







使用 t-SNE 和 Plotly 聚类人工智能生成的鸡尾酒配方
让数据可以直观地探索

Scroll down for the interactive version!
最近,我训练了一个递归神经网络,让根据纽约酒吧死亡&公司的风格生成鸡尾酒配方。事实上,这些食谱中有相当多的特色是配料的奇特组合,通常在实践中会产生很好的效果。然而,尽管品尝一些人工智能生成的鸡尾酒不可否认非常美味,但对鸡尾酒产量的系统分析将非常有益。当然,更好的(也是为未来计划的)是将 cocktailAI 部署为一个 web 工具。作为一种安慰,你在这里得到了下一个最好的东西:数百种人工智能生成的鸡尾酒配方以直观的方式呈现!
但在我们到达那里之前,让我们先做一个有趣的练习,分析一下《现代经典鸡尾酒》一书中的 500 多种鸡尾酒配方,我用这本书作为 cocktaili 的数据库。一种方法是通过聚类,把相似的鸡尾酒分组,把不相似的分开(我们暂时不知道‘相似’是什么意思)。假设一个标准图有两个维度(典型的 x 和 y),我们如何从数据库中的数百种鸡尾酒成分中选择两个变量呢?在这里,我们需要一个被称为降维的工具,它获取我们的数据,并试图在两个维度上根据它们的成分和数量来表示食谱之间的相似性。我们将使用t-SNE(t-分布式随机邻居嵌入)作为一个特别强大的非线性降维工具。我们从 SNE 霸王龙那里得到的数据可以绘制成二维图,现在我们可以开始分析了!
Interactive t-SNE plot of Death & Co cocktail recipes. Hover for cocktail name, drag-select for zoom
在 t-SNE 图中,点的聚类表示一组相似的数据点(在本例中为鸡尾酒配方)。为了便于识别,我冒昧地根据它们的基酒(或主要类型的烈酒;此处定义为 22.5 毫升以上的任何液体)。你可以非常清楚地看到,对于大多数碱基,我们实际上可以检测到明显的簇。如果你还没有注意到,这是使用 Plotly 绘制的,所以你可以将鼠标悬停在某个点上,它会显示相应的死亡& Co 鸡尾酒配方的名称和基础(当然,我不能给你配方本身,因为它来自商业来源)。特别是对于杜松子鸡尾酒,我们可以识别出一组清晰的相似配方。如果你观察威士忌鸡尾酒,可以观察到一个有趣的现象。标记为“威士忌”的三个聚类对应于基于主要威士忌变体的鸡尾酒:波旁威士忌、黑麦威士忌和苏格兰威士忌(加上分别用于爱尔兰威士忌和日本威士忌的较小聚类)。对于龙舌兰酒,我们可以注意到分别依赖布兰科龙舌兰酒和雷萨多龙舌兰酒的鸡尾酒之间的明显区别。当然,白朗姆酒和棕色朗姆酒也有类似的行为。想象一下,也许下一次死亡时& Co 会点一杯不寻常的威士忌鸡尾酒,它不在任何威士忌酒类中!
Interactive t-SNE plot of AI-generated cocktail recipes. Hover for cocktail name+recipe, drag-select for zoom
因此,接下来我们来到了更有趣的主题——人工智能生成的鸡尾酒!我收集了大约 400 只,给它们同样的 t-SNE 聚类处理。而这一次,在上面的 Plotly 图中,当你悬停在该点上时,除了名称之外,你实际上还可以获得大约 400 种人工智能生成的鸡尾酒的每一种的配方!对于杜松子酒和龙舌兰酒鸡尾酒,我们可以看到一个与原始 Death & Co 配方类似的图片(绝对位置在 t-SNE 曲线中并不重要,只有相对位置才重要)。现在,朗姆酒鸡尾酒严重偏向棕色朗姆酒(特别是由于 tiki 鸡尾酒中大量的棕色朗姆酒扭曲了算法),剩下的几个白色朗姆酒点奇怪地与宣称为“其他”的鸡尾酒重叠。至于威士忌,一个强大的黑麦集群可以确定,一个稍微小一点的波旁酒。缺少苏格兰主题的食谱确实很奇怪。让我知道你是否能在图中发现任何其他模式!
所有这些都很棒的一个原因是,您可以根据给定的基础专门搜索配方,而不必滚动列表或 excel 文件。如果你想对你的鸡尾酒配方列表做同样的事情,你可以在 GitHub 上找到我的代码。此外,如果你特别喜欢冒险,你可以在远离他们的地方寻找鸡尾酒配方,看看他们是否有一份时髦的配料清单!请记住,这里显示的这个人工智能生成的食谱数据库是而不是策划的。可能有不存在的必要成分,可能有错误(在拼写和概念上)。此外,一些含有“两种基本成分”的配方中,两种颜色直接重叠在一起,这可能会让人有点困惑。所以,在这个激动人心的新世界里,要小心行事,这个世界充满了有待发现的发现和有待收获的收获!
基于 K-means 的 R 中的聚类分析
了解如何使用最著名的聚类算法之一来识别数据中的组

Photo by Mel Poole on Unsplash
聚类分析的目的是识别数据中的模式,并根据这些模式创建组。因此,如果两个点具有相似的特征,这意味着它们具有相同的模式,因此它们属于同一组。通过聚类分析,我们应该能够检查哪些特征通常一起出现,并了解一个群体的特征。
在这篇文章中,我们将使用 K-means 算法对多个变量进行聚类分析。目的是根据物种乳汁的成分找到哺乳动物的群体。这里涉及的要点是:
- 聚类中使用的数据的简要说明;
- K-means 算法如何工作的解释;
- 如何决定我们想要作为输入的组的数量;
- 使用轮廓宽度的聚类验证。
- 如何解释结果并以可视化的方式显示出来。
描述数据
使用的数据集是包 cluster.datasets 的一部分,包含以下 6 个变量的 25 个观察值:
名称 —动物名称的字符向量
T5【水】T6—牛奶样品中水分含量的数值向量
蛋白质 —牛奶样品中蛋白质含量的数值向量
脂肪 —牛奶样品中脂肪含量的数值向量
乳糖 —牛奶样品中乳糖含量的数值向量
灰分 —数值向量
让我们来看一个数据样本
**library**(cluster.datasets)data(all.mammals.milk.1956)
head(all.mammals.milk.1956)## name water protein fat lactose ash
## 1 Horse 90.1 2.6 1.0 6.9 0.35
## 2 Orangutan 88.5 1.4 3.5 6.0 0.24
## 3 Monkey 88.4 2.2 2.7 6.4 0.18
## 4 Donkey 90.3 1.7 1.4 6.2 0.40
## 5 Hippo 90.4 0.6 4.5 4.4 0.10
## 6 Camel 87.7 3.5 3.4 4.8 0.71
下面的图表显示了每个变量的分布。每个点代表一个哺乳动物物种(总共 25 个)。

每个变量都有不同的行为,我们可以分别识别每个变量上的哺乳动物群体,但这不是这里的目的。
所有变量都将用于线性范围的聚类。有时,当(每个要素的)值范围很大时,例如从 0 到 100 万,使用对数标度会很有趣,因为在对数标度上,我们会突出显示值之间的较大差异,较小的差异会被认为不太重要。由于数据集中的值在 0 到 100 之间变化,我们将使用线性标度,它认为值之间的差异同样重要。
使聚集
我们将要使用的聚类算法是 K-means 算法,我们可以在包 stats 中找到它。K-means 算法接受两个参数作为输入:
- 数据;
- 一个 K 值,这是我们想要创建的组的数量。
从概念上讲,K 均值表现如下:
- 它随机选择 K 个质心;
- 将数据中的每个点(在我们的例子中,每个哺乳动物)与 n 维空间中最近的质心进行匹配,其中 n 是聚类中使用的特征数(在我们的例子中,5 个特征—水、蛋白质、脂肪、乳糖、灰分)。在这一步之后,每个点都属于一个组。
- 现在,它将质心重新计算为组中所有其他点的中点(向量)。
- 它会一直重复第 2 步和第 3 步,直到组稳定下来,即没有点被重新分配给另一个质心,或者达到最大迭代次数(统计库默认使用 10)。
选择一个好 K
您选择的 K 越大,聚类中组内的方差就越低。如果 K 等于观测值的个数,那么每个点就是一组,方差为 0。在组的数量和它们的方差之间找到一个平衡是很有趣的。一个群体的方差意味着这个群体的成员有多么不同。方差越大,组内的差异就越大。
为了找到平衡,我们如何选择 K 的最佳值?
为了回答这个问题,我们将对任意的 K 运行 K-means。我们选 3 吧。
## K-means clustering with 3 clusters of sizes 7, 2, 16
##
## Cluster means:
## water protein fat lactose ash
## 1 69.47143 9.514286 16.28571 2.928571 1.311429
## 2 45.65000 10.150000 38.45000 0.450000 0.690000
## 3 86.06250 4.275000 4.17500 5.118750 0.635625
##
## Clustering vector:
## [1] 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 1 1 1 1 1 1 1 2 2
##
## Within cluster sum of squares by cluster:
## [1] 300.1562 27.1912 377.2215
## (between_SS / total_SS = 89.9 %)
##
## Available components:
##
## [1] "cluster" "centers" "totss" "withinss"
## [5] "tot.withinss" "betweenss" "size" "iter"
## [9] "ifault"
kmeans() 函数输出聚类的结果。我们可以看到质心向量(聚类平均值)、每个观察值被分配到的组(聚类向量)以及表示聚类的紧密度(T8)的百分比(89.9%),即同一组中的成员有多相似。如果一个组中的所有观察值都在 n 维空间中的同一个精确点上,那么我们将达到 100%的紧凑性。
既然我们知道这个,我们将使用这个百分比来帮助我们决定我们的 K 值,也就是说,将有令人满意的方差和紧凑性的组的数量。
下面的函数绘制了一个图表,通过为算法的几次执行选择的组数( K 值)显示“平方和内”(withinss)。平方和内是一个度量标准,它显示了一个组的成员之间的不同程度。和越大,组内的差异就越大。

通过从右到左分析图表,我们可以看到,当组的数量( K )从 4 减少到 3 时,平方和有很大的增加,比之前的任何增加都大。这意味着当它从 4 个组变成 3 个组时,聚类紧密度降低(紧密度是指组内的相似性)。然而,我们的目标不是达到 100%的紧凑性——为此,我们只是将每个观察作为一个组。主要目的是找到能够令人满意地解释相当一部分数据的相当多的组。
所以,让我们选择 K = 4,再次运行 K-means。
## K-means clustering with 4 clusters of sizes 10, 2, 7, 6
##
## Cluster means:
## water protein fat lactose ash
## 1 88.50000 2.570000 2.80000 5.680000 0.4850000
## 2 45.65000 10.150000 38.45000 0.450000 0.6900000
## 3 81.18571 7.428571 6.90000 4.014286 0.9314286
## 4 68.33333 9.550000 17.41667 2.916667 1.3300000
##
## Clustering vector:
## [1] 1 1 1 1 1 1 1 3 3 3 3 1 1 3 1 3 3 4 4 4 4 4 4 2 2
##
## Within cluster sum of squares by cluster:
## [1] 59.41225 27.19120 63.53491 191.96100
## (between_SS / total_SS = 95.1 %)
##
## Available components:
##
## [1] "cluster" "centers" "totss" "withinss"
## [5] "tot.withinss" "betweenss" "size" "iter"
## [9] "ifault"
使用 3 组(K = 3)我们有 89.9%的分组数据。使用 4 组(K = 4)该值提高到 95.1%,这对我们来说是一个好值。
聚类验证
我们可以使用轮廓系数(轮廓宽度)来评估我们的聚类的良好性。
轮廓系数计算如下:
- 对于每个观察值 i ,它计算 i 和 i 所属的同一个聚类内的所有其他点之间的平均相异度。我们姑且称这个平均相异度**“Di”**。
- 现在,我们在 i 和所有其他聚类之间进行相同的相异度计算,并获得它们之间的最小值。也就是说,我们找到了 i 和紧随其自己的集群之后最接近 i 的集群之间的不同之处。让我们称这个值为**“Ci”**
- 轮廓( Si )宽度是 Ci 和 Di(Ci-Di)之差除以这两个值中的最大值(max(Di,Ci))。
Si = (Ci — Di) / max(Di,Ci)
因此,剪影宽度的解释如下:
- Si > 0 意味着观察值被很好地聚集。它越接近 1,它被聚集得越好。
- Si < 0 意味着观察值被放置在错误的簇中。
- Si = 0 意味着观察值在两个聚类之间。
下面的轮廓图为我们提供了证据,证明我们使用四个组的聚类是好的,因为没有负的轮廓宽度,并且大多数值都大于 0.5。
## cluster size ave.sil.width
## 1 1 10 0.65
## 2 2 2 0.76
## 3 3 7 0.58
## 4 4 6 0.49

聚类解释
下图显示了我们聚类的最终结果。实际剧情是互动的,但下图不是。您可以使用下面的代码重现该情节。在交互式绘图中,您可以隔离各组,以便更好地理解每一组。

聚类分析的目的是识别数据中的模式。正如我们在上面的图中看到的,同一组中的观察结果往往具有相似的特征。
我们以绿组为例来评价一下。属于该组的两个哺乳动物物种,即海豹和海豚,它们具有最低的水百分比(44.9%和 46.4%);它们的牛奶中都含有大约 10%的蛋白质;在所有其他物种中,它们的牛奶中脂肪含量最高,乳糖含量最低。这是发现的将海豹和海豚放在同一组的模式。我们也可以在其他群体中发现这样的模式。
感谢您的阅读。我希望这是一次愉快而有益的阅读。
聚类评估策略
聚类是一种无监督的机器学习算法。它有助于将数据点分组。与监督机器学习算法相比,验证聚类算法有点棘手,因为聚类过程不包含基本事实标签。如果想要在存在基础事实标签的情况下进行聚类,可以使用监督机器学习算法的验证方法和度量。这篇博客文章试图解决地面真相标签未知时的评估策略。
如何评估聚类?
评估聚类的三个重要因素是
(a)聚类趋势(b)聚类数量, k ©聚类质量
聚集趋势
在评估聚类性能之前,确保我们正在处理的数据集具有聚类趋势并且不包含均匀分布的点是非常重要的。如果数据不包含聚类趋势,那么由任何现有聚类算法识别的聚类可能是不相关的。数据集中点的非均匀分布在聚类中变得很重要。
为了解决这个问题,可以使用 Hopkins 检验(一种对变量空间随机性的统计检验)来衡量均匀数据分布产生的数据点的概率。

Plot for data from Uniform distribution
零假设(Ho) : 数据点由均匀分布产生(暗示没有有意义的聚类) 交替假设(Ha): 数据点由随机数据点产生(有聚类)
如果 H >为 0.5,可以拒绝零假设,数据很有可能包含聚类。如果 H 更接近 0,则数据集不具有聚类倾向。
最佳聚类数,k
像 K-means 这样的一些聚类算法需要聚类的数目 k 作为聚类参数。在分析中,获得最佳的聚类数是非常重要的。如果 k 太高,每个点将大致开始代表一个聚类,如果 k 太低,则数据点被错误地聚类。找到最佳的集群数量可以提高集群的粒度。
寻找正确的聚类数没有明确的答案,因为它取决于(a)分布形状(b)数据集中的规模©用户要求的聚类分辨率。尽管找到聚类数是一个非常主观的问题。有两种主要的方法来寻找最佳的聚类数目:
(1)领域知识
(2)数据驱动方法
领域知识 —领域知识可能给出一些关于寻找聚类数目的先验知识。例如,在聚类 iris 数据集的情况下,如果我们有物种的先验知识( sertosa,virginica,versicolor ),那么 k = 3。领域知识驱动 k 值给出更多相关见解。
数据驱动方法 —如果领域知识不可用,数学方法有助于找出正确的聚类数。
经验方法:- 寻找聚类数的简单经验方法是 N/2 的平方根,其中 N 是数据点的总数,因此每个聚类包含 2 * N 的平方根
肘方法:- 聚类内方差是聚类紧密度的度量。组内方差的值越低,形成的组的紧密度越高。
对于使用不同 k 值完成的聚类分析,计算类内方差之和W。W是点在分析中聚类程度的累积度量。绘制 k 值及其相应的组内方差之和有助于找到组的数量。

Plot of Sum of within cluster distance vs Number of clusters in Elbow method
该图显示最佳聚类数= 4。
最初,误差度量(组内方差)随着组数的增加而减小。在特定点 k=4 之后,误差测量开始变平。对应于特定点 k=4 的聚类数应该被认为是最优的聚类数。
统计方法:-
间隙统计是一种强有力的统计方法,用来寻找最佳的聚类数, k 。
与 Elbow 方法类似,计算不同 k 值的组内方差之和。
然后生成来自参考零分布的随机数据点,并计算不同 k 值聚类的组内方差之和。
更简单地说,将不同 k 值的原始数据集的组内方差之和与相应 k 值的参考数据集(均匀分布的零参考数据集)的组内方差之和进行比较,以找到两者之间的“偏差”或“差距”最高的理想 k 值。由于间隙统计量化了这种偏差,间隙统计越多意味着偏差越大。

Gap statistic Value-Cluster number (k)
具有最大间隙统计值的聚类数对应于最优的聚类数。
聚类质量
一旦聚类完成,就可以通过许多指标来量化聚类的表现。理想聚类的特征在于最小的类内距离和最大的类间距离。
主要有两种类型的度量来评估聚类性能。
(i) 需要地面真实标签的外在测量。示例有调整后的 Rand 指数、Fowlkes-Mallows 评分、基于互信息的评分、同质性、完整性和 V-measure。
(二)不需要基础真值标签的内在度量。一些聚类性能度量是剪影系数、Calinski-Harabasz 指数、Davies-Bouldin 指数等。
Sklearn 文档对这些指标有非常好的详细描述。
有用链接
聚类趋势 — R 包查找聚类趋势
nbcluster—R 包查找集群数量
sk learn—sk learn 中用于集群性能评估的 Python 包
gap-stat —用于缺口统计的 Python 包
缺口统计笔记本 —解释缺口统计的 Jupyter 笔记本
聚类 FEC 季度活动捐款
对 FEC 数据中的工作角色进行聚类,以创建动画酒吧比赛,直观显示职业贡献
调查 FEC 为民主党个人筹款的情况
民意调查每周都得到大量关注,但新闻通常缺乏对联邦选举委员会文件的深入分析。的文件富含自我识别的捐赠者信息,包括职位、行业和地点。在 2020 年的初选中,几乎所有候选人都发誓不再接受游说者的捐款。从表面上看,这是民主党候选人证明他们不受公司影响的一次高尚尝试。然而,在表面之下挖掘,大量的公司影响可以通过 FEC 数据暴露出来。我将只关注个人捐赠,并试图揭露公司的影响力。
限制
联邦选举委员会要求竞选活动只报告超过 200 美元的捐款;因此,数据在很大程度上是不完整的。Q1/Q2 的汇总数据如下所示。就实际筹集的资金而言,伯尼·桑德斯应该以近 4000 万美元的捐款领先于候选人。不幸的是,这一数据不仅不完整,而且由于申报要求,它偏向于较大的捐款。考虑到我正试图识别企业影响力,这实际上是有益的。企业捐赠可能更大,因此在数据中得到很好的体现。最新的统计数字见政治。我可以参考下面这些汇总的数字。

