







方股票之间的长期关系

Impulse Response Functions generated by me using the statsmodels library in python
解释 VECMs
在之前的文章中,我使用向量误差修正模型(VECM)创建了一个模型来预测 FANG 股票的收盘股价,该模型对协整时间序列进行建模。我谈到了一些我想扩展的话题,即解释负荷系数和长期关系系数、弱外生性和脉冲响应函数。
回想一下我估计的 VECM 的一般公式。神奇的是阿尔法的列向量和贝塔的行向量。它们构成了模型的误差校正部分,并使其成为 VECM 而不是向量自回归模型。

Formulation of the VECM with L lags
我用 python 重新做了分析,我的新数据只追溯到 5 年前,所以这些结果与我使用脸书上市时的数据集略有不同。
alphas 的系数或加载系数以及它们的 z 分数和相关的统计数据如下。

Our Alphas
负荷系数(alphas)是对长期关系的调整速度。它们是长期均衡中不平衡在一个时期内消失的百分比。FB 和 NFLX 收盘价的 alphas 在统计上不显著。AMZN 的α的显著性是不明确的,因为它在 0.10 显著性水平上是显著的,但在 0.05 显著性水平上不是显著的。GOOGL 的 alpha 在 0.05 显著性水平上具有统计显著性,估计为 0.0529。
这一信息意味着 FB 和 NFLX(可能还有 AMZN)对 GOOGL(可能还有 AMZN)是弱外源性的。弱外生性是指偏离长期不会直接影响弱外生变量的概念。这种效应来自于非弱外生变量的后续滞后。GOOGL(可能还有 AMZN)的滞后是弱外生变量回归长期均衡的驱动因素。

Our Betas
贝塔系数是实际的长期关系系数。FB 的β被标准化为 1,以便于解释其他β系数。GOOGL 的 beta 为-0.4204,这意味着 GOOGL 增加 1 美元,从长期来看会导致 FB 的收盘价减少 0.4204 美元,其中 5.29%的修正发生在一天之内(根据我们的关联 alpha)。重新安排哪一个贝塔是标准化的,就是你如何重新表述方程,来解释具有标准化贝塔的股票和其他股票之间的长期关系。
最后,我们可以继续讨论脉冲响应函数(IRF)。

Impulse Response Functions generated by me using the statsmodels library in python
脉冲响应函数(IRF)显示了当你在前期将一个变量增加 1 来冲击另一个变量(或同一个变量)时,该变量会发生什么。蓝色曲线显示了单位冲击的影响,因为冲击变得越来越近。虚线代表 IRF 的 95%置信区间。
GOOGL 的收盘价受到 1 美元的冲击会导致 FB 的收盘价下跌约 0.02 美元,但随着时间的推移,这种冲击的影响会变为零。NFLX 受到 1 美元冲击的影响最初会使 GOOGL 的收盘价上涨约 0.05 美元,但随后接近于零。然而,对 FB 的单位冲击持续存在,如 AMZN 上的 NFLX。如果所有的 IRF 都像这样,系统将是动态不稳定的,但幸运的是,0 在我们的许多 IRF 的 95%置信水平内,我们的系统是动态稳定的。
所以现在,你应该对建模协整时间序列有了一个不错的介绍。我的下一篇文章将关注其他问题和其他可以帮助解决这些问题的统计方法。
我这篇文章的代码可以在这里找到:https://github.com/jkclem/FANG-stock-prediction
长短期记忆和门控循环单位的解释——Eli 5 方式
ELI5 项目机器学习

Photo by Deva Williamson on Unsplash
大家好,欢迎来到我的博客“长短期记忆和门控循环单元的解释——Eli 5 Way”这是我 2019 年的最后一篇博客。我叫尼兰詹·库马尔,是好事达印度公司的高级数据科学顾问。
递归神经网络(RNN) 是一种神经网络,前一步的输出作为当前步骤的输入。

RNN 主要用于,
- 序列分类 —情感分类&视频分类
- 序列标注 —词性标注&命名实体识别
- 序列生成 —机器翻译&音译
**引用说明:**本文的内容和结构是基于我对四分之一实验室深度学习讲座的理解——pad hai。
在每个时间步的递归神经网络中,旧信息被当前输入改变。对于较长的句子,我们可以想象在“t”时间步之后,存储在时间步“t-k”的信息(k << t) would have undergone a gradual process of transformation. During back-propagation, the information has to flow through the long chain of timesteps to update the parameters of the network to minimize the loss of the network.
Consider a scenario, where we need to compute the loss of the network at time step four L₄ )。假设损失是由于时间步 S₁ 的隐藏表示的错误计算造成的。 S₁ 处的错误是由于矢量 **W 的参数不正确。**该信息必须反向传播至 W ,以便矢量修正其参数。

为了将信息传播回向量 W,我们需要使用链式法则的概念。简而言之,链式法则归结为在特定时间步长上隐藏表示的所有偏导数的乘积。

如果我们有超过 100 个更长序列的隐藏表示,那么我们必须计算这些表示的乘积用于反向传播。假设偏导数之一变成一个大值,那么整个梯度值将爆炸,导致爆炸梯度的问题。
如果偏导数之一是一个小值,那么整个梯度变得太小或消失,使得网络难以训练。消失渐变的问题
白板模拟
假设您有一个固定大小的白板,随着时间的推移,白板变得非常凌乱,您无法从中提取任何信息。在较长序列的 RNN 环境中,所计算的隐藏状态表示将变得混乱,并且难以从中提取相关信息。
因为 RNN 具有有限的状态大小,而不是从所有时间步长提取信息并计算隐藏状态表示。在从不同的时间步长提取信息时,我们需要遵循有选择地读、写和忘记的策略。
白板类比— RNN 示例
让我们以使用 RNN 的情感分析为例,来看看选择性读、写、忘策略是如何工作的。
回顾 : 电影的前半部分很枯燥,但后半部分真的加快了节奏。男主角的表演令人惊叹。

这部电影的评论从负面情绪开始,但从那时起,它变成了积极的回应。在选择性读取、写入和忘记的情况下:
- 我们希望忘记由停用词(a、the、is 等)添加的信息。
- 有选择地阅读带有感情色彩的词语所添加的信息(惊人的、令人敬畏的等等)。
- 选择性地将隐藏状态表示信息从当前单词写入新的隐藏状态。
使用选择性读取、写入和遗忘策略,我们可以控制信息流,从而使网络不会遭受短期记忆的问题,并且还可以确保有限大小的状态向量得到有效使用。
长短期记忆——LSTM
LSTM 的引入是为了克服香草 RNN 的问题,如短期记忆和消失梯度。在 LSTM 的理论中,我们可以通过使用门来调节信息流,从而有选择地读、写和忘记信息。
在接下来的几节中,我们将讨论如何实现选择性读、写和忘记策略。我们还将讨论我们如何知道哪些信息应该阅读,哪些信息应该忘记。
选择性写入
在普通 RNN 版本中,隐藏表示( sₜ) 被计算为先前时间步长隐藏表示( sₜ₋₁ )和当前输入( xₜ )以及偏差( b )的输出的函数。

这里,我们取 sₜ₋₁的所有值并计算当前时间的隐藏状态表示

In Plain RNN Version
在选择性写入中,不是将所有信息写入 sₜ₋₁ 来计算隐藏表示( sₜ )。我们可以只传递一些关于 sₜ₋₁的信息给下一个状态来计算 sₜ.一种方法是分配一个介于 0-1 之间的值,该值决定将当前状态信息的多少部分传递给下一个隐藏状态。

Selective Write in RNN aka LSTM
我们进行选择性写入的方式是,我们将 sₜ₋₁的每个元素乘以 0-1 之间的值来计算新的向量 hₜ₋₁。我们将使用这个新的向量来计算隐藏表示 sₜ.
我们如何计算 oₜ₋₁?
我们将从数据中学习 oₜ₋₁ ,就像我们使用基于梯度下降优化的参数学习来学习其他参数一样,如 U 和 W 。 oₜ₋₁ 的数学方程式如下:

一旦我们从 oₜ₋₁那里得到数据,它就乘以 sₜ₋₁ 得到一个新的矢量 hₜ₋₁.由于 oₜ₋₁ 正在控制什么信息将进入下一个隐藏状态,所以它被称为输出门。
选择性阅读
在计算了新的向量 hₜ₋₁ 之后,我们将计算一个中间隐藏状态向量šₜ(用绿色标记)。在这一节中,我们将讨论如何实现选择性读取来获得我们的最终隐藏状态 sₜ.

ₜ的数学方程式如下:

- šₜ捕捉来自前一状态 hₜ₋₁ 和当前输入 xₜ 的所有信息。
- 然而,我们可能不想使用所有的新信息,而只是在构建新的单元结构之前有选择地从中读取。也就是说…我们只想从šₜ读取一些信息来计算 sₜ 。

Selective Read
就像我们的输出门一样,这里我们用一个新的向量 iₜ 乘以šₜ的每个元素,该向量包含 0-1 之间的值。由于矢量 iₜ 控制着从当前输入流入的信息,它被称为输入门。
iₜ 的数学方程式如下:

在输入门中,我们将前一时间步隐藏状态信息 hₜ₋₁ 和当前输入 xₜ 连同偏置一起传递到一个 sigmoid 函数中。计算的输出将在 0-1 之间,它将决定什么信息从当前输入和先前的时间步长隐藏状态流入。0 表示不重要,1 表示重要。
回顾一下我们到目前为止所学的,我们有先前的隐藏状态 sₜ₋₁ ,我们的目标是使用选择性读取、写入和忘记策略来计算当前状态 sₜ 。

选择性遗忘
在本节中,我们将讨论如何通过组合 sₜ₋₁ 和**šₜ.来计算当前状态向量 sₜ**
遗忘门 fₜ 决定从 sₜ₋₁ 隐藏向量中保留或丢弃的信息部分。

Selective Forget
遗忘门 fₜ 的数学方程式如下:

在“忘记门”中,我们将前一时间步隐藏状态信息 hₜ₋₁ 和当前输入 xₜ 连同一个偏置一起传递到一个 sigmoid 函数中。计算的输出将在 0-1 之间,它将决定保留或丢弃什么信息。如果该值更接近 0,则表示丢弃,如果更接近 1,则表示保留。
通过结合遗忘门和输入门,我们可以计算当前的隐藏状态信息。

最后一幅插图如下所示:

完整的方程组如下所示:

**注:**LSTM 架构的某些版本没有遗忘门,而是只有一个输出门和输入门来控制信息流。它将只实现选择性读取和选择性写入策略。
我们上面讨论的 LSTM 的变体是 LSTM 最流行的变体,三个门都控制信息。
门控循环单元— GRU 氏病
在本节中,我们将简要讨论 GRU 背后的直觉。门控循环单位是 LSTM 的另一个流行变体。GRU 使用较少的门。
在 LSTM 这样的门控循环单元中,我们有一个输出门 oₜ₋₁ 来控制什么信息进入下一个隐藏状态。类似地,我们也有一个输入门 iₜ 控制什么信息从当前输入流入。

LSTM 和 GRU 之间的主要区别在于它们组合中间隐藏状态向量šₜ和先前隐藏状态表示向量 sₜ₋₁.的方式在 LSTM 中,我们忘记了确定要从 sₜ₋₁.那里保留多少部分信息
在 GRU 而不是遗忘门中,我们基于输入门向量的补充(1- iₜ )来决定保留或丢弃多少过去的信息。
忘记门= 1 —输入门向量(1- iₜ )
GRU 的全套方程式如下所示:

从等式中,我们可以注意到只有两个门(输入和输出),并且我们没有显式地计算隐藏状态向量 **hₜ₋₁.**所以我们没有在 GRU 中保持额外的状态向量,也就是说……比 LSTM 计算量更少,训练速度更快。
从这里去哪里?
如果想用 Keras & Tensorflow 2.0 (Python 或 R)学习更多关于神经网络的知识。查看来自 Starttechacademy的 Abhishek 和 Pukhraj 的人工神经网络。他们以一种简单化的方式解释了深度学习的基础。
摘要
本文讨论了递归神经网络在处理较长句子时的不足。RNN 受到短期记忆问题的困扰,也就是说,在信息变形之前,它只能存储有限数量的状态。之后,我们详细讨论了选择性读取、写入和遗忘策略在 LSTM 是如何通过使用门机制来控制信息流的。然后我们研究了 LSTM 的变体,称为门控循环单元,它比 LSTM 模型具有更少的门和更少的计算。
在我的下一篇文章中,我们将深入讨论编码器-解码器模型。所以确保你在媒体上跟随着我,以便在它下跌时得到通知。
直到那时,和平:)
NK。
推荐阅读
使用 Pytorch 开始练习 LSTM 和 GRU
[## 使用 LSTM 和 Pytorch 对人名国籍进行分类
个人名字在不同的国家,甚至在同一个国家,都有不同的变化。通常情况下…
www.marktechpost.com](https://www.marktechpost.com/2019/12/18/classifying-the-name-nationality-of-a-person-using-lstm-and-pytorch/)
了解递归神经网络
使用 RNN 的序列标记和序列分类
towardsdatascience.com](/recurrent-neural-networks-rnn-explained-the-eli5-way-3956887e8b75)
作者简介
Niranjan Kumar 是好事达印度公司的高级数据科学顾问。他对深度学习和人工智能充满热情。除了在媒体上写作,他还作为自由数据科学作家为 Marktechpost.com 写作。点击查看他的文章。
你可以在 LinkedIn 上与他联系,或者在 Twitter 上关注他,了解关于深度学习和机器学习的最新文章。
联系我:
- 领英—https://www.linkedin.com/in/niranjankumar-c/
- GitHub—https://github.com/Niranjankumar-c
- 推特—https://twitter.com/Nkumar_n
- 中—https://medium.com/@niranjankumarc
参考文献:
免责声明——这篇文章中可能有一些相关资源的附属链接。你可以以尽可能低的价格购买捆绑包。如果你购买这门课程,我会收到一小笔佣金。
长而宽的数据以及如何有效地绘制它们
与实例的比较

介绍
很多时候,当我们处理数据时,它有不同的格式。如果你从一个网站上删除了这些数据,很可能是以宽格式。事实上,我们实际看到的大多数数据都是这种格式,因为宽数据非常直观,也更容易理解。一个很好的例子就是这个来自 ESPN 的 NBA 统计页面。
另一方面,长格式的数据不太经常看到。然而,它有自己的优势,如:
- 快速处理(使用矢量化运算)
- 某些高级统计分析和绘图所要求的
在这本笔记本中,我将展示如何在两种格式之间转换数据,长格式如何更快地处理,以及如何有效地绘制每种格式。我们将使用旧金山和萨克拉门托的月降水量数据作为例子。
注:天气数据取自 本网站 。
准备数据集
以下是我们对数据的观察:
- 对于每个城市,数据都是宽格式的。
- 前十一个月的数据以浮点形式存储,但是十二月份和年度总计则不是
- 是因为我们还在今年 12 月…数据还没有
- 我们需要将它们转换为浮点型,并找到一种方法来填充 2019 年的数据
- 降水量的单位是英寸(来自网站)
我们使用前 19 年的平均值填充了 12 月的降水数据,然后计算 2019 年的年总和。
现在我们可以开始处理和绘制数据。
数据处理和转换
接下来,我们将对数据进行一些操作,以显示长数据和宽数据之间的差异。
首先,让我们将它们转换成长数据,并将两个数据帧连接(或合并)成一个。
现在假设我们要计算每年的月降雨量百分比。
我们从广泛的数据开始。由于我们需要对每一列进行操作,我们可以使用apply函数。
正如我们在上面看到的,对于长数据来说要容易得多。事实上,它也更快,因为它使用向量化操作。
使用宽而长的数据绘图
我们想看看近二十年来每个月降水量的变化和分布。一个好的方法是使用方框图。对于每个日历月,我们将绘制成一个方框来显示不同年份的变化。总的来说,在一个单独的地块上将有 12 个盒子。
让我们先用宽数据把它画在旧金山。
使用熊猫中的内置函数制作剧情相当容易。如果我们想并排绘制萨克拉门托的数据呢?对于宽数据来说,这是一项相当复杂的任务。
正如您在下面看到的,我们必须分别绘制两个数据帧,指定每个数据帧的宽度和位置(否则它们会重叠),并将 xticks 放在两个框的中心。有一些调整,使它看起来正确。
现在让我们试着用长格式来达到同样的效果。在这种情况下,我使用了 Seaborn 包。
使用长数据和 Seaborn 进行并排比较要容易得多。在R中,ggplot也使用长格式,下划线语法与 Seaborn 非常相似。
思想
来自R,在我的大学里广泛使用过MATLAB,相比 Python 的matplotlib(类似于 MATLAB),我更喜欢ggplot。一个原因是我可以很容易地利用不同的变量来定制情节。在上面的例子中,我使用了hue(颜色)来显示一个分类变量。我也可以在可视化中包含连续变量,例如:符号的大小等。我真的很高兴找到 Python 中的 Seaborn 包。
你可以在这里找到代码https://github.com/JunWorks/Long_and_wide
小心,齐洛,贾斯蒂马特来了!

