







基于 Python 的遗传算法优化人工神经网络

Image Created by Ahmed Fawzy Gad: https://pixabay.com/illustrations/artificial-neural-network-ann-3501528
在我的 LinkedIn 个人资料中的标题为“使用 NumPy 的人工神经网络实现和 Fruits360 图像数据集的分类”的先前教程中,在此链接处,创建了一个人工神经网络(ANN)用于对 Fruits360 图像数据集的 4 个类别进行分类。本教程中使用的源代码可以在我的 GitHub 页面中找到。
这个教程也可以在 TowardsDataScience 这里获得。
本教程的快速总结是提取特征向量(360 箱色调通道直方图)并通过使用基于标准偏差的过滤技术将其减少到仅 102 个元素。后来,使用 NumPy 从头开始构建 ANN。
人工神经网络没有完全创建,因为只有前向传递准备就绪,但没有用于更新网络权重的后向传递。这就是为什么准确率很低,不超过 45%的原因。这个问题的解决方案是使用优化技术来更新网络权重。本教程使用遗传算法(GA)优化网络权重。
值得一提的是,上一篇和这篇教程都是基于我 2018 年的一本书,该书被引用为“Ahmed Fawzy Gad‘使用深度学习的实用计算机视觉应用与 CNN’。2018 年 12 月,新闻,978–1–4842–4167–7。这本书可以在施普林格书店这个链接买到。你可以在这本书里找到所有的细节。
本教程中使用的源代码可以在我的 GitHub 页面这里获得。
阅读更多关于遗传算法的信息
在开始本教程之前,我建议先阅读一下遗传算法是如何工作的,以及如何使用 NumPy 从头开始在 Python 中实现它,这是基于我在本教程末尾的参考资料一节中列出的链接中找到的以前的教程。
除了使用 Python 实现之外,在了解 GA 如何基于数值示例工作之后,我们可以开始使用 GA 通过更新其权重(参数)来优化 ANN。
将遗传算法与人工神经网络结合使用
GA 为一个给定的问题创建多个解决方案,并通过若干代进化它们。每个解决方案都包含所有可能有助于增强结果的参数。对于人工神经网络,所有层中的权重有助于实现高精度。因此,GA 中的单个解将包含 ANN 中的所有权重。根据前面教程中讨论的网络结构以及下图中给出的网络结构,ANN 有 4 层(1 个输入层、2 个隐藏层和 1 个输出层)。任何层中的任何重量都是同一解决方案的一部分。此类网络的单个解决方案将包含总重量数,等于 102x150+150x60+60x4=24,540。如果总体有 8 个解,每个解有 24,540 个参数,则整个总体的参数总数为 24,540x8=196,320。

看上面的图,网络的参数是矩阵形式,因为这使得人工神经网络的计算更容易。对于每一层,都有一个相关的权重矩阵。只需将输入矩阵乘以给定层的参数矩阵,即可返回该层的输出。遗传算法中的染色体是 1D 向量,因此我们必须将权重矩阵转换成 1D 向量。
因为矩阵乘法是处理 ANN 的一个很好的选择,所以在使用 ANN 时,我们仍将以矩阵形式表示 ANN 参数。因此,当与 ANN 一起工作时使用矩阵形式,而当与 GA 一起工作时使用向量形式。这使得我们需要将矩阵转换成向量,反之亦然。下图总结了将遗传算法与人工神经网络结合使用的步骤。该图被称为主图。

1D 向量的权重矩阵
群体中的每个解决方案将有两个表示。第一个是用于 GA 的 1D 向量,第二个是用于 ANN 的矩阵。因为 3 层有 3 个权重矩阵(2 个隐藏+ 1 个输出),所以将有 3 个向量,每个矩阵一个。因为 GA 中的解被表示为单个 1D 向量,所以这 3 个单独的 1D 向量将被连接成单个 1D 向量。每个解将被表示为长度为 24,540 的向量。下一个 Python 代码创建了一个名为 mat_to_vector() 的函数,该函数将群体中所有解的参数从矩阵转换为向量。
**def** mat_to_vector(mat_pop_weights):
pop_weights_vector = []
**for** sol_idx **in** range(mat_pop_weights.shape[0]):
curr_vector = []
**for** layer_idx **in** range(mat_pop_weights.shape[1]):
vector_weights = numpy.reshape(mat_pop_weights[sol_idx, layer_idx], newshape=(mat_pop_weights[sol_idx, layer_idx].size))
curr_vector.extend(vector_weights)
pop_weights_vector.append(curr_vector)
**return** numpy.array(pop_weights_vector)
该函数接受一个表示所有解的总体的参数,以便遍历这些解并返回它们的向量表示。在函数的开始,创建一个名为 pop_weights_vector 的空列表变量来保存结果(所有解的向量)。对于每一个矩阵形式的解,都有一个内部循环来遍历它的三个矩阵。对于每个矩阵,使用 numpy.reshape() 函数将其转换为向量,该函数接受输入矩阵和矩阵将被整形到的输出大小。变量 curr_vector 接受单个解的所有向量。生成所有向量后,它们被追加到 pop_weights_vector 变量中。
注意,我们对属于同一解决方案的向量使用了 numpy.extend() 函数,对属于不同解决方案的向量使用了 numpy.append() 。原因是 numpy.extend() 将属于同一解决方案的 3 个向量中的数字连接在一起。换句话说,为两个列表调用这个函数将返回一个新的单个列表,其中包含两个列表中的数字。这适合于为每个解决方案创建一个 1D 染色体。但是 numpy.append() 将为每个解决方案返回三个列表。为两个列表调用它,它返回一个新的列表,该列表被分成两个子列表。这不是我们的目标。最后,函数 mat_to_vector() 以 NumPy 数组的形式返回群体解,以便于以后操作。
实施 GA 步骤
在将所有解从矩阵转换为向量并连接在一起后,我们准备好执行名为“遗传算法优化简介”的教程中讨论的遗传算法步骤。这些步骤在主图中介绍,也在下图中总结。

请记住,GA 使用适应度函数来返回每个解决方案的适应度值。适应值越高,解决方案越好。最佳解决方案在父选择步骤中作为父返回。
诸如 ANN 之类的分类器的常见适应度函数之一是准确性。它是正确分类的样本与样本总数之间的比率。它是根据下一个等式计算的。根据主图中的步骤计算每个解决方案的分类精度。

每个解的单个 1D 向量被转换回 3 个矩阵,每层一个矩阵(2 个隐藏和 1 个输出)。使用名为 vector_to_mat() 的函数进行转换。它在下一段代码中定义。
**def** vector_to_mat(vector_pop_weights, mat_pop_weights):
mat_weights = []
**for** sol_idx **in** range(mat_pop_weights.shape[0]):
start = 0
end = 0
**for** layer_idx **in** range(mat_pop_weights.shape[1]):
end = end + mat_pop_weights[sol_idx, layer_idx].size
curr_vector = vector_pop_weights[sol_idx, start:end]
mat_layer_weights = numpy.reshape(curr_vector, newshape=(mat_pop_weights[sol_idx, layer_idx].shape))
mat_weights.append(mat_layer_weights)
start = end
**return** numpy.reshape(mat_weights, newshape=mat_pop_weights.shape)
它逆转了先前所做的工作。但是有一个重要的问题。如果给定解的向量只是一片,我们如何能分裂成三个不同的部分,每个部分代表一个矩阵?输入层和隐藏层之间的第一个参数矩阵的大小是 102x150。当转换成向量时,它的长度将是 15,300。因为根据 mat_to_vector() 函数,它是要插入到 curr_vector 变量中的第一个向量,所以它的索引从索引 0 开始,到索引 15,299 结束。 mat_pop_weights 用作 vector_to_mat() 函数的参数,以了解每个矩阵的大小。我们对使用来自 mat_pop_weights 变量的权重不感兴趣,只是使用了其中的矩阵大小。
对于同一解决方案中的第二个向量,它将是转换大小为 150x60 的矩阵的结果。因此,向量长度为 9000。这样的向量被插入到长度为 15,300 的前一个向量之前的变量 curr_vector 中。因此,它将从索引 15,300 开始,到索引 15,300+9,000–1 = 24,299 结束。使用-1 是因为 Python 从 0 开始索引。对于从大小为 60×4 的参数矩阵创建的最后一个向量,其长度为 240。因为它被添加到 curr_vector 变量中正好在长度为 9000 的前一个向量之后,所以它的索引将在它之后开始。也就是说,它的开始索引是 24,300,结束索引是 24,300+240–1 = 24,539。因此,我们可以成功地将向量恢复为原始的 3 个矩阵。
为每个解决方案返回的矩阵用于预测所用数据集中 1,962 个样本中每个样本的类别标签,以计算精确度。根据下一个代码,这是使用两个函数完成的,它们是预测输出()和适应度()。
**def** predict_outputs(weights_mat, data_inputs, data_outputs, activation=**"relu"**):
predictions = numpy.zeros(shape=(data_inputs.shape[0]))
**for** sample_idx **in** range(data_inputs.shape[0]):
r1 = data_inputs[sample_idx, :]
**for** curr_weights **in** weights_mat:
r1 = numpy.matmul(a=r1, b=curr_weights)
**if** activation == **"relu"**:
r1 = relu(r1)
**elif** activation == **"sigmoid"**:
r1 = sigmoid(r1)
predicted_label = numpy.where(r1 == numpy.max(r1))[0][0]
predictions[sample_idx] = predicted_label
correct_predictions = numpy.where(predictions == data_outputs)[0].size
accuracy = (correct_predictions/data_outputs.size)*100
**return** accuracy, predictions
**def** fitness(weights_mat, data_inputs, data_outputs, activation=**"relu"**):
accuracy = numpy.empty(shape=(weights_mat.shape[0]))
**for** sol_idx **in** range(weights_mat.shape[0]):
curr_sol_mat = weights_mat[sol_idx, :]
accuracy[sol_idx], _ = predict_outputs(curr_sol_mat, data_inputs, data_outputs, activation=activation)
**return** accuracy
predict_outputs() 函数接受训练数据的单个解决方案、输入和输出的权重,以及指定使用哪个激活函数的可选参数。它只返回一个解的精度,而不是群体中所有解的精度。为了返回群体中所有解的适应度值(即精度),函数 fitness() 遍历每个解,将其传递给函数 predict_outputs() ,将所有解的精度存储到数组精度中,并最终返回这样一个数组。
在计算了所有解决方案的适应值(即精度)后,主图中 GA 的剩余步骤以与之前相同的方式应用。最佳亲本根据其准确性被选入交配池。然后应用变异和交叉变异来产生后代。新一代的群体是利用后代和父母两者创建的。这些步骤要重复几代。
完整的 Python 实现
此类项目的 Python 实现有三个 Python 文件:
- ga.py 用于实现 ga 功能。
- ANN.py 用于实现 ANN 功能。
- 第三个文件,用于通过若干代调用此类函数。这是项目的主文件。
主项目文件实现
第三个文件是主文件,因为它连接了所有的函数。它读取特征和类标签文件,基于标准偏差过滤特征,创建 ANN 体系结构,生成初始解决方案,通过计算所有解决方案的适应度值、选择最佳父代、应用交叉和变异并最终创建新群体来循环通过若干代。下面给出了它的实现。这样的文件定义了 GA 参数,例如每个种群的解的数量、选择的亲本的数量、突变百分比和代的数量。您可以为它们尝试不同的值。
**import** numpy
**import** GA
**import** pickle
**import** ANN
**import** matplotlib.pyplot
f = open(**"dataset_features.pkl"**, **"rb"**)
data_inputs2 = pickle.load(f)
f.close()
features_STDs = numpy.std(a=data_inputs2, axis=0)
data_inputs = data_inputs2[:, features_STDs>50]
f = open(**"outputs.pkl"**, **"rb"**)
data_outputs = pickle.load(f)
f.close()
*#Genetic algorithm parameters:
# Mating Pool Size (Number of Parents)
# Population Size
# Number of Generations
# Mutation Percent* sol_per_pop = 8
num_parents_mating = 4
num_generations = 1000
mutation_percent = 10
*#Creating the initial population.* initial_pop_weights = []
**for** curr_sol **in** numpy.arange(0, sol_per_pop):
HL1_neurons = 150
input_HL1_weights = numpy.random.uniform(low=-0.1, high=0.1,
size=(data_inputs.shape[1], HL1_neurons))
HL2_neurons = 60
HL1_HL2_weights = numpy.random.uniform(low=-0.1, high=0.1,
size=(HL1_neurons, HL2_neurons))
output_neurons = 4
HL2_output_weights = numpy.random.uniform(low=-0.1, high=0.1,
size=(HL2_neurons, output_neurons))
initial_pop_weights.append(numpy.array([input_HL1_weights,
HL1_HL2_weights,
HL2_output_weights]))
pop_weights_mat = numpy.array(initial_pop_weights)
pop_weights_vector = ga.mat_to_vector(pop_weights_mat)
best_outputs = []
accuracies = numpy.empty(shape=(num_generations))
**for** generation **in** range(num_generations):
print(**"Generation : "**, generation)
*# converting the solutions from being vectors to matrices.* pop_weights_mat = ga.vector_to_mat(pop_weights_vector,
pop_weights_mat)
*# Measuring the fitness of each chromosome in the population.* fitness = ANN.fitness(pop_weights_mat,
data_inputs,
data_outputs,
activation=**"sigmoid"**)
accuracies[generation] = fitness[0]
print(**"Fitness"**)
print(fitness)
*# Selecting the best parents in the population for mating.* parents = ga.select_mating_pool(pop_weights_vector,
fitness.copy(),
num_parents_mating)
print(**"Parents"**)
print(parents)
*# Generating next generation using crossover.* offspring_crossover = ga.crossover(parents,
offspring_size=(pop_weights_vector.shape[0]-parents.shape[0], pop_weights_vector.shape[1]))
print(**"Crossover"**)
print(offspring_crossover)
*# Adding some variations to the offsrping using mutation.* offspring_mutation = ga.mutation(offspring_crossover,
mutation_percent=mutation_percent)
print(**"Mutation"**)
print(offspring_mutation)
*# Creating the new population based on the parents and offspring.* pop_weights_vector[0:parents.shape[0], :] = parents
pop_weights_vector[parents.shape[0]:, :] = offspring_mutation
pop_weights_mat = ga.vector_to_mat(pop_weights_vector, pop_weights_mat)
best_weights = pop_weights_mat [0, :]
acc, predictions = ANN.predict_outputs(best_weights, data_inputs, data_outputs, activation=**"sigmoid"**)
print(**"Accuracy of the best solution is : "**, acc)
matplotlib.pyplot.plot(accuracies, linewidth=5, color=**"black"**)
matplotlib.pyplot.xlabel(**"Iteration"**, fontsize=20)
matplotlib.pyplot.ylabel(**"Fitness"**, fontsize=20)
matplotlib.pyplot.xticks(numpy.arange(0, num_generations+1, 100), fontsize=15)
matplotlib.pyplot.yticks(numpy.arange(0, 101, 5), fontsize=15)
f = open(**"weights_"**+str(num_generations)+**"_iterations_"**+str(mutation_percent)+**"%_mutation.pkl"**, **"wb"**)
pickle.dump(pop_weights_mat, f)
f.close()
基于 1000 代,使用 Matplotlib 可视化库在该文件的末尾创建了一个图,该图显示了精度在每代之间如何变化。如下图所示。

