







代表性相似性分析
从神经科学到深度学习…然后再回来
*TL;博士:*在今天的博客文章中,我们讨论了表征相似性分析(RSA),它可能如何改善我们对大脑的理解,以及 Samy Bengio 和 Geoffrey Hinton 小组最近系统研究深度学习架构中的表征的努力。所以让我们开始吧!
大脑以分布式和层次化的方式处理感觉信息。例如,视觉皮层(神经科学中研究最多的对象)顺序提取低到高水平的特征。光感受器通过双极+神经节细胞投射到外侧膝状体核(LGN)。从那里开始一连串的计算阶段。在腹侧(“什么”vs 背侧——“如何”/“在哪里”)视觉流的不同阶段(V1 → V2 → V4 → IT),活动模式变得越来越趋向于物体识别的任务。虽然 V1 的神经元调谐主要与粗糙的边缘和线条有关,但它展示了更抽象的概念表征能力。这种调制层次对计算机视觉领域和卷积神经网络(CNN)的发展是一个很大的启发。
另一方面,在神经科学中,空间滤波器组模型已经有很长的历史(Sobel 等。)已经被用于研究视觉皮层的激活模式。直到最近,这些都是视觉感知的最先进的模型。这主要是因为**计算模型必须以某种方式与大脑记录相比较。**因此,研究的模型空间受到严重限制。回车:RSA 。RSA 最初是由 Kriegeskorte 等人(2008) 引入的,目的是将认知和计算神经科学社区聚集在一起。它提供了一个简单的框架来比较不同的激活模式(不一定在视觉皮层;见下图)。更具体地,可以在不同条件(例如,猫和卡车的刺激呈现)之间比较基于 fMRI 体素的 GLM 估计或多单位记录。然后,这些激活测量被表示为向量,并且我们可以计算在不同条件下这些向量之间的距离测量。这可以对许多不同的刺激进行,每对刺激允许我们填充所谓的表征相异矩阵的一个条目。

自从 RSA 的最初介绍以来,它已经得到了很多媒体的关注,许多受欢迎的神经科学家,如 James DiCarlo,David Yamins,Niko Kriegeskorte 和 Radek Cichy,一直在将 RSA 与卷积神经网络相结合,以研究腹侧视觉系统。这种方法的优点在于,特征向量的维度无关紧要,因为它被简化为单个距离值,然后在不同模态(即,大脑和模型)之间进行比较。 Cadieu 等人(2014) 例如声称,中枢神经网络是腹侧流的最佳模型。为了做到这一点,他们从 ImageNet-pre-trained Alex net 的倒数第二层提取特征,并将这些特征与两只猕猴的多单位记录进行比较。在一次解码练习中,他们发现 AlexNet 的特征比同时记录的 V4 活动具有更强的预测能力。相当惊人的结果。(就预测而言。)另一项由 Cichy et al. (2016) 进行的强大研究,结合了 fMRI 和 MEG 来研究视觉处理穿越时间和空间。CNN 不知道时间和组织的概念。一层人工神经元很难被视为与新皮层中的一层神经元相类似。然而,作者发现提取的特征序列反映了测量的空间(fMRI)和时间(MEG)的神经激活模式。
这些结果之所以惊人,不是因为 CNN 与大脑“如此相似”,而是因为完全相反。通过 backprop 和 SGD 最小化标准成本函数来训练 CNN。卷积是生物学上难以置信的操作,CNN 在训练期间处理数百万个图像阵列。另一方面,大脑通过遗传操作和无监督学习来利用归纳偏差,以便检测自然图像中的模式。不过 backprop + SGD 和几千年的进化似乎也想出了类似的解决方案。但最终,作为研究人员,我们对理解大脑动态和深层结构背后的因果机制感兴趣。RSA 在这方面能帮我们多少?
RSA 中计算的所有度量都是相关的。RDM 条目基于相关距离。R 平方捕捉由模型 RDM 中的变化解释的神经 RDM 的变化。最终,很难解释任何因果关系。声称 CNN 中的信息是视觉皮层如何工作的最佳模型是廉价的。这真的没有太大帮助。CNN 通过反向传播进行训练,并封装了一个巨大的归纳偏差,其形式是在单个处理层中涉及的所有神经元之间共享核权重。但大脑无法实现这些精确的算法细节(可能已经找到了比莱布尼茨的链式法则更聪明的解决方案)。然而,已经有一堆最近的工作(例如,由 Blake Richards、Walter Senn、Tim Lillicrap、Richard Naud 和其他人)来探索神经回路逼近规范梯度驱动的成本函数优化的能力。所以最终,我们可能不会太远。
在此之前,我坚信必须将 RSA 与实验干预的科学方法结合起来。正如在经济学中一样,我们需要借助于受控操纵的准实验因果关系。这正是最近由 Bashivan 等人(2019) 和 Ponce 等人(2019) 所做的两项研究!更具体地说,他们使用基于深度学习的生成程序来生成一组刺激。最终目标是提供一种形式的神经控制(即驱动特定神经位点的放电率)。具体来说, Ponce 等人(2019) 展示了如何关闭从生成性对抗网络生成刺激、读出神经活动和改变 GAN 的输入噪声之间的环路,以驱动单个单元以及群体的活动。作者能够识别记录位置的可复制的抽象调谐行为。使用灵活的函数逼近法的最大优势在于它们能够清晰地表达我们作为实验者无法用语言表达的模式。
对于许多深度学习架构,权重初始化对于成功的学习至关重要。此外,我们仍然没有真正理解层间表现差异。RSA 提供了一个有效且易于计算的量,可以衡量对这些超参数的稳健性。在最近的 NeuRIPS 会议上,Sami Bengio 的小组( Morcos 等人,2018 )引入了投影加权典型相关分析(PWCCA),以研究泛化以及窄网络和宽网络的差异。基于谷歌式的大型实证分析,得出了以下关键见解:
- **能够泛化的网络收敛到更相似的表示。**直觉上,过拟合可以通过许多不同的方式实现。网络基本上不受训练数据的“约束”,可以在空间的那一部分之外为所欲为。泛化需要利用与真正的底层数据生成过程相关的模式。这只能通过一组更有限的架构配置来实现。
- 网络的宽度与代表性收敛直接相关。更多的宽度=更多的相似表示(跨网络)。作者认为,这是所谓彩票假说的证据:经验表明,宽修剪网络比从一开始就很浅的网络表现更好。这可能是由于宽带网络的不同子网被不同地初始化。然后,修剪程序能够简单地识别具有最佳初始化的子配置,而浅网络从一开始就只有单个初始化。
- 不同的初始化和学习率会导致不同的代表性解决方案集群。这些集群的泛化能力也很好。这可能表明损失面有多个定性不可区分的局部极小值。最终是什么推动了会员的加入还无法确定。
Geoffrey Hinton 的谷歌大脑小组最近的一项扩展( Kornblith 等人,2019 )使用了中心核对齐(CKA),以便将 CCA 扩展到更大的向量维度(人工神经元的数量)。就我个人而言,我真的很喜欢这项工作,因为计算模型给了我们科学家自由去打开所有的 nob。而且在 DL(架构、初始化、学习率、优化器、正则化器)也有不少。正如 Kriegeskorte 所说,网络是白盒。因此,如果我们不能成功地理解一个简单的多层感知器的动态,我们怎么能在大脑中成功呢?
总而言之,我是每一项试图揭示大脑深度学习近似原理的科学发展的超级粉丝。然而,深度学习并不是大脑中计算的因果模型。认为大脑和中枢神经系统在时间和空间上执行相似的顺序操作是一个有限的结论。为了获得真正的洞察力,这个循环必须被关闭。因此,使用生成模型来设计刺激是神经科学中令人兴奋的新尝试。但是如果我们想要理解学习的动力,我们必须走得更远。损失函数和梯度是如何表示的?大脑如何克服将训练和预测阶段分开的必要性?表象只是回答这些基本问题的一个非常间接的窥视孔。展望未来,从跳过和循环连接以及通过漏失采样的贝叶斯 DL 中有很多收获(从建模者的角度来看)。但那是另一篇博文的故事。
使用隐马尔可夫模型用社交网络数据表示人类移动模式
作者 : 王家卫,塞斯·李,蔡贤洙,贺飞
https://github.com/sethlee0111/MobilityHMMGithub

Hidden Markov Model
简介
理解并知道如何利用人类的移动性对于现代的各种应用非常有帮助。例如,通过了解人们如何在城市中移动,城市规划者和开发者可以更有效地设计城市。然而,利用人类的流动性并不容易,因为人们的生活方式多种多样。此外,城市每天都变得越来越复杂,越来越大。因此,我们需要一种更好的方法和模型来分析和描述人类的移动模式。
其中一种方法是使用地理标签社交媒体应用。现在,每个人都有一部随身携带的手机。此外,脸书、Instagram 和 Twitter 等社交媒体应用程序现在为用户的 show others 提供签到服务,并跟踪他们去了哪里。
这个收集的海量数据集包括用户的位置和活动,通过利用这个社交媒体服务,我们可以更好地表示人类的移动性。
对于这个项目,我们分析并利用 FourSquare 手机应用程序数据来建立一个模型,以便更好地预测人类的移动性。
数据集
我们使用 FourSquare 的纽约入住数据集。总共有 227428 个签到数据集,日期范围在 2012 年 4 月到 2013 年 2 月之间。总共有 1083 个用户,每人至少签到 100 次。此外,有 250 个场馆类别,每个场馆有 38333 个不同场馆 id。
adataset 的示例如下所示:

Figure: raw data
数据表现出高度的稀疏性和高度的复杂性。这主要是因为人们不会在所到之处持续不断地签到。此外,纽约市的人类活动非常复杂,因为它的人口密度高,场地密度大,所有东西都在彼此之上。因此,我们必须对数据进行预处理,以收集我们需要的正确和有意义的信息。
轨迹是从包含用户活动模式的用户签到记录中提取的有用特征。轨迹被定义为在定义的时间间隔内连接的用户活动的序列。对于这个时间差,我们使用了 3 个小时,并通过计算用户两次活动之间的时间差和定义轨迹来预处理数据。

Figure: pre-processed data after grouping by user and trajectory
数据集在这里可用。
机动性嗯
现有的移动模型大多使用 隐马尔可夫模型 来表示人体的移动性。隐马尔可夫模型是简单的具有隐藏状态的马尔可夫模型,其将更好地抽象用户的不可观察状态。其中一种是基于隐马尔可夫模型建立的,该模型具有由双变量高斯分布产生的发射概率,并预测用户的下一个位置。然而,我们想要使用所有三个特性;*地点、时间和类别。*这让我们设计并实现了一个隐马尔可夫模型,对于从每个状态观察到的每个特征,该模型具有不同的发射概率。在我们的模型中,一个状态生成三个特征,即位置(经度和纬度)、时间(秒)和类别。为了生成这些特征,高斯分布用于位置和时间,多项式分布用于类别。我们完全实现了这个模型,参考了 hmmlearn 库中 hmm 的现有实现。

Figure: Mobility Hidden Markov Model
简单模型

Figure. Global Model v.s. Personal Model
如上图所示,我们的简单模型有两个层次,一个是全局模型,另一个是个人模型。
全局模型是用所有用户数据训练的,它只代表所有用户的一般生活模式。对于没有足够数据生成高质量个人模型的用户来说,这是一个很好的替代模型,但它并不反映任何个人偏好。
个人模型是用每个用户自己的数据为每个用户训练的,它指示该用户的特定移动模式。然而,如前所述,数据集具有高度稀疏性,这意味着许多用户没有丰富的数据来生成其个性化模型。
总而言之:
全球化模式:
- 只能显示所有人的基本生活模式
- 不显示人的个性,过于概括
个性化模式:
- 只能展示每个人独特的生活方式
- 需要大量的轨迹数据供每个用户个性化
为了避免两种模型中任何一种的缺点,应该开发一些中级模型。
本地化型号
显然,对于这个复杂而难以解决的问题来说,简单的模型过于简单和幼稚。即使使用我们定制的移动性隐马尔可夫模型,这也表现不佳。此外,很明显,对于这个问题来说,全球模型过于一般化,而个人模型过于具体和昂贵。
启发式地,我们的模型的粒度应该被重新考虑。根据分组模式对用户进行分组和预测是一个很好的选择。分组不仅有助于我们最终模型的粒度,而且有助于处理数据稀疏问题。用户不会记录他们每天的活动,通常他们会在一个不可预知的时间登录。而且他们数据的稀疏性给我们预测他们的活动带来了很多麻烦。

Figure: Users sharing similar mobility pattern
而分组有助于发现一定数量的人的模式,这些人可能有相似的工作,有相似的兴趣或经常去相似的地方。只有根据经验,我们才能得出结论,通过预测这些人群的活动能把我们引向更好的结果。我们决定使用场所类别名称对用户进行分组,因为在相同类别场所登记的用户可能具有相似的生活模式。从图中我们可以看出,这三个用户很可能是大学生,他们都有非常相似的生活方式。
我们发明了基于贪婪和随机算法的算法。它被命名为 基于 Jaccard 的随机化算法 。

Alg: Jaccard-based Randomized Grouping Algorithm
Jaccard 相似系数 用来定义两个不同集合之间的相似性。我们随机选择一组,计算所有与其他组的 Jaccard 相似性。然后,我们将选择的组与他们登记入住的用户场地类别上的最大 Jaccard 相似性组相结合。我们一直这样做,直到所需的组数达到我们模型的要求。

Figure: localization model

Figure: users in the same group
幸运的是,我们的本地化模式奏效了。正如我们从上图中看到的,我们从分组算法结果集中抽取了三个用户,显然他们有一些共同的场馆活动签到。
然而,这种基于 Jaccard 的算法确实有一些限制。一方面,我们在整个时间讨论中讨论术语“轨迹”,即某些基于时间的活动的动作序列。在我们的算法中,我们只计算地点类别,这与轨迹不同,因为用户可能有不同类型的轨迹模式,但最终与其他用户在相同的地方登记。然而,他们的生活模式可以完全不同。另一方面,我们的模型侧重于将用户分成特定的组,这在某种程度上降低了他们的个性。例如,用户可以是学生,也可以是舞蹈演员。然而,使用我们的模型,我们只能将这个用户分配到一个特定的组,而不是根据权重或概率将用户分成不同的组。
因此,我们需要更先进的分组技术或算法来解决这个问题。
重组模型
如果这个模型不仅能学习移动模式,还能学习用户的分组方式,那就太棒了。我们的团队已经实现了一个新颖的迭代模型,它从拟合代表组的 hmm,到基于拟合的 hmm 对用户进行分组。

Figure: re-grouping model
在这个模型中,用户不属于一个单独的组。他们有个向量来记录他们属于某个群体的概率。这些向量是随机初始化的。在初始拟合之后,得到一个用户属于一个组的概率,我们计算它的后验概率,并使用贝叶斯定理从那里得到一个近似值。我们重复这个过程,直到模型收敛,这是用户分组没有变化的点。我们认为这可能揭示有意义的分组,因为它是随机初始化的,能够很好地代表其用户特征的组在分组阶段得到加强。

Figure. Weight Regrouping Algorithm
结果&评估

Figure: Best results for models
模型的评估是基于对数似然的度量来完成的。首先,我们使用 forward 算法计算测试数据集中样本的可能性,并根据测试数据集中的数据点数对其进行平均。如上图所示,与个人和全局这两个简单模型相比,本地化模型的性能要好得多。


Figure*😗 hyperparameter tuning, Number of Group(left); Number of State(right)
为了获得我们本地化模型的最佳性能,有一些超参数可以在整个过程中进行调整。
组数:
从上图中我们可以看出,随着组数量的增加,模型表现得更好,这对于更多的组有能力表示不同的个性化组是有意义的。
状态数:
随着状态数量的增加,我们的模型表现得更好。隐马尔可夫模型的状态数说明了该模型表示复杂用户模式的能力。



Figure: re-grouping results
不幸的是,重新分组方案还没有显示出有希望的结果。上面的三个图表明,用户倾向于聚集到最能代表他们的移动模式的两个组,而不是被分组到几个群中。我们认为这是因为我们使用的组数量较少。像本地化模型一样,如果我们使用足够数量的组,它们可能会开始代表一些有意义的东西。然而,由于我们的代码是从基础实现的,所以运行拟合算法需要花费大量时间。我们试图通过实现多处理来克服这个问题,并且实际上成功地将部分实现的学习时间提高了十倍以上,但是还需要做更多的工作来使它更快。
未来工作
对于未来的工作,我们计划测试更多的模型,更好地代表移动模式。有一些现有的工作,通过不仅考虑先前的状态,而且考虑之前的状态,将隐马尔可夫模型向前推进了一步。此外,我们希望将我们的数据与具有类似特征的其他数据集进行测试,这意味着它们是稀疏的,但可以根据它们的模式进行分组。
此外,我们希望使用不同的评估指标,而不是对数似然,并希望能够将该模型推广到更一般的场合。潜在的,我们想在现实生活中应用模型,如广告和营销。
结论
在这个项目中,我们研究了是否可以提出一个模型来表示稀疏的移动数据。我们实现了一种新颖的隐马尔可夫模型 ,它可以采用具有不同发射概率的三个特征。最重要的是,我们试图获得人类移动性的最佳表示,从几个简单的模型到重新分组迭代方案。总之,我们发现基于 Jaccard 的随机算法的定位模型效果最好。然而,我们寻求用更高效的代码和计算能力来进一步开发我们的重新分组方法。
参考
[1]杨,张大庆,郑文生,和。
在 lbsns 中利用用户时空特征对用户活动偏好进行建模。
IEEE 系统、人和控制论汇刊:系统,45(1):129–142,2014。
[2],张克阳,,,张,蒂姆·汉拉蒂和韩佳伟。
Gmove:使用地理标记社交媒体的群体级移动性建模。
第 22 届 ACM SIGKDD 知识发现和数据挖掘国际会议论文集,第 1305–1314 页。ACM,2016。
[3]韦斯利·马休、鲁本·拉波索和布鲁诺·马丁斯。
用隐马尔可夫模型预测未来位置。
《2012 年 ACM 普适计算会议论文集》,第 911-918 页。美国计算机学会,2012 年。
[4] Budhaditya Deb 和 Prithwish Basu。
发现人体运动痕迹中的潜在语义结构。
在欧洲无线传感器网络会议上,第 84-103 页。斯普林格,2015。
[5]格雷厄姆·W·泰勒、杰弗里·E·辛顿和萨姆·T·罗威斯。
产生高维时间序列的两种分布式状态模型。
《机器学习研究杂志》,2011 年第 12 期(3 月):1025–1068 页。
[6]克里斯蒂安·巴雷特、理查德·休伊和凯文·卡普勒斯。
评分隐马尔可夫模型。
生物信息学,13(2):191–199,1997。
用 Word2vec 表现音乐?

