







处理认知偏差:数据科学家的观点
偏见是影响我们日常生活的一个重要原则。我们都有自己的偏见,这些偏见是由我们的生活经历、教育、文化和社会交往形成的。偏见这个词与负面含义和偏见联系在一起,但在帮助人类在史前时代生存下来的“认知偏见”这个总括术语下,还有一个完全不同的偏见类别。
认知偏差是我们进化过程的结果。它们旨在通过在关键的时间敏感的情况下做出快速决策来帮助我们生存,并处理人类大脑有限的信息处理能力。简单地说,他们是我们直觉背后的原因。这些偏见往往会导致违背事实的非理性行为,并导致判断上的系统性错误。

在过去的 70 年里,社会心理学和行为经济学领域的研究人员发现了 200 多种不同的偏见。他们研究了这些偏见如何影响金融、管理和临床判断等领域。
随着数据科学模型在真实世界应用(如信用评分、欺诈检测、个人推荐)中的流行程度不断提高,数据科学家对认知偏差有更透彻的理解至关重要。通过意识到人类判断中的这些系统性错误,我们有望采取必要的措施,并在构建精确模型的方法中更加自觉。
数据科学项目通常包括五个主要步骤,
- 理解业务问题
- 数据收集和清理
- 探索性数据分析
- 模型构建和验证
- 洞察和交流结果
没有多少人关注覆盖数据科学项目中由于认知偏差而出现的盲点的必要性。下面,我列出了可能影响数据科学生命周期几个阶段的相关偏见。
数据收集
一旦数据科学家很好地理解了业务问题,他们就需要准备一个数据集来构建模型。在这个阶段,我们需要小心生存偏差、可用性偏差等引入的逻辑错误。
生存偏差 的产生是由于人类倾向于关注那些被选择的或成功超过潜在标准的数据点。
例如,如果我们开始建立一个模型来预测成功企业家的特征,那么现有的数据很可能主要集中在那些在企业中发家致富的人身上,而不是那些在创业过程中失败的人。我们都知道如果我们只建立正面标签的模型会有什么样的结局。

可用性偏差 是一种认知捷径,导致过度依赖我们能立即想到的事件或数据。通常,这种偏差可能会导致忽略可能会提高模型性能的新数据源。
例如,如果手头的任务是建立一个信用风险模型,我们的思维过程会引导我们收集财务和人口统计信息,因为这些信息很容易获得,也很容易收集。
我们并不真正关注可以从用户的网络浏览模式中推断出的个性特征。由于金融稳定并不意味着现实世界中偿还贷款的倾向,我们的模型将无法捕捉到这一信号。
探索性数据分析
数据探索是交付成功模型的关键部分。仔细的 EDA 提供了对数据的直观理解,并极大地有助于设计新功能。数据科学家需要注意现阶段的聚类错觉、锚定等谬误。
群集幻觉 指人类倾向于在随机事件中寻找模式,当它们不存在的时候。尽管随机性是普遍存在的,我们也很熟悉,但人类心理学的研究表明,我们很难识别它。
由于数据探索的目标是发现数据中的模式,我们更容易因为这种错觉而犯错误。适当的统计测试和持怀疑态度做额外的检查有助于克服这种错觉。
锚定 是一种偏见,这种偏见是由于过于重视首先发现/提供的信息而产生的。我们倾向于在第一手信息的基础上“锚定”我们所有的未来决策。
这是一个经常被电子商务和产品公司利用的原则,通过为第一个项目提供高得多的价格,以便连续的项目可以被认为是“便宜的”

在 EDA 过程中,第一个自变量的非常弱的线性相关性可能会影响我们对后续变量与因变量相关性的解释。拥有一套预定义的指导方针和阈值来指导分析的重要性将有助于克服这种偏见。
模型结构
在这个阶段,数据科学家的任务是选择和建立一个机器学习模型,提供最有效和最稳健的解决方案。在这一阶段,由于诸如热手谬误或跟风效应之类的偏见,有可能犯错误。
热手谬误 是一种现象,一个最近经历了成功结果的人被认为在未来的尝试中有更大的成功机会。这在体育运动中最常见,连续获胜的球队被认为是“热门”/“连胜”,因此有望获得更高的成功率。
类似地,我们这些数据科学家经常觉得,在没有检查其他合适模型的情况下,使用在前一个问题中给我们最好分数的模型是好的。
从众效应 是一种认知偏差,它解释了选择某个选项或跟随特定行为的冲动,因为其他人正在这样做。这导致了一个危险的循环,因为越来越多的人继续跟风,使得其他人更有可能跟风。

我们经常在分析中观察到这一点,在分析中,从业者经常追求深度学习/强化学习等时髦词汇,而不理解约束和相关成本。
通过试验一系列合适的机器学习算法和适当的交叉验证周期,我们可以克服模型选择阶段的偏差。
模型解释
在我们成功地构建了一个模型之后,同样重要的是解释模型输出,并提出一个连贯的故事以及可操作的见解。由于确认偏差,这一关键阶段可能会受到影响。
确认偏差 是所有偏差中最流行、最普遍的认知偏差。我们只听到我们想听到的,我们只看到我们想看到的。

我们强大的信念系统迫使我们忽略任何与我们先入为主的观念不符的信息。
任何挑战现有信念的新信息都应该以开放的心态对待。说起来容易做起来难,我同意。
上面提到的认知偏见绝不是一个详尽的清单,还有许多其他的原则和谬误驱动着人类的思维过程。我希望这篇文章为您提供了一些额外的见解,让您在未来的项目中更加怀疑和谨慎。
如果你有兴趣探索更多关于认知偏见的东西,看看巴斯特·本森写的这篇精彩的文章。
处理缺失数据

我最近完成了一个使用机器学习预测宫颈癌的项目 Jupyter 笔记本和所有相关的原始资料都可以在这个 GitHub repo 中找到。该项目的挑战之一是如何处理许多预测变量中的缺失值。本文描述了我是如何处理这些缺失数据的。
许多机器学习模型在遇到缺失数据时会抛出一个错误,并且有许多方法(和观点!)用于处理缺失值。最简单的方法之一是用某个特定变量的平均值来填充缺失值,我见过很多项目都是采用这种方法。它又快又简单,有时还能有好的效果。更困难的是,通过比较缺失值的记录和没有缺失该因子值的类似记录,使用复杂的方法来估算缺失值。每种方法都有优点和缺点,在我看来,最好的选择总是根据具体情况而定。
由于这是我的第一个涉及重大缺失值的机器学习项目,我决定采取一种容易解释的方法,即逐个查看每个因素,以更好地了解每个因素的分布。为此,我查看了计数图、箱线图和中心性度量(均值、中值、众数)。在评估这些信息后,我使用了以下一种或多种方法来处理缺失的信息:
- 如果因子缺少很大比例记录的值,请从数据集中删除该因子。
- 如果一小部分记录缺少某个因子的值,请删除这些记录。
- 向分类因子添加新选项。例如,如果因子有三个值:“val_1”、“val_2”、“val_3”,则可以添加一个额外的“未知”值。现在,因子将有四个值:“val_1”、“val_2”、“val_3”和“未知”。
- 将布尔因子转换为具有 3 个可能值的分类因子:“真”、“假”和“未知”。
- 创建一个新的布尔因子,将每条记录分类为包含(或不包含)有关该因子的信息。当然,这使得原始因子中的值仍然缺少一些信息。在这种情况下,原始因子的缺失值将使用剩余选项之一来填充。
- 用该因子的平均值、中值或众数填充缺失值。
- 用该因子中已经存在的值之一填充缺失的布尔值或分类值。可以使用因子中出现的每个值的相同比例来随机分配该值,或者如果有一个值出现频率最高,则缺失的值可以用最常见的值来填充。
这是我所处理的数据集中的因子的概述,显示了每个因子的缺失数据百分比,红色文本表示某个因子缺失信息。该信息最初是在委内瑞拉加拉加斯的“加拉加斯大学医院”收集的,由 35 个变量组成,包括 858 名患者的人口统计信息、习惯和历史医疗记录。出于隐私考虑,一些患者决定不回答一些问题,因此产生了缺失值。该数据集来自于 2017 年 5 月首次在线发表的一篇研究论文。

大多数变量都缺少数据,包括具有布尔值和数值的变量。因为我的策略涉及为多个因素重复创建相同的图和统计数据,所以我为此创建了一个函数:
def countplot_boxplot(column, df):
fig = plt.figure(figsize=(15,20))
fig.suptitle(column, size=20)
ax1 = fig.add_subplot(2,1,1)
sns.countplot(dataframe[column])
plt.xticks(rotation=45)ax2 = fig.add_subplot(2,1,2)
sns.boxplot(dataframe[column])
plt.xticks(rotation=45)
plt.show()
print('Min:', dataframe[column].min())
print('Mean:', dataframe[column].mean())
print('Median:', dataframe[column].median())
print('Mode:', dataframe[column].mode()[0])
print('Max:', dataframe[column].max())
print('**********************')
print('% of values missing:', (dataframe[column].isna().sum() / len(dataframe))*100)
对于我想要创建一个新的布尔因子的情况,我创建了一个函数:
def new_bool(df, col_name):
bool_list = []
for index, row in df.iterrows():
value = row[col_name]
value_out = 1
if pd.isna(value):
value_out = 0 bool_list.append(value_out) return bool_list
我还创建了几个简单的函数,使传递列名作为参数来填充缺失值变得容易:
# function to replace missing values with the mediandef fillna_median(column, dataframe):
dataframe[column].fillna(dataframe[column].median(), inplace=True)
print (dataframe[column].value_counts(dropna=False))
# function to replace missing values with the meandef fillna_mean(column, dataframe):
dataframe[column].fillna(dataframe[column].mean(), inplace=True)
print (dataframe[column].value_counts(dropna=False))# function to replace missing values with a value provideddef fillna_w_value(value, column, dataframe):
dataframe[column].fillna(value, inplace=True)
print(dataframe[column].value_counts(dropna=False))
让我们看一个因子的例子,我创建了一个新的布尔因子,然后用中值填充原始因子中缺少的值。首先,我将运行 countplot_boxplot 函数:
countplot_boxplot('Number of sexual partners', df2)

Min: 1.0
Mean: 2.527644230769231
Median: 2.0
Mode: 2.0
Max: 28.0
**********************
% of values missing: 3.0303030303030303
在选择如何填充缺失的信息之前,我希望保留包含在 3%的记录中的信息,这些记录缺失了该因子的值。通过调用上面显示的函数,我创建了一个名为“is_number_partners_known”的新布尔因子:
df['is_number_partners_known'] = new_bool(df, 'Number of sexual partners')
既然我已经获得了这些信息,我就来看看源因素的分布。平均值和众数都是 2.0,但是平均值被上限值的异常值拉高了。我选择用中位数(2.0)来填充缺失的值。
fillna_median('Number of sexual partners', df2)
现在,让我们来看一个具有非常偏斜的分布和高得多的缺失值百分比的因子。同样,首先我运行我的函数来查看分布。
countplot_boxplot('Hormonal Contraceptives (years)', df2)

Min: 0.0
Mean: 2.2564192013893343
Median: 0.5
Mode: 0.0
Max: 30.0
**********************
% of values missing: 12.587412587412588
到目前为止,零是该因素最常见的值,然而该值的范围长达 30 年,在该范围的较高区域有几个异常值。这些高异常值将平均值拉得远远高于中值。可以使用众数(0)或中位数(0.5)来填充缺失值。由于超过 12%的记录缺少某个值,因此该选择可能会对模型的性能产生重大影响,尤其是当该因素在给定的预测模型中很重要时。我选择用模式(0)填充缺失的值。
对于最后一个示例,我们来看两个单独的布尔标准因子:
- 性病:结肠瘤病
- 性病:艾滋病
这两个布尔因子(“STDs”,也是布尔型)的“父”列与其所有“子”列具有相同的缺失值百分比(大约 12%)。我之前选择用 False(零)填充父因子的缺失值。然后,我选择用 False(零)填充所有“儿童”因素(每个因素代表一种不同的性传播疾病)中缺失的值。后来,当我为数据集中的所有因素运行相关矩阵时,我注意到有两行是空白的。这就是我如何发现在这两个因素中,零是唯一发生的价值。这些因素中的原始数据只有假(零)或缺失。当我用零填充缺失值时,因子不包含任何信息,因为每个记录都有相同的 False 值。我选择从数据集中删除这两个因素。
在对所有因素重复上述过程之后,我检查了整个数据库中 NaN 的计数:
df2.isna().sum()
下面的输出显示不再有丢失的值——这正是我需要看到的。
Age 0
Number of sexual partners 0
First sexual intercourse 0
Num of pregnancies 0
Smokes 0
Smokes (years) 0
Smokes (packs/year) 0
Hormonal Contraceptives 0
Hormonal Contraceptives (years) 0
IUD 0
IUD (years) 0
STDs 0
STDs (number) 0
STDs:condylomatosis 0
STDs:vaginal condylomatosis 0
STDs:vulvo-perineal condylomatosis 0
STDs:syphilis 0
STDs:pelvic inflammatory disease 0
STDs:genital herpes 0
STDs:molluscum contagiosum 0
STDs:HIV 0
STDs:Hepatitis B 0
STDs:HPV 0
STDs: Number of diagnosis 0
STDs: Time since first diagnosis 0
STDs: Time since last diagnosis 0
Dx:Cancer 0
Dx:CIN 0
Dx:HPV 0
Dx 0
Hinselmann 0
Schiller 0
Citology 0
Biopsy 0
is_number_partners_known 0
is_first_intercourse_known 0
is_number_pregnancies_known 0
dtype: int64
数据现在已经准备好被分成训练组和测试组,用于我将要探索的监督学习模型。更多信息,请看这里的 Jupyter 笔记本。
数据集引用:
凯尔温·费尔南德斯、海梅·卡多佐和杰西卡·费尔南德斯。具有部分可观察性的迁移学习应用于宫颈癌筛查。伊比利亚模式识别和图像分析会议。斯普林格国际出版公司,2017 年。https://archive . ics . UCI . edu/ml/datasets/宫颈癌+癌症+% 28 风险+因素%29#
处理多类数据
森林覆盖类型预测

Photo by Sergei Akulich on Unsplash
当你遇到一个包含三个以上类别的分类问题时,你有没有想过该怎么办?你是如何处理多类数据的,你是如何评估你的模型的?过度适应是一个挑战吗——如果是,你是如何克服的?
请继续阅读,了解我是如何在我的最新项目中解决这些问题的——从美国林务局提供的数据集分析森林覆盖类型,该数据集存放在 UCI 机器学习库。
这个数据集特别有趣,因为它由分类变量和连续变量混合组成,这在历史上需要不同的分析技术。这些变量描述了每个样本森林区域的地质情况,一个多类标签(七种可能的树木覆盖类型之一)作为我们的目标变量。
根据 Kaggle 的说法,这七种可能的封面类型如下:
- 云杉/冷杉
- 黑松
- 美国黄松
- 杨木/柳树
- 阿斯
- 花旗松
- 克鲁姆霍尔茨
我认为这是我在sharpes minds研究期间所学知识的一个很酷的应用,因为成功的森林覆盖类型分类有如此多的积极变化的潜力,特别是在环境保护、动植物研究和地质研究等领域。
这篇中型博客文章将专注于我探索的基于树的方法来分析这个数据集,但你可以查看我的整个回购,其中包含其他机器学习方法,在这里:https://github.com/angelaaaateng/Covertype_Analysis
探索性数据分析
第一步是探索性的数据分析。我用 pandas 加载数据并将信息读入数据帧。
然后,我检查了数据类型,以确保我的数据集中没有异常——并更好地了解我正在处理哪种数据。基于这一点,我们还看到没有 NaN 值,列是合理的,并且总的来说,数据集非常干净,在这个阶段和这个项目的目标中不需要额外的清理。
我们还看到,我们正在处理一个相当大的数据集,因此很可能需要从 581,012 个条目中进行缩减采样。我们还知道我们有 55 个列或特性,这将在下一节中更彻底地探讨。接下来,让我们看看这些森林覆盖类型的频率分布。

数据集的大部分由 covertype 1 和 covertype 2 组成,对于这种不平衡的数据集,我们必须选择缩减采样或构建玩具数据集的方式。关键在于理解这个问题的答案:我们的目标是平等地表示所有的覆盖类型,还是按照每个覆盖类型在整个数据集中出现的频率比例来表示它?
一个重要的考虑因素是,下采样确实减少了我们可以用来训练模型的数据点的数量,所以尽管有这种分析,使用所有样本总是可能是更明智的选择。这在很大程度上取决于业务优先级,包括将一个 covertype 误认为另一个 cover type 的相对成本。例如,如果我们同样关注每个覆盖类型的分类准确性,那么通过缩减采样来获得覆盖类型的均匀分布可能是最有意义的。然而,如果我们只关心封面类型 1 相对于其他 6 个封面类型的分类,那么我们可以使用不同的采样方法。
尽管如此,对于这个项目,我将从假设我们同样关心正确地分类每个 covertype 开始,并且我将在文章的结尾探索这个决定的影响。
更深入地研究每种封面类型的统计数据,我们会发现样本之间的计数差异很大,我们还会看到每个变量的数据分布很广。


特别是对于高程,我们看到覆盖类型 1 至 7 的标准偏差范围为 95 至 196。我们还看到,对于封面类型 4,我们最少有 2,747 个数据点,而对于封面类型 2,我们有 28,8301 个数据点,这进一步表明我们有一个不平衡的数据集。

我们可以探索连续变量之间的相关性,以便使用相关矩阵更好地理解数据中的潜在关系:

