







在 VGG16 和 VGG19 CNN 模型中提取特征、可视化过滤器和特征地图
了解如何在 VGG16 和 VGG19 CNN 模型中提取特征、可视化过滤器和特征地图


Keras 提供了一组深度学习模型,这些模型与ImageNet数据集上预训练的权重一起可用。这些模型可用于预测、特征提取和微调。在这里,我将讨论如何为给定图像的预训练模型 VGG16 和 VGG19 提取特征、可视化过滤器和特征图。
用 VGG16 提取特征

用 VGG16 提取特征
这里我们先从 tensorflow keras 导入 VGG16 模型。导入 image 模块来预处理图像对象,导入 preprocess_input 模块来为 VGG16 模型适当地缩放像素值。numpy 模块是为数组处理而导入的。然后,使用 imagenet 数据集的预训练权重加载 VGG16 模型。VGG16 模型是一系列卷积层,后跟一个或几个密集(或全连接)层。Include_top 允许您选择是否需要最终的密集层。False 表示加载模型时不包括最终的密集图层。从输入层到最后一个 max pooling 层(标注为 7×7×512)作为模型的特征提取部分**,其余网络作为模型的分类部分。在定义了模型之后,我们需要加载模型期望大小的输入图像,在本例中是 224×224。接下来,图像 PIL 对象需要被转换为像素数据的 NumPy 数组,并从 3D 数组扩展为具有[ 样本、行、列、通道 ]维度的 4D 数组,这里我们只有一个样本。然后,需要针对 VGG 模型对像素值进行适当的缩放。我们现在已经准备好获取特性了。**

输出最后一个最大池图层的要素形状和要素集
用 VGG16 从任意中间层提取特征
这里,我们首先从 tensorflow keras 导入 VGG16 模型。导入 image 模块来预处理图像对象,导入 preprocess_input 模块来为 VGG16 模型适当地缩放像素值。numpy 模块是为数组处理而导入的。此外,模型模块被导入以设计新模型,该新模型是完整 VGG16 模型中的层的子集。该模型将具有与原始模型相同的输入层,但输出将是给定卷积层的输出,我们知道这将是该层或特征图的激活。然后,使用 imagenet 数据集的预训练权重加载 VGG16 模型。例如,加载 VGG 模型后,我们可以定义一个新模型,从 block4 池层输出一个特征图。在定义了模型之后,我们需要加载模型期望大小的输入图像,在本例中是 224×224。接下来,图像 PIL 对象需要被转换为像素数据的 NumPy 数组,并从 3D 数组扩展为具有[ 个样本,行,列,通道 ]的维度的 4D 数组,这里我们只有一个样本。然后,需要针对 VGG 模型对像素值进行适当的缩放。我们现在已经准备好获取特性了。
例如,这里我们提取 block4_pool 层的特征。

用 VGG16 提取 block4_pool 图层的特征
使用 VGG19 提取特征

使用 VGG19 提取特征
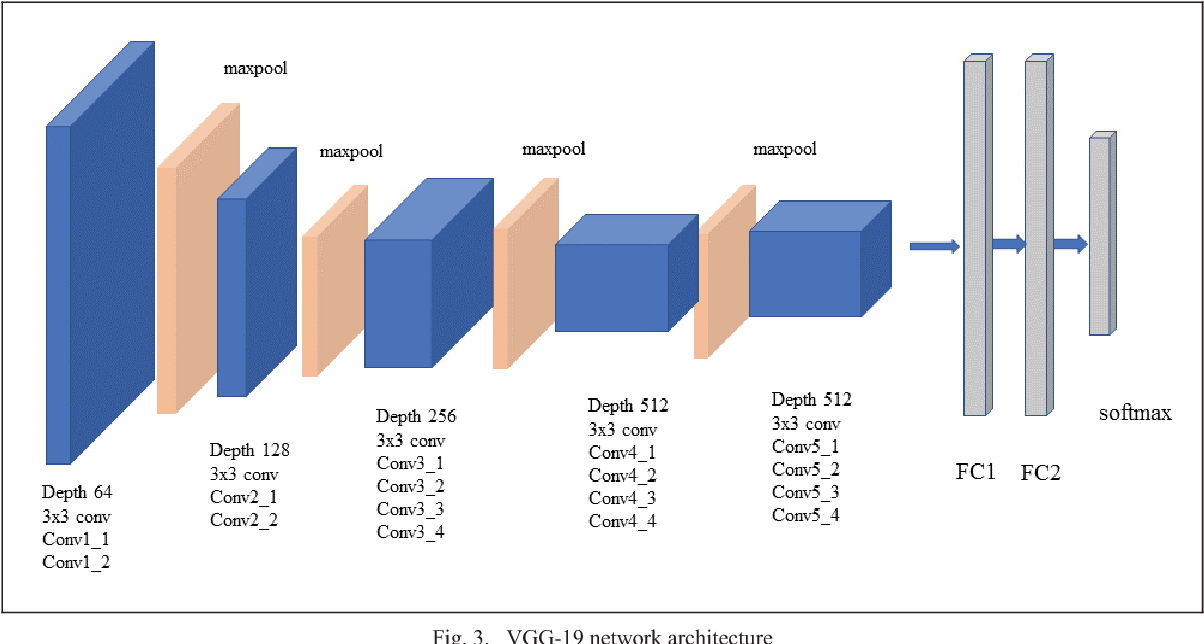
这里我们先从 tensorflow keras 导入 VGG19 模型。导入 image 模块来预处理图像对象,导入 preprocess_input 模块来为 VGG19 模型适当地缩放像素值。numpy 模块是为数组处理而导入的。然后,使用 imagenet 数据集的预训练权重加载 VGG19 模型。VGG19 模型是一系列卷积层,后跟一个或几个密集(或全连接)层。Include_top 允许您选择是否需要最终的密集层。False 表示加载模型时不包括最终的密集图层。从输入层到最后一个 max pooling 层(标注为 7×7×512)作为模型的特征提取部分**,网络的其余部分作为模型的分类部分。在定义了模型之后,我们需要加载模型期望大小的输入图像,在本例中是 224×224。接下来,图像 PIL 对象需要被转换为像素数据的 NumPy 数组,并从 3D 数组扩展为具有[个样本、行、列、通道]维度的 4D 数组,这里我们只有一个样本。然后,需要针对 VGG 模型对像素值进行适当的缩放。我们现在已经准备好获取特性了**
用 VGG19 从任意中间层提取特征
这里,我们首先从 tensorflow keras 导入 VGG19 模型。导入 image 模块来预处理图像对象,导入 preprocess_input 模块来为 VGG19 模型适当地缩放像素值。numpy 模块是为数组处理而导入的。此外,模型模块被导入以设计新模型,该新模型是完整 VGG19 模型中的层的子集。该模型将具有与原始模型相同的输入层,但输出将是给定卷积层的输出,我们知道这将是该层或特征图的激活。然后,使用 imagenet 数据集的预训练权重加载 VGG19 模型。例如,加载 VGG 模型后,我们可以定义一个新模型,从 block4 池层输出一个特征图。在定义了模型之后,我们需要加载模型期望大小的输入图像,在本例中是 224×224。接下来,图像 PIL 对象需要被转换为像素数据的 NumPy 数组,并从 3D 数组扩展为具有[ 个样本,行,列,通道 ]的维度的 4D 数组,这里我们只有一个样本。然后,需要针对 VGG 模型对像素值进行适当的缩放。我们现在已经准备好获取特性了。
例如,这里我们提取 block4_pool 层的特征。

