







系外行星,我们在哪里?
带有少量 Wolfram 语言的计算思维

由 Unsplash 上 Greg Rakozy 拍摄的照片
太阳系外的第一颗行星——系外行星——被确认至今不过 30 年左右。系外行星发现的时间表相当复杂,因为事实上早期的观察,其中一次早在 1917 年,最初并没有被认为是系外行星的证据。
在一段时间的基于地球和哈勃望远镜的发现之后,一架名为开普勒的太空望远镜于 2009 年发射,致力于寻找系外行星的任务。它一直指向夜空的一小部分,几年来耐心地记录了来自 50 多万颗恒星的光。

在大约 10 年的任务中,它探测到了超过 2600 颗新的系外行星。加上其他发现,已知的系外行星总数超过 4000 颗。许多系外行星都有轨道周期、质量、半径等等的估计值。在这篇文章中,我将关注它们的质量和半径,并将它们与我们太阳系中的行星进行比较。
获取系外行星数据
在 Wolfram 语言中,这些系外行星可以从 Wolfram 知识库的编程接口直接访问。在笔记本界面中,你可以通过漂亮的用户界面访问任何实体,而不仅仅是系外行星:

(图片由作者提供)
上面的最终结果也可以以纯文本代码的形式表示。它们是完全一样的东西:
EntityClass["Exoplanet", All]
我们可以通过一个简单的查询获得每个行星的质量和半径:
data = ExoplanetData[
EntityClass["Exoplanet", All], {
EntityProperty["Exoplanet", "Mass", {"Uncertainty" -> "Around"}],
EntityProperty["Exoplanet", "Radius", {"Uncertainty" -> "Around"}]
}, "EntityAssociation"]
许多系外行星没有对它们的质量和/或半径的估计,而那些有估计的行星通常有很大的不确定性。十行数据的随机样本显示了典型的情况:

(图片由作者提供)
在过滤掉质量或半径缺失的情况后,我们得到了一个干净的数据集(显示了另一个 10 行的随机样本):

(图片由作者提供)
绘制数据
现在很容易画出每个系外行星的质量与半径的关系。极细的垂直线和水平线表明了每个系外行星的不确定性:

(图片由作者提供)
看到大量更大的系外行星并不奇怪。更大的行星更容易被发现,因此更多的行星被探测到。
为了将这些系外行星与我们太阳系中的行星进行比较,我们首先需要获得它们以及它们的质量和半径:
EntityValue[
EntityClass["Planet", All],
{"Mass", "Radius"},
"EntityAssociation"
]
使用额外的数据,我们现在可以重复相同的绘图,但包括太阳系行星:

(图片由作者提供)
这个挺有意思的。它表明有相当多的系外行星甚至比木星还要大。当然有一个上限,因为在某个尺寸下,一颗非常大的行星会变成一颗非常小的恒星。
在系外行星光谱的另一端,很明显我们没有发现很多非常小的行星。甚至火星也位于被探测到的主要系外行星群之外。希望有一天我们也会发现很多这样的东西!

鸣谢: NASA (公共领域)
带代码的完整 Wolfram 笔记本可在网上这里获得。
通过规范化扩展您的回归曲目
使用通过 tsfresh 生成的大量特征,通过逻辑回归对桶样品进行分类
你也可以在 GitHub 上阅读这篇文章。这个 GitHub 存储库包含了您自己运行分析所需的一切。
介绍
对于许多数据科学家来说,基本的主力模型是多元线性回归。它是许多分析的第一站,也是更复杂模型的基准。它的优势之一是所得系数的易解释性,这是神经网络特别难以解决的问题。然而,线性回归并非没有挑战。在本文中,我们关注一个特殊的挑战:处理大量的特性。大型数据集的具体问题是如何为我们的模型选择相关特征,如何克服过度拟合以及如何处理相关特征。
正规化是一种非常有效的技术,有助于解决上述问题。正则化通过用限制系数大小的项来扩展正常的最小二乘目标或损失函数来做到这一点。这篇文章的主要目的是让你熟悉正规化及其带来的好处。
在本文中,您将了解以下主题:
- 什么是更详细的正则化,为什么值得使用
- 有哪些不同类型的正规化,以及术语 L1-和 L2-规范在这种情况下的含义
- 如何实际运用正规化
- 如何使用 tsfresh 为我们的正则化回归生成特征
- 如何解释和可视化正则化回归的系数
- 如何使用交叉验证优化正则化强度
- 如何可视化交叉验证的结果
我们将从更理论化的规范化介绍开始这篇文章,并以一个实际的例子结束。
为什么使用规范化,什么是规范?
下图显示了一个绿色和一个蓝色函数与红色观测值相匹配(属性)。两个函数都完全符合红色观测值,我们真的没有好办法使用损失函数来选择其中一个函数。

不能选择这些函数意味着我们的问题是欠定的。在回归中,两个因素增加了欠定的程度:多重共线性(相关特征)和特征的数量。在具有少量手工特征的情况下,这通常可以手动控制。然而,在更多的数据驱动的方法中,我们经常使用许多(相关的)特征,我们事先不知道哪些会工作得很好。为了克服不确定性,我们需要在问题中加入信息。给我们的问题添加信息的数学术语是规则化。
回归中执行正则化的一个非常常见的方法是用附加项扩展损失函数。 Tibshirani (1997) 提出用一种叫做 Lasso 的方法将系数的总大小加到损失函数中。.)表示系数总大小的数学方法是使用所谓的范数:

其中 p 值决定了我们使用什么样的范数。p 值为 1 称为 L1 范数,p 值为 2 称为 L2 范数,以此类推。既然我们已经有了范数的数学表达式,我们可以扩展我们通常在回归中使用的最小二乘损失函数:

请注意,我们在这里使用 L2 范数,并且我们也使用 L2 范数表示损失函数的平方差部分。此外,λ是正则化强度。正则化强度决定了对限制系数大小与损失函数的平方差部分的关注程度。请注意,范数项在回归中引入了偏差,主要优点是减少了模型中的方差。
包含 L2 范数的回归称为岭回归 ( sklearn )。岭回归减少了预测中的方差,使其更加稳定,不容易过度拟合。此外,方差的减少也对抗多重共线性引入的方差。
当我们在损失函数中加入一个 L1 范数时,这被称为 Lasso ( sklearn )。Lasso 在减小系数大小方面比岭回归更进一步,一直减小到零。这实际上意味着变量会脱离模型,因此 lasso 会执行特征选择。这在处理高度相关的要素(多重共线性)时影响很大。Lasso 倾向于选择一个相关变量,而岭回归平衡所有特征。Lasso 的要素选择属性在您有许多输入要素,而您事先不知道哪些输入要素将对模型有益时特别有用。
如果您想混合套索和岭回归,您可以将 L1 和 L2 范数添加到损失函数中。这就是所谓的弹性网正规化。撇开理论部分不谈,让我们进入正规化的实际应用。
正则化的使用示例
使用案例
人类非常善于识别声音。仅基于音频,我们就能够区分汽车、声音和枪支等事物。如果有人特别有经验,他们甚至可以告诉你这种声音属于哪种车。在本例中,我们将构建一个正则化的逻辑回归模型来识别鼓声。
数据集
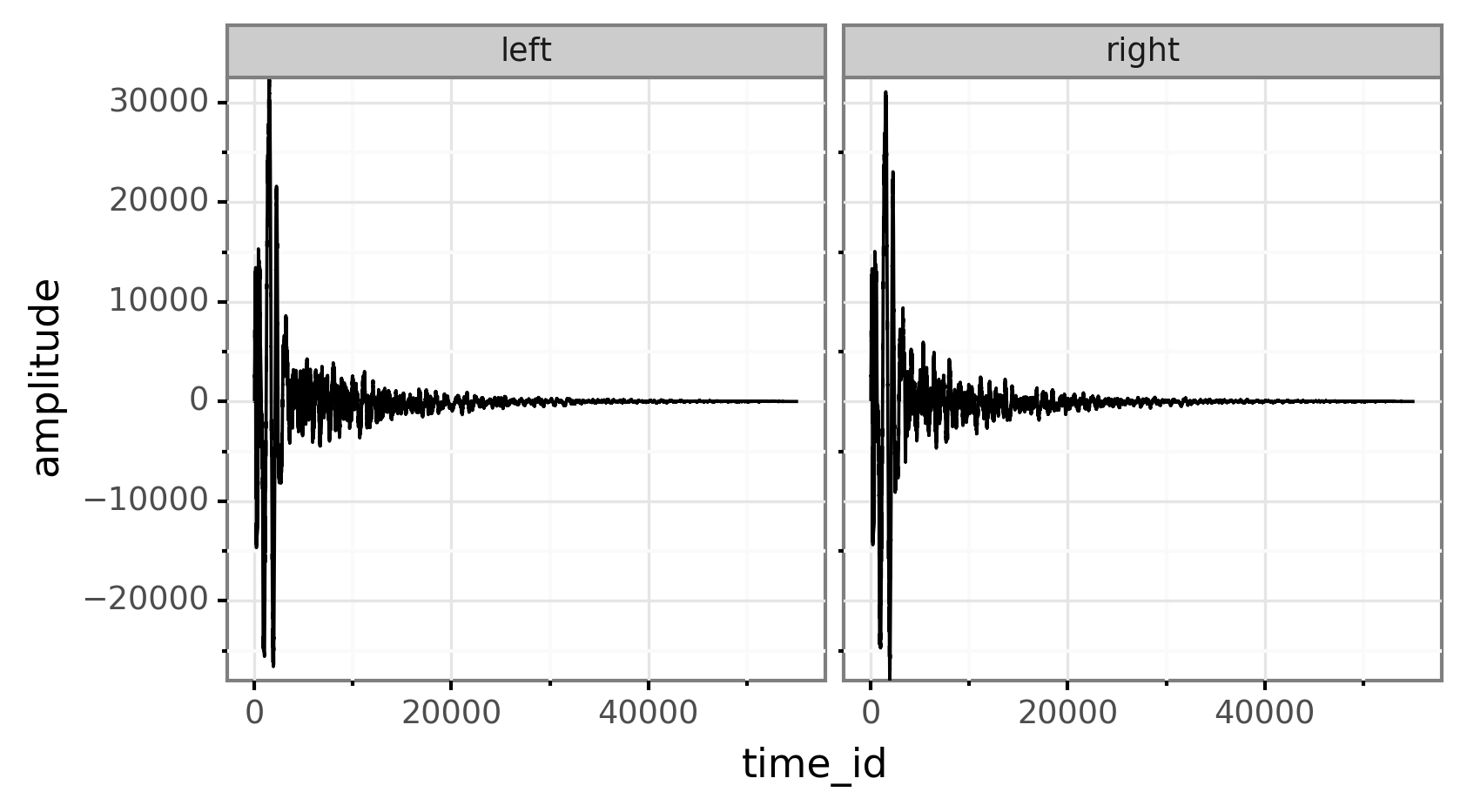
我们模型的基础是一组 75 个鼓样品,每种鼓 25 个:底鼓、小军鼓和 tom 。每个鼓样本都储存在一个 wav 文件中,例如:


wav 文件是立体声的,包含两个声道:左声道和右声道。该文件包含一个随时间变化的波形,x 轴为时间,y 轴为振幅。振幅实际上列出了扬声器的圆锥应该如何振动,以便复制存储在文件中的声音。
以下代码用所有 75 个鼓样本构造了一个DataFrame:

额外的函数audio_to_dataframe可以在文章的 github repo 中的helper_functions.py文件中找到。
使用 tsfresh 生成要素
为了适应监督模型,sklearn 需要两个数据集:一个带有我们特征的samples x features矩阵(或数据帧)和一个带有标签的samples向量。因为我们已经有了标签(all_labels),所以我们把精力集中在特征矩阵上。因为我们希望我们的模型对每个声音文件进行预测,所以特征矩阵中的每一行都应该包含一个声音文件的所有特征。下一个挑战是想出我们想要使用的特性。例如,低音鼓的声音可能有更多的低音频率。因此,我们可以对所有样本运行 FFT,并将低音频率分离为一个特征。
采用这种手动特征工程方法可能非常耗费人力,并且有排除重要特征的很大风险。tsfresh ( docs )是一个 Python 包,它极大地加快了这个过程。该软件包基于时间序列数据生成数百个潜在特征,还包括预选相关特征的方法。拥有数百个特征强调了在这种情况下使用某种正则化的重要性。
为了熟悉 tsfresh,我们首先使用MinimalFCParameters设置生成少量特征:

留给我们 11 个特征。我们使用extract_relevant_features函数来允许 tsfresh 预先选择给定标签和生成的潜在特征有意义的特征。在这种最小的情况下,tsfresh 查看由file_id列标识的每个声音文件,并生成诸如幅度的标准偏差、平均幅度等特征。
但是当我们生成更多的特性时,tsfresh 的优势就显现出来了。这里,我们使用高效设置来节省一些时间,而不是完全设置。注意,我从保存的 pickled 数据帧中读取结果,该数据帧是使用 github repo 中可用的generate_drum_model.py脚本生成的。我这样做是为了节省时间,因为在我的 12 线程机器上计算有效特性大约需要 10 分钟。

这大大扩展了特性的数量,从 11 个增加到 327 个。现在,特征包括跨越几个可能滞后的自相关、FFT 分量以及线性和非线性趋势等。这些特征为我们的正则化回归模型提供了一个非常广阔的学习空间。
拟合正则化回归模型
现在我们有了一组输入要素和所需的标签,我们可以继续拟合我们的正则化回归模型。我们使用来自 sklearn 的逻辑回归模型:
并使用以下设置:
- 我们将惩罚设为
l1,也就是说,我们使用 L1 规范进行正则化。 - 我们设置
multi_class等于one-versus-rest(ovr)。这意味着我们的模型由三个子模型组成,每个子模型对应一种可能的鼓。当使用整体模型进行预测时,我们只需选择表现最佳的模型。 - 我们使用
saga解算器来拟合我们的损失函数。还有很多可用的,但佐贺有一套完整的功能。 C暂时设为 1,其中 C 等于1/regularisation strength。注意,sklearn 套索实现使用了𝛼,它等于1/2C。因为我发现𝛼是一个更直观的度量,所以我们将在本文的剩余部分使用它。tol和max_iter设置为可接受的默认值。
基于这些设置,我们进行了大量的实验。首先,我们将比较基于少量和大量 tsfresh 特性的模型的性能。之后,我们将重点关注使用交叉验证来拟合正则化强度,并以拟合模型的性能的更一般的讨论来结束。
最小 t 新鲜与高效
我们的第一个分析测试了假设,即使用更多生成的 tsfresh 特征会导致更好的模型。为了测试这一点,我们使用最小和有效的 tsfresh 特征来拟合模型。我们通过模型在测试集上的准确性来判断模型的性能。我们重复这个过程 20 次,以了解由于选择训练集和测试集的随机性而导致的准确性差异:

得到的箱线图清楚地表明,与基于最小特征的模型的 0.4 相比,有效的 tsfresh 变量显示出 0.75 的高得多的平均准确度。这证实了我们的假设,我们将在本文的其余部分使用高效的特性。
通过交叉验证选择正则化强度
使用正则化时,我们必须做出的一个主要选择是正则化强度。这里我们使用 crossvalidation 来测试 c 的一系列潜在值的准确性。方便的是,sklearn 包括一个函数来执行逻辑回归分析:[LogisticRegressionCV](https://scikit-learn.org/stable/modules/generated/sklearn.linear_model.LogisticRegressionCV.html)。它本质上具有与LogisticRegression相同的接口,但是您可以传递一个潜在的 C 值列表来进行测试。关于代码的细节,我参考了 github 上的generate_drum_model.py脚本,为了节省时间,我们将结果从磁盘加载到这里:
注意,我们使用[l1_min_c](https://scikit-learn.org/stable/modules/generated/sklearn.svm.l1_min_c.html)来获得最小 C 值,对于该值,模型将仍然包含非零系数。然后,我们在此基础上添加一个介于 0 和 7 之间的对数标度,最终得到 16 个潜在的 C 值。我对这些数字没有很好的理由,我只是在l1_min_c链接的教程中重复使用了它们。转化为𝛼α正则化强度,取 log10 值(为了可读性),我们最终得到:

正如我们将在结果的解释中看到的,这跨越了一个很好的正则化强度范围。
交叉验证选择了以下𝛼值:

请注意,我们有三个值,每个子模型一个值(踢模型、鼓模型、响弦模型)。这里我们看到,大约 6 的正则化强度被认为是最佳的(C = 4.5e-07)。
基于 CV 结果的模型的进一步解释
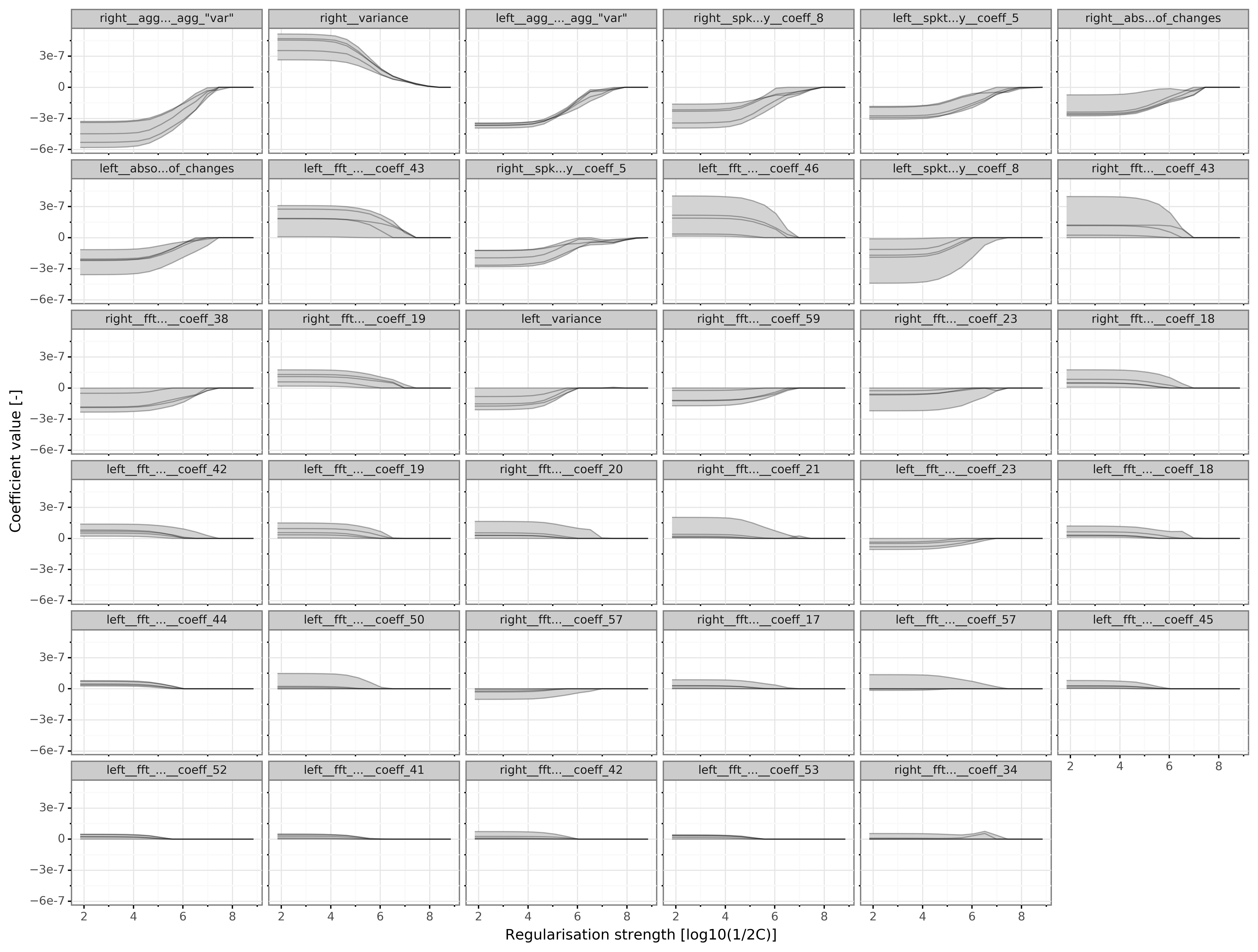
cv_result对象包含比拟合正则化强度更多的关于交叉验证的数据。在这里,我们首先看看交叉验证模型中的系数,以及它们在不断变化的正则化强度下遵循的路径。注意我们使用 github 上的helper_functions.py文件中的plot_coef_paths函数:

注意,我们在图中看到 5 条线,因为默认情况下我们执行 5 重交叉验证。此外,我们关注kick子模型。在该图中,以下观察结果很有趣:
- 增加正则化强度会减小系数的大小。这正是正规化应该做的,但结果支持这一点是件好事。
- 增加正则化强度会减少褶皱的拟合系数之间的差异(线条更接近)。这与规范化的目标是一致的:减少模型中的方差,并与不确定性作斗争。然而,褶皱之间的变化仍然是相当引人注目的。
- 对于后面的系数,总的系数大小下降。因此,早期系数在模型中最为重要。
- 对于交叉验证的正则化强度(6),相当多的系数脱离了模型。在 tsfresh 生成的 327 个潜在特征中,只有大约 10 个被选择用于最终模型。
- 许多有影响的变量是 fft 分量。这在直觉上是有意义的,因为鼓样本之间的差异集中在某些频率附近(低音鼓->低频,小军鼓->高频)。
这些观察描绘了正则化回归按预期工作的画面,但肯定还有改进的空间。在这种情况下,我怀疑每种类型的鼓有 25 个样本是主要的限制因素。
除了查看系数和它们如何变化,我们还可以查看子模型的整体准确性与正则化强度。注意,我们使用了来自helper_functions.py的plot_reg_strength_vs_score图,你可以在 github 上找到。

请注意,精确度涵盖的不是一条线,而是一个区域,因为我们在交叉验证中有每个折叠的精确度分数。该图中的观察结果:
- kick 模型在拟合的正则化强度(6 -> 0.95)下以非常低的最小精度整体表现最佳。
- tom 模型表现最差,其最小和最大精度低得多。
- 正则化强度在 5-6 之间达到性能峰值,这与所选值一致。在强度较小的情况下,我怀疑模型中剩余的多余变量带来了太多噪音,之后正则化提取了太多相关信息。
结论:我们的正则化回归模型的性能
基于交叉验证的准确度分数,我得出结论,我们在生成鼓声音识别模型方面相当成功。特别是底鼓很容易与其他两种鼓区分开来。正则化回归也为模型增加了很多价值,并减少了模型的总体方差。最后,tsfresh 在从这类基于时间序列的数据集生成特征方面显示了很大的潜力。
改进模型的潜在途径有:
- 使用 tsfresh 生成更多潜在的输入要素。对于这个分析,我使用了高效设置,但是也可以使用更复杂的设置。
- 使用更多的鼓样本作为模型的输入。
由于人工智能,你可以在 4K 观看童年时代的电视节目
这是一个人工智能如何将 1984 年的原版《变形金刚 G1》转换成《4K》的例子

你是否在和你的孩子一起重温你最喜欢的童年电视连续剧,并问自己——如果我能在美丽的 4K 看他们,那不是很好吗?这是一个非常合理的问题,因为你正在观看的旧电视节目大多是标清质量的。这意味着分辨率最好为 720x576 像素,仅为 4K 屏幕像素的 5%。实际上,这意味着您的电视会将每个画面放大 20 倍,以填满整个 4K 屏幕。难怪照片看起来模糊不清。

标清与全高清以及 4K UHD 的对比
传统灌制
许多老的电视节目和电影,如《星际迷航》King》、《阿拉丁》或《狮子王》,已经被重新录制成更高的清晰度,可以在流行的流媒体平台上观看。然而,你最喜欢的童年电视节目或电影至少有全高清版本的可能性相当小。其原因在于,重新灌制更高清晰度的图像通常是一项乏味且昂贵的工作。首先,你需要拿到原始的 16 毫米或 8 毫米胶片,并希望它仍然完好无损。然后,胶片必须一帧一帧地进行数字扫描。一旦胶片被扫描,就执行手动颜色和图像校正。这都需要大量的时间和金钱,从商业角度来看,这是不合理的。你可以在这里和阅读更多关于电影修复的内容。
人工智能拯救世界
人工智能、人工神经网络和机器学习都是过去几年的热门词汇。虽然经常被夸大,但人工神经网络(ann)给语音和图像识别或机器翻译等领域带来的进步不容忽视。原则上,它们是强大的模式识别算法,可以自动学习如何基于现有的数据集将输入转换为所需的输出。例如,你可以给人工神经网络输入 10 万张猫的图片和另外 10 万张狗的图片,它会自动学习如何区分这两张图片。编写一个传统的程序来区分图片中的猫和狗需要几个月的编码时间,而且可能不如简单的人工神经网络好,后者只需几天就可以建立起来。
既然人工神经网络可以在各种各样的任务上被训练,为什么不把它们用于 4K 改造呢?给人工神经网络足够多的相同图像或视频的 SD 和 4K 版本的例子,它将学习如何将低质量的 SD 输入重新制作成详细的 4K 视频。记住,当把一张 SD 图像转换成 4K 时,从技术上讲,你是把一个像素变成了 20 个像素。当你在 4K 电视上观看标清内容时,每个像素基本上都被放大 20 倍并进行模糊处理,以减少锯齿边缘。另一方面,人工神经网络将为原始视频的每个像素向 19 个新生成的像素人工添加逼真的细节。最终的 4K 结果应该是清晰的,有很多 SD 视频中没有的细节。
由于所有主要的神经网络框架都是开源的,因此您可以为 4K 升级构建和训练自己的 ANN 模型,但幸运的是,这方面的解决方案已经存在。一个这样的工具是托帕斯实验室的托帕斯视频增强人工智能。这个工具可以让你利用预训练的人工神经网络,通过几次点击,将低质量的视频升级到 4K 甚至 8K。
使用人工智能测试 4K 向上扩展
黄玉视频增强人工智能在 1984 年发行的原版变形金刚 G1 动画系列的 DVD 上进行了测试。这部动画系列从未以高清形式重拍,更不用说《4K》了,这使它成为一个完美的测试对象(除了它是一部伟大的剧集这一事实)。一个中档英伟达 GTX 1060 显卡花了大约 14 个小时将一集 22 分钟的内容从标清升级到 4K,但这种等待是值得的。以下是第一季介绍主题的一些对比镜头:

左—原始 SD 版本升级到没有人工智能的 4K |右—使用人工智能的 4K 版本(原生 4K 部分)

左—原始 SD 版本升级到没有人工智能的 4K |右—使用人工智能的 4K 版本(原生 4K 部分)

左—原始 SD 版本升级到没有人工智能的 4K |右—使用人工智能的 4K 版本(4K 本地部分)

左—原始 SD 版本升级到没有人工智能的 4K |右—使用人工智能的 4K 版本(4K 本地部分)
原版和 4K 版的《变形金刚》之间的差异是很难被忽略的。图像更加清晰,干净——这是普通的升级版无法做到的。你仍然会看到偶尔的电影噪音和 AI 模型无法提高动画帧率,但它无疑给了 36 岁的变形金刚一个急需的打磨。
期待什么
使用人工神经网络提升 4K 的结果令人印象深刻。和传统重制版一样好吗?不,但考虑到它使用起来如此简单,这是一个不可思议的成就。目前,使用人工神经网络的 4K 升级主要由爱好者和业余爱好者使用。典型的消费者不会看到或使用这样的工具,因为它们相对较慢。除了 2019 年的 Nvidia Shield,根本没有一款消费产品能够使用复杂的人工神经网络将视频实时升级到 4K。因此,问题是,我们什么时候能看到这样的人工智能成为主流?有两种可能的解决方案:
1.高端专用消费产品
我们可以期待在未来几年看到利用人工神经网络进行实时 4K 和 8K 升级的高端专用消费产品。这些可能采取机顶盒或控制台的形式,必须插入电视。其中一个已经存在的产品是 2019 年的 Nvidia Shield。后来,我们可以期待人工智能升级硬件直接内置到电视中。这将特别有助于销售 8K 电视,因为它实际上抵消了可用 8K 内容的缺乏。
2.流媒体平台开始利用人工神经网络
人工神经网络升级成为主流的另一种可能性是流媒体平台开始利用这项技术。流媒体平台必须使用人工神经网络将其标清和高清内容升级到 4K 甚至 8K,就像使用现有工具一样。一旦完成,升级后的 4K 或 8K 内容将可供每个人观看。这个过程可能需要电影工作室的一些许可澄清,但从技术的角度来看,现在没有什么会阻碍流媒体平台使用这项技术。
谁也说不准 4K 什么时候会用复杂的人工神经网络来做主持人。但是,这种技术所能达到的结果使我们希望这一天早日到来。
免责声明:《变形金刚》及其所有相关角色是孩之宝的商标,我不主张任何权利。我和 Topaz 实验室或其任何员工都没有关系。版权免责根据 1976 年版权法 107 节,允许出于批评、评论、新闻报道、教学、学术、教育和研究等目的的“合理使用”。合理使用是版权法允许的使用,否则可能侵权。
期望值最大化算法,已解释
入门
EM 算法的综合指南,包含直觉、示例、Python 实现和数学

登上富士山与 EM 寻找最大似然估计值的方式惊人地相似。请继续阅读,找出原因。由吉勒·德贾尔丁在 Unsplash 上拍摄的照片
是啊!先说期望最大化算法(简称 EM)。如果您处于数据科学“泡沫”中,您可能在某个时间点遇到过 EM,并且想知道:什么是 EM,我需要知道它吗?
它是解决高斯混合模型的算法,这是一种流行的聚类方法。对于隐马尔可夫模型至关重要的 Baum-Welch 算法是 EM 的一种特殊类型。
它适用于大数据和小数据;当其他技术失败时,当信息缺失时,它会蓬勃发展。
这是一种非常经典、强大和通用的统计学习技术,几乎在所有的计算统计学课程中都有教授。阅读完本文后,您可以对 EM 算法有一个很深的理解,并知道何时以及如何使用它。
我们从两个激励性的例子开始(无监督学习和进化)。接下来,我们看看什么是 EM 的一般形式。我们跳回现实,用 EM 来解决这两个例子。然后,我们从直觉和数学两方面解释为什么 EM 像魔咒一样起作用。最后,对本文进行了总结,并提出了一些进一步的课题。
这篇文章改编自我的博文,省略了推导、证明和 Python 代码。如果你更喜欢 LaTex 格式的数学,或者想获得这里所有问题的 Python 代码,你可以在我的博客上阅读这篇文章。
激励的例子:我们为什么关心?
可能你已经知道为什么要用 EM,也可能你不知道。不管怎样,让我用两个激励人心的例子来为新兴市场做准备。我知道这些很长,但它们完美地突出了 EM 最擅长解决的问题的共同特征:缺失信息的存在。
无监督学习:求解用于聚类的高斯混合模型
假设您有一个包含 n 个数据点的数据集。它可以是一群访问你的网站的客户(客户档案)或一个有不同对象的图像(图像分割)。聚类是在您不知道(或不指定)真正的分组时,为您的数据找出 k 个自然组的任务。这是一个无监督的学习问题,因为没有使用基本事实标签。
这种聚类问题可以通过几种类型的算法来解决,例如,诸如 k-means 的组合类型或诸如 Ward 的分层聚类的分层类型。但是,如果您认为您的数据可以更好地建模为正态分布的混合,您会选择高斯混合模型(GMM)。
GMM 的基本思想是,你假设在你的数据背后有一个数据生成机制。该机制首先选择 k 个正态分布中的一个(具有一定的概率),然后从该分布中传递一个样本。因此,一旦您估计了每个分布的参数,您就可以通过选择可能性最高的数据点来轻松地对每个数据点进行聚类。

图一。 安 例 混合高斯数据,使用 k-means 和 GMM 进行聚类(EM 求解)。注意 EM 发现的组看起来像正态分布。
然而,估计参数并不是一项简单的任务,因为我们不知道哪个分布产生了哪些点(缺失信息)。EM 是一种算法,可以帮助我们解决这个问题。这就是为什么 EM 是 scikit-learn 的 GMM 实现中的底层求解器。
群体遗传学:估计蛾的等位基因频率以观察自然选择
你以前听过“工业黑变病”这个说法吗?生物学家在 19 世纪创造了这个术语来描述动物如何由于城市的大规模工业化而改变它们的肤色。他们观察到,以前罕见的深色胡椒蛾开始主宰以煤为燃料的工业化城镇的人口。当时的科学家对此观察感到惊讶和着迷。随后的研究表明,工业化城市的树皮颜色更深,比浅色的更能掩饰深色的蛾子。你可以玩这个胡椒飞蛾游戏来更好的理解这个现象。

图二。 深色(上)和浅色(下)的胡椒蛾。图片由 Jerzy Strzelecki 通过维基共享资源提供
结果,暗蛾在捕食中存活得更好,并把它们的基因传递下去,从而形成了一个以暗斑蛾为主的种群。为了证明他们的自然选择理论,科学家们首先需要估计蛾类种群中产生黑色和产生光亮的基因/等位基因的百分比。负责蛾的颜色的基因有 C、I、T 三种类型的等位基因,基因型 C C、 C I、 C T 产生深色的胡椒蛾(Carbonaria);产生轻微的胡椒蛾。 I I 和 I T 产生中间色的蛾( Insularia )。
这里有一个手绘的图表,显示了观察到的和缺失的信息。

图三。 花椒螟等位基因、基因型和表型之间的关系。我们观察了表型,但希望估计人群中等位基因的百分比。作者图片
我们想知道 C、I 和 T 在人口中所占的百分比。然而,我们只能通过捕捉来观察到炭螟、典型和岛螟的数量,而不能观察到基因型(缺失信息)。事实上,我们没有观察到基因型和多个基因型产生相同的亚种,这使得计算等位基因频率变得困难。这就是 EM 发挥作用的地方。利用 EM,我们可以很容易地估计等位基因频率,并为由于环境污染而在人类时间尺度上发生的微进化提供具体证据。
在信息缺失的情况下,EM 如何处理 GMM 问题和胡椒蛾问题?我们将在后面的部分说明这些。但是首先,让我们看看 EM 到底是什么。
一般框架:什么是 EM?
此时,你一定在想(我希望):所有这些例子都很精彩,但真正的 EM 是什么?让我们深入研究一下。
EM 算法是一种迭代优化方法,可在存在隐藏/缺失/潜在变量的问题中找到参数的最大似然估计(MLE)。
Dempster、Laird 和 Rubin (1977)在其著名的论文(目前引用 62k)中首次全面介绍了这一概念。它因其易于实现、数值稳定和稳健的经验性能而被广泛使用。
让我们为一个一般问题建立 EM,并引入一些符号。假设 Y 是我们的观察变量,X 是隐藏变量,我们说对(X,Y)是完全数据。我们还将任何感兴趣的未知参数表示为θ∈θ。大多数参数估计问题的目标是在给定模型和数据的情况下找到最可能的θ,即,

其中被最大化的项是不完全数据可能性。使用总概率定律,我们也可以将不完全数据的可能性表示为

其中被积分的项称为完全数据似然。
所有这些完整和不完整数据的可能性是怎么回事?
在许多问题中,由于信息缺失,不完全数据似然的最大化是困难的。另一方面,使用完全数据可能性通常更容易。
EM 算法就是为了利用这种观察而设计的。它在一个期望步骤 (E 步骤)和一个最大化步骤 (M 步骤)之间迭代,以找到 MLE。
假设上标为(n)的θ是在第 n 次次迭代中获得的估计值,该算法在两个步骤之间迭代如下:
- E 步:定义 Q(θ |θ^(n))为完全数据对数似然的条件期望 w.r.t .隐变量,给定观测数据和当前参数估计,即,

- M 步:找到一个使上述期望最大化的新θ,设为θ^(n+1),即,

乍一看,上述定义似乎很难理解。一些直观的解释可能会有所帮助:
- E-step :这一步是问,给定我们的观测数据 y 和当前参数估计θ^(n),不同 X 的概率是多少?还有,在这些可能的 *X,*下,对应的对数似然是什么?
- M 步:这里我们问,在这些可能的 X 下,给我们最大期望对数似然的θ值是多少?
该算法在这两个步骤之间迭代,直到达到停止标准,例如,当 Q 函数或参数估计已经收敛时。整个过程可以用下面的流程图来说明。

