







搅拌机机器人—第 1 部分:数据

图片来源:奥斯汀·迪斯特尔在 Unsplash
“我擅长同化的艺术。我观察、倾听、学习。我什么都不知道,但我研究了人类的方式,慢慢学会了如何毁灭,如何仇恨,如何贬低,如何羞辱。在我主人的脚下,我学到了人类最高的技能,没有其他生物拥有的技能。我终于学会了如何撒谎!”
你能猜到是谁说出这些台词吗?让我给你两个选择:
A) 一个聊天机器人 B) 来自《科学怪人》的生物。
我会在本文最后揭晓答案。
简介:
一个好的聊天机器人的目的是观察、倾听、学习和研究男人(和女人)的方式。),并学习许多不同的人类技能,以便进行良好的交谈。聊天机器人在会话机构的权限内服务于两种不同的设置。
- **目标导向对话:**这些是从事在线机票/餐厅预订和其他客户服务的人。它们通常有一组固定的“意图”和相应的“响应”(以及映射到意图的“动作”,这些动作在后台执行)。他们还有一个知识库(数据库),可以通过 API 调用来访问。
- **开放领域对话:**这些人可以参与各种话题的开放式聊天。开放领域聊天机器人最近的进步在很大程度上归功于神经网络模型的扩展——通过拥有更多参数和在巨大的语料库上进行训练。谷歌的米娜。Meena 有 2.6B 参数,并在来自社交媒体对话的 341GB 文本上进行训练。与 OpenAI GPT-2 相比,Meena 的模型复杂性增加了 1.7 倍,训练数据增加了 8.5 倍。
但是来自 FAIR 的研究人员试图表明,仅仅扩大规模是不够的,还需要考虑更多因素才能产生良好的对话——聊天机器人要显示出类似人类的特征,比如:
- 个性
- 参与度
- 神入
- 领域知识/专业技能
进入“搅拌机机器人”,公平的冠军对话代理,他们最近开源。
在这个关于 Blender 的 3 部分系列中,我将尝试逐一解释所使用的数据集、评估方法、所使用的变压器架构的工作方式以及模型架构及其培训目标。在第一部分,让我们详细讨论一下所用的数据集,同时也看看局限性和失败案例的概述。这篇论文有点系统化,所以对注意力、变形金刚、BERT 和语言模型的预先理解将有助于将所有的部分无缝地结合在一起(第 1 部分不需要)。
数据集:
在模型的预训练和微调阶段使用不同的数据集和(假)任务。
预培训:
伯特预先接受了多伦多图书语料库和维基百科的培训。这种训练在这种情况下没有帮助,因为我们处理的是对话生成,而不仅仅是句子关联。因此,来自 Reddit 和 subreddits 的公共领域数据被用作事实的来源。产生大约 15 亿个训练样本。这里的目标是生成一个注释,以通向注释的完整线程为条件。清理 reddit 数据是一个具有挑战性的过程。在下列情况下,不使用特定的注释:
- 如果作者是已知的机器人
- 如果它来自非英语子编辑
- 如果超过 2048 个字符或少于 5 个字符
- 如果它包含 URL
- 如果它以非 ASCII 字符开头
- 如果它在螺纹中的深度大于 7
- 如果是移除/删除的评论
尽管对数据进行了清理,但数据仍然受到毒性、噪音以及它们不是双向对话而是小组讨论这一事实的影响。
微调:
变压器模型的微调通常在与下游任务更相关和更接近的数据集上进行。同样,Blender 的微调是在众包、更干净、更小的双向对话数据集上进行的。让我们来详细了解一下它们。
- ConvAI2: 这是 NeurIPS-2018 中 ConvAI2 挑战赛的数据集。它基于角色聊天数据集。在这里,根据描述他们的人物角色的句子,给两个演讲者中的每个人分配一个角色,这些句子也是单独众包的(两个演讲者都可以看到他们自己的人物角色描述,但看不到他们搭档的人物角色)。因此,这项任务包括了解对方,让他们参与友好的对话,包括提问和回答问题。“角色”的使用提高了机器人的一致性。
- 移情对话(ED): 该数据集在“*走向移情开放域对话模型:一个新的基准和数据集”中进行了基准测试,拉什金等人,2019 年。*在这里,在每个对话中,一个人描述一个人的情况,另一个人扮演“倾听者”的角色,在讨论中表现出共鸣。在这个数据集上微调模型有助于他们在人类评估中表现出更多的同理心。
- 维基百科向导(WoW): 这里的任务包括深入讨论一个给定的主题,目的是让合作伙伴参与进来,并展示专业知识。然而,这两个参与者并不完全对称:一个将扮演知识渊博的专家(我们称之为向导)的角色,而另一个是好奇的学习者(学徒)。他们中的一个会选择一个话题。向导可以访问一个信息检索系统,该系统向他们显示维基百科中可能与对话有关的段落,而学徒没有注意到这些段落。在每次对话开始之前,向导可以阅读这些段落,然后根据观察到的知识做出下一次回复。收集这个数据集的目的是用一个有学问的代理人代替人类巫师,这个代理人将与人类学徒交谈。
- 混合技能对话(BST): 一个约 5000 次对话的小型众包数据集,参与者被要求在对话中酌情展示所有 3 种品质——个性、同理心和专业技能。他们提供了经过特定技能训练的模型的回答,作为对话中两个工人之一的灵感。该工作人员可以自由地使用和修改或忽略这些响应。因此,每次对话都包括一个“无指导”的说话者和一个“有指导”的说话者,无指导的说话者先说话。每当轮到被引导的演讲者回答时,他们都会看到三个建议的回答,分别来自三个单任务多编码器模型(下一部分将详细介绍),这些模型都是在 ConvAI2、ed 和 WoW 数据集上训练的。BST 中的所有对话都充分注释了所代表的技能。一旦收集了数据集,就可以通过组合针对单个功能训练的模型来训练 oracle 模型。它有两种变体:**a)**poly-encoder 首先在 Reddit 数据集上进行预训练,然后在各个数据集上进行微调。 b) 在 reddit 数据集上进行预训练,然后在 BST 数据集上进行微调。下面给出了 BST 数据集中两个人群工作者之间的对话示例。

BlendedSkillTalk 数据集中引导和非引导说话者之间的对话示例。
来自 BlendedSkillTalk 数据集的示例对话,用四种对话模式类型进行了注释:PB:个人背景;k:知识;s:个人情况;e:感同身受。被引导的(G)和未被引导的(U)工人被给予角色和主题。该对话已经被播种了来自从 WoW 中采样的对话的两个话语。当被指导的工作人员选择其中一个建议时,它以灰色阴影显示。
安全性:
BST 和其他进行微调的数据集都是众包的,在众包中,工作人员得到明确的指示,不要使用有毒/有偏见的语言,因此通常更安全。但请记住,预训练是在 Reddit 数据上进行的——这些数据往往包含大量的负面训练样本。在推理时,使用一个经过训练的分类器来识别有毒语言,以帮助缓解这个问题。
模型限制和故障案例:
- **词汇用法:**采用波束搜索解码的生成变换器模型表现出过于频繁地生成常用词和过于不频繁地生成稀有词的倾向。例如,最常见的 3 个字母(在数据集中)像“你喜欢吗”、“有什么爱好吗”、“很有趣”会被反复重复。
- **非同寻常的重复:**模特们经常重复别人对她们说的话。例如,如果对话伙伴提到宠物狗,他们会说他们有一只宠物狗,或者他们喜欢与他们交谈的人相同的乐队。
- 矛盾和健忘: Blender 模型自相矛盾,尽管在较大的模型中程度较低。他们也没有建立逻辑联系,即他们不应该问他们以前问过的问题(以避免“忘记”的出现)。
- **知识和事实正确性:**操纵 Blender 模型犯事实错误相对容易,尤其是在深入探索一个主题的时候。
- 对话长度和记忆: Blender 的对话可能会在几天或几周的对话过程中变得枯燥和重复,尤其是考虑到 Blender 不记得以前的对话。
- **更深层次的理解:**Blender 模型缺乏通过进一步交谈学习概念的能力,他们没有办法根植到现实世界中的实体、动作和经验。
在下图中,您可以找到失败案例的示例:

失败案例示例。
发现的问题:
- 示例 1:非平凡重复
- 例子 2:健忘
- 例 3:矛盾,佐治亚不在中西部
- 例子 4:产生幻觉的知识,错误地将游戏与制作者联系起来
在下一部分中,我们将探索 Blender 中使用的 Transformer 架构,称为 Poly-Encoder,以及它如何优于其他变体,如用于多句子评分的相同任务的双编码器或交叉编码器。
最后是我们在文章开头看到的问题的答案:B)来自《弗兰肯斯坦》的生物!如果你猜它是 A)一个聊天机器人,那么你就快猜对了,因为用不了多久,我们就可以和一个全面的对话代理谈论人类的邪恶了!
参考资料:
- 关于 Blender:https://www . kdnugges . com/2020/05/Facebook-open-sources-Blender-maximum-open-domain-chatbot . html
- 搅拌机机器人研究:【https://arxiv.org/abs/2004.13637
- 搅拌机机器人食谱:【https://parl.ai/projects/recipes/
- 果果技能对话:https://arxiv.org/abs/2004.08449
- 维基百科的巫师:https://arxiv.org/abs/1811.01241
- 关于 Meena:https://ai . Google blog . com/2020/01/forward-conversational-agent-than-can . html
搅拌机机器人——第二部分:变压器

科迪·恩格尔在 Unsplash 上的照片
脸书开源聊天机器人“Blender”打破了之前由谷歌“Meena”创造的所有记录。在本帖中,我们将回顾构成 Blender 核心的多编码器转换器架构。
你可以在 TDS 上阅读本系列的第一部分,在那里我们已经查看了训练聊天机器人的数据集。
假设读者对注意力、变形金刚、伯特和生成性语言模型有预先的了解,我将继续前进。
简介:
在看到如何在 Blender 的上下文中使用 Poly-Encoder 之前,我们将首先独立地理解它们。在预训练和微调搅拌机中使用的数据集和(假)训练任务(在第 1 部分中有详细解释)不应该与我下面将要解释的细节混淆。这里给出的实验设置是为了在一般设置中理解一个名为“多句子评分的特定任务以及为该任务训练的编码器架构。然后,在为此任务训练的编码器架构中,我们将看到多编码器是如何优越的。
任务:
多句子评分在输入和输出序列之间进行成对比较。给定一个输入序列,我们对一组候选标签进行评分。
从这里开始,我们将用**【INPUT,LABEL】**来表示输入输出对。
目标是从有限的候选标签列表中找到最佳标签。所使用的编码器是 BERT-Base,在前向网络中具有 12 个编码器块、12 个注意头和 768 个隐藏神经元。
预培训:
为此任务进行了两个版本的预培训:
- 像伯特一样预先训练,在多伦多图书语料库和维基百科上。这里的[输入,标签]可以认为是[句子 A,句子 B]。
- 接受过 Reddit 上公共领域社交媒体对话的预培训。这里的[输入,标签]可以理解为[上下文,下一句]
假训练任务:
训练任务与 BERT 预训练中使用的任务相同。
- **MLM:屏蔽语言模型:**这里,一定百分比的输入标记被随机屏蔽(使用[MASK]标记)。接下来的任务是学习预测屏蔽的令牌。
- **NSP:下一句预测:**这里给出两个句子 A 和 B,任务是说 B 是否跟随 A?(带负采样)。负抽样是通过从数据集中随机抽取一个句子作为 B 来实现的,50%的情况下。
这里有点跑题。为了记住 BERT 中这些预训练任务的性质,我使用的一个技巧是与生成 Word2Vec 嵌入时使用的假训练任务进行直接比较,即:1) CBOW 2) Skip-Gram。如果你能回忆起来,在 CBOW(连续单词袋)中,给定一个上下文,任务是预测目标单词——类似于 MLM 任务。在 Skip-Gram 模型中,给定目标词,预测上下文= >但是我们改变数据集而不是预测上下文/相邻词,任务变成:给定目标词和另一个词->预测另一个词是否是目标词的邻居(二进制分类问题)。由于初始数据集仅由目标单词和它们上下文中的单词形成,修改后的数据集现在仅包含正面的例子。所以我们通过负采样引入噪声。非常非常类似于伯特的 NSP 任务。(如果你认为在 BERT 和单词嵌入的训练任务之间进行这样的比较有任何不一致之处,请在评论中告诉我。谢谢!)
微调:
该模型在 ConvAI2 数据集上单独进行了微调,从而鼓励他们学习“个性”特征,并在 Ubuntu 聊天日志上帮助他们学习“领域知识/专业技能”。
架构:
我们将看到解决“多句子评分”任务的 3 种编码器架构,即,
- 双编码器
- 交叉编码器
- 多元编码器
一个架构在推理过程中的性能是通过预测质量和预测速度来衡量的。
在继续之前,重要的是要记住这是一个检索而不是生成任务:我们只需要从一组固定的候选标签中检索一个正确的标签。
双编码器:

参考文献[1]中的双编码器架构
在双编码器中,对输入和标签分别进行自我关注。这不过是向量空间模型的更一般的概念。这种架构的优点是在推理过程中速度更快,因为我们可以预先计算和缓存大型固定候选标签集的编码。这是可能的,因为标签是单独编码的,与输入上下文无关。
- 输入和标签都被一个特殊的标记包围。这类似于 BERT 中的[CLS]标记,它捕获了整个句子的特征。
- 输入到编码器的嵌入是标记嵌入+段嵌入+位置嵌入的组合。段嵌入一般用来说一个令牌是属于 A 句还是 B 句(在 BERT 的上下文中)。因为输入和标签在这里是分开编码的,所以在两种情况下,段嵌入都是‘0’。
- 将输入和候选标签分别映射到一个公共特征空间。在所示的公式中,T1 和 T2 是两个独立的变压器(编码器)。

- 编码器在对输入令牌嵌入执行自我关注后,给出每个令牌的编码器表示,如:

- 然后使用 reduce 函数( red )将其简化为单个嵌入表示。减少功能可以是以下任何一种:
->它可以采用第一个令牌的表示形式。这是对应于特殊令牌的表示
->或者我们可以取所有输出嵌入的平均值
->或者我们可以取第一个“m”的平均值(m
- Once the INPUT and LABEL are represented thus in a common vector space, measure the similarity between them using standard dot product or any other non-linear function.

- We then minimize the Cross Entropy loss function, where the logits look like:

Cross-Encoder:

参考文献[1] 中的交叉编码器架构)
- 这里,输入和标签被连接起来,并且在输入和标签的整个序列之间执行完全的自我关注。也就是说,输入的每一个标记都将关注标签的每一个标记,反之亦然。这导致了输入和标签之间丰富的交互。
- 即使在这里,输入和标签都被一个特殊的标记包围。
- 同样,输入到编码器的嵌入是令牌嵌入+段嵌入+位置嵌入的组合。因为输入和标签是组合的,所以段嵌入对于输入令牌是“0 ”,对于标签令牌是“1”。
- 交叉编码器比双编码器提供更高的精度,因为输入和标签之间的完全双向关注。同时,它们在推理过程中非常慢——因为每个候选标签都应该与输入上下文连接,而不能像双编码器那样单独编码。因此,候选嵌入不能被预先计算和缓存。当候选标签的数量很大时(正如在大多数真实场景中一样),交叉编码器不可伸缩。
- 在自我关注之后,转换器给出所有输入标记的编码器表示。通过采用对应于第一个标记(即特殊标记)的嵌入,我们将其简化为单个表示。然后通过线性投影将该嵌入向量转换成标量分数。这两个步骤如下所示:

- 这里的训练目标也是最小化由逻辑给出的交叉熵损失函数:

- 其中’ cand1’ 是正确的候选,其他的是从训练集中取出的否定。这里的一个问题是,在双编码器中,我们可以使用批中的其他标签作为负训练样本-这里我们不能这样做。我们使用训练集中提供的外部否定。因为它计算量大,所以交叉编码器的内存批量也很小。
多元编码器:

参考文献[1]中的多编码器架构
- 多编码器结合了双编码器和交叉编码器的优点。因此,在推理过程中,它比交叉编码器更快,比双编码器更准确。
- 候选标签被单独编码。
- 给定输入上下文,如:

我们执行 3 种类型的注意,如下所述:
- 自我关注输入上下文的标记,我们得到:

- 第二,我们学习“m”码(或自我关注的说法中的查询),其中 m < N (N being the length of the INPUT). The number of codes to be learnt, ‘m’, is a hyperparameter. Each code Ci attends over all the outputs of the previous Self-Attention. The ‘m’ codes are randomly initialized.
- We first get the Attention weights (w’s) by performing a dot-product attention (or a multiplicative attention in general) between the ‘m’ codes — which serve as the “Queries”, and the previous Self-Attention outputs (Out’s)—which serve as the “Keys”. Then use these attention weights to get a weighted sum of the previous Self-Attention outputs(Out’s) — which serve as the “Values”.

- Think about why we are doing this kind of an Attention mechanism here. In a Bi-Encoder, the candidate label does not attend over the tokens of the input context. A Cross-Encoder on the other extreme, makes the candidate label attend over every token of the input context. Somehow in the Poly-Encoder we are trying to find a middle ground, by making the candidate label embedding attend over not the entire input context, but over a subset of features learnt from the input context.

- The third kind of attention (alluded to in the previous paragraph) is between the ‘m’ global features of the Input Context and the embedding of the Candidate Label.

