







领先云平台上的无服务器机器学习架构
亚马逊网络服务(AWS)、谷歌云平台(GCP)和微软 Azure 上的机器学习架构

云平台 GCP、AWS、Azure
云平台本身有各种各样的服务,这些服务可以混合和匹配,以满足任何具有分配预算的业务案例的需求。在这里,我将挑选一个这里提到的通用示例,并讨论上述云平台上的架构。
因为架构是无服务器的,所以有一堆功能可以确保事物在服务之间向前移动。
要求:
这项业务有源源不断的支持票。支持代理从客户那里获得的信息很少,因此他们会花更多的时间来了解客户的需求。
在代理开始处理问题之前,他们需要完成以下工作:
- 理解支持票的上下文。
- 确定问题对客户的严重程度。
- 决定使用多少资源来解决问题。
通常,与客户的几次来回交流会获得更多的细节。如果您添加基于票证数据的自动化智能,您可以帮助代理在处理支持请求时做出战略性决策。
通常,用户在填写包含几个字段的表单后,会记录一个票据。对于这个用例,假设没有一个支持票已经被机器学习丰富。另外,假设当前的支持系统已经处理票据几个月了。
要开始丰富支持票证,您必须训练一个使用预先存在的标签数据的 ML 模型。在这种情况下,训练数据集包含在已关闭的支持票证中找到的历史数据。
谷歌云架构
- 基于 Firebase 的数据库更新创建一个云函数事件。
- 客户端向 Firebase 数据库写一张票。
- 云函数触发器执行一些主要任务:
- 使用部署的机器学习算法运行预测。
- 用丰富的数据更新 Firebase 实时数据库。
- 使用整合的数据在您的帮助台系统中创建票证。
无服务器技术和基于事件的触发
- “无服务器技术”可以有多种定义方式,但大多数描述都包含以下假设:
- 服务器应该是一个遥远的概念,对客户来说是看不见的。
- 动作通常由事件触发的功能来执行。
- 函数运行的任务通常是短暂的(持续几秒或几分钟)。
- 大多数时候,函数只有一个目的。
Firebase 和云功能相结合,通过最大限度地减少基础架构管理来简化开发运维。操作流程如下:
- 基于 Firebase 的数据库更新创建一个云函数事件。
- 客户端向 Firebase 数据库写一张票。
- 云函数触发器执行一些主要任务:
- 使用部署的机器学习算法运行预测。
- 用丰富的数据更新 Firebase 实时数据库。
- 使用整合的数据在您的帮助台系统中创建票证。

https://cloud . Google . com/solutions/architecture-of-a-a-server less-ml-model
Firebase 本身是一个大规模的服务,并且该架构使用了给定的上下文:
- Firebase 是一个客户端可以更新的实时数据库,它向其他订阅的客户端显示实时更新。
- Firebase 可以使用云功能来调用外部 API,比如您的帮助台平台提供的 API。
- Firebase 可以在桌面和移动平台上工作,可以用各种语言开发。当 Firebase 遇到不可靠的互联网连接时,它可以在本地缓存数据。
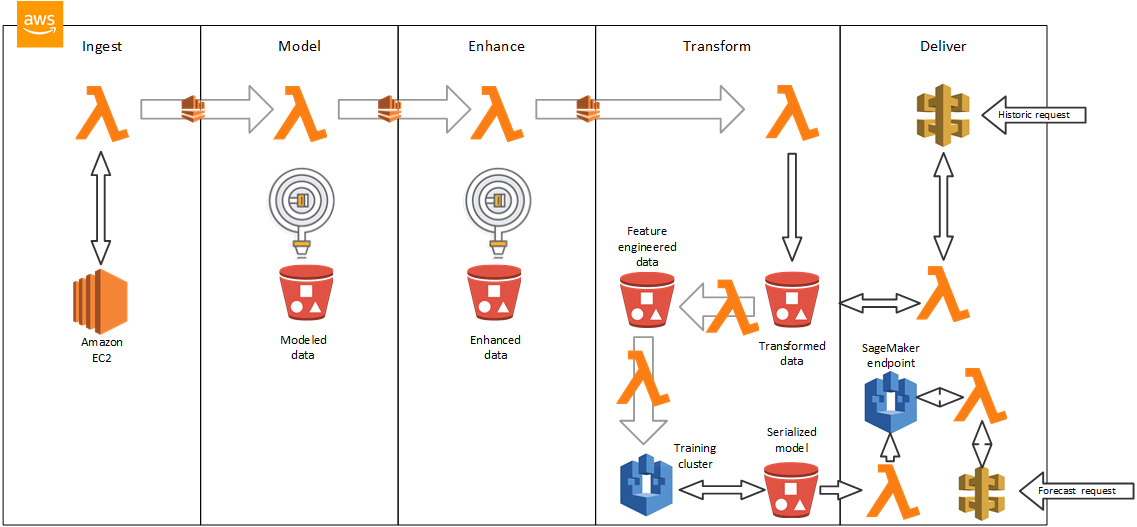
AWS 云架构
- 亚马逊 S3 的结构化数据湖,用于保存原始数据、建模数据、增强数据和转换数据。
- 该功能的暂存桶设计和转换的数据将被纳入 Amazon SageMaker。
- AWS Lambda 上托管的数据转换代码,用于为消费和 ML 模型培训准备原始数据,并转换数据输入和输出。
- Amazon SageMaker automation 通过 Lambda 函数为新模型构建、管理和创建 REST 端点,基于一个时间表或由数据湖中的数据变化触发。
- API 网关端点托管公共 API,使开发人员能够获得其应用程序的历史数据或预测。
- Amazon Kinesis 数据流,支持在接收、建模、增强和转换阶段实时处理新数据。
- 亚马逊 Kinesis Data Firehose 将模型和增强阶段的结果传送到亚马逊 S3 进行持久存储。
- AWS IAM 在每个处理组件上执行最小特权原则。IAM 角色和策略只限制对必要资源的访问。
- 一个为每日亚马逊弹性计算云(Amazon EC2)现货定价构建和更新预测模型的演示场景。

蔚蓝建筑
该架构由以下组件组成:
- 天蓝色管道。这个构建和测试系统基于 Azure DevOps ,用于构建和发布管道。Azure Pipelines 将这些管道分成称为任务的逻辑步骤。例如, Azure CLI 任务使得使用 Azure 资源变得更加容易。
- Azure 机器学习。Azure Machine Learning 是一个云服务,用于大规模培训、评分、部署和管理机器学习模型。这个架构使用用于 Python 3 的 Azure 机器学习 SDK 来创建工作空间、计算资源、机器学习管道和评分图像。Azure 机器学习工作区提供了实验、训练和部署机器学习模型的空间。
- Azure Machine Learning Compute是一个按需虚拟机集群,具有自动扩展和 GPU 及 CPU 节点选项。训练作业在该集群上执行。
- Azure 机器学习管道提供可重用的机器学习工作流,可以跨场景重用。对于这个用例,训练、模型评估、模型注册和图像创建发生在这些管道中的不同步骤中。管道在构建阶段结束时发布或更新,并在新数据到达时触发。
- Azure Blob 存储。Blob 容器用于存储来自评分服务的日志。在这种情况下,将收集输入数据和模型预测。经过一些转换后,这些日志可以用于模型再训练。
- Azure 容器注册表。计分 Python 脚本打包为 Docker 映像,并在注册表中进行版本控制。
- Azure 容器实例。作为发布管道的一部分,通过将评分 web 服务映像部署到容器实例来模拟 QA 和暂存环境,这提供了一种简单、无服务器的方式来运行容器。
- 蔚蓝库伯内特服务。一旦评分 web 服务映像在 QA 环境中经过全面测试,它就会被部署到受管 Kubernetes 集群上的生产环境中。
- Azure 应用洞察。该监控服务用于检测性能异常。

来源:https://docs . Microsoft . com/en-us/azure/architecture/reference-architectures/ai/m lops-python
希望这篇文章能帮助我们从高层次上了解在给定的业务案例中哪些服务在起作用。必须记住,这还不是一成不变的,因为有几个假设,最重要的是没有考虑预算限制。
参考资料和来源:
这一系列文章探索了无服务器机器学习(ML)模型的架构,以丰富支持票…
cloud.google.com](https://cloud.google.com/solutions/architecture-of-a-serverless-ml-model) [## 使用 Azure 机器学习的 Python 模型的 mlop-Azure 参考架构
该参考体系结构展示了如何实施持续集成(CI)、持续交付(CD)和…
docs.microsoft.com](https://docs.microsoft.com/en-us/azure/architecture/reference-architectures/ai/mlops-python) [## 亚马逊 SageMaker 的预测数据科学和 AWS 上的数据湖-快速入门
存储和转换数据以构建预测性和规范性应用程序这一快速入门构建了一个数据湖…
aws.amazon.com](https://aws.amazon.com/quickstart/architecture/predictive-data-science-sagemaker-and-data-lake/)
无服务器 ML:大规模部署轻量级模型
理解大数据

在 Unsplash 上 Zbynek Burival 拍摄的照片
部署难题
将机器学习(ML)模型部署到生产中有时会成为数据科学(DS)团队的绊脚石。一种常见的部署模式是找到一个地方来托管您的模型,并通过 API 公开它们。在实践中,这可以让您的最终用户轻松地将您的模型输出直接集成到他们的应用程序和业务流程中。此外,如果客户信任你的 API 的输出和性能的有效性,这可以驱动巨大的商业价值:你的模型可以对目标商业问题产生直接和持久的影响。
但是,如果您无法获得 DevOps 或 MLOps 团队形式的持续技术支持,那么就要费力地通过云服务来设置负载平衡器、API 网关、持续集成和交付管道、安全设置等。开销会很大。此外,除非你对这些概念非常有信心,否则交付(和监控)一个 ML API 来保证大规模的安全性和性能,从而赢得用户的信任是很有挑战性的。
当然,有越来越多的服务可以帮助你完成这个过程。也许你的第一站会是主要云提供商的托管模型部署服务(比如 SageMaker )。或者,你可能会关注一个蓬勃发展的 MLOps 工具/平台,如 Cortex 或 Seldon ,或者甚至你可能会选择一头扎进类似 Kubeflow 和 TensorFlow Serving 的东西。当你开始工作时,可能会有点困惑。
如果你想大规模地部署模型,你将不得不花费大量的时间学习一些技术,并且熟悉一些软件工程概念。
这里还有另一个问题。虽然这些工具和平台自动化了许多特定于 ML 的任务,并且通常减少了部署 ML 模型的认知负担,但是它们仍然涉及大量的开销:在您可能有信心在实践中使用这些工具之前,您仍然需要花费相当多的时间来阅读文档和使用示例。事实上,一般来说,如果您想要大规模地部署模型,您将不得不花费大量的时间来学习相当多的技术,并且熟悉相当多的软件工程概念。即使有了这些新工具,也没有捷径可走。
虽然这都是事实,但当然总会有特例。在这些特殊情况下,你可以走一些捷径,帮助你以最小的开销快速地将一个 ML 模型投入生产。这就是这篇文章的内容:它将给出一个关于什么是特例的高层次概述;简要介绍无服务器计算的概念;然后介绍一个代码例子(带回购!)来部署一个特例 ML 模型作为 Google Cloud 函数,只需要几行代码。
特殊情况
有一种说法由来已久,经常被引用,但偶尔会被误用(被忽略?)DS、软件工程和其他领域的概念,从小、干净、简单开始,然后随着时间的推移增加复杂性。从 ML 模型的角度来看,这意味着从最简单的 ML 模型开始(即产生有用的商业价值),并从那里开始。例如,这可能意味着——如果给定的业务问题允许的话——在达到一个巨大的梯度提升树或深度神经网络之前,你可能想尝试玩一些简单的线性模型*。*
这些更复杂的建模方法自然对 DS/ML 领域的人有吸引力:它们在许多应用程序中显然非常强大。但是也有不利的一面。对一个人来说,解释可能很快变得困难。在某些情况下,对小数据集的不良概括也是一种真正的危险。从部署的角度来看,也存在一些潜在的问题。首先:提供这些功能的包和库通常很重。它们通常有很大的二进制文件(即占用大量磁盘空间),它们有很高的内存和 CPU(还有 GPU/TPU)需求,它们有时会有(相对)差的推理性能,并且通常有臃肿的图像(例如,如果使用 Docker 这样的技术)。
相比之下,简单的线性模型通常具有最小的依赖性(如果需要,还需要几十行纯 NumPy 代码来从头实现一个轻量级的线性模型),训练后几乎为零的资源需求,以及闪电般的推理性能。冒着听起来过时的风险:你可以用一堆设计良好的线性模型走很长的路。
冒着听起来过时的风险:你可以用一堆设计良好的线性模型走很长的路。
所有这些都是在说:如果你能用线性模型很好地解决一个商业问题,你最好至少从那里开始。如果你从那里开始(并且使用 Python——无服务器的限制,而不是部落的东西!),那你就是特例之一。恭喜你!将轻量级模型部署为无服务器功能可能会为您节省大量时间和痛苦,并且可能是您的用例的理想选择。
走向无服务器
在过去的几年里,无服务器计算的概念已经在软件工程领域得到了迅速发展。其基本思想是,通过在很大程度上消除工程师手动配置其服务器、负载平衡器、容器等的需求,云提供商可以在抽象出(隐藏)将应用部署到生产环境中的复杂性方面大有作为。在能够产生任何商业价值之前。
在某些方面,这类似于上面概述的一些数据科学家面临的问题:在稳定的服务中获得一个模型并最终产生商业价值通常需要大量的开销。无服务器计算旨在消除大部分这种开销:原则上,目标是让您,即开发人员,编写一个简单的函数,并立即以理论上无限可扩展和安全的方式将其部署到“生产”中。
…我们的目标是让开发人员编写一个简单的功能,并立即以理论上无限可扩展和安全的方式将其部署到“生产”中。
此外,无服务器计算明确旨在支持“事件驱动”应用。例如,如果您需要一个函数(模型)在每次云存储中的特定文件发生变化时运行,或者在每天的特定时间运行,或者在每次新客户注册您的服务时运行,您可以轻松地配置您的函数。你可以免费获得这种功能。听起来很酷,对吧?
除了这里的讨论之外,这篇文章不会涉及无服务器的基础知识。如果您想更深入地了解无服务器的工作方式,以及它的相对优势和劣势,那么您应该看看以前的一篇帖子:
这篇文章介绍了无服务器计算的一些基本概念,并帮助您将无服务器应用程序部署到 GCP。
medium.com](https://medium.com/@mark.l.douthwaite/a-brief-introduction-to-serverless-computing-e867eb71b54b)
现在举个例子!
编码时间到了
这个例子将向您展示如何构造和构建一个简单的 ML 管道,用于训练一个 Scikit-Learn 模型(在本例中是一个简单的LogisticRegression模型)来使用 UCI 心脏病数据集预测心脏病,然后将其部署为谷歌云功能。这不是数据分析的练习,所以不要期望对数据探索和建模决策进行太多的讨论!如果你想深入研究代码,可以这样做:
[## markdouthwaite/无服务器-scikit-learn-demo
一个提供演示代码的存储库,用于部署基于轻量级 Scikit-Learn 的 ML 管道心脏病建模…
github.com](https://github.com/markdouthwaite/serverless-scikit-learn-demo)
对于其他人,请继续阅读!
开始之前…
你需要注册一个谷歌云账户,并确保你已经阅读了上一篇介绍无服务器计算的文章。谷歌目前提供 300 美元的“免费”积分,这对于本教程和你自己的一些项目来说已经足够了。只是记得当你完成后禁用你的帐户!声明:这篇文章与谷歌没有任何关系——它只是一个慷慨的提议,对于那些想增长云服务知识的人来说可能很方便!
20 多种免费产品免费体验热门产品,包括计算引擎和云存储,最高可达…
cloud.google.com](https://cloud.google.com/free)
此外,您需要在系统上安装 Python 3.7,并访问 GitHub。如果你经常使用 Python 和 GitHub,应该没问题。如果没有,您可以检查您安装的 Python 版本:
python --version
如果你没有看到Python 3.7.x(其中x将是一些次要版本),你需要安装它。您可能会发现pyenv对此很有帮助。下面是用 pyenv 安装特定版本 Python 的指南。你可以通过 GitHub 的“Hello World”指南了解如何开始使用 GitHub。
克隆存储库
首先:您需要存储库。您可以通过以下方式克隆存储库:
git clone [https://github.com/markdouthwaite/serverless-scikit-learn-demo](https://github.com/markdouthwaite/serverless-scikit-learn-demo)
或者你可以直接从 GitHub 克隆这个库。
盒子里面是什么?
现在,导航到这个新克隆的目录。存储库提供了一个简单的框架,用于构建您的项目和代码,以便将其部署为云功能。有几个文件你应该熟悉一下:
- Python 捕捉项目依赖关系的古老(如果有缺陷的话)惯例。在这里,您可以找到运行云功能所需的软件包列表。Google 的服务会查找这个文件,并在运行您的功能之前自动安装其中列出的文件。
steps/train.py-这个脚本训练你的模型。它构建了一个 Scikit-Learn 管道,提供了一种简洁的“规范”方式将您的预处理和后处理绑定到您的模型,作为一个单独的可移植块。这使得将它部署为云功能(以及一般的 API)变得更加容易和干净。).当它完成训练后,它将对模型进行简单的评估,并将一些统计数据打印到终端。生成的模型将用 joblib 进行酸洗并作为pipeline.joblib保存在artifacts目录中。实际上,你可能会发现将这些文件保存在谷歌云存储中很有用,但现在将它们存储在本地也可以。main.py-这个模块包含你的“处理程序”。这是用户在部署服务时调用您的服务时将与之交互的内容。您可能会注意到init_predict_handler函数的结构有点奇怪。这是因为函数需要在第一次加载main模块时加载您的模型,并且您的函数需要维护一个对已加载模型的引用。当然,您也可以简单地将它加载到函数范围之外,但是所示的结构通过将模型的“可见性”仅限于函数本身,而不是您可能编写的访问该模块的任何其他代码,缓解了我的强迫症。app.py-该模块提供了一个最小的Flask应用程序设置,用于在本地(即在部署之前)测试您的云功能*。你可以用python app.py启动它,然后像平常一样调用它。*datasets/default.csv-本例的“默认”数据集。这是 CSV 格式的 UCI 心脏病数据集。resources/payload.json-一个示例负载,当它被部署时,你可以发送给 API。方便,嗯?notebooks/eda.ipynb-一个虚拟笔记本,用于说明在模型开发过程中您可能需要存储探索性数据分析(EDA)代码的位置。
如果你已经阅读了上一篇关于无服务器概念的文章,这种结构应该对你有所帮助。无论如何,现在是有趣的部分,实际运行代码。
训练模型
自然,要部署一个模型,您首先需要一个模型。为此,您需要使用train.py脚本。这个脚本使用 Fire 来帮助您从命令行配置输入、输出和模型参数。您可以使用以下命令运行该脚本:
python steps/train.py --path=datasets/default.csv --tag=_example --dump
这是在做什么?它告诉脚本从datasets/default.csv加载数据,用标签example标记输出模型,并将模型文件转储(写入)到目标位置(应该是artifacts/pipeline_example.joblib)。您应该会看到如下输出:
Training accuracy: 86.78% Validation accuracy: 88.52% ROC AUC score: 0.95
不是一款可怕的车型呃?全都来自老派的逻辑回归。现在是派对部分:部署模型。
部署模型
现在您已经有了模型,您可以部署它了。你需要安装谷歌云的命令行工具。您可以使用他们的指南为您的系统执行此操作。完成后,在项目目录内的终端中,您可以使用以下命令部署您的新模型:
gcloud functions deploy heart-disease --entry-point=predict_handler --runtime=python37 --allow-unauthenticated --project={project-id} --trigger-http
您需要用{project-id}替换您的项目 ID(您可以从您的 Google Cloud 控制台获得)。几分钟后,您的模型应该是活动的。您可以在以下网址查询您的新 API:
[https://{subdomain}.cloudfunctions.net/heart-disease](https://{subdomain}.cloudfunctions.net/heart-disease)
当您的模型被部署时,终端输出将给出您可以调用的特定 URL(替换您的{subdomain})。简单吧?您新部署的模型基本上可以无限扩展,这很好。
查询模型
最后,是时候做一些预测了。您可以发送:
curl --location --request POST 'https://{subdomain}.cloudfunctions.net/heart-disease' --header 'Content-Type: application/json' -d @resources/payload.json
您应该得到:
{"diagnosis":"heart-disease"}
作为回应。就这样,你有了一个活的 ML API。恭喜你!
要记住的事情
正如您所看到的,将您的 ML 模型部署为无服务器功能可能是获得一个稳定的、可伸缩的 ML API 的最快、最简单的途径。但一如既往,这是有代价的。以下是一些需要记住的事情:
- 无服务器功能(如 Google Cloud 功能)通常会受到资源(CPU、RAM)的限制,因此在无服务器功能中加载和使用“大”模型通常会有问题。
- 无服务器函数在高响应性时工作得最好(例如,在 ML 情况下推理时间非常快)。如果您的模型有点慢,或者依赖于其他慢的服务(例如,慢的 SQL 查询),这可能也不是最佳选择。
- 无服务器功能通常被设计用来处理大量的小请求。如果您的用例涉及大的、批量的查询,它们可能不是一个很好的选择——通常对请求有严格的超时限制。
- 一段时间未使用的无服务器功能会关闭。你一打电话给它们,它们就会转回来。当功能“预热”时,这会产生短暂的延迟。此外,例如,如果您正在使用 Python,Python 解释器众所周知的缓慢启动时间可能会成为问题
- 无服务器功能通常对常见的“基础设施”语言如 Node JS 和 Python 有一流的支持。如果你用的是 R,MATLAB,Julia 等。(包括通过
rpy2作为 Python 的依赖项)支持从不存在到很差不等。有种变通方法,但是这些方法通常会带来性能损失和复杂性增加(在某种程度上降低了“无服务器”概念的价值)。
原载于 2020 年 8 月 13 日https://mark . douthwaite . io。
无服务器:调整 Lambdas
调整 lambdas 以确保不可伸缩资源的高可伸缩性

