







上传大文件到 GitHub
3 种避免在上传过程中收到错误信息的方法

Photo by Jay Wennington on Unsplash
GitHub 有严格的 100MB 文件限制。如果你只是上传几行代码,这不是你需要担心的事情。然而,如果你想上传一点数据,或者二进制的东西,这是一个你可能想要跨越的限制。这里有三种不同的方法来克服 100MB 的限制。
原载于我的博客edenau . github . io。
1.。gitignore
创建一个文件 。gitignore 在存储库的父目录中,存储所有希望 Git 忽略的文件目录。使用*作为通配符,这样您就不需要在每次创建新的大文件时手动添加文件目录。这里有一个例子:
*.nc
*.DS_store
这些被忽略的文件会被 Git 自动忽略,不会上传到 GitHub。不再有错误消息。
2.仓库清理器
如果你不小心在本地提交了超过 100MB 的文件,你将很难把它推送到 GitHub。它不能通过删除大文件并再次提交来解决。这是因为 GitHub 跟踪每一次提交,而不仅仅是最近一次。从技术上讲,您是在整个提交记录中推送文件。

Photo by Samuel Zeller on Unsplash
虽然您可以通过分支在技术上解决它,但这绝不是简单的。幸运的是,您可以运行一个 库清理器 ,它会自动清理所有的大文件提交。
下载 BFG 回购清理器 bfg.jar 并运行以下命令:
java -jar [bfg.jar](https://rtyley.github.io/bfg-repo-cleaner/#download) --strip-blobs-bigger-than 100M <your_repo>
它会自动清理您的提交,并生成一个新的提交,注释为“删除大文件”。按下它,你就可以走了。
3.吉特 LFS
你可能已经注意到,上述两种方法都避免上传大文件。如果您真的想上传它们,以便在另一台设备上访问它们,该怎么办?
Git 大文件存储让你把它们存储在一个远程服务器上,比如 GitHub。将 git-lfs 放入您的 $PATH 中下载并安装 。然后,您需要对每个本地存储库运行一次下面的命令**😗*
git lfs install
大文件由以下人员选择:
git lfs track '*.nc'
git lfs track '*.csv'
这会创建一个名为 的文件。gitattributes ,瞧!您可以正常执行添加和提交操作。然后,你首先需要 a)将文件推送到 LFS,然后 b)将指针推送到 GitHub。以下是命令:
git lfs push --all origin master
git push -u origin master

Photo by Lucas Gallone on Unsplash
Git LFS 上的文件可以在 GitHub 上找到,标签如下。

为了将存储库拉到另一个设备上,只需在那个设备上安装 git-lfs (每个本地存储库)。
相关文章
感谢您的阅读!如果您对数据科学感兴趣,请查看以下文章:
超越 lambda、map 和 filter 的 Python 技巧
towardsdatascience.com](/5-python-features-i-wish-i-had-known-earlier-bc16e4a13bf4) [## 为什么样本方差除以 n-1
解释你的老师没有教过的高中统计学
towardsdatascience.com](/why-sample-variance-is-divided-by-n-1-89821b83ef6d)
原载于我的博客edenau . github . io。
使用 SMOTE 对分类项目进行上采样
或者我是如何学会开始担心阶级不平衡的

你是否曾经对自己说:“世界上没有足够的坏酒。”?
真的吗?只有我吗?好吧,我应该解释一下。我最近在处理一个葡萄酒数据集的分类问题。基本上,我有葡萄酒的化学成分值和平均用户评级,表面上是 1-10 的评级尺度,10 是最高的。
现在看来,人们并不真的很擅长分辨高档酒和廉价酒。这让我的前提变得非常简单:确定对大多数人来说尝起来像醋的葡萄酒,其他任何葡萄酒对大多数餐馆来说都很好。所以我把“坏”酒(在这个实验中,那些评分为 3 和 4 的)和“好”酒(其他的)区分开来。
但是有一个问题:我没有喝足够的烈酒。

Oh bother.
我的红酒数据库中只有 61 种“坏”酒,而有 1286 种“好”酒。“好”和“坏”的比例是 21:1。事实上,我的模型很可能每次都简单地预测多数类。我需要找到一种方法来平衡这些课程。要是以前有人碰到过这个问题就好了…
对,当然。每个数据科学家都遇到过这个问题。我知道。答案显然是重新采样。
重采样与合成采样
首先简单介绍一下重采样。谈到重采样,基本上有两大阵营:过采样和欠采样。欠采样是从多数类(在这种情况下是“好”葡萄酒)中随机选择观察值的过程,以便它具有与少数类相等数量的观察值(例如,我最终得到 61 个“好”葡萄酒和 61 个“坏”葡萄酒)。这在我的情况下不起作用,因为欠采样意味着我会丢失大部分观察结果,从而丢失我的信息。
那么过采样。过采样是指我们为少数类创建新的观察值,这些观察值在我们现有的数据中并不存在。通常,这是通过从少数类中复制观测值并将其添加到数据集中来实现的,因此您可以增加少数类的大小。
好消息是,您的模型将了解更多关于少数民族的信息,而不仅仅是针对给定的观察预测多数民族。坏消息是,它也可能会过度适应那些你已经重复多次的观察的特征。这就是 SMOTE 的用武之地。
击杀
SMOTE 代表合成少数过采样技术。SMOTE 执行与基本重采样相同的基本任务(为少数类创建新的数据点),但它不是简单地复制观测值,而是沿着随机选择的点及其最近邻创建新的观测值。基本上,您是在模拟数据中的一些额外变化(在您的少数类的既定范围内),减少了过度拟合的危险(尽管没有消除)。
下一个问题(对我来说也是一个大问题)是我们应该把少数民族班级扩大到多大?要回答这个问题,我需要思考我在尝试优化我的模型是为了什么。在我的例子中,我试图正确地识别“坏”酒。我不介意错误地将一些实际上还不错的葡萄酒归类为“劣质”,因为世界上有很多葡萄酒可供选择,但我想确保我们找到了劣质酒。这意味着我需要优化召回,以避免假阴性。
现在我知道我在优化什么了,我应该追求什么样的多数:少数比例?我看过很多在少数和多数类之间建立 1:1 关系的教程,但这意味着 1000+新的综合观察。在大量阅读和一些实验之后,我最终得到了一个占最终完整数据集 15%的少数民族班级。
下面是一些代码!
这大概就是你要找的。下面是实际执行上采样的几个函数。请注意,这应该在您完成培训/测试分割后进行。首先,我们将这些类分开:
def resamplingDataPrep(X_train, y_train, target_var):
# concatenate our training data back together
resampling = X_train.copy()
resampling[target_var] = y_train.values
# separate minority and majority classes
majority_class = resampling[resampling[target_var]==0]
minority_class = resampling[resampling[target_var]==1]
# Get a class count to understand the class imbalance.
print('majority_class: '+ str(len(majority_class)))
print('minority_class: '+ str(len(minority_class)))
return majority_class, minority_class
然后执行上采样本身:
def upsample_SMOTE(X_train, y_train, ratio=1.0):
"""Upsamples minority class using SMOTE.
Ratio argument is the percentage of the upsampled minority class in relation
to the majority class. Default is 1.0
"""
sm = SMOTE(random_state=23, sampling_strategy=ratio)
X_train_sm, y_train_sm = sm.fit_resample(X_train, y_train)
print(len(X_train_sm), len(y_train_sm))
return X_train_sm, y_train_sm
就是这样!
互动地图上的美国制药公司:通过排名和人工智能(AI)的使用进行分类

简介:
上周,我有机会参加了由美国孟加拉药物科学家协会在马里兰州贝塞斯达举办的会议。在会议上,我与来自制药行业和 FDA 的人交谈。在那些谈话中,我发现大多数在位于该国东海岸的制药公司工作的人,令人惊讶的是,该国有许多我从未听说过的公司。我合理地问自己,“大多数制药公司都位于东海岸吗?或者它们是如何分布在各州的?为什么我没有听说过这些公司的名字”?。在谷歌上快速搜索“美国制药公司”给了我几个链接。其中,这两个(drugs.com 和 rxlist.com)网站很有帮助,到目前为止,drugs.com 包含了更多的信息。所以,我开始用 python 保存所有公司的信息,包括它们在 drugs.com 的地址。
数据:
这里是我写的代码的快照,但是为了保持文章简短,我不会在这里分享所有的代码。
这个代码让我想到网站上有 404 家公司。所以,我开始从链接中收集这些公司的地址。大约有 80 个链接是灰色的,我发现它们要么被大公司收购,要么是大公司的一部分。所以,我剩下了大约 320 个链接。在第一次尝试中,我保存了 262 家公司的信息,包括名称、完整地址、网站和职业页面链接。在另一次尝试中,它只给了我一些公司的信息(名称和地址)。然后,我手动添加了一些数据,总共创建了 308 家公司的信息,包括它们在该国的实际地址。
第一张地图:
现在,我使用名为“googlegeocoder”的 python 库找到了这 308 个物理地址的纬度和经度。然后,我用 python 的“叶子”库创建了我的第一张地图。现在我想知道,如何在地图上找到顶尖的制药公司?
更多数据:
接下来,我在谷歌上搜索顶级制药公司,结果发现 pharmexec.com 是排名前 50 的制药公司的好来源。由于它们被列为图片或带有各自公司的标志,我无法使用我的编码技能。但我还是想回答之前被问到的问题。因此,当我在实验室用脱脂牛奶封闭蛋白质印迹膜时,我不得不手动收集数据。在我对制药公司的信息进行研究期间,我发现相当多的公司将人工智能(AI)用于药物发现,这篇文章题为“33 家制药公司在药物发现中使用人工智能”。这就是为什么我很好奇,想看看地图,看看哪些公司一直在使用人工智能。
这些数据如下所示:

最终地图:
有了这些数据,我就能制作出我的最终地图了。点击下面的链接查看。
或者在您的浏览器中复制并粘贴以下链接
https://bit.ly/2NWBT7u
你可以放大和缩小左上角的按钮。你也可以用光标拖动和移动页面。
地图上的颜色是如何工作的?
如果你点击彩色图标,它会显示公司的名称和一些其他信息,如下图所示。

- 如果一家公司被列为 50 强并使用人工智能,它将被标记为-红色
- 顶部但不使用人工智能-蓝色
- 不顶但是用 AI-紫色
- 不顶也不用 AI——绿色。
现在,我可以想象你在想什么。你想要资源(代码、数据)还玩它!!所有代码和数据都可以在我的 github_page 上找到
感谢阅读。请不要犹豫,在文章下面评论。
最初发表于 linkedin
参考资料:
- Drugs.com 制药公司。从 https://www.drugs.com/pharmaceutical-companies.html取回
- 克里斯特尔,M. (2019)。pharm Exec 2019 年 50 强企业。从 http://www.pharmexec.com/pharm-execs-top-50-companies-2019取回
- 史密斯,S. (2017)。33 家制药公司在药物研发中使用人工智能。检索自https://blog . bench sci . com/pharma-companies-using-artificial-intelligence-in-drug-discovery
我的 linkedin
[## Yousuf Ali -研究生研究助理-德州理工大学健康科学中心| LinkedIn
孟加拉国达卡 Narayangonj ACI 有限公司产品开发官员。
www.linkedin.com](https://www.linkedin.com/in/yousuf–ali/)
用 AI 用 Cloudsight + Python 为图片写标题
Pythonic API 允许您自动为图像编写人类可读的标题

How would you caption this? Credit: Gado Images.
如今市场上有很多使用人工智能和机器学习来标记图像的解决方案。IBM Watson、Imagga、Cloudsight、Google Vision 和微软 Azure 的解决方案都表现良好,通过 Algorithmia 等服务,你可以轻松地启动和训练自己的图像标记网络。
然而,为图像编写人类可读的句子长度的标题是一项更困难的任务。您生成的句子不仅需要准确描述场景中的对象,还需要捕捉它们彼此之间的关系、上下文等。它需要知道什么才是真正重要的——没有人想要一个对桌子上的每一个物体或背景中的每一株植物都进行详细描述的图像。当人工智能知道得太多时,它可能比知道得太少更糟糕。
总部位于洛杉矶的初创公司 Cloudsight 正致力于解决使用人工智能和机器学习来自动为图像编写句子长度、人类可读的字幕的挑战。
他们为特定应用提供完全定制的人在回路系统,但他们也有一个通用模型,你可以很快开始测试,并返回一些令人印象深刻的结果。这是他们唯一的人工智能系统,但同样,你也可以将其插入人类团队,并获得更好的输出(以更高的价格和更多的训练时间)。
入门指南
要开始使用 Cloudsight API 进行测试,您不能像在 IBM 或 Google Vision 中那样注册一个帐户。Cloudsight 是一家新兴公司,他们喜欢与潜在的新客户进行合作,尤其是在早期测试阶段。
好消息是他们反应很快。通过他们网站上的联系方式联系他们,他们通常会在几个小时后回来。你甚至可能会听到他们的首席执行官或团队的高级成员的消息。Cloudsight 通常可以提供 API 访问和一定数量的免费 API 调用来进行测试。我得到了 1000 个免费的 API 调用来开始。
一旦你联系并设置好了,他们会给你一个 API 密匙。
准备 Python
方便的是,Cloudsight 有一个随时可用的 Python 库。
用 pip 安装。
pip install cloudsight
如果你还没有,我也喜欢通过 Pillow 安装 PIL,这是一个图像处理库。
pip install pillow
预处理
首先,选择要处理的图像。我将使用本文顶部的那张照片,它是由我公司的一位新西兰摄影师拍摄的。
设置基本导入。
from PIL import Imageimport cloudsight
我喜欢先通过 PIL 的缩略图功能将图像缩小到标准尺寸。这使得它更小,更容易上传。如果你不这样做,Cloudsight 会帮你做,但是发送更少的字节更容易,所以你也可以在你这边精简一下。
这是标准的东西——你接收图像,使用缩略图功能使其大小一致,然后再次保存。
im = Image.open('YOURIMAGE.jpg')im.thumbnail((600,600))im.save('cloudsight.jpg')
打电话
现在您已经有了一个经过适当处理的图像,您可以进行实际的 API 调用了。首先,使用 API 密钥进行身份验证。
auth = cloudsight.SimpleAuth('YOUR KEY')
接下来,打开您的图像文件,并发出请求:
with open('cloudsight.jpg', 'rb') as f:
response = api.image_request(f, 'cloudsight.jpg', {'image_request[locale]': 'en-US',})
接下来的一点有点出乎意料。因为 Cloudsight 有时会有人参与,所以您需要给他们几秒钟或更长的时间来完成他们的请求。这与 API 对 Watson 等标签服务的请求略有不同,后者往往会立即完成。
使用 Cloudsight,您可以调用 wait 函数,并定义最大等待时间。30 秒通常足够了。
status = api.wait(response['token'], timeout=30)
最后,打印出响应!
print status
回应
Cloudsight 将返回一个包含响应数据的对象。这是我得到的上面的图像。
{u'status': u'completed', u'name': u'man in gray crew neck t-shirt sitting on brown wooden chair', u'url': u'https://assets.cloudsight.ai/uploads/image_request/image/734/734487/734487841/cloudsight.jpg', u'similar_objects': [u'chair', u't-shirt', u'crew neck'], u'token': u'fgo4F5ufJsQUCLrtwGJkxQ', u'nsfw': False, u'ttl': 54.0, u'structured_output': {u'color': [u'gray', u'brown'], u'gender': [u'man'], u'material': [u'wooden']}, u'categories': [u'fashion-and-jewelry', u'furniture']}
这是非常酷的东西!正如你所看到的,系统给图片加了标题**“一个穿着灰色圆领 t 恤的男人坐在棕色的木椅上。”**说得好极了!
除了非结构化的句子,API 还给我关于图像的结构化数据,比如图像中的颜色(灰色、棕色)、人的性别(男人)、类别和呈现的材料。
在一次调用中结合结构化和非结构化数据非常有帮助——您可以进行标记或语义映射,同时还可以获得人类可读的句子来描述图像。
这是完整的节目单。
from PIL import Imageimport cloudsight im = Image.open('YOUR IMAGE')im.thumbnail((600,600))im.save('cloudsight.jpg')auth = cloudsight.SimpleAuth('YOUR API KEY')api = cloudsight.API(auth)with open('cloudsight.jpg', 'rb') as f:response = api.image_request(f, 'cloudsight.jpg', {'image_request[locale]': 'en-US',})status = api.wait(response['token'], timeout=30)print status
这是一个句子长度的图像字幕,通过人工智能,大约 10 行代码!
从这里去哪里
如果您想在测试后扩大您对 Cloudsight 的使用,该团队可以帮助您为生产做好准备。他们不报一般价格,这完全取决于您的预计数量、使用情形和所需的任何额外培训。
如果通用模型的输出还不错,但并不完美,您还可以与团队合作,根据您的特定用例对其进行定制。例如,我正与他们合作,将人类部分引入到处理历史图像的循环中。定价可能会高于纯人工智能解决方案,但它也将更具体地针对我的用例。这是与新兴公司合作的最大好处,因为他们能更好地满足你的特殊需求。
如果你对自动图像字幕感兴趣,可以看看 Cloudsight!同样,使用 Python,您可以在几分钟内开始为您的图像添加字幕——或者只是使用这一新功能——而且只需很少的代码!
通过 Spring Boot 或 Java 使用 Apache Drill,使用 SQL 查询来查询数据
在过去的几篇文章中,我们看到了如何将 Apache Drill 与 MongoDB 连接起来,以及如何将与 Kafka 连接起来,使用简单的 SQL 查询来查询数据。但是,当您想将它应用到实际的项目中时,您不能整天坐在那里从终端查询数据。你想写一段代码来替你做脏活。但是如何在代码中使用 Apache Drill 呢?今天,我们将看看如何用 Spring Boot 或几乎任何其他 Java 程序来实现这一点。