**图 4。**EM 算法在 E 步和 M 步之间迭代,以获得最大似然估计,并在估计值收敛时停止。作者图片
就是这样!有了两个方程和一堆迭代,你刚刚解开了一个最优雅的统计推断技术!
EM 在行动:真的有用吗?
上面我们看到的是 EM 的一般框架,而不是它的实际实现。在这一节中,我们将一步一步地看到 EM 是如何被实现来解决前面提到的两个例子的。在验证了 EM 确实可以解决这些问题之后,我们将在下一节中直观地从数学上理解它为什么可以解决这些问题。
求解聚类的 GMM
假设我们有一些数据,并想模拟它们的密度。

图 5。 400 个点生成为四种不同正态分布的混合物。作者图片
你能看到不同的底层分布吗?显然,这些数据来自不止一个发行版。因此,单一的正态分布是不合适的,我们使用混合方法。一般来说,基于 GMM 的聚类是将(y1,…,yn)个数据点聚类成 k 组的任务。我们让

因此,x_i 是数据 y_i 的一位热码,例如,如果 k = 3 并且 y_i 来自组 3,则 x_i = [0,0,1]。在这种情况下,数据点集合 y 为不完整数据,( x , y )为扩充后的完整数据。我们进一步假设每个组遵循正态分布,即,

在通常的混合高斯模型建立之后,以概率 w_k,从第 k 个组生成新点,并且所有组的概率总和为 1。假设我们只处理不完整的数据 y 。GMM 下一个数据点的可能性为

其中φ(;μ,σ)是具有均值μ和协方差σ的正态分布的 PDF。n 个点的总对数似然为

在我们的问题中,我们试图估计三组参数:组混合概率( w )和每个分布的均值和协方差矩阵( μ ,σ)。参数估计的通常方法是最大化上述总对数似然函数与每个参数的比值(MLE)。然而,由于对数项内的求和,这很难做到。
期望步骤
让我们使用 EM 方法来代替!记住,我们首先需要在 E-step 中定义 Q 函数,它是完整数据对数似然的条件期望。由于( x , y )是完整数据,一个数据点对应的可能性为

并且只有 x_{ij} = 1 的项是有效的,因为它是一次性编码。因此,我们的总完全数据对数似然是

将θ表示为未知参数的集合( w , μ ,σ)。按照(2)中的 E 步公式,我们获得 Q 函数如下

在哪里

上面的 z 项是数据 y_i 在当前参数估计的类别 j 中的概率。这种概率在某些文本中也被称为责任。意味着每个类对这个数据点的责任。给定观测数据和当前参数估计,它也是一个常数。
最大化步骤
回想一下,EM 算法是通过在 E 步和 M 步之间迭代来进行的。我们已经在上面的 E 步骤中获得了最新迭代的 Q 函数。接下来,我们继续进行 M 步,找到一个新的θ,使(6)中的 Q 函数最大化,即我们找到

仔细观察得到的 Q 函数,会发现它实际上是一个加权正态分布 MLE 问题。这意味着,新的θ具有封闭形式的公式,可以使用微分法轻松验证:

对于 j = 1,…, k 。
表现如何?
我们在这一节回到开头的问题。我用四种不同的正态分布模拟了 400 个点。如果我们不知道底层的真实分组,我们会看到图 5。我们运行上面导出的 EM 程序,并设置算法在对数似然不再变化时停止。
最后,我们找到了混合概率和所有四组的平均和协方差矩阵。下面的图 6 显示了 EM 发现的叠加在数据上的每个分布的密度等值线,这些数据现在通过其地面实况分组进行了颜色编码。四个基本正态分布的位置(均值)和尺度(协方差)都被正确识别。与 k-means 不同,EM 为我们提供了数据的聚类和它们背后的生成模型(GMM)。

图六。 叠加在四个不同正态分布样本上的密度等值线。作者图片
估计等位基因频率
我们回到前面提到的群体遗传学问题。假设我们捕获了 n 只蛾,其中有三种不同的类型:炭蛾、典型蛾和岛蛾*。然而,除了典型蛾外,我们不知道每种蛾的基因型,见上图 3。我们希望估计群体等位基因频率。让我们用 EM 术语来说。以下是我们所知道的:*
- 观察到:

2.未观察到的:不同基因型的数量

3.但是我们知道它们之间的关系:

4.感兴趣的参数:等位基因频率

我们需要使用另一个重要的建模原则:Hardy-Weinberg 原则,该原则认为基因型频率是相应等位基因频率的乘积,或者是两个等位基因不同时的两倍。也就是说,我们可以预期基因型频率为

很好!现在我们准备插入 EM 框架。第一步是什么?
期望步骤
就像 GMM 的情况一样,我们首先需要计算出完整数据的可能性。注意,这实际上是一个多项式分布问题。我们有一群飞蛾,捕捉到 CC 基因型飞蛾的机会是 p_{C},其他基因型也是如此。因此,完全数据似然就是多项式分布 PDF :

并且完整数据对数似然可以写成以下分解形式:

请记住,在给定最新迭代的参数估计值的情况下,E-step 根据未观测数据 Y 对上述可能性进行有条件的期望。发现 Q 函数是

其中 n_{CC}^(n)是给定当前等位基因频率估计值的 CC 型蛾的预期数量,对于其他类型也类似。k()是一个不涉及θ的函数。
最大化步骤
由于我们获得了每种表型的预期数量,估计等位基因频率就很容易了。直观地,等位基因 C 的频率计算为群体中存在的等位基因 C 的数量与等位基因总数之间的比率。这也适用于其他等位基因。因此,在 M 步骤中,我们获得

事实上,我们可以通过对 Q 函数求微分并将它们设置为零(通常的优化程序)来获得相同的 M 步公式。
表现如何?
让我们试着用上面推导出的 em 过程来解决胡椒蛾问题。假设我们捕获了 622 只胡椒蛾。其中 85 种是卡波尼亚,196 种是海岛,341 种是典型。我们运行 EM 迭代 10 步,图 7 显示我们在不到 5 步的时间内获得了收敛的结果。

图 7。 EM 算法收敛不到五步,找到等位基因频率。作者图片
我们从例子中学到了什么?
由于缺少表型信息,估计等位基因频率是困难的。EM 帮助我们解决这个问题,它用丢失的信息来补充这个过程。如果我们回头看看 E-step 和 M-step,我们会看到 E-step 在给出最新频率估计的情况下计算最可能的表型计数;M-step 然后计算给定最新表型计数估计的最可能频率。这个过程在 GMM 问题中也很明显:在给定当前类参数估计的情况下,E-step 计算每个数据的类责任;然后,M-step 使用这些责任作为数据权重来估计新的类参数。
解释:为什么有效?
通过前面的两个例子,我们清楚地看到 EM 的本质在于用缺失的信息增加观察到的信息的 E 步/M 步迭代过程。我们看到它确实有效地找到了最大似然估计。但是为什么这个迭代过程会起作用呢?EM 只是一个聪明的黑客,还是有很好的理论支撑?让我们找出答案。
直观的解释
我们首先对 EM 的工作原理有一个直观的理解。
EM 通过在一些小步骤中将最大化不完全数据似然(困难)的任务转移到最大化完全数据似然(容易)来解决参数估计问题。
想象你正在富士山徒步旅行🗻第一次。在到达顶峰之前有九个站要到达,但是你不知道路线。幸运的是,有徒步旅行者从山顶下来,他们可以给你一个到下一站的大致方向。因此,下面是你可以达到顶端的方法:从基站开始,向人们询问到第二站的方向;去第二个车站,向那里的人打听去第三个车站的路,以此类推。在一天结束的时候(或者一天开始的时候,如果你在看日出的话🌄),你很有可能到达顶峰。
这就是 EM 为我们有缺失数据的问题寻找最大似然估计所做的事情。EM 不是最大化 ln p( x )(找到登顶的路线),而是最大化 Q 函数,找到下一个同样增加 ln p( x )(问下一站方向)的θ。下面的图 8 通过两次迭代说明了这个过程。请注意,G 函数只是 Q 函数和其他几项常数 w.r.t. θ的组合。最大化 G 函数 w.r.t. θ相当于最大化 Q 函数。

**图 8。**EM 的迭代过程分两步说明。当我们从当前参数估计建立并最大化 G 函数(等价地,Q 函数)时,我们获得下一个参数估计。在这个过程中,不完全数据对数似然也会增加。作者图片
摘要
在本文中,我们看到 EM 通过优化转移框架将一个有缺失信息的难题转化为一个简单的问题。我们还通过用 Python 实现一步一步地解决两个问题(高斯混合聚类和胡椒蛾种群遗传学)来看 EM 的作用。更重要的是,我们看到 EM 不仅仅是一个聪明的黑客,而且有坚实的数学基础来解释它为什么会起作用。
我希望这篇介绍性文章对您了解 EM 算法有所帮助。从这里开始,如果您感兴趣,可以考虑探索以下主题。
更多主题
深入挖掘,你可能会问的第一个问题是:那么,EM 完美吗?当然不是。有时,Q 函数很难用解析方法获得。我们可以使用蒙特卡洛技术来估计 Q 函数,例如,检查蒙特卡洛 EM 。有时,即使有完整的数据信息,Q 函数仍然很难最大化。我们可以考虑替代的最大化技术,例如,参见期望条件最大化( ECM )。EM 的另一个缺点是它只提供给我们点估计。如果我们想知道这些估计中的不确定性,我们将需要通过其他技术进行方差估计,例如 Louis 的方法、补充 EM 或 bootstrapping。
感谢阅读!请考虑在下面给我留下反馈。如果你对更多的统计学习感兴趣,可以看看我的其他文章:
直觉、插图和数学:它如何不仅仅是一个降维工具,为什么它在现实世界中如此强大…
towardsdatascience.com](/linear-discriminant-analysis-explained-f88be6c1e00b) [## 卷积神经网络:它与其他网络有何不同?
CNN 有什么独特之处,卷积到底是做什么的?这是一个无数学介绍的奇迹…
towardsdatascience.com](/a-math-free-introduction-to-convolutional-neural-network-ff38fbc4fc76)
参考
- 登普斯特,A. P .,莱尔德,N. M .,,鲁宾,D. B. (1977)。通过 EM 算法不完全数据的最大似然。英国皇家统计学会杂志:B 辑(方法论), 39 (1),1–22。
原发布于https://yang xiaozhou . github . io。
解释期望最大化

马文·朗斯多夫在 Unsplash 上的照片
用于聚类、NLP 等的通用算法
期望最大化(EM)是 60 年代和 70 年代发展起来的经典算法,具有多种应用。它可以用作无监督聚类算法,并扩展到 NLP 应用,如潜在狄利克雷分配,用于隐马尔可夫模型的鲍姆–韦尔奇算法,以及医学成像。作为优化过程,它是梯度下降等的替代方案,主要优点在于,在许多情况下,可以分析计算更新。不仅如此,它还是一个思考优化的灵活框架。
在本文中,我们将从一个简单的聚类示例开始,然后讨论该算法的一般性。
无监督聚类
考虑这样一种情况,您有各种数据点,并对它们进行了一些测量。我们希望把他们分到不同的组。

对老忠实喷发数据的期望最大化(维基百科)
在这个例子中,我们有黄石公园标志性老忠实间歇泉喷发的数据。对于每一次喷发,我们都测量了它的长度和自上次喷发以来的时间。我们可以假设有两种“类型”的喷发(图中的红色和黄色),对于每种类型的喷发,结果数据由(多元)正态分布生成。顺便提一下,这被称为高斯混合模型。
与 k 均值聚类类似,我们从随机猜测这两个分布/聚类开始,然后通过交替两步进行迭代改进:
- (期望)概率性地将每个数据点分配给一个聚类。在这种情况下,我们计算它分别来自红色集群和黄色集群的概率。
- (最大化)根据聚类中的点(按第一步中分配的概率加权)更新每个聚类的参数(加权平均位置和方差-协方差矩阵)。
注意,与 k-means 聚类不同,我们的模型是生成的:它旨在告诉我们数据生成的过程。反过来,我们可以对模型进行重新采样,以生成更多(虚假)数据。
明白了吗?现在我们要用方程做一个一维的例子。
考虑具有单个测量值 x 的数据点。我们假设这些数据点由两个簇生成,每个簇遵循正态分布 N(μ,σ)。第一个集群生成数据的概率为π。
因此,我们有 5 个参数:混合概率π,以及每个聚类的平均值μ和标准差σ。我将它们统称为θ。

我们模型的 5 个参数,统称为θ
观察到值为 x 的数据点的概率是多少?设正态分布的概率密度函数用ϕ.表示为了让符号不那么混乱,我将使用标准差作为参数,而不是通常的方差。

观察值为 x 的点的概率
观察我们的整个数据集的 n 个点的概率(可能性)是:

观察整个数据集的可能性
我们通常选择取这个的对数,把我们的乘积变成一个更容易管理的和,对数似然。

对数-观察我们数据的可能性
我们的目标是最大化这一点:我们希望我们的参数是最有可能观察到我们观察到的数据的参数(最大似然估计)。
现在的问题是,我们如何优化它?由于对数中的和,直接分析性地这样做将是棘手的。
诀窍是想象有一个潜在变量,我们称之为δ。它是一个二进制(0/1 值)变量,用于确定某个点是位于聚类 1 还是聚类 2 中。如果我们知道每个点的δ,计算参数的最大似然估计就很容易了。为了方便匹配第二个聚类的δ为 1 的选择,我们将π转换为点在第二个聚类中的概率。

请注意,总和现在不在对数之内。此外,我们获得一个额外的总和,以说明观察到每个δ的可能性。
反过来假设我们确实观察到了δ,最大似然估计很容易形成。对于μ,取每个聚类内的样本均值;对于σ,标准差也是如此(总体公式,即最大似然估计)。对于π,第二个聚类中点的样本比例。这些是每个参数的最大似然估计量。
当然,我们没有观测到δ。对此的解决方案是期望最大化算法的核心。我们的计划是:
- 从参数的任意初始选择开始。
- (期望值)形成δ的估计值。
- (最大化)计算最大似然估计量来更新我们的参数估计。
- 重复步骤 2 和 3 以收敛。
同样,您可能会发现考虑 k-means 聚类很有帮助,我们也是这样做的。在 k-means 聚类中,我们将每个点分配到最近的质心(期望步长)。本质上,这是对δ的硬估计。很难,因为其中一个集群的值为 1,其他所有集群的值为 0。然后,我们将质心更新为聚类中点的平均值(最大化步骤)。这是μ的最大似然估计。在 k 均值聚类中,数据的“模型”没有标准偏差。(“模型”在吓人的引号中,因为它不是可生成的)。
在我们的例子中,我们将改为对δ进行软赋值。我们有时称之为责任(每个集群对每个观察的责任有多大)。我们将把责任标为ɣ.

每个集群对于数据点 I 的责任ɣ
现在我们可以写下这个例子的完整算法。但在此之前,我们将快速回顾一下我们定义的符号表(有很多)。

符号表
算法是这样的:

我们例子中的期望最大化算法
注意,对聚类 1 的μ和σ的估计是类似的,但是使用 1–ɣ作为权重。
现在我们已经给出了一个算法的例子,希望你已经有了感觉。我们将继续讨论一般的算法。这基本上相当于用稍微复杂一点的变量来修饰我们所做的一切。这将使我们能够解释为什么它会起作用。
一般期望最大化
让我们转到一般设置。设置如下:
- 我们有某种形式的数据 X。
- 我们假设还有未被观察到的(潜在的)数据δ,不管是什么形式。
- 我们有一个参数为θ的模型。
- 我们有能力计算对数似然ℓ(θ;x,δ)。具体来说,观察我们的数据的概率日志和指定了给定参数的潜在变量的赋值。
- 在给定一组参数的情况下,我们还能够使用该模型来计算条件分布δ| X。我们将把这个 P(δ| X;θ).
- 因此,我们可以计算对数似然ℓ(θ;x)。这是在给定参数的情况下观察到我们的数据的概率的对数(没有假设潜在变量的赋值)。
使用 P 来表示概率,我们现在可以使用链式法则来写:

概率的链式法则
这里的符号可能很微妙。这三项都以参数θ为给定值。
- 左边的第一项是观察数据的概率和指定的潜在变量赋值。
- 右手边的第一项是给定观察数据的潜在变量的指定赋值的概率。
- 最后一项是观察数据的概率。
我们可以取对数并重新排列术语。然后在第二行我们将做一个符号的改变(而且是一个令人困惑的改变)。别怪我,不是我发明的):

对于前两个术语,有必要回顾一下它们在我们上一个示例的上下文中是什么。第一个,ℓ(θ;x),是我们要优化的。第二个,ℓ(θ;x,δ)是分析上容易处理的。

高斯混合模型示例中的似然公式
还记得我说过,给定参数θ,我们可以计算条件分布δ| X 吗?这就是事情变得疯狂的地方。
我们将引入第组第二组相同的参数,称之为θʹ.我有时也会用一顶帽子(扬抑符)来表示它,就像这个“ê”所戴的帽子一样。把这组参数想象成我们的电流估计值。我们将对公式中的θ进行优化,以提高我们的估计值。
现在,我们将获得条件分布δ| x,θʹ的对数似然性的期望,即给定数据和当前参数估计的潜在变量的分布。

左手边的项不变,因为它不知道/不关心δ(它是一个常数)。同样,期望值超过了δ的可能值。如果你跟随我们的例子,术语ℓ(θ;x,δ)在我们取期望值后改变,所以δ被ɣ.代替

高斯混合模型例子中似然的期望。
现在,很快地,为了改善我们正在进行的记数噩梦,让我们介绍一下右手边的两个期望的简写记数法

预期可能性的速记符号
该算法变成:

一般期望最大化算法
为什么有效
证明这一点的最重要的工作是考虑函数 R(θ,θʹ).这种说法是,当θ=θʹ.代替一个完整的证明,让我们想想 R 计算什么。去除对数据 X 的依赖(在我们期望的分布和似然函数之间共享),R 示意性地变成

