推断也称为模型预测,它仅使用向前传播,这是一种快得多的计算机操作。即使 CPU 只是进行推理,它也只能在相对较浅的模型(比如 20-30 层)上实时进行推理。对于更深的模型(100+层),我们需要边缘 TPU。截至 2019 年 5 月,TensorFlow 最新的量产版是 1.13 版本(2.0 还是 alpha)
pi@raspberrypi:~ $ **pip3 install tensorflow**
Collecting tensorflow
[omitted...]
pi@raspberrypi:~ $ **pip3 install keras** Collecting keras
[omitted...]
Successfully installed h5py-2.9.0 keras-2.2.4 keras-applications-1.0.7 keras-preprocessing-1.0.9 numpy-1.16.3 pyyaml-5.1 scipy-1.2.1 six-1.12.0
现在让我们测试并确保安装顺利。导入 TensorFlow 时,它会报告一些警告信息。但是它们可以被安全地忽略。您应该看不到任何错误。(如果您确实看到了其他错误,请将您键入的命令和错误信息发布在下面的帖子中,我会尽力帮助您。)
pi@raspberrypi:~ $ **python3**
Python 3.5.3 (default, Sep 27 2018, 17:25:39)
[GCC 6.3.0 20170516] on linux
Type "help", "copyright", "credits" or "license" for more information.
>>> **import numpy**
>>> **import cv2**
>>> **import tensorflow**
/usr/lib/python3.5/importlib/_bootstrap.py:222: RuntimeWarning: compiletime version 3.4 of module 'tensorflow.python.framework.fast_tensor_util' does not match runtime version 3.5
return f(*args, **kwds)
/usr/lib/python3.5/importlib/_bootstrap.py:222: RuntimeWarning: builtins.type size changed, may indicate binary incompatibility. Expected 432, got 412
return f(*args, **kwds)
>>> **import keras**
Using TensorFlow backend.
>>> quit()
为 EdgeTPU 安装 TensorFlow
当深度学习模型非常深度,100 层以上,要达到实时性能,需要运行在 EdgeTPU 协处理器上,而不是 CPU 上。然而,在撰写本文时,EdgeTPU 是如此之新(大约在 2019 年初向公众发布),以至于它无法运行所有可以在 CPU 上运行的模型,因此我们必须仔细选择我们的模型架构,并确保它们可以在 Edge TPU 上工作。关于哪些模型可以在 Edge TPU 上运行的更多细节,请阅读谷歌的这篇文章。
按照下面的说明安装 EdgeTPU 驱动程序和 API。当被问及是否要enable the maximum operating frequency时,回答y。对于 TPU 来说,我们运行的模型相对来说是轻量级的,我从未见过它运行得非常热。
pi@raspberrypi:~ $ **cd**
pi@raspberrypi:~ $ **wget** [**https://dl.google.com/coral/edgetpu_api/edgetpu_api_latest.tar.gz**](https://dl.google.com/coral/edgetpu_api/edgetpu_api_latest.tar.gz) **-O edgetpu_api.tar.gz --trust-server-names**
--2019-04-20 11:55:39-- [https://dl.google.com/coral/edgetpu_api/edgetpu_api_latest.tar.gz](https://dl.google.com/coral/edgetpu_api/edgetpu_api_latest.tar.gz)
Resolving dl.google.com (dl.google.com)... 172.217.10.78
[omitted]
edgetpu_api.tar.gz 100%[===================>] 7.88M 874KB/s in 9.3s
2019-04-20 11:55:49 (867 KB/s) - ‘edgetpu_api.tar.gz’ saved [8268747/8268747]pi@raspberrypi:~ $ **tar xzf edgetpu_api.tar.gz**
pi@raspberrypi:~ $ **cd edgetpu_api/**
pi@raspberrypi:~/edgetpu_api $ **bash ./install.sh
Would you like to enable the maximum operating frequency? Y/N
y**
Using maximum operating frequency.
Installing library dependencies...
[omitted]
Installing Edge TPU Python API...
Processing ./edgetpu-1.9.2-py3-none-any.whl
Installing collected packages: edgetpu
Successfully installed edgetpu-1.9.2# restart the pi just to complete the installation
pi@raspberrypi:~/edgetpu_api $ **sudo reboot now**
重新启动后,让我们通过运行一个活动对象检测程序来测试它。我们将从 DeepPiCar repo 运行一个演示对象检测应用程序。
pi@raspberrypi:~ $ **cd ~/DeepPiCar/models/object_detection/**pi@raspberrypi:~/DeepPiCar/models/object_detection $ **python3 code/coco_object_detection.py**
W0420 12:36:55.728087 7001 package_registry.cc:65] Minimum runtime version required by package (5) is lower than expected (10).couch, 93% [[ 4.81752396 167.15803146]
[381.77787781 475.49484253]] 113.52ms
book, 66% [[456.68899536 145.12086868]
[468.8772583 212.99516678]] 113.52ms
book, 58% [[510.65818787 229.35571671]
[534.6181488 296.00133896]] 113.52ms
book, 58% [[444.65190887 222.51708984]
[467.33409882 290.39138794]] 113.52ms
book, 58% [[523.65917206 142.07738876]
[535.19741058 213.77527237]] 113.52ms
------
2019-04-20 12:36:57.025142: 7.97 FPS, 125.46ms total, 113.52ms in tf
您应该会看到一个实时视频屏幕出现,它会以大约 7-8 帧/秒的速度尝试识别屏幕中的对象。请注意, COCO(上下文中的常见对象)对象检测模型可以检测大约 100 个常见对象,如人、椅子、电视、沙发、书、笔记本电脑、手机等。不要让这个简单的程序欺骗了你,这是深度学习在起作用。这个程序使用的物体检测模型叫做 ssd_mobilenet_coco_v2 ,它包含了 200 多层!(作为比较,我之前曾尝试使用 Pi 的 CPU 运行 COCO 对象检测模型,这是一个长得多的设置,只能以 1 帧/秒的速度运行,CPU 的利用率为 100%,CPU 温度上升非常快。所以不建议在 CPU 上运行深度模型。)当然,这只是一个演示应用程序,它可以确认 Edge TPU 的设置是否正确。我们将在本系列的第 6 部分中利用 Edge TPU 的全部功能,实时交通标志和行人检测与处理。

更新(2020 年 3 月):自从我的博客在 2019 年 4 月发表以来,Coral EdgeTPU 的安装已经更新。请按照目前 Google 这里的官方说明安装 Tensorflow Lite API 和 EdgeTPU 运行时,这样就可以做上面的物体检测例子了。
下一步是什么
恭喜你,我们现在已经给你的车同时赋予了眼睛(摄像头和 OpenCV)和大脑(TensorFlow),所以它确实是一辆 DeepPiCar 。无论何时你准备好了,前往第四部分,在那里我们将教 DeepPiCar 在车道内自主导航。
以下是整个指南的链接:
第 1 部分:概述
第 2 部分: Raspberry Pi 设置和 PiCar 装配
第 3 部分:让 PiCar 看到并思考(本文)
第 4 部分:通过 OpenCV 的自主车道导航
第五部分:自主 通过深度学习进行车道导航
第六部分:交通标志和行人检测处理
DeepPiCar —第 4 部分:通过 OpenCV 的自主车道导航
DeepPiCar 系列
使用 OpenCV 检测颜色、边缘和线段。然后计算转向角度,以便 PiCar 可以在车道内自行导航。


Adaptive Cruise Control (left) and Lane Keep Assist System (right)
行动纲要
随着所有的硬件(第二部分)和软件(第三部分)设置完毕,我们已经准备好享受赛车的乐趣了!在本文中,我们将使用一个流行的开源计算机视觉包 OpenCV 来帮助 PiCar 在车道内自主导航。注意这篇文章只会让我们的 PiCar 成为一辆“自动驾驶汽车”,而不是一辆深度学习,自动驾驶汽车。深度学习部分会出现在 Part 5 和 Part 6 中。
介绍
目前,市场上有几款 2018-2019 款汽车搭载了这两项功能,即自适应巡航控制(ACC)和某些形式的车道保持辅助系统(LKAS)。自适应巡航控制使用雷达来检测并与前方的汽车保持安全距离。这一功能自 2012–2013 年左右就已出现。车道保持辅助系统是一个相对较新的功能,它使用安装在挡风玻璃上的摄像头来检测车道线,并进行转向,以便汽车位于车道中间。当你在高速公路上开车时,这是一个非常有用的功能,无论是在拥挤的交通中还是在长途驾驶中。圣诞节期间,我们全家开车从芝加哥去科罗拉多滑雪,一共开了 35 个小时。我们的沃尔沃 XC 90 拥有 ACC 和 LKAS(沃尔沃称之为 PilotAssit),在高速公路上表现出色,因为 95%漫长而无聊的高速公路里程都是由我们的沃尔沃驾驶的!我所要做的就是把手放在方向盘上(但不一定要转向),然后盯着前方的路。当道路弯弯曲曲时,或者当我们前面的车减速或停车时,甚至当一辆车从另一条车道超车时,我都不需要转向、刹车或加速。它不能自动驾驶的几个小时是当我们开车穿过暴风雪时,车道标志被雪覆盖。(沃尔沃,如果你在读这篇文章,是的,我要代言!:)我很好奇,心想:我想知道这是如何工作的,如果我能自己复制它(在较小的规模上)岂不是很酷?
今天,我们将把 LKAS 建成我们的深海乐园。实现 ACC 需要雷达,我们 PiCar 没有。在以后的文章中,我可能会在 DeepPiCar 上添加一个超声波传感器。类似于雷达,超声波也可以探测距离,除了在更近的范围内,这对于小型机器人汽车来说是完美的。
感知:车道检测
车道保持辅助系统有两个组成部分,即感知(车道检测)和路径/运动规划(转向)。车道检测的工作是将道路的视频转化为检测到的车道线的坐标。实现这一点的一种方法是通过计算机视觉包,我们在第 3 部分 OpenCV 中安装了这个包。但是在我们能够检测视频中的车道线之前,我们必须能够检测单幅图像中的车道线。一旦我们可以做到这一点,检测视频中的车道线只是简单地对视频中的所有帧重复相同的步骤。步骤很多,那就开始吧!
隔离车道的颜色
当我在客厅为我的 DeepPiCar 设置车道线时,我使用了蓝色画家的胶带来标记车道,因为蓝色是我房间的独特颜色,胶带不会在硬木地板上留下永久的粘性残留物。


