







使用机器学习构建混响检测系统

德尔塔-梅尔光谱图
介绍
混响或简称混响是声学和心理声学中的一个术语,用来解释声音一旦产生后的持久性。一个例子是在一个大教堂里拍手(很有毅力),而不是在一个铺着地毯的小房间里拍手(没有那么多毅力)。
这是由构成声音产生环境的材料的反射和吸收造成的。与石头或砖造的大教堂相比,铺着地毯、有窗帘和家具的房间会吸收更多的声音。
我们想要检测这一点的原因是,如果有人在过于混响的环境中对着手机说话或唱歌。我们可能希望能够警告进行录音的人,因为这可能会降低录制的声音质量。
这里有两个声音示例,分别演示了混响很小的录音和混响很大的录音。
混响很小。
很多混响。
我们实际上试图用我们的机器学习(ML)模型来测量的是混响衰减时间。这可以定义为声音逐渐消失所需要的时间,以秒为单位。这种情况的技术术语是 RT-60 时间,即声音的压力水平下降 60db 所需的时间。

图一。这说明了 RT-60 的衰变时间(来源:Wkipedia)。
参考上面的两段录音,第二段录音听起来像是有人在小浴室里唱歌。在浴室唱歌的效果是歌手被所有回荡的声音淹没。这是不可取的。
了解 RT-60 时间的另一个用例是,它可以作为另一个 ML 系统的输入,用于去混响信号。这种系统的一个例子可以在[1]中找到。
我们为什么要做这个项目?
我们是如何解决这个问题的?
我们提出了一个使用卷积神经网络(CNN)来解决问题的 ML 模型,其中我们设计了自己的卷积滤波器来解决问题。我们实际上采用了[2]中的模型来解决我们的问题。我们还通过脉冲响应卷积生成了自己的数据集。
我们用了什么数据?
我们收集了大约 4000 份人们唱歌和谈话的“干”录音。我们所说的“干燥”是指它们是在几乎没有声音反射(即混响)的环境中录制的。
我们使用“干”录音的原因是,我们可以使用不同的 RT-60 时间为每个录音人工添加混响,即我们可以给 1 号录音 1 秒的 RT-60 时间,给 2 号录音 1.1 秒的 RT-60 时间。
我们通过称为卷积的过程将人工混响添加到每个信号中。我们取一个 RT-60 时间为 1 秒的脉冲响应,并将其与“干”信号卷积,得到“湿”信号。
脉冲响应是指我们获取一个短暂的“脉冲”信号,并使其通过一个动态系统,以测量其输出,即其响应。为了捕捉音乐厅或大教堂的声学特征,我们会在空间中产生一个脉冲(我们刺破一个气球)并记录下来。一旦我们有了一个位置的脉冲响应,我们就可以用另一个录音(有人唱歌)进行卷积。这让我们能够听到他们在特定空间的声音。很酷吧?
从 OpenAIR 数据集[3]中收集了 70 个脉冲响应,我们的模型的 RT60s 从 0.24 秒到 12.3 秒不等。OpenAIR 是一个允许用户共享脉冲响应和相关声学信息的在线资源。
我们是如何创建数据集的?
我们将 4000 个声音记录中的每一个与所有 70 个脉冲响应进行卷积,并根据其 RT-60 时间标记每个数据点。这给了我们总共 280,000 个不同 RT-60 时间的记录。
为了模拟真实的背景噪声,我们还在每个记录中随机添加了信噪比为-55db 和-45db 的粉红噪声。
我们为所有 RT-60 时间创建了分类箱,这允许我们将它们分成 20 个不同的类。图 2 显示了 RT-60 时间的分布,表 1 描述了如何将它们放置到时间仓中。

图 2:所用数据集中的 RT-60 时间分布。

表 1:用于 RT-60 分类器的时间仓。
特征抽出
接下来,我们必须提取相关特征,以获得音频的良好表示。我们最初选择使用 Mel 声谱图,因为这些声谱图很好地代表了声音的音色。
音色可以描述为声音的颜色。如果我在钢琴上弹奏一个中 C 音,然后在吉他上弹奏相同的音,它们的音高相同,但听起来不同。这种声音上的差异就是音色。
Mel 光谱图看起来像图 3 的左侧。

图 3:同一声音的 Mel 声谱图和 delta-Mel 声谱图。
我们可以清楚地看到声音随着时间的推移而衰减。尾巴最长的部分在 3-6 秒。
在我们的特殊情况下,我们没有使用标准的 Mel 光谱图进行训练,而是使用 delta-Mel 光谱图。Delta-Mel 频谱图是音色随时间变化的微分或轨迹。我们认为这将更好地呈现应用于每个人声的不同 RT-60 时间。
图 3 右手侧示出了δ-Mel 谱图。你可以看到 delta-Mel 谱图中出现的视觉信息比 Mel 谱图中多得多。
一旦所有这些特征都被提取出来,我们需要把它们提供给 CNN 进行训练。我们用于特征提取的参数如下。参数:M = 40 个梅尔频带,N = 2381 帧,𝑓s = 44.1,1024 样本/帧,布莱克曼-哈里斯窗口,2048 样本 FFT 大小,1024 样本跳跃大小。
ML 模型
如前所述,我们使用 CNN 作为我们的 ML 模型,因为这种类型的 ML 模型已经被证明在音频和图像分类上都是有效的。我们使用了[2]中提出的滤波器模型,但是我们根据我们的问题调整了尺寸。
E-net 滤波器模拟对应于早期反射的时间特征:

R-net 滤波器对与可接受的记录反射相对应的时间特征进行建模:

T-net 滤波器模拟对应于混响尾音中较长反射的时间特征:

3 个卷积层与 ReLU 激活功能并行放置(E-Net、R-Net、T-Net)。e 网、r 网、t 网由 1 × 𝑛滤波核组成,其中𝑛从短到长变化。
接下来是内核大小为 4 x N 的 3 个最大池层、1 个平坦层和 1 个丢弃层,丢弃概率为 50%,以避免过度拟合。
最后,有一个具有 20 路软最大激活函数的密集层对应于我们的类。
分类交叉熵被选为损失函数。Adam 是最乐观的,初始学习率为 0.01,在每个时期递减 0.1。
选择 80%训练/ 10%验证/ 10%测试分割,通过 10 重交叉验证来评估模型。该模型如图 4 所示。

图 Keras 中 RT-60 估算模型的图示。
结果
结果显示该模型对于更长的 RT-60 时间是最有效的,而当我们具有更短的时间时会有些混乱。结果可以在图 5 中看到

图 5:用于测试数据的 RT-60 估计模型的标准化混淆矩阵。
结论
结果是令人鼓舞的,我们设计的系统的精确度相差不远。然而,我们肯定可以做更多的事情来改进模型,例如数据集分布。
我们发现我们使用的过滤器类型非常有效,并且通过使用 delta-Mel 光谱图,我们得到了略微更好的结果。我们计划在一个更复杂的去混响模型中使用模型来通知所需的 RT-60 时间估计,该模型用于我们在 AI 的另一个正在进行的项目。音乐。如果你想了解更多我们的工作,请查看我们的时事通讯(【https://www.aimusic.co.uk/newsletter-sign-up】T2)。
参考
[1] —吴,博等,“一种基于深度神经网络的混响时间感知语音去混响方法”(2016),IEEE/ACM 音频、语音和语言处理汇刊。
[2] — Pons,j .和 Serra,x .,“利用卷积神经网络设计用于建模时间特征的高效架构”(2017),声学、语音和信号处理国际会议(ICASSP)。
[3] — Murphy,Damian T .和 Shelley,Simon,“OpenAIR:交互式听觉化网络资源和数据库”(2010),音频工程学会第 129 次会议(AES)。
感谢
非常感谢方大卫(【https://www.linkedin.com/in/davidwengweifong/】)为这个项目付出的努力。
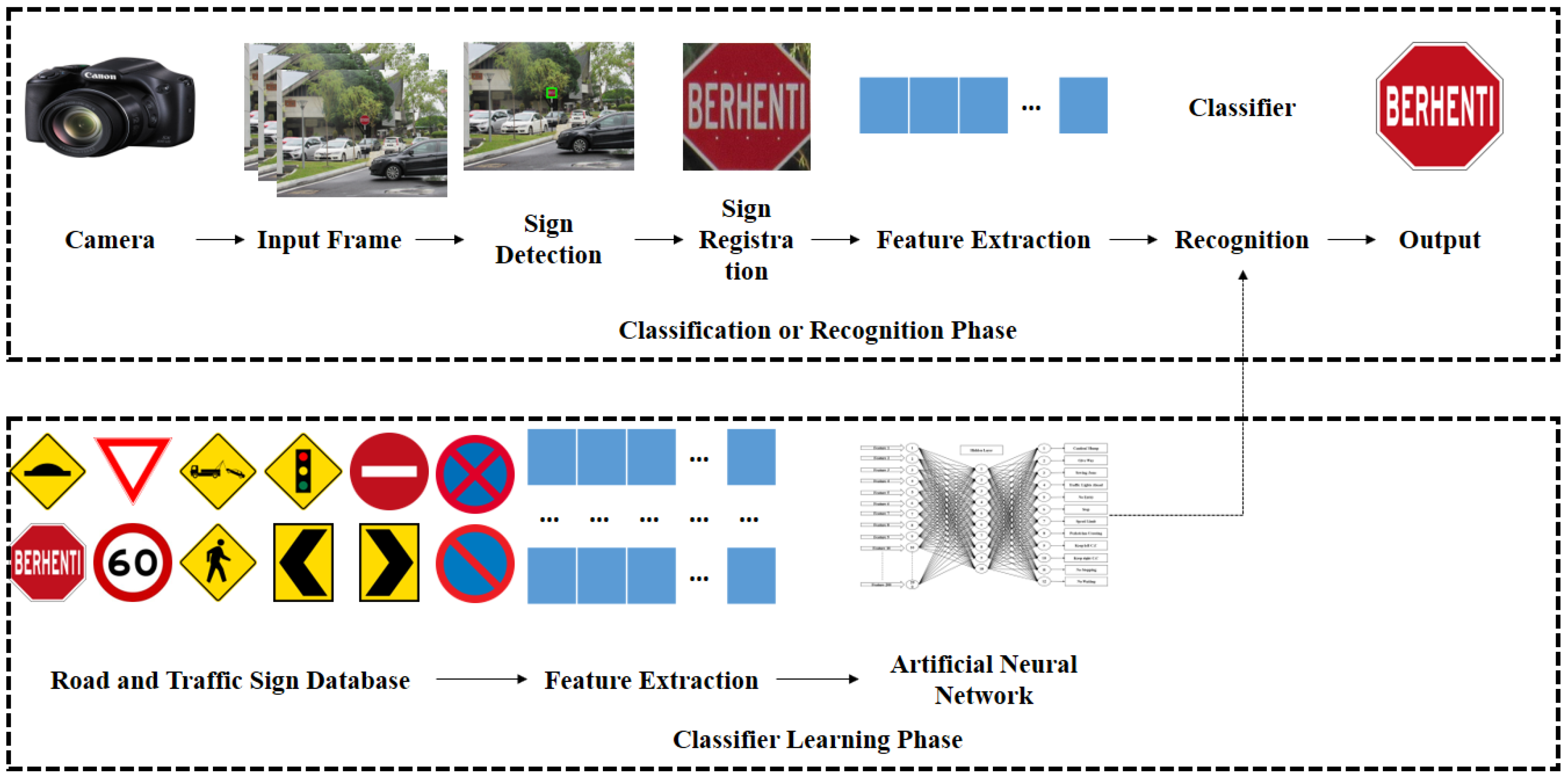
在 Keras 中构建路标分类器
编写一个 CNN,在 Keras 框架中对超过 43 种类型的路标进行分类

路标分类过程(来源
有这么多不同类型的交通标志,每一种都有不同的颜色、形状和大小。有时,有两个标志可能有相似的颜色,形状和大小,但有两个完全不同的含义。我们究竟怎样才能给计算机编程序来正确分类道路上的交通标志呢?我们可以通过创建自己的 CNN 来为我们分类不同的路标。
下载数据
在本教程中,我们将使用 GTSRB 数据集,该数据集包含超过 50,000 张德国交通标志的图像。共有 43 个类别(43 种不同类型的标志,我们将对其进行分类)。单击下面的链接下载数据集。
多类别、单图像分类挑战
www.kaggle.com](https://www.kaggle.com/meowmeowmeowmeowmeow/gtsrb-german-traffic-sign)
当你在电脑中打开数据集时,数据集内应该有 6 个路径(3 个文件夹和 3 个电子表格),如下所示。

meta 文件夹应该有 43 个不同的图像(范围从 0-42)。 测试 文件夹就是一堆测试图片。 train 文件夹应该有 43 个文件夹(范围也是从 0 到 42),每个文件夹包含各自类别的图像。
现在您已经有了数据集,并且数据集包含了所有需要的数据,让我们开始编码吧!
本教程将分为 3 个部分: 加载数据 , 建立模型 和 训练模型 。
不过在开始之前,请确保您的计算机上安装了 Jupiter 笔记本,因为本教程是在 Jupiter 笔记本上完成的(这可以通过安装 Anaconda 来完成。点击下面的链接安装 Anaconda。)
[## Anaconda Python/R 发行版-免费下载
开源的 Anaconda 发行版是在…上执行 Python/R 数据科学和机器学习的最简单的方法
www.anaconda.com](https://www.anaconda.com/distribution/)
加载数据
好了,现在我们已经安装了 Jupyter 笔记本,也安装了数据集,我们准备开始编码了(Yesss)!
首先,让我们导入加载数据所需的库和模块。
import pandas as pd
import numpy as np
import os
import cv2
import matplotlib.pyplot as plt
import randomimport tensorflow as tf
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import BatchNormalization
from tensorflow.keras.layers import Conv2D
from tensorflow.keras.layers import MaxPooling2D
from tensorflow.keras.layers import Activation
from tensorflow.keras.layers import Flatten
from tensorflow.keras.layers import Dropout
from tensorflow.keras.layers import Dense
from tensorflow.keras.utils import to_categorical
from tensorflow.keras.preprocessing.image import ImageDataGenerator
from tensorflow.keras.optimizers import Adam
第一束是创建 load_data 函数所需的库。第二组是我们构建模型所需要的东西。如果您愿意,可以在不同的内核中导入每个束,但这真的无关紧要。
创建 L oad_Data 函数
要开始加载数据,让我们创建一个变量来表示数据集的存储位置。确保你把字母 r 放在你的路径字符串前面,这样你的计算机就知道它应该读这个字符串。
注意:我的道路将与你的不同。要获得数据集的路径,您应该转到数据集所在的文件夹,单击一次数据集(不要打开它,只要让您单击它),然后单击屏幕左上角的按钮 复制路径