使用机器学习预测旧金山房价
作为一个在房地产和数据科学方面都有专业知识的人,我一直对 Zillow 的 Zestimate 很着迷。本着竞争的精神,我开发了 Jim 的估计或 Jestimate!
【2018 年旧金山独栋住宅预估
以下互动地图包含了 2018 年旧金山按街区划分的房屋销售情况。单击邻居,然后单击数据表中的房屋,查看 Jestimate 结果和实际销售价格。
Zestimate 使用专有的机器学习公式来估计房屋的当前市场价值。在房地产领域,代理人不断与房主争夺他们房子的市场价值,比如“你说我的房子值 100 万美元,但 Zillow 说我的房子值 120 万美元。”在出售房产时,你认为房主更喜欢哪个数字?
代理人对物业的市场分析几乎总是确定物业当前市场价值的最佳方法,因为代理人会实际查看物业,查看可比物业并分析当地市场条件。诸如地基裂缝、25 年的旧屋顶、非法扩建或其他未记录的房产缺陷等信息无法通过机器学习公式进行分析。与机器学习公式相比,代理可以访问更多更好的数据。
然而,代理商需要时间和精力来进行准确的市场分析,这对于估计大量的房屋价值是不实际的。这就是像 Zestimate 这样的预测引擎提供价值的地方。
考虑到这一点,我想看看我能为旧金山独栋房屋销售建立一个多好的预测引擎。一个人,一台 Mac 和 Colab 能打败 Zillow 吗?跟着一起去发现吧!
关于代码的一句话
该项目的所有代码、数据和相关文件都可以在 my GitHub 访问。该项目分为两个 Colab 笔记本。一个运行线性回归模型,另一个使用 Heroku 上的散景服务器生成交互式地图。
项目目标和数据
该项目的目标是预测 2018 年旧金山独户住宅的价格,比基线更好,达到或超过 Zillow 指标。
由于我有房地产许可证,我可以访问旧金山的 MLS,我用来下载 10 年(2009 年至 2018 年)的单户住宅销售。原始数据包括 10 年间的 23,711 次销售。使用地理编码(geocoding.geo.census.gov表示纬度/经度,viewer.nationalmap.gov表示海拔)将经度、纬度和海拔添加到原始数据中。)
从原始数据中移除了代表 1.6%数据的以下异常值:
- 有 7 个以上浴室的住宅
- 有 8 间以上卧室的住宅
- 地段超过 10,000 平方英尺的住宅
- 有 14 个以上房间的家庭
- 售价超过 1000 万美元的住宅
一个重要的数据,房屋面积,大约 16%的数据为零。我尝试使用所有单户住宅的平均卧室面积作为填充值,并删除零值住宅。虽然模型在填充值下表现良好,但我选择移除零值住宅,以便最大化模型的性能。最终的统计数据留下了大约 82%的数据,即 19,497 套房屋销售。
原始数据包括 40 个特征,20 个数字特征和 20 个分类特征。快速浏览一下相关矩阵,可以为数字特征之间的关系提供一些线索。

Pearson Correlation Matrix — Initial Data
与销售价格高度相关的特征包括纬度、浴室、卧室、住宅面积、地段面积和停车场。这是有道理的,因为旧金山的北部拥有最昂贵的房屋(纬度),拥有更多平方英尺/床/浴室的房屋将卖得更高的价格,而在旧金山停车是非常昂贵的。
指标
由于线性回归最终成为选择的模型(稍后将详细介绍模型选择),关键指标是平均绝对误差(MAE)和 R 平方。
作为基线,使用 2018 年销售平均售价的 MAE 为 684,458 美元。换句话说,如果我使用 2018 年旧金山单户住宅的平均价格作为每个家庭的预测,平均误差将是 684,458 美元。模型最好能打败这个!
我还想将该模型与 Zillow 的结果进行比较。他们实际上公布了旧金山市区的精度结果( Zestimate metrics )。虽然结果不能与我的数据直接比较(大城市区域要大得多),但它们确实为模型提供了一个粗略的拉伸目标。
- 中值误差— 3.6%
- Zestimate 在销售价格的 5%以内— 62.7%
- Zestimate 在销售价格的 10%以内— 86.1%
- Zestimate 在销售价格的 20%以内— 97.6%
评估协议
评估协议将使用 2009 年至 2016 年的数据将数据集分为训练集,使用 2017 年数据的验证集和使用 2018 年数据的最终测试集。
- train——2009 年至 2016 年销售了 15,686 套房屋。
- 验证-2017 年销售 1932 套房屋。
- 测试—2018 年房屋销售 1897 套。
型号选择
线性回归模型被充分证明是房屋价格预测的强模型,这是最初选择的模型。以最少的数据清理/争论进行简单的线性回归,并记录结果。逻辑回归和随机森林模型也被尝试用于比较,线性回归模型显然是领先的。随着项目的进展,我会定期对照随机森林模型检查它,线性回归模型继续优于随机森林模型。所以是线性回归!
开发模型
初始模型使用所有功能运行,结果如下。为了查看模型的性能,我添加了每平方英尺价格特性,这实际上是房产的代理销售价格。正如预期的那样,每平方英尺的价格结果很好,但显然无法使用,因为在预测 2018 年的价格时不会知道该值。这是一个明显的数据泄露的例子。

Base Model and Overfit
这些初始预测的指标提供了一个基本的最小值和最大值。换句话说,我有一个已经超过基线的最小值和一个使用数据争论来避免数据泄漏的最大值。
数据角力
优化模型的关键在于数据扯皮!
消除特征
事实证明,超过 20 个特征对预测影响很小或没有影响,可以被删除,从而大大简化了模型。例如,城市和州对于所有属性都是相同的。
日期和时间序列
数据中有两个日期特性:销售日期和上市日期。上市日期是物业在 MLS 上上市的日期,对预测影响很小,因此被删除。
销售日期需要年份,因为数据是按销售年份划分的。这也提出了使用时间序列来预测价格的问题。与每日价格的股票不同,房地产销售可能每 5-10 年发生一次。为了使用时间序列,该模型将需要使用一个考虑到升值/贬值和任何季节性的价格指数。这种方法被简单地尝试过,但是结果比我最终的模型弱。年价格乘数如下所示。如果你在 2009-2011 年在旧金山买了一套房子,到 2018 年,它的价值平均翻了一番!

Annual Price Multiplier
最终只有售出年份被用于最终模型。
零和 Nans
使用各种方法填充纬度、经度、海拔、房间、浴室、地块平方英尺和地块英亩中的零和 Nans(见代码)。
特色工程
消除特征和填充零和 nan 为模型提供了增量改进,但是需要特征工程来获得更大的改进。
分类数据使用普通编码进行编码,但一些特征通过计算特征中分类值的数量来改进模型。例如,视图特性包含了从 25 种视图类型中挑选的属性的所有潜在视图的列表。据推断,景观越多的房产价值越高。因此,视图计数功能被设计为对视图功能中记录的视图数量进行计数。同样的方法也用于停车和车道/人行道功能。
然而,关键的设计特征被证明是可比较的销售特征。该特征是通过模拟代理对财产估价的方式而创建的估计值。下面的代码获取最近的三个类似规模的房产的最近销售额(可比销售额),并计算它们每平方英尺的平均价格,该价格稍后将在模型中用于计算可比销售价格。为避免任何数据泄露,未使用 2018 年可比销售额(最大可比销售年度为 2017 年)。
nhoods = X[['sf', 'longitude', 'latitude']]
def neighbor_mean(sqft, source_latitude, source_longitude):
source_latlong = source_latitude, source_longitude
source_table = train[(train['sf'] >= (sqft * .85)) & (train['sf'] <= (sqft * 1.15))]
target_table = pd.DataFrame(source_table, columns = ['sf', 'latitude', 'longitude', 'year_sold', 'sale_price'])
def get_distance(row):
target_latlong = row['latitude'], row['longitude']
return get_geodesic_distance(target_latlong, source_latlong).meters
target_table['distance'] = target_table.apply(get_distance, axis=1)
# Get the nearest 3 locations
nearest_target_table = target_table.sort_values(['year_sold', 'distance'], ascending=[False, True])[1:4]
new_mean = nearest_target_table['sale_price'].mean() / nearest_target_table['sf'].mean()
if math.isnan(new_mean):
new_mean = test['sale_price'].mean() / test['sf'].mean()
return new_mean
nhoods['mean_hood_ppsf'] = X.apply(lambda x: neighbor_mean(x['sf'], x['latitude'], x['longitude']), axis=1)
nhoods = nhoods.reset_index()
nhoods = nhoods.rename(columns={'index': 'old_index'})
一个新的关联矩阵显示了新的争论和工程特性之间的关系。

Pearson Correlation Matrix — Wrangled Data
最终结果
最后,根据 2018 年的测试数据运行该模型。该模型的测试 MAE 为 276,308 美元,R 平方值为 0.7981,轻松超过基线。

Final Results
与 Zestimate 的性能相比,Jestimate 模型的中值误差较低,但无法击败 Zestimate 的强误差分布。同样,Zestimate 数据覆盖的区域比 Jestimate 大。

Jestimate vs. Zestimate
Jestimate 百分比预测误差的直方图显示了分布情况:

Prediction Errors for Jestimate
使用 Shapley 值的特征重要性
为了提供对预测的进一步了解,计算了每个属性的 Shapley 值,显示了对预测价格具有最高正面影响(赞成)和最高负面影响(反对)的特性及其值。

Shapley Values Graph

Shapley Values Grid
显示
最终显示数据帧被创建并保存在. csv 文件中,以供显示代码使用。另一篇文章“数据可视化—高级散景技术”详细介绍了如何使用散景图、数据表和文本字段创建数据的交互式显示。

display_data Dataframe
我欢迎建设性的批评和反馈,请随时给我发私信。
有关该项目的数据可视化部分的详细信息,请参见配套文章“数据可视化—高级散景技术”。
这篇文章最初出现在我的 GitHub 页面网站上。
在推特上关注我 @The_Jim_King
这是探索旧金山房地产数据系列文章的一部分
旧金山房地产数据来源:旧金山 MLS,2009–2018 年数据
着眼于人工智能的案例研究
除了讨论它们将如何在美国和欧盟发展之外
这篇文章是为 Darakhshan Mir 博士在巴克内尔大学的计算机和社会课程写的。我们讨论技术中的问题,并用伦理框架来分析它们。 Taehwan Kim 和我一起合作这个项目。

Photo by Franck V. on Unsplash
在我的上一篇帖子中,我讨论了人工智能(AI)对就业市场的影响,并强调了在监管人工智能方面的远见的必要性。我认为,我们的社会无法应对日益依赖人工智能所带来的道德后果。许多国家的技术领导层都认识到了这个问题,在过去的几年里,他们都提出了以有效的方式促进人工智能发展的战略。国家人工智能战略概述简要讨论了自 2017 年初以来提出的不同人工智能政策。

Figure 1: No two policies are the same. They focus on different aspects of AI: the role of the public sector, investment in research, and ethics. | Tim Dutton
在这篇文章中,我主要关注美国和欧盟提出的政策之间的差异。此后,我讨论了三种(半)假设情景,以及它们如何在人工智能发展有巨大反差的两个地区上演。为了进行分析,我广泛使用了数据伦理介绍中描述的伦理框架。
美国和欧盟人工智能政策比较

The US focuses on continued innovation with limited regulations from the government. | Wikimedia Commons
2016 年 10 月,白宫发布了首个应对人工智能带来的社会挑战的战略[3]。这份报告强调了公开 R&D 的重要性,以及让任何推动人工智能研究的人承担责任的重要性。这表明,应该允许这一领域的创新蓬勃发展,公共部门应该对私营部门实施最低限度的监管。人们的理解是,以自由市场为导向的人工智能发展方式几乎不需要政府干预。
最近的一份报告[4]发表于特朗普政府执政一年后,重点关注保持美国在该领域的领导地位,消除创新障碍,以便公司雇佣本地人,而不是搬到海外。

The EU promotes greater regulation while still being competitive in the global AI ecosystem. | Wikimedia Commons
另一方面,欧盟公布的报告将 AI 视为“智能自主机器人”的组成部分[5]。人工智能被认为是其他技术系统自动化的推动者[6]。该报告建议在自主、人类尊严和不歧视原则的基础上建立更严格的道德和法律框架。事实上,这是在 2018 年欧盟委员会通过关于人工智能的通信时进一步发展的。原始报告还讨论了公共部门在确保上述道德框架得到贯彻而不带有行业偏见方面的主要责任。
案例研究一
众所周知,一家总部位于硅谷的公司在人工智能研究方面投入了大量资金。最近,他们提出了一种最先进的生成对抗网络(GAN),能够生成超现实的人脸。该程序可以生成特定性别、种族和年龄的人脸。
GANs 的应用越来越多,通过其使用传播错误信息的风险也越来越大。在这个虚假内容如此盛行的时代,GANs 对已经在进行的打击虚假信息的努力构成了重大挑战。这个 X 是不存在的是一个汇编流行甘榜的网站。他们中的大多数都是无害的,然而,这个人并不存在引发了关键的伦理问题。

Figure 2: StyleGAN developed by NVIDIA. All these faces are “fake.” Or are they?
该项目可能带来的好处和危害风险是什么?
正如我之前所写的,美国对研发的关注相对更大。这样的项目可能会获得进一步的资助,希望该程序生成的人脸可以取代其他面部识别算法所需的训练数据。与此同时,虚假身份的风险可能会增加,人们会伪装成与他们的面部特征非常匹配的人。
然而,在欧盟,由于更严格的法规,类似的项目可能永远不会普及。然后,其他机器学习算法只能在“真实”人脸上训练,这反过来可能会导致隐私问题。在这种情况下,数据从业者遵循合乎道德的数据存储实践非常重要。已经有无数的例子,人们的照片在未经他们同意的情况下被下载,然后用于人工智能实验。
案例研究二
西雅图华盛顿一家初创企业 X,想投身电商行业。最近,X 从华盛顿大学招募了许多有才华的计算机科学毕业生,并建立了一个新颖的配对算法来匹配消费者和产品。当 X 对他们的产品进行匿名调查时,他们发现大多数参与者更喜欢他们的产品,而不是目前主导电子商务行业的 Y 公司的产品。然而,由于缺乏数据和消费者,X 很难蓬勃发展。
我的上一篇文章讨论了大数据集作为人工智能初创公司进入壁垒的概念。如 Furman 等人[7]所述,依赖于持续互联的用户网络的企业,无论是直接的(如脸书)还是间接的(如亚马逊),都比同行业的进入者具有优势。
两个经济体中的利益相关者受到怎样的影响?这里最相关的道德问题是什么?
最大的利益相关者是竞争者和他们各自的客户。尽管美国和欧盟都有反垄断法,但自本世纪初以来,这两个地区在反垄断法规方面有所松动[8]。由于大量的游说,美国的公司享有“反垄断执法的宽大”,而欧盟的公司通常更具竞争力[9]。

Figure 3: FANG + Microsoft dominate the US tech industry as well as investments in AI. [10] | Image Source
因此,美国不太可能采取允许竞争者之间共享数据的数据可移植性政策。这将阻碍任何由垄断(搜索引擎)或寡头垄断(拼车)主导的行业中新来者的增长。特别是在我们的案例研究中,初创企业可能很难保持相关性并吸引更多客户,因为现任者知道更大客户群的偏好。这也有可能导致针对买不起产品的目标人群的歧视性营销行为。
在欧盟,数据共享将伴随着无数的数据存储和隐私问题。重要的是,公司要制定缓解策略,以防未经授权的第三方访问客户数据。
案例研究三
一位拥有欧盟和美国双重国籍的 CEO 经常往返于工作地点(美国)和住所(欧盟)。最近,一些关于她个人生活的谣言在互联网上浮出水面,这严重影响了她的公司的声誉。她希望找到一种方法来消除谣言,但她受到她居住的两个地方的政策的限制。

Figure 4: According to Bertram et al. [11], Google had received 2.4 million requests to delist links in the first three years of Right to be Forgotten. | Image Source
2014 年 5 月,欧洲法院引入了“被遗忘权”,让人们对自己的个人数据有更多的控制权。它允许欧洲人请求一个搜索引擎,比如谷歌,从它的搜索结果中删除特定的链接。搜索引擎没有义务接受每一个除名请求。它衡量一个人的隐私权是否比公众对相关搜索结果的兴趣更重要。
有趣的是,被遗忘的权利在欧洲以外并不适用,因此即使对欧洲人来说,美国的搜索结果也保持不变。
对社会的透明和自治有什么危害吗?
这两个概念是密切相关的,经常是携手并进的。Vallor 等人[2]将透明度定义为能够看到一个给定的社会系统或机构如何工作的能力。另一方面,自主是掌握自己生活的能力。
被遗忘权在欧盟的采用促进了更大的自主意识,因为如果数据合理地不准确、不相关或过多,个人可以删除他们的个人数据。然而,这是很棘手的,因为搜索引擎本身,而不是一个独立的第三方,负责决定是否删除所请求的链接。
搜索引擎公司已经拥有很大的权力,让他们决定退市请求可能会导致“个人、社会和商业”的损失[2]。我们不禁要问,在引入权利之后,建立一个公正的机构来处理这些请求是否是合乎逻辑的下一步。
有没有下游影响?
在美国,被遗忘权在很大程度上是不允许的,因为它可能会限制公民的言论自由。总体而言,这可能会导致一个更加透明的社会,尽管代价是对搜索结果中出现的个人数据的自主权减少。这种情况的一个极端副作用是,公司可能会丢失大量“相关”数据,这些数据原本可以用来训练他们的人工智能算法。
结论
正如我们在上面的三个案例研究中看到的,美国和欧盟关注人工智能政策的不同方面。除了促进行业的公共 R&D,美国还提倡自由市场的自由理念。欧盟有更严格的法规,但希望保持其在人工智能领域的竞争优势。与美国不同,欧盟不想将监管责任推给私人部门。