从上述数据来看,伯尼和沃伦在从个人捐款中筹集的平均金额上有明显的劣势。拜登和吉利布兰德得到大笔捐款的支持。但蒂格一直被吹捧为拥有强大的个人捐助者基础。虽然在没有所有数据的情况下,这是非常推测性的,但似乎这些个人捐助者向 Buttigeg(平均 330 美元)捐赠了大量资金,达到了他筹集的 3100 万英镑中的近 1700 万英镑。如此高的平均捐款额使人们对强有力的草根运动的想法产生了怀疑。强大的小型捐助者驱动的活动,在政治收到的总捐款和 FEC 个人报告收到的金额之间的比率应该有很大的差距。相比之下,根据政治的数据,桑德斯筹集了 4600 万英镑,而通过 FEC 的数据,仅筹集了 800 万英镑。总的来说,这并不简单,因为政治的数据包括了为竞选活动捐赠了数百万美元的政治行动委员会。对政治和联邦选举委员会数据之间的任何差距的分析都需要排除这种捐赠。
替代方法
Act Blue 是政治筹款的主要捐助者,人们可以专门使用他们的 FEC 数据来比较候选人。这样做可能会描绘出一幅美国人作为一个整体如何向政治活动捐款的不同画面。然而,这篇文章的目的是探讨企业捐赠。更多有联系的个人捐赠的方式不同于从您的计算机进行 Act Blue 捐赠的简单方式。
方法学
在 FEC 报告中,由于缺乏标准化,自我识别数据会导致信息丢失。看一下 FEC 的数据,你会发现 CEO 这个词有许多略微不同的例子。(首席执行官、首席执行官、首席执行官等)。使用正则表达式,我将所有这些角色捆绑成一个单一的 CEO 角色,捕获大量“丢失”的数据。从这里,我会更深入地查看其他自我报告词(创始人、执行董事和总裁等)。这些头衔也代表了他们组织的负责人,因此相当于 CEO。
聚类的例子

在左边,确切的术语 CEO 在当前的 FEC 报告中出现了 2902 次,然而,术语 CEO 在整个数据中出现了 3533 次。通过将左侧表格中的所有条目标记为 CEO,我们捕获的 CEO 增加了 20%以上。
最酷的是我们可以从这里开始扩展。我添加了类似的术语,如总裁、执行董事等,我们有 4459 个额外的受访者代表了 CEO 的实际角色。我们现在有超过 7500 名受访者被确定为首席执行官。比我们最初的 2902 增加了近 300%

Expanded CEO Cluster
我捆绑了高管职位和 c 级高管职位,如下图所示。


Clustered executives on the left and clustered C-level executives on the right
当我们将所有这些高管级别的职位归为一类时,我们有一个来自不同职业的近 2 万名高管(增加了 700%)的团队,我们可以进一步研究他们在捐赠方面的更深层次的关系。
快速验证
在下面的表格中,最下面一行代表捐款在数据中的分布。前两行代表原始数据和聚类数据中的 CEO 捐赠分布。

Distribution of Donations
目测上述分布,没有必要运行任何统计测试。聚类很明显地捕捉到了 CEO 群体。同样清楚的是,CEO 群体的捐赠分布与整体数据有着显著的不同。首席执行官的平均捐赠额为 705 美元,中位数为 250 美元,而普通人的平均捐赠额为 201 美元,中位数为 38 美元。
一些读者可能会混淆 min 是一个负数。个人最多可以捐赠给一个候选人 2800 英镑。最低 2800 美元是竞选团队对意外违反竞选财务法的个人的补偿。
动画比赛
建立跟踪候选人捐款的条形图竞赛


Donations Races by CEO(left) and All Executive Positions (right) measured in millions. Bar color ranges from Blue to Red to represent left and right ideology within Democratic party
累积结果


拜登要到 Q2 才参加竞选,他很快就弥补了捐款缺口。拜登、哈里斯和布蒂格显然是企业级捐赠者的最爱。布克、克洛布查尔和吉利布兰德构成了下一波候选人,而该领域的其他人(英斯利、沃伦、塔尔西、伯尼、卡斯特罗和杨)似乎都没有引起公司资金的关注。
桑德斯和沃伦是目前排名前三的候选人,他们得到的公司资助很少。如果这一趋势保持下去,那么看到即将到来的第三季度报告将会很有意思。作为一名选举的临时观察员,我怀疑尽管沃伦的议程是进步的,但她将在第三季度看到公司捐款的显著增加。我认为,企业利益可能希望从拜登身上分散开来,并可能很快对哈里斯/布蒂格/布克失去信心。
看看其他集群
我深入研究了其他工作领域。如果我们只使用 Act Blue FEC 的数据,这一分析领域将更具可比性,因为这可能会更好地反映整体捐赠数字。然而,这里有一些初步的结果




Cumulative Donations by occupations measured in millions(Please see scale differences)
请注意,这些图表的比例各不相同。哈里斯在退休捐赠者中非常受欢迎。拜登和律师以及法律领域的人相处得非常好。纯粹基于身份的假设,我原本预计卡玛拉作为一名律师会从法律领域筹集更多资金,而拜登作为一名资深律师会在退休人员中有更好的表现。
Bernie 在蓝领工人中遥遥领先,但是,在这部分数据中,Bernie 只收到了蓝领群体捐赠的 15 万美元。这凸显了使用这种不完整 FEC 数据的危险性。蓝领工人可能会推动伯尼的筹款领先,但他们的捐款不会超过 200 美元,因此不会出现在联邦选举委员会的数据中。总的来说,我们的数据缺少数百万的个人捐赠。
假设
在我的数据操作中,我做了几个分类假设。我用来聚类这些组的正则表达式方法将包含不正确的例子。正则表达式是一种用算法对职业进行分类的强力尝试。然而,当我追踪最初的工作职业时,绝大多数这些职位都是正确的。我的汇总数据框架存放在我的 网站 上,我已经用二项式字段对所有已经更改的职位进行了分类,以跟踪它们。请随意查看我所做的假设和集群中的错误捕获。如果您想在自己的分析中采用这种方法,或者开发自己的集群,也请随意。原始的未编辑的职称出现在数据框中。
结论
联邦选举委员会的数据是识别公司权力结构以及它们如何影响选举的有力工具。禁止游说者迫使企业影响力发现与民主党的新的邪恶关系。许多公司求助于超级政治行动委员会来影响公民联盟之后的选举过程。然而,很明显,公司层面的高管仍在向他们青睐的候选人捐赠大量资金。虽然这个故事更多的是关于可视化公司层面的捐款,但在某个时候,我会尝试使用这些数据来开发模型,以确定哪些特征导致捐赠者向每个候选人捐款。
要查看上述文章的代码,请访问我的 github 知识库。该存储库包括一个笔记本文件和 Rpubs 链接,它充当 R 中所有幕后分析的向导
要看我的其他项目请访问我的 网站 。如果您想联系我,请通过Linkedin联系我
详细聚类
它需要上下文、情节、算法、度量和摆弄!
一些数据科学课程的学生向我展示了他们在互联网上找到的关于巴西各州的非常有趣的数据集。
第一个情节就是爱情!
但是要抓住它的一些细微差别,需要的不仅仅是第一个情节。
背景:巴西,一个联邦共和国
如果你不是来自巴西,也不是来自以州为单位的国家,让我给你提个醒。
在巴西,政治体系分为三级政府:联邦政府、州政府和市政府。
美国有 26 个州,外加一个联邦区(DF),分为五个地理区域:

情节:巴西,一个高度不平等的共和国
作为巴西人,我们总是听到人们谈论圣保罗(SP)在经济方面与该国其他地区有何不同。
我去过圣保罗的首府几次,对这个城市的人口过剩有所了解。
但是没有什么能真正让我为这个阴谋做好准备😵:

此时,很容易得出结论,SP 是数据中的一个强异常值,应该将其丢弃,以便我们可以更好地理解剩余的数据:

Zooming by discarding SP from the plot
但是是吗?我们真的应该抛弃它吗?
让我们再坚持一会儿。
算法:从简单的开始
因为这个数据集非常简单,所以在聚类之前没有太多的 EDA(探索性数据分析)要做。
让我们在选择聚类算法时也保持简单。
k 均值
k-means 几乎不需要配置。差不多了。
是的。k-means 假设聚类的数量作为输入, k 。
但是我们不知道。
让我们用橙 3 来帮助我们。
当您打开 k-means 小部件时,Orange3 允许我们为 *k、*选择一系列值,并测试它们以检查我们可以从这些不同的值中获得的轮廓分数:

k-means widget from Orange3
正如所料,我们能做的最好的聚类是将 SP 与其余数据隔离开来。
这显示了 k-means 如何对异常值敏感,但这不是本文的重点。
第二好的 k 值是 4。让我们检查一下侧影图:

Silhoutte plot for k-means with four clusters.
在轮廓图中,如果一个观察值与其聚类邻居的相似度大于与另一个聚类中的观察值的相似度,则该观察值将被评为正值(最大值为 1.0)。
让我们看看这种群集是什么样子的:

Scatter plot for k-means with four clusters. In this plot, São Paulo is the clear outlier.
嗯(表示踌躇等)…很好,但不完美。
是的,这有时会发生在 k-means 身上。
Orange3 显示的分数是 10 次运行的平均值,但单次运行可能不太合适。
分层聚类
另一种简单的集群方法叫做层次化,但是需要更多的工作。
关键的一点是,人们可以使用交互式树形图浏览不同的聚类数可能性:

Hierarchical clustering widget using Euclidean distance and Ward’s linkage
OMG,左边面板这么多选项😱
是的,这是一个非常可配置的算法,你可以谷歌这些选项中的大部分。
我只是想说明,对于六个集群,我们得到了以下轮廓图:

Silhouette plot for hierarchical clustering with six clusters using Euclidean distance and Ward’s linkage
请注意集群的变化,这不仅仅是因为集群数量的变化:

从上面的图中,我们可以看到聚类主要是根据它们到原点的距离来划分的。
k-means 和层次聚类都尝试过这样做,因为它们认为如果两个状态在这个二维空间中接近,它们就是相似的。
那就是欧几里德距离!
没错。
度量:完全改变你的视角
现在,在我们研究的早期,我和我的学生开始注意到这两个属性之间的比率本身就是一个属性。
人均 GDP!
是的,这是一个非常有趣的属性来说明一个国家真正的富裕程度。
所以我们可以通过组合前两个属性来创建第三个属性🙃
是的,但不是。如果我们已经可以从现有的属性中获取信息,我们通常会避免创建新的属性。
为什么?🤔
因为那样的话,我们的绘图将变成 3D 的,更不用说许多其他的问题了(我们正在谈论一个非常简化的数据集)…
等等,我们如何从这个情节中掌握信息?
我们将把该图的对角线作为参考。
位于这条对角线右侧的州人口数量会增加。
相反的情况也是如此:这条对角线左边的州有向更大的 GDP 转移的趋势。
但是,我们如何告诉算法在没有第三个属性的情况下寻找它呢?
我们改变相似性度量:如果两个状态所代表的向量之间的角度很小,余弦距离使这两个状态变得相似。
等等,什么?
检查情节:

Scatter plot for hierarchical clustering using cosine distance and Ward’s linkage, with six clusters.
我不明白。
试试这个:

Regression lines illustrating that the cosine distance values the angle with regard to the origin.
操!😱
是的。
总结:巴西是如何真正分裂的

关于最后一个聚类结果,最有趣的事情之一是,当我们分析它时,它很有意义:
- 当谈到财富时,DF 是巴西最重要的局外人,如果你认为 DF 的商业只是政治,那绝对是疯狂的!
- 巴西东南部通常被认为是该国最富裕的地区,但除了少数例外,南部和中西部地区超过了它!
- 到目前为止,巴西的北部和东北部是该国最危急的地区。
现在让我们把这当成一个练习:想象另一个巴西,政治不是为了致富,在 SP 堆积的企业遍布北部和东北部。
这是我想看的一个情节😆
高效的产品集群可以推动零售销售
无监督学习和统计分析
零售业的聚类与库存预测

Image by author
https://sarit-maitra.medium.com/membership
对未来的预测是商业中必不可少的组成部分。这些技术的有效实施导致成功的客户关系管理(CRM) &商业中的库存管理。通常用作数据挖掘技术的聚类有助于发现数据中有趣的模式。
尽管我们谈论的是 CRM 和库存管理,但是,集群已经成为高级规划和优化流程的主要来源,并且可以在多个方面使业务受益:
- 商店聚类根据绩效和非绩效参数对商店进行分组。
- 减少不必要的库存
- 关注目标细分市场
- 以客户为中心的方法创造一致性和熟悉度
我们将研究销售交易数据,并根据历史记录分析和预测交易。这里,数据是高层次的,不考虑每笔交易的金额和其他业务因素…数据集包含 1 年/ 52 周内每周购买的 800 件产品。
df <- read.csv("Sales_Transactions_Dataset_Weekly.csv", header = TRUE)
print(is.data.frame(df))
print(ncol(df))
print(nrow(df))
print(names(df))


# number of weeks
DF <- data.frame(df[, 2:53], row.names = df$Product_Code)
print(names(DF));#Check whether there is missing value.
print(sum(is.na(DF)))

我们在这个数据集中有 800 种产品,分析所有 800 种产品的数据是不切实际的。因此,让我们根据 52 周内交易的相似性将产品分类。
我们将使用无监督学习进行聚类。
聚类:
这是一个优化问题。为了进行优化,我们需要根据最小距离进行决策,或者根据约束条件确定聚类的数量。在这里,我们将使用一些集群。因为在我们开始算法之前必须设置聚类的数量(k ),所以让我们用几个不同的 k 值进行尝试,并检查结果中的差异。
可以定义上述内容的标准算法是—

其中:xi 是属于聚类 Ck 的数据点,μk 是分配给聚类 Ck 的点的平均值。每个观测 xi 被分配给给定的聚类,使得观测到它们被分配的聚类中心μk 的距离平方和最小。
现在,有相当多的聚类算法可用,但没有简单的方法为我们的数据找到正确的算法。我们必须进行实验,为任何给定的数据集找到最适合的算法。
主成分分析:
# principal component analysis
res.pca <- PCA(DF, graph = FALSE)# Extract eigenvalues/variances
print(get_eig(res.pca))# Visualize eigenvalues/variances
fviz_screeplot(res.pca, addlabels = TRUE, ylim = c(0, 50))

fviz_pca_var(res.pca, col.var="contrib",
gradient.cols = c("#00AFBB", "#E7B800", "#FC4E07"),
repel = TRUE # Avoid text overlapping
)

对主轴的可变贡献:
fviz_contrib(res.pca, choice = "var", axes = 1, top = 10) fviz_contrib(res.pca, choice = "var", axes = 2, top = 10)

# Extract the results for individuals
ind <- get_pca_ind(res.pca)
ind# Coordinates of individuals
head(ind$coord)fviz_pca_ind(res.pca, col.ind = "cos2",
gradient.cols = c("#00AFBB", "#E7B800", "#FC4E07"),
repel = TRUE)

主成分分析让我们清楚地看到我们所拥有的产品的聚类数。这是我们数据挖掘工作的第一步,非常重要。
让我们使用 factoextra 软件包,它可以处理来自几个软件包的 PCA、CA、MCA、MFA、FAMD 和 HMFA 的结果,用于提取和可视化我们数据中包含的最重要的信息。更重要的是,它给出了人类可以理解的输出。
set.seed(123)
k1 <- kmeans(DF, centers = 2, nstart = 25)
k2 <- kmeans(DF, centers = 3, nstart = 25)
k3 <- kmeans(DF, centers = 4, nstart = 25)
k4 <- kmeans(DF, centers = 5, nstart = 25)# plots to compare
p1 <- fviz_cluster(k1, geom = "point", DF) + ggtitle("k = 2")
p2 <- fviz_cluster(k2, geom = "point", DF) + ggtitle("k = 3")
p3 <- fviz_cluster(k3, geom = "point", DF) + ggtitle("k = 4")
p4 <- fviz_cluster(k4, geom = "point", DF) + ggtitle("k = 5")grid.arrange(p1, p2, p3, p4, nrow = 2)

这种评估给了我们关于聚类之间 k=3 或 4 的想法,但是,我们不确定最佳聚类。如果我们知道我们想要的聚类数,那么 k-means 可能是我们用例的一个好选择。
除了肘方法之外,用于确定最佳聚类的其他流行方法是剪影方法和间隙统计
k 均值聚类:
# Elbow method
set.seed(101)
fviz_nbclust(DF, kmeans, method = "wss")# WSS means the sum of distances between the points
# and the corresponding centroids for each cluster

在这里,我们尝试为从 1 到 10 的每一个集群数建模,并收集每个模型的 WSS 值。看下面的剧情。随着集群的增加,WSS 值降低。肘点为 3 表示 3 个簇。
剪影法:
silhouette_score = function(k){
km = kmeans(DF, centers = k, nstart=25)
ss = silhouette(km$cluster, dist(DF))
mean(ss[, 3])}
k = 2:10
avg_sil = sapply(k,silhouette_score )
plot(k, type = 'b', avg_sil, xlab = 'number of clusters', ylab ='average silhouette scores', frame = 'False')

这里,最佳数字看起来也是 3
差距统计:
间隙统计将 log(Wk)图标准化,其中 Wk 是群内离差,通过将其与数据的适当零参考分布下的预期值进行比较。
fviz_nbclust(DF, kmeans, method = "gap_stat")

这将不同的输出显示为 4 个集群。让我们根据 Gap-Statistic 方法的发现将此应用于 4 个聚类,并根据 k-means 列的聚类绘制周模式。
cluster_4 <- kmeans(DF,centers = 4,nstart = 10)
cluster_4$cluster <- as.factor(cluster_4$cluster)
cluster_4# plotting pattern of weeks as per clustering from kmeans columnsggplot(DF, aes(W1,W44,color =cluster_4$cluster)) +geom_point()


这里我们可以解读为,每组分别有 124、197、490 款产品。聚类图显示了明显分开的三个聚类,between_SS / total_SS = 88.6 %表明该聚类模型非常适合该数据。具体来说,有 490 种产品归入第 1 组。

group1 = data.frame(t(DF[cluster_3$cluster == 3,]))
summary(sapply(group1, mean))hist(sapply(group1, mean), main = "Histogram of Product Group 1", xlab = "Number of Transactions")


在这里,平均每周交易量为 1.66。有相当多的产品每周交易少于 1 次(柱状图中的长条)。其他产品的交易看起来遵循正态分布。让我们将第一组分成两部分:
- 平均每周交易< 2 的组 0,以及
- 包含剩余产品的新组 1。
group0 <- group1[,sapply(group1, mean) <= 2]
group1 <- group1[,sapply(group1, mean) > 2]group2 <- data.frame(t(DF[cluster_3$cluster == 1]))
group3 <- data.frame(t(DF[cluster_3$cluster == 2]))# pie chart
slices <- c(ncol(group0), ncol(group1), ncol(group2), ncol(group3))
lbls <- c("Group 0:", "Group 1:", "Group 2:", "Group 3:")
lbls <- paste(lbls, percent(slices/sum(slices)))
pie(slices,labels = lbls, col=rainbow(length(lbls)), main ="Pie Chart of Product Segmentation")