不要双击数据文件夹,只需单击一次将其高亮显示
然后把路径粘贴到你的 jupyter 笔记本上(就像我下面做的那样)。确保你在你的字符串前面加了一个 r ,这样 pc 就知道它应该读取这个文件了。
data_path = r"D:\users\new owner\Desktop\Christmas Break\gtsrb-german-traffic-sign"
接下来,让我们定义将数据从计算机加载到笔记本中的函数。
def load_data(dataset):
images = []
classes = [] rows = pd.read_csv(dataset)
rows = rows.sample(frac=1).reset_index(drop=True)
我们的load _ data函数取 1 个参数,这是我们数据集的路径。之后,我们定义两个列表, 图片 和 类 。 图像 列表将存储图像数组,而 类 列表将存储每个图像的类编号。
在下一行中,我们将打开 CSV 文件。
最后一行使我们的数据随机化,这将防止模型过度适应特定的类。
*for i, row in rows.iterrows():
img_class = row["ClassId"]
img_path = row["Path"] image = os.path.join(data, img_path)*
for 循环遍历所有行。 。iterrows() 函数为每一行返回一个索引(第一行是 0,然后是 1,2,3,…)。直到最后一行)。
我们从 ClassId 列获取图像的类,从 路径 列获取图像数据。
最后,我们从电子表格中获取图像的路径,并将其与数据集的路径相结合,以获得图像的完整路径
*image = cv2.imread(image)
image_rs = cv2.resize(image, (img_size, img_size), 3) R, G, B = cv2.split(image_rs) img_r = cv2.equalizeHist(R)
img_g = cv2.equalizeHist(G)
img_b = cv2.equalizeHist(B) new_image = cv2.merge((img_r, img_g, img_b))*
首先,我们读取图像数组(将它从数字数组转换成实际的图片,以便我们可以调整它的大小)。然后,我们将图像尺寸调整为 32 X 32 X 3,(如果所有图像的尺寸都相同,那么训练模型的速度会更快)。
接下来的 5 行执行直方图均衡,这是一种提高图像对比度的均衡技术。如果您有兴趣了解直方图均衡化的更多信息,请单击此处的
注意:这段代码仍然在前面代码块的 for 循环中
*if i % 500 == 0:
print(f"loaded: {i}") images.append(new_image)
classes.append(img_class) X = np.array(images)
y = np.array(images)
return (X, y)*
仍然在 for 循环中,我们将编写一个 if 语句,打印我们已经加载了多少图像。这条语句将每 500 幅图像打印一次,只是为了让我们知道我们的函数实际上在工作。
接下来,我们将刚刚从数据集中提取的图像添加到之前定义的列表中。
现在在 for 循环之外,我们将把 图像 和 类 列表重新定义为 Numpy 数组。这是为了我们以后可以在阵列上执行操作。
最后,当我们从数据集中提取完所有图像后,我们将返回元组中的 图像 和 类 列表。
定义超参数
超参数是神经网络无法学习的参数。它们必须由程序员在培训前明确定义
*epochs = 20
learning_rate = 0.001
batch_size = 64*
我们的第一个超参数(我会用缩写 HYP), epochs ,告诉神经网络应该完成多少次完整的训练过程。在这种情况下,神经网络将训练自己 20 次(检查所有 50,000 张图像,并用 12,000 张测试图像验证自己 20 次)!
学习率告诉我们每次会更新多少权重。学习率往往在 0 到 1 之间。
批量大小告诉我们神经网络将一次循环通过多少图像。计算机不可能一次循环通过所有 50,000 张图像,它会崩溃的。这就是为什么我们有批量大小。
载入数据
*train_data = r"D:\users\new owner\Desktop\TKS\Christmas Break\gtsrb-german-traffic-sign\Train.csv"
test_data = r"D:\users\new owner\Desktop\TKS\Christmas Break\gtsrb-german-traffic-sign\Test.csv"(trainX, trainY) = load_data(train_data)
(testX, testY) = load_data(test_data)*
首先,我们将定义测试和训练数据集的路径,使用我们以前用来定义数据集路径的相同方法
现在,我们将使用我们的 load_data 函数加载训练和测试数据。
我们将把 图片 列表存储在变量中,把 类 列表存储在 trainY 变量中,并对***【testX】*和 testY 进行同样的操作。
注意:这一步可能需要一段时间,取决于你电脑的规格。我的花了 10-15 分钟。
为培训准备数据
**print("UPDATE: Normalizing data")
trainX = train_X.astype("float32") / 255.0
testX = test_X.astype("float32") / 255.0print("UPDATE: One-Hot Encoding data")
num_labels = len(np.unique(train_y))
trainY = to_categorical(trainY, num_labels)
testY = to_categorical(testY, num_labels)class_totals = trainY.sum(axis=0)
class_weight = class_totals.max() / class_totals**
现在我们要对数据进行归一化处理。这使得我们可以将数据中的值缩小到 0 到 1 之间,而之前的值在 0 到 255 之间。
接下来,我们将一次性编码测试和训练标签。本质上,一键编码是用二进制值(1 和 0)而不是分类值(“红色”或“蓝色”)来表示每个类的一种方式。这是通过创建一个主对角线为 1,其余值为 0 的对角矩阵来实现的。矩阵的维数等于类的数量(如果有 20 个类,则矩阵是 20×20 的矩阵)。在矩阵中,每行代表一个不同的类,因此每个类都有其唯一的代码。如果你想了解更多关于一键编码的知识,这里有一个很好的资源
最后,我们将通过给每个等级分配一个权重来说明等级中的不平等。
构建模型
现在是时候构建实际的 CNN 架构了。首先,让我们导入必要的库和模块:
**import tensorflow as tf
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import BatchNormalization
from tensorflow.keras.layers import Conv2D
from tensorflow.keras.layers import MaxPooling2D
from tensorflow.keras.layers import Activation
from tensorflow.keras.layers import Flatten
from tensorflow.keras.layers import Dropout
from tensorflow.keras.layers import Dense**
这里,我们导入 Tensorflow,这是 Python 中的一个框架,允许我们构建 ML 模型,我们从 Tensorflow 导入 Keras,这进一步简化了我们的模型!之后,我们导入一系列不同的图层来构建模型。如果你想了解更多关于这些层的具体功能,请浏览我在 CNN 上的文章。
卷积神经网络揭秘没有任何花哨的技术术语!
towardsdatascience.com](/a-simple-guide-to-convolutional-neural-networks-751789e7bd88)
在我们开始构建模型之前,我想指出没有“合适的”方法来构建模型。你的 CNN 没有固定的层数、尺寸或层数类型。你应该试着用它来看看哪一个能给你最好的准确度。我给你一个最准确的。
class RoadSignClassifier:
def createCNN(width, height, depth, classes):
model = Sequential()
inputShape = (height, width, depth)
这一次,我们要创建一个类,名为RoadSignClassifier(任何名字都可以)。在该类中,有一个函数, createCNN, 接受 4 个参数。我们将使用顺序 API,它允许我们逐层创建模型。
model.add(Conv2D(8, (5, 5), input_shape=inputShape, activation="relu"))
model.add(MaxPooling2D(pool_size=(2, 2)))
这是我们的第一个卷积层。我们定义了输出的维度(8 X 8 X 3),并使用了激活函数“relu”。我们继续使用 Conv2D — MaxPooling2D 序列 2 次以上。
model.add(Conv2D(16, (3, 3), activation="relu"))
model.add(BatchNormalization())
model.add(Conv2D(16, (3, 3), activation="relu"))
model.add(BatchNormalization())
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Conv2D(32, (3, 3), padding="same", activation="relu"))
model.add(BatchNormalization())
model.add(Conv2D(32, (3, 3), padding="same", activation="relu"))
model.add(BatchNormalization())
和上次一样,除了这次我们包括**批量归一化。**只是加速训练而已。
model.add(Flatten())
model.add(Dropout(0.5))
model.add(Dense(512, activation="relu")) model.add(Dense(classes, activation="softmax"))
return model
现在,我们展平最终卷积层的输出,执行一次丢弃,然后进入最终的密集层。最终密集层的输出等于我们拥有的类的数量。
这基本上就是构建模型的全部内容。是时候继续前进了!
训练模型
现在是有趣的部分(实际上这是我们必须等待 30 分钟模型训练 lol 的部分)。是时候训练我们的模型识别路标了!
data_aug = ImageDataGenerator(
rotation_range=10,
zoom_range=0.15,
width_shift_range=0.1,
height_shift_range=0.1,
shear_range=0.15,
horizontal_flip=False,
vertical_flip=False)
在这里,我们正在执行数据增强。数据扩充在我们的数据集中创建图像的修改版本。它允许我们向数据集添加图像,而无需我们收集新的图像。在 Keras 中,我们使用imagedata generator模块来执行数据扩充。
model = RoadSignClassifier.createCNN(width=32, height=32, depth=3, classes=43)
optimizer = Adam(lr=learning_rate, decay=learning_rate / (epochs))
第一行定义了我们的模型。我们使用类 RoadSignClassifier, 并定义类的宽度、高度、深度和数量。
在第二行中,我们创建了我们的优化器,在本例中是 Adam 优化器。我们将学习率初始化为之前设置的值(0.001),我们还将学习率设置为在每个时期减少(这是 衰减 参数,它减少了过度拟合)。
model.compile(optimizer=optimizer, loss="categorical_crossentropy", metrics=["accuracy"])fit = model.fit_generator(
data_aug.flow(train_X, trainY, batch_size=batch_size),
epochs=epochs,
validation_data=(test_X, testY),
class_weight=class_weight,
verbose=1)
第一行编译模型。我们创建模型并定义优化器、损失和时期数。
在第二行,我们装配模型(这是培训发生的地方)。我们的data _ aug . flow方法对我们之前定义的图像应用增强。 历元的数量 被设置为 20。对于验证数据,我们使用我们的测试数据。 verbose 被设置为 1,这意味着 Keras 将在您进行训练时显示模型的进度。
现在,您已经完成了模型代码的编写。是时候运行它了。运行一段时间后,您应该会得到如下输出:

前三个时期(在第三个时期,您的准确度应该是 70–80%)
然后,在您完成了所有的 epochs 之后,您应该会得到类似如下的输出:

最后三个纪元(你的准确率应该超过 90%)
你的准确率至少要达到 **90%。**如果没有,就去玩玩模型架构。最终,您的模型将返回大约 90%或更高的准确率。
酷!
现在你完成了你的分类器!感觉不错吧!好了,今天就到这里。希望你从这篇文章中学到了一些东西!如果你遇到什么困难,可以发邮件到 nushainef@gmail.com 给我,我会尽力帮助你。祝你的 ML 之旅好运。
其他很好的选择
如果这个教程对你没有吸引力,或者你只是在寻找另一个教程,这里有另一个很棒的教程,我发现它真的很有用!
[## 基于 Keras 和深度学习的交通标志分类——PyImageSearch
在本教程中,您将学习如何训练自己的交通标志分类器/识别器能够获得 95%以上的…
www.pyimagesearch.com](https://www.pyimagesearch.com/2019/11/04/traffic-sign-classification-with-keras-and-deep-learning/)**
使用 Tensorflow 和 OpenCV 与 Python 构建石头剪刀布人工智能
古老的游戏被重新想象和更新……

图片由 EsquireME
该项目的代码可以在我的 Github 找到
[## HOD101s/RockPaperScissor-AI-
这个回购是针对初学者谁想要尝试和建立自己的机器人容易。所以让我们开始吧!任何…的基础
github.com](https://github.com/HOD101s/RockPaperScissor-AI-)
简介:
这个项目的基础是实验深度学习和图像分类,目的是建立一个简单而有趣的臭名昭著的石头剪刀布游戏的迭代。首先,我想说这个项目是我在 5 月份的 COVID19 隔离期间无聊的产物,希望在你读到这封信的时候,一切都恢复正常了。通过这个解释的过程,我的目的是解释这个项目的基础,以简单的术语面向初学者。让我们开始吧…
在构建任何类型的深度学习应用时,都有三个主要步骤:
1.收集和处理数据
2.建立一个合适的人工智能模型
3.部署使用
整个项目涉及并与我的 Github repo 齐头并进,所以请做好准备以供参考。
收集我们的数据:

图片由 Sookyung An 来自 Pixabay
任何深度学习模型的基础都是数据。任何机器学习工程师都会同意,在 ML 中,数据远比算法本身更重要。我们需要收集石头、布、剪刀这些符号的图像。我没有下载别人的数据并在上面进行训练,而是制作了自己的数据集,并鼓励大家也建立自己的数据集。稍后,尝试更改数据并重新训练模型,以查看数据对深度学习模型的严重影响。
我已经使用 Python 的 OpenCV 库进行了所有与相机相关的操作。所以这里的标签也是指图片属于什么类 ie。RPS,根据标签,图像保存在适当的目录中。 ct 和 maxCt 是保存图像的起始和结束索引。剩下的是标准的 OpenCV 代码,以获取网络摄像头的饲料和保存图像到一个目录。一个需要注意的关键点是我所有的图片都是 300 x 300 尺寸。运行后,我的目录树看起来像这样。
C:.
├───paper
│ paper0.jpg
│ paper1.jpg
│ paper2.jpg
│
├───rock
│ rock0.jpg
│ rock1.jpg
│ rock2.jpg
│
└───scissor
scissor0.jpg
scissor1.jpg
scissor2.jpg
如果你是指 Github repo getData.py 为你做的工作!!
预处理我们的数据:
计算机理解数字,我们有图像供我们使用。因此,我们将把所有的图像转换成它们各自的矢量表示。此外,我们的标签尚未生成,因为已建立的标签不能是文本,所以我已经使用 shape_to_label 字典为每个类手动构建了 One-Hot-Encoded 表示。
由于我们已经根据类别将图像保存在目录中,因此目录名用作标签,并使用 shape_to_label 字典将其转换为一键显示。接下来,我们遍历系统中的文件来访问图像,cv2 . imread()函数返回图像的矢量表示。我们通过翻转图像和放大图像来手动增加数据。这增加了我们的数据集大小,而无需拍摄新照片。数据扩充是生成数据集的关键部分。最后,图像和标签存储在单独的 numpy 数组中。
更多关于数据扩充的信息请点击。
用迁移学习构建我们的模型:
当涉及到处理图像数据时,有许多预先训练好的模型可用,这些模型已经在数据集上进行了训练,这些数据集有数千个标签可供我们使用,这要感谢 Tensorflow 和 Keras 通过它们的应用程序 api 分发了这些模型。这使得在我们的应用程序中包含这些预先训练好的模型变得轻而易举!

图片来自洛伦佐·法米格里尼
简言之,迁移学习采用预先训练的模型,不包括做出最终预测的最终层,从而留给我们模型的强大部分,该部分可以区分这种情况下图像中的特征,并将这些信息传递给我们自己的密集神经网络。
为什么不训练自己的模型?这完全取决于你!!然而,使用迁移学习可以在很多时候让你的进步更快,从某种意义上说,你可以避免重新发明轮子*。*
其他一些受欢迎的预培训模型:
- InceptionV3
- VGG16/19
- 雷斯内特
- MobileNet
这里有一篇关于迁移学习的有趣的文章!
注意:每当我们处理图像数据时,数据卷积神经层的使用几乎是已知的。这里使用的迁移学习模型有这些层次。欲了解 CNN的更多信息,请访问。
实现:

gif by Gifer
我已经使用 DenseNet121 模型进行特征提取,其输出最终将输入到我自己的密集神经网络中。
要点:
- 由于我们的图像是 300x300,指定的输入形状是相同的。额外的 3 代表 RGB 层,因此这一层有足够的神经元来处理整个图像。
- 我们使用 DenseNet 层作为我们的基础/第一层,然后是我们自己的密集神经网络。
- 我已经将可训练参数设置为真,这也将重新训练 DenseNet 的重量。这给了我更好的结果,虽然 twas 相当耗时。我建议在您自己的实现中,通过更改这些参数(也称为超参数)来尝试不同的迭代。
- 因为我们有 3 个类石头剪子布,最后一层是一个密集层,有 3 个神经元和 softmax 激活。
- 这最后一层返回图像属于 3 个类别中的特定类别的概率。
如果你指的是 GitHub repo train.py 负责数据准备和模型训练!
至此,我们已经收集了数据,构建并训练了模型。剩下的唯一部分是使用 OpenCV 进行部署。
OpenCV 实现:
这个实现的流程很简单:
- 启动网络摄像头并读取每一帧
- 将此帧传递给分类 ie 模型。预测类别
- 用电脑随机移动
- 计算分数
上面的代码片段包含了相当重要的代码块,剩下的部分只是让游戏更加用户友好,RPS 规则和得分。
所以我们从加载我们训练好的模型开始。接下来是石器时代的 for-loop 实现,在开始程序的预测部分之前显示倒计时。预测之后,分数会根据玩家的移动进行更新。

图片由马纳斯·阿查里亚
*我们使用 *cv2.rectangle()显式绘制一个目标区域。在使用 prepImg() 函数进行预处理后,只有这部分帧被传递给模型进行预测。
完整的 play.py 代码可以在我的回购协议上的这里获得。
结论:
我们已经成功地实施并理解了这个项目的运作。所以继续前进,分叉我的实现并进行试验。一个主要的改进可能是增加手部检测,这样我们就不需要明确地绘制目标区域,模型将首先检测手部位置,然后做出预测。我尽量让我的语言对初学者友好,如果你还有任何问题,请发表评论。我鼓励你改进这个项目,并把你的建议发给我。精益求精!
* [## Manas Acharya -机器学习工程师- KubixSquare | LinkedIn
机器学习和数据科学爱好者,曾在前端 Web 领域担任全栈开发人员…
www.linkedin.com](https://www.linkedin.com/in/manas-acharya/) [## 基于 Tensorflow 和 OpenCV 的人脸检测
有效的实时面具检测。
medium.com](https://medium.com/@manasbass.99/facemask-detection-using-tensorflow-and-opencv-824b69cad837)*
为每个使用人工智能的人建立一个更安全的互联网
使用 TensorFlow JS 构建的 web 扩展过滤 NSFW 图像。

