




Excel 与 SQL:概念上的比较
一位经验丰富的 Excel 用户对 SQL 的看法以及为什么它值得学习。

介绍
我已经在数据分析领域工作了大约 3 年。作为一名医疗保健分析师,我已经在这个领域工作了两年多,最近我完成了数据科学专业的 MBA 课程。
在读硕士期间,我对使用 python 的预测建模技术特别感兴趣(现在仍然如此)。然而,从基本的组织/分析/报告的角度来看,我对使用 Excel 最得心应手。一天花 60-80%的时间盯着 Excel 电子表格对我来说并不陌生。Excel GUI 中嵌套的选项卡、功能区、分组和工具是我的乐队的乐器。他们制造声音,但我指挥并将旋律和和声转化为报告、交付物和分析。在咨询项目、个人预算和兼职工作中,Excel 一直是我的首选工具。
我很早就知道 SQL 及其基本概念。然而,直到最近,由于专业原因,我才决定认真学习它。从一个 Excel 用户的角度来看,SQL 有起有落。在本文中,我希望通过与 Excel 的比较来传达 SQL 的本质和用法。
它们是什么?
Excel 是一个程序。SQL 是一种语言。这是一条需要消化的非常重要的信息。只有点击绿色图标并运行程序后,才能使用 Excel。另一方面,SQL 可以用来与数据库程序进行交互和通信。几个最受欢迎的:
- 神谕
- 关系型数据库
- Microsoft SQL Server
我学习 SQL 的方式是通过 Google 的大查询。通过免费分析 Google cloud 上的大型数据库来学习/使用 SQL 是一种有趣的方式。
数据在哪里?
擅长
Excel 是典型的电子表格工具。你把你的数据保存在你电脑上的一个文件里,它通常被组织在标签、列和行里。excel 文件位于您计算机的本地。你直接与它互动。没有中间人。没有管理员。当然,使用 API 从另一个位置获取数据是可能的;然而,数据最终是你的,你想怎么做就怎么做。如果几个人正在协作 Excel 工作簿,这使得跟踪更改变得很困难……确实有可能跟踪更改,但是不太方便。
结构化查询语言
SQL 是一种与数据库交互的语言。它代表结构化查询语言。在这种情况下,您的数据又前进了一步。您用 SQL 编写并向数据库发送查询,数据库接收这些查询,然后给出您的请求或进行更改。数据存储在数据库中,并通过表格进行组织。查询的美妙之处在于它更具协作性和可追溯性。这些查询可以追溯到谁对哪个表做了什么更改。用户还可以保存有用的查询并与其他人共享,以供将来使用或进行协作。
基于“bikeid”在大型查询中过滤“austin_bikeshare”表,然后按“duration_minutes”对选择进行排序的查询示例。
SELECT
duration_minutes
FROM
`bigquery-public-data.austin_bikeshare.bikeshare_trips`
Where
bikeid = "446"
ORDER BY
duration_minutes desc
一旦你知道语法是如何工作的,使用 SQL 操作数据会比使用 Excel 快得多。另一个很棒的方面是它的语法与英语相似,这使得它可以说是最容易学习的计算机语言。
它们的最佳用途是什么?
擅长
- 较小的数据集:少于 100 万行,甚至超过 100,000 行将会降低你的计算机速度。
- 手动输入数据
- 更灵活的结构:任何单元格都可以是任何数据类型,不管它在哪个列中。
- 输出图表和可视化
- 内置的拼写检查和其他有用的功能
- 独立完成一个项目
结构化查询语言
- 更大的数据集:取决于软件和数据库,这可能非常非常大。不会像 Excel 那样变慢。
- 组织/结构:SQL 表对一致的数据类型有更严格的要求,如果用户试图输入错误的类型,就会受到限制。
- 协作工作
- 为在另一个软件中进一步分析准备数据
- 一致的报告或计算:如前所述,您可以保存和共享查询。
- 更安全,因为更改总是可跟踪和可审计的。
结论

当我第一次学习 SQL 中的 JOIN 子句时,我最初的本能反应是将其标记为无关紧要,因为我已经知道如何在 Excel 中使用 Vlookups。后来我保持了一段时间的这种态度,但是随着我继续上课,现实情况开始出现。当我了解到 JOIN 子句是多么简单和有用时,我想起了 Vlookups 在执行大量行时所花费的时间。我记得如果你在运行计算后不粘贴值,他们会使文件成倍地变大。我还记得一次只带来一个值是多么有限…在我学习的整个过程中,当我比较 SQL 和 Excel 时,也经历了类似的教训。
总之,在数据分析方面,这两种工具都有自己的位置。两者都有其独特的用途,了解两者对经常使用数据的人都有好处。然而,根据我的经验和对该主题的研究,SQL 是数据分析师更需要和有用的技能。Excel 非常适合小企业主、顾问和学生。SQL 更适合分析师和数据科学家。
我在 SQL 学习过程中使用的一些有用资源:
SQL For Data Science With Google Big Query
如果您觉得这很有帮助,请订阅。如果你喜欢我的内容,下面是我参与的一些项目:
HiveQL/SQL 脚本完成的自动电子邮件通知
自动将产量提高 2-3 倍

Stock image from RawPixel.com.
如果你觉得这篇文章有任何帮助,请评论或点击左边的掌声按钮给我免费的虚拟鼓励!
动机
这个脚本对于执行 HiveQL 文件(.hql)或者 SQL 文件(.sql)非常有用。例如,这个脚本提供了电子邮件通知以及所涉及的 Hive/SQL 操作所需的时钟时间记录,而不是必须定期检查CREATE TABLE或JOIN何时结束。这对于连夜完成一系列 Hive/SQL 连接以便第二天进行分析特别有用。
剧本
答作为一名实践中的数据科学家,当我只是为了自己的目的而寻找代码进行回收和修改时,我不喜欢过度解释的琐碎片段,所以请找到下面的脚本。如果除了代码注释之外,你还想了解更多关于脚本的解释,请参见最后的附录。对bash的充分解释、它在位级的转换、HiveQL/SQL 和数据库引擎超出了本文的范围。正如所写的那样,下面的脚本仅在复制粘贴时适用于 HiveQL。您必须对它做一些小的修改,以便与您的 SQL 发行版一起工作。例如,如果使用 MySQL,将hive -f改为mysql source。也可以让脚本向多个电子邮件地址发送电子邮件。
#!/bin/bash
## By Andrew Young
## Contact: andrew.wong@team.neustar
## Last modified date: 13 Dec 2019################
## DIRECTIONS ##
################
## Run the following <commands> without the "<" or ">".
## <chmod u+x scriptname> to make the script executable. (where scriptname is the name of your script)
## To run this script, use the following command:
## ./<yourfilename>.sh#################################
## Ask user for Hive file name ##
#################################
echo Hello. Please enter the HiveQL filename with the file extension. For example, 'script.hql'. To cancel, press 'Control+C'. For your convenience, here is a list of files in the present directory\:
ls -l
read -p 'Enter the HiveQL filename: ' HIVE_FILE_NAME
#read HIVE_FILE_NAME
echo You specified: $HIVE_FILE_NAME
echo Executing...######################
## Define variables ##
######################
start="$(date)"
starttime=$(date +%s)#####################
## Run Hive script ##
#####################
hive -f "$HIVE_FILE_NAME"#################################
## Human readable elapsed time ##
#################################
secs_to_human() {
if [[ -z ${1} || ${1} -lt 60 ]] ;then
min=0 ; secs="${1}"
else
time_mins=$(echo "scale=2; ${1}/60" | bc)
min=$(echo ${time_mins} | cut -d'.' -f1)
secs="0.$(echo ${time_mins} | cut -d'.' -f2)"
secs=$(echo ${secs}*60|bc|awk '{print int($1+0.5)}')
fi
timeelapsed="Clock Time Elapsed : ${min} minutes and ${secs} seconds."
}################
## Send email ##
################
end="$(date)"
endtime=$(date +%s)
secs_to_human $(($(date +%s) - ${starttime}))subject="$HIVE_FILE_NAME started @ $start || finished @ $end"
## message="Note that $start and $end use server time. \n $timeelapsed"## working version:
mail -s "$subject" youremail@wherever.com <<< "$(printf "
Server start time: $start \n
Server end time: $end \n
$timeelapsed")"#################
## FUTURE WORK ##
#################
# 1\. Add a diagnostic report. The report will calculate:
# a. number of rows,
# b. number of distinct observations for each column,
# c. an option for a cutoff threshold for observations that ensures the diagnostic report is only produced for tables of a certain size. this can help prevent computationally expensive diagnostics for a large table
#
# 2\. Option to save output to a text file for inclusion in email notification.
#################
脚本解释
在此,我将解释脚本每一部分的代码。
################
## DIRECTIONS ##
################
## Run the following <commands> without the "<" or ">".
## <chmod u+x scriptname> to make the script executable. (where scriptname is the name of your script)
## To run this script, use the following command:
## ./<yourfilename>.sh
chmod是代表“改变模式”的bash命令我用它来改变文件的权限。它确保您(所有者)被允许在您正在使用的节点/机器上执行您自己的文件。
#################################
## Ask user for Hive file name ##
#################################
echo Hello. Please enter the HiveQL filename with the file extension. For example, 'script.hql'. To cancel, press 'Control+C'. For your convenience, here is a list of files in the present directory\:
ls -l
read -p 'Enter the HiveQL filename: ' HIVE_FILE_NAME
#read HIVE_FILE_NAME
echo You specified: $HIVE_FILE_NAME
echo Executing...
在本节中,我使用命令ls -l列出与保存我的脚本的.sh文件相同的目录(即“文件夹”)中的所有文件。read -p用于保存用户输入,即您想要运行的.hql或.sql文件的名称,保存到一个变量中,稍后在脚本中使用。
######################
## Define variables ##
######################
start="$(date)"
starttime=$(date +%s)
这是记录系统时钟时间的地方。我们将两个版本保存到两个不同的变量:start和starttime。
start="$(date)"保存系统时间和日期。
starttime=$(date +%s)保存系统时间和日期,以数字秒为单位,从 1900 开始偏移。第一个版本稍后在电子邮件中使用,以显示 HiveQL/SQL 脚本开始执行的时间戳和日期。第二个用于计算经过的秒数和分钟数。这为在您提供的 HiveQL/SQL 脚本中构建表所花费的时间提供了一个方便的记录。
#################################
## Human readable elapsed time ##
#################################
secs_to_human() {
if [[ -z ${1} || ${1} -lt 60 ]] ;then
min=0 ; secs="${1}"
else
time_mins=$(echo "scale=2; ${1}/60" | bc)
min=$(echo ${time_mins} | cut -d'.' -f1)
secs="0.$(echo ${time_mins} | cut -d'.' -f2)"
secs=$(echo ${secs}*60|bc|awk '{print int($1+0.5)}')
fi
timeelapsed="Clock Time Elapsed : ${min} minutes and ${secs} seconds."
}
这是一个复杂的解码部分。基本上,有很多代码做一些非常简单的事情:找出开始和结束时间之间的差异,都是以秒为单位,然后将经过的时间以秒为单位转换为分和秒。例如,如果工作需要 605 秒,我们将它转换为 10 分 5 秒,并保存到一个名为timeelapsed的变量中,以便在我们发送给自己和/或各种利益相关者的电子邮件中使用。
################
## Send email ##
################
end="$(date)"
endtime=$(date +%s)
secs_to_human $(($(date +%s) - ${starttime}))subject="$HIVE_FILE_NAME started @ $start || finished @ $end"
## message="Note that $start and $end use server time. \n $timeelapsed"## working version:
mail -s "$subject" youremail@wherever.com <<< "$(printf "
Server start time: $start \n
Server end time: $end \n
$timeelapsed")"
在本节中,我再次以两种不同的格式将系统时间记录为两个不同的变量。我实际上只用了其中一个变量。我决定保留未使用的变量,endtime,以备将来对这个脚本的扩展。电子邮件通知中使用变量$end来报告 HiveQL/SQL 文件完成时的系统时间和日期。
我定义了一个变量subject,不出所料,它成为了电子邮件的主题行。我注释掉了message变量,因为我无法使用printf命令在邮件正文中正确地用新行替换\n。我把它留在原处,因为我想让您可以根据自己的目的编辑它。
mail是一个发送邮件的程序。你可能会有它或类似的东西。mail还有其他选项,如mailx、sendmail、smtp-cli、ssmtp、S waks 等多个选项。这些程序中的一些是彼此的子集或衍生物。
未来的工作
本着合作和进一步努力的精神,以下是对未来工作的一些想法:
- 允许用户指定 HiveQL/SQL 文件的目录,在其中查找要运行的目标文件。一个使用案例是,用户可能根据项目/时间将他们的 HiveQL/SQL 代码组织到多个目录中。
- 改进电子邮件通知的格式。
- 通过自动检测是否输入了 HiveQL 或 SQL 脚本,以及如果是后者,是否有指定分布的选项(即 OracleDB、MySQL 等),增加脚本的健壮性。).
- 为用户添加选项,以指定是否应将查询的输出发送到指定的电子邮件。用例:为探索性数据分析(EDA)运行大量 SELECT 语句。例如,计算表中每个字段的不同值的数量,查找分类字段的不同级别,按组查找计数,数字汇总统计,如平均值、中值、标准偏差等。
- 添加选项,让用户在命令行指定一个或多个电子邮件地址。
- 添加一个选项,让用户指定多个
.hql和/或.sql文件按顺序或并行运行。 - 添加并行化选项。用例:你的截止日期很紧,不需要关心资源利用或同事礼仪。我需要我的结果!
- 添加计划代码执行的选项。可能以用户指定的
sleep的形式。用例:您希望在生产代码运行期间以及在工作日集群使用率较高时保持礼貌并避免运行。 - 通过标志使上述一个或多个选项可用。这将是非常酷的,但也有很多工作只是为了添加顶部的粉末。
- 更多。
新手教程
- 打开您喜欢的任何命令行终端界面。例子包括 MacOS 上的终端和 Windows 上的 Cygwin 。MacOS 已经安装了终端。在 Windows 上,你可以在这里 下载 Cygwin 。
- 导航到包含您的
.hql文件的目录。例如,输入cd anyoung/hqlscripts/来改变你当前的工作目录到那个文件夹。这在概念上相当于双击一个文件夹来打开它,只是这里我们使用的是基于文本的命令。 nano <whateverfilename>.sh
nano是一个命令,它打开一个同名的程序,并要求它创建一个名为<whateverfilename>.sh
的新文件。要修改这个文件,使用相同的命令。- 复制我的脚本并粘贴到这个新的
.sh文件中。将我的脚本中的收件人电子邮件地址从youremail@wherever.com更改为您的。 bash <whateverfilename>.sh
Bash 使用扩展名为.sh的文件。这个命令要求程序bash运行扩展名为.sh的“shell”文件。运行时,该脚本将输出与 shell 脚本位于同一目录中的所有文件的列表。这个列表输出是我为了方便而编写的。- 漫威在你的生产力增益!
关于作者
安德鲁·杨是 Neustar 的 R&D 数据科学家经理。例如,Neustar 是一家信息服务公司,从航空、银行、政府、营销、社交媒体和电信等领域的数百家公司获取结构化和非结构化的文本和图片数据。Neustar 将这些数据成分结合起来,然后向企业客户出售具有附加值的成品,用于咨询、网络安全、欺诈检测和营销等目的。在这种情况下,Young 先生是 R&D 一个小型数据科学团队的实践型首席架构师,该团队构建为所有产品和服务提供信息的系统,为 Neustar 带来超过 10 亿美元的年收入。
附录
创建 HiveQL 脚本
运行上述 shell 脚本的先决条件是要有一个 HiveQL 或 SQL 脚本。下面是一个 HiveQL 脚本示例,example.hql:
CREATE TABLE db.tb1 STORED AS ORC AS
SELECT *
FROM db.tb2
WHERE a >= 5;CREATE TABLE db.tb3 STORED AS ORC AS
SELECT *
FROM db.tb4 a
INNER JOIN db.tb5 b
ON a.col2 = b.col5
WHERE dt >= 20191201 AND DOB != 01-01-1900;
注意,在一个 HiveQL/SQL 脚本中可以有一个或多个CREATE TABLE命令。它们将按顺序执行。如果您可以访问一个节点集群,您还可以从查询的并行化中获益。我可能会在另一篇文章中解释。
基于机器学习的运动分类(上)
在这篇分为两部分的文章中,我们将深入探讨一个具体问题:对人们进行各种锻炼的视频进行分类。

第一篇文章将关注一种更为的算法方法,使用k-最近邻对未知视频进行分类,在第二篇文章中,我们将关注一种专门的机器学习 (ML)方法。
我们将要讨论的所有内容的代码都可以在 GitHub 的 这个 资源库中找到。算法方法(第一部分)是用 Swift 编写的,可以作为一个 CocoaPod 获得。ML 方法(第二部分)是用 Python/TensorFlow 编写的,可以作为 GitHub 资源库的一部分找到。
背景
我们想要构建一个系统,它将一个人进行锻炼的视频作为输入,并输出一个描述该视频的类标签。理想情况下,视频可以是任何长度,任何帧速率,任何摄像机角度。类别标签的子集可能如下所示:
back squats — **correct** formback squats — **incorrect** formpush-ups — **correct** formpush-ups — **incorrect** form- 诸如此类…
如何构建这样的系统?最棘手的部分之一是我们需要识别帧之间的关系——也就是说,人在每帧的位置之间的关系。这意味着我们正在处理时域中的数据结构,我们称之为时间序列。

Timeseries in 2 or more dimensions (at least one dimension is always time!)
给定一些从输入视频构建的“未知”时间序列,我们想要根据我们预测的练习给时间序列分配一个标签。

In this example, “A”, “B”, and “C” are potential labels for the unknown timeseries
如何制作时间系列?
我提到过我们将从一个输入视频中构建时间序列,但是我们怎么做呢?让我们假设每个视频都包含一个人进行某种锻炼的镜头。我的策略是:
- 标准化每个视频的长度
- 对于每一帧,使用 14 个关键身体点来确定人的“姿势”
- 创建表示姿势随时间变化的时间序列数据结构
- 过滤掉数据中的噪音
标准化视频长度
处理一个 5 分钟的视频是不现实的,所以为了加强数据的一致性,我们将标准化每个视频的长度。我从每个视频的中间对一个 5 秒的片段进行子采样,假设中间发生的事情是整个视频的“代表”。

对于 5 秒以下的视频,我们使用整个东西。
确定姿势
给定子剪辑的一帧(图像),我们想要确定图像中人的姿态。已经可以估计身体点(称为姿势估计),例如使用项目 OpenPose 。

https://github.com/CMU-Perceptual-Computing-Lab/openpose
我从这里拿了一个预先训练好的卷积神经网络(CNN)并用它来估计每个视频帧的姿势。使用这个 ML 模型,我们为 14 个身体部位中的每一个都获得了一个(x,y)坐标,以及每个身体部位的位置精度的置信水平[0,1]。你可以在 GitHub repo 上看到实现细节。
把它放在一起
现在,从视频构建时间序列的一切都已就绪。为了把它放在一起,我们简单地连接每个视频帧的姿态数据。由此产生的时间序列有 4 个维度:
- 时间:由视频帧索引
- 身体部位:共 14 个身体部位
- x 位置:身体部位的 x 坐标,从[0,1]开始归一化
- y 位置:身体部位的 y 坐标,从[0,1]开始归一化

由于有 14 个身体部位和每个部位的(x,y)坐标,我们可以将时间序列数据结构想象成 28 个随时间变化的波(14 x2 = 28)。
(x,y)坐标通过将每个身体部位位置分别除以帧的宽度或高度来归一化。框架的左下角作为我们坐标系的原点。
平滑噪声数据
在这一点上,我们有一个时间序列,但当我们试图分类和分配一个类标签时,它包含的噪声可能会导致不准确的预测。为了平滑噪声数据,我使用了一种叫做黄土 ( 局部加权散点平滑)的过滤器。

https://ggbaker.selfip.net/data-science/media/loess.gif
总的想法是,对于每个“原始”数据点,我们通过取相邻点的加权平均来得到更好的估计。离我们考虑的点越近的邻居权重越高,因此对平均值的影响也越大。
黄土的好处是(例如,与卡尔曼滤波器相比)只需要考虑一个参数。此参数控制相邻点对加权平均值的影响程度。它越大,邻居的影响就越大,因此产生的曲线就越平滑。
下面是我们的时间序列数据的一个例子,在之前的和在黄土过滤之后的*😗

Timeseries before and after LOESS filtering
时间序列分析
既然我们有了将输入视频预处理成可用数据的方法,我们需要分析产生的时间序列并对视频进行分类。
分析可以用很多方法来完成,但在这篇文章中,我们将重点关注一种叫做k-最近邻的算法。基本上,我们会将未知时间序列与大量已知时间序列进行比较,找出最接近的匹配(k=1)。比较是使用距离函数来完成的,我们将在后面讨论。

The green item is “unknown,” and we’ll assign it the label of the closest “known” item
一旦我们找到未知视频的最近邻居,我们预测未知视频与已知项目具有相同的类别标签,因为根据我们的距离函数它们是最近的。
距离函数是什么?
在二维空间中寻找两点之间的距离很容易:
dist = sqrt( (x2 — x1)^2 + (y2 — y1)^2 )
但是两波之间的距离呢?还是两个时间序列之间的距离?没那么容易…