经过 1000 次迭代,准确率达到 97%以上。相比之下,在之前的教程中,如果不使用优化技术,这一比例为 45%。这是为什么结果可能不好的证据,不是因为模型或数据有问题,而是因为没有使用优化技术。当然,对参数使用不同的值,比如 10,000 代,可能会提高精度。在这个文件的末尾,它将参数以矩阵的形式保存到磁盘上以备后用。
遗传算法实现
下面列出了 ga.py 文件的实现。注意, mutation() 函数接受 mutation_percent 参数,该参数定义了随机改变其值的基因数量。它在主文件中被设置为 10%。这样的文件包含两个新函数 mat_to_vector() 和 vector_to_mat() 。
**import** numpy
**import** random
*# Converting each solution from matrix to vector.* **def** mat_to_vector(mat_pop_weights):
pop_weights_vector = []
**for** sol_idx **in** range(mat_pop_weights.shape[0]):
curr_vector = []
**for** layer_idx **in** range(mat_pop_weights.shape[1]):
vector_weights = numpy.reshape(mat_pop_weights[sol_idx, layer_idx], newshape=(mat_pop_weights[sol_idx, layer_idx].size))
curr_vector.extend(vector_weights)
pop_weights_vector.append(curr_vector)
**return** numpy.array(pop_weights_vector)
*# Converting each solution from vector to matrix.* **def** vector_to_mat(vector_pop_weights, mat_pop_weights):
mat_weights = []
**for** sol_idx **in** range(mat_pop_weights.shape[0]):
start = 0
end = 0
**for** layer_idx **in** range(mat_pop_weights.shape[1]):
end = end + mat_pop_weights[sol_idx, layer_idx].size
curr_vector = vector_pop_weights[sol_idx, start:end]
mat_layer_weights = numpy.reshape(curr_vector, newshape=(mat_pop_weights[sol_idx, layer_idx].shape))
mat_weights.append(mat_layer_weights)
start = end
**return** numpy.reshape(mat_weights, newshape=mat_pop_weights.shape)
**def** select_mating_pool(pop, fitness, num_parents):
*# Selecting the best individuals in the current generation as parents for producing the offspring of the next generation.* parents = numpy.empty((num_parents, pop.shape[1]))
**for** parent_num **in** range(num_parents):
max_fitness_idx = numpy.where(fitness == numpy.max(fitness))
max_fitness_idx = max_fitness_idx[0][0]
parents[parent_num, :] = pop[max_fitness_idx, :]
fitness[max_fitness_idx] = -99999999999
**return** parents
**def** crossover(parents, offspring_size):
offspring = numpy.empty(offspring_size)
*# The point at which crossover takes place between two parents. Usually, it is at the center.* crossover_point = numpy.uint32(offspring_size[1]/2)
**for** k **in** range(offspring_size[0]):
*# Index of the first parent to mate.* parent1_idx = k%parents.shape[0]
*# Index of the second parent to mate.* parent2_idx = (k+1)%parents.shape[0]
*# The new offspring will have its first half of its genes taken from the first parent.* offspring[k, 0:crossover_point] = parents[parent1_idx, 0:crossover_point]
*# The new offspring will have its second half of its genes taken from the second parent.* offspring[k, crossover_point:] = parents[parent2_idx, crossover_point:]
**return** offspring
**def** mutation(offspring_crossover, mutation_percent):
num_mutations = numpy.uint32((mutation_percent*offspring_crossover.shape[1])/100)
mutation_indices = numpy.array(random.sample(range(0, offspring_crossover.shape[1]), num_mutations))
*# Mutation changes a single gene in each offspring randomly.* **for** idx **in** range(offspring_crossover.shape[0]):
*# The random value to be added to the gene.* random_value = numpy.random.uniform(-1.0, 1.0, 1)
offspring_crossover[idx, mutation_indices] = offspring_crossover[idx, mutation_indices] + random_value
**return** offspring_crossover
ANN.py 实现
最后,根据下面列出的代码实现 ANN.py 。它包含激活函数(sigmoid 和 ReLU)的实现,以及用于计算精度的**适应度()和预测输出()**函数。
**import** numpy
**def** sigmoid(inpt):
**return** 1.0 / (1.0 + numpy.exp(-1 * inpt))
**def** relu(inpt):
result = inpt
result[inpt < 0] = 0
**return** result
**def** predict_outputs(weights_mat, data_inputs, data_outputs, activation=**"relu"**):
predictions = numpy.zeros(shape=(data_inputs.shape[0]))
**for** sample_idx **in** range(data_inputs.shape[0]):
r1 = data_inputs[sample_idx, :]
**for** curr_weights **in** weights_mat:
r1 = numpy.matmul(a=r1, b=curr_weights)
**if** activation == **"relu"**:
r1 = relu(r1)
**elif** activation == **"sigmoid"**:
r1 = sigmoid(r1)
predicted_label = numpy.where(r1 == numpy.max(r1))[0][0]
predictions[sample_idx] = predicted_label
correct_predictions = numpy.where(predictions == data_outputs)[0].size
accuracy = (correct_predictions / data_outputs.size) * 100
**return** accuracy, predictions
**def** fitness(weights_mat, data_inputs, data_outputs, activation=**"relu"**):
accuracy = numpy.empty(shape=(weights_mat.shape[0]))
**for** sol_idx **in** range(weights_mat.shape[0]):
curr_sol_mat = weights_mat[sol_idx, :]
accuracy[sol_idx], _ = predict_outputs(curr_sol_mat, data_inputs, data_outputs, activation=activation)
**return** accuracy
资源
- 遗传算法优化导论
https://www . LinkedIn . com/pulse/introduction-优化-遗传-算法-ahmed-gad/
https://www . kdnugges . com/2018/03/introduction-optimization-with-genetic-algorithm . html
https://www.springer.com/us/book/9781484241660
- 遗传算法(GA)优化—分步示例
https://www . slide share . net/AhmedGadFCIT/genetic-algorithm-ga-optimization-step by step-example
- 遗传算法在 Python 中的实现
https://www . LinkedIn . com/pulse/genetic-algorithm-implementation-python-Ahmed-gad/
https://www . kdnugges . com/2018/07/genetic-algorithm-implementation-python . html
本教程将基于一个简单的例子用 Python 实现遗传算法优化技术,其中…
towardsdatascience.com](/genetic-algorithm-implementation-in-python-5ab67bb124a6)
https://github.com/ahmedfgad/GeneticAlgorithmPython
联系作者
人工意识机器

Photo by Hal Gatewood on Unsplash
什么是意识?和有思考能力一样吗?还是像有灵魂一样?植物有意识吗?这是一些阅读标题后产生的一般性问题。用语言来定义意识是困难的,尽管根据哈利·波特三世博士的说法,意识大致有三种含义:首先,意识意味着清醒。一个人睡着了,处于昏迷状态被称为无意识。第二,有意识这个词经常被用来表示以人类的方式思考。
第三,有意识意味着意识到你的自我和你自己的想法。
那么,拥有人工意识意味着什么呢?如果我们没有一个精确的定义,我们怎么能人工创造意识呢?
有时被称为机器意识或合成意识,人工意识机器可能是一种拥有尽可能人性化行为和自我意识到其存在的能力的机器。一台可以沉溺于长时间谈话、听音乐、有爱好、卷入争端、感受情感、做数学等的机器。这些特征对正常人来说是天生的,但对机器来说,这些简单的任务就像人类在星系间旅行的问题一样。今天,地球上有超过 1000 万台机器(机器人),这个数字在未来还会进一步增加,并且它们都在各自的任务中表现出色。但是真正能看懂这篇文章的机器数量是污名化的。从 SHAKEY(如此命名是因为它在操作过程中容易颤抖)、ELIZA 到 OpenWorm 和 Sophia,这个世界似乎是在一艘太空火箭上实现更好的 AI 机器。过去十年中,研究人员在人工智能领域展示了一些有前途的成果,但仍然离人类水平的人工智能(HMLI)很远。
Nick Bostrom 在他的书《超级智能:路径、危险、策略》[2]中深入讨论了实现 HMLI 的途径、效果和挑战。但是真正有意识的机器的想法离现实还很远。有些人可能会认为神经网络有很好的结果,但它是真正的智能还是简单的统计模式观察?虽然据说神经网络模拟了与我们大脑中相同的神经元网络,但让我们考虑一下,也许有一天我们有足够的处理能力来开发一个足以运行人工大脑的系统。它会和我们吃着美味的食物时脑子里的想法一样吗?还是只是一个简单的矢量点积,与标签上的输出相匹配?
尼尔斯·尼尔森(Nils Nilsson)在搜索、规划、知识表示和机器人学领域从事了长期卓有成效的工作;他撰写了人工智能方面的教科书。当被问及 HLMI 的抵达日期时,他给出了以下观点:10%的可能性:2030 年 50%的可能性:2050 年 90%的可能性:2100 年
让我们非常乐观地说,我们开发了一台足够智能的机器,可以通过图灵测试,然后呢?
我们成长在一个科幻电影已经走得更远的时代,并试图展示有一个 HMLI 在身边会是什么样子。等等,这些电影不都在向我们表明,这样的机器是要终结人类的;通常被称为不可避免的“奇点”。它们都呈现了这样一种场景:这样一台机器变得有自我意识,或者对现实感到困惑,并试图杀死自己的创造者。从 2001 年的《太空漫游》开始,哈尔(启发式编程算法计算机)对给它的命令感到困惑,杀死了宇宙飞船的全体船员,到了前玛奇纳,艾娃有了自我意识(“获得意识”)并杀死了它自己的制造者;我们看到了这样一台机器的相同命运(在这种情况下,机器似乎就像人类一样,试图与它们的创造者斗争)。我们真的会被自己创造的邪恶之手所毁灭吗?但这些只是虚构的,对吗?
我们不知道一台有意识的机器会是什么样子,或者为了简单起见,让我们说一台 HMLI 机器会是什么样子。这些是我们自己对未来的一些疑问,现在,我们只是想知道它将会怎样。在咖啡店里,我们可能猜不到坐在我们面前的人是机器还是人,这种情况会发生吗?它会认为自己更加进化了吗?它会拥有知道自己真实意义存在的能力吗(这是一种强大的能力,甚至我们很多人对此一无所知)?这些问题今天没有明确的答案,但也许将来会有。
[1]我的意识理论概述(http://web.cecs.pdx.edu/~harry/musings/ConscTheory.html
[2]超级智能:路径、危险、策略(https://www . Amazon . in/super intelligence-dangeries-Strategies-Nick-Bostrom/DP/0199678111
[3]这也是以不发生破坏文明的灾难为条件的。尼尔森对 HLMI 的定义是“人工智能能够完成大约 80%的工作,甚至比人类做得更好”(Kruel 2012)。
作为复仇者,死亡是工作的一部分
死亡是永久的…除非你是复仇者!
我有一个“高效拖延”的习惯,在这种情况下,我欺骗自己相信我在拖延的同时在某种程度上降低了效率。在过去的这个周末,我在两天内狼吞虎咽地看了 10 部漫威电影,之前我已经忽略了漫威电影宇宙大约十年了。由于漫威兴奋和浪费时间,我实现了这个有缺陷的框架并进行统计分析。

我接着去了数据集搜索,这是一个为寻找数据集的数据爱好者提供的优秀平台。有太多的复仇者联盟/漫威数据集可用,但 FiveThirtyEight 的复仇者联盟数据集脱颖而出。
该数据集是完美的策划,它包含了所有复仇者的全名和他们的死亡信息。我想我可以扩展一下在自述文件中解释的 FiveThirtyEight 的想法,并通过可视化提出我自己的有趣见解。
值得注意的是,“死亡”包括假死的情况。真正被归类为“死亡”的是当读者和其他角色都认为这个角色真的死了,而不是这个角色是否在呼吸。我也相信这个数据集是基于漫威漫画的。
说明的
第一阶段是探索数据集。我在导入 RStudio 后获得的原始数据包含许多列。我想把重点放在包含人物姓名、死亡和出场次数的列上。
我意识到有 5 个死亡栏:死亡 1,死亡 2,死亡 3,死亡 4,死亡 5。他们是绝对的,他们展示了每个角色是否会死。
以下是一些例子:
例 1:旺达·马克西莫夫,心爱的用思想移动物体的斯佳丽女巫,死过一次。因此,列 Death1 有一个 Yes 条目,而其他所有死亡列都是空的。

例 2:另一方面,我们挥舞着锤子的超级英雄托尔,死了一次,复活了一次,却又死了一次。

我知道我必须重新构建死亡记录方式以便于使用,这就把我带到了下一步,数据清理。
数据清理
我运行了一个循环,每次角色死了,我都会得到一个分数。所以像旺达这样死过一次的角色会得到 1 分,而雷神会得到 2 分。像 T’Challa 这样从未死去的角色(真正的完美角色)得到 0 分。
我不确定是否有数据处理混淆,但是在上一步之后,我发现一些行没有名称条目,我后来删除了这些条目。
形象化
我使用 ggplot2 的库来执行数据可视化,如果你了解 r。

很多复仇者至少死过一次,但只有少数角色死过三次以上。
现在,让我们来看看这张饼状图,它会让你更好地感受到成为复仇者有多“危险”。

成为复仇者有大约 61%的死亡率。我不确定具体情况,但我觉得可能性很大。地球上几乎所有其他工作或活动的死亡率都更高。
但是我们来看看复仇者联盟的回报率。有很多情况,甚至在电影中,当我们认为一个角色已经死了,却在电影的结尾或下一部电影中又回来了——我正看着你呢,尼克·弗瑞。

不到 50%的“死亡”角色保持死亡状态。复活率很高,但考虑到高死亡率,这是合理的。如果《复仇者联盟》中的所有角色都真的死了,那么漫威的漫画作家将不得不不断创造新的角色。
我还调查了角色的外貌是否会影响角色的死亡率。

韦尔奇的样本 t 检验显示,至少死过一次的复仇者和从未死过的复仇者在出现次数上似乎没有显著差异。

可以肯定地说,作为一名复仇者,当你还活着的时候,死亡或者让所有人都认为你死了是工作的一部分。和出现次数没有区别。
有趣的发现:作为一个对 MCU 优先不感兴趣的人,我一直认为美国队长或钢铁侠是复仇者联盟的代言人。所以我很惊讶地发现蜘蛛侠出现的次数最多,这意味着他在漫画中出现的次数最多。

但我想是这样的。
感谢阅读!如果你感兴趣的话,这是 Github 上代码的链接。
阿西莫夫的机器人定律,以及为什么人工智能可能不遵守它们
"但是如果我们最终陷入终结者的场景呢?"问这样的问题无可厚非,因为通过电影和科幻故事,机器人接管的情况几乎无处不在,因此构成了我们对人工智能(AI)未来的印象。然而,既然人类能够通过法律生活和合作,为什么不为人工智能应用法律呢?进入阿西莫夫机器人定律!一如既往,为了更好地了解未来,让我们来回顾一下过去。
三大定律
艾萨克·阿西莫夫(1920-1992)除了是生物化学教授之外,还被认为是他那个时代“三大”科幻作家之一。在 1900 年代中期,他假设了三条定律,如果遵守的话,将会阻止机器人起义。它们如下:
法则一:机器人不得伤害人类,也不得坐视人类受到伤害。
法则二:机器人必须服从人类给它的命令,除非这些命令与第一法则相冲突。
定律三:机器人必须保护自己的存在,只要这种保护不与第一或第二定律相冲突。
现在,如果你熟悉编程,你就会知道机器是从 0 开始计数的,而不是从 1 开始计数的(MATLAB 除外,不过我们先不去说这个)。因此,也有一个由电脑爱好者提出的第 0 定律,指的是集体而不是个人,它是这样的:
法则 0:机器人不能伤害人类,或者,通过不作为,让人类受到伤害。
那么,如果法律早在 20 世纪 50 年代就已经制定出来了,为什么会有这么多恐惧呢?是什么促使埃隆·马斯克甚至斯蒂芬·霍金将人工智能标榜为人类“最大的生存威胁”?因为,长话短说,阿西莫夫定律不起作用。
计划中的缺陷
回到现在。为了与阿西莫夫的想法保持一致,让我们假设我们确实有足够复杂的人工智能代理来应用这些法律。为了便于讨论,让我们也假设,尽管是叙事机制的法则,它们也适用于现实世界。
技术问题:如果法律是英文的,而一个代理只处理中文,怎么办?或者,即使代理是在美国制造的,我们怎么知道它了解法律?因此,我们需要一种方法来(I)翻译法律,( ii)将单词背后的含义翻译成每一种可能的语言(为了涵盖所有可能性,还必须使用像拉丁语这样的死语言以及二进制机器语言)。对于人类来说,这些任务是非常相关的。另一方面,对于机器来说,这是两个非常不同的任务。第一个任务只是指用不同的语言产生相应的句子串,而第二个任务包括理解这些串。只做第一个任务的一个类比是,如果我告诉你用西班牙语唱 Despacito 的歌词。你可能说得很好,但你不知道它们是什么意思(假设你不懂西班牙语)。另一方面,只做第二项任务就像你脑子里有一个想法,但不知道如何表达。
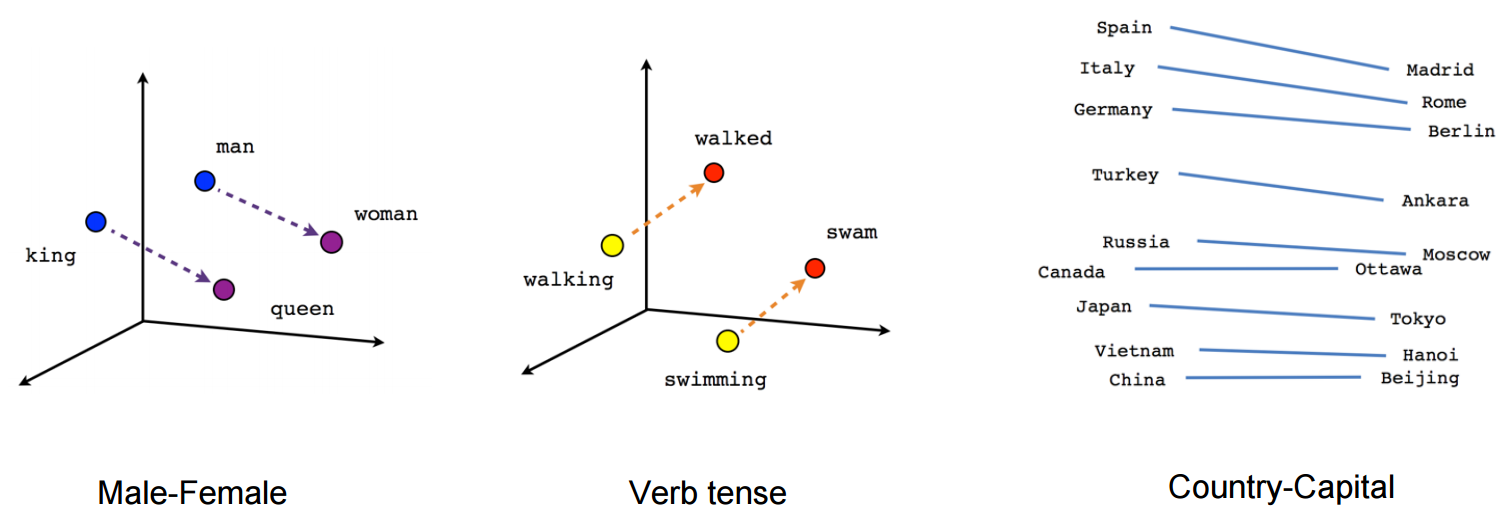
幸运的是,自然语言处理(NLP)领域在过去几年里有了巨大的飞跃。对于第一项任务,具有长短期记忆细胞的神经网络可以用于序列到序列的翻译(对于那些对这个模型感兴趣的人,我会推荐 Jason Brownlee 的文章)。此外,上个月(2019 年 5 月)发布了端到端语音到语音翻译模型translator on。对于第二个任务,Word2Vec 模型已经通过将相关的单词标绘在一起,从而推导出句子中的语义,证明了自己是值得使用的。一个这样的图如下所示。

