







手柄后面的脸——使用神经网络区分唐纳德·特朗普的推文习惯

几乎每一个不朽的宣言都有它的面孔。在我们这个时代,我们有一个推特账号。
纵观历史,总统们都曾为自己搭建平台,宣布重大变革即将到来。富兰克林·罗斯福利用他的私人炉边谈话宣布对日战争和美国加入第二次世界大战;罗纳德·里根通过他在柏林墙的标志性演讲重新统一了德国;约翰·肯尼迪通过电视广播宣布人类登上月球的梦想将成为现实。这些时刻标志着世界历史,表明来自标志性人物的标志性信息永远不会真正消失。

Three iconic presidential speeches throughout history. Left: FDR fireside chat where he announces war on Japan. Middle: Ronald Reagan’s “Ich Bin Ein Berliner.” Right: JFK giving his moonshot speech. All thumbnails taken from the YouTube videos linked above.
然而,时代变了:
虽然没错,这是全球关系的一个重大事件,但它也是特朗普总统的个人推特——他与世界沟通的主要手段。
从承认以色列在戈兰高地的主权到宣布对中国征收 2000 亿美元的新关税,Twitter 上的这些行动一次又一次地证明了它们在世界范围内具有重大影响。事实上,摩根大通甚至创造了一个“Volfefe”指数来跟踪由@realDonaldTrump 的推文引起的美国债券市场的波动。
在标志性的电视事件中,比如 JFK 出色地宣布,是的,我们是 要去月球,你可以清楚地看到高中 AP Lang 老师的清单:他使用了哪些文学手段?他如何在人群中展示自己?他的是什么风气?(如果我给了你一个闪回,我道歉)
然而,有一个问题几乎从未被提及,但却非常重要:世卫组织在讲话?
仅仅因为它来自@realDonaldTrump 并不意味着它来自(是的,我正在这样做)真正的唐纳德·特朗普。难道你不认为知道谁是世界上最强大的推特账户的幕后操纵者很重要吗?幸运的是,有一个理论。
一个流行的(阴谋?)关于唐纳德·特朗普的推文来源的理论是,他更具外交色彩的推文是由工作人员撰写的,而他个人则撰写更具争议性的内容。为了识别真正是谁写了他的推文,我们基于现有的理论训练了几个神经网络。
在 2017 年 3 月 25 日之前, @realDonaldTrump 的推文在 iPhone 和 Android 设备上发布。一个流行的理论是,特朗普的工作人员用 iPhone 发布推文,而特朗普本人则用他的安卓系统发布推文。虽然特朗普在 2017 年换了一部 iPhone,但我们决定测试一下这个理论,看看我们能否根据文本确定每条推文的来源。
下面是两条不同标签的推文的一个很好的例子:
Twitter for Android
Twitter for iPhone
反差很大,不是吗?
我们做了什么

Screenshot of the Trump Twitter Archive
为了将推文分类为工作人员推文或特朗普推文,我们使用了由特朗普推特档案馆存档的推文目录,并将它们分为两组,即 2017 年 3 月之前和之后。在 2017 年 3 月之前的集合中,我们过滤掉了从 Twitter for Web 等其他来源发布的推文,并使用 Android 和 iPhone 推文来建立我们的地面真相数据集。
 ****
****
这里我们有一个基于设备类型的推文频率图,我们发现一般来说,来自 Android 设备(特朗普本人)的推文不如来自 iPhone(他的工作人员)的推文频繁。
检查分布图,我们注意到两个设备的大峰值约为 140 个字符,但来自 Androids 的更多。这可以归因于推特上的字符限制——自 2007 年推特成立以来,每条推特就保持在 140 个字符,很大程度上受短信 160 个字符限制的影响。然而,自 2017 年底以来,该限制增加了一倍,达到 280 个字符,这一点从分布图中 iPhone 推文的最右边峰值可以看出。这两个图说明了我们的数据集中明显的偏向,严重偏向 iPhones,数据点几乎是 iPhones 的三倍,分布也超过了旧的 140 个字符的限制。
准备数据
与任何神经网络一样,需要进行一些预处理:
标记化和格式化
标记化将每个单词映射到字典中的一个索引。为了准备要传递到神经网络的数据,首先使用 Keras 的Tokenizer模块对推文进行标记化。一旦测试和训练集被标记化,我们就必须决定保持输入大小一致的方法。我们认为按长度裁剪推文会导致我们丢失数据,所以我们选择填充推文。我们选择用 65 个单词的长度来填充输入,因为我们发现最长的推文是 50 个单词,我们希望为未来的推文留有足够的余量。
把…嵌入
为了构建我们的单词嵌入,我们在 Kaggle 上找到了预处理的全局向量(手套)单词模型。这种类型的模型映射矩阵中两个单词之间的关系,并根据-1 到 1 的值对该关系进行评分。这是生成单词嵌入层的权重的一种非常常见的方法。首先,我们创建了一个出现在数据集中的单词的字典,然后通过从 GloVe 文本文件中解析这些单词及其嵌入值来创建一个嵌入矩阵。
平衡
正如前面的和所看到的,我们的数据严重失真。与机器人相比,iPhones 的推文数量明显更多。在这种倾斜的数据集上进行训练会有一个有偏见的模型的风险,这意味着模型会过度预测 iPhones,而在大多数时候仍然是正确的。因此,我们试图通过用平衡批次训练我们的模型来解决这个问题。我们通过使用欠采样技术做到了这一点,该技术从 iPhone 推文中提取较小的样本,这有助于我们的模型做出更可靠的预测,因为它暴露于一组平衡的训练数据。
训练/测试分割
在所有数据都被收集到 JSON 文件中之后,每条 tweet 的文本和来源都被传递到 sklearn 的train_test_split中,以便生成一个训练和验证集。
建模
我们选择了五种不同的架构来训练我们的数据集。我们首先看了一个基本的前馈网络作为基线,然后看了 NLP 中流行的其他四个模型。这样做不是为了微调超参数,而是为了探索各种流行的架构,这些架构后来可以扩展为更精细和精确的模型。
每个网络的第一层是嵌入层,具有填充字向量(65)的维度。嵌入层的权重是用我们使用的给定 GloVe 文本文件预先实例化的。通过使用预先制作的单词嵌入文件,这是迁移学习的一个应用。这第一层在每个模型中都是标准的,与后面的层无关。
在训练模型时,我们使用 Keras 中内置的validation_data参数将测试集设置为验证数据。我们测量每个时期改进的验证准确度,并训练模型,直到验证准确度在 50 个时期内停止改进。
如果你想跟随我们,请查看我们的 GitHub 页面 !
正向输送
我们想先尝试前馈模型,因为我们想看看与一些更复杂的模型相比,基本模型的表现如何。
**Model: "sequential_1"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
embedding_1 (Embedding) (None, 65, 100) 2441300
_________________________________________________________________
flatten_1 (Flatten) (None, 6500) 0
_________________________________________________________________
dense_1 (Dense) (None, 1) 6501
=================================================================
Total params: 2,447,801
Trainable params: 6,501
Non-trainable params: 2,441,300Test Score: 0.4719
Test Accuracy: 0.7909**
1D 卷积神经网络(CNN)
1D CNN 将扫描一系列标记化的单词。滤波器长度决定了在单个卷积中要查看多少单词。
**Model: "sequential_8"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
embedding_8 (Embedding) (None, 65, 100) 2441300
_________________________________________________________________
conv1d_4 (Conv1D) (None, 61, 128) 64128
_________________________________________________________________
global_max_pooling1d_4 (Glob (None, 128) 0
_________________________________________________________________
dense_15 (Dense) (None, 128) 16512
_________________________________________________________________
activation_6 (Activation) (None, 128) 0
_________________________________________________________________
dense_16 (Dense) (None, 1) 129
=================================================================
Total params: 2,522,069
Trainable params: 80,769
Non-trainable params: 2,441,300
_________________________________________________________________
NoneTest Score: 0.8156
Test Accuracy: 0.7650**
长短期记忆(LSTM)
LSTM 是一个递归神经网络,擅长在较小(短期)和较大(长期)的上下文中查找单词序列的模式。
**Model: "sequential_10"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
embedding_10 (Embedding) (None, 65, 100) 2441300
_________________________________________________________________
lstm_3 (LSTM) (None, 128) 117248
_________________________________________________________________
dense_20 (Dense) (None, 128) 16512
_________________________________________________________________
activation_8 (Activation) (None, 128) 0
_________________________________________________________________
dense_21 (Dense) (None, 1) 129
=================================================================
Total params: 2,575,189
Trainable params: 133,889
Non-trainable params: 2,441,300
_________________________________________________________________
NoneTest Score: 0.5700
Test Accuracy: 0.7748**
双向 LSTM
这个 LSTM 变体既可以向前也可以向后工作,也可以按逆序计算单词序列。
**Model: "sequential_13"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
embedding_13 (Embedding) (None, 65, 100) 2441300
_________________________________________________________________
bidirectional_2 (Bidirection (None, 256) 234496
_________________________________________________________________
dense_26 (Dense) (None, 128) 32896
_________________________________________________________________
activation_11 (Activation) (None, 128) 0
_________________________________________________________________
dense_27 (Dense) (None, 1) 129
=================================================================
Total params: 2,708,821
Trainable params: 267,521
Non-trainable params: 2,441,300
_________________________________________________________________
NoneTest Score: 2.1170
Test Accuracy: 0.7552**
门控循环单元(GRU)
GRU 是更新的循环神经结构,类似于 LSTM。
**Model: "sequential_16"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
embedding_16 (Embedding) (None, 65, 100) 2441300
_________________________________________________________________
gru_1 (GRU) (None, 128) 87936
_________________________________________________________________
dense_30 (Dense) (None, 128) 16512
_________________________________________________________________
activation_12 (Activation) (None, 128) 0
_________________________________________________________________
dense_31 (Dense) (None, 1) 129
=================================================================
Total params: 2,545,877
Trainable params: 104,577
Non-trainable params: 2,441,300
_________________________________________________________________Test Score: 0.6943
Test Accuracy: 0.2448**
我们发现了什么
不同模型之间的验证准确性差异非常小。虽然我们的前馈网络具有最好的验证准确性,但 LSTM 模型的准确性仅低 2%。
LSTM 预测:不是川普
LSTM 预测:不是川普
LSTM 预测:不是川普
LSTM 预测:川普
在对一些随机推文进行测试后,我们决定在 2017 年 3 月后的所有推文中尝试我们的 LSTM 模型,以了解特朗普和员工推文的比例是否会随着时间的推移而变化。这是我们的发现:

为了便于比较,这是 2017 年 3 月之前的图表:

总结反思
基于我们的结果,我们发现前馈网络表现最好,这可能是由于特朗普推文的简单性质。理想情况下,我们的模型应该考虑大写和标点符号,但是由于嵌入文件的限制,我们不能这样做。如果时间允许,我们可以只在特朗普的推文中训练我们自己的嵌入文件,而不是使用预训练的文件。尽管有这些限制,我们发现我们的结果相当有见地。
所以下次你看到这样的推文,
**[[0.1183652 0.8849327]]
# 88.49% Not Trump**
…也许可以半信半疑。也许实际上美国总统并没有就外交政策发表重大声明。
对我们的数据好奇?想自己玩玩吗?查看我们的 GitHub 回购。
特别感谢 Ulf Aslak 博士的指导 ❤
参考
特朗普的所有 30,000 多条推文都可以立即搜索到
www.trumptwitterarchive.com](http://www.trumptwitterarchive.com/archive) [## 手套. 6B.100d.txt
下载数千个项目的开放数据集+在一个平台上共享项目。探索热门话题,如政府…
www.kaggle.com](https://www.kaggle.com/terenceliu4444/glove6b100dtxt) [## Home - Keras 文档
Keras 是一个高级神经网络 API,用 Python 编写,能够运行在 TensorFlow、CNTK 或…
keras.io](https://keras.io/) [## seaborn:统计数据可视化- seaborn 0.9.0 文档
Seaborn 是一个基于 matplotlib 的 Python 数据可视化库。它为绘图提供了一个高级接口…
seaborn.pydata.org](https://seaborn.pydata.org/index.html)**
那个神奇宝贝是谁?
用 Python 来回答这个古老的问题。
所以我是一个终生的神奇宝贝粉丝,也是一个最近转变的计算机科学书呆子。虽然我的主要兴趣在于数据科学*(为我上一篇关于数据科学伦理的文章***),但我发现自己一直在构思随机编码项目,其中大部分从未实现。
我和我的朋友 Augustine Chang 正在做一个分类项目,在查看我们数据的散点图时,我们看到了一个熟悉的轮廓。

作为一个笑话,我们在演示幻灯片的图表上叠加了神奇宝贝的图像,看起来像是一些有趣的 matplotlib 函数。这个迷你项目就是这样诞生的。

Groudon and Kyogre. If only, matplotlib. If only.
步骤 1:解读(神奇宝贝)图像
我的最终目标是能够让神奇宝贝适合斑点,我首先需要能够找到一种比较图像的方法。我在 Kaggle 上找到了一个数据集,其中方便地包含了所有神奇宝贝的 256 x 256 透明 png 图像,这将是我用来比较我的 blobs 的一组图像。在我写的另一篇关于计算摄影的文章中,我发现图像可以被解释为数组中的数组——张量,如果你愿意,每个像素由一个数组表示,这个数组是该像素的 RGB 值。使用matplotlib.image中的imread方法,我可以很容易地输出给定图像的数组。
最重要的是,matplotlib能够使用imshow将正确维度的数组输出为 2D 图上的图像。

‘paths’ is the routes of the images; where the images are saved
步骤 2:比较数据集中的图像
为了比较图像,我认为最简单的方法是比较两幅图像中每个对应像素的 RGB 值。更具体地说,我采用了两幅图像中每对匹配像素之间的欧几里德距离,并使用它来找到两幅图像中的平均像素距离。
首先,为了避免处理其他图像,我想看看最相似的神奇宝贝是什么,给定一个神奇宝贝。在我的代码中,我希望能够输入神奇宝贝 ID 号并返回其最佳匹配。所以我设置了它:
- 一个函数,将返回原始的和最匹配的图像,并排。
- 返回两幅图像之间的平均像素距离的函数。
- 该函数将返回输入图像和每个神奇宝贝图像之间的距离列表。
- 嵌套了上述三个函数的函数,将输出预期的结果。
以下是目前的一些结果:

Charmander (ID: 4) is most similar to Charmeleon!

Voltorb (ID: 100) is most similar to Electrode!
相当不错!因为我使用的度量是平均像素距离,并且因为图像有透明的背景,所以神奇宝贝的颜色和形状都被考虑在内。
步骤 3:使用任何输入图像
在这里,我所要做的就是对我现有的函数做一些调整,这样它们就可以接受任何图像。一个限制是,我只能使用与神奇宝贝数据集中的图像具有相同维度的图像。因此,我首先在其他 256 x 256 的图像上测试了我的更新功能。
 **
**
酷!但是如果图像不是 256 x 256 呢?Python 的 Pillow 包用名副其实的resizeimage函数很容易地为我们做到了这一点,我写了一个函数来接受图像的文件名,并将其调整到我需要的尺寸。
第四步:把所有东西放在一起
这里是我的函数使用的所有代码,bestfitpokemon()!

The Entire Code!
一个警告:我发现 JPEG 文件不起作用,因为神奇宝贝的 PNG 数据集意味着每个像素都有一个额外的“alpha”值,而 JPEG 文件没有。当查找 3D 和 4D 数组之间的欧几里德距离时,该函数会中断。
我把我们最初的散点图和一些劣质的 photoshop 作品,只提取红色和蓝色的斑点到透明的 PNG 图像,只是为了看看最适合的神奇宝贝会是什么。
 **
**
Best-Fit Pokémon
 **
**
总结一下…
对我来说,这里有一些明显的后续步骤。我可以裁剪和重新缩放,或者找到其他方法来处理空白,这样颜色的权重会更高。我还可以通过输入每只神奇宝贝的多张图片,把它变成一个分类模型。
所以我的博客没有变成 Groudon 或盖欧卡。检查这些结果,似乎返回的神奇宝贝的形状与斑点形状非常相似!所以根据我的模型,Psyduck 和 Marowak 是最适合我的 blobs 的神奇宝贝。
为什么 IQR 异常值检测法中的“1.5”?

Photo by Nick Fewings on Unsplash
如果你不能向一个六岁的孩子解释,你自己也不会理解。
世界仍在等待下一个爱因斯坦,或者也许再也不会有另一个世纪人物了。但我愿意相信:在宇宙中,在上述引文的变体中…
最好的学习方法是教书。
这个帖子的想法来自于我曾经帮助我的一个大三学生完成异常检测的任务。这不是一个非常复杂的问题,只是 IQR 方法在数据集上离群点检测的一个应用。当他问我的时候,这个教程发生了令人兴奋的转变:
“为什么是 IQR 的 1.5 倍?为什么不是 1 或 2 或任何其他数字?”
现在这个问题对那些不熟悉异常值检测的 IQR 方法(解释如下)的人来说不起任何作用,但对那些知道这个方法有多简单的人来说,我希望上面的问题能让你思考一下。毕竟,好的数据科学家不就是这么做的吗?质疑一切,不要相信任何东西。
从最普遍的意义上来说,异常值是一个与其他观察值明显不同的数据点。现在,它的含义可以根据正在研究的统计模型来解释,但为了简单起见,并且不要偏离这篇文章的主要议程太远,我们将考虑一阶统计量以及非常简单的数据集,不失一般性。
异常值检测的 IQR 方法
为了便于解释 IQR 方法,让我们从一个方框图开始。

A box plot from source
箱线图或多或少地告诉我们数据的分布情况。它给出了数据实际上分布了多少,它的范围是什么,以及它的偏斜度。您可能已经在图中注意到,箱线图使我们能够从中推断有序数据,也就是说,它告诉我们按升序排列的数据的各种指标。
在上图中,
- 最小值是数据集中的最小值,
- 并且最大值是数据集中的最大值。
所以两者的区别告诉我们数据集的范围。
- 中位数是数据的中位数(或中心点),也称为第二个四分位数(由数据是有序的这一事实产生)。
- Q1 是数据的第一个四分位数,也就是说有 25%的数据位于最小值和 Q1 之间。
- Q3 是数据的第三个四分位数,也就是说 75%的数据位于最小值和 Q3 之间。
Q3 与 Q1 之差称为四分位距或 IQR 。
IQR = Q3 - Q1
为了使用这种方法检测异常值,我们定义了一个新的范围,让我们称之为决策范围,并且位于该范围之外的任何数据点都被认为是异常值,并且被相应地处理。范围如下所示:
Lower Bound: **(Q1 - 1.5 * IQR)**Upper Bound: **(Q3 + 1.5 * IQR)**
任何小于下限或大于上限的数据点都被视为异常值。
但问题是:为什么只有 IQR 的 1.5 倍?为什么不是其他数字?
嗯,你可能已经猜到了,数字(这里是 1.5,以下是标度)清楚地控制了范围的灵敏度,因此决定了规则。较大的标度会使离群值被认为是数据点,而较小的标度会使一些数据点被认为是离群值。我们很确定,这些情况都不理想。
但这是一种解释原因的抽象方式,它非常有效,但却很幼稚。那么,我们应该把头转向什么呢?
*数学!*当然!(你预见到了,对吗?😐)
从现在开始事情会变得有点“数学化”。但我会尽量减少。
如果我告诉你这个数字,或者说标度,取决于数据遵循的分布,你可能会感到惊讶。
例如,假设我们的数据遵循我们所钟爱的高斯分布。
高斯分布
你们一定都见过高斯分布是什么样子的,对吧?如果没有,在这里(虽然我对你很怀疑👊).

