







数据科学家的实用火花技巧

与 pySpark 一起工作时,让您的生活更加舒适
我知道——Spark 有时令人沮丧。
虽然有时候我们可以使用Rapids或 并行化等工具来管理我们的大数据,但是如果您正在处理数 TB 的数据,就无法避免使用Spark。
在我关于 Spark 的最后几篇文章中,我解释了如何使用 PySpark RDDs 和 T42 数据帧。尽管这些帖子解释了很多关于如何使用 rdd 和 Dataframe 操作的内容,但它们仍然不够。
为什么?因为 spark 经常出现内存错误,而且只有当您真正使用 Spark 处理大数据集时,您才能真正使用 Spark。
这篇文章的主题是“数据科学家实用的火花和内存管理技巧”
1.地图端连接

连接数据框架
Spark 中的连接语法与 pandas 非常相似:
*df3 = df1.join(df2, df1.column == df2.column,how='left')*
但是我面临一个问题。df1大约有 10 亿行,而df2大约有 100 行。当我尝试上述连接时,它不起作用,并在运行 20 分钟后出现内存耗尽错误。
我在一个非常大的集群上编写这段代码,这个集群有 400 多个执行器,每个执行器都有 4GB 以上的 RAM。当我尝试使用多种方案对数据帧进行重新分区时,我被难住了,但似乎没有任何效果。
那我该怎么办呢?Spark 不能处理仅仅十亿行吗?不完全是。我只需要使用 Spark 术语中的地图端连接或广播。
***from** **pyspark.sql.functions** **import** broadcast
df3 = df1.join(broadcast(df2), df1.column == df2.column,how='left')*
使用上面简单的广播代码,我能够将较小的df2发送到所有节点,这并没有花费很多时间或内存。后端发生的事情是将df2的副本发送到所有分区,每个分区使用该副本进行连接。这意味着 df1 没有数据移动,它比 df2 大很多。
2.火花簇构型

根据您的任务大小设置并行度和工作节点
当我开始使用 Spark 时,让我的生活变得困难的还有 Spark 集群需要配置的方式。基于您想要运行的作业,您的 spark 集群可能需要大量定制配置和调优。
一些最重要的配置和选项如下:
a.spark.sql.shuffle.partitions 和 spark.default.parallelism:
spark.sql.shuffle.partitions配置为连接或聚合而重排数据时要使用的分区数量。spark.default.parallelism是 rdd 中由join、reduceByKey和parallelize等转换返回的默认分区数量,当用户没有设置时。这些值的默认值是 200。
简而言之,这些设置了您想要在集群中拥有的并行度。
如果您没有很多数据,值 200 没问题,但是如果您有大量数据,您可能希望增加这些数字。也要看你有多少遗嘱执行人。我的集群相当大,有 400 个执行者,所以我把它保持在 1200。一个经验法则是保持它是执行人数量的倍数,这样每个执行人最终都有多个工作。
*sqlContext.setConf( "spark.sql.shuffle.partitions", 800)
sqlContext.setConf( "spark.default.parallelism", 800)*
b.spark . SQL . parquet . binaryasstring
我在 Spark 中处理.parquet文件,我的大部分数据列都是字符串。但不知何故,每当我在 Spark 中加载数据时,字符串列都会被转换成二进制格式,在这种格式下,我无法使用任何字符串操作函数。我解决这个问题的方法是使用:
*sqlContext.setConf("spark.sql.parquet.binaryAsString","true")*
上述配置在加载拼花文件时将二进制格式转换为字符串。现在这是我在使用 Spark 时设置的默认配置。
c.纱线配置:
您可能需要调整其他配置来定义您的集群。但是这些需要在集群启动时设置,不像上面的那些那样动态。我想放在这里的几个是用于管理 executor 节点上的内存溢出。有时,执行程序核心会承担大量工作。
- spark . yarn . executor . memory overhead:8192
- yarn . node manager . vmem-check-enabled:False
在设置 spark 集群时,您可能需要调整很多配置。你可以在官方文件里看看。
3.分配

让员工处理等量的数据,让他们满意
如果在处理所有转换和连接时,您觉得数据有偏差,您可能需要对数据进行重新分区。最简单的方法是使用:
*df = df.repartition(1000)*
有时,您可能还希望按照已知的方案进行重新分区,因为该方案可能会在以后被某个连接或聚集操作使用。您可以使用多个列通过以下方式进行重新分区:
**df = df.repartition('cola', 'colb','colc','cold')**
您可以使用以下公式获得数据框中的分区数量:
*df.rdd.getNumPartitions()*
您还可以通过使用glom函数来检查分区中记录的分布。这有助于理解在处理各种转换时发生的数据偏差。
**df.glom().map(len).collect()**
结论
有很多事情我们不知道,我们不知道。这些被称为未知的未知。只有通过多次代码失败和读取多个堆栈溢出线程,我们才明白我们需要什么。
在这里,我尝试总结了一些我在使用 Spark 时遇到的内存问题和配置问题,以及如何解决这些问题。Spark 中还有很多其他的配置选项,我没有介绍,但是我希望这篇文章能让你对如何设置和使用它们有所了解。
现在,如果你需要学习 Spark 基础知识,看看我以前的帖子:
不仅仅是介绍
towardsdatascience.com](/the-hitchhikers-guide-to-handle-big-data-using-spark-90b9be0fe89a)
还有,如果你想了解更多关于 Spark 和 Spark DataFrames 的知识,我想调出这些关于 大数据精要的优秀课程:Coursera 上的 HDFS、MapReduce 和 Spark RDD 。
谢谢你的阅读。将来我也会写更多初学者友好的帖子。在 中 关注我或者订阅我的 博客 了解他们。一如既往,我欢迎反馈和建设性的批评,可以通过 Twitter@ mlwhiz联系
此外,一个小小的免责声明——这篇文章中可能会有一些相关资源的附属链接,因为分享知识从来都不是一个坏主意。*
merge、join 和 concat 的实际使用
在 pandas 中组合数据框:使用哪些函数以及何时使用?

介绍
在本文中,我们将讨论数据框的组合。您可能非常熟悉 pandas 中的 load 函数,它允许您访问数据以便进行一些分析。
但是,如果您的数据不在一个文件中,而是分散在多个文件中,会发生什么情况呢?在这种情况下,您需要逐个加载文件,并使用 pandas 函数将数据合并到一个数据框中。
我们将向您展示如何做到这一点,以及根据您想要如何组合数据以及想要实现的目标来使用哪些函数。我们将了解:
concat(),
merge(),
并加入()。
阅读完本文后,您应该能够使用这三种工具以不同的方式组合数据。
我们开始吧!
concat()
如果您有多个具有相同列名的数据文件,我们建议使用这个函数。它可以是一家连锁供应商的销售额,每年都保存在一个单独的电子表格中。
为了说明这一点,我们将使用一些虚假数据创建两个独立的数据框。让我们从创建 2018 年销售数据框架开始:
import pandas as pd
import numpy as np
sales_dictionary_2018 = {'name': ['Michael', 'Ana'],
'revenue': ['1000', '2000'],
'number_of_itmes_sold': [5, 7]}sales_df_2018 = pd.DataFrame(sales_dictionary_2018)sales_df_2018.head()

这是一个非常简单的数据框,其中的列总结了 2018 年的销售额。我们有一个供应商名称、他们售出的数量以及他们创造的收入。
现在让我们创建一个数据框,它具有完全相同的列,但覆盖了一个新的时间段:2019 年。
sales_dictionary_2019 = {'name': ['Michael', 'Ana', 'George'],
'revenue': ['1000', '3000', '2000'],
'number_of_itmes_sold': [5, 8, 7]}sales_df_2019 = pd.DataFrame(sales_dictionary_2019)sales_df_2019.head()

你可以看到,2019 年,除了 2018 年销售部门的迈克尔和安娜之外,我们有了新的销售代表乔治。除此之外,数据结构与我们 2018 年的数据结构相同。
那么,如何将这两个数据框组合在一起,以便将它们放在一个数据框中呢?您可以使用 contact()函数:
pd.concat([sales_df_2018, sales_df_2019], ignore_index=True)

您可以看到,在此操作之后,我们所有的数据现在都在一个数据框中!
Concat()函数获取一列数据帧,并将它们的所有行相加,得到一个数据帧。我们在这里设置 ignore_index=True 否则,结果数据帧的索引将取自原始数据帧。就我们而言,我们不希望这样。请注意,您可以在列表表单中传递任意数量的数据框。
以我们介绍的方式添加数据可能是使用 concat()函数的最常见方式。您还可以使用 concat()函数通过设置 axis=1 来添加列,但是在列中添加新数据有更好的方法,比如 join()和 merge()。这是因为当添加新列时,通常需要指定一些条件来连接数据,而 concat()不允许这样做。
合并()
我们将从学习 merge()函数开始,因为这可能是根据一些常见条件向数据框添加新列的最常见方式。
为了说明 merge()的用法,我们将回到我们的商店示例,其中有 2018 年和 2019 年销售的数据框。
假设您有另一个文件,其中包含每个销售代表的个人数据。现在,您想将这些数据添加到销售数据框中。
让我们首先为个人代表信息创建一个数据框。
rep_info_dictionary = {'name': ['Ana', 'Michael', 'George'],
'location': ['New York', 'San Jose', 'New York']}rep_info_df = pd.DataFrame(rep_info_dictionary)rep_info_df.head()

如您所见,只有两列:名称和位置。这个名字也出现在我们的年度销售数据中。假设您希望将代表的位置添加到 2019 年的数据中。
您可以使用“名称”作为链接这两个数据框的列,将 rep_info_df 合并到 sales_df_2019:
sales_df_2019.merge(rep_info_df, on='name')

您可以看到,我们包含 2019 年销售数据的原始数据框现在有了另一列,位置。是合并 rp_info_df 和 sales_df_2019 的结果。
默认情况下,pandas merge 使用’内部连接’'来执行合并操作。我们不打算在这里讨论连接的类型,但是如果您熟悉 SQL 连接,它们的工作方式是完全一样的。
如果你不熟悉内、左、右和外连接的概念,我建议你找一些解释这些 SQL 概念的文章。一旦你理解了 SQL 连接,你将能够在 pandas merge()函数中使用它们,因为它们的工作方式完全相同。
加入()
这是合并的一种特殊情况,即您要联接的列中至少有一列是索引。让我们修改 2019 年的数据,将名称作为索引:
sales_df_2019.set_index('name', inplace=True)sales_df_2019.head()

正如你所看到的,名称不是一个列,而是我们对其使用 set_index()函数后的数据框的索引。
现在,让我们对代表信息数据框进行同样的操作:
rep_info_df.set_index('name', inplace=True)
rep_info_df.head()

现在 rep_info_df 和 sales_df_2019 都有名称作为索引。现在我可以使用 join()代替 merge()来组合数据,就像我们在上一节中使用 merge()一样。
sales_df_2019.join(rep_info_df)

如您所见,我不需要像 merge()那样在参数上指定*。这是因为 join()函数将数据框的索引作为默认值来组合两个表中的数据。*
通过指定 how 参数,可以修改类似于 merge()的 Join()函数以使用不同类型的 SQL 连接。默认的连接是一个*‘左’*连接,这就是我们在例子中使用的。
摘要
让我们总结一下我们的发现。
当我们试图添加多个具有相同结构的数据块并将它们一个接一个地放在一个数据帧中时,我们使用了 concat() 。
为了将列数据添加到现有条目中,我们使用了 **merge()。**数据是根据正在合并数据帧的列的相同值添加的。
Join() 是 merge()的一个特例,至少有一个条目是索引。
我希望您喜欢这篇文章,并且已经学会了如何使用这些基本的数据框操作来组合数据。
最初发表于 about datablog . com:merge,join,concat 的实际用途,2020 年 6 月 18 日。
PS:我正在 Medium 和aboutdatablog.com上撰写深入浅出地解释基本数据科学概念的文章。你可以订阅我的 邮件列表 每次我写新文章都会收到通知。如果你还不是中等会员,你可以在这里加入。****
下面还有一些你可能喜欢的帖子
学习如何使用折线图、散点图、直方图、箱线图和其他一些可视化技术
towardsdatascience.com](/9-pandas-visualizations-techniques-for-effective-data-analysis-fc17feb651db) [## python 中的 lambda 函数是什么,为什么你现在就应该开始使用它们
初学者在 python 和 pandas 中开始使用 lambda 函数的快速指南。
towardsdatascience.com](/what-are-lambda-functions-in-python-and-why-you-should-start-using-them-right-now-75ab85655dc6) [## Jupyter 笔记本自动完成
数据科学家的最佳生产力工具,如果您还没有使用它,您应该使用它…
towardsdatascience.com](/jupyter-notebook-autocompletion-f291008c66c)***
练习 Python 理解
用于数据准备和特征提取

在 Unsplash 上由 Hitesh Choudhary 拍摄的照片
在这篇文章中,我们在数据准备和特征提取的各种例子上练习 Python 理解。我们希望让读者了解使用这种 Python 机制可以完成的各种任务。这篇文章也会引起数据科学新手的兴趣。
首先,我们先列举两个在数据科学建模中重复出现的核心数据模式。在数据准备和特征提取中。即使在机器学习算法中,尤其是对向量和矩阵进行操作的算法中。
图案是聚合器和变压器。两者都在 python 集合上操作。
一个聚合器从一个集合中计算一个标量,这个集合概括了它的某些方面。例子包括对列表中的值求和、查找列表中的最大值、查找列表的长度等。
转换器将一个集合映射到另一个集合。一个例子是将计数向量转换成概率向量。变换器模式在特征提取中是有用的。
虽然这些模式在概念上看起来很简单,但是用 Python 练习编码将帮助读者认识到何时应用它们,然后轻松地实现它们。
Python 理解在实现转换器时尤其有用。
让我们开始吧。首先,让我们做好准备。我们将关注三种类型的数据。
- 一个特征向量。
- 代表文本文件的一包单词。
- 一种二进制图像的表示。
特征向量只是一个集合,它捕获了我们希望建模的一些固定属性的值。比方说我们要用三个特征来描述一个房子:卧室数量,卫生间数量,面积。我们可以将其建模为一个 python 列表,其元素是三个特性的值。因此[4,2,2000]代表一栋有四间卧室、两间浴室的房子,其面积为 2000 平方英尺。
文本文档的单词包表示捕获每个单词在其中出现的次数。在 python 中,用字典表示一袋单词很方便。这里有一个例子。
bag = { ‘the ’: 5, ‘art’ : 2, ‘of’ : 2, … }
我们将通过二维 python 列表来表示二进制图像。这里有一个例子。
image = [[1,1,1],[1,0,1],[1,1,1]]
聚合器示例
假设我们想从文档的包中知道文档的总字数。在 python 中,我们就是这样做的
sum(bag.values())
假设我们想计算图像中黑色像素的数量。在 python 中,我们会做
import numpy as np
np.sum(image)
我们使用 NumPy,因为它支持任意形状数组上的聚合器。我们的图像是二维的。
变压器实例
假设我们想要将文档的单词包表示转换为单词的概率分布。后者是长度规范化的,这一特性在某些用例中很有吸引力。在 python 中,我们会做
denom = sum(bag.values())
pbag = { word : float(count)/denom for word, count in bag.items() }
第二行使用了字典理解。
考虑我们的图像,想象它是灰度的。这只是意味着 image[i][j]是一个介于 0 和 1 之间的值,而不仅仅是它的极值。对于下游处理,我们可能希望将此图像转换为二进制图像。在 python 中,我们可以
def binarize(x):
if x >= 0.5:
return 1
else:
return 0binarized_image = [[binarize(pixel) for pixel in pixel_row] for pixel_row in image]
在最后一行,我们正在做的可能被称为二维列表理解。
特征提取作为一种变换
假设我们有一个输入向量数组。我们想把它转换成一组特征向量。
以我们的房子为例。有理由推测各个维度是相互关联的。也就是说,更大的房子会有更多的卧室、更多的浴室和更大的面积。我们可能对从这三个特征中派生出一个特征感到好奇。或许,它可以很好地区分大小房屋。
首先,让我们将我们的特征定义为输入向量中三个值的乘积。所以我们正在从三维空间向一维空间转变。(有时候,少可以多。)在 python 中,我们可以将输入向量数组转换为特征向量数组,如下所示。
feature_vectors = [x[0]*x[1]*x[2] for x in input_vectors]
一般来说,特征提取比我们在简单例子中看到的要复杂得多。我们可以将所有的复杂性抽象成一个函数to_feature_vector(x),它将输入向量 x 作为一个参数。然后我们在理解中简单地使用这个函数
feature_vectors = [to_feature_vector(x) for x in input_vectors]
接下来,让我们看一个涉及缺失数据的例子
特征向量的相似度(有缺失数据)
假设我们有两个相同维数的数值向量 X 和 Y,并且缺少一些值。在 python 中,X 和 Y 可能是长度相同的列表,有些值是None。我们想要计算两个向量的相似性度量,考虑它们的缺失值。
下面我们将在忽略 X 或 Y 的值为 None 的维度后计算所谓的点积。
def dp(x,y):
return sum([x[i]*y[i] for i in range(len(x)) if x[i] and y[i]])
让我们看一个数字例子。让我们看看我们的房屋示例中的三个特征向量:
X = [4,2,2000]
Y = [4,None,1800]
Z = [None,1,500]
dp(X,Y)和 dp(X,Z)分别是 3600016 和 1000002。这表明 X 和 Y 比 X 和 z 更相似。这有直观的意义。
也就是说,如果输入向量没有被适当地归一化,dp 会给出非常误导的结果。这是因为矢量的分量处于不同的尺度。在我们的例子中,卧室的数量和浴室的数量通常在 0 到 6 之间,而面积可能在 100 到 1000 之间。
规格化一个数字特征的列
以我们的房子为例。正如上一段所讨论的,平方英尺与前两个(卧室的数量,浴室的数量)有很大的不同。让我们看一个这种规模差异导致的问题的例子。
认为
X = [4,2,2000]
Y = [1,0,2000]
Z = [4,2,1800]
dp(X,Y),dp(X,Z),dp(Y,Z)分别约为 400K,360K,360K。x 和 Z 像 Y 和 Z 一样相似没有意义。
好了,正常化吧!这种规范化将对要素列进行操作,每个要素一列。我们将特征列中的值除以该列的 L2 范数。什么是 L2 规范?您在下面包含denom的行的 rhs 上看到的内容。
import math
def normalize(fc):
denom = math.sqrt(sum([v**2 for v in fc]))
return [v/denom for v in fc]
normalize(fc)输入一个特征列,并将其标准化。
接下来,让我们准备三个特性列,以便可以使用 normalize(fc)。
fcs = [[xyz[i] for xyz in [X,Y,Z]] for i in range(3)]
我们看到 fcs 等于
[[4, 1, 4], [2, 0, 2], [2000, 2000, 1800]]
所以 fcs[i]是特性 I 的值列表。
好了,现在让我们正常化
nfcs = [normalize(fc) for fc in fcs]
让我们看看 NFC。
[
[0.6963106238227914, 0.17407765595569785, 0.6963106238227914], [0.7071067811865475, 0.0, 0.7071067811865475],
[0.5965499862718936, 0.5965499862718936, 0.5368949876447042]
]
这三栋房子的标准平方英尺大致相同。第二所房子的卧室和浴室的标准数量远远低于第一所和第三所房子。理应如此。
下一步是在标准化的特征向量上使用 dp。为此,我们首先需要将规范化的特征列转换成规范化的特征向量。
XYZ = list(zip(nfcs[0],nfcs[1],nfcs[2])
X,Y,Z = [list(XYZ[i]) for i in range(3)]
x、Y 和 Z 现在是三个房屋的特征向量的归一化版本。
X = [0.6963106238227914, 0.7071067811865475, 0.5965499862718936]
Y = [0.17407765595569785, 0.0, 0.5965499862718936]
Z = [0.6963106238227914, 0.7071067811865475, 0.5368949876447042]
我们看到 dp(X,Y),dp(X,Z),dp(Y,Z)分别是 0.477,1.30,0.44。好多了。X 和 Z 比 Y 和 Z(或者 Y 和 X)更相似。
结论
在这篇文章中,我们用简单的例子讨论了在数据表示、准备和特征提取中反复出现的一些核心问题。我们讨论了涉及数字特征向量的例子,以及如何归一化它们,考虑丢失的数据。我们还介绍了单词示例和二进制图像操作。
所有这些例子的共同点是我们使用了 Python 理解。从中得出的信息是,在 Python 中学习和实践这一机制在数据科学环境中非常有帮助。
你必须知道的预提交钩子
在 5 分钟内提高您的生产力和代码质量