我们可以看到,
- 37.2%的产品属于第 0 组,
- 23.2%属于第 1 组,
- 第二组 15.3%,以及
- 24.3%属于第三组。
产品细分的箱线图:
group1_mean <- sapply(group1, mean)
group2_mean <- sapply(group2, mean)
group3_mean <- sapply(group3, mean)
boxplot(group1_mean, group2_mean, group3_mean, main = "Box-Plot of Product Segmentation", names = c("Group 1", "Group 2", "Group 3"))lapply(list(group1_mean, group2_mean, group3_mean), summary)


显示的结果显示,产品分为四个独立的组。
- 组 0 的每周交易次数最少;和
- 组 2 的事务数量最多。
分析和预测:
我们将分别分析每个组,这是一种迭代过程。
分析(第 0 组):
summary(group0_mean)par(mfrow = c(1, 2))
hist(group0_mean, main = "Histogram of Group 1", xlab = "Number of Transactions")
boxplot(group0_mean, main = "Box-plot of Group 1", names = c("Group0"))


根据直方图,组 0 的平均每周交易的分布是右偏的。此外,箱线图显示第三个四分位数约为 0.5,这意味着该组中的大多数产品每周的交易量不到 1 笔。尽管有些产品的周交易量大于 1,但考虑到所有产品中的一小部分,这些产品在箱线图中被视为异常值。因此,可以得出结论,这个群体的需求很低。
为了进一步分析,我们希望选择一种代表性产品,其平均周交易量最接近目标值(即中值或平均值)。在这种情况下,由于分布是右偏的,我们选择中位数作为我们的目标值。这一组的代表产品是交易数量与中位数相差最小的产品。
预测:
idx0 <- which.min(abs(group0_mean-summary(group0_mean)['Median']))
print(idx0)# First row and all columns
DF[215,]#Convert P215 data to time series
ts0 <- ts(group0[,idx0], frequency = 365.25/7)
plot(ts0)

我们已经将数据转换成时间序列。在 儒略历 中,一年的平均长度为 365.25 天。不过这个也可以用 365 试试。第 0 组的代表产品是 P214。

我们可以看到,P214 每周大部分时间都有零个事务,部分时间有 1 个事务,还有 1/4 个事务。
分析(第一组):
summary(group1_mean)par(mfrow = c(1, 2))
hist(group1_mean, main = "Histogram of Group 1", xlab = "Number of Transactions")
boxplot(group1_mean, main = "Box-plot of Group 1", names = c("Group1"))


在这里,分布几乎以 4 为中心。箱线图中的分布有点偏右,有一个异常值。Q3 百分位> 4 (4.23),组 1 中的大多数产品是< 4. Therefore, it can be safely assumed that, the products in this group have low demands too.
idx1 <- which.min(abs(group1_mean-summary(group1_mean)['Mean']))
print(idx1)# First row and all columns
DF[318,]#Convert P215 data to time series
ts1 <- ts(group1[,idx1], frequency = 365.25/7)
plot(ts1)


The representative product of Group1 is P318.
summary(group1[,idx1])
boxplot(group1[,idx1], main = "Box-Plot of P318")

The distribution is a little bit right skewed. The average number of weekly transaction is 3.67.
Decomposition (Group1):
# set up plot region
par(mfrow = c(1, 2))
# plot normal variates with mean
acf(ts1, main = "")whitenoise.test(ts1)

According to the time plot, the majority of the number of transactions is between 2 and 5 per week. It is clear that there is no trend or seasonality in this time series. Moreover, the auto correlation plot displays white noise in the data. In this way, there is no need to perform decomposition for this time series prior building a forecasting model.
We will apply (1) ETS(Exponential Smoothing) and (2) ARIMA (Autoregressive Integrated Moving Average ). Moreover, other forecasting methods e.g. average, drift, and naïve will be applied based on the characteristic of the data. With only 52 weeks of transaction data, it is difficult to make long-term forecasting.
ETS(Exponential Smoothing):
Prediction produced using exponential smoothing methods are weighted averages of past observations, with the weights decaying exponentially as the observations get older.
fit_ets <- ets(ts1)
summary(fit_ets)
checkresiduals(fit_ets)


Ljung-Box statistic p‐value >。显著性水平(\alpha)使我们不拒绝零假设,或者换句话说,时间序列是白色检验。下图显示了模型生成的点预测和预测区间。
autoplot(fit_ets)

plot(forecast(fit_ets, h = 4))

残差图显示残差具有恒定的方差和零均值,并且彼此之间没有显著的自相关。尽管这表明该模型非常适合;此外,Ljung-Box 检验的 p 值也表明了残差的独立性。但是,显示预测区间的预测结果过宽,具有负值。所以,ETS 模型对于这个时间序列来说不是一个好的选择。
ETS(A,N,N)是带有附加误差的简单指数平滑。这是意料之中的,因为原始时间序列是白噪声,没有趋势性和季节性。
ARIMA(第一组):
summary(ur.kpss(ts1))
adf.test(ts1)
ur.df(ts1, type='trend', lags = 10, selectlags = "BIC")

p1 = ggAcf(ts1)
p2 = ggPacf(ts1)
grid.arrange(p1, p2, ncol = 2)

P318 这个时间序列是白噪声,是平稳数据。这里,ACF 和 PACF 图具有相同的平稳性观察。
ARIMA(第一组):
fit_arima = auto.arima(ts1, seasonal = FALSE)
summary(fit_arima)
checkresiduals(fit_arima)


就模型性能而言,ARIMA 可能更好,然而,与 ETS 模型相比,预测输出与 ETS 非常相似,具有不可接受的宽预测区间。
autoplot(forecast(fit_arima, h = 4)) + xlab("Week") +
ylab("Number of Transactions") + ggtitle("Group 1: Forecast using ARIMA Method")

平均法、简单法和漂移法:
p1 = autoplot(ts1) + autolayer(meanf(ts1, h = 4)) + xlab(“Week”) +
ylab(“Number of Transactions”) + ggtitle(“Group 1: Average Method”)p2 = autoplot(ts1) + autolayer(naive(ts1, h = 4)) + xlab(“Week”) +
ylab(“Number of Transactions”) + ggtitle(“Group 1: Naive Method”)p3 = autoplot(ts1) + autolayer(rwf(ts1, h = 4)) + xlab(“Week”) +
ylab(“Number of Transactions”) + ggtitle(“Group 1: Drift Method”)grid.arrange(p1, p2, p3, ncol = 3)

总的来说,这些方法中没有一种比 ARIMA 或 ETS 方法更适合数据。具体来说,使用平均法的预测具有非常相似的结果。然而,朴素方法和漂移方法的预测区间甚至更宽。因此,这些方法不是好的选择。
由于 P318 的原始数据是白噪声,所以很难对这个时间序列进行很好的预测。我们注意到 ARIMA 和 ETS 模型的预测结果都等于 P318 的平均值(3.673/3.68)。
然而,由于预测区间较宽,如果我们只直接使用预测结果,会使业务面临风险。因此,建议不要使用平均值,而是使用第三个四分位值,即每周 5 次交易,这样,我们可以满足 75%的业务需求。
分析(第三组):
idx3 <- which.min(abs(group3_mean-summary(group3_mean)['Median']))
print(idx3)summary(group3_mean)par(mfrow = c(1, 2))
hist(group3_mean, main = "Histogram of Group 3", xlab = "Number of Transactions")
boxplot(group3_mean, main = "Box-plot of Group 3", names = c("Group3"))


根据直方图,每周交易的分布是右偏的。在箱线图中,分布是右偏的,有一些异常值。此外,第 25 百分位是 32.17,这意味着组 3 中的大多数产品的周交易量都大于 32。因此,我们可以得出结论,组 3 中的产品有很高的需求。这里,分布也是居中的,因此,我们选择平均值作为目标值。
summary(group3[,idx3])
boxplot(group3[,idx3], main = "Box-Plot of P209")

数据分布几乎居中。周成交平均数为 9.9,第三四分位数为 12。
分解(第三组):
ts3 = ts(group3[,idx3], frequency = 365.25/7)
p1 = autoplot(ts3) + xlab("Week") + ylab("Number of Transaction") + ggtitle("Time Plot (Group 2)")
p2 = ggAcf(ts3)
grid.arrange(p1, p2, ncol = 2)

从时间图来看,大部分交易次数在每周 6 到 13 次之间。
原始时间序列由趋势分量和不规则分量组成,但没有季节分量。因此,使用简单移动平均法进行平滑是合适的。
autoplot(ts3, series = "Data") + autolayer(ma(ts3, 5), series = "5-MA" ) + autolayer(ma(ma(ts3, 5), 3), series = "3x5-MA") + scale_colour_manual(values=c("Data"="grey50","5-MA"="blue", "3x5-MA" = "red"), breaks=c("Data","5-MA", "3x5-MA"))

阶数为 5 时,估计趋势不会像预期的那样平滑。因此,执行移动平均的移动平均。“3x5-MA”趋势更适合。我们将重复应用 ETS(指数平滑)和 ARIMA(自回归综合移动平均)的类似过程,还将研究其他预测方法,如平均、漂移和朴素等。
这里可以执行类似的练习,如 group0 和 group1,以找到最适合的模型。
关键要点:
聚类在零售业务决策过程中非常重要。它是有效数据挖掘技术的一部分,在处理大数据时,有效的数据挖掘是至关重要的。数据挖掘涵盖了广泛的数据分析和知识发现任务,从数据表征和鉴别到关联和相关分析、分类、回归、聚类、异常值分析、序列分析以及趋势和演变分析。
然而,我们必须记住,现实生活中的数据是杂乱的,可能包含噪音、错误、异常或不确定性。错误和噪声可能会混淆数据挖掘过程,导致错误模式的产生。数据清理、数据预处理、异常值检测和去除以及不确定性推理是需要与数据挖掘过程集成以进行任何有效分割和预测的技术示例。
比肘法更好的聚类度量
我们展示了使用什么样的度量来可视化和确定最佳的集群数量,这比通常的做法好得多——肘方法。
介绍
聚类是利用数据科学的商业或科学企业的机器学习管道的重要部分。顾名思义,它有助于识别数据块中密切相关(通过某种距离度量)的数据点的集合,否则很难理解。
然而,大多数情况下,聚类过程属于无监督机器学习的领域。无人监管的 ML 是一个混乱的行业。
没有已知的答案或标签来指导优化过程或衡量我们的成功。我们处于未知的领域。
聚类与降维:k-means 聚类,层次聚类,PCA,SVD。
medium.com](https://medium.com/machine-learning-for-humans/unsupervised-learning-f45587588294)
因此,毫不奇怪,当我们问这个基本问题时,像 k 均值聚类 这样的流行方法似乎不能提供完全令人满意的答案:
“从开始,我们如何知道集群的实际数量?”
这个问题非常重要,因为聚类过程通常是进一步处理单个聚类数据的先导,因此计算资源的量可能取决于这种测量。
在业务分析问题的情况下,反响可能会更糟。这种分析通常会进行聚类,目的是细分市场。因此,很容易想象,根据集群的数量,适当的营销人员将被分配到该问题。因此,对集群数量的错误评估会导致宝贵资源的次优分配。

Source: https://www.singlegrain.com/digital-marketing/strategists-guide-marketing-segmentation/
肘法
对于 k-means 聚类方法,回答这个问题最常见的方法是所谓的肘方法。它包括在一个循环中多次运行该算法,增加聚类选择的数量,然后绘制聚类分数作为聚类数量的函数。
肘法的得分或衡量标准是什么?为什么叫’肘法?
典型图如下所示:

通常,分数是 k-means 目标函数上的输入数据的度量,即某种形式的类内距离相对于类内距离。
例如,在 Scikit-learn 的 k 均值估计器中,有一种score方法可用于此目的。
但是再看剧情。有时候会让人困惑。在这里,我们应该将 4、5 还是 6 作为集群的最佳数量?
不总是那么明显,是吗?
轮廓系数——一个更好的指标
使用每个样本的平均组内距离(a)和平均最近组距离(b)计算轮廓系数。样本的轮廓系数为(b - a) / max(a, b)。澄清一下,b是样本和样本不属于的最近聚类之间的距离。我们可以计算所有样本的平均轮廓系数,并将其用作判断聚类数量的度量。
这是 Orange 关于这个话题的一个视频,
举例来说,我们使用 Scikit-learn 的make_blob函数在 4 个特征维度和 5 个聚类中心上生成随机数据点。因此,问题的基本事实是数据是围绕 5 个聚类中心生成的。然而,k-means 算法没有办法知道这一点。
可以如下绘制聚类(成对特征),

接下来,我们运行 k 均值算法,选择 k =2 至 k =12,计算每次运行的默认 k 均值得分和平均轮廓系数,并将它们并排绘制。

这种差异再明显不过了。平均轮廓系数增加到当 k =5 时的点,然后对于更高的 k 值急剧减少,即**它在 k =5、**处呈现出清晰的峰值,这是生成原始数据集的聚类数。
与弯管法中的平缓弯曲相比,轮廓系数呈现出峰值特征。这更容易想象和推理。
如果我们在数据生成过程中增加高斯噪声,聚类看起来会更加重叠。

在这种情况下,使用 elbow 方法的默认 k-means 得分会产生更不明确的结果。在下面的肘部图中,很难选择一个合适的点来显示真正的弯曲。是 4,5,6,还是 7?

但是轮廓系数图仍然设法在 4 或 5 个聚类中心附近保持峰值特征,并使我们的生活更容易。
事实上,如果你回头看重叠的聚类,你会看到大多数情况下有 4 个聚类可见-虽然数据是使用 5 个聚类中心生成的,但由于高方差,只有 4 个聚类在结构上显示出来。剪影系数很容易发现这种行为,并显示出介于 4 和 5 之间的最佳聚类数。

高斯混合模型下的 BIC 分数
还有其他优秀的度量来确定聚类的真实计数,例如BaIinformationCriterion(BIC)但是只有当我们愿意将聚类算法扩展到 k-means 以外的更一般化的版本时,才能应用这些度量
基本上,GMM 将一个数据块视为多个具有独立均值和方差的高斯数据集的叠加。然后应用Eexpectation-Maxi mization(EM)算法来近似确定这些均值和方差。

在机器学习领域,我们可以区分两个主要领域:监督学习和非监督学习。主要的…
towardsdatascience.com](/gaussian-mixture-models-explained-6986aaf5a95)
BIC 作为正规化的理念
你可能从统计分析或你以前与线性回归的互动中认识到术语 BIC。BIC 和 AIC(赤池信息标准)被用作变量选择过程的线性回归中的正则化技术。
BIC/AIC 用于线性回归模型的正则化。
这个想法同样适用于 BIC。理论上,极其复杂的数据聚类也可以建模为大量高斯数据集的叠加。对于为此目的使用多少高斯函数没有限制。
但这类似于线性回归中增加模型复杂性,其中大量特征可用于拟合任何任意复杂的数据,但却失去了泛化能力,因为过于复杂的模型拟合了噪声而不是真实模式。
BIC 方法惩罚了大量的高斯分布,并试图保持模型足够简单,以解释给定的数据模式。
BIC 方法不利于大量的高斯模型,即过于复杂的模型。
因此,我们可以对一系列聚类中心运行 GMM 算法,BIC 得分将增加到一个点,但之后将随着惩罚项的增加而开始下降。

摘要
这里是本文的 Jupyter 笔记本 。随意叉着玩。
我们讨论了常用的 elbow 方法的几个替代选项,用于在使用 k-means 算法的无监督学习设置中挑选正确数量的聚类。
我们表明,侧影系数和 BIC 评分(来自 k-means 的 GMM 扩展)是视觉识别最佳聚类数的肘方法的更好替代方法。
如果您有任何问题或想法要分享,请通过tirthajyoti【AT】Gmail . com联系作者。此外,您可以查看作者的 GitHub 资源库中 Python、R 和机器学习资源中其他有趣的代码片段。如果你像我一样对机器学习/数据科学充满热情,请随时在 LinkedIn 上添加我或在 Twitter 上关注我。
[## Tirthajyoti Sarkar - Sr .首席工程师-半导体、人工智能、机器学习- ON…
通过写作使数据科学/ML 概念易于理解:https://medium.com/@tirthajyoti 开源和有趣…
www.linkedin.com](https://www.linkedin.com/in/tirthajyoti-sarkar-2127aa7/)
聚类波洛克
利用数据科学追踪波洛克多年来的调色板

我对艺术不是很有热情:当我参观一个博物馆时,我是一个随意的游客,四处走动观察绘画和雕塑,试图尽可能多地学习,不幸的是没有欣赏到艺术作品背后的深度。
几年前,我参加了在威尼斯佩吉·古根汉姆收藏博物馆举办的鸡尾酒会,我有幸第一次看到了波洛克的画作:炼金术,现场直播。杰森·布拉克是一位颇具影响力的美国画家,也是艺术界抽象表现主义运动的主导力量。波洛克因使用滴画技术而闻名,这是一种抽象艺术形式,将颜料滴或倒在画布上。
我记得我真的很着迷于这样一个事实,在某种程度上,我的思想完全被一幅画吸引住了,这幅画只是由一些颜色随机滴在画布上制成的。我可能在那一刻意识到(喝着非常昂贵的 Aperol Spritz),我看到的不是随机,而是被创造出来的美丽。
这个关于我肤浅的艺术知识的介绍,只是为了解释我为什么和什么时候对波洛克产生了好奇,以及为什么我决定花几个小时做下面的分析。
波洛克的颜色用法是如何随着时间的推移而演变的?为了回答这个问题,我决定做一些聚类实验,应用一些算法并绘制一些图表。
数据
为了对波洛克的绘画进行聚类,我需要一个可靠的来源,从那里我可以下载绘画并提取其他数据。在谷歌上快速搜索关于这位艺术家的信息,我就来到了这个网站(它与波洛克这个人没有正式的联系)。我从网站上刮下这些画,还保存了每幅作品的年份和名称。
波洛克创作了许多大小迥异的杰作;我决定检索每幅画的尺寸:为了理解艺术家对颜色的使用,在混合中包含画布尺寸可能会很有趣。不幸的是,jackson-pollock.org 上没有这些信息,所以我需要在谷歌上手动搜索每件作品。我最终得到了一个csv文件和一堆jpg图像。当然,我的数据集只包含波洛克的部分作品,而不是他的全部作品;对了,接下来的事情就够了。

分析
有了所有需要的信息,我们现在可以开始享受 Python 的乐趣了。
首先,我们需要决定是根据图像的原始大小(也就是画布的大小)重新缩放图像。由于油漆尺寸的可变性相当高,这是一个至关重要的决定。我们至少有两种选择:
- 根据原始尺寸重新缩放图像:我们将加重较大画布中包含的颜色(例如秋韵(数字 30) 是一幅 14 平方米的作品)。这样做,我们将评估波洛克在他的职业生涯中使用的每种颜色“有多少桶”。
- 将图像重新缩放至固定尺寸,每幅画都一样:每幅画都有相同的重量。我们要评估的是画中每种颜色的比例。图像越小,算法越快,聚类结果越差。

