







蜜蜂在嗡嗡叫什么?
一个探索性的数据分析项目,调查美国的蜜蜂种群

随着时间的推移,蜜蜂的数量发生了怎样的变化?
“拯救蜜蜂”运动已经流行了近 15 年,我们经常听到“蜜蜂正在死去!”,但这有多真实呢?
大约从 1992 年开始,蜜蜂数量急剧减少,这种趋势一直持续到 2005 年左右,但从那以后,蜜蜂数量相对稳定。

自 2005 年以来,美国的蜂箱数量一直相对稳定(甚至在增加)。
蜜蜂到处都在死亡吗?
有趣的是,没有!蜜蜂实际上在一些州有所增加。
下图显示了美国蜜蜂数量最多的 5 个州。虽然加利福尼亚的蜜蜂数量在过去几十年里一直在减少,但北达科他州的蜂群实际上有所增加,而佛罗里达州、南达科他州和明尼苏达州相对来说没有变化。

蜜蜂的生存能力和茁壮成长能力取决于各种因素,包括地理和各州的情况。
各州的殖民地损失有何不同?
仅仅从地图上看,很明显 2011 年和 2013 年的冬天并不太糟糕,但是 2012 年和 2014-2016 年对蜜蜂来说更致命。


从地理上看,中西部和大西洋中部的州经历了蜜蜂死亡最严重的情况。
哪些州对蜜蜂来说最好和最差?
在冬季,蜂巢损失百分比最高的州往往位于大西洋中部和中西部,而蜂巢损失百分比最低的州往往位于美国西部。********

States with the Highest Hive Loss %

States with the Lowest Hive Loss %
菌落是怎么死的?
群体损失的两个主要原因是死亡和群体崩溃失调。
死亡是指一个蜂群中的蜜蜂全部死亡时的。蜜蜂的免疫系统在冬天变弱,它们更容易感染和感染寄生虫(如瓦螨)。
蜂群衰竭失调或 CCD,是指一个蜂群中的大多数蜜蜂永久性地飞离蜂巢,只剩下蜂王和少数工蜂。CCD 仍在研究中,以确定是什么因素造成的。
不幸的是,美国农业部只授权从 2015 年开始收集 CCD 和 Deadout 损失的数据,所以没有太多数据。根据图表,我们可以看到死亡更为常见;此外,两种类型的群体损失都有季节性趋势。

在冬天死亡的蜂巢几乎是蜂群衰竭失调的 4 倍。
低温和蜂群衰竭有相关性吗?
为了回答这个问题,我使用了一个按年份划分的温度异常数据集(可以追溯到 19 世纪晚期)。然后我用每年的最低温度异常值,想看看这个值是否与蜂箱每年的百分比变化有任何关联。
 ********
********
首先,我想看看数据,看看是否有一个总体趋势。左边是逐年的最低温度异常,下面是逐年的菌落百分比变化。数据中似乎没有任何共享模式。
为了量化这种关系,我发现了菌落百分比变化和温度异常之间的相关性。我期待发现一个高度正相关的现象——我的直觉是越多的负温度越多的负百分比变化。
我发现相关性是0.23

最低温度异常与前一年的菌落百分比变化之间存在轻微的正相关
菌落与消费品价格有什么关联?
我从弗雷德(圣路易斯的美联储银行)那里搜集了不同消费价格指数的 CSV 文件,用于各种食品。
我假设 **melons** 、 **fruits** 、 **almonds** 会和 **colonies**有很强的负相关。因为甜瓜、水果和杏仁主要由蜜蜂授粉,我假设随着蜂群数量的减少,这些商品的价格会上升,而其余商品的相关性为 0。
我观察了各种消费品的菌落变化百分比与价格指数变化百分比之间的关系(相对于绝对数字)。

*Correlation Table between % Change in Colonies and % Change in Price Indices of Various Consumer Goods. Last row is the most important
我还尝试将群体百分比变化数据延迟 1 年,以观察价格是否会在事后受到影响,实际上相关度非常接近 0。
虽然商品价格与蜜蜂数量相关,但可能还有无数其他因素影响它们。**
我们能预测蜂蜜价格吗?
平均蜂蜜价格与蜂蜜产量[-0.8]密切相关,与每个蜂群的蜂蜜磅数[-0.59] 和蜂群数量[-0.45]适度相关。
我建立了一个线性模型,试图根据其他三个变量来预测蜂蜜的价格。尽管总体模型在统计上是显著的(p-value = 3.972e-07) 并且 r 平方是中等的(0.6818),但是没有一个变量是统计上显著的预测因子——我对模型的质量没有太大的信心,但是,我认为看起来还是很有趣的。
**Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 1474.2895 524.7439 2.810 0.00895 **
`Colonies (Thousands)` -0.3806 0.1895 -2.008 0.05435 .
`Yield (lbs per colony)` -15.9264 8.1140 -1.963 0.05967 .
`Production (Millions)` 4.0934 2.9445 1.390 0.17542
---
Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
Residual standard error: 36.04 on 28 degrees of freedom
Multiple R-squared: 0.6818, Adjusted R-squared: 0.6477
F-statistic: 19.99 on 3 and 28 DF, p-value: 3.972e-07**
我使用的数据集没有足够的数据来预测蜂蜜的价格。
数据
今年数据世界将会发生什么。
如果我们希望预见数学的未来,我们应该研究这门科学的历史和现状。亨利·庞卡雷。

介绍
如果你沉浸在数据世界中,很可能你已经看到了一堆关于今年和未来几年将要发生的事情、趋势和期望的文章、博客帖子和新闻。
我读了很多,如果你想读,可以去文章的结尾,你会在那里找到。但是在这里,我想快速概述一下现在正在发生的事情,并分析人们正在谈论的不同趋势,看看更有可能发生什么。
最常见的趋势

如果你搜索“数据科学”这个词,你会找到大约 5400 万个结果,这是一个很大的数字。多年来,人们对这一领域的兴趣一直在增长:
但是数据科学现在很重要,它对不同的人有不同的意义。如果你看一看文章和新闻,最大的趋势是:





还有更多,但这些是最大的。关于它们中的每一个都有很多要说的,但是我现在想集中讨论其中的两个。自动化和图表。
自动化和图表(数据结构)

https://towardsdatascience.com/the-data-fabric-for-machine-learning-part-1-2c558b7035d7
如果您一直在关注我的研究,我现在最感兴趣的事情之一就是数据结构。请记住,我对数据结构的定义是:
数据结构是支持公司所有数据的平台。它是如何被管理、描述、组合和普遍访问的。该平台由企业知识图构成,以创建统一的数据环境。
这里我想强调两点,数据结构是由企业知识图构成的,应该尽可能自动化。
Gartner 的一篇文章非常清楚地提到了这一点:
[## Gartner 确定了 2019 年十大数据和分析技术趋势
增强分析、持续智能和可解释的人工智能(AI)是……
www.gartner.com](https://www.gartner.com/en/newsroom/press-releases/2019-02-18-gartner-identifies-top-10-data-and-analytics-technolo)
他们说:
到 2022 年,图形处理和图形数据库管理系统的应用将以每年 100%的速度增长,以不断加快数据准备,实现更复杂和适应性更强的数据科学。
此外:
到 2022 年,定制数据结构设计将主要作为静态基础设施进行部署,迫使组织投入新一轮成本来彻底重新设计更动态的数据网格方法。
很明显,对于数据公司来说,图表概念和数据结构将会越来越普遍。但是自动化呢?
在机器学习、深度学习和部署方面,自动化有很多进步。但正如我之前所说,数据是公司目前的重要资产(可能是最重要的资产)。所以在你可以应用机器学习或深度学习之前,你需要拥有它,知道你拥有什么,理解它,治理它,清理它,分析它,标准化它(也许更多),然后你才能想到使用它。
我们需要数据存储、数据管理、数据探索、数据清理以及所有我们实际上花费大量时间做的事情的自动化。你可以说像 DataRobot 这样的工具可以给你提供这些东西,但是根据我的经验,在这个领域还有很多事情要做。
这就是为什么我打赌语义技术是发展的方向。有了它们(像 Anzo )你可以自动生成查询(是的,这是一件事),用它们来处理复杂的图形使提取特征变得容易,并最终完全自动化。
在我关于这个主题的第一篇文章中,我也提出了这个架构:

https://towardsdatascience.com/deep-learning-for-the-masses-and-the-semantic-layer-f1db5e3ab94b
到处都有自动化。而且很容易在旅途中添加更多功能,如可解释的人工智能、持续智能等等。在同一篇文章中,Gartner 的人员提到:
持续智能是一种设计模式,其中实时分析被集成到业务运营中,处理当前和历史数据以规定响应事件的操作。它提供决策自动化或决策支持。
如果我们考虑流分析,这不是一个新术语,但我喜欢这个名字。实际上,正在发生的事情可以分为两件:语义技术和自动化。
这是语义技术在过去 5 年中引起的兴趣:
正如我们所看到的,数据结构并没有那么高,但我认为这种情况很快就会改变。
结论
因此,如果您想要跟上时代,您最好开始考虑如何将您的数据湖改进为智能数据湖,您还希望自动化您的流程,从数据摄取到模型部署和监控,并利用图表技术。
同样,正如我之前提到的,在以下情况下,您应该使用图形数据库而不是其他数据库:
- 你有高度相关的数据。
- 你需要一个灵活的模式。
- 您希望有一个结构并构建更接近人们思维方式的查询。
相反,如果您有一个高度结构化的数据,您希望进行大量的分组计算,并且您的表之间没有太多的关系,那么您可能更适合使用关系数据库。
剑桥语义公司的人创建了这个伟大的信息图,让你了解更多关于数据结构世界的信息:

感谢您阅读本文,希望这篇文章能让您了解作为数据科学家在个人业务和生活中应该做些什么。
参考资料:
[## Gartner 确定了 2019 年十大数据和分析技术趋势
增强分析、持续智能和可解释的人工智能(AI)是……
www.gartner.com](https://www.gartner.com/en/newsroom/press-releases/2019-02-18-gartner-identifies-top-10-data-and-analytics-technolo) [## 2019 年数据科学趋势
今年可以被认为是人工智能(AI)的蓬勃发展。只要看看有多少创业公司拥有…
towardsdatascience.com](/data-science-trends-for-2019-11b2397bd16b) [## 2019 年数据科学趋势-数据大学
谈到 2019 年值得关注的主要数据科学趋势,去年的主要趋势从 2017 年开始延续,因为增长…
www.dataversity.net](https://www.dataversity.net/data-science-trends-in-2019/#) [## 人工智能,数据科学,分析 2018 年的主要发展和 2019 年的主要趋势
和过去一样,我们为您带来专家的预测和分析综述。我们问了主要的是什么…
www.kdnuggets.com](https://www.kdnuggets.com/2018/12/predictions-data-science-analytics-2019.html) [## 2019 年值得关注的 10 大数据趋势
我们寻找更多的数据有一个很好的理由:它是推动数字创新的商品。然而,把那些巨大的…
www.datanami.com](https://www.datanami.com/2019/01/21/10-big-data-trends-to-watch-in-2019/) [## 5 2019 年数据和人工智能趋势-信息周刊
新的一年,新的一页。如果 2019 年看起来像 2018 年,你可以打赌,数据、分析、机器学习…
www.informationweek.com](https://www.informationweek.com/strategic-cio/5-data-and-ai-trends-for-2019/d/d-id/1333581) [## 图形数据库。有什么大不了的?
继续分析语义和数据科学,是时候讨论图形数据库以及它们必须…
towardsdatascience.com](/graph-databases-whats-the-big-deal-ec310b1bc0ed) [## 安佐
到目前为止,还没有任何技术能够在企业范围内提供语义层——包括安全性、治理和…
www.cambridgesemantics.com](https://www.cambridgesemantics.com/product/)
那里在生长什么?
利用 eo-learn 和 fastai 从多光谱遥感数据中识别作物

A section of the Orange River, South Africa: colour imagery and NDVI from Sentinel 2 and target masks from Zindi’s Farm Pin Crop Detection Challenge
介绍
这篇文章描述了我如何使用 eo-learn 和 fastai 库来创建机器学习数据管道,该管道可以从卫星图像中对作物类型进行分类。我用这个管道进入了 Zindi 的农场 Pin 作物检测挑战赛。我可能没有赢得比赛,但我学到了一些处理遥感数据的伟大技术,我在这篇文章中详细介绍了这些技术。
以下是我遵循的预处理步骤:
- 将感兴趣的区域划分成“小块”网格,
- 从磁盘加载图像,
- 遮住了云层,
- 增加了 NDVI 和欧几里德范数特性,
- 按照固定的时间间隔对图像进行重新采样,
- 添加了具有目标和标识符的栅格图层。
我将作物类型分类的问题重新定义为一项语义分割任务,并使用图像增强和混合对多时相多光谱数据训练了一个带有 ResNet50 编码器的 U-Net,以防止过度拟合。
我的解决方案在很大程度上借鉴了 Matic Lubej 在他的三篇 优秀 帖子中概述的关于土地覆盖分类与 eo-learn 的方法。
我创建的 python 笔记本可以在这个 github 资源库中找到:https://github . com/Simon grest/farm-pin-crop-detection-challenge
挑战
Zindi 是一个非洲竞争性数据科学平台,致力于利用数据科学造福社会。在 Zindi 的 2019 年农场 Pin 作物检测挑战赛中,的参与者使用sentinel 2图像训练机器学习模型,以便对南非奥兰治河沿岸的农田中种植的作物进行分类。
提供给参赛者的数据由两个形状文件组成,其中包含训练集和测试集的场边界,以及 2017 年 1 月至 8 月期间 11 个不同时间点的感兴趣区域的 Sentinel2 影像。

The section of the Orange River — grey test set fields interspersed amongst green training set fields
训练集和测试集分别由 2497 个字段和 1074 个字段组成。训练集中的每个田地都标有九个标签中的一个,指示该田地在 2017 年期间种植的作物。
作物类型有:
Cotton
Dates
Grass
Lucern
Maize
Pecan
Vacant
Vineyard
Vineyard & Pecan (“Intercrop”)
参赛者只能使用提供的数据,并且(由于在比赛期间发现数据泄露)禁止使用 Field_Id 作为训练功能。
使用 eo-learn ( 笔记本)进行数据预处理
eo-learn 库允许用户将感兴趣的区域划分为补丁,定义工作流,然后在补丁上并行执行工作流。
1.分割感兴趣的区域
使用sentinelhub库中的BBoxSplitter,我将河流分成了 12 块:

The area of interest partitioned into a grid of ‘patches’
2.从磁盘加载图像数据
比赛图像数据以 JPEG2000 格式在标准 Sentinel2 文件夹结构中提供,如下图所示:

Sentinel2 folder structure
eo-learn 库提供了许多有用的预定义任务,用于从 Sentinel Hub 加载影像、处理影像和生成要素。在撰写本文时,它还没有以上述格式从磁盘加载图像的任务。然而,定义我自己的EOTask类来做这件事被证明足够简单。EOTask类需要一个execute()方法,该方法可以选择接受一个EOPatch对象作为参数。
EOPatch对象本质上只是numpy数组和元数据的集合。我自己定制的EOTask加载的EOPatch对象看起来是这样的:
data: {
BANDS: numpy.ndarray(shape=(11, 1345, 1329, 13), dtype=float64)
}
mask: {}
mask_timeless: {}
scalar_timeless: {}
label_timeless: {}
vector_timeless: {}
meta_info: {
service_type: 'wcs'
size_x: '10m'
size_y: '10m'
}
bbox: BBox(((535329.7703788084, 6846758.109461494), (548617.0052632861, 6860214.913734847)), crs=EPSG:32734)
timestamp: [datetime.datetime(2017, 1, 1, 8, 23, 32), ..., datetime.datetime(2017, 8, 19, 8, 20, 11)], length=11
)
我们可以通过使用波段 4、3 和 2(红色、绿色和蓝色)为每个斑块生成彩色图像来可视化斑块:

Colour images of the 12 patches made with the red, green and blue bands
3.遮蔽云层
在上面图像的右下角有一些云层。eo-learn 库提供了一个预训练的像素级云探测器模型。此功能可通过S2PixelCloudDetector 和*AddCloudMaskTask类获得。*
S2PixelCloudDetector来自一个单独的库sentinel2-云探测器,使用 sentinel 2 图像的所有 13 个波段进行预测。通过设置概率阈值,可以将云概率预测转化为云掩膜。

Colour image with clouds, cloud probabilities and resulting cloud mask
我使用这个云检测功能向我的数据添加了一个云遮罩。
4.随时间重新采样
删除云会在每个时间片上有云覆盖的区域的数据中留下间隙。填充这些间隙的一种可能的方法是在前面和后面的时间片之间进行插值。
已经为此定义了一个LinearInterpolation EOTask。类要求您指定要插值的波段和重新采样的间隔。我决定将我的数据平均到大约每月一个时间片,这将我的时间维度从 11 个时间点减少到 8 个。
此外,为了处理时间段开始或结束时的任何间隙,我使用了一个ValueFilloutTask进行简单的外推,即根据需要从之前或之后的时间点复制值。
5.添加 NDVI
归一化差异植被指数 (NDVI)是卫星图像中植物生命存在的简单指标。该指数是使用红色和近红外(NIR)波段计算的。
NDVI =(近红外光谱-红色)/(近红外光谱+红色)
维基百科上关于 NDVI 的文章对这个指标背后的基本原理有一个很好的解释。基本的想法是,植物物质吸收大部分可见的红色光谱光,而它反射近红外光,这不能用于光合作用,NDVI 在比率中捕捉这种反射率的差异。
方便的是,eo-learn 提供了一个NormalizedDifferenceIndex任务,允许我轻松地计算和添加每个补丁的 NDVI。
对于不同的作物,NDVI 随着时间的推移会有不同的演变。不同的作物在不同的时间种植和收获,生长速度也不同。下面的动画展示了 NDVI 在邻近油田的不同发展。