依赖关系
对于这个概念验证,我将编写一个简单的 Spring Boot CommandLineRunner 程序。但是您可以使用几乎任何其他 Java 框架或普通的 Java 代码来实现这一点。如果你有一个依赖管理工具,比如 Maven 或者 Gradle,你可以在项目中添加依赖,然后继续编码。否则,可以添加所需的*。jar* 文件到类路径,这样应该就可以了。所有需要的*。jar* 文件随 Apache Drill 的发行版一起提供。
这个项目我们会和 Maven 一起去。在项目的 pom.xml 文件的依赖项部分中添加以下 Drill 依赖项。
<dependency>
<groupId>org.apache.drill.exec</groupId>
<artifactId>drill-jdbc-all</artifactId>
<version>1.16.0</version>
</dependency>
这种依赖性在 Maven 中央存储库中是可用的,因此您不需要添加任何额外的存储库。
代码
现在让我们开始有趣的部分。首先,我们需要在 Java 代码中加载 Drill JDBC 驱动程序。为此,我们将使用 Class.forName() 方法:
Class.forName("org.apache.drill.jdbc.Driver");
接下来,我们需要使用 DriverManager 和 Drill JDBC 连接字符串创建一个连接。如果您使用 Apache Drill 的独立本地实例,则需要使用以下连接字符串:
jdbc:drill:drillbit=localhost
如果您将 Drill 与 Zookeeper 一起使用,则必须使用以下连接字符串:
*jdbc:drill:zk=local*
因为我使用的是本地实例,所以我将创建一个连接来进行如下钻取:
Connection connection = DriverManager.getConnection("jdbc:drill:drillbit=localhost");
接下来,我们需要创建一个语句对象,使用它我们将运行实际的查询。一旦我们有了对象,我们将使用*。executeQuery()* 方法在对象上得到我们的 ResultSet :
Statement statement = connection.createStatement();
ResultSet resultSet = statement.executeQuery("select * from kafka.`drill` limit 10");
我使用了与前面的 MongoDB 和 Kafka 示例相同的数据集和示例。
从上面的例子可以看出,我们从 Kafka 主题 *drill 中获取数据。*让我们看看如何访问数据:
while(resultSet.next()){
logger.info("ID: " + resultSet.getString(1));
logger.info("First Name: " + resultSet.getString(2));
logger.info("Last Name: " + resultSet.getString(3));
logger.info("Email: " + resultSet.getString(4));
logger.info("Gender: " + resultSet.getString(5));
logger.info("IP Address: " + resultSet.getString(6));
logger.info("----------------------------------");
}
接下来,让我们查询一个 MongoDB 数据库并从中获取一些数据:
resultSet = statement.executeQuery("select * from mongo.drill.sampleData limit 10");
我们可以使用上面相同的 while() 循环来打印数据。
差不多就是这样。我们现在能够在 Java 程序中使用 Apache Drill 作为简单的 JDBC 源,从 Drill 支持的任何源获取数据。您可以对复杂的 SQL 查询进行同样的尝试,看看 Drill 是如何工作的。
如果你对这个例子中完整的 Spring Boot 项目感兴趣,你可以在我的 GitHub 简介上查看。
Google 的通用句子编码器在生产中的用例

在自然语言处理(NLP)中建立任何深度学习模型之前,文本嵌入起着主要作用。文本嵌入将文本(单词或句子)转换成数字向量。
为什么我们要把文本转换成向量?
向量是特定维度的数字数组。一个 5×1 大小的向量包含 5 个数,我们可以把它看作 5D 空间中的一个点。如果有两个 5 维的向量,它们可以被认为是 5D 空间中的两点。因此,我们可以根据这两个向量之间的距离来计算它们的远近。
因此,在机器学习的研究中,大量的努力被投入到将数据转换成向量中,因为一旦数据被转换成向量,我们就可以通过计算它们的距离来判断两个数据点是否相似。像 Word2vec 和 Glove 这样的技术是通过将单词转换成矢量来实现的。因此“猫”的对应向量将比“鹰”更接近“狗”。但是在嵌入一个句子时,需要在这个向量中捕获整个句子的上下文以及单词。这就是“通用句子编码器”的用武之地。
通用语句编码器将文本编码成高维向量,这些向量可用于文本分类、语义相似性、聚类和其他自然语言任务。预训练的通用句子编码器在 Tensorflow-hub 公开提供。它有两种变化,即一种用变压器编码器训练,另一种用深度平均网络(DAN) 训练。这两者在准确性和计算资源需求之间有一个折衷。虽然具有变换器编码器的那个具有更高的精度,但是它在计算上更加密集。使用 DNA 编码的方法在计算上花费较少,并且准确性也稍低。
这里,我们将使用变压器编码器版本。在 5 GB ram 实例中,它与其他 5 个深度学习模型一起运行时,对我们来说效果很好。此外,我们可以使用这个版本的通用语句编码器在嵌入级别训练一个具有 150 万数据的分类器。我遇到的通用句子编码器的几个用例是:
- 作为深度学习模型开始时的嵌入层。
- 通过寻找语义相似的句子来执行分类。
- 在分析之前去掉重复的句子或短语。
让我们看看如何使用 Tensorflow-hub 上提供的预训练通用句子编码器,用于 python 中的上述用例。
首先,让我们导入所需的库:
import tensorflow as tf
import tensorflow_hub as hub
在生产中使用时,我们需要将预先训练好的通用语句编码器下载到本地,这样我们每次调用它时都不会被下载。
#download the model to local so it can be used again and again
!mkdir ../sentence_wise_email/module/module_useT
# Download the module, and uncompress it to the destination folder.
!curl -L "[https://tfhub.dev/google/universal-sentence-encoder-large/3?tf-hub-format=compressed](https://tfhub.dev/google/universal-sentence-encoder-large/3?tf-hub-format=compressed)" | tar -zxvC ../sentence_wise_email/module/module_useT
在这里,”…/sentence _ wise _ email/module/module _ useT”是下载句子编码器文件的文件夹。该编码器优化了大于单词长度的文本,因此可以应用于句子,短语或短段落。
例如(官方网站示例):
embed = hub.Module("../sentence_wise_email/module/module_useT")# Compute a representation for each message, showing various lengths supported.
word = "Elephant"
sentence = "I am a sentence for which I would like to get its embedding."
paragraph = (
"Universal Sentence Encoder embeddings also support short paragraphs. "
"There is no hard limit on how long the paragraph is. Roughly, the longer "
"the more 'diluted' the embedding will be.")
messages = [word, sentence, paragraph]# Reduce logging output.
tf.logging.set_verbosity(tf.logging.ERROR)with tf.Session() as session:
session.run([tf.global_variables_initializer(), tf.tables_initializer()])
message_embeddings = session.run(embed(messages))for i, message_embedding in enumerate(np.array(message_embeddings).tolist()):
print("Message: {}".format(messages[i]))
print("Embedding size: {}".format(len(message_embedding)))
message_embedding_snippet = ", ".join((str(x) for x in message_embedding[:3]))
print("Embedding[{},...]\n".
format(message_embedding_snippet))
它给出的输出:
Message: Elephant
Embedding size: 512
Embedding: [0.04498474299907684, -0.05743394419550896, 0.002211471786722541, ...]
Message: I am a sentence for which I would like to get its embedding.
Embedding size: 512
Embedding: [0.05568016692996025, -0.009607920423150063, 0.006246279925107956, ...]
Message: Universal Sentence Encoder embeddings also support short paragraphs. There is no hard limit on how long the paragraph is. Roughly, the longer the more 'diluted' the embedding will be.
Embedding size: 512
Embedding: [0.03874940797686577, 0.0765201598405838, -0.0007945669931359589, ...]
可以看出,无论是单词、句子还是短语,句子编码器都能够给出大小为 512 的嵌入向量。
如何在 Rest API 中使用
在 Rest API 中使用它时,您必须多次调用它。一次又一次地调用模块和会话将会非常耗时。(在我们的测试中,每次通话大约需要 16 秒)。可以做的一件事是调用模块并在开始时创建会话,然后继续重用它。(第一次呼叫需要大约 16s,然后连续呼叫需要大约. 3s)。
#Function so that one session can be called multiple times.
#Useful while multiple calls need to be done for embedding.
import tensorflow as tf
import tensorflow_hub as hub
def embed_useT(module):
with tf.Graph().as_default():
sentences = tf.placeholder(tf.string)
embed = hub.Module(module)
embeddings = embed(sentences)
session = tf.train.MonitoredSession()
return lambda x: session.run(embeddings, {sentences: x})embed_fn = embed_useT('../sentence_wise_email/module/module_useT')
messages = [
"we are sorry for the inconvenience",
"we are sorry for the delay",
"we regret for your inconvenience",
"we don't deliver to baner region in pune",
"we will get you the best possible rate"
]
embed_fn(messages)
输出是一个 5*512 维的矩阵。(每个句子是一个大小为 512 的向量)。因为这些值是归一化的,所以编码的内积可以被视为相似性矩阵。
encoding_matrix = embed_fn(messages)
import numpy as np
np.inner(encoding_matrix, encoding_matrix)
输出是:
array([[1\. , 0.87426376, 0.8004891 , 0.23807861, 0.46469775],
[0.87426376, 1.0000001 , 0.60501504, 0.2508136 , 0.4493388 ],
[0.8004891 , 0.60501504, 0.9999998 , 0.1784874 , 0.4195464 ],
[0.23807861, 0.2508136 , 0.1784874 , 1.0000001 , 0.24955797],
[0.46469775, 0.4493388 , 0.4195464 , 0.24955797, 1.0000002 ]],
dtype=float32)
从这里可以看出,“我们对给您带来的不便感到抱歉”和“我们对延迟感到抱歉”之间的相似度是 0.87(第 1 行,第 2 列),而“我们对给您带来的不便感到抱歉”和“我们将为您提供尽可能好的价格”之间的相似度是 0.46(第 1 行,第 5 列),这很惊人。还有其他方法可以从编码中找到相似性得分,如余弦相似性、曼哈顿距离等。(文末提到的我的 Github repo 里有代码)。
删除重复文本
在开发问答验证系统时,一个主要问题是回答语句的重复。遍历我们的可用数据,我们发现语义相似性得分> 0.8(通过上述编码的内积计算)的句子实际上是重复语句,因此我们删除了它们。
#It takes similarity matrix (generated from sentence encoder) as input and gives index of redundant statements
def redundant_sent_idx(sim_matrix):
dup_idx = []
for i in range(sim_matrix.shape[0]):
if i not in dup_idx:
tmp = [t+i+1 for t in list(np.where( sim_matrix[i][i+1:] > 0.8 )[0])]
dup_idx.extend(tmp)
return dup_idx
#indexes of duplicate statements.
dup_indexes = redundant_sent_idx(np.inner(encoding_matrix,
encoding_matrix))unique_messages = np.delete(np.array(messages), dup_indexes)
独特的信息是:
array(['we are sorry for the inconvenience',
"we don't deliver to baner region in pune",
'we will get you the best possible rate'], dtype='<U40')
基本上,它放弃了陈述“我们为延迟感到抱歉”和“我们为你的不便感到抱歉”,因为它们是第一句的重复。
通过查找语义相似的句子进行分类
在构建答案评估系统时,我们遇到了检测后续语句的问题。但是没有足够的数据来训练一个统计模型。多亏了通用句子编码器,我们可以解决这个问题。我们采用的方法是,创建一个所有可用数据的编码矩阵。然后获取用户输入的编码,看是否与任何可用数据的相似度超过 60%,以此作为后续。简单的问候标识可以是:
greets = ["What's up?",
'It is a pleasure to meet you.',
'How do you do?',
'Top of the morning to you!',
'Hi',
'How are you doing?',
'Hello',
'Greetings!',
'Hi, How is it going?',
'Hi, nice to meet you.',
'Nice to meet you.']
greet_matrix = embed_fn(greets)
test_text = "Hey, how are you?"
test_embed = embed_fn([test_text])
np.inner(test_embed, greet_matrix)
sim_matrix = np.inner(test_embed, greet_matrix)
if sim_matrix.max() > 0.8:
print("it is a greetings")
else:
print("it is not a greetings")
深度学习技术在自然语言处理、计算机视觉等领域的实现。-sambit 9238/深度学习
github.com](https://github.com/sambit9238/Deep-Learning/blob/master/tensorflow_hub_useT.ipynb)
https://tfhub.dev/google/universal-sentence-encoder-large/3
[## 通用句子编码器
我们提出了将句子编码成嵌入向量的模型,这些向量专门针对其他自然语言处理的迁移学习
arxiv.org](https://arxiv.org/abs/1803.11175)
使用 Cython 可以将 Python 代码的速度提高 30 倍以上

Cython will give your Python code super-car speed
想获得灵感?快来加入我的 超级行情快讯 。😎
Python 是社区最喜欢的编程语言!这是迄今为止最容易使用的方法之一,因为代码是以直观、人类可读的方式编写的。
然而,你经常会一遍又一遍地听到对 Python 的相同抱怨,尤其是来自 C 代码大师的抱怨: Python 很慢。
他们没有错。
相对于很多其他编程语言,Python 比较慢。基准测试游戏有一些比较各种编程语言在不同任务上速度的坚实基准。
我以前写过几个不同的方法可以加快速度:
(1)使用多处理库来使用所有的 CPU 内核
(2)如果您使用 Numpy、Pandas 或 Scikit-Learn,请使用 Rapids 来加速 GPU 上的处理。
如果您正在做的事情实际上可以并行化,例如数据预处理或矩阵运算,那就太棒了。
但是如果你的代码是纯 Python 呢?如果你有一个大的 for 循环,而你只有有可以使用,并且不能放入一个矩阵中,因为数据必须在序列中处理,那该怎么办?有没有办法加速 Python 本身?
这就是 Cython 加速我们的原始 Python 代码的原因。
Cython 是什么?
就其核心而言,Cython 是 Python 和 C/C++之间的中间步骤。它允许您编写纯 Python 代码,只需稍加修改,然后直接翻译成 C 代码。
您对 Python 代码所做的唯一调整是向每个变量添加类型信息。通常,我们可以像这样在 Python 中声明一个变量:
x = 0.5
使用 Cython,我们将为该变量添加一个类型:
cdef float x = 0.5
这告诉 Cython,我们的变量是浮点型的,就像我们在 c 中做的一样。使用纯 Python,变量的类型是动态确定的。Cython 中类型的显式声明使得到 C 的转换成为可能,因为显式类型声明是必需的+。
安装 Cython 只需要一行 pip:
pip install cython
Cython 中的类型
使用 Cython 时,变量和函数有两组不同的类型。
对于变量,我们有:
- cdef int a、b、c
- cdef char *s
- cdef 浮点型 x = 0.5(单精度)
- cdef double x = 63.4(双精度)
- cdef 列表名称
- cdef 词典进球 _for_each_play
- cdef 对象卡片 _ 卡片组
请注意,所有这些类型都来自 C/C++!对于我们拥有的功能:
- def —常规 python 函数,仅从 Python 调用。
- cdef — Cython only 不能从纯 python 代码访问的函数,即必须在 Cython 内调用
- cpdef — C 和 Python。可以从 C 和 Python 中访问
有了对 Cython 类型的了解,我们就可以开始实施我们的加速了!
如何用 Cython 加速你的代码
我们要做的第一件事是建立一个 Python 代码基准:一个用于计算数字阶乘的 for 循环。原始 Python 代码如下所示:
我们的 Cython 相同的功能看起来非常相似。首先,我们将确保我们的 Cython 代码文件有一个.pyx扩展名。代码本身唯一的变化是我们声明了每个变量和函数的类型。
注意这个函数有一个cpdef来确保我们可以从 Python 中调用它。也看看我们的循环变量i是如何拥有类型的。你需要为函数中的所有变量设置类型,以便 C 编译器知道使用什么类型!
接下来,创建一个setup.py文件,该文件将 Cython 代码编译成 C 代码:
并执行编译:
python setup.py build_ext --inplace
嘣!我们的 C 代码已经编译好了,可以使用了!
你会看到在你的 Cython 代码所在的文件夹中,有运行 C 代码所需的所有文件,包括run_cython.c文件。如果你很好奇,可以看看 Cython 生成的 C 代码!
现在我们已经准备好测试我们新的超快的 C 代码了!查看下面的代码,它实现了一个速度测试来比较原始 Python 代码和 Cython 代码。
代码非常简单。我们以与普通 Python 相同的方式导入文件,并以与普通 Python 相同的方式运行函数!
Cython 几乎可以在任何原始 Python 代码上获得很好的加速,根本不需要太多额外的努力。需要注意的关键是,你经历的循环越多,你处理的数据越多,Cython 就能提供越多的帮助。
查看下表,它显示了 Cython 为我们提供的不同阶乘值的速度。我们通过 Cython 获得了超过 36 倍的速度提升!
喜欢学习?
在 twitter 上关注我,我会在这里发布所有最新最棒的人工智能、技术和科学!也在 LinkedIn 上和我联系吧!
利用数据科学找到你的下一个 Airbnb 度假地
在数据中查找模式并对相似的列表进行分组

