







将对象检测用于复杂的图像分类场景第 4 部分:
使用 Keras RetinaNet 进行策略检测

TLDR;本系列基于在下面的现实生活代码故事中检测复杂策略的工作。该系列的代码可以在这里找到。
对象检测简介
到目前为止,我们一直在对原始图像进行分类如果我们可以使用这些图像来生成有针对性的特征,以帮助我们应对高级分类挑战,那会怎么样。

We will use object detection to extract features for more complex classification Src
端到端对象检测管道:
对象检测需要大量带注释的数据。传统上,这是一项非常手动密集型的任务,理想的管道将标记与模型训练相结合,以实现主动学习。

视觉对象标记工具(VoTT)

视觉对象标记工具 VoTT 为从视频和图像资产生成数据集和验证对象检测模型提供端到端支持。
VoTT 支持以下功能:
- 标记和注释图像目录或独立视频的能力。
- 使用 Camshift 跟踪算法对视频中的对象进行计算机辅助标记和跟踪。
- 将标签和资源导出为 Tensorflow (PascalVOC)或 YOLO 格式,用于训练对象检测模型。
- 在新视频上运行和验证经过训练的对象检测模型,以利用 docker 端点生成更强的模型。
区域提议目标检测算法的基本进展
以下部分将简要强调将用于该任务的区域提议对象检测的进展。对于更深入的教程,我强烈推荐乔纳森·惠的《中级系列》
概观
medium.com](https://medium.com/@jonathan_hui/object-detection-series-24d03a12f904)
滑动窗接近和后退
本系列的最后两篇文章是关于图像分类的。将图像分类器转换成对象检测器的最简单方法是在给定图像上使用一系列不同维度的滑动窗口。

如果我们认为在给定的窗口中有一个我们正在寻找的对象,那么我们可以返回被捕获对象的尺寸。
地区有线电视新闻网
不幸的是,滑动窗口方法虽然简单,但也有一些缺点。评估多个窗口大小很慢,而且不精确,因为我们事先不知道图像中每个对象的正确窗口大小。

如果我们可以只对可能包含对象的感兴趣区域执行分类,而不是在整个图像上使用滑动窗口,会怎么样?这是区域提议对象检测器背后的主要直觉。传统上,我们使用一种叫做选择性搜索的算法来提出感兴趣的区域。
快速 RCNN
虽然传统的 RCNN 方法在准确性方面工作良好,但是它的计算成本非常高,因为必须对每个感兴趣的区域评估神经网络。

快速 R-CNN 通过对每个图像只评估网络的大部分(具体来说:卷积层)一次来解决这个缺点。根据作者的说法,这导致测试期间的速度提高了 213 倍,训练期间的速度提高了 9 倍,而没有损失准确性。
更快的 RCNN

Faster RCNN architecture src
更快的 R-CNN 建立在以前的工作基础上,使用深度卷积网络有效地对对象提议进行分类。与以前的工作相比,更快的 R-CNN 采用了一个区域建议网络,它不需要对候选区域建议进行选择性搜索。
RetinaNet

RetinaNet 是一个对象检测器,它建立在更快的 RCNN 的直觉基础上,提供了特征金字塔和优化的焦损失,实现了比 Faster RCNN 更快的评估时间,并提供了焦损失,有助于防止过度拟合背景类。在撰写本文时,RetinaNet 是当前最先进的区域求婚网络。
更多信息请参见:
这篇博文的最终目的是让读者直观地了解 RetinaNet 的深层工作原理。
medium.com](https://medium.com/@14prakash/the-intuition-behind-retinanet-eb636755607d)
让我们用视网膜网络来解决我们的挑战

VoTT 可用于生成直接数据集,这些数据集可与 Azure 机器学习一起使用,以训练自定义对象检测模型。
[## 快速入门:Python - Azure 机器学习服务入门
Python 中的 Azure 机器学习服务入门。使用 Python SDK 创建一个工作空间,它是…
docs.microsoft.com](https://docs.microsoft.com/en-us/azure/machine-learning/service/quickstart-create-workspace-with-python?WT.mc_id=blog-medium-abornst)
然而,由于培训 RetinaNet 需要访问 N 系列 GPU 机器,出于时间的考虑,并确保本教程仅针对 CPU,我冒昧地对模型进行了预培训。在下一篇文章中,我们将讨论如何用 Azure 机器学习服务来训练这些模型。
让我们看看如何使用我们定制的预训练对象检测模型
*# import keras_retinanet*
**import** **keras**
**from** **keras_retinanet** **import** models
**from** **keras_retinanet.utils.image** **import** read_image_bgr, preprocess_image, resize_image
**from** **keras_retinanet.utils.visualization** **import** draw_box, draw_caption
**from** **keras_retinanet.utils.colors** **import** label_color*# load image*
**def** evaluate_single_image(model, img_path):
image = read_image_bgr(img_path) *# preprocess image for network*
image = preprocess_image(image)
image, scale = resize_image(image) *# process image*
start = time.time()
boxes, scores, labels = model.predict_on_batch(np.expand_dims(image, axis=0))
print("processing time: ", time.time() - start) *# correct for image scale*
boxes /= scale
**return** (boxes[0], scores[0], labels[0])**def** visualize_detection(img_path, model_results):
image = read_image_bgr(img_path)
boxes, scores, labels = model_results *# visualize detections*
draw = image.copy()
draw = cv2.cvtColor(draw, cv2.COLOR_BGR2RGB) **for** box, score, label **in** zip(boxes, scores, labels):
*# scores are sorted so we can break*
**if** score < 0.5:
**break** color = label_color(label)
b = box.astype(int)
draw_box(draw, b, color=color) caption = "**{}** **{:.3f}**".format(labels_to_names[label], score)
draw_caption(draw, b, caption) plt.figure(figsize=(15, 15))
plt.axis('off')
plt.imshow(draw)
plt.show()*# load retinanet model*
soda_model = models.load_model('models/retina_net_soda.h5', backbone_name='resnet50')
labels_to_names = {0: 'shelf1', 1: 'shelf2', 2: 'shelf3'}valid_example_path = 'dataset/Beverages/Test/Valid/IMG_4187.JPG'
detection_results = evaluate_single_image(soda_model, valid_example_path)
visualize_detection(valid_example_path, detection_results)
processing time: 10.065604209899902

挑战:你能想出我们可以用这些盒子来表明政策无效的方法吗?
用瓶子启发式预测
现在,我们有了一个用于寻找瓶子的对象检测模型,让我们开发一个启发式方法来确定货架是否正确存储,并在两个样本图像上测试它。
我们的试探法将按如下方式工作:
- 我们将找到每个架类的最小 y1 和最大 y2 的用法
- 我们将确认汽水架在果汁架之上,果汁架在水架之上
- 对于每个最大值,我们将确保在它们之间没有其他类
**def** predict_bottles(model_results):
bounds = {}
beverages = {0: [], 1: [], 2: []}
boxes, scores, labels = model_results **for** box, score, label **in** zip(boxes, scores, labels):
*# scores are sorted so we can break*
**if** score < 0.5:
**break**
beverages[label].append(box)
*# Find the use the min y1 and max y2 of each of the tag classes*
**for** bev **in** beverages:
**if** len(beverages[bev]) == 0:
**return** **False**
y1 = min(beverages[bev], key=**lambda** b: b[1])[1]
y2 = max(beverages[bev], key=**lambda** b: b[3])[3]
bounds[bev] = {"y1":y1, "y2":y2}
*# Confirm that soda is above juice which is above water*
**if** (bounds[0]["y1"] < bounds[1]["y1"]) **and** (bounds[1]["y1"] < bounds[2]["y1"]):
*# For each of the max's we will ensure that there are no other clases that are in between them*
**for** b **in** bounds.keys():
**for** bev_type **in** (set(bounds.keys()) - set([b])):
**for** bev **in** beverages[bev_type]:
**if** bev[1] > bounds[b]["y1"] **and** bev[3] < bounds[b]["y2"]:
**return** **False**
**return** **True**
**else**:
**return** **False**visualize_detection(valid_example_path, detection_results)
predict_bottles(detection_results)

Trueinvalid_example_path = 'dataset/Beverages/Test/Invalid/IMG_4202.JPG'
detection_results = evaluate_single_image(soda_model, invalid_example_path)
visualize_detection(invalid_example_path, detection_results)
predict_bottles(detection_results)
processing time: 8.053469896316528

False
基准瓶启发式
通常,为了将此应用于我们的整个数据集,我们将使用批处理,因为我们试图节省内存,我们将一次评估一个图像。
**from** **tqdm** **import** tqdm_notebook
**from** **utils** **import** classification_report
**from** **keras.preprocessing.image** **import** ImageDataGeneratory_pred = []
y_true = []print("Testing Invalid Cases")img_dir = 'dataset/Beverages/Test/Invalid/'
**for** img_path **in** tqdm_notebook(os.listdir(img_dir)):
detection_results = evaluate_single_image(soda_model, os.path.join(img_dir, img_path))
y_pred.append(predict_bottles(detection_results))
y_true.append(**False**)print("Testing Valid Cases")
img_dir = 'dataset/Beverages/Test/Valid/'
**for** img_path **in** tqdm_notebook(os.listdir(img_dir)):
detection_results = evaluate_single_image(soda_model, os.path.join(img_dir, img_path))
y_pred.append(predict_bottles(detection_results))
y_true.append(**True**)
分类报告
classification_report(y_true, y_pred)
precision recall f1-score support False 1.00 1.00 1.00 30
True 1.00 1.00 1.00 30 micro avg 1.00 1.00 1.00 60
macro avg 1.00 1.00 1.00 60
weighted avg 1.00 1.00 1.00 60Confusion matrix, without normalization
[[30 0]
[ 0 30]]
Normalized confusion matrix
[[1\. 0.]
[0\. 1.]]

结论
我们可以看到,对于某些任务,使用具有良好启发性的对象检测可以优于定制视觉服务。然而,重要的是要考虑注释我们的数据和构建对象检测模型所需的权衡和工作。
资源
[## Pythic Coder 推荐的 Azure 机器学习入门内容
Tldr 由于 DevOps 资源上的帖子很受欢迎,而且很难找到文档,所以我…
medium.com](https://medium.com/microsoftazure/the-pythic-coders-recommended-content-for-getting-started-with-machine-learning-on-azure-fcd1c5a8dbb4) [## aribornstein —概述
@ pythiccoder。aribornstein 有 68 个存储库。在 GitHub 上关注他们的代码。
github.com](https://github.com/aribornstein) [## 认知服务|微软 Azure
微软 Azure Stack 是 Azure 的扩展——将云计算的灵活性和创新性带到您的…
azure.microsoft.com](https://azure.microsoft.com/en-us/services/cognitive-services/?v=18.44a) [## 物体探测系列
概观
medium.com](https://medium.com/@jonathan_hui/object-detection-series-24d03a12f904)
以前的帖子:
人工智能计算机视觉革命
towardsdatascience.com](/using-object-detection-for-complex-image-classification-scenarios-part-1-779c87d1eecb) [## 将对象检测用于复杂的图像分类场景第 2 部分:
定制视觉服务
towardsdatascience.com](/using-object-detection-for-complex-image-classification-scenarios-part-2-54a3a7c60a63) [## 将对象检测用于复杂的图像分类场景第 3 部分:
利用 MobileNet 和迁移学习进行策略识别
towardsdatascience.com](/using-object-detection-for-complex-image-classification-scenarios-part-3-770d3fc5e3f7)
下一篇文章
本系列的下一篇文章将回顾如何训练你自己的对象检测模型使用 Azure ML 服务的云,后续文章将讨论部署。
如果您有任何问题、评论或希望我讨论的话题,请随时在 Twitter 上关注我。如果您认为我错过了某个里程碑,请告诉我。
关于作者
亚伦(阿里) 是一个狂热的人工智能爱好者,对历史充满热情,致力于新技术和计算医学。作为微软云开发倡导团队的开源工程师,他与以色列高科技社区合作,用改变游戏规则的技术解决现实世界的问题,然后将这些技术记录在案、开源并与世界其他地方共享。
使用开源工具创建交互式政治调查地图
设想英国地区对硬英国退出欧盟的支持

这个星期谁说了谁的坏话?谁将被投票淘汰出局?谁去勾搭这一季的人气先生?不,我们不是在谈论爱情岛或单身汉,而是另一个越来越受欢迎的真人秀节目:BBC 的议会频道。英国退出欧盟可能有点像一辆破车,但它确实提供了一些有趣的民意调查。
我们将使用今年 3 月的民意调查数据(以 SPSS 文件的形式)来查看对无交易英国退出欧盟的支持,并将结果显示为交互式地图。最终结果将如下图所示:

Support for a no-deal Brexit across regions shortly after Theresa May announced that she’d reached a deal with the EU.
轮询数据
为了读取 SPSS 文件并计算我们的结果,我们将使用开源软件库 Quantipy ,这是一个专门为处理调查数据而设计的库。我们以前写过 Jupyter 笔记本环境对于处理调查数据有多好,我们在这里再次使用它。
import quantipy as qp
dataset = qp.DataSet(“Political survey”)
dataset.read_spss(“results.sav”)
现在我们已经导入了数据集,让我们来看看我们想要可视化的问题,Deal_or_no_deal:
dataset.crosstab(“Deal_or_no_deal”, “Regions”, pct=True)

我们还清理空列(“Northern Ireland”和“Other”)的输出,并删除“All”列,以使结果更容易阅读。然后,我们将只提取结果数据行“不再向欧盟让步,必要时不达成协议就离开”,并给它一个漂亮的简短报告标签:“不达成协议”。
vote = dataset.crosstab(‘Deal_or_no_deal’,
“Regions”, pct=True, f=filter)
vote = vote.droplevel(level=0,axis=1)
vote = vote.droplevel(level=0,axis=0)
vote = vote.drop([‘Other’,‘Northern Ireland’,“All”],axis=1)
vote.index.name = ‘No deal’
poll_result = vote.iloc[5,:]

这是我们的数据,但是在地图上看起来像什么呢?
使用 geopandas 通过 python 映射数据
为了绘制我们的结果,我们使用 geopandas python 库,这是一个非常强大但易于使用的库,它可以将地理空间数据转换为 pandas 数据框架。方便的是,有人已经在 GitHub 上收集了英国大部分主要的地理空间数据(这就是使用开源解决方案的好处,通常有人会为你做大部分艰苦的工作),我们使用 UK-geo JSON/JSON/electronic/GB/文件夹中的 eer.json 文件。将其保存到文件后,我们将其导入到 geopandas:
import geopandas
gdata = gpd.read_file(‘eer.json’)
gdaga.head()

请注意,这些区域存储在列“EER13NM”中。我们将这个数据框的结果与我们之前计算的数据合并。
gdata = gdata.join(poll_result, on=”EER13NM”)
gdata.plot(columns=”No more concessions to the EU, leave without a deal if necessary”)

现在我们有进展了。但是我们想知道不同性别和不同地区的投票结果有什么不同。所以我们给 DataSet.crosstab()方法发送了一个过滤器。
dataset.crosstab("Deal_or_no_deal",
"Regions", pct=True,
f={"Gender":[1]})
交互式 Jupyter 小工具
接下来,我们需要一个交互式小部件,允许我们选择要查看的过滤器。我们使用 Jupyter 的 ipywidgets,它允许我们在笔记本中注入交互性。我们使用 dropdown 小部件,并使用 dataset.value_texts()和 dataset.codes()来填充它们。
gender = widgets.Dropdown(
options=[(“All”, None)] +
list(zip(dataset.value_texts(‘Gender’),
dataset.codes(‘Gender’)))[:2],value=None,
description=’Gender:’,
disabled=False
)age = widgets.Dropdown(
options=[(“All”, None)] +
list(zip(dataset.value_texts(‘grouped_age’),
dataset.codes(‘grouped_age’))),
value=None,
description=’Age:’,
disabled=False
)
最后,将 Jupyter 的交互式 dropdown 小部件连接到我们的地图,这样我们就可以使用名为 interactive 的 ipywidgets 库的一部分来控制它所显示的内容(这是一种在笔记本中连接 Jupyter 前端和 python 后端的简单方法)。
interactive(update_map, gender=gender, age=age)
我们的 update_map 方法封装了过滤器的计算和地图的绘制。
def update_map(gender, age): filter = []
if gender:
filter.append( {‘Gender’: [gender]})
if age:
filter.append({‘grouped_age’: [age]}) vote_data = get_vote_data(filter).to_dict() map = gdata.join(get_vote_data(filter),
on=”EER13NM”).plot(vmin=0, vmax=60,
column=”No more consessions to the EU,
leave without a deal if necessary”)
out.clear_output()
# out is a Jupyter Widget that captures output
with out:
display(map.figure)
为了简洁起见,我们省略了图的一些格式(改变颜色图、边框、图例格式)和一个我们调用的方法,以便用不同的过滤器检索数据。但我们现在已经准备好了,有了一张互动地图,可以显示不同地区的人们的观点是如何不同的。

现在你知道了,使用开源解决方案不仅可以计算公众对“不交易英国退出欧盟”意见的地区差异,还可以使这些差异对消费信息的人有意义。
盖尔·弗雷松是 Datasmoothie 的联合创始人,这是一个专门从事调查数据分析和可视化的平台。如果你对使用开源软件进行调查数据分析感兴趣,注册我们的时事通讯,名为自发认知。
使用 OpenStreetMap 切片进行机器学习
使用卷积网络自动提取特征

