







理解机器学习中的数据规范化
如果你是数据科学/机器学习的新手,你可能很想知道“特征规范化”这个时髦词的本质和效果。如果您阅读过任何 Kaggle 内核,很可能在数据预处理部分找到了特性规范化。那么,什么是数据规范化,为什么数据从业者如此重视它?
1.定义
有不同类型的数据规范化。假设您有一个数据集 X ,它有 N 行(条目)和 D 列(特征)。 X[:,i] 表示特征 i ,X[j,:]表示条目 j。我们有:
Z 规范化(标准化):

我曾经错误地认为这种方法会产生标准的高斯结果。事实上,标准化并没有改变分销的类型:

pdf of standardized data
此转换将数据的平均值设置为 0,标准差设置为 1。在大多数情况下,标准化是按功能使用的
最小-最大归一化:

该方法将数据的范围重新调整为[0,1]。在大多数情况下,标准化也是按功能使用的
单位矢量归一化:

缩放到单位长度将一个向量(一行数据可以看作一个 D 维向量)收缩/拉伸到一个单位球体。当在整个数据集上使用时,转换后的数据可以被可视化为在 D 维单位球上具有不同方向的一束向量。
哇,正常化确实是一个宽泛的术语,它们各有利弊!在本文中,我将只关注标准化,否则这篇文章会太长。
2.效果
回归
理论上,回归对标准化不敏感,因为输入数据的任何线性变换都可以通过调整模型参数来抵消。假设我们有一个带有参数 W 和 B 的线性模型:

W is D by 1, B is N by 1
通过减去矩阵 M 并乘以对角矩阵 T 可以实现列方式的改变


很容易证明,我们可以通过调整 W 和 B 来抵消这种转换

因此,输入数据的标准化不应影响输出或准确性。好吧,如果数学上说标准化在回归中起不了什么作用,为什么它仍然如此受欢迎?
答。标准化提高了模型的数值稳定性
如果我们有一个简单的一维数据 X,并使用 MSE 作为损失函数,使用梯度下降的梯度更新是:

Y’ is the prediction
X 在梯度下降公式中,意味着 X 的值决定了更新速率。所以更大的 X 会导致渐变景观更大的飞跃。同时,给定 Y,较大的 X 导致较小的 W:

当 X 很大时,初始 W(随机选取的)和全局最小值之间的距离很可能很小。因此,当 X 较大时(学习率是固定的),该算法更可能失败,因为该算法朝着非常接近的目标 W 进行了巨大的跳跃,而需要小步前进。这种超调会让你的亏损振荡或爆发。
实验:
我使用以下代码人工创建了一个数据集:
X = np.arange(-5,5,0.1)
w = 0.5
b = 0.2
Y = X*w+b+(np.random.rand(X.shape[0],)-0.5)#add some noise to Y
X.reshape(100,1)
Y.reshape(100,1)

我在实验中使用了一个简单的线性回归代码:
class linear_regression:
def fit(self, X,Y, lr=0.00001):
epoch = 0
loss_log = []
while (epoch<8000):
pred = self.predict(X)
l = self.loss(pred,Y)# get loss
loss_log.append(l)
delta_w = 2*np.matmul((Y-pred).T, X) # gradient of w
delta_b = sum(2*(Y-pred))
self.w = self.w + lr*delta_w
self.b = self.b + lr*delta_b
epoch = epoch+1
plt.plot(loss_log)
plt.ylim([0.07,0.1])
print (loss_log[-5:-1])
def loss(self, pred,Y):
error = Y-pred
return sum(error**2)/error.shape[0] # MSE
def predict(self, X):
return X*self.w+self.b# n by 1
def __init__(self):# initial parameters
self.w=0.5# fixed initialization for comparison convenience
self.b=0.5
下表显示了不同学习率和特征范围的最终 MSE。

final loss (MSE) after 8000 iterations
当 X 具有较大的系数(因此范围较大)时,模型需要较小的学习速率来保持稳定性。
b)。标准化可能会加快培训过程
第一个“定理”的推论是,如果不同的特征具有完全不同的范围,则学习率由具有最大范围的特征决定。这带来了标准化的另一个好处:加快了培训过程。
假设我们有两个特征:

由 X2 确定的学习率对于 X1 来说并不“伟大”,因为 X1 对于大得多的学习率来说是可以的。我们正在慢慢地走,而大的跳跃本可以被用来代替,这导致了更长的训练时间。我们可以通过标准化这两个特性来减少训练时间。
实验:
我使用以下代码人工创建了一个包含两个要素的数据集:
X1 = np.arange(-5,5,0.1)
X2 = np.arange(-5,5,0.1)
X = np.column_stack((X1,X2))
W = np.array([[0.1],[0.2]])
b = 0.1
Y = np.matmul(X,W)+b+(np.random.rand(X.shape[0],1) -0.5)
# add some noise to labels
使用稍微修改的线性回归代码:
class linear_regression:
def fit(self, X,Y, lr=1e-4):
epoch = 0
loss_log = []
while (epoch<80000):
pred = self.predict(X)
l = self.loss(pred,Y)# get loss
loss_log.append(l)
if l < 0.0792:
print (epoch)
break
delta_w = 2*np.matmul((Y-pred).T, X) # gradient of w
delta_b = sum(2*(Y-pred))
self.w = self.w + lr*delta_w.T
self.b = self.b + lr*delta_b
epoch = epoch+1
plt.plot(loss_log)
plt.ylim([0.07,0.1])
print (loss_log[-5:-1])
def loss(self, pred,Y):
error = Y-pred
return sum(error**2)/error.shape[0] # MSE
def predict(self, X):
return np.matmul(X,self.w)+self.b# n by 1
def __init__(self):
self.w=np.array([[0.5],[0.5]])# for comparison convenience
self.b=0.3
下表显示了对于给定的系数和学习率,达到全局最小值所需的迭代次数:

iterations to reach the global minimum
我们可以看到,当数据没有标准化时,模型需要更多的迭代(训练时间)才能完成。
基于距离的算法
K-mean 和 K-NN 等基于距离的聚类算法很有可能受到标准化的影响。聚类算法需要计算条目之间的距离。最常用的距离是欧几里德距离:

distance between i and j
很明显,特征缩放将改变节点之间的数值距离。
实验:
使用以下代码创建数据集:
def random_2D_data(x,y,size):
x = (np.random.randn(size)/3.5)+x
y = (np.random.randn(size)*3.5)+y
return x,y
x1,y1 = random_2D_data(2,20,50)
x2,y2 = random_2D_data(2,-20,50)
x3,y3 = random_2D_data(-2,20,50)
x4,y4 = random_2D_data(-2,-20,50)
x = np.concatenate((x1,x2,x3,x4))
y = np.concatenate((y1,y2,y3,y4))

使用 K 均值对数据进行聚类:

clustering without any feature scaling
然而,对标准化数据做同样的事情会产生完全不同的结果:

affected result
太好了,我们有互相矛盾的结果。我应该选择哪个结果?
标准化为每个功能提供了“平等”的考虑。
例如,X 具有两个特征 x1 和 x2


如果直接计算欧氏距离,节点 1 和 2 会比节点 1 和 3 离得更远。然而,节点 3 完全不同于 1,而节点 2 和 1 仅在特征 1 (6%)上不同,并且共享相同的特征 2。这是因为特征 1 是“VIP”特征,以其大数值控制结果。
因此,如果我们不知道哪些特征是“钻石”特征,哪些是“珊瑚”特征,那么使用标准化来平等地考虑它们是一种很好的做法。
基于树的决策算法
决策树或随机森林等基于树的决策算法会在每个特征中寻找最佳分割点。分割点由使用特征正确分类的标注的百分比决定,该百分比对特征缩放具有弹性。因此,标准化对这种类型的 ML 模型没有任何重大影响。
神经网络
神经网络可以像回归一样抵消标准化。因此,理论上,数据标准化不应该影响神经网络的性能。然而,经验证据表明,数据标准化在准确性方面是有益的[1]。目前,我还没有看到原因,但可能与梯度下降有关。
很容易理解为什么标准化会提高训练时间。大输入值使激活函数饱和,如 sigmoid 或 ReLu(负输入)。这些类型的激活函数在饱和区域反馈很小的梯度或者根本没有梯度,因此减慢了训练。

large input kills backward gradient flow
3.摘要
标准化在许多情况下是有益的。它提高了模型的数值稳定性,并且通常减少了训练时间。然而,标准化并不总是好的。假设特征的重要性相等会损害基于距离的聚类算法的性能。如果特性之间存在固有的重要性差异,那么进行标准化通常不是一个好主意。
参考:
[1]: Shanker M,Hu MY,Hung MS,数据标准化对神经网络训练的影响,https://www . science direct . com/science/article/pii/0305048396000102
了解你的张量流模型是如何进行预测的
与 SHAP 一起探索学生贷款数据
介绍
机器学习可以比以往更快更准确地回答问题。随着机器学习在更多任务关键型应用中的使用,理解这些预测是如何得出的变得越来越重要。
在这篇博文中,我们将使用来自 TensorFlow 的 Keras API 构建一个神经网络模型,这是一个开源的机器学习框架。一旦我们的模型被训练,我们将把它与可解释性库 SHAP 集成。我们将使用 SHAP 来了解哪些因素与模型预测相关。

关于模型
我们的模型将预测大学毕业生相对于他们未来收入的毕业债务。这一债务收益比旨在作为一所大学投资回报(ROI)的粗略指标。这些数据来自美国教育部的大学记分卡,这是一个公开其数据的互动网站。
下表列出了模型中的功能。关于数据集的更多细节可以在数据文档中找到。
+-------------------------+--------------------------------------+
| Feature | Description |
+-------------------------+--------------------------------------+
| ADM_RATE | Admission rate |
| SAT_AVG | SAT average |
| TRANS_4 | Transfer rate |
| NPT4 | Net price (list price - average aid) |
| INC_N | Family income |
| PUBLIC | Public institution |
| UGDS | Number of undergraduate students |
| PPTUG_EF | % part-time students |
| FIRST_GEN | % first-generation students |
| MD_INC_COMP_ORIG_YR4_RT | % completed within 4 years |
+-------------------------+--------------------------------------+
我们从数据集中可用的债务和收益数据中推导出目标变量(债务收益比)。具体来说,就是毕业时积累的债务中位数(MD_INC_DEBT_MDN),除以毕业后 6 年的平均收入(MN_EARN_WNE_INC2_P6)。
创建散点图是为了可视化每个特征与我们的目标变量的相关性。下面的每张图表在 X 轴上显示特征,在 Y 轴上显示债务/收益比率。

我们将使用一个Sequential模型,有两个密集连接的隐藏层和一个 ReLU 激活函数:
model = keras.Sequential([
layers.Dense(16, activation=tf.nn.relu, input_shape=[len(df.keys())]),
layers.Dense(16, activation=tf.nn.relu),
layers.Dense(1)
下面我们看到一个训练过程的图表。训练误差和验证误差之间的差距越来越大,这表明有些过度拟合。过度拟合很可能是由于数据集中具有所有所需特征的样本数量有限(1,117 个)。尽管如此,考虑到平均债务收益比大约为 0.45,0.1 的平均绝对误差证明了一个有意义的预测。

要在浏览器中直接运行笔记本,您可以使用 Colab 。在 Github 中也有。
关于 ML 公平的一句话
我们在这篇博文中调查的大学债务问题与更广泛的社会经济问题有着密切的联系。应该仔细评估任何模型及其训练数据,以确保它公平地服务于所有用户。例如,如果我们的训练数据主要包括来自高收入家庭的学生就读的学校,那么模型的预测将会歪曲那些学生通常有许多学生贷款的学校。
在可能的情况下,对中等收入学生的数据值进行了过滤,以便对不同家庭收入水平的学生进行一致的分析。大学记分卡数据将中等收入阶层定义为家庭收入在 3 万美元至 7.5 万美元之间的学生。并非所有可用的数据都提供此过滤器,但它可用于净价、收益、债务和完成率等关键功能。
记住这个思考过程,分析可以进一步扩展到数据集中的其他方面。同样值得注意的是,可解释性揭示了哪些特征对模型的预测贡献最大。它并不表明特征和预测之间是否存在因果关系。
SHAP 简介
可解释性本质上是理解模型中正在发生的事情的能力。通常在模型的准确性和可解释性之间有一个折衷。简单的线性模型易于理解,因为它们直接暴露了变量和系数。非线性模型,包括由神经网络或梯度增强树导出的模型,可能更难以解释。
进入 SHAP。SHAP,或 SHapley Additive exPlanations,是由 Scott Lundberg 创建的 Python 库,可以解释许多机器学习框架的输出。它有助于解释单个预测或汇总更大人群的预测。
SHAP 通过干扰输入数据来评估每个特征的影响。每个特征的贡献在所有可能的特征交互中被平均。这种方法是基于博弈论中 Shapley 值的概念。它提供了一种稳健的近似,相对于 LIME 等其他方法,这种近似在计算上可能更昂贵。关于 SHAP 理论的更多细节可以在图书馆作者的 2017 NeurIPS 论文中找到。
将 SHAP 与张量流 Keras 模型结合使用
SHAP 提供了几个解释器类,它们使用不同的实现,但都利用了基于 Shapley 值的方法。在这篇博文中,我们将演示如何使用 KernelExplainer 和 DeepExplainer 类。KernelExplainer 与模型无关,因为它将模型预测和训练数据作为输入。DeepExplainer 针对深度学习框架(TensorFlow / Keras)进行了优化。
SHAP DeepExplainer 目前不支持急切执行模式或 TensorFlow 2.0。然而,KernelExplainer 将工作得很好,尽管它明显慢了很多。
让我们从使用 KernelExplainer 绘制模型的概要图开始。我们将首先把训练数据总结成 n 个集群。这是一个可选但有用的步骤,因为生成 Shapley 值的时间会随着数据集的大小呈指数增长。
# Summarize the training set to accelerate analysis
df_train_normed_summary = shap.kmeans(df_train_normed.values, 25)# Instantiate an explainer with the model predictions and training data summary
explainer = shap.KernelExplainer(model.predict, df_train_normed_summary)# Extract Shapley values from the explainer
shap_values = explainer.shap_values(df_train_normed.values)# Summarize the Shapley values in a plot
shap.summary_plot(shap_values[0], df_train_normed)
摘要图显示了每个要素的 Shapley 值分布。每个点的颜色在光谱上,该特征的最高值是红色,最低值是蓝色。通过 Shapley 值的绝对值之和对特征进行排序。
我们从剧情来看一些关系。贡献度最高的前三个特征分别是SAT 平均分、 %第一代学生、 %非全日制招生。请注意,这些特征中的每一个都在右侧有显著的蓝点(低特征值),这里有正 SHAP 值。这告诉我们,这些特征的低值导致我们的模型预测高 DTE 比率。列表中的第四个特性净价具有相反的关系,其中净价越高,DTE 比率越高。

也可以使用force_plot()函数解释一个特定的实例:
# Plot the SHAP values for one instance
INSTANCE_NUM = 0shap.force_plot(explainer.expected_value[0], shap_values[0][INSTANCE_NUM], df_train.iloc[INSTANCE_NUM,:])

在这个特殊的例子中,大学的 SAT 平均分对其 0.53 的 DTE 预测贡献最大,推动其值更高。完成率(MD_INC_COMP_ORIG_YR4_RT)是第二重要的特征,将预测值推低。还可以查看整个数据集或一部分 n 实例中显示的一系列 SHAP 值,如下所示:
# Plot the SHAP values for multiple instances
NUM_ROWS = 10
shap.force_plot(explainer.expected_value[0], shap_values[0][0:NUM_ROWS], df_train.iloc[0:NUM_ROWS])

注意相关的特征
SHAP 将在相关变量间分割特征贡献。在为模型选择特征和分析特征重要性时,记住这一点很重要。让我们计算相关矩阵,看看我们会发现什么:
corr = df.corr()
sns.heatmap(corr)

让我们用相关矩阵交叉引用总结图中的前三个特征,看看哪些特征可能会被拆分:
- SAT 平均分与完成率呈正相关,与录取率和一代比呈负相关。
- 一代比与兼职比相关,与完成率负相关。
几个相关的特征被分组在摘要图列表的顶部。值得关注的是榜单中排名靠后的完成率和录取率。
SHAP 有一个dependence_plot()功能,可以帮助揭示更多细节。比如我们来看看一代比和兼职比的相互作用。正如我们在汇总图中观察到的,我们可以看到第一代比率与其 Shapley 值呈负相关。依赖图还向我们显示,当大学的兼职学生比例较低时,相关性更强。
shap.dependence_plot('FIRST_GEN', shap_values[0], df_train, interaction_index='PPTUG_EF')

结论
在这篇博文中,我们展示了如何用 SHAP 解释 tf.keras 模型。我们还回顾了如何使用 SHAP API 和几个 SHAP 绘图类型。最后,为了完整和准确的描述,我们讨论了关于公平性和相关变量的考虑。现在,您拥有了更好地了解 TensorFlow Keras 模型中发生的事情的工具!
要了解我在这里介绍的更多信息,请查看以下资源:
- Colab 笔记本从浏览器运行模型
- GitHub 储存库带笔记本
- 【tf.keras 入门
- SHAP GitHub 库
在推特上让我知道你的想法!
理解 PyTorch 中明凯初始化和实现的细节
初始化很重要!知道如何用明凯均匀函数设置扇入和扇出模式