用 VGG19 提取 block4_pool 图层的特征
总结 VGG16 模型各卷积层中的滤波器

总结 VGG16 模型各卷积层中的滤波器
过滤器是简单的权重,然而由于过滤器的专门的二维结构,权重值彼此具有空间关系,并且将每个过滤器绘制为二维图像是有意义的。这里我们回顾一下 VGG16 模型中的滤波器。这里我们从 tensorflow keras 导入 VGG19 模型。我们可以通过 model.layers 属性访问模型的所有层。每一层都有一个 layer.name 属性,其中卷积层有一个类似于 block#_conv# 的命名卷积,其中“ # ”是一个整数。因此,我们可以检查每个层的名称,并跳过任何不包含字符串’ conv '的层。每个卷积层有两组权重。一个是滤波器模块,另一个是偏置值模块。这些可通过 layer.get_weights() 函数访问。我们可以检索这些重量,然后总结它们的形状。上面给出了总结模型过滤器的完整示例,下面显示了结果。

VGG16 模型各卷积层中的滤波器
所有卷积层都使用 3×3 滤波器,这种滤波器很小,也许很容易解释。卷积神经网络的架构问题是滤波器的深度必须匹配滤波器的输入深度(例如通道的数量)。我们可以看到,对于具有红色、绿色和蓝色三个通道的输入图像,每个过滤器的深度为三(这里我们使用的是通道最后的格式)。我们可以将一个过滤器想象成一个有三个图像的图,每个通道一个图像,或者将所有三个图像压缩成一个彩色图像,或者甚至只看第一个通道,并假设其他通道看起来相同。
在 VGG16 模型的第二层中可视化 64 个过滤器中的前 6 个过滤器

在 VGG16 模型的第二层中可视化 64 个过滤器中的前 6 个过滤器
这里我们从 VGG16 模型的第二个隐藏层检索权重。权重值可能是以 0.0 为中心的小正值和负值。我们可以将它们的值归一化到 0–1 的范围内,使它们易于可视化。我们可以列举该模块 64 个滤波器中的前六个,并绘制每个滤波器的三个通道。我们使用 matplotlib 库,将每个过滤器绘制为新的一行子图,将每个过滤器通道或深度绘制为新的一列。这里,我们绘制了 VGG16 模型中第一个隐藏卷积层的前六个滤波器。

VGG16 模型第二层 64 个滤波器中的前 6 个滤波器
它创建了一个具有六行三个图像或 18 个图像的图形,每个过滤器一行,每个通道一列。我们可以看到,在某些情况下,各通道的滤波器是相同的(第一行),而在其他情况下,滤波器是不同的(最后一行)。深色方块表示较小或抑制性重量,浅色方块表示较大重量。利用这种直觉,我们可以看到第一行的过滤器检测到从左上角的亮到右下角的暗的渐变。
汇总每个 Conv 图层的要素地图大小
激活图称为特征图,捕捉将过滤器应用于输入的结果,例如输入图像或另一个特征图。可视化特定输入图像的特征图的想法是理解在特征图中检测到或保留了输入的什么特征。期望靠近输入的特征地图检测小的或精细的细节,而靠近模型输出的特征地图捕获更一般的特征。为了探索特性图的可视化,我们需要用于创建激活的 VGG16 模型的输入。

使用 VGG16 汇总每个 conv 图层的要素地图大小
我们需要更清楚地了解每个卷积层输出的特征图的形状和层索引号。因此,我们枚举模型中的所有层,并打印每个卷积层的输出大小或特征图大小以及模型中的层索引。

使用 VGG16 时每个 conv 图层的要素地图大小
可视化输入图像的 VGG16 模型中的第一卷积层的特征图

可视化输入图像的 VGG16 模型中的第一卷积层的特征图
这里,我们设计了一个新模型,它是完整 VGG16 模型中各层的子集。该模型将具有与原始模型相同的输入层,但输出将是给定卷积层的输出,我们知道这将是该层或特征图的激活。加载 VGG 模型后,我们可以定义一个新模型,从第一个卷积层输出特征图。利用该模型进行预测将给出给定输入图像的第一卷积层的特征图。在定义了模型之后,我们需要加载模型期望大小的输入图像,在本例中是 224×224。接下来,图像 PIL 对象需要被转换为像素数据的 NumPy 数组,并从 3D 数组扩展为具有[ 个样本,行,列,通道 ]的维度的 4D 数组,这里我们只有一个样本。然后,需要针对 VGG 模型对像素值进行适当的缩放。我们现在准备好得到特征图。我们可以通过调用 model.predict() 函数并传入准备好的单个图像来轻松实现。我们知道结果将是一个 224x224x64 的特征地图。我们可以将所有 64 幅二维图像绘制成一个 8×8 的正方形图像。

输入图像的 VGG16 模型中第一个卷积层的特征映射
对于给定的图像,

输入图像
可视化 VGG16 模型五个主要区块的特征图
在这里,我们从模型的每个块中一次性收集特征图输出,然后创建每个块的图像。图像中有五个主要块(例如,块 1、块 2 等。)结束于汇集层。每个块中最后一个卷积层的层索引是[2,5,9,13,17]。我们可以定义一个具有多个输出的新模型,每个块中的每个最后卷积层有一个特征映射输出。使用这个新模型进行预测将会产生一个特征图列表。我们知道在更深的层中的特征图的数量(例如深度或通道的数量)比 64 多得多,例如 256 或 512。然而,为了一致性,我们可以将可视化的特征地图的数量限制在 64 个。这里,我们为输入图像的 VGG16 模型中的五个块分别创建五个单独的图。

可视化 VGG16 模型五个主要模块的特征图
运行该示例会产生五个图,显示 VGG16 模型的五个主要模块的特征图。我们可以看到,更接近模型输入的特征映射捕获了图像中的许多精细细节,并且随着我们向模型的更深处前进,特征映射显示的细节越来越少。这种模式是意料之中的,因为模型将图像中的特征抽象成更一般的概念,可用于进行分类。虽然从最终的图像看不出模型看到了一辆汽车,但我们普遍失去了解读这些更深层特征地图的能力。