我认为分析比例更有意思,所以我们将选择第二条路线:我们将图像重新调整为 200x200 像素的正方形。
下面的代码是一个简单的片段,它将图像调整到所需的形状(如果size参数是None,那么重新缩放将根据csv文件中的数据来完成)。常量SCALE_FACTOR设置为 1,有助于降低聚类算法的复杂性。实际的重新缩放将使用 OpenCV 来完成。
正如我之前所写的,我们想要做的是分析波洛克在他的活动中如何改变他对颜色的使用。当然,我们不能使用我们在数据集中找到的每一种颜色(我们最终可能会有 1600 多万个可能的值)。相反,我们要做的是尝试执行一个聚类来减少要绘制的颜色的数量;为此,我们将使用k-means。
k-means 的目的是将 n 个观测值划分成 k 个簇,其中每个观测值属于均值最近的簇,作为簇【3】的原型。该算法试图最小化聚类中心和聚类中的点之间的欧几里德距离。在我们的例子中,原型将代表我们将追踪多年的颜色:这个选择背后的直觉是 k 意味着 will(?)将相似的颜色组合在一起,因此,通过跟踪原型,我们将跟踪许多与它相似的颜色。
为了跟随一种颜色跨越几年,我们需要考虑所有的绘画来执行聚类:如果我们在每一幅图像上运行 k-means ,我们将得到 54 个不同的模型和许多不同的原型。
然而,第一步是读取每一张图像,并将它们堆叠成一个数据集。对于聚类任务,我们将使用 RGB(红绿蓝)颜色空间,因此数据集将具有:
- 图像中的每个像素占一行。
- 3 列,一列用于红色通道,一列用于绿色通道,另一列用于蓝色通道。
这不是最有效的堆叠图像的方法,但确实有用。
在stacked_images变量中,我们有我之前描述的数据集。
在拟合模型之前,我们仍然需要一个预处理位:我们正在提升 RGB 格式的图像,每个通道值的范围可以从 0 到 255,我们将重新缩放[0,1]范围内的所有内容。
经过这一步,我们应该已经确定了波洛克在他的画作中使用的 20 种主色!首先,我们来看看他们。
为了创建下面的图像,我将像素转换到 HSV 色彩空间(色调-饱和度-值),并根据色调、饱和度和值对颜色进行排序(按此顺序);分段大小显示该颜色在(所有)绘画中所占的比例。

Top 20 colors used by Pollock, according to k-means clustering on 54 paintings
如果我们看一下一些集群,我们可以看到算法是可行的;仍然存在一些噪点,即颜色看起来与整体原型颜色“不太相似”。这背后的一个原因,是我们用来决定何时将两种颜色放在同一个桶中的距离度量; k-means 使用欧几里德距离:选择其他距离度量和其他算法来查看结果如何变化可能是值得的(我试图使用球形 k-means ,但是结果很差)。
反正产量也没那么差。



现在我们已经有了合适的模型,我们可以把所有的画一幅接一幅地输入进去,看看每个原型在每个作品中的比例(下面是一些例子)。

The Flame — Jackson Pollock — 1938

Eyes in the Heat — Jackson Pollock — 1946
形象化
在这一点上,我们已经有了所有我们需要的可视化的东西。我们将使用的数据是:
- 集群-原型及其 RGB 组件。
- 一堆
csv文件,每个文件对应一个作品,其中我们知道一个特定的颜色原型被使用了多少次:
The output CSV for the clustering performed on a single painting
让我们挑选一些画(我们正在分析的画中我最喜欢的),让我们看看这些画中有哪些颜色:

Alchemy — Jackson Pollock — 1947

Going West — Jackson Pollock — 1934

Out of the web — Jackson Pollock — 1949
不过,这个想法是为了观察波洛克的颜色在多年间的演变。我们能做的,是在时间维度上分析数据。我们已经有了每幅图像的所有比例,所以我们只需要根据相关年份对结果数据帧进行分组。
河图可以显示颜色的使用是如何随着时间的推移而演变的

结论
怎么说呢,从上面的分析来看,杰森·布拉克逐渐去除了饱和色(黄色、红色),将注意力集中在更褪色的背景色上,以灰色为主。
当然,我们只考虑了他画作的一个子集,每当分析整个作品时,看到不同的结果,我不会感到惊讶。请注意,我们在 30 年代绘制的样本较少,因此很明显,最近几年的颜色分布更加均匀。
有时候我对 k-means 的结果并不满意,但是我认为通过增加整形图像的尺寸(我们在这些图像上运行聚类)可以提高性能;顺便说一下,考虑到 54 个 200x200 像素的图像,我们已经需要聚类 216 万个点。
安德烈亚·伊伦蒂
集群:Github 上的软件工程角色
利用开源知识库中的知识挖掘技术应用软件工程角色识别技术

Photo by Austin Distel on Unsplash
一.导言
软件开发方法,或者过程模型,试图描述从软件的概念到部署的过程中应该遵循的步骤。有一些传统的方法关注于离散的和定义明确的步骤的顺序,比如瀑布模型,其中交流渠道是绕过文档实现的,还有一些方法,比如敏捷模型,它强调团队成员之间需要灵活性和持续的、直接的交流。这些较新的模型在不同规模的软件团队中非常受欢迎。由于这些模型所描述的沟通的重要性和方式,希望招聘既拥有技术技能又拥有沟通技能的人。然而,在寻找这样的人时出现的问题在于评估这些技能的难度。
在这个项目的背景下,我们关注这个问题。为此,我们采用数据挖掘技术来识别不同的团队角色,并评估团队成员在软件开发和操作过程中的活动。实现的系统从 GitHub web 平台提取用户活动数据,并将它们作为集群团队成员的输入。通过这种方式,我们试图深入了解开源项目中出现的不同团队成员角色,如 GitHub 中的角色,以及在这些角色下工作的用户的表现。
在对数据集和评估特征的不同组合进行大量实验后,最终呈现的结果被认为提供了对这些问题的关键见解。
二。项目概述
我们的数据集由 GitHub 的 240 个最受关注的项目中的每个贡献者工程师的特征组成,这些项目有 5 到 10 个贡献者。数据收集自 GitHub 的 API [1]。
我们这个项目的第一部分集中在每个收集到的 GitHub 项目中工程师的角色分类上。第二部分着重于工程师在每个角色中的贡献质量。为了总结这些问题,我们将工程师分为三个主要角色:开发、开发运维以及运营。Dev 代表负责创建和验证项目代码的开发人员。DevOps 代表负责发布和项目规划过程的开发人员和操作人员。Ops 代表负责监控和配置的操作。

使用了三种聚类算法(K 均值、DBSCAN 和层次聚类完全连锁)。通过使用不同的参数值重复运行每个算法,并基于每个算法的评估度量比较结果,来评估每个算法的优选参数的选择。
三。系统设计
系统概况
为了回答我们的每个问题,我们选择了数据集的特定指标来确定每个工程师的角色分类和贡献评估。在第一种情况下,我们应用了每种聚类算法,并使用内聚、分离和平均轮廓来评估结果,以确定我们将使用的算法来继续我们的研究。
数据预处理
最终数据集是几个预处理阶段的结果,以便消除我们最终模型中的误差百分比。在每个阶段,只有与该阶段的场景兼容的工程师被保留。每个阶段的数据集是下一个过滤器的入口。因此,每个数据集都是下一个数据集的子集,不包括原始数据集。
第一阶段 :缺失值去除
事先处理数据集中缺失的/null/inf 值也很重要。有许多方法来处理这样的值,选择实现的一个方法是删除它们。
第二阶段 :排除 1 日开发者
第一阶段,只为项目做了一天贡献的工程师被淘汰。这个过滤器背后的想法是,我们可以对他们活动时间短的唯一原因做出合理的结论。过滤器是基于数据集的 activity_period_in_days 指标构建的。
第三阶段 : 排除短期贡献者
在这个阶段,在项目中参与最少的 10%的工程师被排除在外。数据集根据 activity_period_in_days 指标排序,并保留数据集的上 90%。
第四阶段 : 数据归一化
在数据集处理的最后阶段,度量值的范围被归一化,因为每个观测值的特征值被表示为 n 维空间中的坐标(n 是要素的数量),然后计算这些坐标之间的距离。如果这些坐标没有归一化,那么可能会导致错误的结果。
这整个过程是为了优化聚类过程。
四。角色分类
模型构建
为了演示角色分类, 三种聚类算法 1。DBSCAN,2。k 表示和 3。使用具有完全连锁和欧几里德和曼哈顿距离 *的系统聚类。*角色分类基于预处理动作后产生的最终数据集中的 4 个指标(问题 _ 参与、问题 _ 打开、问题 _ 关闭、提交 _ 创作)。每种算法的结果将在下面的章节中分别介绍。
DBSCAN
DBSCAN 是一种已知的基于密度的算法,用于具有不同数据密度的数据集。因此,DBSCAN 无法从我们的数据集中提取信息丰富的聚类,主要是因为数据点集中在零附近,并将它们归类到同一个聚类中。虽然我们可以使用 DBSCAN 作为额外的预处理阶段,以消除一些异常值。这些离群值将形成没有足够数据的聚类,因此很难提取关于每个组的角色评估的结论。因此,我们更倾向于在轴的起点关注数据的主要分布。作为预处理的最后阶段的结果,我们产生了我们称之为无不规则的数据集
K 表示
K 均值的问题在于我们的数据并不是均匀分布的。不幸的是,轴中心周围的数据点密度高于正常预期,导致角色定义不明确。此外,我们的数据密度约为零,这产生了误导性的高评估指标。这一结论很容易通过图 2 的原始数据度量结果来理解。之所以只使用这一指标,是因为我们可以看到,数据集之间的内聚性(以及分离性)无法进行比较。发生这种情况是因为每个观测值的特征距离都非常不同,不能放在同一个单位系统中。



Fig. 1. Role Classification Results with K means




Model 1. Role Classification Results with K means.
层次聚类
在这三种聚类方法中,选择继续使用的是具有完全链接的层次聚类。正如我们从图中看到的,分层聚类提供了聚类之间的最佳划分,以及各种度量中的足够结果。此外,它与我们的数据最兼容,因为它可以处理不规则的集群。这种方法的唯一问题是创建了一个聚类,其值集中在轴的起点,我们无法提取足够的信息。因此,将再次使用分层聚类来进一步检查这个特定的聚类,并确定它所包含的角色。这里我们必须指出,在这次检查中,我们得到的结果只能与聚类内部的值进行比较,而不能与聚类的其他结果进行比较。



Fig. 2. Role Classification Results with Hierarchical Clustering.
A.模型评估
正如我们从图中看到的,使用归一化欧几里德数据集是更优选的。根据肘方法,我们可以使用 6 个、7 个或 8 个集群,而不会对指标结果产生任何显著影响。尽管通过对数据的进一步检查和可视化,我们得出的结论是最好使用 7 个聚类进行分析。




Model 2. Role Classification with Hierarchical Clustering, dataset = normalized, distance = Euclidean, linkage = complete, n_clusters = 7
动词 (verb 的缩写)角色解释
在这一部分中,我们试图根据我们的数据集来确定工程师在项目中可能扮演的特定角色。
B.评价方法
为了得到我们的结论而检查的特征是(“打开的问题”、“关闭的问题”、“提交的问题”、“参与的问题”)。因此,我们有以下几组
- 偏差
- DevOps
- 工作
- 项目所有者
a.创作的提交
b.关闭的问题
为了使一个分类属于一个特定的组,与其他分类相比,它在这些特定类别中的值必须相对较高。尽管应该指出,这不是为了对一个集群进行分类而需要满足的唯一标准。更具体地说,如果一个集群属于 DevOps 组,这并不一定意味着它的值在所有上述类别中都很高,而只是这些类别的相对良好的组合就足够了。此外,分析可能会产生除上述类别之外的新类别。
C.评估结果

如上所示,第一个集群被归类为 Dev。它在数据集中具有最高的提交,其他特征具有较低的值,以及针对开发集群的“已关闭问题”。这是因为正如我们在 Github 所知,只有库所有者才能授予关闭问题的权限。因此,开发集群可能由一些工程师组成,他们为存储库做出贡献,但不是所有者或者没有关闭问题的特权。第二类被归类为未定,因为很难在所有特征都为“低”的情况下得出任何结论。因此,我们需要进一步检查这个特定的集群,因为它包含了我们的大部分数据,不能被忽略。同样在第 7 类中,特征值不同于以前见过的任何东西,这就是它必须被归类为尚未预测的新组的原因。
不及物动词更深层次的角色诠释



Fig. 3. Deep Role Classification Results with Hierarchical Clustering.
这里产生了一个特定的模型,以便进一步检查已经说过的第二组。在这个模型中,层次聚类也被用来获得内聚分离和剪影的度量,如上图所示。再次使用肘方法,我们选择继续对 7 个集群进行分析。




Model 3. Deeper Role Classification with Hierarchical Clustering, dataset = deep_normalized, distance = Euclidean, linkage = complete, n_clusters = 7
A.评价方法
这里我们遵循与第一个模型相同的规则。但重要的是要说,这个模型的值只能互相比较,不能和第一个模型的值比较。因此,“低”“中”“高”的含义在每个模型中是不同的,但在这里我们也有相同的聚类目标。
B.评估结果

这里,第二个包含了大部分数据,但是它的分布和大部分值都非常低,所以我们无法提取任何关于如何表征它的有用信息。虽然第 3 个聚类也包含整体数据集的低值,但它们相对高于第 2 个聚类,这就是为什么我们可以将其归类为 Ops。在其他集群中,遵循与第一个模型相同的方法对它们进行分类。
七。角色评估
在本节中,将分析每个工程师在每个角色中的表现。该评估将采用相同的方法,因为我们将为每个角色创建集群。
将用于此的算法是分层聚类,数据集将是归一化的欧几里德数据集,因为该实验的概念与角色分类保持相同。
- 开发评估
在这种检查中,没有必要寻找大量的独立的集群,但我们宁愿选择在信息方面更丰富的少数集群。我们之所以得出这个结论,是因为现在我们不再寻找工程师的独立角色,而是试图找到开发人员之间的共同特征。在 Dev 集群中,我们包括原始分析的 Dev 和来自第二个集群的进一步检查的 Dev。正如我们从涉及开发群集的图中看到的那样,我们使用肘方法选择了 4 个群集。这些集群的主要特征是:
I .富有成效:如果团队有很高的“每天关闭的问题”
二。响应性:如果团队的“平均问题解决时间”很短
三。优雅:如果团队的“违规增加”很低
2.DevOps 评估
这一评估的不同之处在于,我们考察了一个同时具有开发和运营集群特征的团队。因此,为了有更多不同的角色,比其他两个评估小组稍微多一点的小组会更有用。使用与之前相同的方法并查看 DevOps 数据,我们得出了 8 个不同的团队。
3.运营评估
在这里,我们正在寻找不同的团队,显示在一个特定的项目中,一个操作是多么投入和有帮助。就像之前一样,我们使用肘方法来找到最佳的集群数,即 4。我们遵循与开发评估相同的逻辑,我们可以将一个操作描述为:
一、参与:如果团队“不活动时间”低
二。口头:如果团队的“平均评论长度”很长
三。富有成效:如果团队“每个问题的平均评论数”很高
A.评价方法
为了评估开发、运营和开发运维集群,我们从原始数据中提取了某些指标:
对于开发人员:
a.添加了违规
b.违规已删除
c.关闭问题的平均时间
d.每天关闭的问题
对于 Ops:
a.每期平均评论数
b.平均评论长度
c.打开的问题
d.非活跃期
对于 DevOps:
a.每期平均评论数
b.平均评论长度
c.添加了违规
d.违规已删除
e.关闭问题的平均时间



Fig. 4. Dev Evaluation with Hierarchical Clustering, dataset = normalized, distance = Euclidean, linkage = complete.




Model 4. Dev Evaluation



Fig. 5. DevOps Evaluation with Hierarchical Clustering, dataset = normalised, distance = euclidean, linkage = complete.





Model 4. DevOps Evaluation



Fig. 6. Ops Evaluation with Hierarchical Clustering ,dataset = normalized, distance = euclidean, linkage = complete.




Model 4. Dev Evaluation
B.评估结果
在本节中,我们将展示上述分析的结果,并根据我们从原始数据集中提取的特征将每个原始聚类分组。
八。结论
这项测试的最初目标是成功地识别工程师在项目中可能扮演的不同角色。然后根据一些特征对每个角色进行评估。很明显,当涉及到一个软件项目时,很难对参与其中的人进行评估。因此,不言而喻的是,在某些情况下,我们简化了数据和模型,这些数据和模型是出于复杂性原因而使用的,只有在必要时,我们才会进行更彻底的检查。在这种情况下,我们认为使用 4 种不同的模型就足够了,以便为我们的数据选择最合适的模型。
作为最后的观察,我们必须指出,在角色解释中使用的大多数特征都是针对 Dev 而不是 Ops 的。发生这种情况是因为 GitHub 作为一个平台更吸引开发者,而不是 Ops,并且数据集包含很少的 PureOps 特征。此外,大部分数据都集中在零点附近的坐标轴上。因此,很难用足够的数据点来识别不同的聚类以获得全面的结果。尽管我们认为,通过我们的预处理方法和与我们的数据最相容的聚类,我们已经实现了成功地找到工程师的不同角色的目标。
参考
[1]“GitHubAPI”,可用@https://developer.github.com/v3/
[2] I. Zafeiriou,“通过在 GitHub 知识库源代码和注释上应用数据挖掘技术进行软件工程师档案识别”,毕业论文,希腊塞萨洛尼基亚里士多德大学,2017 年。
在 Github 上找到源代码。
使用光学的聚类
一个看似无参数的算法

See What I Did There?
聚类是目前使用的一种强大的无监督知识发现工具,旨在将数据点划分为具有相似特征的组。然而,每个算法对参数都非常敏感。基于相似性的技术(K-means 等)的任务是指定存在多少个聚类,而分级通常需要人工干预来决定何时分配完成的聚类。最常见的基于密度的方法是 DBSCAN,它只需要两个关于如何定义其“核心点”的参数,但找到这些参数通常是一项极其困难的任务。它也不能找到不同密度的簇。
DBSCAN 有一个亲戚,称为 OPTICS(排序点以识别簇结构),它调用一个不同的过程。它将创建一个可达性图,然后用于提取聚类,虽然仍然有一个输入,最大ε,但它主要是在您希望尝试并加快计算时间时引入的。其他参数没有其他聚类算法中的参数有那么大的影响,并且更容易使用默认值。首先,我将解释一下这个算法是如何工作的,它是如何包含在线异常值检测的,然后它是如何在最近的一个应用中对我非常有用的。
算法
为了理解它是如何创造这个情节的,你必须理解几个定义。你必须先了解 DBSCAN 的工作原理,它使用的参数,以及核心点和边界点的区别。我将把它留在本文的范围之外。我们还将增加几个定义
核心距离- 在给定有限 MinPts 参数的情况下,使不同点成为核心点的最小ε。
可达性距离- 如果 o 是核心对象,则一个对象 p 相对于另一个对象 o 的可达性距离是到 o 的最小距离。它也不能小于核心距离 o。