Gaussian Distribution with steps of standard deviation from source
从该图中可以推断出某些观察结果:
- 整个数据的大约 68.26%位于平均值(μ)的一个标准偏差(<【σ)内,考虑到两边,图中的粉红色区域。
- 整个数据的大约 95.44%位于平均值(μ)的两个标准偏差( 2σ )内,考虑到两边,图中的粉红色+蓝色区域。
- 整个数据的大约 99.72%位于均值(μ)的三个标准差( < 3σ )内,考虑到两边,图中的粉色+蓝色+绿色区域。
- 整个数据的其余 0.28%位于均值(μ)的三个标准差( > 3σ )之外,考虑到两边,图中的小红区域。而这部分数据被认为是异常值。
- 第一个四分位数和第三个四分位数 Q1 和 Q3 分别位于均值的 -0.675σ 和 +0.675σ 。
我本可以向您展示这些推论背后的计算,但这超出了本文的范围。如果你愿意,你可以在cs.uni.edu/~campbell/stat/normfact.html查看这些
让我们用σ来计算 IQR 决策范围
取刻度 = 1:
**Lower Bound:**= Q1 - 1 * IQR
= Q1 - 1 * (Q3 - Q1)
= -0.675σ - 1 * (0.675 - [-0.675])σ
= -0.675σ - 1 * 1.35σ
= **-2.025σ****Upper Bound:**= Q3 + 1 * IQR
= Q3 + 1 * (Q3 - Q1)
= 0.675σ + 1 * (0.675 - [-0.675])σ
= 0.675σ + 1 * 1.35σ
= **2.025σ**
因此,当标度被取为 1 时,那么根据 IQR 方法,任何位于平均值(μ)的 2.025σ 之外的数据,在任何一侧,都应被认为是异常值。但是我们知道,在μ的两边,数据都是有用的。因此,我们不能采用 scale = 1 ,因为这使得决策范围过于排他,意味着这会导致过多的异常值。换句话说,决策范围变得如此之小(与 3σ 相比),以至于将一些数据点视为异常值,这是不可取的。
取标度= 2:
**Lower Bound:**= Q1 - 2 * IQR
= Q1 - 2 * (Q3 - Q1)
= -0.675σ - 2 * (0.675 - [-0.675])σ
= -0.675σ - 2 * 1.35σ
= **-3.375σ****Upper Bound:**= Q3 + 2 * IQR
= Q3 + 2 * (Q3 - Q1)
= 0.675σ + 2 * (0.675 - [-0.675])σ
= 0.675σ + 2 * 1.35σ
= **3.375σ**
因此,当标度取为 2 时,根据 IQR 方法,任何位于平均值(μ)的 3.375σ 之外的数据,在任何一侧都应被视为异常值。但正如我们所知,直到 3σ ,在μ的两边,数据都是有用的。因此,我们不能采用 scale = 2 ,因为这使得决策范围过于宽泛,意味着这导致的异常值太少。换句话说,决策范围变得如此之大(与 3σ 相比),以至于它将一些异常值视为数据点,这也是不可取的。
取标度= 1.5:
**Lower Bound:**= Q1 - 1.5 * IQR
= Q1 - 1.5 * (Q3 - Q1)
= -0.675σ - 1.5 * (0.675 - [-0.675])σ
= -0.675σ - 1.5 * 1.35σ
= **-2.7σ****Upper Bound:**= Q3 + 1.5 * IQR
= Q3 + 1.5 * (Q3 - Q1)
= 0.675σ + 1.5 * (0.675 - [-0.675])σ
= 0.675σ + 1.5 * 1.35σ
= **2.7σ**
当标度取 1.5 时,根据 IQR 方法,任何位于平均值(μ)的 2.7σ 之外的数据,在任何一侧都应被视为异常值。而这个决策范围是最接近高斯分布告诉我们的,即 3σ 。换句话说,这使得决策规则最接近高斯分布对于异常值检测的考虑,这正是我们想要的。
旁注
为了精确地得到 3σ ,我们需要取标度= 1.7,但是 1.5 比 1.7 更“对称”,我们总是更倾向于对称,不是吗!?
此外,异常值检测的 IQR 方法不是唯一的,也绝对不是最佳的异常值检测方法,因此,一点权衡是清晰可辨的,也是可以接受的。
看,这一切用数学展现得多么美丽而优雅。我只是喜欢事物是如何变得清晰,并在通过数学感知时明显成形的。这也是为什么数学是我们这个世界的语言的众多原因之一(尽管对宇宙不太确定😐).
所以,我希望,现在你们知道为什么我们把它定为 1.5,IQR。但是这个标度取决于数据遵循的分布。假设我的数据似乎遵循指数分布,那么这个标度就会改变。
但是,每一个因数学而产生的复杂问题都被数学本身解决了。
听说过中心极限定理吗?没错。同一个定理为什么给了我们假设服从高斯分布的自由。但我想我还是改天再说吧。在那之前,保持好奇!
希望这篇文章对你有用。谢谢!
一路平安!
为什么没有非线性的神经网络只是一条美化了的线——3D 可视化
在本系列的第一部分中,我们创建了一个简单的单神经元神经网络来区分苹果和橙子。如果你是直接到达这里的,你可能想先检查一下(下面的链接)。如果你已经可以用 ReLU 很好地在 3D 中可视化神经元的输出,请继续。
[## 2D 人工神经网络中的神经元如何在三维可视化中弯曲空间
这是为那些想直观了解人工神经网络中神经元内部工作的人准备的。你只需要一个…
medium.com](https://medium.com/@avinash_dubey/how-a-neuron-in-a-2d-artificial-neural-network-bends-space-in-3d-visualization-d234e8a8374e)
为了继续我们的旅程,我们将为分类问题添加另一种水果—香蕉。我认为可以很有把握地说,香蕉离红色还很远,但会很甜(至少在成熟时)。

2D graph for fruits on a plane (x-axis: redness, y-axis: sweetness)
因此,如果我们取几个香蕉样本(熟的和生的都用黄色的球表示)并把它们放在 X-Y 轴水果盘上,我们会得到一个看起来像左边的图。
此外,你们中的大多数人会敏锐地观察到一条新的绿线的存在,这条绿线将香蕉与橙子区分开来。
从线条到神经元
从上一篇文章中,我们已经知道了一条线的神经元等效方程。
粉线: w1 * x + w2 * y + b1 = 0
绿线:w3 * x+w4 * y+B2 = 0

Two 2D neurons each with two inputs and one output
通过在这些方程周围画一些圈和箭头,我们得到了两个 2D 神经元。粉红色和绿色的都接收 2 个输入并产生一个输出。
但是你喜欢 3D…
…我也是

因此,正如我们在之前的帖子中所做的那样,我将使用 3D 神经网络的实际输出来替换这些线条。没有任何激活的 3D 神经元的输出只是一个平面,因为我们有 2 个神经元,所以我们有 2 个平面。
将飞机的输出放在一起
现在,你可能会想(就像我当年那样),把两个神经元的输出放在一起应该能让我们很好地分离我们的 X-Y 水果拼盘。但是,细节决定成败。
新输出 z =粉色平面+绿色平面
或 z = w1 * x+w2 * y+B1+w3 * x+w4 * y+B2
或 z =(w1+w3) x+(w2+w4) y+B1+B2**
或 z = w5 * x + w6 * y + b3

Adding multiple planes together just results in a new one
这是另一个“橙色”平面的方程式。它甚至没有按照我们预期的方式对水果进行分类(正如你在左边看到的)。
事实上,无数隐藏层中的大量神经元加在一起,只能给我们一个 2D 平面。这同样适用于 n 个输入,也就是说,你将有第二个超平面。
添加非线性的神奇公式
现在,让我们加入非线性的神奇公式,重新激活神经元的输出。对于门外汉来说,它只是用零代替了所有的负值。所以,g(z) = max{0,z}

Non-linear planes added together are excellent classifiers
现在,神经网络的行为完全符合我们的预期——非常聪明。这个程序能够区分橙子、苹果和香蕉,但是我们可以很容易地创建一个程序来挑选任何其他水果,或者更好的是,分别挑选所有水果。
如果你仍然不相信,下面是不同角度的相同观点。

Non-linear planes added together are excellent classifiers — different perspective
如果您希望进一步研究图表,请随时访问我的 geogebra 应用程序,网址为https://www.geogebra.org/3d/ege3egjh
大多数对象应该非常简单,但是应用程序不支持某些激活功能,比如 relu。所以,我不得不采用一些简单的变通方法。
供思考,g(z) = max{0,z}与(z+ abs(z)) / 2 相同
其他激活的非线性
我确信,你们中的一些人会是一些其他激活的泄漏、双极或软版本的粉丝。它们都产生不同种类的输出,各有利弊,但都是非线性的。可以说,非线性是任何神经网络的生命线,没有它,它只是一条美化了的线。
为什么人工智能是不平衡的工业全球格局中的全球均衡器

如果你相信机器人和人工智能是人类所有邪恶的原因,因为你在电影中见过它(并且你相信好莱坞=现实),这篇文章不适合你。
如果你是一个理性的人,那么继续阅读。
2000 年代,数千万美国人和欧洲人失去了制造业工作。我出生并成长在这样一个以制造业为主的城市,意大利蒙法尔科内,这座位于地中海最北端的城市以其造船厂而闻名,建造了一些世界上最大最豪华的游轮。
有思想的人类,比如我认识的那些正在造船的人,很久以来就知道机器人和人工智能不是失业的罪魁祸首——人工智能甚至没有达到重要的质量和规模。

亚洲和南美的低工资国家应该受到谴责,而不是人工智能,也不是机器人。
2015 年蒙法尔科内,取代 45 岁的保罗·萨托里工作的不是机器人。是另一个国家的《闪电侠与白骨》里的某个人。
甚至一些学者(再说一次,我也是,艾教授……)终于醒悟过来,得出了其他人类的相同结论。
多年来,自动化的作用越来越大,这被认为是制造业就业岗位流失的罪魁祸首,但在过去几年里,一个更理性、显然更符合逻辑的观点出现了。
例如,大卫·奥特(麻省理工学院)有一个非常不同的观点:在美国,我们大大高估了制造业生产率的增长。这意味着自动化并没有真正发挥主要作用,如果它是失业的罪魁祸首,它应该发挥主要作用,将生产率提高到最终解雇工人的水平。
事情不是这样的。那是什么原因呢?
嗯,奥托尔声称,更简单,更符合逻辑的是,将中国引入全球贸易体系是失业的根本原因。我们还可以加上其他效仿的国家,但 Autor 基本上证实了工人们一直以来都知道的事情:他们的工作被亚洲和拉丁美洲的表亲抢走了,而不是被人工智能机器人抢走了。
从这里去哪里?AI 作为均衡器。
既然我们知道了显而易见的事情,那么我们对于自动化、人工智能和机器人技术的立场应该是什么呢?
我的主张很简单,我希望人们会发现它和上面的论点一样合乎逻辑。
人工智能将为美国和欧盟境况不佳的制造业和工业部门注入所需的“肾上腺素”。
美国和欧盟的制造业面临竞争,并输给了低劳动力成本的国家。人工智能和相关技术,如机器人技术,以及它们的结合,是全球均衡器。
我这么说是什么意思?虽然劳动力成本差异很大,但软件成本——如人工智能——是一样的。
通过优化单个人类工人的工作,美国/欧盟与世界其他地区之间的生产成本差异将缩小,因为人工智能软件将提高工人的生产率,无论他们在哪里。
此外,如果趋势继续,疯子不掌权(你永远不知道),美国和欧盟的推动和当前在人工智能方面的领导地位可能会使这些地区首先受益于人工智能引入带来的生产力提高,重新平衡不平衡的全球情景。

如果从表面上看,以及理解人工智能不会取代人类,而是增强并让美国制造商重新参与竞争,上述推理应该被任何人接受,无论是民主党人还是共和党人,无论是美国人还是欧洲人。
好莱坞,想拍一部关于那个的电影,还是太真实了?
为什么人工智能是个谎言&每个人都知道

Photo by Ben White on Unsplash
是时候失去一些老朋友,结交一些新朋友了!
首先,花点时间提炼和定义什么是智慧。好的。有多少人同意这个定义?可能存在巨大的分歧。在我所属的“学术”团体中,很多人不喜欢这个团体,我们称之为“偏见”。很简单,如果某样东西不能被“普遍地”测量和理解,相对于你在它的“理论”中存在的任何社会宇宙。
好的。什么是“人造”?这个很简单。所以,我们至少知道人工智能的一部分是普遍真实的,它不是真实的,我的意思是…人工的。赞。
我们被一些我们无法普遍定义的不真实的东西炒作。算是吧。
无论你怎么看,你都是聪明的
我们的大脑消耗模式,实际上,他们消耗数学,第一天。第一天在今天也是有争议的,可悲的是,少数几个对婴儿的“第一天”有所研究的团体,因为许多文化原因很早就被压扁了,学术界的“大企业”知道你不能在当时的文化敏感话题上卖得很好。然而,我们学到的是,我们可以有效地翻译非常年轻的模式。我们在类似时期以某种形式进行的“研究”证明了“古典音乐让你的宝宝更聪明”。算是吧。从上下文来说。
不清楚的是它与音乐关系不大,更多的是模式的一致性。我们用这些模式来触发我们今天的反应。如果你非常喜欢音乐,有艺术天赋,或者以任何方式用音乐来引发思考,你很有可能在很小的时候就接触到非常特殊的音乐模式。从很多方面来说,这都是一个“AI”的话题。讲的是“学”。
婴儿时期的大脑,无论是人工的还是有机的,都会相对于正在被消化的数据模式而生长。你必须有训练这些大脑的东西,但你也必须有某种轨迹或你希望训练去哪里的输出。这里有很多小细节,我可以留到下一篇文章再讲,但有相当多的美丽和可怕的数学,这一切可能会让事情变得奇怪。可以说,我们种植的所有东西在很多方面都是我们自身的抽象。你可以称之为世代诅咒、遗产、血统、社会学习、神经网络,选择你的文化偏见。数学不在乎。
我们都是独一无二的可预测的
你是否曾经看够了某种类型的节目,在那里你差不多知道将要发生的一切?同样的音乐,同样的音调,同样的角色,同样的故事情节,但是有点曲折?这部剧并不“真实”,但创作这部剧的人是真实的。间接来说,每个人都是一个观察人,我们都适应我们接触到的模式,即使我们不能总是这样表达。
现在,同样的“逻辑”或模式存在于观看 CSI 直到它不再有趣,也存在于企业。我们往往会忘记,这些大公司只是庞大的政治权力机构,它们赚钱并为自己的社会服务。就像我们自己的政府和他们所服务的人民一样,它们也是可以预测的。就像我们自己的一些政治家一样,他们似乎并不总是明白或者理解为什么人们会把他们视为“恶魔”。
事实是,我讨厌这么说,因为我更像“消费者”,而不是“企业家、开发人员、工程师、人工智能、令人毛骨悚然的数据怪人”,但“邪恶”这个话题是相对于对其采取行动的人而言的。我们也以这种方式在电影中看到一些最令人惊讶的反派角色,在那里我们理解得如此之多,邪恶变得更加人性化,在故事的某个点上一切都变了。乔治·卢卡斯实际上对人性的模式有很强的把握,但我认为当他开始谈论原力科学时,他有点失去了这种联系。哇,乔治,在我们不太真实的科幻电影中,我们不需要任何那样的现实。
机器的崛起
事实上,我们一直在制造越来越多的机器来抵消体力或脑力的使用,以使我们的生活更轻松。即使迁移到计算器和计算机,也不是有人不能做这些事情,而是一个人会花费太多时间,或者让自己的大脑以非常混乱的方式接受训练,或者甚至需要更多时间来适当地分解工作,让其他人以富有成效的方式帮助他们。这就是“怪人”所做的,这些怪人最终会改变世界,或者至少成为你的老板。
计算器所做的,实际上是机器学习在数据科学中所做的,这只是一个不同的抽象和业务用例。这是一种带有更多政治、更多直觉的数学,事物发展如此之快,以至于你甚至不知道数据科学是否在做它应该做的事情。也就是说,他们已经尽力了。这里的主题是,当我们称之为“人工智能”时,我们大多数人的意思是“机器驱动的计算”,和/或在数字环境中可以做出决策的位置。
在数据科学领域,我们正在构建“数据科学平台”,在人工智能领域,我们正在构建“人工智能平台”。在我的行业中,我们正在全力以赴的“游戏行业”说人工智能永远无法取代创造力!天哪,当他们意识到公平竞争有多近时,这将对我的行业造成沉重打击。Nvidia 正在接近确保这一点。和许多事情一样,他们从不同的角度,用同样的痛苦,解决着同样的问题。
事实是,如果你做决定,你可以访问数据,你理解各种实践的模式,你可以被人工智能赋予权力,或者不可避免地被它取代。它始于工厂,发生在物流(人和货物)中,“创造力”和“商业直觉”是下一个需要注意的话题。即使你试着忽略它,它现在已经在路上了。
它就在你的鼻子底下
今天,人工智能是一个主要由“计算机科学”拥有的话题,正如工程师喜欢做的那样,从数据库到人工智能,我们消费所有的东西。如果你给我们一点灵活性,我们更符合物理学家而不是实际开发者。我们都没办法。我们几乎从娘胎里就被设计成这样。但是我们中的许多人因为某种原因变得冷酷古怪,当杰出的计算机科学家开始成为哲学家时,我们变得有点太接近疯狂了。应该有一些关注,我也在走这条线(发送帮助!).
最近,我和一位在人工智能领域才华横溢、备受尊敬的头脑进行了一次交流,他在人工智能领域领导着一家价值数百万美元的公司。如果你正在读这篇文章,可能不是你,我和你们很多人谈过,你已经知道我是个话匣子。或者是你和我在努力挽回我们的关系(❤大学)。但是我问他们如何处理他们的数据架构和数据库,他们拒绝了,好像我是个疯子。平心而论,这是一个相对真实的说法。不同的文章。但我也很清楚,因为我不展示我的“学术背景”,我的对话将受制于个人观点的偏见。
这个主题之所以重要,是因为训练人工智能是关于数据消耗的“频率”和“上下文”,如使用什么信息来训练“人工智能”(或人)产生输出。不可避免的是,如果你带着自己的偏见和依赖“博士”,你会忽略你正在做的事情的背景和几十年前做的研究,几乎是字面上的意思,学术界以前也做过同样的事情。事实是,今天在许多方面实际的“人工智能”是很可能的,在许多方面,它是在 80 年代的第一次繁荣时期完成的,我们只是忘记了。学术界通过忘记旧的研究并重新包装来赚大钱。
你吃什么就是什么
如果你不能定义智能,而你有自己的观点和方法来使用机器和上下文数据构建人工智能,那么你的输出,你创造的东西,将不可避免地只是你的延伸。就像你的艺术是你的延伸,或者你的商业或文化也是一样。因此,如果你致力于训练大量的模拟数据,而忽略大脑如何工作的基础话题,这是我们几十年前就确定的,你最终会做出和你一样怪异的东西。
我们不能通过把所有的东西都塞进去来训练人,而不在真正理解人的过程中存在一些分歧。因为我们的大脑实际上是数学、模式消费机器,受制于有限的能力(认知负荷),当涉及到我们的机器时,我们将创造我们设定的东西。但这正是为什么今天的人工智能不是你所看到的人工智能的确切话题。很有可能,一个人工智能团队越“独角兽”,它做人工智能的可能性就越小。具有逻辑讽刺意味的是,独角兽并不真实。
今天的人工智能平台专注于“集中数据”或“自动化机器”,它们都将自称为人工智能或数据科学平台。他们获得的资金数额与他们认识的人、他们取得的成功以及一个团体在出售幻想时的哲学程度有关。问题是,你不能以这种方式扩展,因为要让人工智能平台实际工作,现有的组织需要愿意释放对几乎所有数据的控制。如果你这样做,这是对信任和安全的破坏,人们将失去工作,这将使现有的报告结构变得一团糟。
不信任人工智能是件好事,算是吧
今天,我们有许多才华横溢的人在探索各种主题的人工智能。叙事,商业,语言,机器人,物流。如果一个有机大脑可以确定一种模式,而人工智能这个词让他们过于兴奋,他们会因此得到所有的钱。可悲的事实是,它的特点更可能是有人目前不信任人工智能,或不想了解它,这是最适合使用它。
发生这种情况是因为他们有足够的经验和接触,他们自己的头脑受过强大的“直觉”训练。从“认知”角度来说,他们自己的大脑已经消耗了足够多的历史数据,在当前市场中看到了足够多的模式(也不喜欢社交),他们的大脑在许多方面都像机器一样有效,他们只是用创造力处理自己的过载,这让一些人更难工作。这表现在抑郁、焦虑、饮酒,或者个人为了得到认可或联系而不得不弥补的任何输出。
这些人没有意识到的是,人工智能的思考方式实际上更接近他们的思考方式。如果那些头脑可以找到理解人工智能的方法,如果一个计算机科学家可以绕过他们自己的“计算”或“人工智能”理论,一些真正令人惊讶的事情将会发生。我们在文化上还没有达到这一步,但应该很快就会实现。当谈到创造力、商业或学术研究时,我们对分离有很大的争议。我们实际上都有相似的目标,只是我们真的不擅长用各自的语言来表达。
AI 代表所有的东西
人工智能在实践中实际上很简单,但我们今天采取的方法是由于“社会傲慢”。很难被挑战,交流也很敏感。在实践中,在这个帖子上链接参考文献、文章和数学会引发一系列的辩论和对话,以反驳几十年来重新创造和孤立的理论。或者告诉某个刚刚以 10 亿美元的估值筹集了资金的人,他们并不卑鄙,他们只是用不同的语言重新包装了相同的“机器”,并大声说出它是如何不起作用的,他们如何出售它也不是结交朋友的最佳方式。
但问题是。如果你挖得足够深,绕过你对使用什么语言、什么平台、如何训练数据、什么是数据科学等等的偏见,这是一件相当容易弄清楚的事情。真正困难的是,要真正从头开始建立一家人工智能公司,需要真正的“文化合作”愿望。这也是为什么我强烈认为今天的大公司,独角兽,上市公司,投资集团等不太可能成为破解人工智能的公司,至少不会以他们销售人工智能的方式。
主要是因为我们几年前就解决了这个问题,“创新”的本质就是当我们采用一些旧的想法,并想出如何绕过文化障碍来创造一些新的东西,而这些东西实际上比我们意识到的要古老。当从事神经网络工作的人兴奋地意识到它就像大脑,然后发表一篇我知道十年前看过的论文时,我仍然会笑。或者,当我们看到一个领域中的算法存在于另一个领域中时,有人称之为“机器学习”,并且有许多击掌者忘记了首先做这件事的书呆子。
有趣的事实是,学术界比今天承认的更“兄弟文化”。你心目中的书呆子可能偏离了轨道。谢谢,流行文化!
天网大战贾维斯
我认为我们没有给予人们足够的信任,我们解决问题和让社会控制事情的能力在数学上是不可避免的。无论政府监管有多严,产品有多不平衡,或者思想有多有启发性,社会智慧总是占上风。有时“坏”事情的发生会让更好的事情发生,失败的力量也会改变。
我现在可以告诉你的是,在接触了许多“人工智能”、“数据科学”和“数据”公司之后,他们自己的领导目标将不可避免地导致一些反映他们是谁以及他们周围是谁的东西。如果你有一个推销炒作的首席执行官,投资者为炒作提供资金,或者一个对情绪做出反应的公共市场,他们将保持自己动机的平衡,这将系统性地影响他们下面的每个人。
事实是,为了理解人工智能,你需要从事实上、数学上、科学上和文化上理解人。如果你今天忙于控制人工智能,你很可能不会为明天创造人工智能。因为最终,社会需要贾维斯,即使他们不知道,他们的行动将系统地确保天网不会发生。如果你是一个害怕世界末日的聪明人,那么你对你所服务的人不够了解。你应该多陪陪他们。
除非我们已经在母体里了。对黑客好点。
为什么人工智能必须是道德的——以及我们如何做到这一点