Performance of the network when predicting the population of a given tile
OpenStreetMap 是一个不可思议的数据源。1000 名志愿者的集体努力创造了一套丰富的信息,几乎覆盖了地球上的每个地方。
在许多问题中,地图信息可能会有所帮助:
- 城市规划,描述街区的特征
- 研究土地使用、公共交通基础设施
- 确定营销活动的合适地点
- 识别犯罪和交通热点
然而,对于每个单独的问题,都需要进行大量的思考,以决定如何将用于制作地图的数据转换为对当前任务有用的要素。对于每项任务,您需要了解可用的功能,并编写代码从 OpenStreetMap 数据库中提取这些功能。
这种手动特征工程方法的替代方法是在渲染的地图块上使用卷积网络。
如何使用卷积网络?
如果地图切片图像和响应变量之间存在足够强的关系,则卷积网络可能能够学习对每个问题都有帮助的地图切片的视觉组件。OpenStreetMap 的设计者已经做了大量的工作来确保地图渲染尽可能多地展示我们的视觉系统所能理解的信息。卷积网络已经被证明非常能够模仿视觉系统的性能,因此卷积网络可以学习从图像中提取哪些特征是可行的,这对于每个特定的问题领域来说都是耗时的编程工作。
检验假设
为了测试卷积网络是否可以从地图切片中学习有用的特征,我选择了简单的测试问题:估计给定地图切片的人口。美国人口普查提供了人口普查区域级别的人口数量数据,我们可以使用区域的人口来近似地图区块的人口。
涉及的步骤:
- 从人口普查局下载人口普查区域级别的人口数据。
- 对于给定的缩放级别,识别与一个或多个人口普查区域相交的 OpenStreetMap 切片。
- 从 MapTiler 下载 OpenMapTiles 的本地实例中的图块。
- 对每个分块内的区域人口进行求和,并添加与分块相交的区域的分数人口

Visualizing the census tracts which overlap with the 3 example tiles
这给了我们:
- 输入 X:OpenStreetMap 图块的 RGB 位图表示
- 目标 Y :瓦片的估计人口
再重复一遍,网络用来预测人口的唯一信息是 OpenStreetMap 图块的 RGB 值。
在这个实验中,我为加利福尼亚的瓦片和土地生成了一个数据集,但是同样的过程可以在美国的每个州进行。
模特培训和表演
通过使用简化的 Densenet 架构,并最小化对数标度的均方误差,网络在几个时期后实现了以下交叉验证性能:

0.45 的平方误差是对 0.85 的改进,如果你每次只是猜测平均人口,你会得到 0.85。这相当于每个瓦片的对数标度的平均绝对误差为 0.51。因此预测往往是正确的数量级,但是相差 3 倍(我们没有做任何事情来优化性能,所以这是一个不错的开始)。
摘要
- 在估计人口的示例中,OpenStreetMap 切片中有足够的信息,显著优于人口的简单估计。
- 对于信号足够强的问题,OpenStreetMap 切片可用作数据源,无需手动进行要素工程
学分:
- 非常感谢所有支持 OpenStreetMap 的志愿者
- 免费提供人口普查数据的美国政府
- OpenMapTiles 为研究目的提供地图渲染服务
最初发布于shuggiefisher . github . io。
使用 Panda 的“转换”和“应用”在组级别处理缺失数据

Image by Brett Hondow from Pixabay
了解当您不想简单地丢弃丢失的数据时应该怎么做。
根据 Businessbroadway 进行的一项分析,数据专业人员花费高达 60%的时间来收集、清理数据和可视化数据。

Source: Businessbroadway
清理和可视化数据的一个关键方面是如何处理丢失的数据。 Pandas 以 **fillna** 方法的形式提供了一些基本功能。虽然fillna在最简单的情况下工作得很好,但是一旦数据中的组或数据的顺序变得相关时,它就不够用了。本文将讨论解决这些更复杂情况的技术。
这些案例通常是由不同制度(时间序列)、组甚至子组组成的数据集。不同情况的例子有几个月、几个季度(一般时间范围)或一段暴雨期。数据中的组的一个例子是性别。亚组的例子有年龄组和种族。
本文旨在作为一篇代码文章。因此,请随意启动笔记本电脑,开始工作。
文章的结构:
- 熊猫的 fillna
- 当订单与不相关时,处理缺失数据
- 当订单与相关时,处理缺失数据
熊猫概述fillna

Pandas 通过调用fillna()有三种处理丢失数据的模式:
**method='ffill':**Ffill 或 forward-fill 将最后一个观察到的非空值向前传播,直到遇到另一个非空值**method='bfill':**Bfill 或 backward-fill 将第一个观察到的非空值向后传播,直到遇到另一个非空值**explicit value:**也可以设置一个精确值来替换所有缺失。例如,这种替换可以是-999,表示缺少该值。
例如:
**IN:** demo = pd.Series(range(6))
demo.loc[2:4] = np.nan
demo**OUT:** 0 0.0
1 1.0
*2 NaN
3 NaN
4 NaN*
5 5.0
dtype: float64**# Forward-Fill
IN:** demo.fillna(method='ffill')**OUT:** 0 0.0
1 1.0
*2 1.0
3 1.0
4 1.0*
5 5.0
dtype: float64**# Backward-Fill**
**IN:** demo.fillna(method='bfill')**OUT:** 0 0.0
1 1.0
*2 5.0
3 5.0
4 5.0*
5 5.0
dtype: float64**# Explicit value**
**IN:** demo.fillna(-999)**OUT:** 0 0.0
1 1.0
*2 -999.0
3 -999.0
4 -999.0*
5 5.0
dtype: float64
当订单与不相关时,处理缺失数据

Image by PublicDomainPictures from Pixabay
通常,在处理缺失数据时,排序并不重要,因此,用于替换缺失值的值可以基于全部可用数据。在这种情况下,您通常会用自己的最佳猜测(即,可用数据的平均值或中间值)替换缺失值
让我们快速回顾一下为什么应该小心使用这个选项。让我们假设你调查了 1000 个男孩和 1000 个女孩的体重。不幸的是,在收集数据的过程中,一些数据丢失了。
**# imports**
import numpy as np**# sample 1000 boys and 1000 girls**
boys = np.random.normal(70,5,1000)
girls = np.random.normal(50,3,1000)**# unfortunately, the intern running the survey on the girls got distracted and lost 100 samples** for i in range(100):
girls[np.random.randint(0,1000)] = np.nan**# build DataFrame**
boys = pd.DataFrame(boys, columns=['weight'])
boys['gender'] = 'boy'girls = pd.DataFrame(girls, columns=['weight'])
girls['gender'] = 'girl'df = pd.concat([girls,boys],axis=0)
df['weight'] = df['weight'].astype(float)
一个分组
不用多想,我们可能会用整个样本的平均值来填充缺失值。不过,结果看起来有些奇怪。女孩的 KDE 有两个驼峰。有人可能会得出结论,在我们的样本中有一个较重的女孩子群。因为我们预先构建了发行版,所以我们知道情况并非如此。但是如果这是真实的数据,我们可能会从这些数据中得出错误的结论。

KDE of weights for boys and girls where we replaced missing data with the sample mean (code below the chart)
**# PLOT CODE:**
sns.set_style('white')
fig, ax = plt.subplots(figsize=(16, 7))**mean = df['weight'].mean()**sns.distplot(
**df[df['gender'] == 'girl']['weight'].fillna(mean),**
kde=True,
hist=False,
ax=ax,
label='girls'
)sns.distplot(
df[df['gender'] == 'boy']['weight'],
kde=True,
hist=False,
ax=ax,
label='boys'
)plt.title('Kernel density estimation of weight for boys and girls')sns.despine()
用组的平均值填充缺失值
在这种情况下,Panda 的转换功能就派上了用场。使用 transform 提供了一种在组级别解决问题的便捷方法,如下所示:
df['filled_weight'] = df.groupby('gender')['weight'].transform(
lambda grp: grp.fillna(np.mean(grp))
)
运行上述命令并绘制filled_weight值的 KDE,结果如下:

KDE of weights for boys and girls where we replaced missing values with the group mean (code below the chart)
**# PLOT CODE:**
sns.set_style('white')
fig, ax = plt.subplots(figsize=(16, 7))sns.distplot(
df[df['gender'] == 'girl']['filled_weight'],
kde=True,
hist=False,
ax=ax,
label='girls')
sns.distplot(
df[df['gender'] == 'boy']['filled_weight'],
kde=True,
hist=False,
ax=ax,
label='boys'
)plt.title('Kernel density estimation of weight for boys and girls')sns.despine()
多个子组
让我们使用前面的例子,但这一次,我们走得更远一点,另外将我们的数据分成年龄组。让我们创建一些模拟数据:
**# paramter for the weight distribution (mean, std)**
param_map = {
'boy':{
'<10':(40,4),
'<20':(60,4),
'20+':(70,5),
},
'girl':{
'<10':(30,2),
'<20':(40,3),
'20+':(50,3),
}
}**# generate 10k records**
df = pd.DataFrame({
'gender':np.random.choice(['girl','boy'],10000),
'age_cohort':np.random.choice(['<10','<20','20+'],10000)
})**# set random weight based on parameters**
df['weight'] = df.apply(
lambda x: np.random.normal(
loc=param_map[x['gender']][x['age_cohort']][0],
scale=param_map[x['gender']][x['age_cohort']][1]
),axis=1
)**# set 500 values missing**
for i in range(500):
df.loc[np.random.randint(0,len(df)),'weight'] = np.nan
绘制数据揭示了有点奇怪的双峰分布(代码如下)。

KDE of weight by age_cohort and gender were we replaced missing values with the sample mean
**# PLOT CODE**
df['filled_weight'] = df['weight'].fillna(
df['weight'].mean()
)g = sns.FacetGrid(
df,
col='age_cohort',
row='gender',
col_order=['<10','<20','20+']
)g.map(sns.kdeplot,'filled_weight')
现在,如果我们只是用各自性别的平均值来代替缺失值,这还不够,因为不仅男孩和女孩的体重不同,而且不同年龄组的体重也有很大差异。
幸运的是,transform可以像以前一样应用。我们将在两列上分组,而不是像这样只在一列上分组:
df['filled_weight'] = df.groupby(['gender','age_cohort'])['weight'].transform(
lambda grp: grp.fillna(np.mean(grp))
)
运行上面的代码片段将生成这个更加清晰的图:

KDE of weight by age_cohort and gender were we replaced missing values with each group’s mean
当订单与相关时,处理缺失数据

Photo by Jake Hills on Unsplash
在处理时序数据时,经常会出现两种情况。
- **调整日期范围:**假设你按年查看各国的 GDP、教育水平和人口增长。对一些国家来说,你错过了最初的几年,后来的几年,或者中间的几年。当然,你可以忽略它们。尽管如此,出于可视化的目的,您可能希望保留它们,并将您的第一个观察值投影到开始,将您的最后一个观察值投影到调查期结束,并得出对中间值有意义的东西。
- **插值:**查看时间序列数据插值,从而排序变得非常相关。用基于截至 2019 年的数据计算出的平均值替换 2012 年缺失的股票数据,肯定会产生一些古怪的结果。
我们将根据 2019 年世界幸福报告的数据来看一个例子,我们解决了这两种情况。《世界幸福报告》试图回答哪些因素影响着全世界的幸福。该报告调查了 2005 年至 2018 年的数据。
加载数据
**# Load the data**
df = pd.read_csv('[https://raw.githubusercontent.com/FBosler/you-datascientist/master/happiness_with_continent.csv'](https://raw.githubusercontent.com/FBosler/you-datascientist/master/happiness_with_continent.csv'))
样品检验
df.sample(5)与df.head(5)相反,选择五个随机行,从而给你一个更公正的数据视图。

Data sample from the downloaded DataFrame
让我们来看看每年我们有数据的国家的数量。

Number of countries we have data for per year
**# PLOT CODE:**
df.groupby(['Year']).size().plot(
kind='bar',
title='Number of countries with data',
figsize=(10,5)
)
我们可以看到,特别是前几年,我们没有很多国家的数据,而且在整个样本期间也有一些波动。为了减轻丢失数据的影响,我们将执行以下操作:
- 按国家分组并重新索引整个日期范围
- 根据我们对每个国家的观察结果,对之间的年份进行插值,并对范围之外的年份进行外推
1.按国家和重新索引日期范围分组
**# Define helper function**
def add_missing_years(grp):
_ = grp.set_index('Year')
_ = _.reindex(list(range(2005,2019)))
del _['Country name']
return _**# Group by country name and extend**
df = df.groupby('Country name').apply(add_missing_years)
df = df.reset_index()
我们现在大约有 600 多行。然而,那些观察现在都是null

Extended DataFrame, where every country has rows for every year between 2005 and 2018
2.根据我们对每个国家的观察结果,对之间的年份进行插值,并对范围之外的年份进行外推
**# Define helper function**
def fill_missing(grp):
res = grp.set_index('Year')\
.interpolate(method='linear',limit=5)\
.fillna(method='ffill')\
.fillna(method='bfill')
del res['Country name']
return res**# Group by country name and fill missing**
df = df.groupby(['Country name']).apply(
lambda grp: fill_missing(grp)
)df = df.reset_index()
fill_missing函数向终点和起点进行插值和外推,结果是:

**完美!**现在我们有了样本中所有国家从 2005 年到 2018 年的数据。当我写这篇关于可视化的文章时,上面的方法对我来说很有意义。如果你想了解更多关于幸福报告的信息,可以去看看。
[## 了解如何使用 Python 创建漂亮而有洞察力的图表——快速、漂亮和…
数据显示,金钱可以买到幸福。用 Python 可视化的综合代码指南,解释了…
towardsdatascience.com](/plotting-with-python-c2561b8c0f1f)
总结和结束语
今天到此为止。在本文中,您学习了如何使用transform和apply用比之前或之后的值更有意义的值来替换丢失的值。
如果你发现了一些奇妙的新的可视化效果,想要提供反馈或进行聊天,请在 LinkedIn 上联系我。
如果你喜欢你所读的,看看我在 Medium 上写的其他文章。
使用 Python 和 Robinhood 创建一个简单的低买高卖交易机器人

Photo by Ishant Mishra on Unsplash
所以我最近一直在折腾 Robinhood,一直在努力理解股票。我不是金融顾问或其他什么人,但我想创建一个简单的交易机器人,这样我就可以在创建更复杂的代码之前多理解一点。对于那些还没有查看的人,我创建了一篇关于如何使用 Python 连接 Robinhood 数据的文章。
让我们自动化一些股票,可以用来建造一个交易机器人。
towardsdatascience.com](/using-python-to-get-robinhood-data-2c95c6e4edc8)
我做的第一件事就是把我所有的股票都存到一个数据框里。我不喜欢如何布局的数据帧和我的需要转置它会使我的机器人更简单。然后将索引移动到滚动条列中。我还将某些列切换为 floats,因为它们当前被表示为一个字符串。代码在下面,输出的数据帧也在下面。
所以我创造了低买高卖。我只想玩玩average_buy_price中低于 25 美元的股票,并给自己设定每只股票限购 5 只。然后我把它分成两个独立的数据框架,一个是买入,一个是卖出。
对于买入,如果percent_change跌破. 50%,那么只有当股票数量为 1 时才会触发买入。然后,它以市场价格购买 4 只股票。
对于 sell 来说,基本上是相反的。如果percent_change上涨超过 0.50%,数量为 5,触发卖出。这是我的代码,需要一些清理,但我只是测试出来。我将滚动条移动到一个列表中,然后使用robin_stocks来执行命令。
我通常只在工作日开市时运行一次。到目前为止,我已经取得了几美分的正回报。它不多,但它可以发展成更好的东西。
将来,一旦我做了更多的研究,我会计划增加更复杂的交易策略。股票对我来说是相当新的,所以请不要把这当成财务建议。我不对你的任何输赢负责。但希望这能激发一些想法。
在这里进入代码。
别忘了在 LinkedIn 上联系我。
使用 Python 和 Selenium 实现鼠标点击和表单填写的自动化
对于这个例子,我们将通过 Instagram 的网站应用程序登录。
实际上,我在日常工作流程中使用 Python 和 Selenium。在我工作的公司,我们有自己的网络应用程序,可以在线发送报告。每份报告都有一个账户。
由于我们每天都有客户加入,我们还需要创建新的帐户。随着我们雇佣更多销售团队成员,客户数量呈指数级增长。创建新账户是一个非常手工的过程,看一份报告,然后输入信息。这是我发现硒的地方。
硒 是一款针对网页浏览器的自动化工具。除了 Python 之外,您还可以将它用于许多不同的编程语言。他们也有一个版本,你可以记录你使用浏览器的过程,他们能够模仿他们。
如果你有任何容易重复的任务,这是非常有用的。例如,在我的工作中,我从客户成功团队那里获得了一份新客户列表。在该文件中,它有帐户名、帐户 ID 和地址。我必须为每个新账户手工输入。硒可以解决这个问题。
让我们从简单的东西开始,自动登录 Instagram。登录任何网站基本上都是我们发送的一个小表格。我们将填写凭证的“表格”,然后单击提交按钮。
要求: 1。Python w/ selenium 模块
2。chrome driver(selenium 使用的特殊谷歌 chrome)
首先要做的是下载并在必要时安装需求。假设你已经安装了 Python,你可以在模块上做一个pip install。我们需要的 chromedriver 可以在这里找到。
我们现在可以创建一个新的 Python 文件。让我们从我们的进口开始。
from selenium import webdriver
因为我们使用 chromedriver 作为应用程序。我们需要告诉 Python 它的位置。我刚刚下载了它,并把它放在我的下载文件夹中。我可以用它的路径设定它的位置。
chromedriver_location = "/Users/Downloads/chromedriver"
一旦我们知道了 chromedriver 的位置,我们现在就可以使用 Selenium 的 webdriver 调用它,告诉它去 Instagram 主页。
driver = webdriver.Chrome(chromedriver_location)
driver.get(‘https://www.instagram.com/')
我们现在可以试着运行这个脚本,看看会得到什么。如果设置正确,将会弹出一个新的 Google Chrome 实例,并把你带到所请求的站点。
让我们回到我们的代码,假设我们已经有了 Instagram 凭证。我们想告诉 Selenium 点击蓝色的链接中的日志:

Selenium 通过在 web 页面中查找元素来简化自动化。有多种方法可以找到 web 元素,比如 id、类名、文本等等。在这种情况下,我们将使用 Selenium webdriver 的find_element_by_xpath。
回到谷歌浏览器窗口,右键点击蓝色的登录链接。你想点击 inspect,应该会弹出一个窗口,显示所有的 web 元素和一个高亮显示的行。您现在想要点击高亮显示的行并复制 xpath。

一旦完成,你应该有这样的东西,当你粘贴下来。
//*[[@id](http://twitter.com/id)=”react-root”]/section/main/article/div[2]/div[2]/p/a

