







网络卡车对执法和人工智能的影响
你不能错过特斯拉的 Cybertruck 的公告,它带有与碎玻璃相关的“可爱”片段。价格点和两极分化的设计是关键的讨论点。

The image of the Cybertruck (from tesla.com)
“bladerunner”的设计伴随着通常的粉丝热情和对福特、通用、康明斯、艾利森变速器影响的强制性金融分析师报告。
令人不安的是合金钢和防弹玻璃中“坚不可摧”材料的使用。
执法部门可能想再看看一辆类似坦克的汽车在街道上行驶的可能性,它也有内置电源。
模仿恐怖主义是全世界人民的祸害。传统和社交媒体引发的病毒式传播刺激了模仿者:从校园枪击案到人们驾驶卡车冲进人群和建筑物。
像这样的卡车需要背景调查吗?如果它被用于帮派暴力呢?问题比比皆是,社会需要对不断变化的技术做出反应。
例如,NHTSA 校车的安全标准可能需要重新审视。行人安全也是要检查的。
艾在这里也有一出戏。这种卡车的行驶里程超过 500 英里,可以邀请司机前往偏远地区,如国家公园和越野。计算机视觉系统对周围环境并不熟悉。就我而言,我很想看看视觉系统对鹿、野牛和熊的反应。
优步事故突出了行人检测(或缺乏检测),行人直到很晚才被识别为人。请记住,特斯拉花了很长时间和一些事件才开始认识到道路施工、分流和汽车从公路路肩并入。
对于像沙漠、丘陵和雪地这样的偏远地区和地形,人工智能需要为此进行训练。
识别雪人或稻草人,并将其与人区分开来也是一项任务。毫无疑问,这将是一个小学生想玩的游戏——试图欺骗人工智能计算机视觉。
伦理人工智能和可解释人工智能再次成为焦点。举例来说,偏僻狭窄的道路可能会让你在一辆停下来的、抛锚的汽车和一辆救护车之间做出选择。
我们生活在有趣的时代。
隐式解码器部分 1 - 3D 重建
内部人工智能
使用深度学习从单幅图像进行 3D 重建
一种编码-解码类型的神经网络,用于对 2D 图像中形状的 3D 结构进行编码,然后对该结构进行解码并重建 3D 形状。这是我见过的最高质量的 3D 图像重建。
一些细节
- 输入图像:128X128 像素
- 透明图像背景
- 训练和生成是基于相似对象的类别来完成的
- 输出体素:基本分辨率为 64X64X64 体素。但是,可以产生任何所需分辨率的输出(!)而无需重新训练神经网络
神经网络结构:
- 2D 编码器—基于 ResNet18。从输入图像生成大小为 128 的编码向量(z 向量)
- 解码器——简单的 6 个全连接层,带 1 个分类输出神经元。接收空间中的 z 向量和- 1 - 3D 坐标作为输入,并分类该坐标是否属于物体的质量。

Neural Network Structure
重建是如何从这个网络发生的?
为了重建物体的整个结构,空间中的所有 3D 坐标被发送到解码器(在该论文的情况下,每个物体有 64X64X64 坐标),以及来自图像的单个 z 向量。解码器对每个坐标进行分类,并创建 3D 结构的表示。这创建了 3D 对象的体素表示。然后,使用行进立方体算法来创建网格表示。
汽车类别重建示例

第一列是输入图像,第二列是 AI 3D 重建,最后一列是汽车的原始 3D 对象(或者,用技术语言来说,是地面真相)。这个图像案例中的神经网络是在汽车模型上训练的。在论文中有在椅子、飞机等上面训练的结果。请注意,本文中的输入输出图像和体素分辨率是特定的,但可以根据任何所需的实现进行相应的更改。
等等!最后一辆车是怎么改造的?
软件甚至没有看到图像中的车头。这就是 DL 培训的力量所在。由于我们通过许多以前的汽车例子来训练网络,它知道如何推断它从未见过的新车的形状。外推是可能的,因为网络是在来自相似类别的对象上训练的,所以网络有效地重建它之前被训练的相似结构,该结构匹配它在图像中看到的结构。
现有的三维重建软件
现在有很多工具可以从图像中进行三维重建。这些工具使用经典的摄影测量技术,从同一物体的多个图像中重建 3D 模型。两个例子:
这种类型的软件可以从当前的 AI 研究中受益。简单平面的重建,即使它们在图像中不完全可见,处理图像中的光反射或像差,更好的比例估计等等。所有这些都可以使用类似的神经网络解决方案来改进。
类似的研究
由于编码-解码架构和 GANs,单图像 3D 重建目前正在发展。这种研究的一个很好的例子是:单幅图像的 3D 场景重建 —用于场景重建。单个物体重建的质量看起来不是很好,但令人印象深刻的是,他们是从自然场景图像中实现的。
ShapeNet
与 ImageNet 的图像类似,ShapeNet 是一个大型的带注释的 3D 模型数据集,以及围绕 3D 主题进行 ML 研究的竞赛和人群。大多数(如果不是全部的话)3D ML 研究使用该数据集进行训练和基准测试,包括隐式解码器研究。有两个主要的 Shapenet 数据集,最新的是 ShapeNetCore.v2:
- 55 个常见对象类别
- 大约 51,300 个独特的 3D 模型
- 验证每个 3D 模型的类别和对齐(位置和方向)。
参考
- 博文原文:https://2d3d.ai/index.php/2019/10/11/implicit-decoder-part-1-3d-reconstruction/
- 研究:[1]陈、、。"学习生成式形状建模的隐式场."IEEE 计算机视觉和模式识别会议论文集。2019.
- shape net:https://www.shapenet.org/
隐式解码器第 2 部分–3D 生成
内部人工智能
深度学习和 3D 的 3D 生成和限制
前一篇文章— 隐式解码器第 1 部分—3D 重建
3D 生成

3D Airplane Generation
还记得甘斯吗?嗯,同样的技术可以用来生成你在左边看到的飞机。
它是如何发生的?诀窍是使用相同的解码器网络如下所示。特别是与编码器一起训练的同一个解码器。我们训练一个 GAN 网络来生成一个假的 z 向量。
鉴别器从编码器-解码器网络获得真实的 z 向量作为输入,同时从生成器网络获得虚假的 z 向量作为输入。生成器网络被训练为仅基于随机输入产生新的 z 向量。由于解码器知道获得 z 向量作为输入,并从中重建 3D 模型,并且生成器被训练以产生类似真实的 z 向量,因此可以使用两个网络组合来重建新的 3D 模型。
此外,我们可以看到 gif 显示一个飞机模型变形为一个新的。这是通过获取第一个和最后一个 3D 模型的 z 向量来完成的,让我们将这些向量称为 z_start 和 z_end,然后新的 z 向量被计算为 z_start 和 z_end 的线性组合。具体来说,选取一个介于 0 和 1 之间的数字(假设为 alpha),然后计算一个新的 z-z _ new:z _ new =(z _ start * alpha+z _ end *(1-alpha))。然后,z_new 被馈送到解码器网络中,并且可以计算中间 3D 模型。

Encoder-Decoder
在不同的 3D 模型之间存在这样的平滑过渡的原因是隐式解码器网络被训练来基于 z 向量识别模型的底层 3D 构造,并且更具体地,识别特定模型类别中的模型。因此,z_vector 的微小变化将导致 3D 模型的微小变化,但仍然保持模型类别的 3D 结构,这样就可以从 z_start 到 z_end 连续地改变模型。

Generating z-vectors
深度学习和 3D 重建\生成的局限性
这些结果被带到这里和其他地方,使神经网络似乎是全能的,易于使用和推广到其他场景,用例和产品。有时候是这样,但很多时候不是。在 3D 生成和重建中,神经网络存在局限性。仅举几个例子:
数据集限制
正如我们已经证明的,神经网络每次都需要针对特定的模型类别进行训练。每个类别中需要有足够多的模型(通常至少数百个),并且足够多的类别允许这种类型的神经网络的任何类型的现实生活应用,ShapeNet 正在为学术界做这项工作,即使在学术界,类别和每个类别中的模型的数量也是有限的。为了使它在商业上可行,我们需要更多的型号和种类。此外,每个模型需要贴上标签,以其确切的类别,需要调整翻译和规模准确,需要以正确的格式保存。此外,对于每个模型,我们需要不同角度、不同照明位置和相机参数、不同比例对齐和平移的图像。同样,ShapeNet 和其他研究计划有助于建立这一系统,以帮助科学进步。但是,这也意味着,为了将这项研究转化为产品,在数据集创建和处理方面会有大量开销。
准确度测量
一个反复出现的问题是 3D 重建或生成有多精确。对此的一个回答是——如何测量 3D 重建的精确度?假设一个人类 3D 设计师从一幅图像重建一个 3D 模型,我们怎么能说他的工作准确与否呢?即使我们有了原始的 3D 模型,又怎么能说两个 3D 模型是相似的,或者说重建的 3D 模型与原点相似,又怎么能量化这种相似性呢?老派的方法,如 MSE、IoU、F1 分数、切角和法向距离[[添加参考—https://2d 3d . ai/index . PHP/2019/10/09/3D-scene-re construction-from-single-image/]]是不考虑对象的 3D 结构的直接度量。例如,IoU 检查与两个形状的联合体积相比,重建的 3D 形状的体积有多少与原始 3D 形状重叠。如果重建的形状被移动到空间中的不同体积中,即使形状是相同的,IoU 也可能为零(因为没有重叠)。
在隐式解码器论文中,作者使用了一种不同的 3D 形状相似性度量方法—【LFD】。该度量对于模型的比例、对齐和位置(平移)是不变的。基本想法是从十二面体上的角度拍摄模型的 10 个轮廓图像,并且每个模型拍摄 10 个不同的十二面体。

然后,当在两个模型之间进行比较时,使用傅立叶和泽尼克系数来比较来自这 10 个十二面体的图像的视觉相似性。
参考
- 陈,,和。"学习生成式形状建模的隐式场."IEEE 计算机视觉和模式识别会议论文集。2019.
- shape net:https://www.shapenet.org/
- ,陈,丁云,等,“基于视觉相似性的三维模型检索研究”计算机图形学论坛。第 22 卷。№3.英国牛津:布莱克威尔出版公司,2003 年。
原载于 2019 年 11 月 16 日https://2d3d . ai。
数据可视化对获得可行见解的重要性

数据可视化本身不是关于洞察力,而是关于交流洞察力。
从搅动大量数据中获得的定量洞察通常是微妙的、令人惊讶的、技术上复杂的。鉴于此,向任何受众,尤其是可能有兴趣/时间了解技术细节的业务受众传达这些见解变得更加困难。尽管如此,还是有一些人更喜欢用平淡无奇的黑白数字表格和方程式来展示结果,而不是更具视觉刺激的演示,但是这种人的比例非常小。
作为一名咨询出身的人,我们必须准备好面对各种类型的客户&喜欢表格和方程式的客户,以及想要好看的视觉效果的客户。
根据我的经验,以下是我得到的一些经验法则:
1.清楚
- 每张图讲述一个非常重要的观点,并找出讲述故事的元素
- 你陈述的每一件事都应该与整个故事相联系或引导整个故事
- 保持形象简单直接
- 简化但不要过度简化,以免丢失调查结果或关键数据特征
让我们来看一个我最喜欢的例子,数据可视化对于获得洞察力是多么重要。

上面的图表出现在《彭博》上,结论是在过去的 40 年里,所有年龄段的美国男性工人的收入中值都在急剧下降。但这真的是真的吗?让我们看看下面的视觉代表相同的数据集。

现在,从上面的图像中,你可以清楚地看到,在仅仅代表了 2 个数据点(1972 年和 2012 年)后,许多局部扰动被消除了
同样,如果你观察 y 轴,它不应该从零开始。

完全相同的数据和图表视觉效果,只是 y 轴变为零。
完整阅读请参考 Eric 的原文此处。
2.透明度
- 解释获得适当深度洞察力的方法
- 陈述分析所依据的假设

Source: http://www.delphianalytics.net
没有 y 轴,上面的图表毫无意义。显然,数据增长和数据分析师增长的规模/单位完全不同。如果不考虑单个度量的比例/单位,你就无法将两个视觉效果叠加在一起。讲述故事最重要的元素应该取 X 轴和 Y 轴;在得出任何结论之前,一定要检查这一点(很多方法会误导观众)。
3.完整
- 准确、诚实地描述不确定性和局限性,因为夸大数据的含义是非常普遍和诱人的。
- 卓越的图形化始于讲述数据的真相。—爱德华·塔夫特,定量信息的可视化展示,2001

Source: http://www.verticalmeasures.com
这篇博客的灵感来源于 Dakshinamurthy V Kolluru 博士主持的数据可视化会议,并引用了其中的内容。
请在评论区告诉我们你的想法。
这些内容最初发表在我的个人博客网站:http://datascienceninja.com/。点击此处查看并订阅即时接收最新博客更新。
距离度量在机器学习建模中的重要性

许多机器学习算法——有监督的或无监督的——使用距离度量来了解输入数据模式,以便做出任何基于数据的决策。良好的距离度量有助于显著提高分类、聚类和信息检索过程的性能。在本文中,我们将讨论不同的距离度量,以及它们如何帮助机器学习建模。
介绍
在许多现实世界的应用中,我们使用机器学习算法来分类或识别图像,并通过图像的内容检索信息。例如,人脸识别、在线审查图像、零售目录、推荐系统等。在这里,选择一个好的距离度量变得非常重要。距离度量有助于算法识别内容之间的相似性。
基础数学定义(来源维基百科),
距离度量使用距离函数来提供数据集中每个元素之间的关系度量。
你们有些人可能会想,这个距离函数是什么?它是如何工作的?它如何决定数据中的特定内容或元素与另一个内容或元素有某种关系?让我们在接下来的几节里试着找出答案。
距离函数
你记得学过勾股定理吗?如果你这样做了,那么你可能还记得用这个定理计算两个数据点之间的距离。

Source: Khan Academy’s Distance Formula Tutorial
为了计算数据点 A 和 B 之间的距离,勾股定理考虑了 x 轴和 y 轴的长度。

Source: Khan Academy’s Distance Formula Tutorial
你们中的许多人一定想知道,我们在机器学习算法中使用这个定理来寻找距离吗?回答你的问题,是的,我们确实使用它。在许多机器学习算法中,我们使用上述公式作为距离函数。我们将讨论使用它的算法。
现在你可能已经知道什么是距离函数了。下面是一个简化的定义。
来自 Math.net 的基本定义,
距离函数提供集合中元素之间的距离。如果距离为零,那么元素是等价的,否则它们彼此不同。
距离函数只不过是距离度量使用的数学公式。不同的距离度量的距离函数可以不同。让我们讨论不同的距离度量,并了解它们在机器学习建模中的作用。
距离度量
有许多距离度量,但是为了使本文简洁,我们将只讨论几个广泛使用的距离度量。我们将首先尝试理解这些度量背后的数学,然后我们将确定使用这些距离度量的机器学习算法。
以下是常用的距离度量-
闵可夫斯基距离:
闵可夫斯基距离是赋范向量空间中的度量。什么是赋范向量空间?赋范向量空间是在其上定义了范数的向量空间。假设 X 是一个向量空间,那么 X 上的范数是一个实值函数| |X| |它满足以下条件
- 零矢量- 零矢量的长度为零。
- 标量因子- 当你把向量乘以一个正数时,它的方向不变,尽管它的长度会改变。
- 三角形不等式- 如果距离是一个范数,那么两点之间的计算距离将始终是一条直线。
你可能想知道为什么我们需要赋范向量,我们能不能不要简单的度量?由于赋范向量具有上述性质,这有助于保持范数诱导的度量齐次和平移不变。更多细节可以在这里找到。
可以使用下面的公式计算距离

闵可夫斯基距离是广义距离度量。这里的广义是指我们可以操纵上述公式,以不同的方式计算两个数据点之间的距离。
如上所述,我们可以操作 p 的值,并以三种不同的方式计算距离-
p = 1,曼哈顿距离
p = 2,欧几里德距离
p = ∞,切比雪夫距离
我们将在下面详细讨论这些距离度量。
曼哈顿距离:
如果我们需要计算网格状路径中两个数据点之间的距离,我们使用曼哈顿距离。如上所述,我们使用 闵可夫斯基距离 公式,通过设置 p 的 值为 1 来求曼哈顿距离。
比方说,我们要计算两个数据点- x 和 y 之间的距离, d 。