当人工智能决定谁是值得的,谁是对的,谁是罪犯时,你只能希望它做出正确的决定。
现在是 2021 年。外面正下着瓢泼大雨。你在喝下午茶,同时在笔记本电脑上处理下一个项目。一个电话打断了你的工作流程。我是《微妙》的丹妮尔。上周五你去参加了一个令你兴奋的工作面试。满怀期待,你接了电话。丹妮尔说,她不得不遗憾地告诉你,他们已经和其他申请人一起走了——这是你没有得到这份工作的一种委婉说法。“为什么?”,你问,希望至少能得到建设性的反馈,让你在下一次面试中做得更好。“我们的系统确定你不是这个职位的合适人选”,Danielle 解释道。“为什么不呢?”,你问。“我真的不知道”,丹妮尔回答。微妙不太清楚他们的人工智能系统如何决定哪些候选人被认为是职位的好选择。他们的人工智能分析简历和测试,比较经验,在搜索引擎上对候选人进行彻底的自动搜索——简而言之,它检查了数十万个数据点。微妙对人工智能看什么有一个粗略的想法,但不能说人工智能更重视什么,或者它如何决定哪种体验比任何其他体验更好。你感谢丹妮尔抽出时间,然后挂断电话。你的思维开始加速——为什么他们的人工智能认为你不合适?你停顿一下。当然了。这不是什么新鲜事。你生命中的每一天都会经历这种情况。是因为你的种族。又是一年,又是一种创新的辨别方式,你心里想。你又喝了一口茶,把注意力放回到你的笔记本电脑上。
**现在是 2023 年。**你刚刚下班回家。外面很冷,今年冬天来得很早。你收到了一些邮件,大部分是广告,但有一个信封很突出。是亚马逊 Go 的。你打开它,发现里面有一张金额适中的发票。奇怪的是,你心里想,你什么也没买,却整整齐齐地列了十五样东西。没错,你在 Amazendor 有一个帐户,但是你已经有半年多没去过他们的 Go 商店了。Amazendor 的 Go 连锁商店使用面部识别——顾客只需走进去,挑选他们想买的任何东西,出去时他们只需看一眼相机,他们的钱就会自动从他们的银行账户中取出。或者,如果用户愿意,他们可以通过发票支付。相机一定是把别人误认为你了。烦人,但这只是一笔不多的钱,你不想浪费时间争论,所以你付了帐,继续你的夜晚。
现在是 2024 年。你一大早醒来,听到一声砰砰的敲门声。“是警察,开门!”,一个声音从另一边喊道。你发现自己进入的困倦状态是短暂的,因为你很快进入了恐惧和不确定的状态。你或你认识的人发生了什么事吗?或者你的一个邻居出了事,警察想知道你是否看到了什么?嗯,当你走到门口打开门时,你不必考虑太久。三个警察进来了。“乔纳森?”。你点头。你被捕了。为什么?一个人工智能辅助安全系统看到你偷了一辆车,在实际看到你的脸后,警察同意你与安全摄像头的镜头相匹配。人工智能说有 93%的把握是你。你被带到警察局。你试图通过解释你不在那里来证明你的清白,但一个人工智能测谎仪认为你在撒谎。幸运的是,你能够证明在抢劫发生时你在其他地方,使用你的谷歌地图历史,以及一张借记卡购买,发生在离盗窃现场太远的地方,以至于你无法偷到车。你可以回家了。那天晚上你睡不着。你想知道如果你无法证明自己的清白会发生什么。

Photo by John Noonan.
这就是为什么我们需要有道德的人工智能。
以上短篇故事中描述的所有技术都已经存在。它们在 2019 年的采用率相当有限,但在未来几年将会增加。
错误可以、已经并将继续发生。
- **面部识别。**去年,一个主要的人工智能面部识别工具错误地将 28 名美国国会议员识别为因犯罪而被捕的人,另一个工具同样错误地将一名中国亿万富翁识别为乱穿马路者。虽然面部识别将随着时间的推移而改进,并且通常是一种相当可靠的工具,但它仍然会出错,同样,人类在解释面部识别工具产生的结果时也会出错。
- 偏见。如果训练不当,人工智能会产生强烈的偏见。2018 年,亚马逊放弃了一个人工智能招聘工具,因为它开始偏爱一种性别而不是另一种性别。这种偏差可能发生在任何变量上,并且比你想象的更难避免。例如,不幸的是,避免性别偏见并不像告诉人工智能不要在乎性别那么简单。其原因是不同性别可能以不同的方式写作和说话,而人工智能可以学习更喜欢一种风格。这也适用于除性别之外的许多其他变量,如种族、社会地位、经济财富,或者坦率地说,绝对是任何可以想象的数据变量。由于人工智能是在历史数据上训练的,它也将学习根据我们非常种族主义和性别歧视的人类历史上存在的理想做出决定,这已经给被送进监狱的人带来了问题。
- 过度依赖。人工智能也会犯错。严重的错误。 AI 已经因过度依赖而杀人。当像亚马逊这样的公司积极试图创建一个监视社会,将恐惧作为一种产品出售时,你最好相信我希望人工智能的用户知道,尽管训练有素的人工智能往往比人类更擅长预测,但它也可能犯错误。谢天谢地,佛罗里达朱庇特医院的医生明白这一点,当时 IBM Watson 推荐了可能有致命后果的治疗方法。
人工智能可以错误地识别、错误地分析或曲解任何人和任何事。
不要误会我的意思,我坚信人工智能是一项非常有用的技术,它将带来巨大的好处。它可以使我们的生活方便、快捷、简单。它可以发现疾病的治疗方法,它可以使我们富有创造力,它可以使我们的生活更加有趣。但必须加以规范。
AI 必须有一个可解释的日志。
如果不能解释,就不能相信。AI 必须是透明的。人类必须总是能够知道为什么人工智能会做出特定的决定。
人类必须负责。
我们的未来无疑将由人机协作组成。计算机和智能手机等机器已经大大增强了人类的能力,人工智能只会在这方面有所增加。但是人类必须一直控制人工智能。
必须减轻偏见。
一个人工智能系统总是会偏向某一方,但它可以被训练得不那么偏向某一方。人工智能在做出判断时必须公平。输入给人工智能的数据必须是多样的。
AI 必须治理。
毫无疑问:人类总是要对任何技术做出的任何行为负责。唯一的问题是谁。责任必须明确。
人类不能过度依赖 AI。
一般来说,在做出预测性的、基于数据的决策时,机器比人类更好,人工智能应该成为任何企业战略的一部分。但这并不意味着人们应该过度依赖机器,尤其是在人工智能与人类打交道的时候。

Photo by Laurentiu Robu.
AI 一定是伦理的。
不得不说,AI 在实现得当的情况下是很奇妙的。还必须说,AI 不受监管的时候是很可怕的。
人工智能的开拓者们正致力于建立人工智能伦理——取得了不同程度的成功。一些早期的尝试已经失败,比如谷歌今年早些时候试图建立一个人工智能道德委员会,但仅仅一周之后就被解散了。相反,我认为建立道德人工智能的未来在于合作。例如,欧洲委员会邀请欧洲人讨论伦理人工智能。在我看来,邀请广泛的个人和实体建立道德准则是处理人工智能道德的最佳方法。希望在不久的将来,此类举措将开始以更大的规模出现。
为了确保人工智能变得——并保持——道德,我们必须通过广泛、包容性的讨论实现多元化的道德委员会。
因为很快有一天,AI 会决定你是不是罪犯。
你所能做的就是希望人工智能做出正确的决定。
像脸书和达能这样的全球品牌为什么以及如何投资市场研究

上周,我收到了以下来自脸书的电子邮件:

“你好,乔伊,
脸书正在向在脸书、Instagram 和其他平台上制作在线视频的人寻求坦诚的反馈。请在这里做一个简单的调查来帮助我们…………
谢谢,
脸书研究小组"
这让我想到:如果世界上发展最快的科技巨头之一脸书有一个专门的研究团队,这一定意味着积极的市场研究在全球商业中有真正的一席之地?
但是为什么呢?他们不是已经收集了大量的数据吗(多到让他们陷入麻烦)?还有,难道没有比电子邮件更好的方法来收集数据吗?
但是脸书并不是唯一的例子。谷歌在研究上投入巨资,Hubspot 也是如此。像乐高和麦当劳这样的消费巨头严重依赖市场调查来改进他们的产品和营销策略。
在本帖中,我们将探讨全球公司为什么以及如何继续投资于市场研究,他们采取的不同方法,以及每种方法的利弊。
为什么企业投资市场研究?
对市场的深刻理解现在比以往任何时候都更加重要,原因有二:
- 竞争激烈。你的竞争对手通常只需点击一下鼠标。如果客户对你的产品不满意,他们会毫不犹豫地转向其他产品。站在市场的顶端意味着了解客户的想法。
- 顾客有很高的期望。因为有如此多的选择,客户期望高质量的服务和产品。品牌需要通过更好地了解顾客想要什么来跟上这些期望。
具体来说,传统的市场研究允许企业跟踪:
- 随着时间的推移对其品牌的认知。
- 影响他们产品的趋势和细分市场。
- 他们的广告活动和社交媒体营销的影响。
- 他们客户群体的偏好。
- 与他们每个品牌相关的独特价值。
基本上,品牌可以利用市场研究来指导他们的营销和产品策略——获得新客户,同时与现有客户建立更好的关系。
正如留住客户与获得新客户一样重要,企业需要跟上不断变化的客户期望和购买行为,以保持领先地位。
或者,简单地说避免像百事可乐那样的公关失误:

这有助于解释为什么像脸书这样的公司近年来稳步增加营销支出。
看一看这些数字:

Source: Statista
这笔支出包括对经典市场研究方法的持续投入。
但是当我们使用这个术语时,我们指的是什么呢?
市场研究中的常用方法
当我们谈论传统市场调查方法时,我们谈论的是:
- 焦点小组:聚集在一起讨论现有产品或为新产品的开发或推出提供反馈的人群。
- 调查:向预先确定的一组人提供问题和提示,以获得关于产品和服务的信息和见解。
- 问卷:一系列问题,旨在获取在线或面对面的客户反馈。
我们可以在脸书的用户体验研究方法中看到这些技术在起作用。在脸书,“用户体验研究经理”专注于以下五种类型的研究,以将产品从早期的想法变为准备推出的东西:
- 了解用户和客户需求的基础研究。
- 情境调查关注用户如何参与技术,包括花更多时间与真实用户在一起。
- 描述性研究允许脸书获得反馈,了解用户到底想要一个新功能做什么。
- 参与式设计,给予用户不同的设计元素,并询问用户与产品的理想交互是什么样的。
- 产品研究,脸书观察人们与特定产品的互动,以便在产品发布前做最后的调整。

Source: Techcrunch
现在我们已经讨论了基础知识,让我们来看看阻碍传统市场研究的一些因素。
经典市场研究方法的局限性
公司长期依赖传统研究来帮助识别市场机会,并确定他们的产品如何被看待。
这些可靠的方法有其优势,但也有主要的局限性:
- **顾客需要参与。**如今,每个人的时间都很紧张,填写一份调查或问卷并不是最重要的事情。(例如,我没有回复脸书的电子邮件来参与他们的研究。)
- **调查和问卷侧重于过去的经验。**只要产品有更新或变更,数据就会过时。
- 观察者的偏见会导致研究人员改变结果以反映先入为主的信念。
- 市场调查可能很耗时,尤其是在分析大量数据的时候。这可能会大幅推高研究的价格。不仅如此,过多的调查会让顾客望而却步。
- 真正的代表性可能很难达到。获得足够大的样本量是一个真正的挑战,因为愿意完成问卷或调查的客户可能有太多的时间。
- 最后,这些传统方法没有提供足够的灵活性——通过关注预先确定的问题,这些方法只和提出的问题一样好。
那么,品牌有什么选择来解决这些限制呢?
经典市场研究方法的替代方法
历史上,像可口可乐和百事可乐这样的消费巨头仅仅依靠传统的市场研究,像迪奥和欧莱雅这样的奢侈品牌也是如此。
焦点小组和调查仍然是相关和有用的。然而,品牌正在看到这些方法的局限性。
大多数品牌现在通过采取不同的市场研究方法来解决这些限制;将传统方法与人工智能和其他数据源(如社交媒体)结合起来。
例如,人工智能让问卷根据用户之前回答的内容制定“智能”问题。这避开了所提问题的静态性质,有助于品牌更深入地获取客户反馈。
社会数据研究:一种新的选择
特别是,品牌正在转向社交媒体作为数据来源。
全球有22 亿活跃的脸书用户,每天有 5 亿条推文,每天有 9500 万条 instagram 帖子,社交媒体为品牌提供了可以想象的最大的焦点群体。
这个数字只会越来越大:

Source: Statista
有了社交数据研究,品牌可以利用这一庞大的意见网络,并将其用于营销和产品开发。
达能如何使用社交数据
Linkfluence 的长期客户达能利用社交倾听来推动他们的产品和营销战略。一个很好的例子是他们利用社交倾听来发现西班牙市场的缺口。意识到对无乳糖产品的需求,达能开发并推广了 Activia 无乳糖酸奶。

但是达能不只是利用社交倾听来发现他们的客户想要什么产品;他们还利用数据为产品包装提供灵感。
例如,作为对社交媒体评论的回应,达能为其 A tu gusto 酸奶系列开发了除单杯服务之外的四包选项。
“社交媒体上的反馈有助于我们了解人们在说什么、感觉什么以及对我们的要求,”达能营销 CRM 和数字经理 Isabel María Gonzalez 说。“它赋予我们反应的能力。”
达能利用推特、快照、Insta-stories 和其他在线数据获得即时反馈,而不是等待数月才能从传统研究方法中获得消费者洞察。
社会数据研究如何填补传统市场研究的空白
社交数据研究有几种方法来解决传统市场研究的局限性:
实时洞察
社交倾听工具以避免偏见的方式实时收集品牌信息。通过实时市场研究,品牌可以分析数以千计的产品参考,同时仍能捕捉到个人对话和意想不到的观点。
大规模、高质量的研究
随着数十亿社交媒体用户每天在推特上发布他们的想法和感受,品牌可以大规模地获取客户见解,同时仍然可以提出严格定义的问题。
捕捉更广泛的背景
社会数据研究让你分析大量的在线讨论。但是你也可以将这种分析与对现实世界事件的理解联系起来。
例如,某个品牌可能会在某个事件之后的对话中出现峰值,或者某个名人或公众人物的提及。
正如麦肯锡在 2014 年指出的那样,社交倾听让公司和品牌能够识别社交媒体数据中的有价值的信号:“随着信息在数字经济中轰鸣,很容易错过往往隐藏在噪音中的有价值的‘微弱信号’。这些信号可以帮助公司了解客户的需求,并在竞争对手之前发现即将到来的行业和市场混乱。”
对于寻求对其在线感知进行深入细致评估的品牌和企业而言,社交倾听至关重要。当与更传统的市场研究方法相结合时,社会数据研究为品牌提供了消费者所想和期望的 360 度视角。
考虑多样化的市场研究方法
正如我们所见,市场研究给品牌带来了难以置信的洞察力。从产品到营销策略,品牌需要研究来更好地了解和服务他们的客户。
好消息是,品牌进行市场调查的选择越来越多。
当然,传统的研究方法仍然有一席之地,比如焦点小组、调查和问卷。
但随着社交媒体和人工智能技术的兴起,品牌现在可以实时收集和获取更大规模的消费者洞察。
本文原载于 Linkfluence 博客 。
关于作者
Joei Chan 是全球领先的全球品牌社交媒体情报公司 Linkfluence 的全球内容主管。
为什么以及如何对机器学习进行交叉验证

想获得灵感?快来加入我的 超级行情快讯 。😎
交叉验证是一种测试机器学习模型性能的统计技术。特别是,一个好的交叉验证方法给了我们一个模型在整个数据集中的性能的综合度量。
所有交叉验证方法都遵循相同的基本程序:
(1)将数据集分成两部分:训练和测试
(2)在训练集上训练模型
(3)在测试集上评估模型
(4)可选地,对一组不同的数据点重复步骤 1 至 3
包括步骤 4 的更彻底的交叉验证方法,因为这样的测量对于选择特定分割可能带来的偏差更稳健。选择数据的特定部分产生的偏差称为 选择偏差 。
这种方法将花费更多的时间,因为模型将被多次训练和验证。但它确实提供了更彻底的显著优势,以及有机会潜在地找到挤出最后一点准确性的分裂。
除了选择偏差,交叉验证也有助于我们避免过度拟合。通过将数据集划分为训练集和验证集,我们可以具体地检查我们的模型在训练期间看到的数据上是否表现良好。如果没有交叉验证,我们永远不会知道我们的模型是在全球范围内令人惊叹,还是仅仅在我们的保护性训练中令人惊叹!
说了这么多理论之后,让我们来看看 3 种常见的交叉验证技术。

An illustration of how overfitting works
坚持
维持交叉验证是最简单也是最常见的。我们简单地将数据分成两组:训练和测试。训练和测试数据不能有任何相同的数据点。通常,这种分割将接近 85%的数据用于训练,15%的数据用于测试。下图说明了维持交叉验证的工作方式。

使用非常简单的维持交叉验证的优点是我们只需要训练一个模型。如果它表现得足够好,我们可以继续在任何我们想要的应用程序中使用它。只要您的数据集在分布和“难度”方面相对一致,这就非常合适
当数据集不完全均匀时,会出现维持交叉验证的危险和缺点。在分割我们的数据集时,我们可能会以这样一种方式结束分割,即我们的训练集与测试集非常不同,或更容易,或更难。
因此,我们对维持执行的单一测试不够全面,不足以正确评估我们的模型。我们最终会遇到一些不好的事情,比如过度拟合或者不准确地测量我们的模型预测的真实世界的性能。
如何在 Scikit-Learn 中实现维持交叉验证:sklearn.model_selection.train_test_split
k 倍交叉验证
使用 K-Fold 交叉验证将帮助您克服使用 Holdout 带来的许多缺点。
使用 K-Fold,我们将把我们的数据集随机分成 K 个大小相等的部分。然后我们将训练我们的模型 K 次。对于每次训练运行,我们从我们的 K 部分中选择一个分区作为测试集,并使用其余的进行训练。
例如,如果我们在下面的示例中设置 K = 10,那么我们将训练 10 个模型。每个模型都将在一个独特的训练集上接受训练——蓝色显示的部分。每个模型也将在一个独特的测试装置上进行测试——绿色部分。
为了获得最终的准确性度量,我们对每个模型在各自的测试集上评估的结果进行平均。

K-Fold 交叉验证带来的最大优势是它不容易产生选择偏差,因为训练和测试是在几个不同的部分上进行的。特别是,如果我们增加 K 的值,我们甚至可以更加确定我们模型的稳健性,因为我们已经在如此多的不同子数据集上进行了训练和测试。
这种方法唯一可能的缺点是,当我们通过增加 K 来获得鲁棒性时,我们还必须训练更多的模型——这是一个潜在的冗长且昂贵的过程。
如何在 Scikit-Learn 中实现 K-Fold 交叉验证:sklearn.model_selection.KFold
重复随机子采样
重复随机子抽样也许是交叉验证方法中最稳健的。
类似于 K-Fold,我们为 K 设置一个值,它表示我们将训练我们的模型的次数。然而,在这种情况下,K 将而不是表示大小相等的分区的数量。
相反,在每次训练迭代中,我们随机选择点作为测试集。我们选择的点数将是我们为测试集设置的某个百分比。例如,如果我们选择 15%,那么在每次训练迭代中,我们将在数据集中随机选择 15%的点来进行训练。
其余的程序以与 K-Fold 相同的方式继续。在训练集上进行训练,在其独特的测试集上测试每个模型,最后平均结果以获得最终精度。

这种方法相对于 K-Fold 的明显优势是训练-测试分割的比例不依赖于迭代的次数。如果我们愿意,我们甚至可以在每次迭代中为测试集设置不同的百分比。随机化也可能对选择偏差更具鲁棒性。
这种方法的缺点是,有些点可能永远不会被选入测试子集中,同时,有些点可能会被选择多次。这是随机化的直接结果。然而,使用 K-Fold 可以保证所有点在某个时候都将被测试。
喜欢学习?
在 twitter 上关注我,我会在这里发布所有最新最棒的人工智能、技术和科学!也在 LinkedIn 上和我联系吧!
为什么以及如何在 Python 中使用与熊猫合并

无论您是数据科学家、数据分析师、业务分析师还是数据工程师,都没有关系。
如果你一直在工作中使用 Python—特别是数据预处理/清理——你可能在某些方面使用了 Pandas。
为什么要“合并”?
您可能遇到过多个数据表,这些数据表包含您希望在一个地方看到的各种信息,在本例中是一个数据帧。
这就是 merge 的威力所在,它以一种良好有序的方式高效地将多个数据表组合成一个数据帧,以供进一步分析。
“合并”两个数据集是将两个数据集合并成一个数据集,并根据公共属性或列对齐每个数据集的行的过程。
“合并”和“加入”这两个词在熊猫和其他语言中可以相对互换使用。尽管熊猫有“合并”和“加入”的功能,但本质上它们做的是相似的事情。
也就是说,在本文中,我们将只关注 Pandas 中使用的“合并”功能。
“合并”到底是什么?