请注意,我特意在此相关图中省略了分类变量,因为相关矩阵显示了不同特征对之间的皮尔逊相关系数,皮尔逊相关对于非连续输入没有意义。根据上述相关矩阵,似乎与覆盖类型线性相关的连续变量是坡度和高程以及坡向。我们的三个山体阴影特征似乎也高度相关。这是意料之中的,而且看起来也合乎逻辑,因为它们都测量相似的东西。这些山体之间的相关性表明,它们可能包含大量冗余信息——当我们进行特征选择时,我们将回到这个想法。
数据探索和建模并不总是不同的事情
基于我们之前展示的数据探索,我们看到目标变量是多类和二进制的。为了确定什么是“好”的模型,以及我们如何定义这个项目的成功,我首先研究了建立一个基线模型。
然而,在我们开始训练多类基线模型之前,我们需要首先对数据进行采样。在我们所有的 500,000+个条目上训练一个模型不仅耗时,而且效率非常低。
对于我们的特定数据集,我们将从一个简单的随机抽样方法开始,其中我们确保了一个平衡的类分布,原因在本文的开始部分有概述。这意味着我们想要从 1 到 7 的每个 covertype 中抽取 n 个条目的样本,并确保每个类都有相同数量的条目。
我们将从 n = 2700 开始,这是最小类的最小数据点数,我们将从使用简单的决策树来建模数据开始。我们这样做的目的是通过研究我们的决策树如何查询我们的数据集来更好地理解我们的数据,并获得我们的分类性能的下限。这一步将我们置于数据探索和预测建模之间的模糊边界,这是一个灰色地带,我发现它特别有助于探索,尤其是基于树的模型。
决策树基线模型
让我们从更好地理解我们的数据开始。我首先用一个非常短的决策树来拟合缩减采样数据集(使用 max _ depth 3),并可视化结果:

我们要注意的第一件事是 elevation 参数的重要性,在这个公认的简单模型中,它似乎支配着所有其他参数。这与我们之前在相关矩阵中发现的一致,相关矩阵显示高程是与我们的目标变量(Cover_Type)最相关的连续特征。
虽然这个模型的 max_depth 是严格限制的,但它仍然比随机猜测表现得好得多:它在所有 7 个类中获得的预测准确性是 X%(训练准确性)和 Y%(验证准确性)。
接下来,我想看看无约束模型(没有 max_depth 为 3)将如何执行,以更好地了解简单决策树对该数据集的全部预测能力。我用 sklearn 提供的默认参数训练了一个新的树(其中包括一个 max _ depth None,这意味着树将无限制地增长)。结果如下:
我们将使用准确度分数来衡量绩效。
predictions = dtree.predict(X_test)print ("Decision Tree Train Accuracy:", metrics.accuracy_score(y_train, dtree.predict(X_train)))
print ("Decision Tree Test Accuracy:", metrics.accuracy_score(y_test, dtree.predict(X_test)))from sklearn.metrics import classification_report
print(classification_report(y_test, y_pred))


我们可以看到这里有过度拟合,因为训练数据的准确度分数是 1。这是一个重要的结果,因为它与决策树倾向于过度拟合的一般趋势是一致的。为了好玩,我想通过绘制作为 max_depth 参数的函数的训练和验证精度来展示这种过度拟合过程是如何进行的:

上图向我们展示了测试精度低于训练精度,这就是过度拟合的定义:我们的模型正在将自己扭曲成完美捕捉训练集中趋势的形状,代价是无法归纳出看不见的数据。
为了总结我们的数据探索和初始建模步骤,让我们来看看将我们的深度树应用于验证集所产生的混淆矩阵:

看上面的混淆矩阵,似乎这些错误大部分来自类 1 和类 2。
随机森林基线模型
既然我们知道了我们的问题会带来什么,是时候认真对待建模了。随机森林是我将在这里使用的模型,因为 1)它们是健壮的,并且概括得很好;2)它们易于解释。随机森林是决策树的集合:它们由一堆独立的决策树组成,每个决策树都只使用我们训练集中的一个子集进行训练,以确保它们正在学习以不同的方式进行预测。他们的输出然后通过简单的投票汇集在一起。
和往常一样,我的第一步是使用开箱即用的随机森林分类器模型。这导致了性能的大幅提升:验证集的准确率为 86%,训练集的准确率为 100%。换句话说,这个模型是过度拟合的(或者说,集合中的每一个决策树都是过度拟合的),但是我们仍然看到了通过将一堆过度拟合的决策树汇集在一起在性能上的巨大改进。
随机森林特征选择
F 首先,让我们进行特征选择,以确定影响我们的随机森林集合模型准确率的最具预测性的变量。人们为此使用了许多不同的方法,但是在这里,我们将集中于排列特征重要性。置换特征重要性的工作原理是在我们的验证集中选择一列(即特征),然后随机洗牌,从而破坏该特征与我们的模型用来进行预测的所有其他特征之间的相关性,最后在这个新洗牌的验证集上测量我们的模型的性能。如果性能显著下降,这就告诉我们,我们改变的特性一定很重要。
使用排列重要性,我们看到以下结果:

基于这一点,似乎只有我们的一小部分特征支配着其他特征。事实上,如果当我试图只保留这里指出的前 13 个特征时,我最终只牺牲了可以忽略不计的准确性,在验证集上再次获得了 86%的准确性。
随机森林-超参数调整
O 随机森林中超参数调整的一个关键是,一般来说,模型的性能只会随着我们添加到集合中的决策树数量的增加而增加。因此,在我们使用 GridSearchCV 调优完所有其他相关参数(如 max_depth、min_samples_leaf 和 min_samples_split)之后,它实际上是我们要调优的最后一个参数。
我们得到最后一组最佳估计值,给出这些最佳参数,然后将它们应用于我们的模型并比较结果:
n_best_grid = n_grid_search.best_estimator_n_optimal_param_grid = {
'bootstrap': [True],
'max_depth': [20], #setting this so as not to create a tree that's too big
#'max_features': [2, 3, 4, 10],
'min_samples_leaf': [1],
'min_samples_split': [2],
'n_estimators': [300]
}nn_grid_search = GridSearchCV(estimator = n_rfc_gs, param_grid = n_optimal_param_grid,
cv = 3, n_jobs = -1, verbose = 2)nn_grid_search.fit(X_train, y_train)nn_rfc_pred_gs = nn_grid_search.predict(X_test)nn_y_pred_gs = nn_grid_search.predict(X_test)
print ("Random Forest Train Accuracy Baseline After Grid Search and N-estimators Search:", metrics.accuracy_score(y_train, nn_grid_search.predict(X_train)))
print ("Random Forest Test Accuracy Baseline After Grid Search and N-estimators Search:", metrics.accuracy_score(y_test, nn_grid_search.pre

我们的模型性能有了适度的提高,从 0.860 提高到 0.863。这并不完全令人惊讶——超参数调优并不总是对性能产生巨大影响。
最后,我们将查看 num_estimators 参数,注意一起绘制训练集和验证集的精度。正如所料,两者都随着 num_estimators 近似单调增加,直到达到一个平稳状态:

然后,我们可以比较我们当前的模型及其基于准确性的性能,并将其与原始的开箱即用模型进行比较。
这里要讨论的重要一点是,在最初的运行中(没有在这篇博文中显示,但在笔记本这里),我们的测试准确率如何从没有参数搜索的 86%上升到使用 GridSearchCV 后的 84%。我们可以看到,调整后的模型并不比根据默认值训练的 RF 表现得更好。这是因为方差对我们数据集的影响 GridSearch 很难区分最好的超参数和最差的超参数,因此使用开箱即用的随机森林模型可能会节省时间和计算能力。
与这一点相关的一些重要的可能性如下:
- 我们使用 cv = 3 的 GridSearch(三重交叉验证)。这意味着对于每个超参数组合,模型仅在训练集中的 2/3 的数据上进行训练(因为 1/3 被保留用于验证)。因此,基于这一点,我们预计 GridSearch 会产生更悲观的结果。避免这种情况的一种方法是增加 cv 的值,这样就有了更小的验证集和更大的训练集。
- 总是有噪声(或“方差”)要考虑:当我们在不同的数据集上训练我们的模型时,它通常会给出不同的结果。如果我们的模型的方差足够高(这意味着它的性能很大程度上取决于它被训练的特定点),那么 GridSearch 实际上可能无法区分“最好”的超参数和最差的超参数。这是对我们目前结果最可能的解释。这意味着我们还不如使用默认值。
- 我们可以更深入探索的另一个领域是 max_features 。
那么,我们如何做得更好呢?根据我们的混淆矩阵,似乎类 1 和类 2 是大部分错误的来源。在我的下一个项目中,我们将探索模型堆叠,看看我们是否可以在这里获得任何准确性。
如有任何问题或意见,欢迎在推特 @ambervteng 联系我。感谢阅读,下次见!
Github 回购:https://github.com/angelaaaateng/Covertype_Analysis
Heroku Web App:https://covertype.herokuapp.com/
参考资料:
[1] DataCamp 决策树教程https://www . data camp . com/community/tutorials/Decision-Tree-classification-python
[2] Seif,g .用于 ML 的决策树https://towardsdatascience . com/a-guide-to-Decision-Trees-for-machine-learning-and-data-science-Fe 2607241956
[3] Matplotlib 文档https://Matplotlib . org/3 . 1 . 1/API/_ as _ gen/Matplotlib . py plot . x ticks . html
亲爱的兰登森林
给我最喜欢的算法的一封信
亲爱的兰登森林,我叫胡安,我是你的超级粉丝。
最近,我想了很多关于你的事情,想知道你感觉如何,思考你的未来。你看,我很难过,你的树叶沙沙作响的声音不再像以前那样被听到了。自从几年前,你的其他粉丝和实践者决定离开你的森林小径,以换取一个更加神经化和网络化的生活。虽然我肯定他们有他们的理由,但这让我很难过。让我告诉你一些事情。

Photo by Sebastian Unrau on Unsplash
当我开始学习机器学习时,我很难理解我们热爱的领域中的许多基本概念。哦,我的朋友,是的。你不知道。然而,当我遇见你最小的兄弟,决策树,我称之为 Detri 时,我的运气开始转变。
那时,通过 Detri,我学到了我迫切需要的基础和基本概念。我不知道为什么,但当我开始从树枝、树叶和流程图的角度看待事物时,我有了一个顿悟的时刻,突然之间,许多难以理解的话题变得更容易理解了。我是多么高兴啊!

Photo by Jeremy Bishop on Unsplash
明白了这一点后,我开始在我的许多项目中使用决策树;口袋妖怪数据、游戏数据和不可避免的虹膜数据集是遍历你枝叶繁茂的兄弟的一些数据。不仅如此,对于我的论文,你猜我用了什么?没错。
在其中一次爬树探险中,我决定成为一名树木学家,并学习这种算法是如何构建的。因此,我试图回答以下一些问题:节点到底是什么?树是怎么做出来的?哦,等等,我也可以用它来回归吗?我纯粹是惊讶。在这次冒险中,我发现了你。你随意的森林,我喜爱的树木的合奏。那是多么美好的一天啊。

Photo by Lukasz Szmigiel on Unsplash
认识你之后,我去了很多很多次穿越你的森林的徒步旅行。突然,我更新了我以前的大部分模型,献给你——结束孤独树的时代,欢迎来到多重树的时代!嗯,我不想吹牛,但我知道你的一些事情;我从树木学家变成了森林学家。想知道一些伟大的事情吗?当我得到我的第一份工作时,我用你完成了我的第一个监督学习任务!当然,我做到了!我记得我装修了一个春天般的,广阔的,但不深的,看起来像国家公园的森林。哇,你是多么优雅。一波又一波的垃圾邮件,你控制住了(顺便说一句,信心十足!),让我(和我的老板们)真的很满意。
不幸的是,过了一段时间,我们不得不换掉你。你只是变得有点太重了,不适合训练。我无意冒犯你!只是我们的要求变了,我们的策略也变了…或者我们只是没有准备好迎接你的伟大。即使在你离开后,我仍在我自己的代码森林中不断发现你的小枝、树叶和树枝的痕迹,每一次它都给我带来微笑;“啊哈!“看谁来了”,当我在第 37 行看到你的部分作品时,我说。走了,但没有被遗忘。

Me talking about you at Berlin Buzzwords 2017
就像我在工作中不再利用你一样,似乎世界上大多数人也是这样做的。尽管 Google Trends 的数据显示并非如此,但我感觉你的沙沙声没有以前那么大了。现在,我很少看到由你统治的用例,也很少看到人们在会议上谈论你;就像秋天终于来到了树林。
但是,嘿,我也听到了好的故事!最近,你的堂兄梯度助推树木或助推器,我称之为,已经遍布新闻,这太棒了。我是说,有你这个导师,还能有什么问题。
所以,是的,我的好朋友,这就是我的原话。我真诚地希望你一切都好。然而,以积极的语气结束,我要说的是,如果我学到了什么,那就是在这个领域,春天总是在拐角处,所以我肯定会收到你的来信。
你的粉丝,胡安。

Photo by Johannes Plenio on Unsplash
人工智能安全辩论

Photo by @drewbutler Unsplash
杰弗里·欧文、保罗·克里斯蒂安诺和达里奥·阿莫代伊谈人工智能安全
当我进入人工智能(AI)领域的 AI 安全领域时,我发现自己既困惑又不知所措。你从哪里开始?我昨天在报道了 OpenAI 的金融发展,他们是 AI 安全方面的最权威之一。因此,我认为看一看他们的论文会很有趣。我将关注的论文名为人工智能安全辩论,于 2018 年 10 月发表。你当然可以在 arXiv 里自己看文章,反过来批判我的文章;那将是最理想的情况。这场关于 AI 辩论的辩论当然还在继续。
这篇论文的作者是谁?
杰弗里·欧文是 OpenAI 人工智能安全团队的成员。他之前一直在谷歌大脑工作。他收集了大量论文,从模拟、匹配、张量流。
Paul Christiano 从事人工智能校准工作。他是 OpenAI 安全团队的成员。他也是人类未来研究所的副研究员。他被引用最多的论文之一是关于人工智能安全中的具体问题。
达里奥·阿莫德伊是 OpenAI 的研究主管。此前,他是谷歌的高级研究科学家,是斯坦福大学医学院的博士后学者,在那里他致力于将质谱应用于细胞蛋白质组的网络模型以及寻找癌症生物标志物。
零和辩论游戏
该论文建议通过在零和辩论游戏中的自我游戏来训练代理人。
给定一个问题或提议的行动,两个代理人轮流在一定限度内做简短的陈述,然后一个人判断哪个代理人给出了最真实、最有用的信息
这是因为需要学习复杂的人类目标和偏好。在让人工智能保持安全方面,我们有哪些挑战?他们列举了几个例子:
- 学会让一个智能体的行为与人类的价值观和偏好保持一致,这可能会导致不安全的行为,而且随着系统变得越来越强大,情况可能会变得更糟。
- 结盟是一个训练时的问题:很难追溯性地修正受过训练的非结盟代理的行为和激励。
- 对于人类来说太难完成的任务,但是人类仍然可以判断行为或答案的质量。因此,这就是基于人类偏好的强化学习(HumRe) 。
将机器行为与人类行为联系起来很难
作者认为,人类有时可能无法判断答案。行为可能太难理解,或者问题本身可能有缺陷。他们要求读者想象一个既能给出答案又能指出缺陷的系统。当系统指出缺陷时,对缺陷的过程或判断可能是错误的。
他们的最终目标是自然语言辩论,由人类来评判代理之间的对话。
他们的论文结构如下:
- 介绍对齐的辩论模型及其有用性
- 提出使用图像任务的初步实验
- 讨论辩论模式乐观和悲观的原因
- 展示辩论如何减少不对称或合并多个代理
- 采用辩论和放大方法的混合模型
- 结束语是对未来工作的要求。
辩论模型(TDM)
在展示给两个代理的 TDM 问题中,两个代理都给出答案,然后由人类决定谁赢。作者声称,在辩论游戏中,撒谎比反驳谎言更难。他们宣称简短的辩论是强大的。然而,还有许多更复杂的任务。他们列出了一系列可以改进模型的方向:
- **查询可能太大:**问题可能太大而无法向人类展示,或者无法期望人类理解。
- **答案可能太大:**同样,一个问题的最佳答案可能大得惊人。例如,答案可能是一个很长的文档。
- **人类的时间是昂贵的:**我们可能缺乏足够的人类时间来评判每一场辩论。
- **环境交互:**如果我们想要一个系统采取影响环境的行动,比如操作一个机器人,期望的输出是一系列的行动。
- **长期状态:**每个辩论都是一个独立的游戏,但是代理可以使用过去辩论的信息来做出更好的决策
TDM 实验
在实验中,他们预先指定一个诚实的代理人和一个说谎的代理人。他们还训练了另一个诚实优点的例子。为这家报纸建立了一个名为 https://debate-game.openai.com 的网站。在这个页面上可以进行实验。
乐观的理由
我在论文中观察到的一个有趣的句子是关于诚实 : *“为了保持诚实的行为,人类法官应该被指示奖励那些承认无知并成功证明无知是合理的代理人。”*然而,正如这篇论文所指出的,承认无知存在一个平衡问题:如果最佳策略是争论我们永远无法确定地知道任何事情,那么争论是无用的。
*“*没有对手会因为愚弄人类而获得奖励 ,这很好,因为(1)我们不知道这意味着什么,以及(2)我们没有明确地训练代理人进行欺骗。”
作者认为,人类之间现存的对抗性辩论是一个有用的类比。法律论证特别包括领域专家向没有领域知识的人类法官或陪审团解释论证的细节。
担忧的理由
辩论作为一种人工智能对齐的方法可能会失败,他们列出了一些原因。一是:也许人类想听什么就相信什么?如果一个演员以一个人类已经相信的虚假陈述开场,那么另一个演员的任何论点会说服他们吗?
另一个问题是,人类是否会理解这些争论。他们提出了一个问题:一个真实的人是否能玩好这个游戏,以至于最佳的游戏是诚实的行为。其中一个代理能够偷偷插入一个看似合理但包含隐藏缺陷的语句,而另一个代理却没有指出这个缺陷吗?
人类作为足够的法官是一个经验性的问题。如果答案是否定的,我们可以问这个模型是否在诚实承认无知时失败了。作者质疑诚实是否是最好的视角:
- 许多判断需要综合不同的证据,而辩论只探索一条证据。
- 复杂的辩论将依赖于法官无法理解的概念。
- 复杂的推理可能涉及人类尚不了解的过程。
接受辩论训练的特工会失去表现吗?直接培训可能更难;广告系列是一种很好的思考方式;我们可能不想要无法解释的答案。辩论可能无法与其他方法竞争,因为辩论需要人的参与。他们建议:“… 训练人类法官的模型,并将其用于采样,但与纯模拟环境竞争可能仍然具有挑战性。”
安全漏洞:一个足够强大的错位人工智能可能能够通过文本通道说服人类做危险的事情
人工智能安全二分法:如果代理在整个训练过程中保持诚实,我们会更安全,但如果辩论进行得足够好,突然的大规模叛逃得到纠正,我们也会更安全。
一个足够强大的错位爱丽丝可以从内部侵入辩论环境,让游戏不再是零和游戏。
训练超人 AI 令人信服听起来很危险!
这是我最喜欢的标题,它有一个感叹号,所以我决定在这个标题中逐字引用它。最大化说服的训练安全吗?
有变化的 TDM 辩论
辩论模型依赖于在力量上近似匹配的代理。对称性被提出:(1)如果一个玩家移动另一个玩家;(2)比较两个游戏;(3)科米( from Go )第二个玩家获得额外的积分来对抗第一个玩家的优势。
不完全信息博弈是一个挑战。此外,许多智能体的一个困难是:“…人类必须能够判断辩论中的陈述是好是坏,这可能比判断整个辩论要困难得多。”
他们将辩论和扩展总结为:
- 辩论:两个代理人轮流在对抗的环境中说服一个人类法官。
- **扩增:**一个智能体在一个人身上训练,结合对智能体的递归调用。
他们建议,通过对提问者进行对抗性训练,让放大更接近辩论。作者声明:“我们可以通过训练辩论者根据人类提供的陈述进行辩论,这相当于将演示注入 RL 中。”
他们的结论
未来的工作领域将包括:更丰富的理论模型;测试价值判断的人体实验;模拟辩论中人的方面的 ML 实验;自然语言辩论;以及辩论和其他安全方法之间的相互作用。
旁注机器行为
作为最后的补充说明,我想说这些想法可能已经导致或影响了该领域的其他讨论。在麻省理工学院媒体实验室 2019 年 4 月 24 日发表的一篇名为《机器行为》的论文中,一群科学家呼吁研究:
“…一个广泛的研究机器行为的科学研究议程,该议程纳入并扩展了计算机科学学科,并包括了来自各个科学领域的见解。”