同样,用户名、密码和登录按钮的输入字段也是同样的过程。
我们可以在当前页面上继续操作。我们可以将这些 xpaths 作为字符串存储在代码中,以使其可读。
我们应该有三个来自这个页面的 xpaths 和一个来自初始登录的 xpaths。
first_login = '//*[[@id](http://twitter.com/id)=”react-root”]/section/main/article/div[2]/div[2]/p/a'username_input = '//*[[@id](http://twitter.com/id)="react-root"]/section/main/div/article/div/div[1]/div/form/div[2]/div/label/input'password_input = '//*[[@id](http://twitter.com/id)="react-root"]/section/main/div/article/div/div[1]/div/form/div[3]/div/label/input'login_submit = '//*[[@id](http://twitter.com/id)="react-root"]/section/main/div/article/div/div[1]/div/form/div[4]/button/div'
既然我们已经定义了 xpaths,现在我们可以告诉 Selenium webdriver 单击并发送一些输入字段的键!
让我们再次从第一次登录开始。我们使用find_element_by_xpath,并给它一个first_login变量。然后我们可以告诉它点击。
driver.find_element_by_xpath(first_login).click()
现在,它会将您带到带有输入字段的凭证页面。类似的过程,但现在我们希望 Selenium 用我们的用户名和密码填充这些字段。Selenium 有另一个叫做send_keys的方法,它让我们可以很容易地自动化打字。我们只要放一个字符串进去,它就会为我们打字。我们现在可以尝试虚拟变量,看看它是否有效。此外,尝试登录,知道我们会被拒绝。
driver.find_element_by_xpath(username_input).send_keys(“username”)
driver.find_element_by_xpath(password_input).send_keys(“password”)
driver.find_element_by_xpath(login_submit).click()
如果一切设置正确,我们的最终代码应该如下所示:
from selenium import webdriverchromedriver = "/Users/Downloads/chromedriver"driver = webdriver.Chrome(chromedriver)driver.get('https://www.instagram.com/')first_login = '//*[@id="react-root"]/section/main/article/div[2]/div[2]/p/a'username_input = '//*[@id="react-root"]/section/main/div/article/div/div[1]/div/form/div[2]/div/label/input'password_input = '//*[@id="react-root"]/section/main/div/article/div/div[1]/div/form/div[3]/div/label/input'login_submit = '//*[@id="react-root"]/section/main/div/article/div/div[1]/div/form/div[4]/button/div'driver.find_element_by_xpath(first_login).click()driver.find_element_by_xpath(username_input).send_keys("username")driver.find_element_by_xpath(password_input).send_keys("password")driver.find_element_by_xpath(login_submit).click()
我们现在可以运行这个脚本,并在浏览器中看到自动化。这个特定的脚本将工作,但从 Instagram 得到一个错误,因为我们没有适当的凭据。继续使用您自己的信息更改send_keys周围的用户名和密码字符串,它应该会让您成功登录。
正如你所看到的,这只是一个简单的例子,不同的人有不同的情况。可能性是无限的。
我还提供 家教和 职业指导在这里!
如果你喜欢这些内容,请随时在 Patreon 上支持我!
如果你们有任何问题、意见或担忧,请不要忘记通过 LinkedIn 与我联系!
使用 Python 创建一个 Slack Bot

Photo by Lenin Estrada on Unsplash
在一家初创公司工作时,我们需要自动处理消息,以便获得某些事件和触发的通知。例如,我工作的公司处理与某些商店的联系。如果连接中断,Python 将读取我们数据库中的信息。我们现在可以将该数据发送到一个 Slack 通道,专门用于重新连接该存储。
我们可以为这个 Slack Bot 创造许多可能性,我的同事创造的另一个例子是将 Python 错误消息输出到通道。不仅创建通知,还创建持续的错误日志。
我们现在可以做些简单的事情。对于这个项目,我们将构建一个 Slack Bot,如果它检测到脚本运行的日期是美国假日,它将输出一条消息。
这个项目需要什么:
1。 Python
2。松弛工作空间/帐户
所需 Python 模块:
1。 datetime (告知脚本运行的日期并标准化日期时间)
2。 熊猫 (主要用于将数据组织成 dataframe)
3 . 请求 (连接到我们从网站获取的数据,并将数据发送到 slack API)
4 . bs4 (我们正在从网站获取的数据的数据解析)
5。 json (对数据进行编码,以便 slack API 可以使用)
首先,让我们创建一个新的 Python 文件并导入所需的模块。
from datetime import date, datetime, timedelta
import pandas as pd
import requestsfrom bs4
import BeautifulSoup
import json
我们可以使用datetime模块获取今天的日期时间,并将其存储为年-月-日这样的字符串格式。
today = datetime.now().strftime(‘%Y-%m-%d’)
#today = '2019-10-29'
使用模块requests,我们现在可以连接到我们想要获取数据的网站。为此,我连接到这个 网站 获取假期。当我们从一个网站获取数据时,它会发送我们在该页面上看到的所有内容。我们只想要这个数据中的假期。这就是 BeautifulSoup 发挥作用的地方,使用模块bs4我们可以很容易地解析这些数据。我们现在可以把它放到一个数据框架中。
这不是将数据传输到数据帧的最佳方式,但我们只需要完成这项工作。
regionalHolidaysList = []
for result in results:
date = result.contents[0].text + ', ' + datetime.today().strftime('%Y')
weekday = result.contents[1].text
holidayName = result.contents[2].text
observance = result.contents[3].text
stateObserved = result.contents[4].text
regionalHolidaysList.append((date, weekday, holidayName, observance, stateObserved))regionalHolidayDf = pd.DataFrame(regionalHolidaysList, columns = ['date', 'weekday', 'holidayName', 'observance', 'stateObserved'])regionalHolidayDf['date'] = regionalHolidayDf['date'].apply(lambda x: (datetime.strptime(x, '%b %d, %Y').strftime('%Y-%m-%d')))
我们现在可以从这个数据帧创建一个日期时间列表
dateList = regionalHolidayDf['date'].tolist()
如果today在这个dateList中,我们可以告诉它打印到请求的空闲通道。为了让 Python 使用 Slack 发送东西,我们需要创建一个传入的 webhook。Slack 有一些关于如何做到这一点的文档,在 https://api.slack.com/messaging/webhooks。
如果一切都做得正确,那么我们应该有这样的东西:
https://hooks.slack.com/services/T00000000/B00000000/XXXXXXXXXXXXXXXXXXXXXXXX
最后一部分变得有点复杂,所以我将在代码中用标签来发布我的评论。
#So we get the date if it is in this list it will send a message in slackif today in dateList:
todayHoliday = regionalHolidayDf[regionalHolidayDf['date'] == today]
info=[]
for holiday in todayHoliday.itertuples():
info.append(':umbrella_on_ground:' + holiday.holidayName + ' in ' + holiday.stateObserved.replace('*', ''))
if len(info) >1:
infoFinal = '\n'.join(info)
else:
infoFinal = info[0]#Here is where we can format the slack message, it will output any holiday with todays
message = f'@here Fun fact! \n Today({today}) is: \n {infoFinal}'
print('Sending message to the happyholiday channel...')
slackmsg = {'text': message} #Using the module json it formats it where the slack API can accept it
#we can store the slack link into a variable called webhook webhook='https://hooks.slack.com/services/T00000000/B00000000/XXXXXXXXXXXXXXXXXXXXXXXX'
response = requests.post(webhook, data=json.dumps(slackmsg), headers={'Content-Type': 'application/json'})
if response.status_code != 200:
raise ValueError('Request to slack returned an error %s, the response is:\n%s' % (response.status_code, response.text) )
print('Request completed!')
else:
print('No regional holiday today! See you next time!')
现在我们终于可以运行这个脚本了,如果成功,它将根据脚本运行的日期输出一个假日。
为了进一步自动化,我们可以将它放在 EC2 上,让它每天运行!但这需要更多的证书和设置,让我知道如果这是另一个话题,你们有兴趣!
访问我的代码这里!
我在这里也有家教和职业指导。
如果你们有任何问题、评论或顾虑,请不要忘记通过 LinkedIn与我联系!
使用 Python 获取罗宾汉数据

Photo by Ray Hennessy on Unsplash
让我们自动化一些股票,可以用来建造一个交易机器人。
所以我已经和罗宾汉纠缠了几个月了。谈到股票或交易,我不是专家。但我认为用 Python 连接到我的 Robinhood 帐户会很酷。
在网上看了之后,我偶然发现了一个叫做robin_stocks.的 Python 模块,所以这个模块非常方便,它可以做你在网站上可以做的任何事情。所以如果你想下订单,这是给你的。或者如果你想卖这个也是给你的。它还可以为您检索历史数据。
让我们开始假设你已经知道 Python 是如何工作的,我只做一个pip install robin_stocks。
我做的第一行代码是导入,我还导入了pandas来把它放入一个数据帧,并导入了matplotlib.pyplot来绘制它。导入之后,我们现在需要登录 Robinhood。只需在正确的字段中替换您的用户名和密码。
当我们运行脚本时,它应该要求一个代码,通常发送到您的手机号码。输入,你现在应该连接上了。我们现在可以使用build_holdings()获得所有的股票信息。当我们打印出my_stocks时,它看起来会像这样:
对于我个人的使用,我想把它放入一个数据框中。我尝试了df = pd.DataFrame(my_stocks),但是结果是股票代码被作为索引读取,数据旋转不符合我的喜好。所以我多加了一点代码。
对不起,我的股票我不确定我在买卖什么,但是数据框架应该是这样的:

我们还可以获得某些股票的历史数据,对于这个例子,我将获得特斯拉的周数据并绘制它。代码、数据帧和绘图如下所示:


正如你可以告诉我还没有探索这个模块的能力。此外,我对股票市场有点缺乏经验,还没有玩过。但希望这能延伸到更有知识的人,这样他们就可以在日常生活中使用它。非常有可能建立自己的机器人投资者!
访问我的代码这里!
我在这里也可以得到辅导和职业指导!
如果你们有任何问题、评论或顾虑,请不要忘记通过 LinkedIn与我联系!
如何使用 Python 获取 SalesForce 数据

Photo by Denys Nevozhai on Unsplash
我在一家大量使用 SalesForce 的初创公司工作。
当我第一次开始时,我们必须通过 Salesforce 网站登录。转到“报告”选项卡,创建一个包含必要字段的报告。下载逗号分隔值电子表格。在这里和那里做一些数据清理。主要是过滤字段,看看有没有空值或细微差别。再次导出 CSV,并在 Excel 中做一个 Vlookup,看看我们有什么数据。
我心想,一定有一种更简单的方法,我只需运行一个 Python 脚本就可以完成这项工作。做了一些谷歌搜索,发现了[simple_salesforce](https://github.com/simple-salesforce/simple-salesforce/blob/master/README.rst)。
来自他们的网站 — Simple Salesforce 是一个为 Python 2.6、2.7、3.3、3.4、3.5 和 3.6 构建的基本 Salesforce.com REST API 客户端。目标是为 REST 资源和 APEX API 提供一个非常底层的接口,返回 API JSON 响应的字典。
使用 Python 拉 Salesforce 数据需要的东西:
1。Python 模块simple _ sales force
2。具有 API 访问权限的 SalesForce 凭据
假设你已经掌握了 Python 的基本知识,那么继续在你的机器上安装simple_salesforce 。
pip install simple_salesforce
完成后,我们可以继续创建我们的 Python 文件,并进行必要的导入。我们还需要我们的 SalesForce 凭据。如果不能联系您的 SalesForce 开发人员,帐户必须具有 API 访问权限。
from simple_salesforce import Salesforcesf = Salesforce(
username='myemail@example.com',
password='password',
security_token='token')
如果您还没有 SalesForce 安全令牌,请登录到 SalesForce 网站。导航到设置。然后到我的个人信息,在那个下拉菜单下应该重置我的安全令牌。这将以带有字母数字代码的电子邮件形式发送给您。
使用 SOQL 查询 SalesForce 数据
我们现在可以使用 Python 登录到 SalesForce。为了查询数据,simple_salesforce有一个叫做query_all的方法,这使得获取数据变得非常容易。SalesForce 有自己的方式来编写查询,称为 SalesForce 对象查询语言。
以下是使用 Python 和自定义字段进行查询的示例:
"SELECT Owner.Name, store_id__c, account_number__c, username__c, password__c, program_status__c, FROM Account WHERE program_status__c IN ('Live','Test')"
我们现在可以将这个 SOQL 代码插入到方法中,并将其提取到一个变量中:
sf_data = sf.query_all("SELECT Owner.Name, store_id__c, account_number__c, username__c, password__c, program_status__c, FROM Account WHERE program_status__c IN ('Live','Test')")
输出将是 JSON 格式,但是我们可以使用[pandas](https://pandas.pydata.org/pandas-docs/stable/index.html)很容易地将其转换成数据帧。JSON 返回了一些我认为不必要的属性,所以我放弃了它们。
sf_df = pd.DataFrame(sf_data['records']).drop(columns='attributes')
我们现在有了一个数据框架,可以进行数据分析和数据清理。
访问我的代码这里!
我在这里也有家教和职业指导!
如果你们有任何问题、评论或担忧,别忘了在 LinkedIn 上联系我!
使用 Python 将您的熊猫数据框推送到 Google Sheets

Photo by Christian Kielberg on Unsplash
这也可以作为像使用数据库一样使用 Google Sheets 的简单方法。
假设您已经安装了最新版本的 Python。为此需要的 Python 模块有:
pandas(获取和读取数据)gspread(连接到谷歌工作表)df2gspread(与谷歌工作表互动)
仔细安装这些模块后,我们现在可以创建一个 Python 文件,并开始导入。
import pandas as pd
import gspread
import df2gspread as d2g
现在我们需要任何类型的数据,我们可以从 CSV 或其他来源获取。利用熊猫,我们可以把它组织成一个数据框架。任何类型的数据框架都可以。如果你还没有,让我们用熊猫做一个。
d = {'col1': [1, 2], 'col2': [3, 4]}
df = pd.DataFrame(data=d)
现在棘手的部分,获得凭证访问。为了使用 Python,我们需要从 Google 获得某种形式的 密钥 。这个 键 主要是出于安全目的,将采用 JSON 文件的格式。
让我们登录我们希望使用的谷歌账户,并按照这里的说明进行操作。如果一切顺利,JSON 文件应该看起来像这样:
{
"private_key_id": "2cd … ba4",
"private_key": "-----BEGIN PRIVATE KEY-----**\n**NrDyLw … jINQh/9**\n**-----END PRIVATE KEY-----**\n**",
"client_email": "473000000000-yoursisdifferent@developer.gserviceaccount.com",
"client_id": "473 … hd.apps.googleusercontent.com",
"type": "service_account"
}
这个 JSON 文件需要与 Python 脚本在同一个文件夹中。对于这个例子,我将其命名为jsonFileFromGoogle.json。我们可以在代码中调用 JSON 文件,并将其设置为连接的凭证。我们还可以设置*范围,*我们希望凭证被发送到哪里以便进行连接。
scope = ['[https://spreadsheets.google.com/feeds'](https://spreadsheets.google.com/feeds'),
'[https://www.googleapis.com/auth/drive'](https://www.googleapis.com/auth/drive')]credentials = ServiceAccountCredentials.from_json_keyfile_name(
'jsonFileFromGoogle.json', scope)gc = gspread.authorize(credentials)
您现在应该能够以这种方式连接到 Google。是时候把数据帧发送到谷歌电子表格了。对于我的目的,我发现创建一个新的工作表并获取电子表格键更容易。电子表格密钥可以在这里用红色标记的 URL 中找到。

复制它,并将其设置为一个名为spreadsheet_key的变量。如果您的工作表有多个工作表,也要设置工作表名称。我在我的代码里设置为wks_name,默认情况下会叫“Master”。
spreadsheet_key = 'red_url_code_goes_here'
wks_name = 'Master'
d2g.upload(df, spreadsheet_key, wks_name, credentials=credentials, row_names=True)
现在,当您最终运行这个脚本时,您设置的 DataFrame 将把它上传到 Google Sheets。这有许多其他的可能性,但是你可以用它作为一个更新的小数据库,你可以和你的同伴分享。
我在这里也有家教和职业指导!
如果你喜欢这些内容,请随时在 Patreon 上支持我!
如果你们有任何问题、意见或担忧,请不要忘记通过 LinkedIn 与我联系!
使用 PyTorch 生成疟疾感染细胞的图像
不同的自动编码器和不同的初始化方案
在我寻求掌握机器学习和深度学习(为了做出令人兴奋的生物学发现)的过程中,我将变分自动编码器(VAEs)作为我清单上的下一个目标。看似简单,VAE 包括一个编码器,一个解码器和一个适当的损失函数。然而 VAEs 创造性应用的例子比比皆是,包括生成图像、音乐和蛋白质部分。我们马上就会看到为什么他们在这些事情上如此受欢迎!出于某种原因,人们似乎喜欢用 VAEs 生成数字为和面部为和的图像,所以我想尝试一些不同的东西。在寻找了一段时间后,我在 Kaggle 上发现了一个关于人类血细胞(健康的以及被疟疾病原体感染的恶性疟原虫)的数据集(顺便说一下,对数据集来说很棒)。由于这两个类别都包含了大约 14000 张图片,这并不算太差,所以我决定继续这样做,为这两个类别建立 VAEs 来生成健康的受感染细胞的图片。那有用吗?我不知道(可能不是太多),但这是一个很好的学习经历,看起来肯定很愉快!