看了一下合并函数(熊猫版= 0.24.1)的文档,乍一看好像是外国的,不太容易被读者(至少对我来说)理解。
在从我的一些朋友和网上资源中寻求更多的信息和解释后,我开始理解这个概念——合并实际上可以用一种更简单的方式来解释,并开始欣赏熊猫合并功能的美丽。
为了理解pd.merge,让我们从下面一行简单的代码开始。这行代码的作用是根据两个数据帧的值将两个数据帧——left_df和right_df——合并成一个,两个数据帧中都有相同的column_name。使用how='inner',它将执行内部合并,只合并column_name中匹配的值。
pd.merge(left_df, right_df, on='column_name', how='inner'
由于方法how有不同的参数(默认情况下 Pandas 使用inner,我们将研究不同的参数( left,right,inner,outer )及其用例。
之后,我们将解释方法on,并进一步阐述如果两个数据帧有不同的列名,如何合并它们(提示:将不使用方法on)。
下面的解释主要来自 Shane Lynn 的优秀教程,使用的数据(3 个 CSV 文件)来自 KillBiller 应用程序。
你可以在这里得到数据。
我们开始吧!
快速浏览数据
让我们首先了解一下每个数据帧上的以下解释所使用的数据集。
- 用户使用 —包含用户每月移动使用统计的第一个数据集
- 用户设备 —第二个数据集,包含个人“使用”系统的详细信息,以及日期和设备信息
- android_device —第三个数据集,包含设备和制造商数据,列出了所有 android 设备及其型号代码

user_usage

user_device

android_device
这里需要注意的是:
- 列名
use_id由用户使用和用户设备共享 - 用户设备的
device列和安卓设备数据帧的Model列包含通用代码
1.左侧合并
保留左侧数据框中的每一行。如果右侧数据框中缺少“on”变量的值,则在结果中添加空值/ NaN 值。

LEFT Merge
通过上面的操作, left_merge 与 user_usage 具有相同的大小,因为我们使用方法how的left参数来保留左侧数据帧中的所有行。

LEFT Merge (Top 5 rows)

LEFT Merge (Last 5 rows)
正如所料,列use_id已经被合并在一起。我们还看到,右侧数据帧中的空值被 NaN 替代— 用户设备。
2.右合并
要执行正确的合并,我们只需简单地将how的参数从left更改为right即可重复上面的代码。

RIGHT Merge
通过上面的操作, right_merge 与 user_device 具有相同的大小,因为我们使用方法how的right参数保留了右数据帧中的所有行。

RIGHT Merge (Top 5 rows)

RIGHT Merge (Last 5 rows)
这一次,我们看到左侧数据帧中的空值被 NaN 替代— user_usage 。
3.内部合并
Pandas 默认使用“内部”合并。这仅保留合并数据的左右数据帧中的公共值。
在我们的例子中,只有包含在 user_usage 和 user_device 之间共有的use_id值的行保留在合并数据 inner_merge 中。

INNER Merge
虽然 Pandas 默认使用“内部”合并,但是上面指定的参数inner是显式的。
通过以上操作,合并的数据— inner_merge 与原始的左右数据帧(user _ usage&user _ device)相比具有不同的大小,因为只有公共值被合并。
4.外部合并
最后,我们有“外部”合并。
当行中没有匹配的值时,“外部”合并用 NaN 组合左右数据帧的所有行。

OUTER Merge
注意,方法indicator被设置为True,以指示每一行在合并数据 outer_merge 中的来源。

Specified rows in outer_merge
为了进一步说明“外部”合并是如何工作的,我们特意指定了 outer_merge 的某些行,以了解这些行来自哪里。
对于第行和第 2 行,这些行来自两个数据帧,因为它们具有相同的要合并的use_id值。
对于第 3 行和第 4 行,这些行来自左侧数据帧,因为右侧数据帧没有use_id的公共值。
对于第 5 和第 6 行,这些行来自右侧数据帧,因为左侧数据帧没有use_id的公共值。
💡合并具有不同列名的数据帧
我们已经讨论了如何使用不同的方式合并数据——左合并、右合并、内合并和外合并。
但是方法on只适用于左边和右边数据帧中相同的列名。
因此,我们用left_on和right_on来代替方法on,如下图所示。

LEFT Merge for dataframes with different columns names
在这里,我们将用户设备与安卓设备合并,因为它们分别在列device和Model中包含相同的代码。

LEFT Merge for dataframes with different column names
最后的想法

感谢您的阅读。
合并不同数据表中的数据是我们作为数据专业人员必须完成的最常见的任务之一。
希望这篇分享在某些方面对你有益。
一如既往,如果您有任何问题或意见,请随时在下面留下您的反馈,或者您可以随时通过 LinkedIn 联系我。在那之前,下一篇文章再见!😄
关于作者
阿德蒙德·李 目前是东南亚排名第一的商业银行 API 平台 Staq — 的联合创始人/首席技术官。
想要获得免费的每周数据科学和创业见解吗?
你可以在 LinkedIn 、 Medium 、 Twitter 、脸书上和他联系。
让每个人都能接触到数据科学。Admond 正在通过先进的社交分析和机器学习,利用可操作的见解帮助公司和数字营销机构实现营销投资回报。
www.admondlee.com](https://www.admondlee.com/)
Apache Spark 为什么快,如何让它跑得更快

Apache Spark logo
Spark 做事很快。自 2010 年首次推出以来,这一直是该框架的主要卖点。
为 Map-Reduce 提供基于内存的替代方案极大地推动了大数据生态系统的发展,在过去几年中,这是公司采用大数据系统的主要原因之一。
凭借其广泛的用例、易用性和创纪录的能力,Spark 迅速成为每个人在大数据架构中处理数据的首选框架。
第一部分:火花 ABC
Spark 的关键组件之一是其 SparkSQL 模块,该模块提供了将批量 Spark 作业编写为类似 SQL 的查询的可能性。为此,Spark 在幕后依靠一种复杂的机制来通过执行引擎运行这些查询。这种机制的核心是 Catalyst: Spark 的查询优化器,它通过生成作业的物理执行计划来完成大量繁重的工作。
尽管这一过程的每一步都经过了细致的改进,以优化工作的各个方面。为了让你的 Spark 工作运行得更快,你仍然有很多事情可以做。但是在深入讨论之前,让我们更深入地了解一下 Catalyst 是如何工作的。
首先,让我们从基础开始
Spark 提供了多种方式与其 SparkSQL 接口进行交互,主要的 API 是 DataSet 和 DataFrame。这些高级 API 建立在面向对象的 RDD API 之上。他们保留了它的主要特征,同时增加了一些关键特性,比如模式的使用。(详细对比请参考在 Databricks 博客上的这篇文章)。
要使用的 API 的选择主要取决于您正在使用的语言。DataSet 仅在 Scala / Java 中可用,并且自 Spark 2.0 发布以来取代了这些语言的 DataFrame。每一个都提供一定的额外津贴和优势。好消息是,Spark 使用相同的执行引擎来运行您的计算,因此您可以轻松地从一个 API 切换到另一个 API,而不用担心执行级会发生什么。
这意味着,无论您使用哪种 API,当您提交作业时,它都会经过一个统一的优化过程。
火花如何看待世界
您可以在 Spark 应用程序中执行的操作分为两种类型:
- 转换:当应用于 RDD 时,这些操作返回对通过转换创建的新 RDD 的引用。一些最常用的转换是
filter和map。(这里是可用转换的完整列表) - 动作:当应用于 RDD 时,这些操作返回一个非 RDD 值。一个很好的例子是
count动作,它将一个 RDD 中的元素数返回给 Spark 驱动程序,或者是collect,它将一个 RDD 的内容发送给驱动程序。(请参考此链接了解可应用于 rdd 的完整操作列表)。
数据帧和数据集操作被分为相同的类别,因为这些 API 是基于 RDD 机制构建的。
下一个要区分的是以下两种类型的转换:
- 窄转换:当这些转换应用于 RDD 时,分区之间没有数据移动。该变换应用于 RDD 的每个分区的数据,并生成具有相同分区数量的新 RDD,如下图所示。例如,
filter是一个狭义的转换,因为过滤器被应用于每个分区的数据,并且结果数据代表新创建的 RDD 中的一个分区。

A narrow transformation (Source: Databricks)
- 大范围转换:这些转换需要在分区之间移动数据,也就是所谓的洗牌。数据在网络间移动,新创建的 RDD 的分区基于多个输入分区的数据,如下所示。一个很好的例子就是
sortBy操作,在这个操作中,来自所有输入分区的数据都是基于某个列进行排序的,这个列是一个生成新分区的 RDD 的过程。

A wide transformation (Source: Databricks)
因此,当您向 Spark 提交作业时,您提交的基本上是一组动作和转换,Catalyst 会在生成理想的物理计划之前将它们转化为作业的逻辑计划。
第二部分:火花魔法
现在我们已经知道了 Spark 如何看待我们提交给它的作业,让我们来看看将动作和转换列表转化为作业的物理执行计划的机制。
火花是一个懒惰的魔术师
首先,使用 Spark 时需要记住的一个重要概念是,它依赖于懒惰评估。这意味着当你提交一个作业时,Spark 只会在必要的时候施展魔法——也就是说,当它收到一个动作时(比如当司机要求一些数据或者当它需要将数据存储到 HDFS 中时)。
Spark 不是一收到转换就一个接一个地运行它们,而是将这些转换存储在 DAG(有向无环图)中,并且一收到动作,它就运行整个 DAG 并交付所请求的输出。这使它能够根据作业的 DAG 优化其执行计划,而不是按顺序运行转换。
这一切是如何发生的
Spark 依靠 Catalyst(它的优化器)来执行必要的优化,以生成最有效的执行计划。Catalyst 的核心包括一个通用库,专门用于表示树并应用规则来操作它们。它利用了 Scala 中的函数式编程结构,并提供了特定于关系查询处理的库。
Catalyst 的主要数据类型是由节点对象组成的树,它应用一组规则来优化它。这些优化通过四个不同的阶段来执行,如下图所示:

Catalyst’s optimization phases (source: Databricks)
逻辑/物理计划
一开始可能不太清楚的一个区别是术语“逻辑规划”和“物理规划”的用法。简而言之,逻辑计划由描述需要做什么的树组成,没有暗示如何做,而物理计划准确地描述了树中的每个节点将做什么。
例如,一个逻辑计划简单地表明有一个连接操作需要完成,而物理计划为这个特定的操作确定连接类型(例如 ShuffleHashJoin)。
现在让我们通过这四个步骤,更深入地研究 Catalyst 的逻辑。
第一步:分析
Catalyst 优化管道的起点是一组未解析的属性引用或关系。无论您使用的是 SQL 还是 data frame/Dataset API,SparkSQL 一开始都不知道您的数据类型,甚至不知道您所引用的列是否存在(这就是我们所说的未解析)。如果您提交一个select 查询,SparkSQL 将首先使用 Catalyst 来确定您传递的每个列的类型,以及您使用的列是否实际存在。为此,它主要依靠 Catalyst 的树和规则机制。
它首先为未解决的逻辑计划创建一个树,然后开始对它应用规则,直到它解决了所有的属性引用和关系。在整个过程中,Catalyst 依赖于一个 Catalog 对象来跟踪所有数据源中的表。
第二步:逻辑优化
在这个阶段,Catalyst 得到了一些帮助。随着 2017 年 Spark 2.2 的发布,引入了基于成本的优化器框架。与基于规则的优化相反,基于成本的优化器使用统计数据和基数来寻找最有效的执行计划,而不是简单地应用一组规则。
分析步骤的输出是一个逻辑计划,然后在第二步中经过一系列基于规则和基于成本的优化。Catalyst 将所有优化规则应用于逻辑计划,并与基于成本的优化器合作,将优化的逻辑计划交付给下一步。
第三步:物理规划
就像上一步一样,SparkSQL 使用 Catalyst 和基于成本的优化器进行物理规划。它基于优化的逻辑计划生成多个物理计划,然后利用一组物理规则和统计数据来提供最有效的物理计划。
步骤 4:代码生成
最后,Catalyst 使用 quasi quotes(Scala 提供的一个特殊特性)来生成 Java 字节码,以便在每台机器上运行。Catalyst 通过将作业树转换为抽象语法树(AST)来使用这一特性,然后 Scala 对抽象语法树进行评估,然后编译并运行生成的代码。
综上
Spark SQL 依靠一个复杂的管道来优化它需要执行的作业,它在这个过程的所有步骤中都使用 Catalyst,它的优化器。这种优化机制是 Spark 的天文性能和有效性的主要原因之一。
第三部分:让 Spark 更上一层楼
现在我们已经检查了 Spark 复杂的优化过程,我们很清楚 Spark 依靠精心制作的机制来实现其令人难以置信的速度。但是认为不管你怎么做,火花都会给你带来最佳结果是错误的。
这种假设很容易做出,尤其是在从另一种数据处理工具迁移时。与您一直使用的工具相比,处理时间缩短了 50%,这可能会让您认为 Spark 正在全速运行,并且您无法进一步减少执行时间。问题是,你可以。
Spark SQL 和它的优化器 Catalyst,通过我们上面讨论的过程,可以自己创造奇迹,但是通过一些扭曲和技术,您可以将 Spark 带到下一个级别。因此,让我们来讨论如何从您的角度优化 Spark 作业
总是看一下引擎盖下面
使用 Spark 时要记住的第一件事是,执行时间本身并没有太大的意义。要评估作业的性能,了解它运行时发生了什么很重要。在开发和测试阶段,您需要经常使用explain函数来查看您希望分析的语句生成的物理计划,为了进行深入分析,您可以添加extended标志来查看 Spark SQL 选择的不同计划(从解析的逻辑计划到物理计划)。这是检测潜在问题和不必要阶段的好方法,甚至不需要实际执行作业。
知道何时使用缓存
在处理大型数据集和复杂作业时,缓存非常重要。它允许您保存您计划在后续阶段使用的数据集,以便 Spark 不会从头开始再次创建它们。这种优势有时会将开发人员推向“过度缓存”,使缓存的数据集成为一种负担,降低了您的工作速度,而不是优化它。要决定您需要缓存哪些数据集,您必须准备好整个作业,然后通过测试尝试找出哪些数据集实际上值得缓存,以及在什么情况下您可以取消它们的持久化,以释放缓存时它们在内存中占用的空间。高效地使用缓存可以让 Spark 以 10 倍的速度运行某些计算,这可以显著减少作业的总执行时间。
了解您的集群和数据
充分利用 Spark 的一个关键要素是根据集群对其配置进行微调。在某些情况下,依赖默认配置可能是可行的,但通常情况下,您离获得更令人印象深刻的结果还差一个参数。选择适当的执行器数量、每个执行器的内核数量以及每个执行器的内存大小都是可能极大地影响您的作业性能的因素,因此请不要犹豫执行基准测试,看看某些参数是否可以优化。
最后,要记住的一个重要因素是,您需要知道您正在处理的数据以及从每个操作中可以得到什么。当一个阶段花费的时间太长,即使它处理的数据比其他阶段少,那么您应该检查另一个阶段发生了什么。Spark 在处理繁重的工作和运行代码方面非常出色,但是只有您能够发现与业务相关的问题,这些问题可能与您定义工作的方式有关。
如果您在开发和实现 Spark 作业时应用了所有这些规则,那么您可以期待破纪录的处理工具会给您带来令人瞠目结舌的结果。
这些建议仅仅是掌握 Apache Spark 的第一步。在接下来的文章中,我们将详细讨论它的不同模块,以便更好地理解 Spark 的工作原理。
这篇文章最初发表在 INVIVOO 的科技博客上。
要了解更多数据工程内容,您可以订阅我的双周刊时事通讯 Data Espresso,我将在其中讨论与数据工程和技术相关的各种主题:
数据工程更新和评论伴随您的午后咖啡。点击阅读数据咖啡,由马赫迪…
dataespresso.substack.com](https://dataespresso.substack.com/)
为什么数据工程师与数据科学家同等重要
数据工程师重要吗?

Photo by Proxyclick Visitor Management System on Unsplash
我的读者朋友们,你们好。我希望这篇文章能让你心情愉快,因为我可能会惹恼一些人。在过去的几周里,我写了很多基于教程/指南的文章。我想稍微改变一下。本周我们不会接触任何代码。相反,我们将讨论为什么我们应该对所有的数据工程师表现出一些爱心。

Photo by Krista Mangulsone on Unsplash
我一再提到它。数据是 20 世纪公司的新燃料。如果你不根据现有数据采取行动,你就错过了。数据从业者利用数据解决业务问题,引入新技术,创新新产品。
你认为 Google Home 是如何诞生的?数据
你觉得 Youtube 是怎么知道给你推荐什么视频的?数据
数据,数据,数据。
公司能够通过查看你的网络浏览模式来预测你的年龄、性别、收入范围和许多其他属性,并据此向你推荐产品,而你甚至不会注意到这一点!数据科学家正在相互竞争,看谁的模型更好,能让他们致富。
正如数据科学家喜欢说的:
给我你所有的数据,我会让你变得富有——每一个数据科学家
然而,在所有的幕后,在所有华而不实的模特背后,隐藏着一个真正的英雄。它是一个沉默的守护者,守护着我们部署的模型、自动化系统、数据架构。提供真实燃料进行加工的人。一个完全了解数据的人。确切知道获取什么数据、在哪里、何时、如何以及为什么获取数据的人。我们称他/她为数据工程师。
个人认为数据工程师没有得到足够的认可。如今,一切都与数据科学家有关。

每个公司都需要一个。每个人都想成为其中一员。每个人都是一体的。
为什么我没看到有人吹嘘自己是数据工程师?我的工程师同事在哪里?
好吧,我在这里解释一下为什么数据工程师如此重要。我在这里解释为什么数据工程师应该昂首挺胸。没有他们,甚至没有数据来建模。为了做到这一点,让我们深入了解一下这些职业都做些什么。
数据科学家

欢迎来到 2019 年,
“数据科学家”一词被如此盲目地抛来抛去,以至于没有人真正知道数据科学家具体负责什么任务。根据我的经验,这很大程度上取决于公司的性质。
有些 DS 更面向分析。
DS 被期望在他们工作的行业中拥有某种领域/商业知识。除了提出正确的问题,他们还通过解释他们从分析中发现的可能会或可能不会为该公司带来更高(在此插入指标)的结果,为该公司提供业务解决方案、见解和应采取的步骤。他们做出惊人的可视化来帮助他们向利益相关者解释他们的发现,希望说服他们在业务中采取正确的方向。有一个巨大的分析分支要做,客户,流失率,收入,细分,分配和许多更多的,我不打算进入细节。
一些 DS 为公司建造模型。
越走越深。一些 DS 为某些类型的数据集建立机器学习模型,这些数据集很难进行分析。这些模型需要一定程度的数学和编程。举下面这个例子。

这是一个关于网站上职位发布的数据集。根据给出的数据,网站的利益相关者想知道什么样的招聘广告得到最多的广告回复。
也许是主题更长的广告?更高的薪水?
好福利?
某些工作类别?
DS 能够运行机器学习模型来回答这样的问题。这可以为管理层带来最佳决策,以增加他们优先考虑的任何指标。DS 也能够预测一个新广告的
广告回复。
一些 DS 更加面向技术。
以 Spotify 为例,你注意到他们能够向你推荐歌曲(你甚至没有意识到你喜欢这些歌曲)。另一个例子是 Google Home,它实现了一个语音识别机器人,可以回答你几乎所有的问题。像这样的技术是由机器使用人工神经网络创造的。DS 用大量数据训练这些机器,让它学会做一些事情作为回报。这个过程并不像你想的那么简单。人们需要知道如何根据某种适当的模型训练机器,优化模型,并在应用程序/网站/产品或任何你命名的东西上部署模型。
问题是,DS 并不局限于一种特定的类型。你可以是一个面向技术的 DS,但仍然为公司做分析。同样,这很大程度上取决于公司对你的要求。
对于数据科学家的官方定义,我们必须回到“科学”的定义。这是剑桥的定义:

source: Cambridge
简而言之,基本上,科学意味着关于事物如何运作的知识。
将“数据”加入其中,你将获得关于数据如何工作的知识。
在我看来,数据科学家应该了解数据的本质,它是如何工作的,以及你如何使用它来给出你需要的具体结果。数据科学家将确切地知道在给定需求的情况下对数据集执行哪种方法。数据科学家知道如何将数据处理成所需的任何形状或形式,以便可以对该形状或形式的数据进行某些处理。数据科学家应该了解数据的一切。
但是在科学领域,有像物理、生物和化学这样的专业。因此我们得到:
数据科学—工程学
数据科学—分析学
数据科学—机器学习
这样的例子不胜枚举。
然而,现在有些人自称是数据科学家,他们只懂一点 excel 知识,一些简单的 SQL 和一些可视化技能。我不会说他们这样做是错误的,但我要知道,这个术语被如此明目张胆地到处乱用,以至于如今很难找到一位真正的数据科学家。每个人对 DS 的定义都不一样,所以当你打算称自己为 DS 时,请准备好解释原因。