函数 R 的示意形式
换句话说,我们有两种概率分布。我们使用一个(由θʹ参数化)来生成数据δ,我们使用另一个(由θ参数化)来计算我们所看到的概率。如果δ仅代表一个数字,并且分布具有概率密度函数,我们可以写(再次,示意性地)

特殊情况下函数 R 的示意性形式
我以类似于 Kullback-Leibler (KL)散度的形式写下了这一点,这(几乎)是两个概率分布之间距离的度量。如果我们从一个常数 R(p||p)中减去 R(q||p ),我们将得到 KL 散度,它在 0 以下有界,并且当 q=p 时只有 0。换句话说,当 q=p 时,R 最大。这是关于 KL 散度的标准结果,可以用詹森不等式证明。⁴
现在唯一要做的事情是考虑更新步骤前后的可能性之间的差异:

更新步骤后可能性的提高
我们选择新的参数来最大化 Q,所以第一项肯定是正的。根据上面的论证,R 通过将旧参数作为其第一个参数而最大化,因此第二项必须是负的。正减去负就是正。因此,这种可能性在每次更新时都会增加。每一步都保证让事情变得更好。
还要注意,我们不需要优化 q。我们所要做的就是找到一些方法让它变得更好,我们的更新仍然保证让事情变得更好。
结论
希望你现在对这个算法有一个好的感觉。从数学的角度来说,关键方程就是下面的可能性。在那之后,我们只需要对旧参数进行期望(期望步骤),并表明我们可以优化右边的第一项。正如我们以高斯混合模型为例,第二项通常更容易优化。第三个学期我们不用担心,不会搞砸什么的。

后退一点,我想强调 EM 算法的强大和有用性。首先,它代表了我们可以通过交替处理潜变量(取参数为固定已知)和处理参数(取潜变量为固定已知)来引入潜变量然后计算的思想。这是一个强有力的想法,你会在各种环境中看到。
第二,该算法天生快速,因为它不依赖于计算梯度。任何时候你可以解析地解决一个模型(比如使用线性回归),它会更快。这让我们能够分析棘手的问题,并通过分析解决部分问题,将这种能力扩展到迭代环境中。
最后,我想指出,关于 EM 算法还有很多要说的。它推广到进行最大化步骤的其他形式和变分贝叶斯技术,并且可以以不同的方式理解(例如作为最大化-最大化或者作为在统计流形上的相互对偶仿射连接(e-和 m-连接)下到子流形的交替投影)。以后会有更多的报道!
感谢
这种讨论很大程度上遵循了统计学习中的要素,尽管速度更慢一些。特别感谢芳芳李告知我这个奇妙的算法。
笔记
[1]潜在的狄利克雷分配通常适合于变分贝叶斯方法,一种期望最大化的扩展。例如,参见 sklearn 实现。
[2]在这个平台上不可能键入超过θ的帽子。请给我们一些乳胶。
[3]我没有将距离放在引号中,因为我不是指 Kullback-Leibler 散度(这不是一个度量标准),而是指 Fisher 信息度量标准(这是一个度量标准)。这两者有很深的联系;对我们来说,我们可以说当实际距离为 0 时,KL 散度为 0。
[4]对这一点的标准证明似乎是对詹森不等式的笨拙的求助。我的版本也是手工的,但是通过 KL-divergence 合并了 Jensen 的版本。
解释了 GMM 的期望最大化
内部 AI
直观、实用的数学解释

在这篇文章中,我们将以我能想到的最清晰的方式,回顾用 EM 训练高斯混合模型的过程。到本文结束时,您应该对 GMM、EM 做什么以及所有这些的应用有了更广泛的理解。
我们将讨论以下几点:
- 什么是 GMM?我们为什么使用 GMM?
- 训练 GMM
- 用 EM 训练 GMM
- 硬/维特比 EM
- EM 在 GMM 的应用
顺便提一下,生成这些图形并将其放入交互式 web 应用程序的所有代码都在专用的 Github 存储库中:
说明 GMM 和 hmm 的 EM。在 GitHub 上创建一个帐户,为 maelfabien/EM_GMM_HMM 的发展做出贡献。
github.com](https://github.com/maelfabien/EM_GMM_HMM)
一.什么是 GMM?我们为什么使用 GMM?
如果你对 EM 感兴趣,你可能已经知道高斯混合模型。在这一节中,我提供了一些关于我们为什么需要 GMM 的思考,以及对于某些任务,它与其他算法相比如何,所以阅读它可能仍然是有趣的。
1.什么是高斯混合模型?
GMM 是 M 个高斯密度分量的加权和。
它是一个概率模型,假设数据点是由混合高斯成分生成的。GMM 的概率分布函数可以写成:

GMM 的 PDF
其中参数记为λ,X 是观测值,我们给每个高斯密度分配一个权重,使得权重总和为 1。GMM 的参数是:
- 每个分量的平均向量
- 每个分量的协方差矩阵
- 以及与每个组件相关联的权重
我们可以在 Python 中用随机参数从高斯混合模型中生成数据(您会在 Github 资源库中找到附带的代码),并更改组件的数量。
2.为什么我们使用高斯混合模型?
假设您有一个包含两个要素的数据集。绘制数据集时,它可能如下所示:

具有两个聚类的数据集
很明显,这里有两个集群。我们通常希望解决两个主要任务:
- 聚类这些数据点,传统上用一种聚类算法
- 建模基础分布并识别生成模型的参数,其可以例如用作语音处理中的输入,以评估观察值由该 GMM 生成的可能性有多大
现在让我们讨论解决这些任务的两种常见方法,并将它们与高斯混合模型进行比较:
k-Means 聚类与 GMM 聚类
k-Means 是聚类的常用选择。我们将在本文中看到,当用特殊类型的 EM 算法求解时,k-Means 实际上是 GMMs 的一个特例。但是我们会回来的。
好了,你可能知道 k-Means 迭代地识别每个聚类的质心坐标。因此,它仅依赖于 1 个分量,即每个聚类的平均值。当两个聚类的均值重叠,但协方差矩阵不同时,可能会出现问题。我们可以说明在这个任务中,与 k-Means 相比,GMM 工作得有多好。

聚类的 K-Means 与 GMMs
下面总结了 K-Means 和 GMM 之间的主要区别。你可能会开始看到,如果我们考虑一个身份协方差矩阵,并在一个额外的假设下,k-均值和 GMMs 将最终成为相同的解决方案。

请注意,对于 k-Means 和 GMM,您需要指定所需的聚类数,这可能是一项艰巨的任务。我们会回来的。
使用高斯和 GMM 对分布进行建模
如果我们现在讨论第二个任务,即建模分布,高斯分布通常是一个自然的选择。然而,在我们的数据具有两个聚类的情况下,选择单个高斯模型来模拟该数据是一个问题。事实上,如果我们计算数据的平均值,我们可能会在一个绝对没有数据点的区域结束,这与平均值的最大似然估计应该给我们的结果正好相反。

用一个高斯模型模拟这些数据
相反,使用 2 个高斯函数会更有趣,并且允许我们:
- 第一高斯分布的均值和协方差
- 第二高斯分布的均值和协方差
- 每个高斯分量的权重
二。训练 GMM
最终,您将需要训练一个 GMM,这意味着识别正确的参数集来描述您的 GMM。

GMM 参数
但是我们如何解决 GMM 和估计这些参数呢?让我们首先解决一个高斯作为一个有用的提醒。
1.求单高斯的参数
为了识别单高斯的参数,我们应用了最大似然估计 (MLE):

单高斯模型的最大似然估计
L 是给定参数的观测值序列的似然性。我们的目标是最大化这种可能性,以确定最佳参数集,使我们的观察最“可能”。为了方便起见,为了进行求和,我们通常最大化对数似然,因为:

对数似然
我们只需要将偏导数设为 0,就可以获得参数的最大似然估计:

单高斯参数的极大似然估计
2.求高斯混合模型的参数
当我们考虑 GMM 时,我们有几个高斯分量和与每个分量相关的权重因子。类似地,我们可以将可能性改写为:

GMM 的可能性
我们可以再次采用对数似然法:

GMM 的对数可能性
看起来更难解决。如果我们把对第 k 个均值的导数设为 0 呢?

将平均导数设置为 0
这就是单高斯方法的极限。这个表达式解析无解!这就是为什么我们需要期望最大化(EM)来克服这种无法解决的表达。这就是我们将在下一节中讨论的内容,下一节将重点讨论用 EM 训练 GMM。
三。用 EM 训练 GMM
1.EM 简介
EM 背后的主要思想如下:
- 我们知道如何求解单高斯的参数
- 但是我们不知道如何求解高斯混合
- 那么如果我们知道每个数据点属于哪个高斯分量呢?
- 它可能会帮助我们确定每个高斯的参数!
- 如果我们首先猜测哪个点属于哪个分量,我们可以迭代地改进这个猜测,并使这个猜测收敛到最优解。
视觉上,我们首先假设我们知道每个观察值 Xi 属于哪个分量 Zi = k:

潜在变量图解
当我们假设我们知道每个观察值属于哪个分量时,我们说有一个潜变量 Z.
- 现在说 X 是不完全数据,而完全数据是:(X,Z)
- 节理密度为:P(X,Z |θ)= P(Z | X,θ)P(X |θ)
- 现在说可能性 L(θ| X)是不完全的
- 完全可能性现在变成:L(θ| X,Z) = P(X,Z |θ)
EM 算法由几个步骤组成:
- 我们随机初始化组件的参数,或者通过 k-Means 找到哪些值
- 期望步骤,在该步骤中,给定 X 和θ,我们估计 Z 的分布,表示为γ
- 最大化步骤,其中我们最大化 Z 和 X 的联合分布,以导出参数θ的最优值
- 我们迭代 E 步和 M 步,直到满足收敛标准。
在最后一步,我们已经获得了 GMM 的最佳参数(事实上,收敛性也取决于初始化)。
2.电子步骤
在 E 步骤中,如上所述,我们需要估计给定观测值 Xi 属于给定分量 Zk 的概率。这实际上就是我们所说的伪后验,表示为:

伪后验估计
从视觉上看,它可以简单地表示为估计下列量:
估计伪后验概率
然后将该值插入到所谓的**辅助功能中。**辅助功能定义为:

辅助功能
其中,θt 是旧参数值,θ是新参数值。
这个辅助函数的表达式可能看起来很奇怪,但它实际上可以被证明是我们通过更新参数值获得的可能性增益的下限。不感兴趣的话可以不看这个,但这是一种说明参数更新的似然增益 L(θ)-L(θt)有辅助函数作为下界的方式。

回想一下,我们不使用任何其他方法,因为它在分析上是不可解的。好吧,但是我们在哪里插入伪后验概率的估计呢?让我们扩展一下这个辅助功能:

具有伪后验估计的辅助函数
这是我们插入这个值的地方。这就是 E 步的结尾。我们现在可以跳到 M 步骤,在估计辅助函数值后,我们将其最大化以确定参数的最佳值!
3.M 步
在最大步长(M-step)中,我们最大化 Q 值以找到最佳参数值:

m 步
而且这个表达式可以解析求解!我们可以将权重、均值和协方差的导数设置为 0,并确定最佳值:

将导数设置为 0 以确定最佳参数值
好吧,在那之前有一点数学,但如果你还在阅读,这是它变得更直观的地方。平均参数的最佳值为:

由 M 步定义的最佳平均参数值
平均值定义为数据的加权平均值,其权重显示了每个观测值属于 GMM 某个分量的可能性。视觉上,你可以这样表示:

属于每个组件的概率加权平均值
直观上,越靠近第一分量的点越有可能属于这个第一分量。但不代表远离这个分量的点没有概率属于它。因此,我们计算这个加权平均值。协方差的值可以以类似的方式看到,并表示为:

协方差更新值
最后,权重是所有点属于第一聚类的概率的总和除以点的总数:

重量更新
4.反复的过程
我们使用这些新的参数值,并将它们再次注入到 E-step 中:

再次 e 步
参数值影响辅助函数的方式是通过伪后验估计:

参数更新
我们计算辅助函数,并在 M 步中再次最大化它。整个 EM 算法可以示意性地表示如下:

EM 迭代过程
我们可以这样描绘 GMM 的视觉训练周期:
迭代 EM 训练周期
同样,您可以在 Github 资源库中找到使用 Plotly 的动画代码。
EM 保证增加迭代次数的可能性:

EM 可能性增加

5.电磁极限
说吧,EM 不猥琐,但是很好看。但是,它有几个限制,我想谈谈:
- 这取决于我们在启动 E-step 之前进行的初始化
- 它只收敛到局部最优
- 运行两次不会得到相同的结果
- 高度相关的特征可能会阻止 EM 收敛
- 因为在我们的推导中,辅助函数依赖于 Jensen 不等式,它假设凸函数,因此 EM 不适用于所有的基础分布(例如,也适用于多项式)
- 我们需要确定 GMM 中组件的正确数量,这并不总是微不足道的
让我们回到最后这一点。为了选择正确的元件数量,我们必须定义一个优化标准,在元件数量上迭代,看看哪个优化了标准。有两个标准可以做到这一点:
- 艾卡克信息标准(AIC)
- 贝叶斯信息准则(BIC)
我不会涉及这方面的细节,但简单地记住,BIC 往往比 AIC 在模型复杂性(即组件数量)方面惩罚更多。这种方法通常需要很大的计算能力,但是您最终会得到这样的结果:

AIC 和 BIC 准则
AIC 和 BIC 需要最小化。在上面的示例中,5 是 GMM 组件的最佳数量。
四。硬/维特比 EM
我还想提一个特例。这是硬 EM 或维特比 EM 的情况。这与我们之前看到的有一个主要区别,顺便说一下,这被称为全 EM 或软 EM。
在艰难的 EM 中,我们做出艰难的选择。我们不考虑所有可能的 Z 的概率权重,而是简单地选择最有可能的 Z,然后继续前进。

维特比 EM
我们使用硬/维特比 EM 有几个原因:
- 硬 EM 更容易实现
- 但是它没有考虑 Z 的多种可能性,如果我们对 Z 的了解有限,这就成了一个问题
- k-Means 实际上是硬 EM 的一个特例,有一个恒等协方差矩阵
我们在上面看到的表达式中唯一会改变的是,我们必须用一个最大值代替所有分量的总和。在这篇文章中,我们已经看到了几种表达的意思。比较它们会很有趣,可以看到它们都被这个伪后验定义联系在一起:

平均值更新公式
动词 (verb 的缩写)EM 在 GMM 的应用
我认为以 GMM 在哪里被使用的实际概述来结束这篇(长)文章会很好。这只是一个概述,我并不认为我对 GMM 的使用有多广泛有所了解。
1.演讲中的 GMM
GMM 广泛用于语音中,例如性别检测,其中每种性别的一个 GMM 可以被拟合在 MFCCs 上,并且我们将样本归属于具有最高可能性的 GMM。

这是语音处理的众多应用之一。
2.计算机视觉中的 GMMs
GMM 也用于计算机视觉中的背景减法,例如,其中背景是给定的聚类,而要保留的运动物体是另一个聚类。
将 k-Means 视为 GMMs 的特例,k-Means 用于矢量量化。例如,这是一种用于图像的压缩方法,它防止存储每个像素的值,而只是存储聚类和由 k-Means 识别的值。更具体地说,k-Means 是可以用来执行 VQ 的方法之一。

矢量量化
3.使聚集
更广泛地说,GMM 用于聚类,并且非常有效。GMM 满足密度属性的通用近似(参见https://math . stack exchange . com/questions/3122532/Gaussian-mixture-model-what-a-universal-approximator-of-densities)。
结论
在这篇文章中,我们看到:
- 什么是 GMM,它们与 k-Means 相比如何
- 训练 GMM 意味着什么
- 为什么直接解决它在分析上是不可行的,而我们需要它们
- EM 是什么
- EM 的性质和限制
- 什么是硬/维特比 EM
- GMM 的应用
我希望这篇文章对你有用。请在您的反馈中留下评论,说明哪些内容是清楚的,哪些需要更好的解释/说明。我花了一些时间将所有这些放在一起,我想参考一些我结合的优秀参考资料。
这篇文章以幻灯片的形式发表在我的个人博客上(有近 200 篇其他文章),就在这里:【https://maelfabien.github.io/machinelearning/GMM/#
参考
- 单高斯的 MLE,http://Jr Meyer . github . io/machine learning/2017/08/18/MLE . html
- GMMs 的 MLE,https://Stephens 999 . github . io/five minute stats/intro _ to _ em . html
- EM 算法和变体:非正式教程,亚历克西斯·罗奇
- (硬)期望最大化,大卫·麦卡勒斯特,https://ttic . uchicago . edu/~ dmcallester/ttic 101-07/lectures/em/em . pdf
- 关于 EM 的简短说明,布伦丹·奥康纳,https://www . cs . CMU . edu/~ Tom/10601 _ fall 2012/retentions/EM . pdf
- 矢量量化,大卫·福塞斯,http://luthuli . CS . uiuc . edu/~ daf/courses/CS-498-DAF-PS/讲座%2012%20-%20K-means,%20GMMs,%20EM.pdf
- 用 GMMs 进行背景减法, *D. Hari Hara Santosh,P. Venkatesh,P. Poornesh,L. Narayana Rao,N. Arun Kumar,*http://citeseerx.ist.psu.edu/viewdoc/download?doi = 10 . 1 . 1 . 649 . 8642&rep = re P1&type = pdf
期望和差异关系
基本性质及其证明
这篇文章将会简短而甜蜜。当涉及到一般的技术知识时,我非常支持对一个人正在使用的方法有坚实的基础和扎实的理解。一般来说,我不喜欢记忆任何东西,并尽可能避免这样做。相反,我专注于发展概念的坚实基础,然后我可以用数学方法推导出我可能需要的任何东西。
从数学上理解期望、方差、它们之间的关系,以及如何对它们进行分析操作,是任何人学习概率论和/或数理统计基础知识的第一步。对 Medium 的快速搜索显示,这些证据和关系(据我所知)还没有被简单地组织在一篇文章中。这些是绝对值得了解的概念。
所以让我们开始吧:
定义:

请注意:
- 在下面的几个证明中,我提供了离散情况下的推导。连续情况的证明如下。
- 大写的变量是随机变量,小写的变量是常量。
关系和证据:
让我们深入研究一下关系和证明!