图片由来自 Pixabay 的 Ryan McGuire 拍摄
无服务器编程很容易部署。无服务器的可伸缩性只受您指定的上限的限制(至少文档是这么说的)。然而,除非你做了正确的设计,否则整个系统可能会立刻失效。这是因为我们插入到 AWS 部署中的大部分外部资源不像 lambda 函数那样可伸缩。此外,您的设计应该基于您正在为无服务器环境编写程序的想法。
在这篇文章中,我将分享我在一个具有大并发性的大中型项目中工作时所面临的困难。我将使用节点。JS 作为编程环境。
基础知识
有几个事实你应该记住。
- 您永远不应该假设同一个实例将用于处理请求,尽管我们可能会利用这种可能性来提高性能。
- 没有用于数据序列化的永久存储。然而,您可以访问一个小的 /tmp 路径来在单个调用中进行序列化。因此,确保使用唯一的文件名以避免冲突,并在同一次调用中完成。
- 不应对服务请求的顺序做出任何假设。
- 根据 CPU 小时数(和 RAM)收取使用费。所以要确保你的代码运行得很快,没有太多的颠簸。
处理瓶颈资源
几乎在所有场景中,web 应用程序都希望连接到数据库并读取/写入数据。然而,数据库的并发连接数是有限的,可以通过 lambda 函数的并发级别轻松通过。此外,您可以拥有多个独立的函数,这些函数都有数据库连接。例如,如果几乎同时调用 10 个函数,那么最少需要 10 个连接。然而,在高峰场景中,这很容易被乘以一个大到足以使数据库达到极限的因子。
降低可扩展性
大多数情况下,您不会达到希望有 1000 个并发调用的程度。您可以从 AWS 控制台或在 serverless.yml 中更改此设置。(看看我的无服务器样板文章,了解更多关于组织无服务器项目的信息)。
functions:
hello:
handler: handler.hello
events:
- http:
path: /hello
method: get
provisionedConcurrency: 5
reservedConcurrency: 5
保留的并发性将确保函数总是可以伸缩那么多倍,而提供的并发性决定最初将有多少实例是活动的。这确保了扩展时间不会增加服务延迟。在一个示例场景中,您可能希望在主页上设置多一点的并发性,而在用户管理服务上设置很少的并发性,因为它们不能应对高需求。
缓存数据并避免数据库连接
在某些情况下,不要求数据一致。例如,博客网站可能不希望总是从数据库中获取数据。用户可能很乐意阅读一些陈旧的数据,但他们永远不会注意到。看看下面的函数。
exports.main = (event, context, callback) => {
// connect to database, send data in callback(null, data);
}
这将始终与数据库通信。然而,可以这样做。
// cache data in a variable and close DB
exports.main = (event, context, callback) => {
// send data if event.queryParameters are same
// else: fetch data and send over
}
通过这种修改,很可能不再从数据库中一次又一次地寻找冗余数据。甚至可以使用时间戳来检查数据是否太陈旧。通过使用一个 chron 作业调用函数,可以有更多的技巧来保持函数的热度。如果负载分布随时间不均匀,则不应这样做。
保持功能温暖
这是 AWS 自己提出的一个著名的保持功能温暖的建议。我们可以简单地通过回调发送数据来做到这一点,而不必完成事件循环。
exports.main = (event, context, callback) => {
context.callbackWaitsForEmptyEventLoop = false;
}
可以在上下文对象中将callbackWaitsForEmptyEventLoop设置为假。这有助于维护数据库连接,同时在关闭数据库连接之前处理请求。这类似于在全局变量中缓存数据,但在这里,我们缓存整个连接。确保检查连接是否处于活动状态,因为它可能会被数据库服务本身中断。
在这种方法中,有可能超出数据库连接限制。但是这可能是一个方便的技巧,因为建立数据库连接本身可能会增加一些延迟。
处理 CPU 密集型任务
CPU 密集型任务主要是矩阵计算。然而,我们可以把 水印 图像看作是这样一个任务。让我们看看下面的例子。
const Jimp = require('jimp');create_watermarks = async (key) => {
// get the images from s3
const s3Obj = await s3.getObject(params).promise();
// read watermark image
// for each image from s3
watermarkImage = await Jimp.read(__dirname + '/wm.png');
const img = await Jimp.read(s3Obj.Body);
// add watermark
}
在这个函数中,我们多次读取图像。但是,添加以下内容可以节省大量时间,加快一切。
const img = await Jimp.read(watermark);
watermarkImage = await Jimp.read(__dirname + '/wm.png');
// for each image from s3
const watermarkCopy = watermarkImage.clone();
// add watermakr
这可以通过在全局变量中缓存已经读取的水印图像来进一步优化。
const Jimp = require('jimp');
watermarkCache = null;create_watermarks = async (key) => {
if watermarkCache==null <- read and set variable
// copy watermark and add to each image
}
管理函数内部的并发性
节点。JS 有事件循环架构。在这种情况下,所有项目都在单个线程中调度和运行。这就是为什么我们在节点没有观察到任何竞争情况。JS 并发。事件循环不断轮询异步任务以获得结果。所以有太多的并发任务会使事件循环更长。此外,如果并发任务使用衍生的进程,系统可能会被不必要的颠簸淹没。
add_watermark (img, wm) => {add watermark, return new image}
现在,如果你用下面的函数从 S3 和水印中加载 100 个潜在的图像键,会发生什么?
s3keys_list = [...100 keys...]
await Promise.all(map(add_watermark, s3keys_list))
事件循环将发出 100 个并发的 S3 对象请求。这可能会使您超过内存限制,甚至可能会在 S3 或其他地方产生并发费用。我们如何解决这个问题?一个简单的解决方案如下。
s3keys_list = [...100 keys...]
tmp_list = []
for(x = 0; x < s3keys_list.length; x++)
{
// s3keys_list[x] to tmp_list
// if tmp_list.length == 5
// await Promise.all(map(add_watermark, tmp_list))
tmp_list = []
{
// process any remaining items in tmp_list the same way
使用这种方法,可以保证有特定的并发性。你不会有一大群超过 RAM 的克隆水印。
除了我讨论的上述技巧之外,我们还可以根据领域和应用程序的知识使用许多其他的优化。此外,我们可以简单地观察日志,并使用它们来进一步调整并发性需求。有时,以牺牲并发性为代价增加一点内存甚至是值得的。这是因为很多人很少使用站点维护端点。
我希望你喜欢阅读这篇文章。这些是我们在开发有许多用户的平台时使用的一些技巧。这有助于我们应对大范围促销活动期间的一次性高需求,在该活动中,许多用户进行了注册。
通过 REST API 服务于机器学习模型
利用 Flask 服务于机器学习模型

照片由 Lefteris kallergis 在 Unsplash 拍摄
对于那些不熟悉我的作品的人,在过去一篇题为“ 使用机器学习检测欺诈 ”的帖子中,我们开始制造我们机器学习包的第一部分。
现在,包装完成了,但是我们下一步做什么呢?我们如何将它集成到我们需要使用它的任何地方——Github 上的包存储库。
此时您不能执行该操作。您已使用另一个标签页或窗口登录。您已在另一个选项卡中注销,或者…
github.com](https://github.com/kurtispykes/credit-card-fraud-detection/tree/master/packages/random_forest_model)
在此向大家介绍一下 REST API。
注意:这个项目很大程度上受到 Udemy 上的“部署机器学习模型”课程的启发,因此会有来自那个项目的源代码片段。
什么是 REST API?
API 是 A 应用 P 编程 I 接口的缩写。从本质上讲,它是一个软件中介,允许两个应用程序相互对话。如果你不熟悉 API,那么你就不会知道你很可能每天都在使用它。不相信我?你上一次发即时短信是什么时候?你当时用的是 API。
REST 缩写代表REpresentationSstateTtransfer,它决定了 API 的外观。像任何其他的架构风格一样,REST 有它自己的指导约束,如果一个接口被称为 RESTful,那么应该满足这些约束——关于 REST 的更多信息,请参见“ 什么是 REST ”。
简单地说,REST API 将被请求资源的状态传输给客户机。在我们的例子中,请求的资源将是来自我们的机器学习模型的预测。因此,我们的服务器将把预测传递给客户端,客户端可能是从 web 应用程序到移动设备的任何东西。
为什么要使用 REST API?
这样设计我们的系统有很多好处。例如,通过 REST API 服务我们的模型也允许我们这样做;
- 即时提供预测以增加客户数量
- 可能在不同的 API 端点组合多个模型
- 通过在负载平衡器后添加更多应用程序实例来进行扩展
- 将我们的模型环境从面向客户的层中分离出来——团队可以独立工作
烧瓶介绍
为了构建我们的 API,我们将利用 Flask 微框架。由于各种原因,例如极其强大、易于使用和非常好的文档,Flask 是 Python 中微服务的流行选择——参见文档。
“微型”并不意味着您的整个 web 应用程序必须适合一个 Python 文件(尽管它确实可以),也不意味着 Flask 缺乏功能。微框架中的“微”意味着 Flask 旨在保持核心简单但可扩展。

来源 : 烧瓶文件
我们的 REST API
基本结构
让我们先来看看我们的目录结构…

图 1: 回购目录结构
最顶层的目录是ml_api,在这个目录中有requirements.txt和run.py。requirements.txt就是我们在虚拟环境中需要的产品包。

图 2:requirements . txt 的内容—我们正在安装 flask 版本 1.1.2 和我们做了包的 random _ forest _ model 因此,我们将能够执行导入语句来调用包。
因此,我们开始用pip install -r path\to\requirements.txt将requirements.txt文件安装到我们的虚拟环境中,这将安装flask并找到我们的random_forest_model包的发行版。
run.py文件是一个入口点,我们将使用在app.py模块中定义的create_app()函数来启动 flask。
图 3 :启动砂箱的入口点。
让我们看看app.py模块。从图 1 我们可以看到,我们可以通过api子目录导航到该文件。
图 4
在app.py中,我们有自己的工厂函数,它创建了我们的 flask API 并设置了蓝图,蓝图创建了一个位于controller.py中的端点。
图 5
控制器是一个简单的健康端点,在 HTTP GET 请求期间出现,它返回“工作正常”。
在我们启动这个实例之前,在命令提示符下设置 flask 应用程序的入口点是很重要的。在命令提示符下导航到我们的ml_api目录,然后简单地输入set FLASK_APP=run.py就可以了。当我们完成后,我们只需输入python run.py,结果如下…

图 6 :终点
太好了,我们的终点也如我们所希望的那样工作了。现在我们有了基本的框架,我们可以添加一些更复杂的东西。
注意:添加配置和日志超出了本文的范围,但是在更新的存储库中,你会看到它们存在。因此,下一节将讨论添加预测端点。
下一步是在controller.py中为我们的健康端点添加一个推理端点
图 7 :追加预测终点
我们已经从我们的random_forest_model包中调用了predict函数来从我们的模型中获取结果。任何软件工程项目的一个非常重要的部分是测试,所以让我们测试我们的端点,看看它是否如我们所期望的那样工作。
图 8 :测试我们的预测终点是否按预期工作
PyTest 超出了本文的范围,但是为了运行我们的测试,我们必须运行pytest path\to\test_dir,这将运行我们的测试目录中的所有测试——如果我们通过了测试,那么我们的预测端点是健康的并且正在运行。

图 9 :端点通过测试!
现在你知道了!
谢谢你看完,我们在 LinkedIn 上连线吧…
[## Kurtis Pykes -人工智能作家-走向数据科学| LinkedIn
在世界上最大的职业社区 LinkedIn 上查看 Kurtis Pykes 的个人资料。Kurtis 有一个工作列在他们的…
www.linkedin.com](https://www.linkedin.com/in/kurtispykes/)
将深度学习算法作为服务运行
现实世界中的 DS
如何将深度学习算法作为服务
所以,你想把深度学习算法作为服务来服务。