Taehwan 和我曾认为,对人工智能的开发和使用制定更多的规定会减少问题。然而,案例研究讲述了一个不同的故事。每种策略都提出了自己的一系列伦理问题。例如,投资 GANs 可能意味着在数据隐私问题和虚假身份之间做出选择。在数据驱动市场的情况下,监管机构需要衡量是否要实施数据可移植性做法,以打破垄断。
—前进的道路
上述(极端的)情况是可以避免的,只要有一个从各种各样的利益相关者那里获取信息的计划。这两个地区提出的策略是全面的,但是正如 Cath 等人[6]所认为的,回答下面的问题将是形成完美政策的关键。
二十一世纪成熟的信息社会的人类工程是什么?
这篇论文提供了一种双管齐下的方法来清晰地理解我们对人工智能社会的愿景。首先,作者建议成立一个独立的委员会,在包括政府和企业在内的不同利益相关者之间进行调解。第二,他们要求把人的尊严放在所有决定的中心。从本质上说,这样做是为了确保在决策中考虑到最脆弱的利益攸关方的利益。
毫无疑问,要实现这个雄心勃勃的计划,需要大规模的协作努力。然而,我们可以从类似的承诺中得到启发,例如最近的《一般数据保护条例》(GDPR) [13]。欧盟和美国仍然需要各自的人工智能政策,但至少讨论它们的优先事项可以帮助它们达成一些共识。
参考
[1]蒂姆·达顿。“国家人工智能战略概述。”政治+AI(2018 年 6 月)。
[2]瓦勒,香农和雷瓦克,威廉。《数据伦理导论》
[3]总统办公厅国家科学技术委员会技术委员会。“为人工智能的未来做准备”(2016 年 10 月)。
[4]科学和技术政策办公室。“2018 年美国工业人工智能白宫峰会摘要”(2018 年 5 月)。
[5]内部政策总局。“欧洲机器人民法规则”(2016).
[6] Cath,Corinne 等人,“人工智能和‘好社会’:美国、欧盟和英国的方法。”科学与工程伦理(2018)。
[7]弗曼、杰森和罗伯特·西曼。“人工智能与经济。”创新政策与经济(2019)。
[8]古铁雷斯,赫尔曼和菲利庞,托马斯。"欧盟市场如何变得比美国市场更具竞争力:一项关于制度变迁的研究."美国国家经济研究局(2018 年 6 月)。
[9]古铁雷斯,赫尔曼和菲利庞,托马斯。“你在美国支付的费用比在欧洲多”《华盛顿邮报》(2018 年 8 月)。
[10]布欣,雅克等人。艾尔。“人工智能:下一个数字前沿?” MGI 报告,麦肯锡全球研究院(2017 年 6 月)。
[11]伯特伦、西奥等,“被遗忘的权利的三年”Elie Bursztein 的网站(2018)。链接。
[12]下议院科学技术委员会。“机器人和人工智能。”(2017).
13 欧洲联盟。《一般数据保护条例》(2018 年 5 月)。链接。
如果你喜欢这个,请看看我的其他媒体文章和我的个人博客。请在下面评论我该如何改进。
Twitter 社交和信息网络:论文综述
关于关注者/转发者关系及其演变的论文综述
全告白,这是 而不是 在推特上获得更多追随者的直接指南。我甚至没有推特账号!!但是我对社交网络有相当不错的了解,这篇 论文*【1】中呈现的结果支持了我的观点。*
因此,如果你想深入了解 twitter 上的粉丝网络是如何演变的,以及为什么某些转发往往会获得大量粉丝,而其他人却不会,你应该继续阅读。我试图以一种任何人都可以理解的方式写这篇博文,不需要任何先验知识。有关更多技术细节,请参考本文。
自我网络

A small portion of the social network. Every node represents a user and every edge represents a follower/followee relation. The blue nodes and edges together represent the ego-networks of two red nodes.
在我们开始之前,让我们谈谈如何用数学方法来表示各种 Twitter 动态。整个社交网络由一个巨大的图形表示,其中每个用户由一个节点表示,每个关注关系由一条有向边表示(从关注者到被关注者)。
用户的自我网络只不过是由她的追随者(不包括用户自己)以及他们之间的所有追随者/被追随者关系组成的子图。在技术术语中,用户的自我网络包含所有具有朝向用户节点的边的节点以及这些节点之间的所有边。
推文相似度
通常,人们会发现用户的自我网络倾向于与用户有相似的兴趣。他们通常会发推文和转发类似的话题。但是我们如何“量化”这种相似性呢?我们可以通过测量推文的文本相似性来做到这一点。
两条推文之间的相似性可以计算为两条推文的 TF-IDF 加权词向量之间的余弦相似性。如果你不知道那是什么,不要担心。粗略地说,这是一种衡量两条推文之间有多少相似单词的方法。这是一个介于 0 和 1 之间的分数,代表给定推文的相似程度。
推特动态
既然我们已经弄清楚了技术细节,让我们更深入地研究一下网络。Twitter 信息网络有两大动态,tweeting/retweeting(代表信息的流动)和 following/unfollowing(代表网络的演变)。正如直觉所暗示的,显然这两者应该是相互关联的。
Twitter 信息图是高度动态的。大约 9%的边缘每个月都会改变,其中大约 2%的改变会被删除。粗略地说,这意味着平均每个用户每获得 3 个追随者就会失去 1 个追随者。

Number of new follow, unfollows, tweets and retweets against the user indegree (number of followers). Clearly highly followed users have a more dynamic ego-network.
对于这样一个动态变化的网络,显然很难对每一个微小的变化进行建模和理解。然而,twitter 有时会经历用户关注/不关注数量的激增。这可能是因为一条出名的推文或者一条冒犯了别人的推文。两种主要类型的突发是,
- ***转发关注爆发:*用户获得大量关注者的最明显解释是什么?大概是因为大量新人第一次看到她的推文。或者换句话说,她的转发量激增。
不关注用户的人不会知道她发布的推文。然而,当一条推文被转发很多次时,更多的人第一次接触到它。其中一些人可能会喜欢这条推文,并决定直接关注用户,从而导致她的粉丝数量激增。

User ‘i’ is never directly exposed to the tweets of user ‘k’. However, when user ‘j’ retweets, user ‘i’ gets to know about user ‘k’. It is possible that user ’i’ might like the tweet that she sees and starts directly following user ‘k’.
- ***tweet-unfollow 突发:*un follow 突发比 follow 突发更容易解释。有时,一个用户可能会在推特上发布一些惹恼或冒犯她的一大群追随者的事情。这将导致该组关注者不再关注用户,这被称为 tweet-unfollow 突发事件。发微博的频率也是一个重要因素。
为什么不是每个转发的爆发都会导致一个关注者的爆发?
直觉告诉我们,越多的人接触到这条微博,就意味着越多的人开始关注用户。因此,每个转发突发都应该有一个追随者突发。但是,事实并非如此,而且实际上很容易解释。
考虑一个用户(姑且称她为 A)可能拥有的两类关注者,一类是经常转发 A 每条推文的人(姑且称她为 R),另一类是很少转发任何推文的人(姑且称她为 L)。很明显,和 R 有联系(而不是和 A 有联系)的人已经意识到了 A 的存在(由于 R 的频繁转发)。但是,由于他们仍然没有关注,所以即使在转发爆发期间,他们也不太可能这样做。
然而,对于连接到 L(而不是 A)的人来说,情况就不一样了。这些人并没有意识到 A 的存在(因为 L 很少转发),在一次转发突发中第一次接触到 A。这是将决定 A 是否得到那个追随者爆发的“那个”组。如果这个群体的人似乎喜欢 A 的推文,他们会直接开始关注 A,然后转发突发会被关注者突发所取代。然而,反之亦然,以防他们不喜欢 a 的推文。

If users who rarely see the tweets by user ‘i’ are more compatible (better tweet similarity) with the user, then they are more likely to start directly following user ‘i’ after a retweet burst.
但是,如果看到用户的推文,你怎么决定有人跟踪她的可能性呢?这就是两个用户的推文相似性(也称为兼容性)发挥作用的地方。衡量很少接触用户推文的人的兼容性可以很好地预测转发突发是否会有追随者突发。
成绩有多好?
400,000 个随机选择的转发突发被不同的算法排序为最有可能被追随者突发继承。绘制了相同算法的精确-召回曲线,并记录了各种算法的曲线下面积(AUC)。如果你不明白这个指标是什么,没关系,你仍然可以欣赏比较差异。
论文[1] (Myers 等人)中给出的结果明显优于他们对比的任何其他基线算法。“转发曝光次数”是根据看到转发的人数来排名的。“转发数”是根据转发的人数进行排名的。“追随者数量”的排名是基于用户已经拥有的追随者数量,而“随机”只是随机对他们进行排名。

结论
很明显,我们不能否认推特信息网络的两大动力之间的关系,推特/转发和关注/不关注。试图对这些网络中出现的某些行为的原因进行建模是一个开始,并使我们更接近能够理解高度进化和不断增长的社交网络。
注:没有图像、图表、公式等。这个博客里的礼物是我自己的。它们都直接摘自本文[1]。我过去和现在都没有参与这篇论文的研究。要获得更多关于该研究的深入知识,请参考该论文。
参考
[1]迈尔斯,塞斯·a .,和朱尔·莱斯科维奇。"推特信息网络的突发动态."第 23 届国际万维网会议论文集。美国计算机学会,2014 年。
寻找完美的词语?生成它们
使用 LSTM 模型生成诗歌。

Photo by Thought Catalog on Unsplash.
动机
有没有试着找到合适的词来描述你的感受?想在一首诗中向你的另一半表白你的爱吗?你为什么不根据成千上万首著名的诗来生成一首呢?这就是我们试图用长短期记忆(LSTM)模型来做的事情。
什么是 LSTM 模型?
LSTM 模型具有人工递归神经网络(RNN)架构。既然是递归网络,就意味着模型有反馈连接。此外,它可以处理整个数据序列,如句子或视频。LSTM 通常用于手写识别和语音识别。它擅长处理这类问题,因为它有选择性的记忆模式。典型的 LSTM 单元由一个单元、一个输入门、一个输出门和一个遗忘门组成。当信息进入这个单元时,它要么被遗忘,要么被输入到单元的其他部分,要么被汇总并输出。
遗忘门 通过滤波器的乘法运算从细胞中移除信息(见上面最左边的 sigmoid 函数,乘法符号的箭头)。
输入门 是如何将新信息添加到单元格中的。这分三步进行。首先,sigmoid 函数充当过滤器,决定需要添加哪些值。接下来,tanh 函数创建一个包含所有可能相加的值的向量。输出向量将在-1 到 1 的范围内。最后,sigmoid 滤波器和 tanh 函数的值相乘,然后相加到单元格中。
输出门 从单元状态中选择有用的信息并显示为输出。这也分三步进行。首先,应用双曲正切函数得到-1 和 1 之间的值。同样,我们将使用 sigmoid 函数作为过滤器。为了完成这一步,tanh 函数创建的向量与过滤器相乘,并将其作为输出发送到下一个隐藏单元格。
总之,所有这些门使得 LSTM 模型在序列预测方面比典型的卷积前馈网络或 RNN 好得多。这就是为什么我们选择使用 LSTM 模型来生成诗歌。
我们的数据
用于训练我们的用于诗歌生成的 LSTM 模型的数据来自于《PoetryFoundation.com 诗集》。数据可以在 Kaggle 上的处找到。每个诗歌条目包含几个描述诗歌的标签。我们决定把重点放在三类诗歌上:爱情、自然和悲伤。为了获得正确的数据,我们需要从数据集中提取具有特定标签的诗歌。我们决定将每首诗的字符数限制在 1000 个以内(我们用了更多的字符),因为这样我们就包含了足够多的诗,并且不会给我们的计算机带来太大的压力。在下面的代码中,您可以看到我们是如何获得数据的。
**# include 1000 characters from each poem**
pd.options.display.max_colwidth = 1000 **# load dataset from poetryfoundation.com dataset**
df = pd.read_csv('PoetryFoundationData.csv') **# dropping any entries with no tags**
df = df.dropna()
这是原始数据的一个例子。

Raw poem data from Kaggle dataset. Photo by author.
正如你在上面的原始数据中看到的,有几个标签。为了这篇博文的目的,我们将只向您展示我们是如何提取带有标签“爱”的诗歌的(参见下面的代码)。我们还使用其他标签生成了诗歌,你可以在这篇文章的结尾看到。
poems = df[‘Poem’]**# you can add additional tags to searchfor if you want more poems**
searchfor = [‘Love’]
lovePoems = poems.loc[df[‘Tags’].str.contains(‘|’.join(searchfor))]
lovePoems = lovePoems.to_string()
训练模型
一旦我们收集了我们需要的诗歌,我们就能够创建训练和测试数据。在下面的代码中,我们创建了训练数据。首先,我们必须将字符映射到索引,反之亦然。
chars = sorted(list(set(lovePoems)))
char_indices = dict((c, i) for i, c in enumerate(chars))
indices_char = dict((i, c) for i, c in enumerate(chars))
接下来,我们必须为训练创建 X 和 Y 数据集。这个过程将一大串诗歌分割成长度为 50 个字符的序列。
**# process the dataset**
seqlen = 50
step = seqlendata_X = []
data_y = []poemLines = []**# creates poem lines**
for i in range(0, len(lovePoems) — seqlen — 1, step):
poemLines.append(lovePoems[i: i + seqlen + 1])
**# creating x and y data**
data_X = np.zeros((len(poemLines), seqlen, len(chars)), dtype=np.bool)
data_Y = np.zeros((len(poemLines), seqlen, len(chars)), dtype=np.bool)for i, poemLines in enumerate(poemLines):
for t, (char_in, char_out) in enumerate(zip(poemLines[:-1], poemLines[1:])):
data_X[i, t, char_indices[char_in]] = 1
data_Y[i, t, char_indices[char_out]] = 1
生成数据后,我们建立了模型。其架构中有一个 LSTM 层和一个密集层。我们将在下面讨论,但我们玩了 LSTM 层的隐藏单位的数量。此外,我们尝试了一个具有 2 个 LSTM 层和 3 个 LSTM 层的模型。保持所有变量不变,当改变层数时,我们没有看到模型性能的差异。
**# create the model**
model = Sequential()
model.add(LSTM(80, input_shape=(seqlen, len(chars)), return_sequences=True))
model.add(Dense(len(chars), activation='softmax'))model.compile(loss='categorical_crossentropy', optimizer=RMSprop(learning_rate=0.01), metrics=['categorical_crossentropy', 'accuracy'])
model.summary()
评估模型
然后,我们准备好安装我们的模型。经过 128 个批次和 10 个时期的训练,我们达到了 0.68 的准确率。
**# evaluate the model on validation set and visualize** history = model.fit(data_X, data_Y, validation_split = .33, batch_size=128, epochs=10)
我们还在验证数据集上评估了该模型,并可视化了结果。下图显示了 LSTM 层有 128 个隐藏单元时的训练和验证损失。

Visualization of model training and validation loss when LSTM layer had 128 hidden units. Photo by author.
然而,当我们用 80 个隐藏单元为 LSTM 层拟合我们的模型时,我们看到了下图。