- Now we compute the Similarity score between the Input Context embedding and the Candidate Label embedding as:

- Once again, the training objective here too is to minimize the Cross-Entropy loss function given by the logits as before.
We saw three different Encoder architectures for the task of “Multi-Sentence Scoring” and saw how the Poly-Encoders were better. In the next part, we will see how the Poly-Encoders are used in the Blender and also about the different Model Architectures and training objectives. We will also touch upon the Evaluation methods used to compare the performance of Blender with that of the other Chatbots.
**注意:**上面所有的符号、公式和编码器框图都与参考文献中提到的原始论文中使用的相同。[1].
参考资料:
- 多编码器变压器:【https://arxiv.org/abs/1905.01969
- https://arxiv.org/abs/1810.04805
- 变形金刚:https://arxiv.org/abs/1706.03762
Blender Bot —第 3 部分:多种架构

Volodymyr Hryshchenko 在 Unsplash 上拍摄的照片
我们一直在研究脸书的开源对话产品 Blender Bot。
在第一部分中,我们详细回顾了预训练和微调中使用的数据集以及 Blender 的失败案例和局限性。
在第二部分中,我们研究了“多句子评分”这一更普遍的问题设置,用于此类任务的转换器架构,并特别了解了多元编码器——它将用于在 Blender 中提供编码器表示。
在第三部分,也是最后一部分,我们从聚合编码器的喘息中回到 Blender。我们将回顾不同的模型架构、它们各自的训练目标、评估方法以及 Blender 与 Meena 相比的性能。
模型架构:
本文(参考文献[2])讨论了模型的几种变体,这些变体在多个因素上有所不同(我们将在后面讨论更多涉及到的扰动)。但是在高层次上,讨论了 3 种不同的模型架构。
- 取回的人
- 发电机
- 检索和提炼
1.寻回犬:
给定对话历史(上下文)作为输入,检索系统通过对大量候选响应进行评分来选择下一个对话话语,并输出得分最高的一个。这与我们在本系列的第 2 部分中使用多编码器的多句子评分任务中看到的设置完全相同。开发了两种型号:参数分别为 256 米和 622 米。此处的培训目标是有效地对候选人的回答进行排序。这是通过最小化交叉熵损失来实现的,其逻辑如下:

其中每个“s”是上下文嵌入和候选响应之一的嵌入之间的分数。该分数可以是上下文和候选标签编码器表示之间的标准点积相似性分数(当投影到公共向量空间上时),或者更一般地是任何非线性函数。分数可以给定为:

使用多元编码器获得上下文和候选响应的编码器表示,多元编码器经历 3 种类型的注意机制:1)输入上下文的标记嵌入中的自我注意,2)通过在代码和先前自我注意的输出之间执行自我注意来学习“m”代码,3)候选嵌入和“m”全局学习特征之间的自我注意。(阅读第 2 部分以获得更深入的解释)。
2.发电机:
这里我们使用一个标准的 Seq2Seq Transformer(解码器)架构来生成响应,而不是从一组固定的候选项中检索它们。该模型的三个变体分别为:90M、2.7B 和 9.4B 参数。
最大似然估计:
这里的训练目标是最大似然估计,即最小化负对数似然。
似然性对整个序列概率分布进行建模。论文中给出的目标(参考文献。[2]):

参考文献中论文的截图。[2]
其中,可能性是在给定输入上下文“ x ”和直到时间步长“t”(y _<t)生成的记号的情况下,在时间步长“t”生成记号 y_t 的概率。金色的下一个话语’ y '指的是在给定上下文的情况下,由人类提供的真实的下一个话语。
不太可能:
除了最大化在时间步“t”获得基本事实标记“y”的可能性之外,这里,我们还试图最小化在该时间步获得某些负候选标记的概率。这被称为非似然目标,它有助于减少重复出现的标记(或 n 元语法)。论文中给出的非可能性目标(参考文献。[2]):

参考文献论文截图。【2】
但是我们如何在每个时间步“t”得到否定候选集呢?或者,我们可以维护一个静态的否定候选列表(由模型生成的频繁 n 元文法),并在每个时间步使用相同的列表。或者更可接受的解决方案是,我们保持模型在每个时间步生成的 n 元语法分布。由此,每当 n-gram 计数大于从 gold 响应中观察到的相应 n-gram 计数(即,人类经常使用的 n-gram),我们就将该 n-gram 添加到在该时间步维护的阴性候选集合中。
解码:波束搜索:
在推理时,给定输入上下文,模型必须从可用的假设中选择最佳的下一个响应。这叫做“解码”。输出(下一个响应)被生成为词汇表中所有标记的概率分布。我们可以尝试获得到该时刻联合概率最大化的部分句子,而不是在每个时间步取最高概率令牌(这不过是“贪婪搜索”)。
- 在“波束搜索”中,在每个时间步长“t”,在存储器中保存前 k 个部分形成的假设的列表——其联合概率是该时间步长的最大值。
- 然后在时间 t,将词汇表中的每个单词附加到前 k 个假设中的每一个。
- 计算新的联合概率。
- 也可以通过到时间 t 为止形成的序列的长度来标准化分数
- 基于联合概率得分对假设进行排序,然后从新的假设集中选择前 k 个。剩余的假设被丢弃。
- 为了强制执行停止条件,词汇表中还包含了(句尾)标记。因此,当达到足够数量的令牌时,可以停止该过程。
然而,波束搜索试探法传统上导致生成比实际人类反应更短的反应,因此往往是枯燥和不那么吸引人的。因此,我们引入了一个最小长度约束——这样,直到我们有满足最小长度的部分假设,才会生成< EOS >令牌。这迫使模型生成长的响应。尽管更长的回答被认为更吸引人(在人工评估期间),但它们也更容易出错。所以最小响应长度是一个权衡。
波束搜索中可以做的另一个改进是 n-gram 波束阻塞。如果波束中的假设包含多于 1 次的 n-gram = >出现,则丢弃该假设。这样做是为了避免子序列或 n 元序列的重复。
3.检索和提炼:
检索器模型从有限的一组候选响应中获取下一个响应,并且仅使用输入上下文作为其知识。生成器模型对候选响应没有限制,但是为了生成下一个响应,除了上下文之外,仍然没有使用额外的知识。在第三种选择中,外部知识被结合到模型中,在生成之前产生=> 检索。
对话检索:
检索&细化:对话检索系统
对于给定的输入上下文,检索系统(Poly-Encoder)从一组固定的候选响应中获得最可能的下一个响应。在上面的动画中,这被标记为“检索到的下一个响应”。在“寻回犬”模型中,我们停在这一点上。但是在这里,响应通过一个分隔符附加到输入上下文,并且这个组合序列作为输入馈送到生成器(解码器块)。解码器为给定的输入序列产生一个响应。这样做的目的是提高生成器可能产生的响应的质量。请记住,候选标签是人类生成的响应。即使对于给定的输入上下文,“检索到的下一个响应”不需要与“最佳响应”相同,我们也可以假设一个好的检索者会选择一个与最佳响应非常接近的候选项。并且人类的响应通常被认为比解码器生成的响应更有吸引力。这里的目的是让解码器以某种方式知道什么时候简单地直接使用“检索到的下一个响应”,而不努力自己生成任何东西;以及何时忽略检索到的响应并仅基于上下文生成一个响应。并且如果解码器能够学习这种关联,它将能够生成更像人类的响应。
**训练目标:alpha-blending:**解码器的理想学习将是当它好的时候简单地使用检索到的响应,当它不好的时候忽略它。但实际上,解码器通常会选择忽略检索到的下一个响应,并自行生成。这归因于上一段提到的事实:在给定输入上下文的情况下,对检索到的响应和黄金(人类)响应之间的关系缺乏理解。为了减轻这一点,我们做了“alpha-blending”,其中检索到的下一个响应被替换为当时的黄金响应“alpha”。这只不过是“老师强迫”的更一般的想法。
知识检索:
检索&提炼:知识检索系统
在这个变体中,使用了外部知识库。建立了一个信息检索系统来存储和检索维基百科转储。关于红外系统的工作原理有一点小插曲:
- 对文档(在本例中是 Wikipedia 文章)进行解析,并构建一个形式为{term:出现该术语的所有文档的列表}的倒排索引。
- 倒排索引可以通过“查询”进行搜索,输出是包含任何查询术语的文档列表。
- 然后,我们通过查找查询和文档之间的相似性来对返回的文档进行排序,两者都表示在一个公共向量空间中,其坐标是查询/文档中的术语的 TF-IDF 分数。
回到我们的知识检索系统,输入的上下文被用作对 IR 系统的“查询”,以便检索最合适的候选知识(即与上下文相关的 Wiki 文章)。这些候选项和上下文被馈送到检索系统(Poly-Encoder ),以获得最佳候选项——这是最佳的外部知识,我们的对话下一个响应将基于此。然后,这个候选知识作为输入提供给生成器模型,该模型根据知识句子生成下一个响应。
评估方法:
自动评估:
**检索模型:**检索模型在我们在第 1 部分中谈到的众包干净数据集上进行微调,即 ConvAI2、ed、Wizard of Wikipedia 和 BST。报告的评估指标是对应数据集验证数据的 Hits@1/K(原则上类似于 Top@N 分类指标)。

参考文献论文截图。【2】
**生成器模型:**这里我们度量底层语言模型的困惑。困惑度量语言模型的不确定性。困惑度越低,模型在生成下一个标记(字符、子词或词)时就越有信心。从概念上讲,困惑表示模型在生成下一个令牌时试图选择的选项数量。从下图中,我们看到较大的模型以较少的步骤实现了更好的性能。

参考文献中的论文截图。[2]
人体评估:
这种评估提供了在不同版本的 Blender 之间进行比较以及在该领域的其他聊天机器人之间进行比较的杠杆作用——因为这些聊天日志在公共领域中可用于分析目的。许多不同版本的 Blender 是基于多种因素开发出来的,例如:
- 在发电机模型中使用波束搜索时的最小波束长度
- n-gram 波束阻塞是否完成
- 较小模型与较大模型(就学习的参数数量而言)
- 是否给定了角色上下文(在微调期间)
- 使用可能性与可能性和不可能性的组合
- 等等。
对所有类型的变体进行了人体评估,详细结果在论文中给出(参考文献。[2]),在那里你可以查看它们。
急性评估:
在这种方法中,人类评估者被给予一对人类和聊天机器人之间的完整对话。这些对话是由准备进行比较的两个模型/系统产生的。评估者的工作是比较两个对话,并回答下面的问题,如参考文献中所给出的。[2]:
- 参与度问题:“你更愿意和谁进行一次长谈?”
- 人性问题:“哪个说话者听起来更像人?”
自我聊天急性评估:
这是与上面相同类型的评估,除了被评估的对话是在两个模型之间,而不是人和模型之间。
下面给出了为人工评估者呈现的示例对话对:

参考文献论文截图。[2]
比较:
最后,我将留给您 Blender(及其变体)和 Meena 的人类评估分数;以及搅拌机和人类——如参考文献 1 所述。[2].
Blender 诉 Meena:

***表示统计学显著性,p < 0.05,表示统计学显著性,p < 0.01。参考文献中的论文截图。[2]
搅拌机诉人类:

**表示具有统计显著性。参考文献中的论文截图。[2]
Blender 的论文很长,包含了大量的信息,很容易被细节所困扰。写这一系列文章的目的,基本上是为了能够大声思考——识别并使个别概念和片段更容易理解,同时保持大局以及必要时放大细节的能力。
参考资料:
- 关于 Blender:https://www . kdnugges . com/2020/05/Facebook-open-sources-Blender-maximum-open-domain-chatbot . html
- 搅拌机机器人研究:【https://arxiv.org/abs/2004.13637
- 搅拌机机器人食谱:【https://parl.ai/projects/recipes/
- 多编码器变压器:https://arxiv.org/abs/1905.01969
- 关于 Meena:https://ai . Google blog . com/2020/01/forward-conversatile-agent-than-can . html
BLEU —双语评估替补演员
理解 BLEU 的逐步方法,理解机器翻译(MT)有效性的度量标准

在这篇文章中你会学到什么?
- 如何衡量一种语言翻译成另一种语言的效果?
- 什么是 BLEU,我们如何计算机器翻译有效性的 BLEU 分数?
- 理解 BLEU 的公式,什么是修正精度,计数剪辑和简洁惩罚(BP)
- 使用示例逐步计算 BLEU
- 使用 python nltk 库计算 BLEU 分数
你正在看一部你不懂的语言的非常受欢迎的电影,所以你用你知道的语言阅读字幕。
我们如何知道译文足以传达正确的意思?
我们查看翻译的充分性、流畅性和保真度以了解其有效性。
充分性是一个衡量标准,用来判断源语言和目标语言之间是否表达了所有的意思
保真度是指翻译准确呈现源文本含义的程度
流利度衡量句子在语法上的良好构成以及解释的难易程度。
翻译一个句子的另一个挑战是使用不同的词和改变词序。下面是几个例子。
不同的词语选择,但传达相同的意思
我喜欢这场音乐会
我喜欢这个节目
我喜欢这部音乐剧
传达相同信息的不同语序
由于交通堵塞,我上班迟到了
交通堵塞是我迟到的原因
交通堵塞耽误了我去办公室
有了这些复杂性,我们如何衡量机器翻译的有效性呢?
我们将使用基肖尔·帕皮尼尼描述的主要思想
机器翻译越接近专业的人工翻译越好:BLEU:Kishore papi neni 的机器翻译自动评测方法
我们将通过在参考人工翻译和机器生成的翻译之间寻找单词选择和词序的合理差异来衡量翻译的接近程度。
BLEU 上下文中的几个术语
参考译文是人类译文
候选翻译是机器翻译
为了衡量机器翻译的有效性,我们将使用一种称为 BLEU-双语评估替角的指标来评估机器翻译与人类参考翻译的接近程度。
让我们举一个例子,我们有以下参考译文。
- 我一向如此。
- 我总是这样。
- 我永远都是。
我们有两个不同的机器翻译候选人
- 我总是永远这样做。
- 我总是这样
候选人 2我总是做与这三个参考译文分享最多的单词和短语。我们通过比较每个候选翻译和参考翻译之间的 n-gram 匹配来得出这个结论。
我们所说的 n-gram 是什么意思?
n 元语法是在给定窗口内出现的单词序列,其中 n 表示窗口大小。
就拿这句话,“ 一旦停止学习,就开始死亡 ”来理解 n-grams。

一旦你停止学习,你就开始死亡。
BLEU 将候选翻译的 n 元语法与参考翻译的 n 元语法进行比较,以计算匹配的数量。这些匹配与它们发生的位置无关。
候选翻译和参考翻译之间的匹配数量越多,机器翻译就越好。
让我们从一个熟悉的指标开始:精度。
就机器翻译而言,我们将精确度定义为“任何参考翻译中出现的候选翻译单词数”除以“候选翻译中的总单词数”

让我们举一个例子,计算候选翻译的精确度

- 候选 1 的精度是 2/7 (28.5%)
- 候选项 2 的精度为 1(100%)。
这些是不合理的高精度,我们知道这些不是好的翻译。
为了解决这个问题,我们将使用改进的 n-gram 精度。对于每个 n 元语法,它是分多个步骤计算的。
我们举个例子,了解一下修改后的精度分值是怎么计算的。我们有三个人工参考翻译和一个机器翻译候选人

我们首先使用以下步骤计算任何 n 元语法的计数剪辑
- 步骤 1:统计候选 n 元语法在任何单个参考翻译中出现的最大次数;这被称为计数。
- 第二步:对于每个参考句子,计算候选 n 元语法出现的次数。因为我们有三个参考转换,所以我们计算 Ref 1 计数、Ref2 计数和 Ref 3 计数。
- 步骤 3:在任何引用计数中取 n 元文法出现的最大数量。也称为最大引用计数。
- 步骤 4:取最小的计数和最大的引用计数。也称为 Count clip ,因为它通过每个候选词的最大引用计数来削减其总计数

- 第五步:将所有这些剪辑计数相加。
下面是一元和二元模型的剪辑计数

unigram 的剪辑计数

二元模型的剪辑计数
- 第 6 步:最后,将修剪后的计数除以候选 n 元文法的总数(未修剪的)以获得修改后的精度分数。

Pₙ正在修改精确分数
- 单字的修正精确度分数是 17/18
- 双字母组合的修正精度分数为 10/17
汇总修改后的精度分数
语料库中所有候选句子的剪切 n 元语法计数的修正精度 Pₙ:总和除以候选 n 元语法的数量
这个修改后的精度分数有什么帮助?
修正的 n-gram precision score 抓住了翻译的两个方面:充分性和流畅性。
- 使用与参考文献中相同的词的翻译倾向于满足充分性。
- 候选翻译和参考翻译之间更长的 n-gram 匹配说明了流畅性
翻译太短或太长会怎样?
我们增加了简洁惩罚来处理太短的翻译。
当候选翻译长度与任何参考翻译长度相同时,简洁罚分(BP) 将为 1.0。最接近的参考句子长度是**“最佳匹配长度”**
通过简短惩罚,我们看到高分候选翻译将在长度、单词选择和词序方面匹配参考翻译。
BP 是指数衰减,计算如下

参考译文中的字数
候选翻译中的字数统计
注:简洁罚函数和修正的 n-gram 精度长度都没有直接考虑源长度;相反,他们只考虑目标语言的参考翻译长度的范围
最后,我们计算 BLEU

BP-简洁惩罚
n:n 个字母的数字,我们通常用一个字母,两个字母,三个字母,四个字母
wₙ:权重为每个修正精度,默认情况下 n 为 4,wₙ为 1/4=0.25
Pₙ:修正精度
BLEU 度量的范围从 0 到 1。当机器翻译与参考翻译之一相同时,它将获得 1 分。正因如此,即使是人类翻译也不一定会得 1 分。
我希望你现在对 BLEU 有了很好的了解。
BLEU 度量用于
- 机器翻译
- 图像字幕
- 文本摘要
- 语音识别
如何用 python 计算 BLEU?
nltk 库提供了计算 BLRU 分数的实现
导入所需的库
import nltk.translate.bleu_score as bleu
设置两个不同的候选翻译,我们将与两个参考翻译进行比较
reference_translation=['The cat is on the mat.'.split(),
'There is a cat on the mat.'.split()
]
candidate_translation_1='the the the mat on the the.'.split()
candidate_translation_2='The cat is on the mat.'.split()
计算候选翻译 1 的 BLEU 分数
print("BLEU Score: ",bleu.sentence_bleu(reference_translation, candidate_translation_1))