数据工程师

Photo by Danial RiCaRoS on Unsplash
数据工程师在科技公司尤其重要。不管你处理的是哪种媒介,数据团队通常不会干预主数据库中的数据。这是因为它对数据库来说很重,可能会导致崩溃、介质本身的延迟等问题。还有几个数据库可以存放数据。例如,如果你同时有一个网站和一个应用程序,你的数据可能不会驻留在一个地方。
当 DS 在展示他们的模型时,数据工程师正试图找出他们的数据在数据仓库中如何组织和结构化的核心基础,数据分析师/科学家从数据仓库中获得数据。数据工程师创建可扩展的高性能基础设施来满足公司的所有数据需求,无论需求来自数据科学家同事还是财务同事。他们通过编写 ETL ,或者在我的情况下,编写 ELT 管道来将来自多个来源的原始数据提取到一个数据仓库中,这样团队就可以对它们执行奇特的操作,如机器学习、可视化等。由于他们是数据仓库基础设施的所有者,数据工程师也在数据仓库本身上构建自动化、功能、实时分析解决方案。函数的一个例子是类似于 Gmail 数据管道——一个直接从你的 Gmail 收件箱中提取数据的数据管道。
数据工程师通过使用不同的技术如 GCP 和 AWS 来完成上述所有任务,表明他们在这些领域的知识。他们在研究哪种技术能为他们试图实现的目标提供最佳解决方案方面发挥着重要作用。就我而言,我对使用
Apache Airflow 很有经验,因为它是我在公司提取数据的主要 ELT 工具。我还接触了谷歌云功能、谷歌应用脚本、谷歌 BQ、AWS 和其他一些技术。我也写过一篇如何从零开始操作阿帕奇气流的文章,你可以在这里阅读。
在我看来,数据的工程方面是 it 科学的一部分。就像积木一样,工程师是将碎片组装在一起的人。他们就像数据管道工,从零开始了解数据。他们能够回答以下问题:
- 当站点上发生事件时,主数据库中会发生什么?
- 为什么数据仓库中的表是这样构造的?
- 为什么我们使用 GCP 而不是 AWS?
- 为什么上报的数据总是不准确?
- 为什么我们每天提取数据,而不是每小时?
- 表格中的这一栏是什么意思?
也就是说,公司的利益相关者只关心我们是否能以他们的方式回答他们的业务问题。因此,使用数据仓库中的数据来做他/她想做的任何事情,以实现这一目标,这取决于数据科学家。许多人没有意识到,数据科学家通常会获得已经由数据工程师在内部转换的数据,这些数据可以轻松阅读、理解并输入复杂的机器学习模型,以便产生他们的研究结果。不从他们那里拿走荣誉,数据科学家必须对业务进行实验、试运行和深入研究,以知道如何处理数据。然而,工程师们已经部分完成了大量的数据工作。这里有一个例子:

这是一个关于商店导向网站中商店的数据集。
假设我们可以从数据仓库中的 Stores 表中获得这个数据集。它非常简单易懂。
商店、商店的参数以及访问量指标。
然而,数据并未记录在主数据库中。相反,在母版中记录数据的规则和方法通常对用户不友好。为了更好地解释它,我做了一个流程图:

Note: Not all columns are included
下面是在主机中发生的事情。
一旦存储注册,存储动作状态表中就会出现一行,指示新存储的注册以及该存储附带的所有参数。然而,该商店的用户可以在任何给定时间改变商店参数。例如,如果商店类别是珠宝,店主可能在一段时间后想卖其他东西,他/她于是将商店类别改为电子产品。这也被记录在商店动作状态表中,作为具有新的状态 ID 的新行。与此同时,商店活动表记录了一个新行,说明商店的活动,即“参数更改”活动。然后,存储更改表记录多行,指示被更改的列的更改。系统批准更改后,更改的新值将在存储和存储参数表中更新。然后,存储动作状态表记录一个具有新的状态 ID 的新行,表明它已经被批准。
如果我在这里失去了你,那就是重点!
这种形式的数据对于正常人来说既不可读也不容易理解。每个数据库记录数据的方式不同,这只是众多例子中的一个。如果你要回答这样的问题:
- 如果商店类别现在是“X ”,那么一天前也是“X”吗?
- 商店什么时候改变了它的商店名称?
- 五月份“柔佛”地区有多少家商店?
这种表格形式不能直接翻译。因此,数据工程师制作转换后的表格,这样每个人都可以很容易地阅读这些信息,这也是数据科学家通常得到的。他们的主要关注点之一是设计数据仓库中这些表的架构,以便所有信息都可以通过简单的 SQL 连接轻松访问。所以,请我的数据从业者同事们,明天请你们的数据工程师喝杯咖啡吧。

Photo by Tyler Nix on Unsplash
判决
你难道不喜欢一点戏剧的味道吗?你认为谁更相关?
科学家可以发现一颗新星,但他不能制造一颗。他将不得不请一位工程师为他做这件事。戈登·林赛·格莱格
让我们把事实摆出来。没有数据工程师,科学家们甚至不会有任何数据。如果没有他们,当科学家们问:“这个专栏是什么意思?”这个问题比你想象的更常被问到。你可能会反驳,到时候他们会问开发商!在这种情况下,开发人员就是数据工程师。简单地说,数据科学家是数据工程师的内部客户,他们依靠数据工程师获得可靠、有用和“好”的数据,这让他们的生活轻松 10 倍。
然而,工程师无法回答商业问题,因为他们在那个领域没有经验。数据科学家通常拥有他们所在领域的业务知识,能够提出正确的问题,建议正确的解决方案,并为特定需求找到正确的指标。他们就像首席执行官的大脑,以便他做出正确的决定。
因此,我认为角色与相辅相成。两者缺一不可。你不会希望在没有建立适当的数据管道的公司雇用一名数据科学家,希望他/她会钻研所需的核心数据工程。这完全是浪费你公司的资源、这个人的时间、能力和技能。数据工程师和科学家的技能组合对于确定组织中数据的价值至关重要。两者协调工作,互相沟通也很重要。
现在有许多种数据团队正在形成,其中一些由数据工程师和科学家组成,而另一些则纯粹由科学家组成。就我而言,我大量参与工程任务,同时也为公司进行分析。如果你不喜欢其中的一个,我建议在进入之前先问清楚你申请的职位的性质。
然而,当谈到部署机器学习模型时,我不会把所有鸡蛋都放在数据科学家的篮子里。如果你已经读到这里,你会明白工程师们完全理解所有他们可用的(和不可用的)数据。因此,我认为他们是为你的媒体实现机器学习模型的最佳候选人之一。如果你不理解你的数据,你将如何决定在你的模型中包含什么和排除什么来优化它?
你应该对什么是什么有个大概的了解。
此外,数据工程师更擅长各种各样的技术。他们习惯于在网站和应用程序上部署模型,他们理解容器的工作方式,他们理解 API 的工作方式,以及许多其他科学家没有经验的解决方案。他们在编写干净的代码、诊断和调试方面更有经验。他们可以很好地处理缺失数据、不一致的数据类型和格式、时区、模型的可伸缩性和持久性,因为他们习惯于转换和清理数据。他们有很酷的 GitHub 推/拉方法。更好的是,如果他们意识到数据集中缺少了什么,他们可以立即得到它,即使它不在数据仓库中。因此,你会看到如今数据工程师越来越多,称自己为
**机器学习工程师。**这些人完成了以上所有工作,还有一些。
希望看完我的文章,你更了解数据工程师。你意识到他们是让世界运转的人。所以请给他们一些爱。不要歧视,继续学习。
毕竟数据从不睡觉。
订阅我的时事通讯,保持联系。
感谢 的阅读!如果你想与我取得联系,请随时在 nickmydata@gmail.com 上联系我或我的 linkedIn 个人资料 。也可以在我的Github中查看代码。
为什么 p 值像针一样?分享它们很危险!
这是一场关于 p 值的战争…双方都是错的

Image source: istock.com/brianajackson
对于一个几乎在每个 STAT101 课堂上教授的概念,围绕 p 值的争论数量是惊人的(T2)。作为一名统计学家,我既支持 T4 的观点,也支持贝叶斯的观点,让我试着帮你避开这些噪音。我将愉快地对双方都不敬。
如果你是 p 值的新手,花点时间看看我用小狗做的简单解释或者上面的视频,让你熟悉一下。简而言之,p 值是一种决策工具,它告诉你是否应该对你的无效假设感到可笑。
反对 p 值的理由
当人们(通常是贝叶斯人)批评 p 值时,通常可以归结为两个论点之一:
- 涉及定义或公式的东西。通常包括*“后验概率更好”*在某处。
- 涉及对潜在滥用的焦虑。
请允许我把这些翻译成我听起来的样子:
- 我不喜欢你制定统计决策的方式。
- 懒人就是懒。
论据 1(反对)
如果你一直在做第一个论证…好吧,这会让你看起来很糟糕。那就是你忘记了统计学是改变你想法的科学,你可以根据自己的想法来制定决策,然后选择合适的工具。(此外,如果你更擅长数学而不是做决定,那就退出吧!)
选择正确的方法取决于决策者希望如何做出决定。
如果你想要一种合理的选择行动的方式,并且你在考虑如何最小化选择错误行动的风险,那么频繁主义者的方法并不是那么邪恶。如果你更喜欢考虑用数据来发展你的个人观点,那么贝叶斯方法更有意义。
选择正确的方法取决于决策者希望如何做出决策,因此这里没有放之四海而皆准的方法。这种东西有许多正确的答案……偏好和哲学立场与它息息相关。为什么有些人对把事情做好如此趾高气扬,而那些事情本来就是主观的,没有正确的答案?这让我困惑。
论据 2(反对)
论点 2(滥用的可能性)是合理的,但这不是 T2 p 值 T3 的错。事实证明,使用统计数据仔细做决定需要努力,但人们一直在寻找神奇的不费力气的魔法,这能给他们带来一个水晶球。神秘的 p 值很诱人——它的大多数用户不知道如何使用它,由此导致的电话故障已经达到了可笑的程度。我支持你。

这就是为什么我大力提倡放松。换句话说,我喜欢做出基于数据的决策,如果你不愿意付出努力,就不要把自己当回事。对那些感觉懒惰的人来说,最好的解决办法是:做描述性分析,保持谦逊。
如果你不愿意付出努力,选择描述性分析并保持谦逊。
只有当你以一种完全尊重你建立决策框架和假设的有意方式的方式严谨地进行时,统计推断才有意义。这不是一个 p 值的问题。这是一个蛇油问题:统计数据经常被当作神奇的万灵药出售,声称提供的保证如果你停下来想一想就会觉得很疯狂。没有魔法能把不确定性变成确定性……但不知何故,有许多骗子却在暗示相反的事情。
p 值的情况
你也应该怀疑任何宣称狂热热爱 p 值的人。它们只在非常特殊的情况下有用。但是当 p 值有用时,它们非常有用。
它们是以特定方式做出决策的有用工具。
很难挑战这一点。对于希望在不确定的世界中尽最大努力并以特定方式做出决策的决策者来说,p 值是完美的。不要因为你喜欢用不同的方式做决定而扫他们的兴——当轮到你做决策者时,你可以随心所欲地做。
p 值的另一种情况
如果你对分析(而不是统计)感兴趣, p 值可能是总结数据和迭代搜索的有用方法。请不要像统计学家那样解读它们。除了在这些数据中有一个模式之外,它们没有任何意义。统计学家和分析师可能会大打出手,如果他们没有意识到分析是关于数据中的内容(仅限!)而统计是关于数据之外的东西。
当你在做分析的时候,不要使用假设 T21这个词,否则你会听起来像个白痴。
对于一个分析师,一个 p 值仅仅是另一个统计量,除了之外没有任何解释“这是我以一种特定方式摇动数据集时得到的数字,当它很小时,这意味着我的数据集具有某种模式”——把它想象成一种有效可视化复杂和大型数据集的方式。当你用 analytics探索数据时,不要使用 假设 这个词,否则你会听起来像个白痴。你用事实工作:这些数据有这个*模式。句号。

To learn more about the difference between the subfields of data science, see bit.ly/quaesita_datasci.
受够了分析——没有战斗(就像没有超越的规则一样,“不要做出超越数据的结论!”)。回到的统计数据,这里的争论很激烈!
置信区间代替 p 值的情况
你走错房间了,伙计。回到分析,置信区间是一种更有效的可视化和汇总数据的方式。在统计决策中,没人在乎。为什么?使用置信区间和 p 值得到的决策是相同的。如果你在做真正的统计推断,你应该对任何非美学的理由漠不关心。
(的确,这对未来的数据探索者——分析师——是一种恩惠,如果你用置信区间报告你的结果,但这与你决策的质量无关。)
回归基础
让我们回顾一下 p 值具有统计学意义的情况。首先,你围绕默认行为的概念建立你的决策,你给数据一个说服你放弃它的机会。你没有试图形成数学上可描述的观点(用贝叶斯理论)。你愿意按照这篇博文中的逻辑做出决定。如果不是,p 值不适合你。没什么好争的。对于某些工作来说,它们是很好的工具,但是如果那不是你需要做的工作,那就去找一个更好的工具。从什么时候开始,我们希望一种工具适合所有工作?!
既然你已经决定用经典方法测试假设,让我们看看你如何计算 p 值。
创造零世界
一旦你正式陈述了你的零假设(在你完成了这个之后),大部分工作将是可视化零假设世界,并弄清楚那里的事情是如何运作的,这样我们就可以制作一个玩具模型。
这就是你可能还记得的统计课上那些晦涩难懂的涂鸦的要点——它们归结为建立一个宇宙的数学模型,其规则由零假设支配。你用方程式(或通过模拟)来构建宇宙!)这样下一步就可以考察了。
数学就是建立一个零假设宇宙的玩具模型。这就是获得 p 值的方法。

The math is all about making and examining toy universes (how cool is that, fellow megalomaniacs!? So cool!) to see how likely they are to spawn datasets like yours. If your toy model of the null hypothesis universe is unlikely to give you data like the data you got from the real world, your p-value will be low and you’ll end up rejecting the null hypothesis… change your mind!
假设,假设,假设
自然,你必须做出一些简化的假设,否则你会很快不知所措。没有人有时间去创造一个像我们实际生活的宇宙那样丰富和复杂的世界,这就是为什么统计不会给你一个大写的真相,而是一个在不确定性下做出合理决定的方法……受制于你愿意走的一些捷径。(这也是为什么统计学究看起来那么傻。)
在 STAT101 中,那些假设往往会被灌输给你因为“数据是正态分布的……等等等等。“在现实生活中,你必须自己提出假设,这可能会让人感到害怕,因为突然间没有正确的答案了。
在现实生活中,没有正确的答案。我们能做的最好的事情就是以一种感觉合理的方式做决定。
如果 p 值是为别人计算的,对你可能没用。它应该只在选择做出相同的简化假设并以相同的方式制定决策的人之间分享。
使用别人的 p 值是很危险的…它们就像针一样:如果你要使用它们,就去用你自己的!
统计决策总是主观的,无论是贝叶斯还是频率主义,因为你总是要做出简化的假设。这些结论只有在你接受这些假设的情况下才有效,这就是为什么如果有人没有看到你的笑点所基于的假设,就期望他们同意你的笑点是很奇怪的。我们为什么要这么做?不知道。我不知道。如果我不愿意考虑我想如何做决定,以及陈述的假设是否适合我(在我看到数据或 p 值之前),那么我在 p 值中看到的就是一个分析师看到的:在一些设置被扭曲后,你看到了一个模式。真可爱。当我看云的时候,有时我也会看到动物。如果我想认真对待它,我会在其他数据中跟进这个“洞见”。否则,我会把它当作模糊的灵感…在这种质量下,谁会在乎它有多好呢?
这个证据让你吃惊吗?
既然你已经想象了描述你的零假设的世界,你将会问你得到的证据——你的数据——在那个世界里是否令人惊讶。p 值就是你的零世界吐出的数据至少和你的一样糟糕的概率。当它很低时,这意味着你的数据在这样的世界里看起来很怪异,这让你觉得自己好像生活在那个世界里很可笑。当它对你的口味来说足够低时——低于你选择的一个称为显著性水平的阈值——这意味着你足够惊讶地改变你的想法,改变你的行动,远离你的默认。否则,你继续做你本来要做的事。
将低 p 值解释为:“某人对某事感到惊讶。”
谁来定义“荒谬”的含义?决策者(选择假设和显著性水平的人)。如果你没有设置分析,那么对低 p 值的唯一有效解释是:“有人被某事惊到了。”让我们一起思考一下,如果你不太了解正在讨论的某人或某事,这能告诉你多少。
这就是为什么 p 值有点像医用针头:它们是供个人使用的,分享它们是危险的。
感谢阅读!喜欢作者?
如果你渴望阅读更多我的作品,这篇文章中的大部分链接会带你去我的其他思考。喜欢我的最佳列表吗?试试这个:
关于数据科学的十篇人人友好的文章
medium.com](https://medium.com/hackernoon/best-of-data-science-overviews-1e73b9c7682)
附录:技术异议

*技术异议你的技术异议(用行话,不好意思):
- 对于那些将要抗议的人来说,“这个假设被用于置信区间的计算,这就是为什么我们会使用这个词,而且凯西称每个人(每个人!)傻逼?!"…虽然计算确实使用了假设,但让我提醒你,分析中的游戏是速度。为什么要滚动自己的测试反演进行探索?有很多包裹准备好了。
- 对于那些将要抗议*“如果我们有所有的数据来* 确定地测试一个假设 *的人,那么我们会在我们的真理的光辉中焚化它之前说出‘假设’……*伙计们,这的另一个名字是“查找答案”,是的,你可以使用分析进行基于事实的决策,但是严肃地说:为什么我们在这种情况下谈论 p 值(0)或置信区间,置信点?你已经有了事实,所以不需要统计数据。当你掌握了所有的事实后,可以随意忽略带有标签 #statistics 的文章中的任何该死的谎言,包括这篇文章。
感谢阅读!人工智能课程怎么样?
如果你在这里玩得开心,并且你正在寻找一个为初学者和专家设计的有趣的应用人工智能课程,这里有一个我为你制作的娱乐课程:
Enjoy the entire course playlist here: bit.ly/machinefriend
喜欢作者?与凯西·科兹尔科夫联系
让我们做朋友吧!你可以在 Twitter 、 YouTube 、 Substack 和 LinkedIn 上找到我。有兴趣让我在你的活动上发言吗?用这个表格联系。
为什么推进 AI 民主化和数据优先的方法不一定是好事?
AI 无处不在。或者是?