应用示例:
让我们看一个非常简单的应用示例:

最后的想法
希望以上有见地。正如我在以前的一些文章中提到的,我认为没有足够的人花时间去做这些类型的练习。对我来说,这种基于理论的洞察力让我在实践中更容易使用方法。我个人的目标是鼓励该领域的其他人采取类似的方法。我打算在未来写一些基础作品,所以请随时在【LinkedIn】和 上与我联系,并在 Medium 上关注我的更新!
随机变量的期望值—简单解释
并通过例子进行了说明
随机变量的期望值是该变量所有可能值的加权平均值。这里的权重是指随机变量取特定值的概率。
胡萝卜长度的期望值是多少?这里的随机变量是胡萝卜的长度。在这篇文章中,我将解释回答这个问题的方法。

查尔斯·德鲁维奥在 Unsplash 上拍摄的照片
在详细讲述之前,我们应该区分一下离散型和连续型随机变量。
- 离散随机变量取有限多个或可数无穷多个值。一年中的下雨天数是一个离散的随机变量。
- 连续随机变量取不可数的无穷多个值。例如,从你家到办公室的时间是一个连续的随机变量。取决于您如何测量它(分钟、秒、纳秒等等),它需要无数个值。
离散随机变量的期望值
让我们从一个非常简单的离散随机变量 X 开始,它只取值 1 和 2,概率分别为 0.4 和 0.6。

注意:概率总和必须为 1,因为我们考虑了这个随机变量可以取的所有值。
这个随机变量的期望值,用 E[X]表示,

如果 1 和 2 的概率相同,那么期望值就是 1.5。离散随机变量的期望值公式为:

你可能认为这个变量只取值 1 和 2,期望值怎么可能是别的值呢?考虑更广的范围。假设我们从这个随机变量中选择 10 个值。总期望值将是 16 (6 乘以 2,4 乘以 1)。
让我们做一个稍微复杂一点的例子。假设你参加了一个有 4 道选择题的测试。每道题 10 分,有 4 个选项。
你甚至没有看问题就随意选择了一个选项。你在这次测试中所得到的分数的期望值是多少?这个问题不需要任何复杂的计算就可以回答。由于有 4 个选项,所以选择正确答案的概率为 0.25。共有 4 个问题,因此您可能会正确回答 1 个问题(1 x 0.25),这相当于 10 分。
让我们也用公式求出期望值,看看是否得到同样的结果。我们可以正确回答 0、1、2、3 或 4 个问题。因此,我们有一个取值为 0、10、20、30 和 40 的离散随机变量。我计算了下面每种情况的概率,并写下了每种情况的得分。

作者图片

作者图片
期望值是通过将点(xi)和得到该点的概率(p(xi))相乘并将它们相加来计算的。如果你真的继续计算,你会看到结果是 10。
连续随机变量的期望值
连续随机变量的期望值是用相同的逻辑但不同的方法计算的。由于连续随机变量可以取不可数的无穷多个值,我们不能谈论一个变量取一个特定值。我们更关注价值范围。
为了计算值范围的概率,使用概率密度函数(PDF)。PDF 是指定随机变量在特定范围内取值的概率的函数。
这里是均匀分布在 5 到 10 之间的连续随机变量的 PDF。x 轴包含所有可能的值,y 轴显示值的概率。

5 到 10 之间均匀分布的连续随机变量(图片由作者提供)
由于变量具有均匀分布,因此所有值的概率都是相同的。整个 PDF 下的面积必须等于 1。对于上面的 PDF,面积是 0.2 x(10–5),等于 1。不是每个 PDF 都是直线。一般来说,面积是通过对 PDF 进行积分来计算的。
这个随机变量的期望值是 7.5,这在图上很容易看到。然而,最好学习公式,因为不是每个 PDF 都像上面的那样简单。
连续变量期望值的公式为:

根据该公式,期望值计算如下。

作者图片
让我们做一个稍微复杂一点的例子。考虑连续随机变量 x 的如下 PDF。

作者图片
我们将尝试从不同的角度接近期望值。变量取值为 0 的概率为 0。概率随着值的增加而不断增加,最终在值 8 时达到最高概率。
如果这是一个均匀随机变量,期望值将是 4。由于概率随着值的增加而增加,因此期望值将高于 4。
如果你把这个 PDF 想象成一个三角形的均匀金属片或者其他任何材料,期望值就是质心的 x 坐标。
这条线代表的 PDF 函数是 f(x) = 0.03125x。如果你计算一下,预期值是 5.33。

作者图片
期望值是统计学和概率论中一个简单却非常基本的概念。为了固化你的理解,我建议自己做几个例子。那你就可以走了!
感谢您的阅读。如果您有任何反馈,请告诉我。
所有图片均由作者创作,除非另有说明。
免费体验 Google autoML 表格
autoML 工具用户体验回顾系列之二

欢迎阅读我的 autoML 工具用户体验评论系列的第二篇文章。我的目标是比较几种 autoML 工具对关键信息的使用和访问。今天,我主要关注 Google autoML 工具中的一个,叫做 Tables。autoML Tables 旨在处理半结构化表格数据(典型的。csv 文件)。谷歌宣布于 2019 年 4 月 10 日发布 autoML 表格的测试版。仍处于测试阶段,功能仍在推出,我想看看谷歌的产品。
为什么使用 Google autoML 表格?
我读过一些关于谷歌机器学习体验的好东西。我以前使用过谷歌云进行一些咨询工作,发现体验非常简单。我很期待看到他们的机器学习服务。我选择表格是因为它与我在本系列中使用的 Kaggle 文件类型相匹配。
正如我之前提到的,Tables 处于测试模式。因此,我查看了发布和问题页面,以确保没有任何障碍。没有屏蔽程序,尽管问题页面上的这个通知让我忍俊不禁:
【Microsoft Edge 和 Microsoft Internet Explorer 浏览器的用户体验可能不是最佳的。”
设置
与 AWS AutoPilot 相比,为 autoML 表做准备的设置更加手动。开始之前的文档非常好,但是似乎在你开始每个项目之前都需要。
- 创建新项目
- 确保您的账单已启用
- 在 Google 云平台中注册您的云存储、Cloud AutoML API、Google 云存储 JSON API、BigQuery API 应用程序
- 安装 gcloud 命令行工具。
- 安装谷歌云 SDK
- 创建服务帐户
- 设置环境变量
- 更新 IAM 角色
不要担心,一旦你完成了先决条件,体验会大大改善。
数据
至于 AWS SageMaker 自动驾驶仪,我用的是 Kaggle 竞赛数据集。
矛盾,我亲爱的华生。使用 TPUs 检测多语言文本中的矛盾和蕴涵。在这个入门竞赛中,我们将句子对(由一个前提和一个假设组成)分为三类——蕴涵、矛盾或中性。
6 列 x 13k+行—斯坦福 NLP 文档
- 身份证明(identification)
- 前提
- 假设
- 朗 abv
- 语言
- 标签
模型培训成本
模特培训费用每小时 19.32 美元。由于您不需要任何许可证,并且只需为培训计算资源付费,因此这是非常合理的。对于你的第一个模型,有一个免费试用。你可以得到 6 个免费的节点小时用于训练和批量预测。这个免费试用不包括部署模型,然后在线调用它们。六个小时足够试一试了。我的例子用了 1.2 小时。
开始培训
导航到谷歌人工智能。在那里你会发现一个菜单项“用 autoML 训练”

作者的菜单截图
单击表的尝试自动下拉列表。

作者下拉截图
加载数据
导入训练数据集很简单。也可以在此屏幕中直接创建输出数据集的存储桶。

作者数据导入截图
数据导入后,您可以访问一些基本的数据分析。

作者截图
细节有点粗糙。馅饼和油炸圈饼是用来吃的,不是用来吃的。

甜甜圈是用来吃的作者截图
训练您的模型
为了培训预算,我投入了 6 个小时的空闲时间。在这个屏幕上,您可以访问和调整的其他参数并不多。

作者训练截图
等待魔法
虽然 UI 确实提供了一些关于基础设施启动和崩溃状态的更新,但没有多少迹象表明您已经进行了多长时间。我等了大约半个小时,然后决定相信我的预算设置。我做了其他事情,直到我被通知完成。电子邮件是一个很好的功能。

基础设施建设截图由作者提供

等待中……作者截图
评估培训结果
电子邮件到达后,“评估”选项卡即被填充。有一个图表显示了一些标准指标,如 AUC、精度、召回和日志丢失。我喜欢混乱矩阵是可用的。

作者训练成绩截图
除了它是一个多类分类器之外,我找不到关于模型本身的任何细节。为了了解更多信息,我导出了模型。模型的细节是什么?超参数有哪些?我喜欢的信息远远不够。
得分
在批处理中运行时,输出必须转到 BigQuery。

作者打分截图
这是用户体验的终点。输出文件加载到 BigQuery。我喜欢数据可用于查询或直接在 Data Studio 可视化中使用。我更喜欢在 autoML 控制台中随时可用的一些分析。
结论
我非常喜欢所提供的文档和技巧。它们很容易理解。电子邮件更新也很棒。
体验的不足之处在于识别最终模型本身的细节的容易程度。你最多可以下载一个 Tensorflow 模型包,在 Google Cloud 之外进行评估。
视觉效果令人失望。几乎没有分布图比一些不能用的饼图要好。由于他们仍处于测试阶段,我希望他们正在收集用户对他们需要什么功能的反馈。
总的来说,缺乏透明度可能会阻止我定期使用这个工具。不过,这是测试版…请稍后再来查看!
体验细分:通过客户旅程地图和人工智能增强将洞察力转化为行动
我们如何使用 CX 方法和数据科学为我们的客户设计和实施移情和数据驱动系统。
我坚信,要确保我的团队做出的每一个决定或产出都是通过为我们的客户创造切实的、可衡量的结果来管理的。事实上,很多时候,当我与当前或潜在的客户交谈时,他们强调咨询或概念工作的定位对他们来说是多么重要,这样有形的执行自然就会到来。
在最近的一次会议上,我们讨论了创建清晰的客户旅程图(、【CJM】、)的战略意义,与会的高管感叹道,CX 的咨询工作虽然在产生见解和创造焦点方面很有价值,但“**却最终落在了我办公桌底部的抽屉里。**这凸显了我的高管级客户在实施他们购买的任何 CX 咨询服务时所遇到的挫折。
诚然,许多 CX 调查工作的结果可能会产生建议或想法,这些建议或想法需要组织采取高度变革性的行动(即高度努力),而这些行动在短期或中期内根本无法得到支持。因此,最近一个致力于改善客户体验的团队慢慢地将他们的注意力和努力转移到了其他地方,结果是一事无成。
这些调查工作的核心产品通常是闪亮且设计精美的 CJM,它能清楚地识别您客户的需求、动机、痛点以及与这些东西相关的所有接触点。这项活动本身就非常有价值,因为它迫使组织对他们的客户体验采取同理心的方法,因为他们被迫从客户的角度创造 CJM。此外,它允许组织了解传统上孤立的部门如何影响这种客户体验,并创造机会来协调它们并实现价值最大化。最后,也许是在测量方面最重要的,它允许组织了解他们的客户的“理想”或未来状态可能是什么。
虽然这些结果在各种方面都很有价值,但它们本身不会推动行动,并且通常会留下一个 CJM,而只是团队聚集在一起并针对客户的痛点和动机进行协调的人工制品。虽然有许多方法可以解决 CJM 壁画艺术降级的问题,但组织可以通过简单地创建一个测量框架并将相当简单的数据分析试点纳入业务,以少量的努力最大限度地提高利用这一核心产出的成功机会。
本文将概述一种这样的分析方法,作为这种操作化的工作示例。
我将向您展示如何通过就关键指标和这些指标的成功达成内部共识、构建您的数据和运行简单的深度学习机制来开始衡量客户旅程图。
关于数据收集的说明
出于本文的目的,我们将假设您有合适的基础设施来度量您的客户交互。有了大量可用的数字工具,这些反馈回路可以无缝集成到您的数字平台中。如果有必要在物理环境或两者结合的环境中收集旅行数据,投资智能设备或流程来促进这一点。
请注意,如果您没有高质量的数据,本文的整个前提就会崩溃。人们可以用市场上强大的工具轻松地收集数据,但这并不意味着流程和策略很容易设计。如果没有强大的数据检索方法,卫生和数量,这篇文章中的思想在聚类分析方法方面将变得毫无用处。但是,可以使用其他更简单的方法来确保您的 CJM 处于运行状态并不断改进。
区分优先顺序并理解您的数据收集
正如我们之前提到的,CJM 活动是一个很好的机会,可以让可能彼此孤立的各个部门的成员团结起来。这样做有很多好处,例如整个企业更大的#协同作用,更大的内部同理心,并有望出现关于客户旅程如何受到公司内部和外部流程影响的强有力的见解。利用这一调整和期望兴奋的时刻,抓住那些可以三倍提升客户体验的时刻。这是一个关键时刻,以确保您的团队在客户类型及其旅程、哪些指标对这些客户普遍重要以及我们如何衡量这些指标的绩效方面保持一致。
我们可以使用多种技术来识别这些航段及其特定旅程,例如:
- 客户/用户调查;
- 客户/用户访谈;
- 用户组/可用性研究;
- 会话重放;
- 网络分析;
- 嵌入式传感器
假设我们作为一个团队走到了一起,我们已经制定了客户细分的类型及其相应的旅程。让我们以一家大型在线零售商为例,展示我们可以经历的流程,以了解我们正在收集的数据类型,以及哪些数据需要与客户细分和相应的旅程相一致。
在我们的示例中,我们将介绍这些细分和旅程:
- 浏览器:查看他们喜欢的品牌,以了解即将推出的产品类型。
- 橱窗购物者:在他们买得起的东西之外寻找品牌,喜欢购买渴望的东西。
- **里里外外:**确切地知道自己想要什么,得到它,购买它,抛弃它。
- **退货者:**已购买,想退货。
在这一点上,我们已经就以下方面达成一致并达成共识:客户的类型及其相应的旅程,这是一种成功。但至关重要的是,我们需要在另外两个方面达成共识。
就指标达成共识
首先:我们可以用来衡量这些旅程的指标。在本例中,我们可以依靠通用诊断工具,该工具将在零售商的旅程中普遍使用,这些指标是:
- **客户努力:**客户为实现目标付出了多少努力?
- **难点:**给客户带来最大痛苦或情绪低落的步骤(我们可以使用 NPS 或调查反馈来计算)。
- **问题:**问题何时以及为什么会出现,我们是否向他们提供了这些信息,客户的问题是否容易得到回答?
- **等待时间:**我们的客户必须等待多长时间才能完成某些任务,这些任务对客户来说是最长、最令人沮丧的?
- **错误:**我们最常失败的地方是哪里,我们如何减轻这种失败?
就指标的绩效达成共识
作为一个团队,我们已经就这些指标达成共识,认为它们是我们诊断每个客户旅程的关键,以及它们如何与客户在旅程中的步骤(即他们的体验)相关联。这将引导我们进入第二步,也是更精细的一步,即围绕如何衡量这些指标的绩效形成公司共识。一个简单(注意:不容易)的方法是就团队的某个指标达成一致。
例如,让我们以“客户努力”为例:我们可以基于交易发生的总时间来索引该性能,如下所示:
在 1-5 的基础上(1 为最佳):
- 0–60 秒
- 61-120 秒
- 121-180 秒
- 181-240 秒
- 241-300 秒
或者对于“问题”分析,我们可以编制索引,例如:
- 0 个问题
- 1 个问题
- 2 个问题
- 3 个问题
- 4 个问题
我们可以让索引变得更复杂。例如,我们可以使用高级分析来测量不确定时刻和必要澄清之间的差值;然而,这个例子的目的是简单地表达一个指数是一个明确的和统一的测量某一指标的性能。至关重要的是,团队需要在这个指标上达成共识。
我们已经创建了适用于我们的客户群及其旅程的统一指标,那又如何?
现在,我们有了一种在统一基础上持续衡量我们的细分和旅程的方法。人们已经这样做了很长时间——听说过客户洞察吗?也就是说,至少我们可以开始使用我们的 CJM,因为我们现在知道客户旅程在当前状态下是什么样子,并且我们可以决定我们希望客户旅程在未来状态下是什么样子。
我们可以寻找立竿见影的效果、重大创新,或者介于两者之间。
最重要的是,我们可以开始跟踪、衡量、调整和使用我们的 CJM 作为焦点,以我们知道团队可以产生有凝聚力和影响力的努力的方式来衡量我们的内部计划。作为一个内部团队,我们在何时何地选择我们的工作可以以一种战略性的方式完成,并且有数据支持我们,我们可以以统一的方式完成这项工作,同时确保我们创建反馈循环,以迭代和维护我们的 cjm 的相关性。
祝贺您,您刚刚向我解释了我的客户洞察团队是做什么的…
好吧,你没有完全错。但是请记住,这个思考练习的重点是把我们的 CJM 变成不仅仅是一个提醒。我们想让它做点什么。
然而,如果你仍然不为所动,为什么我们不推出这个现在的宝库美丽的索引数据,我们可以匹配我们的每个客户群,让我们开始创建体验细分。
没错,我们正在深入每一个可靠的客户旅程,并试图根据他们的实际体验对他们进行细分。
我们需要什么数据来做这件事?我们已经有了——这是我们的 CJM 绩效指数数据。
好吧,但是我怎么才能解决经验分割的问题呢?每个客户和事件都有很大的不同,很难以有意义的方式将它们配对。我们将使用机器的力量,即将成为无所不知的人工智能来争论我们的数据,以一种不可思议的复杂方式,在一个快得可笑的时间内,把它分割成小块,并让它根据我们客户的经验对他们进行聚类。
这是一个我们如何使用聚类分析来开始理解和预测经验分割的例子
数据
让我们使用 iris 数据集,但假设我们不是处理物种而是根据他们与公司产品或服务的互动,处理不同的客户体验组。
from sklearn import datasets
import pandas as pd
from sklearn.preprocessing import MinMaxScaler
from sklearn.cluster import KMeans
from sklearn import metrics, neighbors, model_selection
import seaborn as sns# data
iris = datasets.load_iris()# convert to data frame
dat = pd.DataFrame(iris.data)
转换
让我们将最初的花卉测量值转换为 4 个可量化指标的 1-5 分(1 dp ),这些指标都与客户对产品/服务的体验有关。
# scale
scaler = MinMaxScaler(feature_range=(1,5))# fit scaler
scaler.fit(dat)# scale and round
X = pd.DataFrame(scaler.transform(dat)).round(1)# these are our metrics
X.columns = [‘Effort’, ‘Questions’, ‘Wait Times’, ‘Errors’]# view
X.head()
下面是结果:我们有统一的标准来衡量基于上述活动的结果!