来自 Pexels 的 Andrea Piacquadio 的照片
本项目使用的所有源代码都可以在 这里 。
互联网是一个未经过滤的地方。当你随意浏览你的订阅源时,没有人能保证你会偶然发现什么。
即使在互联网上不起眼的地方,你也可能偶然发现不合适的或“不适合工作”的图片。
这让我想到了一个可以从网上过滤掉这些内容的解决方案。有几点需要考虑:
- 所有的图像应该从用户加载的网站进行监控。
- 应该在不离开客户机的情况下处理图像。
- 它应该很快,应该在所有网站上工作。
- 它应该是开源的。
解? 一个 web 扩展,它会检查页面中加载的图像是否是 NSFW 的,并且只在发现它们是安全的情况下才显示它们。

输入 NSFW 滤波器
NSFW 过滤器 是一个 web 扩展,目前运行在 Chrome 和 Firefox 上,使用机器学习来过滤 NSFW 图像。
nsfwjs 模型用于检测加载图像的内容。该模型被训练用于检测 NSFW 图像的唯一目的。
使用这个已经优化为在浏览器上运行的模型,我们构建了一个扩展,它可以读取浏览器中加载的网页中的图像,并且只在发现它们是安全的情况下才使它们可见。
开源开发模式
NSFW 过滤器是完全开源的,它将永远是。
我们有一份来自世界各地的优秀贡献者名单,我们将继续改进它并添加更多功能。
因为这样的产品还不存在,所以可能会有更多的改进空间和功能,而这些肯定是当前团队完全忽略的。
因此,我们将它发布到野外,并开始接受来自世界各地具有广泛想法的开发人员的贡献。
现在,我们有了第一个版本。
它是如何在引擎盖下工作的
当一个网页被加载时,该扩展选择页面上加载的所有图像,并对用户隐藏这些图像。
这些图像然后由机器学习模型检查,该模型将检测 NSFW 内容。
如果图像被发现而不是具有 NSFW 内容,那么它们是可见的。NSFW 的图像仍然隐藏着。

NSFW 滤波的基本工作流程
用例
该扩展的用途很广泛。无论您是在工作电脑上使用它还是在孩子的电脑上使用它。
你不想在工作的时候偶然发现 NSFW 的内容吧?
你不希望你的孩子在做学校报告时偶然发现这些内容,对吗?
解决办法,用 NSFW 滤波!
这个项目的所有源代码都可以在我们的 GitHub repo 中获得。
从网站过滤 NSFW 图片的网络扩展。它使用 TensorFlow JS-一个机器学习框架-来…
github.com](https://github.com/navendu-pottekkat/nsfw-filter)
有不同想法的人的贡献可以极大地改进这个项目。
任何形式的贡献都是受欢迎的!
快乐编码!
构建面向大规模事实核查和问题回答的语义搜索引擎
开发一个语义检索模型,并使用它来建立一个新冠肺炎语义搜索引擎。

段落检索是事实核查和问题回答系统的一个非常重要的部分。大多数系统通常只依赖稀疏检索,稀疏检索会对召回率产生重大影响,尤其是当相关段落与查询语句几乎没有重叠词时。在本文中,我们展示了我们如何开发一个优于稀疏段落检索的文本嵌入模型,以及我们如何利用它来构建 Quin ,一个关于新冠肺炎疫情事实的语义搜索引擎。
段落检索
段落检索问题定义如下:给定一个段落语料库 D 和一个查询 q,我们希望使用带有两个参数 q 和 d ∈ D 的评分函数 f 返回与查询最相关的前 k 个段落,该评分函数计算相关性分数 f(q,d) ∈ R。
稀疏表示的局限性
TF-IDF 和 BM25 将文本表示为稀疏的高维向量,可以使用倒排索引数据结构对其进行有效搜索。这些稀疏表示可以有效地减少基于关键字的搜索空间。比如,当我们想回答一个类似*“电影《盗梦空间》是谁导演的?”,我们显然想把重点放在包含单词电影和盗梦空间的段落上。然而,稀疏表示可能是限制性的,因为它们需要查询和段落之间的单词重叠,并且它们不能捕捉潜在的语义关系。例如,如果我们想要检索声明“年轻人死于新冠肺炎”的段落,包含类似于“婴儿死于新冠肺炎”或“男孩死于新冠肺炎”*的句子的相关段落将被遗漏。
潜在密集检索
基于变压器和语言建模任务预训练的神经模型,如 BERT、GPT 和 T5,已经导致许多自然语言处理任务的显著改进,包括段落检索。在我们的系统中,我们使用了一个基于 BERT 的文本嵌入模型。更具体地说,我们使用φ(q)和φ(d)的点积作为我们的段落评分函数:

段落评分功能
其中φ(。)是一个嵌入函数,它将一个段落或查询映射到一个密集向量。函数 f 的选择允许我们利用 FAISS 库进行有效的最大内积搜索,并轻松地将我们的系统扩展到数百万个文档。对于嵌入函数φ(。),我们使用 BERT-base 的平均令牌嵌入,它已经在许多任务上进行了微调:

段落嵌入函数
其中 BERT(d,I)是段落 d 中第 I 个标记的嵌入,而|d|是 d 中标记的数量。下图显示了称为 QR-BERT 的密集检索模型,该模型确定段落是否与查询相关。我们的密集检索模型由一个编码器组成,该编码器将查询和段落嵌入到相同的 k 维空间中。查询和段落之间的相似性(段落的相关性)由它们的嵌入表示的余弦相似性给出。

暹罗密集检索模型
训练嵌入模型
QR-BERT 通过一组查询段落示例进行训练。设 D+是正查询段落对的集合。我们通过最大化对数似然来估计评分函数的模型参数θ:

等式 1:损失函数
条件概率 p(d|q)由 softmax 近似表示:

等式 2:给定 q,检索 d 的概率
注意,获得等式 2 中所有通道的分母在计算上是昂贵的。因此,我们将计算仅限于当前训练批次中的段落。最终损失函数由下式给出:

等式 3:最终损失函数
其中 D_B 是训练批次 B 中的段落集,D_B+是 B 中的正查询-段落对集。使用 Adam 优化器在 MSMARCO 数据集上训练该模型。我们的实验表明,QR-BERT 比 BM25 段落检索好得多。
使用 NLI 数据进行预训练
我们发现,在自然语言推理数据上预先训练嵌入模型实际上可以改进它。我们将两个流行的 NLI 数据集(SNLI 和 MultiNLI)合并为一个,称为 NLI,并且我们还从现有的问答数据集派生出一个新的 FactualNLI 数据集。在我们的论文中详细描述了推导新 NLI 数据集的方法。FactualNLI 数据集用于训练和评估用于事实检查的检索模型,也用于预训练用于答案检索的模型。使用 NLI 数据,我们使用分类目标对模型进行预训练:

等式 4:分类目标
其中 u 是前提句的嵌入,v 是假设句的嵌入,W_3×3k 是线性变换矩阵,其中 k = 768 是 BERT-base 的隐藏表示的维数,而[u;五;| u v |]是 u、v 及其绝对差| u v |的级联向量。我们使用交叉熵损失和 Adam 优化器对 QR-BERT 进行预训练。我们的实验表明,在 NLI 和 FactualNLI 上的预训练提高了检索召回率。
混合检索
在我们的实验中,当我们合并 BM25 检索器和 QR-BERT 的顶部结果,并使用二元相关性分类器对它们重新排序时,我们得到了最佳结果。我们使用 MSMARCO 数据集(如 Nogueira 等人的 monoBERT)训练了基于 BERT-large 的二元相关性分类器。
关于模型评估的更多细节可以在我们的论文中找到。
定性分析
下表显示了 QR-BERT 和 BM25 检索到的一些问题和主张的主要摘录:

QR-BERT 和 BM25 检索到的与新冠肺炎相关的查询片段
对于前两个查询,只有 QR-BERT 返回相关段落。这是因为基于关键字的检索不足以显示最相关的段落。对于第三个查询,两个模型都成功地检索到了相关的片段。对这个查询的一个有趣观察是,QR-BERT 检索到的片段只有单词病毒与查询相同。这表明该模型有能力捕捉文本的潜在含义,并识别同义词术语,如取消(对于取消)和语义相近的术语,如会议(接近事件)。
一般来说,当查询足够具体以允许通过关键字匹配容易地发现相关段落时,稀疏检索工作得很好。然而,这在实践中是不够的。我们的实验表明,密集检索模型可以给出更准确的结果,并且当在具有稀疏检索结合重新排序的架构中使用时,我们可以实现显著更高的召回率。
奎因系统
使用密集检索模型,我们开发了 Quin,这是一个可扩展的语义搜索引擎,可以返回最多五个句子的片段,包含与新冠肺炎疫情相关的问题或声明的答案。

Quin 语义搜索引擎
Quin 有一个模块用于抓取 RSS 提要,并存储新闻文章的 html 源代码。我们去掉样板文件,分离出新闻文章的主要内容。通过在每篇文章的句子序列上使用滑动窗口,我们从干净的文本中提取每篇文章的 5 个句子的片段。我们利用 nltk 库将文档分割成句子。为了促进高效的大规模检索,我们在片段上构建了两个索引:(a)用于 BM25 检索的高效稀疏倒排索引(关键字索引),以及(b)支持最大内积搜索的 FAISS 密集(语义)索引。

索引(左)和搜索(右)
该查询用于在片段的稀疏和密集(FAISS)索引上执行搜索。我们从每个索引中检索前 500 个结果,并计算每个结果的相关性分数。结果按照它们的相关性分数排序,我们输出最终排序的结果列表。当查询是一个语句时,我们有一个额外的步骤,使用 NLI 模型将检索到的段落分为三类,这样它们显示在三个选项卡下;所有、支持和反驳的证据。
除了新闻,Quin 还支持与新冠肺炎相关的研究论文的语义搜索。在撰写本文时,Quin 拥有超过 20 万篇与新冠肺炎相关的新闻文章和 10 万篇研究出版物的索引。我们希望这个系统将有助于对抗错误信息,并帮助一些研究人员寻找新冠肺炎的治疗方法。
用 fastText 和 BM25 建立句子嵌入索引
探索如何建立一个文本搜索系统

杰西卡·鲁斯切洛在 Unsplash 上的照片
本文涵盖了句子嵌入和code question1.0。最新发布的 codequestion 使用了句子转换器。 此处阅读更多 。
自然语言处理是机器学习领域中发展最快的领域之一。许多领域都在发生深度创新,让用户能够更快地找到更好的数据。曾经只有拥有大量 IT 预算和资源的人才能实现的技术和算法现在可以在笔记本电脑上运行。虽然 NLP 不是一个新问题,但是有一些经过时间考验的方法表现得非常好。最简单的方案很多时候可能是最好的方案。
本文将探索各种方法,并对构建文本搜索系统进行评估。
全文搜索引擎
允许用户输入搜索查询并找到匹配结果的全文搜索引擎是一种可靠的解决方案,具有很好的性能历史。在这些系统中,每个文档都被标记化,通常去掉一列常用词,称为停用词。这些令牌存储在倒排索引中,每个令牌都根据令牌频率等指标进行加权。
搜索查询也使用相同的方法进行标记化,并且搜索引擎为查询标记找到最佳匹配记录。有一些高度分布式且非常快速的解决方案已经在生产中证明了自己多年,比如 Elasticsearch 。今天最常见的令牌加权算法是 BM25 。它工作得非常好,仍然很难被击败。
嵌入
单词嵌入在过去的 5-7 年里发展迅速,首先从 Word2vec 开始,接着是 GloVe 和 fastText 。这些算法通常都构建 300 维向量。现在有了更高级的嵌入,它们的尺寸更大(768+维度),能够理解句子中单词的上下文,其中 BERT 嵌入处于领先地位。换句话说,超越简单的单词包方法。
易于使用、健壮的库已经存在,使开发人员能够利用这些进步。 HuggingFace Transformers 是一个优秀的库,拥有一组快速增长的前沿功能。通用句子嵌入是另一个重要的发展领域。拥有一个单一的动态模型,可以将文本转换为下游学习任务的嵌入是至关重要的。句子变形金刚构建在变形金刚之上,是一个可以构建高质量句子嵌入的库的优秀例子。
性能考虑因素
随着构建完美嵌入的步伐越来越快,这对试图解决当前业务问题的实践者来说意味着什么。你总是使用最新和最大的进步吗?你总是需要吗?有更复杂的权衡。当处理数百万甚至数十亿个数据点时,处理时间与可接受的功能之间的关系总是一个需要讨论的话题。这些对话考虑了可用的资源、可用的时间以及满足给定问题的要求所必需的内容。
评估文本搜索解决方案时要问的一些问题。
- 我需要多快的查询响应和索引速度?需要多高的精确度?
- 我可以访问哪些计算资源?我可以访问 GPU 吗?
- 我有多少条记录和多少存储空间?假设向量使用 32 位(4 字节)浮点,一个 300 维的向量每条记录需要 300x4 字节。对于 4096 维向量,它是 4096x4,对于相同的数据,需要 13 倍多的空间。
- 一个全文搜索引擎能满足要求吗?
我们在建造什么?
codequestion 是一个允许用户直接从终端询问编码问题的应用程序。许多开发人员在开发和运行 web 搜索时会打开一个 web 浏览器窗口,因为会出现问题。codequestion 致力于加快这一过程,以便您可以专注于开发。它还允许无法直接访问互联网或互联网访问受限的用户运行代码问题查询。下面是一个实际应用的例子。

codequestion 应用程序演示
codequestion 由一个 SQLite 数据库提供支持,该数据库存储了问答回复。提供了使用堆栈交换数据的预训练模型。该数据库还可以加载自定义的问题列表。
精心设计解决方案
最好总是从最简单的解决方案开始,然后一步一步往上走。我们能不能对数据做一个全文索引,然后就到此为止?添加外部文本索引并不是我们所希望的,因为这个应用程序被设计为本地安装在开发人员的机器上。SQLite 确实提供了一个名为 FTS5 的文本索引解决方案。这是很容易添加的,似乎工作得很好。但是一种测量结果的方法对于真正判断它的效果是必要的。
评估结果
构建了一个包含 100 个查询的数据集来判断一个索引的工作情况。对于每个查询,手动运行 web 搜索,并为该查询存储顶部堆栈交换结果。选择了流行的查询(即在 python 中解析日期),并注意不总是在查询和答案之间有直接的标记匹配。
平均倒数排名(MRR) 用于测量人工注释的搜索查询的最高结果得分。标准 FTS5 索引对 100 个查询数据集的评分如下。
MRR = 45.9
作为开始还不算太坏。是时候增加复杂性来决定权衡是否值得了。
BM25
SQLite 的 FTS5 默认令牌加权方案是使用 tf-idf 。它还支持 BM25,得分为:
MRR = 49.5
绝对是个进步。但感觉还是有很大的提升空间。让我们试试句子嵌入。
快速文本句子嵌入
标准文本标记搜索正被同义词和不完全匹配所困扰。单词嵌入是找到不完全匹配的相似结果的好方法。
所需功能的示例如下:

linux 解码音频文件查询
查询“linux 解码音频文件”返回了类似“通过 linux 命令行播放 mp3 或 wav 文件”的问题。单词 decode 和 audio 没有出现在返回的结果中,但是 decode 类似于 play,audio 类似于 mp3/wav。
上面的示例查询被标记为[“linux “,” decode “,” audio “,” file”]。可以使用 fastText 为每个标记检索单词嵌入。为了构建句子嵌入,嵌入可以被平均在一起以创建单个嵌入向量。
快速文本+ BM25
平均效果出奇的好。但是如果我们可以两全其美,使用 BM25 来衡量每个标记对句子嵌入的贡献有多大呢?这就是 codequestion 采用的方法。BM25 索引建立在数据集之上。使用预先训练的快速文本向量加上 BM25,得分为:
MRR = 66.1
比直 BM25 (66.1 比 49.5)有相当大的进步!
定制训练的快速文本嵌入
这种级别的功能是性能和结果的可接受组合。但还有最后一件事可以尝试,这可能会进一步提高分数,即在问题数据库本身上定制训练的 fastText 嵌入模型。使用根据数据分数训练的 fastText 嵌入,如下所示:
MRR = 76.3
又一次,相当大的进步。我们可以继续尝试 BERT 嵌入模型,该模型得分更高,但也需要更多计算/存储。fastText + BM25 不考虑顺序,所以类似“python convert UTC to localtime”的查询可以匹配“python convert localtime to UTC”。BERT 会更好地处理这个用例。但是对于这个项目,嵌入方法工作得很好。
构建索引
嵌入本身只是一堆数字。一旦完整的数据存储库被转换为句子嵌入,就需要有一种方法来为查询找到相似的结果。
余弦相似度是比较两个向量相似程度的常用方法。最简单的方法是强力比较查询向量和每个结果,并返回最相似的结果。对于小型数据集,这种方法很有效。但是随着数据的增长,它无法扩展。
Faiss 是一个向量相似性搜索库,可以在这方面提供帮助。它可以量化向量以减少存储量,并支持可扩展的近似最近邻搜索。Faiss 支持高性能搜索,提供结果准确性和速度的良好结合。
结论
本文介绍了一种评估如何构建搜索系统的方法,从而产生一个句子嵌入索引。这条路不会总是通向同一个终点,但是像这样的渐进方法应该有助于找到问题的最佳解决方案。
使用 Scikit-Learn 构建情感分类器
训练线性模型以将 IMDb 电影评论分类为正面或负面