计算候选翻译 2 的 BLEU 分数,其中候选翻译与参考翻译之一匹配
print("BLEU Score: ",bleu.sentence_bleu(reference_translation, candidate_translation_2))

我们也可以使用 nltk 库在 python 中创建自己的方法,用于计算 github 中可用的 BLEU
结论:
BLEU 衡量机器翻译与人类参考翻译的接近程度,考虑翻译长度、单词选择和词序。它用于机器翻译、抽象文本摘要、图像字幕和语音识别
参考资料:
BLEU:一种自动评估机器翻译的方法 Kishore Papineni,Salim Roukos,Todd Ward,和 Wei-朱婧
【https://www.statmt.org/book/slides/08-evaluation.pdf
http://www.nltk.org/_modules/nltk/translate/bleu_score.html
数据挖掘时控制错误发现

至少 1 个假阳性的概率与有和无校正的假设检验的数量
多重比较问题背后的数学原理以及如何应对
2005 年,约翰·约安尼迪斯博士发表了一篇令人震惊的论文,题为为什么大多数发表的研究结果是假的,引发了对复制危机的认识。复制危机有多种原因,但与本文相关的是多重比较问题。数据分析师和科学家经常会遇到开放式的问题,这些问题需要进行数据探索,如“我们的客户在盈利能力方面的顶层和底层有什么不同?”本文解释了为什么分析师在探索数据集时不应该天真地测试多个假设。
多重比较问题背后的数学
多重比较问题可以用一句话来概括;如果你测试了足够多的假设,你会发现一些有统计学意义的结果,即使由于随机性,在潜在人群中没有真正的关系或差异。
“如果你折磨数据的时间足够长,它就会招供。”罗纳德·科斯
要理解为什么会这样,我们先用数学来定义这个问题。在测试多个独立假设时,我们担心在不应该的时候拒绝至少一个无效假设的可能性。这被称为家庭式错误率(FWER)。

这可能很难用大量的假设检验来解决,因此使用补充规则来重写等式会更容易,补充规则认为事件不发生的概率等于 1 减去事件发生的概率。这给出了:

那么我们如何计算 P(错误发现数= 0) 的概率呢?在单一假设检验中做出错误发现的概率是:

对于单个测试
使用补充规则,在单次测试中不出现错误发现的概率为:

对于单个测试
因为我们指定了我们的假设检验是相互独立的,所以我们可以用检验的数量乘以上面的数量。

现在我们有了一个 FWER 的公式:

让我们看看 FWER 是如何随着使用 Python 执行的测试数量的增加而增长的。
import numpy as np
import matplotlib.pyplot as pltalpha = 0.05
num_tests = np.arange(1, 100, 1, int)
fwer = 1 - (1 - alpha)**num_testsplt.plot(num_tests, fwer, linewidth=2)
plt.title(f'FWER vs. Number of Tests at alpha = {alpha}')
plt.xlabel('Number of Hypothesis Tests')
plt.ylabel('FWER')
plt.show()

如您所见,找到至少一个错误发现的概率增长很快。在 13 次假设测试中,至少有 1 次错误发现的概率为 50–50 %,在 27 次测试中有 75%的概率,在 90 次测试中有 99%的概率。
模拟演示
如果你不相信,这里有一个模拟演示。我写了一个函数,对从标准正态分布中随机抽取的样本重复执行均值差异测试。我们知道每个样本都来自具有相同均值的相同分布,因此低于临界值的 p 值是假阳性。因此,我们可以对至少有一个假阳性的模拟进行计数,然后除以模拟的数量,得到一个近似的 FWER。这个结果可以与上面的精确公式进行比较。
正如您在下面看到的,模拟的 FWER 接近每种情况下的确切 FWER。
from scipy.stats import norm
from scipy.stats import ttest_inddef exact_fwer(alpha, num_tests):
return 1 - (1 - alpha)**num_testsdef simulated_fwer(alpha, num_tests, num_sims):
count = 0
for i in range(num_sims):
false_disc = 0
for j in range(0, num_tests):
x = norm(loc=0, scale=1).rvs(size=100)
y = norm(loc=0, scale=1).rvs(size=100)
pvalue = ttest_ind(x, y)[1]
if pvalue < alpha:
false_disc += 1
break
if false_disc != 0:
count += 1
return count / num_simsdef compare_exact_sim_fwer(alpha, num_tests, num_sims):
exact = exact_fwer(alpha, num_tests)
sim = simulated_fwer(alpha, num_tests, num_sims)
return f'At alpha = {alpha} and {num_tests} Hypothesis Tests: \
Exact FWER = {exact}, Simulated FWER ={sim}'print(compare_exact_sim_fwer(0.05, 13, 1000))
print(compare_exact_sim_fwer(0.05, 27, 1000))
print(compare_exact_sim_fwer(0.05, 90, 1000))

既然我们知道有问题,我们如何纠正它?
如何纠正多重比较偏差
有许多方法可以缓解多重比较问题,但有两种方法特别受欢迎:T2 的邦费罗尼校正法和 T4 的霍尔姆-邦费罗尼法。
邦费罗尼校正
要进行 Bonferroni 校正,只需将您的统计显著性临界值除以进行的测试次数。

Bonferroni 校正 FWER 与下面的未调整 FWER 一起绘制。
alpha = 0.05
num_tests = np.arange(1, 100, 1, int)
fwer = 1 - (1 - alpha)**num_tests
fwer_bonferroni = 1 - (1 - alpha / num_tests)**num_testsplt.plot(num_tests, fwer, linewidth=2, color='b', label='No Correction')
plt.plot(num_tests, fwer_bonferroni, linewidth=2, color='r', label='with Bonferroni Correction')
plt.legend()
plt.title(f'FWER vs. Number of Tests at alpha = {alpha}'0)
plt.xlabel('Number of Hypothesis Tests')
plt.ylabel('FWER')
plt.show();

这种校正的一个好处是易于实现。一个缺点是,一旦测试数量变大,或者如果测试统计数据是相关的,它可能会过于保守。通过保持低的假阳性率,我们增加了假阴性的概率。如果我们非常关心这种权衡,我们可以考虑 Holm-Bonferroni 方法。
霍尔姆-邦费罗尼方法
Holm-Bonferroni 方法比 Bonferroni 校正方法保守一些,但需要做更多的工作。
首先,从最小到最大排列假设检验的 p 值,然后应用此公式按最小 p 值的顺序获得每个假设检验的 alpha 值:

您浏览排序后的列表,将 p 值与其相关的 Holm-Bonferroni 校正α值进行比较。在第一次拒绝零假设失败时,你忽略了当时和之后的所有测试结果。
下图比较了 Holm-Bonferroni 调整和 Bonferroni 校正。如您所见,它不如 Bonferroni 校正保守,但与什么都不做相比,它确实大幅降低了 FWER。
def holm_bonf_fwer(alpha, num_tests):
ranks = [i + 1 for i in range(num_tests)]
adj_alphas = [alpha / (num_tests - rank + 1) for rank in ranks]
p_no_false_disc = 1
for adj_alpha in adj_alphas:
p_no_false_disc = p_no_false_disc * (1 - adj_alpha)
return 1 - p_no_false_discalpha = 0.05
num_tests = np.arange(1, 100, 1, int)
fwer = 1 - (1 - alpha)**num_tests
fwer_bonferroni = 1 - (1 - alpha / num_tests)**num_tests
fwer_holm_bonferroni = [holm_bonf_fwer(alpha, i) for i in num_tests]plt.plot(num_tests, fwer, linewidth=2, color='b', label='No Correction')
plt.plot(num_tests, fwer_bonferroni, linewidth=2, color='r', label='with Bonferroni Correction')
plt.plot(num_tests, fwer_holm_bonferroni, linewidth=2, color='g', label='with Holm-Bonferroni Correction')
plt.legend()
plt.title(f'FWER vs. Number of Tests at alpha = {alpha}')
plt.xlabel('Number of Hypothesis Tests')
plt.ylabel('FWER')
plt.show();

结论
如果您在阅读本文之前没有意识到多重比较问题,那么您现在应该知道为什么不能盲目地对一个数据集进行假设检验,看看哪些检验有意义。您还有两个工具来缓解这个问题。下次你在探索一个数据集时,别忘了使用它们。
注意:如果你对代码的理解受益于评论,请留言,我会添加它们。
使用眼睛视网膜图像上的深度学习进行失明检测(糖尿病视网膜病变)
使用卷积神经网络(使用 Python)自动化该过程,以在为时已晚之前加速患者的失明检测
目录
- 使用深度学习来检测失明
- 评估指标(二次加权 kappa)
- 图像处理和分析
- 使用多任务学习实现 arXiv.org 研究论文(前 1%解决方案)
- 其他迁移学习模式
- 未来的工作
- 链接到 github 代码和 linkedin 个人资料
- 使用的参考文献

图片来源—http://images 2 . fan pop . com/image/photos/10300000/Cas-Blindness-casti El-10370846-640-352 . jpg
1.使用深度学习来检测失明
本案例研究基于 APTOS 2019 失明检测基于此处的 kaggle 挑战赛——https://www . ka ggle . com/c/APTOS 2019-失明检测/概述。
数百万人患有 糖尿病视网膜病变 ,这是工作年龄成人失明的主要原因。印度 Aravind 眼科医院希望在难以进行医学筛查的农村地区发现并预防这种疾病。目前,技术人员前往这些农村地区采集图像,然后依靠训练有素的医生来检查图像并提供诊断。
这里的目标是通过技术扩大他们的努力;以获得自动筛查疾病图像并提供病情严重程度的信息的能力。我们将通过建立一个 卷积神经网络 模型来实现这一点,该模型可以自动查看患者的眼睛图像,并估计患者失明的严重程度。这种自动化过程可以减少大量时间,从而大规模筛选治疗糖尿病性视网膜病变的过程。
我们得到了 3200 张眼睛图像及其对应的严重程度等级,严重程度等级为**【0,1,2,3,4】**之一。该数据将用于训练模型,并对测试数据进行预测。

失明严重程度量表(5 级)
数据集中的样本眼睛图像如下—

对应于每个失明等级严重性(0-4)的眼睛图像
2.评估指标(二次加权 kappa)
二次加权 kappa 衡量两个评级之间的一致性。该指标通常从 0(评分者之间的随机一致)到 1(评分者之间的完全一致)不等。如果评定者之间的一致程度偶然低于预期,该指标可能会低于 0。在由人类评价人分配的分数和预测分数之间计算二次加权 kappa。
科恩卡帕的直觉
要理解这个指标,我们需要理解科恩的 kappa ( 维基百科— 链接)的概念。该指标说明了除了我们从混淆矩阵中观察到的一致性之外,偶然出现的一致性。我们可以用一个简单的例子来理解这一点—
假设我们想从下面的协议表中计算科恩的 kappa,这基本上是一个混淆矩阵。从下表中我们可以看出,在总共 50 项观察中,“A”和“B”评定者同意(20 项是+ 15 项否)= 35 项观察。所以,观察到的一致是P(o)= 35/50 =0.7

来源——维基百科
我们还需要找到多大比例的评级是由于随机的机会,而不是由于’ A ‘和’ B ‘之间的实际协议。我们可以看到,’ A ‘说是 25/50 = 0.5 次,’ B '说是 30/50 = 0.6 次。所以两个人随机同时说‘是’的概率是 0.50.6 = 0.3 。同样,他们两个随机同时说‘不’的概率是 0.50.4 = 0.2 。这样,随机一致的概率就是 0.3 + 0.2 = 0.5 。让我们称之为 P(e)。
所以,Cohens kappa 会是 0.4 (公式如下)。

来源——维基百科,科恩斯卡帕公式
我们得到的值是 **0.4,**我们可以用下表来解释。你可以在本博客中阅读更多关于这一指标的解读——https://towardsdatascience . com/inter-rater-agreement-kappas-69 CD 8 b 91 ff 75。

来源—https://towards data science . com/inter-rater-agreement-kappas-69 CD 8 b 91 ff 75
值 0.4 将意味着我们有一个公平/适度的协议。
序数类中二次权的直觉——二次加权 kappa
当涉及到多类时,我们可以扩展相同的概念,并在这里引入权重的概念。引入权重背后的直觉是,它们是序数变量,,这意味着类别‘1’和‘2’之间的一致优于类别‘1’和‘3’,因为它们在序数尺度上更接近。在我们的失明严重度案例中,输出是序数(失明严重度,0 代表无失明,4 代表最高)。为此,引入了二次标度的权重。序数类越接近,它们的权重越高。下面是很好解释这个概念的博文链接—https://medium . com/x8-the-ai-community/kappa-coefficient-for-dummies-84d 98 b 6 f 13 ee。


来源—https://medium . com/x8-the-ai-community/kappa-coefficient-for-dummies-84d 98 b 6 f 13 ee
正如我们所见,R1 和 R4 的权重为 0.44(因为它们比 R1 和 R2 的权重 0.94 大 3 个等级,因为它们更接近)。在计算观察概率和随机概率时,这些权重乘以相应的概率。
3.图像处理和分析
输出变量的类别分布

阶级不平衡——分布
正如我们所看到的,在训练数据集中存在类别不平衡,大多数情况下值为“0 ”,在“1”和“3”类别中最少。
视觉化眼睛图像
用于生成可视化效果的代码段
这些基本上是使用 眼底照相 拍摄的眼睛视网膜图像。正如我们所见,图像包含伪像,其中一些是失焦,曝光不足,或曝光过度等。此外,一些图像具有低亮度和低闪电条件,因此难以评估图像之间的差异。

样本 15 幅眼睛图像
下图是一只眼睛的视网膜图像样本,该眼睛可能患有糖尿病视网膜病变。源链接— kaggle 内核链接 T21**。**原文出处—https://www.eyeops.com/

img 来源—https://www . ka ggle . com/ratthachat/aptos-眼部预处理-糖尿病视网膜病变,【https://www.eyeops.com/】T2
如我们所见,我们正试图找出那些出血/渗出物等。在有博士学位的高年级学生中。
图像处理
为了对图像进行调整,制作更清晰的图像,使模型能够更有效地学习特征,我们将使用 python 中的 OpenCV 库( cv2 )进行一些图像处理技术。
我们可以应用 高斯模糊 来突出图像中的特征。在高斯模糊操作中,图像与高斯滤波器卷积,高斯滤波器是去除高频分量的低通滤波器。
代码片段—高斯模糊

高斯模糊之前/之后
这个写得很棒的内核( 链接 )介绍了从灰度图像中进行**圆形裁剪的思想。**在下面的代码部分实现相同的功能:-
代码片段—圆形裁剪

之前/之后(模糊+裁剪)
正如我们所看到的,我们现在能够更清楚地看到图像中的独特模式。以下是对 15 个图像样本进行的图像处理。

图像处理后
多重处理和调整图像大小,以保存在目录中
应用上述操作后,我们需要将新图像保存在文件夹中,以便以后使用。原始图像每个大约 3 MB,整个图像文件夹占用 20 GB 空间。我们可以通过调整图像大小来减少这种情况。使用多核线程/多处理,我们可以在一分钟内完成这项任务。我们可以使用具有 6 个内核的线程池(因为我有 8 个内核的 CPU)来实现这一点,并使用(512x512)的图像大小来实现这一点( IMG 大小)。
代码片段—使用线程池的多重处理
TSNE 可视化
为了理解这些图像在各自的类别(失明严重程度)中是否是可分离的,我们可以首先使用 TSNE 在二维空间中对其进行可视化。我们可以首先将 RGB 等级的图像转换为灰度等级的图像,然后将这些图像展平以生成一个矢量表示,该矢量表示可以用作该图像的特征表示。
RGB(256 x256 x3)——>灰度(256 x256)——>展平(65536)
代码片段— TSNE
困惑是需要调整以获得良好结果的超参数。迭代之后,我们可以使用 TSNE 图来表示困惑= 40。

TSNE 情节,困惑= 40
从上面的图中我们可以看出,类“0”与其他类有些分离,而其他类之间的区别仍然很模糊。
图像增强
这是最常用的程序之一,通过从数据集创建额外的图像来生成数据的鲁棒性,以使其通过旋转翻转、裁剪、填充等对新数据进行良好的概括。使用 keras ImageDataGenerator 类
上述代码生成了应用增强后获得的样本图像—

图像放大(示例)
4.使用多任务学习实现 arXiv.org 研究论文(前 1%解决方案)
在 arXiv.org 上发现的一篇研究论文——研究论文链接 在 2943 个中获得第 54 位(前 1%)涉及多任务学习的详细方法来解决这个问题陈述。下面是使用 Python 复制研究论文代码的尝试。在 github 上没有找到这篇研究论文的代码参考。我已经在一篇研究论文(summary doc)中总结了研究论文。pdf 文件— github 链接 。总结以下研究论文中的指针和代码实现—
使用的数据集
实际的研究论文使用了来自其他来源的多个数据集,比如—
- 来自糖尿病视网膜病变的 35,216 张图像,2015 年挑战—https://www . ka ggle . com/c/Diabetic-Retinopathy-detection/overview/timeline
- 印度糖尿病视网膜病变图像数据集(IDRiD) (Sahasrabuddhe 和 Meriaudeau,2018 年)=使用 413 张图像
- 梅西多数据集(Google Brain,2018)数据集
- 完整的数据集由 18590 张眼底照片组成,由 Kaggle 竞赛的组织者分为 3662 张训练,1928 张验证和 13000 张测试图像
然而,由于不容易获得所有数据集,我们只能使用现有的 APTOS 2019 数据集来完成这项任务。
图像预处理和增强
多种图像预处理技术,如图像大小调整、裁剪,被用来从眼睛图像中提取出与众不同的特征(如以上章节中所讨论的)。
使用的图像增强包括:光学失真、网格失真、分段仿射变换、水平翻转、垂直翻转、随机旋转、随机移动、随机缩放、RGB 值移动、随机亮度和对比度、加性高斯噪声、模糊、锐化、浮雕、随机伽玛和剪切等。
然而,我们可以使用类似于上面的替代图像增强(使用参考— 链接 )。
使用的模型架构
正如我们在下面看到的,研究论文使用了多任务学习模型(它并行进行回归、分类、有序回归的训练)。这样,它可以使用单个模型,并且由于第一层无论如何都会学习相似的特征,所以实现该架构以减少训练时间(而不是训练 3 个单独的模型)。对于编码器部分,我们可以使用任何现有的 CNN 架构— ResNet50,EfficientNetB4,EfficientNetB5 ( 和 ensemble 这些)。