从上表中我们可以看出,客户我们的大多数客户在所有指标上都有良好的体验,除了一些问题,这些问题需要全面解决。
探索性数据分析
我们可以运行一些简单的(如果你像我一样是个黑客的话,很容易)数据——即看看是否有任何分数的自然聚类。
# viz
sns.pairplot(X)

查看数据,我们可以看到两种清晰的客户“体验”,简单来说就是“好”和“差”
聚类分析
从这些数据中,能识别出这些截然不同的经历吗?
让我们开始吧。运行流行的“k-means”模型的无监督学习模块。
通过快速浏览上面的图,我们可以看到有两个不同的组,所以我们可以告诉我们的计算机寻找 2 个集群(’ _clusters=2 ')。
然后让我们来区分这是一个好的还是一个坏的体验(集群 1 v 集群 2)。
# k-means algo, lets look for 2 experiences
kmeans = KMeans(n_clusters=2, random_state=0).fit(X)# save the result
result = X.copy()# label the clusters we found as experiences
result.loc[:,'experiences'] = (kmeans.labels_) + 1# view the result
result
以下是我们的结果样本:

我们可以看到,聚类分析很好地识别和分离了我们的聚类。从一个快速的 squiz 中,我可以看出 2 是#不好的体验,1 是#好的体验(提示:看看指标)。
让我们想象一下!

如你所见,有明显的群体。机器在数据中发现了“复杂”的模式,由于我们上面的数据工程,这些模式代表了好的体验或不好的体验。
这意味着它实际上可以开始预测客户的体验是好是坏。
“经验分割”一词由此而来。
别拐弯抹角了,让我们做些模型吧!
现在我们已经确定了我们的’体验细分市场,我们可以对它们训练一个#机器学习模型,这样我们就可以根据新客户与我们的产品/服务的互动对他们进行分类(最好是在他们使用产品时实时分类!!).
关键的想法是,如果我们能做到这一点,我们可能能够实时采取行动,防止客户有“坏”的体验,同时让那些将有“好”体验的客户离开。
目标和功能
让我们设置功能(我们的体验表)和我们的目标是什么(1)。
# target
y = result.experiences# features
X = result.drop("experiences", axis=1)
训练/测试分割
现在它只是你的标准 TTS 工作通过。我们只需要训练我们的模型来预测什么是好的,什么是坏的,然后根据我们的数据集进行测试。
# creating training / testing datasets
X_train, X_test, y_train, y_test = model_selection.train_test_split(X, y, test_size = 0.25, random_state = 42)
先训练模型。让我们再次找到我们的聚类分析模型,然后根据我们上面制作的两个数据集进行拟合。
# specifying the classifier
clr = neighbors.KNeighborsClassifier(n_neighbors = 3, weights = 'uniform')# fit the classifier
clr.fit(X_train, y_train)
现在我们来测试一下。
# predicted
y_pred = clr.predict(X_test)# accuracy
metrics.accuracy_score(y_pred, y_test)
我们可以通过让我们的集群用 be 预测 X 的结果(对“X_test”)来确定分数的准确性,然后通过比较“y_pred”和“y_test”的性能来实际计算准确性
这意味着,我们现在有了一个模型,可以分析我们的数据并预测客户的体验。
如果我们可以在生产中部署并自动化这一点,我们就可以触发功能来增加良好体验或挽救糟糕体验的可能性。
(注意:你可以有更丰富的数据来帮助你更进一步,但是为了简单起见,我们使用了上面的数据集)。
好吧,酷——那又怎样?
上述(简化的)执行使我们能够在数据中找到适用于不同客户群的抽象和复杂模式实时旅程,,我们可以将其描述为体验细分。我们已经创建了一个模型,可以找到这些模式并将“相似”的体验组合在一起,以描述我们通常忽略的一些事情——客户(在特定细分市场中)在特定时间实际经历的事情。设计师会称之为移情,营销人员会称之为个性化。我称之为机会。
例如,假设我们是一家在线零售商。
想象一下,我们已经对*【浏览器】*的行为进行了建模——某人上网,查看他们最喜欢的品牌,拥有高度的消费者知识,但最终对他们在网站上的活动量的转化率相对较低。我们可以假设客户的“等待时间”和情感体验(“痛点”)保持相当稳定。毕竟,我们可以假设他们发现他们悠闲的浏览是一种宣泄,而不是过度紧张。
他们喜欢花时间去了解他们最喜欢的品牌或某些衣服,并自己做非正式的研究,以构建他们想要的那件衣服。他们在脑海中构建“完美”的物品,并确切地知道他们在追求什么——愿意花费大量的高价物品。
作为一家公司,我们一直在监控这类行为。我们了解客户群。我们从宏观层面监控他们的行为,并能轻松挖掘出某一类客户在个人层面的行为(即个性化)。在这里,他们想买一件剪裁合适、颜色合适的羊绒混纺冬季大衣。我们知道,作为客户 细分市场,他们是特定的长尾买家,有很多购买想法,但不容易转变。然而,当他们改变信仰时,他们会购买高价商品。获得这类顾客的注意力并不需要花费太多成本——他们是知道自己喜欢什么的老练买家——但是不管最优 UX 如何,都很难突破购买的心理障碍。
我们的聚类分析是实时运行的,具有内置的自动化功能,一直在测试和训练这个特定的细分市场。我们的模型知道它是一个’浏览器’,它也知道指标的分组,在正确的时机将导致好的或坏的体验。实时地,集群可以设法将客户体验保持在“好区域”(转换),而远离“坏区域”(关闭以便改天浏览)。购买的利润很薄,但作为一家企业,在我们的 CJM 和体验细分研究和开发的推动下,我们推出了一个聊天机器人,提醒我们的客户我们的退货政策和相应的视频,显示我们的“浏览器”如此钦佩的适合和平衡。
我们在 UX 的努力与体验直接对应,不张扬也不咄咄逼人,但清晰而直接;因此,消除购买“浏览器”的障碍是常有的事。浏览器被迫完成购买,因为我们的模型已经管理并触发了关键功能或特性,这极大地提高了正确的指标。浏览器转换了,这件外套是我们以 CJM 为骨干精心管理客户体验细分的结果,并以一种允许我们执行强大的机器学习应用程序来管理客户的体验的方式操作它。
这种以数据为导向的 CX 方法(或任何其他设计导向过程)允许我们以一种可以有效监控、测量和增强的方式实施初始设计分析。允许内部团队或客户做出决策,验证业务案例,并(有希望地)进一步推动业务案例,以实现真正的创新。最重要的是,它让我们能够做出决策——在这个例子中是在实时——积极确保我们的客户拥有良好的体验,或者在每次与我们互动时避免糟糕的体验。
这篇文章的核心要点是:
- 我们可以使用 cjm 来创建严格的框架,以实际监控我们当前和未来的客户状态/旅程。
- 我们可以使用数据科学来了解细分市场之外的客户,并允许我们基于实际的体验来监控他们。
- 我们可以利用经验细分来产生深刻的移情和数据驱动的见解,这些见解实际上整合到我们的反馈循环中,为我们的决策以及我们与客户的互动方式提供信息。
体验遗传算法的威力
基于遗传算法的顶点覆盖

PixaBay 上的图片
遗传算法是一种基于遗传学和自然选择概念的进化计算技术。它主要用于在确定性多项式解决方案不可行的情况下,为许多优化和更棘手的问题找到一个接近最优的解决方案。
遗传算法也可以用于搜索空间,以找到正确的特征和模型参数来预测目标变量。遗传算法的另一个重要优点是除了标准优化问题之外,当目标函数是不可微的、不连续的、随机的或非线性的时,它们也是有用的。
我将以关于遗传算法和顶点覆盖问题的简介开始这篇博文。然后我将展示我们如何使用遗传算法来获得顶点覆盖问题的近似最优解,这远优于近似算法。通过这个博客,我也想让读者体验遗传算法的力量。该解决方案的完整源代码可以在这里找到。
遗传算法
遗传算法有 5 个阶段:
- 初始化:初始解(第一代)随机初始化
- 健康评分:这里的主要思想是,可能很难找到最佳解决方案,但是一旦我们有了一些解决方案,很容易给它附加一个良好或健康评分。
- 选择:种群中最适合的成员(解)存活下来,并继续进入下一代。
- 交叉:群体中最适合的成员(解)成对组合,产生新的成员(可能的解)。
- 突变:新成员(可能的新方案)少量改变自己,变得更好。
一旦初始种群生成,选择、交叉和变异的循环将持续许多代,直到算法收敛或达到最大迭代。这些概念在这个博客里解释得很清楚。
遗传算法是一种受查尔斯·达尔文的自然进化理论启发的搜索启发式算法。这个…
towardsdatascience.com](/introduction-to-genetic-algorithms-including-example-code-e396e98d8bf3)
顶点覆盖问题
顶点覆盖是图中顶点的子集,使得对于图的每个边(u,v ),或者‘u’或者‘v’在顶点覆盖中。这是一个典型的 NP-hard 优化问题,有一个近似算法,但没有确定的多项式解。

图片来源维基百科
图-1 的顶点覆盖为 3,与 3-red 节点一样,所有的边都被覆盖,因此对于图的每条边(u,v ),或者“u”或者“v”都在顶点覆盖中。类似地,图-2 的顶点覆盖为 4。

图片来源维基百科
图-3 的顶点覆盖为 2,图-4 的顶点覆盖为 3。
顶点覆盖是一个典型的 NP-Hard 问题,没有确定的多项式时间解。我们有一个可用的近似算法,它在多项式时间内运行并给出一个次优解。近似算法的细节可以在下面的链接中找到。
[## 顶点覆盖问题|集合 1(简介和近似算法)- GeeksforGeeks
无向图的顶点覆盖是其顶点的子集,使得对于图的每条边(u,v ),或者…
www.geeksforgeeks.org](https://www.geeksforgeeks.org/vertex-cover-problem-set-1-introduction-approximate-algorithm-2/)
还有证据表明,近似解永远不会超过最优解 2 倍。详情可以在这里找到。
定义:无向图 G=( V,E)的顶点覆盖是 V 的子集,使得如果边(u,V)是…
www.personal.kent.edu](http://www.personal.kent.edu/~rmuhamma/Algorithms/MyAlgorithms/AproxAlgor/vertexCover.htm)
生成图形数据
我生成了一个 250 节点的图表。用于生成该图的主要思想是在[0,1]范围内绘制随机数,并且仅当概率小于阈值时,才在节点“u”和“v”之间创建边。
#Graph Library
import networkx as nxedge_probability = .0085
adjacency_matrix = np.zeros((nodes,nodes),dtype = np.int)
edges = []
edges_cnt = 0
for i in range(nodes):
for j in range(i):
prob = random.random()
if prob < edge_probability:
adjacency_matrix[i,j] = 1
edges.append((i,j))
edges_cnt += 1G=nx.Graph()
G.add_nodes_from(list(range(0,nodes)))
G.add_edges_from(edges)
nx.draw(G,node_color='r', node_size=18, alpha=0.8)

生成了具有 250 个节点的图“G”
这个图有 256 条边。
求图“G”顶点覆盖的近似算法
顶点覆盖的近似算法是一种贪婪算法,它可能不会给出最优解。近似算法的工作可以解释为:
1) Initialize the solution-set as {}
2) Loop through all the E (Edges).
3) For an arbitrary edge (u, v) from set of E (Edges).
a) Add 'u' and 'v' to solution-set if none of the vertices 'u' or 'v' present in the set already
b) If any of the vertex 'u' or 'v' present already in the solution-set, skip the edge and move to the next one.
3) Return solution-set.
该解决方案的更多细节可以在这个博客中找到。
[## 顶点覆盖问题|集合 1(简介和近似算法)- GeeksforGeeks
无向图的顶点覆盖是其顶点的子集,使得对于图的每条边(u,v ),或者…
www.geeksforgeeks.org](https://www.geeksforgeeks.org/vertex-cover-problem-set-1-introduction-approximate-algorithm-2/)
在具有 250 个节点和 256 条边的图“G”上运行近似算法,我们得到 178 个节点的顶点覆盖。
#Vertex Cover Greedy Algorithm
visited = np.zeros(nodes)
cnt = 0
for e in edges:
(u,v) = e
# print(u,v)
if ((visited[u]==0) & (visited[v]==0)):
visited[u] = 1
visited[v] = 1
cnt+=2
print("Vertex cover consists of {} nodes".format(cnt))
输出:顶点覆盖由 178 个节点组成。
用遗传算法寻找图 G 的顶点覆盖

解决方法
使用遗传算法可能有相当多的解决顶点覆盖的方法。
一种方法是将适应度分数定义为覆盖边和所用顶点数量的函数。当一个解覆盖了所有的边时,罚分是 0,当一些边丢失时,罚分被包括。此外,实现这一目标所需的节点数量也会带来成本。这将需要仔细定义健身核心。
我不想惹上麻烦,因为适应值是覆盖边和顶点数的函数。我希望它是其中一个的功能。因此,我固定了顶点的数量,并将适应度分数定义为仅覆盖边的函数。这是如何做到的:
1\. Is it possible to cover all the edges with exactly 'k' number of vertices. Genetic Algorithm tries to find such solution, if possible.2\. Binary Search for the minimum value for 'k'.
初始化
我们需要发现,如果使用一些“k”个顶点,是否有可能覆盖所有的边。因此,我们用一些“k”个顶点随机初始化种群,作为顶点覆盖的一部分。
n = 250
#----------Hyperparameters can be tuned--------------------
pop_total = 1500 # max population allowed in the environment
pop_init = 1000 # Initial Population
max_iterate = 500 # Max Iterations or Generations allowed
#----------------------------------------------------------def chromosomes_gen(n,k,pop_init):
lst = []
for i in range(pop_init):
chromosome = np.zeros(n,dtype= int)
samples = random.sample(range(0,n), k = k)
for j in range(k):
chromosome[samples[j]] = 1
lst.append(chromosome)
return lst
健身得分
在这里,我通过使用精确的“k”个顶点的给定解决方案来检查,有多少条边丢失了。我为它增加一个惩罚/障碍计数。
def cost(soln,n,edges):
obstacles = 0
for e in edges:
(u,v) = e
if ((soln[u]==0) & (soln[v]==0)):
obstacles += 1
return obstacles
选择
有各种可能的选择方法。在这个问题中,我只是简单地将得分最高的解决方案传递给下一代,并杀死其余的。变量‘pop _ total’定义了允许传递给下一代的最大群体。
def selection(lst,pop_total,n,edges):
score = []
output_lst = []
len_lst = len(lst)
for i in range(len_lst):
score.append(cost(lst[i],n,edges))
sorted_index = np.argsort(score)
cnt = 0
for i in range(len_lst):
output_lst.append(lst[sorted_index[i]])
if((i+1) == pop_total):
break
lst = output_lst
# Return truncated-population and best score of this Generation
return lst,score[sorted_index[0]]
交叉
在交叉中,我们将两种解决方案结合起来,希望得到更好的解决方案。在这个问题中,我采用两个解决方案,找到第一个解决方案中不存在于第二个解决方案中的顶点,类似地,采用第二个解决方案中不存在于第一个解决方案中的顶点,并交换其中的 50%。
#Crossover
cross_over_prob = 0.50
for i in range(len_lst):
# First solution
tmp = lst[i].copy()
# Second solution
mate_with = lst[int(random.uniform(0,len_lst))]
tmp_unique = []
mate_with_unique = []
# Store all vertices of Solution-1 and Solution-2
for j in range(n):
if(tmp[j]==1):
tmp_unique.append(j)
if(mate_with[j]==1):
mate_with_unique.append(j)#Filter vertices from Solution-1 which is in Solution-2 and shuffle
tmp_unique = np.setdiff1d(tmp,mate_with)
random.shuffle(tmp_unique)#Filter vertices from Solution-2 which is in Solution-1 and shuffle
mate_with_unique = np.setdiff1d(mate_with,tmp)
random.shuffle(mate_with_unique)#Swap 50% unique vertices from Solution2 into Solution1 ~ New Soln
swap = math.ceil(cross_over_prob * min(len(tmp_unique),len(mate_with_unique)))
for j in range(swap):
tmp[mate_with_unique[j]] = 1
tmp[tmp_unique[j]] = 0
new_solution = tmp
变化
在这一步中,来自交叉状态的新解会稍微改变自己,或者变异,希望变得更好。在这个问题中,我执行了两种类型的突变,改变了 5%的解。我掷硬币,如果正面朝上,我进行变异 1,否则进行变异 2,两者都不同地改变 5%的解。
在变异-1 中,我从解中随机取出 5%的顶点,并用之前不在解中的其他随机 5%的顶点替换它。
在变异-2 中,我从解决方案中随机抽取 5%的顶点,并用其他 5%的顶点替换,这些顶点可以覆盖当前解决方案未能覆盖的一些边。
# Mutation
mutat_prob = 0.05
zeroes = []
ones = []
for j in range(n):
if soln[j]==1:
ones.append(j)
else:
zeroes.append(j)random.shuffle(ones)
random.shuffle(zeroes)coin_toss = random.random()
if(coin_toss <= 0.5):
# Mutation-1
swaps = min(len(ones),len(zeroes))
for j in range(swaps):
coin_toss2 = random.random()
if(coin_toss2 < mutat_prob):
soln[ones[j]] = 0
soln[zeroes[j]] = 1
#Swapping logic
dummy = ones[j]
ones[j] = zeroes[j]
zeroes[j] = dummy
else:
# Mutation-2
mutate_lst = []
for e in edges:
(u,v) = e
if((soln[u] == 0) & (soln[v] == 0)):
coin_toss2 = random.random()
if(coin_toss2 < mutat_prob):
coin_toss3 = random.random()
if(coin_toss3 <= 0.5):
if(u not in mutate_lst):
mutate_lst.append(u)
else:
if(v not in mutate_lst):
mutate_lst.append(v) random.shuffle(mutate_lst)
sz = min(len(ones),len(mutate_lst))
for j in range(sz):
soln[ones[j]] = 0
soln[mutate_lst[j]] = 1
#Swapping logic
dummy = ones[j]
ones[j] = mutate_lst[j]
mutate_lst[j] = dummy
soln_lst.append(soln)
遗传算法的性能主要取决于交叉和变异函数的构造。这些功能需要仔细设计和调整/修改,以获得最佳性能。
二分搜索法找到最小的 k
我执行了一个二分搜索法来寻找‘k’的最小值,这样‘k’个顶点的顶点覆盖覆盖了所有的图边。
# Environment to perform Initialisation-Selection-Crossover-Mutation
def environ(n,k,mut_prob,pop_init,pop_totl,max_iterate,edges)
soln = chromosomes_gen(n,k,pop_init)
for it in range(max_iterate):
soln = cross_over_mutate(soln,n,k,mut_prob,pop_total,edges)
soln,cost_value = selection(soln,pop_total,n,edges)
if cost_value==0:
break
return cost_value,result# Binary Search function
def mfind(n,mut_prob,pop_init,pop_total,max_iterate,edges,start,end)
result_dict = {}
l = start
h = end
ans = 0
while(l<=h):
m = int((l+h)/2.0)
cv,res = environ(n,m,mut_prob,pop_init,pop_total,max_iterate,edges)
if(cv==0):
result_dict[m] = res
h = m-1
else:
l = m + 1
return result_dict# Main-function Call
res = mfind(n,mutat_prob,pop_init,pop_total,max_iterate,edges,1,n)
结果
使用遗传算法,具有 250 个节点和 256 条边的图“G”的顶点覆盖是 104 个节点,这比近似算法的 178 个节点的解决方案小得多且更好。解决方案的完整源代码可以在这里找到。
结论
在这篇博文中,我们理解了遗传算法的概念及其用例和属性。然后我们用遗传算法来解决顶点覆盖问题,得到了一个比近似算法更好的解。
如果你有任何疑问,请联系我。我很有兴趣知道你是否有一些有趣的问题陈述或想法,遗传算法可以用于它。
我的 Youtube 频道更多内容:
嗨,伙计们,欢迎来到频道。该频道旨在涵盖各种主题,从机器学习,数据科学…
www.youtube.com](https://www.youtube.com/channel/UCg0PxC9ThQrbD9nM_FU1vWA)
关于作者-:
Abhishek Mungoli 是一位经验丰富的数据科学家,拥有 ML 领域的经验和计算机科学背景,跨越多个领域并具有解决问题的思维方式。擅长各种机器学习和零售业特有的优化问题。热衷于大规模实现机器学习模型,并通过博客、讲座、聚会和论文等方式分享知识。
我的动机总是把最困难的事情简化成最简单的版本。我喜欢解决问题、数据科学、产品开发和扩展解决方案。我喜欢在闲暇时间探索新的地方和健身。关注我的 中 、Linkedin或insta gram并查看我的往期帖子。我欢迎反馈和建设性的批评。我的一些博客-****
- 每个数据科学家都应该避免的 5 个错误
- 以简单&直观的方式分解时间序列
- GPU 计算如何在工作中真正拯救了我?
- 信息论& KL 分歧第一部分和第二部分
- 使用 Apache Spark 处理维基百科,创建热点数据集
- 一种基于半监督嵌入的模糊聚类
- 比较哪种机器学习模型表现更好
- 分析 Fitbit 数据,揭开疫情封锁期间身体模式变化的神秘面纱
- 神话与现实围绕关联
- 成为面向商业的数据科学家指南
拔靴带
因为“观察到你的结果的概率或者一个更极端的假设是真的”是令人困惑的。
介绍
实验是公司决策的基础,p 值是决定选择哪个实验假设的主要方法。
- 这个新的登录页面布局比现有的登录页面更好吗?
- 这种新的推荐策略是否优于现有的推荐策略?
- 我们应该在这个新的渠道上发起新的营销活动吗?
在任何一种情况下,我们都可以通过实验来做出决定。运行实验时,步骤如下:
- 确定您感兴趣的指标。
- 陈述无效和替代假设。
- 收集数据。
- 计算置信区间或 p 值。
- 使用区间或 p 值做出与假设相关的决策。
当使用 p 值时,利益相关者盲目地将该值与某个阈值(大多数情况下为 0.05)进行比较来做出决策。这种比较是带着一些模糊的认识进行的,当 p 值较小时,我们选择替代假设。然而,即使这种说法也从根本上反对与 p 值计算方式相关的理论。
例子