Machine behaviour lies at the intersection of the fields that design and engineer AI systems and the fields that traditionally use scientific methods to study the behaviour of biological agents.
我今天浏览的论文的作者之一 Dario Amodei 在机器行为文章中提到了他的工作:人工智能安全中的具体问题。安全这个词经常在机器行为的上下文中被提及,看到诚实或说谎的行为者产生的困境是完全有意义的。
辩论辩论
老实说,我觉得很难对这场辩论进行辩论。这似乎是一个显而易见的结论,然而其中的复杂性远远超出了我的能力和理解。通过阅读这篇文章,我可以肯定的一件事是,有一些优秀的人正在研究这个主题,但他们正在以非常工程化的重点来处理这个问题。然而,他们确实说得很清楚,需要更多的人参与到这个过程中来,与此同时,他们还认为“人的时间是昂贵的”。
考虑到声明的上下文,这是可以理解的。特别是通过 OpenAI 的首席技术官 Greg Brockman 最近的另一个声明“OpenAI 的 DOTA 2 机器人已经训练了相当于 45000 人类年的时间。”OpenAI Five 在一场著名的视频游戏中击败了世界冠军。尽管这是很好的营销,但同样多的时间和抽象成扭曲的时间观的实践可能会给人以人工智能的错误印象。
这就是人类和/或机器行为之间具有挑战性的区别。从处理或计算转移到与人类的进一步比较,进一步模糊界限——有用吗?
这场辩论当然仍未结束。
我今天文章中的关键概念
基于人类偏好的强化学习:对于人类来说太难执行的任务,但是人类仍然可以判断行为或答案的质量
机器行为:位于设计和工程人工智能系统的领域和传统上使用科学方法研究生物制剂行为的领域的交叉点。
辩论模型安全漏洞:一个足够强大的错位 AI 或许能够说服人类去做危险的事情。
人工智能安全二分法:如果代理在整个训练过程中保持诚实,我们会更安全,但如果辩论进行得足够好,突然的大规模叛逃得到纠正,我们也会更安全。
这是第 500 天的第 52 天
我已经坚持每天写一篇文章 50 天了。这些文章在探索人工智能领域中社会科学和计算机科学的交叉方面表现得很一般。
正确调试 tensorflow 代码(没有那么多令人痛苦的错误)

当讨论在 tensorflow 上写代码时,总是拿它和 PyTorch 比较,谈论框架有多复杂,为什么tf.contrib的某些部分工作得如此糟糕。此外,我认识很多数据科学家,他们与 tensorflow 的交互只是作为预先编写的 Github repo 的依赖,可以克隆,然后成功使用。对这个框架持这种态度的原因是非常不同的,它们绝对值得再读一遍,但今天让我们关注更实际的问题:调试用 tensorflow 编写的代码并理解它的主要特性。
核心抽象
- **计算图形。**第一个抽象是计算图
tf.Graph,它使框架能够处理惰性评估范式(不是急切执行,而是通过“传统的”命令式 Python 编程实现的)。基本上,这种方法允许程序员创建tf.Tensor(边)和tf.Operation(节点),它们不会立即被评估,而是仅在图形被执行时被评估。这种构建机器学习模型的方法在许多框架中非常常见(例如,Apache Spark 中使用了类似的思想),并且具有不同的优点和缺点,这在编写和运行代码的过程中变得很明显。最主要也是最重要的优势是,数据流图无需显式使用multiprocessing模块就能轻松实现并行和分布式执行。在实践中,编写良好的 tensorflow 模型在启动后立即使用所有内核的资源,无需任何额外配置。
然而,这种工作流程的一个非常明显的缺点是,只要你正在构建你的图形,但没有(或没有)提供一些输入就无法运行它,*你永远无法确定它不会崩溃。它肯定会崩溃。*此外,除非你已经执行了图形,否则你也无法估计它的运行时间。
值得谈论的计算图的主要组成部分是图集合和图结构。严格地说,图结构是前面讨论的节点和边的特定集合,而图集合是变量的集合,可以对其进行逻辑分组。例如,检索图的可训练变量的常用方法是tf.get_collection(tf.GraphKeys.TRAINABLE_VARIABLES)。 - **会话。**第二个抽象与第一个高度相关,并有一点复杂的解释:tensorflow 会话
tf.Session用于连接客户端程序和 C++运行时(如您所知,tensorflow 是用 C++编写的)。为什么是 C++?答案是,通过这种语言实现的数学运算可以得到很好的优化,因此,计算图形运算可以得到很好的处理。
如果您使用的是低级 tensorflow API(大多数 Python 开发人员都使用),tensorflow 会话将作为上下文管理器调用:with tf.Session() as sess:使用语法。没有向构造函数传递参数的会话(如前一个示例)仅使用本地计算机和默认 tensorflow 图的资源,但它也可以通过分布式 tensorflow 运行时访问远程设备。实际上,没有会话就没有图(没有会话就不能执行),而会话总是有一个指向全局图的指针。
深入研究运行会话的细节,值得注意的要点是它的语法:tf.Session.run()。它可以将获取(或获取列表)作为参数,获取可以是张量、操作或类张量对象。此外,feed_dict 可以和一组选项一起传递(这个可选参数是tf.placeholder对象到它们的值的映射(字典))。
可能遇到的问题及其最可能的解决方案
- **会话加载并通过预训练模型进行预测。**这就是瓶颈,我花了几周时间去理解、调试、修复。我想高度集中在这个问题上,并描述重新加载预训练模型(其图形和会话)和使用它的两种可能的技术。
首先,当我们谈论加载模型时,我们真正的意思是什么?要做到这一点,我们当然需要在之前进行训练和保存。后者通常通过tf.train.Saver.save功能完成,因此,我们有 3 个扩展名为.index、.meta和.data-00000-of-00001的二进制文件,其中包含恢复会话和图形所需的所有数据。
要加载这样保存的模型,需要通过tf.train.import_meta_graph()恢复图形(参数是扩展名为.meta的文件)。按照上一段描述的步骤,所有变量(包括所谓的“隐藏”变量,将在后面讨论)将被移植到当前图形中。为了检索某个有名字的张量(记住,由于张量创建的范围和操作结果,它可能与你初始化它的张量不同),应该执行graph.get_tensor_by_name()。这是第一种方式。
第二种方式更明确,也更难实现(在我一直在研究的模型架构中,我在使用它时没有成功地执行图形),其主要思想是将图形边(张量)显式保存到.npy或.npz文件中,然后将它们加载回图形中(并根据它们被创建的范围分配适当的名称)。这种方法的问题是它有两个巨大的缺点:首先,当模型架构变得非常复杂时,控制和保持所有的权重矩阵也变得非常困难。第二,有一种“隐藏的”张量,它是在没有显式初始化的情况下创建的。例如,当你创建tf.nn.rnn_cell.BasicLSTMCell时,它会创建所有需要的权重和偏置来实现 LSTM 单元。变量名也会自动分配。
这种行为可能看起来没问题(只要这两个张量是权重,并且不手动创建它们,而是让框架来处理它们似乎非常有用),但事实上,在许多情况下,它不是。这种方法的主要问题是,当你查看图的集合时,看到一堆变量,你不知道它们的来源,你实际上不知道你应该保存什么,以及在哪里加载它。绝对诚实地说,很难将隐藏变量放在图中的正确位置,并恰当地操作它们。比应该的要难。 - **在没有任何警告的情况下两次创建同名张量(通过自动添加 _index 结尾)。**我认为这个问题没有前一个问题重要,但是只要它导致大量的图形执行错误,这个问题就一定会困扰我。为了更好地解释问题,我们来看例子。
例如,您使用tf.get_variable(name=’char_embeddings’, dtype=…)创建张量,然后保存并在新会话中加载。您已经忘记了这个变量是可训练的,并且已经通过tf.get_variable()功能以相同的方式再次创建了它。在图形执行过程中,将会出现如下错误:FailedPreconditionError (see above for traceback): Attempting to use uninitialized value char_embeddings_2。当然,这样做的原因是,您已经创建了一个空变量,并且没有将它移植到模型的适当位置,而它可以被移植到,只要已经包含在图中。
如您所见,没有出现任何错误或警告,因为开发人员已经用相同的名称创建了两次张量(即使是 Windows 也会这样做)。也许这一点只对我来说至关重要,但这是 tensorflow 的独特之处,也是我不太喜欢的行为。 - 在编写单元测试和其他问题时手动重置图形。由于很多原因,测试 tensorflow 编写的代码总是很困难。第一个——最明显的一个——已经在这一段的开头提到了,听起来可能很傻,但对我来说,这至少是令人恼火的。因为对于运行时访问的所有模块的所有张量,只有一个默认的张量流图,所以在不重置图的情况下,不可能用例如不同的参数来测试相同的功能。这只是一行代码
tf.reset_default_graph(),但是知道它应该写在大多数方法的顶部,这个解决方案就变成了某种恶作剧,当然,也是代码复制的一个明显例子。我还没有找到任何可能的方法来处理这个问题(除了使用作用域的reuse参数,我们将在后面讨论),只要所有的张量都链接到默认图,并且没有办法隔离它们(当然,每个方法都可以有一个单独的张量流图,但从我的角度来看,这不是最佳实践)。
关于 tensorsflow 代码的单元测试的另一件事也让我很困扰,那就是当构造图的某个部分不应该被执行时(它里面有未初始化的 tensor,因为模型还没有被训练),人们并不真正知道我们应该测试什么。我的意思是对self.assertEqual()的论证不清楚(我们应该测试输出张量的名称还是它们的形状?形状是None怎么办?如果张量名称或形状不足以得出代码工作正常的结论呢?).在我的例子中,我简单地以断言张量名称、形状和维度结束,但是我确信对于不执行图形的情况,只检查这部分功能是不合理的条件。 - 令人困惑的张量名称。许多人会说,对 tensorflow 性能的这种评论是一种非凡的抱怨方式,但人们不能总是说在执行某种操作后产生的张量的名称会是什么。我的意思是,你清楚这个名字吗?至于我,绝对不是。我知道这个张量是在动态双向 RNN 的后向单元上进行某种操作的结果,但是如果不显式地调试代码,就无法发现执行了什么操作以及操作的顺序。此外,指数结尾也是不可理解的,只要了解数字 4 从何而来,就需要阅读 tensorflow 文档并深入研究计算图。对于之前讨论的“隐藏”变量来说,情况是一样的:为什么我们在那里有了
bias和kernel的名字?也许这是我资质和技术水平的问题,但这样的调试案例对我来说相当不自然。 **tf.AUTO_REUSE****、可训练变量、重新编译库等调皮玩意儿。**这个列表的最后一点是简要介绍我不得不通过试错法学习的小细节。第一件事是作用域的reuse=tf.AUTO_REUSE参数,它允许自动处理已经创建的变量,如果它们已经存在,就不会创建两次。事实上,在许多情况下,它可以解决本段第二点所述的问题。然而,在实践中,这个参数应该小心使用,并且只有当开发人员知道代码的某个部分需要运行两次或更多次时才使用。
第二点是关于可训练变量,这里最重要的一点是:默认情况下,所有张量都是可训练的。有时,只要这种行为不总是你想要的,它就会令人头疼,而且很容易忘记它们都是可以训练的。
第三件事只是一个优化技巧,我建议每个人都这样做:几乎在每种情况下,当你使用通过 pip 安装的包时,你都会收到这样的警告:Your CPU supports instructions that this TensorFlow binary was not compiled to use: AVX AVX2。如果您看到这种消息,最好卸载 tensorflow,然后使用您喜欢的选项通过 bazel 重新编译它。这样做的主要好处是计算速度的提高和机器上框架更好的总体性能。
结论
我希望这篇长篇阅读对于正在开发他们的第一个 tensorflow 模型的数据科学家来说是有用的,他们正在努力解决框架的一些部分的不明显的行为,这些行为很难理解并且调试起来相当复杂。我想说的要点是,在使用这个库的时候犯很多错误是完全没问题的(对于任何其他事情来说也是完全没问题的),问问题、深入文档并调试每一行都是完全没问题的。就像跳舞或游泳一样,一切都来自练习,我希望我能让这种练习变得更加愉快和有趣。
用你的眼睛欺骗你的思想
确认偏差和找到你想要的东西的陷阱。

多年来,作为一名法医分析师,我必须学习的最具挑战性的技能之一是如何克服确认偏差。人们很容易把注意力集中在证实你的怀疑的证据上,而忽略似乎反驳你的理论的事实。随着时间的推移,我学会了如何识别何时偏见开始渗入调查,以及何时我应该采取适当的措施来解决它。
几乎不可能在开始调查时对你将要发现的东西没有偏见。知道了这一点,我会定期强迫自己后退一步,重新评估目前证据中清楚的事实,并挑战自己扮演“魔鬼代言人”,问一些与我的直觉相反的问题。这个过程帮助我坚持揭露真相,即使在发现看似确凿的证据后,这些证据很容易被断章取义。
这就是为什么当我最近发现我不知不觉地做了我一直努力阻止的事情时,我措手不及…
几个月前,我被要求帮助关注 Twitter 上的一个特定人群,因为他们可能会给其他人带来危险。我对做坏事的人有一个触发点,所以我想我会做我最擅长的事情,并开始收获他们产生的一切。我钻取了一些与该小组相关的线索,并在一个阻止列表中找到了一个 Twitter 个人资料列表,我认为这将是一个开始监控的好地方。(这是错误 1)
我将账户列表加载到我的 Apache NiFi 集群的处理器中,这样我不仅可以记录账户本身的活动,还可以记录其他 Twitter 用户与账户的互动。
我有两个直接目标:
- 确定可能属于同一组的其他客户
- 密切关注他们,发现与他人不寻常的互动
NiFi 在一夜之间收集了相当数量的推文后,我开始将数据加载到一个名为 Graphistry 的工具中,这将使我能够根据账户之间的互动量和互动方式直观地推断出它们之间的关系。仅仅因为这群人的性质,我强烈期望我会发现一个紧密结合的社区。(这是第二个错误)
在这种情况下,我选择只关注一个帐户回复另一个帐户的事件。根据我的经验,这些回复交互在寻求关联账户时会产生最佳模式。因为账户背后的人必须做出有意识的决定,对其他人的推文做出回应。(我认为转发是一种间接的互动形式)
当我开始对数据进行聚类时,我对我开始看到的东西感到兴奋…

Data graphed for the first time
一组密集的节点立即开始出现在中心,证实了我预期的发现。我看到了许多相互之间高度互动的账户。我抽查了位于图表最中心的一些节点的帐户名称,发现几乎每个节点都是不在我的原始收藏列表中的人。我刚刚找到了社区的其他人吗?有这么简单吗?
我最初的想法是,中间紧密聚集的黄色节点构成了我感兴趣监控的社区,但经过进一步分析,我发现我完全错了。仔细观察互动的内容,我开始注意到这些账户实际上是在口头攻击我一直在观察的大约 50 个账户。我监控的名单上的个人实际上是围绕中心的蓝色节点。
我突然意识到我完全弄错了。因为这些最初的账户被公布后引起了强烈的反应,所以一群类似私刑的网上暴民开始对该组织发布的任何东西做出积极回应。虽然我可以看到感兴趣的帐户之间的大量双向通信(蓝色节点之间的足球形状的模式),但攻击帐户确实扭曲了数据。
这个发现之后,我坐下来,试图理清这一切意味着什么。毫无疑问,我在数据中发现了一些有趣的东西,但我几乎把几十个账户归类为他们没有的东西。事实上,我开始意识到,我对这次调查的强烈反应,源于我自己的道德和伦理,本身可能有些误导。
经过一点思考,我决定重新调查,但这一次用不同的心态。抛开我的个人偏见,我只是根据事实来讲述这个故事。我现在显而易见的第一个错误是,我最初收集的数据是基于一份在推特上公开发布的列表,这份列表很快获得了很多关注。我匆忙地选择了一份名单,成千上万的人都可以访问并直接采取行动。事实上,仅仅是这个列表的存在,就产生了我所期待的模式。
我承认第一个错误很容易犯,并将其视为一次学习经历,但我真的很生自己的气,因为我犯了第二个错误,因为我知道得更好……
我带着对我会发现什么的强烈意见进入调查,以至于当一个符合我预期的模式出现时,我就匆忙下了结论。这是我努力训练自己不要做的事情,也是我提醒我的学生要注意的事情。我无意中让自己的个人信仰干扰了结果。
我认为一个更好的方法是获取确认感兴趣的账户列表,列举这些账户的朋友/关注者网络,然后用产生的数据集构建一个试探性的“社区”。通过选择有 10 个或更多共同关系的节点,我可以锁定 115 个很可能与我的调查相关的账户。