尽管在这些计算中使用了 MinPts 参数,但这并不会产生太大的影响,因为所有距离的缩放率大致相同。
我们将使用这些定义来创建可达性图,然后用它来提取聚类。首先,我们从计算集合中所有数据点的核心距离开始。然后,我们将遍历整个数据集,更新可达性距离,每个点只处理一次。我们将只更新有待改进且尚未处理的点的可达性距离。这是因为当我们处理一个点时,我们已经确定了它的顺序和到达距离。选择处理的下一个数据点将是具有最近可达性距离的数据点。这就是该算法在输出排序中保持聚类彼此靠近的方式。原始可达性图的示例如下所示。
下一步是从图中提取实际的聚类标签。最常见的方法是使用局部最小值和最大值在图中搜索“谷”。根据所采用的方法,这里还会有一些参数发挥作用。
请参见下文,了解一些生成的样本数据与生成的光学标签和可达性图的对比。彩色点是那些被识别为集群的点,而灰色点代表噪声。

This example was taken directly from the Scikit-Learn development version
请注意,在这个生成的示例中,有大量的点被识别为噪声点。它们的密度与黄色星团相似,但在本次提取中没有被识别出来,因为它侧重于分离密度更大的区域。这就是微调提取参数的好处。在这种情况下,也可以使用提取聚类的其他方法。
异常值检测
OPTICS 算法的另一个有趣的方面是它用于异常值检测的扩展,称为 OPTICS-of(异常值因子的 OF)。这将给出每个点的异常值,即与其最近邻居的比较,而不是整个集合的比较。由于这种“局部”原则,这是一种独特类型的异常值检测。我们也可以在创建它时使用一些以前的计算。
首先,它创建了一个新的度量,“局部可达性密度”,这是 MinPts-neighbors 的平均可达性(相对于正在计算的点)的倒数。

一旦我们对每个点都这样做了,我们将计算离群因子。要做到这一点,您需要对该特定点的 MinPts-neighbors 比率取平均值,如下所示。

OPTICS-OF 的“局部”部分是它区别于其他异常值检测方法的关键,因为它试图考虑特定选项的邻域。它还能够给它一个相对的离群值,而不仅仅是一个二进制值。显示了下面讨论的项目中的一个示例,异常对象显示为红色,异常因子的截止值为 2。

光学检测的一个缺点是不能很好地处理复制品。如果足够多的点占据相同的空间,它们的可达距离可以是 0,这在我们的局部异常值因子计算中引起问题。在这个场景中,我简单地删除了所有重复的内容,
用例
我最近在一个项目中使用了光学,这个项目可能很好地展示了它在哪里可以有效,同时也给出了一个无耻的插头。我想在仓储/物流领域建立一个自动化的知识发现工具。优化仓库的一个关键部分是理解你的 SKU 基地的模式,以及当其他人完全不同时,他们中的一些人是如何行动的。过于一般化一个操作,你会错过标准化和整合过程的机会,所以集群是有帮助的。强迫每个 SKU 归入一个组会降低你要寻找的模式的准确性和有用性,所以我想采用一种基于密度的方法。使用 DBSCAN 会很有用,但是需要对每个数据集进行调优,而且有些模式会有不同的密度,很难找到。光学可以用在它的情况下伴随这两个。
不规则的动作项目也可能导致比它们的体积大得多的劳动量。这些通常是你通常不会注意到的较慢的项目,并且可能与其他类似的 SKU 有不一致的排序模式。这可能来自处理单位、季节性、订单通用性或其他因素的差异。但是它们不一定容易被发现,因为它不是一个单独的值,而是一个奇怪的组合。使用局部异常值因子来尝试并找到这些。
结论
尽管无论如何都不是一种新的聚类算法,但光学是一种非常有趣的技术,我还没有看到大量的讨论。它的优点包括寻找不同的密度,以及很少的参数调整。
参考文献
Ankerst、Mihael、Markus M. Breunig、Hans-Peter Kriegel 和 rg Sander。"光学:排序点以识别集群结构."美国计算机学会西格蒙德记录,第 28 卷,第 2 期,第 49-60 页。美国计算机学会,1999 年。
Ankerst、Mihael、Markus M. Breunig、Hans-Peter Kriegel 和 rg Sander。在 J.M. Zytkow 和 J. Rauch (Eds .):1999 年 PKDD,LNAI,1704 年,第 262-270 页,1999 年
使用 Doc2Vec 和 WebGL 对旅行者的故事进行聚类和可视化

深入分析
成千上万个旅行故事的互动可视化
这篇文章深入研究了数千个旅行故事的互动可视化 的结果及其联系。可视化的目标是使有抱负的作家的提交有趣的发现。它面向广泛的用户群体;无论是有抱负的旅行作家,想探索新目的地的白日做梦的办公室职员,还是对理解人们为什么和如何旅行感兴趣的社会科学家。
在一个感觉国家和人民之间的差异被放大的时代,我希望这能提醒我们,我们许多人通过体验我们的星球和彼此的方式联系在一起。
动机
虽然我偶尔会抽出时间写下对生活和宇宙的思考,但它们很少能吸引你的想象力。相比之下,我的妻子奥利维亚是一个天才的故事讲述者和作家。我们休假期间,她的目标之一是写一篇短篇小说。自然,她是这次旅行的官方旅行作家,给朋友和家人发了几封日记电子邮件,他们每次都回信称赞。
因此,当我发现我们的旅游保险提供商(found 游牧民)正在赞助一个旅游写作比赛时,我说服她提交了一份摘录。起初,我确信她会赢;然而,当我们意识到有超过 10,000 份申请时,很明显胜算不大。
果然,结果出来了,她没有入围。虽然令人失望,但整件事让我想到有多少其他精彩的故事被分享,而其中有多少会被阅读。我发现自己在思考不同的问题:
- 评委们是怎么看完这么多故事并打分的?
- 如果他们能公开这些评分来看看她的排名,那不是很好吗?
- 不幸的是,他们没有——那么我怎么知道奥利维亚的故事有多好或独特呢?
- 除了 3 个获奖者和 10 个入围者,我如何才能找到其他伟大的故事?
- 给定所有的数据,我能让计算机生成类似的故事吗?
考虑到这一点,我开始尝试用这个数据集做一些有趣的事情。我知道这将是一个挑战,因为除了每个计算机系学生在某个时候都会做的朴素贝叶斯垃圾邮件过滤作业,我在自然语言处理(NLP)方面没有任何经验。尽管如此,我认为这将是一个学习机器学习工具如何用于文档的好机会。这也与我们在斯里兰卡的最后一周相吻合——就在那时,回归现实生活的前景开始成为现实,我迫切地想在回到全职工作之前做点“有趣”的事情(我一点也不知道,在我最终重新开始工作之前,我又去了 2 个国家,花了 4 个月的时间)

探索故事
我做了一些研究,看看我可以用什么工具来提取故事之间的有趣关系。我偶然发现了 Doc2Vec,这是一种越来越流行的神经网络技术,它将集合中的文档转换为高维向量,因此可以使用向量表示之间的距离来比较文档。
但在深入研究技术细节之前,我认为谈论这些结果有多么酷是值得和有趣的(在博客上写很棒——我不能在同行评议的论文上说这些!)您可以向下滚动到How部分,了解 scraper、模型构建/调整以及可视化网站的设计/编码。
呼叫银河,银河,完毕
这是奥利维亚故事的标题。当我们的朋友想要我们过来吃晚饭或者需要借用备用的小艇马达时,我们就会听到这种无线电广播。故事发生在桑给巴尔海岸的一艘帆船上,桑给巴尔是一个田园诗般的群岛,有荒凉的海滩和热情的人们。介绍是这样的:
我们在银河号上和我们的临时家庭一起度过了圣诞节,这是一群快乐地不匹配的人类,就像我们用来分享食物的餐具一样。一名瑞士船长在一种退化性眼疾夺去他的生命之前环游了世界。一对加拿大夫妇哀悼一个婴儿。在空巢中找到探索空间的南非父母。猎犬莫莉。我和祖海尔。我想知道别人会如何描述我们。
在 10,000 多个条目中,第二个与奥利维亚最相似的故事是贾斯汀的12 天转换,它的介绍很快吸引你:
我们乘着破旧的船旅行,船上沾满了海藻,但它的舵柄、收音机和手摇橘子榨汁机还在工作。一层新鲜的开心果。有三名船员:一名船长,一名领航员,一名厨师。其中一个是鬼;他们知道他们中的一个是鬼,每天晚上都听到咔哒咔哒的铁链声,但另外两个还没弄清楚是哪一个。
光是这一点就感觉像是一个小小的成功:模型确定了另一个以帆船为背景的故事,有一个船长和一些同伴,以及(如果你眯着眼睛)类似的写作风格!相似之处是显而易见的,这并不令人惊讶,因为两个故事使用了相似的词语,因为它们都发生在一艘帆船上。
但让我们来看看与奥利维亚最相似的故事。根据模型,那将是克斯丁的休息一下。乍一看,很难找出与这个在墨西哥迷失的澳大利亚人的故事的相似之处。会不会是因为 Kirstin 谈到了到达一个海滩并找到了乐于助人的人,而 Olivia 描述了当我们在 Pemba 的海滩上着陆时孩子们的好奇心和人们的热烈欢迎?也许吧,但我愿意相信这种强烈的相似性来自故事的结尾段落。这是克斯丁的:
每次我们在厨房提供帮助时,威利都会拿出他最喜欢的口头禅“休息一下”。他的内心仍然是一个孩子,他敬畏我们年轻的莫邪,将一切抛在身后去旅行,当他梦见过去时,他的眼睛变得呆滞,他希望自己也能这样做。我们仍然不敢相信海伦和威利会如此慷慨地收养我们这些流浪儿。仅仅两个月后,我们得知威利中风了。这是那种发人深省的陈词滥调,“人生苦短,趁年轻做吧”。
所以我们休息了一下。
这是奥利维亚的结束语:
尽管有奇迹,但也有同样的艰难。浪漫主义者把这种除了天气之外没有主人的生活描绘成自由的顶峰。但我觉得被困在这艘船上了。尽管 b*tch 不停地摇摆,但 Galaxy 还是劝我坐着别动,为此我很讨厌她。[……]银河根本不在乎我想要什么。也许是因为她一直专注于给我我需要的东西。是时候停下来消化一下突然发生的重大生活变化了。一个面对我的恐惧和发现我的优势的机会。地平线的景色,以及地平线后面可能会有什么。
事实就是这样:两个故事都有着复杂情感的结局。尽管一个人突然死亡,另一个人生活艰难,但都提到了花时间旅行和消化生活的重要性。
…
好吧,你可能认为我在吹牛,这是一个合理的批评。不过这很难说,因为这说明了神经网络和其他 ML 技术的困难之一:可解释性。该模型表示,根据它被训练的故事,这两个是相似的,但如果不深入研究其细节,很难知道为什么。比如它遇到的词汇很重要,这些故事只是在它目前看到的“语料库”的语境内相似。要对此有一个直觉,看看这篇(国王-男人)+女人=王后的帖子,它给出了对 Word2Vec 的分析,这是 Doc2Vec 背后的基础。不是 NLP 专家,我不确定是否有类似的方法来分析 Doc2Vec 的输出,以理解为什么两个文档相似。

Galaxie
地理集群
到目前为止,我一直专注于奥利维亚的故事,但我也花了几个小时阅读其他各种各样的故事来取乐。我很快发现自己手动做了很多这样的故事比较:从语料库中随机选择一个,并运行代码来显示与其最相似的故事。我想要一个更精简的替代方案,我认为这是一个与更广泛的受众分享所有这些旅行者故事的好方法。
起初我想,也许使用计算出的距离来生成一个树状图会揭示故事中有趣的结构。然而,事实证明,显示有这么多节点的树状图并不能提供很多信息,也不容易使用。相反,我认为从在地图上按地理位置排列故事开始会更容易。

虽然在概念上最容易理解,但它花了最长的时间让这个视图工作,因为它是第一个。我需要找到合适的框架来使用。鉴于我最近在 DivetheData 项目中的经历,我最初倾向于使用 Plotly/Dash。但是在经历了几次失败之后,我最终选择了 VivaGraphJS,它被誉为最快的图形可视化框架;它实现了它的承诺!
我选择将节点放在故事发生地点的中心,并根据作者的出生地给它们涂上颜色。由于元数据缺乏准确的地理位置细节,我创造性地进行了定位,并使搭配的故事构建成一个螺旋。最终的界面丰富多彩、快速流畅;它很快暴露了一些有趣的见解:
- 人口稠密的国家往往有很大比例的“本地”旅行者。美国的大多数圆点是绿色的(北美旅行者写的故事),同样,印度和印度尼西亚的圆点是黄色的(亚洲旅行者写的故事),尼日利亚和南非的圆点是橙色的(非洲旅行者写的故事);紫色圆点代表巴西(南美人的故事)。这与受欢迎的旅游目的地形成了对比,这些目的地有更多的混合:英国、法国、西班牙、葡萄牙、意大利、摩洛哥、土耳其、泰国、越南、尼泊尔和日本都有来自世界各地作家的混合故事。
- 故事很少通过地点联系起来。除了印度,如果你把鼠标放在故事上,你会发现这些故事通常不是发生在同一个国家。我特意避免使用任何元数据(作者国家、提交类别等。)在模型中,因为我只想要故事文本来影响关系。
- 很多故事的地点都被贴错了。如果你花时间阅读一些条目,你会很快意识到作家有时会错误地把他们的原籍国作为拍摄地。
相似星座

除了不变的布局,VivaGraphJS 还实现了强制定向图形绘制,这是一种超级漂亮的图形布局方式。它基本上是一个 N 体模拟,其中节点之间的链接就像弹簧一样将相关节点拉在一起,因此也是一个聚类算法。
我最初试图对所有的连接都这样做,但是连接太多了,结果是一团糟。然而,当链接仅限于最相似的连接时,结果图是有趣的。我喜欢把它想象成一个星座的集合,每个星座都有一个共同的线索,更容易通过“话题”来探索故事。不幸的是,没有一种优雅的方式来标记主题,正如这篇关于使用 Doc2Vec 的自动主题聚类的文章中所讨论的,它最终使用新闻文章标题中最频繁出现的单词。
尽管如此,当人们探索这些星座时,有趣的是聚集在一起的故事通常会共享相似的背景(徒步旅行、海洋、城市/市区、机场、火车等)。).这并不奇怪,因为即使是一个基本的“单词包”方法也应该能够将它们聚集在一起。然而,冰冷的是当相似之处似乎是由故事的结构或情绪驱动时:开始时迷路并从当地人那里获得帮助,与移民官员的麻烦最终得到解决,等等。以下是一些我认为值得强调的具体例子。
克服恐惧无论是对独自旅行、飞行、跳伞还是跳船的恐惧;这是最大的星座之一,不言自明。以下是集群中故事的示例:
- 恐惧是暂时的,遗憾是永远的莎拉·科里甘(美国)讲述她在澳洲留学的故事是最大的集群之一。它包含了几乎所有在其他电影中发现的元素:独自旅行,被恐惧或社会压力所阻碍,对飞行/飞行中的反胃感觉,变得更加冒险,以及跳跃!
- 独自骑行迈克尔·休斯顿(英国)讲述了他克服独自去柏林旅行的恐惧。
- 介绍 Kay Cabernet Kyndra Rothermel(美国)描述了她如何克服成为一名外籍人士的困难,并最终成为一名肾上腺素上瘾者,与鲨鱼一起玩滑翔伞和笼子潜水。
这组故事描述了因国籍、身份和/或宗教冲突而产生的挑战
- 你好 Libertat!在这个故事中,Tsz Kwan Lam(香港)发现了加泰罗尼亚人为保护他们在西班牙的独特文化而进行的斗争与他的香港同胞为从中国获得政治自由而进行的斗争之间的相似之处。
- 庞雅文·诺维科娃(哈萨克斯坦)描述了“英国退出欧盟脾气”是如何让她亲爱的东道国“听起来像一场充满种族色彩的公共汽车大战”,并指责它差点被赶出她的租房。
- 祖国的微笑讲述了印尼华人成长的困难。
- 黎巴嫩的光彩理查德·切马利(南非)思考着梅龙派教徒如何为宗教自由而战,为黎巴嫩的群山带来了一种独特的美。
与翻译一起迷路这是一组有点复杂的解释,但我认为它基本上是买票、不说当地语言、迷路和获得当地人帮助的混合:
- 为了逃离游客众多的慕尼黑,詹娜·加内瓦(保加利亚)在买了一张去萨尔斯堡的机票后,意外地发现自己来到了奥地利。
- 俄罗斯眼镜 Giovanni D’Amico(意大利)与西里尔字母斗争,但幸运的是在购买火车票时得到了 Masha 的帮助。
- 给我一个结束讲话的朋友的门 Nicole Da Silva Fleck(巴西)从讲芬兰语的航空公司工作人员那里得知她的行李丢失了,并得到了讲芬兰语的邻居的帮助。
值得一提的一些其他集群:
- 岛屿海滩的小册子这些故事读起来几乎像广告,描述了果阿、长滩岛、婆罗洲、马尔代夫和普吉岛等标志性岛屿的海滩美景。
- 旅行纪要故事以详细的“一小时一小时,一天一天”的时间顺序写成
- 丛林和它们的噪音这是一小群关于人们在森林和丛林中发现的不和谐声音的故事。
双相似核