距离 d 将使用其笛卡尔坐标之间的 差 的绝对和来计算,如下所示:

其中,易 分别为二维向量空间中向量 x 和 y 的变量。即 x = (x1,x2,x3,…) 和 y = (y1,y2,y3,…) 。
现在距离 d 将被计算为-
【x1-y1】+**+(x2-y2)++(x3-y3)+…+(xn-yn)**。
如果您尝试将距离计算可视化,它将如下所示:

Source — Taxicab geometry Wikipedia
曼哈顿距离也被称为出租车几何,城市街区距离等。
欧几里德距离:
欧几里德距离是最常用的距离度量之一。通过将 p 的 值设置为 2 ,使用闵可夫斯基距离公式进行计算。这将更新距离**【d】**公式如下:

我们停一会儿吧!这个公式看着眼熟吗?嗯是的,我们刚刚在这篇文章上面讨论 “勾股定理”的时候看到了这个公式。
欧几里德距离公式可以用来计算平面上两个数据点之间的距离。

余弦距离:
余弦距离度量主要用于发现不同文档之间的相似性。在余弦度量中,我们测量两个文档/向量之间的角度(作为度量收集的不同文档中的术语频率)。当向量之间的大小无关紧要但方向重要时,使用这种特定的度量。
余弦相似性公式可以从点积公式中导出

现在,你一定在想余弦角的哪个值会有助于找出相似点。

现在我们有了用来衡量相似性的值,我们需要知道 1,0 和-1 代表什么。
这里余弦值 1 用于指向相同方向的向量,即在文档/数据点之间存在相似性。正交向量为零,即不相关(发现一些相似性)。指向相反方向的向量的值为-1(无相似性)。
马氏距离:
Mahalanobis 距离用于计算多元空间中两个数据点之间的距离。
根据维基百科的定义,
Mahalanobis 距离是一个点 P 和分布 d 之间距离的度量。测量的想法是,P 离 d 的平均值有多少标准差。
使用 mahalanobis 距离的好处是,它考虑了协方差,这有助于测量两个不同数据对象之间的强度/相似性。观察值和平均值之间的距离可以计算如下-

这里,S 是协方差矩阵。我们使用协方差度量的倒数来获得方差归一化的距离方程。
现在,我们对不同的距离度量有了基本的了解,我们可以进入下一步,即使用这些距离度量的机器学习技术/建模。
机器学习建模和距离度量
在这一部分,我们将研究一些基本的分类和聚类用例。这将有助于我们理解距离度量在机器学习建模中的用途。我们将从监督和非监督算法的快速介绍开始,然后慢慢转向例子。
1.分类
K-最近邻(KNN)-
KNN 是一种非概率监督学习算法,即它不产生任何数据点的隶属概率,而是 KNN 根据硬分配对数据进行分类,例如数据点将属于 0 或 1。现在,你一定在想,如果没有概率方程,KNN 是怎么工作的。KNN 使用距离度量来找出相似点或不同点。
让我们看看 iris 数据集,它有三个类,看看 KNN 将如何识别测试数据的类。

在黑色方块上方的#2 图像中是一个测试数据点。现在,我们需要借助 KNN 算法找到这个测试数据点属于哪一类。我们现在将准备数据集来创建机器学习模型,以预测我们的测试数据的类别。
*#Import required libraries#Import required librariesimport numpy as np
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.neighbors import KNeighborsClassifier
from sklearn.metrics import accuracy_score#Load the dataset
url = "[https://raw.githubusercontent.com/SharmaNatasha/Machine-Learning-using-Python/master/Datasets/IRIS.csv](https://raw.githubusercontent.com/SharmaNatasha/Machine-Learning-using-Python/master/Datasets/IRIS.csv)"
df = pd.read_csv(url)#quick look into the data
df.head(5)#Separate data and label
x = df.iloc[:,1:4]
y = df.iloc[:,4]#Prepare data for classification process
x_train, x_test, y_train, y_test = train_test_split(x, y, test_size=0.3, random_state=0)*
在 KNN 分类算法中,我们定义了常数“K”。* K 是一个测试数据点的最近邻数。然后,这 K 个数据点将用于决定测试数据点的类别。(注意这是在训练数据集中)*

你是否想知道我们如何找到最近的邻居。这就是距离度量进入图片的地方。首先,我们计算每列火车和测试数据点之间的距离,然后根据 k 的值选择最接近的顶部
我们不会从头开始创建 KNN,但会使用 scikit KNN 分类器。
*#Create a modelKNN_Classifier = KNeighborsClassifier(n_neighbors = 6, p = 2, metric='minkowski')*
你可以在上面的代码中看到,我们使用的是闵可夫斯基距离度量,p 值为 2,即 KNN 分类器将使用欧几里德距离度量公式。
随着机器学习建模的发展,我们现在可以训练我们的模型,并开始预测测试数据的类别。
*#Train the model
KNN_Classifier.fit(x_train, y_train)#Let's predict the classes for test data
pred_test = KNN_Classifier.predict(x_test)*
一旦选择了顶部最近的邻居,我们检查邻居中投票最多的类-

从上图中,你能猜出考点的类别吗?它是 1 类,因为它是投票最多的类。
通过这个小例子,我们看到了距离度量*对于 KNN 分类器的重要性。*这有助于我们获得已知类别的最接近的列车数据点。使用不同的距离指标,我们可能会得到更好的结果。所以,在像 KNN 这样的非概率算法中,距离度量起着重要的作用。
2.使聚集
K-means-
在概率或非概率的分类算法中,我们将获得带标签的数据,因此预测类别变得更容易。尽管在聚类算法中我们不知道哪个数据点属于哪个类。距离度量是这类算法的重要组成部分。
*在 K-means 中,我们选择定义聚类数的质心数。*然后使用距离度量(欧几里德)将每个数据点分配到其最近的质心。我们将使用 iris 数据来理解 K-means 的基本过程。

在上面的图像#1 中,你可以看到我们随机放置了质心,在图像#2 中,使用距离度量试图找到它们最近的聚类类。
*import numpy as np
import pandas as pd
from sklearn.cluster import KMeans
import matplotlib.pyplot as plt#Load the dataset
url = "[https://raw.githubusercontent.com/SharmaNatasha/Machine-Learning-using-Python/master/Datasets/IRIS.csv](https://raw.githubusercontent.com/SharmaNatasha/Machine-Learning-using-Python/master/Datasets/IRIS.csv)"
df = pd.read_csv(url)#quick look into the data
df.head(5)#Separate data and label
x = df.iloc[:,1:4].values#Creating the kmeans classifier
KMeans_Cluster = KMeans(n_clusters = 3)
y_class = KMeans_Cluster.fit_predict(x)*
我们将需要不断重复分配质心,直到我们有一个清晰的集群结构。

正如我们在上面的例子中看到的,在 K-Means 中的距离度量的帮助下,在没有关于标签的任何知识的情况下,我们将数据聚类成 3 类。
3.自然语言处理
信息检索
在信息检索中,我们处理非结构化数据。数据可以是文章、网站、电子邮件、短信、社交媒体帖子等。借助 NLP 中使用的技术,我们可以创建矢量数据,以便在查询时可以用来检索信息。一旦将非结构化数据转换成向量形式,我们就可以使用余弦相似性度量从语料库中过滤掉不相关的文档。
我们举个例子,了解一下余弦相似度的用法。
- 为语料库和查询创建向量形式-
*import math
import numpy as np
import pandas as pd
import matplotlib.pyplot as pyplot
from sklearn.metrics.pairwise import cosine_similarity
from sklearn.feature_extraction.text import TfidfVectorizervectorizer = TfidfVectorizer()corpus = [
'the brown fox jumped over the brown dog',
'the quick brown fox',
'the brown brown dog',
'the fox ate the dog'
]query = ["brown"]X = vectorizer.fit_transform(corpus)
Y = vectorizer.transform(query)*
2.检查相似性,即找到语料库中与我们的查询相关的文档-
*cosine_similarity(Y, X.toarray())**Results:**
**array([[0.54267123, 0.44181486, 0.84003859, 0\. ]])***
从上面的例子可以看出,我们查询单词“布朗”,在语料库中只有三个文档包含单词“布朗”。当使用余弦相似性度量检查时,除第四个文档外,其他三个文档的>值均为 0,从而给出了相同的结果。
结论
通过这篇文章,我们了解了一些流行的距离/相似性度量,以及如何使用这些度量来解决复杂的机器学习问题。希望这能对初入机器学习/数据科学的人有所帮助。
参考
排气数据在数据科学中的重要性

Image Credit: NASA/JPL-Caltech
当我第一次听到排气数据这个术语时,我被迷住了。关于同一个主题有很多不同的定义,我想深入探讨一下。简而言之,耗尽型数据是在没有特定目的的情况下生成的数据,可能不会立即显示出对组织在管理、存储和使用这些数据上花费金钱的重要性。嗯,让我们再举几个例子,同时我们会尝试将这些例子与数据科学联系起来。
几个例子(我们这里只是触及冰山一角!):
**网购活动:**假设你去一家网店买鞋。你看了几十个,最后选了一个放在购物车里。一个小时后你回来了,最后买下了它。对于在线商店,主要信息是您点击了哪双鞋,您将哪双鞋放在购物车上,您的鞋码,以及最终的交易信息。现在,让我们考虑一下尾气数据。这可能是你的位置信息,你在其他产品上花费的时间,你搜索的短语,鞋子在购物车中的时间,你使用的设备,安全日志,cookies 等。利用这些废气数据,您可以使用数据科学获得一些可行的见解,如产品推荐、欺诈检测、高效营销、改善客户体验、价格优化等。
**有人发微博吗?😗*假设有人发微博说“第一场雪就像初恋——劳拉·比尤斯。”仅仅这条推文和用户名可能不会给我们太多的见解。以元数据的形式用尽数据,比如位置、设备 id、发布时间、用户的关注者数量、用户关注的用户数量、帐户的创建日期等等。现在,零售商店可以使用这些数据来储备药品、供应品、冬靴,媒体流媒体公司可以使用这些数据来播放假日电影,紧急服务可以使用这些数据,导航服务可以提醒司机等等。
**视频:**这是一个非常有趣的空间。视频自然带有一些元数据,如时长、文件大小、格式、创作者/导演、演员等。然而,数据科学在这方面的范围相当有限。进入机器学习,我们可以根据声音、场景的情感(想想静止图像上的情感,因为视频只是一系列超快的静止图像)、场景的位置、历史重要性、成人内容识别来自动生成文本。自然,这些元数据大量用于个性化视频分段、内容审核、视频推荐、基于内容的搜索和索引视频、个性化广告制作、成人内容过滤等。
**物联网空间:**同样,这是一个非常广泛的话题,与其他例子类似,工业物联网中的尾气数据可能是最大的。例如,世界上最大的金属和矿业公司之一 Rio Tinto 每分钟产生 2.4 万亿字节的数据,而地震数据的总量可达数十亿字节[1]。我觉得这里有两件事改变了游戏规则。得益于云计算,存储和计算的成本在过去十年中以指数速度下降。2.边缘计算尺寸减小,功耗增加(例如 FPGAs)。由于这种技术进步,这些公司可以在本地边缘运行机器学习模型,并保持存储大量数据以进行历史分析。
当然,这些只是收集尾气数据的热情日益高涨的几个例子。在这个蓬勃发展的信息社会中,每个工业部门都在利用尾气数据的力量来获得竞争优势,并在客户满意度方面出类拔萃。
总之,虽然收集尾气数据提供了一个很好的机会,但它也带来了保护个人和敏感信息的责任。一个例子是国家安全局大规模收集电话记录[2]。两名斯坦福大学的研究生在他们的研究中发现,监控元数据可以用来查找呼叫者的信息、医疗状况、财务和法律关系[3]。本着开放、积极和道德的心态,我认为利用尾气数据的领域将在未来成为游戏规则的改变者。
参考
[1]
G.Goidel,“https://rctom.hbs.org”,2018 年 11 月 12 日。【在线】。可用:https://rctom . HBS . org/submission/data-is-the-new-oil-Rio-Tinto-builds-new-intelligent-mine/。
[2]
E.中岛,“www.washingtonpost.com”,2015 年 11 月 27 日。【在线】。可用:https://www . Washington post . com/world/national-security/NSAs-bulk-collection-of-Americans-phone-records-ends-Sunday/2015/11/27/75d c62e 2-9546-11e 5-a2d 6-f 57908580 b1f _ story . html?no redirect = on&UTM _ term = . 2f 344 e 00 EB 33 .
[3]
C.b .帕克," news.stanford.edu ",2014 年 3 月 12 日。【在线】。可用:https://news . Stanford . edu/news/2014/March/NSA-phone-surveillance-031214 . html?UTM _ content = buffer 07d 49&UTM _ medium = social&UTM _ source = Twitter . com&UTM _ campaign = buffer。
特征工程方法的重要性
特征工程方法及其对不同机器学习算法的影响分析

Photo by Fabrizio Verrecchia on Unsplash
机器学习算法接受一些输入,然后生成一个输出。例如,这可能是一只股票第二天的价格,使用的是前几天的价格。从给定的输入数据,它建立一个数学模型。该模型以自动化的方式发现数据中的模式。这些模式提供了洞察力,这些洞察力被用于做出决策或预测。为了提高这种算法的性能,特征工程是有益的。特征工程是一个数据准备过程。一种是修改数据,使机器学习算法识别更多的模式。这是通过将现有特征组合并转换成新特征来实现的。
应用机器学习从根本上来说是特征工程。但是这也是困难和费时的。它需要大量的经验和领域知识。评估哪些类型的工程特征性能最佳可以节省大量时间。如果一个算法可以自己学习一个特性,就没有太大的必要提供。
特征工程方法的前期分析
杰夫·希顿在[1]中研究了公共特征工程方法。他评估了机器学习算法综合这些特征的能力。起初,他采样均匀随机值作为输入特征 x 。接下来,他用特定的方法设计了一个功能。他用这个工程特征作为标签 y 。然后使用预测性能来测量该能力。研究的特征工程方法有:

Counts

Differences

Logarithms

Polynomials

Powers (square)

Ratios

Ratio differences

Ratio polynomials

Root distance (quadratic)

Square root
他一次只测试一种特征工程方法。他对输入要素进行采样的范围各不相同。在每种情况下,他评估了四种不同模型的均方根误差(RMSE)。其中包括:
- 神经网络
- 高斯核支持向量机(SVM)
- 随机森林
- 梯度推进决策树(BDT)
他在自己的 GitHub 页面上发布了 RMSE 结果。希顿得出以下结论:
- 所有的算法都不能综合比值差特征。
- 基于决策树的算法不能综合计数特征。
- 神经网络和 SVM 不能合成比率特征。
- SVM 未能综合二次特征。
因此,结果表明,算法可以综合一些特征,但不是全部。尽管根据算法的类型有一些不同。
然而,均方根误差对标签的绝对值很敏感。并且实验的标签值在不同的数量级上变化。此外,分布也不相同。在某些情况下,当从稍微不同的范围对输入要素进行采样时,可能会得出不同的结论。因此,不同实验中的 RMSE 值不具有可比性。只是同一实验中不同模型的 RMSE 值。为了说明这一点,我用改进的评估方法重复了这个实验。这揭示了一些有趣的差异。
改进的分析设置和结果
我改变了评估方法,使标签值均匀随机抽样。我选择的范围在 1 到 10 之间。所有实验都使用相同的取样标签。之后,我在标注上使用逆变换创建了输入要素。例如,我没有使用输入要素的平方来创建标注,而是使用标注的平方根来创建输入要素。

Inversion
在反演有多个解的情况下,只使用一个解。在多输入的实验中,我随机采样了除一个输入特征之外的所有输入特征。我选择了采样范围,以便所有输入要素都在同一范围内。此外,我使用所有模型的标准化来缩放数据。最后,我在每个实验中尝试了神经网络和 BDT 的不同学习速率。取学习率,即各个模型表现最好的学习率。我用了希顿分析中剩下的装置。结果如图 1 所示。