更复杂的是,想象以下场景:
我们有一个“已知”标记的时间序列,来自一个人做俯卧撑的视频。他每 2 秒做 1 个俯卧撑,并在视频开始 1 秒做**。现在,我们想从其他人做俯卧撑的视频中标记一个“未知”的时间序列。他每 3 秒做 1 个俯卧撑,并在视频的 2 秒后开始做。**
即使这些时间序列来自相同的练习(俯卧撑),当我们试图比较“未知”时间序列和“已知”时间序列时,会出现两个问题:不同的频率和不同的相移。

Differing frequency (e.g. push-up rate)

Differing phase shift (e.g. push-up starting time)
比较时间序列
为了帮助解决不同频率和相移的问题,我们将采用一种叫做动态时间扭曲 (DTW)的算法。这是使用动态编程的非线性对齐策略。

https://www.cs.unm.edu/~mueen/DTW.pdf
与许多动态规划算法一样,在 DTW 中,我们填充一个矩阵,其中每个单元的值是相对于相邻单元的函数。
假设我们正在比较长度为M的时间序列s和长度为N的时间序列q。矩阵的每一行对应于s的一个时间点,每一列对应于q的一个时间点。这样矩阵就是MxN。第m ( 0 <= m < M)行和第n ( 0 <= n < N)列的单元成本如下:
cost[m, n] =
distance(s[m], q[n]) +
min(cost[m-1, n], cost[m, n-1], cost[m-1, n-1])
将s[m]想象为未知视频中的人在m时刻的姿势,将q[n]想象为已知视频中的人在n时刻的姿势。它们之间的距离distance(s[m], q[n])是各个身体部位坐标之间的 2D 距离的和。
我还对身体各部分之间的距离进行了加权求和,给与特定锻炼相关的身体部分分配了更多的权重。例如,在分析下蹲时脚是不相关的(因为它们不移动),所以它们的权重较小。但是对于跳来说,脚动的多,重量也大。这项技术稍微提高了算法的准确性。
一旦我们填满了 DTW 成本矩阵,我们计算的最后一个单元实际上是两个时间序列之间的最小“距离”。

Visualization of DTW (image has been modified from this presentation)
可以通过使用一种叫做“扭曲窗口”的东西来提高 DTW 的效率简而言之,这意味着我们不计算整个成本矩阵,而是计算矩阵的一个较小的对角线部分。如果您有兴趣了解更多信息,请查阅论文 快速时间序列分类使用数量缩减 。
结果
现在我们已经建立了一个系统,它将一个未知的视频作为输入,将其转换为时间序列,并使用 DTW 将其与来自一组已标记视频的时间序列进行比较。最匹配的已知时间序列的标签将用于对未知视频进行分类。
为了评估这个系统,我使用了大约 100 个视频和 3 个练习的数据集:负重深蹲、引体向上和俯卧撑。每个视频中的练习要么是正确的要么是不正确的(使用不适当的技术)。从人的正面、侧面和背面记录视频。对于侧面角度,我通过在 y 轴上翻转原始图像生成了第二个视频。 80% 的视频被用作“标记”数据,剩余的 20% 被保留用于测试算法的准确性。**
测试结果表明,该算法非常擅长区分练习之间的(90–100%准确度),但不太擅长对练习中的变化进行分类(正确与不正确的技术)。这些变化可能很微妙,很难跟踪,在这方面我能达到的最大精度是 ~65% 。**
丰富
k-最近邻算法的一个主要缺点是推理时间——即对未知视频进行分类的时间——随着标记数据集的大小成比例增长,因为我们将未知时间序列与每个标记项目进行比较。
在第二部分中,我们将探索一种使用 ML 模型对视频进行分类的端到端方法,从而使推理时间保持恒定**。**
资源
- 主 GitHub 库带有视频处理和 DTW
- 打开姿势
- iOS 上的姿态估计
- 局部加权散点图平滑(黄土)
- 动态时间扭曲 (DTW)
- DTW《翘曲的窗户》
基于机器学习的运动分类(下)
在这篇分为两部分的文章中,我们将深入探讨一个具体问题:对人们进行各种锻炼的视频进行分类。

在的上一篇文章中,我们重点关注了一种更为的算法方法,使用k-最近邻对未知视频进行分类。在这篇文章中,我们将关注一种专门的机器学习 (ML)方法。
我们将要讨论的所有内容的代码都可以在这个 GitHub 库的 中找到。算法方法(第一部分)用 Swift 编写,可作为 CocoaPod 获得。ML 方法(第二部分)是用 Python/TensorFlow 编写的,可以作为 GitHub 资源库的一部分找到。
背景
视频分类与图像分类的根本区别在于我们必须考虑时间维度。无论我们使用什么样的 ML 模型,它都需要学习具有时间成分的特征。为此开发了各种架构,现在我们将讨论其中一些。
递归神经网络

Unrolled RNN with many-to-one architecture (source)
rnn 非常适合输入数据序列,比如文本,或者在我们的例子中,是视频帧。RNN 的每一步都是特定时间点输入的函数,也是前一步的“隐藏状态”。以这种方式,RNN 能够学习时间特征。权重和偏差通常在步骤之间共享。
rnn 的缺点是它们经常遭受消失/爆炸梯度问题。另外,反向传播在计算上是昂贵的,因为我们必须通过网络中的所有步骤进行传播。
长短期记忆网络

https://colah.github.io/posts/2015-08-Understanding-LSTMs/
LSTMs 是普通 rnn 的一个更复杂的变体,旨在捕获长期依赖关系。LSTM 的一个“单元”包含 4 个可训练门:
- 遗忘门:一个 sigmoid 函数,确定从先前单元的状态中“遗忘”什么
- 输入门:一个 sigmoid 函数,决定我们将哪些输入值写入单元格
- 双曲正切门:双曲正切函数,将输入门的结果映射为-1 和 1 之间的值
- 输出门:一个 sigmoid 函数,过滤前面门的输出
一般来说,LSTM 架构有助于防止消失梯度,因为它的附加相互作用。
三维卷积神经网络(CNN)
神经网络的 2D 卷积层使用一组“过滤器”(内核),这些过滤器滑过输入数据并将其映射到输出空间。下面,我们可以看到一个过滤器的动画示例:

https://mlnotebook.github.io/img/CNN/convSobel.gif
将 2D 卷积层扩展到时间维度相对简单,我们有一个 3D 输入,其中第三维是时间,而不是 2D 滤波器,我们使用一个 3D 滤波器(想象一个小盒子),它在 3D 输入(一个大盒子)中滑动,执行矩阵乘法。
通过这个简单的 3D 膨胀,我们现在可以(希望)使用 CNN 来学习时间特征。然而,将内核扩展到 3D 意味着我们有更多的参数,因此模型变得更加难以训练。
膨胀的 3D ConvNet (I3D)
让我们回到文章的目标:对人们进行锻炼的视频进行分类。我选择了最后一个架构的变体,3D CNN,基于论文“ Quo Vadis,动作识别?新模型和动力学数据集。
在本文中,作者介绍了一种称为“膨胀 3D conv nets”(I3D)的新架构,该架构将过滤器和池层扩展到 3D 中。I3D 模型基于 Inception v1 和批量规格化,因此非常深入。
迁移学习
我们训练 ML 模型变得善于检测数据中的特定特征,例如边缘、直线、曲线等。如果两个领域相似,则模型用于检测一个领域中的特征的权重和偏差对于检测另一个领域中的特征通常很有效。这叫做迁移学习。

General guidelines for transfer learning
I3D 的创造者依靠迁移学习,使用 Inception v1 模型的权重和偏差,该模型在 ImageNet 上预先训练。当将 2D 模型膨胀到 3D 时,他们只是简单地将每个 2D 层的权重和偏差“叠加”起来,形成第三维度。以这种方式初始化权重和偏差(与从头开始训练相比)提高了测试精度。
最终的 I3D 架构是在 Kinetics 数据集上训练出来的,该数据集是 YouTube 上 400 多个人类动作和每个动作 400 多个视频样本的大规模汇编。鉴于动力学数据集和手头任务(对人们做运动的视频进行分类)之间的相似性,我相信使用公开可用的 I3D 模型进行迁移学习有很大的机会。
数据预处理
先说数据预处理。I3D 模型使用双流架构,其中视频被预处理成两个流: RGB 和光流。我用来创建这些流的代码在这里可用并且基于 I3D GitHub repo 的实现细节。

RBG and optical flow visualizations of a long jump
我使用 Python 的cv2库中的函数calcOpticalFlowFarneback()生成了光流数据。注意,I3D 模型不像在 RNN 或 LSTM 中那样具有显式递归关系,然而光流数据是隐式递归的,因此我们获得了类似的优点。
在测试时,通过添加具有相等权重的逻辑并使用结果来形成类预测,来组合这两个流。
进一步的细节
我剥离了 I3D 模型的最后两层(逻辑层和预测层)并用类似的层替换它们,这样新的逻辑层就有了我的用例的正确数量的output_channels(下面列出了 6 个类)。
bw-squat_correct
bw-squat_not-low
pull-up_chin-below-bar
pull-up_correct
push-up_correct
push-up_upper-body-first
每个流的逻辑值、 RGB 和光流被组合并用于形成类似于原始实现中的预测。我使用了一个由 128 个视频组成的数据集(不幸的是这个数据集很小),这些视频是从不同的摄像机角度录制的,我只对新图层和进行了反向传播,依靠现有图层的权重和偏差将视频映射到相关的特征中。
我用的是批量1,正则化强度0.25 (L 范数),学习率5e-4的tf.train.AdamOptimizer。训练-测试分割为 80% — 20%,在训练数据集中,另外 20%被保留用于验证和超参数调整。TensorBoard 的计算图如下所示:

Modified I3D computational graph from TensorBoard
结果
训练通常需要大约 30 个历元,直到损失达到稳定,在最好的情况下,最后 100 次迭代的平均损失是0.03058。测试精度达到69.23%。
这个项目的结果受到小数据集大小的限制,但随着更多的视频,我相信一个微调版本的 I3D 模型可以实现更高的测试精度。
将端到端的 ML 模型集成到移动客户端提出了一个不同的挑战。例如,在 iOS 领域,模型必须采用 CoreML 可接受的格式。存在诸如 tfcoreml 的工具,用于将 TensorFlow 模型转换为 coreml 模型,但是支持转换的 op 数量有限。
在撰写本文时,tfcoreml 不支持 T2 或任何三维操作,这意味着还不能将 I3D 模型集成到 iOS 应用程序中。
系外行星 I:方法和发现
用数据科学了解系外行星
探索宇宙

Source: L. Calçada, ESO.
7 年前,17 岁的我在高中最后一年选择探索系外行星领域,名为“成熟之旅”。我联系了第一颗系外行星的共同发现者 Didier Queloz ,他曾在日内瓦大学任教,讨论我论文的分析部分,并征求他对可居住性前景以及系外行星重要性的看法。他很大方地抽出时间和我见面接受采访,后来还带我参观了日内瓦天文台和他的实验室。
我的项目工作获得了满分,随后我也被邀请到CERN在一个著名的瑞法学生科学分享活动上公开展示我的见解。
我的演讲很受欢迎,尤其是在理论和研究驱动的领域,如天体物理学,带来了与人类生存相关的焦点。事实上,在别处发现生命的前景,可以帮助我们更好地了解作为人类的自己,受到了观众的赞赏,并植根于我自己的经历中。


Left: CERN ‘Science-Sharing’ event flyer. Right: Group picture of presenters and public at the event in question.
2019 年 10 月,同样是迪迪埃·奎洛兹教授,与米歇尔·马约尔、詹姆斯·皮布尔斯共同被授予 诺贝尔物理学奖 。


Left: observatory tour by Didier Queloz, 2012. (I was too naive to think of taking a selfie). Right: Nobel Prize Winners, 2019.
这篇文章是我当时用他的投入写的报告的一部分,作为对系外行星的介绍。鉴于最近的新闻,我现在可以查看它,因为它非常相关,并在数据科学的背景下,即如何收集、分析和解释数据的背景下,提供了对系外行星发现的见解。我们还可以将这些发现与许多物理定律联系起来,如开普勒第三定律,并观察宇宙中的所有行星如何遵循完全相同的模式。
我已经将内容分成多个部分,如下所示:
外行星学简史
安金德很久以来就一直在推测除了我们自己以外的行星系统。几个世纪前,哲学家们就假设我们的太阳系不是独一无二的;事实上在看似无限的恒星海洋中存在着无数更多的恒星。围绕另一颗恒星运行的行星上存在生命的可能性不仅仅是一个似是而非的理论,而且它还具有优势。事实上,在可观测的宇宙中有几千亿个星系,每个星系包含几千亿颗恒星;认为地球可能是整个宇宙中唯一有能力支持生命的星球,这看起来几乎是荒谬的。
然而,缺乏科学证据来支持这一富有远见的观点意味着在过去的两千年里,这种思想跨越了所有的极端。一方面,有些人——比如伊壁鸠鲁——相信宇宙中除了我们之外还存在其他世界,并且相信它们有能力容纳生命。另一方面,许多人——比如亚里士多德——坚信地球在宇宙中是独一无二的,其他类似的世界不可能存在。基督教和其他信仰也声称上帝之手创造了地球和所有生物。
因此,寻找太阳系外的行星成了一个紧张的科学研究课题。由于缺乏证据,我们不知道它们有多普遍,它们与太阳系的行星有多相似,或者与其他恒星周围的行星系统相比,我们自己的太阳系的构成有多典型。可居住性也是一个重要的问题。如果有其他行星,它们是否也有必要的表面条件来支持某种形式的生命?问题很多,但答案很少。主要的障碍在于无法直接观察这些未知的天体。
哈勃太空望远镜也许宠坏了我们所有人——我们现在开始期望经常看到遥远星系和星云的图像。因此,拍摄一颗太阳系外行星的图像应该不会比拍摄一个遥远星系的图像更困难。然而,问题出现了,因为主星完全超过了它的小而暗淡的行星。在大多数情况下,行星离它们各自的恒星太近,无法直接成像,特别是从地球表面,考虑到我们大气层的干扰效应。
直到 1995 年,日内瓦大学的米歇尔·马约尔和迪迪埃·奎洛兹才首次报告了对太阳系外行星的明确探测。尽管几年前射电天文学家亚历山大·沃尔兹森和戴尔·弗莱尔已经进行了一些其他的探测,但它们不是在一颗普通恒星周围发现的,而是在一颗脉冲星周围发现的——一颗作为超新星爆炸的大质量恒星的超致密残余物。马约尔和奎洛兹于 1995 年 10 月在日内瓦宣布了太阳系外行星 Pegasi b 51 T1,这被认为是第一次明确的太阳系外行星探测。多年来,还有其他几个可以被视为里程碑的发现,如探测到多个行星系统和首次探测到行星大气层。
自 1995 年以来,这一领域取得了惊人的进展。新的发现和重大发展继续以每月一次的速度公布,这在任何科学领域都是前所未有的进步。截至 2019 年 11 月,通过使用几种不同的探测方法,共发现了 4128 颗系外行星。寻找系外行星已经迅速成为一个受人尊敬的科学研究领域和一个能够独立存在的天文学领域。这一领域的进步不仅伴随着数千篇科学论文的发表,还见证了光学天文仪器的改进,这导致了开普勒望远镜的发射和新的探测技术。
检测的方法
在过去的二十年里,几种不同的技术被用来探测系外行星。如前所述,母星发出的光总是会冲掉其行星反射的少量光。因此,科学家必须想出替代和间接的方法来探测系外行星,因为直接观察它们几乎是不可能的。本章概述了已经取得成功的最成熟的方法以及它们背后的逻辑和科学,同时讨论了每种方法的优缺点。
径向速度法
也被称为 RV 方法,是迄今为止最成功的技术。1995 年,米歇尔·马约尔和迪迪埃·奎洛兹用这种方法发现了第一颗公认的系外行星。此后它被用于定位 863 颗太阳系外行星(截至 2019 年 11 月)。
如图 1 所示,多年来,科学家们已经能够探测到各种各样的行星。系外行星的质量是相对于木星质量来表示的,即木星质量。然而,行星的质量测量不确定性高达 sin(i) ,其中 i 是行星围绕其恒星运行的倾角。因此,质量被绘制为 Msin(i) ,而不仅仅是 M 。多年来,这项技术在灵敏度和准确性方面都有所提高,科学家们现在已经发现了许多木星质量低于 0.1 的行星,这一壮举直到 2004 年左右才得以实现。*
这种技术对于探测围绕其母星运行的大质量行星最为有效。值得注意的是,这种方法只提供了行星质量的下限,这是它最大的缺点。一颗行星的真实质量只有当这项技术和凌日法结合起来使用时才能确定,这将在后面描述。
RV 方法基于自然重力系统和轨道,由牛顿万有引力定律定义。
如前所述,行星的引力使其母星在自己的小轨道上摇摆。虽然恒星和行星相互施加的力是相同的,但它们的加速度之间的差异是巨大的,因为恒星和行星的质量不同,至少等于 10^3。由于行星的加速度是基于恒星的质量,而恒星的质量非常高,所以行星的移动量很大。相反,恒星的加速度很小,因为它是基于行星的质量,而行星的质量相对较小。这种微弱的加速度导致恒星在其小轨道上“摇摆”。
这种“摆动”会对恒星的可观测属性造成微小的扰动,比如它在天空中相对于地球的角位置。一个更重要的变化是变化在速度上,恒星以这种速度靠近或远离地球,在那里它被观察到。为了更好地理解 RV 方法,我们首先需要对多普勒效应和普通光谱学有一个基本的了解,因为这两者被结合起来用于探测系外行星。
多普勒效应
让我们以消防车的警笛为例来理解这个概念。让我们想象一辆不动的消防车开着警报器。这个固定声源产生恒定频率λ的声波,声波以恒定的声速c= 340m/s向外传播。由于声波从声源向所有方向传播,如果它们可见,它们将呈现为圆形,所有观察者将听到相同的频率,在这种情况下,这是声源的实际频率。换句话说,观测频率等于发射频率 0。

A stationary and moving fire-truck emitting sound waves at a constant frequency.
但是,如果消防车开始向一个方向移动,由于波长的差异,声波会变得不均匀。在两种情况下,警报器发出的声波的频率相同。然而,由于震源现在正在移动,每个新波的中心在消防车的方向上略有位移(如右图所示)。结果,声波开始在消防车的前部聚集,并在后面扩散。这种现象被称为多普勒效应。由于声波的波长不同,观察到的频率也会受到影响。因此,声源前方的观察者会听到较高频率的汽笛声,而其后方的观察者会听到较低频率的汽笛声。观察到的频率变化是导致警报声音调变化的原因。观察到的频率可以使用以下公式计算:

其中:
- c 是介质中波的速度,在我们的例子中是空气,大约等于 340 [m/s]。
- v_observer 是观测者的速度,用【m/s】表示。如果观察者正朝着光源移动,它将是正的,如果远离光源,它将是负的。
- v_source 是震源的速度,也用[m/s]表示。如果观察者正朝着光源移动,它将是正的,如果远离光源,它将是负的。类似地,如果源远离接收器,它将是正的,如果向接收器移动,它将是负的。
- \ _ 0 是声源发出的频率,单位为[Hz]。
为了观察到这种效应,相对运动必须沿着观察者和波源的连线,也就是朝向或远离观察者。沿着这条直线方向的运动称为径向运动,该运动的速度称为 径向速度 。如果观察者相对于波源既不靠近也不远离,就没有影响。多普勒效应是一种影响任何形式波动的波长和频率的现象,例如声波、水波、光波以及所有电磁波。
现在让我们把我们的类比与天文学联系起来。让我们想象一颗恒星发出光波,而不是消防车发出声波。我们,地球上的人类,是观察者,恒星是光波的来源。如果这颗恒星没有系外行星,它就不会有明显的径向速度,因为它是静止的。然而,如前所述,当一颗行星绕着一颗恒星运行时,后者也在其非常小的轨道上运动,以响应前者的引力。或者更确切地说,它们都绕着它们共同的质量中心运行,而这个质量中心恰好在恒星本身的内*,这导致了恒星的轻微摆动。因此,如果我们可以观察到这种“摆动”,那么我们可以得出结论,一颗真正的系外行星可能正在围绕它旋转。这种“摆动”实际上是恒星径向速度的变化。天文学家可以通过将光谱学应用于多普勒效应来探测这些变化。*
光谱学
现在让我们想象我们上面提到的恒星有一颗外行星围绕它运行,导致它的径向速度变化,这被我们这些观察者“看到”。就像消防车一样,当恒星看起来朝着我们移动时,它发出的波长会更小,也就是说,被压缩和聚集得更多,因此观察到的频率更高。相反,当它移动远离我们时,波长将会更大,也就是说,更加拉伸和分散,观察到的频率更低。然而,光波的行为与声波略有不同:光波改变的不是其可听的音调*,而是其光谱颜色。换句话说,光波的频率、波长和光谱颜色都是相互关联的。*

The Electromagnetic Spectrum, with the visible light section highlighted.
对应于可见光谱的波长如下:

Variation in wavelength and frequency by colour

Wavelengths according to colour
当光波的波长很短且频率很高时,光波会发生蓝移,这意味着它们具有蓝色光谱。当光波波长较长且频率较低时,它们会发生红移,这意味着它们获得了红色光谱。

Change of Spectrum Colour due to the direction of the Radial Motion of the Star
由于多普勒效应,我们知道当光波红移时,由于波长增加(因此频率降低),它们会以径向运动的方式远离。同样,当光波蓝移时,我们知道它们正在向我们移动,因为波长变短,频率变高。
因此,当我们观察我们选择的恒星发出的光波的光谱颜色时,我们看到它们不断地从红色变为蓝色。这种周期性的光谱移动之所以发生,是因为恒星在它的小轨道上不断运动,从而周期性地缩短和增加它与我们观察者的距离。

