







起锚!更多你希望知道的 R 正则表达式概念
教程| R |正则表达式(Regex)
在 R 中使用高级正则表达式工具处理文本的秘密

所以你已经知道了 r 中正则表达式的基本知识,比如如何使用字符集、元字符、量词和捕获组。这些是基本的构建模块,但是你是一个超级用户,永远不会满足于仅仅是基本的。你的文本争论问题比你希望用这些工具解决的要复杂得多。幸运的是,R 中有更多的正则表达式概念需要学习。这是更多文本争论善良的锚!
不确定基本的?请查看我在 r。
正则表达式是数据科学家对付非结构化文本最强大的武器。他们曾经是野餐…
towardsdatascience.com](/a-gentle-introduction-to-regular-expressions-with-r-df5e897ca432)
(正文)起锚了!
在我们开始 SS 正则表达式之前,我们需要讨论锚。更具体地说,文本锚。文本锚表示在字符串的开头或结尾查找匹配。在 R 中,有两种类型的锚:
^:匹配字符串开头的以下正则表达式$:匹配字符串末尾的前一个正则表达式
提醒一下,要在 R 中使用 regex,您需要使用stringr包。在尝试新的正则表达式主题(比如锚点)时,str_extract_all()函数特别有用。它将返回一个包含字符串中匹配项实际值的向量的列表。确保在开始之前加载stringr包。
library(stringr)
起锚,^起锚
要起航,我们必须在旅行开始时起锚。当处理文本数据时,您可能需要匹配一个正则表达式模式,但前提是它出现在字符串中的第一项。为此,我们使用^锚。
为了演示,我们的目标是找到单词“the”,但前提是它出现在字符串的开头。这里有几个示例字符串供您试用。
anchor <- "The ship sets sail on the ocean"
anchor_n <- "Ships set sail on the ocean to go places"
从anchor字符串开始,当我们使用^锚查找“the”时,我们只返回了它的一个实例。
str_extract_all(anchor, "^[Tt]he")[[1]]
[1] "The"
我们知道这是第一个实例,因为字符串开头的“the”是大写的。现在用anchor_n,不返回任何结果。正则表达式通常匹配句子中的“The ”,但是使用^定位符时,它只检查句子的开头。
str_extract_all(anchor_n, "^[Tt]he")[[1]]
character(0)
抛锚,$锚
在我们的正则表达式巡航结束时,我们需要放下锚。有时,只有当正则表达式出现在字符串末尾时,才需要匹配它。这是通过$锚完成的。
让我们再来看一下anchor字符串,这次是在字符串的末尾寻找“海洋”。我们会有一个结果,“海洋。”
str_extract_all(anchor, "ocean$")[[1]]
[1] "ocean"
同样,如果我们查看anchor_n,这次使用$或结束锚,我们将得不到匹配,即使“海洋”出现在字符串中。如果它不在绳子的末端,$号锚就不会把它捡起来。
str_extract_all(anchor_n, "ocean$")[[1]]
character(0)
正则表达式否定(避免冰山)

安妮·斯普拉特在 Unsplash 上的照片
现在我们知道了如何匹配字符串开头和结尾的模式(提升和降低 SS 正则表达式的锚),我们可以继续下一个概念:告诉 regex 匹配什么不匹配。
想象一下,你是一艘大船的船长,这艘船正在进行它的处女航。让我们称这艘船为泰坦尼克号。作为那艘船的船长,你可能对而不是撞上冰山非常感兴趣。
在字符串中,您可能希望指定某些模式来避免。要做到这一点,使用否定。这些将匹配除了您指定的内容之外的任何内容。在 R 中有两种主要的方法来处理它们:
- 大写元字符:元字符匹配一组特定的字符。一个大写的元字符通常会匹配除该字符集之外的所有内容
^和字符集:使用一个^和一个字符集将匹配除了在字符集中指定的以外的所有内容
大写元字符
在我上一篇关于 R 中正则表达式的文章中,我们介绍了三种不同的元字符:\\s、\\w和\\d。作为复习,它们匹配字符串中的一组字符:\\s匹配空白字符(空格、制表符和换行符),\\w匹配字母数字字符(字母和数字),而\\d匹配任何数字(数字)。
当您大写这些元字符中的任何一个时,它将匹配除了正常匹配之外的所有内容。要查看它们的运行情况,让我们创建一个包含空格、数字、字母和标点符号的新字符串:
negation <- "I sail my 3 ships on the 7 seas."
当我们看一看我们的大写元字符时,我们会看到它们与小写元字符的操作方式有所不同。
- 这将匹配除空格之外的任何内容。我们在输出中看到来自
negation字符串的所有字母、数字和标点符号
str_extract_all(negation, "\\S")[[1]]
[1] "I" "s" "a" "i" "l" "m" "y" "3" "s" "h" "i" "p" "s" "o" "n" "t" "h" "e" "7" "s" "e" "a" "s" "."
\\W:这将匹配除了字母和数字以外的任何内容。我们这里的输出是每个空格和句尾的句号
str_extract_all(negation, "\\W")[[1]]
[1] " " " " " " " " " " " " " " " " "."
\\D:这将匹配除数字以外的任何内容。您可能已经猜到,输出中有字母、空格和标点符号
str_extract_all(negation, "\\D")[[1]]
[1] "I" " " "s" "a" "i" "l" " " "m" "y" " " " " "s" "h" "i" "p" "s" " " "o" "n" " " "t" "h" "e" " " " " "s" "e" "a" "s" "."
^和字符集
一些用例需要比元字符更灵活的否定。让我们看一个示例场景:
- 匹配给定字符串中的所有辅音
我们来分解一下这个问题。字母表里有 21 个辅音,我们想要全部。它们是不连续的,所以我们不能仅仅用一个字符集中的一系列字母来得到它们。我们确实知道元音和辅音是互斥的,而且只有 5 个元音。如果我们可以找到所有的元音,我们应该能够否定它得到所有的辅音。让我们从复习如何用字符集查找元音开始。
str_extract_all(negation, "[AEIOUaeiou]")[[1]]
[1] "I" "a" "i" "i" "o" "e" "e" "a"
括号内的字符定义了字符集。在这种情况下,每个元音都匹配。为了获得除元音以外的所有内容,我们可以使用字符集内的^。这会否定里面的一切。
str_extract_all(negation, "[^AEIOUaeiou]")[[1]]
[1] " " "s" "l" " " "m" "y" " " "3" " " "s" "h" "p" "s" " " "n" " " "t" "h" " " "7" " " "s" "s" "."
…但那不是辅音。还有一点工作要做。我们的结果中有空格、数字和标点符号。由于捕获组中的所有内容都被否定,所以我们只需在结果中匹配所有不想要的内容。\\s负责空格,\\d负责数字,\\.负责句点。
注意:
\\.不是元字符,是转义句号。
str_extract_all(negation, "[^AEIOUaeiou\\s\\d\\.]")[[1]]
[1] "s" "l" "m" "y" "s" "h" "p" "s" "n" "t" "h" "s" "s"
在添加了所有需要的字符后,我们最终只需要辅音字母,也许这并不比输入 21 个不同的辅音字母更快,但它确实演示了我们如何将所有字符相加,并使用正则表达式来获得我们想要的结果。
环顾四周(观赏野生动物)

马丁·韦特斯坦在 Unsplash 上拍摄的照片
出海时,我们可能会留意一些东西。看到一些野生动物将会是一次更有趣的旅行。我们寻找野生动物,这样我们就可以找到一个靠近它的地方来停泊我们的船。作为一名经验丰富的船长,我们并不真正关心野生动物本身,只关心附近的安全空间,以便驾驶船只。
类似于我们想通过野生动物寻找一个停车的地方,我们可能想在一些字符串周围寻找我们真正想要的信息。与大多数任务一样,正则表达式使这变得容易得多。为此,我们使用了一种叫做环视的东西。Look arounds 在字符串中搜索特定的匹配项,然后返回它之前或之后的某个值。这给我们留下了两种主要的环视方式:向前看和向后看。
让我们用下面的字符串作为例子来说明这两者是如何工作的。
lookaround <- "A penguin costs 2.99, a whale costs 5.99, I only have 3.50 left."
对于我们想从这个字符串中提取什么信息,我们有两个场景。
- 每只动物的成本是多少?
- 卖什么动物?
起初,你可能会想为什么我们需要环顾四周才能做到这一点。你可以简单地寻找一个数字,句号,和另外两个数字。大概是这样的:
str_extract_all(lookaround, "\\d\\.\\d{2}")
这是一个不错的开始,但是这一行代码的输出会给出三种价格。
[[1]]
[1] "2.99" "5.99" "3.50"
只有两种动物价格,最后一种是不相关的,所以我们想排除它。环顾四周将有助于我们删除最后一个,并把一切都很好地纳入一个数据框架。
向后看
查看lookaround字符串,我们看到每种动物的价格前面都有单词“costs”我们将在后面使用一个外观。这将匹配我们通常匹配的任何内容,但前提是它之前有其他内容的匹配。前瞻的通用公式是"(?<=if preceded by this)match_this"。在我们的例子中,这将翻译如下(\\s被添加以说明单词和数字之间的空间):
# Look behind
prices <- str_extract_all(lookaround, "(?<=costs)\\s\\d\\.\\d{2}")
prices
现在我们有了每只动物的价格,不包括我在绳子上剩下的钱。
[[1]]
[1] " 2.99" " 5.99"
如果你仔细看,你会注意到琴弦上有空隙。现在不要担心这些,当我们建立一个数据框架来保存我们的价目表时,我们会处理这些问题。
向前看
现在,我们已经从字符串中获得了动物的价格,我们希望为价格列表数据框获取动物的名称。
为此,我们现在需要匹配单词“costs”前面的单词。为此,我们将使用前瞻。前瞻的基本公式如下:"match this(?=if followed by this)"。要从我们的字符串中获取动物名称,应该是这样的:
# Look Aheads
animals <- str_extract_all(lookaround, "\\w+\\s(?=costs)")
animals
就这样,我们抓住了单词 costs 之前的每个单词。在我们的字符串中是所有动物的名字。
[[1]]
[1] "penguin " "whale "
创建动物价格数据框
为了创建动物价格的数据框架,我们已经拥有了大部分我们需要的东西。我们只是创建一个数据帧,用向量animals和prices作为列。
animal_prices <- data.frame(
animals=animals[[1]],
prices=prices[[1]],
stringsAsFactors=FALSE
)
如果你忘了,当我们使用str_extract_all()时,它返回一个包含字符串向量的列表。为了访问字符串向量,我们使用了双括号符号(animals[[1]])。参数stringsAsFactors被设置为 false,否则 R 将把列创建为因子,而不是字符串。
我们的下一步是解决这些多余的空间。对于包含更多列的数据框,我们可以考虑使用purrr包中的map函数,但是由于我们的函数很小,我们可以手动完成这个过程。我们将使用str_trim()功能。默认情况下,它会删除字符串开头和结尾的空格。
animal_prices$animals <- str_trim(animal_prices$animals)
animal_prices$prices <- as.numeric(str_trim(animal_prices$prices))
添加了as.numeric()函数来将prices列的类型从字符更正为数字。生成的数据框如下所示:
animals prices
1 penguin 2.99
2 whale 5.99
结论
就这样,你在 SS 正则表达式上的巡航结束了。你学到了:
- 如何匹配出现在字符串开头或结尾的模式
- 如何使用否定来匹配除指定内容之外的任何内容
- 如何使用 look arounds 来匹配后面或前面有您指定的其他内容的内容
下面是一些与 R 中的正则表达式相关的资源,您可能会觉得有帮助:
- tidy verse 网站官方
[stringr](https://stringr.tidyverse.org/index.html)页面:r studio的伙计们整理了资源帮助学习stringr之类的包。他们甚至包括一个[stringr](https://github.com/rstudio/cheatsheets/blob/master/strings.pdf)备忘单,你可以打印出来参考。 - R for Data Science :由 Hadley Wickham 编写,
stringrpackage 的作者,这本书对于 R 中的一切都是很好的参考。甚至有一章介绍了 R 中的高级正则表达式。它可以在网上免费获得这里,或者你可以在这里购买硬拷贝(付费链接)。 - Datacamp 课程(付费链接):一个致力于数据科学、机器学习和数据可视化的在线学习社区。查看他们的课程“用 r 中的 stringr 进行字符串操作”,Datacamp 上每个课程的第一章都是免费的!
[## 通过我的推荐链接加入 Medium-Drew Seewald
作为一个媒体会员,你的会员费的一部分会给你阅读的作家,你可以完全接触到每一个故事…
realdrewdata.medium.com](https://realdrewdata.medium.com/membership)
自行车上的古丝绸之路——游牧自行车人问题
旅行商问题的分步指南及其在自行车旅游规划中的应用
丝绸之路是一个古老的路线网络,包括中国西部、中亚、西亚和南亚的几十个城市。过去,从一个城市到另一个城市的最短已知路径通常成为路线的一部分。例外是为了避免暴徒,恶劣的天气和耗尽食物和水的风险。

沿着古丝绸之路的一条路线——(与OpenStreetMap.org一起画的路线)
我的几个朋友计划明年骑自行车穿越古丝绸之路。这将是一次人力驱动的旅行,就像过去大多数人通过这些路线旅行一样。我的朋友不是职业自行车运动员。所以,在这数千公里的旅程中,每一桨都必须划向正确的方向。
我最初认为这是一个疯狂的想法,但后来我意识到这将是一生一次的旅行。所以,我决定尝试编程来计划这次旅行。
城市
这些骑自行车的人已经计划好了以下几个丝绸之路上不可错过的主要古城:
中国🇨🇳Xi(丝绸贸易的起源地)
中国🇨🇳兰州
中国🇨🇳敦煌
中国🇨🇳高昌
中国🇨🇳乌鲁木齐市
哈萨克斯坦阿拉木图🇰🇿
吉尔吉斯斯坦🇰🇬比什凯克
乌兹别克斯坦🇺🇿塔什干
塔吉克斯坦🇹🇯杜尚别
乌兹别克斯坦🇺🇿boy sun
乌兹别克斯坦🇺🇿撒马尔罕
乌兹别克斯坦布哈拉🇺🇿
土库曼斯坦🇹🇲梅尔夫
土库曼斯坦🇹🇲阿什哈巴德
伊朗🇮🇷德黑兰
伊朗🇮🇷大不里士
土耳其🇹🇷安卡拉
土耳其🇹🇷伊斯坦布尔
沿途有很多城市有丰富的历史遗迹,在古代贸易中有重要意义,但是不可能在人力自行车旅行中包括所有的城市。比如巴基斯坦的塔西拉,中国的喀什。
旅行推销员问题
为了找到穿过所有这些城市的最短路线,让我们使用经典的旅行商问题(以下简称 TSP)算法。TSP 是一个优化问题。TSP 说
“给定一个要游览的城市列表以及这些城市之间的距离,游览所有这些地点并返回我们出发地点的最短路径是什么”
在原始 TSP 中,我们计算的路线是一条封闭路线,并且我们的开始和结束位置必须相同。

旅行推销员问题——点代表城市,线代表道路——(TSP on Wikipedia)
但是作为骑自行车的人,我们感兴趣的是沿途的城市,而不是回到起点。TSP 有许多变体,让我们把 TSP 的这种变体称为“游牧自行车手问题”。

开放旅游旅行推销员问题(图片由作者提供)
距离矩阵
距离矩阵是制定几乎所有涉及路径的优化问题的起点。例如最短路径问题、旅行商问题、车辆路径问题和物流路径优化。
看看下面的距离矩阵:

丝绸之路距离矩阵—第一部分(图片由作者提供)
第 2 行第 1 列的单元格的值为 626。这是从兰州到西安的公里数。然而,从西安到兰州的距离是 627,由第一行第二列中的单元表示。
上表中每个像元的值是以公里为单位的道路长度,从左侧的城市到顶部标题中的城市。
我们将使用 2D 数组(或者 Python 中的 2D 列表)来存储距离矩阵值。
*# distance matrix* D **=** [[0, 627, 1724, 2396, 2531, 3179],
[626, 0, 1096, 1768, 1903, 2551],
[1723, 1095, 0, 929, 1064, 1713],
[2395, 1766, 849, 0, 163, 811],
[2531, 1903, 985, 163, 0, 656],
[3186, 2557, 1640, 817, 664, 0]]
对于真实世界的位置,我们可以使用简单的 API 调用,使用谷歌地图距离矩阵 API 和 Mapbox 的矩阵 API 轻松计算我们位置的距离矩阵。
计算距离矩阵
手动计算多个城市的距离矩阵变得很烦人。让我们写一些脚本来为我们计算距离矩阵。
要使用 Google Maps Matrix API 计算距离矩阵,我们只需提供地点的名称。但是我决定硬编码城市的经度,纬度坐标。我认为当不止一个地方有相似的名字时,坐标可以避免混淆。
getCities方法给出了城市+坐标的列表。
**def** **getCities**():
*# locations to visit
* cities **=** [
{
"name": "Xi'an, Shaanxi, China",
"location": [34.341576, 108.939774]
},
{
"name": "Lanzhou, China",
"location": [36.061089, 103.834305]
},
...
{
"name": "Istanbul, Turkey",
"location": [41.022576, 28.961477]
}
]
**return** cities
计算距离矩阵
计算距离矩阵现在很容易。我们只需要调用一个 gmap API 端点,提供两个列表:起点和终点,我们希望计算它们之间的距离,并以 JSON 的形式返回我们的距离矩阵,该矩阵将被解析并转换为我们在上面看到的 2D 列表D。
import requests, traceback
**def** **gmapMatrix**(origins, destinations):
API_KEY **=** GET_GMAP_API_KEY() *# <<= gmap api key
* URL **=**f"https://maps.googleapis.com/maps/api/distancematrix/json?units=metric&origins={origins}&destinations={destinations}&key={API_KEY}"
**try**:
r **=** requests.get(URL)
jsn **=** r.json()
**return** jsn
**except** Exception:
traceback.print_exc()
**return** None
让我们找到我们的距离矩阵。好吧,没那么容易。原来谷歌的 Matrix APIs 有一些限制。
根据谷歌地图矩阵 API:
- 发送到距离矩阵 API 的每个查询都会生成元素,其中起点数量乘以目标数量等于元素数量
- 每个请求最多允许 25 个起点或 25 个目的地
- 每个服务器端请求最多允许 100 个元素
计算超过 100 个元素的距离矩阵
我们有大约 20 个城市。20*20 等于 400。我们超过了 100 个元素的限制。我们必须将我们的请求分成 100 个一批,获取距离并构建我们的20 x 20距离矩阵。
如果你熟悉深度学习中的卷积神经网络,你可能知道我们取一小部分矩阵,做一些运算,计算另一个矩阵的卷积技术。这个过程是一步一步的,每次只对矩阵的一小部分起作用。

一次查看矩阵的一小部分(卷积神经网络,维基百科)
别担心,我们处理 100 个元素限制的计算比卷积神经网络简单得多。
看看项目代码中的[convolveAndComputeDistMatrix](https://github.com/emadehsan/nomad-cyclist/blob/0f42ef8a06bdf2be0b7c0fdec32661d16efded38/distance_matrix.py#L26)方法。该方法遍历距离矩阵,仅挑选 100 个项目来寻找距离,并构造一个距离矩阵20 x 20…我们想要的距离矩阵。
履行
让我们把我们的游牧自行车手问题(TSP)公式化为一个线性规划问题。为了解决一个线性规划问题,我们通常需要 4 样东西
- 决策变量
- 限制
- 目标
- 解决者
解决者
(优化)解算器是一个软件或库,它采用以某种方式定义(建模)的优化问题,并试图找到该问题的最佳解决方案。我们的工作是对问题进行适当的建模,求解者承担繁重的工作。
我们将使用 OR-Tools,这是一个由 Google AI 团队开发的开源库,用于解决优化问题。
让我们看看如何为或工具初始化或工具的线性规划求解问题建模
from ortools.linear_solver import pywraplp
s **=** pywraplp.Solver('TSP', \
pywraplp.Solver.GLOP_LINEAR_PROGRAMMING)
决策变量
简而言之,决策变量是包含线性规划算法输出的变量。我们的算法做出的决定!
对于 TSP,决策变量将是与距离矩阵大小相同的 2D 列表。它将在像元中包含1,其对应的道路必须被访问,因此是输出路径的一部分。以及0在不得通行的道路上。

可视化旅行商问题的决策变量(图片由作者提供)
根据 OR-Tools 线性求解器文档,我们使用IntVar定义一个整数决策变量。
如果在普通的 Python 代码中,我们将创建一个名为count的变量,它将保存某个任务完成的次数。我们可能会从 0 开始,并随着每个任务不断增加,直到程序结束,其中会包含一些我们感兴趣的有用值。
count **=** 0
如果我们想要定义相同的变量,但要由 OR-Tools 线性求解器使用,我们将按如下方式定义它(现在它将被称为决策变量)。
*# IntVar(lowerBound, upperBound, name)* count **=** s.IntVar(0, 100, 'count_var')
注意,我们也必须提供界限。这告诉规划求解找到一个从下限到上限的整数值。这有助于缩小可能的输出范围,求解器可以更快地找到解决方案。
现在我们定义 TSP 的决策变量。这将是一个由IntVar组成的 2d Python 列表。但是在这里,城市的边界将是从0到1,除了那些没有找到内部距离的城市,它们的边界将是从0到0。
x **=** [[s.IntVar(0, 0 **if** D[i][j] **is** None **else** 1, '') \
**for** j **in** range(n)] **for** i **in** range(n)]
限制
将约束视为必须遵守的限制或规则。根据 TSP,
“我们必须在一条封闭的道路上游览每一个城市一次.”
首先我们将解决一个封闭旅游的 TSP 问题。然后我们将修改它,为我们的游牧骑行者提供一条开放的最短路径。因此,在我们的解决方案中,必须只有一条路通往城市,并且只有一条路通往城外。
**for** i **in** range(n):
*# in i-th row, only one element can be used in the tour
* *# i.e. only 1 outgoing road from i-th city must be used
# in the tour
* s.Add(1 **==** sum(x[i][j] **for** j **in** range(n)))
*# in j-th column, only one element can be used in the tour
* *# i.e. only 1 incoming road to j-th city must be used in tour
* s.Add(1 **==** sum(x[j][i] **for** j **in** range(n)))
*# a city must not be assigned a path to itself in the tour
* *# no direct road from i-th city to i-th city again must be taken
* s.Add(0 **==** x[i][i])
以上约束是不够的。有时存在有问题的子区域,每个子区域覆盖不同城市的子集,但没有一个子区域覆盖所有城市。我们想在所有城市进行一次(最短的)旅行。

有问题的(断开的)子旅行团(图片由作者提供)
我们知道,任何由 6 个城市组成的封闭路径都有 6 条弧线(边/路)连接它们(如上图)。因此,我们告诉我们的求解程序,如果一个旅行是一个子旅行(即它覆盖的城市少于距离矩阵中的城市总数),连接这些城市的道路必须少于这个子旅行中的城市数。这将强制求解程序查找未闭合的子区域,最终成功找到连接所有城市的闭合(最短)旅行。
但是我们不能找到所有可能的次区域,并把它们包含在我们的约束中。避免这种子区域的方法是,在第一次运行我们的算法时,我们找到一个解决方案,如果它包含子区域,我们再次运行算法,这次我们告诉它保持这些子区域不闭合。我们不断重复这个过程,直到我们找到一个覆盖所有城市的最佳旅游路线,而不是小的不相连的子区域。
让我们对这个约束进行建模:
*# Subtours from previous run (if any)* **for** sub **in** Subtours:
*# list containing total outgoing+incoming arcs to
* *# each city in this subtour
* K **=** [ x[sub[i]][sub[j]] **+** x[sub[j]][sub[i]] \
**for** i **in** range(len(sub)**-**1) **for** j **in** range(i**+**1,len(sub)) ]
*# sum of arcs (roads used) between these cities must
* *# be less than number of cities in this subtour
* s.Add(len(sub)**-**1 **>=** sum(K))
目标
我们整数规划算法的目标。在我们的例子中,我们希望尽可能缩短我们访问所有城市的距离。
*# minimize the total distance of the tour* s.Minimize(s.Sum(x[i][j]*****(0 **if** D[i][j] **is** None **else** D[i][j]) \
**for** i **in** range(n) **for** j **in** range(n)))
换句话说,找到一条穿过这些城市的最短路径,同时遵守上述约束。这是一条最短的路径。因为可能有多条长度相同的最短路径。
游牧骑自行车者问题
TSP 与开放路线将是我们的游牧自行车的问题。让我们现有的算法找到开放路线而不是封闭路线的一个简单技巧是在距离矩阵中添加一个虚拟城市。将这个虚拟城市到所有其他城市的距离设置为 0。
当求解程序找到最优解时,在封闭路径上的某个地方会有一个虚拟城市。我们简单地删除这个虚拟城市和它的进出弧线(道路),为我们的游牧自行车手提供一条开放的路线。
*# to make the loops run 1 more time then current size of
# our lists so we could add another row / column item* n1 **=** n **+** 1
*# if i or j are equal to n, that means we are in the last
# row / column. just add a 0 element here* E **=** [[0 **if** n **in** (i,j) **else** D[i][j] \
**for** j **in** range(n1)] **for** i **in** range(n1)]
由此产生的路线将是最短的单程和开放的旅游覆盖所有城市。
手动 v 计算路线比较
根据我们的求解程序,我们必须按照这个顺序在城市中循环
Shortest Path for our Cycling Tour:
Cities: Xi'an Lanzhou Dunhuang Gaochang Urumqi Khorgas Horgos Almaty Bishkek Tashkent Samarqand Dushanbe Baysun Bukhara Merv Ashgabat Tehran Tabriz Ankara Istanbul
City Index 0 1 2 3 4 5 6 7 8 9 12 10 11 13 14 15 16 17 18 19
Distance 0 627 1096 929 163 656 -1 332 237 631 310 292 196 341 353 400 948 632 1463 451
Cumulative 0 627 1723 2652 2815 3471 3470 3802 4039 4670 4980 5272 5468 5809 6162 6562 7510 8142 9605 10056
在上述输出不可读的情况下,相同输出的照片:

算法计算的游牧骑行旅行(图片由作者提供)
在决定了要参观的城市之后,我们对参观这些地方的顺序做了一个粗略的计划。在谷歌地图上,你不能在超过 10 个地方之间创建一条路线(我想)。
我们之前计划的中国丝绸之路城市路线的第一站,与我们的算法建议的路线相匹配:

丝绸之路的中国部分—(在谷歌地图上绘制)
我们计划的中东到欧洲之旅的最后一站…这也与算法输出相匹配:

穿越中东的丝绸之路—(在谷歌地图上绘制)
我们手动规划的中亚城市路线的第二段(中间):

中亚——丝绸之路——(在谷歌地图上绘制)
根据我们的算法,除了中亚的几个城市之外,最短路线与我们手动规划的路线的 90%匹配:

中亚——最短路径——丝绸之路——(谷歌地图)
当骑自行车数千公里时,即使少走几百公里也能让我们感觉如释重负。我们希望这是对旅行推销员问题和游牧自行车手问题的一个很好的指导。我们接下来要考虑的一个重要问题是海拔。
规划自己的路线
所有的项目代码都在 GitHub 上,上面有很多有用的评论。您可以随意定制它并提出拉取请求。
这里使用的(TSP)线性规划算法摘自 Serge Kruk 的实用 Python AI 项目一书。如果你想学习路线优化算法或者一般的优化算法,强烈推荐。
接下来,我们将增加考虑海拔和攀爬难度的选项,这对于计划游览的骑行者来说是非常重要的。
原载于 2020 年 10 月 19 日https://alternate . parts。
使用 Chaquopy 实现概念自动化的 Android 应用程序
使用 Android、Chaqopy 和 opinion-py 实现观念的自动化。

这个应用程序是如何工作的?
我最近写了一篇文章,讲述了我如何使用 idea-py 自动将我的费用添加到 idea 的费用管理器数据库中。
在发现使用 idea-py 添加费用是多么容易之后,我继续创建了一个简单的 android 应用程序,它允许我输入一个简单的文本字符串,然后将数据迁移到 idea 的数据库中。我使用 chaquoy 在 android 中运行我的 python 脚本。这个项目在 git-hub 上是开源的,欢迎你来查看并让我知道你的想法。如果您希望合作,请阅读 github 上的自述文件。
因此,这个应用程序基本上做的,是采取一个字符串’费用,金额,评论,标签’并将其添加到概念的费用数据库。因为你可以在 github 上查看完整的代码,所以我只解释核心代码。
# -*- coding: utf-8 -*-
"""
Created on Sat May 3 15:22:31 2020
@author: Prathmesh D
"""
def addRecord(Expense,Amount,Comment,Category,v2,db):
import datetime
from notion.client import NotionClient
Date = datetime.datetime.now()
print(v2)
print(db)
# Obtain the `token_v2` value by inspecting your browser cookies on a logged-in session on Notion.so
try:
client = NotionClient(token_v2=v2)
print("Client Connected..")
except:
s ="V2Error"
return s
try:
cv = client.get_collection_view(db)
print("Connected to db")
except:
s="dbError"
return s
try:
row = cv.collection.add_row()
row.Expense = Expense
row.Amount = Amount
row.Comment = Comment
row.Category = Category
row.Date=Date
return "Success"
except Exception as e:
s = str(e)
#Get the values from the database
filter_params = [{
"property": "Expense",
}]
result = cv.build_query(filter=filter_params).execute()
#Get size of db
size = len(result)
#Remove last entry
result[size-1].remove()
return s
基本脚本和我之前的帖子中的一样。唯一增加的是 catch 块,其中我删除了最新的记录,因为有一些错误,并将生成的错误返回给 android 应用程序。
在 android 应用程序中,我使用 AsyncTask 向 python 脚本发送请求,并返回结果。如果您不熟悉 AsyncTask,它有 4 个主要部分:
- onPreExecute() —在调用新线程之前准备数据。在 UI 线程上运行。
- doInBackground(Params…) —创建新线程并在后台运行的异步调用。这是我们将使用 chaqopy 调用脚本的地方。
- onProgressUpdate(Progress…) —该方法在 UI 线程上运行,您可以更新在 doInBackground()方法中完成的流程或操作。我还没有在我的应用程序中使用它,但是使用它的一种方法是显示在一次调用中添加多个条目时完成了多少个条目。
- onPostExecute(Result) —此函数在 doInBackground()完成执行后调用。它也运行在 UI 线程上。
以下是我如何使用这些方法的:
- onPreExecute()
@Override
protected void onPreExecute() {
super.onPreExecute();
editTextString[0] = getData.getText().toString();
getData.setText("");
d[0] = editTextString[0].split(Pattern.quote(","));
amount[0] = Integer.parseInt(d[0][1]);
date[0] = Calendar.getInstance().getTime();
}
2.doInBackround(参数…)
@Override
protected String doInBackground(String... params) {
try{
//Call to chaquopy library
returned_value = viewSource(MainActivity.this, d[0], amount[0], date[0], TOKEN_V2, DB_URL);
return returned_value;
}catch (Exception e){
return returned_value;
}
}
2.1 viewSource(参数…)
Chaquopy 码
@Override
protected String doInBackground(String... params) {
try{
//Call to chaquopy library
returned_value = viewSource(MainActivity.this, d[0], amount[0], date[0], TOKEN_V2, DB_URL);
return returned_value;
}catch (Exception e){
return returned_value;
}
}
3.onPostExecute(结果)
在这个方法中,我们主要检查用户是否正确输入了他的 v2_Token 和数据库 URL,我们检查 python 脚本的结果,并相应地在主 UI 线程上显示结果。
@Override
protected void onPostExecute(String result) {
super.onPostExecute(result);
SharedPreferences.Editor putEditor = getSharedPreferences(SAVED_PREFERENCES, MODE_PRIVATE).edit();
if(result.equals("Success")) {
Toast.makeText(MainActivity.this, result, Toast.LENGTH_SHORT).show();
}
else{
if(result.equals("V2Error")){
Toast.makeText(MainActivity.this, "Your V2 Token is wrong. Please Enter Details again!", Toast.LENGTH_LONG).show();
putEditor.remove("Init");
putEditor.commit();
Intent intent = new Intent(MainActivity.this,userDetails.class);
startActivityForResult(intent,2);
}
else if(result.equals("dbError")){
Toast.makeText(MainActivity.this, "Your db URL is wrong. Please Enter Details again!", Toast.LENGTH_LONG).show();
putEditor.remove("Init");
putEditor.commit();
Intent intent = new Intent(MainActivity.this,userDetails.class);
startActivityForResult(intent,2);
}
else{
String sourceString = "<b>" + result + "</b> " ;
tv.setText(Html.fromHtml(sourceString, Html.FROM_HTML_MODE_LEGACY));
Toast.makeText(MainActivity.this, "Record Deleted!\\nPlease add again.", Toast.LENGTH_LONG).show();
}
}
我希望这在某种程度上对你有所帮助。
下次见。干杯!
使用 PyTorch 和卷积神经网络的动物分类