通过相似性距离进行聚类是直观的。然而,我有一个假设,某些故事可能如此不同,以至于它们应该出现多次,作为多个其他故事中最不相似的。我决定通过使用相同的强制定向布局方法生成集群来测试这一点,但这一次图形边缘连接不同的故事。由此产生的集群通常在它们的中心有我喜欢称之为二相似核的东西,即模型反复识别为最不相似的故事。
Bea Gilbert(英国)的《发现蒙古的无声秘密》展示了这种方法是如何产生一些独特的条目的。Bea 提交的作品与其他 20 多份作品相比是最不相似的,快速浏览一下她的介绍段落就可以明显看出她的写作风格(和用词)是独一无二的:
当我们向北行进时,面包屑般的头骨痕迹布满了森林。每一个都让人回想起前一天晚上,一只山羊死在黑暗中。珍珠般的皮肤被紧紧地拴在一个蒙古包肿胀的顶蓬上,磨损的蹄子还伸着,扎进了砾石里。[……]我的旅程一直被杂乱、喧闹和噪音打断。一位咳嗽声令人不寒而栗的机场出租车司机把我带到了乌兰巴托:这是苏联入侵和无组织的现代化冲刺之间的灰色和汽车堵塞的矛盾。
不幸的是,有许多故事的写作风格不是很好。好的一面是,这些故事通常会围绕着另一个风格明显不同、因而也更好的故事。例如,荣继敏·巴巴罗(澳大利亚)写的《不要停下来》讲述了一次平缓的远足变成陡峭的攀登,以一种愉快的风格写道:
当那辆锈迹斑斑、嘎嘎作响的旧货车驶过欣欣向荣的绿色稻田和纯净的乡村时,我的思绪停留在这个田园诗般的背景下可能正在修复的暴行上。当我们驶过一扇天蓝色的大门,驶上一条土路车道时,我没想到会看到像树屋一样充满活力的彩绘木屋。这是阳光之家,一个离金边 90 分钟路程的孤儿院,是 50 多个被剥削和遗弃的孩子的家。它与我先前对孤儿院的想法相去甚远。这是一个避难所;一个避难所。
对比这两个摘录,荣继敏的条目出现最不相似:
如果我们谈论葡萄牙,你一定记得葡萄牙的一个著名足球运动员,对吗?没错,他就是 c 罗。葡萄牙和罗纳尔多一样,他是一个出生在那里的足球运动员。如果我们谈论葡萄牙,这个国家以他们的足球历史而闻名。即使在 2016 年,葡萄牙也赢得了 2016 年欧洲冠军杯🏆⚽️和他们从未停止是世界杯的参与者。很神奇吧?但是你知道吗?
我一直梦想有一次航行,我的梦想将通过不独自这样做来实现,所以我从未停止梦想。我从来没有指望找到一个海上旅行,而看着我的资源,但冲动和梦想既没有停止,我也没有做任何事情来阻止它,而是我总是在寻找一个机会,站在前甲板上,感觉自己在一个完全不同的平面上。
最后,这些二相似性聚类的另一个特殊性是它们偶尔包含外语故事。这有点耐人寻味,比如亚当·赫弗南(爱尔兰)的《我们的小 T2》与 20 个西班牙作品最不相似。这仅仅是因为语言,还是这个模型学到了一些关于西班牙故事的有意义的语义,使它们与亚当的故事不同?朱莉·斯巴库尔的鸡肉也是如此,出于某种原因,它与半打阿拉伯语作品最不相似。

数据搜集和模型训练
当我第一次开始做这个项目时,我想我会用 python 来完成大部分工作。毕竟,这是当今事实上的脚本语言,ML 工具数量的增加使它成为一种自然的选择。果然,我使用BeautifulSoup编写了 webscraper,这使得下载故事和将它们与相关元数据一起存储变得简单明了。事实上,下载故事比写剧本花费的时间还要长,但这主要是因为斯里兰卡没有最快的宽带连接。
一旦故事被存储到 Yaml 文件中,我花了一些时间来选择我要用它们做什么。有很多 NLP 包,但是 Word2Vec 和 Doc2Vec 反复出现,因为它们易于理解和实现,并且显然产生了良好的结果。我最终遵循了 GenSim 的教程,果然,在一些 python 脚本和使用 Jupyter 笔记本进行实验的一天内,我有了能够开始比较故事的第一批结果。
Doc2Vec 方法的巧妙之处在于它是无人监管的,因此不需要任何标记。然而,不利的一面是,它可能会受到限制。例如,如上所述和这篇使用 Doc2Vec 帖子的自动主题聚类,虽然 Doc2Vec 生成的向量对于聚类是有用的,但它们不一定有助于自动标记它们。
图形和地图可视化
可视化数据比我想象的要困难得多。我最初倾向于使用 Dash/Plotly,因为我在以前的 DataViz 项目中有过使用它的经验。它看起来很有前景,特别是因为 Plotly 有一个用于细胞景观的包装器。随着我进一步探索这个选项,我意识到在服务器端我不需要做太多事情,因此很难证明使用 Dash 的必要性。我还决定绕过 Plotly,因为我需要使用 Cytoscape 的一些更高级的功能。的结果是一个很好的概念证明,但是由于节点数量太多,结果证明它太慢了,不太实用。
我最终找到了被誉为最快的图形可视化框架的 VivaGraphJS。虽然没有 Cytoscape 流行,也不容易设计,但 VivaGraph 有一个主要优势:它可以将 WebGL 用作渲染器。WebGL 使用 GPU 来生成可视化,因此显著提高了性能和交互性。
我花了比预期更长的时间在地图上布置节点。我最初认为为网页设置一个可以平移和缩放的背景就可以了,但由于屏幕和 WebGL 画布之间不同的参考框架,这变得有些复杂。当我最终得到它的工作,我不满意的背景质量恶化。相反,我转向了地图框,它提供了一些在两个坐标之间投影和反投影的功能。它仍然需要一些编码和实验来正确处理最小/最大缩放和平移边界,但结果更令人满意。
Web 框架
VivaGraph 的学习曲线比预期的要陡峭一些,但这主要是因为我不熟悉用 Javascript 开发。请记住,我从期望自己主要用 python 编码,到突然不得不理解 JS 闭包、promises、webpack 和 npm!更糟糕的是,我还在学习如何使用 Vue.js 。Vue 使得轻松地添加组件来与故事交互成为可能,比如搜索框、阅读窗格和布局选项框。
如果我坚持使用 Dash(其组件使用 React.js),事情可能会简单一些。好处是,在这个过程中,我现在对 Javascript 和反应式框架有了更多的了解。

下一步是什么?
到目前为止,我对项目的状态很满意:可以很容易地探索故事,找到它们之间的关系,并识别有趣的故事。但是,还有一些额外的功能我很想花点时间去了解,具体来说就是:
- 实现故事生成。也许使用双向 LSTM,正如在这个系列文章中所描述的。事实上,看看一个模型是否能生成一个与提交内容(或一组提交内容)最相似或最不相似的故事将会很有趣。
- 插图故事:为每个故事找到一张“封面图片”会很酷。由于文本太短,无法概括,这种方法将有助于快速浏览故事的内容。或许利用注意力生成网络?
- 使直接链接到一个故事或特定的布局成为可能。同样,如果能够对故事进行收藏或投票,那就太好了。
- 修复界面错误:虽然我花了很多时间来润色它,但界面仍然有问题,偶尔会有一些角落情况会使显示出现奇怪的行为。
- 让所有的故事都可以搜索。目前,只有元数据是可搜索的。让所有的文本都可以搜索可能需要一个服务器端的实现,或者将故事转移到数据库中。
我本周开始了一项新工作,所以我们将看到我有多少空闲时间来做这些改进。如果有人想尝试一下,所有的代码都在 G ithub 上。请随意派生和提交拉式请求。
原载于 2019 年 8 月 5 日https://zouhairm . github . io。
CNN 架构,深度挖掘
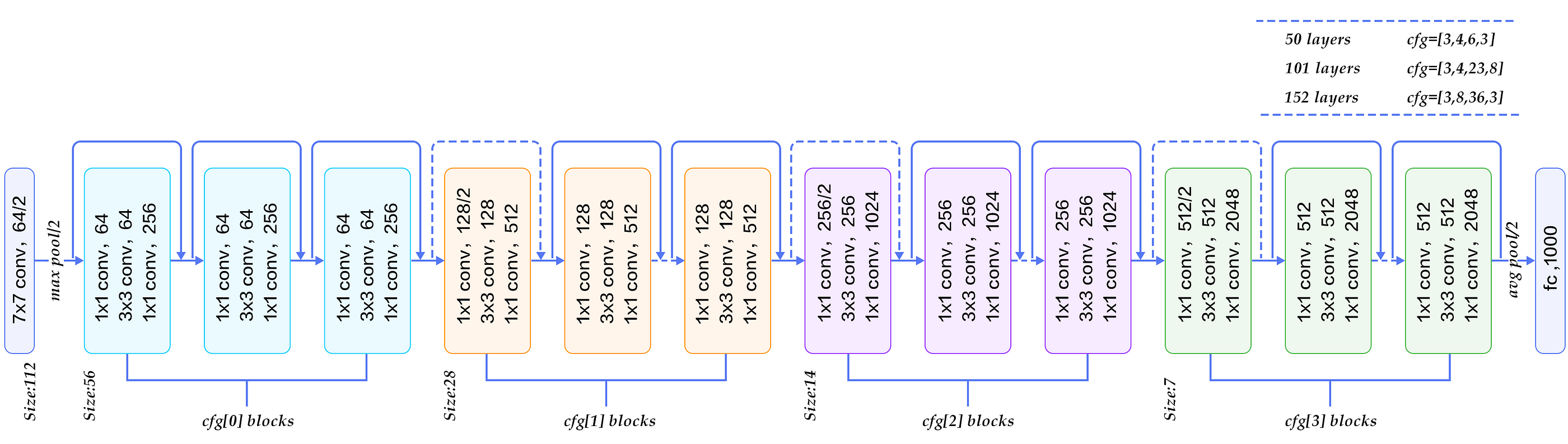
实现所有流行的 CNN 架构。



Various CNN Architectures Image Sources
在深度学习中,卷积神经网络(CNN)是一类深度神经网络,最常用于分析视觉图像。卷积神经网络是用于图像分类、分割、对象检测和许多其他图像处理任务的最先进的模型。为了开始进入图像处理领域或提高定制 CNN 模型的预测准确性,一些著名的 CNN 架构的知识将使我们在这个竞争激烈的世界中跟上步伐。因此,在这篇文章中,我将介绍一些著名的 CNN 架构。我主要强调如何在 Keras 中实现它们,也就是说,用那些体系结构的思想和结构制作定制模型。
在这篇文章中,我将介绍以下架构:
- VGG 网
- 雷斯内特
- 密集网
- 初始网络
- 例外网
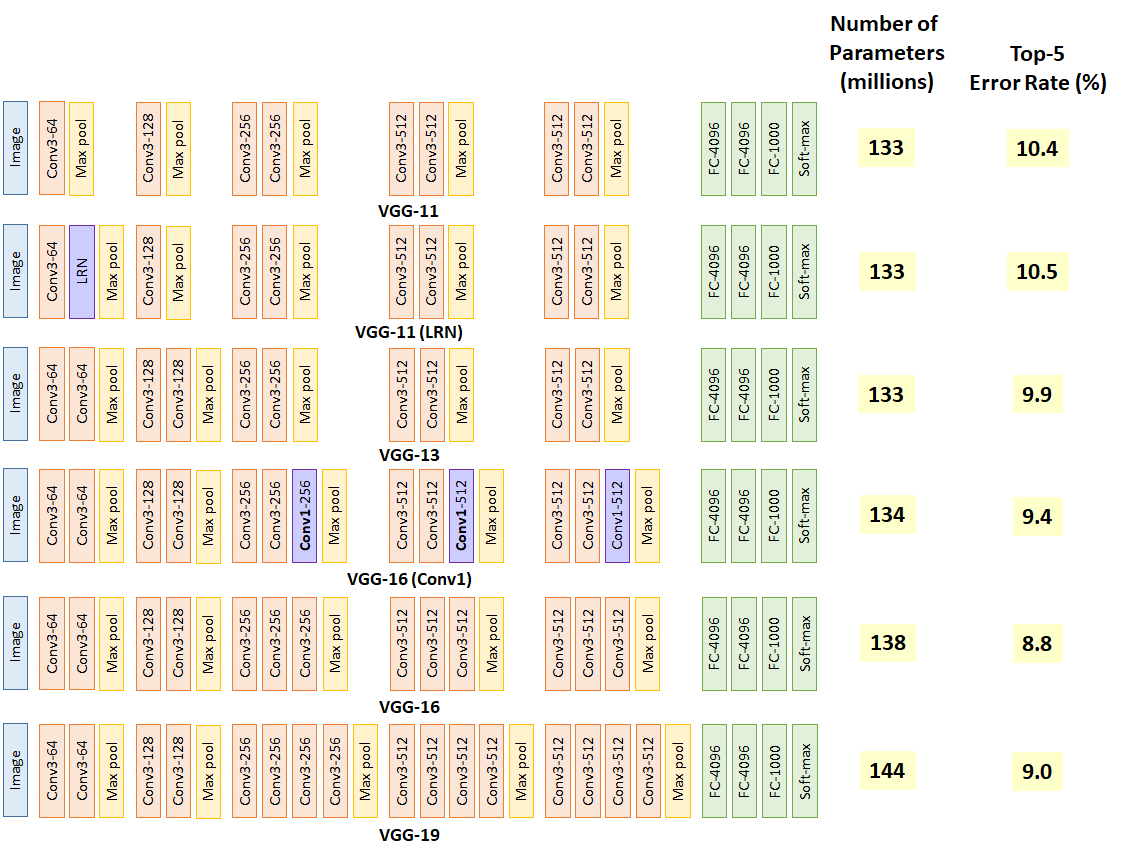
VGG 网(视觉几何组)

Image showing various VGGNet Architectures. Image Source
VGG 网络是一个简单明了的 CNN 架构。虽然它看起来很简单,但它确实胜过许多复杂的架构。它是 2014 年 ImageNet 挑战赛的亚军。如上图所示,总共有 6 个 VGGNet 架构。其中,VGG 16 号和 VGG 19 号最受欢迎。
VGG 建筑的想法很简单。我们必须用越来越大的滤波器尺寸来堆叠卷积层。即,如果层 1 具有 16 个过滤器,那么层 2 必须具有 16 个或更多过滤器。
另一个值得注意的点是,在每个 VGG 架构中,所有的过滤器都是 33 的大小。这里的想法是,两个 33 滤波器几乎覆盖了 55 滤波器将覆盖的区域,并且两个 33 滤波器比一个 5*5 滤波器更便宜(在要执行的乘法总数的意义上更便宜)。
让我们在 Keras 中创建一个具有 6 个卷积层的自定义 VGG 网络。
Implementing Custom VGG Architecture in Keras. Snippet Source
上面的代码将创建一个简单的六层卷积 VGG 网络。在每个卷积层之后,我添加了一个 Dropout 层以减少过拟合,并在每对卷积层之后添加了 MaxPooling 层以进行降维。
VGG 的问题在于,这种幼稚的架构不利于更深层次的网络,随着网络越深入,就越容易出现消失梯度的问题。更多的训练和更多的参数必须在更深层次的 VGG 架构中进行调整。
然而,VGG 网对于迁移学习和小的分类任务是方便的。
剩余网络

ResNet Architecture. Image Source
残余网络是第一个在 ImageNet 挑战赛中获胜的深层网络。2015 年 ImageNet 使用的 ResNet 有 152 层。在那之前,训练这种更深层次网络的想法只是一个梦想。然而,ResNet 实现了 3.57%的错误率(前 5 名错误率)。
ResNet 训练这种深度(152 层)网络的成功秘诀是,它有剩余连接。在 VGG,每一层都与前一层相连,从前一层获得输入。这确保了在从一层传播到另一层时,越来越多的有用特征被携带,而不太重要的特征被丢弃。这不是最好的方法,因为后面的层看不到前面的层所看到的。ResNet 不仅将前一层连接到当前层,还将前一层后面的一层连接到当前层,从而解决了这个问题。通过合并,现在每一层可以看到的不仅仅是前一层的观察结果。

Identity Shortcut Connection. Image Source
ResNets 有许多变体。核心思想是,让我们把 x 看作某个 Conv2D 层的输出。将几个 Conv2D 层添加到 x,然后将输出添加到 x ,并将其作为输入发送到下一层。
通过在每个卷积层之后使用批处理标准化层,这种深度残差网络的训练是可能的。批量标准化层将提高权重值,因此在训练时可以使用更高的学习率,这将有助于训练更快,也可以最小化消失梯度问题。
让我们将 ResNet 的概念转换成一段代码,这段代码可以是任意的,以实现我们想要的架构。
Snippet to create a custom Residual Layer. Snippet Source
上述函数采用如下参数:
***x*** : input to the res_layer.
***filters*** : number of filters in each convolutional layer.
***pooling*** : whether to add a pooling layer (default is False).
***dropout*** : whether to add a dropout layer (default is No).
过程是,它将输入层连接到 Conv2D 层,Conv2D 层具有我们函数调用中指定的过滤器,然后附加 BatchNormalization 层,在 batch normalization 层上添加 ReLU Activation 层,然后堆叠另一个 Conv2D 层。现在,这个堆叠输出与初始输入相加,但初始输入通过给定滤波器的 Conv2D 层进行转换。完成此步骤是为了匹配将要添加的两个图层的输出大小。然后,如果我们希望有一个 MaxPooling2D 层,我们添加它,如果给定了任何 dropool 值,那么也添加一个 dropool 层,最后再添加一个 BatchNormalization 层和 Activation 层,然后这个最终层由我们的 res_layer 函数返回。

Custom res_layer architecture.
现在我们已经创建了 res_layer,让我们创建一个自定义的 resnet。
Custom ResNet. Snippet Source
上面的代码创建了一个简单的 ResNet 模型。res_layer 函数用于简化堆叠多个层并多次添加它们的过程,这使得我们的代码具有可读性和可管理性。
ResNet 的优势在于,我们可以用这种架构训练更深层次的网络。
DenseNet

Dense Layer architecture. Image Source.
在 ResNet 中,我们添加了堆叠层及其输入层。在 DenseNet 中,对于一个给定的层,在它之前的所有其他层被连接并作为当前层的输入。通过这样的安排,我们可以使用更小的滤波器数量,并且这将最小化消失梯度问题,因为所有层都直接连接到输出,梯度可以直接从每个层的输出计算。
类似于 res_layer 函数,让我们为 dense_layer 开发一个函数。
Custom dense_layer function. Snippet Source
Inputs
***x*** : input layer.
***layer_configs***: a list of dictionaries, where each dictionary is of the below format.
Example of dense_layer configuration list. Snippet Source
Inside the layer_configs, the dictionaries have the following keys:"***layer_type***" : which type of layer we are going to create. Currently only Conv2D layer is supported by the above dense_layer function."***filters***" : determining number of filters in that layer. An integer is given as value."***kernel_size***" : size of the kernel. A tuple of kernel size is given as value. like (3, 3)."***strides***" : step size of stride. An integer is given as value."***padding***" : type of padding to be applied to the layer."***activation***" : type of activation to be applied to the layer.
现在我们已经定义了我们的函数,让我们创建一些自定义层配置。
custom layer_configs. Snippet Source
现在,让我们创建一个自定义的 DenseNet。
Custom DenseNet model. Snippet Source
与 ResNet 相比,DenseNet 有更多的中间连接。此外,我们可以在密集层中使用较小的过滤器数量,这对于较小的模型是有益的。
初始网络

Inception Net architecture. Image Source.
盗梦空间意味着更深入。在 ResNet 中,我们创建了更深层次的网络。盗梦空间网的理念是让网络更广。这可以通过并行连接具有不同过滤器的多个层,然后最终连接所有这些并行路径以传递到下一层来实现。

