







为了更大的利益重组社交媒体平台
如果我们通过从零开始重新构建算法来重组社交媒体空间,以实现更好、更健康的公共辩论,会怎么样?

来源:艾琳娜·阿布拉热维奇/Shutterstock.com
从俄罗斯影响美国选举的虚假信息运动到假新闻和过滤泡沫,许多人认为社交媒体平台不再有利于健康的公共话语。
结果,数百家公司现在联合抵制价值数百万美元的脸书广告。抵制的目的?坚持认为社交媒体平台在监控仇恨言论方面做得更好。
这些公司和其他个人一样,认为这些社交媒体平台在我们的国家辩论中发挥着关键作用。随着这种强大的力量而来的是以积极的方式引导这些辩论的责任。
推荐引擎如何鼓励极端主义
这里有一个想法:如果我们通过从头开始重建算法来重组空间呢?
我们已经写了算法的公平性和组织如何在收集数据的早期阶段最好地避免有偏见的数据分析。但是现在我们要特别关注一个算法:推荐引擎。
根据许多媒体专家的观点,推荐引擎是社会两极分化的罪魁祸首。他们应该节省时间和寻找“正确选择”的书籍或文章阅读的焦虑。但通常它们最终会限制我们的选择和世界观。脸书和谷歌的个性化引擎并不是真正针对每个人的个性化。“为你推荐”是根据与你行为相似的用户提出推荐的算法。他们开发的目的不是真正的个性化,而是广告优化和推动收入。这是一个重要的区别。
这就是个性化引擎受到限制的原因。例如,一个纯粹出于对脸书的好奇而追随白人至上主义者的用户,将会在随后的一个月里获得充满极端主义内容的提要。或者真正想要阅读超出他们通常阅读习惯的内容的用户只能根据过去的偏好来阅读。或者为他的侄子买了婴儿礼物的用户现在被婴儿用品的日常销售淹没,尽管那些广告对他的日常生活没有用。
支持新算法的高质量网络数据
制造更好的个性化引擎的一个解决方案是收集高质量的网络数据并开发新的算法。
这里有几个例子:
- 耶鲁大学的一个团队设计了一个个性化引擎,目标是最小化两极分化的影响。他们的个性化引擎结果包括来自政治光谱两边的同等数量的文章。他们用来开发这种算法的数据集包括过去 30 天从 Webhose 的新闻 API 收集的新闻文章。
- 海是一个推荐引擎,它不像大多数推荐引擎那样从一个领域收集数据。相反,它整合了来自网飞、Hulu、Spotify 等一系列应用的数据集。它还使用人工智能根据你的个人品味和偏好进行推荐,而不是“与你相似的用户也喜欢什么。”
西蒙弗雷泽大学的另一组研究人员更进一步。他们决定尽可能地消除两极分化的内容——甚至在推荐引擎建议之前。他们在数据的帮助下建立了自己的算法,将真实的新闻文章与虚假的进行比较。这些假新闻来自俄罗斯互联网研究机构,而来自 Webhose 的真实新闻文章包括来自总共 172 个新闻来源的 2500 个数据项。研究的结果?一个假新闻检测器,可以在虚假信息发布之前识别出来。
努力让人们团结起来
像脸书和 Twitter 这样的社交媒体平台归根结底是受利润驱动的,它们的个性化引擎并不符合公众的最佳利益。但是健康的民主需要健康的空间——以及更健康的社交媒体平台——来进行公共辩论。对于 Webhose 来说,这意味着向组织提供网络数据,以便他们可以建立更公平的推荐引擎,将人们聚集在一起,而不是分裂他们。
如何建立一个像求职者跟踪系统(ATS)一样的简历推荐系统
一个人头。1000 份简历。先看哪个?

图片由经由 Shutterstock.com拍摄
2014 年,谷歌在其职业网站上有 7000 个职位空缺,在这些职位空缺中,该公司当年也收到了 300 万份简历。
现在,有很多简历需要筛选,只有不到 1%的申请人!毫无疑问,招聘是劳动密集型的,候选人越多,就越难筛选出最合格的候选人。随着公司的扩张和增长,招聘团队也随着公司的发展而增长,这可能会变得低效和昂贵。我们如何优化这种筛选这无数简历的劳动密集型过程?
目标
我们可以创建一个推荐系统,根据你的工作列表推荐最匹配的简历!

为此,我们将使用自然语言处理(NLP)技术来处理简历和工作列表,并按余弦相似度降序排列简历,以创建这个终极简历筛选工具!
自然语言处理是人工智能的一个分支,它允许计算机阅读、理解人类语言并从中获取意义。

图片由赖特工作室通过 Shutterstock.com 提供
方法
1.数据收集和简单 EDA
该数据集是在 Kaggle 上找到的,共有 8653 个求职者经历条目和 80000 个职位列表。请注意,这些申请人经历并不专门针对任何工作列表。
摘要
为了用这些数据制作一份简历,我将所有的工作经历按申请人 ID 连接起来。职位/经历不完整的简历被删除,以确保有足够的文本供以后建模。例如,对于applicant_id 10001,其工作描述显示为前三行的Nan,因此这些观察值将被删除,不会在数据集中考虑。

employer和salary对我们的推荐引擎没有帮助,所以我们也将它们移除。
工作说明

对于工作描述,为了简单起见,我只在工作列表的数据框中保留了job_title和job_description。正如你在上面的栏目列表中看到的,有很多关于工作地点的信息(city、State.Name、State.Code、Address、Latitude、Longitude),我们不会用这些信息来推荐简历。其余的专栏要么似乎没有为我们的用例增加很多价值,要么有很多缺失的价值。

2.文本预处理
文本预处理是清理和准备文本数据的实践。使用 SpaCy 和 NLTK,简历和工作描述将进行如下预处理:
- 停止单词删除
- 词性标注
- 词汇化
- 仅字母字符
因为经过预处理后,长度较短的简历变得更短,也就是少于 20 个单词。我已经决定删除少于 23 个单词的简历,以便在数据集中仍然有至少 1000 份简历,确保有足够的文本供模型训练。
3.矢量器
为什么选择词频-逆文档频率(TF-IDF)而不是计数矢量器(又称词频)?
Count Vectorizer 让流行词占据主导地位。有些词可能在一份简历中和所有简历中被多次提及,这使得这些词成为“流行”词。篇幅较长的简历也更有可能不止一次包含这些“流行”词汇。Count Vectorizer 得出结论,简历中提到的这些“流行”词彼此更相似,因为它更强调这些流行词,即使它们在我们的上下文中可能并不重要。
**TF-IDF 更看重生僻字。**没有在所有简历中提及,但只在这两份简历中出现的单词——表明这些文档可能比其他文档更相似。

在清理完所有文本后,将 TF-IDF 放在简历上以比较简历之间的相似性。我们已经设置了 2 个单词和 3 个单词的短语(二元和三元),每个短语需要在至少 12 个文档中出现,以便在以后作为主题出现。
4.主题建模(降维)
我尝试了 3 种不同的主题建模技术:潜在狄利克雷分配(LDA),潜在语义分析(LSA)和非负矩阵分解(NMF)。
一开始,我使用 LDA 和 pyLDAvis 来衡量简历中合适的主题数量、放入 TF-IDF 中的 grams/terms 数量以及包含 grams/terms 的最小文档数量。然后,对于每种主题建模技术,我创建了一个 UMAP,并检查了每个主题中的术语。似乎 LDA 对于主题具有最好的可分性。

下面是使用 PyLDAvis 创建的图表,它呈现了我们的主题建模的全局视图。

皮尔戴维斯图表
如何解读 pyLDAvis 生成的图表?
在左侧面板上,是包含 8 个圆圈的主题间距离图,这表明我们的简历数据集中有 8 个主题。每个主题都由最相关/最重要的术语组成,显示在图表的右侧面板中。右侧面板显示了与每个主题最相关的前 10 个术语。对于主题 2,一些最相关的术语是“销售助理”、“客户服务”、“回答问题”和“收银机”,这听起来像是零售业中潜在的销售角色。最后,蓝色条表示总的术语频率,而红色条表示该主题中的估计术语频率。
PyLDAvis 图表的目标是什么?
简而言之,您希望您的 PyLDAvis 图表看起来与我们这里的相似。
主题间距离图(左)— 请注意,每个圆圈的间距相当大,大小也差不多,这意味着每个主题几乎均匀地分布在文档(简历)中,并且这些主题都有自己独特的术语。然而,由于人们可以有不同层次的经验,例如,3 年后从管理员到数据科学家,主题仍然不可避免地有很少的术语相互重叠。
与主题 2(右)最相关的前 10 个术语— 您可以看到红色条非常接近填满蓝色条,这意味着这些术语大多在该主题中,与其他主题几乎没有重叠。
5.基于余弦相似度的推荐系统
最后,我们需要在工作描述和简历之间找到某种相似性。我在争论是用点积还是余弦相似度。见下面我的思维过程。
**余弦相似度是两个向量之间夹角的余弦,它决定了两个向量是否大致指向同一方向。**在我们的案例中,这些术语(我们之前在 TFIDF 中定义的二元和三元语法)是否同时出现在简历和职位描述中。

点积是两个向量的欧几里得幅度与它们之间夹角的余弦的乘积。除了术语出现,简历中出现术语的频率也会提升匹配度。

我们应该使用哪种相似性度量?
点积听起来像是一个双赢的局面,我们将考虑这些术语是否出现以及在每个文档中出现的频率。这听起来可能是一个好主意,但回想一下,这是我们之前试图避免的缺点(TF vs . TF-IDF)——把重点放在这些经常提到的词上。

想象一下 a 和 b 之间的点积,就好像我们正在将 a 投影到 b 上(反之亦然),然后取投影长度为 a ( | a |)与长度为 b (| b |)的乘积。
- 当 a 与 b 正交时,点积为零。***a到 b 的投影产生一个零长度的向量,因此零相似度**。*****
- 当 a 和b指向同一方向时,点积产生的最大值*。*****
- 当 a 和 b 指向相反方向时,点积产生最低值*。*****
点积将 大小 考虑在内,因此点积随着向量长度的增加而增加。为了归一化点积,然后将其除以归一化向量。输出是余弦相似度,它对于缩放是不变的,并且将值限制在-1 和 1 之间。余弦值为 0 表示这两个向量互成 90 度(正交)且不匹配。余弦值越接近 1,角度越小,向量之间的匹配度越大。
从上面的公式中可以看出, cos θ实际上就是两个向量的点积除以两个向量的长度(或幅度)的乘积。一般来说, cos θ根据矢量的方向来表示相似性。随着维数(也称为向量,也称为术语)的增加,这仍然成立,因此 cos θ是多维空间中一个有用的度量。**
例子
这是我找到的一份工作清单,“旧金山史泰博零售销售助理”。


 ********
********
未来的工作
将来,如果有更多的时间和对公司数据的访问,我愿意做以下事情来改进推荐引擎。
- 获取关于职位描述、候选人简历和其他内部信息的公司数据,例如,该角色的工作级别是什么?这是人事经理的角色吗?
- 一次对一个工作类别或角色的文本数据建模。由于该项目基于一个简历数据集,该数据集涉及广泛的工作职能,只有 1000 个观察值,因此主题主要是工作职能的更高层次的细分。当只对一个工作角色建模时,我们可以缩小主题范围,使其更具体地针对该角色,这可以带来更好的推荐引擎。
- 与招聘人员合作应用监督学习技术,使用筛选过的简历作为一个指标,表明这份简历是一份好的推荐。
- 与工程部门合作,应用用户反馈循环来持续改进推荐引擎。
用 Python 恢复筛选
Python 用于文本分析
分析空缺职位的候选人简历

图片由斯科特·格雷厄姆拍摄,可在 Unsplash 获得
介绍
写一份简历不是一件小事,尤其是在正确选择关键词的时候。人们花费数小时撰写和格式化完美的简历,希望它能被人才招聘专家阅读,并最终帮助他们获得工作面试。不幸的是,大约 75%提交的简历从未被人看到过。
由于大量的申请人和简历提交到职位发布,对于人才招聘专业人员来说,手动简历筛选过程变得繁琐、低效且耗时。因此,标准化的自动化筛选方法是必要的,以便根据背景、教育和专业经验更快地将合格的与不合格的候选人进行分类,从而以更高的效率和更准确的结果简化招聘流程。
筛选程序中的人工智能
人工智能以及文本挖掘和自然语言处理算法可以用于开发程序(即申请人跟踪系统),这些程序能够在几分钟内客观地筛选数千份简历,并根据阈值、特定标准或分数无偏见地确定最适合某个职位空缺的简历。
这些程序通常寻找特定的关键字;他们对简历进行分类和排名,以确定招聘人员应该进一步审查的工作申请。虽然每个公司可能都有自己的简历筛选系统,但对于候选人来说,了解他们如何根据他们申请的职位空缺来改进他们的关键词选择是至关重要的。
工程师简历筛选示例
由于我是工业和系统工程师,下面这个例子就落地在这个专业领域吧。在工业和系统工程领域,有广泛的集中领域,包括但不限于质量保证、运营管理、制造、供应链、物流、项目管理、数据分析和医疗保健系统。其中每一个都有相关的关键术语和概念,在工业和系统工程领域内众所周知。
尽管工业工程师必须具备每个集中领域的知识和背景,但通常建议他们在该领域的特定集中领域从事职业。此外,考虑到我们目前正处于专业化时代,招聘经理更有可能优先考虑在特定领域拥有强大背景、知识和经验的候选人,而不是“多面手”候选人。不幸的是,在候选人之间存在一种误解,即“擅长并精通”每一件事和在某一特定主题上“专业且高度熟练”。
对于以下示例,让我们构建一个简历筛选 Python 程序,该程序能够将关键字分类到六个不同的集中领域(例如,质量/六西格玛、运营管理、供应链、项目管理、数据分析和医疗保健系统),并确定工业和系统工程师简历中具有最高专业水平的一个。让我们在我的简历上测试一下,看看结果吧!
Python 代码
下面的 Python 代码将分为六个主要步骤。包含的注释行提供了简短的解释,并指导您完成编码过程。
步骤#1: PDF 文件打开、阅读和文本提取
步骤#2:文本清理
步骤#3:按区域设置的关键术语字典*
*免责声明:本词典每个领域中包含的关键术语是通过研究工业和系统工程职位招聘中最常见的关键术语获得的。该词典可以根据招聘经理的标准定制添加/删除关键术语。
步骤#4:计算每个区域的分数
步骤#5:用于最终分数创建的排序数据帧

分数汇总数据框
步骤#6:饼图创建
最终结果

简历筛选结果
成果解读
有意思。根据我的简历筛选结果,我的主要工业和系统工程集中领域是运营管理,其次是与数据分析相关的质量/六西格玛。结果显示了一定程度的医疗保健和项目管理角色的经验。
有两种可能的方法来分析这些结果。通过查看分数汇总数据框,招聘经理可以确定给定列表中每个集中区域包含了多少关键术语。另一方面,通过查看饼状图,招聘经理可以确定我的主要专注领域,并确定我在多大程度上可以被考虑从事与其他领域相关的工作。分数会受到每个集中区域的关键字数量的很大影响,这就是为什么强烈建议均匀分布关键字以避免对结果产生不希望的偏差。
如前所述,由招聘经理和人才获取专业人员来定义阈值、指标和分数,以确定候选人对于给定工作类型的资格。
现在轮到你了
试试看!在这里下载 Python 代码,加载 PDF 格式的简历并运行代码。根据简历找出你最强的工业和系统工程专长领域!
总结想法
在本教程中,我们已经经历了人工智能和文本挖掘在简历筛选程序中的许多可能应用之一。真正的申请人跟踪系统比这里内置的程序要复杂和先进得多;他们不仅浏览简历内容,还浏览简历格式。对于候选人来说,了解简历筛选系统如何击败他们,并让他们的简历被人才招聘专业人员查看是至关重要的。
科技使求职过程变得越来越容易和困难。大量的申请人和有限的机会迫使候选人写出能够击败“机器人”的优秀简历。强烈建议应聘者对简历关键词进行优化,以体现自己的软硬技能,避免包含流行语。不要放弃!努力完善你的简历,对你的技能和专业能力充满信心。祝你在求职过程中一切顺利!
— —
如果你觉得这篇文章有用,欢迎在 GitHub 上下载我的个人代码。也可以直接发邮件到rsalaza4@binghamton.edu找我,在LinkedIn找我。有兴趣了解工程领域的数据分析、数据科学和机器学习应用的更多信息吗?通过访问我的媒体 个人资料 来探索我以前的文章。感谢阅读。
——罗伯特
简历—总结和匹配

艾玛·马修斯数字内容制作在 Unsplash 拍摄的照片
仅仅在17 周内,将近 5100 万美国人申请失业保险——这比大萧条期间申请失业保险的人数还要多。随后,找到一份符合自己兴趣的合适工作并不容易。因为企业已经将业务转移到网上,从而造成了机会的匮乏。
显而易见,如果你在这里,你正在努力增加获得梦想工作的机会。然而,在 indeed.com、LinkedIn.com 或其他招聘网站上寻找新工作却是一项艰巨的任务。这种寻找需要没完没了地阅读职位描述,不断更新简历以适应感兴趣的组织需求。
我向你提交这个,如果有一种方法可以让机器总结并匹配你的简历和职位描述,会怎么样?而且,它给你提供了一个方向,你需要在这个方向上付出额外的努力。
让我们看看这是可能的还是只是一个想法。
总结
“说说你自己吧?”——这是一个臭名昭著的问题,但在招聘人员中很流行。一位招聘人员要求(或者至少已经要求我)更多地了解候选人的兴趣,并评估你是否适合这个角色。在这种情况下,一个人想要总结他们的简历,而不是按时间顺序背诵你的简历。
让我们在 Jupyter 笔记本中导入一些库。
# Import summarize from gensim
from gensim.summarization.summarizer import summarizefrom gensim.summarization import keywords# Import the library# to convert MSword doc to txt for processing.import docx2txt
现在让我们阅读和理解你和你的有趣的立场。
# Store the resume in a variableresume = docx2txt.process(“babandeep.docx”)text_resume = str(resume)#Summarize the text with ratio 0.1 (10% of the total words.)summarize(text_resume, ratio=0.1)
丰富的有监督和无监督机器学习模型经验-回归:线性,逻辑,套索,岭,分类器:SVM,K-NN,决策树,感知器,随机梯度下降生成:朴素贝叶斯,LDA,集成:随机森林,XgBoost,GBM,无监督:K-means,DBSCAN,分层聚类,深度学习:CNN,RNN (LSTM,比尔斯特姆)。\ n 利用 python 中的 SVM、决策树、k-NN、逻辑回归(使用 t 检验、卡方检验、单变量和双变量分析)\ n 利用朴素贝叶斯分类器、集成(随机森林)、回归(决策树、逻辑)和分类器(SVM、k-NN),在 r 中具有 87%的准确性
听起来很有希望:它很好地概括了我的简历的要旨和我所具备的重要的解决问题的能力。
这里我用了 机器学习工程师 来试试这个。
text = input(“ Enter Job description : “) # Prompt for the Job description.# Convert text to string formattext = str(text)#Summarize the text with ratio 0.1 (10% of the total words.)summarize(text, ratio=0.1)
输出:
“Triplebyte 每月筛选和评估数千名工程师,为我们的合作伙伴公司寻找最佳候选人。\作为一名机器学习工程师,您将负责设计和运行实验的端到端流程,以便为大规模生产模型提供服务。\ n 我们的一些管道使用现成的组件,但我们也在实施来自最新研究论文的自定义模型和技术。\ n 我们的最终目标是收集最大的数据集,并以此建立世界上最好的技术招聘流程。”
有趣的是,这是我正在调查的事情,只需一秒钟,我就可以了解这家公司以及他们的期望。
相称的
所以,现在我知道这家公司在期待什么,这就引出了下一个令人困惑的问题:我符合他们对理想候选人的描述吗?
# recycle the text variable from summarizing# creating A list of texttext_list = [text_resume, text]from sklearn.feature_extraction.text import CountVectorizercv = CountVectorizer()count_matrix = cv.fit_transform(text_list)
CountVectorizer:将一组文本文档转换成一个令牌计数矩阵。该实现使用 scipy.sparse.csr_matrix 生成计数的稀疏表示。如果您不提供先验词典,并且不使用进行某种特征选择的分析器,那么特征的数量将等于通过分析数据找到的词汇大小。
余弦相似度是什么?
余弦相似性是一种度量标准,用于衡量文档的相似程度,而不考虑其大小。在数学上,它测量的是在多维空间中投影的两个向量之间的角度余弦。余弦相似性是有利的,因为即使两个相似的文档相距欧几里德距离很远(由于文档的大小),它们仍有可能更靠近在一起。角度越小,余弦相似度越高。
from sklearn.metrics.pairwise import cosine_similarity# get the match percentage
matchPercentage = cosine_similarity(count_matrix)[0][1] * 100matchPercentage = round(matchPercentage, 2) # round to two decimalprint(“Your resume matches about “+ str(matchPercentage)+ “% of the job description.”)# outputYour resume matches about 33.33% of the job description.#keywordsprint(keywords(text, ratio=0.25))
# gives you the keywords of the job description
哦!我不是很匹配这份工作(33.33%或只有 1/3),即使我有所有需要的库和调制的经验。我最初认为这是成为一名机器学习工程师的核心要求,然而,现在我知道我必须专注于什么才能在 TripleByte 获得面试机会。
这种情况下我能做什么?
到目前为止,我想到了两种方法:
- 要么用职位描述的总结来更新我的简历。
- 使用关键字并将其纳入我的简历中,使我的相似度得分达到 80%以上。
后面的部分为我节省了更多的时间,这也是本文的主旨。
如果这种方法在任何方面对你有帮助,或者如果你有任何我们可以从中得出的见解,请随意留下评论。
在接下来的任务中,我计划将复制粘贴职位描述的过程自动化为爬行并节省更多时间,并且只显示最匹配的职位描述。
参考资料:
- https://sci kit-learn . org/stable/modules/generated/sk learn . feature _ extraction . text . count vectorizer . html
- https://www . machine learning plus . com/NLP/Cosine-similarity/#:~:text = Cosine % 20 similarity % 20 is % 20a % 20 metric,in % 20a % 20 multi % 2d dimensional % 20 space。
零售分析:寻找替代品和补充品的新颖而直观的方式
零售分析:零售数据科学