截至 2019 年 8 月,纽约市五个区约有 5 万个 Airbnb 房源。假设您根据自己的旅行兴趣将搜索范围缩小到一两个街区。每个街区的 Airbnb 房源密度如此之高,以至于你最终仍会有数百个房源可供选择。我们是否可以让机器学习算法在数据中找到模式,并将相似的房源分组,而不是通读每一个房源的描述、提供的便利设施和各种其他功能?
Figure 1: Each point represents an Airbnb Listing. The points closer to each other have similar characteristics: eg: amenities offered, their description, price and hundreds of other features. The price is encoded as the size of the bubble, so larger bubbles are higher price. An interactive plot is embedded in the results section below.
**方法:在数据科学中寻找许多解决方案的一个常见流程是跨行业数据挖掘标准流程(CRISP-DM)。**它有六个主要阶段:
- 业务理解-发展业务理解。
- 数据理解-形成数据理解。
- 数据准备-准备您要分析的数据。
- 建模-对数据建模。
- 评价-评价结果回答你感兴趣的问题。
- 部署-根据您的分析结果部署您的模型。
我利用这个过程从 airbnb 收集数据,并在 Heroku 上部署了一个交互式数据仪表板,让用户可以找到类似的 Airbnb 房源。

Figure 2: A subset of the phases of a CRISP-DM process starting from data preparation to deployment.
**业务理解:**这个阶段的目标是弄清楚我们到底要解决什么。基于问题陈述,我们的主要目的是帮助用户快速、可靠地找到 airbnb 房源。因此,我们的商业目标是:更好的用户体验和增加对搜索结果的信任度。这些目标转化为一系列问题/任务:
- *创建一个可视化界面,显示各个社区的价格分布:*这样做可以让用户根据价格缩小搜索范围。
- *创建一个数据仪表板,让用户选择一个街区,并找到类似的 airbnb 房源:*这将允许用户轻松找到类似的位置。
- *建立一个交互式地图来显示 airbnb 房源的聚类:*这将允许用户不仅根据相似性,还根据地理位置来挑选房源。
**数据理解:**在这个阶段,我们需要理解回答问题所需的数据,以及构建我们在业务理解阶段确定的应用程序所需的数据。在我们的例子中,我们可以从 Airbnb 网站内的获取数据,该网站发布了几个城市的 Airbnb 房源数据。数据集由几个 csv 文件组成,每个文件捕获关于列表的信息。在我的分析中,我使用了详细列表,它包含了 48,884 airbnb 列表的 106 个特征。

Figure 3: Overview of the datasets released by Inside Airbnb website. (Source: http://insideairbnb.com/get-the-data.html)
遵循 CRISP-DM 流程,我创建了一系列博客文章,详细介绍了数据收集、预处理、建模和部署步骤(以及代码),解释了为获得结果所做的选择。这些博文可以在本文末尾找到。
结果:
在这里,我想分享我的分析结果,并解释我们可以从这些结果中收集的见解。
不同社区的价格分布:
缩小搜索范围的一个很好的起点是了解哪些社区价格昂贵。此处显示的价格是每个街区的中间价格。乍看之下,我们知道有些地区相对于其他地区来说相当昂贵,尤其是曼哈顿下城的那些地区。可以为其他行政区收集类似的见解,帮助您缩小价格范围内的社区范围,并满足您的出行需求。

Figure 4: The median price per neighborhood is displayed here. We can gather from this plot that price tends to differ greatly based on location.
假设你希望住在曼哈顿中央公园附近,并决定在切尔西区搜索 Airbnb 房源。仅在这一个社区就有 980 个房源。图 5 中的*显示的是该社区 Airbnb 房源的密度。正如你所看到的,这是一个相当大的列表,这是我们可以使用机器学习 在数据中找到模式,并将相似的列表分组为集群的地方。*

Figure 5: Density of Airbnb listings in the Chelsea neighborhood
现在,我们的任务是根据我们从描述、便利设施和其他几个因素为每个列表构建的特征找到相似的列表。对于每个列表,从最初的 106 个特性中总共设计了 2151 个特性。完整的特性列表可以在这里找到:【2151 特性】 。
处理包含许多要素的数据集时,很难可视化/探索要素之间的关系。这就是降维的用武之地。在机器学习中,降维是通过获得一组主变量来减少所考虑的随机变量的数量的过程。主成分分析(PCA) 是一种线性降维技术,适用于具有许多相关特征的数据集。简而言之,主成分分析试图减少数据集中的要素数量,同时保留“主成分”,主成分被定义为现有要素的加权线性组合,旨在实现线性独立,并解释数据中最大可能的可变性。您可以将这种方法视为采用许多功能(2151)并将相似或冗余的功能组合在一起,以形成一个新的、更小的功能集。下面显示的是前 50 个主成分以及每个主成分解释的差异量。

Figure 6: Variance explained by each of the first 50 principal components
由于每个主成分都是原始特征的线性组合,因此可以查看这些成分的构成。通过查看*图 7,*由前两个主要部分组成的部分,我们可以看到最显著的特征是每个 airbnb 房源提供的便利设施。解释部件组成的一种方法是说:
有助于区分切尔西区 Airbnb 房源的主要特征是所提供的便利设施。

Figure 7: Component make up of the first two principal components.
为了构建我们的数据仪表板,我们可以采用前 3 个主要组件,但是,如果我们丢弃剩余的 47 个组件,我们将丢弃许多有用的信息。
另一种方法是应用t-分布式随机邻居嵌入(t-SNE)——这是一种非线性降维技术,特别适合高维数据集的可视化。t-SNE 将多维数据映射到低维空间,并试图通过基于具有多个特征的数据点的相似性识别观察到的聚类来发现数据中的模式。在我们的例子中,我们将采用前 50 个主成分,并应用 t-SNE 将数据集减少到 3 维。
在切尔西附近找到类似的 Airbnb 房源:
通过减少到 3 维,我们现在能够在 3-D 散点图中可视化。每个数据点对应一个 airbnb 房源。距离较近的点具有相似的特征,即提供的便利设施、主机身份验证等。您可以与下面的 Plotly 可视化交互,如果您喜欢,甚至可以修改它!
Figure 8: A 3D-scatter plot constructed from t-SNE features. Each point represents an Airbnb Listing. The points closer to each other have similar features: eg: amenities offered, their description, price and hundreds of other features. The price is encoded as the size of the bubble, so larger bubbles are higher price. Hover over each of the data points to see more details.
这个情节有什么用处?
- **省钱:**由于彼此距离较近的点具有相似的特征,因此我们可以找到在我们价格范围内的房源。
在一个较大的泡泡旁边找一个较小的泡泡,你就可以省点钱了!
- **找到独一无二的东西:**一个远离其余的数据点,表明它有非常独特的东西,要么是坏的,要么是好的。你可以自己调查一下。
- **比较:**假设您喜欢某个列表,并且希望找到相似的列表,您可以找到该数据点并查看其最近的邻居。
对数据仪表板的需求
一次可视化所有列表不是一个好主意,因为阅读情节变得非常困难。这就是数据仪表板的用武之地。使用数据仪表板,我们可以基于某些属性过滤可视化,并更轻松地调查数据点之间的关系。
例如,下面的演示显示了我们如何在 Chelsea 社区找到两个类似的 3 居室 airbnb 房源,并与 West Village 等其他社区的价格进行比较。
您可以在这里与部署到 Heroku 的应用程序进行交互:【Airbnb 数据仪表板】 。这里记录了构建和部署它的步骤: [ 将 data dashboard 应用程序部署到 Heroku]
Demo: Select the neighborhood from the drop-down menu, move the slider to filter based on number of bedrooms. Using the tools at the top right, you can zoom, pan and rotate the plot to find similar listings. Hover over each data point to see more details.
使用 K-means 聚类相似的 airbnb 列表:
上面的 t-SNE 可视化让我们可以根据它们在组件空间的接近程度找到类似的 airbnb 列表。但是它没有将单个列表分组到聚类中,并且将每个列表标记为聚类的一部分。这就是 K 均值聚类派上用场的地方!
*考虑这个场景:*假设您在第 10 大道和西 20 街找到了一个非常好的列表,并且您希望在**第 34 街宾州车站附近找到一个类似的列表。**通过选择同一个集群中更靠近宾州车站的另一个成员,你可以相信这两个位置之间有一些相似之处。
Figure 9: Results of K-means clustering — shown here are three clusters represented by three colors.
相似的 T21 这个词在这里有着比仅仅说相似的价格、相似的生活设施等更深刻的含义。它是我们使用 NLP 和特征工程创建的 2151 个特征的组合,然后要求像 K-Means 这样的无监督机器学习算法根据它们在向量/分量空间中的距离的接近程度对它们进行分组。
结论:
每个数据科学问题都始于一个问题。我们感兴趣的问题是:*我们能根据 Airbnb 提供的信息找到类似的房源吗?*通过使用 CRISP-DM 流程,我们从了解问题开始了我们的旅程,从 Airbnb 获取数据,预处理数据,建立数据模型,最后部署了一个数据仪表板,让用户可以轻松找到类似的房源。虽然仅仅为了找到一个 Airbnb 房源,这看起来有点过分,但是发现独特事物的快乐让这一切都是值得的!
CRISP-DM 步骤:
博客系列,涵盖了实现上述结果的每个步骤:
- 纽约市 Airbnb 数据清理(https://shra van-kuch kula . github . io/NYC-Airbnb-Data-Cleaning/):涵盖数据集的提取、数据清理、缺失值的识别和处理。
- 纽约市 Airbnb 特征缩放(https://shra van-kuch kula . github . io/NYC-Airbnb-data-preprocessing/):处理离群值,确定要使用的正确缩放器。
- 纽约市 Airbnb Feature Engineering(https://shra van-kuch kula . github . io/NYC-Airbnb-Feature-Engineering/):创建了便利设施和其他基于列表的列的二进制单词包表示,对文本列进行了规范化和矢量化。
- 纽约市 Airbnb 建模:PCA(https://shravan-kuchkula.github.io/nyc-airbnb-pca/):使用降维将特征从 2100 个减少到 50 个。
- 纽约市 Airbnb 建模:t-SNE 可视化(https://shravan-kuchkula.github.io/nyc-airbnb-tsne-visual/):涵盖了我们如何使用 plotly express 实现上面的 3D 散点图可视化。
- 纽约市 airbnb 建模:K 均值聚类(https://shravan-kuchkula.github.io/nyc-airbnb-kmeans/):使用 K 均值聚类找到相似的 Airbnb 房源。使用了一个 follow 地图来显示聚类结果以便于交互,并根据位置查找相似的列表。
- 将数据仪表板 app 部署到 Heroku:(https://shra van-kuch kula . github . io/NYC-Airbnb-Deploy-to-Heroku/):使用 Flask + Pandas + Plotly + Dash 将数据仪表板应用部署到云端。
本帖中用于构建可视化效果的工具:
所有的可视化都是用 python 创建的🐍
- geo pandas:让使用 python 处理地理空间数据变得更加容易。如果您有纬度和经度信息,那么您可以构建一个 geopandas 数据框架,并开始使用 pandas 的所有功能,如过滤、分组、合并空间组件。我被它的简单和强大迷住了。在这里阅读如何安装它:【安装 geo pandas】
- leave:
folium使用 Python 处理的数据在交互式活页地图上可视化变得容易。它既可以将数据绑定到地图上进行choropleth可视化,也可以将丰富的矢量/栅格/HTML 可视化作为地图上的标记进行传递。 - plot ly Express:plot ly 这些年来有了很大的改进,最新的版本用 plotly.express 做出来易如反掌。现在你几乎可以在任何地方嵌入 plotly 可视化。阅读这篇博客,看看它能做些什么:【Plotly 4.0】
- Dash:它写在 Flask、Plotly.js 和 React.js 之上,Dash 非常适合用纯 Python 构建具有高度自定义用户界面的数据可视化 app。它特别适合任何使用 Python 处理数据的人。
- Giphy:我用这个创建了 gif。就像上传一个视频并从中挑选你想要的一样简单。Medium 只允许 Embed.ly 支持嵌入,giphy 是其中之一。
- Heroku: 在我看来,在云上拥有 python app 最快的方法就是使用 Heroku PaaS。他们让它变得非常简单,下面是从头开始的步骤。【将数据仪表板部署到 Heroku】
- Github 链接到代码
使用我的不安预测模型来挑选 NCAA 锦标赛中的失败者
机器学习模型给出了 3 个需要寻找的关键干扰信号
NCAA 锦标赛场地已经设置好,现在是开始填写你的括号的时候了。每年都有一些顶级球队被提前淘汰,所以挑几个冷门是有意义的,尤其是在前几轮。正确挑选冷门是在支架竞赛的前几轮中获得优势并使你的支架与竞争对手区分开来的好方法。
问题是,很难准确预测不愉快。当不被看好的人赢了,他们只有 1/5 的机会被选中。每个人都预计会发生一些令人沮丧的事情,而且有很多关于应该挑选多少的建议。但大多数括号玩家仍然很难选择正确的。
根据 2003 年以来所有锦标赛球队的数据,我使用机器学习创建了一个预测模型,具有很好的准确性来检测冷门,我将冷门定义为一个不被看好的球队获胜,他们的种子比对手低至少 4 个位置(a 5 击败 a 1,a 6 击败 a 2,等等。).去年的锦标赛有 12 场冷门。我的模型预测了其中的 10 个,还有 5 个假阳性。不完美,但比随机猜测好得多。
今天,我利用我的模型中的见解,给你提供由硬数据支持的颠覆性指导。我在这里关注的是处于劣势的球队的品质,不管对手是谁,这些品质都预示着更大的翻盘机会。我的目标不是告诉你应该挑选哪些令人沮丧的事情,因为这有什么意思呢?相反,我想给你三个明确的不安信号,当你在自己的分类中寻找不安时可以考虑。
冷门信号 1:由上届锦标赛冠军教练带领的弱队
篮球专家经常讨论好教练在锦标赛中的重要性,但通常是指像肯塔基、北卡罗来纳和密歇根州立大学这样的精英项目的教练。但事实证明,教练在锦标赛中的成功记录也能对弱队产生很大影响。
当我查看弱队教练成功的几个指标时,有一个因素很突出:弱队教练之前参加第四轮比赛的次数,也就是“精英 8 强”。