Inception layer Architecture. Image Source.
我们可以通过编写 inception_layer 函数来做到这一点,它可以创建任意配置的 inception_layer。
custom Inception layer function. Snippet Source
Inputs
***x*** : input layer.
***layer_configs*** : a list of lists, where each list have dictionaries.
让我们看一个演示层配置列表来了解这个想法。
Demo layer_configs format. Snippet Source
The keys in the dictionaries are:"***layer_type***" : which type of layer we are going to create. Currently only Conv2D layer is supported by the above dense_layer function."***filters***" : determining number of filters in that layer. An integer is given as value."***kernel_size***" : size of the kernel. A tuple of kernel size is given as value. like (3, 3)."***strides***" : step size of stride. An integer is given as value."***padding***" : type of padding to be applied to the layer."***activation***" : type of activation to be applied to the layer.
现在我们已经创建了一个 inception_layer 函数,让我们创建一个定制的 Inception Net。本例中不同层的 layer _ configs 可在本 要点 中找到。
最后,让我们创建一个定制的初始网络。
Custom Inception Net. Snippet Source
有许多不同的初始网络。它们之间的区别是:
- 不要使用 55 的过滤器,使用两个 33 的过滤器,因为它们计算效率高(如 VGGNet 中所讨论的)。
- 在执行任何具有较大滤波器尺寸的 Conv2D 层之前,使用具有较小滤波器数量的 11 Conv2D 层作为具有较少滤波器数量的 11 滤波器,将减少输入的深度,因此计算效率高。
- 不是执行 33 滤波,而是先执行 13 滤波,然后执行 3*1 滤波。这将大大提高计算效率。
使用我们的 inception_layer 函数,我们可以通过相应地编写我们的 layer _ configs 来定制上述所有类型的 InceptionNet 架构。
概念网更可取,因为它们不仅更深,而且更宽,我们可以堆叠许多这样的层,而且与所有其他架构相比,要训练的输出参数更少。
例外网

Xception Net Architecture. Image Source.
Xception Net 是在计算效率方面对 InceptionNet 的即兴发挥。异常意味着极端的开始。上图中呈现的 Xception 架构更像是一个 ResNet,而不是 InceptionNet。Xception Net 优于 Inception Net v3。
初始网络和例外网络之间的区别在于,在初始网络中执行正常的卷积运算,而在例外网络中执行深度方向可分离的卷积运算。深度方向可分离卷积不同于普通卷积,在普通 Conv2D 层中,对于(32,32,3)图像的输入,我们可以在 Conv 层中使用任意数量的滤波器。这些滤波器中的每一个都将在所有三个通道上工作,并且输出是所有对应值的总和。但是在深度方向可分离卷积中,每个通道只有一个核来做卷积。因此,通过执行深度方向可分离卷积,我们可以降低计算复杂度,因为每个核仅是二维的,并且仅在一个通道上进行卷积。在 Keras 中,我们可以通过使用 DepthwiseConv2D 层来实现这一点。
让我们创建一个简单的异常网络架构。
Custom Xception Net architecture. Snippet Source
以上是 Xception Net 架构的一个比较简单的实现。我们可以在低功耗器件中使用 XceptionNet,因为 Conv 层的计算量较少,而且与普通卷积层相比,精度相当。
本文背后的主要思想是通过实际创建 CNN 架构来熟悉它们。这将建立和提高我们对 CNN 的直觉和理解,以及如何和何时使用它们。还有许多其他流行的 CNN 架构。它们看起来或多或少类似于上述架构,只是增加了一些功能。
例如,让我们以 MobileNet 为例。它执行深度方向可分离的卷积,而不是正常的卷积。这使得它更适合用于低功耗设备和响应速度更快的型号。
总而言之,我更喜欢在较小的分类任务中使用像这样的定制架构,数据集大小适中,在较小的数据集情况下转移学习。就响应速度而言,我们倾向于较小的型号。此外,通过使用集成方法,我们可以在定制架构中获得相当好的精度。
帮助我做到这一点的文章和论文有:
盗梦空间网https://arxiv.org/pdf/1409.4842v1.pdf
https://arxiv.org/pdf/1608.06993v3.pdf,https://towardsdatascience.com/densenet-2810936aeebb密网
Xception Nethttp://zpastal . Net/cvpr 2017/Chollet _ Xception _ Deep _ Learning _ CVPR _ 2017 _ paper . pdf
CNN 热图:类别激活映射(CAM)
这是即将发布的一系列文章中的第一篇,这些文章讲述了不同的可视化技术,这些技术是 CNN 为了做出决定而查看图像的哪一部分。类别激活映射(CAM)是一种生成热图以突出图像的特定类别区域的技术。
热图的效用
下面是一个热图示例:

在这张来自Jacob Gil/py torch-grad-cam的图片中,一只猫以红色突出显示为“猫”类,这表明网络在做出分类决定时正在寻找正确的地方。
可视化神经网络在看哪里是有用的,因为这有助于我们理解神经网络是否在看图像的适当部分,或者神经网络是否在作弊。以下是一些神经网络在做出分类决策时可能会作弊并查看错误位置的示例:
- CNN 将一幅图像归类为“火车”,而实际上它正在寻找“火车轨道”(这意味着它将错误地将一幅只有火车轨道的图片归类为“火车”)
- 美国有线电视新闻网(CNN)将胸部 x 光图像归类为“高患病概率”,不是基于疾病的实际表现,而是基于放置在患者左肩上的金属“L”标记。关键是,只有当病人躺下时,这个“L”标记才直接放在病人身上,只有当病人太虚弱而不能站立时,病人才会躺下接受 x 光检查。因此,CNN 知道了“肩膀上的金属 L”和“病得无法站立的病人”之间的关联——但我们希望 CNN 寻找疾病的实际视觉迹象,而不是金属标志。(参见 Zech 等人 2018“混杂变量会降低放射学深度学习模型的泛化性能。”)
- CNN 学习基于在数据集中五分之一的马图像中存在左下角源标签来将图像分类为“马”。如果这个“马源标签”被放置在汽车的图像上,那么网络将该图像分类为“马”(参见 Lapuschkin 等人 2019 年揭示了聪明的 Hans 预测器并评估了机器真正学习的内容。)
一组相关论文
这里有一个图表,显示了 CNN 热图可视化的几篇论文之间的关系。你可以在左上角看到 CAM,这是这篇文章的重点:

以下是完整 CAM 论文的链接:周等 2016《学习深度特征进行判别定位》我特别推荐看图 1 和图 2。
CAM:类激活映射
凸轮架构
CAM 背后的想法是利用一种特定的卷积神经网络架构来产生热图可视化。(参见这篇文章对卷积神经网络的回顾。)
架构如下:卷积层,然后是全局平均池,然后是一个输出分类决策的全连接层。

在上面的草图中,我们可以看到一些通用的卷积层,导致了“倒数第二个卷积层”(即网络中的倒数第二层,也是最后一个卷积层)。)在这个“倒数第二个 conv 层”中,我们有 K 个特征地图。在该草图中,对于特征地图 A1、A2 和 A3,K = 3。
但是实际上 K 可以是任何值——例如,你可能有 64 个特征地图,或者 512 个特征地图。
按照本文的符号,每个特征图具有高度 v 和宽度 u:

全球平均统筹(缺口)
全局平均池通过对某个特征映射中的数字取平均值,将该特征映射转换为单个数字。因此,如果我们有 K=3 个特征地图,在全局平均汇集之后,我们将最终得到 K=3 个数字。这三个数字在上图中用这三个小方块表示:

下面是用和来描述差距的符号:

于是,在 GAP 中,我们把特征图 Aij 的元素相加,从 i = 1 到 u(全宽),从 j = 1 到 v(全高),然后除以特征图中的元素总数,Z = uv。
全连通层和分类得分
在我们执行全局平均池后,我们有 K 个数字。我们使用单个全连接层将这些 K 数转化为分类决策:

请注意,在图中,我没有显示完全连接层中的每个权重,以避免混淆绘图。实际上,红色数字(来自 GAP(A1)的输出)通过权重连接到每个输出类,绿色数字(来自 GAP(A2)的输出)通过权重连接到每个输出类,蓝色数字(来自 GAP(A3)的输出)通过权重连接到每个输出类。全连接层回顾见本帖。
只关注“cat”输出类,我们有三个权重 w1、w2 和 w3,它们将我们的全局平均池的输出连接到“cat”输出节点。我们使用上图所示的等式为类别“cat”生成一个得分 y^cat,对应于
y^cat = (w1)(红色)+ (w2)(绿色)+ (w3)(蓝色)
类激活映射
现在我们已经浏览了整个架构,从输入图像到分类分数。最后一步是获取我们的 CAM 热图可视化,具体如下:

这看起来与我们计算得分 y^cat 的方式非常相似,但不同之处在于,我们不是将权重 w1、w2 和 w3 乘以由特征地图 Ak 上的全局平均池产生的单独数字,而是将权重直接乘以特征地图。因此,虽然分数的输出是单个数字,但 CAM 的输出实际上是一个数字网格。这个 CAM 数字网格就是我们的热图!
总结
以下是我总结整个 CAM 文档的一页草图:

参考文献
原载于 2019 年 6 月 11 日http://glassboxmedicine.com。
CNN 热图:梯度对比去耦合对比引导反向传播

这篇文章总结了创建显著图的三种密切相关的方法:梯度(2013),去卷积(2014)和引导反向传播(2014)。显著图是热图,旨在提供对卷积神经网络正在使用输入图像的哪些方面进行预测的洞察。这篇文章中讨论的所有三种方法都是一种事后注意力的形式,不同于可训练的注意力。虽然在最初的论文中,这些方法以不同的方式描述,但是除了它们通过 ReLU 非线性处理反向传播的方式之外,它们都是相同的。
请继续关注下一篇帖子,“CNN 热图:显著图的健全性检查”,讨论阿德巴约等人在 2018 年发表的论文,该论文提出,在这三种流行的方法中,只有“梯度”是有效的。具体来说,“梯度”通过了 Adebayo 等人的健全性检查,DeconvNets 没有经过测试,而导向反向传播没有通过健全性检查。
尽管导向反向传播的健全性检查结果令人沮丧(推而广之,它也令人沮丧,因为我们将看到,用于去配置的方法与导向反向传播的方法重叠),我仍然在这篇文章中写关于去配置和导向反向传播的内容,原因如下:
- 历史知名度。DeconvNet 和指导性反向传播论文都被引用了 1000 多次。
- 在同一篇文章中同时考虑梯度、去卷积和引导反向传播方法是一个有趣的案例研究,说明了类似的想法如何以不同的方式在研究社区中相对同时地呈现。
- 考虑这些方法需要理解通过 ReLU 非线性的反向传播是如何工作的。
论文
- 梯度: Simonyan K,Vedaldi A,Zisserman A .卷积网络深处:可视化图像分类模型和显著图。arXiv 2013 被 1720引用
- 泽勒医学博士,弗格斯 r。可视化和理解卷积网络。ECCV 2014 被 7131引用
- 导向反向传播:斯普林根贝格·JT,多索维茨基 A,布罗克斯 T,里德米勒 m。力求简单:全卷积网络。arXiv 2014 被 1504引用
术语注释:在本文中被称为“梯度”的方法(在 Adebayo 等人之后)有时也被称为“反向传播”,甚至只是“显著性映射”,尽管其他两种技术(去卷积和引导反向传播)也是实现“显著性映射”的方法
概述
所有这些方法都产生了可视化效果,旨在显示神经网络使用哪些输入来进行特定的预测。它们已被用于弱监督的对象定位(因为对象的近似位置被突出显示)和洞察网络的错误分类。
在 iPython 笔记本中,“显著图和引导反向传播”, Jan Schluter 解释了这三种相关方法之间的关系:
通常的想法是在权重固定的情况下,计算网络预测相对于输入的梯度。这确定了哪些输入元素(例如,在输入图像的情况下是哪些像素)需要改变最少以对预测影响最大。这三种方法之间的唯一区别是它们如何通过线性整流器[(ReLU)]反向传播。只有【Simonyan 等人。al 的“梯度”方法]实际上是计算梯度;其他人修改反向传播步骤,做一些稍微不同的事情。正如我们将会看到的,这对于显著图来说是一个至关重要的区别!
(注:本 iPython 笔记本创建于 2015 年,远在 Adebayo 等人的健全性检查表明引导式反向传播无效之前。)
渐变(普通反向传播)
关于这种方法的详细讨论,见文章“CNN 热图:显著性/反向传播。”“梯度”方法利用了通过 ConvNet 的普通反向传播。
解除配置
除了通过 ReLU 非线性的反向传播不同之外,解卷积与“梯度”方法相同。
Adebayo 等人的健全性检查没有专门测试 DeconvNet 方法。
请注意,“反卷积”可能是一个容易混淆的术语。在这种情况下,“去卷积”指的是用转置的相同滤波器执行卷积。这种反卷积也称为“转置卷积”转置卷积是任何 ConvNet 中反向传递的关键部分,即转置卷积也用于普通反向传播。
再次引用 Jan Schluter 的话(带一些括号插入),
泽勒等人【在 DeconvNet 论文中】的中心思想是通过“DeconvNet”运行一个 convNet 的层激活来可视化它们——一个撤销 ConvNet 的卷积和汇集操作直到它到达输入空间的网络。去卷积定义为使用相同的转置滤波器对图像进行卷积,而去卷积定义为将输入复制到 ConvNet 中最大的(较大)输出中的点(即,去卷积层使用来自其相应池层的开关进行重建)。ConvNet 中的任何线性整流器[(ReLU)]都被简单地复制到 de ConvNet[这是与传统反向传播的关键区别]。[……]
除了线性整流器[:在去卷积网络中,我们只]传播回所有正误差信号之外,去卷积网络的定义完全对应于通过卷积网络的简单反向传播[即标准梯度方法]。注意,这相当于对误差信号应用线性整流器。
详细地说,下面是从一个训练过的 convNet 构建一个 DeconvNet 可视化的步骤。这些步骤基于 Samarth Brahmbhatt 在 Quora 上发布的一个有用的帖子:
- 选择要可视化的过滤器激活。例如第二 conv 层的第十滤波器。您希望找到图像空间中导致此过滤器激活较高的模式。你应该选择一个有大量激活的过滤器。
2.通过 ConvNet 向前传递图像,直到并包括您选择的激活所在的层。
3.将所选图层中除了要可视化的滤镜激活之外的所有通道(滤镜)归零。
4.通过一个与 convNet 结构相同的 DeconvNet 返回到图像空间,除了反向操作:
Unpooling:在 ConvNet 中,您必须记住最大下层激活的位置,将该位置存储在“开关变量”中。然后在 DeconvNet 中,将上层的激活复制/粘贴到 switch 变量所指示的位置,其余的下层激活都被设置为零。保存在开关变量中的位置将根据输入图像而改变。(这与您在普通反向传播中所做的相同。)
ReLU:将线性整流器(ReLU)应用于误差信号。(这不是普通反向传播中 ReLUs 的处理方式。因此,这一步是显著性映射的“梯度”方法和显著性映射的 DeconvNet 方法之间的关键区别,前者使用普通的反向传播。)
反卷积:使用与相应的卷积层相同的过滤器,除了水平和垂直翻转。(这与您在普通反向传播中所做的相同。有关翻转卷积滤波器的详细讨论,请参见文章“卷积与互相关”)
5.在图像层中,您将看到一个图案,该图案是所选激活对其敏感的图案。
关于解卷积和去卷积的其他参考资料:
导向反向传播
导向反向传播,也称为导向显著性,是我们三种相关技术中的最后一种。导向反向传播产生的可视化看起来像这样(图来自utkuozbulak/py torch-CNN-visualizations):


你可以看到蛇、獒犬和蜘蛛都用细线“突出”了出来。
处理 ReLU 非线性时,导向反向传播基本上结合了普通反向传播和去配置:
- 与解卷积一样,在导向反向传播中,我们仅反向传播正误差信号,即我们将负梯度设置为零(参考)。这是在反向传递期间将 ReLU 应用于误差信号本身。
- 像普通的反向传播一样,我们也把自己限制在只有正的输入。
因此,梯度由输入和误差信号“引导”。
如果这三种方法之间的区别还不清楚,不要害怕!下一节将从另一个角度深入探讨梯度、去卷积和引导反向传播,这将使用更多的图形和公式。
梯度(普通反向传播)ReLU 图&方程
正如我们已经多次强调的,所有三种方法都以不同的方式处理通过 ReLU 的反向传播。
springen Berg 等人的图 1比较了三种方法:

让我们解剖并重新排列这个图形来详细研究它。
首先,这里有一个通过 ReLU(“梯度”)的普通反向传播的总结。在该图中, f 代表 CNN 某层产生的特征图, R 代表反向传播计算中的中间结果。(当我们再次到达网络的最开始时,在完成反向传播之后, R 是我们的重建图像。)

在此图的顶部,我们看到了一个正向传递中的 ReLU 操作示例。概括地说,下面是 ReLU(用于前向传递)和 ReLU 导数(用于后向传递)的方程式(方程式来自这里是):

在图的中间,我们看到了用于向后传球的 (f_i^l > 0) 的计算。这只是计算出前面的特征图中哪些元素大于零。我们得到了 (f_i^l > 0) 的二元映射,其中任何小于或等于零的都是零,任何正的都是 1——因为在 x 为正的任何地方,ReLU 的导数都等于 1。
最后,在图的最后一部分,我们看到如何在向后传递中使用 (f_i^l > 0) 。我们只需将 (f_i^l > 0) 乘以 R_i^{l+1} (我们到目前为止的中间反向传播结果)就可以得到 R_i^l.
这就是普通反向传播通过 ReLU 单元工作的方式,这也是在“梯度”显著图技术中使用的方式。
解卷积图&方程
现在我们来看看 DeconvNet 如何通过 ReLU 处理反向传播。DeconvNet 仅反向传播正误差信号(即,它将所有负误差信号设置为零):

我们首先计算所有 R_i^{l+1}大于 0 的地方——也就是说,所有有正误差信号的地方。然后,我们将这个二进制掩码乘以误差信号本身 R_i^{l+1} 。注意这和计算 ReLU( R_i^{l+1} )是一样的。
从上面的图和等式中我们可以看出,这种解卷积方法不同于传统的反向传播方法。
导向反向传播关系图&方程
最后,我们将看看引导反向传播如何处理 ReLUs。本质上,引导反向传播结合了传统反向传播方法和去卷积方法:
- 在导向反向传播中,我们只反向传播正误差信号(如解卷积黄方程)
- 在引导反向传播中,我们还限制为仅正输入,即 f_i^l 的正部分(像普通反向传播 red 方程一样):

因此,与其他任何一种方法相比,导向反向传播最终会在最终输出中产生更多的零。
总结
我们现在已经完成了对三种创建 CNN 显著图的流行技术的比较:梯度(普通反向传播)、去卷积和引导反向传播。
- “渐变”使用普通的反向传播,包括在 ReLUs 处。在传统的反向传播中,ReLUs 是通过利用在前面的特征映射中哪些元素是正的来处理的。
- 除了在 ReLUs 处,“解耦网络”使用普通的反向传播*。在 DeconvNets 中,在 ReLU 时,只有正误差信号被反向传播,这相当于对误差信号本身应用 ReLU 操作。*
- “导向反向传播”使用普通反向传播,除了在 relu处。导向反向传播将 ReLUs 处的普通反向传播(利用前面特征图中哪些元素是正的)与 DeconvNets(仅保留正误差信号)相结合。)
在这三个选项中,阿德巴约等人推荐选择“渐变”,我们将在以后的文章中看到。
特色图片
特色图像是 Springenberg 等人的论文图 3 中的一种作物的明亮版本,显示了引导反向传播可视化。
原载于 2019 年 10 月 6 日http://glassboxmedicine.com。
CNN 热图:显著性/反向传播