马里乌斯·马萨拉尔在 Unsplash 上的照片
你有一个用 Python 和 tensor flow/Keras/一些其他平台编写的非常酷的算法库,它需要在 GPU 上运行工作负载,你希望能够大规模地服务它,并让它快速运行。
芹菜是基于分布式消息传递的开源异步任务队列。在阅读了所有可能的博客帖子和 Youtube 上所有关于芹菜的视频后,我决定这是手头任务的正确解决方案。
有请我们的剧情主角:
- API :获取一个请求,创建一个 Celery 异步任务,并将其放入一个队列中。(我推荐使用 flask 来完成这项任务,它很轻,但是可以扩展)
- 消息队列:又名芹菜的经纪人。将 API 创建的任务存储在队列中。最好的做法是选择 RabbitMQ。
- Workers :我们将在 GPU 上运行的 python/celery 进程,它将从队列中获取任务。这是完成所有繁重工作的地方。
- 结果的后端:将存储任务返回值。最佳实践是使用 redis,它支持复杂的工作流(一个任务依赖于另一个任务)而无需轮询。
最佳实践是使用 Celery,用 RabbitMQ 作为消息的代理,用 redis 作为结果的后端,以便使用 Celery 能够提供的所有独特特性。我们知道软件需求的变化经常比我们预期的要快,这应该给我们提供最大的灵活性,这样我们甚至可以使用芹菜最复杂的特性。当选择 RabbitMQ 和 redis 时,每个新任务都被转换成一条消息,然后 Celery 将这条消息发送到 RabbitMQ 中的一个队列,一个工人执行的任务的每个返回值都会自动写回 redis(您可以使用" click to deploy "在 GCP 上轻松托管 RabbitMQ,使用 AWS Elastic Cache 托管 redis)。
一旦表示任务的消息在队列中,我们需要一个 GPU 工作器来计算它。GPU 工作器将从队列中读取一条消息并执行任务。例如,如果这是一个计算机视觉算法,一名工作人员将从 S3 自动气象站下载原始图像,对其进行处理,然后将新图像上传回 S3。图像的 URL 将作为任务的一部分被传递。
但是等等,有个问题。
总有一个陷阱。
GPU 是非常昂贵的机器。P2 的一个例子。AWS 中的 Xlarge 每月花费超过 2,000 美元(在写这几行的时候, 3.06 美元一小时),如果是 spot 实例,大约 600 美元。这显然意味着,如果没有必要,我们不希望它们一直处于运行状态。它们必须按需开启,然后关闭。事实是,Elastic Beanstalk 没有根据 RabbitMQ 队列指标自动伸缩的特性。
我们该怎么办?
我们必须编写自己的自定义自动缩放器。这是一个小 Python 脚本的大名,它每 30 秒运行并轮询 RabbitMQ 队列中的任务数。如果队列中有消息,它会调用 AWS API 并相应地启动 GPU workers。
每个工人都是用算法库的 docker 容器引导的(存储在 ECR,弹性容器注册表中)。一旦容器启动并运行,它就连接到 RabbitMQ 和 redis。然后,它从队列中取出一个任务并计算它。输出由工人写给 S3。如果任务成功完成,那么芹菜任务的返回值是一个 json,包含保存到 S3 的输出的 URL 及其元数据。Celery 会自动将返回值保存到 redis 中,也会保存到 Postgres DB 中。如果任务未能完成,异常将保存到 redis。
查看下图,了解上面解释的架构:

Nir Orman 将深度学习算法作为服务运行
听起来很轻松?使用芹菜的一个主要挑战是如何正确配置它。
这里有一个很好的配置,当你试图大规模执行深度学习任务时,它可以节省你的时间和眼泪。请查看以下内容,然后我们将深入了解它的每个细节:
from celery import Celery
from api.celery_jobs_app.celery_config import BROKER_URI, BACKEND_URI
APP = Celery(
'celery_app',
broker=BROKER_URI,
backend=BACKEND_URI,
include=['api.celery_jobs_app.tasks']
)
APP.conf.update({
'imports': (
'api.celery_jobs_app.tasks.tasks'
),
'task_routes': {
'calculate-image-task': {'queue': 'images-queue'}
}
},
'task_serializer': 'json',
'result_serializer': 'json',
'accept_content': ['json'],
'worker_prefetch_multiplier': 1,
'task_acks_late': True,
'task_track_started': True,
'result_expires': 604800, # one week
'task_reject_on_worker_lost': True,
'task_queue_max_priority': 10
})
注:为了更容易理解,对配置进行了简化。
我们来分解一下。
打破它!
片段中的第一段只是一些导入,微不足道。
第二段定义了芹菜 app 本身,它有一个代理和后端(如前所述,最佳实践是使用 RabbitMQ 和 redis)。
第三段更新了芹菜的配置,这是有趣的部分。
“导入”部分说明了芹菜应该在我们的哪个 python 包中寻找任务。
’ tasks_routes '部分在任务名称和它应该被存储的队列之间进行映射。在上面的代码片段中,所有类型为“计算-图像-任务”的任务将被推入一个名为“图像-队列”的队列中。如果你不写你的任务应该被路由到哪个队列,它将默认地被路由到名为‘celery’的默认队列。顺便说一句,如果你愿意,可以通过定义“task_default_queue”属性来更改默认队列的名称。
仅供参考:一旦第一个任务被路由到 RabbitMQ 上,队列本身就会自动创建。酷:)
酷毙了。
task _ serializer’:这是任务一旦被放入队列后将被序列化的方式,也是任务到达工作线程后被反序列化的方式。在图像处理的情况下,我们不希望图像本身被序列化和反序列化,最佳实践是存储它并只传递它的位置或 URL。我们将使用 json 作为序列化器。
result _ serializer**’😗*请记住,如果您将序列化类型声明为 json 并返回一个对象或异常的结果(这是在出现未被捕获的异常的情况下的返回类型),那么您的结果序列化将会抛出一个异常,因为任何不是 json 的对象都会抛出一个未能序列化的异常。你可以在这里阅读更多关于连载器的内容。
'accept _ content**'😗*允许的内容类型/序列化程序的白名单。
提示:不推荐使用‘pickle’序列化器,因为它存在安全问题。从芹菜 4.0 版开始,json 其实就是序列化的默认选项,但是“显式比隐式好”(Python 的禅宗)。

Python 的禅
worker _ prefetch _ multiplier’:Celery 的缺省值是每个 worker 接受 4 个任务,并在返回进行下一个任务之前计算完所有任务。他们的想法是优化网络往返。在我们的情况下,深度学习任务往往很长(比网络时间长得多)。这意味着我们不希望一个工人拿着一堆任务,一个接一个地执行它们。我们希望每个工人一次接受一个单任务,然后在前一个任务完成后回来接受下一个任务。这样,如果一个任务需要很长的计算时间,其他工作人员可以同时处理下一个任务,因为只要第一个工作人员没有处理它们,它们就会被保留在队列中。
'task _ acks _ late**'😗*默认情况下,当工人接受一个任务时,该任务会在 执行前 被“确认”。在深度学习任务的情况下,这需要很长时间来计算,我们希望它们只在计算完 之后 被“确认”。这在我们使用 spot 实例时特别有用,它降低了我们的平均任务价格,但如果 GPU 实例短缺,并且我们的投标价格不够有竞争力,也可能会失去它。
task _ track _ started’:有助于跟踪任务已经开始,因为当您的任务长时间运行时,您希望知道它不再在队列中(它将被标记为“pending”)。)我推荐使用 Flower 作为芹菜的监控解决方案,它可以让你确切地看到每个任务的状态。
result _ expires’:默认情况下,芹菜在 redis 上只保留你的结果 1 天。如果您希望保留更长时间,请在配置文件中以不同方式定义“result_expires”。我建议最多保留 1 周,并将结果写入一个更有组织的数据库,比如 PostgreSQL。
【task _ reject _ on _ worker _ lost’:我们将此设置为 True。当我们使用 spot 实例时,当一个 spot 实例从我们身边拿走时,有可能会丢失一个工人。我们希望将任务放回队列中,由另一个工作者来计算。小心,如果一个工人丢失是由于硬件错误,如“内存不足”等。,那么任务将在一个循环中一次又一次地被部分计算,因为工作者将在每次试图计算它时丢失。如果您看到一个无限循环的任务,这就是您应该怀疑的配置。
task _ queue _ max _ priority’:这是你可以确保重要任务先完成的地方。您可以为每个 Celery 任务设置一个优先级(通过给它分配一个表示其优先级的 int)。如果设置该属性,还必须将其设置到 RabbitMQ 队列中,它不会自动设置。如果具有优先级的任务进入没有 priority 属性的队列,将会引发异常,并且该任务不会进入队列。如果您有一个任务应该首先计算的高级客户,则此属性很有用。
如果您正在考虑使用该属性,以便将快速运行的任务优先于慢速任务(例如长 GPU 计算任务),那么可以考虑添加另一组工作人员,即 CPU 工作人员,而不是昂贵的 GPU 工作人员。这会更便宜也更快。
正如您在顶部的架构图中看到的,您也可以让工作人员在完全不同的云上运行。
完全不同的云
例如,您可以在 Azure AKS 上运行您的员工,这是 Azure 的 Kubernetes。但那是一篇完全不同的博文。
祝你用芹菜服务你的深度学习算法好运,如果你有任何问题,请随时在 LinkedIn 上联系我。
如何使用 gRPC API 服务一个深度学习模型?
理解什么是 gRPC 以及如何使用 gRPC API 服务深度学习模型的快速简单指南。
在本帖中,你将学习什么是 gRPC,它是如何工作的,gRPC 的好处,gRPC 和 REST API 的区别,最后用 Tensorflow Serving 实现 gRPC API 来服务生产中的一个模型?
gRPC 是 Google 开发的远程过程调用平台。
GRPC 是一个现代的开源、高性能、低延迟和高速吞吐量的 RPC 框架,它使用 HTTP/2 作为传输协议,使用协议缓冲区作为接口定义语言(IDL)以及它的底层消息交换格式
gRPC 是如何工作的?

灵感来源:https://www.grpc.io/docs/what-is-grpc/introduction/
创建了一个 gRPC 通道,该通道在指定的端口上提供到 gRPC 服务器的连接。客户端调用存根上的方法,就好像它是本地对象一样;服务器被通知客户端 gRPC 请求。gRPC 使用 协议缓冲区在客户端和服务器之间交换消息。协议缓冲区是一种以高效、可扩展的格式对结构化数据进行编码的方式。
一旦服务器接收到客户端的请求,它就执行该方法,并将客户端的响应连同状态代码和可选元数据一起发回。gRPC 允许客户端指定等待时间,以允许服务器在 RPC 调用终止之前做出响应。
使用 gRPC 有什么好处?
- gRPC 使用二进制有效负载,这对于创建和解析是有效的,因此是轻量级的。
- 双向流在 gRPC 中是可能的,但在 REST API 中却不是这样
- gRPC API 建立在 HTTP/2 之上,支持传统的请求和响应流以及双向流
- 消息传输速度比 REST API 快 10 倍,因为 gRPC 使用序列化协议缓冲区和 HTTP/2
- 客户机和服务器之间的松散耦合使得修改变得容易
- gRPC 允许集成用不同语言编程的 API
gRPC 和 REST API 有什么区别?
- 有效载荷格式 : REST 使用 JSON 在客户端和服务器之间交换消息,而 gRPC 使用协议缓冲区。协议缓冲区比 JSON 压缩得更好,从而使 gRPC 更有效地通过网络传输数据。
- 传输协议 : REST 大量使用 HTTP 1.1 协议,这是文本的,而 gRPC 是建立在新的 HTTP/2 二进制协议之上的,这种协议通过高效的解析来压缩报头,并且安全得多。
- 流与请求-响应 : REST 支持 HTTP1.1 中可用的请求-响应模型。 gRPC 使用 HTTP/2 中可用的双向流功能,其中客户端和服务器使用读写流相互发送一系列消息。
深度学习模型如何用 Python 实现 gRPC AI?
使用 TF 服务为深度学习模型创建 gRPC API 的步骤
- 创建从客户端到服务器的请求负载作为协议缓冲区(。原型)文件。客户端通过存根调用 API。
- 运行 docker 映像,公开端口 8500 以接受 gRPC 请求并将响应发送回客户端
- 运行服务器和客户端。
实现 gRPC API
要使用 Tensorflow 服务实现 REST API,请关注这个博客。
对于 Windows 10,我们将使用 TensorFlow 服务图像。
第一步:安装 Docker App
步骤 2:提取 TensorFlow 服务图像
**docker pull tensorflow/serving**
一旦你有了张量流服务图像
- 为 gRPC 显示端口 8500
- 可选环境变量
**MODEL_NAME**(默认为model) - 可选环境变量
**MODEL_BASE_PATH**(默认为/models)
步骤 3:创建并训练模型
这里,我从张量流数据集中提取了 MNIST 数据集
#Importing required libraries
**import os
import json
import tempfile
import requests
import numpy as np
import tensorflow as tf
import tensorflow_datasets as tfds**#Loading MNIST train and test dataset
#as_supervised=True, will return tuple instead of a dictionary for image and label
**(ds_train, ds_test), ds_info = tfds.load("mnist", split=['train','test'], with_info=True, as_supervised=True)**#to select the 'image' and 'label' using indexing coverting train and test dataset to a numpy array
**array = np.vstack(tfds.as_numpy(ds_train))
X_train = np.array(list(map(lambda x: x[0], array)))
y_train = np.array(list(map(lambda x: x[1], array)))
X_test = np.array(list(map(lambda x: x[0], array)))
y_test = np.array(list(map(lambda x: x[1], array)))**#setting batch_size and epochs
**epoch=10
batch_size=128**#Creating input data pipeline for train and test dataset
# Function to normalize the images**def normalize_image(image, label):
#Normalizes images from uint8` to float32
return tf.cast(image, tf.float32) / 255., label**# Input data pipeline for test dataset
#Normalize the image using map function then cache and shuffle the #train dataset
# Create a batch of the training dataset and then prefecth for #overlapiing image preprocessing(producer) and model execution work #(consumer)**ds_train = ds_train.map(
normalize_img, num_parallel_calls=tf.data.experimental.AUTOTUNE)
ds_train = ds_train.cache()
ds_train = ds_train.shuffle(ds_info.splits['train'].num_examples)
ds_train = ds_train.batch(batch_size)
ds_train = ds_train.prefetch(tf.data.experimental.AUTOTUNE)**# Input data pipeline for test dataset (No need to shuffle the test #dataset)
**ds_test = ds_test.map(
normalize_image, num_parallel_calls=tf.data.experimental.AUTOTUNE)
ds_test = ds_test.batch(batch_size)
ds_test = ds_test.cache()
ds_test = ds_test.prefetch(tf.data.experimental.AUTOTUNE)**# Build the model
**model = tf.keras.models.Sequential([
tf.keras.layers.Flatten(input_shape=(28, 28, 1)),
tf.keras.layers.Dense(128,activation='relu'),
tf.keras.layers.Dense(196, activation='softmax')
])**#Compile the model
**model.compile(
loss='sparse_categorical_crossentropy',
optimizer=tf.keras.optimizers.Adam(0.001),
metrics=['accuracy'],)**#Fit the model
**model.fit(
ds_train,
epochs=epoch,
validation_data=ds_test,
verbose=2)**
步骤 4:保存模型
通过将 save_format 指定为“tf”将模型保存到协议缓冲文件中。
**MODEL_DIR='tf_model'
version = "1"
export_path = os.path.join(MODEL_DIR, str(version))**#Save the model
**model.save(export_path, save_format="tf")
print('\nexport_path = {}'.format(export_path))
!dir {export_path}**
您可以使用saved _ model _ CLI命令检查模型。
**!saved_model_cli show --dir {export_path} --all**

对输入和输出及其数据类型和大小进行建模
步骤 5:使用 gRPC 服务模型
为 gRPC 实施导入库
**import grpc
from tensorflow_serving.apis import predict_pb2
from tensorflow_serving.apis import prediction_service_pb2_grpc
from tensorboard.compat.proto import types_pb2**
使用 gRCP 端口 8500 在客户端和服务器之间建立通道。为客户机创建客户机存根,以便与服务器通信
**channel = grpc.insecure_channel('127.0.0.1:8500')**
**stub = prediction_service_pb2_grpc.PredictionServiceStub(channel)**
通过指定模型名称和模型输入、数据类型以及数据大小和形状,为服务器创建请求负载作为协议缓冲区。
**request = predict_pb2.PredictRequest()
request.model_spec.name = 'mnist'
request.inputs['flatten_input'].CopyFrom(tf.make_tensor_proto(X_test[0],dtype=types_pb2.DT_FLOAT, shape=[28,28,1]))**
如果数据类型和数据大小与模型输入不匹配,您将得到错误“输入大小与签名不匹配”。
要解决此错误,请检查模型输入数据的类型和大小,并将其与发送给 gRPC 的请求进行匹配。
运行 docker 镜像,展示端口 8500 以接受 gRPC 请求
**docker run -p 8500:8500 --mount type=bind,source=C:\TF_serving\tf_model,target=/models/mnist/ -e MODEL_NAME=mnist -t tensorflow/serving**
源应该是绝对路径。
服务器现在准备好接受客户端请求
为了预测请求的结果,从存根调用 predict 方法
**result=stub.Predict(request, 10.0)
result**

来自 gRPC 服务器的结果响应
**res=np.argmax(result.outputs['dense_1'].float_val)
print(" predicted output :", res)**