Underdog coaches with Elite 8 experience are more likely to lead their team to a win
在左边我展示了“冷门率”,定义为导致冷门的游戏的百分比。由简历上没有“精英 8”访问记录的教练领导的失败者只有大约 16%的胜率,但由“精英 8”教练领导的失败者表现得好得多,失误率接近 40%。
根据定义,每个有精英 8 经验的教练以前都在锦标赛中至少赢过 3 场。这些跑步可能有助于给教练宝贵的经验,或者可能只是代表教练在管理激烈的比赛压力,为下一个对手制定比赛计划,或者两者兼而有之的技能的证据。
下面我展示了今年所有拥有精英教练的潜在弱势球队(种子 5-16)。对于每支队伍,我会展示他们第一次被认为处于劣势的比赛回合和对手。在第一轮中只有两支队伍符合这个标准,但是在第二轮和以后的比赛中,有几个潜在的冷门在等着我们。

Underdogs led by coaches with previous Elite 8 experience
请注意,无论谁在第一轮赢得贝勒-锡拉丘兹,冈萨加都将在第二轮面对一位精英 8 教练,要么是斯科特德鲁,要么是吉姆·伯海姆。对于头号种子冈萨加来说,这两场比赛都是艰难的第二轮比赛,这意味着选择他们逃离这个地区可能是有风险的。锡拉丘兹去年处于类似的 10 号种子的位置,当时我的模型正确预测了他们将在第二轮击败 2 号种子密歇根州立大学。
冷门信号 2:中期主要弱队在艰难的赛程中保持强劲的胜利记录
对于遴选委员会而言,日程安排的强度是决定邀请哪些网络普通用户团队的一个重要因素。事实证明,赛程的强度也是预测弱队在锦标赛中获胜的一个有用因素。
对于“中大型”团队来说尤其如此,这些团队不属于“Power 5”会议(ACC、SEC、Big 12、Big 10、PAC-12)。当我特别观察中等职业球队时,赛程的强度和高胜率都是预测冷门的潜在因素。

Among mid-majors, underdogs with both strong schedules and winning records are most likely to pull an upset
对于所有涉及不被看好的中等球队的锦标赛,我会在纵轴上显示不被看好的球队在锦标赛前的总胜场数。横轴显示了球队在赛程中的赛前实力,数值越高表示球队遇到的对手越难对付。进度表的平均中主要强度以蓝色显示。请注意,扰乱(绿色)清楚地聚集在右上角。这意味着当弱队的赛程强度高于平均水平并且至少赢了 20 场比赛时,冷门往往会发生。
为了使用这两个因素创建更具体的指导,我按照赛程强度(平均或更低,平均以上)对中-大比分落选者进行了分组,并针对总胜率的 3 个类别分别绘制了每组的沮丧率:少于 18,18-23 和超过 23 胜。

这里的数据讲述了一个有趣的故事。拥有强大胜利记录的中职棒球队确实更有可能取得冷门,正如两个中职棒球队从左(少于 18 场胜利)到右(超过 23 场胜利)的整体冷门率增加所示。然而,对于时间表更紧的中等专业(绿色/蓝色线),增长幅度更大。这种模式符合常识:那些通过战胜更难对付的对手来证明自己价值的中等职业者,也是那些更有可能在大舞台上翻盘的人。
上面的图表显示,冷门对于拥有超过 18 场胜利和艰难赛程的中期主要弱队来说是最常见的。下面我展示了今年符合这两个标准的 11 支中型球队。对于每支球队,我还展示了他们第一轮的对手(11-16 号种子队)或他们预计的未来比赛(5-10 号种子队)。

Mid-major underdogs with at least 18 wins and a difficult season schedule
坦普尔和圣玛丽看起来像是第一轮中强劲的冷门竞争者,尽管坦普尔必须在前四轮中首先通过另一个中期专业(贝尔蒙特)。在第二轮比赛中,UCF 对杜克大学和辛辛那提对田纳西大学都以获胜记录和赛程证明脱颖而出。
将这些数据与上面的教练表联系起来,我还注意到密歇根肯定会在第二轮面对一个艰难的中期联盟(内华达州)或一个经验丰富的教练(佛罗里达州),还有另一个艰难的中期联盟(水牛城)或全国最有效率的三号种子选手(德州理工)在第三轮等待着。密歇根是一支伟大的球队,但像这样一连串艰难的比赛是可以打破支架的地雷,伟大的球队每年都会提前出局,包括第二轮三分之一的 2 号种子。狼獾队可能是你可以考虑尽早淘汰的队伍之一。
不安信号 3:在家门口的比赛中处于劣势的精英
因为每场锦标赛都是在一个中立的场地进行,所以没有哪支球队有真正的主场优势。然而,不被看好的球队通常会在离家更远的地方比赛,这可能会使他们处于劣势,可能是因为长途旅行和减少的球迷到场人数。
但有时,失败者很幸运,最终比最受欢迎者走了相似(甚至更短)的距离。当这些球队碰巧是非常熟练的失败者时,不安分的手表就处于警戒状态。
我用术语“精英”失败者来描述具有关键不安信号的团队,我在之前的帖子中讨论过:肯波调整后的效率余量超过 10。只有 40%的不被看好的球队达到了这个基准,但是这些球队在大约 30%的时间里击败了热门球队,相比之下,其他不被看好的球队只有 10%。作为挑选冷门的唯一规则,你可以做得更糟…但我认为我们也可以做得更好。

Elite underdogs (those with Kenpom efficiency margin over 10) who play close to home upset the favorite 40% of the time
在“精英”阶层的失败者中,在离家近的地方比赛是一个明显的沮丧信号。正如我在左边展示的,在距离校园不到 400 英里的地方打球的“精英”失败者的失望率在 40%左右,而其他精英的失望率在 30%以下。精英失败者只有 20%的时间在校园附近玩这种游戏,但当他们这样做时,就会大大增加冷门的几率。
下面我展示了今年锦标赛的相关游戏。辛辛那提(我们已经知道他们有获胜记录和赛程强度的冷门信号)再次出现在俄亥俄州哥伦布市与田纳西的第二轮比赛中。我还注意到,对于杜克大学在南卡罗莱纳州的第二轮比赛,他们的两个潜在对手(VCU 和 UCF)都符合旅行标准。足够疯狂的是,两支球队都有上面讨论过的胜利记录和赛程实力。

Elite underdogs who will travel less than 400 miles to their game
杜克是头号种子选手,拥有我们所见过的最有天赋的首发阵容之一。我会选择杜克大学在一场比赛中输给 UCF 或 VCU 吗?不,我不会。但在括号池中,最小化风险是成功的重要组成部分,这包括识别哪些顶级团队进入四强的道路更加艰难。因此,在自动将头衔授予杜克大学之前,你可能会三思而行。
闭幕词
即使是遇到这些令人沮丧的信号的失败者也有超过 50%的机会输掉比赛,还有许多其他因素影响着 NCAA 锦标赛中每场比赛的结果。那么,你应该如何利用这些信息来挑选烦恼呢?
我的建议是把信号作为工具,而不是硬性规定。如果你对处于劣势的团队有预感,对照这些信号检查他们,看看他们是否通过测试。试着想出你自己的信号,看看他们今年表现如何。
在未来,我还计划发布带有信心指标和其他数据的完整预测,所以如果你想了解更多,请在 Medium 或 Twitter @bracket_vision 上关注我。
使用物体识别来确保你的车没有被偷
什么?一篇博文的标题真奇怪。这就像说“不要为了避免不打电话而不使用你的电话”。但我认为它准确地描述了我将向你展示如何使用机器学习来确保你的车仍然在你的车道上。
几年前,有人决定在半夜大摇大摆地走进我的车道,偷走我的车。这不是一次愉快的经历,这当然让我想到了防止这种事情再次发生的聪明方法。
一种方法是在每个地方安装安全摄像头,然后设置它们在有任何动静时提醒我。但是,我相信你能猜到,如此多的小事情触发了运动检测,以至于通知很快变成了噪音,然后我忽略了它,这违背了最初获得通知的目的。

Source: https://cdn.macrumors.com/article-new/2018/07/groupednotifications-800x646.jpg
但是如果我可以告诉你,你可以建立一个系统,只有在你的车丢了的时候提醒你,而不会提醒你任何其他的事情,那会怎么样呢?
嗯…我不能告诉你…所以…我现在告诉你。
怎么会?
魔法。
所谓魔法,我指的是相对简单的技术,基于非常坚实的数学基础,比如 2+2=4,6/2=3,三角形=有趣。
显然,你首先需要的是一台照相机。接下来你需要做的是安装一些 DIY 家庭自动化设备。我推荐看看这些家伙。他们有很多开源家庭自动化的东西,你可以很容易地设置,以实现如下的工作流程。
我想说这是为技术爱好者准备的。你可能应该成为一名开发人员,或者至少在电视上扮演一名开发人员。
现在,给你自己找一些训练数据。也就是说,你的车停在平时停放的地方的一些视频文件。
我的情况是这样的。

注意到背景中的回收箱了吗?我的建议是从一周中获取视频示例,使用不同的照明,街道上不同的“场景”,如汽车、垃圾箱、动物、鬼魂,以及任何其他常见的场景。就我而言,我需要有和没有这些箱子的视频。
现在有趣的部分来了。
给…作注解
按照说明使用 Objectbox 中的注释工具进行设置,并将您的视频放入boxdata/files目录。
然后通过访问http://localhost:8080点击注释工具打开注释应用,并选择您的一个示例视频。播放视频,然后暂停,并在您的汽车周围画一个方框。给它一个有意义的标签,再次播放视频,几秒钟后再次点击暂停,然后在你的车周围再画一个方框。冲洗,每个视频重复 2 到 3 次。

我的建议是在尽可能多的不同场景中抓取大约 20 个例子。例如,你看到我的好车旁边的那只笨猫了吗?这次我确保它包含在盒子里,但不是为了后续的注释。我希望模型每次都能学习什么是相同的,什么是不同的。Objectbox 将整个框架放入上下文中,所以你真的需要在一天的不同时间和一周的不同日子的真实生活的例子来获得最佳结果。
我们表现如何?
我最喜欢 Objectbox 的一点(因为我是它的产品经理,也是我要求的)是能够立即获得对你的培训的反馈。你提供了足够多的例子吗?你做得对吗?很棒的问题。Objectbox 通过让你点击“训练”,然后在一帧上播放和暂停视频来给你答案。它会根据这个框架进行训练,然后马上给你一个答案。
例如,这里有一个 Objectbox 从未见过的新框架。

Objectbox draws a box around the car and labels it ‘Mazda’
搞定了。现在,让我们看看当一些视频中没有美味的马自达出现时会发生什么:

完美—没有检测到。
下面是我设置 pleasedontstealmycar 工作流程的方法:
- 从 Objectbox 下载状态文件(training)(在检查了几个视频之后)。
- 建立我的相机定期检查下载一帧,张贴到 Objectbox 运行与我的状态文件,这将检查看看是否马自达=真。
- 如果马自达=被盗,发送警报到我的手机和国民警卫队。
- 当你预计马自达在别的地方的时候,可能安排这个不提醒你。
这将大大减少你从爱洛,环,巢等收到的通知数量。等等。等等。只在应该在那里的东西不在的时候提醒你。
你还能用 Objectbox 做什么?当你驶入车道时打开车库,当你的邮件到达时提醒你,如果你的回收箱不在街上时通知你,因为你一直在忙着做很酷的事情…我相信你可以想到许多伟大的使用案例。
更上一层楼
如果你是一个大机构或小办公室,你想开始考虑使用机器学习来发出更多相关的警报,看看这个。使用 aiWARE ,一个由 Veritone (谁收购了机器盒子)开发的平台,你就可以开始考虑规模化做这种事情了。
只需将您的状态文件上传到 aiWARE 的库应用程序,然后使用 Objectbox 来运行您的所有相机馈送。你不必担心编排 Docker 容器或管理视频的处理。您甚至不需要做太多事情来让通知工作,aiWARE 有一个定制的 Node-RED 实现,让您可以轻松地处理这样的工作流,而无需做太多的编码。
在 AWS EMR 群集中使用 Pyspark 和 Jupyter 笔记本电脑
Jupyter Notebook 是学习和解决代码问题的一个不可思议的工具。这里有一个博客来展示如何在学习 Spark 时利用这个强大的工具!
如果您正在做任何可以并行化的计算密集型工作,Spark 会很有帮助。查看这个 Quora 问题获取更多信息。
这篇博客将通过 AWS Elastic Map Reduce (AWS EMR)和 Jupyter Notebook 来设置使用 Spark 的基础设施。

导航至 AWS EMR
您将在屏幕顶部看到以下内容:

Click ‘Create cluster’
选择高级选项
在屏幕的顶部

复制以下截图
我用黄色突出显示了需要更改的默认项目,除了第 2 步中的节点类型。这将取决于你的任务的计算强度。如果你只是在测试,资源可能会很少。以’ g-'开头的实例是 GPU 实例,最适合运行 Spark。


For more information about how to choose which types of instances to use, check out the AWS docs: https://docs.aws.amazon.com/emr/latest/ManagementGuide/emr-plan-instances-guidelines.html
如果您计划从 S3 存储桶调入数据或文件,请确保您与 S3 存储桶位于同一个 VPC。

See the “Add bootstrap action” ?
好的,这里是你安装引导动作的地方。默认情况下,引导操作以 Hadoop 用户的身份执行。您可以使用 sudo 以 root 权限执行引导操作。
引导操作是将额外的 Python 包安装到其他内核的最有效方式。根据我们在软件配置中选择安装的软件,Anaconda 已经安装在它们上面了。对于我希望运行的脚本,我需要的附加包是 xmltodict。
为了安装 python 库 xmltodict,我需要保存一个包含以下脚本的引导操作,并将其存储在 S3 桶中。这就是在您将要引用的 S3 所在的 VPC 上安装 EMR 集群的重要性所在。这是一个 shell 脚本,将在 S3 保存为. sh 文件:
sudo pip install xmltodict
一定要包括须藤!
如果你需要比xmltodict更多的包,你可以把它们放在同一行代码中,用空格隔开。示例:sudo pip install xmltodict s3fs

Make sure you choose an EC2 key pair you have access to
`为什么选择这些安全组?:
在 EC2 仪表板中,应该有以下入站规则。
在本例中,源是 0.0.0.0/0,这是所有的 IP 地址。为了更加安全,请输入您自己的 IP 地址。
如何检查:转到 EC2 仪表板,单击安全组,找到您的组并添加自定义规则:

The 22 one allows you to SSH in from a local computer, the 888x one allows you to see Jupyter Notebook. As a note, this is an old screenshot; I made mine 8880 for this example.
关于入境交通规则的更多信息,查看 AWS 文档。
现在转到您的本地命令行;我们将通过 SSH 进入 EMR 集群。

In general, don’t share your public DNS on the internet. This is one of my old ones.
结果:现在你在 EMR 命令行中。

找到你的蟒蛇版本
https://repo.continuum.io/archive/并在下一步复制/粘贴文件路径。选择 Python 3.6 或更低版本,因为在这个时候,我认为不可能将 worker 节点一直更新到 3.7。如果是的话,请在评论中给我留言吧!
安装 Anaconda
将上一步中的文件路径放在这里:
wget [https://repo.continuum.io/archive/Anaconda2-2018.12-Linux-x86_64.sh](https://repo.continuum.io/archive/Anaconda2-2018.12-Linux-x86_64.sh)
按回车键
bash Anaconda2–2018.12-Linux-x86_64.sh
按 enter 键,并继续按 enter 键浏览条款和条件
键入 yes,
按回车键确认位置
等待软件包安装。
键入 yes 添加到环境变量中,以便 Python 能够工作
which python /usr/bin/python
按回车键
source .bashrc
配置带 Jupyter 的火花
在 EMR 命令提示符下键入以下每一行,并在每一行之间按 enter 键:
export PYSPARK_DRIVER_PYTHON=jupyterexport PYSPARK_DRIVER_PYTHON_OPTS='notebook --no-browser --port=8888'source .bashrc
在 EMR 命令提示符下键入 pyspark
结果:

See that highlighted token? copy it.
在网络浏览器中打开 Jupyter 笔记本
在地址栏中键入以下内容:localhost:8880
结果:粘贴上一步中的令牌并登录的页面。

耶!你做到了!
现在,您可以在 Jupyter 笔记本中查看您的 spark 上下文:

资源:
Python 错误的版本错误:
https://AWS . Amazon . com/premium support/knowledge-center/EMR-pyspark-python-3x/
使用 Python 包装上市公司报告中的业务数据(tabula-py)
(声明:这是一个只教 Python 的教育帖。内容仅供参考。它无意成为投资建议。)
对于一家上市公司来说,它不断在网上发布不同的报告和数据,让投资者和潜在投资者更好地了解企业。然而,大多数报告都是 PDF 格式的,我们都知道很难复制和处理数字。对于大型投资公司和机构来说,他们肯定有专门的和复杂的工具来阅读 pdf 报告。但是像你我这样的个人投资者呢?有什么方法可以自动读取 pdf 报告并存储或分析?幸运的是,在 Python 的帮助下,答案是肯定的。

This is the result. Impressed? You can do it also.
我将使用的主要模块叫做“tabula”。还有一些其他的模块可以读取 pdf 文件,但是到目前为止,经过多次测试,“tabula”是从 pdf 文件包装表格并存储为 dataframe 的最佳模块。因此,包装后,您可以将结果存储为 csv 文件或与历史数据相结合。
我将使用的公司是国泰航空公司。国泰航空是香港的上市航空公司。每个月,它都会通过不同的目的地释放大量的乘客和货物。因此,通过了解每月的数据,您可以更好地了解其收入流,并帮助您做出更好的投资判断。
第一步是获取 pdf 报告。我将使用更直接的方法在线访问文件并阅读 pdf 文件,而不是手动下载。因此,有必要知道存储这些报告的路径。

https://www.cathaypacific.com/cx/en_HK/about-us/investor-relations/announcements.html
上图是下载各种公告的页面。“交通数字”报告是我们感兴趣的一个。

输入关键词后,可以看到所有的流量数字报告。
下一步是研究如何在线获取这些报告。幸运的是,文件路径是标准化的。

如上图所示,唯一的变化就是最后显示年和月的数字。第一部分不变。
但是,在某些月份,文件路径的子前缀不是“pdf”,而是“PDF”(全部大写)。因此,在编写 Python 脚本时,有必要处理这种情况。

Please keep the format unchanged!!
所以文件路径是“’ https://www . cathay Pacific . com/dam/CX/about-us/investor-relations/announcements/en/{ year _ month } _ cxtraffic _ en . pdf(或 PDF)”。
我们感兴趣的页面显示了每个月的流量和容量。它们存储在两个独立的表中。这是我们下一阶段需要努力的地方。

遗憾的是,显示这些表的页面并不是恒定的。相反,它们显示在每个报告的倒数第二页。所以在包装之前,有必要知道每份报告的页数。
下面显示了 Python 脚本应该执行的列表:
通过文件路径访问文件
所需模块:请求
由于文件路径中的{year_month}变量每个月都会发生变化,因此变量“link”与格式一起使用,以便包含变量“month”。
link = 'https://www.cathaypacific.com/dam/cx/about-us/investor-relations/announcements/en/{}_cxtraffic_en.pdf'.format(month)
下一步是使用请求模块来访问文件
import requests
response = requests.get(link)
如前所述,在某些月份子 fix 是 pdf,所以上面的链接不会给你 PDF 文件,而只是一个错误页面。所以有必要检查一下反应。如果响应是 404(错误),则更改链接并以 PDF 结尾。通过键入 response.status_code 可以获得响应代码。
if response.status_code == 404:
link = 'https://www.cathaypacific.com/dam/cx/about-us/investor-relations/announcements/en/{}_cxtraffic_en.PDF'.format(month)
response = requests.get(link)
检查总页数
所需模块:io,PyPDF2
成功访问文件路径后,下一步是读取文件并获得页数。
这里,内置模块“io”与“BytesIO”一起使用,从请求中读取响应的内容。
import io
io.BytesIO(response.content)
现在是时候引入另一个模块来读取 pdf 文件了,PyPDF2。不像 tabula,PyPDF2 可以让你获得关于 PDF 文件的信息,甚至合并 pdf 文件。您可以通过在线阅读 PyPDF2 文档来了解更多信息。
[## PyPDF2 文档- PyPDF2 1.26.0 文档
编辑描述
pythonhosted.org](https://pythonhosted.org/PyPDF2/index.html)
我们需要使用的类是“PdfFileReader ”,并使用“getNumPages”返回页数。
import PyPDF2
with io.BytesIO(response.content) as open_pdf_file:
pdf_file = PyPDF2.PdfFileReader(open_pdf_file)
num_pages = pdf_file.getNumPages()
翻到倒数第二页,把两张表包起来
所需模块:白板
在这个阶段,您需要做的就是转到那个特定的页面,复制这两个表。很简单,对吧?不完全是。
之前说过,pdf 是给人类看的,不是给机器看的。因此,当您使用 tabula 来包装表格时,tabula 很有可能无法成功读取表格或读取不正确。
Tabula 允许您定义 pdf 文件中指定的区域。但是,在这种情况下,由于两个表在同一页上,所以先包装整个页面,然后再拆分成两个表会更容易。使用 tabula.read_pdf 来完成此操作。
table = read_pdf(link, pages = num_pages-1)
PS:如果你想指定一个特定的区域,你可以在函数中包含“区域”选项。首先,您可以在 Acrobat Reader 中使用 Measure 来获得上、左、下和右(以英寸为单位)的距离,然后乘以 72。

Click “Tool” tab and select “Measure” in Acrobat Reader

table = read_pdf(link, pages = 4 , area = [1.1*72, 0.9*72, 4.8*72, 7.26*72])
最好包含一个稍微大一点的区域,这样 tabula 可以正确地包裹表格。
如果成功,返回的表将是您想要的结果。通常在结果数据帧中有一些不必要的行或列,所以你需要在换行后清理表格。
现在,您不需要手动复制和保存任何公司报告中的数据。您还可以使用这种方法包装任何 pdf 文件中的数字,例如您部门的月销售额。这可以为你节省很多做无聊工作的时间,这样你就可以做更重要的工作了。
这是这篇文章的结尾。希望你看完能有所收获。给我一个评论或者鼓掌表示支持。下次见。
完整的代码可以在https://github.com/wyfok/Cathay_Pacific_Monthly_figures找到
使用 Scikit-Learn 管道更快地清理数据和训练模型
将管道纳入机器学习工作流程的快速指南

Photo by Gerd Altmann from Pixabay
如果您正在寻找一种方法来组织您的数据处理工作流并减少代码冗余,Scikit-Learn 管道将是您的数据科学工具包的一个很好的补充。在解释了它们是什么以及为什么使用它们之后,我将向你展示如何使用它们来自动化数据处理,通过使用它们来预测全球票房收入。
什么是 Scikit-Learn 管道?
管道可能是一个非常模糊的术语,但一旦你意识到它在建立机器学习模型的背景下做什么,它就非常合适了。Scikit-Learn 管道将多个数据处理步骤链接成一个可调用的方法。
例如,假设您想要从电影数据中转换连续的特征。

Continuous features from movie data
要处理回归模型的连续数据,标准处理工作流包括输入缺失值、转换倾斜变量以及标准化数据。您可以在单独的步骤中处理数据,就像这样。
cont_vars = ['budget', 'popularity', 'runtime']imputer = SimpleImputer(strategy = 'median')
transformer = PowerTransformer(method = 'yeo-johnson', standardize = False)
scaler = StandardScaler()X_train[cont_vars] = imputer.fit_transform(X_train[cont_vars])
X_train[cont_vars] = transformer.fit_transform(X_train[cont_vars])
X_train[cont_vars] = scaler.fit_transform(X_train[cont_vars])
但是如果你只是使用一个管道来一次应用所有的数据转换,那将会更干净、更高效、更简洁。
cont_pipeline = make_pipeline(
SimpleImputer(strategy = 'median'),
PowerTransformer(method = 'yeo-johnson', standardize = False),
StandardScaler()
)X_train[cont_vars] = cont_pipeline.fit_transform(train[cont_vars], columns = cont_vars)
通过使用管道,您可以清楚地看到您的处理步骤,并快速添加或删除步骤。你也只需要调用fit_transform()一次,而不是三次。
使用管道同步处理不同的数据类型
我使用管道来处理连续数据,但是在电影数据中也有离散的数字列、分类列和 JSON 类型的列。每种数据类型都需要不同的处理方法,因此您可以为每种数据类型构建唯一的管道。
disc_vars = list(X_train.select_dtypes(include = int).columns)disc_pipeline = make_pipeline(
SimpleImputer(strategy = 'constant', fill_value = -1)
)cat_vars = ['original_language', 'release_season']cat_pipeline = make_pipeline(
SimpleImputer(strategy = 'constant', fill_value = 'unknown'),
OneHotEncoder()
)json_vars = ['Keywords', 'crew_department', 'production_countries', 'cast_name', 'crew_job', 'production_companies', 'crew_name', 'genres', 'spoken_languages']json_pipeline = make_pipeline(
TopCatEncoder()
)
TopCatEncoder()是我专门为电影数据编写的自定义转换器。一些数据列包含以 JSON 格式编码的信息,所以我定义了TopCatEncoder()和一些帮助函数来根据键将 JSON 解析成分类变量,然后保留每个新分类变量的顶级类别。这就是你需要知道的关于 transformer 的全部内容,但是如果你想了解更多,你也可以查看我的 GitHub 中的代码。
现在我已经有了处理数据所需的所有管道——cont_pipeline、disc_pipeline、cat_pipeline和json_pipeline——我可以将它们组装成一个管道,使用ColumnTransformer()来指定哪个管道转换哪个变量。变形金刚被指定为一个元组列表,看起来像这样:(name, transformer, columns)。
preprocessor = ColumnTransformer(
transformers = [
('continuous', cont_pipeline, cont_vars),
('discrete', disc_pipeline, disc_vars),
('categorical', cat_pipeline, cat_vars),
('json', json_pipeline, json_vars)
]
)
要使用这条管道转换我的所有数据,我只需调用preprocessor.fit_transform(X_train)。
使用管道测试机器学习算法
这里,我使用一个名为quick_eval()的效用函数来训练我的模型并进行测试预测。
通过将processor管道与回归模型相结合,pipe可以同时处理数据处理、模型训练和模型评估,因此我们可以快速比较 8 个不同模型的基线模型性能。输出如下所示。

接下来的步骤:模型选择、特征选择和最终模型
随着数据处理和模型原型化步骤的完成,我们可以选择一个模型子集来关注。我使用了随机森林回归器,因为它的表现相对较好,而且很容易解释。
在此基础上,我们可以继续进行特征工程、特征选择和超参数调整,以获得最终模型。我使用了基于随机森林的交叉验证的变量选择程序,将我的数据从 194 个特征减少到 57 个特征,并改进了测试 RMSE。

5-fold CV model performance, p_hat is number of features fed into Random Forest regressor
这个变量选择实现不是这篇文章的重点,但是你可以在我的代码的函数rf_variable_selection()中找到它的实现。
上面的TopFeatureSelector()是另一个定制的转换器,它选择前 k 个特性来保持使用预先计算的特性重要性。

这就是你的最终模型!它的性能比具有较少特性的基线要好一点。
要采取的其他步骤
由于我专注于 Scikit-Learn 管道,所以我跳过了一些步骤,如**合并外部数据、特性工程和超参数调整。**如果我重新审视这个项目,让我的模型变得更强大,我会专注于这三件事。我也没有在quick_eval()函数中使用交叉验证,但是实现交叉验证会使这个工作流更加健壮。
感谢阅读!我是 Scikit-Learn Pipelines 的新手,这篇博文帮助我巩固了迄今为止所做的工作。我将用我遇到的新用例来更新这个文档。
你可以在这里 查看这个项目的 Jupyter 笔记本 。有关管道的更多信息,请查看丽贝卡·维克里的 帖子 和 Scikit-Learn 的 管道官方指南 。
Python 异常检测手册— (4)隔离森林

Figure (A)
(2022 年 10 月 13 日修订)
如果让你把上面的树一棵一棵分开,哪棵树会是第一棵开始的?你可以选择左边的那个,因为它是独立的。去掉那棵树后,下一棵容易分离的树是什么?可能是大星团左下方的那颗。移走那棵树后,下一棵树是哪棵?可能是左上角的那个,以此类推。这里我提出一个很重要的直觉:离群值应该是最容易被孤立的。就像剥洋葱一样,离群值在外层。这就是 Isolate Forest 寻找离群值的直觉。
隔离林速度很快,并且不会消耗太多内存,因为它不使用任何距离度量来检测异常。这一优势使其适用于大数据量和高维问题。
什么是孤立森林?
许多异常值检测方法首先分析正常数据点,然后识别那些不符合正常数据模式的观察值。由刘,廷,周(2008) 提出的隔离林或森林与这些方法不同。I forest直接识别异常,而不是分析正常数据点以发现异常值。它应用树结构来隔离每个观察。异常将是首先被挑选出来的数据点;而正常点往往隐藏在树的深处。他们称每棵树为隔离树或隔离树。他们的算法建立了一个 iTrees 集合。异常是那些在 iTrees 上具有短平均路径长度的观测值。**
图(A)使用一个分区图和一棵树来解释 iTree 是如何隔离数据点的。红点是离其他点最远的点,然后是绿点,然后是蓝点。在分区图中,只需要一个“切口”就可以将红点与其他点分开。第二次切割是为了绿点,第三次切割是为了蓝点,以此类推。分割一个点需要的切割越多,它在树中的位置就越深。切割次数的倒数是异常分数。图(A)右边的树形结构讲述了同样的故事。它需要一次分裂来挑出红点,然后第二次分裂来达到绿点,然后第三次分裂来达到蓝点,以此类推。深度的数量成为异常分数的良好代表。为了符合异常与高分相关联的惯例,异常分数被定义为深度数的倒数。

Figure (A): iTree (Image by author)
一棵 iTree 是一棵二叉树,其中树中的每个节点恰好有零个或两个子节点。一棵 iTree 开始增长,直到满足其中一个条件:(I)结束节点只有一个数据点,(ii)节点中的所有数据都具有相同的值,或者(iii)树达到了(由研究人员设置的)高度限制。直到所有的端节点都有一个数据点,iTree 才需要完全开发。通常当高度达到设定的极限时,它就会停止生长。这是因为我们的兴趣在于更接近根部的异常。因此,没有必要构建大的 iTree,因为 iTree 中的大多数数据都是正常的数据点。小样本量产生更好的 iTrees,因为淹没和掩蔽效应减少了。注意,这个 iTree 算法不同于决策树算法,因为 iTree 不使用目标变量来训练树。它是一种无监督的学习方法。
(B)为什么是“森林”?
你可能更经常听到随机森林而不是孤立森林。“森林”指的是为树木构建森林的集合学习。为什么需要这样做?我们都知道单个决策树的缺点是过度拟合,这意味着模型对训练数据的预测很好,但对新数据的预测很差。集成策略通过构建许多树,然后平均这些树的预测来克服这个问题。

Figure (B): Isolation Forest
图(B)显示了一个数据矩阵,其中每一行都是具有多维值的观察值。IForest 的目标是给每个观察值分配一个异常值。首先,它随机选择任意数量的行和任意数量的列来创建表,如(1)、(2)和(3)。观察将出现在至少一个表中。为每个表构建一个 iTree 来呈现异常值。表格(1)有 6 行 3 列。表(1)的第一个切割可能是第 6 个观察值,因为它的值与其他值非常不同。之后,表(1)的第二次切割可能是第四次观察。类似地,在表(3)中,第一次切割可能是第 6 次观察(这是第三次记录)。第二次切割是第 4 次观察(这是表中的第一条记录)。简而言之,如果有 N 个表,就会有 N 个树。一次观察最多可以有 N 个分数。IForest 计算分数的算术平均值,得到最终分数。
[## 通过我的推荐链接加入 Medium-Chris Kuo/data man 博士
阅读 Chris Kuo/data man 博士的每一个故事。你的会员费直接支持郭怡广/戴塔曼博士和其他…
dataman-ai.medium.com](https://dataman-ai.medium.com/membership)
©建模程序
像其他章节一样,我使用以下建模过程进行模型开发、评估和结果解释。
- 模型开发
- 阈值确定
- 描述正常和异常组
对两个组的剖析对于交流模型的可靠性是很重要的。你的商业知识会告诉你一个特征的平均值在异常组中应该更高还是更低。如果与直觉相反,建议您调查、修改或放弃该特性。您应该迭代建模过程,直到所有的特性都有意义。