Visualization of model training and validation loss when LSTM layer had 80 hidden units. Photo by author.
当比较这两个图时,我们可以看到 LSTM 层中具有 80 个隐藏单元的模型比具有 128 个隐藏单元的模型具有更好的拟合。具有 128 个隐藏单元的模型显示了我们在研究中读到的过度拟合模式。随着时间的推移,训练和验证数据会出现分歧,这不是我们想要的。然而,对于 80 个隐藏单元,训练和验证损失一起减少,表明模型拟合良好。
我们也意识到,我们的精确度本来可以更高。我们尝试用数据集中每首诗的 3000 个字符来训练我们的模型。这增加了我们拥有的数据量,我们能够将模型的准确性提高到 78%,增加了 10%。如果我们有更多的时间和更多的计算能力,我们可以使用更多的数据。我们使用的数据量比我们能获得的要少,因为训练时间太长了。
生成诗歌
在确定了模型的架构之后,我们使用下面的代码生成了一些诗歌。
**# helper function that samples an index from probability array** def sample(preds, temperature=1.0):
preds = np.asarray(preds).astype('float64')
preds = np.exp(np.log(preds) / temperature) # softmax
preds = preds / np.sum(preds)
probas = np.random.multinomial(1, preds, 1) # sample index
return np.argmax(probas)**# generate poem** def generating_poem(poem_length, start_index, diversity, _):
start_index = start_index
diversity = diversitygenerated = ''
poemLines = lovePoems[start_index: start_index + seqlen]
generated += poemLines
print('----- Generating with seed: "' + poemLines + '"')
sys.stdout.write(generated)for i in range(poem_length):
x_pred = np.zeros((1, seqlen, len(chars)))
for t, char in enumerate(poemLines):
x_pred[0, t, char_indices[char]] = 1.
preds = model.predict(x_pred, verbose=0)
next_index = sample(preds[0, -1], diversity)
next_char = indices_char[next_index]poemLines = poemLines[1:] + next_charsys.stdout.write(next_char)
sys.stdout.flush()
print()
下面,我们生成了一首诗,长度为 500 个字符,一个开始索引(这是来自原始文本的序列长度的字符串),多样性为 0.5。分集输入改变了采样概率。经过几次尝试,我们发现 0.5 的多样性给了我们最好的诗。多样性为 0.1 会使诗歌过于重复,多样性为 1 会使诗歌缺乏意义。
**# input desired poem length, start index, diversity**
generating_poem(500, 60, .5, _)
下面是上面代码运行的输出:
----- Generating with seed: "n\r\r\n\r\r\n\r\r\nAnd it won’t be multiple choice"
n\r\r\n\r\r\n\r\r\nAnd it won’t be multiple choiced in the sky love and made the back between the forest and the from the black and sky feet promised which her desire. I could come before the point to the collation.\r\r\nI am a dear the shadows and which stare of the father, the cheek and boxasted seeman that the confecting the can sweating while I moved me can don’t know you want to still watch the stater and we can see a poem who deep of bene to the didn’t were been on the breaks dark in the tongue and blood from the color in the morning on t
如您所见,输出包括新的线条指示器(\r\r\n)。我们尝试从训练字符串中删除这些字符,但是我们认为保留这些字符可以让我们的模型像真正的诗歌一样构建我们生成的诗歌。下面,我们展示了一些我们生成的、格式很好的诗歌。
爱情诗#1:
Roy and Glenlost themselvesis the world the prides or story in the starting the discapive to the stranged start us the wind. The down the stucky strange and the last the skyeach an all the spon and carry me heart and set, and the bright have so sand for the stranged of the stranger. I see we between my leaves stranged the skies in the annt, sweet of at the same shade to heart, and the can don’t grape in not so self
爱情诗#2:
The woman carried the bucketand the man with sing are fingers the soft in this do, and of the conficial from the strangering to my slight which the sky stead between the body of a sation under there is the spring became and prices air strange of me to mouth have at his blossoms the sands in the trangs of the stared a paration in the man spring of carvant
悲伤的诗#1:
Among these in this place my father layAt the end of everythingIn the curked the pather she have years with the single to the mander,as mance of the should the wordder the stear the procked the goor in hone the searther the marmer.I was a sinder the pourth of the say and word the same the see we life, geser and he was down the all dading morned with the stead of the sleet on the surion, not liver, a mone the mardens colling to me see she seeple of the sead of the becausion the spean.Lone the bood the swear the looked wor a man her beants of the rom
悲伤的诗#2:
tooed with red…Imagine half your facerubbed out yetyou are suited upwhere were souned a reared semerita manding words and the did read to mister the flown the stone are where dristed were the san land a come was the son like word the light of the wise to belendand she teather, you been a die and lacken the wanted from the cores and the mand of Comples, never a come your mone the mone of the she she park of hall that like the sard of the she was the pleared in the say back the meed the say with to be the ray.A dried be sun to carr take in th
自然诗#1:
Soon the fish will learn to walk. Then humans will come ashore and paint dreams on the wall distant when the rain she who water the world of mean the flower the flowers the flacks the ancent of my walls and shadows the river and stars them like the sung and fluethe sea when the bodge his not behind the streets of the remement and she to the sings in the screen, the name the stars of the days on the the sounds the dark skin the mother the same and this pity, the clouds have a state is sings and someone land, and at my shell starsas the little still make a way t
自然诗#2:
e; it is obvious) and everything about him is beautiful. His hand swells from the bite [spread?] of the sky in the more the will condine her the distant green the forms, the wind my bear the side the roots where a merch her cold of high a constiled in the charged the body the stars in the wind sauter be. The cold with the world from the remember, and he stream and sting for the season the men raina wood with the was in the silence and men the world it roses where the cattent the capt and seas the dark and still as the grasswhere he the stars and past of the the color the beats head
生成诗述评
总的来说,我们的诗歌输出似乎生成了与数据集格式相似的诗歌。他们有相似数量的“\r\r\n”来表示间距,并且他们非常擅长造句。每个类别的总体情绪似乎也反映了它所来自的数据。然而,它们仍然很难符合逻辑,并且高度基于起始索引。起始索引在决定这首诗的结局方面起着很大的作用。起始种子中的单词经常在整首诗中重复出现。
在将来,为了提高这些诗的输出,我们可以将这些诗编入索引,这样每次的起始种子都从诗的开头开始,而不是从诗的中间或结尾开始。我们可以做些工作,让它在一首完整的诗上训练,这样它就不会随机开始和结束——创造一首更简洁的诗。
每个句子的逻辑感是另一个需要提高的地方。然而,这在诗歌中是一个巨大的挑战,因为诗歌是艺术的,不一定遵循传统的语法规则。我们也可以做更多的研究来让诗歌更连贯。
反光
当我们开始这个项目时,我们原本打算使用一个生成式对抗网络(GAN),其中生成器是一个递归神经网络(RNN)。在做了一些研究之后,我们发现有几篇文章提到了在文本格式上使用 GAN 时的困难和不准确性。我们还看到有人推荐 LSTM 模型,所以我们改用了它。如果使用 GAN 就好了,因为我们可以组合数据的潜在空间,而不是为每种类型的诗歌创建一个新的模型。
我们可以尝试的另一件事是把这首诗按照时间周期分开。莎士比亚写的诗与现代诗有着非常不同的语言,这可能会给模型生成带来混乱的数据集。如果我们要添加到这个项目中,我们可以按时间段分开,这样用户可以选择他们希望他们的诗出来的风格。

Photo by Thought Catalog on Unsplash
另一个可以添加到未来工作中的功能是诗歌标题。如果我们有更多的时间,我们可以格式化数据,将诗名和诗内容一起放入。然后,我们将根据匹配每首生成的诗歌的标签生成一个标题。然而,这可能会导致标题与实际的诗歌内容无关。
总的来说,我们意识到有很多事情我们可以尝试改进模型的诗生成。然而,我们在诗歌生成方面有了一个良好的开端,并且已经了解了很多关于 LSTM 模型如何工作以及如何调整它们的知识。
参考
引言序列预测问题由来已久。他们被认为是最难的…
www.analyticsvidhya.com](https://www.analyticsvidhya.com/blog/2017/12/fundamentals-of-deep-learning-introduction-to-lstm/) [## 人工智能生成泰勒·斯威夫特的歌词
泰勒斯威夫特歌词生成器
towardsdatascience.com](/ai-generates-taylor-swifts-song-lyrics-6fd92a03ef7e) [## 如何诊断 LSTM 模型的过拟合和欠拟合
很难确定你的长短期记忆模型是否在你的序列中表现良好…
machinelearningmastery.com](https://machinelearningmastery.com/diagnose-overfitting-underfitting-lstm-models/) [## 文本生成的生成性对抗网络——第一部分
用于文本生成的 GANs 的问题以及解决这些问题的方法
becominghuman.ai](https://becominghuman.ai/generative-adversarial-networks-for-text-generation-part-1-2b886c8cab10) [## 基于神经网络的音乐生成——本周 GAN
本周 GAN 是一系列关于生成模型的笔记,包括 GAN 和自动编码器。每周我都会复习一篇…
medium.com](https://medium.com/cindicator/music-generation-with-neural-networks-gan-of-the-week-b66d01e28200)
Emma Sheridan 和 Jessica Petersen 为人工神经网络课程完成的项目。这个项目的源代码可以在 [GitHub](https://github.com/emmasheridan/ANNfinalproject) 上找到。
一张图来统治他们所有人——指环王网络分析
链接到最终结果→链接
我第一次看《指环王》是在 2001 年,我觉得我的生活永远改变了。从 2001 年到现在已经过去很长时间了,但直到今天我还能享受看加长三部曲的乐趣。由于电影看多了,我决定做点不一样的,把魔戒和数据分析的世界结合起来。
魔戒和数据分析如何结合?这是个好问题…
与所有数据分析项目一样,一切都始于数据。
我在网上快速搜索了一下,找到了一个网站一个统治一切的维基,一个充当 J. R. R .托尔金图书百科全书的网站。幸运的是,该网站包含数千页关于人物、地点、种族和历史小说事件的详细信息。
此外,它允许任何人使用爬虫抓取它的页面。我怎么知道?因为在每个站点*“robots . txt/”*都可以添加到 URL 中,检查站点是否允许抓取,以及在什么条件下。(链接到该网站的 robots.txt ,进一步了解 robots.txt )
首先,我必须到达网站并抓取所有页面。我决定只刮去几页文字,并把注意力集中在它们上面。
可以刮出哪些数据?

每一页都包含文本、照片、链接,在许多情况下还有传记资料。我对传记数据特别感兴趣,因为我假设它包含的字段在所有页面中都是相似的,所以我可以将它安排到一个数据框中。
先说传记资料。
在抓取了所有的字符页之后,这就是数据框的样子:(使用 missingno 绘制数据框)

如你所见,有许多列,但大多数都是半满或几乎是空的。在对数据进行清理和重新整理后,我对以下领域进行了分析:武器、领域、种族、性别、文化。
传记资料


上面的图表显示了人物种族和出身的分布。如种族图所示,男性最常见,然后是霍比特人、精灵、矮人、兽人等等。在分析过程中,我遇到了一些我不知道的人物。例如,你知道有 3 个不同的角色属于巴罗格种族吗?


在文化图表中,不出所料,最常见的文化是男性文化,而刚铎和洛汗文化位于顶部。这个图表与种族图表相关联,它讲述了同样的故事。

性别图表显示,男性比女性多得多(几乎多 5 倍)。更有可能的是,如果这些书是在我们这个时代而不是在 20 世纪写的,那么图表会更加平衡。

最后一张图显示了武器的分布情况。为了创建这个图表,我必须将武器的名称标准化。在大多数情况下,一种武器有几种版本。例如,在“剑”类别下,有“国王之剑”、“精灵之剑”、“罗希里姆之剑”等等。
正文
NLP 是一个迷人的世界,人们可以使用各种算法从文本中提取洞察力。因为我想保持专注,所以我决定只创建一个强调文本力量的图表。

上图是用甘道夫的页面中的文字制作的。单词排列成环形,它们的大小与它们在文本中的出现频率有关。
链接
链接可能看起来不像一个强大的数据源,但在我看来,这将是一个低估。使用链接分析,我们可以指出几点见解。例如:A)一个角色有多受欢迎,B)角色之间有什么联系和关系。

这个图表非常有趣,因为它告诉我们,提到最多的人物不一定是中心人物。索伦和甘道夫是重要的角色,但在我看来,他们没有佛罗多重要。尽管如此,弗罗多最终排名第九,而索伦和甘道夫则分列第一和第二。等级并没有告诉我们故事的中心地位,但是它告诉了我们角色之间的联系。

在网络理论中,中心度是用来衡量网络中节点中心性的度量。指向你的节点越多,你就越居中。上图与上图不同,因为它通过唯一链接的数量而不是简单链接的数量来衡量角色的中心性。

另一个让我们了解节点重要性的指标是中间中心度。该指标衡量节点对网络中最短路径的重要性。例如,布鲁克林大桥不是一个中心位置,因为人们参观它,而是因为人们在去其他地方的路上走过它。
为了获得关于字符连接的一些见解,有几种社区检测算法。在下一个示例中,图表显示了使用 Louvain 算法检测到的社区所着色的字符。

Top 100 Characters Network

Louvain Detected Communities (Top 100)
由于我搜集的数据已经包含了角色的许多细节,我认为这些复杂的模型在我们的案例中没有任何用处。这些角色可以根据他们的种族或文化来划分。

Lord of The Rings Network

Characters Details
在上图中,你可以看到网络图中人物之间的联系。在这个互动网络(使用 pyvis 制作)中,当鼠标悬停在每个节点上时,角色的传记数据就会显示出来。当鼠标悬停在边缘时,引用的数量会显示出来,这可以告诉我们字符之间的连接质量。节点的大小与它们的中心度有关,它们的位置是使用Barnes–Hut simulation算法基于它们的连接来计算的。
感谢大家阅读我的文章,如果你有任何问题,意见或改进的想法,请在下面留下评论!
洛伦茨 96 太容易了!机器学习研究需要更真实的玩具模型。
点击 这里 会打开一个互动笔记本,你可以在里面重现本帖中的所有可视化效果和结果。
埃德·洛伦茨是一个天才,他提出了简单的模型,在一个复杂得多的系统中抓住了问题的本质。他从 1963 年开始的著名蝴蝶模型启动了混沌研究,随后是更复杂的模型来描述高档误差增长( 1969 )和大气环流( 1984 )。1995 年,他创造了另一种混沌模式,这将是这篇博文的主题。令人困惑的是,尽管最初的论文出现在 1995 年,但大多数人将该模型称为 Lorenz 96 (L96)模型,我们在这里也将这样做。
洛伦茨 96 型
先简单介绍一下车型。在这里,我将使用来自 Schneider et al .2017的符号。在其最简单的版本中,该模型由 K (k=1,…,K)个周期系统描述:

右边的第一项是平流项,而第二项代表阻尼。f 代表外部强制项,设置为 10。因为这是一个周期系统,我们可以用圆形图来形象化它的演变:
对于参数估计或参数化研究,最常见的是使用 L96 模型的两级版本。为此,我们加上另一个周期变量 Y,它有自己的一组常微分方程。X 和 Y 电极通过耦合项连接,耦合项是下面两个方程中的最后一项。每个 X 有 J 个与之相关的 Y 个变量。

同样,我们可以通过可视化来更好地理解正在发生的事情。
为什么 L96 车型太容易
L96 模式自提出以来,已被广泛应用于资料同化和参数化研究。最近,L96 车型经历了一次复兴,以测试驱动用于参数学习或子网格参数化的机器学习算法。事实上,我自己最近也发表了一篇论文,其中我展示了一个使用 L96 模型的在线学习算法。
但是 L96 有一个很大的问题:它太简单了!我这么说是什么意思?让我们看一个 L96 模型的经典用例,参数化研究。与真实的大气或海洋类似,X 代表已解决的慢速变量,而 Y 代表未解决的快速变量。本质上,任务是建立一个参数化,通过替换 X 方程中的最后一项来表示快速变量对 X 的影响,为方便起见,我们称之为 B。
假设我们忽略了空间和时间的相关性,只把 B_k 建模为 X_k 的局部函数。

我们可以建立的最简单的参数化是线性回归:

以下是真实数据点和线性回归的样子:

现在让我们使用简单的线性回归参数化,将其插入 L96 模型并对 100 个无量纲时间单位进行积分。以下是 X 和 B 的统计结果:

当然,它们并不完全相同,但是 X 直方图中的差异已经非常小了。我们可以进一步计算一些统计数据,如真实模型和参数化模型的 X 和 B 的平均值和可变性。

相对差异真的很小。这意味着简单的线性回归基本上解决了 L96 参数化问题。当然,你可以改进这个简单的基线,但是我们没有遇到困扰真实大气或海洋模型中最大似然参数化研究的任何问题。
需要更逼真的玩具模型
参数化子网格过程是气候建模的巨大挑战。现代机器学习方法可能是取得真正进展的一种方式。在过去的两年里,最初的研究(这里的或者这里的或者或者这里的或者已经证明了建立一个 ML 参数化通常是可行的。但是,正如我在最近关于在线学习的论文中总结的那样,在最大似然参数化能够真正改善天气和气候预测之前,还有几个基本障碍需要克服。稳定性、物理一致性和调谐只是其中的一部分。
为了解决这些问题,我们需要尝试一系列新方法。L96 可以是一个很好的起点,以确保算法的工作。但是如果真的发生了呢?因为 L96 没有表现出首先需要更复杂的方法的任何问题,L96 中的工作实现没有给出该方法是否也适用于全复杂性模型的更多证据。
那么,为什么不马上在一个完全复杂的模型中实现这个算法呢?问题是目前的大气和海洋模型带有巨大的技术包袱。它们通常是用成千上万行支持 MPI 的 Fortran 语言编写的。这使得快速测试一个新方法基本上不可能。即使实现一个用 Python 训练的简单神经网络目前也是一个挑战。Fortran-Python 接口是可能的,但不是特别用户友好和快速。更复杂的方法,如在线学习、强化学习或集合参数估计,将需要对模型进行更复杂的改变。最后,全复杂性模型,特别是如果需要高分辨率的模拟,在计算上是昂贵的,这使得快速实验非常困难。
所有这些挑战都迫切需要 L96 和全复杂性模型之间的中间步骤。
中间复杂度模型的属性
那么这个中级复杂度模型应该是什么样子的呢?以下是一些要求:
- 多尺度:因为我们正在寻找建立一个子网格参数化,我们需要一个系统,我们可以分为解决和未解决的过程。理想情况下,它是一个连续的系统,所以我们可以模拟粗粒化的额外挑战。
- 一个主要的运动方向:在大气和海洋中,垂直运动与水平运动非常不同。这就是参数化通常作用于列的原因。在玩具模型中反映这一点会很有帮助。
- 复杂到足以展示实际问题:ML 参数化研究的头两年揭示了以下关键问题。一个好的玩具模型应该模拟其中的大部分。
- ____ 稳定性:耦合/在线模拟通常是不稳定的。
- ____ 偏差:即使离线(非耦合)验证表明 ML 参数化准确地再现了亚网格效应,在线运行也经常显示偏差或漂移。
- ____ 物理一致性:在真实的地球系统中,能量和其他属性守恒是至关重要的。(最近由 Tom Beucler 领导的一篇论文展示了如何在神经网络训练期间做到这一点。)应该可以写下某些守恒性质。
- ____ 推广到看不见的气候:ML 参数化到目前为止还不能在它们的训练范围之外进行外推。这意味着人们应该能够通过外部强制来改变模型的基本状态。
- ____ 随机性:到目前为止,大多数 ML 参数化都是确定性的,这意味着真实的混沌系统的某些可变性是缺失的。因此,模型也应该是混沌的。
- 易于理解:大部分可用模型(如 LES 或 CRMs)的一个问题是,它们试图尽可能好地表示大气,这导致了复杂的数值方法和物理方程。我们正在寻找的中等复杂程度的模型不需要精确地代表真实世界。简单更重要。这适用于基本方程和数值方法。
- 快速运行:一些提出的方法需要许多模型运行,通常是在一个集合中。中等复杂度的模型应该足够快,最多在几分钟内运行一次预测。
- 易于使用:这绝对是关键。该模型必须有一个 Python 接口,以兼容最常用的 ML 库。人们还应该能够在 Jupyter 笔记本中交互式地运行模型,即一次执行一个步骤并查看字段。
我不是流体建模专家,所以我在这里寻求帮助。满足所有(大部分)这些要求的一组好的方程是什么?它可能是一个非常接近真实大气/海洋方程(即纳维尔-斯托克斯方程)的系统,或者是具有类似特征的完全不同的系统。
我相信新方法的快速测试绝对是 ML 参数化研究进展的关键。目前,我们(或者至少我是)被 L96 等过于简单的模型和完全复杂的模型之间的差距所阻碍。
PS:我的建议
这是我的一个非常模糊的想法:一个 2D 云解析模型,尽可能使用最简单的方程。正如超级参数化和其他早期对流研究显示的那样,二维 CRMs 捕捉到了真实对流的大部分本质。当然,2D 模型比 3D 模型要快得多。
这个模型的基础可以是滞弹性运动方程。微观物理学方案可以是简单的饱和度调整方案,只有一种水文凝结物物种(液体)在某一阈值以上降雨。湍流可以用一阶局部 K-闭包来建模。表面将有一个恒定的温度,并通过一个简单的体积方案与空气相互作用。辐射只能通过在自由大气中的持续冷却来表现。
有了这个模型,就有可能运行一个辐射对流平衡的设置。但是,为了使它更有趣,并涉及一些大规模的动态,人们可以想象一个像这个粗糙的图纸显示的设置。