Examples of input images (not particularly pretty but hey you take what you can get, right?). Upper row are three healthy blood cells, lower row are three blood cells infected by the malaria pathogen P. falciparum (easily seen through the purple spots).
但是在我们沉浸在深度学习的乐趣中之前,先了解一些背景知识。VAEs 对大部件的标称任务在于预测它们的输入,称为重构。虽然这听起来可能微不足道,但是所有的自动编码器、vae 都有一个瓶颈结构。体系结构边缘的层比中间的层有更多的节点。因此,宽编码器通向最窄的瓶颈层,相应的解码器从那里开始,将输入恢复到原始尺寸。这阻止了 VAE 简单地将身份转换应用于其输入并完成它。

Structure of a standard autoencoder. Variational autoencoders replace the ‘z’ layer with vectors of means and variances to create sampling distributions. Source
因此,网络必须学习图像的基本特征,以便重新创建它。瓶颈层所必需的这种受限表示是自动编码器通常用于去噪的主要原因。由于只有图像的真实特征才会出现在潜在特征中,因此在重建时会去除噪声。通过比较原始图像和重建图像并最小化它们的差异(理解为:最小化重建误差,例如可以是均方误差),我们已经有了损失函数。或者说,对于普通的自动编码器来说,我们已经做到了。
然而,可变自动编码器也有一个生成组件。实际上,它们可以让你得到输入图像的调整变体,而不是陈腐的复制,这就是为什么它们在音乐或视觉艺术等创意领域如此受欢迎。架构的不同之处在于,VAE 编码器输出的是均值向量和标准差向量,而不是永无止境的密集层阵列。这些现在可以用来形成样本分布。然后,我们从每个分布中抽取一个值,这些值填充瓶颈层。这就是导致变化的随机性发挥作用的地方。由于我们从分布中取样,所以每次运行 VAE 时,即使所有权重保持不变,输出也会不同。
到目前为止,一切顺利。如果我们按照指示改变架构,那么我们完成了吗?不完全是。我们仍然需要修改我们的损失函数。对于重建误差,我们将使用二值交叉熵。然而,我们还需要损失函数中的另一项,即kull back–lei bler 散度 (KL 损失)。简单来说,这就是概率分布之间的差异。在我们的情况下,它将是 VAE 生成的概率分布和正态分布之间的差异之和。通过最小化这一点,我们迫使潜在空间中的分布围绕中心聚集(正态分布)。这导致在潜在空间中生成分布的重叠,并改善图像生成。因为否则,VAE 可能会通过为每种输入类型创建清晰分离的概率分布来“记忆”输入。通过对重建误差& KL 损失求和,我们得到我们的最终损失函数,我们试图在训练期间使其最小化。
现在我们可以建造了!如果你想尝试或者只是为你自己的项目窃取代码,我在 Jupyter 笔记本这里有全部内容。VAE 在 PyTorch 中实现,这是一个深度学习框架,甚至像我这样的生命科学人士都觉得使用它足够舒适。我开始无耻地从 PyTorch repo 中窃取 VAE 代码,然后调整&修改它,直到它符合我的需要。通常我会在谷歌的联合实验室上运行这些东西,因为它会免费给你一个特斯拉 K80 GPU,这绝对很棒!您可以将它与 Jupyter 笔记本电脑配合使用,连续运行长达 12 小时。
获得图像后,您必须将它们转换成 PyTorch 数据集。在我的笔记本中,这个实现非常简单,但是通常 PyTorch 数据集对象需要一个索引器(getitem)和一个长度(len)。我们可以利用这个机会对图像进行一些变换,比如使它们的大小相同,并使它们正常化。然后,我们可以将数据集馈送到数据加载器,数据加载器会将它分解成可用于训练的小批次。很简单,对吧?对于 VAE 本身,我们在 init 部分实例化层,并在“forward”部分定义层交互。基本上就是一堆线性图层加上偶尔的 ReLU 激活功能。因为 VAEs 在训练中可能有点棘手(想想消失和爆炸的渐变,耶!),我还在编码器和解码器上加了两个批归一化层。通过减少协变量偏移(增加两个交互层的独立性),它们允许在训练期间更稳定,甚至具有轻微的正则化效果(这就是为什么如果您将模型切换到 eval 模式,它们会被关闭)。最后,我们需要一个 sigmoid 激活函数用于二进制交叉熵损失,以便所有值都在 0 和 1 之间。
显著增加训练稳定性的最后一点是层初始化。输入某一组权重可以在训练稳定性方面产生巨大的差异,尤其是对于深度神经网络。我开始用 Xavier 初始化我所有的线性层,这最终允许我训练 VAE 没有任何爆炸。这种方法从受给定层的输入&输出连接数量影响的随机均匀分布中采样初始权重。但是最近我偶然发现了一篇关于初始化方案的优秀博文,包括明凯初始化,所以我决定也尝试一下那个,并与 Xavier 初始化的 VAE 进行比较。显然,这种方法最适合类似 ReLU 的激活函数,它由一个从标准正态分布中提取的权重张量乘以一个与该层的传入连接数成反比的因子组成。

VAE-generated images of blood cells, either healthy (left panel) or infected with malaria (right panel). Here, the VAE was initialized with Xavier initialization.
此外,我添加了一个衰减的学习率(每一个时期后减半)以获得更好的性能。经过 10 个时期的训练后,我开始用训练好的 VAEs 生成图像。为此,从标准正态分布中采样随机值,将它们输入到训练好的 VAE 的瓶颈层,并将它们解码成生成的图像就足够了。如果我们看一看由 Xavier 初始化的 VAE 产生的图像,我们可以清楚地看到 VAE 确实从图像中学到了一些东西。未感染细胞(黄色)和感染细胞(紫色)之间的颜色差异非常明显。然后,如果你仔细观察,未感染的细胞似乎比感染的细胞更圆,形状更均匀。虽然你可以在受感染的细胞中看到一些粒度,但它并不真的像输入图像中一样清晰。对于从明凯初始化的 VAEs 生成的图像,我们也可以观察到明显的色差,但这里的粒度似乎更不明显。此外,图像似乎相当模糊。事实上,VAE 生成的图像已经被指出有点嘈杂。有时候,这并不一定是坏事。如果您还记得输入图像的粗糙边缘,那么边缘周围的一点模糊至少会使生成的图像更加美观。

VAE-generated images of blood cells, either healthy (left panel) or infected with malaria (right panel). Here, the VAE was initialized with Kaiming initialization.
从这里去哪里?据报道,与 VAEs 相比,生成敌对网络(GANs)可以创建分辨率更高的图像,因此如果这是一个因素,GANs 可能会有吸引力。此外,尤其是对于图像,使用线性图层可能不如使用卷积图层。建立一个 CNN-VAE 可能会大大提高生成图像的质量,所以如果你喜欢,就去试试吧!原则上,对这种未感染/感染细胞设置使用自动编码器可以让您了解相应细胞状态的特征(通过研究构建的潜在空间中的参数),并可能有助于疟疾的自动诊断。无论如何,我非常喜欢做这个小东西,并且学到了更多关于深度学习& PyTorch 的知识。期待下一个项目!
额外收获:如果你设置正确的参数,你可以强制你的 VAE 生成看起来像宝石或彩色鹅卵石的细胞图像。因为我们都值得美丽的形象!

Can you figure out how to get those beautiful cells from a different universe?
使用 R 进行探索性数据分析(EDA) —分析高尔夫统计数据

无论您是数据架构师、数据工程师、数据分析师还是数据科学家,在开始一个新的数据项目时,我们都必须使用不熟悉的数据集。有点像和新数据集相亲。在感到舒适之前,你会想更多地了解它。
那么,我们怎么去呢?答案是探索性数据分析(EDA) 。
探索性数据分析是对数据集进行初步分析和发现的术语,通常在分析过程的早期进行。
作为一名数据专家,经历过这个过程后,我们会睡得更香。如果忽略这一步,在以后的步骤中会浪费很多时间…在架构基础和数据处理管道建立之后,需要重新工作来解决数据问题。
样本数据集
四大赛事结束后,泰格赢得了历史性的大师赛冠军,为什么不看看一些高尔夫统计数据呢?我在 espn.com 网站【http://www.espn.com/golf/statistics 上找到了 2019 年的高级统计数据。我把内容放在一个 Googlesheet 中以便于访问。正如您将很快看到的,这是一个非常基本的数据集,但它将让我们专注于 EDA 过程。
下面是我们数据集的样本行。

espn golf stats
我们将使用“googlesheets”库将数据集加载到 R 中。(Googlesheet 文件名为“golf_stats_espn”,sheetname 为“2019_stats”)。
library(googlesheets)googlesheet <- gs_title(“golf_stats_espn”)
df_2019 <- googlesheet %>% gs_read(ws = “2019_stats”)
EDA 步骤 1:数据验证和数据质量
函数将对结构进行健全性检查,并显示每个变量的样本数据。
str(df_2019)

str() function
如果你有使用 R 的经验,你可能很熟悉 summary() 函数。它工作得很好,但是一个更完整的函数是“skimr”包中的 skim() 函数。它按类型分解变量,并提供相关的摘要信息,以及每个数值变量的小直方图。
library(skimr)
skim(df_2019)

skim() function
除了“年龄”变量的看起来不错**。使用 R 和许多其他分析工具,在读入内容时会自动分配数据类型,称为“读取时模式”。对于“年龄”,我们的变量被赋予了字符类型,而不是数字类型。然而,我想把 AGE 作为一个数值类型,以便在下游应用数值函数。为什么 R 创建年龄变量作为字符类型?**
让我们做更多的 EDA,并对年龄变量运行一个 table() 函数。
with(df_2019, table(AGE))

table() function
table()函数在第一行显示变量的不同值,并在下一行显示出现的次数。对于年龄变量,我们可以看到“-”出现 1 次。r 别无选择,只能将变量定义为“字符”类型。
我们可以通过使用“DPLYR”包来解决这个问题。DPLYR 专门研究“数据角力”。使用这个包,您可以高效地完成很多工作——数据帧操作、转换、过滤、聚合等。
下面的 R 命令在执行了项目符号所描述的操作后创建了一个新的数据帧。
df_2019_filtered <- df_2019 %>% # create new dataframe
mutate(AGE_numeric = !(is.na(as.numeric(AGE)))) %>%
filter(AGE_numeric == TRUE) %>%
mutate(AGE = as.numeric(AGE))
- mutate →创建一个新的布尔变量,标识它的值是否为数字
- filter →使用在上面的 mutate 行中创建的新布尔变量过滤掉非数字变量
- 突变→替换“年龄”变量;现在定义为数值变量
下面是我们新的数据框架。

str() function
还有一个调整,我将把列“RK”重命名为一个更好的名称。
df_2019_filtered <- rename(df_2019_filtered, “RANK_DRV_ACC” = “RK”)
让我们在这里暂停一分钟。
处理脏数据
- 对于本文,缺失的年龄行被过滤掉了。在一个真正的分析项目中,我们将不得不寻找最佳的行动方案(过滤行,替换字符数据,用 NULL 替换,等等)。
探索性数据分析(EDA)——第二部分
随着我们的数据集被检查和清理…
第 2 部分更倾向于数据分析师和数据科学家。您可能会对在此阶段获得的见解感到惊讶,即使是在这个非常基础的数据集上。
【plot _ histogram()】
我们将使用“DataExplorer”库来了解关于我们的数据集的更多信息。 plot_histogram() 函数将为我们的每个数字变量返回一个单独的条形图。它显示了变量中每个值的频率(出现的次数)。
*library(DataExplorer)
plot_histogram(df_2019_filtered)*

plot_histogram() function
例如,“GREENS_REG”变量包含的值大约在 55 到 75 之间。根据条形图,我们看到大多数高尔夫球手大约有 65-70%的时间在果岭上击球。
plot _ box plot()
箱线图(盒须图)显示变量的数据分布。这个方框向我们展示了“五个数字的总结”——最小值、第一个四分位数、中间值、第三个四分位数和最大值。
下面的 plot_boxplot() 函数创建了 5 个箱/分区。我们将首先关注每驱动码数(YDS 驱动)变量。
plot_boxplot(df_2019_filtered, by = “YDS_DRIVE”)

plot_boxplot() function
我们可以看到一些非常有趣的相关性,将“年龄”变量与“每次驾驶的 YDS”进行比较。
- 年纪大的人打不了那么远。
- 有一个异常值。与同年龄组的其他人相比,一些 50 多岁的人仍在努力。
接下来,我们从“年龄”的角度再做一个箱线图。
plot_boxplot(df_2019_filtered, by = “AGE”)

plot_boxplot() function
- 左上角年龄最大的群体(48–55)的“驾驶准确率”(DRIVING_ACC)非常低。我希望年纪大的球员击球更短,但更准确…这不是真的,数据不会说谎。
- 年龄较大的群体(48-55 岁)也在推杆方面有困难。他们有最高的平均每洞推杆数(AVG 推杆)。
探索性数据分析(EDA)——第三部分
让我们把这个分析带到另一个层次。
这个库中的功能更接近数据科学家花费时间的地方。
“ggcorrplot”为我们提供了一个“热图”,显示了关系之间的显著性(或不显著性)。人类不可能盯着电子表格并确定数据的列和行之间的模式/关系。
让我们使用“ggcorrplot”库。有时候,关键是更聪明地工作,而不是更努力地工作!
*library(ggcorrplot)ggcorrplot(corr, type = “lower”, outline.col = “black”,
lab=TRUE,
ggtheme = ggplot2::theme_gray,
colors = c(“#6D9EC1”, “white”, “#E46726”))*

ggcorrplot() function
1 =高度相关;0 =无关系;-1 =反比关系
运行该函数比盯着电子表格,试图查看行和列之间的关系要容易得多!
1 .我们的变量之间最重要的关系是“每次击球的码数”和“规则中的果岭数”。
2 .相反,最显著的反比关系存在于“年龄”和“每次行驶码数”之间。
如果你喜欢圆形胜过正方形,下面是使用圆形方法得到的相同数据。
*ggcorrplot(corr, type = “lower”, outline.col = “black”,
method=”circle”,
ggtheme = ggplot2::theme_gray,
colors = c(“#6D9EC1”, “white”, “#E46726”))*

结论
尽管 EDA 过程至关重要,但它只是典型数据分析项目生命周期的开始。最有可能的是,一个组织的有价值的数据将不会来自 googlesheet,而是更有可能被埋藏在不同的数据库中,或者来自第三方供应商,甚至可能来自物联网数据流。
利用 R 和 EDA 过程将有助于为成功的分析项目铺平道路。
Jeff Griesemer 是 Froedtert Health 的一名分析开发人员。
使用随机森林来判断是否有代表性的验证集
这是一个快速检查,检查您最重要的机器学习任务之一是否设置正确

Photo by João Silas on Unsplash
当运行预测模型时,无论是在 Kaggle 比赛中还是在现实世界中,您都需要一个代表性的验证集来检查您正在训练的模型是否具有良好的泛化能力,也就是说,该模型可以对它从未见过的数据做出良好的预测。
那么,我所说的“代表”是什么意思呢?嗯,它真正的意思是,你的训练和验证数据集是相似的,即遵循相同的分布或模式。如果不是这样,那么你就用苹果来训练你的模型,然后试着用橙子来预测。结果将是非常糟糕的预测。
您可以进行大量探索性数据分析(EDA ),并检查两个数据集中的每个要素的行为是否相似。但那可能真的很费时间。测试您是否有一个有代表性的或好的验证集的一个简洁而快速的方法是运行一个随机的森林分类器。
在这个 Kaggle 内核中,我正是这样做的。我首先准备了训练和验证数据,然后添加了一个额外的列“train ”,当数据是训练数据时,它的值为 1,当数据是验证数据时,它的值为 0。这是随机森林分类器将要预测的目标。
# Create the new target
train_set['train'] = 1
validation_set['train'] = 0# Concatenate the two datasets
train_validation = pd.concat([train_set, validation_set], axis=0)
下一步是准备好独立(X)和从属(y)特性,设置随机森林分类器,并运行交叉验证。
我使用的是度量标准 ROC AUC ,这是分类任务的常用度量标准。如果指标是 1,那么你的预测是完美的。如果分数是 0.5,那么你和基线一样好,这是如果你总是预测最常见的结果,你会得到的分数。如果分数低于 0.5,那么你做错了。
# Import the libraries
from sklearn.ensemble import RandomForestClassifier
from sklearn.model_selection import cross_val_score# Split up the dependent and independent variables
X = train_validation.drop('train', axis=1)
y = train_validation['train']# Set up the model
rfc = RandomForestClassifier(n_estimators=10, random_state=1)# Run cross validation
cv_results = cross_val_score(rfc, X, y, cv=5, scoring='roc_auc')
现在,如果训练集和验证集表现相同,您认为 ROC AUC 应该是多少?……没错, 0.5 !如果分数是 0.5,那么这意味着训练和验证数据是不可区分的,这正是我们想要的。
一旦我们运行了交叉验证,让我们得到分数…和好消息!分数确实是 0.5。这意味着 Kaggle 主机已经为我们建立了一个代表性的验证集。有时情况并非如此,这是一个很好的快速检查方法。然而,在现实生活中,你必须自己想出一个验证集,这有望派上用场,以确保你设置了一个正确的验证集。
print(cv_results)
print(np.mean(cv_results))[0.5000814 0.50310124 0.50416737 0.49976049 0.50078978]
0.5015800562639847
使用 RandomForest 预测医疗预约失约

Photo by Adhy Savala on Unsplash
对医疗机构来说,失约或错过预约的患者很常见,而且代价高昂。美国一项研究发现,多达 30%的患者会错过他们的预约,每年因此损失 1500 亿美元。
识别潜在的失约可以帮助医疗机构采取有针对性的干预措施(例如,提醒电话、重复预约预约时段)来减少失约和财务损失。
资料组
Kaggle 数据集包含了来自巴西一个城市的公共医疗机构的 11 万份预约记录。这些约会发生在 2016 年的 6 周内。
以下是数据集功能的总结:

Table summarising the dataset’s original variables
患者 id 是不唯一的,这表明同一患者在 6 周内有多次预约。为了避免数据泄露(如果将同一患者的数据用于验证和测试,就会发生这种情况),我们将只在模型中包含患者的最新预约。
数据清理
有两个主要的清洁步骤:
- 二进制编码(1,0)失约,性别和障碍。我假设障碍应该是二进制的,因为它在 Kaggle 上有描述。
- 删除逻辑不一致的观察结果,如负年龄,以及计划日期晚于预约日期。
特征工程
特征工程用于记录日期时间特征,并保留从以前的约会(最近的约会之前的约会)中捕获的信息。

List of original dataset features and engineered features. Colours indicate the features from which the engineered features were created from.
通过从每个患者的失约和预约总数中分别减去 1 来计算先前失约和先前预约。
计划日期和约会日期分为星期几(DoW)和月几。预定时间也被分成一天中的几个小时。
天数差是指预定日期和约会日期之间的天数差。
总病情是高血压、糖尿病、残疾和酒精中毒的总和。换句话说,它显示了病人所患疾病的数量。
特征选择
特征是根据它们的信息值(IV) 选择的,这些信息值根据它们对目标的预测程度对特征进行排序和评分。