(C.1)第一步:建立模型
我生成了一个包含六个变量和 500 个观察值的模拟数据集。尽管这个模拟数据集有目标变量 Y,但无监督模型只使用 X 变量。Y 变量只是用于验证。“污染=0.05”时,异常值的百分比设置为 5%我们可以绘制前两个变量的散点图。黄色点是异常值,紫色点是正常数据点。


Figure (C.1)
下面我们声明并拟合模型。树“max_samples”的大小被设置为 40 个观察值。在 IForest 中,没有必要指定大的树大小,小的样本大小可以产生更好的 I tree。

让我解释一下污染率。在大多数实际应用中,我们不知道离群值的百分比。我将在第(C.2)节中说明,当事先不知道异常值的百分比时,如何确定一个合理的阈值。PyOD 默认污染率为 10%。在这里,我将污染设置为 5%,因为它在训练样本中是 5%。此参数不影响异常值分数的计算。内置函数threshold_计算污染率下训练数据的阈值。在这种情况下,当污染率为 0.05 时,阈值为-5.082e-15。函数decision_functions()生成异常值分数,函数predict()基于阈值分配标签(1 或 0)。
(C.1.1)超参数
我将用.get_params()解释一些重要参数:

- “max_samples”:从 X 中抽取的样本数,用于训练每个基本估计量。这是一棵树的大小,是一个重要的参数。
- “n_estimators”:集合中树的数量。默认值是 100 棵树。
- “max_features”:从 X 中抽取的特征数,用于训练每个基本估计量。默认值为 1.0。
- “n_jobs”:为“fit”和“predict”并行运行的作业数。默认值为 1.0。如果设置为-1,则作业数量将设置为核心数量。
(C.1.2)可变重要性
因为 IForest 应用了一个树形框架,我们将能够理解特性在确定离群值时的相对重要性。特征的重要性通过基尼系数来衡量。这些值的总和为 1.0。

我们可以像基于树的模型一样绘制特征重要性。图(C.1.2)显示了特征在确定异常值时的相对强度。

Figure (C.1.2): Variable importance of IForest for Outliers
(C.2)步骤 2——为模型确定一个合理的阈值
阈值将由异常值分数的直方图来确定。图(C.2)建议阈值为 0.0 左右。这意味着大多数正常数据的异常值小于 0.0。异常数据的异常值在高范围内。

Figure (C.2)
(C.3)步骤 3 —呈现正常组和异常组的描述性统计数据
描述正常组和异常组是证明模型可靠性的关键步骤。我创建了一个简短的函数descriptive_stat_threshold()来显示正常组和异常组的特征的大小和描述性统计。下面我简单地采用设定污染率的阈值。您可以测试阈值范围,以确定离群值组的合理大小。

Table (C.3)
上表包括模型评估和模型结果的基本要素。提醒您使用功能名称来标记功能,以便有效地进行演示。
- **离群组的大小:**记住离群组的大小是由阈值决定的。如果为阈值选择较高的值,大小将会缩小。
- **各组的特征统计:**特征统计要与任何之前的业务知识一致。如果任何特征显示出与直觉相反的结果,则该特征应该被重新检查或移除。应该重新迭代模型,直到所有特性都有意义。
- **平均异常分:**异常组的平均异常分远高于正常组(0.18 > -0.10)。你不需要对分数解读太多。
因为我们在数据生成中有基础事实,所以我们可以生成混淆矩阵来理解模型性能。该模型提供了一个体面的工作,并确定了所有 25 个异常值。

(D)通过聚合多个模型实现模型稳定性
由于 IForest 是一种基于邻近度的算法,因此它对异常值很敏感,并且可能会过度拟合。为了产生稳定的预测结果,我们可以汇总多个模型产生的分数。在所有的超参数中,树的数量n_estimators可能是最重要的一个。我将为一系列的树木制作 5 个模型。这些模型的平均预测将是最终的模型预测。PyOD 模块提供了四种汇总结果的方法。记住使用pip install combo功能。你只需要使用一种方法来产生你的综合结果。
对 5 个模型的预测进行平均,以获得平均异常值分数(“y_by_average”)。我在图(D)中创建了它的直方图。

Figure (D): The histogram of the average score
图(D)表明阈值等于 1.0。这样,我在表(D)中描绘了正常组和异常组的特征。它将 25 个数据点识别为异常值。读者应对表(C.3)进行类似的解释。

Table (D)
(E)摘要
- 大多数现有的基于模型的异常检测方法构建正常实例的简档,然后将不符合正常简档的实例识别为异常值。但是 IForest 直接且明确地隔离了异常。
- IForest 采用树形结构来隔离每一个数据点。异常是首先被挑选出来的奇异数据点;而正常点倾向于在树中聚集在一起。
- 因为隔离林不使用任何距离度量来检测异常,所以它速度很快,适合于大数据量和高维问题。
**(F) Python 笔记本:**点击此处为笔记本。
参考文献
- 刘福亭,丁克明,周志宏(2008)。隔离森林。 2008 年第八届 IEEE 数据挖掘国际会议(第 413-422 页)。
为了便于导航到章节,我在最后列出了章节。
- 第 1 章—简介
- 第 2 章—基于直方图的异常值得分(HBOS)
- 第 3 章——经验累积异常值检测(ECOD)
- 第 4 章——隔离林(IForest)
- 第 5 章——主成分分析
- 第六章——单类支持向量机
- 第七章——高斯混合模型(GMM)
- 第八章——K 近邻(KNN)
- 第 9 章—局部异常因素(LOF)
- 第十章——基于聚类的局部异常因子(CBLOF)
- 第 11 章——基于极端增强的异常检测(XGBOD)
- 第 12 章——自动编码器
- 第 13 章——极度不平衡数据的欠采样
- 第 14 章—极度不平衡数据的过采样
[## 通过我的推荐链接加入 Medium-Chris Kuo/data man 博士
阅读 Chris Kuo/data man 博士的每一个故事。你的会员费直接支持郭怡广/戴塔曼博士和其他…
dataman-ai.medium.com](https://dataman-ai.medium.com/membership)
建议读者购买郭怡广的书籍:

- 可解释的人工智能:https://a.co/d/cNL8Hu4
- 图像分类的迁移学习:https://a.co/d/hLdCkMH
- 现代时间序列异常检测:https://a.co/d/ieIbAxM
- 异常检测手册:https://a.co/d/5sKS8bI
对数据科学家有用的命令行工具
适用于您的 linux 终端的各种便利工具
从命令行工作可能令人畏惧,但对于任何数据科学家来说,这都是一项重要的技能。当在远程 linux 实例上工作时,您不再能够访问您最喜欢的 GUI,而是必须使用命令行来导航您的远程实例。这个工具列表并不是命令行入门指南,而是我觉得有用的工具大杂烩,我希望你也一样!
我们的好朋友 grep
grep 是一个命令行工具,用于在文件中搜索模式。grep 将打印文件中与标准输出(终端屏幕)模式匹配的每一行。当我们可能希望使用给定模式对我们的数据子集进行建模或执行 EDA 时,这可能特别有用:
grep "2017" orders.csv > orders_2017.csv
在上面的命令中,我们从“orders.csv”数据集中捕获所有包含模式“2017”的行,然后将包含此字符串的行写入名为“orders_2017.csv”的新文件。当然,如果我们对 order_date 列感兴趣,而另一个不同的列,如 address 包含模式“2017”(即 2017 Wallaby Lane) 、,那么我们可能会得到错误年份的数据;然而,这在熊猫身上可以很快得到解决。在马上使用 pandas 之前使用 grep 的一个原因是命令行工具通常是用 C 编写的,所以它们非常快。另一个原因是,使用 os.system()可以很容易地将它们放在 python 脚本中:
Grep is great and can also be used with all kinds of regular expressions using the -E option.
htop
有没有在熊猫工作,收到内存错误的?您是否并行运行了一些操作(即使用 n_jobs=-1 来拟合 sklearn 模型)并且不确定是否所有的 CPU 都在使用中?那么 htop 是给你的! htop 很棒,因为它允许您查看机器上当前的 CPU 和 RAM 使用情况:
在我的例子中,我的机器有四个 CPU,所以前四行显示了每个 CPU 的使用统计。第五行显示了我的电脑 8GB 内存的使用情况。下表显示了正在运行的进程以及相关的进程 id (PID)、内存和 CPU 使用情况以及一些其他有用的统计信息。
假设我们在 Jupyter 笔记本中遇到了熊猫操作的内存问题,使用 htop 可以帮助我们监控每个操作对 RAM 使用的影响。如果我们有这样的代码:
在上面的代码段中,我们正在为我们的熊猫数据帧制作大量副本,htop 可以帮助我们更好地认识到我们何时接近 RAM 阈值。此外,如果我们的机器上正在运行其他我们目前不需要的内存密集型进程,我们可以使用 kill 命令行工具终止或暂停它们( kill 的-9 选项将终止该进程,确保您终止的进程是非必要的/不是系统进程)。看 htop 或者 ps 输出得到 PID。
kill -9 {insert PID here}
df
df 是一个有用的工具,用来验证我们的机器上有多少可用的磁盘空间。当在没有指定任何文件名的情况下使用时, df 返回所有当前挂载的文件系统上的可用空间;但是,如果我想查看整个机器上有多少可用空间,我可以运行:
df -h /
h 选项返回人类可读的格式,而“/”表示根文件系统中有多少可用空间:

当需要在远程 AWS EC2 实例上为大量下载创建空间时, df 有助于确定还需要清理多少空间。如果您正在从一个包含大量大文件的旧项目中释放磁盘空间,您可以运行“ls -hlS”来查看可读的长格式(-l,意味着您可以查看权限/文件大小/最后修改日期)的文件,这些文件在给定的目录中按文件大小降序(-S)排序。这样可以快速确定删除哪些文件可以释放最多的空间:

看
watch 是一个易于使用的命令,当你需要一个命令的输出每 n 秒刷新一次时,这个命令可以派上用场。我过去从 pushshift reddit 评论数据库下载大型 JSON 文件时使用过这个命令。每个解压后的月评论是一个 100GB 的文件,所以我写了一个脚本一次下载一个文件,从 subreddits 中过滤掉我不感兴趣的评论,写到 MongoDB,删除大的 JSON 文件。在这种情况下,我使用手表反复检查是否正确的文件被下载,解压缩,然后在下载后删除。

正如我们在上面看到的,watch 的默认设置是每两秒钟重复一次命令,尽管我们可以用“ -n {number_seconds} ”选项来修改它。
单细胞蛋白质
scp 代表 secure copy,是一个有用的命令,我们可以用它在远程实例之间发送文件。
发送到远程:
scp -i ~/.ssh/path/to_pem_file /path/to/local/file ubuntu@IPv4:./desired/file/location
在上面的命令中,“ubuntu”是 ubuntu 实例的默认 AMI ssh 用户名,因此这可以根据您使用的 linux 发行版而改变。您的 IPv4 通常被格式化为由句点分隔的四个 8 位字段(即 32.14.152.68)。I 选项只是指定我们将使用一个身份文件,该文件包含公钥认证所必需的私钥。
从遥控器下载:
scp -i ~/.ssh/path/to_pem_file ubuntu@IPv4:./path/to/desired/file/ ~/my_projects/
注意,这个下载命令仍然是从我们的本地终端执行的。我们刚刚交换了本地文件系统和远程文件系统的写入顺序。此外,值得一提的是,如果我们对该命令使用-r 选项,我们可以递归地复制目录,而不仅仅是文件:
scp -i ~/.ssh/path/to_pem_file -r ubuntu@IPv4:./path/to/desired/folder/ ~/my_projects/
结论
linux 命令行提供了一系列功能强大的工具,可以真正帮助提高生产率,并了解机器的当前状态(即磁盘空间、正在运行的进程、RAM、CPU 使用情况)。在远程 linux 实例上工作通常是熟悉命令行的一个很好的方式,因为您被迫使用它,并且不能依靠 Mac 的 Finder 来导航文件系统。上面讨论的工具是我最喜欢/最常用的(除了 ls 和 cd 之外),我希望如果你以前不知道它们,你能把它们结合到你的工作流程中。感谢您的阅读!
进一步阅读
有用的命令列表:T3【http://www.slackstu.net/171/171-class-19f.xhtml】T5
命令行的数据科学:https://www . datascienceathecommandline . com/chapter-5-scrubping-data . html
诊断神经网络的有用图表
训练神经网络不是一项容易的任务,有时会产生比预期好得多的结果,或者表现得差得多,产生的只是噪音。

让我们面对它…训练一个神经网络很难,如果你认为它很容易,那么很有可能你还没有完全理解深度学习。典型的深度学习模型由数百万个可学习的参数组成。分析他们中的每一个人在训练中如何变化,以及一个人如何影响其他人,是一项不可能完成的任务。
幸运的是,我们有一定的数量可以观察训练的进展。这些措施让我们得以一窥黑箱,了解它们是如何变化的。
随着每一次网络培训的开始,让我们从数据开始。
数据
对于每一个机器学习模型,数据的重要性高于所有其他因素。我不能强调这一点…看看你的数据!!!。数据可能会解释为什么你在训练时会有问题。您的数据可能会让您了解为什么您的模型没有像预期的那样运行。让我解释一下。
在训练分类模型之后,可能存在模型的输出完全或大部分属于一个类别的情况,即模型有偏差的情况。这主要是由于不平衡的数据集。
人们可能面临的另一个问题是没有足够的数据来支持问题陈述。为了说明这一点,我来分享一个经历。几个月前(在我发表这篇文章的时候),我的一个朋友请我帮个忙。他让我用很少的数据点重新生成一个图形,即训练一个神经网络作为函数逼近器。
光是看原图照片,就知道是指数曲线。但这还不够,因为他需要对情节进行推理。他需要精确的曲线。他设法给了我一些从图表中手动提取的数据点。当我训练网络并预测一个小域的值时,我得到的只是一条略微弯曲的线。我没想到会是这样的曲线。无论我做什么,图表都保持不变。
当我将数据可视化时,我发现数据是不够的。网络仅仅理解它是一条指数曲线是不够的。
这种情况在数据收集期间是一个严重的问题。我们可能认为我们得到了一切,但我们可能只收集了所需数据的一个子集。这可能不足以解决问题。想想吧…
损失曲线
调试神经网络最常用的图之一是训练期间的损失曲线。它为我们提供了训练过程和网络学习方向的快照。斯坦福大学的安德烈·卡帕西在这个链接上给出了一个令人惊叹的解释。这一节深受它的启发。

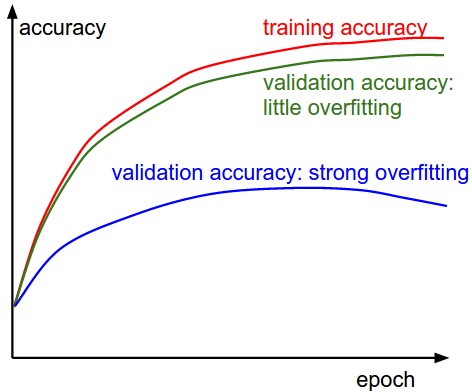
Effect of Learning rate on Loss (Source: CS231n Convolutional Neural Networks for Visual Recognition)
这个图像很容易理解。您可以在两个时间段内记录您的损失:
- 在每个时代之后
- 每次迭代后
据说绘制跨时期的损失比迭代更理想。
在一个历元期间,跨每个数据项计算损失函数,并且保证在给定的历元给出定量的损失度量。但是跨迭代绘制曲线仅给出整个数据集的子集的损失。
通过绘制验证损失和训练损失图,可以获得更多的信息。
精确度曲线
另一个最常用于理解神经网络进展的曲线是精度曲线。对于任何在深度学习方面有一些经验的人来说,使用准确度和损失曲线是显而易见的。
更重要的曲线是同时具有训练和验证准确性的曲线。