Original DashCam Image (left) and Blue Masking Tape for Lane Line (right)
上面是来自我们 DeepPiCar 的 DashCam 的典型视频帧。首先要做的是隔离图像上所有的蓝色区域。为此,我们首先需要将图像使用的颜色空间,即 RGB(红/绿/蓝)转换为 HSV(色调/饱和度/值)颜色空间。(阅读此处了解更多关于 HSV 色彩空间的详细信息。)这背后的主要思想是,在 RGB 图像中,蓝色胶带的不同部分可能被不同的光照亮,导致它们看起来像深蓝色或浅蓝色。然而,在 HSV 色彩空间中,色调组件将整个蓝色带渲染为一种颜色,而不管其阴影如何。最好用下图来说明。请注意,现在两条车道线的洋红色大致相同。

Image in HSV Color Space
下面是实现这一点的 OpenCV 命令。
注意,我们用的是到 HSV 的转化,而不是到 HSV 的转化。这是因为 OpenCV 由于一些传统原因,默认情况下将图像读入 BGR(蓝/绿/红)色彩空间,而不是更常用的 RGB(红/绿/蓝)色彩空间。它们本质上是等价的颜色空间,只是交换了颜色的顺序。****
一旦图像在 HSV 中,我们可以从图像中“提升”所有的蓝色。这是通过指定蓝色的范围来实现的。
在色调色彩空间中,蓝色大约在 120-300 度范围内,在 0-360 度标度上。您可以为蓝色指定一个更窄的范围,比如 180-300 度,但这没有太大关系。

Hue in 0–360 degrees scale
下面是通过 OpenCV 提升蓝色的代码,以及渲染的蒙版图像。

Blue Area Mask
注意 OpenCV 使用的范围是 0–180,而不是 0–360,所以我们需要在 OpenCV 中指定的蓝色范围是 60–150(而不是 120–300)。这些是下限和上限数组的第一个参数。第二个参数(饱和度)和第三个参数(值)并不重要,我发现 40-255 的范围对于饱和度和值来说都相当不错。
注意这种技术正是电影工作室和天气预报员每天使用的。他们通常使用绿色屏幕作为背景,这样他们就可以将绿色与霸王龙向我们冲过来的惊险视频(电影)或实时多普勒雷达图(天气预报员)进行交换。
 ********
********
检测车道线的边缘
接下来,我们需要检测蓝色遮罩中的边缘,以便我们可以有几条不同的线来表示蓝色车道线。
Canny 边缘检测功能是检测图像边缘的强大命令。在下面的代码中,第一个参数是上一步中的蓝色遮罩。第二个和第三个参数是边缘检测的下限和上限,OpenCV 建议为(100,200)或(200,400),因此我们使用(200,400)。

Edges of all Blue Areas
将上面的命令放在一起,下面是隔离图像上的蓝色并提取所有蓝色区域的边缘的函数。
隔离感兴趣区域
从上面的图像中,我们看到我们发现了相当多的蓝色区域不是我们的车道线。仔细一看,发现它们都在屏幕的上半部分。事实上,在进行车道导航时,我们只关心检测离汽车更近的车道线,即屏幕底部。因此,我们将简单地裁剪掉上半部分。嘣!如右图所示,两条明显标记的车道线!
**** ********
********
Edges (left) and Cropped Edges (right)****
下面是实现这一点的代码。我们首先为屏幕的下半部分创建一个遮罩。然后当我们将mask和edges图像合并,得到右边的cropped_edges图像。
检测线段
在上面的裁剪边缘图像中,对我们人类来说,很明显我们发现了四条线,代表两条车道线。然而,对于计算机来说,它们只是黑色背景上的一堆白色像素。不知何故,我们需要从这些白色像素中提取出这些车道线的坐标。幸运的是,OpenCV 包含了一个神奇的函数,叫做 Hough Transform,它可以做到这一点。霍夫变换是一种用于图像处理的技术,用于提取直线、圆和椭圆等特征。我们将使用它从一堆似乎形成一条线的像素中找到直线。函数 HoughLinesP 本质上试图拟合许多穿过所有白色像素的线,并返回最可能的线集合,服从某些最小阈值约束。(阅读此处深入解释霍夫线变换。)
 ********
********
Hough Line Detection (left), Votes (middle), detected lines (right)
下面是检测线段的代码。在内部,HoughLineP 使用极坐标检测直线。极坐标(仰角和离原点的距离)优于笛卡尔坐标(斜率和截距),因为它可以表示任何线,包括笛卡尔坐标不能表示的垂直线,因为垂直线的斜率是无穷大。HoughLineP 有很多参数:
- rho 是以像素为单位的距离精度。我们将使用一个像素。
- 角度是以弧度为单位的角度精度。(三角学快速复习:弧度是表示角度度数的另一种方式。即弧度 180 度就是 3.14159,也就是π)我们就用一度。
- min_threshold 是被认为是线段所需的投票数。如果一条线有更多的投票,霍夫变换认为它们更有可能检测到线段
- minLineLength 是线段的最小长度,以像素为单位。霍夫变换不会返回任何短于此最小长度的线段。
- maxLineGap 是可以分开但仍被视为单个线段的两条线段的最大像素值。例如,如果我们有虚线车道标记,通过指定合理的最大线间隙,霍夫变换会将整个虚线车道线视为一条直线,这是可取的。
设置这些参数实际上是一个反复试验的过程。下面是我的机器人汽车在 320x240 分辨率的摄像机运行在纯蓝色车道线之间时工作良好的值。当然,它们需要重新调整,以适应一辆实物大小的汽车,配有高分辨率摄像头,在真实的道路上以白色/黄色虚线行驶。
如果我们打印出检测到的线段,它将显示端点(x1,y1)后接(x2,y2)和每条线段的长度。
**INFO:root:Creating a HandCodedLaneFollower...
DEBUG:root:detecting lane lines...
DEBUG:root:detected line_segment:
DEBUG:root:[[ 7 193 107 120]] of length 123
DEBUG:root:detected line_segment:
DEBUG:root:[[226 131 305 210]] of length 111
DEBUG:root:detected line_segment:
DEBUG:root:[[ 1 179 100 120]] of length 115
DEBUG:root:detected line_segment:
DEBUG:root:[[287 194 295 202]] of length 11
DEBUG:root:detected line_segment:
DEBUG:root:[[241 135 311 192]] of length 90**

Line segments detected by Hough Transform
将线段合并成两条车道线
现在我们有了许多端点坐标为(x1,y1)和(x2,y2)的小线段,我们如何将它们组合成我们真正关心的两条线,即左车道线和右车道线?一种方法是根据这些线段的斜率对它们进行分类。从上图中我们可以看到,属于左车道线的所有线段都应该是屏幕左侧的上斜和,而属于右车道线的所有线段都应该是屏幕右侧的下斜和。一旦线段被分成两组,我们只需取线段的斜率和截距的平均值,就可以得到左右车道线的斜率和截距。****
下面的average_slope_intercept函数实现了上面的逻辑。
make_points是average_slope_intercept函数的辅助函数,它获取直线的斜率和截距,并返回线段的端点。
除了上面描述的逻辑之外,还有一些特殊情况值得讨论。
- 图像中的一条车道线:在正常情况下,我们希望摄像机能看到两条车道线。然而,有时汽车开始偏离车道,可能是由于转向逻辑有缺陷,或者是当车道转弯太急。此时,摄像机可能只捕捉到一条车道线。这就是为什么上面的代码需要检查
len(right_fit)>0和len(left_fit)>0 - 垂直线段:当汽车转弯时,偶尔会检测到垂直线段。虽然它们不是错误的检测,但是因为垂直线具有无穷大的斜率,所以我们不能将它们与其他线段的斜率进行平均。为了简单起见,我选择忽略它们。由于垂直线不是很常见,这样做不会影响车道检测算法的整体性能。或者,可以翻转图像的 X 和 Y 坐标,因此垂直线的斜率为零,这可以包括在平均值中。但是水平线段的斜率为无穷大,但这种情况非常罕见,因为仪表板摄像头通常指向与车道线相同的方向,而不是垂直于车道线。另一种方法是用极坐标表示线段,然后对角度和到原点的距离取平均值。
** ****
****
Only one lane line (left), Vertical Line segment in left lane line (right)**
车道检测摘要
将以上步骤放在一起,这里是 detect_lane()函数,它给定一个视频帧作为输入,返回(最多)两条车道线的坐标。
我们将在原始视频帧的顶部绘制车道线:
这是检测到的车道线以绿色绘制的最终图像。
** ****
****
Original Frame (left) and Frame with Detected Lane Lines (right)**
运动规划:转向
现在我们有了车道线的坐标,我们需要驾驶汽车,使它保持在车道线内,更好的是,我们应该尽量把它保持在车道的中间**。基本上,我们需要根据检测到的车道线计算汽车的转向角度。**
两条检测到的车道线
这是一个简单的场景,因为我们可以通过简单地平均两条车道线的远端点来计算前进方向。下面显示的红线是标题。请注意,红色标题线的下端总是在屏幕底部的中间,这是因为我们假设 dashcam 安装在汽车的中间,并指向正前方。