零售(弗兰克·科尔多瓦在 Unsplash 上拍照)
零售业向顾客出售商品和服务。有了大量可用的消费者购买历史,我们可以应用数据分析来正确预测库存需求、供应链移动、商品放置、推荐商品之间的关系等,这就创造了零售分析这一术语。
零售分析的一个重要部分是找到面包和黄油搭配以及牙膏和牙刷搭配等物品之间的关系。替代品是用于同一目的的不同品牌的替代产品。替代品的例子可以是茶和咖啡或不同品牌的牙膏(Pepsodent 和高露洁)。这几项基本都是彼此的竞争对手。另一方面,补品是一起购买和使用的物品。这些商品有助于提升客户购物篮中彼此的销售额。补充的例子可以是面包和黄油或航班和出租车服务等。
了解这种关系有助于做出有数据支持的决策。确定替代物和补充物后的可能优势是-
- 商店中的物品摆放。互补物品可以放在一起/更近。
- 在电子商务网站中,每当购买物品时,推荐其赠品,因为这些是一起购买的物品。
- 在一个项目不可用时,推荐它的替代品。
- 提供该商品及其补充品的组合报价,以提高销售额或清理库存。
- 每当某个商品的价格上涨/下跌时,监控对其替代品的销售/需求的影响。这有助于做出有意识和有计划的定价决策。
关联规则挖掘是数据挖掘技术的一个分支,它引入了像支持度、置信度、提升度、确信度、先验算法这样的概念,有助于发现这样的关系。通过这篇博文,我打算提出一种替代的、直观的方法来寻找项目关系。因此,一个人不需要有任何先验知识,因为这是一种新颖的方式,没有任何先决条件。
为了演示算法的工作和有效性,我们将在 Kaggle 的 Instacart 数据集上运行所提出的方案。使用的代码可以从这里下载。
寻找补充
补充品是通常一起购买的物品“X”和“Y”。找到这种商品对的一种策略是,在所有顾客购物篮中,找到一起购买“X”和“Y”的次数与购买“X”和“Y”的次数的比率。
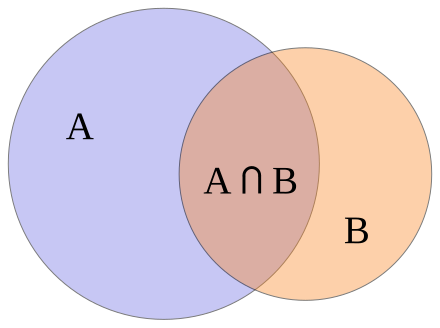
补码比率= (X ∩ Y)/(X ⋃ Y)
对于要成为补码的项目“X”和“Y ”,补码比率需要尽可能高。它的上限为 1。在所有的项目对中,我们将找到称赞率最高的项目对。
同样,从集合论中,我们知道,

集合 A 和集合 B 的并集(图像源

我们将从 Instacart 数据集找到跨部门的补充。我们先来看看数据集。

订单表快照
总共有 320 万份订单,这些订单中订购了 3240 万件商品。

产品表的快照
共有 49.6K 个不同的项目。

部门表快照
总共有 21 个部门。
接下来,我们将执行 orders 表的交叉连接,以查找商品一起购买的次数。我们还将它与 product 和 department 表连接起来,以查找产品的详细信息。按补码比率降序排列的最终输出表如下所示

结果快照(算法建议的补充)
让我们看看算法建议什么作为补充:



结果看起来真的很好。人们用碱化水购买甜叶菊透明甜味剂是有道理的,因为当与水混合时,几滴甜味剂会给它带来良好的味道。
类似地,人们更喜欢吃配有能量饮料的比萨饼和配有鹰嘴豆泥或洋葱蘸酱的皮塔饼或薯片。
寻找替代品
替代品是用于同一目的的不同品牌的替代产品。如果商品“X”和“Y”是彼此的直接竞争对手,并且人们通常会购买其中之一,那么它们就是替代品。一种商品价格的上涨或下跌不太可能以相反的方式影响其替代销售。
替代率=(X∩Y)/最小值(X,Y)
对于要替代的两个项目‘X’和‘Y’,我们倾向于替代率越低越好。
为什么公式中有最小值函数?
一些像香蕉或苹果这样的东西会很受欢迎,是许多篮子的一部分。最小函数有助于消除这种偏差,并使比较达到公平的标准。
我们将从 Instacart 数据集中找到同一部门的替代者。我们将执行 orders 表的交叉连接,以查找一起购买的商品与分开购买的商品的次数。我们还将它与 product 和 department 表连接起来,以查找产品的详细信息。按补码比率升序排序时,最终输出表如下所示

结果快照(算法建议的替代)
结果看起来不错。人们大多购买大型露天鸡蛋或有机大型棕色鸡蛋是有道理的。
同样,人们购买 2%的低脂牛奶或含有维生素 D 的有机牛奶或脱脂牛奶。
结论
通过这篇博文,我们找到了一种替代和直观的方法来寻找替代和补充。这些简单的指标给了我比寻找支持、信心、提升、信念或其他关联规则挖掘算法更好的结果。同样,这些指标非常直观,并且易于大规模实施。结果支持这些指标的良好性。数据集可以从 Kaggle 的 Instacart 数据集下载。使用的代码可以从这里下载。请点击这里查看我在零售分析上的另一篇有趣的帖子。
我的 Youtube 频道获取更多内容:
嗨,伙计们,欢迎来到频道。该频道旨在涵盖各种主题,从机器学习,数据科学…
www.youtube.com](https://www.youtube.com/channel/UCg0PxC9ThQrbD9nM_FU1vWA)
关于作者-:
Abhishek Mungoli 是一位经验丰富的数据科学家,拥有 ML 领域的经验和计算机科学背景,跨越多个领域并具有解决问题的思维方式。擅长各种机器学习和零售业特有的优化问题。热衷于大规模实现机器学习模型,并通过博客、讲座、聚会和论文等方式分享知识。
我的动机总是把最困难的事情简化成最简单的版本。我喜欢解决问题、数据科学、产品开发和扩展解决方案。我喜欢在闲暇时间探索新的地方和健身。在 中 、Linkedin或insta gram关注我,查看我以前的帖子。我欢迎反馈和建设性的批评。我的一些博客-****
- 统计决定胜负的力量
- 以简单&直观的方式分解时间序列
- 挑哪个?GPU 计算 vs Apache Spark 扩展您的下一个大任务
- GPU 计算如何在工作中真正拯救了我?
- 信息论& KL 分歧第一部分和第二部分
- 使用 Apache Spark 处理维基百科,创建热点数据集
- 一种基于半监督嵌入的模糊聚类
- 比较哪个机器学习模型表现更好
零售分析:寻找季节性商品的排序
零售分析:零售数据科学

Aj Povey 在像素上拍摄的照片
零售业向顾客出售商品和服务。我有在零售行业工作的经验,也写过一些关于零售分析的博客,可以在这里找到。
零售分析通过分析客户的购买历史来做出基于数据的决策。在这篇博文中,我想强调影响销售的因素,并对最受这些因素影响的项目进行排名。
这些商品的销售受到各种因素的影响,比如-
雨伞的销量在雨季会更多,而冰淇淋的销量在夏季会更多。同样,促销/折扣或一些特殊事件,相同的百分比折扣可能导致项目“X”和“Y”的不同销售,这取决于它们的季节性。通过这篇博客,我打算建议一种根据季节性给物品排序的方法。这不是一件小事,它有自己的挑战。我会列出挑战和应对方法。敬请期待,阅读愉快。
为了证明该方法的工作和有效性,我们将在 Kaggle 的商店商品需求预测挑战赛上运行提议的方案。使用的代码可以从这里下载。
根据季节性对项目进行排序的挑战
1.销售规模
第一个挑战是不同商品的销售规模。商品“X”在正常季节的销量可能达到 10 件,在最有利的季节可能达到 100 件。而另一方面,在正常到最有利的季节中,一些其它商品“Y”的销售可能从 100 到 1000 不等。
2.不同项目的季节不同
不同的项目有不同的有利季节。例如,雨伞的最佳季节是雨季,而冰淇淋的最佳季节是夏季。同样,毛毯在冬天卖得更多,火鸡在感恩节卖得更多。
我们的目标是想出一种方法,能够解决所有这些挑战,并根据它们随季节的变化对项目进行排序。我们打算最终根据物品的季节性对它们进行排序。
季节性项目的排序方法
方法是-
- 首先,为每个项目找到一个月度季节指数。月指数是用月销售额除以平均销售额得到的。作为这一步的结果,我们得到每个月每个项目的 12 个值。由于月度季节性指数是比率,因此可以跨项目进行比较。
- 接下来,为每个项目计算季节指数的方差/标准差。作为这一步的结果,我们将得到每个项目的一个值,即每月季节性指数的方差/标准差。
- 根据项目的方差/标准差对项目进行排序。方差/标准差最大的项目是季节性最强的项目。
此外,由于这一点,我们得到了一个根据季节性排序的项目。
实施和测试该方法
我们将在 Kaggle 的商店商品需求预测挑战上测试该方法。我们先来看看数据集。

资料组
该数据集由 2013 年 1 月至 2017 年 12 月的商店商品销售数据组成。总共有 50 个项目和 10 个商店。
在本练习中,我们将筛选与商店 1 和 2017 年相对应的数据。过滤后的数据如下所示。

1 号店和 2017 年的数据
接下来,我们计算每个项目的月度季节指数。
用于合计销售额并计算商品月度季节性指数的 Python 代码
某项商品的月度季节性指数看起来像-

项目 1 的月度季节性指数
接下来,我们计算所有 50 个项目的月度指数的方差和标准差。按方差/标准差降序排列的项目的最终排名如下

根据每月季节性指数的变化对所有 50 个项目进行排名
该方法建议列表中的 项 47 最具季节性(易出现高方差) 项 5 最不具季节性。让我们把结果可视化来检查一下

销售&项目 5 月度季节性指数

第 5 项的销售额如何变化

销售&第 47 项月度季节指数

第 47 项的销售变化
从图中可以明显看出,第 47 项的销售偏离比第 5 项更大。与项目 5 的平坦曲线相比,项目 47 具有更多的峰值和谷值。此外,项目 47 的最低和最高月销售额之间有 101.9%的涨幅(最低 451 个单位,最高 911 个单位),而项目 5 的最低和最高月销售额之间只有 71.7%的涨幅(最低 407 个单位,最高 699 个单位)。因此,该算法在根据季节性对项目进行排序方面做得很好。该方法中季节性最强和最弱商品的图表和销售数据也表明了同样的情况。
我的 Youtube 频道获取更多内容:
嗨,伙计们,欢迎来到频道。该频道旨在涵盖各种主题,从机器学习,数据科学…
www.youtube.com](https://www.youtube.com/channel/UCg0PxC9ThQrbD9nM_FU1vWA)
结论
在这篇博客文章中,我们设计了一种根据季节性对物品进行排序的方法。存在挑战,但这种方法能够解决这些问题。通过该方法得到的季节性最强和最弱商品的图表和销售数据证明了该方法的有效性。该数据集可从 Kaggle 的商店商品需求预测挑战中下载。使用的代码可以从这里下载。
关于作者:
Abhishek Mungoli 是一位经验丰富的数据科学家,拥有 ML 领域的经验和计算机科学背景,跨越多个领域并具有解决问题的思维方式。擅长各种机器学习和零售业特有的优化问题。热衷于大规模实现机器学习模型,并通过博客、讲座、聚会和论文等方式分享知识。
我的动机总是把最困难的事情简化成最简单的版本。我喜欢解决问题、数据科学、产品开发和扩展解决方案。我喜欢在闲暇时间探索新的地方和健身。在 Medium 、 Linkedin 或 Instagram 关注我,查看我的以前的帖子。我欢迎反馈和建设性的批评。我的一些博客-
- 零售分析:寻找替代品和补充品的新颖而直观的方式
- 统计决定胜负的力量
- 以简单直观的方式分解时间序列&
- 挑哪个?GPU 计算 vs Apache Spark 扩展您的下一个大任务
- GPU 计算如何在工作中拯救了我?
- 信息论& KL 分歧第一部分和第二部分
- 使用 Apache Spark 处理维基百科,创建热点数据集
- 一种基于半监督嵌入的模糊聚类
- 比较哪种机器学习模型表现更好
零售客户分析
在线零售商客户细分和分析
介绍
在本文中,我们将对一个在线零售店数据集进行探索性分析,以了解其客户。让我们假设,我们拥有一家经营得非常好的零售店,我们想找到一种高效和有效地扩展业务的方法。为了做到这一点,我们需要确保我们了解我们的客户,并根据我们客户的特定子集定制我们的营销或扩展工作。在这种情况下,主要的业务问题是“我如何以最有效的方式扩展我目前做得非常好的业务?”。支持主要业务目标的子问题可能是“为了获得最佳投资回报,我们可以为每个客户执行什么类型的营销计划?”。
关于数据
数据集是一个非常常见的数据集,可以在许多公开可用的数据源中找到,旨在用作在线零售商店数据的示例。每个变量的描述都是简单明了的。
数据收集和清理



缺少 1454 个“描述”和 135,080 个“客户 ID”值。保留缺失的“描述”值不会对分析产生任何影响,因为我们将专注于了解我们的客户。基于每个缺失的“CustomerID”代表一个新客户的假设(意味着缺失的“CustomerID”值对于数据集是唯一的),我们还可以假设缺失的“CustomerID”值也不会对我们的分析产生任何影响。
我们注意到“InvoiceDate”数据类型是 object,需要更新为 Date 数据类型。我们还可以从“InvoiceDate”变量中获取月份和年份,并创建带有“InvoiceMonth”和“InvoiceYear”的新列。
我们加载了在线商店数据集,并对其进行了少量清理。我们可以进一步分析客户。
数据探索
最初,我们将执行基本的探索性统计分析,以了解变量分布。此外,我们将了解我们在客户中的收入情况。谈到在线零售商店的商业模式,收入是最常见和最重要的指标之一。我们希望确保我们的收入增长,因为我们正在定义我们业务的可扩展性。




当我们查看月度收入增长时,我们意识到我们的数据集从 2010 年 12 月开始,一直到 2011 年 12 月。我们注意到收入在 2011 年 12 月左右下滑。我们需要了解这是由于客户没有购买我们的商品,还是与数据集中的问题有关。

根据 2011 年 12 月的数据,我们了解到该数据集不包括 2011 年 12 月 9 日之后的任何购买。我们需要确保在我们的分析和结论中考虑到这一点。
单独说明;我们可以看到,从 2011 年 9 月到 2011 年 12 月,收入稳步增长,11 月是收入最好的月份。



正如预期的那样,每月售出的商品、每月活跃用户和每月平均收入与每月收入增长呈正相关。

在大多数情况下,除了级别之外,我们看到新客户和现有客户的正收入增长和负收入增长是一致的。然而,当我们查看 2011 年 1 月至 2 月和 10 月至 11 月的收入时,我们发现即使现有客户收入增长,新客户收入却下降了。
客户细分
我们根据收入、活动、新客户和现有客户的月收入分析了我们的客户,我们肯定有一些可以采取行动的见解。我们还可以对客户进行细分,以便根据我们正在努力解决的主要业务问题来确定我们的行动目标。
我们将使用 RFM(近期、频率和货币价值)策略来分析和评估每个客户的价值,并相应地进一步细分他们。通过查看最近发生的事情,我们可以了解客户购买的时间、频率以及购买的频率,而货币价值可以让我们了解他们消费的频率。





我们将客户分为 4 个不同的类别,从 0 到 4。集群 0 中有 524 个客户,集群 1 中有 2157 个客户,集群 2 中有 632 个客户,集群 3 中有 1059 个客户。当我们比较最近时,聚类 0 是表现最好的客户集,而聚类 1 是表现最差的客户集。
我们可以进一步考察频率,并根据客户的购买频率对他们进行细分。




根据频率,分类 0 的客户最多,分类 2 的客户最少。基于这种划分,我们看到聚类 0 的客户频率最低,但客户数量最多。
最后,我们可以根据客户的货币价值对他们进行细分。



结论
通过新近性、频率、货币价值细分和我们对客户的探索性分析,我们可以进一步决定我们产品的购买周期,确定我们营销活动的优先顺序和定义。例如,我们可以查看我们当前的营销活动、库存购买策略和 1 月和 10 月的运营,看看我们是否可以吸引更多的新用户,以便将新用户的负收入增长转变为正收入增长。我们可以调查历史营销活动,以了解它们对每个新近性和频率群集的影响。我们可以进一步将此应用于我们的主要业务目标,以扩大业务规模。我们还可以为 RFM 的每个类别分配 1-10 分。例如,如果客户一年没有购物,他们的最近得分为 1,如果他们在上个月购物,他们的最近得分为 10。我们可以进一步将每个类别的所有分数相加,并为每个聚类创建一个客户价值。这些行动将极大地有助于我们在业务可扩展性方面取得成功。
零售预测(天气的影响)
为您的企业提供一些方便的基于 R 的统计数据