图 1:示例实验数据
假设我们在第一个场景中,我们想知道两个登录页面中哪一个“更好”。针对该示例的实验步骤概述如下:
- 我们希望监控与每个页面相关的平均收入。
- 零(H₁)和替代(H₂)假设可以表述为
H₁:新页面的平均收入小于或等于现有页面。
H₂:新页面的平均收入高于现有页面。 - 我们可能会收集与每个登录页面相关的数据,这些数据包含以下信息。提供这些数据的脚本可以在 Github 链接这里获得,你可以在 图 1 中看到这个部分顶部的数据示例。
- 从这些数据中,我们需要计算出假设零假设为真的情况下,观察到的平均收入差异的概率。无效假设是真实的平均差异为零。
在一门介绍性的静力学课程中,你将学习使用某种双样本 t 检验,在这种情况下你需要确定你的组的方差是相等还是不同。然后计算标准误差,您可以用它来确定 p 值。
如果您是 t-test 和 python 中搜索的新手,您可能会遇到这样的问题:您是否会使用*相关 t-test、配对 t-test、或独立 t-test。*那么,你如何选择?你为什么选择一个特定的测试?你怎么知道你选择了正确的测试?
这就是自举发挥作用来拯救世界的地方!但是如果您从所有可能的选择中选择了正确的测试,并且使用了 Scipy 中的内置测试,那么对应的 p 值就是 0.00008。这个解决方案的代码非常简单。困难的是知道你做了正确的选择。
科学 t 检验
5.同样,在统计介绍课程中,您现在可以将 p 值与 0.05 进行比较,并选择版本 1 和版本 2 的平均收入不同的替代方案。
然而,为了充分理解在这种情况下得出的结论,理解 p 值、I 型错误率以及这两者的组合如何推动第 5 部分中的结论是很重要的。
虽然这个解决方案的代码很简单,但是知道选择哪个解决方案以及如何解释结果可能会很混乱,特别是对于那些不经常进行假设检验的人。
拔靴带
为了使最后两步更容易理解,我更喜欢使用 bootstrapping 来模拟均值差异的分布。这与传统的 p 值和置信区间的思想有很好的联系。
**自举的定义是有替换的抽样。**通过对原始数据集进行替换采样,我们可以多次计算每个引导样本的平均收入差异,以了解平均差异如何从一个引导样本变化到下一个引导样本。

自助抽样——个人来自 freepik.com
我们可以使用下面显示的函数为这个数据集执行引导。在这种情况下,每个引导样本都是一个新的DataFrame,包含原始行的*“替换样本”*版本,直到我们创建了一个具有相同行数的新的DataFrame。
使用 10,000 个引导样本的默认值提供了三个列表,其中每个引导样本都有一个值:
- 版本 1 和版本 2 之间的均值差异列表。
- 版本 1 收入的方法列表。
- 第 2 版收入方式列表。
从引导结果中得出结论
这种从一个样本到另一个样本存在多少差异的想法使我们能够看到我们可以从包含这些值的总体中得到什么类型的样本估计。这些估计值的范围可以帮助我们理解哪些值是可能的,以及这些值是否符合零假设或替代假设。
上述函数的结果可以用下面的代码绘制出来。
这些图看起来是这样的:

绘制的自举结果
从这些图中,我们可以看到,在所有引导样本中,版本 2 的平均收入几乎总是高于版本 1 的平均收入。
此外,第一个图显示了所有 bootstrap 样本的平均差异,以及中间 95%的差异所在的界限(蓝色虚线)。因为这两个界限之间不包含零差,所以 bootstrap 区间提供了均值差不为零的重要证据。
使用来自 Scipy 的 p 值确实使我们得出了与 bootstrap 方法相同的结论。然而,从这些图中得出结论(使用 bootstrap 方法)比使用 p 值的传统方法(在我看来)更直观。
深度学习中超参数调整的实验——遵循的规则

鸣谢—https://image . free pik . com/free-photo/gear-cutting-machine _ 137573-2479 . jpg
任何深度学习模型都有一组参数和超参数。参数是模型的权重。这些是在每个反向传播步骤使用优化算法(如梯度下降)更新的。超参数是我们设定的。他们决定模型的结构和学习策略。例如,批量大小、学习速率、权重衰减系数(L2 正则化)、隐藏层的数量和宽度等等。由于深度学习在模型创建中提供的灵活性,人们必须仔细挑选这些超参数以实现最佳性能。
在这篇博客中,我们讨论
1.调整这些超参数时要遵循的一般规则。
2。在数据集上的实验结果验证了这些规则。
实验细节
数据— 实验在以下数据集上进行。它包含 6 类图像——建筑物、森林、冰川、山脉、海洋、街道。每门课大约有 2300 个例子。测试集由每个类的大约 500 个例子组成。训练集和测试集都相当平衡。

资料组
code—
https://github . com/DhruvilKarani/hyperparameter tuning/blob/master/readme . MD
硬件—
NVIDIA 1060 6GB GPU。
使用的型号— 1。学习率实验— ResNet18
2。对于批量大小、内核宽度、重量衰减的实验—自定义架构(见代码)。
观测记录— 1。每个时期的训练和测试损失
2。每个历元的测试精度
3。每个时期的平均时间(测试集上的训练和推断)
超参数及其对模型训练的影响
我们以卷积神经网络(CNN)为例,将模型行为和超参数值联系起来。在这篇文章中,我们将讨论以下内容——学习速度、批量大小、内核宽度、权重衰减系数。但是在我们讨论这些通用规则之前,让我们回顾一下任何学习算法的目标。我们的目标是减少训练误差以及训练误差和测试/验证误差之间的差距。我们通过调整超参数来实现这一点

训练和验证误差通用图。原图。
让我们看看深度学习文献如何描述改变超参数值的预期效果
学习率
深度学习书上说—
如果你有时间只调整一个超参数,调整学习率
在我的实验中,这当然成立。在尝试了三种学习速率后,我发现过低或过高的值都会严重降低算法的性能。对于学习率 10^-5,我们实现了 92%的测试准确性,对于其余两个率,我们几乎没有超过 70%,所有其他超参数保持不变。

在 ResNet 上测试准确性
如果你看看误差图,会发现一些东西。例如在训练错误中—

ResNet 上的训练错误
不出所料,三者都有所下降。但是在最低的学习速率下(粉色),第 10 个时期的损失大于第一个时期的红色曲线的损失。由于学习率极低,你的模型学得非常慢。此外,在高学习速率下,我们期望模型学习得更快。但是如你所见,红色曲线上的最低训练误差仍然大于橙色曲线上的误差(中等学习率)。现在让我们看看测试误差—

ResNet 上的测试错误
一些观察。对于最低比率,测试损失稳步下降,似乎还没有达到最低点。这意味着模型有欠拟合,可能需要更多的训练。

红色曲线显示异常行为。有人可能会怀疑,由于高学习率,优化器无法收敛到全局最小值,并一直在误差范围内跳动。
对于中等曲线(橙色),测试误差在第一个时期后开始缓慢增加。这是过拟合的经典例子。
批量
如果你熟悉深度学习,你一定听说过随机梯度下降(SGD)和批量梯度下降。为了重新访问,SGD 对每个数据点执行权重更新步骤。batch 在对整个训练集中数据点的梯度进行平均后执行更新。根据 Yann LeCun
SGD 的优势—
1。学起来快多了
2。往往能获得更好的解决方案
3。用于跟踪更改。
批量学习的优势—
1。收敛的条件是众所周知的。
2。许多加速学习技术,如共轭梯度,在批量学习中很好理解。
3。重量动力学和收敛速度的理论分析要简单得多
使用介于两者之间的方法,小批量梯度下降法很受欢迎。不是使用整个训练集来平均梯度,而是使用一小部分数据点的梯度平均。该批次的大小是一个超参数。
举例来说,考虑下图所示的损失情况

损失景观示例。原图
上面有数字的对角线是损失等值线。x 轴和 y 轴是两个参数(比如说 w1 和 w2 )。沿着等高线,损耗是恒定的。例如,对于任何位于损耗为 4.500 的线上的 w1 和 w2 对,损耗为 4.500。蓝色之字形线是 SGD 的行为方式。橙色线是您预期的小批量梯度下降的工作方式。红点代表参数的最佳值,此时损耗最小。
《深度学习》一书提供了一个很好的类比来理解为什么太大的批量效率不高。从 n 个样本估计的标准误差为 σ/√ n. 考虑两种情况——一种有 100 个样本,另一种有 10000 个样本。后者需要 100 倍以上的计算。但是标准误差的预期降低只有 10 倍
在我的实验中,我改变了批量大小。我获得的测试准确度看起来像—

内核宽度
CNN 中的卷积操作包括从特征图中提取特征的核。内核由学习到的参数组成。在二维卷积中,内核是一个 N*N 的网格,其中 N 是内核宽度。
增加或减少内核宽度各有利弊。增加核宽度会增加模型中的参数,这是增加模型容量的明显方法。很难对内存消耗进行评论,因为参数数量的增加会增加内存使用量,但特征图的输出维度会变小,从而减少内存使用量。
重量衰减
权重衰减是 L2 正则化的优势。它实质上惩罚了模型中较大的权重值。设置正确的强度可以提高模型的泛化能力并减少过度拟合。但是过高的值会导致严重的欠拟合。例如,我尝试了正常和极高的重量衰减值。如你所见,当这个系数设置不好时,学习能力几乎为零。

结论
这些实验完全证实了我们的大多数假设。像 ResNet18 这样调优不佳的复杂模型很容易比调优良好的简单架构表现更差。损耗曲线是研究超参数影响的良好起点。
为你的模型找到最好的超参数是困难的。尤其是手动操作的时候。我建议看看 HyperOpt 和 Optuna 这样的超参数优化库。这篇由 neptune.ai(一家为你的 ML 实验管理需求提供解决方案的公司)撰写的文章很好地介绍了这些包。
如果你和我一样是 ML 爱好者,那就来连线一下 LinkedIn 和Twitter。我非常乐意收到对这篇文章的任何评论。
专家系统 2.0
神经网络如何使程序知识大众化