从 VGG16 模型中的块 1 提取的特征图的可视化

VGG16 模型中从区块 2 提取的特征图的可视化

VGG16 模型中从区块 3 提取的特征图的可视化

VGG16 模型中从区块 4 提取的特征图的可视化

VGG16 模型中从区块 5 提取的特征图的可视化
对于给定的图像,

输入图像
希望您已经获得了一些关于如何在 VGG16 和 VGG19 CNN 模型中提取特征、可视化过滤器和特征图的良好知识。更多精彩文章敬请期待。
从您的三星设备中提取健康数据
从 Samsung Health 导出和解释健康数据
每次你把手机放在口袋里的时候,健康数据都会被收集。无论是苹果还是安卓,这些手机都配有计步器,可以计算你的步数。因此,记录了健康数据。这些数据可能是一个简单的机器学习或其他一些与健康数据相关的项目的免费数据集市。它是你的,可以免费使用!。让我们看看如何从三星 S-Health 应用程序中导出数据。
从手机导出
三星健康应用程序提供数据下载功能。
- 打开健康应用程序
- 打开左侧面板—单击设置轮
- 找到**【下载个人资料】**按钮
- 按照说明(你需要登录)点击下载
- 您将看到查找您的健康数据的位置

导出健康数据的步骤
这可能是最容易做到的事情。但是,理解数据有点复杂。让我们浏览每个文件及其内容,以了解三星健康应用程序如何存储数据。
导出的数据
您将看到下面一组包含数据的文件。您将看到导出时间戳,而不是T。在文件文件夹中,您会看到个人资料图片。在名为 jsons 的文件夹中,可以找到 CSV 文件中引用的数据的 JSON 对象(在本文中我就不说 JSON 了)。请注意,CSV 文件的数据列还将包含包扩展名 com.samsung.health 。然而,为了文本的简单,当我解释 CSV 文件的内容时,我将忽略它。
**com.samsung.health.device_profile.T.csv com.samsung.shealth.preferences.T.csv com.samsung.health.floors_climbed.T.csv com.samsung.shealth.report.T.csv com.samsung.health.food_info.T.csv com.samsung.shealth.rewards.T.csv com.samsung.health.height.T.csv com.samsung.shealth.sleep.T.csv com.samsung.health.sleep_stage.T.csv com.samsung.shealth.social.leaderboard.T.csv com.samsung.health.user_profile.T.csv com.samsung.shealth.social.public_challenge.T.csv com.samsung.health.water_intake.T.csv com.samsung.shealth.social.public_challenge.detail.T.csv com.samsung.health.weight.T.csv com.samsung.shealth.social.public_challenge.extra.T.csv com.samsung.shealth.activity.day_summary.T.csv com.samsung.shealth.social.public_challenge.history.T.csv com.samsung.shealth.activity.goal.T.csv com.samsung.shealth.social.public_challenge.leaderboard.T.csv com.samsung.shealth.activity_level.T.csv com.samsung.shealth.social.service_status.T.csv com.samsung.shealth.best_records.T.csv com.samsung.shealth.stand_day_summary.T.csv com.samsung.shealth.breathing.T.csv com.samsung.shealth.step_daily_trend.T.csv com.samsung.shealth.caloric_balance_goal.T.csv com.samsung.shealth.stress.T.csv com.samsung.shealth.calories_burned.details.T.csv com.samsung.shealth.stress.histogram.T.csv com.samsung.shealth.exercise.T.csv com.samsung.shealth.tracker.heart_rate.T.csv com.samsung.shealth.exercise.weather.T.csv com.samsung.shealth.tracker.pedometer_day_summary.T.csv com.samsung.shealth.food_frequent.T.csv com.samsung.shealth.tracker.pedometer_event.T.csv com.samsung.shealth.food_goal.T.csv com.samsung.shealth.tracker.pedometer_recommendation.T.csv com.samsung.shealth.goal.T.csv com.samsung.shealth.tracker.pedometer_step_count.T.csv com.samsung.shealth.goal_history.T.csv com.samsung.shealth.insight.milestones.T.csv com.samsung.shealth.permission.T.csv
jsons
files**
来自传感器的健康数据

这些文件包含来自传感器的数据,包括来自 Galaxy Watch 和手机本身的心率数据和步数。从计步器和加速度计传感器收集步数。心率是通过手表中的 **PPG(光电容积描记图)**传感器来测量的。对于这些数据,您必须查看以下文件。
心率数据
心率数据包含在以下文件中。
**com.samsung.shealth.tracker.heart_rate.T.csv**
该文件中的重要信息是更新时间和心率栏。您还可以找到最小值和最大值以及显示录制结束的结束时间。

心率信息
出于好奇,我绘制了一张我的心率直方图,看看我的心脏是如何工作的。我的心率似乎在 65-80bp 之间,谷歌搜索的结果是“成年人的正常静息心率在每分钟 60-100 次之间”。我猜直方图是有道理的。当我买手表时,我最关心的一件事就是记录我的心率。因为,通常在医生那里,我有高于平均水平的心率和惊慌失措的人的血压。如果你想了解更多关于医生的情况,请点击这里阅读。

听力比率直方图
步进跟踪器数据

以下文件中提供了步进跟踪器数据;
**com.samsung.shealth.step_daily_trend.202008162231.csv
com.samsung.shealth.tracker.pedometer_step_count.202008162231.csv
com.samsung.shealth.tracker.pedometer_day_summary.202008162231.csv**

每日摘要
在步数每日趋势中,您将看到计步数、消耗的卡路里、行走距离和速度的每日数值。但是,在计步器 _ 步数 _ 计数中,您会找到所有步数信息,包括跑步步数、步行步数。基本上,这个文件包含计步器跟踪信息。在最后一个文件(计步器 _ 日 _ 摘要)中,你可以找到每天的步数摘要。这对于大多数任务来说已经足够了。
我们试着对这些数据做一些简单的分析。

步骤计数与日期
上面的观察结果与澳大利亚的季节变化有点一致。在六月到十二月期间,我们有寒冷的温度。从 12 月到 6 月,我们有更好的跑步天气。然而,新冠肺炎在四月和五月开始在坎培拉演出,因此活动量很低。然而,在六月,我和我的妻子散步并试图恢复身材,这样我们就可以在周年纪念日的时候出去吃很多东西。
步数并不是衡量活动的通用指标。一个人可以在健身房锻炼,不用计算步数,但却燃烧了大量脂肪。这种活动通常使用心率传感器通过卡路里来测量。然而,正如你在下面看到的,我的卡路里数和步数多少有些关联(X 轴有一点偏差,但很接近)。这是因为我唯一喜欢的锻炼是跑步或慢跑。

燃烧的卡路里与日期
有趣的东西是可见的。在我跑步的日子里,我没走多少步。相比之下,在步行的日子里,我走了 10000 多步。我想知道,是我走路的时候累了,还是跑步的步数没有计入每天的步数。不过,我将在另一篇文章中对此进行研究。
其他信息
还有更多信息,包括体重和碳水化合物摄入量。为此,您必须手动记录它们。然而,在下面的文件中有一些有见地的数据。
**com.samsung.shealth.exercise.weather.T.csv**