作者图片
介绍
PyTorch 是脸书 AI 研究实验室(FAIR)开发的深度学习框架。由于其 C++和 CUDA 后端,称为 Tensors 的 N 维数组也可以在 GPU 中使用。
卷积神经网络(ConvNet/CNN) 是一种深度学习,它获取输入图像,并为各种特征分配重要性(权重和偏差),以帮助区分图像。

作者图片
神经网络大致分为 3 层:
- 输入层
- 隐藏层(可以由一个或多个这样的层组成)
- 输出层
隐藏层可以进一步主要分为两层-
- 卷积层:从给定的输入图像中提取特征。
- 完全连通的密集图层:它为卷积图层中的要素分配重要性以生成输出。
卷积神经网络过程通常包括两个步骤
- 前向传播:权重和偏差被随机初始化,这在最后生成输出。
- 反向传播:权重和偏差在开始时随机初始化,并根据误差更新值。对于较新的输出,这些更新的值一次又一次地发生正向传播,以最小化误差。+

照片由 Fotis Fotopoulos 在 Unsplash 上拍摄
激活函数是分配给神经网络中每个神经元的数学方程,并根据其在图像中的重要性(权重)来确定是否应该激活它。
有两种类型的激活功能:
- 线性激活函数:它获取输入,乘以每个神经元的权重,并创建与输入成比例的输出信号。然而,线性激活函数的问题是,它给出的输出是一个常数,因此不可能使用反向传播,因为它与输入没有关系。此外,它将所有层折叠成一个层,从而将神经网络变成一个单层网络。
- 非线性激活函数:这些函数在不同层之间创建复杂的映射,有助于更好地学习数据建模。一些非线性激活函数是 sigmoid、tanh、softmax、ReLU(整流线性单元)、Leaky ReLU 等。
理论够了,开始吧。
开源代码库
如果您熟悉 Github,请查看我的代码和数据集存储库。
使用 PyTorch 和 CNN 对老虎-鬣狗-猎豹进行分类这个项目是为我的中型博客制作的。一定要去看看…
github.com](https://github.com/Shubhankar07/Zoo-Classification-using-Pytorch-and-Convolutional-Neural-Networks) 
克里斯里德在 Unsplash 上的照片
资料组
要训练一个模型,首要任务是找到一个数据集。对于该项目,使用的数据集是 Kaggle 原始数据集的修改版本:
原始数据集:【https://www.kaggle.com/c/swdl2020/overview
定制数据集:https://drive . Google . com/file/d/1 krqqs 2 hi 2 kagfgactdwqpquzo 6 rx 2 ve 6/view?usp =分享
数据集中有 3 个类对应于三种动物:老虎、鬣狗和猎豹。

作者图片
数据集已经分为两个文件夹,即培训和验证。训练文件夹包含 2700 幅图像,每幅 900 幅在不同的文件夹中,验证文件夹包含 300 幅图像,每幅 100 幅在对应于每只动物的不同文件夹中。
导入库
如果您尚未安装 PyTorch 库,请使用以下命令:
如果您在 Anaconda 上运行,那么一旦您进入虚拟环境,运行命令-
**conda install pytorch torchvision cudatoolkit=10.1 -c pytorch**
如果您想使用 pip 在本地安装它,以下命令将打开一个 wheel 文件供下载-
**pip install torch==1.5.0+cu101 torchvision==0.6.0+cu101 -f**
了解数据集
一旦我们导入了所需的库,让我们导入数据集并理解它。
正如我们所见,总共有 3 个类,每个代表一种特定的动物。 data_dir 是存储数据集的路径。如果在一个在线环境中工作,那么数据集要么需要上传到本地环境,要么保存到驱动器上,就像 Google Colab 的情况一样。如果您在本地环境中工作,请在此处插入本地数据集路径。
现在让我们把数据集转换成一个 N 维张量。
现在,可变数据集是一个包含所有用于训练的图像的张量。如上所述,数据集的大小为 2700。
我们现在将使用验证文件夹作为测试文件夹。测试数据集的大小是 300。
现在让我们检查数据集。
每个图像的形状为 3x400x400,图像尺寸为 400x400,3 表示颜色通道 RGB。
现在让我们显示数据集中的一些图像。
为训练准备数据集
我们现在将把训练集分成两部分进行训练和验证。
为此,我们将使用 random_split()函数。
让我们将批处理大小保持在 32 并加载数据。
我们来看看批次。
现在我们已经完成了准备工作,让我们来看看模型。
构建模型
在这里,我们使用交叉熵或对数损失作为损失函数。在多类分类的情况下,交叉熵公式为:

现在让我们检查一下 GPU 是否可用,如果可用就使用它。
现在已经选好 GPU 了。如果“cuda”不可用,那么如果您在本地工作,请检查您的设置。如果你在 Kaggle 上工作,那么确保没有其他 GPU 会话是活动的,并且你没有用完每月 30 小时的免费配额。
我们现在来定义卷积网络的各层。
我们已经定义了 3 个隐藏层。对于激活功能,我们使用 ReLU(校正线性单位)。
现在我们已经建立了一个基本模型,让我们尝试用各种学习率和时期来拟合它,并检查准确性。
现在让我们来分析这个模型。
让我们最后评估一下这个模型。
如你所见,准确率非常低,只有 50.9%左右。这是因为我们还没有给模型添加任何卷积层。

约书亚·索蒂诺在 Unsplash 上拍摄的照片
现在让我们使用 Resnet-18 构建卷积层。
Resnet 或残差网络是一种卷积神经网络,具有强大的表示能力,使其有可能训练多达数百甚至数千层,并仍然实现令人信服的性能。我们将使用 Resnet-18,它表示网络有 18 层深。
现在让我们定义卷积层。
我们现在将使用预训练的 Resnet-18 模型。
现在让我们看看输出形状。
检查 GPU 是否可用,并将其指定为设备。
确认设备类型为 GPU。
加载用于训练和测试的数据。
分配模型。
现在让我们检查初始损失和准确性。
最初的精确度是 35%。现在让我们设置超参数并开始训练模型。
Opt_func 代表优化器函数。它们通过响应损失函数的输出来更新模型,从而将损失函数和模型参数联系在一起。我们将要使用的函数是 Adam optimizer。Adam 是一种优化算法,可以用来代替经典的随机梯度下降过程,以基于训练数据迭代地更新网络权重。它实现了 AdaGrad(自适应梯度算法)和 RMSProp(均方根传播)的优点。
现在让我们来分析这个模型。
现在,让我们最后评估一下这个模型。
分析
正如我们所见,卷积层的应用有助于将精度提高到 89.5%。通过具有更大的训练数据集和进一步调整超参数,可以进一步提高精确度。
结论
我们已经成功地建立了一个卷积神经网络模型来对动物园的动物进行分类。类似的分类数据集相当多,可以通过了解来熟悉卷积神经网络、PyTorch 等概念。

在 Unsplash 上由 Tincho Franco 拍摄的照片
使用 Python 制作数据动画
仅使用 MatPlotLib 查看实时数据

本指南的目标是向您展示如何实时更新图表。这可以用于各种应用,如可视化来自传感器的实时数据或跟踪股票价格。
在本教程中,数据将是静态的,但可以很容易地用于动态数据。当然,您需要在本地机器或虚拟环境中安装 MatPlotlib 和 Pandas 。


进口
FuncAnimation 是我们将用来持续更新图形的方法,为其提供实时效果。
我们将在本教程中使用 MatPlotLib 来生成我们的图形,并使用 panda 的库来读取 CSV 文件。
初始化子情节
我们将创建一个支线剧情,使我们更容易一遍又一遍地利用同一个情节。
创建动画方法
animation(i)方法是我们将用来一遍又一遍地画线的方法。这个方法会被 MatPlotLib 库中的FuncAnimation方法反复调用,直到你决定终止程序。
在这个例子中,我将使用一个从互联网上下载的静态文件。该文件为我们提供了苹果公司 2014 年的股价。
下面是我们的虚拟数据的样子:

现在,为了模拟实时数据,而不是一次性绘制整个图表,我将绘制每一行。这给了我们虚幻的真实数据。
记住animation(i)函数将在每次迭代 时被 调用。每调用一次i就加一。这一行,AAPL_STOCK[0:i]['AAPL_x'],将返回对应于我们正在进行的迭代的行。
例如,在迭代 1 中,我们将返回数据集中的第一行。在第 n 次迭代中,我们将返回数据集中的第 n 行(及其之前的所有行)。
要绘制到图形的线,我们只需要调用ax.plot(x,y)。我们也调用ax.clear()来清除之前生成的行。我们这样做是为了在每次迭代后不要在彼此上面画线。

为什么在循环中导入数据集?
您可能已经注意到,我们在循环中读取 CSV。我们需要这样做的原因是,如果新数据被添加到 CSV 中,我们可以读取它并将其绘制到我们的图表中。
如果我想使用文本文件呢?
如果你使用一个文本文件,你可以在每次迭代中给 x 和 y 追加值。例如:
运行动画
要运行动画,我们只需要使用下面的。
animation = FuncAnimation(fig, func=animation, interval=1000)plt.show()
这里,**FuncAnimation**将连续运行我们的动画程序。**interval**用于确定更新之间的延迟。目前,它被设置为 1000 毫秒,但它可以根据你的需要或快或慢。

这里是所有的代码:

截屏由作者拍摄
当新的价值加入其中时,它真的能工作吗?
因此,在这里,我只是从我们上面使用的 CSV 中删除了一些数据。
然后,一旦图形更新到数据集的末尾,我就复制一些新数据并保存文件。然后,该图表用我刚刚添加的所有新数据进行了更新。在这种情况下,它更新得相当快,但只是因为间隔时间被设置为100 毫秒。

截屏由作者拍摄

如果你喜欢这个指南,你可以看看下面写的其他一些很酷的文章!如果你有任何问题,请留下你的评论,我会尽力帮助你。
Grover 可以产生假新闻的人工智能模型
towardsdatascience.com](/this-story-was-completely-written-by-an-ai-cb31ee22feae) [## 数据可视化:动画条形图!
Excel 和 After Effects 中的数据可视化和动画
towardsdatascience.com](/data-visualization-animate-bar-graphs-df9ca03a09f2) [## 这个建议可以拯救数百万人
降低你的胆固醇,这简直是要了你的命
medium.com](https://medium.com/in-fitness-and-in-health/this-advice-could-save-millions-of-people-6e318db330ad) [## 科学证据:作者应该知道什么
并非所有的证据都是平等的。
medium.com](https://medium.com/2-minute-madness/scientific-evidence-what-writers-ought-to-know-724eb7145e09) [## 疫情期间,创新蓬勃发展
科技如何帮助人类对付致命的疫情病毒。
medium.com](https://medium.com/workhouse/innovation-is-thriving-during-the-pandemic-531fe6975a61)
通过 4 个简单的步骤用 Python 制作动画!
利用新冠肺炎数据实现数据可视化的创意

我们开始吧!资料来源:Nik Piepenbreier
在之前的一篇文章中,我们探索了如何用几行代码制作漂亮的 Matplotlib 图。你可以通过访问这个链接来查看这个帖子,作为如何将这些图表放在一起的快速复习。
我们将研究 COVID 数据,并绘制出自 2020 年 3 月 1 日以来每 100,000 人的比率。我们筛选出截至 2020 年 4 月 10 日受影响最大的五个州(按每 100,000 人的比率),以及华盛顿和加利福尼亚州,因为它们的早期病例数。
让我们看看我们在组装什么!