一条检测到的车道线
如果我们只检测到一条车道线,这将有点棘手,因为我们不能再平均两个端点。但是请注意,当我们只看到一条车道线时,比如说只看到左(右)车道,这意味着我们需要向右(左)使劲转向,这样我们就可以继续沿着车道行驶。一种解决方案是将标题线设置为与唯一车道线相同的坡度,如下所示。
 ****
****
转向角
现在我们知道我们要去哪里,我们需要把它转换成转向角,这样我们就可以告诉汽车转向。记住,对于这辆皮卡来说,90 度的转向角是直行,45-89 度是左转,91-135 度是右转。下面是一些将航向坐标转换成以度为单位的转向角的三角方法。请注意,PiCar 是为普通男性创建的,因此它使用的是度数而不是弧度。但是所有的三角数学都是用弧度表示的。
显示标题行
我们在上面展示了几幅带有标题行的图片。下面是呈现它的代码。输入实际上是转向角。
稳定化
最初,当我从每个视频帧计算转向角度时,我只是告诉 PiCar 以这个角度转向。然而,在实际的道路测试中,我发现 PiCar 有时会像醉酒司机一样在车道线之间左右弹跳,有时会完全冲出车道。然后我发现这是由于从一个视频帧到下一个视频帧计算的转向角度不太稳定造成的。你应该在没有稳定逻辑的车道上开车,明白我的意思。有时,转向角可能暂时在 90 度左右(直线行驶),但是,无论什么原因,计算出的转向角可能会突然剧烈跳动,比如 120 度(向右急转弯)或 70 度(向左急转弯)。结果,汽车会在车道内左右颠簸。显然,这是不可取的。我们需要稳定驾驶。的确,在现实生活中,我们有一个方向盘,所以如果我们想向右转向,我们就平稳地转动方向盘,转向角作为一个连续的值发送给汽车,即 90°、91°、92°…。132,133,134,135 度,不是一毫秒 90 度,下一毫秒 135 度。
所以我稳定转向角度的策略如下:如果新的角度与当前角度相差超过max_angle_deviation度,就在新角度的方向上最多转向max_angle_deviation度。
在上面的代码中,我使用了两种风格的max_angle_deviation,如果两条车道线都被检测到,则为 5 度,这意味着我们更加确信我们的方向是正确的;1 度,如果只检测到一条车道线,这意味着我们不太有信心。这些是你可以为自己的车调整的参数。
把它放在一起
执行 LKAS(车道跟踪)的完整代码在我的 DeepPiCar GitHub repo 中。在 DeepPiCar/driver/code 文件夹中,这些是感兴趣的文件:
deep_pi_car.py:这是 DeepPiCar 的主要入口hand_coded_lane_follower.py:这是车道检测和跟随逻辑。
只需运行以下命令来启动您的汽车。(当然,我假设你已经记下了车道线并将 PiCar 放在车道上。)
# skip this line if you have already cloned the repo
pi@raspberrypi:~ $ **git clone** [**https://github.com/dctian/DeepPiCar.git**](https://github.com/dctian/DeepPiCar.git)pi@raspberrypi:~ $ **cd DeepPiCar/driver/code**
pi@raspberrypi:~/DeepPiCar/driver/code $ **python3 deep_pi_car.py**
INFO :2019-05-08 01:52:56,073: Creating a DeepPiCar...
DEBUG:2019-05-08 01:52:56,093: Set up camera
DEBUG:2019-05-08 01:52:57,639: Set up back wheels
DEBUG "back_wheels.py": Set debug off
DEBUG "TB6612.py": Set debug off
DEBUG "TB6612.py": Set debug off
DEBUG "PCA9685.py": Set debug off
DEBUG:2019-05-08 01:52:57,646: Set up front wheels
DEBUG "front_wheels.py": Set debug off
DEBUG "front_wheels.py": Set wheel debug off
DEBUG "Servo.py": Set debug off
INFO :2019-05-08 01:52:57,665: Creating a HandCodedLaneFollower...
如果你的设置和我的非常相似,你的 PiCar 应该像下面这样在房间里走来走去!键入Q退出程序。
下一步是什么
在这篇文章中,我们教会了我们的 DeepPiCar 在车道线内自主导航(LKAS),这非常棒,因为市场上的大多数汽车还不能做到这一点。然而,这并不十分令人满意,因为我们不得不用 python 和 OpenCV 编写大量手工调整的代码来检测颜色、检测边缘、检测线段,然后不得不猜测哪些线段属于左车道线或右车道线。在这篇文章中,我们必须设置许多参数,如蓝色的上限和下限,霍夫变换中检测线段的许多参数,以及稳定期间的最大转向偏差。事实上,我们在这个项目中没有使用任何深度学习技术。如果我们可以“展示”DeepPiCar 如何驾驶,并让它知道如何驾驶,岂不是很酷?这就是深度学习和大数据的承诺,不是吗?在下一篇文章中,这正是我们将要建造的,一辆深度学习的自动驾驶汽车,它可以通过观察一个优秀的司机如何驾驶来学习。《T2》第五部再见。
以下是整个指南的链接:
第一部分:概述
第 2 部分: Raspberry Pi 设置和 PiCar 装配
第 3 部分:让 PiCar 看到并思考
第 4 部分:通过 OpenCV 的自主车道导航(本文)
第五部分:自主 通过深度学习进行车道导航
第六部分:交通标志和行人检测与处理
DeepPiCar 第 5 部分:通过深度学习实现自主车道导航
DeepPiCar 系列
使用英伟达的端到端深度学习方法来教会我们的 PiCar 自主导航车道。
行动纲要
欢迎回来!如果你已经通读了 DeepPiCar 第四部,你应该有一辆自动驾驶汽车,它可以在车道内相当平稳地自动驾驶。在本文中,我们将使用深度学习方法来教我们的 PiCar 做同样的事情,将它变成一个 DeepPiCar 。这类似于你我是如何学会开车的,通过观察好的司机(比如我们的父母或者驾校教练)是如何开车的,然后开始自己开车,一路上从自己的错误中学习。请注意,对于本文的大部分内容,您不需要使用 DeepPiCar 来理解,因为我们将在 Google 的 Colab 上进行深度学习,这是免费的。

介绍
回想一下第 4 部分,我们手工设计了驾驶汽车所需的所有步骤,即颜色隔离、边缘检测、线段检测、转向角度计算和转向稳定性。此外,有相当多的参数需要手动调整,如蓝色的上限和下限,通过霍夫变换检测线段的许多参数,以及稳定期间的最大转向偏差等。如果我们没有正确调整所有这些参数,我们的汽车就不会平稳运行。此外,每当我们遇到新的路况时,我们都必须想出新的检测算法,并将其编程到汽车中,这非常耗时,也很难维护。在人工智能和机器学习的时代,我们不应该只是向机器“展示”要做什么,并让它向我们学习,而不是我们“告诉”它具体的步骤吗?幸运的是,Nvidia 的研究人员在这篇出色的论文中展示了,通过“展示”一辆全尺寸汽车如何驾驶,汽车将学会自动驾驶。这听起来很神奇,对吧?让我们看看这是如何做到的,以及如何将其应用到我们的 DeepPiCar。
Nvidia 型号
在高层次上,Nvidia 模型的输入是来自汽车上仪表板摄像头的视频图像,输出是汽车的转向角度。该模型使用视频图像,从中提取信息,并试图预测汽车的转向角度。这被称为监督机器学习程序,其中视频图像(称为特征)和转向角度(称为标签)被用于训练。因为转向角度是数值,这是一个回归问题,而不是分类问题,其中模型需要预测图像中是狗还是猫,或者哪一种类型的花。
在英伟达模型的核心,有一个卷积神经网络 (CNN,不是有线电视网)。细胞神经网络广泛用于图像识别深度学习模型。直觉是,CNN 特别擅长从其各个层面的图像中提取视觉特征(又名。过滤器)。例如,对于面部识别 CNN 模型,早期层将提取基本特征,如线条和边缘,中间层将提取更高级的特征,如眼睛、鼻子、耳朵、嘴唇等,后期层将提取部分或全部面部,如下所示。关于 CNN 的全面讨论,请查看卷积神经网络的维基百科页面。

Nvidia 模型中使用的 CNN 图层与上面非常相似,因为它在早期图层中提取线条和边缘,在后期图层中提取复杂的形状。完全连接的层功能可以被认为是用于转向的控制器。

上图来自英伟达的论文。它总共包含大约 30 层,以今天的标准来看并不是一个很深的模型。模型的输入图像(图的底部)是一个 66x200 像素的图像,这是一个分辨率非常低的图像。该图像首先被归一化,然后通过 5 组卷积层,最后通过 4 个全连接的神经层并到达单个输出,这是汽车的模型预测转向角。

然后将该模型预测角度与给定视频图像的期望转向角度进行比较,误差通过反向传播反馈到 CNN 训练过程中。从上图可以看出,这个过程会循环重复,直到误差(又名损失或均方差)足够低,这意味着模型已经学会了如何合理地驾驶。事实上,这是一个非常典型的图像识别训练过程,除了预测输出是一个数值(回归)而不是物体的类型(分类)。
为 DeepPiCar 调整 Nvidia 模型
除了尺寸之外,我们的 DeepPiCar 与 Nvidia 使用的汽车非常相似,因为它有一个仪表板摄像头,可以通过指定转向角度来控制。Nvidia 通过让其司机在不同的州和多辆汽车上行驶 70 小时的公路里程来收集数据。因此,我们需要收集一些 DeepPiCar 的视频镜头,并记录每个视频图像的正确转向角度。