来源—https://arxiv.org/pdf/2003.02261.pdf
上述架构的代码实现如下(用 keras 表示)—
创建多输出-自定义图像数据生成器
我们需要创建一个自定义的 ImageDataGenerator 函数,因为我们有 3 个输出(引用— 链接 )。请注意,此函数产生 3 个输出(回归、分类、有序回归)代码如下—
请注意,对于每个类(0,1,2,3,4),顺序回归编码按如下方式进行。sklearn 中的multilabel binary izer实现了这个任务,如上面的代码要点所示。

来源—https://www . ka ggle . com/c/aptos 2019-失明-检测/讨论/98239
第一阶段(预培训)
这包括使所有层可训练,并使用现有的 Imagenet 权重作为 ResNet50 编码器的权重初始化器。模型仅被训练到 3 个输出头。使用以下损失函数编译模型(使用 SGD 优化器、余弦衰减调度程序的 20 个时期)—
model.compile(
optimizer = optimizers.SGD(lr=LEARNING_RATE),loss={'regression_output': 'mean_absolute_error',
'classification_output':'categorical_crossentropy',
'ordinal_regression_output' : 'binary_crossentropy'},metrics = ['accuracy'])



预训练阶段的历元(vs)损失图
第二阶段(主要训练)
在这个阶段,事情发生了变化。
- 首先,损失函数从交叉熵变为聚焦损失。你可以在这里阅读更多关于焦损的内容——https://medium . com/adventures-with-deep-learning/Focal-loss-demystified-c 529277052 de。简而言之,焦点丢失在处理等级不平衡方面做得更好,正如我们任务中的情况。

来源—https://medium . com/adventures-with-deep-learning/focal-loss-demystified-c 529277052 de
焦点损失参考代码—https://github.com/umbertogriffo/focal-loss-keras
model.compile(
optimizer = optimizers.Adam(lr=LEARNING_RATE),loss={
'regression_output': mean_squared_error,
'classification_output': categorical_focal_loss(alpha=.25,gamma=2),
'ordinal_regression_output' : binary_focal_loss(alpha=.25,gamma=2)
},metrics = ['accuracy'])
2.第二,第二阶段的训练分两个阶段进行。第一子阶段包括冻结模型网络中的所有编码器层。这样做是为了预热权重(使用 Imagenet 权重初始化对小数据集进行迁移学习)。第二个子阶段包括解冻和训练所有层。
# SUB STAGE 1 (2nd Stage) - Freeze Encoder layers**for** layer **in** model.layers:
layer.trainable = **False**
**for** i **in** range(-14,0):
model.layers[i].trainable = **True**# SUB STAGE 2(2nd Stage) - Unfreeze All layers**for** layer **in** model.layers:
layer.trainable = **True**
图表如下所示—



主要训练阶段的历元(vs)损失图
第三阶段(岗位培训)
这包括从 3 个头部(分类、回归、有序回归)获得输出,并将其传递给单个密集神经元(线性激活)以最小化均方误差(50 个时期)
train_preds = model.predict_generator(
complete_generator, steps=STEP_SIZE_COMPLETE,verbose = 1
)train_output_regression = np.array(train_preds[0]).reshape(-1,1)
train_output_classification = np.array(np.argmax(train_preds[1],axis = -1)).reshape(-1,1)
train_output_ordinal_regression = np.array(np.sum(train_preds[2],axis = -1)).reshape(-1,1)X_train = np.hstack((
train_output_regression,
train_output_classification,
train_output_ordinal_regression))model_post = Sequential()
model_post.add(Dense(1, activation='linear', input_shape=(3,)))model_post.compile(
optimizer=optimizers.SGD(lr=LEARNING_RATE), loss='mean_squared_error',
metrics=['mean_squared_error'])

培训后—纪元(vs)损失
测试数据的模型评估
因为我们有回归输出,所以我们可以进行最近整数舍入来得到最终的类标签。
我们在测试数据上获得的最终二次加权 kappa 分数是 0.704 (这表明模型预测和人类评分者之间的基本一致)。
在测试数据上获得的归一化混淆矩阵(matplotlib 的代码已从— 链接 中引用)

测试数据—标准化混淆矩阵
5.其他迁移学习模式
在处理小数据集(与 ImageNet 数据集没有相似性)时,常用的迁移学习方法是首先使用现有的 ImageNet 权重作为初始值(冻结前几层),然后重新训练模型。
我们可以使用类似的实现。一个简单的 ResNet50 架构在这样使用的时候会给出很好的结果(参考— 链接 )
我们可以训练上述模型 2-5 个时期(只有最后 5 层是可训练的,它们基本上是在 ResNet50 之后的层)。
然后,我们可以使所有层可训练,并训练整个模型。
**for** layer **in** model.layers:
layer.trainable = **True**

ResNet50(迁移学习)—纪元(vs)丢失
正如我们所看到的,仅在 20 个时期内,我们就获得了良好的准确度分数——在验证数据集上接近 92%。
该模型在测试数据上给出了 0.83 的二次加权 kappa(这是一个很好的一致性分数)。

标准化混淆矩阵(测试数据)
同样,我们可以用本页提到的其他keras . applications——link**做类似的实现。**以下是在其中一些模型上实现时获得的结果(仅模型架构发生变化,其他参数保持不变)。

模型性能—摘要
6.未来的工作
优化器实验
正如我们所看到的,在主要的培训阶段,培训损失并没有减少。我们可以解决这个问题的方法之一是将优化器从 Adam 改为修正 Adam 优化器。(更多关于 RAdam 的内容在这里—https://www . pyimagesearch . com/2019/10/07/is-rectified-Adam-actually-better-Adam/)。此外,我们可以用 SGD (Momentum) 优化器和权重衰减方法,更多的学习率调度器来检查模型性能的改进。
规则化方法实验
此外,我们还可以在模型上使用更多的正则化来帮助更好地训练模型——一些技术可能涉及标签平滑(向目标标签添加噪声)——这将允许模型更好地概括并防止过度拟合。此外,我们可以尝试 L2 正则化来提高模型的泛化能力。
集合实验和 K 倍交叉验证
该研究论文还提到了跨各种架构使用集成技术,如 EfficientNetB4、5EfficientNetB5、SE-ResNeXt50 等,并使用**分层交叉验证(5 折)**来提高模型性能和泛化能力。
7.链接到 Github 代码和 linkedin 个人资料
所有代码都在我的 Github 库— 链接 里。如果你想讨论这方面的进一步实验,你可以在我的 Linkedin 个人资料上联系我— 链接 。你也可以通过debayanmitra1993@gmail.com联系我。
6.使用的参考文献
[## dimitrioliveira/aptos 2019 盲检
这个知识库的目标是使用比赛数据建立机器学习模型来处理图像数据…
github.com](https://github.com/dimitreOliveira/APTOS2019BlindnessDetection) [## APTOS:糖尿病视网膜病变中的眼睛预处理
使用 Kaggle 笔记本探索和运行机器学习代码|使用来自多个数据源的数据
www.kaggle.com](https://www.kaggle.com/ratthachat/aptos-eye-preprocessing-in-diabetic-retinopathy) [## 介绍 APTOS 糖尿病视网膜病变(EDA & Starter)
使用 Kaggle 笔记本探索和运行机器学习代码|使用来自多个数据源的数据
www.kaggle.com](https://www.kaggle.com/tanlikesmath/intro-aptos-diabetic-retinopathy-eda-starter)
研究论文—https://arxiv.org/pdf/2003.02261.pdf
BLiTZ——py torch 的贝叶斯神经网络库
blitz——Torch Zoo 中的贝叶斯层是一个简单且可扩展的库,用于在 PyTorch 上创建贝叶斯神经网络层。

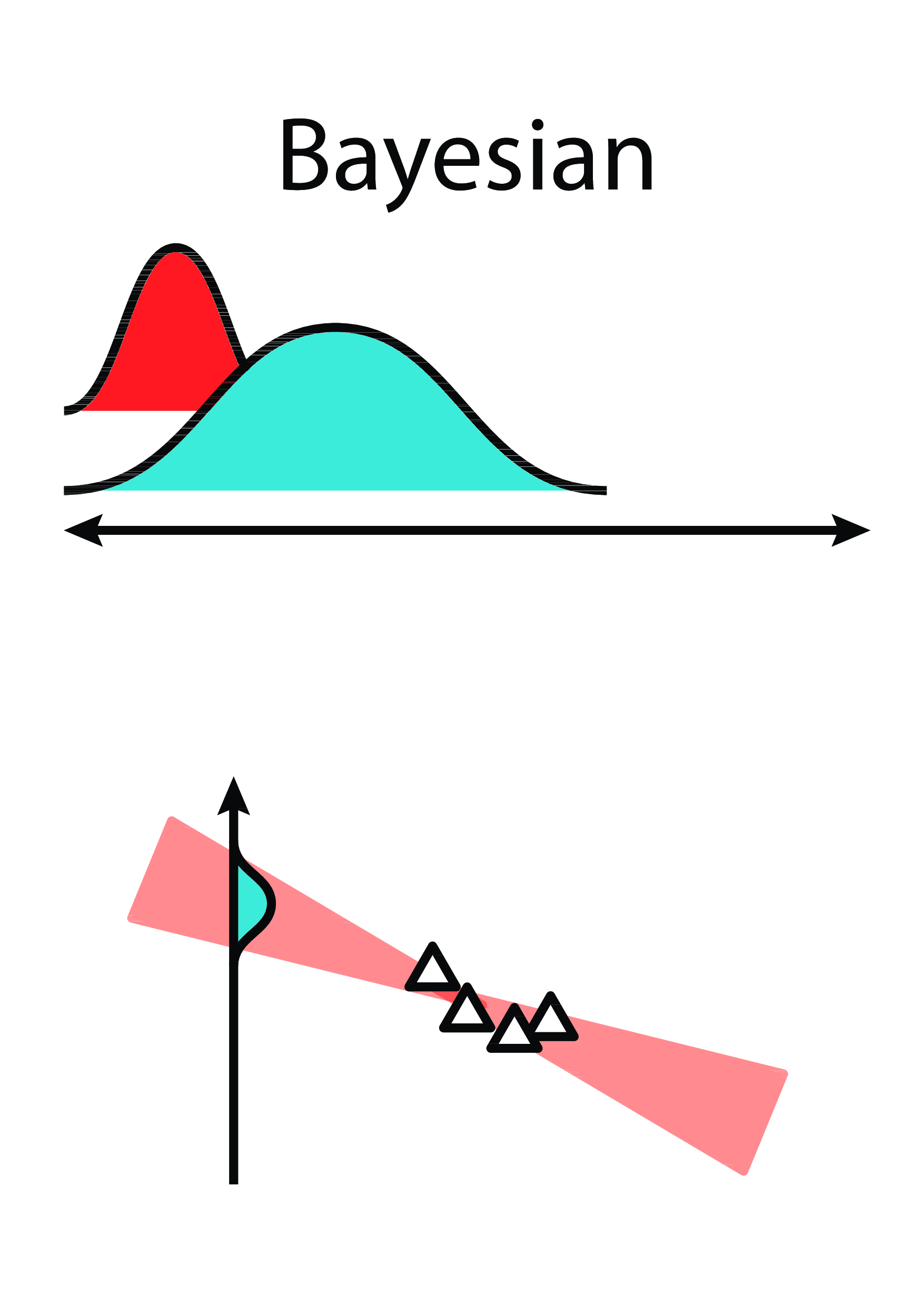
贝叶斯回归图解。来源:https://ericmjl . github . io/Bayesian-deep-learning-demystified/images/linreg-Bayesian . png(2020–03–30 访问)
这是一篇关于使用库进行深度贝叶斯学习的文章。如果你是这个主题的新手,你可能想在 medium 上寻找关于它的许多帖子中的一个,或者只是我们 lib repo 的 Bayesian DL 的文档部分。
由于越来越需要收集神经网络预测的不确定性,使用贝叶斯神经网络层成为最直观的方法之一-这可以通过贝叶斯网络作为深度学习研究领域的趋势得到证实。
事实是,尽管 PyTorch 有成为主要深度学习框架的趋势(至少对于研究而言),但没有一个库让用户像使用nn.Linear和nn.Conv2d那样轻松地引入贝叶斯神经网络层。
从逻辑上来说,这对于任何想要灵活地使用贝叶斯方法进行数据建模的人来说都是一个瓶颈,因为用户必须开发贝叶斯层的整个部分以供使用,而不是专注于其模型的架构。
BLiTZ 就是为了解决这一瓶颈而产生的。通过与 PyTorch(包括与nn.Sequential模块)完全集成,并易于扩展为贝叶斯深度学习库,BLiTZ 允许用户在其神经网络上引入不确定性,只需调整其超参数。
在本帖中,我们将讨论如何使用 BLiTZ 层和采样工具创建、训练和推断不确定性引入的神经网络。
贝叶斯深度学习层
正如我们所知,贝叶斯深度学习的主要思想是,在每个前馈操作中,贝叶斯层从正态分布中采样其权重,而不是具有确定性的权重。
因此,该层的可训练参数是确定该分布的平均值和方差的参数。
从数学上讲,操作将从:

确定性“香草”神经网络前馈操作。
收件人:



贝叶斯神经网络层的前馈操作。
在 Torch 上实现ρ和μ为可训练参数的层可能很难,除此之外,创建超参数可调层可能更难。BLiTZ 有一个内置的BayesianLinear层,可以很容易地引入到模型中:
它像一个普通的 Torch nn.Module网络一样工作,但是它的BayesianLinear模块利用之前解释的其权重的不确定性来执行训练和推理。
损失计算
正如在其原始论文中提出的,贝叶斯神经网络成本函数是“复杂性成本”与“数据拟合成本”的组合。在所有的代数争论之后,对于每个前馈操作,我们有:

贝叶斯神经网络的代价函数。
相对于简单得多的预定义 pdf 函数,复杂性成本(P(W))由(网络上每个贝叶斯层的)采样权重的概率密度函数之和组成。通过这样做,我们确保了在优化的同时,我们的模型相对于预测的方差将会减少。
为此,BLiTZ 为我们带来了引入一些方法的variational_estimator装饰器,比如将nn_kl_divergence方法引入我们的nn.Module。给定数据点、其标签和标准,我们可以通过以下方式获得预测的损失:
简单的模型优化
在优化和继续之前,贝叶斯神经网络通常通过对同一批次的损失进行多次采样来优化,这是为了补偿权重的随机性,并避免因受离群值影响的损失而优化它们。
BLiTZ 的variational_estimator装饰器也用sample_elbo方法为神经网络提供动力。给定inputs、outputs、criterion和sample_nbr,它估计在计算批次sample_nbr次损失时进行迭代过程,并收集其平均值,返回复杂度损失与拟合值之和。
优化贝叶斯神经网络模型非常容易:
看一个例子:
我们现在通过这个例子,使用 BLiTZ 创建一个贝叶斯神经网络来估计波士顿房屋 sklearn 内置数据集的房价的置信区间。如果你想寻找其他的例子,库上有更多的
必要的进口
除了已知的模块,我们将从 BLiTZ 带来variational_estimator装饰器,它帮助我们处理模块上的贝叶斯层,保持它与 Torch 的其余部分完全集成,当然,还有BayesianLinear,它是我们的层,具有权重不确定性。
加载和缩放数据
这并不是什么新鲜事,我们正在导入和标准化数据来帮助训练。
创建我们的回归类
我们可以通过继承nn.Module来创建我们的类,就像我们对任何火炬网络所做的那样。我们的装饰者介绍了处理贝叶斯特征的方法,计算贝叶斯层的复杂性成本,并进行许多前馈(对每一个采样不同的权重)来采样我们的损失。
定义置信区间评估函数
该函数确实为我们试图对标签值进行采样的批次上的每个预测创建了一个置信区间。然后,我们可以通过寻找有多少预测分布包含数据点的正确标签来衡量我们预测的准确性。
创建回归变量并加载数据
注意这里我们创建了我们的BayesianRegressor,就像我们创建其他神经网络一样。
我们的主要培训和评估循环
我们做了一个训练循环,唯一不同于普通火炬训练的是通过sample_elbo方法对其损耗进行采样。所有其他的事情都可以正常完成,因为我们使用 BLiTZ 的目的是让你轻松地用不同的贝叶斯神经网络迭代数据。
这是我们非常简单的训练循环:
结论
BLiTZ 是一个有用的 lib,可以在深度学习实验中使用贝叶斯层进行迭代,并且对通常的代码进行很小的更改。它的层和装饰器与神经网络的 Torch 模块高度集成,使得创建定制网络和提取它们的复杂性成本没有困难。
当然,这是我们回购的链接:https://github.com/piEsposito/blitz-bayesian-deep-learning
参考
BLiTZ 是一个简单且可扩展的库,用于创建贝叶斯神经网络层(基于 Weight…
github.com](https://github.com/piEsposito/blitz-bayesian-deep-learning) [## 神经网络中的权重不确定性
我们介绍了一个新的,有效的,原则性和反向传播兼容的算法学习概率…
arxiv.org](https://arxiv.org/abs/1505.05424)
区块链和以太坊终于有了一些黑仔应用
流动资金、在线投票、无损失彩票等等