使用 matplotlib 显示输入图像
**import matplotlib.pyplot as plt
%matplotlib inline
img = X_test[0].reshape(28,28)
plt.title(res)
plt.imshow(img, cmap="gray")**

结论:
gRPC 是 Google 新的远程过程调用 API,比 REST API 快大约 10 倍。gRPC 建立在 HTTP/2 之上,它使用协议缓冲区在客户机和服务器之间高效地交换双向消息。
参考资料:
【https://grpc.io/docs/what-is-grpc/core-concepts/
使用 tensor flow Serving-TF 2 . x 部署 Keras 模型
如何使用 TensorFlow Serving 和 Docker 在本地主机上部署自己的 Keras 模型

张量流— 2.1.0
概观
创造了一个很棒的深度学习模型?恭喜你!
不知道如何使用 Keras 创建深度学习模型?别担心!
我将介绍如何创建一个基本的和超级简单的 Keras 模型,以及如何在您的本地机器上部署它。这个模型肯定比您计划部署的任何模型都要简单(嗯,我希望如此!).但是由于这篇文章的目标是使您能够部署您的 Keras 模型,所以我想确保我们不会偏离我们的目标。
现在,我们为什么需要在本地服务器上部署它呢?验证我们用模型想要解决的任何问题都可以在现实世界中得到解决。您会期望您的模型以相同的方式工作,并在真实世界的数据上提供与您在本地 IDE 或笔记本上的测试输入相同的性能。但事实是,它很难做到这一点。如果是的话,太好了!但是,在您部署了供消费的模型之后,您不会希望意识到您的测试数据和真实世界数据之间的差距。
如果真实世界的图像不同于您用来训练、验证和测试模型的白色背景工作室图像,该怎么办?如果由于延迟问题,在网络调用中处理数据的时间比在 IDE 中长,该怎么办?尽早发现这些问题是将你的模型从舒适的笔记本电脑成功过渡到现实世界的关键。
张量流服务
TensorFlow 提供的是什么?
TensorFlow Serving 是一个面向机器学习模型的灵活、高性能的服务系统,专为生产环境而设计。TensorFlow 服务可以轻松部署新的算法和实验,同时保持相同的服务器架构和 API。TensorFlow 服务提供了与 TensorFlow 模型的现成集成,但可以轻松扩展为服务于其他类型的模型和数据。
为什么 TensorFlow 服务?
如果您习惯于使用 TensorFlow 或 Keras 构建模型,那么部署模型最简单的方法就是使用 TensorFlow 服务器。
大多数 TensorFlow 文档是为 TensorFlow-1.0 编写的,遗憾的是,它不能像 TensorFlow-2.0 那样工作。因此需要这个博客。
构建一个超级简单的 Keras 模型
[如果您已经以 SavedModel 格式准备好了模型,请跳过这一部分。]
在这里,我将创建一个预测线性关系的模型:
y = 2x + 1
我使用了 Google Colab,但是你可以使用你选择的任何工具,只要生成的模型保持不变。
让我们开始吃吧。
我们首先加载必要的库
然后我们创建数据集
然后我们建立我们的模型。既然是简单的线性关系,单个神经元就够了。
我们现在为我们的模型训练 20 个纪元。经过 20 个时期后,我们的模型在训练和验证时的损失约为 2e-12。然后,我们在测试数据上评估我们的模型。我们的测试损失大约是 2e-12。你可以尝试预测一些值来验证结果,就像我在这里做的那样。我收到的输出是 15.866。
一切看起来都很棒。现在让我们以 SavedModel 格式保存并下载我们的模型。
从这一步开始,该过程将独立于所使用的输入和输出数据的类型。它可以是数字数组、文本、图像、音频或视频。在 Colab 中,您应该能够看到在您的目录中创建了一个名为“linear_model”的文件夹。这里的“export_path”变量表示我们的模型被命名为“linear_model ”,这是它的第一个版本。使用 TensorFlow 服务进行部署时,必须有版本号,因此请确保您的“export_path”采用{MODEL}/{VERSION}的形式,其中版本是不带任何字母或特殊字符的数字。
现在要下载这个模型,我们将压缩这个文件夹,然后使用“google.colab.files”来下载压缩文件。
一旦您在本地机器上解压缩这个 zip 文件,您应该能够看到一个名为’ linear_model ‘的文件夹,其中包含一个名为’ 1 '的文件夹,该文件夹包含您的变量和模型架构。
设置您的机器
这是一次性设置活动。
要启动本地服务器,我们需要在本地机器上安装一个 TensorFlow 服务实例。我们将使用推荐的 Docker 使用方式,而不是下载并安装所有必要的库。
你可以在指南这里阅读更多细节。
我们不会遵循指南中提到的所有步骤,因为有些事情是特定于 TF 1.0 的,有些事情是特定于重用已经可用的模型的。
一旦你从这里下载 Docker 到你的系统上,继续完成安装步骤。您需要重新启动系统,以便保存您的所有工作。
安装成功完成后,进入命令提示符(Mac 和 Linux 用户,请使用适当的工具)并键入
docker pull tensorflow/serving
就是这样!现在让我们开始部署我们的模型。
在本地主机上部署 Keras 模型
如果我告诉您,部署模型只是一行命令脚本,会怎么样呢?
你所需要的是到你的“线性模型”文件夹的绝对路径。不要忘记使用绝对路径,因为这将导致错误,你需要花时间和打破你的头来解决。
我的“线性模型”保存在“D:/my_own_models/”中。所以我的命令看起来像:
docker run -p 8038:8501 — mount type=bind,source=D:/my_own_models/linear_model,target=/models/linear_model -e MODEL_NAME=linear_model -t tensorflow/serving
这都是一条线。对于您的后续模型,您只需要更改您的“源”路径。更改您的“目标”和 MODEL_NAME 是可选的,但是,根据上下文,这当然是必要的。
现在,让我们试着理解上面的命令脚本意味着什么。这个脚本的一般形式是
docker run -p {LOCAL_PORT}:8501 — mount type=bind,source={ABSOLUTE_PATH},target=/models/{MODEL_NAME} -e MODEL_NAME={MODEL_NAME} -t tensorflow/serving
{LOCAL_PORT}:这是您机器的本地端口,所以请确保您没有在那里运行任何其他程序。我们将它映射到 TensorFlow Serving 为 REST API 调用公开的 8501 端口
{绝对路径}:这是模型的绝对路径。这告诉 TensorFlow 服务你的模型位于哪里(很明显)。
{MODEL_NAME}:这是带有前缀“/models/”的 REST API 调用的服务端点。不要更改目标变量中的“/models/”前缀,只根据您的需要更改{MODEL_NAME}部分
当您在命令窗口中看到以下消息时,您的模型已成功托管。您还可以在 Docker 仪表板中看到一个成功运行的容器。
[evhttp_server.cc : 238] NET_LOG: Entering the event loop …
测试我们的模型
我使用 Postman 来测试我的查询,但是您可以使用任何形式的 API 调用。
[注意:您将无法从浏览器或任何其他主机直接调用您的 REST API,因为 TensorFlow 服务不支持 CORS。然而,有一些方法可以实现从浏览器到您的模型的调用,我将在另一篇文章中介绍。]
您需要一个 POST 查询来测试我们的模型。我们的请求 URL 看起来像:
[http://localhost:8509/v1/models/linear_model:predict](http://localhost:8509/v1/models/linear_model:predict)
同样,一般形式是:
[http://localhost:{LOCAL_PORT}}/v1/models/{MODEL_NAME}:predict](http://localhost:{LOCAL_PORT}}/v1/models/{MODEL_NAME}:predict)
在标题中添加“内容类型”作为“应用程序/json ”,在正文中添加:
{
"instances": [[
0
]]
}
请确保您的 JSON 键是“instances ”,并且您的值在一个数组中。因为我们的输入是[0],所以我们把它写成[[0]]。
请记住,我们创建了一个模型来预测 y = 2x + 1 ,这意味着对于输入值 0,我们的预测值应该为 1(或接近 1)。
让我们发送我们的查询。响应看起来像:
{
"predictions": [[
0.999998748
]]
}
对我来说这看起来很像 1。通过进行 POST 查询来摆弄您的模型。
结论
我们能够从头开始创建一个模型,并将其部署在本地服务器上。这是一个很好的方法,可以看看您的模型在真实世界中的工作方式是否和在您的 IDE 中一样。
然而,正如我前面提到的,除了 Postman(或类似的工具),您将无法调用这个模型。如何克服这一点?我将在另一篇文章中讨论这个问题,因为这篇文章已经太长了。
如果您已经到达这里,感谢您的阅读。如果你有任何疑问,建议或意见,请随时评论这篇文章。这是我第一个关于机器学习的博客,我会很高兴地感谢所有的反馈。
服务化和排队论:导出 M/M/1 模型

注意到两者的共同点了吗?两个都是队列!图片来源:https://www.flickr.com/photos/psit/5605605412和https://www.geograph.org.uk/photo/5831116
服务化是制造企业从销售纯产品转向提供解决方案(服务)的一种现象。 Neely (2013) 简要介绍了各行各业的公司如何采用这种商业模式。
有趣的是,服务化也导致制造企业和服务企业之间的界限变得不那么清晰。事实上,我们可以看到,制造业和服务业的某些方面可以抽象成类似的数学概念。比如,把一条流水线比作一群排队买食物的人。请注意,两者基本上都是队列,并且通常具有相似的特征(吞吐量或卖家服务客户的速度、队列长度或有多少人在等待,等等)。
我最近了解到数学中有一个分支专门研究这个问题,叫做排队论。根据理论,任何队列都可以用这 6 个参数建模: A | B | c | D | E | F 。a 是到达过程,B 是服务者过程,c 是服务者数量,D 是队列容量,E 是群体大小,F 是排队规则。在这篇博文中,我们将关注最简单的队列类型 M|M|1|∞|∞|FIFO 或者通常缩写为 M|M|1 。
M|M|1 型号
想象一个无限容量的队列( ∞ ),也就是说,等待的长度没有限制。假设人口规模也是无限的(∞),即潜在客户的数量是无限的。顾客是在先进先出( FIFO )的基础上得到服务的。让我们假设我们正在运行一条只有一个服务器的生产线( 1 ),例如,想象一辆有一条队列的基本食品卡车。然后,我们可以用速率为λ ( M )的泊松过程对客户到达率进行建模。我们还假设我们的服务时间是指数分布的,因此也可以用速率为μ ( M )的泊松过程建模。
我们把这个过程表示为马尔可夫链。状态(节点)表示队列中有多少物品,而转移率表示接收/服务客户的概率。例如,S2 表示在该州的队列中有 2 个项目。因为只有一台服务器,所以只能一个接一个地顺序处理项目。λ的到达率意味着平均在 1 个时间单位内,将有λ个项目到达队列。μ的服务率意味着平均来说,在 1 个时间单位内,μ个项目将被服务并因此从队列中移除。

M/M/1 排队马尔可夫链
假设到达和服务同步发生,即我们在 h 的同一时间窗内从一个状态移动到另一个状态,马尔可夫转移概率可以这样写。

我们的目标是只根据λ和μ(不考虑初始状态是什么),计算长期处于任何状态 Sn 的概率。
要做到这一点,我们必须首先对 n = 0 的 P(Sn)进行边缘化。我们可以用两种方式边缘化 P(Sn ),要么是相对于先前的状态,要么是相对于随后的状态。请注意,S0 有 1 个前一状态(s 1)和 1 个后一状态(S1)。只有从长远来看,这才是正确的。

经过替换和重新排列,我们得到了 P(S1)和 P(S0)之间的关系。对于其他 n > 0,我们现在对 P(Sn)执行相同的边缘化。在这种情况下,Sn 具有 2 个先前状态(Sn-1,Sn+1)和 2 个后续状态(Sn-1,Sn+1)。

我们现在有了一个关于 P(Sn+1),P(Sn)和 P(Sn-1)的等式。我们可以计算出 n=2 时的这个值。用我们以前得到的结果代替 P(S1)得到下面的等式。

现在我们可以对更高的 n 值做同样的替换和重排,得到如下迭代方程(需要更严格的证明;我们将在本帖中跳过这一点)。

我们快到了!唯一的问题是我们还有一个未知项 P(S0)。好消息是,我们也可以基于λ和μ来表征 P(S0)。为此,我们将利用概率的和性质,即所有状态的概率之和等于 1。因为我们有无限多的可能状态,求和项趋于无穷大。

该等式表明,只有当到达率小于服务率时,和的收敛才成立。直观地说,这意味着只有当我们能够以比客户到达速度更快的速度服务客户时,我们才会有一个正常工作的队列。否则,队列将无限增长。

我们现在可以根据λ和μ来刻画 P(S0)的特征。将该值代入 P(Sn)的迭代方程,得到以下结果。

我们已经实现了最初的目标,即仅根据到达率和服务率来衡量处于任何状态的概率。
那又怎样?
有了这个模型,我们可以回到我们最初的问题,并试图回答它们。举个例子,
假设我们每周三开一辆快餐车。在过去的几个月里,我们已经大致了解了顾客来的频率以及我们能以多快的速度为他们服务。使用我们新学到的排队论知识,我们现在可以估计我们的队列平均有多长。然后,我们可以将这个数字与我们操作的场地大小进行比较,看看是否有足够的空间让人们排队。我们还可以决定我们应该在加快服务时间以减少排队长度方面进行多少投资。
这个用例在数学上等同于计算队列 n 中的预期项目数。

不幸的是,等式中有一个无穷和项。为了找出这相当于什么(再次假设λ < μ), we’ll make use of the derivation of a geometric series sum.

We can now substitute this to the original equation, resulting in an expected value that is characterised based on λ and μ alone.

Let’s return to our food truck example. Suppose 4 customers arrive per hour to our food truck and we have enough capacity to serve 6 of them per hour. Using the above equation, we can calculate the expected number of people in our queue across time.

On average, we expect 2 people to queue in our waiting line. We can calculate also calculate 更多的 KPI如服务器利用率、平均等待时间、平均排队时间都基于λ和μ)。
结论
我们已经看到了排队论是如何帮助我们描述排队等候的特点的。制造业和服务业都可以使用这种数学抽象。在实践中,我们可能希望用更现实的参数来建模我们的队列,例如,我们可以有多个服务器,而不是一个服务器;或者我们可以假设容量有限而不是无限。然后,该模型可以提供关于如何改进排队系统的管理见解。
主要的限制是对到达和服务过程有很强的假设。在这种情况下,我们假设泊松过程,但更好的方法是更加数据驱动,看看哪个分布更适合。请记住,使用参数分布(无论是泊松分布还是其他分布)需要完全理解每个模型假设的潜在前提。
用于时间序列分类的集合注意模型
ICML2020
真实世界时间序列数据的深度学习算法

由 Fabrizio Verrecchia 在 Unsplash 上拍摄
作为一名主要处理业务数据(有时也称为“表格数据”)的数据科学家,我总是在寻找数据科学领域的最新发展,以帮助处理更现实的数据。其中一个领域解决了这样一个事实,即业务数据很少是“表格”形式的,而通常本质上是关系型的。我已经在另一篇博文的中讨论了使用关系数据。深度集算法帮助您从不具有矩形形状的数据中学习,但可以表示为表的集合或图形。因此,在今年 7 月参加 ICML 2020 大会时,我特别关注了那些使用深度集合学习的论文。
其中一篇论文是 Max Horn 等人的《时间序列的集合函数》[1]:
[## 为时间序列设置函数
尽管深度神经网络取得了显著的成功,但许多架构通常很难移植到…
arxiv.org](https://arxiv.org/abs/1909.12064)
在我看来,这是会议的最佳文件。如题,这篇论文是关于学习时间序列的集合函数。在继续之前,让我提醒你什么是 set 函数。
设置功能
集合函数是对一组数据的函数,可以包含零到无穷大的元素。集合函数的例子有 count()、min()、max()、sum()、mean()、std()等。在 SQL 中,我们称之为聚合函数。集合中的元素也可以是复杂的,例如,表示一行数据。集合函数不同于机器学习中常见的表格函数。相比之下,表格函数将一行固定数量的变量作为参数。处理潜在大型集合的方法是使用两个辅助函数和一个聚合函数来表示集合函数[2,3]:

来源:https://arxiv.org/abs/1909.12064
函数 h()应用于集合中的单个元素(假设是一行数据),并将集合中的元素映射到一个高维向量空间。聚合函数将一个集合中的所有这样的向量组合成一个向量,从而处理不定数量的元素。然后,一个新的函数 g()将向量映射到最终结果。这里的聚合函数是 mean(),但也可以使用其他聚合函数,例如 sum()。函数 f()和 g()可以被训练为神经网络,并且整个模型在所有可用的集合上被训练。
不规则和错位的时间序列
经典的时间序列分析总是假设测量是以固定的时间间隔进行的,如果进行了几次测量,它们是对齐的。使用插补技术来填补偶然缺失的测量值。
实际上,时间序列经常是不对齐的,测量是以不规则的间隔进行的。电子病历(EMR)和其他类型的医疗数据就是一个很好的例子。看看这张报纸海报上的图表:

来源:https://slides live . com/38928275/set-functions-for-time-series
这四次测量以不同的频率和不规则的时间进行。是的,您仍然可以使用插补,但是因为这里您需要插补大量数据,所以预测的方差会非常高。
主要思想
文献[1]的主要思想是把时间序列看作一个集合。如果你这样做,你可以使用集合函数学习算法,而不必估算任何数据。整个时间序列是一组元组(t,z,m),其中 t 是时间,z 是测量值,m 是模态。在我们的例子中,m 取血压、心率、体温和葡萄糖的值。请注意,时间仍然是一个变量,但是模型失去了下一个度量对上一个度量的显式依赖性。
这种范式的转变类似于由论文引发的变形金刚革命【4】。此外,作为递归神经网络的显式序列建模被表示为集合的序列和使用注意机制的学习所取代。
立正
如果你再看一下文章开头的等式,你会发现集合中的所有元素对结果的贡献是相等的。实际上,情况可能并非如此。例如,与超过 6 小时的平均血压相比,血压的突然变化是败血症发作的更好指标。正如我已经提到的,聚合函数不一定是 sum()或 mean(),事实上可以是任何接受一组向量并返回单个向量的函数。您可以尝试手工制作聚合函数,但是如果神经网络可以学习该函数,岂不是很酷?
同样,受[4]的启发,作者引入了集合注意力作为权重,决定集合中每个元素对整体结果的贡献。

来源:https://arxiv.org/abs/1909.12064
因此,您有一个加权集合函数,而不是普通的集合函数:

来源:https://arxiv.org/abs/1909.12064
权重α(S,s_j)取决于整个集合以及特定的集合元素。这张幻灯片示意性地展示了完整的模型:

来源:https://slides live . com/38928275/set-functions-for-time-series
索引 I 表示几个注意头。索引 j 表示集合中的一个元素。密钥矩阵表示为:

来源:https://arxiv.org/abs/1909.12064
这里 f '(S)是第二个集合函数,它使用 mean 作为聚合函数。这意味着多了两个学习 f '()的神经网络。所得向量与 s_j 连接,并乘以权重矩阵 W。注意,W 的维数不取决于集合中元素的数量,而是由神经网络架构定义。

来源:https://arxiv.org/abs/1909.12064
这里 d 是潜在层的尺寸。查询矩阵还定义了维度:

来源:https://arxiv.org/abs/1909.12064
和[4]一样,权重使用 softmax 定义:

资料来源:https://arxiv.org/abs/1909.12064
完整的神经网络架构图如下:

来源:https://arxiv.org/abs/1909.12064
时间的位置编码
受[4]启发的另一件事是时间的位置编码。
我们这些处理表格数据的人习惯于从日期/时间变量中提取特征。通常我们提取日期/时间成分,比如一天中的小时,一周中的天,等等。然后应用 sin()和 cos()等周期性函数来确保平滑度。当[4]的作者在研究 Transformer 体系结构时,他们决定使用这种技术对单词位置进行编码。这一思想被带到[1]没有太大的变化。时间编码如下:

来源:https://arxiv.org/abs/1909.12064
这里粗体的 t 是最大时标(实际上是一个超参数), k 是整数

来源:https://arxiv.org/abs/1909.12064
您可以使用一个简单的 python 脚本轻松实现这一点。

使用上面的脚本生成的位置编码函数图。
如你所见,时间有几个周期函数,有几个频率值。我相信位置编码是[4]和[1]成功的主要因素之一。然而,当处理实时而不是单词的位置时,编码对时间缩放非常敏感,因为与 NLP 中的位置相反,时间是连续变量。它还添加了额外的超参数来调整模型。虽然它对 NLP 很有效,但没有讨论其他类型的编码对时间序列是否更有效。这让我想起了手动卷积滤波器,尤其是计算机视觉系统。有没有可能增强这种神经网络架构,让它自动学习时间编码,而不是手动设置?也许一维卷积可以解决这个问题。
结论
Set functions 提供了一个关于时间序列数据的新视图,允许将它们视为独立的观测值,这简化了不规则和非对齐测量情况下的数据预处理。注意力机制允许模型学习对结果至关重要的观察结果(从而提高模型的可解释性)。实验研究表明,该算法是有竞争力的最先进的,而更快,更容易解释。所有代码都可以在作者 github repo 中找到。
参考
[1]马克斯·霍恩等人 al,为时间序列设置函数, arXiv:1909.12064
[2]曼齐尔·扎希尔等人。艾尔,深套, arXiv:1703.06114
[3]彼得·巴塔格利亚等人。al,关系归纳偏差、深度学习和图网络, arXiv:1806.01261
[4]阿希什·瓦斯瓦尼等人。艾尔,你所需要的只是关注, arXiv:1706.03762
Set-TSP 的动态规划方法

因为有不止一个地方可以买到面包
旅行推销员问题 (TSP)提出了一个简单的难题:你想要访问一组地方,例如,你在镇上的差事,并且想要以最有效的方式这样做。这个问题已经用无数不同的方法解决了,既有最优也有启发式。
你会问,我们今天在这里做什么?嗯,生活的事实是,有不止一个地方可以买到面包,或者意大利面,或者你的差事单上的任何东西。在生活中,很多时候我们想要完成一组任务,而不太关心每项任务是如何完成的。
想象一个星期五的早晨,我想(a)从我所在地区的三家面包店之一买面包,(b)从我所在地区的三家商店之一买蔬菜,©在镇中心的两家酒吧之一喝杯啤酒。

既然有人问我,我就分享一下:想知道我是如何制作这些插图的吗?我从 s2map 中拍摄了一张快照,并在稍后使用 Google Slides 添加了这些图像。是的,那是我懒惰的秘密;)
那么,完成这三项任务的最快方法是什么呢?
这正是 Set-TSP (Set -旅行推销员问题)的动机——完成所有任务,每个任务只完成一次,这样每个任务就有几个选项可以完成。
在这篇文章中,我们将使用动态规划 (DP)构建一个解决方案,这将为我们提供一个最优的解决方案,并且在未来我们还将找到一个启发式的解决方案,它可以用于更大的输入,而不会在最优性上损失太多(或者是这样吗???敬请期待一探究竟!).

关于这篇文章后面的完整代码,你可以去 这里 。
奠定基础
为了解决我们的问题,我们需要决定一种表示输入数据的方式,并从中导出用于计算所需最短路径的距离度量。
在处理地理数据时,正如我们在这里所做的,习惯上使用经纬度坐标来标识位置。令我们沮丧的是,这些是非欧几里得坐标,因此计算简单的欧几里得距离大多是错误的。
声明:在之前的一篇帖子中,我确实使用了欧几里德距离来表示非欧几里德坐标,但是……这是一篇介绍性的帖子,我不想跑题;)
所以——让我们来谈谈房间里的大象吧!我们如何计算距离?

很高兴,这个世界已经为我们搭好了舞台——我们可以使用哈弗辛公式,并从这个得到一些帮助:
现在我们可以正确计算距离,我们可以建立我们的解决方案。
构建 DP 树
构建动态规划(DP)算法需要了解我们希望如何遍历解空间,以及我们希望如何跟踪我们的当前状态。
就我个人而言,我发现直接进入集合-TSP 问题相当令人困惑,因此决定先解决一个更简单的问题——“只是”TSP,没有“集合”。
我现在将描述使用 DP 的 Set-TSP 解决方案的整个管道,但是如果你发现自己有些困惑,就像我一样,我建议首先阅读这个。
类似于许多经典的 DP 算法,我们将使用一个字典存储器,其关键字是状态,值是到达该状态的最佳方式的“方向”。更准确地说,该值是一个到键的最短路径中的直接前任。让我们举例说明一下,以便更好地理解这个过程:

这里,关键字([s1,s2,s3,s4],s4,v9)表示已经访问了所有集合的状态,使得 s4 是最后访问的集合,而 v9 是该集合中访问的点。该键的值是(s2,v4,1.5),因为以步骤 v4->v9 结束的路径最短。

代码可能看起来很混乱,而且充满了变量,但是一旦你理解了 DP 的一般方法,并且理解了你想要使用的备忘录的逻辑,它就“只是”另一个 DP 实现。
回溯最短路径
一旦我们到达了树的末端,意味着我们在备忘录中保存的路径是完整的,那么“剩下的一切”就是折回我们的步骤以找到最佳路径。
幸运的是,我们记住了每个部分路径中的最后一个和倒数第二个集合和点!

我们的红色最优路径:[(s1,v3),(s4,v9),(s2,v4),(s3,v6)]
因此,第一步将是查看最终图层,包括所有完整的路径,并选择总成本最低的最后一个集合和点。
从那里,我们可以使用倒数第二个集合和点来追溯我们的步骤。

宝贝,不画出来就不会结束
在我为这篇文章准备的 jupyter 笔记本中,你可以找到一个有用的绘图功能,让你在 geojson.io 上绘制你的解决方案:

在同一个笔记本里,你还可以找到一个输入量大得多的例子。由于集合 TSP 的复杂度在集合数量上是指数,在每个集合中的点的数量上是多项式,所以我们可以得到相当大的输入的最优解:

收场白
当我第一次了解 Set-TSP 时,关于这个问题的结构的一些东西向我尖叫,它应该有一个使用动态编程(DP)的优雅的解决方案。的确,这篇文章中的算法让我相信我的直觉是正确的。
老实说,这个算法对我来说并不容易。因此,我的过程的一部分是首先解决一个类似的,但更简单的问题。我决定先找到 TSP 的 DP 解,然后才把解扩展到 Set-TSP。这对我来说是一个巨大的成功,因为我没有一次绞尽脑汁,而是获得了两次轻松的胜利!而且,两次解决几乎同一个问题的经历,帮助我更好地“铭记”了 DP 技能,给了我“我得到了这个”的定心丸。
所以下次你手头有一个棘手的任务时,试着先解决一个简单的。你很可能会更快地找到解决方案,而且你也会从第二次更好的成功中获得信心💪🏿
希望你喜欢我的旅程,并在下一篇文章中看到,我们将找到一个启发式的解决方案来设置 TSP,并比较结果🤓
这篇文章后面的完整代码你可以去 这里 。

为分布式机器学习建立一个 Dask 集群
使用 Python 和 Dask 的分布式机器学习
通过使用 SSH 连接机器来创建 Dask 环境
由 Pablo Salvador Lopez 和 Aadarsh Vadakattu 合作撰写

如果你知道 Dask 有什么能力,以及它如何分发你的机器学习过程,那你就来对地方了!本文将解释如何创建一个简单的 SSH 集群,您可以使用它作为实现 Dask 环境的基础,该环境可以分发您的机器学习工作流。
顺便问一下,我们可以用多少种方法来加速 Dask 集群?
Dask 集群可以通过多种方式加速:
- 使用 SSH 连接
- 在 Hadoop 集群上,本质上是借助 HDFS 和 YARN 的力量运行
- 在 Kubernetes 和一堆 Docker 容器的帮助下
- 在超级计算机上
- 在像 AWS 或 Azure 这样的云环境中
在本文中,我们将展示如何通过使用 SSH 连接构建一个工作的 Dask 测试环境。
这是最好的方法吗?
使用 SSH 连接建立 Dask 集群似乎是最容易的,但是它也是最不稳定、最不安全和最乏味的。这种方法仅用于测试目的,不用于生产中的某个地方。基于您的生产环境,您可以尝试使用 Hadoop、Kubernetes 或云解决方案来实现 Dask,因为它们更有组织性和稳定性。
应该建什么?
Dask 运行在调度器-工作器网络上,调度器分配任务,节点相互通信以完成分配的任务。因此,网络中的每台机器都必须能够相互连接和联系。Dask 有时也会尝试从一个源节点连接到同一个源节点,所以我们应该确保所有机器上的每个连接网关都可用,包括到自身的连接。
在您找到一堆可以用来实现分布式集群的机器之后,
- 必须设置防火墙规则,使连接成为可能
- 必须使用 SSH 设置无密码登录
- 必须在所有机器上建立一个唯一的安装目录,该目录将包含我们的训练/测试数据,并提供给 Dask
- Python 必须安装在所有要安装相同版本库的机器上。
下面的测试设置是在一堆运行 Red Hat Enterprise Linux 7 (RHEL 7)的机器上实现的。您可以在任何地方开发或部署这种架构,方法是在本地或云中启动一组虚拟机,或者在可通过网络访问的真实机器上启动。
设置防火墙
- 确保关闭防火墙或允许通过防火墙访问所有其他机器。
- 如果您想使您的测试设置安全,允许从每台机器到每台机器的访问,包括它自己。假设您正在从任何其他机器上访问 IP
10.10.10.10,执行如下命令。在这里,24 决定了通用的 TCP 端口,8786 是 Dask 通常需要进行通信的端口。通过使用相同的命令并更改端口号,您可以根据需要打开任何其他端口。
firewall-cmd --permanent --zone=public --add-source=10.10.10.10/24
firewall-cmd --permanent --zone=public --add-source=10.10.10.10/8787

如果您的防火墙连接规则被添加,您将看到如下消息。
您可以使用ping命令确认您的连接没有被阻塞。如果您没有通过 ping 收到传输的数据包,则说明您的网络有问题。

您的 ping 应该返回传输的数据包,如上所示。如果没有,您将看到收到 0,这确定您的网络可能有问题。
如果安全性对您的测试设置不重要,您可以禁用防火墙以减少一些麻烦。为此,请在所有计算机上运行此命令。这将关闭您运行的计算机上的防火墙。
systemctl stop firewalld
您可以通过运行以下命令来检查防火墙状态:
systemctl status firewalld

如果您有活动的防火墙,您可以看到状态为活动。

如果您停止了防火墙,防火墙的状态将变为非活动。
设置无密码 SSH
当您的所有机器都可以被其他机器发现后,您需要让它们使用 SSH 连接,以便它们可以通信和传输数据。
通常,登录到一台机器需要一个系统的 IP 和一个认证密码。这种类型的登录可以手动完成,但是如果目标机器请求密码,Dask 不知道如何以及在哪里输入密码。为了克服这个问题,我们可以将计划的集群中所有其他可能的目的地机器作为 SSH 已知主机,使登录安全且无需密码。
如果您以前没有创建过 SSH 密钥,运行如下所示的ssh-keygen命令。如果需要,您可以输入密码,也可以留空。

这将创建一个 SSH 密钥,您可以使用它跨设备进行身份验证,从而使您的登录更加安全且无需密码。
现在运行下面的命令来复制目标机器的 SSH ID。假设是10.1.1.93,
ssh-copy-id 10.1.1.93
运行上面的命令可能会显示类似如下的输出:

添加密钥后,您无需输入密码即可从当前机器登录到该机器。
您还可以通过检查~/.ssh/known_hosts文件来确认集群中所有可能的目的地是否都被设置为主机。

在您复制了所有机器的 id 之后,您应该在这个文件中看到所有机器的 id 以及它们的 IP。
确保对计划包含在集群中的每台计算机运行此步骤(包括您可能正在使用的当前计算机的 IP)。如前所述,Dask 有时会尝试连接到自己,但会失败,因为没有 SSH 授权。)
在所有机器上运行这些程序后,您应该能够不使用密码无缝地从一台机器登录到另一台机器。下面的例子显示了两台机器,其中10.1.1.107没有复制 SSH ID,而10.1.1.93在当前工作的机器上复制了它的 ID。