See the similarities? No Hands on the steering wheel!
数据采集
有多种方法可以收集训练数据。
一种方法是编写一个远程控制程序,这样我们就可以远程控制 PiCar,并让它保存视频帧以及汽车在每一帧的转向角度。这可能是最好的方法,因为它将模拟一个真实的人的驾驶行为,但需要我们编写一个远程控制程序。一种更简单的方法是利用我们在第 4 部分中构建的东西,即通过 OpenCV 的车道跟随器。因为它运行得相当好,我们可以使用该实现作为我们的“模型”驱动程序。机器从另一台机器学习!我们所要做的就是在赛道上运行我们的 OpenCV 实现几次,保存视频文件和相应的转向角度。然后我们可以用它们来训练我们的 Nvidia 模型。在第 4 部分,deep_pi_car.py会自动保存下来一个视频文件(AVI 文件)每次你运行汽车。
下面是获取视频文件并保存单个视频帧用于训练的代码。为了简单起见,我将转向角作为图像文件名的一部分嵌入,因此我不必维护图像名称和转向角之间的映射文件。
假设您有第 4 部分中录制的名为 video01.avi 的 dashcam 视频,
这是一个 DashCam 视频示例。
下面是保存静态图像的命令,并用转向角度标记它。
pi@raspberrypi:~/DeepPiCar/driver/code $ **python3 save_training_data.py ~/DeepPiCar/models/lane_navigation/data/images/video01**
以下是生成的图像文件。请注意。png 后缀是转向角。从下面,我们可以知道汽车正在左转,因为角度都小于 90 度,这是从上面观看 DashCam 视频确认的。
pi@raspberrypi:~/DeepPiCar/driver/code $ **ls ~/DeepPiCar/models/lane_navigation/data/images |more**
video01_000_**085**.png
video01_001_**080**.png
video01_002_**077**.png
video01_003_**075**.png
video01_004_**072**.png
video01_005_**073**.png
video01_006_**069**.png
培训/深度学习
现在我们有了特征(视频图像)和标签(转向角度),是时候做一些深度学习了!事实上,这是我们在这个 DeepPiCar 博客系列中第一次做深度学习。尽管目前 D eep Learning 都是炒作,但重要的是要注意它只是整个工程项目的一小部分。大部分时间/工作实际上花费在硬件工程、软件工程、数据收集/清理上,最后将深度学习模型的预测连接到生产系统(像一辆行驶的汽车)等。
做深度学习模型训练,不能用树莓派的 CPU,需要一些 GPU 肌肉!然而,我们的预算很少,所以我们不想购买配备最新 GPU 的昂贵机器,也不想从云中租用 GPU 时间。幸运的是,谷歌在这个名为谷歌实验室的网站上免费提供了一些 GPU 甚至 TPU 动力**!感谢谷歌给了我们机器学习爱好者一个学习的好地方!**

Colab 是一个免费的基于云的 Jupyter 笔记本,让你用 Python 编写和训练深度学习模型。支持的流行 python 库有 TensorFlow、Keras、OpenCV、Pandas 等。最酷的是,TensorFlow for GPU 已经预装,因此您不必花几个小时来摆弄 pip 或 CUDA 驱动程序或软件设置,并且可以直接投入到训练您的模型中。
事不宜迟,让我们开始 Jupyter 笔记本。我假设读者相对精通 Python 和 Keras 库。
这里是我在 GitHub 上的整个端到端深度学习车道导航笔记本。我将在下面介绍它的关键部分。
导入库
首先,我们需要导入我们将在培训过程中使用的 python 库。
加载训练数据
然后我们需要加载训练数据。对于本文,我已经将生成的图像文件的样本集上传到我的 GitHub,以便读者可以克隆它并跟随它。记住,图像文件命名为videoXX_FFF_SSS.png,其中videoXX是视频的名称,FFF是视频中的帧数,SSS是以度为单位的转向角度。生成的训练数据被读入image_paths和steering_angles变量。比如video01_054_110.png表示这张图片来自video01.avi视频文件,是第 54 帧,转向角度 110 度(右转)。
分成训练/测试组
我们将使用 sklearn 的train_test_split方法将训练数据分成 80/20 的训练/验证集。
图像增强
样本训练数据集只有大约 200 幅图像。显然,这不足以训练我们的深度学习模型。然而,我们可以采用一种简单的技术,称为图像增强。一些常见的增强操作有缩放、平移、更改曝光值、模糊和图像翻转。通过在原始图像上随机应用这 5 种操作中的任何一种或全部,我们可以从原始的 200 幅图像中生成更多的训练数据,这使得我们最终训练的模型更加健壮。我将在下面举例说明缩放和翻转。其他操作非常相似,在我的 GitHub 中的 Jupyter 笔记本中有所介绍。
缩放
这是随机缩放的代码,在 100%和 130%之间,以及结果缩放图像(右)。

翻转
这是随机翻转的代码。请注意,翻转操作不同于其他图像增强操作,因为当我们翻转图像时,我们需要改变转向角度。例如,下图(左)的原始图像有一条向左弯曲的车道线,因此转向角为 85°。但是当我们翻转图像时,车道线现在指向右边,所以正确的角度是180 -original_angle,是 95 度。

我们有一个函数将所有的增强操作组合在一起,因此一个图像可以应用任何或所有的操作。
图像预处理
我们还需要将我们的图像转换成 Nvidia 模型接受的颜色空间和大小。首先, Nvidia 研究论文要求输入图像为 200x66 像素分辨率。类似于我们在第 4 部分中所做的,图像的上半部分与预测转向角无关,所以我们将把它裁剪掉。其次,它要求图像在 YUV 颜色空间中。我们将简单地使用cv2.cvtColor()来做到这一点。最后,它要求我们将图像标准化。
英伟达型号
这里我们再次呈现 Nvidia 模型架构,所以我们可以很容易地在代码中将其与我们的模型进行比较。

请注意,我们已经相当忠实地实现了 Nvidia 模型架构,只是我们移除了标准化层,因为我们会在模型外部这样做,并添加一些丢弃层,以使模型更加健壮。我们使用的损失函数是均方误差(MSE ),因为我们是在做回归训练。我们还使用了 eLU(指数线性单位)激活函数,而不是我们熟悉的 ReLU(校正线性单位)激活函数,因为当 x 为负时,ELU 不存在“垂死 RELU”问题。


ReLU (left) and ELU (right)
当我们创建模型并打印出它的参数列表时,显示它包含大约 250,000 个参数。这是一个很好的检查,我们的模型的每一层都是按照我们的期望创建的。
Model: "Nvidia_Model" _________________________________________________________________ Layer (type) Output Shape Param # ================================================================= conv2d (Conv2D) (None, 31, 98, 24) 1824 _________________________________________________________________ conv2d_1 (Conv2D) (None, 14, 47, 36) 21636 _________________________________________________________________ conv2d_2 (Conv2D) (None, 5, 22, 48) 43248 _________________________________________________________________ conv2d_3 (Conv2D) (None, 3, 20, 64) 27712 _________________________________________________________________ dropout (Dropout) (None, 3, 20, 64) 0 _________________________________________________________________ conv2d_4 (Conv2D) (None, 1, 18, 64) 36928 _________________________________________________________________ flatten (Flatten) (None, 1152) 0 _________________________________________________________________ dropout_1 (Dropout) (None, 1152) 0 _________________________________________________________________ dense (Dense) (None, 100) 115300 _________________________________________________________________ dense_1 (Dense) (None, 50) 5050 _________________________________________________________________ dense_2 (Dense) (None, 10) 510 _________________________________________________________________ dense_3 (Dense) (None, 1) 11 ================================================================= Total params: 252,219 Trainable params: 252,219 Non-trainable params: 0
训练
现在数据和模型都准备好了,我们将开始训练数据。
对于已经使用 Keras 训练深度学习模型的人,我们通常使用model.fit()命令。但是请注意,今天我们使用了model.fit_generator()命令。这是因为我们没有使用静态的训练数据集,我们的训练数据是通过前面讨论的图像增强从我们的原始 200 幅图像中动态生成的。为了实现这一点,我们需要创建一个助手函数来进行增强,然后在每次迭代中向model.fit_generator()返回一批新的训练数据。
下面是这个助手的代码,image_data_generator()。
评估已训练的模型
训练 30 分钟后,模型将完成 10 个周期。现在是时候看看训练进行得如何了。首先要绘制训练集和验证集的损失函数。很高兴看到训练和验证损失一起快速下降,然后在第 5 个纪元后保持在非常低的水平。似乎没有任何过度拟合的问题,因为验证损失保持在低水平和培训损失。

检验我们的模型是否表现良好的另一个指标是 R 指标。R 接近 100%意味着模型表现得相当好。正如我们可以看到的,我们的模型,即使有 200 张图像,也有 93%的 R,这是非常好的,这主要是因为我们使用了图像增强。
mse = 9.9
r_squared = 93.54%
下面是 GitHub 上的全 Jupyter 笔记本源代码训练深度学习车道导航模型,最好直接用 Google Colab 打开。这样,一旦您提供了 Google 凭据,您就可以自己运行代码。
在旅途中
一个车型是不是真的好,需要在橡胶遇到路面的时候进行最终的检验。下面是驱动 PiCar 的核心逻辑。与我们手动编码的车道导航实现相比,检测蓝色、检测车道和计算转向角度等所有步骤(大约 200 行代码)都消失了。取而代之的是这些简单的命令,load_model和model.predict()。当然,这是因为所有的校准都是在训练阶段完成的,3Mb 的 HDFS 格式的训练模型文件包含多达 250,000 个参数。
下面是使用训练好的深度学习模型的车道导航代码的完整源代码。注意文件中有几个助手和测试函数来帮助显示和测试。
下面是 DeepPiCar 在车道上跑步的视频。是的,现在的才是真正的名副其实, DeepPiCar 。我们可以看到它在大部分时间里表现不错,但在接近终点时偏离了车道。因为这是使用深度学习,要解决这个问题,我们要做的就是给模型更多良好驾驶行为的视频片段,要么通过远程控制驾驶汽车,要么使用更好的手动编码车道导航仪。如果我们希望汽车在白色/黄色标记的道路上导航,那么我们可以给它提供带有白色/黄色标记的道路和转向角度的视频,模型也会学习这些,而无需我们手动调整白色和黄色的颜色遮罩。多酷啊!
下一步是什么
在这篇文章中,我们教会了我们的 DeepPiCar 在车道内自主导航,只需让它“观察”一个好司机如何驾驶。将深度学习通道导航实现与我们上一篇文章中手动调整的实现进行对比,它要短得多,也更容易理解。它的准确率也相当高,达到了 94%的 R,当然,我们不得不先训练深度学习模型,它包含了 25 万个参数。但是它仅仅通过观察我们如何驾驶就学会了所有的参数。在下一篇文章中,我们将构建自动驾驶汽车的另一个重要功能,即观察和响应周围环境,最常见的是响应交通标志和行人。希望能在第六部见到你!
以下是整个指南的链接:
第一部分:概述
第二部分:树莓 Pi 设置和 PiCar 装配
第 3 部分:让 PiCar 看到并思考
第 4 部分:通过 OpenCV 的自主车道导航
第五部分:自主 通过深度学习进行车道导航(本文)
第六部分:交通标志和行人检测与处理
DeepPiCar 第 6 部分:交通标志和行人检测与处理
DeepPiCar 系列
使用迁移学习来调整预训练的 MobileNet SSD 深度学习模型,以通过谷歌的 Edge TPU 检测交通标志和行人。
行动纲要