Photo by Jukan Tateisi on Unsplash
TL;速度三角形定位法(dead reckoning)
如果你通过创建一个线性层来隐式地创建权重,你应该设置modle='fan_in'。
linear = torch.nn.Linear(node_in, node_out)
init.kaiming_normal_(linear.weight, mode=’fan_in’)
t = relu(linear(x_valid))
如果你通过创建一个随机矩阵显式地创建权重,你应该设置modle='fan_out'。
w1 = torch.randn(node_in, node_out)
init.kaiming_normal_(w1, mode=’fan_out’)
b1 = torch.randn(node_out)
t = relu(linear(x_valid, w1, b1))
内容结构如下。
- 重量初始化很重要!
- 什么是明凯初始化?
- 为什么明凯初始化有效?
- 理解 Pytorch 实现中的扇入和扇出模式
重量初始化很重要!
初始化是一个创建权重的过程。在下面的代码片段中,我们随机创建了一个大小为(784, 50)的权重w1。
*torhc.randn(*sizes)*从均值为 0、方差为 1 的正态分布返回一个填充了随机数的张量(也称为标准正态分布)。张量的形状由变量 argument*sizes*定义。
并且该权重将在训练阶段被更新。
*# random init*
w1 = torch.randn(784, 50)
b1 = torch.randn(50)
**def** linear(x, w, b):
**return** x@w + b
t1 = linear(x_valid, w1, b1)print(t1.mean(), t1.std())############# output ##############
tensor(3.5744) tensor(28.4110)
你可能想知道如果权重可以在训练阶段更新,为什么我们需要关心初始化。无论如何初始化权重,最终都会被“很好地”更新。
但现实并不那么甜蜜。如果我们随机初始化权重,就会引起两个问题,即 消失渐变问题 和 爆炸渐变问题 。
消失渐变问题 表示权重消失为 0。因为这些权重在反向传播阶段与层一起被相乘。如果我们将权重初始化得很小(< 1),在反向传播过程中,当我们使用隐藏层进行反向传播时,梯度会变得越来越小。前几层的神经元比后几层的神经元学习慢得多。这导致轻微的重量更新。
爆炸渐变问题 表示权重爆炸到无穷大(NaN)。因为这些权重在反向传播阶段与层一起被相乘。如果我们将权重初始化得很大(> 1),当我们在反向传播过程中使用隐藏层时,梯度会变得越来越大。早期层中的神经元以巨大的步长更新,W = W — ⍺ * dW,并且向下的力矩将增加。
什么是明凯初始化?
明凯等人通过对 ReLUs 的非线性进行谨慎建模,推导出一种合理的初始化方法,使得极深模型(> 30 层)收敛。下面是明凯初始化函数。

- a:该层之后使用的整流器的负斜率(默认情况下,ReLU 为 0)
- fan_in:输入维数。如果我们创建一个
(784, 50),扇入是 784。fan_in用于前馈阶段的**。如果我们将其设置为fan_out,则扇出为 50。fan_out用于反向传播阶段。后面我会详细解释两种模式。**
为什么明凯初始化有效?
我们通过比较随机初始化和明凯初始化来说明明凯初始化的有效性。
随机初始化
# random init
w1 = torch.randn(784, 50)
b1 = torch.randn(50)
w2 = torch.randn(50, 10)
b2 = torch.randn(10)
w3 = torch.randn(10, 1)
b3 = torch.randn(1)def linear(x, w, b):
return x@w + bdef relu(x):
return x.clamp_min(0.)t1 = relu(linear(x_valid, w1, b1))
t2 = relu(linear(t1, w2, b2))
t3 = relu(linear(t2, w3, b3))print(t1.mean(), t1.std())
print(t2.mean(), t2.std())
print(t3.mean(), t3.std())############# output ##############
tensor(13.0542) tensor(17.9457)
tensor(93.5488) tensor(113.1659)
tensor(336.6660) tensor(208.7496)
我们用均值为 0、方差为 1 的正态分布来初始化权重,ReLU 后的理想权重分布应该是逐层略微递增的均值和接近 1 的方差。但是在前馈阶段,经过一些层之后,分布变化很大。
为什么权重的均值要逐层小幅递增?
因为我们使用 ReLU 作为激活函数。如果输入值大于 0,ReLU 将返回提供的值,如果输入值小于 0,将返回 0。

if input < 0:
return 0
else:
return input
ReLU 之后,所有负值都变成 0。当层变得更深时,平均值将变得更大。
明凯初始化
# kaiming init
node_in = 784
node_out = 50# random init
w1 = torch.randn(784, 50) * math.sqrt(2/784)
b1 = torch.randn(50)
w2 = torch.randn(50, 10) * math.sqrt(2/50)
b2 = torch.randn(10)
w3 = torch.randn(10, 1) * math.sqrt(2/10)
b3 = torch.randn(1)def linear(x, w, b):
return x@w + bdef relu(x):
return x.clamp_min(0.)t1 = relu(linear(x_valid, w1, b1))
t2 = relu(linear(t1, w2, b2))
t3 = relu(linear(t2, w3, b3))print(t1.mean(), t1.std())
print(t2.mean(), t2.std())
print(t3.mean(), t3.std())############# output ##############
tensor(0.7418) tensor(1.0053)
tensor(1.3356) tensor(1.4079)
tensor(3.2972) tensor(1.1409)
我们用均值为 0、方差为 **std**的正态分布初始化权重,relu 后的理想权重分布应该是均值逐层略微递增,方差接近 1。我们可以看到输出接近我们的预期。在前馈阶段,平均增量缓慢,std 接近 1 。并且这种稳定性将避免在反向传播阶段中的消失梯度问题和爆炸梯度问题。
明凯初始化显示出比随机初始化更好的稳定性。
了解 Pytorch 实现中的 fan_in 和 fan_out 模式
[nn.init.kaiming_normal_()](https://pytorch.org/docs/stable/nn.html#torch.nn.init.kaiming_normal_)将返回具有从均值 0 和方差std中采样的值的张量。有两种方法可以做到。
一种方法是通过创建线性层来隐式创建权重。我们设置mode='fan_in'来表示使用node_in计算 std
from torch.nn import init# linear layer implementation
node_in, node_out = 784, 50**layer = torch.nn.Linear(node_in, node_out)
init.kaiming_normal_(layer.weight, mode='*fan_in*')
t = relu(layer(x_valid))**print(t.mean(), t.std())############# output ##############
tensor(0.4974, grad_fn=<MeanBackward0>) tensor(0.8027, grad_fn=<StdBackward0>)
另一种方法是通过创建随机矩阵来显式创建权重,你应该设置mode='fan_out'。
def linear(x, w, b):
return x@w + b# weight matrix implementation
node_in, node_out = 784, 50**w1 = torch.randn(node_in, node_out)
init.kaiming_normal_(w1, mode='*fan_out*')** b1 = torch.randn(node_out)
**t = relu(linear(x_valid, w1, b1))**print(t.mean(), t.std())############# output ##############
tensor(0.6424) tensor(0.9772)
两种实现方法都是对的。平均值接近 0.5,标准差接近 1。但是等一下,你有没有发现一些奇怪的事情?
为什么模式不同?
根据文件,选择'fan_in'保留了正向传递中权重的方差大小。选择'fan_out'保留反向过程中的幅度。我们可以这样写。
node_in, node_out = 784, 50# fan_in mode
W = torch.randn(node_in, node_out) * math.sqrt(2 / node_in)# fan_out mode
W = np.random.randn(node_in, node_out) * math.sqrt(2/ node_out)
在线性层实现中,我们设置mode='fan_in'。是的,这是前馈阶段,我们应该设置mode='fan_in'。没什么问题。
但是为什么我们在权重矩阵实现中设置模式为 **fan_out** ?
[nn.init.kaiming_normal_()](https://pytorch.org/docs/stable/nn.html#torch.nn.init.kaiming_normal_)的源代码背后的原因
def _calculate_fan_in_and_fan_out(tensor):
dimensions = tensor.dim()
if dimensions < 2:
raise ValueError("Fan in and fan out can not be computed for tensor with fewer than 2 dimensions")if dimensions == 2: # Linear
**fan_in = tensor.size(1)
fan_out = tensor.size(0)**
else:
num_input_fmaps = tensor.size(1)
num_output_fmaps = tensor.size(0)
receptive_field_size = 1
if tensor.dim() > 2:
receptive_field_size = tensor[0][0].numel()
fan_in = num_input_fmaps * receptive_field_size
fan_out = num_output_fmaps * receptive_field_sizereturn fan_in, fan_out
这是获得正确模式的源代码。tensor是尺寸为(784,50)的w1。所以fan_in = 50, fan_out=784。当我们在权重矩阵实现中将模式设置为fan_out时。init.kaiming_normal_()实际计算如下。
node_in, node_out = 784, 50W = np.random.randn(node_in, node_out)
**init.kaiming_normal_(W, mode='*fan_out*')**# what init.kaiming_normal_() actually does
# fan_in = 50
# fan_out = 784W = W * torch.sqrt(784 / 2)
好吧,有道理。但是如何解释在线性层实现中使用 **fan_in** ?
当我们使用线性隐式创建权重时,权重被隐式转置。下面是torch . nn . functional . linear的源代码。
def linear(input, weight, bias=None):
# type: (Tensor, Tensor, Optional[Tensor]) -> Tensor
r"""
Applies a linear transformation to the incoming data: :math:`y = xA^T + b`.
Shape:
- Input: :math:`(N, *, in\_features)` where `*` means any number of
additional dimensions
- **Weight: :math:`(out\_features, in\_features)`**
- Bias: :math:`(out\_features)`
- Output: :math:`(N, *, out\_features)`
"""
if input.dim() == 2 and bias is not None:
# fused op is marginally faster
ret = torch.addmm(bias, input, **weight.t()**)
else:
**output = input.matmul(weight.t())**
if bias is not None:
output += bias
ret = output
return ret
权重初始化为(out_features, in_features)的大小。例如,如果我们输入尺寸(784, 50),重量的大小实际上是(50, 784)。
torch.nn.Linear(784, 50).weight.shape############# output ##############
torch.Size([50, 784])
这就是为什么 linear 需要先转置权重,再做 matmul 运算的原因。
if input.dim() == 2 and bias is not None:
# fused op is marginally faster
ret = torch.addmm(bias, input, **weight.t()**)
else:
output = input.matmul(**weight.t()**)
因为线性层中的权重大小为(50, 784),所以init.kaiming_normal_()实际计算如下。
node_in, node_out = 784, 50**layer = torch.nn.Linear(node_in, node_out)**
**init.kaiming_normal_(layer.weight, mode='*fan_out*')**# the size of layer.weightis (50, 784)# what init.kaiming_normal_() actually does
# fan_in = 784
# fan_out = 50W = W * torch.sqrt(784 / 2)
摘要
在这篇文章中,我首先谈到了为什么初始化很重要,什么是明凯初始化。我将分解如何使用 PyTorch 来实现它。希望这个帖子对你有帮助。有什么建议就留言吧。
这个片段中的完整代码。
查看我的其他帖子 中等 同 分类查看 !
GitHub:bramble Xu LinkedIn:徐亮 博客:bramble Xu
参考
- 为什么谨慎初始化深度神经网络很重要?
- 深度学习最佳实践(1) —权重初始化
- 明凯初始化论文:深入研究整流器:在 ImageNet 分类上超越人类水平的性能
- 整流线性单元(ReLU)简介
- Fast.ai 的《程序员深度学习》课程第八课
6 分钟理解机器学习
看完这个帖子,
- 你将对什么是机器学习以及它是如何工作的有一个高层次的理解
- 你将能够考虑机器学习在你的业务或部门中的可能性
如果这值得你花六分钟时间——那就往下跳……

设置场景
理论上,软件程序每次运行时都会做同样的事情。这是因为它们采取的行动是显式编程的。
相反,随着经验的积累,机器学习程序会试图提高与目标相关的性能。这是因为只有目标是显式编程的,他们采取的行动是隐含的。
大多数人认为机器学习依赖于花哨的算法。也许有 40%是对的——虽然你需要算法,但它们不是性能或可能性的根本驱动力。重要的是算法用来学习的数据。
如何看待数据
不严格地说,数据只是存储的信息。在现实世界中,我们可以将数据集合分为结构化和非结构化。机器学习可以应用于结构化和非结构化数据,但理解其中的区别很重要。
结构数据
结构化数据存在于由行和列组成的表中。例如:

You’ll also hear ‘tabular data’ as a reference to structured data
非结构化数据
非结构化数据是指不存在于由行和列组成的表格中的所有数据。但是不要烦恼,仅仅因为它的结构更少,并不意味着我们不能用它来进行机器学习。非结构化数据的常见示例包括:
- 文本
- 形象
- 录像
- 语音记录
- 文档(例如 1000 个 pdf)
机器学习的类型
机器学习程序分为三类:
- 监督学习 ,这里我们的算法给出了我们想要预测的目标答案的例子
- 无监督学习 ,其中我们的算法没有可供学习的答案示例,而是从数据中生成新的发现
- 强化学习 ,机器被暴露在一个新的环境中,并被要求从试错中学习
监督学习无疑是当今世界上使用最多的框架。如果你开始考虑机器学习的潜在应用,那么监督学习应该是你的第一站。
不过,不要睡在无监督学习上,它有特定的用例,我们很快就会谈到。与此同时,强化学习是一个仍在发展的框架,目前最广为人知的是在复杂游戏中击败人类。
结构化数据的监督学习
都在名字里,我们的模型需要 学会 如何找到目标变量,才会 知道 如何找到变量。机器需要一个数据集来学习,这个数据集必须包含目标变量。
让我们假设我们正在训练一个算法来预测动物的最大寿命。我们可以使用之前的数据集:

我们的算法将检查黄色因变量和绿色目标变量之间的关系。一旦经过训练,我们可以用机器人从未见过的新数据来测试我们的机器人。

如果我们的训练数据是好的,那么我们的算法将高度准确地预测动物(我们的目标变量)的最大寿命。
非结构化数据的监督学习
对于图像和其他非结构化数据,也是同样的逻辑。我们可以训练机器寻找某样东西,但首先,我们需要告诉它要寻找什么。给一个算法几千张有标签的猫和狗的照片,它会很快计算出如何分类你当地的家养动物。

Welcome to the most cliche machine learning example possible
这适用于图像情感、面部识别或任何其他图像分类问题。同样,数据质量是成功的最重要因素。给定高质量的标记数据集,训练模型相对容易。
无监督学习
无监督的机器学习算法检查数据中的模式,以识别新的趋势。一个常见的例子是聚类,其中算法将识别数据集中我们以前不知道的组。

无监督学习在特定的用例中非常有用。众所周知的例子包括:
- 探测飞机发动机中的危险异常
- 基于独特的行为将客户分成不同的群组
- 检测奇怪的、潜在的欺诈性银行交易
强化学习
强化学习涉及动态环境中的算法,例如视频游戏或作为能源系统的控制器。该算法能够探索和尝试不同的行动——它对积极的决定给予奖励,对消极的决定给予惩罚。在一般意义上,强化学习人工复制了人类通过试错来学习的能力。

Humans learn from their mistakes right?
虽然现实世界的应用正在出现,但强化学习在很大程度上集中在研究领域。对于那些对强化学习和人工智能的加速发展感兴趣的人来说, AlphaGo 纪录片是一部精彩的电影。
思考什么是可能的
现在我们已经完成了机器学习 101,我们可以开始考虑潜在的机器学习应用。
x 标记了地点
首先要问的问题是,目标是什么?我们想知道什么?我们可以选择的一些目标变量示例:
- 温度->预测每日最高温度
- 物种->预测照片中的动物属于哪个物种
- 价格->预测什么样的价格能使产品或业务的利润最大化
一旦我们有了目标,我们就可以开始构建相关的数据集。例如,如果预测温度,我们将收集历史天气数据。或者如果识别物种,我们会尽可能多地寻找动物的照片。
测量不确定性
很容易看到机器学习有无限的应用。很难说哪些潜在项目会成功。确定目标后,新的、更难的问题出现了——仅举几个例子:
- 我们有足够的数据准确地代表目标吗?
- 我们的数据中是否存在我们不想让模型知道的偏差?
- 我们的算法会比人类表现得更好吗?需要吗?
可以想象,这些问题很少能在项目开始时得到回答。但这并不意味着它们不值得一问。在进行实验之前,理解你所做的假设是很重要的。
然而,虽然计划和风险评估很重要,但你永远不知道你的项目会有多成功。或者需要多长时间。或者你的数据是否带有不必要的偏见。在某些时候,你必须承认这种不确定性并投入其中。这是有趣的部分。
感谢阅读。你可以在推特上的@麦克德拉尼和互联网上的mackdelany@gmail.com找到我
直观地理解伯特的自我关注
解释什么是自我关注中的查询向量、关键向量和价值向量,以及它们是如何工作的