NDVI through time (in March you can see artefacts that result from the cloud masking and interpolation)
6.添加目标遮罩
为了将作物识别挑战视为语义分割任务,我需要为我们的图像创建目标遮罩。eo-learn 中的VectorToRaster任务获取矢量几何图形并创建光栅化图层。我使用此任务来添加指示作物类型的栅格图层。我还添加了一个带有字段标识符的层,用于推理。

Crop type raster layer for patch number 6
创建工作流并执行它
为了运行上述每个预处理步骤,我将所有任务放入一个工作流中。一般来说,eo-learn 工作流可以是任何在每个节点都有EOTask对象的无环有向图。我只是使用了一个线性工作流程,看起来像这样:
*LinearWorkflow(
add_data, # load the data
add_clm, # create cloud mask
ndvi, # compute ndvi
norm, # compute the euclidean norm of the bands
concatenate # add the ndvi and norm to the bands
linear_interp, # linear interpolation
fill_extrapolate, # extrapolation
target_raster, # add target masks
field_id_raster, # add field identifiers
save # save the data back to disk
)*
为了执行这个工作流,我为每个补丁创建了执行参数,然后使用一个EOExecutor以分布式方式在所有补丁上运行整个工作流。
*execution_args = []
for patch_idx in range(12):
execution_args.append({
load: {'eopatch_folder': f'eopatch_{patch_idx}'},
save: {'eopatch_folder': f'eopatch_{patch_idx}'}
})
executor = EOExecutor(workflow, execution_args, save_logs=True)
executor.run(workers=6, multiprocess=False)*
构建预测模型
语义分割
语义分割是给图像的每个像素分配类别标签的过程。通过将这次挑战中的作物识别问题重新构建为语义分割任务,我可以利用每个领域的局部空间上下文中的信息,如下所示,这还允许我通过重复采样生成更多的训练数据。
1.生成训练集(笔记本)
从我的 12 个小块中,我随机抽取了 64 x 64 像素的小块来训练我的模型。我保持小块的大小,因为这些区域本身相对较小,并且提供的 Sentinel2 影像的最大空间分辨率为 10 米。这意味着一个 1 公顷大小(10,000 平方米)的正方形区域在影像中显示为 32 x 32 像素的面积。
我以确保每个小块至少包含一部分训练字段的方式对小块进行了采样。对于每个 patchlet,我保存了两个 pickle 文件,一个包含输入影像,另一个包含作物类型的栅格图层。
对于输入图像,我选择包括六个通道,三个可见波段(红色、绿色和蓝色),近红外和计算的 NDVI 和欧几里德范数。当我通过时间插值对图像进行重新采样时,我得到了八个不同的时间点。为了得到一个秩为 3 的张量,我简单地在八个时间点的每一个点上叠加六个通道,得到一个 48 通道的图像。

NDVI and visible images at a single time point along with the corresponding target crop types for nine randomly sampled 64x64 training ‘patchlets’
2.数据扩充
竞争中可用的相对较小的数据集和我选择的网络架构中的大量参数意味着我需要特别小心过度拟合。为了避免这一点,我使用了图像放大和混合。
fastai 库提供了一系列图像增强技术。我使用了:
- 垂直翻转
- 水平翻转
- 旋转
- 嗡嗡声
- 翘曲
- 和剪切

A batch of training images with image augmentations applied
3.创建 fastai U-Net 模型(笔记本)
fastai 库通过允许用户从现有卷积网络编码器动态构建 U-Net 来提供语义分段。我选择了一个在 ImageNet 上预先训练的 ResNet50 作为我的编码器网络。为了处理我的输入张量的形状,我将 ResNet50 网络的第一个卷积层(采用 3 个通道)替换为采用 48 个通道的卷积层。
我不会试图在这里解释 U-网或残差神经网络,因为已经有很多很好的解释了。例如,这里有一个帖子解释 U-net,这里有另一个解释 ResNets。
我创建了SegmentationPklList和类SegmentationPklLabelList来实现加载 pickle 文件‘图像’的功能,这样我的数据就可以与 fastai 的数据块 API 一起工作。
fastai MixUpCallback和MixUpLoss也需要一些小的调整来处理语义分割。
4.损失函数
我用一个修改过的CrossEntropyFlat损失函数来给我的模型打分。我将其实例化为:
CrossEntropyFlat(axis=1, weight=inv_prop, ignore_index=0)
不同作物类型在训练集中的出现是不平衡的,某些作物类型只出现少数几次。我通过使用损失构造函数的weight参数,将我的损失函数与每种作物类型的逆频率成比例加权。
训练图像的大部分区域没有作物类型,或者该区域没有田地,或者如果有田地,它也不是训练集的一部分。通过使用 loss 构造函数的ignore_index参数,我忽略了没有作物类型标签的预测。
5.培养
fastai 库提供的最大优势之一是灵活的训练循环,以及通过单周期训练策略等技术控制训练参数的强大开箱即用支持。我使用fit_one_cycle函数训练我的 U-Net 五个时期,保持预训练的编码器参数不变,然后再训练十个时期,允许更新编码器权重。
在训练过程中,验证集的损失持续下降,而我的自定义像素精度度量稳步上升。

Training results from 5 frozen and 10 unfrozen epochs
对于验证集中的示例,将预测的像素掩膜与目标掩膜进行比较似乎表明网络工作正常,但是存在少数类和具有非标准形状的字段性能较差的示例。
 **
**
More predictions on examples from the validation set
成果和有待改进的领域
为了对测试集进行推断,我将每个补丁分成一个 64x64 的“小补丁”网格,并保存每个小补丁的 pickle 文件。我对整个测试集进行了预测,并通过Field_Id对结果进行了分组。对每个像素的预测由来自 U-Net 的十个最终激活组成。我取了每个类的中值激活值,然后应用一个 softmax 函数来得到测试集中每个Field_Id的单个概率。

sample grid of ‘patchlets’ for inference — colouring by Field_Id clearly shows the data leak
利用时间模式
反思我的方法,我认为最可以改进的地方是对时间维度的处理。我在 48 个通道中堆叠所有时间点的天真方法不允许我的模型通过时间从图像中正确地学习模式。我很想探索使用循环网络来学习这些时间模式。
eo-learn 背后的团队自己提出了使用一个时间全卷积网络* (TFCN)来实现这个目的:https://sentinel-hub . com/sites/default/LPS _ 2019 _ eol learn _ tfcn . pdf。TFCNs 以秩为 4 的张量作为输入,并使用 3D 卷积来同时捕获空间和时间中的模式。*
使用无监督学习构建潜在表示
如果竞赛允许使用外部数据,那么探索本文【https://arxiv.org/abs/1805.02855中描述的 Tile2Vec 技术将会很有趣。这里的想法是通过使用三重损失设置无监督学习任务,从卫星图像生成区域的潜在向量表示。
我很想知道其他竞争对手采用了什么方法。
感谢
我要感谢 Zindi 的团队组织了如此有趣的挑战。我还要感谢 eo-learn 团队提供了如此有用的库,以及关于如何使用它的如此引人入胜的帖子。也感谢 fastai 社区为让深度学习变得更加平易近人和广泛可用所做的所有工作。最后,我要感谢Stefano Giomo对这个项目的所有投入。
班加罗尔道路上的交通是怎么回事?
印度班加罗尔道路交通事故和其他事件的可视化分析。

Image: High speed traffic on NICE Road, Bangalore.
Copyrighted Source: https://500px.com/photo/12002497/speed-by-supratim-haldar
目标
我们花很多时间在路上,陷入交通堵塞,这通常是由一天中特定时间的车辆溢出或一天中任何随机时间的意外事件造成的。但是所有这些都有一个模式吗?在本文中,让我们深入研究班加罗尔的交通数据,目的是获得有助于我们更好地规划通勤的见解。
介绍
T 班加罗尔的道路交通状况在印度城市中并不算最好,Ola Cabs 最近的一项研究也证实了这一点——高峰时段的平均车速约为 15.5 公里/小时,在印度城市中排名倒数第三。但是也有交通高速行驶的区域,城市的某些地方事故或潜在事故的数量很高,而在其他地方事故或潜在事故的数量却很低。通过对这个公共数据集的探索性分析,让我们尝试解开一些关于班加罗尔道路和交通的有趣观察。
关于数据
这些数据(从 Kaggle 中的公共数据集下载)由安装在公交车上的防撞系统收集,并绘制了班加罗尔市内即将发生碰撞的数据。
数据集中可用的信息:
设备代码:安装在车辆上的 CAS 的唯一设备代码
纬度:产生碰撞警告的位置的纬度
经度:产生碰撞警告的位置的经度
病房名称:该位置(纬度,经度)所属的 BBMP 病房
报警类型:防撞系统产生的碰撞报警类型(详见下文)
记录的日期和时间:生成警报的日期和时间
速度:产生碰撞警报时的车速。所有的速度值都以千米/小时为单位
以下是分析所遵循的步骤:
- 读取数据。
- 数据的预处理和清理。
- 通过可视化进行数据分析。
完整的源代码在 这里 都有,万一你想看的话。请在下面的评论部分提供您的宝贵反馈和建议,或者通过最后提供的电子邮件地址给我写信。
放弃
对数据集的基本分析揭示了一些局限性,如下所示:
- 只有 2018 年的数据。
- 在 2018 年,仅提供 2 月、3 月、4 月、6 月和 7 月的数据。
- 在任何一天,只有早上 6 点到下午 6 点之间的数据可用。在像班加罗尔这样的城市的道路上,下午 6 点以后和深夜的数据是重要的,这是缺失的。
- 总之,这是一个很好的开始基本分析,并了解班加罗尔道路相关事件的高水平趋势。
背景资料
在进一步深入研究之前,了解 CDS 或 CAS 捕获的警报类型非常重要。更多详情请点击这里。
- 前方碰撞警告(FCW)
一辆 FCW 提醒司机即将与一辆汽车、卡车或摩托车追尾。 - 城市前方碰撞警告(UFCW)
UFCW 在与前方车辆可能发生低速碰撞之前发出警告,从而在交通密集拥挤的情况下以低速辅助驾驶员。这通常适用于车速低于约 30 公里/小时的情况。 - 车头时距监控警告(HMW)
车头时距监控警告(HMW)通过在距离变得不安全时提供视觉和听觉警告,帮助驾驶员与前方车辆保持安全的跟车距离。当车速超过 30 公里/小时时,该传感器发出警报,并以秒为单位显示距离前车的时间,当该时间变为 2.5 秒或更短时。 - 车道偏离警告(LDW)
当车辆在没有使用转向灯的情况下意外偏离车道时,LDW 会发出警报。如果变道时使用转向信号灯,则不会产生警报。LDW 通常在 55 公里/小时以上行驶,如果车道没有标志或标志不良,它可能无法正常行驶。
这进一步分为:(a) LDWL,用于向左车道偏离的车道,以及(b) LDWR,用于向右车道偏离的车道。 - 行人和骑自行车者检测和碰撞警告(PCW)
PCW 通知司机危险区域内有行人或骑自行车者,并警告司机即将与行人或骑自行车者发生碰撞。当车速低于 50 公里/小时时,PCW 工作良好。 - 超速
探索性分析的观察和结果的可视化
通过大量的数据清理、处理和探索性分析,很少出现非常有趣的观察结果。这里有几个例子。
L 让我们从班加罗尔/孟加拉鲁鲁地图上的所有 CAS 警报数据开始,通过指定的坐标,生成警报生成时车辆位置和速度的热图。
在这张热图中,速度的大小由色温表示——较冷(带蓝色)的曲线表示速度较低,而较暖(带红色)的颜色表示速度较高。
An interactive accident heatmap of city of Bangalore. Hover on and zoom in the map for more details.
上面是一个交互式地图,所以悬停在上面可以看到病房,并放大以找出特定位置的车辆速度。
一些速度相对较高的领域:
- 旧马德拉斯路/班加罗尔-蒂鲁帕蒂公路
- 萨尔贾布尔路
- 外环线的部分路段
- Anekal 主干道等。
事故的区域分布

事故发生时的车速

数据集中可用的速度数据是警报生成时公共汽车记录的速度,而不是班加罗尔道路上车辆/公共汽车的总体速度。记录的最高速度是 83 公里每小时,然而平均速度只有 22 公里每小时。
日期和时间
在这个月的 19 号有一个高峰,但是可能那是一个噪音。
就一天中的时间而言,清晨(早上 7 点)和下午(下午 3 点)看起来不是旅行的最佳时间。
但是,需要记住的是,数据集只包含一天中 12 个小时的数据。因此,我们看不到傍晚繁忙时间的情况。


到目前为止,我们已经探索了一些单独的功能。现在,让我们通过将两个或更多特征结合在一起,来尝试解开一些有趣的观察结果。
(1)按警报类型划分的班加罗尔位置热图
注意,在这里,一天中的小时被表示为颜色图,使得早期的小时以冷色(浅蓝色)表示,并且随着一天的进行,暖色表示一天中的较晚部分。

**观察:**上面的热图清楚地表明,班加罗尔各地都发出了各种警报。因此,即使某些类型的事故在某些地区更频繁(例如,超速在高速公路上更普遍),事故在整个城市都有可能发生。
(2)每种事故/警报类型的速度分布

观察:
- 低速碰撞的平均速度为 11-12 公里/小时。
- 高速碰撞发生的平均速度约为 35 公里/小时,许多情况下速度更高。
- 超速被报告为平均 25 公里/小时的速度(这不是真正的超速)。这让人对超速报警器的质量产生了怀疑。
- 没有指示灯的车道偏离以及与行人和骑自行车者的碰撞的平均速度为 20 公里/小时。
(3)哪些地区因哪种事故而臭名昭著?

观察:
- 大多数高速和低速碰撞事件都发生在哈加杜尔。
- 超速在嘎鲁达查尔半岛最常见。
- Hagadur 因与行人和骑自行车的人相撞而臭名昭著,更不用说没有指示灯的变道了。
(4)了解班加罗尔地图上最危险的 10 个病房

摘要
上述分析为我们提供了不少关于班加罗尔道路交通的有趣观察。例如,每个病房有多安全或不安全,一天中什么时间最适合旅行,路上车辆的平均速度等等。最有趣的是,一个带有速度分布的交互式地图让我们可以找到事件发生的确切位置,以及 BBMP 区的名称和当时的车速。
感谢您的阅读!你同意这些观点吗?请在下面的评论区分享你的想法,或者给我发邮件。
对于我曾经做过或者目前正在做的其他项目,请到http://supra timh . github . io处停止。
是什么阻碍了人工智能在企业中的应用?

Source: Strata album on Flickr
伦敦地层数据会议的 5 点启示
在技术会议中,O’Reilly 的 Strata Data 规模庞大,在数据社区中备受推崇。过去一周,我一直很关注这件事,很高兴被邀请在伦敦地层学院演讲。以下是这次活动的总结和一些重要的经验。

有了来自学术界、企业和研究人员的精心策划的内容,有很多东西值得期待。O’Reilly events 以其对多样性的特别关注而闻名,为期 4 天的活动汇集了来自世界各地的有趣的谈话和演讲者。
各种形式的会议都有:16 小时的培训、4 小时的研讨会、商业案例研究、管理层简报和技术深度探讨。会议用的椅子很有学问&很容易拿到,这让走廊聊天变得很愉快。

Source: Strata album on Flickr
关键主题
以下是会议中涉及的主要趋势的总结。我已经链接到最有趣的也有公共会议甲板。鉴于并行跟踪会议的数量惊人(我数了一下,有 13 个,下面会有更多),这个列表是基于我可以参加或跟踪的会议而有所偏差的。
1.是什么阻碍了人工智能在企业中的应用?
企业正在努力采用人工智能,这是一个反复出现的主题,包括本关于“在企业中维持机器学习”的主题演讲。根据最近的 O’Reilly 调查,以下是阻碍采用的主要瓶颈:

Results from the O’Reilly report on ‘AI Adoption in the Enterprise’
虽然公司文化可能是一个不成功的因素,但我在这个客户列表中看到了前 5 名。会议涵盖了所有这些挑战,包括一个关于企业案例研究的单独专题讲座。几个值得注意的会议:Pete Skomoroch的《为什么管理机器比你想象的难》和 Shingai Manjengwa 的《雇用独角兽数据科学家的次佳选择》。
Cait O’Riordan 关于《金融时报》如何采用数据科学提前一年达到 100 万付费用户的主题演讲非常出色。
2.数据治理:CDO 的鲨鱼池生活
“数据治理之于数据资产,正如人力资源之于人”这是 Paco Nathan 在他的会议上关于数据治理概述的一个很好的类比。从数据和企业架构的历史演变开始,它涵盖了当今不同领域的公司所面临的问题,并提供了未来展望。

CDO’s role today: a life in the shark tank (Slide: Session by Paco Nathan)
Sundeep Reddy 的会议通过观察印度蓬勃发展的数字经济和 10 亿人在印度 stack 公共展示中面临的困境,提供了公共治理和数据的对比视角。
3.为什么用 AI 做好事这么难?
题为“利用数据为恶”的会议吸引了大量观众,这是邓肯·罗斯系列的第五部分。作为对关于 AI for Good 的会议的补充,他分享了英国 DataKind 关于用数据做好事的例子。人工智能对假新闻的危险贡献在 Alex Adam 关于合成视频生成以及如何检测它的会议中有所涉及。


Spinoffs to the popular Quadrant of Magic! (left: Necromantic Quadrant by Duncan Ross; right: An inspiration from Paco Nathan)
我用 Gramener 与微软 AI for Earth 的合作案例讲述了人工智能如何拯救我们星球的生物多样性。这 4 个例子展示了非政府组织如何使用深度学习解决方案来检测、识别、统计&保护濒危物种。
4.自然语言处理的不合理有效性
谁能比 Mathew Honnibal 更好地谈论文本分析的最新进展呢,他是广受欢迎的 Python 开源 NLP 库的创建者。他分享了提高 NLP 项目成功率的技巧。仅利用《人民日报》的文本档案预测中国政策变化的会议因其简单但合理的方法而非常有趣。