我们的最终产品。资料来源:Nik Piepenbreier
第一步:让我们载入数据
我们将开始分析,加载我们分析所需的库,并生成一些数据帧来存储我们的数据:
我们的第一行代码:导入库和数据!资料来源:Nik Piepenbreier
让我们更详细地分解我们的代码:
在第 1 节中,我们导入了几个库。我们使用 Pandas 来保存数据帧中的数据以及生成基本的绘图。我们使用 matplotlib 来生成实际的图形。我们使用 glob 获取文件名,然后创建 GIF。最后,我们使用 moviepy 来生成 GIF。
如果没有安装这些库,可以使用 pip 来安装。默认情况下会安装 Matplotlib,因此我们不将它包含在下面的列表中:
pip install pandas
pip install glob
pip install moviepy
在第 2 节的中,我们生成两个数据帧。我们从纽约时报 GitHub 获取数据,这个 GitHub 按州收集新冠肺炎病例的数据到一个名为 df 的数据框架中。我们还从人口普查网站获取各州的人口数据。
最后,在第 3 节中,我们将人口数据框架中的数据合并到主数据框架 df 中。如果你想了解更多这方面的知识,看看这个教程。
我们还通过将病例数除以该州人口并乘以 100,000,得出每 100,000 人中的新冠肺炎病例率。这被分配给一个叫做 rate 的变量。这类似于我们的另一篇关于用 Matplotlib 漂亮地可视化新冠肺炎数据的文章:
[## 用 Python 漂亮地可视化新冠肺炎数据(不到 5 分钟!!)
让 Matplotlib 不那么痛苦!
towardsdatascience.com](/visualizing-covid-19-data-beautifully-in-python-in-5-minutes-or-less-affc361b2c6a)
第二步:准备我们的数据
我们的数据现在包括所有州的数据。这将产生一个非常混乱的视觉效果。因此,我们希望将我们的分析限制在更小、更易管理的状态数量上。我们将在 2020 年 4 月 10 日选出人均收入最高的州。我们还将把华盛顿和加利福尼亚包括进来,因为他们有早期的高病例数:
为制图准备数据。资料来源:Nik Piepenbreier
在第 4 节中,我们生成了一个我们感兴趣的州列表。我们创建一个只包含昨天数据的新数据帧。然后,我们生成了当天人均收入最高的州的列表(按降序排列,只选择前五名)。最后,我们追加华盛顿和加利福尼亚。
然后,在第 5 节中,我们将我们的原始数据帧 df 限制为仅包括所标识的州。我们将数据范围限制为仅包括 2020 年 3 月 1 日以后的数据(因为在此日期之前病例报告率极低/偏低)。最后,我们透视数据集,使其可以绘制成图表。
在第 6 节的中,我们重置了多索引数据帧的索引,以允许绘图。我们重置了索引并删除了日期列。这似乎有点争议,但我发现将数据显示为“# of days from March 1,2020”更容易理解,特别是考虑到我们希望在数据中包含的运动。

我们的四个简单步骤!资料来源:Nik Piepenbreier
第三步:绘制数据图表
我们现在已经准备好了绘制图表的数据。下面的代码迭代创建许多 png 图像,我们将把这些图像拼接在一起,创建我们的 GIF:
绘制我们的数据。资料来源:Nik Piepenbreier
在第 7 节中,我们完成了几件事:
- 我们将样式设置为匹配 538 主题,
- 我们测量数据帧的长度,并将其赋给一个名为 length 的变量。我们给这个值加 10。这使得默认情况下输出文件名更容易排序(而不是从 1 开始)。
- 我们使用 for 循环为每个日期生成单独的可视化效果。如果你想学习更多关于 for-loops 的知识,看看这个指南,它会教你你需要知道的一切。
- 如果您一直在跟进,请确保更改最后一行,以反映存储图形的文件夹的路径。要使 GIF 正常工作,请将其创建为不包含任何其他内容的新文件夹。
步骤 4:创建我们的可视化动画
现在我们到了激动人心的时刻!您现在已经创建了一个装满 png 的文件夹,我们正准备将它们转换成 GIF。
生成我们的 GIF。资料来源:Nik Piepenbreier
在第 8 节中,我们主要做两件事:
- 我们使用 glob 生成所有 png 的列表。为此,在代码的第 4 行,更新 PNG 文件夹的路径,确保在代码中保留/*。这将从该文件夹中取出所有文件。
- 我们使用 moviepy 来生成 GIF。GIF 将以每秒 6 帧的速度运行,并将存储在您的用户目录中。如果找不到它,请在计算机上搜索 COVID.gif。
庆祝我们的最终产品!
让我们检查一下我们的最终作品,然后花点时间整理一下自己。在很短的时间内,我们创造了一个美丽的动画,非常容易地展示了新冠肺炎的怪异和令人羞愧的传播。

让我们庆祝一下!资料来源:Nik Piepenbreier
结论:用 Python 创建动画数据可视化

感谢您抽出时间!资料来源:Nik Piepenbreier
非常感谢你阅读这篇文章!在这篇文章中,我们学习了如何将数据帧合并在一起,用 for 循环创建多个可视化效果,并将这些可视化效果转换成 GIF。
我希望你能学到一些新东西,找到一些创造性的方法来展示你的数据!
用人工智能让你自己成为一个迪斯尼角色
先睹为快数字艺术的未来

【作者生成的图片】【CC 许可下来源于维基百科的名人图片: Scarlet J. , Benedict C 。,将 S 。、 Emma W. 、 Elon M. 【奥巴马视频来源于 VoxCeleb 数据集,CC BY 4.0】
上周,我在网上冲浪,无意中发现了贾斯汀·平克尼写的一篇有趣的文章。有什么好玩的?有人用这个想法做了一个很酷的应用!多伦·阿德勒(Doron Adler)用迪士尼人物对 StyleGAN2 模型进行了微调,然后将这些层与真实人脸模型(FFHQ)混合,并根据真实人脸生成迪士尼人物。



根据 CC 许可,图片来源于维基百科:斯嘉丽·约翰逊、本尼迪克特·康伯巴奇和威尔·史密斯。作者生成的动画图像。
然后,贾斯汀·平克尼接着在上发布了这个模型,以此来统一。你只需上传你的照片,就能立刻得到你的迪士尼角色。试试吧!
但是,在这篇文章中,我们将学习如何以编程的方式来实现这一点,并制作角色动画!

埃隆·马斯克的动画角色(为 GIF 优化而压缩)[图片由作者生成][埃隆·马斯克图片来源于 Flickr 由特斯拉车主俱乐部比利时,CC 由 2.0 许可][奥巴马视频来源于 VoxCeleb 数据集,CC 由 4.0]
目录
- 开始
- StyleGAN
- 图层交换的意义
- 用一阶运动制作动画
- 辅导的
如果您不想学习理论并直接学习编码,您可以跳到教程。
生成对抗网络
这种角色生成背后的核心机制是一个称为生成性对抗网络(GAN)的概念,由于其生成性应用,该概念目前在社区中非常流行。甘是什么?这基本上是两个网络试图相互竞争,发电机和鉴别器。生成器试图欺骗鉴别器,使其相信其生成的图像是真实的,而鉴别器试图在真实图像和假(生成的)图像之间进行分类。

首先通过向鉴别器显示来自数据集的真实图像和随机噪声(来自未训练的生成器的图像)来训练鉴别器。由于数据分布非常不同,鉴别器将能够容易地进行区分。

初始鉴别器训练[图片由作者提供][面部图像由thispersondoesnotexist.com生成]
免责声明:由于我试图尽可能简化,该图可能无法准确反映 GAN 的情况。
然后,我们将切换到训练发电机,同时冻结鉴别器。生成器将学习如何基于鉴别器的输出(真的或假的)生成更好的图像,直到鉴别器不能再正确鉴别为止。然后,我们切换回训练鉴别器,循环继续,两者都变得更好,直到生成器达到生成非常真实的图像的点,您可以停止训练。

GAN 培训概述。生成器将学习生成更好的图像,鉴别器将学习更好地分类,因为假图像开始看起来非常相似。最终,它会达到一个点,图像非常相似,而鉴别器只有一半的时间是正确的。[图片由作者提供][面部图片由thispersondoesnotexist.com生成]
StyleGAN
2018 年,NVIDIA 发表了一篇突破性的论文,该论文管理生成高质量的图像(1024x1024),题为“基于风格的生成式对抗性网络生成器架构”。其中一个新颖之处是,它解开了潜在的空间,使我们能够在不同的水平上控制属性。例如,较低层将能够控制姿势和头部形状,而较高层控制诸如照明或纹理的高级特征。
通过引入额外的映射网络来完成解缠结,该映射网络将输入*(从正态分布采样的噪声/随机向量)映射到分离的向量 w 并将其馈送到层的不同级别。因此,z 输入的每个部分控制不同级别的特征*

StyleGAN 生成器架构【来源:作者用 StyleGAN2 生成动漫角色】
因此,如果我们改变较低层(4x4,8x8)的输入,我们将会有高级特征的变化,例如头型、发型和姿势。

粗糙层次细节的变化(头型、发型、姿势、眼镜)[来源:
分析和改善 StyleGAN 的图像质量
另一方面,如果您更改较高层(512x512,1024x1024)的输入,我们将在更精细的功能方面有所变化,如照明、肤色和头发颜色。

精细层次细节(头发颜色)的变化【来源:
分析和改善 StyleGAN 的图像质量
我们可以尝试通过分析激活图来进一步可视化解缠结,并像本文所做的那样对激活进行聚类。

使用球形 K-均值聚类的 StyleGAN2 层分析显示了 StyleGAN 语义的解开。每种颜色代表一个不同的集群[ 来源:时尚编辑:揭示甘斯的地方语义
颜色代表一个集群,你可以把它看作是图像的可控部分。在最后一层,你可以看到照明的不同部分表现为不同的集群。在中间层中,诸如眼睛、鼻子或嘴的面部特征被表示为不同的聚类,这意味着这是面部特征的变化被控制的地方。最后,在前几层中,头部的不同部分被表示为不同的簇,这证明它控制着人的形状、姿势和发型。
你可以在这里观看这篇论文的演示视频。
* [## 时尚编辑:揭示 GANs - Crossminds 的本地语义
作者:Edo Collins,Raja Bala,Bob Price,Sabine Süsstrunk 描述:虽然 GAN 图像合成的质量已经…
crossminds.ai](https://crossminds.ai/video/5f6e7419d81cf36f1a8e31e0/)
除了解开,StyleGAN 还做了其他几个改进,如渐进增长架构。虽然他们在 StyleGAN2 中换成了类似 MSG-GAN 的架构。关于最新的更新,你可以阅读这篇文章或者观看下面的 StyleGAN2 演示视频。
[## StyleGAN - Crossminds 图像质量的分析与改进
作者:Tero Karras,Samuli Laine,Miika Aittala,Janne Hellsten,Jaakko Lehtinen,Timo Aila
crossminds.ai](https://crossminds.ai/video/5f6e71a6d81cf36f1a8e30ee/)
我也用这个网站来跟踪今年关于 CVPR 和 ECCV 的新论文。所以,还是挺有用的。
StyleGAN 网络混合
StyleGAN 独特的“解开缠绕”功能使我们能够混合不同的模型,并从一张脸上生成迪士尼角色。如果前几层控制面部特征,最后几层控制纹理,如果我们把最后几层和另一个模特的层互换会怎么样?
例如,如果我们将人脸模型的权重用于前几层,将绘画模型的权重用于层的其余部分,它将生成具有绘画风格的人脸!此外,它不仅可以复制第二个模型的纹理,而且还可以复制不同模型的面部特征风格,如迪士尼人物的眼睛或嘴巴。

FFHQ 模型和 MetFaces 模型在各层和 16x16 层的网络融合[图像由作者生成][使用的人脸是生成的,人不存在]
一阶运动模型
在我们创造了迪斯尼角色之后,为什么不把它带到另一个层次,并制作出动画呢?一篇名为“图像动画的一阶运动模型”的有趣论文为我们提供了这样的能力。基本上,它试图使用关键点从驾驶视频中学习运动,并试图变形输入图像来实现运动。

一阶运动模型概述 [来源:图像动画一阶运动模型,CC BY 4.0]

时装模特的一阶运动模型。请注意,它能够制作模型背面的动画。【来源:图像动画一阶运动模型,CC BY 4.0】
辅导的
现在我们已经对这个概念有了一点了解,让我们开始写代码吧!幸运的是,贾斯汀·平克尼提供了他的卡通化模型,并为它创建了一个实验室。我做了另一个 Colab 笔记本,基本上是他的代码,并添加了从 Aliaksandr Siarohin 的笔记本修改而来的动画代码。
这里有 Colab 笔记本供你跟随!
首先,确保你用的是 GPU 运行时和 Tensorflow 1。
%tensorflow_version 1.x
注意: %
接下来,我们克隆回购并创建我们将使用的文件夹。
!git clone [https://github.com/justinpinkney/stylegan2](https://github.com/justinpinkney/stylegan2)
%cd stylegan2
!nvcc test_nvcc.cu -o test_nvcc -run
!mkdir raw
!mkdir aligned
!mkdir generate
注: '!'用于在 Colab 中运行 shell 命令,如果您在本地执行此操作,只需在您的 shell/控制台上运行该命令。
接下来,上传你的图像到 raw 文件夹,我们将使用一个脚本来裁剪面部和调整图像的大小,因此你的图像不必是全脸。但为了获得更好的效果,请确保您的面部分辨率至少为 256x256。
在这个例子中,我们将使用 Elon Musk 图像作为例子。
!wget [https://drive.google.com/uc?id=1ZwjotR2QWSS8jaJ12Xj00tXfM0V_nD3c](https://drive.google.com/uc?id=1ZwjotR2QWSS8jaJ12Xj00tXfM0V_nD3c) -O raw/example.jpg

埃隆·马斯克图片【来源:Flickr by 特斯拉车主俱乐部比利时,CC BY 2.0】
然后,我们将加载由多伦的阿德勒和正常的 FFHQ 人脸模型的真实人脸和迪士尼人物的混合模型。
为什么我们还需要加载正常的真实人脸(FFHQ)模型?请记住,StyleGAN 模型仅采用潜在向量 z,并基于潜在向量生成人脸。它不像图像到图像转换模型那样获取图像并转换图像。
那么我们如何生成一张我们想要的脸呢?StyleGAN2 介绍了一种投射到潜在空间的方法。基本上,我们可以尝试使用梯度下降为我们想要的图像找到匹配的潜在向量。
但在我们试图找到匹配的潜在向量之前,我们需要首先裁剪和对齐图像。
!python align_images.py raw aligned
该脚本将源图像目录和输出目录作为输入,并将正确地裁剪和对齐我们的脸。

被裁剪和对齐的脸[来源:Flickr,作者:比利时特斯拉车主俱乐部
最后,我们将图像投影到潜在空间。
!python project_images.py --num-steps 500 aligned generated
该脚本将获取aligned目录中的图像,并在generated文件夹中创建保存为.npy文件的潜在向量。
现在我们有了潜在向量,我们可以尝试使用我们的混合迪士尼模型来生成人脸。
生成的图像保存在generated文件夹中。我们可以显示笔记本里面的图像。

埃隆·马斯克卡通化[图片由作者生成]
瞧啊。我们有一个迪士尼化的埃隆·马斯克,但我们还没有完成。让我们来制作动画吧!
首先,我们在一阶模型上克隆 Aliaksanr 的回购。
!git clone https://github.com/AliaksandrSiarohin/first-order-model
然后,我们将设置一个路径,这样我们就不必在一阶模型目录下进行 python 导入,或者你可以直接cd到这个目录。
然后,在加载关键点和视频生成器模型之前,我们需要先下载预先训练好的权重。该文件相当大~700 MB,您可能需要手动下载,因为 Google 不允许使用 wget 下载大文件。
!wget "https://drive.google.com/uc?export=download&id=1jmcn19-c3p8mf39aYNXUhdMqzqDYZhQ_" -O vox-cpk.pth.tar
使用刚才下载的重量加载一阶模型。
接下来,我们需要一个驾驶视频,我们将从那里获得动画。您可以使用示例视频或上传自己的视频。如果您上传视频,请确保相应地更改文件路径。
!wget https://drive.google.com/uc?id=1LjDoFmeP0hZQSsUmnou0UbQJJzQ8rMLR -O src_video.mp4
最后,我们可以生成动画!