Photo by Stefan Cosma on Unsplash
先决条件
本文的目标是进一步解释什么是自我关注中的查询向量、关键向量和价值向量。如果你忘记了一些概念,你可以通过阅读插图变压器和解剖伯特第一部分:编码器来回忆。
什么是自我关注
在插图变压器的中的“高层次的自我关注”部分,它在跳到代码之前给出了一个非常清晰的概念。
当模型处理每个单词(输入序列中的每个位置)时,自我注意允许它查看输入序列中的其他位置,以寻找有助于更好地编码该单词的线索。
让我重新措辞一下我的话。当模型处理一个句子时,自我注意允许句子中的每个单词查看其他单词,以更好地知道哪个单词对当前单词有贡献。更直观地说,我们可以认为“自我关注”是指句子会审视自身,以确定如何表示每个标记。

例如,当模型处理上图右栏中的单词it时,自我注意查看其他单词以便更好地编码(理解*)当前单词it。这就是伯特如何根据上下文(句子)理解每个单词的神奇之处。一个单词在不同的句子(上下文)中可以有不同的含义,自我关注可以基于上下文单词为当前单词编码(理解)每个单词。*
直观理解自我关注中的 Q,K,V
我将用上面两篇文章中的例子和图表来解释什么是 Q,K,v。

taken from Attention Is All You Need
我们更简单地改写上述自我注意功能。

Q、K、V 分别称为查询、键、值。不要被他们的名字搞糊涂了。唯一的区别是三个代表的权重不同。你可以在下图中看到。
但是直观上,我们可以认为查询(Q)代表我们在寻找什么样的信息,键(K)代表与查询的相关性,值(V)代表输入的实际内容。因为它们在模型中扮演不同的角色。

这里 X 矩阵中的每一行表示一个记号的嵌入向量,所以这个 X 矩阵有 2 个记号。我们使用三个权重W^Q, W^K, W^V乘以相同的输入 X 得到 Q,K,v
为什么要计算查询(Q)和键(K)的点积

首先,点积的物理意义可以表示两个向量之间的相似性。所以你可以认为 Q 和 K 的点积是为了得到不同 tokens 之间的相似度(注意力得分)。比如我们有一个句子,Hello, how are you?。句子长度为 6,嵌入维数为 300。所以 Q,K,V 的大小都是(6, 300)。
Q 和 K 的矩阵相乘如下图(softmax 之后)。矩阵乘法是点生成的快速版本。但是基本思想是相同的,计算任意两个标记对之间的注意力分数。
注意力得分的大小是(6,6)。您可能已经注意到,关注分数的大小只与序列长度有关。

每条线代表一个记号和其他记号之间的相似性。当当前令牌是Hello时,我们只需查看关注度矩阵中的第一行,就可以知道从Hello到其他令牌的相似度。比如Hello和how的相似度是6.51*10e-40。我们添加 softmax 来标准化数据。
为什么我们需要值(V)?
注意力得分矩阵可以表示任意两个标记对之间的相似性,但是由于缺少嵌入向量,我们不能用它来表示原句。这就是为什么我们需要 V,这里 V 还是代表原句。

我们用注意力得分(6x6)乘以 V(6300),得到一个加权求和结果。

直观上,我们用嵌入向量来表示每个记号,并且我们假设它们彼此不相关。但是在与关注分数相乘之后,在 V 中嵌入向量的每个令牌(“Hello”)将根据从当前(“Hello”)到其他令牌的关注来调整其在每个维度(列)中的值。

我们可以认为关注度矩阵是一个过滤矩阵,可以让价值矩阵更加关注那些重要的词,而对不重要的词关注很少。
为什么我们用不同的权重来得到 K 和 Q?
一些读者可能想知道为什么我们必须使用不同的权重来得到 K 和 Q?换句话说,我们可以通过 K 和 K 或者 Q 和 Q 的矩阵相乘来计算注意力得分,一个原因是两种计算不会有太大的差别,后一种也可以减少训练时的参数。
我觉得用不同的权重来得到 K 和 Q 是为了提高模型的泛化能力。因为有两个权重 W_K 和 W_Q,把同一个 X 投影到不同的空间。
如果我们用 K 和 K 之间的矩阵乘法,你会发现关注度得分矩阵会变成一个对称矩阵。因为它用了一个权重 W_K,把 X 投影到同一个空间。所以泛化能力会下降。在这种情况下,注意力分数过滤效果对于 value (V)来说不会很好。
查看我的其他帖子 中等 同 一分类查看 !
GitHub:bramble Xu LinkedIn:徐亮 博客:bramble Xu
参考
讨论:黑客新闻(65 分,4 条评论),Reddit r/MachineLearning (29 分,3 条评论)翻译…
jalammar.github.io](http://jalammar.github.io/illustrated-transformer/) [## 剖析 BERT 第 1 部分:编码器
这是由米盖尔·罗梅罗和弗朗西斯科·英厄姆共同撰写的《理解伯特》的 1/2 部分。如果你已经明白了…
medium.com](https://medium.com/dissecting-bert/dissecting-bert-part-1-d3c3d495cdb3) [## 自然语言处理中的自我注意机制
在过去的几年里,注意机制在各种自然语言处理中得到了广泛的应用
medium.com](https://medium.com/@Alibaba_Cloud/self-attention-mechanisms-in-natural-language-processing-9f28315ff905) [## 《Attention is All You Need》浅读(简介+代码) — 科学空间|Scientific Spaces
2017 年中,有两篇类似同时也是笔者非常欣赏的论文,分别是 FaceBook 的《Convolutional Sequence to Sequence Learning》和 Google 的《Atten…
科学. fm](https://kexue.fm/archives/4765)
了解 CNN 的架构

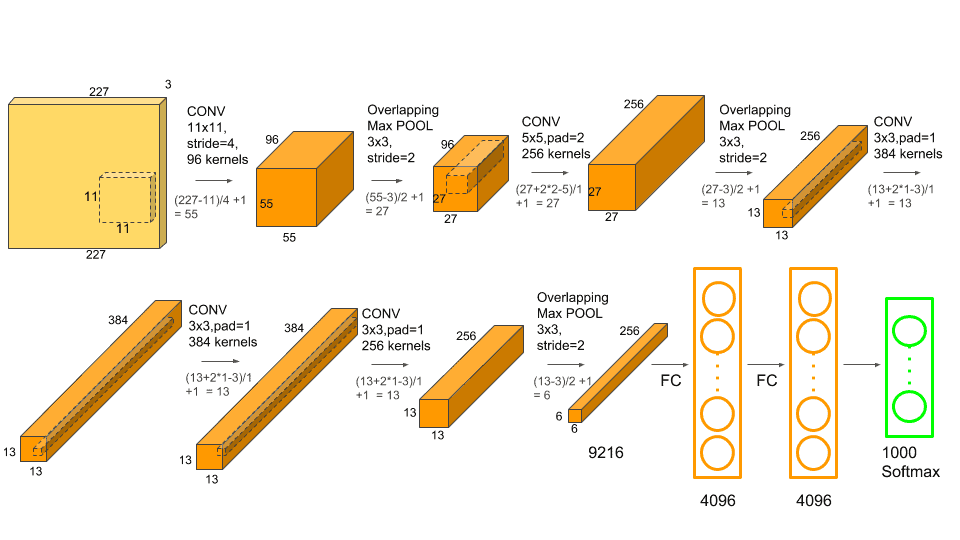
Architecture of VGG16 (a CNN model)
2012 年,一场革命发生了:在一年一度的 ILSVRC 计算机视觉比赛期间,一种新的深度学习算法打破了记录!这是一个名为 Alexnet 的卷积神经网络。
卷积神经网络的方法论类似于传统的监督学习方法:它们接收输入图像,检测每个图像的特征,然后在其上拖动一个分类器。
但是,功能是自动学习的!CNN 自己执行提取和描述特征的所有繁琐工作:在训练阶段,分类误差被最小化以优化分类器的参数和特征!
什么是 CNN?
卷积神经网络是指神经网络的一个子类:因此,它们具有神经网络的所有特征。然而,CNN 是专门为处理输入图像而设计的。他们的架构更加具体:它由两个主要模块组成。
第一个模块使这种类型的神经网络具有特殊性,因为它起着特征提取器的作用。为此,它通过应用卷积过滤操作来执行模板匹配。第一层使用几个卷积核对图像进行滤波,并返回“特征图,然后对其进行归一化(使用激活函数)和/或调整大小。
这个过程可以重复几次:我们过滤用新内核获得的特征图,这给了我们新的特征图来归一化和调整大小,我们可以再次过滤,等等。最后,最后的特征映射的值被连接成一个向量。这个向量定义了第一个模块的输出和第二个模块的输入。

The first block is encircled in black
第二块不是 CNN 的特征:事实上,它位于所有用于分类的神经网络的末端。输入向量值被转换(使用几个线性组合和激活函数)以向输出返回一个新的向量。这最后一个向量包含与类别一样多的元素:元素 I 表示图像属于类别 I 的概率。因此,每个元素在 0 和 1 之间,并且所有元素的总和等于 1。这些概率由该块的最后一层(因此也是网络的最后一层)计算,该层使用一个逻辑函数(二元分类)或一个 softmax 函数(多类分类)作为激活函数。
与普通神经网络一样,层的参数由梯度反向传播确定:在训练阶段,交叉熵被最小化。但是在 CNN 的情况下,这些参数特别指的是图像特征。

The second block is encircled in black
有线电视新闻网的不同层次
卷积神经网络有四种类型的层:卷积层、汇集层、 ReLU 校正层和全连接层。
卷积层
卷积层是卷积神经网络的关键组成部分,并且总是至少是它们的第一层。
其目的是检测作为输入接收的图像中一组特征的存在。这是通过卷积滤波来实现的:原理是在图像上“拖动”一个表示特征的窗口,并计算该特征与扫描图像各部分之间的卷积积。一个特征被视为一个过滤器:这两个术语在上下文中是等价的。
因此,卷积层接收几个图像作为输入,并用每个滤波器计算每个图像的卷积。过滤器与我们想要在图像中找到的特征完全对应。
我们为每一对(图像,过滤器)获得一个特征图,它告诉我们特征在图像中的位置:值越高,图像中相应的位置就越像特征。

Convolutional layer (source: https://www.embedded-vision.com)
与传统方法不同,特征不是根据特定的形式(例如 SIFT)预先定义的,而是由网络在训练阶段学习的!滤波器核指的是卷积层权重。它们被初始化,然后使用梯度下降通过反向传播进行更新。
汇集层
这种类型的图层通常位于两个卷积图层之间:它接收多个要素地图,并对每个要素地图应用汇集操作。
汇集操作包括减小图像的尺寸,同时保留它们的重要特征。
为此,我们将图像切割成规则的单元格,然后在每个单元格内保留最大值。在实践中,经常使用小正方形单元格来避免丢失太多信息。最常见的选择是不与重叠的 2x2 相邻单元格,或 3x3 单元格,彼此相隔 2 个像素的步长(因此与重叠)。
我们在输出中得到与输入相同数量的特征地图,但是这些要小得多。
池层减少了网络中的参数和计算的数量。这提高了网络的效率,避免了过度学习。
与输入中接收到的最大值相比,合并后获得的最大值在要素地图中的定位不太准确,这是一个很大的优势!例如,当你想识别一只狗时,它的耳朵不需要尽可能精确地定位:知道它们几乎位于头部旁边就足够了!
ReLU 校正层
ReLU(整流线性单位)是指由 ReLU(x)=max(0,x) 定义的实非线性函数。从视觉上看,它如下所示:

ReLU 校正层用零替换作为输入接收的所有负值。它作为一个激活功能。
全连接层
无论是否卷积,全连接层总是神经网络的最后一层,因此它不是 CNN 的特征。
这种类型的层接收输入向量并产生新的输出向量。为此,它对接收到的输入值应用一个线性组合和**,然后可能应用一个激活函数**。
最后一个全连接层将图像分类为网络的输入:它返回大小为 N 的向量,其中 N 是我们的图像分类问题中的类的数量。向量的每个元素指示输入图像属于一个类别的概率。
因此,为了计算概率,全连接层将每个输入元素乘以权重,进行求和,然后应用激活函数(如果 N=2,则为逻辑,如果 N>2,则为 softmax)。这相当于将输入向量乘以包含权重的矩阵。每个输入值都与所有输出值相连接,这一事实解释了术语“完全连接”的含义。
卷积神经网络学习权重值的方式与其学习卷积层滤波器的方式相同:在训练阶段,通过梯度的反向传播。
完全连接的图层决定了影像中要素的位置与类之间的关系。实际上,输入表是前一层的结果,它对应于给定特征的特征图:高值指示图像中该特征的位置(根据汇集的不同,更精确或更不精确)。如果图像中某一点的特征位置是某一类别的特征,则表中的相应值被赋予显著的权重。
各层的参数化
卷积神经网络与其他网络的不同之处在于层的堆叠方式,以及参数化。
卷积层和池层确实有超参数,也就是说您必须首先定义其值的参数。
卷积图层和池图层的输出要素地图的大小取决于超参数。
每个图像(或特征图)都是 W×H×D,其中 W 是其宽度(以像素为单位), H 是其高度(以像素为单位), D 是通道数(黑白图像为 1,彩色图像为 3)。
卷积层有四个超参数:
1.过滤器的数量 K
2.过滤器的尺寸:每个过滤器的尺寸为 F×F×D 像素。
3.拖动与图像上的滤镜相对应的窗口的步骤。例如,步长为 1 意味着一次移动窗口一个像素。
4.零填充 P:给图层的输入图像添加一个 P 像素厚的黑色轮廓。没有该轮廓,出口尺寸更小。因此,P=0 的卷积层叠得越多,网络的输入图像就越小。我们很快丢失了大量信息,这使得提取特征的任务变得困难。
对于每个尺寸为 W×H×D 的输入图像,池层返回一个尺寸为 Wc×Hc×Dc 的矩阵,其中:

选择 P=F-1/2 和 S=1 给出与输入中接收到的相同宽度和高度的特征地图。
池层有两个超参数:
1.单元格的大小 F:图像被分成大小为 F×F 像素的正方形单元格。
2.步骤 S:单元格之间相隔 S 个像素。
对于每个尺寸为 W×H×D 的输入图像,池层返回一个尺寸为 Wp×Hp×Dp 的矩阵,其中:

就像叠加一样,超参数的选择是根据一个经典方案进行的:
- 对于卷积层,滤镜很小,每次在图像上拖动一个像素。选择零填充值,以便输入音量的宽度和高度在输出时不会改变。一般来说,我们然后选择 F=3,P=1,S=1 或者 F=5,P=2,S=1
- 对于池层, F=2,S=2 是明智的选择。这个消除了 75%的输入像素。我们也可以选择 F=3,S=2:在这种情况下,单元格重叠。选择较大的小区会导致太多的信息丢失,并且在实践中导致不太好的结果
在这里,你有建立自己的 CNN 的基础!但是不要厌倦这样做:已经有许多适合大多数应用程序的体系结构。
在实践中,我强烈建议你不要从零开始创建一个卷积神经网络来解决你的问题:最有效的策略是采用一个现有的对大量图像进行良好分类的网络(如 ImageNet)并应用迁移学习。
2019 年底前了解计算机视觉格局
简要概述计算机视觉在过去 50 年中的发展,并了解像*‘AI Winter’*这样的流行语及其含义。
2019 年即将结束,但在此之前,了解一下我们十年来在机器学习方面的一个流行语不是很好吗?这篇文章将帮助你对计算机视觉有一个简单的了解,足够的知识让你在圣诞晚宴上看起来聪明。
看完这篇文章,你会对计算机视觉、深度学习、机器学习、AI Winter、天网……这些好东西变得熟悉。
我一直听说的计算机视觉是什么?
当有人问你这个问题时,你可以用“计算机视觉就是计算机如何看东西”来回答他们嗯,不完全是,试试下面的解释,肯定会让一些人惊讶。
计算机视觉是机器或系统通过调用一种或多种作用于所提供信息的算法来生成对视觉信息的理解的过程。这种理解被转化为决策、分类、模式观察等等。现在你又回头了。
让我们快速上一堂历史课,看看计算机视觉领域是如何发展的。
当我们开始模仿人体内的感知和视觉系统时,对计算机视觉的需求就出现了。因此,这一旅程始于 20 世纪 60 年代,当时学术界研究了人类的感知,并试图在计算机系统上复制其基本功能。我们的先驱学者旨在为机器人提供看到并描述机器人所观察到的东西的能力。这是天网的第一步(是的,就像电影一样,但这是在那之前)。