锻炼天气数据
然而,为了使用这个文件,您必须将它与练习文件结合起来。那是另一篇文章!
我希望这篇文章能对你最常丢弃的数据产生有用的结果。快乐阅读!
在 BigQuery 中提取嵌套结构而不交叉连接数据
分享一个不太常见但非常有用的 BigQuery 标准 SQL 语法的例子
作为一名专注于数据和分析领域的谷歌云顾问,我花了很多时间在 BigQuery 上,这是谷歌云的 Pb 级数据仓库即服务,在很大程度上,我喜欢它。它非常强大,没有基础设施管理,并且具有各种内置的分析和人工智能功能。
但是,由于其列式数据存储的性质,BigQuery SQL 语法有时使用起来并不直观。Google 推荐的查询性能和成本优化的最佳实践是对您的数据进行反规范化,或者换句话说,使用专门的数据类型(如数组和键值存储)将分散在多个表中的数据合并到一个表中。
查询非规范化数据可能比大规模连接数据更高效,但如果你习惯于在规范化的表中处理数据,查询数据就没那么容易了,这是我加入 Cloudbakers 之前的经验。因此,在本文中,我将使用一个与 BigQuery billing export 结构相同的模拟 GCP 计费数据集,介绍 BigQuery 中常见和不常见的非规范化数据结构的查询语法。
基本的结构或键值字段非常简单,因为您可以简单地使用点符号来选择子字段:
-- service is a STRUCT field and id is one of its keys
SELECT service.id AS service_id
FROM `gcp-sandbox.gcp_billing_demo.gcp_billing_export`
LIMIT 1000

查询结果:使用点符号展平的键值对
当处理数组或重复的字段时,事情变得稍微复杂一点。您可以使用数组索引选择数组的单个组件,如果元素的顺序是预先确定的或者无关紧要,这将非常有用(您可以从下面的前两行结果中看到,在这种情况下,顺序不是预先确定的)。
SELECT credits[OFFSET(0)] as credit_offset_0,
credits[OFFSET(1)] AS credit_offset_1
FROM `gcp-sandbox.gcp_billing_demo.gcp_billing_export`
WHERE ARRAY_LENGTH(credits) > 1

查询结果:按索引选择的数组元素
您还可以选择使用所谓的相关交叉连接来扁平化数据。这将接受任何重复的字段,对其进行透视,以便数组中的每个元素都是一个新行,然后将该新的表格数据与原始表连接,为原始重复字段中的每个元素创建一个具有重复行的扁平模式。
SELECT billing.credits,
c.*
FROM `gcp-sandbox.gcp_billing_demo.gcp_billing_export` billing,
UNNEST(credits) c
WHERE ARRAY_LENGTH(credits) > 1

查询结果:由相关交叉连接展平的数组
如果您需要展平数据并基于数组中包含的数据计算聚合值或指标,这将非常有用-例如,如果您需要计算 2019 年 12 月开具发票的 GCP 消费的每种信用类型的总信用额,您将使用以下查询:
SELECT c.name AS credit_type,
SUM(c.amount) AS total_credit_amount
FROM `gcp-sandbox.gcp_billing_demo.gcp_billing_export` billing,
UNNEST(credits) c
WHERE billing.invoice.month = '201912'
GROUP BY credit_type
ORDER BY credit_type

查询结果:由相关交叉连接展平并聚集的数组
但是,如果您只是需要对数组数据进行透视,以便它可以被另一个系统使用或导出到 Excel 或 Google Sheets 等电子表格软件中,该怎么办呢?同样,由于其列式数据存储的性质,BigQuery 不容易支持类似于 Pandas 库的 unstack 方法的语法。
作为一个具体的例子,让我们以 BigQuery billing 导出中四个重复字段中的两个为例:
- 项目标签
- 资源标签
如果您还不熟悉这个概念,项目和资源标签允许您作为一个组织将业务概念和流程应用于 GCP 计算资源。因为应用于您的计算资源的标签会传播到您的计费数据,所以如果您正确且一致地设置标签,您可以按不同的环境、组织部门或计划来分解您的 GCP 成本消耗。您还可以启动一些流程,如向各个部门退款。
长话短说,标签是或应该是你的 GCP 成本管理战略的一个重要方面。这使得 BigQuery billing 导出中的项目标签和资源标签都位于重复的 struct 对象的字段中,或者说是作为键-值对的数组写入表中,这更加令人沮丧。
如果在这种情况下对项目标签进行相关交叉连接,因为成本字段并不包含在项目标签数组中,而信用成本与信用数组中的特定信用类型相关联,所以展平项目标签数据会导致成本字段在每个项目标签中重复一次。如果在资源标签上进行相关交叉连接,情况也是如此。
SELECT project,
project_labels,
cost
FROM `gcp-sandbox.gcp_billing_demo.gcp_billing_export` billing,
unnest(project.labels) project_labels
WHERE cost > 1

查询结果:非数组值重复
如果您尝试在这种情况下进行分组和求和,您的 GCP 成本可能会比实际成本高得多,这取决于您对每个项目应用了多少标签。如果您的表中每一行都有一个唯一的标识符,您可以使用它来连接一个除了一个标签之外过滤掉所有标签的扁平数组,并且可以重复这样做来集成每个不同的项目标签。但是计费数据导出没有唯一的行标识符,所以这不是一个真正的选项。那么你能做什么呢?
所有的希望都没有失去,这要感谢来自 Google Cloud 的 Lak Lakshmanan 的这篇文章,它探索了 BigQuery 中一些强大的查询模式。我强烈建议您阅读整篇文章,但特别是有一个组件我发现有助于解决上述计费问题,那就是应用表达式子查询来解包 BigQuery 表中的嵌套结构对象。您可以在下面的示例中看到如何使用此查询语法拆分项目标签数据,从而创建可以在 BigQuery 或其他数据分析系统中轻松处理的表格结果:
SELECT project.labels,
(
SELECT value
FROM UNNEST(project.labels)
WHERE KEY='creator') AS project_creator,
(
SELECT value
FROM UNNEST(project.labels)
WHERE KEY='account') AS project_account,
cost
FROM `gcp-sandbox-213315.gcp_billing_demo.gcp_billing_export`
WHERE array_length(project.labels) > 0
AND cost > 1

查询结果:使用表达式子查询将嵌套的键值“拆分”到表格数据中
这就是我今天的全部内容——尽管我今天提出的查询不一定非常复杂,但我发现它们很有用(尤其是表达式子查询),希望您也能如此。
用 Python & R 从数据帧中提取行/列
这里有一个简单的 Python 和 R 数据帧操作的备忘单,以防你像我一样对混合两种语言的命令感到不安。