Accuracy Plot (Source: CS231n Convolutional Neural Networks for Visual Recognition)
训练和验证准确性之间的差距是过度拟合的明显标志。间隙越大,过度拟合程度越高。
不确定
另一个可能被削弱的量是不确定性。不确定性是一个有点高深的话题,但我建议每个人都应该理解这个概念。它更像是一个定量的衡量,而不是一个情节。不确定性有两种类型:
- 随机不确定性/数据不确定性
- 认知不确定性/模型不确定性
在本节中,我们将重点关注模型的不确定性。
模型不确定性是关于模型参数和模型结构的不确定性。两种神经网络架构可以具有不同的不确定性值。因此,我们得到了一个量化的方法来比较这些体系结构,并找到更好的一个。
在我个人看来,完全偏向准确性不是一个好的方法。
在下面的例子中,我绘制了一个建筑的不确定性,这个建筑是在波士顿房价数据集上训练出来的。模型的不确定性被记录在整个训练时期。
模型的不确定性随着训练而降低……这是有道理的。我已经训练了 250 个时期的模型,只是为了向你们展示不确定性是如何变化的。
结论
当一个模型没有给出想要的结果时,试着去理解发生了什么。这些措施可以让我们一窥神经网络的训练。此外,可视化隐藏层输出(尤其是在卷积网络中)在很大程度上有所帮助。
谢谢大家!!😁
Python 中有用的字符串方法
了解一些 Python 内置的可用于字符串的方法

original Image: Terri Bleeker on Unsplash
字符串是一系列字符。Python 中内置的 string 类表示基于 Unicode 国际字符集的字符串。字符串实现了 Python 中常见的操作序列,以及一些它们独有的附加方法。下图显示了所有这些可用的方法:

Built-in String Functions in Python
在这篇文章中,我们将了解一些更常用的。这里需要注意的重要一点是,所有的字符串方法总是返回新值,并且不改变或操作原始字符串。
这篇文章的代码可以从相关的 Github 库获得,或者你可以点击下面的图片在我的活页夹上查看。

1.居中( )
[center()](https://docs.python.org/3.7/library/stdtypes.html#str.center)方法居中对齐字符串。对齐是使用指定的字符完成的(缺省情况下是空白)
句法
str.**center**(length, fillchar),其中:
- 长度是字符串的长度要求
- fillchar 是指定对齐的字符[ 可选
例子

2.计数( )
[count()](https://docs.python.org/3.7/library/stdtypes.html#str.count)方法返回特定值在字符串中出现的次数。
句法
str.**count**(value, start, end),其中:
- 值是要在字符串[ 必选 ]中搜索的子字符串
- start 是字符串中开始搜索指定值的起始索引[ 可选
- end 是字符串中结束搜索指定值的结束索引[ 可选
例子

3.查找( )
[find()](https://docs.python.org/3.7/library/stdtypes.html#str.find)方法返回字符串中特定子串的最低索引。如果找不到子字符串,则返回-1。
句法
str.**find**(value, start, end),其中:
- 在字符串[ 必选 ]中要搜索的值或子字符串
- start 是字符串中开始搜索指定值的起始索引[ 可选 ]
- end 是字符串中结束搜索指定值的结束索引[ 可选
类型
rfind():rfind()方法类似于 find(),只是它返回子串的最高索引值
例子

4.交换情况( )
方法返回一个字符串的副本,所有的大写字母都转换成小写,反之亦然。
句法
string.swapcase()
例子

5.startswith()和 endswith()
如果字符串以指定的值开始,则[startswith()](https://docs.python.org/3.7/library/stdtypes.html#str.startswith)方法返回 True 否则,它返回 False。
另一方面,如果字符串以指定的值结束,函数endswith()返回 True,否则返回 False。
句法
string.startswith(value, start, end)
string.endsswith(value, start, end)
- 值是在字符串[ 必选 ]中查找的字符串
- start 是字符串中开始搜索指定值的起始索引[ 可选
- end 是字符串中结束搜索指定值的结束索引[ 可选
例子

6.拆分( )
split() 方法返回一个字符串中的单词列表,其中默认分隔符是任何空格。
句法
string.split(sep, maxsplit)
- sep :用于分割字符串的分隔符。如果没有指定,空白是默认分隔符[ 可选 ]
- **最大分割:**表示分割的次数。默认值为-1,表示“所有事件”可选 T43
版本
- 【rsplit():从右侧拆分一个字符串。
例子

7.字符串大写
1.大写( )
方法只将字符串的第一个字符大写。
语法
string.capitalize()
2.上部( )
upper() 方法将字符串中的所有字母大写。
语法
string.upper()
3.string.title()
title() 方法将给定字符串的所有首字母大写。
语法
string.title()
例子

8.ljust()和 rjust()
方法使用一个指定的字符返回给定字符串的左对齐版本,默认为空白。rjust()方法将字符串右对齐。
句法
string.rjust/ljust(length, character)
- length: 要返回的字符串的长度[ 必选
- **字符:**用于填充缺省空格的字符[ 可选 ]
例子

9.条状( )
方法返回一个去掉了前导和尾随字符的字符串的副本。要删除的默认字符是空白。
句法
string.strip(character)
**字符:**要删除的字符集[ 可选
版本

10.零填充( )
zfill()方法在字符串的开头添加零(0)。返回字符串的长度取决于提供的宽度。
句法
string.zfill(width)
- width :指定返回字符串的长度。但是,如果宽度参数小于原始字符串的长度,则不会添加零。
例子

结论
这些是 Python 中一些有用的内置字符串方法。还有一些文章中没有提到,但同样重要。如果您想更深入地了解细节,Python 文档是一个很好的资源。
使用 Spark 进行用户流失预测
Udacity 数据科学家纳米学位计划顶点项目

该项目是 Udacity **数据科学家纳米学位项目:数据科学家顶点计划的最终项目。**目标是预测用户是否会从虚拟的数字音乐服务中流失 Sparkify
流失预测是商业中最受欢迎的大数据用例之一。正如这篇帖子中更好地解释的那样,它的目标是确定客户是否会取消他的服务订阅
让我们从使用 CRISP-DM 流程(数据挖掘的跨行业流程)开始:
- 业务理解
- 数据理解
- 准备资料
- 数据建模
- 评估结果
- 展开
业务理解
Sparkify 是一项数字音乐服务,可以免费使用,方法是在歌曲之间收听一些广告,或者支付每月订阅费以获得无广告体验。在任何时候,用户都可以决定从高级降级到免费,从免费升级到高级或者取消服务。

https://www.udacity.com/course/data-scientist-nanodegree–nd025
数据理解
所提供的数据集基本上由平台上每个用户操作的日志组成。每个动作都标有时间戳 ts

Dataset attributes

First 5 records as example
在这个小数据集中,我们有来自 225 个用户的 286500 条记录:
46%的女性和 54%的男性

Gender distribution in the small dataset
54%的互动来自免费用户,46%来自高级用户

Level distribution in the small dataset

Page distribution in the small dataset

% page distribution in the small dataset
这些记录的时间跨度从 2018 年 10 月到 2018 年 12 月
准备数据
第一步是删除所有用户 Id 为空的记录。空字符串 userId 很可能指的是尚未注册的用户,或者已经注销并即将登录的用户,因此我们可以删除这些记录。
然后我定义了一个新的Churn列,它将被用作模型的标签。基本上,如果用户曾经访问过Cancellation Confirmation页面,我们会将其标记为搅动。当然,这个事件对于付费和免费用户都可能发生。
我们获得了 23%的流失用户和 77 %的未流失用户,因此数据集非常不平衡。正如这篇精彩的帖子中所解释的,当我们在评估结果部分讨论指标时,我们必须记住这一点

Churn distribution in the small dataset
然后,我对一些特性进行了比较,同时也考虑了Churn值:

Churn Gender distribution in the small dataset

Churn Level distribution in the small dataset

Churn Page distribution in the small dataset

% churn page distribution in the small dataset
数据建模
所有对我们的任务有用的分类特征都已经通过用户 Id :
-性别
-级别
-页面进行了一次性编码和聚合

Engineered dataset attributes
然后,我们通过提出以下问题添加了一些有趣的工程特性:
-用户订阅该服务多久了?流失与此有关吗?
-上个月的活动(对于不满意的用户,取消是取消前的最后一个月)以周为单位划分
-一个用户听了多少艺术家的音乐?

Churn Registration days distribution in the small dataset

Churn Last week average activity distribution in the small dataset

Churn Artist distribution in the small dataset
为 ML 准备的最终数据集如下所示:

Engineered dataset attributes in input to the model
重要的是不要考虑像page_Cancellation_Confirmation或page_Cancel这样的属性,因为它们精确地映射了标签列,所以准确率总是 100%,因为我们基本上是在学习我们想要预测的值
评估结果
混淆矩阵是一个表格,通常用于描述一个分类模型对一组真实值已知的测试数据的性能。

准确性衡量分类器做出正确预测的频率。它是正确预测数与总预测数的比率:
Accuracy = (True Positives + True Negative) / (True Positives + False Positives + True Negatives + False Negatives)
精度告诉我们正确的预测中有多少是正确的。它是真阳性与所有阳性的比率:
Precision = True Positives / (True Positives + False Positives)
回忆(敏感度)告诉我们实际上正确预测中有多少被我们归类为正确的。它是真阳性与所有实际阳性预测的比率:
Recall = True Positives / (True Positives + False Negative)
F-beta 评分是一个同时考虑精确度和召回率的指标:

生成朴素预测器的目的只是为了显示没有任何智能的基础模型是什么样子。如前所述,通过观察数据的分布,很明显大多数用户不会流失。因此,总是预测'0'(即用户不访问页面Cancellation Confirmation)的模型通常是正确的。

将所有用户标记为流失= 0 的朴素模型在测试集上做得很好,准确率为 81.2%,F1 分数为 0.7284
数据集不平衡的事实也意味着精确度没有太大帮助,因为即使我们获得高精确度,实际预测也不一定那么好。在这种情况下,通常建议使用精度和召回
让我们比较 3 个模型的结果:
- 逻辑回归
- 梯度提升树
- 支持向量机
第一步是删除培训中不必要的列
colonne = df.columns[1:-1]
colonne

Features used for ML training
然后所有的特征都被矢量化(不需要转换,因为所有的特征都是数字)
assembler = VectorAssembler(inputCols = colonne, outputCol = ‘features’)data = assembler.transform(df)
StandarScaler()用于缩放数据
scaler = StandardScaler(inputCol = 'features', outputCol = 'scaled_features', withStd = True)scaler_model = scaler.fit(data)data = scaler_model.transform(data)
然后,我将数据分为训练、测试和验证数据集
train, rest = data.randomSplit([0.6, 0.4], seed = 42)validation, test = rest.randomSplit([0.5, 0.5], seed = 42)
对于所有车型,我都使用了 F1 分数作为衡量标准
f1_evaluator = MulticlassClassificationEvaluator(metricName = ‘f1’)
以及ParamGridBuilder()和 3 倍CrossValidator()来确定考虑所有参数的模型的最佳超参数
param_grid = ParamGridBuilder().build()
逻辑回归
logistic_regression = LogisticRegression(maxIter = 10)crossvalidator_logistic_regression = CrossValidator(
estimator = logistic_regression, evaluator = f1_evaluator, estimatorParamMaps = param_grid, numFolds = 3)cv_logistic_regression_model = crossvalidator_logistic_regression.fit(train)

Best parameters
梯度提升树
gradient_boosted_trees = GBTClassifier(maxIter = 10, seed = 42)crossvalidator_gradient_boosted_trees = CrossValidator(
estimator = gradient_boosted_trees, evaluator = f1_evaluator, estimatorParamMaps = param_grid, numFolds = 3)cv_gradient_boosted_trees_model = crossvalidator_gradient_boosted_trees.fit(train)

Best parameters
GBT 也允许看到特性的重要性:

Feature importances from GBT
我们可以看到registration_days和count_page_last_week具有最高的重要性
支持向量机
linear_svc = LinearSVC(maxIter = 10)crossvalidator_linear_svc = CrossValidator(
estimator = linear_svc, evaluator = f1_evaluator, estimatorParamMaps = param_grid, numFolds = 3)cv_linear_svc_model = crossvalidator_linear_svc.fit(train)

Best parameters
总的来说,逻辑回归具有最好的结果,在测试数据集上 F-1 得分为 0.8218,在验证数据集上为 0.7546

Results on test and validation datasets
细化
我第一次尝试手动调整模型的一些参数,但是通过让ParamGridBuilder()和CrossValidator()搜索所有参数获得了最佳结果
部署
根据 DSND 顶点项目的云部署说明的建议,我已经用 AWS 创建了一个集群

My cluster configuration
正如这里更好地解释的m3 . xlarge是第二代通用 EC2 实例,配备了高频英特尔至强 E5–2670和 2 个基于 40 GB 固态硬盘的实例存储

My cluster summary
然后我创建了一个笔记本并复制粘贴了必要的代码

sparkify notebook summary
在真实数据集上,我们有来自 22278 个用户的 26259199 条记录:
47%的女性和 53%的男性

Gender distribution in the full dataset
21%的互动来自免费用户,79%来自高级用户

Level distribution in the full dataset

Page distribution in the full dataset
22%的用户感到不适,78 %没有
这个小数据集很好地代表了真实数据集,这意味着它似乎没有偏见
结论
我们的目标是预测用户是否会取消服务,以使公司能够为他提供优惠或折扣,从而留住这些用户。在清理数据并将它们建模为准备用于 ML 训练的数据集之后,我们测试了三个不同模型的性能。所有产生的模型都成功地预测了用户是否会离开服务,比给出总是答案的'0'(用户不会流失)的天真预测器好不了多少。考虑到 F-1 得分最好的模型是**逻辑回归。**尽管结果很好,但该模型可以通过精心设计更多的工程特征来捕捉一些可能与用户对服务的满意度相关的行为模式来改进:推荐引擎好吗?意思是推荐给用户的歌真的符合他们的口味。从 GBT 的功能重要性来看,原始功能page_Thumbs_Up和page_Thumbs_Down相当重要,因此捕捉用户音乐品味的新功能确实可以改善模型
这个项目的代码可以在这个 github 资源库中找到,在我的博客上有一个意大利语的帖子。
我的第一个数据产品的用户指南:中等邮政公制显示器
用数据更好地了解你的媒体文章
原点
作为一名媒体上的定期作家和数据极客,在忙碌的 2018 年之后,我想在我的媒体博客上反映一下我所取得的成就。此外,根据 2018 年的表现,我计划在 2019 年制定更积极的写作计划。
我想大多数媒体作者都知道媒体分析平台的反数据为中心的界面设计。对我来说太简单了。这种设计让我很不情愿去研究数据并做出决定。
这是我决定开发我的第一个数据产品的主要原因。在下面的文章中,我将向读者展示这个产品和我用来创建这个产品的代码。我将使用我自己的数据在中型分析平台,以及展示我的产品如何运行。
整个思考和执行过程也会被详细记录下来。任何热衷于了解他或她自己的 Medium post 性能的人,都可以随意使用我的代码来提供一些数据。

from https://medium.com/membership
问题陈述和痛点
问题陈述:以更健壮、更形象化的方式知道哪篇文章表现好,很烦。此外,文章可能无法分组或分类。在所有的指标中,哪些指标对于不同的文章组可能是最有区别的?
痛点:中型用户可能会发现很难充分利用 Medium 提供的分析平台(Stat 选项卡)。这些数据无法下载,也几乎没有告诉我们下一步该做什么。
约束
这个产品的约束非常明显。对我来说,我仍然不能以一种更自动化的方式从介质中抓取或输出每篇文章的性能数据。因此,用户需要手动记录这些数据,就像我在这个 excel 中所做的那样。列名应该与我的相同。用户只需要定期按季度(每季度或每半年)记录这些指标