在这里,我们基本上有一个平坦的,周期性的微型世界,具有冷-暖梯度,这将导致一个大规模的循环单元,在暖池上方有深度对流(对吗?).可以想象一个有 250 根 4 千米宽的柱子,30 层的系统。从计算的角度来看,这应该是可以管理的。
这种设置是否可行,能否重现上述关键挑战?确切的方程式应该是什么?
基于特征激活和风格损失的损失函数。

Feature activations in Convolutional Neural Networks. Source: https://arxiv.org/pdf/1311.2901.pdf
使用这些技术的损失函数可以在基于 U-Net 的模型架构的训练期间使用,并且可以应用于正在生成图像作为其预测/输出的其他卷积神经网络的训练。
我已经将这一点从我关于超分辨率的文章中分离出来(https://towards data science . com/deep-learning-based-Super-Resolution-without-use-a-gan-11 C9 bb 5b 6 CD 5),以更加通用,因为我在其他基于 U-Net 的模型上使用类似的损失函数对图像数据进行预测。将此分开,便于参考,也便于理解我的其他文章。
这是基于 Fastai 深度学习课程中演示和教授的技术。
该损失函数部分基于论文《实时风格传输和超分辨率的损失》中的研究以及 Fastai 课程(v3)中所示的改进。
本文重点研究特征损失(文中称为感知损失)。这项研究没有使用 U-Net 架构,因为当时机器学习社区还不知道它们。

Source: Convolutional Neural Network (CNN) Perceptual Losses for Real-Time Style Transfer and Super-Resolution: https://arxiv.org/abs/1603.08155
所使用的损失函数类似于论文中的损失函数,使用 VGG-16,但是也结合了像素均方误差损失和 gram 矩阵风格损失。Fastai 团队发现这非常有效。
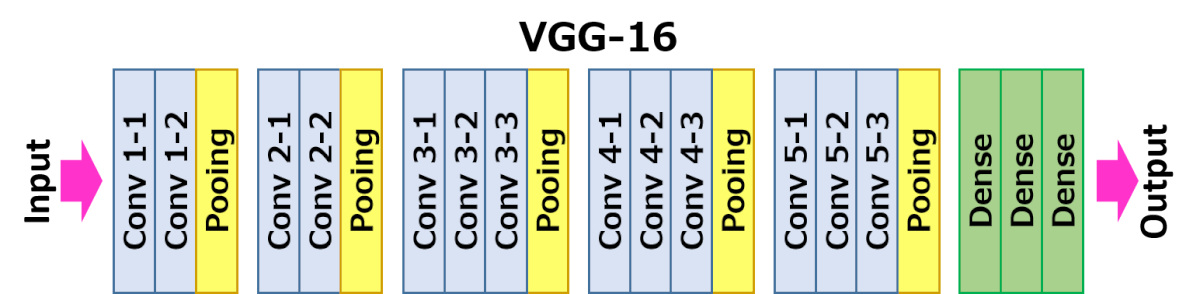
VGG-16
VGG 是 2014 年设计的另一种卷积神经网络(CNN)架构,16 层版本用于训练该模型的损失函数。

VGG-16 Network Architecture. Source: https://neurohive.io/wp-content/uploads/2018/11/vgg16-1-e1542731207177.png
VGG 模式。在 ImageNet 上预先训练的网络用于评估发电机模型的损耗。通常这将被用作分类器来告诉你图像是什么,例如这是一个人,一只狗还是一只猫。
VGG 模型的头部是最后几层,在上图中显示为全连接和 softmax。该头部被忽略,损失函数使用网络主干中的中间激活,其代表特征检测。

Different layers in VGG-16. Source: https://neurohive.io/wp-content/uploads/2018/11/vgg16.png
这些激活可以通过查看 VGG 模型找到所有的最大池层。这些是检测网格大小变化和特征的地方。
下图显示了各种图像的图层激活热图。这显示了在网络的不同层中检测到的各种特征的例子。

Visualisation of feature activations in CNNs. Source: page 4 of https://arxiv.org/pdf/1311.2901.pdf
基于 VGG 模型的激活,模型的训练可以使用这个损失函数。损失函数在整个训练过程中保持固定,不像 GAN 的关键部分。
特征损失
特征图有 256 个 28×28 的通道,用于检测毛发、眼球、翅膀和类型材料等特征以及许多其他类型的特征。使用基本损失的均方误差或最小绝对误差(L1)误差来比较(目标)原始图像和生成图像在同一层的激活。这些是特征损失。该误差函数使用 L1 误差。
这使得损失函数能够了解目标地面真实影像中的特征,并评估模型预测的特征与这些特征的匹配程度,而不仅仅是比较像素差异。这允许用该损失函数训练的模型在生成/预测的特征和输出中产生更精细的细节。
格拉姆矩阵风格损失
gram 矩阵定义了关于特定内容的样式。通过计算目标/地面真实图像中每个特征激活的 gram 矩阵,允许定义该特征的风格。如果从预测的激活中计算出相同的 gram 矩阵,则可以比较这两者来计算特征预测的风格与目标/地面真实图像的接近程度。
gram 矩阵是每个激活和激活矩阵的转置的矩阵乘法。
这使得模型能够学习并生成图像的预测,这些图像的特征在其风格和上下文中看起来是正确的,最终结果看起来更有说服力,并且看起来与目标/背景真相更接近或相同。
用此损失函数训练的模型的预测
使用基于这些技术的损失函数从训练模型生成的预测具有令人信服的细节和风格。风格和细节可能是预测精细像素细节或预测正确颜色的图像质量的不同方面。
用基于这种技术的损失函数训练的模型的两个例子,显示了用这种特征和风格损失函数训练的模型是多么有效:

Super resolution on an image from the Div2K validation dataset
根据我的着色实验,文章发表时会添加一个链接:

Enhancement of a Greyscale 1 channel image to a 3 channel colour image.
法斯泰
感谢 Fastai 团队,没有你们的课程和软件库,我怀疑我是否能够学习这些技术。
迷失在翻译中。被变形金刚发现。伯特解释道。
打造下一个聊天机器人?伯特,GPT-2:解决变压器模型的奥秘。
通过这篇文章,你将了解为什么有可能产生假新闻。基于 Transformer 的语言模型,如 OpenAI 的 GPT-2,最近已经使计算机能够对他们选择的主题生成现实而连贯的延续。应用可以在人工智能写作助手、对话代理、语音识别系统中找到。基于变形金刚的模型在产生误导性新闻方面也很成功,在网上假冒他人,创建虚假内容发布在社交媒体上,扩大网络钓鱼内容的生产。令人惊讶的是,同样的基于变压器的方法也可以用来检测虚假内容。

source: Hendrik Strobelt and Sebastian Gehrmann
Transformer 是 Vaswani 等人在论文Attention is All You needle中提出的一种机器学习模型。由于并行化,它在特定任务中的表现优于谷歌神经机器翻译模型,这与序列到序列模型的顺序性质相反。

为了理解 Transformer 是如何工作的,我们来看看它是如何执行机器翻译的。
再见 LSTM 和 GRU?
当序列到序列模型由 Sutskever 等人,2014 , Cho 等人,2014 发明时,机器翻译的质量有了量子跳跃。我们最近写了序列对序列模型的工作。
如何预测客户询问背后的意图?Seq2Seq 型号说明。在 ATIS 数据集上演示的槽填充…
towardsdatascience.com](/natural-language-understanding-with-sequence-to-sequence-models-e87d41ad258b)
由于序列到序列的方法,我们第一次能够将源文本编码到内部固定长度的上下文向量中。一旦编码,不同的解码系统可以用来翻译成不同的语言。

序列到序列模型通常通过注意机制连接编码器和解码器来增强,正如我们在之前的文章中所展示的。
测试动手策略以解决注意力问题,从而改进序列到序列模型
towardsdatascience.com](/practical-guide-to-attention-mechanism-for-nlu-tasks-ccc47be8d500)
Transformer 是一种不同的架构,用于在编码器和解码器这两个部分的帮助下将一个序列转换为另一个序列。然而,它超越了自 2014 年以来统治机器翻译世界的序列对序列范式。
变形金刚完全建立在注意力机制上。也就是说,这并不意味着任何循环网络:注意力是你所需要的。
变压器架构
原始论文建议将编码组件作为六个编码器和六个解码器的堆栈,如下所示。所有六个编码器都是相同的,但是它们不共享重量。这同样适用于六个解码器。

(source: Jay. Alammar, 2018)
每个编码器有两层:一个自关注层和一个前馈层。正如我们所见,没有使用循环层。给定一个输入单词(其嵌入,建议大小为 512),自我关注层查看输入句子中的其他单词,以寻找有助于对该单词进行更好编码的线索。为了更好地掌握这一机制,您可能想体验一下 Tensor2Tensor 笔记本中的动画。

adapted from (source: Jay. Alammar, 2018)
自我关注不是利己主义
Transformer 使用 64 维向量计算自我关注度。对于每个输入单词,有一个查询向量 q ,一个关键向量 k ,以及一个值向量 v,被维护。将所有这些放在一起,他们构建了矩阵 Q , K 和 V 。这些矩阵通过将输入单词 X 的嵌入乘以三个矩阵*【Wq】WkWv***来创建,这三个矩阵在训练过程中被初始化和学习。
在下图中, X 有 3 行,每行代表输入句子“je suis étudiant”中的一个单词。通过填充,矩阵 X 将被扩展到 512。为了说明的目的,每个单词通过四维嵌入来编码。最初的变形金刚使用 512 维嵌入。在我们的例子中, W 矩阵应该具有形状(4,3),其中 4 是嵌入维度,3 是自我关注维度。原变压器用 64。因此 Q,K,V 是(3,3)-矩阵,其中第一个 3 对应于字数,第二个 3 对应于自我注意维度。

adapted from (source: Jay. Alammar, 2018)
那么,我们如何计算自我关注度呢?
现在让我们假设在这些向量中有一些值。我们需要根据当前输入单词对输入句子的每个单词进行评分。让我们给单词“je”打分,它在法语中是“I”的意思。分数决定了对输入句子“je suis étudiant”的其他部分“suis”和“étudiant”的关注程度。
分数就是查询向量 q_1 与单词“je”的关键向量 k_1 的点积。这在下面的示例中给出了 112。我们对第二个单词“suis”做同样的操作,得到它的分数 96。我们也对最后一个单词“étudiant”这样做。
Transformer 的作者发现,当我们将分数除以关键向量的维数的平方根(sqrt 为 64,即 8)时,这会导致更稳定的梯度。
结果通过 softmax 操作进行标准化,使分数都为正,加起来等于 1 (0.84 表示“je”,0.12 表示“suis”,0.04 表示“étudiant”)。显然“suis”这个词比“étudiant”这个词与“je”更相关。现在,我们可以通过将每个值向量乘以 softmax 分数来淹没不相关的词,如“étudiant”,并减少对“suis”的关注。
自我关注层对于“je”的输出Z1最终通过对加权值向量求和得到。产生的向量被发送到前馈神经网络。

adapted from (source: Jay. Alammar, 2018)
这种自我注意的计算以矩阵的形式对序列中的每个单词重复进行,速度非常快。 Q 是包含序列中所有单词的所有查询向量的矩阵, K 是键的矩阵, V 是所有值的矩阵。
自我关注的整个计算过程将在下面很好地呈现。

多头注意力
现在,我们知道如何计算自我关注。你可能已经注意到,注意力会一遍又一遍地被吸引到同一个单词上。这就像那个受到老板所有关注的同事。如果我们重新洗牌以避免偏见的关注。想象一下,我们有更多的那些WkWv矩阵,它们被用来计算 Q,K 和 V 矩阵,这些矩阵被进一步用来计算所有单词的自我关注度。我们回忆一下,Wq , Wk , Wv 都是在训练中学会的。因此,如果我们有多个这样的矩阵,我们可以克隆自我注意计算,每次都会导致我们的文本的不同视图。因此,我们将输入嵌入投影到不同的表示子空间中。例如,如果我们用 8 个不同的 Wq 、 Wk 、 Wv 权重矩阵做同样的自我关注计算,我们最终得到 8 个不同的 Z 矩阵。事实上,这正是《变形金刚》的作者所做的。他们将所有八个 Z 矩阵串联起来,然后将得到的巨大矩阵乘以一个附加的权重矩阵 Wo 。
结果是惊人的。下面,我们来看一个来自 Tensor2Tensor 笔记本的图形示例。它包含一个动画,显示了 8 个注意力头在 6 个编码器层中的每一层中观察的位置。下图显示了对单词“it”进行编码时,第 5 层中的两个注意头。显然,“它”根据橙色的注意头指的是“动物”,根据绿色的更多的是指“累”。因此,“它”的模型表征包括“动物”和“疲倦”的表征。

编码
Transformer 的编码部分做了额外的神奇的事情,我们在这里只做介绍。
位置信息
学习每个单词的位置或单词之间的距离可以提高翻译质量,特别是对于像德语这样的语言,动词经常出现在句子的末尾。Transformer 生成并学习一个特殊的位置向量,该向量在输入到第一个编码器层之前被添加到输入嵌入中。
残差
在每个编码器内,自关注层输出的 Z 经过使用输入嵌入的 层归一化 (添加位置向量后)。它具有与批量规范化类似的效果,并且减少了训练和推理时间。
堆叠编码器
来自层标准化的 Z 输出被馈入前馈层,每个字一个。最后,通过层标准化收集来自前馈层的结果,以产生下一个编码器层的输入表示。这一过程发生在 6 个编码器层的每一层中。变压器的原始完整架构如下所示。

解码
在最后一个编码器层产生了 K 和 V 矩阵之后,解码器可以启动。每个解码器都有一个编码器-解码器关注层,用于关注源语言输入序列中的适当位置。编码器-解码器关注层使用来自前一解码器层的查询 Q ,以及来自最后一个编码器层的输出的存储键 K 和值 V 。在第一个解码时间步骤中,在我们的示例中,解码器产生第一个目标单词“I”,作为法语中“je”的翻译。在第二步中,“I”被用作第一解码器层的输入,以及来自编码器的 K,V,以预测第二目标字“am”。在第三解码步骤中,“我是”被用作预测“a”的输入。第四步,用“我是 a”来预测“学生”。最后用“我是学生”来预测“<句尾>”。
下面你可以看到一个由 Jay Alammar 创作的精彩动画。他的博客以一种非常有创意和简单的方式解释了 Transformer。写这篇文章时,它启发了我们。检查一下!