机器学习算法已经改变了视野和自然语言处理。但是音乐呢?近几年来,音乐信息检索领域发展迅速。我们将研究如何将自然语言处理中的一些技术移植到音乐领域。在最近由川,阿格雷斯,& Herremans (2018) 发表的一篇论文中,他们探索了 NLP 的一种流行技术,即 word2vec,如何用于表示复调音乐。让我们深入了解一下这是如何做到的…
Word2vec
单词嵌入模型使我们有可能以一种有意义的方式来表示单词,以便机器学习模型可以更容易地处理它们。它们允许我们用一个表示语义的向量来表示单词。Word2vec 是 Mikolov 等人(2013)开发的一种流行的向量嵌入模型,它可以以非常有效的方式创建语义向量空间。
word2vec 的本质是一个简单的单层神经网络,以两种可能的方式构建:1)使用连续词袋(CBOW);或者 2)使用跳格结构。这两种架构都非常高效,并且可以相对快速地进行训练。在这项研究中,我们使用 skip-gram 模型,因为 Mikolov 等人(2013 年)暗示它们对于较小的数据集更有效。跳格结构采用当前单词 w_t(输入层)并尝试在上下文窗口(输出层)中预测周围的单词:

Figure from Chuan et al (2018). Illustration of a word t and its surrounding context window.
由于网上流传的一些流行图片,人们对跳过程序的架构看起来有些困惑。网络输出不是由多个单词组成,而是由上下文窗口中的一个单词组成。它如何学会表示整个上下文窗口?在训练网络时,我们使用采样对,由输入单词和来自上下文窗口的随机单词组成。
这种类型的网络的传统训练目标包括计算𝑝(𝑤_{𝑡+𝑖}|𝑤_𝑡的 softmax 函数,其梯度的计算是昂贵的。幸运的是,噪声对比估计(Gutmann & Hyvä rine,2012 年)和负采样(Mikolov 等人,2013 年 b)等技术提供了一个解决方案。我们使用负采样来定义一个新的目标:最大化真实单词的概率,最小化噪声样本的概率。简单的二元逻辑回归将噪声样本从真实单词中分类出来。
一旦训练了 word2vec 模型,隐藏层的权重基本上代表了学习到的多维嵌入。
音乐作为文字?
音乐和语言有着内在的联系。两者都由一系列遵循一套语法规则的连续事件组成。更重要的是,它们都创造了期望。想象一下,我说:“我要去比萨店买一个…”。这产生了一个明确的期望…比萨饼。现在想象一下,我为你哼唱生日快乐的旋律,但我在最后一个音符前停下了…就像一个句子,旋律会产生期望。期望如此之高,以至于可以通过脑电图来测量,例如,大脑中的 N400 事件相关电位(Besson & Schö,2002)。
鉴于语言和文字之间的相似性,让我们看看一个流行的语言模型是否可以用作音乐的有意义的表示。为了将一个 midi 文件转换成“语言”,我们定义了音乐的“片段”(相当于单词)。我们数据集中的每个音乐片段都被分割成等时长、不重叠的一拍片段。每首乐曲的节拍时长可能不同,由 MIDI 工具箱估算。对于这些切片中的每一个,我们保留所有音高类别的列表,即没有八度音程信息的音高。
下图显示了肖邦玛祖卡舞曲作品 67 №4 的第一小节的切片是如何确定的。一拍在这里是四分之一音长。

Figure from Chuan et al (2018) — Creating words from slices of music
Word2vec 学习音调——音乐的分布语义学假说
在语言中,分布语义假设驱动矢量嵌入背后的动机。它认为“出现在相同语境中的词往往有相似的意思”(哈里斯,1954)。转换到向量空间,这意味着这些单词将在几何上彼此接近。让我们看看 word2vec 模型是否学习了音乐的类似表示。
数据集
川等人使用了一个包含八种不同风格(从古典到金属)的 MIDI 数据集。基于流派标签的存在,从总共 130,000 个作品中,仅选择了 23,178 个作品。在这些碎片中,有 4076 个独特的切片
超参数
仅使用 500 个最常出现的片段(或单词)来训练该模型,使用虚拟单词来替换其他单词。该过程增加了模型的准确性,因为更多的信息(出现)可用于所包括的单词。其他超参数包括学习率 0.1、跳过窗口大小 4、训练步骤数(1,000,000)和嵌入大小 256。
和弦
为了评估音乐片段的语义是否被模型捕获,让我们看一下和弦。
在切片词汇表中,所有包含三元组的切片都被识别。然后用罗马数字标注它们的音阶等级(在音乐理论中经常这样做)。例如,在 C 调中,和弦 C 是 I,另一方面,G 和弦被表示为 v。余弦距离然后被用于计算不同音阶度的和弦在嵌入中彼此相距多远。
在 n- 维空间,中,两个非零向量 A 和 B 之间的余弦距离 Ds(A,B)计算如下:
D𝑐(A,B)=1−cos(𝜃)=1−D𝑠(A,B)
其中𝜃是 a 和 b 之间的角度,Ds 是余弦相似度:

从音乐理论的角度来看,I 和弦与 V 和弦之间的“音调”距离应该小于 I 和弦与 III 和弦之间的距离。下图显示了 c 大调三和弦与其他和弦之间的距离。

Figure from Chuan et al (2018) — Cosine distance between triads and the tonic chord = C major triad.
一个 I 三和弦到 V,IV,vi 的距离更小!这与它们在音乐理论中被视为“音调更接近”的方式相对应,并表明 word2vec 模型学习了我们片段之间有意义的关系。
word 2 vec 空间中和弦之间的余弦距离似乎反映了和弦在乐理中的功能作用!
键
看看巴赫的《调和的克拉维尔》( WTC)的 24 首前奏曲,其中 24 个调(大调和小调)中的每一个都包含一段,我们可以研究新的嵌入空间是否捕获了关于调的信息。
为了扩充数据集,每个片段都被转置到其他每个主要或次要键(取决于原始键),这导致每个片段有 12 个版本。这些键中的每一个的切片被映射到先前训练的向量空间上,并且使用 k-means 进行聚类,使得我们获得新数据集中每一个片段的质心。通过将片段转置到每个键,我们确保质心之间的余弦距离只受一个元素的影响:键。
下图显示了不同调中各棋子形心之间的余弦距离。正如所料,相隔五分音符在音调上很接近,并表示为对角线旁边的较暗区域。音调相距较远的键(例如 F 和 F#)具有橙色,这证实了我们的假设,即 word2vec 空格反映了键之间的音调距离!

Figure from Chuan et al (2018)— similarity matrix based on cosine distance between pairs of preludes in different keys.
比喻
word2vec 的一个突出例子是图像,它显示了向量空间中国王→王后和男人→女人之间的翻译(Mikolov 等人,2013c)。这表明意义可以通过矢量翻译提出来。这也适用于音乐吗?
我们首先从和弦切片中检测和弦,并查看和弦对向量,从 c 大调到 G 大调(I-V)。不同 I-V 向量之间的角度非常相似(见右图),甚至可以认为是五分之一的多维圆。这再次证实了类比的概念可能存在于音乐的 word2vec 空间中,尽管需要更多的研究来揭示更清晰的例子。

Figure from Chuan et al (2018) — angle between chord-pair vectors.
其他应用—音乐生成?
Chuan 等人(2018)简要介绍了该模型如何用于替换音乐片段以形成新音乐。他们表示,这只是一个初步的测试,但该系统可以作为一个更全面的系统,如 LSTM 的代表方法。科学论文中给出了更多的细节,但下图给出了结果的印象。

Figure from Chuan et al (2018) — Replacing slices with geometrically close slices.
结论
Chuan,Agres 和 Herremans (2018)建立了一个 word2vec 模型,该模型可以捕捉复调音乐的音调属性,而无需将实际音符输入模型。这篇文章展示了令人信服的证据,表明关于和弦和键的信息可以在小说《嵌入》中找到,所以要回答标题中的问题:是的,我们可以用 word2vec 来表示复调音乐!现在,将这种表达嵌入到其他也捕捉音乐时间方面的模型中的道路是开放的。
参考
Besson M,schn D(2001)语言和音乐的比较。安纽约科学院科学 930(1):232–258。
传,陈春华,阿格雷斯,k .,&赫里曼斯,D. (2018)。从语境到概念:用 word2vec 探索音乐中的语义关系。神经计算与应用——音乐与音频深度学习特刊,1–14。 Arxiv 预印本。
Gutmann MU,hyv rinen A(2012)非标准化统计模型的噪声对比估计,以及对自然图像统计的应用。马赫学习研究 13(二月):307–361
哈里斯·ZS(1954)的分布结构。单词 10(2–3):146–162。
Mikolov,Chen,k .,Corrado,g .,& Dean,J. (2013 年)。向量空间中单词表示的有效估计。 arXiv 预印本 arXiv:1301.3781。
Mikolov T,Sutskever I,Chen K,Corrado GS,Dean J (2013b)对单词和短语及其组合性进行了分布式表征。《神经信息处理系统进展会议录》,第 3111-3119 页
Mikolov T,Yih Wt,Zweig G (2013c)连续空间单词表征中的语言规则。摘自:计算语言学协会北美分会 2013 年会议记录:人类语言技术,第 746-751 页
自然语言处理中的文本表示
理解书面单词:温习 Word2vec、GloVe、TF-IDF、单词袋、N-grams、1-hot 编码技术

本文着眼于自然语言处理(NLP)的语言表示。如果你是那些罕见的深度学习大师之一,你可能不会在这里学到任何新东西。如果没有,请和我一起进入将单词转换成算法可以理解的一些表示的迷人世界。我们激励我们为什么要这样做,存在哪些方法,以及它们如何在简单的例子中工作。我们将尽可能避免数学,我们将使用轻松的写作风格,以增加你真正读到文章结尾的机会。虽然文章看起来比较长,但是冲浪挺好玩的。

我们为什么关心语言?
每当婴儿开始说话时,语言起源的历史就会重演。事实上,当人类开始命名现实生活中出现的物体、动作和现象时,语言就开始了。当看到数十亿人共有的对神的创造的信仰时,我们可以认为语言和人类一样古老。每当我们写一条短信、一条推文、一次聊天、一封电子邮件、一个帖子甚至一个网页、一篇文章、一个博客或一本书时,我们都将思想转化为文字或符号。多亏了语言,人类能够将看不见的想法变成看得见的东西。此外,人类的思想变得可以被其他人获取,还有…,猜猜看?电脑!如果人类能够从文字中重建思想,计算机也能做到吗?
随着最近被称为人工智能的大肆宣传,让计算机能够处理、理解和生成人类语言是非常有用的。谷歌翻译是一个很好的例子,一个有用的例子。谷歌开始扫描大学图书馆的大量书籍并废弃网页,包括它们的人工翻译,并学习源和目标之间的模式(统计机器翻译)。今天,多亏了谷歌翻译和它的序列对序列模型(神经机器翻译),我们可以访问用我们还不会说的任何语言编码的思想。
在开始是神经元:梯度下降,反向传播,回归,自动编码器,细胞神经网络…
towardsdatascience.com](/why-deep-learning-works-289f17cab01a)
再比如文本分类。人类非常善于将事物分成不同的类别,例如“好”和“坏”。他们这样做已经很久了。同时,人类也非常善于以文本的形式生成和记录信息。根据谷歌的数据,全世界大约有 129,864,880 本书。我们敢打赌,你不会想用手将它们分类,即使给你世界上最大的图书馆,有足够的空间和书架。同时,你真的需要把这些书至少按类型分类:漫画、烹饪、商业、传记等等。在那里,你可以接受一个计算机程序,它可以读取书的内容并自动检测它的类型。让我们暂时离开书本。我们当中有越来越多的人不读书,他们更喜欢新闻。他们通常每天会收到数百条消息、帖子或文章。从相关更新(例如关于行业和市场的更新)中挑选出垃圾消息和假新闻,对于他们来说已经成为非常相关的任务,只要这是由计算机程序来完成的。你读这篇文章很可能是因为一个推荐算法把它从许多其他文章中整理出来,并发送到你的收件箱或移动应用程序中。该算法必须对成千上万篇文章进行分类,并根据你的阅读历史和你聪明的外表,选择这篇你可能会喜欢的文章。
问答机器人是如今的另一个炒作。想象一下,作为客户支持专家,如果你有一份自己的副本,每天接听客户打来的几十个电话,一遍又一遍地问同样的问题,你会节省多少时间。我们都听说过亚马逊 Alexa,苹果 Siri 或者谷歌助手。这些系统会自动回答人类用自然语言提出的问题。
希望上面的例子能激发为什么让计算机处理自然语言对你来说是一个吸引人的话题。如果没有,看看进一步说明语音识别、语音模仿和语音合成的例子肯定会让你大吃一惊。
电脑喜欢数字
现在,为什么所有这些谈论语言和计算机?你每天都在你最喜欢的文字处理器或电子邮件软件中输入文本。那么,为什么计算机很难理解你的文本呢?语言在各个层面都是模糊的:词汇、短语、语义。语言假设听者意识到世界,语境和交流技巧。如果你在搜索引擎中输入“鼠标信息”,你是在寻找一只宠物还是一个工具?文本的表示对于许多现实应用程序的性能非常重要。
现在,我们如何把语言变成计算机算法喜欢的东西?在基础上,计算机中的处理器执行简单的算术运算,如数字的加法和乘法。这就是计算机喜欢数字的原因吗?谁知道呢。无论如何,这个问题很好地解决了图像。例如,下图中标有圆圈的区域由三个数字矩阵表示,每个数字矩阵对应一个颜色通道:红色、绿色和蓝色。每个数字表示像素位置的红色、绿色或蓝色等级。(0,0,0)显示为黑色,颜色分量为(255,255,255)的像素显示为白色。

将文本转换成数字的过程,类似于我们对上图所做的,通常是通过构建一个语言模型来完成的。这些模型通常为单词、单词序列、单词组、文档部分或整个文档分配概率、频率或一些模糊的数字。最常见的技术有:1-热编码、N-grams、词袋、向量语义(tf-idf)、分布式语义(Word2vec、GloVe)。让我们看看我们是否理解这一切意味着什么。我们应该可以。我们不是电脑。至少是你。
1-热编码模型
如果一个文档的词汇表有 1000 个单词,我们可以用一个热点向量来表示这些单词。换句话说,我们有 1000 维的表示向量,我们将每个唯一的单词与这个向量中的一个索引相关联。为了表示一个唯一的单词,我们将向量的分量设置为 1,并将所有其他分量置零。

source: Fundamentals of Deep Learning, N. Buduma, 2017
这种表述是相当武断的。它忽略了单词之间的关系,并且没有传达关于它们周围环境的信息。这种方法对于大词汇量来说非常无效。在接下来的几节中,我们将会看到一些更令人兴奋的方法。
n 元语言模型
我们开始看最基本的 N-gram 模型。让我们来考虑一下我们从小最喜欢的一句话:“请吃你的食物”。2-gram(或 bigram)是由两个单词组成的单词序列,如“请吃饭”、“吃你的”或“你的食物”。一个三字组(或三元组)将是一个三个单词的单词序列,如“请吃你的”,或“吃你的食物”。N-gram 语言模型估计给定前面单词的最后一个单词的概率。例如,给定单词“请吃你的”的顺序,下一个单词“食物”的可能性比“勺子”高。在后一种情况下,我们的妈妈会不太高兴。计算任何一对、三对、四对……单词的这种可能性的最好方法是使用大量的文本。下图显示了从包含与餐馆和食物相关的问题和答案的相对较小的文本体中获得的几个概率。“我”后面经常跟动词“想要”、“吃”或“花”。

source: Jurafsky et al., 1994
谷歌(再次)实际上在多种语言中为 1 字、2 字、3 字、4 字和 5 字提供了更大的概率集。他们是根据 1500 年至 2008 年间印刷的资料计算出来的!Google Ngram Viewer 允许你下载并使用这个 n 元语法的大集合,用于拼写检查、自动完成、语言识别、文本生成和语音识别。
我们训练 N-gram 模型的上下文越长,我们可以生成的句子就越连贯。下图显示了从 1 克、2 克和 3 克模型中随机生成的 3 个句子,这些模型是从《华尔街日报》的 4000 万字中计算出来的。

source: Jurafsky et al., 2018
即使有非常大的语料库,一般来说,N-gram 也不是一个充分的语言模型,因为语言具有长距离依赖性。例如,在句子“我刚放进五楼机房的电脑死机了。”,虽然“计算机”和“崩溃”这两个词相距 15 个位置,但它们是相关的。一个 5 克重的模型将会错过这个链接,我们的计算机管理员可能会一直认为五楼的计算机运行良好。现在,如何处理德国文学中号称有 1077 个单词的最长句子呢!谁想训练一个 N-gram 语言模型来理解那些通常很长的交错的德语句子?
此外,N-gram 模型严重依赖于用于计算概率的训练语料库。这意味着概率通常编码了关于给定训练文本的特定事实,这不一定适用于新文本。这些原因促使我们进一步研究语言模型。
词袋语言模型
当我们对文本分类感兴趣时,基于情感对其分类,或者验证它是否是垃圾邮件时,我们通常不希望查看单词的顺序模式,如 N-gram 语言模型所建议的。相反,我们会将文本表示为一个单词包,好像它是一组无序的单词,而忽略它们在文本中的原始位置,只保留它们的频率。

source: Jurafsky et al., 2018
让我们在一个简单的情感分析示例中用两个类正(+)和负(-)来说明文本的单词包表示。下面我们有 5 个已知类别的句子(也称为文档),以及 1 个未知类别的句子。目的是将最后一句归类为肯定或否定。

source: Jurafsky et al., 2018
这项任务由所谓的朴素贝叶斯分类器来解决,它使用每个类别的词袋中的词频来计算每个类别的概率 c ,以及给定类别的每个词的条件概率,如下所示。

在我们的例子中,负类的概率是 3/5。正类将有 2/5 的概率。一点代数就会显示,给定负类的“可预测”、“有”、“没有”、“好玩”这些词的概率,比给定正类的样本概率要高。因此,基于训练数据,句子“可预测但没有乐趣”将被分类为负面的。
词袋语言模型依赖于词频 TF,它被定义为一个词在给定文本或文档中出现的次数。词汇袋有助于情感分析。这对于检测一篇文章是用哪种语言写的非常有用。它还用于确定作者身份,如性别和年龄。我们还可以使用术语频率信息来设计额外的特征,例如正面词汇的数量(“棒极了”、“不错”、“令人愉快”),或者第一和第二代名词的数量(“我”、“我”、“你”),并基于逻辑回归甚至神经网络来训练更复杂的分类器。但是,我们现在不要走那条令人头痛的路。
尽管有这样的荣耀,N-gram 和单词袋模型本身并不能让我们得出有用的推论来帮助我们解决与意义相关的任务,如问答、总结和对话。这就是为什么我们将在下一节研究语义。
向量语义学
我们应该如何表达一个词的意思?单词“mouse”可以在词汇词典中找到,但是它的复数形式“mice”将不单独描述。类似地,“sing”作为“sing”、“sang”、“sung”的引理将被描述,但是它的时态形式将不被描述。我们如何告诉计算机所有这些单词的意思是一样的?“工厂”一词根据上下文可能有不同的含义(例如,“特斯拉正在建造新工厂”,“气候变化对工厂有负面影响”)。向量语义学是目前建立计算模型的最佳方法,该模型成功地处理词义的不同方面,包括词义、上下位词、上位词、反义词、同义词、同形异义词、相似性、关联性、词汇场、词汇框架、内涵。我们为语言术语道歉。让我们通过查看上下文的概念来建立对向量语义的直觉。
在我们的例句“特斯拉正在建造新工厂”中,如果我们在人类写的许多其他句子中计算“工厂”一词的上下文,我们会倾向于看到像“建造”、“机器”、“工人”甚至“特斯拉”这样的词。这些词和其他类似的上下文词也出现在“工厂”一词周围,这一事实可以帮助我们发现“植物”和“工厂”之间的相似性。在这种情况下,我们不会倾向于将“植物”的含义与“特斯拉正在建造新工厂”这句话中的“植物”联系起来。我们宁愿认为特斯拉在建设新工厂。
因此,我们可以通过计算在一个单词的环境中出现的其他单词来定义这个单词,我们可以用一个向量、一列数字、N 维空间中的一个点来表示这个单词。这样的表示通常被称为嵌入。计算机可以利用这种欺骗手段来理解单词在上下文中的意思。
Word 文档表示法
为了更好地掌握向量语义,让我们假设我们有一组文本(文档),我们希望找到彼此相似的文档。这个任务与信息检索相关,例如在搜索引擎中,文档是网页。作为说明,下表中的每一列代表具有以下标题的 4 个文档之一:“如你所愿”、“第十二夜”、“朱利叶斯·凯撒”和“亨利五世”。文档中出现的单词表示为行。这些单词构成了我们的词汇。表格告诉我们,单词“battle”在文献“Julius Caesar”中出现了 7 次。这个表格也被称为术语-文档矩阵,其中每行代表词汇表中的一个单词,每列代表一个文档、一个章节、一个段落、一条推文、一条短信、一封电子邮件或其他任何内容。

source: Jurafsky et al., 2018
现在我们可以用一个文档向量来表示每个文档,例如“Julius Caecar”的[7 62 1 2]。我们甚至可以在二维向量空间中为任何一对单词画出这样的向量。下面我们有这样一个图表的例子。我们看到由“傻瓜”和“战斗”维度构建的空间的文档向量的空间可视化。我们可以得出结论,文献《亨利五世》和《尤利乌斯·恺撒》有类似的内容,与“战斗”的关系大于与“傻子”的关系。对于信息检索,我们也用一个文档向量来表示一个查询,长度也是 4,表示单词“battle”、“good”、“fool”和“wit”在查询中出现的频率。将通过将查询向量与所有四个文档向量进行比较以发现它们有多相似来获得搜索结果。

source: Jurafsky et al., 2018
单词-单词表示法
通过查看术语-文档矩阵的行,我们可以提取单词向量而不是列向量。正如我们看到的,相似的文档往往有相似的单词,相似的单词有相似的向量,因为它们往往出现在相似的文档中。如果我们现在使用单词而不是文档作为术语-文档矩阵的列,我们得到所谓的单词-单词矩阵,术语-术语矩阵,也称为术语-上下文矩阵。每个单元描述了行(目标)单词和列(上下文)单词在某个训练语料库的某个上下文中同时出现的次数。一个简单的例子是当上下文是一个文档时,那么单元格将告诉两个单词在同一个文档中出现的频率。一种更常见的情况是计算列字在行字周围的字窗口中出现的频率。在下面的例子中,当考虑“信息”周围的 7 个单词窗口时,“数据”在“信息”的上下文中出现了 6 次。

source: Jurafsky et al., 2018
上面的矩阵表明“杏子”和“菠萝”彼此相似,因为“pinch”和“糖”往往出现在它们的上下文中。两个单词 v 和 w 之间的相似度可以通过计算所谓的余弦相似度使用它们相应的单词向量来精确计算,定义如下:

在下面的例子中,“数字”和“信息”之间的相似度等于单词向量[0 1 2]和[1 6 1]之间的余弦相似度。通过应用上面的公式,我们获得 0.58,这高于“杏”和“信息”之间的余弦相似度 0.16。

词向量和余弦相似度是处理自然语言内容的有力工具。然而,有些情况下他们的锻炼效果并不好,我们将在下一节看到。
TF-IDF 语言模型
向量语义模型使用两个单词同时出现的原始频率。在自然语言中,原始频率是非常倾斜的,并且不具有很强的辨别能力。如下面的直方图所示,单词“the”只是一个常用单词,在每个文档或上下文中具有大致相同的高频率。

处理这个问题的方法很少。TF-IDF 算法是目前自然语言处理,特别是信息检索中对共生矩阵进行加权的主要方法。TF-IDF 权重被计算为术语频率和逆文档频率的乘积。这有助于我们重视更具区别性的单词。在我们的文件 d 中,用于计算每一项 t 的 TF-IDF 重量的两个分量描述如下。
词频

术语或词频计算为该词在文档中出现的次数。因为一个单词在一个文档中出现 100 次并不会使这个单词与文档的意义相关的可能性增加 100 倍,所以我们使用自然对数来稍微降低原始频率。在文档中出现 10 次的单词将具有 tf=2。在文档中出现 100 次的单词意味着 tf=3,1000 次意味着 tf=4,等等。
逆文档频率
给定术语或词的文档频率是它出现在文档中的数量。逆文档频率是文档总数与文档频率之比。这使得只在少数文档中出现的单词具有更高的权重。因为在许多集合中有大量的文档,所以通常对逆文档频率应用自然对数,以避免 IDF 的偏斜分布。

在下图的左侧,我们可以看到为前面介绍的例子中的单词计算的 TF 和 IDF。在图像的右侧,我们显示了给定文档中每个单词的原始频率,以及它在底部表格中的加权 TF-IDF 值。因为“good”这个词在所有文档中出现的频率很高,所以它的 TF-IDF 值就变成了零。这使得原本出现频率很低的区别性单词“battle”的权重更大。

source: Jurafsky et al., 2018
虽然用 TF-IDF 扩充的词袋模型是很好的模型,但是它们不能捕捉语义上的细微差别。让我们用下面的句子来说明这一点:“猫坐在破墙上*”,“狗跳过砖结构”。虽然这两个句子描述的是两个独立的事件,但是它们的语义却是相似的。一只狗和一只猫相似,因为它们共享一个叫做的动物实体。一面墙可以被视为类似于一个砖*结构。因此,虽然这些句子讨论不同的事件,但它们在语义上彼此相关。在经典的单词袋模型中(单词在它们自己的维度中被编码),编码这样的语义相似性是不可能的。此外,当使用大量词汇和单词向量变大时,这种模型表现出很少的计算问题。我们将在下一节介绍一种更好的方法。
Word2vec 语言模型
用稀疏而长的向量来表示单词或文档实际上是没有效率的。这些向量通常是稀疏的,因为许多位置被零值填充。它们很长,因为它们的维数等于词汇表的大小或文档集合的大小。
什么是单词嵌入?
与稀疏向量相反,密集向量可以更成功地作为特征包含在许多机器学习系统中。密集向量也意味着需要估计的参数更少。在上一节中,我们看到了如何计算语料库中任何给定单词的 tf 和 tf-idf 值。如果我们不是计算每个单词 w 在另一个单词 v 的上下文中出现的频率,而是训练一个二进制预测任务的分类器“单词 w 可能出现在 v 附近吗?”,那么我们可以使用学习的分类器权重作为单词嵌入。这些成为单词的连续矢量表示。如果我们想要计算单词之间的语义相似度,我们可以通过查看两个嵌入之间的角度来实现,即它们的余弦相似度,正如我们之前看到的。
我们如何计算单词嵌入?
嵌入向量通常至少约 100 维长才能有效,这意味着当我们有 100,000 个单词的词汇表时,分类器需要调整数千万个数字。对于给定的语料库,我们如何确定这些嵌入呢?这正是 word2vec 语言模型的设计目的。
Word2vec 有两种型号:CBOW 型号和 skip-gram 型号(由 Mikolov 等人提出)。艾尔。,2013,在谷歌(又来了!)).在 skip-gram 变体中,使用目标单词预测上下文单词,而使用周围单词预测目标单词的变体是 CBOW 模型。通常人们会在大型语料库中使用 word2vec 实现和预训练嵌入。
我们现在将开发 word2vec 模型的 skip-gram 变体背后的直觉。让我们假设下面的句子,其中“杏子”是目标单词,“汤匙”、“of”、“果酱”和“a”是考虑双单词窗口时的上下文单词。

我们可以构建一个二元分类器,它将任意一对单词 (t,c) 作为输入,如果 c 是 t 和 False 的真实上下文单词,则预测为真。例如,分类器将为*(杏,汤匙)返回真*,为*(杏,捏)返回假。下面我们看到更多正面和负面类的例子,当把杏*作为目标时。

更进一步,我们必须将每个(上下文窗口,目标)对分成(输入,输出)示例,其中输入是目标,输出是上下文中的一个单词。出于说明的目的,对*(【of,杏,a,pinch】,果酱)将产生正例(果酱,杏),,因为杏是果酱的真实上下文词。(果酱、柠檬)*会是一个反面例子。我们继续对每个(上下文窗口、目标)对应用该操作来构建我们的数据集。最后,我们用词汇表中的唯一索引替换每个单词,以便使用独热向量表示。
给定一组正的和负的训练样本,以及用于目标的初始组
嵌入 W 和用于上下文单词的初始组 C ,分类器的目标是调整这些嵌入,使得我们最大化正样本嵌入的相似性(点积),并且最小化负样本嵌入的相似性。典型地,逻辑回归将解决这个任务。或者,使用具有 softmax 的神经网络。

d-dimentional embeddings training on a V-size vocabulary — source: Jurafsky et al., 2018
我们为什么喜欢 Word2vec?
令人惊讶的是,Word2vec 嵌入允许探索单词之间有趣的数学关系。例如,如果我们从单词“king”的向量中减去单词“man”的向量,然后将结果向量加上单词“woman”的向量,我们将得到单词“queen”的向量。

source: Z. Djordjevic, Harvard
我们还可以使用嵌入向量元素的元素相加来询问诸如“德国+航空公司”之类的问题,并通过查看与复合向量最接近的标记来得出令人印象深刻的答案,如下所示。

source: Z. Djordjevic, Harvard
当在不同语言的可比语料库上训练时,Word2vec 向量应该具有相似的结构,从而允许我们执行机器翻译。

source: Z. Djordjevic, Harvard
嵌入还用于查找与用户指定的单词最接近的单词。他们还可以检测单词之间的性别关系和复数-单数关系。单词向量也可以用于从庞大的数据集中导出单词类别,例如通过在单词向量的顶部执行 K-means 聚类。
在本节中,我们讨论了 Word2vec 变体 CBOW 和 Skip gram,它们是本地上下文窗口方法。它们可以很好地处理少量的训练数据,甚至可以表示被认为是罕见的单词。然而,它们没有充分利用关于单词共现的全局统计信息。因此,让我们看看另一种声称可以解决这个问题的方法。
手套语言模型
GloVe(全局向量)采用了与 Word2vec 不同的方法。GloVe 不是从设计用于执行分类任务(预测相邻单词)的神经网络或逻辑回归中提取嵌入,而是直接优化嵌入,使得两个单词向量的点积等于这两个单词在彼此附近出现的次数的对数(例如,在两个单词的窗口内)。这迫使嵌入向量对在它们附近出现的单词的频率分布进行编码。我们认为有些读者可能在整篇文章中遗漏了 Python 代码。从现在开始,我们会让他们开心一点。
下面我们将说明如何使用来自预训练手套模型的单词嵌入。我们利用 Python 包 Gensim 。
嵌入(词向量)的美妙之处在于,你不必实现任何 Skip gram 算法,也不必构建大量文本并自己计算权重。你可以使用向量,慷慨的人们已经通过使用非常大的语料库和大量的 GPU 为公众准备了向量。我们将使用预训练的单词向量 glove.6B ,它是在 60 亿个标记的语料库上训练的,包含 40 万个单词的词汇量,从不同的大规模网络数据集(维基百科等)中获得。每个单词分别由 50、100、200 或 300 维的嵌入向量表示。我们将使用 100 维向量,它们存储在一个文件中。第一步是将 GloVe 文件格式转换为 word2vec 文件格式。唯一的区别是增加了一个小标题行。这可以通过调用 glove2word2vec()函数来完成。每一行都以单词开头,后面是该单词对应的所有向量值,每一行都用一个空格隔开,就像下图中单词“the”的情况一样。

正如我们在上一节中解释的那样,这些实值词向量已被证明对各种自然语言处理任务都很有用,包括解析、命名实体识别和机器翻译。例如,我们发现类似以下的声明适用于相关的单词向量:
国王男人+女人≈王后
也就是说,从“国王”中减去“男人”的概念并加上“女人”这个词,“女王”是最接近的词。“国王”中的“男子气”被“女子气”所取代,给了我们“女王”。这种关于向量的基本代数可以让你进行有趣的语义推理。
>>> result = model.most_similar(positive=['woman', 'king'],
negative=['man'],
topn=1)
>>> print(result)[('queen', 0.7698541283607483)]
使用单词嵌入的类比工具,我们甚至可以问哪个单词是“俄罗斯”,就像“巴黎”是“法国”一样?
>>> result = model.most_similar(positive=['russia', 'paris'],
negative=['france'],
topn=1)
>>> print(result)[('moscow', 0.8845715522766113)]
为什么这个效果这么好?让我们仔细看看“俄罗斯”、“莫斯科”、“法国”、“巴黎”这四个词的嵌入。我们可以使用 PCA 变换的前两个分量将 100 个单词的向量投影到 2D 空间中。我们也可以使用 t 分布随机邻居嵌入(t-SNE)方法绘制类似的图。下面的 PCA 图显示“法国”和“莫斯科”之间的直线几乎平行于“法国”和“巴黎”之间的直线。使用 t-SNE,我们获得的谱线比使用 PCA 获得的谱线更加平行。t-SNE 是一种降维技术,特别适合于高维数据集的可视化。与 PCA 相反,它不是一种数学技术,而是一种概率技术。

100 维向量也非常擅长回答以下形式的类比问题:“ a 对 b 就像 c 对?”。例如:
- 巴黎对于法国来说是什么?
- 女人和国王对男人有什么关系?
- 什么是狗,什么是猫?
- 对于厨师来说,什么是石头对于雕刻家?
- 什么是蜜蜂,什么是熊的巢穴?
下面,我们寻求这些问题的答案,并展示计算机如何使用单词嵌入赢得下一个电视节目的问答比赛。

上面的图清楚地显示了嵌入向量能够找到“莫斯科”作为“俄罗斯”的首都,因为“巴黎”是“法国”的首都。同样,“蜂巢”对于“蜜蜂”就像“巢穴”对于“熊”一样。
结论
在本文中,我们探讨了为什么用数字格式表示文本对于自然语言处理很重要。我们还介绍了最常用的方法,温和而直观地涵盖了底层算法的关键方面。我们讨论了几种语言模型:一键编码、N-gram、单词包、td-idf、word2vec 和 glove。有一些流行的语言模型没有被介绍。例如,fastText 是 word2vec 模型的扩展,它不是直接学习单词的向量,而是将每个单词表示为 n 元字符。这对于检测后缀和前缀特别有用。本文没有探讨的另一个领域是主题建模。有各种各样的技术用于主题建模,其中大多数涉及术语-文档矩阵的某种形式的矩阵分解(潜在语义索引、潜在狄利克雷分配)。
最近,开发了非常强大的语言模型,如 OpenAI GPT-2 和 Google BERT。在我关于谷歌 BERT 的文章中,我解释了如何微调一个预先训练的模型,以利用强大的单词向量表示来完成机器学习任务。
变压器 DIY 实用指南。经过实践验证的 PyTorch 代码,用于对 BERT 进行微调的意图分类。
towardsdatascience.com](/bert-for-dummies-step-by-step-tutorial-fb90890ffe03)
恰当地表达文本对结交新朋友很有帮助。为了能够在下面的句子中正确地大写我们朋友的名字,我们需要识别第一个“石头”是人名,第二个是物体。在我关于自然语言处理中的true caseing 的文章中,这个主题得到了进一步的发展。

如果你真的对表示自然语言文本的问题感兴趣,我们推荐以下书籍作为进一步阅读: 语音和语言处理,第 3 版。作者丹·茹拉夫斯基和詹姆斯·马丁,2018T5。我们在这篇文章中孜孜不倦地使用了那本书中的观点。
感谢您的阅读。请随意查看我下面的文章。
在开始是神经元:梯度下降,反向传播,回归,自动编码器,细胞神经网络…
towardsdatascience.com](/why-deep-learning-works-289f17cab01a) [## 基于 LSTM 的非洲语言分类
厌倦了德法数据集?看看 Yemba,脱颖而出。力学的 LSTM,GRU 解释和应用,与…
towardsdatascience.com](/lstm-based-african-language-classification-e4f644c0f29e) [## 基于序列对序列模型的自然语言理解
如何预测客户询问背后的意图?Seq2Seq 型号说明。在 ATIS 数据集上演示的槽填充…
towardsdatascience.com](/natural-language-understanding-with-sequence-to-sequence-models-e87d41ad258b) [## NLU 任务注意机制实用指南
测试动手策略以解决注意力问题,从而改进序列到序列模型
towardsdatascience.com](/practical-guide-to-attention-mechanism-for-nlu-tasks-ccc47be8d500) [## 自然语言处理中的真实大小写
恢复推文和短信中的大写字母可以提高可读性。正确的正确大小写对于…至关重要
towardsdatascience.com](/truecasing-in-natural-language-processing-12c4df086c21)
使用 Kaggle 和 GitHub 操作的可再现数据科学
本教程演示了如何将 Kaggle 与 GitHub 操作集成在一起,以便更好地再现数据科学项目。

Reproducibility means hitting the right target, every time (Photo by Oliver Buchmann on Unsplash)
随着数据科学中出现的再现性危机,对数据科学研究人员来说,提供对其代码的开放访问变得越来越重要。其中一个基本要素是确保现有实验在代码变化时的持续性能。通过使用测试和记录良好的代码,可以提高正在进行的项目的可重复性。
Kaggle 和 GitHub 操作
Kaggle 是最知名的数据科学社区之一,致力于寻找数据集、与其他数据科学家合作以及参加竞赛。对于所有级别的从业者来说,这是一个极好的资源,并且提供了一个强大的 API 来访问它的资源。通过使用这个 API,可以创建自动下载数据集的测试,算法可以根据这些数据集运行,确保算法在代码更新时继续按预期执行。
GitHub 最近发布了 GitHub Actions ,这是一个直接从 GitHub 仓库自动化工作流的集成平台。本文的其余部分演示了如何将 GitHub 动作与 Kaggle API 一起使用,以允许对数据科学应用程序进行连续测试。使用 Kaggle API 的 GitHub 动作的完整实现可以在这里找到。
工作流程分解
下面详细介绍了将 Kaggle 与 GitHub 动作集成的最基本设置。这不包括数据科学测试脚本的实际执行,因为它们依赖于语言。相反,它展示了如何在 GitHub 动作中运行 Kaggle API 命令,到达可以执行测试脚本的地方。
工作流程的基本要素如下:
- 在测试环境中设置 Python
- 安装 Kaggle Python API
- 执行 Kaggle 命令
- 运行测试脚本(省略)
履行
GitHub 操作是使用 YAML 文件创建作业并指定作业中的步骤来实现的。以下作业中的每个步骤都与上面工作流中的元素相对应。
- name: Setup python
uses: actions/setup-python@v1
with:
python-version: 3.6
architecture: x64
- name: Setup Kaggle
run: pip install kaggle
- name: Run Kaggle command
run: kaggle competitions list
env:
KAGGLE_USERNAME: ${{ secrets.KaggleUsername }}
KAGGLE_KEY: ${{ secrets.KaggleKey }}
这个实现利用了 Kaggle PyPi 包,该包允许 Kaggle API 命令通过命令行运行。在这个例子中,job 简单地列出了 Kaggle 上可用的竞争对手。可用 Kaggle API 命令的分类可以在这里找到。
也可以像 GitHub actions 中的其他任务一样,将多个 Kaggle 命令链接在一起。在这里,工作流步骤显示 Kaggle 版本,然后列出所有可用的竞赛。
- name: Run multiple Kaggle commands
run: |
kaggle --version
kaggle competitions list
env:
KAGGLE_USERNAME: ${{ secrets.KaggleUsername }}
KAGGLE_KEY: ${{ secrets.KaggleKey }}
向 Kaggle 认证
使用 Kaggle API 需要一个访问令牌。这些可以在 Kaggle 网站上创建。令牌通常通过文件提供给 Kaggle API,但是 KAGGLE_USERNAME 和 KAGGLE_KEY 环境变量也可以用来进行身份验证。可以在 GitHub actions 中配置环境变量,如上面代码中的 env 参数所示。令牌变量被保存为 GitHub secrets 以确保个人令牌不被暴露。
这段代码的完整实现可以在这里找到。希望本指南为您提供了在 GitHub actions 中使用 Kaggle API 的快速介绍,并允许您开始更彻底地测试您的数据科学代码!
可重复的模型训练:深度潜水
可重复的研究很容易。只需在某处记录您的参数和指标,修复种子,您就可以开始了
—我,大约两周前。
哦,天啊,我错了。
有很多关于可重复研究的研讨会、教程和会议。
大量的实用程序、工具和框架被用来帮助我们做出良好的可复制的解决方案。
然而,仍然存在问题。这些陷阱在一个简单的辅导项目中并不明显,但在任何真正的研究中必然会发生。很少有人谈论它们,所以我想分享我关于这些话题的知识。
在这篇文章中,我将讲述一个关于我对能够持续训练模型的追求的故事(所以每次跑步都给相同的重量)。
意想不到的问题
从前,我有一个与计算机视觉(笔迹作者识别)相关的项目。
在某个时候,我决定花时间重构代码和整理项目。我将我的大型 Keras 模型分成几个阶段,为每个阶段设计测试集,并使用 ML Flow 来跟踪每个阶段的结果和性能(这很难,但这是另一个故事了)。
经过一周左右的重构,我已经构建了一个很好的管道,捕获了一些 bug,设法摆弄了一下超参数,并略微提高了性能。
然而,我注意到一件奇怪的事情。我修复了所有随机种子,正如许多向导建议的那样:
def fix_seeds(seed):
random.seed(seed)
np.random.seed(seed)
tf.set_random_seed(seed)
session_conf = tf.ConfigProto(intra_op_parallelism_threads=1, inter_op_parallelism_threads=1)
sess = tf.Session(graph=tf.get_default_graph(), config=session_conf)
K.set_session(sess)
但是由于某种原因,连续两次使用相同的超参数得到了不同的结果。
由于无法跟踪项目中的问题,我决定用一个小模型制作一个脚本来重现这个问题。
我定义了一个简单的神经网络:
def create_mlp(dim):
model = Sequential()
model.add(Dense(8, input_dim=dim))
model.add(Dense(1))
return model
因为数据在这里并不重要,所以我生成了一些随机数据来处理。之后,我们准备训练我们的模型:
model = create_mlp(10)
init_weights = np.array(model.get_weights()[0]).sum()
model.compile(optimizer=keras.optimizers.RMSprop(lr=1e-2),
loss=keras.losses.MSE)
model.fit(Xs, Ys, batch_size=10, epochs=10)
训练后,我们可以检查再现性。assert _ same _ cross _ runs是一个简单的函数,它检查传递的值在两次运行之间是否相同(通过将值写入文件来完成):
assert_same_across_runs("dense model data", Ys.sum())
assert_same_across_runs("dense model weight after training",
init_weights)
assert_same_across_runs("dense model weight after training",
np.array(model.get_weights()[0]).sum())
我运行了几次。每次执行的模型权重完全相同。
奇怪!我通过插入卷积层给模型增加了一点复杂性:
def create_nnet(dim):
input = Input(shape=dim)
conv = Conv2D(5, (3, 3), activation="relu")(input)
flat = Flatten()(conv)
output = Dense(1)(flat)
return Model([input], [output])
训练过程非常相似:我们创建模型,生成一些数据,训练我们的模型,然后检查指标。
瞧,它碎了。每次运行脚本时,都会打印不同的数字。
这个问题不会发生在没有 GPU 的机器上。如果你的机器有 GPU,你可以通过从控制台设置 CUDA_VISIBLE_DEVICES 环境变量为"",在脚本中隐藏它。
快速调查发现了丑陋的事实:再现性存在问题,一些层使模型不可再现,至少在默认情况下(对所有“你因为使用 Keras 而受苦”的人来说,Pytorch 有一个类似的问题
为什么会这样?
一些复杂的操作没有明确定义的子操作顺序。
比如卷积就是一堆加法,但是这些加法的顺序并没有定义。
因此,每次执行都会导致不同的求和顺序。因为我们使用有限精度的浮点运算,卷积产生的结果略有不同。
是的,求和的顺序很重要,(a+b)+c!= a+(b+c)!你甚至可以自己检查:
import numpy as np
np.random.seed(42)xs = np.random.normal(size=10000)
a = 0.0
for x in xs:
a += xb = 0
for x in reversed(xs):
b += xprint(a, b)
print("Difference: ", a - b)
应该打印
-21.359833684261957 -21.359833684262377
Difference: 4.192202140984591e-13
没错,就是“就 4e-13”。但是因为这种不精确发生在深度神经网络的每一层,并且对于每一批,这种误差随着层和时间而累积,并且模型权重显著偏离。因此,连续两次运行的损失可能如下所示:

重要吗?
有人可能会说,运行之间的这些小差异不应该影响模型的性能,事实上,固定随机种子和精确的再现性并不那么重要。
嗯,这个论点有可取之处。随机性影响权重;因此,模型性能在技术上取决于随机种子。与添加新功能或改变架构相比,改变种子对准确性的影响应该较小。此外,因为随机种子不是模型的重要部分,所以对不同的种子多次评估模型(或者让 GPU 随机化)并报告平均值和置信区间可能是有用的。
然而,在实践中,很少有论文这样做。相反,模型与基于点估计的基线进行比较。此外,还有担心论文报告的改进比这种随机性少*,并且不恰当的汇总会扭曲结果。*
更糟糕的是,这会导致代码中不可约的随机性。您不能编写单元测试。这通常不会困扰数据科学家,所以想象一种情况。
你已经找到了一篇描述一个奇特模型的论文——并且它已经清晰地组织了开源实现。你下载代码和模型,开始训练它。几天后(这是一个非常奇特的模型)
你测试这个模型。它不起作用。是超参数的问题吗?您的硬件或驱动程序版本?数据集?也许,回购作者是骗子,问题出在存储库本身?你永远不会知道。
在实验完全重现之前,故障排除是极其麻烦的,因为你不知道管道的哪一部分出现了问题。**
因此,拥有复制模型的能力似乎非常方便。
哦不。我们该怎么办?
求和的顺序未定义?好吧。我们可以自己定义,也就是把卷积重写为一堆求和。是的,它会带来一些开销,但是它会解决我们的问题。
令人高兴的是,CuDNN 已经有了大多数操作的“可再现”实现(而且确实更慢)。首先,你不需要自己写任何东西,你只需要告诉 CuDNN 使用它。其次,CuDNN 在堆栈中的位置
很低——因此,您不会得到太多的开销:

在你的代码和硬件之间有一个分层的管道
因为我们不直接与 CuDNN 交互,所以我们必须告诉我们选择的库使用特定的实现。换句话说,我们必须打开“我可以接受较慢的训练,让我每次跑步都有稳定的结果”的标志。
不幸的是,Keras 还没有那个功能,如
这些 问题中所述。
看来是 PyTorch 大放异彩的时候了。它具有支持使用 CuDNN 确定性实现的设置:
火炬能拯救我们吗?
让我们写一个简单的单卷积网络,用随机数据进行训练。确切的架构或数据并不重要,因为我们只是在测试再现性。
**class Net(nn.Module):
def __init__(self, in_shape: int):
super(Net, self).__init__()
self.conv1 = nn.Conv2d(3, 5, 3)
self.hidden_size = int((in_shape — 2) * (in_shape — 2) / 4) * 5
self.fc1 = nn.Linear(self.hidden_size, 1)def forward(self, x):
x = F.relu(self.conv1(x))
x = F.max_pool2d(x, 2)
x = x.view(-1, self.hidden_size)
x = F.relu(self.fc1(x))
return x**
fix_seeds 函数也被修改为包括
**def fix_seeds(seed):
random.seed(seed)
np.random.seed(seed)
torch.manual_seed(42)
torch.backends.cudnn.deterministic = True
torch.backends.cudnn.benchmark = False**
同样,我们将使用合成数据来训练网络。
初始化后,我们确保权重之和等于特定值。类似地,在训练网络之后,我们检查模型权重。如果有任何差异或随机性,脚本会告诉我们。
**python3 reproducibility_cnn_torch.py**
给出一致的结果,这意味着在 PyTorch 中训练神经网络给出完全相同的权重。
有一些警告。首先,这些设置会影响训练时间,但是测试显示的差异可以忽略不计( 1.14 ± 0.07 秒对于非确定性版本; 1.17 ± 0.08 秒为确定性一)。其次,CuDNN 文档警告我们有几种算法没有再现性保证。这些算法通常比它们的确定性变体更快,但是如果设置了标志,PyTorch 就不会使用它们。最后,有些模块是不确定的(我自己无法重现这个问题)。
无论如何,这些问题很少成为障碍。所以,Torch 有内置的再现性支持,而 Keras 现在没有这样的功能。
**但是等等!有一些 猜测由于 Keras 和 Torch 共享后端,在 PyTorch 中设置这些变量会影响 Keras。如果变量影响某些全过程参数,则可能出现这种情况。这样,我们就可以利用这些标志,并使用 Keras 轻松地编写模型。
首先,让我们看看这些标志是如何工作的。
我们再深入一点!从 Python 端
设置确定性/基准标志调用 C 源代码中定义的函数。这里,状态存储在内部。
之后,该标志影响卷积期间算法的选择。换句话说,设置这个标志不会影响全局状态(例如,环境变量)。
因此,PyTorch 设置似乎不会影响 Keras 内部(实际的测试 证实了这一点)。
补充:一些用户报告说,对于一些层(CuDNNLSTM 是一个明显的例子)和一些硬件和软件的组合,这个黑客可能会工作。这绝对是一个有趣的效果,但是我不鼓励在实践中使用它。使用一种有时有效有时无效的技术会破坏可复制学习的整体理念。
结论
修复随机种子非常有用,因为它有助于模型调试。此外,运行之间减少的度量方差有助于决定某个特性是否会提高模型的性能。
但有时这还不够。某些模型(卷积、递归)需要设置额外的 CuDNN 设置。Keras 还没有这样的功能,而 PyTorch 有:
**torch.backends.cudnn.deterministic = True
torch.backends.cudnn.benchmark = False**
再现谷歌研究足球 RL 结果
这篇文章记录了我试图(并成功)重现谷歌足球研究(GRF)论文中一些结果的旅程。具体来说,我成功地在单 GPU 云实例上使用 OpenAI 的 PPO 训练了一个强化学习(RL)代理,仅用了两天的最长时间。它复制了纸上的数字。
设置:云实例
我们先从用 PPO 设置好准备 RL 的云机器开始。如果你已经有这样做的机器,你可以跳过这一部分。
在你的谷歌云账户上,进入“市场”,搜索“深度学习虚拟机”模板。我变得很好奇,想看看你可以选择的各种 GPU、CPU 内核和 RAM 的成本/收益权衡,所以我用三种不同的设置进行了我的实验。我将在这里提供最具成本效益的方法,并在下面的“成本/时间权衡”一节中详细介绍这三种方法。我建议使用 12 个虚拟 CPU、12GB 内存、64GB 磁盘空间和一个英伟达 P100 GPU。务必选中“安装 NVIDIA 驱动程序”复选框
一旦机器被创建,SSH 进入它。
设置:软件和驱动程序
一旦你在你的机器上,我们可以开始设置软件。
注意:如果您在任何时候遇到由于
libGL导致的错误,请参阅本文末尾的“修复 libGL 问题”一节。
首先,有一小组工具我再也离不开了,但是你可以跳过:sudo apt install tmux fish,然后以env SHELL=which fish tmux的身份开始一个新的 tmux 会话。
接下来,我总是更喜欢使用 python 虚拟环境,所以让我们创建一个并在本教程的剩余部分使用它:sudo apt install python3-venv,然后用python3 -m venv venv在一个名为venv的文件夹中创建它,然后通过. venv/bin/activate.fish开始使用它(是的,该命令以点开始。)
如果您使用云实例,首先将 TensorFlow 的优化版本安装到 virtualenv 中,在撰写本文时,这是使用pip3 install /opt/deeplearning/binaries/tensorflow/tensorflow_gpu-1.14.0-cp35-cp35m-linux_x86_64.whl完成的,在您阅读时,文件名可能会略有变化。
现在,我们终于可以按照 README 安装 gfootball 及其所有依赖项,使用“克隆的 repo”方式,因为我们将做一些轻微的更改。为了完整起见,这些是命令:
> **sudo** apt-get install git cmake build-essential libgl1-mesa-dev libsdl2-dev libsdl2-image-dev libsdl2-ttf-dev libsdl2-gfx-dev libboost-all-dev libdirectfb-dev libst-dev mesa-utils xvfb x11vnc libsdl-sge-dev python3-pip
然后克隆 repo,切换到文件夹,并将其安装到 virtualenv 中,这需要一点时间:
> **git** clone https://github.com/google-research/football.git
> **cd** football
> **pip3** install .
接下来,我们想从 OpenAI 基线运行 PPO 算法,所以也要安装它和它的依赖项,同样按照自述文件,为了完整起见复制到这里:pip3 install "tensorflow-gpu<2.0" dm-sonnet git+https://github.com/openai/baselines.git@master。
运行 PPO 培训
我正在复制的实验是在“简单”模式下的 11vs11 游戏,因为这似乎是导致在合理数量的步骤中合理地玩好 PPO 代理的原因。以下是我们试图复制的论文中的具体数字:

我们可以在论文的附录中找到所有的超参数。
让我们将带有所有参数的完整命令(可在本文的附录中找到)放在一个名为gfootball/examples/repro_scoring_easy.sh的脚本文件中,以便于参考和运行:
#!/bin/bashpython3 -u -m gfootball.examples.run_ppo2 \
--level 11_vs_11_easy_stochastic \
--reward_experiment scoring \
--policy impala_cnn \
--cliprange 0.115 \
--gamma 0.997 \
--ent_coef 0.00155 \
--num_timesteps 50000000 \
--max_grad_norm 0.76 \
--lr 0.00011879 \
--num_envs 16 \
--noptepochs 2 \
--nminibatches 4 \
--nsteps 512 \
"$@"
max_grad_norm是唯一不可用的设置,但是我准备了一个拉请求来暴露它。最后一位("$@")只是转发所有附加参数,因此现在我们可以如下调用它来运行训练:
> **gfootball/examples/repro_checkpoint_easy.sh** --dump_scores 2>&1 | tee repro_checkpoint_easy.txt
我喜欢将输出明确地tee到一个日志文件中,以便于参考,但是请注意,OpenAI baselines 会在/tmp/openai-[datetime]/的某个地方生成一个包含日志的文件夹,包括所有输出。虽然它们在/tmp 中,但是要注意它们 最终会 消失。
--dump_scores标志指示环境也存储导致进球的两百帧的.dump文件(在 16 个环境中的第一个上),因此我们可以稍后观看那些进球。另一个将使用更多磁盘空间的选项是使用--dump_full_episodes标志为每个完整剧集(16 个环境中的第一个)生成一个转储。如果您想要创建高质量的渲染视频,这是当前必需的。
这里有趣的是最后一个(按日期时间)文件夹中的progress.csv文件,包含整体训练进度,如果您启用了视频转储,第一个文件夹应该包含许多“得分转储”,这是两队得分前 20 秒的简短片段。
您可以使用标准的 unix 工具在训练期间获得一些统计数据,例如,我使用以下命令来计算平均 FPS 计数:
> **grep** fps repro_scoring_easy.txt | **awk** '{ FS="|"; total += $3; count++ } END { print total/count }'156.545
再现的结果
在使用“得分奖励”的三次跑步中(即只有当代理人得分时才给予奖励),我在训练 50 米步后达到了平均每集奖励 1.57、2.42、4.12,对应于2.70±1.06(标准偏差)。论文附录中的表 5 报告了该设置的 2.75-1.31。我只对“检查点奖励”进行了一次实验,它达到了平均每集奖励 6.31 ,落在报告的5.53±1.28内。
因此,虽然这再现了结果,但你可以从三次重复的原始数字中看到,在三次重复中,学习到的策略的质量变化相当大。为了让 RL 更可靠,我们还有很多工作要做!
训练后要做的事情
一旦训练完成,我们可以报告训练曲线,并查看平均每集奖励,这通常是研究论文所必需的。例如,这个命令给了我一段时间的平均剧集奖励:
**> grep** eprewmean repro_scoring_easy.txt | **awk** 'BEGIN{FS="|"} { print $3 }'
或者,我们甚至可以使用gnuplot立即创建一个图,如下所示,在本例中为三种药剂中的最佳 PPO 药剂:
**> grep** eprewmean repro_scoring_easy3.txt | **awk** 'BEGIN{FS="|"} { print NR $3 }' | **gnuplot** -p -e "set terminal png size 400,300; set output 'eprewmean.png'; plot '< cat -' with lines title 'reward'"

但是我们也可以做一些更有趣的事情,比如看我们经纪人的视频,甚至和他比赛!
制作和观看视频
人们可以在事后使用dump_to_video工具从“分数转储”中创建一个视频,比如:python -u -m gfootball.dump_to_video — trace_file /tmp/openai-2019–09–13–16–00–43–638465/score_20190913–204112398339.dump。
它会在命令行输出中告诉您视频文件的存储位置,如下所示:
I0916 18:03:21.296118 139929219241792 observation_processor.py:383] Start dump episode_doneI0916 18:03:22.525743 139929219241792 observation_processor.py:234] Dump written to /tmp/openai-2019–09–13–16–00–43–638465/episode_done_20190916–180321296073.dumpI0916 18:03:22.525876 139929219241792 observation_processor.py:236] **Video written to /tmp/openai-2019–09–13–16–00–43–638465/episode_done_20190916–180321296073.avi**
默认情况下,这个视频是一个“调试视频”,它不是游戏的真实呈现,但有更多关于当前正在发生的事情的信息。下面展示了一个很好的视频,我们的球队(绿色 H )跑向对手(蓝色 A ),丢球(红色 B ),捡球得分。

要查看(并保存)一个轨迹的实际渲染视频,需要使用replay工具,比如:python -u -m gfootball.replay --trace_file /tmp/openai-2019-09–13–16–00–43–638465/episode_done_20190913–161055711125.dump。这将打开游戏窗口,并再次播放完整的游戏供您观看。一旦游戏结束,当它保存完整游戏的.avi视频时,屏幕会出现大约 30 秒的停滞——请耐心等待它结束。我就是这样创作了文章顶部的视频。如果你想剪切出一个容易共享的.gif文件,这个是怎么做的:
**> ffmpeg** -ss 98 -t 11 -i /tmp/dumps/episode_done_20191022-181100113944.avi -vf "scale=320:-1:lanczos,split[s0][s1];[s0]palettegen[p];[s1][p]paletteuse" -loop 0 game.gif

看起来,至少在我写这篇文章的时候,它只能渲染从游戏开始时开始的痕迹,所以还没有完整图形的“得分转储”。
和我们训练有素的特工比赛
这可能是最令人兴奋的事情:)它非常简单,在自述文件中有很好的解释,但仅供参考,我使用以下命令来对抗如上所述训练的 PPO 代理:
**> python** -m gfootball.play_game --players "keyboard:right_players:1;ppo2_cnn:left_players=1,policy=impala_cnn,checkpoint=/path/to/checkpoint"
关于使用哪个键,参见自述文件,但本质上是箭头和 WASD。游戏结束时会写一个完整剧集的转储,你可以像上面一样使用它(使用gfootball.replay命令)来创建一个完整的渲染。游戏的 avi 视频,就像这篇文章上面的那个。
使用这个命令的一个小变体,您可以观看它与内置 AI 的比赛:
**> python** -m gfootball.play_game --players "ppo2_cnn:left_players=1,policy=impala_cnn,checkpoint=/path/to/checkpoint" --level=11_vs_11_easy_stochastic
我的结论是,那个叫达芬奇的玩家确实不错!
成本/时间权衡
我很好奇这个项目最具成本效益的设置是什么,因为我想重复运行三次以获得置信区间,所以我尝试了三种不同的设置,并将它们的速度和成本总结如下:
- 首先我试了单个 V100 GPU,12 个 vCPU 核,32 GB 内存,128Gb 普通磁盘。在这台机器上,我在每种环境下实现了大约 17 SPS(每秒步数)和大约 50–60 FPS(每秒帧数)。我们将并行运行 16 个环境,每个环境平均每秒 280 帧。预计需要 50 小时,5000 万步需要 108 美元。
- 第二次尝试使用便宜得多的机器:8 个 vCPUs、8GB 内存、64GB 磁盘空间和一个 K80 GPU。这给了每个环境大约 10 SPS 和 50–60 游戏 FPS,平均总共大约 160 FPS。预计需要 89 小时,5000 万步的总成本为 51 美元。
- 第三,尝试一台“普通”的深度学习机器:12vCPUs、12GB 内存、64GB 磁盘空间和一个 P100 GPU。这给了每个环境大约 20 SPS 和 70–80 游戏 FPS,平均总共大约 320 FPS。预计 5000 万步需要 43 小时,总成本为 64 美元。

Screenshot of the most cost-efficient machine that I used: the “second try” i.e. the K80 GPU.
修复 libGL 问题
这个问题是我在云上想到的,但我假设它也可能发生在其他(基于 ubuntu 的)系统上,因为有许多 报告 或这个问题。我们无法回避的依赖项之一是libgl1-mesa-dev包,它实际上破坏了/usr/lib/x86_64-linux-gnu/libGL.so符号链接。
网上报道的一个明显的解决方案是强制重新安装sudo apt-get install --reinstall libgl1-mesa-glx。我不知道这有多有效。我推荐的替代方案是,至少在 Google Cloud 上,简单地重新安装 GPU 驱动程序如下:/opt/deeplearning/install-driver.sh这个问题就会被修复。
RescueForest:用随机森林预测紧急响应