伊丽莎白·凯在 Unsplash 上的照片
我已经和数据打交道很长时间了。然而,我有时仍然需要谷歌“如何在 Python/R 中从数据帧中提取行/列?”当我从一种语言环境转换到另一种语言环境时。
我很确定我已经这样做了上千次了,但是似乎我的大脑拒绝将这些命令储存在记忆中。
如果你需要同时使用 R 和 Python 进行数据操作,你一定知道我的感受。
因此,我想在本文中总结一下 R 和 Python 在从数据框中提取行/列时的用法,并为需要的人制作一个简单的备忘单图片。
注意,为了并排比较命令行,我将只使用 Python 中的 Pandas 和 R 中的基本函数。有些综合库,比如‘dplyr’就不在考虑之列。我正尽力使文章简短。
我们开始吧。
要使用的玩具数据集。
我们将在整篇文章中使用阿伦艾弗森的游戏统计数据玩具数据集。数据帧的尺寸和标题如下所示。
# R
dim(df)
head(df)

r 输出 1
# Python
df.shape
df.head()

Python 输出 1
按位置提取行/列。
首先,让我们用 R 和 Python 从数据框中提取行。在 R 中是通过简单的索引来完成的,但是在 Python 中是通过来完成的。iloc 。让我们看看下面的例子。
# R
## Extract the third row
df[3,]## Extract the first three rows
df[1:3,]
### or ###
df[c(1,2,3),]
这产生了,

r 输出 2
# Python
## Extract the third row
df.iloc[2]
### or ###
df.iloc[2,]
### or ###
df.iloc[2,:]## Extract the first three rows
df.iloc[:3]
### or ###
df.iloc[0:3]
### or ###
df.iloc[0:3,:]
这产生了,

Python 输出 2
请注意,在从数据框中提取单行的示例中,R 中的输出仍然是数据框格式,但是 Python 中的输出是熊猫系列格式。这是 R 和 Python 在从数据框中提取单个行时的本质区别。
类似地,我们可以从数据框中提取列。
# R
## Extract the 5th column
df[,5]## Extract the first 5 columns
df[,1:5]
这产生了,

r 输出 3
# Python
## Extract the 5th column
df.iloc[:,4]## Extract the first 5 columns
df.iloc[:,:5]
### or ###
df.iloc[:,0:5]
这产生了,

Python 输出 3
提取列时,我们必须将冒号和逗号放在方括号内的行位置,这与提取行有很大的不同。
按索引或条件提取行/列。
在我们的数据集中,数据框的行索引和列索引分别是 NBA 赛季和艾弗森的统计数据。我们可以使用它们从数据框中提取特定的行/列。
例如,我们对 1999-2000 年这个季节感兴趣。
# R
## Extract 1999-2000 season.
df["1999-00",]## Extract 1999-2000 and 2001-2002 seasons.
df[c("1999-00","2000-01"),]
这产生了,

r 输出 4
# Python
## Extract 1999-2000 season.
df.loc["1999-00"]## Extract 1999-2000 and 2001-2002 seasons.
df.loc[["1999-00","2000-01"]]
这产生了,

Python 输出 4
请再次注意,在 Python 中,如果我们只提取一行/列,输出是 Pandas Series 格式,但是如果我们提取多行/列,它将是 Pandas DataFrame 格式。
当我们只对列的子集感兴趣时,我们也可以添加列索引。
# R
## Extract Iverson's team and minutes played in the 1999-2000 season.
df["1999-00",c("Tm","MP")]
这产生了,

r 输出 5
# Python
## Extract Iverson's team and minutes played in the 1999-2000 season.
df.loc["1999-00",["Tm","MP"]]
这产生了,

Python 输出 5
除了通过索引提取行/列,我们还可以根据条件进行子集化。比如我们想提取艾弗森上场时间超过 3000 分钟的赛季。
# R
## Extract MP over 3k
df[df$MP > 3000,] ## the comma cannot be omitted
这产生了,

r 输出 6
# Python
## Extract MP over 3k
df.loc[df.MP > 3000,:] ## both the comma and colon can be omitted
这产生了,

Python 输出 6
当然,更复杂的条件可以传递给方括号,它只需要一个 True/False 列表,其长度为数据帧的行号。
比如我们要提取艾弗森真实投篮命中率(TS%)超过 50%,上场时间超过 3000 分钟,位置(Pos)不是得分后卫(SG)就是控卫(PG)的赛季。
# R
## Extract rows with TS.> 50%, MP > 3000 and Pos is SG/PG### define condition as cond_
cond_ = (df$TS. > 0.5) & (df$MP > 3000) & (df$Pos %in% c("SG","PG"))
df[cond_,]
这产生了,

r 输出 7
# Python
## Extract rows with TS.> 50%, MP> 3000 and Pos is SG/PG### define condition as cond_
cond_ = (df["TS."] > 0.5) & (df["MP"] > 3000) & (df["Pos"].isin(["SG","PG"]))df.loc[cond_,:] ## both the comma and colon can be omitted
这产生了,

Python 输出 7
我们可以在“cond_”位置应用任何类型的布尔值。
备忘单图像。
这是一个备忘单,我希望当你像我一样同时使用 Python 和 R 时,它能节省你的时间。

Cheatsheet by 俞峰
就是这样!对 R/Pandas 中的表切片的简单总结。希望有帮助!
感谢您的阅读!如果你喜欢这篇文章,请在 上关注我的 。以下是我之前在数据科学发表的一些文章:
一个关于如何在 r 中用 pheatmap 生成漂亮的热图的教程。
towardsdatascience.com](/pheatmap-draws-pretty-heatmaps-483dab9a3cc) [## 给出了随机森林分类器的特征重要性
如何建立一个随机森林分类器,提取特征重要性,并漂亮地呈现出来。
towardsdatascience.com](/present-the-feature-importance-of-the-random-forest-classifier-99bb042be4cc) [## 使用三种机器学习模型基于勒布朗数据的端到端游戏预测方案
综合指导一个二元分类问题使用三个不同的分类器,包括逻辑…
towardsdatascience.com](/end-to-end-project-of-game-prediction-based-on-lebrons-stats-using-three-machine-learning-models-38c20f49af5f) 
提取、转换、加载(ETL) — AWS 粘合
了解如何在 Spark 中对新的 Corona 病毒数据集使用 AWS Glue 进行 ETL 操作