SSH 请求密码,因为它没有找到 id 令牌。您必须在此输入密码才能登录机器。

复制 ID 后的 SSH。在这里,您无需密码即可登录,因为登录是通过您之前复制的 ID 进行身份验证的。
跨集群设置挂载目录
现在,您可以设置一个地方,让 Dask 可以访问您的数据。您可以在一个名为 SSHFS 的应用程序的帮助下完成这项工作,该应用程序会在您在任何机器上指定的目录下创建挂载点。当您在目标计算机上指定装载源时,这会将数据从源传输到目标,并从目标传输到源,以保持该特定目录中的所有文件和文件夹在计算机之间同步。这种方法的好处是—它从两个位置拷贝和同步数据,而不仅仅是在创建装载点源的位置。
如果您将要处理的数据放在机器上不同的目录路径中,Dask 有时会感到困惑。因此,请确保选择一个跨机器通用的特定目录。简单的例子可以是/tmp/daskdata/。
要将该目录指定为挂载点,
- 在所有机器上创建公共目录
- 使用以下命令在所有机器上安装 SSHFS(如果您在 RHEL 上)
wget [https://download-ib01.fedoraproject.org/pub/epel/7/x86_64/Packages/e/epel-release-7-12.noarch.rpm](https://download-ib01.fedoraproject.org/pub/epel/7/x86_64/Packages/e/epel-release-7-12.noarch.rpm)yum install fuse-sshfs
- 登录到所有机器,并在该目录下创建一个挂载点,将其指向源机器的目录。假设您的源机器是
10.10.10.10,输入如下命令:
sshfs 10.10.10.10:/tmp/daskdata /tmp/daskdata
上面的命令假设您已经登录到一台机器,并且您正在将这台机器上的/tmp/daskdata/指向10.10.10.10上的/tmp/daskdata/,这可能是源。
正确实现挂载点后,通过在任何机器的挂载目录中创建一个文件来确保它正在运行。您可以使用touch dummy轻松创建一个测试文件,它会创建一个名为“dummy”的空文件。在任何一个位置创建这个文件都必须将文件复制到所有位置,这意味着它应该可以在所有机器的/tmp/daskdata/目录中找到。
在集群中匹配 Python 库的版本
最后,您必须确保您需要的所有 Python 库都在所有集群上以相同的版本运行。为此,
- 尝试使用调度器在本地运行和调试一个简单的 Dask 分布式程序。如果这行得通,您就可以确定 Dask 需要运行的特定库版本集。通常,这一步会失败,因为 Dask 需要安装其他版本的库。根据这个程序抛出的错误获取必要的库,并尝试安装它们。
from dask.distributed import Client
import dask# Import a sample dataset
df = dask.datasets.timeseries()# Connect to distributed cluster. To run locally, pass no arguments # in the Client function.
client = Client()# This now runs on the distributed system
df.groupby('name').x.mean().compute()
- 这里有一个链接指向 Dask 可能需要的依赖项,以及支持的最低版本。检查这个,确保你已经满足所有要求。
- 有了库的版本后,您可以使用
pip freeze命令收集所有已安装的版本,并安装所有这些需求,如下所示:
pip freeze > requirements.txt #on a machine where all libraries are #installedpip install -r requirements.txt #on another machine where all #libraries should be installed
- 同样为了减少麻烦,您可以创建一个 pip 或 conda 环境,并使用
venv-pack或conda-pack将库导出到其他机器。这将在目标机器上复制您创建的环境。这里有很好的视频解释如何做到这一点: - https://conda.github.io/conda-pack/
- https://jcrist.github.io/venv-pack/
现在,您可以将数据放入挂载的文件夹中,并编写 Dask 应用程序了!
为 Dask 构建 SSH 集群的利弊是什么?
优点:
- 这是一个完全从零开始构建的集群,可以在不安装 HDFS 的情况下运行,这可能很繁琐。如果您有一个包含许多机器的小型集群,可以使用这种方式快速测试 Dask。
缺点:
- 挂载点需要精确地位于所有机器上的相同位置。HDFS 在这里大获全胜,因为如果以这种方式实现,Dask 只需要知道文件在 HDFS 的什么地方。
- 大量文件会破坏每台机器上的磁盘,并且会破坏网络上的 SSHFS 连接。
- SSHFS 挂载可能很难跟踪,并且 SSHFS 应用程序在跟踪正在运行的挂载点方面做得不好。
请继续关注有效运行 Dask 的其他方式,包括通过 HDFS 和 YARN 设置的**,使用 Kubernetes 设置的和在 Azure Cloud 设置的。**
非常感谢你的阅读!既然您已经设置了集群,那么您可以创建并运行 Dask 程序,并在 Dask 仪表板中查看所有运行统计数据!
使用 Ubuntu 20.04 设置用于机器学习的个人 GPU 服务器
TensorFlowGPU,JupyterLab,CUDA,cuDNN,端口转发,DNS 配置,SSHFS,bash

卡斯帕·卡米尔·鲁宾在 Unsplash 上的照片。奶昔是可选的 GPU 设置。
在你的 ML 工作流程中使用 GPU 的好处已经在前面讨论过了。本文的目标是总结为个人 ML 项目设置机器的步骤。我从 2017 年开始遵循一个类似的指南,发现从那时起到 2020 年,很多步骤都变了——变得更好。此外,根据我在攻读博士学位期间使用 DAQ 系统的经验,我将建议一些程序,使您的远程工作流程更简单、更安全。
到本文结束时,您将能够从您的笔记本电脑启动运行在 GPU 主机上的远程 JupyterLab 会话。此外,您将能够从任何地方远程打开机器,并将它的文件系统直接安装到您的笔记本电脑上。
大纲:
- 安装和设置 Ubuntu 20.04 (独立/双引导/WLS2)
- 设置远程访问( ssh 、WOL、DNS 配置、端口转发)
- 照顾 NVIDIA 驱动程序和库(CUDA,cuDNN)
- 为 ML 创建 Python 环境
- 易用工具:用 SSHFS 挂载远程目录,将一些常用命令设置为 bash 别名
要求:
-
您通常在其上工作的笔记本电脑/台式机。我用的是运行 macOS 10.15 的 MacBook Pro 2015。
-
一台带有 GPU 的机器,例如,这可以是你当前的游戏 PC。你不需要花费预算在昂贵的 GPU 上来开始训练你的 DNNs!我的硬件目前比较一般:
CPU: AMD 锐龙 5 2600X (3.6 GHz,六核)
GPU: 英伟达 GTX 1660(6GB VRAM)
**RAM:**16gb(DDR 4 3200 MHz)
存储: 512 GB NVMe M.2 (SSD)、512 GB HDD -
对路由器设置的管理员级访问权限(可选)
-
熟悉 Linux 和终端
1.安装和设置 Ubuntu 20.04
在我和其他人看来,Windows 操作系统都不适合做任何 ML 开发或网络工作。因此,我们将为此目的设置一个 Linux 操作系统。Ubuntu Desktop 20.04 ( 在这里下载)是一个理想的选择,因为许多功能都是现成的,与其他 Linux 发行版相比,它允许我们节省设置时间。您有三种选择:
- 只安装 Ubuntu。
- 双启动 Ubuntu 和现有的 Windows 操作系统。此处按照 i 指令 (推荐选项)。
- 使用 WSL2 (Windows 子系统 for Linux);这就是这里讨论的。警告:我从来没有测试过这个选项(这里你自己看吧!).
我推荐选项#2 ,保留对窗口的访问(例如,出于游戏相关的目的)。确保在安装期间将您的计算机连接到互联网,以获取最新的更新和驱动程序。
安装后,登录并更新和安装必要的软件包,例如
sudo apt-get update &&
sudo apt-get -y upgrade &&
sudo apt-get -y install build-essential gcc g++ make binutils &&
sudo apt-get -y install software-properties-common git &&
sudo apt-get install build-essential cmake git pkg-config
2.设置远程访问
在本节中,我们将设置一种安全的远程登录机器的方式。还讨论了从任何网络访问 GPU 机器的选项。
嘘
现在,登录 Ubuntu,打开终端并安装 ssh-server:
sudo apt update &&
sudo apt install openssh-server
之后,验证 ssh-server 安装是否正确
sudo systemctl status ssh
打开防火墙
sudo ufw allow ssh
通过从您的笔记本电脑 (假设与您的 GPU 机器连接到同一个网络)运行 来测试您的 ssh 连接
ssh **user**@<**local-ip-address**>
其中 用户 是你的 Ubuntu 用户名,而你在 Ubuntu 上的本地 IP 地址(如 172.148.0.14)可以用ip add找到,产生(如)
*link/ether* ***b3:21:88:6k:17:24*** *brd ff:ff:ff:ff:ff:ff
inet* ***172.148.0.14****/32 scope global noprefixroute* ***enp7s3***
记下您的 MAC 地址(如 b3:21:88:6k:17:24 )和网卡名称(如 enp7s3 ),以备后用。
#only ssh-key logins
PermitRootLogin no
ChallengeResponseAuthentication no
PasswordAuthentication no
UsePAM no
AllowUsers user
PubkeyAuthentication yes# keep ssh connection alive
ClientAliveInterval 60
TCPKeepAlive yes
ClientAliveCountMax 10000
不要忘记重新启动 ssh-service,让它通过
sudo restart ssh
域名服务器(Domain Name Server)
如果您想从家庭网络之外通过 ssh 连接到您的计算机,您需要建立一个永久的 DNS“主机名”,它独立于您的计算机的全局 IP 地址,您的 ISP 可以随时更改该地址。我个人使用过 no-IP 的免费服务(链接此处,从 Ubuntu 的浏览器 )开始使用“立即创建你的免费主机名”);存在替代 DNS 服务,如 FreeDNS、Dynu 等。请创造性地使用您的主机名;我真不敢相信 mlgpu.ddns.net 还没被录取。这个主机名将在本文中作为一个例子。****
@reboot su -l **user** && sudo noip2
重启你的机器。
端口转发
默认情况下,ssh 使用端口 22 进行连接。我们需要通过路由器打开这个端口(TCP 和 UDP 协议),以便能够从外部网络 ssh 到机器(您仍然希望从咖啡店提交那些 GPU 密集型作业,对吗?).此设置通常位于“高级/安全”选项卡下。下面是我的路由器设置的截图

UDP 和 TCP 协议都允许通过 Ubuntu 网卡的端口 22。
可选:在挖掘你的路由器设置时,将你的 Ubuntu 的网卡 MAC 地址和本地 IP** 添加到保留列表(“添加保留规则”),并将你的路由器设置保存到一个文件中(以防你日后需要重新加载)。**
最后,在你的笔记本电脑 上 ,编辑~/.ssh/config用你的 Ubuntu 用户名替换用户,用你的 DNS 主机名替换主机名****
# keep ssh connection alive
TCPKeepAlive yes
ServerAliveInterval 60# assign a 'shortcut' for hostname and enable graphical display over ssh (X11)
Host **mlgpu**
HostName **mlgpu.ddns.net**
GSSAPIAuthentication yes
User **user**
ForwardX11Trusted yes
ForwardX11 yes
GSSAPIDelegateCredentials yes
这将允许您快速 ssh 到您的机器,并测试 DNS 和端口转发正在工作
ssh mlgpu
这应该不会要求您输入密码,您现在可以从任何网络 ssh 到您的 GPU 机器!
局域网唤醒
想象一个场景,你正在参加一个会议(在 2020 年之前,这些会议在远离你家的地方举行——我知道这很奇怪!)并且你想在你的 GPU 机器上训练你的 DNN。但是等等,你在离开家之前把它关掉了——哦,天哪!
这就是 沃尔和 的神奇之处!
在 Ubuntu 上,编辑/etc/systemd/system/wol@.service
[Unit]
Description=Wake-on-LAN for %i
Requires=network.target
After=network.target[Service]
ExecStart=/sbin/ethtool -s %i wol g
Type=oneshot[Install]
WantedBy=multi-user.target
之后,通过以下方式启用 WOL 服务
sudo systemctl enable wol@enp7s3 &&
systemctl is-enabled wol@np7s3
这将返回“enabled”; enp7s3 是用ip add命令返回的网卡名称。最后,检查您的 BIOS 设置“wake-on-LAN”= enabled。
现在,在你的笔记本电脑上,通过
brew install wakeonlan
要测试 WOL 是否正常工作,请关闭 Ubuntu,并使用您的 DNS 主机名(或 IP 地址)和 MAC 地址从您的笔记本电脑发出以下命令
wakeonlan -i **mlgpu.ddns.net** -p 22 **b3:21:88:6k:17:24**
这将唤醒你的 GPU 机器从睡眠或关机状态(当然,确保它仍然连接到电源!).如果你选择了双引导选项,并且 Ubuntu 不是引导菜单中的第一个操作系统,用 GRUB 调整它。
就是这样:从你的 GPU 机器上拔下你的显示器、键盘和鼠标,从这里我们将从你的笔记本电脑上运行的远程 ssh 会话中发出所有命令——太棒了!
3.管理 NVIDIA 驱动程序和库
更多好消息在前方。Ubuntu 20.04 应该会自动为你安装 Nvidia 驱动(而不是新出的那些)。让我们用nvidia-smi来验证一下

确认检测到您的 GPU 后,使用正确数量的 VRAM,记下驱动程序和 CUDA 版本。
这不是最新版本的驱动程序。然而,我们可能想让他们从标准的 Ubuntu 库安装 CUDA 和 cuDNN。
库达
只需安装 CUDA
sudo apt update &&
sudo apt install nvidia-cuda-toolkit
用nvcc --version验证

CUDA toolkit (v10.1)是从 Ubuntu 库获得的。
最后,使用这里的文件构建您的第一个 CUDA“Hello World”示例
nvcc -o hello hello.cu &&
./hello
“最大误差:0.000000”意味着您的 CUDA 库工作正常!
cuDNN
最后,为 CUDA 10.1 (或为您从nvcc --version发布的 CUDA 版本)下载cud nn v 7 . 6 . 5(2019 年 11 月 5 日)。你需要注册一个 NVIDIA 开发者计划的免费帐户来下载 cuDNN。
使用以下命令从解压缩的 tarball 中复制库:
sudo cp cuda/include/cudnn.h /usr/lib/cuda/include/ &&
sudo cp cuda/lib64/libcudnn* /usr/lib/cuda/lib64/ &&
sudo chmod a+r /usr/lib/cuda/include/cudnn.h /usr/lib/cuda/lib64/libcudnn*
并将库导出到$LD_LIBRARY_PATH
echo 'export LD_LIBRARY_PATH=/usr/lib/cuda/lib64:$LD_LIBRARY_PATH' >> ~/.bashrc &&
echo 'export LD_LIBRARY_PATH=/usr/lib/cuda/include:$LD_LIBRARY_PATH' >> ~/.bashrc &&
source ~/.bashrc
任务完成了。
4.为 ML 创建 Python 环境
在 Linux 和 macOS 上,我个人的偏好是使用 pip 而不是 conda 来管理 Python 包和环境。下面是设置 ML Python3 环境的说明:
首先,获取最新的 Python3
sudo apt update &&
sudo apt install python3-pip python3-dev
然后,升级 pip 并安装环境管理器
sudo -H pip3 install --upgrade pip
sudo -H pip3 install virtualenv
接下来,我们将为基于 GPU 的项目创建一个新目录
mkdir ~/gpu_ml &&
cd ~/gpu_ml
并在那里实例化一个新的 Python 环境
virtualenv gpu_ml_env
这将允许我们直接在那个环境中安装软件包,而不是“全局”安装。该环境需要用以下命令激活(每次登录)
source ~/gpu_ml/bin/activate
你应该在你的终端里看到(gpu_ml_env)。现在,让我们在那个环境中安装 Python 包(在那个环境中 pip == pip3)
pip install jupyterlab &&
pip install tensorflow &&
pip install tensorflow-gpu
您需要的任何其他 Python 包都可以类似地安装。
5.易用的工具
尝试
我推荐你在 Ubuntu 的~/.bash_aliases中添加一些命令。他们会在每次登录时激活gpu_ml环境,以及添加一些有帮助的“终端快捷方式”(人生苦短,不能键入‘jupyter lab’而不是‘jlab’,对!?).命令如下(替代链接)
****在您的笔记本电脑上,您可能希望将这些行添加到您的~/.profile, 中,用您的 DNS 主机名(或 IP 地址)替换 ML,并使用步骤#2 中的 MAC 地址。这些命令如下(替代链接)
SSHFS
从这里安装 macOS 的 FUSE,调整下面的脚本,其中remotedir="user@$ML:/home/user/",和mountdir="/Users/user/Documents/Ubuntu_mount"是你的 macOS 上的目录,Ubuntu 上的文件将被挂载到这个目录。脚本如下(备选链接)
使用运行脚本
. ./mount.sh
在你的 macOS 上导航到/Users/user/Documents/Ubuntu_mount(或者简单地输入cd_ML)来查看作为“本地文件”的 Ubuntu 文件。你现在可以在你的笔记本电脑上用你最喜欢的编辑器打开和编辑远程 Ubuntu 文件,等等——太棒了!
让我们做这个设置的最后测试(手指交叉!).从您的笔记本电脑上
sg
在我们的“bash shortcuts”中,它代表ssh -L 8899:localhost:8899 mlgpu.ddns.net。这应该会在端口 8899 上打开一个 ssh 隧道,并从该会话类型登录到 Ubuntu
jlab
哪个是jupyter lab --port=8899的 bash 快捷键?
现在,在笔记本电脑上打开您最喜欢的网络浏览器,导航至[http://localhost:8899/lab](http://localhost:8899/lab)。第一次,您需要将令牌从终端粘贴到浏览器中(例如The Jupyter Notebook is running at:http://localhost:8899/?token=**583049XXYZ…**)
在 JupyterLab 中,检查我们确实是从 Linux 运行这台笔记本
import platform
platform.system()
张量流检测 GPU
import tensorflow as tf
tf.config.list_physical_devices(‘GPU’)