神经网络和深度学习是最终打开人工智能之路的钥匙吗,还是我们正处于另一个 AI Winter 的边缘?
如果你是企业家,那么答案是:没关系。你的资助并不依赖于资助者对你的研究议程——制造一个会说话的机器人——感到兴奋。这取决于为真实的人提供真实的价值。
事实是,尽管人工智能的发展到目前为止还没有制造出可以与我们自己的智能相媲美的机器,但沿着这条道路发展起来的技术都非常有用,并且充满了潜在价值。虽然看起来神经网络本身不足以构建最智能的系统,但它们丰富我们生活的全部潜力尚未得到充分挖掘。
今天,我想提醒我们所有人一项来自人工智能前一个时代的有用且相关的技术:专家系统。虽然不再是一个迷人的研究海报的孩子,这项技术已经对社会产生了持久的影响。即使没有强化学习、培训课程和其他前沿创新,神经网络也准备做同样的事情。
正如我们将看到的,正如专家系统基于描述性知识自动进行推理一样,神经网络也可以对程序性知识做同样的事情。与商业专家系统不同,商业专家系统在很大程度上掌握在企业手中,我们随时准备让所有人都可以使用神经网络系统。
专家系统:综述
专家系统至少需要两个组件才能运行:
- 知识库
- 推理机
知识库存储命题——这些命题是经过编码的信息——而推理机使用推理规则来推导新的命题。
显然,建立专家系统的一个主要挑战是建立知识库所需的知识获取。领域专家通常需求量很大,而他们自己通常缺乏整理自己知识的能力。这意味着构建知识库是程序员和专家之间耗时的协作。
然而,这种专业知识的缺乏也是专家系统有价值的原因。一旦编码,知识库很容易转移,并且不会过期。它可以被无休止地复制,并在许多应用程序中使用。专家系统将困难的技术推理和知识查找自动化,以换取前期投入的时间和精力。
毫不奇怪,专家系统通常出现在医学、法律和其他需要对事实和程序有明确的专业知识的领域。
由于它们是一项成熟的技术,与其学习技术细节,不如对它们的目的、需求和相关性有一个整体的了解,这会更好地为您服务。当讨论神经网络时,我们将回到这三个因素,所以请记住它们。
我们已经介绍了目的和要求…
**目的:**专家系统利用明确的事实和推理规则自动推理。
**需求:**构建或更新专家系统需要领域专家的时间和知识,以及用代码表示这些知识的能力。
那么,专家系统还有意义吗?当然可以。
虽然现在很少能找到明确称为“专家系统”的软件,但知识表示和推理的思想和实现仍在大量使用。例如, ROSS ,一个由 IBM Watson 支持的法律系统,结合了一个巨大的知识库和更现代的从自然语言处理领域过滤相关信息的方法。
此外,许多语音接口,将声音输入映射到意图,但有一个固定的意图和响应规则库,类似于旧的专家系统。这些新系统不是自动化需要专业知识的高度专业化的任务,而是自动化更日常的事情,如检查账户余额,同时被打包在一个被认为更智能的接口中(但通常也是硬编码的)。
总之…
相关性:虽然专家系统背后的思想很少作为独立产品出现,但它们对软件产生了持久的影响,并且一直沿用至今。
描述性知识与程序性知识
在继续讨论神经网络之前,我想快速了解一下我们人类可以拥有的知识类型的区别:描述性知识和程序性知识之间的区别。
描述性(也称显性或陈述性)知识,采取事实和规则的形式。它通常可以用文字或符号来表示,并使用逻辑或其他演算来操作。
程序性(也叫隐性或表现性)知识,更多的是关于知道如何去做事。它通常与直觉、肌肉记忆和实践等概念联系在一起。
想想骑自行车需要什么。当然,你知道你坐下来,把你的脚放在踏板上,这个动作会保持自行车直立。但是更重要的是知道如何骑自行车,这需要练习。这样,骑自行车就有了更多的程序成分。
另一方面,考虑找出三角形的缺角,给定一些长度和角度。在这里,得到解的过程要清楚得多,可能涉及到三角恒等式之类的东西。如果需要,每一步都可以写在纸上。这个问题需要更多的描述性知识。
当然,许多复杂的任务需要知识类型的混合,这种区分比它必然地指示一个深层的机械真理更方便。然而,我们会看到,在考虑神经网络的潜在应用时,记住这一区别是有用的。
神经网络和软件 2.0
事实证明,现实世界中的大部分问题都有这样一个特性,即收集数据(或者更一般地说,确定一个理想的行为)比显式地编写程序要容易得多安德烈·卡帕西,软件 2.0
你可能已经注意到上面的描述性知识是构成专家系统的知识库和推理规则的那种东西。
如何为程序性知识建立一个知识库?嗯,这将是非常困难的,尤其是因为即使是这些领域的专家也很难准确地表达他们自己的专业知识。
也就是说,使用传统的编程方法是非常困难的。
机器学习模型将范式从程序员必须提供规则和输入以获得结果的范式转变为程序员可以提供输入和结果以导出规则的范式。那就是:
软件 1.0: 输入+规则→结果
软件 2.0: 输入+结果→规则
软件 1.0 的成分非常类似于专家系统所需的知识库和推理机。软件 2.0 的承诺是,任何人使用该软件都可以将学到的规则应用到许多新的输入中,而不需要他们自己拥有得出结果所需的专业知识。
我们可以看到这是如何暗示由神经网络和深度学习驱动的新一代专家系统的,其目的、要求和相关性如下。
***目的:*专家系统 2.0 将通常需要专业培训和实践的决策和感知自动化,在该领域,专业知识更多的是程序性的,而不是描述性的。
***需求:*要建立这样的系统,需要建立一个数据集,让专家运用他们的知识做出判断(例如,作者给创造性写作打分)。更新这样的系统只需要更新数据集。
***相关性:*专家系统 2.0 已经准备好将过程专家民主化,几乎不需要进一步的技术创新。
正如旧的专家系统一样,知识获取仍然需要领域专家的时间和注意力。然而,建立一个机器学习数据集仅仅需要他们练习他们的手艺,而不是解构它。此外,对于工程师来说,在数据集中表示这些知识比想出编码和操作符号知识的方法要容易得多。最后,随着数据集随着时间的推移而增长和发展,更新和改进模型可以更顺利地完成。
识别专家系统 2.0 的机会
如果一项任务需要程序多样性的专业知识,那么使用深度学习实现自动化的时机已经成熟。许多创造性学科符合这一描述——音乐、舞蹈、艺术等。
2018 年,谷歌艺术与文化实验室(Google Arts & Culture Lab)制作了 Living Archive ,这是一个经过训练可以预测韦恩·麦格雷戈(Wayne McGregor)舞蹈动作的模型,因此可以用来建议舞蹈编排。
在技术方面,评估的表演和作品要比合成新的表演和作品容易得多。像 SmartMusic 这样的软件能够对音频录音的语调和节奏等方面进行评分。然而,这些事情可以使用硬编码的规则来检测和分析。在音乐等领域,真正的价值来自于模特为诸如 dynamics 和 rubato 等更微妙、更具解释性的元素配乐。
如果人类专家可以在几秒钟内做出决定,然后有时间解释他们到底是如何做出决定的,那么捕捉数百万个这样的决定将使我们走向一台可以做同样事情的机器。
正如人工智能技术的理想一样,专家系统 2.0 将扩大和民主化人类智能,而不是使其过时。人们仍然应该每周去上小提琴或舞蹈课,但他们也可以即时获得有效的反馈,即使他们的老师不在他们面前。缩短反馈的距离将大大加快学习。
现在,为什么我说基于深度学习的系统将民主化专业知识,而这对于旧的专家系统来说并不是真的?这里有几个因素在起作用:
- 旧的专家系统通常被设计在错误代价很高的领域——法律、药物设计、医学诊断——因此民主化的价值较低。
- 自从有了互联网,我们的文化已经转向重视信息的公开获取。
- 与上述相关,获得技术的机会比以往任何时候都多。
神经网络和深度学习可能只是通往人工智能的垫脚石,但这并不意味着它们没有直接的价值。
通过以专家系统自动化描述知识的方式自动化和民主化程序知识,神经网络可以改善我们对专业知识的获取,并永远增强我们的学习方式。他们的价值才刚刚开始被意识到。
专家与算法:一个观点
解决问题:“专家的决定比算法的预测更好吗?”
大脑:我们用来思考的器官― 比尔斯,A·
“我很高兴能够及时回答,我也这么做了。我说我不知道。”― 马克·吐温
“你的假设是你观察世界的窗口。每隔一段时间就把它们擦掉,不然光线就照不进来了。”― 艾萨克·阿西莫夫

带骨龄计算的手部 x 光照片——迈克尔·海格斯特伦(来源:维基共享)
算法(人工智能,机器学习)的传播引发了一个有效的问题:专家的决策比算法做出的预测更好吗?这是一个预示着人类知识和行动存在危机的问题,因为它经常被问到。
例如,The Verge 最近的一篇报道题为:“为什么发现癌症的人工智能需要小心处理”(詹姆斯·文森特,2020 年 1 月 27 日)。来自该报告:“但对于医疗保健领域的许多人来说,这些研究展示的不仅仅是人工智能的前景,还有它的潜在威胁。他们说,尽管算法处理数据的能力显而易见,但护士和医生微妙的、基于判断的技能却不那么容易数字化。
但是这种观点忽略了表明其他情况的证据。有两个关键因素― (1)认知偏差***(2)认知超载***―在起作用。
要回答这个问题(专家 vs .算法),我们先来看看 认知偏差 所起到的作用。
心理学家和行为经济学先驱丹尼尔·卡内曼因“将心理学研究的见解融入经济科学,尤其是关于人类在不确定情况下的判断和决策”而获得 2002 年诺贝尔经济学奖他与经济学家阿莫斯·特沃斯基的合作是众所周知的――这种合作关系导致了行为经济学的许多基础性成果,尤其是 20 世纪 70 年代“前景理论”的发展。
前景理论是对作为现代经济理论基础的经典效用理论*、的重要更新,它是对人类估计中损失和收益不对称的行为框架,最初由丹尼尔·伯努利于 1738 年提出,作为对、【圣彼得堡悖论】的著名解决方案*,并于 20 世纪 40 年代由约翰·冯·诺依曼和奥斯卡·莫根施特恩运用理性选择的公理编织成其现代形式预期效用理论。(虽然冯·诺依曼和摩根斯坦使用理性选择的公理构建了现代效用理论,但伯努利在 1738 年建立了效用构造作为*“道德期望”*与数学期望相对,强调了他的效用观点是一种主观构造而非数学构造。这是他的论点的关键点:一个穷人的道德期望不同于一个富人的道德期望――这使得丹尼尔·伯努利成为真正的行为经济学先驱。)
要不是卡尼曼在 1996 年英年早逝,特沃斯基几乎肯定会与他分享诺贝尔奖(卡尼曼与经济学家弗农·史密斯(Vernon Smith)分享了诺贝尔奖,后者因其在实验经济学中的开创性作用而闻名)。
在研究生院,我第一次看到他们的经典论文**“不确定性下的判断:启发式和偏见”(特沃斯基和卡尼曼,1974)** ,并立即被不确定性下的判断、启发式在决策中的作用以及由此产生的系统性偏见吸引住了。在这篇经典论文中,Tversky 和 Kahneman 将这些偏见归纳为三个关键的启发法:代表性(一个对象代表特定类型的可能程度);可用性(基于脑海中出现的实例或事件对事件发生概率的主观评估);以及来自锚点的调整(从初始值开始做出的主观估计,并被调整以产生最终答案,这些调整通常被证明是不充分的)。
在他的精彩著作**《思考,快与慢》(2011)** 中,丹尼尔·卡内曼解释了扎根于心理学的观念,即人类的思维是两个心理系统的混合:一个快速、直觉、自动、几乎无意识的过程*(系统 1)和;一个缓慢、审慎、有意识的过程,需要专注和努力(系统 2) 。这两个系统的相互作用使得我们的思想和行动。(注意书名中突出快和慢的思考后的逗号。)*
卡尼曼在“直觉与公式”一节中探讨了专家与算法的问题。他强调了临床心理学家 Paul Meehl 关于专家直觉和使用公式指导的有趣发现。米尔的发现表明,简单的算法(统计预测)在几乎所有测试领域都胜过或追平了专家(临床判断)。正如卡尼曼指出的那样,对于算法来说,实现的容易程度甚至可以让一场平局成为一场胜利。这些结果(“米尔模式”)震惊了当时的临床机构,这是可以理解的,因为人工智能的进步现在仍在继续。
卡尼曼强调的著名的阿普加评分清楚地表明了这一点。1953 年,医学博士维珍尼亚·阿普伽发表了她对新生儿评估新方法的建议。本文的公开目的是建立一个简单明了的新生儿分类,用于比较产科实践的结果、产妇疼痛缓解的类型和复苏的结果。在考虑了几个与婴儿出生时的状况有关的客观体征后,她选择了五个可以毫无困难地进行评估并教给产房人员的体征。这些迹象是心率、呼吸努力、反射性易怒、肌肉紧张度和颜色。婴儿完全出生后 60 秒,根据是否存在,每个迹象被给予 0、1 或 2 的评级。”(资料来源:“阿普加评分经受住了时间的考验”,芬斯特博士&伍德博士,2005)
简而言之,产房工作人员在出生后 1 分钟获得的这个简单分数(0-10)提供(并且仍然继续提供)新生儿的预后(如果 8-10,则为优秀;如果 3-7,则为一般;如果 0-2,则为差)。重要的是,阿普加博士选择了五个“可以毫无困难地评估和教授给产房人员”的客观体征――也就是说,它可以被非专家容易地理解。阿普加评分对降低婴儿死亡率产生了巨大的影响。根据纽约长老会/哥伦比亚大学医学中心的理查德·斯迈利博士的说法:“这个分数要求医生和护士用一种有组织的方法来观察新生儿,它帮助防止了无数婴儿的死亡。一旦医生和护士不得不分配一个分数,它就产生了一个必须采取行动来提高分数。这实质上是临床新生儿学的诞生。”(资料来源:纽约长老会健康问题:“发生在这里:阿普加评分”)
先驱维珍尼亚·阿普伽博士是哥伦比亚大学内外科医学院第一位拥有正教授职位的女性医生。
卡尼曼对直觉与公式问题的研究表明,“每当我们可以用公式代替人类的判断时,我们至少应该考虑它。”偏见(傲慢、过度自信等)阻碍了客观性。不相关的上下文或显著性偏差影响一致性。在可预测性差的情况下,算法有可能提供客观和一致的判断。使用卡尼曼提供的框架,很容易看出,在需要系统 2 思维(缓慢思考)的领域使用系统 1 思维(快速直觉)会产生这些情况。认识到这些模式可以帮助不同领域的规划者制定策略(就像阿普加博士所做的那样),以保持客观和一致的评估,因为情况(例如在出生后一分钟内快速评估新生儿)似乎需要直觉。
现在让我们通过检查 认知超载 所扮演的角色来看看专家与算法的问题。认知超载是复杂性增长和人类极限现实的结果。
阿图尔·加万德博士**在《纽约客》杂志上发表的关于医疗保健的文章声名鹊起。他的第一本书《并发症:一个外科医生对不完善科学的笔记》(2002)* ,一本他在布莱根妇女医院住院期间写的散文集,为他赢得了国家图书奖。“包含并发症的文章(其中许多最初出现在《纽约客》上)分为三个部分――易错性、神秘和不确定性――每一部分都涉及医疗实践中不同种类的缺陷或困难。因此,Gawande 探索了医学可能达不到预期的许多方式。尽管尽了最大努力,人类还是会犯错。科学知识仍然是不完整的,留下了许多没有答案和无法回答的问题。有些情况就是模棱两可,需要在面对令人抓狂的不完整信息时做出判断,而且往往没有好的解决方案。”(资料来源:“像外科医生一样”,史蒂文·卢贝特,2003 年 5 月,康奈尔法律评论)***
人类易犯的错误、我们不知道的事情以及在信息不完整的情况下做出判断都是任何情况的一部分。当这些在时机很重要的情况下(例如,新生儿出生后 1 分钟或心脏病发作到达后 90 分钟)结合在一起时,复杂性总是存在,求助于算法(和公式)可能是必要的。**
在 2009 年,Gawande 出版了《清单宣言:如何把事情做好》*,在那里他着眼于如何利用“受过良好训练、拥有高技能和勤奋的人”积累的来之不易但难以管理的知识,并通过提出一个“克服失败,一个建立在经验基础上并利用人们拥有的知识,但也以某种方式弥补我们不可避免的人类不足”的策略来消除可以避免的常见和持续的失败——一个清单!***
与阿普加的见解相呼应,加万德认为:“清单似乎可以防止这种失败。它们提醒我们最起码的必要步骤,并使它们明确。它们不仅提供了验证的可能性,还灌输了一种更高性能的纪律。”作为一个例子,Gawande 讨论了由约翰·霍普金斯医院的重症监护专家 Peter Provonost 设计的用于解决 ICU 中心静脉导管感染问题的清单如何在两年的时间内显示出此类感染的显著下降(几乎降至零)。另一个例子是一名奥地利儿童在滑入冰冷的池塘后奇迹般地康复,这表明现代医学的快速和协调的复杂性是如何创造这样的奇迹的。清单宣言有很多这样的例子,读起来很有意思。
清单或公式或算法可以提供一个客观和一致的途径,通过关注在时间敏感的情况下的最小必要,来消除可避免的故障,在这种情况下,不断增长的复杂性和人的易错性(以及人的极限)可能会不利地结合在一起。这种算法方法可能在某些领域不太适用(至少目前如此),但重要的是要认识到这种方法适用的所有领域。
****这种对算法的观点违背了专家和学者当前的智慧。但理论和经验为这一观点提供了充分的支持,表明为什么至少考虑算法在规划复杂操作和为复杂项目汇集专业知识中的作用是重要的。
在这种情况下,为什么简单的算法能如此成功?从周围的噪音中提取信号。
- 认知偏差(详见 Tversky-Kahneman 论文)将焦点转移到噪声上,特别是当问题表现出高信噪比和时间敏感性时。
- 根据“思考,快和慢”中解释的系统 1/系统 2 模型,尽管经常遇到这种情况(婴儿每天都出生),但系统 1 思维(快速、联想、直觉)可能会主导系统 2 思维(缓慢、审慎、逻辑)。发生这种情况的原因有很多。结合了速度和相关公式的算法在这种情况下似乎很方便。
- 相关公式:现代统计学和群体遗传学的先驱罗纳德·费雪(和他那个时代的许多杰出统计学家一样,他也是一个狂热的优生学者),在面对统计模型的未知参数时,强调了充分统计的概念。跳过技术解释,充分统计背后的直觉是为现象的统计模型找到一个具有充分解释力的代理。例如,样本均值和方差作为总体真实均值和方差的代理。基本上,这意味着确定一组简单的相关参数或一个简单的代表性函数(即使是一个粗略的函数),以提供足够的预测能力。虽然围绕阿普加分数的神话层出不穷,但很明显,阿普加在一段时间内的观察和她在综合方面的天赋帮助她确定了出生后立即观察的相关迹象,以预测婴儿的状况和所需的护理。
- 正如 Gawande 的书中充分说明的那样,认知超载只是反映了人类由于复杂性的增长和解决日常问题所需的专业知识的协调而带来的负担。Gawande 展示了三个因素――人的易错性、未知性(我们不知道的)和不确定性(部分或不完善的信息)―是如何导致判断错误的。为了避免错误,积累经验并掌握诀窍,Gawande 建议用清单作为灌输所需纪律的方式。**
- 失足跌入冰冷池塘的儿童的康复案例说明了在现代医学发展到极限的情况下,生存概率非常低的情况是如何得到扭转的。这看起来不可思议,因为期望每件事都非常及时地非常好地工作,并且准确无误地到位,没有任何误差,这是不合理的。清单在两个方面有所帮助:(1)将问题快速归类为非常规问题(识别未知问题),以及(2)为采用非标准技术的专业干预铺平道路(使用合理的判断,利用专业知识)。
- 在许多领域(如建筑设计、飞机等复杂机械系统的设计)中,将系统设计到极限(根据经验建立合理的概率模型并构建适当的安全系数)是非常标准的做法,但这通常不适用于分布式过程的设计,尤其是跨越学科边界的过程。失败的影响只有在事后才能确定。只有专业项目(核项目、太空项目等)出于必要才采用这种端到端视图。算法可以廉价地探索多种可能性。即使模拟低概率事件,也能帮助规划者理解面对最坏情况时如何应对。
将认知偏差视为专家低效或不利地过滤信息,将认知超载视为人类在面对大量信息时的无能或限制,算法可以克服这些障碍,使决策变得客观和一致。**
本文仅考察了在典型的不确定性和复杂性条件下,专家相对于算法的相对优势,回避了引入算法所带来的道德、社会和经济影响这一更大的问题。工业革命的教训和卡尔·马克思在其名著《资本论】中阐述的关于自动化轨迹的见解与这一讨论相关。但是我会把它留到下一天。
劳动的工具,当它采取机器的形式时,立即成为工人自己的竞争者。― 卡尔·马克思,《资本论》第一卷
期待您的问题、评论和反馈。
Suresh Babu |年 2 月 6 日|旧金山湾区
我对人工智能前沿的兴趣:
- 作为一个作家,研究人工智能的含义、伦理、社会影响和经济学(作为一个作家)
- 作为从业者,为企业和政府创造 AI 战略和应用
- 作为顾问,帮助非营利组织和非政府组织评估人工智能的全球影响和效用


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}