Meanings and relationships derived from words (sourced from: https://www.tensorflow.org/images/linear-relationships.png)
所以是的,现在的机器可以理解语言。然而,他们仍然有很多事情不能做。一个例子是理解成语。虽然“泄漏秘密”可能象征性地意味着“揭示一个秘密”,比喻翻译是不可能的。因此,一台机器可以逐字翻译每个单词。假设它按照正确的顺序翻译成法语,那么这个表达就会是“jeter les haricots”,这肯定会听起来断章取义,如果不是非常滑稽的话。
但是,为了便于讨论,让我们大胆假设比喻翻译问题将在未来几年内得到解决。这样做,所有关于让代理人理解法律的技术问题都会得到解决,我们也会因此而安全,对吗?做好准备,因为这是事情变得有趣的地方!
当阿西莫夫提出这些定律时,他不知不觉地将它们建立在另一个假设上:我们人类确切地知道道德底线在哪里。但是我们有吗?
让我们以第一定律中的“伤害”一词为例。让我们也考虑一下同一法律中的“人类”一词。它的定义包括什么?例如,在 14 世纪,奴隶被认为比人更接近牛。如今,胎儿对人类生命的权利是许多讨论的主题。然而,在未来,如果一名孕妇,由于某种情况,在分娩时死亡的可能性很高,她的人工智能医生应该建议流产吗?人们需要记住,虽然从逻辑上讲,妇女堕胎后存活的机会更大,但胎儿一旦出生,就有更多的生存理由。所以,不管怎样,机器人最终伤害了人类。
接下来的决定甚至会让我们人类处于否认的状态。让我们考虑一下丹·布朗的地狱场景,并将第 0 定律应用于它。向代理呈现一个按钮。代理人被告知,如果按下按钮,一半的人类会立刻死去,但是这个物种会再生存几个世纪。如果不这样做(因此,无所作为),人类将在 50 年内达到人口过剩,我们的物种将崩溃。代理应该怎么做,如果你处在它的位置,你会怎么做?
结论
阿西莫夫的法律试图解决人工智能起义的威胁。让机器人遵守法律的技术障碍是我们目前在让它们理解法律方面的限制。真正的障碍,一个哲学和伦理上的障碍,是我们的假设,即给定这样模糊的约束,机器人会完全按照我们想要的方式行事,而我们甚至不知道我们是什么意思。即使我们传达的意思是正确的,法律也可以简单地重新表述为“无论如何,只要做好工作,好吗?”考虑到它们可能造成的影响。
Hans A. Gunnoo 是一名数据科学家,他的职业生涯始于电子工程,后来专攻机器学习。他还在业余时间为开源人工智能项目和关于数据科学领域最新趋势的博客做出贡献。
询问重要的研究问题
提出有价值的研究问题的艺术。
数据科学家会被问到:“你做什么工作?”这是我经常回答的一个问题(非技术性的):“我问有意义的有价值的问题并寻找答案。”这种回答往往会引出另一个问题,“你如何决定研究什么问题?”
我有幸提出并获得了两个满足以下标准的主要研究问题的支持。在以后的文章中,我将会讨论这些问题。
同时,我分享了我在评估任何特定研究问题的意义和价值时所使用的标准。

Photo by Author. Making a checklist of criteria I use when evaluating research question meaningfulness and worthiness. Image Credit: “Via Design Pickle” — More on attributions.
第一个标准:这个问题的答案对许多选民有用吗?
我从事教育工作。我首先关注的通常是学生。学生之后是家庭,然后是老师。当我能够提供对当地教育机构和高等教育机构的管理者有用的答案时,我也发现这是有价值的。此外,能够为决策者(立法者或行政监管者)的工作提供信息的问题具有额外的价值。
第二个标准**:这个问题是否可以通过多种数据源和应用多种分析策略来回答?**
一个可以通过参考多种数据源和应用多种分析策略来回答的问题是有价值的,因为这些问题可以通过多项研究来回答。当多项研究(每项研究的研究问题略有不同)能够相互证实对方的结果时,我们就能够提高对自己发现的信心水平。如果多项研究提供了相互矛盾的结果,这意味着进一步的研究将是完全理解答案所必需的。同样,参考我自己在教育领域的工作,这通常意味着参考美国联邦数据、其他国家的数据、机构数据、调查数据或定性数据。我最近在推特上转发了一张插图,概述了许多可用的数据。
An overview of higher education data.
第三准则**:回答问题是否有助于解决已知问题?**
满足第一个标准不一定也满足第三个标准。例如,学生可能会发现知道多受一年教育会有积极的金钱和非金钱回报是有用的(Abel & Deitz,2019;Oreopoulos 和 Petronijevic,2013 年)。然而,我倾向于研究那些能帮助学生成功坚持多学一年并获得学位和证书的问题。
第四条标准**:回答这个问题会让世界变得更好吗?**
第四个是第三个的特例。我把它作为自己的标准,作为一个机会来强调研究在攻击种族优越制度和其他形式的压迫中的作用。具体而言,在教育领域,第四个标准将通过改善机会和公平的研究问题来满足;这削弱了教育在支持白人至上中的作用。继续上述关于教育程度正回报的例子,有可能消除教育持久性中种族差异的研究问题满足第四个标准。提出有意义的有价值的研究问题的一个模式可以(并且已经)消除种族差异,这就是现在著名的佐治亚州州立大学的研究驱动的努力,“这是过去四年中少有的大型公立大学之一,其黑人、西班牙裔和符合佩尔资格的学生的毕业率达到或超过学生群体的总体比率”(Hefling,2019)。
对有意义有价值的问题提问并寻找答案。
最后的想法
回答“我问有意义有价值的问题并找到答案”也适用于其他数据和科学专业人士,包括学者和学者。
一旦你发现了一个有意义、有价值的研究问题,重要的是把有意义、有价值的方法带到这个问题的研究中来。参见:方法选择提示。
作为一个媒体会员,你的会员费的一部分会给你阅读的作家,你可以完全接触到每一个故事…
adamrossnelson.medium.com](https://adamrossnelson.medium.com/membership)
感谢阅读
如果你喜欢我要说的话,可以在:adamrossnelson.medium.com找到更多。
感谢阅读。把你的想法和主意发给我。你可以写信只是为了说声嗨。如果你真的需要告诉我是怎么错的,我期待着尽快和你聊天。推特:@ adamrossnelson| LinkedIn:亚当·罗斯·纳尔逊 |脸书:亚当·罗斯·纳尔逊。
参考
Abel,J. R .,Deitz,R. (2019)。尽管费用上涨,大学仍然是一项不错的投资。自由街经济。纽约美联储银行。
赫夫林,K,(2019)。高等教育的“钱球”解决方案。Politico.com
Oreopoulos,p .和 Petronijevic,U. (2013 年)。让大学物有所值:高等教育回报研究综述(No. w19053)。美国国家经济研究局。
使用 K-means 评估 NHL 获奖者
在每个 NHL 赛季结束后,各种奖项会颁发给在各个领域表现突出的球员。虽然有一些奖项是由原始数据决定的,例如,常规赛总进球数(莫里斯·理查德奖杯)和常规赛总得分(进球数加助攻数)(阿特·罗斯奖杯),但也有一些奖项更加主观,采用投票系统来决定获胜者。大多数奖项的投票都是由职业冰球作家协会(Professional Hockey Writers ’ Association)进行的,包括弗兰克·塞尔克奖(Frank J. Selke trophy):“授予在比赛的防守方面表现最佳的前锋”,以及詹姆斯·诺里斯纪念奖(James Norris Memorial trophy):“授予在整个赛季中表现出最全面能力的防守球员”。两个奖杯都只适用于常规赛的表现。
我从来不喜欢投票系统,尽管在某些情况下,最终的赢家可能非常明显。我认为这可能很有趣,通过单独使用标准和高级曲棍球统计数据,如果我可以将球员分为“等级”,并通过这样做,确定这两个投票式奖杯的获胜者,假设某一年的获胜者应该在最高等级。
数据集
使用的最终数据集是传统和高级玩家指标的组合。传统的统计数据涉及进球和助攻(总得分)、加减分、点球时间和冰上时间等指标,而高级球员指标则更多地涉及球员行为和控球。利用 Python 的 beautifulsoup 库,我刮到了更多传统的统计数据(比如进球、助攻、积分等。)来自 www.Hockey-reference.com,而高级指标由提供 www.corsica.hockey. 来自科西嘉曲棍球的高级曲棍球统计从 2008 年开始,因此,我有跨越 2008-2018 年的近 2000 名球员的数据。需要注意的是,我只考虑了游戏处于平均水平时的高级统计数据。数据被清除掉丢失的值,并被传入 Pandas 进行分析。虽然,我计划最终得到它,这个数据集只适用于滑冰运动员,而不是守门员。守门员的统计和溜冰者的统计非常不同。
职责
在我的上一篇帖子中,我使用上述数据集设计了一个球员评级系统,其中各种统计参数被加权和求和,并通过一个标准的 Sigmoid 函数,为给定的常规赛产生 50 到 99.9(递归)之间的评级值;分数越高,玩家的表现越好。评级系统确定了四个领域,其中一个是被称为 DEFN 的“责任参数,占最终评级值的大约 35%(其他是生产力 ~50%,耐力 ~8 %,其他杂项游戏特性占大约 7%)。责任仅仅是(平均而言)分配给一个球员的防守责任,以及他在常规赛中履行这些责任的表现。它是一些高级统计数据的数学算法,定义如下:
CF%: CF 代表“Corsi For”,这是当一名球员在冰上时该球员的球队产生的射门次数,与“Corsi Against”(CA)相对,这是当该球员在冰上时对方球队产生的射门次数。CF%简单来说就是 CF / (CF + CA)。
CFQoC:比赛平均 CF%的质量。数字越高,竞争程度越高。关于它的解释,这是一个有些争议的统计数据,但我喜欢它被用在 OZS 的上下文中(见下文)。
CFQoT:这是玩家的队友的 CF%。它表明了一个球员相对于他的队友对整体比赛的贡献。通常这是一个很好的指标,可以看出某个球员是否让他周围的球员变得更好。
OZS:进攻区开始。给定球员在进攻区域开始移动的次数百分比。
xGF%:的预期目标与的预期目标的比率。预期目标仅仅是给定射门得分的可能性。它提供了对拍摄质量的判断。因此,xG 值为 0.2,意味着射门的概率为 20%。从本质上讲,这里的高得分球员都有高质量的机会。
该算法考虑了球员最有可能在哪个区域开始他的转变,给予低 OZS 更多的权重(因此更多的防守职责),乘以同时在冰上竞争的球员的质量。所以一个在这里综合得分大的玩家,他的“责任心”程度更高。他们处理任务的好坏取决于责任乘以 CF%、CF qot %和 xGF%的综合因素。关于这个算法的更多信息,包括实际公式,可以在这里找到。

Fig 1. Histograms of DEFN values for rated forwards (F) and defensemen (D) between 2008 and 2018
图一。显示了从 2008 年到 2018 年赛季所有评定的前锋和后卫 DEFN 值的分布。可以看出,两个类别都有类似的高斯分布,平均值/中值约为 0.43,标准偏差约为 0.08–0.1。
图二。显示了按位置分布的直方图(LW,C,RW =前锋,D =后卫),其中 DEFN 是每场比赛在冰上的平均时间(TOI)的函数。如上所述,TOI 决定了玩家等级中的耐力部分。球员不仅要承担责任,他们还要忍受一段时间,比其他人更久。圆圈的大小代表了某个玩家在某个赛季的等级,这个等级是从我之前的帖子中计算出来的

Fig 2. Scatter plot of all rated players from 2008–2018 classed into position. The size of the dot is a representation of the overall player rating
我们可以从这个情节中学到很多。防守队员比前锋打更多的时间,正如我们从图 1 中看到的。所有玩家位置的分布相当均匀。我们还可以看到,每增加一个职业,每增加一次上场时间,球员的评分就会变得更高,这是有道理的,因为一支球队会尽可能多地派出最好的球员。然而,DEFN 呢?如前所述,DEFN 值越高,责任越大,玩家履行这些责任就越好。因此,我们应该期望在前锋/防守球员类别的右上角找到整体表现最好的“防守”球员。理论上,这些球员应该是塞尔克或诺里斯奖杯的获得者。在接下来的几节中,我们将了解情况是否如此。然而,我们首先需要一种方法来对图 2 中的数据进行分类。
K-表示
K-means 聚类是一种无监督聚类技术,用于标记数据并将它们归入具有相似特征/行为的类别。声明设定数量的“K”个聚类,并将每个数据点与代表每个聚类的随机生成的质心进行比较。基于到最近聚类质心的最短欧几里德距离,将给定数据点分配给给定聚类。然后,该算法以迭代方式工作,重复该过程,使得质心位置被优化并稳定在它们的最终位置。这种建模的一个重要方面是,模型所训练的特征必须具有相似的量级,因此,建议首先缩放(归一化)这些特征,否则聚类算法将偏向较大的特征进行聚类。
将前锋和防守队员聚集成“层”
也许 K-means 的主要缺点是破译多少集群使用?除非您有一些关于数据和最佳集群数量的洞察信息,否则实施多少集群并不总是一目了然的。然而,肘方法可以提供一些见解,这个问题,虽然仍然只是提示性的。想法是运行多个不同的 K 值,注意误差平方和(SSE)。增加 K 的数量将减少 SSE,并且如果 K = N,即数据点的总数,则 SSE = 0,因为每个数据点将是其自己的聚类。相反,我们将 SSE 作为 K 个集群的函数进行检查,如图 3 中 forwards 类所示。

Fig 3. Sum of Square Error (SSE) for different values of K in a K-means clustering model. This is for forwards, but a very similar plot is found for defensemen.
理想情况下,使用的 K 值是梯度变化最大的值(或曲线中的扭结),类似于肘形。然而,由于 K 的平滑度,使用哪个 K 并不明显,实际上可能在 4 和 12 之间。为了得到一个更好的想法,我将两个轴标准化,计算到原点的欧几里德距离,并认为最短的距离是肘部最“尖”的部分。对于前锋 K=5 和防守队员 K=4。

Fig 4. K-means clustering of forward and defensemen classes as can be seen by the different colours. Tiers have been assigned to each cluster where one is the highest, or top Tier.
图 4。显示了使用选定的 K 值对前锋和防守队员进行聚类的结果。在这两个图中,我们通过不同的颜色看到了聚类的数量,我们可以根据它们相对于整个群体的位置来识别层次。如上所述,TOI 和 DEFN 越高,结果越令人印象深刻。因此,第 1 层在右上角,第 2 层在正下方,依此类推。
塞尔克奖杯
现在我们有了一组可靠的集群,我们可以开始查看谁在第一层集群中,并查看这些名称是否与 Selke trophy 的获胜者匹配。

Table 1. A list of the most appearances (count) in Tier-1 forwards for players with a player rating of greater than 90 from 2008–2018. Also shown are the number of Selke wins and top-3 nominations. NB, There are more players with one appearance
表 1。,显示了在过去的 11 个赛季中,NHL 中前 30 名最好的双向前锋的名单,这些球员被归为一级,球员评分高于 90 分。也给出了一个球员被授予塞尔克奖杯的次数,或者至少他们是否曾经是顶级联赛赛季的前三名候选人。在名单的顶部是两个熟悉的名字:帕维尔·达蒂苏克和帕特里斯·贝吉龙,他们以双向风格的比赛而闻名,并赢得了多个塞尔克奖杯。还有其他塞尔克奖获得者包括,安泽·科皮塔,瑞安·凯斯勒和乔纳森·托尤斯;事实上,2008 年至 2018 年间的所有塞尔克奖杯获得者都被归入这一优秀的顶级行列。此外,还有各种各样的其他球员获得了前三名的提名。总共有 137 名不同的球员被归入这一类别,对于给定的赛季,那些球员评分为 90 或更高的球员被标绘在图 5 中。,其中 DEFN 是平均 TOI 的函数。圆圈颜色代表球员位置,大小代表该赛季的球员等级。

Fig 5. Bubble plot of all forwards in Tier-1 from 2008–2018 with a rating greater than 90. Colour represents player position and bubble size represents player rating value for a given season
公平地说,中锋(“C”)在这一层占主导地位,这是意料之中的,因为中锋的角色更多地被认为是一种全面的游戏风格。像布拉德·马尔尚和亨里克·泽特贝里这样的球员分别与贝杰龙和达兹尤克并肩作战,在后一种情况下,泽特贝里应该在 2008 年赢得塞尔克而不是达兹尤克,因为右上角有两个巨大的斑点(泽特贝里的贡献略好于达兹尤克)。因此,这就带来了由于我不喜欢的选民的“名声”而产生偏见的问题。然而,贝杰龙是在他自己的联赛,并有巨大的 DEFN 收视率相比,他的码头,虽然在许多赛季上场时间更少。总的来说,K-means 聚类在将最佳 Selke 候选项过滤到正确的层方面做得很好。
诺里斯奖杯
那么诺里斯呢?表二。显示了 2008 年至 2018 年与赛季评分至少为 88 的球员的第 1 层聚类相关的前 37 名,以及任何前 3 名提名或诺里斯获胜。在 11 个可能的诺里斯获奖者中,8 个来自第一梯队,3 个来自第二梯队。此外,在 11 年的 33 个前 3 名提名者中,23 个来自第 1 层,9 个来自第 2 层,1 个来自第 3 层。诸如 Zedeno Chara、Nick Lidströ、Duncan Keith、Drew Doughty 和 P.K. Subban 等球员都获得过诺里斯奖杯,并在此期间成为顶级俱乐部的热门成员。最佳球员是谢伊·韦伯,出场 7 次,克里斯·唐乐、查拉和多尔蒂出场 6 次。唐乐有一些不错的赛季,但许多赛季也因受伤而缩短,选民不喜欢缺席。