Edge Detection. (2019). [image] Available at mathwork.com
让天网看起来像人类并不容易,所以我们期待数字图像处理技术来理解呈现给计算机视觉系统的图像内容。我所说的理解就是从图像中提取边缘信息、轮廓、线条、形状。70 年代都是关于从数字图像中提取信息的算法。
有一点要注意的是第一个 艾冬 发生在 20 世纪 70 年代。对于那些不熟悉术语“*人工智能冬天”、*的人来说,它可以被描述为一个对人工智能相关领域(如计算机视觉、机器学习等)的兴趣、资金、士气(炒作)和正在进行的研究越来越缺乏的时期。
80 年代和 90 年代的计算机视觉专注于数学和统计学。研究人员和学者开始将计算机视觉技术与数学算法结合起来。描绘数学在计算机视觉和图像处理技术中的应用的一个很好的例子是边缘检测算法。
边缘检测是大多数计算机视觉课程中教授的主要图像处理技术之一。1986 年,约翰·f·卡尼研制出一种奇特而有用的边缘检测器。它被称为 狡猾的边缘探测器 。通过利用数学概念,如微积分、微分和函数优化,John F. Canny 开发了一个非常受欢迎的边缘检测器,它仍然在硕士课程中讲授。
快进到之前的十年;对计算机视觉来说,2000 年是一个颇具革命性的时代。深度学习出现了,计算机视觉再次成为媒体、研究人员和学者的热门话题。
另一个关键定义即将出现。
深度学习是机器学习的一个分支,其中算法利用几层神经网络从输入数据中提取更丰富的特征。深度学习技术的例子有深度卷积神经网络(CNN) 和递归神经网络(RNN) 。
这么多术语,在我们继续之前,下面是一些与机器学习相关的术语的链接。
你在数据科学或机器学习职业生涯中会遇到的有用的机器学习术语列表。
towardsdatascience.com](/30-pocket-sized-terms-for-machine-learning-beginners-5e381ed93055)
2012 年是计算机视觉领域的关键一年。你可能已经知道我要在这里提到什么(嘘,不要破坏了别人的)。有一个名为“ImageNet 大规模视觉识别挑战赛”的比赛,这个比赛每年举行一次,主要是学者,研究人员和爱好者的聚会,比较对图像中的对象进行分类和检测的软件算法。在 2012 年的比赛中,引入了一种深度卷积神经网络(AlexNet) ,其错误率超过了当年和之前几年的其他比赛。
我不会深究 AlexNet 是如何设计的太多细节,网上有很多这方面的资源。但我会提到 AlexNet 给景观带来的两个显著好处。
首先,GPU。AlexNet 令人惊叹的性能是使用图形处理单元(GPU)实现的。虽然 GPU 之前已经在比赛中使用过,但 AlexNet 对 GPU 的利用引起了计算机视觉社区的注意。
其次,CNN 成为标准。AlexNet 展示 CNN 有效性的能力意味着 CNN 变得普及。从那年开始到现在,在大多数计算机视觉应用和研究中都发现了 CNN 的实现。
我将不得不在这里暂停,也许在将来的另一篇文章中继续这个主题。有很多主题和领域我还没有涉及到,但是下面是一些中型文章,它们详细解释了本文中提到的关键术语以及更多内容。
现在你可以去 2020 年,了解计算机视觉及其自 20 世纪 60 年代以来的发展。
如果你喜欢这篇文章,并且想要更多这样的文章,那么就给我一个关注,让我扩展你在机器学习方面的知识。
查看来自 Dhruv Parthasarathy 、西达尔特 Das 和詹姆斯勒的关于计算机视觉和一些技术的文章。
[## CNN 在图像分割中的简史:从 R-CNN 到掩模 R-CNN
在 Athelas,我们使用卷积神经网络(CNN)不仅仅是为了分类!在本帖中,我们将看到…
blog.athelas.com](https://blog.athelas.com/a-brief-history-of-cnns-in-image-segmentation-from-r-cnn-to-mask-r-cnn-34ea83205de4) [## CNN 架构:LeNet、AlexNet、VGG、GoogLeNet、ResNet 等等
ILSVRC 中开创性的 CNN 模型以及卷积神经网络的历史
medium.com](https://medium.com/analytics-vidhya/cnns-architectures-lenet-alexnet-vgg-googlenet-resnet-and-more-666091488df5) [## 将改变你看待世界方式的 5 种计算机视觉技术
heartbeat.fritz.ai](https://heartbeat.fritz.ai/the-5-computer-vision-techniques-that-will-change-how-you-see-the-world-1ee19334354b)
O(n)是改进你的算法的唯一方法吗?
蟒蛇短裤
理解问题陈述如何帮助您优化代码

Photo by Patrick Tomasso on Unsplash
每当我们谈论优化代码时,我们总是讨论代码的计算复杂性。
是 O(n)还是 O(n 的平方)?
但是,有时候我们需要超越算法,看看算法在现实世界中是如何被使用的。
在这篇文章中,我将谈谈类似的情况以及我是如何解决的。
问题是:
最近我在处理一个 NLP 问题,不得不从文本中清除数字。
从表面上看,这似乎是一个微不足道的问题。一个人可以用许多方法做到这一点。
我用下面给出的方法做了这件事。该函数将问题字符串中的数字替换为#s。
def clean_numbers(x):
x = re.sub('[0-9]{5,}', '#####', x)
x = re.sub('[0-9]{4}', '####', x)
x = re.sub('[0-9]{3}', '###', x)
x = re.sub('[0-9]{2}', '##', x)
return x
这些都是干净的代码,但是我们能优化它的运行时间吗?在继续下一步之前思考。
诀窍是:

优化的诀窍在于理解代码的目标。
虽然我们大多数人都理解 O(n)范式,并且总是可以去寻找更好的算法,但优化代码的一个被遗忘的方法是回答一个问题:
这段代码将如何使用?
你知道吗,如果我们在替换字符串之前只检查一个数字,我们可以获得 10 倍的运行时间改进!!!
由于大多数字符串没有数字,我们不会评估对re.sub.的 4 次函数调用
它只需要一个简单的 if 语句。
def clean_numbers(x):
if bool(re.search(r'\d', x)):
x = re.sub('[0-9]{5,}', '#####', x)
x = re.sub('[0-9]{4}', '####', x)
x = re.sub('[0-9]{3}', '###', x)
x = re.sub('[0-9]{2}', '##', x)
return x
这样做有什么必要?
对我们使用的数据的理解和对问题陈述的理解。
这些改进当然是隐藏的,你可能需要考虑这段代码要运行多少次?或者谁会触发功能?做这样的改进。
但这是值得的。
把你写的每一个函数都当成你的孩子,尽你所能去改进它。
我们可以使用 Jupyter 笔记本中的%%timeit魔法功能来查看性能结果。
%%timeit
clean_numbers(“This is a string with 99 and 100 in it”)
clean_numbers(“This is a string without any numbers”)
使用第一个函数调用上述简单函数的结果是:
17.2 µs ± 332 ns per loop (mean ± std. dev. of 7 runs, 100000 loops each)
使用第二个函数:
12.2 µs ± 324 ns per loop (mean ± std. dev. of 7 runs, 100000 loops each)
即使我们 50%的句子都有数字,我们还是提高了两倍。
由于我们在数据库中不会有那么多包含数字的句子,我们可以这样做并得到很好的改进。
结论
有不同的方法来改进一个算法,甚至上面的问题可以用一些我想不到的逻辑来进一步改进。
但我想说的是,在封闭的盒子里思考并想出解决方案永远不会帮助你。
如果您理解了问题陈述和您试图实现的目标,您将能够编写更好、更优化的代码。
所以,下次你的老板让你降低算法的计算复杂度时,告诉他,虽然你无法降低复杂度,但你可以使用一些定制的业务逻辑让算法变得更快。我猜他会印象深刻。
另外,如果你想了解更多关于 Python 3 的知识,我想向你推荐一门来自密歇根大学的关于学习 T2 中级 Python 3 的优秀课程。一定要去看看。
将来我也会写更多初学者友好的帖子。让我知道你对这个系列的看法。在 媒体 关注我,或者订阅我的 博客 了解他们。
一如既往,我欢迎反馈和建设性的批评,可以通过 Twitter @mlwhiz 联系到我。
了解 1D 和 3D 卷积神经网络| Keras

Image by WallpeperSafari
当我们说卷积神经网络 (CNN)时,通常我们指的是用于图像分类的二维 CNN。但是在现实世界中使用了两种其他类型的卷积神经网络,它们是 1 维和 3 维 CNN。在本指南中,我们将介绍 1D 和3DCNN 及其在现实世界中的应用。我假设你已经熟悉卷积网络的一般概念。
二维 CNN | Conv2D
这是在 Lenet-5 架构中首次引入的标准卷积神经网络。 Conv2D 一般用于图像数据。它被称为二维 CNN,因为内核在数据上沿二维滑动,如下图所示。

Kernal sliding over the Image
使用 CNN 的整体优势在于,它可以使用其内核从数据中提取空间特征,这是其他网络无法做到的。例如,CNN 可以检测图像中的边缘、颜色分布等,这使得这些网络在图像分类和包含空间属性的其他类似数据中非常健壮。
以下是在 keras 中添加一个 Conv2D 层的代码。
Conv2D Layer in Keras
参数 input_shape (128,128,3)表示图像的(高度,宽度,深度)。参数 kernel_size (3,3)表示内核的(高度,宽度),内核深度将与图像的深度相同。
一维 CNN | Conv1D
在看完《T21》之前,让我给你一个提示。在 Conv1D 中,内核沿一维滑动。现在让我们在这里暂停博客,想一想哪种类型的数据只需要在一维上进行内核滑动,并且具有空间属性?
答案是时间序列数据。我们来看下面的数据。

Time series data from an accelerometer
这个数据是从一个人戴在手臂上的加速度计收集的。数据代表所有 3 个轴上的加速度。1D CNN 可以从加速度计数据中执行活动识别任务,例如人是否站立、行走、跳跃等。这个数据有两个维度。第一维是时间步长,另一维是 3 个轴上的加速度值。
下面的图说明了内核将如何处理加速度计数据。每行代表某个轴的时间序列加速度。内核只能沿着时间轴在一维上移动。

Kernel sliding over accelerometer data
下面是在 keras 中添加一个 Conv1D 层的代码。
Conv1D Layer in Keras
自变量 input_shape (120,3),表示 120 个时间步长,每个时间步长中有 3 个数据点。这 3 个数据点是 x、y 和 z 轴的加速度。参数 kernel_size 为 5,代表内核的宽度,内核高度将与每个时间步的数据点数相同。
类似地,1D CNN 也用于音频和文本数据,因为我们也可以将声音和文本表示为时间序列数据。请参考下面的图片。

Text data as Time Series
Conv1D 广泛应用于传感数据,加速度计数据就是其中之一。
三维 CNN | Conv3D
在 Conv3D 中,内核在三维空间滑动,如下图所示。让我们再想想哪种数据类型需要内核在三维空间中移动?

Kernel sliding on 3D data
Conv3D 主要用于 3D 图像数据。如磁共振成像 (MRI)数据。MRI 数据被广泛用于检查大脑、脊髓、内部器官等。计算机断层扫描 (CT)也是 3D 数据的一个例子,它是通过组合从身体周围不同角度拍摄的一系列 X 射线图像而创建的。我们可以使用 Conv3D 对这些医疗数据进行分类,或者从中提取特征。

Cross Section of 3D Image of CT Scan and MRI
3D 数据的另一个例子是视频。视频只不过是一系列图像帧的组合。我们也可以在视频上应用 Conv3D,因为它具有空间特征。
以下是在 keras 中添加 Conv3D 层的代码。
Conv3D Layer in Keras
这里参数输入形状 (128,128,128,3)有 4 个维度。3D 图像是四维数据,其中第四维表示颜色通道的数量。就像平面 2D 图像具有三维,其中第三维表示颜色通道。参数 kernel_size (3,3,3)表示内核的(高度,宽度,深度),内核的第四维将与颜色通道相同。
摘要
- 在 1D CNN 中,内核向 1 方向移动。1D CNN 的输入输出数据是 2 维的。主要用于时间序列数据。
- 在 2D CNN 中,内核向 2 方向移动。2D CNN 的输入输出数据是 3 维的。主要用于图像数据。
- 在 3D CNN 中,内核在 3 方向移动。3D CNN 的输入输出数据为 4 维。主要用于 3D 图像数据(MRI、CT 扫描、视频)。
接下来是
迈向艾将军的一步?
shiva-verma.medium.com](https://shiva-verma.medium.com/understanding-self-supervised-learning-with-examples-d6c92768fafb)
理解演员评论方法和 A2C
深度强化学习中的重要概念
预赛
在我之前的文章中,我们导出了策略梯度并实现了加强算法(也称为蒙特卡罗策略梯度)。然而,普通的政策梯度有一些突出的问题:嘈杂的梯度和高方差。
但是为什么会这样呢?
回想一下政策梯度:

如同在增强算法中一样,我们通过蒙特卡罗更新(即随机取样)来更新策略参数。这在对数概率(策略分布的对数)和累积奖励值中引入了固有的高可变性,因为训练期间的每个轨迹可以彼此偏离很大程度。
因此,对数概率和累积奖励值的高度可变性将产生有噪声的梯度,并导致不稳定的学习和/或向非最佳方向倾斜的策略分布。
除了梯度的高方差之外,策略梯度的另一个问题是轨迹的累积报酬为 0。政策梯度的实质是在政策分布中增加“好”行为的概率,减少“坏”行为的概率;如果累积奖励为 0,则不会学习“好”和“坏”行为。
总的来说,这些问题导致了普通政策梯度方法的不稳定性和缓慢收敛。
改善政策梯度:用基线减少差异
减少方差和增加稳定性的一种方法是用基线减去累积奖励:

直觉上,通过用基线减去累积奖励来使累积奖励变小,将产生更小的梯度,从而产生更小且更稳定的更新。
下面是一个很有说明性的解释,摘自 Jerry Liu 的帖子“为什么政策梯度法有很高的方差”:

[Taken from Jerry Liu’s post “Why does the policy gradient method have high variance”]
常见基线功能概述
基线可以采用不同的值。下面的方程组说明了演员评论家方法的经典变体(关于加强)。在本帖中,我们将看看 Q 演员评论家和优势演员评论家。

Image taken from CMU CS10703 lecture slides
演员评论方法
在我们回到基线之前,让我们首先再次看一看普通的政策梯度,看看演员批评家架构是如何进来的(以及实际上是什么)。回想一下:

然后,我们可以将期望值分解为:

第二个期望项应该很熟悉;就是 Q 值!(如果你还不知道这一点,我建议你阅读一下价值迭代和 Q 学习)。

将它代入,我们可以将更新等式改写如下:

正如我们所知,Q 值可以通过用神经网络(上面用下标w表示)参数化 Q 函数来学习。
这就引出了 演员的评论家方法, 的地方:
- “评论家”估计价值函数。这可以是动作值( Q 值)或状态值( V 值)。
- “行动者”按照批评者建议的方向更新策略分布(例如使用策略梯度)。
评论家和演员函数都用神经网络参数化。在上面的推导中,Critic 神经网络将 Q 值参数化—因此,它被称为 Q Actor Critic。
以下是 Q-Actor-Critic 的伪代码:

Adapted from Lilian Weng’s post “Policy Gradient algorithms”
如图所示,我们在每个更新步骤更新评论家网络和价值网络。
回到基线
从权威的角度来说(因为我找不到原因),状态值函数是一个最佳的基线函数。这在卡内基梅隆大学 CS10703 和 Berekely CS294 讲座幻灯片中有所陈述,但没有提供任何理由。
因此,使用 V 函数作为基线函数,我们用 V 值减去 Q 值项。直观地说,这意味着在给定的状态下,采取特定的行动比一般的一般行动好多少。我们将这个值称为 优势值 :

这是否意味着我们必须为 Q 值和 V 值构建两个神经网络(除了策略网络之外)?不行。那样效率会很低。相反,我们可以使用贝尔曼最优方程中 Q 和 V 之间的关系:

所以,我们可以把优势改写为:

然后,我们只需要对 V 函数使用一个神经网络(由上面的v参数化)。因此,我们可以将更新等式改写为:

这是 优势演员评论家。
优势行动者评论家(A2C)对异步优势行动者评论家(A3C)
优势行动者批评家 有两个主要变体:异步优势行动者批评家(A3C) 和优势行动者批评家(A2C)。
A3C 是在 Deepmind 的论文《深度强化学习的异步方法》(Mnih et al,2016) 中引入的。本质上,A3C 实现了并行训练,其中并行环境**中的多个工人独立更新全局值函数——因此是“异步的”拥有异步参与者的一个主要好处是有效且高效地探索状态空间。

High Level Architecture of A3C (image taken from GroundAI blog post)
A2C 类似 A3C 但没有异步部分;这意味着 A3C 的单工人变体。经验表明,A2C 的性能与 A3C 相当,但效率更高。根据这篇 OpenAI 博客文章,研究人员并不完全确定异步是否或者如何有益于学习:
在阅读了这篇论文之后,人工智能研究人员想知道异步是否会导致性能的提高(例如,“也许添加的噪声会提供一些正则化或探索?”),或者它只是一个实现细节,允许使用基于 CPU 的实现进行更快的训练…
我们的同步 A2C 实现比异步实现性能更好——我们没有看到任何证据表明异步引入的噪声提供了任何性能优势。当使用单 GPU 机器时,这种 A2C 实现比 A3C 更具成本效益,并且当使用更大的策略时,比仅使用 CPU 的 A3C 实现更快。
无论如何,我们将在本帖中实现 A2C ,因为它实现起来更简单。(这很容易扩展到 A3C)
实施 A2C
因此,回想一下新的更新公式,用优势函数替换普通保单梯度中的折扣累积奖励:

在每个学习步骤中,我们更新 Actor 参数(用策略梯度和优势值)和 Critic 参数(用 Bellman 更新方程最小化均方误差)。让我们看看这在代码中是什么样子的:
以下是包含和超参数:
首先,让我们从实现 Actor Critic 网络开始,配置如下:
主循环和更新循环,如上所述:
运行代码,我们可以看到 OpenAI Gym CartPole-v0 环境的性能如何提高:

Blue: Raw rewards; Orange: Smoothed rewards
在此找到完整的实现:
https://github.com/thechrisyoon08/Reinforcement-Learning/
参考资料:
- 加州大学柏克莱分校 CS294 讲座幻灯片
- 卡内基梅隆大学 CS10703 讲座幻灯片
- Lilian Weng 关于政策梯度算法的帖子
- Jerry Liu 在 Quora Post 上回答“为什么政策梯度法有很高的方差”
- Naver D2 RLCode 讲座视频
- OpenAI 关于 A2C 和 ACKTR 的博文
- 图表来自 [GroundAI 的博客文章](http://Figure 4: Schematic representation of Asynchronous Advantage Actor Critic algorithm (A3C) algorithm.)“图 4:异步优势行动者评价算法(A3C)算法的示意图。”
其他职位:
查看我关于强化学习的其他帖子:
感谢阅读!
了解 AdaBoost

任何开始学习增强技术的人都应该首先从 AdaBoost 或自适应增强开始。这里我试着从概念上解释一下。
当一切都不起作用时,助推会起作用。现在许多人使用 XGBoost 或 LightGBM 或 CatBoost 来赢得 Kaggle 或黑客马拉松比赛。AdaBoost 是 Boosting 世界的第一块敲门砖。
AdaBoost 是第一个用于解决实际问题的 boosting 算法。Adaboost 帮助您将多个“弱分类器”组合成一个“强分类器”。这里有一些关于 Adaboost 的(有趣)事实!
AdaBoost 中的弱学习器是单分裂的决策树,称为决策树桩。
→ AdaBoost 的工作原理是对难以分类的实例给予更多的权重,而对已经处理得很好的实例给予较少的权重。
→ AdaBoost 算法可用于分类和回归问题。
第 1 部分:使用决策树桩理解 AdaBoost
集合的力量是这样的,即使集合中的单个模型非常简单,我们仍然可以构建强大的集合模型。
D 决策树桩是我们可以构建的最简单的模型,它会为每个新的例子猜测相同的标签,不管它看起来像什么。如果我们猜测数据中最常见的答案是 1 还是 0,那么这种模型的准确性将是最好的。如果,比方说,60%的例子是 1,那么我们只要每次猜 1 就能得到 60%的准确率。
决策桩通过基于一个特征的值将例子分成两个子集来改进这一点。每个树桩选择一个特征,比如说 X2,和一个阈值 T,然后将样本分成阈值两边的两组。
为了找到最适合这些例子的决策树桩,我们可以尝试输入的每个特征以及每个可能的阈值,看看哪一个给出了最好的准确性。虽然这看起来很天真,似乎阈值有无限多的选择,但两个不同的阈值只有在它们将一些例子放在分裂的不同侧时才有意义上的不同。为了尝试每一种可能性,我们可以根据所讨论的特征对示例进行分类,并尝试在每对相邻的示例之间设置一个阈值。
刚刚描述的算法可以进一步改进,但是与其他 ML 算法(例如,训练神经网络)相比,即使这个简单的版本也非常快。
到看看这个算法的运行,让我们考虑一个 NFL 总经理需要解决的问题:预测大学的外接球手在 NFL 中的表现。我们可以通过使用过去的玩家作为例子,将这作为监督学习问题来处理。以下是 2014 年起草的接收器示例。每一个都包括一些当时已知的关于他们的信息,以及他们在 2014 年至 2016 年在 NFL 每场比赛中的平均接收码数:

任何将这些技术应用于外接球员的方法都会试图从许多因素中预测 NFL 的表现,这些因素至少包括对球员运动能力的一些测量和对他们大学表现的一些测量。在这里,我已经简化为每种只有一个:他们在 40 码短跑中的时间(运动能力的一个衡量标准)和他们在大学每场比赛中的接收码数。
我们可以把这作为一个回归问题来解决,如上表所示,或者我们可以把它重新表述为分类,根据他们的 NFL 产量,把每个例子标记为成功(1,橙色)或失败(0,蓝色)。以下是后者在将我们的例子扩展到包括 2015 年选秀的球员后的样子:

The X-axis shows each player’s college receiving yards per game and the Y-axis shows their 40-time.
回到我们的 boosting 算法,回想一下,集合中的每个单个模型都是基于一个示例高于还是低于该模型的特征阈值来对该示例进行投票的。当我们应用 AdaBoost 并在这些数据上构建一个决策树桩集合时,这些分裂看起来是这样的:

1st iteration of AdaBoosting
整个系综包括五个树桩,其阈值显示为虚线。两个树桩看着 40 码的虚线(垂直轴),在 4.55 和 4.60 之间的值分裂。其他三个树桩看的是大学每场比赛的接发球码数。在这里,阈值落在 70、90 和 110 左右。
在分裂的每一边,树桩将与那一边的大多数例子一起投票。对于水平线,线以上的成功比失败多,线以下的失败比成功多,所以 40 码冲刺时间落在这些线以上的例子会得到那些树桩的赞成票,而线以下的得不到任何选票。对于垂直线来说,线右边的成功比失败多,线左边的失败比成功多,所以例子对线右边的树桩投赞成票。
虽然集合模型对这些投票进行加权平均,但如果我们想象树桩具有相同的重量,这种情况就不会太离谱。在这种情况下,我们至少需要获得 5 票中的 3 票,才能获得全体投票成功所需的多数票。更具体地说,对于至少 3 行以上或右边的例子,集合预测成功。结果看起来像这样:

如您所见,这个简单的模型捕捉到了成功出现的大致形状(以非线性的方式)。它有一些假阳性,而唯一的假阴性是小奥德尔·贝克汉姆,一个明显的异常值。正如我们将在本文后面的一些投资示例中看到的那样,针对特征和结果之间的非线性关系进行调整的能力,可能是优于许多投资因素模型中使用的传统线性(& logistic)回归的一个关键优势。
第 2 部分:可视化决策树桩集合
如果我们有两个以上的特征,那么就很难像上图中那样看到完整的系综。(有时有人说,如果人类可以在高维空间中看到东西,那么 ML 就没有必要了。)然而,即使当有许多特征时,我们仍然可以通过分析它如何看待每一个单独的特征来理解决策树桩的集合。
为了说明这一点,让我们再来看一下该合集中所有树桩的图片:

正如我们在这里看到的,有两个基于 40 码冲刺时间决定的树桩。如果一个例子的 40 码冲刺时间超过了 4.59,那么它就会从这两个树桩那里得到一个成功的投票。如果它的时间低于 4.555,那么它会收到双方的反对票。最后,如果它在 4.55 和 4.59 之间失败,那么它会收到一个树桩的成功投票,而不是另一个树桩。整体画面看起来如下。

这幅图说明了这样一个事实,即全体是树桩的加权平均值,而不是简单的多数票。那些 40 码冲刺时间超过 4.55 的例子从第一个树桩获得了成功票,但该票的权重为 0.30。那些时间超过 4.59 的人也可以从第二个树桩获得成功投票,但该树桩的权重仅为 0.16,使赞成票的总权重达到 0.46。当你看到这张图片和下一张图片时,请记住,为了让模型预测一个新的外接球手的“成功”,该球员需要累积至少 0.5 的总权重。
另一个功能“大学每场比赛接收码数”的图片如下所示:

有三个树桩关注这个特性。第一个权重为 0.10,在每场比赛接发球码数至少为 72 码(约 72 码)的所有例子中,它都是成功的。下一个 stump,权重为 0.22,在所有高于 88(或左右)的例子中投票成功。码数高于 88 的例子从两个树桩获得成功票,给出至少 0.32 的权重(0.10 加 0.22)。第三个树桩增加了一个额外的成功投票,对于每场比赛接发球码数在 112 码以上(左右)的例子,权重约为 0.22。这使得该范围内的成功投票的总权重达到约 0.54。
这些图片中的每一张都显示了一个示例将从使用该特定特征的集合子集中获得的成功投票的总权重。如果我们基于它们检查的特征将单个模型分组到子集成中,那么整个模型就很容易描述为:一个例子的成功投票的总权重是来自每个子集成的权重的总和,同样,如果该总和超过 0.5,那么集成预测该例子是成功的。
在训练一个任意级别的分类器后,ada-boost 为每个训练项目分配权重。错误分类的项目被赋予较高的权重,以便它以较高的概率出现在下一个分类器的训练子集中。在每个分类器被训练之后,权重也被基于准确度分配给分类器。越准确的分类器被赋予越大的权重,从而对最终结果产生更大的影响。准确度为 50%的分类器被赋予零权重,准确度低于 50%的分类器被赋予负权重。
相比之下,线性模型迫使我们做出在每个参数中线性缩放的预测。如果某个特征的权重是正的,那么增加该特征预示着更高的成功几率,不管它有多高。不受该限制约束的树桩集合不会建立该形状的模型,除非它可以在数据中找到足够的证据证明这是真的。决策树桩的集合概括了线性模型,增加了查看标注和单个要素之间的非线性关系的能力。
第 3 部分(奖金):比较线性(&逻辑)回归与 AdaBoosting
如果你愿意,你可以跳过这一步,但我坚持要你读。
为了看到应用这些技术的更现实的例子,我们将扩展上面考虑的例子。实际上,我们希望包含更多信息以提高准确性。
我们将增加年龄,垂直跳跃,重量和每场比赛的绝对接球次数,码数和得分,以及球队在这些方面的市场份额。我们将包括他们大学最后一季的数据以及职业生涯的总成绩。总之,这给我们带来了总共 16 个功能。
上面,我们只看了两年的数据。无论用什么标准来衡量,这仍然是一个很小的数据集,这给了线性模型更多的优势,因为过度拟合的风险比通常情况下更大。
在以 8:2 的比例随机分割数据后,逻辑回归仅错误标记了 13.7%的训练样本。这相当于相当可观的 0.29 的“伪 R2”(R2 回归的分类类似物)。然而,在测试集上,它错误标记了 23.8%的例子。这表明,即使使用标准统计技术,样本内误差率也不是样本外误差的良好预测指标。
由逻辑回归产生的模型有一些预期的参数值:如果接球者更年轻、更快、更重,并且接住更多的触地得分,他们就更有可能成功。它不会给垂直跳跃带来任何重量。另一方面还是包含了一些挠头参数值。比如球队接码的市场份额较大是好事,但场均接码的绝对数量较大就是坏事。(也许可解释性问题并不是机器学习模型独有的!)
树桩集成模型将错误率从 23.8%降低到 22.6%。虽然这种下降在理论上看起来很小,但请记住,每年都有值得注意的选秀失利,即使是由全职研究这些球员的 NFL 总经理做出决定。我的猜测是,在这种情况下,20%左右的错误率可能是我们可以预期的绝对最小值,所以提高到 22.6%是一个不小的成就。
像逻辑回归模型一样,树桩群喜欢更重更快的宽接收器。
通过对大学产出的最重要的测量,我们看到了一些明显的非线性,而逻辑回归肯定漏掉了这一点。
结论
正如这些例子所展示的,真实世界的数据包括一些线性模式,但也包括许多非线性模式。从线性回归转换到决策树桩集成(又名 AdaBoost)使我们能够捕捉许多非线性关系,这转化为对感兴趣的问题的更好的预测准确性,无论是找到最佳的广泛接收器来起草还是购买最佳的股票。
如果你想了解背后的数学,这里有一个很好的来源
[## 升压算法:AdaBoost
作为一名消费行业的数据科学家,我通常的感觉是,提升算法对于大多数情况来说已经足够了…
towardsdatascience.com](/boosting-algorithm-adaboost-b6737a9ee60c)
理解亚当:损失函数如何最小化?
Adam:一种随机优化方法
简介
W 在使用基于 PyTorch 构建的 fast.ai 库时,我意识到迄今为止我从未与优化器进行过交互。由于 fast.ai 在调用 fit_one_cycle 方法时已经处理了它,所以我不需要参数化优化器,也不需要了解它是如何工作的。
由于其简单性和速度,Adam 可能是机器学习中使用最多的优化器。它是由迪德里克·金玛和吉米·巴雷在 2015 年开发的,并在一篇名为亚当:随机优化方法的论文中介绍。
和往常一样,这篇博文是我写的一张备忘单,用来检查我对一个概念的理解。如果你发现一些不清楚或不正确的地方,不要犹豫,写在评论区。

算法
首先,Adam 指的是自适应矩估计。Adam 背后的基本原理是提出一种优化目标函数的高效算法。该研究论文主要研究高维参数空间中随机目标的优化。
Adam 是随机梯度下降的修改版,这里就不解释了。对于 memo,随机梯度下降更新规则为:

The SGD’s update rule : here J is a cost function
Adam 算法的伪代码如下:

Adam algorithm pseudo-code
每一步我都会讲清楚,但首先我需要介绍一些量。
由于 Adam 是一个迭代过程,我们需要一个索引 t ,它在每一步都增加 1。
α 是步长,相当于随机梯度下降的学习速率。
G(t) 是目标函数 f 在步骤 t 相对于参数向量 θ的梯度。
M(t) 是梯度 G(t) 的一阶矩的指数移动平均线(EMA)。因此 β1 均线的指数衰减率。
V(t) 是梯度 G(t) 的二阶矩的指数移动平均。因此 β2 均线的指数衰减率。
最后, ε 是一个非常小的超参数,防止算法被零除。
为什么亚当用渐变 EMA 而不用渐变?
当计算梯度时,一些小批量可能具有异常值,这可能产生大的信息梯度,因此通过计算每个小批量的梯度的 EMA,无信息梯度的影响被最小化。此外,均线是新旧梯度的加权平均值。如果 Adam 使用算术平均值,所有梯度(第 1 步和第 t 步之间)将具有相同的权重。
让我们注意到,均线作为梯度的估计,我们将在后面看到。
亚当的更新法则
如上所述,亚当的更新规则只不过是梯度下降的更新规则的修改版本。在 Adam 中,梯度的第一个矩的 EMA 被矩的第二个矩的平方根缩放,减去参数向量θ。

Adam’s update rule
在论文中,作者将其定义为 SNR (信噪比)。
SNR 是将期望信号(这里是梯度,即目标函数曲线的方向)的水平与背景噪声(二阶梯度,即该方向周围的噪声)的水平进行比较的度量。
平方根缩放来自 RMSProp (RMS 表示均方根)算法。这个想法是,由于梯度是在多个小批量上累积的,我们需要在每一步的梯度保持稳定。由于一个小批量可以具有与另一个小批量完全不同的数据样本,为了限制梯度的变化,梯度的一阶矩的 EMA 被二阶矩的 RMS 缩放。人们可以将这种技术视为一种标准化,即梯度除以一种标准偏差。
自动退火
SNR 越小,有效步长越接近于零,这意味着与实际信号相比存在大量噪声,因此一阶梯度的方向是否对应于最优方向的不确定性越大。这是一个理想的特性,因为步长较小,从而限制了偏离局部最优值。
SNR 通常变得更接近于 0,趋向于最佳值,导致参数空间中的小有效步长。这使得能够更稳健、更快速地收敛到最优。
初始化偏置-校正
由于 EMA 向量被初始化为 0 的向量,所以矩估计偏向于 0,尤其是在初始时间步长期间,尤其是当衰减率很小时(β接近于 1)。
为了抵消这一点,力矩估计值被偏差修正。
使用 v(t) 和 v(t-1) 之间的递归关系,可以得出:

在通过将它与期望值组合来使用这个等式之后,很快就可以得出, E[v(t)]等于

Zeta is a residual parameter to adjust the equation
这就是为什么在每一步初始化权重时,**e【v(t)】**除以 (1-β2^t) 。
对于第一梯度矩,遵循同样的推理。
adamax:Adam 扩展
Adamax 是 Adam 的扩展。它用一个加权无穷范数代替梯度的二阶矩。

Adamax pseudo-code
使用这种变体是因为当特征矩阵稀疏时,作者已经提出了一种令人惊讶的稳定解决方案(像在嵌入中一样,考虑一下一键编码)。事实上,由于用于 u(t) 的更新规则不仅仅依赖于梯度,所以该解决方案是健壮的。