King County SAR on the job
我正在完成 fast . aiML入门课程的材料,这太棒了。这种学习哲学,被导师杰里米描述为自上而下的方法,对我的学习方式非常有效。总的想法是,在你知道为什么它会起作用之前,你先要知道如何做 ML——就像你先知道如何打棒球,然后才知道为什么你会在给定的时间使用一种特定的策略一样。
我想做一个小的顶点项目来实践我学到的东西,所以我决定研究应急响应预测——特别是为一个名为金县搜救 (SAR)的组织,我是该组织的志愿者成员。我们执行各种各样的救援任务,但最常见的呼叫是帮助西雅图周围荒野中受伤或迷路的徒步旅行者。它大多是一个志愿者经营的组织,所以资源本来就有限。拥有一种方法来预测在任何给定的一天打电话的可能性可能会帮助我们优先考虑资源和准备,以最好地为社区服务。
我把这个项目分成了三个步骤,这三个步骤在本课程中都有涉及:1 .数据探索和清理 2。建立一个简单的模型并用它来研究特征重要性 3。特征工程和调整模型
这篇文章将涵盖我的一般方法和发现。详细代码和笔记本可以在我项目的回购中找到。
数据浏览,清理
在建立模型之前,我想了解我们拥有的数据的性质。有几个我们正在使用的数据源,我们将在日期前把它们连接在一起。Python 的 datetime 库对此很关键,并使这些操作变得更加容易。
结果数据
该项目的目标是预测在特定的一天是否有搜救呼叫发生。我从组织的内部数据库下载了这个,并删除了一些隐私信息。将数据加载到 python 和 pandas 允许一些简单的绘图,以确保我们专注于最相关的数据。我不得不缩小日期范围,从 2002 年到现在,因为在此之前的数据是不完整的。
一些探索图显示,我们在 29%的日子里有调用,这意味着数据有些不平衡,但并不可怕。电话在周末和夏天最频繁。我们凭直觉知道这一点,数据也支持这一点。这也证实了仅在日期内就可能有一些信息具有某种预测能力。


但首先,我们需要一个整洁的数据集。本质上,我们用一个表来表示我们所考虑的范围内的每个日期,并给出一个布尔值来报告当天是否有电话。通过利用 panda 的 date_range 函数,一个简单的脚本将 raw sar_data转换成了一个clean_table。
date_range **=** pd**.**date_range(start**=**'1/1/2002', end**=**'4/01/2019')
clean_table **=** []
**for** d **in** date_range:
**if** sar_data**.**date**.**isin([d])**.**any(): *# check if date in in table containing all calls*
clean_table**.**append([d,1])
**else**:
clean_table**.**append([d,0])
sar_clean **=** pd**.**DataFrame(clean_table)
sar_clean**.**columns **=** ['date','mission']
特征
通过使用clean_table表中的日期列,我们可以使用漂亮的 fast.ai 函数提取信息,如星期、年、月等。从日期时间对象。在把它应用到我们整洁的桌子上之后,我们有了大约 13 个特性。
除此之外,我们还将整合一些来自 NOAA 的天气信息。他们提供了很多很酷的工具,数据科学家会发现这些工具很有用,我鼓励任何对整合天气数据感兴趣的人去看看。
理想情况下,我们可以在这个项目中使用天气预报数据,而不是实际的天气数据。当我们提前计划时,我们只能得到天气预报,而天气预报显然经常与实际天气不同。我找到的所有保存这些数据的资源都是付费服务,所以现在我不得不接受 NOAA 的数据。
我从两个当地气象站下载了天气数据——西雅图南部的波音机场和我们大部分任务发生的山脉中的加德纳山。我们得到温度、风、太阳和降水的信息,这是一幅给定一天的天气图。一些健全性检查确保数据按照我们预期的方式组织(夏天热,冬天多雨)。使用pandas.merge将这些与clean_table合并,得到包含以下特征的初始数据集:
`[Year’, ‘Month’, ‘Week’, ‘Day’, ‘Dayofweek’, ‘Dayofyear’, ‘Is_month_end’, ‘Is_month_start’, ‘Is_quarter_end’, ‘Is_quarter_start’, ‘Is_year_end’, ‘Is_year_start’, ‘Elapsed’, ‘DATE’, ‘AWND_x’, ‘PRCP_x’, ‘TAVG_x’, ‘TMAX_x’, ‘TMIN_x’, ‘TSUN’, ‘WT01’, ‘WT02’, ‘WT03’, ‘WT05’, ‘WT08’, ‘WT10’, ‘AWND_y’, ‘PRCP_y’, ‘SNWD’, ‘TAVG_y’, ‘TMAX_y’, ‘TMIN_y’, ‘TOBS’, ‘WESD’]``
特征工程
测试、训练、初始模型
选择合适的验证和测试集是课程中的一个重要主题。我在这里采用了与杰里米讨论的推土机拍卖和杂货店销售预测的 Kaggle 竞赛相似的方法。在这些情况下,我们需要使用过去的数据来预测未来,因此我们按日期对数据进行排序,并为验证集保留最近的 15–20%的数据。我们会在这里做同样的事情。
对于测试集,我将使用一种更“真实”的方法,只在今年实时测试我的模型。
对于模型评估,内置的评分函数可能并不理想。只有 29%的时间有任务,所以一个天真的模型总是预测“没有呼叫”将是正确的,准确率为 71%。对于这种情况,ROC 曲线是一种不错的方法,所以我用它来进行模型评估。这些在 fast.ai 课程中没有广泛讨论,因为它们主要集中在回归问题上。作为复习,我发现这篇文章很有帮助。
接下来,用 scikit-learn 构建的一个简单的随机森林在 ROC 曲线中给出了一些信号(AUC=0.61),因此我继续进行这项工作,以便更好地理解手头的数据。

当深入研究模型中使用的特性重要性时,事情似乎变得有意义了。一周中的某一天、过去的天数(只是从数据集开始算起的连续天数)和一年中的某一天是三个最重要的特征。最重要的天气特征是西雅图的风,这可能预示着暴风雨的来临?接下来的几个天气特征是温度,这并不奇怪。
在课程中,Jeremy 保留了所有显示重要性的特征,即使它们可能是相关的。毫无疑问,附近地方的温度是相关的,但该模型应该用集合方法来处理这个问题。将来,做一些额外的功能工程来消除一些冗余可能是值得的。我确实删除了一些不太重要的功能,而且删除后不会影响性能。
假期数据
添加假期数据对模型有帮助吗?我使用了包含美国假期数据库的pandas.tseries.holiday,并尝试了几种不同的方法,总结如下:-为is_holiday添加一个布尔值列;-为days_until_next_holiday和days_since_last_holiday添加列;-为days_away_from_nearest_holiday添加一个列
最后一种方法是最有效的,这是有道理的。节假日前后的几天最有可能是休息日,这与徒步旅行者的增加相对应。通过包含这些信息,ROC 从 61%提高到 65%。
谷歌趋势
在这个项目中,我发现了谷歌趋势数据的一个很酷的特性。虽然没有 API,但只是在网络界面上玩了玩,我就能得到关于国王县地区“徒步旅行”这个一般主题的搜索频率——这正是我们的准确反应区域。正如预期的那样,这些数据是季节性的,我希望它们可以捕捉到正在发生的其他事件,这些事件可能会增加或减少短期内对徒步旅行的兴趣。

添加这个特性给出了一个令人困惑的结果 ROC 没有提高,但是当您考虑特性的重要性时,它是第二重要的特性。这是否仅仅意味着趋势数据对于某些日期特征来说是多余的?我决定留着它继续前进。
构建最终模型
好了,现在是最终模型。我比较了具有相同基本参数的三种基于树的算法,AUC 总结如下。
- 随机森林:0.59
- AdaBoost: 0.61
- XGBoost: 0.63
XGBoost 做得最好,所以工具提供了学习如何调优这些模型的机会。我使用的主要方法是 sklearn 内置的网格搜索功能。这花了很长时间来运行,但结果给了我模型可以找到的最佳组合参数。这使我们的 AUC 上升到 0.67。
模型评估
我将全年监控该模型的性能,但是在撰写本文时,该模型有 23 的时间是正确预测的。这是个很难的问题,随机性很大,数据量很小。也就是说,到目前为止,它已经对我的生活产生了影响,让我在预测高呼叫概率的日子里提前做好准备。
尽管如此,仍有改进的空间。我将继续尝试新的模型,并在发现新的模型时添加新的数据。我也很高兴听到任何人对我可以改进我的方法的功能或方式的其他想法的建议。感谢 Jeremy、Rachel 和 fast.ai 团队带给我们如此美好的体验!
改编自我的网站
什么是自然实验?
实验和因果推理
方法、途径和应用

Photo by Andreas Gücklhorn on Unsplash
介绍
我喜欢阅读 Craig 等人(2017 )关于自然实验的综述文章(关于方法、途径和对公共卫生干预研究的贡献的概述)。在这篇文章中,我想总结它的要点,并附上我对因果推理发展的一些思考。这篇综述文章介绍了什么是 NE 以及对 NE 数据可用的方法和途径。通常情况下,年度综述,比如由克雷格等人撰写的这一篇,提供了对该领域近期发展状况和未来方向的快速回顾。这是学习数据科学的好方法。强烈推荐!
什么是 NE?
根据英国医学研究委员会的说法,任何不受研究人员控制的事件,将人群分为暴露组和未暴露组。
由于缺乏对分配过程的直接控制,研究人员不得不依靠统计工具来确定操纵暴露于治疗条件的变化的因果影响。
NEs 的关键挑战是排除选择进入治疗组的可能性,这将违反忽略假设。这种违反也使得治疗组和对照组不具有可比性,我们不能将结果变量的差异归因于干预的存在。
为了解决这个问题,数据科学家提出了潜在结果框架。POF 代表如果一个人暴露于和不暴露于干预时会发生的结果。
然而,棘手的是,这两种结果中只有一种是可观察到的,我们必须依靠反事实来推断单位之间的平均治疗效果。
如果分配是随机的,如在随机对照试验(RCTs)中,那么治疗组和对照组是可交换的**。我们可以将这两组之间的差距归因于干预的存在。**
如果分配不是随机的,如在 NEs 中,数据科学家必须依靠分配机制和统计方法的领域知识来实现有条件交换。
这是定性研究和领域知识发挥作用的时候,并确定在分配过程背后是否有一个因果故事。
我想说,由于实践和伦理的原因,NEs 在现实世界中比 RCT 有更广泛的应用范围。因此,正如 Craig et al. (2017 )建议的那样,选择合适的方法/设计对 NE 数据进行因果推断变得至关重要。
这样做主要有八种技术。我将在这里用一些研究笔记和实际应用的链接来介绍每种方法。请参考原始文章(这里是)来更全面地讨论每种技术。
方法
- 前后分析 。就我个人而言,如果没有更好的选择,这将是我的最后手段。没有多个数据点的单个案例比较。我们如何控制混杂因素?不是因果推理的理想选择。
- 回归调整 。当我们试图比较案例时,它有很多应用。
- 倾向得分匹配 。也适用于观测数据,但是 Gary King 最近否定了使用 PSM 的想法。
- 差异中的差异 。这是一种强有力的因果推理技术,具有简单明了的研究思想。
- 中断的时间序列 。具有多个数据项的因果方法。
- 合成控件 。这是工业界和学术界的一种流行方法,政治学家为此做出了巨大贡献。简而言之,如果对照组中没有与治疗组匹配的病例,我们可以人为地创建对照组的加权平均值作为基点。例如,我们使用其他案例的加权值创建一个人工控制场景,并比较这两组之间的差异。这是一个如此巧妙的想法,但有潜在的陷阱,对此我将在另一篇文章中详细阐述。
- T5【回归不连续设计】T6。强大的因果技术与一个伟大的视觉插图。
- 工具变量 。IV 方法包含很强的推理能力,但是众所周知很难找到。因此,它的应用有限。
如何让 NEs 在因果推理上更强?
这篇综述文章提供了三种解决方案:
- 加入定性成分以理解工作机制。我的两点看法是,在大数据和机器学习的时代,我们不应忘记定性研究的重要性。足够好地理解这个过程或领域知识,有助于我们开发更好的统计模型。
- 多种定量方法和目视检查相结合,检查 RDD 和 ITS 的不连续性。目视检查对于识别异常情况至关重要且简单明了。如果可能的话,更多更明智地使用它们。
- 引入伪造/安慰剂测试来评估因果归因的合理性。例如,我们可以使用不等价的因变量来测试未受干预影响的结果与受干预影响的结果的变化。这里,潜在的想法是使用多个 dv 交叉检查结果,这是一种广泛用于社会科学的研究思想。
Medium 最近进化出了它的 作家伙伴计划 ,支持像我这样的普通作家。如果你还不是订户,通过下面的链接注册,我会收到一部分会员费。
[## 阅读叶雷华博士研究员(以及其他成千上万的媒体作家)的每一个故事
作为一个媒体会员,你的会员费的一部分会给你阅读的作家,你可以完全接触到每一个故事…
leihua-ye.medium.com](https://leihua-ye.medium.com/membership)
实验和因果推理
如何不让你的在线控制实验失败
towardsdatascience.com](/online-controlled-experiment-8-common-pitfalls-and-solutions-ea4488e5a82e) [## 相关性并不意味着因果关系。现在怎么办?
数据科学中因果关系和相关性之间的地盘之争
towardsdatascience.com](/the-turf-war-between-causality-and-correlation-in-data-science-which-one-is-more-important-9256f609ab92) [## 数据科学家应该有充分的理由进行更多的实验
好的,坏的,丑陋的
towardsdatascience.com](/why-do-we-do-and-how-can-we-benefit-from-experimental-studies-a3bbdab313fe)
喜欢读这本书吗?
还有,看看我其他关于人工智能和机器学习的帖子。
线下和线上社交网络中的影响力研究
关系强度和网络度在决定社会影响力中的作用。

几乎所有关于社交网络和信息流分析的文章都是从提到斯坦利·米尔格拉姆在 20 世纪 60 年代著名的小世界实验开始的。我们照着做吧。
本文的前半部分是关于通过社会网络的信息传播的经典研究的主要发现。之后,我们将关注一种特殊的社交网络:在线社交网络。我们在 YouTube、Twitter 和脸书等社交媒体平台上发现了同样的离线社交网络特征吗?
注:本文是社交网络分析和影响者营销系列文章的一部分,全部基于我的硕士论文“Instagram 上的影响者欺诈:全球最大参与社区的描述性分析” 、 其中 你可以在这里 完整阅读。由于现在几乎没有人有时间阅读 140 多页的相关内容,我决定将我的硕士论文分成几篇中等长度的独立文章,让读者自己决定她感兴趣的内容。
insta gram 上相关标签的社交网络分析(使用 InstaCrawlR)
insta gram 上的影响者欺诈——对世界上最大的互动社区的描述性分析(乔纳斯·施罗德的硕士论文)
请随时关注我的个人资料以获取更新或稍后回来。我会继续添加其他文章的链接。
世界真小——离线社交网络的经典研究结果

Taken from Milgram (1967)
在 1967 年的实验中,米尔格拉姆要求随机选择的美国公民向随机目标传递一封信,只使用他们认识的朋友和熟人的名字。由此得出的路径长度中值为 5,这意味着人们通常只需几步就能彼此联系起来。这种“知识”进入了流行文化和常识(例如,S ix Degrees of 凯文·贝肯)。然而,更有趣的是他关于中介角色的发现。米尔格拉姆写给他们的信有一半是通过同样的三个人:雅各布斯先生、布朗先生和琼斯先生。这些人是高度联系的个人,或社会中心,基本上汇集了整个美国公民网络。
Granovetter (1973)将这些人称为桥梁,即信息通过社交网络流动的瓶颈。他认为,社交网络重叠的程度取决于连接它们的纽带的强度。越是相似或同性的个体,他们越有可能互动并形成牢固的关系。有道理:我们信任我们认识的人,他们往往和我们有相同的背景和兴趣。

然而,为了传播新的信息,我们需要关注那些联系不紧密的个体,他们将不同兴趣的社会圈子联系在一起。因此,弱关系在新信息的传播中起着特殊的作用,例如新产品或流行趋势。Brown 和 Reingen (1987)从经验上证明了这一假设。弱关系确实被发现与新思想的传播和子社区之间的传播不成比例地更相关。
米尔格拉姆经典实验的数字复制品也支持这一发现。在 Dodds,Muhamad 和 Watts (2003)的实验中,6 万名参与者被要求向来自几个国家的 18 个目标转发电子邮件。他们发现,在成功的连锁中,信息被转发给发送者描述为关系相当“随便”和“不密切”的人,因此:关系薄弱。然而,他们没有从米尔格拉姆的研究中找到雅各布斯先生的数字等价物。他们没有发现真正的桥梁。
从任何一个关系紧密的社区的立场来看,局外人都是局外人。他们很奇怪。然而,如上所述,局外人对于新思想的传播是很重要的。我们从许多关于创新传播的书籍和文章中知道,技术的早期采用者在开始时总是被认为是怪异的。

“为什么这个人在和他的手说话?”,是 90 年代许多人的想法。现在,每个人都有一部 iPhone,在乘地铁上下班的时候,可以和自己通话。
在他经常被引用的书《引爆点》(2000)中,格拉德威尔分析了任何趋势或社会流行病的传播——无论是技术采用、时尚趋势,甚至是犯罪。他认为有三种人必须像野火一样传播信息:连接器、专家和推销员。
连接器是像雅各布斯先生这样的人,他们通过自己的庞大网络将世界联系在一起。专家是有社会动机的人,他们通过分享信息在个人和市场之间充当中间人。当你想买一台新的笔记本电脑时,你最好在你的社交圈里寻找行家。销售人员被描述为天生的说服者,他们使用微妙的、主要是非语言的暗示来影响人们的观点。
专家是数据库。他们提供信息。连接器是社会粘合剂:他们传播它。当我们不相信我们所听到的时,推销员会说服我们。—马尔孔·格拉德威尔
格拉德威尔认为这些人最重要的功能之一就是充当翻译。他们获取创新者的信息,并将其翻译给更广泛的受众。因此,它们有助于解决摩尔(1991)的鸿沟问题。这对于那些试图将客户群从早期用户扩大到大众市场的公司来说非常重要。连接器、专家和销售人员——或者更现代的术语:影响者——可以帮助完成这项工作。

这么多关于与人面对面或通过模拟方式互动的旧世界。让我们继续研究在线社交网络中的影响力。
你好,扎克,我是汤姆!关于在线社交网络的一些研究结果
关于社会影响力和通过离线社交网络传播信息的经典研究人员不仅受到了他们所处时代的计算限制的挑战。他们不得不处理许多未经证实的假设和有限的数据,因为人们关系的本质和他们的个性不是很容易观察到的,而是可以通过调查解决的。
今天,由于技术进步和社交媒体平台的普及,社交网络分析如今更加富有成果。人们之间的联系很容易以关注者关系或朋友图表的形式观察到。构建和分析巨大的交互模型不再困难。
此外,人们乐于在网上分享大量关于自己和兴趣的信息。没有必要进行调查研究来确定个体群体的异质性和同质性——只需看看他们追随谁,喜欢什么。
这有可能解决 Manski(1993)在网络分析中经常发现的反射问题。一个社区的成员会因为群体对他们的影响而分享某些特征吗?还是说组成这个团体的人一开始就很相似?