图片作者:马丁·托马斯
预提交钩子是版本控制系统 git 的一种机制。他们让你在提交之前执行代码。令人困惑的是,还有一个叫做pre-commit的 Python 包,它允许你用一种更简单的接口创建和使用预提交钩子。Python 包有一个插件系统来自动创建 git 预提交钩子。它不仅适用于 Python 项目,也适用于任何项目。
看完这篇文章,你就知道我最喜欢的专业软件开发插件了。我们开始吧!
提交前基础知识
通过以下方式安装预提交
pip install pre-commit
在您的项目中创建一个.pre-commit-config.yaml文件。这个文件包含每次提交前要运行的预提交钩子。看起来是这样的:
repos:
- repo: [https://github.com/pre-commit/pre-commit-hooks](https://github.com/pre-commit/pre-commit-hooks)
rev: v3.2.0
hooks:
- id: trailing-whitespace
- id: mixed-line-ending- repo: [https://github.com/psf/black](https://github.com/psf/black)
rev: 20.8b1
hooks:
- id: black
pre-commit将在这两个带有指定 git 标签的存储库中查找名为.pre-commit-hooks.yaml的文件。在这个文件中可以任意定义许多钩子。它们都需要一个id,这样你就可以选择你想用的。上面的 git-commit 配置将使用 3 个钩子。
最后,您需要运行pre-commit install来告诉预提交总是为这个存储库运行。
在我使用它之前,我担心会失控。我想确切地知道我提交了哪些更改。如果它改变了什么,将中止提交。所以你还是可以看一下代码,检查一下改动是否合理。您也可以选择不运行预提交,方法是
git commit --no-verify

图片由 CC-BY-3.0 下的 geek-and-poke 提供
文件格式
以类似的方式格式化文件通过提高一致性来帮助可读性,并保持 git 提交的整洁。例如,您通常不想要尾随空格。您希望文本文件恰好以一个换行符结尾,这样一些 Linux 命令行工具就能正常工作。您希望 Linux ( \n)、Mac ( \r — Mac 之间的换行符一致,将改为\n🎉)和 windows ( \r\n)。我的配置是
# pre-commit run --all-files
repos:
- repo: [https://github.com/pre-commit/pre-commit-hooks](https://github.com/pre-commit/pre-commit-hooks)
rev: v3.2.0
hooks:
- id: check-byte-order-marker # Forbid UTF-8 byte-order markers
# Check for files with names that would conflict on a case-insensitive
# filesystem like MacOS HFS+ or Windows FAT.
- id: check-case-conflict
- id: check-json
- id: check-yaml
- id: end-of-file-fixer
- id: trailing-whitespace
- id: mixed-line-ending

由马丁·托马斯通过 imgflip.com创建
代码风格
我们可以用很多不同的方式编写代码。它们中的许多在运行时几乎没有区别,但在可读性方面有所不同。
代码自动格式器

当你的代码看起来丑陋的时候,不要浪费时间学习风格指南和手工应用它。运行代码格式化程序。图片由兰道尔·门罗( XKCD )拍摄
自动代码格式化与文件格式化具有相同的优点。此外,它还能防止无意义的讨论。因此,它让你和你的团队专注于重要和复杂的部分。
我喜欢 Pythons 自动格式化程序 black,在关于静态代码分析的文章中已经提到过:
- repo: [https://github.com/psf/black](https://github.com/psf/black)
rev: 20.8b1
hooks:
- id: black
- repo: [https://github.com/asottile/blacken-docs](https://github.com/asottile/blacken-docs)
rev: v1.8.0
hooks:
- id: blacken-docs
additional_dependencies: [black==20.8b1]
第一个是 black 本身,第二个是一个将黑色格式应用于 docstrings 中的代码字符串的项目。
此外,我希望我的导入被排序:
- repo: [https://github.com/asottile/seed-isort-config](https://github.com/asottile/seed-isort-config)
rev: v2.2.0
hooks:
- id: seed-isort-config
- repo: [https://github.com/pre-commit/mirrors-isort](https://github.com/pre-commit/mirrors-isort)
rev: v5.4.2
hooks:
- id: isort
许多语言都有带预提交挂钩的自动套用格式器:
- 更漂亮的 : HTML、CSS、JavaScript、GraphQL 等等。
- Clang-format : C,C++,Java,JavaScript,Objective-C,Protobuf,C#
- 生锈:生锈
现代 Python
pyupgrade 运行您的 Python 代码,并自动将旧式语法更改为新式语法。请看一些例子:
dict([(a, b) for a, b in y]) # -> {a: b for a, b in y}
class C(object): pass # -> class C: pass
from mock import patch # -> from unittest.mock import patch
你想要吗?给你:
- repo: [https://github.com/asottile/pyupgrade](https://github.com/asottile/pyupgrade)
rev: v2.7.2
hooks:
- id: pyupgrade
args: [--py36-plus]
测试您的代码
我考虑过通过预提交自动运行单元测试。我决定不这样做,因为这可能需要一段时间。但是,有一些快速测试可以每次自动运行:
- repo: [https://github.com/pre-commit/pre-commit-hooks](https://github.com/pre-commit/pre-commit-hooks)
rev: v3.2.0
hooks:
- id: check-ast # Is it valid Python?
# Check for debugger imports and py37+ breakpoint() calls
# in python source.
- id: debug-statements- repo: [https://github.com/pre-commit/mirrors-mypy](https://github.com/pre-commit/mirrors-mypy)
rev: v0.782
hooks:
- id: mypy
args: [--ignore-missing-imports]- repo: [https://gitlab.com/pycqa/flake8](https://gitlab.com/pycqa/flake8)
rev: '3.8.3'
hooks:
- id: flake8
安全性
签入凭证是一个非常常见的错误。以下是防止这种情况的方法:
- repo: [https://github.com/pre-commit/pre-commit-hooks](https://github.com/pre-commit/pre-commit-hooks)
rev: v3.2.0
hooks:
- id: detect-aws-credentials
- id: detect-private-key
杂项提交前挂钩
有些挂钩不属于上述类别,但仍然有用。例如,这可以防止提交大文件:
- repo: [https://github.com/pre-commit/pre-commit-hooks](https://github.com/pre-commit/pre-commit-hooks)
rev: v3.2.0
hooks:
- id: check-added-large-files
在团队中工作
预提交挂钩安装在本地,因此每个开发人员都可以自己决定是否需要预提交挂钩以及需要哪些挂钩。但是,我认为提供一个.pre-commit-config.yaml有你推荐执行的插件是有帮助的。
所有的钩子!
如果您正在寻找一个现成的完整的.pre-commit-config.yaml,这里就是:
# Apply to all files without commiting:
# pre-commit run --all-files
# Update this file:
# pre-commit autoupdate
repos:
- repo: [https://github.com/pre-commit/pre-commit-hooks](https://github.com/pre-commit/pre-commit-hooks)
rev: v3.2.0
hooks:
- id: check-ast
- id: check-byte-order-marker
- id: check-case-conflict
- id: check-docstring-first
- id: check-executables-have-shebangs
- id: check-json
- id: check-yaml
- id: debug-statements
- id: detect-aws-credentials
- id: detect-private-key
- id: end-of-file-fixer
- id: trailing-whitespace
- id: mixed-line-ending
- repo: [https://github.com/pre-commit/mirrors-mypy](https://github.com/pre-commit/mirrors-mypy)
rev: v0.782
hooks:
- id: mypy
args: [--ignore-missing-imports]
- repo: [https://github.com/asottile/seed-isort-config](https://github.com/asottile/seed-isort-config)
rev: v2.2.0
hooks:
- id: seed-isort-config
- repo: [https://github.com/pre-commit/mirrors-isort](https://github.com/pre-commit/mirrors-isort)
rev: v5.4.2
hooks:
- id: isort
- repo: [https://github.com/psf/black](https://github.com/psf/black)
rev: 20.8b1
hooks:
- id: black
- repo: [https://github.com/asottile/pyupgrade](https://github.com/asottile/pyupgrade)
rev: v2.7.2
hooks:
- id: pyupgrade
args: [--py36-plus]
- repo: [https://github.com/asottile/blacken-docs](https://github.com/asottile/blacken-docs)
rev: v1.8.0
hooks:
- id: blacken-docs
additional_dependencies: [black==20.8b1]
摘要
我喜欢预提交,因为它非常适合我的工作流程。我只是像往常一样提交,预提交会做我有时会忘记的所有检查。它加快了开发速度,因为 CI/CD 管道比在本地执行同样的步骤要慢得多。特别是对林挺来说,快速运行代码而不是提交,等待 CI/CD 管道,找到错误,在本地修复错误,推送,然后再次等待 CI/CD 管道,可以节省大量时间。
如果有你喜欢的其他预提交挂钩,请通过评论或电子邮件(info@martin-thoma.de)告诉我!
选举前情绪分析
单词云和条形图中的新加坡#GE2020SG

由 Unsplash 上的 Swapnil Bapat 拍摄的照片
我们是两个对数据科学充满热情的新加坡本科生。
随着即将到来的新加坡大选的临近,我们决定借此机会利用我们的数据科学技能在这一领域进行分析,截至 2020 年 6 月 28 日。这绝不是为了影响选举,也不暗示任何人或任何党派。这只是一些好的、干净的、数据科学的乐趣。
介绍
我们试图调查的问题陈述有:
- 各政党的公众情绪分布如何?
- 与公众情绪相比,报纸上表达的情绪有统计学上的显著差异吗?

堆积条形图显示了对 Twitter 上各方的不同看法
我们使用 Twitter 情绪分析作为量化公众情绪的方法,并在《海峡时报》上进行了单独的情绪分析。此外,我们可以比较双方在两个平台上的情绪。
通过我们的工作,我们能够看到对每一方的正面和负面情绪的明显差异,尽管这在 0.05α值时在统计上是不显著的。
在α值为 0.05 时,我们发现总体主观性和对 PAP 的主观性之间存在统计学显著差异。
方法学
使用 python:
- 我们针对 Twitter 和《海峡时报》进行了一系列的网络清理。
- 使用 Textblob 库对每个平台进行情感分析
- 通过 matplotlib 和 wordclouds 将结果可视化。
- 进行了一个简单的假设检验来评估主观性和极性的差异。
假设&限制
- 情感分析是通过 TextBlob 完成的,它使用自己的标准来确定积极、消极和中性的词语。这些标准可能并不代表实际使用的单词,也没有考虑到讽刺、音调和单词使用的上下文,因此可能会出现单词分类错误的情况。
- 由于某个主题可能有大量的标签,我们假设每个想要发布某个主题(例如 PAP)的人都会使用相同的标签(" #PAPSingapore ")。
- Twitter 被选为删除我们数据的平台之一,因为我们认为这是一个社区中任何人都可以发表评论、发表观点的免费平台,而海峡时报被选为另一个平台,因为我们认为它是通用电气相关新闻的官方渠道。
- 一些新加坡政党在 Twitter 和《海峡时报》上的影响力相对较小,因此在本研究中不予考虑。
- 一个很大的限制是,这项研究采用了 6 月 26 日至 6 月 29 日的数据,这不是完整的“选举前”时间长度。

在 Unsplash 上由 Dane Deaner 拍摄的照片
刮削过程
推特
使用#PAP、#wpsg、#ProgressSgParty、#GE2020SG 这四个标签,包含每个标签的推文可以很容易地使用 twitterscraper 库抓取并整理到一个 csv 文件中。
海峡时报
通过使用请求库,《海峡时报》被反复废弃。与“政治”相关的网址根据它们所属的党派被贴上标签,并被编译成 csv 格式。这些政党是 WP,PSP,PAP,我们将性别作为一般新闻文章,包含了大选的行政信息。
刮削结果
1。word cloud
我们能够为 Twitter 和海峡时报生成文字云,如下所示。单词云用于可视化最常见的相关单词,分别对应标签(Twitter)和过滤器(海峡时报)。
1.1。推特
我们可以看到,它们有相似的常用词,如“新加坡”和“GE2020”,而在其他“较小”的词上有所不同。

Twitter wordcloud
1.2 海峡时报
我们可以观察到与 twitter wordcloud 类似的结果,如下所示。

海峡时报词汇云
2。极性与主观性
极性指的是情绪化的、判断性的词语出现的频率更高。
主观性指的是更倾向于一种观点,而不是事实信息。
我们将这些指标可视化,y 轴表示主观性,x 轴表示极性。这些已绘制在下面的散点图中。
2.1。极性 vs 主观性(推特)**

【极性 vs 主观性(推特)
2.2。极性 vs 主观性(海峡时报)**

【极性 vs 主观性(海峡时报)
2.3。推特和《海峡时报》的对比
我们在这里使用了双样本 t 检验来确定是否有足够的证据来拒绝零假设。我们的无效假设是不同媒介的情感是相同的,相反,另一个假设是不同媒介的情感是不同的。
假设检验(主观性和极性)

主观性和极性双样本 t 检验结果
当 alpha 值为 0.05 时,我们发现当来自 Twitter 的观点与来自海峡时报的观点相比较时,在 General 和 PAP 中的主观性之间存在统计显著差异。
这表明,关于一般和 PAP,两个来源之间的信息的主观性存在显著差异。
通过参考 #GE2020SG vs *GEN,*的散点图,我们确实可以看到 #GE2020SG 中的主观推文数量明显多于《海峡时报》( GEN)。
从*# PAP SingaporevsPAP散点图的对比也可以看出这个趋势。*我们可以看到,与 Twitter 相比,《海峡时报》的主观信息数量要多得多。
3。情绪点分析
在生成每方每种媒体各自的情绪后,我们将这些指标在堆积条形图上进行比较,如下所示。然后,我们进行了双样本 t 检验,类似于上面的主观性和极性。
3.1 推特

堆积条形图显示了对 Twitter 上各方的不同看法
使用以下积极和消极情绪的数字,我们能够生成上面的条形图。

用于生成上述堆积条形图的情感点数
观察结果
1)只有 4.0%带有#PAPSingapore 标签的推文是负面的,比#GE2020SG 的平均 18.3%低 14.3%
2)标签为#ProgressSgParty 的推文有 50%是正面的,这表明正面评价比平均水平高 12.5%
3.2 海峡时报

堆积条形图显示了对 Twitter 上各方的不同看法
观察结果
1)《海峡时报》上关于葛的文章大多是以非常正面的方式写的,没有太多负面或中性的词语。
3.3 推特和海峡时报的对比
假设检验(感性分析)

情感分析双样本 t 检验结果
当 alpha 值为 0.05 时,我们发现 Twitter 和《海峡时报》的观点没有显著差异。有趣的是,所有缔约方都是如此。
4。结论
回到最初的问题陈述:
公众情绪在各个党派中的分布情况如何?
由于《海峡时报》的情绪分析似乎在各方中相当平均,我们决定 Twitter 情绪分析(如下)能够最好地回答这个问题。请参考下面的堆积条形图。

新加坡政党间的情感分布
报纸和公众的情绪有统计学上的显著差异吗?
在 alpha 值为 0.05 时,我们发现一般信息和 PAP 在这两种媒介之间的主观性存在**统计上的显著差异。**除此之外,其余政党的媒介在主观性和极性方面没有显著差异。也许这些政党的支持者在某种程度上更加“热情”地支持他们。
此外,我们发现,在两种媒体上,各方的情绪在统计上没有显著差异。这可能是因为每个政党的支持者似乎都使用 Twitter,并以类似的语气为《海峡时报》撰稿。
5.未来的改进
对于未来的研究,我们肯定会建议对整个选举前时期进行研究;这项研究是在 6 月 26 日至 6 月 29 日进行的,也许 6 月 26 日至 7 月 10 日会随着时间的推移揭示一些更深刻的见解。
我们还建议进一步深入了解脸书和 Instagram 等替代社交媒体平台。
感谢你的阅读!
为了给数据科学从业者提供免费的开源信息,请在这里找到代码!
如果您对这个项目有任何疑问,请随时通过 Linkedin或 Linkedin或 Linkedin联系我们,我们希望能友好地讨论!
我们希望我们能够以某种方式帮助您使用数据科学方法!
[## 冯伟万-数据分析实习生- Aon | LinkedIn
我是倒数第二名本科生,正在攻读会计和商业双学士学位(专业是…
www.linkedin.com](https://www.linkedin.com/in/feng-wei-wan-44336b180/) [## 韩德-大数据实习生-雷蛇公司| LinkedIn
我是 SMU 的倒数第二名学生,读经济学(数量轨道),第二专业是数据科学…
www.linkedin.com](https://www.linkedin.com/in/dehan-c-948045177/)
这里还有一篇文章给你!
使用深度学习神经网络模型
towardsdatascience.com](/predicting-energy-production-d18fabd60f4f)
浓缩咖啡的预浸泡:更好的浓缩咖啡的视觉提示
根据预输注时间覆盖过滤器,而不是恒定时间
当用手动机器拉球时,我发现预输注是必要的,但是预输注应该持续多长时间?几年来,我用 10 秒,在过去的几个月里,我把它提高到接近 30 秒。这改善了味道和提取,但仍有一些可变性。大部分参数相同的两次注射有不同的提取,一旦我开始用一个额外的参数跟踪预输注,我发现了一种确定适当预输注量的方法。该度量是覆盖过滤器(TCF)的时间。