Figure 1: Capacity of Machine Learning algorithms to synthesize common Feature Engineering methods. Label values ranged uniformly between 1 and 10. Simply predicting the mean of the labels, would result in an RMSE value of 2.6.
与希顿的分析一致,所有算法都无法合成比率差异特征。此外,计数和比率功能也有相似之处。基于决策树的算法比其他具有计数特征的算法性能更差。决策树没有总结不同特征的固有方式。他们需要为每种可能的组合创建一片叶子,以便很好地合成计数特征。此外,神经网络和 SVM 在比率特征方面表现较差。最后,实验结果证实了决策树可以综合单调变换特征。正如所料。
与希顿的分析相反,我的分析显示了二次特征的巨大差异。所有模型在综合这些特征时都有问题。在希顿的二次特征实验中,许多标签的值为零。其余的价值很小。这就解释了区别。此外,线性模型在综合对数特征方面存在更多问题。这个实验中的标记比其他实验中的标记小一个数量级。这导致了差异。
结论
该分析评估了特征工程方法在建模过程中的重要性。这是通过测量机器学习算法合成特征的能力来完成的。所有被测试的模型都可以学习简单的转换,比如只包含一个特征的转换。因此,专注于基于多个特征的工程特征可以更有效地利用时间。尤其是二次特征和包含除法的特征非常有用。
此外,这解释了为什么集合不同的模型通常会导致显著的性能提高。基于相似算法的集成模型则不会。例如,在具有类似计数和对数模式的数据集中,组合随机森林和增强决策树仅受益于对数特征。而组合神经网络和随机森林从两种特征类型中获益。
[1] J .希顿,预测建模的特征工程实证分析 (2016),arXiv
利用机器学习的创新指标的重要性
希腊的例子

Photo by Anastasia Zhenina on Unsplash
这篇文章对希腊进行了创新分析。利用多种机器学习算法的基于模型的特征重要性来确定影响希腊创新产出得分波动的最重要指标。使用的分类器有逻辑回归、随机森林、额外树和支持向量机。这项研究的数据由 欧洲创新记分牌 免费提供。
介绍
创新可以定义为一个过程,它为组织、供应商和客户提供附加值和一定程度的新颖性,开发新的程序、解决方案、产品和服务以及新的营销方式[1]。这是每个组织最关心的问题之一。它在市场发展和协调中的作用是固有的。创新应用的重要性在从产品开发、管理方法到工作方式的所有人类领域都至关重要[2]。
背景资料
相关资料
欧盟委员会提供了各种工具来绘制、监测和评估欧盟在不同创新领域的表现。所提供的信息有助于欧盟、国家和区域层面的政策制定者和实践者衡量其绩效和政策,并了解新趋势和新出现的商业机会,从而为循证决策提供信息[3]。欧洲创新记分牌 ( EIS )就是这样一个工具,它提供了对欧洲研究和创新绩效的比较评估。它评估国家研究和创新系统的相对优势和弱点,并帮助各国和各区域确定它们需要解决的领域。

Photo by Sara Kurfeß on Unsplash
2018 年的 EIS 版本区分了四种主要类型的指标和十个创新维度,总共捕获了 27 个不同的指标[4]。包括综合指标在内的四个主要类别是:
- 框架条件:企业外部创新绩效的主要驱动因素,区分三个综合指标(人力资源、研究系统、创新友好型环境)。
- 投资:对公共和商业部门的投资,区分两个综合指标(金融和支持、企业投资)。
- 创新活动:商业部门创新的不同方面,并区分三个综合指标(创新者、联系、知识资产)。
- 影响:企业创新活动的影响以及两个综合指标之间的差异(就业影响、销售影响)。
EIS 2018 的时序数据是指 2010-2017 年的时间框架。
机器学习
特征选择是机器学习中的基本技术[5]。人们不能随意保留或删除特征。有几种特征选择方法,包括降维[6]。一般来说,有两种主要的特征重要性方法,模型无关的和基于模型的。与模型无关的特征选择技术,例如前向特征选择,提取所选关键性能指标的最佳值所需的最重要的特征。然而,这种方法通常有一个缺点,即时间复杂度大。为了避免这个问题,可以从被训练模型中直接获得特征重要性。上面的方法是基于模型的方法。因此,上述方法被用于估计特征的重要性。
Logistic 回归是一种二元分类算法。它的目标是在 k 维空间中找到分隔这两个类别的最佳超平面,最小化逻辑损失[7]。为了估计每个特征对模型输出的重要性,使用了 k 维权重向量。第 j 个权重的大绝对值表示第 j 个特征在类别预测中的较高重要性。
随机森林是决策树模型的变种。这是一个使用多个决策树作为基础学习器的集成模型。基础学习者是高方差、低偏差的模型。通过汇总所有基础学习者做出的决策来预测响应变量,减少了整个模型的方差。这个想法是为了确保每个基础学习者学习数据的不同方面。这是通过行和列采样实现的[8]。在分类设置中,聚合是通过采取多数表决来完成的。在决策树的每个节点,基于信息增益标准或计算成本更低的基尼系数杂质减少来决定用于分割数据集的特征。选择最大化信息增益(或减少基尼系数杂质)的特征作为分裂特征。通过使用基尼重要度,特征重要度被计算为通过到达该节点的概率加权的节点杂质的减少。节点概率可以通过到达节点的样本数除以样本总数来计算。因此,很容易理解,值越高,特征越重要。
Extra-Trees 代表极度随机化的树。该分类器是一种基本上基于决策树的集成学习方法。 Extra-Trees 分类器将某些决策和数据子集随机化,以最大限度地减少数据的过度学习和过度拟合。多余的树就像随机森林。这种算法建立和适应多棵树,并使用随机特征子集分割节点[9]。然而,随机森林和额外树分类器之间的两个关键区别如下:
- 额外树不引导观察。该算法使用无替换的采样。
- 额外树节点根据在每个节点选择的特征的随机子集的随机分裂来分裂,而不是最佳分裂。
从统计学的角度来看,放弃 bootstrapping 的想法会导致偏倚方面的优势,而分裂点随机化通常具有极好的方差减少效果。如上所述,在随机森林中使用基尼系数计算特征重要性。
支持向量机 ( SVM )是一个强大的监督学习模型,用于预测和分类。 SVM 的基本思想是使用非线性映射函数将训练数据映射到高维空间,然后在高维空间执行“线性”回归以分离数据。预定的核函数用于数据映射。通过寻找最佳超平面来完成数据分离。这个最优超平面被称为支持向量,其具有来自分离类的最大余量【10】。
与人工神经网络、决策树等经典分类方法相比,SVM 有许多优点。在高维空间中的良好性能可以被认为是一种优势。此外,支持向量依赖于训练数据的一个小子集,这给了 SVM 惊人的计算优势。
在这项研究中,使用了线性核的 SVM 算法。因此,为了估计每个特征对模型输出的重要性,使用了 k 维权重向量。第 j 个权重的大绝对值表示第 j 个特征在类别预测中的较高重要性。权重系数彼此之间的绝对大小可以用于从数据中确定特征重要性。
数据收集和预处理
使用来自 2018 年欧洲创新记分牌 ( EIS )数据库版本的数据,包括 2010-2017 年期间的希腊数据。数据是从 欧洲创新记分牌 网站免费收集的。希腊的数据质量很高,只有少量遗漏的观测数据。
数据库被过滤以仅选择关于希腊的指标。数据中丢失的值将被清除。此外,这两个指标的值在希腊层面缺失,因此在分析中不予考虑。这些指标是“外国博士研究生占所有博士研究生的百分比”和“在快速增长的企业中就业的百分比”。对于每个指标,使用数据库提供的标准化分数构建了 2010 年至 2017 年的时间序列数据。总体而言,时间序列数据由 25 个指标和汇总创新指数组成。
为了便于阅读,指示器的名称被截断。指示器的全名如下所示:
- 宽带 _ 渗透:宽带渗透。
- Venture_capital :风险资本占 GDP 的百分比。
- 设计 _ 应用:每十亿 GDP 的设计应用(PPS)。
- Trademark_apps :每十亿 GDP 的商标申请量(pps)。
- 就业 _ 活动:知识密集型活动的就业(占总就业的%)。
- 企业 _ 培训:提供培训以发展或提升其员工信息和通信技术技能的企业。
- 创新型中小企业:与他人合作的创新型中小企业(中小企业的%)。
- 国际 _ 出版物:每百万人口的国际科学合作出版物。
- 知识 _ 出口:知识密集型服务出口占总服务出口的百分比。
- 新博士毕业生:每 1000 名 25-34 岁人口中的新博士毕业生。
- 非研发:非研发&创新支出(占营业额的百分比)。
- Opportunity_enterpre :机会驱动型创业(动机指数)。
- Pct_patent :每十亿 GDP 的 Pct 专利申请量(PPS)。
- 百分比 _ 高等教育 _ edu:25-34 岁人口完成高等教育的百分比。
- 百分比 _ 终身学习:参与终身学习的 25-64 岁人口的百分比。
- 私人共同出资:公共研发支出的私人共同出资(占国内生产总值的百分比)。
- Public_private_pubs :每百万人口公私合作出版物。
- Rd_business : R & D 商业部门的支出(占国内生产总值的%)。
- Rd_public : R & D 公共部门的支出(占国内生产总值的%)。
- 销售额:新上市和新公司创新的销售额占营业额的百分比。
- Scientific_pubs :世界范围内被引用次数最多的前 10%的科学出版物占该国全部科学出版物的百分比。
- 内部中小企业:内部创新的中小企业占中小企业的百分比。
- 中小企业 _ 营销:引入营销或组织创新的中小企业占中小企业的百分比。
建模和实施
首先,使用相关性分析来避免在分析中包括高度相关的特征。然后,简要描述了时间序列分类过程的建模技术。
下图显示了希腊指标的关联热图。出于可视化和解释的目的,热图用于呈现成对相关分析。为避免多重共线性问题,丢弃高度相关要素的阈值设置为 0.90 。但是,这个阈值仍然被认为是一个高值。使用阈值 0.70 当然更好,但是数据特征的数量有限。因此,具有 0.90 相关性的特征将从分析中删除。

因此,应删除以下指标:
- 每十亿国内生产总值的商标申请量(PPS)
- 知识密集型活动中的就业(占总就业的%)
- 每百万人口的国际科学合作出版物,
- 知识密集型服务出口占总服务出口的百分比,
- 25-64 岁参与终身学习人口百分比,
- 商业部门的研发支出(占国内生产总值的%)
- 公共部门的研发支出(占国内生产总值的%)
- 新上市和新公司创新的销售额占营业额的百分比,
- 世界上被引用次数最多的前 10%的科学出版物占该国全部科学出版物的百分比,
- 内部创新的中小企业占中小企业的百分比,
- 采用营销或组织创新的中小企业占中小企业的百分比,
- 引入产品或工艺创新的中小企业占中小企业的百分比。
接下来,描述了用于分类目的的时间序列建模技术。构建了一个向量 v ,该向量使用以下技术对时间范围(2010-2017)内的综合创新指数波动进行建模:
- 步长等于一年的滑动窗口从时间帧的开始开始,并且如果本年度的汇总创新指数的值高于上一年度的值,则 v =1,否则 v =0。因此,这是一个二元分类问题,特征矩阵为 X 指标,标号为 y 向量为 v 。
然后,使用三重交叉验证方法训练四个机器学习模型,即逻辑回归、 SVM (线性核)、随机森林分类器和额外树分类器。数据实例有限的事实导致我们对模型进行交叉验证训练,特别是三重交叉验证。保持模型对 3 个折叠中每个折叠的特征重要性的估计。然后,重要性的最终值是每个模型的这 3 个折叠的平均值。每个基于模型的重要性值被转换为每个模型的百分比。最后,特征重要性的总结是来自每个模型的指标重要性的所有百分比值的平均值。
结果
下面是一个图表,以百分比形式总结了希腊指标的特征重要性。

毫无疑问,风险资本在希腊的创新产出中发挥着重要作用。具体来说,这是初创企业和企业家最关心的问题之一。它为创新铺平了道路,并允许它们被设计成适销对路的产品。它有助于为商业想法提供资金,否则这些想法将没有机会获得必要的资本。因此,创新技术和服务的发展在国家创新产出中发挥着关键作用。
此外,希腊还倾向于严重依赖受过良好教育的人和有创造力的中小企业来增加创新生产。新的博士毕业生和 25-34 岁的大学毕业生无疑在创新生产中发挥着重要作用。大多数创新的想法来自受过教育的人。在希腊,中小企业占该国私营部门总数的 99.9%。具体来说,微型企业约占私营部门的 96.6%,约占希腊经济总就业人数的 56%。换言之,中小企业是希腊经济中最重要的部分,直接影响着经济生活的金融和社会层面。与其他公司或组织合作的创新型中小企业是希腊企业家精神的一个重要标志。公共研究机构和公司之间以及公司和其他企业之间的专业知识转移似乎对创新的产生很重要。
结论
在这篇文章中,使用机器学习对创新指标的重要性进行了分析。通过对希腊综合创新指数采用建模技术,评估了希腊指标对其波动的影响。基于模型的希腊特征重要性分析是使用四个众所周知的分类器模型实现的。结果显示,排名前五位的重要特征是设计申请、风险投资、25-34 岁完成高等教育的人口比例、每 1000 名 25-34 岁人口中新增博士毕业生和与他人合作的创新型中小企业。
参考
[1] R .卡内基和澳大利亚商业理事会。管理创新企业:澳大利亚公司与世界最佳竞争。商业图书馆,1993 年,第 427 页,ISBN: 1863501517。【在线】。可用:https://catalogue . nla . gov.au/Record/1573090。
[2] H. Tohidi 和 M. M. Jabbari,“创新的重要性及其在组织成长、生存和成功中的关键作用”,《Procedia 技术》,第 1 卷,第 535-538 页,2012 年 1 月,ISSN:2212-0173。DOI:10.1016/j . protcy . 2012 . 02 . 116 .[在线]。可用:https://www . science direct . com/science/article/pii/s 221201731200117 x
[3]监测创新|内部市场、工业、企业家精神和中小企业。【在线】。可用:https://ec.europa.eu/growth/industry/innovation/事实-数字 _en 。
[4]欧盟委员会,DocsRoom —欧盟委员会 EIS 2018 方法论报告,2018。【在线】。可用:https://ec.europa.eu/docsroom/documents/30081。
[5] I. Guyon 和 A. Elisseeff,“变量和特征选择导论”,机器学习研究杂志,第 3 卷,第 3 号,第 1157-1182 页,2003 年,ISSN:ISSN 1533-7928。【在线】。可用:【http://jmlr.csail.mit.edu/papers/v3/guyon03a.html】T2。
[6] M. L. Bermingham,R. Pong-Wong,A. Spiliopoulou,C. Hayward,I. Rudan,H. Campbell,A. F. Wright,J. F. Wilson,F. Agakov,P. Navarro 和 C. S. Haley,“高维特征选择的应用:对人类基因组预测的评估”,《科学报告》,第 5 卷,第 1 期,第 10-312 页,2015 年 9 月,ISSN:2045-2322。DOI: 10.1038/srep10312。【在线】。可用:【https://www.nature.com/articles/srep10312】T4。
[7] D. W. Hosmer 和 S. Lemeshow,应用逻辑回归。美国新泽西州霍博肯:约翰威利父子公司,2000 年 9 月,ISBN: 9780471722144。DOI: 10.1002/ 0471722146。【在线】。可用:http://doi.wiley.com/10.1002/0471722146.
[8] T. K. Ho,“随机决策森林”,载于第三届国际文件分析和识别会议录(第 1 卷)——第 1 卷,ser 美国 DC 华盛顿州 IC Dar ’ 95:IEEE 计算机学会,1995 年,第 278 页,ISBN:0–8186–7128–9。【在线】。可用:https://dl.acm.org/citation.cfm?id=%20844379.844681。
[9] P. Geurts、D. Ernst 和 L. Wehenkel,“极度随机化的树”,Mach Learn (2006 年。DOI:10.1007/s 10994–006–6226–1。【在线】。可用:http://citeseerx.ist.psu.edu/viewdoc/download?doi = 10 . 1 . 1 . 65 . 7485&rep = re P1&type = pdf。
[10] V. Vapnik,“统计学习理论概述”,IEEE 神经网络汇刊,第 10 卷,第 5 期,第 988-999 页,1999 年,ISSN: 10459227。DOI: 10.1109/72.788640。【在线】。可用:https://ieeexplore.ieee.org/document/788640。
损失函数在机器学习中的重要性
最初发表于 OpenGenus IQ 。
答假设给你一个任务,用 10 公斤沙子装满一个袋子。你把它装满,直到测量机器给你一个 10 公斤的精确读数,或者如果读数超过 10 公斤,你就把沙子拿出来。
就像那个称重机,如果你的预测是错的,你的损失函数会输出一个更高的数字。如果他们很好,它会输出一个较低的数字。当你试验你的算法来尝试和改进你的模型时,你的损失函数会告诉你是否有所进展。
“我们要最小化或最大化的函数叫做目标函数或准则。当我们将其最小化时,我们也可以称之为成本函数、损失函数或误差函数”——来源
本质上,损失函数是对预测模型在预测预期结果(或价值)方面表现的度量。我们将学习问题转化为优化问题,定义一个损失函数,然后优化算法以最小化损失函数。