在博客系列的第 4 部分和第 5 部分中,我们讨论了车道检测和导航。一辆真正的自动驾驶汽车还需要时刻意识到周围的情况。在本文中,我们将讨论另一个重要的感知特征,即检测交通标志和行人。注意,这项功能在任何 2019 款车辆上都不可用,除了可能是特斯拉。我们将训练 DeepPiCar 去识别和实时响应(微型)交通标志和行人**。我们还将利用 2019 年初刚刚推出的 75 美元的谷歌 Edge TPU 加速器!**
没有购买任何硬件的读者请注意:对于本文的前半部分,您可以只带一台 PC,因为我们将在云中训练我们的模型。
介绍
当我驾驶沃尔沃 XC90 的 PilotAssist 从芝加哥驶往科罗拉多时,我的沃尔沃在高速公路上表现出色,因为我不需要转向或刹车。不过有一点让我很困扰的是,在一些有红绿灯的高速公路上,它无法检测到红绿灯或者交通标志,看到红灯就要刹车。我想,如果它也能做到这一点,那不是很好吗?这就是我写这篇文章的动机,我想让这辆 DeepPiCar 比我的沃尔沃更智能!
就像第 5 部分中的车道导航项目一样,有一个感知步骤和一个规划/控制步骤。我们首先需要检测汽车前面的是什么。然后我们可以用这个信息告诉汽车停下、前进、转弯或改变速度等。
感知:交通标志和行人检测
目标检测是计算机视觉和深度学习中的一个众所周知的问题。目标检测模型有两个组成部分,即基本神经网络和检测神经网络。
首先, 基神经网络 是从图像中提取特征的 CNN,从线、边、圆等低层特征到人脸、人、红绿灯、站牌等高层特征。一些众所周知的基本神经网络是 LeNet、InceptionNet(又名。GoogleNet)、ResNet、VGG 网、AlexNet 和 MobileNet 等。这篇优秀的文章在下面讨论了这些基础神经网络之间的区别。

Base Neural Networks detect features in an image
然后 检测神经网络 被附加到基本神经网络的末端,并用于借助于提取的特征从单个图像中同时识别多个对象。一些流行的检测网络是 SSD(单次多盒检测器)、R-CNN(具有 CNN 特征的区域)、更快的 R-CNN 和 YOLO(你只看一次)等。这篇优秀文章讨论了这些检测神经网络的区别。


Detection Neural Networks detect the type of the object and its bounding box (x,y,w,h)
对象检测模型通常被命名为其基本网络类型和检测网络类型的组合。例如,“MobileNet SSD”模型,或“Inception SSD”模型,或“ResNet fast R-CNN”模型,仅举几个例子。
最后,对于预训练的检测模型,模型名称还将包括它被训练的图像数据集的类型。用于训练图像分类器和检测器的几个知名数据集是 COCO 数据集(大约 100 种常见的家用对象) Open Images 数据集(大约 20000 种对象)和自然主义者数据集(大约 200000 种动植物物种)中的**。例如,ssd_mobilenet_v2_coco模型使用第二版 MobileNet 提取特征,SSD 检测对象,并在 COCO 数据集上进行预训练。**
跟踪所有这些模型的组合不是一件容易的事情。但是多亏了谷歌,他们用 TensorFlow(称为模型动物园,实际上是模型动物园)发布了一个预训练模型的列表,所以你可以下载一个适合你需要的模型,并直接在你的项目中使用它进行检测推理。


Source: Google’s Detection Model Zoo
回想一下,我们在第三部分中使用了在 COCO 数据集上预先训练的 MobileNet SSD 模型,它识别了我客厅书架和沙发上的书籍。

迁移学习
然而,这篇文章是关于检测我们的迷你交通标志和行人,而不是书或沙发。但我们不想收集和标记成千上万的图像,并花费数周或数月从零开始构建和训练一个深度检测模型。我们可以做的是利用转移学习 — ,它从预训练模型的模型参数开始,只为它提供 50–100 张我们自己的图像和标签,只花几个小时来训练检测神经网络的部分。直觉是,在预训练的模型中,基本 CNN 层已经擅长于从图像中提取特征,因为这些模型是在大量和各种各样的图像上训练的。区别在于,我们现在有一组不同于预训练模型的对象类型(约 100–100,000 种)。


Miniaturized versions of traffic signs and pedestrians used for training
建模培训
模型训练包括几个步骤。
- 图像收集和标记(20-30 分钟)
- 型号选择
- 转移学习/模型培训(3-4 小时)
- 以边缘 TPU 格式保存模型输出(5 分钟)
- 在树莓 Pi 上运行模型推理
图像采集和标记

我们有 6 种对象类型,即红灯、绿灯、停车标志、40 英里/小时限速、25 英里/小时限速,以及一些作为行人的乐高小雕像。于是我拍了大概 50 张类似上面的照片,把物体随机放在每张图片里。
然后,我用图像上的每个对象的边界框来标记每个图像。这看起来需要几个小时,但是有一个免费的工具,叫做 labelImg (用于 windows/Mac/Linux),让这项艰巨的任务变得轻而易举。我所要做的就是将 labelImg 指向存储训练图像的文件夹,对于每个图像,在图像上的每个对象周围拖一个框,并选择一个对象类型(如果是新类型,我可以快速创建一个新类型)。因此,如果您使用键盘快捷键,每张照片只需 20-30 秒,因此我只花了 20 分钟就标记了大约 50 张照片(大约 200-300 个对象实例)。之后,我只是随机地将图像(以及它的标签 xml 文件)分成训练和测试文件夹。你可以在models/object_detection/data下的 DeepPiCar 的 GitHub repo 中找到我的训练/测试数据集。

Labeling Images with LabelImg Tool
型号选择
在 Raspberry Pi 上,由于我们的计算能力有限,我们必须选择一个既运行相对快速又准确的模型。在试验了几个模型后,我选定了MobileNet v2 SSD COCO模型作为速度和准确性之间的最佳平衡。此外,为了让我们的模型在边缘 TPU 加速器上工作,我们必须选择MobileNet v2 SSD COCO **Quantized** 模型。量化是一种通过将模型参数存储为整数值而不是双精度值来使模型推断运行更快的方法,预测精度几乎不会下降。Edge TPU 硬件经过优化,可以只运行量化模型。这篇文章对 Edge TPU 的硬件和性能基准进行了深入分析,供感兴趣的读者阅读。
转移学习/模型训练/测试
对于这一步,我们将再次使用 Google Colab。本节基于程维的优秀教程“如何免费轻松训练一个物体检测模型”。我们需要在树莓派上运行,使用边缘 TPU 加速器。由于整个笔记本及其输出相当长,我将在下面介绍我的 Jupyter 笔记本的关键部分。完整的笔记本代码可以在我的 GitHub 上找到,里面对每一步都有非常详细的解释。
设置培训环境
上面的代码选择MobileNet v2 SSD COCO **Quantized** 模型,从 TensorFlow GitHub 下载训练好的模型。如果我们想选择不同的检测模型,这一部分设计得很灵活。
准备培训数据
上面的代码将 LabelImg 工具生成的 xml 标签文件转换为二进制格式(。记录)以便 TensorFlow 快速处理。
下载预训练模型
'/content/models/research/pretrained_model/model.ckpt'
上述代码将下载ssd_mobilenet_v2_quantized_300x300_coco_2019_01_03模型的预训练模型文件,我们将仅使用model.ckpt文件,我们将从该文件应用迁移学习。
训练模型
这一步需要 3-4 个小时,取决于你训练的步数(又名纪元或num_steps)。训练完成后,你会在model_dir里看到一堆文件。我们正在寻找最新的model.ckpt-xxxx.meta文件。在这种情况下,由于我们运行了 2000 步,我们将使用来自model_dir的**model.ckpt-2000.meta**文件。
!ls -ltra '{model_dir}/*.meta'-rw------- 1 root root 17817892 Apr 16 23:10 model.ckpt-1815.meta
-rw------- 1 root root 17817892 Apr 16 23:20 model.ckpt-1874.meta
-rw------- 1 root root 17817892 Apr 16 23:30 model.ckpt-1934.meta
-rw------- 1 root root 17817892 Apr 16 23:40 model.ckpt-1991.meta
**-rw------- 1 root root 17817892 Apr 16 23:42 model.ckpt-2000.meta**
在训练期间,我们可以通过 TensorBoard(上面我的 GitHub 链接中的源代码)来监控损失和精度的进展。我们可以看到,在整个培训过程中,测试数据集的丢失率在下降,精确度在提高,这是一个很好的迹象,表明我们的培训正在按预期进行。

Total Loss (lower right) keeps on dropping

mAP (top left), a measure of precision, keeps on increasing
测试训练好的模型
训练结束后,我们通过新模型运行了测试数据集中的一些图像。正如所料,图像中几乎所有的物体都以相对较高的置信度被识别。有一些图像中的物体离得更远,没有被探测到。这对我们的目的来说很好,因为我们只想检测附近的物体,这样我们就可以对它们做出反应。当我们的车靠近远处的物体时,它们会变得更大,更容易被发现。

以边缘 TPU 格式保存模型输出
一旦模型被训练,我们必须将模型meta文件导出到 Google ProtoBuf 格式的推理图,然后导出到 Edge TPU 加速器可以理解和处理的格式。这似乎是一个简单的步骤,但在撰写本文时,在线资源(包括 Edge TPU 自己的网站)非常稀缺,以至于我花了数小时研究正确的参数和命令,以转换成 Edge TPU 可以使用的格式。
幸运的是,经过几个小时的搜索和实验,我已经找到了下面的命令来做到这一点。
最终我们得到一个road_signs_quantized.tflite文件,适合移动设备和 Raspberry Pi CPU 进行模型推断,但还不适合 Edge TPU 加速器。
!ls -ltra '/content/gdrive/My Drive/Colab Notebooks/TransferLearning/Training/fine_tuned_model/*.tflite'root root 4793504 Apr 16 23:43 **road_signs_quantized.tflite**
对于边缘 TPU 加速器,我们需要再执行一个步骤。那就是通过 Edge TPU 模型 Web 编译器运行road_signs_quantized.tflite。

将road_signs_**quantized**.tflite上传到 web 编译器后,可以下载另一个 tflite 文件,保存为road_signs_**quantized_edgetpu**.tflite。现在你完成了!会有一些警告,但是可以安全地忽略。请注意,99%的模型将在边缘 TPU,这是伟大的!