我最近和一个潜在的零售客户通了电话,他们表示怀疑天气影响了他们的销售。“完全正确,”我想,“人们对不同的天气会有不同的反应。当然可以。”这当然不是他们的主要关注点,更多的是好奇,但我仍然想知道我将如何着手调查这个问题(并通过快速转身产生一个有意义的答案)。
从他们的 POS 上可以很容易地获得汇总的销售数据,每天的天气数据也是可用的,按位置,从 BOM (每小时会更好,所以我们可以知道天气事件是发生在之前还是在工作时间内*——但现在保持事情简单)。*
很明显,这是一个统计学问题,而我这个数学呆子热衷于研究这个问题。但是,当然,在我们去那里之前,我必须思考“那又怎么样?”问题:
他们在此类调查中的投资会有什么回报?
这一知识能为哪些业务行动提供信息?
也许意识到他们可能会忙一天,可以让他们安排一个额外的员工。相反,在一个安静的日子里,他们可能会在展示中少放一些易腐的“小玩意”。
天气的影响(我们现在主要关注降雨)只是他们对导致销售波动的原因的更广泛理解的一个方面。每一个“位”信息,指导他们的业务优化,减少“惊喜”。这个特定“位”的即时值实际上取决于所发现的效应大小。因此,快速,低预算的调查将是出路。
我继续进行并生成了一些虚拟数据,供我们进行一个假想的(但仍然真实的)调查。
让我们首先保持我们的焦点非常简单。在下图中,每一天都是一个点。

“最佳拟合线”显示出非常轻微的上升趋势。我们可以通过统计来确定这一趋势。

在一年的时间里,平均日销售额增加了 20 (0.0539 * 365 = 19.6)。好样的。
但这种上升趋势可能只是因为有或多或少的雨天(以及对客户的相应影响),而不是你所有的辛勤工作!
在上图中,很难说雨天和非雨天是否有明显的区别。在下面的图表中,多雨的分布似乎稍微向右移动了一点(表明更多的销售)。

下图向我们展示了差异确实存在。

一般来说,雨天更有利于销售。我们可以通过另一个简单的回归来检测这是否具有“统计显著性”。

是的(p.value < 0.05).
If we were going to guess the number of sales, our results would certainly be more accurate if we included our rainy day feature. The trend (from the day_index) has also stayed significant -so we can say that the increasing trend is independent of the rate of rainy days.
It looks like rain adds 34.5 extra sales to a day. We could bring in the standard error measurement to qualify that statement a bit, by saying that, 大部分时间 (~95%的时间),下雨会给一天增加 23 到 45 的额外销售额(34 +/- 1.96*5.71)。
但是这种“额外的降雨”可能会被其他一些我们已经知道的因素减轻,比如一周中的某一天。

我们可以看到一个非常一致的模式。每一天都有不同的表现;而且,在这些天里,我们可以看到更高值的雨天。除了星期五。
下面的回归向我们展示了影响。

对于这些数字,我们的基本估计是一个不下雨的星期一(在我们时间线的开始)。我们可以看到,即使给定了一周中的某一天以及我们在时间轴上走了多远,雨仍然会产生“显著”的影响。
周二的销售额通常比周一多 21.9 倍。
周三通常比周一多 48.7 英镑,等等……
……无论哪一天下雨,通常都会增加 41.2 英镑的额外销售额。
所以现在,我们对下雨影响的猜测从 34.5 变成了 41.2 额外销售。
但是上面的模型没有考虑到这样一个事实:星期五**,下雨有不同的影响。我们需要添加一个工作日/雨天的“互动”。**

这里我们可以看到模型中的重要术语。
星期几系数略有变化。我们可以看到 rain 现在为任何一天增加了 56.2 的销售额。周五除外,周五导致销售额下降约 43.8(56.2–100)。
太棒了。
所以,这代表了我可以舒服地向客户展示的复杂程度。这也代表了“虚拟”销售数据中的全部效果(因为是我自己在编写数据时放进去的)。
还有更复杂的模型和更有趣的“特征”有待研究:
- 降雨量(或何时下雨)有影响吗?
- 连续几天下雨有影响吗?
- 忙碌的一天会影响第二天的销售吗?
此外,还有要问的“如果”问题,例如“如果我们在雨天叫一个额外的员工怎么办?这有什么影响?”
简单模型的好处是,你可以非常快速和(相对)容易地对你正在处理的效果大小有一个清晰的认识。
从那里,更容易确定增加调查是否可能导致更有利可图的商业决策,从而值得额外的投资。
通常,业务的其他方面也需要类似的基本可见性。
对于那些好奇的人,我的代码可以在下面找到。
通过在 GitHub 上创建一个帐户,为 Tadge-Analytics/天气对零售销售的影响的发展做出贡献。
github.com](https://github.com/Tadge-Analytics/weather-impact-on-retail-sales)**
原载于 2020 年 6 月 27 日 https://tadge-analytics.com.au。****
重新思考数据科学的持续集成
数据科学软件工程
软件工程中广泛使用的实践应该在我们的领域中有自己的风格

前奏:数据科学中的软件开发实践
随着数据科学和机器学习得到更广泛的行业采用,从业者意识到部署数据产品会带来高昂的(往往是意想不到的)维护成本。正如斯卡利和合著者在他们著名的论文中所说:
(ML 系统)具有传统代码的所有维护问题,外加一组 ML 特有的问题。
矛盾的是,尽管数据密集型系统比传统的软件系统有更高的维护成本,但是软件工程的最佳实践却常常被忽视。根据我与其他数据科学家的交谈,我认为这种做法被忽略了,主要是因为它们被视为不必要的额外工作,原因是动机不正确。
数据项目的最终目标是影响业务,但是这种影响在开发过程中很难评估。仪表板会产生多大的影响?预测模型的影响如何?如果产品尚未投入生产,则很难估计业务影响,我们不得不求助于代理指标:对于决策工具,业务利益相关者可能会主观判断新的仪表板在多大程度上可以帮助他们改善决策,对于预测模型,我们可以根据模型的性能进行粗略估计。
这导致工具(例如仪表板或模型)被视为数据管道中唯一有价值的部分,因为它是代理指标所依据的。结果,大部分时间和精力都花在了尝试改进这个最终的可交付成果上,而所有之前的中间步骤得到的关注较少。
如果项目进入生产阶段,根据整体的代码质量,团队可能需要重构大量的代码库以准备投入生产。这种重构的范围可以从做小的改进到彻底的检修,项目经历的变化越多,就越难重现最初的结果。所有这些都可能严重推迟或危及发射。
一个更好的方法是始终让我们的代码随时(或几乎随时)准备好部署。这需要一个工作流来确保我们的代码得到测试,并且结果总是可重复的。这个概念被称为持续集成,是软件工程中广泛采用的实践。这篇博文介绍了一个经过修改的 CI 过程,它可以通过现有的开源工具有效地应用于数据项目。
摘要
- 将您的管道组织成几个任务,每个任务将中间结果保存到磁盘
- 以可以参数化的方式实现管道
- 第一个参数应该对原始数据进行采样,以便进行快速的端到端测试
- 第二个参数应该改变工件的位置,以分离测试和生产环境
- 在每次推送时,CI 服务都会运行单元测试来验证每个任务内部的逻辑
- 然后使用数据样本执行流水线,集成测试验证中间结果的完整性
什么是持续集成?
持续集成(CI)是一种软件开发实践,在这种实践中,小的变化被持续地集成到项目的代码库中。每一项变更都会被自动测试,以确保项目在生产环境中按照最终用户的预期运行。
为了对比传统软件和数据项目之间的差异,我们比较了两个用例:一个在电子商务网站上工作的软件工程师和一个开发数据管道的数据科学家,该管道输出每日销售额报告。
在电子商务门户用例中,生产环境是实时网站,最终用户是使用它的人;在数据管道用例中,生产环境是运行日常管道以生成报告的服务器,而最终用户是使用报告为决策提供信息的业务分析师。
我们将数据管道定义为一系列有序的任务,其输入是原始数据集,中间任务生成转换后的数据集(保存到磁盘),最终任务产生数据产品,在这种情况下,是具有每日销售额的报告(但这也可以是其他东西,如机器学习模型)。下图显示了我们的每日报告管道示例:

作者图片
每个蓝色块代表一个管道任务,绿色块代表一个生成最终报告的脚本。橙色块包含原始源的模式。每个任务生成一个产品:蓝色块生成数据文件(但也可以是数据库中的表/视图),而绿色块生成带有图表和表格的报告。
数据科学的持续集成:理想的工作流
正如我在序言中提到的,数据管道中的最后一个任务通常是最受关注的(例如,机器学习管道中的训练模型)。毫不奇怪,现有的关于数据科学/机器学习的 CI 的文章也关注这一点;但是为了有效地应用 CI 框架,我们必须考虑整个计算链:从获取原始数据到交付数据产品。不承认数据管道具有更丰富的结构,会导致数据科学家过于关注最末端,而忽略其余任务中的代码质量。
根据我的经验,大多数错误都是在这个过程中产生的,更糟糕的是,在许多情况下,错误不会破坏管道,但会污染您的数据并损害您的结果。每一步都应该同等重要。
让我们通过描述提议的工作流来使事情更加具体:
- 数据科学家推动代码变更(例如,修改管道中的一个任务)
- 推送触发 CI 服务端到端地运行管道,并测试每个生成的工件(例如,一个测试可以验证
customers表中的所有行都具有非空的customer_id值) - 如果测试通过,接下来是代码审查
- 如果审阅者批准了更改,则合并代码
- 每天早上,“生产”管道(主分支中的最新提交)端到端运行,并将报告发送给业务分析师
这种工作流程有两个主要优点:
- 早期缺陷检测:缺陷是在开发阶段检测到的,而不是在生产阶段
- 总是生产就绪:由于我们要求代码更改在集成到主分支之前通过所有测试,我们确保我们可以通过在主分支中部署最新的提交来持续部署我们最新的稳定特性
这个工作流程就是软件工程师在传统软件项目中所做的。我称之为理想的工作流程,因为如果我们能够在合理的时间内完成端到端的管道运行,我们就会这么做。由于数据规模的原因,这对于很多项目来说是不正确的:如果我们的管道需要几个小时来端到端地运行,那么每次我们做一个小的改变时都运行它是不可行的。这就是为什么我们不能简单地将标准 CI 工作流(步骤 1 至 4)应用于数据科学。我们将做一些改变,使它对于运行时间是一个挑战的项目是可行的。
软件测试
CI 允许开发人员通过运行自动化测试来持续集成代码变更:如果任何测试失败,提交将被拒绝。这确保了我们在主分支中总是有一个工作项目。
传统的软件是在小的、很大程度上独立的模块中开发的。这种分离是很自然的,因为组件之间有明确的界限(例如注册、计费、通知等)。回到电子商务网站用例,工程师的待办事项列表可能是这样的:
- 人们可以使用电子邮件和密码创建新账户
- 可以通过向注册的电子邮件发送消息来找回密码
- 用户可以使用以前保存的凭据登录
一旦工程师编写了支持这种功能的代码(甚至更早!),他/她将通过编写一些测试来确保代码工作,这些测试将执行被测试的代码并检查它是否如预期的那样运行:
但是单元测试不是唯一的测试类型,我们将在下一节看到。
测试级别
软件测试有四个级别。理解这些差异对于为我们的项目开发有效的测试是很重要的。在这篇文章中,我们将关注前两个。
单元测试
我在上一节中展示的代码片段被称为单元测试。单元测试验证单个单元工作。对于单元没有严格的定义,但是它通常等同于调用一个单独的过程,在我们的例子中,我们正在测试create_account过程。
单元测试在传统的软件项目中是有效的,因为模块被设计成在很大程度上相互独立;通过分别对它们进行单元测试,我们可以快速查明错误。有时,新的变化破坏测试不是因为变化本身,而是因为它们有副作用,如果模块是独立的,它给我们保证我们应该在模块的范围内寻找错误。
拥有过程的效用在于,我们可以通过使用输入参数定制它们的行为来重用它们。我们的create_account函数的输入空间是所有可能的电子邮件地址和所有可能的密码的组合。组合的数量是无限的,但是可以合理地说,如果我们针对有代表性的数量的情况来测试我们的代码,我们就可以得出结论,这个过程是可行的(如果我们发现一个不可行的情况,我们就修正代码并添加一个新的测试用例)。在实践中,这归结为针对一组代表性案例和已知边缘案例的测试过程。
假设测试以自动化的方式运行,我们需要一个通过/失败的标准。在软件工程术语中,这被称为测试 oracle 。提出好的测试预言对测试来说是必不可少的:测试在评估正确结果的程度上是有用的。
集成测试
第二个测试级别是集成测试。单元测试有点简单,因为它们独立地测试单元,这种简化对效率是有用的,因为不需要启动整个系统来测试它的一小部分。
但是当输入和输出跨越模块边界时,有时会出现错误。尽管我们的模块在很大程度上是独立的,但它们仍然必须在某个点上相互交互(例如,计费模块必须与通知模块对话才能发送收据)。为了在这个交互过程中捕捉潜在的错误,我们使用集成测试。
编写集成测试比编写单元测试更复杂,因为需要考虑更多的元素。这就是为什么传统的软件系统被设计成松散耦合的 T2,通过限制交互的数量和避免跨模块的副作用。正如我们将在下一节中看到的,集成测试对于测试数据项目是必不可少的。
有效测试
编写测试本身就是一门艺术,测试的目的是在开发过程中尽可能多地捕捉错误,这样它们就不会出现在产品中。在某种程度上,测试是模拟用户的行为,并检查系统是否如预期的那样运行,因此,有效的测试是模拟现实场景并适当评估系统是否做了正确的事情。
有效的测试应该满足四个要求:
1。当用户与系统交互时,系统的模拟状态必须代表系统
测试的目标是防止生产中的错误,所以我们必须尽可能接近地表现系统状态。尽管我们的电子商务网站可能有几十个模块(用户注册、账单、产品列表、客户支持等),但它们被设计成尽可能独立,这使得模拟我们的系统更容易。我们可以说,当新用户注册时,有一个虚拟数据库就足以模拟系统,任何其他模块的存在或不存在都不会对被测试的模块产生影响。组件之间的交互越多,就越难在生产中测试真实的场景。
2。输入数据代表真实的用户输入
当测试一个过程时,我们想知道给定一个输入,这个过程是否做了它应该做的事情。由于我们不能运行每一个可能的输入,我们必须考虑足够多的情况来代表常规操作以及可能的边缘情况(例如,如果用户使用无效的电子邮件地址注册会发生什么)。为了测试我们的create_account过程,我们应该传递一些常规的电子邮件帐户和一些无效的帐户,并验证是否创建了帐户或显示了适当的错误消息。
3。适当的测试甲骨文
正如我们在上一节中提到的,测试 oracle 是我们的通过/失败标准。要测试的程序越简单越小,就越容易想出一个。如果我们没有测试出正确的结果,我们的测试就没有用。我们对create_account的测试意味着检查数据库中的 users 表是评估我们函数的一种合适的方式。
4。合理运行时间
测试运行时,开发人员必须等待结果返回。如果测试很慢,我们将不得不等待很长时间,这可能会导致开发人员完全忽略 CI 系统。这会导致代码变更越来越多,使得调试更加困难(当我们更改 5 行代码时,比更改 100 行代码时更容易发现错误)。
数据管道的有效测试
在前面的章节中,我们描述了软件测试的前两个层次以及有效测试的四个属性。本节讨论了如何将测试技术从传统的软件开发应用到数据项目中。
数据管道的单元测试
与传统软件中的模块不同,我们的流水线任务(图中的块)不是独立的,它们有一个逻辑执行。为了准确地表示我们系统的状态,我们必须尊重这样的顺序。因为一个任务的输入依赖于上游依赖项的输出,所以错误的根本原因可能在失败的任务中,也可能在任何上游任务中。这对我们没有好处,因为它增加了搜索 bug 的潜在位置的数量,在更小的过程中抽象逻辑并对它们进行单元测试有助于减少这个问题。
假设我们的任务add_product_information在加入产品销售之前执行一些数据清理:
我们将清理逻辑抽象为两个子过程clean.fix_timestamps和clean.remove_discontinued,任何子过程中的错误都会传播到输出,从而传播到任何下游任务。为了防止这种情况,我们应该添加一些单元测试,单独验证每个子过程的逻辑。
有时,转换数据的管道任务仅由对外部包(例如 pandas)的几个调用组成,几乎没有自定义逻辑。在这种情况下,单元测试不会非常有效。想象您管道中的一个任务如下所示:
假设您已经对清理逻辑进行了单元测试,那么就没有太多关于转换的单元测试了,为这样简单的过程编写单元测试并不是一个很好的时间投资。这就是集成测试的用武之地。
数据管道的集成测试
我们的管道传递输入和输出,直到产生最终结果。如果任务输入预期不真实(例如列名),这个流程可能会中断,此外,每个数据转换都编码了我们对数据做出的某些假设*。集成测试帮助我们验证输出正确地流经管道。*
如果我们想要通过上面显示的转换来测试组,我们可以运行流水线任务,并使用输出数据来评估我们的期望:
这四个断言写起来很快,并且清楚地编码了我们的输出期望。现在让我们看看如何详细地编写有效的集成测试。
系统状态
正如我们在上一节中提到的,管道任务有依赖关系。为了在我们的测试中准确地表示系统状态,我们必须遵守执行顺序,并在每个任务完成后运行我们的集成测试,让我们修改我们的原始图表来反映这一点:

作者图片
测试甲骨文
测试管道任务的挑战是没有唯一正确的答案。当开发一个create_user过程时,我们可以说为新用户检查数据库是成功的一个适当的度量,但是清理数据的过程呢?
没有唯一的答案,因为干净数据的概念取决于我们项目的具体情况。我们能做的最好的事情就是明确地将我们的输出期望编码为一系列的测试。要避免的常见情况包括分析中的无效观察、空值、重复、意外的列名等。这种期望是集成测试的良好候选,以防止脏数据泄漏到我们的管道中。即使是提取原始数据的任务也应该进行测试,以检测数据变化:列被删除、重命名等。测试原始数据属性有助于我们快速识别源数据何时发生了变化。
即使我们不编写测试,一些更改(如列重命名)也会破坏我们的管道,但显式测试有一个很大的优势:我们可以在正确的位置修复错误,避免多余的修复。想象一下,如果重命名列会破坏两个下游任务,每个任务由不同的同事开发,一旦他们遇到错误,就会试图在代码中重命名列(两个下游任务),而正确的方法是修复上游任务。
此外,破坏我们管道的错误应该是我们最不担心的,数据管道中最危险的错误是偷偷摸摸的;它们不会破坏您的管道,但会以微妙的方式污染所有下游任务,这可能会严重破坏您的数据分析,甚至推翻您的结论,这是最糟糕的情况。正因为如此,我不能强调将数据期望编码作为任何数据分析项目的一部分有多重要。
管道任务不一定是 Python 过程,它们通常是 SQL 脚本,您应该以同样的方式测试它们。例如,您可以使用以下查询测试某一列中没有空值:
对于输出不是数据集的过程,提出一个测试 oracle 变得更加棘手。数据管道中的常见输出是人类可读的文档(即报告)。虽然技术上可以测试图形输出,如表格或图表,但这需要更多的设置。第一种(通常也是足够好的)方法是对生成可视化输出的输入进行单元测试(例如,测试为绘图而不是实际绘图准备数据的函数)。如果你对试验田感兴趣,点击这里。
现实输入数据和运行时间
我们提到过,真实的输入数据对于测试非常重要。在数据项目中,我们已经有了可以在测试中使用的真实数据,但是,传递完整的数据集进行测试是不可行的,因为数据管道有计算开销很大的任务,需要花费很多时间来完成。
为了减少运行时间并保持输入数据的真实性,我们传递了一个数据样本。如何获取样本取决于项目的具体情况。目标是获得一个具有代表性的数据样本,其属性类似于完整的数据集。在我们的例子中,我们可以随机抽取昨天的销售额。然后,如果我们想要测试某些属性(例如,我们的管道正确处理 NAs),我们可以在随机样本中插入一些 NAs,或者使用另一种采样方法,例如分层采样。采样只需要发生在提取原始数据的任务中,下游任务将只处理来自上游依赖项的任何输出。
仅在测试期间启用采样。确保您的管道被设计为容易关闭该设置,并保持生成的工件(测试与生产)被清楚地标记:
上面的代码片段假设我们可以将管道表示为“管道对象”,并使用参数调用它。这是一个非常强大的抽象,使您的管道可以灵活地在不同的设置下执行。任务成功执行后,您应该运行相应的集成测试。例如,假设我们想要测试我们的add_product_information过程,一旦这样的任务完成,我们的管道应该调用下面的函数:
请注意,我们将数据的路径作为参数传递给函数,这将允许我们轻松地切换加载数据的路径。这对于避免管道运行相互干扰非常重要。例如,如果你有几个 git 分支,你可以在一个名为/data/{branch-name}的文件夹中按分支组织工件;如果您与同事共享一个服务器,每个人都可以将其工件保存到/data/{username}。
如果您正在使用 SQL 脚本,您可以应用相同的测试模式:
除了采样,我们还可以通过并行运行任务来进一步加速测试。尽管我们能做的并行化是有限的,这是由流水线结构决定的:我们不能运行一个任务,直到它们的上游依赖完成。
我们的库 Ploomber 支持参数化管道和任务执行时执行测试。
数据科学中的测试权衡
数据项目比传统软件有更多的不确定性。有时候我们甚至不知道这个项目在技术上是否可行,所以我们必须投入一些时间来给出答案。这种不确定性不利于好的软件实践:因为我们想要减少不确定性来估计项目的影响,好的软件实践(比如测试)可能不会被认为是实际的进展而被忽视。
我的建议是随着你的进步不断增加测试。在早期阶段,关注集成测试是很重要的,因为它们可以快速实现并且非常有效。数据转换中最常见的错误很容易使用简单的断言检测出来:检查 id 是否唯一、没有重复、没有空值、列是否在预期的范围内。你会惊讶地发现,用几行代码就能发现多少错误。一旦你看了数据,这些错误是显而易见的,但甚至可能不会破坏你的管道,它们只会产生错误的结果,集成测试防止了这一点。
第二,尽可能利用现成的软件包,尤其是对于高度复杂的数据转换或算法;但是要注意质量,喜欢维护包,即使它们不能提供最先进的性能。第三方软件包自带测试,可以减少您的工作量。
也可能有不太重要或者很难测试的部分。绘图过程是一个常见的例子:除非您正在生成一个高度定制的绘图,否则测试一个只调用 matplotlib 并稍微定制 axis 的小绘图函数没有什么好处。重点测试进入绘图功能的输入。
随着项目的成熟,您可以开始专注于增加您的测试覆盖范围并支付一些技术债务。
调试数据管道
当测试失败时,就是调试的时候了。我们的第一道防线是日志记录:无论何时运行管道,我们都应该生成一组相关的日志记录供我们查看。我建议您看看 Python 标准库中的[logging](https://docs.python.org/3/library/logging.html) 模块,它为此提供了一个灵活的框架(不要使用print进行日志记录),一个好的做法是保存一个文件,其中包含每次管道运行的日志。
虽然日志可以提示您问题出在哪里,但是设计易于调试的管道是至关重要的。让我们回忆一下我们对数据管道的定义:
输入为原始数据集的一系列有序任务,中间任务生成转换数据集(保存 到磁盘 ),最终任务生成数据产品。
将所有中间结果保存在内存中肯定更快,因为磁盘操作比内存慢。但是,将结果保存到磁盘会使调试更加容易。如果我们不将中间结果保存到磁盘,调试意味着我们必须再次重新执行我们的管道来复制错误条件,如果我们保留中间结果,我们只需重新加载失败任务的上游依赖项。让我们看看如何使用标准库中的 Python 调试器来调试我们的add_product_information过程:
由于我们的任务是相互隔离的,只通过输入和输出进行交互,所以我们可以很容易地复制错误条件。只需确保您向函数传递了正确的输入参数。如果您使用 Ploomber 的调试功能,您可以很容易地应用这个工作流程。
调试 SQL 脚本更加困难,因为我们没有 Python 中的调试器。我的建议是将您的 SQL 脚本保持在一个合理的大小:一旦一个 SQL 脚本变得太大,您应该考虑将它分成两个独立的任务。使用WITH组织您的 SQL 代码有助于提高可读性,并且可以帮助您调试复杂的语句:
如果您在这样组织的 SQL 脚本中发现一个错误,您可以将最后一个SELECT语句替换为类似SELECT * FROM customers_subset的语句,以查看中间结果。
在生产中运行集成测试
在传统的软件中,测试只在开发环境中运行,它假设如果一段代码进入生产环境,它一定已经被测试并正常工作。
对于数据管道,集成测试是管道本身的一部分,由您决定是否执行它们。这里起作用的两个变量是响应时间和最终用户。如果运行频率很低(例如,每天执行的管道)并且最终用户是内部的(例如,业务分析师),您应该考虑将测试保持在生产中。机器学习训练管道也遵循这种模式,它的运行频率很低,因为它是按需执行的(每当你想训练一个模型时),最终用户是你和团队中的任何其他人。这一点很重要,因为我们最初是用数据样本运行测试的,如果我们的采样方法没有捕捉到数据中的某些属性,那么用整个数据集运行测试可能会得到不同的结果。
另一个常见的(通常不可预见的)场景是数据更改。让您自己了解上游数据的计划变更(例如,迁移到不同的仓库平台)是很重要的,但是在您通过管道传递新数据之前,您仍然有机会发现数据变更。在最好的情况下,您的管道将引发一个您能够检测到的异常,在最坏的情况下,您的管道将正常执行,但输出将包含错误的结果。因此,保持您的集成测试在生产环境中运行是非常重要的。
底线:如果你可以允许一个管道延迟它的最终输出(例如每日销售报告),保持测试在生产中,并确保你被适当地通知,最简单的解决方案是让你的管道给你发一封电子邮件。
对于需要经常快速输出的管道(如 API),您可以改变策略。对于非关键错误,您可以记录而不是引发异常,但是对于关键情况,如果您知道失败的测试会阻止您返回适当的结果(例如,用户为“年龄”列输入了负值),您应该返回一条信息性的错误消息。处理生产中的错误是模型监控的一部分,我们将在接下来的帖子中介绍。
重新审视工作流程

作者图片
我们现在根据前面章节的观察重新审视工作流。在每次推送时,首先运行单元测试,然后使用数据样本执行管道,在每次任务执行时,运行集成测试来验证每个输出,如果所有测试都通过,则提交被标记为成功。CI 流程到此结束,应该只需要几分钟。
假设我们持续测试每个代码变更,我们应该能够随时部署。这种持续部署软件的想法被称为持续部署,它值得一个专门的帖子,但这里是摘要。
因为我们需要生成每日报告,所以管道每天早上运行。第一步是(从存储库或工件存储中)提取可用的最新稳定版本,并将其安装在生产服务器中,对每个成功的任务运行集成测试,以检查数据预期,如果这些测试中的任何一个失败,将发送通知。如果一切顺利,管道会将报告通过电子邮件发送给业务分析师。
实施细节
本节提供了使用现有工具实施 CI 工作流的一般指南和资源。
单元测试
为了在每个数据管道任务中单元测试逻辑,我们可以利用现有的工具。我强烈推荐使用 pytest 。它对基本用法的学习曲线很小;随着你对它越来越熟悉,我建议你探索它的更多特性(例如夹具)。成为任何测试框架的超级用户都有很大的好处,因为您将投入更少的时间来编写测试,并最大限度地提高它们捕捉 bug 的效率。坚持练习,直到编写测试成为编写任何实际代码之前的第一步。这种首先编写测试的技术被称为测试驱动开发(TDD) 。
运行集成测试
集成测试有更多的工具需求,因为它们需要考虑数据管道结构(按顺序运行任务)、参数化(用于采样)和测试执行(在每个任务之后运行测试)。最近工作流管理工具激增,在某种程度上有助于做到这一点。
我们的库 Ploomber 支持实现该工作流所需的所有特性:将您的管道表示为 DAG ,分离开发/测试/生产环境,参数化管道,在任务执行时运行测试功能,与 Python 调试器集成,以及其他特性。
外部系统
许多简单到中等复杂的数据应用程序是在单个服务器上开发的:第一个管道任务从仓库中转储原始数据,所有下游任务将中间结果输出为本地文件(例如 parquet 或 csv 文件)。这种架构允许在不同的系统中轻松地包含和执行管道:要在本地测试,只需运行管道并将工件保存在您选择的文件夹中,要在 CI 服务器中运行管道,只需复制源代码并在那里执行管道,不依赖于任何外部系统。
然而,对于数据规模是一个挑战的情况,管道可能只是作为一个执行协调器,几乎不做任何实际的计算,例如一个纯粹的 SQL 管道,它只向分析数据库发送 SQL 脚本并等待完成。
当执行依赖于外部系统时,实现 CI 会更加困难,因为您依赖于另一个系统来执行您的管道。在传统的软件项目中,这是通过创建模拟来解决的,它模仿另一个对象的行为。想想电子商务网站:生产数据库是一个支持所有用户的大型服务器。在开发和测试期间,不需要如此大的系统,一个有一些数据(可能是真实数据甚至是虚假数据的样本)的较小系统就足够了,只要它准确地模仿生产数据库的行为。
这在数据项目中通常是不可能的。如果我们使用一个大的外部服务器来加速计算,我们很可能只有那个系统(例如一个公司范围的 Hadoop 集群),模仿它是不可行的。解决这个问题的一个方法是将管道工件存储在不同的“环境”中。例如,如果您为您的项目使用一个大型的分析数据库,那么将生产工件存储在一个prod模式中,将测试工件存储在一个test模式中。如果您不能创建模式,您也可以为所有的表和视图添加前缀(例如prod_customers和test_customers)。参数化管道可以帮助您轻松切换模式/后缀。
CI 服务器
为了自动化测试执行,您需要一个 CI 服务器。每当您推送到存储库时,CI 服务器将针对新提交运行测试。有许多选项可用,验证您工作的公司是否已经有 CI 服务。如果没有,您将不会得到自动化的过程,但是您仍然可以通过在每次提交时本地运行您的测试来实现它。
扩展:机器学习管道

作者图片
让我们修改之前的每日报告管道,以涵盖一个重要的用例:开发机器学习模型。假设我们现在想要预测下个月的日销售额。我们可以通过获取历史销售额(而不仅仅是昨天的销售额)、生成特征和训练模型来做到这一点。
我们的端到端过程有两个阶段:首先,我们处理数据以生成训练集,然后我们训练模型并选择最佳模型。如果我们在整个过程中对每个任务都遵循同样严格的测试方法,我们将能够从进入我们的模型中捕获脏数据,记住:垃圾入,垃圾出。有时,实践者通过尝试许多花哨的模型或复杂的超参数调优模式,过于关注训练任务。虽然这种方法肯定是有价值的,但在数据准备过程中通常会有很多容易实现的结果,这些结果会对我们模型的性能产生重大影响。但是为了最大化这种影响,我们必须确保数据准备阶段是可靠的和可重复的。
数据准备中的错误导致好得不真实(即数据泄露)的结果或次优模型;我们的测试应该解决这两种情况。为了防止数据泄漏,我们可以测试训练集中是否存在有问题的列(例如,只有在我们的目标变量可见后才知道其值的列)。为了避免次优性能,验证我们的数据假设的集成测试起着重要作用,但我们可以包括其他测试来检查我们最终数据集中的质量,例如验证我们有跨所有年份的数据,并且被认为不适合训练的数据不会出现。
获取历史数据会增加 CI 的总体运行时间,但数据采样(正如我们在每日报告管道中所做的)会有所帮助。更好的是,您可以缓存数据样本的本地副本,以避免每次运行测试时都提取样本。
为了确保完整的模型再现性,我们应该只使用从自动化过程中生成的工件来训练模型。一旦测试通过,流程可以自动触发完整数据集的端到端管道执行,以生成训练数据。
保留历史工件也有助于模型的可读性,给定一个散列提交,我们应该能够定位生成的训练数据,此外,从同一个提交重新执行管道应该产生相同的结果。
模型评估是 CI 工作流程的一部分
我们当前的 CI 工作流使用数据样本测试我们的管道,以确保最终输出适合培训。如果我们也能测试训练程序,那不是很好吗?
回想一下,CI 的目的是允许开发人员迭代地集成小的变更,为了有效,反馈需要快速返回。训练 ML 模型通常需要很长的运行时间;除非我们有办法在几分钟内完成我们的训练程序,否则我们将不得不考虑如何快速测试。
让我们分析两个微妙不同的场景,以了解如何将它们集成到 CI 工作流中。
测试训练算法
如果您正在实现自己的训练算法,您应该独立于管道的其余部分来测试您的实现。这些测试验证了您的实现的正确性。
这是任何 ML 框架都会做的事情(scikit-learn,keras 等)。),因为他们必须确保对当前实现的改进不会破坏它们。在大多数情况下,除非您正在处理一个非常数据饥渴的算法,否则这不会带来运行时间问题,因为您可以用一个合成/玩具数据集对您的实现进行单元测试。这个逻辑同样适用于任何训练预处理程序(比如数据缩放)。
测试您的培训渠道
实际上,培训不是一个单一阶段的过程。第一步是加载您的数据,然后您可能会做一些最后的清理,如删除 id 或热编码分类特征。之后,您将数据传递到一个多阶段训练管道,该管道涉及分割、数据预处理(例如标准化、PCA 等)、超参数调整和模型选择。这些步骤中的任何一步都可能出错,尤其是如果您的管道具有高度定制的过程。
测试你的培训渠道是困难的,因为没有明显的测试预言。我的建议是,通过利用现有的实现(scikit-learn 为这个提供了惊人的工具)来减少要测试的代码量,从而尽可能地简化您的管道。
在实践中,我发现相对于之前的结果定义一个测试标准是很有用的。如果我第一次训练一个模型,我得到的精度是 X,那么我保存这个数字,并把它作为参考。后续实验应在 X 的合理范围内失败:性能的突然下降或上升会触发警报以手动查看结果。有时这是好消息,这意味着性能正在提高,因为新功能正在工作,但有时这是坏消息:性能的突然提高可能来自信息泄漏,而性能的突然下降可能来自数据处理不当或意外删除行/列。**
为了保持运行时间的可行性,请使用数据样本运行训练管道,并让您的测试将性能与使用相同采样过程获得的指标进行比较。这比听起来更复杂,因为如果你用更少的数据训练,结果差异会增加,这使得得出合理范围更具挑战性。
如果上述策略不起作用,您可以尝试在您的 CI 管道中使用一个代理模型,它可以更快地训练和增加您的数据样本大小。例如,如果您正在训练一个神经网络,您可以使用一个更简单的体系结构进行训练,以使训练更快,并增加 CI 中使用的数据样本,以减少 CI 运行中的差异。
下一个前沿:数据科学光盘
CI 允许我们在短周期内集成代码,但这并不是故事的结尾。在某些时候,我们必须部署我们的项目,这就是连续交付和连续部署的用武之地。
部署的第一步是发布我们的项目。发布是指获取所有必要的文件(即源代码、配置文件等),并将其转换成可用于在生产环境中安装项目的格式。例如,发布一个 Python 包需要将我们的代码上传到 Python 包索引中。
持续交付保证了软件可以随时发布,但是部署仍然是一个手动过程(即必须有人在生产环境中执行指令),换句话说,它只是自动化了发布过程。持续部署包括自动化发布和部署。现在让我们从数据项目的角度来分析这个概念。
对于产生人类可读文档(例如报告)的管道,连续部署是简单的。在 CI 通过之后,另一个过程应该获取所有必要的文件并创建一个可安装的工件,然后,生产环境可以使用这个工件来设置和安装我们的项目。下次管道运行时,它应该使用最新的稳定版本。
另一方面,ML 管道的连续部署要困难得多。管道的输出不是唯一的模型,而是几个候选模型,应该对它们进行比较以部署最佳模型。如果我们已经有了生产中的模型,事情会变得更加复杂,因为没有部署可能是最好的选择(例如,如果新模型没有显著提高预测能力,并且带来了运行时间的增加或更多的数据依赖性)。
一个比预测能力更重要(也更难)评估的属性是模型公平性。必须评估每个新部署是否偏向敏感群体。想出一个自动的方法来评估一个模型的预测能力和公平性是困难和有风险的。如果你想了解更多关于模型公平性的知识,这是一个很好的起点。
但是 ML 的持续输送仍然是一个可管理的过程。一旦提交通过了带有数据样本(CI)的所有测试,另一个进程就会运行带有完整数据集的管道,并将最终数据集存储在对象存储中(CD 阶段 1)。
然后,训练过程加载工件,并通过调整每个选定算法的超参数来找到最佳模型。最后,它将最佳模型规范(即算法及其最佳超参数)与评估报告一起序列化(CD 阶段 2)。完成所有工作后,我们查看报告并选择部署模型。
在上一节中,我们讨论了如何在 CI 工作流中包含模型评估。所提出的解决方案受到 CI 运行时间要求的限制;在 CD 过程的第一阶段完成后,我们可以通过使用完整数据集训练最新的最佳模型规范来包含更健壮的解决方案,这将捕获导致性能下降的错误,而不是必须等待第二阶段完成,因为第二阶段具有更长的运行时间。CD 工作流程如下所示:

作者图片
从成功的 CI 运行中触发 CD 可以是手动的,数据科学家可能不希望为每个传递的提交生成数据集,但在给定提交哈希的情况下,应该很容易做到这一点(例如,通过单击或命令)。
允许手动执行第二阶段也很方便,因为数据科学家经常通过定制训练管道使用同一个数据集来运行几个实验,因此,单个数据集可能会触发许多训练工作。
在 ML 管道中,实验再现性至关重要。在提交、CI 运行和数据准备运行(CD 阶段 1)之间存在一对一的关系,因此,我们可以通过生成数据集的提交散列来唯一地标识数据集。我们应该能够通过再次运行数据准备步骤并使用相同的训练参数运行训练阶段来重现任何实验。
结束语
随着数据科学的 CI/CD 流程开始成熟和标准化,我们将开始看到简化实施的新工具。目前,许多数据科学家甚至不考虑将 CI/CD 作为他们工作流程的一部分。在某些情况下,他们只是不知道,在其他情况下,因为有效地实施 CI/CD 需要一个复杂的重新利用现有工具的设置过程。数据科学家不应该担心设置 CI/CD 服务,他们应该专注于编写代码、测试和推送。
除了专门为数据项目定制的 CI/CD 工具,我们还需要数据管道管理工具来标准化管道开发。在过去的几年里,我看到了很多新项目,不幸的是,其中大多数都专注于调度或扩展等方面,而不是用户体验,如果我们希望模块化和测试等软件工程实践被所有数据科学家接受,这是至关重要的。这就是我们构建 Ploomber 的原因,以帮助数据科学家轻松、渐进地采用更好的开发实践。
缩短 CI-开发人员反馈循环对 CI 的成功至关重要。虽然数据采样是一种有效的方法,但是通过使用增量运行,我们可以做得更好:通过重用先前计算的工件,在管道中更改单个任务应该只触发最少量的工作。Ploomber 已经提供了一些限制,我们正在试验改进这个特性的方法。
我认为 CI 是数据科学软件堆栈中最重要的缺失部分:我们已经有很好的工具来执行 AutoML、一键式模型部署和模型监控。CI 将缩小这个差距,允许团队自信地、持续地训练和部署模型。
为了推进我们的领域,我们必须开始更加关注我们的开发过程。
在这篇文章中发现一个错误?点击这里让我们知道。
最初发布于 ploomber.io
视网膜图像具有奇怪的预测性
请密切关注深度学习的这些发展