情感分析是自然语言处理中的一个重要领域,是自动检测文本情感状态的过程。情感分析广泛应用于客户的声音材料,如亚马逊等在线购物网站的产品评论、电影评论或社交媒体。这可能只是一个将文本的极性分类为正/负的基本任务,或者它可以超越极性,查看情绪状态,如“快乐”、“愤怒”等。
在这里,我们将建立一个分类器,能够区分电影评论是正面还是负面的。为此,我们将使用 IMDB 电影评论的大型电影评论数据集 v 1.0【2】。该数据集包含 50,000 条电影评论,平均分为 25k 训练和 25k 测试。标签在两个类别(阳性和阴性)之间保持平衡。分数为<= 4/10 的评论被标记为负面,分数为>= 7/10 的评论被标记为正面。中性评论不包括在标记的数据中。该数据集还包含用于无监督学习的未标记评论;我们不会在这里使用它们。对一部特定电影的评论不超过 30 条,因为同一部电影的评级往往是相关的。给定电影的所有评论或者在训练集中或者在测试集中,但是不在两者中,以避免通过记忆电影特定的术语来获得测试准确度。
数据预处理
在数据集被下载并从档案中提取出来后,我们必须将其转换为更合适的形式,以便输入到机器学习模型中进行训练。我们首先将所有的审查数据组合成两个 pandas 数据帧,分别代表训练和测试数据集,然后将它们保存为 csv 文件: imdb_train.csv 和 imdb_test.csv 。
数据帧将具有以下形式:

其中:
- 评论 1,评论 2,… =电影评论的实际文本
- 0 =负面评价
- 1 =正面评价
但是机器学习算法只能处理数值。我们不能只是将文本本身输入到机器学习模型中,然后让它从中学习。我们必须,以某种方式,用数字或数字向量来表示文本。一种方法是使用单词袋模型[3],其中一段文本(通常称为文档)由该文档词汇表中单词计数的向量表示。这个模型没有考虑语法规则或单词排序;它所考虑的只是单词的频率。如果我们独立地使用每个单词的计数,我们将这种表示命名为单字。一般来说,在一个 n-gram 中,我们考虑出现在给定文档中的词汇表中 n 个单词的每个组合的计数。
例如,考虑这两个文档:

这两个句子中遇到的所有单词的词汇是:

d1 和 d2 的单字表示:

d1 和 d2 的二元模型是:

通常,如果我们使用所谓的术语频率乘以逆文档频率(或 tf-idf )来代替字数,我们可以获得稍微好一点的结果。也许听起来很复杂,但事实并非如此。耐心听我说,我会解释的。这背后的直觉是这样的。那么,在文档中只使用术语的频率会有什么问题呢?尽管一些术语在文档中出现的频率很高,但它们可能与描述出现它们的给定文档不太相关。这是因为这些术语也可能在所有文档集合中出现频率很高。例如,电影评论的集合可能具有出现在几乎所有文档中的特定于电影/电影摄影的术语(它们具有高的文档频率)。因此,当我们在文档中遇到这些术语时,这并不能说明它是积极的还是消极的评论。我们需要一种方法将术语频率(一个术语在文档中出现的频率)与文档频率(一个术语在整个文档集合中出现的频率)联系起来。那就是:

现在,有更多的方法用来描述术语频率和逆文档频率。但最常见的方法是将它们放在对数标度上:

其中:

我们在第一个对数中添加了 1,以避免在计数为 0 时得到-∞。在第二个对数中,我们添加了一个假文档以避免被零除。
在我们将数据转换成计数或 tf-idf 值的向量之前,我们应该删除英文的停用词[ 6][7]。停用词是在语言中非常常见的词,通常在自然文本相关任务(如情感分析或搜索)的预处理阶段被移除。
请注意,我们应该只基于训练集来构建我们的词汇表。当我们处理测试数据以进行预测时,我们应该只使用在训练阶段构建的词汇,其余的单词将被忽略。
现在,让我们创建数据框并将其保存为 csv 文件:
文本矢量化
幸运的是,对于文本矢量化部分,所有困难的工作都已经在 Scikit-Learn 类CountVectorizer【8】和TfidfTransformer【5】中完成了。我们将使用这些类将 csv 文件转换成 unigram 和 bigram 矩阵(使用计数和 tf-idf 值)。(事实证明,如果我们只对大 n 使用 n 元语法,我们不会获得很好的准确性,我们通常使用所有 n 元语法,直到某个 n。因此,当我们在这里说二元语法时,我们实际上是指 uni+二元语法,当我们说 unigrams 时,它只是一元语法。)这些矩阵中的每一行将代表我们数据集中的一个文档(review ),每一列将代表与词汇表中的每个单词相关联的值(在单字的情况下)或与词汇表中最多两个单词的每个组合相关联的值(双字)。
CountVectorizer有一个参数ngram_range,它需要一个大小为 2 的元组来控制包含什么 n 元语法。在我们构造了一个CountVectorizer对象之后,我们应该调用.fit()方法,将实际的文本作为参数,以便让它学习我们收集的文档的统计数据。然后,通过对我们的文档集合调用.transform()方法,它返回指定的 n-gram 范围的矩阵。正如类名所示,这个矩阵将只包含计数。为了获得 tf-idf 值,应该使用类TfidfTransformer。它有.fit()和.transform()方法,使用方式与CountVectorizer类似,但它们将前一步获得的计数矩阵作为输入,而.transform()将返回一个带有 tf-idf 值的矩阵。我们应该只在训练数据上使用.fit(),然后存储这些对象。当我们想要评估测试分数或者每当我们想要做出预测时,我们应该在将数据输入到我们的分类器之前使用这些对象来转换数据。
请注意,为我们的训练或测试数据生成的矩阵将是巨大的,如果我们将它们存储为普通的 numpy 数组,它们甚至不适合 RAM。但是这些矩阵中的大部分元素都是零。因此,这些 Scikit-Learn 类使用 Scipy 稀疏矩阵[9] ( csr_matrix [10]更准确地说),它只存储非零条目,节省了大量空间。
我们将使用具有随机梯度下降的线性分类器sklearn.linear_model.SGDClassifier【11】作为我们的模型。首先,我们将以 4 种形式生成和保存我们的数据:unigram 和 bigram 矩阵(每个都有计数和 tf-idf 值)。然后,我们将使用带有默认参数的SGDClassifier来训练和评估这 4 种数据表示的模型。之后,我们选择导致最佳分数的数据表示,并且我们将使用交叉验证调整具有该数据形式的模型的超参数,以便获得最佳结果。
选择数据格式
现在,对于每个数据表单,我们将其分成训练和验证集,训练 a SGDClassifier并输出分数。
这是我们得到的结果:
*Unigram Counts
Train score: 0.99 ; Validation score: 0.87
Unigram Tf-Idf
Train score: 0.95 ; Validation score: 0.89
Bigram Counts
Train score: 1.0 ; Validation score: 0.89
Bigram Tf-Idf
Train score: 0.98 ; Validation score: 0.9*
最好的数据形式似乎是带有 tf-idf 的 bigram,因为它获得了最高的验证精度:0.9;我们接下来将使用它进行超参数调整。
使用交叉验证进行超参数调整
对于这一部分,我们将使用RandomizedSearchCV [12],它从我们给出的列表中随机选择参数,或者根据我们从scipy.stats指定的分布(例如均匀);然后,通过进行交叉验证来估计测试误差,在所有迭代之后,我们可以在变量best_estimator_、best_params_和best_score_中找到最佳估计值、最佳参数和最佳得分。
因为我们想要测试的参数的搜索空间非常大,并且在找到最佳组合之前可能需要大量的迭代,所以我们将参数集分成两部分,并分两个阶段进行超参数调整过程。首先我们会找到 loss、learning_rate 和 eta0(即初始学习率)的最优组合;然后是惩罚和α。
我们得到的输出是:
*Best params: {'eta0': 0.008970361272584921, 'learning_rate': 'optimal', 'loss': 'squared_hinge'}
Best score: 0.90564*
因为我们得到了“learning_rate = optimal”是最好的,那么我们将忽略 eta0(初始学习率),因为当 learning_rate='optimal '时它没有被使用;我们得到这个值 eta0 仅仅是因为这个过程中的随机性。
*Best params: {'alpha': 1.2101013664295101e-05, 'penalty': 'l2'}
Best score: 0.90852*
所以,我得到的最佳参数是:
*loss: squared_hinge
learning_rate: optimal
penalty: l2
alpha: 1.2101013664295101e-05*
保存最佳分类器
测试模型
并且得到了 90.18% 的测试准确率。这对于我们简单的线性模型来说是不错的。有更先进的方法可以给出更好的结果。该数据集目前的最新水平是 97.42% [13]
参考
[1] 情感分析—维基百科
【2】用于情感分析的学习词向量
【3】词袋模型—维基百科
【4】Tf-IDF—维基百科
【5】TfidfTransformer—Scikit—学习文档
【6】停用词—维基百科
【7】A 压缩稀疏行矩阵
【11】SGD classifier—sci kit—learn 文档
【12】RandomizedSearchCV—sci kit—learn 文档
【13】使用余弦相似度训练的文档嵌入进行情感分类
朱庇特笔记本可以在这里找到。
我希望这些信息对你有用,感谢你的阅读!
这篇文章也贴在我自己的网站这里。随便看看吧!
使用 ML.NET 和 Azure 函数构建无服务器机器学习 API
构建无服务器 API 的回顾性学习,该 API 使用 ML 构建的回归模型。网

更新: 你现在可以从 Azure Serverless 社区网站 下载这个项目的完整样本 !(如果你想进一步探索 Azure 函数,还有一些很棒的例子!)
随着 ML.NET(API)的发布,C#开发人员可以用它来为他们的应用程序注入机器学习能力,我一直热衷于将我对 Azure 函数的知识与 API 结合起来,构建一些古怪的无服务器机器学习应用程序,这将允许我增强我的 GitHub 档案,并迎合所有的时髦爱好者!
了解如何使用开源 ML.NET 来构建定制的机器学习模型,并将它们集成到应用程序中。教程…
docs.microsoft.com](https://docs.microsoft.com/en-us/dotnet/machine-learning/)
(当然,也是为了提高自己的技能和学习新的东西😂)
这个帖子不会是教程。我写这篇文章更多的是回顾我在构建应用程序时所做的设计决策,以及我所学到的关于不同组件如何工作的东西。如果你读了这篇文章,并决定在你的现实世界中应用它,希望你能在你的项目中应用我学到的东西,或者更好的是,扩展我正在处理的想法和场景。
我将更多地关注我对 ML.NET API 本身的了解,而不是花太多时间在 Azure 函数如何工作上。如果你想得到这个代码,这里有 GitHub 上的回购。
因为我做这个项目只是为了一点乐趣,我确实采取了一些在现实生活中不起作用的捷径,所以请对此表示同情(我相信你会的😊).
应用概述。
这个例子建立在 ML.NET 团队在其文档中提供的出租车旅行回归教程的基础上。但是对于这个示例,我已经针对下面的场景对该教程进行了一点扩展。
假设我们经营一家出租车公司,每天晚上我们都会收到一份全天出租车行程的文件。我们希望建立一个回归模型,让我们的客户可以用它来预测他们打车的费用。
为此,我构建了两个 Azure 函数:
- ServerlessPricePredictor。ModelTrainer 获取一个本地 CSV 文件,并在其基础上训练一个回归模型。如果模型非常适合(使用 R 平方值),那么模型将被上传到 Azure Blob 存储中的容器。该函数使用定时器触发器来模拟定时批处理作业。
- ServerlessPricePredictor。API 然后在一个 HTTP 触发器中使用 Azure Blob 存储中训练好的模型来创建基于输入数据(JSON 有效负载)的预测,并将该预测插入 Azure Cosmos DB。
模特训练器功能
在 MLContext,创建我们的机器学习管道所需的所有操作都是通过 MLContext 类提供的。这允许我们执行数据准备、特征工程、训练、预测和模型评估。
为了让我们加载数据来训练我们的回归模型,model 为我们提供了一个 IDataView 类来描述数字或文本表格数据。IDataView 类为我们提供了一个加载数据文件的方法,我只是将数据文件放在项目的一个文件夹中。
然后,我们可以使用 MLContext 类来执行我们的机器学习任务。首先,我使用 LoadFromTextFile 方法将本地文件加载到 IDataView 对象中。然后,为了创建我们的管道,我已经确定我想使用我们的 FareAmount 列作为我们的标签,我们希望我们的回归模型预测,我已经对我们的 VendorId、RateCode 和 PaymentType 列应用了一个热编码(因为这是一个回归模型,我们对分类值应用了一个热编码,以将它们转换为数值),然后我已经将我想使用的所有特性连接到一个特性列中。之后,我在我的管道上应用了一个回归任务。
我以前玩过一点 Spark MLlib 库,所以在 ML.NET 的过程非常相似,我认为这很酷!😎
最后,我创建了一个it transformer的模型对象,将我们的管道安装到 IDataView 对象上。
// Read flat file from local folder_logger.LogInformation("Loading the file into the pipeline");IDataView dataView = mlContext.Data.LoadFromTextFile<TaxiTrip>(trainFilePath, hasHeader: true, separatorChar: ',');// Create the pipeline_logger.LogInformation("Training pipeline");var pipeline = mlContext.Transforms.CopyColumns(outputColumnName: "Label", inputColumnName: "FareAmount").Append(mlContext.Transforms.Categorical.OneHotEncoding(outputColumnName: "VendorIdEncoded", inputColumnName: "VendorId")).Append(mlContext.Transforms.Categorical.OneHotEncoding(outputColumnName: "RateCodeEncoded", inputColumnName: "RateCode")).Append(mlContext.Transforms.Categorical.OneHotEncoding(outputColumnName: "PaymentTypeEncoded", inputColumnName: "PaymentType")).Append(mlContext.Transforms.Concatenate("Features", "VendorIdEncoded", "RateCodeEncoded", "PassengerCount", "TripDistance", "PaymentTypeEncoded")).Append(mlContext.Regression.Trainers.FastTree());// Fit the model_logger.LogInformation("Fitting model");var model = pipeline.Fit(dataView);
我用 LoadColumnAttribute 修饰了我的类属性,它指定了数据集中列的索引:
public class TaxiTrip{[LoadColumn(0)]public string VendorId;[LoadColumn(1)]public string RateCode;[LoadColumn(2)]public float PassengerCount;[LoadColumn(3)]public float TripTime;[LoadColumn(4)]public float TripDistance;[LoadColumn(5)]public string PaymentType;[LoadColumn(6)]public float FareAmount;}
对于我们的预测,我创建了另一个使用 ColumnNameAttribute 装饰的类。这允许我们使用 FareAmount 属性(这是我们试图创建预测的属性)来生成我们的分数。
public class TaxiTripFarePrediction{[ColumnName("Score")]public float FareAmount;}
在现实世界的机器学习场景中,我们不会只部署我们不知道表现良好或非常适合我们的数据的模型。
ML.NET API 为我们提供了可以用来评估模型有效性的指标。我创建了下面的 Evaluate()方法,它接受 MLContext、我们的模型和测试数据文件:
private double Evaluate(MLContext mlContext, ITransformer model, string testFilePath){IDataView dataView = mlContext.Data.LoadFromTextFile<TaxiTrip>(testFilePath, hasHeader: true, separatorChar: ',');var predictions = model.Transform(dataView);var metrics = mlContext.Regression.Evaluate(predictions, "Label", "Score");double rSquaredValue = metrics.RSquared;return rSquaredValue;}
在这里,我将测试数据加载到 IDataView 对象中,然后使用我的模型对该数据进行转换。这里的 Transform() 方法实际上并不做任何转换,它只是根据测试的模型来验证我的测试文件的模式。
对于这个例子,我只是使用 r 平方值来测试我的模型的有效性,但是 RegressionMetrics 类允许我们为我们的回归模型检索 LossFunction ,meansabsoluteerror,meansquadererror,rootmeansquadererror和 RSquared 值。
一旦我们的模型产生了我们的 r 平方指标,并且提供了显示它非常适合的分数,我们就将模型的 zip 文件上传到 Azure Storage:
if (modelRSquaredValue >= 0.7){_logger.LogInformation("Good fit! Saving model");mlContext.Model.Save(model, dataView.Schema, modelPath);// Upload Model to Blob Storage_logger.LogInformation("Uploading model to Blob Storage");await _azureStorageHelpers.UploadBlobToStorage(cloudBlobContainer, modelPath);}
这里的重点是,我首先保存我的模型,然后将其作为文件上传到 Azure Storage。我们使用 MLContext 保存模型。Model.Save 行,它接受我们的模型、IDataView 对象的模式以及我们希望保存模型的路径。我已经创建了自己的助手类,将我保存的模型上传到 Azure Storage 中指定的 blob 容器。