“Wobble” of star causing a Periodic Spectral Colour Change. The motion of the star has been exaggerated to illustrate the point.
总之,通过使用高精度光谱仪器,我们可以有效地探测到主星光谱颜色的周期性光谱变化,这意味着其可见光波长的周期性变化,进而表明一种明显的径向运动,这种运动只能由系外行星的引力引起,因为它迫使恒星围绕两个天体的质量中心运动,从而证实了它的存在。
运输方法
另一种已经在探测系外行星方面取得成果的方法是凌日法,这种方法因基于太空的任务而广为人知,如 CoRoT 和开普勒。这项技术的基本原理很简单:如果一颗行星从它所绕转的恒星前面经过,地球上接收到的光的强度会有小幅下降。

The Observable Drop of Light during a Transit
通过观察由行星凌日引起的恒星光亮度的变化,人们能够探测到系外行星。虽然光度的下降取决于恒星和行星的相对大小,但典型的量估计在 0.01%和 1.7%之间。凌日的持续时间也取决于行星离恒星的距离和恒星的大小。
这种技术有一个明显的缺陷:只有当行星的轨道平面与我们的视线对齐时才适用,这样我们就可以目睹行星挡住了恒星的一些光线。

Varying Orbital Inclinations determine the Observation of a Planetary Transit from Earth
一颗行星以日地距离(1 AU)围绕一颗太阳大小的恒星运行,将有 0.47%的概率产生可观测的凌日。因此,人们会认为这种方法可能是不切实际和无益的。然而,通过在包含数千颗恒星的大面积天空中扫描恒星,原则上可以发现太阳系外的行星,其速度可能超过径向速度法。正是出于这种希望,许多任务已经启动,特别是开普勒任务。2012 年 12 月,用这种方法已经发现了 291 颗行星,开普勒发现的 2000 多颗候选系外行星正在等待确认。今天,使用凌日方法,已确认的行星数量为 2966 颗,候选行星为 2428 颗。
凌日方法的另一个缺点是需要很长时间来确认候选行星的真实性。事实上,由于高错误探测率,单次凌日的观测不足以被完全接受为一颗行星。因此,候选行星可能需要很多年才能被确认为太阳系外行星,因为人们必须等待它绕轨道运行几次。这种方法也更倾向于检测轨道较小的大型行星,这些行星被称为热木星,因为它们过境更频繁,因此更容易被检测到。
另一方面,凌日法的优点之一是光线的下降提供了对行星大小的估计。但到目前为止,最大的优势是我们可以确定系外行星的大气成分,这对确定其可居住性的潜力至关重要。当行星凌日恒星时,星光在到达地球之前会穿过行星的大气层,让我们有机会探测其中是否存在氧等元素。
当穿过恒星的行星有大气层时,恒星发出的光会下降更多,因为除了已经被行星主体阻挡的光波之外,行星中的元素还会吸收一些光波。行星的大气层本质上就像是恒星光波的过滤器,根据大气元素的不同,阻挡一些,释放一些。
大气中存在的元素阻挡了相应的波长,导致光谱中出现黑线,被称为吸收线。

An example of Absorption Lines
每种元素都与一组特定的波长相关联,由于其化学性质,这些波长会被阻挡。因此,当我们在一颗有行星经过的恒星的光谱中发现吸收线时,我们就知道这颗行星有大气层。通过分析吸收线,我们可以通过观察与波长相对应的元素来确定大气的化学成分。如果恒星光谱的吸收线与一种元素的吸收光谱完全一致,那么它就表明它的存在。

Absorption Lines in the Spectrum of a star matching those of Hydrogen, confirming its presence
例如,通过在恒星的光谱中找到与氧相匹配的吸收线,我们可以确定围绕它运行的系外行星是否可能适合居住。
延伸阅读:
- 第二部分 : 数据解释
- 第三部分 : 可居住性和结论
- 原报道:https://eklavyafcb.github.io/exoplanets.html
参考资料:
- 长度卡尔萨达,埃索。https://luiscalcada.com/
- 美国宇航局的想象宇宙,多普勒频移。
- 美国宇航局,可见光波。 (2013)。
- 拉斯坎布雷斯天文台全球望远镜网络,凌日法。 (2013)。
维基百科,https://www.wikipedia.com【2013 年访问】:
- 红移
- 径向速度
- 灯
系外行星 II:数据解释
用数据科学了解系外行星
了解宇宙

Discovered Exoplanets Visualised
这是系外行星系列的第二部分。
现在我们已经看到并理解了历史背景、研究的科学价值以及这些发现的意义,我们将看看太空任务发现并编辑的实际数据,这样我们就可以将它们与实际物理联系起来。通过绘制数据图表,我们可以直观地看到与几个世纪前由著名物理学家如牛顿和开普勒建立的理论或物理定律的相关性。
为了充分理解系外行星领域背后的科学,人们必须查看经常公开的实际研究数据。几个团队已经将所有信息汇编成大型数据库,供公众通过互联网查看,如美国宇航局系外行星档案馆或太阳系外行星百科全书。这些网站中最有用的工具是绘图仪,它允许人们以几种不同的方式直观地探索、理解和分析数据。
在接下来的几页中,我们将分析一组使用来自www.exoplanets.org的数据生成的有趣图表,这是一个由加州行星调查联盟维护的网站,显示了已确认的系外行星(即没有候选行星)的列表,以及它们的特征。
轨道周期的概率分布;

Graph 2: The Number of Exoplanets found for each value of Orbital Period
上图显示了探测到的系外行星的数量与其轨道周期的关系,即它们围绕母星完成一个完整轨道所需的天数。
快速浏览一下,该图中有几个突出的特征。首先,有两个大的峰值,一个在 3 到 4 个轨道周期日之间,窄而长,另一个短而宽,峰值在大约 400 个轨道周期日。另一个值得注意的特征是两个峰值之间的深度下降。
现在,如果我们把我们太阳系行星的轨道周期,八个行星中的五个将符合第二个峰值。然而,我们似乎在第一个峰值的参数范围内找到了同样多的系外行星。此外,似乎还没有发现任何行星的轨道周期超过 5000 天,这仅仅比木星的轨道周期多一点点。即使许多被探测到的行星似乎没有木星的轨道周期,但它们中的大量确实具有木星的质量。
该图显示了两个彩色部分。较小的黄色部分代表类木星,即在质量和轨道周期方面与我们的木星相似的系外行星。较大的红色部分代表热木星,它们在质量上也类似于木星,但它们的轨道周期要小得多,这意味着它们的轨道非常靠近它们的母星,因此接收到大量的光和热,正如它们的名字所示,使它们变得很热。如(第二张)图表所示,这些热木星的轨道比水星的轨道小,水星是我们太阳系中离其主星最近的行星。图中显示了 125 颗热木星,但只有 11 颗木星类似物。这是寻找系外行星的最大惊喜。
研究人员已经发现了许多这种有趣的模式,与预期不符。让热木星的发现对我们来说不同寻常的是,在我们开始发现许多行星之前,普遍的共识是,较小的行星会靠近恒星运行,而大质量的行星可能会留在行星系统的外围。然而,许多新发现的行星绕其恒星运行的距离相对较小,不到太阳到太阳系最内层行星水星距离的六分之一。没有人预料到类似木星的行星会存在于离它们的恒星如此之近的地方。有了这些新数据,我们认为是太阳系的基础知识现在不再是最新的了。我们现在也必须重新评估我们在宇宙中的位置:我们太阳系的类型有多普遍?是独一无二的吗?我们是稀有类型还是典型类型?我们真正了解和理解了多少?
目前,系外行星是通过使用其母星作为工具来探测的。换句话说,我们正在发现新的太阳系外行星系统,并且已经有足够的数据得出以下统计数据:迄今为止发现的至少 50%的系外行星在行星定位方面与我们的太阳系不同。这意味着我们的太阳系充其量只占宇宙中所有行星系统的一半*。本质上,当我们观察恒星时,我们看到每两颗恒星中只有一颗有类地行星。这表明像我们这样的系统不是宇宙中的大多数,而是 T4。即使是已经发现的类地行星也比地球大几倍,因此被称为“超级地球”。*
提出来解释热木星之谜的理论之一是迁移理论,该理论认为行星随着时间向内迁移,因此我们看到它们处于形成的后期阶段。事实上,这些巨大的行星一定是从 100 倍远的地方开始的,随着时间的推移,它们向内迁移,达到了现在与恒星的距离。
这当然引出了一个问题,即假设他们迁移了,他们是如何迁移的,更重要的是,为什么要迁移?它们最初的轨道不稳定吗?是什么产生了能量给这些巨大的物体以动力?也许真相永远不会为我们所知,但是行星迁移理论确实为我们提供了一些热木星出现的解释。
相对于半长轴的最小质量:
下图很好地说明了热木星:

Graph 3
该图的 X 轴代表半长轴,即恒星到其轨道行星的距离。Y 轴代表系外行星的质量,这是相对于木星的质量来测量的,以使尺度与热木星的问题更相关。
最后,添加一个色标,如图表右侧所示,来表示每个行星的轨道偏心率。轨道偏心率是行星轨道偏离正圆的程度。零度时,行星的轨道是完美的圆形,用蓝色表示。随着偏心率的增加,轨道变得更加抛物线化,如上图 3 中的红色部分所示。

Variations in Orbital Eccentricities
在图 3 中,人们可以清楚地看到两个主要的集中的行星群。如前所述,大多数的质量与木星相同。左上角的星系团由温度更高的行星组成,因为它们离恒星更近。这些是典型的热木星,大多数是用凌日法探测到的。我们还可以看到,几乎所有这些行星都用蓝色表示,这意味着它们的轨道偏心率接近于零,意味着圆形轨道。
然而,另一个行星群在一个更冷的区域,离它的恒星更远。半长轴约为 1 AU。与之前的星团不同,这个星团具有混合的轨道偏心率:它们的范围从 0 到 0.8,这意味着它们倾向于具有更偏心的轨道。这些似乎是典型的气态巨行星,也称为木星类似物,主要是通过径向速度方法检测到的,如下图 4 所示。

Planets detected by Transit Method (Red) and Radial Velocity (Green)
这两个团块之间的偏心率差异是惊人的。左边行星丛中的大多数行星都有完美的圆形轨道,而右边行星丛中的行星则更加多样,更倾向于偏心。正是两个团块之间的半长轴的差异造成了这种差异。左边的行星群有一个较小的半长轴,这意味着它们更靠近它们的恒星,因此被其巨大的引力锁定*。一个潮汐锁定的天体绕着它自己的轴旋转的时间和它绕着它的伙伴旋转的时间一样长。这导致一边不断面对伴侣的身体。说明这种现象的一个主要例子是月球,它被潮汐锁定在地球上,因为它总是向我们展示同一个半球。然而,右手边的行星没有被潮汐锁定,因为它们离恒星太远,因此受到的引力较弱。在 1 AU 处,它们是地球的镜像:它们有必要的角动量来持续环绕它们的母星,但没有被它锁定。*
图表 3 也提出了一个有趣的问题:来自两个不同星系团的两颗行星会存在于同一个行星系统中吗?换句话说,一个行星系统可能同时包含一颗热木星和一颗木星类似物吗?到目前为止,只发现了一个*,被认为是稀有配置。*
然而,要正确回答这个问题,我们需要增进我们对热木星形成的了解。回想一下,这些类型的行星大多是用凌日法发现的。当一颗行星从它的恒星前面经过时,我们可以有效地测量它的轨道倾角。当我们查看统计数据时,我们看到大多数热木星的轨道不垂直于恒星的旋转轴,这很奇怪,因为它不像我们太阳系中的任何行星。对于行星以一个倾斜的平面绕其恒星运行,人们认为发生了某种暴力事件或机制。因此,热木星可能是由一些未知的戏剧性和动态现象形成的,这些现象“打破”了这些行星的整个系统。这也意味著,迁移理论无法解释热木星形成的所有原因,因为热木星本身不可能是暴力机制的催化剂。因此,只有一颗行星变成热木星,而同一星系中的另一颗行星保持不变的概率非常低,而且会被认为是奇怪的。大多数被确认的热木星是孤立的,这意味着它们是绕其恒星运行的单一行星。他们确实过着孤独的生活。
但也许这个图表中最引人注目的特征是间隙的存在。事实上,我们似乎没有在右下角和更低的范围内找到任何行星,在 0.01 木星质量之间,这是岩石类地行星应该在的地方,这令人惊讶。如果我们输入我们自己行星的数据,金星和地球会发现自己处于图表的底部,孤独而孤立。我们所有的行星都不会被放在左边的丛中。
此外,两个团块之间还有一个很大的间隙。真实的宇宙是这样的吗?类地行星真的如此罕见,还是我们所看到的实际上是一种选择效应,被我们的探测方法所偏向?**
事实上,我们没有探测到右下角行星的原因不是因为选择效应,而是因为我们处于当前探测能力的阈值。让我们考虑图上的一个小质量,比如 0.03 木星质量。对于这个给定的质量,我们可以看到我们能够在短距离内相对容易地探测到系外行星。然而,当我们增加距离,即半长轴,行星变得更加难以探测。事实上,对于我们选择的质量,在 0.4 天文单位之后,我们似乎根本找不到任何行星。这是因为径向速度方法探测行星所需的振幅信号减弱了。这种减弱是因为所需的信号直接取决于系外行星的轨道周期。
对于任何系外行星,RV 方法的以下方程与其振幅和轨道周期(以及半长轴,因为两者直接相关)相关:
 **
**
- *m_psin(i) 是系外行星的固定最小质量,用木星质量单位表示[ M_Jupiters ]。
- i 是行星轨道相对于天球切线平面的倾角。
- k 是信号的振幅,单位为米/秒[ m/s ]
- p 是系外行星的轨道周期,以年年计量。

The relation between the orbital period p and the amplitude k, in a graphical form
由于系外行星的质量和倾角是固定的,我们可以简化原始方程,看到振幅和轨道周期的乘积等于一个常数。这意味着两个变量之间成反比关系。我们可以看到,随着轨道周期 p 增加,振幅 k 减小。相反,随着轨道周期的减少,振幅增加。径向速度方法不能探测具有高半长轴值(即大轨道周期)的行星,因为信号的振幅变得非常低。因此,参照图 3,我们无法探测到该区域中发出低振幅信号的任何行星。这就是为什么在左上角探测到了很多行星,而在右下角却没有。
为了能够检测到图表右下角区域的行星,我们必须提高测量仪器的灵敏度,以便更准确地检测到信号的幅度。自从检测到 51 Pegasi b 以来,我们已经取得了重大进展,并将继续这样做。图 5 描述了该过程,该图还显示了检测线。检测线对应于信号的幅度 k 。我们看到,我们实际上是从左上角到右下角沿对角线移动。左上方的对角线检测线具有较大的振幅,而下方的检测线具有较小的振幅,最小的振幅约为每秒 1 米。

The lines in this graph have been manually added to better illustrate the point. They are not accurate.
与轨道周期相关的半长轴:

Graph 6
图表 6 清楚地显示了半长轴和系外行星轨道周期之间的惊人关系。与之前的图表不同,我们可以看到行星绕其轨道运行一周所用的时间与距其恒星的距离之间存在紧密的相关性。我们简单地改变了 Y 轴的参数,我们得到了一个完全不同的视图。这一次,如果我们放入我们自己的行星,它们将会完全适合。
这张图表也许是一个特殊的图表,因为它证明了物理学基本定律之一的普遍应用:开普勒行星运动第三定律,早在发现系外行星之前就已经存在。这对寻找系外行星很重要,因为它可以有效地用于计算系外行星与其恒星之间的距离,并确定它是否位于可居住带内。
根据该定律,半长轴 a^3 的立方与轨道周期 p^2 的平方之比是常数,即:

然而,在基于从系外行星获得的数值的图表 6 中,我们注意到这条线代表相同的比率。如果在上图的对数刻度中,我们选择 x 轴上的两点(a1;a2 )和 y 轴上的对应点(P1;p2 ,则:

如果 a1 = 0.1、 a2 = 1,那么 p1 = 10、 p2 = 320。因此:

这证明了对于线上的任何给定点,即对于任何行星的值,这两个参数的比率是恒定的。这和开普勒第三定律是一致的。开普勒通过观察我们太阳系的行星得出的定律适用于现在正在被发现的太阳系外行星,大约三四百年后。我们可以看到,图 5 和图 6 中直线的斜率是相同的。这证明了重力在行星系统中的作用是一样的。开普勒定律表明,跨越不同系统和不同环境的所有行星都以完全相同的方式服从重力。
我们还可以观察到,除了左下角的数据看起来更分散之外,大多数数据的线都是直的。这个区域中的行星与图 3 中左侧星团中的行星相同。我们可以看到在 1 天的轨道周期之上的行星比之之下要多。这就引出了一个问题,为什么散射只是单侧的。一个可能的解释是,我们目前的科学技术还不够先进,不足以正确测量不到一天的行星轨道。通过检查左下栏中 11 颗行星的数据,我们看到其中 7 颗行星是使用凌日方法探测到的,另外 4 颗是通过径向速度方法探测到的。**

Planets detected by Transit Method (Red) and Radial Velocity (Green)
另一个问题是为什么散射只出现在半长轴小的区域。为什么右上角没有散点反而?原因是行星离它们的恒星很近。在小距离上,行星受到宿主恒星更强的引力,使它们的轨道更圆。如图 8 所示,蓝色表示轨道偏心率低,意味着轨道更圆。

它们实际上变得像月亮对地球一样:它们被潮汐锁定并以圆周运动的方式旋转。随着偏心率的增加,轨道变得更加椭圆。在轨道偏心率低的情况下,更难正确地确定半长轴。因此,蓝色点比其他点有更大的误差。因此,我们可以假设这些行星要么由于它们的低偏心率和与恒星的极度接近而不完全符合开普勒定律,要么它们确实符合该定律,但我们在测量轨道周期时犯了微小的错误。
总之,我们可以看到,在图表上绘制数据不仅有助于直观地表示所有已发现的系外行星,而且有助于对它们进行分类和区分。通过解释图表,我们可以质疑不同现象的原因,如热木星,并试图通过阐述行星迁移等理论来解释它们。另一方面,我们也可以注意到所有的系外行星在遵守相同的引力和运动定律方面是如何相似的,这使我们得出结论,某些物理规则适用于宇宙中的每一种元素。
此外,通过解释这些图表,我们还认识到了目前天文仪器的局限性,并试图对其进行改进,以探测更广泛的系外行星。通过尝试进一步完善技术,我们可以专注于实现在这些图表的未探索区域中找到可居住的类地行星的目标。
延伸阅读:
- 第一部分 : 方法和发现
- 第三部分 : 可居住性和结论
- 原报道:https://eklavyafcb.github.io/exoplanets.html
参考资料:这项研究利用了系外行星轨道数据库
和 www.exoplanets.org的系外行星数据探测器
系外行星 III:可居住性和结论
用数据科学了解系外行星
生活在宇宙中

Source: NASA, ESA, and G. Bacon (STScI)
这是系外行星系列的第三部分。
存在两种可能性:要么我们在宇宙中是孤独的,要么我们不是。两者都同样可怕。
-亚瑟·C·克拉克
可居住
虽然寻找其他行星的部分动机是为了了解它们的形成和增进对我们自己的太阳系的了解,但最终目标是找到地外生命。现在,我们已经看到并分析了由太空任务收集的实际数据,并将它们与实际的物理定律联系起来,我们到了这出戏的最后一幕:可居住性。到目前为止,我们只谈到了对已确认的系外行星的探测和定位,但我们对它们孕育生命的能力了解不多,即它们的可居住性。
对于一颗孕育任何形式生命的行星来说,它必须满足某些特定的参数,才能适合居住。生命只存在于某些条件下,这些条件对于创造生命生长和进化所必需的可持续环境是必不可少的。目前没有理由相信满足这些条件的行星不会大量存在。虽然到目前为止我们还不能找到这样的行星,但这很可能只是时间问题。
人们应该记住,对一颗行星是否适合支持生命的评估在很大程度上是基于地球的特征,因为它是宇宙中我们确定可居住的唯一一颗行星。因此,我们只能寻找我们所知的生命。很可能生命存在于不同的条件下,但我们只能推测它的存在。这最后一章将涵盖生命(正如我们所知)在系外行星上生存所需的主要因素,如距离、质量和大气。
德雷克方程
在我们开始定义生命的不同条件之前,让我们先来看看天文学中的两位著名人物,以及他们对其他地方存在生命的可能性的看法。
卡尔·萨根是美国著名的天文学家,以他对外星生命可能性的研究和思考而闻名。像许多天文学家一样,他认为我们的银河系充满了生命,理论上应该存在大量的地外文明。然而,由于缺乏这种文明的证据,他相信这样一种理论,即一旦它们在技术上足够先进,它们就会自毁。
第一颗太阳系外行星的共同发现者迪迪埃·奎洛兹(Didier Queloz)同意萨根的观点,即宇宙中的其他地方也存在生命,但他强调,生命的出现需要一系列连续的事件,因此“运气”是一个关键因素。因此,这个星系可能不太拥挤。
萨根和奎洛兹都坚信地外生命的存在,这仅仅是因为可能性很小。另一位著名的天体物理学家弗兰克·德雷克提出了一个数学方程,理论上可以估计银河系中可探测到的地外文明的数量。它指出:

Drake’s Equation
其中:
- N 是我们银河系中可以进行通信的文明的数量(通过检测它们的电磁辐射)。
- R* 是我们银河系每年恒星形成的平均速率,用[ 颗/年表示。
- f_p 是那些有行星系统的恒星的分数。
- n_e 是每一个太阳系中可能维持生命的行星数量。
- f_l 是适合生命实际出现的行星的比例。
- f_i 是有智慧生命出现的行星的一部分。
- f_c 是开发出一种技术的文明的一部分,这种技术可以向太空释放它们存在的可探测的迹象。
- L 是此类文明向太空释放可探测信号的时间长度,以年表示。
德雷克的方程不同于之前任何一个与系外行星探测相关的方程,因为它包含了大量的未知变量。由于目前的这些不确定性,没有明确的“正确”或“错误”答案,而只是一个估计。随着我们对我们在宇宙中的位置了解得越来越多,一些未知慢慢变得越来越清晰,最终结果也越来越准确。
科学家们承认德雷克方程中存在非常大的不确定性,并往往倾向于做出非常粗略的估计来取得进展。以我们目前的知识水平,我们知道方程的前三项更接近于 10 而不是 1,并且所有的因子都比 1 小。然而,仍然是最大的未知数。通过做一些假设,我们可以简化这个方程,得到一个可能更有用的德雷克方程:

这将意味着我们可能接触的文明的数量大约等于它们的寿命,这也是德雷克和他的同事在 1961 年得出的结论。这也意味着,除非很大,否则会很小。如果 SETI 成功探测到外星文明发出的信号,这将意味着平均来说信号一定很大,因为我们不可能通过观察银河系中的一小部分恒星来发现信号。由于探测到的外星信号传播的速度是有限的,当它们到达我们这里时,它会告诉我们它们的过去,因为它们离我们有许多光年远。但是因为外星文明必须足够大,我们才能探测到这样的信号,这可以告诉我们我们自己的未来是否漫长。另一个出现的问题是,即使我们真的发现了生命迹象,我们如何与他们交流,用什么与他们交流?
生活的秘诀
当我们从太空看地球时,我们看到几乎 75%的地球被水覆盖,水是所有生物的重要自然资源。植物用水从土壤中的矿物质中获取一些养分。这些矿物质必须溶于水才能被植物吸收。广阔的海洋和其他水体为各种海洋生物提供了庇护所。地球的大气层是由水分子构成的云调节的。当然,为了生存,所有动物都需要定期喝水。地球上的生命是围绕水建立的。
因此,正如我们所知,一颗行星要孕育生命,它必须含有水。与普遍的看法不同,水不是宇宙中的稀有商品。相反,它在宇宙中到处都大量存在。在我们银河系和其他星系的星际云中已经发现了水。人们只要看看水的化学性质就能理解它的平凡。一个水分子由两个氢原子和一个氧原子共价键合而成。

The Atomic Structure of a Water Molecule
氢是整个宇宙中最丰富的元素,在“大爆炸”期间产生。氧是第三丰富的元素,由恒星的核聚变产生。这两者一起形成水。除了天王星和海王星之外,太阳系中的所有行星在其大气层中都有少量的水蒸气,范围从 0.0004%(木星)到 3.4%(水星)。土星的卫星之一,恩克拉多斯,有 91%的水蒸气组成,被认为是太阳系中最有可能居住的地方之一。
然而,对于生命的发展来说,水不是以蒸汽或冰的形式存在,而是以液体的形式存在,这种液体非常罕见,因为它取决于表面温度,而表面温度又取决于大气压力,而大气压力是由行星的表面重力决定的。所有这些要求只能同时在可居住区找到。此外,液体只能存在于表面,这意味着气态行星无法维持水。

Different states of water
本质上,任何行星上孕育生命所需的主要因素似乎都取决于它的质量、大气层以及与母星的距离。这些将在下面详细阐述。
1)距离
一颗行星必须有一个坚固的岩石表面,并且与它的恒星保持完美的距离,以保持其表面的液态水。在太远的地方,行星将会太冷而无法维持其表面的液态水,因为表面温度将会降至冰点以下,导致海洋变成冰。太近的话,地球的温度会超过水的沸点,海洋会变成蒸汽。因此,水能够以液体形式存在的完美区域是这两个极端之间的地带,称为可居住区。

The Habitable Zone (green) of our solar system.
这个地区也被称为“金发姑娘区”,源于著名的故事“T2”、“金发姑娘和三只熊”,在这里,金发姑娘选择不冷不热的汤。同样,对于遵循这一原则的行星来说,它既不应该离它的恒星太近,也不应该太远,而是应该在适当的距离。
每个行星系统的宜居带将从离其恒星不同的距离开始,因为它取决于中心恒星的质量。恒星的质量越大,散发的热量就越多,将可居住区域的内部边缘推得越远,如下图所示。

The Habitable Region (blue) depending on the Star’s Mass. Source: Astrobiology Magazine
因此,当我们寻找系外行星时,我们会在可居住区内寻找,因为这是找到类地行星的最佳选择。目前还不知道在可居住带发现的几颗行星是类地行星还是气态行星。被确认为类地行星的不是位于适居带。此外,仅仅在可居住区找到行星并不能保证存在生命,因为还有其他几个关键因素发挥着重要作用。
2)质量
对于位于可居住区的行星来说,行星的引力必须足够强,才能容纳大气层,大气层可以作为缓冲,有助于保持稳定的表面温度。行星的表面重力可以用下面的公式计算:

其中:
- g 是引力常数= 6.67 * 10^-11 [ N ]
- m 是行星的质量[ kg
- r 是行星的半径[ 米
正如我们所见,重力取决于行星的质量和半径。这很关键。例如,如果地球更小,比方说大约有火星那么大,重力就会弱得多,因为质量和半径都会更小,因此它无法阻止水分子飞入太空,导致大气层非常稀薄。这将降低大气缓冲的有效性,允许极端温度的存在,从而防止水的积累。这就是为什么液态水不能在火星上存在,尽管它位于可居住带的边缘。小质量几乎不允许水在极地冰盖以固态存在。这就是为什么为了评估一颗系外行星的可居住性,了解它的质量是至关重要的。
3)大气
这也许是判断一个星球维持生命能力的最重要的因素。没有大气的压力,液态水无法生存。让我们以月球为例:它没有大气层,甚至没有像火星那样稀薄的大气层。因此,如果我们在月球上洒一些水,它要么会蒸发成蒸汽,要么会冻结固体,形成冰。因此,为了孕育生命,一颗行星必须有大气层,并且足够厚,足以让行星保持恒定的温度,并对水施加压力,使其保持液态。
然而,大气层的厚度并不是可居住性之谜的唯一重要组成部分。它的实际成分也必须正确。让我们以金星为例。金星在物理特征上是最接近地球的行星:同样位于宜居带,表面重力 8.9 [ m/s^2 ],是地球重力的 90%,质量是地球的 82%,体积是地球的 86%,密度几乎相同。一个观察我们太阳系的外星天文学家会认为金星是生命存在的好机会。

Size comparison of Venus and Earth, drawn to scale. Source: NASA, Wikipedia Commons.
然而,正如我们所知,金星不适合生命居住,因为它太热了。它的大气层是太阳系中密度最大的类地行星,其表面压力是地球的 92 倍。它的大气层几乎完全由二氧化碳和其他温室气体组成,并且完全没有任何分子氧。因此,金星的平均表面温度约为 464 摄氏度,是太阳系中最高的,远远高于水的沸点。与地球不同,它也缺乏磁场,这使得太阳风无法将游离氢(水的基本成分)吹到行星际空间。因此金星的表面非常干燥,并被沙漠覆盖。尽管金星在许多方面与地球相似,但它肯定不适合居住。
因此,寻找与地球质量、距离和大气相同的系外行星仅仅是个开始。与金星一样,这些因素不一定足以让生命发展。我们必须仔细观察构成大气的**,并确定那些至关重要的元素,如氢、氧,还有氮和碳,是否以正确的的百分比存在。这些为我们所知的生命的基础和发展奠定了 基础 。实际的生命成分清单要大得多,而且可以无止境地详细列出。正确的行星轨道和自转,正确的地球化学和地质机制都可以将行星的状态从宜居变为不宜居。因素是无限的。**
然而,生命出现所需的一系列连续现象依赖于一个无法控制或分类的因素:偶然性。根据我们目前的理解,是偶然使一个小天体与另一个小天体碰撞形成星子,这些星子后来发展成为类地行星。也许正是由于一颗彗星与地球相撞的偶然机会,水被引进了这个星球。事实上,“运气”可能是创造生命本身的另一个必要成分。
而我们不知道的生活呢?如果它需要一种液体而不是水才能出现并繁荣呢?也许是我们是不同的生物,生活在一个不寻常和极端的环境中。或者也许地球只是众多可居住世界中的一种。我们可以无休止地推测,但唯一能确定的方法是走出去探索。****
结论
在这篇论文中,我提出了一个关于系外行星的广泛文献综述的精华,并解释了将它们与基本物理定律联系起来的探测方法。我使用了公开可用的系外行星研究数据,并在一位天文学专家的指导下,使用相关参数的组合生成了一系列图表。我研究了这些图表,并将它们与基本的物理定律联系起来,比如开普勒的行星运动第三定律和牛顿的万有引力定律。以图表为基础,我采访了著名的天体物理学家 Didier Queloz 教授,以进一步了解当前的发现和对热点木星反复出现的发现等问题的科学思考。最后,我确定并解释了影响生命出现的一些因素,包括偶然性等非理性因素。基于这一回顾和分析,我能够解释为什么我们寻找系外行星,以及这一探索实际上有多么有意义。**
自从 1995 年发现第一颗系外行星以来,我们已经走过了漫长的道路。这个领域已经发展成为一个巨大的科学领域,超越了纯粹的物理学,并慢慢深入到天体生物学和化学领域。我们已经看到,系外行星的发现率一直在稳步上升,在我们的银河系中,行星似乎在它们的恒星周围很常见。一些已经在可居住区被探测到,但是不幸的是它们看起来不像是地球上的。事实上,发现的行星系统并不像我们的太阳系,因为它们中的许多都含有热木星和超级地球,这两者在我们的系统中都不存在。这可能是由于我们有限的探测方法的选择效应,或者可能是宇宙的方式。
通过对系外行星的探测,我们已经了解了地球本身的性质以及它自近 40 亿年以来所维持的不同生命形式。我们对我们在浩瀚宇宙中的独特位置有了批判性的认识,并且有实际的科学证据证明,我们似乎处于一张图中的一个孤立的角落,不同于我们所有其他的宇宙邻居。通过寻找和,我们不仅扩展了我们的物理和概念边界,而且理解了在地球上这里所发生的独特性。在这个过程中,一个人更好地将的价值观根植于我们自己的生活中。我们确实是幸运的活着,并且像许多信仰自古以来宣称的那样是特别的。自早期哲学家开始思考以来,没有任何其他科学领域给了我们如此多的实质内容来回答这些问题。这就是我们继续寻找系外行星的原因。
尽管我们还没有发现其他生命,但我们正在积极地向自己提问,并通过开展新的科学项目来寻找答案,这一事实表明我们正在不断地努力扩展我们的知识。亚瑟·C·克拉克曾经说过,我们在宇宙中要么孤独,要么不孤独,这两种可能性都同样可怕。我想说两者都同样令人敬畏。因为即使我们是单独的,我们思考、思考、梦想和问这些问题的事实实际上可能是宇宙中最重要和最有用的元素之一。这表明我们对知识和理解的追求永远不会变得乏味。事实上,我们知道的越多,我们的宇宙似乎就越不可思议,更多的问题似乎就要浮出水面。
正是这些没有答案的问题驱使我们的好奇心去推动当前科学思想和努力的前沿。因此,通过提出更多的问题,也许是自然本身推动人类不断努力寻找答案。如果外星生物真的存在于这个看似空虚的海洋中的某个地方,我衷心希望我们分享对知识的渴望,因为这是将我们聚集在一起的唯一力量。与此同时,我们只能尝试短暂地捕捉大自然的美,因为它在宇宙的尺度上顺其自然。
延伸阅读:
- 第一部分 : 方法和发现
- 第二部分 : 数据解释
- 原报道:https://eklavyafcb.github.io/exoplanets.html
参考资料:
利用功效分析计算实验样本量

如果你用实验来评估一个产品的特性,我希望你这样做,那么得到有统计学意义的结果所需的最小样本量的问题经常被提出来。在本文中,我们解释了如何应用数理统计和功效分析来计算 AB 测试样本量。
在启动实验之前,计算 ROI 和估计获得统计显著性所需的时间是至关重要的。AB 测试不可能永远持续下去。然而,如果我们没有收集足够的数据,我们的实验得到的统计能力很小,这不允许我们确定获胜者并做出正确的决定。
什么是统计能力

先说术语。统计功效是在替代假设 H1 为真的情况下,一个或另一个统计标准能够正确拒绝零假设 H0 的概率。统计测试的能力越高,你犯第二类错误的可能性就越小。
第二类错误与以下因素密切相关
- 样本之间的差异幅度—影响大小
- 观察次数
- 数据的传播
功效分析允许您确定具有特定置信水平的样本量,该置信水平是识别效应大小所必需的。此外,这种分析可以估计在给定样本量下检测差异的概率。
对于“足够”大的样本,即使很小的差异也具有统计学意义,反之亦然,对于小样本,即使很大的差异也难以识别。
最重要的是观察次数:样本量越大,统计功效越高。对于“足够”大的样本,即使很小的差异也具有统计学意义,反之亦然,对于小样本,即使很大的差异也难以识别。通过了解这些模式,我们可以预先确定获得有统计学意义的结果所需的最小样本量。在实践中,通常,等于或大于 80%的检验功效被认为是可接受的(相当于 20%的β风险)。这一水平是α风险和β风险水平之间所谓的“一比四权衡”关系的结果:如果我们接受显著性水平α = 0.05,那么β = 0.05 × 4 = 0.20,标准的功效为 P = 1–0.20 = 0.80。
现在我们来看看效果尺寸。计算所需样本有两种方法
- 使用置信水平、效应大小和功效水平进行计算
- 应用顺序分析,允许在实验过程中计算所需的样本量
让我们研究第一种情况,对两个独立的样本使用 t 检验

让我们假设我们测试了一个旨在提高“商品到愿望清单”转化率的假设。Delta,涵盖了六个月回报率> = 5%的实验成本。这种> = 5%的收益导致了额外的利润,这涵盖了实验中投入的所有资源。除此之外,你要有 90%的把握你会发现差异,如果它们存在的话,还有 95%的把握——你不接受随机波动的差异。
d — delta,siglevel —置信水平,power —功率水平
pwr.t.test(d=.05, sig.level=.05, power=.9, alternative="two.sided") ## Two-sample t test power calculation
##
## n = 8406.896
## d = 0.05
## sig.level = 0.05
## power = 0.9
## alternative = two.sided
##
## NOTE: n is number in *each* group
让我们看看另一个案例,利益相关者希望在几周内得到结果。在这种情况下,我们有一个大约 4000 名访问者的样本量,delta >=5%。我们想知道在上述情况下获得统计显著结果的概率。
添加 n,移除电源
pwr.t.test(d=.05, n=2000, sig.level=.05, alternative="two.sided") ## Two-sample t test power calculation
##
## n = 2000
## d = 0.05
## sig.level = 0.05
## power = 0.3524674
## alternative = two.sided
##
## NOTE: n is number in *each* group
确定差异的概率(如果有的话)是 35%,这不算太低,而错过期望效果的概率是 65%,这太高了。
让我们看看下面的图表。它清楚地表明,效应越大,获得显著结果所需的样本越少。

在计划实验时,计算所需的数据量至关重要,因为任何实验都需要资金和时间成本。因此,为了估计实验的潜在 ROI,提前计划所有未知变量是很重要的。
最初发表于【awsmd.com】。
数据科学时代的实验数学
两个关于我们如何使用猜测和统计工作来做真正的数学的故事
在我们高中的第一堂数学课后,我们的新老师给了我们一页纸,上面有 7 个涉及多项式的问题。虽然我不记得任何具体的问题,但我记得接下来几天课堂上的恐慌程度。全班都很震惊,因为以前我们最多只遇到过二次方程……现在他要我们解决涉及这些神秘生物的问题,这些生物可以达到他们想要的 n,谁知道他们是否有解析解?(伽罗瓦知道。他们大多不会)
他教我们的下一件事是生成函数和递归。他向我们展示了斐波那契数列的一般公式,以及欧拉如何得出他著名的巴塞尔问题的求和。

然后,我取得了我的第一个数学学位。令我惊讶的是,我再也没有遇到过这些东西。回到高中,我确信这就是数学的全部,但现在作为一个更成熟、更有教养的学者,我知道这些是古老的数学和儿童游戏。
想象一下,当我攻读硕士学位,处理与博弈论相关的问题时,我的第二个惊喜是,多项式和递归这些精确的主题以最自然的方式出现了…!
抛开我感人的个人故事,我希望在这篇文章中给出一些实验在数学中的重要地位,以及如何“像数据科学家一样做数学”。当然,将数学视为实验被认为是完全的异端——这是归纳谬误,对吗?但实际上,猜测的艺术在数学中有很多位置,如果你能在以后用一个完整的论证来包装你的猜测,那么你就能得到严格有效的结果。
让我们从一些必备软件开始。有很多符号数学软件——CoQ、sage、maple 等等。在这个世界里,你不能像在软件开发创业世界里那样吹毛求疵——对于软件的任何特定用途,如果它不是完全标准的,很可能只有一种实现——所以无论是在 Maple、Matlab 还是在某人为微波芯片汇编开发的专有框架中,你都必须学会使用它。无论如何,为了阅读这篇文章,我建议你安装 python,Mathematica 和 Matlab。如果您不知道,您仍然可以跟踪简单的代码解释和结果。
10 行 Mathematica 中的一篇欧拉文章
在奥地利林茨的 RISC 研究所,他们为 Mathematica 开发了令人惊叹的 RISCErgosum 包。这个包基本可以证明你能想到的任何身份。让我们看看它如何证明 250 年前的欧拉论文——正如这篇精彩文章摘要中所描述的。
在这篇文章中,欧拉用求中心三项式系数满足的递推公式的方法,导出了中心三项式系数的一般公式。他用了整整一章来讲述他的一次失败的尝试,其中一个基于斐波那契数列的简单递归似乎成立,但通过计算该数列的足够多的项,欧拉最终设法发现这个递归一般不成立,并找到了正确的表达式。我们可以用下面简单的 10 行代码继续他在 Mathematica 方面的努力:
- 首先我们定义欧拉试图确定的级数,作为 myf 的通称。
- 我们还将其拆分为奇数和偶数索引系列(myfodd,myfeven),这样就可以避免使用 Floor[]。这将使 Mathematica 更容易证明我们提取的递归实际上一般成立。
- 我们将它的前 20 个值导出为 fres。
- 然后我们定义欧拉怀疑能够表达原始序列的序列,并将其前 20 个值导出为 GRE。
- Guess 成功地分别为 frec 和 grec 两个系列找到了一个递归。但是它们是不同的。
- 现在,我们将原始级数的符号项输入到递归中,FullSimplify 象征性地为我们验证了它确实在一般情况下成立,产生了应用于项的递归关系,它们的总和等于零。
- 瞧啊。我们完了。
下面是代码和结果:

我只欺骗了一点点——full simplify 并不总是值得信任的,实际上可能会出错。但是考虑到这种循环,无论是通过计算机代数还是手工,都有可能验证它确实普遍成立。“困难的部分”是猜测。
通过简单模拟得到随机过程练习解
让我们来看另一个在更新过程中解决问题的实验方法的例子。想象一下下面这个由无聊少年管理的宠物动物园。
孩子们轮流去宠物动物园。每当一群孩子进来,id 间隔 T1,T2,T3,…分布为 Geo§,因为青少年有时做他的工作,但有时也懈怠了越来越长的时间。但是因为他知道他要偷懒,他输入了许多孩子 Nk,所以 Nk-s 是独立的,但是给定 Tk+1 = n 的 Nk 的条件分布是 Uni{1,…,n+2}。所以即使他在偷懒,还是会有更多的孩子进去,所以应该没问题。问题是,从长远来看,孩子们在宠物动物园的平均时间是多少?
解析地解决它并不太难——你定义一个匹配的奖励更新过程,通过奖励更新定理和一些总结,你最终会得出公式

p 是几何分布参数。但这需要一些随机过程分析和基本概率方面的知识。即使你对自己的分析能力很有把握,也可以和模拟进行比较。因此,即使不了解太多,您也可以编写以下代码:
- 你做了一百万次实验
- 当你模仿问题的描述时,你会有下一组孩子在某个随机的几何时间间隔内到来,相应地,他们的数量是一致随机的。你把孩子们在网站上花的时间加起来,最后除以访问网站的孩子总数。然后,您将它视为对我们结果的模拟估计。
以下是实现此过程的简单 python 代码:
我们对不同的 p 值运行这个代码,然后我们有一个解的 p 中的函数的估计。但是这怎么能给我们一个公式呢?嗯,即使不做精确的计算,你也可以很确定我们要找的公式是一个有理函数。这是因为它将是涉及均匀分布和几何分布的期望之间的某个比率,这可能是 p 中的低阶多项式。然后我们可以使用任何工具来拟合我们获得的模拟数据的有理函数,我使用了 Matlab 的 cftool
在解释器中键入:
X = 1:100
X = X/100
Y = python_simulation_results
cftool(X,Y)