损失函数有哪些类型?
最常用的损失函数有:
- 均方误差
- 绝对平均误差
- 对数似然损失
- 铰链损耗
- 胡伯损失
- 均方误差
均方差(MSE)是基本损失函数的工作空间,因为它易于理解和实现,并且通常工作得很好。要计算 MSE,您需要获取模型预测值和地面真实值之间的差异,将其平方,然后在整个数据集内取平均值。
无论预测值和实际值的符号如何,结果总是正的,理想值为 0.0。
# function to calculate MSE
def MSE(y_predicted, y_actual): squared_error = (y_predicted - y_actual) ** 2
sum_squared_error = np.sum(squared_error)
mse = sum_squared_error / y_actual.size return mse
2。平均绝对误差
平均绝对误差(MAE)在定义上与 MSE 略有不同,但有趣的是,它提供了几乎完全相反的性质。要计算 MAE,您需要获取模型预测和地面实况之间的差异,将绝对值应用于该差异,然后在整个数据集内进行平均。
# function to calculate MAE
def MAE(y_predicted, y_actual):
abs_error = np.abs(y_predicted - y_actual)
sum_abs_error = np.sum(abs_error)
mae = sum_abs_error / y_actual.size
return mae

MSE (blue) and MAE (red) loss functions
3。对数似然损失
这个损失函数也比较简单,常用于分类问题。在此,
使用交叉熵来测量两个概率分布之间的误差。
-(y_actual * log(y_predicted) + (1 - y_actual) * log(1 - y_predicted))
这里可以看到,当实际类为 1 时,函数的后半部分消失,当实际类为 0 时,前半部分下降。那样的话,我们最终会乘以实际预测概率的对数。

Source: fast.ai
二元或两类预测问题的交叉熵实际上是作为所有示例的平均交叉熵来计算的。
from math import log
# function to calculate binary cross entropy
def binary_cross_entropy(actual, predicted):
sum_score = 0.0
for i in range(len(actual)):
sum_score += actual[i] * log(1e-15 + predicted[i])
mean_sum_score = 1.0 / len(actual) * sum_score
return -mean_sum_score
这个函数是 Kaggle 竞赛中最受欢迎的度量之一。这只是对数似然函数的简单修改。
4。铰链损耗
铰链损失函数在支持向量机中很流行。这些用于训练分类器。假设“t”是目标输出,使得 t = -1 或 1,并且分类器得分是“y”,则预测的铰链损失被给出为:L(y) = max(0, 1-t.y)
5。胡贝尔损失
我们知道 MSE 非常适合学习异常值,而 MAE 非常适合忽略它们。但是中间的东西呢?
考虑一个例子,我们有一个 100 个值的数据集,我们希望我们的模型被训练来预测。在所有这些数据中,25%的预期值是 5,而另外 75%是 10。
由于我们没有“异常值”,一个 MSE 损失不会完全解决问题;25%绝不是一个小分数。另一方面,我们不一定要用 MAE 来衡量太低的 25%。这些值 5 并不接近中值(10——因为 75%的点的值为 10 ),但它们也不是异常值。
我们的解决方案?
胡伯损失函数。
Huber Loss 通过同时平衡 MSE 和 MAE 提供了两个世界的最佳选择。我们可以使用以下分段函数来定义它:

这个等式的实际意思是,对于小于δ的损耗值,使用 MSE 对于大于 delta 的损失值,使用 MAE。这有效地结合了两个损失函数的优点。
# function to calculate Huber loss
def huber_loss(y_predicted, y_actual, delta=1.0): huber_mse = 0.5*(y_actual-y_predicted)**2
huber_mae = delta * (np.abs(y_actual - y_predicted) - 0.5 * delta)
return np.where(np.abs(y_actual - y_predicted) <= delta,
huber_mse, huber_mae)

MSE (blue), MAE (red) and Huber (green) loss functions
结论
损失函数提供的不仅仅是模型执行情况的静态表示,而是算法如何首先拟合数据。大多数机器学习算法在优化或为您的数据寻找最佳参数(权重)的过程中使用某种损失函数。
重要的是,损失函数的选择与神经网络输出层中使用的激活函数直接相关。这两个设计元素是联系在一起的。
将输出图层的配置视为对预测问题框架的选择,将损失函数的选择视为对问题给定框架的误差计算方式。
进一步阅读
深度学习书作者伊恩·古德菲勒、约舒阿·本吉奥和亚伦·库维尔。
大数据时代采样的重要性
1936 年的教训

数字时代的进步帮助我们克服了调查、研究和质量保证领域的统计抽样传统上面临的一些挑战。传统上,数据收集和处理的边际成本很高。现在,只需动动手指,收集、存储和处理大量数据就变得更加容易和快捷。在某些情况下,这导致了所谓的 大数据傲慢 —假设大数据分析可以作为传统分析手段的替代而非补充。
本文的目的不是淡化大数据和大数据分析带来的优势,而是仅仅强调抽样的重要性。此外,应该警惕拥有大量数据将弥补分析中其他挑战的观念。
1936 年美国总统竞选的文学文摘民意调查
在某种程度上,这可以被认为是 20 世纪 30 年代的“大数据”实验。1936 年,阿尔弗雷德·m·兰登(时任堪萨斯州州长)和在任的富兰克林·d·罗斯福分别代表共和党和民主党进行总统竞选。
《文学文摘》是当时备受尊重的新闻周刊。在那之前,他们一直顺风顺水——正确预测了自 1916 年以来总统选举的获胜者。他们大胆宣称将在 10 月举行 11 月的选举,发起了一场规模宏大的民意测验,邮件列表超过 1000 万。每个成员都收到了一张模拟选票,并被要求交回一张有标记的选票。约有 240 万人回复。根据这些回答,人们预测兰登将获得 57%的选票,而罗斯福将获得 43%的选票。但现实远非如此。罗斯福赢得了 46 个州和 60.8%的选票。

Predicted vs. Actual share of popular vote Source: Qualtrics
与此同时,乔治·盖洛普通过仔细获取约 5 万人的样本,预测出了获胜者。
我们能从中学到什么?
即使您拥有的数据非常“大”,它也可能只代表一部分人口,而不代表全部人口!
在《文学文摘》的案例中,他们的邮件列表来源于电话簿、杂志订户列表、俱乐部会员名册等等。嗯……在 20 世纪 30 年代,电话是一种奢侈品,这个国家一直受到大萧条的困扰,经济问题成为竞选的主题是有原因的!有明显的迹象表明,对低收入群体存在选择偏见。
在 机器学习 中,采样偏差会影响你的模型的性能。在训练和测试阶段,确保数据样本反映了您试图建模的相同基础分布是很重要的。
在一个问题上投入计算资源(或金钱)并不总能解决问题
花时间和精力选择合适的取样技术比对整个可及人群进行强力数据收集更有效。的重点不应该是增加样本量,而是减少采样偏差或其他误差。
有时候,少即是多!
当数据量有限时,更容易控制数据的质量。花时间去了解你的数据和收集数据的背景是非常重要的。在通过模型运行数据之前,可视化和检查数据中的异常值或缺失值非常重要。此外,在错误分类中更容易发现错误。
当我们每天坐在越来越多的数据上时,你认为哪个统计概念更重要?欢迎在下面评论…
参考资料:
在之前的帖子中,我们简要提到了 1936 年选举中一个经常被引用的投票错误。为了选举的荣誉…
www.qualtrics.com](https://www.qualtrics.com/blog/the-1936-election-a-polling-catastrophe/)
设定现实期望的重要性

如果产品所有者有现实的期望,你的模型会更快地产生更大的影响
似乎每个公司现在都在建立数据科学团队,并投资机器学习平台,无论是第三方还是内部构建的。
然而,研究表明,很少有公司将机器学习模型部署到生产中[1]。虽然技术复杂性是原因之一,但不切实际的期望也是原因之一。
设定合理的期望值
开发机器学习模型需要大量投资。你需要雇佣数据科学家,投资大数据工具,建立/购买模型服务平台。因此,期望往往很高,有时过高。
为了确保人工智能项目的成功,数据科学家需要确保他们在开始建立模型之前就设定了现实的预期。如果预期无法实现,您将获得开发模型的批准,但它们永远不会投入生产。
设定期望可能会很复杂,但你可以做一些事情来帮助引导对话:
- 使用现有流程作为基线
- 谈谈误报和漏报——你在优化什么?
- 用一个简单的模型来设定期望值
使用现有流程作为基线
机器学习模型通常会取代或自动化现有流程。查看这些流程,并尝试量化其整体性能(准确性、假阳性/假阴性率、预测时间等)。这将给你一个你的模型需要达到的基线。
除非您的模型与现有流程的性能相匹配,否则无论节省多少成本,都不会部署该模型
不要花太多时间考虑解决方案的总体成本,更多地关注整体模型的性能。这里的目标不是定义企业通过实施机器学习解决方案可以节省多少成本,而是了解您的模型预计将达到什么样的性能水平。
定义可接受的误报率和漏报率
在设定期望值时,我们首先考虑的是准确性。它很容易理解,通常是与产品负责人交谈时的神起点。
然而,仅仅同意一个目标精度是不够的。几乎在所有应用中,误报的业务成本都不同于漏报的成本。在很多情况下,成本可以相差一个数量级!
以欺诈预测为例。让我们假设你以 100 英镑的价格出售一件产品,利润率为 20%。这意味着一次销售将产生 20 英镑的利润但如果有人用偷来的卡购买产品你将损失 80 英镑(生产成本)外加支付处理商收取的费用(可能在 20 英镑左右)。在这种情况下,误报的成本是 20,而误报的成本是 100!因此,你的模型理论上可以有一个比假阳性率高 5 倍的假阴性率,并且仍然是有利可图的。
用一个简单的模型来设定期望值
部署一个机器学习模型涉及许多活动部件,从服务到监控。您部署的第一个模型必须相对简单,因为重点是围绕该模型的基础设施和流程。
模型的第一次迭代是关于建立流程,而不是关于性能
在花太多时间在其他事情上之前,开始开发一个非常简单的模型,很少或没有特征工程。假设这将是部署的第一个模型。
如果简单模型没有达到在阶段 1 和阶段 2 中与产品所有者达成一致的指标,您可以采取两种方法:
- 构建特征处理和复杂的模型,但是由于部署成本的原因,存在无法部署模型的风险
- 让产品负责人重新参与进来,为模型的第一个版本设定更现实的期望
在这些选项之间进行选择将取决于您的组织以及您正在开发的模型的战略性。在任何情况下,不要在没有与产品负责人讨论之前就开始。这可能看起来不多,但这可以将开发周期加快 10 倍。
结论
为了让机器学习模型在组织中得到广泛采用,数据科学团队需要在构建第一个模型之前让业务参与进来。
在项目开始时就性能度量标准达成一致,并定期与产品所有者进行核对,将有助于确保模型被快速部署。
参考资料:
理解机器学习算法复杂性的重要性
运行时分析
解释理解机器学习算法的内部工作的重要性,它在实现和评估中的不同。

Photo by Vincent Botta on Unsplash
机器学习工程师经常会发现自己需要为手头的问题选择正确的算法。通常情况下,他们首先理解他们提供解决方案的问题的结构。然后他们研究手边的数据集。经过最初的观察和关键的总结,他们最终为任务选择了正确的算法。
决定应用于手头数据集的最佳算法似乎是一项微不足道的工作。工程师经常在这些情况下创建捷径。如果任务有 0–1 标签,就应用逻辑回归,对吗?不对!我们应该意识到这些捷径,并时刻提醒自己,尽管某些算法对特定问题很有效,但在为问题选择最佳算法时,并没有“处方”。然而,算法的复杂性和运行时分析应该经常被讨论和考虑。
算法的运行时分析不仅对理解算法的内部工作至关重要,而且还能产生更成功的实现。
在本文的其余部分,我将描述一种情况,忽略对算法的运行时分析,在这种情况下 k 意味着集群,会导致工程师损失大量的时间和精力。
什么是 K 均值聚类
K-means 聚类是最流行且易于实现的无监督机器学习算法之一。也是容易理解的机器学习算法之一。
通常,无监督的机器学习算法仅使用特征向量从输入数据集进行推断。因此,这些算法适用于没有标签数据的数据集。当想要从大量结构化和非结构化数据中提取价值或洞察力时,它们也非常有用。K-means 聚类是这些探索性数据分析技术中的一种,其目标是提取数据点子组,使得同一聚类中的数据点在定义的特征方面非常相似。
K-均值聚类是如何工作的
K-means 聚类从第一组随机选择的数据点开始,这些数据点被用作质心的初始种子。然后,该算法执行迭代计算,将剩余的数据点分配给最近的聚类。当根据定义的距离函数执行这些计算时,质心的位置被更新。当出现以下任一情况时,它会停止优化聚类中心:
- 质心的位置是稳定的,即它们的值的变化不超过预定的阈值。
- 该算法超过了最大迭代次数。
因此,算法的复杂度是
O(n * K * I * d)n : number of points
K : number of clusters
I : number of iterations
d : number of attributes
K-means 算法例题
我将分享一个 k 均值聚类任务的代码片段。我的唯一目的是演示一个例子,其中未能理解运行时的复杂性会导致对算法的糟糕评估。我所采取的步骤并没有针对算法进行优化,也就是说,你可以更好地预处理数据并得到更好的聚类。涉及的步骤概述如下:
- 导入库,并读取数据集。在这里,我导入相关的库并读取数据集,我已经将数据集下载到了本地文件夹中。
- 预处理。在这一步中,我放弃了字符串类型的列,只关注数字特性。由于 k-means 聚类分析计算数据点之间的距离,因此它适用于数值列。
- 应用主成分分析进行降维。在应用 k-means 聚类之前降低数据集的维度通常是一种好的做法,因为在高维空间中,距离度量并不十分有效。
- 计算剪影分数。K-means 聚类不直接应用。它涉及到寻找最佳聚类数的问题。轮廓分数是可用于确定最佳聚类数的技术之一。不理解剪影分数分析中所涉及的计算的复杂性将导致较差的实现。
- 替代方案。在这里,我列出了一些找到最佳集群数量的备选解决方案。就运行时间复杂性而言,与剪影分数相比,它们是有利的。
您可以重现问题来试一试。数据集的链接:https://www.kaggle.com/sobhanmoosavi/us-accidents。
步骤 1:导入库并读取数据集
第二步:预处理
出于说明目的,我们仅根据道路相关特征对数据点进行聚类。
第三步:应用主成分分析降低维数


似乎 3 是最佳的。
步骤 4:计算剪影分数
有许多指标和方法可用于确定最佳聚类数。但我将集中讨论其中的几个。轮廓分数是这些度量之一。它是使用每个实例的平均类内距离和平均最近类距离来计算的。它计算每个样本与各个聚类中其余样本之间的距离。因此它的运行时间复杂度是 O(n)。如果不执行运行时分析,您可能需要等待数小时(如果不是数天)才能完成对大型数据集的分析。由于当前数据集有数百万行,一种解决方法是使用更简单的度量标准,如惯性或对数据集应用随机抽样。我将展示这两种选择。
第五步:替代解决方案
- 肘法
这种方法使用惯性或类内平方和作为输入。它描述了随着聚类数量的增加惯性值的减少。“肘”(曲线上的拐点)是惯性值的减少没有显著变化的点的良好指示。使用这种技术的优点是组内平方和不像轮廓分数那样计算昂贵,并且已经作为度量包括在算法中。