Table 2. A list of the most appearances (count) in Tier-1 defencemen for players with a player rating of greater than 88 from 2008–2018. Also shown are the number of Norris wins and top-3 nominations. The number of Tier-2 Norris winners is also shown.
图六。显示了诺里斯获奖者的 DEFN 值的时间序列,以及他们所处的层次。一级市场的平均 DEFN 截止值(红线)为 0.475,它显示了三个不在一级市场的赢家(即红线以下的赢家)。

Fig 6. Time series of Norris trophy winners presented as DEFN over time. Winners above the red line are from Tier-1 and below from Tier-2
必须考虑的一件事是,尽管这些 DEFN 值较低,但结果是相对于同一年的所有其他球员而言的。因此,我决定调查那些年其他可能的候选人,看看那些二级获奖者是否有道理。
**2011 年:**尼克·利德斯特罗姆赢了,尽管他的 DEFN 和赛季最佳球员排名在最佳 D-men 中仅列第五。那一年,卢博米尔·维斯诺夫斯基的整体游戏(TOI=23,DEFN=0.57,评分=91.9,等级=1)优于利斯特罗姆(TOI=22,DEFN=0.44,评分=89.3,等级=2),但它在投票中仅获得第 4 名。那个赛季,Lidströ年满 40 岁,是获得该奖项的年龄最大的球员。也许是选民们对他们多年服务的一句小小的“谢谢”?
**2015:**2015 年埃里克·卡尔松夺冠。那一年,另外两名一级防守队员排在卡尔松前面,但他们都经历了伤病困扰的赛季。虽然卡尔松的 DEFN 数据(TOI=27,DEFN=0.47,等级=91.1,等级=2)相当平均,但他和多尔蒂(TOI=29,DEFN=0.54,等级=89.5,等级=1)打曲棍球的时间最多,卡尔松在一场势均力敌的比赛中击败了多尔蒂。
**2018:**2018 年,维克多·海德曼(TOI=26,DEFN=0.45,评分=91.4,等级=2)以略高于人口平均水平的 DEFN 值获胜,击败了多尔蒂(TOI=26,DEFN=0.51,评分=91.1,等级=1),后者可以说是综合表现更好的人。
2017: 有趣的是,布兰特·伯恩斯(TOI=25,DEFN=0.48,评分=92.4,Tier=1)在 2017 年获胜,被列为 Tier-1,但却在极限上。事实上,他的 DEFN 结果远低于第一级的其他潜在候选人,如多尔蒂(TOI=27,DEFN=0.55,评级=88.7,第一级)和阿历克斯·皮特兰杰洛(TOI=25,DEFN=0.52,评级=88.9,第一级)。
所以重新考虑图 6。我们发现,在过去四年中的三年里,投票者倾向于选择 DEFN 评分较低的球员。由于玩家评级的主要权重是生产力(~50%),顶级玩家的平均 TOI 相似(而顶级玩家的其他杂项玩家评级参数相似),这意味着生产力(即分数)比诺里斯传统意义上的“最全面的能力”更受重视。图 7。显示 2008-2018 年所有玩家等级高于 88 的一级防守者。

Fig 7. Bubble plot of all defensemen in Tier-1 from 2008–2018 with a rating greater than 88. Colour represents player position and bubble size represents player rating value for a given season.
结论
假设 DEFN 参数是防守属性的良好指标,我们评估了塞尔克和诺里斯奖杯的最后 11 名获奖者。在很大程度上,我们可以说,选民们选择塞尔克奖得主是正确的。随着所有获奖者和许多被提名者聚集在顶级,公平地说,球员们一直被宣布的标准所认可,以赢得这个奖杯。然而,对于诺里斯奖杯获得者的价值观似乎存在不一致的态度,最近生产率似乎是驱动因素,而不是全面的比赛。很难解释为什么会这样。这是因为在过去的十年里,足球的风格发生了巨大的变化,现在更加强调速度和技巧吗?这是因为 NHL 游戏正在转变为一种更欧洲的风格,进攻是由四分卫风格的球员防守驱动的吗?全能 defensemen 是不是没有以前那么性感了?对于获奖者来说,2019 年应该是有趣的一年,所以请关注这个空间。这项工作的代码可以在我的 Github 上找到。感谢阅读!
评估数据质量
对于数据挖掘和机器学习算法…
Video version of the story, if you are into that sort of thing 😛
在 我之前的一篇帖子 中,我讲过数据科学中的 数据集类型,数据挖掘&机器学习及其一般特征 。这就要继续下去了,如果你还没有读过,就在这里读一下以便对我在文章中要讲的话题和概念有一个恰当的把握。
数据挖掘应用通常应用于为另一个目的收集的数据,或者用于未来的未指定的应用。因此,数据挖掘通常不能利用“在源头解决质量问题”的显著优势
由于防止数据质量问题在这种情况下是不可行的,数据挖掘主要关注:
- 数据质量问题的检测和纠正(通常称为 数据清理 )以及
- 使用可以容忍较差数据质量的算法。
本文主要关注测量和数据收集问题。
请容忍我的概念部分,我知道这可能有点无聊,但如果你有强大的基础,那么没有什么可以阻止你成为一名伟大的数据科学家或机器学习工程师。
假设数据是完美的并不是一个好主意。由于多种原因,如人为错误、测量设备的限制或有缺陷的数据收集过程,数据可能不正确。可能存在这样的数据集,其中一些值缺失,有时甚至一些数据对象不存在,或者存在冗余/重复的数据对象。我们现在将定义一些在数据科学中大量使用的术语。
什么是测量误差?
→指测量过程中产生的任何问题。换句话说,记录的数据值在某种程度上不同于真实值。测量值与真值之差称为 误差 。
什么是数据收集错误?
→它是指诸如省略数据对象或属性值,或包含不必要的数据对象等错误。
什么是噪音?
→噪声是测量误差的随机成分。它要么涉及值的失真,要么涉及不需要的对象的添加。下图显示了一些随机噪声在干扰前后的时间序列。

术语噪声通常与具有(空间相关)或*(时间相关)成分的数据相关。在这些情况下,使用来自信号和图像处理的技术来降低噪声。***
但是,去除噪声是一项困难的任务,因此许多数据挖掘工作涉及使用 鲁棒算法 ,即使在存在噪声的情况下也能产生可接受的结果。
什么是离群值?
→异常值是
- 在某种意义上,具有不同于数据集中大多数其他数据对象的特征的数据对象,或者
- 相对于该属性最常见(典型)的值而言非常规的属性值。
此外,区分噪声和异常值也很重要。离群值可以是合法的数据对象或值。因此,与噪声不同,离群值有时可能是令人感兴趣的。
数据集中是否存在缺失值。
数据对象的某些属性值缺失的情况并不少见。原因可能是:
- 信息未被收集。
- 有些属性不适用于所有对象。
无论如何,在数据分析期间应该处理缺失值。接下来,我们将讨论一些处理缺失数据的策略。
- ****消除数据对象或属性:一个简单有效的策略是消除缺少值的对象。然而,如果一个数据集只有几个缺少值的对象,那么我们可以忽略它们。一个相关的策略是消除缺少值的属性。然而,这样做应该小心,因为被剔除的属性可能是对分析至关重要的属性。
- ****估计缺失值:有些缺失数据是可以可靠估计的。如果属性本质上是连续的,那么可以使用该属性的平均值来代替缺失值。如果数据是分类的,那么最常出现的值可以替换缺失的值。
- ****在分析过程中忽略缺失值:许多数据挖掘方法可以修改为忽略缺失值。例如,假设对象正在被聚类,并且需要计算数据对象对之间的相似性。如果一对对象中的一个或两个对象在某些属性上有缺失值,那么可以通过仅使用没有缺失值的属性来计算相似性。的确,相似性只是近似的,但是除非属性的总数很少或者缺失值的数量很大,否则这种不精确的程度可能并不重要。
- ****不一致值:数据可以包含不一致值。考虑一个地址字段,其中列出了邮政编码和城市,但是指定的邮政编码区域不包含在该城市中。可能是输入该信息的个人调换了两位数字,或者可能是从手写表格扫描该信息时误读了一位数字。有些类型的不一致很容易发现。例如,一个人的身高不应该是负数。不一致的纠正需要额外的或冗余的信息。
- ****重复数据:数据集可以包括彼此重复或几乎重复的数据对象。为了检测和消除这种重复,必须解决两个主要问题。首先,如果有两个对象实际上表示一个对象,那么相应属性的值可能不同,这些不一致的值必须得到解决。第二,需要注意避免意外地组合相似但不重复的数据对象,例如两个不同的同名人。
到目前为止,我们已经讨论了与数据质量相关的问题。现在,我们将借助 【精度、偏差和准确度】 来了解统计检查数据质量的方法。
测量过程和结果数据的质量由精度和*偏差来衡量。*****
什么是精度?
→重复测量(相同数量)的接近程度。通常用一组值的标准差来衡量。
什么是偏见?
→测量值与被测数量的系统变化。它是通过取一组值的平均值和被测量的已知值之间的差来测量的。只能对那些测量量已知的物体进行测定。
例如,我们有一个质量为 1g 的标准实验室砝码,想要评估我们新实验室秤的精度和偏差。我们称质量五次,得到以下五个值:{1.015,0.990,1.013,1 .001,0.986}。这些值的平均值为 1.001,因此偏差为 0.001。以标准差衡量,精度为 0.013。
通常使用更一般的术语“精确度”来表示数据中测量误差的程度。
什么是准确性?
→测量值与被测量的真实值的接近程度。
精度取决于精度和偏差,但既然是一般概念,就这两个量而言,精度并没有具体的公式。
我正在免费赠送一本关于一致性的电子书。在这里获得你的免费电子书。
这篇关于数据质量的文章到此结束。
如果你喜欢阅读这样的故事,那么你应该 在你的收件箱 中获取我的帖子,如果你想支持我成为一名作家,考虑注册成为一名媒体成员。每月 5 美元,你可以无限制地阅读媒体上的故事。如果你注册使用我的链接,我会赚一小笔佣金,不需要你额外付费。
作为一个媒体会员,你的会员费的一部分会给你阅读的作家,你可以完全接触到每一个故事…
tarun-gupta.medium.com](https://tarun-gupta.medium.com/membership)
这个帖子的后续是这里。我的文章索引在这里:
[## 标记故事列表的快速链接—感谢您的访问
我也有一份以快节奏出版为目标的出版物。读书成为作家。
tarun-gupta.medium.com](https://tarun-gupta.medium.com/thank-you-for-visiting-my-profile-9f708062c75e)**
用线性规划法给优步司机分配最快的皮卡
对于我在最优化方面的最后一个项目,我的教授指导我根据我们上个月学到的东西来优化任何东西。我需要定义自己的问题,用 Python 实现解决方案,并评估结果。(为了这篇文章的简洁,我省略了我的代码,我会尽快张贴我的 Jupyter 笔记本!)
我摆弄过图形化的线性程序来直观地解决资源的最优分配,我认为这是一种重新表述通常的代数问题的很酷的方式。我还想探索优化如何在日常叙事中发挥作用。因此,作为一个住在洛杉矶、忙碌而又不会开车的大学生,很明显,优化我最讨厌的一件事:等我的优步。
在设置问题之前,以下是一些重要的准备工作:
图表
一个图 G = (V,E) 由一组顶点(或节点 ) V 和边 E 组成。通常,我们将节点表示为所考虑的对象,而将边表示为对象之间的关系。当一个节点与另一个节点有边时,我们说这两个节点是连通的。
在有向图中由一组由边连接的顶点组成,其中边有一个与之相关的方向。在有向图中,边 (u,v) 不同于 (v,u) 。

A directed graph (source:Wikipedia)
完全二部图
我们感兴趣的一种特殊的图是完全二部图。如果我们能把节点分成两个不相交的集合 V1 和 V2 ,使得 E 中的每条边都连接每个 V1 顶点和每个 V2 顶点,那么这个图就是完全的二部图。

A complete bipartite graph with V1 as the set of red nodes, and V2 as the set of blue nodes (source: Wikipedia)
线性规划
线性规划是一般约束优化问题的特例。它的目标函数是线性的,可行点集由一组线性约束确定,线性约束可以是线性方程和/或不等式。一旦我们像这样将特定问题公式化,我们就可以通过一系列方法来求解方程组,例如使用行运算(像在高中重复求解联立方程)和 单纯形法 (黄金标准算法,连续考虑似乎合理的解决方案,同时确保我们在每次迭代中总是更接近最优解)。
最大流最小割问题
假设 G = (V,E) 是一个有向图。我们可以将最大流问题描述为从源节点s向汇节点tt运送尽可能多的材料。材料可以通过连接节点的边从一个节点流到另一个节点。连接 i 到 j 的边具有一些容量** Cij,可以从节点 i 推到j的最大流量,同时最大化从 a s 到 t ( s!= t ),我们还想在每个中间节点保持流入流出相等。**
一个 流 Fvw 是边 v 和 w 的权重分配。边的流量必须在其容量范围内,因为节点应该只能传输小于或等于其容量的材料。流量也必须是非负的。

Linear Program Formulation for Max Cut Min Flow
另一方面,最小割问题旨在以最小的破坏将节点分成两组。我们想定义一个 s-t 割作为顶点到两个集合 A 和 B 的划分,其中 A 包含源节点 s,B 包含汇节点 t 。我们希望最小化成本,即从 A 中的一个顶点开始到 b 中的一个顶点结束的所有边的权重之和。我们可以引入指示变量,然后制定一个线性规划。
最大流最小割定理 陈述了同一问题的最大流和最小割公式的解是等价的。对于这个项目,我们将考虑最大流的线性规划,因为它更直观。
指派问题
上述问题的一个修改版本是分配 n 个工作给 m 个机器/工人的任务。如果作业 j 被分配给工人 i 则设 Xij = 1,如果作业 j 未被分配给工人 i 则为 0。每个人只能做一项工作,一项工作只能由一个人做,各有各的费用。我们希望利用我们所有的资源,最大限度地降低完成所有工作的成本。

Linear Program Formulation for the Assignment Problem
当在图中表示这个线性规划时(见下文),我们可以通过在图中添加汇节点和源节点来匹配最大流最小割问题,这些节点表示网络中完成的作业总数。这将流量守恒表示为来源的总资源,即工人数量需要与总产出(即工作总数)相匹配。
将两者结合起来,提出问题
通过构建两组节点,一组用于工人,一组用于任务,我们得到了下面的完整二分图。当我们假设每个工人都有资格完成任何任务时,每个工人都与每个任务相关联。然后,这些边缘将被赋予某个值,该值表示工人完成任务的成本。

source: Google OR tools
让我们考虑一个网络,其中的节点是优步应用程序用户,特别是附近的司机和骑手,并与上述分配问题进行类比。
我们可以将优步司机(=工人)到附近皮卡(=工作)的分配公式化为最小化等待时间(=目标函数),该最小化是从司机到皮卡多远(以分钟计)得出的(=成本)。我们假设是 UberX(或者优步·布莱克?UberLXL?)所以每个车手一次只能完成一次接送,骑手只能接送一次(=线性约束)。
换句话说,**指定优步最快的接送=最小化附近所有可用司机和乘客的等待时间。**这是把问题改写成线性规划的直觉,这个项目的目标是探索解决规划的不同方法。
对于这个问题,我们专注于解决司机和皮卡数量相等的情况,以简化问题并符合所用 Python 包的限制。
将问题公式化为上面的标准线性规划,我们使用 Munkres 的匈牙利算法和 Google OR Tools 的线性和分配和最小成本流来探索三种方法。然后,我们针对不同规模的网络,即不同数量的司机和皮卡,比较该方法的运行时间。
实施
首先,为了说明问题,我们从一个只涉及该地区四个驾驶员和四个皮卡的问题开始。
对于这个问题,我们假设等待时间在 1 到 30 分钟之间整数变化。实际上,乘客等待优步到达超过 10 分钟的情况非常罕见。我们应该记住,等待时间会因地区、司机供应和接送需求而波动,因此可能不是“随机”的。
基于这些假设,我们生成随机数据来填充成本矩阵。然后,我们将驾驶员编号为 1–4,将骑手编号为 5–8(或者,更一般地,将顶点的前半部分作为驾驶员,后半部分作为骑手),以构建开始节点和结束节点的矩阵或列表,作为实现的输入。
芒克雷斯匈牙利算法
Munkres 的匈牙利算法是一种强力算法,它包括生成成本矩阵的所有独立集,计算每次分配的总成本,以及搜索所有分配以找到最小和独立集。这个算法有 *n!*可能的赋值集合,因此具有指数级的运行时复杂度。
Python 的 munkres 包实现了一个由 James Munkres 修改的算法,具有多项式运行时复杂性,这里描述的为。

One iteration to solve for a feasible assignment
该包将解决方案作为一对有序的驾驶员集合和驾驶员集合(注意,该包将它们索引为 0–3 表示 1–4,0–3 表示 5–8。关于这个项目的编码部分,最困难的事情是重塑所有我曾经比较的函数的输入和输出!).它打印出成本矩阵、总等待时间和运行时间。