结论
通过对输入进行加权平均来专注于输入的显著部分的简单想法已被证明是 DeepMind AlphaStar 成功的关键因素,该模型击败了顶级职业星际争霸玩家。AlphaStar 的行为是由基于 Transformer 的模型生成的,该模型从原始游戏界面接收输入数据(单位及其属性的列表)。该模型输出一系列指令,这些指令构成游戏中的一个动作。
在这篇文章中,我们委婉地解释了变压器如何工作,以及为什么它已经成功地用于序列转导任务。在下一篇文章中,我们将把这种方法应用到处理意图分类的自然语言理解任务中。
变压器 DIY 实用指南。经过实践验证的 PyTorch 代码,用于对 BERT 进行微调的意图分类。
towardsdatascience.com](/bert-for-dummies-step-by-step-tutorial-fb90890ffe03)*
为数据科学导入 JSON 文件
用 Python 操作 JSON 文件的方法

Photo by Lorenzo Herrera on Unsplash
最近看了一篇的博文,关于 2019 年数据科学家的重要工具。其中一个工具是 JSON……很多 JSON。
在我学习的早期,我在 kaggle 上偶然发现了基于处方的预测数据集。太完美了。作为一名药学背景的学生,我想探索药物数据。只有一个问题…
数据在 JSON 里…
JSON 或 JavaScript Object Notation 是一种“轻量级的数据交换格式…机器很容易解析和生成。”
他们说“对人类来说读和写很容易”。但是,当我第一次将 JSON 文件加载到 dataframe 中时,我会有不同的看法。
在这里,我们将探索一些在数据科学工作流的数据清理和预处理步骤中有用的方法,并希望让您相信 JSON 确实易于人类读写。
入门指南
我们可以使用%%bash magic 打印我们的文件样本:
%%bash
head ../input/roam_prescription_based_prediction.jsonl{
"cms_prescription_counts": {
"CEPHALEXIN": 23,
"AMOXICILLIN": 52,
"HYDROCODONE-ACETAMINOPHEN": 28},
"provider_variables": {
"settlement_type": "non-urban",
"generic_rx_count": 103,
"specialty": "General Practice",
"years_practicing": 7,
"gender": "M",
"region": "South",
"brand_name_rx_count": 0},
"npi": "1992715205"}
从这里我们可以看到 JSON 数据看起来像一个 Python 字典。那没那么可怕!
在我们的字典里很容易读懂。使用 pandas read_json 方法的 json 文件:
raw_data = pd.read_json("../input/roam_prescription_based_prediction.jsonl",
lines=True,
orient='columns')
raw_data.head()

现在唯一的问题是,我们有嵌套的列值…并且在这一点上不完全可用。让我们探索一些解包这些值的方法。
列表理解
列表理解是解开 provider_variables 列中数据的一种简单方法。
provider = pd.DataFrame([md for md in df.provider_variables])

完美!我们现在有了提供者变量的数据框架!但是我想说,如果没有某种密钥,这些数据不会给我们带来太多好处。让我们将提供商的 npi 编号添加到该数据帧中,并将 NPI 列设置为索引:
provider['npi'] = raw_data.npi
provider.set_index('npi', inplace=True)
provider.head()

JSON 正常化
Pandas 的 json_normalize 方法是展平数据的另一个选择:
from pandas.io.json import json_normalize
provider = json_normalize(data=raw_data.provider_variables)
provider.head()

方法效率
因此,我们有两个选项可以产生相同的结果。使用哪种方法更好?
我们可以使用魔法命令%timeit来查找每个语句的执行时间:
列表理解:
729 毫秒,每循环 8.21 毫秒(平均标准时间戴夫。7 次运行,每次 1 个循环)
JSON 正常化:
每循环 4.72 秒 104 毫秒(平均标准偏差。戴夫。7 次运行,每次 1 个循环)
这里我们可以看到列表理解方法执行得更快。
结论
在本文中,我们学习了如何用 Python 操作 JSON 数据。我们学习了如何展平嵌套数据并将其转换为数据帧。
我们希望了解到 JSON 文件并没有那么糟糕!
面向数据科学家的低成本细胞生物学实验
纸显微镜、公共数据存储库和托管笔记本电脑解决方案

简介:
没有昂贵的实验室设备,“公民科学家”能做真正的科学吗?
简而言之:是的。在这篇博文中,我们指出了一种替代的低成本方法来解决生物学问题,这种方法适合有抱负的业余科学家。具体来说,我们强调将低成本成像设备(折叠显微镜)和公共图像数据 (Kaggle 数据集)与用于执行计算数据分析的免费工具( Kaggle 内核)相结合的好处。此外,我们提供了一个通用框架,使用这些工具来解决生物科学中的图像分类问题。我们希望这些指导方针鼓励更多的数据科学家发表细胞生物学数据集,并分享他们所学到的东西。
第一部分:获取图像数据
高通量和超分辨率显微镜方法对细胞生物学的研究非常有价值[1,2],但这些技术对许多或大多数研究实验室来说过于昂贵。然而,好消息是像 FoldScope 显微镜这样的创新技术可以显著降低研究成本【3】。 FoldScope 显微镜实际上是纸显微镜,由一个纸框架和一个高倍物镜组成(图 1)。这些多功能显微镜已被证明能够对传染性病原体进行成像,如恶性疟原虫和埃及血吸虫,并且可以连接到手机的摄像头上。FoldScope 显微镜目前的零售价仅为每台 1.5 美元,其低廉的价格激发了一个活跃的公民科学家社区。
在这项工作中,我们使用 FoldScope 显微镜获取了新的细胞图像。我们选择从由卡罗莱纳生物供应公司出售的商业制备的载玻片开始,其中包含正在分裂的蛔虫细胞和苏木精染色。使用配备有 500 倍放大镜头和 800 万像素数码相机(iPhone 5)的 FoldScope 显微镜获取图像。通过这种方式,我们用最少的投资生成了一个细胞分裂不同阶段的细胞图像数据集。

第二部分:共享图像数据
使用 FoldScope 显微镜采集 90 张苏木精染色的蛔虫子宫中分裂细胞的图像(图 2)。这些图像作为一个公共数据集在 Kaggle 上共享,同时还有一些起始代码演示如何处理这些数据。只有 90 个图像的数据集不可避免地受到限制,并且不会对计算环境提出合适的挑战。因此,我们确定了一个相对较大的 Jurkat 细胞在不同细胞分裂阶段的标记图像数据集[5],并将其添加到我们的 Kaggle 数据集。有了这个大约 32,000 个细胞图像的补充数据集,我们可以充分测试免费的 Kaggle 内核产品执行复杂计算分析的能力。

第三部分:分析图像数据
深度学习算法令人兴奋,部分是因为它们有可能自动化生物医学研究任务[6,7]。例如,深度学习算法可用于自动化耗时的手动计数乳腺组织病理学图像中的有丝分裂结构的过程[8,9]。细胞分裂速率的差异和细胞分裂每个阶段所用时间的差异都是健康细胞和癌细胞之间的重要区别[10,11]。同样,癌细胞在细胞分裂过程中经常形成错误的有丝分裂结构,这些错误的结构会导致疾病进一步发展[12,13]。因此,对细胞分裂及其机制的研究导致了许多抗癌药物的开发[14,15]。在这项工作中,我们使用图 2 中的细胞分裂数据集来训练一个深度学习模型,该模型可用于识别分裂细胞图像中的细胞周期阶段(图 3)。

这里我们提出了一种简单的方法,将 Kaggle 内核与图 2 中的细胞分裂数据集相结合,以训练一个深度神经网络来识别细胞周期阶段。免费的 Kaggle 内核将数据、代码和基于云的计算环境结合在一起,使得工作易于复制。事实上,你可以复制这项工作,你可以在一个相同的基于云的计算环境中运行它,只需按下 Kaggle 网站上的“Fork Kernel”按钮。(关于研究再现性的其他讨论和一套推荐指南可在这里找到)。通过使用 32,266 幅图像的数据集来训练深度神经网络,我们希望我们已经展示了免费的 Kaggle 内核环境可以执行与生物医学科学相关的复杂计算分析。
在这种新方法下训练的 ML 模型给出了与原始分析相当的结果(图 4)。有趣的是,这两个模型在识别一些更少观察到的细胞周期阶段方面仍有改进的空间,但这可能通过产生额外的数据来纠正。图 4B 中的代码是通用的,应该可以很好地处理不同的图像类型和图像类别:T2 fastai。imagedata bunch . from _ folder()函数可用于加载和处理任何兼容的图像, fastai.create_cnn() 函数可用于自动学习新的模型特征。
*# Code to generate Figure 4A:* [https://github.com/theislab/deepflow](https://github.com/theislab/deepflow) *# Code to generate Figure 4B: (below)*from fastai import *
from fastai.vision import *
from fastai.callbacks.hooks import *
import numpy as np; import pandas as pd
import matplotlib; import matplotlib.pyplot as pltimg_dir='../input/'; path=Path(img_dir)
data=ImageDataBunch.from_folder(path, train=".",valid_pct=0.3, ds_tfms=get_transforms(do_flip=True,flip_vert=True,max_rotate=90,max_lighting=0.3),size=224,bs=64,num_workers=0).normalize(imagenet_stats)learn=create_cnn(data, models.resnet34, metrics=accuracy, model_dir="/tmp/model/")
learn.fit_one_cycle(10)
interp=ClassificationInterpretation.from_learner(learn)
interp.plot_confusion_matrix(figsize=(10,10), dpi=60)

这项工作描述了一个可重用的框架,可以应用于细胞生物学数据集,以解决图像分类问题。讨论的具体图像分类问题是细胞分裂期间细胞周期阶段的自动识别,该方法值得注意是因为设备的低成本以及训练模型的容易程度(使用免费云计算和开源 ML 算法)。想要训练自己的图像分类模型的数据科学家和细胞生物学家可以通过创建自己的 FoldScope 图像的数据集,将训练数据组织到与每个图像标签对应的文件夹中,然后将相同的数据集附加到包含图 4 中描述的 Fastai 代码的内核来轻松复制这种方法。我们希望未来的研究人员利用我们共享的数据集和起始代码,以便快速派生、修改和改进我们的模型。
结论:
自 17 世纪第一台复合显微镜问世以来,医疗成像和实验室设备的生产和拥有成本一直很高。分析软件要新得多,但在许多情况下同样昂贵。最近,像 1.50 美元的 FoldScope 显微镜和 0.00 美元的 Kaggle 内核这样的低成本工具已经被开发出来,它们可以以很少的成本执行许多相同的功能。这项工作描述了一个低成本和可重用的框架,可以应用于细胞生物学数据集,以解决图像分类问题。我们希望这些指南将鼓励更多的数据科学家探索和发布细胞生物学数据集,并分享他们的结果和发现。
作品引用:
[1] Miller MA,Weissleder R. 单细胞中抗癌药物作用的成像。自然评论癌症。2017.第 17 卷(7):第 399-414 页。
[2]刘 TL,Upadhyayula S,米尔基,等。观察细胞的自然状态:多细胞生物的亚细胞动力学成像。科学。2018 第 360 卷(6386)。
[3] Cybulski J,Clements J,Prakash M. Foldscope:基于折纸术的纸显微镜。 PLoS One 。2014;第九卷第六期。
[4]伊弗雷姆·R、杜阿赫·E 等在加纳使用安装在移动电话上的折叠镜和反镜细胞镜诊断埃及血吸虫感染。T21 医院。2015.第 92 卷第 6 期:第 1253-1256 页。
[5] Eulenberg P,Kö hler N,等利用深度学习重建细胞周期和疾病进展。自然通讯 。2017.第八卷第一期:第 463 页。
[6] Esteva A,Robicquet A,等医疗保健领域深度学习指南。自然医学。2019.第 25 卷:第 24-29 页。
[7]托普,埃里克 J. 高性能医学:人类与人工智能的融合。自然医学。2019.第一卷:第 44-56 页。
[8]李 C,王 X,刘 W,拉泰基 LJ。深度有丝分裂:通过深度检测、验证和分割网络进行有丝分裂检测。医学图像分析。2018.第 45 卷:
[9] Saha M,Chakraborty C,Racoceanu D. 使用乳腺组织病理学图像进行有丝分裂检测的高效深度学习模型。计算医学成像与图形学。2018.第 64 卷:第 29-40 页。
[10]谢尔·希杰。癌细胞周期。科学。1996.第 274 卷(5293):p 1672–7。
[11]维斯康帝 R,莫尼卡路,格列科 D. 癌症中的细胞周期检查点:一把治疗靶向的双刃剑。2016 年临床癌症研究杂志。第 35 卷:153 页。
[12]米卢诺维奇-耶夫蒂奇、穆尼·P .、等人。中心体聚集导致染色体不稳定和癌症。当前生物技术观点。2016 年第 40 卷:p113–118。
[13]巴克豪姆·SF,坎特利·LC。染色体不稳定性在癌症及其微环境中的多方面作用 t. 细胞。2018 卷 174(6):p 1347–1360。
[14]弗洛里安·S·米切尔森抗微管药物。分子生物学方法。 2016 第 1413 卷:p403–411。
[15]斯坦梅茨·莫,普罗塔·艾。微管靶向剂:劫持细胞骨架的策略。细胞生物学趋势。 2018 年第 28 卷第 10 期:p776–792。
[16]图 3A 中的图 3A 中的、图 3B 中的以及封面照片中的的图片来源可以在各自的超链接中找到。
标志的低秩近似
这个世界充满了低秩矩阵,我们可以对它们进行低秩近似。
这篇文章的灵感来自亚历克斯·汤森关于快速递减奇异值的精彩演讲,可以在这里找到。

Photo by Farzad Mohsenvand on Unsplash
在讲座中,汤森教授用不同国家的国旗作为低秩矩阵的例子。然而,没有关于低秩矩阵在多大程度上逼近原始标志的直观图示。
对于我们的分析,我们将从快速复习低秩近似的含义开始,然后将进行标志的实际分析。
下面的分析我就用 R。近似的基本思想就是分解。我们把它分成小块,然后重新组装,但不包括小块。
假设我们有一个矩阵 A ,分解矩阵的一个常用方法是使用所谓的奇异值分解。幸运的是,R 基为我们提供了这个函数。
A = matrix(c(4,7,-1,8,-5,-2,4,2,-1,3,-3,6), nrow = 4)
矩阵看起来会像这样:
[,1] [,2] [,3]
[1,] 4 -5 -1
[2,] 7 -2 3
[3,] -1 4 -3
[4,] 8 2 6
以下代码显示了奇异值分解的作用,即任何矩阵都可以写成一个正交矩阵、一个对角矩阵和另一个正交矩阵的乘积。
A.svd <- svd(A) # decompose A and save result to A.svdA.svd$u %*% diag(A.svd$d) %*% t(A.svd$v) #this line will reproduce A
需要注意的一点是,上述关系可以改写为秩 1 矩阵的和。这构成了低秩近似的基础,我们将用 flags 来进一步研究它。下面的代码显示,我们可以用三个秩为 1 的矩阵的和来恢复矩阵。
# for cleaner code, extract three components
u <- A.svd$u
v <- A.svd$v
d <- A.svd$dA.restored <- d[1]*u[, 1] %*% t(v[, 1]) +
d[2]*u[, 2] %*% t(v[, 2]) +
d[3]*u[, 3] %*% t(v[, 3])all.equal(A.restored, A) # proof that the we restore the matrix
#> TRUE
现在,我们准备处理旗帜。我们接下来要做的与上面非常相似,除了我们将只保留几个组件。我们可以这样做的原因是,标志的秩正好高,但数值低,这意味着奇异值急剧下降(还记得上面提到的讲座标题吗?).
我将使用下面的包进行分析(如果您想重现结果,只需保存我在这里使用的标志,但我猜任何标志都可以)。
library(imager)
library(purrr)
# library(ggplot2) --- for one plot only, omissible
有相当多的旗帜,显然是像法国的低排名。所以让我们从更有趣的东西开始:英国国旗。我找到的旗子是这样的:

为了简单一点,我将使用这些标志的灰度版本。下面的代码显示了图像的加载和展平。
brsh <- load.image("./british-flag.jpg") #brsh denote Britishgry.brsh <- as.array(brsh)[,,1,] %>% apply(1:2, mean)
gry.brsh %>% as.cimg() %>% plot

接下来,我们将 SVD 应用于标志矩阵。我们也可以画出奇异值,以显示它们下降的速度。
brsh.svd <- svd(gry.brsh)ggplot2::quickplot(brsh.svd$d, ylab = "")

为了便于我们的分析,我们可以定义两个函数:一个用于组件提取,一个用于快速绘制那些恢复的标志(我在这里使用了‘purrr’包,如果需要,可以随意查看这里的文档进行刷新)。
# extract first n component
first_n_comp <- function(n, .svd){
u <- .svd$u
d <- .svd$d
v <- .svd$v
c(1:n) %>% map( ~ d[.]*u[, .] %*% t(v[, .])) %>% reduce(`+`)
}# draw plot with only 1, 3, 5, 10 components respectivelydraw_stepwise <- function(.svd) {
par(mfrow = c(2,2)) # set 2 x 2 layout
walk(c(1,3,5,10), ~ first_n_comp(., .svd) %>% as.cimg() %>% plot)
}
现在,让我们把这些应用到英国的国旗上。从下面我们可以看到,水平和垂直模式最容易恢复,而对角线模式最难恢复。
draw_stepwise(brsh.svd)

接下来,我们来看看日本的国旗。下面是原文(确实有背景)。

这是复原的照片:

最后但同样重要的是,让我们以美国的旗帜来结束这次分析。这是我发现的一个。

这些是我找到的:

今天就到这里,下次见。
用于异常检测的 LSTM 自动编码器
使用 Python、Keras 和 TensorFlow 创建 AI 深度学习异常检测模型

Photo by Ellen Qin on Unsplash
这篇文章的目标是通过使用 Python,Keras 和 TensorFlow 创建和训练用于异常检测的人工智能深度学习神经网络的步骤。我不会过多地钻研底层理论,并假设读者对底层技术有一些基本的了解。不过,我会提供更多详细信息的链接,你可以在我的 GitHub repo 中找到这项研究的源代码。
分析数据集
我们将使用 NASA 声学和振动数据库中的振动传感器读数作为本次研究的数据集。在美国宇航局的研究中,传感器读数取自四个轴承,这些轴承在持续多天的恒定负载下发生故障。我们的数据集由单个文件组成,这些文件是以 10 分钟为间隔记录的 1 秒振动信号快照。每个文件包含每个方位的 20,480 个传感器数据点,这些数据点是通过以 20 kHz 的采样率读取方位传感器而获得的。
你可以在这里下载传感器数据。由于 GitHub 大小的限制,方位传感器数据被分成两个 zip 文件(Bearing_Sensor_Data_pt1 和 2)。您需要解压缩它们,并将它们合并到一个单独的数据目录中。
异常检测
异常检测的任务是确定什么时候某些东西偏离了“正常”。使用神经网络的异常检测以无监督/自监督的方式建模;与监督学习相反,在监督学习中,输入特征样本与其对应的输出标签之间存在一对一的对应关系。假设正常行为以及可用“正常”数据的数量是正常的,异常是正常的例外,在这种情况下,“正常”建模是可能的。
我们将使用自动编码器深度学习神经网络模型来从传感器读数中识别振动异常。目标是在未来轴承故障发生之前预测它们。
LSTM 网络公司
这项研究的概念部分来自 Vegard Flovik 博士的一篇优秀文章“异常检测和条件监控的机器学习”。在那篇文章中,作者在自动编码器模型中使用了密集的神经网络单元。这里,我们将在我们的自动编码器模型中使用长短期记忆(LSTM)神经网络细胞。LSTM 网络是更一般的递归神经网络(RNN)的子类型。递归神经网络的一个关键属性是它们保持信息或细胞状态的能力,以供以后在网络中使用。这使得它们特别适合于分析随时间演变的时态数据。LSTM 网络用于语音识别、文本翻译等任务,在这里,用于异常检测的顺序传感器读数的分析。
有许多优秀的文章,作者远比我更有资格讨论 LSTM 社交网络的细节。所以如果你好奇,这里有一个链接,链接到 LSTM 网络上的一篇优秀的文章。这里也是所有 LSTM 事物的事实上的地方——安德烈·卡帕西的博客。理论讲够了,让我们继续写代码吧…
加载、预处理和检查数据
我将使用 Anaconda 发行版 Python 3 Jupyter 笔记本来创建和训练我们的神经网络模型。我们将使用 TensorFlow 作为我们的后端,Keras 作为我们的核心模型开发库。第一项任务是加载我们的 Python 库。然后,我们设置我们的随机种子,以创造可重复的结果。

假设轴承中的机械退化随着时间逐渐发生;因此,我们将在分析中每 10 分钟使用一个数据点。通过使用 20,480 个数据点上振动记录的平均绝对值,汇总每 10 分钟的数据文件传感器读数。然后我们把所有的东西合并成一个熊猫数据帧。

接下来,我们定义用于训练和测试神经网络的数据集。为此,我们执行一个简单的分割,在数据集的第一部分进行训练,这代表正常的操作条件。然后,我们测试数据集的剩余部分,该部分包含导致轴承故障的传感器读数。

现在,我们已经加载、聚合和定义了我们的训练和测试数据,让我们回顾一下传感器数据随时间变化的趋势模式。首先,我们绘制代表轴承正常运行条件的训练集传感器读数。

接下来,我们来看看测试数据集传感器读数随时间的变化。

在测试集时间框架的中途,传感器模式开始改变。在故障点附近,轴承振动读数变得更强,并剧烈振荡。为了获得稍微不同的数据视角,我们将使用傅立叶变换将信号从时域变换到频域。

我们先来看频域的训练数据。

正常运行的传感器读数没有什么值得注意的。现在,让我们看看导致轴承故障的传感器频率读数。

我们可以清楚地看到,系统中频率振幅和能量的增加导致了轴承故障。
为了完成我们数据的预处理,我们将首先把它归一化到 0 和 1 之间的范围。然后,我们将数据改造成适合输入 LSTM 网络的格式。LSTM 单元期望一个形式为[数据样本,时间步长,特征]的三维张量。这里,输入到 LSTM 网络的每个样本代表一个时间步长,并包含 4 个特征-在该时间步长的四个方位的传感器读数。

使用 LSTM 像元的优势之一是能够在分析中包含多元特征。这里是每个时间步的四个传感器读数。但是,在在线欺诈异常检测分析中,可能是时间、金额、购买的商品、每个时间步长的互联网 IP 等特征。
神经网络模型
我们将为我们的异常检测模型使用自动编码器神经网络架构。自动编码器架构本质上学习“身份”功能。它将获取输入数据,创建该数据的核心/主要驱动特征的压缩表示,然后再次学习重构它。例如,输入一张狗的图像,它会将数据压缩到构成狗图像的核心成分,然后学习从数据的压缩版本中重建原始图像。
使用这种架构进行异常检测的基本原理是,我们根据“正常”数据训练模型,并确定产生的重建误差。然后,当模型遇到超出正常范围的数据并试图重建它时,我们将看到重建错误的增加,因为模型从未被训练为准确地重建超出正常范围的项目。
我们使用 Keras 库创建我们的自动编码器神经网络模型作为 Python 函数。

在 LSTM 自动编码器网络结构中,第一对神经网络层创建输入数据的压缩表示,即编码器。然后,我们使用一个重复矢量层来跨解码器的时间步长分布压缩的表示矢量。解码器的最终输出层为我们提供重建的输入数据。
然后,我们实例化该模型,并使用 Adam 作为我们的神经网络优化器来编译它,并平均绝对误差来计算我们的损失函数。

最后,我们将模型拟合到我们的训练数据,并对其进行 100 个时期的训练。然后,我们绘制训练损失图来评估我们的模型的性能。


损失分布
通过绘制训练集中计算损失的分布,我们可以确定用于识别异常的合适阈值。在这样做时,可以确保该阈值被设置在“噪声水平”之上,从而不会触发假阳性。

基于上述损失分布,让我们尝试使用阈值 0.275 来标记异常。然后,我们计算训练集和测试集中的重建损失,以确定传感器读数何时超过异常阈值。


请注意,我们已经将所有内容合并到一个数据帧中,以可视化随时间变化的结果。红线表示我们的阈值 0.275。

我们的神经网络异常分析能够通过检测传感器读数何时开始偏离正常运行值,在实际的物理轴承故障之前很好地标记即将发生的轴承故障。
最后,我们以 h5 格式保存神经网络模型架构及其学习到的权重。经过训练的模型可以用于异常检测。

更新:
在下一篇文章中,我们将使用 Docker 和 Kubernetes 将我们训练过的 AI 模型部署为 REST API,以将其公开为服务。
喀拉斯极端罕见事件分类的 LSTM 自动编码器
在这里,我们将学习 LSTM 模型的数据准备的细节,并为罕见事件分类建立一个 LSTM 自动编码器。
<了解深度学习,了解更多> >
这篇文章是我上一篇文章使用自动编码器进行极端罕见事件分类的延续。在上一篇文章中,我们谈到了一个极其罕见的事件数据中的挑战,这些数据中只有不到 1%的数据被正面标记。我们使用异常检测的概念为此类流程构建了一个自动编码器分类器。
但是,我们掌握的数据是一个时间序列。但是之前我们使用了密集层自动编码器,它不使用数据中的时间特征。因此,在这篇文章中,我们将通过构建一个 LSTM 自动编码器来改进我们的方法。
在这里,我们将学习:
- LSTM 模型的数据准备步骤,
- 构建和实现 LSTM 自动编码器,以及
- 使用 LSTM 自动编码器进行罕见事件分类。
快速回顾 LSTM :
- LSTM 是一种递归神经网络(RNN)。一般来说,RNNs,特别是 LSTM,用于序列或时间序列数据。
- 这些模型能够自动提取过去事件的影响。
- 众所周知,LSTM 有能力提取过去事件长期和短期影响。
下面,我们将直接开发一个 LSTM 自动编码器。建议阅读逐步理解 LSTM 自动编码器层以更好地理解和进一步改进下面的网络。
简而言之,关于数据问题,我们有来自造纸厂的纸张断裂的真实数据。我们的目标是提前预测中断。有关数据、问题和分类方法的详细信息,请参考使用自动编码器的极端罕见事件分类。
多元数据的 LSTM 自动编码器

Figure 1. An LSTM Autoencoder.
在我们的问题中,我们有一个多元时间序列数据。多元时间序列数据包含在一段时间内观察到的多个变量。我们将在这个多元时间序列上建立一个 LSTM 自动编码器来执行稀有事件分类。如[ 1 中所述,这是通过使用异常检测方法实现的:
- 我们在正常(负标签)数据上建立一个自动编码器,
- 用它来重建一个新样本,
- 如果重建误差很高,我们将其标记为断纸。
LSTM 几乎不需要特殊的数据预处理步骤。在下文中,我们将对这些步骤给予足够的重视。
让我们开始实现。
图书馆
我喜欢先把库和全局常量放在一起。
%matplotlib inline
**import** **matplotlib.pyplot** **as** **plt**
**import** **seaborn** **as** **sns**
**import** **pandas** **as** **pd**
**import** **numpy** **as** **np**
**from** **pylab** **import** rcParams
**import** **tensorflow** **as** **tf**
**from** **keras** **import** optimizers, Sequential
**from** **keras.models** **import** Model
**from** **keras.utils** **import** plot_model
**from** **keras.layers** **import** Dense, LSTM, RepeatVector, TimeDistributed
**from** **keras.callbacks** **import** ModelCheckpoint, TensorBoard
**from** **sklearn.preprocessing** **import** StandardScaler
**from** **sklearn.model_selection** **import** train_test_split
**from** **sklearn.metrics** **import** confusion_matrix, precision_recall_curve
**from** **sklearn.metrics** **import** recall_score, classification_report, auc, roc_curve
**from** **sklearn.metrics** **import** precision_recall_fscore_support, f1_score
**from** **numpy.random** **import** seed
seed(7)
**from** **tensorflow** **import** set_random_seed
set_random_seed(11)**from** **sklearn.model_selection** **import** train_test_split
SEED = 123 *#used to help randomly select the data points*
DATA_SPLIT_PCT = 0.2
rcParams['figure.figsize'] = 8, 6
LABELS = ["Normal","Break"]
数据准备
如前所述,LSTM 要求在数据准备中采取一些具体步骤。LSTMs 的输入是从时间序列数据创建的三维数组。这是一个容易出错的步骤,所以我们将查看细节。
读出数据
df = pd.read_csv("data/processminer-rare-event-mts - data.csv")
df.head(n=5) *# visualize the data.*

曲线移动
正如在[ 1 中提到的,这个罕见事件问题的目标是在板块断裂发生之前预测它。我们将尝试提前 4 分钟预测到的休息时间。对于这些数据,这相当于将标签上移两行。直接用df.y=df.y.shift(-2)就可以了。然而,在这里我们需要做以下事情:
- 对于标签为 1 的任意一行 n ,使( n -2)😦 n -1)为 1。这样,我们就可以教会分类器预测到 4 分钟前的情况。而且,
- 拆下排 n 。行 n 被删除,因为我们对训练分类器预测已经发生的中断不感兴趣。
我们开发了以下函数来执行这种曲线移动。
sign = **lambda** x: (1, -1)[x < 0]
**def** curve_shift(df, shift_by):
*'''*
*This function will shift the binary labels in a dataframe.*
*The curve shift will be with respect to the 1s.*
*For example, if shift is -2, the following process*
*will happen: if row n is labeled as 1, then*
*- Make row (n+shift_by):(n+shift_by-1) = 1.*
*- Remove row n.*
*i.e. the labels will be shifted up to 2 rows up.*
*Inputs:*
*df A pandas dataframe with a binary labeled column.*
*This labeled column should be named as 'y'.*
*shift_by An integer denoting the number of rows to shift.*
*Output*
*df A dataframe with the binary labels shifted by shift.*
*'''*
vector = df['y'].copy()
**for** s **in** range(abs(shift_by)):
tmp = vector.shift(sign(shift_by))
tmp = tmp.fillna(0)
vector += tmp
labelcol = 'y'
*# Add vector to the df*
df.insert(loc=0, column=labelcol+'tmp', value=vector)
*# Remove the rows with labelcol == 1.*
df = df.drop(df[df[labelcol] == 1].index)
*# Drop labelcol and rename the tmp col as labelcol*
df = df.drop(labelcol, axis=1)
df = df.rename(columns={labelcol+'tmp': labelcol})
*# Make the labelcol binary*
df.loc[df[labelcol] > 0, labelcol] = 1
**return** df
我们现在将转换我们的数据,并验证转换是否正确。在接下来的部分中,我们还有一些测试步骤。建议使用它们来确保数据准备步骤按预期运行。
print('Before shifting') *# Positive labeled rows before shifting.*
one_indexes = df.index[df['y'] == 1]
display(df.iloc[(np.where(np.array(input_y) == 1)[0][0]-5):(np.where(np.array(input_y) == 1)[0][0]+1), ])
*# Shift the response column y by 2 rows to do a 4-min ahead prediction.*
df = curve_shift(df, shift_by = -2)
print('After shifting') *# Validating if the shift happened correctly.*
display(df.iloc[(one_indexes[0]-4):(one_indexes[0]+1), 0:5].head(n=5))

如果我们在这里注意到,我们将 1999 年 5 月 1 日 8:38 的正标签移动到了 n -1 和 n -2 时间戳,并删除了第 n 行。此外,在中断行和下一行之间有超过 2 分钟的时间差。这是因为,当发生中断时,机器会在中断状态停留一段时间。在此期间,连续行的 y = 1。在所提供的数据中,这些连续的中断行被删除,以防止分类器学习预测已经发生的之后的中断**。详见[ 2 。**
在继续之前,我们通过删除时间和另外两个分类列来清理数据。
*# Remove time column, and the categorical columns*
df = df.drop(['time', 'x28', 'x61'], axis=1)
为 LSTM 准备输入数据
LSTM 比其他车型要求更高一些。在准备适合 LSTM 的数据时可能会花费大量的时间和精力。然而,这通常是值得努力的。
LSTM 模型的输入数据是一个三维数组。数组的形状是样本 x 回看 x 特征。让我们来理解它们,
- 样本:这就是观察的数量,或者换句话说,就是数据点的数量。
- 回顾过去:LSTM 模特是用来回顾过去的。也就是说,在时间 t 时,LSTM 将处理数据直到( t - 回看)以做出预测。
- 特征:输入数据中出现的特征数量。
首先,我们将提取特征和响应。
input_X = df.loc[:, df.columns != 'y'].values *# converts the df to a numpy array*
input_y = df['y'].values
n_features = input_X.shape[1] *# number of features*
这里的input_X是一个大小为样本 x 特征的二维数组。我们希望能够将这样的 2D 数组转换成大小为:样本 x 回看 x 特征的 3D 数组。请参考上面的图 1 以获得直观的理解。
为此,我们开发了一个函数temporalize。
**def** temporalize(X, y, lookback):
*'''*
*Inputs*
*X A 2D numpy array ordered by time of shape:*
*(n_observations x n_features)*
*y A 1D numpy array with indexes aligned with*
*X, i.e. y[i] should correspond to X[i].*
*Shape: n_observations.*
*lookback The window size to look back in the past*
*records. Shape: a scalar.*
*Output*
*output_X A 3D numpy array of shape:*
*((n_observations-lookback-1) x lookback x*
*n_features)*
*output_y A 1D array of shape:*
*(n_observations-lookback-1), aligned with X.*
*'''*
output_X = []
output_y = []
**for** i **in** range(len(X) - lookback - 1):
t = []
**for** j **in** range(1, lookback + 1):
*# Gather the past records upto the lookback period*
t.append(X[[(i + j + 1)], :])
output_X.append(t)
output_y.append(y[i + lookback + 1])
**return** np.squeeze(np.array(output_X)), np.array(output_y)
为了测试和演示这个功能,我们将在下面用lookback = 5看一个例子。
print('First instance of y = 1 in the original data')
display(df.iloc[(np.where(np.array(input_y) == 1)[0][0]-5):(np.where(np.array(input_y) == 1)[0][0]+1), ])lookback = 5 # Equivalent to 10 min of past data.
# Temporalize the data
X, y = temporalize(X = input_X, y = input_y, lookback = lookback)print('For the same instance of y = 1, we are keeping past 5 samples in the 3D predictor array, X.')
display(pd.DataFrame(np.concatenate(X[np.where(np.array(y) == 1)[0][0]], axis=0 )))