在这种情况下,TCF 是 13 岁
当我踏上浓缩咖啡之路时,我没有意识到并非所有的机器都生而平等。我碰巧发现了一台便宜的手动浓缩咖啡机(Kim Express),但这台机器比一般的浓缩咖啡机需要更多的关注。从手动机器中抓拍看起来像是一门艺术,但随着时间的推移,我已经能够看到这种努力中的科学。在手动机器上造成差异的一个变量是预注入,更昂贵的热泵机器也允许预注入。
人们一直在争论预注入的必要性,但通常对于手动杠杆式机器来说,预注入是必要的,因为水从圆筒的侧面进入腔室。预浸泡是让水以 1 到 2 巴的低压进入咖啡罐,这对于开水器来说是典型的。一段时间后,你拉下杠杆,提取咖啡。
初始预输注程序
当我开始收集浓缩咖啡的数据时,我没有收集太多与时间相关的数据。通常,我会做 10 秒钟的预注入,推动直到过滤器被覆盖,让它开花 5 秒钟,然后提取,无论需要多长时间。
我在脑子里算了一下预输液和开花,什么都没记录。一旦我开始录像我所有的镜头来回放,我就开始更明确地跟踪这些时间。大约在那个时候,我也停止了绽放,只专注于预输注。我不记得为什么,但我想这是因为当我开始提取时,我的预输注已经延伸到过滤器已经被覆盖的地方,所以开花似乎无关紧要。
我想我发现了一些关于开花的东西。我不是第一个做 bloom 的人,但我认为它没有被很好地研究过,也没有作为浓缩咖啡的标准做法。然而,开花迫使咖啡从过滤器的大部分出来,确保冰球是饱和的。
该盖上过滤器了(TCF)
直到我开始进行更长时间的预注射,我才开始跟踪 TCF。我有更多的时间进行实验,我注意到稍长一点会导致提取量增加。所以我就顺其自然了。我甚至尝试了整个注射作为预灌注,但它缺少一些东西。根据咖啡出来的速度,我到达了 20 到 40 岁的范围。

我有每个镜头的视频,我开始注意到有些镜头比其他镜头更快地覆盖了滤镜,所以我开始跟踪这个变量。此外,我开始注意到这里和那里的镜头覆盖过滤器越快出来越好。我开始考虑将预输注的时间长短与 TCF 联系起来。
达到 10 毫升的时间(T10)
另一个度量是输出量或重量,其可以用作应该结束预输注的指示器。我检查了一组较小的数据来收集 10 毫升(T10)的时间,因为我用作子弹杯的量杯上有 10 毫升的标记。虽然这种测量不像秤那样精确,但它是查看预输注的另一种方式。如果我有使用秤的数据,我会使用该数据(即,我不喜欢体积测量,但可以免费获得)。
我目前的建议是在 TCF 或 T10 后的一定时间结束预输注。我希望在决定什么是确定适当指标的最佳方式时,能够以数据为导向。所以我收集了一些数据。
使用我为每个镜头收集的视频,我找到了视频中我可以看到咖啡从每个过滤孔流出的时间,以记录为 TCF,然后我寻找杯子上达到 10 毫升的线,以记录为 T10。

绩效指标
我使用了两个指标来评估过滤器之间的差异:最终得分和咖啡萃取。
最终得分是 7 个指标(强烈、浓郁、糖浆、甜味、酸味、苦味和余味)记分卡的平均值。当然,这些分数是主观的,但它们符合我的口味,帮助我提高了我的拍摄水平。分数有一些变化。我的目标是保持每个指标的一致性,但有时粒度很难,会影响最终得分。
使用折射仪测量总溶解固体(TDS ),该数字与一杯咖啡的输出重量和输入重量相结合,用于确定提取到杯中的咖啡的百分比,称为提取率(EY)。
数据
在拍摄的时候,我有大约 60 个 TCF 的镜头,但我有其余的视频。所以我回去注释了 392 张照片的数据。这些数据跨越了烤肉、机器、新技术,比如辣味研磨和断续捣实。也许他们会讲一个故事。
从这个初始数据集来看,与预灌输(PI)有一些相关性,但对于 TCF 本身,EY 或味道(最终得分)似乎没有太大的趋势。然而,当观察圆周率- TCF 时,这一趋势变得更加明显。这个度量实际上是圆盘完全湿润时 PI 持续发生的时间。

聚焦数据集
为了查看 T10,我想将数据集缩小一些,因为为 TCF 做标注非常耗时。另一个问题是,在 6 个多月的时间里,我做的技术发生了很多变化。在那段时间里,我研究了在研磨之前加热咖啡豆,在酿造之前冷却咖啡渣,夯实压力,以及圆盘分层(即断续夯实)。
这个更小的集合有 62 个样本,变化的变量更少。这是我收集的数据的一部分,用来比较两个过滤篮,这也是我开始关注 TCF 的原因。
EY 和 taste(最终得分)的数据趋势更加清晰:
- PI 越长,拍摄效果越好,但由于定时 PI 的原因,数据中没有粒度。
- 对于 TCF,趋势线的 R^2 为 0.69,这意味着绘制的趋势线相当不错。
- π-TCF 的度量也很强。
- 与 TCF 相比,T10 的趋势较弱,但它仍然是一个变量,我将继续收集数据。
- TCF/圆周率似乎是良好业绩的最强指标。


然后我做了几个变量的相关矩阵。相关性并不意味着因果关系,但它让我们更清楚地知道如何找到根本原因,在这种情况下,如何更好地利用圆周率。相关性衡量两个变量的相互趋势:
- 更接近 1 意味着两个变量彼此成比例。
- 更接近-1 意味着这两个变量彼此成反比。
- 更接近 0 意味着这两个变量彼此没有关系。
- 相关矩阵是沿对角线的一面镜子。

仅关注最终得分(口味),EY、TCF 和皮- TCF 与 EY 的相关性较好,最终得分略低。另一个有趣的变量是 TCF/π或π中滤波器未覆盖的部分。

当观察总提取时间的比例时,PI/总时间之间没有相关性,但是 TCF/总时间和(PI-TCF)/总时间之间有相关性。这两个指标非常简单,易于衡量。

走进那个兔子洞,看看 TCF/圆周率给出了一个比 TCF/总时间稍微好一点的度量,在拍摄过程中也更容易调整和控制。这允许你扩展圆周率,直到你达到某个比率。

为了获得更多可操作的数据,我们需要看看 PI/TCF。由此,一个好的比例是 3 比 1,所以圆周率需要是 TCF 长度的 3 倍。

总的来说,这个分析让我知道了下一步该怎么走。在过去的六个月里,我的 PI 例行程序是通过达到某个时间数字来驱动的,而不是达到与圆盘饱和度更相关的东西。展望未来,我打算以 TCF 为基础做事:
- TCF 衡量成功
- 当它是 TCF 长度的 3 倍时,结束预灌注(PI ),但是这将在太多环形通道的情况下变化。
我的希望是,通过使预输注时间可变,我将能够为预 I 融合的优化公式做进一步的分析。
如果你愿意,可以在 Twitter 和 YouTube 上关注我,我会在那里发布不同机器上的浓缩咖啡视频和浓缩咖啡相关的东西。你也可以在 LinkedIn 上找到我。
我的进一步阅读:
浓缩咖啡模拟:计算机模型的第一步
被盗浓缩咖啡机的故事
克鲁夫筛:一项分析
预处理和训练数据
转变数据和训练模型以获得最佳性能是一个整体过程。

图片由皮克斯拜的 Gerd Altmann 提供
预处理
那么,什么是预处理呢?常见的例子包括
- 输入缺失值
- 转换数值(线性或非线性)
- 编码分类变量
输入缺失值
你的数据中经常有漏洞。有人没有回答调查问题。传感器故障。数据丢失了。价值缺失及其原因多种多样。缺少的值可以用一个特殊的“值”NaN(在 Python 中,来自 NumPy)或 NA(在 R 中)来表示。但是思念并不总是由这些特殊的标记来表示。负值表示缺少数据,例如-999 表示某人的年龄。这可能取决于原始系统或软件,以及在您收到数据之前数据是如何处理的。在您的上下文中,空字符串可能被归类为“丢失”,也可能不被归类为“丢失”。
你现在应该已经解决的一个重要问题是,在丢失的数据中是否有任何模式。您在之前的 EDA 阶段确实探索过这一点,对吗?这些河流水位传感器读数丢失是因为站点被淹没吗?或者,丢失的值是随机散布在数据中的,暗示着一些更无害的原因,比如间歇性的无线电干扰?如果是前者,那么我希望您已经添加了一个新特性来捕获值丢失的事实。无论如何,大多数机器学习算法不喜欢丢失值,所以你需要采取措施,比如,坦白地说,猜测值可能是多少。这是归罪。
有许多输入缺失值的方案。您可以使用剩余值的平均值。或者中间值。或者取最后一个已知值。是的,选择最佳策略需要反复试验。
转变价值观
有几个原因需要转换要素的值。您可能有高度偏斜的分布,而非线性变换可以使这些分布正常化,这有助于许多算法。您可能有一组以非常不同的比例测量的要素,例如以英尺为单位的土地高程和以英亩为单位的面积。或者以磅为单位的体重和以华氏度为单位的体温,与以千克为单位的体重和以摄氏度为单位的体温。事实上,这些单位并没有太大的不同,但是这让我们有了另一个理由去转换特性值;计算点与点之间距离的算法和正则化(惩罚)它们的系数的算法可以任意产生非常不同的结果,因为这种单位上的差异。缩放要素将所有要素置于同等地位。
编码分类变量
像数字这样的算法。他们对字符串(文本)不太感兴趣。可以说,大部分数据科学都是寻求将数据转换成机器学习算法可以处理的适当数字表示。与其让名为“Animal”的列具有“Cat”或“Dog”的值,不如创建一个“Cat”列,用值 0 或 1 表示“not a cat”或“is a cat”,用值 0 或 1 表示“not a dog”或“is a dog”。即使这种相对简单的方案也有一些微妙之处,比如需要为包含截距的线性回归等模型删除其中一列。这是为了避免虚拟变量陷阱。
列车测试分离
如果在训练机器学习模型之前有这么多可能的决定要做,我们如何决定使用哪个?我们可以使我们的预处理和模型变得越来越复杂,以适应数据中越来越多的任意结构。我们如何知道我们的预处理决策是正确的,而不仅仅是适应数据中的噪声?这就是所谓的过度拟合。评估一个模型是否过度拟合它所知道的数据的基础是,在训练它时不要给它所有的数据,保留一些数据,然后观察它的表现。
一个巧妙的变化是将训练数据进一步分割成多个部分,除了一个部分之外,对所有部分进行训练,并对剩下的部分进行测试。通过旋转这样保留的分区,我们最终得到了对一个验证集的许多性能估计(其中验证集每次都是不同的)。这是交叉验证,在执行模型选择时特别有用。当然,我们仍然可以保留一组数据,以确保我们有一些我们的模型从未见过的数据。在对多个模型进行测试的多个交叉验证回合之后,这样的最终测试集是对预期未来性能的有用的最终检查。
韵律学
但是我们如何衡量绩效呢?有许多可能的度量或指标,最合适的一个取决于用例。如果我们正在执行分类,例如“猫”或“狗”,那么一个能捕捉我们得到正确答案的次数与我们得到错误答案的次数的指标是合适的。但如果我们在做回归,我们试图预测一个连续变量,如某人的工资,或房价,那么反映我们倾向于接近真实值的平均水平的度量是最好的。这里一个常见的度量是平均绝对误差,顾名思义,它是误差大小的平均值。
齐心协力
现在我们实际上已经有了所有需要的材料。对于我们特定类型的机器学习问题,我们可以选择一个度量标准。有了度量标准,我们就可以衡量成功(或失败)的程度。拥有一个训练测试分割给了我们一种方法,可以将这个度量应用到算法不知道的数据分区。这些共同允许我们尝试许多不同类型的模型和预处理步骤,并评估哪一个执行得最好。
嘿,很快!如果您已经尝试了各种预处理步骤和算法,并且应用了适当的度量标准,并且根据测试集评估了您的整个过程(例如,通过交叉验证),那么您已经获得了一个训练好的模型。具体来说,您已经建立了预处理步骤和算法性质的组合。
关于这篇文章
这是一个链接系列的第五篇文章,旨在简单介绍如何开始数据科学过程。你可以在这里找到简介,在这里找到上一篇文章,在这里找到系列文章。
使用预先训练的单词嵌入来检测真实的灾难推文
端-2-端方法

在这篇文章中,我们将经历整个文本分类流程,尤其是数据预处理步骤,我们将使用一个手套预先训练的单词嵌入。
文本特征处理比线性或分类特征稍微复杂一点。事实上,机器学习算法更多的是关于标量和向量,而不是字符或单词。因此,我们必须将文本输入转换成标量,而 keystone 🗝元素在于如何找出输入单词的最佳表示。这是自然语言处理背后的主要思想
我们将使用一个名为的 Kaggle 竞赛的数据集,真实与否?灾难推文 NLP。这项任务在于预测一条推文是否是关于一场真正的灾难。为了解决这个文本分类任务,我们将使用单词嵌入变换,然后是递归深度学习模型。其他不太复杂但仍然有效的解决方案也是可能的,比如结合 tf-idf 编码和朴素贝叶斯分类器(查看我上一篇帖子)。
此外,我将包括一些方便的 Python 代码,可以在其他 NLP 任务中重现。整个源代码可以在这个 kaggle 笔记本中获得。
简介:
LSTM 或 CNN 等模型在捕捉词序和它们之间的语义关系方面更有效,这通常对文本的意义至关重要:来自我们数据集的一个样本被标记为真正的灾难:
#RockyFire 更新= >加州高速公路。20 个双向关闭,由于莱克县火灾-# CAfire #野火’
很明显,单词顺序在上面的例子中很重要。
另一方面,我们需要将输入文本转换成机器可读的格式。它存在许多技术,如
- one-hot encoding :每个序列文本输入在 d 维空间中表示,其中 d 是数据集词汇的大小。如果每个术语出现在文档中,则该术语将得到 1,否则将得到 0。对于大型语料库,词汇表将大约有数万个标记,这使得一次性向量非常稀疏和低效。
- TF-IDF 编码:单词被映射成使用 TF-IDF 度量生成的数字。该平台集成了快速算法,使得保持所有单元和二元 tf-idf 编码成为可能,而无需应用降维
- 单词嵌入变换:单词被投影到一个密集的向量空间,在这个空间中,单词之间的语义距离被保留:(见下图):

https://developers . Google . com/machine-learning/crash-course/images/linear-relationships . SVG
什么是预训练单词嵌入?
嵌入是表示一个单词(或一个符号)的密集向量。默认情况下,嵌入向量是随机初始化的,然后将在训练阶段逐渐改进,在每个反向传播步骤使用梯度下降算法,以便相似的单词或相同词汇域中的单词或具有共同词干的单词…将在新向量空间中的距离方面以接近结束;(见下图):

作者:Zeineb Ghrib
预训练单词嵌入是迁移学习的一个例子。其背后的主要思想是使用已经在大型数据集上训练过的公共嵌入。具体来说,我们将将这些预训练的嵌入设置为初始化权重,而不是随机初始化我们的神经网络权重。这个技巧有助于加速训练和提高 NLP 模型的性能。
步骤 0:导入和设置:
首先,让我们导入所需的库和工具,它们将帮助我们执行 NLP 处理和
import pandas as pd
import numpy as np
from nltk.corpus import stopwords
from nltk.util import ngrams
from sklearn.feature_extraction.text import CountVectorizer
from collections import defaultdict
from collections import Counter
stop=set(stopwords.words('english'))
import re
from nltk.tokenize import word_tokenize
import gensim
import string
from keras.preprocessing.text import Tokenizer
from keras.preprocessing.sequence import pad_sequences
from tqdm import tqdm
from keras.models import Sequential
from keras.layers import Embedding,LSTM,Dense,SpatialDropout1D
from keras.initializers import Constant
from sklearn.model_selection import train_test_split
from keras.optimizers import Adam
第一步:文本清理:🧹
不考虑 EDA 步骤可以带出未清理的元素并帮助我们自定义清理代码,我们可以应用一些在 tweeters 中反复出现的基本数据清理,如删除标点符号,html 标签 URL 和表情符号,拼写纠正,…
下面是一段 python 代码,可以在其他类似的用例中重现😉
然后,我们将数据集拆分为:
- 一个训练数据集(训练数据集的 80%)
- 一个验证数据集:剩余 20%的训练数据集将用于验证每个时期的模型性能
- 测试数据集(此处可选) :由 kaggle 提供,用于进行预测
train = df[~df['target'].isna()]
X_train, X_val, y_train, y_val = train_test_split(train, train['target'], test_size=0.2, random_state=42)
第二步:文本预处理🤖
如前所述,机器学习算法将数字作为输入,而不是文本,这意味着我们需要将文本转换为数字向量。
我们进行如下操作:
1.标记化
它包括将文本划分为单词或更小的子文本,允许我们确定数据集的“词汇”(数据中存在的一组唯一标记)。通常我们使用单词级表示。对于我们的例子,我们将使用 NLTK Tokenizer()
2.单词索引:
基于词频构建一个词汇索引映射器:索引将与整个数据集中的词频成反比。最频繁的世界的索引=1…每个单词都会有一个唯一的索引。
这两个步骤分解如下:
关于 NLTK 标记器的一些解释:
fit_on_texts()方法🤖:它根据词频创建词汇索引。
例:“外壳中的幽灵"会生成 word _ index[” the "]= 1;word_index[“ghost”] = 2…-
所以每个单词都得到一个唯一的整数值。从 1 开始(0 保留用于填充),单词越频繁,对应的索引越低。
(PS 往往前几个是停用词,因为出现很多但是建议在数据清理的时候去掉)。
-
textes_to_sequences()法📟:将每个文本转换为整数序列:每个单词都映射到 word_index 字典中的索引。pad_sequences()方法🎞:为了使输出的形状标准化,我们定义了一个唯一的向量长度(在我们的例子中MAX_SEQUENCE_LENGTH将其固定为 50):任何更长的序列都将被截断,任何更短的序列都将用 0 填充。
步骤 3:构建嵌入矩阵🧱
首先,我们将从官方网站下载手套预训练嵌入(由于一些技术限制,我必须通过代码下载:
然后,我们将创建一个嵌入矩阵,将每个单词索引映射到其对应的嵌入向量:

步骤 4:创建和训练模型:

我们将使用顺序 keras 模型创建一个递归神经网络,该模型将包含:
- 以嵌入矩阵为初始权重的嵌入层
- 一个脱落层以避免过度拟合(查看这篇关于神经网络中脱落层及其效用的优秀帖子
- 一个 LSTM 层:包括长短期存储单元
- 使用二元交叉熵损失函数的激活层
如果我们想要计算我们的二元 keras 分类器模型的准确度、精确度、召回率和 F1 分数,我们必须手动计算它们,因为自 2.0 版本以来,Keras 不支持这些指标。
(解决方案来自此处)
现在编译和训练模型:
要获得验证性能结果,使用evaluate()方法:
loss, accuracy, f1_score, precision, recall = model.evaluate(tokenized_val, y_val, verbose=0)
让我们检查结果:

由 Zeineb Ghrib 从这里
这些结果似乎相当不错,但当然可以通过微调神经网络超参数或使用 auto-ml 工具(如 prevision )来增强,除了 wor2vec 之外,这些工具还应用了许多其他转换,如 ngram 令牌化、tf-idf 或更先进的技术(如 BERT transformers)。
结论:
在这篇文章中,我一步一步地向您展示了如何从 Glove 预训练的单词嵌入应用 wor2vec 变换,以及如何使用它来训练一个递归神经网络。请注意,该方法和代码可以在其他类似的用例中重用。整体源代码可以在这个 kaggle 笔记本中找到。
我还在同一个数据集上应用了完全不同的方法:我使用了 tf-idf 朴素贝叶斯分类器,如果你想获得更多信息,请访问我的上一篇文章。
我打算写一篇关于如何使用名为 Bert 的突破性算法的文章,并将其与其他 NLP 算法进行比较
感谢您阅读我的帖子🤗!!如果您有任何问题,可以在 prevision cloud instance 的聊天会话中找到我,或者发送电子邮件至:zeineb.ghrib@prevision.io
精准医疗和机器学习
数据科学
数据科学可能是个人医学的未来

长期以来,个性化或精确的药物一直是未来治疗的试金石。它包括使用特定于患者的知识**,如生物标记、人口统计学或生活方式特征,来最好地治疗他们的疾病,而不是一般的平均最佳实践。在最好的情况下,它可以利用数千名从业者的专业知识和数百万其他患者的成果来提供经过验证的有效护理。**
精准医疗对患者和医生都有很多好处(改编自frh lich):
- 提高治疗效果
- 减少副作用
- 降低患者和提供商的成本
- 使用生物标志物的早期诊断
- 改进的预后估计
实现个性化治疗所需的原始数据量需要机器学习。我之前的一篇文章涉及了这一点,特别是机器学习在肿瘤学中的其他应用,因为这可能是最接近实现精确医疗结果的领域。
药物基因组学是一个完整的领域,致力于研究病人的基因如何影响他们对药物的反应。这主要用于限制由于长期暴露或敏感性增加而产生的药物副作用,但一些药物需要特定基因表达才能达到其靶点。例如,赫赛汀(曲妥珠单抗)靶向 HER2/ neu 受体,因此该基因必须在患者的癌症中过表达,才能开出赫赛汀处方。

图片来源:西蒙·考尔顿带 CC BY-SA 3.0 牌照
一个成功的模型使用了来自梅奥诊所 800 名患者超过 10 年的基因数据来确定各种药物缓解抑郁症状的功效。该模型能够达到 85%的准确率,相比之下,精神病学家的准确率只有 55%,他们经常不得不通过对患者进行反复试验来找到最有效的药物。
改善护理的其他潜在途径包括识别致病基因、了解患者之间的表型和基因型差异、基因-基因相互作用和新药发现。由普林斯顿大学开发的深度学习模型 DeepSEA 已经成功预测了 DNA 中单核苷酸畸变的染色质效应。诸如此类的模型在预测成功方面具有巨大的潜力,但它们也应该阐明基因型、疾病诊断、治疗方案等之间的机制关系。
挑战
虽然这些不同的精准医疗方法令人兴奋,并正在积极探索,但仍有许多挑战需要克服。你应该阅读这篇文章进行更深入的研究,但是下面总结了一些要点。
首先,我们经常听到“啊,如果我们有更多的数据,那么我们的模型会更好”,但这并没有抓住现实,特别是在医学中,数据质量往往被忽略,而有利于数据数量。通俗点说,垃圾进,垃圾出。虽然经常需要大量数据,但是这些数据必须具有能够将噪声从信号中分离出来的基本模式。正如 Frö hlich 所指出的,一些噪音是来自采样的误差(没有用),一些是生物变异(非常有用),但我们和我们的模型都无法区分它们。
其次,虽然我们的模型可以发现数据中的新模式,甚至可以对新的例子做出非常准确的预测,但它们无法证明因果关系。正是这种特殊的品质使它们成为非常有用的工具,而不是科学方法的真正替代品。现代媒体喜欢将“人工智能”描述为任何工作或任务的替代品,当它根本不可能的时候。看看 IBM 的沃森在的不太理想的实现。
第三,预测模型依赖于它在看不见的数据上的表现。这是训练/测试分割、交叉验证、数据扩充等背后的基本原理。如果一个模型不能很好地概括,那么它就没有多大用处。部署精确医疗模型的原因是,绩效不佳的影响可能很大。我们必须意识到用不知情的病人的健康来验证我们的模型的伦理陷阱。因此,仍然需要昂贵的临床试验来证实该模型,并向展示它如何改善护理(如果有的话)。
未来
精准医疗在根据患者的特定表型和基因组改善护理方面有着令人兴奋的未来。特定模型在药物发现、治疗效果、指导诊断等方面取得了成功。 IBM 的沃森通用人工智能甚至已经被纳入世界各地的少数肿瘤部门,尽管结果喜忧参半。事实上,机器学习在精准医疗方面面临的挑战是多种多样且难以应对的。但是,创造未来从来都不容易。
来源
[1]福布斯洞察团队,机器学习如何打造精准医疗 (2019),福布斯洞察。
[2] G.Z. Papadakis,A.H. Karantanas,M. Tsiknakis 等,深度学习开启个性化医疗新视野 (2019),《生物医学报告》10(4):215–217。
[3] M. Uddin,Y. Wang 和 M. Woodbury-Smith,神经发育障碍精准医疗的人工智能 (2019),npj 数字医学 2: 112。
[4] J. Zhou 和 O.G. Troyanskaya,用基于深度学习的序列模型预测非编码变体的效果 (2015),Nature Methods 12:941–934。
机器学习在宫颈癌预测中的应用
OSEMN 代表什么?

从 Adobe Stock 获得许可的图像
机器学习通常被描述为人工智能的一个子集,通常涉及创建能够以各种方式分析数据以做出预测的“模型”。它已经在无数领域证明了自己的用处,包括像“推荐引擎”这样众所周知的应用程序,它根据“学习”用户过去的行为来推荐用户喜欢的内容。作为我进入数据科学之旅的一部分,我编写并测试了几个机器学习模型,以使用关于女性的数据集进行预测,以及在哪里进行活检以确定是否存在宫颈癌。
数据集是从加州大学欧文分校(UCI)的机器学习库中获得的,位于这个链接。这些信息是在委内瑞拉加拉加斯的“加拉加斯大学医院”收集的,由 35 个因素组成,包括 858 名患者的人口统计信息、习惯和历史医疗记录。由于隐私问题(缺少值),一些患者选择不回答一些问题。我之前写过一篇关于处理丢失数据的简短文章这里。该数据集来自于 2017 年 5 月首次在线发表的一篇研究论文。
目标、挑战和‘目标’
这个项目的目标是开发一个机器学习模型,该模型可以使用每个妇女可能的风险因素的 35 个变量尽可能好地预测宫颈癌的存在。使用这种类型的数据开发预测模型时面临的一个挑战是精确度和召回率之间的平衡:
- 精度表示模型预测的癌症中实际存在癌症的比例。
- 回忆表示模型准确预测的所有癌症病例的比例。

图片由沃尔伯提供—自己的作品,CC BY-SA 4.0
[## Precisionrecall.svg
来自维基共享,自由媒体仓库
commons.wikimedia.org](https://commons.wikimedia.org/w/index.php?curid=36926283)
因为不“捕捉”甚至一个癌症病例都可能导致死亡,所以模型应该强调回忆分数。更可取的做法是不“遗漏”任何癌症患者,即使这意味着将一些实际上没有患病的患者“标记”为患有癌症。
使用此类数据创建预测模型的另一个挑战是,阳性病例(存在癌症)通常只占数据集中患者总数的一小部分。这就产生了所谓的“不平衡”数据集,即。在我们试图预测的两个类别中,个体的数量是不相等的。不平衡的数据使得机器学习模型的预测更加困难,因为与阴性(没有癌症)病例相比,可以学习的“阳性”(存在癌症)病例更少。有了这样不平衡的数据,预测模型可以很容易地以牺牲精度为代价获得很高的召回率,反之亦然。例如,想象一个包含 1,000 名患者的数据集,其中 10 人患有癌症,这是一个非常现实的场景:
- 一个预测每个人都患有癌症的模型的召回率为 100%,但精确度为 1%。像这样的预测模型没有任何价值。然后,所有的病人都要接受活组织检查,记录所有的癌症病例,但对 990 名妇女进行不必要的检查。
在这种情况下,预测模型的目标是以尽可能少的“假阳性”(预测有癌症,但实际上没有癌症)识别尽可能高百分比的癌症病例。
每个模型 I 测试将首先通过查看召回率进行评估,然后是 F1 分数,F1 分数是反映精确度和召回率同等平衡权重的衡量标准:

我开发模型的方法遵循 OSEMN 协议:
- 获得
- 矮树
- 探索
- 模型
- 口译
该项目是在 Jupyter 笔记本中开发的,使用了 scikit-learn 的数据科学包以及笔记本中记录的其他一些资源。笔记本和运行它所需的所有文件可以在我的 GitHub 库这里获得。
获得&磨砂
在初始化笔记本并将数据集加载到 Pandas 数据框架后,我查看了它包含的值的类型以及哪些因素缺少信息。在 dataframe 导入阶段,我用 NumPy“NaN”填充了所有缺失的值。以下是用红色显示缺少值的变量的数据概述:

创造一些新的因素
尽管某些因素中缺失值的百分比相对较小,但我不想丢失这些因素中可能存在的任何信息:
- 性伴侣数量
- 第一次性交
- 怀孕数量
我创建了新的布尔因子来区分已知信息的记录和未给出数据的记录。如果记录有值,则这些新因子的值为 true (1),如果记录缺少该因子的数据,则这些新因子的值为 false (0):
- 已知有 _ number _ partners _ 吗
- 第一次性交是已知的
- 已知怀孕次数吗
为此,我编写了一个从现有列创建新列的函数:
def new_bool(df, col_name):
bool_list = []
for index, row in df.iterrows():
value = row[col_name]
value_out = 1
if pd.isna(value):
value_out = 0
bool_list.append(value_out)
return bool_list
以下是如何使用此函数创建每个新因子(列)的示例:
# create new factor ‘is_number_partners_known’
df[‘is_number_partners_known’] = new_bool(df, ‘Number of sexual partners’)
这三个原始因子也有缺失值,我稍后会将它们与所有其他缺失值一起处理。
处理数据中的“漏洞”
我创建了一个函数来显示给定因子的计数图、箱线图和一些汇总统计数据,这样我可以更好地了解这些因子的分布情况:
def countplot_boxplot(column, dataframe):
fig = plt.figure(figsize=(15,20))
fig.suptitle(column, size=20)
ax1 = fig.add_subplot(2,1,1)
sns.countplot(dataframe[column])
plt.xticks(rotation=45) ax2 = fig.add_subplot(2,1,2)
sns.boxplot(dataframe[column])
plt.xticks(rotation=45)
plt.show()
print(‘Min:’, df2[column].min())
print(‘Mean:’, df2[column].mean())
print(‘Median:’, df2[column].median())
print(‘Mode:’, df2[column].mode()[0])
print(‘Max:’, df2[column].max())
print(‘**********************’)
print(‘% of values missing:’, (df2[column].isna().sum() / len(df2))*100)
在评估了每个因素后,我决定如何最好地处理缺失的值。这里有一个“第一次性交”因素的流程示例,它代表女性第一次经历性交的年龄。我运行了上面的函数,传递了列名:
countplot_boxplot('First sexual intercourse', df2)
以下是输出结果:

Min: 10.0
Mean: 16.995299647473562
Median: 17.0
Mode: 15.0
Max: 32.0
**********************
% of values missing: 0.8158508158508158
通过观察这两个图,很明显,分布是有点正常的,在范围的高端有一个长“尾巴”。同样重要的是,这个因子只有不到 1%的值丢失,所以无论我用什么来填充丢失的值,对模型的影响都是最小的。我选择用中间值来填充这里缺失的值。
我继续检查每个因子,用零、平均值或中值替换缺失值,但有几个因子需要一些额外的思考:
- STDs:自首次诊断以来的时间
- STDs:自上次诊断以来的时间
超过 90%的患者对这些因素没有价值。我可以简单地删除这些因素——机器学习模型无法处理缺失值——但我不想丢失 10%患者的信息,这些信息对这些因素有价值。我注意到“父”因子“STDs:Number of diagnostics”也缺少相同数量的值。我的假设是,这些女性拒绝回答这个问题和这两个相关的问题。我选择用零填充所有三个因子中缺失的值:
- 性传播疾病:诊断数量
- STDs:自首次诊断以来的时间
- STDs:自上次诊断以来的时间
我在“STD’s (number)”因素上遇到了类似的情况。我再次运行我的函数来可视化数据:
countplot_boxplot('STDs (number)', df2)

Min: 0.0
Mean: 0.17662682602921648
Median: 0.0
Mode: 0.0
Max: 4.0
**********************
% of values missing: 12.237762237762238
这里的值几乎为零,大约有 12%的数据丢失。由于零在这个因子的分布中占主导地位,我觉得用零代替缺失值是最好的选择。此外,12 个单独的布尔因子中的每一个都有大约 12%的缺失值。我还用零替换了所有单个布尔“STD”因子中缺失的值。
探索
填充所有缺失值后,关联热图显示两个因素完全没有信息:
- 性病:宫颈湿疣
- 性病:艾滋病
我从数据库中删除了这些因素,然后运行了一个关联热图,显示每个因素如何单独与目标变量“活检”相关。

这张热图表明自身的因素:
- 席勒
- 欣塞尔曼
- 城市学
是最有用的。
型号
下一步是将数据分成训练集和测试集:
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.20, random_state= 10)
我使用 80%的数据进行训练,并指定一个 random_state 以确保可重复性。
该数据集中的非布尔因子:
- 年龄
- 性伴侣数量
- 第一次性交
- 怀孕数量
- 吸烟(年)
- 烟(包/年)
- 激素避孕药(年)
- 宫内节育器(年)
- 性传播疾病(数量)
- STD(诊断数量)
- STDs:自首次诊断以来的时间
- STDs:自上次诊断以来的时间
有非常不同的范围。我标准化了每个因素的值(使每个因素的范围从 0 到 1),以便机器学习算法不会仅仅因为它的范围较大而偏向任何因素。对于给定的因素,每个患者的值之间的关系保持不变,但现在每个因素都有相同的尺度。这防止了不同因素之间的不同等级,从而使模型对该因素的重要性的评估产生偏差。值得注意的是,标准化(或规范化)是对训练和测试数据集分别进行的。我不想让模型对将要测试的数据有任何了解。模型必须只从测试集中学习。
如前所述,这是一个“不平衡”的数据集,只有大约 10%的记录具有目标变量的“真”值。一些机器学习模型具有内置功能来补偿这一点,而一些没有。我测试了来自不平衡学习的一个名为 SMOTE(合成少数过采样技术)的包,以创建一个平衡的数据集——其中有相等数量的真和假目标变量记录。这只在训练数据上进行,而不在测试数据上进行。下面是创建这种重采样训练数据的语法:
sm = SMOTE(sampling_strategy='auto', random_state=10)X_train_res, y_train_res = sm.fit_resample(X_train, y_train)
查看原始数据和重采样数据的差异:
X_train.shape #the original data(686, 36) X_train_res.shape #the resampled data(1294, 36)
创建了 608 条“虚构”记录(1,294 减去 686)来“平衡”数据集。这些新记录被创建为与目标变量为真的现有记录相似。
现在,我可以用原始的“不平衡”数据集或重新采样的“平衡”数据集来测试任何模型。我发现,当给定这种重新采样的训练数据时,逻辑回归和 KNN 模型表现得更好,但是决策树、随机森林和支持向量机(SVM)模型在使用原始不平衡数据但实现它们自己的内置类权重参数时表现得更好。
为了方便测试每个模型,我创建了一个函数来返回我想了解的每个模型的性能信息:
def analysis(model, X_train, y_train):
model.fit(X_train, y_train)# predict probabilities
probs = model.predict_proba(X_test)# keep probabilities for the positive outcome only
probs = probs[:, 1]# predict class values
preds = model.predict(X_test)# calculate precision-recall curve
precision, recall, thresholds = precision_recall_curve(y_test, probs)# calculate average precision
average_precision = average_precision_score(y_test, probs)
# recall score for class 1 (Predict that Biopsy is True)
rs = recall_score(y_test, preds)# calculate F1 score
f1 = f1_score(y_test, preds)# calculate precision-recall AUC
auc_score = auc(recall, precision)# create chart
# In matplotlib < 1.5, plt.fill_between does not have a 'step' argument
step_kwargs = ({'step': 'post'}
if 'step' in signature(plt.fill_between).parameters
else {})
plt.step(recall, precision, color='b', alpha=0.2, where='post')
plt.fill_between(recall, precision, alpha=0.2, color='b', **step_kwargs)# plot a "no skill" line
plt.plot([0, 1], [0.5, 0.5], linestyle='--')plt.xlabel('Recall')
plt.ylabel('Precision')
plt.ylim([0.0, 1.05])
plt.xlim([0.0, 1.0])
plt.title('Precision-Recall curve: Average Precision={0:0.3f}'.format(average_precision))
plt.show()# print(confusion_matrix(y_test, preds))
print('Classification Report:')
print(classification_report(y_test, preds))print('f1=%.3f auc=%.3f recall=%.3f' % (f1, auc_score, rs))
GridSearchCV 方法用于搜索我测试的大多数模型的最佳参数。下面是一个使用 GridSearchCV 和随机森林分类器的示例:
forest = RandomForestClassifier(random_state=10, n_jobs=-1)forest_param_grid = {
'class_weight': ['balanced'],
'criterion': ['gini', 'entropy' ],
'max_depth': [2, 3, 4, 5, 6, 7, 8],
'n_estimators': [20, 40, 50, 60, 80, 100, 200]}forest_grid_search = GridSearchCV(forest,
param_grid = forest_param_grid,
scoring = 'recall',
cv=3,
return_train_score=True)
在本例中,“class_weight”被设置为“balanced ”,以让随机森林实现其内置方法,这些方法针对其正在接受训练的不平衡数据进行调整。然后,我使用测试数据拟合模型:
forest_grid_search.fit(X_train, y_train)
GridSearchCV 发现以下参数值效果最佳:
Optimal Parameters: {'class_weight': 'balanced', 'criterion': 'gini', 'max_depth': 2, 'n_estimators': 20}
基于这些信息,我重新运行了另一个 GridSearchCV 来进一步细化参数值:
forest_param_grid = {
'class_weight': ['balanced'],
'criterion': ['gini'],
'max_depth': [2, 3, 4],
'n_estimators': [10, 15, 20, 25, 30]}forest_grid_search = GridSearchCV(forest,
param_grid = forest_param_grid,
scoring = 'recall',
cv=3,
return_train_score=True)
找到的最佳值是:
Optimal Parameters: {'class_weight': 'balanced', 'criterion': 'gini', 'max_depth': 2, 'n_estimators': 10}
使用这些值创建了一个新的随机林,然后使用测试数据进行预测:
口译
以下是优化随机森林的结果:

Classification Report:
precision recall f1-score support
0 0.99 0.96 0.97 156
1 0.67 0.88 0.76 16
accuracy 0.95 172
macro avg 0.83 0.92 0.86 172
weighted avg 0.96 0.95 0.95 172
f1=0.757 auc=0.555 recall=0.875
该模型能够“找到”88%的癌症女性(回忆),并且其 67%的癌症预测是正确的(精确度)。
为了查看这个模型使用了什么特性,我使用了一个特性重要性图表。红色条代表每个特征的重要性,每个红色条顶部的黑线代表该特征在所有树中重要性的标准偏差。

有趣的是,“年龄”因素和“性学”因素——一种诊断测试——一样重要。
决策树和随机森林的一个优点是它们的可解释性。下图显示了该项目中表现最佳的单一决策树是如何工作的:

该树仅使用这些因素:
- 席勒
- Dx:CIN
- 年龄
对每个病人进行分类。随机森林模型在 10 种不同的树中使用了 15 个因子,以获得稍好的性能。(查看 Jupyter 笔记本以查看所有的树)。
在对我研究的所有模型进行调优和测试之后,以下是每种模型的最佳结果:

使用原始不平衡数据的随机森林模型表现最好,其次是决策树模型。
在未来的帖子中,我打算探索神经网络预测模型是否可以改善这些 F1 和回忆分数。
感谢阅读。我一直对了解数据科学如何让世界更好地为每个人服务很感兴趣。如果您知道数据科学“发挥作用”的情况,请分享!
数据集引用:
凯尔温·费尔南德斯、海梅·卡多佐和杰西卡·费尔南德斯。具有部分可观察性的迁移学习应用于宫颈癌筛查。伊比利亚模式识别和图像分析会议。斯普林格国际出版公司,2017 年。https://archive . ics . UCI . edu/ml/datasets/子宫颈+癌症+% 28 风险+因素%29#
Spark 3 中的谓词与投影下推
谓词和投影下推及其在 PySpark 3 中实现的比较

(来源)
处理大数据伴随着大量处理成本和花费大量时间扩展这些成本的挑战。It 需要了解适当的大数据过滤技术,以便从中受益。对于希望在过滤子领域(尤其是在嵌套结构化数据上)使用 Apache Spark 的最新增强功能的数据科学家和数据工程师来说,这篇文章是必不可少的。
Spark 2.x 和 Spark 3.0 在嵌套过滤方面的差异
用 Spark 2.x ,用最大 2 级嵌套结构的文件。json 和**。拼花地板**扩展可以被读取。
示例:
过滤器(col(’ library.books ')。isNotNull())
使用 Spark 3 ,现在可以同时使用和 读取文件。2+级嵌套结构中的 snappy parquet 扩展,无需任何模式展平操作。
例如:
过滤器(col(‘library . books . title’)。isNotNull())
用于下推过滤的火花会话配置
创建 spark 会话时,应启用以下配置,以使用 Spark 3 的下推功能。默认情况下,链接到下推过滤活动的设置值被激活。
*"spark.sql.parquet.filterPushdown", "true"
"spark.hadoop.parquet.filter.stats.enabled", "true"
"spark.sql.optimizer.nestedSchemaPruning.enabled","true"
"spark.sql.optimizer.dynamicPartitionPruning.enabled", "true"*
Spark 中有和两种下推过滤技术,分别是谓词下推和投影下推,它们具有以下不同的特性,如本文以下部分所述。
1.谓词下推
谓词下推指向影响返回行数的 where 或过滤器子句。基本上关系到哪些行* 会被过滤,而不是哪些列。由于这个原因,在嵌套列上应用过滤器作为***【library . books】**仅仅返回值不为空的记录时,谓词下推函数将使 parquet 读取指定列中不包含空值的块。
1.1.带有分区修剪的谓词下推
分区消除技术允许在从相应的文件系统读取文件夹时优化性能,以便可以读取指定分区中的所需文件。它将致力于将数据过滤转移到尽可能靠近源的位置,以防止将不必要的数据保存在内存中,从而减少磁盘 I/O。
下面,可以观察到 filter of partition 的下推动作,也就是’ library . books . title ’ = ’ HOST 'filter 被下推进入 parquet 文件扫描。该操作能够最小化文件和扫描数据。
*data.filter(col('library.books.title') == 'THE HOST').explain()*
对于更详细的输出,包括解析的逻辑计划、分析的逻辑计划、优化的逻辑计划、物理计划、****‘扩展’参数可以添加到 explain()函数中,如下所示。**
*****data.filter(col('library.books.title') == 'THE HOST').explain(**'extended'**)*****
它还可以减少传递回 Spark 引擎的数据量,以便在’ price’ 列的聚合函数中进行平均运算。
*****data.filter(col('library.books.title') == 'THE HOST').groupBy('publisher').agg(avg('price')).explain()*****
Parquet 格式的文件为每一列保留了一些不同的统计指标,包括它们的最小值和最大值。谓词下推有助于跳过不相关的数据,处理所需的数据。
2.投影下推
Projection Pushdown 代表带有 select 子句的选定列,该子句影响返回的列数。它将数据存储在列中,因此当您的投影将查询限制到指定的列时,将会返回这些列。
*****data.select('library.books.title','library.books.author').explain()*****
这意味着对‘library . books . title’,‘library . books . author’
列的扫描意味着在将数据发送回 Spark 引擎之前,将在文件系统/数据库中进行扫描。**
结论
对于投影和谓词下推*,有一些关键点需要强调。下推过滤作用于分区的列,这些列是根据拼花格式文件的性质计算的。为了能够从中获得最大的好处,分区列应该携带具有足够匹配数据的较小值,以便将正确的文件分散到目录中。*****
防止过多的小文件会导致扫描效率因过度并行而降低。此外,阻止接受太少的大文件可能会损害并行性。
****投影下推功能通过消除表格扫描过程中不必要的字段,使文件系统/数据库和 Spark 引擎之间的数据传输最小化。它主要在数据集包含太多列时有用。
另一方面,谓词下推通过在过滤数据时减少文件系统/数据库和 Spark 引擎之间传递的数据量来提高性能。
****投影下推通过基于列的和谓词下推通过基于行的过滤来区分。
非常感谢您的提问和评论!
参考文献
使用全球新闻预测任何应用 NLP 的加密货币
使用 Python 的分步教程。

图片来自shutterstuck.com
来自《走向数据科学》编辑的提示: 虽然我们允许独立作者根据我们的 规则和指导方针 发表文章,但我们不认可每个作者的贡献。你不应该在没有寻求专业建议的情况下依赖一个作者的作品。详见我们的 读者术语 。
在当今严峻的全球经济条件下,传统的指标和技术可能表现不佳(至少可以这么说)。
在本教程中,我们将搜索关于新闻的有用信息,并使用 NLP 将其转换为数字格式**,以训练一个机器学习模型,该模型将预测任何给定加密货币的上涨或下跌(使用 Python)。**
先决条件
- 安装 Python 3.1 以上版本
- 安装熊猫、sklearn 和 openblender(带 pip)
$ pip install pandas OpenBlender scikit-learn
第一步。获取数据
我们可以使用任何加密货币。对于这个例子,让我们使用这个比特币数据集。
我们来拉一下 2020 年初的日价蜡烛。
import pandas as pd
import numpy as np
import OpenBlender
import jsontoken = '**YOUR_TOKEN_HERE**'action = 'API_getObservationsFromDataset'# ANCHOR: 'Bitcoin vs USD'
parameters = {
'token' : token,
'id_dataset' : '5d4c3af79516290b01c83f51',
'date_filter':{"start_date" : "2020-01-01",
"end_date" : "2020-08-29"}
}df = pd.read_json(json.dumps(OpenBlender.call(action, parameters)['sample']), convert_dates=False, convert_axes=False).sort_values('timestamp', ascending=False)df.reset_index(drop=True, inplace=True)
df['date'] = [OpenBlender.unixToDate(ts, timezone = 'GMT') for ts in df.timestamp]
df = df.drop('timestamp', axis = 1)
注意:你需要在 openblender.io (免费)上创建一个帐户,然后添加你的令牌(你会在“帐户”部分找到它)。
让我们来看看。
print(df.shape)
df.head()

自年初以来,我们每天有 254 次对比特币价格的观察。
*注意:将应用于这些 24 小时蜡烛的同一管道可以应用于任何大小的蜡烛(甚至每秒)。
第二步。定义并理解我们的目标
在我们的比特币数据中,我们有一列“价格和当天的收盘价,以及“开盘”和当天的开盘价。
我们希望得到收盘价相对于开盘价的百分比差**,这样我们就有了当天表现的变量。**
为了得到这个变量,我们将计算收盘价和开盘价之间的**对数差。**
****df['log_diff'] = np.log(df['price']) - np.log(df['open'])
df****

’ log_diff '可以被认为是近似的百分比变化,对于本教程来说,它们实际上是等价的。****
(我们可以看到与’变化’的相关性非常高)
让我们来看看。

我们可以看到全年的看跌行为和-0.1 到 0.1 之间的稳定变化(注意剧烈的异常值)。
**现在,让我们**通过设置“1”来生成我们的 目标变量,如果性能为正(log_diff > 0),否则设置“ 0 ”。
df['target'] = [1 if log_diff > 0 else 0 for log_diff in df['log_diff']]df

简单地说,我们的目标是预测第二天的表现是** 正还是(这样我们就可以做出潜在的交易决定)。**
第三步。用我们自己的数据获取新闻
现在,我们想将外部数据与我们的比特币数据进行时间混合。简单地说,这意味着使用时间戳作为键来外连接另一个数据集。
我们可以用 OpenBlender API 很容易地做到这一点,但是首先我们需要创建一个 Unix 时间戳变量。
Unix 时间戳是 UTC 上自 1970 年以来的秒数,这是一种非常方便的格式,因为它在世界上的每个时区都与和相同!
format = '%d-%m-%Y %H:%M:%S'
timezone = 'GMT'df['u_timestamp'] = OpenBlender.dateToUnix(df['date'],
date_format = format,
timezone = timezone)df = df[['date', 'timestamp', 'price', 'target']]
df.head()

现在,让我们搜索与我们的时间交叉的有用数据集。
search_keyword = 'bitcoin'df = df.sort_values('timestamp').reset_index(drop = True)print('From : ' + OpenBlender.unixToDate(min(df.timestamp)))
print('Until: ' + OpenBlender.unixToDate(max(df.timestamp)))OpenBlender.searchTimeBlends(token,
df.timestamp,
search_keyword)

我们在一个列表中检索了几个数据集,包括它们的名称、描述、界面的 url 甚至是特征,但更重要的是,与我们的数据集重叠(相交)的时间百分比。****
浏览了一些后,这一篇关于比特币的新闻和最新的线程看起来很有趣。
 ****
****
比特币新闻数据集截图
现在,从上面的数据集中,我们只对包含新闻的“文本”特征感兴趣。所以让我们混合过去 24 小时的新闻**。**
# We need to add the '**id_dataset**' and the '**feature**' name we want.blend_source = {
'id_dataset':'**5ea2039095162936337156c9**',
'feature' : '**text**'
} # Now, let's 'timeBlend' it to our datasetdf_blend = OpenBlender.timeBlend( token = token,
anchor_ts = **df.timestamp**,
blend_source = **blend_source**,
blend_type = 'agg_in_intervals',
interval_size = 60 * 60 * 24,
direction = 'time_prior',
interval_output = 'list',
missing_values = 'raw')df = pd.concat([df, df_blend.loc[:, df_blend.columns != 'timestamp']], axis = 1)df.head()

时间混合的参数:
- anchor_ts :我们只需要发送我们的时间戳列,这样它就可以作为一个锚来混合外部数据。
- blend_source :关于我们想要的特性的信息。
- blend _ type:‘agg _ in _ intervals’因为我们想要对我们的每个观察值进行 24 小时间隔聚合。
- inverval_size :间隔的大小,以秒为单位(本例中为 24 小时)。
- 方向:‘time _ prior’因为我们希望时间间隔收集之前 24 小时的观察结果,而不是向前。
现在我们有了相同的数据集,但是增加了 2 列**。一个包含 24 小时间隔(“过去 1 天”)内收集的文本列表,另一个包含计数。**
现在让我们更具体一点,让我们试着用一个添加了一些 ngrams 的过滤器来收集‘正面’和‘负面’消息**(我马上想到的)。**
# We add the ngrams to match on a 'positive' feature.
**positive_filter** = {'name' : '**positive**',
'match_ngrams': [**'positive', 'buy',
'bull', 'boost'**]}blend_source = {
'id_dataset':'5ea2039095162936337156c9',
'feature' : 'text',
'filter_text' : **positive_filter**
}df_blend = OpenBlender.timeBlend( token = token,
anchor_ts = df.timestamp,
blend_source = blend_source,
blend_type = 'agg_in_intervals',
interval_size = 60 * 60 * 24,
direction = 'time_prior',
interval_output = 'list',
missing_values = 'raw')df = pd.concat([df, df_blend.loc[:, df_blend.columns != 'timestamp']], axis = 1) # And now the negatives
**negative_filter** = {'name' : '**negative**',
'match_ngrams': [**'negative', 'loss', 'drop', 'plummet', 'sell', 'fundraising'**]}blend_source = {
'id_dataset':'5ea2039095162936337156c9',
'feature' : 'text',
'filter_text' : **negative_filter**
}df_blend = OpenBlender.timeBlend( token = token,
anchor_ts = df.timestamp,
blend_source = blend_source,
blend_type = 'agg_in_intervals', #closest_observation
interval_size = 60 * 60 * 24,
direction = 'time_prior',
interval_output = 'list',
missing_values = 'raw')df = pd.concat([df, df_blend.loc[:, df_blend.columns != 'timestamp']], axis = 1)
现在我们有了 4 个新栏目,即“正面”和“负面”新闻的数量和列表。

让我们看看目标和其他数字特征之间的相关性。
features = ['target', 'BITCOIN_NE.text_COUNT_last1days:positive', 'BITCOIN_NE.text_COUNT_last1days:negative']df_anchor[features].corr()['target']

我们可以注意到与新生成的特征分别存在轻微的负相关和正相关。
现在,让我们使用 TextVectorizer 来获得大量自动生成的令牌特征。
我在 OpenBlender 上创建了这个 TextVectorizer,用于 BTC 新闻数据集的“文本”功能,该数据集有超过 1200 个 ngrams。

让我们把这些特点与我们的结合起来。我们可以使用完全相同的代码,我们只需要在 blend_source 上传递“id_textVectorizer”。
# BTC Text Vectorizer
blend_source = {
'**id_textVectorizer**':'**5f739fe7951629649472e167**'
}df_blend = OpenBlender.timeBlend( token = token,
anchor_ts = df_anchor.timestamp,
blend_source = blend_source,
blend_type = 'agg_in_intervals',
interval_size = 60 * 60 * 24,
direction = 'time_prior',
interval_output = 'list',
missing_values = 'raw') .add_prefix('VEC.')df_anchor = pd.concat([df_anchor, df_blend.loc[:, df_blend.columns != 'timestamp']], axis = 1)
df_anchor.head()

现在我们有了一个 1229 列的数据集,在每个时间间隔的聚合新闻上有 ngram 出现的二进制特征,与我们的目标一致。
第四步。应用 ML 并查看结果
现在,让我们应用一些简单的 ML 来查看一些结果。
from sklearn.ensemble import RandomForestRegressor
from sklearn.metrics import accuracy_score
from sklearn.metrics import precision_score# We drop correlated features because with so many binary
# ngram variables there's a lot of noisecorr_matrix = df_anchor.corr().abs()
upper = corr_matrix.where(np.triu(np.ones(corr_matrix.shape), k=1).astype(np.bool))
df_anchor.drop([column for column in upper.columns if any(upper[column] > 0.5)], axis=1, inplace=True) # Now we separate in train/test setsX = df_.loc[:, df_.columns != 'target'].select_dtypes(include=[np.number]).drop(drop_cols, axis = 1).values
y = df_.loc[:,['target']].values
div = int(round(len(X) * 0.2))
X_train = X[:div]
y_train = y[:div]
X_test = X[div:]
y_test = y[div:]# Finally, we perform ML and see resultsrf = RandomForestRegressor(n_estimators = 1000, random_state=0)
rf.fit(X_train, y_train)
y_pred = rf.predict(X_test)
df_res = pd.DataFrame({'y_test':y_test[:, 0], 'y_pred':y_pred})threshold = 0.5
preds = [1 if val > threshold else 0 for val in df_res['y_pred']]
print(metrics.confusion_matrix(preds, df_res['y_test']))
print('Accuracy Score:')
print(accuracy_score(preds, df_res['y_test']))
print('Precision Score:')
print(precision_score(preds, df_res['y_test']))