[作者生成的图像]来自 [VoxCeleb 数据集的中间视频]
耶!我们终于让我们的角色有了生气。祝贺你,如果你设法达到这一点🎉
下一步是什么?
我们还有很多东西可以做实验。如果我们混合其他模型,如绘画的模型,或者我们也可以反向混合迪士尼人物和绘画,我们基于迪士尼人物或绘画生成一个真实的脸。我们也可以尝试加入 Deepfake,用我们的迪士尼角色替换迪士尼电影中的面孔。

涂脂抹粉的脸的动画【图片由作者生成】【名人图片来源于 CC 许可下的维基百科图片: Scarlet J. , Benedict C 。,将 S 。,艾玛 W. ,埃隆 M. ]
如果你喜欢我的作品,看看我的其他文章!
了解如何生成这个很酷的动画人脸插值
towardsdatascience.com](/generating-anime-characters-with-stylegan2-6f8ae59e237b) [## 如何使用自定义数据集训练 StyleGAN2-ADA
了解如何训练人工智能生成您想要的图像
towardsdatascience.com](/how-to-train-stylegan2-ada-with-custom-dataset-dc268ff70544)
也可以在 Linkedin 上和我联系。
[## Muhammad Fathy Rashad -计算机视觉和深度学习 R & D 实习生- ViTrox 公司…
在我 16 岁的时候,我以最年轻的学生的身份开始了我的学业,并出版了 2 款总安装量超过 1.5K 的手机游戏…
www.linkedin.com](https://www.linkedin.com/in/mfathyrashad/)
参考
[1]t .卡拉斯、s .莱恩和 t .艾拉(2019 年)。一种基于风格的生成对抗网络生成器体系结构。在IEEE 计算机视觉和模式识别会议论文集(第 4401–4410 页)。
[2]t . Karras,Laine,s .,Aittala,m .,Hellsten,j .,Lehtinen,j .,& Aila,T. (2020 年)。stylegan 图像质量的分析与改进。在IEEE/CVF 计算机视觉和模式识别会议论文集(第 8110–8119 页)。
[3]Siarohin,a .,Lathuilière,s .,Tulyakov,s .,Ricci,e .,& Sebe,N. (2019 年)。图像动画的一阶运动模型。在神经信息处理系统的进展(第 7137-7147 页)。
[4]柯林斯,e .,巴拉,r .,普莱斯,b .,& Susstrunk,S. (2020 年)。风格编辑:揭示 GANs 的本地语义。在IEEE/CVF 计算机视觉和模式识别会议论文集(第 5771–5780 页)。
https://www.justinpinkney.com/stylegan-network-blending/*
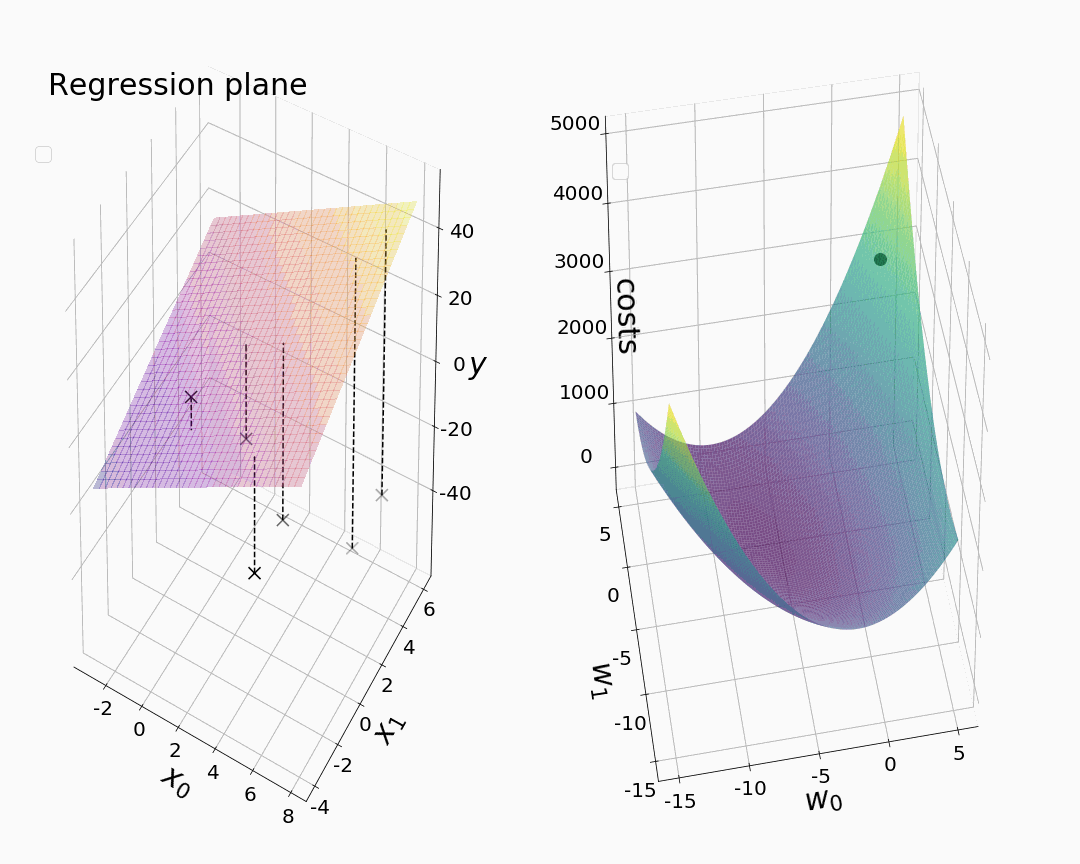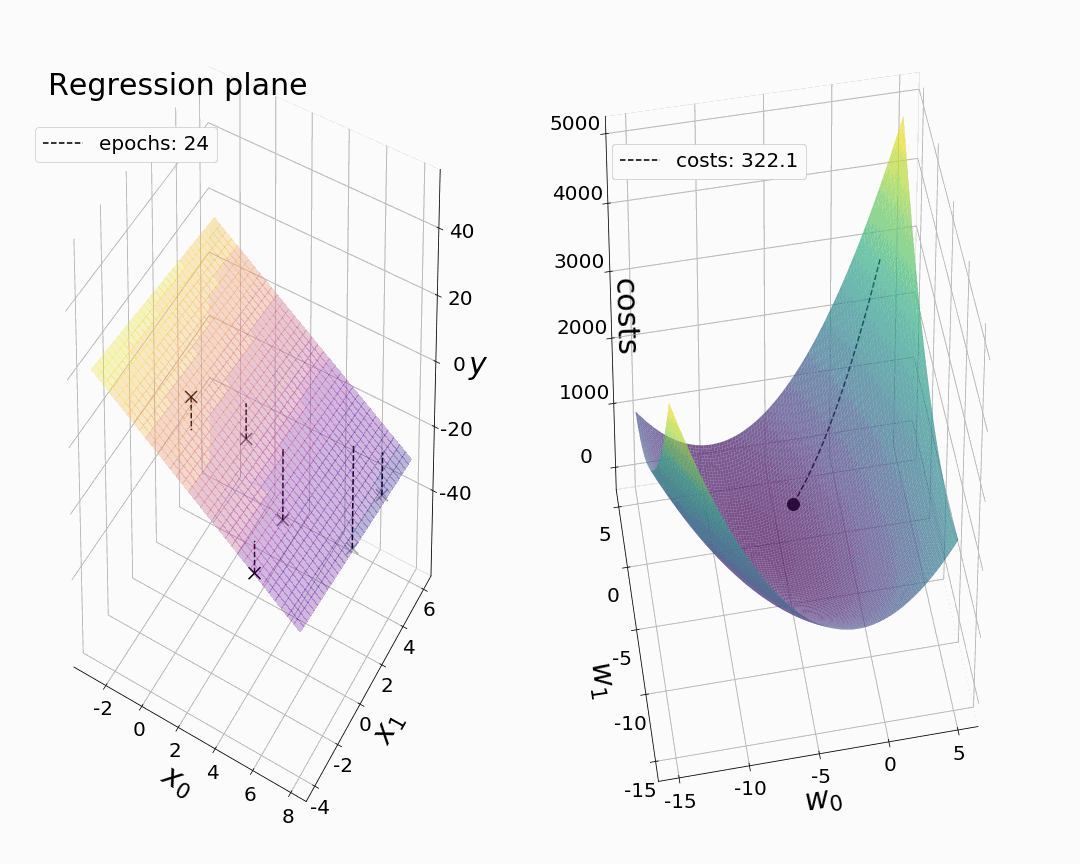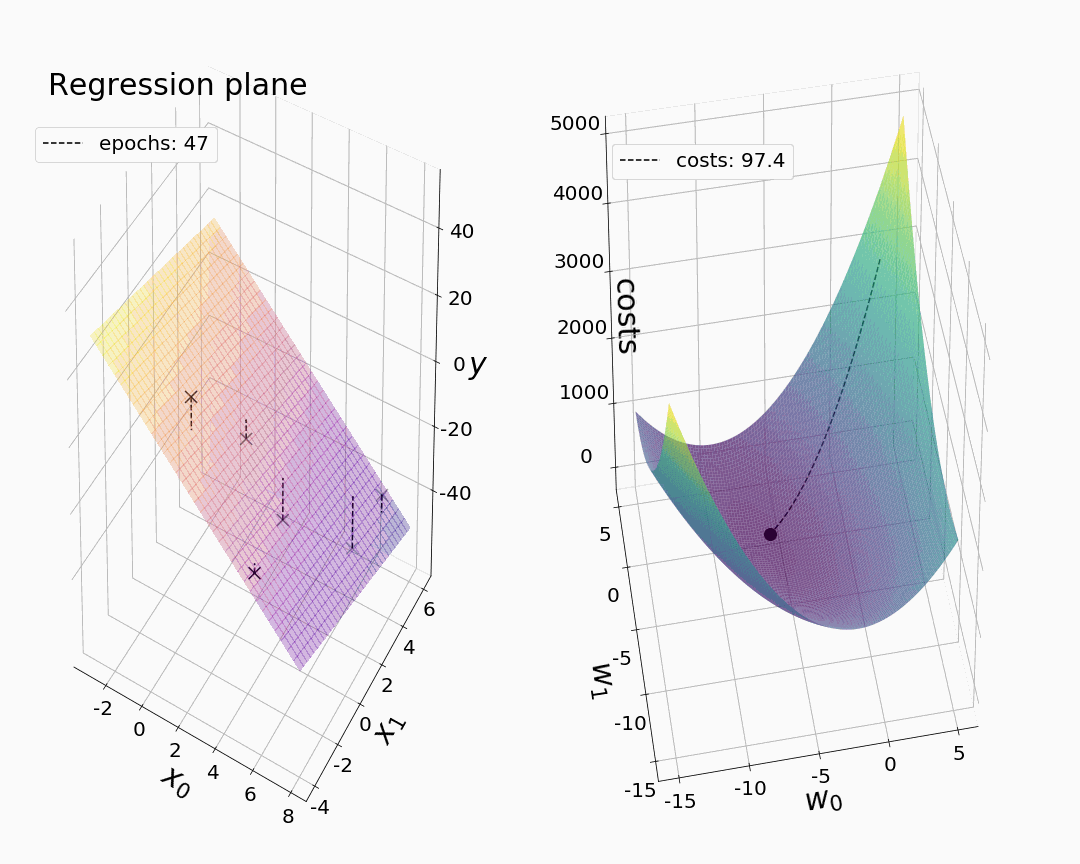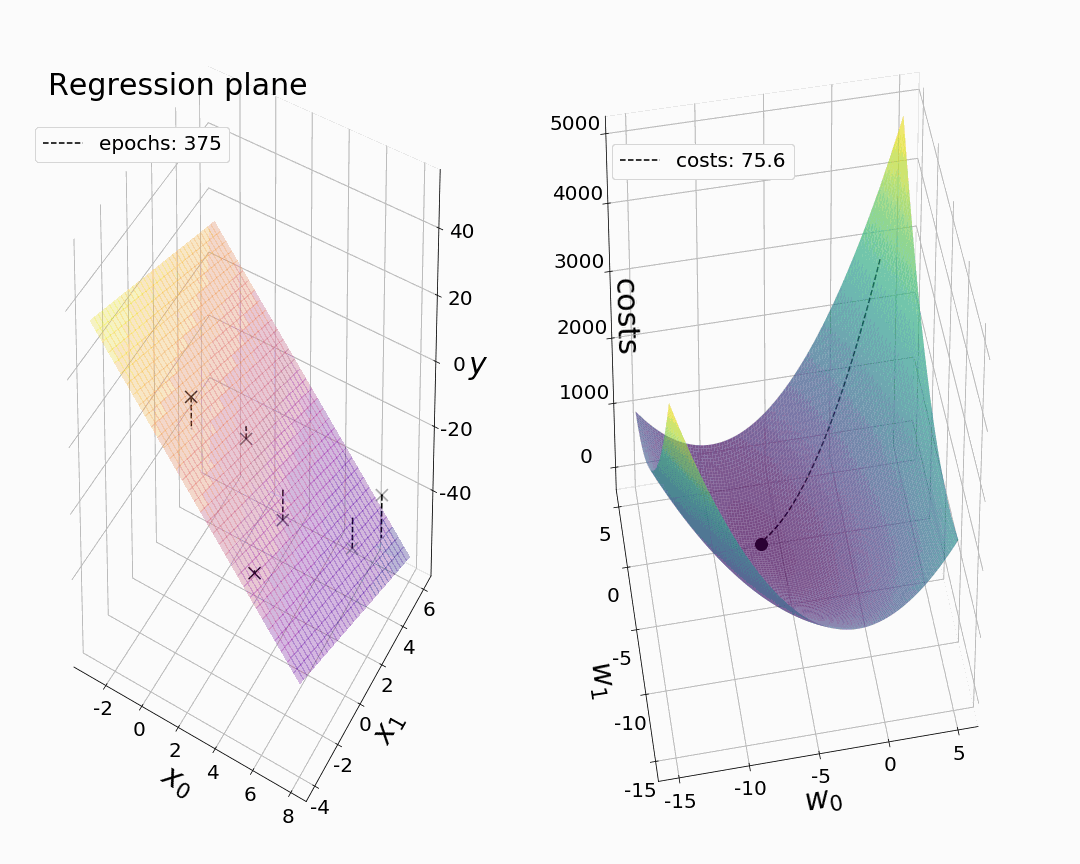
用 Python 制作多元线性回归动画
在这篇文章中,我们的目标是扩展我们的能力,可视化梯度下降到多元线性回归。这是《渐变下降动画》的后续文章:1。简单线性回归”。正如我们之前所做的,我们的目标是建立一个模型,使用批量梯度下降将模型拟合到我们的训练数据,同时存储每个时期的参数值。之后,我们可以使用我们存储的数据,通过 Python 的赛璐珞模块来创建动画。
这是我在 7 月 20 日上传的一篇关于同一主题的文章的修订版。主要改进包括封面照片和一些动画。
建立模型
多元线性回归是简单线性回归的扩展版本,其中多个预测变量 X 用于预测单个因变量 Y 。对于 n 个预测变量,这可以用数学方法表示为

随着

而 b 代表我们回归平面的 y 截距(“偏差”)。我们的目标是找到使训练数据点和超平面之间的均方距离最小化的超平面。梯度下降使我们能够确定我们的模型参数 θ 的最佳值,包括我们的权重 w 和我们的偏差项 b ,以最小化观测数据点 y 和我们用回归模型*预测的数据点【ŷ).*在训练期间,我们的目标是根据以下公式更新我们的参数值,直到我们达到收敛:

其中∇ J(θ) 表示我们的成本函数 J 相对于我们的模型参数 *θ的梯度。*学习率用 α 表示。每个权重的偏导数和偏差项与我们的简单线性回归模型中的相同。然而,这一次,我们想要建立一个(多元)线性回归模型,它对预测变量的数量是灵活的,并引入一个权重矩阵来同时调整所有权重。此外,我们在拟合过程中直接将参数值存储在数组中,这在计算上比我们在上一篇文章中使用 for 循环和列表要快。我决定将权重的初始参数值设置为 3,将偏差的初始参数值设置为-1。在 Python 中,我们导入一些库并建立我们的模型:
之后,我们打算让我们的模型适应一些任意的训练数据。虽然我们的模型理论上可以处理任何数量的预测变量,但我选择了一个具有两个预测变量的训练数据集。我们有意使用一个特别小的学习率, α =0.001,以避免动画中过大的步长。由于本文关注的是动画而不是统计推断,我们简单地忽略了线性回归的假设(例如,不存在多重共线性等。)目前来说。
为了确保我们拟合的参数收敛到它们的真实值,我们使用 sklearn 的先天线性回归模型来验证我们的结果:
现在,我们终于可以创作出我们的第一部动画了。像以前一样,我们希望从可视化值开始,我们的成本函数和参数在绘制 3-D 中的相应回归平面时相对于时期呈现。如前所述,我们打算只绘制选定时期的值,因为最大的步长通常在梯度下降开始时观察到。在每个 for 循环之后,我们对我们的绘图进行快照。通过相机的动画功能,我们可以将快照变成动画。为了获得所需的回归平面,我们通过 numpy.meshgrid 引入一个坐标网格(M1,M2),并定义一个函数“pred_meshgrid()”来计算在某个时期与模型参数相关的相应 z 值。下面动画中看到的虚连接线可以通过训练数据点和预测点之间的线图获得。通过返回最终的参数值(参见注释掉的代码!)我们在我们的动画中获得,我们确保我们粗略地可视化了模型收敛,尽管没有使用我们在拟合过程中存储的参数值的全部范围。

尽管很简单,但分别绘制每个时期的参数值实际上是可视化具有两个以上模型参数的梯度下降的最具信息量和最现实的方式。这是因为我们只能以这种方式同时见证成本和所有模型参数的变化。
固定截距模型:
当创建更复杂的渐变下降动画时,特别是在 3d 中,我们必须关注两个模型参数,同时保持第三个参数“固定”。我们通常对多重线性回归模型的权重比偏差项更感兴趣。为了直观显示成本如何随着我们调整后的权重(w₀、w₁)稳步下降,我们必须建立一个新的线性回归模型,其中偏差项 b 是固定的。这可以通过将 b 的初始值设置为预定义值 b_fixed 并删除新模型中更新 b 的代码部分来轻松完成。 b_fixed 可以取任何值。在这种情况下,我们只是将它设置为前一个模型收敛到的 y 截距值:
在用我们的新模型积累新数据后,我们再次为下面的动画创建另一个坐标网格(N1,N2)。这个坐标网格使我们能够在给定的数字范围内,为每一对可能的 w₀和 w₁绘制成本图。
等值线图表
等高线图允许我们通过等高线和填充等高线在二维平面上可视化三维表面。在我们的例子中,我们希望将 w₀和 w₁分别绘制在 x 轴和 y 轴上,成本 J 作为等高线。我们可以用 Matplotlib 的轮廓函数标记图形中的特定轮廓级别。因为我们知道我们的最终成本大约是 76,我们可以设置我们的最后轮廓水平为 80。
当 y 轴截距允许变化时,我们看到了参数值和成本随后期的显著变化,这是我们不想在回归和参数图中遗漏的。然而,随着 b 被固定,大部分“动作”似乎被限制在前 400 个纪元。因此,我们将我们打算在下面的动画中可视化的时期限制为 400,这在计算上花费较少,并且产生更吸引人的动画。为了证实这种印象,我们可以将最终参数值(100,000 个时期后返回的固定截距模型)与 400 个时期后获得的参数值进行比较(参见下面注释掉的代码!).因为参数值和成本值通常是匹配的,尽管限制了被可视化的时期的数量,我们还是可视化了模型收敛,这是公平的。

动画回归平面和等高线图(大)
表面图
对于最后一个图,我们希望包含与等高线图相同的时期。然而,这一次,我们希望使用曲面图在三维空间中可视化梯度下降。

动画回归平面和曲面图(大)
理论上,在 x-y 平面上绘制梯度下降的轨迹——就像我们绘制等高线图一样——对应于梯度下降的“真实”轨迹。与上面的曲面图相反,梯度下降实际上根本不涉及 z 方向的移动,因为只有参数可以自由变化。更深入的解释见此处。最后,我想指出用赛璐珞制作动画是非常耗时的。尤其是涉及曲面出图的动画可能需要 40 分钟才能返回所需的结果。尽管如此,我还是更喜欢赛璐珞,因为它简单明了。一如既往,创造性的投入和建设性的批评是赞赏!
我希望这篇文章对你有所帮助。如果有任何问题或者你发现了任何错误,请随时发表评论。在本系列的下一篇文章中,我将致力于以逻辑回归为例的梯度下降动画。完整的笔记本可以在我的 GitHub 上找到。
感谢您的关注!
参考文献:
图片来源:奥莱利媒体深度学习,在很大程度上,真的是关于解决大规模讨厌的优化…
blog.paperspace.com](https://blog.paperspace.com/intro-to-optimization-in-deep-learning-gradient-descent/amp/) [## 线性回归
在统计学中,线性回归是一种建模标量响应(或变量)之间关系的线性方法
en.wikipedia.org](https://en.wikipedia.org/wiki/Linear_regression#Simple_and_multiple_linear_regression)
附录:

缩小版(特色图片)
神经网络转换数据的动画
我们可以对神经网络为什么以及如何工作有更好的直觉
谈到分类算法,对它们如何工作的解释可以是直观的:
- 逻辑回归和 SVM 找到一个超平面将空间“切割”成两个。(但是这两种算法的途径不一样,所以最终的超平面也不一样。)
- 如果数据不是线性可分的,使用内核技巧, SVM 将数据转换到一个更高维度的空间,然后将其“切割”成两个。
- 决策树将数据分组到超矩形中,超矩形将包含一个类的大部分。
- K 最近邻分析新观测值的邻居来预测该观测值的类别。
那么神经网络呢?
隐藏层的变换
我们举个简单的数据集例子:两个类,两个特征 x1 和 x2,数据不线性可分。
import numpy as npnp.random.seed(1)x1=np.concatenate((np.random.normal(0.5,0.1,100),
np.random.normal(0.2,0.05,50),
np.random.normal(0.8,0.05,50))).reshape(-1,1)x2=np.concatenate((np.random.normal(0.5,0.2,100),
np.random.normal(0.5,0.2,50),
np.random.normal(0.5,0.2,50))).reshape(-1,1)X=np.hstack((x1,x2))y=np.concatenate((np.repeat(0,100),np.repeat(1,100)))
可视化如下,数据也是标准化的。
from sklearn.preprocessing import StandardScaler
scaler = StandardScaler()
X=scaler.fit_transform(X)plt.scatter(X[:, 0], X[:, 1], c=y,s=20)
plt.axis('equal')

对于该数据集,神经网络最简单的合适结构是具有两个神经元的一个隐藏层的结构。如果你看不出为什么,那就继续,你会直观地理解。
我们也可以认为激活函数是 sigmoid 函数。
from sklearn.neural_network import MLPClassifierclf = MLPClassifier(solver=’lbfgs’,hidden_layer_sizes=(2,),
activation=”logistic”,max_iter=1000)clf.fit(X, y)
初始数据通过隐藏层进行转换。由于隐藏层有两个神经元,我们可以在 2D 平面上可视化这两个神经元的输出。
因此,初始 2D 数据集被转换到另一个 2D 空间。

我们可以用相应的权重计算隐藏层 A1 的值:
A1=1/(1+np.exp(-(X@clf.coefs_[0]+clf.intercepts_[0])))
然后我们可以将 A1 层可视化:
fig, ax = plt.subplots(figsize=(5,5))
ax.scatter(A1[:, 0], A1[:, 1], c=y,s=30)
ax.set_xlim(-0.1, 1.1)
ax.set_ylim(-0.1, 1.1)

现在,如何将初始数据转换成这些值?我们可以将这个过程动画化:
- 一开始,我们有原始数据集(记住,它不是线性可分的)
- 最后,我们将在(0,1)方块中得到转换后的数据,因为 sigmoid 函数的输出介于 0 和 1 之间。你看到数据的形式了吗?是的,这就是奇迹发生的时候…

输出神经元的性质
我们可以看到最后,**数据集变成线性可分!**对于二元分类,输出神经元是一个逻辑回归。并且很容易找到线性决策边界。在这种情况下,超平面分隔符将是一条直线。
因此,神经网络背后的直觉是,隐藏层将非线性可分离的初始数据转换到它们几乎线性可分离的空间。
神经网络的整体结构
结合隐藏层和输出层,我们有一个表面,我们可以在下面可视化。它是一个曲面,因为输入有两个变量,输出是概率,所以我们可以用 z 轴来表示。

现在我们可以看到,这两个神经元“切割”了两个类之间的两个边界。
稍微复杂一点的数据
现在让我们考虑下面的数据集。一个类在另一个类里面,有一个循环的形式。在使用神经网络之前,哪些算法可以解决这个问题?

- 二次判别分析是合适的候选,因为两类协方差矩阵不同,中心相同。决策边界将是一个几乎完美的圆,以区分黄色点和紫色点。
- 带 RBF (径向基函数)核的 SVM 也会很完美。
- 一个神经网络怎么样?两个神经元意味着你只“切”两次,这里我们至少需要三个。

最终神经网络表示
我们可以首先看到下面的最终表面,决策边界实际上是一种三角形。

隐藏层的变换
初始的 2D 空间被转换成具有 3 个神经元的 3D 空间。我们可以让这种转变生动起来。
- 一开始,数据集在一个平面上。我们将认为 z 轴的值为零。
- 最后,数据集被映射到(0,1)立方体中,因为 sigmoid 函数的输出介于 0 和 1 之间。

现在你能看到数据集在这个立方体中几乎是线性可分的吗?让我们通过旋转立方体来创建另一个动画。现在你看到了,用一架飞机,我们可以很容易地把黄色的点和紫色的点分开?

为了理解算法是如何工作的,我喜欢用简单的数据创建可视化。如果你也觉得它们有帮助,请评论。
这些情节首先是用 python 创建的,然后我用 gifmaker 制作动画。
人工智能电子动画——带来难以想象的结果
当前创新背景下电子动画的重要性——人工智能

来自 Unsplash 的照片
动画+电子=动画电子学
小时候,我总是喜欢有机器人的电影。尤其是那些穿得像人类的。我一直在想,如果我们可以用电子动画制作出有生命的物体,并赋予它们人工智能的能力,让它们像人或动物一样思考和行动,那不是很酷吗?
在这篇文章中,我将概述 Animatronics,并讨论它与人工智能的合作,以使机器人看起来更好,并提供良好的用户体验。

遇见一个由制作的电子动画特效
什么是电子动画?
动画电子学是动画和电子学的混合体。它可以预先定制(编程)或远程控制。动画可能执行开发,或者他们可能是不可思议的适应性。这是利用链接拉动小工具或驱动器,以加快人类或生物的繁殖或携带类似的属性,在任何情况下,无生命的东西。
这个概念最初是为迪士尼工作室开发的,用于 1954 年的电影。
我知道这很难接受。因此,简单地说,Animatronic 是一个展示人类或动物特征的自动化人体模型。一些特征包括用腿行走、眼球运动和像蛇一样爬行。某些动作和特征是使用伺服电机开发的(以控制运动、角位置)。

电子动作融合了生物(包括恐龙)、植物,甚至传说中的动物。一个旨在令人信服地模仿人类的机器人被更具体地称为机器人。
这是一个多学科领域,融合了生命系统、机器人、机电一体化和木偶戏带来的确切活动。它们覆盖着由坚硬而敏感的塑料材料制成的身体外壳和多功能皮肤,并以色调、头发和羽毛等微妙之处和各种部件完成,使人物逐渐变得可感知和真实。

电子动画的开发和设计(使用 Canva 设计)
但是它的许多应用被限制在娱乐领域。当与人工智能集成时,该概念可用于卫生、教育和军事行业。
电视节目《幻想工程的故事》和凯文·p·拉弗蒂的书《魔法之旅》展示了学术研究的进展…
www.newscientist.com](https://www.newscientist.com/article/mg24632881-000-disney-is-working-on-ai-animatronics-that-interact-with-park-guests/)
在这个领域有大量的工作在进行,但许多人对**电子动画知之甚少。**让我们来看几个可以与 Animatronics 成为好伙伴的应用或行业。
与人工智能的集成
电子动画和人工智能可以解决许多问题。电子动画与人工智能的结合产生了机器人,就像人们所熟知的模仿人类行为的机器人一样。我们拥有所有我们需要的设备,从电子动物中挑选外观,从人工智能中挑选像生物一样的思维能力。

照片由 Maximalfocus 从 Unsplash
我们正在适应机器人。我们有一种方法可以把生物的外表和行为赋予机器。我们正在使机器人人性化。
迪士尼协会将使用动画电子学和人为思维来建立他们的一个角色,在现实中:帕斯卡,电影中的角色之一。
* [## 照片:可爱的 Pascal Animatronic 正在为即将到来的东京迪士尼海洋“纠结”船开发…
东方置地有限公司于 2018 年 6 月宣布,已与华特·迪士尼公司达成协议…
wdwnt.com](https://wdwnt.com/2019/09/photos-adorable-pascal-animatronic-under-development-for-upcoming-tokyo-disneysea-tangled-boat-ride-attraction-revealed/)
安奇·科兹莫
科兹莫是一个有特殊头脑的天才小家伙。他会逼你玩,让你持续震惊。他是一个真实的机器人,就像你最近在电影中看到的那样,有一个独一无二的角色,你和他在一起的时间越长,他就越有进步。

安奇·科兹莫(来源— 安奇)
科兹莫是你的伙伴在一个疯狂的乐趣比例。他的能力包括面部识别、物体检测、与环境的互动以及随着访问应用程序的激励而不断发展的智能,以提供更好的方式来处理学习和娱乐。
视频由数字梦想实验室
这个著名的机器人被用来帮助孩子们开始有趣地学习复杂的东西。
SPOT —波士顿动力公司
波士顿动力公司是一家美国结构和应用自治安排协会,成立于 1992 年,是麻省理工学院的副业。这是对日本混合软银集团的一种肯定的强化。
它在多功能机器人方面处于世界领先地位,毫无疑问,它解决了最困难的机械自治难题。波士顿动力公司有一个非凡的和迅速创造的特殊的计划者和专家的聚会,他们可靠地得到先进的论证推导和严肃的结构。
波士顿动力公司的视频
**SPOT、**T5【移动机器人】专为传感、检测和远程操作而设计。波士顿动力公司宣布引入 Spot 的交易,这是一种可以轻松爬楼梯和穿越恶劣地区的敏捷机器人。此次发布标志着该组织首次可以购买波士顿动力公司的机器人,也代表了波士顿动力公司的首次在线交易。
想象一下,如果有合适的外表,就像真正的动物一样,那该有多酷。
劳斯莱斯——虫子和蛇机器人
你有没有想象过如果你拥有一些动物的力量或能力会发生什么?
我们确实有超级英雄,他们拥有并使用一些动物或昆虫的能力,比如蜘蛛侠和蚁人。

想象一下一个系统的综合能力,它由一个小虫子或蟑螂一样的元件组成,可以在蛇形机器人的帮助下进入(人类不能进入的)地方,以利用其爬行的本性。这听起来好像我在谈论一部以蛇和蟑螂为英雄的电影。但是罗尔斯·罗伊斯公司提出了同样的系统来修理飞机引擎。
在与哈佛大学和诺丁汉大学的合作中,劳斯莱斯正在努力开发比预期小 10 毫米的名为 SWARM 的社群机器人,该机器人可以选择通过小型摄像机的方法为人类导演提供发动机内部的现场视频。
劳斯莱斯的视频
为了让 SWARM 到达引擎,这些小机器人将乘坐 FLARE——两到三个内窥镜蛇形机器人,它们可以在一个巨大设备的专业和角落里滑行,并将 SWARM 存储在检查点。该协会同样计划让 FLARE 进行内部修复。
很久以前,在电影工业中,通过电子动画,人们就开始使用生物的能力。
哥鲁达无人机