当 g(t) 变得非常小时,由于 max 函数,更新规则选择 β2*u(t-1) 。
结果

比较 MNIST 数据集上的结果,我们观察到 Adam 比 Adagrad、RMSProp 或 AdaDelta 收敛得更快且更接近最优。
理解 AlphaGo:人工智能如何思考和学习(基础)
本文将教你游戏人工智能的基础…
“我想象有一天,我们对机器人的重要性就像狗对人类的重要性一样,我支持机器人。”
—克劳德·香农
由 DeepMind 开发的 AlphaGo 在 2016 年的一场围棋比赛中击败了世界顶级人类选手后,获得了全世界的关注。更强大的版本名为 AlphaZero,继续在围棋和国际象棋等游戏中蓬勃发展。一个名为 AlphaStar 的变种在与职业玩家的实时战略游戏中表现越来越好。我们正处于机器接管我们工作的时代,在某些特定领域,机器比我们人类做得更好。

Robot Playing a Game of Chess, Image from Smithsonian.com
但是那些人工智能到底是怎么工作的呢?在这篇文章中,我们将从基础开始讲述这些游戏人工智能是如何工作的。我们将从老式的对抗性搜索和状态机开始。然后,我们将在机器学习领域进行一些探索,从强化学习到蒙特卡罗树搜索,我们将了解现代人工智能如何自我学习(以神奇宝贝ϟϟ(๑⚈․̫⚈๑)∩为例)。
然后我们将进入第 2 部分,在那里我们将更深入地研究深度学习,主要关注人工神经网络和卷积神经网络。在此之后,我们应该能够理解 AlphaGo 的政策网络和价值网络。
不要被这些术语吓跑,因为在本文结束时,你会像专家一样理解它们。我希望这篇文章可以消除对人工智能的一些误解,解答疑问,并鼓励对这一研究领域的更多兴趣。如果你准备好了,让我们的旅程开始吧!
人工智能、历史和基础
“我们的智力是我们成为人类的原因,而人工智能是这种素质的延伸。”
——扬·勒昆
人工智能的第一个概念可以追溯到古希腊神话。赫菲斯托斯是希腊的铁匠、金工、木匠、工匠、工匠、雕刻家、冶金、火和火山之神,他应父亲宙斯的请求,制作了一个青铜机器人塔洛斯,以保护宙斯的配偶欧罗巴不被绑架。赫菲斯托斯还被认为是潘多拉的创造者——一个作为礼物送给人类的完美女人,手里拿着*“潘多拉的盒子”——一个邪恶的罐子,它向人类释放了所有邪恶的罪恶,同时在罐子的唇边有【希望】*。

Talos, a bronze automaton, Image from FANDOM
早在公元前 350 年左右,伟大的哲学家亚里士多德描述了一种通过演绎推理进行正式、机械思考的方法,称为*“三段论”。在 1206 年,Ismail al-Jazari 创造了一个可编程的机器人,被称为、【音乐机器人乐队】*。几个世纪以来,许多其他杰出的人都受到了启发。一个著名的例子是艾伦·图灵,他在 1950 年发明了一种算法,可以在计算机发明之前和他的朋友下棋。(顺便说一下,他输掉了那场比赛)当然,图灵也因他的“图灵测试”而闻名,我们稍后会更详细地讨论这个测试。

Al-Jazari’s musical robot band, Image from Wikipedia
1956 年夏天,人工智能研究领域在新罕布什尔州汉诺威达特茅斯学院的一个车间里正式启动。术语*“人工智能”*描述了人类发明的具有认知能力的机器。这项研究有许多子领域,如计算机视觉、自然语言处理、机器学习、专家系统,以及我们今天将要讨论的主题——游戏人工智能。

A view of East Campus from Baker Tower of Dartmouth College, Image from Wikipedia
我们将从游戏中人工智能使用的两个基本算法开始——对抗性搜索和状态机。从这些构件开始,我们可以更深入地研究更高级的算法。
对抗性搜索
敌对搜索,有时被称为极小极大搜索,是一种经常在涉及玩家之间敌对关系的游戏中使用的算法。游戏通常可以通过 alpha-beta 剪枝进行优化,这将在本节稍后介绍。
该算法可以应用于井字游戏或 Nim 游戏,我在下面附上了游戏规则。你可以试试在游戏里玩电脑——提示:你永远不会赢,一会儿我们就知道为什么了。
井字游戏
井字游戏是一种游戏,双方玩家都试图将他们的*【X】或【O】*符号放入一个 3x 3 的棋盘中。玩家通过使他们的符号形成长度为 3 的连接而获胜。连接可以是水平的、垂直的或对角的。
尼姆
Nim 是一种游戏,玩家试图从一组筹码中抽取一定数量的筹码,玩家每回合至少要抽取 1 个筹码。从游戏中拿走最后筹码的玩家赢得游戏。
对抗性搜索
现在让我们进入今天的严肃话题——对抗性搜索。对抗性搜索创建了一个所有可能的游戏状态的树,由可用的选择分支。例如,在一个最多拿 3 个筹码的 Nim 游戏中,每个玩家可以拿 1、2 或 3 个筹码,这样每个树节点就有 3 个分支,如下所示。

Adversarial Search Illustrated with Nim, Part 1
当没有更多的芯片剩余时,树结束。拿到最后一个筹码的玩家赢得游戏。

Adversarial Search Illustrated with Nim, Part 2
该树包含所有可能的游戏状态,在这种情况下, 177 个状态。通过搜索所有的游戏状态,计算机将在采取任何行动之前知道游戏的结果。
🤖机器人 A:“143 移动中的伴侣。”
🤖机器人 B:“哦维尼,你又赢了。”
——Futurama 第二季第二集 Brannigan,重新开始

Robots Playing Chess, Futurama S2E02 Brannigan, Begin Again
在计算机科学领域,我们也重视算法的效率。更少的计算量和存储器消耗意味着更轻的硬件负载和电力消耗,导致运行算法的成本降低。因此,有许多方法可以简化问题,而不是遍历所有可能的状态。
例如,下面显示的井字游戏的 8 种状态是旋转等价的,因此我们可以将它们视为 2 种状态。这些类型的平移和旋转等效将在我们在后面的章节深入研究卷积神经网络时进行更详细的讨论。

The Tic-Tac-Toe States are Rotationally Equivalent
通过消除额外的状态,搜索树的大小可以大大减小。如果不应用这种缩减,在搜索树的前 4 层中有超过 3500 个状态。对于现代计算机来说,搜索 3500 个状态并不是一项很大的任务,但这个数字呈指数增长,当它进入更大的棋盘(如国际象棋)时,可以达到我们宇宙年龄的微秒级。

Reduced Search Tree for Tic-Tac-Toe
消除第一层中的相同状态可以减少 2/3 的额外状态,但是我们能做得更好吗?有一个叫做 alpha-beta 修剪的小技巧,我们将在下一节讨论。
阿尔法-贝塔剪枝
“我从不低估对手,但也从不低估自己的天赋。”
—黑尔·欧文
想象一下,当你在玩井字游戏时,当你的对手已经有两个相连的棋子时,你总是想在另一端挡住他。为什么?因为你可以假设如果你不赢他下一轮会赢。这就是阿尔法-贝塔修剪的思想,你总是期望你的对手尽最大努力去赢。

Illustration of Alpha-Beta Pruning, Player 1 will always choose the winning move
对于井字游戏,结果通常被评估为二进制。然而,对于一些更复杂的游戏,如国际象棋,棋盘可以用分数来评估。例如,白色棋子的得分之和减去黑色棋子的得分之和。这就是 alpha-beta 修剪有助于消除分支的时候。下面有一个视频解释了用象棋进行 alpha-beta 剪枝。
算法解释—极大极小和阿尔法-贝塔剪枝
至于 Nim 游戏,人工智能使用一个简单得多的规则库。我们看了搜索树,只是因为用 Nim 解释搜索树更容易。AI 会将筹码分成大小比最大允许拾取量大 1 个筹码的卡盘,并确保每次通过拾取大块大小和玩家拾取量之间的差异来拾取整个大块。如果卡盘是不可分的,AI 将首先移动并选择余数。这样,玩家就没有办法赢了。

Illustration of Nim AI
对于像国际象棋这样的游戏来说,所有可能的状态都不能像井字游戏或 nim 游戏那样容易地被搜索到。但是一台可以搜索超过 30 层深度的计算机已经很难被击败,因为大多数玩家无法预见那么多的移动。
状态机
“简单可能比复杂更难:你必须努力让自己的思维变得清晰,才能变得简单。”
—史蒂夫·乔布斯
状态机,通常指的是有限状态机,是当今游戏 AI 中经常被低估的概念,尤其是在机器学习多年来获得巨大普及之后。然而,在与其他使用机器学习的星际争霸 AI 进行的 SSCAIT 2018 挑战赛中,这种老派设计以 96.15%的胜率占据了主导地位。

Image of SSCAIT and StarCraft, a Real-Time Strategy (RTS) game that requires high skill to play
在游戏人工智能领域之外,状态机也广泛应用于其他领域,比如谷歌的这款很酷的手机助手人工智能。在这一节中,我们将探究所有这些奇迹背后的理论。
谷歌人工智能助手演示
有限状态机,有时称为有限状态自动机,通常由一组连接的节点表示,正式名称为*“图”。下面的图*展示了典型读者如何与我的文章互动。

Despite Medium asks to not ask for claps, I realize people who ask for claps get more claps
圆圈内是我们称之为*“状态”,箭头称为“状态转换函数”。状态转移函数通常由一个条件来描述。例如,当我的读者处于“读者喜欢我的文章”状态时,如果“我请求鼓掌”或“读者记得鼓掌”,他们可能会转换到“读者为我的文章鼓掌”*状态。有限状态机的更正式的数学定义可以在这里找到。
围绕它发展了许多有趣的理论,最终导致了计算机科学中的两大主题,NP 与 P 问题和图灵机。马尔可夫链等机器学习算法也分享了状态机中的一些概念。我们将在下一节学习强化学习时讨论马尔可夫决策过程。
机器如何学习,强化学习介绍(带神奇宝贝)
如果一个计算机程序在某类任务 T 和性能测量 P 上的性能(由 P 测量)随着经验 E 而提高,则称该程序从经验 E 中学习
汤姆·米切尔

Tom M. Mitchell, Machine Learning professor at Carnegie Mellon University
作为一个被广泛使用的引用,Tom M. Mitchell 将机器学习的概念正式定义为一个计算机程序,它通过积累经验来逐步提高性能。在机器学习算法的驱动下,这些机器将利用它们接收到的新信息不断前进。相关算法被广泛应用于许多正在改变我们生活的领域,如检测我们面部的 Snapchat 过滤器,或帮助我们理解其他说外语的人的谷歌翻译。如果你对其中的一些应用感兴趣,我也写了一个关于面部检测的教程,可以在这里找到。
在这一部分,我们将了解游戏人工智能的机器学习的一个热门领域——强化学习。流行的神经网络将在随后的深度学习部分讨论。
强化学习
“失败只是重新开始的机会,这次会更聪明.”
—亨利·福特
“强化学习(RL)是机器学习的一个领域,涉及软件代理应该如何在一个环境中采取行动,以便最大化某种累积回报的概念。”
—维基百科
为了便于理解,下图是一个说明强化学习基本概念的例子。

The truth is, asking for claps also generates more claps.
强化学习有几个概念,我们可以从上面的例子中理解,掌声鼓励作者写更好的文章(并要求更多的掌声)。
- **环境:**环境是智能体相互作用的地方,在这种情况下,媒介社区就是环境。
- **代理人:**代理人就是与他人和环境相互作用的东西,在这里,作家就是代理人。读取器也是代理,可以用前面提到的状态机来描述。
- **状态:**状态包括环境和代理的可能状态。例如,一个作家可能睡着了或者很忙,不能写作。媒体期刊可能会引入合作项目的变化或策划一篇文章,这会影响可见性。
- **动作:**动作是代理可以做的与环境和其他代理交互的事情。例如,作者可以选择写一个有吸引力的标题,这有机会增加浏览量和潜在的掌声。
- **解释器:**解释器是一套为代理评估结果的规则,比如每次拍手让我开心 1 个单位,每次关注让我开心 50 个单位。
代理将尝试优化解释器评估的结果,有几种方法。在这一节中,我们将介绍游戏中人工智能使用的两种流行方法——Q 学习和蒙特卡罗树搜索。一旦我们理解了这两点,我们就应该能够理解后面章节中的深度 Q 学习。
q 学习
Q-Learning 是强化学习的最简单形式。Q-Learning 的目标是学习一个优化代理评估结果的策略。下面的流程图解释了玩家如何找到最好的神奇宝贝。

Flow-Diagram Explaining Q-Learning with Pokémon
策略通常由记录每个状态下每个动作的机会的矩阵来定义。代理将根据策略执行操作,然后根据操作的结果更新策略。例如,如果对手召唤了杰尼龟,代理将随机挑选一个神奇宝贝。如果代理商选择了皮卡丘,并发现对杰尼龟非常有效,代理商将更新政策,因此它更有可能在未来用皮卡丘对抗杰尼龟。还有另外两个值得注意的概念,学习率和马尔可夫决策过程。
1。学习率
学习描述了模型学习的速度。例如,对于*“非常有效”*的相同结果,低学习率的百分比可以增加 1%,高学习率的百分比可以增加 15%。
2。马尔可夫决策过程
马尔可夫决策过程是描述主体和环境的状态和行为的状态图。它还描述了每个状态之间的转移概率和每个状态的奖励。

Markov Decision Process Illustrated with Pokémon
关于 Q-learning 收敛的严肃数学定义和证明的更多信息,你可以在这里阅读它们。
蒙特卡罗树搜索
蒙特卡洛树搜索(MCTS)的工作方式类似于上一节中介绍的对抗性搜索。主要区别是 MCTS 随机选择一个分支,而不是试图遍历所有的分支。然后,该算法根据该分支的结果建立一个配置文件。

Illustration of Monte Carlo Tree Search
形式上,蒙特卡洛树搜索具有以下 4 种状态:
1。选择
- 通常通过选择具有最高胜率的节点来进行选择,但是具有一些随机性,因此可以探索新的策略。
2。扩展
- 扩展是算法扩展到未探索的状态。该算法选择随机的未探索的新状态来探索。
3。模拟
- 模拟是资料片后模拟随机玩法的时候,所以可以评估状态。
4。反向传播
- 反向传播是用从模拟中获得的新信息更新状态值的过程。
这种算法在状态数量很大的游戏中特别有用,因为要遍历所有的状态几乎是不可能的。通过学习从以前的游戏中获得的经验,将来可以做出更明智的决策。更多关于决定勘探和开发之间的节点的阅读可以在这里找到。
下面是一个关于人工智能如何用算法玩超级马里奥的视频。
人工智能用蒙特卡罗树搜索玩马里奥
强化学习是一个有趣的研究领域,有许多不同的分支。我们在本节中讨论的两个问题肯定会帮助我们理解后面章节中更高级的内容。
未完待续…
祝贺你走到这一步,我们已经在理解现代游戏人工智能如何思考和学习的旅程中走了一半。在本文的第二部分中,我们将回顾深度学习和神经网络,然后我们最终可以进入那些 DeepMind AI 的架构。
还有,让我知道你最喜欢哪种写作风格,我可以做经典的纪录片,严肃的论文,或者那些华而不实的神奇宝贝例子。您的反馈让我能够了解最佳政策矩阵🤖。
理解和计算卷积神经网络中的参数个数

https://www.learnopencv.com/wp-content/uploads/2018/05/AlexNet-1.png

Example taken from coursera: https://www.coursera.org/learn/convolutional-neural-networks/lecture/uRYL1/cnn-example
仅供参考:上图并不代表正确的参数数量。请参考标题为“更正”的部分。如果你只想要数字,你可以跳到那一部分。
如果你一直在玩 CNN,经常会看到上图中的参数摘要。我们都知道计算激活尺寸很容易,因为它仅仅是宽度、高度和该层中通道数量的乘积。
例如,如 coursera 的上图所示,输入层的形状为(32,32,3),该层的激活大小为 32 * 32 * 3 = 3072。如果你想计算任何其他层的激活形状,同样适用。比方说,我们想计算 CONV2 的激活大小。我们所要做的只是乘以(10,10,16),即 101016 = 1600,你就完成了激活大小的计算。
然而,有时可能变得棘手的是计算给定层中参数数量的方法。也就是说,这里有一些简单的想法可以让我记住。
一些上下文(如果你知道术语“参数”在我们上下文中的意思,跳过这个):
让我问你这个问题:CNN 是如何学习的?
这又回到了理解我们用卷积神经网络做什么的想法,卷积神经网络基本上是试图使用反向传播来学习滤波器的值。换句话说,如果一个层有权重矩阵,那就是一个“可学习的”层。
基本上,给定层中的参数数量是过滤器的“可学习的”(假设这样的词存在)元素的计数,也称为该层的过滤器的参数。
参数通常是在训练期间学习的重量。它们是有助于模型预测能力权重矩阵,在反向传播过程中会发生变化。谁来管理变革?嗯,你选择的训练算法,尤其是优化策略,会让它们改变自己的值。
现在你知道什么是“参数”,让我们开始计算我们上面看到的示例图像中的参数数量。但是,我想在这里再次包含该图像,以避免您的滚动努力和时间。

Example taken from Coursera: https://www.coursera.org/learn/convolutional-neural-networks/lecture/uRYL1/cnn-example
- 输入层:输入层不需要学习什么,它的核心是提供输入图像的形状。所以这里没有可学习的参数。因此参数的数量= 0 。
- CONV 层:这是 CNN 学习的地方,所以我们肯定会有权重矩阵。为了计算这里的可学习参数,我们所要做的只是将乘以形状的宽度 m 、高度 n 、前一层的过滤器 d ,并考虑当前层中所有这样的过滤器 k。不要忘记每个滤波器的偏置项。CONV 层中的参数数量将是: ((m * n * d)+1) k) ,由于每个滤波器的偏置项而增加 1。同样的表达式可以写成:*((滤镜宽度的形状滤镜高度的形状上一层滤镜数+1)*滤镜数)。其中术语“过滤器”指当前层中过滤器的数量。
- 池层:它没有可学习的参数,因为它所做的只是计算一个特定的数字,不涉及反向传播学习!因此参数的数量= 0 。
- 全连接层(FC): 这当然有可学习的参数,事实上,与其他层相比,这类层有最多的参数,为什么?因为,每一个神经元都与其他神经元相连!那么,如何计算这里的参数个数呢?你可能知道,它是当前层的神经元数量 c 和前一层的神经元数量 p 的乘积,而且一如既往,不要忘记偏置项。因此这里的参数数量为:((当前层神经元 c 前一层神经元 p)+1c) 。
现在让我们跟着这些指针计算参数的个数,好吗?
还记得这个练习吗?我们不想滚动,是吗?