如果你曾经去看过眼科医生,你可能经历过一个常规的程序,专家会给你的眼球后部拍一张照片。
听说视网膜图像对诊断眼疾相当方便,你不会感到惊讶。然而,你可能没有想到,它们还可以提供许多关于一个人患心血管疾病风险的见解。视网膜成像是一种检查某人血管状况的非侵入性方法,这可能预示着此人更广泛的心血管健康状况。
如果你以前见过这些视网膜图像中的一张,你可能会指出视盘和各种血管(如果你没有,请尝试在谷歌上搜索“视网膜图像”——或“眼底”,这是眼睛后部的医学术语)。
医生将能够更进一步,通过识别异常并建议可能需要进一步调查或治疗的特征。
然而,把它喂给一台机器,它就能预测:
- 你多大了;
- 你的性别;
- 你的种族;
- 无论你是否吸烟;甚至
- 那天早上你吃了什么?
好吧,最后一条可能是我编的,但值得注意的是,其余的都是真的。毫无疑问,视网膜图像有着怪异的预测能力。
眼睛有
谷歌的研究人员在 2017 年写了一篇论文阐述了一项关于深度学习如何用于从视网膜图像中预测一系列心血管风险因素的调查。论文简要解释了医学发现的更传统的方法:首先观察潜在风险因素和疾病之间的联系和相关性,然后才设计和测试假设。Ryan Poplin 等人接着演示了深度学习架构如何在没有被告知要寻找什么的情况下,自己获取这些关联。
我相信我们都在某个时候听说过这样的断言,即某些医学专家将被人工智能算法取代,人工智能算法将能够在识别医学图像中的异常方面胜过他们。这项研究将事情引向一个稍微不同的方向——不寻求在现有的任务中胜过医生,而是看看新的信息机器可以从这些特定的图像中收集到什么。
在研究的早期,该团队发现他们的模型非常擅长预测年龄和性别等变量——以至于他们最初认为这是模型中的一个错误(Ryan 向我们介绍了该项目是如何在 TWiML talk 112 上开发的)。但是随着他们对事物的深入研究,他们发现这些都是真实的预测。不仅如此,它们也是令人难以置信的强健——例如,年龄可以被成功预测,平均绝对误差为 3.26 年。
发现了许多其他关联,结果表明,该团队可以获得比他们的基线模型更好的预测能力,包括血压、血糖水平甚至种族——所有心血管疾病的风险因素。
观察这些结果后,研究小组推断,如果心血管风险因素的范围可以预测得如此之好,那么该模型甚至可以在识别哪些患者未来最有可能患主要心血管事件(如中风或心脏病发作)时具有预测能力。尽管他们的训练数据存在一些限制,但仅在视网膜图像上训练的模型(因此没有明确给定的风险因素)能够实现 0.70 的 AUC(浏览本文的 ROC/AUC 部分,以了解更多关于 AUC 作为性能指标的信息)——这与另一个现有风险评分系统获得的 0.72 相比变得尤其令人印象深刻,该系统利用了更多的输入变量。
不仅仅是心灵的窗户

利亚姆·韦尔奇在 Unsplash 上的照片
在前面提到的 TWiML 播客中,Ryan 推测了一种可能的未来,即视网膜图像被用作生命体征,以提供患者整体健康状况的图片,而不仅仅是用于诊断眼部疾病。正如我们所见,这不仅仅是幻想——这种简单的非侵入性程序可以提供比我们之前预期的更广泛的患者健康快照。
总结一下——心血管疾病仍然是全世界死亡的主要原因,但是 80%的过早心脏病和中风是可以预防的。像上面讨论的论文这样的研究可以帮助我们更好地了解谁是心血管疾病的高危人群,以及如何最好地管理这些人群——适当的早期干预可以在很大程度上延长和改善人类生活质量。
学分和更多信息
Andrew Hetherington 是英国伦敦的一名见习精算师和数据爱好者。
论文讨论:R. Poplin 等人,“使用深度学习从视网膜眼底照片预测心血管风险因素”,DOI10.1038/s 41551–018–0195–0,https://arxiv.org/abs/1708.09843v2。
nrd 和 Liam Welch 在 Unsplash 上的照片。
RetinaNet:用 5 行代码进行自定义对象检测训练
使用 Monk,低代码深度学习工具和计算机视觉的统一包装器,使计算机视觉变得简单。

室内物体检测
在之前的文章中,我们已经使用和尚的 EfficientDet 构建了一个自定义的对象检测器。在本文中,我们将使用和尚的 RetinaNet 构建一个室内物体检测器,构建于 PyTorch RetinaNet 之上。
如今,从自动驾驶汽车到监控摄像头等等,计算机视觉无处不在。要开始学习计算机视觉,我们必须学习各种深度学习框架,如 TensorFlow、PyTorch 和 Mxnet,这是一个乏味的过程。
借此机会,我想向您介绍一下 Monk ,这是一个功能齐全、低代码、易于安装的对象检测管道。
[## 镶嵌成像/Monk_Object_Detection
低代码、易于安装的对象检测管道的一站式存储库。
github.com](https://github.com/Tessellate-Imaging/Monk_Object_Detection)
我们开始吧!!
目录
- 数据收集
- 转换为 COCO 格式
- 培训模式
- 检测对象检测器
数据收集
这里我们使用的是 OpenImages 。使用 OIDv4_ToolKit 收集数据。我从数据集中选择了 25 个类,你可以随意选择。
用于收集数据的命令示例
python main.py downloader --classes Apple Orange --type_csv validation
打开命令提示符,运行以下命令从整个数据集中收集 Alarm_clock 类。您可以使用这个过程来下载其他类。
$ git clone [https://github.com/EscVM/OIDv4_ToolKit](https://github.com/EscVM/OIDv4_ToolKit)
$ cd OIDv4_ToolKit
$ python main.py downloader --classes Alarm_clock --type_csv train
$ mv OID/Dataset/train/Alarm\ clock OID/Dataset/train/Alarm_clock
您可以使用直接下载格式化的数据集
$ wget --load-cookies /tmp/cookies.txt "https://docs.google.com/uc?export=download&confirm=$(wget --save-cookies /tmp/cookies.txt --keep-session-cookies --no-check-certificate 'https://docs.google.com/uc?export=download&id=1bXzK3SYRCoUj9-zsiLOSWM86LJ6z9p0t' -O- | sed -rn 's/.*confirm=([0-9A-Za-z_]+).*/**\1\n**/p')&id=1bXzK3SYRCoUj9-zsiLOSWM86LJ6z9p0t" -O OIDv4_ToolKit.zip && rm -rf /tmp/cookies.txt
转换为 COCO 格式
COCO 格式
./ (root_dir)
|
|------Dataset (coco_dir)
|
|------Images (set_dir)
| |
| |----Alarm_clock
| |
| |---------img1.jpg
| |---------img2.jpg
| |---------..........(and so on)
|
| |-----Curtain
| |
| |---------img1.jpg
| |---------img2.jpg
| |---------..........(and so on)
|
| |-----...........(and so on)
|
|
|
|------annotations
|----------|
|--------------------instances_Images.json (instances_<set_dir>.json)
|--------------------classes.txt
- instances_Train.json ->正确的 COCO 格式
- classes.txt ->按字母顺序排列的类列表
对于列车组
- root _ dir = " oid v4 _ ToolKit/OID/";
- coco _ dir = " Dataset
- img_dir = “。/”;
- set _ dir = " Images
注意:注释文件名与 set_dir 一致
我们通过 Monk 格式转换成 COCO 格式
1.从当前格式转换为 Monk 格式。
2.从 Monk 格式转换为 COCO 格式
运行 classes.txt
对于。“json”文件运行
培训模式
我们选择“resnet50”来进行这个实验。您可以按照代码中的建议设置超参数。如果你使用的是 GPU,那么设置 use_gpu=True,默认为 False。我们使用 4 个 GPU,所以 gpu_devices=[0,1,2,3]。如果您使用的是一个 GPU,请更改 gpu_devices=[0]。用’设置时期数和型号名称。pt '分机。
正如标题中提到的,我们只需要 5 行代码进行训练,这里是 Train.py
检测物体探测器
在训练模型之后,我们可以得到权重文件。加载重量并开始预测。
一些形象的推论,你可以看到:

推论 1

推论 2
你可以在 Github 上找到完整的代码。如果你喜欢蒙克,给我们 GitHub 回购⭐️。
在这个实验中,我们使用 Retinanet 创建了一个自定义对象检测,只需要基本的编程技能,甚至不需要了解架构和 PyTorch 框架。
有关自定义对象检测的更多示例,请查看
[## 镶嵌成像/Monk_Object_Detection
github.com](https://github.com/Tessellate-Imaging/Monk_Object_Detection/tree/master/example_notebooks)
有问题可以联系 Abhishek 和 Akash 。请随意联系他们。
我对计算机视觉和深度学习充满热情。我是 Monk 库的开源贡献者。
你也可以在以下网址看到我的其他作品:
阅读阿库拉·赫曼思·库马尔在媒介上的作品。计算机视觉爱好者。每天,阿库拉·赫曼思·库马尔和…
medium.com](https://medium.com/@akulahemanth) 
照片由 Srilekha 拍摄
检索、分析和可视化地理参考数据
使用叶地图和标准 Python 库

在地理数据科学中,往往很难得到准确可靠的数据进行分析和展示。地理数据来自不同的来源,在不同的时间通过不同的技术收集,因此,人们总是关注用于从地理空间数据中获取信息的数据的质量和可靠性[1]。获取地理空间数据是每个地理信息系统(GIS)项目的关键步骤。据估计,获取阶段通常会消耗花费在 GIS 项目上的 70%到 80%的时间和金钱。
有两种类型的地理空间数据捕获:原始数据捕获(PDC)和二次数据捕获(SDC)。PDC 指的是直接数据采集,通常与使用全球定位系统( GPS )或全站仪【2】的现场勘测相关。在这一类别中,我们包括来自卫星、无人驾驶飞机、飞机和其他类型的太空、空中或手持传感器的遥感数据。
SDC 涉及检索地理空间数据的间接方法。有大量的在线资源允许我们为我们的地理空间项目挖掘在线资源。这些来源包括来自国际机构、政府、大学、商业网站和数据仓库的数据。这些类型的数据通常是免费的,并且格式与许多 GIS 软件兼容。在这一类别中,我们还包括可以从非数字格式检索的其他地理空间信息来源,例如纸质地图[2]。
在本文中,我们将讨论获取地理空间数据的 SDC 方式。具体来说,我们将简要展示如何检索、分析和可视化自 1964 年以来斐济附近地震的地理参考数据。为此,我们写了一套三本木星笔记本:
- reading_dataset :包含读取数据集集合并查找包含单词 纬度 或 经度 的数据集链接的代码。
- db _ seismics从选择的数据集创建一个数据库,并计算一些空间统计数据。
- 地图 _ 地震获取数据库数据并使用叶子包创建网络地图。
我们不会给你很多关于我们使用的代码的细节。如果你想访问整个库,点击这里或者这篇文章的末尾。
读取数据集
我们使用了来自数据集的可用数据集列表。CSV 格式的列表被导入、打开和阅读。然后,我们在每个数据集的 HTML 代码(网页抓取)中寻找单词latitude或longitude。最后,从结果列表中,我们选择了一个用于创建数据库和地图的数据集。
# open the collection dataset
with open('datasets.csv', newline='') as csvfile:
reader = csv.DictReader(csvfile)
# append in a list all the content of the Doc column
for row in reader:
url_list.append(row['Doc'])
for url in url_list:
ctx = ssl.create_default_context()
ctx.check_hostname = False
ctx.verify_mode = ssl.CERT_NONE
r = requests.get(url)
if r.status_code == 200:
html = urlopen(url, context=ctx).read()
soup = BeautifulSoup(html, "html.parser")
for item in soup:
# find latitude or longitude word
if soup.find_all(text=re.compile(r'\blatitude\b | \blongitude\b', flags=re.I | re.X)):
sel_list.append(url)
else:
continue
else:
continue
for item2 in sel_list:
if item2 not in sel_list2:
sel_list2.append(item2)
print('List of datasets containing the terms latitude or longitude: \n', sel_list2)
从 1340 个数据集中,我们获得了 20 个包含单词纬度或经度的 HTML 链接,接下来我们为接下来的步骤选择了一个数据集。
print('The selected dataset is: ', sel_list2[8])
所选数据集是:
创建数据库和计算空间统计数据
我们使用了所选数据集的 CSV 文件。该数据集包含自 1964 年以来斐济附近发生的地震事件的位置数据、深度和震级。然后,我们创建了一个数据库,并使用这个 CSV 文件填充它。最后,我们查询数据库并计算一些统计数据。
我们创建了一个轻量级的 SQLite 数据库和一个名为quakes的表,与所选数据集具有相同的列名。为此,我们使用了 SQL CREATE TABLE 语句。
*# create database*
conn = sqlite3.connect('eartquakes.sqlite')
cur = conn.cursor()*# create table*
cur.execute('''CREATE TABLE IF NOT EXISTS quakes (id INTEGER PRIMARY KEY, lat REAL, lon REAL, depth INTEGER, mag REAL, stations INTEGER)''')
接下来,我们用地震数据填充数据库。我们检索 URL 的数据集,并使用这些数据填充数据库。然后,我们丢下一些行代码和 SQL 语句来计算:总地震、平均震级和深度、最强和最小地震。
*# get and read data (on line)*
**with** closing(requests.get(url, stream=**True**)) **as** r:
f = (line.decode('utf-8') **for** line **in** r.iter_lines())
reader = csv.reader(f, delimiter=',', quotechar='"')
next(reader)
*# populate the database*
list = []
**for** row **in** reader:
list.append(row)
**for** item **in** list:
cur.execute('INSERT OR IGNORE INTO quakes (id, lat, lon, depth, mag, stations) VALUES ( ?, ?, ?, ?, ?, ?)', ( item[0],item[1],item[2],item[3],item[4],item[5], ) )
conn.commit()
*# total earthquakes*
cur.execute("SELECT COUNT(*) from quakes")
**for** row **in** cur:
count = row[0]
*# average magnitude*
cur.execute("SELECT AVG(mag) from quakes")
**for** row **in** cur:
magAvg = row[0]
*# average depth*
cur.execute("SELECT AVG(depth) from quakes")
**for** row **in** cur:
depAvg = row[0]
*# strong and first minor earthquake in the dataset*
cur.execute("SELECT MAX(mag), id, lat, lon, depth FROM quakes")
**for** row **in** cur:
mag = row[0]
id = row[1]
lat = row[2]
lon = row[3]
depth = row[4]
cur.execute("SELECT MIN(mag), id, lat, lon, depth FROM quakes")
**for** row **in** cur:
mag2 = row[0]
id2 = row[1]
lat2 = row[2]
lon2 = row[3]
depth2 = row[4]*# id and magnitude dictionary*
cur.execute("SELECT id, mag FROM quakes")
dict = {rows[0]:rows[1] **for** rows **in** cur}
cur.close()
当打印结果时,我们得到在我们的研究区域有 1000 次地震,平均震级为 4.6,平均深度为 311.37 千米。此外,我们计算出最强地震的震级为 6.4,深度为 127 公里,而最小地震的震级为 4.0,深度为 649 公里。
接下来,我们计算了最大和最小震级之间的距离。为了做到这一点,我们使用了计算两个坐标之间最短距离的哈弗辛公式。这与欧几里德距离非常相似,除了它允许我们考虑地球的球形形状【3】。
*# Haversine distance formula*
**import** **math**
x_dist = math.radians(lon2-lon)
y_dist = math.radians(lat2-lat)
y1_rad = math.radians(lat)
y2_rad = math.radians(lat2)
a = math.sin(y_dist/2)**2 + math.sin(x_dist/2)**2 \
* math.cos(y1_rad) * math.cos(y2_rad)
c = 2*math.asin(math.sqrt(a))
distance = c * 6371 *# kilometers*
print()
print("Distance between the strongest earthquake (ID:"+str(id) +") and weakest earthquake **\**
(ID:"+str(id2)+"): "+str(round(distance,2))+" km.**\n**")
我们的结果显示,最强地震(ID:152)和最小地震(ID:5)之间的距离为 1609.06 公里。
最后,我们根据麦卡利烈度表对地震进行了震级分类。我们遍历了之前创建的包含每个事件的 id 和震级数据的字典,然后根据麦卡利等级阈值过滤这些事件,并计算发生的百分比。
*# dictionary length*
dictLen= len(dict)*# calculate percentage mercaly intensity I*
mer_I = [item **for** item, occurrences **in** dict.items() **if** occurrences < 2.0]
merIPerc = round((len(mer_I)/dictLen)*100, 2)*# calculate percentage mercaly intensity II*
mer_II = [item **for** item, occurrences **in** dict.items() **if** occurrences >= 2.0 **and** occurrences <= 2.9 ]
merIIPerc = round((len(mer_II)/dictLen)*100,2)*# calculate percentage mercaly intensity III*
mer_III = [item **for** item, occurrences **in** dict.items() **if** occurrences >= 3.0 **and** occurrences <= 3.9 ]
merIIIPerc = round((len(mer_III)/dictLen)*100,2)...
根据我们的结果,研究区内 80%的地震属于麦卡利烈度表 IV-V 。这些类型的事件被分类为轻度到中度地震。许多人在室内都能感觉到。轻),几乎每个人都感觉到了(中等)[4]。
绘制地震事件图
在我们系列笔记本的最后一部分,我们使用了在第 2 部分中创建的数据库,其中包含自 1964 年以来在斐济附近发生的地震事件的位置数据(经度和纬度)、深度和震级。从那个数据库中,我们通过叶子地图库提取了一些构建地震事件网络地图所需的数据。该 web 地图包含一个基础图层、地震事件位置和两个热图:地震的震级和深度。
我们阅读了我们的数据库并提取了以下数据:地震事件的纬度、经度、震级和深度。这些数据存储在列表对象中。为此,我们使用了嵌入在 Python 代码中的 SQL 语句。Python 有自己的内置模块来连接 Python 程序和数据库。
**# read dataset*
conn = sqlite3.connect('eartquakes.sqlite')
cur = conn.cursor()*# create a list of latitude, longitude, mag and depth*
lats=[]
lons =[]
mags =[]
depths =[]
cur.execute("SELECT lat, lon, mag, depth FROM quakes")
**for** row **in** cur:
lat = row[0]
lon = row[1]
mag = row[2]
depth = row[3]
lats.append(lat)
lons.append(lon)
mags.append(mag)
depths.append(depth)
cur.close()*# get a list of latitude and longitude values*
locations = list(zip(lats, lons))*# get a list of magnitude and depth values*
magdepth = list(zip(mags, depths))*
我们使用了的地图库来建立我们的地震事件网络地图。首先,我们配置了一个弹出窗口来显示每个地震的震级和深度。接下来,我们建立了 Cartodb 正电子作为底图。我们利用标记聚类技术来制作地震事件的动画点聚类可视化。最后,我们创建了地震震级和地震深度的热图。更多关于热图技术的信息请点击。
**# configure map popup*
popups = ['magnitude:**{}**<br>depth:**{}**'.format(mags, depths) **for** (mags, depths) **in** magdepth]*# create basemap*
map = folium.Map(
location=[np.mean(lats), np.mean(lons)],
tiles='Cartodb Positron',
zoom_start=5
)*# create marker clusters*
marker_cluster = MarkerCluster(
locations=locations,
popups=popups,
name='Earthquake Locations',
overlay=**True**,
control=**True**,)
marker_cluster.add_to(map)*# create heatmap of earthquake magnitude*
data_heat_mag = list(zip(lats, lons, mags))
mag_hm = plugins.HeatMap(data_heat_mag,
name='Heatmap of Earthquake Magnitudes',
overlay=**True**,
control=**True**,
show=**False**
)
mag_hm.add_to(map)*# create heatmap of earthquake depth*
data_heat_depth = list(zip(lats, lons,depths))
dep_hm = plugins.HeatMap(data_heat_depth,
name='Heatmap of Earthquake Depths',
overlay=**True**,
control=**True**,
show=**False**
)
dep_hm.add_to(map)*# add map control layer*
folium.LayerControl(collapsed=**False**).add_to(map)*
这是我们的最终地图

点击此处获取网络版(图片作者)
结论
尽管使用像 pandas 和 geopandas 这样的专业库也有可能达到我们在这里提出的相同目标,但是我们演示了(可能更详细),通过 Folium 和标准 Python 库检索、分析和可视化地理参考数据是可能的。一如既往,欢迎任何与此相关的反馈!
参考
[1] Gervais,m .,Bédard,y .,Andree Levesque,m .,Bernier,e .,Devillers,R. (2009 年)。数据质量问题和地理知识发现。在米勒,h,韩,j。)地理数据挖掘和知识发现(第 99–115 页),美国纽约:泰勒&弗朗西斯集团。
[3]https://en.wikipedia.org/wiki/Haversine_formula。哈弗辛公式。
[4]https://en . Wikipedia . org/wiki/Modified _ Mercalli _ intensity _ scale。改良麦卡利烈度表。
检索、分析和可视化 1964 年以来斐济附近地震的地理参考数据
github.com](https://github.com/acoiman/mapping_earthquakes)*
机器学习的投资回报
与其问“我们如何获得 100%的准确率?”,正确的问题是“我们如何最大化投资回报率?”