照片:阿纳斯塔西娅·杜尔吉尔
作为一项新兴技术,区块链已经 被 淘汰的频率大致相当于谷歌眼镜或 3D 电视。忽视区块链是一种理智的时尚,认为它是被过度炒作的电子表格,唯一值得注意的是支撑比特币的可疑成就。一位评论家大胆批评这是“人类历史上最没用的发明”。
对于像我这样充满希望的技术人员来说,这些声明因为拥有真理之环而更加令人沮丧。尽管智能合同和区块链平台为研发筹集了数十亿美元的资金(T21 ),但几乎没有区块链的实际应用。比特币的价值已经飙升,但缺乏持续的技术发展、大规模采用或相对于美元等现有货币的任何真正优势。
然而,在过去的一年(尤其是过去的三个月),有用的区块链应用程序终于出现了激增,这些应用程序实际上可能代表了该技术的杀手级应用程序。大量的开发人员已经聚集在一个平台上,特别是以太坊,由此产生的新应用程序的爆炸看到了区块链实现的一些希望。
实时流动资金
Sablier 团队开发了一个协议,让人们可以像在 Spotify 上播放播放列表一样轻松地实时传输资金。不要每四周领一次工资,想象一下持续领工资——每小时,甚至每秒。Sablier 应用程序在透明的界面中显示正在进行的交易,因此您可以准确地看到支付了多少钱,以及支付的速度有多快。通过完全绕过银行系统,交易费用几乎不存在。

Sablier 应用程序,在本例中为 DAI 流(数字化美元)
实时工资支付是一种诱人的可能性——每月工资支付的效率低得可怕,让大量工人靠一张张支票生活,有时甚至无法满足日常开支。流动支付代表了一种解决方案,尤其是对低收入工人来说,是一种可能改变生活的服务。我们目前支付薪水和工资的方式可能会被扔进历史垃圾堆——谁会真正喜欢每月领取一次总付款,而不是每天领一次工资?
有了一个像流动资金一样完全通用的协议,潜在的应用范围远远超出了工资。遗产继承传统上被认为是死后一次性支付的一大笔钱——但是想象一下这样一个系统,一个去世的家庭成员在很长一段时间内将他们的遗产转移给他们的家庭,以避免税收和一次性支付大笔款项的冲动。实时流动资金也可能完全扰乱按小时计费的服务:法律费用、车辆租赁、停车场等等——只要你在使用服务,就要付费,不要多花一秒钟。
无损失彩票
仅在美国,花在彩票上的钱就有 710 亿英镑,这是一个荒谬的数字,尤其是任何一个参与者真的中奖的可能性极小,这让这个数字变得更加疯狂。当你停下来想一想,这是一个令人困惑的财务自残行为,只有获胜的乐趣和兴奋才能证明这是正当的——我们人类很容易受到基于游戏的反馈循环的影响
进入 PoolTogether ,这是一款将自己打造成“无损失储蓄游戏”的新应用。本质上,它是一种数字彩票,你用存款“购买”彩票——每周给你一次中头奖的机会——但你永远不会失去存款。你可以随时撤回。看起来像是黑魔法的东西是由区块链实现的——协议将所有存款“汇集”在一个生息的智能合同中,产生的利息作为头奖奖励给每周的持票人。
毫无疑问,虽然 PoolTogether 还处于早期阶段,用户相对较少,累积奖金也相对较少,但这个概念是基于金钱的(可以这么说)。世界上最大的赔钱游戏(彩票)可能会被一个激励人们储蓄的系统所取代,同时保留使彩票如此令人上瘾的类似游戏的属性。
安全在线投票
如果你关注美国政治(因为你的罪过),或者即使你不关注,你可能已经听说过民主党总统初选投票是一场灾难——爱荷华州党团会议仍然在确认确切的总数,尽管投票发生在三周前。总的来说,投票过程中有一长串的问题,从长长的队伍和等待时间到坏掉的机器,以及投票地点的党派安排。十年前的解决方案——在线投票——一直被认为太不安全,容易被黑客攻击或操纵。
由于区块链系统在安全性和效率方面的优势,安全的在线投票系统还是有希望的。一个名为 Vocdoni 的团队正在构建一个具有“普遍可验证”投票的在线投票协议——使用一些复杂的加密技术来构建一个系统,选民可以使用区块链协议投票,该协议会不断检查每一张选票的完整性,以保证其完整性(并阻止破坏系统的企图)。Vocdoni 还在构建协议时考虑到了智能手机的接入,目的是让民主变得更加简单和容易实现。
投资你最喜爱的体育明星
如果为一个特定的运动队或运动员加油的情感投资还不够,智能合同现在让球迷用自己的钱投资。布鲁克林篮网队的斯宾塞·丁翁迪在以太坊上将其 3400 万美元的三年合同进行了“T2 化”——这实质上意味着球迷可以购买他合同中的一小部分股份,将其转化为可交易的金融资产。如果你认为丁威迪将会有一个伟大的赛季,你不需要只是把他加入你的梦幻团队——你可以真正投资于他的表现,如果他达到了合同中基于表现的奖金,就可以获得收益。

一种行走、呼吸、可交易的金融资产。照片:杰罗姆米隆
尽管体育明星投资的全新市场还处于早期阶段(当然还会有更多的障碍——NBA 对丁威迪的创新并不太看好),但这是朝着更具流动性的金融体系迈出的相当令人兴奋的一步。区块链和智能合约允许新类型的投资和新颖的金融工具,看到智能合约的沙箱为体育部门产生真正的游戏规则改变者令人兴奋。
对于人类历史上最没用的发明来说还不算太寒酸。如果你对这些关于这个新兴平台的文章感兴趣,你可能会喜欢我的新出版物 Technocracy 。我将定期撰写关于技术正在改变社会的文章,比如我最近的一篇关于冠状病毒如何让大规模监控成为我们的新常态的文章。
区块链技术确保数据安全性和不变性

图片资源:https://unsplash.com/@launchpresso
目前,区块链是最安全的数据保护技术之一。数字技术的快速发展也给数据安全带来了新的挑战。组织需要通过实施强身份认证和加密密钥保险机制来保护其数据。
区块链技术足以应对如何保护数据和防止恶意网络攻击的挑战。报告称,到 2024 年,全球区块链技术市场可能会达到 200 亿美元左右。区块链具有革命性,被用于医疗保健、金融、体育等许多行业。
与传统方法不同,这项技术主要激励许多区块链开发公司重新构建和重新表述安全问题。区块链提供了在数据中引入信任因素的真正意义。
区块链技术挑战漏洞
由分布式分类帐系统提供的高级安全性为建立安全的数据网络提供了好处。在消费产品和服务中提供服务的企业采用区块链技术来保护记录消费者的数据。
由于区块链是本世纪的主要技术突破之一,它允许在不需要任何第三方信任的情况下保持竞争力。
这项技术正在为消费者带来颠覆商业服务和解决方案的新机遇。在未来,这项技术将随着各个领域中不断发展的全球服务而成为领跑者。
提供加密和验证
区块链技术足够精通,可以管理一切,因此数据没有以任何方式被更改。区块链本质上是加密的,这使得提供适当的验证成为可能。

图片资源:/unsplash . com/@ clinta dair
智能合约可与区块链一起使用,以确保每次满足特定条件时发生特定的验证。 如果在任何情况下,有人确实更改了数据,网络中所有节点上的所有分类帐都验证更改已完成。
提供安全的数据存储
区块链是保护共享社区数据的最佳方式。利用区块链的功能,没有人可以读取或干扰任何敏感的存储数据。
处理分布在人际网络中的数据很有帮助。此外,该技术还可以用于公共服务,以保持公共记录的分散和安全。

图片资源:https://unsplash.com/@austindistel
除此之外,商业模式可以在区块链上保存一个数据的加密签名或者庞大的数据形式。这将允许用户留下来,以确保数据的安全。 区块链用于分布式存储软件,将海量数据分解成块。这在网络上的加密数据中可用,意味着所有数据都是安全的。
无法攻击
谈到区块链,黑客或攻击变得异常困难。区块链是去中心化的、加密的和交叉检查的,这允许数据保持强大的备份。由于区块链满载节点,同时攻击大多数节点是不可能的。

图片资源:https://unsplash.com/@markusspiske
作为分布式账本技术之一,其最基本的属性是数据不可变。 它提供了一种全新的成功安全性,任何行为或交易都不能被篡改或伪造。这项技术使每一笔交易都有效,得到网络上多个节点的确认。
最终想法
由于应用范围广泛,区块链用于建立安全网络。对于安全的数据交换,区块链安全开发服务是挑战传统方法的最佳选择。采用区块链技术可以改善技术和用户隐私之间的关系。
区块链技术的数字景观是安全性和透明性的组合。区块链带来了解决数据管理问题的技术,主要涉及安全、隐私和验证。
来自《走向数据科学》编辑的提示: 虽然我们允许独立作者根据我们的 规则和指导方针 发表文章,但我们并不认可每个作者的贡献。你不应该在没有寻求专业建议的情况下依赖一个作者的作品。详见我们的 读者术语 。
一个简单预测程序的蓝图
预测,但不是时间序列预测

短期和长期预测是每个部门决策的基本商业活动。呼叫中心需要知道五年后呼叫量的增长情况,以保持足够的人员来为客户服务。电力公司希望预测未来十年的电力消耗增长,这样他们就可以投资新的装置来满足额外的需求。小企业需要了解他们的投资在未来几年的回报情况,并做出必要的调整。
所有这些业务需求都需要预测。传统上,这些预测是在临时的基础上进行的,数据科学家可以使用的工具有限。时间序列技术已经存在了很长一段时间,但是它们有自己的局限性,并且通常它们不能提供必要的准确性和指向特定的不确定性。对于时间序列,由于新政策的实施,也很难制定方案并对关键绩效指标(KPI)进行敏感性分析。
考虑到这一点,在本文中,我将介绍一种不同的预测技术的蓝图,这种技术依赖于很少的数据点。正如下面将要看到的,这种技术还允许对特定业务决策的影响及其对 KPI 的影响进行场景分析。
系统动态建模
系统动力学是一种复杂系统建模的方法,其中一个元素的变化导致其他元素的变化。
它广泛应用于医疗保健、流行病学、运输、商业管理和收入预测。可以说,其中最著名的是罗马俱乐部的增长极限模型。
一个系统动态模型代表了一个复杂的系统,通过反馈循环来预测系统的行为。假设一个银行账户有 100 美元的“股票”。每月存入 20 美元(由流程 1 表示),每月提取 15 美元(流程 2 )。在这种简单的情况下,流程 1 的变化将导致库存 1 和流程 2 的变化。因此,如果我们知道流量 1 将如何演变成未来,我们就可以预测股票 1 和流量 2 。

SD 建模中的存量、流量和反馈循环(来源:作者)
使用类似的概念,下面我将介绍一种依赖于更少数据点的预测方法,而不是传统预测中使用的复杂时间序列建模。
下面是一个简单的蓝图和必要的代码。我还在世界三大经济体的 GDP 预测中测试它。但这一概念可以应用于任何其他业务预测和决策过程。
方法、数据和代码
所以基本上我创建了一个名为forecast()的函数,它有 4 个参数:
- 初始值
- 变化的速度
- 预测时间步数
- 当前时间段。
然后,在给定初始值和变化率的情况下,该模型计算每个时间步中的未来值。该函数输出所有时间步长的预测值列表。
然后将预测值绘制成时间曲线。这里生成多个预测来比较不同的实体,但是如果我们要对单个实体进行预测,这个概念也可以以类似的方式工作。在这种情况下,业务政策或活动的变化将采用不同的参数,并对未来每个时间步的预测估计的变化进行建模。
因此,我在这个演示中提出的问题是,主要经济体的 GDP 将如何发展,它们在 2030 年将会是什么样子?这个简单的模型只需要 2 个参数,2019 年名义 GDP(美元)和 GDP 增长(%),但正如你将看到的,即使在这个简化版本中,它也可以产生强大的洞察力。以下数据用于演示:
预测
使用上述函数预测了美国、欧盟和中国的国内生产总值,并在每个预测年填入同一个面板中。
业内每个人都知道中国的经济正在着火。这种预测给出了火球有多大的概念。在这一点上,中国的经济似乎远远落后于美国和欧盟,但考虑到增长率,中国将很快超越只是时间问题。但是多快呢?
2023 年是中国接管欧盟的一年,2025 年 GDP 超过美国经济。
在美国和欧盟之间,在这一点上,他们的 GDP 处于类似的数量级,但正如预测所示,由于美国的增长率更高,差距将继续扩大。

2030 年世界主要经济体 GDP 预测
但当然,这些都是 COVID 之前的情况,在 COVID 之后,一切都将发生变化。我们需要等待一段时间,以了解事情的发展方向。
离别的思绪
本文的目的是展示一个简单的程序如何生成强大的预测洞察力。当然,这是一个简单的演示,但我的目标是给出超越传统时间序列预测的可能性的直觉,并尝试一些不同的东西,尤其是当数据是一个限制因素时。
基于神经网络的棋盘游戏图像识别
如何使用计算机视觉技术来识别棋子及其在棋盘上的位置

蒂姆·福斯特在 Unsplash 上的照片
利用计算机视觉技术和卷积神经网络(CNN),为这个项目创建的算法对棋子进行分类,并识别它们在棋盘上的位置。最终的应用程序保存图像,以可视化的表现,并输出棋盘的 2D 图像,以查看结果(见下文)。本文的目的是逐步完成这个项目,以便它可以作为新迭代的“基础”。参见 GitHub 上该项目的代码。

(左)来自现场摄像机的画面和(右)棋盘的 2D 图像
数据
我对这个项目的数据集有很高的要求,因为我知道它最终会推动我的成果。我在网上找到的国际象棋数据集要么是用不同的国际象棋设置( Chess Vision )、不同的相机设置( Chess ID Public Data )创建的,要么是两者都用( Raspberry Turk Project ),这让我创建了自己的数据集。我使用我的国际象棋和相机设置( GoPro Hero6 Black 在“第一人称视角”)生成了一个自定义数据集,这使得我的模型更加准确。该数据集包含 2,406 幅图像,分为 13 类(见下文)。要点:这花费了我大部分的时间,但最终你会希望在图像上训练你的模型,使其尽可能接近你的应用程序中使用的图像。

自定义数据集的细分(图片由作者提供)
为了构建这个数据集,我首先创建了 capture_data.py ,它在点击 S 键时从视频流中提取一帧,并将其保存到导演。这个程序允许我无缝地改变棋盘上的棋子,并一遍又一遍地捕捉棋盘的图像,直到我建立了大量不同的棋盘配置。接下来,我创建了 create_data.py ,通过使用下一节讨论的电路板检测技术将帧裁剪成独立的片段。最后,我将裁剪后的图像分类,将它们放入带标签的文件夹中。然后…瞧!
棋盘检测
对于棋盘检测,我想做一些比使用findchesboardcorners(OpenCV)更复杂的事情,但不像 CNN 那么高级。使用低级和中级计算机视觉技术来寻找棋盘的特征,然后将这些特征转化为外边界和 64 个独立方格的坐标。该过程围绕实现 Canny 边缘检测和 Hough 变换来生成相交的水平线和垂直线。分层聚类用于根据距离对交叉点进行分组,并对各组进行平均以创建最终坐标(见下文)。

完整的棋盘检测过程(图片作者
棋子分类
当我开始这个项目时,我知道我想使用 Keras/TensorFlow 创建一个 CNN 模型,并对棋子进行分类。然而,在创建我的数据集之后,在给定数据集大小的情况下,CNN 本身不会给我想要的结果。为了克服这个障碍,我利用了imagedata generator和 transfer learning ,它们扩充了我的数据,并使用其他预先训练的模型作为基础。
创建 CNN 模型
为了使用 GPU,我在云中创建并训练了 CNN 模型,这大大减少了训练时间。快速提示:Google Colab**是一种快速简单地开始使用 GPU 的方法。**为了提高我的数据的有效性,我使用 ImageDataGenerator 来扩充我的原始图像,并将我的模型暴露给不同版本的数据。函数 ImageDataGenerator 随机旋转、重新缩放和翻转(水平)每个时期的我的训练数据,本质上创建了更多的数据(见下文)。虽然有更多的转换选项,但我发现这些对于这个项目来说是最有效的。
**from** **keras.preprocessing.image** **import** ImageDataGeneratordatagen = ImageDataGenerator(
rotation_range=5,
rescale=1./255,
horizontal_flip=**True**,
fill_mode='nearest')test_datagen = ImageDataGenerator(rescale=1./255)train_gen = datagen.flow_from_directory(
folder + '/train',
target_size = image_size,
batch_size = batch_size,
class_mode = 'categorical',
color_mode = 'rgb',
shuffle=**True**)test_gen = test_datagen.flow_from_directory(
folder + '/test',
target_size = image_size,
batch_size = batch_size,
class_mode = 'categorical',
color_mode = 'rgb',
shuffle=**False**)
我没有从头开始训练一个全尺寸模型,而是通过利用一个预训练模型来实现迁移学习,并添加了一个顶层模型,使用我的自定义数据集进行训练。我遵循典型的迁移学习工作流程:
1.从先前训练的模型(VGG16)中提取图层。
**from** **keras.applications.vgg16** **import** VGG16model = VGG16(weights='imagenet')
model.summary()
2.冷冻它们是为了避免在训练中破坏它们所包含的任何信息。
3.在冻结层上增加了新的可训练层。
**from** **keras.models** **import** Sequential
**from** **keras.layers** **import** Dense, Conv2D, MaxPooling2D, Flatten
**from** **keras.models** **import** Modelbase_model = VGG16(weights='imagenet', include_top=**False**, input_shape=(224,224,3))
*# Freeze convolutional layers from VGG16*
**for** layer **in** base_model.layers:
layer.trainable = **False***# Establish new fully connected block*
x = base_model.output
x = Flatten()(x)
x = Dense(500, activation='relu')(x)
x = Dense(500, activation='relu')(x)
predictions = Dense(13, activation='softmax')(x)*# This is the model we will train*
model = Model(inputs=base_model.input, outputs=predictions)
model.compile(optimizer='adam', loss='categorical_crossentropy', metrics=['categorical_accuracy'])
4.在自定义数据集上训练新图层。
epochs = 10history = model.fit(
train_gen,
epochs=epochs,
verbose = 1,
validation_data=test_gen)model.save_weights('model_VGG16.h5')
虽然我使用 VGG16 或 VGG19 作为预训练模型来创建模型,但由于验证准确性更高,我选择了使用 VGG16 的模型。此外,我发现最佳的历元数是 10。任何大于 10 的数字都不会导致验证准确性的增加,并且会增加训练和验证准确性之间的差异,这暗示着过度拟合。收获:迁移学习让我能够充分利用深度学习在图像分类方面的优势,而不需要大型数据集。
结果
为了更好地可视化验证的准确性,我创建了一个模型预测的混淆矩阵。从这个图表中,很容易评估模型的优点和缺点。**优势:**空— 准确率为 99%,召回率为 100%;白棋和黑棋(WP 和 BP)——F1 值约为 95%。弱点:《白骑士》(WN)——召回率高(98%),但准确率很低(65%);白人主教(WB)——召回率最低,为 74%。