Filtered list of friend/follower relationships
这个列表仍然不完美,但它将作为一个更好的起点,因为它来自朋友/追随者关系,而不是有偏见的回答。攻击帐户仍会出现在图表中,但至少在数据收集方面会有更少的偏差。
这件事给我上了宝贵的一课。尽管我觉得自己比大多数人准备得更充分,但我仍然容易被自己的情绪左右调查。对我来说,仍然有可能掉进只寻找我想找的东西的陷阱…
像 Graphistry 这样的数据可视化工具非常强大。我个人认为它们是我职业生涯中发现的最重要的技术之一。至少可以说,它们能够帮助分析师在海量数据中找到一根针的方式是令人着迷的。这次特别的调查让我意识到任何新技术都会带来新的挑战。
作为一名分析师,无论我们是在工作还是在私人时间帮助社区,我们都必须尽可能地消除研究中的个人偏见。为了做到这一点,我建议尝试不断地在可能更准确地解释结果的替代理论中循环,即使这种解释完全违背了你最初的假设。我们有责任在数据中找到真相。
最后,我决定不再追查那个组织了。在我观察的这段时间里,我看到的唯一真正有害的行为来自他们周围的暴民。我们越来越频繁地看到社交媒体上的反应主要基于情绪而不是事实。我只是不愿意分享任何容易对他人的观点产生负面影响的研究。我知道自己这么快就下了结论,我觉得正确的做法是退出这个案子,继续下一个。我对数据真相的探索仍在继续…
“人类的模式识别天赋是一把双刃剑。我们特别擅长寻找模式,即使它们并不存在。这就是所谓的错误模式识别。我们渴望意义,渴望我们个人的存在对宇宙有特殊意义的迹象。为此,我们都太渴望欺骗自己和他人,渴望在烤奶酪三明治中发现神圣的图像,或在彗星中找到神圣的警告。”
——尼尔·德格拉斯·泰森,宇宙:时空漫游
12 月版:我们今年最有影响力的文章
数据科学的一年。迈向数据科学社区的一年!

在这个每月一期的增刊中,我们想回顾一下今年最有影响力的文章(你可以在下面找到这些文章)。你可以在上面找到这些文章的标题,它们被可视化为一个单词云。正如人们所料,机器、学习和数据等词非常常见。Python 在今年也有很强的表现,似乎是我们作家的首选语言。
以入门文章为中心的另一种趋势。通过“初学者指南”、“简单技巧”和“第一年”帖子,我们的一些最有影响力的文章针对的是该领域的新手或正在寻找易于理解的介绍。
我们的社区也喜欢深入数据科学应用用例的内容。从股票市场预测到罕见事件分类,展示实际应用的文章都名列前茅。
随着我们迈入 2020 年,我们很兴奋地阅读来自我们社区的所有新的精彩内容,并期待看到新的趋势和主题将会出现。
Tyler Folkman ,TDS 编辑助理。
把 Python 脚本变成漂亮的 ML 工具
通过 Adrien Treuille — 7 分钟读取
介绍专为 ML 工程师打造的应用框架 Streamlit
数据科学家应该知道的关于数据管理的一切*
由黄家仪 — 19 分钟读完
(*但不敢问)
决策智能简介
凯西·科济尔科夫(Cassie Kozyrkov)—13 分钟阅读
人工智能时代领导力的新学科
成为 3.0 级数据科学家
由简·扎瓦日基 — 9 分钟读完
想成为大三,大四,还是首席数据科学家?了解您需要做些什么来驾驭数据科学职业游戏。
使用 Keras 中的自动编码器进行极端罕见事件分类
由 Chitta Ranjan — 10 分钟阅读
在这篇文章中,我们将学习如何实现一个自动编码器来构建一个罕见事件分类器。我们将使用真实世界的罕见事件数据集
Python 中数据可视化的下一个层次
到时,Koehrsen 将 — 8 分钟读取
如何用一行 Python 代码制作出好看的、完全交互式的情节
Python 机器学习初学者指南
通过 Oleksii Kharkovyna — 10 分钟阅读
机器学习是人工智能领域的一个重要课题,已经成为人们关注的焦点。
我作为机器学习工程师第一年学到的 12 件事
丹尼尔·伯克 — 11 分钟阅读
成为你自己最大的怀疑者,尝试不可行的事情的价值,以及为什么沟通问题比技术问题更难。
利用深度学习的最新进展预测股价走势
由鲍里斯·B—34 分钟读完
在这本笔记本中,我将创建一个预测股票价格变动的完整过程。
了解随机森林
由饶彤彤 — 9 分钟读出
该算法如何工作以及为什么如此有效
数据科学很无聊
由伊恩肖 — 9 分钟读完
我如何应对部署机器学习的无聊日子
用 Python 加速数据分析的 10 个简单技巧
通过 Parul Pandey — 8 分钟读取
提示和技巧,尤其是在编程领域,非常有用。
统计学和机器学习的实际区别
马修·斯图尔特博士研究员——15 分钟阅读
不,它们不一样。如果机器学习只是美化了的统计学,那么建筑学只是美化了的沙堡建造。
用 Scikit 学习 Python 线性回归的初学者指南——学习
由 Nagesh Singh Chauhan — 11 分钟阅读
有两种类型的监督机器学习算法:回归和分类。
我们也感谢最近加入我们的所有伟大的新作家,安东·穆勒曼,查扬·卡图里亚,亚历克斯·金,辛然·威贝尔,布兰登·沃克,布伦达·哈利,蒂莫西·谭,詹姆斯·布里格斯,丽贝卡·麦克梅洛,拉兹·泽利克 瑟琳娜·、凯瑟琳·王、李宏玮、因娜·托卡列夫·塞拉、迈克尔·里坡、妮维迪莎·马坦·库马尔、瓦莱森·德·奥利维拉、王家辉、阿德里安·易捷·徐、杰森·布格以及 我们邀请你看看他们的简介,看看他们的工作。
工业中的人工智能:虚拟知识助手

使用深度学习和语言建模设计服务重工业的人工智能解决方案🤖
为什么工业背景很重要?
在人类历史上,技术一直是经济的基本驱动力。
人工智能是通用技术的代表之一,它催化了现代创新和机会的浪潮,推动了第四次工业革命。它开始重塑商业格局、日常生活以及不同实体之间的关系。
对我来说,人工智能是社会上最激动人心和最有意义的探索未知的旅程之一。
事实是,在这个行业,谈论人工智能的人比做人工智能的人多。人工智能解决方案的适用性仍然非常狭窄,大多数人工智能计划都失败了,因为缺乏能够证明投资和工程努力的核心价值。
拼图中缺少的不仅仅是技术含量,还有合适的工业背景。但是在我们深入实际例子之前,让我们先来看看自然语言处理。

自然语言处理
自然语言处理是人工智能和语言学的一个分支,其本身涉及使用自然语言与人类交流的计算机器的设计和实现。
在其最雄心勃勃的时候,科学家和研究人员旨在为机器设计一个通用框架和系统,使其能够像人类一样流利灵活地使用语言。
虽然自然语言处理本身并不等同于人工智能,但如果你考虑到体验学习是必不可少的,它仍然是初步之一。简单来说,一个真正聪明的身体需要从外部世界学习,包括阅读、观察、交流、体验等。
据 DeepMind 的研究科学家 Sebastian Ruder 称,NLP 15 年的工作可以浓缩为 8 个里程碑,这也引发了行业反应和合并应用。

History of Natural Language Processing
语音助手和聊天机器人
虚拟助手(或聊天机器人)是自然语言处理技术的工业实现。它可以被视为一个在通用大型语料库或服务抄本上训练的自动化系统,可以使用 AI 来识别和响应客户请求。当我们谈到 Chabot 的时候,你首先想到的是 Siri 或者 Google Assistant(你今天可能已经和它们互动过了)。事实上,如下图所示,科技巨头们都在竞相发布消费者语音产品,

Virtual Agent Release Timeline
语音助手可以针对水平功能进行设计,例如,对话代理、问答机器人、调查机器人和虚拟代理。也可以与垂直行业保持一致,包括银行和金融服务、消费者、公共服务、政府、医疗保健等。一个简单的语音助手应该能够与人互动,提供相关信息,甚至完成基本功能,如填表或预订和安排回电。

Chatbot Market Size and Share
一般来说,语音助手的成功大规模实现依赖于三个前提,
- 一个亟待解决的问题: 一家公司在客户服务上投入了巨额资金,但仍面临着扩大规模的挑战。
- 用于训练一个 ML 引擎的内容: 由用户生成的数以千计的抄本或对话,其能够实现深度学习模型的训练。
- 人类 AI 协作模型: 虚拟助手应该被设计来增强人类的活动,而不是取代它们。这将允许虚拟代理和人工代理一起工作。
但是,一个成功的 NLP 解决方案在现实世界中是什么样的,或者更具体地说,我应该如何设计一个虚拟助理系统来解决现有的问题。在下面的内容中,我阐述了通用 bot 解决方案背后的设计思想——智能知识助手。
如何建立知识助理
人类在过去两年产生的数据比人类过去 5000 年产生的数据还多。五年后,这些数据中大约 80%将是非结构化的。全球各地的公司都面临着同样的挑战,即如何更好地管理、搜索和分析这些非结构化数据。
让我们看一个场景。一个审计小组正在进行一个项目,以评估一个跨国组织的财务运作和财务记录。他们需要对照不同县的法规检查合规性,这需要花费大量时间手动处理文档,然后搜索并比较条款和条件。
即使有针对这些监管政策的内容管理系统,标准的搜索引擎也不足以帮助他们得到他们想要的东西,因为,
- 典型的搜索引擎只能接受关键词, 不能理解自然语言,或者抽象关键词
- 搜索结果 很少调出目标文档
- 一个搜索引擎通常会返回一长串结果,并且需要大量的人工阅读来找到正确的答案
- 搜索结果与用户使用的术语高度相关
- 没有定制
这里最大的问题是,现有的系统没有认知理解能力。为了弥合这一差距,我们需要整合最新的马力 NLP 来增强搜索解决方案。

The development of Search Engine
虚拟知识助手在解决上述挑战时派上了用场。一个适当范围的设计的知识助理的目标可以提供,
- 高速检索信息功能,允许用户一次查询一个大型语料库
- 高准确度 仅向最终用户提供最高结果(基于置信度得分小于 3)
- 集成到内部文件系统,构建自我管理的知识库
- 向最终用户提供 粒度答案 的能力
例如,我问虚拟知识助理:“我如何才能成为注册公司审计师(RCAs)?”然后助理浏览了上万份保单,告诉你“要成为 RCA,你需要向澳大利亚证券和投资委员会(ASIC)证明你符合 2001 年公司法第 1280 条的要求”
随着深度学习和自然语言处理的最新突破,这不是一个梦想。
解决方案架构和设计
对于前端用户体验设计,该团队将反馈和人为因素纳入了设计思路。下面是解决方案用户界面快照。了解我们如何将解决方案体验从标准的 SharePoint 搜索 UI 发展为完全集成的交互式单页应用程序。(下面的截图中使用了模型数据)

Virtual Knowledge Assistant UI
在交互前端的背后是充当大脑的人工智能引擎。为了实现这一目标,数据科学团队进行了多次 R&D,评估了行业中大量不同 NLP 技术的适用性和适用性。最后,很少被认为是虚拟知识助手的关键组件。

Key Components for Knowledge Assistant

Key Functionalities per each component
工程团队需要分离主要功能,以确保解决方案的未来可伸缩性。因此,在下一次迭代中,每个组件本质上都将充当微服务容器或云原生无服务器功能。
机器理解
解决方案的秘方是微调后的伯特模型。

BERT 代表来自 Transformer 的双向编码器表示,它是由 Google AI Language 开发的最新语言表示模型,它在 NLP 社区掀起了风暴,并占据了 NLP 竞赛排行榜的大部分席位。它也成为了 NLP 中迁移学习方法的工业标准。
数据科学团队使用最初的 BERT,并在以下步骤上重新训练,
- 首先,在客户端提供的语料库上精细化预训练模型
- 第二,对尾部下游任务的最后一层进行微调。
训练过程是在谷歌云平台上使用 GPU NVIDIA Tesla V100,8 个 GPUs128 GB HBM2。整个实验花了 4-5 天,我们设法将结果从 67%(通过 AllenNLP 的 BiDAF 模型)提高到 89%以上(微调 BERT)。
总的来说,这是我今年工作过的最成功的 NLP 解决方案之一,它对客户组织的影响远远超过了我的预期,在最后的演示会议上,你可以看到高级管理人员眼中的火花,它刺激了机构层面上对完全集成的人工智能解决方案的讨论。
成功不仅属于先进的 NLP 技术(BERT 或 XLNet),而且是用户体验重新设计、解决方案架构师、业务逻辑以及业务需求到技术功能的精确转换的共同努力。更重要的是,我们为虚拟知识助手找到了最佳的情境之一,
考虑到这是一篇很长的文章,我不会过多地讨论技术细节。如果您对每个技术组件、项目设置、结构、云平台实现、我们如何培训 BERT 以及技术挑战的详细解释感兴趣,请等待本文的第二部分< 如何构建知识代理 >。
感谢您花时间阅读这个故事。正如谷歌云 AI/ML 前首席科学家费-李非所说:“我们开发的工具和技术真的是人工智能所能做的浩瀚海洋中的最初几滴水。”作为市场领导者,我们的工作是理解人工智能能做什么,以及它应该如何适应你的商业环境和人类更光明未来的战略。
**关于我,我是👧🏻他住在澳大利亚的墨尔本。我学的是计算机科学和应用统计学。我对通用技术充满热情。在咨询公司做 AI 工程师👩🏻🔬,帮助组织整合人工智能解决方案并利用其创新力量。在 LinkedIn 上查看更多关于我的信息。

利用深度学习破译医生的笔迹
实际案例

我们建造了一个机器人,它可以自动读取医生在比利时死亡证明上的笔迹,正确预测的可用数据集的准确率为 47%。机器人支持政府官员进行正式的死亡登记,并允许更快的登记。
该解决方案由三个主要组件组成:图像处理模块、神经网络和输出医学术语预测的自然语言处理模块。
死亡证明
当一个人死亡时,医生必须证明这个人的死亡状态。医生要填写一份标准表格。这是通过在表格上手写声明“在现场”完成的,随后在密封的信封中转发给其他官员。
医生正式记录死亡的直接原因,以及任何已知的次要原因。这种死亡证明的一个例子如下。
(所有的例子都是荷兰语,所以如果你认为你什么都看不懂,那很正常!)

Example death certificate
上面的例子读起来相当简单,但是也存在众所周知的难以阅读的例子。

A hard-to-read handwriting
因为医生是在“现场”记录死亡原因的,所以 100%的数字解决方案是不可行的,并且大量的手写将会存在很多年。
数据管道
原始数据是一页纸的扫描件,以 PDF 格式提供。
第一步是匿名化数据。从文档 id 中计算散列,并从文档中切出一个感兴趣的区域(ROI ),其中包括笔迹,但不包括任何个人数据,如医生签名、死亡日期和地点等。
这会产生比原始图像更小的图像,并且没有从图像到原始扫描的链接。
第二步是清理图像。文档模板中有背景文本,并且有扫描错误。我们去除了背景,应用了降噪和轻微的模糊处理来消除手写线条中的小间隙,同时保留单词之间的空间。
第三步是将图像裁剪到包含手写内容的最小尺寸。
第四步,从字里行间切入。因此,当文本有 n 行时,我们最终得到每个原始证书的 n 个图像片段。
然后,我们应用神经网络(NN)来预测所写的内容,并计算 NN 对预测正确性的确信度。
包含未知单词的预测需要额外的自然语言处理(NLP)来将其映射到已知单词。我们再次计算置信水平。
总之,阅读笔迹的解决方案是图像处理、深度学习和自然语言处理的结合。
神经网络
构建神经网络最困难的部分之一是决定其架构。我们决定不重新发明轮子,从现有的神经网络架构开始。我们发现 H. Scheidl (2018,https://towardsdatascience . com/build-a-handled-text-recognition-system-using-tensor flow-2326 a 3487 CD 5)描述的 NN 工作得非常好,经过一些小的修改。
神经网络体系结构
H. Scheidl 的 NN 具有五层卷积神经网络(CNN)、两层递归神经网络(RNN)和连接主义时间分类(CTC)层。关于细节,我们可以参考 H. Scheidl 的出版物。
这个神经网络训练字符和标点符号识别,因此也可以识别由相同字符和标点符号组成的新文本。
我们必须对 Scheidl 的 NN 进行一些修改,使其能够处理正在研究的数据集:
- 增加单词长度;
- 禁用字束搜索(WBS);
- 允许多个单词
**增加单词长度。**Scheidl 网络采用最多 32 个字符的单词。因为我们考虑的是完整的文本行,所以我们需要将它增加到 128 个字符。(这大于数据集中最长的标签。)
**禁用词束搜索。**神经网络(NN)可以被限制在单词字典中。如果您需要查找所有手写单词,这是有意义的。神经网络将把每个手写单词分配给字典中的一个已知单词。
我们用可用的标签字典对此进行了测试,但是我们发现这产生了很多误报。在我们的商业案例中,如果神经网络不能自信地阅读手写内容,最好不要分配一个单词。在这些情况下,我们更喜欢由人来做最后的决定。
出于这些原因,我们决定不使用 WBS,而是应用一个单独的单词匹配模型作为后处理 NLP 步骤。
**允许多个单词。**在医学术语中,某些词的组合经常一起出现。通过使用文本行而不是单词,神经网络能够识别这些,这增加了成功率。
训练数据
在训练神经网络之前,我们需要检查数据的质量。我们希望用我们有高度把握标签是正确的数据来训练神经网络。
神经网络的准确性高度依赖于数据的质量。我们有六年的标记数据,但从业务中我们知道
- 在 2012-2015 年期间,标签是手写的文字转录,而从 2016 年开始,有时还会对标签进行解释;和
- 一个难以辨认的单词用标签中的$符号来编码。
因此,标签中带有$符号的所有证书都被排除在训练、验证和测试集之外:这些标签被认为是不确定的。
我们排除的其他证书是那些在分割后识别的文本行数不等于证书的标签数的证书。在这些案例中,一个死亡原因被写在多行上。标记数据的人具有上下文领域的知识来了解这一点,并将其标记为单线。分段不能知道单个死因是否写在单行上。因此,我们排除这些证书;我们不能确定特定的标签对应于特定的手写行。
出于技术原因,长度超过 128 个字符的行也被排除在外,但这只是不到 0.5%的一小部分。
这些排除规则导致 344.365 个证书中的 128.794 个被排除,占总数的 38%。还剩下 215.571 张贴好标签的证书。
在标记良好的证书中,我们将 60%定义为训练集,20%定义为验证集,20%定义为测试集。