在一个不确定的世界里,你仍然可以保持一致。由micha Parzuchowski在 Unsplash 拍摄的照片
机器学习处理概率,这意味着总有出错的可能。这种内在的不确定性导致许多决策者对实现机器学习感到不舒服,并使他们陷入对神奇的 100%准确性的无休止的追逐中。当我与迈出智能自动化第一步的公司合作时,对错误的恐惧几乎总是会出现,有人问我“如果算法做出错误的预测怎么办?”
如果这个问题得不到解决,公司很可能会在机器学习上花费大量的资源和数年的开发时间,而不会获得投资回报。在本文中,我将向您展示一个简单的等式,我用它来缓解这些担忧,让决策者对不确定性更加放心。
机器学习什么时候值得
就像任何投资一样,机器学习的可行性归结于它产生的价值是否大于它的成本。这是一种正常的投资回报(ROI)计算,在机器学习的背景下,它将产生的价值与错误和准确性的成本进行权衡。因此,与其问“我们如何获得 100%的准确率?”,正确的问题是“我们如何最大化投资回报率?”
确定预期回报非常简单。我通常通过用数学术语比较机器学习的好处和潜在成本,来开始打开机器学习实现的商业案例。这可以形式化为一个等式,基本上就是“在考虑了错误的成本之后,所产生的价值还剩下什么?”解这个简单的方程让我们可以估计不同情况下的利润。

让我们看看变量:
- 返回:每次预测产生的净值或利润
- value :每次预测生成的新值(例如,将文档分配到正确的类别现在需要 0.01 秒,而不是 5 分钟,因此节省了 5 分钟)
- 精度:算法预测的精度
- 错误成本:错误预测导致的额外成本(例如,有人需要 20 分钟来纠正系统中的错误)
通过翻转等式并将回报率设为零,我们得到了产生净值所需的最低精确度。这被称为盈亏平衡精度:

在图表中绘制时,等式变得更加直观:

图中的盈亏平衡点
假设每个预测为你节省了 5 分钟的工作时间,但是要修正一个错误的预测却需要 20 分钟的额外工作时间。我们现在可以计算出盈亏平衡准确度为*1–5/20 =*75%。此后的任何改进都会带来具体的利润。
上面的等式假设我们盲目地接受算法做出的任何预测,然后修正错误。听起来很冒险?我们可以做得更好,用置信度分数来扩展等式,以降低风险。
优化投资回报率
一个机器学习算法(做对了)不仅仅会喷涌出预测,它还会告诉我们它对每一个预测有多有信心。大多数错误发生在算法不确定其答案时,这使我们可以将自动化集中在最高确定性的预测上,同时手动审查最低确定性的预测。尽管人工审查确实要花费一些人力,但通常比以后修复错误要便宜得多。
让我们选择一个阈值,挑选出 10%最不自信的预测进行人工审查。剩下的 90%会自动处理。这个比例叫做置信分割。由于许多错误出现在小的不自信括号中,高自信括号中的准确度现在将会好得多。这将我们引向扩展方程。它说“在考虑了错误和人工审查的成本之后,所产生的价值还剩下什么?”

看起来很可怕,但一旦你知道它包含什么,它就很简单:
- 返回:每次预测产生的净值或利润
- 值:每次预测产生的新值
- 置信精度:高置信区间的预测精度
- 错误成本:错误预测所产生的额外成本
- 置信度分割:高置信度预测的比率(在我们的例子中是 90%)
- 人工审核成本:人工审核预测的成本
我们可以再次翻转等式,通过将回报设置为零来计算盈亏平衡精度,如下所示:

我们将使用以下变量来求解:
- 价值=节省了 5 分钟
- 错误的代价= 20 分钟
- 人工审核的成本= 5 分钟
- 置信区间= 0.9
现在新的盈亏平衡精度是 78% 。等等,这比更简单的方程要高,是不是变得更糟了?不完全是!请记住,许多错误都出现在低置信度类别中,这大大提高了高置信度类别的准确性。即使盈亏平衡的最低精度要求变得更高,现在也更容易实现。
计算运行中的机器学习算法的盈利能力,可以让你找到最佳的准确性。不,不是 100%。正如我在我的上一篇文章中所讨论的,任何系统的开发成本都是指数增长的,而回报却是递减的。有了上面的等式,您可以估计一个现实的 ROI,并计算在您选择的时间框架内,准确性的提高比回报的增加产生更多开发成本的点。这是 ROI 优化的精度。
实际例子
让我们来看一个真实世界的场景,并贯穿整个过程。假设您的应付账款团队每个月要处理 5000 张发票,并且您已经有了自动化部分流程的想法。更具体地说,拟议的自动化将对收到的发票进行分类,以匹配复杂的内部供应商代码,目前这是手工完成的。你需要弄清楚一种机器学习方法是否值得花力气来解决这个任务。
就数据而言,以下是您将要处理的内容。您有以前处理过的发票的历史记录以及每张发票的正确“供应商代码”值。任务是为任何新发票预测正确的“供应商代码”。你可以在这里 找到原来的数据集 。

先睹为快
首先,使用您喜欢的任何机器学习库或工具,并对数据进行基本的准确性测试。我使用的是 aito.ai ,经过 4000 行的训练和 1500 行的测试,我的准确率达到了 78%。如果我们使用和以前一样的价值和成本,我们可以用第一个等式计算月回报:

使用忽略置信度分数的简单方法,算法以 78%的准确率做出的每个预测平均为您节省 0.59 分钟的工作,或 35 秒。这意味着通过处理 5000 张发票,每个月可以节省将近 50 个小时的工作时间。还不错。
现在让我们来看看考虑置信度得分的等式。我将每个预测的结果和可信度分数整理成一个简洁的表格,如下所示,这样我们就可以将它们分为高可信度和低可信度两类。在这种情况下,任何置信度低于 0.21 的预测都将被手动审核。这个阈值给了我们 90/10 的置信区间。

预测结果
在我们的高信心等级中,准确率达到了令人印象深刻的 84%,而在低信心等级中,准确率只有区区 22%。这使得利用置信度得分的影响非常明显。现在,当信心和人工审查成本成为等式的一部分时,我们可以计算新的回报:

扩展的方法几乎使回报翻倍!每次预测平均节省 1.15 分钟。现在,处理你每月 5000 张发票的工作量减少了 95 个小时,即使算上错误成本和人工审核 10%的预测。太棒了!
现在你知道你目前可以达到的盈利水平。更好的是,您现在有了一个工具来确定进一步机器学习开发的可行性。例如,使用该等式,您可以计算假设 90%准确率的回报,并发现回报为每月节省 183 小时。将它与达到 90%准确率的估计开发成本进行比较,您将有事实数据来决定进一步的开发是否值得投资。
总结一下
正如你所看到的,机器学习应该像任何其他投资一样进行。不可避免的错误只是做生意的成本,它们是我们计算中的正常变量。有了这些等式,你就知道什么时候开始收获机器学习的好处,而不是玩猜谜游戏,并且你可以更早地将算法投入生产。从永无止境的追求 100%准确度的苦差事中解脱出来,并开始创造价值。
做得比完美更好。
我在aito . ai为不同平台开发机器学习集成,让机器学习的好处大众化。
修改我的音高质量标准
从头到尾对 Ethan 改进后的新指标进行了全面分析
作者注:本文(QOP)讨论的度量在未来的工作中将被称为 xRV(预期运行值)。
有关 QOS+的信息,一个本文中描述的姐妹指标, 点击此处 或滚动到本文底部。
今年早些时候,我创建了一个模型,试图量化一个 MLB 项目的质量。这个想法是,每个音高都可以根据它的区域位置、释放点和一些音高特性来给定一个预期的运行值。虽然我最初对我的度量结果(最初在这里介绍了)和我能够做的后续分析(这里的、这里的、这里的和这里的)感到满意,但我承认从建模的角度来看还有改进的空间。
在过去的几天里,我决定使用一个更具统计学意义的模型构建过程,彻底重建我的音高质量指标。本文将详细描述这个过程,并附有我的可复制代码,在这里找到。
问题
对于这个项目,我首先问
在 2020 赛季的每一场比赛中,我们期望得到多少分?
为了回答这个问题,我决定使用线性权重框架,它给出了每一个投球结果(球、好球、一垒打、本垒打、出局等)。)基于该事件在先前游戏中的价值的运行值。这个想法是,投出更多可能得到好结果(比赛中球的全垒打和出局)的投手应该得到奖励,而投出更多可能导致坏结果(比赛中球和球的跑垒员)的投手应该受到惩罚。
以前的方法问题
以前的度量标准,期望运行值(xRV)有什么问题,以至于我不得不改变它?一些事情。首先,它是使用一种叫做 k-最近邻的模型制作的,这种模型对于像这样的大型高维模型来说不是非常严格。在那个模型中,我使用了 100 个最近邻,这是一个任意的值,我没有特别的理由就选择了这个值。我没有进行特征选择,只使用了视觉测试来评估这个指标是否足够好。我的结论是,它的糟糕的 RMSE 分数证明了我是错的。这是很好的第一步,但我知道我可以做得更好,所以我做了。结果是一个改进的度量,其蓝图完全包含在本文中。
新方法
在进入杂草之前,我想概述一下这个新的度量,我称之为音高质量(简称 QOP),是如何计算的。我根据投手惯用手、击球手惯用手和投球类型,将本赛季的每一次投球分为 16 类。稍后我将详细介绍这些群体。对于每一组,我在该类别的一个音高子集上制作了一个单独的随机森林模型,确认该模型是有用的,然后将该模型应用于该类别的所有音高。数据集中的每个音高只属于一个类别,因此只能从 16 个模型中的一个得到预测。
最后,我将所有 16 个模型的预测汇总在一起,并通过均方根误差(RMSE)评估模型的质量。这个模型比我最初在三月份做的这个度量的第一次迭代有了显著的改进。
我们走进杂草中。
数据采集
本项目使用的所有数据都来自于通过比尔·佩蒂的 baseballR 包公开提供的BaseballSavant.com,使用了以下函数和参数:
data = scrape_statcast_savant(start_date = “2020–07–23”,
end_date = “2020–09–05”, player_type = “pitcher”)
这种方法往往一次只能获取 40,000 个音高,所以我将它分解成更多日期范围更小的函数调用,并使用 rbind()命令将所有数据帧合并成一个。
数据清理和特征创建
不幸的是,这个公开可用的数据集不包括每个事件的线性权重值,就像我需要回答我的研究问题一样,所以我从头开始计算线性权重。我确信 2020 年的线性权重值存在于互联网上的其他地方,我可以找到并加入数据集,但我已经有了以前项目的代码,除了初始数据采集之外,我不希望在这个项目的任何部分依赖任何外部来源。公平的警告,这段代码,也可以在我的 GitHub 这里找到,有点乱,但最终完成了工作。
我想指出的是,我选择了将导致三振的投球赋予与典型三振相同的跑垒值(不是三振),而导致保送的投球被赋予典型球的跑垒值。因为这个指标是上下文无关的,击球次数不会成为这个模型的一个特征,所以我觉得这个改变是必要的。
一旦我获得了数据中每一行的线性权重值,我就根据下表将所有音高分组为四个音高类型组:

所有其他球场类型的球场,如指关节球、椭圆球等。已从数据集中删除。在这一步中,大约有 250 个球丢失了,我只剩下大约 170,000 个。(注:本文使用的数据是通过 9 月 5 日玩的游戏)
最后,我创造了三个新的变量来量化每一个速投和投手的平均快速球速度和移动之间的速度和移动差异。我这样做是因为我希望在以后的最终模型中包含这些变量,如果它们被证明是有用的话。
特征选择和重要性
如我之前所说,这个指标实际上是 16 个不同随机森林模型的组合。2020 年的每一次投球都属于 16 个类别之一,如下所示:

虽然我总共创造了 16 个模型,但是只有两个模型方程式:一个是快速球,一个是慢速球。
快速球特征选择
在筛选出恰到好处的快速球和恰到好处的快速球并随机抽取 10%的数据后,我用所有可能的特征运行了 Boruta 特征选择算法。(使用所有的数据会花费太多的时间,并且会产生相似的结果,所以我使用这个较小的子集来代替。)Boruta 是一种基于树的算法,特别适用于随机森林模型中的特征选择。
library(Boruta)Boruta_FS <- Boruta(lin_weight ~ release_speed + release_pos_x + release_pos_y + release_pos_z + pfx_x + pfx_z + plate_x + plate_z + balls + strikes + outs_when_up + release_spin_rate,
data = rr_fb_data_sampled)print(Boruta_FS)
该算法发现,除了一局中的球、击球和出局之外,上述所有变量在 0.01 水平上都是显著的,这是有意义的,因为我的上下文中性方法计算线性权重,即响应变量。
所以在我最终的快速球模型中的特征是投球速度、释放点、旋转速度和球板位置。因为我使用的是随机森林,所以我不需要担心运动和旋转速率等特征之间的潜在协方差。以下是模型中的最终特征,根据 Boruta 根据其对线性重量游程值预测的重要性进行排序。

用简单的语言来说,这些是对快速球质量最重要的变量。垂直运动是第一名,速度是第二名,伸展是第三名,这不应该是一个惊喜,而且肯定通过了嗅觉测试。
对于偏速模型,我遵循了一个非常相似的程序,为了特征选择的目的,子集化到随机的 10%的右对右偏速音高。我再次使用了具有相同潜在特性的 Boruta,但这次也包括了我之前创建的变量:每个投球和投手典型快速球之间的速度和运动差异。
Boruta_OS <- Boruta(lin_weight ~ release_speed + release_pos_x + release_pos_y + release_pos_z + pfx_x + pfx_z + plate_x + plate_z + balls + strikes + outs_when_up + release_spin_rate + velo_diff + hmov_diff + vmov_diff, data = rr_os_data_sampled)print(Boruta_OS)
结果如下:

我要做一个决定。保持原始的速度和移动值,还是使用基于投手快速球的值?该表显示,我们选择哪一个并不重要,因为两组变量具有非常相似的重要性分数。因此,我将使用包含原始值的变量。这里是个人偏好选择,但同样,与备选方案相比,它不应该对指标的准确性产生太大影响。
此外,即使博鲁塔发现罢工非常重要,我还是要排除这个变量,因为在我看来,它在我们的环境中立的情况下没有什么意义。所以偏离速度方程的最终变量是…

…除了释放延伸之外,与快速球方程式中的变数相同。很高兴事情是这样发展的。请注意不同重要性顺序的不同。到目前为止,移动似乎是变速球最重要的特征,这也是有道理的(特别是因为它混合了变速球、滑球和曲球)。
模型验证和评估
正如敏锐的观察家指出的,我完全没有验证我最初的音高质量模型,这是一个问题!我怎么知道它好不好?我几乎没有。我不会再犯同样的错误了!回顾过去,我之前的指标的 RMSE 是 0.21。考虑到 0.21 是响应列的标准偏差,线性权重,这是不好的。我希望通过这个新的指标,用一个更小的最终 RMSE 来改善这个数字。
为了验证这一指标,我使用了一种以前从未使用过的方法,将模型嵌套在一个数据框架中,一次性训练和测试我的所有 16 个模型。我从这篇 StackOverflow 帖子中大量借用了这篇文章,我的代码版本可以在我的 GitHub 这里看到。
按照惯例,我用 70%的数据训练每个模型,并将其应用于另 30%的数据,即我的测试集。
快速球训练和验证
#Fastball Training and Validating
fbs_predictions <- fb_nested %>%
mutate(my_model = map(myorigdata, rf_model_fb))%>%
full_join(new_fb_nested, by = c("p_throws", "stand", "grouped_pitch_type"))%>%
mutate(my_new_pred = map2(my_model, mynewdata, predict))%>%
select(p_throws,stand,grouped_pitch_type, mynewdata, my_new_pred)%>%
unnest(c(mynewdata, my_new_pred))%>%
rename(preds = my_new_pred)rmse(fbs_predictions$preds, fbs_predictions$lin_weight)
超速训练和验证
os_predictions <- os_nested %>%
mutate(my_model = map(myorigdata, rf_model_os))%>%
full_join(new_os_nested, by = c("p_throws", "stand", "grouped_pitch_type"))%>%
mutate(my_new_pred = map2(my_model, mynewdata, predict))%>%
select(p_throws,stand,grouped_pitch_type, mynewdata, my_new_pred)%>%
unnest(c(mynewdata, my_new_pred))%>%
rename(preds = my_new_pred)rmse(os_predictions$preds, os_predictions$lin_weight)
我对快速球模型的验证 RMSE 是 0.105,对慢速球模型的验证 RMSE 是 0.099,这两个指标都比我预期的好得多,表明这个指标在准确性和预测能力方面比我以前的指标有了真正的改善。
知道了我们对模型在验证集上的表现的了解,我对将这些模型应用到 2020 年迄今为止的每一场比赛感到很舒服。在这样做的时候,我给了 2020 年的每一个音高它的预期运行值。
当我这样做并结合预测时,我最终的总体 RMSE 是 0.145,比我之前的 0.21 RMSE 有了很大的提高!
我可以自信地说,这个模型在量化 MLB 音高的预期运行值方面优于我以前的音高质量模型。
限制
我想重申这个模型的目的和功能,以便揭示它的缺陷。正如乔治·博克斯的名言所说,“所有的模型都是错的,但有些是有用的。”这个模型根据 2020 年 MLB 赛季中每一场比赛的结果在真空中的可能性为每一场比赛赋值。虽然它看起来做得相当好,但这个指标没有考虑到
- 音高排序,以前的音高对当前音高的影响
- 对方击球手的强项和弱项
- 比赛情况(得分、局数、投球数)
- 击球情况(计数、跑垒员、出局数)
与任何模型一样,理解限制和适当的用例与理解模型本身的机制一样重要。也许在未来的迭代中,这些特性中的一些可以被集成到模型中,并且有可能提高它的性能。
结果
与我过去的一些文章不同,这些文章包括了以前的音高质量模型的结果的完整分析,我将保持这一部分的简短,以便将重点放在这一指标的创建过程上,而不是对其最终排行榜的争论。
也就是说,这里有一些来自这个模型的有趣的见解。请记住,QOP 的所有单位都是“每 100 场比赛阻止的预期得分”,所有排行榜都是准确的,直到 9 月 5 日的比赛。
快速球 QOP 2020 年迄今领先