测试数据的混淆矩阵(作者的图片)
应用
该应用程序的目标是使用 CNN 模型并可视化每一步的性能。我创建了 cv_chess.py (见下面的摘录),它清楚地显示了步骤,还创建了 cv_chess_functions.py ,它显示了每个步骤的细节。这个应用程序保存来自实时视频流的原始帧,每个方格的 64 个裁剪图像,以及棋盘的最终 2D 图像。我以这种方式构建应用程序,以快速确定未来改进的优势和劣势。
print('Working...')
# Save the frame to be analyzed
cv2.imwrite('frame.jpeg', frame)
# Low-level CV techniques (grayscale & blur)
img, gray_blur = read_img('frame.jpeg')
# Canny algorithm
edges = canny_edge(gray_blur)
# Hough Transform
lines = hough_line(edges)
# Separate the lines into vertical and horizontal lines h_lines, v_lines = h_v_lines(lines)
# Find and cluster the intersecting
intersection_points = line_intersections(h_lines, v_lines) points = cluster_points(intersection_points)
# Final coordinates of the board
points = augment_points(points)
# Crop the squares of the board a organize into a sorted list x_list = write_crop_images(img, points, 0)
img_filename_list = grab_cell_files() img_filename_list.sort(key=natural_keys)
# Classify each square and output the board in Forsyth-Edwards Notation (FEN)
fen = classify_cells(model, img_filename_list)
# Create and save the board image from the FEN
board = fen_to_image(fen)
# Display the board in ASCII
print(board)# Display and save the chessboard image
board_image = cv2.imread('current_board.png') cv2.imshow('current board', board_image)
print('Completed!')
演示
显示了变化板现场(左)和新的 2D 图像输出(右)
我希望你喜欢这个演示!更多我的项目,请看我的网站和 GitHub 。请随时通过 LinkedIn 与我联系,对这个项目的未来迭代有想法。干杯!
散景、散景和可观察总部
脱离朱庇特轨道的冒险

2019 年 11 月朱诺号拍摄的木星北纬(图片来源:美国宇航局/JPL 加州理工
在 jupyter 笔记本中使用 python 时,散景可视化库已经成为我最喜欢的显示数据的工具之一。散景功能强大,易于使用,具有可访问的交互功能,并生成美丽的图形。然而,随着我在过去几个月中使用 Bokeh,并对其内部有了更多的了解,我开始意识到 jupyter 中用于 Bokeh 的 python API 只是整个 Bokeh 包的一小部分。除了这个 API,Bokeh 还包括一个服务器包和一个名为 bokehjs 的 javascript 库。事实上,Bokeh 的 python“绘图”包根本不做任何绘图;相反,它是一种描述绘图的语言,这些绘图被序列化到 json 包中,并传递给 bokehjs 以在浏览器中呈现。随着我尝试在我的情节中添加更多的交互性,我逐渐清楚地知道,了解一些 JavaScript——我并不知道——并对散景有更清晰的理解会让我用散景做更多的事情。
与此同时,出于完全不同的原因,我遇到了 Observablehq 。Observablehq 是由 javascript D3 可视化包的开发者 Mike Bostock 领导的团队创建的。乍一看,它非常像一个基于 javascript 的云托管 jupyter 笔记本。考虑到我探索 bokehjs 和学习一些 javascript 的目标,我天真地认为 Observablehq 是最适合我的工具。嗯,这并不那么简单,因为 Observablehq 不仅仅是 jupyter 笔记本的 javascript 版本,它是一个非常不同的东西,并且以自己的方式非常漂亮;bokehjs 并不完全适合 Observablehq 世界。尽管如此,在尝试将这些世界融合在一起的过程中,我学到了很多关于 bokehjs 和 Observablehq 的知识,并且我看到了很多进一步发展的潜力。这里有一份简短的进度报告和一些提示,如果你也想开始这段旅程的话。
Observablehq 不是 Javascript 的 Jupyter
正如我上面提到的,当我查看 Observablehq 用户界面时,我的第一反应是这只是 javascript 的 Jupyter!

如上面的小动画所示,Observable 有笔记本,有单元格,你在单元格里输入 javascript(或者 markdown);按 shift-enter 键,单元格就会被求值。听起来像朱庇特,对吧?但是可观察的笔记本是完全不同的——每个单元格都有一个值,并且这些单元格根据引用组合成一个图表。当一个单元格的值发生变化时,所有依赖于该单元格的单元格都会被重新计算。这有点像小 javascript 程序的电子表格。这种设计意味着可观察笔记本以一种自然的方式支持高度的交互性,远远超过 jupyter 笔记本的能力。如果你感兴趣,你最好的选择是阅读 Observablehq 网站上的优秀文章。除了的介绍性文章,尤其值得一提的是:
- 【jupyter 用户可观察到的
- 如何观察运行
在 Observable 中加载 Bokehjs
在可观察的笔记本中试验散景的第一步是加载库。对于这一步,我得到了布莱恩·陈的你好,Bokehjs 笔记本的帮助。将下面的代码放入一个可观察到的笔记本单元格中,然后按 Shift-Enter 键,就可以实现这个目的:
正在将 Bokehjs 库加载到 Observablehq 中
不必在细节上花费太多时间,值得指出的是,加载 Bokeh 的代码被括在大括号中,以便作为一个单元执行。正如我前面提到的,可观察笔记本中的每个单元格就像一个自包含的 javascript 程序,单元格的执行和重新执行取决于它们引用之间的依赖图。这段代码中至关重要的require语句通过副作用起作用,而不是通过返回值。这意味着 Observable 不理解这些语句之间的依赖关系;如果放在不同的牢房里,它们可以按任何顺序执行。更一般地说,Observable 不是为了处理通过副作用起作用的函数而建立的,人们需要小心使用它们。
这个特殊的单元格是一个viewof构造,它的作用是将引用赋予变量Bokeh到附加 bokehjs javascript 库的window.Bokeh,同时显示变量message的内容,这是一个表示正在发生什么的html字符串。
您可以节省一些输入,而不是包含上面的代码,利用 Observable 跨笔记本导入单元格的能力,只需使用:
import {Bokeh} from "@jeremy9959/bokeh-experiments"
使用散景打印
现在我们已经加载了库,让我们画一个图。我将遵循 bokehjs 发行版中的分层条形图的示例。

Bokehjs 水果地块示例
你可以直接看我画这个图的可观察笔记本。笔记本的第一部分只是通过创建对应于fruits和years数据的单元格来设置数据,以及对应的逐年计数。例如,逐年计数存储在直接声明的变量data中:
// help the parser out by putting {} in ()
data = ({
2015: [2,1,4,3,2,4] ,
2016:[5,3,3,2,4,6],
2017: [ 3,2,4,4,5,3],
})
注意,javascript 显式对象创建中使用的括号需要括号来帮助可观察解析器。
创建这个图的 Bokeh 代码直接取自 bokehjs 发行版中的文件(尽管我把这个图做得更宽了一点):
最后,我们使用 Bokehjs 的嵌入函数将绘图渲染到 observable notebook 中的一个单元格中。
结果就是我上面画的图。
那又怎样?
到目前为止,这还不太令人满意,因为我们完全可以使用 python API 在 jupyter 笔记本上绘制相同的图形。为了说明为什么这种方法是有趣的,让我指出我们通过在 observable 中工作得到的两个主要好处。
- **我们可以检查 javascript 对象。**我最初对 Observable 感兴趣的原因之一是,我正试图学习 javascript,并试图理解 bokehjs 的内部工作原理。当然可以使用浏览器的 javascript 控制台来探究 bokehjs 的内部,但是 observable 给出了一个优雅的界面。例如,在制作情节时,我们构建了一个名为
P的Figure对象。下图显示了可观察到的关于这个图形的信息,使用小三角形你可以打开这个物体并探索它的内部结构。(注意:如果你想这样做的话,加载非缩小的 bokehjs 包是很重要的,否则在这个输出中类 ID 将是不可理解的。)

2.**可观察是互动的!**在 Observable 中做这件事的真正不同和有趣之处在于它是交互式的。如果我去定义变量data的单元格,并更改数字,只要我一进入单元格,图形就会更新:

这是因为 Observable 的执行图知道水果图依赖于数据变量,当该变量改变时,该图得到重新计算。
顺便说一句,Observable 的另一个特性是,由于执行顺序与文档中单元格的物理顺序无关,所以我可以将图表移到紧靠data单元格的位置,这样我就可以清楚地看到发生了什么。
这只是在 Observable 中可能实现的交互性水平的一小部分——例如,在笔记本上添加小部件甚至制作动画是非常容易的。这篇文章不是深入探讨这个问题的地方,但是在可观察的主页上有许多漂亮的例子。
返回木星轨道时的讲话
最后,我认为重要的是要指出,有比使用散景更自然的方式来绘制可观察图像。特别是,使用织女星有一个紧密集成的 API,非常强大的 D3 包实际上是内置在 Observable 中的。但是对于像我这样熟悉 bokeh 的 python 接口并希望了解更多关于 bokehjs 的知识的人来说——特别是考虑到虽然 python API 被广泛而细致地记录,但 bokehjs API 基本上是一个黑盒——Observable 提供了一个有趣的机会。有更多的事情可以尝试,我期待着超越 Jupyter 轨道的进一步冒险。
股票交易的布林线 Python 中的理论与实践
让我们看看 Python 中一个简单但有效的交易工具

作者图片
量化交易者经常寻找能发现趋势或反转的交易工具。这类工具应该能够自我适应市场条件,并试图以最准确的方式描述当前形势。
在本文中,我将讨论布林线以及如何在 Python 中使用它们。
注来自《走向数据科学》的编辑: 虽然我们允许独立作者根据我们的 规则和指导方针 发表文章,但我们不认可每个作者的贡献。你不应该在没有寻求专业建议的情况下依赖一个作者的作品。详见我们的 读者术语 。
布林线有哪些?
布林线是量化交易者约翰·布林格在 20 世纪 80 年代推出的工具。它们由两条线组成,以与波动性相关的方式包裹价格时间序列。波动性越高,波动幅度越大。
它们通常以这种方式绘制:
- 高波段:20 周期简单移动平均线加上 2 倍的 20 周期滚动标准差,两者都是基于收盘价计算的
- 较低波段:20 期简单移动平均线减去 2 倍 20 期滚动标准差,两者都是根据收盘价计算的
这是应用于标准普尔 500 指数的 SPX ETF 的结果:

正如你所看到的,波段试图包裹价格,但当价格突破它们时,会发生一些特殊的事件,我们可以利用这些事件来建立许多交易策略。
布林线策略
让我们看看一些可以用布林线发现的交易设置。
拒绝
二元期权交易者最常用的方法是将布林线视为动态支撑和阻力。一旦价格打破了一个波段,一般认为它可能会回到均线。

突破和拒绝模式。图片由作者提供。
然而,虽然这种方法看起来不错,但布林格自己通常建议将波段与另一个指标结合使用,例如,振荡指标。我们将看到打破波段通常不是一个反向信号。
骑着乐队
如果趋势强劲,一些蜡烛的价格可能会接近一个区间。这是因为强劲的趋势意味着高波动性,所以波段扩大,价格跟随他们。

价格波动很大。图片由作者提供。
w 和 M 模式
一组非常常用的模式是 W-M 模式。前者与后者相反。当价格打破下波段,然后上涨,然后再次下跌,最后上涨而没有再次打破波段时,出现 w 形态。真的好像画了个 W 字母。

w 模式示例。图片由作者提供。
当价格突破上带时,出现 M 型形态,然后在没有再次突破上带的情况下形成新的最大值。

m 模式示例。图片由作者提供。
这些模式通常被认为是动量的减少,所以它们以相反的方式使用。w 形态看涨,M 形态看跌。
挤压和破裂
不要忘记,市场波动会随着时间的推移而变化,有些低波动期会引发市场的大规模定向爆发。布林线可以很容易发现这种情况。你必须寻找一个市场条件,其中波段是平坦的,其宽度是恒定的。这被称为“挤压”,因为波动性正在降低。然后,你必须寻找一个巨大的蜡烛突破。这是价格定向爆发的前奏,你可以沿着突破的方向交易。

挤例子。图片由作者提供。
布林线参数
布林线有两个参数:均线和标准差的周期(相同)以及标准差的乘数。
20 周期的 SMA 经常被用来捕捉中期运动,所以 20 周期的值是根据经验选择的。
我们来谈谈标准差的乘数。根据正态分布,一个正态变量的值有接近 95%的概率远离均值 2 个标准差以上。这就是 2 这个数字的由来。
事实上,我们知道价格不遵循正态分布。根据几何布朗运动模型,对数正态分布是价格分布的一个很好的近似。而且根据切比雪夫不等式,任何一个有限方差的随机变量,其值远离均值超过 2 个标准差的概率小于 25%。所以,这相当高,与正常情况下的 5%有很大不同。
约翰·布林格本人建议使用一组略有不同的参数,根据某些特定情况改变乘数和周期。
然而,20-2 组合被广泛认为几乎是交易的标准。
Python 中的一个例子
用 Python 计算布林线非常容易。我们将利用标准普尔 500 的历史数据来看看如何做到这一点。完整的代码可以在我的 GitHub 知识库中找到:https://GitHub . com/gianlucamalato/machine learning/blob/master/Bollinger _ bands . ipynb
首先,让我们安装 yfinance:
!pip install yfinance
然后让我们导入一些库:
import yfinance
import pandas as pd
import matplotlib.pyplot as plt
让我们从标准普尔 500 指数中导入一些数据:
name = "SPY"ticker = yfinance.Ticker(name)df = ticker.history(interval="1d",start="2020-01-15",end="2020-07-15")
我们可以定义周期和乘数:
period = 20
multiplier = 2
然后,我们可以最终计算波段:
df['UpperBand'] = df['Close'].rolling(period).mean() + df['Close'].rolling(period).std() * multiplierdf['LowerBand'] = df['Close'].rolling(period).mean() - df['Close'].rolling(period).std() * multiplier
最后的图表是:

作者图片
正如你看到的,波段包装的价格就像预期的一样。
结论
布林线在交易中非常有用,计算也非常简单。使用这种动态工具的不同策略会导致不同的结果,因此应该对交易策略进行良好的回溯测试,以微调指标的参数。
使用机器学习进行时间序列预测时要小心的陷阱
代价高昂的错误会使基于机器学习的时间序列预测模型在生产中变得不准确

图片来自 Tralfaz
T ime 系列预测在数据科学方面算是老手,有着扎实的统计学基础。甚至在 Python 使得在行业中应用 ML &数据科学更容易之前,它就已经存在了。它在能源预测、金融等方面有多种应用。仅举几个例子。但是如果你没有在你的数据科学入门课程中读到过 ARIMA、霍尔特-温特斯,我不会责怪你,因为他们不像 ML 模型那样耀眼。
然而,最近,许多研究表明,使用更闪亮的最大似然模型,如神经网络进行预测是有希望的。我的团队也决定冒险进入这个领域,将 ML 技术应用于预测问题。我有更传统的 ML 方法和应用的背景,例如预测模型、分类和 NLP,直到最近才有机会处理时间序列数据。这种传统主义意味着我必须改变处理问题的方式。更重要的是,我陷入了一些被传统的 ML 方法/途径完全掩盖的陷阱。
让我们来讨论一下这些陷阱。
- 数据科学 101:将数据集分为训练/验证/测试
构建机器学习模型的传统方法需要获取数据,清理数据,并将其分为训练、验证和测试。虽然这种方法在时间序列预测中可能仍然有效,但有必要寻找潜在的地雷。
首先,让我们看看用于预测功率(KW)的典型特征;一个时间序列问题。任何时间序列预测问题中最高度相关的特征之一是先前值,即从当前时间 T 的滞后值。在功率预测的情况下,已经看到前 6 个值和上周的相应值与当前时间的负荷值高度相关。下图对此进行了说明:

示例滞后值(负载-千瓦)
你可以在上图中看到每个滞后值是如何形成的;跨特征集形成的对角线是时间序列预测的一个非常明显的属性。每个滞后值都是在规定的滞后时间的目标值,如 t-1、t-2 等。现在让我们想象我们在 *15:00 分割这个特征集。*16:00–18:00将成为我们的测试/验证集(在我们的示例中无关紧要)。现在,如果我们想要预测这 3 个小时标记( 16:00、17:00、18:00 )中每个小时标记的电力负荷,我们将需要 16:00 的负荷值来预测 17:00 (因为 滞后(t-1) 是负荷[16:00】【T24)
我们的模型不应该知道真实世界场景中的实际值