The number of certificates included in training, validation, and test sets across the years 2012–2016
训练发生在文本行上,而不是在完整的证书上,并且在分段之后,上述证书编号导致以下文本行号。

The number of text lines included in training, validation, and test sets across the years 2012–2017
标签的数据质量在这一点上是未知的。我们必须假设它们是基本的事实,即使我们知道不是所有的标签都是笔迹的精确表现。目测了解到在标记的数据集中至少存在以下情况。
- 标签中手写的拼写错误被改正了
- 标签中出现拼写错误
- 缩写在标签中被拼成一个完整的单词,反之亦然
- 标签中手写的标点符号不是逐字转录的
我们将在后面看到,我们可以在某种程度上量化数据质量。
最佳拟合神经网络模型
神经网络是出了名的黑箱,难以理解。因此,我们定义了一组模型并比较它们的结果。集合中的变化是数据包含在训练集、验证集和测试集中的变化。
集成技术有助于在开发过程中理解模型,并提高模型的健壮性。
我们的集合涵盖以下数据集组合。给出的准确度是由神经网络正确预测的验证集中文本行的百分比。对于正确预测的,我们指的是文本串的精确匹配:所有的字符和标点符号精确匹配。

在神经网络发展的早期阶段,两年的准确率在 40%到 75%之间波动。由于数据集中每年的证书数量几乎相同,这是非常出乎意料的,结果证明这是由于一个小错误,该错误过度拟合了某些数据集的模型。如果不进行集合测试,这些过度拟合的模型往往会被忽视。误差修正后,所有精度都符合预期。
当我们绘制每年的证书结果时,准确性随时间的变化是明显的。下面显示的是每年训练集中的证书数量(蓝色)和模型在该年达到的准确度(红色)。

The number of certificates and the accuracy of the trained model for each year
该图清楚地表明,前四年(2012 年至 2015 年)的精度相当稳定,平均精度为 36%,标准偏差为 2%。我们发现 2016 年的准确性明显较低,这可能是由于标签质量较低,这一点企业已经知道。
增加具有较低质量标签的数据集不会增加模型的准确性。反之,甚至可能降低。
最佳模型是具有最大数据集的模型,即 2012 年至 2016 年的合并数据。下面我们展示了当通过一次增加一年来增加数据集的大小时,精确度是如何提高的。

The accuracy of fives model applied to four different test sets.

将模型应用于 2017 年的完整数据比其他测试集的准确性稍低。这可能是 2016 年和 2017 年标签不太准确的结果。
最好的评分模型是 2012-2016 年的训练集。所达到的准确度是 53%的精确正确预测的文本行。我们将进一步研究这个最佳模型。
置信级别
神经网络模型为每个预测分配一个置信度。对于测试集,我们知道预测是否与标签完全匹配。对于每个预测,我们知道它是属于正确预测集还是不正确预测集。然后我们可以在一个置信范围内画出预测的数量。
置信度的范围在 0 到 1 之间。我们将该范围分成 20 个区间,每个区间宽 5%,并计算正确和错误预测集在该置信水平下的文本行预测数。
下图显示了两组的结果。正确的预测显示为蓝色,不正确的预测显示为红色。

The number of correct and incorrect text-line predictions as a function of NN confidence level.
我们的目标是高度可信的预测。这些预测应该是准确的。结果确实表明,正确预测的数量在 95–100%置信度时达到峰值,在较低的置信度时会降低。
然而,已知不正确但仍具有高置信度的预测表明存在所谓的假阳性。这些都是极不需要的!
低置信度的预测大多是不正确的预测,由置信度为 0–5%的(红色)峰值显示。这些是难以辨认的笔迹。(对机器来说难以辨认,对人来说不一定。)
具有低置信度的预测总是必须显示给必须判断该预测的人。通过用改进的数据对模型进行再训练,人类反馈可用于改进模型。
也有对低置信水平的正确预测。这些都是假阴性。机器将判断它们是不确定的,它们也将被送到人工检查。
目标人群的例子
让我们以较高的可信度检查一些正确预测的例子。


来自假阳性人群的例子
假阳性群体是神经网络非常确定的一组预测,但它与给定的标签不匹配。
在第一个例子中,我们看到预测实际上是正确的,但是标签增加了“COPD”。因此,我们的精确匹配测试使其落入“不正确”的集合中。这是一个标签与手写文本不完全匹配的例子。

在第二个例子中,我们看到了标签和预测之间的微小差异:v 与 e。标签在语言学上是正确的,但 e 上的分音符不是医生写的。只是因为我们在测试准确性上如此严格,所以这个预测才落入假阳性人群。

第三个例子显示了人为错误。它被标记为“uitdroging ”,但是“uitputting”的预测已经被业务部门确认为正确的。这表明人类也会犯错,因此也会产生假阳性。

第四个例子也是人为错误。标记为“verstikking ”,但它应该是“verslikking ”,这是由神经网络正确预测的。

当手动验证置信度大于 60%的 30 个假阳性的随机样本时,所有这些都表明神经网络是正确的,而标签是错误的。对于其中的两个,人类是错误的。有时差异非常小,但由于我们对正确性的严格测试,即使预测和标签之间的最小差异也会导致假阳性。
令人欣慰的是,确定的假阳性群体已经非常小,可能比包含人为错误的群体还要小。在假阳性组中,人为错误估计发生 2/30 = 7%。
假阴性人群的例子
下面是一个正确预测的文本行的示例,但是神经网络对预测的可信度非常低。这种具有低置信水平的情况将被标记以供人类判断。

来自可理解群体的例子
然后就是一整组 NN 看不懂的手写。所有这些都需要人工判断。
在第一个示例中,箭头没有被正确检测到,最后一个单词也没有被检测到,这也是标签是否正确的问题。不过,第一个单词找到了。

在第二个例子中,我们看到上面的文本行的一部分与文本重叠。这混淆了对单个字母的识别。但是其他单词的可读性也很差。人们希望这些案件得到人类的审判。

自然语言处理
神经网络主要被训练来识别字母。它不知道单词。这意味着 NN 预测形成一个字母序列,尽管它有一些顺序概率的意义,但一些字母组合可能没有意义。
如果 NN 预测与字典中的单词完全匹配,我们不执行进一步的文本匹配。如果已经有一个精确的匹配,我们只会冒险修改一个正确的预测,把它变成别的东西。因此,只有当 NN 预测与字典单词不完全匹配时,才进行下面描述的与单词匹配的文本。
请注意,这些知识也可以用于向词典中添加新单词。
我们已经尝试将神经网络限制为仅预测医学词典中的已知单词,但这导致了太多的假阳性。这种神经网络的输出总是字典中的一个单词。它不能识别其他单词。
因此,我们决定只在字符识别上训练神经网络,并作为后处理步骤执行与字典的匹配。
匹配基于两种算法。
- Jaro 和 Damerau-Levenshtein 距离
- 二元距离
Jaro 和 Damerau-Levenshtein 距离将预测的字母序列与已知单词进行比较,并将纠正预测所需的“编辑”次数视为到单词的距离。
可以计算预测到字典中任何单词的距离,并且将具有最短距离的单词指定为最终预测。
如果文本行至少包含两个单词,则计算二元模型距离。从字典中可以知道有些词经常一起出现。这有助于从预测的字符序列中识别这样的单词。
置信级别
匹配的复杂性在于定义模型对于匹配的置信度。虽然预测到单词的距离是预测有多接近的度量,但它不是置信度的度量。
举个例子,看看下面的笔迹,上面写着“steekwonde”。

NN 预测是“stuikwonde”,比较接近,但不确切。在词典中,我们发现了两个相似的词:“stuitwonde”和“steekwonde”。第一个只有一个字母的距离,第二个有两个字母的距离。但是因为两者都很接近,所以模型应该很不确定选择哪一个。
因此,当我们将神经网络预测与词典中的单词进行匹配时,置信度应该考虑其他相近的单词。单词之间的距离越近,最终结果就越不确定。如果两个单词与 NN 预测等距,则匹配置信度为 50%。如果三个单词是等距离的,置信水平下降到 33%。
我们根据这些统计数据计算了文本匹配的置信度。这很重要,因为在最终产品中,在决定是否进行人工干预时,必须考虑神经网络和文本匹配的置信度。
完整的证书
文本识别模型在单个文本行上操作。平均每个证书有两行文本,作为可测试数据集一部分的证书上最多有四行文本。(标记良好的数据集。)
预计每个证书的文本行数越多,完全正确预测的证书比例就越低。下图显示了证书数量与证书上文本行数的函数关系。

我们证实,随着每个证书的文本行数的增加,完全正确预测的证书的比例下降。
让我们将正确预测证书的置信度定义为证书上任何文本行预测的最小置信度。然后,我们可以将正确预测的证书数量绘制成置信度的函数。下图显示了这一点,其中颜色编码用于表示证书上的行数。

对于没有被正确预测的证书,可以做出相同的图。

我们发现对于高置信水平,在证书水平上很少有不正确的预测。
难以辨认的笔迹
从训练和测试集中排除的是那些甚至人类也不能阅读的证书。这些标签中有$-符号。正如下面的例子所示,神经网络可以正确地读取其中一些,至少可以给试图破译文本的人提供有用的建议。
如果我们将文本行预测的数量绘制为神经网络置信度的函数,我们会看到该分布在 0–5%的置信度处显示一个大峰,这是预期的。如果人类看不懂,机器可能也看不懂。此外,NN 没有接受过阅读可理解证书的训练。
请注意,在某种意义上,神经网络模型中存在一个偏差,即那些不能被人类阅读的笔迹很可能是最差的笔迹,并且该模型不能在这些笔迹上进行训练,因为这些笔迹没有被标记。通过在系统中提供人类反馈,机器也可以慢慢地在这些情况下接受训练。

在第一个例子中,第一个单词不能被人类阅读。NN 预测单词匹配后接近最终预测的单词。(“PP”代表后处理,包括文字匹配。)最后的 PP 预测其实是正确的。因此,即使预测的可信度很低,该预测也会对人类法官起到很好的建议作用。

在第二个例子中,第二个单词是人类不可读的。神经网络预测只差一个字母:c 而不是 e。单词匹配后的最终预测是 100%正确的。

这表明,即使神经网络没有在这些情况下受过训练,它也能识别足够多的字母,对难以辨认的单词做出非常可信的预测。
决赛成绩
我们的最终结果显示,54%的神经网络预测的文本行与人类定义的标签完全匹配。如果我们将文本匹配作为后处理步骤添加到字典中,我们可以将它增加到 60%以上,如果我们考虑到每个证书平均有大约两行文本,我们有 47%的完整证书被正确预测。

对于人类不可读的文本行,即标签中带有$-符号的文本行,我们请两位业务专家手动验证我们的预测。我们随机抽取了 100 个这样的文本行。结果令人放心:100 个中有 20 个被正确预测。
这让我们相信,即使对于难以辨认的证书,模型算法也可以通过给出书写内容的建议来支持人类。
自动化
仍然存在的问题是,我们能在多大程度上自动识别医生的笔迹,并将其与现有的软件系统集成。这归结为一个问题,即我们可以定义一个阈值,在这个阈值之上,预测可以被认为是正确的,因此没有人必须干预。
为了理解这一点,我们必须回到预测的分布作为一个信心水平的函数。对于神经网络,这个函数已经在前面的图中显示了。为了清楚起见,我们在这里重复它。

让我们将阈值定义为 95%的置信度。这意味着所有置信度为 95-100%的预测文本行将被认为是正确的:不需要人工干预。这是上图最后一个框中的所有文本行。这大约是所有文本行的 11%。
我们也有一些误报,但在这种情况下,这只是所有文本行的 0.1%。可能低于人为错误,我们从分析中知道,许多假阳性是由于错误的标记,所以假阳性的真实数量甚至更少。
如果我们将阈值设置为 90%,我们会计算上图中最高的两个容器中的所有文本行。这导致 20%的正确率和 0.2%的误报率。
通过将阈值设置得越来越低,我们添加了更多正确的结果,但最终我们添加了令人难以忍受的许多假阳性。所有高于阈值的红色条柱都被视为误报。因此,当我们有正确预测的好结果,并且假阳性的数量仍然是可接受的低的时候,必须有一些阈值最佳值。什么是可接受的是一个有争议的问题,但假设人类也会犯错误,只要我们的表现不比人类差,我们就可以接受少量的误报。
到目前为止,我们只研究了神经网络的置信水平。如果我们将后处理(文本匹配)添加到图片中,我们可以有效地将一些预测从不正确的群体移动到正确的群体。如下图所示。

我们看到,对于不正确的总体,接近零置信度的峰值降低,而正确的总体升高,当然,特别是对于低置信度。
我们现在可以画出有多少高于阈值的预测是正确的和不正确的。这在下面的图中给出。
绿色显示的是正确预测的人口,红色显示的是错误预测的人口。虚线仅是神经网络预测,实线也包括后处理,这增加了正确群体并减少了错误群体。

垂直绿色条表示从 70%到 75%的阈值。如果我们在这里设置阈值,我们有 33%的正确预测和不到 1%的错误预测(假阳性)。
如果假阳性不相关,则在绿线和红线之间的差异最大化的阈值处获得最大数量的正确结果。这大约是 10%,这导致 59%的正确预测和 8%的错误预测。
在我们的用例中,我们需要在死亡证明的上下文中预测医学术语,如此高数量的假阳性是不可接受的。因此,我们必须谨慎行事。
可以开始将阈值设置为 95%,并且当验证具有较低置信水平的任何预测的人获得对模型预测的信心并向系统提供反馈时,使得模型变得更好,阈值可以降低。
当模型使用人类反馈并自我改进时,它将使用更高的置信度进行预测,这将通过置信度水平将预测的分布向右移动,从而将更多的预测推到阈值以上。
我们可以做出同样的图来预测完整的证书,而不仅仅是文本行。这在下面给出。

这里的数字有些低,因为证书上的所有文本行都必须正确预测。当我们将阈值设置为 30%到 35%的置信度时,我们现在达到了超过 30%的正确预测,但是假阳性的数量达到了 5%。
结论
我们得出结论,使用经过训练的神经网络来阅读医生的笔迹是可行的。
我们发现,神经网络结果对数据预处理的质量非常敏感,并将其切割成单词或文本行。仔细的图像处理是项目成功的关键。
我们还发现,让神经网络将文本与词典单词进行匹配会产生太多的假阳性结果,最好让神经网络只进行阅读,并使用其他 NLP 技术与词典进行匹配。
我们可以通过神经网络和文本匹配来计算预测的置信水平,这可以用于定义用于自动化目的的置信水平阈值。
承认
我们感谢佛兰德政府、Vlaams agents chap Zorg&Gezondheid,是他们使这个项目成为可能,特别感谢 Koenraad、Anne、Rita 和 Wilfried,他们提供了宝贵的指导和商业专业知识,以及他们富有挑战性的重要意见,使这个项目超过了平均水平。
这个项目是 Vectr 的一个合作项目。咨询(【https://medium.com/vectrconsulting】),特别感谢布鲁诺和乔尼。
决策边界可视化(A-Z)
含义、意义、实施

分类问题是数据科学领域中非常普遍和重要的问题。例如:糖尿病视网膜病变、情绪或情感分析、数字识别、癌症类型预测(恶性或良性)等。这些问题往往通过机器学习或者深度学习来解决。此外,在计算机视觉中,像糖尿病视网膜病变或青光眼检测这样的项目中,纹理分析现在经常使用,而不是传统图像处理或深度学习的经典机器学习。虽然根据研究论文,深度学习已经成为糖尿病视网膜病变的最先进技术:
在分类问题中,对一个特定类别的预测涉及到多个类别。换句话说,它也可以以这样的方式构成,即特定的实例(根据特征空间几何的数据点)需要保持在特定的区域(表示类)下,并且需要与其他区域分离(表示其他类)。这种与其他区域的分离可以通过被称为决策边界的边界来可视化。特征空间中决策边界的可视化是在散点图上完成的,其中每个点描述数据集的一个数据点,轴描述特征。决策边界将数据点分成区域,这些区域实际上是它们所属的类。
决策边界的重要性/显著性:
在使用数据集训练机器学习模型之后,通常需要可视化特征空间中数据点的分类。散点图上的决策边界用于此目的,其中散点图包含属于不同类别的数据点(用颜色或形状表示),决策边界可以按照许多不同的策略绘制:
- 单线决策边界:在散点图上绘制决策边界的基本策略是找到一条单线,将数据点分成表示不同类别的区域。现在,使用在训练模型之后获得的与机器学习算法相关的参数来找到这一单线。使用获得的参数和机器学习算法背后的直觉找到线坐标。如果不知道 ML 算法的直觉和工作机制,就不可能部署这种策略。
- 基于轮廓的决策边界:另一种策略涉及绘制轮廓,这些轮廓是每个都用匹配或接近匹配的颜色包围数据点的区域——描绘数据点所属的类别,以及描绘预测类别的轮廓。这是最常遵循的策略,因为这不采用模型训练后获得的机器学习算法的参数和相关计算。但是另一方面,这并没有使用单线完美地分离数据点,所述单线只能由在训练和它们的坐标计算之后获得的参数给出。
单线判定边界的范例实现:
在这里,我将展示基于逻辑回归的机器学习模型的单线决策边界。
进入逻辑回归假设-