当我们回顾 2019 年时,这绝对是人工智能和民主化的一年。人工智能(或人工愚蠢,我稍后会解释)和民主化无处不在。你的冰箱是“智能的”,你的智能手表是“智能的”,你的汽车是超级“智能的”。更不用说计算机软件和你的 CRM 系统了——它们是如此“智能”,如果你相信这种宣传,你应该打包,换工作,让人工智能销售和购买东西。我们不再需要人类了。或者,也许我们真的需要它们。用低代码/无代码的大众化编程接口“编程”人工智能…
人工智能狂热分子把“人工智能”变成了一把万能钥匙,用来吓唬世界,卖得更多。每个人(好吧,几乎每个人)都知道,即使在围棋上取得了著名的胜利之后,计算机也只是在智能地执行命令,智能汽车是智能的,直到……开始下雨或者有人在停车标志上贴了一张贴纸,它再也无法识别它。所谓“智”止于此。
这篇文章并不是要否定我们在人工智能方面已经取得的成就,尤其是在 2006 年之后,当时深度学习在深度信念网络中确实表现得相当好。这是一部回归现实的电影,讲述人工智能在销售、营销以及生活和商业的许多其他领域能为我们做些什么。它还表明,盲目遵循“数据第一”的方法可能会非常糟糕,而且肯定会产生误导。
现实远不是所有“人工智能初创企业”和“数据驱动的领导者”希望我们想的那样。
截至 2019 年,人工智能是如此狭窄,仅此而已…
如今,许多“人工智能企业家”喜欢宣称,为了销售他们的“人工智能支持的产品”,计算机统治着我们的商业和生活。计算机在围棋中获胜的事实是他们最喜欢的口头禅,用那些“人工智能狂热分子”的话来说,最终证明了计算机是智能的。当然,在围棋中获胜是一项伟大的成就!但是声称它证明了计算机现在有直觉是相当误导人的。首先,它证明了强化学习(作为机器学习技术之一)是可行的。第二,证明了一个有足够多 GPU 的分布式网络,现在可以在围棋上战胜人类。第三,……没有第三。AlphaGo 在与地球上所有人的围棋比赛中获胜(并且一直获胜)。然而,它无法区分正方形和圆形,也无法在井字游戏中获胜。
如果你现在说“哦,是的,当然可以!只要重新编程就够了“你支持这篇文章背后的整个想法和论点——**计算机听从命令,很听话,但绝对不是智能的。**至于 2019 年底,包括深度学习在内的机器学习只是寻找模型和模式(比人类更快),与智能完全无关。
好了,让我们进入这篇文章的主要论点——进一步的人工智能民主化和“数据优先”的方法是有风险和危险的。
什么是 AI 民主化?
“民主化”的简单定义是,每个人都获得平等的机会和获取特定资源的途径。在“AI 民主化”中,我们显然指的是平等获取“人工智能”资源。它们包括但不限于:
- 互联网上免费提供的公共数据源
- 统计时间序列和数据
- 每个人都可以访问的在线平台,以建立“人工智能实验”
- 构建、测试和部署机器学习模型的离线工具
- 最后,“拖放”平台允许任何没有基本数学技能的人在他们的公司使用人工智能
最后一点是最危险的…我一会儿会解释为什么。
什么是数据优先方法?
最近著名的数据优先方法是将数据放在所有业务活动的前面。此外,它指出数据是新的黄金。或者说,数据是最重要的资产。或者,这是任何其他类似于 2019 年每天在 it 和商业界听到的夸大其词。
数据不重要吗?当然是了。但是没有理解的数据什么都不是。这也是我写这篇文章的原因…
那么,为什么 AI 民主化不一定是好事呢?
big-techs(微软、Salesforce、谷歌和其他公司)提供的人工智能平台在 2019 年达到了一个很快就会弊大于利的水平。也就是说,每个人都可以通过简单的拖拽&来“做人工智能”,而不需要理解任何基本原理。只要低代码平台的民主化开发有助于世界各地的公司,民主化人工智能就不会。有几个原因,我把它们列在下面。
R isk #1 —“人人都能做 AI”的事实和缺乏有经验的从业者
事实上,在为期两周的在线课程后,每个人都可以做人工智能,“只需点击几下鼠标”,正如它所说的那样——每个人现在都可以做人工智能。不仅仅是拥有丰富领域知识的人,拥有出色统计技能的人,理解相关性和因果关系的人。所有人。那是危险的。
“数据科学家”在过去 3 年里一直是世界上最性感的工作,鼓励许多人转向成为数据科学家。数据科学家对他们想要研究的主题一无所知。更不用说,在适当的人工智能和机器学习的“引擎盖”下,统计和算法知识非常有限。这些人,成千上万的人,使用简单的在线人工智能工具…对数据做出结论。存在的问题?给你:
- 谁来检验一个业余 AI 从业者选择的算法好不好?
- 谁能证明这不是通过“数据折磨”和“数据按摩”在数据中发现的虚假关联?
- 如果现在几乎每个人都在没有适当基础知识的情况下开始学习机器学习,谁能在 2 年内担任机器学习的高级职位?
可以说民主化也发生在代码开发中,程序员不需要构建主板,然后用汇编语言编码。这是完全正确的。但是,不理解底层计算机架构的单个软件开发人员甚至没有自称的数据科学家危险,这些数据科学家发现肿瘤时甚至不知道他们为什么选择他们所做的算法。
风险 2——在线人工智能平台太容易得出结论
随着人工智能民主化,人们开始相信数字和数据就是一切。事实上,如果没有正确的理解,它们只是…数字和数据。民主化的人工智能平台不会验证你输入模型的数据是否真实、有效或相关。它们允许你将任何东西放入模型中(在许多情况下选择错误),并且…它们提供预测。而且,由于人工智能已经民主化到不需要任何数学技能的程度,我们最终只能基于错误的数据和错误的模型进行预测。更糟糕的是,所有那些“人工智能初创公司”和“数据科学家”经常让我们相信这些预测是有效的,因为“它们得到了人工智能和机器学习的支持”。
风险# 3——民主化的人工智能与清理输入数据、选择模型并验证其结果的人一样聪明
由于人工智能的民主化让每个人都可以接触到人工智能,这意味着人工智能和玩它的人一样聪明……我们甚至不需要更深入地研究对抗性学习或有目的的模型挑战方法,以表明“民主化的人工智能”做出的预测往往是无效的,简直是愚蠢的。不是因为 AI 线上平台蠢。这是因为人们被鼓励玩机器学习,因为它是一种简单的数据输入数据输出机制,有着花哨的名字,但不理解其背后的基本原理。
风险# 4——民主化的人工智能平台鼓励可视化数据并显示相关性
是的,数据的轻松可视化是人们将注意力放在“民主化的人工智能”平台上的最常见原因之一。将数据可视化没有错(一张图胜过千言万语),但错的是……在没有真正相关性的地方得出相关性的结论。漂亮的彩色图表让所有用户都能看到它们之间的关系。关系并不总是因果关系。
上个月有多少次我听说另一家“人工智能初创公司”可以根据历史数据向我展示我们的客户在 2020 年将购买多少产品的预测?你呢?在所有情况下,我很容易就能证明,预测未来的客户行为和订单需要的不仅仅是运行聚类来细分客户,然后进行多项式回归来显示订单增加/减少的概率。这是一个非常简单的例子,但是…所有这些平台很少比这个简单的例子更简单。是的,他们自称为“人工智能支持的销售/数字营销引擎”😄。
风险 5——民主化的人工智能平台不知道也不验证你的意图
假设你是一家公司的数据科学家,你想用机器学习来证明你的假设。你是做什么的?你摆弄这个模型太久了,它最终证明了那个假设。然后呢?你把它展示给你的董事会或你的客户,作为机器学习做出的一个伟大的知识发现。
如果这种“知识发现”只是为了你的公司,那就这样吧。但我不希望从这样的数据科学家那里获得数据来预测图像上看到的是癌症还是仅仅是图像异常。
为什么数据优先的方法是一件坏事?
首先,让我解释一下我对数据优先方法的理解。我不是说收集数据、使用历史数据或使用结构化/非结构化数据进行分析来帮助您的公司发展。我所说的坏数据优先的方法是我们越来越经常听到的——数据,也只有数据应该定义你如何经营你的公司,你应该如何修改你的流程,以及你应该如何选择你的客户。
如今,我们经常遇到“数据优先,假设随后” 方法的问题,通常被聪明的家伙隐藏在“我们用我们顶尖的云 AI 平台提供知识发现”的背后。
你看到这里发生了什么吗?他们使用数据创建一个假设(通过知识发现),然后用相同的数据证明这个错误的假设。很好。但没那么聪明。而且把不好的数据集分成训练和测试数据集也不是办法……😃。“数据优先”方法的主要问题是,它鼓励业余爱好者在数据点之间的关系薄弱的地方寻找相关性和原因。证明?
真实世界示例:
考虑一个“领先的人工智能营销”平台(你说吧;全世界有无数的例子)。让我们玩一会儿吧。让我们输入我们的历史客户数据(尽可能复杂,因为它可以处理有价值的预测)和来自 Kaggle 或任何其他基于时间序列的统计数据公共来源的一组随机数据。
上面的练习是从一个人工智能平台学习的一个完美方式,即应该成为我们最佳客户的客户是那些满足以下所有条件的客户:
- 在移动设备上使用我们的网站,然后在桌面上跟进(很公平)
- 周二写点最多的邮件(蠢,哈?)
- 第一次联系我们的时候,佛得角的温度低于 25 摄氏度(在我开始让这些人工智能平台变得愚蠢之前,我不知道它的存在)
够糟吗?作为人类,你会做出如此愚蠢的推断吗?如果这个伟大的“人工智能支持的公司”代表会告诉你,为了取得这些伟大的成果,他们已经运行:
- 堆叠去噪自动编码器
- 自然语言处理
- 关联规则学习
听起来更可信吗?确实如此。他们可能完全按照这个顺序来做,并得出完全相同的结论。众所周知,人们倾向于相信更多的科学词汇。甚至,如果它们在特定的语境下只不过是扯淡。
为什么会觉得结果一文不值?很简单——这些平台**都不理解数据,它们只看到数字。**如果要求他们做“知识发现”,他们就会去做。
当然,有人可能会说我是故意放坏数据的。是的,我做到了。但是,当你允许任何用户将他们的数据拖放到一个“人工智能,超级酷的机器学习平台”,确保“使用人工智能进行预测”,你怎么能确保这些糟糕的数据没有被使用,并且得到适当的验证?我希望你现在明白我的意思。现在还不是智力的问题。它是关于更复杂、快速计算的统计和计量模型(是的,其中一些是从基于模型的机器学习中的数据推断出来的,但仍然只是模型)。
在不强迫用户理解基本原理的情况下将人工智能民主化,注定会发现相关性,并做出不仅糟糕、愚蠢,而且最重要的是危险的“发现”。只要这些愚蠢的预测和发现与销售和市场营销有关,并且有人想要使用它们,那就好。但在医学、司法和心理学领域,同样的业余方法也被用来民主化人工智能。
这……是不对的。
请分享你的观点和评论。我很乐意阅读/讨论它们。
为什么 AutoML 是数据科学家必不可少的新工具

机器学习(ML)是当前通过利用利用计算机智能的算法来建模统计现象的范例。常见的地方是建立预测房价的 ML 模型,根据用户的潜在营销兴趣聚集用户,并使用图像识别技术来识别脑瘤。然而,到目前为止,这些模型都需要小心翼翼地反复试验,以便在看不见的数据上优化模型性能。
自动机器学习(AutoML)的出现旨在通过提供设计良好的管道来处理数据预处理、特征选择以及模型创建和评估,从而抑制所需的资源(时间和专业知识)。虽然 AutoML 最初可能只吸引那些希望利用 ML 的力量而不消耗宝贵的预算和雇用熟练的数据从业者的企业,但它也包含了成为有经验的数据科学家的无价工具的非常强的承诺。
由于当前机器学习工具的谬误,数据科学家经常难以在拥挤的时间线内产生有效的模型。他们与不灵活的框架、缺乏跨平台的可复制性、协作障碍以及尚未完全开发的软件工具作斗争。目前市面上有许多不同的 AutoML 工具,但它们都有各自的缺点。通常,它们将用户限制在一个严格的工作流程中,并且可以充当黑盒;他们产生了令人印象深刻的结果,但几乎没有可解释性和再现性。对于自动建模软件实际上是如何得到最佳模型的,或者为什么它选择保留某些特征而不保留其他特征,几乎没有给出解释。一些数据科学家也觉得避免使用这些工具是一种骄傲。毕竟,如果数据科学家的整个工作流程可以被自动化工具取代,那么他们存在的理由是什么?
AutoML 领域非常拥挤,有许多 AutoML 选择,从免费的开源工具如 WEKA 或 Auto-Sklearn 到最昂贵的平台如 Data Robot、H2O 无人驾驶 AI 和 Dataiku。虽然网上有很多关于这些工具的文章,但我想我会根据我最近参加的一个由设计者和作者参加的演示来尝试一下这个领域的一个新成员。
输入 Auto_ViML
该工具被称为“Auto_ViML”或“自动变体可解释机器学习”(发音为“Auto_Vimal”),这是一个开发的库,作为一个功能齐全但免费的 AutoML 管道如何有效地促进当代数据工作流的主要示例。
AutoViML 是输入不可知的,这使它能够接受任何熊猫数据帧形式的数据集。它执行类别特征转换和简单的数据清理步骤,例如将缺失值标识为“缺失”,以便让模型决定如何使用它们。
该库的独特优势之一是它自动执行特征缩减(或特征选择),以产生最简单的模型,在这种情况下,该模型具有产生合理的高性能所需的最少数量的特征。我发现 AutoML 生成的模型自动减少了所选特征集中的多重共线性,并通过迭代一系列超过 15 个不同的 ML 选项生成了一个性能良好的模型(详见下文)。最重要的是,它不仅产生了性能最好的模型(基于您的评分标准),而且还提供了详细而冗长的输出,允许大量的理解和模型可解释性(因此 Auto_ViML 名称中有术语“可解释性”)。
我决定用几个著名的数据集来测试 Auto_ViML。开始使用 Auto_ViML 就像 1–2–3 一样简单:
- 通过“pip install”安装 Auto_ViML
- 将数据集加载到数据帧中,并将其分为训练和测试
- 用一行函数调用 Auto_ViML
我已经把我实验用的 Jupyter 笔记本附在这里了。
埃姆斯住宅数据集的线性回归
通过使用 Auto_ViML 测试各种不同的数据集,Auto_ViML 工作流的优势得到了有效的展示。automodeller 首先创建了一个非常有效的线性回归模型,用于使用 Ames Housing 数据集预测房屋的销售价格。数据被分成训练集和测试集,并提供一个目标变量作为 Auto_ViML 的参数。所有这些都可以在一行中完成:
回归分析为处理住房数据的最有效方法提供了强有力的见解。通过让 Auto_ViML 创建多项式项(包括交互)来创建最佳拟合线。这种内置的功能工程将 RMSE 从 25640.78 美元降低到 23255.65 美元,在预测房价方面有了明显的改善。根据外部评估,最终模型的 R2 为 0 . 91。

该库还生成了一个要素重要度图,该图表明新添加的地下室总平方英尺和地面居住面积平方英尺多项式变换与目标变量具有很强的指数关系。最终的模型采用了套索正则化和 79 的 alpha。能够让 Auto_ViML 过程理解哪些特征转换最相关,哪些特征在对目标变量建模时最没用,以及最适合这个问题的模型正则化的类型和强度,这是很有见地的。

当 verbose = 2 和 Boosting_Flag = True 时,Auto_ViML 智能地合并了 SHAP 特性重要性图,以便采用 XGBoost 模型。
员工流失分类
Auto_ViML 以类似的洞察力处理了一个二进制分类问题。它发现,当使用 IBM Watson HR 数据集时,高度正则化的逻辑回归模型(C = 20)能够最好地预测员工的流失概率。自动建模器直观地知道优先召回积极类(一个选择离开公司的雇员),这是一个适合这个特殊问题的优化。Auto_ViML 计算出 F1 分数为 0.94 的最佳阈值为 0.49,得出的结论是单个模型在这项任务中表现非常好。

员工流失问题不仅需要强大的预测准确性,还需要了解员工流失的潜在动态。AutoViML 的特性重要性图表准确地指出了识别员工流失的一些更具预测性的因素,如员工的工作投入程度以及他们是否必须加班或拥有股票期权。在一个有如此多内置特性的数据集中,这个 Auto_ViML 管道还指出了那些与其他特性高度相关从而冗余的特性。Auto_ViML 发现,员工的总工作年限、在当前职位上的工作年限、在现任经理手下的工作年限以及年薪并不是特别有用的特征。其中一些观察结果令人惊讶,因为数据科学家可能会认为他们应该在对员工流失建模时突出这些特征属性。来自 AutoML 的见解有助于指导数据科学工作流,成功地引导建模管道清除可能在功能工程流程中转移注意力的不必要功能。

使用 Auto_ViML 进行犯罪预测
包含数百万条观测数据的大型数据集通常会给数据科学家带来巨大挑战。这些数据存储迫使数据从业者处理争论和清理数据,同时还试图揭示隐藏在数据中的潜在趋势和预测因素。为了观察 Auto_ViML 处理大型数据集的能力,我选择了来自 Kaggle 的具有 1m+行和 7 个特征的伦敦犯罪记录数据集进行下一次测试。
为了预测伦敦警察记录数据集中出现的各种犯罪,能够使用 Auto_ViML 的不平衡标志来完成这项任务是很有用的。大量的数据观察也有助于试验 Auto_ViML 的模型堆叠功能,如下所示:
运行有和没有叠加的两个测试表明,模型叠加提供了更强的宏观平均 F1 分数(从 0.06 提高到 0.31)以及更强的 ROC-AUC 分数,这意味着模型置信度已经提高。
ROC 曲线的比较证实了这种改善。


ROC 曲线表明,与单一模型输出(顶部)相比,采用模型堆叠(底部)后,模型具有更大的置信度。
可悲的是,模型堆叠导致了可解释性的丧失;最初的单一模型实验解释说,犯罪的月份和地点是预测犯罪类型的两个最重要的特征,但堆叠输出只是将决策树输出作为最重要的特征。这表明,就性能而言,模型堆叠是解决这个问题的合适方案,但是通过改变 Auto_ViML 测试的属性来获得多个视角仍然是有用的。

Auto_ViML 的默认特性重要性图表,没有 SHAP。
结束语
AutoML 不仅能够快速创建准确的模型,而且如果一个库提供了适当的详细输出,那么就可以收集很好的见解,从而加快理解问题的过程。Auto_ViML 的可解释性是它的主要优势之一;这与当前使用深度神经网络的趋势形成鲜明对比。Cynthia Rudin (2019)感叹道:“准确性和可解释性之间总是存在权衡的信念导致许多研究人员放弃了建立可解释模型的尝试。这个问题因研究人员现在接受深度学习培训,而不是可解释的机器学习培训而变得更加复杂。更糟糕的是,机器学习算法的工具包几乎没有为可解释的机器学习方法提供有用的接口。”像 Auto_ViML 这样的库可以抵制黑盒自动化工具的趋势,并为透明的自动建模提供有力的支持。
AutoML 可以为数据科学家指出特定数据管道的正确模型和正则化工具。自动化过程能够过滤掉可能误导模型的要素,并动态确定多项式要素变换的有效性。数据科学家的偏见常常会扭曲建模过程的结果,并可能将数据从业者引入死胡同。因此,为了获得对问题的完全无偏见的见解,能够将数据集放入 AutoML 管道是非常宝贵的。
虽然数据科学家最终可能仍然会寻求手动调整和评估他们自己的模型,但 AutoML 仍然是收集对问题的初步见解并获得对特征和目标变量关系的客观观点的不可或缺的工具。许多数据科学家现在对使用 AutoML 工具犹豫不决,但在可预见的未来,看到这些资产被纳入探索性数据分析或初始模型实验也就不足为奇了。最好是认可 AutoML 过程,这些过程重新引入了可解读的机器学习模型的范式,而不是快速的黑盒解决方案。然后,这些 AutoML 工具可以有效地成为团队中另一个数据科学家的等价物:一个已经对手头的问题有强大见解和独特解决方案的人。
你可以在这里访问 Auto_ViML 的 github 库。
特别感谢 Ram Seshadri 对 Auto_ViML 数据实验的支持和指导。
书目
C. Rudin,“停止解释高风险决策的黑盒机器学习模型,改用可解释的模型,”arXiv:1811.10154 [cs,stat],2019 年 9 月。
原载于 2019 年 11 月 10 日https://danrothdatascience . github . io。
为什么成为数据科学经理让我想成为一个不同的超级英雄
你会是哪个超级英雄?我的答案总是蜘蛛侠…直到我成为一名数据科学经理。

The Avengers. Image source.
警告:我会自由引用漫威电影宇宙的复仇者联盟电影,假设你已经看过了。如果你不喜欢超级英雄,我不确定我们能成为朋友。此外,你可能更喜欢另一篇关于数据科学领导力的文章,如 Robert Chang 的“,所以你想成为一名数据科学经理?“方敏”作为新的数据科学领导者的 6 个经验教训,“或者 Cassie Kozyrkov 的“数据科学领导者:有太多你”和“人工智能和数据科学的 10 大角色”
为什么是蜘蛛侠?他会爬墙,会做很棒的空翻,很友好,而且,作为一个澳大利亚人,我认为蜘蛛很酷!