上面代码片段的挂钟时间是:
27.9 s ± 247 ms per loop (mean ± std. dev. of 7 runs, 1 loop each)
- 随机下采样
缩减采样允许您处理更小的数据集。这样做的好处是算法完成的时间大大减少了。这使得分析师能够更快地工作。缺点是,如果随机进行下采样,可能无法表示原始数据集。因此,任何涉及缩减采样数据集的分析都可能导致不准确的结果。但是,您可以始终采取预防措施,确保缩减采样数据集代表原始数据集。
上面代码片段的挂钟时间是:
3min 25s ± 640 ms per loop (mean ± std. dev. of 2 runs, 1 loop each)
结束语
在这篇文章中,我试图强调理解机器学习算法的复杂性的重要性。算法的运行时分析不仅对特定任务中的算法选择至关重要,而且对成功实现也很重要。这也是大多数雇主在数据科学领域寻求的关键技能之一。因此,做运行时分析和理解算法的复杂性总是一个好的实践。
如果你对这个帖子有任何疑问,或者对数据科学有任何疑问,你可以在Linkedin上找到我。
重要性抽样介绍
估计不同分布的期望值
重要抽样是一种近似方法,而不是抽样方法。它来源于一个小小的数学变换,能够以另一种方式表述问题。在这篇文章中,我们将:
- 学习重要性抽样的概念
- 通过实施流程获得更深入的理解
- 比较不同抽样分布的结果

什么是重要性抽样?
考虑一个场景,你试图计算函数f(x)的期望值,其中x ~ p(x)服从某种分布。我们对E(f(x))有如下估计:

蒙特卡罗抽样方法是简单地从分布p(x)中抽取x样本,并取所有样本的平均值,从而得到期望值的估计值。那么问题来了,如果p(x)很难采样呢?我们能够根据一些已知的和容易抽样的分布来估计期望值吗?
答案是肯定的。它来自一个简单的公式转换:

其中x是从分布q(x)中取样的,且q(x)不应为 0。通过这种方式,估计期望能够从另一个分布中抽样q(x),p(x)/q(x)被称为抽样比率或抽样权重,它作为一个校正权重来抵消从不同分布中抽样的概率。
我们需要讨论的另一件事是估计的方差:

其中在这种情况下,X是f(x)p(x)/q(x),所以如果p(x)/q(x)很大,这将导致很大的方差,这是我们肯定希望避免的。另一方面,也可以选择适当的q(x)来产生更小的变化。我们来举个例子。
示范
首先,让我们定义函数f(x)和样本分布:
f(x)的曲线看起来像:

现在我们来定义p(x)和q(x)的分布:
为了简单起见,这里p(x)和q(x)都是正态分布,你可以试着定义一些很难采样的p(x)。在我们的第一个演示中,让我们设置两个分布,它们具有相似的平均值(3 和 3.5)和相同的 sigma 1:

现在我们能够计算从分布p(x)中采样的真实值
我们得到的估计值是 0.954。现在让我们从q(x)中取样,看看它的表现如何:
请注意,这里的x_i是从近似分布q(x)中抽取的,我们得到的估计值为 0.949,方差为 0.304。请注意,我们能够通过从不同的分布中取样来获得估计值!
比较
分布q(x)可能与p(x)过于相似,以至于你可能会怀疑重要性抽样的能力,现在让我们试试另一个分布:
带直方图:

这里我们将n设置为 5000,当分布不同时,通常我们需要更多的样本来逼近该值。这次我们得到的估计值是 0.995,但是方差是 83.36。
原因来自p(x)/q(x),因为两个分布相差太大可能会导致该值的巨大差异,从而增加方差。经验法则是定义q(x),其中p(x)|f(x)|较大。(全面实施)
参考:
[1]https://www.youtube.com/watch?v=3Mw6ivkDVZc
[2]https://astro statistics . PSU . edu/su14/lectures/cisewski _ is . pdf
你需要知道的机器学习的重要话题
机器学习基础

Robots (Photo by Daniel Cheung on Unsplash)
机器学习现在是一个热门话题,每个人都试图获得任何关于这个话题的信息。关于机器学习的信息量如此之大,人们可能会不知所措。在这篇文章中,我列出了一些你需要知道的机器学习中最重要的主题,以及一些可以帮助你进一步阅读你有兴趣深入了解的主题的资源。
人工智能
人工智能是计算机科学的一个分支,旨在创造模仿人类行为的智能机器,如知识、推理、解决问题、感知、学习、规划、操纵和移动物体的能力
人工智能是计算机科学的一个领域,它强调创造像人类一样工作和反应的智能机器。
在计算机科学中,人工智能(AI),有时称为机器智能,是智能证明…
en.wikipedia.org](https://en.wikipedia.org/wiki/Artificial_intelligence) [## 什么是 AI(人工智能)?-WhatIs.com 的定义
人工智能是机器,尤其是计算机对人类智能过程的模拟
searchenterpriseai.techtarget.com](https://searchenterpriseai.techtarget.com/definition/AI-Artificial-Intelligence)
机器学习(ML)
机器学习属于人工智能的范畴,它为系统提供了自动学习和根据经验改进的能力,而无需显式编程。
学习的过程始于观察或数据,如例子、直接经验或指导,以便在数据中寻找模式,并根据我们提供的例子在未来做出更好的决策。
主要目的是让计算机在没有人类干预或帮助的情况下自动学习,并相应地调整行动。
机器学习(ML)是对算法和统计模型的科学研究,计算机系统使用这些算法和统计模型来…
en.wikipedia.org](https://en.wikipedia.org/wiki/Machine_learning) [## 什么是机器学习?定义专家系统
机器学习是人工智能(AI)的一种应用,它为系统提供了自动…
www.expertsystem.com](https://www.expertsystem.com/machine-learning-definition/) [## 人工智能/人工智能初学者指南🤖👶
机器学习终极指南。简单明了的英语解释伴随着数学,代码和现实世界…
medium.com](https://medium.com/machine-learning-for-humans/why-machine-learning-matters-6164faf1df12)
监督学习
监督学习是基于示例输入-输出对学习将输入映射到输出的函数的机器学习任务。监督学习算法分析训练数据并产生推断的函数,该函数可用于映射新的示例。
在监督学习中,我们已经标记了训练数据。
监督学习是一种机器学习任务,它学习一个函数,该函数基于…
en.wikipedia.org](https://en.wikipedia.org/wiki/Supervised_learning) [## 监督学习-简介| Coursera
本课程视频抄本机器学习是让计算机在没有明确…
www.coursera.org](https://www.coursera.org/lecture/machine-learning/supervised-learning-1VkCb)
无监督学习
无监督学习是一种机器学习任务,它从由没有标记响应的输入数据组成的数据集进行推断。无监督学习的目标是对数据中的底层结构或分布进行建模,以便了解更多关于数据的信息。
聚类和关联是一些非监督学习子类别。

Photo by Hans-Peter Gauster on Unsplash
无监督学习是一种自组织的 Hebbian 学习,有助于在数据中发现以前未知的模式…
en.wikipedia.org](https://en.wikipedia.org/wiki/Unsupervised_learning) [## 什么是无监督机器学习?数据机器人
无监督的机器学习算法从数据集推断模式,而不参考已知的或标记的…
www.datarobot.com](https://www.datarobot.com/wiki/unsupervised-machine-learning/) [## 有监督学习和无监督学习有什么区别?
维基监督学习的定义监督学习是数据挖掘的任务,从标签中推断出一个函数
dataconomy.com](https://dataconomy.com/2015/01/whats-the-difference-between-supervised-and-unsupervised-learning/)
神经网络或人工神经网络
神经网络是一种生物启发的编程范式,它使计算机能够从观察数据中学习。人工神经网络的设计受到了人脑生物神经网络的启发,导致了一个远比标准机器学习模型更有能力的学习过程。
神经网络也称为人工神经网络,由输入层和输出层以及隐藏层组成,隐藏层由将输入转换为输出层可以使用的东西的单元组成。他们在需要寻找模式的任务中表现得非常好。
我们探索神经网络如何运作,以建立对深度学习的直观理解
towardsdatascience.com](/understanding-neural-networks-19020b758230) [## 神经网络和深度学习
人类视觉系统是世界奇迹之一。考虑下面的手写数字序列:大多数…
neuralnetworksanddeeplearning.com](http://neuralnetworksanddeeplearning.com/chap1.html) [## 什么是神经网络?
神经网络是一种机器学习类型,它模仿人脑来模拟自身。这就造成了一种人为的…
www.techradar.com](https://www.techradar.com/au/news/what-is-a-neural-network)
反向传播
这是神经网络中的一个概念,它允许网络在结果与创造者希望的不匹配的情况下调整其隐藏的神经元层。
反向传播算法是一系列用于有效训练人工神经网络的方法
en.wikipedia.org](https://en.wikipedia.org/wiki/Backpropagation) [## 人工神经网络中的反向传播是如何工作的?
自从机器学习的世界被引入到递归工作的非线性函数(即人工…
towardsdatascience.com](/how-does-back-propagation-in-artificial-neural-networks-work-c7cad873ea7)
深度神经网络(DNN)或深度学习
深度学习是机器学习的一个子集,其中多层神经网络堆叠在一起,创建了一个巨大的网络,将输入映射到输出。它允许网络提取不同的特征,直到它能够识别它正在寻找什么。
[## 什么是深度神经网络?-来自 Techopedia 的定义
深度神经网络定义-深度神经网络是一种具有一定复杂程度的神经网络,一种神经…
www.techopedia.com](https://www.techopedia.com/definition/32902/deep-neural-network) [## 深度神经网络的基础
随着 Tensorflow 2.0 和 Fastai 等库的兴起,实现深度学习已经变得触手可及
towardsdatascience.com](/the-basics-of-deep-neural-networks-4dc39bff2c96) [## 神经网络和深度学习| Coursera
从 deeplearning.ai 学习神经网络和深度学习,如果你想打入前沿 ai,这门课…
www.coursera.org](https://www.coursera.org/learn/neural-networks-deep-learning)
线性回归
线性回归是一种基于监督学习的机器学习算法。它执行回归任务。回归基于独立变量对目标预测值进行建模。它主要用于找出变量和预测之间的关系。可以使用线性回归的任务的一个例子是根据过去的价值预测房价。
线性回归的成本函数是预测 y 值(pred)和真实 y 值(y)之间的均方根误差(RMSE)。

Linear Regression (By Sewaqu — Own work, Public Domain, https://commons.wikimedia.org/w/index.php?curid=11967659)
在统计学中,线性回归是一种建模标量响应(或变量)之间关系的线性方法
en.wikipedia.org](https://en.wikipedia.org/wiki/Linear_regression) [## 线性回归-详细视图
线性回归用于寻找目标和一个或多个预测值之间的线性关系。有两个…
towardsdatascience.com](/linear-regression-detailed-view-ea73175f6e86) [## 机器学习的线性回归
线性回归也许是统计学和机器中最著名和最容易理解的算法之一
machinelearningmastery.com](https://machinelearningmastery.com/linear-regression-for-machine-learning/)
逻辑回归
逻辑回归是用于分类问题的监督机器学习算法。这是一种分类算法,用于将观察值分配给一组离散的类。分类问题的一些例子是垃圾邮件或非垃圾邮件、在线交易欺诈或非欺诈。
逻辑回归使用逻辑 sigmoid 函数转换其输出,以返回概率值。
有两种类型的逻辑回归:
- 二进制的
- 多类

Logistic Regression (By Michaelg2015 — Own work, CC BY-SA 4.0, https://commons.wikimedia.org/w/index.php?curid=42442194)
逻辑回归在二十世纪早期被用于生物科学。它后来被用于许多社会…
towardsdatascience.com](/logistic-regression-detailed-overview-46c4da4303bc) [## 逻辑回归
在统计学中,逻辑模型(或 logit 模型)用于模拟某一类或某一事件的概率…
en.wikipedia.org](https://en.wikipedia.org/wiki/Logistic_regression) [## 什么是逻辑回归?-统计解决方案
一个人体重每增加一磅,患肺癌的概率(是与否)会有怎样的变化…
www.statisticssolutions.com](https://www.statisticssolutions.com/what-is-logistic-regression/)
K-最近邻(K-NN)
k-最近邻(KNN)算法是一种简单、易于实现的监督机器学习算法,可用于解决分类和回归问题。
KNN 算法假设相似的事物存在于附近。换句话说,相似的事物彼此靠近。
可以用在推荐系统上。
KNN 的工作方式是找出查询和数据中所有示例之间的距离,选择最接近查询的指定数量的示例(K),然后投票选择最频繁的标签(在分类的情况下)或平均标签(在回归的情况下)。

K-NN (Photo by Antti Ajanki AnAj [CC BY-SA 3.0 (http://creativecommons.org/licenses/by-sa/3.0/)])
机器学习算法介绍系列的第 1 部分
medium.com](https://medium.com/capital-one-tech/k-nearest-neighbors-knn-algorithm-for-machine-learning-e883219c8f26) [## K-最近邻算法快速介绍
大家好!今天我想谈谈 K-最近邻算法(或 KNN)。KNN 算法是一种…
blog.usejournal.com](https://blog.usejournal.com/a-quick-introduction-to-k-nearest-neighbors-algorithm-62214cea29c7) [## KNN 分类
编辑描述
www.saedsayad.com](https://www.saedsayad.com/k_nearest_neighbors.htm)
随机森林
随机森林就像一种通用的机器学习技术,可用于回归和分类目的。它由大量单独的决策树组成,这些决策树作为一个整体运行。随机森林中的每个单独的决策树都给出一个类别预测,拥有最多票数的类别成为我们模型的预测。
一般来说,随机森林模型不会过度拟合,即使过度拟合,也很容易阻止它过度拟合。
随机森林模型不需要单独的验证集。
它只做了一些统计假设。不假设您的数据是正态分布的,也不假设关系是线性的。
它只需要很少的特征工程。

Random Forest (Source)
第一课概述:Fast.ai 机器学习课程随机森林介绍
towardsdatascience.com](/things-i-learned-about-random-forest-machine-learning-algorithm-40fde28fa89e) [## 了解随机森林
该算法如何工作以及为什么如此有效
towardsdatascience.com](/understanding-random-forest-58381e0602d2)
合奏学习
集成学习通过组合几个模型来帮助改善机器学习结果。与单一模型相比,这种方法可以产生更好的性能。
集成方法是一种元算法,它将几种机器学习技术结合到一个预测模型中,以减少方差(bagging)、偏差(boosting)或改善预测(stacking)。
例子是随机森林,梯度提升决策树,ADA 提升。

Ensembling (Source)
什么,为什么,如何和装袋——推进去神秘化,而非传统的解释,读下去:)
towardsdatascience.com](/simple-guide-for-ensemble-learning-methods-d87cc68705a2) [## 整体方法:装袋、助推和堆叠
理解集成学习的关键概念。
towardsdatascience.com](/ensemble-methods-bagging-boosting-and-stacking-c9214a10a205)
梯度提升决策树
Boosting 是一种集成技术,其中预测器不是独立产生的,而是顺序产生的。
这是一种将弱学习者转化为强学习者的方法。梯度增强是增强的一个例子。它是一种用于回归和分类问题的机器学习技术,它以集成或弱预测模型的形式产生预测模型,通常是决策树。
简化复杂的算法
medium.com](https://medium.com/mlreview/gradient-boosting-from-scratch-1e317ae4587d) [## 一位 Kaggle 大师解释梯度推进
如果线性回归是丰田凯美瑞,那么梯度推进将是 UH-60 黑鹰直升机。一个特别的…
blog.kaggle.com](http://blog.kaggle.com/2017/01/23/a-kaggle-master-explains-gradient-boosting/)
过拟合
当模型对训练数据建模得太好时,就会发生过度拟合。
当模型学习训练数据中的细节和噪声达到对新数据的模型性能产生负面影响的程度时,就会发生过度拟合。它会对模型的概括能力产生负面影响。
可以通过以下方式预防:
- 交叉验证
- 正规化