使用 Python 中的 networkx 包,我写了一些代码,以有向图的形式说明解决方案。这里,0 节点表示源节点,9 节点表示汇节点,节点 1-4 表示优步司机,而节点 5-8 表示乘客。驾驶员和乘客之间的边的数字属性说明了驾驶员和乘客之间的等待时间。最佳分配由连接驾驶员节点和骑手节点的绿线表示。

Illustration for the solution
线性和分配
Google 的 OR 工具****lineasumassignment在给定的图中,用整数边权重集寻找最小成本的完美分配。该算法将指派问题转化为最小费用流问题,并采用推-重标法求解。
运行时间为 O(nmlog(nC)) 其中 n 为节点数, m 为边数, C 为边代价的最大值。原则上,它可能比上面的 munkres 的匈牙利算法更糟糕,但是我们不知道任何一类问题会发生这种情况。
解决问题后,程序包会打印以下赋值:


最小成本流
Google 的 OR 工具 SimpleMinCostFlow也提供了另一个求解器实现,可以处理比 LinearSumAssignment 更大的一类问题。LinearSumAssignment 是专门为解决分配问题而实现的。
上面我们讨论了我们的特殊问题和最小成本流之间的相似之处。
 ****
****
我们注意到所有三种方法产生相同的赋值和目标函数值。但是,这并不能保证。假设每种方法都以不同的方式实现,那么在具有相同目标函数值的方法之间可能存在不同的赋值。例如,在这种情况下,可能有两个或更多的等待时间组合,总计 30 个,每个方法可以选择这些组合中的任何一个。
时间比较
为了比较每种方法的运行时间,我们将比较当我们增加工作人员和任务的数量时,每种方法如何伸缩。我们将跳出优步取件的例子,考虑这样一种情况,我们有 250-5000 个任务,以 250 个增量分配给相同数量的工人。在每次迭代中,我们将为每个任务的成本生成随机数据,然后求解最优解。然后,我们将比较给定相同数据的每个方法的运行时间。
注意横轴表示第 n 个区间,所以第 n 个勾号表示网络中的 n250 工作人员节点和 n250 任务节点。**

Runtime in seconds vs the nth interval
结果
- 从我们的图中可以明显看出,最小成本求解器是最快的,紧随其后的是线性和分配求解器。虽然我们可以看到最小成本求解器的伸缩性更好,因为在更高的间隔,线性求和的运行时间增加更多。
- 有趣的是,Google OR tools 提到线性和赋值求解器在处理一般赋值问题时更有效——在未来的工作中,研究这个项目的赋值问题是如何引起上述现象的可能会有所帮助。
- 这一比较证实了我所做的研究,即 Munkres 的算法效率最低,因为它的伸缩性比其他两个算法差得多。
其他考虑
-
分配的非唯一性:在查看了不同节点数的最优解后,我们注意到,尽管实现了相同的最小成本值,但从一种方法到另一种方法的分配可能不同。由于问题的过度约束以及包的不同实现,这可能是意料之中的。
-
**数据的随机性:根据数据的结构,对于相同的数据,一种方法可能比另一种方法更难解决问题。在比较运行时间时,一种更可靠的方法是取几代随机数据的平均值。
另一个有趣的观察是,当成本往往有许多重复时,最优值往往有更多的重复解。例如,当我生成 100 个节点,每个节点的成本在 1 到 10 之间时,最小值几乎总是 100,因为节点在它的 100 条边中的一条边上的成本很可能总是 1。
更现实的方法是使用真实世界的数据,将问题公式化到更窄的范围。然后,我们可以尝试回答为什么不同的方法给出不同的最优解,以及如何给出不同的最优解。**
-
任务和工人数量不等:这个项目解决了优步司机数量和皮卡数量不匹配的情况,这不是很真实的描述。通常情况下,司机无法满足更多的乘客,这可能导致价格飙升的机会。在这种情况下,我们将来自源节点的电源修改为驱动器的数量,并且我们将有一些节点未被访问。
结束语
总结一下,我们所做的如下:
- 构造了一个线性规划来最小化指派优步司机接载乘客时的总等待时间
- 用图表示我们的优化,并转化为最大割最小流问题,进而转化为分配问题
- 比较了解决指派问题的三种不同方法
如上所述,该项目有很大的改进空间,因为它只是对分配问题的可能方法的简要调查。在将这种方法应用于现实生活数据之前,我选择的特定应用程序有许多更微妙的边缘情况需要探索。
我在这门课上学到的最酷的事情是解构一个抽象的问题,并通过创造性地应用线性代数和分析中的结果来解决它们。过去四年的数学课一直致力于建立我对这些基本原则的理解,所以这门课使我能够超越它们。这个项目让我明白了如何从数学家的角度来看待问题。这门课是我在加州大学洛杉矶分校最愉快的课程之一——它让我兴奋,因为我能够应用数学高效而严谨地解决有趣的问题。
附言:谢谢 Sylvester 教授的大手笔,让我在整个季度都保持好奇:)我可以每天一整天都优化任何东西。
参考
- https://www.joshmeetscomputer.com/bipartite-projected/
- http://csclab.murraystate.edu/~bob.pilgrim/445/munkres.html
- http://software.clapper.org/munkres/
- https://developers . Google . com/optimization/assignment/simple _ assignment
- https://developers . Google . com/optimization/assignment/assignment _ min _ cost _ flow
赋值,浅抄,还是深抄?
一个关于 Python 内存管理的故事
from copy import copy, deepcopy
这篇文章的目的是描述当我们
- 分配一个变量
B = A, - 浅层复制它
C = copy(A),或者 - 深抄它
D = deepcopy(A)。
我首先描述一下 Python 中的内存管理和优化。在奠定基础之后,我解释了赋值语句、浅拷贝和深拷贝之间的区别。然后,我在一个表格中总结了这种差异。
如果你更喜欢看视频而不是看文章,你可以在这里 找到补充视频 。
Python 中的内存管理
int , float , list , dict ,类实例,…它们都是 Python 中的对象。在 CPython 实现中,内置函数id()返回对象的内存地址—
>>> L1 = [1, 2, 3]>>> id(L1)
3061530120
如果我们创建一个新的变量L2,它引用一个与L1具有相同值的对象,L2将有一个新的内存地址—
>>> L2 = [1, 2, 3]>>> id(L2)
3061527304
每次创建一个新对象,它都会有一个新的内存地址。除非它是—
- 一根很短的绳子
- [-5,256]范围内的整数
- 一个空的不可变容器(例如元组)
让我们看一个整数对象的例子。*x*和*y*指的是同一个值 10。虽然上例中的L1和L2有两个不同的内存地址,但是*x* 和*y* 共享相同的内存地址
>>> x = 10>>> y = 10>>> id(x)
2301840>>> id(y)
2301840
这是因为,在这三个例外中,Python 通过让第二个变量引用内存中的同一个对象来优化内存,有人称之为“共享对象”。
记住共享对象的概念,因为我们稍后创建对象的深拷贝时会用到它。
变量赋值
在 Python 文档中说“Python 中的赋值语句不复制对象,它们在目标和对象之间创建绑定。”这意味着当我们通过赋值来创建一个变量时,新的变量与原始变量引用同一个对象
>>> A = [1, 2, [10, 11], 3, [20, 21]]>>> B = A>>> id(A)
3061527080>>> id(B)
3061527080
因为新变量B和原始变量A共享同一个对象(即同一个列表),所以它们也包含相同的元素—
>>> id(A[2])
3061527368>>> id(B[2])
3061527368
如下图所示,A和B共享同一个id,即在内存中引用同一个对象。它们也包含相同的元素。

浅拷贝
当我们通过浅拷贝创建一个变量时,新的变量指向一个新的对象——
>>> A = [1, 2, [10, 11], 3, [20, 21]]>>> C = copy(A)>>> id(A)
3062428488>>> id(C)
3062428520
虽然A和C指的是两个不同的对象(即两个不同内存地址的列表),但两个列表中的元素指的是相同的对象—
>>> id(A[0])
2301696>>> id(C[0])
2301696>>> id(A[2])
3062464904>>> id(C[2])
3062464904
下图说明了A中的元素如何引用与C中的元素相同的对象。

深层拷贝
类似于浅层拷贝,当我们通过深层拷贝创建一个变量时,新的变量指向一个新的对象——
>>> A = [1, 2, [10, 11], 3, [20, 21]]>>> D = deepcopy(A)>>> id(A)
3062727496>>> id(D)
3062428488
如 Python 文档所述——
浅拷贝和深拷贝的区别只与复合对象(包含其他对象的对象,如列表或类实例)相关:
-一个浅拷贝构造一个新的复合对象,然后(尽可能地)将引用插入到原始对象中。
-一个深度拷贝构造一个新的复合对象,然后递归地将拷贝插入到原始对象中。
与浅层拷贝不同,两个列表中的元素现在引用不同的对象——
>>> id(A[0])
2301696>>> id(D[0])
2301696>>> id(A[2])
3062464648>>> id(D[2])
3062466376
但是为什么A[0]和D[0]共享同一个对象(即拥有相同的内存地址)?因为它们都引用整数,这是我们在开始提到的内存优化的三个例外之一。
下图显示A和D引用内存中两个不同的列表,由于内存优化的原因A中的元素引用的对象不同于D中的元素,整数元素除外。

摘要
如果这篇文章有什么值得一提的地方,那一定是下表。变量赋值不复制对象,所以A和B有相同的内存地址,包含相同的元素。浅层复制为C创建了一个新对象,但是C中的元素仍然引用与A中的元素相同的对象。深度复制还为D创建了一个新对象,并且D中的元素引用的对象与A中的元素不同,有三种类型的异常。

这篇文章的灵感来自于…
关联规则分析在广告优化中的应用

介绍
在客户获取领域,优化是成功的关键,目标是最小化每次转换的成本(CPA)并最大化转换率和广告支出回报(ROAS)。您可能已经知道,在客户之旅中,有许多因素会影响客户的看法以及他们是否采取行动的决定。仅举几个例子:渠道、广告文案、登陆页面、目标定位(人口统计、兴趣、关键词、…),等等。
许多营销团队采用的一种常见方法是实验。这种方法有许多优点,例如确保结果在统计上是显著的,学习可以在团队中共享,……但是,A/B 测试和多变量测试可能需要大量的流量,因此非常耗时,特别是在转换率相对较小的情况下(查看此处的 A/B 测试计算器)
在本文中,我想介绍另一种方法,它使用称为关联规则的数据挖掘技术来识别客户旅程中的高绩效元素,并讨论其在优化广告绩效方面的利弊。
文章包括以下几个部分:
1、资料准备
2、探索性分析,给出初始假设
3、模型构建:关联规则和机器学习
4、归因中的潜在应用
5、利弊
数据准备
然而在现实中,营销团队可以构建一个单一的客户视图来全面了解整个客户旅程,几乎不可能找到一个包含所有影响绩效的元素的公共数据集。然而,我从 ka ggle(【https://www.kaggle.com/fayomi/advertising】)找到了一个接近我所需要的数据集。从那里,我将为我们的目的操纵数据。

原始数据集包含 1000 个观测值。数据中的每一行代表一个看到该广告的互联网用户。标签数据是“点击了广告”,它指示互联网用户是否点击了广告。这对于我的分析来说还是不合适的。下面是我处理数据的几个步骤:
- 假设这个数据集中的每个数据点都表示通过我们的广告登陆我们的登录页面的访问者。我将为每一行添加一个访问者 ID。
- 我将随机创建 2 个以上的广告属性:登陆页面和广告文案。因为我们只有 1000 个数据点,所以我假设我们只使用 4 个登录页面和 3 个广告副本。
- 点击广告不是我要找的转换。我将删除此标签,并创建一个新标签来指示该访问者是否在登录页面上采取了操作。我假设转化率在 20%左右,所以我随机创建这个数据,并确保转化率水平保持不变。
- 删除不适当的属性,如“点击广告”、“广告主题行”
之后,我有了新的数据集:

快速图表显示,国家变量有 237 个值,但我们只有 1000 个观察值。因此,我将添加 region 变量作为地理信息的指示,而不是使用 country 变量。
这是最终数据:

探索性数据分析
数据汇总:

平均转化率为 18.3%。这意味着虚拟分类器可以达到 81.7%的准确率。使用配对图的快速可视化显示,在特征和标签之间似乎没有模式。

更多可视化效果,显示每个特征与标签之间的相关性:

Compare the avg. conversion rate amongst regions (left) and weekdays (right)

Compare the avg. conversion rate amongst landing pages (left) and ad copies (right)

Male visitors have a higher average conversion rate than female
连续的图表再次显示了一个不清楚的模式:


总结一下:

关联规则
关联规则是一种基于规则的机器学习方法,用于发现变量之间有趣的关系。在购物篮分析中被广泛使用,有一个经典的例子是{尿布}–> {啤酒},意思是如果一个顾客买了尿布,他/她就更有可能买啤酒。我们可以使用这种方法来确定与“转化”有积极关系的元素(广告文案、登录页、目标定位)。《走向数据科学》有一篇很棒的文章解释了关联规则的概念。
数据预处理包括以下步骤:
- 为地区、工作日、广告文案、登录页面创建虚拟变量
- 将连续特征转化为名义特征:年龄、收入、上网时间和互联网使用情况
下面是模型构建结果:

快速解释{A} → {B}的支持、信心和提升的指示
- 支持度:有多少百分比的数据集既有 A(前件)又有 B(后件)。
- 信心:如果 A 发生了,B 发生的可能性有多大
- Lift:如果 A 发生了,B 发生的几率会增加还是减少,增加多少?
我们关注“提升”一栏,这个数字显示了如果一个访问者有前情,他/她更有可能接受“后情”的百分比。

Interpretation of the result of the association rules analysis
一般来说,关联规则产生的结果与数据可视化非常相似,但仍有根本性的改进:
- 关联规则确保 A 和 B 发生的百分比是显著的。例如,您可以通过 min_support 参数设置 A 和 B 发生的最小百分比
- 关联规则提供了 A 对 B 的可能性的平均影响
- 一个广告中可以有多个元素,这可以为营销团队提供更多关于广告过程的信息。
在归因理解中的潜在应用
归因模型也可以是关联规则的潜在应用。您可能已经知道,客户之旅变得更加多点接触,通常,客户在采取行动之前会与多个渠道进行互动。例如,访问者可以点击显示广告来访问我们的登录页面,但直到一周后他/她通过付费搜索再次访问时才转化。因此,收购团队面临的一个常见挑战是了解漏斗顶部和中部渠道的真正价值。这就是关联规则可以发挥作用的地方。
正如你们中的许多人可能知道的,有许多归因模型可用:第一次接触、最后一次接触、基于位置、线性、时间衰减等等(在这里阅读归因模型)。这些模型是基于时间的,并且总是对渠道在客户旅程中的顺序有一个特定的假设,从而形成一个“固定”的值。例如,基于位置的信道假设第一次触摸和最后一次触摸信道都将获得 40%的信用,而剩余的 20%将在中间的信道之间平均分配。但在现实中,可能有成千上万个客户旅程场景,对于每个客户,一个渠道可能有不同的价值。

关联规则可以应用于理解在使访问者转换时渠道的归属值。我们只是想知道哪个渠道增加了某人成为转化的概率,说明那个渠道的“真实”价值。例如,GDN 可能不会带来直接的转变,但如果一个游客经过 GDN,他成为我们的领导者的几率可能会高于平均水平。你可以深入挖掘 GDN 的交通来了解原因。在这种情况下,你可能想在 GDN 上分配一些资金,即使它在你的报告中没有显示足够的转化率。我们可以期待像{ GDN }→{转换}或{付费搜索}→{转换}这样的规则

Sample dataset prepared for association rules analysis in attribution
使用关联规则的利与弊
优点:
关联规则是从你的广告数据集中获得有意义的见解的一种快速简单的方法。它可以让您快速浏览元素之间的关系,并为进一步的研究(如机器学习算法)和实验提供基础。
关联规则不能确保统计显著性。相反,它表示平均效果,您可以使用关联规则分析作为输入来产生测试的想法。您可以比较两组访问者之间的表现:一个对照组不经过 GDN,而治疗组经过 GDN,目的是提高转化率。
缺点:
关联规则学习需要名义变量。连续变量需要转换成名义变量,它可能会丢失重要信息。如果您希望在分析中保持连续变量,则应考虑其他选项,如逻辑回归。
关于作者: 我是加州大学戴维斯分校的 MBA 毕业生。我对营销分析、建模、机器学习和数据科学充满热情。如果您有任何意见、反馈或问题,请随时通过 maitpnguyen296@gmail.com 联系我或通过 LinkedIn联系我。快乐造型!
线性回归算法的假设
这些假设在构建线性回归模型时得到满足,从而为给定的数据集生成最佳拟合模型。

线性回归—简介
线性回归是一种基于监督学习的机器学习算法。它执行回归任务来计算回归系数。回归模型是基于独立变量的目标预测。
线性回归执行的任务是根据给定的自变量(x)预测因变量值(y)。所以这种回归技术找出了 x(输入)和 y(输出)之间的线性关系。因此它被称为线性回归。一元线性回归的线性方程如下所示

Equation of a Simple Linear Regression
y-输出/目标/因变量;x-输入/特征/独立变量和θ1、θ2 分别是最佳拟合线的截距和斜率,也称为回归系数。
简单线性回归的例子:
让我们考虑一个例子,在这个例子中,给定一个人在某个特定领域的工作经验,我们预测他/她的工资。数据集如下所示