Selected features and their Information Value (IV) scores.
IV 分数< 0.02(非常差的预测因子的阈值)的特征被丢弃。使用保守阈值有助于确保有用的特征不会过早地从模型中排除。
事实证明,大多数特征对目标的预测能力很差。
此外,还去除了 ID 特征、冗余特征和邻域。邻域被删除是因为我找不到关于它们的额外信息,而且在模型中包含 80 个虚拟变量是不可取的。
在数据清理和特征选择之后,大约 62k 的观测值仍然存在。其中 20%没有出现。
五重交叉验证
数据集被分成 20%的测试数据集和 80%的交叉验证数据集。
使用 5 个训练-验证折叠,数据适合四个监督学习算法:
- 逻辑回归
- 朴素贝叶斯
- k-最近邻(KNN)
- 随机森林
RandomCVSearch (5 倍,10 次迭代,50 次拟合)用于调整 KNN 和随机森林的超参数。

根据模型的平均准确性和受试者工作特征曲线下面积(ROC AUC)评分对模型进行评估。
不幸的是,这些型号的性能相似,我无法选择最佳型号。
注意:我没有使用 F1 分数,因为它取决于所选的分类阈值,我打算在选择模型后对其进行调整。我使用 ROC AUC 评分和准确性,因为我想要最好的模型,而不考虑阈值。
使用更多数据进行验证。
由于交叉验证对模型选择没有用,用于训练和验证的 80%被重新分成 60%训练和 20%验证。(以前交叉验证使用 64%用于训练,16%用于每个折叠的验证)。希望有一个更大的验证集会使模型之间的差异更加明显。

Graph depicting models’ ROC curves, and table of models’ accuracy scores
从 ROC 曲线分析,我们可以看到 RandomForest 优于其他算法。它的精确度也与其他的相当。我们将使用 RandomForest 作为未来的模型。
调整分类阈值
RandomForest 的分类阈值是基于这样的假设进行调整的,即医疗机构希望在大规模推广干预措施之前对其进行测试。因此,精确度优先于回忆。
我选择的阈值是 0.38,因为这大约是两条曲线逐渐变细的时间。这个阈值意味着 74%的时间(精确度)可以正确识别未出现者,并且大约四分之一的未出现者可以被识别(回忆)。

测试
使用 80%的数据重新训练该模型,并对剩余的 20%进行测试。
测试分数与验证分数相似,这表明该模型概括得很好。

近距离观察 RandomForest

RandomForest 的特征重要性表明,时差和先前的未出现在预测未出现中是重要的。

Histograms depicting the differences in distributions for shows and no-shows, for prior no shows and day difference.
特别是,失约者的预定日期和约定日期之间的差异更大,而且有失约的历史。
特征重要性的知识对于选择干预措施是有用的。例如,那些提前预约的病人可能会忘记他们的预约。一个可能的干预措施是建立更多的个人患者接触点(例如电话,因为短信似乎没有效果)。
另一方面,对于有失约史的患者来说,原因可能更习惯性。如果机构无法说服这些病人出现,重复预约他们的位置可能是一个可行的解决方案。
结论
总之,似乎可以从患者信息和预约数据中预测失约。更多关于诊所位置(如交通便利)、寻求的护理类型(如初级、专科)和患者(如教育、收入)的信息可能会改进模型。该模型还可以受益于对可能的干预措施的成本效益分析,以实现最具商业意义的精确度和召回率之间的平衡。
** * 查看我的GitHub上的代码
用 Python 在遗传学中使用正则表达式
如何在生物序列数据中发现模式

Image Courtesy of National cancer Institute via Unsplash
Python 中的正则表达式(regex)可以用来帮助我们发现遗传学中的模式。当我们分析生物序列数据时,我们可以利用正则表达式,因为我们经常在 DNA、RNA 或蛋白质中寻找模式。这些序列数据类型只是字符串,因此非常适合使用 regex 进行模式分析。我们可能有兴趣寻找:导致人类疾病的核苷酸重复序列、DNA 转录因子结合位点、限制性酶切位点和特定突变。为了能够使用 regex 实现这一点,我们必须首先掌握 regex 的基本语法和一些特定于 regex 模块的函数。在本教程的第一部分,例子将使用 4 个 DNA 核苷酸;a,T,G,c。
这个简短的教程旨在:
1.介绍正则表达式语法,并举例说明遗传学
2.展示我们如何使用普通的正则表达式函数来寻找模式
正则表达式
以下字符在正则表达式中是特殊的:KaTeX parse error: Undefined control sequence: \并 at position 16: ^.*+?{ } [ ] | \̲并̲在表 1 中显示了相应的描述。…元字符被称为锚点,代表输入字符串中的位置。^匹配字符串的开头,而 匹配字符串的结尾。模 式 C C C 将匹配 C C C G G G ,但不匹配 G G G C C C 。模式 A A A 匹配字符串的结尾。模式^CCC 将匹配 CCCGGG,但不匹配 GGGCCC。模式 AAA 匹配字符串的结尾。模式CCC将匹配CCCGGG,但不匹配GGGCCC。模式AAA将匹配 TTTAAA,但不匹配 AAAGGG。
答。句点(或小数点)是查找任何字符的通配符。如果蛋白激酶具有共有序列“RXYVHXFDEXK ”,其中 X 表示任何氨基酸,那么正则表达式“R.YVH.FDE.K”将成功搜索底物。但是,需要注意的是,句号(。),将匹配任何甚至不是字母的字符。因此,模式“R.YVH.FDE.K”将匹配“R8YVH FDE&K”,这可能不是我们想要的。
元字符,,+,?、和{ }是量词运算符。这些用于指定字符或字符组的重复。字符或组后面的星号表示该字符或组是可选的,但也可以重复。遗传学领域中使用星号元字符的一个例子是,当我们搜索 RNA-seq reads 以通过搜索 AAAAAA找到 3’-聚腺苷酸化的序列时。这个正则表达式将精确地找到 5 个 A,后面跟着零个或更多个 A。+元字符类似于*,只是它会一次或多次找到该字符。答?零次或一次查找前面的字符或字符组。
如果需要具体或者匹配特定的重复次数,我们可以使用花括号符号。花括号中的单个数字将与前面的字符或组中的重复次数完全匹配。例如,CA{3}GATT 将匹配 CAAAGATT,但不匹配 CAAGATT 或 CAAAGATT。要指定一个范围,我们可以使用相同的花括号语法,并使用一般模式,其中{ n , x }查找在 n 和 x 时间之间的前一个字符或组。例如,TCG{2,4}A 将匹配模式 TCGGA、TCGGGA、TCGGGA,但不匹配 TCGA 或 TCGGGGGA。表 1 总结了这些元字符。

匹配一个图案
re 模块用于在 Python 中编写正则表达式(regex)。要加载这个模块,我们需要使用 import 语句。以下代码行必须包含在代码的顶部:
进口 re
为了使用正则表达式模块中的工具,有必要在它前面加上模块名。最简单的正则表达式函数 re.search()确定模式是否存在于字符串中的某个位置。re.search()有两个参数,都是字符串。第一个参数是要搜索的模式,第二个参数是要搜索的字符串。为了清楚起见,在下面的例子中,我包含了两个参数作为关键字参数。通常没有必要包含这些关键字参数。为了完整起见,我包括了被注释掉的另一个 syntaxic 版本。
下面的代码演示了一个简单的例子;在这里,我们正在寻找一个硬编码 DNA 变量中 A 碱基的三核苷酸重复序列的存在。
许多 re 函数调用的输出是一个匹配对象。如果我们查看上面的匹配对象,我们可以确定是否有匹配。span 标识出现匹配的字符串的索引,而 match 标识得到匹配的确切字符串。
正则表达式搜索也可以用作条件语句的一部分:
提取匹配对象值
通常在我们的脚本中,我们不仅要确定是否匹配,还要确定匹配发生在哪里。我们可能还想提取匹配本身。幸运的是,Python 使得提取匹配对象值变得很简单,比如匹配的索引位置和匹配的确切字符串。这可以通过在 match 对象上使用一些方法来实现。
交替和字符组
re.search()也可以用来寻找更灵活的模式。举例来说,NCII 限制酶识别核苷酸序列模式“CCSGG”,其中核苷酸代码“S”可以是 C 或 g。我们可以使用一个改变来捕获这种变化,而不是编写两个正则表达式搜索。这里,为了表示许多不同的替代项,我们将替代项写在括号内,并使用管道字符将它们分隔开(元字符|也称为交替运算符,请参见表 1)。
交替组的实用性来自于它们作为重复单位的能力。例如,为了确定一个序列是否由起始和终止密码子限定,并因此有可能成为开放阅读框,我们可以编写以下正则表达式:
这个正则表达式将在序列的末尾搜索 UAA、UAG 和 UGA。为了改进这个正则表达式,并确保起始和终止密码子在同一个框架中,我们可以将正则表达式改为:
这将检查起始和终止密码子之间的所有字符都是 3 的倍数。
字符组
字符组也可以用来捕捉单个模式中的变化。考虑蛋白质中共有的 N-糖基化位点。该序列基序具有以下模式:Asn,后跟除 Pro 以外的任何东西,后跟 Ser 或 Thr,后跟除 Pro 以外的任何东西。
使用相应的单字母氨基酸代码和字符组,我们可以将此模式写为:
这种模式将识别单个字母代码 N,后跟任何不是 P 的字符(参见表 1,取反的字符组),后跟 S 或 T,再后跟任何不是 P 的字符。一对带有字符列表的方括号可以表示这些字符中的任何(参见表 1)。
Regex 的威力
当这些工具一起使用时,regex 的真正威力就发挥出来了。考虑下面的场景。许多人类遗传性神经退行性疾病,如亨廷顿氏病(HD ),都与特定基因中三核苷酸重复数目的异常扩增有关。HD 的病理严重程度与编码亨廷顿蛋白的基因 htt 的外显子-1 中的(CAG) n 重复的数量相关。在亨廷顿氏病中,重复次数越多意味着疾病发作越早,疾病进展越快。CAG 密码子指定谷氨酰胺,HD 属于一大类多谷氨酰胺疾病。这种基因的健康(野生型)变异体具有 6-35 个串联重复,而超过 35 个重复几乎肯定会患病。
我们可以使用正则表达式来破译多聚谷氨酰胺重复数。这首先包括写一个模式以找到高于设定阈值的三核苷酸重复数。
密码子 CAA 也编码谷氨酰胺,因此,在上面的 htt_pattern 中,我们必须使用| alternation 操作符。然后,我们可以使用上面讨论的花括号符号来指定我们希望找到这个模式的次数。在这里,我选择了 18 次或更多次,通过故意离开上限。

我首先在 NCBI 核苷酸数据库中搜索了 htt mRNA 序列,并将其下载到我的工作目录中。然后我读取了这个序列,并使用我的模式来确定谷氨酰胺串联重复序列的长度超过 18。为了清楚起见,我在 NCBI·法斯特的文件中突出了这场比赛。我还使用了 re.findall()函数,因为 re.search()只会找到第一个匹配项,在这种情况下可能会找到许多匹配项。
结论:
本教程简要介绍了正则表达式在遗传学中的具体应用。正则表达式中的知识是高度可转移的,特别是在 Python 和许多其他主流编程语言(如 Perl 和 r)中,语法形式和功能表现大致相似。
使用强化学习在 NES 上玩超级马里奥兄弟

强化学习是目前机器学习领域最热门的话题之一。对于我们最近参加的一次会议(在慕尼黑举行的令人敬畏的数据节),我们开发了一个强化学习模型,学习在 NES 上玩超级马里奥兄弟,这样一来,来到我们展台的参观者就可以在关卡完成时间方面与代理竞争。

推广活动取得了巨大成功,人们喜欢“人机”竞赛。只有一名选手能够通过一条人工智能不知道的秘密捷径打败人工智能。此外,用 Python 开发模型非常有趣。因此,我决定写一篇关于它的博文,涵盖强化学习的一些基本概念以及我们的超级马里奥代理在 TensorFlow 中的实际实现(注意,我使用的是 TensorFlow 1.13.1,在撰写本文时 TensorFlow 2.0 尚未发布)。
回顾:强化学习
大多数机器学习模型在输入和输出之间有明确的联系,这种联系在训练期间不会改变。因此,很难对输入或目标本身依赖于先前预测的系统进行建模或预测。然而,通常情况下,模型周围的世界会随着所做的每一个预测而自我更新。听起来很抽象的东西实际上是现实世界中非常常见的情况:自动驾驶、机器控制、过程自动化等。—在许多情况下,模型做出的决策会对其周围环境产生影响,从而影响下一步要采取的行动。在这种情况下,经典的监督学习方法只能在有限的范围内使用。为了解决后者,需要能够处理相互依赖的输入和输出的时间相关变化的机器学习模型。这就是强化学习发挥作用的地方。
在强化学习中,模型(称为代理)通过从环境的每个状态中的一组可能的动作(动作空间)中进行选择,与它的环境进行交互,这些动作从环境中引起正面或负面的回报。把奖励想象成一个抽象的概念,表明所采取的行动是好是坏。因此,由环境发出的奖励可以是即时的,也可以延迟到将来。通过从环境状态、动作和相应的奖励的组合中学习(所谓的转换,代理试图达到一组最优的决策规则(策略策略),使代理在每个状态下收集的总奖励最大化。
Q 学习和深度 Q 学习
在强化学习中,我们经常使用一个叫做 Q-learning 的学习概念。Q-learning 基于所谓的 Q 值,它帮助代理在给定当前环境状态的情况下确定最佳行动。q 值是“贴现”的未来奖励,是我们的代理在培训期间通过采取行动和在不同环境状态中移动收集的。q 值本身试图在训练期间被近似,或者通过简单的环境探索,或者通过使用函数近似器,例如深度神经网络(如我们这里的情况)。通常,我们在每个状态中选择具有最高 Q 值的行动,即,给定环境的当前状态,最高的贴现未来回报。
当使用神经网络作为 Q 函数逼近器时,我们通过计算预测 Q 值和“真实”Q 值之间的差异进行学习,即当前状态下最佳决策的表示。基于计算的损失,我们使用梯度下降更新网络的参数,就像在任何其他神经网络模型中一样。通过经常这样做,我们的网络收敛到一个状态,在给定当前环境状态的情况下,它可以近似下一个状态的 Q 值。如果近似足够好,我们简单地选择具有最高 Q 值的动作。通过这样做,代理人能够在每种情况下决定哪种行为在奖励收集方面产生最好的结果。
在大多数深度强化学习模型中,实际上涉及两个深度神经网络:在线网络和目标网络。这样做是因为在训练期间,单个神经网络的损失函数是针对稳定变化的目标(Q 值)计算的,这些目标是基于网络权重本身的。这增加了优化问题的难度,或者可能导致根本不收敛。目标网络基本上是在线网络的副本,具有不直接训练的冻结权重。相反,在一定数量的训练步骤之后,目标网络的权重与在线网络同步。强制在每个训练步骤之后不改变的目标网络的“稳定输出”确保了计算损耗所需的计算的目标 Q 值不会稳定地改变,这支持了优化问题的收敛。
深度双 Q 学习
Q-learning 的另一个可能的问题是,由于选择最大 Q 值来确定最佳动作,模型有时会在训练期间产生非常高的 Q 值。基本上,这并不总是一个问题,但可能会变成一个问题,如果对某些行为的强烈关注导致对不太有利但“值得一试”的行为的忽视。如果一直忽略后者,模型可能会陷入局部最优解,甚至更糟的是一直选择相同的动作。处理这个问题的一个方法是引入 Q-learning 的更新版本,称为双 Q-learning 。
在双 Q 学习中,每个状态中的动作不是简单地通过选择具有目标网络的最大 Q 值的动作来选择的。相反,选择过程分为三个不同的步骤:(1)首先,目标网络在采取行动后计算状态的目标 Q 值。然后,(2)在线网络计算采取行动后状态的 Q 值,并通过找到最大 Q 值来选择最佳行动。最后,(3)使用目标网络的目标 Q 值来计算目标 Q 值,但是是在在线网络的所选动作指数处。这保证了不会出现对 Q 值的高估,因为 Q 值不是基于它们自身更新的。
健身房环境
为了构建一个强化学习应用程序,我们需要两样东西:(1)一个代理可以与之交互并向其学习的环境(2)代理,它观察环境的状态并使用 Q 值选择适当的动作,这(理想情况下)会给代理带来高回报。环境通常被提供为所谓的体育馆(gym ),一个包含必要代码的类,以模拟作为代理的动作的函数的环境的状态和回报以及进一步的信息,例如关于可能的动作空间。以下是 Python 中一个简单环境类的示例:
class Environment:
""" A simple environment skeleton """
def __init__(self):
# Initializes the environment
pass
def step(self, action):
# Changes the environment based on agents action
return next_state, reward, done, infodef reset(self):
# Resets the environment to its initial state
passdef render(self):
# Show the state of the environment on screen
pass
环境有三个主要的类函数:(1) step()执行环境代码作为代理选择的动作的函数,并返回环境的下一个状态、关于action的奖励、指示环境是否已经到达其终止状态的done标志以及关于环境及其状态的附加信息的字典,(2) reset()将环境重置为其原始状态,以及(3) render()在屏幕上打印当前状态(例如显示超级马里奥兄弟游戏的当前帧)。
对于 Python 来说,寻找健身房的必去之地是 OpenAI 。它包含许多不同的游戏和问题,非常适合使用强化学习来解决。此外,还有一个名为 Gym Retro 的开放人工智能项目,包含数百个世嘉和 SNES 游戏,随时可以通过强化学习算法解决。
代理人
代理消耗环境的当前状态,并基于选择策略选择适当的动作。该策略将环境状态映射到代理要采取的操作。寻找正确的策略是强化学习中的一个关键问题,通常涉及深度神经网络的使用。下面的代理只是观察环境的状态,如果state大于 0,则返回action = 1,否则返回action = 0。
class Agent:
""" A simple agent """
def __init__(self):
passdef action(self, state):
if state > 0:
return 1
else:
return 0
这当然是一个非常简单化的政策。在实际的强化学习应用中,环境的状态可能是非常复杂和高维的。一个例子是视频游戏。环境的状态由屏幕上的像素和玩家之前的动作决定。我们的代理人需要找到一种策略,将屏幕像素映射为从环境中产生回报的行为。
环境包装
健身房环境包含在强化学习场景中使用它们所需的大部分功能。然而,有一些功能并不是健身房中预先内置的,例如图像缩小、跳帧和堆叠、奖励剪辑等等。幸运的是,有所谓的健身房包装器提供这种实用功能。在这里可以找到一个可以用于很多视频游戏的例子,比如 Atari 或者 NES。对于视频游戏健身房来说,为了实现代理的良好性能,使用包装函数是非常常见的。下面的例子展示了一个简单的奖励剪辑包装器。
import gymclass ClipRewardEnv(gym.RewardWrapper):
""" Example wrapper for reward clipping """
def __init__(self, env):
gym.RewardWrapper.__init__(self, env)def reward(self, reward):
# Clip reward to {1, 0, -1} by its sign
return np.sign(reward)
从上面的例子可以看出,通过“覆盖”环境的核心功能,可以改变环境的默认行为。这里,基于奖励的符号,使用np.sign()将环境的奖励修剪为[-1,0,1]。
超级马里奥兄弟 NES 环境
对于我们的超级马里奥兄弟强化学习实验,我使用了 gym-super-mario-bros 。这个 API 很简单,非常类似于开放人工智能健身房 API 。下面的代码显示了一个随机代理玩超级马里奥。这导致马里奥在屏幕上扭动,当然,不会导致游戏成功完成。
from nes_py.wrappers import BinarySpaceToDiscreteSpaceEnv
import gym_super_mario_bros
from gym_super_mario_bros.actions import SIMPLE_MOVEMENT# Make gym environment
env = gym_super_mario_bros.make('SuperMarioBros-v0')
env = BinarySpaceToDiscreteSpaceEnv(env, SIMPLE_MOVEMENT)# Play random
done = True
for step in range(5000):
if done:
state = env.reset()
state, reward, done, info = env.step(env.action_space.sample())
env.render()# Close device
env.close()
代理通过从环境的动作空间中选择随机动作来与环境交互。视频游戏的动作空间实际上相当大,因为你可以同时按下多个按钮。这里动作空间缩减为SIMPLE_MOVEMENT,涵盖了四面八方跑、跳、鸭等基本游戏动作。BinarySpaceToDiscreteSpaceEnv将二进制动作空间(所有按钮和方向的虚拟指示器变量)转换为单个整数。例如,整数动作 12 对应于按下右键和 A(跑步)。
使用深度学习模型作为代理
当在 NES 上玩超级马里奥兄弟时,人类看到的是游戏屏幕——更准确地说,他们看到的是高速显示在屏幕上的连续像素帧。我们人类的大脑能够将来自我们眼睛的原始感官输入转换为电信号,这些电信号由我们的大脑处理,从而触发相应的动作(按下控制器上的按钮),这些动作(有希望)将马里奥引向终点线。
在训练代理人时,健身房根据代理人采取的相应动作,将每个游戏帧呈现为像素矩阵。基本上,这些像素可以用作任何机器学习模型的输入。然而,在强化学习中,我们经常使用卷积神经网络(CNN ),与其他 ML 模型相比,它擅长图像识别问题。我不会在这里深入 CNN 的技术细节,有太多关于 CNN 的精彩介绍文章,比如这篇。
不仅仅使用当前游戏屏幕作为模型的输入,通常使用多个堆叠的帧作为 CNN 的输入。通过这样做,模型可以处理屏幕上连续帧之间的变化和“运动”,这在仅使用单个游戏帧时是不可能的。这里,我们模型的输入张量的大小是[84, 84, 4]。这对应于 4 个灰度帧的堆栈,每个帧的大小为 84×84 像素。这对应于二维卷积的默认张量大小。
深度学习模型的架构包括三个卷积层,随后是一个扁平化和一个具有 512 个神经元的全连接层,以及一个输出层,由actions = 6个神经元组成,对应于游戏的动作空间(在这种情况下是RIGHT_ONLY,即向右移动马里奥的动作——扩大动作空间通常会导致问题复杂性和训练时间的增加)。
如果你仔细看看下面的 TensorBoard 图像,你会注意到这个模型实际上不仅由一个,而是由两个相同的卷积分支组成。一个是在线网络分支,另一个是目标网络分支。在线网络实际上是使用梯度下降来训练的。目标网络不是直接训练的,而是通过将权重从网络的在线分支复制到目标分支,定期同步每个copy = 10000步骤。通过使用分支输出层周围的tf.stop_gradient()函数,将目标网络分支排除在梯度下降训练之外。这将导致输出层的梯度流停止,因此它们无法沿分支传播,因此权重不会更新。