_edgetpu.tflite文件和常规.tflite文件的区别在于,使用**_edgetpu**.tffile文件,所有(99%)模型推理将在 TPU 边缘运行,而不是在 Pi 的 CPU 上运行。出于实用目的,这意味着您每秒可以处理大约 20 幅 320x240 分辨率的图像(又名。FPS,每秒帧数),但是单独使用 Pi CPU 时只有大约 1 FPS。20 FPS 对于 DeepPiCar 来说是(接近)实时的,这值 75 美元。(嗯,考虑到整个树莓派——CPU+电路板才 30 美元,我觉得这 75 美元的成本应该更低!)
规划和运动控制
现在 DeepPiCar 已经可以检测和识别它面前有什么物体了,我们仍然需要告诉它如何处理它们,也就是运动控制。运动控制有两种方法,即基于规则的和端到端的。基于规则的方法意味着我们需要告诉汽车当它遇到每个物体时该做什么。例如,告诉汽车如果看到红灯或行人就停下来,或者如果看到限速标志就开慢点,等等。这类似于我们在第 4 部分中所做的,在第 4 部分中,我们通过一组代码/规则告诉汽车如何在车道内导航。端到端方法只是向汽车输入大量优秀驾驶员的视频片段,汽车通过深度学习,自动计算出它应该在红灯和行人面前停下来,或者在限速下降时减速。这类似于我们在第 5 部分“端到端车道导航”中所做的。
对于本文,我选择了基于规则的方法,因为 1)这是我们人类通过学习道路规则来学习如何驾驶的方式,2)它更容易实现。
由于我们有六种类型的对象(红灯、绿灯、40 英里/小时限制、25 英里/小时限制、停车标志、行人),我将说明如何处理一些对象类型,您可以在 GitHub 上的这两个文件中阅读我的完整实现,[traffic_objects.py](https://github.com/dctian/DeepPiCar/blob/master/driver/code/traffic_objects.py)和[object_on_road_processor.py](https://github.com/dctian/DeepPiCar/blob/master/driver/code/objects_on_road_processor.py)。
规则很简单:如果没有探测到物体,就以最后已知的速度限制行驶。如果检测到某个物体,该物体将修改汽车的速度或速度限制。例如,当你探测到足够近的红灯时停止,当你没有探测到红灯时继续。
首先,我们将定义一个基类TrafficObject,它表示道路上可以检测到的任何交通标志或行人。它包含一个方法,set_car_state(car_state)。car_state字典包含两个变量,即speed和speed_limit,这两个变量将被方法改变。它还有一个助手方法is_close_by(),检查检测到的对象是否足够近。(嗯,由于我们的单个相机不能确定距离,我用物体的高度来近似距离。为了精确确定距离,我们需要激光雷达,或者它的小兄弟,超声波传感器,或者像特斯拉一样的立体视觉摄像系统。)
红灯和行人的实现很简单,只需将汽车速度设置为 0。
25 Mph 和 40 Mph 速度限制只能使用一个 SpeedLimit 类,该类将 speed_limit 作为其初始化参数。当检测到该标志时,只需将车速限制设置到适当的极限即可。
绿光实现甚至更简单,因为它除了检测到打印绿光之外什么也不做(代码未显示)。停止标志的实现稍微复杂一些,因为它需要跟踪状态,这意味着它需要记住它已经在停止标志处停了几秒钟,然后在汽车经过标志时继续前进,即使后续的视频图像包含非常大的停止标志。具体可以参考我在[traffic_objects.py](https://github.com/dctian/DeepPiCar/blob/master/driver/code/traffic_objects.py)的实现。
一旦我们定义了每个交通标志的行为,我们需要一个类将它们联系在一起,这个类就是ObjectsOnRoadProcessor类。该类首先加载边缘 TPU 的训练模型,然后用该模型检测实时视频中的对象,最后调用每个交通对象来改变汽车的速度和速度限制。下面是[objects_on_road_processor.py](https://github.com/dctian/DeepPiCar/blob/master/driver/code/objects_on_road_processor.py)的关键部位。
注意,每个 TrafficObject 只是改变了car_state对象中的speed和speed_limit,而没有实际改变汽车的速度。是ObjectsOnRoadProcessor在检测和处理所有交通标志和行人后,改变汽车的实际速度。
把它放在一起
这是这个项目的最终成果。请注意,我们的 DeepPiCar 在停车标志和红灯前停下来,不等任何行人,继续前行。此外,它在 25 英里/小时的标志下减速,在 40 英里/小时的标志下加速。
感兴趣的完整源代码在 DeepPiCar 的 GitHub 上:
- Colab Jupyter 笔记本用于物体检测和迁移学习
- Python 中的规划和运动控制逻辑
- DeepPiCar 主驱动程序。
下一步是什么
在这篇文章中,我们教会了我们的 DeepPiCar 识别交通标志和行人,并对它们做出相应的反应。这不是一个小壮举,因为路上的大多数汽车还不能做到这一点。我们采取了一种捷径,使用了预先训练的对象检测模型,并在其上应用了迁移学习。事实上,当一个人无法收集足够的训练数据来从头创建深度学习模型,或者没有足够的 GPU 能力来训练模型数周或数月时,迁移学习在人工智能行业中非常普遍。那么为什么不站在巨人的肩膀上呢?
在以后的文章中,我有相当多的想法。这里有一些好玩的项目,以后可以试试。
嘿,贾维斯,开始开车!
我想在车上装一个麦克风,训练它识别我的声音和我的唤醒词,这样我就可以说:“嘿,贾维斯,开始开车!”或者“嘿贾维斯,左转!”我们在吴恩达的深度学习课程中做了一个唤醒词项目,那么能够召唤 DeepPiCar 的超级酷岂不是更好,就像钢铁侠或者蝙蝠侠一样?

JARVIS, Tony Stark’s (Ironman) AI Assistant
自适应巡航控制
另一个想法是在 DeepPiCar 上安装一个超声波传感器。这类似于现实生活中车辆上的激光雷达,而我们可以感知 DeepPiCar 和其他物体之间的距离。例如,使用超声波传感器,我们将能够实现 ACC(自适应巡航控制),这是自动驾驶汽车的一个基本功能,或者我们可以通过仅检测特定范围内的对象来增强我们的对象检测算法。
端到端深度驾驶
我还想尝试完全端到端的驾驶,我将远程控制汽车一段时间,保存视频片段,速度和转向角度,并应用深度学习。希望深度学习将教会它如何驾驶,即通过模仿我的驾驶行为,既遵循车道,又对交通标志和行人做出反应。这将是一个超级酷的项目*,如果*它实际工作。这意味着我们不需要告诉汽车任何规则,它只是通过观察来解决一切问题!!这将是自动驾驶汽车的圣杯,这类似于 AlphaZero 如何在没有任何人类输入启发的情况下学习下围棋或象棋。
谢谢!
如果你已经读到这里(或者和我一起构建/编码),那么恭喜你!如果到目前为止一切正常,你应该有一辆深度学习、自动驾驶的机器人汽车在你的客厅里运行,并且能够在它观察到停止标志或红灯时停下来!如果没有,请在下面留言,我会尽力帮助你。我真的很高兴能和你一起分享这美妙的旅程。事实上,比起编写代码、训练模型和在我的客厅里测试 DeepPiCar加起来,我写这些文章花费的时间要长得多。这也是我第一次写博客,既害怕又兴奋。我现在意识到,我喜欢建造东西,就像向别人展示如何建造东西一样。
像往常一样,这里是整个指南的链接,以防你需要参考以前的文章。现在需要给自己找一份自动驾驶汽车公司的机器学习工程师的工作!一会儿见!
第 1 部分:概述
第 2 部分: Raspberry Pi 设置和 PiCar 装配
第 3 部分:让 PiCar 看到并思考
第 4 部分:通过 OpenCV 的自主车道导航
第五部分:自主 通过深度学习进行车道导航
第六部分:交通标志和行人检测与处理(本文)
黑暗防御统计

如今,从政治到医疗保健到广告,统计、机器学习和大数据似乎处于几乎所有可以想象的领域的前沿。虽然这场稳步的革命无疑令人兴奋,但它也促使我们更加密切地关注蜘蛛侠叔叔本的明智之言:“权力越大,责任越大”。

Wise words from Uncle Ben.
事实上,正如这些领域有巨大的力量给世界带来持久的积极变化,它们也有力量被用来实现自私、阴暗、彻头彻尾的邪恶目标。
在这篇文章的持续时间里,假设你是一个邪恶制药公司的领导。你的最新计划是向市场投放一种“神奇药丸”,承诺抑制一个人访问脸书、Instagram 等社交媒体网站的欲望。作为一个恶魔,你计划出售一个完全虚假的药丸,并使用高度扭曲的统计数据来获得人们的信任。
你的卑鄙计划只有三个组成部分:证明对你的神奇药丸有很大的需求,证明你的神奇药丸抑制了上社交媒体的欲望,证明你的神奇药丸在上市一段时间后发挥了作用。

Your evil 3 step plan.
证明你的神奇药丸的必要性
为了开始你的计划,你需要让每个人相信社交媒体的使用已经完全失控,因此需要你的神奇药丸。你在脸书做了一个智能手机调查,询问人们每天花多少时间在社交媒体上。取回结果后,你发现普通人每天花 4 个小时在社交媒体上!