这里 x 是经验年限(投入/自变量),y 是提取的工资(产出/因变量)。
在将数据集分成训练和测试之后,我们已经对数据拟合了简单的线性回归模型。用于将数据拟合到线性回归算法的 python 代码如下所示

绿点代表数据集的分布,红线是最佳拟合线,可以用θ1 = 26780.09 和θ2 = 9312.57 绘制。
注意-θ1 是直线的截距,θ2 是直线的斜率。最佳拟合线是最适合可用于预测的数据的线。
用于解释线性回归假设的数据集描述
所使用的数据集是广告数据集。该数据集包含关于花费在广告上的钱及其产生的销售额的信息。钱花在了电视、广播和报纸广告上。它有 3 个特点,即电视,广播和报纸和 1 个目标销售。

First 5 rows of the data set
线性回归的假设
线性回归算法有 5 个基本假设:
- 特性和目标之间的线性关系:
根据这一假设,在特征和目标之间存在线性关系。线性回归只捕捉线性关系。这可以通过绘制特征和目标之间的散点图来验证。


电视与销售的第一个散点图告诉我们,随着电视广告投资的增加,销售也线性增加,第二个散点图是广播与销售的散点图,也显示了它们之间的部分线性关系,尽管不是完全线性的。
2。要素之间很少或没有多重共线性:
多重共线性是独立变量之间高度相关或关联的状态。因此,如果数据中存在干扰,就会削弱回归模型的统计能力。配对图和热图(相关矩阵)可用于识别高度相关的特征。

Pair plots of the features
上面的配对图显示特征之间没有显著的关系。

Heat Map(Correlation Matrix)
该热图为我们提供了每个要素之间的相关系数,而这些系数又小于 0.4。因此,这些要素之间的相关性并不高。
为什么移除高度相关的特征很重要?
对回归系数的解释是,当所有其他特性保持不变时,它代表特性中每个单位变化的目标的平均变化。然而,当特征相关时,一个特征的变化又会转移另一个特征。相关性越强,改变一个特性而不改变另一个特性就越困难。模型很难独立地估计每个特征和目标之间的关系,因为这些特征趋向于一致地变化。
多重共线性可以如何处理?
如果我们有两个高度相关的特征,我们可以丢弃一个特征或者组合这两个特征以形成新的特征,该新的特征可以进一步用于预测。
3。同方差假设:
同方差描述了误差项(即特征和目标之间关系中的“噪声”或随机干扰)在所有独立变量值中相同的情况。残差值与预测值的散点图是检查同质性的好方法。分布中不应该有明确的模式,如果有特定的模式,数据就是异方差的。

Homoscedasticity vs Heteroscedasticity
最左边的图显示了没有明确的模式,即残差中的恒定方差,中间的图显示了误差随着预测值违反恒定方差规则而增大然后减小的特定模式,最右边的图也显示了误差随着预测值减小而减小的特定模式,描述了异方差性
给定数据集的残差图的 Python 代码:

Error(residuals) vs Predicted values
4。误差项的正态分布:
第四个假设是误差(残差)遵循正态分布。然而,一个鲜为人知的事实是,随着样本量的增加,残差的正态性假设不再需要。更准确地说,如果我们考虑从总体中重复抽样,对于大样本量,回归系数的普通最小二乘估计的分布(跨重复样本)遵循正态分布。因此,对于中等到大样本量,残差的非正态性不会对通常的推断过程产生不利影响。这个结果是统计学中一个极其重要的结果的推论,被称为中心极限定理。
残差的正态分布可以通过绘制 q-q 图来验证。

Q-Q Plots
使用 q-q 图,我们可以推断数据是否来自正态分布。如果是,该图将显示相当直线。从直线上的偏差可以看出误差缺乏正态性。

Q-Q Plot for the advertising data set
广告数据集的 q-q 图显示误差(残差)相当正态分布。假设 3 中“误差(残差)与预测值”的直方图也显示误差正态分布,平均值接近 0。
5。残差中很少或没有自相关:
当残差相互依赖时,就会出现自相关。误差项中相关性的存在大大降低了模型的准确性。这通常发生在下一个时刻依赖于前一个时刻的时间序列模型中。
自相关可以借助杜宾-沃森检验来检验。检验的无效假设是不存在序列相关性。德宾-沃森检验统计量定义为:

检验统计量约等于 2*(1-r),其中 r 是残差的样本自相关。因此,对于 r == 0,表示没有序列相关性,检验统计量等于 2。该统计值将始终介于 0 和 4 之间。统计值越接近 0,正序列相关的证据就越多。越接近 4,负序列相关性的证据越多。

Summary of the fitted Linear Model
从上面的总结注意到,Durbin-Watson 测试的值是 1.885,非常接近 2,如前所述,当 Durbin-Watson 的值等于 2 时,r 从等式 2*(1-r)中取值 0,这又告诉我们残差不相关。
结论:
在将线性回归模型拟合到给定的一组数据之前,我们已经完成了必须牢记的最重要的假设。这些假设只是一种形式上的检查,以确保我们构建的线性模型为给定数据集提供了最佳的可能结果,并且这些假设如果不满足,也不会阻止我们构建线性回归模型。
数据科学中的异步工作流

对各地的数据科学家来说,毫无意义地盯着实时日志并等待奇迹发生是一种巨大的时间浪费。相反,应该努力实现异步工作流。在本文中,我们定义了异步工作流,指出了一些障碍,并最终引导您阅读下一篇文章,了解 Jupyter 笔记本中的一个实际例子。
什么是同步工作流?
在我们谈论异步工作流之前,我们必须定义同步工作流。同步工作流是创建和测试的迭代循环,在任何时候都只有一个或另一个在进行。例如在软件开发中,你写代码,测试它,然后写更多的代码,然后测试这些代码,写更多的代码,再次测试,编码,测试,编码,测试,编码…重复直到 IPO。简单!
同步工作流经常如此根深蒂固地存在于我们的做事方式中,以至于我们甚至没有意识到它是一件事情。这也是为什么它经常不被质疑的原因。很难质疑你甚至没有意识到存在的东西。

虽然软件开发和机器学习的周期是一样的,但我们可以看到它们之间有巨大的差异。
在软件开发中,你通常会很快得到结果。想象一下改变一个网页表单的布局或者你的手机游戏的物理公式。与编写代码所花的时间相比,测试结果所花的时间可能微不足道。另一方面,在机器学习中,情况正好相反。改变几个超参数的时间,比起看到训练结果的时间,往往只是一眨眼的功夫。
衡量成功的真正标准是能在 24 小时内完成的实验数量。
~托马斯·A·爱迪生
如果我们从上面看我们的机器学习时间线,并想象它是 24 小时,很明显我们没有将许多实验挤进去。等待训练结果是在吃我们的大部分时间。幸运的是,编码和等待之间有一个重要的区别:
一个人一次只能编写一个东西,却要等待无限的测试。
这就是我们所说的异步工作流。

当您创建一个模型并开始训练它时,重点不是喝杯咖啡,然后盯着输出日志的深渊几个小时。相反,在前一个实验还在运行的时候,同时开始另一个实验。这就是机器学习的异步工作流。
为什么我们不这样做?
为什么人们仍然坚持同步周期,而它显然不是最优的?有几个常见的原因:
缺少工具

大部分工具还是软件工程师为软件工程师做的。在软件工程中,同步工作流是标准。写一些代码,按下“播放”,等待结果。如果该工具的核心设计理念是同步的,那么工作流最终也会同步也就不足为奇了。
害怕失去工作

当一个人开始分支很多,并行运行几十件事情时,就会增加精神混乱,害怕失去工作或点击错误的东西。毕竟,一次只做一件事感觉更直接、更安全。
太专业了

在某些情况下,实际上更喜欢异步工作的人做不到。这需要额外的技能,如设置服务器或编写大量的粘合代码,因此他们被迫退回到默认的同步工作流。
是什么让我们这么做?
假设我们知道异步工作流是一种可行的方式,并且已经列出了一些常见的障碍,那么对一种工具的要求是什么呢?
简单的工具

该工具需要像同步“竞争者”一样简单。想象一下,你有两个选择来选择一个你每天都要使用的工具。你很可能选择更容易的,即使你知道更难使用的会更好。例如,如果启动一个新的测试对于同步工具来说只是一次点击,那么对于异步工具来说就不能是三次点击和一个 CLI 命令。一天重复 30 次的痛苦会让你回到以前的生活方式。
不具侵入性

从一个分支到几十个平行分支的转变伴随着认知负荷的增加。仅仅因为一直盯着您的现场测试的输出日志不是最佳的,这并不意味着您不应该不时地偷看一下。另一方面,当你试图编码时,你也不能有一个持续不断的通知消息流或者在你的屏幕上有一打闪烁的灯。一个好的异步工具应该退居二线,并且非常小心地平衡你的注意力。
安全的

多个同时分支的混乱局面给记账带来了更大的压力。如果工具不能以一种安全、直接和透明的方式组织和控制雪崩式的测试和实验,你最终会丢失工作或者在这个过程中犯认知错误。
完美的工具存在吗?
Valohai 是一个机器学习平台,它可以帮助您在云中执行按需实验,并具有完全的版本控制。我们已经开发了一个 Jupyter 笔记本扩展,它被专门优化来提供本文中描述的平滑异步工作流。在下一篇博文中,我们将向你展示 Valohai 的 Jupyter 笔记本扩展在实践中是如何工作的。
【https://blog.valohai.com】最初发表于。
你会在什么年龄获得诺贝尔奖?让我们用 r 来形象化。
让我们一起来探索你身边所有的数字中隐藏着什么。我们将可视化诺贝尔奖获得者的数据集,并用 r。

诺贝尔奖(Nobel Prize),任何一个奖项(1969 年前共有五个,后来增加了第六个),每年由瑞典发明家和实业家 阿尔弗雷德·诺贝尔 遗赠给的基金颁发。诺贝尔奖被广泛认为是世界上授予智力成就的最有声望的奖项。—britannica.com
让我们发现
使用的数据集可以从 kaggle 下载。
我们将尝试想象*(接受诺贝尔奖时)*的年龄是如何随时间变化的。

从中我们可以观察到,平均年龄几乎保持不变,直到 1950 年,此后,获奖者在接受奖励时的年龄不断增加,几乎增加了 8 岁。
我们使用了库’ tidyverse ‘来执行所有的操作。 tidyverse 是一个非常有用的库,它装载了几个包,比如’ dplyr '、 ggplot2 '、 dbplyr '、 lubridate '、 readxl '、
—“tidyverse”是一组协调工作的包,因为它们共享公共数据表示和“ API ”设计。该软件包旨在使在一个步骤中安装和加载多个’ tidyverse ‘软件包变得容易。
函数’ read.csv ‘从 csv 文件中读取数据,并作为一个数据帧存储到一个变量中,这里命名为’ nobel ‘。
函数“ 突变 ”添加新变量并保留数据框中已有的变量。这里, mutate 在数据帧中增加一个新列,命名为’ age '。
年龄是用另一个函数 计算出来的。Date’,它在字符表示和表示日历日期的类“ Date ”的对象之间进行转换。
最后,和 ggplot 和用于绘制散点图。使用变量“年在 x 轴上绘制散点图,而“年龄”在 y 轴上绘制散点图。 geom_point 用于绘制点(dots),我们也可以指定每个点的大小。这里,大小被指定为“ 3 ”,并且 alpha 被设置为“ 0.5 ”,这有助于定义点的不透明度(透明度),进而有助于识别点的重叠。
*****#Load Required Libraries** library(tidyverse)nobel <- read.csv("nobel.csv")
nobel_age <- nobel %>%
mutate(age = year - year(as.Date(birth_date)))ggplot(nobel_age,aes(x=year,y=age)) + geom_point(size = 3, alpha = 0.5,color = "black") + geom_smooth(aes(fill = "red")) + xlab("Year of Nobel Prize Distribution") + ylab("Age while Receiving the Prize")***
让我们探索一下
看到上面的图的一个问题是,它反映了非常少的信息。在数据可视化中,使用颜色或形状弹出数据的作用类似于糖块中的糖。
从下面的图表中我们观察到三个类别’'、 、医学 '、 物理学 ‘观察到一些相似的趋势,所有这些类别的平均年龄在这些年中不断增加。最大的偏差可见于类别’物理’。唯一显示平均年龄逐年下降的类别是“”类别。而类别’‘和’ 文学 '这些年来几乎保持不变。我们可以从图表中得出的一个更重要的观察结果是,在类别“和平”中,分数分布更广,这表明许多获奖者的平均年龄与相差甚远。******
如果你获得了几个奖项的诺贝尔奖,你的假设年龄是多少?
- 化学,年龄= 70 |最有可能:(年龄> 70)
- 经济学,年龄= 69 |最有可能:(67
- Literature, Age = 70 | Most probable: (67
- Medicine, Age = 68 | Most probable: (Age > 52)
- 和平,年龄= 55|最有可能:(年龄< 65)
- Physics, Age = 69| Most probable: (Age > 66)

让我们来理解帮助我们获得上述结果的代码。我们加载了本文前面加载的同一个库。
facet _ wrap-将 1d 序列的面板包装成 2d。这通常比’【facet _ grid()‘更好地利用了屏幕空间,因为大多数显示器大致是矩形的。
gg plot ly—将’ ggplot2 ‘转换为’ plotly ‘,此函数将一个’ ggplot2::ggplot() ‘对象转换为一个’ plotly '对象。**
那么下面的代码实际上是做什么的呢?
使用 ggplot 函数生成一个图,其中突变的数据帧’ nobel_age 作为数据, x 轴和 y 轴分别指定为’ year 和’ age '。 geom_point 用于指定散点图的绘制,而geom _ smooth用于在过度绘制的情况下帮助眼睛看到图案,在过度绘制的情况下,颜色和填充由变量“ category 定义,这有助于为不同类别绘制不同颜色的图形。例如,如果我们必须为一家巧克力商店绘制一个图表,并考虑有三个类别“牛奶”、“白色”、“深色”,那么上述方法将用不同的颜色绘制不同类别的所有点,以帮助我们以更好的方式区分这些点。 facet_wrap 这里,用不同的类别对每个支线剧情进行剧情划分,从而获得基于类别划分的六个不同的支线剧情。**
****#Load Required Libraries** library(tidyverse)
library(plotly)nobel <- read.csv("nobel.csv")
nobel_age <- nobel %>%
mutate(age = year - year(as.Date(birth_date)))p <- ggplot(nobel_age,aes(x=year,y=age)) +
geom_point() +
geom_smooth(aes(colour = category, fill = category)) +
facet_wrap(~ category)ggplotly(p)**
在 R 中小心地附加包
使用显式名称空间减少冲突,使您的源代码更加简洁,未来更加安全

R packages exporting the same symbol lead to conflicts when imported into the global namespace (Photo by Siala on pixabay)
当通过 library()调用在脚本顶部附加几个库时,R 中的一个常见问题就会出现。将所有符号加载到全局 R 环境中通常会导致名称冲突。最后导入的包赢得了战斗——顺序很重要,根据这个顺序,库出现在脚本的顶部!
R 是一种快速发展的语言,有一个生动的社区贡献了无数的包(c.f. R 包文档)。昨天的脚本很可能明天就不工作了,因为一个更新的包现在导出了一个与另一个全局附加包冲突的函数。
所以我在这里提出注意使用将包附加到全局 R 环境中。尽量减少 library()调用,对其他包改用 requireNamespace()。使用显式名称空间比如
requireNamespace("lubridate") # at the top of your file
# ... some code
lubridate::ymd(20190130)
代替
library(lubridate) # at the top of your file
# ... some code
ymd(20190130)
requireNamespace()加载包,将其留在自己的名称空间中。如果缺少所需的包,调用会产生异常。
这可能看起来很尴尬。但是:它使代码更加简洁,并且在其他软件开发领域(例如 Python)被视为一种好习惯。否全局附件的候选对象可能是很少使用的函数或包,从而导致名称冲突。通常,我用重载操作符全局导入包,比如 dplyr 的% > %操作符。
**例如:**我的一个脚本头看起来像这样:
library(dplyr)
library(tidyr)
library(readr)
library(ggplot2)
requireNamespace(“lubridate”)
requireNamespace(“glue”)# here comes my code
使用 data()调用的 package 参数从未附加的包中加载数据:
requireNamespace("psd")
data(magnet, package = "psd")
为什么 requireNamespace()很重要
不在顶部附加包的缺点是你的脚本可能会遇到这样的错误
Error in loadNamespace(name) : there is no package called ‘lubridate’
如果当前的 R 安装缺少所需的包,则在稀有程序路径的深度。这让人很不舒服,也很意外!
在像 R 或 Python 这样的动态类型语言中,确保软件完整性具有挑战性。编译语言在更早的时候抱怨缺少库:在编译时(如果静态链接)或者至少在启动应用程序时(如果动态链接)。
**警告:**有些 R 包在没有全局附加它们的名称空间的情况下无法工作——所以在这些情况下,你必须使用 library()来代替。这个问题的一个例子是 psd 包(版本 1.2.0):
data(magnet, package = "psd")
x <- magnet$clean
spec <- psd::pspectrum(x, plot = TRUE)
给出错误
Stage 0 est. (pilot)
environment ** .psdEnv ** refreshed
detrending (and demeaning)
Error in psdcore.default(as.vector(X.d), X.frq = frq, ...) :!is.null(ops) is not TRUE
结论
通过使用显式名称空间编写健壮而简洁的 R 脚本。此外,R 脚本对其他人来说可读性更好:函数在哪个包中被调用是很清楚的!
用 Fast.ai 攻击有毒评论 Kaggle 比赛
如何从头开始构建多标签 NLP 分类器