你可以看到它非常合身。在现实生活中,我没有使用 cftool,而是因为我在分析计算中不断出现算术错误,所以我使用模拟通过猜测一些值来确定确切的表达式。如果我在最初的几次猜测中遇到困难,我会求助于某种有理函数拟合程序。
多少次实验就够了?
现在,也许关于进行实验最重要的问题是什么时候停止。试几次就够了?
对于一些有度数或维数概念的代数实体,我们知道答案。n 次多项式由 n+1 个点决定。因此,对多项式的 n+1 个点进行采样就足以唯一地确定其完整形式。类似的事情适用于 n 阶递归——如果我们知道递归适用于我们的级数,并且我们有 n 个点,其中我们的级数表达式与递归的解一致,那么假设递归表达式没有太坏的事情发生,我们可以归纳并获得真正的一致。
至于更新过程和一般的马尔可夫链,模拟可以产生非常精确的数字,有时比分析计算要少得多,并且保证如下:
我将从那里引用一个很酷的结果:
当你想得到一副均匀分布的牌时,最安全的方法是先随机拿一张牌,然后再从剩下的牌中随机拿一张,以此类推。但是这需要你在第一步从 52 张牌中做出选择,第二步从 51 张中做出选择…你最终需要从可能的 52 张牌中选择一副牌!。
但是,现实生活中也会发生这样的事情,你拿着一副不是随机的牌,你相信经过几次洗牌后,它会和随机的一样好。很明显,如果你只移动一两张牌,不会有什么不同。而且很明显,如果你一直这样做,那么这副牌将会被随机化。什么时候停止比较合适?阅读概述,你会看到,大约 NlogN ~ 400 单卡更换应该做到这一点。这里他们想出了 277 这个数字。当然,如果你做步枪走步,它会花更少的时间,因为在每一次“走步”中,你会有更多的单步发生。
如果这篇文章让你对计算机代数、实验数学或随机模拟产生了一点兴趣,我强烈推荐这些作为进一步的阅读材料:
A=B ,一本关于使用递归关系证明恒等式的艺术和科学的巨著
《A=B》一书的作者多伦·泽尔伯格的实验数学宣言
一本关于随机模拟的伟大而实用的书

数据科学实验
当 AB 测试没有切断它
今天,我要谈谈数据科学中的实验,为什么它如此重要,以及当 AB 测试不合适时,我们可能考虑使用的一些不同的技术。实验旨在确定变量之间的因果关系,这在许多领域都是一个非常重要的概念,对于今天的数据科学家来说尤其重要。假设我们是在产品团队中工作的数据科学家。很有可能,我们的很大一部分职责将是确定新特性是否会对我们关心的指标产生积极影响。也就是说,如果我们引入一个新的特性,使用户更容易向他们的朋友推荐我们的应用,这是否会提高用户增长?这些是产品团队感兴趣的问题类型,实验可以帮助提供答案。然而,因果关系很少是容易识别的,在许多情况下,我们需要稍微深入思考我们的实验设计,这样我们就不会做出不正确的推断。在这种情况下,我们可以使用经常使用的技术取自计量经济学和我将讨论其中一些下面。希望到最后,您将更好地了解这些技术何时应用以及如何有效地使用它们。
AB 测试
大多数读过这篇文章的人可能听说过 AB 测试,因为这是一种极其常见的工业实验方法,用来了解我们对产品所做的更改所产生的影响。这可能很简单,只需更改网页布局或按钮颜色,然后衡量这一更改对点击率等关键指标的影响。在这里,我不会过多地介绍细节,因为我想重点介绍一些替代技术,但是对于那些有兴趣进一步了解 AB 测试的人来说,下面关于 Udacity 的课程提供了一个非常好的概述。一般来说,我们可以采用两种不同的方法来进行 AB 测试。我们可以使用频繁方法和贝叶斯方法,这两种方法各有利弊。
频率论者
我会说 frequentist AB 测试是迄今为止最常见的 AB 测试类型,直接遵循 frequentist 统计学的原则。这里的目标是通过观察我们在 A 组和 B 组中的度量之间的差异是否在某种显著性水平上具有统计学显著性来测量我们治疗的因果效应,通常选择 5%或 1%。更具体地说,我们需要定义一个零假设和替代假设,并确定我们是否能够拒绝零假设。根据我们选择的指标类型,我们可能会使用不同的统计测试,但在实践中通常会使用卡方检验和 t 检验。然而,频率主义方法有一些限制,我认为与贝叶斯方法相比,它更难解释和说明,但可能因为贝叶斯设置中的基础数学更复杂,所以它不常用。frequentist 方法的一个关键点是,我们计算的参数或度量是一个常数。因此,没有与之相关的概率分布。
贝叶斯定理的
贝叶斯方法的关键区别在于,我们的指标是一个随机变量,因此有一个概率分布。这是非常有用的,因为我们现在可以结合我们的估计的不确定性,并作出概率陈述,这对于人们来说往往比频率主义者的解释更直观。使用贝叶斯方法的另一个优点是,与 AB 测试相比,我们可以更快地找到解决方案,因为我们不一定需要为每个变量分配相同数量的数据。这意味着贝叶斯方法可以使用更少的资源更快地收敛到一个解决方案。选择哪种方法显然取决于个人情况,这在很大程度上取决于数据科学家。无论你选择哪种方法,它们都是识别因果关系的强有力的方法。
当 AB 测试不奏效时
然而,在许多情况下,抗体检测并不适合用来鉴定因果关系。例如,为了使 AB 测试有效,我们必须将随机选择到 A 组和 B 组。这并不总是可能的,因为一些干预措施可能因特定原因针对个人,使他们与其他使用者有根本的不同。换句话说,进入每个组的选择是非随机的。稍后,我将讨论并提供我最近遇到的一个具体例子的代码。
AB 测试可能无效的另一个原因是当我们有*混淆时。在这种情况下,查看变量之间的相关性可能会产生误导。我们想知道 X 是否导致 Y,但也可能是其他变量 Z 驱动了两者。这使得不可能理清 X 对 Y 的影响,从而很难推断出任何因果关系。这也经常被称为 省略变量偏差 ,会导致我们高估或者低估 X 对 Y **的真实影响。*除此之外,从商业角度来看,设计随机实验可能不可行,因为如果我们给一些用户提供新功能,而不给其他用户提供这些功能,可能会花费太多资金,或者被视为不公平。在这种情况下,我们必须依靠准随机实验。
好了,我们已经讨论了我们可能无法应用 AB 测试的一些原因,但是我们能做些什么来代替呢?这就是 计量经济学 的用武之地。与机器学习相比,计量经济学更关注因果关系,因此,经济学家/社会科学家开发了一系列统计技术,旨在了解一个变量对另一个变量的因果影响。下面我将展示一些技术,数据科学家可以也应该从计量经济学中借鉴这些技术,以避免从实验中得出错误的推论,而这些实验会受到上述问题的困扰。
工具变量
假设我们是一家拥有类似 medium 的应用程序的公司,用户可以订阅主题以获取与这些主题相关的内容更新。 现在想象你的产品负责人带着一个假设来找你:订阅更多的话题会让用户更投入,因为他们会获得更多相关和有趣的新内容来阅读 。嗯,这听起来像是一个合理的假设,我们可能认为这很可能是真的,但我们如何用实验来测量呢?
您可能考虑做的第一件事是通过将用户随机分成两组来进行传统的 AB 测试。然而,这将是非常困难的,因为用户已经有不同数量的主题订阅,我们不能真正随机地给用户分配主题订阅。主要的问题是,由于一些不为人知的原因,订阅更多主题的用户可能会比其他用户更投入。这本质上是 内生性 ,因为有一些看不见的因素在推动这些用户的参与度。
幸运的是,经济学有答案。我们可以使用被称为 的工具变量 来帮助我们解决这个内生性问题。如果我们可以找到一个变量(工具)与我们的内生变量(订阅数量)相关,但与我们的因变量(参与度)无关,我们可以用它来清除看不见的因素的影响,并获得订阅数量对参与度的影响的无偏因果估计。但是我们能用什么作为工具呢?这通常是经济学中最大的问题,因为在许多情况下很难找到工具。然而,在我们的案例中,如果我们在一家进行大量 AB 测试的公司,我们可以利用这一点。要获得有效的工具,我们需要两个假设:
- 强第一阶段
- 排除限制
假设过去我们运行了一个 AB 测试,将用户随机分成两组,并在主页上向 B 组显示订阅主题的提示。让我们假设这个 AB 测试也显示了积极的影响,接受治疗的用户最终比控制组订阅了更多的主题。我们可以用这个实验作为工具,来帮助我们识别参与度问题中的因果关系。为什么会这样?嗯,第 个假设 已经得到满足,因为 AB 测试对订阅数量产生了统计上显著的正面影响。 第二个假设 也得到满足,因为分配是随机的,因此被处理与敬业度无关,仅通过增加订阅数量来影响敬业度。**
现在,为了实际实现这一点,我们可以使用所谓的两阶段最小二乘法。好消息是这很容易做到,只需要估计两个回归。顾名思义,有两个阶段,在第一阶段,我们将回归处理变量(虚拟变量,识别用户是否在 AB 测试的处理或控制组中)的订阅数量。这将为我们提供治疗组和对照组的预测订阅数。在第二阶段,我们回归第一阶段的预测值。这将为我们提供订阅数量对参与度的因果影响的无偏估计。
概要:
- 对订阅数进行回归处理:得到预测值
- 回归约定的预测值。
您可以使用 statsmodels 库在 Python 中实现这一点,它看起来类似于下面的代码。
***import** **statsmodels.formula.api** **as** **smf****reg1 = smf.ols(formula = "number_of_subscriptions ~ treated", data = data).fit()
pred = reg1.predict()****reg2 = smf.ols(forumla = "engagement ~ pred", data = data)***
回归不连续设计(RDD)
RDD 是另一种可以从经济学中获得的技术,当我们有一个连续的自然分界点时,它特别适合。那些刚好低于临界值的人得不到治疗,而那些刚好高于临界值的人得到了治疗。这个想法是,这两组人非常相似,所以他们之间唯一的系统性差异是他们是否接受过治疗。因为这些组被认为非常相似,这些分配基本上近似于随机选择。特别是,两组间 Y 变量的任何差异都归因于治疗。
使用 RDD 的经典例子有望使这个观点更加清晰,那就是杰出的学术成就获得社会认可(奖状)会有什么影响?与那些没有得到这种社会认可的人相比,它会带来更好的结果吗?我们可以将 RDD 应用到这个例子中的原因是,奖状只颁发给那些在测试中得分超过某个阈值的个人。使用这种方法,我们现在可以在阈值比较两组之间的平均结果,看看是否有统计学上的显著影响。
这可能有助于想象 RDD。下图显示了低于和高于阈值的平均结果。实际上,我们所做的只是测量截止点旁边两条蓝线之间的差异。在经济学中使用 RDD 的例子还有很多,这里的一些例子有望让你了解不同的用例。对于那些想了解这些话题更多背景知识的人,你可以查看以下免费的课程。

Source: Example: RDD cutoff: Threshold at 50 on the x-axis
差异中的差异(差异中的差异)
我将在 Diff 中更详细地介绍 Diff,因为我最近在一个项目中使用了这种技术。这个问题是许多数据科学家在日常工作中可能会遇到的,并且与防止流失有关。对于公司来说,尝试识别可能流失的客户,然后设计干预措施来防止它是非常常见的。现在,识别客户流失是机器学习的一个问题,我不会在这里深入探讨。我们关心的是,我们能否找到一种方法来衡量我们的流失干预措施的有效性。能够凭经验衡量我们决策的有效性是非常重要的,因为我们希望量化我们特征的效果(通常以货币形式),这是为企业做出明智决策的重要部分。其中一种干预措施是给那些有被大量购买风险的人发一封电子邮件,提醒他们注意自己的账户,实际上是试图让他们更多地参与我们的产品。这是我们将在这里研究的问题的基础。
好的,我们想知道这封电子邮件活动是否有效,我们该怎么做呢?嗯,我们需要做的第一件事是想出一些我们想要衡量的指标,我们预计会受到活动的影响。从逻辑上考虑,如果我们阻止用户搅动,那么他们将继续使用我们的产品,并为公司创造收入。这似乎有道理,所以让我们使用平均收入作为我们的衡量标准。您选择的指标在很大程度上取决于问题,如果我们不希望我们的指标以相对直接的方式影响收入,那么它可能不是本实验的最佳选择。总而言之,我们的假设是 将这封邮件发送给有客户流失风险的人会阻止他们流失,从而提高这些客户 的平均收入。如果这个假设是真的,我们可以预计治疗组的平均收入将高于对照组(那些没有收到电子邮件的人)的平均收入。
现在你可能认为这听起来像一个常规的老 AB 测试,但是这种方法有一个主要问题。A 组和 B 组根本不同,因为进入这两个组的选择不是随机的。根据我们的机器学习模型的结果,B 组中的用户更有可能流失,而 A 组中的用户不太可能流失。在这种情况下,我们不会比较苹果,这将导致我们的结果有偏差。专业术语称之为选择偏差。
然而,我们可以用 Diff 中的 Diff 来处理这个问题。本质上,它比较了治疗发生前后对照组和治疗组中度量的差异。这样做允许我们控制组间预先存在的差异,减少选择偏差。在方程形式中,它看起来与下面类似:其中 a 是对照组,b 是治疗组,t 表示干预前的时间段,t+1 是干预后的时间段。

Figure 1: diff in diff estimator
这种方法的好处是它很容易估计,我们可以使用回归框架来完成。这还提供了额外的好处,即能够控制其他特征,如用户的年龄和位置,从而减少遗漏可变偏差的可能性。使用这种方法时需要注意的一点是,要使该技术有效,必须满足某些假设。其中最重要的可能是平行趋势假设。简而言之,它表明如果没有干预,那么治疗组和对照组之间的差异将随着时间的推移而保持不变。这在实践中很难测试,通常最好的方法是直观地观察一段时间内的趋势。
接下来,我将通过一个使用 python 的 Diff 中的 Diff 的快速示例来演示如何在实践中评估这种类型的模型。注意:不幸的是,因为我使用的数据是敏感的,我不能深入数据集,但是 这里的 是一个类似的数据集,包含客户人口统计信息和交易信息。
差异案例研究中的差异
继续上面的解释,我们现在将在 Python 中实现 Diff 中的 Diff,向您展示在实践中估计它是多么简单。在下面的代码中,我假设我们有两个主要的数据源,一个是记录每个用户交易的交易表,另一个是包含客户信息(如年龄和位置等)的用户表。我们的目标是估计以下形式的方程:

Figure 2: Diff in Diff regression equation
- y 是我们的平均收入指标
- 如果用户属于治疗组,Treat = 1,否则为 0
- 如果是后处理,时间= 1,如果是预处理,时间= 0
- 𝛿 是上图 1 中的差分估计量(DD)
- x 是我们控制变量的矩阵
根据上面的等式,我们首先需要定义治疗和时间虚拟变量,这将有助于我们将用户分为对照组和治疗组,以及治疗前和治疗后。然后,我们可以通过将这两个特征相乘来定义 DD 相互作用项。最终结果是一个数据帧,包含我们的用户特征(X)、两个虚拟变量和我们最感兴趣的交互项。现在,我们要做的就是在我们的平均收入指标上回归这些变量,看看 𝛿 在我们选择的显著性水平(5%)上是否具有统计显著性。statsmodels 库使得回归的实现非常简单。为简洁起见,我省略了任何数据清理和特征工程,但这是该过程的重要部分,是您应该作为正常工作流程的一部分来做的事情。
***import** **statsmodels.formula.api** **as** **smf****reg1 = smf.ols(formula='revenue ~ treated + time_dummy + DD + X', data = data)
res = reg1.fit()***

Figure 3: Diff in Diff Results
我们可以从图 3 的结果中看到,我们的 DD 估计值在 5%的水平上是显著的和正的,表明我们的治疗产生了积极的影响。更具体地说,这个 p 值意味着,假设零假设(干预没有效果)为真,我们观察到如此大的影响的概率非常小。因此,我们可以拒绝零假设,并得出结论,我们的电子邮件活动已经成功地减少了客户流失,因此,我们为该群体带来了更高的平均收入,因为他们继续使用我们的产品。
好了,伙计们,这个帖子到此为止。希望这突出了在数据科学中进行实验的相关性,以及当我们面临内生性和样本选择偏差等问题时,计量经济学技术如何在确定因果关系方面特别有用。下面是一些有用的链接,可以帮助任何想更深入了解这些概念的人。
参考资料及有用资源:
- https://github . com/Nate matias/research _ in _ python/blob/master/Regression _ discontinuity/Regression % 20 discontinuity % 20 analysis . ipynb
- http://pub docs . world bank . org/en/555311525379751882/TT 6 regressiondiscontinuity ferre . pdf
受控实验的 3 个常见陷阱
实验和因果推断
不合规、外部有效性和伦理考虑

Photo by Michal Matlon on Unsplash
2021 年 2 月 21 日更新
在两篇文章中(为什么要进行更多的实验和双向因果关系),我提出了我们应该进行更多受控实验并做出明智的商业决策的想法。实验擅长于提高内部效度,区分因果关系和相关性,以及产生和检验假设。
有一个心理陷阱经常绊倒数据科学家:他们选择最熟悉的方法,而不是选择最能回答问题的方法。
“如果你只有一把锤子,所有的东西看起来都像钉子.”
伯纳德·巴鲁克
为了谨慎起见,我在今天的帖子中详细阐述了实验的陷阱。采用这种方法时,数据科学家应该首先考虑研究问题,然后检查方法的适用性和局限性。也就是检查你要回答什么,检查你有什么信息和约束。
何时不使用
如果这三种情况中的一种或多种发生了,你可能要对实验三思:
1。高度不合规
采用实验的全部意义在于它的高内部效度,这源于一个随机化过程(我的解释)。也就是说,研究参与者被随机分配到治疗组和对照组。
然而,高不符合率或退出率表明设计有问题,并损害了研究的可信度。
这里有一个假设的场景。数据科学和 UX 团队在谷歌合作,试图在搜索算法更新后跟踪用户的行为变化。一位名叫约翰的用户被选中接触新设计,但他在研究中途退出了。例如,用户在一段时间后清空他们的 cookies 后会流失。研究人员争先恐后地寻找与约翰的用户属性相似的替代品。然而,替换不是约翰,并且在实验中间的用户替换对统计假设提出了挑战(例如,缺失数据、依赖性)。
此外,实验组之间的交叉污染会产生有偏见的估计。约翰可能无意中向对照组暴露了治疗状况(例如,更新他的脸书状态并让他的朋友知道该研究)。
2。社会实验的外部效度很低
实验环境并不是真实的世界,一旦用户意识到自己被监视,他们就会改变自己的行为。这两个世界之间存在差距,研究人员应该缩小差距,并确定他们设计的范围和限制。
在社会科学中,有一种现象叫做社会合意性。也就是说,如果可能的话,人们以社会可接受的方式表达自己和行为,并避免对抗。每个人都想成为社区的一部分。
作为一名政治学博士生,这是我最喜欢的现实生活中的例子。在 2016 年的总统选举中,多波民调研究表明希拉里将以较大优势获胜。最终结果出来时,真是一个巨大的惊喜。许多受访者隐藏了他们真实的政治偏好,给出了符合社会需求的回答。
此外,一个地区的实验发现在其他地区并不成立。欧洲用户的认知和行为模式与美国用户不同。任何来自欧洲用户的实验结果在应用于美国的案例时都应该持保留态度。
换句话说,你的研究适用性范围是什么?你的研究有高/低的外部效度吗?当你试图推广到更广泛的案例时,请格外小心,因为实验案例是独特的。
3。道德考量
一些实验给研究参与者带来压力和伤害。例如,研究人员曾经用积极和消极的情绪操纵社交媒体订阅,试图看看人类的情绪如何在虚拟环境中传播。
在这种情况下,研究人员应该告知研究参与者任何潜在的风险和危害。在用户明确同意参与之前,研究不应继续。
权衡的结果是,如果用户知道他们正在参与一项研究,他们可能会以一种意想不到的方式行事。此外,研究参与者和非参与者之间可能存在根本不同的属性。这两种情况都对我们的结果产生了有偏见的估计。
外卖食品
- 不合规
- 我们需要多少个实验组?
- 如何控制交叉污染?
- 我们如何更好地构建潜在的结果框架(例如,提供积极的激励,如亚马逊礼品卡)?
2。外部有效性
- 我们的研究条件看起来是真的还是假的?
- 我们研究的局限性是什么?有更好的选择吗?
- 如何获得真诚的回应?
3。道德考量
- 讲道德!
- 通知用户
- 明确同意参与
进一步阅读:
数据科学中因果关系和相关性之间的地盘之争
towardsdatascience.com](/the-turf-war-between-causality-and-correlation-in-data-science-which-one-is-more-important-9256f609ab92) [## 数据科学家应该有充分的理由进行更多的实验
好的,坏的,丑陋的
towardsdatascience.com](/why-do-we-do-and-how-can-we-benefit-from-experimental-studies-a3bbdab313fe)
喜欢读这本书吗?
还有,看看我其他关于人工智能和机器学习的帖子。
住宅水流分类实验
我从中了解到筛选另一个人的 IOT 数据有点令人毛骨悚然。
去年,我花了大量时间阅读机器学习算法——它们能做什么,以及如何在 Python 中使用它们。一天晚上,我和几个朋友在吃饭时讨论这些问题,其中一个朋友告诉我,他家里的主水管上连接了一个流量计,看看我们能用它做什么可能会很有趣。在查看数据后,我决定看看我们是否可以训练一个分类器来识别水流并对其进行分类。然后你就可以知道有多少水被用来冲厕所、洗碗池、淋浴等等。一天之内。
流量计每秒记录一次流量。一长串随时间变化的值称为“时间序列”,这类问题称为“时间序列分类”。
我使用的是一种叫做监督学习的机器学习,在这种学习中,你提出一种算法,它可以学习一些带标签的例子,然后它对以前从未见过的新数据进行分类。用于实验的训练数据是一小组手写标记的事件,每个事件有 1-4 个示例。我们手动识别了每种类型事件中的一些,很明显房子里的一些东西有不同的波形。早期的一系列训练活动如下所示:

你可以看到事件很容易用肉眼区分。从左到右,这些是马桶冲水、淋浴、浴缸注水、水槽水流和一些电器运行的示例。
隐私问题
当我在筛选我朋友的水流传感器的数据时,我被你能从某人家里的一个传感器推断出的东西震惊了。很简单,你可以看到有人在家。你可以看到房子的主人半夜起床,早上起床,睡觉的时候。人们洗不同的淋浴——观察几天后,你就能知道哪个淋浴属于哪个人。如果一个人离开了一天,也许是去旅行了,你也能看出来。厕所有一个标志,你不仅可以知道哪个冲了水,还可以知道是哪个。由于成年人通常不怎么洗澡,你可以通过对水流分类来推测谁有小孩。这让我想到我想把哪些传感器数据传输到云中,因为如果你有多个不同类型的传感器,我怀疑你可以非常准确地描述谁住在家里。
尝试过的方法
有两种对时间序列数据进行分类的基本方法。第一种是从时间序列中提取特征,如滚动平均值、最小值/最大值等。并将其呈现给学习算法进行分类。这就是使用 RandomForestClassifiers 和 XGBoost 进行学习算法的最初几次程序迭代的工作方式。后来的测试版本使用了一个名为 TSFresh 的特性提取库,从这个系列中提取了几百个特性。在文献中似乎没有关于最佳方法的共识。在尝试这种方法时,我用 TSFresh 特征提取和 XGBoost 得到了最好的结果。
第二种方法是将时间序列数据直接呈现给学习算法。根据文献,公认的最佳方法是使用动态时间弯曲(DTW)的距离度量将时间序列切片呈现给 K-最近邻分类器,其中 K 设置为 1。KNN 非常简单,它只是将测试波形分类为与它最匹配的训练示例相同的类别。衡量匹配程度的标准是距离度量,DTW。
KNN 与 DTW 的表现优于特征提取方法,虽然它更计算密集型。
在尝试了这些方法之后,我偶然发现了一篇很棒的文章“基于软计算技术的水终端使用分解”,它提供了特征提取方法的一种变体。如果您提取每个流量事件,并计算流量、持续时间和平均速率,您会得到一组三个值。如果你把它们用图表表示出来,你可以看到这些事件很好地聚集在一起。下面的 3D 图显示了一个例子:

现在,您将每个流量事件总结为一组数字:平均流量、总流量和持续时间。这些可以输入到各种学习算法中。我得到的最好结果是通过用已识别的示例事件制作标记的训练数据,然后在其上训练 KNN 或 XGBoost 分类器来实现的。它的计算量非常小——它可以在不到一分钟的时间内对一天的数据进行分类,包括生成可视化效果。这是迄今为止最成功的方法。
可视化
Matplotlib 和 Seaborn 用于生成图形,每个流用颜色编码以显示分类。
分类流量的样本图如下所示。



分类性能
厕所、淋浴、水槽和浴缸填充通常被正确分类。很容易将这些事件相加,以了解每个事件在某一天使用了多少水。尽管有一些限制。在复杂的流程中,许多事情同时发生,这是很难验证的。该算法对流量进行分类,但我无法判断它做得有多好,因为我无法判断发生了什么。此外,一些设备流量实际上无法与水槽流量或马桶流量区分开来。作为示例,洗碗机的全流程如下所示。

开始于样本 920 附近的波形很容易识别。然而,即使对人类来说,较大的尖峰看起来像厕所,较小的看起来像水槽。准确分类这些流量的唯一方法是注意它们出现在识别波形附近。将它们作为洗碗机流量包括在训练数据集中的努力导致高的假阳性率,将水槽流量误分类为洗碗机流量。这就是为什么水槽和设备流量被集中在一个分类下。
关于图形颜色的注释
Seaborn 的 Color Brewer 调色板工具文档指出,对于像这样的图,您可以区分类别,并且没有增加/减少值的含义,您需要“定性调色板”。这些都是为了易于区分类别而优化的。示例图使用了这些调色板中的一种,可读性比吸引力更好。
完整的可用调色板列表可在 https://jiffyclub.github.io/palettable/colorbrewer/获得,自定义调色板很容易定义。
树状图和快乐小意外的实验
在我的目标导向图表实验中,数据集中的每一项都由一个小矩形表示。根据用户想要看到的内容,它们会飞来飞去,堆叠成各种形状。因此,我需要针对分类和/或定量维度的不同组合的可视化类型。
例如,假设我们的矩形是电影,用户想看看他们有多少预算。我们有 1 个量化维度来表示,因此我们可以简单地根据预算按比例调整每部电影的大小:

这是一个简单类型的树形图。
现在用户想知道电影的预算是多少,取决于它们的类型。我们增加了一个范畴。矩形飞来飞去形成一个条形图,每个条形代表一个流派的电影总预算。与一个简单的条形图相比,条形图是一个树形图,我们可以看到各个元素,这给了我们额外的洞察力:这种类型的第一名是因为一些大型电影,还是许多普通电影?

用户再一次添加了另一个分类维度:他们想按类型和来源国查看电影的预算。矩形再次飞来飞去,这次为每个流派/国家组合形成一个树状图。它们按流派垂直排列,但现在水平分布在每个国家的一栏中。

已满的“单元格”(第 2 列,第 5 行)是总预算最大的一个,其余部分的大小与此相比。
这是一种热图,我们确实可以使用每个单元格的整体大小,并使用梯度来显示它们各自承载的价值。但在我看来,这让事情更难比较:

最后,让我们添加第三个分类维度。这一次我们可以使用颜色——每个树形图都被分割成子部分,每种颜色一个子部分。部分在树形图中按总值降序排序:

对于二维版本,我们还可以使用条形图和颜色:

关于实现的一些注意事项。
当构建一个树形图时,我们有以下问题:我们需要定位和确定矩形的大小,以便它们填充一个目标区域,同时每个矩形的表面等于它的重量。这是一个挑战,因为解决方案还必须使可视化对人类有用——我们需要看到有多少个项目,它们各自的大小是多少,并能够按需点击它们查看详细信息。
我发现可读性最好的方法是将它们“方形化”,使它们看起来尽可能的方形,同时满足上面的约束。不幸的是,为了进行计算,我们不能独立地逐个放置矩形,我们需要在每次迭代中考虑整个数据集。这使得一个完美的解决方案规模很小,实际上这是一个 NP 难题。所以我们需要寻求妥协。来自埃因霍温大学的这篇论文提出了一种实用、高效的方法,并产生了非常令人满意的结果。它也很容易理解和实现,绝对是我推荐的一本有趣的读物。
这就是我在应用程序中编写的代码。然而,当我在为那个模块搭建脚手架的时候,我有一个占位符 treemap 函数来提前开始测试整个模块。它使用了最简单的方法:只在一个维度上进行插值,即只在一行薄矩形上进行插值:

我并不期望这是一个非常有用的可视化,然而就在那时,一些意想不到的有趣的事情发生了。我使用了一个带有简单 2D 上下文的 HTML 画布。事实证明,如果在有限的区域中有成千上万个这样的矩形,尤其是在这样薄的布局中,浏览器没有足够的像素来显示所有的矩形及其 1 像素宽的白色分隔符。所以它试图平滑事物,1 蓝+ 1 白+ 1 蓝变成了 1 淡蓝色。
它创造了这样的梯度:

这非常有用,因为它回答了我们的问题:条形的大小是由几个大元素(亮色部分)还是许多小元素(亮色部分)决定的。我最终在应用程序中保留了这一点,以防我们有大量的矩形,而“方形”算法开始出现问题。诸如此类的事情使得数据可视化的开发变得非常有趣。
专业知识和推理
理解的统计探索
推理被定义为“基于证据和推理的结论”。我们在生活中做的许多或大多数事情都是基于某种形式的推理。有些,我们有很多经验,比如知道小心地过马路是非常安全的,而有些,我们不知道,比如是否接受某个工作邀请,或者搬到另一个国家。然而,在这两种情况下,我们最终都必须做出一些决定,主要是基于从我们所拥有的(通常是有限的)信息中得出的结论。
案例研究:圭亚那人饮酒
如果你是来决定移居哪个国家的,那么你来错了地方,因为这篇文章的目的不是通过哲学来研究推理,而是从数学这个受限的、可预测的世界来研究推理。让我们说,你试图估计一个随机选择的圭亚那人在周五晚上喝酒的概率。为了这个思想实验的目的,我假设你对圭亚那或其人口的饮酒习惯一无所知。如果你有这方面的知识,请原谅我,想象一个你没有的世界。
在没有任何信息的情况下,我们应该假设概率应该是多少?让我们进一步忽略我们对饮酒或周五可能性的认知。在没有信息的情况下,我们最好的“猜测”概率是 50%。但是如果我们随便问一个圭亚那人,他们正在喝酒,会怎么样呢?如果我们发现另外两个圭亚那人不是呢?我建议探索这个问题的方法是使用贝叶斯定理。这是一种基于新信息更新你对世界的“看法”的有力方式。
编码解决方案
我导入了 math 和 numpy Python 模块来帮助我:
import numpy as np
import math as math
由于我们没有关于这些习惯的信息,我们现在可以假设 0 到 100%之间的每个概率都是同等可能的,因此,我们应该给它们同等的权重:
probs= np.linspace(0,1,101)
weights= np.ones(len(probs))
似是而非
但是当信息开始出现时,我们如何处理它呢?当我们看到第一个人,他正在喝酒,我们知道概率不可能是 0%。这也是一个结果,我们看到 90%的概率是 10%的概率的 9 倍。根据贝叶斯定理,概括这种直觉,每个概率的“似真性得分”等于其先验权重乘以该概率下“现实”发生的可能性。实际概率不可能是 0%,所以给它一个‘似真得分’0。
我们如何看到在某种假设下,某种结果发生的可能性有多大?在我们的简单模型中,我们使用所谓的二项分布。我使用了一个名为“f”的辅助函数来使二项式函数看起来更漂亮:
def f(num):
return math.factorial(num)def binomial_prob(n,x,p):
return (f(n)/ (f(n-x)*f(x) ) * p**(x) * (1-p)**(n-x))
我们结合所有这些来创建我们的贝叶斯概率估计函数。我们用可能性的权重来平均概率。我们设置了概率和先验概率的默认值,以使用户的工作更容易:
def bayes_prob_est(n,x, probs=np.linspace(0,1,101), priors='q')):
if type(probs)==list:
probs=np.array(probs)
if len(probs)!= len(priors): priors= np.ones(len(probs)) if type(priors)== list:
priors== np.array(priors) plausability = priors* binomial_prob(n,x,probs)
return sum(plausability*probs)/sum(plausability)
圭亚那实验的结论
现在我们已经准备好了贝叶斯函数,我们终于可以做一些估计了。下表显示了接受调查的人数、饮酒人数以及随机选择的人饮酒的可能性,使用的是我们的推断方法:

由此产生的有趣模式是,我们对概率的最佳猜测是(x+1)/(n+2),这在逻辑上相当于在我们的样本中添加一个饮酒者和一个不饮酒者。这是一种特殊形式的拉普拉斯平滑
案例分析:扑克
小样
这是否意味着推论就像(x+1)/(n+2)那么简单?这是不是意味着世界上所有的专业知识都可以用(x+1)/(n+2)代替?听到答案是否定的,你不会感到惊讶。这听起来像是常识,但数学并不纯粹通过常识工作,它需要逻辑证据。让我们看一个不同的例子来强调专业知识的价值。
假设我们在一个赌场玩扑克游戏,一桌有 9 个人。一名新玩家来到牌桌前,开始玩他的前 3 手牌。他可能会玩多少手牌?使用我们的贝叶斯函数或上表,我们得到以下结果:
bayes_prob_est(3,3) #0.80
那么我们应该假设他玩了大约 80%的牌吗?完全没有扑克知识,是的,这是一个公平的假设。然而,之前我们定义了一个先验函数,并决定每个概率都是同等可能的。任何一个扑克玩家都会告诉你,80%的牌局是一个令人厌恶的数字。让我们替代性地假设一个扑克高手认为 10%的玩家比较鲁莽,玩了 60%的手牌,80%的玩家比较理智,玩了 20%,10%的玩家比较害怕,玩了 10%。如果我们现在将这些信息放入我们的贝叶斯函数,我们会得到以下结果:
bayes_prob_est(3,3, [.6, .2, .1], [10,80,10]) #0.51
因此,专家可以根据他的专业知识将他的概率从 80%调整到大约 51%。这是一个巨大的意见分歧,这是有道理的,因为复杂的游戏,如扑克,是非常难以理解没有太多的经验。让我们看看,如果我们观察同一个玩家 200 手牌会发生什么,但现在他已经玩了 200 手牌中的 45 手。
大样本
非专家:
bayes_prob_est(200,45) #0.23
专家:
bayes_prob_est(200,45, [.6, .2, .1], [10,80,10]) #0.20
在这种情况下,非专家推断的概率约为 23%,而专家推断的概率约为 20%。两者之间的差距已经明显缩小,几乎相同。随着样本越来越大,这些值越来越接近。
结论:专业知识的价值
我们在上面已经看到,在面对有限的信息时,先前的专业知识可以给你一个非常不同的世界感知,然而,在“足够”的时间后,这收敛到一个天真但有感知的观察者的感知。那么,人们一定想知道,在这个我们可以获得关于各种主题的数千甚至数百万个数据点的时代,在仅仅几百次观察之后,观点似乎趋于一致,为什么还需要专业知识。
在某种程度上,这是对的,面对铺天盖地的数据,先前的观点确实变得不那么重要了。然而,许多重要的问题并不像估计一种简单结果的可能性那样简单。现实生活中有很多输入,例如,在给定 50 种不同的社会经济统计数据的情况下,确定一个社区中不同类型犯罪的可能频率。
最后,即使我们能够从数据中提取概率,我们也必须知道如何使用它们。这些概率最多只能给我们相关性,但要改变世界上的结果(研究数据的目的),我们需要理解原因,而这尤其需要专业知识。因此,虽然数据降低了某些形式的专业知识的价值,但其他形式在这个数据驱动的世界中仍然有价值。
解释任何具有 SHAP 值的模型—使用内核解释器
对 SHAP 值使用 KernelExplainer

自从我发表了文章“用 SHAP 值解释你的模型”,这是建立在一个随机的森林树上,读者们一直在问是否有一个通用的 SHAP 解释器适用于任何 ML 算法——无论是基于树的还是非基于树的算法。这正是内核解释器,一个模型不可知的方法,被设计来做的。在本文中,我将演示如何使用 KernelExplainer 构建 KNN、SVM、Random Forest、GBM 或 H2O 模块的模型。如果你想了解更多关于 SHAP 价值观的背景,我强烈推荐“用 SHAP 价值观解释你的模型”,其中我详细描述了 SHAP 价值观是如何从沙普利价值观中产生的,什么是博弈论中的沙普利价值观,以及 SHAP 价值观是如何在 Python 中工作的。除了 SHAP,你可能还想在“用 LIME 解释你的模型”中查看 LIME,在“用微软的 InterpretML 解释你的模型”中查看微软的 InterpretML。我还在“SHAP 和更优雅的图表”和“SHAP 价值和 H2O 模型”中记录了 SHAP 的最新发展。
想深入了解机器学习算法的读者,可以查看我的帖子我的随机森林、梯度提升、正则化、H2O.ai 讲义。对于深度学习,请查看“以回归友好的方式解释深度学习”。对于 RNN/LSTM/GRU,查看“RNN/LSTM/GRU 股价预测技术指南”。
用 SHAP 价值观诠释你的精致模型
考虑这个问题:“你复杂的机器学习模型容易理解吗?”这意味着您的模型可以通过具有商业意义的输入变量来理解。你的变量将符合用户的期望,他们已经从先前的知识中学习。
Lundberg 等人在其出色的论文“解释模型预测的统一方法”中提出了 SHAP (SHapley 附加解释)值,该值为模型提供了高水平的可解释性。SHAP 价值观提供了两大优势:
- 全局可解释性-SHAP 值可以显示每个预测值对目标变量的贡献大小,无论是正面还是负面。这类似于变量重要性图,但它可以显示每个变量与目标之间的正或负关系(参见下面的汇总图)。
- 局部可解释性——每个观察值都有自己的一套 SHAP 值(见下面的个体力图)。这大大增加了它的透明度。我们可以解释为什么一个案例得到它的预测和预测者的贡献。传统的可变重要性算法只显示整个群体的结果,而不是每个案例的结果。本地可解释性使我们能够精确定位和对比这些因素的影响。
SHAP 值可以由 Python 模块 SHAP 产生。
模型的可解释性并不意味着因果关系
需要指出的是,SHAP 值并不提供因果关系。在“识别因果关系”系列文章中,我展示了识别因果关系的计量经济学技术。这些文章涵盖了以下技术:回归不连续性(参见“通过回归不连续性确定因果关系”)、差异中的差异(DiD)(参见“通过差异中的差异确定因果关系”)、固定效应模型(参见“通过固定效应模型确定因果关系”)以及采用因子设计的随机对照试验(参见“您的变更管理实验设计”)。
内核解释器是做什么的?
KernelExplainer 通过使用您的数据、预测以及预测预测值的任何函数来构建加权线性回归。它根据博弈论的 Shapley 值和局部线性回归的系数计算可变的重要性值。
KernelExplainer 的缺点是运行时间长。如果你的模型是基于树的机器学习模型,你应该使用已经优化的树解释器TreeExplainer()来快速渲染结果。如果你的模型是深度学习模型,使用深度学习讲解器DeepExplainer()。SHAP Python 模块还没有专门针对所有类型算法的优化算法(比如 KNNs)。
在“用 SHAP 值解释你的模型”中,我用函数TreeExplainer()创建了一个随机森林模型。为了让您比较结果,我将使用相同的数据源,但是使用函数KernelExplainer()。
我将为所有算法重复以下四个图:
- 摘要情节:使用
summary_plot() - 依赖情节:
dependence_plot() - 个体力图:
force_plot()对于给定的观察值 - 集体力剧情:
force_plot()。
完整的代码可以在文章末尾找到,或者通过 Github 找到。
[## 通过我的推荐链接加入 Medium-Chris Kuo/data man 博士
阅读 Chris Kuo/data man 博士的每一个故事。你的会员费直接支持郭怡广/戴塔曼博士和其他…
dataman-ai.medium.com](https://dataman-ai.medium.com/membership)
随机森林
首先,让我们加载在“用 SHAP 值解释您的模型”中使用的相同数据。
import pandas as pd
import numpy as np
np.random.seed(0)
import matplotlib.pyplot as plt
df = pd.read_csv('/winequality-red.csv') # Load the data
from sklearn.model_selection import train_test_split
from sklearn import preprocessing
from sklearn.ensemble import RandomForestRegressor
# The target variable is 'quality'.
Y = df['quality']
X = df[['fixed acidity', 'volatile acidity', 'citric acid', 'residual sugar','chlorides', 'free sulfur dioxide', 'total sulfur dioxide', 'density','pH', 'sulphates', 'alcohol']]
# Split the data into train and test data:
X_train, X_test, Y_train, Y_test = train_test_split(X, Y, test_size = 0.2)
让我们构建一个随机森林模型,并打印出变量重要性。SHAP 建立在最大似然算法的基础上。如果你想深入了解机器学习算法,可以查看我的帖子“我关于随机森林、梯度提升、正则化、H2O.ai 的讲义”。
rf = RandomForestRegressor(max_depth=6, random_state=0, n_estimators=10)
rf.fit(X_train, Y_train)
print(rf.feature_importances_)importances = rf.feature_importances_
indices = np.argsort(importances)features = X_train.columns
plt.title('Feature Importances')
plt.barh(range(len(indices)), importances[indices], color='b', align='center')
plt.yticks(range(len(indices)), [features[i] for i in indices])
plt.xlabel('Relative Importance')
plt.show()

Figure (A) Random Forest Variable Importance Plot
你可以从这个Githubpip 安装 SHAP。下面的函数KernelExplainer()通过采用预测方法rf.predict和您想要执行 SHAP 值的数据来执行局部回归。这里我使用测试数据集 X_test,它有 160 个观察值。这一步可能需要一段时间。
import shap
rf_shap_values = shap.KernelExplainer(rf.predict,X_test)
- 概要情节
此图加载了信息。该图与常规变量重要性图(图 A)的最大区别在于,它显示了预测值与目标变量之间的正相关和负相关关系。它看起来有点古怪,因为它是由列车数据中的所有点组成的。让我向您介绍一下:
shap.summary_plot(rf_shap_values, X_test)

- *特征重要性:*变量按降序排列。
- 影响:水平位置显示该值的影响是否与更高或更低的预测相关联。
- *原始值:*颜色显示该变量对于该观察值是高(红色)还是低(蓝色)。
- 相关性:高水平的“酒精”含量对质量评级有高和正的影响。“高”来自红色,而“积极的”影响显示在 X 轴上。同样,我们会说“挥发性酸度”与目标变量负相关。
您想要保存汇总图。虽然 SHAP 没有内置的保存图的功能,但是您可以使用matplotlib输出图:
2.依赖图
部分依赖图,简称依赖图,在机器学习结果中很重要( J. H. Friedman 2001 )。它显示了一个或两个变量对预测结果的边际效应。它表明目标和变量之间的关系是线性的、单调的还是更复杂的。我在文章“中提供了更多详细信息:如何计算部分相关图?”
假设我们想得到“酒精”的依赖图。SHAP 模块包括另一个与“酒精”互动最多的变量。下图显示“酒精”与目标变量之间存在近似线性的正趋势,“酒精”与“残糖”频繁交互。
*shap.dependence_plot("alcohol", rf_shap_values, X_test)*