Your conduct a smartphone Facebook survey asking about social media use.
**那么你的调查到底有什么邪恶之处呢?事实上,你在社交媒体平台脸书上询问社交媒体的使用情况,几乎可以肯定会使你的结果偏向于在社交媒体上报告的更长时间。换句话说:回答你的调查的人必须去过脸书才能找到你的调查。当然,你会在新闻稿中忽略这个小细节。
这种类型的统计误用被称为过度概括,发生在样本不代表总体时。这里我们的人口是所有的美国人,但是我们的样本只包括那些已经有脸书账户的人。**
那么,我们如何抵御这种类型的统计攻击呢?正如我们不久将看到的对统计数据的其他误用一样,我们可以通过要求回答一些关键问题来为自己辩护。为了泛化,我们想问一个“谁?”问题: “谁在样本中,他们是否代表我们试图测量的人群?”

How to defend against overgeneralization.
证明你的神奇药丸的可行性
好的,事情正在按计划进行。你已经让所有人相信社交媒体的使用正在失控,并为你的神奇药丸获得了大量资金。接下来,你需要对你的药丸进行临床试验,证明它确实降低了人们上社交网站的欲望。当然唯一的问题是你的药丸是一颗完全假冒的。
不过嘿!你是个邪恶的科学家;你绝不会让像真相这样微不足道的事情阻碍你的计划。在你的大量资助下,你进行了 100 次试验,每次都有几个参与者,并给每个参与者服用不同数量的神奇药丸。你跟踪他们在一段时间内的社交媒体使用情况,并对每一批参与者衡量是否存在正相关(社交媒体使用增加)、负相关(社交媒体使用减少)或无相关(社交媒体使用无显著变化)。
您的结果如下所示。

The results of your clinical trials.
好吧,很明显你的药是无用的。在 100 项试验中,只有 5 项表明社交媒体使用率下降,5 项实际上表明社交媒体使用率增加,而多达 90 项试验表明社交媒体使用率没有显著变化。不要担心!你只会报告显示社交媒体使用下降的 5。你将新闻稿的标题框定为:“奇迹药丸在 5 次独立试验中持续显示社交媒体使用率下降”。严格来说,你没有说谎对吧?
这种对统计数据的误用被称为 樱桃采摘。 它是只选择确认一个结果的证据片段,而忽略其他所有证据的行为。很容易看出为什么它确实非常险恶。一个不知情的公众成员甚至不会知道所有反驳这一说法的证据。
防止我们摘樱桃的最好方法是什么?我们应该总是问一个“有多少?”问题: “有多少试验讲述了一个不同于参考文献的故事?”

How to defend against cherry picking.
证明你神奇药丸的效果
****完美!你向所有人展示了你的神奇药丸是绝对必要的,然后让所有人相信你的药丸确实如其所言。因此,你的药丸现在已经上市几个月了,你只需要证明它对社交媒体的使用产生了预期的效果。你让你的市场部为你制作了这张漂亮的图表。

You create a chart showing social media use over time.
很明显 ,从这个图表很明显,自从你的神奇药丸上市以来,社交媒体的使用一直在下降。很明显这一定是你药丸的原因。
这个故事有几个问题。首先,即使在你的药片发布之前,社交媒体的使用似乎也在下降。第二,对于为什么社交媒体在假期使用下降,有一个强有力的替代解释:人们可能花更多的时间与家人、朋友和爱人在一起,而花更少的时间在社交媒体上。
这种对统计数据的误用非常普遍,被称为 虚假因果关系 或“相关性并不意味着因果关系”。也就是说,仅仅因为奇迹药丸的销售和社交媒体使用的减少之间存在关联,并不意味着使用的减少是由药丸引起的。
我们怎样才能抵御虚假的因果关系?我们最好问一个“为什么?”问题: “为什么我会看到我看到的结果?是因为陈述的原因还是有其他可能的解释?”

How to defend against the False Causality trap.
在上图中,我们问自己,是 A 导致了 B,还是 A 和 B 都是不同变量 c 的结果。同样,我们需要问自己,是药丸销量增加导致了社交媒体使用率下降,还是药丸销量增加和社交媒体使用率下降都是由即将到来的假日季节造成的。**
关键要点
当然,上面的例子是现实生活中发生的高度简化的版本。不幸的是,当我们在花哨、专业的图表或统计报告的伪装下被欺骗时,通常很难发现。此外,误导性的图表和对统计数据的严重滥用通常不是某些恶意制药公司所为,而仅仅是人们没有仔细制定他们的统计模型*。***
因此,在查看任何统计分析时,培养一种健康的怀疑变得越来越重要。我们在这篇文章中提出的简单关键问题可以帮助我们抵御黑暗统计。
定义数据科学问题
数据科学家最重要的非技术性技能

Photo by Kelly Sikkema on Unsplash
根据 Cameron Warren 在他的《走向数据科学》文章 中的说法,不要做数据科学,解决业务问题 ,“…对于一个数据科学家来说,最重要的技能是清晰地评估和定义问题的能力,这超过了任何技术专长。”
作为一名数据科学家,您会经常发现或遇到需要解决的问题。您的最初目标应该是确定您的问题实际上是否是数据科学问题,如果是,是什么类型的问题。能够将一个商业想法或问题转化为一个清晰的问题陈述是非常有价值的。并且能够有效地传达该问题是否可以通过应用适当的机器学习算法来解决。
是数据科学问题吗?
真正的数据科学问题可能是:
- 对数据进行分类或分组
- 识别模式
- 识别异常
- 显示相关性
- 预测结果
一个好的数据科学问题应该是具体的、结论性的。例如:
- 随着个人财富的增加,关键健康指标如何变化?
- 在加州,大多数心脏病患者住在哪里?
相反,模糊和不可测量的问题可能不适合数据科学解决方案。例如:
- 财务和健康有什么联系?
- 加州人更健康吗?
这是什么类型的数据科学问题?
一旦你决定你的问题是数据科学的一个很好的候选,你将需要确定你正在处理的问题的类型。为了知道哪种类型的机器学习算法可以被有效地应用,这个步骤是必要的。
机器学习问题通常分为两类:
- 监督 — 根据标记输入&输出数据预测未来输出
- 无监督 — 在未标记的输入数据中寻找隐藏的模式或分组

Image per MathWorks
*还有第三个桶( 强化学习 )不在本帖讨论范围内,不过你可以在这里 阅读一下 。
有监督的学习可以分为另外两个部分:
- 分类 — 预测离散分类反应(例如:良性或恶性)
- 回归 — 预测连续的数字响应(例如:20 万美元的房价或 5%的降雨概率)
每种机器学习问题的用例是什么?
- 无人监管的(主要被认为是“集群”)—市场细分、政治投票、零售推荐系统等等
- 分类— 医学成像、自然语言处理和图像识别等
- 回归— 天气预报、投票率、房屋销售价格等等
Pro 提示: 通过使用条件逻辑将连续的数值响应转化为离散的分类响应,可以将回归问题转化为分类问题!例如:
- 问题 : 估计有人投票的概率。
- 回归反应 : 60%概率
- 分类响应 : 是(如果回归响应大于 50%),否(如果回归响应小于 50%)
细化您的问题的子类型
在确定最终的问题定义之前,您需要非常具体地了解您的问题的机器学习子类型。弄清楚术语将有助于你决定选择哪种算法。下图说明了决定分类子类型(基于类)和回归子类型(基于数值)的示例工作流。

Image per Google Developers

Image per Google Developers
最终确定问题陈述
一旦您确定了具体的问题类型,您应该能够清楚地阐明一个精炼的问题陈述,包括模型将预测什么。例如:
这是一个多类分类问题,预测一幅医学图像是否会属于三类中的一类——*{benign, malignant, inconclusive}*。
您还应该能够表达模型预测的预期结果或预期用途。例如:
理想的结果是,当预测结果为 *malignant* 或 *inconclusive* 时,立即通知医疗保健提供者。
结论
一个好的数据科学问题将旨在做出决策,而不仅仅是预测。当你思考你面临的每一个问题时,记住这个目标。在上面的例子中,可能会采取一些措施来减少*inconclusive*预测的数量,从而避免后续几轮测试的需要,或者延迟所需的治疗。最终,你的模型的预测应该让你的利益相关者做出明智的决定——并采取行动!

Photo by Kid Circus on Unsplash
为 GPU 定义用户限制
如何在用户之间共享多个 GPU 而不出现 OOM 错误?
我们正在南加州大学使用λ实验室的 4-GPU 工作站。由于多个用户可以同时在服务器上运行作业,处理内存不足(OOM)错误和公平性有点困难。我们可以在网上找到的解决方案如下:
- 英伟达的 GPU 虚拟化软件,可以添加到虚拟化管理程序之上。不过,目前仅支持NVIDIA Turing、Volta、Pascal和MaxwellGPU 架构。

NVIDIA’s GPU virtualization stack. [Source]
2.Slurm 是一个开源的、高度可伸缩的作业调度系统,适用于大型和小型 Linux 集群。它支持 GPU 资源调度。对于大型团队来说似乎是一个非常合适的选择。它还支持每 GPU 内存分配,如果有足够的内存和未充分利用的计算单元,则可以在单个 GPU 上运行多个进程。