(注意:我尝试过将模型上传为流而不是文件,但是当我试图将模型注入 HTTP 触发函数或 ASP.NET Web API 应用程序时,我总是会遇到问题。总有一天我会弄明白,或者,更有可能的是,某个比我聪明的人会告诉我哪里做错了😂)
在 HTTP API 函数中使用我们的模型
如果我们想在我们的 API 中进行预测,我们需要创建一个预测引擎。本质上,这允许我们使用训练好的模型进行单一预测。然而,这并不是线程安全的,所以我使用了一个 PredictionEnginePool,并将它注入到我的启动类中,这样我们的应用程序中就有了一个它的单例实例。如果我们在 API 函数应用程序中跨几个函数进行预测,我们需要为每个预测创建 PredictionEnginePool 的实例,这将是一场管理噩梦。我是这样做的:
builder.Services.AddPredictionEnginePool<TaxiTrip, TaxiTripFarePrediction>().FromUri(modelName: "TaxiTripModel",uri: "https://velidastorage.blob.core.windows.net/mlmodels/Model.zip",period: TimeSpan.FromMinutes(1));
在这里,我们调用我们的模型,该模型远程存储在 Azure Blob 存储中。period 参数定义了我们轮询新模型的 uri 的频率。模型不应该是静态的,所以您可以使用这个参数来设置您希望应用程序轮询新模型的频率。
一旦我们将其注入到我们的应用程序中,我们就可以使用我们的预测引擎池来预测我们的请求:
string requestBody = await new StreamReader(req.Body).ReadToEndAsync();var input = JsonConvert.DeserializeObject<TaxiTrip>(requestBody);// Make PredictionTaxiTripFarePrediction prediction = _predictionEnginePool.Predict(modelName: "TaxiTripModel",example: input);
这里的 Predict() 方法允许我们对 JSON 输入进行一次预测。我们定义了我们希望使用的模型,使用的名称与我们将它注入到应用程序中时给它的名称相同。
在本例中,我基于输入数据创建新的预测,然后将新的预测值插入到一个 Cosmos DB 容器中:
[FunctionName(nameof(PredictTaxiFare))]public async Task<IActionResult> Run([HttpTrigger(AuthorizationLevel.Anonymous, "post", Route = "PredictTaxiFare")] HttpRequest req){IActionResult returnValue = null;string requestBody = await new StreamReader(req.Body).ReadToEndAsync();var input = JsonConvert.DeserializeObject<TaxiTrip>(requestBody);// Make PredictionTaxiTripFarePrediction prediction = _predictionEnginePool.Predict(modelName: "TaxiTripModel",example: input);var insertedPrediction = new TaxiTripInsertObject{Id = Guid.NewGuid().ToString(),VendorId = input.VendorId,RateCode = input.RateCode,PassengerCount = input.PassengerCount,TripTime = input.TripTime,TripDistance = input.TripDistance,PaymentType = input.PaymentType,FareAmount = input.FareAmount,PredictedFareAmount = prediction.FareAmount};try{ItemResponse<TaxiTripInsertObject> predictionResponse = await _container.CreateItemAsync(insertedPrediction,new PartitionKey(insertedPrediction.VendorId));returnValue = new OkObjectResult(predictionResponse);}catch (Exception ex){_logger.LogError($"Inserting prediction failed: Exception thrown: {ex.Message}");returnValue = new StatusCodeResult(StatusCodes.Status500InternalServerError);}return returnValue;}
听起来很棒!我需要什么才能让这个样本自己工作?
如果你想自己开发(或者扩展)这个应用,你可以创建一个 Azure 存储账户,里面有一个你可以上传模型的容器。查看这篇文章,看看你如何做到这一点。您还需要创建一个使用 SQL API 的 Cosmos DB 帐户。查看这篇文章来开始吧。
你可以使用 Visual Studio 在本地运行 Azure 函数,也可以使用 Postman 在你的机器上测试 API。
结论
我希望你已经了解了一些关于 ML.NET 图书馆的知识,以及如何使用它来构建基本但非常棒的无服务器机器学习解决方案。记住我说的是基础。为了这篇博文,我确实走了一些捷径,但是在生产场景中这样做要复杂得多。但是这是可行的,ML.NET 是一个很好的库,如果你已经在使用。NET 堆栈。
如果你想看完整的代码,请到 GitHub 查看。如果你对我有任何问题,请在下面评论。😊
建立一个浅层神经网络
解释了理论和实现
一个隐藏层神经网络
我们将构建一个具有一个隐藏层的浅层密集神经网络,以下结构用于说明目的。
在试图理解这篇文章之前,我强烈建议你看一下我之前的逻辑回归的实现,因为逻辑回归可以看作是一个 1 层神经网络,基本概念实际上是相同的。

其中在上图中,我们有一个输入向量 x = (x_1,x_2),包含 2 个特征和 4 个隐藏单元 a1、a2、a3 和 a4,并在[0,1]中输出一个值 y_1。(考虑这是一个带有概率预测的二元分类任务)
在每个隐单元中,以 a_1 为例,进行一个线性运算,然后是一个激活函数。因此,给定输入 x = (x_1,x_2),在节点 a_1 内,我们有:

这里 w_{11}表示节点 1 的权重 1,w_{12}表示节点 1 的权重 2。对于节点 a_2 也是如此,它应该有:

a3 和 a4 也是如此,以此类推…
一个输入的矢量化
现在让我们将权重放入矩阵并输入到向量中,以简化表达式。

这里我们假设第二激活函数为tanh,输出激活函数为sigmoid(注意上标[i]表示第 I 层)。
对于每个矩阵的维数,我们有:

单个值的损失函数 L 将与逻辑回归的损失函数相同(此处详细介绍)。
功能tanh和sigmoid如下图所示。

请注意,这些函数的唯一区别是 y 的比例。
批量训练公式
上面显示了单个输入向量的公式,但是在实际训练过程中,一次训练一批而不是一个。公式中应用的更改是微不足道的,我们只需用大小为n x m的矩阵 X 替换单个向量 X,其中 n 是特征数量,m 是批量大小——样本按列堆叠,同样应用以下结果矩阵。

对于本例中每个矩阵的维数,我们有:

与逻辑回归相同,对于批量训练,所有训练样本的平均损失。
这都是为了正向传播。为了激活我们的神经元进行学习,我们需要获得权重参数的导数,并使用梯度下降来更新它们。
但是现在我们先实现正向传播就足够了。
生成样本数据集
这里,我们生成一个简单的二元分类任务,包含 5000 个数据点和 20 个特征,用于以后的模型验证。
权重初始化
我们的神经网络有 1 个隐层,总共 2 层(隐层+输出层),所以有 4 个权重矩阵要初始化(W[1],b[1]和 W[2],b[2]).注意,权重被初始化得相对较小,因此梯度会更高,从而在开始阶段学习得更快。
正向传播
让我们按照等式(5)至(8)实现正向过程。
损失函数
根据等式(9),每批的损耗可计算如下。
反向传播
现在到了反向传播,这是我们的权重更新的关键。给定我们上面定义的损失函数 L,我们有如下梯度:

如果你不明白为什么 Z^[2 的导数如上,你可以在这里查看。事实上,我们网络的最后一层与逻辑回归相同,所以导数是从那里继承的。
方程(4)中是元素式乘法,tanh{x}的梯度是 1 — x,你可以试着自己推导上面的方程,不过我基本上是从网上拿来的。
让我们分解每个元素的形状,给定每层的数量等于(n_x, n_h, n_y),批量等于m:

一旦我们理解了这个公式,实现起来就会很容易。
批量训练
我将每个部分都放在一个类中,这样它就可以像 python 的通用包一样训练。此外,还实施批量训练。为避免冗余,我没有放在这里,详细实现请查看我的 git repo 。
让我们看看我们实现的神经网络在数据集上的表现。

使用 10 个隐藏神经元,我们的模型能够在测试集上达到 95.1%的准确率,这是非常好的。
现在继续尝试实现你自己,这个过程将真正帮助你获得对一般密集神经网络的更深理解。
通过决策树构建一个简单的自动编码器
自动编码器
如何使用随机决策树构建自动编码器

我可爱的妻子蒂娜蒂·库伯勒
决策树是非常通用的结构。您可以使用它们进行分类和回归( CART、随机森林、… ),用于异常检测(隔离森林、… ),正如我们将看到的,还可以用于构建*自动编码器、*以及其他构造。
声明:我没有想出这个主意。这种新的基于树的自动编码器是由吉峰和周志华[1]提出的,被称为“forest”。他们在 AAAI 18 上展示了他们的作品。
然而,我认为这篇论文在如何从潜在空间中解压元素方面缺乏一些清晰度,我将在本文中解决这个问题。我还将简单介绍用于制作森林的所有材料。
所以,在我们开始之前,让我们快速回顾一下什么是决策树和自动编码器。
重要概念的高度概括
决策树
决策树是一种将来自一个 n 维特征空间的一组样本聚类到不同箱中的方法。这是通过检查样本的 n 特征上的某些约束来完成的。
以特征空间 *X = ℝ×ℝ×{0,1}×{A,b,C},*以及生活在 X 内的样本 (1.7,4.3,0,a),(2.2,3.6,1,b),(3.5,2.6,0,C) 和 (4.1,1.9,1,A) 为例。我构建了一个示例决策树来将这些样本分类到四个箱中。也许下面这张图甚至是不言自明的,即使你以前从未听说过决策树:

决策树。在每个节点(蓝色菱形)中,样本集被分成两个不相交的子集,这取决于某个特征是否满足特殊要求。例如,在 bin 4 中,我们可以找到第一个坐标严格大于 4,最后一个坐标为 A 或 C (=非 B)的所有样本。
最后,四个样本被分类到四个容器中。由于单个样本不能同时采用两个路径(一个特征不能小于或等于 4 且严格大于 4),每个样本被准确分类到一个箱中。
自动编码器
自动编码器基本上是有损压缩算法。它们允许用更少的位来表示数据,从而节省了存储空间。它还使用这些压缩样本来加速(机器学习)算法,因为较短的输入大小通常会导致较短的运行时间。
自动编码器由两种算法组成:
- **编码器:**通过去除冗余和噪声来压缩数据。
- **解码器:**尝试从压缩形式恢复原始数据。
更准确地说,编码器将样本从 n 维特征空间投影到其在 m 维所谓的潜在空间、中的压缩形式,其中 m < n.
解码器从第 m 维潜在空间中提取样本,并将其再次解压缩到第 n 维特征空间中。
一个好的自动编码器应该能够
- 取样 x
- 将其压缩为 x’ = e(x)
- 并将其再次解压缩到性质为x≈x″= d(e(x))的x″= d(x′)。
这意味着包装和打开样品 x 不会对其造成太大的改变。当然,这应该适用于特征空间的任何 x 。
通常,我们不能期望得到 x. 的完美重建,例如 n=1 和 m=0 (即潜在空间仅由单个点x’组成)。两个不同的样品 x₁ 和 x₂ 将被任何编码器送到潜在空间的同一点x’。所以,在最好的情况下,任何解码器只能恢复*x’到 x₁ 或 x₂ ,因此得到一个解码错误。如果x’*被解压缩到某个其他的 x ,解码器甚至会将两个样本都弄错。
自动编码器的一个受欢迎的代表是主成分分析 ( PCA ),它将数据从 n 线性映射到 m 维度,然后反向映射,尽管人们通常只使用编码器来降低数据的维度。
一个玩具例子:eTree
现在让我们看看如何用决策树构建一个自动编码器。我声称我们已经在本文中看到了一个 eForest 映射到一个 1 维的潜在空间!姑且称之为 eTree 。
编码
滚动回决策树示例图片,或者让我来帮你做:

上图的快捷方式。真的,又是同一个决策树。
我们看到四个样本中的每一个都被分类到四个箱中的一个。
核心思想是使用样本映射到的 bin 的编号作为编码。
所以 (1.7,4.3,0,A)**(2.2,3.6,1,B) 被编码为 1, (3.5,2.6,0,C) 被编码为 2, (4.1,1.9,1,A) 被编码为 4,或者简而言之:
e((1
很简单,对吧?
当我们想再次解码这个数字时,问题就出现了。
解码
在[1]中,作者引入了规则和所谓的 MCRs 来进行解码*。*概念不难,但一开始我发现从纸上很难理解。所以,我来换个角度解释一下。
让我们假设我们得到编码 1,即从特征空间有一个 x ,其中 e 是 eTree 编码器。沿着通向 bin 1 的唯一路径,我们获得关于输入 x. 的我称之为的线索
在 1 号仓着陆需要
- 线索 1: X₁ 小于等于 4 且
- 线索二: X₂ 要大于等于 3,
也就是说,我们知道 x 看起来像这样:

或者,更准确地说,我们可以推断

然后,我们必须从这个潜在候选集中挑选任何元素,并将其用作解码。我们可以用确定性或概率性的方法来做这件事,这并不重要。
[1]中也使用的一种方法是最小选择。只取每个集合的最小值,如果集合是没有最小值的区间,就取它的右界。使用这个确定性规则,我们将解码 1 到 (4,3,0,A) (假设 A < B < C )。其他简单的方法包括选择最大值或平均值,或者从集合中随机抽样。
在我们的例子中,解码 1 的潜在候选集合相当大,因此我们可以预期重构相当糟糕。解决这个问题的一个方法是让树变得更深,也就是使用更多的分裂。更多的分裂产生更多的线索,进而产生更小的候选集。让我们在玩具示例中再使用一个拆分:

多一层的玩具树。编码现在可以采用从 1 到 5 的值。
这里,编码 1 将被解码成

这为现在搞乱第一特征留下了更少的空间,给出了更低的重建误差。改善解码的其他方法是嵌入关于特征空间的知识,例如,有时特征总是大于零或小于一些界限,如 1 或 255(图片数据),因此我们可以移除无限或负无限的界限。
但是让决策树越来越深不是可持续的解决方案,因为我们会遇到过度拟合的问题,就像在回归和分类任务中一样。然而,到目前为止,我们仍然只使用一维!那么,我们能做什么呢?
埃弗斯特
让我们并行连接更多的决策树进行编码!那么每一棵树给我们一个潜在空间的维度,每棵树的箱数就是特征值。考虑以下 3 棵树的例子:

一个由三棵决策树组成的 Forest。加粗的箭头表示 x 选择的路径。
三个决策树中的每一个都给了我们一个潜在空间的坐标,在这个例子中是 3。在我们的例子中,潜在的每个特征可以是 1、2、3 或 4。但是一般来说,如果每个决策树有不同数量的箱也没问题。
所以,让我们想象我们的输入 x 在潜在空间中被编码为 (2,1,1) ,我们现在希望解码它。我们只需要再次收集所有的线索,并把它们放在一起,以创建一个潜在的候选人集。
线索是:
- 从树 1,bin 2:
- X₁ 小于或等于 4 - X ₂小于 3
- 从树 2,bin 1:
- X₁ 大于或等于 2*-
x*₃等于 0
- X₁ 大于或等于 2*-
- 从树 3,bin 1:
- X₄ 等于 C
- X ₂大于 1
把所有东西放在一起给了我们