虽然整体准确性并不令人印象深刻,但我们对“精确得分”特别感兴趣,因为我们的目标是检测未来几天最有可能上涨(并避免下跌)。
我们如何解读上述混淆矩阵:
- 我们的模型预测“起义”102 次,其中 84 次是实际的起义,17 次不是(0.83 精度分数)。
- 总共有 157 次起义。我们的模型检测到了其中的 84 个,漏掉了 73 个。
- 总共有 32 个“垮台”(或者仅仅不是“起义”)案例,我们的模型检测到了其中的 15 个,漏掉了 17 个。
换句话说,如果当务之急是避免垮台——即使这意味着牺牲大量‘起义’案例——这种模式在这段时间内运行良好。
我们也可以说,如果优先考虑的是避免错过起义(即使有一些落马渗透),这个有这个阈值的模型根本不是一个好的选择。
用 Python 预测客户流失
使用 Python 中的监督机器学习算法预测客户流失的逐步方法

Emile Perron 在 Unsplash 上的照片
客户流失(又名客户流失)是任何组织最大的支出之一。如果我们能够合理准确地找出客户离开的原因和时间,这将极大地帮助组织制定多方面的保留计划。让我们利用来自 Kaggle 的客户交易数据集来理解在 Python 中预测客户流失所涉及的关键步骤。
有监督的机器学习只不过是学习一个基于示例输入-输出对将输入映射到输出的函数。监督机器学习算法分析训练数据并产生推断的函数,该函数可用于映射新的示例。假设我们在电信数据集中有当前和以前客户交易的数据,这是一个标准化的监督分类问题,试图预测二元结果(Y/N)。
在本文结束时,让我们尝试解决一些与客户流失相关的关键业务挑战,比如说,(1)活跃客户离开组织的可能性有多大?(2)客户流失的关键指标是什么?(3)根据调查结果,可以实施哪些保留策略来减少潜在客户流失?
在现实世界中,我们需要经历七个主要阶段来成功预测客户流失:
A 部分:数据预处理
B 部分:数据评估
C 部分:型号选择
D 部分:模型评估
E 部分:模型改进
F 部分:未来预测
G 部分:模型部署
为了了解业务挑战和建议的解决方案,我建议您下载数据集,并与我一起编写代码。如果你在工作中有任何问题,请随时问我。让我们在下面详细研究一下上述每一个步骤
A 部分:数据预处理
如果你问 20 岁的我,我会直接跳到模型选择,作为机器学习中最酷的事情。但是就像在生活中一样,智慧是在较晚的阶段发挥作用的!在目睹了真实世界的机器学习业务挑战之后,我不能强调数据预处理和数据评估的重要性。
永远记住预测分析中的以下黄金法则:
“你的模型和你的数据一样好”
理解数据集的端到端结构并重塑变量是定性预测建模计划的起点。
**步骤 0:重启会话:**在我们开始编码之前,重启会话并从交互式开发环境中移除所有临时变量是一个好的做法。因此,让我们重新启动会话,清除缓存并重新开始!
try:
from IPython import get_ipython
get_ipython().magic('clear')
get_ipython().magic('reset -f')
except:
pass
**第一步:导入相关库:**导入所有相关的 python 库,用于构建有监督的机器学习算法。
#Standard libraries for data analysis:
import numpy as np
import matplotlib.pyplot as plt
import pandas as pd
from scipy.stats import norm, skew
from scipy import stats
import statsmodels.api as sm# sklearn modules for data preprocessing:from sklearn.impute import SimpleImputer
from sklearn.preprocessing import LabelEncoder, OneHotEncoder
from sklearn.compose import ColumnTransformer
from sklearn.preprocessing import OneHotEncoder
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler#sklearn modules for Model Selection:from sklearn import svm, tree, linear_model, neighbors
from sklearn import naive_bayes, ensemble, discriminant_analysis, gaussian_process
from sklearn.neighbors import KNeighborsClassifier
from sklearn.discriminant_analysis import LinearDiscriminantAnalysis
from xgboost import XGBClassifier
from sklearn.linear_model import LogisticRegression
from sklearn.svm import SVC
from sklearn.neighbors import KNeighborsClassifier
from sklearn.naive_bayes import GaussianNB
from sklearn.tree import DecisionTreeClassifier
from sklearn.ensemble import RandomForestClassifier#sklearn modules for Model Evaluation & Improvement:
from sklearn.metrics import confusion_matrix, accuracy_score
from sklearn.metrics import f1_score, precision_score, recall_score, fbeta_score
from statsmodels.stats.outliers_influence import variance_inflation_factor
from sklearn.model_selection import cross_val_score
from sklearn.model_selection import GridSearchCV
from sklearn.model_selection import ShuffleSplit
from sklearn.model_selection import KFold
from sklearn import feature_selection
from sklearn import model_selection
from sklearn import metrics
from sklearn.metrics import classification_report, precision_recall_curve
from sklearn.metrics import auc, roc_auc_score, roc_curve
from sklearn.metrics import make_scorer, recall_score, log_loss
from sklearn.metrics import average_precision_score#Standard libraries for data visualization:import seaborn as sn
from matplotlib import pyplot
import matplotlib.pyplot as plt
import matplotlib.pylab as pylab
import matplotlib
%matplotlib inline
color = sn.color_palette()
import matplotlib.ticker as mtick
from IPython.display import display
pd.options.display.max_columns = None
from pandas.plotting import scatter_matrix
from sklearn.metrics import roc_curve#Miscellaneous Utilitiy Libraries:
import random
import os
import re
import sys
import timeit
import string
import time
from datetime import datetime
from time import time
from dateutil.parser import parse
import joblib
第二步:设置当前工作目录:
os.chdir(r”C:/Users/srees/Propensity Scoring Models/Predict Customer Churn/”)
**第三步:导入数据集:**让我们将输入数据集加载到当前工作目录下的 python 笔记本中。
dataset = pd.read_csv('1.Input/customer_churn_data.csv')
**第 4 步:评估数据结构:**在这一部分,我们需要大致了解数据集以及每一列的细节,以便更好地理解输入数据,从而在需要时聚合字段。
从 head & column 方法中,我们了解到这是一个电信客户流失数据集,其中每个记录都包含订阅、任期、付款频率和流失的性质(表示他们的当前状态)。
dataset.head()

输入数据集的快照(图片由作者提供)
dataset.columns

列名列表(作者图片)
快速描述法显示,电信客户平均停留 32 个月,每月支付 64 美元。但是,这可能是因为不同的客户有不同的合同。
dataset.describe()

描述方法(图片由作者提供)
从表面上看,我们可以假设数据集包含几个数字和分类列,提供关于客户交易的各种信息。
dataset.dtypes

列数据类型(作者图片)
**重新验证列数据类型和缺失值:**始终关注数据集中缺失的值。缺少的值可能会扰乱模型的构建和准确性。因此,在比较和选择模型之前,我们需要考虑缺失值(如果有的话)。
dataset.columns.to_series().groupby(dataset.dtypes).groups

聚合列数据类型(按作者分类的图片)
数据集包含 7043 行和 21 列,数据集中似乎没有缺失值。
dataset.info()

数据结构(图片由作者提供)
dataset.isna().any()

检查 NA(图片由作者提供)
识别唯一值:“付款方式”和“合同”是数据集中的两个分类变量。当我们查看每个分类变量中的唯一值时,我们会发现客户要么是按月滚动合同,要么是一年/两年的固定合同。此外,他们通过信用卡、银行转账或电子支票支付账单。
#Unique values in each categorical variable:dataset["PaymentMethod"].nunique()dataset["PaymentMethod"].unique()dataset["Contract"].nunique()dataset["Contract"].unique()
**第五步:检查目标变量分布:**我们来看看流失值的分布。这是检验数据集是否支持任何类别不平衡问题的一个非常简单而关键的步骤。正如您在下面看到的,数据集是不平衡的,活跃客户的比例比他们的对手高。
dataset["Churn"].value_counts()

流失值的分布(按作者分类的图片)
第六步:清理数据集:
dataset['TotalCharges'] = pd.to_numeric(dataset['TotalCharges'],errors='coerce')dataset['TotalCharges'] = dataset['TotalCharges'].astype("float")
**第 7 步:处理缺失数据:**正如我们前面看到的,所提供的数据没有缺失值,因此这一步对于所选的数据集是不需要的。我想在这里展示这些步骤,以供将来参考。
dataset.info()

数据结构(图片由作者提供)
dataset.isna().any()

检查 NA(图片由作者提供)
**以编程方式查找平均值并填充缺失值:**如果我们在数据集的数字列中有任何缺失值,那么我们应该查找每一列的平均值并填充它们缺失的值。下面是以编程方式执行相同步骤的一段代码。
na_cols = dataset.isna().any()na_cols = na_cols[na_cols == True].reset_index()na_cols = na_cols["index"].tolist()for col in dataset.columns[1:]:
if col in na_cols:
if dataset[col].dtype != 'object':
dataset[col] = dataset[col].fillna(dataset[col].mean()).round(0)
**重新验证 NA:**重新验证并确保数据集中不再有空值总是一个好的做法。
dataset.isna().any()

重新验证 NA(图片由作者提供)
**步骤 8:标签编码二进制数据:**机器学习算法通常只能将数值作为它们的独立变量。因此,标签编码非常关键,因为它们用适当的数值对分类标签进行编码。这里我们对所有只有两个唯一值的分类变量进行标签编码。任何具有两个以上唯一值的分类变量都将在后面的部分中用标签编码和一键编码来处理。
#Create a label encoder objectle = LabelEncoder()# Label Encoding will be used for columns with 2 or less unique values
le_count = 0
for col in dataset.columns[1:]:
if dataset[col].dtype == 'object':
if len(list(dataset[col].unique())) <= 2:
le.fit(dataset[col])
dataset[col] = le.transform(dataset[col])
le_count += 1
print('{} columns were label encoded.'.format(le_count))
B 部分:数据评估
**第 9 步:探索性数据分析:**让我们尝试通过独立变量的分布来探索和可视化我们的数据集,以更好地理解数据中的模式,并潜在地形成一些假设。
步骤 9.1。绘制数值列的直方图:
dataset2 = dataset[['gender',
'SeniorCitizen', 'Partner','Dependents',
'tenure', 'PhoneService', 'PaperlessBilling',
'MonthlyCharges', 'TotalCharges']]#Histogram:
fig = plt.figure(figsize=(15, 12))
plt.suptitle('Histograms of Numerical Columns\n',horizontalalignment="center",fontstyle = "normal", fontsize = 24, fontfamily = "sans-serif")
for i in range(dataset2.shape[1]):
plt.subplot(6, 3, i + 1)
f = plt.gca()
f.set_title(dataset2.columns.values[i])vals = np.size(dataset2.iloc[:, i].unique())
if vals >= 100:
vals = 100
plt.hist(dataset2.iloc[:, i], bins=vals, color = '#ec838a')
plt.tight_layout(rect=[0, 0.03, 1, 0.95])

数字柱直方图(图片由作者提供)
可以根据数值变量的直方图进行一些观察:
- 性别分布显示,该数据集的特点是男性和女性客户的比例相对相等。在我们的数据集中,几乎一半的顾客是女性,而另一半是男性。
- 数据集中的大多数客户都是年轻人。
- 似乎没有多少顾客有家属,而几乎一半的顾客有伴侣。
- 组织中有许多新客户(不到 10 个月),然后是平均停留超过 70 个月的忠诚客户群。
- 大多数客户似乎有电话服务,3/4 的客户选择了无纸化计费
- 每个客户的月费在 18 美元到 118 美元之间,其中 20 美元的客户占很大比例。
第 9.2 步。分析分类变量的分布:
**9.2.1。合同类型分布:**大多数客户似乎都与电信公司建立了预付费连接。另一方面,1 年期和 2 年期合同的客户比例大致相同。
contract_split = dataset[[ "customerID", "Contract"]]
sectors = contract_split .groupby ("Contract")
contract_split = pd.DataFrame(sectors["customerID"].count())
contract_split.rename(columns={'customerID':'No. of customers'}, inplace=True)ax = contract_split[["No. of customers"]].plot.bar(title = 'Customers by Contract Type',legend =True, table = False,
grid = False, subplots = False,figsize =(12, 7), color ='#ec838a',
fontsize = 15, stacked=False)plt.ylabel('No. of Customers\n',
horizontalalignment="center",fontstyle = "normal",
fontsize = "large", fontfamily = "sans-serif")plt.xlabel('\n Contract Type',
horizontalalignment="center",fontstyle = "normal",
fontsize = "large", fontfamily = "sans-serif")plt.title('Customers by Contract Type \n',
horizontalalignment="center",fontstyle = "normal",
fontsize = "22", fontfamily = "sans-serif")plt.legend(loc='top right', fontsize = "medium")
plt.xticks(rotation=0, horizontalalignment="center")
plt.yticks(rotation=0, horizontalalignment="right")x_labels = np.array(contract_split[["No. of customers"]])def add_value_labels(ax, spacing=5):
for rect in ax.patches:
y_value = rect.get_height()
x_value = rect.get_x() + rect.get_width() / 2
space = spacing
va = 'bottom'
if y_value < 0:
space *= -1
va = 'top'
label = "{:.0f}".format(y_value)
ax.annotate(
label,
(x_value, y_value),
xytext=(0, space),
textcoords="offset points",
ha='center',
va=va)
add_value_labels(ax)

按合同类型划分的客户分布(按作者划分的图片)
**9.2.2 支付方式类型分布:**数据集表明,客户最喜欢以电子方式支付账单,其次是银行转账、信用卡和邮寄支票。
payment_method_split = dataset[[ "customerID", "PaymentMethod"]]
sectors = payment_method_split .groupby ("PaymentMethod")
payment_method_split = pd.DataFrame(sectors["customerID"].count())
payment_method_split.rename(columns={'customerID':'No. of customers'}, inplace=True)ax = payment_method_split [["No. of customers"]].plot.bar(title = 'Customers by Payment Method', legend =True, table = False, grid = False, subplots = False, figsize =(15, 10),color ='#ec838a', fontsize = 15, stacked=False)plt.ylabel('No. of Customers\n',
horizontalalignment="center",fontstyle = "normal",
fontsize = "large", fontfamily = "sans-serif")plt.xlabel('\n Contract Type',
horizontalalignment="center",fontstyle = "normal",
fontsize = "large", fontfamily = "sans-serif")plt.title('Customers by Payment Method \n',
horizontalalignment="center", fontstyle = "normal", fontsize = "22", fontfamily = "sans-serif")plt.legend(loc='top right', fontsize = "medium")
plt.xticks(rotation=0, horizontalalignment="center")
plt.yticks(rotation=0, horizontalalignment="right")x_labels = np.array(payment_method_split [["No. of customers"]])def add_value_labels(ax, spacing=5):
for rect in ax.patches:
y_value = rect.get_height()
x_value = rect.get_x() + rect.get_width() / 2
space = spacing
va = 'bottom'
if y_value < 0:
space *= -1
va = 'top'
label = "{:.0f}".format(y_value)
ax.annotate(label,
(x_value, y_value),
xytext=(0, space),textcoords="offset points",
ha='center',va=va)add_value_labels(ax)

按支付方式划分的客户分布(按作者划分的图片)
9.2.3。标签编码分类变量的分布:
services= ['PhoneService','MultipleLines',
'InternetService','OnlineSecurity', 'OnlineBackup','DeviceProtection',
'TechSupport','StreamingTV','StreamingMovies']fig, axes = plt.subplots(nrows = 3,ncols = 3,
figsize = (15,12))
for i, item in enumerate(services): if i < 3:
ax = dataset[item].value_counts().plot(
kind = 'bar',ax=axes[i,0],
rot = 0, color ='#f3babc' )
elif i >=3 and i < 6:
ax = dataset[item].value_counts().plot(
kind = 'bar',ax=axes[i-3,1],
rot = 0,color ='#9b9c9a')
elif i < 9:
ax = dataset[item].value_counts().plot(
kind = 'bar',ax=axes[i-6,2],rot = 0,
color = '#ec838a')ax.set_title(item)

标签编码分类变量的分布(图片由作者提供)
- 大多数客户拥有电话服务,其中几乎一半的客户拥有多条线路。
- 四分之三的客户选择了通过光纤和 DSL 连接的互联网服务,近一半的互联网用户订阅了流媒体电视和电影。
- 利用在线备份、设备保护、技术支持和在线安全功能的客户是少数。
第 9.3 步:通过分类变量分析流失率:
**9.3.1。整体流失率:**对整体流失率的初步观察显示,约 74%的客户是活跃的。如下图所示,这是一个不平衡的分类问题。当每个类的实例数量大致相等时,机器学习算法工作得很好。由于数据集是倾斜的,我们在选择模型选择的指标时需要记住这一点。
import matplotlib.ticker as mtick
churn_rate = dataset[["Churn", "customerID"]]
churn_rate ["churn_label"] = pd.Series(
np.where((churn_rate["Churn"] == 0), "No", "Yes"))sectors = churn_rate .groupby ("churn_label")
churn_rate = pd.DataFrame(sectors["customerID"].count())churn_rate ["Churn Rate"] = (
churn_rate ["customerID"]/ sum(churn_rate ["customerID"]) )*100ax = churn_rate[["Churn Rate"]].plot.bar(title = 'Overall Churn Rate',legend =True, table = False,grid = False, subplots = False,
figsize =(12, 7), color = '#ec838a', fontsize = 15, stacked=False,
ylim =(0,100))plt.ylabel('Proportion of Customers',horizontalalignment="center",
fontstyle = "normal", fontsize = "large", fontfamily = "sans-serif")plt.xlabel('Churn',horizontalalignment="center",fontstyle = "normal", fontsize = "large", fontfamily = "sans-serif")plt.title('Overall Churn Rate \n',horizontalalignment="center",
fontstyle = "normal", fontsize = "22", fontfamily = "sans-serif")plt.legend(loc='top right', fontsize = "medium")
plt.xticks(rotation=0, horizontalalignment="center")
plt.yticks(rotation=0, horizontalalignment="right")
ax.yaxis.set_major_formatter(mtick.PercentFormatter())x_labels = np.array(churn_rate[["customerID"]])def add_value_labels(ax, spacing=5):
for rect in ax.patches:
y_value = rect.get_height()
x_value = rect.get_x() + rect.get_width() / 2
space = spacing
va = 'bottom'
if y_value < 0:
space *= -1
va = 'top'
label = "{:.1f}%".format(y_value)
ax.annotate(label,
(x_value, y_value),
xytext=(0, space),
textcoords="offset points",
ha='center',va=va)add_value_labels(ax)
ax.autoscale(enable=False, axis='both', tight=False)