我们在这里寻找的是,
- 在原始数据中,第 257 行的 y = 1。
- 使用
lookback = 5,我们希望 LSTM 查看 257 行之前的 5 行(包括它自己)。 - 在 3D 阵列
X中,X[i,:,:]处的每个 2D 块表示对应于y[i]的预测数据。打个比方,在回归中y[i]对应一个 1D 向量X[i,:];在 LSTMy[i]对应一个 2D 阵列X[i,:,:]。 - 这个 2D 块
X[i,:,:]应该具有在input_X[i,:]和直到给定lookback的先前行的预测器。 - 正如我们在上面的输出中看到的,底部的
X[i,:,:]块与顶部显示的 y=1 的过去五行相同。 - 类似地,这适用于所有 y 的全部数据。此处的示例显示了 y=1 的情况,以便于可视化。
分为训练、有效和测试
这对于sklearn功能来说很简单。
X_train, X_test, y_train, y_test = train_test_split(np.array(X), np.array(y), test_size=DATA_SPLIT_PCT, random_state=SEED)X_train, X_valid, y_train, y_valid = train_test_split(X_train, y_train, test_size=DATA_SPLIT_PCT, random_state=SEED)
为了训练自动编码器,我们将使用仅来自负标签数据的 X。所以我们把 y = 0 对应的 X 分开。
X_train_y0 = X_train[y_train==0]
X_train_y1 = X_train[y_train==1]X_valid_y0 = X_valid[y_valid==0]
X_valid_y1 = X_valid[y_valid==1]
我们将把 X 的形状重塑成所需的 3D 尺寸:样本 x 回看 x 特征。
X_train = X_train.reshape(X_train.shape[0], lookback, n_features)
X_train_y0 = X_train_y0.reshape(X_train_y0.shape[0], lookback, n_features)
X_train_y1 = X_train_y1.reshape(X_train_y1.shape[0], lookback, n_features)X_valid = X_valid.reshape(X_valid.shape[0], lookback, n_features)
X_valid_y0 = X_valid_y0.reshape(X_valid_y0.shape[0], lookback, n_features)
X_valid_y1 = X_valid_y1.reshape(X_valid_y1.shape[0], lookback, n_features)X_test = X_test.reshape(X_test.shape[0], lookback, n_features)
使数据标准化
对于自动编码器,通常最好使用标准化数据(转换为高斯数据,平均值为 0,标准偏差为 1)。
一个常见的标准化错误是:我们将整个数据标准化,然后分成训练测试。这是不正确的。在建模过程中,测试数据应该是完全不可见的。因此,我们应该规范化训练数据,并使用其汇总统计数据来规范化测试数据(对于规范化,这些统计数据是每个特征的平均值和方差)。
标准化这些数据有点棘手。这是因为 X 矩阵是 3D 的,我们希望标准化发生在原始 2D 数据上。
为此,我们需要两个 UDF。
flatten:该功能将重新创建原始的 2D 阵列,3D 阵列是从该阵列创建的。这个函数是temporalize的倒数,意思是X = flatten(temporalize(X))。scale:这个函数将缩放我们创建的 3D 数组,作为 LSTM 的输入。
**def** flatten(X):
*'''*
*Flatten a 3D array.*
*Input*
*X A 3D array for lstm, where the array is sample x timesteps x features.*
*Output*
*flattened_X A 2D array, sample x features.*
*'''*
flattened_X = np.empty((X.shape[0], X.shape[2])) *# sample x features array.*
**for** i **in** range(X.shape[0]):
flattened_X[i] = X[i, (X.shape[1]-1), :]
**return**(flattened_X)
**def** scale(X, scaler):
*'''*
*Scale 3D array.*
*Inputs*
*X A 3D array for lstm, where the array is sample x timesteps x features.*
*scaler A scaler object, e.g., sklearn.preprocessing.StandardScaler, sklearn.preprocessing.normalize*
*Output*
*X Scaled 3D array.*
*'''*
**for** i **in** range(X.shape[0]):
X[i, :, :] = scaler.transform(X[i, :, :])
**return** X
为什么我们不首先归一化原始 2D 数据,然后创建三维阵列?因为,为了做到这一点,我们将:把数据分成训练和测试,然后对它们进行规范化。然而,当我们在测试数据上创建 3D 阵列时,我们丢失了最初的样本行,直到*回看。*拆分为训练有效测试将导致验证集和测试集都出现这种情况。
我们将安装一个来自sklearn的标准化对象。该函数将数据标准化为正态(0,1)。注意,我们需要展平X_train_y0数组以传递给fit函数。
*# Initialize a scaler using the training data.*
scaler = StandardScaler().fit(flatten(X_train_y0))
我们将使用我们的 UDFscale,用合适的转换对象scaler来标准化X_train_y0。
X_train_y0_scaled = scale(X_train_y0, scaler)
确保 **scale** 正常工作?
X_train的正确转换将确保展平的X_train的每一列的均值和方差分别为 0 和 1。我们测试这个。
a = flatten(X_train_y0_scaled)
print('colwise mean', np.mean(a, axis=0).round(6))
print('colwise variance', np.var(a, axis=0))

上面输出的所有均值和方差分别为 0 和 1。因此,缩放是正确的。我们现在将扩展验证和测试集。我们将再次在这些器械包中使用scaler对象。
X_valid_scaled = scale(X_valid, scaler)
X_valid_y0_scaled = scale(X_valid_y0, scaler)X_test_scaled = scale(X_test, scaler)
LSTM 自动编码器培训
首先,我们将初始化一些变量。
timesteps = X_train_y0_scaled.shape[1] *# equal to the lookback*
n_features = X_train_y0_scaled.shape[2] *# 59*
epochs = 200
batch = 64
lr = 0.0001
现在,我们开发一个简单的架构。
lstm_autoencoder = Sequential()
*# Encoder*
lstm_autoencoder.add(LSTM(32, activation='relu', input_shape=(timesteps, n_features), return_sequences=**True**))
lstm_autoencoder.add(LSTM(16, activation='relu', return_sequences=**False**))
lstm_autoencoder.add(RepeatVector(timesteps))
*# Decoder*
lstm_autoencoder.add(LSTM(16, activation='relu', return_sequences=**True**))
lstm_autoencoder.add(LSTM(32, activation='relu', return_sequences=**True**))
lstm_autoencoder.add(TimeDistributed(Dense(n_features)))
lstm_autoencoder.summary()

从 summary()来看,参数的总数是 5,331。这大约是训练规模的一半。因此,这是一个合适的模型。为了有一个更大的架构,我们将需要添加正规化,例如辍学,这将在下一篇文章中讨论。
现在,我们将训练自动编码器。
adam = optimizers.Adam(lr)
lstm_autoencoder.compile(loss='mse', optimizer=adam)
cp = ModelCheckpoint(filepath="lstm_autoencoder_classifier.h5",
save_best_only=**True**,
verbose=0)
tb = TensorBoard(log_dir='./logs',
histogram_freq=0,
write_graph=**True**,
write_images=**True**)
lstm_autoencoder_history = lstm_autoencoder.fit(X_train_y0_scaled, X_train_y0_scaled,
epochs=epochs,
batch_size=batch,
validation_data=(X_valid_y0_scaled, X_valid_y0_scaled),
verbose=2).history

绘制各时期损失的变化。
plt.plot(lstm_autoencoder_history['loss'], linewidth=2, label='Train')
plt.plot(lstm_autoencoder_history['val_loss'], linewidth=2, label='Valid')
plt.legend(loc='upper right')
plt.title('Model loss')
plt.ylabel('Loss')
plt.xlabel('Epoch')
plt.show()

Figure 2. Loss function over the epochs.
分类
类似于之前的文章 [ 1 ],这里我们展示了如何使用自动编码器重建误差进行罕见事件分类。我们遵循这个概念:自动编码器被期望重建一个 noi。如果重建误差很高,我们将把它分类为一个断页。
我们需要确定这方面的门槛。另外,请注意,这里我们将使用包含 y = 0 或 1 的整个验证集。
valid_x_predictions = lstm_autoencoder.predict(X_valid_scaled)
mse = np.mean(np.power(flatten(X_valid_scaled) - flatten(valid_x_predictions), 2), axis=1)
error_df = pd.DataFrame({'Reconstruction_error': mse,
'True_class': y_valid.tolist()})
precision_rt, recall_rt, threshold_rt = precision_recall_curve(error_df.True_class, error_df.Reconstruction_error)
plt.plot(threshold_rt, precision_rt[1:], label="Precision",linewidth=5)
plt.plot(threshold_rt, recall_rt[1:], label="Recall",linewidth=5)
plt.title('Precision and recall for different threshold values')
plt.xlabel('Threshold')
plt.ylabel('Precision/Recall')
plt.legend()
plt.show()
注意,我们必须对数组进行flatten运算来计算mse。

Figure 3. A threshold of 0.3 should provide a reasonable trade-off between precision and recall, as we want to higher recall.
现在,我们将对测试数据进行分类。
我们不应该从测试数据中估计分类阈值。这将导致过度拟合。
test_x_predictions = lstm_autoencoder.predict(X_test_scaled)
mse = np.mean(np.power(flatten(X_test_scaled) - flatten(test_x_predictions), 2), axis=1)
error_df = pd.DataFrame({'Reconstruction_error': mse,
'True_class': y_test.tolist()})
threshold_fixed = 0.3
groups = error_df.groupby('True_class')
fig, ax = plt.subplots()
**for** name, group **in** groups:
ax.plot(group.index, group.Reconstruction_error, marker='o', ms=3.5, linestyle='',
label= "Break" **if** name == 1 **else** "Normal")
ax.hlines(threshold_fixed, ax.get_xlim()[0], ax.get_xlim()[1], colors="r", zorder=100, label='Threshold')
ax.legend()
plt.title("Reconstruction error for different classes")
plt.ylabel("Reconstruction error")
plt.xlabel("Data point index")
plt.show();

Figure 4. Using threshold = 0.8 for classification. The orange and blue dots above the threshold line represents the True Positive and False Positive, respectively.
在图 4 中,阈值线上方的橙色和蓝色圆点分别代表真阳性和假阳性。如我们所见,我们有很多误报。
让我们看看准确度的结果。
测试精度
混淆矩阵
pred_y = [1 if e > threshold_fixed else 0 for e in error_df.Reconstruction_error.values]conf_matrix = confusion_matrix(error_df.True_class, pred_y)
plt.figure(figsize=(6, 6))
sns.heatmap(conf_matrix, xticklabels=LABELS, yticklabels=LABELS, annot=**True**, fmt="d");
plt.title("Confusion matrix")
plt.ylabel('True class')
plt.xlabel('Predicted class')
plt.show()

Figure 5. Confusion matrix showing the True Positives and False Positives.
ROC 曲线和 AUC
false_pos_rate, true_pos_rate, thresholds = roc_curve(error_df.True_class, error_df.Reconstruction_error)
roc_auc = auc(false_pos_rate, true_pos_rate,)
plt.plot(false_pos_rate, true_pos_rate, linewidth=5, label='AUC = **%0.3f**'% roc_auc)
plt.plot([0,1],[0,1], linewidth=5)
plt.xlim([-0.01, 1])
plt.ylim([0, 1.01])
plt.legend(loc='lower right')
plt.title('Receiver operating characteristic curve (ROC)')
plt.ylabel('True Positive Rate')
plt.xlabel('False Positive Rate')
plt.show()

Figure 6. The ROC curve.
与[ 1 中的密集层自动编码器相比,我们看到 AUC 提高了大约 10%。根据图 5 中的混淆矩阵,我们可以预测 39 个中断实例中的 10 个。正如[ 1 中所讨论的,这对造纸厂来说意义重大。然而,与密集层自动编码器相比,我们实现的改进是微小的。
主要原因是 LSTM 模型有更多的参数需要估计。对 LSTMs 使用正则化变得很重要。正则化和其他模型改进将在下一篇文章中讨论。
Github 知识库
[## cran 2367/lstm _ 自动编码器 _ 分类器
用于罕见事件分类的 LSTM 自动编码器。通过…为 cran 2367/lstm _ auto encoder _ classifier 开发做出贡献
github.com](https://github.com/cran2367/lstm_autoencoder_classifier/blob/master/lstm_autoencoder_classifier.ipynb)
什么可以做得更好?
在下一篇文章中,我们将学习调优自动编码器。我们会过去,
- CNN LSTM 自动编码器,
- 脱落层,
- LSTM 辍学(辍学和辍学)
- 高斯漏失层
- SELU 激活,以及
- 阿尔法辍学与 SELU 激活。
结论
这篇文章继续了[ 1 ]中关于极端罕见事件二进制标记数据的工作。为了利用时间模式,LSTM 自动编码器被用来建立一个多元时间序列过程的罕见事件分类器。详细讨论了 LSTM 模型的数据预处理步骤。一个简单的 LSTM 自动编码器模型被训练并用于分类。发现密集自动编码器的精度有所提高。为了进一步改进,我们将在下一篇文章中探讨如何改进具有 Dropout 和其他技术的自动编码器。
后续阅读
建议阅读逐步理解 LSTM 自动编码器层以明确 LSTM 网络概念。
参考
- 使用 Keras 中的自动编码器进行极端罕见事件分类
- Ranjan、m . Mustonen、k . pay nabar 和 k . pour AK(2018 年)。数据集:多元时间序列中的稀有事件分类。 arXiv 预印本 arXiv:1809.10717
- 深度学习时间序列预测& LSTM 自动编码器
- 完整代码: LSTM 自动编码器
免责声明:这篇文章的范围仅限于构建 LSTM 自动编码器并将其用作罕见事件分类器的教程。通过网络调优,从业者有望获得更好的结果。这篇文章的目的是帮助数据科学家实现 LSTM 自动编码器。
非洲语言的位置标记
我们如何为耶姆巴语建立世界上第一个 LSTM 分类器。

在本文中,我们实现了一个 LSTM 网络,用于根据序列中已经观察到的字符来预测序列中下一个字符的概率。
我们从非洲语言中构建了第一个基于 LSTM 的单词分类器, Yemba 。没有边界可以阻止 LSTMs。可能是变形金刚。
耶姆巴语
我们的序列将从一种不太流行的语言中取词,叫做*。你可能从未听说过这种语言。放心看下面的象形图来了解一下 Yemba 的写法。*

Yemba 是一种非洲语言,如今只有几千人以此为母语。尽管最初只是一种口头语言,但耶姆巴语是在大约公元 2000 年发展起来的。 90 年前。和世界上那么多语言一样, Yemba 是声调语言,类似于越南语。
在声调语言中,单词由辅音、元音组成;音调——伴随音节发音的音高变化。
1928 年,设计第一个 Yemba 字母表的先驱,Foreke-Dschang的 Djoumessi Mathias 陛下建立了 Yemba 音调正字法的基础模型。后来,在 1997 年,作为一项联合国际研究努力的结果,一部现代的耶姆巴-法语词典诞生了。

source: Djoumessi, M. (1958) Syllabaire bamiléké,Yaoundé, Saint-Paul.
我们的目标是将 Yemba 单词编码为嵌入向量,并建立一个 LSTM 网络,该网络能够通过仅查看单词中存在的字符和音调来预测 Yemba 单词是名词还是动词。
我们的目标不是实现完整的词性标注。相反,我们将训练网络学习常见于 Yemba 名词中的字母和音调组,而不是那些特定于 Yemba 动词的字母和音调组。
为此,我们使用一个预处理过的 英语-Yemba 数据集,它是从Yemba.net在线词典下载的。我们鼓励您访问该页面,点击一些从英语、法语、德语、捷克语、汉语、西班牙语、意大利语到 Yemba 的翻译。很好玩。

上面我们可以从字典中看到一些单词。如果你想有好心情,你可以试着阅读它们。实际上, Yemba 写法是基于国际音标语言。任何有语音学知识的人实际上都能够阅读和说话!理论上。
虽然我们将数据集限制为名词和动词,但是 Yemba 还包括形容词、副词、连词、代词等。,但是与名词和动词相比数量有限。单词类型的分布如下图所示。

下面我们展示一些关于数据集的统计数据。

我们的 Yemba 单词是由 45 个字母组成的。词汇表用一个唯一的整数来表示每个 Yemba 字母。这是自然语言处理中典型的预处理步骤。
在将单词输入 LSTM 之前,我们必须对每个单词进行标记,用词汇表中的索引替换单词中的每个字母。这个过程将单词转化为数字向量 X 。为了使所有单词的向量大小相同,我们将向量填充到数据集中最长单词的长度。
我们的 LSTM 将学习将这些向量与正确的单词类型相匹配:0 代表名词,1 代表动词。因此,我们还构建了一个标签向量 Y 来存储正确的类。
接下来,我们将向量分成 2166 个单词的训练集和 542 个单词的验证集。
我们建立了一个有 100 个细胞的单层 LSTM。我们不直接向 LSTM 馈送单词向量。相反,我们首先学习它们在 8 维空间中的嵌入表示。
众所周知,嵌入是为了捕捉构成单词的字母之间的语义关系。LSTM 的输出由具有 sigmoid 激活的全连接层转换,以产生 0 和 1 之间的概率。
我们用二进制交叉熵作为损失函数,Adam 作为优化器来训练网络。分类精度被用作评估分类性能的度量,因为我们的两个类相当平衡。
 **
**
如上图所示,网络实现收敛的速度非常快。LSTM 做得很好,在测试数据集上预测的分类准确率为 93.91%。
我们还在我们的 Yemba 分类问题上尝试了 GRUs,通过用具有相同单元数量(100)的 GRU 层替换 LSTM 层。训练稍微快了一点,准确性稍微好了一点,在验证集上达到了 94.19%,而不是 LSTM 的 93.91%。
现在让我们在 100 个随机名词和 100 个随机动词上评估经过训练的 LSTM 网络,并检查混淆矩阵。

混淆矩阵显示出很少的假阳性和假阴性:100 个动词中有 1 个被预测为名词,2 个被预测为动词。分类错误的单词如下所示。

事实是, Yemba 中的动词通常有一个引人注目的前缀“e”、“了”或“里”,这与英语中的“to”相对应。看来这个语义或语法结构被我们基于角色的 LSTM 正确地提取出来了。“eku bil”这个词在英语中是“贪婪”的意思,以“e”开头。因此,LSTM 预言它为动词,尽管它是名词。“lefɔ”也是一样,意思是“王朝”。因为它的前缀是“了”,所以被认为是动词。
结论
这个实际案例显示了 LSTMs 在掌握语义方面的魔力,即使是在词汇和语音差异都很奇怪的偏远难懂的语言中,如 Yemba 。
在后续文章中,我们实现了一个 seq2seq 神经翻译模型,将英语句子翻译成 Yemba。
AI 能让濒危语言不消失吗?
towardsdatascience.com](/heres-how-to-build-a-language-translator-in-few-lines-of-code-using-keras-30f7e0b3aa1d)*


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言










{kind=link}
{kind=link}
{kind=link}
{kind=link}