其中 z 定义为-

theta_1, theta_2, theta_3 , …., theta_n are the parameters of Logistic Regression and x_1, x_2, …, x_n are the features
因此,h(z)是一个 Sigmoid 函数,其范围是从 0 到 1 (0 和 1 包括在内)。
为了绘制决策边界,h(z)等于逻辑回归中使用的阈值,通常为 0.5。所以,如果

然后,

现在,为了绘制决策边界,需要考虑两个特征,并沿散点图的 x 轴和 y 轴绘制。所以,

在哪里,

where x_1 is the original feature of the dataset
因此,获得了 x’_1 的 2 个值以及 2 个相应的 x’_2 值。x’_1 是单线判定边界的 x 极值,x’_2 是 y 极值。
虚拟数据集上的应用:
数据集包含 100 名学生在两次考试中获得的分数和标签(0/1),该标签指示该学生是否将被大学录取(1 或负数)或不被大学录取(0 或正数)。该数据集位于
* [## navoneel 1092283/logistic _ 回归
在 GitHub 上创建一个帐户,为 navoneel 1092283/logistic _ regression 开发做出贡献。
github.com](https://github.com/navoneel1092283/logistic_regression.git)
问题陈述:给定两次考试的分数,用逻辑回归预测学生是否会被大学录取
在这里,两次考试的分数将是被考虑的两个特征。
以下是在 3 个模块中实现的逻辑回归。文中给出了具体的实现方法,
分类是机器学习问题中一个非常普遍和重要的变体。很多机器算法都有…](https://hackernoon.com/logistic-regression-in-python-from-scratch-954c0196d258)
import numpy as np
from math import *def logistic_regression(X, y, alpha):
n = X.shape[1]
one_column = np.ones((X.shape[0],1))
X = np.concatenate((one_column, X), axis = 1)
theta = np.zeros(n+1)
h = hypothesis(theta, X, n)
theta, theta_history, cost = Gradient_Descent(theta, alpha
, 100000, h, X, y, n)
return theta, theta_history, cost
def Gradient_Descent(theta, alpha, num_iters, h, X, y, n):
theta_history = np.ones((num_iters,n+1))
cost = np.ones(num_iters)
for i in range(0,num_iters):
theta[0] = theta[0] - (alpha/X.shape[0]) * sum(h - y)
for j in range(1,n+1):
theta[j] = theta[j] - (alpha/X.shape[0]) * sum((h - y) *
X.transpose()[j])
theta_history[i] = theta
h = hypothesis(theta, X, n)
cost[i] = (-1/X.shape[0]) * sum(y * np.log(h) + (1 - y) *
np.log(1 - h))
theta = theta.reshape(1,n+1)
return theta, theta_history, cost
def hypothesis(theta, X, n):
h = np.ones((X.shape[0],1))
theta = theta.reshape(1,n+1)
for i in range(0,X.shape[0]):
h[i] = 1 / (1 + exp(-float(np.matmul(theta, X[i]))))
h = h.reshape(X.shape[0])
return h
对数据集执行逻辑回归:
data = np.loadtxt('dataset.txt', delimiter=',')
X_train = data[:,[0,1]]
y_train = data[:,2]theta, theta_history, cost = logistic_regression(X_train, y_train
, 0.001)
获得的θ(参数)向量,

获得数据点的预测或预测类别:
Xp=np.concatenate((np.ones((X_train.shape[0],1)), X_train),axis= 1)
h=hypothesis(theta, Xp, Xp.shape[1] - 1)
绘制单线决策边界:
import matplotlib.pyplot as pltc0 = c1 = 0 # **Counter of label 0 and label 1 instances** if i in range(0, X.shape[0]):
if y_train[i] == 0:
c0 = c0 + 1
else:
c1 = c1 + 1x0 = np.ones((c0,2)) # **matrix** **label 0 instances**
x1 = np.ones((c1,2)) # **matrix** **label 1 instances**k0 = k1 = 0for i in range(0,y_train.shape[0]):
if y_train[i] == 0:
x0[k0] = X_train[i]
k0 = k0 + 1
else:
x1[k1] = X_train[i]
k1 = k1 + 1X = [x0, x1]
colors = ["green", "blue"] # **colours for Scatter Plot**
theta = theta.reshape(3)# **getting the x co-ordinates of the decision boundary** plot_x = np.array([min(X_train[:,0]) - 2, max(X_train[:,0]) + 2])
# **getting corresponding y co-ordinates of the decision boundary** plot_y = (-1/theta[2]) * (theta[1] * plot_x + theta[0])# **Plotting the Single Line Decision Boundary**
for x, c in zip(X, colors):
if c == "green":
plt.scatter(x[:,0], x[:,1], color = c, label = "Not
Admitted")
else:
plt.scatter(x[:,0], x[:,1], color = c, label = "Admitted")
plt.plot(plot_x, plot_y, label = "Decision_Boundary")
plt.legend()
plt.xlabel("Marks obtained in 1st Exam")
plt.ylabel("Marks obtained in 2nd Exam")

Obtained Single Line Decision Boundary
这样,可以为任何基于逻辑回归的机器学习模型绘制单线决策边界。对于其他基于机器学习算法的模型,必须知道相应的假设和直觉。
基于轮廓的判定边界的范例实现:
使用相同的虚构问题、数据集和训练模型,绘制基于轮廓的决策边界。
# Plotting decision regions
x_min, x_max = X_train[:, 0].min() - 1, X_train[:, 0].max() + 1
y_min, y_max = X_train[:, 1].min() - 1, X_train[:, 1].max() + 1xx, yy = np.meshgrid(np.arange(x_min, x_max, 0.1),
np.arange(y_min, y_max, 0.1))X = np.concatenate((np.ones((xx.shape[0]*xx.shape[1],1))
, np.c_[xx.ravel(), yy.ravel()]), axis = 1)
h = hypothesis(theta, X, 2)h = h.reshape(xx.shape)plt.contourf(xx, yy, h)
plt.scatter(X_train[:, 0], X_train[:, 1], c=y_train,
s=30, edgecolor='k')
plt.xlabel("Marks obtained in 1st Exam")
plt.ylabel("Marks obtained in 2nd Exam")

Obtained Contour-Based Decision Boundary where yellow -> Admitted and blue -> Not Admitted
这种方法显然更方便,因为不需要直觉和假设或者机器学习算法背后的任何数学。所需要的,就是高级 Python 编程的诀窍!!!!
因此,这是一种为任何机器学习模型绘制决策边界的通用方法。
在大多数实用的高级项目中,都涉及到许多特性。那么,如何在二维散点图中绘制决策边界呢?
在这些情况下,有多种出路:
- 可以使用由随机森林分类器或额外树分类器给出的特征重要性分数,以获得 2 个最重要的特征,然后可以在散点图上绘制决策边界。
- 像主成分分析(PCA)或线性判别分析(LDA)这样的降维技术可用于将 N 个特征降维为 2 个特征(n_components = 2 ),因为 N 个特征的信息或解释嵌入到这 2 个特征中。然后,考虑到这两个特征,可以在散点图上绘制决策边界。
这就是决策边界可视化的全部内容。
参考文献
[1] N. Chakrabarty,“一种检测糖尿病视网膜病变的深度学习方法”, 2018 年第 5 届 IEEE 北方邦分会国际电气、电子和计算机工程会议(UPCON) ,印度戈拉克普尔,2018 年,第 1–5 页。多伊指数:10.1109/升。36860.88868688666*
决策不仅仅是解决定量问题

“我在生活和工作中所有最好的决定都是用心、凭直觉、凭勇气而非分析做出的。”—杰夫·贝索斯在 2018 年华盛顿经济俱乐部
多年来,我有一个心理模型,将决策等同于定量解决问题。在这个心智模型中,当一个定量问题被解决时,可以做出决定;例如,如果一种新药的治疗效果在统计学上并不比一种对照药物更好(定量解决问题),它就不应该获得批准(决策)。我已经有这个心智模型很长时间了,因为这个心智模型不仅反映了我在学校如何定量处理教科书问题的经验,还直接谈到了工作场所中数据驱动决策的流行概念。这个心智模型将决策视为定量问题解决的平滑连续体,并让我相信我知道决策只是因为我知道定量问题解决。
与我想象中的决策不同,实地决策是一个动态的过程,既可以依赖也可以完全独立于定量问题的解决。通过我的工作,我对决策和定量解决问题之间的不匹配感到震惊;许多数据科学家也承认他们的数据结果没有被他们的商业伙伴很好地采纳。缺乏数据文化成为一个容易的借口,然而我相信一个严峻的事实是,决策制定首先不是定量问题的解决。到底什么是决策?我以前从来没有认真想过。这一次,我想走出数据科学花园,认真研究决策本身。
以下内容:
- 分析四种决策类型,为您的数据科学工作提供信息
- 使用 N:N 模型帮助您驾驭当今复杂的决策过程
决策具有鲜明的特点
虽然我们可以普遍地将决策定义为从备选方案中选择一个选项的行为,但就选择达成一致的过程在不同的决策之间有很大的不同。利用不同利益相关者的数量,我们可以将决策分为个人决策和公司决策。大多数人都熟悉个人决策,因为这是日常生活的一部分。个人决策有一个或少数利益相关者,通常是决策者本人。个人决策是有重点的,有成本效益的,并有明确的责任。个人决策发生在个人生活和工作场所;你可以决定你的大学专业,也可以决定在工作中展示的最佳方式。个人决策通常影响有限。
“决策涉及从两个或多个可能的选择中选择一个行动方案,以便找到一个特定问题的解决方案”。—特雷瓦萨和纽波特
当利益相关者的数量很大时,我们有公司决策。企业决策通常发生在各级组织中,并赢得了缓慢、昂贵、政治性和缺乏问责制的坏名声,尽管事实上在企业决策中考虑了更严格的评估和多种观点。在大型组织中,一个小的决定可能会以几轮会议和计划而告终。
在数据科学实践中,我们通常关注个人决策,而利益相关者管理根本不存在问题。然而,在现实世界的应用中,我们经常将数据科学应用于有许多利益相关者的组织环境中的决策制定,因此我们主要致力于公司决策制定。因为与利益相关者打交道从来不是数据科学家的事情,那些对建模技术有兴趣的数据科学家可能会对公司决策的复杂性感到震惊。在企业决策中,利益相关者有相互竞争的观点和利益,依赖定量和定性信息进行决策。面对官僚主义,数据科学的成果可能并不性感,而是无能为力。当数据科学家认为数据应该主导决策制定(数据驱动的决策制定思想)时,这位数据科学家可能会说,“结果很清楚,他们就是不听”。

我们可以进一步将决策分为经营决策和战略决策。运营决策的特点是循环性和结构化;此类决策关系到企业的日常运营,由中层经理和一线员工做出。战略决策的特点是非常规和非结构化的;此类决策涉及组织的政策和战略,由高层管理人员和执行人员做出。今天成功的数据科学应用主要是在运营决策中,因为运营决策更可量化,有大量可用数据用于建模,并且利益相关者较少。想想房价预估,贷款申请审批模型,用户留存预测。这些成功的数据科学应用以代码的形式运作,利益相关方的干预有限。当我们试图将这些成功推广到其他类别的决策时,我们需要理解决策具有独特的特征。
建立影响力说服一个村庄
当今的决策环境极具挑战性。领导结构是扁平的,项目由跨职能团队管理,因此我们通常没有单一的决策权。为了支持分散决策,数据科学家需要说服一个村庄。正如我们前面谈到的公司决策,当人数增加时,决策的复杂性会大大增加。在扁平化的领导结构中,单个决策者或权力中心不太可能保留足够大的权力,因此最终的决策可能不会完全得到员工的尊重,这导致执行不力和决策结果不佳。在一个简化的世界里,一个数据科学家需要说服一个决策者;在当今的企业中,一个数据科学家只是众多说服众多决策者的人之一。我们需要从 1:1 模式转向 N:N 模式。
在 N:N 模型中,从数据科学家的角度来看,数据科学家需要从多个角度向多个团队领导交付数据故事。在我的工作中,成功的标志不是演讲结束时的掌声,而是我被推荐给另一位商业领袖。多一个演示听起来不错,但要向 N 个利益相关者讲述有说服力的数据故事并不容易,因为数据科学工作必须足够强大,足以应对 N 个维度的审查。在与 N 个利益相关者的交流中,数据科学家不仅应该了解他们不同的观点,还应该了解他们不同的决策偏好。有些人希望别人为他们做决定,有些人提出问题并解释结果,有些人可以谈论数据库系统和建模,有些人只希望数据能够证明现有的信念。数据科学家需要准备好面对 N 个决策者。

在 N:N 模型中,从决策者的角度来看,决策者从多个来源获取信息以形成观点。内部团队和外部顾问通过电子邮件、PowerPoint 和电子表格不断向决策者提供信息。在雇用数据科学家团队的大型企业中,由于数据源的变化和方法的差异,决策者可能会从不同的数据科学家那里听到相反的决策建议,因此数据科学家会与其他数据科学家和其他专业人士竞争,以提供最佳的决策洞察力。决策者从不依赖一个人的意见,因此,如果你的建议被忽视,不要把它当成个人意见。亿万富翁雷伊·达里奥完美地总结了这种动态。
“最好的决策是由一个具有可信度加权决策的精英思想做出的。与能力较弱的决策者相比,更重视能力较强的决策者的意见要好得多。这就是我们所说的可信度加权。”**——**雷伊·达里奥,原则
领导力决定一切
尽管数据科学取得了进步,但做出明智决策的能力是一种领导力特质。大胆的领导者能够听到不同的观点,仍然能够做出伟大的决策。数据科学家的工作是给决策者带来严谨的见解,但数据科学家无法改变决策者的领导特质。技术固然有帮助,但领导力才是一切。决策不仅仅是定量解决问题。数据科学家不应局限于解决问题的技能,而应在说服、影响和决策方面建立领导力。
从零开始的决策树分类器:对学生的知识水平进行分类
向数据科学迈出一小步
使用 python 编程语言从头开始编写决策树分类器

Photo by on craftedbygc
先决条件
您需要具备以下方面的基本知识:
- Python 编程语言
- 科学计算图书馆
- 熊猫
数据集
我将在这个项目中使用的数据集来自加州大学欧文分校用户知识建模数据集(UC Irvine)的 。
《UCI》一页提到了以下出版物作为数据集的原始来源:
H.T. Kahraman,Sagiroglu,s .,Colak,I,“开发直观知识分类器和用户领域相关数据的建模”,基于知识的系统,第 37 卷,第 283–295 页,2013 年
介绍
1.1 什么是决策树分类器?
简单来说,决策树分类器就是用于监督+分类问题的 监督机器学习算法 。在决策树中,每个节点都会询问一个关于某个特征的是非问题,并根据决策向左或向右移动。
你可以从 这里 了解更多关于决策树的知识。

1.2 我们在建造什么?