Your friendly neighbourhood Spiderman. Image source.
在我们谈论管理之前,随着我成长为一名高级数据科学家,我对蜘蛛侠的忠诚软化了。我很惊讶地感觉自己热衷于更强大的角色,如雷神托尔。为什么?可能是因为我和扮演他的澳大利亚人克里斯·海姆斯沃斯有惊人的相似之处(我希望如此)。
不管怎样,一个发人深省的现实让我明白了:最有影响力的超级英雄拥有最大的超能力。蜘蛛侠可以拯救邻居,但它需要托尔的力量或惊奇队长的力量来打击疯狂的泰坦灭霸,并拯救宇宙。

Thor, the God of Thunder. Image source.
为了增加我作为一名数据科学家的影响力,我必须在我已经喜欢做的事情上做得更好,并帮助其他人也这样做。我在开发更深层次的统计和机器学习技能,更好更快地编写代码,并教我的同龄人如何做同样的事情。我加快了我的数据科学游戏,致力于更困难和更大规模的项目。但是我想走多远呢?
“最有影响力的超级英雄拥有最大的超能力”
我很快渴望一个不同的挑战,并没有充分意识到我正在进入的,步入了领导的角色,很快成为经理。扮演这个角色一段时间后,我看了最新也是最具史诗性的漫威电影《复仇者联盟 4:终局之战》。接近尾声是一个葬礼场景,镜头扫过所有伟大的角色,包括蜘蛛侠和雷神!它的结尾是一个在后面的角色,他很少出现,但却在监视着每个人。那一刻,我意识到我想成为一个不同的英雄,我已经改变了多少。如果我能成为超级英雄——请敲鼓…——我会成为尼克·弗瑞!
“呃,尼克·弗瑞是谁?”我听到你们有些人在问。“他不是超级!”我听别人说。谁会想成为一个没有超能力的角色(我知道,我知道,可以说不是超级英雄),说的比打的多,连自己的电影都没有的角色呢?事实证明是我。但是为什么呢?很明显,因为弗瑞是由秃头塞缪尔·L·杰克逊扮演的。

Nick Fury, founder of the Avengers. Image source.
除了闪亮的头像和普通的姓氏,这对我来说是一个深刻的时刻。尼克·弗瑞是神盾局的导演,也是复仇者联盟的创始人。他没有亲自拯救宇宙,但弗瑞知道,在任何人之前,它需要被拯救。更重要的是,他知道这是一个任何人都无法独自完成的巨大任务。他有远见,并能够组织地球上最强大的英雄来实现它。
“他没有亲自拯救宇宙,但弗瑞知道,在任何人之前,它需要被拯救。”
我意识到我已经更加清楚地理解了个人贡献和领导力之间的区别。更重要的是,我知道我喜欢后者:当蜘蛛侠是我的首选时,我会认为这是不可能的。我在解决不同的问题,发展不同的技能,寻找不同的回报。对于其他想知道进入数据科学领导层意味着什么的人,下面是我对每个问题的看法。
领导者解决不同的问题
当终极超级英雄惊奇队长去工作时,她在解决什么问题?主要是如何打败最新最厉害的超级恶棍。当尼克·弗瑞开始工作时,他在想一些不同的事情。他正在研究如何打败所有的恶棍,甚至是那些他还没听说过的恶棍。惊奇队长和弗瑞都在为一个更安全的宇宙而战,但解决了不同(且互补)的问题。

Captain Marvel taking on the mad Titan, Thanos. Image source.
对于数据科学家和领导他们的管理者来说也是如此。作为一名数据科学家(个人贡献者),我会致力于特定的项目,尝试并改进特定的决策。作为一名数据科学领导者,我一直在思考我们应该如何利用数据并提升所有决策的质量。我一直在努力提高这两个角色的决策能力,但以非常不同的方式为这个使命做出贡献。
“作为一名数据科学领导者,我一直在思考我们应该如何利用数据并提升整个企业所有决策的质量。”
领导者需要不同的技能
弗瑞在漫威电影宇宙没有自己的电影,但你知道吗,他在电影中出现的次数几乎比其他所有角色都多(我想除了钢铁侠)?
因为个人贡献者和他们的领导者面临不同的问题,所以他们以不同的方式工作并需要不同的技能是有道理的。钢铁侠是怎么打败坏人的?他详细了解他们并与他们战斗,依靠他的工程能力,动力服,人工智能支持,飞行和激光!弗瑞是如何让数百人在多年的时间里朝着一个共同的目标努力的?他需要放眼全局,制定长期计划,依靠远见、战略思维和影响他人的能力。钢铁侠在激烈的爆发中发展和展示他的技能,足以成为一部电影。弗瑞的努力是分散的,以帮助推动每个超级英雄在正确的地方,在正确的时间,用正确的技能完成工作。

Fury and the Black Widow telling Iron Man, “You’re part of a bigger universe, you just don’t know it yet.” Image source.
像钢铁侠一样,数据科学家需要将大量数据转化为具体有用的东西的能力。他们需要大量的编码技能、统计模型和机器学习算法。然而,他们的领导者需要技能来集合众多数据科学家的力量,以追求共同的目标。他们需要理解他人的长处和短处,在不同的工作和沟通方式中灵活变通,并且能够无条件地信任他人。他们不需要成为高深的技术专家,但他们需要对这门手艺有足够的了解,以便从这些独特的技术人员那里获得最好的东西。像 Fury 一样,数据科学领导者需要成为一种粘合剂,稍微接触一下每个人的工作。
“弗瑞的努力是分散的,以帮助推动每个超级英雄在正确的地方,在正确的时间,用正确的技能完成工作。”
领导者体验不同的奖励
解决不同的问题也意味着体验不同的回报。蜘蛛侠打倒一个坏人感觉很棒,但他也很兴奋只是测试他的新能力。很好玩!弗瑞看不到自己能跳多高,只能通过别人来发挥作用。当他看到他的战略拼图的许多块组合在一起达到一个目的时,他感觉很好。当第一个复仇者的队伍走到一起,打败了恶作剧之神和雷神的哥哥洛基,这不是偶然的。弗瑞不得不鼓励和培养许多人,并推动许多事件超时来实现它。超级英雄们因扳倒洛基而受到称赞。看到超级英雄们作为一个团队工作,看到他的战略努力取得了成果,即使很少有人知道他的角色,弗瑞也会有一种回报感。

“They needed the push.” Nick Fury motivating superheroes to become the Avengers. Image source.
作为一名数据科学家,我喜欢征服新算法,喜欢“破解代码”。当然,交付产生业务影响的解决方案让我感觉很有成就感,但这并不是我进入这个领域的真正动机。作为一个领导者,我没有大锤或闪电来玩。只有通过团队合作才能实现的精心策划的影响是我的毒品。我的任务要求我跨越时间和人群分散精力去完成。当我的团队成功时,我会有一种成就感,因为我知道我帮助创造了他们需要的环境。
“当我的团队取得成功时,我会有一种成就感,因为我知道我帮助创造了他们需要的环境。”
那么为什么愤怒呢?
所以你们中的一些人可能会问,“为什么愤怒?”我说,我可能不再是超级英雄了,但我有一个独特的特权地位。每天早上,我都要向猩红女巫问好,并确保她拥有让数据科学大显身手所需的一切。我坐在托尔旁边,帮助他思考如何应对我们最艰难的商业决策。我和后卫们一起吃午饭,聊他们想成为什么样的英雄。我发现蜘蛛侠用我以前不知道的数据做事情。我甚至可以帮助指导像美国队长和黑寡妇这样的团队领导,看着他们激发惊人的合作。我花时间想象一个世界,在这个世界中,数据被充分利用,每个人都做出伟大的决策,我为实现这一目标设定了一条路线。最重要的部分是什么?建立和支持一支超级英雄的军队,他们可以实现这一目标。

Nick Fury leading the team. Image source.
我可能还不是数据科学的主任,但我知道为什么我希望有一天成为主任。
停止广播
感谢阅读,我希望你喜欢这篇文章。您是否正在考虑进入数据科学领导岗位,并希望更好地了解这意味着什么?在 Medium 、 Twitter 或 LinkedIn 上问我你的问题,我很乐意分享我的经历!
为什么更好的权重初始化在神经网络中很重要?
在我深度学习之旅的开始,我总是低估权重初始化。我认为权重应该初始化为随机值,而不知道为什么要随机初始化?为什么没有其他方法呢?权重初始化应该有多大的威力或意义?等等。
这一系列的问题激发了我写博客的灵感,我将在博客中讨论不同的权重初始化技术,每种技术的优缺点,对个别技术的需求等。用更简单的方式。
补充说明
本文假设读者对神经网络的概念、前向和后向传播、激活函数、优化算法等有基本的了解。如果你不熟悉,那么我会推荐你关注我的其他 关于这些话题的文章。
在继续之前,首先让我们看看整篇文章中使用的参数符号。
使用的术语
考虑一个 L 层网络,具有 L-2 (不包括输入输出层)隐藏层。任意层 l 的参数表示为

为了得到具有更好和最优结果的神经网络,权重初始化是首先要考虑的步骤。权重初始化不当的网络会使整个学习过程变得繁琐而耗时。因此,要实现更好的优化、更快的收敛,可行的学习过程权重初始化是非常关键的。现在让我们从一些重量初始化问题开始。
为什么不简单地将所有权重初始化为零?
考虑一个场景,其中所有的权重被初始化为 0 。参考下面为多类分类问题设计的网络。使用来自sklearn.datasets的make_blobs()函数生成数据集。数据集有四个不同的类,包含两种不同的要素。网络有一个具有两个神经元的隐藏和输入层,一个具有四个神经元的输出层。

其中 W1 是 2×2 矩阵,W2 是 4×2 矩阵。B1 和 B2 分别是大小为 2 和 4 的列向量。

在隐藏层预激活期间
a11 = w1x1 + w2x2 + b1
a12 = w3x1 + w4x2 + b2
a11 = a12(假设 b1 = b2)那么 h11 = h12
类似地,a21 = a22 = a23 =a24,那么 h21 = h22 = h23 =h24
在 w1 和 w3 的反向传播期间

注- 此处所示 w1 和 w3 的梯度仅通过单路径计算,事实上,这些梯度是通过考虑多条可能路径上的所有导数计算的。
如果梯度相等,那么权重将被更新相同的量。连接到同一神经元的权重在整个训练期间继续保持不变。它使隐藏的单元对称,这个问题被称为 对称问题 。
因此,为了打破这种对称性,连接到同一神经元的权重不应被初始化为相同的值。
要点
- 切勿将所有重量初始化为零。
- 切勿将所有重量初始化为相同的值。
我们可以将权重初始化为大值吗?
如果权重被初始化为大值,并且如果使用了 sigmoid 激活函数(logistic,tanh ),则饱和问题可能发生,这导致消失梯度问题。因此,梯度变化缓慢,学习变得乏味。类似地爆炸梯度问题也可能发生。
要点
- 切勿将权重初始化为 大的 值。
- 最好将 标准化 / 标准化 输入,使它们位于一个小的公共范围内。
什么在实践中有效?
知道了零初始化和高值初始化的问题后,还有什么可行的初始化方法呢?
嗯,我们可以按照特定的分布(均匀分布、正态分布、截尾正态分布等)随机初始化权重。
例如,我可以在 Python 中使用np.random.randn(size_l, size_l-1)来随机初始化权重,遵循均值为 0、标准差为 1 的标准正态分布。
但是对于更深更广的网络,隐含层神经元数量多,隐含层数量大,随机初始化可能会产生问题。
例如,如果在一个隐藏层中有 n 个神经元,并且如果 n 是一个非常大的数字,那么在预激活期间

在 a21 中,由于大量的神经元,所有这些加权和都会爆炸。因为 a21 值很高,所以会再次出现饱和问题,这导致梯度消失问题。类似地爆炸梯度问题也可能发生。
如何克服这一点?
为了处理这些梯度问题,我们可以以合适的分布方式初始化随机权重。不使用标准的正态分布,而是使用具有 k/n 方差的正态分布,其中 k 是基于激活函数选择的。
Xavier Glorot 和 He 等人是更好的随机权重初始化这一概念的第一贡献者。
tanh 和逻辑激活函数的 Xavier 初始化
Xavier 提出了一种更好的随机权重初始化方法,该方法在初始化权重时还包括网络的大小(输入和输出神经元的数量)。
根据这种方法,权重应该与前一层中神经元数量的平方根成反比。

其中权重可以在 Python 中初始化为np.random.randn(sizes[i-1],sizes[i])*np.sqrt(1/sizes[i-1])
按照这种方法,隐藏层输入的加权和将不会取很大的值,并且减少了消失 / 爆发梯度问题的机会。
ReLu 和泄漏 ReLu 激活功能的初始化
He 初始化类似于 Xavier 初始化,其中前一层中神经元的数量被赋予重要性。但是因子是乘以两个而不是一个和*。*

其中权重可以在 Python 中初始化为np.random.randn(sizes[i-1],sizes[i])*np.sqrt(2/sizes[i-1])
濒死神经元 是 ReLu 激活功能的常见问题。使用 ReLu 激活功能, 多达 50% 的神经元可能在训练过程中死亡。为了处理这种情况,在初始化中,该因子乘以两个。
结束注释
在这个旅程中,到目前为止,我们已经讨论了各种 权重初始化 方法以及与每种方法相关的问题。建议使用 Xavier 初始化用于sigmoid 基础激活函数 He 初始化 用于 ReLu 和 Leaky ReLu 激活函数。******
为什么在彩票上下注是一个非常糟糕的主意(如果你真的想赢的话)
使用数据可视化来透视我们在衡量决策结果方面的失败程度

Photo by dylan nolte on Unsplash
我们一次又一次地听到彩票中奖很难。但是我们仍然玩它。
难道 13,983,816*中有 1%的机会中头奖听起来不是近乎不可能和令人畏惧的吗?显然不是。
或者,435,461/998,844*的时间里,你最终得到 0 个匹配的号码,却什么也没赚到?似乎还不够令人沮丧。
那么,为什么人们不能感受到赢得头奖的机会有多遥远呢?是因为我们没有能力理解这些巨大数字的庞大程度吗?为了弄清楚这一点,我决定找到一种方法来具体化这些数字背后的真正含义。
*概率来源于标准的 49 (6/49)彩票中的 6。如果你在考虑像强力球或百万彩票这样的其他彩票变体,中奖几率会比 T2 差很多。
视觉化
就在昨天,我想到一个主意,把从 49 个数字中选择 6 个数字(或球)的所有可能结果可视化。
然后,我会将这 13,983,816 个不同的结果分成 7 个不同的集合(或事件),每个集合代表所有 6 个数字的组合,这些组合将与任意获胜的 6 个数字组合精确匹配 k (其中 k 是 0 到 6 之间的任意整数)。
如果你现在真的对术语“结果”和“事件”感到困惑,这里有一个 1 分钟的速成课程:
试验:产生结果的程序(即从 49 个数字中选择 6 个数字的行为)
结果:一个试验的可能结果(即你抽中的数字,[8,13,34,35,41,49])
事件:包含满足特定标准的实验结果的集合(即,与获胜组合[1,2,3,4,5,6]有 6 个精确匹配的结果的集合是包含唯一结果[1,2,3,4,5,6]的集合)
每个结果将由一个像素表示,并且表示所有结果的所有 13,983,816 个像素将并排绘制,以给出每个集合相对于彼此有多大的指示。
瞧,观想不是为胆小的人准备的:

Outcomes of drawing 6-number combination from a set of 49 numbers that matches with a winning 6-number combination
现在,在你真正开始尝试像在普通图表上那样读取轴之前,请注意,边上和底部的数字不构成任何轴的一部分。它们只是数量标记,帮助您计算图形中的像素(代表结果),特别是因为它们有这么多。
那么这意味着什么呢?有 0 个匹配数字的集合几乎占据了整个结果空间的一半,这表明答对 0 个数字的概率很高,接近一半。
然后,我们看到彩色块变得越来越小。在 3 个匹配的数字(橙色块),事情开始变得微小,我添加了 2 个放大部分,以帮助您欣赏它们的相对大小。
但是等等,左上角的小红点是怎么回事?是的,它就是你认为的那样,一个像素代表中大奖的唯一结果。它甚至需要被放大才能被看到。
不服气它小?尝试使用数量标记来帮助您了解单个像素与整个图相比有多小,图的长度约为 3500 像素。它的高度也是如此。
还认为选择中奖的头奖组合很容易吗?
以不同的方式看待事物——骨灰盒和球
如果你发现组合学和概率很难,理解彩票背后的数学的另一个简单得多的方法是将问题转化为经典的瓮球问题:

This urn will certainly not fit the number of balls we need to simulate the probabilities found in a lottery (Photo: MoMath)
什么是瓮球问题?
想象一下,里面有一个瓮和一些不同颜色的球。你从瓮中随机抽取一个球,它的颜色将决定你得到的结果。假设它是黑色的,你输了,但如果它是红色的,你赢了。
用一个球代表从 49 个数字中抽取 6 个数字的每个结果,用一种颜色(例如橙色)代表属于同一组的所有球(例如 3 个匹配数字的结果),我们可以想象将 13,983,816 个 7 种不同颜色的球放入一个瓮中,然后随机抽取一个球来确定我们将得到什么结果。以下是我们需要放入的每种颜色的球的数量:
灰色(0 个匹配数字):6,096,454
粉色(1 个匹配号码):5,775,588
棕色(两个匹配的数字):1,851,150
橙色(3 个匹配号码):246,820
紫色(4 个匹配的数字):13,545
蓝色(5 个匹配的数字):258
红色(6 个匹配号码/头奖):1
你还觉得抽那个红球就能中头奖容易吗?这实际上相当于从图中随机选择一个像素,并希望它是红色的。
其他见解
就在昨天,我在 subreddit /r/dataisbeautiful 上发布了我的观想,令我惊讶的是,它产生了许多积极的回应(19.3 千次投票!)和关于赌博的有趣讨论。
一些 redditors 在他们的评论中分享了其他方式来透视人类在彩票投注方面做出的非理性决策。
一个人提到,鉴于[1,2,3,4,5,6]看起来很荒谬,大多数彩票玩家都不会考虑将赌注下在上面,但事实上,这个组合与其他任何组合一样有机会赢得头奖。
为了利用这种非理性的人类行为,另一位 redditor 建议,我们也许应该只购买历史上很少被其他人购买的组合,因为这将确保奖金池不会在头奖事件中被分割。听起来合理吗?
房间里的大象
现在我已经向你展示了彩票的概率是如何起作用的,以及它们是如何对你不利的,重要的是要指出这只是评估是否值得玩彩票的一种方式。

There’s always a catch… like always. (Photo : Smithsonian Channel)
我忽略的另一个重要因素是成本。你每张彩票花多少钱?还有获得 x 匹配号码的奖金是多少?单程票的预期价值是多少?如果你想要一个快速的答案,看看在彩票游戏中这种考虑是否会站在你这边,只要再想想有多少彩票运营商,以及谁在经营*。*
但是,除了几乎不可能中奖,而且玩起来可能非常昂贵之外,彩票真的有任何价值吗?值得思考的一个有趣的方面是玩彩票实际上带来的乐趣和兴奋。
正如一位 redditor 评论的那样,买彩票就像是“为致富的白日梦买单”。也许玩彩票带来的价值远远超出了统计和金钱的衡量。
但现在的问题是,你会不会因为在无数次为之付出后却无法实现那个“白日梦”而感到恼火?
如果你喜欢我的文章,可以看看我对澳大利亚学生移民数字的分析和思考。我也写更多的技术文章,比如这篇关于如何使用 Tableau 创建动画条形图的教程。
为什么生物学对人工智能持怀疑态度
生命科学的深度学习
为什么精准医疗不是

这是生命科学的 深度学习 专栏的第六篇文章,我在这里演示了深度学习如何用于古代 DNA 、单细胞生物学、生物医学组学集成、临床诊断学和显微成像。今天我将解释这一系列帖子的动机,并分享为什么生物学和医学 在概念上 对 AI 有不同的观点 ,这是我多年来与具有生物学和医学背景的人一起工作所学到的。
超越全基因组关联研究
我来机器学习并不是因为它很酷,每个人都在谈论它,而是在寻找一种常用统计学的替代方法时发现了它。当来自所有基因的遗传变异被扫描与疾病的相关性时,我正在通过基于 p 值的排名进行统计分析,搜索与疾病相关的基因全基因组关联研究,就像下面二型糖尿病(T2D)的曼哈顿图。

Manhattan plot for Type 2 Diabetes (T2D) from DIAGRAM, Nature Genetics 42 (7), 579–589 (2010)
如果你不熟悉曼哈顿图,一个点是一个遗传变异体,x 轴是该遗传变异体在人类基因组上的位置,y 轴是该遗传变异体与疾病的相关性/关联性的 -log10(p 值)。曼哈顿图上的峰值表明与该疾病有最强关联的基因片段。通过这种方式,发现了许多与人类疾病相关的基因,希望这些知识能够用于 临床诊断 对疾病的预测和预防。然而,人们很快意识到,在关联研究中发现的基因不能预测常见疾病,如糖尿病、心血管、精神分裂症等。我在这里详细讨论了。我觉得失败是由于基因的 p 值排序,并开始编写我自己的算法,该算法优化了预测能力 **而不是关联的 p 值。**后来我意识到我所编码的东西被称为 随机森林 在研究中被称为机器学习。这就是我对这个迷人领域感兴趣的原因。
生物怀疑论
然而,我对机器/深度学习/人工智能的热情并没有被我的大多数具有生物学背景的同事分享。当我主张向 Google Deep Mind 学习,试图找到我们的修辞问题的答案,如 【缺失的遗传性问题】、 时,我感觉到消极的沉默突然拥抱了观众中的每个人,我很快被学术教授包围,他们解释说机器学习是一种炒作、一个黑盒和**“我们不需要预测** ,但希望 理解生物机制”。

From B.Maher, Nature, volume 456, 2008
他们中的许多人想知道为什么他们应该关心深度学习在国际象棋、围棋和星际争霸中的进展,这是在谈论深度学习时通常强调的。事实上,对于一个典型的生物学家来说,很难看出星际争霸与活细胞有什么关系。人工智能努力构建的一般智能和生物学之间肯定有联系,但在文献中很少解释。当与生物学家交谈时,我通常会尝试给出更多令人赞赏的例子,说明深度学习解决了长期存在的蛋白质折叠问题。

为什么生物学不喜欢预测
现在让我们简单讨论一下上面提到的关于深度学习的刻板印象。嗯,关于炒作我同意,但如果它提高了我们的生活质量,这是一个坏的炒作吗?具有讽刺意味的是,即使是为显微镜图像分析进行深度学习的生物学家也往往不喜欢和不信任深度学习,但他们不得不这样做,因为 a)这是一种宣传,b)与手动分割相比,它通过自动特征提取提供了更高的准确性。

This is how I feel talking Deep Learning to biologists
关于黑盒,任何机器学习都给你按照对你感兴趣的生物过程的重要性排列的特征,也就是说,你得到了这个过程的关键人物。如果你知道你的生物过程的驱动因素,你应该对这个过程有相当多的了解,不是吗?所以我一直不明白他们为什么叫它黑匣子。