Preview from https://www.jstor.org/stable/2298123
苏萨拉、吴和谭(2011)分析了 YouTube 的网络结构。他们能够通过系统地分离某些因素来区分社会影响和用户的自我选择,从而控制反思问题。他们的主要发现是,对 YouTube 的影响力来自于一个节点的网络中心性,而同性对社会传染起着至关重要的作用。
Bakshy 等人(2011)研究了对 Twitter 的影响力,这种影响力可以被定义为持续播种超越他人的级联的能力。他们发现,拥有许多过去有影响力的追随者的人确实更有可能继续他们的影响力。然而,研究人员指出,在颗粒基础上预测影响是不可靠的。持续影响的效果只对平均值成立,对个体不成立。他们建议营销人员使用一种分散祈祷式的投资组合策略,而不是把所有赌注都押在一匹马上。

Taken from Bakshy et al. (2011): Everyone’s an Influencer — Quantifying Influence on Twitter.
尽管 2018 年有各种坏消息和动荡的股票表现,脸书仍然是目前最大的社交媒体平台之一。用户可以通过双向联系与朋友联系,通过单向联系关注他们喜欢的艺术家。NewsFeed 算法决定了每个用户在浏览应用程序或网站时可以看到哪些内容。你可能会收到你的朋友保罗昨天分享的一个链接,你也想和你的网络分享它。
链接共享行为可以被视为影响力的一个指标。脸书在网络中的影响力显而易见。然而,有许多外部影响来源,如面对面接触或电子邮件交流。通过操纵 2.53 亿脸书用户的新闻源,Bakshy 等人(2012)能够确定社交媒体平台在信息传播过程中的作用。
他们创建了两个组:一个组中的某些信息被从新闻源中过滤出来,并且只能在脸书之外获取(无新闻源条件),另一个组中的信息可以从内部或外部获取(新闻源条件)。

Taken from Bakshy et al. (2012): The Role of Social Networks in Information Diffusion
像这样的实验设置的一大优势是,研究人员可以通过控制与同性相关的混杂因素来解决反射问题。通过比较两组的行为,研究人员发现,暴露于朋友分享行为(喂食条件)的受试者比没有喂食的受试者分享相同信息的可能性高 7.37 倍。因此,我们的朋友在某种程度上影响我们的行为。
此外,Bakshy 等人(2012 年)使用多种互动类型来衡量关系强度,例如,通过脸书信息进行私人交流的频率或通过评论进行公共交流的频率。Granovetter 的假设,即弱关系对新信息的传播更为重要,再次得到了经验上的支持。
为脸书再做一次研究。孙等人(2009)的研究重点是版面的扩散事件。当 Sally 喜欢 Metallica 的粉丝页时,这种粉丝行为可以被广播到她的一些网络中。保罗看到这一幕,立刻想到了圣安格尔的金属小军鼓声。他认为这是一支很酷的乐队,并对金属乐队也给予了好评。结果就是一个巨大的树状扩散网络。下面由此产生的网络,与少数人足以以流行病的方式传播信息的普遍假设形成对比(你好,格拉德威尔!).

Taken from Sun et al. (2009): Gesundheit! Modeling Contagion through Facebook News Feed
孙等发现扩散链一般都很长,但不是单个链式反应事件的结果。相反,它们是由大量用户发起的,这些用户的短链被合并在一起。此外,他们注意到,在控制受欢迎程度后,一个起始节点的最大扩散链长度不能用用户的人口统计或脸书使用特征来预测,包括朋友的数量。在此之后,识别潮流引领者将变得困难。
结论
影响的力量在一个网络中的个体之间并不是平均分配的。它可以被描述为一个社会网络中的连接数量(数量)以及每个纽带的强度(质量)的函数。如果你的联系质量不高,认识很多人可能还不够。
因此,与拥有成千上万追随者的有影响力的人合作本身还不令人信服,不管他们是真是假。微影响者的巨大吸引力在于他们与粉丝的关系质量,这比那些不在乎的广大观众更重要。
但这是另一个时间的话题。
请随时关注我的个人资料,获取关于这个主题的最新消息。你可以在 LinkedIn 或 Twitter 上联系我,如果你想谈谈我在市场营销方面的研究或数据科学的话。
感谢阅读,
乔纳斯·施罗德
PS:如果你想知道更多关于在线社交网络的研究,以及一些影响者是如何伪造的,直到他们成功,一定要看看我的大量研究论文:insta gram 上的影响者欺诈——对世界上最大的参与社区的描述性分析(Jonas Schrö der 的硕士论文)
引用文献
米尔格拉姆,斯坦利(1967),“小世界问题”,*《今日心理学》,*第 1 卷,№1,61–67 页。
马克·s·格兰诺维特(1973),“弱关系的力量”,《美国社会学杂志》,第 78 卷,第 6 期,1360–1380 页。
Brown,Jacqueline Johnson 和 Peter H. Reingen (1987),“社会关系和口碑推荐行为”,*《消费者研究杂志》,*第 14 卷,№3,350–362。
Dodds,Peter Sheridan,Roby Muhamad 和 Duncan J. Watts (2003),“全球社会网络中搜索的实验研究”,《科学》, 301,827–829。
查尔斯·f·曼斯基(1993),“内生社会效应的识别:反思问题”,《经济研究评论》,第 60 卷,第 3531–542 页。
苏萨拉、安贾纳、吴正河和谭勇(2011),“社交网络和用户生成内容的扩散:来自 YouTube 的证据”,*信息系统研究,文章预告,*1–19。
Bakshy、Eytan、Itamar Rosenn、Cameron Marlow 和 Lada Adamic (2012 年),“社交网络在信息传播中的作用”,国际万维网会议委员会(IW3C2) 2012 年会议录,[可用 athttps://arxiv . org/pdf/1201.4145 . pdf],1–10。
Bakshy,Eytan,Jake M. Hofman,Winter A. Mason 和 Duncan J. Watts (2011),“每个人都是影响者:量化对 Twitter 的影响”,第四届 ACM 网络搜索和数据挖掘国际会议(WSDM,2011 年),【可在http://snap . Stanford . edu/class/cs 224 w-readings/bak shy 11 influencers . pdf 获得】,1–10。
孙、埃里克、伊塔马尔·罗森、卡梅隆·a·马洛和托马斯·m·伦托(2009 年),《科学!通过脸书新闻源进行传染建模”,第三届国际 ICWSM 会议记录(2009) ,146–153。
注:本文将是社交网络分析和影响者营销系列的一部分,全部基于我的硕士论文“Instagram 上的影响者欺诈:对世界上最大的参与社区的描述性分析”的研究。相关文章的链接以后会在这里汇总。
AI/ML 项目中面向研究的代码

Photo by Vitaly Taranov on Unsplash
面向研究的代码概念化,以弥合数据科学和工程之间的差距
最近,web 应用工程师比以前有更多的机会与数据科学家或研究人员一起工作。同时,他们还经常面对由数据科学家或研究人员编写的面向研究的代码。代码往往是为涉及人工智能(AI)或机器学习(ML)的产品编写的。这篇文章可能会帮助初级/中级工程师或数据科学家理解为 AI/ML 产品编写的代码。
什么是面向研究的代码?
面向研究的代码是主要由研究人员或科学家编写的代码,它指的是分析脚本和/或原型代码。是基于科研范式写的。可以通过以下三个迭代过程来开发产品:1)编写分析脚本、 2)基于分析脚本开发原型,以及 3)将原型转化为应用产品。(如图 1 所示)

Figure 1 created by Jesse Tetsuya
数据科学家和研究人员往往在数学和算法建模方面有很强的背景。他们可以利用自己的技能来帮助开发工作,比如编写分析脚本和开发原型。在许多与 AI/ML 相关的项目中,他们可能会频繁地编写原型级别的分析脚本和代码。
虽然一些数据科学家和研究人员拥有工程技能,但生产级代码主要由 web 应用工程师编写。 Web 应用工程师有责任提高产品代码本身的质量,并使代码在服务器上运行。例如,为了将科学家或研究人员编写的代码与 API 等系统集成,web 应用工程师需要对其进行重构。
AI/ML 项目中的分析脚本是如何编写的?
为了缩小分析脚本的含义,弄清楚在业务情况下编写分析脚本的过程可能更有益。这是因为分析脚本在学术界和商业中使用,这可能会极大地影响对分析脚本的理解。
编写分析脚本是学术界研究过程的一部分。如图 2 所示,传统研究倾向于演绎和功能主义性质的。写分析脚本是为了找出新的知识并把它写在论文上。需要严格和准确的证据来支持新知识的存在和论文中的论点,无论它在商业上如何有益。除了涉及商业的情况,研究人员可能不需要考虑学术会议或期刊的严格资源规划和预计交付日期。

Figure 2 created by Jesse Tetsuya
在商业环境中的实际工作中,特别是关于 AI/ML 项目的工作中,分析脚本本身可以是原型和产品的基础。通过查看原型的演示,决策者需要在其他公司开始相同的业务之前判断它在业务上是否有益。因此,需要分析脚本的快速迭代输出,它也可以是原型。下面的流程适用于归纳、迭代和有机的情况。

Figure 3 created by Jesse Tetsuya
上面图 3 中黄色方框的循环将在下面详细讨论。
研究方法
- 在研究中,有两种分析方法; 1) 定性分析如观察和非结构化访谈,它使用基于不可量化信息的主观判断,以及 2) 定量分析,它试图通过使用数学和统计建模、测量和研究来理解行为。
- 在 AI/ML 项目中,选择第二种方式,项目的利益相关者需要选择分析方法,如回归、分类或神经网络。还有,什么分析工具 (python,R,SPSS,等等。)他们应该用意志来决定。
数据收集
- 首先,需要从数据库等中收集二级数据,如日志数据。在他们开始收集数据之前,涉众判断哪些数据能够恰当地代表他们想要知道的。在学术界的研究中,数据库或数据本身有时在校园或实验室之外。
- 另一方面,大多数 IT 公司倾向于将数据存储在他们自己的数据库中。这可以使项目更容易在数据收集、数据分析和研究方法决策之间来回切换。
数据分析
- 在学术界和商界,收集的数据是经过预处理的。预处理的方式取决于分析方法和工具。编码人员将经过预处理的数据输入到分析模型中,并验证输出是否适合了解他们想要了解的内容。
原型的类型
原型可以分为两组可见的如客户端应用程序和 web 应用程序和不可见的如 API 或统计/数学模型。(如图 4 所示)在 AI/ML 项目中,后者可以是通过上述编写分析脚本的周期开发的原型。

Figure 4 created by Jesse Tetsuya
评估面向研究的代码的五种方法
最后一节描述了哪些评估指标对于修复和编写实际的编程代码是有用的。理解这些指标可以帮助编码人员更好地进行编写分析脚本的迭代循环。
面向研究的代码可以通过使用由 Zina O’Leary 撰写的做你的研究项目的基本指南中建议的科学研究指标来评估。这是因为它基于上一节所述的科学研究范式。这五个指标可以应用到 AI/ML 项目中编写面向研究的代码的实际过程中。
1)客观性
客观性意味着研究者和被研究对象之间的距离,并表明这种关系是由协议、理论和方法调节的。该标准的存在是为了防止个人偏见“污染”结果。主观性是否得到承认和管理?
**情况:**在对数据进行预处理时,程序员或研究人员需要决定对分析不重要的数据,并删除它们,如离群值。让第三个人查看数据可能会提供有价值的见解,并且是避免个人偏见的有效方法。拥有一个稳定的环境来快速地在数据分析、数据收集和研究方法选择之间来回切换可能是解决方案之一。
2)有效性
有效性的前提是假设所研究的内容可以被测量或捕捉,并试图确认测量和捕捉的“数据”的真实性和准确性,以及从数据中得出的任何发现或结论的真实性和准确性。说明你得出的结论是可信的。是否捕捉到了‘真本质’?
**情况:**当时分析算法没有输出准确的结果或者学习模型没有很好地工作。这些都是通过使用精度等机器学习度量标准来防止的。
3)可靠性
可靠性的前提是这样一个概念,即在被测量的东西中有某种统一或标准化的感觉,并且方法需要一致地捕捉正在探索的东西。因此,可靠性是指一项措施、程序或仪器在重复试验中提供相同结果的程度。方法是否一致?
**情况:**如果预处理代码输出不一致的结果,则不可靠。例如,如果预处理过程、数据输入流程和参数检查都在代码中定义,则可靠性取决于该代码的质量
4)概化
概化是指样本的发现直接适用于更大的人群。虽然来自样本的发现可能与总体的发现不同,但被认为是可概括的发现显示了具有代表性的统计概率。研究结果是否适用于直接参照系之外?
**情况:**除了极端情况,输入数据的大小和数据类型会极大地影响算法的输出。概化由输入数据的数量和属性控制。算法的弱概括能力会导致数据的过拟合或数据泄漏。这些可以通过交叉验证、正则化和查看学习曲线来进行参数调整。
5)再现性
再现性与可信度问题直接相关,表明研究过程可以被复制以验证研究结果。换句话说,如果在相同/相似背景下的不同研究中使用相同的方法,结论将得到支持。研究可以验证吗?
**情况:**当编程代码根据不同的运行环境或服务器输出不同的结果,代码不可靠。基础设施的配置可能有一些问题,或者操作环境或服务器可能不适合使代码很好地工作。
简而言之, 1)客观性和 5)再现性似乎是与分析脚本本身相关的指标。另一方面, 2)效度、 3)信度和 4)概化与分析算法直接相关。使用内置于 scikit-learn 中的机器学习指标对于测量机器学习算法本身可能是有用的。
“面向研究的代码”是一个有用的词,可以将问题分成小块,从工程师或研究人员的角度来看待它们。工程师和研究人员的技能似乎有点重叠,所以有时他们的工作职责在 AI/ML 项目中似乎是模糊的。特别是,经验不足的工程师/数据科学家可能会比资深工程师对他们自己在 AI/ML 项目中的实际任务感到更加模糊。这也是我将 AI/ML 项目中面向研究的代码概念化并详细描述的原因。
参考
Bhattacherjee,a .,南佛罗里达大学,学者共享和开放教科书图书馆,(2012 年)。社会科学研究:原则、方法和实践,可在:【https://open.umn.edu/opentextbooks/BookDetail.aspx? 查阅 bookId=79 。
奥利里,z .(2014 年)。做研究项目的基本指南第二版。,洛杉矶:鼠尾草。
来自www.flaticon.com的桉树制作的图标(图 4 中的大脑图标、web 应用图标/图 1 和图 4 中的原型图标和生产代码图标/图 1 中的面向研究的代码图标/图 3 中的问题图标)
来自www.flaticon.com的原符号制作的图标(图 4 中的 API 应用图标)
来自www.flaticon.com的 Freepik 制作的图标(图 4 中的睁开的眼睛图标、闭上的眼睛图标和客户端应用程序图标/图 1 和图 3 中的分析脚本图标)
🐳从研究到生产:集装箱化的培训工作
这篇文章演示了如何使用 Docker 将训练代码容器化,并将适合的模型部署为 web 应用程序。虽然它在一定程度上建立在我之前的帖子上🤖 用于情绪分析的变压器微调,记住这里描述的方法是通用的;它可以作为机器学习实践者的标准解决方案来封装他们的研究代码,并促进可重复性。
为什么使用 Docker?为什么要在集装箱里训练?

Figure 1: Docker containers share the host OS kernel and do not require virtualized hardware, resulting in smaller footprint.
本质上,容器是轻量级的简洁胶囊,包含使用共享操作系统的应用程序,而不是需要模拟虚拟硬件的虚拟机。Docker 使我们能够轻松地将应用打包成小型、便携、自给自足的容器,几乎可以在任何地方运行。容器是进程,虚拟机是服务器(更多)。
以容器化的方式训练机器学习(ML)模型并不是一种常见的做法。大多数人倾向于使用简单的 Python 脚本和 requirement.txt 文件。然而,我认为,一般来说,在生产中的 ML 模型的整个生命周期中,容器化训练代码可以为我们节省大量的时间和麻烦。

Figure 2: Containerized training comes handy once our monitored metrics show model performance deterioration. Source: https://towardsdatascience.com/flask-and-heroku-for-online-machine-learning-deployment-425beb54a274
比方说,我们有一个根据我们收集的用户数据训练的生产模型。但是,随着时间的推移,用户行为会发生变化,这可能会导致数据分布发生显著的变化。
因此,随着生产模型的老化,它的质量会下降,很可能做出不再有用甚至更糟的预测,对我们的业务有潜在的危害。运行训练作业允许我们毫不费力地根据新的数据分布重新训练我们的模型。进一步来说,容器化有助于定期运行作业——或者在监控指标的性能下降时——自动测试和部署作业,确保预测一致,让我们的用户满意。
另一种情况是,我们的基础设施中有多台服务器用于计算,可能使用不同的 Linux 发行版、CUDA 工具包、Python 版本、库等等。可以说,我们无法预测每一个场景,我们心爱的训练脚本很可能会在某些环境中崩溃。在这种情况下,拥有 Docker 化的作业确实可以节省我们的时间和精力,因为只要安装了 Docker,它就可以在任何环境中运行。
或者,你可以把一个容器化的培训工作想象成一个给定任务的封装解决方案。比方说,我们的任务是对员工报告进行分类。在原型开发上投入了几个月后,我们希望以某种方式坚持我们的解决方案,因为结果可能必须在以后重现,或者模型可能在将来应用于类似的问题。
注意,当然,在容器内执行代码仍然需要主机有足够的硬件(计算和内存)和驱动程序(例如,支持 CUDA 工具包的 Nvidia 驱动程序等等)。
集装箱化
到目前为止,我们已经有了一些输出经过测试的、健壮的 ML 模型的训练代码,我们现在希望以某种方式保持它(或 productionalize )并可能作为服务部署。
此外,假设模型的测试性能符合我们的预期,我们结束研究阶段。对于这个演示,我将采用我以前的帖子 情感分析的变压器微调 *中的培训程序。*然而,请注意,以下部分完全与底层 ML 模型无关,是所有类型模型拟合任务的通用方法。
出于上述原因,我们决定将整个微调代码封装到一个自包含的 Docker 容器中。🐳
结构
在下文中,我们假设对接器安装在主机上。让我们简单地将这个 docker 作业模板克隆到我们选择的目录中:
git clone [https://github.com/ben0it8/docker-job-template](https://github.com/ben0it8/docker-job-template)
mv docker-job-template docker-transformer-finetuning

我们的项目包含两个主要文件夹:research和production。前者是研究代码所在的地方,从实验性的 Jupyter 笔记本到端到端的完善的培训脚本,任何东西都放在这里(在我们的例子中是一个笔记本)。production包含训练工作。所有从研究阶段提炼出来的需要微调的代码都作为一个单独的utils.py模块,和包含我们的依赖关系的requirements.txt一起送到docker-res。最终,训练逻辑在docker-res/run.py中定义,web 应用在docker-res/app.py中定义。
Web 应用程序
使用令人惊叹的 FastAPI 框架,组装一个可以作为服务执行推理的玩具 web 应用程序非常简单。FastAPI 是高性能,简单易学,编码速度快,随时可以投入生产。它建立在 OpenAPI 和 JSON Schema 等开放标准之上,使用 Pydantic 的类型声明,并附带自动 API 文档。
首先,脚本加载我们之前保存的文件metadata.bin(包含配置和 int-to-label 映射)和model_weights.pth(最终参数)以及用于微调的tokenizer。然后我们初始化我们的应用程序,并定义一个调用函数inference的 POST 端点/inference。这个函数有一个参数,一个Input(这个类定义了我们的请求数据模型)并使用predict函数返回一个预测字典和它们相应的概率。
Figure 6: Simple web app for inference, implemented using FastAPI.
通过uvicorn app:app --host 0.0.0.0 --port 8000执行这个脚本启动一个可以从浏览器访问和测试的本地服务器,并返回任意输入文本的预测情感。
Dockerfile 文件
Dockerfile 本质上是Docker 建立我们形象所需的所有指令的“配方”。为了简洁起见,我将在我们的Dockerfile中强调一些关键部分,更多信息参见原始参考。
我们没有从头开始构建容器,而是从nvidia/cuda:10.0-cud nn7-devel-Ubuntu 16.04映像中派生出来,因为我们希望使用 Nvidia 容器运行时进行 GPU 加速(更多信息请点击):
在这之后,一堆包,tini 和 Miniconda 被下载和设置。然后我们安装一些 Python 基础并将 conda 添加到$PATH:
接下来,我们安装培训和应用程序要求:
通过在运行作业时将环境变量传递给容器,可以很容易地配置作业,从而对训练过程提供一些控制。这些变量的默认值也在 docker 文件中定义:
这些变量是不言自明的,除了几个:
NVIDIA_VISIBLE_DEVICES:控制容器内哪些 GPU 可以访问(仅限 GPU)OMP_NUM_THREADS:设置 PyTorch 用于 MKL 加速的线程数量,通常不应超过我们机器中物理 CPU 内核的数量(仅当我们没有 GPU 时相关)TRAIN_BODY:控制是否训练变压器本体的参数(当然分类器反正是要训练的)
注意,我们的模型通常很大,但是我们希望我们的容器在不知道主机可用资源的情况下运行。因此,为了便于演示,我们将使用一个只有 8 的BATCH_SIZE。这个批量大小有望适合大多数硬件的内存,不管是在 GPU 还是 CPU 上训练(因为较大的批量导致更快的训练,如果有足够的内存可用,可以随意增加它)。
最后,我们将 Python 文件复制到RESOURCES_PATH,并告诉 Docker 在映像加载后使用 tini 执行run.py:
建设
build.py 管理我们的 Docker 构建、部署(例如部署到 Docker 注册表)和版本控制。该命令构建一个名为 *finetuning-job 的映像,*默认情况下将其标记为“最新”:
python build.py --name finetuning-job
更多信息见python build.py --help或training-job/README.md。
奔跑
Docker 容器是运行在主机上的独立进程,具有自己的文件系统、网络和进程树。尽管在运行时有很多选项来配置容器,我将只强调与我们相关的选项。
一旦构建了映像,我们就可以运行容器,可选地通过标志-e覆盖 Dockerfile 中定义的某些环境变量,或者通过--env-file=config.env传递 env-file:
# pass env variables to parametrize training
docker run -e LR=0.001 -e N_EPOCHS=2 finetuning-job# or by using an env-file:
docker run --env-file=config.env finetuning-job
如果我们可以访问 GPU,我们当然应该使用 Nvidia 容器运行时来运行容器:
docker run --runtime=nvidia finetuning-job
为了访问运行在容器内部的 web 应用程序,我们必须用-p标志向外界公开它的一个端口:
docker run -p 8000:8000 finetuning-job
推理
当容器运行时,它将执行run.py,首先微调我们的分类器,然后使用 uvicorn 在 http://0.0.0.0:8000 本地部署它。让我们通过发送 json 格式的 POST 请求来测试服务:

将浏览器指向http://localhost:8000/docs,查看自动生成的 API 文档。
使用 Ctrl+C 停止正在运行的容器,或者在终端中键入docker ps列出正在运行的容器,键入docker stop [id]杀死一个容器,其中[id]是容器 ID 的前 4 位数字:

🎉演示到此结束——我们已经完成了一个简单的容器化培训工作,允许我们微调一个强大的情感分析转换器,它能够在任何环境中重现我们的结果,并将模型部署为 web 服务。我希望一些 ML 从业者会发现这篇文章对将研究代码转化为产品有用!
🔮集装箱变压器微调的代码可以在我的 g ithub 上找到🌈本帖基于 SAP 在柏林
✉️所做的工作。如果您有任何问题/意见,请在下面留下评论,或者通过Twitter联系我!
用 Python 重塑 numpy 数组——一步到位的图示教程
numpy 整形和堆叠的备忘单和教程
可视化 numpy 如何重塑多维数组

Cheatsheet for Python numpy reshape, stack, and flatten (created by Hause Lin and available here)
numpy reshape() 方法如何重塑数组?你是否感到困惑,或者在理解它是如何工作的过程中挣扎过?本教程将带你完成 numpy 中的整形。如果您想要上述备忘单的 pdf 副本,您可以在此下载。
你可能也会喜欢我的重塑熊猫数据帧的教程:
[## 用 Python 中的 pivot_table 重塑熊猫数据框—教程和可视化
使用 pd.pivot_table 将 long 转换为 wide
towardsdatascience.com](/reshape-pandas-dataframe-with-pivot-table-in-python-tutorial-and-visualization-2248c2012a31) [## 使用 Python 中的 melt 重塑熊猫数据框—教程和可视化
想象一下 pd.melt 是如何将熊猫数据帧从宽到长进行整形的
towardsdatascience.com](/reshape-pandas-dataframe-with-melt-in-python-tutorial-and-visualization-29ec1450bb02)
创建一个 Python numpy 数组
使用np.arange()生成一个 numpy 数组,其中包含一系列从 1 到 12 的数字。在这里看文档。
import numpy as npa1 = np.arange(1, 13) # numbers 1 to 12print(a1.shape)
> (12,)print(a1)
> [ 1 2 3 4 5 6 7 8 9 10 11 12]

np.arange() creates a range of numbers
用*整形()*方法整形
使用reshape()方法将我们的 a1 数组改造成一个 3 乘 4 维的数组。我们用 3_4 来指代 it 维度:3 是第 0 个维度(轴),4 是第 1 个维度(轴)(注意 Python 索引从 0 开始)。在这里见文档。
a1_2d = a1.reshape(3, 4) # 3_4print(a1_2d.shape)
> (3, 4)print(a1_2d)
> [[ 1 2 3 4]
[ 5 6 7 8]
[ 9 10 11 12]]

3 by 4 numpy array
如果你想让 numpy 自动决定一个特定尺寸的大小/长度,将该尺寸指定为-1。
a1.reshape(3, 4)
a1.reshape(-1, 4) # same as above: a1.reshape(3, 4)a1.reshape(3, 4)
a1.reshape(3, -1) # same as above: a1.reshape(3, 4)a1.reshape(2, 6)
a1.reshape(2, -1) # same as above: a1.reshape(2, 6)
沿不同维度重塑
默认情况下,reshape()沿着第 0 维(行)对数组进行整形。此行为可通过order参数(默认值为'C')进行更改。更多信息参见文档。
a1.reshape(3, 4) # reshapes or ‘fills in’ row by row
a1.reshape(3, 4, order='C') # same results as above
我们可以通过将order改为'F'来沿着第一维(列)进行整形。对于熟悉 MATLAB 的人来说,MATLAB 使用的是这个顺序。
a1.reshape(3, 4, order='F') # reshapes column by column
> [[ 1 4 7 10]
[ 2 5 8 11]
[ 3 6 9 12]]

3 by 4 numpy array
测试:数组 a1 的尺寸/形状是多少?
a1 是一个 1D 数组——它只有一维,尽管你可能认为它的维数应该是 1_12 (1 行乘 12 列)。要转换成 1_12 数组,请使用reshape()。
print(a1) # what's the shape?
> [ 1 2 3 4 5 6 7 8 9 10 11 12]print(a1.shape)
> (12,)a1_1_by_12 = a1.reshape(1, -1) # reshape to 1_12print(a1_1_by_12) # note the double square brackets!
> [[ 1 2 3 4 5 6 7 8 9 10 11 12]]print(a1_1_by_12.shape) # 1_12 array
> (1, 12)
用 ravel()将 1D 数组展平/散开
ravel()方法允许你将多维数组转换成 1D 数组(参见文档这里的)。我们的 2D 数组( 3_4 )将被拉平或散开,从而成为一个 12 元素的 1D 数组。
如果你不指定任何参数,ravel()将沿着行(第 0 维/轴)拉平/散开我们的 2D 数组。即第 0 行[1,2,3,4] +第 1 行[5,6,7,8] +第 2 行[9,10,11,12]。
如果您想沿列(第一维)拉平/散开,使用order参数。
print(a1_2d) # 3_4
> [[ 1 2 3 4]
[ 5 6 7 8]
[ 9 10 11 12]]print(a1_2d.ravel()) # ravel by row (default order='C')
> [ 1 2 3 4 5 6 7 8 9 10 11 12]print(a1_2d.ravel(order='F')) # ravel by column
> [ 1 5 9 2 6 10 3 7 11 4 8 12]
用np.stack()和np.hstack()连接/堆叠阵列

Stacking numpy arrays
创建两个 1D 阵列
a1 = np.arange(1, 13)
print(a1)
> [ 1 2 3 4 5 6 7 8 9 10 11 12]a2 = np.arange(13, 25)
print(a2)> [13 14 15 16 17 18 19 20 21 22 23 24]
使用np.stack()连接/堆叠数组。默认情况下,np.stack()沿着第 0 维(行)堆叠数组(参数axis=0)。更多信息参见文档。
stack0 = np.stack((a1, a1, a2, a2)) # default stack along 0th axis
print(stack0.shape)
> (4, 12)print(stack0)
> [[ 1 2 3 4 5 6 7 8 9 10 11 12]
[ 1 2 3 4 5 6 7 8 9 10 11 12]
[13 14 15 16 17 18 19 20 21 22 23 24]
[13 14 15 16 17 18 19 20 21 22 23 24]]
沿第一维堆叠(axis=1)
stack1 = np.stack((a1, a1, a2, a2), axis=1)
print(stack1.shape)
> (12, 4)print(stack1)
> [[ 1 1 13 13]
[ 2 2 14 14]
[ 3 3 15 15]
[ 4 4 16 16]
[ 5 5 17 17]
[ 6 6 18 18]
[ 7 7 19 19]
[ 8 8 20 20]
[ 9 9 21 21]
[10 10 22 22]
[11 11 23 23]
[12 12 24 24]]
用np.hstack()连接成一个长 1D 数组(水平堆叠)
stack_long = np.hstack((a1, a2))
print(stack_long.shape)
> (24,)print(stack_long)
> [ 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24]
创建多维数组(3D)
多维数组非常常见,被称为张量。它们在深度学习和神经网络中被大量使用。如果你对深度学习感兴趣,你会定期重塑张量或多维数组。
让我们首先创建两个不同的 3x 4 数组。稍后我们将把它们组合起来形成一个 3D 数组。
a1 = np.arange(1, 13).reshape(3, -1) # 3_4
a2 = np.arange(13, 25).reshape(3, -1) # 3_4print(a1)
> [[ 1 2 3 4]
[ 5 6 7 8]
[ 9 10 11 12]]print(a2)
> [[13 14 15 16]
[17 18 19 20]
[21 22 23 24]]

Two 3 by 4 numpy arrays
通过沿不同的轴/维度堆叠阵列来创建 3D 阵列
a3_0 = np.stack((a1, a2)) # default axis=0 (dimension 0)
a3_1 = np.stack((a1, a2), axis=1) # along dimension 1
a3_2 = np.stack((a1, a2), axis=2) # along dimension 2print(a3_0.shape)
> (2, 3, 4)
print(a3_1.shape)
> (3, 2, 4)
print(a3_2.shape)
> (3, 4, 2)

Create 3D numpy arrays from 2D numpy arrays
让我们打印数组,看看它们是什么样子的。可视化效果见上图。
print(a3_0)
> [[[ 1 2 3 4]
[ 5 6 7 8]
[ 9 10 11 12]]
[[13 14 15 16]
[17 18 19 20]
[21 22 23 24]]]print(a3_1)
> [[[ 1 2 3 4]
[13 14 15 16]]
[[ 5 6 7 8]
[17 18 19 20]]
[[ 9 10 11 12]
[21 22 23 24]]]print(a3_2)
> [[[ 1 13]
[ 2 14]
[ 3 15]
[ 4 16]]
[[ 5 17]
[ 6 18]
[ 7 19]
[ 8 20]]
[[ 9 21]
[10 22]
[11 23]
[12 24]]]
因为这三个 3D 数组是通过沿着不同的维度堆叠两个数组而创建的,所以如果我们想要从这些 3D 数组中检索原始的两个数组,我们必须沿着正确的维度/轴进行子集化。
测试:我们如何从这些 3D 数组中检索出我们的a1数组?
print(a1) # check what's a1
> [[ 1 2 3 4]
[ 5 6 7 8]
[ 9 10 11 12]]# solutions
a3_0[0, :, :]
a3_0[0] # same as abovea3_1[:, 0, :]a3_2[:, :, 0]
展平多维数组
我们也可以用ravel()扁平化多维数组。下面,我们逐行(默认order='C')遍历 1D 数组。

Flatten arrays with .ravel()
print(a3_0)
> [[[ 1 2 3 4]
[ 5 6 7 8]
[ 9 10 11 12]]
[[13 14 15 16]
[17 18 19 20]
[21 22 23 24]]]print(a3_0.ravel())
> [ 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24]
逐列(order='F')移动到 1D 阵列
print(a3_0.ravel(order='F'))
> [ 1 13 5 17 9 21 2 14 6 18 10 22 3 15 7 19 11 23 4 16 8 20 12 24]
重塑多维数组
我们也可以用reshape()来重塑多维数组。
# reshape row by row (default order=C) to 2D arrayprint(a3_0) # 2_3_4
> [[[ 1 2 3 4]
[ 5 6 7 8]
[ 9 10 11 12]]
[[13 14 15 16]
[17 18 19 20]
[21 22 23 24]]]print(a3_0.reshape(4, -1)) # reshape to 4_6 (row by row)
> [[ 1 2 3 4 5 6]
[ 7 8 9 10 11 12]
[13 14 15 16 17 18]
[19 20 21 22 23 24]]print(a3_0.reshape(4, -1, order='F')) # reshape (column by column)
> [[ 1 9 6 3 11 8]
[13 21 18 15 23 20]
[ 5 2 10 7 4 12]
[17 14 22 19 16 24]]print(a3_0.reshape(4, 2, 3)) # reshape to 4_2_3 (row by row)
> [[[ 1 2 3]
[ 4 5 6]] [[ 7 8 9]
[10 11 12]] [[13 14 15]
[16 17 18]] [[19 20 21]
[22 23 24]]]
结束语
我希望现在你对 numpy 如何重塑多维数组有了更好的理解。期待大家的想法和评论。另外,看看这个对 numpy 和数据表示的可视化介绍。
如果您想要上述备忘单的 pdf 副本,您可以在此下载。如果你觉得这篇文章有用,请关注我并访问我的网站获取更多数据科学教程。
如果您对提高数据科学技能感兴趣,以下文章可能会有所帮助:
使用枚举和压缩编写更好的 Python 循环
towardsdatascience.com](/two-simple-ways-to-loop-more-effectively-in-python-886526008a70) [## 使用终端多路复用器 tmux 提高编码和开发效率
简单的 tmux 命令来提高您的生产力
medium.com](https://medium.com/better-programming/code-and-develop-more-productively-with-terminal-multiplexer-tmux-eeac8763d273) [## 新冠肺炎危机期间的免费在线数据科学课程
像 Udacity、Codecademy 和 Dataquest 这样的平台现在免费提供课程
towardsdatascience.com](/free-online-data-science-courses-during-covid-19-crisis-764720084a2)
更多帖子, 订阅我的邮件列表 。
剩余网络:在 Pytorch 中实现 ResNet

Image by the Author
我在LinkedIn,快来打个招呼 👋
今天我们将在 Pytorch 中实现何等人(微软研究院)著名的 ResNet。它在 ILSVRC 2015 分类任务中获得第一名。
ResNet 及其所有变种已经在我的库中实现 眼镜
代码是这里,这篇文章的互动版可以在这里下载原文可以从这里阅读(很容易理解)附加材料可以在这个 quora 答案中找到

介绍
这不是一篇技术文章,我也没有聪明到比原作者更好地解释剩余连接。因此我们将仅限于快速概述。
*越深的神经网络越难训练。*为什么?深层网络的一个大问题是消失梯度问题。基本上是越深越难练。
为了解决这个问题,作者建议使用对前一层的引用来计算给定层的输出。在 ResNet 中,上一层的输出(称为残差)被添加到当前层的输出中。下图显示了这一操作
我们将使用大多数数据科学家都不知道的东西:面向对象编程,使我们的实现尽可能具有可伸缩性
基本块
好的,首先要考虑我们需要什么。首先,我们必须有一个卷积层,因为 PyTorch 在 Conv2d 中没有“自动”填充,我们必须自己编码!
Conv2dAuto(32, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
接下来,我们使用ModuleDict创建一个具有不同激活功能的字典,这在以后会很方便。
如果你对ModuleDict不熟悉,我建议阅读我以前的文章 Pytorch:如何以及何时使用模块、顺序、模块列表和模块指令
残余块
创建干净的代码必须考虑应用程序的主要构件,或者在我们的例子中是网络的主要构件。残差块采用带有in_channels的输入,应用卷积层的一些块将其减少到out_channels,并将其加起来作为原始输入。如果它们的大小不匹配,那么输入进入identity。我们可以抽象这个过程,并创建一个可扩展的接口。
ResidualBlock(
(blocks): Identity()
(activate): ReLU(inplace)
(shortcut): Identity()
)
让我们用一个 1 的虚拟向量来测试它,我们应该得到一个 2 的向量
tensor([[[[2.]]]])
在 ResNet 中,每个块都有一个扩展参数,以便在需要时增加out_channels。同样,身份被定义为一个卷积,后跟一个 BatchNorm 层,这被称为shortcut。然后,我们可以扩展ResidualBlock并定义shortcut函数。
ResNetResidualBlock(
(blocks): Identity()
(activate): ReLU(inplace)
(shortcut): Sequential(
(0): Conv2d(32, 64, kernel_size=(1, 1), stride=(1, 1), bias=False)
(1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
基本块
一个基本的 ResNet 块由两层3x3 conv/batchnorm/relu 组成。图中,线条代表剩余运算。虚线表示应用了快捷方式来匹配输入和输出维度。

Basic ResNet Block
让我们首先创建一个方便的函数来堆叠一个 conv 和 batchnorm 层
ResNetBasicBlock(
(blocks): Sequential(
(0): Sequential(
(0): Conv2dAuto(32, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
(1): ReLU(inplace)
(2): Sequential(
(0): Conv2dAuto(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(activate): ReLU(inplace)
(shortcut): Sequential(
(0): Conv2d(32, 64, kernel_size=(1, 1), stride=(1, 1), bias=False)
(1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
瓶颈
为了增加网络深度,同时保持参数大小尽可能低,作者定义了一个瓶颈块,即“三层是 1x1、3x3 和 1x1 卷积,其中 1×1 层负责减少然后增加(恢复)维度,而 3×3 层是具有较小输入/输出维度的瓶颈。”我们可以扩展ResNetResidualBlock并创建这些块。
ResNetBottleNeckBlock(
(blocks): Sequential(
(0): Sequential(
(0): Conv2dAuto(32, 64, kernel_size=(1, 1), stride=(1, 1), bias=False)
(1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
(1): ReLU(inplace)
(2): Sequential(
(0): Conv2dAuto(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
(3): ReLU(inplace)
(4): Sequential(
(0): Conv2dAuto(64, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(activate): ReLU(inplace)
(shortcut): Sequential(
(0): Conv2d(32, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
层
ResNet 的层由一个接一个堆叠的相同块组成。

ResNet Layer
我们可以通过一个接一个地粘贴n块来轻松定义它,只需记住第一个卷积块的步长为 2,因为“我们通过步长为 2 的卷积层直接执行下采样”。
torch.Size([1, 128, 24, 24])
编码器
类似地,编码器由特征尺寸逐渐增加的多层组成。

ResNet Encoder
解码器
解码器是我们创建完整网络所需的最后一块。它是一个完全连接的层,将网络学习到的特征映射到它们各自的类。很容易,我们可以将其定义为:
雷斯内特
最后,我们可以将所有的部分放在一起,创建最终的模型。