代理通过以下方式进行学习:(1)随机抽取历史转换样本,(2)使用目标网络分支和双 Q 学习规则,根据行动后的环境状态next_state计算“真实”Q 值,(3)使用gamma = 0.9对目标 Q 值进行贴现,(4)根据网络内部 Q 预测和target_q提供的真实 Q 值运行批量梯度下降步骤。为了加快训练过程,代理不是在每个动作后进行训练,而是每隔train_each = 3帧进行训练,这相当于每隔 4 帧进行一次训练。此外,不是每一帧都存储在重放缓冲器中,而是每第 4 帧。这叫做跳帧。更具体地,执行最大汇集操作,该操作聚集最后 4 个连续帧之间的信息。这是由于连续的帧包含几乎相同的信息,这不会给学习问题增加新的信息,并且可能引入强自相关的数据点。
说到相关数据:我们的网络使用自适应矩估计(ADAM)和梯度下降在 a learning_rate = 0.00025进行训练,这需要 i.i.d .数据点才能正常工作。这意味着,我们不能简单地随后使用所有新的转移元组进行训练,因为它们高度相关。为了解决这个问题,我们使用了一个叫做经验重放缓冲区的概念。因此,我们将游戏的每个过渡存储在一个环形缓冲区对象中(Python 中的deque()函数),当我们获取batch_size = 32的训练数据时,会随机从中抽取样本。通过使用随机采样策略和足够大的重放缓冲区,我们可以假设得到的数据点(希望)是不相关的。下面的代码框显示了DQNAgent类。
import time
import random
import numpy as np
from collections import deque
import tensorflow as tf
from matplotlib import pyplot as plt class DQNAgent:
""" DQN agent """
def __init__(self, states, actions, max_memory, double_q):
self.states = states
self.actions = actions
self.session = tf.Session()
self.build_model()
self.saver = tf.train.Saver(max_to_keep=10)
self.session.run(tf.global_variables_initializer())
self.saver = tf.train.Saver()
self.memory = deque(maxlen=max_memory)
self.eps = 1
self.eps_decay = 0.99999975
self.eps_min = 0.1
self.gamma = 0.90
self.batch_size = 32
self.burnin = 100000
self.copy = 10000
self.step = 0
self.learn_each = 3
self.learn_step = 0
self.save_each = 500000
self.double_q = double_qdef build_model(self):
""" Model builder function """
self.input = tf.placeholder(dtype=tf.float32, shape=(None, ) + self.states, name='input')
self.q_true = tf.placeholder(dtype=tf.float32, shape=[None], name='labels')
self.a_true = tf.placeholder(dtype=tf.int32, shape=[None], name='actions')
self.reward = tf.placeholder(dtype=tf.float32, shape=[], name='reward')
self.input_float = tf.to_float(self.input) / 255.
# Online network
with tf.variable_scope('online'):
self.conv_1 = tf.layers.conv2d(inputs=self.input_float, filters=32, kernel_size=8, strides=4, activation=tf.nn.relu)
self.conv_2 = tf.layers.conv2d(inputs=self.conv_1, filters=64, kernel_size=4, strides=2, activation=tf.nn.relu)
self.conv_3 = tf.layers.conv2d(inputs=self.conv_2, filters=64, kernel_size=3, strides=1, activation=tf.nn.relu)
self.flatten = tf.layers.flatten(inputs=self.conv_3)
self.dense = tf.layers.dense(inputs=self.flatten, units=512, activation=tf.nn.relu)
self.output = tf.layers.dense(inputs=self.dense, units=self.actions, name='output')
# Target network
with tf.variable_scope('target'):
self.conv_1_target = tf.layers.conv2d(inputs=self.input_float, filters=32, kernel_size=8, strides=4, activation=tf.nn.relu)
self.conv_2_target = tf.layers.conv2d(inputs=self.conv_1_target, filters=64, kernel_size=4, strides=2, activation=tf.nn.relu)
self.conv_3_target = tf.layers.conv2d(inputs=self.conv_2_target, filters=64, kernel_size=3, strides=1, activation=tf.nn.relu)
self.flatten_target = tf.layers.flatten(inputs=self.conv_3_target)
self.dense_target = tf.layers.dense(inputs=self.flatten_target, units=512, activation=tf.nn.relu)
self.output_target = tf.stop_gradient(tf.layers.dense(inputs=self.dense_target, units=self.actions, name='output_target'))
# Optimizer
self.action = tf.argmax(input=self.output, axis=1)
self.q_pred = tf.gather_nd(params=self.output, indices=tf.stack([tf.range(tf.shape(self.a_true)[0]), self.a_true], axis=1))
self.loss = tf.losses.huber_loss(labels=self.q_true, predictions=self.q_pred)
self.train = tf.train.AdamOptimizer(learning_rate=0.00025).minimize(self.loss)
# Summaries
self.summaries = tf.summary.merge([
tf.summary.scalar('reward', self.reward),
tf.summary.scalar('loss', self.loss),
tf.summary.scalar('max_q', tf.reduce_max(self.output))
])
self.writer = tf.summary.FileWriter(logdir='./logs', graph=self.session.graph)def copy_model(self):
""" Copy weights to target network """
self.session.run([tf.assign(new, old) for (new, old) in zip(tf.trainable_variables('target'), tf.trainable_variables('online'))])def save_model(self):
""" Saves current model to disk """
self.saver.save(sess=self.session, save_path='./models/model', global_step=self.step)def add(self, experience):
""" Add observation to experience """
self.memory.append(experience)def predict(self, model, state):
""" Prediction """
if model == 'online':
return self.session.run(fetches=self.output, feed_dict={self.input: np.array(state)})
if model == 'target':
return self.session.run(fetches=self.output_target, feed_dict={self.input: np.array(state)})def run(self, state):
""" Perform action """
if np.random.rand() < self.eps:
# Random action
action = np.random.randint(low=0, high=self.actions)
else:
# Policy action
q = self.predict('online', np.expand_dims(state, 0))
action = np.argmax(q)
# Decrease eps
self.eps *= self.eps_decay
self.eps = max(self.eps_min, self.eps)
# Increment step
self.step += 1
return actiondef learn(self):
""" Gradient descent """
# Sync target network
if self.step % self.copy == 0:
self.copy_model()
# Checkpoint model
if self.step % self.save_each == 0:
self.save_model()
# Break if burn-in
if self.step < self.burnin:
return
# Break if no training
if self.learn_step < self.learn_each:
self.learn_step += 1
return
# Sample batch
batch = random.sample(self.memory, self.batch_size)
state, next_state, action, reward, done = map(np.array, zip(*batch))
# Get next q values from target network
next_q = self.predict('target', next_state)
# Calculate discounted future reward
if self.double_q:
q = self.predict('online', next_state)
a = np.argmax(q, axis=1)
target_q = reward + (1\. - done) * self.gamma * next_q[np.arange(0, self.batch_size), a]
else:
target_q = reward + (1\. - done) * self.gamma * np.amax(next_q, axis=1)
# Update model
summary, _ = self.session.run(fetches=[self.summaries, self.train],
feed_dict={self.input: state,
self.q_true: np.array(target_q),
self.a_true: np.array(action),
self.reward: np.mean(reward)})
# Reset learn step
self.learn_step = 0
# Write
self.writer.add_summary(summary, self.step)
训练代理玩游戏
首先,我们需要实例化环境。在这里,我们使用第一级的超级马里奥兄弟,SuperMarioBros-1-1-v0,以及一个离散的事件空间与RIGHT_ONLY的行动空间。此外,我们使用了一个包装器,该包装器将帧大小调整、堆叠和最大池、奖励剪辑以及惰性帧加载应用到环境中。
当训练开始时,代理通过采取随机行动开始探索环境。这样做是为了积累初步经验,作为实际学习过程的起点。在burin = 100000游戏帧之后,代理慢慢开始用 CNN 政策决定的动作来代替随机动作。这被称为ε贪婪政策。ε-同意意味着代理以概率\ε采取随机动作,或者以概率(1-\ε)采取基于策略的动作。这里,\epsilon 在训练期间以因子eps_decay = 0.99999975线性减小,直到它达到eps = 0.1,在训练过程的剩余时间内保持不变。重要的是不要完全消除训练过程中的随机行为,以避免陷入局部最优解。
对于采取的每个动作,环境返回四个对象:(1)下一个游戏状态,(2)采取动作的奖励,(3)如果一集结束,则返回一个标志,以及(4)包含来自环境的附加信息的信息字典。在采取动作之后,返回对象的元组被添加到重放缓冲区,并且代理执行学习步骤。学习后,当前state用next_state更新,循环递增。如果done标志为True,则 while 循环中断。这相当于马里奥的死亡或者成功完成关卡。在这里,特工接受 10000 集的训练。
import time
import numpy as np
from nes_py.wrappers import BinarySpaceToDiscreteSpaceEnv
import gym_super_mario_bros
from gym_super_mario_bros.actions import RIGHT_ONLY
from agent import DQNAgent
from wrappers import wrapper # Build env (first level, right only)
env = gym_super_mario_bros.make('SuperMarioBros-1-1-v0')
env = BinarySpaceToDiscreteSpaceEnv(env, RIGHT_ONLY)
env = wrapper(env)# Parameters
states = (84, 84, 4)
actions = env.action_space.n# Agent
agent = DQNAgent(states=states, actions=actions, max_memory=100000, double_q=True)# Episodes
episodes = 10000
rewards = []# Timing
start = time.time()
step = 0# Main loop
for e in range(episodes): # Reset env
state = env.reset() # Reward
total_reward = 0
iter = 0 # Play
while True: # Show env (disabled)
# env.render() # Run agent
action = agent.run(state=state) # Perform action
next_state, reward, done, info = env.step(action=action) # Remember transition
agent.add(experience=(state, next_state, action, reward, done)) # Update agent
agent.learn() # Total reward
total_reward += reward # Update state
state = next_state # Increment
iter += 1 # If done break loop
if done or info['flag_get']:
break # Rewards
rewards.append(total_reward / iter) # Print
if e % 100 == 0:
print('Episode {e} - +'
'Frame {f} - +'
'Frames/sec {fs} - +'
'Epsilon {eps} - +'
'Mean Reward {r}'.format(e=e,
f=agent.step,
fs=np.round((agent.step - step) / (time.time() - start)),
eps=np.round(agent.eps, 4),
r=np.mean(rewards[-100:])))
start = time.time()
step = agent.step# Save rewards
np.save('rewards.npy', rewards)
在每一集游戏结束后,这一集的平均奖励将被添加到rewards列表中。此外,每 100 集后会打印不同的统计数据,如每秒帧数和当前 epsilon。
重播
在训练期间,程序在save_each = 500000帧检查当前网络,并在磁盘上保存 10 个最新型号。我在培训期间下载了几个模型版本到我的本地机器上,并制作了下面的视频。
看到代理人的学习进步真是太牛逼了!在 Google Cloud 上的 GPU 加速虚拟机上,培训过程花费了大约 20 个小时。
总结与展望
强化学习是机器学习中令人兴奋的领域,同样在科学和商业中提供了广泛的可能应用。然而,强化学习代理的训练仍然相当麻烦,并且通常需要对超参数和网络体系结构进行冗长的调整,以便很好地工作。最近有一些进展,如 RAINBOW (多种 RL 学习策略的组合),旨在为训练强化学习代理提供更强大的框架,但该领域仍然是一个活跃的研究领域。除了 Q-learning,强化学习中还有许多其他有趣的训练概念被开发出来。如果您想尝试不同的 RL 代理和培训方法,我建议您查看稳定基线,这是一个轻松使用最先进的 RL 代理和培训概念的好方法。
如果你是一个深度学习初学者,并且想了解更多,你应该查看我们全新的 STATWORX 深度学习训练营,这是一个为期 5 天的现场介绍,涵盖了开发你的第一个深度学习模型所需知道的一切:神经网络理论,反向传播和梯度下降,Python,TensorFlow 和 Keras 中的编程模型,CNN 和其他图像识别模型,时间序列数据和 NLP 的递归网络和 LSTMs,以及深度强化学习和 GANs 等高级主题。
如果您对我的帖子有任何意见或问题,请随时联系我!此外,请随意使用我的代码(链接到 GitHub repo )或在你选择的社交平台上与你的同行分享这篇文章。
如果你对更多类似的内容感兴趣,请加入我们的邮件列表,不断为你带来来自我和我在 STATWORX 的团队的新鲜数据科学、机器学习和人工智能阅读和对待!
最后,如果你对更多感兴趣,请在 LinkedIn 上关注我,或者在 Twitter 上关注我的公司网站!
原载于 2019 年 5 月 29 日https://www.statworx.com。
使用最先进的技术优化深度学习交易机器人
让我们教我们的深度 RL 代理使用特征工程和贝叶斯优化赚更多的钱