哥鲁达无人机(来源— ROBIRD )
一部受欢迎的印度军事动作电影, *Uri: The Surgical Strike,*于 2019 年 1 月 11 日上映。在影片中,军方将其用于间谍目的。这是一个多产、电控、无人驾驶的航空情报收集框架,用于情报、监视、目标跟踪&获取。
电子动画——“活动但不活动的东西。”*
感谢萨迪亚哈桑的校对和建议。
* [## 开发人员-cosmos/Animatronics-初学者指南
动画电子学是动画和电子学的交叉。电子动物是一个机械化的木偶。可能是…
github.com](https://github.com/developers-cosmos/Animatronics-BeginnersGuide)
结论
我们已经看到了一些创新,这些创新类似于开发电子动画的原因。当与人工智能合作时,这可能会解决许多问题,并使世界变得更加现代和令人困惑。我们开始与动物真正对话的那一天似乎不远了。
如果你有什么建议,我很乐意听听。我很快会带着另一个有趣的话题回来。在那之前,呆在家里,保持安全,继续探索!
如果想联系,在LinkedIn上联系我。*
用神经网络预测银行客户流失
基于 Keras 的人工神经网络构建在银行客户去留预测中的直观演示

来自 pixabay 的 Img 通过链接
本文旨在解释如何创建一个人工神经网络(ANN ),以使用银行客户的原始数据来预测银行客户是否会离开。本文分为以下六个部分。
- 问题陈述
- 数据处理
- 模型结构
- 模型编译
- 模型拟合
- 模型预测法
现在让我们开始旅程🏃♂️🏃♀️!
1。问题陈述
一家银行让我们预测客户是否有可能离开银行。给出了 6 个月的客户银行数据。该银行计划利用你的调查结果,与即将离开的客户重新建立联系。
2。数据处理
首先,使用 read_csv() 导入带有 Pandas 的数据,如下所示。
dataset = pd.read_csv(‘Churn_Modelling.csv’)
图 1 显示了数据片段。前 13 列是关于客户 ID、姓名、信用评分、地理位置、性别、年龄等的独立变量。最后一列是因变量决定客户是离开还是留下。

图 1 导入数据片段
现在,让我们开始数据处理。
1)特征选择
第一个问题:我们需要所有的自变量来拟合模型吗🤔*?*答案是否。例如,行号、客户 ID 或姓氏对客户的去留没有影响。但是客户的年龄可能有变化,因为年轻的客户可能会离开银行。根据这个逻辑,我们可以判断哪些独立变量会影响结果。但是请记住,只有神经网络才能判断哪些特征对结果有很大影响。
所以自变量 X 是:
X = dataset.iloc[:, 3: 13].values
因变量 y 为:
y = dataset.iloc[:, 13].values
2)分类编码
神经网络只取数值进行学习。
因此,分类变量,如地理和性别需要编码成数字变量。这里我们用fit _ transform()的方法label encoderfromsk learn。我们为每一列创建两个标签编码器。
from sklearn.preprocessing import LabelEncoder
labelencoder_X_1 = LabelEncoder()
X[:, 1] = labelencoder_X_1.fit_transform(X[:, 1])
注意上面,我们输入索引 1,因为 X 中地理列的索引是 1。编码后,国家德语变为 1,法国为 0,西班牙为 2。用同样的方法,对性别列进行如下编码。
labelencoder_X_2 = LabelEncoder()
X[:, 2] = labelencoder_X_2.fit_transform(X[:, 2])
现在,男性是 1,女性变成 0(希望亲爱的女士不会觉得被冒犯,因为这纯粹是随机的😊).
3)一键编码
注意上面的编码后,德语变成了 1,法国是 0,西班牙是 2。然而,国与国之间没有关系秩序。即西班牙不比德国高,法国不比西班牙低。所以我们需要为分类变量创建 虚拟变量 来去除分类编码引入的数值关系。这里只需要为地理列做这件事,因为性别列只有 2 个类别。
from sklearn.preprocessing import OneHotEncoder
onehotencoder = OneHotEncoder(categorical_features = [1])
X = onehotencoder.fit_transform(X).toarray()
图 2 是编码数据。请注意,前 3 列是针对德国、法国和西班牙国家的一次性编码虚拟变量。

图 2 编码数据片段
为了避免伪数据陷阱,我们删除了第 1 列,因为具有 0 和 1 的两列足以编码 3 个国家。
X = X[:, 1:]
4)数据分割
接下来,将数据分为训练集和测试集,测试集占 20%。我们使用 random_state 来确保每次分割保持不变。
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y,test_size = 0.2, random_state = 0)
5)特征缩放
缩放特征是为了避免密集的计算,也是为了避免一个变量支配其他变量。对于二元分类问题,不需要缩放因变量。但是对于回归,我们需要缩放因变量。
正常的方法包括标准化和规范化,如图 3 所示。这里我们拿标准化来说。

图 3 特征缩放方法(作者创建的 Img)
from sklearn.preprocessing import StandardScaler
sc = StandardScaler()
X_train = sc.fit_transform(X_train)
X_test = sc.transform(X_test)
注意,我们使用来自训练集的标度集来转换测试集。这一步,数据处理就完成了。图 4 是您应该得到的测试数据。

图 4 最终测试数据片段
3。模型构建
这里我们使用 Keras 建立一个序列模型。第一步是初始化顺序模型。
classifier = Sequential()
对于这个问题,模型由两个密集层构成。
#add input layer and first hidden layer
classifier.add(Dense(output_dim = 6, init = ‘uniform’, activation = ‘relu’, input_dim = 11))#add 2nd hidden layer
classifier.add(Dense(output_dim = 6, init = ‘uniform’, activation = ‘relu’))
注意 Output_dim 对于隐藏层来说是一种艺术的选择,看你的经验了。作为提示,基于实验,选择它作为输入层节点数和输出层节点数的平均值。一个更明智的方法是使用参数调整,使用类似 k-fold 交叉验证的技术,用不同的参数测试不同的模型。这里,输入维度是 11 个特征,输出维度是 1,因此输出维度是 6。这里我们使用 均匀 分布来随机化 0 和 1 之间的权重。使用 ReLU 函数进行隐藏层激活,根据我的实验,这是最好的。请随意尝试你的。
下面添加输出层。
classifier.add(Dense(output_dim = 1, init = ‘uniform’, activation = ‘sigmoid’))
对于输出层,我们使用 Sigmoid 函数来获得客户离开或留在银行的概率。如果处理多分类,使用 Softmax 功能。
4。模型编译
模型编译是在网络上应用随机梯度下降(SGD) 。
classifier.compile(optimizer = ‘Adam’, loss =’binary_crossentropy’, metrics = [‘accuracy’])
这里我们使用 Adam (一种 SGD )作为优化器,寻找使神经网络最强大的优化权重。优化器所依据的损失函数是 二元交叉熵 。我们用来评估模型性能的指标是 准确性 。
5。模型拟合
由于我们使用 SGD ,批量被设置为 10,表明神经网络在 10 次观察后更新其权重。Epoch 是通过网络的一轮完整数据流。这里我们选 100。
classifier.fit(X_train, y_train, batch_size = 10, epochs = 100)
现在是拟合模型的时候了。大约 35 个历元后,模型精度收敛到 0.837 。不错吧,✨✨?
6。模型预测
随着模型的拟合,我们在测试数据上测试模型。使用阈值 0.5,将数据转换为真(离开)和假(停留)数据。
y_pred = classifier.predict(X_test)
y_pred = (y_pred > 0.5)
然后我们使用 混淆 _ 矩阵 在测试集上考察模型性能。
from sklearn.metrics import confusion_matrix
cm = confusion_matrix(y_test, y_pred
精度为 0.859,高于训练精度,暗示过拟合。
有了上面的模型,银行可以测试新客户,得到离开或留下的概率。然后,银行可以抽取 10%可能性最高的客户,对客户数据进行深度挖掘,了解他们为什么有可能离开。这就是人工神经网络的目的。
**现在最后一个问题:**如何对新客户数据进行预测🤔?例如,图 5 中的客户数据:

图 5 新客户数据
正如你所想象的,我们需要遵循同样的数据处理。首先,对变量进行编码。例如,在虚拟变量中,地理位置法国被编码为(0,0),性别男性为 1。按照这个方法,我们产生了下面的数组。
new_customer = [[0, 0, 600, 1, 40, 3, 60000, 2, 1, 1, 50000]]
好了,一个家庭作业问题:为什么我们使用 [[]] 来创建数组🤔?
下一步是将变量调整到与训练集相同的范围。
new_customer = sc.transform(sc.transform(new_customer))
数据准备就绪后,通过以下方式进行预测:
new_prediction = classifier.predict(new_customer)
new_prediction = (new_prediction > 0.5)
预测结果为假,可能性为 0.418% ,表明该客户不太可能离开银行👍👍。
太好了!仅此而已。如果你需要一些额外的,请访问我的 Github 回购(仅供参考,回购是积极维护的)💕💕。
神经网络优化的模型评估和参数调整
使用 Keras 的交叉验证和网格搜索的分步走查

Img 改编自 pixabay 通过链接
在之前的文章中,我们构建了一个人工神经网络来解决一个二元分类问题。如果你还记得的话,留做家庭作业的一个问题是为什么我们对新客户数据使用[[]]。 答案是我们需要将客户数据放入一个水平向量中,而不是垂直向量中,因为输入数据中的所有观察值都是行而不是列。希望你没弄错😎。**
本文主要关注模型优化的交叉验证和网格搜索,分为两个部分:
- 模型评估
- 参数调谐
- 摘要
现在让我们开始旅程🏃♀️🏃♂️.
- 模型评估
你可能想知道为什么我们要花精力在模型评估上🤔*?*问题是如果我们重新运行 ANN,每次模型不仅在训练集和测试集上产生不同的精度。因此,在一次测试中评估模型性能并不是最恰当的方式。
典型的方法是使用 K-fold 交叉验证。图 1 展示了它是如何工作的。

图 1 K 倍交叉验证图(作者创建的 Img)
我们将训练集分成 K 个折叠(例如,K=10)。然后在 9 个褶皱上训练模型,在最后剩下的褶皱上测试。10 折,我们用 9 个训练集和 1 个测试集做 10 个不同的组合,训练/测试模型 10 次。之后,我们取 10 次评估的平均值,并计算标准偏差。这样,我们可以确定模型属于哪个类别,如图 2 所示。

图 2 偏差-方差权衡图(Img 由作者创建)
为了实现 K-fold 交叉验证,我们在Keras:Keras classifier中使用了一个 scikit_learn 包装器。具体来说,我们使用 Keras 构建模型,使用 scikit_learn 进行交叉验证。首先要为模型架构构建一个函数,因为该函数是 Keras 包装器的必需参数。正如你在下面注意到的,这和我们之前建立的人工神经网络结构是一样的。
from keras.wrappers.scikit_learn import KerasClassifier
from sklearn.model_selection import cross_val_score
from keras.models import Sequential
from keras.layers import Densedef build_classifier():
classifier = Sequential()
classifier.add(Dense(units = 6, kernel_initializer = ‘uniform’, activation = ‘relu’, input_dim = 11))
classifier.add(Dense(units = 6, kernel_initializer = ‘uniform’, activation = ‘relu’))
classifier.add(Dense(units = 1, kernel_initializer = ‘uniform’, activation = ‘sigmoid’))
classifier.compile(optimizer = ‘adam’, loss = ‘binary_crossentropy’, metrics = [‘accuracy’])
return classifier
通过使用上述函数构建的分类器,我们创建了一个 KerasClassifier 对象。下面我们指定批量大小为 10,需要训练的模型的时期数为 100。
classifier = KerasClassifier(build_fn = build_classifier, batch_size = 10, epochs = 100)
现在,让我们使用***cross _ val _ score()***方法对分类器应用 K-fold 交叉验证。这个函数返回一个训练精度列表。参数 cv 是我们用于交叉验证的折叠数。这里,分类器将在 10 个不同的训练集上进行训练,这些训练集是从初始训练集中分离出来的。
accuracies = cross_val_score(estimator = classifier, X = X_train, y = y_train, cv = 10)
mean = accuracies.mean()
std = accuracies.std()
在这里,交叉验证可能需要一段时间。最终,我们得到了如图 2 所示的准确度为 10 的评估。平均准确度为 0.843,标准偏差为 1.60%🤪。

图 2 交叉验证的准确性
2.参数调谐
有了可靠的模型准确性,让我们尝试使用两种技术来提高它。
2.1 辍学正规化
我们没有提到的一个技术是退出正则化。**这是与高方差相关的过拟合的解决方案。**辍学是如何进行的?在每次训练迭代中,一些神经元被随机禁用,以防止它们相互依赖。通过覆盖这些神经元,神经网络每次都会保留不同的神经元配置,帮助神经网络学习数据的独立相关性。这可以防止神经元过度学习。
让我们使用 Keras 来实现它。基本上,我们在每个隐藏层后添加一个退出层。注意 p =0.1 意味着每次迭代将禁用 10%的神经元。
from keras.layers import Dropout
classifier.add(Dense(output_dim = 6, init = ‘uniform’, activation = ‘relu’, input_dim = 11))
#add dropout layer
**classifier.add(Dropout(p =0.1))** classifier.add(Dense(output_dim = 6, init = ‘uniform’, activation = ‘relu’))
#add dropout layer
**classifier.add(Dropout(p =0.1))** #add output layer
classifier.add(Dense(output_dim = 1, init = ‘uniform’, activation = ‘sigmoid’))
2.2 参数调整
神经网络有一些超参数,如时期数、批量大小和学习速率。参数调整就是找到模型的最佳参数。这里我们使用网格搜索来测试参数的不同组合。
为了实现它,我们在Keras:Keras classifier中使用一个 scikit_learn 包装器来包装神经网络。然后创建一个网格搜索对象,并在包装的分类器上应用参数调整。首先,如下构建分类器函数。
def build_classifier(optimizer):
classifier = Sequential()
classifier.add(Dense(units = 6, kernel_initializer = ‘uniform’, activation = ‘relu’, input_dim = 11))
classifier.add(Dense(units = 6, kernel_initializer = ‘uniform’, activation = ‘relu’))
classifier.add(Dense(units = 1, kernel_initializer = ‘uniform’, activation = ‘sigmoid’))
classifier.compile(optimizer = optimizer, loss = ‘binary_crossentropy’, metrics = [‘accuracy’])
return classifierclassifier = KerasClassifier(build_fn = build_classifier)
上面注意,没有指定历元数和批量大小,因为它们是我们计划调优的参数,将在下面的网格搜索对象中指定。
让我们为参数创建一个字典,其中包含我们希望模型尝试的值。
parameters = {‘batch_size’: [25, 32], ‘nb_epoch’: [100, 500], ‘optimizer’: [‘adam’, ‘rmsprop’]}
如果你注意到上面,我们有一个参数优化器用于 build_classifier() 函数。该参数提供了一种调优优化器的方法。为了实现网格搜索,我们首先用分类器和参数创建一个 GridSearchCV 类的对象。
grid_search = GridSearchCV(estimator=classifier, param_grid =parameters, scoring = ‘accuracy, cv = 10’)
最后,让我们在运行网格搜索以找到最佳参数的同时,在训练集上拟合 ANN。
grid_search = grid_search.fit(X_train, y_train)
我们最感兴趣的是产生最高精度的最佳参数。所以有了下文:
best_parameters = grid_search.best_params_
best_accuracy = grid_search.best_score_
最后,几个小时后,我们的精确度提高到了 0.849 ✨✨.最佳参数是批处理大小 25、纪元编号 500 和优化器 Adam,如图 3 所示。