ResNet34
我们现在可以定义作者提出的五个模型,resnet18,34,50,101,152
让我们用火炬概要来测试这个模型
----------------------------------------------------------------
Layer (type) Output Shape Param #
================================================================
Conv2d-1 [-1, 64, 112, 112] 9,408
BatchNorm2d-2 [-1, 64, 112, 112] 128
ReLU-3 [-1, 64, 112, 112] 0
MaxPool2d-4 [-1, 64, 56, 56] 0
Conv2dAuto-5 [-1, 64, 56, 56] 36,864
BatchNorm2d-6 [-1, 64, 56, 56] 128
ReLU-7 [-1, 64, 56, 56] 0
Conv2dAuto-8 [-1, 64, 56, 56] 36,864
BatchNorm2d-9 [-1, 64, 56, 56] 128
ReLU-10 [-1, 64, 56, 56] 0
ResNetBasicBlock-11 [-1, 64, 56, 56] 0
Conv2dAuto-12 [-1, 64, 56, 56] 36,864
BatchNorm2d-13 [-1, 64, 56, 56] 128
ReLU-14 [-1, 64, 56, 56] 0
Conv2dAuto-15 [-1, 64, 56, 56] 36,864
BatchNorm2d-16 [-1, 64, 56, 56] 128
ReLU-17 [-1, 64, 56, 56] 0
ResNetBasicBlock-18 [-1, 64, 56, 56] 0
ResNetLayer-19 [-1, 64, 56, 56] 0
Conv2d-20 [-1, 128, 28, 28] 8,192
BatchNorm2d-21 [-1, 128, 28, 28] 256
Conv2dAuto-22 [-1, 128, 28, 28] 73,728
BatchNorm2d-23 [-1, 128, 28, 28] 256
ReLU-24 [-1, 128, 28, 28] 0
Conv2dAuto-25 [-1, 128, 28, 28] 147,456
BatchNorm2d-26 [-1, 128, 28, 28] 256
ReLU-27 [-1, 128, 28, 28] 0
ResNetBasicBlock-28 [-1, 128, 28, 28] 0
Conv2dAuto-29 [-1, 128, 28, 28] 147,456
BatchNorm2d-30 [-1, 128, 28, 28] 256
ReLU-31 [-1, 128, 28, 28] 0
Conv2dAuto-32 [-1, 128, 28, 28] 147,456
BatchNorm2d-33 [-1, 128, 28, 28] 256
ReLU-34 [-1, 128, 28, 28] 0
ResNetBasicBlock-35 [-1, 128, 28, 28] 0
ResNetLayer-36 [-1, 128, 28, 28] 0
Conv2d-37 [-1, 256, 14, 14] 32,768
BatchNorm2d-38 [-1, 256, 14, 14] 512
Conv2dAuto-39 [-1, 256, 14, 14] 294,912
BatchNorm2d-40 [-1, 256, 14, 14] 512
ReLU-41 [-1, 256, 14, 14] 0
Conv2dAuto-42 [-1, 256, 14, 14] 589,824
BatchNorm2d-43 [-1, 256, 14, 14] 512
ReLU-44 [-1, 256, 14, 14] 0
ResNetBasicBlock-45 [-1, 256, 14, 14] 0
Conv2dAuto-46 [-1, 256, 14, 14] 589,824
BatchNorm2d-47 [-1, 256, 14, 14] 512
ReLU-48 [-1, 256, 14, 14] 0
Conv2dAuto-49 [-1, 256, 14, 14] 589,824
BatchNorm2d-50 [-1, 256, 14, 14] 512
ReLU-51 [-1, 256, 14, 14] 0
ResNetBasicBlock-52 [-1, 256, 14, 14] 0
ResNetLayer-53 [-1, 256, 14, 14] 0
Conv2d-54 [-1, 512, 7, 7] 131,072
BatchNorm2d-55 [-1, 512, 7, 7] 1,024
Conv2dAuto-56 [-1, 512, 7, 7] 1,179,648
BatchNorm2d-57 [-1, 512, 7, 7] 1,024
ReLU-58 [-1, 512, 7, 7] 0
Conv2dAuto-59 [-1, 512, 7, 7] 2,359,296
BatchNorm2d-60 [-1, 512, 7, 7] 1,024
ReLU-61 [-1, 512, 7, 7] 0
ResNetBasicBlock-62 [-1, 512, 7, 7] 0
Conv2dAuto-63 [-1, 512, 7, 7] 2,359,296
BatchNorm2d-64 [-1, 512, 7, 7] 1,024
ReLU-65 [-1, 512, 7, 7] 0
Conv2dAuto-66 [-1, 512, 7, 7] 2,359,296
BatchNorm2d-67 [-1, 512, 7, 7] 1,024
ReLU-68 [-1, 512, 7, 7] 0
ResNetBasicBlock-69 [-1, 512, 7, 7] 0
ResNetLayer-70 [-1, 512, 7, 7] 0
ResNetEncoder-71 [-1, 512, 7, 7] 0
AdaptiveAvgPool2d-72 [-1, 512, 1, 1] 0
Linear-73 [-1, 1000] 513,000
ResnetDecoder-74 [-1, 1000] 0
================================================================
Total params: 11,689,512
Trainable params: 11,689,512
Non-trainable params: 0
----------------------------------------------------------------
Input size (MB): 0.57
Forward/backward pass size (MB): 65.86
Params size (MB): 44.59
Estimated Total Size (MB): 111.03
----------------------------------------------------------------
为了检查正确性,让我们看看原始实现的参数数量
----------------------------------------------------------------
Layer (type) Output Shape Param #
================================================================
Conv2d-1 [-1, 64, 112, 112] 9,408
BatchNorm2d-2 [-1, 64, 112, 112] 128
ReLU-3 [-1, 64, 112, 112] 0
MaxPool2d-4 [-1, 64, 56, 56] 0
Conv2d-5 [-1, 64, 56, 56] 36,864
BatchNorm2d-6 [-1, 64, 56, 56] 128
ReLU-7 [-1, 64, 56, 56] 0
Conv2d-8 [-1, 64, 56, 56] 36,864
BatchNorm2d-9 [-1, 64, 56, 56] 128
ReLU-10 [-1, 64, 56, 56] 0
BasicBlock-11 [-1, 64, 56, 56] 0
Conv2d-12 [-1, 64, 56, 56] 36,864
BatchNorm2d-13 [-1, 64, 56, 56] 128
ReLU-14 [-1, 64, 56, 56] 0
Conv2d-15 [-1, 64, 56, 56] 36,864
BatchNorm2d-16 [-1, 64, 56, 56] 128
ReLU-17 [-1, 64, 56, 56] 0
BasicBlock-18 [-1, 64, 56, 56] 0
Conv2d-19 [-1, 128, 28, 28] 73,728
BatchNorm2d-20 [-1, 128, 28, 28] 256
ReLU-21 [-1, 128, 28, 28] 0
Conv2d-22 [-1, 128, 28, 28] 147,456
BatchNorm2d-23 [-1, 128, 28, 28] 256
Conv2d-24 [-1, 128, 28, 28] 8,192
BatchNorm2d-25 [-1, 128, 28, 28] 256
ReLU-26 [-1, 128, 28, 28] 0
BasicBlock-27 [-1, 128, 28, 28] 0
Conv2d-28 [-1, 128, 28, 28] 147,456
BatchNorm2d-29 [-1, 128, 28, 28] 256
ReLU-30 [-1, 128, 28, 28] 0
Conv2d-31 [-1, 128, 28, 28] 147,456
BatchNorm2d-32 [-1, 128, 28, 28] 256
ReLU-33 [-1, 128, 28, 28] 0
BasicBlock-34 [-1, 128, 28, 28] 0
Conv2d-35 [-1, 256, 14, 14] 294,912
BatchNorm2d-36 [-1, 256, 14, 14] 512
ReLU-37 [-1, 256, 14, 14] 0
Conv2d-38 [-1, 256, 14, 14] 589,824
BatchNorm2d-39 [-1, 256, 14, 14] 512
Conv2d-40 [-1, 256, 14, 14] 32,768
BatchNorm2d-41 [-1, 256, 14, 14] 512
ReLU-42 [-1, 256, 14, 14] 0
BasicBlock-43 [-1, 256, 14, 14] 0
Conv2d-44 [-1, 256, 14, 14] 589,824
BatchNorm2d-45 [-1, 256, 14, 14] 512
ReLU-46 [-1, 256, 14, 14] 0
Conv2d-47 [-1, 256, 14, 14] 589,824
BatchNorm2d-48 [-1, 256, 14, 14] 512
ReLU-49 [-1, 256, 14, 14] 0
BasicBlock-50 [-1, 256, 14, 14] 0
Conv2d-51 [-1, 512, 7, 7] 1,179,648
BatchNorm2d-52 [-1, 512, 7, 7] 1,024
ReLU-53 [-1, 512, 7, 7] 0
Conv2d-54 [-1, 512, 7, 7] 2,359,296
BatchNorm2d-55 [-1, 512, 7, 7] 1,024
Conv2d-56 [-1, 512, 7, 7] 131,072
BatchNorm2d-57 [-1, 512, 7, 7] 1,024
ReLU-58 [-1, 512, 7, 7] 0
BasicBlock-59 [-1, 512, 7, 7] 0
Conv2d-60 [-1, 512, 7, 7] 2,359,296
BatchNorm2d-61 [-1, 512, 7, 7] 1,024
ReLU-62 [-1, 512, 7, 7] 0
Conv2d-63 [-1, 512, 7, 7] 2,359,296
BatchNorm2d-64 [-1, 512, 7, 7] 1,024
ReLU-65 [-1, 512, 7, 7] 0
BasicBlock-66 [-1, 512, 7, 7] 0
AdaptiveAvgPool2d-67 [-1, 512, 1, 1] 0
Linear-68 [-1, 1000] 513,000
================================================================
Total params: 11,689,512
Trainable params: 11,689,512
Non-trainable params: 0
----------------------------------------------------------------
Input size (MB): 0.57
Forward/backward pass size (MB): 62.79
Params size (MB): 44.59
Estimated Total Size (MB): 107.96
----------------------------------------------------------------
是一样的!
用户化
面向对象编程的一个优点是我们可以很容易地定制我们的网络。
改变街区
如果我们想使用不同的基本块呢?也许我们只想要一个 3x3 的 conv,也许还要退学?。在这种情况下,我们可以子类化ResNetResidualBlock并改变.blocks字段!
让我们把这个新的区块交给resnet18,创建一个新的架构!
----------------------------------------------------------------
Layer (type) Output Shape Param #
================================================================
Conv2d-1 [-1, 64, 112, 112] 9,408
BatchNorm2d-2 [-1, 64, 112, 112] 128
ReLU-3 [-1, 64, 112, 112] 0
MaxPool2d-4 [-1, 64, 56, 56] 0
Conv2dAuto-5 [-1, 64, 56, 56] 36,864
Dropout2d-6 [-1, 64, 56, 56] 0
ReLU-7 [-1, 64, 56, 56] 0
ReLU-8 [-1, 64, 56, 56] 0
AnOtherResNetBlock-9 [-1, 64, 56, 56] 0
Conv2dAuto-10 [-1, 64, 56, 56] 36,864
Dropout2d-11 [-1, 64, 56, 56] 0
ReLU-12 [-1, 64, 56, 56] 0
ReLU-13 [-1, 64, 56, 56] 0
AnOtherResNetBlock-14 [-1, 64, 56, 56] 0
ResNetLayer-15 [-1, 64, 56, 56] 0
Conv2d-16 [-1, 128, 28, 28] 8,192
BatchNorm2d-17 [-1, 128, 28, 28] 256
Conv2dAuto-18 [-1, 128, 28, 28] 73,728
Dropout2d-19 [-1, 128, 28, 28] 0
ReLU-20 [-1, 128, 28, 28] 0
ReLU-21 [-1, 128, 28, 28] 0
AnOtherResNetBlock-22 [-1, 128, 28, 28] 0
Conv2dAuto-23 [-1, 128, 28, 28] 147,456
Dropout2d-24 [-1, 128, 28, 28] 0
ReLU-25 [-1, 128, 28, 28] 0
ReLU-26 [-1, 128, 28, 28] 0
AnOtherResNetBlock-27 [-1, 128, 28, 28] 0
ResNetLayer-28 [-1, 128, 28, 28] 0
Conv2d-29 [-1, 256, 14, 14] 32,768
BatchNorm2d-30 [-1, 256, 14, 14] 512
Conv2dAuto-31 [-1, 256, 14, 14] 294,912
Dropout2d-32 [-1, 256, 14, 14] 0
ReLU-33 [-1, 256, 14, 14] 0
ReLU-34 [-1, 256, 14, 14] 0
AnOtherResNetBlock-35 [-1, 256, 14, 14] 0
Conv2dAuto-36 [-1, 256, 14, 14] 589,824
Dropout2d-37 [-1, 256, 14, 14] 0
ReLU-38 [-1, 256, 14, 14] 0
ReLU-39 [-1, 256, 14, 14] 0
AnOtherResNetBlock-40 [-1, 256, 14, 14] 0
ResNetLayer-41 [-1, 256, 14, 14] 0
Conv2d-42 [-1, 512, 7, 7] 131,072
BatchNorm2d-43 [-1, 512, 7, 7] 1,024
Conv2dAuto-44 [-1, 512, 7, 7] 1,179,648
Dropout2d-45 [-1, 512, 7, 7] 0
ReLU-46 [-1, 512, 7, 7] 0
ReLU-47 [-1, 512, 7, 7] 0
AnOtherResNetBlock-48 [-1, 512, 7, 7] 0
Conv2dAuto-49 [-1, 512, 7, 7] 2,359,296
Dropout2d-50 [-1, 512, 7, 7] 0
ReLU-51 [-1, 512, 7, 7] 0
ReLU-52 [-1, 512, 7, 7] 0
AnOtherResNetBlock-53 [-1, 512, 7, 7] 0
ResNetLayer-54 [-1, 512, 7, 7] 0
ResNetEncoder-55 [-1, 512, 7, 7] 0
AdaptiveAvgPool2d-56 [-1, 512, 1, 1] 0
Linear-57 [-1, 1000] 513,000
ResnetDecoder-58 [-1, 1000] 0
================================================================
Total params: 5,414,952
Trainable params: 5,414,952
Non-trainable params: 0
----------------------------------------------------------------
Input size (MB): 0.57
Forward/backward pass size (MB): 54.38
Params size (MB): 20.66
Estimated Total Size (MB): 75.61
----------------------------------------------------------------
改变激活功能
容易的事
----------------------------------------------------------------
Layer (type) Output Shape Param #
================================================================
Conv2d-1 [-1, 64, 112, 112] 9,408
BatchNorm2d-2 [-1, 64, 112, 112] 128
LeakyReLU-3 [-1, 64, 112, 112] 0
MaxPool2d-4 [-1, 64, 56, 56] 0
Conv2dAuto-5 [-1, 64, 56, 56] 36,864
BatchNorm2d-6 [-1, 64, 56, 56] 128
LeakyReLU-7 [-1, 64, 56, 56] 0
Conv2dAuto-8 [-1, 64, 56, 56] 36,864
BatchNorm2d-9 [-1, 64, 56, 56] 128
LeakyReLU-10 [-1, 64, 56, 56] 0
ResNetBasicBlock-11 [-1, 64, 56, 56] 0
Conv2dAuto-12 [-1, 64, 56, 56] 36,864
BatchNorm2d-13 [-1, 64, 56, 56] 128
LeakyReLU-14 [-1, 64, 56, 56] 0
Conv2dAuto-15 [-1, 64, 56, 56] 36,864
BatchNorm2d-16 [-1, 64, 56, 56] 128
LeakyReLU-17 [-1, 64, 56, 56] 0
ResNetBasicBlock-18 [-1, 64, 56, 56] 0
ResNetLayer-19 [-1, 64, 56, 56] 0
Conv2d-20 [-1, 128, 28, 28] 8,192
BatchNorm2d-21 [-1, 128, 28, 28] 256
Conv2dAuto-22 [-1, 128, 28, 28] 73,728
BatchNorm2d-23 [-1, 128, 28, 28] 256
LeakyReLU-24 [-1, 128, 28, 28] 0
Conv2dAuto-25 [-1, 128, 28, 28] 147,456
BatchNorm2d-26 [-1, 128, 28, 28] 256
LeakyReLU-27 [-1, 128, 28, 28] 0
ResNetBasicBlock-28 [-1, 128, 28, 28] 0
Conv2dAuto-29 [-1, 128, 28, 28] 147,456
BatchNorm2d-30 [-1, 128, 28, 28] 256
LeakyReLU-31 [-1, 128, 28, 28] 0
Conv2dAuto-32 [-1, 128, 28, 28] 147,456
BatchNorm2d-33 [-1, 128, 28, 28] 256
LeakyReLU-34 [-1, 128, 28, 28] 0
ResNetBasicBlock-35 [-1, 128, 28, 28] 0
ResNetLayer-36 [-1, 128, 28, 28] 0
Conv2d-37 [-1, 256, 14, 14] 32,768
BatchNorm2d-38 [-1, 256, 14, 14] 512
Conv2dAuto-39 [-1, 256, 14, 14] 294,912
BatchNorm2d-40 [-1, 256, 14, 14] 512
LeakyReLU-41 [-1, 256, 14, 14] 0
Conv2dAuto-42 [-1, 256, 14, 14] 589,824
BatchNorm2d-43 [-1, 256, 14, 14] 512
LeakyReLU-44 [-1, 256, 14, 14] 0
ResNetBasicBlock-45 [-1, 256, 14, 14] 0
Conv2dAuto-46 [-1, 256, 14, 14] 589,824
BatchNorm2d-47 [-1, 256, 14, 14] 512
LeakyReLU-48 [-1, 256, 14, 14] 0
Conv2dAuto-49 [-1, 256, 14, 14] 589,824
BatchNorm2d-50 [-1, 256, 14, 14] 512
LeakyReLU-51 [-1, 256, 14, 14] 0
ResNetBasicBlock-52 [-1, 256, 14, 14] 0
ResNetLayer-53 [-1, 256, 14, 14] 0
Conv2d-54 [-1, 512, 7, 7] 131,072
BatchNorm2d-55 [-1, 512, 7, 7] 1,024
Conv2dAuto-56 [-1, 512, 7, 7] 1,179,648
BatchNorm2d-57 [-1, 512, 7, 7] 1,024
LeakyReLU-58 [-1, 512, 7, 7] 0
Conv2dAuto-59 [-1, 512, 7, 7] 2,359,296
BatchNorm2d-60 [-1, 512, 7, 7] 1,024
LeakyReLU-61 [-1, 512, 7, 7] 0
ResNetBasicBlock-62 [-1, 512, 7, 7] 0
Conv2dAuto-63 [-1, 512, 7, 7] 2,359,296
BatchNorm2d-64 [-1, 512, 7, 7] 1,024
LeakyReLU-65 [-1, 512, 7, 7] 0
Conv2dAuto-66 [-1, 512, 7, 7] 2,359,296
BatchNorm2d-67 [-1, 512, 7, 7] 1,024
LeakyReLU-68 [-1, 512, 7, 7] 0
ResNetBasicBlock-69 [-1, 512, 7, 7] 0
ResNetLayer-70 [-1, 512, 7, 7] 0
ResNetEncoder-71 [-1, 512, 7, 7] 0
AdaptiveAvgPool2d-72 [-1, 512, 1, 1] 0
Linear-73 [-1, 1000] 513,000
ResnetDecoder-74 [-1, 1000] 0
================================================================
Total params: 11,689,512
Trainable params: 11,689,512
Non-trainable params: 0
----------------------------------------------------------------
Input size (MB): 0.57
Forward/backward pass size (MB): 65.86
Params size (MB): 44.59
Estimated Total Size (MB): 111.03
----------------------------------------------------------------
结论
在本文中,我们看到了如何以一种良好的、可伸缩的和可定制的方式实现 ResNet。在下一篇文章中,我们将进一步扩展这个架构,训练它并使用另外两个技巧:预激活和挤压和激励。
这里所有的代码都是这里是
如果你对理解更好的神经网络感兴趣,我建议你读一读我写的另一篇文章
弗朗西斯科·萨维里奥·祖皮奇尼
towardsdatascience.com](/a-journey-into-convolutional-neural-network-visualization-1abc71605209)
想知道如何实现 RepVGG?ResNet 的更好版本?
让您的 CNN 速度快 100 倍以上
towardsdatascience.com](/implementing-repvgg-in-pytorch-fc8562be58f9)
了解 PyTorch 中的非最大抑制
在 PyTorch 中实现非最大抑制
medium.com](https://medium.com/@FrancescoZ/non-max-suppression-nms-in-pytorch-35f77397a0aa)
感谢您的阅读
弗朗西斯科·萨维里奥·祖皮奇尼


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言










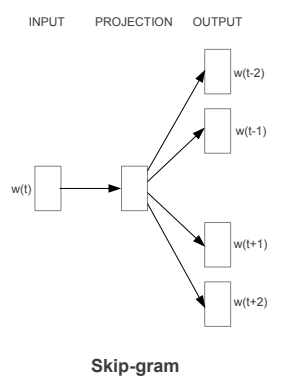{kind=link}
{kind=link}