在上一篇文章中,我们使用深度强化学习创造了不赔钱的比特币交易机器人。虽然代理商盈利了,但结果并不令人印象深刻,所以这次我们要更上一层楼,大幅提高我们模型的盈利能力。
提醒一下,这一系列文章的目的是试验最先进的深度强化学习技术,看看我们能否创造出盈利的比特币交易机器人。现状似乎是迅速关闭任何创建强化学习算法的尝试,因为这是“构建交易算法的错误方式”。然而,该领域的最新进展表明,在相同的问题域内,RL 代理通常能够比监督学习代理学习更多的东西。出于这个原因,我写这些文章是为了看看这些交易代理能给我们带来多大的利润,或者说现状的存在是有原因的。
我们将首先改进我们的模型的策略网络,并使输入数据集保持稳定,这样我们就可以从更少的数据中学习更多的知识。接下来,我们将使用高级特征工程来改善我们的代理的观察空间,并微调我们的奖励函数,以产生更有吸引力的策略。最后,我们将使用一种称为贝叶斯优化的技术,在训练和测试最终代理盈利能力之前,锁定最有利可图的超参数。各位坐稳了,这将是一场疯狂的旅程。
深入探讨 TensorTrade——一个用于培训、评估和部署稳健交易的开源 Python 框架…
towardsdatascience.com](/trade-smarter-w-reinforcement-learning-a5e91163f315)
当你读完这篇文章后,看看TensorTrade——这篇文章中产生的代码库的后继框架。
修改
为了提高我们模型的盈利能力,我们需要做的第一件事是对我们在上一篇文章中写的代码做一些改进。如果你还没有代码,可以从我的 GitHub 中抓取。
循环网络
我们需要做的第一个改变是更新我们的策略,使用一个循环的长短期记忆(LSTM)网络,代替我们以前的多层感知器(MLP)网络。由于循环网络能够随着时间的推移保持内部状态,我们不再需要滑动的“回顾”窗口来捕捉价格行为的运动。相反,它被网络的递归性质所固有地捕获。在每个时间步,来自数据集的输入与来自最后一个时间步的输出一起被传递到算法中。

Source: https://adventuresinmachinelearning.com/recurrent-neural-networks-lstm-tutorial-tensorflow/
这允许 LSTM 维护一个内部状态,当代理“记住”和“忘记”特定的数据关系时,该状态在每个时间步得到更新。

Source: https://adventuresinmachinelearning.com/recurrent-neural-networks-lstm-tutorial-tensorflow/
Here we update our PPO2 model to use the MlpLstmPolicy, to take advantage of its recurrent nature.
平稳数据
我在上一篇文章中还指出,我们的时间序列数据不是稳定的,因此,任何机器学习模型都将很难预测未来的值。
平稳时间序列的均值、方差和自相关(与自身的滞后相关)是恒定的。
底线是,我们的时间序列包含一个明显的趋势和季节性,这两个影响我们的算法准确预测时间序列的能力。我们可以通过使用差分和转换技术从现有的时间序列中产生一个更正态的分布来解决这个问题。
差分是从每个时间步长的值中减去该时间步长的导数(回报率)的过程。在我们的例子中,这有消除趋势的预期结果,但是,数据仍然有明显的季节性。我们可以尝试通过在差分前对每个时间步长取对数来消除这种影响,这将产生最终的平稳时间序列,如下图右侧所示。

我们可以通过运行一个增强的 Dickey-Fuller 测试来验证产生的时间序列是平稳的。这样做得到的 p 值为 0.00,允许我们拒绝测试的零假设,并确认我们的时间序列是平稳的。
Here we run the Augmented Dicker-Fuller Test on our transformed data set to ensure stationarity.
现在我们已经解决了这个问题,我们将使用一点特征工程来进一步更新我们的观察空间。
特征工程
为了进一步改进我们的模型,我们将做一些功能工程。
特征工程是使用特定领域的知识来创建额外输入数据以改进机器学习模型的过程。
在我们的案例中,我们将向我们的数据集添加一些常见但有见地的技术指标,以及来自 StatsModels SARIMAX 预测模型的输出。技术指标应该向我们的数据集添加一些相关的滞后信息,这将由我们的预测模型的预测数据很好地补充。这些特性的组合应该为我们的模型提供一个很好的有用观察的平衡。
技术分析
为了选择我们的技术指标集,我们将比较[ta](https://github.com/bukosabino/ta) 库中所有 32 个指标(58 个特征)的相关性。我们可以使用pandas找到同一类型(动量、成交量、趋势、波动)的每个指标之间的相关性,然后从每个类型中只选择相关性最小的指标作为特征。这样,我们可以从这些技术指标中获得尽可能多的好处,而不会给我们的观察空间增加太多的噪音。

Seaborn heatmap of technical indicator correlation on BTC data set.
事实证明,波动率指标和一些动量指标都是高度相关的。当我们移除所有重复的特征(在它们的组内具有绝对平均相关性> 0.5 的特征)时,我们剩下 38 个技术特征添加到我们的观察空间。这是完美的,所以我们将创建一个名为add_indicators的实用方法来将这些特征添加到我们的数据框中,并在我们的环境初始化中调用它,以避免必须在每个时间步长上计算这些值。
Here we initialize our environment, adding the indicators to our data frame before making it stationary.
统计分析
接下来我们需要添加我们的预测模型。我们选择使用季节性自回归综合移动平均(SARIMA)模型来提供价格预测,因为它可以在每一步快速计算,并且在我们的静态数据集上相当准确。另外,它实现起来非常简单,并且允许我们为它的未来预测创建一个置信区间,这通常比单个值更有洞察力。例如,当置信区间很小时,我们的主体可以学习更加谨慎地相信预测,而当置信区间很大时,我们的主体可以学习冒更大的风险。
Here we add the SARIMAX predictions and confidence intervals to our observation space.
既然我们已经更新了政策,使用了更适用的循环网络,并通过上下文特征工程改善了我们的观察空间,现在是优化所有事情的时候了。
奖励优化

有人可能会认为我们上一篇文章中的奖励函数(即奖励增加的净值收益)是我们所能做到的最好的,然而,进一步的研究表明这与事实相差甚远。虽然我们上次的简单回报函数能够盈利,但它产生了不稳定的策略,经常导致资本的巨大损失。为了改善这一点,除了简单的未实现利润之外,我们还需要考虑其他奖励指标。
正如 Sean O’Gordman 在我上一篇文章的评论中提到的,对这个策略的一个简单的改进是,不仅在价格上涨时奖励持有 BTC 的利润,而且在价格下跌时奖励不持有 BTC 的利润。例如,当我们的代理持有 BTC/美元头寸时,我们可以对其净值的任何增量增加进行奖励,而当其不持有任何头寸时,我们可以对其 BTC/美元价值的增量减少进行奖励。
虽然这种策略在奖励增加的回报方面很棒,但它没有考虑到产生这些高回报的风险。投资者早就发现了简单利润指标的这一缺陷,传统上转向风险调整后的回报指标来解释这一缺陷。
基于波动性的指标
最常见的风险调整回报指标是夏普比率。这是一个简单的投资组合的超额收益与波动性的比率,在一段特定的时间内测量。为了保持高夏普比率,投资必须同时具有高回报和低波动性(即风险)。其数学原理如下:

这一指标经受住了时间的考验,然而它对我们的目的来说也是有缺陷的,因为它惩罚了上行波动。对于比特币来说,这可能会有问题,因为参与上行波动(价格大幅上涨)通常会非常有利可图。这就引出了我们将与代理一起测试的第一个奖励指标。
索蒂诺比率与夏普比率非常相似,只是它只将下行波动视为风险,而不是整体波动。因此,这一比率不会对上行波动造成不利影响。数学是这样的:

其他指标
我们将在该数据集上测试的第二个奖励指标是 Calmar 比率。到目前为止,我们的所有指标都没有考虑到的缩减。
提取是衡量投资组合价值从高峰到低谷的具体损失。
大额提款可能不利于成功的交易策略,因为长期的高回报可能会被突然的大额提款迅速逆转。

为了鼓励积极防止大规模提款的策略,我们可以使用专门说明这些资本损失的奖励指标,如卡尔马比率。这个比率与夏普比率相同,除了它使用最大提款来代替投资组合价值的标准差。

我们的最后一个指标是欧米伽比率,在对冲基金行业被大量使用。理论上,在衡量风险与回报时,Omega 比率应优于 Sortino 和 Calmar 比率,因为它能够在单一指标中说明风险与回报分布的整体情况。要找到它,我们需要计算一个投资组合在特定基准之上或之下移动的概率分布,然后取两者之比。比率越高,上涨潜力超过下跌潜力的概率就越高。

If this looks complicated, don’t worry. It get’s simpler in code.
代码
虽然为这些奖励指标中的每一个写代码听起来真的 有趣,但是我选择使用[empyrical](https://github.com/quantopian/empyrical) 库来计算它们。幸运的是,这个库恰好包含了我们上面定义的三个奖励标准。获取每个时间步长的比率非常简单,只需向相应的经验函数提供一段时间内的回报和基准回报列表。
Here we set the reward at each time step based on our pre-defined reward function
既然我们已经决定了如何衡量一个成功的交易策略,是时候找出这些指标中哪一个能产生最吸引人的结果了。让我们将这些奖励函数中的每一个都插入到 Optuna 中,并使用传统的贝叶斯优化来为我们的数据集找到最佳策略。
工具集
任何优秀的技术人员都需要一套优秀的工具。我们不会重新发明轮子,而是要利用我们之前的程序员的痛苦和折磨。对于今天的工作,我们最重要的工具将是optuna库,它使用树结构 Parzen 估计器 (TPEs)实现贝叶斯优化。TPE 是可并行化的,这允许我们利用我们的 GPU,大大减少了我们的总搜索时间。简而言之,
贝叶斯优化是一种有效搜索超空间以找到最大化给定目标函数的参数集的技术。
简单来说,贝叶斯优化是改进任何黑盒模型的有效方法。它通过使用代理函数或代理函数的分布来建模您想要优化的目标函数。随着算法探索超空间和产生最大价值的区域,这种分布会随着时间而改善。
这如何适用于我们的比特币交易机器人?本质上,我们可以使用这种技术来找到使我们的模型最有利可图的一组超参数。我们正在大海捞针,贝叶斯优化是我们的磁铁。让我们开始吧。
实施 Optuna

用 Optuna 优化超参数相当简单。首先,我们需要创建一个optuna研究,它是我们所有超参数试验的父容器。试验包含超参数的特定配置及其从目标函数产生的成本。然后我们可以调用study.optimize()并传入我们的目标函数,Optuna 将使用贝叶斯优化来找到产生最低成本的超参数配置。
在这种情况下,我们的目标函数包括在我们的比特币交易环境中训练和测试我们的 PPO2 模型。我们从函数中返回的成本是测试期间的平均回报,被否定。我们需要否定平均回报,因为 Optuna 将较低的回报值解释为更好的试验。optimize函数为我们的目标函数提供了一个试验对象,然后我们用它来指定要优化的每个变量。
optimize_ppo2()和optimize_envs()方法接受一个试验对象并返回一个参数字典进行测试。我们每个变量的搜索空间由我们在试验中调用的特定suggest函数定义,我们将参数传递给该函数。
例如,trial.suggest_loguniform('n_steps', 16, 2048)将以对数方式建议 16–2048 之间的新浮点数(16,32,64,…,1024,2048)。此外,trial.suggest_uniform('cliprange’, 0.1, 0.4)将以一种简单的、相加的方式建议浮点数(0.1,0.2,0.3,0.4)。我们在这里不使用它,但是 Optuna 也提供了一个建议分类变量的方法:suggest_categorical('categorical', ['option_one', ‘option_two'])。
稍后,在使用合适的 CPU/GPU 组合运行我们的优化功能一夜之后,我们可以从我们告诉 Optuna 创建的 sqlite 数据库中加载研究。这项研究跟踪其测试中的最佳试验,我们可以用它来获取我们环境的最佳超参数集。
我们修改了我们的模型,改进了我们的功能集,优化了我们所有的超参数。现在是时候看看我们的代理商如何使用他们的新奖励机制了。我已经训练了一个代理人来优化我们的四个回报指标:简单利润、索提诺比率、卡尔马尔比率和奥米加比率。让我们在一个测试环境中运行每一个优化的代理,这个测试环境是用它们没有被训练过的价格数据初始化的,看看它们是否有利可图。
标杆管理
在我们看结果之前,我们需要知道成功的交易策略是什么样的。对于这种叛逆,我们将参照几个常见但有效的交易比特币获利的策略。信不信由你,在过去的十年里,交易 BTC 最有效的策略之一就是买入并持有。我们将要测试的另外两个策略使用非常简单,但是有效的技术分析来产生买入和卖出信号。
- 买入并持有
这个想法是尽可能多的购买,并尽最大努力持有(HODL)。虽然这种策略并不特别复杂,但它在过去取得了很高的成功率。
2.RSI 背离
当连续收盘价随着 RSI 继续下降而继续上涨时,这是一个负面趋势反转(卖出)的信号。当收盘价随着 RSI 连续上升而连续下跌时,表明趋势正反转(买入)。
3.简单移动平均线交叉
当长期的 SMA 在短期的 SMA 上面交叉时,一个负面的趋势反转(卖出)信号被发出。当短期的 SMA 在长期的 SMA 上面交叉时,一个积极的趋势反转(买入)被发出信号。
根据这些简单的基准测试的目的是证明我们的 RL 代理实际上在市场上创造 alpha。如果我们不能击败这些简单的基准测试,那么我们就是在浪费无数小时的开发时间和 GPU 周期,只是为了做一个很酷的科学项目。让我们证明事实并非如此。
结果呢
我必须在这一节之前声明,这一节中的正利润是错误代码的直接结果。由于当时的日期排序方式,代理商可以随时提前 12 小时看到价格,这是一种明显的前瞻偏差。这个问题已经得到了解决,尽管还没有投入时间来替换下面的每个结果集。请理解,这些结果是完全无效的,极不可能被复制。
也就是说,仍然有大量的研究进入了这篇文章,目的从来不是为了赚大量的钱,而是为了看看当前最先进的强化学习和优化技术有什么可能。因此,为了让这篇文章尽可能地接近原文,我将把旧的(无效的)结果留在这里,直到我有时间用新的、有效的结果来替换它们。
代理在数据集的前 80%接受训练(来自 CryptoDataDownload 的每小时 OHCLV 数据),并在最后 20%接受测试,以查看策略如何推广到新数据。这种简单的交叉验证足以满足我们的需求,因为当我们最终将这些算法发布到野外时,我们可以在整个数据集上进行训练,并将新的输入数据视为新的测试集。
让我们快速浏览失败者,这样我们就能得到好的东西。首先,我们有欧米茄策略,这最终是对我们的数据集相当无用的交易。

Average net worth of Omega-based agents over 3500 hours of trading
观察这个代理交易,很明显这个奖励机制产生了过度交易的策略,并且不能利用市场机会。
基于 Calmar 的策略比基于 Omega 的策略稍有改进,但最终结果非常相似。看起来我们已经投入了大量的时间和精力,只是为了让事情变得更糟…

Average net worth of Calmar-based agents over 3500 hours of trading
还记得我们的老朋友,简单的增量利润吗?虽然在我们的上一篇文章中,这种奖励机制并不太成功,但我们所做的所有修改和优化似乎都极大地提高了代理的成功率。
在我们四个月的测试期内,平均利润刚刚超过初始账户余额的 350% 。如果你不知道平均市场回报,这种结果绝对是疯狂的。当然,这是我们在强化学习中所能做到的最好的了…对吗?

Average net worth of Profit-based agents over 3500 hours of trading
不对。按排序比例奖励的代理商产生的平均利润接近 850% 。当我看到这些策略的成功时,我必须快速检查以确保没有错误。编者注:准备好接受下面这句话的讽刺吧。]经过彻底检查后,很明显代码没有错误,这些代理只是非常擅长交易比特币。

Average net worth of Sortino-based agents over 3500 hours of trading
这些代理人没有过度交易和资金不足,而是似乎明白低买高卖的重要性,同时将持有 BTC 的风险降至最低。不管代理人学会了什么具体策略,我们的交易机器人显然已经学会了交易比特币并从中获利。如果你不相信我,你自己看吧。

One of the Sortino-based agents trading BTC/USD. Green triangles signal buys, red triangles signal sells.
我不是傻瓜。我明白,这些测试的成功可能[阅读:不会]推广到现场交易。也就是说,这些结果远比我迄今为止见过的任何算法交易策略都令人印象深刻(这应该是出了问题的第一个线索……)。考虑到这些代理人事先不知道市场如何运作或如何盈利交易,而是通过反复试验(以及一些良好的前瞻性偏见)学会了获得巨大成功,这确实令人惊讶。很多很多的尝试和错误。
结论
在这篇文章中,我们优化了我们的强化学习代理,以便在交易比特币时做出更好的决策,从而赚更多的钱!这需要做相当多的工作,但我们通过以下方式成功完成了这项工作:
- 升级现有模型,使用具有固定数据的循环 LSTM 政策网络
- 工程师使用特定领域的技术和统计分析为代理学习 40 多项新功能
- 改善代理人的报酬系统,考虑风险,而不是简单的利润
- 使用贝叶斯优化微调模型的超参数
- 以普通交易策略为基准,确保机器人总是跑赢市场
理论上,高利润的交易机器人是伟大的。然而,我收到了相当多的反馈,声称这些代理人只是在学习拟合曲线,因此,在实时数据上交易永远不会盈利。虽然我们在独立数据集上训练/测试的方法应该可以解决这个问题,但是我们的模型可能过度适合这个数据集,而可能不能很好地推广到新数据。也就是说,我有一种感觉,这些代理正在学习的不仅仅是简单的曲线拟合,因此,他们将能够在实时交易中获利。
为了对这一假设进行实验,在社区的帮助下,我建立了一个成熟的强化学习框架,用于交易股票、外汇、加密货币和任何其他带有 API 的金融工具。下面来看看吧。
深入探讨 TensorTrade——一个用于培训、评估和部署稳健交易的开源 Python 框架…
towardsdatascience.com](/trade-smarter-w-reinforcement-learning-a5e91163f315)
作为一个题外话,仍然有很多事情可以做,以提高这些代理的性能,但是我只有这么多时间,我已经在这篇文章上工作了太长时间,不能再推迟发布了。如果你感兴趣,拿着我做的和去改进它吧!如果你能击败我的结果,把你得到的发给我,我们谈谈。
重要的是要明白,本文中记录的所有研究都是出于教育目的,不应作为交易建议。你不应该根据本文定义的任何算法或策略进行交易,因为你很可能会失去你的投资。
感谢阅读!一如既往,本教程的所有代码都可以在我的 GitHub 上找到。如果您有任何问题或反馈,请在下面留下评论,我很乐意收到您的来信!我也可以通过@notadamking 上的Twitter联系到。
你也可以通过下面的链接在 Github 赞助商 或者Patreon上赞助我。
嗨,我是亚当。我是一名开发人员、作家和企业家,尤其对深度…
github.com](https://github.com/users/notadamking/sponsorship)
Github 赞助商目前正在 1:1 匹配所有捐款,最高可达 5000 美元!
嗨,我是亚当。我是一名开发人员、作家和企业家,尤其对深度…
patreon.com](https://patreon.com/notadamking)
资源
[1.]《Python 和 TensorFlow 中的递归神经网络和 LSTM 教程》机器学习历险记,2017 年 10 月 9 日。
[2.] “用 Python 进行时间序列预测的 SARIMA 简介。”机器学习掌握,2019 年 5 月 12 日。
[3.】辛格,艾西瓦娅。"用 Python 处理非平稳时间序列的简明介绍."分析 Vidhya ,2019 年 5 月 7 日。
[4.] “超参数优化算法”神经信息处理系统进展 24 (NIPS 2011),2011。
[5.] 普拉多马科斯洛佩斯德。金融机器学习的进展。威利,2018。
使用 RNNs 进行机器翻译