2020 年迄今换台 QOP 领导人

滑块 2020 年 QOP 领导人至今

QOP 2020 年迄今领先

顺便提一下,里奇希尔排名第 11
写下来并公开代码对我来说真的很重要,算是结束了我这个非常活跃的研究夏天。我希望有人将能够采取这一点,并改善它,以进一步了解棒球比赛在公共领域!
一如既往,感谢您的阅读,如果您有任何问题、反馈或理想的工作机会😅,请在推特上告诉我 @Moore_Stats !
QOS+详情
东西的质量+(简称 QOS+)与本文概述的度量标准密切相关,QOP。我与《运动》杂志的 Eno Sarris 合作,为他的双周刊《材料与命令》撰写了这一指标。
以下是 QOS+和 QOP 的相关区别:
- QOS+不包括板位置作为其快速球或偏速模型方程的特征,以隔离投手的“材料”对其投球的预期跑分值的影响
- QOS+使用速度和移动值,相对于投手在其越速模式下的典型快速球
- QOS+的标度与 QOP 不同,100 是联盟平均水平,110 是比联盟平均水平高一个标准差
QOS+和 QOP 的排行榜预计会有所不同,QOS+排行榜更倾向于拥有好“东西”的投手,而不是 QOP,这也是投手的指挥。
逆向工程谷歌的技术,以赢得 95%以上的准确性
等等,你没看错😃让我们像专业人士一样设计神经网络吧!
我们看到谷歌如何提出许多突破性的科学构建,即使是在深度学习时代的早期阶段。他们拥有世界上最好的资源,硬件、软件和工程师。我们将研究如何对谷歌的一项新服务进行逆向工程,以获得惊人的结果。
我想给你讲一个故事。两年前,谷歌提出了一个想法,即开发一个平台,任何人都可以在这个平台上开发自己强大的深度学习模型,而无需事先有编码经验。这个平台的早期版本只允许用户使用他们的网络摄像头创建分类模型。这个想法很简单,走到讲台上,打开你的相机,给它看几张不同班级的照片。这个模型是在谷歌的计算机中训练出来的。所有这些事情的发生只是时间问题。该平台的最初版本非常简单。最近,谷歌更新了平台,为多个类别、姿势估计、音频分类、不同格式的下载模型等提供了巨大的支持。谷歌称之为 可教机器 。当前版本支持以下内容。
- 根据图像数据训练模型
- 根据音频数据训练模型
- 根据姿势数据训练模型(像在 Posenet 中)
- 将您自己的数据集上传到训练模型
- 每个模型培训 3 个以上的班级
- 禁用类别
- 保存您的 TensorFlow.js 模型
- 下载您的模型
- 部署您的模型以用于您自己的项目(网站、应用程序、物理机器等)。)
怎么样?对我来说,太棒了。
为了更好地了解这个平台,请观看下面由 Google 制作的视频。
谷歌可教机器视频
这个逆向工程任务是如何工作的?
我们要逆向工程的服务不过是 可教的机器 。首先也是最重要的,我们去平台,输入一些不同类别的图片。我选择了 摇滚 - 纸 - 剪刀 。您可以使用网络摄像头实时捕捉图像,或者上传您自己的自定义数据集。为了说明,我使用网络摄像头的方法。

截图取自https://teachablemachine.withgoogle.com/
如您所见,数据集已经准备好了。每个类由 200 幅图像组成。接下来就是训练模型了,我们只要点击 训练模型 选项就可以开始训练模型了。

截图取自https://teachablemachine.withgoogle.com/
我们的模特不到一分钟就能完成训练。剩下的是,我们必须看看我们的模型在现实世界中的表现。为此,我们可以使用现场演示选项。下面是一张 GIF 图,展示了我们训练的模型的结果。

截图取自https://teachablemachine.withgoogle.com/
一切正常,对吧?精度栏每次都打到 100。我做的每个测试都得到了几乎相似的结果。这只是一个例子,你可以用更复杂的数据集来尝试。对于这个解决方法的主要部分,我们必须将模型导出为某种格式。在这里,我使用了 Keras 模型的变体。如果您愿意,可以在相同的 Tensoflow.js 或 Tensorflow Lite 版本之间进行选择。

截图来自https://teachablemachine.withgoogle.com/
我们已经完成了模型训练部分。现在,我们必须开始问题的核心部分,即逆向工程。我们将要看到的是 模型是如何建立的 ,所有的层配置都使用了什么,有多少层,内核大小是什么,前馈网络的维数等等。为此,我们使用一个叫做netron的工具。深度学习模型不是一堆简单的层,对吗?
Netron 是一个开源工具,我们可以用它来看看深度学习模型是如何设计的以及相关的权重。我们必须访问他们的网站,并安装基于操作系统的客户端应用程序。我一直在用 Ubuntu,所以我下载了它的 Linux 版本。这个项目的主页将如下所示。

截图取自https://github.com/lutzroeder/netron
我们最后要做的就是用 netron app 打开下载的模型。抓住你了!我们成功了。

截图来自 netron app
你在上图中看到的是我们模型的架构。这是一个非常长的设计,不能放在一张截图里。放大后,我们得到了下面的图片。

截图来自 netron app
我们可以看到一些熟悉的层,对不对?在右侧,也给出了模型权重和超参数。如果我们可以通过查看层配置从零开始创建相同的模型,那就太棒了。我们可以在下一个项目中尝试这种配置。谷歌应该做了很多功课。所以采用同样的方法应该会有回报。
这是一种新的深度学习方法,可以极大地改善最终结果。希望这对您有所帮助。干杯,大家。

逆向工程图卷积网络

让我们对 GCN 进行逆向工程。在 Unsplash 上拍摄的 ThisisEngineering RAEng
这篇博客文章将总结“简化图卷积网络【1】”这篇文章试图对图卷积网络进行逆向工程。因此,让我们向后发展图卷积网络。
图是结构的普遍模型。它们无处不在,从社交网络到化学分子。各种事物都可以用图表来表示。然而,将机器学习应用于这些结构并不是我们直接想到的。机器学习中的一切都来自于一个小的简单的想法或模型,它根据需要随着时间变得复杂。举个例子,最初,我们有发展成多层感知的感知机,类似地,我们有发展成非线性 CNN 的图像滤波器,等等。然而,图卷积网络,被称为 GCN,是我们直接从现有的想法中衍生出来的,并有一个更复杂的开始。因此,为了揭穿 GCNs,本文试图对 GCN 进行逆向工程,并提出一种简化的线性模型,称为简单图卷积(SGC)。 SGC 在应用时可提供与 GCNs 相当的性能,甚至比快速 GCN 还要快。
基本符号
图卷积网络的输入是:
1。节点标签
2。邻接矩阵
**邻接矩阵:**邻接矩阵 A 为 **n x n,**矩阵其中 n 为节点个数,若节点 I 与节点 j 相连则 a(i,j) = 1 否则 a(i,j) = 0。如果边是加权的,那么 a(i,j) =边权重。
**对角矩阵:**对角矩阵 D 是 n×n 矩阵,d(i,i) =邻接矩阵的第 i 行之和。
输入特征: X 是大小为 n x c 的输入特征矩阵,c 为类别数。
在逆向工程之前,让我们看看 GCNs 实际上是如何工作的。
图卷积网络在行动
当我们通过 CNN 层输入图像时,会发生什么?它使用一个像素及其相邻像素来给出特定索引的输出。同样的行为在 GCNs 中也很普遍。对于每一层,我们传播一个新的特征:

正向传播步长
此外,该步骤可以矩阵形式表示为:

第 k 个输出通过将 S 乘以前一个输出获得

归一化邻接矩阵
因此,每下一步都可以表示为 S 与 H(i-1)的稀疏矩阵乘法
这就是平滑局部隐藏的表示。怎么会?每一步都从邻居传播特征。因此,在第一步之后,节点 x 具有其自身以及其邻居的信息。在第二步之后,它再次从它的邻居那里获取信息,但是他们已经有了它的 2 步远邻居的信息,所以这些添加到节点 x 上。同样,信息是在每一跳收集的。现在,将结果乘以权重矩阵 W ,并且应用逐点非线性函数(ReLU)来获得下一个特征矩阵。

非线性激活函数
由此获得的结果可以被输入到 softmax 层以获得分类概率。

使用 GCNs 分类(等式 1)
图卷积网络可以用下图来概括:

GCN 在行动| 来源 [1]
简单图形卷积:GCN 简化
让我们回忆一下 MLP 和 CNN。在 CNN 的节目中,每一层都有一个局部的感知,形成了我们的特征地图,随着我们越走越深,每个值都比以前有更多的接收。类似地,GCNs 从每一跳的邻居获得信息,因此每一层之后,每个节点都有更多关于整个网络的信息。这是从邻居提取特征的部分。
然而,每一层都有一个非线性函数,但它不会增加网络的接收能力。因此,除去非线性部分,我们得到一个简单的模型:

线性 GCN 被称为 SGC,在去除了 GCN 的非线性功能之后

简化的 SGC 方程(相当于线性化的方程 1)
这是简单图形卷积的方程。我们可以清楚地看到,这个模型被简化为一个简单的预处理步骤,采用直接多类回归。多酷啊!需要注意的一点是,当 S 和 X 都是输入时,上面的等式有一个可学习的参数θ。所以 S ᵏ X 可以重写给 x ':

X (输出)相当于作者的特征工程化输入|图像

得到的分类器方程
因此,我们可以在下图中看到,我们如何对 GCNs 进行逆向工程,并实现删除非线性层,这有助于我们理解跳跃只不过是机器学习中的一个特征工程步骤。这部分的实现可以在 GitHub 上找到。此外,SGC 可以总结为下图所示。

简单图卷积| 来源 [1]
图形卷积网络的数学基础
这一部分将解释 GCNs 的数学流程,给出图卷积网络的半监督分类【3】
- 图拉普拉斯:
矩阵是表示图形的好方法。我们将图拉普拉斯算子及其归一化版本定义为:

图拉普拉斯(D =对角矩阵,A =邻接矩阵)

标准化形式
- 特征分解
每个半定矩阵都可以分解成以下形式:

特征分解
其中 U 包括标准正交特征向量,λ是以特征值作为其对角元素的对角矩阵。
现在,你有正交向量,我们能定义关于它们的图形傅立叶变换吗?绝对是!阅读关于 DFT 的内容。我们把 x 的傅立叶变换写成:

傅里叶变换
和逆变换为:

逆变换
- 根据傅立叶变换的图形卷积
现在,我们从信号和系统知识中知道,我们可以把任意两个信号的卷积写成它们在傅里叶变换中的乘积!使用这个我们得到:

滤波器与输入的卷积
这里 G 是以对角线作为滤波器系数的对角矩阵(你要学习的参数)
最后,我们使用一个使用 k 阶多项式拉普拉斯的近似来给出:

G 是大括号内的近似值!!
- 最终表情
上述近似通过使用(导致一阶切比雪夫滤波器)进一步近似:

给予

基本 GCN 卷积运算
此外,矩阵 I + D(-1/2)AD(-1/2 可写成:

其中 A’ = A + I,D’ = D + I。
简单图形卷积和低通滤波
我们导出的传播矩阵 S 是一阶切比雪夫滤波器。根据归一化拉普拉斯算子,它可以写成:

因此,第 k 阶滤波器系数变为:


Cora 数据集上不同传播矩阵的特征(红色)和过滤器(蓝色)光谱系数|来自 SGC 论文 [1]的结果
如图所示,K 值越大,滤波器系数爆炸并过度放大信号。

归一化的 S 给出了归一化的拉普拉斯算子,其进一步影响特征值
这就是在 GCN 帮助中使用重正化技巧的地方。通过重正化,滤波器系数变成重正化传播矩阵的多项式。
此外,添加自环γ > 0 后,归一化图拉普拉斯的最大特征值变小
结论
gcn 是神经网络复兴的结果,神经网络直接进化为复杂的网络来研究。在这里,GCN 被简化成它可能的前身 SGC。首先,我们研究了 GCNs 的工作原理,然后将其逆向工程为一个简化的回归模型,并通过特征工程增加了复杂性*。*进一步使用 GCNs 的数学表达式,网络被表示为切比雪夫滤波器!从而简化了网络!
接下来呢?
关于 SGC 和 GCNs 实现和比较更多细节,可以在参考文献[2]中找到作者实现。我在 CORA 数据集上实现的 SGC 可以在 GitHub 上找到。
参考文献:
- 图卷积网络|图论 2020
- 吴,费利克斯,等,“简化图卷积网络” arXiv 预印本 arXiv:1902.07153 (2019)。
- 实现可以在 GitHub 上找到
- 作者编写的简单图形卷积的代码可在 Github 上获得
- 基普夫、托马斯·n 和马克斯·韦林。“图卷积网络的半监督分类.” arXiv 预印本 arXiv:1609.02907 (2016)。
对您进入数据科学的道路进行逆向工程
如何组织你的自学之旅并获得你梦想中的角色

自学成为数据科学家似乎是一项几乎不可能完成的任务。有太多的东西要学,太多的东西要理解,因此,关于如何成为一名数据科学家,互联网上不乏各种观点。如果没有一些指导,很难判断你是否在朝着正确的方向前进。
别害怕。自学路线比你想象的要容易管理得多。用正确的策略武装自己的技能,你可以学习如何成为一名非常受欢迎的数据科学家,并获得你梦想的角色。
在这篇文章中,我将向您展示如何通过逆向工程实现您梦想中的数据科学角色。我们都是从某个地方开始我们的旅程的,我希望为你进入这个行业提供第一块垫脚石。
逆向工程路径——定义你的目标
逆向工程是把一个物体拆开,看看它是如何工作的,以便复制或增强所述物体。这里的目标将是你的最终目标,定义你梦想中的角色是什么。你梦想的数据科学角色是什么?请考虑以下情况:
- 你想从事什么领域的工作?你想解决什么样的商业问题?你想贡献什么样的工作?
- 你认为自己会使用哪些技术?你很想了解哪些技术?为什么?
- 你想要什么样的工作文化?你是想从一家规模较小的初创公司开始,还是想从一家已经很有名气的公司开始?或许介于两者之间?
一旦你有了想成为哪种数据科学家的想法,就很容易逆向开发你需要学习的技能来实现你的目标。记住你的最终目标会随着你旅程的进展而改变。随着学习的进展,你会发现你喜欢使用哪种数据和技术。
如果你还不完全确定你的理想角色是什么,不要担心。对你来说,列出你不想要的角色可能是个更好的主意。这样你就可以集中精力探索你可能喜欢的技术和行业。
所有这一切的关键是你的旅程是一个迭代的过程,它永远不会是完美的。一旦你开始并开始前进,道路就会变得越来越清晰。
找到你的垫脚石
既然你已经对自己想成为什么样的数据科学家有了一些大致的了解,我们现在需要找到你有一天真的想成为的真正角色。然后,我们将需要提取所需的技能,以获得面试机会,从而获得上述职位。
根据你刚刚为自己定义的理想角色,找到 5 个符合你要求的职位。哪 5 份工作会让你欣喜若狂?
一旦你有了 5 分,是时候让我们为你建立一个技能清单,让你在自学之旅中掌握。这一部分可能有点棘手,因为某些招聘信息对他们想要的技能非常模糊,而其他的则非常具体。在任何情况下,单独通读每一条招聘信息,记下雇主正在寻找的特定技术和非技术技能。
然后你要比较和对比这些技能列表,寻找它们之间的共性。你最常看到的共性是“必须学习”的技能,你需要首先掌握的技能。该技能出现得越频繁,该角色的日常操作就越需要它。
那些不太常见的技能将会是更“专业”的技能,这些技能你将会优先考虑最后掌握。这些技能也很重要,但它们更适合特定的角色和行业。
让我们来看看 LinkedIn 上的一些招聘信息,我会告诉你如何提取你需要的信息,为你的旅程制作一份技能清单:

X 公司数据科学家的工作要求
我们可以从 X 公司的招聘启事中获得什么信息?
这一职位的强有力候选人似乎需要具备以下条件:
- 对统计学有很好的理解,具有优秀的批判性思维技能和定量问题解决技能
- 非常强的沟通和数据可视化技能
- 精通编程语言(最好是 Python)
- 精通 SQL
- 精通数据清理、操作和可视化
- 深度学习和机器学习
- 有大数据、云平台和计量经济学模型的经验更好(但不是必需的)。
这是一个非常好的技能列表,事实上,大多数核心数据科学家技能都列在第一个列表中。但是,让我们来看看另一家公司的第二份招聘启事,这样你就能明白我的意思了:)在阅读过程中,请注意与第一份工作描述的一些相似之处:

Y 公司数据科学家职位的工作描述
我们可以从 Y 公司的招聘启事中获得什么信息?
这一职位的强有力候选人似乎需要具备以下条件:
- 对统计学有很好的理解,具有优秀的批判性思维能力
- 非常强的沟通和数据可视化技能。
- 编程语言(最好是 Python,因为它是最流行的)
- 结构化查询语言
- 数据清理和数据操作。
- 机器学习(对特定模型有不同的侧重)
- 时间序列分析(预测)
- 对于这一特定角色,销售背景将受到高度重视
第二个角色比第一个角色更专业,但是你看到两者之间的所有相似之处了吗?使用这种逆向工程策略可以消除在计算成为数据科学家需要学习哪些技能时的猜测。雇主实际上是在告诉你他们想让你知道的事情。想象一下,通过 5 个职位,你将能够收集到多少额外的信息,非常令人兴奋。
一旦你完成了最常见和最特殊的技能的汇总,你就为你的学习创造了“检查点”,为了成功,你必须带你去那里。现在,我们实际上可以构建您自己的行业发展道路
建设你的道路
现在你知道了什么是踏脚石,你可以开始规划你想如何开始你的学习。没有正确或错误的方法,但理想情况下,您会希望首先专注于数据科学家的核心技能,从学习 Python 语法开始。我建议在学习熊猫、Numpy 和 SciPy 之前先学习属性(或者你可以一起学习:)
大多数职位招聘都需要以下技能(我也提到了与之相关的 Python 库):
- 统计数据(熟悉使用 SciPy 和 Numpy 来分析关于数据的统计数据)
- Python 编程(免费学习 Python 基础知识这里
- 数据清理、争论和形状操纵(Numpy 和 Pandas)
- 数据可视化(Pandas、Seaborn、Matplotlib、Pyplot 等等)
- 监督和非监督机器学习(Scikit Learn)
学习上面的 Python 包的一个很好的资源是Python 数据科学手册以及搜索文档的特定库
学习策略
作为给你的临别礼物,我强烈推荐看看这篇关于基于项目的学习的文章。因为您有如此多的东西要学,有如此多的技能要掌握,所以您会希望通过创建不同的项目来开发您在真实世界数据上的技能,从而在真实世界的场景中实践它们。
通过使用基于项目的学习,你不仅可以更容易地单独掌握每项技能,还可以开发将多项技能结合使用的方法,以从数据中获得强大的洞察力。如果您需要访问真实世界的数据资源,请点击这里查看这篇文章。随着你完成越来越多的项目,并进一步发展你的技能,你可以随时回到你以前的项目,并对它们进行修改,使它们成为你简历中的最佳分析。
好吧,那对我来说就够了。非常感谢您花时间阅读我的文章,我希望我能够为您的数据科学之旅提供一点帮助。下次再见,祝你这周过得愉快!