I will put this file in my GitHub as well, feel free to download it
我的产品能彻底处理那些 excel 文件。一旦有了特定数据文件。我们准备好出发了。
技能和工具
工具:Python Jupyter 笔记本
技能:用 Pandas 进行数据处理和管理,用 Matplotlib 进行可视化,用 Sklearn 进行聚类加 PCA,为重复操作创建大量函数
产品展望
这个产品很简单。我还没有创建它的布局或界面,但相反,我将介绍这个产品背后的操作逻辑。中邮公制显示器包括许多小而方便的功能。一旦用户将 excel 文件(我们用于记录数据)传递给这些函数,就会自动生成结果。
它包含该产品的两个功能。第一个是仪表板和可视化产品。第二个是集群产品。
这是我的产品路线图的第一阶段。(我不确定我是否会继续扩展它的功能)。然而,我认为这个测试版的 Displayer 足够全面,可以为作者做出决定提供一些见解。这就是我决定在这个时候软发布我的产品的原因。
请随意获取我的 Github 代码,并愉快地使用这个产品!
[## 云汉风/medium_metric_data_product
我的第一个数据产品,为媒体作者提供数据解决方案来跟踪帖子的表现…
github.com](https://github.com/yunhanfeng/medium_metric_data_product)
第 0 部分:预检数据导入
在介绍产品本身之前,我们先来看看我们的数据集。
可以肯定的是 python 中需要的包是导入的。熊猫、Numpy、Matplotlib 是我熟悉的朋友。这次我用了 Goolgetrans 的翻译。背后的原因是我有时用中文写文章,而我的大部分读者来自台湾。他们也可能用中文写帖子。将中文标题翻译成英文将更符合 Matplotlib 的约束,因为 Matplotlib 不能显示中文。
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
from googletrans import Translator
我后来读入 excel 文件并显示它的前几行,进一步检查列的类型和形状。从介质中提取和记录的数据来看,有七个基本特征。从我的媒体网站,我已经写了 45 篇文章了。
df = pd.read_excel('medium_performance_data.xlsx')
df.head()

df.dtypesdates datetime64[ns]
title object
view int64
additional_view int64
read int64
read_ratio float64
fans int64
dtype: objectdf.shape
(45, 7)
第一部分:仪表盘和可视化产品
在这个产品中,我设计了八加一功能,使用户能够通过简单的 excel 文件输入返回不同指标的类似图表和图形。基于这些图表,作者能够对他们的文章表现的好坏有所了解,并进一步制定下一步的策略。
下面是 Medium post 上的用户参与度漏斗。基本上,我只是按照漏斗来设计我的产品。

功能 0
此功能主要处理中文标题的翻译问题。多亏了强大的谷歌翻译,它帮助把这些书名翻译成英文。
def translate(df):
import numpy as np
import matplotlib.pyplot as plt
from googletrans import Translator
translator = Translator()
df['title'] = df["title"].map(lambda x: translator.translate(x, src="zh-TW", dest="en").text)
return df
功能 1
该函数返回总视图的静态值。它是所有中等职位的基本数字,显示了对你的表现的一般描述。
def total_view(file):
import pandas as pd
df = pd.read_excel(file)
df = translate(df)
total_view = df['view'].sum() + df['additional_view'].sum()
return 'The total view of your medium post is {}'.format(total_view)
我把我的文件传入这个函数,它返回我的总浏览量大约是 15K。
total_view('medium_performance_data.xlsx')>> 'The total view of your medium post is 15086'
功能 2
函数 2 返回浏览量最多的前 5 篇文章。结果将以表格和条形图的形式显示。你也可以一瞥这 5 个对你的总浏览量的贡献。
def top_view(file):
import pandas as pd df = pd.read_excel(file)
df = translate(df)
top_view = df.nlargest(5, 'view')[['title','view']]
ax = top_view.plot.barh(x='title', y='view')
return display(top_view) , ax
操作该功能
top_view('medium_performance_data.xlsx')

我的前 5 篇文章的结果显示如下。看来我写的关于 MSBA 申请的文章吸引了大部分的关注。
功能 3
与函数 2 类似,该函数返回带有附加视图的前 5 篇文章的表格和条形图。额外的看法,对我来说,是一个相当奇怪的衡量标准。来自 Medium 的定义是“来自 RSS 阅读器、FB 即时文章和 AMP 的观点,它们不计入阅读率。”并不是一个作者发布的每篇文章都会有额外的观点。根据我的经验,只有当你的文章被 Medium 上的其他出版网站策划时,附加浏览量才有可能增加。它提供了一些见解,如何好这些出站文章的表现。
def top_additional_view(file):
import pandas as pd df = pd.read_excel(file)
df = translate(df)
top_view = df.nlargest(5, 'additional_view' [['title','additional_view']]
top_view = top_view[top_view['additional_view']>0]
ax = top_view.plot.barh(x='title', y='additional_view')
return display(top_view) , ax
操作该功能。
top_additional_view('medium_performance_data.xlsx')

功能 4
Read 是关于敬业度的更深层次的指标。如果用户一直滚动到底部,则 Read 是指标,这表示用户通读了帖子。该函数采用文件名作为参数,并返回表格和条形图。
def top_read(file):
import pandas as pd
df = pd.read_excel(file)
df = translate(df)
top_read = df.nlargest(5, 'read')[['title','read']]
top_read = top_read[top_read['read']>0]
ax = top_read.plot.barh(x='title', y='read')
return display(top_read) , ax
操作该功能。
top_read('medium_performance_data.xlsx')

结果与大多数观点的前 5 篇文章略有不同。阅读量最多的前 5 都是中文帖子。背后有多种可能的原因。
第一,我的大多数读者来自台湾,中文对我的大多数用户来说是一种相对熟悉的语言。他们倾向于读完更多的文章。
第二,它可能表明我的英文写作太长或太复杂,用户无法通读。我可能需要润色我的帖子,让它更简洁。
第三,除了语言问题,阅读量最多的前 5 个帖子都与信息相关的话题,如如何准备申请,如何提问以及 MSBA 课程的复习。也许这种话题可以引发更多的阅读兴趣。
功能 5
阅读率是另一个棘手的指标。阅读率=阅读/浏览(点击)。据说,中等算法将奖励阅读率较高的文章以较高的排名和优先级显示在用户面前。
该函数的工作方式与上面的相同,以显示表格和条形图的形式返回阅读率最高的前 5 篇文章。
def top_readratio(file):
import pandas as pd
df = pd.read_excel(file)
df = translate(df)
top_read = df.nlargest(5, 'read_ratio')[['title','read_ratio']]
top_read = top_read[top_read['read_ratio']>0]
ax = top_read.plot.barh(x='title', y='read_ratio')
return display(top_read) , ax
操作该功能。
top_readratio('medium_performance_data.xlsx')

从某些方面来说,对结果的解释是很复杂的。
第一,文章越短,就越有可能获得更高的阅读率。我所有帖子中的第一篇文章只是一个链接。当然,它将获得最高的读取率。
其次,浏览量少的文章也可能导致阅读率高,就像我的文章“[创造]。”
结论是,有一些内生性影响这一指标。我建议用户用上面的函数交叉验证这个指标。
功能 6
该函数返回所有文章的平均阅读率。因为读取率是中等算法的关键指标。我建议作者偶尔使用这个功能来跟踪文章表现的进度。
def avg_readratio(file):
import pandas as pd
df = pd.read_excel(file)
avg_rr = round(df.read_ratio.mean(),3)
return 'The avg. read ratio of your medium post is {}'.format(avg_rr)
操作该功能。
avg_readratio('medium_performance_data.xlsx')>> 'The avg. read ratio of your medium post is 0.528'
还应该根据内容的特征和类别进行设置。一些轻松易消化的文章可能有更高的平均阅读率,反之亦然。我的文章,平均阅读比是 0.528,对我来说,还不错。
我将努力把这作为我的目标,来提高我的媒体网站的阅读率。写结构清晰、可读性强、简洁明了的帖子是一个很好的方法。
功能 7
下一个功能是关于显示粉丝数最高的前 5 篇文章。粉丝指标是表示对文章更深入参与的指标。读者为帖子鼓掌,并展示了他们的“喜欢”它是公制漏斗的最后一步,可以更难实现。
def top_fans(file):
import pandas as pd
df = pd.read_excel(file)
df = translate(df)
top_read = df.nlargest(5, 'fans')[['title','fans']]
top_read = top_read[top_read['fans']>0]
ax = top_read.plot.barh(x='title', y='fans')
return display(top_read) , ax
操作该功能。
top_fans('medium_performance_data.xlsx')

功能 8
产品第一部分的最后一个功能是显示“过去几天的平均视图”我创建这个新指标来捕捉帖子的每日额外浏览量。公式是:从今天到文章发表那天的总浏览量/天数。对我来说,它计算的是这篇文章每天的浏览量。
def top_view_per_day(file):
import pandas as pd
df = pd.read_excel(file)
df = translate(df)
df['time_elapse'] =pd.datetime.now().date() - df['dates']
df['time_elapse'] = df['time_elapse'].dt.days
df['total_view'] = df['view'] + df['additional_view']
df['view_per_day'] = round(df['total_view'] / df['time_elapse'], 2)
top_read = df.nlargest(5, 'view_per_day')[['title','view_per_day']]
top_read = top_read[top_read['view_per_day']>0]
ax = top_read.plot.barh(x='title', y='view_per_day')
return display(top_read) , ax
操作该功能
top_view_per_day('medium_performance_data.xlsx')

我认为这个指标非常重要。这表明,文章仍然带来了每天的流量。那些文章将用户导向作者的媒体网站。它帮助用户识别你的媒体博客的“摇钱树”。了解这些文章后,定期在社交媒体上推广它们或让它们被关联者引用是保持新鲜流量流入你的媒体的好策略。
第二部分:集群产品
就像我在功能 8 中提到的,识别哪些文章是摇钱树很重要。这正是我提出并创造这个集群产品的初衷。通过对所提供的特征进行无监督学习,可以将文章分割成不同的组。每个群体都有不同的特征。他们可以在用户获取、保留和参与方面扮演不同的角色。通过使用这种聚类产品,用户只需传递 excel 文件,并进一步输入他想要创建的聚类数,结果就会自动生成。有几个功能也与可视化集群相关。
我将在下一篇文章中介绍四加一函数。
功能 9
这个函数只是管理数据的辅助函数。我从原始数据框架中创建了“总视图”和“每日视图”。
def medium_data_munge(file):
import pandas as pd
df = pd.read_excel(file)
df = translate(df)
df['time_elapse'] =pd.datetime.now().date() - df['dates']
df['time_elapse'] = df['time_elapse'].dt.days
df['total_view'] = df['view'] + df['additional_view']
df['view_per_day'] = round(df['total_view'] / df['time_elapse'], 2)
return dfmedium_data_munge("medium_performance_data.xlsx").head()

功能 10 和 11
这两个函数用于聚类。我使用 K-means 对文章进行聚类。我记录了阅读量、阅读率、粉丝数、总浏览量、每日浏览量。并且分割基于这五个特征。
从这里开始的函数,用户需要将 excel 文件和集群号传递给函数。
函数 10 返回带有簇标签的数据帧。用户可能把它看作是一个助手功能或产品功能。它返回的数据帧很容易被看到和播放。
函数 11 返回每个集群的摘要。它让用户清楚地了解每个集群的性能和质量。我认为这非常有帮助,因为用户最终可以针对不同的集群设计合适的推广策略。每当你想重新分享或者盘活流量的时候,使用这个产品功能真的可以证明你的选择是正确的。我也建议不要在论证中使用太多的聚类,你可以输入不同的数字,然后看看哪个数字给出了最有解释力的结果。
### Function 10
def create_cluster_df(file, n):
from sklearn.preprocessing import StandardScaler
from sklearn.cluster import KMeans
df = medium_data_munge(file)
# Select proper feature
features = ['read','read_ratio','fans','total_view','view_per_day']
x = df.loc[:, features].values
# Normalized data
x = StandardScaler().fit_transform(x)
# Conduct K-mean
km = KMeans(n_clusters = n, random_state=0)
km.fit(x)
labels = km.labels_
cluster = labels.tolist()
final_cluster = pd.DataFrame(dict(cluster_label = cluster, title = df['title']))
df_new = pd.merge(df, final_cluster, how = 'left', on = ['title'])
return df_new### Function 11
def cluster_df_desc(file, n):
# create dataframe with cluster label
df_new = create_cluster_df(file, n)
# summarize the clustered dataframe
col = ['cluster_label', 'total_view' , 'read', 'read_ratio', 'fans','view_per_day']
final_df = df_new[col].groupby(['cluster_label']).agg({'cluster_label' : 'size', \
'total_view': lambda x:x.mean(), \
'read': lambda x: x.mean(), \
'read_ratio': lambda x: x.mean(), \
'fans': lambda x:x.mean(), \
'view_per_day': lambda x:x.mean()})
return display(final_df)
操作功能 10
create_cluster_df("medium_performance_data.xlsx", 3).head()

操作功能 11
cluster_df_desc("medium_performance_data.xlsx",3)
cluster_df_desc("medium_performance_data.xlsx",5)

I demo n = 3 and n = 5 and show the result here
功能 12
这个函数是前一个函数的后续函数。一旦您返回理想的集群概述。你可能想想象一下。因此,我利用主成分分析(PCA)将五个特征维度转化为两个维度。并且不同组中的所有物品可以在这个 2D 平面上被标记。
只需传递文件和簇号,就可以得到结果。它还将返回主成分 1 和 2 的解释比率。我将在这里尝试 n = 3 和 n = 5。
def pca_vis(file, n):
from sklearn.preprocessing import StandardScaler
from sklearn.decomposition import PCA
df_new = create_cluster_df(file, n)
# Select proper feature
features = ['read','read_ratio','fans','total_view','view_per_day']
x = df_new.loc[:, features].values
# Normalized data
x = StandardScaler().fit_transform(x)
pca = PCA(n_components=2)
principalComponents = pca.fit_transform(x)
principalDf = pd.DataFrame(data = principalComponents, columns = ['principal component 1', 'principal component 2'])
finalDf = pd.concat([principalDf, df_new[['cluster_label']]], axis = 1)
# plot the PCA two-dimensional graph
fig = plt.figure(figsize = (6,6))
ax = fig.add_subplot(1,1,1)
ax.set_xlabel('Principal Component 1', fontsize = 13)
ax.set_ylabel('Principal Component 2', fontsize = 13)
ax.set_title('2 component PCA', fontsize = 15)
targets = list(range(0,n))
colors = ['b', 'g', 'r', 'c', 'm', 'y', 'k', 'w']
colors = colors[:n]for target, color in zip(targets,colors):
indicesToKeep = finalDf['cluster_label'] == target
ax.scatter(finalDf.loc[indicesToKeep, 'principal component 1']
, finalDf.loc[indicesToKeep, 'principal component 2']
, c = color
, s = 50)
ax.legend(targets)
ax.grid()
return 'The explained ratio for component 1 is {0:.2f} and for component 2 is {1:.2f}'. \
format(pca.explained_variance_ratio_[0], pca.explained_variance_ratio_[1] )
操作代码
pca_vis("medium_performance_data.xlsx",3)
pca_vis("medium_performance_data.xlsx",5)


功能 13
最后一个功能也与聚类有关。该功能创建了所谓的平行坐标图。它展示了不同聚类中每个特征的贡献程度。简而言之,它揭示了集群背后的逻辑。并且作者能够基于该结果做出进一步的决定。
例如,我将尝试 cluster = 3 和 5。
def parallel_coordinates(file, n):
df_new = create_cluster_df(file, n)
cols = ['total_view', 'read', 'read_ratio', 'fans', 'view_per_day' ]
df_new_sub = df_new[cols]
from sklearn.preprocessing import StandardScaler
from pandas.plotting import parallel_coordinates
ss = StandardScaler()scaled_df = ss.fit_transform(df_new_sub)
scaled_df = pd.DataFrame(scaled_df, columns=cols)
final_df = pd.concat([scaled_df, df_new['cluster_label']], axis=1)
parallel_coordinates(final_df, "cluster_label")
plt.title("Parallel Coordinates Graph on Each Metric")
plt.show()
操作该功能
parallel_coordinates("medium_performance_data.xlsx", 3)
parallel_coordinates("medium_performance_data.xlsx", 5)


如果 n = 3,我可以得出结论,集群 1,表现最好的两篇文章在总浏览量、阅读量、粉丝量和每日浏览量方面都很出色,但它们的阅读率相对较差。集群 0 和集群 2 之间的区别主要基于读取率,这意味着该指标在我的大部分文章中发挥了很大的影响。今年我可能会把写作策略集中在提高阅读率上。
用我的数据产品做的一些策略
- 我平台上的中文文章可能会达到更高的阅读率。我仍然应该花时间写一些中文文章,使我的基于平台算法的媒体更加可见。
- 利用每日较高浏览量的文章将更多新鲜的一次性用户带入我的媒体,并促使他们关注以扩大我的关注者基础。
- 一些每日浏览量较高的文章属于第一类。它符合聚类结果,绝对是我的流量摇钱树。
- 专注于提高第 2 类文章的阅读率或防止文章落入第 2 类是 2019 年的关键目标。
结论
在媒体分析平台(统计选项卡)中有许多限制。然而,通过创建这个数据产品,我希望我可以让媒体社区受益,让作者具备一些数据驱动的思维模式,并根据这个产品产生的结果改进写作策略。
快乐分析!!!
Remember to follow me on Medium to get instant notification of my new article.Thank for the reading


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言










{kind=link}
{kind=link}
{kind=link}