Overfitting (Source)
[## 机器学习中的过度拟合:什么是过度拟合以及如何防止过度拟合
你知道有一个错误吗…成千上万的数据科学初学者在不知不觉中犯的错误?还有这个…
elitedatascience.com](https://elitedatascience.com/overfitting-in-machine-learning) [## 机器学习算法的过拟合和欠拟合
机器学习性能不佳的原因是数据过拟合或欠拟合。在这篇文章中,你…
machinelearningmastery.com](https://machinelearningmastery.com/overfitting-and-underfitting-with-machine-learning-algorithms/)
欠适
欠拟合指的是既不能对训练数据建模也不能推广到新数据的模型。它将在训练数据上表现不佳。

Underfitting (Source)
当统计模型或机器学习算法捕捉到数据的噪声时,就会发生过拟合。直觉上…
chemicalstatistician.wordpress.com](https://chemicalstatistician.wordpress.com/2014/03/19/machine-learning-lesson-of-the-day-overfitting-and-underfitting/) [## 机器学习中什么是欠拟合和过拟合,如何处理。
每当处理一个数据集来预测或分类一个问题时,我们倾向于通过实现一个设计…
medium.com](https://medium.com/greyatom/what-is-underfitting-and-overfitting-in-machine-learning-and-how-to-deal-with-it-6803a989c76) [## 什么是欠拟合|数据机器人人工智能维基
当机器学习模型不够复杂,无法准确地…
www.datarobot.com](https://www.datarobot.com/wiki/underfitting/)
正规化
正则化是一种修改机器学习模型以避免过拟合问题的技术。你可以将正则化应用于任何机器学习模型。正则化通过向目标函数添加惩罚项来简化容易过度拟合的过于复杂的模型。如果一个模型过度拟合,它将有泛化的问题,因此当它暴露于新的数据集时,将给出不准确的预测。
训练机器学习模型的一个主要方面是避免过度拟合。该模型将有一个低…
towardsdatascience.com](/regularization-in-machine-learning-76441ddcf99a) [## 关于正规化,你需要知道的是
艾丽斯:嘿,鲍勃!!!我已经训练了我的模型 10 个小时了,但是我的模型精度很差,虽然它…
towardsdatascience.com](/all-you-need-to-know-about-regularization-b04fc4300369)
L1 vs L2 正规化
使用 L1 正则化技术的回归模型称为 Lasso 回归。使用 L2 正则化技术的模型被称为刚性回归。
两者之间的关键区别是添加到损失函数中的惩罚项。
刚性回归将系数的“平方值”作为惩罚项添加到损失函数中。Lasso 回归(最小绝对收缩和选择算子)将系数的“绝对值”作为惩罚项添加到损失函数中。
在这篇文章中,我们将了解为什么我们需要正规化,什么是正规化,什么是不同类型的…
medium.com](https://medium.com/datadriveninvestor/l1-l2-regularization-7f1b4fe948f2) [## 为了简单而正规化:L₂正规化|机器学习速成班|谷歌…
估计时间:7 分钟考虑以下一般化曲线,该曲线显示了训练集…
developers.google.com](https://developers.google.com/machine-learning/crash-course/regularization-for-simplicity/l2-regularization) [## L1 和 L2 作为损失函数和正则化的差异
2014/11/30:通过经过验证的方案图更新了 L1-诺姆与 L2-诺姆损失函数。感谢读者的…
www.chioka.in](http://www.chioka.in/differences-between-l1-and-l2-as-loss-function-and-regularization/)
交叉验证
交叉验证是一种评估机器学习模型的技术,通过在可用输入数据的子集上训练几个 ML 模型,并在数据的互补子集上评估它们。它用于防止模型过度拟合。
不同类型的交叉验证技术有:
- 保持方法
- k 倍(最受欢迎)
- 漏接
验证可能是数据科学家使用的最重要的技术之一,因为总是需要…
towardsdatascience.com](/cross-validation-70289113a072) [## 为什么以及如何交叉验证模型?
一旦我们完成了对模型的训练,我们就不能假设它会在数据上很好地工作,如果它没有…
towardsdatascience.com](/why-and-how-to-cross-validate-a-model-d6424b45261f)
回归性能指标
平均绝对误差(MAE): 测量实际值和预测值之间的平均绝对差值。
均方根误差(RMSE): 测量实际值和预测值之间的平方差的平均值的平方根。
请不要让你的表现退步。
becominghuman.ai](https://becominghuman.ai/understand-regression-performance-metrics-bdb0e7fcc1b3) [## 为评估机器学习模型选择正确的度量标准—第 1 部分
本系列的第一部分关注回归度量
medium.com](https://medium.com/usf-msds/choosing-the-right-metric-for-machine-learning-models-part-1-a99d7d7414e4) [## 梅和 RMSE——哪个指标更好?
平均绝对误差与均方根误差
medium.com](https://medium.com/human-in-a-machine-world/mae-and-rmse-which-metric-is-better-e60ac3bde13d)
分类问题的性能指标
**混淆矩阵:**它是用于发现模型正确性和准确性的最直观和最容易的度量之一。它用于分类问题,其中输出可以是两种或多种类型的类。

Confusion Matrix (Source)
真阳性(TP): 是数据点的实际类别为 1(真)且预测类别也为 1(真)的情况。
真阴性(TN): 是数据点的实际类别为 0(假)且预测类别也为 0(假)的情况。
假阳性(FP): 是数据点的实际类别为 0(假)而预测类别为 1(真)的情况。False 是因为模型预测不正确,而正数是因为预测的类是正数。
假阴性(FN): 是数据点的实际类别为 1(真)而预测类别为 0(假)的情况。False 是因为模型预测不正确,负值是因为预测的类为负(0)。
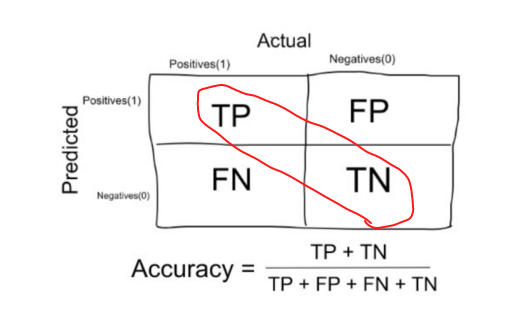
**准确性:**分类问题中的准确性是模型在所有预测中做出的正确预测的数量。

Accuracy in the confusion matrix (Source)
**何时使用精度:**当数据中的目标变量类接近平衡时,精度是一个很好的度量。
何时不使用精确度:当数据中的目标变量类是一个类的大多数时,精确度决不应该被用作度量。
**Precision(hits)😗*Precision 是一种度量,它告诉我们预测值为真的比例实际上是真的。

**回忆或敏感度(缺失)😗*回忆是一种度量,它告诉我们有多少比例的患者实际上是真实的,而被模型预测为真实的。

**F1 评分:**同时代表了查准率和查全率。

F1 Score (Source)
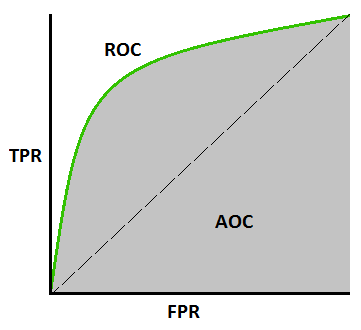
**受试者工作特性(ROC)曲线:**ROC 曲线是显示分类模型在所有分类阈值下的性能的图表。
该曲线绘制了两个参数:
- 真实阳性率(回忆)
- 假阳性率(特异性)

ROC Curve (Source)
AUC(ROC 曲线下面积): AUC 测量整个 ROC 曲线下的整个二维面积。
它提供了跨所有可能的分类阈值的综合性能度量。

Area under ROC curve (Source)
“数字有一个重要的故事要讲。他们依靠你给他们一个声音。”—斯蒂芬·诺
medium.com](https://medium.com/thalus-ai/performance-metrics-for-classification-problems-in-machine-learning-part-i-b085d432082b) [## 理解混淆矩阵
当我们得到数据,经过数据清洗,预处理和争论,我们做的第一步是把它提供给一个…
towardsdatascience.com](/understanding-confusion-matrix-a9ad42dcfd62)
上面讨论的主题是机器学习的基础。我们讨论了人工智能、机器学习和深度学习等基本术语,不同类型的机器学习:监督和非监督学习,一些机器学习算法,如线性回归、逻辑回归、k-nn 和随机森林,以及不同算法的性能评估矩阵。
你认为哪个话题最重要?请在下面留下你的想法。
帮助您成为更好的数据科学经理的重要特征
管理点,基于我管理两个数据科学家团队的经验。

Pão de Açúcar, Rio de Janeiro, Brazil. Ori Cohen.
以下几点是基于我领导一个小型数据科学家团队的经验,但是,我相信它们可以让任何未来或现有的经理受益,不仅仅是研究和数据科学。这些是我一直努力坚持的价值观,去年,我和两个非常有才华的数据科学家团队一起,改进、推进并成功管理了 56 个项目,从小概念验证到大型项目。
一般管理:
- 向你过去最好和最差的经理学习。我学会了将团队成员视为同事,而不是“我的员工”,授权、信任并允许他们领导自己的项目。另一方面,我认识到微观管理是一个可怕的想法,因为它不会带来最好的人。
- 保持一个可以犯错的良好环境,研究不是防弹的,结果是未知的,我们需要犯错来提供一个可行的解决方案。这样的环境可以减少压力和恐惧。因此,你的团队成员永远不会害怕向你提出错误。总的来说,错误帮助我们前进,更不用说我们总能改正错误。
- 信任你的团队成员,听从他们的想法和建议,让他们尽可能地发挥创造力。你是经理并不意味着你什么都知道。试着向你周围的每个人学习,包括你的团队,因为这将帮助你成为一个更好的管理者。
- 当批评来临时,做他们的墙,防止他们偏离和偏离焦点。
- 永远相信参与其中的每个人。感谢他人,尤其是如果你做了大部分工作,不会减少你的成就或投资。
数据科学管理
- 灵活管理 DS 项目(数据科学?敏捷?周期?我管理高科技行业数据科学项目的方法
- 通过每天坐下来和你的团队成员保持高水平的交流和冗余。当每个人都同步时,每个人都可以交叉交流,并在需要时代替你。
- 提前停止——停止一个看起来没有成功机会或者已经达到饱和点的项目。
- 打包您的可交付成果,确保它们已经过测试并准备好投入生产。
- 如果可能的话,试着在项目中期制作一个“婴儿”产品,让你的数据工程师在完成项目的同时准备一个解决方案。
- 有些时候,公司里的其他人会有一个想法,而你会有冲突或有义务去做。建议 A/B 测试可以调和利益相关者的竞争性本质,允许你测试两个想法或间接说服对方他们的想法的时间和精力太昂贵。
- 当利益相关者要求某个指标时,比如准确性,询问这是否真的是适合他们的指标。
- 当有人问你在一个新的未定义项目中能达到什么样的成功水平时,告诉他们需要一个一到两周的 POC 来给他们一个答案。
追求知识
- 始终处于当前研究的顶端( TDS 、 Arxiv Sanity、 ML review 、 Ruder.io )
- 始终将新技术和研究整合到现有项目中,这可以为您和您的团队积累经验,或者,创建简短的 POC 以验证新的研究想法。
- 维护一个知识库(我的有 250 页长)以便当你需要学习旧的东西时有 O(1)的时间复杂度。好的链接应该被总结和保存,第二次在谷歌上搜索同样的东西是浪费时间,它很容易缩短你的工作。
- 让你的团队有时间获取知识。阅读新的研究不是浪费开发时间,它让我们在工作中做得更好。允许这种情况发生在项目的每一步。如果我们不掌握先进的研究、新的方法和想法,我们就会在专业上停滞不前。
- 当一种新的研究方法证明了自己时,所有团队成员都应该了解它。
- 在媒体、 TDS 或学术渠道上发布您的结果,并且始终将基于代码的文章与 Github 资源库一起发布。
尝试新事物
- 深入了解产品管理,这将使你成为一名更好的数据科学家,尤其是当你正在开发产品的新功能时。
- 协作是关键!对与其他公司或团队的外部和内部协作持开放态度。合作能在短时间内丰富你的经验,并有助于积极的工作关系。合作加强了你作为领导者的地位。
- 试着向前看,看看你的公司正在走向何方,如果这对你有意义,试着成为第一批沿着这条道路前进的人。
- 不断地向你的朋友咨询研究的想法和方法,有人有不同的角度,比你知道的更多。
- 通过参加他们的会议、与他们共进午餐或召开联合团队会议,与公司的其他团队保持联系。
- 在指导上投入时间,这可以通过建立一个实习项目来实现。辅导提高了经常被忽视的教学技能。
我要感谢我的同事 Samuel Jefroykin 和 Yoav Talmi 提供的宝贵意见。
Ori Cohen 博士拥有计算机科学博士学位,专注于机器学习。他领导着 Zencity.io 的研究团队,试图积极影响市民的生活。
用你新获得的壳技能打动旁观者
数据科学家的 10 分钟外壳/终端技能

Photo by Adam Littman Davis on Unsplash
我敢打赌,我们大多数人都见过有人坐在咖啡馆里对着黑/绿屏幕乱砍一气。
每当这种情况发生时,我第一个想到的就是——“这看起来太酷了。”
没有图形用户界面。这就像你在玩你的操作系统的内部。
你要去的地方是和汇编语言一样接近的地方。
外壳命令功能强大。它们看起来也很酷。
所以我想给他们一个尝试。我意识到,它们也可能是我数据科学工作流程的重要组成部分。
这篇文章是关于我在使用 shell/terminal 时发现的最有用的命令,主要关注数据科学。
您何时会使用 shell/terminal 进行数据分析?

有一件事我们都认为是理所当然的——您不会一直拥有 Python。
可能是新公司的 Linux 服务器没有安装 python。
或者您想对大文件进行一些检查,而不真正将它们加载到内存中。
考虑这样一种情况,当您的笔记本电脑/服务器上有一个 6 GB 管道分隔的文件,并且您想要找出某一特定列中不同值的计数。
你可能有不止一种方法可以做到这一点。您可以将该文件放入数据库并运行 SQL 命令,或者您可以编写一个 Python/Perl 脚本。
但是如果服务器上没有安装 SQL/Python 呢?或者,如果你想在黑屏上看起来很酷呢?
无论如何, 无论你做什么,都不会比这个更简单/耗时更少:
cat data.txt | cut -d "|" -f 1 | sort -u | wc -l
-------------------------------------------------
30
这将比你用 Perl/Python 脚本做的任何事情运行得更快。
现在,让我们稍微违背这个命令。这个命令说:
- 使用 cat 命令将文件内容打印/流式输出到标准输出。
- 使用|命令将流内容从我们的 cat 命令传输到下一个命令 cut 。
- 在 cut 命令中,通过参数 -d 指定分隔符“|”(注意管道周围的分号,因为我们不想将管道用作流),并通过参数 -f. 选择第一列
- 将流内容传输到对输入进行排序的排序命令。它采用参数 -u 来指定我们需要唯一的值。
- 通过管道将输出传递给 wc -l 命令,该命令计算输入中的行数。
也许你还不明白。但是不要担心,我保证你在文章结束时会明白的。 我还会在本帖结束前尝试解释比上述命令更高级的概念。
现在,我在工作中广泛使用 shell 命令。作为一名数据科学家,我将根据我在日常工作中几乎每天都会遇到的用例来解释每个命令的用法。
我使用来自 Lahman Baseball 数据库的 Salaries.csv 数据来说明不同的 shell 函数。你可能想要下载数据来配合你自己的文章。
从基本命令开始

Think of every command as a color in your palette
每当试图学习一门新语言时,从基础开始总是有帮助的。shell 是一种新语言。我们将逐一讲解一些基本命令。
1.猫:
有很多时候你需要看到你的数据。一种方法是在记事本中打开 txt/CSV 文件。对于小文件来说,这可能是最好的方法。
但是大数据是个问题。有时文件会非常大,以至于你无法在 sublime 或任何其他软件工具中打开它们,在那里我们可以使用 cat 命令。
你可能需要等一会儿。gif 文件来显示。
cat salaries.csv