现在我们来到生物学家和自然科学家心态的基石点。预测。由于这个词在这个社区名声不好,我尽量不在和生物学家交流时使用这个词。人们通常认为,在进行预测时,人工智能人员过于关注他们模型的准确性,而忽视了他们所研究过程的潜在机制。这有一些根据,但通常是一个令人难以置信的刻板印象。
不了解潜在的机制,怎么能做出好的预测呢?
如果一个模型可以预测,应该总有办法回滚它,看看模型里面是什么,以及为什么它会预测。或者,全基因组关联研究提供了一系列具有生物学意义的特征/基因,但它们不能预测疾病,这意味着它们不能用于临床,所以它们的选择方式有问题。如果基因不能用于临床,那么基于生物学意义选择基因又有什么意义呢?关心准确性,分析师间接关心潜在的生物机制。
在我看来,这种怀疑和保守主义减缓了生命科学中诸如古 DNA进化生物学 这些机器/深度学习/AI 基本缺席的领域的进展。我的预测是,强化学习可能是进化生物学计算分析的未来。
Reinforcement Learning bipedal organism walking
为什么医学是开放的
相比之下,和有医学背景的同事聊起来,感觉就完全不一样了。他们对 AI 非常热情和好奇,即使他们不完全遵循我对神经网络的推理。这种开放的态度部分是因为机器/深度学习/AI 已经存在,广泛用于(其中早期疾病预测是主要目标之一),并在癌症诊断的放射成像方面取得进展。Deep Mind 最近发布了一种令人印象深刻的临床应用算法,可以在 48 小时内早期预测急性肾损伤。****

From Tomasev et al., Nature, 572, 116–119 (2019)
医学界对人工智能产生浓厚兴趣的另一个原因是,他们迫切希望利用一切可用的手段来帮助他们的病人。如果人工智能可以早期预测疾病,这是最重要的,因为我们没有时间深入研究潜在的生物机制。事实上,几次去诊所和看到痛苦中的人让我大开眼界,我当然更清楚地理解了为什么我要做研究。
摘要
在本文中,我们了解到机器/深度学习/AI 与传统的基于 p 值的统计方法相比,更具有 临床适用性 框架,因为它特别优化了对临床至关重要的 预测能力。尽管预测在生物界名声不佳,但当试图达到更高的准确性时,它不一定会牺牲生物学理解的深度。****
像往常一样,让我在评论中知道你最喜欢的生命科学领域,你想在深度学习框架内解决这个问题。在媒体尼古拉·奥斯科尔科夫关注我,在 Twitter @尼古拉·奥斯科尔科夫关注我,在 Linkedin 关注我。我计划写下一篇关于如何用深度学习检测尼安德特人渗入的区域的帖子,敬请关注。
为什么业务和产品应该始终定义数据科学的 KPI 和目标
为什么企业或产品应该选择适合他们的 KPI,为什么研究人员应该选择满足企业或产品需求的数学 KPI。

关键绩效指标(KPI)是一种绩效衡量指标,用于评估所参与的组织、项目或产品的绩效。我们需要 KPIs & Goals,以便有一组所有相关利益相关者都同意的期望,这允许我们测量业务影响,并朝着单个结果进行优化。
在业务或产品(BP)团队已经建立的公司中,与数据科学(DS)的良好沟通是必不可少的。DS 团队需要两种类型的 KPI,一种来自 BP 方面,另一种由 DS 团队创建,以满足 BP KPIs &目标。在大多数情况下,DS KPIs 将不同于 BP KPIs。这反过来允许我们定义与之一致的 KPI。很多情况下,这些 KPI 不需要相同!
想象一下,你需要启动一个新项目或修复一个旧模型,但没有 BP KPI。你被告知尽你所能,反复迭代,直到找到一个合适的解决方案。然后你认为你已经弄清楚了 BP 的需求是什么,并为它制定了一个数学 KPI。
这就是为什么我不建议使用迭代过程来拟合 DS KPI 和不是来自 BP 的 BP KPI:
- 研究过程需要时间。
- 为了实现某个目标,研究人员可能会检查许多可能的解决方案。
- 实际上,这可能需要几周时间!
拥有 BP KPI 首先允许利益相关者达成一致,允许我们(DS)专注于满足业务需求的解决方案,最后它更加敏捷,因为它防止了没有明确定义的目标的不必要的长时间迭代。
"为了达到某个目标,研究人员可能会检查许多可能的解决方案."例如,假设你的利益相关者对分类器有意见,他们抱怨分类器更喜欢对某些类进行分类。有许多可能的解决方案,有些在时间或金钱方面很昂贵,例如注释更多的样本。其他的可以便宜一点;诸如过采样或欠采样、合成采样、影响类别权重或样本权重、推拉精度和召回等解决方案…
以下是描述某项任务、BP KPI 或目标以及如何将其转化为 DS KPI 的四个示例,请注意,这些数字是为了解释总体思路而编造的:
任务 1 :创建模型,预测房子是否有空调、t 型洗衣干衣机或热水锅炉等。
注:电力公司有每家每户电器的统计。
- 产品 KPI :匹配电子公司统计报表。目标:贴近电力公司的期望。
- DS KPI :精度,目标 : 81%。
- DS KPI :目标分布。目标:与电力公司报告相同。即,已知 40%的房屋具有烘干机。因此,我们在分类器上设置了一个阈值,这样 40%的房子都会有烘干机。
任务二:改善和优化公司各种场景下的管理费用支出
- 业务 KPI :华润。目标:减少 10%。
- DS KPI :标注能力。目标:使用相同的资源支持多两倍的客户端。
- DS KPI :批注速度。目标:提供一个能够将样品注释速度提高 3 倍的解决方案。即,更多的注释允许支持更多的客户端并获得更多的数据。
- DS KPI :关注最相关的标注样本。目标:减少 75%的不相关标注。
任务 3:帮助其中一个团队提高工作效率
- 业务 KPI :投产时间。目标:减少一半。
- DS KPI :精度、召回、任务完成时间。目标:创建一个解决任务的自动化流程,准确率 80%,召回率 90%,完成时间不超过 5 分钟。
任务 4 :基于异常检测创建信号警报
- 业务 KPI :客户投诉垃圾邮件提醒的次数。目标:减少 50%。
- DS KPI :误报。目标:只允许 1%的误报。
右度量的虚幻性
在某些场合,你会发现自己处于这样一种情况:产品、业务甚至销售向客户承诺某个产品的某个精确度。我知道有时这是不可避免的,但是,这里有一些关于为什么准确性不总是要考虑的适当 KPI 的争论。
不同的度量组合可以达到相同的精度。某个准确率高的模型,可以有高准确率,低召回率。另一个具有较低精确度的模型可以具有相似的精确度和较高的召回率。我假设大多数客户会选择第一个模型,因为它具有更好的准确性,然而,BP 的需求可能会满足于第二个模型,因为我们希望捕捉更多更精确的样本。
高精度并不能保证好的结果。例如,在图 1 中,我们看到了 4 个多类算法的比较,特别显示了准确性和 F1。如果我们只考虑准确性,算法 3 似乎是最佳候选,但是,由于相似的准确性和最重要的低召回水平,算法 1、2 和 3 不应被考虑,因为算法 4 捕获更多的样本。

Figure1: a comparison of accuracy vs F1 for 4 multi-class algorithms,
底线是准确性并不总是与我们的期望或 BP 的需求相关,选择正确的数学指标应该留给您的研究人员,即 BP 应该选择适合他们的 KPI,ds 应该将其转化为满足 BP KPI 的数学。
我提议的流程
下面的流程(图 2。)试图弥合 BP 和 DS 在工作关系、设定 KPI、验证 KPI 并最终交付一个大家都满意的解决方案方面的差距

Figure 2: a proposed flow for when working side by side with business and product
我们从紫色方框开始,BP 有一个新项目,他们定义了 KPI 和目标。DS 团队接受它们(粉色)并开始制定数学 KPIs &目标来满足 BP 的需求。一旦公式化,DS 应该与 BP 进行数学交流,以查看是否有比对。准备就绪后,DS 团队开始研究(橙色),对 KPI 和目标进行内部验证(黄色)。比如试图达到某个精度点。当 DS-验证步骤完成时,可交付物被传递给 BP 进行验证。BP 通过他们自己的验证阶段(青色),如果不成功,他们将它交还给 DS 团队进行另一次迭代,如果成功,则交付一个解决方案,每个人都满意(绿色)。在决定需要一个新的 KPI 或一个新的目标的情况下,这个过程从紫色的盒子开始,也就是说,这就像说“我们正在开始一个新的项目”。
我完全承认,一些利益相关方不会完全配合这一想法,可以相当肯定地认为,您将会听到以下评论:
- 定性的反馈就足够了,因此,我们不需要 KPI 和目标。
- 某个团队不擅长定义 KPI 和目标。这是产品的工作,以帮助这一点。
定性反馈可能不会很好地转化为满足原始需求的解决方案,此外,如果没有 KPI,当有多个利益相关者和无限数量的可能解决方案时,可能不可能有“完成的定义”。因此,建议联系产品团队,与他们合作定义这些指标。
我希望这些想法能给开始一个新项目或给你的产品添加新功能时出现的混乱带来一些秩序,为你节省一些时间,并希望有助于业务经理、产品经理、数据科学家和研究人员之间的复杂关系。
我要感谢我的同事 Sefi Keller、Samuel Jefroykin、Yoav Talmi 和 Ido Ivry 提供的宝贵意见。
Ori Cohen 博士拥有计算机科学博士学位,专注于机器学习。他领导着 Zencity.io 的研究团队,试图积极影响市民的生活。
为什么脑波强化器的发布是一件大事

大脑的芯片可以成为深度学习的事实上的芯片
深度学习模型的最大问题之一是,它们变得太大,无法在单个 GPU 中训练。如果在单个 GPU 中训练当前的模型,它们将花费太长时间。为了及时地训练模型,有必要用多个 GPU 来训练它们。
我们需要将训练方法规模化到使用 100 个甚至 1000 个 GPU。例如,的一位著名研究员能够将 ImageNet 的训练时间从 2 周减少到 18 分钟,或者在 2 周内而不是 4 年内训练出最大和最先进的 Transformer-XL。他使用了 100 个 GPU 来完成这个任务。
随着型号越来越大,需要的处理器也越来越多。每当将这些模型的训练扩展到几个 GPU 时,都会有一些瓶颈会显著增加训练它们的时间。但有两个主要瓶颈阻碍了这一领域的发展:处理器之间的网络速度和每个 GPU 可以存储多少内存。让我们覆盖它们:
网络速度
网络的速度成为一个瓶颈,因为为了训练这些神经网络,你需要传递每个节点的梯度,以便算法可以找出如何更新其权重。像 Ring AllReduce 这样的算法通常用于同步不同节点之间的工作。芯片之间的通信速度如此重要,以至于 Nvidia 花了 68 亿美元收购了一家名为 Mellanox 的公司,以改善其 GPU 之间的通信。
GPU 内存
将模型扩展到多个 GPU 的挑战的第二部分是每个 GPU 拥有的内存量。神经网络可以消耗 GB 的内存,GPU 只有 MB 的片上内存。目前,为了解决这个问题,GPU 将神经网络存储在焊接在它旁边的外部存储器上。问题是外部存储器比片内存储器慢 10 到 100 倍&更耗电。
像谷歌的神经机器翻译这样的大型模型甚至不适合放在一个 GPU 外部存储器中。通常,它们必须被分散到数十个 GPU 上。这又增加了 10 到 100 倍的延迟。
因此,在每个 GPU 上存储权重和用于训练的数据集对于快速训练模型非常重要。它的内存越大,训练模型的速度就越快,消耗的能量也就越少。理想情况下,整个模型可以放在一个芯片上。
大脑综合方法
今天最快的人工智能芯片也是最大的,这不是巧合。面积越大,内核和内存就越多。问题是,今天制造芯片的工艺使用 ASML 制造的标准光刻机,其刻线尺寸约为 858 纳米,几乎与英伟达 V100 的尺寸相同。已经到极限了。

ASML machinery to produce chips of size of around 858nm²
脑波强化器用新方法整合了制造芯片的旧流程。脑波强化器所做的是将单个晶片构建成一个“巨型芯片”。它的新“芯片”包含总共 1.2 万亿个晶体管。这比 Nvidia 生产的最先进的 GPU 芯片高出 50 倍。更重要的是,随着所有这些芯片合并成一个大芯片,脑波强化器的芯片实现了它们之间更高的通信速度。它也有更多的内存!据报道,它拥有 Nvidia 旗舰 GPU 的 3000 倍内存芯片和 10000 倍 GPU 之前可以实现的带宽。

Cerebras’ co-founder Sean Lie and the Cerebras’ Wafer Scale Engine (WSE). It holds 400,000 cores and 18GB of memory
在 80 年代,有公司试图建造一个大的集成芯片,就像脑波强化器那样,但是他们失败了。这些公司由于缺乏资金而失败了。他们没有能够克服很多工程问题来做到这一点。脑波强化器做到了。
脑波强化器制造了有史以来最大的芯片,一个有整个晶片大小的芯片。Cerebras 的芯片(大晶片)仍然使用与旧芯片相同的方法来构建每个“单独的芯片”,但晶片是按部分“蚀刻”的。脑波强化器与 TSMC(制造商)合作添加额外的电线,所以所有的芯片一起工作,作为一个整体而不是单独的。为了制造晶片大小的芯片,脑波强化器克服了 5 大挑战:
挑战
1.划线之间的通信
首先,为了实现这一点,脑波强化器团队必须处理跨越“划线”的通信。通过与 TSMC 合作,他们不仅发明了新的通信渠道,还必须编写新的软件来处理超过万亿晶体管的芯片。
2.芯片产量
第二个挑战是产量。当芯片覆盖整个硅晶片时,该晶片蚀刻中的一个缺陷就可能使整个芯片失效。Cerebras 通过在整个芯片中添加额外的核心来解决这个问题,这些核心在晶片上的核心附近出现错误时用作备份
3.热膨胀
他们处理的第三个问题是热变化。芯片在工作时会变得非常热,但是不同的材料会以不同的速度膨胀。这意味着将芯片固定在主板上的连接器也需要以同样的速度热膨胀。他们发明了一种可以吸收部分温差的材料。
4.包装和制造流程
他们的第四个挑战是基本上与现有的服务器基础架构集成。没有人有工具来处理这么大的芯片。所以他们不得不为它建造包装,并创造一个新的生产流程。不仅如此,他们还开发了软件来测试这一切。
5.冷却
最后,一个芯片中的所有处理能力需要巨大的电力和冷却。比“更小”的芯片多得多。他们基本上是通过翻转芯片来解决问题的。冷却在芯片上的所有点垂直传递,而不仅仅是水平传递。
前方道路
在克服了所有这些挑战之后,脑波强化系统还有很长的路要走,这并不容易。在成为主流之前,他们仍然需要证明自己。他们开始向少数客户发布原型,客户需要一段时间才能在生产中使用它的芯片。
不仅如此,Nvidia 还为开发人员建立了许多工具,以便在多个 GPU 中创建和部署他们的模型。开发人员还需要时间来获得与脑波强化器的芯片相匹配的类似工具。但这种芯片将代表着向更大更好的神经网络迈出的一大步,也将是向建设 AGI 迈出的一大步。
为什么选择数据科学作为你的职业
数据科学已经成为一项革命性的技术,似乎每个人都在谈论它。被誉为“21 世纪最性感的工作”的数据科学是一个时髦词,很少有人真正了解这项技术。虽然许多人希望成为数据科学家,但权衡数据科学的利弊并给出真实的图景是至关重要的。在本文中,我们将详细讨论这些要点,并为您提供关于数据科学的必要见解。

Pros and Cons of Data Science
数据科学导论
数据科学是对数据的研究。它是关于提取、分析、可视化、管理和存储数据以创造洞察力。这些见解有助于公司做出强大的数据驱动型决策。数据科学需要使用非结构化数据和结构化数据。这是一个多学科领域,其根源在于统计学、数学和计算机科学。由于大量的数据科学职位和丰厚的薪水,这是最受欢迎的工作之一。这是对数据科学的简要介绍,现在我们来探讨一下数据科学的利弊。
数据科学的利与弊
数据科学领域规模庞大,有其自身的优势和局限性。因此,在这里我们将衡量数据科学的利弊。本文将帮助您评估自己,并在数据科学领域采取正确的措施。
a.数据科学的优势
数据科学的各种好处如下:
1.它很受欢迎
数据科学非常受欢迎。未来的求职者有很多机会。这是 Linkedin 上增长最快的工作,预计到 2026 年将创造 1150 万个工作岗位。这使得数据科学成为一个高度可雇佣的工作领域。
2.丰富的职位
很少有人具备成为一名完整的数据科学家所需的技能。与其他 IT 部门相比,这使得数据科学不那么饱和。因此,数据科学是一个非常丰富的领域,有很多机会。数据科学领域对数据科学家的需求很大,但供应不足。
3.高薪职业
数据科学是收入最高的工作之一。根据 Glassdoor 的数据,数据科学家的平均年薪为 116,100 美元。这使得数据科学成为一个非常有利可图的职业选择。
4.数据科学是多功能的
数据科学有许多应用。它广泛应用于医疗保健、银行、咨询服务和电子商务行业。数据科学是一个非常通用的领域。因此,你将有机会在各个领域工作。
5.数据科学让数据变得更好
公司需要熟练的数据科学家来处理和分析他们的数据。他们不仅分析数据,还提高数据质量。因此,数据科学处理丰富的数据,并使其更好地为他们的公司服务。
6.数据科学家声望很高
数据科学家让公司做出更明智的商业决策。公司依赖数据科学家,并利用他们的专业知识为客户提供更好的结果。这使得数据科学家在公司中占据重要位置。
7.不再有无聊的任务
数据科学已经帮助各行各业将冗余任务自动化。公司正在使用历史数据来训练机器,以便执行重复的任务。这简化了以前人类承担的艰巨工作。
8.数据科学让产品更智能
数据科学涉及机器学习的用途,这使得各行各业能够创造出更好的专门为客户体验定制的产品。例如,电子商务网站使用的推荐系统根据用户的历史购买记录向用户提供个性化的见解。这使得计算机能够理解人类行为并做出数据驱动的决策。
9.数据科学可以拯救生命
由于数据科学,医疗保健行业得到了极大的改善。随着机器学习的出现,检测早期肿瘤变得更加容易。此外,许多其他医疗保健行业正在使用数据科学来帮助他们的客户。
10.数据科学可以让你成为更好的人
数据科学不仅会给你一个伟大的职业生涯,还会帮助你的个人成长。你将能够拥有解决问题的态度。由于许多数据科学角色在 IT 和管理之间架起了桥梁,您将能够享受两个世界的优势。
b.数据科学的缺点
虽然数据科学是一个非常有利可图的职业选择,但这个领域也有各种各样的缺点。为了了解数据科学的全貌,我们还必须知道数据科学的局限性。其中一些如下:
1.数据科学是一个模糊术语
数据科学是一个非常笼统的术语,没有明确的定义。虽然它已经成为一个流行词,但是很难写下数据科学家的的确切含义。一个数据科学家的具体角色取决于公司所专攻的领域。虽然有些人将数据科学描述为科学的第四范式,但很少有批评者称之为仅仅是统计学的更名。
2.掌握数据科学几乎是不可能的
作为许多领域的混合体,数据科学源于统计学、计算机科学和数学。要精通每一个领域并在所有领域都成为专家是不可能的。虽然许多在线课程一直试图填补数据科学行业面临的技能缺口,但考虑到该领域的广阔性,要精通它仍然是不可能的。一个有统计学背景的人可能无法在短时间内掌握计算机科学,以便成为一名精通数据的科学家。因此,这是一个不断变化的动态领域,需要人们不断学习数据科学的各种途径。
3.需要大量的领域知识
数据科学的另一个缺点是它依赖于领域知识。一个在统计学和计算机科学方面有相当背景的人,如果没有其背景知识,会发现很难解决数据科学问题。反之亦然。例如,从事基因组序列分析的医疗保健行业需要一名具备遗传学和分子生物学知识的合适员工。这使得数据科学家能够做出经过计算的决策,以帮助公司。然而,来自不同背景的数据科学家很难获得特定领域的知识。这也使得从一个行业迁移到另一个行业变得困难。
4.任意数据可能会产生意想不到的结果
数据科学家分析数据并做出谨慎的预测,以促进决策过程。很多时候,所提供的数据是任意的,不会产生预期的结果。这也可能由于管理薄弱和资源利用率低而失败。
5.数据隐私问题
对于许多行业来说,数据是他们的燃料。数据科学家帮助公司做出数据驱动的决策。但是,流程中使用的数据可能会侵犯客户的隐私。客户的个人数据对母公司来说是可见的,有时可能会由于安全漏洞而导致数据泄露。关于保护数据隐私及其使用的伦理问题一直是许多行业关注的问题。
摘要
在权衡了数据科学的利弊之后,我们能够展望这个领域的全貌。虽然数据科学是一个有许多有利可图的优势的领域,但它也有自己的缺点。作为一个不太饱和的高薪领域,它已经彻底改变了几个行业,当考虑到这个领域的广阔性和跨学科性质时,它也有自己的背景。数据科学是一个不断发展的领域,需要数年才能精通。最后,由你来决定是数据科学的优点激励你把它作为你未来的职业,还是缺点帮助你做出谨慎的决定!
希望您喜欢我们关于数据科学利弊的文章。通过评论分享您的反馈。
必读-
许多其他大公司像脸书、亚马逊、优步都在使用它。看看— 数据科学使用案例


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言










{kind=link}
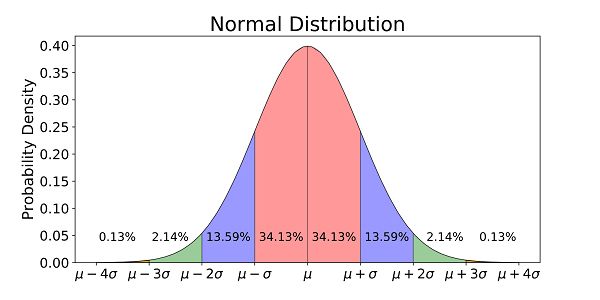{kind=link}