我们通过笔记本电脑在远程 GPU 服务器上运行 JupyterLab 笔记本。不太令人兴奋的输出#2 实际上是一个好消息,TensorFlow 检测到了我们的 GPU。
从这里开始,你就可以实施你的 DNN 培训等。使用图形处理器。如果您遵循了第 1 节到第 5 节中的所有步骤,那么您的工作流程相当简单:
1.用sg
2 打开一个到你的 GPU 服务器的 ssh 隧道。用jlab
3 在 GPU 服务器上启动 JupyterLab。在笔记本电脑上打开网络浏览器,并转至[http://localhost:8899/lab](http://localhost:8899/lab)
4。快乐训练——真正的工作从这里开始!
编后记
我希望这篇文章对帮助你设置远程 GPU 服务器以满足你的 ML 需求有所帮助。如果您发现本文中的过程有任何改进,请告诉我,我会尽我所能在这里添加它们。
在 R: Grid search 与 auto.arima()中设置 ARIMA 模型参数
让最佳模型适合您的时间序列数据。
概观
表示和预测时间序列数据的最流行的方法之一是通过自回归综合移动平均(ARIMA)模型。这些模型由三个参数定义:
- p :滞后阶数(包括滞后观测数)
- d :平稳性所需的差分程度(数据被差分的次数)
- q :均线的顺序
如果你是 ARIMA 模特界的新手,有很多很棒的指导网页和分步指南,比如来自 otexts.com 的和来自 oracle.com 的和的,它们给出了更全面的概述。
然而,这些指南中的绝大多数都建议使用 auto.arima()函数或手动使用 ACF 和 PACF 图来设置 p、d 和 q 参数。作为一个经常使用 ARIMA 模型的人,我觉得我仍然需要一个更好的选择。auto.arima()向我推荐的模型通常具有较高的 AIC 值(一种用于比较模型的方法,最好的模型通常是 AIC 最低的模型)和显著的滞后,这表明模型拟合度较差。虽然我可以通过手动更改参数来实现较低的 AIC 值并消除显著的滞后,但这个过程感觉有些武断,我从来没有信心为我的数据真正选择了最好的模型。
我最终开始使用网格搜索来帮助我选择参数(借用本指南中的一些代码)。虽然对数据进行探索性分析、测试假设和批判性思考 ACF 和 PACF 图总是很重要,但我发现有一个数据驱动的地方来开始我的参数选择非常有用。下面我将通过示例代码和输出来比较 auto.arima()和 grid 搜索方法。
代码和输出比较
首先,您需要加载 tidyverse 和 tseries 包:
library('tidyverse')
library('tseries')
library('forecast')
还需要使用您的训练数据创建移动平均对象:
training_data$hits_ma = ma(training_data$seattle_hits, order = 7)hits_ma = ts(na.omit(training_data$hits_ma), frequency = 52)
auto.arima()
创建和查看 auto.arima()对象非常简单:
auto_1 = auto.arima(hits_ma, seasonal = TRUE)
auto_1

使用 auto.arima()选择的参数为( 0,1,0 ) ,该模型的关联 AIC 为 234.99。寻找 ACF 和 PACF 图中的显著滞后也很重要:
tsdisplay(residuals(auto_1), lag.max = 45, main = '(0,1,0) Model Residuals')

显著的滞后延伸到蓝色虚线之外,表明模型拟合不佳。两个图在 7 处显示出显著的滞后,ACF 图在 14 处具有额外的显著滞后。
网格搜索
首先,您必须指出您想要在网格搜索中测试哪些参数。鉴于这些值的显著滞后,我决定考虑 0 到 7(p 和 d)和 0 到 14(q)之间的所有参数。最终结果是一个名为“orderdf”的数据帧,包含所有可能的参数组合:
order_list = list(seq(0, 7),
seq(0, 7),
seq(0, 14)) %>%
cross() %>%
map(lift(c))orderdf = tibble("order" = order_list)
接下来,绘制该数据帧,确定 AIC 最低的型号:
models_df = orderdf %>%
mutate(models = map(order, ~possibly(arima, otherwise = NULL)(x = hits_ma, order = .x))) %>%
filter(models != 'NULL') %>%
mutate(aic = map_dbl(models, "aic"))best_model = models_df %>%
filter(aic == min(models_df$aic, na.rm = TRUE))
我已经将具有最低 AIC 的模型提取为“best_model ”,以便我稍后可以使用该对象,但是您也可以通过最低 AIC 对数据进行排序,以便探索最佳的几个选项。
查看“最佳模型”对象会显示网格搜索方法选择的参数:

网格搜索已经确定( 7,1,0 )为最佳参数,并且与该模型相关联的 AIC 208.89 远低于来自 auto.arima()方法的 234.99。

此外,在 ACF 或 PACF 图中不再出现任何显著的滞后,并且残差更小。这个模型似乎比使用 auto.arima()生成的模型更适合我的数据。
与使用 auto.arima()函数或手动选择相比,我一直使用网格搜索获得更好的结果,我强烈建议在将 arima 模型拟合到您的数据时使用这种方法。
为阿帕奇·卡夫卡设定场景
此高级事件流平台的简介和关键概念解释。

(图片来自 Photogenica Sp。授权给 Wojciech Nowak)
简介
据说卡夫卡是一个信息系统。许多人认为它是将消息从一个地方移动到另一个地方的消息总线。这当然是真的,但事实上远不止如此。
Kafka 是一个开源的分布式事件流平台,可以处理整个系统中的所有数据和所有事件。这是一个可以构建实时应用程序的平台,它可以通过事件的力量将不同的系统集成在一起。
它以容错、持久的方式传输记录,提供背压、集成点,并将源系统与接收系统分离。这些特性与灵活的架构相结合,使 Kafka 成为保证高性能和低延迟的强大工具。
Kafka 是基于发布-订阅模式构建的,这种模式使应用程序能够向多个感兴趣的消费者异步发布消息,而无需将发送者与接收者耦合起来。Kafka 是作为一个集群在一个或多个服务器上运行的,这使得满足 Kafka 的创造者给出的保证变得容易。
卡夫卡建筑的这种(某种)正式/普遍的概念可能看起来势不可挡。因此,卡夫卡的核心概念已在下一章介绍。
核心理念
过去,信息存储在数据库中。这种方法使得开发人员从事物的角度来理解编程(例如,票、卡车、照相机)。每一件事物都有它自己的状态,并存储在数据库中。
最近,一些人提出用事件来理解编程。每个事件都有其状态(就像存储在 DB 中的“事情”),但也有对发生的事情的描述和“事情”发生的时间指示。
将事件存储在数据库中似乎是过去和现在的一个很好的调和,然而这有点不方便。取而代之的是被称为“日志”的结构。一旦事件发生,就写入日志。这意味着日志是事件有序序列。
日志很容易思考。它们也很容易大规模构建,这在历史上对数据库来说并不完全正确。Apache Kafka 是一个用于管理这些日志的系统(或平台),具有一系列高级功能,其中一部分已经提到过。
在过去,当数据库统治编程世界时,构建一个使用单个数据库的巨大应用程序是非常流行的。出于许多原因,这种方法是合理且常见的。然而,随着时间的推移,这些应用程序的复杂性也在增加。他们变得难以思考,难以理解,最终难以改变。
目前,有一种趋势是编写大量的小程序,每一个程序都小到足以思考、改变和进化。这些程序可以通过面向日志的代理相互通信。

过去与现在(作者图片)
每个服务都可以使用给定日志中的一条消息,执行一些计算或处理一条消息,并将结果生成一个日志(或数据库)。输出可以持久地(甚至永久地)记录在那里,用于系统中的其他应用。
现在你应该对卡夫卡背后的关键概念有了一个不错的想法。此外,你不仅应该真正理解 kafka 是什么,还应该真正理解 kafka 倾向于提出的构建软件的方法。
消息,话题&分区
您已经知道 kafka 有助于在源系统和接收系统之间移动数据。让我们深入了解阿帕奇卡夫卡的一些要点。
一个单独的数据片段被称为消息。当信息被发送时,卡夫卡对其进行索引,并将其放入适当的 T4 主题 T5。
主题是特定的数据流(你可以把它们想象成 RDBMS 中的一个表,但是没有关系和约束)。每个主题由其名称标识,并被分成个分区。每个分区都有标识号。这些数字从 0 开始,一直到 n-1,其中 n 是给定主题内的分区数量。

主题剖析(图片由作者提供)
分区是有序且不可变的消息序列。每个分区独立于所有其他分区,这意味着在一个主题内创建的分区之间没有顺序。当需要平衡负载时,它们也可以作为一个并行单元工作。分区中的每条消息都有一个称为 offset 的顺序 id 号,它唯一地标识分区内的每条消息。

深入了解分区(图片由作者提供)
总结
现在,当你知道卡夫卡是什么,它是如何工作的,幕后是什么,你能做的最好的事情就是在实践中使用这些知识。此外,了解了一些关键定义,如消息、主题、分区和偏移,您可以了解 kafka 更高级的方面,如生产者、消费者、交付语义或 kafka 集群的内部。
本文附有一些可能有助于你探索卡夫卡的资料。如果你想了解更多关于卡夫卡的知识,它的文档是最好的地方。当你想获得更详细的信息时,《卡夫卡——权威指南》应该能满足你的需求。最后,如果你的目标是找到更多关于日志概念的第三个位置——“我心日志:事件数据、流处理和数据集成”将是最好的知识来源。
继续前进,祝你好运!
WN。
来源
[1]阿帕奇卡夫卡 2.3 文档【https://kafka.apache.org/documentation/
[2]卡夫卡:权威指南|尼哈·纳克赫德、格温·沙皮拉、托德·帕利诺|奥莱利媒体公司| 2017 年 11 月 1 日
[3] I Heart Logs:事件数据、流处理和数据集成| Jay Kreps | O’Reilly Media,Inc . | 2014 年 9 月 23 日
使用 LibTorch 1.6 在 Visual Studio 2019 中设置 C++项目
关于如何使用 python 在 PyTorch 中训练模型,如何使用 flask 或者 Amazon SageMaker 部署模型等等的教程数不胜数。然而,关于如何在 C++中工作的资源是有限的,对于 Visual Studio 项目设置来说更是如此。当你想在现实世界的应用程序中使用你的模型时,速度是你关心的问题,并且由于隐私/安全的考虑,你不想把模型存储在云上,那么你需要求助于我们的老朋友 C++。
Pytorch 现在对 C++有了很好的支持,从 v1.3.0 开始就有了。他们有很好的关于如何使用 C++前端的教程,可以在这里找到:https://pytorch.org/tutorials/advanced/cpp_frontend.html
他们利用 cmake 来构建他们的应用程序,并且没有针对广泛用于 C++开发的 Visual Studio 的官方文档。在本教程中,我将解释如何在最新的 Visual Studio 2019 版本上以发布和调试模式设置 torchlib 项目。
第一步
从这个链接下载安装 Visual Studio 2019 社区版。安装时选择“使用 C++进行桌面开发”,这将安装所有必需的组件。
第二步
你必须从 PyTorch 下载页面下载 LibTorch 压缩文件。我选择了不支持 Cuda 的 Windows 版本。如果您有 GPU,可以选择安装在您机器上的 Cuda 版本。下载链接出现在“运行此命令”行中。我已经把 CPU 版本的贴在这里了。
您必须解压缩这两个文件,然后有选择地移动到存储库文件夹。

来源:https://pytorch.org/get-started/locally/
第三步
先说 Visual Studio 中的 C++项目。创建新项目

来源:作者
第四步
项目设置中需要为项目正常工作而设置的设置很少。文件夹结构如下。

来源:作者
我们从 C/C++设置下的附加包含目录开始。请注意,您可以用提取 LibTorch 库的绝对路径来替换它们。您需要添加以下两个条目:
发布配置:
- $(项目目录)…\ lib torch-win-shared-with-deps-1 . 6 . 0+CPU \ lib torch \ include
- $(项目目录)…\ lib torch-win-shared-with-deps-1 . 6 . 0+CPU \ lib torch \ include \ torch \ CSRC \ API \ include
调试配置:
- $(project dir)……\ lib torch-win-shared-with-deps-debug-1 . 6 . 0+CPU \ lib torch \ include
- $(project dir)……\ lib torch-win-shared-with-deps-debug-1 . 6 . 0+CPU \ lib torch \ include \ torch \ CSRC \ API \ include
$(ProjectDir)是一个扩展到项目目录路径的 visual studio 宏。我们返回三个目录以获得 LibTorch 文件夹,然后指定相对路径。

来源:作者
接下来,我们将 C/C++ →语言→一致性模式下的一致性模式设置设置为 No。或者选择所有配置并更改此设置。

来源:作者
接下来,是链接器设置。我们从 General 选项卡下的附加库目录开始。
发布配置:
- $(project dir)……\ lib torch-win-shared-with-deps-1 . 6 . 0+CPU \ lib torch \ lib
调试配置:
- $(project dir)……\ lib torch-win-shared-with-deps-debug-1 . 6 . 0+CPU \ lib torch \ lib

来源:作者
接下来是输入选项卡。我们需要在这里指定附加的依赖项。
- CPU 版本: torch_cpu.lib,c10.lib,torch.lib
- GPU 版本: torch.lib,torch_cuda.lib,caffe2_nvrtc.lib,c10.lib,c10_cuda.lib,torch_cpu.lib,-包含:?warp _ size @ cuda @ at @ @ YAHXZ(https://github . com/py torch/py torch/issues/31611 # issue comment-594383154

来源:作者
最后,我们需要将 DLL 文件复制到项目中。您可以手动执行此操作,或者将这些 xcopy 命令添加到构建事件→后期构建事件→命令行中。我已经编写了复制所有 dll 的命令。但是,您可以只选择和复制您需要的那些。
xcopy $(ProjectDir)..\..\..\libtorch-win-shared-with-deps-1.6.0+cpu\libtorch\lib\*.dll $(SolutionDir)$(Platform)\$(Configuration)\ /c /y

来源:作者
这就完成了在 Visual Studio 2019 中设置您的 LibTorch 1.6 项目。
最后,为了测试您的项目是否有效,让我们添加一个来自 PyTorch repo examples for c++的示例项目。
你必须从这个链接下载 MNIST 数据集。请下载所有四个文件,并将它们解压缩到之前结构中显示的数据文件夹中。只要确保提取工具没有用点替换其中一个连字符,因为那会导致代码抛出异常。我已经在这个资源库中提供了解决方案文件和代码:https://github . com/msminhas 93/lib torch-Mn ist-visual-studio/tree/main/learning lib torch。输出应该如下所示:

希望这有用。欢迎您的建议、反馈和评论。
参考
[2]https://github.com/pytorch/examples/tree/master/cpp/mnist
http://yann.lecun.com/exdb/mnist/
[4]https://github . com/py torch/py torch/issues/31611 # issue comment-594383154
使用 dbt 云和雪花设置配置项
融合到大师,晚上睡觉

在 HousingAnywhere ,我们正在使用 dbt 和雪花对我们的数据进行建模,以便为我们的业务分析师和数据科学家提供有意义的视图和物化。我们的数据仓库充满了来自各种不同来源的原始结构化数据,其中大部分是通过 Stitch 复制的;一个简单且可扩展的即插即用的托管 ETL 工具。其他人需要更多的个人接触,并使用气流与临时定期任务相结合。在这两种情况下,从这些来源提取有意义的见解可能会令人沮丧,因为普遍存在肮脏、不一致和/或存储在过度设计的结构中的数据,这些结构在设计时没有考虑到易于访问和信息提取。

HousingAnywhere 的 ETL 架构的简化表示
dbt 本身是一个命令行工具,允许数据工程师高效地转换他们数据仓库中的数据。当需要更复杂的逻辑或访问关于作业执行或目标模式/表的信息时,它使用用 Jinja 模板丰富的 SQL。数据仓库被用作一个数据源,数据从这个数据源被转换并推回到同一个仓库中,尽管是在不同的位置。dbt 的结果通常更容易理解和维护,通常由可能来自不同数据源的表的多个连接组成。BI 工具(如 Mode、Looker 等)通常只能看到这些结果表,而不是原始的原始数据源。
dbt 的结果通常更容易理解和维护,通常由可能来自不同数据源的表的多个连接组成。
举一个例子:假设有一个表,包含关于一个属性的各种信息,用纬度和经度来描述它的位置。查询这种数据不容易。我们使用 dbt 创建了一个模型,该模型添加了一个“城市”列,通过计算从酒店位置到我们业务感兴趣的城市的 haversine 距离来检索。计算这些距离,并将最近的城市分配给该物业,以用于报告目的。业务分析师可以简单地查询第二个表,而不必担心幕后复杂的逻辑。
dbt 是分布在 pypi 上的 Python 模块,可以部署在任何运行 Python 的机器上。也就是说,使用 dbt Cloud 肯定更方便,它允许您免费进行高效的 dbt 部署(当然,最初是随增长付费的模式)。dbt Cloud 还为核心产品添加了许多有趣的功能,用户友好的 web 界面使其成为在生产环境中实现 dbt 的最佳方式。由于与 Github 的无缝集成,所有的模型和配置都可以使用 git 进行代码版本化,开发过程可以像任何其他经典软件工程项目一样进行,并行打开多个分支,并通过 pull requests (PR)合并 master 上的更改。在预定的时间,dbt Cloud 选取主分支,并针对生产数据运行所选的模型,按照代码中的定义转换它们,并交付更改。
由于与 Github 的无缝集成,所有模型和配置都可以使用 git 进行代码版本化,开发过程可以像任何其他经典软件工程项目一样进行。
这允许一个高效、可观察且易于维护的环境,尽管让 master 直接连接到生产仓库并不是最可靠的做法。dbt 语法很容易出错,即使理想情况下可以在本地编译(Jinja 模板必须翻译成 SQL),也不容易评估这些变化是否破坏了数据中的一些语义约束。在一个简单的实现中,没有什么可以阻止您通过一个破坏某些东西的 commit 来合并到 master,只是当计划的任务在晚上某个时候运行时,您会发现您的方法中的错误。不理想。

dbt 云上的“请求时运行”功能
幸运的是,dbt Cloud 来帮忙了,当从连接的存储库上打开的 PR 触发时,允许针对自定义分支运行作业。换句话说:生产作业的精确副本可以使用每次打开 PR 时在分支上找到的模型来运行,在相同的生产环境中根据临时模式来具体化。当 PR 关闭或合并时,临时模式被删除,但是当 PR 打开时,它可以像数据库上的任何其他模式一样被访问,以运行测试或手动检查东西——如果需要的话。这个特性对于检查分支内容的语法和高级一致性特别有用,可以防止参与者合并重大变更。如果生产中的 dbt 管道已经包含测试,那么这些测试也将针对临时模式运行,以便在语义级别上检查其内容。