Slurm workload manager [Source]
在本文的其余部分,我们将解释我们为在用户之间共享多个 GPU 所做的工作。在多 GPU 工作站中,为每个 GPU 驱动程序文件创建用户组允许我们授予特定用户使用特定 GPU 的权限。现在,只有指定的 GPU 对用户可见。我们解释了在 4 GPU 工作站上创建 GPU 用户限制所需的命令。
步骤 1: 创建组,并将用户添加到组中。我们需要创建 4 个组,因为我们有 4 个 GPU:
# Adding groups
sudo groupadd nvidia0
sudo groupadd nvidia1
sudo groupadd nvidia2
sudo groupadd nvidia3# Adding users to the groups
sudo usermod -a -G nvidia0 olivia
sudo usermod -a -G nvidia1 peter
**第二步:*在/etc/modprob . d/NVIDIA . conf*创建一个配置文件,内容如下:
#!/bin/bash
options nvidia NVreg_DeviceFileUID=0 NVreg_DeviceFileGID=0 NVreg_DeviceFileMode=0777 NVreg_ModifyDeviceFiles=0
这个配置文件将把 4 个 NVIDIA 的驱动参数加载到 Linux 的内核中。NVIDIA 的驱动程序文件的一个问题是,它们在每次会话后都会重新生成,这破坏了我们将要在驱动程序文件上设置的用户访问限制。 NVreg_ModifyDeviceFiles 保证驱动文件一次生成,以后不会更改。其他参数是设置具有 777 访问权限的默认用户和组 id。如果在 */etc/modprob.d/,*已经有一个 NVIDIA 配置文件,你可以保留它的备份,并用我们提供的脚本替换它的内容。
**第三步:**在 /etc/init.d/gpu-restriction 创建一个脚本来加载 NVIDIA 的驱动。
#!/bin/bash
### BEGIN INIT INFO
# Provides: gpu-restriction
# Required-Start: $all
# Required-Stop:
# Default-Start: 2 3 4 5
# Default-Stop:
# Short-Description: Start daemon at boot time
# Description: Enable service provided by daemon.
# permissions if needed.
### END INIT INFOset -estart() {
/sbin/modprobe --ignore-install nvidia; /sbin/modprobe nvidia_uvm; test -c /dev/nvidia-uvm || mknod -m 777 /dev/nvidia-uvm c $(cat /proc/devices | while read major device; do if [ "$device" == "nvidia-uvm" ]; then echo $major; break; fi ; done) 0 && chown :root /dev/nvidia-uvm; test -c /dev/nvidiactl || mknod -m 777 /dev/nvidiactl c 195 255 && chown :root /dev/nvidiactl; devid=-1; for dev in $(ls -d /sys/bus/pci/devices/*); do vendorid=$(cat $dev/vendor); if [ "$vendorid" == "0x10de" ]; then class=$(cat $dev/class); classid=${class%%00}; if [ "$classid" == "0x0300" -o "$classid" == "0x0302" ]; then devid=$((devid+1)); test -c /dev/nvidia${devid} || mknod -m 660 /dev/nvidia${devid} c 195 ${devid} && chown :nvidia${devid} /dev/nvidia${devid}; fi; fi; done
}stop() {
:
}case "$1" in
start)
start
;;
stop)
stop
;;
restart)
stop
start
;;
status)
# code to check status of app comes here
# example: status program_name
;;
*)
echo "Usage: $0 {start|stop|status|restart}"
esacexit 0
然后,输入以下命令,该命令将告诉 Linux 在重新启动后加载脚本:
sudo update-rc.d gpu-restriction defaults
sudo update-rc.d gpu-restriction enable
现在,我们有了一个 Linux 服务,可以通过以下命令启动它:
sudo service gpu-restriction start
重启机器。您现在一切就绪!
检查脚本:
加载 NVIDIA 驱动程序的脚本的核心部分是:
/sbin/modprobe --ignore-install nvidia;
/sbin/modprobe nvidia_uvm;
test -c /dev/nvidia-uvm || mknod -m 777 /dev/nvidia-uvm c $(cat /proc/devices | while read major device; do if [ "$device" == "nvidia-uvm" ]; then echo $major; break; fi ; done) 0 && chown :root /dev/nvidia-uvm; test -c /dev/nvidiactl || mknod -m 777 /dev/nvidiactl c 195 255 && chown :root /dev/nvidiactl; devid=-1; for dev in $(ls -d /sys/bus/pci/devices/*); do vendorid=$(cat $dev/vendor); if [ "$vendorid" == "0x10de" ]; then class=$(cat $dev/class); classid=${class%%00}; if [ "$classid" == "0x0300" -o "$classid" == "0x0302" ]; then devid=$((devid+1)); test -c /dev/nvidia${devid} || mknod -m 660 /dev/nvidia${devid} c 195 ${devid} && chown :nvidia${devid} /dev/nvidia${devid}; fi; fi; done
上面的脚本首先会加载 NVIDIA 模块 nvidia 和 nvidia_uvm。为了设置用户访问限制,在所有 PCI express 设备的循环中,我们发现它们的供应商和类别 id 是否与 NVIDIA GPU 卡匹配。之后,我们创建每个 GPU 的驱动程序文件,然后我们在它们上面设置组和访问限制(660)。驱动文件位于 /dev/nvidia0 ,…, /dev/nvidia3 设置。
我们建议首先在一个可执行文件中运行上述脚本,以测试它是否工作正常。如果您在教程中发现任何问题,请告诉我,我将不胜感激。
自由度和数独
对自由度以及自由度如何影响数独的直观解释

Source : Pixabay
许多有抱负的数据科学家学习统计学课程,对自由度的概念感到困惑。有些人把它死记硬背成“n-1”。
但为什么是‘n-1’,有一个直观的原因。
直观的解释
让我们考虑下面的例子。
想象一下,让你选择 5 个总和为 100 的数字。为了简单起见,你说 20,20,20,20。在你说出第五个数字之前,我告诉你,你的第五个数字也是 20。这是因为你选择的前 4 个数字加起来是 80,而条件是选择 5 个数字加起来是 100。
所以 100 -80 = 20。第五个数字是 20。
第五个数字在某种意义上选择了自己由于指定的条件。
你可以看到你有 4 个自由度。只需要前四个数字。
这也直观地解释了 n-1。这里 n 是 5,n-1 =4。
你因为**“5 个数之和应为 100”**的条件而失去了一个自由度
或者
换句话说,你有 4 个自由度。
数独连接
数独是我们大多数人都非常熟悉的游戏。维基百科给出了如下定义
数独最初被称为数字位置)是一个基于逻辑的组合数字位置难题。目标是用数字填充一个 9×9 的网格,以便每一列、每一行以及组成网格的九个 3×3 子网格(也称为“框”、“块”或“区域”)中的每一个都包含从 1 到 9 的所有数字。难题设置器提供了一个部分完成的网格,对于一个适定的难题,它只有一个解。
我正在解一个数独游戏,只是为了消磨时间。我意识到数独和自由度之间有某种联系。
我不确定网络版的游戏是否考虑了自由度来给游戏评分“容易”、“中等”、“专家”。但是也许这个游戏可以这样评价!!
让我用一个取自在线数独谜题的例子来说明。
在线数独游戏的“简单”、“中等”、“困难”和“邪恶”等级如下所示。
请注意,数独游戏中有 81 个单元格。

Source : websudoku
更多的自由度=更难的数独
在每一层,我们都注意到一些有趣的事情。随着等级从易到恶,填充的单元格数量不断变小!!
基本上,当你有更多的单元格要填充(空白单元格)时,关卡会变得越来越难。你的自由度越多,解谜就越难!!至少在这种情况下,拥有很多自由并不理想。
这是一篇将自由度的统计概念与数独这样的日常游戏联系起来的小文章。
我希望在不久的将来写一个代码来描述上述内容。
你可以联系我


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言










{kind=link}
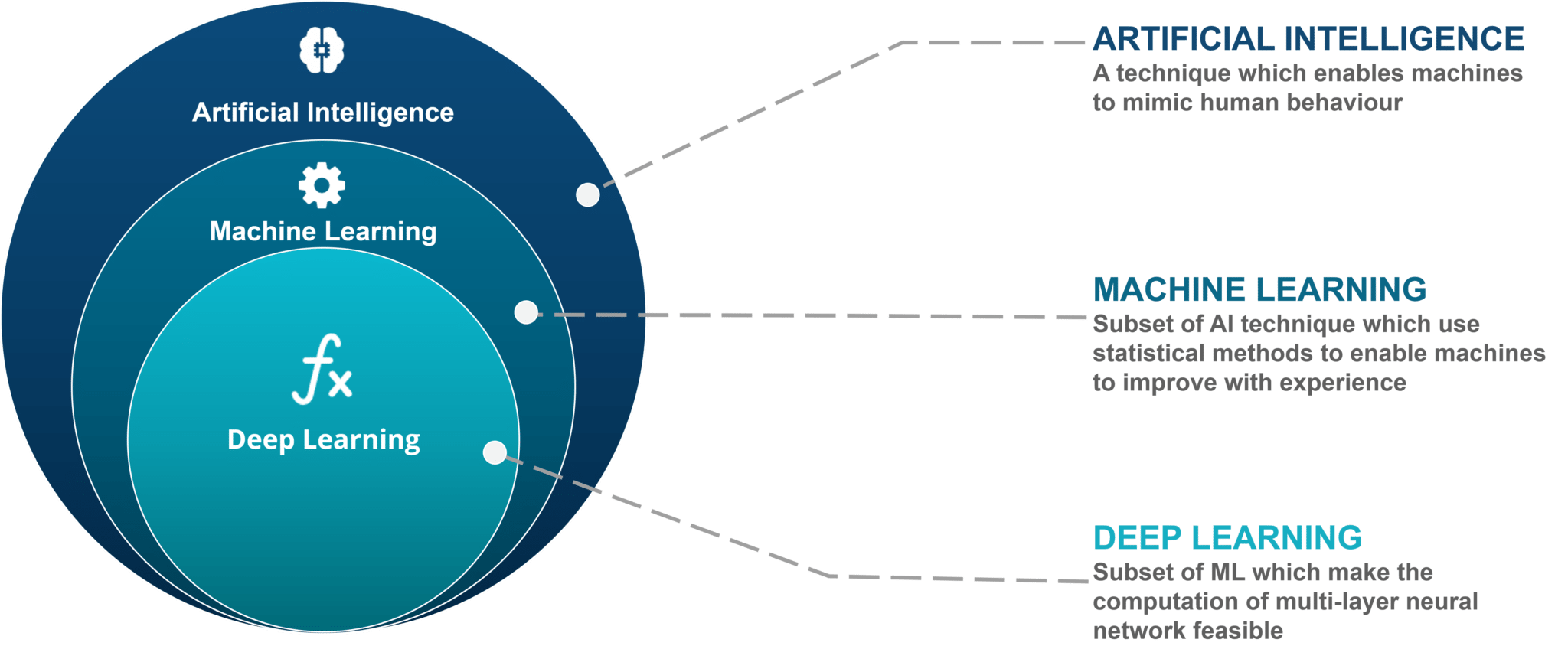{kind=link}