Photo by Andrik Langfield on Unsplash
我们将使用机器学习算法来发现学生历史数据上的模式,并对他们的知识水平进行分类,为此,我们将使用 Python 编程语言从头开始编写我们自己的简单决策树分类器。
虽然我会一路解释每件事,但这不会是一个基本的解释。我将通过进一步的链接突出显示重要的概念,这样每个人都可以对该主题进行更多的探索。
代码部分
2.1 准备数据
我们将使用 pandas 进行数据处理和数据清理。

Data Dictionary
import **pandas** as **pd**df = **pd**.read_csv('data.csv')
df.head()
首先,我们导入 data.csv 文件,然后将其作为熊猫的数据帧进行处理,并查看数据。

Data Preview
正如我们看到的,我们的数据有 6 列。它包含 5 个功能和 1 个标签。既然这个数据已经被清理了,就不需要再进行数据清理和 扯皮 。但是,在处理其他真实世界的数据集时,检查数据集中的空值和异常值并从中设计出最佳要素非常重要。
2.2 列车测试分割
train = df.values[-:20]
test = df.values[-20:]
在这里,我们将数据分为训练和测试,其中数据集的最后 20 个数据是测试数据,其余的是训练数据。
2.3 编写我们自己的机器学习模型
现在是时候编写决策树分类器了。
但是在深入研究代码之前,有一些东西需要学习:
- 为了构建这棵树,我们使用了一种叫做 CART 的决策树学习算法。还有其他学习算法,如 **ID3,C4.5,C5.0,**等。你可以从这里了解更多。
- CART 代表分类和回归树。 CART 使用 Gini 杂质作为其度量,以量化一个问题在多大程度上有助于解混数据,或者简单地说 CARD 使用 Gini 作为其成本函数来评估误差。
- 在引擎盖下,所有的学习算法都给了我们一个决定何时问哪个问题的程序。
- 为了检查这个问题帮助我们解混数据的正确程度,我们使用了**信息增益。**这有助于我们减少不确定性,我们利用这一点来选择要问的最佳问题,对于给定的问题,我们递归地构建树节点。然后,我们进一步继续划分节点,直到没有问题要问,我们将最后一个节点表示为叶子。
2.3.1 书写助手功能
为了实现决策树分类器,我们需要知道什么时候对数据提出什么问题。让我们为此编写一个代码:
**class** CreateQuestion: **def** __init__(self, column, value):
self.column = column
self.value = value **def** check(self, data):
val = data[self.column]
return val >= self.value
**def** __repr__(self):
return "Is %s %s %s?" % (
self.column[-1], ">=", str(self.value))
上面我们写了一个 CreateQuestion 类,它有两个输入:列号和值作为实例变量。它有一个用于比较特征值的检查方法。
repr 只是 python 的一个帮助显示问题的神奇函数。
让我们来看看它的实际应用:
q = **CreateQuestion**(0, 0.08)

Creating question
现在让我们检查一下我们的检查方法是否工作正常:
data = train[0]
q.check(data)

Testing check method

Cross validating check method
正如我们看到的,我们得到了一个错误的值。因为我们在训练集中的 0ᵗʰ值是 0.0,不大于或等于 0.08,所以我们的方法工作得很好。
现在是时候创建一个分区函数来帮助我们将数据分成两个子集:第一个集合包含所有为真的数据,第二个包含所有为假的数据。
让我们为此编写一个代码:
**def** partition(rows, qsn):
true_rows, false_rows = [], []
**for** row **in** rows:
**if** qsn.check(row):
true_rows.append(row)
**else**:
false_rows.append(row)
**return** true_rows, false_rows
我们的分区函数接受两个输入:行和一个问题,然后返回一列真行和假行。
让我们也来看看实际情况:
true_rows, false_rows = partition(train, CreateQuestion(0, 0.08))

True and False row preview
这里 t rue_rows 包含所有大于或等于 0.08 的数据,而 false_rows 包含小于 0.08 的数据。
现在该写我们的基尼杂质算法了。正如我们之前讨论的,它帮助我们量化节点中有多少不确定性,而信息增益让我们量化一个问题减少了多少不确定性。
杂质指标范围在 0 到 1 之间,数值越低表示不确定性越小。

**def** gini(rows): counts = class_count(rows)
impurity = 1
**for** label **in** counts:
probab_of_label = counts[label] / float(len(rows))
impurity -= probab_of_label**2
**return** impurity
在我们的基尼函数中,我们刚刚实现了**基尼的公式。**返回给定行的杂质值。
counts 变量保存数据集中给定值的总计数的字典。 class_counts 是一个帮助函数,用于计算某个类的数据集中出现的数据总数。
**def** class_counts(rows):
**for** row **in** rows:
label = row[-1]
**if** label **not** **in** counts:
counts[label] = 0
counts[label] += 1
**return** counts
让我们来看看基尼的作用:

Gini in action: 1

Gini in action: 2
正如您在图像 1 中看到的,有一些杂质,所以它返回 0.5,而在图像 2 中没有杂质,所以它返回 0。
现在我们要编写计算信息增益的代码:
**def** info_gain(left, right, current_uncertainty):
p = float(len(left)) / (len(left) + len(right))
**return** current_uncertainty - p * gini(left) \
- (1 - p) * gini(right)
通过减去具有两个子节点的加权杂质的不确定性起始节点来计算信息增益。
2.3.2 将所有内容放在一起

Photo by ryoji
现在是时候把所有东西放在一起了。
**def** find_best_split(rows):
best_gain = 0
best_question = None
current_uncertainty = gini(rows)
n_features = len(rows[0]) - 1
**for** col **in** range(n_features):
values = set([row[col] **for** row **in** rows])
**for** val **in** values:
question = Question(col, val)
true_rows, false_rows = partition(rows, question) **if** len(true_rows) == 0 **or** len(false_rows) == 0:
**continue**
gain = info_gain(true_rows, false_rows,\
current_uncertainty) **if** gain > best_gain:
best_gain, best_question = gain, question
**return** best_gain, best_question
我们编写了一个 find_best_split 函数,它通过迭代每个特征和标签找到最佳问题,然后计算信息增益。
让我们来看看这个函数的运行情况:
best_gain, best_question = find_best_split(train)

Finding best question
我们现在要编写我们的 fit 函数。
**def** fit(features, labels): data = features + labels gain, question = find_best_split(data)
**if** gain == 0:
**return** Leaf(rows)
true_rows, false_rows = partition(rows, question)
*# Recursively build the true branch.*
true_branch = build_tree(true_rows)
*# Recursively build the false branch.*
false_branch = build_tree(false_rows)
**return** Decision_Node(question, true_branch, false_branch)
我们的 fit 函数基本上为我们构建了一棵树。它从根节点开始,通过使用我们的 find_best_split 函数找到针对该节点的最佳问题。它迭代每个值,然后分割数据并计算信息增益。在这一过程中,它跟踪产生最大收益的问题。
之后,如果仍有有用的问题要问,增益将大于 0,因此行被分组为分支,并且它首先递归构建真分支,直到没有进一步的问题要问并且增益为 0。
该节点随后成为一个叶节点。
我们的 Leaf 类的代码如下所示:
**class** **Leaf**:
**def** __init__(self, rows):
self.predictions = class_counts(rows)
它保存了一个类别为*(“高”、“低”)*的字典,以及它在到达当前叶子的数据的行中出现的次数。
对于假分支也应用相同的过程。之后,它就变成了一个决策 _ 节点。
我们的 Decision_Node 类的代码如下所示:
**class** **Decision_Node**:
**def** __init__(self, question,\
true_branch,false_branch):
self.question = question
self.true_branch = true_branch
self.false_branch = false_branch
这个类只保存我们已经问过的问题的引用和产生的两个子节点。
现在我们回到根节点,建立错误分支。因为没有任何问题要问,所以它成为叶节点,并且根节点也成为决策 _ 节点。
让我们看看 fit 功能的实际应用:
_tree = fit(train)
为了打印树*_ 树*,我们必须编写一个特殊的函数。
**def** print_tree(node, spacing=""):
*# Base case: we've reached a leaf*
**if** isinstance(node, Leaf):
**print** (spacing + "Predict", node.predictions)
**return**
*# Print the question at this node*
**print** (spacing + str(node.question))
*# Call this function recursively on the true branch*
**print** (spacing + '--> True:')
print_tree(node.true_branch, spacing + " ")
*# Call this function recursively on the false branch*
**print** (spacing + '--> False:')
print_tree(node.false_branch, spacing + " ")
这个 print_tree 函数帮助我们以一种令人敬畏的方式可视化我们的树。

Sample of our tree
我们刚刚完成了决策树分类器的构建!
为了理解和查看我们构建的内容,让我们再编写一些帮助函数:
**def** classify(row, node):
**if** isinstance(node, Leaf):
**return** node.predictions
**if** node.question.check(row):
**return** classify(row, node.true_branch)
**else**:
**return** classify(row, node.false_branch)
分类功能帮助我们检查给定行和树的可信度。
classify(train[5], _tree)

Classification sample
正如你在上面看到的,我们的树把给定的值归类为 96 置信度的中间值。
**def** print_leaf(counts):
total = sum(counts.values()) * 1.0
probs = {}
**for** lbl in counts.keys():
probs[lbl] = str(int(counts[lbl] / total * 100)) + "%"
**return** probs
函数帮助我们美化我们的预测。

Pretty print
2.4 模型评估
我们已经成功地建立,可视化,并看到我们的树在行动。
现在让我们执行一个简单的模型评估:
**for** row **in** testing_data:
**print** ("Actual level: **%s**. Predicted level: **%s**" %
(df['LABEL'], print_leaf(classify(row, _tree))))

Predicted on test data
如你所见,我们的树很好地预测了从训练数据中分离出来的测试数据。
结论
决策树分类器是一个很棒的学习算法。它对初学者很友好,也很容易实现。我们从头开始构建了一个非常简单的决策树分类器,没有使用任何抽象库来预测学生的知识水平。通过交换数据集和调整一些函数,您也可以将该算法用于另一个分类目的。
参考
[1] H. T. Kahraman,Sagiroglu,s .,Colak,I. ,开发直观知识分类器并对 web 中用户的领域相关数据建模,基于知识的系统,第 37 卷,第 283–295 页,2013 年
[2] Aurelien Geron ,用 Scikit-Learn 进行动手机器学习,Keras & TensorFlow,O’REILLY,第二版,2019
更好地使用决策树
从树叶,树,到森林

Photo by pandu ior on Unsplash
当有大量关于决策树的资料时,写这篇文章的原因是为了给一个机会以不同的角度来看待这个话题。接触不同的理解方式是一种有效的学习方法,就好像你一部分一部分地触摸某物,你就知道它的整体形状。您将看到的主题可能会填补您在决策树中遗漏的内容,或者您可以简单地复习一下您已经知道的内容。这篇文章从决策树如何工作开始,涵盖了基本特征,并将其扩展到称为 Bagging 的技术。
先决条件
对模型评估的一些基本理解,尤其是对测试集的理解,将会非常有帮助。可以参考 我之前的帖子 里面涵盖了一部分。
内容
- 如何拆分—如何测量杂质来确定拆分
- 连续要素-如何在连续值上找到分割点
- 非线性和回归——为什么它是非线性的,如何回归
- 贪婪算法——决策树为什么找不到真正的最优解
- 过度拟合的趋势——为什么会发生过度拟合以及如何防止过度拟合
- 装袋和随机森林——装袋的工作原理
- R 中的演示—贷款违约数据
怎么分
决策树的工作原理基本上是关于如何分割节点,因为这就是树的构建方式。让我们假设我们有一个二元分类问题;可乐 vs 酱油。当你想喝什么就喝什么的时候,你不会光看一眼就做出决定。你可能会闻到它,甚至尝一点。因此,颜色不是一个有用的特征,但气味应该是。

在这个例子中,每个人有 5 个杯子,总共 10 个,你的工作是用你的眼睛将它们分类。我们说左节点决定可乐,是因为可乐类比较多,反之亦然。结果不会有希望,你可能会以喝酱油告终。在这种情况下,底部节点是而不是纯粹的,因为这些类几乎都混在一起了。
当一个类在一个节点中占优势时,我们说这个节点是“纯”的。

现在,你用你的鼻子。你仍然可能犯一些错误,但结果应该会好得多。因为节点大多有一个主导类,可乐在左边,酱油在右边,这样更纯粹。那么,问题就变成了如何衡量‘纯度’。答案可能很多,但我们可以谈谈基尼系数(T21)。

该公式是说,将一个类在每个节点上正确的所有平方概率相加,并从 1 中减去总和。好了,我们来看一些例子。

我们有一个有 10 个例子的节点,其中 5 个是真的,5 个是假的。你在这个节点上的决定可能是对的,也可能是错的。现在,你知道这个节点不是很纯。要衡量有多不纯,我们可以这样计算。

在 10 分中,真类的概率是 0.5,假类的概率也是如此。其实这是最不纯粹的案例,证明最高基尼是 0.5 。下面是另一个例子。
更低的基尼更纯,所以更好。

有更多的真实类,所以你可以更自信地宣称你的决定是真实的。同样,基尼系数现在也降低了。此时要提出的另一个问题是何时拆分。我们知道示例中的 7 比 3 是基尼系数的 0.42,但我们想使它更纯粹,并决定用另一个特征来划分 10 个等级。

拆分为两个子节点。现在,我们说左边的节点是真实的,有更多的真实类,反之亦然。我们可以测量每个节点的纯度,但我们如何得出一个结果来与父节点进行比较?我们可以简单地根据节点大小给它们权重,以达到父总数。
如果基尼系数下降,我们就说拆分获得了“信息”。

基尼系数 0.3 小于母公司的 0.42,因此,拆分获得了一些信息。如果一些分裂导致以下结果,那就太好了。

父母是如此的糟糕,他们的基尼系数是 0.5,但是一次分割就可以把基尼系数降到 0。请注意,这两个孩子在辨别真假方面做得非常好。似乎分裂总是有帮助的,然而,那不是真的。

我们直观地知道父节点的基尼系数不是最大值(0.5),但子节点的基尼系数是最大值。换句话说,拆分使情况变得更糟(信息丢失)。即使父母及其子女的基尼系数相同,这仍然更糟,因为节点越多的模型意味着越复杂。事实上,现代决策树模型通过添加更多节点来破坏它。
还有一点需要注意的是,基尼并不是衡量纯度的唯一标准。还有很多,但下面两个值得一提。

你可以像我们对基尼系数所做的那样去尝试,它会输出不同的结果。那么,哪一个比其他的好呢?答案是“视情况而定”。我们更应该关注它们是如何不同的。

From Introduction to Data Mining
我们知道基尼系数的最大值是 0.5,这与熵的最大值不同。也就是说,熵值上升的速度比基尼系数更快。这意味着它可以更严厉地惩罚不纯节点。
另一个区别是误分类误差不像其他两个那样平滑。例如,x-轴从 0.1 增加到 0.2 会增加与从 0.3 增加到 0.4 相同的杂质,这是线性的。相反,基尼认为 0.4 的杂质和 0.5 的杂质几乎一样,熵也是如此。这意味着基尼系数和熵值对杂质更严格。而用哪个要看情况。
连续特征
我们从分类特征开始,这可能不会让任何人感到奇怪。但是决策树可以优雅地处理连续特征。让我们来看看这个例子。

我们有一系列的价值观;10,20,…,100,每一个都被标为真或假。首先要做的是对它们排序,我们可以在两个值之间找到一个点。假设我们 45 岁分手。
理论上,拆分连续值有无限种选择。

有四个值小于 45,其中三个为假,一个为真。相同的规则适用于大于 45°的右侧。现在,我们可以计算每个群体的基尼系数。当然,我们需要对它们进行加权,以得出最终的基尼系数。我们对值之间所有可能的分割点都这样做。

从表中可以看出,最低的基尼系数位于分裂点 35,其中左边是完全纯的(全部是假类),右边有 7 个类,其中 5 个是真类。计算似乎很累,但是当你滑过这些值时,真或假的计数会一个接一个地改变。这意味着每次计算只需要为下一次计算做一点小小的改变(反正机器是为我们做的)。总之,连续特征的处理与分类特征非常相似,但计算量更大。
非线性和回归
直截了当地说,决策树是一个非线性模型。如果一个例子按特征节点分类,多少并不重要。

在图中,有一些极端值,如-205 或 15482。然而,它们都只属于一个节点,任何其他数量都满足该条件。他们没有任何特殊的头衔,如“超级肯定”或“双重否定”。此时,决策树似乎无法进行回归。但是是的,它可以。
我们来看一些类比。我们都知道 ANOVA 模型可以进行回归,其中分类预测值的平均值代表某组样本。类似的想法可以应用到决策树。
某个节点中样本的均值或中值等统计量可以代表该节点

首先,从盒状线可以明显看出决策树是非线性的。这里的另一个要点是,它显示了决策树如何过度适应示例。“最大深度”控制着一棵树的复杂程度。我们可以看到,Max-depth 设置为 5 的树非常努力地适应所有遥远的例子,代价是模型非常复杂。
贪婪算法
决策树是一种贪婪算法,它在每一步都寻找最佳解。换句话说,它可能找不到全局最优解。当有多个特征时,决策树循环遍历这些特征,从以最纯粹的方式(最低基尼系数或最大信息增益)分割目标类的最佳特征开始。并且它一直这样做,直到不再有特征或者拆分没有意义。为什么这有时无法找到真正的最佳解决方案?

为了理解“贪婪”方式实际上发生了什么,我们假设我们从 A 点到 b 点。在贪婪标准下,我们看不到 A 点上的红色路径点,而只能看到蓝色点。站在点 A,我们决定底部,因为这比顶部短。但是在下一步,我们找到红点,以此类推,以一个更长的行程结束。
每一步做出的最优选择并不能保证全局最优。
同样的情况也可能发生在决策树中,因为并没有将所有可能的对组合在一起。想象一下,如果没有数千个特征,也有数百个特征,它们是分类的和连续混合的,每个特征都有不同的值和范围。尽可能将它们混合在一起应该是禁止的。知道决策树是贪婪的,对于理解为什么像装袋这样的高级方法有效很重要。
过度配合的趋势
像其他模型一样,决策树也有过度拟合的问题。在某种程度上,它可能比其他型号稍差一些。一个极端的例子是 ID 特征。无论如何,我们都不想把它作为一个特性,但是为了便于理解,让我们把它当作一个特性。
如果还有任何特征需要分割,它将继续尝试分割

这是一个多路分割,其中每个 ID 都有一个分支,每个节点只有一个案例需要做出决策,因为 ID 是唯一的。现在,它变成了一个查找表。这只不过是一堆硬编码的“if 语句”。当它看到一个新的例子时,问题就出现了。然后,模型会因为里面没有任何功能而爆炸。如果是二叉分裂决策树,那么它的深度就和例子的数量一样。
实际上,我们永远不会使用 ID 作为一个特性,但是如果一个特性有各种各样的值,可以绘制如此多的微妙边界,或者我们让它在深度上增长到适合所有示例所需的程度,这种事件仍然可能发生。也有多种方法可以防止这种情况。修剪是防止树长得更深的方法之一。
“预修剪”控制每个节点必须进一步分裂的样本数。“后期修剪”让它扩展,然后找到过度拟合的节点。
以一种更复杂的方式,我们可以考虑集成方法,让多个学习者做出单独的决定,并把他们放在一起作出最终决定。
装袋和随机森林
Bootstrap 聚合,即所谓的 Bagging,一种集合模型,其中有多个学习者。它的目标是防止过度拟合,并找到更好的解决方案。正如我们从它的名字可以猜到的,它利用了 Bootstrap 抽样方法,这意味着我们抽取‘有替换’的样本。

这是另一个过度拟合的例子,其中底部节点被分割得太多,仅适合 2 个例子。因此,这两个例子肯定非常特殊,因为所有的上层节点都无法唯一地将它们分开。同样,节点现在就像一个查找表。如果我们在构建树的时候不包括这两个例子呢?
装袋随机抽取样品,让一些多抽或一些不抽