Example taken from coursera https://www.coursera.org/learn/convolutional-neural-networks/lecture/uRYL1/cnn-example
- 第一个输入层没有参数。你知道为什么。
- 第二个 CONV1(滤镜形状=5*5,步距=1)层中的参数为: *((滤镜宽度形状滤镜高度形状上一层滤镜数量+1)滤镜数量)= (((55*3)+1)8) = 608。
- 第三个 POOL1 层没有参数。你知道为什么。
- 第四个 CONV2(滤镜形状=5*5,步距=1)层中的参数为 : *((滤镜宽度形状滤镜高度形状上一层滤镜数量+1) 滤镜数量)= (((55*8)+1)16) = 3216。
5.第五个 POOL2 层没有参数。你知道为什么。
6.中的参数第六个 FC3 层为((当前层 c 上一层 p)+1c) = 120400+1120= 48120。
7.T5 里的参数第七个 FC4 层是:((当前层 c 上一层 p)+1c) = 84120+1 84 = 10164。
8.第八个 Softmax 层有((当前层 c 上一层 p)+1c)参数= 1084+110 = 850。
更新 V2:
感谢观察力敏锐的读者的评论。感谢指正。为了更好的理解改变了图像。
参考消息:
- 我已经非常宽松地使用了术语“层”来解释分离。理想情况下,CONV +池被称为一个层。
2.仅仅因为池层中没有参数,并不意味着池在 backprop 中没有作用。池层负责分别在向前和向后传播期间将值传递给下一层和上一层。
在这篇文章中,我们看到了参数的含义,我们看到了如何计算激活大小,我们也了解了如何计算 CNN 中的参数数量。
如果你有足够的带宽,我会推荐你使用下面链接的安德鲁博士的 coursera 课程。
来源:
我用千层面为 MNIST 数据集创建了一个 CNN。我正在密切关注这个例子:卷积神经…
stackoverflow.com](https://stackoverflow.com/questions/42786717/how-to-calculate-the-number-of-parameters-for-convolutional-neural-network) [## 卷积神经网络| Coursera
本课程将教你如何建立卷积神经网络…
www.coursera.org](https://www.coursera.org/learn/convolutional-neural-networks)
如果你喜欢这篇文章,那就鼓掌吧!:)也许一个跟随?
在 Linkedin 上与我联系:
https://www.linkedin.com/in/rakshith-vasudev/
在 Keras 中理解和编码 ResNet
用数据做很酷的事情!
ResNet 是残差网络的缩写,是一种经典的神经网络,用作许多计算机视觉任务的主干。这款车型是 2015 年 ImageNet 挑战赛的冠军。ResNet 的根本突破是它允许我们成功地训练具有 150+层的非常深的神经网络。在 ResNet 训练之前,由于梯度消失的问题,非常深的神经网络是困难的。
AlexNet 是 2012 年 ImageNet 的获胜者,也是显然启动了对深度学习的关注的模型,它只有 8 层卷积层,VGG 网络有 19 层,Inception 或 GoogleNet 有 22 层,ResNet 152 有 152 层。在这篇博客中,我们将编写一个 ResNet-50,它是 ResNet 152 的一个较小版本,经常被用作迁移学习的起点。

Revolution of Depth
然而,通过简单地将层堆叠在一起,增加网络深度是不起作用的。由于众所周知的梯度消失问题,深层网络很难训练,因为梯度会反向传播到更早的层,重复乘法可能会使梯度变得非常小。因此,随着网络越来越深入,其性能会饱和,甚至开始迅速下降。
我从 DeepLearning 了解到编码 ResNets。AI 课程由吴恩达主讲。我强烈推荐这道菜。
在我的 Github repo 上,我分享了两个笔记本,其中一个按照深度学习中的解释从头开始编写 ResNet。AI 和另一个使用 Keras 中的预训练模型。希望你拉代码自己试试。
跳过连接 ResNet 的优势
ResNet 首先引入了跳过连接的概念。下图说明了跳过连接。左图是一个接一个地将卷积层堆叠在一起。在右边,我们仍然像以前一样堆叠卷积层,但我们现在也将原始输入添加到卷积块的输出。这被称为跳过连接

Skip Connection Image from DeepLearning.AI
它可以写成两行代码:
X_shortcut = X # Store the initial value of X in a variable
## Perform convolution + batch norm operations on XX = Add()([X, X_shortcut]) # SKIP Connection
编码非常简单,但有一个重要的考虑因素——因为上面的 X,X_shortcut 是两个矩阵,只有当它们具有相同的形状时,才能将它们相加。因此,如果卷积+批量范数运算以输出形状相同的方式进行,那么我们可以简单地将它们相加,如下所示。

When x and x_shortcut are the same shape
否则,x_shortcut 会经过一个卷积层,该卷积层的输出与卷积块的输出具有相同的维度,如下所示:

X_shortcut goes through convolution block
在 Github 上的笔记本中,上面实现了两个函数 identity_block 和 convolution_block。这些函数使用 Keras 实现带有 ReLU 激活的卷积和批范数层。跳过连接技术上是一条线X = Add()([X, X_shortcut])。
这里需要注意的一点是,如上图所示,跳过连接是在 RELU 激活之前应用的。研究发现这有最好的效果。
为什么跳过连接有效?
这是一个有趣的问题。我认为跳过连接在这里起作用有两个原因:
- 它们通过允许渐变流过这种替代的快捷路径来缓解渐变消失的问题
- 它们允许模型学习一个标识函数,该函数确保较高层的性能至少与较低层一样好,而不是更差
事实上,因为 ResNet skip 连接被用于更多的模型架构,如全卷积网络(FCN) 和 U-Net 。它们用于将信息从模型中的早期层传递到后期层。在这些架构中,它们用于将信息从下采样层传递到上采样层。
测试我们构建的 ResNet 模型
然后将笔记本中编码的单位和卷积块组合起来,创建一个 ResNet-50 模型,其架构如下所示:

ResNet-50 Model
ResNet-50 模型由 5 个阶段组成,每个阶段都有一个卷积和标识块。每个卷积块有 3 个卷积层,每个单位块也有 3 个卷积层。ResNet-50 拥有超过 2300 万个可训练参数。
我在 signs 数据集上测试了这个模型,这个数据集也包含在我的 Github repo 中。该数据集具有对应于 6 个类别的手部图像。我们有 1080 张训练图像和 120 张测试图像。

Signs Data Set
我们的 ResNet-50 在 25 个训练周期中达到 86%的测试准确率。还不错!
使用预训练库在 Keras 中构建 ResNet
我喜欢自己编写 ResNet 模型,因为它让我更好地理解我在许多与图像分类、对象定位、分割等相关的迁移学习任务中经常使用的网络。
然而,对于更经常的使用,在 Keras 中使用预训练的 ResNet-50 更快。Keras 的库中有许多这样的骨干模型及其 Imagenet 权重。

Keras Pretrained Model
我已经在我的 Github 上上传了一个笔记本,它使用 Keras 加载预训练的 ResNet-50。您可以用一行代码加载模型:
base_model = applications.resnet50.ResNet50(weights= **None**, include_top=**False**, input_shape= (img_height,img_width,3))
这里 weights=None,因为我想用随机权重初始化模型,就像我在 ResNet-50 上编码的那样。否则,我也可以加载预训练的 ImageNet 权重。我将 include_top=False 设置为不包括原始模型中的最终池化和完全连接层。我在 ResNet-50 模型中添加了全局平均池和密集输出层。
x = base_model.output
x = GlobalAveragePooling2D()(x)
x = Dropout(0.7)(x)
predictions = Dense(num_classes, activation= 'softmax')(x)
model = Model(inputs = base_model.input, outputs = predictions)
如上所示,Keras 提供了一个非常方便的接口来加载预训练的模型,但重要的是至少自己编写一次 ResNet,这样您就可以理解这个概念,并可能将这种学习应用到您正在创建的另一个新架构中。
Keras ResNet 在使用 Adam optimizer 和 0.0001 的学习率对 100 个时期进行训练后,达到了 75%的准确率。精确度比我们自己的编码模型稍低,我猜这与权重初始化有关。
Keras 还为数据扩充提供了一个简单的接口,所以如果你有机会的话,试着扩充这个数据集,看看这是否会带来更好的性能。
结论
- ResNet 是一个强大的主干模型,在许多计算机视觉任务中经常使用
- ResNet 使用跳过连接将早期层的输出添加到后期层。这有助于缓解渐变消失的问题
- 你可以用 Keras 加载他们预训练的 ResNet 50 或者用我分享的代码自己编写 ResNet。
我有自己的深度学习咨询公司,喜欢研究有趣的问题。我已经帮助许多初创公司部署了基于人工智能的创新解决方案。在 http://deeplearninganalytics.org/的入住我们的酒店。
你也可以在https://medium.com/@priya.dwivedi看到我的其他作品
如果你有一个我们可以合作的项目,请通过我的网站或 info@deeplearninganalytics.org 联系我
参考
了解和实施分布式优先体验回放(Horgan 等人,2018 年)
利用分布式架构加速深度强化学习
在当前的技术水平下,许多强化学习算法利用了积极的并行化和分布。在本文中,我们将审查和实施 ApeX 框架(Horgan 等人,2018 年),也称为分布式优先化体验重放。特别是,我们将实现顶点 DQN 算法。
在这篇文章中,我试图做到以下几点:
- 讨论分布式强化学习的动机,介绍分布式框架的前身(gorilla)。然后,介绍 ApeX 框架。
- 简要回顾优先化的经验重放,并让读者参考这篇论文和其他博客文章进行深入讨论。
- 简要介绍 Ray,这是一个前沿的并行/分布式计算库,我将使用它来实现 ApeX。
- 运行我的(简化的)ApeX DQN 实现。
分布式 RL 是从哪里开始的,为什么?
第一个推广分布式强化学习架构的工作是 *Gorila(通用强化学习框架;我也在某处看到过“Google 强化学习框架”,但论文写的是“通用”)*在 Google 的 Nair et al. (2015)上提出。

Gorila framework from “Massively Parallel Methods in Deep Reinforcement Learning” (Nair et al, 2015)
在 Gorila 中,我们有一个分离的参与者(数据生成/收集)和学习者(参数优化)过程。然后,我们有一个参数服务器和一个中央重放缓冲区,由每个学习者和参与者进程共享。参与者执行轨迹展开,并将其发送到集中重放缓冲区,学习者从该缓冲区采样体验并更新其参数。在学习器更新其参数后,它将新的神经网络权重发送到参数服务器,参与者同步其自己的神经网络权重。所有这些过程都是异步发生的,彼此独立。
Gorila 框架似乎是现代分布式强化学习架构的底层结构——比如 ApeX 。特别地, ApeX 通过使用优先化重放缓冲器(优先化经验重放,由 Schaul 等人(2015)提出)来修改上述结构;我们将在下一节对此进行简要讨论)。
这种架构的动机来自于这样一个事实,即 RL 的大部分计算时间都花在生成数据上,而不是更新神经网络。因此,如果我们使这些过程彼此异步,我们可以执行更多的更新。
除了来自异步结构的加速之外,这种分布式架构具有改进探索的概念优势;我们可以在不同的种子环境中运行每个 actor 流程,以允许收集不同的数据集。例如,A3C (Mnih 等人,2016 年)将其相对于同步版本 A2C 的显著改进归功于改进的探索。因此,算法的分布式实现也受益于这种效果。
优先体验重放的简要回顾
在强化学习中,并不是所有的经验数据都是相等的:直觉上,有些经验比其他经验更能对主体的学习做出贡献。Schaul 等人(2015 年)建议我们根据时间差(TD)误差对体验进行优先排序:

回忆一下规范的 q 学习算法;我们正试图最小化我们的 Q 值的当前预测和我们的引导目标 Q 值之间的距离(即,时间差异误差)。也就是说,该误差越高,神经网络权重的更新程度就越大。因此,我们可以通过采样具有较高 TD 误差的经验来获得更快的学习。
然而,纯粹基于 TD 误差的采样会给学习带来偏差。例如,具有低 TD 误差的经历可能在很长一段时间内不会被重放,减少了重放记忆的限制,并使模型易于过度拟合。为了补救这一点,Schaul 等人(2015)使用重要性采样权重进行偏差校正。也就是说,对于每个更新步骤,我们将梯度乘以体验的重要性采样权重,计算如下:

当实现优先重放缓冲区时,我们希望有两个独立的数据结构来存储经验数据及其各自的优先级值。为了提高采样效率,Schaul 等人(2015 年)建议使用段树(或总和树)来存储优先级值。我们将使用 OpenAI 基线实现来实现 ApeX,但是请查看的这篇博客文章和的实际论文,以获得关于优先体验重放的更详细的讨论。
雷简介
下面是使用 Ray 的一个极其简短的介绍:
Click the jupyter notebook file to get a clearer view!
这应该足以完成代码。我建议查看他们的教程和文档,特别是如果您想用 Ray 实现自己的并行/分布式程序。
履行
我们将使用 Ray 进行多处理,而不是内置的 python-多处理模块——从我个人的经验来看,我在调试多处理队列时遇到了很多麻烦,并且用 Ray 实现 ApeX 更容易。
虽然实现运行正常,但我目前正在修复可能的瓶颈和内存泄漏。为此,我的实现仍在进行中——我建议不要用它们大量并行化任务。一旦内存使用问题得到解决,我会更新这篇文章。
我们将这样分解实现过程:我们将把 actor 和 replay buffer 组合在一起,然后是学习器和参数服务器。下面的 jupyter 笔记本文件是我的完整实现的简化版本,只是为了展示如何实现 ApeX 如果您对完整的实现细节感兴趣,并且希望在您的设备上运行它,请查看我的 GitHub 资源库!
演员和重播缓冲区
每次推出后,参与者都将它们的转换数据异步发送到集中式重放缓冲区。集中式缓冲区为体验分配优先级(如优先体验重放中所述),并将成批的采样体验发送给学习者。
我们将实现下面的 actor 过程,并使用优先重放缓冲区的 OpenAI 基线实现。我们必须修改重放缓冲区的基线实现,使其与 Ray 兼容:
演员
Click the jupyter notebook file to get a cleaner view!
我们可以让参与者保留一个本地缓冲区,并定期将所有内容发送到中央缓冲区,从而使参与者进程的内存效率更高——我将很快更新代码。
优先重放缓冲区
Click the jupyter notebook file to get a clearer view!
学习者和参数服务器
利用从中央重放缓冲器发送的经验批次,学习者更新其参数。由于我们使用优先体验重放,学习者还必须更新所用体验的优先级值,并将该信息发送到缓冲区。
一旦学习器参数被更新,它就将其神经网络权重发送到参数服务器。Ray 的一个优点是它支持零成本读取 numpy 数组;也就是说,我们希望学习者发送其网络权重的 numpy 数组,而不是 PyTorch 对象。然后,行动者周期性地用存储的参数拉和同步他们的 q 网络。
我们将从参数服务器开始,并实现学习者流程:
参数服务器:
Click the jupyter notebook file to get a clearer view!
学员:
Click the jupyter notebook file to get a clearer view!
全面实施
要查找 ApeX DQN 和 ApeX DDPG 的运行实现,请在下面的链接中查看我的 GitHub 库:
分布式强化学习算法的单机实现。请看下面的…
github.com](https://github.com/cyoon1729/Distributed-Reinforcement-Learning)
参考
理解和减少机器学习中的偏差
'…“即使在观察了对象的频繁或持续的联系之后,我们也没有理由得出关于任何超出我们经验的对象的任何推论”——休谟,一篇关于人性的论文
米蕾尤·希尔德布兰特是一名从事法律和技术交叉领域工作的律师和哲学家,他就机器学习算法中的偏见和公平问题发表了大量的文章和演讲。在即将发表的一篇关于不可知论者和无偏见机器学习的论文中(Hildebrandt,2019 年),她认为无偏见机器学习不存在,生产性偏见是算法能够对数据建模并做出相关预测的必要条件。预测系统中可能出现的三种主要偏差类型如下:
任何行动感知系统固有的偏差(生产性偏差)
一些人认为不公平的偏见
基于被禁止的法律理由进行歧视的偏见
机器学习的性能是通过最小化成本函数来实现的。选择一个成本函数,从而选择搜索空间和最小值的可能值,将我们所说的生产偏差引入到系统中。生产偏差的其他来源来自上下文、目的、足够的训练和测试数据的可用性、使用的优化方法以及速度、准确性、过度拟合和过度概括之间的权衡,每个选择都与相应的成本相关联。因此,机器学习没有偏见的假设是错误的,偏见是归纳学习系统的一个基本属性。此外,训练数据也必然有偏差,研究设计的功能是将接近我们要发现的数据模式的偏差与有区别的偏差或只是计算假象的偏差分开。
机器学习中的偏见被定义为观察结果由于错误的假设而受到系统性偏见的现象。然而,如果没有假设,一个算法在一项任务中不会比随机选择结果有更好的表现,这是一个由 Wolpert 在 1996 年正式形成的原则,我们称之为没有免费的午餐定理。
根据“没有免费的午餐定理”(Macready,1997),当对所有可能的数据生成分布进行平均时,所有分类器都具有相同的错误率。因此,某个分类器必须对某些分布和函数有一定的偏好,才能更好地对这些分布进行建模,这同时会使它在对其他类型的分布进行建模时变得更差。