AWS Glue 是一个完全托管的、无服务器的 ETL 服务,可用于为数据分析目的准备和加载数据。该服务可用于对数据进行编目、清理、丰富,并在不同的数据存储之间可靠地移动数据。在本文中,我将解释我们如何使用 AWS Glue 在 Spark 中对新的 Corona 病毒数据集执行 ETL 操作。
本文将涵盖以下主题:
- 粘合组件。
- 完成教程作者胶水火花工作。
- 从 S3 自动气象站提取数据。
- 使用 Spark 转换数据。
- 将转换后的数据以拼花格式存储回 S3。
粘合组件
简而言之,AWS 胶水包含以下重要成分:
- **数据源和数据目标:**作为输入提供的数据存储称为数据源,存储转换数据的数据存储称为数据目标。
- **数据目录:**数据目录是 AWS Glue 的中央元数据存储库,在一个地区的所有服务之间共享。这个目录包含表定义、作业定义和其他控制信息,用于管理您的 AWS Glue 环境。
- **爬虫和分类器:**爬虫是从数据存储中检索数据模式的程序(s3)。Crawler 使用自定义或内置分类器来识别数据格式,并填充目录中的元数据表。
- **数据库和表:**每次成功的爬虫运行都会在数据目录中填充一个数据库表。目录中的数据库是一组相关联的表。每个表只有数据的元数据信息,如列名、数据类型定义、分区信息,而实际数据保留在数据存储中。在 ETL 作业运行中,源和目标使用数据库中的一个或多个表。
- **作业和触发器:**执行 ETL 任务的实际业务逻辑。作业由转换脚本、数据源和数据目标组成。我们可以用 python 或 pyspark 来定义我们的工作。作业运行由触发器启动,这些触发器可以由事件计划或触发。
我留下了一些组件,因为它们不在本文的讨论范围之内。关于 AWS Glue 的详细研究,你可以访问官方的开发者指南。
在 AWS Glue 上使用 PySpark 的 ETL
现在我们已经了解了 Glue 的不同组成部分,我们现在可以开始讨论如何在 AWS 中创作 Glue 作业,并执行实际的提取、转换和加载(ETL)操作。
新型冠状病毒数据集:
数据集是从 Kaggle 数据集中获得的。我正在使用的版本最后更新于 2020 年 5 月 2 日。该数据集中的主文件是covid_19_data.csv,数据集的详细描述如下。
- Sno —序列号
- 观察日期—观察的日期,以年/月/日为单位
- 省/州-观察的省或州(缺少时可以为空)
- 国家/地区—观察国
- 上次更新时间—以 UTC 表示的给定省份或国家/地区的行更新时间。(未标准化,因此请在使用前清洁)
- 已确认——截至该日期的累计已确认病例数
- 死亡——截至该日期的累计死亡人数
- 已恢复—截至该日期已恢复案例的累计数量
1)设置我们的数据存储:
作为开发端到端 ETL 工作的第一步,我们将首先设置我们的数据存储。转到 yout s3 控制台,并在那里创建一个存储桶。我们将使用以下分区方案在 bucket 中上传数据集文件:
s3://bucket-name/dataset/year=<year>/month=<month>/day=<day>/hour=<hour>/
现在我们正在处理单个文件,所以你可以手动创建分区和上传文件,但如果处理大量文件,你可以使用我的 FTP 文件摄取代码,我在我的上一篇文章中解释为你做这项工作。在使用 AWS Athena 时,以这种方式对数据进行分区有助于查询优化。

2)创建 AWS 粘合角色
创建一个 Glue 角色,允许 Glue 访问不同的 AWS 资源,例如 s3。转到 IAM 控制台,添加一个新角色,并将 AWSGlueServiceRole 策略附加到该角色。此策略包含访问 Glue、CloudWatch、EC2、S3 和 IAM 的权限。有关如何为 Glue 设置 IAM 角色的更多细节,请考虑下面的链接。
3)设置爬虫来编目数据
执行以下步骤来添加 crawler:
- 在左侧菜单中,单击数据库并添加一个数据库。

- 现在去爬虫和一个新的爬虫

- 选择数据存储

- 提供 s3 存储桶路径


- 选择粘合角色

- 设置按需运行的频率

- 选择数据库


- 最后检查并单击“完成”

- 现在,您的爬虫已经创建好了。单击“运行 Crawler”对数据集进行编目

- Crawler 可能需要一些时间来对数据进行分类。成功运行后,必须在指定的数据库中创建表




4)为 ETL 工作添加胶合工作
既然我们已经编目了我们的数据集,现在我们可以开始添加一个粘合工作,它将在我们的数据集上完成 ETL 工作。
- 在左侧菜单中,单击“作业”并添加一个新作业。Glue 可以自动生成一个 python 或 pyspark 脚本,我们可以用它来执行 ETL 操作。然而,在我们的例子中,我们将提供一个新的脚本。

- 按如下方式设置作业属性

- 将以下内容保留为默认值


- 将最大容量设置为 2,作业超时设置为 40 分钟。您设置的 dpu 数量(最大容量)越高,您将承担的成本就越多。


- 因为我们没有连接到任何 RDBMS,所以我们不必设置任何连接。单击“保存作业并编辑脚本”。

- 我们将看到以下屏幕。将我的 GitHub 库中的代码复制粘贴到下面的编辑器中,点击保存。现在,单击“运行作业”按钮。

- 根据工作的不同,执行作业可能需要一段时间(在本例中为 15 到 30 分钟)。到目前为止,胶合作业有至少 10 分钟的冷启动时间,之后作业开始执行。

- 如果作业执行成功,您将在胶合作业中指定的目标桶中获得拼花格式的聚合结果。


了解 Spark 工作
如果您遵循了上面提到的所有步骤,那么您应该可以通过 AWS Glue 成功执行 ETL 作业。在这一节中,我将深入研究执行实际 ETL 操作的 Spark 代码。
胶水和火花导入和参数
在最顶端,我们有必要的胶水和火花进口。
导入后,我们有几个参数设置。这包括获取作业名、设置 spark 和 glue 上下文、初始化作业、定义目录数据库和表名以及 s3 输出路径。
提取
ETL 操作的“提取”部分除了连接到某个数据存储并从中获取数据之外什么也不做。代码的提取部分执行以下操作:
- 使用粘附目录中的创建粘附动态框架。已经提供了目录数据库和表名。
- 创建动态帧后,我们使用 toDF() 方法将其转换为 Spark 数据帧。转换为 spark 数据帧将允许我们使用所有的 spark 转换和动作。
改变
在 ETL 操作的“转换”部分,我们对数据应用不同的转换。代码的转换部分执行以下操作:
- 首先,我们在 spark 中使用 drop() 方法删除“最后更新”列(没有特殊原因)。
- 然后使用 spark 中的 dropna() 方法删除任何包含 4 个以上空字段的行。
- 然后,我们使用 spark 中的 fillna() 方法,用自定义值“na_province_state”填充“province/state”列中缺少的值。
- 接下来,我们对数据集执行聚合。已经执行了 3 个不同的聚合。我们检查一个国家/地区的哪个省/州有最多的病例、最多的死亡和最多的康复。这是通过使用 groupBy() 方法将记录按省/州和国家/地区列分组,使用 max() 方法将记录与 **max(已确认)、max(死亡)和 max(已恢复)**列聚合,然后使用 orderBy() 方法将它们按降序排序来完成的。
- 最后,我们使用 fromDF() 方法将数据帧转换回 Glue DynamicFrame,并将结果保存在 S3 中。它接受三个参数 dataframe、glue 上下文和结果 DynamicFrame 的名称。
加载
在 ETL 操作的加载部分,我们将转换后的数据存储到一些持久存储中,比如 s3。代码的加载部分执行以下操作:
我们使用 DynamicFrame()的 from_options() 方法将结果保存到 s3。该方法采用以下参数:
- frame :我们要写的 DynamicFrame。
- connection_type :我们正在写入的目标数据存储,在本例中是 s3。
- connection_options :这里我们指定目标 s3 路径和数据格式(本例中为 parquet)来保存数据。
- transformation_ctx :可选的转换上下文。
所有 3 个聚合结果都以拼花格式保存在目标路径上。
摘要
在本文中,我们学习了如何使用 AWS Glue 在 Spark 中进行 ETL 操作。我们学习了如何设置数据源和数据目标,创建爬虫来编目 s3 上的数据,并编写 Glue Spark 作业来执行提取、转换和加载(ETL)操作。
完整的 spark 代码可以在我的 GitHub 资源库中找到:
[## furqanshahid 85-python/AWS-Glue-Pyspark-ETL-Job
该模块对 noval corona 病毒数据集进行统计分析。具体实施如下…
github.com](https://github.com/furqanshahid85-python/AWS-Glue-Pyspark-ETL-Job)
感谢你阅读❤.
利用 Tesseract 和 OpenCV 从 RAOB 软件生成的图像中提取空气稳定指数数据
如何正确裁剪图像以提高立方体性能的说明