总体流失率(图片由作者提供)
9.3.2。按合同类型划分的客户流失率:与 1 年或 2 年合同的同行相比,预付费或按月连接的客户流失率非常高。
import matplotlib.ticker as mtick
contract_churn =
dataset.groupby(
['Contract','Churn']).size().unstack()contract_churn.rename(
columns={0:'No', 1:'Yes'}, inplace=True)colors = ['#ec838a','#9b9c9a']ax = (contract_churn.T*100.0 / contract_churn.T.sum()).T.plot(kind='bar',width = 0.3,stacked = True,rot = 0,figsize = (12,7),color = colors)plt.ylabel('Proportion of Customers\n',
horizontalalignment="center",fontstyle = "normal",
fontsize = "large", fontfamily = "sans-serif")plt.xlabel('Contract Type\n',horizontalalignment="center",
fontstyle = "normal", fontsize = "large",
fontfamily = "sans-serif")plt.title('Churn Rate by Contract type \n',
horizontalalignment="center", fontstyle = "normal",
fontsize = "22", fontfamily = "sans-serif")plt.legend(loc='top right', fontsize = "medium")
plt.xticks(rotation=0, horizontalalignment="center")
plt.yticks(rotation=0, horizontalalignment="right")
ax.yaxis.set_major_formatter(mtick.PercentFormatter())for p in ax.patches:
width, height = p.get_width(), p.get_height()
x, y = p.get_xy()
ax.text(x+width/2,
y+height/2,
'{:.1f}%'.format(height),
horizontalalignment='center',
verticalalignment='center')ax.autoscale(enable=False, axis='both', tight=False)

按合同类型分类的流失率(按作者分类的图片)
9.3.3。按付款方式分类的流失率:通过银行转账付款的客户似乎在所有付款方式类别中流失率最低。
import matplotlib.ticker as mtick
contract_churn = dataset.groupby(['Contract',
'PaymentMethod']).size().unstack()contract_churn.rename(columns=
{0:'No', 1:'Yes'}, inplace=True)colors = ['#ec838a','#9b9c9a', '#f3babc' , '#4d4f4c']ax = (contract_churn.T*100.0 / contract_churn.T.sum()).T.plot(
kind='bar',width = 0.3,stacked = True,rot = 0,figsize = (12,7),
color = colors)plt.ylabel('Proportion of Customers\n',
horizontalalignment="center",fontstyle = "normal",
fontsize = "large", fontfamily = "sans-serif")plt.xlabel('Contract Type\n',horizontalalignment="center",
fontstyle = "normal", fontsize = "large",
fontfamily = "sans-serif")plt.title('Churn Rate by Payment Method \n',
horizontalalignment="center", fontstyle = "normal",
fontsize = "22", fontfamily = "sans-serif")plt.legend(loc='top right', fontsize = "medium")
plt.xticks(rotation=0, horizontalalignment="center")
plt.yticks(rotation=0, horizontalalignment="right")
ax.yaxis.set_major_formatter(mtick.PercentFormatter())for p in ax.patches:
width, height = p.get_width(), p.get_height()
x, y = p.get_xy()
ax.text(x+width/2,
y+height/2,
'{:.1f}%'.format(height),
horizontalalignment='center',
verticalalignment='center')ax.autoscale(enable=False, axis='both', tight=False

按合同类型分类的流失率(按作者分类的图片)
**步骤 9.4。找到正相关和负相关:**有趣的是,流失率随着月费和年龄的增长而增加。相反,伴侣、受抚养人和任期似乎与流失负相关。让我们在下一步中用图表来看看正相关和负相关。
dataset2 = dataset[['SeniorCitizen', 'Partner', 'Dependents',
'tenure', 'PhoneService', 'PaperlessBilling',
'MonthlyCharges', 'TotalCharges']]correlations = dataset2.corrwith(dataset.Churn)
correlations = correlations[correlations!=1]
positive_correlations = correlations[
correlations >0].sort_values(ascending = False)
negative_correlations =correlations[
correlations<0].sort_values(ascending = False)print('Most Positive Correlations: \n', positive_correlations)
print('\nMost Negative Correlations: \n', negative_correlations)
第 9.5 步。图正&负相关:
correlations = dataset2.corrwith(dataset.Churn)
correlations = correlations[correlations!=1]correlations.plot.bar(
figsize = (18, 10),
fontsize = 15,
color = '#ec838a',
rot = 45, grid = True)plt.title('Correlation with Churn Rate \n',
horizontalalignment="center", fontstyle = "normal",
fontsize = "22", fontfamily = "sans-serif")

与流失率的相关性(图片由作者提供)
**第 9.6 步。绘制所有自变量的相关矩阵:**相关矩阵有助于我们发现数据集中自变量之间的二元关系。
#Set and compute the Correlation Matrix:sn.set(style="white")
corr = dataset2.corr()#Generate a mask for the upper triangle:mask = np.zeros_like(corr, dtype=np.bool)
mask[np.triu_indices_from(mask)] = True#Set up the matplotlib figure and a diverging colormap:f, ax = plt.subplots(figsize=(18, 15))
cmap = sn.diverging_palette(220, 10, as_cmap=True)#Draw the heatmap with the mask and correct aspect ratio:sn.heatmap(corr, mask=mask, cmap=cmap, vmax=.3, center=0,
square=True, linewidths=.5, cbar_kws={"shrink": .5})

自变量的相关矩阵(图片由作者提供)
**步骤 9.7:使用 VIF 检查多重共线性:**让我们尝试使用可变通货膨胀系数(VIF)来研究多重共线性。与相关矩阵不同,VIF 确定一个变量与数据集中一组其他独立变量的相关性强度。VIF 通常从 1 开始,任何超过 10 的地方都表明自变量之间的高度多重共线性。
def calc_vif(X):# Calculating VIF
vif = pd.DataFrame()
vif["variables"] = X.columns
vif["VIF"] = [variance_inflation_factor(X.values, i)
for i in range(X.shape[1])]return(vif)dataset2 = dataset[['gender',
'SeniorCitizen', 'Partner', 'Dependents',
'tenure', 'PhoneService',
'PaperlessBilling','MonthlyCharges',
'TotalCharges']]calc_vif(dataset2)

计算 VIF(图片作者)
我们可以看到“每月费用”和“总费用”具有很高的 VIF 值。
'Total Charges' seem to be collinear with 'Monthly Charges'.#Check colinearity:
dataset2[['MonthlyCharges', 'TotalCharges']].
plot.scatter(
figsize = (15, 10),
x ='MonthlyCharges',
y='TotalCharges',
color = '#ec838a')plt.title('Collinearity of Monthly Charges and Total Charges \n',
horizontalalignment="center", fontstyle = "normal", fontsize = "22", fontfamily = "sans-serif")

每月费用和总费用的共线性(图片由作者提供)
让我们尝试删除其中一个相关要素,看看它是否有助于降低相关要素之间的多重共线性:
#Dropping 'TotalCharges':
dataset2 = dataset2.drop(columns = "TotalCharges")#Revalidate Colinearity:dataset2 = dataset[['gender',
'SeniorCitizen', 'Partner', 'Dependents',
'tenure', 'PhoneService', 'PaperlessBilling',
'MonthlyCharges']]calc_vif(dataset2)#Applying changes in the main dataset:
dataset = dataset.drop(columns = "TotalCharges")

计算 VIF(图片作者)
在我们的例子中,在去掉“总费用”变量后,所有独立变量的 VIF 值都大大降低了。
探索性数据分析结束语:
让我们试着总结一下这次 EDA 的一些关键发现:
- 数据集没有任何缺失或错误的数据值。
- 与目标特征最强正相关的是月费和年龄,而与伴侣、家属和任期负相关。
- 数据集不平衡,大多数客户都很活跃。
- 每月费用和总费用之间存在多重共线性。总费用的下降大大降低了 VIF 值。
- 数据集中的大多数客户都是年轻人。
- 组织中有许多新客户(不到 10 个月),随后是 70 个月以上的忠实客户群。
- 大多数客户似乎都有电话服务,每个客户的月费在 18 美元到 118 美元之间。
- 如果订阅了通过电子支票支付的服务,月结用户也很有可能流失。
**步骤 10:对分类数据进行编码:**任何具有两个以上唯一值的分类变量都已经在 pandas 中使用 get_dummies 方法进行了标签编码和一键编码。
#Incase if user_id is an object:
identity = dataset["customerID"]dataset = dataset.drop(columns="customerID")#Convert rest of categorical variable into dummy:dataset= pd.get_dummies(dataset)#Rejoin userid to dataset:dataset = pd.concat([dataset, identity], axis = 1)
**第 11 步:将数据集分成因变量和自变量:**现在我们需要将数据集分成 X 和 y 值。y 将是“变动”列,而 X 将是数据集中独立变量的剩余列表。
#Identify response variable:
response = dataset["Churn"]dataset = dataset.drop(columns="Churn")
**第十二步:生成训练和测试数据集:**让我们将主数据集解耦为 80%-20%比例的训练和测试集。
X_train, X_test, y_train, y_test = train_test_split(dataset, response,stratify=response, test_size = 0.2, #use 0.9 if data is huge.random_state = 0)#to resolve any class imbalance - use stratify parameter.print("Number transactions X_train dataset: ", X_train.shape)
print("Number transactions y_train dataset: ", y_train.shape)
print("Number transactions X_test dataset: ", X_test.shape)
print("Number transactions y_test dataset: ", y_test.shape)

训练和测试数据集(图片由作者提供)
**步骤 13:移除标识符:**将“customerID”从训练和测试数据帧中分离出来。
train_identity = X_train['customerID']
X_train = X_train.drop(columns = ['customerID'])test_identity = X_test['customerID']
X_test = X_test.drop(columns = ['customerID'])
**步骤 14:进行特征缩放:**在进行任何机器学习(分类)算法之前,标准化变量是非常重要的,以便所有的训练和测试变量都在 0 到 1 的范围内缩放。
sc_X = StandardScaler()
X_train2 = pd.DataFrame(sc_X.fit_transform(X_train))
X_train2.columns = X_train.columns.values
X_train2.index = X_train.index.values
X_train = X_train2X_test2 = pd.DataFrame(sc_X.transform(X_test))
X_test2.columns = X_test.columns.values
X_test2.index = X_test.index.values
X_test = X_test2
C 部分:型号选择
**步骤 15.1:比较基线分类算法(第一次迭代)😗*让我们在训练数据集上对每个分类算法进行建模,并评估它们的准确性和标准偏差分数。
分类准确性是比较基准算法的最常见的分类评估指标之一,因为它是正确预测的数量与总预测的比率。然而,当我们有阶级不平衡的问题时,这不是理想的衡量标准。因此,让我们根据“平均 AUC”值对结果进行排序,该值只不过是模型区分阳性和阴性类别的能力。
models = []models.append(('Logistic Regression', LogisticRegression(solver='liblinear', random_state = 0,
class_weight='balanced')))models.append(('SVC', SVC(kernel = 'linear', random_state = 0)))models.append(('Kernel SVM', SVC(kernel = 'rbf', random_state = 0)))models.append(('KNN', KNeighborsClassifier(n_neighbors = 5, metric = 'minkowski', p = 2)))models.append(('Gaussian NB', GaussianNB()))models.append(('Decision Tree Classifier',
DecisionTreeClassifier(criterion = 'entropy', random_state = 0)))models.append(('Random Forest', RandomForestClassifier(
n_estimators=100, criterion = 'entropy', random_state = 0)))#Evaluating Model Results:acc_results = []
auc_results = []
names = []# set table to table to populate with performance results
col = ['Algorithm', 'ROC AUC Mean', 'ROC AUC STD',
'Accuracy Mean', 'Accuracy STD']model_results = pd.DataFrame(columns=col)
i = 0# Evaluate each model using k-fold cross-validation:for name, model in models:
kfold = model_selection.KFold(
n_splits=10, random_state=0)# accuracy scoring:
cv_acc_results = model_selection.cross_val_score(
model, X_train, y_train, cv=kfold, scoring='accuracy')# roc_auc scoring:
cv_auc_results = model_selection.cross_val_score(
model, X_train, y_train, cv=kfold, scoring='roc_auc')acc_results.append(cv_acc_results)
auc_results.append(cv_auc_results)
names.append(name)
model_results.loc[i] = [name,
round(cv_auc_results.mean()*100, 2),
round(cv_auc_results.std()*100, 2),
round(cv_acc_results.mean()*100, 2),
round(cv_acc_results.std()*100, 2)
]
i += 1
model_results.sort_values(by=['ROC AUC Mean'], ascending=False)

比较基线分类算法第一次迭代(图片由作者提供)
第 15.2 步。可视化分类算法精度对比:
使用精度均值:
fig = plt.figure(figsize=(15, 7))
ax = fig.add_subplot(111)
plt.boxplot(acc_results)
ax.set_xticklabels(names)#plt.ylabel('ROC AUC Score\n',
horizontalalignment="center",fontstyle = "normal",
fontsize = "large", fontfamily = "sans-serif")#plt.xlabel('\n Baseline Classification Algorithms\n',
horizontalalignment="center",fontstyle = "normal",
fontsize = "large", fontfamily = "sans-serif")plt.title('Accuracy Score Comparison \n',
horizontalalignment="center", fontstyle = "normal",
fontsize = "22", fontfamily = "sans-serif")#plt.legend(loc='top right', fontsize = "medium")
plt.xticks(rotation=0, horizontalalignment="center")
plt.yticks(rotation=0, horizontalalignment="right")plt.show()

准确度分数比较(图片由作者提供)
**使用 ROC 曲线下面积:**从基线分类算法的第一次迭代中,我们可以看到,对于具有最高平均 AUC 分数的所选数据集,逻辑回归和 SVC 已经优于其他五个模型。让我们在第二次迭代中再次确认我们的结果,如下面的步骤所示。
fig = plt.figure(figsize=(15, 7))
ax = fig.add_subplot(111)
plt.boxplot(auc_results)
ax.set_xticklabels(names)#plt.ylabel('ROC AUC Score\n',
horizontalalignment="center",fontstyle = "normal",
fontsize = "large", fontfamily = "sans-serif")#plt.xlabel('\n Baseline Classification Algorithms\n',
horizontalalignment="center",fontstyle = "normal",
fontsize = "large", fontfamily = "sans-serif")plt.title('ROC AUC Comparison \n',horizontalalignment="center", fontstyle = "normal", fontsize = "22",
fontfamily = "sans-serif")#plt.legend(loc='top right', fontsize = "medium")
plt.xticks(rotation=0, horizontalalignment="center")
plt.yticks(rotation=0, horizontalalignment="right")plt.show()

ROC AUC 比较(图片由作者提供)
**步骤 15.3。为基线模型获取正确的参数:**在进行第二次迭代之前,让我们优化参数并最终确定模型选择的评估指标。
**为 KNN 模型确定 K 个邻居的最佳数量:**在第一次迭代中,我们假设 K = 3,但实际上,我们不知道为所选训练数据集提供最大准确度的最佳 K 值是什么。因此,让我们编写一个迭代 20 到 30 次的 for 循环,并给出每次迭代的精度,以便计算出 KNN 模型的 K 个邻居的最佳数量。
score_array = []
for each in range(1,25):
knn_loop = KNeighborsClassifier(n_neighbors = each) #set K neighbor as 3
knn_loop.fit(X_train,y_train)
score_array.append(knn_loop.score(X_test,y_test))fig = plt.figure(figsize=(15, 7))
plt.plot(range(1,25),score_array, color = '#ec838a')plt.ylabel('Range\n',horizontalalignment="center",
fontstyle = "normal", fontsize = "large",
fontfamily = "sans-serif")plt.xlabel('Score\n',horizontalalignment="center",
fontstyle = "normal", fontsize = "large",
fontfamily = "sans-serif")plt.title('Optimal Number of K Neighbors \n',
horizontalalignment="center", fontstyle = "normal",
fontsize = "22", fontfamily = "sans-serif")#plt.legend(loc='top right', fontsize = "medium")
plt.xticks(rotation=0, horizontalalignment="center")
plt.yticks(rotation=0, horizontalalignment="right")plt.show()

K 近邻的最佳数量(图片由作者提供)
从上面的迭代可以看出,如果我们使用 K = 22,那么我们将得到 78%的最高分。
**确定随机森林模型的最佳树木数量:**与 KNN 模型中的迭代非常相似,这里我们试图找到最佳决策树数量,以组成最佳随机森林。
score_array = []
for each in range(1,100):
rf_loop = RandomForestClassifier(
n_estimators = each, random_state = 1) rf_loop.fit(X_train,y_train) score_array.append(rf_loop.score(X_test,y_test))
fig = plt.figure(figsize=(15, 7))
plt.plot(range(1,100),score_array, color = '#ec838a')plt.ylabel('Range\n',horizontalalignment="center",
fontstyle = "normal", fontsize = "large",
fontfamily = "sans-serif")plt.xlabel('Score\n',horizontalalignment="center",
fontstyle = "normal", fontsize = "large",
fontfamily = "sans-serif")plt.title('Optimal Number of Trees for Random Forest Model \n',horizontalalignment="center", fontstyle = "normal", fontsize = "22", fontfamily = "sans-serif")#plt.legend(loc='top right', fontsize = "medium")
plt.xticks(rotation=0, horizontalalignment="center")
plt.yticks(rotation=0, horizontalalignment="right")plt.show()

随机森林模型的最佳树数(图片由作者提供)
从上面的迭代中我们可以看出,当 n_estimators = 72 时,随机森林模型将获得最高的精度分数。
第 15.4 步。比较基线分类算法(第二次迭代):
在比较基线分类算法的第二次迭代中,我们将使用 KNN 和随机森林模型的优化参数。此外,我们知道,在流失中,假阴性比假阳性的成本更高,因此让我们使用精确度、召回率和 F2 分数作为模型选择的理想指标。
步骤 15.4.1。逻辑回归:
# Fitting Logistic Regression to the Training set
classifier = LogisticRegression(random_state = 0)
classifier.fit(X_train, y_train)# Predicting the Test set results
y_pred = classifier.predict(X_test)#Evaluate results
acc = accuracy_score(y_test, y_pred )
prec = precision_score(y_test, y_pred )
rec = recall_score(y_test, y_pred )
f1 = f1_score(y_test, y_pred )
f2 = fbeta_score(y_test, y_pred, beta=2.0)results = pd.DataFrame([['Logistic Regression',
acc, prec, rec, f1, f2]], columns = ['Model',
'Accuracy', 'Precision', 'Recall', 'F1 Score',
'F2 Score'])results = results.sort_values(["Precision",
"Recall", "F2 Score"], ascending = False)print (results)

逻辑回归结果(图片由作者提供)
步骤 15.4.2。支持向量机(线性分类器):
# Fitting SVM (SVC class) to the Training set
classifier = SVC(kernel = 'linear', random_state = 0)
classifier.fit(X_train, y_train)# Predicting the Test set results y_pred = classifier.predict(X_test)#Evaluate results
acc = accuracy_score(y_test, y_pred )
prec = precision_score(y_test, y_pred )
rec = recall_score(y_test, y_pred)
f1 = f1_score(y_test, y_pred )
f2 = fbeta_score(y_test, y_pred, beta=2.0)model_results = pd.DataFrame(
[['SVM (Linear)', acc, prec, rec, f1, f2]],
columns = ['Model', 'Accuracy', 'Precision',
'Recall', 'F1 Score', 'F2 Score'])results = results.append(model_results, ignore_index = True)results = results.sort_values(["Precision",
"Recall", "F2 Score"], ascending = False)print (results)