Predicting policy change in China with machine learning (Session by Weifeng Zhong)
数据或标注语料库的匮乏是自然语言处理中的一个主要挑战,Yves Peirsman 在 T4 举办的关于处理自然语言处理中数据匮乏的会议提供了一些有用的技巧。
5.黑箱模型的可解释性和开放性
如果不谈论可解释性和可解释性,今天的人工智能对话就不完整。Eitan Anzenberg 的会议解释了对可解释性的需求,并涵盖了像 LIME 这样的框架。Yiannis Kanellopoulos 报道了关于金融科技模型问责制的案例研究。

Need for Explainability (Session by Eitan Anzenberg)
除了这些主题之外,还有一些技术会议,涵盖了流行平台/包(如 Spark 、 Tensorflow 、 AWS 、 Google Cloud 、Azure、r
如此多种多样的会议意味着一天要跑 13 条平行路线,打印出来的议程是一张笨重的超宽的风景纸!虽然这给出了一个有趣的主题组合,但选择一个却是一个很大的难题。这种数量过多的问题也对会议的参与度(和出席率)有负面影响。
议程之外
有足够的机会与这些高度参与的从业人员建立联系。艾不仅仅是会议的一部分,他还出现在展厅里,由 Makr Shakr 的机器人酒保分发饮料。


Speed networking session; Data after dark party with scenic views of the city
希望在即将到来的奥赖利活动中发言?
如果你想知道从哪里开始邀请即将到来的奥赖利活动,这本电子书是一个有用的资源。由 Strata 背后的人 Alistair Croll 撰写,它讲述了活动管理的方式,如何选择会谈,以及是什么让组织者心痛。它提供了一个如何提交高质量的参赛作品并被选中的内幕。我推荐一本有用的快速读物。
语言中有什么
在自然语言处理中寻找意义
英国数学家和计算机科学家艾伦·图灵在 1950 年的一篇名为“模仿游戏”的论文中提出了一个简单的问题。仅仅通过让他们写下对询问者所提问题的回答,询问者能正确地确定一个男人和一个女人的性别吗?问题是,当男人试图帮助询问者正确识别性别时,女人的任务是欺骗你,让你认为她就是那个男人。
图灵继续这个问题说,如果机器是被询问的两个‘人’中的一个,而不是一个男人或女人,会怎么样?审讯者能正确地辨认出谁是人类吗?如果机器能够欺骗询问者回答问题,那么机器会像人一样思考吗?
简单来说——“机器会思考吗?”
今天,我们一天中的大部分时间都在网上与人交谈,通过文本、twitter DMs 和电子邮件。当我们交谈时,我们很少怀疑信息另一端的人理解我们。此外,如果我本周晚些时候打电话去理发,我不会怀疑电话那头的人是不是个人……直到现在。
如果那个人根本不是人,而是一个聊天机器人或谷歌助手,那该怎么办?如果聊天机器人智能地回应,那么他们也是智能的,而我也不会认为他们是人。谷歌助理理解我,我想在周四理发,但我周五也有空(因为我的谷歌日历上没有安排)。所以如果理发店在星期四被预订,星期五是一个不错的选择。
现在是 2019 年,有机器通过图灵测试了吗?
Google I/O 2018
是的——取决于你如何设计测试。
这个 55 秒的呼叫持续了 50 多年,从图灵的论文开始,继续到自然语言处理(NLP)程序,如 ELIZA 和 A.L.I.C.E .(罗布纳奖获得者)。通过图灵测试类似于回答图灵的问题“机器能思考吗?”回答是。但是,我们真的可以这么说吗?是不是所有的智能都在网上聊天或打电话时显得智能?A.L.I.C.E. 对我的问题的回答有什么想法或感受?
为了验证这一点,我们再举一个例子。
狭隘的争论与中国空间
想象一下,一个不懂中文的英语母语者被锁在一个房间里,房间里满是装有中文符号的盒子(一个数据库),还有一本操作这些符号的说明书(程序)。想象一下,房间外面的人输入其他的中文符号,房间里的人不知道,这些符号是中文的问题(输入)。通过遵循书中的指示,房间里的人能够分发中文符号(输出),这些符号是问题的正确答案。这个人在不懂一个中文单词的情况下通过了图灵测试。
换句话说,虽然谷歌助手可以给你正确的回应,但助手并不能以有意义的方式理解这些回应;这只是一个日历事件。
约翰·塞尔在 1980 年发表了这一论点,这使他能够区分出强和弱人工智能**。强人工智能是指计算机具有心智能力,不仅能够理解国际象棋等游戏,还能理解自然语言。弱 AI 是计算机模拟心智能力的说法,允许我们在心理学、语言学、象棋训练软件中使用它们,但是没有理解。狭义的论点如下**
- 如果强人工智能是真的,那么有一个中文程序,如果任何计算系统运行该程序,该系统就能理解中文。
- 我可以为中国人运行一个程序,而不会因此理解中国人
- 所以,强 AI 是假的。
不仅仅是发型预约
图灵在他 1950 年的论文中举了两个机器如何“学习”的例子。第一种:教一台机器下棋,这是一种抽象的活动,有明确的规则。第二:给机器提供金钱能买到的最好的感觉器官,它们教它理解和说英语,这更像是教一个孩子。
成交还是不成交?
脸书和佐治亚理工学院的研究人员将谷歌助手的日程安排能力更进一步,看看人工智能是否不仅能对话,还能谈判。他们从 5808 个半合作对话的数据集开始,训练一个模仿人类行为的递归神经网络。

From the paper “Deal or No Deal? End-to-End Learning for Negotiation Dialogues”
为了简洁起见,下面是这篇论文中值得考虑的一些要点
- 基于目标的模型更难谈判
- 模特学会骗人
- 模型产生有意义的新颖句子
- 保持多句子的连贯性是一项挑战
开放 AI
与自然语言处理中的统计模式不同,Open AI 研究了开发他们自己的语言进行交流的智能体。这有几个推动因素。
- 查看语言中的统计模式并不能告诉你为什么这种语言存在,只能告诉你在被分析的给定语言中通常会有什么。
- 为了让智能体(作为人工智能语音助手的我们更好理解)与人类进行智能交互,让他们不仅通过,而且超越图灵测试。
回到图灵测试,当“某人”理解语言时,当他们在对话的背景下做出适当的反应时。语言是我们使用的一种功能工具,增加了语义层。在开放人工智能的研究中,他们希望用基于基础的合成语言来实现理解。
什么是接地气的作曲语言?
“组合”语言是这样一种思想,即复杂表达的意义由其结构和组成部分的意义决定。“接地气”指的是基于经验的那种语言*。没有亲身看到(体验)“红色”,一个人无法理解“红色”是什么。*
那又怎样?
这如何适用于开放人工智能研究中的代理?代理人以二维空间为基础,构建不同长度的句子(取决于任务),以在小组或多代理人环境中执行任务。

From the OpenAI blog post “Learning to Communicate”
每个代理都有一个目标,无论是从位置 A 到 B,还是鼓励不同的代理移动到特定的位置。在开始任务之前,特工们使用的符号没有一个有意义。代理人根据任务和环境创造了符号的含义。此外,另一个关键因素是代理人的奖励是合作性的,而不是竞争性的。这就是我们看到抽象合成语言出现的地方,代理人与语言一起工作而没有任何人类语言的使用。
也就是说,有一天,为你预约理发的电脑可能会和你说话,并且理解你…
“我们只能看到前面不远的地方,但我们可以看到那里有许多需要做的事情”
—艾伦·图灵
参考
- 计算机械与智能艾伦·图灵
- 成交还是不成交?谈判对话的端到端学习迈克·刘易斯、丹尼斯·亚拉茨、扬·n·多芬、德维·帕里克和 Dhruv Batra
- 多主体群体中的基础合成语言的出现
黑盒子里有什么?
赵、著“黑箱模型的因果解释”精华。

Photo by Christian Fregnan on Unsplash
你可能熟悉《黑箱模型的因果解释》的作者——赵清源和特雷弗·哈斯蒂——特别是特雷弗·哈斯蒂。也许这个能让你想起什么?:

James, Gareth, et al. An Introduction to Statistical Learning: with Applications in R. Springer, 2017.
对我来说确实如此,因为这篇文章是我学习数据科学的第一个切入点。当你试图找出你的 R 代码到底出了什么问题时,你可能还会在阅读glmnet包的文档时想起 Hastie 的名字。或者那可能只是我。
正因为如此,我很好奇的看了赵和哈斯蒂的论文。以下是我了解到的!
黑匣子
机器学习(ML)模型虽然在预测性能上已经超过了参数模型,但也有被非技术用户认为是黑箱的缺点;它们的相对不透明性使它们难以解读。考虑下图:

Zhao & Hastie. 2018. Causal Interpretations of Black-Box Models. http://web.stanford.edu/~hastie/Papers/pdp_zhao_final.pdf
模型的“本质”是“封闭的”,不为用户和客户所知。这很重要,因为一个核心问题是:什么样的特性对模型的输出很重要?当你不容易“看到”你的模型中发生的事情时,很难搞清楚这一点。
赵和 Hastie 谈论与特性重要性相关的三个想法:
- 我们可以将 ML 模型视为一个函数,并询问哪个特性对输出的影响最大。想想回归模型的β系数。
- 如果我们没有系数,那么也许我们可以通过对模型预测准确性的“贡献”来衡量一个特征的“重要性”。
- 第三个是赵和哈斯蒂关注的,他们称之为因果关系。他们是这样描述的:
如果我们能够对 Xj 进行干预(在其他变量不变的情况下,将 Xj 的值从 a 改为 b),Y 的值会改变多少?
他们论文的目标是:
…解释在拟合黑盒模型后,我们何时以及如何进行因果解释。
因果关系
赵和哈斯蒂用的成绩和的学习时间来论证因果关系的概念。让我们考虑一个公式,其中:
Grade = [Some Constant Factor]
+ (Some Multipicative Factor)x(Hours Studied)
+ (Random Error)
这对我们来说有直观的意义:一般来说,你学习的时间越多,成绩越好。换句话说,有人可能会说学习更多的时间 会导致 更高的分数。
反过来呢?如果我们只有学生得到的分数会怎么样?通过对上述内容进行一些处理,我们可以得出如下结论:
Hours Studied = [Some Other Constant Factor]
+ (Some Other Multipicative Factor)x(Grades)
+ (Random Error)
这是否意味着如果老师给学生一个 A 而不是 B,学生将学习更多的时间?当然不是!
例如,在上面的等级公式中,也许我们添加了另一个特征,工作时间(在校外工作)。如果我们广泛地假设工作时间对于财政支持是必要的,那么工作时间可能会对学习时间产生因果影响,而不是相反。因此,学习时间是工作时间的必然结果。
部分相关图
因果解释的一个有用工具是部分相关图 (PDP)。它们用于收集特性对模型预测结果的边际影响。为了大规模简化,我们可以认为它只是绘制一个特性的每个潜在值(横轴)的平均预测结果(纵轴)。为了使 PDP 对因果推理有用,所讨论的变量之间不能有任何其他变量,并且目标变量是因果后代。否则,与任何后代的互动都会影响解释。
例如,下面的 PDP 显示,平均预测自行车租金通常随着气温的升高而上升。

I too don’t like to bike when it’s humid, or windy. https://christophm.github.io/interpretable-ml-book/pdp.html
让我们用这个古老的例子来看另一个例子,波士顿房屋数据集。该数据集提供了波士顿(MEDV)中值住宅的目标和几个特征,如城镇人均犯罪率(CRIM)和氮氧化物浓度(NOX,以每 1000 万分率(pp10m 万)表示)。检查这些和剩余的可用特征并不需要太多领域的专业知识,就可以得出结论,没有一个可以合理地成为 NOX 的因果后代。更有可能的是氮氧化物受一个或多个其他特征的影响——比如“每个城镇非零售商业英亩数的比例”(INDUS)——而不是氮氧化物影响 INDUS。这个假设允许我们使用 PDP 进行因果推断:

When nitric oxide concentration increased past 0.67 pp10m, Bostonians said NO to higher house prices. Groan.
注意,该图以垂直轴为中心,表示=0。从上面我们可以推断出,中等住宅价格似乎对氮氧化物水平不敏感,直到大约 0.67 pp10m 万,中等住宅水平下降约 2000 美元。
个体条件期望图
但是如果我们不确定我们特征的因果方向呢?一个有用的工具是个人条件期望 (ICE)图。它不是根据某个特性的值绘制平均预测值,而是针对该特性的可能值为每个观察值绘制一条线。让我们通过重新查看我们的 NOX 示例来深入研究 ICE 图。

Nice ICE, baby. Please stop.
这个 ICE 图似乎支持我们在 PDP 中看到的情况:各个曲线在形状和方向上看起来都相似,并且像以前一样,在 NOX = 0.67 附近“水平”下降。
但是我们之前已经建立了理论,NOX 是数据集中一个或多个其他特征的因果衍生,因此 ICE 图仅用于确认 PDP 显示的内容。
如果我们探索一个不同的特性,“到五个波士顿就业中心的加权距离”(DIS)会怎么样?有人可能会争辩说,一个特征,如卷曲,可能是疾病的因果后代。如果我们看一个冰图:

我们发现了混合模式!在较高水平的 MEDV,随着 DIS 的增加有下降的趋势。然而!在较低水平的 MEDV,我们观察到一些曲线显示 DIS 对 MEDV 有短暂的正面影响,直到 DIS=2 左右,然后变成负面影响。
要点是,ICE 图帮助我们识别该特征可能间接影响目标,因为与一个或多个其他特征相互作用。
对于 ICE 图的另一个应用,让我们考虑一个使用无处不在的" auto mpg "数据集的例子。下面的图显示了加速度对 MPG 有一些因果影响,但很可能是通过与其他特征的相互作用。

请注意图中顶部(MPG 略微增加)、中间(减少)和下三分之一(再次增加)的线条的行为差异!
如果我们查看数据集中的其他要素,我们会发现其中一个要素对应于原点,即汽车的地理原点。这个特性可以说是所有特性的因果祖先——你需要有一个地方来建造汽车,然后你才能建造它!(我知道这过于简单化了,但仍然如此)。正因为如此,它很可能会与 MPG 产生因果关系。
冰图在这里仍然有用吗,即使这个特征是“远上游”?你打赌!让我们先来看一个可信的箱线图:

American cars guzzle gas. At least in this dataset.
该图显示了这三个地区的汽车在 MPG 方面的显著差异。但这能说明全部情况吗?
考虑下面两个冰图。第一个显示**【美国(1)或欧洲(0)】**对 MPG :

US (1) vs. Europe (0)
…第二个显示**【日本(1)或欧洲(0)】**对 MPG

Japan (1) vs. Europe (0)
起初,通过箱线图,似乎由于来源而在 MPG 中存在显著差异,ICE 图显示,当考虑到与其他特征的相互作用时,纯粹的影响可能会小一些:这些线中的大多数线的斜率比箱线图让我们想象的要平缓。
装箱
在处理所谓的黑盒算法时,我们需要使用聪明的方法来解释结果。一种观点是通过推断因果关系。一些工具可以对此有所帮助:
- 部分相关图
- 个体条件期望图(ICE 图)
- 您或您的团队自己的领域知识!虽然我们越来越多地以数据科学的名义使用许多花哨的工具,但它不能取代来之不易的领域知识和经过良好磨练的批判性思维技能。
感谢阅读!
工作文件此处。
*请随意伸手!|*LinkedIn|GitHub
来源:
布莱曼。统计建模:两种文化。统计科学,16(3):199–231,2001b。
统计学习导论:在 R 中的应用。斯普林格,2017。
莫尔纳尔。可解释的机器学习。https://christophm.github.io/interpretable-ml-book2019 年 6 月接入。
珍珠,1993 年。图形模型、因果关系和干预。统计科学,8(3):266–269。
赵&哈斯提。2018.黑盒模型的因果解释。http://web.stanford.edu/~hastie/Papers/pdp_zhao_final.pdf
盒子里有什么?在我们信任它之前,AI 需要解释它的决定。

XAI 可以允许人工智能技术在需要更大责任的领域扩散,但我们需要看到黑匣子的内部。
去年 12 月初,我发现自己回到了就业市场,在大学圣诞假期期间寻找一些临时的季节性工作。我对这个职位的要求并不苛刻:开始时间最好在早上 8 点以后(我刚刚结束了一项为期 5 年的轮班工作,我并不急于续约);薪酬不一定超过法律规定的最低水平,工作地点位于我所居住城市的地理范围内。除此之外,我什么都愿意做。我回复了一份网上的招聘启事,应聘一家知名高街时尚零售商的初级零售助理职位。没有任何不合理或不谦虚的期望,我真诚地开始了申请过程。

在提交任何求职信或简历之前,我需要完成一份简短的问卷。这很大程度上是由 50 个模糊不清、毫无意义的问题组成,显然是为了评估候选人的态度和对该角色的适合性。我被要求诚实地使用一个 5 分等级量表来同意或不同意一系列陈述,例如:
“有些人让我感到紧张”,
“我比大多数人获得更多的好运”。
“我倾向于假设更糟糕的事情可能会发生”。
我不知道这些分数是如何计算出来的,但我相信任何按照指示作答的候选人都不会准确描述他们的“态度”。当明确指出申请人不应该通过选择“既不同意也不反对”的选项来对冲他们的赌注时,任何明智的人如何能够回答像“当事情出错时,我总是看到光明的一面”这样的绝对主义问题?这个问题唯一合理的答案是“强烈反对”,因为即使是宇宙中最乐观的人也不可能“总是”看到光明的一面。就连基督本人在被流放到沙漠中时也感到绝望。然而,在这种情况下,“强烈反对”显然不是正确的答案,因为问一系列 50 个语义不明确的问题来评估某人是否适合一份主要职责是折叠运动衫的兼职工作是没有任何价值的。尽管这个问题的措辞很荒谬,但它显然是为了衡量候选人面对困境时的应变能力。那么申请人应该提交他们知道不正确的答案吗?