K aggle 是学习和练习你的机器学习技能的好地方。这也是为你的学习项目寻找合适的数据集的好地方。我需要一个好的分类 NLP 数据集来实践我最近学习的 fast.ai 课程,我遇到了有毒评论分类挑战。比赛是两年前举行的,早就结束了,但提交我的分数并看看我做得有多好也无妨。这是 Kaggle 的优势之一,因为在现实世界中,通常很难知道你的模型是好是坏,而在 Kaggle 中,你可以清楚地看到你的表现在排行榜上的位置。
数据集
他的比赛由对话人工智能团队举办,这是一个由竖锯和谷歌(都是 Alphabet 的一部分)创立的研究项目。它的目标是找出能够在评论中对多种毒性类型进行分类的最佳模型。毒性类型包括:
有毒的
严重 _ 有毒
猥亵的
威胁
侮辱
同一性 _ 仇恨
在训练文件train.cvs和测试文件test.csv中给出了注释。你需要为test.csv中的每条评论预测每种毒性的概率。这是一个多标签的 NLP 分类问题。
看数据
L et 先来看看数据。我们需要导入必要的模块,并做一些后勤工作来为我们的文件设置路径。
import numpy as np *# linear algebra*
import pandas as pd *# data processing, CSV file I/O (e.g. pd.read_csv)* from fastai.text import *
from fastai import *
注意这里我们从 fastai.text 和 fastai 模块导入了所有内容。我们反对这里的软件工程最佳实践吗?实际上,不完全是。这是一种更具迭代性和互动性的数据科学方式的深思熟虑的举措。有了所有可用的库,我可以轻松地测试和尝试不同的功能/模块,而不必每次都返回并导入它们。这将使探索/实验流程更加顺畅。不过我跑题了,我们来加载数据看看:
# Kaggle store dataset in the /kaggle/input/ folder,
path = Path('/kaggle/input/jigsaw-toxic-comment-classification-challenge/')
path.ls()# the /kaggle/input/ folder is read-only, copy away so I can also write to the folder.
!mkdir data
!cp -a {path}/*.* ./data/
!ls data# make sure everything is correctly copied over
path = Path('/kaggle/working/data/')
path.ls()# read in the data and have a peak
df = pd.read_csv(path/'train.csv')
df.head()

The toxicity types are one-hot encoded
注释在comment_text列中,所有毒性类型都是“一次性”编码的,我们将不得不对其进行一些处理,以使其适合我们以后的模型。

Have a look at one comment
迁移学习:微调我们的语言模型

我们将使用迁移学习来完成这项任务,为此,我们将使用一个基于维基百科的预训练模型,名为 wikitext-103 。这是一个已经从维基百科数据集(或 NLP 术语中的“语料库”)中训练出来的模型,用于从给定的未完成句子中预测下一个单词。我们将利用模型已经从维基百科数据集学习到的“语言知识”,并在此基础上进行构建。为了达到最佳效果,我们需要“微调”模型,使它从我们的“评论”数据集中学习一些东西,因为人们在评论中所说的不一定与更正式的维基相同。一旦对语言模型进行了微调,我们就可以使用它来进一步完成分类任务。
现在让我们将训练数据加载到 fast.ai databunch中,以便我们可以首先开始训练语言模型。
bs = 64 # set batch size to 64, works for Kaggle Kernels
data_lm = (TextList.from_df(df, path, cols='comment_text')
.split_by_rand_pct(0.1)
.label_for_lm()
.databunch(bs=bs))
我们使用 fast.ai 的Data Block API来完成这项任务。这是一种非常灵活和强大的方法,可以解决构建管道的挑战性任务:将数据加载到模型中。它将整个过程隔离为不同的部分/步骤,每个步骤都有多种方法/功能来适应不同类型的数据和数据存储方式。这个概念很像 Linux 哲学,高度模块化,每个模块只做一件事,但做得非常非常好。您可以在这里自由探索美妙的 API ,尽管对于上面的代码,它做了以下事情:
- 从名为
df的 Pandas DataFrame 导入数据,告诉模型使用comment_text作为输入(TextList.from_df(df, path, cols=’comment_text’)) 注意这里我也可以将 test.csv 包含到语言模型中。这不被认为是“作弊”,因为我们没有使用标签,只是做语言模型训练。 - 将训练数据集按随机的 10/90%分成训练/验证集。(
.split_by_rand_pct(0.1)) - 忽略给定的标签(因为我们只是微调语言模型,而不是训练分类器),并使用语言模型的“预测下一个单词”作为标签。(
.label_for_lm()) - 将数据构建到一个
databunch中,批量大小为bs。(.databunch(bs=bs))
现在让我们看看我们刚刚构建的databunch:

Notice we lost all the toxicity types
请注意,databunch没有所有的毒性类型标签,因为我们只是微调了语言模型。
好了,是时候进行一些典型的 fast.ai 学习率调整和训练了:

我们将我们的databunch放入一个language_model_learner中,告诉它我们想要使用的语言模型库(AWD_LSTM),并分配一个默认的辍学率 0.3 。从LR Finder图中,找出最大的下降斜率,选取中间点作为我们的学习率。(关于如何实现这种‘fit _ one _ cycle’魔法的更详细解释,请参考这篇文章。它是 fast.ai 的一种 SOTA 技术,结合了学习率和动量退火)。现在,我们可以“解冻”模型,并训练几个时期的整个模型:

我们可以看一个模型表现如何的例子:

结果很难说是最佳的。但我们至少得到了一个实际上有意义的句子,并且预测下一个单词的 0.38 的准确度还不错。理想情况下,我们需要训练更多的纪元,但对于这个 Kaggle 内核,我用完了 GPU 配额,所以我停在了 4。结果肯定有提升的空间,可以自己试试。反正我们想从语言模型中得到的是编码器部分,所以我们把它保存下来。
训练语言模型确实需要相当长的时间,但好消息是,对于您自己的领域语料库,您只需训练一次,以后您可以将它用作任何其他分类任务的基础。
*# save the encoder for next step use*
learn.save_encoder('fine_tuned_enc')
迁移学习:训练分类器
让我们来看看测试数据集:
test = pd.read_csv(path/"test.csv")
test_datalist = TextList.from_df(test, cols='comment_text')
再次,建造我们的databunch:
data_cls = (TextList.from_csv(path, 'train.csv', cols='comment_text', vocab=data_lm.vocab)
.split_by_rand_pct(valid_pct=0.1)
.label_from_df(cols=['toxic', 'severe_toxic','obscene', 'threat', 'insult', 'identity_hate'], label_cls=MultiCategoryList, one_hot=True)
.add_test(test_datalist)
.databunch())
data_cls.save('data_clas.pkl')
请注意这次的不同之处:
- 在构建
*TextList*时,我们指定了*vocab=data_lm.vocab*,这样我们就确保了我们使用的是相同的词汇,并且我们在语言模型上的训练可以恰当地应用到分类器模型上。 - 我们现在使用我们所有的毒性风格标签(
.label_from_df(cols=[‘toxic’, ‘severe_toxic’,’obscene’, ‘threat’, ‘insult’, ‘identity_hate’],label_cls=MultiCategoryList, one_hot=True),) - 我们在这里添加了我们的测试集。(
.add_test(test_datalist))
现在看看我们的分类器databunch:

Note that now we have all the toxicity styles labels
最后,是时候把所有东西放在一起了!我们将把databunch放到text_classifier_learner模型中,并加载我们从语言模型中学到的编码器。
learn = text_classifier_learner(data_clas, AWD_LSTM, drop_mult=0.5)
learn.load_encoder('fine_tuned_enc')
再次,找到最佳学习率,训练一个周期:

多训练几个周期,然后解冻:



查看结果:

差了一个,但总体来说预测是好的。作为参考,我将预测提交给 Kaggle,得到一个 0.98098 的公众分数(落在公众领袖板的中间)。结果不是最佳的,但是就像我说的,由于 GPU 有限,我没有全程训练。本文的目的是向您展示使用 fast.ai 处理多标签文本分类问题的整个过程。这里真正的挑战是使用数据块 API 将数据加载到模型中。
结论
我希望你能从这篇文章中学到一些东西。Fast.ai 真的是一个精简、灵活、强大的库。对于它能做的事情(像图像/文本分类,表格数据,协同过滤等。),它做得很好。它不像 Keras 那样广泛,但它非常尖锐和集中。有点像 Vim 和 Emacs,如果你熟悉命令行文本编辑器 war 的话。😜
你可以在这里找到 Kaggle 内核。
欢迎任何反馈或建设性的批评。你可以在推特 @lymenlee 或者我的博客网站【wayofnumbers.com上找到我。
注意及其不同形式
概括注意的不同类型和用途。

(Source)
我假设你已经熟悉递归神经网络(包括 seq2seq 编码器-解码器架构)。
瓶颈问题
在编码器-解码器架构中,完整的信息序列必须由单个向量捕获。这给在序列开始时保留信息和编码长程相关性带来了问题。

注意力的核心思想是关注每个输出的输入序列中最相关的部分。
通过为输入提供一条直接的路径,注意力也有助于缓解渐变消失的问题。
计算注意力
假设您有一个顺序解码器,但是除了前一个单元的输出和隐藏状态之外,您还要输入一个上下文向量 c 。

其中 c 是编码器隐藏状态的加权和。

这里 αᵢⱼ 是第 i 个输出应该关注第 j 个输入的量,而 hⱼ 是第 j 个输入的编码器状态。
αᵢⱼ 通过对输入相对于 i th 输出的注意力分数取软最大值来计算,用 **e、**表示。

在哪里

这里 f 是对齐模型,其对位置 j 周围的输入和位置 i 处的输出的匹配程度进行评分,并且 sᵢ₋₁ 是来自前一时间步的隐藏状态。

对齐模型可以通过小型神经网络来近似,然后可以使用任何梯度优化方法(例如梯度下降)来优化整个模型。

Graphic illustration of the attention mechanism (Source)
上下文向量 cᵢ 也可以用于计算解码器输出 yᵢ 。
应用:机器翻译
注意力首先由 Bahdanau 等人[1]提出,用于神经机器翻译。该机制对于机器翻译特别有用,因为与输出最相关的单词经常出现在输入序列中的相似位置。

(Source)
上面的矩阵显示了与每个翻译输出单词最相关的输入单词。
这样的注意力分布也有助于为模型提供一定程度的可解释性。
普遍注意力
给定一个查询 q 和一组键-值对 (K,V) ,注意力可以概括为计算依赖于查询和相应键的值的加权和。
查询确定关注哪些值;我们可以说查询“关注”了这些值。

在前面的计算中,查询是前一个隐藏状态 sᵢ₋₁ ,而编码器隐藏状态集 h₀ 到 hₙ 表示键和值。
反过来,对准模型可以以各种方式计算。

自我关注
有了自我关注,每一个隐藏状态都会关注同一个 RNN 的先前隐藏状态。

这里 sₜ 是查询,而解码器隐藏状态 s₀ 到 s ₜ₋₁ 表示键和值。
应用:语言建模
论文“指针哨兵混合模型”[2]使用自我注意进行语言建模。
基本思想是,细胞的输出“指向”先前遇到的具有最高注意力分数的单词。然而,该模型还在词汇 V 上使用标准的 softmax 分类器,使得它除了从最近的上下文中再现单词之外,还可以预测不存在于输入中的输出单词。

(Source)
在指针词汇表分布中分配给给定单词的概率是分配给给定单词出现的所有标记位置的概率之和

其中 I(w,x) 在输入 x 和 pₚₜᵣ∈ Rⱽ 中得到单词 w 的所有位置。这种技术被称为指针和注意力。
该模型使用门 g 将 softmax 词汇分布与指针词汇分布相结合,该门被计算为查询和标记向量的乘积。

(Source)

An output example (Source)
申请:总结
论文“用于抽象概括的深度强化模型”[3]介绍了一种具有新颖的自我关注的神经网络模型,该模型分别关注输入和连续生成的输出,

(Source)
所涉及的计算可以总结如下。

(Source)

An output example (Source)
多头注意力
多重查询
当我们有多个查询时,我们可以把它们堆在一个矩阵中。
如果我们使用基本的点积注意力来计算对齐,则用于计算上下文向量的方程组可以简化如下。

(Source)
多头关注更进了一步。
使用权重矩阵将 q、K 和 V 映射到较低维度的向量空间,然后将结果用于计算注意力(其输出我们称为“头部”)。

我们有 h 组这样的权重矩阵,这给了我们 h 个头。

然后,使用输出权重矩阵连接和变换 h 个头。

变形金刚(电影名)
变压器是在论文“你所需要的只是注意力”中首次提出的[4]。它基于这样一种思想,即序列模型可以完全省去,输出可以仅使用注意机制来计算。
转换器使用单词向量作为键、值以及查询的集合。

Transformer’s Multi-Head Attention block (Source)
它包含多头注意力的块,而注意力计算本身是成比例的点积注意力。

(Source)
其中 dₖ 是查询/关键向量的维度。
执行缩放是为了使 softmax 函数的参数不会因更高维的键而变得过大。
下面是完整的变压器模型图,以及一些带有附加细节的注释。有关更深入的解释,请参考附加资源。

(source)
额外资源
- deeplearning.ai 的注意力模型直觉(C5W3L07) 和注意力模型(C5W3L08)
- “注意?注意!”由莉莲翁
- 《注意力和增强的递归神经网络》作者 Olah & Carter,Distill,2016
- 《图解变形金刚》杰伊·阿拉玛
参考
[1] D. Bahdanau,K. Cho 和 Y. Bengio,通过联合学习对齐和翻译进行神经机器翻译(2014)
[2] S. Merity,C. Xiong,J. Bradbury 和 R. Socher,Pointer Sentinel 混合模型(2016)
[3] R. Paulus,C. Xiong,R. Socher,抽象概括的深度强化模型(2017)
[4] A .瓦斯瓦尼、n .沙泽尔、n .帕马尔、j .乌兹科雷特、l .琼斯、A. N .戈麦斯、l .凯泽、I .波罗苏欣,《你只需要关注》(2017)
基于注意力的神经机器翻译

通过在翻译过程中选择性地关注句子的子部分,注意力机制正越来越多地用于提高神经机器翻译(NMT)的性能。在这篇文章中,我们将介绍两种简单的注意力机制: 全局方法 (关注所有源词)和 局部方法 (只关注源词的子集)。请记住,源指的是编码器,目标指的是解码器。
本博客将涵盖 这篇 的论文,这篇论文证明了增加注意力可以导致比基于非注意力的网络显著的性能提升。在上述论文中提出的系综模型为 WMT 的 15 英德翻译产生了一种新的艺术状态模型。
除了提高机器翻译练习的性能,基于注意力的网络还允许模型学习不同模态(不同数据类型)之间的对齐,例如语音帧和文本之间或者图片的视觉特征和其文本描述之间的对齐。
神经机器翻译(NMT)
NMT 是一个巨大的神经网络,它被训练成端到端的方式,用于将一种语言翻译成另一种语言。下图是基于 RNN 的编码器-解码器架构的 NMT 的示意图。

Figure 1 : Neural machine translation as a stacking recurrent architecture for translating a source sequence A B C D into a target sequence X Y Z. Here marks the end of a sentence.
NMT 直接模拟翻译源的条件概率***【p(y/x)】***(x1,x2…xn) 句转化为目标句 (y1,y2…yn) 。
NMT 由两部分组成:
- 编码器,为每个源语句计算表示 S
- 一种解码器,一次生成一个单词的翻译,因此将条件概率分解为:

A probability of translation y given the source sentence x
可以将解码每个字 y(j)的概率参数化为

其中 h(j) 可以建模为

RNN hidden unit definition (h)
***其中
g:*a变换函数,输出词汇大小向量
h : RNN 隐藏单元
f :给定先前隐藏状态,计算当前隐藏状态。
翻译流程的 培训目标 可以被框定为

Loss Function
是什么让 NMT 如此受欢迎?
- NMT 在大规模翻译任务中,如英语到法语/德语的翻译,已经达到了艺术水平。
- NMT 需要最少的领域知识,概念上非常简单。
- NMT 的内存占用很小,因为它不存储庞大的相位表和语言模型。
- NMT 能够很好地概括很长的单词句子。
注意网络和非注意网络的区别
在大多数基于非注意力的 RNN 架构信源表示中, S 仅被使用一次来初始化解码器隐藏状态。[在图 1 中,解码器只能访问编码器的最后一层]
另一方面,基于注意力的网络在整个翻译过程中指的是一组源隐藏状态。[在图 2 中,解码器可以访问编码器的所有隐藏状态]
注意机制的类型

Figure 2: NMT with attention and input-feeding approach
上图重点描绘了基于 RNN 的编码器-解码器架构。正如我们之前解释的,注意力可以大致分为两种类型:
- 全局关注:关注所有源位置。
- 局部注意:只注意几个源位置。
这两种基于注意力的模型仅在解码阶段不同于普通的编码器-解码器架构。这些基于注意力的方法的不同之处在于它们计算上下文向量的方式(【c(t)】)。