CI 检查失败,阻止开发人员合并
然而,尽管在临时模式上复制整个生产环境在理论上很有吸引力,但是实现每次提交都有数亿行的表是不可行的。拥有 CI 的主要目的是为开发人员提供对他们工作的快速检查,而一些表的完全重新填充在最好的情况下可能需要几个小时。在执行 dbt 作业时,很容易区分生产运行和 CI 运行,考虑到严格的命名模式和用于此目的的临时模式(本文发布时的 dbt_cloud_pr_xx)。在 dbt 模型中克服对原始表的引用,并在执行 CI 作业时减少被引用的临时实例的大小,这样就可以让 CI 运行使用一小部分生产数据,从而大大减少对每个 PR 进行可靠检查所需的时间。

第一步:删除 dbt 模型中对原始表的硬编码引用
从语法上来说,缩小表的范围以避免篡改数据结构的外部引用是一项简单的工作,没有任何经验法则可以正确地完成这项工作。我们决定在一个主表上限制时间范围,并填充其他表,以便保留连接和引用。

第二步:在针对 CI 模式运行时,缩小原始表的范围
这里有一个离现实不远的例子:想象一个数据库模式,其中有租户和广告商之间关于一些房屋属性(列表)的对话。最合乎逻辑的决定是只选择在特定时间间隔内创建的对话(例如,2019 年 1 月,大约数万个样本),以强制存在与这些对话相关的列表,当然还有双方涉及的用户。产生的模式大小减小了,但仍然一致。按照这个方向推理,我们可以关闭与模式的这一部分相关的所有可传递的依赖关系,可能的话,在同一时期对与这些没有直接依赖关系的其他表进行时间约束。
感谢 Julian Smidek 和 Stephen O’ Farrell 对这个项目和这个职位的贡献。
建立新的 PyTorch 深度学习环境

无论您是开始一个新项目,还是在远程机器上运行,您都不想浪费时间去寻找依赖项和安装软件库。
本教程将提供一种从空白开始设置的最快方法。
我测试了这种方法,在 Amazon Web Services 上运行的一个简单的 EC2 实例上完成。
管理您的包
PyTorch 中的深度学习工作流是用 Python 编程语言编写的,您会发现自己需要安装许多额外的 Python 包才能获得作为数据科学家所需的所有功能。
为了保持整洁,您需要一个工具来帮助您管理 Python 环境。Conda 是管理软件包、依赖项和环境的强大工具。我们将首先安装它。
Miniconda 是 conda 的免费极简安装程序。为您的操作系统找到正确的 Miniconda。

请注意,虽然我是在 Mac 上工作,但我是在 AWS 上运行的 Linux 实例上安装 Miniconda 的。
我在 64 位 Linux 上使用 Python 3.8:
$ wget [https://repo.anaconda.com/miniconda/Miniconda3-latest-Linux-x86_64.sh](https://repo.anaconda.com/miniconda/Miniconda3-latest-Linux-x86_64.sh)
上面的命令下载了一个 bash 脚本,我们现在运行它:
$ bash Miniconda3-latest-Linux-x86_64.sh
您需要查看许可协议。按下翻到底部,在那里你将键入yes同意它的条款。
接受并安装。在安装过程中,您可能需要接受或修改一些设置,但这应该很简单。您可能会收到此警告:
WARNING:You currently have a PYTHONPATH environment variable set. This may cause unexpected behavior when running the Python interpreter in Miniconda3.For best results, please verify that your PYTHONPATH only points to directories of packages that are compatible with the Python interpreter in Miniconda3: /home/klassm/miniconda3
PYTHONPATH环境变量告诉您的系统在哪里寻找 Python 和适用的包。你可以检查这个被设置到什么目录。在 Linux 上:
$ echo $PYTHONPATH
列出该目录的内容后,我发现它只用于少量系统范围的站点包。我认为不重新分配我的PYTHONPATH变量是安全的。
退出并返回以重置外壳。康达已经把你安置在它的“基础”环境中。

请注意命令行前面的“(base)”。
现在conda应用程序已经安装好了,可以从命令行使用了。我可以通过键入以下内容来验证这一点
$ conda
在命令行中。您应该会看到如下所示的输出:
usage: conda [-h] [-V] command ...conda is a tool for managing and deploying applications, environments and packages.Options:positional arguments:...
创建虚拟环境
现在我们来创建一个深度学习的虚拟环境。最佳实践是为每个项目创建一个虚拟环境。这样,您可以分离每个项目的所有依赖项。即使您认为您将重用相同的 Python 包,有时您将需要相同库的不同版本。事情会很快失去控制。帮你自己一个忙,创造一个虚拟的环境。
当你不在虚拟环境中运行 Python 代码时,我的反应是。
以下内容指导 Conda 创建一个名为“pytorch”的虚拟环境:
$ conda create -n pytorch
Conda 会让你知道它计划做什么,并询问你是否同意。同意继续。您应该会看到类似这样的内容:
## Package Plan ##environment location: /home/ec2-user/miniconda3/envs/pytorchProceed ([y]/n)? yPreparing transaction: done
Verifying transaction: done
Executing transaction: done
#
# To activate this environment, use
#
# $ conda activate pytorch
#
# To deactivate an active environment, use
#
# $ conda deactivate
使用以下命令激活 pytorch 环境
conda activate pytorch
您将注意到命令行中的“(base)”如何变成了“(pytorch)”,通知您现在处于新的虚拟环境中。
安装 CUDA(可选)
下一步是可选的。如果不打算在 GPU 上运行,可以直接跳到前面。
如果你计划在大型数据集上训练大型神经网络,GPU 几乎是必不可少的。由于其架构与 CPU 的不同,GPU 是运行大型并行矩阵计算的理想选择。顺便说一下,训练一个神经网络主要是矩阵计算。
CUDA 是 Nvidia 的一个库,允许开发人员与 GPU 进行交互。由于安装说明会因操作系统而异,请遵循 Nvidia 的安装指南中的说明。
安装软件包
现在安装您需要的 Python 包。Matplotlib 对于创建数据图很有用,但不是绝对必要的。
以下命令将安装这些包及其依赖项。这在我的机器上占用了大约 1 GB 的空间。
conda install -c conda-forge matplotlib pytorch torchvision
根据您的项目,您可能需要一些其他的 Python 库,如 scikit-learn 或 pandas。这些你可以用同样的方法轻松安装。
确认
让我们确保一切安装正确。打开 Python shell 并键入:
>>> import torch
>>> x = torch.rand(5,3)
>>> print(x)
这创建了一个填充了随机值的 5x3 维张量。输出应该如下所示:
tensor([[0.1279, 0.4032, 0.7045],
[0.2979, 0.1128, 0.7660],
[0.9651, 0.1172, 0.2716],
[0.9355, 0.1351, 0.3755],
[0.3469, 0.9118, 0.0110]])
全部完成
恭喜你!您已经为在 PyTorch 中运行深度学习工作负载做好了准备。
当然,现在由你来设计一个神经网络并训练它。注意你的计算成本。
警告
所以这个教程给人的印象是建立一个深度学习环境很容易,而且可以做到。然而,困难/冗长的部分是正确设置 CUDA。
避免任何头痛的最简单方法是从预配置的深度学习环境开始。有一些很好的资源可以帮你完成繁重的工作。
在 AWS 上,您可以从预先构建了所有必要的深度学习库和 CUDA 的 Amazon 机器映像启动 EC2 实例。选择 AMI 时只需搜索“深度学习”,你会发现几个选项。

为您的 EC2 实例选择 AMI 时,只需搜索“深度学习”。
为深度学习而预先配置的虚拟机也可以在谷歌的云和微软 Azure 上使用。使用你最喜欢的云。
当选择在哪种类型的机器上运行时,如果您打算利用 GPU,请记住选择一个连接了 GPU 的实例。使用完实例后,不要忘记关闭它们!这些机器运行起来往往很昂贵。
如果您只想在自己的机器上运行,另一个选择是使用一体化的预构建 Docker 映像。查看 Deepo 的一些例子。如果你家里有一个强大的钻机,这可能是更划算的选择。
在云上设置 PostgreSQL 实例,免费⛅
比较 AWS、GCP 和 Heroku 的“免费层”产品,以建立一个云 Postgres 实例。

在最近的一篇文章中,我详细介绍了如何开始使用本地安装的 PostgreSQL,使用 pgAdmin 和 SQLAlchemy 来建立数据库,加载数据并从 Python 脚本中查询数据。然而,有时候,仅仅有一个本地安装是不够的。如果我们想将一个 web 应用程序连接到我们的数据库,该怎么办?或者设置一个 ETL 过程,按照计划将数据从 API 提取到我们的数据库?
本文旨在向您展示任何人都可以完全免费地建立自己的云托管 Postgres 实例。我们将比较三大云提供商的产品:AWS、GCP 和 Heroku。
如果你想在继续之前看看我以前的文章,你可以在这里找到它:
Python 的 PostgreSQL、pgAdmin 和 SQLAlchemy 入门。将 SQL 融入 Python 的核心…
towardsdatascience.com](/a-practical-guide-to-getting-set-up-with-postgresql-a1bf37a0cfd7)
亚马逊网络服务

卢卡斯·坎波伊在 Unsplash 上的照片
AWS 自由层
AWS 可能是目前云计算领域最大的名字,它提供了一个丰富的“免费层”,非常适合想要学习和尝试预算的爱好者。在 12 个月里,我们可以免费使用所有这些。本文特别感兴趣的是,我们每月被提供 750 小时的 RDS,这是亚马逊的托管关系数据库服务。要访问 AWS 免费层,我们只需要注册一个帐户,并用信用卡验证;我们为期 12 个月的“免费层”访问将从此开始。
设置 RDS Postgres 实例
一旦您设置了 AWS 帐户并通过信用卡验证,要在 AWS RDS 上设置 Postgres 实例,我们只需从管理控制台导航到 RDS 页面,并填写简单的配置表单。

我们可以选择一个 Postgres 实例,然后选择“自由层”模板来开始。其他需要配置的重要选项有’‘和’ 备份’ ,,这两个选项都应该禁用,以防止我们超出可能会产生费用的限制。我们还需要导航到’ 附加连接配置 ’ ,并确保我们将’ 公共访问 ’ 设置为’ 是’ ,以允许我们从 EC2 实例外部访问数据库,即在我们的本地机器上。
为了连接到我们已经建立的数据库,我们首先需要从我们的 IP 地址启用入站流量。为此,我们可以编辑分配给 RDS 实例的安全组的’ 入站规则 ’ ,以允许来自’My IP’的流量。

一旦这一步完成,我们可以使用 pgAdmin 或 Python 连接到我们的数据库,正如我在之前的帖子中所解释的。我们所需要的是实例的端点和端口,这在我们的数据库页面的’ 连接性和安全性 ’ 部分中提供。
优势
- 免费一年(只要我们不超过使用限制)。
- 访问大量其他"免费层"云解决方案。
不足之处
- 如果你不小心,很容易超过使用限制。
- 需要信用卡详细信息才能注册。
GCP(谷歌云平台)

由 Pero Kalimero 在 Unsplash 上拍摄的照片
GCP 免费试用
谷歌云平台还有一个“免费试用”选项,相当于 AWS 免费层。尽管这里我们结合了两种产品:
首先,在注册和验证信用卡后,我们有资格在前 3 个月内获得 300 美元的固定预算。这样做的好处是,我们可以访问全套的谷歌云产品,因为我们只受限于我们账户上剩余的点数,而不是特定的产品。我们在这里还增加了安全性,我们不能在不知不觉中超过使用限制,因为我们必须明确地将我们的帐户升级到要收费的“付费帐户”(见此处)。
除此之外,如果我们升级到“付费账户,谷歌还提供几个“永远免费的产品。这些以类似于 AWS 免费层的方式运作,每月有津贴。只要我们保持在使用限制范围内,我们就不会被收费,而且我们还有一个额外的好处,那就是这项服务没有截止日期;与 AWS " 免费层"不同,我们的访问权限永远不会过期,我们可以无限期地继续使用我们的配额。然而不幸的是,Postgres 不包括在 Google 提供的“永远免费的”产品中,因此,为了本文的目的,我们将限于 3 个月的“免费试用”选项。
设置云 SQL Postgres 实例
要启动并运行 Postgres,我们只需创建一个新项目,在导航菜单中选择“ SQL ”,并选择一个 Postgres 实例。和以前一样,我已经禁用了自动备份功能以降低成本。

同样,我们需要允许访问我们的 IP 地址,以便我们可以在本地连接到这个实例。为此,我们可以导航到“ 连接” ,在“ 公共 IP ”下,我们可以添加我们希望允许访问的 IP 地址。

我们可以在实例页面的"【Connect to this instance】、 下的" Overview" 部分中找到实例的公共 IP 地址,它与端口一起允许我们以通常的方式连接到数据库。
优势
- 没有不必要费用的机会(除非我们明确升级到“付费账户”)。
- 获得全套 GCP 产品。
不足之处
- 试用仅持续 3 个月。
- 一旦我们的信用没了,就永远没了。
赫罗库

Heroku 自由层
Heroku 与我们之前讨论的两个例子略有不同,它更像是一个 PaaS(平台即服务),而不是一个云服务提供商。它倾向于提供更多可管理的、低配置的服务,如果你刚开始接触云技术领域,这很好,但是如果你是一个经验丰富的开发人员,这就有点限制了。对于给定的任务,Heroku 通常也会比 AWS/GCP 更昂贵,尽管它的简单性使它非常容易启动和运行——消除了 AWS 和 GCP 服务的广度有时可能带来的选择悖论。Heroku 还有一个额外的好处,它的“免费层”不需要信用卡验证,因此如果你担心产生费用,它提供了一个安全的赌注。也就是说,Heroku 在其" Free Tier " Postgres 实例中的 10,000 行限制对我们实际上可以用它做什么造成了很大的限制,使得它不太可能在项目中有用,除了简单的实验。
设置 Heroku Postgres

建立一个 Heroku Postgres 数据库。
建立一个 Heroku Postgres 数据库再简单不过了。首先,我们需要在 Heroku 建立一个账户(不需要信用卡验证,但如果我们这样做,我们会得到额外的好处)。我们可以创建一个新的应用程序来存放我们的数据库,并导航到data.heroku.com,在那里我们可以指定我们想要设置一个 Heroku Postgres 实例。然后,我们可以安装,将我们的数据库分配给我们创建的应用程序,并检查“ 设置 ”选项卡以显示我们的数据库凭证。
从这一点开始,与 pgAdmin 连接并查询我们的数据库的过程与 GCP 和 AWS 相同(在我以前的文章 中解释过,这里 )。这里唯一的警告是,我们需要将数据库访问限制到我们凭证中的特定数据库名称,否则我们将会看到许多其他数据库以及我们自己的数据库。

正在连接 Heroku Postgres 并使用 pgAdmin 限制 DB。
优势
- 不需要卡验证。
- 不可能被收费,除非我们特别选择付费选项。
不足之处
- 限于 10,000 行
- Heroku 只提供 GCP 或 AWS 上可用服务的一小部分。
结论

图片来自 Pixabay
现在我们已经看到了三种方法,通过这三种方法我们可以建立一个云托管的 Postgres 实例,根据您的需求和舒适程度,这三种方法各有利弊。
总的来说,如果你愿意遵守使用限制,我会推荐 AWS,因为我们有全年访问 RDS 和一套其他“免费层”服务的优势。如果你想在收费上更安全一点,但又拥有 AWS 提供的同等灵活性和成套服务,GCP 可能是一个不错的中间选择。最后,如果你是一个完全的初学者,或者想在没有信用卡验证承诺的情况下使用云 Postgres 数据库,Heroku 可能是一个很好的起点。
感谢阅读!
如果你喜欢这篇文章,可以看看我的其他文章:
Python 的 PostgreSQL、pgAdmin 和 SQLAlchemy 入门。将 SQL 融入 Python 的核心…
towardsdatascience.com](/a-practical-guide-to-getting-set-up-with-postgresql-a1bf37a0cfd7) [## 聪明的方法是找到一个杂货递送点
使用 Python、Heroku 和 Twilio 从一个杂货网站的 API 中抓取数据,并在出现插槽时获得文本通知…
towardsdatascience.com](/finding-a-grocery-delivery-slot-the-smart-way-f4f0800c4afe) [## 使用 GitHub 页面,通过 5 个简单的步骤免费创建一个网站
不到 10 分钟就能在网上建立你的个人投资组合网站。
towardsdatascience.com](/launch-a-website-for-free-in-5-simple-steps-with-github-pages-e9680bcd94aa)*


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言










{kind=link}