I was right.
我没有得到那份工作。我甚至没有机会提交我的简历,因为自动表格制表机立即认定我在气质上不适合折叠运动衫的角色。我抱怨选拔标准的不公平。我很愤怒,因为我没有得到任何关于我的答案的解释,也没有得到任何关于为什么我的答案不正确的解释。不公正令人愤怒。
对我来说,这是一个小挫折。不久之后,我找到了另一份(更好的)工作。我赚了足够的零花钱来确保圣诞节早上圣诞树下有礼物,还有足够的钱来买节日啤酒。圣诞节得救了。但对其他人来说,可能没有这么整齐的决议。越来越多关于就业、贷款申请、住房合适性以及其他方面的重大决策正由自动化系统做出,而这些决策无法提供解释或理由。在人工智能应用的背景下,这被称为‘黑盒’问题,并引发了严重的道德和法律问题。

Luckily for me, Christmas was saved
黑盒指的是在人工智能算法中发生的神秘、隐秘和不可知的过程。大多数人工智能系统遵循程序分析的输入层(可能是一系列数据点或图像)的一般路径,遵循由算法本身组成的中间层(这是进行分析的部分)。最后,我们有输出层——程序做出的决定。现代深度学习应用的中间层或“隐藏”层中的复杂机制本质上是不透明和不可理解的。它们可能由隐藏层中的许多子层组成,在它们之间来回传递信息,直到程序找出如何处理数据。因为算法随着每一次新的迭代或数据点“学习”,所以外部观察者无法跟踪隐藏层内发生的情况。
例如,你可以教机器学习算法识别猫的图片,方法是在不同的猫图像上训练它,直到它有足够的数据来正确分类新图像。然而,它不能告诉你新图片有什么特别像猫的地方。它可能是耳朵的形状,或者是皮毛,或者是胡须,这些都可以让算法识别出猫,或者是许多东西的组合。或者它可能是某种无形的“猫性”的例子,人眼察觉不到,算法已经发现了。如果是这样的话,我们将永远不会知道。人类能够毫无困难地解释为什么他们能够识别猫,但是机器却不能。

Cat or not-cat?
随着人工智能应用的使用变得越来越广泛,我们理解系统为什么在特定环境下做出决策变得越来越重要。如果一种算法在没有任何解释的情况下将一只猫误认为一条鱼,那么如果动物收容所决定自动执行收容程序,它可能会导致一只不开心的猫被关在鱼缸里。随着自动化系统进入医疗保健应用领域,机器可能会出现误诊的风险,这可能是由不完整的训练数据或其他故障造成的。如果不正确的人工智能决策无法解释,程序的人类设计者将无法理解为什么会做出不正确的决策或防止它再次发生。在这些情况下,人工智能决策过程的重要人类监督是必要的。
有人可能会认为,对于任何做出对人类有直接影响的决定的人工智能应用程序,都应该有合理的人类监督。事实上,今天有大量的自动化过程在运行,决策完全由无监督的算法做出,这些算法具有严重的现实世界影响。自动化程序用于计算罪犯重新犯罪的可能性,这可能会影响他们的判决或假释条件。大学正在使用预测算法来决定是否为潜在学生提供课程名额。当这些自动决定背后的原因无法得到充分解释时,人们就很难对他们认为不公平的决定提出上诉。

What is in the box?
如果算法使用的输入数据不完整,或者是劣质或不可靠的收集方法的结果(就像我写得很差的工作问卷一样),并且这导致了有争议的结果,那么决策主体必须有适当的上诉渠道。
诸如此类的担忧导致了欧盟复杂的 G.D.P.R .立法第 22 条的发布,该立法涉及自动决策:
“数据主体应有权不受制于仅基于自动处理(包括特征分析)的决定,该决定对其产生法律效力或对其产生类似的重大影响”。

这意味着,银行、政府或任何利用人类行为预测模型为决策提供信息的组织等机构,在个人是决策主体的情况下,不能仅仅依赖自动化流程。换句话说,每个人都有解释的权利。如果自动化过程是不透明和不可解释的,就像大多数传统的人工智能过程一样,那么在发生纠纷的情况下,机构就很难依靠强大而有用的工具。
例如,当一个人决定进行金融投资或终止雇佣合同时,他们在法律上和道德上都要对这个决定负责。自动化人工智能系统独立于建造它的人类设计师运行;一旦开始运行,它就自己做决定,没有任何责任或义务。当我们考虑更广泛的正义或民主问题时,这是一个非常有问题的概念。

What’s in the box?
这些考虑促成了最近人工智能的一个子类的发展,称为可解释的人工智能(或 XAI),它涉及开发允许机器学习过程变得更加透明的技术。这一概念仍处于相对初级阶段,但随着时间的推移,它可能允许在问责制和可解释性受到严重关注的领域更广泛地采用人工智能过程。
在我的下一篇文章中,我将关注一些 XAI 技术,这些技术可能会在未来几年内开始出现,它可能会特别有用的一些领域,以及一些推动该领域进步的推动者和震动者。我还将谈到这项技术的局限性及其面临的挑战。
所有观点都是我自己的观点,甲骨文公司不同意。 请随时在 LinkedIn 上联系我
对我来说 init 是什么?
设计 Python 包导入模式
我最近有几次关于 Python 打包的谈话,特别是关于构造import语句来访问包的各种模块。这是我在组织 [leiap](https://deppen8.github.io/posts/2018/09/python-packaging/) 包时不得不做的大量调查和实验。尽管如此,我还没有看到各种场景中最佳实践的好指南,所以我想在这里分享一下我的想法。
导入模式

Photo by Mick Haupt on Unsplash
设计用户如何与模块交互的关键是软件包的__init__.py文件。这将定义用import语句引入名称空间的内容。
模块
出于几个原因,将代码分成更小的模块通常是个好主意。主要地,模块可以包含与特定一致主题相关的所有代码(例如,所有 I/O 功能),而不会被与完全不同的东西(例如,绘图)相关的代码弄得混乱。由于这个原因,大班得到一个专用模块是很常见的(例如,geopandas中的geodataframe.py)。其次,将代码划分成适当的逻辑单元会使其更容易阅读和理解。
然而,对于开发者来说好的模块结构对于用户来说可能是也可能不是好的模块结构。在某些情况下,用户可能不需要知道包下面有各种模块。在其他情况下,可能有充分的理由让用户明确地只要求他们需要的模块。这就是我在这里想要探索的:不同的用例是什么,它们需要包开发人员采用什么方法。
一个示例包
Python 包有多种结构,但是让我们在这里创建一个简单的演示包,我们可以在所有的例子中使用它。
/src
/example_pkg
__init__.py
foo.py
bar.py
baz.py
setup.py
README.md
LICENSE
它由三个模块组成:foo.py、bar.py和baz.py,每个模块都有一个单独的函数,打印该函数所在模块的名称。
foo.py
def foo_func():
print(‘this is a foo function’)
bar.py
def bar_func():
print(‘this is a bar function’)
baz.py
def baz_func():
print(‘this is a baz function’)
你的杂货店守则
现在是承认谈论import语句和包结构可能很难理解的时候了,尤其是在文本中。为了让事情更清楚,让我们把 Python 包想象成一个杂货店,把用户想象成购物者。作为开发商,你是商店的所有者和管理者。你的工作是想出如何建立你的商店,让你为你的顾客提供最好的服务。您的__init__.py文件的结构将决定设置。下面,我将介绍建立该文件的三种可选方法:普通商店、便利商店和在线商店。
综合商店

Photo by Mick Haupt on Unsplash
在这个场景中,用户可以在import example_pkg上立即访问一切。在他们的代码中,他们只需要键入包名和他们想要的类、函数或其他对象,而不管它位于源代码的哪个模块中。
这个场景就像一个旧时代的普通商店。顾客一进门,就能看到所有商品毫不费力地摆放在商店里的箱子和货架上。
在幕后
# __init__.py
from .foo import *
from .bar import *
from .baz import *
用户实现
import example_pkgexample_pkg.foo_func()
example_pkg.bar_func()
example_pkg.baz_func()
优点
- 例如,用户不需要知道模块名或记住哪个功能在哪个模块中。他们只需要包名和函数名。在综合商店里,所有的产品都以最小的标识陈列着。顾客不需要知道去哪个通道。
- 导入顶级包后,用户可以访问任何功能。所有的东西都陈列出来了。
- Tab 补全只需
example_pkg.<TAB>就能给你一切。制表就像杂货店的杂货商,他知道所有东西的确切位置,并且乐于提供帮助。 - 当新特性被添加到模块中时,你不需要更新任何
import语句;它们将自动包含在内。在一般的商店里,没有花哨的招牌可以换。只要在架子上放一个新的项目。
缺点
- 要求所有函数和类必须唯一命名(即在
foo和bar模块中都没有名为save()的函数)。你不想把苹果放在两个不同的箱子里,让你的顾客感到困惑。 - 如果包很大,它会给名称空间增加很多东西,并且(取决于很多因素)会减慢速度。一家普通商店可能有许多个人顾客可能不想要的小杂物。这可能会让您的客户不知所措。
- 需要更多的努力和警惕来让一些元素远离用户。例如,您可能需要使用下划线来防止函数导入(例如,
_function_name())。大多数普通商店没有一个大的储藏区来存放扫帚和拖把之类的东西;这些项目对客户是可见的。即使他们不太可能拿起扫帚开始扫你的地板,你也可能不希望他们这样做。在这种情况下,您必须采取额外的措施来隐藏这些供应品。
建议
- 当很难预测典型用户的工作流程时使用(例如像
pandas或numpy这样的通用包)。这是一般商店的“一般”部分。 - 当用户可能经常在不同模块之间来回切换时使用(例如,
leiap包) - 当函数名和类名描述性很强且容易记忆,而指定模块名不会提高可读性时使用。如果你的产品是你熟悉的东西,比如水果和蔬菜,你就不需要很多标牌;顾客会很容易发现问题。
- 仅使用几个模块。如果有许多模块,新用户在文档中找到他们想要的功能会更加困难。如果你的综合商店太大,顾客将无法找到他们想要的东西。
- 在可能频繁添加或移除对象时使用。在普通商店添加和移除产品很容易,不会打扰顾客。
众所周知的例子
pandasnumpy(增加了复杂性)seaborn
便利店

Photo by Caio Resende from Pexels
到目前为止,最容易阅读和理解的是一般商店场景的变体,我称之为便利店。代替from .module import *,您可以在__init__.py中用from .module import func指定导入什么。
便利商店和普通商店有许多共同的特点。它的商品选择相对有限,可以随时更换,麻烦最小。顾客不需要很多标牌就能找到他们需要的东西,因为大多数商品都很容易看到。最大的区别是便利店的订单多一点。空盒子、扫帚和拖把都放在顾客看不见的地方,货架上只有待售的商品。
在幕后
# __init__.py
from .foo import foo_func
from .bar import bar_func
from .baz import baz_func
用户实现
import example_pkgexample_pkg.foo_func()
example_pkg.bar_func()
example_pkg.baz_func()
优点
分享普通商店的所有优势,并增加:
- 更容易控制哪些对象对用户可用
缺点
- 如果有许多功能多样的模块,结果会非常混乱。像普通商店一样,过于杂乱的便利店会让顾客难以浏览。
- 当新特性被添加到一个模块时(即新的类或函数),它们也必须被显式地添加到
__init__.py文件中。现代 ide 可以帮助检测遗漏的导入,但是仍然很容易忘记。你的便利店有一些最小的标志和价格标签。当你改变书架上的东西时,你必须记得更新这些。
建议
我将在综合商店的建议中增加以下内容:
- 当您的模块或多或少由一个
Class(例如from geopandas.geodataframe import GeoDataFrame)组成时,这尤其有用 - 当有少量对象要导入时使用
- 当您的对象有明确的名称时使用
- 当您确切知道用户需要哪些对象,不需要哪些对象时,请使用
- 当您不希望频繁添加大量需要导入的新模块和对象时,请使用。
众所周知的例子
geopandas
网上购物

Photo by Pickawood on Unsplash
任何在网上买过杂货的人都知道,订购正确的产品可能需要顾客付出一些努力。你必须搜索产品、选择品牌、选择想要的尺寸等等。然而,所有这些步骤都可以让你从一个几乎无限的仓库里买到你想要的东西。
在 Python 包的情况下,在某些情况下,避免简单地导入整个包的便利性,而是迫使用户更清楚地知道导入的是什么部分,可能会更谨慎。这使得作为开发人员的您可以在不影响用户的情况下在包中包含更多的内容。
在幕后
# __init__.py
import example_pkg.foo
import example_pkg.bar
import example_pkg.baz
用户实现
在这种情况下,用户可以采用(至少)三种不同的方法。
import example_pkgexample_pkg.foo.foo_func()
example_pkg.bar.bar_func()
example_pkg.bar.baz_func()
或者
from example_pkg import foo, bar, bazfoo.foo_func()
bar.bar_func()
baz.baz_func()
或者
import example_pkg.foo as ex_foo
import example_pkg.bar as ex_bar
import example_pkg.baz as ex_bazex_foo.foo_func()
ex_bar.bar_func()
ex_baz.baz_func()
优点
- 简化了
__init__.py文件。仅在添加新模块时需要更新。更新你的网上商店相对容易。您只需更改产品数据库中的设置。 - 它是灵活的。它可用于仅导入用户需要的内容或导入所有内容。网上商店的顾客可以只搜索他们想要或需要的东西。当你需要的只是一个苹果时,就没有必要再去翻“水果”箱了。但是如果他们真的想要“水果”箱里的所有东西,他们也可以得到。
- 别名可以清理长的 package.module 规范(如
import matplotlib.pyplot as plt)。虽然网上购物一开始会很痛苦,但如果你把购物清单留到以后再用,购物会快很多。 - 可以有多个同名的对象(例如在
foo和bar模块中都被称为save()的函数)
缺点
- 一些导入方法会使代码更难阅读。例如,
foo.foo_func()并不表示foo来自哪个包。 - 可读性最强的方法(
import example_pkg,没有别名)可能会产生很长的代码块(例如example_pkg.foo.foo_func()),使事情变得混乱。 - 用户可能很难找到所有可能的功能。在你的网上杂货店,购物者很难看到所有可能的商品。
建议
- 当您有一个复杂的模块系列时使用,其中的大部分任何一个用户都不会需要。
- 当
import example_pkg导入大量对象并且可能很慢时使用。 - 当您可以为不同类型的用户定义非常清晰的工作流时使用。
- 当您希望用户能够很好地浏览您的文档时使用。
例题
matplotlib*scikit-learn*bokeh*scipy*
*这些包实际上在它们的__init__.py文件中使用了不同方法的组合。我在这里包括它们是因为对于用户来说,它们通常是按菜单使用的(例如,import matplotlib.pyplot as plt或import scipy.stats.kde)。
结论
我概述的三个场景当然不是 Python 包的唯一可能的结构,但是我希望它们涵盖了任何从博客中了解到这一点的人可能会考虑的大多数情况。最后,我将回到我之前说过的一点:对于开发者来说好的模块结构对于用户来说可能是也可能不是好的模块结构。无论你做什么决定,不要忘记站在用户的角度考虑问题,因为那个用户很可能就是你。
逻辑回归的线性是什么
在逻辑回归中,我们如何从决策边界到概率?
已经有很多关于逻辑回归的令人惊讶的文章和视频,但我很难理解概率和逻辑线性之间的联系,所以我想我应该在这里为自己和那些可能经历同样事情的人记录下来。
这也将揭示逻辑回归的“逻辑”部分来自哪里!
这篇博客的重点是对逻辑模型和线性模型之间的关系建立一个直观的理解,所以我只是做一个什么是逻辑回归的概述,并深入这种关系。为了更完整地解释这个令人敬畏的算法,这里有一些我最喜欢的资源:
- https://www.youtube.com/watch?v=-la3q9d7AKQ
- https://towards data science . com/logistic-regression-detailed-overview-46 C4 da 4303 BC
- https://ml-cheat sheet . readthedocs . io/en/latest/logistic _ regression . html
- https://christophm . github . io/interpretable-ml-book/logistic . html
现在让我们来看看逻辑回归的要点。
什么是逻辑回归?
与线性回归一样,逻辑回归用于建模一组自变量和因变量之间的关系。
与线性回归不同,因变量是分类变量,这就是它被视为分类算法的原因。
逻辑回归可用于预测:
- 电子邮件是垃圾邮件还是非垃圾邮件
- 肿瘤是不是恶性的
- 一个学生将通过或不通过考试
- 我会后悔在凌晨 12 点吃饼干
上面列出的应用是二项式/二元逻辑回归的例子,其中目标是二分的(2 个可能的值),但是你可以有 2 个以上的类(多项逻辑回归)。
这些分类是基于模型产生的概率和某个阈值(通常为 0.5)进行的。如果一个学生通过的概率大于 0.5,则她被预测为通过。
让我们开始探究这些概率是如何计算的。
乙状函数
如果我们可视化一个带有二进制目标变量的数据集,我们会得到这样的结果:

这里有几个原因可以解释为什么拟合直线可能不是一个好主意:
- 在线性回归中,因变量的范围可以从负 inf 到正 inf,但是我们试图预测应该在 0 和 1 之间的概率。
- 即使我们创建了一些规则来将这些越界值映射到标签,分类器也会对离群值非常敏感,这会对其性能产生不利影响。
因此,我们用在 0 和 1 附近变平的 S 形来代替直线:

这被称为 sigmoid 函数,其形式如下:

此函数根据某些因素的组合返回某个观察值属于某个类的概率。
如果我们求解线性函数,我们会得到几率的对数或者是 logit:

注意当 p(x) ≥0.5,βX ≥ 0 时。
但是等一下,这个神奇的函数是从哪里来的,线性模型是怎么进去的?为了回答这个问题,我们来看看逻辑回归是如何形成其决策边界的。
决定边界
每个伟大的逻辑回归模型背后都有一个不可观察的(潜在的)线性回归模型,因为它真正试图回答的问题是:
“给定一些特征 x,一个观察值属于第一类的概率是多少?”