3.个体力图
您可以为每个观察值绘制一个非常优雅的图,称为力图*。我任意选择了 X_test 数据的第 10 个观测值。下面是 X_test 的平均值,以及第 10 次观察的值。*

Pandas 像 base R 一样使用.iloc()来划分数据帧的行。其他语言开发者可以看我的帖子“你是双语吗?精通 R 和 Python ”中,我比较了 R dply 和 Python Pandas 中最常见的数据争论任务。
*# plot the SHAP values for the 10th observation
shap.force_plot(rf_explainer.expected_value, rf_shap_values[10,:], X_test.iloc[10,:])*

- **输出值是该观测值的预测值(该观测值的预测值为 5.11)。
- 基值:原始论文解释说,基值 E(y_hat)是“如果我们不知道当前输出的任何特征,将会预测的值。”换句话说,它是均值预测,或均值(yhat)。你可能会奇怪为什么是 5.634。这是因为 Y_test 的预测均值为 5.634。你可以通过产生 5.634 的
Y_test.mean()来测试一下。 - 红色/蓝色:将预测值推高(向右)的特征显示为红色,将预测值推低的特征显示为蓝色。
- 酒精:对质量评级有积极影响。这种酒的酒精度是 9.4,低于平均值 10.48。所以它把预测推到左边。
- 二氧化硫总量:与质量等级正相关。高于平均水平的二氧化硫(= 18 > 14.98)将预测推向右边。
- 该图以位于
explainer.expected_value的 x 轴为中心。所有 SHAP 值都与模型的期望值相关,就像线性模型的效果与截距相关一样。
4.集体力量图
每个观察都有它的力图。如果把所有的力图组合起来,旋转 90 度,水平叠加,我们就得到整个数据 X_test 的力图(见 Lundberg 等贡献者的 GitHub 的解释)。
*shap.force_plot(rf_explainer.expected_value, rf_shap_values, X_test)*

合力图上面的 Y 轴是单个力图的 X 轴。在我们的 X_test 中有 160 个数据点,所以 X 轴有 160 个观察值。
GBM
我用 500 棵树(缺省值是 100)构建了 GBM,这对于过度拟合应该是相当健壮的。我使用超参数validation_fraction=0.2指定 20%的训练数据提前停止。如果验证结果在 5 次后没有改善,该超参数和n_iter_no_change=5将帮助模型更早停止。
*from sklearn import ensemble
n_estimators = 500
gbm = ensemble.GradientBoostingClassifier(
n_estimators=n_estimators,
validation_fraction=0.2,
n_iter_no_change=5,
tol=0.01,
random_state=0)
gbm = ensemble.GradientBoostingClassifier(
n_estimators=n_estimators,
random_state=0)
gbm.fit(X_train, Y_train)*
像上面的随机森林部分一样,我使用函数KernelExplainer()来生成 SHAP 值。那我就提供四个情节。
*import shap
gbm_shap_values = shap.KernelExplainer(gbm.predict,X_test)*
- 概要情节
当与随机森林的输出相比较时,GBM 对于前四个变量显示相同的变量排序,但是对于其余变量不同。
*shap.summary_plot(gbm_shap_values, X_test)*

2.依赖图
GBM 的依赖图也显示“酒精”和目标变量之间存在近似线性的正趋势。与随机森林的输出相反,GBM 显示“酒精”与“密度”频繁交互。
*shap.dependence_plot("alcohol", gbm_shap_values, X_test)*

3.个体力图
我继续为 X_test 数据的第 10 次观察制作力图。
*# plot the SHAP values for the 10th observation
shap.force_plot(gbm_explainer.expected_value,gbm_shap_values[10,:], X_test.iloc[10,:])*

该观察的 GBM 预测是 5.00,不同于随机森林的 5.11。推动预测的力量与随机森林的力量相似:酒精、硫酸盐和残余糖分。但是推动预测上升的力量是不同的。
4.集体力量图
*shap.force_plot(gbm_explainer.expected_value, gbm_shap_values, X_test)*

KNN
因为这里的目标是展示 SHAP 价值观,所以我只设置了 KNN 15 个邻居,而不太关心优化 KNN 模型。
*# Train the KNN model
from sklearn import neighbors
n_neighbors = 15
knn = neighbors.KNeighborsClassifier(n_neighbors,weights='distance')
knn.fit(X_train,Y_train)# Produce the SHAP values
knn_explainer = shap.KernelExplainer(knn.predict,X_test)
knn_shap_values = knn_explainer.shap_values(X_test)*
- 概要情节
有趣的是,与随机森林或 GBM 的输出相比,KNN 显示了不同的变量排序。这种背离是意料之中的,因为 KNN 容易出现异常值,这里我们只训练一个 KNN 模型。为了缓解这一问题,建议您使用不同数量的邻居构建几个 KNN 模型,然后获取平均值。我的文章“异常检测与 PyOD ”也分享了这种直觉。
*shap.summary_plot(knn_shap_values, X_test)*

2.依赖图
KNN 的输出显示在“酒精”和目标变量之间存在近似线性的正趋势。与随机森林的输出不同,KNN 显示“酒精”与“总二氧化硫”的交互频繁。
*shap.dependence_plot("alcohol", knn_shap_values, X_test)*

3.个体力图
*# plot the SHAP values for the 10th observation
shap.force_plot(knn_explainer.expected_value,knn_shap_values[10,:], X_test.iloc[10,:])*

该观察的预测值为 5.00,与 GBM 的预测值相似。KNN 确定的驱动力是:“游离二氧化硫”、“酒精”和“残糖”。
4.集体力量图
*shap.force_plot(knn_explainer.expected_value, knn_shap_values, X_test)*

SVM
支持向量机(AVM)找到最佳超平面以将观察结果分成类别。SVM 使用核函数变换到更高维度的空间中进行分离。为什么在更高维的空间中分离会变得更容易?这还得回到 Vapnik-Chervonenkis (VC)理论。它说,映射到更高维度的空间通常会提供更大的分类能力。关于进一步的解释,请参见我的文章“使用 Python 的维度缩减技术”。常见的核函数有径向基函数(RBF)、高斯函数、多项式函数和 Sigmoid 函数。
在这个例子中,我使用带参数gamma的径向基函数(RBF)。当gamma的值很小时,模型受到的约束太大,无法捕捉数据的复杂性或“形状”。有两种选择:gamma='auto'或gamma='scale'(参见 scikit-learn api )。
另一个重要的超参数是decision_function_shape。超参数decision_function_shape告诉 SVM 一个数据点离超平面有多近。靠近边界的数据点意味着低置信度决策。有两个选项:一对一对休息(’ ovr ‘)或一对一(’ ovo ')(参见 scikit-learn api )。
*# Build the SVM model
from sklearn import svm
svm = svm.SVC(gamma='scale',decision_function_shape='ovo')
svm.fit(X_train,Y_train)# The SHAP values
svm_explainer = shap.KernelExplainer(svm.predict,X_test)
svm_shap_values = svm_explainer.shap_values(X_test)*
- 概要情节
这里,我们再次从随机森林和 GBM 的输出中看到不同的汇总图。这是意料之中的,因为我们只训练了一个 SVM 模型,而 SVM 也容易出现异常值。
*shap.summary_plot(svm_shap_values, X_test)*

2.依赖图
SVM 的输出在“酒精”和目标变量之间显示出温和的线性正趋势。与随机森林的输出相反,SVM 表明“酒精”经常与“固定酸度”相互作用。
*shap.dependence_plot("alcohol", svm_shap_values, X_test)*

3.个体力图
*# plot the SHAP values for the 10th observation
shap.force_plot(svm_explainer.expected_value,svm_shap_values[10,:], X_test.iloc[10,:])*

此次观测的 SVM 预测值为 6.00,不同于随机森林的 5.11。驱使预测降低的力量类似于随机森林的力量;相比之下,“二氧化硫总量”是推动预测上升的强大力量。
4.集体力量图
*shap.force_plot(svm_explainer.expected_value, svm_shap_values, X_test)*

型号内置开源 H2O
许多数据科学家(包括我自己)喜欢开源的 H2O。它是一个完全分布式的内存平台,支持最广泛使用的算法,如 GBM、RF、GLM、DL 等。它的 AutoML 功能自动运行所有算法及其超参数,生成最佳模型排行榜。其企业版 H2O 无人驾驶 AI 内置 SHAP 功能。
如何将 SHAP 价值观应用于开源的 H2O?我非常感谢 seanPLeary 在如何用 AutoML 产生 SHAP 价值观方面为 H2O 社区做出的贡献。我使用他的类“H2OProbWrapper”来计算 SHAP 值。
*# The code builds a random forest model
import h2o
from h2o.estimators.random_forest import H2ORandomForestEstimator
h2o.init()X_train, X_test = train_test_split(df, test_size = 0.1)
X_train_hex = h2o.H2OFrame(X_train)
X_test_hex = h2o.H2OFrame(X_test)
X_names = ['fixed acidity', 'volatile acidity', 'citric acid', 'residual sugar','chlorides', 'free sulfur dioxide', 'total sulfur dioxide', 'density','pH', 'sulphates', 'alcohol']# Define model
h2o_rf = H2ORandomForestEstimator(ntrees=200, max_depth=20, nfolds=10)# Train model
h2o_rf.train(x=X_names, y='quality', training_frame=X_train_hex)X_test = X_test_hex.drop('quality').as_data_frame()*
让我们仔细看看 SVM 的代码shap.KernelExplainer(svm.predict, X_test)。它采用了类svm的函数predict,以及数据集X_test。因此,当我们应用 H2O 时,我们需要传递(I)预测函数,(ii)一个类,以及(iii)一个数据集。棘手的是,H2O 有自己的数据框架结构。为了将 h2O 的预测函数h2o.preict()传递给shap.KernelExplainer(),Sean pleay将 H2O 的预测函数h2o.preict()包装在一个名为H2OProbWrapper的类中。这个漂亮的包装器允许shap.KernelExplainer()接受类H2OProbWrapper的函数predict和数据集X_test。
*class H2OProbWrapper:
def __init__(self, h2o_model, feature_names):
self.h2o_model = h2o_model
self.feature_names = feature_namesdef predict_binary_prob(self, X):
if isinstance(X, pd.Series):
X = X.values.reshape(1,-1)
self.dataframe= pd.DataFrame(X, columns=self.feature_names)
self.predictions = self.h2o_model.predict(h2o.H2OFrame(self.dataframe)).as_data_frame().values
return self.predictions.astype('float64')[:,-1]*
因此,我们将计算 H2O 随机森林模型的 SHAP 值:
*h2o_wrapper = H2OProbWrapper(h2o_rf,X_names)h2o_rf_explainer = shap.KernelExplainer(h2o_wrapper.predict_binary_prob, X_test)
h2o_rf_shap_values = h2o_rf_explainer.shap_values(X_test)*
- 概要情节
当与随机森林的输出相比较时,H2O 随机森林对于前三个变量显示出相同的变量排序。
*shap.summary_plot(h2o_rf_shap_values, X_test)*

2.依赖图
输出显示“酒精”和目标变量之间存在线性的正趋势。H2O·兰登森林发现“酒精”经常与“柠檬酸”相互作用。
*shap.dependence_plot("alcohol", h2o_rf_shap_values, X_test)*

3.个体力图
此次观测的 H2O 随机森林预测值为 6.07。推动预测向右的力量是“酒精”、“密度”、“残糖”、“总二氧化硫”;左边是“固定酸度”和“硫酸盐”。
*# plot the SHAP values for the 10th observation
shap.force_plot(h2o_rf_explainer.expected_value,h2o_rf_shap_values[10,:], X_test.iloc[10,:])*

4.集体力量图
*shap.force_plot(h2o_rf_explainer.expected_value, h2o_rf_shap_values, X_test)*

R 中的 SHAP 值如何?
这里提到几个 SHAP 值的 R 包很有意思。R package shapper 是 Python 库 SHAP 的一个端口。R 包 xgboost 有内置函数。另一个包是 iml (可解释机器学习)。最后,R 包 DALEX (描述性机器学习解释)也包含各种解释器,帮助理解输入变量和模型输出之间的联系。
SHAP 价值观没有做到的事情
自从我发表了这篇文章和它的姊妹文章“用 SHAP 价值观解释你的模型”之后,读者们分享了他们与客户会面时提出的问题。这些问题不是关于 SHAP 价值观的计算,而是观众思考 SHAP 价值观能做什么。一个主要的评论是“你能为我们确定制定策略的驱动因素吗?”
*上面的评论是可信的,表明数据科学家已经提供了有效的内容。然而,这个问题涉及到相关性和因果性。**SHAP 值不能识别因果关系,通过实验设计或类似方法可以更好地识别因果关系。*有兴趣的读者,请阅读我的另外两篇文章《为你的变革管理设计实验》和《机器学习还是计量经济学?
所有代码
为了方便起见,所有的行都放在下面的代码块中,或者通过这个 Github 。
如果您发现这篇文章很有帮助,您可能想要查看模型可解释性系列:
第一部分:用 SHAP 值解释你的模型
第二部分:图表更优雅的 SHAP
第三部分:部分依赖图是如何计算的?
第六部分:对可解释人工智能的解释
第五部分:解释任何具有 SHAP 值的模型——使用内核解释器
第六部分:H2O 模型的 SHAP 值
第七部分:用石灰解释你的模型
第八部分:用微软的 InterpretML 解释你的模型
* [## 通过我的推荐链接加入 Medium-Chris Kuo/data man 博士
阅读 Chris Kuo/data man 博士的每一个故事。你的会员费直接支持郭怡广/戴塔曼博士和其他…
dataman-ai.medium.com](https://dataman-ai.medium.com/membership)
建议读者购买郭怡广的书籍:

- 可解释的人工智能:https://a.co/d/cNL8Hu4
- 图像分类的迁移学习:https://a.co/d/hLdCkMH
- 现代时间序列异常检测:https://a.co/d/ieIbAxM
- 异常检测手册:https://a.co/d/5sKS8bI*
特征变化解释
在 Scikit-Learn 中使用 PCA

Visualization of PCA results[1]
作为一种多元排序技术,主成分分析(PCA)可以对多元数据集中的因变量进行分析,以探索它们之间的关系。这导致以更少的维度显示数据点的相对位置,同时保留尽可能多的信息[2]。
在本文中,我将使用 Scikit-learn 库对 auto-mpg 数据集(来自 GitHub)应用 PCA。本文分为数据预处理、主成分分析和主成分可视化三个部分。
a)数据预处理
我们首先需要导入数据集预处理所需的库:
import tensorflow as tf
from tensorflow import kerasimport numpy as np
import pandas as pd
import seaborn as sns!pip install -q git+https://github.com/tensorflow/docs
import tensorflow_docs as tfdocs
import tensorflow_docs.plots
import tensorflow_docs.modeling
然后,我们可以导入数据:
datapath = keras.utils.get_file(“auto-mpg.data”, “http://archive.ics.uci.edu/ml/machine-learning-databases/auto-mpg/auto-mpg.data")datapath
并更改列的标题:
columnTitles = [‘MPG’,’Cylinders’,’Displacement’,’Horsepower’,’Weight’, ‘Acceleration’, ‘Model Year’, ‘Origin’]rawData = pd.read_csv(dataPath, names=columnTitles, na_values = “?”, comment=’\t’, sep=” “, skipinitialspace=True)
数据如下所示:
data = rawData.copy()
data.head()

然后,我们需要清理数据:
data.isna().sum()

data = data.dropna()
下一步是定义特征,将它们从响应变量中分离出来,并将其标准化为 PCA 的输入:
from sklearn.preprocessing import StandardScalerdf = pd.DataFrame(data)features = [‘Cylinders’, ‘Displacement’, ‘Horsepower’, ‘Weight’, ‘Acceleration’]X = df.loc[:, features].valuesy = df.loc[:,[‘MPG’]].valuesX = StandardScaler().fit_transform(X)
b)五氯苯甲醚
在 PCA 中,我们首先需要知道需要多少成分来解释至少 90%的特征变化:
from sklearn.decomposition import PCApca = PCA().fit(X)plt.plot(np.cumsum(pca.explained_variance_ratio_))plt.xlabel(‘number of components’)plt.ylabel(‘cumulative explained variance’)

在本案例研究中,选择了两个组件作为组件的最佳数量。然后,我们可以开始进行 PCA:
from sklearn.decomposition import PCApca = PCA(n_components=2)principalComponents = pca.fit_transform(X)
如下所示,总体而言,这两个组件解释了数据集约 95%的特征变化:
pca.explained_variance_ratio_array([0.81437196, 0.13877225])
c)主成分可视化
给定响应变量值(当前数据集中的 MPG ),两个主要成分可以如下所示:
plt.scatter(principalComponents[:, 0], principalComponents[:, 1],c=data.MPG, edgecolor=’none’, alpha=0.5,cmap=plt.cm.get_cmap(‘Spectral’, 10))plt.xlabel(‘Principal component 1’)plt.ylabel(‘Pricipal component 2’)plt.colorbar()

结论
主成分分析(PCA)降低了大数据集的维数,增加了数据的可解释性,同时最小化了信息损失。它通过创建新的不相关成分来实现方差的最大化[3]。
参考文献
[1]https://commons . wikimedia . org/wiki/File:PCA _ vs _ Linear _ auto encoder . png
[2] C. Syms。主成分分析。(2008),生态百科,2940–2949。doi:10.1016/b978–008045405–4.00538–3。
[3] T. I .乔利夫和 j .卡迪马。“主成分分析:回顾与最新发展.”(2016),英国皇家学会哲学汇刊 A:数学、物理与工程科学,第 374 卷,第 2065 期,第 2015–2020 页,doi:10.1098/rsta.2015.0202。
用莱姆和 SHAP 解释自然语言处理模型

文本分类解释
上周,我在 QCon New York 做了一个关于 NLP 的“ 动手特征工程”的演讲。作为演示的一小部分,我简单演示了一下LIME&SHAP在文本分类解释方面是如何工作的。
我决定写一篇关于它们的博客,因为它们很有趣,易于使用,视觉上引人注目。
所有在比人脑可以直接可视化的维度更高的维度上运行的机器学习模型都可以被称为黑盒模型,这归结于模型的可解释性。特别是在 NLP 领域,总是出现特征维数非常巨大的情况,解释特征重要性变得更加复杂。
石灰&SHAP帮助我们不仅向最终用户,也向我们自己提供一个关于 NLP 模型如何工作的解释。
利用栈溢出问题标签分类数据集,我们将构建一个多类文本分类模型,然后分别应用*&***【SHAP】**来解释该模型。因为我们之前已经做了很多次文本分类,我们将快速构建 NLP 模型,并关注模型的可解释性。
数据预处理、特征工程和逻辑回归
preprocessing_featureEngineering_logreg.py

我们在这里的目标不是产生最高的结果。我想尽快潜入莱姆 SHAP,这就是接下来发生的事情。
用 LIME 解释文本预测
从现在开始,这是有趣的部分。下面的代码片段大部分是从 LIME 教程中借来的。
explainer.py

我们在测试集中随机选择一个文档,它恰好是一个标记为 sql 的文档,我们的模型预测它也是 sql 。使用该文档,我们为标签 4(即 sql 和标签 8(即 python )生成解释。
*print ('Explanation for class %s' % class_names[4])
print ('\n'.join(map(str, exp.as_list(label=4))))*

*print ('Explanation for class %s' % class_names[8])
print ('\n'.join(map(str, exp.as_list(label=8))))*

很明显这个文档对标签 sql 的解释最高。 我们还注意到,正负符号都是相对于某个特定标签而言的,比如单词“sql”正对类 sql 而负对类 python ,反之亦然。
我们将为该文档的前两个类生成标签。
*exp = explainer.explain_instance(X_test[idx], c.predict_proba, num_features=6, top_labels=2)
print(exp.available_labels())*

它给了我们 sql 和 python。
*exp.show_in_notebook(text=False)*

Figure 1
让我试着解释一下这种形象化:
- 对于该文档,单词“sql”对于类别 sql 具有最高的正面得分。
- 我们的模型预测这个文档应该以 100%的概率被标记为 sql 。
- 如果我们将单词“sql”从文档中删除,我们会期望模型以 100% — 65% = 35%的概率预测标签 sql 。
- 另一方面,word“SQL”对于 class python 是负数,我们的模型已经了解到 word“range”对于 class python 有一个很小的正数分数。
我们可能想要放大并研究对类 sql 的解释,以及文档本身。
*exp.show_in_notebook(text=y_test[idx], labels=(4,))*

Figure 2
用 SHAP 解释文本预测
以下过程都是从本教程中学到的。
tf_model.py
- 在模型被训练后,我们使用前 200 个训练文档作为我们的背景数据集进行集成,并创建一个 SHAP 解释器对象。
- 我们在测试集的子集上得到个体预测的属性值。
- 将索引转换为单词。
- 使用 SHAP 的
summary_plot方法显示影响模型预测的主要特征。
*attrib_data = X_train[:200]
explainer = shap.DeepExplainer(model, attrib_data)
num_explanations = 20
shap_vals = explainer.shap_values(X_test[:num_explanations])words = processor._tokenizer.word_index
word_lookup = list()
for i in words.keys():
word_lookup.append(i)word_lookup = [''] + word_lookup
shap.summary_plot(shap_vals, feature_names=word_lookup, class_names=tag_encoder.classes_)*

Figure 3
- 单词“want”是我们的模型使用的最大信号词,对类 jquery 预测贡献最大。
- 单词“php”是我们的模型使用的第四大信号词,当然对类 php 贡献最大。
- 另一方面,单词“php”可能对另一个类产生负面信号,因为它不太可能出现在 python 文档中。
就机器学习的可解释性而言,莱姆& SHAP 有很多东西需要学习。我只介绍了 NLP 的一小部分。 Jupyter 笔记本可以在 Github 上找到。享受乐趣!
用特征重要性解释你的机器学习
让我们想象一下,你在一家银行找到了一份咨询工作,这家银行要求你找出那些很有可能拖欠下个月账单的人。有了你所学习和实践的机器学习技术,假设你开始分析你的客户给出的数据集,并且使用了一个随机森林算法,它达到了相当高的准确度。您的下一个任务是向客户团队的业务利益相关者展示您是如何实现这些结果的。你会对他们说什么?他们能理解你为了最终模型而调整的算法的所有超参数吗?当你开始谈论随机森林的估计数和基尼系数时,他们会有什么反应?