我叫 Kishen Sharma,是一名数据科学家,在旧金山湾区工作。我的使命是教授和激励全世界有抱负的数据科学家。
请随时在 Instagram 上与我联系,并在这里查看我的附加内容。你也可以在这里查看我的其他文章。
综述:药物发现中的深度学习
深度学习算法已经在许多不同的任务中实现了最先进的性能。卷积神经网络(CNN)可用于在图像分类、对象检测和语义分割任务中实现出色的性能。递归神经网络(RNNs)及其后代,如 LSTMs 和 GRUs 以及 transformers,是人们首先想到的解决神经语言翻译、语音识别等问题的方法,甚至可以用来生成新的文本和音乐。
药物发现是可以从深度学习的成功中受益匪浅的领域之一。药物发现是一项非常耗时且昂贵的任务,深度学习可以用来使这一过程更快、更便宜。
最近,围绕这个主题发表了许多论文,在这篇文章中,我将详细回顾一下如何在这个领域使用深度学习。
我可以将深度学习在药物发现中的应用主要分为三个不同的类别:
- 药物性质预测
- 从头药物设计
- 药物-靶标相互作用(DTI)预测

图 1:深度学习可以帮助和促进药物发现的三个领域。
在下文中,我试图详细阐述每一类并讨论一些相关的论文。
药物性质预测
机器学习问题大致分为三个子组:监督学习、非监督学习(自我监督学习)和强化学习。药物性质预测可以被框架化为监督学习问题。算法的输入是药物(化合物),输出是药物性质(例如,药物毒性或溶解度)。
- 输入:一种药物(小分子)
- 输出:0–1 个标签,表示药物是否具有某些特性。它也可以被设计为多标签分类或回归任务。

图 2:表示分子的不同方式。
因此,有不同的方法来表示一种药物(化合物):
- 分子指纹
- 基于文本的表示(例如,微笑、InChIKey、自拍)
- 图形结构(二维或三维图形)
分子指纹
在机器学习框架的输入管道中表示药物的一种方式是分子指纹。最普遍的指纹类型是一系列二进制数字(位),代表分子中特定亚结构的存在或不存在。因此,药物(小化合物)被描述为 0 和 1 的向量(阵列)。

图 3:如何用二元向量表示一个分子。
它在文献中被广泛使用[1]。但是,很明显,将分子编码为矢量不是一个可逆的过程(这是一个有损变换);也就是说,我们不能从指纹中完全重建一个分子,这表明在这个操作过程中丢失了许多信息。
代表一个小分子有许多不同的指纹。你可以跟随这份指南【2】去了解更多。
微笑代码
另一种表示分子的方式是将结构编码成文本。它是将图形结构数据转换为文本内容并在机器学习管道中使用文本(编码字符串)的方式。标准之一和最流行的代表是简化的分子输入行输入系统(SMILES)。转换后,我们可以使用自然语言处理(NLP)文献中的强大算法来处理药物,例如,预测属性、副作用,甚至化学-化学相互作用。孙英权【3】。

图 4:如何用 SMILES 代码表示一个分子。
如果你有兴趣了解更多关于微笑的知识,你可以点击这个链接【4】。虽然 SMILES 在化学家和机器学习研究人员中非常流行,但它不是唯一可用于表示药物的基于文本的表示。InChIKey 是另一个你可以在文学作品中找到的流行代表。 Mario Krenn 等人 [5]提出的自拍照(自引用嵌入字符串),基于乔姆斯基 type-2 语法。我在从头药物设计部分更多地谈论它们(优点)。
图形结构数据
对图结构数据进行深度学习的流行,如图卷积网络[ Thomas Kipf ] [6],使得直接使用图数据作为深度学习管道的输入成为可能。
例如,化合物可以认为是一个图,其中顶点是原子,原子之间的化学键是边。我们已经看到在图形神经网络领域取得了显著的成功
,并且有诸如深度图形库、 PyTorch-Geometric 、 PyTorch-BigGraph 等库专门致力于这项工作。
药物-靶标相互作用预测
蛋白质在生物中起着核心作用;即蛋白质是生物细胞内外大多数功能的关键角色。例如,有一些蛋白质负责凋亡、细胞分化和其他关键功能。另一个重要的事实是,蛋白质的功能直接依赖于它的三维结构。即改变蛋白质的结构可以显著改变蛋白质的功能,这是药物发现的重要事实之一。许多药物(小分子)被设计成与特定的蛋白质结合,改变它们的结构,从而改变功能。此外,至关重要的是要注意到,仅改变一种蛋白质的功能就能对细胞功能产生巨大影响。蛋白质直接相互作用(例如,你可以看到蛋白质-蛋白质网络),而且一些蛋白质充当转录因子,这意味着它们可以抑制或激活细胞中其他基因的表达。因此,改变一种蛋白质的功能可以对细胞产生巨大的影响,并可以改变不同的细胞途径。

图 5:胶原粘附素和胶原复合物结构。
因此,计算药物发现中的一个重要问题是预测特定药物是否能与特定蛋白质结合。这是一个被称为药物-靶标相互作用(DTI)预测的概念,近年来受到了极大的关注。
我们可以按如下方式构建 DTI 预测任务:
- 描述:预测化合物和蛋白质结合亲和力的二元分类(它可以形式化为回归任务或二元分类)
- 输入:化合物和蛋白质表示
- 输出:0–1 或[0–1]中的实数
冯庆元等【7】提出了一个基于深度学习的药物-靶标相互作用预测框架。大多数用于 DTI 预测的深度学习框架都将化合物和蛋白质信息作为输入,但区别在于它们使用什么表示来输入神经网络。正如我在上一节中提到的,化合物可以用多种方式表示(二进制指纹、微笑代码、从图形卷积网络提取的特征),蛋白质也可以有不同的表示方式。根据输入表示,可以使用各种架构来处理 DTI 预测。
例如,如果我们要对化合物和蛋白质使用基于文本的表示(化合物和氨基酸的 SMILES 代码或蛋白质的其他基于序列的描述符),首先想到的就是基于 RNNs 的架构。
Matthew Ragoza 等人提出了一种利用卷积神经网络进行蛋白质配体评分的方法【8】。他们利用蛋白质配体的三维(3D)表示,而不是基于文本的表示。因此,他们决定使用卷积神经网络,该网络可以作用于这种 3D 结构,并提取有意义的适当特征来预测蛋白质配体结合亲和力。
最近, Bo Ram Beck et al. 建议采用分子转换器药物靶点相互作用(MT-DTI)来识别可作用于 2019-nCoV 病毒蛋白的市售药物。
虽然提出深度学习算法用于计算机模拟 DTI 预测已经成为一种趋势,并且在某些情况下取得了令人印象深刻的结果,但这些论文非常相似,我在其中发现的唯一创新是输入表示的选择,以及随后对输入进行操作的架构。因此,我可以将这项任务总结如下:
- 查找包含化合物和目标信息的数据库,以及它们是否相互作用(例如,缝合数据库)。
- 最常见的是,在 DTI 预测中,网络将一对化合物和蛋白质作为输入。
- 你应该选择你认为适合化合物和蛋白质的表示法。我回顾了其中一些,但还有其他的表述。
- 根据您选择的表示,您应该考虑合适的神经网络架构来处理输入。根据经验,在基于文本的输入表示的情况下,可以使用基于 RNNs 的架构(GRU、LSTM……)和转换器,在图像或 3D 结构的情况下,可以使用卷积神经网络。
- 该问题可以被认为是二元分类(化合物是否与靶结合)或回归(预测化合物和蛋白质之间的亲和力强度)。
所以,这就是 DTI 预测。起初,这可能看起来是一个困难和具有挑战性的任务,但是我读过的论文使用了非常简单的技术和策略来解决这个问题。
从头药物设计
到目前为止,我们只是观察了判别算法;即,给定一种药物,算法可以预测副作用和其他相关属性,或者给定化合物-蛋白质对,它将预测它们是否可以结合。然而,如果我们对设计一种具有某些特性的化合物感兴趣呢?例如,我们希望设计一种化合物,它可以结合特定的蛋白质,修饰某些途径,并且不与其他途径相互作用,还具有某些物理性质,如特定的溶解度范围。
我们不能用我们在前面章节中介绍的工具包来解决这个问题。这个问题最好在生成模型的领域中实现。
生成模型,从自回归算法、归一化流、变分自动编码器(VAEs)到生成对抗网络(GANs),已经在机器学习社区中变得普遍和广泛。然而,在重新设计药物的任务中利用它们的尝试并不是很早。
问题是,产生一种化合物,给定某些期望的性质。显而易见,这比我们在上一节中讨论的另外两个问题更难。
可能的化学分子空间非常大,在这个空间中寻找合适的药物非常耗时,几乎是不可能完成的任务。我看到了应用生成模型设计化学分子的最新趋势。虽然文献中有一些有希望的结果,但这一领域还处于起步阶段,需要更成熟的方法。在这里,我将回顾我在这一领域读过的一些最好的论文。
你可以在文献中找到很多论文,这些论文把微笑作为输出,最后,把微笑转换成化学空间。
Rafael Gomez-Bombarelli 等人提出了一种利用数据驱动的分子连续表示进行自动化学设计的方法【9】。

图 5:使用变分自动编码器生成具有期望属性的化合物。来源:拉斐尔·戈麦斯-邦巴里等人。
他们使用 VAEs 来产生分子。输入表示是 SMILES 代码,输出也是 SMILES 代码。
本文中的巧妙之处在于使用潜在空间(连续空间)中的高斯过程来达到具有期望属性的点。
然后,使用解码器将潜在空间中的该点转换(解码)为 SMILES 码。论文写得很好,绝对值得推荐阅读。
然而问题是,SMILES 码和分子之间并不是一一对应的。即,不是所有产生的代码都可以转换回原始(化学)空间,因此,产生的 SMILES 代码通常不对应于有效分子。
微笑是非常受欢迎的表示,但是它们有一个很大的缺点:微笑不是健壮的表示。即,改变微笑中的一个字符(字符突变)可以将分子从有效变为无效。
Matt J. Kusner 等人提出了语法 VAE 来专门解决这个问题(产生与有效分子不对应的微笑代码)[10]。
他们不是将 SMILES 字符串直接输入网络并生成 SMILES 代码,而是将 SMILES 代码转换成解析树(通过利用 SMILES 上下文无关语法)。使用语法,他们可以生成更多语法上有效的分子。此外,提交人指出:
令人惊讶的是,我们表明,我们的模型不仅更经常地生成有效输出,它还学习了一个更连贯的潜在空间,其中附近的点
解码为类似的离散输出。
最近,Mario Krenn 等人提出了另一种基于 VAE 和自拍表现的方法[5]。自拍的主要优点是结实耐用。
但是,这些都是深度学习领域产生小分子的作品的小样本。基于化合物的表示(微笑、自拍、图形……)和生成算法(、甘、标准化流、遗传算法),您可以在文献中找到不同的方法(下表)。

结论
在这篇文章中,我试图回顾深度学习在药物发现中的一些应用。显然,这篇综述并不完整,我也没有时间覆盖更多的领域(我也不想让这篇文章更长),但我试图为好奇的读者提供参考。我希望这篇文章能鼓励你为这个领域做出贡献,让药物发现变得更便宜,更简单。
参考
- 数据库指纹(DFP):一种表示分子数据库的方法, Eli Fernández-de Gortari 等人
- RDKit 中的指纹
- DeepCCI:用于化学-化学相互作用预测的端到端深度学习, Sunyoung Kwon
- OpenSMILES 规范。链接
- 自拍:语义约束图的鲁棒表示,以及在化学中的示例应用, Mario Krenn 等人
- 图卷积网络,托马斯·基普夫
- PADME:基于深度学习的药物-靶点相互作用预测框架,冯庆元等
- 用卷积神经网络进行蛋白质-配体评分, Matthew Ragoza 等人
- 使用数据驱动的连续分子表示进行自动化学设计, Rafael Gomez-Bombarelli 等人
- 语法变分自动编码器,马特 j .库斯纳等人
- 针对序列生成模型的目标增强型生成对抗网络(ORGAN), Gabriel Guimaraes 等人
- 用于分子图生成的连接树变分自动编码器,晋文公等
- 深度学习能够快速识别有效的 DDR1 激酶抑制剂, Alex Zhavoronkov 等人
- 用深度神经网络增强遗传算法以探索化学空间, AkshatKumar Nigam 等人
- 寻找可合成分子的模型,约翰·布拉德肖等人。
回顾:纽维尔·ECCV 16 年和纽维尔·POCV 16 年——堆叠沙漏网络(人体姿势估计)
使用堆叠沙漏网络的自下而上和自上而下的重复处理,胜过了 DeepCut 、 IEF 、汤普森 CVPR 15和 CPM 。

多重堆叠沙漏网络
在这个故事里,16 级的纽维尔·ECCV 和 16 级的纽维尔·POCV,由密执安大学创作,回顾。在纽维尔·POCV 的 16 中,仅使用了 2 个堆叠沙漏网络,而在纽维尔·ECCV 的 16 中,使用了 8 个堆叠沙漏网络。ECCV 的版本更详细,引用了 1500 多次。因此,这里介绍 ECCV 的情况。( Sik-Ho Tsang @中)。
概述
- 网络架构
- 中间监督
- 一些训练细节
- 消融研究
- 与 SOTA 方法的比较
- 进一步分析
1。网络架构

单个“沙漏”模块(不包括最后的 1×1 层)。每个盒子对应于如下剩余模块。

一个剩余模块。
- 卷积层和最大池层用于处理低至极低分辨率的特征。
- 达到最低分辨率后,网络开始自上而下的上采样序列和跨尺度的特征组合。
- 对于上采样路径,完成较低分辨率的最近邻上采样**,随后是两组特征的逐元素相加**。
- 在达到网络的输出分辨率后,应用两轮连续的 1×1 卷积来产生最终的网络预测。
- 最终设计大量使用了剩余模块。
- 从不使用大于 3×3 的过滤器。
2.中间监督

中间监督
- 网络分裂并产生一组热图(蓝色轮廓),其中可以应用损失。
- 1×1 卷积重新映射热图以匹配中间特征的通道数量。这些要素与前面沙漏中的要素一起添加。
- 在最终的网络设计中,使用了八个沙漏。
3.一些训练细节
- FLIC : 5003 张图片(3987 次训练,1016 次测试)取自电影。
- MPII 人体姿态 : 25k 带注释的图像,供多人使用,提供 40k 带注释的样本(28k 训练,11k 测试)。
- 约 3000 个样本的验证集。
- 然后,所有输入图像的大小都被调整为 256×256 像素。我们进行数据扩充,包括旋转(30 度)和缩放(0.75-1.25 度)。
- Torch7,在 12GB 的 NVIDIA TitanX GPU 上训练需要 3 天左右。
- 使用批量标准化。
- 为了生成最终的测试预测,我们通过网络运行原始输入和图像的翻转版本,并将热图平均在一起。

示例输出(从左到右:脖子、左肘、左手腕、右膝盖、右脚踝)
- 如上所示,网络的最终预测是给定关节的热图的最大激活位置。
4。消融研究
4.1.变体

随着培训的进展验证准确性
- HG-Half :表现最差的单个沙漏。
- HG: 单个长沙漏,性能更好。
- HG-Int :单个长沙漏,中间监督,性能更好。
- HG-Stack :两个堆叠沙漏但没有中间监管,性能类似。
- HG-Stack-Int :两个堆叠沙漏中间监督,性能最佳。
4.2.沙漏数

- 左:示例验证图像,说明从中间阶段(第二个沙漏)(左)到最终预测(第八个沙漏)(右)的预测变化。
- 右:比较不同堆叠方式下网络中间阶段的验证精度。
- 从 87.4%到 87.8%再到 88.1 %的每一次叠加,最终性能都会有适度的提高。
5.与 SOTA 方法的比较
5.1.警察

- 99%的 PCK@0.2 精度在肘部,97%在腕部。
- 所提出的方法优于 SOTA 的方法,例如 DeepPose 、汤普森 CVPR 15和 CPM 。
5.2.MPII

- 所提出的方法优于 SOTA 的方法,包括 DeepCut 、 IEF 、汤普森 CVPR和 CPM 。
- 在像手腕、肘部、膝盖和脚踝这样的困难关节上,所提出的方法在 SOTA 结果的基础上平均提高了 3.5% (PCKh@0.5),平均错误率从 16.3 %下降到 12.8%。
- 最终肘关节准确率为 91.2%,腕关节准确率为 87.1 %。

MPII 的一些例子
6.进一步分析
6.1 多人

多个人靠在一起甚至重叠
- 检测多人超出了本文的范围。但是作者仍然分析它。
- 通过轻微平移和改变输入图像的比例,检测到不同的人或没有人。
6.2.闭塞

左图 : PCKh 曲线,验证比较仅考虑可见(或不可见)接头时的性能。右:显示预测一个关节是否存在注释的精确度的精确召回曲线。
- 在仅考虑可见关节的情况下,腕部准确度从 85.5%上升到 93.6%(验证性能略差于测试集性能 87.1 %)。另一方面,在完全闭塞的关节上的性能是 61.1 %。
- 对于肘部,对于可见关节,准确率从 90.5%到 95.1%,对于遮挡关节,准确率下降到 74.0%。
- 在存在注释的情况下,获得了 AUC 为 92.1%的膝盖和 AUC 为 96.0%的脚踝。这是在 2958 个样本的验证集上完成的,其中 16.1%的可能膝盖和 28.4%的可能脚踝没有地面真实注释。
参考
【2016 ECCV】【纽维尔·ECCV’16用于人体姿态估计的堆叠沙漏网络
【2016 POCV】【纽维尔·POCV’16用于人体姿态估计的堆叠沙漏网络
(我已经下载了但是抱歉现在找不到链接。这是一篇只有 2 页的论文,还不如看 ECCV 版,哈哈。)
我以前的评论
图像分类[lenet][alexnet][max out][in][znet][] [ 感受性-v3 ] [ 感受性-v4 ] [ 异常][mobile netv 1][resnet][[预活化 ResNeXt ] [ 致密 ] [ 金字塔网][drn][dpn][残馀关注网络【t】
物体检测 [ 过食 ] [ R-CNN ] [ 快 R-CNN ] [ 快 R-CNN][MR-CNN&S-CNN][DeepID-Net][CRAFT][R-FCN][离子 [G-RMI][TDM][SSD][DSSD][yolo v1][yolo v2/yolo 9000][yolo v3][FPN[retina net[DCN
语义分割 [ FCN ] [ 解码网络 ] [ 深层波 1&][CRF-rnn][] [fc-denne][idw-CNN][说][sdn][deep labv 3+
生物医学图像分割[][【T2/DCA】][【u-net】[【CFS-fcn】 [ 注意 u-net][ru-net&r2u-net][voxrsnet][致密电子数码 ][ UNet++
实例分割 [ SDS ] [ 超列 ] [ 深度掩码 ] [ 清晰度掩码 ] [ 多路径网络 ] [ MNC ] [ 实例中心 ] [ FCIS
超分辨率[SR CNN][fsr CNN][VDSR][ESPCN][红网][DRCN][DRRN][LapSRN&MS-LapSRN][SRDenseNet][【T20
人体姿势估计深层姿势][tompson nips’14][tompson cvpr’15][CPM[fcgn
后处理编码解码器【arcnn】][【Lin DCC ’ 16】][【ifcnn】][【Li icme ’ 17】[vrcnn【t】
生成对抗网络 [ 甘


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}