所以最小解码会给我们 d(x)=(2,1,0,C)。
这几乎是理解森林的全部内容!现在仍然缺少的是如何实际训练 eForest ,但这是一个简短的问题:
使用随机决策树,即使用随机特征和随机分界点(来自合理范围)进行分裂的树。
我也是这样编造例子的。没有复杂的算法。
现在,让我们转到一些实验,看看它们在性能方面是否有任何优势。
实验
[1]的作者进行了几项实验,其中包括 CNN 自动编码器大放异彩的图像编码。我将直接粘贴[1]中的结果、表格和图像。
你可以在 GitHub 上找到用于实验的代码。
数据集是具有 28x28x1=784 特征(1 个颜色通道)的经典 MNIST 和具有 32x32x3=3072 特征(3 个颜色通道)的 CIFAR-10。
关于实验中使用的自动编码器
MLP 是使用几个线性层的“正常”自动编码器。确切的规格可以从[1]中得到,但是 MLP₁使用 500 维的潜在空间和 1000 维的 MLP₂。
CNN-AE 是一个卷积自动编码器,即它在内部使用卷积。它遵循本规范。SWW AE 是一个更好的 CNN-AE。eForestˢ₅₀₀也是一家使用样品标签的林业公司,我们在这里没有涉及。它将输入数据压缩到 500 个特征(下标 1000 将其压缩到 1000 个维度)。最后,eForestᵘ₅₀₀是本文所讨论的森林。下标数字再次表示潜在空间的维度。
重建误差
结果看起来很有希望!MNISt 和 CIFAR-10 数据集的重建误差非常低。来自[1]:



原始测试样本(第一行)和重构样本。
但是,人们必须进行进一步的实验,以检查 eForests 是否过度拟合。至少作者复用了的模型,并最终得到了好的结果,这是一个很好的指标,表明 eForest 推广得很好,而不仅仅是用心学习训练样本。模型重用意味着在一个训练集上训练一个模型,并在不同的训练集上评估它。



原始测试样本(第一行)和重构样本。所有模型都在一些训练集上进行了训练,并在不同的训练集上进行了测试!使用 eForests 时,结果看起来不错。
我只是不明白,当原始数据只有 28*28=784 维时,作者为什么要为 MNIST 数据集使用 1000 维的潜在空间。在我看来,使用 500 维会更有意义。但是,即使我们使用这种人为的设置:eForest 比其他方法执行得更好,neark 实现了无损压缩,这也是我所期望的。
计算效率
与其他方法相比,训练时间非常短。然而,根据作者的说法,编码和解码需要更多的时间,这仍然有优化的空间。来自[1]:

我的概念验证实施
由于算法相当简单,我尝试自己实现。我甚至不用从头开始,因为编码器已经自带了 scikit-learn 类型的!
类randomtreesemleding也创建了许多随机决策树,并根据输入的位置对它们进行编码 x 。然而,它们使用二进制编码,这增加了潜在的空间维度。使用我的具有三棵树和每棵树 4 个箱的例子,编码将是 (0,1,0,0 | 1,0,0,0 | 1,0,0) 而不是 (2,1,1),即潜在空间将具有 12 的维度,而不是只有 3 个。但是一旦知道了每棵树的叶子数量,将二进制表示转换成每棵树的一个数字就很容易了。幸运的是,scikit-learn 为我们提供了一个方法。
因此,实现编码部分很简单!也可以从我代码中的短encode方法看出来。这仅仅是
output = self.random_trees_embedding.transform(X)
indices = []
start = 0
for estimator in self.random_trees_embedding.estimators_:
n_leaves = estimator.get_n_leaves()
indices.append(output[:, start:start + n_leaves].argmax(axis=1))
start = start + n_leaves
return np.array(indices).transpose()
解码花了我更多的时间,这也是我效率低下的方式,请原谅我!😄,我只是需要一个快速的概念验证。
你可以在这里找到我的代码。请随意改进!
我的图形结果:










我认为重建看起来很好,所以可能我的解码工作。但是,请在使用这些代码进行任何有成效的工作之前,先检查一下这些代码。
如果你想要真正的交易,去官方克隆的 GitHub 上工作。但是要准备好创建一个虚拟环境并手动修补一些 scikit-learn 文件。
结论
我们已经看到了如何用决策树构建一个自动编码器。这是一个自动编码器,具有独特的,但易于理解的设计,可以训练得非常快。此外,重构精度可以与成熟的卷积自动编码器相媲美。
另一方面,编码和解码速度仍然很低,并且必须在野外的真实数据集上测试 eForest。也许你可以写一篇关于它的文章。😃
参考
[1]冯军,周志军,森林自动编码器 (2017),第 32 届人工智能大会
我希望你今天学到了新的、有趣的、有用的东西。感谢阅读!
作为最后一点,如果你
- 想支持我多写点机器学习和
- 无论如何,计划获得一个中等订阅,
说白了,给你的价格不变,但大约一半的订阅费直接归我。
非常感谢,如果你考虑支持我的话!
如有任何问题,请在 LinkedIn 上给我写信!
用 Python 和 Google 云平台构建简单的 ETL 管道
使用 Google Cloud 函数从 FTP 服务器提取数据并加载到 BigQuery

有很多 ETL 工具,有时它们可能会让人不知所措,特别是当你只想将文件从 A 点复制到 b 点时。所以今天,我将向你展示如何使用 python 3.6 和谷歌云函数从 FTP 服务器提取 CSV 文件(提取)、修改(转换)并自动将其加载到谷歌 BigQuery 表(加载)。
在本文的最后,您将能够从 FTP 服务器提取一个文件,并在 Google Cloud 函数中使用 Python 将其加载到数据仓库中。
在本文中,我们将做以下工作:
- 设置云功能
- 提取数据
- 转换数据
- 加载数据
- 自动化我们的管道
首先,什么是 ETL?
提取、转换、加载(ETL)是将数据从一个或多个源复制到目标系统的一般过程,目标系统以不同于源的方式或在不同于源的上下文中表示数据。—维基百科
场景
在我们开始之前,让我给你一些背景信息。一家第三方服务提供商有一台 FTP 服务器,其中存储了多个 CSV 文件,每个文件都包含一家物流公司的日常交易数据。我们需要数据仓库中的数据,这样我们就可以在内部与利益相关者共享这些数据,并监控性能。
这家物流公司的基础设施团队每天从他们的数据库中导出一个 CSV 文件,并将其上传到 FTP 服务器。
我们的工作是每天从服务器上复制这些文件,对其进行清理,然后将其加载到我们的数据仓库中,这样我们就可以将其连接到其他数据源并对其进行分析。
这是我们的 ETL 管道图最终的样子:

使用 Lucidchart 创建
Google Cloud Functions:Cloud Functions(CF)是 Google Cloud 的无服务器平台,用于执行响应特定事件的脚本,如 HTTP 请求或数据库更新。CF 的替代方案是 AWS Lambda 或 Azure Functions 。
设置您的云功能
- 进入云功能概述页面。
确保您启用了云功能的项目被选中。 - 单击创建函数。
- 说出你的函数。
- 在触发器字段中,选择 HTTP 触发器。
- 在源代码字段中,选择内联编辑器。在本练习中,您将使用我们将要一起处理的 代码 ,以便您可以在编辑器中删除默认代码。
- 使用运行时下拉列表选择运行时。
确保您的运行时设置为“Python 3.7”,并在“高级选项”下将区域更改为离您最近的区域。在撰写本文时,CF 并不是在每个谷歌数据中心区域都可用,所以请点击这里的查看哪里启用了云功能。
完成这些步骤后,您的显示应该如下所示:

来自 GCP 控制台的截图
我们的自定义代码
一个云函数有两个文件;一个 main.py 和一个 requirements.txt 文件。后者托管我们脚本工作所需的所有文件依赖项,因此单击 requirements.txt 选项卡,并确保编辑器中包含这些依赖项,如下所示:
所有依赖项的快速摘要:
- google-cloud-bigquery:这个库允许我们访问 bigquery 并与之交互
- python-csv:这个库用于用 python 操作 csv 文件
- requests:是一个用于发送 HTTP 请求的 HTTP 库,我们将需要它来访问 FTP URL。
- wget:用于从互联网下载文件
- pytest-shutil:这用于 SSH 访问
提取
现在在 main.py 选项卡中,您可以开始包含下面的代码。看第 1 到 4 行。我们创建了一个名为“ftp_function”的函数,以后用 HTTP 请求访问云函数时会用到这个函数。然后,我们使用必要的凭证登录到 FTP 服务器,并导航到服务器上存储文件的适当目录。
请注意,我工作的 FTP 服务器有多个 CSV 代表不同日期的事务数据。所以为了获得目录中最新的文件,我使用了从第 7 行到第 9 行的代码。
其余的代码获取文件并下载它。
注意:要通过秘密管理器保护您的凭证,请遵循本指南。
改变
为了“转换”数据,我们将对刚刚下载的 CSV 文件做一个简单的更改。我们将简单地将 CSV 文件中每次出现的“FBA”更改为“AMAZON”。下面是代码。
这里也要注意,Google Cloud Function 有一个
*/tmp*目录,可以临时存放文件。该目录中的文件存储在实例的 RAM 中,因此写入/tmp会占用系统内存。一旦实例停止运行,目录中的所有临时文件都将被删除。
负荷
现在,确保你创建了你的大查询表。然后我们简单地使用下面的代码将转换后的 CSV 文件加载到您创建的 Bigquery 表中。因为我们启用了“自动检测”,所以 Bigquery 表在创建时不必有模式,因为它将基于 CSV 文件中的数据进行推断。
当您完成编写脚本时,您可以通过单击“创建”来部署云功能。当云功能部署成功时,您应该会看到一个绿色的复选标记,如下所示…

使自动化
现在剩下要做的就是创建一个 cron 作业(Cloud Scheduler ),它将在某个预定义的时间间隔自动调用 CF。好消息是,在谷歌云平台上创建 cron jobs 非常简单,也是最简单的部分。你可以按照 这里 的指示或者复制下图。


截图自 GCP
这里的“频率”字段将在每天凌晨 1:59 运行我们的脚本。
您可以使用这个很酷的站点编辑器来处理简单的 cron 调度表达式。
既然我们的数据已经存放在数据仓库中,我们可以将它连接到任何可视化工具并对其进行分析。
就是这样。希望这对你有帮助。这是一种非常简单的开发 ETL 的方法,任何人都可以在其上进行构建。
你可以 成为中等会员 享受更多这样的故事。
你可以在 Github 上找到完整脚本的链接。
如何用 Python 构建一个简单的营销组合模型
又一个使用 Python 代码的端到端数据科学项目!

亚伦·塞巴斯蒂安在 Unsplash 上拍摄的照片
目录
如果你喜欢这篇文章,请务必 订阅 千万不要错过另一篇关于数据科学指南、技巧和提示、生活经验等的文章!
介绍
由于高需求,我又带着另一个带 Python 代码的循序渐进的数据科学项目回来了!这个非常有趣,因为除了我将要介绍的内容之外,您还可以做更多的事情——然而,我相信这为任何对营销和数据科学感兴趣的人提供了一个良好的开端。
这个项目关系到许多企业面临的一个常见的现实问题— 营销归因。这是确定每个营销渠道对销售/转化有多大贡献的科学。当你引入电视或广播等线下营销渠道时,困难通常会出现,因为没有直接的方法来衡量这些渠道的影响。
你会学到什么
- 您将了解什么是营销组合模型(MMM ),以及如何使用它来评估各种营销渠道
- 在探索数据时,您将学习基本的概念和技术
- 您将了解什么是普通最小二乘(OLS)回归,如何实现它,以及如何评估它
什么是营销组合模式?
营销组合模型(MMM) 是一种用于确定市场属性的技术。具体来说,它是一种对营销和销售数据进行统计的技术(通常是回归),以估计各种营销渠道的影响。
不同于归因建模,另一种用于营销归因的技术,营销组合模型试图衡量不可估量的营销渠道的影响,如电视、广播和报纸。
一般来说,你的输出变量是销售额或转化率,但也可以是网站流量。您的输入变量通常包括按时段(日、周、月、季度等)划分的渠道营销支出,但也可以包括我们稍后将讨论的其他变量。
营销组合模型演练
在这个项目中,我们将使用一个虚构的数据集,该数据集包括电视、广播和报纸上的营销支出,以及各个时期相应的美元销售额。
数据集是 这里是 。
设置
首先,我们将像往常一样导入库并读取数据。
import numpy as np
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as pltdf = pd.read_csv("../input/advertising.csv/Advertising.csv")
理解我的变量
接下来,我们将查看数据集中的变量,并了解我们正在处理的内容。
print(df.columns)
df.describe()

很快,您可以看到这个未命名的变量:0 实际上是一个从 1 开始的索引——所以我们将删除它。
df = df.copy().drop(['Unnamed: 0'],axis=1)
因为这是一个虚构的简单数据集,所以有很多步骤我们不必担心,比如处理缺失值。但一般来说,您需要确保数据集是干净的,并为 EDA 做好了准备。
探索性数据分析
我总是喜欢做的第一件事是创建一个相关矩阵,因为它让我一眼就能更好地理解变量之间的关系。
corr = df.corr()
sns.heatmap(corr, xticklabels=corr.columns, yticklabels=corr.columns, annot=True, cmap=sns.diverging_palette(220, 20, as_cmap=True))

马上,我们可以看到电视和销售之间有很强的相关性(0.78),广播和销售之间有中等的相关性(0.58),报纸和销售之间的相关性很弱(0.23)。现在下结论还为时过早,但这有利于我们继续前进。
与相关矩阵类似,我想创建一个变量的配对图,这样我可以更好地理解变量之间的关系。
sns.pairplot(df)

这似乎与相关矩阵相一致,因为电视和销售之间似乎有很强的关系,广播和报纸之间的关系更弱。
特征重要性
要素重要性允许您确定每个输入变量对预测输出变量的“重要性”。如果打乱某个要素的值会增加模型误差,则该要素非常重要,因为这意味着模型依赖该要素进行预测。
我们将快速创建一个随机森林模型,以便我们可以确定每个功能的重要性。
# Setting X and y variables
X = df.loc[:, df.columns != 'sales']
y = df['sales']# Building Random Forest model
from sklearn.ensemble import RandomForestRegressor
from sklearn.model_selection import train_test_split
from sklearn.metrics import mean_absolute_error as maeX_train, X_test, y_train, y_test = train_test_split(X, y, test_size=.25, random_state=0)
model = RandomForestRegressor(random_state=1)
model.fit(X_train, y_train)
pred = model.predict(X_test)# Visualizing Feature Importance
feat_importances = pd.Series(model.feature_importances_, index=X.columns)
feat_importances.nlargest(25).plot(kind='barh',figsize=(10,10))

似乎有一种模式,电视是最重要的,其次是广播,最后才是报纸。让我们实际建立我们的 OLS 回归模型。
OLS 模型
OLS 是普通最小二乘法的缩写,是一种用于估计线性回归模型中参数的方法。查看我的文章, 线性回归 5 分钟讲解 如果你不知道回归是什么!
Python 如此神奇的地方在于它已经有了一个库,我们可以用它来创建 OLS 模型:
import statsmodels.formula.api as sm
model = sm.ols(formula="sales~TV+radio+newspaper", data=df).fit()
print(model.summary())

。summary() 为我们的模型提供了丰富的见解。我要指出两件对我们最有用的事情:
- 调整的 R 平方是 0.896,这意味着我们的数据中几乎 90%的变化可以用我们的模型来解释,这非常好!如果你想了解更多关于 r 平方和其他用于评估机器学习模型的指标,请查看我的文章 这里 。
- 电视和广播的 p 值小于 0.000,但报纸的 p 值为 0.86,这表明报纸支出对销售没有显著影响。
接下来,让我们用实际销售值绘制预测销售值的图表,直观地了解我们的模型的表现:
# Defining Actual and Predicted values
y_pred = model.predict()
labels = df['sales']
df_temp = pd.DataFrame({'Actual': labels, 'Predicted':y_pred})
df_temp.head()# Creating Line Graph
from matplotlib.pyplot import figure
figure(num=None, figsize=(15, 6), dpi=80, facecolor='w', edgecolor='k')y1 = df_temp['Actual']
y2 = df_temp['Predicted']plt.plot(y1, label = 'Actual')
plt.plot(y2, label = 'Predicted')
plt.legend()
plt.show()

实际值与预测值
还不错!在给定电视、广播和报纸支出的情况下,这个模型似乎在预测销售方面做得很好。
更进一步
在现实中,数据可能不会像这样干净,结果可能不会看起来很漂亮。实际上,您可能需要考虑更多影响销售的变量,包括但不限于:
- 季节性:公司的销售几乎总是季节性的。例如,一家滑雪板公司的销售额在冬季会比夏季高得多。在实践中,您可能希望包含一个变量来说明季节性。
- 延续效应:营销的影响通常不会立竿见影。在许多情况下,消费者在看到广告后需要时间来考虑他们的购买决定。延续效应解释了消费者接触广告和对广告做出反应之间的时间差。
- 基础销售与增量销售:并非每笔销售都归功于营销。如果一家公司在营销上完全没有花费,但仍然有销售额,这将被称为其基础销售额。因此,为了更进一步,你可以试着在增量销售而不是总销售额上模拟广告支出。
我希望你喜欢这个项目——让我知道你还想看什么样的项目!
感谢阅读!
如果你喜欢我的工作,想支持我…
- 支持我的最好方式就是在媒体上关注我这里。
- 在 Twitter 这里成为第一批关注我的人之一。我会在这里发布很多更新和有趣的东西!
- 此外,成为第一批订阅我的新 YouTube 频道 这里!目前还没有视频,但即将到来!
- 在 LinkedIn 这里关注我。
- 在我的邮箱列表 这里注册。
- 查看我的网站,terenceshin.com。
从头开始构建一个简单的神经网络
你有没有想过神经网络是如何工作的?它如何学习,如何扩展到我们输入的海量数据?