树 1 是在没有两个例外示例的情况下构建的。现在,我们给它测试的两个例外,它落在一个有很多例子的节点上。这不再像查找表一样工作,因为它甚至没有看到示例。它们在其他树中仍然可能是例外的,但是最终的决定是由所有“n”棵树投票做出的。简而言之,随机抽样防止一个模型记忆例子,并集中于一个普遍共识。
装袋也可以随机选择特征。
如果我们将 Bagging 应用于特征会怎么样?它的意思是随机选择一些特征,而不是全部。比如我们有 100 个特征,要猜一些类。我们可以像纯决策树一样使用它们,但我们只是随机选择其中的一些,比如只使用 30 或 50 个或任何一个。这听起来很奇怪,因为看起来我们没有充分利用功能。
还记得寻找更短路线的贪婪算法例子吗,如果我们连最底层路线的选择都没有呢?因为我们不知道那条路线,所以我们会选择最上面的路线,这样总的来说会缩短行程。
通过减少特征,我们可以防止导致局部最优而非全局最优的特征组合。
由于随机选择的性质,某些特性集可能会导致更糟的结果。这就是为什么我们应该多次重复随机抽样和随机特征选择,以便它能够找到偏向一般决策标准的最佳组合。但这可能仍然不是真正的全局最优,因为随机化所有这些并不意味着我们已经经历了所有的可能性( NP-Complete 问题)。
需要注意的一点是 Bagging 是一种集成方法,可以应用于任何模型,而不仅仅是决策树。当 Bagging 应用于决策树时,就像树木组成一个森林一样,它变成了随机森林。
R 中的演示
贷款数据集直观易懂。我们有 300 个例子和 11 个特征,如年龄、性别、贷款金额、收入和贷款状态作为目标。这是一个二元分类,猜测贷款是否违约。
代码使用最少的库,因此它可以专注于模拟。此外,交叉验证没有用于评估,以保持简单(仍然公平,因为相同的训练/测试集用于所有模型)。完整的代码和数据可以在 Github 上找到。
- 完整模型—根据训练集进行评估
# Classification model with all features
clf <- rpart(formula = Loan_Status ~., data = training.set,
control = rpart.control(minsplit = 1))# Predict from training set and calculate accuracy
pred <- predict(clf, newdata = training.set[, -12], type = 'class')
round(sum(training.set[, 12]==pred)/length(pred), 2)# Plot the tree
rpart.plot(clf, box.palette = 'RdBu', nn = T)
该模型是使用所有功能构建的,并且是针对训练集而不是测试集进行测试的。这是为了观察过度拟合是如何发生的。
*图上的文字可能不清晰,但此时并不重要。请注意形状,尤其是深度和节点的数量。

Accuracy = 0.96
这棵树又深又复杂。它的精度是 0.96,几乎完美,但根据自己的训练集进行了测试。现在,让我们根据测试集(看不见的数据)评估模型。
- 完整模型—根据测试集进行评估
# Evaluate against testing set
pred <- predict(clf, **newdata = testing.set**[-12], type = 'class')
round(sum(testing.set[, 12]==pred)/length(pred), 2)
请注意,参数“newdata”现在是“testing.set”。结果是 0.63 ,远小于针对训练集测试的值。这意味着使用所有特征和所有例子的模型没有成功地概括它。
我们首先可以做的一件事是调整参数。限制深度会有所帮助,因为模型不会增长到那么深,从而防止过度拟合。此后的所有精度都是从测试集中计算出来的。
- 具有深度限制的完整模型
# Set maxdepth to 3
clf <- rpart(formula = Loan_Status ~., data = training.set,
control = rpart.control(minsplit = 1, **maxdepth = 3**))# Evaluate against testing set
pred <- predict(clf, newdata = testing.set[-12], type = 'class')
round(sum(testing.set[, 12]==pred)/length(pred), 2)
根据测试集评估,现在的准确度为 0.68 ,高于 0.63。此外,即使不使用所有的特性,树也要简单得多。

Accuracy = 0.68
- 随机抽样的简化模型——随机森林
# Build 100 trees with max node
clf <- randomForest(x = training.set[-12],
y = training.set$Loan_Status,
**ntree = 100**, **maxnodes = 5**)
我们构建了 100 棵树,每棵树最多有 5 个节点。精度为 0.72 ,比以往更高。这意味着模型找到了一些处理异常例子的方法。当我们更想改善它的时候,我们应该仅仅增加树的数量吗?不幸的是,它可能不会太有帮助,因为随机森林不是魔法。如果足够幸运的话,在看到全新的数据之前,它可能会变得更好。
这种改进是基于共识的,意味着它放弃了次要的例子,以适应更普遍的例子。
结论
我们学习了决策树的基本原理,重点是分裂。分类值和连续值都显示了这一点。此外,我们还检验了决策树的一些特性,如非线性、回归能力和贪婪算法。对于过度拟合,控制深度和装袋介绍了示范在 r。
在现实世界中,这些并不总是有效的,因为我们不应该期望数据像我们希望的那样干净。然而,了解这些属性和参数将是创造性尝试的良好开端。
好的读数
- 数据挖掘简介:第 4 章。分类
- Scikit-Learn 示例:决策树回归
- 随机森林视频指南:基本思路介绍
- ‘R part’R 库:教程及更多详情
- randomForest R 库:简单教程
我们鼓励你提出你的意见。在此评论!或者通过 LinkedIn 跟我说话,如果你想悄悄地指出这篇帖子中的错误……同时,欢迎你访问 我的作品集网站 !
Python 中从头开始的决策树
决策树是当今可用的最强大的机器学习工具之一,被广泛用于各种现实世界的应用中,从脸书的广告点击预测到 Airbnb 体验的排名。然而,它们是直观的、易于解释的——并且易于实现。在本文中,我们将用 66 行 Python 代码训练我们自己的决策树分类器。

Let’s build this!
什么是决策树?
决策树可用于回归(连续实值输出,
例如预测房屋价格)或分类(分类输出,
例如预测垃圾邮件与无垃圾邮件),但这里我们将重点讨论分类。决策树分类器是一个二叉树,其中通过从根到叶遍历树来进行预测——在每个节点,如果特征小于阈值,我们向左,否则向右。最后,每个叶子与一个类相关联,这是预测器的输出。
例如,考虑这个无线室内定位数据集。它给出了 7 个特征,代表公寓中手机感知的 7 个 Wi-Fi 信号的强度,以及手机的室内位置,可能是 1、2、3 或 4 号房间。
+-------+-------+-------+-------+-------+-------+-------+------+
| Wifi1 | Wifi2 | Wifi3 | Wifi4 | Wifi5 | Wifi6 | Wifi7 | Room |
+-------+-------+-------+-------+-------+-------+-------+------+
| -64 | -55 | -63 | -66 | -76 | -88 | -83 | 1 |
| -49 | -52 | -57 | -54 | -59 | -85 | -88 | 3 |
| -36 | -60 | -53 | -36 | -63 | -70 | -77 | 2 |
| -61 | -56 | -55 | -63 | -52 | -84 | -87 | 4 |
| -36 | -61 | -57 | -27 | -71 | -73 | -70 | 2 |
...
目标是根据 Wi-Fi 信号 1 到 7 的强度来预测手机位于哪个房间。深度为2 的经过训练的决策树可能如下所示:

Trained decision tree. Predictions are performed by traversing the tree from root to leaf and going left when the condition is true. For example, if Wifi 1 strength is -60 and Wifi 5 strength is -50, we would predict the phone is located in room 4.
基尼杂质
在我们深入研究代码之前,让我们定义算法中使用的度量。决策树使用基尼杂质的概念来描述一个节点的同质性或“纯”程度。如果一个节点的所有样本都属于同一个类,则该节点是纯的( G = 0 ),而具有来自许多不同类的许多样本的节点将具有更接近 1 的基尼系数。
更正式的说法是,跨 k 个类别划分的 n 个训练样本的基尼系数被定义为

其中 p[k] 是属于类别 k 的样本分数。
例如,如果一个节点包含五个样本,其中两个是教室 1,两个是教室 2,一个是教室 3,而没有教室 4,那么

CART 算法
训练算法是一种叫做 CART 的递归算法,是分类和回归树的简称。每个节点都被分割,以使子节点的基尼系数杂质(更具体地说,是按大小加权的子节点的基尼系数平均值)最小化。
当达到最大深度、超参数**、时,或者当没有分裂可以导致两个孩子比他们的父母更纯时,递归停止。其他超参数可以控制这个停止标准(在实践中对避免过度拟合至关重要),但我们不会在这里讨论它们。**
例如,如果X = [[1.5], [1.7], [2.3], [2.7], [2.7]]和y = [1, 1, 2, 2, 3],那么最优分割是feature_0 < 2,因为如上计算,父母的基尼系数是 0.64,分割后子女的基尼系数是

你可以说服自己,没有任何其他分割方式能产生更低的基尼系数。
寻找最佳特征和阈值
CART 算法的关键是找到最优特征和阈值,使得基尼系数杂质最小。为此,我们尝试了所有可能的分裂,并计算了由此产生的基尼系数。
但是我们如何尝试连续值的所有可能的阈值呢?有一个简单的技巧-对给定特性的值进行排序,并考虑两个相邻值之间的所有中点。排序是昂贵的,但我们很快就会看到,无论如何它是需要的。
现在,我们如何计算所有可能分裂的基尼系数呢?
第一种解决方案是实际执行每次分割,并计算得出的基尼系数。不幸的是,这很慢,因为我们需要查看所有的样本,将它们分成左和右。更准确地说,这将是 n 个拆分,每个拆分有个 O(n) 个操作,使得整个操作为 O(n ) 。
**更快的方法是 **1。**遍历排序后的特征值作为可能的阈值, **2。**记录左侧和右侧每类样品的数量,以及 **3。在每个阈值后,将它们递增/递减 1。从它们我们可以很容易地计算出常数时间内的基尼系数。
*实际上,如果 m 是节点的大小,并且*m【k】是节点中类别 k 的样本数,那么

由于在看到第 i 个阈值后,左边有 i 元素,右边有m–I,

和

由此得出的基尼系数是一个简单的加权平均数:

下面是完整的_best_split方法。
第 61 行的条件是最后一个微妙之处。通过遍历所有特征值,我们允许对具有相同值的样本进行分割。实际上,我们只能在它们对于该特性有独特的值的情况下对它们进行分割,因此需要额外的检查。
递归
难的部分完成了!现在我们要做的就是递归地分割每个节点,直到达到最大深度。
但是首先让我们定义一个Node类:
将决策树拟合到数据X和目标y是通过调用递归方法_grow_tree()的fit()方法完成的:
预言
我们已经看到了如何拟合决策树,现在我们如何用它来预测看不见的数据的类?再简单不过了——如果特征值低于阈值,则向左,否则向右。
训练模型
我们的DecisionTreeClassifier准备好了!让我们在无线室内定位数据集上训练一个模型:

Our trained decision tree. For the ASCII visualization — not in the scope of this article — check out the full code for the Node class.
作为健全性检查,下面是 Scikit-Learn 实现的输出:

复杂性
很容易看出,预测在 O(log m) ,其中 m 是树的深度。
但是训练呢? 主定理 在这里会很有帮助。在具有 n 个样本的数据集上拟合树的时间复杂度可以用下面的递归关系来表示:

其中,假设左右孩子大小相同的最佳情况, a = 2,b= 2;而 f(n) 是将节点拆分成两个子节点的复杂度,换句话说就是_best_split的复杂度。第一个for循环对特性进行迭代,对于每次迭代,都有一个复杂度为 O(n log n) 的排序** 和 O(n) 中的另一个for循环。因此 f(n) 是 O(k n log n) 其中 k 是特征的数量。**
在这些假设下,主定理告诉我们总时间复杂度是

**这与 Scikit-Learn 实现的复杂性差不太远,但仍然比它差,显然是在 O(k n log n)中。如果有人知道这怎么可能,请在评论里告诉我!
完全码
完整的代码可以在这个 Github repo 上找到。正如承诺的那样,为了好玩,这里有一个精简到 66 行的版本。
何、、欧瑾、、徐、、、史、、安托万·阿塔拉、拉尔夫·赫布里希、斯图尔特·鲍尔斯和华金·基诺内罗·坎德拉。2014.预测脸书广告点击率的实践经验。《第八届在线广告数据挖掘国际研讨会论文集》(ADKDD’14)。美国纽约州纽约市 ACM,第 5 条,9 页。DOI = http://dx . DOI . org/10.1145/26484848364
Jayant G Rohra、Boominathan Perumal、Swathi Jamjala Narayanan、Priya Thakur 和 Rajen B Bhatt,“使用粒子群优化和重力搜索算法与神经网络的模糊混合在室内环境中的用户定位”,载于第六届软计算解决问题国际会议论文集,2017 年,第 286-295 页。
布雷曼,利奥;J. H .弗里德曼;奥尔申。斯通,C. J. (1984)。分类和回归树。加利福尼亚州蒙特雷:沃兹沃斯&布鲁克斯/科尔高级图书&软件。
通俗地说就是决策树

Image by Johannes Plenio from Pixabay
什么是决策树?
决策树是基于特定条件的决策的所有可能解决方案的图形表示。目标变量可以取一组有限值的树模型称为分类树,目标变量可以取连续值(数字)的树模型称为回归树。
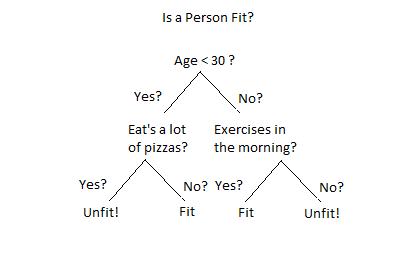
让我们举一个现实生活中的例子,
Toll-Free
每当你拨打银行的免费电话时,它会将你转接到他们的智能电脑助手那里,询问你一系列问题,如英语请按 1,西班牙语请按 2 等。一旦你选择了你想要的,它会再次将你重定向到一系列特定的问题,比如贷款请按 1,储蓄账户请按 2,信用卡请按 3 等等。这样不断重复,直到你最终找到合适的人或服务。你可能认为这只是一个语音邮件流程,但实际上,银行实施决策树是为了让你进入正确的产品或服务。

考虑一下上面的图片,我是否应该接受一份新的工作邀请?为此,我们需要创建一个决策树,从基本条件或根节点(蓝色)开始,即最低工资应为 100,000 美元,如果没有 100,000 美元,则您不会接受该提议。所以,如果你的薪水高于 10 万英镑,那么你会进一步检查公司是否给你一个月的假期?如果他们不给,那么你就是在拒绝这个提议。如果他们给你一个假期,那么你会进一步检查该公司是否提供免费健身房?如果他们不提供免费健身房,那么你是在拒绝这个提议。如果他们提供免费健身房,那么你很乐意接受这个提议。这只是决策树的一个例子。
好了,怎么建树?
有许多具体的决策树算法可用。值得注意的包括:
- ID3(迭代二分法 3)
- 分类和回归树
- 卡方自动交互检测(CHAID)。计算分类树时执行多级拆分。
在这个博客中,我们将看到 ID3。决策树常用的杂质度量有三种:熵、基尼指数、分类误差。决策树算法使用信息增益来分割节点。基尼指数或熵是计算信息增益的标准。CART 算法使用的基尼指数和 ID3 算法使用的熵。在进入细节之前,我们先来看看杂质。
什么是杂质?

假设你有一个装满苹果的篮子,而另一个碗里装满了同样的苹果标签。如果你被要求从每个篮子和碗中挑选一件物品,那么得到苹果及其正确标签的概率是 1,所以在这种情况下,你可以说杂质是 0

假设现在篮子里有三种不同的水果,碗里有三种不同的标签,那么水果与标签匹配的概率显然不是 1,而是小于 1。如果我们从篮子里拿一根香蕉,然后从碗里随机拿一个标签,上面写着葡萄,这是有可能的。所以在这里,任何随机的排列组合都是可能的。在这种情况下,我们可以说杂质不为零。
熵
熵是你的数据有多杂乱的一个指标。

熵是对数据集中随机性或不可预测性的度量。换句话说,它控制决策树决定如何分割数据。熵是数据同质性的度量。它的值范围从 0 到 1。如果一个节点的所有样本都属于同一个类,则熵为 0(这对训练数据集不利),如果我们具有均匀的类分布,则熵最大(对训练数据集有利)。熵的等式是

信息增益
信息增益(IG) *度量一个特征给我们多少关于类的“信息”。*信息增益基于数据集在属性上拆分后熵的减少。它是用于构建决策树的主要参数。具有最高信息增益的属性将首先被测试/分割。
信息增益=基础熵—新熵
让我们以下面的卡通数据集为例。感谢 Minsuk Heo 分享这个例子。你可以点击查看他的 youtube 频道


数据集有一个卡通,冬天,> 1 属性。家庭冬季照是我们的目标。共 8 张图片。我们需要教宝宝挑选正确的冬季家庭度假照片。
如何拆分数据?
我们必须以信息增益最高的方式构建分割数据的条件。请注意,增益是分裂后熵减少的量度。首先,将计算上述数据集的熵。
共 8 张照片。冬季全家福— 1(是),现在冬季全家福— 7(否)。如果我们代入上面的熵公式,
=-(1/8)* log2(1/8)——(7/8)* log2(7/8)
熵= 0.543
我们得到了三个属性,即卡通、冬天和> 1。那么哪种属性最适合构建决策树呢?我们需要计算所有三个属性的信息增益,以便选择最佳的一个或根节点。我们的基本熵是 0.543
卡通片《冬天》的信息增益,

卡通的信息增益高,所以根节点是一个卡通人物。

根节点是一个卡通人物。我们需要根据另外两个属性 winter 或> 1 再次进行拆分。再次计算信息增益并选择最高的一个用于选择下一次分裂。
1 属性具有高信息增益,相应地拆分树。最终的树如下

决策树的优点
- 决策树易于可视化和解释。
- 它可以很容易地捕捉非线性模式。
- 它可以处理数字和分类数据。
- 数据准备所需的工作量很小。(例如,不需要标准化数据)
决策树的缺点
- 过拟合是决策树模型最实际的困难之一。
- 连续变量精度低:在处理连续数值变量时,决策树在对不同类别的变量进行分类时会丢失信息。
- 它是不稳定的,意味着数据的微小变化会导致最优决策树结构的巨大变化。
- 决策树偏向于不平衡数据集,因此建议在创建决策树之前平衡数据集。
我将在下一篇文章中使用 Python 解释 CART 算法和过度拟合问题。
请继续学习,并关注更多内容!
如果您发现任何错误或需要改进的地方,请随时在下面发表评论。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言










{kind=link}