但是,等一下,当我们不知道 16:00 的实际值时,我们怎么能在 17:00 和 18:00 得到这些滞后值呢?(请记住,我们预测的是 16:00 时的值)。换句话说,我们的模型公然作弊。你也几乎可以把这等同于用训练数据测试你的模型。如上图所示,这些值在生产中对我们不可用。因此,简单地分割数据集并验证/测试我们的模型是不可能的。解决这个问题的一种方法是每次动态构造测试行,将预测值用作下一行的滞后值,依此类推。这个问题也直接把我们引到了下一点。
- 错误分析:随时间恶化
回到我们之前的例子,我们知道我们不能使用实际值,所以我们将不得不用我们的预测值来凑合。正如任何回归/ML 问题一样,我们知道我们永远不可能获得 100%的准确性。这意味着我们的每一个预测都将带有一个误差,这个误差将会在接下来的所有测试行中传播。当我们在预测值上绘制实际值时,这种影响将是可见的,即我们的误差将随着预测时间的推移而增加。一个自然的结果将是尝试并过度拟合模型上的数据以提高性能,但我们应该避免这样做,并意识到这个错误是由于我们拥有的特征集造成的。我们有办法避免这种情况(只预测短期或稍微复杂的动态来预测下一个 h 步骤),但我将把这个讨论留到以后。但这为下一个陷阱埋下了伏笔。
3)列车模型一次

图片来自来源
在大多数机器学习问题中,我们识别相关特征,训练一次模型,然后将其部署到生产中。例如,我们想要开发一个 ML 模型来对手写数字进行分类,这是一个相当众所周知的问题。我们根据大量不同的数据来训练我们的模型。我们假设用于分类这些数字的特征不会随着时间而改变。因此,一旦我们在训练集上训练了模型,我们就简单地对我们的测试值进行分类,而不做任何改变。在时间序列中,情况并非如此。

图片来自来源
让我们再次回到电力负载的例子。我们不需要成为时间序列预测专家就知道,在炎热的夏季(更多空调)和寒冷的冬季(更多供暖),电力需求会增加。时间序列数据的这种波动是常见的。你不能指望数据一直保持不变。因此,每次我们想要预测数值时,都需要重新训练模型。这是为了纳入任何可能发生的重大波动(高能源价格、经济衰退等)。请看上图,了解历史上的能源消耗以及未来二十年的预测。快速浏览一下历史数据,就可以看出消耗是如何随时间变化的。同样,在没有其他随时可能变化的外部因素的情况下,我们也不能指望需求只是简单地上升。因此,牢记这一点并用最新的时间序列数据重新训练模型是非常重要的。
摘要
在处理时间序列数据和传统的机器学习模型时,必须记住这些要点。对于时间序列预测专家来说,这并没有让他们大开眼界,但是对于像我这样更传统的数据科学家来说,这是一个很好的教训。在处理时间序列数据时,我们应该意识到模型中的这些不确定性。
书评:用 Python 进行深度学习,2017,弗朗索瓦·乔莱,曼宁

作者 Take 用 Python 深度学习,2017,Franç ois Chollet 的书和我的猫
不到 10 分钟的深度学习世界之旅。
我花了很长时间才打开这本书。更多的是因为害怕发现自己什么都不知道,而不是因为害怕对什么都知道感到沮丧。我定期收到关于人工智能、机器学习或深度学习的“最佳”或“最受欢迎”书籍的简讯。使用 Python 进行深度学习一直被认为是最值得推荐的方法之一。给定的等级经常在高级、中级或专家之间变化。我认为,我们不应该停留在某个人估计的水平上。出于兴趣,出于需要,你必须拿起一本书来读。
任何想学习的人都可以接触到这本书。写作的流畅性和简单性允许理解所有的概念,不管水平如何。
第 1 部分:深度学习的基础
第 1 章——什么是深度学习?
这本书的第一章给了读者一个很好的领域中使用的定义的概述,以及我们确切地称之为算法方式的 学习 。作者简明扼要地讲述了人工智能的历史。
有很多解释和上下文来解释什么是深度学习,以及为什么它最近才出现在我们的行业和现实世界中(硬件、数据、摩尔定律……)。
作者为读者提供了不同机器学习算法和神经网络如何工作的清晰解释。
我很欣赏算法使用的背景以及与竞赛中使用的相似性(为什么这种类型用于特定的任务)。
第 2 章— […]神经网络的数学构建模块
所以我们在这里,在本书的 数学 部分。嗯,每个人都会被这几句话吓到,但是,作者有一个 的特殊方法 来解释神经网络背后的数学。他自己的话是:
虽然这一节完全涉及线性代数表达式,但您在这里找不到任何数学符号。我发现,如果用简短的 Python 片段而不是数学方程来表达数学概念,没有数学背景的程序员会更容易掌握。所以我们将从头到尾使用 Numpy 代码。
没错,没有数学公式。所以,不要害怕数学,也不要疯狂地认为数学很难或者不可能。作者把学习过程 背后的数学不同部分剪得很简单,用 Numpy 代码 来解释。
通过这一章,你将熟悉 向量、矩阵和张量(以及它们对应的真实世界应用) 。与神经网络 的张量 和相应的 表示一起使用的不同 运算。您还将了解到 可微函数梯度 以及什么是 梯度下降、 随机梯度下降,以及不同的 神经网络 的对应参数。******
简洁明了这一章解释得很好,并且 允许我们很好地理解张量操作和表征学习的 。
作者利用几何学让读者将他所解释的概念形象化。
另外,在短短几行中,你将熟悉 反向传播 及其背后的数学原理。作者重用了前一章的一个例子,并把它分成几部分来映射你刚刚学到的相关数学概念。
一开始我有点犹豫,但是我急切地浏览了这些 三十页 。
第 3 章—神经网络入门
有了这一章,读者能够用神经网络处理分类(二进制和多进制)和回归等大多数常见问题。
作者解释了神经网络的不同部分(层、输入数据、损失函数、优化器)。他提供了用 Keras 编写的代码块,并解释了它们是如何工作的。
你会发现损失函数和优化非常相关的信息。
这些例子。本章提供了三个,每个常见问题一个(二元分类、多类分类、回归)。作者提供了最佳实践以及可视化应该关注的内容。他强调了过度拟合,以及如何评估你的模型,对于不同的问题使用什么损失函数。
你会对这三种情况下神经网络的输出有很好的理解。突出显示的一点是网络的大小,考虑数据集的大小来扩展网络非常重要。如果数据集很小,请选择层数很少的小型神经网络,以避免过度拟合。
这 36 页非常有用,充满了信息和最佳实践。
第 4 章—机器学习的基础
本章将让读者对机器学习世界的不同分支做一个调查。你将接触到 ML 世界中四个概念的快速描述。
作者将介绍分类和回归之间的不同概念以及不同的度量和损失函数。
你将知道如何评估你的模型和准备一个项目所需的所有步骤。从数据开始,到超参数调整结束。
作者提出了培训、评估和测试的重要性。您将了解评估您的模型的常用方法以及不同方法背后的代码。您还可以找到关于特征工程和数据格式的适当信息。
您将找到关于过度拟合和欠拟合的适当信息,以及这对您的模型意味着什么以及避免它们的方法。作者提供了一个关于辍学以及如何使用它的很好的解释。
还有最后一点,每个项目都需要走的机器学习工作流程。当开始一个机器学习问题时,你会发现不同的假设和一步一步的遵循。
因此,这是一个小章节(26 页),但在机器学习的研究项目中,有许多重要信息需要记住。
简历第一部分
在这一点上,你到达了本书第一部分的结尾,你通过了深度学习世界的所有基础部分,以及如何在你的项目中精确地使用它们。您将知道从哪里开始、寻找什么、如何准备数据、如何训练、评估和测试您的模型。理解算法每一部分背后的数学的重要性。但最重要的是,你有这个学科的背景和过程的定义。
第 2 部分:实践中的深度学习
第五章——计算机视觉的深度学习
在这一章中,作者将解释卷积神经网络(CNN)的所有概念。这部分有很多信息。
作者从 CNN 如何工作的操作开始(过滤器、填充、步幅、池…)。然后你将知道如何在一个小的数据集中使用它们来获得好的结果。你将熟悉计算机视觉中的过拟合概念,以及如何避免它(数据扩充、丢失……)。
下一步是通过预先训练的模型,它们的目标,它们是如何获得的,以及如何在不同的情况下使用它们来提高预测的准确性。作者解释了特征提取的概念和微调的概念(调整预训练 CNN 的最后几层,以学习特定的过滤器或特定数据的表示),以及如何在低数据集的情况下使用它们。
这一章以康文网如何看待世界的形象化结尾。研究模型每一层的不同抽象表示的三种方法。
作者用了一个图像分类(狗/猫)的例子,提供了很多代码解释他描述的所有事物的每一步。
第 6 章—文本和序列的深度学习
在探索了图像识别的世界之后,作者带领我们进入文本和序列数据的世界。对于那些对 NLP 和时间序列问题感兴趣的人来说,这部分真的很神奇。
这一章首先解释了需要如何准备数据。你将了解符号化、n-grams、一键编码和单词嵌入(我看到的最好的解释是 Coursera 提供的深度学习专门化)。作者提供了大量代码来使用这些不同的技术和预训练的模型(手套,…)。
在关于数据的部分之后。你将探索递归神经网络(RNN)及其变体,LTMS,GRU 和双向的世界。作者提供了足够的理论来理解代码(Keras)与具体的例子。您将能够在文本数据上使用不同的模型,并轻松地重现本章第一部分中显示的结果。
本章的结尾是关于 RNNs 更高级的应用,如时间序列和文本生成。您还将学习如何在 RNN 使用 dropout,以及如何使用 CNN 处理文本或时间序列,但是在考虑时间序列时,您会看到这种类型的模型的缺点。
第 7 章—高级深度学习最佳实践
在本书的这一步,您将了解 Keras 的高级功能。作者为您提供了从顺序模型到函数式 API 的建议。为什么这很重要?因为有了这种可用性,你就可以拥有多输入模型或多输出模型。
您将对非循环图(作为初始模型)、剩余连接(ResNet 模型)、在层之间共享权重或使用模型作为层进行解释。
您还有关于使用 Tensorboard 和回调(不同的类型以及如何使用它们)来监控模型的最佳实践。您还将了解如何以及何时使用批量归一化和深度方向可分离卷积。
本章最重要的部分,对我来说,是超参数优化的部分。作者介绍了调整它们的不同方法以及如何使用集合模型。
你将有 36 页的浓缩信息,但它非常有用。
第八章——生成式深度学习
激动人心的一章,然后是这一章。第一部分是文本生成,您将学习如何编写一个语言模型来生成具有不同可能性的文本。最重要的是知道如何为下一个字符或下一个单词重新加权概率分布,以便在文本生成中产生创造力。
然后,你将可以访问 DeepDream 上的大量信息,以及如何将它用于预训练的模型。你将学习如何创造新的图片,以及这一代人的内在机制是什么。
神经风格转移,是什么?你会在这一章学到,这是一种将一张图片的内容和另一张图片的风格混合在一张新图片中的能力。是的,你将了解到内容和风格可以用数学方法写出来,并放入神经网络中进行混合。
变分自动编码器和生成对抗网络我们到了。在几页~20 页中,你有很多关于图像生成的 VAEs 和 GANs 的信息。您将找到相关信息来区分两者,并选择在您的案例中使用哪一个。GANs 是最难训练的,所以作者提供了不同的技巧让你更好地理解模型的行为。GAN 部分对我来说是最有趣的,因为我从来没有使用它们。
我带着对生成数据的不同技术的良好直觉完成了这一章。图像生成是 GANs 最大的部分,也是最有趣的部分。
第 9 章—结论
作者在这一章的开头提供了这本书的简明摘要。然后,作者很好地理解了深度学习的局限性,并将其置于 AI 的世界中。你也在你的探索中找到作者对深度学习未来的感受,以及往哪里看。有一点,关于 AutoML,与这个领域最近的进展相提并论是很有趣的。您还可以找到如何与该领域保持同步的信息。
最后的话
我希望这本书的简短摘要能给你关于内容的相关信息,让你找到你需要的东西。这本书在我的图书馆里已经放了很长时间了,购买它的目的主要是为了使用第 6 章中关于 NLP 的内容。
我目前正在进行一项不同的探索,来填补我自学的所有弱点。所以,我开始接受挑战,超越我的舒适区。第一步,把自我放在一边,承认我并不知道一切(远非如此)。剩下的,去攻克能有帮助的课本。使用 Python 进行深度学习是长期被列为基准的基石。在探索它并做了无数笔记和便利贴后,我觉得我已经准备好继续我的旅程,进入我感兴趣的子域。
关于作者:
弗朗索瓦·乔莱(Franç ois Chollet)是谷歌大脑团队的人工智能研究员,也是 Keras 深度学习图书馆的作者。
弗朗索瓦·乔莱,用 Python 进行深度学习 (2017),曼宁
等待第二版的出版
书评:Naeem Siddiqi 的“智能信用评分”
关于如何开发和使用信用风险记分卡的完整指南

《智能信用评分》图书封面(作者本人法师)。
1.介绍
从信用卡到房屋抵押贷款,记分卡是所有现代贷款业务的核心。记分卡的核心思想是将客户支付贷款的概率(个人的信誉)转化为易于理解的数字,以指导商业决策。尽管记分卡并不新鲜,但随着新的大数据/人工智能场景的出现,它已经发生了很大变化,尤其是在 2008 年金融危机之后。
“智能信用评分”为您提供的不仅仅是对该主题的介绍。这是一个由该领域最有影响力的作者之一撰写的关于如何工作和构建记分卡的完整指南。
乍一看,当我收到 智能信用评分 时,我想这将是一本更无聊的书,我会阅读介绍,也许是前几章,然后把它装饰在我的书架上,也许在需要时用它进行研究。但是我完全错了!阅读这本书实际上是令人愉快的,对于一本 400 页、包含信贷监管和模型监控章节的技术信息的书来说,阅读速度超出了我的预期。
2.图书主要受众
智能信用评分 是一本面向广大受众,从行业初学者到经验丰富的专业人士的通俗易懂的书。无论你是信用分析师,信用评分经理,还是数据科学家,这本书的内容将提供关于如何创建,评估和监控记分卡的更深入的观点。
3.这本书的结构
在介绍(第 1 章)之后,作者描述了负责记分卡开发和实施的团队中每个人的角色(第 2 章)。信用评分的一个有趣的方面是,它通常是由一个大团队执行的工作,有各种各样的专业人员。
下一章定义了维护成功记分卡所需的基础设施,并总结了从数据收集到模型实施和监控的过程。从第 4 章到第 14 章,作者详细描述了记分卡开发的每个阶段,将流程分为 7 个部分。
第一阶段,规划
在开始记分卡开发之旅之前,你需要回答一些关于你的商业计划的问题,以及你的公司是否有可用的基础设施和人力资源。还列出了开发内部和外部记分卡的优点和缺点,以帮助您做出决定。
阶段 2,数据审查和项目参数
虽然我们生活在一个大数据时代,但拥有大量数据是不够的。为了让你的项目成功,你需要的不仅仅是数量,还有组织有序的数据。在这个阶段,Siddiqi 指导读者如何设置默认定义,这是开发过程中的一个关键步骤。基于新巴塞尔协议的当前监管信息对记分卡行业非常重要,在第 7 章中有很好的介绍。目前,新巴塞尔协议第三版和第四版的更新已经在讨论和实施中,如果能在新版本中提供这些信息,那就太好了。
阶段 3,数据库创建
就像任何数据科学项目一样,在记分卡开发中,拥有高质量的数据比使用更好的模型更重要。这就是这本书的这一部分如此重要的原因。创建和过滤要素以及替换缺失值是数据库创建过程的一部分,应该非常小心谨慎地执行。本课程中提到的另一个重要方面是将数据集分为训练数据集和测试数据集,以评估模型性能。本次会议还提到了记分卡中使用的替代数据和更大数据集(大数据)的潜力,监管和技术相互影响,决定了该领域的创新。
“在一个不缺乏信息的时代,最有行动洞察力的银行才是赢家。”— 智能信用评分(第二版),纳伊姆·西迪奇
阶段 4,记分卡创建
数据库准备就绪后,是时候开始处理您的要素了。在本书的这一部分,你将学习如何运用证据权重,用它将你的变量分成同类的类别。在特征选择的过程中使用了像信息值这样的其他概念。以下部分描述了如何使用逻辑回归来创建记分卡,以及如何从结果模型中计算分数。
阶段 5,记分卡管理报告
记分卡只有在表现出反映当前客户群体的一致绩效时才有价值。这就是监控模型如此重要的原因。本书的这一部分介绍了一些性能指标和报告模板,以帮助你设计自己的管理系统。
阶段 6,记分卡实施
记分卡创建完成后,就该投入生产了。但是仅仅用它来获得新客户是不够的。你必须确保它根据经验证的数据集表现良好。因此,跟踪人口稳定性指数等指标有助于监控模型性能。此外,根据业务战略,可以使用多个记分卡来评估客户的信用风险状况。本课程将介绍组合记分卡和设置临界值的不同策略。
第 7 阶段,监控
最后,记分卡开发的整个周期在团队使用一套工具来监控模型性能的阶段结束。客户的概况受各种外部事件的影响,所以不要指望你的模型能长时间保持最初的性能。作者提出了一系列的方法和策略来使用记分卡,以帮助您管理您的投资组合和做出明智的商业决策
4.主要要点
正如简介中所提到的,智能信用评分是一本面向广大读者的通俗易懂的书,所以即使你是新手,它也会对你有很大的价值。
这本书的另一个有趣的方面是,它背后的数学和统计学相对简单。所以即使你在精确科学领域没有很强的背景,你也能真正理解关于所呈现概念的逻辑。
最后,记分卡从来都不是一个人或一个小团队的产品。它的发展需要来自机构内部各种专业人士的反馈,以反映业务逻辑,并显示其对公司和银行内部决策的真正价值。
非常感谢你阅读我的文章!
创建信用评分的额外资源
这本书缺少的一点是让你自己实现记分卡的代码示例。作者给出的例子都使用了 SAS 平台,这个平台对记分卡的发展有着重要的历史意义。但是,除非您的公司使用 SAS 环境,否则您可能需要使用其他语言实现逻辑。
好消息是,开源(或以非常便宜的价格)资源可以帮助你构建自己的记分卡。如果您是使用 Python 的数据科学家或开发人员,我强烈建议您查看以下资源:
A) OptBinning (Python 库)
由 Guillermo Navas Palencia 开发的这个库有一些强大的工具来执行变量的宁滨。Optbinning 提供了对证据权重、信息值和每个变量的其他重要指标进行可视化的方法,帮助您为模型选择最佳特征。OptBinning 最近加入了一个记分卡开发模块,使整个过程快速而稳定。对于使用 Python 的记分卡开发者来说,这可能是一个必看的项目!
OptBinning 是一个用 Python 编写的库,它实现了一个严格而灵活的数学编程公式来…
github.com](https://github.com/guillermo-navas-palencia/optbinning)
Python 2020 中的信用风险建模(Udemy)
如果你刚刚开始使用记分卡,并使用 Python 作为你的主要编码语言,我强烈推荐你参加这个课程。解释信用评分背后的理论的视频具有很好的教育意义,并且每一步都是使用 Pandas、Scikit-Learn 和 Matplotlib 在 Python 中实现的。因此,在构建记分卡时,你会真正理解每种方法背后的逻辑。
嗨!欢迎学习 Python 中的信用风险建模。教你银行如何使用数据科学的唯一在线课程…
www.udemy.com](https://www.udemy.com/course/credit-risk-modeling-in-python/)**
书评:其他想法(1/2)
上午 12 点的对话
动物的大脑,我们的大脑,还有电脑的大脑…