2.头部和尾部:
现在你可能会问我为什么要在终端上打印整个文件?一般不会。但我只想告诉你关于猫的命令。
对于用例,当您只需要数据的顶部/底部 n 行时,您通常会使用 head / tail 命令。你可以如下使用它们。
head Salaries.csv
tail Salaries.csv
head -n 3 Salaries.csv
tail -n 3 Salaries.csv

请注意这里的 shell 命令的结构:
CommandName [-arg1name] [arg1value] [-arg2name] [arg2value] filename
它是CommandName,后跟几个argnames和argvalues,最后是文件名。通常,shell 命令有很多参数。您可以通过使用man命令来查看命令支持的所有参数的列表。你可以把man看作是帮助。
man cat
3.wc:

Count the Lines
wc 是一个相当有用的 shell 实用程序/命令,它让我们计算给定文件中的行数(-l) 、字数(-w) 或字符(-c) 。
wc -l Salaries.csv
wc -w Salaries.csv
wc -c Salaries.csv

4.grep:
有时,您可能希望在文件中查找特定的行。或者您可能希望打印文件中包含特定单词的所有行。
或者你可能想看看 2000 年球队的薪水。
grep 是你的朋友。
在本例中,我们打印了文件中包含“2000,BAL”的所有行。
grep "2000,BAL" Salaries.csv| head

你也可以在 grep 中使用正则表达式。
管道——这使得外壳很有用

既然我们现在知道了 shell 的基本命令,我现在可以谈谈 Shell 用法的基本概念之一— 管道 。
如果不使用这个概念,您将无法利用 shell 提供的全部功能。
这个想法很简单。
还记得我们之前如何使用 head 命令查看文件的前几行吗?
现在,您也可以编写如下的head命令:
cat Salaries.csv | head

我的建议: 把命令里的“|”读成“把数据传到”
所以我会把上面的命令理解为:
cat (打印)整个数据流,将数据传递给 head ,这样它就可以只给我前几行。
你知道管道的作用吗?
它为我们提供了一种连续使用基本命令的方法。有许多命令都是相对基本的,它让我们可以按顺序使用这些基本命令来做一些相当重要的事情。
现在让我告诉你几个不那么基本的命令,然后我会向你展示我们如何链接它们来完成相当高级的任务。
一些中间命令

1.排序:
你可能想在特定的列上对你的数据集进行排序。sort是你的朋友。
假设您想找出数据集中任何球员的前 10 名最高工资。我们可以如下使用排序。
sort -t "," -k 5 -r -n Salaries.csv | head -10

所以这个命令中确实有很多选项。让我们一个一个地看。
- -t :使用哪个分隔符?“,”
- -k :按哪一列排序?5
- -n :如果要数值排序。如果您希望进行字母排序,请不要使用此选项。
- -r :我想降序排序。默认情况下,升序排序。
然后显然是管道——或者把数据传递给head指挥部。
2.剪切:
此命令允许您从数据中选择特定的列。有时,您可能希望只查看数据中的某些列。
例如,您可能只想查看年份、团队和薪水,而不想查看其他列。切割是要使用的命令。
cut -d "," -f 1,2,5 Salaries.csv | head

这些选项包括:
- -d :使用哪个分隔符?“,”
- -f :剪切哪一列/哪些列?1,2,5
然后,显然是管道——或者将数据传递给head命令。
3.uniq:
uniq 有一点棘手,因为你可能想在排序中使用这个命令。
此命令删除连续的重复项。比如:1,1,2 会转换成 1,2。
所以结合 sort,它可以用来获得数据中的不同值。
例如,如果我想在数据中找出十个不同的团队,我会使用:
cat Salaries.csv| cut -d "," -f 2 | sort | uniq | head

该命令也可以与参数 -c 一起使用,以计算这些不同值的出现次数。
类似于的东西算不同的。
cat Salaries.csv | cut -d "," -f 2 | sort | uniq -c | head

其他一些实用程序命令

这里有一些其他的命令行工具,你可以不用深入细节就可以使用,因为细节很难。 就把这个帖子收藏起来吧。
1.更改文件中的分隔符:
有时您可能需要更改文件中的分隔符,因为某个应用程序可能需要特定的分隔符才能工作。Excel 需要“,”作为分隔符。
寻找并替换魔法。:您可能想使用[tr](https://en.wikipedia.org/wiki/Tr_%28Unix%29)命令将文件中的某些字符替换为其他字符。

2.文件中一列的总和:
使用 awk 命令,您可以找到文件中一列的总和。除以行数(wc -l),就可以得到平均值。

awk 是一个强大的命令,它本身就是一门完整的语言。请务必查看 awk 的 wiki 页面,其中有很多关于 awk 的好的用例。
3.在目录中查找满足特定条件的文件:
有时,您需要在包含大量文件的目录中找到一个文件。您可以使用 find 命令来完成此操作。假设您想要找到所有的。当前工作目录中的 txt 文件即以开头。

去找所有人。以 A 或 B 开头的 txt 文件我们可以使用 regex。
最后>和>>
有时,您希望通过命令行实用程序(Shell 命令/ Python 脚本)获得的数据不显示在 stdout 上,而是存储在文本文件中。
你可以使用 " > " 操作符。例如,您可以在将上一个示例中的分隔符替换到另一个名为 newdata.txt 的文件中后存储该文件,如下所示:
cat data.txt | tr ',' '|' > newdata.txt
开始的时候,我经常搞不清 “|” (管道)和 " > " (to_file)操作。
记住的一个方法是,当你想写一些东西到一个文件时,你应该只使用**>**。
**“|”不能用于写入文件。另一个你应该知道的操作是>>**操作。它类似于 " > " ,但它附加到一个现有的文件,而不是替换文件和重写。
结论

这只是冰山一角。
虽然我不是 shell 使用方面的专家,但是这些命令在很大程度上减少了我的工作量。
试着将它们融入你的工作流程。我通常在 jupyter 笔记本中使用它们(如果您以!开始命令,您可以在 jupyter 代码块中编写 shell 命令)。永远记住:
技工要完善他的工作,必须先磨利他的工具。——孔子
所以,现在给一些人留下深刻印象。
如果你想了解更多关于命令行的知识,我想你会的,Coursera 上有UNIX 工作台课程,你可以试试。
我以后也会写更多这样的帖子。让我知道你对这个系列的看法。在 媒体 关注我或者订阅我的 博客 了解他们。一如既往,我欢迎反馈和建设性的批评,可以通过 Twitter @mlwhiz 联系到我。
通过使用 pandas 库和 Python 提高数据质量

数据质量是一个具有多个维度的宽泛概念。我在的另一篇介绍性文章中详细介绍了这一信息。本教程探索了一个真实的例子。我们确定我们想要改进什么,创建代码来实现我们的目标,并以一些关于现实生活中可能发生的事情的评论结束。要继续学习,您需要对 Python 有一个基本的了解。
熊猫图书馆
Python 数据分析库( pandas )是一个开源的、BSD 许可的库,它为 Python 编程语言提供了高性能、易于使用的数据结构和数据分析工具。
您可以通过在命令行中输入以下代码来安装 pandas:python 3-m pip install—upgrade pandas。
pandas 中有两种主要的数据结构:
- **系列。**可以包含任何类型数据的单个列。
- **数据帧。**具有行和命名列的关系数据表。
数据帧包含一个或多个系列以及每个系列的名称。数据帧是通常用于数据操作的抽象或复杂性管理器。
系列结构
系列就像是字典和列表的混合体。物品按顺序存放,并贴上标签,以便您可以检索。序列列表中的第一项是特殊索引,它很像一个字典键。第二项是你的实际数据。需要注意的是,每个数据列都有自己的索引标签。您可以通过使用。名称属性。这部分结构不同于字典,它对于合并多列数据很有用。
这个简单的例子向您展示了一个系列是什么样子的:
import pandas as pd **carbs = [‘pizza’, ‘hamburger‘, ‘rice’]
pd.Series(carbs)**0 ‘pizza’
1 ‘hamburger’
2 ‘rice’dType: object
我们还可以创建带有标签属性的系列:
**foods = pd.Series( [‘pizza’, ‘hamburger’, ‘rice’], index=[‘Italy’, ‘USA’, ‘Japan’]**Italy ‘pizza’
USA ‘hamburger’
Japan ‘rice’dType: object
查询系列
您可以通过索引位置或索引标签来查询序列。如果不为系列指定索引,则位置和标签具有相同的值。要按数字位置进行查询,请使用 iloc 属性。
**foods.iloc[2]**
‘rice’
要通过索引标签进行查询,请使用 loc 属性。
**foods.loc[‘USA’]**
‘hamburger’
请记住,一个键可以返回多个结果。这个例子展示了基础知识。还有许多其他系列主题,如矢量化、内存管理等。但我们不会在本文中深入探讨。
数据帧结构

数据框架是熊猫图书馆的主要结构。它是您在数据分析和清理任务中工作的主要对象。
从概念上讲,DataFrame 是一个二维序列对象。它有一个索引和多列内容,每一列都有标签。但是列和行之间的区别只是概念上的。将 DataFrame 想象成一个双轴标签数组。
您可以使用系列创建如下数据帧表:
purchase_1 = pd.Series({ ‘Name’: ‘John’, ‘Ordered’:’Pizza’, ‘Cost’: 11 })
purchase_2 = pd.Series({ ‘Name’: ‘Mary’, ‘Ordered’:’Brioche’, ‘Cost’: 21.20 })
purchase_3 = pd.Series({ ‘Name’: ‘Timothy’, ‘Ordered’:’Steak’, ‘Cost’: 30.00 })**df = pd.DataFrame([purchase_1, purchase_2, purchase_3], index=[‘Restaurant 1’, ‘Restaurant 1’, ‘Restaurant 2’])**+--------------+-------+---------+---------+
| | Cost | Ordered | Name |
+--------------+-------+---------+---------+
| Restaurant 1 | 11 | Pizza | John |
| Restaurant 1 | 21.20 | Brioche | Mary |
| Restaurant 2 | 30.00 | Steak | Timothy |
+--------------+-------+---------+---------+
和 Series 一样,我们可以通过使用 iloc 和 loc 属性来提取数据。数据帧是二维的。因此,当我们向 loc 传递单个值时,如果只有一行要返回,那么索引操作符将返回一个序列。
让我们查询这个数据帧。
**df.loc[‘Restaurant 2’]**Cost 30.00
Ordered ‘Steak’
Name ‘Timothy’
该函数返回一个 Series 类型的对象。
pandas DataFrame 的一个强大特性是,您可以基于多个轴快速选择数据。因为 iloc 和 loc 用于行选择,pandas 开发人员直接在数据帧上为列选择保留了索引操作符。在数据帧中,列总是有一个名称。所以这个选择总是基于标签的。
例如,我们可以用以下代码重写所有餐馆 1 成本的查询:
**df.loc[‘Restaurant 1’][‘Cost’]**Restaurant 1 11
Restaurant 1 21.20Name: Cost, dType: float64
表演时间到了。
现在我们处理一个简单但常见的数据问题:缺少值。在数据去神秘化——数据质量,中,我解释了为什么完整性是评估数据质量时要考虑的因素之一。缺失数据还可能与另外两个方面有关:缺乏准确性或一致性。还有很多东西需要学习,但是我想直接跳到一个例子,并随着我们的进行引入新的概念。
我们可以从任何来源读取大型数据集。一些例子是关系数据库、文件和 NoSQL 数据库。这个库示例展示了一组与关系数据库交互的方法:
import pandas.io.sql as psql
注意 connect 和 read_sql 是关键方法。
为了简单起见,我们将使用 CSV 文件。假设我们有一个存储在 logs.csv 中的日志文件,该日志每隔 100 毫秒存储一次鼠标指针的位置。如果鼠标没有变化,算法会存储一个空值,但会向该行添加一个新条目。为什么?因为如果信息没有改变,通过网络发送这些信息是没有效率的。
我们的目标是用正确的坐标存储 CSV 文件中的所有行。如下表所示,我们可以用以下代码存储这些行:
df = pd.read_csv(‘logs.csv’)
df+----+-----------+---------+---------+-----+-----+
| | timestamp | page | user | x | y |
+----+-----------+---------+---------+-----+-----+
| 0 | 169971476 | landing | admin | 744 | 220 |
| 1 | 169971576 | landing | admin | NaN | NaN |
| 2 | 169971591 | profile | maryb | 321 | 774 |
| 3 | 169971691 | profile | maryb | NaN | NaN |
| 4 | 169972003 | landing | joshf | 432 | 553 |
| 5 | 169971776 | landing | admin | 722 | 459 |
| 6 | 169971876 | landing | admin | NaN | NaN |
| 7 | 169971891 | profile | maryb | 221 | 333 |
| 8 | 169971976 | landing | admin | NaN | NaN |
| 9 | 169971991 | profile | maryb | NaN | NaN |
| 10 | 169972003 | landing | johnive | 312 | 3 |
| 11 | 169971791 | profile | maryb | NaN | NaN |
| 12 | 169971676 | landing | admin | NaN | NaN |
+----+-----------+---------+---------+-----+-----+
当我们检查数据时,我们发现了多个问题。有许多空值,并且文件不是按时间戳排序的。这个问题在高度并行的系统中很常见。
可以处理空数据的一个函数是 fillna。更多信息请输入 df.fillna?在命令行中。使用这种方法有许多选项:
- 一种选择是传入单个标量值,将所有丢失的数据都变成一个值。但是这种改变不是我们想要的。
- 另一个选择是传递一个方法参数。两个常见的值是 ffill 和 bfill。ffill 向前填充单元格。它使用前一行中的值更新单元格中的 NaN 值。为了使此更新有意义,您的数据需要按顺序排序。但是传统的数据库管理系统通常不能保证你从中提取的数据的顺序。
所以,我们先把数据整理一下。我们可以按索引或值排序。在这个例子中,时间戳是索引,我们对索引字段进行排序:
df = df.set_index(‘timestamp’)
df = df.sort_index()
我们创建了下表:
+-----------+---------+---------+-----+-----+
| | page | user | x | y |
+-----------+---------+---------+-----+-----+
| time | | | | |
| 169971476 | landing | admin | 744 | 220 |
| 169971576 | landing | admin | NaN | NaN |
| 169971591 | profile | maryb | 321 | 774 |
| 169971676 | landing | admin | NaN | NaN |
| 169971691 | profile | maryb | NaN | NaN |
| 169971776 | landing | admin | 722 | 459 |
| 169971791 | profile | maryb | NaN | NaN |
| 169971876 | landing | admin | NaN | NaN |
| 169971891 | profile | maryb | 221 | 333 |
| 169971976 | landing | admin | NaN | NaN |
| 169971991 | profile | maryb | NaN | NaN |
| 169972003 | landing | johnive | 312 | 3 |
| 169972003 | landing | joshf | 432 | 553 |
+-----------+---------+---------+-----+-----+
如你所见,还有一个问题。我们的时间戳不是唯一的。两个用户可能同时与平台交互。
让我们重置索引,并使用时间戳和用户名创建一个复合索引:
df = df.reset_index()
df = df.set_index([‘timestamp’, ‘user’])
df
我们创建了下表:
+-----------+---------+---------+-----+-----+
| | | page | x | y |
+-----------+---------+---------+-----+-----+
| time | user | | | |
| 169971476 | admin | landing | 744 | 220 |
| 169971576 | admin | landing | NaN | NaN |
| 169971676 | admin | landing | NaN | NaN |
| 169971776 | admin | landing | 722 | 459 |
| 169971876 | admin | landing | NaN | NaN |
| 169971976 | admin | landing | NaN | NaN |
| 169971591 | maryb | profile | 321 | 774 |
| 169971691 | maryb | profile | NaN | NaN |
| 169971791 | maryb | profile | NaN | NaN |
| 169971891 | maryb | profile | 221 | 333 |
| 169971991 | maryb | profile | NaN | NaN |
| 169972003 | johnive | landing | 312 | 3 |
| | joshf | landing | 432 | 553 |
+-----------+---------+---------+-----+-----+
现在我们可以用 ffill 来填充缺失的数据:
**df = df.fillna(method='ffill')**
下表显示了结果:
+-----------+---------+---------+-----+-----+
| | | page | x | y |
+-----------+---------+---------+-----+-----+
| time | user | | | |
| 169971476 | admin | landing | 744 | 220 |
| 169971576 | admin | landing | 744 | 220 |
| 169971676 | admin | landing | 744 | 220 |
| 169971776 | admin | landing | 722 | 459 |
| 169971876 | admin | landing | 722 | 459 |
| 169971976 | admin | landing | 722 | 459 |
| 169971591 | maryb | profile | 321 | 774 |
| 169971691 | maryb | profile | 321 | 774 |
| 169971791 | maryb | profile | 321 | 774 |
| 169971891 | maryb | profile | 221 | 333 |
| 169971991 | maryb | profile | 221 | 333 |
| 169972003 | johnive | landing | 312 | 3 |
| | joshf | landing | 432 | 553 |
+-----------+---------+---------+-----+-----+
熊猫大战 PostgreSQL