Figure 1: Depiction of the No Free Lunch theorem, where better performance at a certain type of problem comes with the loss of generality (Fedden, 2017)
还应该始终记住,用于训练算法的数据是有限的,因此不能反映现实。这也导致了由训练和测试数据的选择以及它们对真实总体的表示而产生的偏差。我们做出的另一个假设是,假设有限的训练数据能够对测试数据进行建模和准确分类。
“[……]大多数当前的机器学习理论都基于一个重要假设,即训练样本的分布与测试样本的分布相同。尽管我们需要做出这种假设以获得理论结果,但重要的是要记住,这种假设在实践中必须经常被违反。”
——蒂姆·米切尔
即使我们成功地让我们的系统摆脱了上述偏见,随着时间的推移,偏见仍有可能蔓延:一旦算法经过训练,表现良好,并投入生产,算法是如何更新的,谁来决定系统两年后是否仍然表现良好,谁来决定系统表现良好意味着什么?
意识到这些系统中存在的不同偏见需要解释和诠释它们如何工作的能力,这呼应了阿德里安·韦勒(Adrian Weller)演讲的透明度主题:如果你无法测试它,你就无法质疑它。我们需要清楚确保这些系统功能的生产偏差,并找出训练集或算法中剩余的不公平性。这将使我们能够推断第三种也是最严重的偏见,即基于被禁止的法律理由的歧视。
Krishna Gummadi 是 Max Planck Institute for Software Systems 网络系统研究小组的负责人,他在减少分类器中的歧视性偏见方面做了大量工作,他在该领域的研究从计算的角度处理歧视,并开发了算法技术来最小化歧视。
随着机器学习系统在自动化决策中变得越来越普遍,我们使这些系统对导致歧视的偏见类型敏感是至关重要的,特别是基于非法理由的歧视。机器学习已经被用于在以下领域做出或辅助决策:招聘(筛选求职者)、银行(信用评级/贷款审批)、司法(累犯风险评估)、福利(福利津贴资格)、新闻(新闻推荐系统)等。鉴于这些行业的规模和影响,我们必须采取措施,通过法律和技术手段来防止这些行业中的不公平歧视。
为了说明他的技术,Krishna Gummadi 重点介绍了 Northpointe 公司开发的有争议的累犯预测工具 COMPAS,该工具的输出结果在美国各地被法官用于审前和判决。该算法基于对一份 137 项问卷的回答,其中包括关于他们的家族史、居住环境、学校表现等问题。来预测他们未来犯罪的风险。
算法的结果被法官用来决定量刑的长度和类型,同时将投入产出关系视为一个黑箱。虽然一些研究表明,COMPAS(替代制裁的矫正罪犯管理概况)在预测累犯风险方面并不比随机招募的互联网陌生人更好,但其他研究更侧重于测试不同突出社会群体的算法处理。

Figure 2: Study by Propublica that finds discrimination in the rate at which the algorithm misclassifies non-reoffending defenders at different rates for blacks and whites
ProPublica (Jeff Larson,2016 年)的一项研究表明,与白人辩护人相比,该算法将最终没有再次犯罪的黑人辩护人标记为高风险的可能性是两倍。这是由于黑人被告的假阳性率(FP 率)为 44.85(即 44.85%被归类为再次犯罪的黑人被告没有再次犯罪),而白人被告的假阳性率为 23.45。然而,Northpointe 反驳说,根据他们使用的方法,黑人和白人捍卫者的错误分类率是一样的。

Figure 3: Northpointe’s rebuttal that their scoring on a 10-point scaled classified blacks or whites correctly at similar rates
事实证明,双方都是正确的,这是因为他们使用不同的公平措施。如果黑人和白人的基础累犯率不同,那么没有算法可以在这两种公平性度量上表现得一样好。这两种公平性度量都代表了内在的权衡。
我们需要能够理解这些公平性度量的权衡,以便对它们的区分能力做出明智的决定。这就是为什么我们需要计算视角。因此,让我们先从这个角度来理解什么是歧视。
使用的规范定义是:
将 相对劣势 强加于人 基于 他们隶属于某个显著的社会群体例如种族或性别**
我们如何操作这个定义,并在算法中实现它?上面的表述包含了几个模糊的概念,需要正式化,“相对劣势”,“错误强加”,“突出的社会群体”等。如果我们只关注“相对劣势”部分,我们将恢复算法中可能出现的第一种歧视,即完全不同的待遇。

Figure 4: Example of a binary classification problem where the algorithm learns whether a loan will be repaid based on m+1 features, of which z is a sensitive feature
克里希纳用上面的二元分类问题来更好地理解不同类型的歧视。问题是基于 m+1 个特征来预测贷款是否会被偿还,其中一个特征是敏感特征,例如客户的种族。
完全不同的待遇:
如果用户的预测结果随着敏感特征的改变而改变,则可以检测到这种类型的相对区分。在上面的例子中,这意味着算法预测白人的还贷标签为正,黑人的还贷标签为负,即使所有其他特征都完全相同。为了防止对种族的任何依赖,我们需要从数据集中移除敏感特征
我们可以将其形式化为:

即输出的概率 P 不应依赖于输出或随输出而变化
完全不同的影响:
如果不同敏感组的阳性(阴性)结果的比例存在差异,则可以检测到这种类型的相对歧视。在上述情况下,如果与白人相比,更多的黑人被归类为违约者,就会发生这种情况。
我们将这一要求正式化为:

即 z=1(白人客户)的正标签(归还贷款)的概率与 z=0(黑人客户)的正标签的概率相同。
完全不同的影响衡量对一个群体的间接歧视程度,也经常出现在人类决策中。即使我们通过删除敏感特征来消除完全不同的待遇,通过其他相关特征(如邮政编码)仍然会发生歧视。衡量和纠正不同的影响可以确保这种情况得到纠正。当训练数据集有偏差时,应该使用此要求。同时被许多人认为是一个有争议的措施,特别是批评家,他们认为一些情况不能摆脱不相称的结果。
完全不同的虐待:
当我们测量不同敏感群体的准确结果的差异时,这种类型的相对歧视是可检测的。这是 Propublica 在 Northpointe 算法中发现的歧视类型,该算法将无辜的黑人捍卫者错误地归类为重新犯罪的比率是白人的两倍。我们可以通过要求所有相关的敏感群体获得相同比例的准确结果来纠正这种不公平。
我们将这一要求正式化为:

其中 z=0,1 代表不同的敏感基团。
非歧视性机器学习的机制:
在正式确定纠正算法中的歧视的机制之前,我们需要考虑这样一个事实,即算法并不像流行的叙述那样是无偏见的。与人类相比,算法是客观的,但这并不使它们公平,只是使它们客观上具有歧视性。算法的工作是优化一个成本函数,以达到产生我们想要预测的输出的实际函数的最佳近似。如果最佳函数是将弱势群体的所有成员分类为重新犯罪或无力支付贷款的函数,那么这就是算法将要选择的函数。因此,客观的决定可能是不公平和歧视性的。
简而言之,算法通过逼近以要素为输入并逼近输出的函数来学习输出的模型。它根据最小化函数输出和实际结果之间差异的参数来决定该函数的最佳参数。这被称为优化问题。我们可以通过要求近似函数也必须服从上述公式化要求中的一个或全部来避免歧视,从而对此问题添加进一步的约束。那就是:

这要求模型以所有敏感组的准确率相同的方式近似。然而,添加约束会导致折衷,这是一种相对公平的算法,但代价是一些精度。克里希纳将这一约束应用于累犯预测算法,并以一点准确性为代价,设法获得了一种对黑人和白人被告具有类似错误率的算法。他对假阳性率(FPR)和假阴性率(FNR)进行了限制,假阳性率是无辜被告被归类为累犯的概率,假阴性率是未来再次犯罪的被告被归类为非再次犯罪的概率。正如我们在图 8 中看到的,随着约束条件的收紧,黑人和白人被告的 FPR 和 FNR 的差异接近于 0,而准确性只有很小的损失(约 66.7%至约 65.8%)。

Figure 5: Correcting Disparate mistreatment for Recidivism prediction dataset.
简而言之,尽管担心算法只会进一步巩固和传播人类的偏见,但人工智能社区仍在努力避免和纠正算法中的歧视性偏见,同时使它们更加透明。此外,GDPR 的出现使这些努力正式化和结构化,以确保各行业在存储和处理大量公民个人数据时有动力遵循最佳实践,并以牺牲一些准确性为代价优先考虑公平。最终,算法系统将是它们试图模拟和近似的社会的反映,这将需要政府和私营部门的积极努力,以确保它不仅能够巩固和进一步加剧我们结构中固有的不平等,而且能够通过采取严厉的惩罚措施和约束来纠正它们。这让我们可以设想这样一个社会,在这个社会中,决策可以通过用客观的算法决策来取代人类偏见的主观性,即使不能完全消除偏见,也能意识到自己的偏见。
如果你喜欢阅读这样的故事,并想支持我的写作,请考虑注册成为一名媒体会员。每月 5 美元,你可以无限制地阅读媒体上的所有报道。如果你使用 我的链接 注册,我会收到一点佣金。
引用的作品
安萨罗。(2017 年 10 月 12 日)。检索自https://medium . com/ansaro-blog/interpreting-machine-learning-models-1234d 735 d6c 9
费登大学(2017 年)。检索自 Medium Inc .:https://Medium . com/@ LeonFedden/the-no-free-lunch-theory-62 AE 2c 3 ed 10 c
希尔德布兰特,M. (2019)。隐私作为不可计算自我的保护:从不可知论者到竞争机器学习。(第 19 (1)页)。即将出版的法律理论研究。
杰夫·拉森,S. M. (2016 年 5 月)。检索自 ProPublica:https://www . ProPublica . org/article/how-we-analyzed-the-compas-recidivis-algorithm
凯文·艾克霍尔特,即(2018)。对深度学习视觉分类的鲁棒物理世界攻击。 CVPR。
兰格(1978)。表面上深思熟虑的行动的盲目:人际互动中“地点”信息的作用。《人格与社会心理学杂志》,36 卷 6 期,635–642 页。
麦克瑞德博士(1997 年)。最优化没有免费的午餐定理。IEEE 进化计算汇刊,第 1 卷,№1。
马尔科·图利奥·里贝罗(2016 年)。“我为什么要相信你?”:解释任何分类器的预测。第 22 届 ACM SIGKDD 知识发现和数据挖掘国际会议论文集(第 1135-1144 页)。ACM。
麻省理工新闻。(2018 年 2 月 11 日)。检索自http://news . MIT . edu/2018/study-finds-gender-skin-type-bias-artificial-intelligence-systems-0212
打开 AI 博客。(2017 年 2 月 24 日)。从 https://blog.openai.com/adversarial-example-research/取回
Rich Caruana 等人(未注明)。医疗保健的可理解模型:预测肺炎风险和住院 30 天再入院。第 21 届 ACM SIGKDD 知识发现和数据挖掘国际会议论文集(第 1721-1730 页)。美国纽约。
连线公司(2018 年 3 月 29 日)。编码员如何对抗面部识别软件中的偏见。检索自https://www . wired . com/story/how-coders-are-fighting-bias-in-face-recognition-software/
理解和使用 Python 类

Python 是一种解释的、面向对象的、具有动态语义的高级编程语言。后者是官方网站python.org给出的正式定义。让我们打破它,试着理解它:
- 解释型:与编译型编程语言(源代码必须转换成机器可读的代码)不同,解释型语言不直接由目标机器执行。取而代之的是,它们被称为解释器的其他计算机程序读取和执行;
- 面向对象:这意味着 python 像任何其他面向对象编程(OOP)语言一样,是围绕对象组织的。python 中的一切(列表、字典、类等等)都是对象;
- 高级:这意味着代码的语法更容易被人类理解。也就是说,如果你必须在屏幕上显示一些东西,这个内置函数叫做print;
- 动态语义:动态对象是包含在代码结构中的值的实例,它们存在于运行时级别。此外,我们可以给一个对象分配多个值,因为它会自我更新,这与静态语义语言不同。也就是说,如果我们设置 a=2 ,然后a =‘hello’,那么一旦执行了该行,字符串值将替换整数 1。
在本文中,我想更深入地研究类的概念。类是一种特殊类型的对象。更具体地说,它们是对象构造器,能够构建数据表示和我们可以用来与该对象交互的过程(因此是方法、函数等等)。
要在 Python 中创建一个类,我们需要给这个类一个名称和一些属性。让我们从下面的例子开始:
class Actor:
def __init__(self, name, surname, age, years_on_stage):
self.name=name
self.surname=surname
self.age=age
self.years_on_stage=years_on_stage
于是我们创建了一个名为 Actor 的类,它定义了一些特征(名字、姓氏、年龄、登台年数)。有两个要素需要关注:
- init() :用于初始化数据属性的特殊方法。我们可以把它看作一个初始化器。
- self :这是一个标准符号,用来指向参数。
现在,我们可以使用我们的类并创建一个类 Actor 的对象:
mario=Actor(
'Mario',
'Rossi',
40,
13
)
现在,我们可以访问 mario 的所有属性(我们在 init() 中定义的):
mario.name"mario"mario.age40
现在,假设我们想知道 mario 的具体信息,而这些信息并没有存储在它的属性中。更具体地说,我们想知道出道的年份,但只提供给我们在舞台上的年份。所以我们想要的是一个从当前日期减去舞台上的年份的函数,这样它就返回出道的年份。
我们可以这样直接进入我们的演员类:
class Actor:
def __init__(self, name, surname, age, years_on_stage):
self.name=name
self.surname=surname
self.age=age
self.years_on_stage=years_on_stage
def year_of_debut(self, current_year):
self.current_year=current_year
year_of_debut=self.current_year-self.years_on_stage
return year_of_debut
现在让我们在我们的对象 mario 上测试它:
mario.year_of_debut(2019)2006
最后我要讲的是 python 类的一个非常有趣且有用的属性,叫做类继承。其思想是,如果您必须创建一个类(称为子类),它是您已经创建的类(称为父类)的子集,您可以很容易地将其属性导入子类。
让我们通过下面的例子来看看如何做到这一点。假设您想要创建一个名为 Comedian 的子类,它与父类 Actor 有一些共同的属性:
class Comedian(Actor):
def __init__(self, n_shows, field, shows_schedule, name, surname, age, years_on_stage):
self.n_shows=n_shows
self.field=field
self.shows_schedule=shows_schedule
super().__init__(name,surname,age,years_on_stage)
可以看到,我们没有为的名字、姓氏、年龄和 years_on_stage 指定 self.attribute=attribute ,而是通过函数 super() 直接由父类继承。现在,我们可以创建一个子类的对象,并像在父类示例中一样访问它的属性:
a_comedian=Comedian(
21,
'politics',
'late night',
'amelia',
'smith',
'33',
'10'
)a_comedian.name'amelia'a_comedian.field'politics'
Python 类的优势显而易见。特别是,它们使得 Python 语言非常具有可定制性:不仅可以创建个性化的函数(除了那些内置的函数),还可以创建能够完美满足您需求的对象生成器。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言










{kind=link}