虽然精通理解算法的内部工作很重要,但更重要的是能够将发现传达给可能没有任何机器学习理论/实践知识的观众。仅仅表明算法预测得好是不够的。您必须将预测归因于对准确性有贡献的输入数据元素。幸运的是, sklearn 的随机森林实现给出了一个名为“特征重要性的输出,这有助于我们解释数据集中特征的预测能力。但是,这种方法有一些缺点,我们将在本文中探讨,还有一种评估特性重要性的替代技术可以克服这些缺点。
数据集
正如我们在简介中看到的,我们将使用来自 UCI 机器学习库的信用卡默认数据集,该数据集托管在 Kaggle 上。该数据集包含从 2005 年 4 月到 2005 年 9 月台湾信用卡客户的违约付款、人口统计因素、信用数据、付款历史和账单等信息,并且包含连续变量和分类变量的良好组合,如下所示:

Columns available in the dataset and their descriptions


default.payment.next.month 是我们的目标变量。值 1 表示客户将在下个月拖欠付款。让我们看看这个变量的分布:
credit.groupby([‘default.payment.next.month’]).size()
>default.payment.next.month
>0 23364
>1 6636
>dtype: int64
这是一个不平衡的数据集,约有 22%的记录的默认值为 1。因为我们的重点是评估特性的重要性,所以在这篇文章中,我不会深入研究数据集及其特性。相反,我会快速建立一个模型,并开始查看分数。在建立模型之前,让我们先对分类变量进行一次性编码。
让我们看看普通随机森林模型在该数据集上的表现:

很明显我们有一个过度拟合的算法。测试集上的准确率低于训练集,但不算太差。因为我们正在处理一个不平衡的数据集,所以精度和召回数量更加重要。训练集和测试集之间在精确度和召回率上有巨大的差异。
让我们来看看该模型背后的主要特性:
Feature importances of the Random Forest model
令人惊讶的是,年龄是影响模型预测的首要因素。我们还应该注意随机森林模型中特征重要性的一个重要方面:
随机森林中的要素重要性是根据提供给模型的定型数据计算的,而不是根据测试数据集的预测。
因此,这些数字并不能表明模型的真实预测能力,尤其是过度拟合的模型!此外,我们看到模型在训练数据集和测试数据集上的性能有很大的不同。因此,我们需要一种替代技术,能够计算测试数据集上的特征重要性,并基于不同的度量标准(如准确度、精确度或召回率)来计算它。
置换特征重要性
置换特征重要性技术用一个非常简单的概念克服了我们在上面看到的缺点:如果只有一个特征的值被随机打乱,模型会如何执行?换句话说,如果我们使一个特征对模型不可用,对性能有什么影响?
关于这项技术的一些想法:
- 如果我们想要评估模型的性能,为什么要打乱数据集中的某个要素,而不是将其完全移除?删除该功能意味着需要重新进行培训。我们想用这个特性来训练模型,但却不用它来测试模型。
- 如果我们让特征全为零呢?在某些情况下,零对模型确实有一些价值。此外,在一个要素中调整值可以确保值保持在数据范围内。
对于我们的场景,让我们将排列重要性定义为由一个特性的排列引起的基线度量的差异。当给定一个已经训练好的分类器时,下面的函数计算排列重要性:
现在,让我们通过置换所有特征,在测试数据集上绘制召回分数的百分比变化:
Percentage change in recall scores
令人惊讶的是,当我们绘制排列重要性时,年龄并没有出现在前 25 个特征中。这是因为随机森林的要素重要性方法倾向于具有高基数的要素。在我们的数据集中,年龄有 55 个唯一值,这使得算法认为它是最重要的特征。
特征重要性构成了机器学习解释和可解释性的关键部分。希望这篇文章能帮助你了解更多。
这篇文章的代码可以在 Github 上找到。
我们讲述的关于自己的故事
…人工智能研究中遇到的问题如何反映了我们自己的认知偏差

Photo by David Matos on Unsplash
大脑是一个复杂的器官,数十亿个神经元通过数万亿个连接形成了一个非常复杂的非线性动力系统。这可以说是宇宙中最复杂的结构(至少是我们所知道的)。它可以解决看似无穷无尽的任务,让我们在不断变化的环境中导航和生存。
这可能是你熟悉的说唱,但同时它的一些后果很容易被忽视。因为我们和我们的个性是大脑行为的产物,我们和我们的个性与它的复杂性联系在一起。
这篇文章深入探讨了构成我们的(大部分)不可言喻的机制与我们不断渴望拥有一个关于我们在做什么和想什么的令人信服和连贯的故事之间的冲突。 理解我们自己的输出 的问题与人工智能研究中的 可解释性 有一些相似之处。
这种冲突的一些副产品在心理学上被称为 认知偏差 ,其中我们发现了两种可爱的效应,称为 认知失调 和 虚构、 ,这使我们对自己内心的理解程度产生了疑问。
潜意识
“你没注意到,但你的大脑注意到了。”
在西格蒙德·弗洛伊德假设潜意识存在的 100 多年后,他认为我们在自己的房子里不是真正的主人的观点在某种程度上已经融入了我们的身份。
考虑到大脑的复杂性,你可能会说,大多数时候,我们不知道自己到底在做什么是很自然的,但只是在二十世纪的过程中,人们才开始接受这样一个事实,即我们内心发生的事情比我们有意识意识到的要多得多。我们生活的大部分时间都处于自动驾驶状态,只有当紧急的事情发生时,我们的意识注意力才会集中到它上面(正如我在我之前的文章中提到的关于注意力)。
大脑每秒钟过滤 数量惊人的信息 ,而有意识的头脑只意识到其中的极小一部分,其中大部分都经过了 重重的预过滤 。几乎所有的过程,无论是运动的、认知的还是情感的, 都是自动化的,并在主动意识控制之外受到调节 。
不仅信息摄取是自动化的,而且决策的做出也与我们每天看到的截然不同:研究表明,如果我们将大脑的情感成分排除在外,仅仅依靠前额叶活动,决策几乎是不可能的(参见安东尼奥·达马西奥的 书 事物的奇怪顺序 中的概述)。
相反,我们的许多决定严重依赖于身体和内脏脑的 模拟能力 ,与特殊类型的非回肠化神经元进行分布式并行处理。根据你的 直觉行动 有着比你可能认为的更精确的科学含义。
正如 丹尼·卡尼曼和 阿莫斯·特沃斯基指出的,由启动或锚定 引起的偏见会对我们在不确定情况下的决策产生强烈影响,我们通常对它们的发生很警觉。
更糟糕的是:有意识地知道我们正在被锚定或启动,仍然不能让我们对它们可能引发的偏见免疫。
机器学习和可解释性
人工智能和计算神经科学的研究人员面临着一个有点类似的问题,总结在术语 可解释性 下。我们如何解释我们的人工智能系统中的新兴智能,并让系统向我们解释它们如何做出决策,同时仍然能够解释它们如何处理信息的细节?
现代机器学习方法不是构建算法来解决某些任务并将它们硬连线到计算机中,而是允许计算机通过处理指定的输入和期望的输出来自行开发算法(有关更详细的概述,请参见 Pedro Domingos 的“主算法 ”)。

Photo by Sai Kiran Anagani on Unsplash
这向我们表明,理解机器在做什么变得越来越困难,而矛盾的是,它们在做各种事情(图像分类、语音识别、下围棋等)方面变得越来越成功。).
有时,它们似乎在没有任何人工干预或试图手动教授它们知识的情况下表现得最好。这促使 Frederick Jelinek(语音识别之父之一)在 IBM 开发语音识别软件时宣称*“每当我解雇一名语言学家,语音识别器的性能就会提高”。*
大型神经网络中的计算 分布 在整个网络中(在深度神经网络中,也通过几个层,称为隐藏层,具有非线性激活函数),使得 几乎不可能通过构成网络 的层来跟踪计算的细节。
网络所代表的算法中隐含的知识同样 分布在网络 的整个权重结构中,所以你无法看一眼权重就直观地掌握网络擅长的,比如说,对猫或狗的分类。
正如我在我的一些其他文章(例如蚂蚁和神经网络的问题)中所述,请注意,这是一种与图灵机的符号操作非常不同的方法(尽管你当然可以在图灵机上运行神经网络,就像我们在自己的计算机上所做的那样),现代计算机基于图灵机,其符号操作更类似于理性的逐步推理。
因此,当涉及到“理解”复杂分布式系统中的信息处理时,我们可能会面临原则性的限制,或者至少当涉及到构建高效且能够对自己的行为保持满分的智能系统时,我们会面临限制。
叙事的需要
所以毫不奇怪,对于我们大脑中正在进行的一些信息处理,我们人类对于的可解释性有自己的问题。
行为主义者将大脑视为一个黑匣子(类似地专注于输入-输出-关系),但在心理和社会背景下,我们不断需要找到一种叙事来解释我们正在做什么以及为什么要这样做。
但这种叙述,真的有多靠谱?
人类是从动物进化而来的,动物们做得非常好,没有不断地告诉彼此是什么激发了它们的故事。
但后来我们发展出了不祥的能力,可以互相交谈(更重要的是,可以和自己交谈)。社会和性压力(正如我在关于性选择的文章中所详述的那样)可能是引发像语言这样的高级认知能力发展的最前沿。即使在今天,我们的大量脑力都花在了八卦上,花在了跟踪我们周围的人发生的事情上。
从进化的角度来说, 新皮层 ,也就是我们的语言能力所在的地方,是我们神经回路的最新成员(在我的文章为什么智力可能比我们想象的简单中有更多关于新皮层及其架构的内容)。就其绝对质量而言,它构成了我们大脑的大部分,但这并不意味着它一直在负责,一直“知道”发生了什么。
这是大脑功能观的结果:如果大脑的一部分(如语言中心或创建自我模型的大脑区域)想要了解另一部分的活动,指定所述活动的信号需要传播到该大脑区域。
应该清楚的是,对于所有时间的所有大脑活动来说,这既不可行也没有效率,甚至在任何情况下都没有必要。**
因此,这最终只会增加可解释性的问题:试图进行解释的大脑区域有时会简单地从信息流 中 切断,而信息流会给它们必要的洞察力,就像我们将在裂脑症患者的案例中看到的那样。
还有,我们试着解释一下。
能够保持一个持续不断的叙述有它的用处,而且似乎是社会功能成员非常渴望的。但是我们应该意识到,这并不意味着我们对自己或他人的所思所言都是真实的。
实际上完全相反。
我们讲述的关于自己的故事
“如果一个特定的观念已经在人类头脑中存在了许多代,就像我们几乎所有的共同观念一样,需要真诚和持续的努力才能消除它;如果这是我们所拥有的最古老的思想之一,一个伟大的、普遍的、不容置疑的世界思想之一,那么那些寻求改变它的人的劳动是巨大的。”夏洛特·珀金斯·吉尔曼

Even people within stories like compelling stories. Photo by Road Trip with Raj on Unsplash
我们对故事有一种强烈的心理倾向。我们在叙述中感知世界(看看海德尔-西美尔错觉,它让我们相信两个点和一个三角形参与了一场戏剧性的打斗场景)。作为我们过度社交的副产品,我们一直在寻找外部世界的代理和因果关系。随之而来的是对我们自己有一个连贯的叙述的渴望:因为这个或那个原因,我是这样或那样的。
但正如我们所见,对于许多任务来说,大脑和身体中有大量分布式并行计算,这使得理解和描述我们的动机变得很棘手。
因此,我们最终会不断猜测自己行为的原因。
此外,很难实现消除矛盾想法的过程。这意味着我们最终都会带着巨大的矛盾走来走去,这只能通过艰苦的批判性思维来克服,即使是受过良好教育的批判性思考者也无法持续练习这一技能。
老实说,从进化的角度来说,我们的生存并不真的需要一个 完全一致的世界观 ,所以如果他们不太妨碍彼此,我们的大脑就让他们这样。
故事有塑造我们感知的力量,即使我们没有注意到它。大脑(正如我在关于贝叶斯大脑假说的文章中所回避的)不断预测其感知输入的内容,所以你会根据你对世界状态的预期看到和听到不同的东西(这使得认知科学家将现实虚构为 受控幻觉 )。当我们不断试图将世界上复杂和混乱的现象转化为简单的,有时明显自相矛盾的故事时,这些故事最终会戏剧性地改变我们对现实的看法。
认知偏差和认知失调
**“他很少怀疑,当事实与他对生活的看法相矛盾时,他闭上眼睛表示反对。”
― **赫尔曼·黑塞,赫尔曼·黑塞的童话
1957 年,利奥·费斯汀格引入了术语 认知失调 来表示当我们经历一些与我们的世界观相矛盾的事情时所感到的不适。但这种不适往往是潜意识的,我们倾向于通过对我们不喜欢的事件提出替代性解释,或简单地抛弃它们来应对它。
我们避免认知失调的冲动让我们停留在世界观的舒适区,让我们下意识地忽略信息或重构我们认知中令人不安的方面。
认知失调通常通过自我辩护来解决,这可能发生在外部和内部。
在她的书 中,错误是犯了,但不是由我犯的卡罗尔·塔弗里斯** 描述了许多案例 认知失调回避战术 产生了严重后果,从法西斯国家公民社会道德的下降,越战期间的美国政府(参见本·伯恩斯和琳恩·诺维克的精彩而令人震惊的纪录片)或伊拉克战争,法律制度在面对迟来的无罪证据时的偏见**
许多决定,特别是道德决定, 是在对其基础 没有任何清晰和理性的理解的情况下做出的(当受试者被巧妙地操纵时,这在实验中变得很明显),但在做出决定后,它们会导致过度的 自我辩护 ,这反过来会引起受试者世界观的调整,以恢复连贯性并最小化认知失调。
一个流行的例子是吸烟者。他或她可能下意识地意识到吸烟的不健康和不合理,但当被问到时,他或她总是以这样或那样的方式为自己辩护(“我只是喜欢这种味道/仪式/社交/在外面/无论哪种方式都不是那么不健康”)。我们中的许多人都有过类似的情况(用吸烟来换取酒精或任何其他不健康的习惯)。我们经常这样做。
分裂的大脑和虚构的艺术
有时,大脑试图在事实 变得 透明到模仿 的程度后,用 来证明自己的行为。
也许没有任何地方像裂脑患者这样清楚,他们连接左右半球的胼胝体已经被切断(在这个短视频,你可以看到 迈克尔·加扎尼加 ,这些实验背后的先驱之一,解释了基本的前提)。
左右半球不能再交流了,所以左右视野是独立处理的。语言中枢位于 左半球 ,意味着它无法进入(记住视觉是交叉连线的,所以左半球处理右视野,反之亦然)。**
如果你只在左视野显示某些东西,这些信息在右半球进行处理,这可以表现为身体反应(例如,当你显示裸体人的照片时,紧张的脸红或傻笑,或者用左手指着某个地方),但不能被大脑的语言处理部分直接访问。因此,当被问及他/她为什么咯咯笑或指指点点时,病人会当场做出解释。
当我们在猜测对自己行为的解释却没有一条至关重要的信息时,我们通常不会说 【我不知道】 ,而只是简单地以 编造一些 ,然后回溯性地将这条信息解释为。**
这被称为 虚构 ,每个人几乎一直都在做。虽然在日常生活中,通常无法清楚地表明我们对行为原因的无知程度,但可以肯定地说,我们 永远不会完全理解 是什么决定了我们的决定(根源可以追溯到复杂信息处理系统的可解释性问题),因此我们总是编造东西到 来理顺叙述 。
从中我们能学到什么
探究认知偏见可能有点可怕(维基百科列出了 157 个,是的,我数过了),但正如有人曾经说过的,知识是走向智慧的第一步。后退一步,观察你对自己不断的评论,并将其与你内心生活的复杂性进行对比,这可能会很有趣。
这可以帮助我们更加留意自己的偏见和虚构。我试着记录那些我发现自己公然胡说八道自己的行为,或者明显试图为自己辩护的时刻,但我并不幻想自己摆脱了偏见。它们在我们心中根深蒂固,以至于认为我们可以克服它们可能只是另一种认知偏见*。如果连丹尼尔·卡内曼都说他没有取得太大的进步,这可能是不可能的。*****
最后,我认为人工智能社区也应该注意这一点。我们的偏见表明,当涉及到我们自己的行为时,我们严重高估了 可解释性 ,所以我们应该意识到机器为自己的行为辩护的能力的潜在局限性。我们强烈希望他们能与我们交流,并公开他们的动机(正如 Lex Fridman 和 David Ferrucci 所言花一些时间在这里讨论),但我们应该注意他们不会变得太像我们人类。
毕竟,我们不希望有整天闲聊的机器人霸主。

















 893
893

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言










{kind=link}
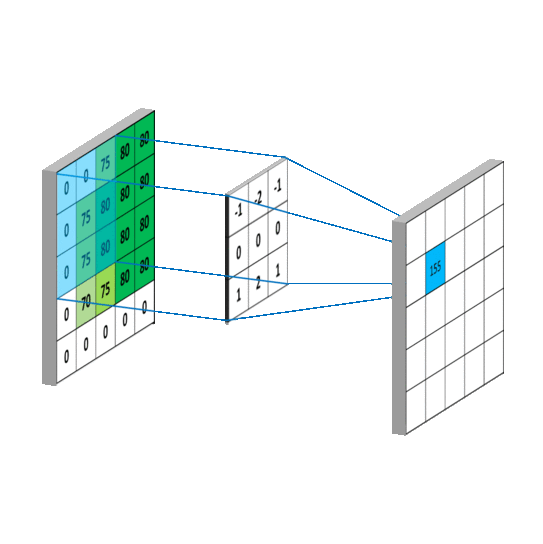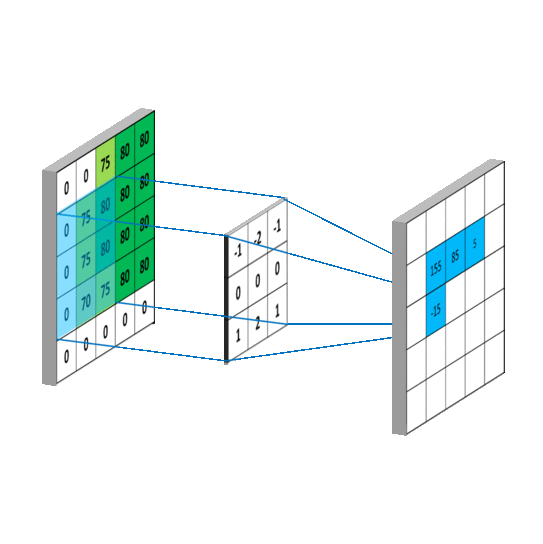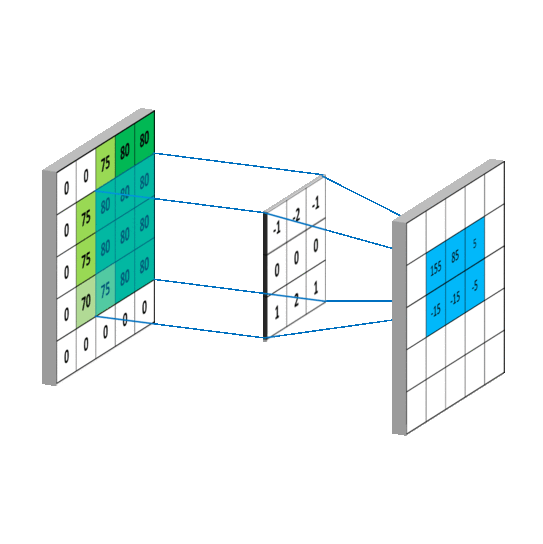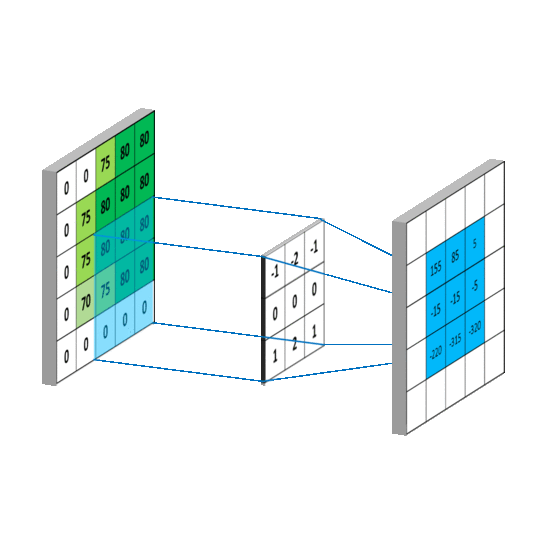{kind=link}
{kind=link}