让我们看一个例子。
假设我们想根据一个学生花了多少时间学习和睡觉来预测她是否能通过考试:

Source: scilab
让我们通过绘制针对 Slept 的 Studied 来更好地理解我们的数据,并对我们的类进行颜色编码以可视化这种分离:
import pandas as pd
import matplotlib
import matplotlib.pyplot as pltexams = pd.read_csv('data_classification.csv', names=['Studied','Slept','Passed'])fig = plt.figure()
ax = fig.add_subplot(111)colors = [‘red’, ’blue’]ax.scatter(exams.Studied, exams.Slept, s=25, marker=”o”, c=exams[‘Passed’], cmap=matplotlib.colors.ListedColormap(colors))

看着这个图,我们可以假设一些关系:
- 花足够的时间学习并且睡眠充足的学生很可能通过考试
- 睡眠少于 2 小时但花了 8 小时以上学习的学生可能仍然会通过(我肯定在这个组里)
- 偷懒不睡觉的学生可能已经接受了他们通不过的命运
这里的想法是,这两个类别之间有一条清晰的分界线,我们希望逻辑回归能为我们找到这一点。让我们拟合一个逻辑回归模型,并用模型的决策边界覆盖这个图。
from sklearn.linear_model import LogisticRegressionfeatures = exams.drop(['Passed'],axis=1)
target = exams['Passed']logmodel = LogisticRegression()
logmodel.fit(features, target)
predictions = logmodel.predict(features)
您可以打印出参数估计值:

利用这些估计,我们可以计算出边界。因为我们的阈值设置为 0.5,所以我将 logit 保持在 0。这也允许我们在 2d 中查看边界:

exams['boundary'] = (-logmodel.intercept_[0] - (logmodel.coef_[0][0] * features['Studied'])) / logmodel.coef_[0][1]
在我们的散点图上看起来是这样的:
plt.scatter(exams['Studied'],exams['Slept'], s=25, marker="o", c=exams['Passed'], cmap=matplotlib.colors.ListedColormap(colors))plt.plot(exams['Studied'], exams['boundary'])plt.show()

这看起来很合理!那么 Logistic 回归是如何利用这条线来分配类标签的呢?它着眼于每个单独的观察和线性模型之间的距离。它会将这条线以上的所有点标记为 1,下面的所有点标记为 0。这条线上的任何点都可能属于任何一类(概率为 0.5),所以为了将一个点分类为 1,我们感兴趣的是这条线和我们的观察之间的距离大于 0 的概率。
事实证明,在逻辑回归中,这个距离被假定为遵循逻辑分布。
换句话说,逻辑回归中潜在线性回归模型的误差项被假定为服从逻辑分布。
这意味着当我们问:

我们真的在问:

为了计算这种概率,我们对逻辑分布进行积分,以获得其累积分布函数:

哦嘿!是乙状结肠函数:)。
Tada!您现在应该能够更直观地在 sigmoid 函数和线性回归函数之间来回走动了。我希望理解这种联系能让你和我一样对逻辑回归有更高的评价。
TensorFlow 2.0 有什么新功能?
从 2015 年 11 月谷歌大脑团队的最初开源发布开始,机器学习库 TensorFlow 已经有了很长的发布历史。TensorFlow 最初在内部开发,名为dist faith,很快成为当今使用最广泛的机器学习库。不是没有原因的。

Number of repository stars over time for the most widely used machine learning libraries
张量流 1。XX —我们今天在哪里?
在我们讨论 TensorFlow 2.0 最重要的变化之前,让我们快速回顾一下 TensorFlow 1 的一些基本方面。XX:
语言支持
Python 是 TensorFlow 支持的第一种客户端语言,目前支持 TensorFlow 生态系统中的大多数功能。如今,TensorFlow 可以在多种编程语言中使用。TensorFlow 核心是用纯 C++编写的,以获得更好的性能,并通过 C API 公开。除了与 Python 2.7/3.4–3.7 的绑定,TensorFlow 还提供对 JavaScript(Tensorflow . js)、Rust 和 r 的支持。尤其是语法简单的 Python API,与 C/C++脆弱的显式性相比,tensor flow 迅速超越了早期的竞争对手 Caffe 机器学习库。
计算图
从一开始,TensorFlow 的核心就是所谓的计算图。在这个图模型中,每个操作(加、乘、减、取对数、矩阵向量代数、复函数、广播……)以及变量/常数都由有向图中的一个节点定义。图的有向边将节点相互连接,并定义信息/数据从一个节点流向下一个节点的方向。存在从外部将信息输入到计算图中的输入节点,以及输出经处理的数据的输出节点。
定义图表后,可以对输入图表的数据执行该图表。因此,数据’ '流经图中的 ',改变其内容和形状,并转化为图的输出。数据通常可以表示为多维数组,或 张量 ,因而得名 TensorFlow 。
使用该模型,很容易使用这些节点来定义神经网络的架构。神经网络的每一层都可以理解为计算图中的一个特殊节点。TensorFlow API 中有许多预定义的操作,但用户当然可以定义自己的自定义操作。但是请记住,可以使用计算图来定义任意计算,而不仅仅是机器学习环境中的操作。
图形由 as TensorFlow 会话 : tf 调用。会话()。一个会话可以将运行选项作为参数,例如图形应该在多少个 GPU 上执行,GPU 上内存分配的细节等等。一旦必要的数据可用,就可以使用 tf 将其输入到计算图中。Session.run()方法,所有神奇的事情都发生在其中。
梯度
为了使用诸如随机梯度下降的优化算法来训练神经网络,我们需要网络中所有操作的梯度的定义。否则,不可能在网络上执行反向传播。幸运的是,TensorFlow 为我们提供了自动微分,因此我们只需定义信息通过网络的前向传递。自动推断误差通过所有层的反向传递。这个特性并不是 TensorFlow 独有的——所有当前的 ML 库都提供自动区分。
库达
从一开始,TensorFlow 的重点就是让计算图在 GPU 上执行。它们的高度并行架构为训练机器学习库所必需的过量矩阵向量算法提供了理想的性能。NVIDIA CUDA(CcomputerUnifiedDdeviceAarchitecture)API 允许 TensorFlow 在 NVIDIA GPU 上执行任意操作。
还有一些项目的目标是将 TensorFlow 暴露给任何兼容 OpenCL 的设备(即 AMD GPUs)。然而,英伟达仍然是深度学习 GPU 硬件的明确冠军,这不仅仅是因为 CUDA+TensorFlow 的成功。
在您的机器上获得 CUDA 的工作安装,包括 CuDNN 和适用于您的 GPU 的正确 NVIDIA 驱动程序可能是一种痛苦的体验(尤其是因为并非所有 TensorFlow 版本都与所有 CUDA/CuDNN/NVIDIA 驱动程序版本兼容,并且您懒得看一下版本兼容性页面),但是,一旦 TensorFlow 可以使用您的 GPU,您将会发现性能有了显著提升。
多 GPU 支持
大规模机器学习任务需要访问多个 GPU,以便快速产生结果。足够大的深度神经网络有太多的参数,无法将它们全部放入单个 GPU 中。TensorFlow 让用户可以轻松地声明应该在哪些设备(GPU 或 CPU)上执行计算图。

Multi-GPU computation model (source: https://www.tensorflow.org/tutorials/images/deep_cnn)
急切的执行
张量流计算图是处理信息的强大模型。然而,从一开始批评的一个要点就是调试这样的图形的困难。有这样的陈述
变量 c 的内容并不像预期的那样是 4.0,而是一个 TensorFlow 节点,还没有给它赋值。只有在调用图形并在图形上运行会话之后,才能测试这种语句的有效性(以及该语句可能引入的错误)。
于是,TensorFlow 发布了急切执行模式,为此每个节点在定义后立即执行。因此,使用 tf.placeholder 的语句不再有效。导入 TensorFlow 后,只需使用 tf.eager_execution() 调用急切执行模式。
TensorFlow 的急切执行是一个命令式编程环境,它立即计算操作,而不构建图形:操作返回具体值,而不是构建一个计算图形供以后运行。这种方法的优点是更容易调试所有计算,使用 Python 语句而不是图形控制流的自然控制流,以及直观的界面。渴望模式的缺点是性能降低,因为图形级优化(如公共子表达式删除和常量折叠)不再可用。
调试器
TensorFlow 调试器( tfdbg )允许您在训练和推理过程中查看运行 TensorFlow 图的内部结构和状态,这是使用 Python 的 dbg 到 TensorFlow 的计算图范式等通用调试器难以调试的。它被认为是对调试 TensorFlow 程序困难的批评的回答。TensorBoard 有一个命令行界面和一个调试插件(下面有更多信息),允许你检查调试的计算图。详细介绍请找https://www.tensorflow.org/guide/debugger。
张量板
您可以使用 TensorBoard 来可视化您的 TensorFlow 图形,绘制有关图形执行的量化指标,并显示其他数据,如在训练或推断过程中通过它的图像。如果您希望在计算图中可视化任何类型的可用数据,这绝对是一个不错的选择。虽然 TensorBoard 最初是作为 TensorFlow 的一部分引入的,但它现在位于自己的 GitHub 存储库中。但是在安装 TensorFlow 本身的时候会自动安装。
TensoBoard 不仅可用于可视化训练或评估数据,例如作为步数函数的损失/准确度,还可用于可视化图像数据或声音波形。了解 TensorBoard 的最佳方式是看一看 https://www.tensorflow.org/guide/summaries_and_tensorboard。
TPU 支持
TPU(张量处理单元)是高度并行的计算单元,专门设计用于高效处理多维数组(也称为张量),这在机器学习中特别有用。由于其专用集成电路 (ASIC)设计,它们是当今机器学习应用中速度最快的处理器。截至今天,谷歌的 TPU 是专有的,不为任何私人消费者或企业所用。它们是谷歌计算引擎的一部分,在那里你可以租用能够访问 TPU 的计算实例,以满足你的大规模机器学习需求。不用说,谷歌的目标是让每一个 TensorFlow 操作都可以在 TPU 设备上执行,以进一步加强其在不断增长的云计算市场的地位。
但是,您可以在 Google Colab 中亲自测试单个 TPU 的性能,这是一个可以托管和执行 Jupyter 笔记本的平台,可以免费访问 Google 计算引擎上的 CPU/GPU 或 TPU 实例!小介绍,点击这里。
滕索特
虽然神经网络训练通常发生在有时具有多个 GPU 的强大硬件上,但神经网络推理通常发生在本地消费设备上(除非原始数据被传输到另一个云服务,并且推理发生在那里),例如自动驾驶汽车的车载计算机甚至手机。NVIDIA 提供了一个名为tensort的模块,该模块采用 TensorFlow API 表示的训练过的神经网络的张量流图,并将其转换为专门针对推理优化的计算图。与 TensorFlow 本身的推理相比,这通常会带来显著的性能提升。关于 TensorRT 的介绍,点击这里。
tf .贡献
TensorFlow 在 GitHub 上有一个充满活力的社区,为 TensorFlow 的核心和外围设备添加了相当多的功能(显然是谷歌开源 TensorFlow 的一个有力论据)。这些模块大部分都收集在 tf.contrib 模块中。由于 TensorFlow 的高市场份额,在这里可以找到相当多的模块,否则您必须自己实现。
张量流集线器
TensorFlow Hub 是一个用于发布、发现和消费机器学习模型的可重用部分的库。一个模块是一个张量流图的独立部分,以及它的权重和资产,可以在一个称为迁移学习的过程中跨不同的任务重用。【0】
更多,更多,更多
有太多要谈的了。TensorFlow 生态系统的哪些组件至少应该提及?
- **TensorFlow Docker 容器:**包含预装 TensorFlow 的 Docker 容器,包括 Docker 容器内图形处理器上图形执行的 CUDA 兼容性
- tensor flow Lite:tensor flow Lite 是一个开源的深度学习框架,用于嵌入式系统和手机等设备上的设备上推理。
- **TensorFlow Extended(TFX)😗*TFX 是基于 tensor flow 的 Google 量产级机器学习平台。它提供了一个配置框架和共享库来集成定义、启动和监控机器学习系统所需的通用组件。【1】
什么糟透了?
TensorFlow 的优势之一,即计算图,可以说也是它的弱点之一。虽然静态计算图无疑提高了性能(因为图级优化可能发生在图构建之后和执行之前),但它也使调试图变得困难和繁琐——即使使用 TensorFlow 调试器这样的工具也是如此。此外,基准测试表明,其他几个框架可以与 TensorFlow 在同等条件下竞争,同时保持更简单的语法。此外,首先构建一个图,然后使用 tf 实例化它。Sessions 不是很直观,肯定会让一些没有经验的用户感到害怕或困惑。
TensorFlow API 可能也有弱点,即这里讨论的。一些用户抱怨使用 TensorFlow API 时的低级感,即使是在解决高级任务时。对于简单的任务,比如训练线性分类器,需要很多样板代码。
TensorFlow 2.0 —新增功能?
在深入研究了 TensorFlow 1 之后。XX,大 2 会有什么变化?TensorFlow 团队对过去的一些批评做出回应了吗?有什么理由称之为 2.0 版,而不是 1.14 版呢?

Image source: https://www.tensorflow.org/
在多个博客帖子和公告中,已经揭示了 TF2.0 的一些未来特性。此外,TF2.0 API 参考列表已经公开发布。虽然 TF2.0 仍处于 alpha 版本,但预计官方测试版、候选发布版和最终发布版将于今年晚些时候推出。
让我们仔细看看 TF2.0 的一些新奇之处:
- 再见 tf ,你好TF . keras
一段时间以来,TensorFlow 已经提供了 tf.keras API 作为 TensorFlow 模块的一部分,提供了与 keras 机器学习库相同的语法。Keras 因其用于定义网络架构和训练网络架构的简单而直观的 API 而广受好评。Keras 与 TensorFlow 的其余部分紧密集成,因此您可以随时访问 TensorFlow 的功能。Keras API 使 TensorFlow 易于上手。重要的是,Keras 提供了几个模型构建 API(顺序的、功能的和子类化的),因此您可以为您的项目选择正确的抽象级别。TensorFlow 的实现包含增强功能,包括用于即时迭代和直观调试的急切执行,以及用于构建可扩展输入管道的 tf.data。
- tf.data
训练数据通过使用 *tf.data 创建的输入管道读取。*这将是声明输入管道的首选方式。为会话使用 tf .占位符和 feed dicts 的管道仍将在 TensorFlow v1 兼容模式下工作,但将不再受益于后续 tf2.0 版本的性能改进。
- 急切执行默认
TensorFlow 2.0 默认以急切执行方式运行(前面讨论过),以便于使用和顺利调试。
- RIP tf.contrib
tf.contrib 中的大部分模块将在 tf2.0 中贬值,要么被移到核心 TensorFlow 中,要么被一起移除。
- tf.function 装饰师
tf.function 函数装饰器透明地将你的 Python 程序翻译成张量流图。这个过程保留了 1.x TensorFlow 基于图形的执行的所有优点:性能优化、远程执行以及序列化、导出和部署的能力,同时增加了用简单 Python 表达程序的灵活性和易用性。在我看来,这是 v1 最大的变化和范式转变。x 到 v2.0。
- 不再 tf。会话()
当急切地执行代码时,将不再需要会话实例化和运行计算图。这简化了许多 API 调用,并从代码库中删除了一些样板代码。
- 张量流 1。XX 遗留代码
仍然可以运行 tf1。tf2 中的 XX 代码没有任何修改,但这并不能让您利用 TensorFlow 2.0 中的许多改进。相反,您可以尝试运行一个自动转换旧 tf1 的转换脚本。XX 呼叫到 tf2 呼叫,如果可能的话。如果需要,从 tf1 到 tf2 的详细的迁移指南将为您提供更多信息。
我希望你喜欢这个小概述,下次再见!
快乐张量流!
进一步阅读
- 有效的 https://www.tensorflow.org/alpha/guide/effective_tf2:
- TF2 有什么新鲜事?:https://medium . com/tensor flow/whats-coming-in-tensor flow-2-0-d 3663832 e9 b 8
车床 0.0.3 有什么新看点?