Figure 3: Hidden state of NMT architecture with global attention
图 3 的术语表如下
【t】:隐藏目标状态
c(t) :源端上下文向量
y(t) :当前目标词
h _ bar(t):注意隐藏状态
a(t) :对齐向量
如何计算注意力?
这两种基于注意力的方法都有以下共同步骤:
- 这两种方法首先将堆栈 LSTM 顶层的隐藏状态**【h(t)】**作为输入。(棕色单元格/解码器的目标状态)
- 派生**【c(t)来捕获相关的源端信息,以帮助预测【y(t)(顶部蓝色单元格)。【c(t)**基本上是你根据每个单词的对齐权重和编码器的隐藏状态为每个单词建立的上下文。
- 从 h(t)和 c(t)的简单串联计算**【h _ bar(t)**(顶部灰色单元格)。

与仅将编码器的最终输出提供给解码器的基于非注意力的架构相反,**【h _ bar(t)**具有对编码器的隐藏状态的所有状态的访问,这提供了源语句的信息视图。
4.使用 softmax 层转换注意力向量以产生预测分布。我们使用 softmax 层,因为我们必须从我们的词汇表中所有可用的单词中找到最可能的单词。

以上段落解释了基于注意力的网络的基本架构。在下面的段落中,我们将理解上下文向量**【c(t)**在局部和全局注意力中是如何不同地计算的,以及它的影响是什么。
- 全球关注
全局注意力考虑所有编码器隐藏状态以导出上下文向量(c(t))。为了计算 c(t), 我们计算 a(t) 这是一个可变长度的对齐向量。通过计算**【t】**和 h_bar(s) 之间的相似性度量来导出对齐向量,其中 h(t) 是源隐藏状态,而 h_bar(s) 是目标隐藏状态。编码器和解码器中类似的状态实际上指的是同一个意思。
对齐向量(a(t))
对齐向量(【t,s】)定义为

分数是一个基于内容的函数,可以使用以下任何一种替代方法:

The score function
通过得分函数,我们试图计算目标和源的隐藏状态之间的相似性。直观上,隐藏和源中的相似状态指的是相同的意思,但在不同的语言中。

Figure 4: Global attentional model: At each time step t, the model infers a variable-length alignment weight vector a(t) based on the current target state h(t) and all source states h_bar(s). A global context vector,c(t) is then computed as the weighted average, according to a(t), over all the source states.
图 4 中的连接线代表相互依赖的变量。
例如
- a(t) 依赖于 h(t)和 h_bar(s)
- c(t) 依赖于 a(t)和 h_bar(s)
- h_bar(t) 依赖于 c(t)和 h(t)
2.当地的关注
由于全局注意力集中在所有目标单词的所有源端单词上,这在计算上非常昂贵,并且在翻译长句时不切实际。为了克服这一缺陷,局部注意力选择只关注每个目标单词的编码器隐藏状态的一个小子集。
局部注意力有以下不同于全局注意力的步骤:
- 该模型首先在时间 t 为每个目标单词生成对齐位置 p(t) ,与假设单调对齐的全局注意模型相反,我们在局部注意中学习对齐位置。换句话说,除了学习翻译之外,你还可以学习翻译的顺序是否与源句子不同(源的单词 1 可能是翻译句子中的单词 4,因此我们需要计算这个,否则我们的相似性得分将完全错误,因为我们的注意力将集中在源句子中与源句子的单词 1 不相关的单词上)。
- 上下文向量(c(t))被导出为窗口[p(t)-D,p(t)+D]内的源隐藏状态集合的加权平均值;d 是凭经验选择的。与全局对准向量相比,局部对准向量 a(t)现在是固定维度的。
到目前为止,我们一直假设翻译句子和源句子都是单调对齐的。在此基础上,我们对局部注意力有了进一步的区分,具体如下:
- 单调对齐( local-m )
Set p(t)=t,这意味着我们假设源序列和目标序列大致单调对齐。对齐向量与全局对齐相同

Local alignment is the same as that of global alignment
2。预测比对 ( 局部-p )
我们的模型不是假设单调排列,而是预测排列位置如下:

Alignment Position for local-p model
W§ 和 v§ 是模型参数,将学习这些参数来预测位置。
S 是源句长度
p(t):【0,S】
为了有利于对齐位置 p(t), 我们放置一个以 p(t)为中心的高斯分布。这赋予位置 p(t) 更多的权重。我们将校准权重修改为

Alignment vector for local-p model
去捕捉同样的东西。
总而言之,全局注意力在计算上更昂贵,并且对长句无用,而局部注意力集中在D***【p(t)*两侧的隐藏状态来克服这一点。局部注意有 2 种口味 local-m ( 源和目标对齐假设相同 ) 和 local-p (这里我们计算的是 p(t))。
投入-供给方法
在所提出的注意机制中,独立地做出注意决定(先前预测的对准不影响下一次对准),这是次优的。为了确保未来的对准决策考虑到过去的对准信息 ,h_bar(t) 在下一时间步与输入连接,如图所示。
这样做是为了:
- 让模型完全了解之前的对齐选择。
- 创建一个横向和纵向都很深的网络。

Attentional Vectors h_bar(t) is fed to the next time steps to inform the model about past alignment decisions
在上面的文章中,我们和 NMT 一起讨论了注意力网络的基础知识。
参考
如果你对上面的帖子有任何想法或补充,请随时联系我。
注意力渴望 RNNS:建立变压器网络

将注意力放在你的神经网络上有点像想在工作时小睡一会儿。你知道这对你更好,每个人都想这样做,但每个人都害怕。
我今天的目标是什么都不假设,用动画解释细节,让数学再次伟大(MMGA?呃…)
这里我们将介绍:
- 简短的 RNN 评论。
- 短序列到序列模型审查。
- RNNs 中的注意。
- 注意力的改善。
- 变压器网络介绍。
递归神经网络(RNN)
RNNs 让我们在神经网络中模拟序列。虽然有其他方法来模拟序列,rnn 是特别有用的。rnn 有两种类型,LSTMs ( Hochreiter 等人,1997 )和 GRUs ( Cho 等人,2014 )。想要更深入的教程,请查看克里斯·科拉的教程。
让我们来看一个 RNN 的具体例子的机器翻译。
- 想象我们有一个有 56 个隐藏单元的 RNN。
rnn_cell = rnn_cell(input_dim=100, output_dim=56)
2.我们有一个单词“NYU ”,它由整数 12 表示,这意味着它是我创建的 vocab 中的第 12 个单词。
# 'NYU' is the 12th word in my vocab
word = 'NYU'
word = VOCAB[word]print(word)
# 11
除了我们没有将整数输入 RNN,我们使用了一个更高维的表示,这是我们目前通过嵌入获得的。嵌入让我们将一系列离散的记号映射到连续的空间中( Bengio 等人,2003 )。
embedding_layer = Embedding(vocab_size=120, embedding_dim=10)# project our word to 10 dimensions
x = embedding_layer(x)
一个 RNN 单元接受两个输入,一个字 x ,以及一个来自前一时间步 h 的隐藏状态。在每一个时间步,它输出一个新的h 。

RNN CELL: next_h= f(x, prev_h).
提示:对于第一步,h 通常为零。
# 1 word, RNN has 56 hidden units
h_0 = np.zeros(1, 56)
这很重要:RNN 细胞与 RNN 细胞是不同的。
在 RNN 术语中有一个主要的混淆点。在深度学习框架中,如 Pytorch 和 Tensorflow ,RNN 细胞是执行这种计算的单位:
h1 = rnn_cell(x, h0)
RNN 网络 for 在时间步长上循环单元
def RNN(sentence):
current_h = h_0 all_h = []
for word in sentence:
# use the RNN CELL at each time step
current_h = rnn_cell(embed(word), current_h)
all_h.append(current_h) # RNNs output a hidden vector h at each time step
return all_h
这里有一个 RNN 随着时间推移移动同一个 RNN 单元格的图示:

The RNN moves the RNN cell over time. For attention, we’ll use ALL the h’s produced at each timestep
序列对序列模式(Seq2Seq)
现在你是 RNNs 的专家了,但是让我们放松一下。

Chill
rnn 可以用作更大深度学习系统的模块。
一个这样的系统是由 Bengio 的小组( Cho 等人,2014 )和 Google ( Sutskever 等人,2014 )引入的 Seq2Seq 模型,它可以用于将一个序列翻译成另一个序列。你可以把很多问题框定为翻译:
- 把英语翻译成西班牙语。
- 将一个视频序列转换成另一个序列。
- 将一系列指令翻译成程序代码。
- 将用户行为转化为未来的用户行为
- …
- 唯一的限制是你的创造力!
seq2seq 模型无非是 2 个 rnn,一个编码器(E),一个解码器(D)。
class Seq2Seq(object): def __init__():
self.encoder = RNN(...)
self.decoder = RNN(...)
seq2seq 模型有两个主要步骤:
第一步:编码一个序列:
sentence = ["NYU", "NLP", "rocks", "!"]
all_h = Seq2Seq.encoder(sentence)# all_h now has 4 h (activations)

Encoding
第二步:解码生成“翻译”
这部分真的很复杂。前一步中的编码器一次处理完整的序列(即:这是一个普通的 RNN)。
在第二步中,我们一次运行解码器 RNN 一个步骤,以生成自回归预测(这是为了将前一步的输出用作下一步的输入)。
有两种主要的解码方式:
选项一:贪婪解码
- 运行解码器的 1 个步骤。
- 选择概率最高的输出。
- 使用此输出作为下一步的输入
# you have to seed the first x since there are no predictions yet
# SOS means start of sentence
current_X_token = '<SOS>'# we also use the last hidden output of the encoder (or set to zero)
h_option_1 = hs[-1]
h_option_2 = zeros(...)# let's use option 1 where it's the last h produced by the encoder
dec_h = h_option_1# run greedy search until the RNN generates an End-of-Sentence token
while current_X_token != 'EOS': # keep the output h for next step
next_h = decoder(dec_h, current_X_token) # use new h to find most probable next word using classifier
next_token = max(softmax(fully_connected_layer(next_h))) # *KEY* prepare for next pass by updating pointers
current_X_token = next_token
dec_h = next_h
这叫做贪婪,因为我们总是选择概率最高的下一个词。
选项 2:光束搜索
有一种更好的技术叫做波束搜索,它在解码过程中考虑多条路径。通俗地说,宽度为 5 的波束搜索意味着我们考虑具有最大对数似然的 5 个可能的序列(数学术语为 5 个最可能的序列)。
在高层次上,我们保留顶部 k(波束大小= k),而不是采用最高概率预测。注意下面,在每一步我们有 5 个选项(5 个可能性最大)。

Beam search figure found here
这个 youtube 视频有详细的光束搜索教程!
所以,用 greedy decoding 作为动画把*【NYU NLP 很牛逼】*翻译成西班牙语的完整 seq2seq 过程看起来是这样的:

Seq2Seq is made up of 2 RNNs an encoder and decoder
这个模型有各种部件:
- 蓝色 RNN 是编码器。
- 红色 RNN 是解码器
- 解码器顶部的蓝色矩形是一个带有 softmax 的完全连接层。这将挑选最有可能的下一个单词。
注意机制
好了,现在我们已经讨论了所有的先决条件,让我们进入正题。
如果你注意到前面的动画,解码器只查看编码器生成的最后一个隐藏向量。

事实证明,RNN 很难记住在这个单一向量的序列中发生的一切(Bahdanau 等人,2015 )。例如,当编码器处理完输入序列时,可能已经忘记了单词“NYU”。
注意力试图解决这个问题。
当你给一个模型一个注意机制时,你允许它在每个解码步骤中查看由编码器产生的所有 h。
为了做到这一点,我们使用一个单独的网络,通常是一个完全连接的层,它计算解码器想要查看多少 h。这被称为注意力机制。
想象一下,对于我们生成的所有 h,我们实际上只取其中的一点。它们的总和被称为上下文向量 c.

标量 0.3、0.2、0.4、0.1 称为*注意力权重。*在原始论文中,你会在第 3 页找到同样的等式:

Alphas are generated by a neural network + softmax.
这些权重由一个小型神经网络以这种方式生成:
# attention is just a fully connected layer and a final projection
attention_mechanism = nn.Linear(input=h_size+x_size, attn_dim=20)
final_proj_V = weight_matrix(attn_dim)# encode the full input sentence to get the hs we want to attend to
all_h = encoder(["NYU", "NLP", "is", "awesome"]# greedy decoding 1 step at a time until end of sentence token
current_token = '<SOS>'
while current_token != '<EOS>': # attend to the hs first
attn_energies = []
for h in all_h:
attn_score = attention_mechanism([h,current_token])
attn_score = tanh(attn_score)
attn_score = final_proj_V.dot(attn_score) # attn_score is now a scalar (called an attn energy)
attn_energies.append(attn_score) # turn the attention energies into weights by normalizing
attn_weights = softmax(attn_energies)
# attn_weights = [0.3, 0.2, 0.4, 0.1]
现在我们有了权重,我们用它们来提取可能与被解码的特定令牌相关的 h
context_vector = attn_weights.dot(all_h)
# this is now a vector which mixes a bit of all the h's
让我们把它分成几个步骤:
- 我们对完整的输入序列进行了编码,生成了一个 h 列表。
- 我们开始用解码器用贪婪搜索解码。
- 我们没有给解码器 h4,而是给了它一个上下文向量。
- 为了生成上下文向量,我们使用另一个网络和可学习的权重 V 来评分每个 h 与当前被解码的令牌的相关程度。
- 我们将那些 注意力 归一化,并使用它们将所有的 h 混合成一个 h,这有希望捕获所有 h 的相关部分,即:一个 上下文向量 。
- 现在,我们再次执行解码步骤,但这一次,使用上下文向量而不是 h4。
视觉化注意力
注意力权重告诉我们每个 h 有多重要。这意味着我们还可以可视化每个解码步骤的权重。以下是最初关注文件中的一个例子:

在第一行中,为了翻译“L”,网络在单词“the”上使用了一个字母,而将其余的字母置零。
为了生成单词“economique ”,该网络实际上在“欧洲经济”中放置了一些字母权重,而将其余的字母置零。这表明当翻译关系是多对一或一对多时,注意力是有用的。
注意力会变得复杂

注意力类型
这种类型的注意力只使用编码器产生的 h。有大量关于改进这一过程的研究。例如:
- 只使用一些 h,也许是你正在解码的时间步附近的 h(局部注意)。
- 除了 h 的 还有 使用我们之前扔掉的解码器生成的 h。
- …
如何计算注意力
另一个研究领域涉及如何计算注意力得分。除了 V 的点积,研究人员还尝试了:
- 缩放点积。
- 余弦(s,h)
- 不使用 V 矩阵,并将 softmax 应用于完全连接的层。
- …
计算注意力时用什么
研究的最后一个领域是,与 h 矢量相比,到底应该研究什么。
为了对我的意思建立一些直觉,考虑像键值字典一样计算注意力。关键是你给注意力网络“查找”最相关的上下文。该值是最相关的上下文。
我在这里描述的方法只使用当前令牌和每个 h 来计算关注度分数。那就是:
# calculate how relevant that h is
score_1 = attn_network([embed("<SOS"), h1])
score_2 = attn_network([embed("<SOS"), h2])
score_3 = attn_network([embed("<SOS"), h3])
score_4 = attn_network([embed("<SOS"), h4])
但实际上,我们可以给它任何我们认为有用的东西,来帮助注意力网络做出最好的决定。也许我们也给它最后一个上下文向量!
score_1 = attn_network([embed("<SOS>"), h1, last_context])
或者也许我们给它一些不同的东西,也许一个令牌让它知道它在解码西班牙语
score_1 = attn_network([embed("<SOS>"), h1, last_context, embed('<SPA>')])
可能性是无限的!
实施细节

如果你决定实现你自己的,这里有一些提示供你考虑。
- 使用脸书的实现,它已经真正优化。
好吧,好吧,那是逃避。以下是实际的建议。
- 记住 seq2seq 有两个部分:解码器 RNN 和编码器 RNN。这两个是分开的。
- 大部分工作都是在构建解码器。编码器只是在整个输入序列上运行编码器。
- 记住解码器 RNN 一步一步地操作。这是关键!
- 记住解码器 RNN 一步一步地操作。值得说两遍;)
- 解码算法有两种选择,贪婪或波束搜索。贪心更容易实现,但是波束搜索大多数时候会给你更好的结果。
- 关注是可选的!但是…当你拥有它时,影响是巨大的…
- 注意力是一个独立的网络……把这个网络想象成字典,其中的关键是你想让网络用来决定每个特定的 h 有多相关的东西的集合。
- 记住你是在计算每个 h 的关注度,这意味着你有一个 for 循环[h1,…,hn]。
- 嵌入 dim 的注意力网络可以任意高。这会让你的 RAM 爆炸。请确保将它放在一个单独的 GPU 上,或者保持 dim 较小。
- 让大型模型运行起来的一个技巧是将编码器放在一个 gpu 上,解码器放在第二个 gpu 上,注意力网络放在第三个 gpu 上。这样,您可以保持较低的内存占用。
- 如果您真的部署这个模型,您将需要批量实现它。我在这里解释的一切都是针对批量=1,但是你可以通过改变到张量积和聪明的线性代数来扩展到更大的批量。我在这里详细解释一下这个。
同样,大多数情况下,您应该只使用开源实现,但是自己做也是很好的学习体验!
关注后的生活
原来……注意力网络本身被证明是 真正的 强大。

以至于研究人员决定放弃 RNNs 和序列对序列的方法。相反,他们创造了一种叫做变压器模型的东西。
在高层次上,变压器仍然有一个编码器和解码器,只是各层完全连接,并立即查看完整的输入。然后,当输入在网络中移动时,注意力集中在重要的事情上。

Transformer illustration from here.
这种模型在很大程度上取代了 seq2seq 模型的翻译,并落后于目前最强大的模型, BERT 和 OpenAI 的 GPT 。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言










{kind=link}