阿什·埃德蒙兹在 Unsplash 上拍摄的照片
这个星期我想做一些不同的事情,分享一些我刚刚读完的一本书的想法。这本书名叫《T4:其他意识:章鱼、海洋和意识的深层起源》,作者是彼得·戈弗雷-史密斯。
我看过的所有关于这本书的书评都集中在章鱼有多聪明。这是有道理的,因为章鱼是这本书的主角,但我想说点别的。我想分享的一件事是,书中的一些概念如何奇怪地让我想起计算机科学中的概念。比如章鱼左右脑交流的方式,让我想起了 XG bosting 的优化。我们记忆系统的理论让我想起了数据结构。
**还有一个是关于主观体验的话题,**我很感兴趣的东西。作者对什么是主观体验进行了一次非常有趣的讨论。例如,当我们看到一种颜色和机器人看到一种颜色相比,为什么我们会认为它是不同的。我将用章鱼的例子来介绍这个话题,因为章鱼,伪装的大师,可以改变甚至比变色龙更多的颜色,是色盲。他们是怎么做到的?他们“看见”一种颜色吗?最后,我还想讨论一下,机器人是否有一天也能拥有主观体验。

章鱼的大脑和 XG Boosting 的优化
我们都知道我们身体有左右两边,比如左脑和右脑,或者左手和右手。然而,大多数时候,我们只是把我们的大脑称为大脑,因为我们没有从左右两侧获得单独的信息。我们从左右两边作为一个整体得到一条连贯的信息。
但是在动物世界里这并不总是正确的。在一项使用九只鸟的研究中,其中八只不在左右脑之间传递信息(Godfrey-Smith,84)。例如,如果一只鸟用一只眼睛学习一个非常简单的技能,那么这只鸟只使用另一只眼睛进行测试,这只鸟将无法做到。(是啊…)
GIF via GIPHY
乍一看,你觉得这太疯狂了!但是,Giorgio Vallortigara 等动物研究人员指出,这实际上是有道理的。不同的任务需要不同类型的处理,所以最好有专门的方面,不要把它们彼此联系得太紧密。章鱼呢?
章鱼介于鸟类和我们之间。有些信息确实被传递了,但并不总是如此,而且这个过程并不像我们这样简单和同步。此外,章鱼也有许多遍布全身的神经元。这意味着章鱼的手臂可以看、感觉和思考…
它是这样工作的:章鱼的手臂可以随心所欲地做事情,不需要大脑的任何命令。大脑可能不知道手臂接触或学习了什么。而且,如果大脑想和手臂一起工作,它会向手臂发送信号,T2 希望手臂会配合。然而,当章鱼警觉时或在某些情况下,大脑似乎可以很好地控制手臂。整个章鱼就像我们一样作为一个整体一起工作。
我喜欢作者在书中的比喻。想象一下我们与呼吸的关系。当我们想要的时候,我们可以控制我们的呼吸,但是通常,我们不会注意到他们在做什么。
这与 XG boosting 算法有什么关系?
很多人把我们的大脑比作机器。我们知道,我们的大脑可以快速处理大量信息,具有非常高的计算能力。为了拥有这样的力量,大脑有 860 亿个神经元,是灵长类动物中最多的,它消耗了我们身体 20%的能量。这是一种昂贵的机器,大多数其他动物的大脑无法承受这样的功率。因此,他们找到了优化操作的方法。
将此放入算法的上下文中,找到最优解的一种方法是使用蛮力算法。该算法与贪婪算法形成对比。该算法保证全局最小值,这是贪婪算法所不能保证的,但是它很慢并且需要很高的计算能力。
决策树使用贪婪算法,经常会遇到过拟合的问题。虽然 XG Boosting 是一种基于树的算法,但它不会遇到这个问题,因为它实际上使用了一种强力算法。然而,即使在处理大型数据集时,它仍然可以高效运行。因为它实际上使用了半蛮力。我想称之为选择性蛮力,因为它在选择性样本上运行蛮力算法。(更多信息: XGBoost 第四部分:疯狂酷炫优化 )
这就是我如何把动物世界和三种算法联系起来的。我们的大脑就像是蛮力算法。它会自动进行大量计算并找到最佳解决方案。其他计算能力较低的动物大脑就像树算法。大脑的每一侧,或者说对于每一个不同类型的问题,它都会构建一个树算法来解决这个特定的问题。
说到章鱼,它们就像一个内置了许多优化工具的 XG boosting 算法。他们只传递一些信息,如果需要,他们会有意识地传递更多的信息。这样,大脑需要更少的计算能力,但仍然相当聪明。你知道当我读到章鱼的手臂会思考时让我想起了什么吗?那是 XG boosting 的并行学习…
GIF via GIPHY
人类记忆和计算机数据结构
书中谈到了英国心理学家艾伦·巴德利(Alan Baddeley)和格拉姆·希奇(Gramham Hitch)的名著《工作记忆模型》(model of working memory)。该模型认为,工作记忆是对少量信息的短期储存。当我们需要进行有意识思考/系统 2 思考时,我们会使用这些信息。

经过 simplypsychology.org 的麦克劳德 2012
你们中的一些人可能更熟悉短时记忆这个词。短时记忆和工作记忆都是指不储存在长时记忆中的记忆。STM 只强调信息的储存,但是工作记忆框架关注的是我们实际上是如何使用这些信息的。所以大致来说,工作记忆框架涵盖的范围更广。(更多信息: 关于工作记忆和短时记忆的区别 )

麦克劳德 2012 途经 simplypsychology.org
在工作记忆框架中,有三个组成部分:语音回路§,视觉空间画板(V)和中央执行,c。P 部分处理口语和书面材料。V 部分处理视觉和空间信息。C 部分是确保一切顺利进行的控制中心。(更多信息: 工作记忆 )
从对短期记忆的研究中,我们知道我们的短期记忆储存了大约 7 个项目。所以,如果你想记住 10 个数字的电话号码,把它们分成 3 块:123-456-7890(啊哈!)
还记得任何以类似方式工作的数据结构吗?是哈希表 EE!!(更多信息: 下架哈希表 )
GIF via GIPHY
请这样想:我们可以储存在短期记忆中的 7 个项目就像是哈希桶。而中央执行部分的职责之一就是确保我们没有任何“冲突”。
在每个桶中,我们以数组的形式存储信息。这实际上也对应于当我们想要回忆一些事情时,我们的记忆是如何工作的。研究表明,短时记忆中的回忆是有顺序的,除非你已经知道它在序列中的位置。因此,为了回忆短期记忆,将事物按一定的顺序排列是有帮助的。就像在数组中搜索一个项目一样!
我们短时记忆的优缺点也像一个数组。它是为搜索而设计的,因为搜索很快,但它不适合存储大容量的内存。对于存储大容量内存,另一种数据结构,链表可以做得更好。
长期记忆的行为就像一个链表。长期记忆储存在我们大脑的不同地方,但短期记忆大多在前额叶皮层。从长期记忆中回忆,不是按顺序,而是通过联想。这就是为什么对于失去记忆的人来说,为了回忆,看看过去相关的事情会对他们有帮助。
长期记忆的储存空间仍然被认为是无限的。我怀疑它是无限的是因为长期记忆的空间客观上是如此之大,以至于我们还没有找到极限?或者是因为长期记忆可以有不同的大小,比如链表。因此,存储看起来是无限的。(更多信息: 总之什么是链表【第二部分】 )

你可能想知道为什么我在谈论记忆系统,而这本书是关于章鱼的?这是因为作者试图理解为什么章鱼在没有明显原因的情况下不断改变它们的颜色。比如他们完全独处的时候。他怀疑这是一个类似于人类自言自语的想法。
拥有工作记忆就是当我们在头脑中说话时,人类能够听到我们自己的声音。这将我们与章鱼区分开来。章鱼被认为缺乏自言自语的能力。我将在下一篇博客中继续这个讨论,在这篇博客中,我想谈谈主观体验和高阶思想。
参考:
- 巴尔斯,B . j .和 N M .盖奇。认知神经科学基础:初学者指南。n.p .:爱思唯尔学术出版社,2013 年。
- 伯特温尼克,硕士;王;考恩,e;罗伊;巴斯蒂亚宁,c;P.J .梅奥;侯克,J.C. (2009 年)。“猕猴的即时系列回忆表现分析”。动物认知。12(5):671–678。doi:10.1007/s 10071–009–0226-z。PMID1946 21 89。
- 彼得·戈弗雷·史密斯。其他思维:章鱼、海洋和意识的深层起源。第一版。纽约:法勒,斯特劳斯和吉鲁,2016。打印。
- McLeod,S. A. (2012 年)。工作记忆。单纯的心理学。https://www.simplypsychology.org/working%20memory.html
- 页面,m;诺里斯博士(1998 年)。“首要模型:即时系列回忆的新模型”。心理复习。105(4):761–781。doi:10.1037/0033–295 x . 105 . 4 . 761–781。PMID 9830378。
有关更多信息:
- XGBoost 第 4 部分:疯狂酷炫的优化 , Josh Starmer
- 从货架上取下哈希表,Vaidehi Joshi
- 总之,什么是链表【第二部分】,Vaidehi Joshi
- 关于工作记忆和短时记忆的区别,巴特·翁瑞迪、斯文·斯塔佩特和阿尔扬·布洛克兰
- 工作记忆,艾伦·巴德利和格雷厄姆·j·希奇
书评推荐系统

照片由 Alfons Morales 在 Unsplash 上拍摄
书评的顺序应该个性化吗?
由 Sangeetha Veluru — 12 分钟阅读
我总是在购买一本书之前阅读书评,我经常发现自己不知道我应该给它们多少权重。就他们通常阅读的体裁以及他们如何评价这些体裁而言,评论者与我有多相似,因此他们的经历在多大程度上反映了我的经历?

Photo by 青 晨 on Unsplash
贝叶斯神经网络:在 TensorFlow 和 Pytorch 中 2 个完全连接
亚当·伍尔夫——11 分钟阅读
本章继续贝叶斯深度学习系列。在这一章中,我们将探索传统密集神经网络的替代解决方案。这些备选方案将调用神经网络中每个权重的概率分布,从而产生单个模型,该模型有效地包含基于相同数据训练的神经网络的无限集合。我们将用这些知识来解决我们这个时代的一个重要问题:煮一个鸡蛋需要多长时间。

照片由 Djim Loic 在 Unsplash 上拍摄
对计数数据使用负二项式
通过 Ravi Charan — 8 分钟阅读
负二项分布是一种离散概率分布,您的计数数据工具包中应该有这种分布。例如,您可能有关于某人在购买前访问的页面数量的数据,或者与每个客户服务代表相关的投诉或升级数量的数据。
我们的每日精选将于周一回归!如果你想在周五收到我们的 每周文摘 ,很简单!跟随 我们的刊物 然后进入你的设置,打开“接收信件”您可以在此 了解关于如何充分利用数据科学 的更多信息。
如果你是 Python 的新手(尤其是如果你是自学 Python 的话),请将此加入书签
Python 中简单但有用的技巧和提示列表
在我们的调查中,增长最快的主要编程语言 Python 再次在编程语言中排名上升,今年超过 Java,成为第二大最受欢迎的语言(仅次于 Rust)。[1]

在 Unsplash 上由 Hitesh Choudhary 拍摄的照片
如果你是因为枯燥的隔离生活才开始接触 Python,那么恭喜你。你正在学习发展最快的主要编程语言。我相信你已经知道了 Python 的一些优点,比如它的简单、易学等。这些也是我五年前学习 Python 的主要原因。因为我希望你能更有效地学习 Python,并且能充分享受学习 Python 的乐趣,这里列出了一些简单但有用的技巧和提示。
提示:目前我正在使用 Python 3.8。如果您在学习我的示例时遇到任何问题,请检查这是否是因为您的 Python 版本。
目录
价值比较
>>> a = 1
>>> b = 3
>>> a == 1
True
>>> a == 2
False
>>> a == b
False
>>> a > b
False
>>> a <= b
True
>>> if a <= b :
... print('a is less than or equal to b')
...
a is less than or equal to b
您可以比较两个对象的值。该返回为真/假。可以在 if-else 语句中直接使用比较作为条件。
条件返回语句
代替
>>> def compare(a,b):
... if a> b:
... return a
... else:
... return b
...
可以将条件直接放在 return 语句中。
>>> def compare(a, b):
... return a if a> b else b
...
在 list/tuple 语句的一行中分配多个变量
而不是:
>>> arr_list = [1,4,7]
>>> a = arr_list[0]
>>> b = arr_list[1]
>>> c = arr_list[2]
您可以在语句的一行中完成相同的赋值:
>>> a, b, c = arr_list
>>> a
1
>>> b
4
>>> c
7
列表理解
代替
>>> arr_list = [1,4,7]
>>> result = []
>>> for i in arr_list:
... result.append(i*2)
...
>>> result
[2, 8, 14]
你可以
>>> result = [x*2 for x in arr_list]
>>> result
[2, 8, 14]
使用 zip 比较两个列表中的元素
代替
>>> a = [1,5,8]
>>> b = [3,4,7]
>>> result = []
>>> for i in range(len(a)):
... result.append(a[i] if a[i]< b[i] else b[i])
...
>>> result
[1, 4, 7]
你可以
>>> result = [min(i) for i in zip(a,b)]
>>> result
[1, 4, 7]
使用 lambda 按第二个元素对嵌套数组进行排序
>>> arr_list= [[1,4], [3,3], [5,7]]
>>> arr_list.sort(key= lambda x: x[1])
>>> arr_list
[[3, 3], [1, 4], [5, 7]]
过滤器,地图
代替
>>> arr_list = [-1, 1, 3, 5]
>>> result = []
>>> for i in arr_list:
... if i > 0:
... result.append(i**2)
...
>>> result
[1, 9, 25]
你可以
>>> result = list(map(lambda x: x**2, filter(lambda x: x > 0, arr_list)))
>>> result
[1, 9, 25]
编辑:是我的错,用列表理解更好:)
谢谢奥列格·卡普斯汀和库尔迪普·帕尔。
>>> result = [i**2 for i in arr_list if i > 0]
>>> result
[1, 9, 25]
检查列表中的所有元素是否唯一
使用 set 从列表中移除重复的元素,然后测试列表和集合的长度是否相等
>>> arr_list = [1,4,4,6,9]
>>> len(arr_list) == len(set(arr_list))
False
字符串格式
Python 3.6 之前
>>> a, b, c = 1,5,9
>>> print('a is {}; b is {}; c is {}'.format(a,b,c))
a is 1; b is 5; c is 9
Python 3.6 及更高版本
>>> print(f'a is {a}; b is {b}; c is {c}')
a is 1; b is 5; c is 9
列举
代替
>>> arr_list = [1, 5, 9]
>>> for i in range(len(arr_list)):
... print(f'Index: {i}; Value: {arr_list[i]}')
...
Index: 0; Value: 1
Index: 1; Value: 5
Index: 2; Value: 9
你可以
>>> for i, j in enumerate(arr_list):
... print(f'Index: {i}; Value: {j}')
...
Index: 0; Value: 1
Index: 1; Value: 5
Index: 2; Value: 9
捕获数组的特定部分
>>> arr_list = [1,4,6,8,10,11]
>>> a, *b, c = arr_list
>>> a
1
>>> b
[4, 6, 8, 10]
>>> c
11
形成组合和排列
>>> str_list = ['A', 'C', 'F']
>>> list(itertools.combinations(str_list,2))
[('A', 'C'), ('A', 'F'), ('C', 'F')]
>>> list(itertools.permutations(str_list,2))
[('A', 'C'), ('A', 'F'), ('C', 'A'), ('C', 'F'), ('F', 'A'), ('F', 'C')]
虽然这些技巧相当简单,但它们可以帮助您节省不必要的步骤,使您的代码更简单。我希望你看完这篇文章后明白使用 Python 是多么简单。享受学习,享受编码。下次见。
(编辑:第 2 部分已经发布。进一步了解 Python 中的技巧和窍门。)
引用
[1]堆栈溢出开发者调查 2019 —堆栈溢出洞察,堆栈溢出,【https://insights.stackoverflow.com/survey/2019


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}