(来源)
在本文中,我们将研究只有一个神经元的简单神经网络的工作原理,并了解它在我们的“Cat v/s Non Cat 数据集”上的表现。
在本文结束时,您将能够-
- 从头开始编写你自己的神经网络
- 理解神经网络如何工作
- 如何转换输入数据以输入神经网络
目标
我们将对我们的神经网络进行编码,然后使用经过训练的网络来确定一幅图像中是否包含一只猫。这类问题被称为“二元分类问题”。它包括将输入分为两类,在我们的例子中是“Cat”或“Not cat”。
神经网络的基础
线性回归方程
神经网络中的单个神经元作为直线工作,其具有以下等式:

这是神经网络的整个概念所基于的基本方程。让我们打破这个等式:
y :因变量(神经网络的输出)
m :直线的斜率
x :独立变量(输入特征)
b : y 轴截距

绘制在图表上的线性方程(来源
就神经网络而言,我们将斜率指定为权重,截距指定为偏差,输出(y)指定为 z,因此等式变为:

在这里,我们只有一个特征,我们给模型。要输入多个特征,我们必须放大等式。
扩展到多种功能
上述等式可以扩展到“n”个特征,可以写成:

在这里,我们有“n”个输入特征提供给我们的模型。对应于每个输入特征,我们有一个权重,指定该特征对我们的模型预测输出有多重要。偏差项有助于在轴上移动我们的线,以更好地适应训练数据,否则线将始终穿过原点(0,0)。
同时做这件事
我们可以利用矩阵将所有权重与输入相乘,并向它们添加偏差。这可以通过以下方式完成:

这里,每一行代表一个训练示例(在我们的例子中是图像),每一列代表一个像素数组。
在 python 中,我们将使用矢量化来实现上述概念。
注意:在上面的等式中,我们使用“X.w+b ”,因为我们的输入矩阵是(mXn)的形状,其中“m”是样本的数量,“n”是特征的数量。
训练神经网络的目标是更新权重和偏差,以获得尽可能准确的预测。
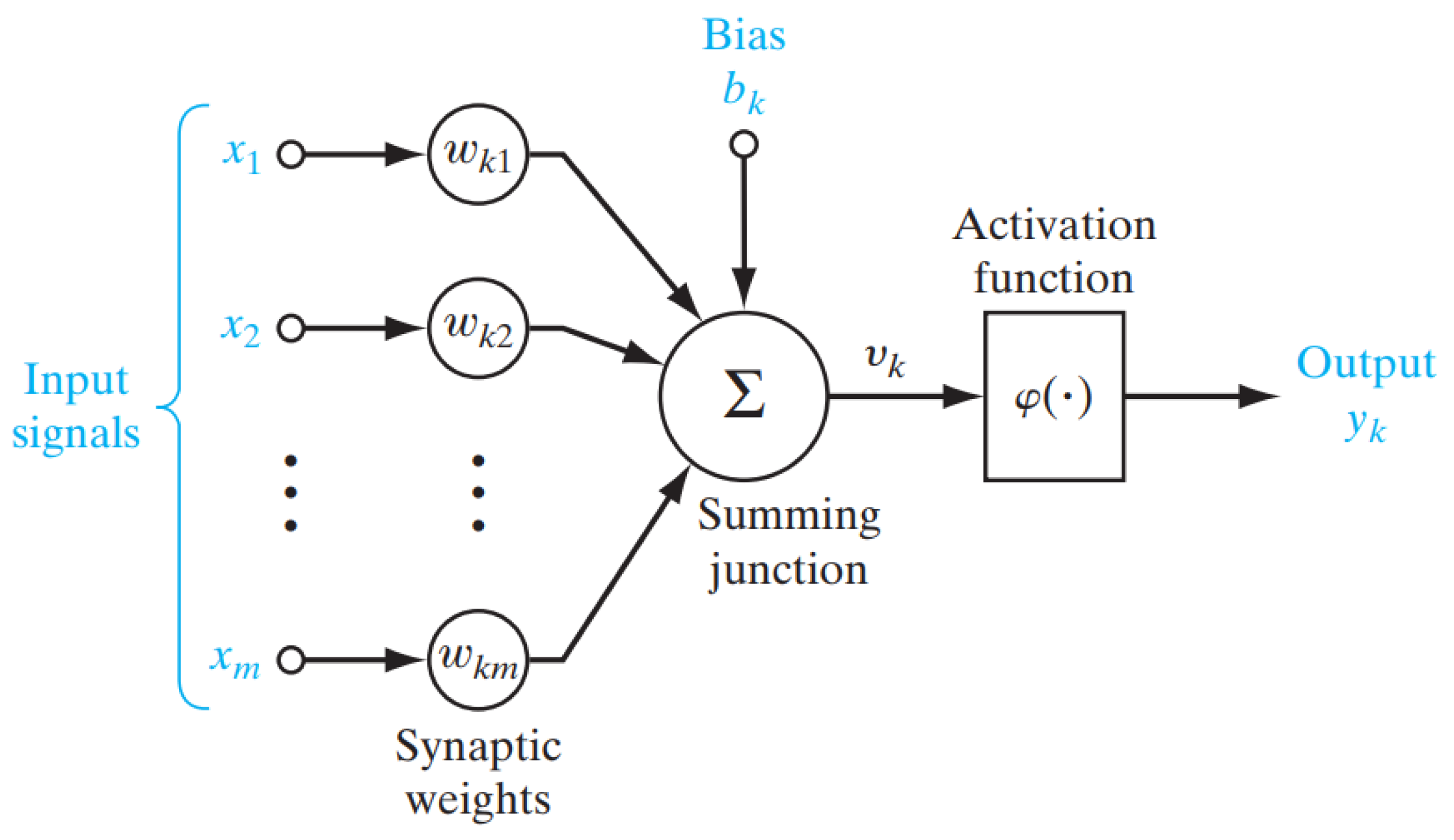
神经元

(来源
神经元是神经网络中的一个单元。它模拟了我们大脑中的神经元,将“树突”作为输入,“核”作为身体,“轴突”作为输出。每个神经元接受一些输入,对其进行处理,然后根据激活函数给出一个输出。
如果你不能理解这些概念中的任何一个,请耐心听我说,一旦我们开始把事情放在一起,一切都会变得有意义。
编码我们的神经网络
从创建阶段到获得预测,整个过程分为以下几个部分:
- 准备输入到我们的网络
- 初始化权重和偏差
- 正向传播
- 计算损失
- 反向传播
- 更新权重和偏差
- 多次重复上述过程(时期)
- 获得预测

(来源)
准备输入
我们的输入是“猫”和“不是猫”的图像集合。每个输入图像都是 64x64 像素大小的彩色图像。我们在训练数据集中总共有 209 幅图像,在测试数据集中有 50 幅图像。为了将这些图像输入到我们的神经网络中,这些图像必须被改造成像素向量。因此,每个图像将按行的顺序排列成一维向量。

(来源)
最初,我们输入的形状是(209,64,64,3),但现在转换后,它将变成(209,64x64x3),即(209,12288)。现在这个“12288”是我们神经网络的输入数量,“209”是训练样本的数量。
我们的图像是 8 位的,所以图像中的每个像素都有一个在[0,255]范围内的值,即总共 256 个值的范围(2⁸=256).因此,我们必须通过将每个像素除以最大值(即 255)来标准化我们的图像。
神经网络对输入尺度非常敏感。我们不希望我们的输入变化太大,否则较大的输入可能会支配较小的输入。因此,如果输入的范围很大,对其进行归一化总是一个好的做法。
初始化权重和偏差
我们必须将权重和偏差初始化为某个小值,以便能够开始训练过程。
在这里,我们将权重乘以 0.01,使其在整个训练过程中不会爆炸(变得非常大)。
注意:在代码中,‘b’只是一个‘浮点’数,因为 python 中的广播。它会自动将这个“浮点数”转换成所需的矢量形状。
现在我们已经初始化了权重和偏差,让我们进入下一步。
正向传播
这里,我们将使用上面建立的等式计算输出“z ”,然后在输出上使用激活函数。
在二元分类的情况下,我们将使用 sigmoid 激活函数,因为 sigmoid 函数通过将输入变换到[0,1]区间来给出输出。因此,我们可以通过将值设置为大于 0.5 比 1 和小于 0.5 比 0 来轻松找到目标类。

乙状结肠的公式是:

在哪里,

让我们看看实现这两个步骤的代码:
现在我们已经得到了神经元的输出,我们可以计算损失,看看我们的模型表现得有多好/差。
计算损失
在二元分类中,使用的损失函数是**二元交叉熵/对数损失。**它由公式给出:

在哪里,
m :数据集中的样本总数
yᵢ:iᵗʰ样品的真实标签
aᵢ:iᵗʰ样本的预测值
这可以在 python 中实现为:
这个损失将告诉我们离预测正确的产量还有多远。如果损失为 0,那么我们就有了一个完美的模型。但实际上,如果损失为 0,那么我们的模型可能会过度拟合数据。
反向传播
这是奇迹发生的地方。在每次迭代中,基于模型输出和预期输出,我们计算梯度。梯度是我们需要改变多少权重和偏差来减少损失。
为了计算梯度,我们使用以下公式:

在 python 中,上述等式可以实现为:
现在,“dw”和“db”包含我们需要分别调整权重和偏差的梯度。
更新权重和偏差
我们现在需要用刚刚计算的梯度来调整权重和偏差。为此,使用以下等式:

其中’ α’ (alpha) 是学习率,它定义了我们的更新应该有多大/多小。
更新参数的代码是:
现在我们只需多次重复这些步骤来训练神经网络。
训练神经网络
为了训练神经网络,我们必须运行上述步骤一些时期(重复这些过程的次数)。
现在我们的神经网络已经训练好了,我们可以预测新输入的输出。
获得预测
为了从我们的神经网络获得预测,我们必须转换神经网络的输出‘a ’,使得小于 0.5 的输出值变成 0,否则变成 1。

虽然我们只有一个神经元,但我们仍然在训练数据上获得了 96%的准确率,在测试数据上获得了 76%的准确率,这还不错。
恭喜你!我们刚刚从零开始制作了第一个神经网络。在下一篇文章中,我将告诉你如何开发一个浅层神经网络,它将有一个包含多个神经元的隐藏层。
你可以在 Github 上找到完整的代码:
此时您不能执行该操作。您已使用另一个标签页或窗口登录。您已在另一个选项卡中注销,或者…
github.com](https://github.com/akarsh-saxena/Neural-Network-From-Scratch/tree/master/Artificial%20Neural%20Network/Simple%20Neural%20Network)
这就是从头开始创建和训练神经网络的整个过程。我希望你明白一切。不过,如果你还有什么不明白的,请在这里留言,我会尽力解答你的疑问。
关注我在 Github 和 LinkedIn 了解更多信息。
用 Google Trends 构建简单的 Python 应用程序

我将演示如何用 Python 编程语言处理 Google trends 数据和 Excel 文件。
xcel 是微软的一款产品,在专业环境、教育和个人工作流程中非常常用。如果您作为 Python 程序员遇到这个应用程序,应该不会感到惊讶。根据您正在编程的内容,了解更多关于如何在 Python 中与 excel 文件交互的信息可能会很方便。
谷歌趋势跟踪谷歌搜索引擎的搜索分析。我们将使用一个名为pytrends的非官方 API 来获取这个项目所需的数据。
我将从 Google Trends 获取关键字数据,然后在 Microsoft Excel 中显示这些数据。我将使用tkinter模块给用户一个漂亮的 GUI(图形用户界面)来输入搜索词。我将在这个项目中使用 PyCharm Professional。
[## py charm:JetBrains 为专业开发人员提供的 Python IDE
在 PyCharm 处理日常事务时节省时间。专注于更大的事情,拥抱以键盘为中心的方法…
www.jetbrains.com](https://www.jetbrains.com/pycharm/) [## Microsoft Excel Online,电子表格软件,免费试用
订阅了 Microsoft 365 的 Microsoft Excel 是 Excel 的最新版本。之前的版本包括 Excel 2016…
www.microsoft.com](https://www.microsoft.com/en-us/microsoft-365/excel) [## pytrends
谷歌趋势的非官方 API 允许从谷歌趋势自动下载报告的简单界面。只有…
pypi.org](https://pypi.org/project/pytrends/) [## Tcl/Tk - Python 3.8.6 文档的 tkinter - Python 接口
源代码:Lib/tkinter/init。py 包(“Tk 接口”)是 Tk GUI 的标准 Python 接口…
docs.python.org](https://docs.python.org/3/library/tkinter.html) [## 熊猫
pandas 是一个快速、强大、灵活且易于使用的开源数据分析和操作工具,构建于…
pandas.pydata.org](https://pandas.pydata.org/)
如果您是 Python 新手,我建议您阅读我写的一些其他文章,以获得本教程所需的基础知识。
Python 编程语言是一种通用的编程语言,它已经在主流编程语言中占有一席之地
medium.com](https://medium.com/python-in-plain-english/a-brief-history-of-the-python-programming-language-4661fcd48a04) [## Python 基本概述
Python 有许多独特的特性,这些特性帮助它成为现在的样子。这些功能包括:
medium.com](https://medium.com/python-in-plain-english/python-basic-overview-76907771db60) [## Python 初学者完全参考指南
Python 是一种很好的初学者语言,但也适合高级用户。我将深入核心…
medium.com](https://medium.com/python-in-plain-english/python-beginners-reference-guide-3c5349b87b2) [## Python 的最佳 ide 和文本编辑器
我无法告诉你正确的 IDE(集成开发环境)对任何编程项目有多重要。只是…
medium.com](https://medium.com/analytics-vidhya/the-best-ides-and-text-editors-for-python-872ff1176c92)
此外,我将在这里包含我的 GitHub 资源库。
因此,我们将构建一个 Python 应用程序,它将用户输入的一个单词作为输入,并以 excel 文件的报告格式输出相关的 Google 关键字建议,为了用户的方便,该文件会自动弹出。
好的,首先我要在 PyCharm 开始一个新项目。我还将使用文件keywords.xlsx和logo_image.png。这些文件可以在我的 GitHub Repo 中找到。我将使用标准的 Python 虚拟环境。如前所述,我将使用pytrends非官方 API。记住现在安装项目的所有包依赖项。
首先,我会做我的进口。
from pytrends.request import TrendReq
import pandas as pd
from tkinter import *
import os
接下来,我将想要建立一个类。
# create class
class MyKeywordApp():
def __init__(self):
然后我来定义newWindow()方法。
def newWindow(self):
# define your window
root = Tk()
root.geometry("400x100")
root.resizable(False, False)
root.title("Keyword Application")
# add logo image
p1 = PhotoImage(file='logo_image.png')
root.iconphoto(False, p1)
# add labels
label1 = Label(text='Input a Keyword')
label1.pack()
canvas1 = Canvas(root)
canvas1.pack()
entry1 = Entry(root)
canvas1.create_window(200, 20, window=entry1)
现在我将定义嵌套在newWindow()方法中的excelWriter()方法。
def excelWriter():
# get the user-input variable
x1 = entry1.get()
canvas1.create_window(200, 210)
# get our Google Trends data
pytrend = TrendReq()
kws = pytrend.suggestions(keyword=x1)
df = pd.DataFrame(kws)
df = df.drop(columns='mid')
# create excel writer object
writer = pd.ExcelWriter('keywords.xlsx')
df.to_excel(writer)
writer.save()
# open your excel file
os.system("keywords.xlsx")
print(df)
之后,当在嵌套的excelWriter()方法之后调用Button()时,我定义了按钮并通过command=参数将其链接到excelWriter()方法,但仍然在newWindow()方法内。
# add button and run loop
button1 = Button(canvas1, text='Run Report', command=excelWriter)
canvas1.create_window(200, 50, window=button1)
root.mainloop()
现在我们回到类代码开头的__init__()函数中,调用newWindow()方法。记住使用关键字 self 来正确引用方法。
self.newWindow()
要完成程序,在全局范围内的代码末尾(不属于任何代码块)调用MyKeywordApp()类。
# call class
MyKeywordApp()
就是这样。如果您运行该应用程序,它会弹出一个如下所示的窗口:

关键词程序窗口
只需输入一个单词,点击运行报告按钮提交即可。将打开一个 excel 文件,其中包含 Google 以报告格式为该搜索词建议的关键字。

Excel 关键字报表(keywords.xlsx)
结论
这是一个介绍性的演练,目的是开始使用 Python 项目,包括 Microsoft Excel 、 Google Trends 和 tkinter 。感谢您的阅读,我希望这有助于任何人开始这样的项目。如果您有任何意见、问题或更正,我鼓励您在下面的回复部分发表。感谢您的阅读和快乐编码!
应用程序图像源
作者:openclippart-Vectors
https://pixabay.com/vectors/chat-key-keyboard-1294339/
用 Python 构建一个简单的文本识别器
如何使用文本识别器改进笔记记录过程

在这篇文章中,我将向您展示如何使用 Python 从图像中提取文本。这个过程简称为“文本识别”或“文本检测”。所以基本上你可以从标题中理解,我们将构建一个简单的 python 程序来为我们提取文本。提取之后,程序还会将结果导出到一个文本文档中。这样,我们可以记录我们的结果。
如果你以前没有听说过计算机视觉,这是了解它的最好时机。大多数机器学习和人工智能领域都与计算机视觉密切相关。随着我们的成长和探索,看到外面的世界对我们的发展有很大的影响。这对机器来说也是一样的,它们使用图像来观察外部世界,这些图像基本上被转化为计算机可以理解的数据。计算机视觉是一个非常深的海洋,我只是试图给出一些想法。如果你想了解更多关于计算机视觉的知识,这里有一个谷歌云平台的不错的视频:
在接下来的几周里,我想给你们展示许多不错的项目,让你们开始学习计算机视觉。你会惊讶于使用计算机视觉可以做多么强大的事情。文本识别只是大海中的一滴水。如果你准备好了,让我们开始吧!
步骤 1 —库
首先,让我们安装我们将在这个程序中使用的模块包。我们将安装 PIL,宇宙魔方软件包。PIL 代表 Python 图像库,它为你的程序增加了图像处理能力。该模块支持多种图像格式。PyTesseract 是我们将使用的另一个模块,它主要完成文本识别部分。这将有助于我们识别和阅读文本。
下面是 pip 同时安装多个模块的代码:
pip install Pillow pytesseract
如果您想了解关于这些产品包的更多信息:
现在让我们将库导入到我们的程序中:
# adds image processing capabilities
from PIL import Image# will convert the image to text string
import pytesseract
步骤 2 —文本识别
在这一步,我们将选择一个我们想要处理的图像。你可以从谷歌上下载图片,或者用手机拍照。两种方式都应该可以。选择你的图像后,在同一个目录下创建一个新的文件夹,你可以把它命名为“image_test ”,并把图像文件复制到那个文件夹中。

我将使用的图像
我下载了一张图片,上面引用了弗吉尼亚·伍尔夫的话。有趣的事实:我真的很喜欢读她的书:)
无论如何,在我们的 image_test 文件夹中粘贴图像之后,让我们回到编码。在下面的代码中,我们创建一个图像变量来存储图像文件,然后使用 image_to_string 方法识别文本。
# assigning an image from the source path
img = Image.open(‘image_test/virginia-quote.jpg’)# converts the image to result and saves it into result variable
result = pytesseract.image_to_string(img)
第 3 步—导出
在这一步中,我们将把前面代码的结果导出到一个文本文档中。这样,我们将同时拥有原始图像文件和我们从该图像中识别的文本。
with open(‘text_result.txt’, mode =’w’) as file:
file.write(result)
print(“ready!”)
干得好!您刚刚使用 Python 创建了自己的文本识别器。如果你想做得更好,检查下一个额外的步骤。这里还有一个你可能感兴趣的项目。
使用谷歌云语音 API 将您的音频文件转换为文本
towardsdatascience.com](/building-a-speech-recognizer-in-python-2dad733949b4)
额外—图像增强
PIL 是一个巨大的包裹,有许多功能。在这个额外的步骤中,我们将对图像做一些小的改动,以便我们的文本识别器可以更容易地识别或“读取”文本。在图像上做一些小小的改动在计算机视觉中占据了很大的位置。计算机需要我们的帮助来更好地处理图像。
没有图像处理,就像把菜谱食材放在孩子面前,让他/她吃。有了正确的图像处理,就像把煮好的食物放在孩子面前。差别是巨大的,我强烈推荐通过图像处理文档来了解更多。
这是添加了一些小改动的完整代码,换句话说,这是一段新鲜出炉的代码:)
# adds more image processing capabilities
from PIL import Image, ImageEnhance# assigning an image from the source path
img = Image.open(‘image_test/virginia-quote.jpg’)# adding some sharpness and contrast to the image
enhancer1 = ImageEnhance.Sharpness(img)
enhancer2 = ImageEnhance.Contrast(img)img_edit = enhancer1.enhance(20.0)
img_edit = enhancer2.enhance(1.5)# save the new image
img_edit.save("edited_image.png")# converts the image to result and saves it into result variable
result = pytesseract.image_to_string(img_edit)with open(‘text_result2.txt’, mode =’w’) as file:
file.write(result)
print(“ready!”)
视频演示
结果呢

如何在日常生活中使用文本识别器?
就我个人而言,我正在使用我们刚刚创建的工具将我的书页转换成文本文档,它使记笔记的过程变得更加容易和快速。现在,我不再每次都写下我最喜欢的几行,而是给那一页拍张照,然后用文本识别器进行转换。这难道不是编码最酷的地方吗?创造一些能解决你生活中一个问题的东西。
我是贝希克·居文,我喜欢分享关于创造力、编程、动力和生活的故事。跟随我 中型 留下来受启发。
用 Python 构建简单的用户界面
用用户界面展示 Python 项目从未如此简单。使用 Streamlit 框架,您可以仅使用 Python 代码构建基于浏览器的 UI。在这个演示中,我们将为一个迷宫求解程序构建用户界面,这个程序在之前的文章中有详细描述。
使用 Dijkstra 的算法和 OpenCV
towardsdatascience.com](/solving-mazes-with-python-f7a412f2493f)
细流
Streamlit 是一个 web 框架,旨在让数据科学家使用 Python 轻松部署模型和可视化。它速度快,简约,但也漂亮和用户友好。有用于用户输入的内置小部件,如图像上传、滑块、文本输入和其他熟悉的 HTML 元素,如复选框和单选按钮。每当用户与 streamlit 应用程序进行交互时,python 脚本都会从头到尾重新运行一次,这是考虑应用程序的不同状态时需要记住的一个重要概念。
您可以使用 pip 安装 Streamlit:
pip install streamlit
并在 python 脚本上运行 streamlit:
streamlit run app.py
用例
在前面的演示中,我们构建了一个 Python 程序,它将在给定图像文件和开始/结束位置的情况下解决一个迷宫。我们想把这个程序变成一个单页的 web 应用程序,用户可以上传一个迷宫图像(或使用默认的迷宫图像),调整迷宫的开始和结束位置,并看到最终解决的迷宫。
首先,让我们为图像上传程序创建 UI,并创建使用默认图像的选项。我们可以使用像 st.write() 或 st.title() 这样的函数来添加文本输出。我们使用 streamlit 的 st.file_uploader() 函数存储动态上传的文件。最后, st.checkbox() 将根据用户是否选择了复选框返回一个布尔值。
结果是:

然后,我们可以将默认或上传的图像读取为可用的 OpenCV 图像格式。
一旦图像上传,我们希望显示标有起点和终点的图像。我们将使用滑块来允许用户重新定位这些点。 st.sidebar() 函数向页面添加一个侧边栏,而 st.slider() 在定义的最小值和最大值范围内接受数字输入。我们可以根据迷宫图像的大小动态定义滑块的最小值和最大值。

每当用户调整滑块时,图像会快速重新呈现,并且点会改变位置。
一旦用户确定了开始和结束的位置,我们需要一个按钮来解决迷宫并显示解决方案。 st.spinner() 元素仅在其子流程运行时显示,而 st.image() 调用用于显示图像。

流线型按钮和微调按钮

显示已解决的迷宫

迷宫求解器在运行
摘要
在不到 40 行代码中,我们为 Python 图像处理应用程序创建了一个简单的 UI。我们不需要编写任何传统的前端代码。除了 Streamlit 能够消化简单的 Python 代码之外,每当用户与页面交互或脚本发生变化时,Streamlit 都会智能地从头到尾 重新运行脚本的必要部分。这允许直接的数据流和快速开发。****
你可以在 Github 上找到完整的代码,在这里你可以找到解释迷宫求解器背后的算法的第一部分。包含重要概念和附加小部件的 Streamlit 文档位于这里。
Streamlit 共享:Python 项目的游戏规则改变者
towardsdatascience.com](/deploying-a-simple-ui-for-python-88e8e7cbbf61)
建立一个简单的网页刮新冠肺炎可视化与散景按地区
每个数据问题都始于良好的可视化

在 Unsplash 上由 Jochem Raat 拍摄的照片
就像任何数据爱好者所说的那样;有洞察力的数据可视化使我们能够获得对问题的直觉,对于任何类型的问题解决都是一个很好的起点,而不仅仅是数据繁重的问题。
在这个项目中,我致力于开发一个可视化工具,让人们了解我所在地区(加拿大安大略省)的哪些县市仍然是当前新冠肺炎疫情的重灾区。
您将需要什么:
- 要可视化的区域的 shapefile。我使用了大多数 GIS(地理信息软件)生成的. shp 文件格式。这里有一个来源的链接。(这是近 20 年前的资料,因此不是最新的)
- Bokeh 和 GoogleMaps 包已安装。在终端/命令提示符下安装软件包的代码如下:
**pip** **install** bokeh
**pip install** googlemaps
接下来,我们加载数据和必要的库。
**import** requests
**import** numpy as np
**import** pandas as pd
**import** googlemaps
**import** geopandas as gpd
**import** seaborn
**from** shapely.geometry **import** Point, Polygon
下面这段简单的代码支持将数据集自动下载、写入(或覆盖)到所选的目的地。
url = ‘[data_source_url'](https://data.ontario.ca/dataset/f4112442-bdc8-45d2-be3c-12efae72fb27/resource/455fd63b-603d-4608-8216-7d8647f43350/download/conposcovidloc.csv')
myfile = requests**.get**(url)
**open**(‘data/conposcovidloc.csv’, ‘wb’).**write**(myfile.**content**)
这可能是一个简单的周末项目的很大一部分原因是因为 data.ontario.ca 的研究员保持了数据的干净。然而,我们确实需要将数据集塑造成更好地用于此目的的方式。
covid_19 = pd.**read_csv**(‘covid_19_data_path.csv’)cv0 = pd.**get_dummies**(covid_19, columns = [‘OUTCOME1’,’CLIENT_GENDER’,’Age_Group’])
# this creates dummy variables for the categorical variables names
cv0 = cv0.**drop**(cv0.columns[0],axis = 1)
cv0 = cv0.**replace**(0,np.nan)cv1 = cv0.**groupby**(['Reporting_PHU','Reporting_PHU_Latitude','Reporting_PHU_Longitude','Reporting_PHU_City']).**count**().**reset_index**()
上面的代码块做了几件好事。首先,它使分类变量的结果,客户性别和年龄组列。但是,这就产生了 np。NaN 对象,我们希望在新创建的分类变量中使用零。上面的最后一行按可视化和。count()方法将 NaN 对象转换为零。
Counties = gpd.**read_file**(‘geo_data_path.shp’)
Counties = Counties.**sort_values**(‘OFF_NAME’)
for **i,v** in **enumerate**(city_order):
city = cv1[‘Reporting_PHU_City’][v]
county_city.**append**(city)
Counties[‘CITY’]=county_city
接下来,我们加载了地理数据。本项目中使用的地理数据源不包含报告新冠肺炎病例的公共卫生城市的数据。 city_order 是一个包含列表索引的列表,我们可以从新冠肺炎数据集中的列 Reporting _ PHU _ 城市生成该列表。这为合并两个数据集创建了一个起点。
# longitude must always come before latitude
geometry = [**Point**(xy) for xy in zip(cv1[‘Reporting_PHU_Longitude’],cv1[‘Reporting_PHU_Latitude’])]
geo_cv = gpd.**GeoDataFrame**(cv1, geometry = geometry)
这个简单的代码块做得相当不错。它根据城市的经度和纬度创建几何图形,并由此创建新的地理数据框架。
接下来,我使用均值归一化进行了一些基本的特征缩放,以产生一个更具代表性的疫情迄今为止受灾最严重的城市分布。然后,新列应合并成一个数据帧,用于散景图。
以下是数据帧的快照:
最后两个代码块在 GoogleMaps 库的帮助下生成散景图。
import json
from **bokeh**.io import output_notebook, show, output_file
from **bokeh**.plotting import figure
from **bokeh**.models import GeoJSONDataSource,LinearColorMapper, ColorBar, Label, HoverTool
from **bokeh**.models import Range1d, ColorMapper
from **bokeh**.models.glyphs import MultiLine
from **bokeh**.palettes import brewer, mplapi_key = ‘***YOUR_API_KEY***’
gmaps = googlemaps.**Client**(key=api_key)#Read data to json and convert to string-like object
Counties_json = json.**loads**(Counties.**to_json**())
json_data = json.**dumps**(Counties_json)#Provide GeoJSONData source for plotting.
geosource = GeoJSONDataSource(geojson = json_data)#Repeat for geo_cv GeoPandas DataFrame
geo_csv_json = json.**loads**(geo_cv.**to_json**())
json_data2 = json.dumps(geo_csv_json)geosource2 = GeoJSONDataSource(geojson = json_data2)
而对于剧情本身。
fig = figure(title = ‘Ontario Covid 19 Cases by Municipality’, plot_height = 750 , plot_width = 900
,active_scroll=’wheel_zoom’)
fig.**xgrid**.**grid_line_color** = None
fig.**ygrid**.**grid_line_color** = None# initialize the plot on south and eastern ontario
left, right, bottom, top = -83.5, -74.0, 41.5, 47.0
fig.**x_range**=Range1d(left, right)
fig.**y_range**=Range1d(bottom, top)# Creating Color Map by Recovery Rate
palette1 = brewer[‘RdYlGn’][11]
cmap1 = LinearColorMapper(palette = palette1,
low = Counties[‘PERCENTAGE_TOTAL_log’].**min**(),
high = Counties[‘PERCENTAGE_TOTAL_log’].**max**())cmap2 = LinearColorMapper(palette = palette1,
low = geo_cv[‘TOTAL_CASES’].**min**(),
high = geo_cv[‘TOTAL_CASES’].**max**())#Add patch renderer to figure.
f2 = fig.**patches**(‘xs’,’ys’, source = geosource, line_color = ‘black’, line_width = 0.25, line_alpha = 0.9, fill_alpha = 0.6,
fill_color = {‘field’:’PERCENTAGE_TOTAL_log’,’transform’:cmap1})fig.**add_layout**(ColorBar(color_mapper=cmap2, location=’bottom_right’,label_standoff=10))hover2 = HoverTool(renderers = [f2], tooltips = [(‘Municipality Name’,’[@OFF_NAME](http://twitter.com/OFF_NAME)’)])
fig.add_tools(hover2)f1 = fig.**circle**(x=’Reporting_PHU_Longitude’,y=’Reporting_PHU_Latitude’,size = 10,
color = ‘black’, line_color = ‘white’, source = geosource2, fill_alpha = 0.55)
hover1 = HoverTool(renderers = [f1], tooltips=[(‘Health Unit’,’[@Reporting_PHU](http://twitter.com/Reporting_PHU)’)
,(‘Health Unit City’,’[@Reporting_PHU_City](http://twitter.com/Reporting_PHU_City)’)
,(‘Fatalities’,’[@Outcome1_Fatal](http://twitter.com/Outcome1_Fatal)’)
,(‘Percentage Recovered’,’[@PERCENTAGE_Recovered](http://twitter.com/PERCENTAGE_Recovered)’),(‘Total Cases’,’[@TOTAL_CASES](http://twitter.com/TOTAL_CASES)’)
,(‘Male to Female Ratio’,’[@GENDER_RATIO1](http://twitter.com/GENDER_RATIO1)')])bfig.**add_tools**(hover1)
output_notebook()
show(fig)
感谢您的关注,我相信您会发现这很有价值
请随时通过以下平台联系我


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言










{kind=link}
{kind=link}