熊猫胜过 PostgreSQL。对于大型数据集,它的运行速度要快 5 到 10 倍。PostgreSQL 唯一表现更好的时候是在小数据集上,通常少于一千行。在 pandas 中选择列是高效的,时间为 O(1)。这是因为数据帧存储在内存中。
出于同样的原因,pandas 也有局限性,仍然需要 SQL。熊猫的数据存储在内存中。所以很难加载大于系统内存一半的 CSV 文件。数据集通常包含数百列,这为超过一百万行的数据集创建了大约 10 GB 的文件大小。
PostgreSQL 和 pandas 是两种不同的工具,具有重叠的功能。创建 PostgreSQL 和其他基于 SQL 的语言是为了管理数据库。它们使用户能够轻松地访问和检索数据,尤其是跨多个表的数据。
- 运行 PostgreSQL 的服务器将所有数据集存储为系统中的表。对于用户来说,将所需的表传输到他们的系统,然后使用 pandas 在客户端执行像 join 和 group 这样的任务是不现实的。
- 熊猫的专长是数据处理和复杂的数据分析操作。
这两种工具在技术市场上并不竞争。相反,它们增加了数据科学计算堆栈中可用的工具范围。
额外小费
pandas 团队最近引入了一种方法,用与数据帧长度相同的序列来填充缺失值。使用这种新方法,如果需要的话,很容易得到缺失的值。
参考
Fox,D. (2018),用 pandas 和 PostgreSQL 操纵数据:哪个更好?、数据孵化器。
熊猫(2019), Python 数据分析库。
通过尝试不同的方法来改进你的 ML 模型
基于机器学习的二手车价格预测

Photo by Jen Theodore on Unsplash
在这篇文章中,我们将看看我最近完成的项目,在这个项目中,我根据许多因素预测了二手车的价格。我在 Kaggle 上找到了数据集。
这个项目是特殊的,因为我尝试了许多不同的东西,然后在笔记本上完成,作为存储库的一部分。我会解释我所想的每一步,以及结果如何。包含代码的存储库如下:
[## kb22/二手车价格预测
此时您不能执行该操作。您已使用另一个标签页或窗口登录。您已在另一个选项卡中注销,或者…
github.com](https://github.com/kb22/Used-Car-Price-Prediction)
太久了,不会读
这篇文章的关键是:
- 创建新特征可能会有帮助,例如我从
Name创建了特征Manufacturer。 - 尝试不同的方法来处理同一列。当直接使用
Year栏时会产生不好的结果,所以我使用了从它派生出来的每辆车的年龄,这要有用得多。New_Price首先填充了基于Manufacturer的平均值,但是没有用,所以我在第二次迭代中删除了这个列。 - 看起来不相关的栏目应该被删除。我掉了
Index、Location、Name、New_Price。 - 创建虚拟数据需要处理测试数据中缺失的列。
- 摆弄 ML 模型的参数,因为它可能是有用的。当我将值设置为 100 时,RandomForestRegressor 中的参数
n_estimators改进了r2_score。我也尝试了 1000,但它只是花了很长时间没有任何明显的改善。
如果你还想要完整的细节,请继续阅读!
导入库
我将导入datetime库来处理Year列。numpy和pandas库帮助我处理数据集。matplotlib和seaborn有助于绘图,我在这个项目中没有做太多。最后,我从sklearn导入了一些东西,尤其是度量和模型。
读取数据集
原始 Kaggle 数据集有两个文件:train-data.csv和test-data.csv。然而,文件test-data.csv的最终输出标签没有给出,因此,我将永远无法测试我的模型。因此,我决定只使用train-data.csv,并在data文件夹中将其重命名为dataset.csv。

dataset.csv (Part 1)

dataset.csv (Part 2)
然后,我将数据集分成 70%的训练数据和 30%的测试数据。
我输出训练数据信息,看看数据是什么样的。我们发现有些列像Mileage、Engine、Power和Seats有一些空值,而New_Price的大部分值都丢失了。为了更好地理解每一列真正代表了什么,我们可以看一下有数据描述的 Kaggle 仪表板。

Columns description
数据集现在已经加载,我们知道每一列的含义。现在是做一些探索性分析的时候了。请注意,我将始终使用培训部分,然后仅基于培训部分转换测试部分。
探索性数据分析
在这里,我们将探究上面的每一个专栏,并讨论它们的相关性。
索引
数据集中的第一列未命名。它实际上只是每一行的索引,因此,我们可以安全地删除这一列。
名字
Name列定义了每辆车的名称。我认为汽车的名字可能不会有很大的影响,但汽车制造商可以。例如,如果一般人发现Maruti生产可靠的汽车,他们的转售价值应该更高。因此,我决定从每个Name中提取Manufacturer。每个Name的第一个字就是厂家。
让我们根据制造商绘制并查看每辆汽车的数量。

Manufacturer plot
正如我们在上面的图中看到的,在整个训练数据中,马鲁蒂的汽车数量最多,兰博基尼的汽车数量最少。另外,我不需要Name列,所以我删除了它。
位置
我最初尝试使用Location,但它导致了许多热门专栏,对预测帮助没有多大贡献。这意味着销售地点对汽车最终转售价格的影响几乎可以忽略不计。因此,我决定放弃这个专栏。
年
我最初保留Year是为了定义模型的构造。但后来我意识到,影响转售价值的不是年份,而是车的年龄。因此,受 Kaggle 的启发,我决定通过从当前年份中减去年份来用车龄替换Year。
燃料类型、变速器和所有者类型
所有这些列都是分类列。因此,我将为这些列中的每一列创建虚拟列,并将其用于预测。
公里驱动
数据输出显示列中存在的高值。我们应该调整数据,否则像Kilometers_Driven这样的列会比其他列对预测产生更大的影响。
英里数
Mileage定义汽车的行驶里程。然而,里程单位因发动机类型而异,例如,有些是每千克,有些是每升,但在这种情况下,我们将认为它们是等效的,只从这一列中提取数字。
正如我们之前检查的那样,Mileage列有一些缺失值,所以让我们检查它们并用该列的平均值更新空值。
发动机、动力和座椅
Engine值是在 CC 中定义的,所以我需要从数据中删除 CC。同样,Power有 bhp,我把 bhp 去掉。此外,由于这三个值都有缺失值,我将再次用平均值替换它们,就像我对Mileage所做的那样。
我使用pd.to_numeric()来处理空值,并且在从字符串转换为数字(int 或 float)时不会产生错误。
新价格
该列中的大多数值都丢失了。我最初决定把它们装满。我会根据制造商填写平均值。例如,对于福特,我会取所有存在的值,取它们的平均值,然后用该平均值替换福特 New_Price 的所有空值。然而,这仍然遗漏了一些空值。然后,我会用该列中所有值的平均值来填充这些空值。测试数据也是如此。
然而,这种方法并不真正成功。我试着对它运行随机森林回归器,结果是非常小的r2_score值。接下来,我决定简单地删除该列,这样r2_score的值会显著提高。
数据处理
这里,我将使用pd.get_dummies为所有分类变量创建虚拟列。
然而,由于测试数据中缺少所有类型,很可能会有缺失的列。我们用一个例子来理解一下。例如在列Transmission中,训练数据包括Manual和Automatic,因此虚拟对象将类似于Transmission_Manual和Transmission_Automatic。但是如果测试数据只有Manual值而没有Automatic值呢?在这种情况下,假人只会导致Transmission_Manual。这将使测试数据集比训练数据少一列,预测将不起作用。为了处理这个问题,我们在测试数据中创建缺失的列,并用零填充它们。最后,我们对测试数据进行排序,就像训练数据一样。
最后,我会缩放数据。
训练和预测
我将创建一个线性回归和随机森林模型来训练数据,并比较r2_score值以选择最佳选择。
我得到线性回归的r2_score为0.70,随机森林为0.88。因此,随机森林在测试数据上表现得非常好。
结论
在这篇文章中,我们看到了如何处理现实生活中的机器学习问题,以及我们如何根据它们的相关性和它们给出的信息来调整功能。
您可能还喜欢:
[## 我是如何使用 Python 和 R 来分析和预测医疗预约的!
一个 R 和 Python 共存的世界
towardsdatascience.com](/how-i-used-python-and-r-to-analyze-and-predict-medical-appointment-show-ups-cd290cd3fad0) [## seaborn——让绘图变得有趣
Python 中的 Seaborn 库简介
towardsdatascience.com](/seaborn-lets-make-plotting-fun-4951b89a0c07) [## 使用深度学习通过确保驾驶员的注意力来拯救生命
现实生活中的卷积神经网络
towardsdatascience.com](/using-deep-learning-to-save-lives-by-ensuring-drivers-attention-e9ab39c03d07) [## 使用 Python 中的多个绘图库在地图上绘制商业位置
比较地图打印库
towardsdatascience.com](/plotting-business-locations-on-maps-using-multiple-plotting-libraries-in-python-45a00ea770af)
请随意分享你的想法和想法。我很想收到你的来信!
通过使用 Sacred 管理您的机器学习实验来改进您的工作流程

Me building experiments before using Sacred (Thanks Nicolas for the pick)
作为一名数据科学家,模型调优是我最不喜欢的任务。我 讨厌 它。我想这是因为管理实验总是会变得非常混乱。在寻找帮助我的工具时,我看到很多人提到神圣的,所以我决定试一试。
在这篇文章中,我们将看到如何使用神圣和全面的来管理我们的实验。剧透警告:这个工具很棒,现在做实验真的很有趣。
神圣是如何工作的?
我们在模型训练脚本中使用神圣的装饰者。就是这样!该工具会自动存储每次运行的实验信息。今天,我们将使用 MongoDB 存储信息,并使用 Omniboard 工具将其可视化。好了,我们开始吧。
使用神圣的
这里有一个逐步指南:
- 创造一个实验
- 定义实验的主要功能
- 添加配置参数
- 添加其他指标
- 进行实验
1 —创建一个实验
首先我们需要创建一个实验。很简单:
from **sacred** import **Experiment****ex = Experiment("our_experiment")**
搞定了。
2 —定义实验的主要功能
run方法运行实验的主要功能。当我们运行 Python 脚本时,@ex.automain装饰器定义并且运行实验的主要功能。它相当于:
from sacred import Experimentex = Experiment("our_experiment")**@ex.main
def run():
pass**
**if __name__ == '__main__':
ex.run_commandline()**
让我们用@ex.automain来代替:
from sacred import Experimentex = Experiment("our_experiment")**@ex.automain
def run():
pass**
3-添加配置参数
每次运行时,配置参数也会存储在数据库中。设置的方式有很多:通过配置范围、字典、配置文件。让我们坚持这里的配置范围。
我们将使用这个在线零售数据集并使用 scikit-learn 的时间序列交叉验证器来拆分数据。该模型将预测订单是否会被取消。让我们定义criterion参数:
from sklearn.tree import DecisionTreeClassifier
from sklearn.model_selection import TimeSeriesSplit
import pandas as pd
from sacred import Experiment ex = Experiment('online_retail_tree') **@ex.config
def cfg():
criterion = "entropy"** @ex.automain
def run(**criterion**):
dateparse = lambda x: pd.datetime.strptime(x, '%d/%m/%Y %H:%M') df = pd.read_csv("Online Retail.csv", parse_dates["InvoiceDate"], date_parser=dateparse, decimal=",") df = df.sort_values(by="InvoiceDate") df["canceled"] = df["InvoiceNo"].apply(lambda x: x[0] == "C") X = df.loc[:,["Quantity","UnitPrice"]]
y = df.loc[:, ["canceled"]] ts_split = TimeSeriesSplit(n_splits=10)
clf = DecisionTreeClassifier(criterion=criterion)
for train_index, test_index in ts_split.split(X):
X_train = X.iloc[train_index]
y_train = y.iloc[train_index] X_test = X.iloc[test_index]
y_test = y.iloc[test_index] clf.fit(X_train, y_train.values.ravel())
y_pred = clf.predict(X_test)
4 —添加其他指标
神圣收集关于实验的信息,但我们通常也想测量其他东西。在我们的例子中,我想知道每次分割中取消订单的数量。我们可以为此使用 Metrics API。
神圣支持使用 Metrics API 跟踪数字序列(例如 int、float)。
_run.log_scalar(metric_name, value, step)方法采用一个度量名称(例如“training.loss”)、测量值和获取该值的迭代步骤。如果未指定步长,则会为每个度量设置一个自动递增 1 的计数器。— 指标 API
from sklearn.tree import DecisionTreeClassifier
from sklearn.model_selection import TimeSeriesSplit
import pandas as pd
from sacred import Experimentex = Experiment('online_retail_tree')@ex.config
def cfg():
criterion = "entropy"@ex.automain
def run(criterion):
dateparse = lambda x: pd.datetime.strptime(x, '%d/%m/%Y %H:%M') df = pd.read_csv("Online Retail.csv", parse_dates["InvoiceDate"], date_parser=dateparse, decimal=",") df = df.sort_values(by="InvoiceDate") df["canceled"] = df["InvoiceNo"].apply(lambda x: x[0] == "C") X = df.loc[:,["Quantity","UnitPrice"]]
y = df.loc[:, ["canceled"]] ts_split = TimeSeriesSplit(n_splits=10)
clf = DecisionTreeClassifier(criterion=criterion)
for train_index, test_index in ts_split.split(X):
X_train = X.iloc[train_index]
y_train = y.iloc[train_index] X_test = X.iloc[test_index]
y_test = y.iloc[test_index] clf.fit(X_train, y_train.values.ravel())
y_pred = clf.predict(X_test)5 — Running the experiment true_cancel_count = y_test["canceled"].value_counts().tolist()[1]
pred_cancel_count = y_pred.tolist().count(True)
train_cancel_count = y_train["canceled"].value_counts().tolist()[1] **ex.log_scalar("true_cancel_count", true_cancel_count)
ex.log_scalar("pred_cancel_count", pred_cancel_count)
ex.log_scalar("train_cancel_orders", train_cancel_count)**
5 —运行实验
我们将使用 MongoDB Observer 来存储关于实验的信息:
神圣通过为你的实验提供一个观察者界面来帮助你。通过附加一个观察器,您可以收集关于运行的所有信息,即使它还在运行。— 观察实验
为了将数据保存到名为 my_database 的 mongo 数据库中,我们只需运行python3 my_experiment.py -m my_database。
现在有了关于实验的数据,但我们需要将它可视化。为此,我们将使用综合。
使用 OMNIBOARD
Omniboard 是用 React,Node.js,Express 和 Bootstrap 写的一个神圣的仪表盘。
要安装它,运行npm install -g omniboard,并开始我们运行omniboard -m hostname:port:database,在我们的例子中:omniboard -m localhost:27017:my_database。

Omniboard listing our experiments
我们可以看到一个实验是否失败,实验持续时间,添加注释等等。

Detailed view of an experiment
detail 视图显示了我们跟踪的指标的图表,我们还可以查看命令行输出、源代码(awesome)和其他实验细节。
那又怎样?
神圣是一个伟大的工具,因为现在我们不必担心保存我们的实验结果。一切都被自动存储,我们可以回去分析任何实验。
这个工具被设计成只引入最小的开销,在我看来这就是它的伟大之处。
这里的主要信息是:给神圣一个尝试!我可以说我现在的工作流程因为它好了很多。🙂
为了同样的目的,你使用另一个工具吗?我也想听听其他替代方案。感谢您的阅读!


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}