在这篇文章中,我将描述 CNN 可视化技术,通常称为“显著性映射”,有时也称为“反向传播”(不要与用于训练 CNN 的反向传播混淆。)显著性图帮助我们理解 CNN 在分类过程中在看什么。关于为什么这很有用的总结,请看这篇文章。
显著图示例
下图显示了三幅图像——一条蛇、一只狗和一只蜘蛛——以及每幅图像的显著性图。显著图以彩色和灰度显示。这个数字来自utkuozbulak/py torch-CNN-visualizations:

上面,“彩色香草反向传播”是指用 RGB 颜色通道创建的显著图。“香草反向传播显著性”是将“彩色香草反向传播”图像转换成灰度图像的结果。你可以在py torch-CNN-visualizations/src/vanilla _ back prop . py看到用来创建这些显著图的代码。
定义
谷歌将“显著”定义为“最显著或最重要”“显著图”的概念不限于神经网络。显著图是图像的任何可视化,其中最显著/最重要的像素被突出显示。有传统的计算机视觉显著性检测算法(如 OpenCV 显著性 API & 教程)。然而,这篇文章的重点将是从训练过的 CNN 创建的显著图。
论文参考
如果你想阅读为 CNN 引入显著性图的论文,请参见 Simonyan K,Vedaldi A,Zisserman A,《卷积网络深处:可视化图像分类模型和显著性图》。arXiv 预印本 arXiv:1312.6034。2013 年 12 月 20 日。 被 1479引用
显著图的讨论从第 3 页第 3 节“特定图像类别显著可视化”开始(本文还包括一种为每个类创建“规范”映像的单独技术。)
回顾反向传播算法
反向传播算法允许神经网络学习。基于训练示例,反向传播算法确定神经网络中的每个权重增加或减少多少,以便减少损失(即,为了使神经网络“更少出错”)。)它通过求导来做到这一点。经过足够的神经网络迭代,当它看到许多训练示例时变得“错误更少”,网络已经变得“基本正确”,即对于解决你要求它解决的问题是有用的。关于反向传播算法的清晰解释,见这篇文章。
显著图有时被称为“反向传播”,因为它们是使用反向传播计算的导数的可视化。然而,显著图不用于训练网络。显著图是在网络完成训练之后计算的。
显著图的用途
显著图方法的目的是向已经训练好的分类 CNN 查询特定图像中特定类别的空间支持度,,即“在没有任何显式位置标签的情况下,找出猫在猫照片中的位置。”
简单线性例子
Simonyan 等人从一个简单的线性例子开始,这个例子激发了显著图。首先,一些符号:

使用这种符号,我们可以将显著性图的目的重新表述如下:

最后,这里是 Simonyan 等人的简单线性示例的总结,其中线性分类模型的每个权重表示相应图像像素在分类任务中的重要性:

本质上,具有较大幅度的权重对最终分类分数具有更大的影响,并且如果模型表现合理,则我们期望大幅度的重要权重对应于图像的相关部分,例如对应于猫图像中的猫。
CNN 举例
不幸的是,CNN 是一个高度非线性的得分函数,所以上面简单的线性例子并不直接适用。然而,我们仍然可以通过进行以下操作来利用类似的推理:让我们使用图像邻域中的线性函数来近似 CNN 的非线性评分函数。作者将这种线性近似框架为一阶泰勒展开式:

泰勒级数兔子洞

一只巨大的安哥拉兔
根据维基百科,
泰勒级数是将函数表示为无穷多个项的和,这些项是根据函数在单个点的导数的值计算的。[……]在实数或复数处无限可微的实值或复值函数 f(x) 的泰勒级数 a 是幂级数

- 分子的解释:回想一下, f 后面的撇表示导数。 f 是函数本身, f’ 是一阶导数, f"’ 是三阶导数, f"“”"’ 是九阶导数。
- 分母的解释:回想一下数字后面的感叹号,比如 5!,表示一个阶乘,计算方式为例如 5!= 5 x 4 x 3 x 2 x 1。
- 与 CNN 的连接:在 CNN 的情况下,函数 f() 是训练好的 CNN 本身, a 是感兴趣的特定图像, x 是代表 CNN 输入的变量,即任意图像。
泰勒级数很酷,因为它意味着如果你知道一个函数的值和该函数在某一点的导数,那么你可以使用泰勒级数近似来估计该函数在任何其他点的值。例如,您可能知道函数及其导数在 a = 6 处的值,因此您可以使用泰勒级数近似来估计函数在 x = 10,369 处的值。
在考虑了本文上下文中的泰勒级数之后,我不认为理解显著图的最佳方式是考虑泰勒级数。为了帮助其他人,我把我的想法写在这里:
这篇论文说他们正在使用“一阶泰勒展开”,从技术上讲应该是这个:

即包括 f(a) ,在这种情况下,这将是应用于我们感兴趣的特定图像的 CNN。然而,在显著图的实际实现中,似乎根本没有使用 CNN 的计算输出 f(a) 。相反,只使用一阶导数:

即使在那里,在他们的解释中也只关注了片段f’(a)(x):

其中 a = *I_zero,*f’(a)为导数

并且 x 是 I.
此外,在实践中,实际上只有导数片用于制作显著图!衍生部分是显著图:

即,显著性图是分数相对于图像变量的导数的视觉表示,在点(特定图像)I_zero 处评估。
思考显著图
为什么我们要计算分数相对于图像的导数?作者解释说,
使用类得分导数计算特定于图像的类显著性的另一种解释是,导数的大小指示哪些像素需要改变最少以影响类得分最多。人们可以预期这些像素对应于图像中的物体位置。
因此,如果我们有一张猫的图像,它在类别“猫”中得分很高,我们想知道猫图像中的哪些像素对于计算类别“猫”的高分很重要我们对类别“猫”的分数相对于我们特定的猫图像进行求导。具有大幅度导数的像素是对类别“猫”的分数具有大影响的像素,因此,除非神经网络“欺骗”并查看图像中的非猫线索来分类“猫”,否则这些重要像素对应于猫的位置。因此,显著图实现了一种弱监督的对象定位形式:我们可以从只在类别标签上训练的模型中获得对象的近似位置。
计算显著图的步骤
(参考:论文第 4 页顶部)
(1)找到分数相对于图像的导数。
(2)对于由 m×n 个像素组成的图像,导数是一个 m×n 矩阵。取导数矩阵每个元素的绝对值。
(3)如果您有一个三通道彩色图像(RGB ),则取每个像素处三个颜色通道导数值的最大值。
(3)绘制绝对值导数矩阵,就像它是一幅图像一样,这就是你的显著图。
这里是用于计算显著图的 Pytorch 代码。它缺少一个显式的“绝对值”步骤,但结果看起来应该有些相似。
下面是 Tensorflow 代码(下面猫图来源);在代码的第 83 行,你可以看到步骤(2)中导数矩阵的绝对值。

你可以在论文的第 5 页和第 6 页看到更多显著性图的可视化(图 2 和图 3)。
结论
显著图可用于突出显示图像中对象的大致位置。显著图是类别分数相对于输入图像的导数。
显著性图是导向显著性/导向反向传播的前身,而导向反向传播又用于导向 Grad-CAM 中。这两种技术都将是未来文章的主题。
关于特色图片
特色形象是一只兔子,。“下兔子洞”这个短语来源于 Lewis Carrol 的儿童读物爱丽丝漫游奇境记 。
原载于 2019 年 6 月 21 日http://glassboxmedicine.com*。*
CNN & ResNets——一种更自由的理解
这个博客解释了卷积网络背后发生的事情,以及它们是如何工作的。我将使用 fastai 和 PyTorch 库。如果你想更广泛地了解 fastai cnn 的实现,可以参考文章 这里 。让我们开始吧。

Photo by Sven Read on Unsplash
❓如何创建一个卷积神经网络
如果你熟悉 fastai,特别是 fastai 中的计算机视觉,那么你就知道我们是如何创建卷积神经网络的。我们用来创建网络。如果想了解create_cnn背后的语义,可以参考介绍中分享的链接。
现在,我们有了 CNN,我们想知道 CNN 正在发生什么。幕后发生的事情如下:

Basic neural network
现在,在卷积神经网络中,卷积发生,而不是矩阵乘法。卷积也是一种矩阵乘法,但它也有一些其他的磁性。让我们深入了解卷积神经网络。
- 卷积神经网络由内核组成。内核是另一个任意大小的矩阵,如 2X2、3X3、4X4 或 1X1。这个矩阵有一些数字,它们基本上定义了一个特定的特征。
- 我的意思是,第一层中的核可以滤除输入矩阵(表示图像的像素矩阵)中的顶部边缘,第二层中的核可以滤除左角,第三层中的核可以滤除对角线图案,等等。
- 现在,当输入矩阵与内核相乘时,输出被称为
Channel。现在,我们想要多少层就有多少层。ResNet34 有 34 层以上操作。 - 因此,大体上,我们可以说,我们有许多层矩阵乘法,在每一层矩阵乘法中,我们将一个内核与输入像素矩阵相乘,在输出中得到一个通道。
用新手的语言,想出任何一个图像,把手电筒的光照在图像上。让光线从左上到右下穿过图像的小部分。图像的一小部分变亮的部分实际上是核心,火炬光在整个图像上运行的过程是一种卷积。
让我们用图解法来理解上面的操作。

Convolution()

Output of convolution
形成的方程式数量如下:

因此,输入图像被简化为一个更小的矩阵,称为表示某个特征的通道。
现在,我们可能以如下的传统神经网络方式理解它:

我们可以用传统的神经网络方式进行运算,但这需要大量的内存和时间。相反,我们用上面提到的另一种方式来执行它,这样会花费更少的时间和内存。
现在,让我们考虑卷积神经网络的另一种情况。如果我们的输入矩阵和内核大小相同会怎样?处理这种情况有两种选择:
- 我们可以对完整的输入矩阵进行卷积,得到秩为 1 的张量。
- 否则,我们在输入矩阵周围添加零填充或反射填充,然后卷积输入矩阵,如下所述。Fastai 尽可能频繁地使用反射填充。

换句话说,卷积就是一个矩阵乘法,其中会发生两件事:
- 一些条目一直被设置为零
- 相同的核权重被相乘以计算不同的通道
所以当你有多个重量相同的东西时,这叫做重量捆绑。
这就是对卷积神经网络的大部分理论理解。现在,让我们从实用的角度来理解卷积神经网络。
- 实际上,我们有 3D 输入图像,而不是 2D 图像。每个图像具有不同的红色、绿色和蓝色像素。因此,我们没有秩 2 张量核,而是秩 3 张量核,代表红色、绿色和蓝色的不同值。因此,我们不是对 9 个事物进行逐元素的乘法运算(如果 2D 核有 9 个值),而是对 27 个事物进行逐元素的乘法运算(3 乘 3 乘 3),然后我们仍然要将它们相加为一个数字。
- 现在,当我们卷积图像时,我们不仅要找到顶部边缘,还要检测图像中的重复、颜色梯度等。为了涵盖所有不同的特性,我们需要越来越多的内核,这就是实际发生的情况。在每一层中,我们使用许多内核来处理图像。因此,每一层都由大量的通道组成。
- 为了避免我们的内存由于大量通道而失控,我们不时地创建一个卷积,其中我们不跨越每一个 3x3 的集合(考虑到内核的大小),而是一次跳过两个。我们将从一个以(2,2)为中心的 3x3 开始,然后跳到(2,4),(2,6),(2,8),等等。那叫一步两回旋。它的作用是,看起来是一样的,它仍然只是一堆内核,但我们只是一次跳过两个。我们跳过每隔一个输入像素。所以它的输出是 H/2 乘以 W/2。(我们可以定义步长-n 卷积
让我们看看步幅-4 卷积。

stride-4 convolution as we are shifting by 4 places.
现在,让我们评估 MNIST 数据集,并使用我们的卷积神经网络。我使用 google colab 是出于实际目的。
from fastai.vision import *
Fastai 提供学术数据集,我们可以解开并使用它。
path = untar_data(URLs.MNIST)
path.ls()

It consists of training and validation data
提取数据后,我们必须创建数据串。让我们来证明这一点。
你首先说的是你有什么样的物品清单。所以,在这种情况下,它是图像列表。那你从哪里得到的文件名列表?在这种情况下,我们有文件夹。
imagelist = ImageList.from_folder(path); imagelist

It has a total of 7000 images. Each image has three channels and is 28*28.
所以在一个条目列表里面是一个items属性,而items属性是你赋予它的那种东西。它将用于创建您的项目。在这种情况下,你给它的是一个文件名列表。这是它从文件夹里得到的。
imagelist.items

It consists of a list of images from training and testing folder
当你显示图像时,它通常以 RGB 显示。在这种情况下,我们希望使用二进制颜色图。
defaults.cmap='binary'
imagelist[22].show()

一旦你有了一个图片列表,你就可以把它分成训练和验证两部分。你几乎总是想要被认可。如果没有,可以使用.no_split方法创建一个空的验证集。不能完全跳过。所有这些都在 fastai 数据块 API 中定义。
splitData = imagelist.split_by_folder(train='training', valid='testing'); splitData

60000 items in training dataset and 10000 items in the validation dataset
顺序总是这样。首先,创建你的物品清单,然后决定如何分割。在这种情况下,我们将基于文件夹进行操作。MNIST 的验证文件夹叫做 *testing* ,因此我们在方法中也提到了它。
现在,我们想要标记我们的数据,并且我们想要使用数据所在的文件夹来标记数据。

Number 4 images are present in 4 numbered folder and same for others also.
labelist = splitData.label_from_folder()

The category list is defined for the sample images in the image.
所以首先你要创建一个物品列表,然后分割它,再给它贴上标签。
x,y = labelist.train[0] or labelist.valid[0]x.show()
print(x.shape, y)

现在,添加变换。转换是数据扩充的一部分。我们为表格数据添加的过程和为图像添加的转换之间有很大的区别。
- 在训练数据上添加一次过程,并且对验证和测试数据进行相同的验证
- 每次我们需要一堆图像时,都会应用变换。
由于我们正在进行数字识别,因此我们不想对数据应用默认值,因为它包含一些我们确实不想要的转换,如垂直/水平翻转数字会改变数字,缩放文本会改变图像的像素,图像会变得模糊。因此,我们将添加我们的转换,他们毫不费力,添加随机填充和少量的裁剪。
tfms = ([*rand_pad(padding=3, size=28, mode='zeros')], [])
*(empty array refers to the validaion set transforms)*transformedlist = labelist.transform(tfms)
现在是最后一步的时候了,那就是创建数据束。这里我没有使用图像统计数据进行标准化,因为我没有使用预先训练的模型,如 ResNet34、ResNet56 等。另外,我将使用 128 的批量大小。
bs = 128
data = transformedlist.databunch(bs=bs).normalize()x,y = data.train_ds[0]
x.show()
print(y)

最有趣的是,训练数据集现在有了数据扩充,因为我们添加了转换。plot_multi是一个 fast.ai 函数,它将绘制对每个项目调用某个函数的结果。
def _plot(i,j,ax): data.train_ds[0][0].show(ax, cmap='gray')
plot_multi(_plot, 3, 3, figsize=(7, 7))

Check different padding and cropping in the images
xb,yb = data.one_batch()
xb.shape,yb.shape

Since we selected the batch size of 128. Thus there are 128 images.
data.show_batch(rows=3, figsize=(5,5))

Images with the labels
现在,我们完成了数据束。现在,我们将创建学习者,并通过我们自己的 CNN 对其进行训练。
批量归一化的基本 CNN
def **conv**(ni,nf): return nn.Conv2d(ni, nf, kernel_size=3, stride=2, padding=1)model = nn.Sequential(
conv(3, 8), ***# 14***
nn.BatchNorm2d(8),
nn.ReLU(),conv(8, 16), ***# 7***
nn.BatchNorm2d(16),
nn.ReLU(),conv(16, 32), ***# 4***
nn.BatchNorm2d(32),
nn.ReLU(),conv(32, 16), ***# 2***
nn.BatchNorm2d(16),
nn.ReLU(),conv(16, 10), ***# 1***
nn.BatchNorm2d(10),
Flatten() ***# remove (1,1) grid***
)
让我们来理解一下上面的函数。
- 我们声明内核大小为 3 * 3。
- 我们要执行步长为 2 的卷积。
- 现在,我们想执行顺序操作,这就是为什么我们写了
nn.Sequential。 - 模型的第一层是 conv(3,8)。
3暗示要输入的通道数。因为我们的图像有三个输入通道,所以我们声明了这个数字。见下图。

Images with 3 channels
8是输出的通道总数。正如上一节所讨论的,这个数字意味着过滤器的总数。- 一层输出的通道数输入到下一层。我们已经提到过使用步长 2 卷积。因此,我们从 28 * 28 的图像尺寸开始。在第二层,它将变成 14 * 14,在下一层变成 7 * 7,然后变成 4 * 4,然后变成 2 * 2,最后变成 1 * 1。
- 输出将采用[128,10,1,1]的形式,这一批 128 个图像中的每个图像在输出中有 10 个 1 * 1 的通道,作为秩 3 张量。我们把它拉平,排列成一个张量。
- 在卷积层之间,我们添加了批量标准化和 ReLu 作为非线性层。
这就是全部(͡ᵔ ͜ʖ ͡ᵔ),我们已经创建了我们的卷积神经网络。
现在是按照 fastai 中的定义创建学习者的时候了。
learn = Learner(data, model, loss_func = nn.CrossEntropyLoss(), metrics=accuracy)learn.summary()

[8, 14, 14] — [channels, dimension, dimention]
learn.lr_find(end_lr=100)learn.recorder.plot()

Learning rate plot
learn.fit_one_cycle(10, max_lr=0.1)

We have reached 99% accuracy
现在,让我们了解 ResNet,然后我会将它包括在我们的模型中,看看精度提高了多少。
❓什么是 ResNet
设 X 为输出。根据 ResNet,而不是做喜欢
Y = conv2(conv1(X)),
的确如此,
Y = X + conv2(conv1(X))——这个东西叫做身份连接或者跳过连接。

Basics of ResNet — ResBlock
ResNet 极大地改善了损失函数曲面。没有 ResNet,损失函数有很多凸起,而有了 ResNet,它就变得平滑了。
我们可以像下面这样创建 ResBock:
class ResBlock(nn.Module):
def __init__(self, nf):
super().__init__()
self.conv1 = conv_layer(nf,nf)
self.conv2 = conv_layer(nf,nf)
def forward(self, x): return x + self.conv2(self.conv1(x))
让我们更改我们的模型,以包含 ResNet 块。让我们稍微重构一下。fast.ai 已经有了一个名为conv_layer的东西,可以让你创建 conv、批处理范数、ReLU 组合,而不是一直说 conv、批处理范数、ReLU。
def conv2(ni,nf): return conv_layer(ni,nf,stride=2)model = nn.Sequential(
conv2(1, 8),
res_block(8),
conv2(8, 16),
res_block(16),
conv2(16, 32),
res_block(32),
conv2(32, 16),
res_block(16),
conv2(16, 10),
Flatten()
)learn = Learner(data, model, loss_func = nn.CrossEntropyLoss(), metrics=accuracy)
learn.fit_one_cycle(12, max_lr=0.05)

Accuracy is improved a bit to 99.23%.
仅此而已。我希望你可能已经理解了 CNN 和 ResNets 背后的逻辑。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言










{kind=link}
{kind=link}
{kind=link}
{kind=link}