Photo by Atharva Tulsi on Unsplash
介绍 RNN 和 LSTM 网络及其应用。
故事是人类文化的精髓。它们包含了我们过去的信息和未来的理论。它们让我们能够深入人类思维的内部运作和微妙之处,发现传统上不可能分析的方面。
虽然过去故事总是由我们人类撰写,但随着深度学习领域的发展和研究,我们看到计算机程序能够编写故事,并像人类一样使用语言,但如何做到呢?
当你读最后两段时,你对每个单词的理解都是基于前面的句子和单词。你用以前的数据来理解现在的数据。传统的神经网络会查看循环中的每个单词,并且只理解每个单词的字面意思,而不考虑其上下文或之前可能添加了信息的任何单词。这使得它们在试图理解上下文(和过去的信息)重要的信息时非常糟糕。那么我们如何解决这个问题呢?
递归神经网络
RNNs 是一种特殊类型的神经网络,具有循环,允许信息在网络的不同步骤中保持不变。

该循环使神经网络在决定当前单词的实际意思之前,返回并检查所有先前单词中发生的事情。RNN 可以被认为是一次又一次地复制粘贴同一个网络,每一次新的复制粘贴都会比前一次添加更多的信息。

RNN 神经网络的应用与传统神经网络有很大的不同,因为它们没有一个输出和输入集作为一个具体的值,相反,它们把序列作为输入或输出。
那么我们可以用 RNNs 做什么呢?
- 自然语言处理
- 股票市场数据(时间序列分析)
- 图像/视频字幕
- 翻译
- 还有更多
RNN 也有不同的模式可以效仿。
- 固定到序列
RNN 接受固定大小的输入,并输出一个序列。

Image captioning takes an image and outputs a sentence of words
2.序列到固定
RNN 接受一个输入序列并输出一个固定的大小。

Sentiment analysis where a given sentence is classified as expressing positive or negative sentiment
3.序列到序列
RNN 接收一个输入序列并输出一个序列。

Machine Translation: an RNN reads a sentence in one language and then outputs it in another
这应该有助于你对 RNNs 有一个高层次的理解,如果你想了解更多关于 RNN 运算背后的数学知识,我推荐你查看这个链接!
消失梯度问题
这个问题发生在任何使用基于梯度的优化技术的网络中。当计算反向传播时(计算相对于权重的损失梯度),随着反向传播算法在网络中移动,梯度变得非常小。这导致早期层的学习速度比后期层慢。这降低了 rnn 的有效性,因为它们通常不能完全考虑长序列。随着所需信息之间的差距越来越大,RNN 变得越来越低效。

现在,这个问题的一个常见解决方案是使用不会导致渐变消失的激活函数,如 RELU,而不是其他激活函数,如 sigmoid 或双曲线正切。一个更好的解决方法是使用长短期记忆网络!
长短期记忆
LSTM 网络的建立只有一个目的——解决传统无线网络的长期依赖性问题。记住很久以前的事情是他们与生俱来的天性,他们根本不会为此而挣扎。

The repeating module in an LSTM contains 4 layers, as opposed to only one in an RNN.
LSTMs 工作良好的原因主要是由于网络中存在的小区状态。这是您在图中看到的穿过网络顶部的线。信息很容易在细胞状态中流动而不会改变。连接到单元状态的门能够在需要时添加或删除信息。有一堆更复杂的数学材料,你可以在这里阅读更多关于的内容,但总的来说,LSTMs 真的很擅长记忆旧信息。
神经机器翻译
既然我们对 LSTMs 和 RNNs 有了基本的了解,让我们试着用 Keras 开发一个机器翻译模型。
这将演示一个序列到序列 LSTM 网络如何被用来将文本从英语翻译成法语。数据可以在这里找到。
我们从 Keras 导入 LSTM 层,并在这里设置几个重要的变量。
现在我们需要将我们的文本矢量化成数字格式,这使得神经网络更容易处理。你可以在这里阅读更多关于这是如何工作的。
现在我们需要创建我们的模型。因为这是一个序列到序列模型,我们需要两个部分——编码器和解码器。编码器抛出一个隐藏状态,它包含了作为输入获得的所有信息。然后,解码器获取这些信息,然后生成指定格式的输出(在本例中是法语)。
在这之后,就像训练模型和使用它一样简单。所有代码的详细回顾可以在这里找到。在我的网站上查看现场演示。
TL;速度三角形定位法(dead reckoning)
RNNs 和 LSTM 网络今天正在提供非常酷的用例,我们看到它在大量技术中得到应用。
递归神经网络不同于传统的人工神经网络,因为它们不需要固定的输入/输出大小,并且它们还使用以前的数据来进行预测。
LSTM 网络是专门为解决 rnn 中的长期依赖性问题而制造的,并且它们超级擅长通过使用小区状态来利用来自前一段时间的数据(这是其本质所固有的)。
如果你喜欢我的文章或者学到了新东西,请务必:
- 在 LinkedIn 上和我联系。
- 给我发一些反馈和评论(aryanmisra@outlook.com)。
- 在我的网站上查看现场演示:https://aryanmisra.com/translate/
使用 Rtweet R package 与肯尼亚电力和照明公司(KPLC)一起分析肯尼亚人的困境。

Kenyans on the streets demonstrating against KPLC.
引言。
肯尼亚电力和照明公司(KPLC)向肯尼亚各地的客户输送、分配和零售电力。它是服务的唯一提供者。
在过去的几周里,肯尼亚人在推特上表达了他们对公用事业公司糟糕的服务的不满。KPLC 意识到了困境,但正在花时间解决这个问题。
在本文中,我们将使用 Rtweet 包来收集和分析针对 KPLC 的 twitter 投诉,并更好地了解肯尼亚人在使用 KPLC 服务时所面临的问题。
入门。
我们必须建立一个 twitter 账户(如果你没有的话)。
使用这个帐户,我们将建立一个应用程序,能够使用 r 访问 twitter。
关于在 twitter 中设置应用程序以访问推文的全面指南,请阅读使用您的 twitter 帐户设置 twitter 应用程序中的指南。
我们将使用 rtweet、tidy text和tidy verse软件包,并使用以下命令安装它们:**
***Install.packages(c(“rtweet”,”tidytext”,”tidyverse”))***
然后,我们将使用以下命令加载库:
*****#loading required libraries*** *library(rtweet)
library(tidyverse)
library(tidytext)***
在推特上搜索对 KPLC 的投诉。
让我们首先找到所有带有 KPLC 标签的推文。我们将使用带有以下参数的*search _ tweets()*函数:
问 —这是我们要寻找的查询词。
n —我们希望返回的推文数量。twitter 设定的最大限额是 18000 条推文。
Include_rts() —如果我们想要包含共享的推文(retweets),我们将它设置为 TRUE,否则我们使用 FALSE。
郎:我们将只过滤那些英文推文。
****#collecting tweets**kplc<-search_tweets(q=”KPLC”,n=15000,lang=”en”,include_rts = FALSE)**
策划推文。
下图显示了从 7 月 24 日到 7 月 31 日每天生成的推文的时间序列。大多数推文都是在 7 月 24 日生成的,有趣的是,这一天正是示威游行在街头举行的日子。
****#plot time series of the tweets**
kplc %>% ts_plot(by="days",trim = 1L)+
geom_point()+
theme_minimal()+
theme(plot.title = element_text(size=15, hjust=0.5, face="bold", colour="red", vjust=-1),
plot.subtitle=element_text(size=10, hjust=0.5, face="italic", color="red"))+
labs(x="Day of Tweet",y="Tweet Count",title = "COMPLAINTS TWEETS COUNTS FOR THE PAST DAYS",
subtitle = "Tweet Count Generated on a daily basis")**

Tweet counts per day by the KPLC customers
清洁&分析客户投诉推文。
我们将分析推特上使用的文本,以理解肯尼亚人对公用事业公司的困境。
****#preview of the text elements**
head(kplc$text)
[1] "[@KenyaPower_Care](http://twitter.com/KenyaPower_Care) Dear Kenya Power. It's been 5months since our power was disconnected ostensibly to investigate unlawful connection of power by an individual living among us in Utawala. We have made countless trips to KPLC offices to pursue this matter in vain. This darkness is a security threat."
[2] "[@KenyaPower_Care](http://twitter.com/KenyaPower_Care) Dear Kenya Power. It's been 5months since our power was disconnected ostensibly to investigate unlawful connection of power by an individual living among us in Utawala. We have made countless trips to KPLC offices to pursue this matter in vain. This darkness is a security threat."
[3] "[@KenyaPower_Care](http://twitter.com/KenyaPower_Care) [@kot](http://twitter.com/kot) [@citizentvkenya](http://twitter.com/citizentvkenya) how long do one need to visit kplc office for your matter to be solved?\n#kplcmonoply should stop"**
在进行分析时,URL 并不重要,我们将通过以下命令消除它们:
****#removing http element**
kplc$text<-gsub("http.*","",kplc$text)**
然后我们将使用 tidytext 包中的 unnest_tokens() 函数来神奇地清理文本。该函数清除以下内容:
与文本相关的所有标点符号(逗号、句号)都将被删除。
添加与每个 tweeted 单词的出现相关联的唯一 id。
推文被转换成小写。
我们创建一个新的变量单词来保存清理后的文本。
****#remove punctuation, convert to lowercase, add id for each** tweettext_clean<-kplc %>% select(text) %>% unnest_tokens(word,text)**
然后,我们将按照出现的顺序对前 20 个单词进行排序,并绘制结果。
****#plotting the top 20 words in the tweets**text_clean %>% count(word,sort = TRUE) %>%top_n(20) %>%mutate(word=reorder(word,n)) %>%ggplot(aes(x=word,y=n))+geom_col()+coord_flip()+theme_minimal()+theme(plot.title = element_text(size=15, hjust=0.5, face="bold", colour="red", vjust=-1))+labs(x="Unique Words",y="Word Count",title="Count Of Unique Words Used")**

Unique words used in the complaints tweets
从我们的情节来看,有些独特的词,如 to、From、on、at,对我们的分析来说并不重要。这些字是 停止字 ,我们将使用 anti_join() 命令删除它们。
****#removing stop words**
kplc_clean<-text_clean %>% anti_join(stop_words)**
然后,我们只过滤推文中使用的前 10 个词,然后绘制结果。
****#plotting top 10 words**
kplc_clean %>% count(word,sort = TRUE) %>%
top_n(10) %>%
mutate(word=reorder(word,n)) %>%
ggplot(aes(x=word,y=n))+
geom_col()+
coord_flip()+
theme_minimal()+
theme(plot.title = element_text(size=15, hjust=0.5, face="bold", colour="red", vjust=-1))+
labs(x="Unique Words",y="Word Count",
title="Count Of Unique Words Used")**

Top unique words used in the text
结果。
Kenyapower_care 是公用事业公司的客户关怀 twitter 句柄,因此大多数投诉都引用该句柄,同时在 Twitter 上发布他们的问题。
账户、预付费、已确认、mpesa、transcation、余额 都是向 KPLC 某预付费账户的移动资金转账报文。大多数发推的客户都有他们预付 KPLC 账户的问题,希望服务提供商解决这个问题。
探索一起出现的单词。
我们希望通过探索一起出现的单词来对文本做进一步的分析,以获得更多的见解。
我们将使用 widyr 软件包进行分析。
*****#loading package***
library(widyr)**
我们将使用*unnest _ token()*函数对文本进行清理,并保存在一个名为 paired_words 的变量中。 ngrams 指定单词是成对的, n 是单词在一起的个数。
我们对一起使用的前 10 个单词进行排序,然后输出一个图。
*****#exploring words that occur together***
library(widyr)
kpl_pairs<-kplc %>% select(text) %>% unnest_tokens(paired_words,text,token = "ngrams",n=5)kpl_pairs %>% count(paired_words,sort = TRUE) %>% top_n(10) %>%
mutate(paired_words=reorder(paired_words,n)) %>%
ggplot(aes(x=paired_words,y=n))+
geom_col()+
coord_flip()+
theme_minimal()+
theme(plot.title = element_text(size=15, hjust=0.5, face="bold", colour="red", vjust=-1))+
labs(x="Unique Words",y="Word Count",
title="Count Of Unique Words Used")**

Exploring words used together in the tweets
为预付 KPLC 账户发送的大部分移动货币(M-Pesa)金额在 【凯斯 500】凯斯 1000凯斯 100 和 凯斯 300 的维度中。
分析 KPLC 对投诉的回应。
在这个分析中,我们将分析公用事业公司 customer care 如何回应 twitter 投诉。
我们将使用*get _ timeline()*函数来获取客户关怀 twitter 句柄专门发送的推文数量(n)。
*****# obtaining customer care response tweets***
kplc_timeline<-get_timeline("KenyaPower_Care",n=10000)**
我们将清理后的文本保存在变量 care_response 中,然后绘制输出。

Response by Kenya power customer care
KPLC 客户服务部无法立即解决该问题,并要求客户在处理令牌生成问题时保持耐心。
结论。
我们从 twitter 文本分析中获得了关于肯尼亚人与公用事业公司 KPLC 的困境的宝贵见解。
有关收集和分析 Twitter 数据的更多指导,您可以查看以下链接:
https://mkearney.github.io/nicar_tworkshop/#1
** [## 用 R 中的 TidyText 挖掘 Twitter 数据
完成本教程后,您将能够:清理或“管理”社交媒体数据,为分析做准备。使用…
www.earthdatascience.org](https://www.earthdatascience.org/courses/earth-analytics/get-data-using-apis/text-mining-twitter-data-intro-r/) [## 社交媒体分析的力量:使用 R
介绍
medium.com](https://medium.com/@wanjirumaggie45/the-power-of-social-media-analytics-twitter-text-mining-using-r-1fceb26ac32b)
欢迎喜欢、评论和分享这篇文章。更多讨论,你可以通过 Linkedln 或 twitter 联系我。**


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言










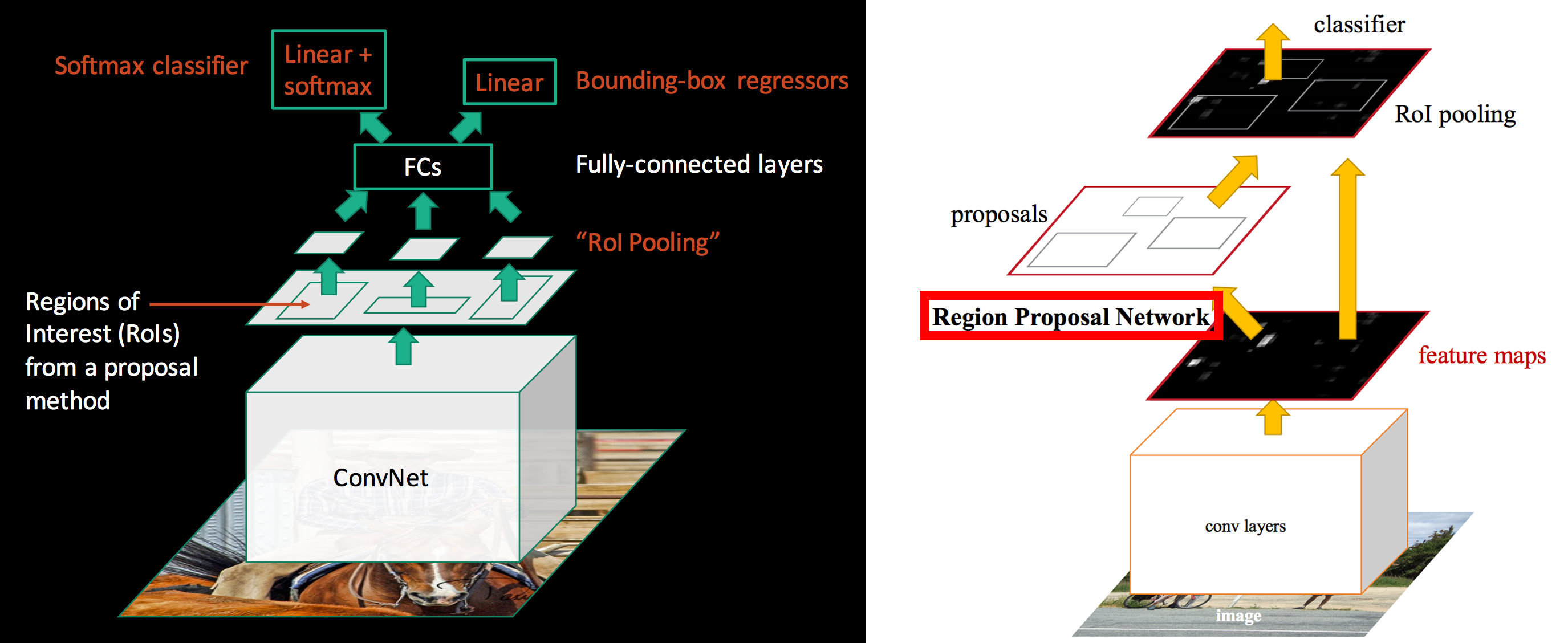{kind=link}
{kind=link}