作者图片
动机
RAOB 探空仪是气象学家处理高空数据的主要软件。气象学家用它来绘制当地的大气分布图,并获得当地大气的稳定指数,以帮助他们预测天气。大多数情况下,我们需要大量处理这些指数数据,例如,在 30 年内对其进行平均以获得正常值,在地图上绘制(来自多个地方的指数)。问题是,这些指标出现在当地大气剖面图旁边的图像中。所以,你需要记下每一张 RAOB 图像中的每一个索引,然后才能处理它。这是一项非常平凡和令人疲惫的任务。我们需要一个工具来从图像中自动提取这些索引。
宇宙魔方来了

宇宙魔方是一种光学字符识别工具。使用是将图像中的文本数据提取到文本文件或你需要的任何东西中。你可以在这里找到它。让我们安装并测试它。让我们看看它的性能是否与下图相符。

这是结果

结果很完美!让我们看看它是否能处理真实的 RAOB 图像。我们将使用这个样本图像。

作者图片
结果是

因为它的源图像不是结构化的文本图像,所以很明显这里提取的字符串的结果是混乱的。我们不能把它用于我们的计划。此外,这里有一些被 tesseract 错误识别的字符,并且几乎所有我们想要提取的索引字符串都没有被提取。
每个目标检测/识别算法总是定义其感兴趣区域(RoI) 。如果它的 ROI 是混乱的,那么它被错误识别的可能性就更大。让我们通过使用 tesseract 包装库来看看它的 RoI,这里我们将使用pytesseract。这是代码
结果是

看,它的投资回报率非常混乱。有一些图像不是一个角色,但却成为 RoI-ed。我们要提取的只是这里的这一段(下面红框中的那一段)。

我的猜测是宇宙魔方的性能变得很差是因为在原来的 RAOB 图像中有许多“干扰”。让我们看看,如果我们裁剪图像,只留下下面的索引部分。

让我们用这张图片来看看宇宙魔方的投资回报率。

我们从这张图片中得到的字符串是

还是穷。让我们裁剪图像,只留下一个包含 1 个索引的字符串。

运行宇宙魔方,结果是

当不再有“干扰”时,它终于完美地提取了索引。所以现在我们需要自动裁剪原始图像,只留下每个现有索引的索引字符串。我们做了一个硬代码来自动裁剪图像,但是当图像有微小的变化时,我们必须重新校准代码。让我们做一个更优雅的解决方案。我们将使用相似性度量算法。我们必须提供一个字符串索引的图像样本,并将其与整个原始图像进行匹配,以找到索引字符串的位置。
OpenCV 拯救世界
实际上,我们从一开始就已经使用 OpenCV 来读取图像文件。现在,我们将使用 OpenCV 函数matchTemplate()来匹配我们裁剪的字符串索引,以找到索引值的位置。找到位置后,扩展它的裁剪区域以包含索引值,然后裁剪它并将其提供给宇宙魔方,这样它就可以提取索引值。例如,我们想用这个图像模板提取对流层顶的数据。

在我们找到它的位置后

扩大种植的“面积”

把它输入宇宙魔方,我们就得到了数据。哦,不!我不知道为什么,但是在我们裁剪图像后宇宙魔方不能识别任何字符。可能是因为裁剪图像部分的区域太窄。那为什么之前的裁剪被宇宙魔方成功识别?不知道,那张图片是我用 pinta手动裁剪的。
根据这个猜测,我们添加了一个大的白色画布作为裁剪图像的背景。

让我们用宇宙魔方提取这个图像,结果是

字符串被完全识别。这是我们将用来自动提取 RAOB 图像中的索引数据的算法。对于这个任务,我们将使用pytesseract来提取 RAOB 图像。
从 RAOB 图像中提取索引
这里是提取 RAOB 图像中的索引的完整代码
在extract_str()中,我添加了一些代码来清理一些被宇宙魔方错误识别的字符。
让我们用我们的原始图像来试试这个代码。

结果是

很少有错误识别的字符,并且一些索引没有被检测到。总的来说这比我们的第一次尝试要好。
让我们试着用同样的图片,但是不同的是我截屏了 RAOB 的显示,而不是使用从 RAOB 生成的图像。

作者图片
结果是

一样。因此,我们的代码足够持久,可以提取 RAOB 图像中的索引,尽管图像中有细微的差异。此处本帖中我们实验的完整资源库。
收场白
这是我们第一次尝试从图像中提取字符。这远非完美。嗯,也许下次我会用 CNN,用 RAOB 使用的字体训练它。另一篇文章再见。
参考
http://opencv-python-tutro als . readthe docs . io/en/latest/py _ tutorials/py _ img proc/py _ template _ matching/py _ template _ matching . html2020 年 8 月 16 日访问
提取 OpenCV 人脸检测 DNN 模型的系数