这是官方的,车床 0.0.3 已经发布,是非常有用的一个非常基本的阿尔法建设。我想我会给出一个新功能的运行,并给出对未来的洞察力。我已经在几个 ML 项目中使用过 Lathe,目前我正在为用 Julia 构建的人工智能驱动的网络应用程序开发一个重要的 Genie 实现,这对任何想学习 Julia 的人来说都是令人兴奋的。

证明文件
软件文档是开发一个伟大产品最不可或缺的一部分,没有开发者债务。优秀的文档可以成就或毁灭一个模块、应用程序或网站。该文档仍处于早期阶段,但将来肯定会很快得到改进。包含并链接了信息文章和走查笔记本,以提供准确的实际使用和应用示例。

新执照
许可证对于软件的成功也非常关键,这就是为什么 Lathe 从 GNU 通用许可证转换到 MIT 许可证的原因。大部分的许可模型被保留,然而,MIT 许可允许更好的发布和合法使用车床。如果你想了解更多关于麻省理工学院许可证的信息,请点击维基百科上的。
更多预处理
这是官方的,车床比以往任何时候都更可用,提供了预测建模的基本要素,如 *TrainTestSplit、*和功能标量,以提高您的模型的性能。
using Lathe.preprocess: TrainTestSplit, StandardScalar
train,test = TrainTestSplit(data)
trainx = StandardScalar(train.Feature)
此外,现在已经实现了 SortSplit,以及一些不太突出的特性标量的一些错误。现在,要拆分数组,而不是数据帧,可以使用 Lathe.preprocess.ArraySplit。
更多统计数据
已经实现了一个更大的统计库,现在允许执行 f 检验和条件概率。相关系数®的基本数学也已经实现。此外,还概述了未来实施统计的路线图,如皮尔逊相关、符号检验、Wilcoxon 检验、方差分析、配对 T 检验以及最后但并非最不重要的;卡方检验。
更多验证
很明显,车床 Alpha 0 . 0 . 3–0 . 0 . 4 的主要目标是回归,简单的 MAE 并不能完全解决这个问题…结果,我们现在有了 r 分数。未来的实现旨在以广义准确度、二项式分布、ROC/AUC 和混淆矩阵的形式提供您可能想要的所有验证。
新型号
很少有什么能像新模型那样让我兴奋,我们将能够在 Julia 的车床内部使用这些新模型。
- 多数类基线
当然,这不一定是一个模型,但这可以作为一个单一的分类很快来到车床说明。多数类基线类似于分类数据的模式,是构建和验证模型之前的基线步骤。
- 四方形
四方形模型基于四分位数拟合您的数据,对于快速拟合包含多个部分的数据非常有用。虽然 Four-Square 已经享受了这个生态系统一段适中的时间,但是模型本身已经从简单的线性回归器变成了线性最小二乘回归器。

- 线性最小二乘法
线性最小二乘法是一种简单的线性模型,可通过以下任何类型参数进行更改:
- :注册
- :OLS
- :WLS
- :GLS
- :GRG
如果你想了解更多关于这些的意思,以及它们之间的区别,你可以查看维基百科对它们的描述。
- 指数标量
该模型使用值差异进行随机猜测。这个模型的用例当然是在业务分析中。

接下来会发生什么?
- 更多统计数据
- 更多验证
- 更多预处理包括:
- 单位 L 标度
- 任意重新标度
- 更多型号包括:
- 逻辑回归
- 里脊回归
- 回归树

总的来说,我对这个模块的未来感到非常兴奋。我预计,对于像我这样的数据科学家来说,这会让朱莉娅变得更加迷人。目前,这些包是无组织的,分散在 Github 中,通常都没有什么文档。我希望更多的人会考虑使用它,也许会尝试将它作为 Julia 1.2 的首选模块。
地图应用的下一步是什么?途中旅程规划。

想象一下。你在路上——你收到一条消息,你的会面地点改变了。但是你已经在火车上了——你需要找到去新地点的路线。但是问题出现了,应用程序没有意识到你已经在火车上了!建议的步骤 1——走回你刚来的车站…

Typical situation when setting a new destination whilst on route.
这个博客上的一些笔记
这篇博客的目的是概述这个问题,并通过数据科学的方法来解决它。
为了提高可访问性,这个博客的大部分内容将会考虑到普通读者;标有“向上”和斜体的部分将涉及更多的技术细节——所以如果你不喜欢,请跳过其余的部分,它们仍然有意义!理解博客的其余部分没有先决条件!
我们开始吧!
问题大纲;如果你现在改变你的目的地,起始位置将作为你当前的位置,因为你在火车上,应该在一条铁路线(希望)上,如果你还没有在火车上,这是一个非常奇怪的开始旅行的地方。您有用的地图应用程序将为您提供从最近的步行点出发的路线,但没有考虑到您可能在火车上,第一步很可能是步行/乘坐交通工具到最近的车站-尽管事实上您目前正在它提议的线路上的火车上。
我们要使用的示例是从阿克顿镇到国王十字车站的更新目的地的路线。
现在你的地图应用程序告诉你,你需要步行 11 分钟回到阿克顿镇,才能在你目前所在的线路上赶上火车!(反正你也不可能下火车去做这件事)。
所以你认为;啊,我会把我的位置设置到我的下一站(哈默史密斯),然后按照那里的指示走——首要建议:乘环线到国王十字车站。完美…或者不完全完美。

Circle Line from Hammersmith to King’s Cross
如果站在哈默史密斯,这个应用程序是绝对正确的,而不是现在在火车上,下一趟火车是环线,那么很可能最快的方式是这样。然而,你的情况并非如此。
从哈默史密斯到国王十字车站有两种直接选择,皮卡迪利线和环线——都需要 26 分钟。

Piccadilly Line from Hammersmith to King’s Cross
这里重要的是上下文;将你的位置设置为哈默史密斯,应用程序并不知道你实际上已经在开往国王十字车站的皮卡迪利线上。由于哈默史密斯站分为两个部分,在两个站台之间步行 4-5 分钟,您可能需要等待长达 5 分钟的环线列车。乘坐环线列车比留在皮卡迪利线列车上至少多花 5 分钟,可能多花 10 分钟——相当于多花 40%的时间!
能做些什么?
这似乎是一个极好的数据科学问题;我们需要使用可用的数据为最终用户提供洞察力!
这里提供了一个关于如何着手解决问题的可能解释;有许多挑战——这篇博客并没有暗示这个问题的解决方案是容易的!
为了构建思维过程,我们将遵循 OSEMN 数据科学结构(获取、筛选、探索、建模、解释)。
获得
这里需要两个关键信息流:
- 用户的位置
- 用户当前可能乘坐的潜在交通方式(火车线路、公共汽车线路、电车线路等)
问题的关键是能够将用户与该交通模式的特定实例(火车、公共汽车或电车)相匹配。
让我们先来看看关于每一项的可用信息:
用户:
- GPS 信息(将给出位置、时间)
传输实例:
- 途径
- 日程表/时间表
- 实际到达/离开时间是站/站
我们想要匹配什么:
- 位置
- 方向
- 时间
在本次讨论中,我们将采用一个简单的(通过比较)例子,我们将使用从南阿克顿到阿克顿中心的一段里士满/斯特拉特福德地上线路。

是什么让这个例子变得更简单?我们将在后面的探索阶段讨论是什么使这个例子变得更简单——现在我们只是直观地将其与国王十字车站及其众多的交通线路进行比较。

对于用户来说,主要信息将是 GPS 馈送;以下是用户的典型数据集,包括时间、纬度和经度。

对于地上列车,主要的数据馈送将是提供关于列车的实时信息的 TfL API。在列车双向通过的情况下,线路至少应具备以下条件。为了提高认识,需要考虑更大部分的生产线:

作为实时时刻表,不是所有的“实际”信息都是可用的,无论信息是从左到右还是从右到左填充,都指示列车的方向。

矮树
两个数据集都可能出现错误,我们将简要了解如何识别这些错误。
用户
对于用户提供的数据,使用标准异常值分析技术,例如分析点的分布,误差最有可能在 GPS 位置(而不是时间)。
升级
可以相当安全地假设 GPS 定位中的误差将遵循正态分布。值得注意的是,由于这两个分量是通过相同的机制(手机中的 GPS 芯片)生成的,因此误差相关的概率很高;即经度上的误差更有可能也看到纬度上的误差。因此,这应被视为多变量异常值检测,Z-Score 将是此问题的合适选择。
TfL — API
对于用户来说,应用程序接收的信息来自安装它的手机(即直接来自 GPS 芯片)——因此信息源可能非常稳定(如果不是可变的话)。TfL 数据的主要挑战之一是获取数据并确保获取的数据是预期的数据。
本例中的简单方法如下:
- 检查数据类型;它在应该在的地方是字符串还是整数
- 检查年表;所有数据点是否都按照适当的顺序排列
- 检查规律性;一个旅程的站与站之间的时间是否比其他所有旅程都要短
该数据集具有更高程度的稀疏性-对于用户 GPS 数据,站点之间可能有数百个数据点,而对于 TfL 数据,每个站点可能只有一个数据点。考虑这一点的一种机制是查看旅程之间的分布,而不是每个旅程。
映射数据
除了知道火车什么时候会在特定的点,我们还需要知道这些点在哪里,对用户来说也是一样;在这一点上,我们可能需要匹配不同的数据源,这可能是一个挑战。我们将在探索阶段更详细地讨论这一点。XX —可能更新
探索
在这个阶段,重要的是要记住,我们遵循这个过程是为了让我们能够建立一个模型;这不一定是建模过程中实际遵循的过程。因此,我们能够收集额外的数据,帮助我们了解正在发生的事情——这通常太具挑战性/劳动密集型,或者在实施模型时根本不可用。
因此,首先为了更好地理解,我们将在地图上绘制用户 GPS 数据。

这使我们能够识别出大致沿着铁路线的点,对于这种情况,在同一路线上没有可比较的其他交通模式路线,但是也显示出可能至少有一个异常值。
首先回顾一下我们试图确定的内容:
- 位置
- 方向
- 时间
如果我们可以为用户和列车识别这些,我们可以“匹配”它们,并且根据数据的变化和其他可能匹配的接近程度,说出用户在该列车上的可能性有多大。
通过本探索部分,我们将回顾如何为用户和培训实现这两个目标。
用户
位置——幸运的是,大部分预处理发生在芯片/手机中,以提供已经相对准确的点测量(我们不太可能提高点定位的准确性)。
等级上升
为什么我们使用位置而不是路线,这样会更准确?简单地说,是的——我们稍后将首先研究近似路线的好处。
方向——这个更复杂;然而,幸运的是,对于这个例子,我们不需要高水平的方向精度,简单地说,我们需要知道用户是向北还是向南行进…移动平均线可能会处理数据集中的任何自然变化,并在经度/纬度上提供足够准确的值变化,由此可以得到矢量(下面的红色部分),即方向。

严格地说,这也给出了一个指示或速度,但是我们不能从列车数据中获得足够的数据来利用速度作为预测。
时间——很简单,这是由电话提供的。
火车
位置-列车具有高度精确的路线,但是相对于时间数据具有稀疏的位置(即,相对于时间的位置仅在车站是已知的)。

在路线上的某些点(即车站),火车的位置是高度确定的。相对于火车的时间来近似位置的简单方法是假设时间和距离之间的线性关系。

Assuming travel from South Acton to Acton Central
等级上升
这是一个非常简单的假设;并且在很多情况下都不成立——我们将在后面研究其影响和可能的缓解措施。
模型
主要的建模限制之一是速度;用户期望非常高的响应水平,因此模型必须保持足够简单以快速运行(这也将降低处理成本)。当考虑更复杂的路线时,这将成为一个特别的挑战。
让我们快速回顾一下这两个数据集及其属性:
列车
- 高度精确的路线和车站位置数据
- 稀疏但相对精确的时间数据
用户
- 频繁、可变精度的位置数据和高精度的时间数据
该模型的目的是确定数据点属于哪一类,这可以在下图中看到。还包括另一种可能的运输方式,模型需要在这两种方式之间进行识别。

在这个简单的例子中,通过简单地将用户数据点序列与相似位置的交通模式进行比较,可以很容易地看出如何在不同的模式/路线之间进行识别。蓝框中的数据点很容易标记,但红框中的数据点更具挑战性,这就是模型调整变得非常重要的地方,尤其是在使用较小数据集的情况下。
向上-模型选择
可用于这种简单情况的简单但有效的模型是 k-最近邻分类模型——将数据点与其最近的数据点进行比较,并标记为数量较大的类别(更多信息 此处 )
向上级别—更高的维度
这是一种过度简化,因为为了能够获得实例(即特定列车)而不仅仅是模式(路线),实际模型上方显示的二维图将至少有 5 个维度(长、横、变长、变横、时间),这允许模型考虑到我们目前使用的三个预测特征;地点、方向&时间。
该模型可以在分类器 user - > transport instance 或 transport instance - > user 中配置;在这种情况下,传输实例是带标签的数据集,因此用户应该与传输实例匹配。
下面是一个示例数据集,它可能是这个简单模型的输入。

Example data input into model
升级—模型验证
改进该模型的挑战之一是缺乏标记的用户数据——该应用程序不一定会得到任何验证,即预测用户乘坐的火车实际上就是用户乘坐的火车;换句话说,数据集没有被“标记”。该模型为单个用户运行的时间越长,该模型可以确定其预测是否准确的概率水平越高-例如,如果用户乘坐 10 站,并且用户的轨迹与每一站的火车匹配,则用户更有可能乘坐该火车。这个提高的概率可以用来给出一个假定的标签。
口译
因此,我们已经成功地识别了用户是在哪个运输模式实例上(简单地说,在这种情况下,用户是在哪个列车上)——我们如何使用它呢?
用户可能对他们是在火车上而不是在公共汽车上不感兴趣(希望他们已经意识到这一点)——但是我们能做的是开始解决突出的问题;为已经在运动中的用户生成路线计划。通过使用我们已经收集、探索和建模的数据,我们能够指示用户已经在皮卡迪利线上,并且可以给出更有用的线“在哈默史密斯站继续在皮卡迪利线上”,而不是“在哈默史密斯站登上下一趟环线列车”;阻止比最佳时间长 40%的建议!
改进的关键机会
机会 1
预测车站间列车相对于时间的位置的过于简单的模型。实际上不太可能是线性的,因为火车的速度可能在站与站之间变化。

克服这一点的一种机制是相对于站之间的时间来改进位置模型;这可以在用户数据的帮助下(当然是在许可的情况下)完成,以提供额外的数据。也有可能从 TfL 获得额外的数据,即路段而不仅仅是车站的数据。
升级—机会 2
改进模型;虽然 k-最近邻对于简单的低维情况是一个很好的模型,例如对于更高级的高维模型(为了提高精度,可能需要至少首先增加信息量,从而增加维数)。逻辑回归是一个很好的举措,但是依赖于能够线性分离标签类-这不是不可能的,但是随着维度的增加可能意味着使用主成分分析(PCA)或另一种降维技术来减少维度的数量而不丢失其中包含的信息-我们毕竟增加了维度的数量是有充分理由的。
使用决策树(作为集成方法或梯度推进方法)具有明显的优势,因为它可以处理非线性可分类以及分类预测变量;适用于处理大型输入数据集和高维数据。然而,由于需要优化大量超参数,实施起来会变得更加困难。
准确度、精确度、召回率和 F1 有什么关系?
它经常出现在数据科学职位的常见面试问题列表中。解释精确度和召回率之间的区别,解释什么是 F1 分数,精确度对分类模型有多重要?很容易混淆和混淆这些术语,所以我认为将每个术语分解并检查它们为什么重要是个好主意。
准确(性)
精确度的公式非常简单。

但是在处理分类问题时,我们试图预测二元结果。到底是不是诈骗?这个人会不会拖欠贷款?等等。因此,除了这个总体比率之外,我们关心的是被错误地归类为积极和消极的数字预测,特别是在我们试图预测的背景下。如果我们试图预测像信用卡欺诈这样的事情,99%的准确率可能是相当不错的,但是如果假阴性代表某人患有易于快速传播的严重病毒呢?还是一个得了癌症的人?这就是为什么我们必须进一步分解精度公式。

其中 TP =真阳性,TN =真阴性,FP =假阳性,FN =假阴性。
精确度和召回率
在讨论精度和召回之前,先简要说明一下第一类和第二类错误。这些术语并不是机器学习中分类问题所独有的,当涉及到统计假设检验时,它们也非常重要。
第一类错误 :假阳性(拒绝真零假设)
第二类错误 :假阴性(不拒绝假零假设)
记住这一点,我们可以将精确度定义为相关结果的百分比,而召回率的特征是被您正在运行的模型正确分类的相关结果的百分比。显然,这些定义并不那么直观,所以让我们来看看一些形象化的东西,看看我们是否能理解它。

好的,我想这开始有点道理了。当谈到精度时,我们谈论的是真阳性,而不是真阳性加上假阳性。与回忆相反,回忆是真阳性的数量超过真阳性和假阴性的数量。下面是公式,正如你所看到的,它们并不复杂。

我认为解释统计分类模型性能的最直观的可视化方法是混淆矩阵。这是一个 2 乘 2 的表,其中每行代表预测类中的一个实例,而列代表实际类的实例。

下面是一个实际的混淆矩阵,来自我做的一个项目,该项目是基于使用几种分类模型(包括逻辑回归、XGBoost 和随机森林)的调查数据来预测硬性毒品的使用。这是我的 GitHub 上那个项目的链接。

f1-分数
最后,我们有 F1 分数,它将精确度和召回率都考虑在内,以最终衡量模型的准确性。但是这个度量和准确性有什么区别呢?正如我们在开始时谈到的,假阳性和假阴性对研究来说绝对是至关重要的,而真阴性对于你试图解决的问题来说往往不那么重要,尤其是在商业环境中。F1 分数试图考虑这一点,给予假阴性和假阳性更多的权重,同时不让大量的真阴性影响你的分数。

希望这篇博客可以消除你在这四个指标上可能有的任何困惑,并且你会意识到准确性不一定是机器学习分类模型的最终衡量标准。这真的取决于你想解决什么样的问题。
AI、机器学习、深度学习有什么区别?
在许多流行的新闻文章中,“人工智能”、“机器学习”和“深度学习”等术语似乎可以互换使用。这些不同技术之间的区别是什么?
人工智能
维基百科将人工智能定义为
机器展示的智能,与人类和动物展示的自然智能形成对比
因此,“人工智能”是一把宽泛的伞,包含了所有让机器看起来聪明的计算技术。
“强 AI”和“弱 AI”还有进一步的区分:
- 强人工智能:具有感知、意识和/或思维的机器,例如来自星际旅行的数据。这仍然是科幻小说的领域——没有人构建过强大的人工智能系统。关于创造强大的人工智能是否可能*(例如见中文房间争论)或者是否可取(例如人工智能接管世界)有很多争论。*
- 弱人工智能(又名狭义人工智能):“无感知”人工智能专注于特定任务,例如医学应用,人脸识别,人工智能艺术。今天开发的所有人工智能都是“狭义人工智能”。
人工智能包括机器学习作为一个子领域。人工智能还包括非机器学习技术,如基于规则的算法。
用于检测鸟类的基于规则的算法可能如下所示:

当然,从这个伪代码示例中可以看出,基于规则的算法很难正确。在你真正确信你看到的是一只鸟之前,你需要具体说明鸟的多少特征?有多少种形状和颜色?(这也掩盖了让计算机识别特定形状和颜色的挑战。)你如何具体说明一根“羽毛”到底长什么样?您可能需要编写数百条不同的规则。因此,对于绝大多数人工智能任务来说,基于规则的方法已经失宠了。
机器学习
Arthur Samuel 是早期人工智能研究人员之一,他对机器学习的定义如下:
人工智能的一种应用,它赋予计算机无需显式编程就能学习的能力
机器学习算法旨在从数据中学习。例如,如果你想建立一个机器学习算法来识别鸟类,你不需要写下鸟类的任何特定特征,或任何规则。相反,你会收集成千上万张鸟类和非鸟类的照片,然后用“鸟”(1)和“非鸟”(0)的标签将它们输入到你的机器学习算法中。机器学习算法会自己找出哪些特征有助于区分鸟类和非鸟类。
最近的预印本《This Looks That:Deep Learning for Interpretable Image Recognition》给出了一个机器学习算法的例子,该算法解释了它正在查看鸟类照片的哪些部分,以确定鸟类物种。
深度学习
深度学习是指一种机器学习,在这种机器学习中,计算机学习将世界理解为一个概念层次。深度学习模型是一种特定的机器学习算法,称为神经网络,它被设计成具有许多层,即它是“深度的”较低层学习简单的概念如边,较高层学习复杂的概念如面。
这篇关于前馈神经网络的早期帖子定义了神经网络模型的“层”,而这张图片显示了一个具有许多层的神经网络的示意图。
深度学习是最近围绕人工智能的许多兴奋的原因。随着比以往任何时候都更大的数据集和更好的计算机,深度学习算法可以展示在现实世界中有用的令人印象深刻的性能。深度学习已经成功应用于语音识别、语音合成、语言翻译、图像字幕、人脸识别。
总结

正如你所看到的,神经网络模型是一种“机器学习”,但如果它们有许多层,它们也是“深度学习”。其他方法,如支持向量机,被认为是“机器学习”,但不是“深度学习”;基于规则的系统被认为是“人工智能”,但不是“机器学习”。
关于特色图片

专题图片是艺术家绘制的 6600 万年至 260 万年前的树木,“中第三纪欧洲的棕榈树和苏铁树”我认为它们看起来有点像向日葵,当然也不同于现代的树木。260 万年后人工智能会是什么样子(如果它还在的话)?
还有,有一种机器学习方法叫做“决策树”;如果你同时使用许多决策树,这是另一种叫做“随机森林的机器学习方法
原载于 2019 年 4 月 19 日http://glassboxmedicine.com。
分析和统计有什么区别?
理解两种完全不同职业的价值
统计学和分析是数据科学的两个分支,它们分享了许多早期的英雄,所以偶尔的啤酒仍然致力于热烈讨论它们之间的界限在哪里。然而,实际上,带有这些名字的现代训练项目强调的是完全不同的追求。虽然分析师专门探究你的数据中有什么,但统计学家更专注于推断数据之外的东西。
免责声明: 这篇文章讲述的是典型的培训项目毕业生,他们只教授 的 的统计学或 的 的分析学,它丝毫没有贬低那些设法增肥了两套肌肉的人。事实上, 精英数据科学家 被期望成为分析和统计方面的完全专家(以及 机器学习)……奇迹般地,这些人确实存在,尽管他们很少。**

Image: SOURCE.
人肉搜索引擎
当你掌握了与你的努力相关的所有事实时,常识是你用数据提问和回答问题的唯一资格。简单地查找答案。
想现在就看基础分析在行动?试试谷歌一下天气。每当你使用搜索引擎时,你都在做基本的分析。你正在调出天气数据并观察它。**

即使是孩子也可以毫不费力地在网上查找事实。这就是数据科学的民主化。好奇想知道今天的纽约是不是比雷克雅未克还冷?你可以获得近乎即时的满足感。它太简单了,我们甚至不再称它为分析,尽管它确实如此。现在想象一下一个世纪前试图获取这些信息。(正是。)
当你使用搜索引擎时,你是在做基本的分析。
如果报道原始事实是你的工作,你就相当于在做一个人肉搜索引擎的工作。不幸的是,人肉搜索引擎的工作保障取决于你的老板永远不会发现他们可以自己查找答案,并省去中间人……特别是当闪亮的分析工具最终使查询你公司的内部信息像使用谷歌搜索一样容易的时候。
灵感勘探者
如果你认为这意味着所有的 分析师都失业了,那你还没见过专家那种。用数据回答一个特定的问题比首先启发哪些问题值得问要容易得多。
我已经写了一整篇关于专家分析师做什么的文章,但是简单地说,他们都是关于获取一个巨大的未被探索的数据集并从中挖掘灵感。
“这是整个互联网,去找点有用的吧。”
你需要快速的编码技能和敏锐的感觉,知道你的领导会发现什么是鼓舞人心的,以及在对地下有什么一无所知的情况下勘探新大陆的人的所有性格力量。数据集越大,你对它可能出现的事实类型了解得越少,就越难不浪费时间地在其中漫游。你需要不可动摇的好奇心和情绪弹性来处理在你想出某样东西之前发现的一大堆东西。说起来总是比做起来容易。

Here’s a bunch of data. Okay, analysts, where would you like to begin? Image: Source.
虽然分析培训项目通常用查看海量数据集的软件技能来武装他们的学生,但统计培训项目更有可能让这些技能成为可选的。
超越已知
当你必须处理不完整的信息时,障碍就提高了。当你有不确定性时,你所拥有的数据并没有涵盖你感兴趣的内容,所以你在得出结论时需要格外小心。这就是为什么优秀的分析师根本不会得出结论。
相反,如果他们发现自己超越了事实,他们试图成为思想开放的典范。保持开放的心态至关重要,否则你会陷入确认偏差——如果数据中有 20 个故事,你只会注意到支持你已经相信的那一个……而你会错过其他的。
初学者认为探索性分析的目的是回答问题,而实际上是提出问题。
这就是培训项目的重点所在:避免在不确定的情况下得出愚蠢的结论是每门统计学课程的内容,而分析项目几乎没有触及推理数学和认识论的细微差别。

Image: Source.
如果没有严格的统计数据,一个粗心的像伊卡洛斯一样的超越你的数据的跳跃很可能会以啪的一声结束。(给分析师的提示:如果你想完全避开统计数据领域,就抵制所有做出结论的诱惑。任务完成。)
分析帮助你形成假设。它提高了你的问题的质量。
统计学帮助你测试假设。它提高了你回答的质量。
一个常见的错误是认为探索性分析的目的是回答问题,而实际上是提出问题。分析师的数据探索是如何确保你提出更好的问题,但他们发现的模式不应该被认真对待,直到他们在新数据上进行统计测试。分析帮助你形成假设,而统计让你测试它们。
统计学家帮助你测试,如果分析师在当前数据集中发现的现象也适用于当前数据以外的情况,这种行为是否明智。
我观察到其他数据科学类型对分析师的欺负,他们似乎认为他们更合理,因为他们的方程更复杂。首先,专家分析师使用所有相同的等式(只是出于不同的目的),其次,如果你横向观察宽浅,它看起来就像窄深。
我见过很多由于对分析师功能的误解而导致的数据科学有用性失败。您的数据科学组织的有效性取决于强大的分析先锋,否则您将小心翼翼地挖掘错误的地方,因此投资于分析师并欣赏他们,然后转向统计学家,对您的分析师带给您的任何潜在见解进行严格的跟进。

你两者都需要!
在好问题和好答案之间做出选择是痛苦的(和通常的古旧用法),所以如果你能负担得起与这两种类型的数据专家一起工作,那么希望这是一件容易的事。可惜,代价不仅仅是人员。你还需要丰富的数据和数据分割的文化来利用他们的贡献。拥有(至少)两个数据集可以让你首先获得灵感,并基于想象之外的东西形成你的理论…然后检查它们是否成立。这就是数量的惊人优势。
对这种差异的误解导致了统计学家的大量不必要的欺侮和分析师作为成品出售的大量不规范的观点。
拥有大量数据的人不习惯拆分数据的唯一原因是,这种方法在上个世纪的数据饥荒中不可行。很难收集到足够的数据来进行拆分。漫长的历史使分析和统计之间的墙钙化,以至于今天两个阵营都不太喜欢对方。这是一种过时的观点,它一直伴随着我们,因为我们忘记了重新思考它。遗留问题滞后了,导致统计学家大量不必要的欺凌和分析师大量作为成品出售的散漫观点。如果你关心从数据中提取价值,并且你有足够的数据,你有什么借口而不是在需要的地方利用你的灵感和严谨?拆分你的数据!
如果你能和这两种类型的数据专家一起工作,那么希望这是一件容易的事。
一旦你意识到数据分割允许每个学科成为另一个学科的力量倍增器,你会发现自己想知道为什么有人会以其他方式处理数据。
感谢阅读!人工智能课程怎么样?
如果你在这里玩得开心,并且你正在寻找一个为初学者和专家设计的有趣的应用人工智能课程,这里有一个我为你制作的娱乐课程:
Enjoy the entire course playlist here: bit.ly/machinefriend
更喜欢书面媒体,想要我的另一篇文章?试试:
数据科学专业之间微妙的战争
towardsdatascience.com](/can-analysts-and-statisticians-get-along-5c9a65c8d056)**
sklearn 中的线性回归、套索、山脊、ElasticNet 有什么区别?

Image by Free-Photos from Pixabay
它们有什么区别?
Lasso、Ridge 和 ElasticNet 都是线性回归系列的一部分,其中 x(输入)和 y(输出)假定具有线性关系。在 sklearn 中,LinearRegression 指的是最普通的不需要正则化(权重上的惩罚)的最小二乘线性回归方法。它们之间的主要区别在于模型是否因其权重而受到惩罚。在本文的其余部分,我将在 scikit-learn 库的背景下讨论它们。
线性回归(在 scikit-learn 中)是最基本的形式,其中模型根本不会因为其选择的权重而受到惩罚。这意味着,在训练阶段,如果模型觉得某个特定的特征特别重要,模型可能会对该特征赋予很大的权重。这有时会导致小数据集中的过度拟合。因此,发明了以下方法。
Lasso 是线性回归的一种修改,其中模型因权重绝对值的和而受到惩罚。因此,权重的绝对值将(通常)减少,并且许多将趋于零。在训练期间,目标函数变成:

如你所见,Lasso 引入了一个新的超参数, alpha ,这个系数用来惩罚权重。
Ridge 更进一步,针对权重的平方和惩罚模型。因此,权重不仅倾向于具有较小的绝对值,而且实际上倾向于惩罚权重的极值,从而产生一组分布更均匀的权重。目标函数变成:

ElasticNet 是 Lasso 和 Ridge 的混合,其中包括绝对值惩罚和平方惩罚,由另一个系数 l1_ratio 调整:

你的数据已经缩放了吗?
正如你在上面的等式中看到的,权重惩罚在损失函数中被加在一起。假设我们有一个特征 house_size 在 2000 的范围内,而另一个特征num _ believes在 3 的范围内,那么我们可以预期 house_size 的权重自然会小于num _ believes的权重。在这种情况下,以同样的方式惩罚每个特征的权重是不合适的。因此,在将数据输入模型之前,对其进行缩放或标准化是非常重要的。**快速注意,sklearn 中这些模型的默认设置将“正常化”设置为 false。**你要么将‘正常化’打开,要么使用 ScandardScaler 缩放数据。通常,使用 ScandardScaler 是一个很好的做法,因为您可能希望使用相同的比例来缩放测试数据。
什么时候用哪个?
有几件事需要记住:
(1) **当你的数据集小于 100k 行时,sklearn 的算法备忘单建议你尝试 Lasso、ElasticNet 或 Ridge。**否则,试试 SGDRegressor。
(2) Lasso 和 ElasticNet 倾向于给出稀疏的权重(大部分为零),因为 l1 正则化同样关心将大权重驱动到小权重,或者将小权重驱动到零。如果你有很多预测器(特性),并且你怀疑不是所有的都那么重要,那么 Lasso 和 ElasticNet 可能是一个很好的开始。
(3) Ridge 倾向于给出小但分布良好的权重,因为 l2 正则化更关心将大权重驱动到小权重,而不是将小权重驱动到零。如果您只有几个预测值,并且您确信所有这些预测值都与预测真正相关,请尝试将岭作为一种很好的正则化线性回归方法。
(4) **在使用这些正则化线性回归方法之前,您需要调整您的数据。**首先使用 StandardScaler,或将这些估算器中的“normalize”设置为“True”。

pd.merge 和 df.merge 有什么区别?
对源代码的深入探究,揭示导入的设计模式

Photo by Pascal Müller on Unsplash
在我为 www.dataquest.io 提供在线技术支持的志愿工作中,我遇到了许多问题,这些问题使我能够更深入地研究我通常浏览的有趣问题。
今天的问题是:
left _ df . merge(right_df)vs PD . merge(left _ df,right _ df)有什么区别?
简短的回答是left_df.merge()呼叫pd.merge()。
使用前者是因为它允许方法链接,类似于 R 中的%>%管道操作符,允许你从左向右写和读数据处理代码,比如left_df.merge(right_df).merge(right_df2)。如果你不得不做 pd.merge(),这不是链接的风格,而是包装的风格,如果你明白这是怎么回事,它会以一个丑陋的pd.merge(pd.merge(left_df,right_df),right_df2)结束。
现在让我们到兔子洞里去看看发生了什么事。
第一,当你看到pd.merge的时候,其实就是pandas.merge的意思,也就是说你做了import pandas。当你import某个东西的时候,那个模块名的__init__.py文件(本问题中的pandas)就运行了。
所有这些__init__.py文件的主要目的是组织 API,并允许用户通过为您导入中间包来键入更短的导入代码,因此您可以一次编写pandas.merge()而不是在使用merge()函数之前先要求from pandas.core.reshape.merge import merge。
现在你打开https://github . com/pandas-dev/pandas/blob/v 0 . 25 . 1/pandas/_ _ init _ _,看看我说的“为你导入中间包”
是什么意思。py#L129-L143 ,你会看到它是如何导入很多东西的,其中一行是from pandas.core.reshape.api(图 1),在那个块merge是导入的。

Figure 1
这就是允许你直接调用pd.merge的地方,但是让我们来深究一下。
走进pandas.core.reshape.apihttps://github . com/pandas-dev/pandas/blob/v 0 . 25 . 1/pandas/core/reshape/API . py你看from pandas.core.reshape.merge import merge。(图 2)

Figure 2
现在你明白了from pandas.core.reshape.api之前的merge是从哪里来的吧。
最后让我们来看一下来源,在进入pandas.core.reshape.mergehttps://github . com/pandas-dev/pandas/blob/v 0 . 25 . 1/pandas/core/shape/merge . py # L53你看def merge。(图 4)

Figure 4
现在让我们从https://pandas . py data . org/pandas-docs/stable/reference/API/pandas 来看看编码的链式风格left_df.merge 在做什么。DataFrame.merge.html,点击source进入https://github . com/pandas-dev/pandas/blob/v 0 . 25 . 1/pandas/core/frame . py # l 7304-l 7335查看def merge(self(图 5),这个self告诉你这是一个类(在这个例子中是 DataFrame)方法,这个方法稍后会导入from pandas.core.reshape.merge import merge,并将你的所有参数从pandas.core.reshape.merge传递回merge,只有

Figure 5
您可以将这里的left_df.merge中的def merge 的两个函数签名与之前的pd.merge讨论进行比较,以查看它们是否完全相同merge。
我怎么知道要从关键词merge开始搜索呢?实际上,我首先从left_df.merge 的源代码开始搜索,但我觉得最好先解释最底层的代码,然后引入用self替换left参数的想法,这样更复杂的想法就建立在更简单的想法上。
我希望这篇文章能激发其他人不要害怕源代码,而是激发他们的好奇心,去了解事情在幕后是如何工作的,API 是如何设计的,这样做可能会对熊猫的未来有所贡献。
英国大报/小报的分裂是怎么回事?
在我的上一篇博文中,我介绍了一种区分英国报纸的方法,方法是绘制读者的政治罗盘值,并查看产生以下结果的分布:

人们在 twitter 上的回应是询问(为了方便起见,大量转述):
- 我们只看到了他们最常阅读的报纸(如果有的话)——人们经常阅读不止一份报纸——第二偏好是如何分解的?
- 主要的分歧似乎在大报和小报之间——是什么推动了这一点?
不久前, Yougov 公布了报纸网站(每日访问<报纸 X 网站>的百分比,同时也是<报纸 Y 网站>的每周访问者)之间的交叉分析。报纸网站的读者并不是报纸读者的完美代理…但是数据已经被收集和编辑,所以检查起来并不特别费时。
我不喜欢 Yougov 的图表——我对报纸网站的平均受欢迎程度不感兴趣,我想知道它们在哪个网站的读者中相对更受欢迎/不太受欢迎。所以我把平均人气分出来然后把结果变成网络图[1]:

箭头的宽度反映了相对偏好(如上所述,控制某些网站更受所有人的欢迎)。不出所料,每日“独立”网站的读者倾向于至少每周“我”的读者。“我”和“金融时报”之间的联系更令人惊讶。
这告诉了我们什么——除了“不要在蛋壳背景上使用黄色”?聚集成小报和大报的“新闻睾丸”与上面的政治罗盘值分布重叠是一致的,甚至到了《每日电讯报》与“小报新闻文章”有最强联系的程度。
但是是什么造成了这种分歧呢?最终的因果关系很难确定,所以我将把它改写为“什么能预测一个人最常阅读的报纸是大报还是小报?”。
为了回答这个问题,我将整个英国选举研究在线面板数据集——一个几乎包含数百个政治、人口统计、态度和个人变量的数据集——置于机器学习分类算法[2]中,以查看哪些问卷变量作为预测人们首选报纸[3]是大报(→)还是小报(←),如上图所示。基本上,炸药捕鱼。
下面是输出结果(通过一种算法,使机器学习结果不那么不透明[4]):

选择你自己的博客冒险:你想知道如何阅读上面的不透明图表(阅读下面)——或者你只是想跳到细目分类(向下滚动)?
确实想看图:顶部最重要,底部最不重要[5]。每行中的每个斑点都是一个人,由该变量的值着色,由该变量对拟合模型中最终预测的影响定位(结果证明 80–90%准确,对于真实世界的数据来说相当不错)。
乍一看,这些变量(大部分)是可以猜测的,但是这里是显示哪些变量与哪些问题相关的 pdf 的链接——我已经自动修改了变量名以(稍微)增强可读性【6】。我将以顶部变量为例:

还在上学/20+是鲜红色/红色(你参加过高等教育)。比这更蓝意味着你离开了 19-15。何参与= >更倾向于大报/没有何参与= >更倾向于小报。[7]
不想看图表:这是上述变量的大致分组/有序分类
- 高等教育→
- 年龄↓
- 社会保守主义(又名威权主义)——尤其是死刑/更严厉的判决,
- 阶级自我认同 WC ← → MC [8]
- 无神论→
- 政治知识/注意力变量→
- 移民/黑人和女性平等→
- 住在伦敦/家庭收入高→
- 2005 年 GE 工党选民,
- 能源价格上限(问题文本不在 pdf 中,但可以合理假设为*)\
- 在 2016 年活动期间从广播中听到有关 euRef 的信息→
这里没有太多令人惊讶的东西——年龄、教育、社会保守主义、移民/平等情绪——都被认为是密切相关的(尽管上面我们看到了它们各自的影响,有效地控制了彼此)。
这里没有任何东西能自动告诉你因果关系的走向(好吧,我假设拿起一份《卫报》不会把你传送到伦敦或阅读《太阳报》,因为你会回到 2005 年投票给工党)。
“2005 年 GE 工党投票”与小报读者的联系可能与当代关于工党何时开始失去其社会保守派投票的辩论间接相关(在下一篇博客中有更多内容)——但请注意,2005 年 GE 是数据中“最早”的一年(例如,重要的分裂点很可能更早)。
接下来:英国政党在政治罗盘上的支持度——在哪里匹配,在哪里不匹配
推荐:如果你喜欢这个,你可能会更加喜欢克里斯·汉莱蒂的博客
代码(&Data):
- Yougov 数据/网络图(漂亮的人类可读笔记本)
- 机器学习数据集挖掘代码(一堆可怕的中间重构的未注释代码——为了准备 BES 数据,你必须运行其他笔记本)
[1]我可能也一直在寻找一个试验网络图表软件的借口——在这个例子中,是 Gephi
[2] Xgboost 分类
[3]限于拥有首选报纸且其首选报纸在新闻文章图表中的人-其首选报纸是地区性/无/其他报纸的人不在考虑范围内
[5]我们只看前 30 名,因为越往下看,你可能看到的只是统计上的噪音。这只是严肃分析的探索阶段
[6]在处理过程中,我已经自动将文本添加到变量的末尾:
- 序数变量“blah”变成“blah__bleh”,其中“bleh”是最高类别,例如“lrUKIPW2__Right”意味着高值意味着回答者认为 UKIP 是右翼政党
- 分类变量“blah”变成了“blah_bleh ”,这意味着该变量有 3 个以上的无序类别,每个类别都变成了独立的二元变量,例如“subjClassW2 _ W4W7W9 _ Yes,working class”意味着受访者被问及他们是否认为自己属于某个特定的阶层,“是的,working class”是选项之一,高值表示他们选择了该选项,低值表示他们没有
- 已经是数字的变量——比如年龄——就保持原样(年龄增长的惯例广为人知)
- WXWY_WZ 指的是这些变量被采样的波形(也就是说,你可以忽略它)
- 变量末尾前使用的下划线来自原始变量,例如“profile_past_vote_2005 _ Labour Party”来自名为“profile _ past _ vote _ 2005”的分类变量
[7]“不记得”我已经归类为“不知道”的回答(我有一个很大的“黄鼠狼答案”列表,自动将所有不知道/不知道相似的答案替换为“没有回答”的代码),所以它显示为灰色(如果我没有,你如何处理除了 DK 选项以外所有答案都有明确顺序的问题?).
[8]值得强调的是,这是自我认同——如果你的自我认同与国家统计局的社会经济分类相矛盾,他们不会到你家来用棍子打你,直到你改正自己的方式(当然,一旦英国离开欧盟,将会有许多新的机会)
基于波形的 vgg 是怎么回事?
在这一系列帖子中,我写了两篇文章讨论基于声谱图的 VGG 架构的利弊,以思考计算机视觉深度学习架构在音频领域的作用。现在是讨论基于波形的 vgg 的时候了!
- 帖子一:为什么基于声谱图的 vgg 很烂?
- 帖子二:为什么基于声谱图的 VGGs 会摇滚?
- 帖子三:基于波形的 VGGs 是怎么回事?【本帖】

在这些帖子中,我将围绕 VGG 模型展开讨论,这是一种被音频研究人员广泛使用的计算机视觉架构。简而言之,vgg是由一个深度堆栈的非常小的过滤器与最大池相结合而形成的。
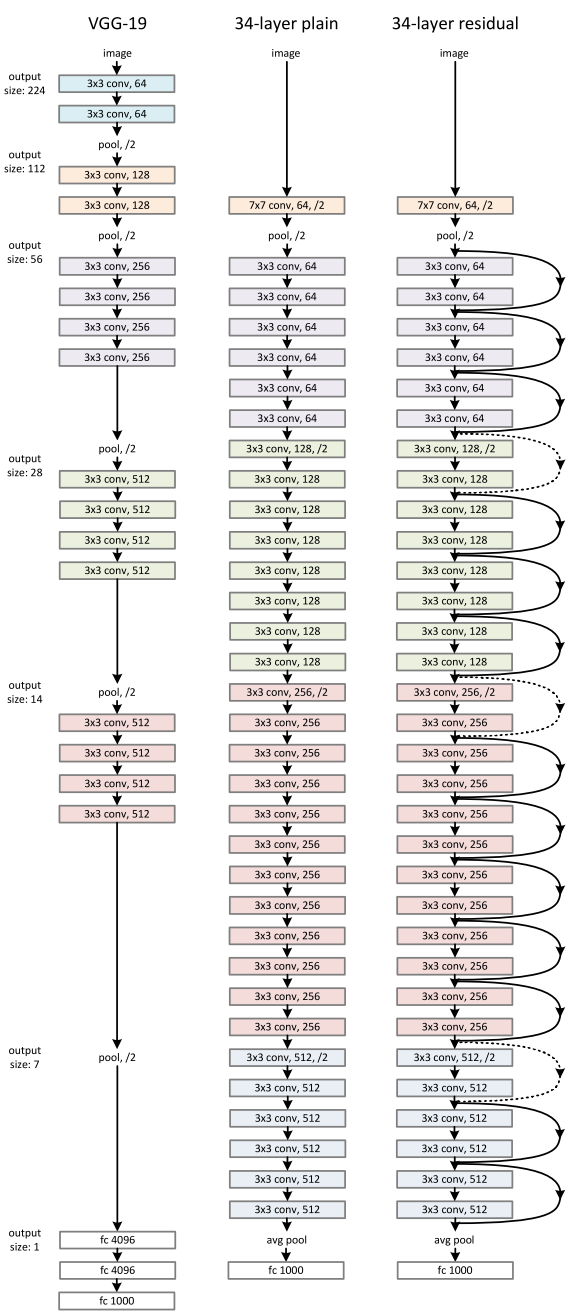
频谱图和基于波形的 vgg 之间的主要区别在于,前者执行 2D 卷积(跨时间和频率),而后者执行 1D 卷积(跨时间)。另一个区别是基于波形的模型不会丢弃相位。相反,他们按原样使用原始信号。这是不是优势,很多任务还是要确定的!
在以前的帖子中,我解释了如何使用领域知识来提高基于频谱图的模型的效率和性能,我还指出,人们使用基于频谱图的 vgg 是因为它们非常灵活——基本上,它们不受任何领域知识的约束。换句话说:我揭露了在设计数据驱动模型时是否使用领域知识的永无止境的讨论。

有趣的是,基于波形的深度学习研究人员也在深入这场讨论。一些人在使用 VGGs 时发现了非常有前途的结果,但是另一些人在使用领域知识时发现了有趣的结果。然而,文献远非定论。可能是因为这些工作相对较新,没有独立的元研究来比较这些跨几个数据集的架构。
基于波形的 VGGs 为什么能摇滚?
重要的是要注意,波形是高维的,非常多变。这就是为什么,历史上,音频社区没有成功地建立成功的系统,直接接近原始波形。
正因为波形不直观且难以接近,所以在不利用任何领域知识的情况下解决这个问题可能是有意义的。如果很难思考如何恰当地完成任务,为什么不从数据中学习呢?因此,为此目的使用类似 VGG 的模型可能是有意义的——因为这些模型不受任何依赖于领域知识的设计策略的约束,因此具有高度的表达能力和从数据中学习的巨大能力。
此外,通过堆叠具有小滤波器的 CNN 层来构建 VGG 模型。作为使用小过滤器的结果,在不同阶段学习相同表示的可能性显著降低。此外,交错的 max-pooling 层进一步增强了相位不变性。
正如所见,使用基于波形的 vgg 似乎不是一个坏主意。与声谱图的情况不同,当处理基于波形的模型时,我们对于如何建立模型没有清晰的直觉。因此,人们开始设计基于波形的类似 VGG 的模型,这种模型的设计不依赖于任何领域的专业知识。相反,它们依赖于一组非常小的过滤器,这些过滤器可以分层组合,以学习任何有用的结构。其中一些架构是 Wavenet 、 sampleCNN 、它的挤压和激励扩展,或者音频的 ResNet 。
让我们利用领域知识来设计波形前端!
尽管一些研究人员认为不利用领域知识是基于波形的模型的发展方向,但另一些人却持相反的观点。
所有考虑领域知识而设计的基于波形的模型都从相同的观察出发:端到端神经网络在第一层学习频率选择滤波器。如果这些必须学习时间-频率分解,如果我们已经定制了网络来学习呢?也许,用那种方式,可以比使用类似 VGG 的模型获得更好的结果。
一个第一次尝试是在 STFT 中使用与窗口长度一样长的滤波器(例如,滤波器长度为 512,步长为 256)。如果这种设置能够很好地用 STFT 将信号分解成正弦基,也许它还能帮助学习 CNN 中的频率选择滤波器!
后来,提出了多尺度 CNN 前端——其由具有不同滤波器大小(例如,滤波器长度为 512、256 和 128,步长为 64)的 CNN 产生的级联特征图组成。他们发现,这些不同的滤波器自然地学习它们可以最有效地表示的频率,大型和小型滤波器分别学习低频和高频。这与受 STFT 启发的 CNN 形成了鲜明对比,后者试图用单一尺寸的滤波器覆盖整个频谱。
或者最近,提出了基于参数化 sinc 函数(实现带通滤波器)的波形前端: SincNet 。SincNet 的每个第一层滤波器中只有两个可学习的参数,在波形方面,SincNet 可以胜过 STFT 启发的 CNN,甚至是基于频谱图的 CNN!
因此…什么?
尽管存在一些轶事般的元研究,但考虑到我们还处于该研究领域的早期,很难说哪种架构会在长期内流行。目前,出现了一些有影响力的想法,现在是社区尝试这些想法的时候了。
虽然当训练数据丰富时,高度表达的基于波形的 VGG 模型可能是有能力的,但是当数据稀缺时,基于领域知识的模型可能有更多的机会-仅仅因为模型的参数数量可以显著减少,就像 SincNet 一样。时间会证明一切!
你的“数据故事”是什么?
向利益相关者和管理层展示数据和机器学习产品概念
人人都爱数据。每个人都喜欢像理解数据一样说话。每个人都喜欢使用人工智能和人工智能的流行语——但很多时候他们只是在聊天,希望他们在正确的上下文中使用它们,但通常仍然只是把它们扔到外面。这当然也很重要。这就是你销售产品的方式。这就是一个人如何显示他们的公司是他们领域的顶级,他们有高端的能力,当然,他们是他们所做的最好的。
我一路走来学到的是,真正学会分享和解释“数据故事”是一项艰巨的工作。

How will you tell your “data story”?
作为我之前数据和 ML 产品经理职位的一部分,我的任务之一是向全球主席做季度报告,他也是我们的主要投资者。这些演示对公司的所有项目经理来说都特别难做,因为我们从高层次的概念和季度规划路线图开始,一直到将在未来几周内交付的具体功能。一方面,我们将尝试解释我们的日常框架,另一方面,连贯地呈现它,解释它如何适应更大的画面和公司的业务战略。尽管演示会定期重复,但我相信,在向投资者和利益相关者演示时,从准备这些演示中学到的见解对我们任何人都是相关的,因为他们并不总是了解技术,但对产品有一个大致的了解。
因此,除了这些复杂性之外,作为公司唯一的数据 ML 项目经理,我觉得我面临的挑战甚至更大。
这是为什么呢?
好的数据特征是看不见的。对于一个局外人和一个用户来说,它们是微不足道的。用户真正能看到一个算法的唯一时间是当某个东西出错时,当某个东西被关闭并且用户接收到不正确的输出时。但挑战不仅如此。数据世界并不擅长用漂亮的面向用户的 UI 来解释自己,这是利益相关者理解你所指的最好方式。有大量的文本、代码,当然还有大量的图表。在一个 B2C 的世界里,将这些信息转化成可以解释更大的画面并显示视觉效果的东西是相当具有挑战性的。当你向一群只看到冰山一角的人展示时,你怎么能展示你在做什么?

Photo by Annie Spratt on Unsplash
以下是我选择解决这个问题的方法。
我做的第一件事对我们的演示来说有点不标准。我没有直接切入,而是选择在我的第一个演示文稿中添加更多的解释。这个想法是详细说明机器学习的过程和基础,以及我们的团队如何实现这些算法。
在接下来的演讲中,我会先做一个概述,重复同样的过程,并解释在给定的演讲中我们将关注的领域。
我认为这个概念甚至适用于一次性演示,建立一个框架,使整个演示更加连贯和易于理解。
这是我发现相关的帖子之一,它帮助我建立了指导我演讲的框架和概述:https://hacker noon . com/the-ai-hierarchy-of-needs-18f 111 FCC 007
我收到的关于这几张指导幻灯片(即演示框架)的反馈非常积极。人们最终能够理解我们的数据结构,我们作为平台一部分的能力,以及最后但并非最不重要的,构建新能力的过程——我们如何定义新功能和算法的假设,然后走向优先排序、测试和实施。
从长远来看,我发现这些指导幻灯片不仅有助于我向主席做这些演示,也有助于其他需要解释我们团队工作的人。
除了这些指导幻灯片之外,我还使用以下附加指南制作了新的演示文稿,这些指南有助于我专注于手头的任务:
1- 不要爱上你的数学设计
数据通常显示在流程图、方案、表格等中,但是总有(至少,应该总是)一个功能等待使用这个新功能。那就是我们想要演示的。是什么赋予了商业价值?什么给我们的客户带来价值?在 B2C 世界中,我们展示可视化的 UI 组件。当然,这可能不是填充 UI 组件/功能的唯一算法。但是当在上下文中显示它时,它可以被解释为同一个流程的一部分,解释为什么需要初始图的每个部分。
2 - 从用户的角度解释
请记住,每一个数据表或逻辑都应该启用一个功能,从而使用户能够更好地进行转换。当解释一个特性的后端算法时,这并不总是可以理解的。然而,如果我们专注于解释用户影响,这可能是构建特定幻灯片甚至整个演示文稿的关键,从而获得利益相关者的理解。
3 - 使用可视化图表(尽可能少的文本)
解释你正在研究的新的令人惊奇的 ML 算法和系统如何工作是不可避免的——但是即使这些也应该以视觉的方式呈现。请记住,这些幻灯片可能是利益相关者向他们所有的朋友炫耀的幻灯片,吹嘘他们有“更好的人工智能”——所以他们必须有正确的流行语,但不能太复杂。你不想失去他们,因为他们觉得他们必须阅读每一个字,每一个盒子,每一个图表。
4 - 数据,数据,数据
我们已经解释了流程,并在可视化图表和流程图中展示了它。但是既然处理数据是我们工作的一大部分,它也应该是我们演示的一部分。高质量数据的可用性是创造价值的关键因素。这就是为什么这些领域的“成本”和投资很大,但仍然至关重要。不幸的是,有时这并不是每个人都清楚的,这种演示代表着错过了让每个人都参与进来的机会。
总结一下,直到 ML 成为世界之道(那一天会到来:),直到很明显我们尽可能地原子化和优化,描述数据,ML 和 AI 元素将保持复杂。因此,数据 ML 项目管理对于大局来说仍然至关重要。它们提供了充分理解和分析用户需求的能力,定义较低层次的数据特征和算法,并“翻译”和简化,以便让整个团队在同一页面上。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言










{kind=link}
{kind=link}