SVM 线性结果(图片由作者提供)
步骤 15.4.3。k-最近邻:
# Fitting KNN to the Training set:
classifier = KNeighborsClassifier(
n_neighbors = 22,
metric = 'minkowski', p = 2)
classifier.fit(X_train, y_train)# Predicting the Test set results
y_pred = classifier.predict(X_test)#Evaluate results
acc = accuracy_score(y_test, y_pred )
prec = precision_score(y_test, y_pred )
rec = recall_score(y_test, y_pred )
f1 = f1_score(y_test, y_pred )
f2 = fbeta_score(y_test, y_pred, beta=2.0)model_results = pd.DataFrame([['K-Nearest Neighbours',
acc, prec, rec, f1, f2]], columns = ['Model',
'Accuracy', 'Precision', 'Recall',
'F1 Score', 'F2 Score'])results = results.append(model_results, ignore_index = True)results = results.sort_values(["Precision",
"Recall", "F2 Score"], ascending = False)print (results)

k-最近邻(图片由作者提供)
步骤 15.4.4。内核 SVM:
# Fitting Kernel SVM to the Training set:
classifier = SVC(kernel = 'rbf', random_state = 0)
classifier.fit(X_train, y_train)# Predicting the Test set results
y_pred = classifier.predict(X_test)#Evaluate results
acc = accuracy_score(y_test, y_pred )
prec = precision_score(y_test, y_pred )
rec = recall_score(y_test, y_pred )
f1 = f1_score(y_test, y_pred )
f2 = fbeta_score(y_test, y_pred, beta=2.0)model_results = pd.DataFrame([[
'Kernel SVM', acc, prec, rec, f1, f2]],
columns = ['Model', 'Accuracy', 'Precision',
'Recall', 'F1 Score', 'F2 Score'])results = results.append(model_results, ignore_index = True)results = results.sort_values(["Precision",
"Recall", "F2 Score"], ascending = False)print (results)

内核 SVM 结果(图片由作者提供)
步骤 15.4.5。天真的轮空:
# Fitting Naive Byes to the Training set:
classifier = GaussianNB()
classifier.fit(X_train, y_train)# Predicting the Test set results
y_pred = classifier.predict(X_test)#Evaluate results
acc = accuracy_score(y_test, y_pred )
prec = precision_score(y_test, y_pred )
rec = recall_score(y_test, y_pred )
f1 = f1_score(y_test, y_pred )
f2 = fbeta_score(y_test, y_pred, beta=2.0)model_results = pd.DataFrame([[
'Naive Byes', acc, prec, rec, f1, f2]],
columns = ['Model', 'Accuracy', 'Precision',
'Recall', 'F1 Score', 'F2 Score'])results = results.append(model_results, ignore_index = True)results = results.sort_values(["Precision",
"Recall", "F2 Score"], ascending = False)print (results)

天真的 Byes 结果(作者图片)
步骤 15.4.6。决策树:
# Fitting Decision Tree to the Training set:classifier = DecisionTreeClassifier(criterion = 'entropy', random_state = 0)
classifier.fit(X_train, y_train)# Predicting the Test set results
y_pred = classifier.predict(X_test)#Evaluate results
acc = accuracy_score(y_test, y_pred )
prec = precision_score(y_test, y_pred )
rec = recall_score(y_test, y_pred )
f1 = f1_score(y_test, y_pred )
f2 = fbeta_score(y_test, y_pred, beta=2.0)model_results = pd.DataFrame([[
'Decision Tree', acc, prec, rec, f1, f2]],
columns = ['Model', 'Accuracy', 'Precision',
'Recall', 'F1 Score', 'F2 Score'])results = results.append(model_results, ignore_index = True)results = results.sort_values(["Precision",
"Recall", "F2 Score"], ascending = False)print (results)

决策树结果(图片由作者提供)
步骤 15.4.7。随机森林:
# Fitting Random Forest to the Training set:
classifier = RandomForestClassifier(n_estimators = 72,
criterion = 'entropy', random_state = 0)
classifier.fit(X_train, y_train)# Predicting the Test set results
y_pred = classifier.predict(X_test)#Evaluate results
from sklearn.metrics import confusion_matrix,
accuracy_score, f1_score, precision_score, recall_score
acc = accuracy_score(y_test, y_pred )
prec = precision_score(y_test, y_pred )
rec = recall_score(y_test, y_pred )
f1 = f1_score(y_test, y_pred )
f2 = fbeta_score(y_test, y_pred, beta=2.0)model_results = pd.DataFrame([['Random Forest',
acc, prec, rec, f1, f2]],
columns = ['Model', 'Accuracy', 'Precision',
'Recall', 'F1 Score', 'F2 Score'])results = results.append(model_results, ignore_index = True)results = results.sort_values(["Precision",
"Recall", "F2 Score"], ascending = False)print (results)

比较基线分类算法第二次迭代(图片由作者提供)
从第二次迭代,我们可以明确地得出结论,逻辑回归是给定数据集的最佳选择模型,因为它具有相对最高的精确度、召回率和 F2 分数的组合;给出最大数量的正确肯定预测,同时最小化假否定。因此,让我们在接下来的章节中尝试使用逻辑回归并评估其性能。
D 部分:模型评估
**步骤 16:训练&评估选择的模型:**让我们将选择的模型(在这种情况下是逻辑回归)拟合到训练数据集上,并评估结果。
classifier = LogisticRegression(random_state = 0,
penalty = 'l2')
classifier.fit(X_train, y_train)# Predict the Test set results
y_pred = classifier.predict(X_test)#Evaluate Model Results on Test Set:
acc = accuracy_score(y_test, y_pred )
prec = precision_score(y_test, y_pred )
rec = recall_score(y_test, y_pred )
f1 = f1_score(y_test, y_pred )
f2 = fbeta_score(y_test, y_pred, beta=2.0)results = pd.DataFrame([['Logistic Regression',
acc, prec, rec, f1, f2]],columns = ['Model', 'Accuracy', 'Precision', 'Recall', 'F1 Score', 'F2 Score'])print (results)
**k-Fold 交叉验证:**模型评估通常通过“k-Fold 交叉验证”技术完成,该技术主要帮助我们修正方差。当我们在训练集和测试集上运行模型时获得了良好的准确性,但当模型在另一个测试集上运行时,准确性看起来有所不同,这时就会出现方差问题。
因此,为了解决方差问题,k 折叠交叉验证基本上将训练集分成 10 个折叠,并在测试折叠上测试之前,在 9 个折叠(训练数据集的 9 个子集)上训练模型。这给了我们在所有十种 9 折组合上训练模型的灵活性;为最终确定差异提供了充足的空间。
accuracies = cross_val_score(estimator = classifier,
X = X_train, y = y_train, cv = 10)print("Logistic Regression Classifier Accuracy:
%0.2f (+/- %0.2f)" % (accuracies.mean(),
accuracies.std() * 2))

k 倍交叉验证结果(图片由作者提供)
因此,我们的 k-fold 交叉验证结果表明,在任何测试集上运行该模型时,我们的准确率都在 76%到 84%之间。
**在混淆矩阵上可视化结果:**混淆矩阵表明我们有 208+924 个正确预测和 166+111 个错误预测。
准确率=正确预测数/总预测数* 100
错误率=错误预测数/总预测数* 100
我们有 80%的准确率;标志着一个相当好的模型的特征。
cm = confusion_matrix(y_test, y_pred)
df_cm = pd.DataFrame(cm, index = (0, 1), columns = (0, 1))
plt.figure(figsize = (28,20))fig, ax = plt.subplots()
sn.set(font_scale=1.4)
sn.heatmap(df_cm, annot=True, fmt='g'#,cmap="YlGnBu"
)
class_names=[0,1]
tick_marks = np.arange(len(class_names))plt.tight_layout()
plt.title('Confusion matrix\n', y=1.1)
plt.xticks(tick_marks, class_names)
plt.yticks(tick_marks, class_names)
ax.xaxis.set_label_position("top")plt.ylabel('Actual label\n')
plt.xlabel('Predicted label\n')

困惑矩阵(图片由作者提供)
**用 ROC 图评估模型:**用 ROC 图重新评估模型很好。ROC 图向我们展示了一个模型基于 AUC 平均分数区分类别的能力。橙色线代表随机分类器的 ROC 曲线,而好的分类器试图尽可能远离该线。如下图所示,微调后的逻辑回归模型显示了更高的 AUC 得分。
classifier.fit(X_train, y_train)
probs = classifier.predict_proba(X_test)
probs = probs[:, 1]
classifier_roc_auc = accuracy_score(y_test, y_pred )rf_fpr, rf_tpr, rf_thresholds = roc_curve(y_test, classifier.predict_proba(X_test)[:,1])
plt.figure(figsize=(14, 6))# Plot Logistic Regression ROCplt.plot(rf_fpr, rf_tpr,
label='Logistic Regression (area = %0.2f)' % classifier_roc_auc)# Plot Base Rate ROC
plt.plot([0,1], [0,1],label='Base Rate' 'k--')plt.xlim([0.0, 1.0])
plt.ylim([0.0, 1.05])plt.ylabel('True Positive Rate \n',horizontalalignment="center",
fontstyle = "normal", fontsize = "medium",
fontfamily = "sans-serif")plt.xlabel('\nFalse Positive Rate \n',horizontalalignment="center",
fontstyle = "normal", fontsize = "medium",
fontfamily = "sans-serif")plt.title('ROC Graph \n',horizontalalignment="center",
fontstyle = "normal", fontsize = "22",
fontfamily = "sans-serif")plt.legend(loc="lower right", fontsize = "medium")
plt.xticks(rotation=0, horizontalalignment="center")
plt.yticks(rotation=0, horizontalalignment="right")plt.show()

ROC 图(图片由作者提供)
**步骤 17:预测特征重要性:**逻辑回归允许我们确定对预测目标属性有意义的关键特征(在这个项目中为“流失”)。
逻辑回归模型预测,流失率将随着逐月合同、光纤互联网服务、电子支票、支付安全和技术支持的缺失而正增长。
另一方面,如果任何客户订阅了在线证券、一年期合同或选择邮寄支票作为支付媒介,该模型预测与客户流失呈负相关。
# Analyzing Coefficientsfeature_importances = pd.concat([
pd.DataFrame(dataset.drop(columns = 'customerID').
columns, columns = ["features"]),
pd.DataFrame(np.transpose(classifier.coef_),
columns = ["coef"])],axis = 1)
feature_importances.sort_values("coef", ascending = False)

预测功能的重要性(图片由作者提供)
E 部分:模型改进
模型改进基本上包括为我们提出的机器学习模型选择最佳参数。任何机器学习模型中都有两种类型的参数——第一种类型是模型学习的参数类型;通过运行模型自动找到最佳值。第二类参数是用户在运行模型时可以选择的参数。这样的参数被称为超参数;模型外部的一组可配置值,这些值无法由数据确定,我们正试图通过随机搜索或网格搜索等参数调整技术来优化这些值。
超参数调整可能不会每次都改进模型。例如,当我们试图进一步调优模型时,我们最终得到的准确度分数低于默认分数。我只是在这里演示超参数调整的步骤,以供将来参考。
步骤 18:通过网格搜索进行超参数调谐:
# Round 1:
# Select Regularization Method
import time
penalty = ['l1', 'l2']# Create regularization hyperparameter space
C = [0.001, 0.01, 0.1, 1, 10, 100, 1000]# Combine Parameters
parameters = dict(C=C, penalty=penalty)lr_classifier = GridSearchCV(estimator = classifier,
param_grid = parameters,
scoring = "balanced_accuracy",
cv = 10,
n_jobs = -1)
t0 = time.time()
lr_classifier = lr_classifier .fit(X_train, y_train)
t1 = time.time()
print("Took %0.2f seconds" % (t1 - t0))lr_best_accuracy = lr_classifier.best_score_
lr_best_parameters = lr_classifier.best_params_
lr_best_accuracy, lr_best_parameters

超参数调整-第一轮(图片由作者提供)
# Round 2:# Select Regularization Method
import time
penalty = ['l2']# Create regularization hyperparameter space
C = [ 0.0001, 0.001, 0.01, 0.02, 0.05]# Combine Parameters
parameters = dict(C=C, penalty=penalty)lr_classifier = GridSearchCV(estimator = classifier,
param_grid = parameters,
scoring = "balanced_accuracy",
cv = 10,
n_jobs = -1)
t0 = time.time()
lr_classifier = lr_classifier .fit(X_train, y_train)
t1 = time.time()
print("Took %0.2f seconds" % (t1 - t0))lr_best_accuracy = lr_classifier.best_score_
lr_best_parameters = lr_classifier.best_params_
lr_best_accuracy, lr_best_parameters

超参数调整-第二轮(图片由作者提供)
步骤 18.2:最终超参数调整和选择:
lr_classifier = LogisticRegression(random_state = 0, penalty = 'l2')
lr_classifier.fit(X_train, y_train)# Predict the Test set resultsy_pred = lr_classifier.predict(X_test)#probability score
y_pred_probs = lr_classifier.predict_proba(X_test)
y_pred_probs = y_pred_probs [:, 1]
F 部分:未来预测
步骤 19:将预测与测试集进行比较:
#Revalidate final results with Confusion Matrix:cm = confusion_matrix(y_test, y_pred)
print (cm)#Confusion Matrix as a quick Crosstab:
pd.crosstab(y_test,pd.Series(y_pred),
rownames=['ACTUAL'],colnames=['PRED'])#visualize Confusion Matrix:cm = confusion_matrix(y_test, y_pred)
df_cm = pd.DataFrame(cm, index = (0, 1), columns = (0, 1))
plt.figure(figsize = (28,20))fig, ax = plt.subplots()
sn.set(font_scale=1.4)
sn.heatmap(df_cm, annot=True, fmt='g'#,cmap="YlGnBu"
)
class_names=[0,1]
tick_marks = np.arange(len(class_names))
plt.tight_layout()
plt.title('Confusion matrix\n', y=1.1)
plt.xticks(tick_marks, class_names)
plt.yticks(tick_marks, class_names)
ax.xaxis.set_label_position("top")
plt.ylabel('Actual label\n')
plt.xlabel('Predicted label\n')print("Test Data Accuracy: %0.4f" % accuracy_score(y_test, y_pred))

困惑矩阵(图片由作者提供)
**步骤 20:格式化最终结果:**不可预测性和风险是任何预测模型的亲密伴侣。因此,在现实世界中,除了绝对的预测结果之外,建立一个倾向评分总是一个好的做法。除了检索二进制估计目标结果(0 或 1),每个“客户 ID”都可以获得一个额外的倾向得分层,突出显示他们采取目标行动的概率百分比。
final_results = pd.concat([test_identity, y_test], axis = 1).dropna()final_results['predictions'] = y_predfinal_results["propensity_to_churn(%)"] = y_pred_probsfinal_results["propensity_to_churn(%)"] = final_results["propensity_to_churn(%)"]*100final_results["propensity_to_churn(%)"]=final_results["propensity_to_churn(%)"].round(2)final_results = final_results[['customerID', 'Churn', 'predictions', 'propensity_to_churn(%)']]final_results ['Ranking'] = pd.qcut(final_results['propensity_to_churn(%)'].rank(method = 'first'),10,labels=range(10,0,-1))print (final_results)

高风险类别(图片由作者提供)

低风险类别(图片由作者提供)
G 部分:模型部署
最后,使用“joblib”库将模型部署到服务器上,这样我们就可以生产端到端的机器学习框架。稍后,我们可以在任何新的数据集上运行该模型,以预测未来几个月内任何客户流失的概率。
第 21 步:保存模型:
filename = 'final_model.model'
i = [lr_classifier]
joblib.dump(i,filename)
结论
因此,简而言之,我们利用 Kaggle 的客户流失数据集来建立一个机器学习分类器,该分类器可以预测任何客户在未来几个月内的流失倾向,准确率达到 76%至 84%。
接下来是什么?
- 与组织的销售和营销团队分享您从探索性数据分析部分获得的关于客户人口统计和流失率的关键见解。让销售团队了解与客户流失有积极和消极关系的特征,以便他们能够相应地制定保留计划。
- 此外,根据倾向得分将即将到来的客户分为高风险(倾向得分> 80%的客户)、中风险(倾向得分在 60-80%之间的客户)和最后低风险类别(倾向得分< 60%的客户)。预先关注每个客户群,确保他们的需求得到充分满足。
- 最后,通过计算当前财务季度的流失率来衡量这项任务的投资回报(ROI)。将季度结果与去年或前年的同一季度进行比较,并与贵组织的高级管理层分享结果。
GitHub 库
我已经从 Github 的许多人那里学到了(并且还在继续学到)。因此,在一个公共的 GitHub 库中分享我的整个 python 脚本和支持文件,以防它对任何在线搜索者有益。此外,如果您在理解 Python 中有监督的机器学习算法的基础方面需要任何帮助,请随时联系我。乐于分享我所知道的:)希望这有所帮助!
关于作者
[## Sreejith Sreedharan - Sree
数据爱好者。不多不少!你好!我是 Sreejith Sreedharan,又名 Sree 一个永远好奇的数据驱动的…
srees.org](https://srees.org/about)

















 2286
2286

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言










{kind=link}
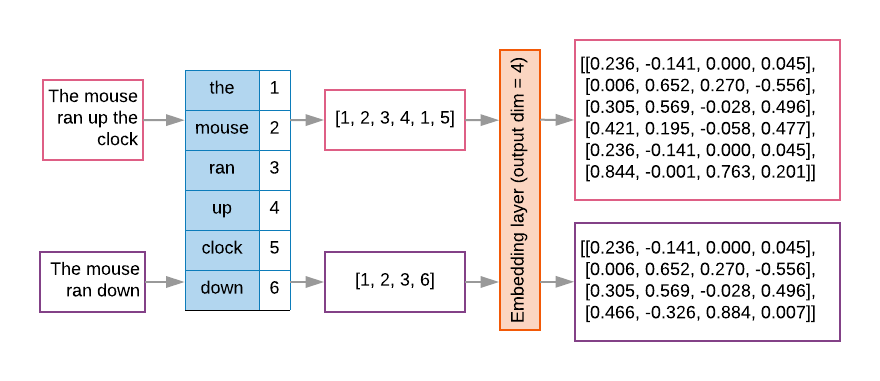{kind=link}