图 3 参数调整的精度
3.总结
综上所述,通过交叉验证,我们发现该模型的精度约为 0.843。通过使用随机丢弃正则化和网格搜索,我们将模型精度提高到 0.849。通常,网格搜索可以分两步进行,第一步是找到大致范围,另一小步是细化最佳范围。
太好了!仅此而已!✨✨If 你需要一些额外的,访问我的 Github 页面。(仅供参考,回购得到积极维护💕💕)
使用 NVIDIA Clara 在 TrainingData.io 上自动检测胸部 CT 中的新冠肺炎感染(第二部分)
注释数据并训练您自己的分割模型,用于检测胸部 CT 中的新冠肺炎。请注意training data . io 上生成的 ggo/consolidation 仅用于研究目的,不用于临床诊断。
2020 年 3 月,为了帮助数据科学家研究新冠肺炎诊断工具,TrainingData.io 提供了一个免费的协作工作区,预装了开源数据集,包括胸部 X 射线和胸部 CT 图像。我们要感谢用户的贡献。我们从用户身上学到了很多。现在,TrainingData.io 推出了拖放式用户体验,将人工智能的力量带给世界各地抗击新冠肺炎感染的每一位数据科学家、医院和诊所。

患者胸部 CT 显示的新冠肺炎感染。
在与新冠肺炎的斗争中,医务人员有四种不同的诊断数据可供他们使用:a)RT-聚合酶链式反应测试结果,b)抗体测试结果,c)胸部 x 光成像,以及 d)胸部 CT 成像。RT-聚合酶链式反应测试结果和抗体检测结果正被用作检测新冠肺炎的第一步。胸部 x 光和胸部 CT 成像被用于通过被诊断患有新冠肺炎的患者的肺部观察疾病的进展。
无症状病例中的肺损伤:研究人员研究了无症状感染的临床模式,并在自然医学发表。他们发现,无症状的新冠肺炎病例会对肺部造成长期损害。在一项这样的研究中,发现无症状患者的胸部 CT 检查显示“条纹状阴影”,并且在某些情况下显示“毛玻璃阴影”,这是肺部炎症的迹象。
由于受这种病毒影响的人群规模庞大,研究无症状病例肺损伤的能力依赖于在胸部 ct 检查中自动检测和可视化新冠肺炎感染的软件工具的容易获得性。
胸部 CT 数据中的新冠肺炎磨玻璃影和实变
当新冠肺炎患者体内的病毒扩散时,肺部被称为肺泡的小气囊中就会积聚液体。这种液体的存在导致肺部发炎。肺部炎症的增长可以在 x 光和 CT 成像中观察到。肺部炎症表现为磨玻璃样阴影(GGOs ),随后是磨玻璃样实变。
医务人员必须使用一些标准来决定是给病人使用氧气治疗或呼吸机系统,还是让康复中的病人脱离呼吸机系统。在 CT 成像中可视化 GGOs 实变模式在帮助医务人员做出正确决策方面起着重要作用。
新冠肺炎培训数据的 GGOs 整合细分. io
从在 PCR 测试中被诊断患有新冠肺炎的患者的胸部 CT 数据集开始,数据科学家需要创建肺部的分割掩模和毛玻璃阴影(新冠肺炎感染)的分割掩模。TrainingData.io 提供了一个隐私保护的并行分布式框架,用于将注释工作外包给多个放射科医生。CT 检查中的所有切片都可以在像素级别进行精确注释,并在 TrainingData.io 提供的 3D 注释客户端中进行可视化。
GGOs 合并的半自动人工智能辅助分割
TrainingData.io 提供了一个分割 ML 模型,为输入胸部 CT 检查生成毛玻璃阴影/实变。该模型可用于初始分割的种子。放射科医生可以稍后修复自动分割的结果。

使用 TrainingData.io 自动分割新冠肺炎的 GGOs 合并
从带注释的胸部 CT 数据集到 ML(分割)模型,只需点击几下鼠标
为什么区域医院或诊所需要 ML 模型来分割使用其数据集训练的 GGOs 合并?这个问题的答案在于病毒变异背后的科学。新冠肺炎是由一种叫做新型冠状病毒的病毒引起的。已经发现这种病毒变异速度很快,在所有受影响的国家都发现有很大比例的遗传多样性。病毒的不同变异可能以不同方式影响当地人口。
一旦 CT 数据集和分割掩模准备就绪,数据科学家就必须重新训练现有的机器学习模型,以更好地适应当地的人口统计数据。这可以通过在 TrainingData.io 网络应用程序中点击几下来实现。
注意:training data . io 上生成的 ggo/consolidation 仅用于研究目的,不用于临床诊断。
[1]https://www.nature.com/articles/s41591-020-0965-6.pdf
[2]https://www.webmd.com/lung/what-does-covid-do-to-your-lungs
本博客最早发表于 TrainingData.io 博客。
系列第一篇:https://towards data science . com/新冠肺炎-成像-数据集-胸部-x 光-CT-用于注释-协作-5f6e076f5f22
使用在线注释工具注释您的图像!
图像标记变得简单

门的图像(由 Unsplash 上的 Robert Anasch 拍摄)
你刚刚得到了一个令人兴奋的项目,你必须建立一个程序来使用图像检测门是开着还是关着。你已经收集了几百张开门和关门的照片。现在,你需要注释和标记图像中的每扇门,以便你可以训练一个机器学习模型来检测开/关的门。
图像标注是为诸如对象检测、图像分类和图像分割等任务创建机器学习模型的重要步骤。
你在谷歌上搜索注释工具,找到了很多选项,但现在不知道该用哪种工具来注释你的图像。如果这是你,我将通过一个现有的开源注释工具,让你的决策过程变得简单一些。

不同的计算机视觉任务,每个任务都有注释类型
如果您想详细了解不同的图像注释类型:包围盒、多边形分割、语义分割、3D 长方体、关键点和界标、直线和样条线,在此阅读更多信息。
让我们进入开源在线注释工具——make sense。
MakeSense 是一个开放源代码的注释工具,在 GPLv3 许可下可以免费使用。它不需要任何高级安装,只需要一个网络浏览器来运行它。
- 开源
- 免费
- 基于网络的
用户界面简单易用。您只需上传您想要注释的图像,注释图像并导出标签。MakeSense 支持多种标注:包围盒、多边形和点标注。您可以导出不同格式的标签,包括 YOLO,VOC XML,VGG JSON 和 CSV。
根据该网站的说法,MakeSense 不存储图像,因为它们不会将图像发送到任何地方。
以下是使用 MakeSense 注释工具的分步指南。

MakeSense 主页
2.点击右下角的框进入注释页面,你会看到下面的页面,你可以上传你想注释的图片。

MakeSense 图像选择页面
3.选择并上传图像后,点击*“物体检测”*按钮。

MakeSense 上传图像页面
4.因为您没有加载任何标签,所以会要求您为项目创建标签名称列表。
要添加新标签,点击消息框左上角的+号,在*“插入标签”文本框中输入标签。对所有标签重复上述步骤。
添加完所有标签后,选择“开始项目”*。

MakeSense 创建标签页
5.在这里,您可以选择使用预先训练好的模型来帮助您进行标记,或者自己进行标记。对于这篇文章,让我们用*“我自己去”*并手动完成所有的标记。

MakeSense 手动注释选项
6.您将在左栏看到已上传的图像,在右栏看到注释,在中间栏看到当前选择进行注释的图像。
在注释栏中,您可以选择不同的注释类型:边界框、点、和多边形。对于这篇文章,让我们使用边界框注释,并在图像中注释开门和关门。

MakeSense 图像标签
要注释对象,只需将鼠标悬停在所选图像中的对象上,单击并拖动鼠标,即可创建一个所需大小的矩形框。
创建边界框后,会在右侧的边界框列下添加一个新条目。单击为对象选择所需的标签。
7.对所有图像中的所有对象重复注释步骤。
8.当您注释完所有图像后,就可以导出标签了。要导出,点击页面右上角的*“导出标签”按钮,选择您想要的输出格式,然后点击“导出”*。

MakeSense 出口标签
通过这些简单的步骤,您现在已经注释了您的数据集,并准备好训练您的机器学习模型。
使用该工具时,您需要记住以下几点:
- MakeSense 是一个在线网络工具。这意味着,您需要将您的所有图像加载到 web 门户来对其进行注释。
- MakeSense 不提供上传 zip 文件的选项。您将不得不通过选择您想要注释的所有图像来上传。
- MakeSense 并没有提供一种保存注释项目的方法。这意味着,如果您有意或无意地刷新您的 web 浏览器,您的所有注释进度都将消失,您将不得不从头开始(上传所有图像)。
- 您不能与您的团队协作处理同一个注释项目。
- 你可以使用人工智能来帮助加速你的图像注释任务。您可以选择两个选项:COCO SSD 对象检测模型用于包围盒注释,POSE-NET 姿势估计用于关键点注释。请注意,要使用 AI,您需要在开始项目之前选择此选项。一旦你选择不使用人工智能模式的帮助,你不能改变它。
考虑到以上几点,当您有多达几百个图像要注释时,比如在开/关门的例子中,MakeSense 是一个很好的选择。由于不需要设置或安装,当您有一个小数据集时,该工具会变得非常方便,您可以一次标注。你可以上传开放门户的图片,添加注释并导出标签。
如果一幅图像包含两扇门,并且您使用边界框注释,平均来说,您可以在 1 分钟内注释 10 幅图像。在一个小时内,您可以使用此工具注释大约 600 张图像。
如果您有一个大型数据集,比如说 10,000 张图像,我建议您查看其他离线注释工具(如果您单独工作),或者在线注释工具(如果您在团队中工作),它们可以选择暂停和恢复注释任务。另一种选择是将图像标注任务外包给其他公司,这些公司专门从事这项工作。
在这篇文章中,我们讨论了如何使用名为 MakeSense 的开源在线注释工具来注释图像数据,何时使用 MakeSense 以及一些限制。
您使用哪种图像注释工具? 在下面留下你的想法作为评论。
原载于*【www.xailient.com/blog】*。**
找一个预先训练好的人脸检测模型。点击这里下载。
查看这篇文章了解更多关于创建一个健壮的对象检测模型的细节。
关于作者
Sabina Pokhrel 在 Xailient 工作,这是一家计算机视觉初创公司,已经建立了世界上最快的边缘优化物体探测器。
宣布 PyCaret 2.0

https://www.pycaret.org
我们很高兴今天宣布 PyCaret 的第二次发布。
PyCaret 是一个开源的、Python 中的低代码机器学习库,可以自动化机器学习工作流。它是一个端到端的机器学习和模型管理工具,可以加快机器学习实验周期,让你更有效率。
与其他开源机器学习库相比,PyCaret 是一个替代的低代码库,可以用来替换数百行代码,只需要几个单词。这使得实验快速有效。
请参见 PyCaret 2.0 的详细发行说明。
为什么使用 PyCaret?

PyCaret 2.0 功能
正在安装 PyCaret 2.0
安装 PyCaret 非常容易,只需要几分钟。我们强烈建议使用虚拟环境来避免与其他库的潜在冲突。参见下面的示例代码,创建一个 conda 环境 并在该 conda 环境中安装 pycaret:
**# create a conda environment**
conda create --name yourenvname python=3.6 **# activate environment**
conda activate yourenvname **# install pycaret**
pip install **pycaret==2.0** **# create notebook kernel linked with the conda environment python -m** ipykernel install --user --name yourenvname --display-name "display-name"
如果你使用的是 Azure 笔记本或者 Google Colab,运行下面的代码来安装 PyCaret。
!pip install **pycaret==2.0**
当您使用 pip 安装 PyCaret 时,所有硬依赖项都会自动安装。点击此处查看依赖关系的完整列表。
👉PyCaret 2.0 入门
PyCaret 中任何机器学习实验的第一步都是通过导入相关模块来设置环境,并通过传递数据帧和目标变量的名称来初始化设置函数。参见示例代码:
样本输出:

输出被截断
所有预处理转换都在设置功能中应用。 PyCaret 提供超过 20 种不同的预处理转换,可以在设置函数中定义。点击这里了解更多关于 PyCaret 的预处理能力。

https://www.pycaret.org/preprocessing
👉对比车型
这是我们建议任何监督机器学习任务的第一步。此函数使用默认超参数训练模型库中的所有模型,并使用交叉验证评估性能指标。它返回训练好的模型对象类。使用的评估指标包括:
- **用于分类:**准确度、AUC、召回率、精确度、F1、Kappa、MCC
- 用于回归: MAE、MSE、RMSE、R2、RMSLE、MAPE
以下是使用 compare_models 函数的几种方法:
样本输出:

compare_models 函数的输出示例
👉创建模型
创建模型功能使用默认超参数训练模型,并使用交叉验证评估性能指标。这个函数是 PyCaret 中几乎所有其他函数基础。它返回训练好的模型对象类。以下是使用该功能的几种方法:
样本输出:

create_model 函数的示例输出
要了解更多关于创建模型功能的信息,点击此处。
👉调整模型
调整模型函数调整作为估计量传递的模型的超参数。它使用随机网格搜索和预定义的完全可定制的调谐网格。以下是使用该功能的几种方法:
要了解更多关于调谐模式功能的信息,点击此处。
👉集合模型
对于合奏基础学习者来说,可用的功能很少。 ensemble_model 、 blend_models 和 stack_models 就是其中的三个。以下是使用该功能的几种方法:
要了解更多关于 PyCaret 中集合模型的信息,请点击此处。
👉预测模型
顾名思义,这个函数用于推断/预测。你可以这样使用它:
👉绘图模型
绘图模型函数用于评估训练好的机器学习模型的性能。这里有一个例子:

plot_model 函数的输出示例
点击此处了解 PyCaret 中不同可视化的更多信息。
或者,您可以使用 evaluate_model 功能,通过笔记本内的用户界面查看图*。*

PyCaret 中的 evaluate_model 函数
👉实用函数
PyCaret 2.0 包括几个新的 util 函数,在使用 PyCaret 管理您的机器学习实验时非常方便。其中一些如下所示:
要查看 PyCaret 2.0 中实现的所有新功能,请参见发行说明。
👉实验记录
PyCaret 2.0 嵌入了 MLflow 跟踪组件作为后端 API 和 UI,用于在运行机器学习代码时记录参数、代码版本、指标和输出文件,并用于以后可视化结果。以下是你如何在 PyCaret 中记录你的实验。
输出(在本地主机上:5000)

https://本地主机:5000
👉将所有这些放在一起—创建您自己的 AutoML 软件
使用所有函数,让我们创建一个简单的命令行软件,它将使用默认参数训练多个模型,调整顶级候选模型的超参数,尝试不同的集成技术,并返回/保存最佳模型。下面是命令行脚本:
该脚本将动态选择并保存最佳模型。在短短的几行代码中,你已经开发了你自己的 Auto ML 软件,它有一个完全成熟的登录系统,甚至还有一个呈现漂亮排行榜的用户界面。
使用 Python 中的轻量级工作流自动化库,您可以实现的目标是无限的。如果你觉得这有用,请不要忘记给我们 github 回购⭐️,如果你喜欢 PyCaret。
想了解更多关于 PyCaret 的信息,请在 LinkedIn 和 Youtube 上关注我们。
重要链接
【PyCaret 2.0 发行说明
用户指南/文档 Github
安装 PyCaret
笔记本教程
投稿于 PyCaret
想了解某个特定模块?
单击下面的链接查看文档和工作示例。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}