图片来自 pixabay.com
最新的 OpenCV 包括一个深度神经网络(DNN)模块,它带有一个很好的预先训练的人脸检测卷积神经网络(CNN)。与 Haar 等传统模型相比,新模型提高了人脸检测性能。用于训练新模型的框架是 Caffe。然而,一些人试图在其他地方使用这种预先训练好的模型时遇到了困难,例如在英特尔的神经计算棒上运行它,将其转换为其他框架中的模型等。原因主要是自模型被训练以来,Caffe 发生了相当大的变化,使得预训练的模型与最新的 Caffe 版本不兼容。在这篇文章中,我将向您展示一种快速简单的方法,通过提取所有预先训练的神经网络系数,将模型移植到最新的 Caffe 中。
基本想法是两个步骤:
1.提取 OpenCV DNN 人脸检测器中所有神经网络层的系数。
2.使用最新的 Caffe 创建新的神经网络,将提取的系数插入其中,并保存新模型。
使用下面的脚本可以完成步骤 1。
在 pickle 文件中卸载每个网络的参数
在上面的脚本中,opencv_face_detector.prototxt是模型配置文件,opencv_face_detector_model.caffemodel是带有训练系数的实际模型文件。详细解释可以在 OpenCV 的官方 Github repo 中找到。
使用下面的脚本可以完成第 2 步。
将参数加载到新咖啡馆
一旦您使用新的咖啡馆保存了模型,它现在就与新的咖啡馆兼容了。
我希望这个小技巧对你们有帮助😄。
从蜘蛛图中提取数据
当原始数据只存在于图表中时
通常,当人们发表研究时,他们不会分享原始数据集。通常,这些数据集具有更严格的访问权限。我以前遇到过这个问题,我想重新组织一些数据,所以我做了一个半手工的过程来从发布的图表中提取数据。这个问题出现在一个更复杂的图形上,即蜘蛛图。
咖啡分数显示为一个蜘蛛图。我想从一个有 300 多个咖啡得分的数据集中提取,但是所有的数据都在一个蜘蛛图中。这个数据集是以前由Sweet Maria’s出售的所有咖啡的档案,我通常从他们那里购买我的绿咖啡。他们没有将数据保存在数据库中,我对挖掘这些数据很感兴趣。与编写代码从图表中提取数据相比,我可以用更少的时间手动输入数据,但是我担心会感到无聊和出错。
我在这里解释了如何提取数据并测量每个指标的潜在错误率。我能够得到非常精确的数字,误差在 0.05 以内,所以 8 分的误差在 0.6%左右。

来自https://www . sweet marias . com/Burundi-dry-process-gate Rama-aga hore-6431 . html经他们同意
方法学
我拿起图像,把它编入一个 16 色的小色图。这使得蓝色的数据行很容易分割出来。然后图中的其他线是相似的灰色,我可以把它们分开。我还确保对所有图像使用相同的颜色图,以减少因颜色轻微变化而产生的误差。


作者提供的图片
从环中,我标记了阈值处理后的所有对象。对于每个对象,我填充了对象(在应用了形态学闭合操作之后),并计算了圆的面积。我还确定了该对象是否包含所有对象的整体质心。然后我通过在一个范围(最小尺寸,最大尺寸)内找到那些物体的最大和最小,找到了内环(分数 6 级)和外环(分数 10 级)。


作者提供的图片
使用形态学闭合操作以及随后的骨架操作来稍微修改刻划线。结果是,对于高频点(或大的过渡),该点被稍微平滑,这引入了一些误差。
在这里,我用粉紫色的环和绿色的线标出分数。对于内部和外部对象,使用最佳拟合圆霍夫变换来制作环。

作者图片
利用每个分数的已知程度位置,我使用上面的简单等式来计算每个分数。
数据误差
我计算出总分,并用手记录下了每张唱片的纸杯校正。我计算总分,并将其与我已经手动提取的总分进行比较。该差值除以 10 个指标,如下所示:

作者图片
大多数误差低于 0.1 甚至 0.05,这意味着误差在四舍五入到 1 位有效数字后很可能不会出现。
图像处理工具对于业余爱好类型的任务非常有用,对于从事艺术的人来说,这是一项非常直接的任务。我很高兴我花时间制作了这个提取工具,而不是手动提取数据,因为这更能激发智力,而不一定能节省时间。
如果你愿意,可以在 Twitter 和 YouTube 上关注我,我会在那里发布不同机器上的浓缩咖啡视频和浓缩咖啡相关的东西。你也可以在 LinkedIn 上找到我。
我的进一步阅读:
使用 Pandas 和 regex 从半结构化推文中提取数据
使用系列字符串函数和正则表达式从文本中提取数字数据

今天,我们将华盛顿州渡轮推文转化为以小时为单位的等待时间。推文有一些结构,但似乎不是自动化的。目标是转变:
- Edm/King —埃德蒙兹和金斯敦码头状态—等待 2 小时
- Edm/King —金斯敦码头状态—等待两小时
- Edm/King —埃德蒙兹终端状态—等待一小时
- Edm/King —离开埃德蒙兹的司机无需长时间等待
- Edm/King —从金斯敦和埃德蒙兹出发需等待一小时
输入特定位置的等待时间(以小时为单位)(例如,埃德蒙兹:2,n/a,1,0,1。金斯敦:2,2,不适用,不适用,1。)
有趣的是,还有一些更不标准的推文:
- Edm/King —更新—埃德蒙兹和金斯敦码头状态,2 小时 Edm,1 小时 King
- EDM/King——在金斯敦没有长时间等待——在埃德蒙兹等待一小时,晚班船
- Edm/King —金斯敦早上 6:25 发车取消。一小时,等等
- EDM/King——从埃德蒙兹或金斯敦出发不再需要长时间等待
- Edm/King —埃德蒙兹和金斯敦码头状态—等待 2 小时
- Edm/King —埃德蒙兹终端状态—等待 90 分钟
- Ed/Ki —埃德蒙兹等待时间— 60 分钟
您可以看到,这是一个非常特殊的任务,但它可以转移到各种设置,例如 1)操作 Pandas 字符串系列数据,2)使用正则表达式在字符串中搜索目标信息。所以我们去兜兜风吧!

用熊猫操纵弦系列
在任何清理之前,我的推文实际上(大部分)遵循这样的模式:Edm/King——无论什么——无论什么……有时[没有] WSP 登机牌……链接到华盛顿州轮渡通知页面”。我想删除这些对我当前意图无用的部分,以得到我需要的位置和时间数据。
pandas 通过 Series.str.method()方便地提供了各种字符串处理方法。点击查看总结文档。向上滚动查看更多创意和使用细节。
在这种情况下,我使用了.str.lower()、.str.strip()和.str.replace()。注意.str.replace()默认为 regex=True,不像基本的 python 字符串函数。
# changing text to lowercase and removing the url,
df['tweet_text'] = df['tweet_text'].str.lower()\
.str.replace('https:.*', '')# removing route indicator ('edm/king -'), extra whitespace
df['tweet_text'] = df['tweet_text'].str.replace('edm/king -', '')\
.str.strip()# removing wsp boarding pass indicataor
wsp = ', no wsp boarding pass required|, wsp boarding pass required'
df['tweet_text'] = df['tweet_text'].str.replace(wsp, '')
我还用它将我的列名从[‘Tweet permalink ‘,’ Tweet text ‘,’ time’]修改为[‘tweet_permalink ‘,’ tweet_text ‘,’ time’]
df.columns = df.columns.str.lower().str.replace(‘ ‘, ‘_’)

Jordan Steranka 在 Unsplash 拍摄的照片
使用正则表达式(regex)
正则表达式。包含带有或的()
我想说,如果 tweet.contains(‘1 ‘或’ 1 ‘或’ 60 分钟’),那么返回 1。
不幸的是,python 字符串没有方法.contains()。您可以使用bool(string.find() +1)来解决这个问题。但是这个不支持正则表达式。所以我的代码应该是这样的:
if (bool(tweet.find('1') +1) or bool(tweet.find('one') +1)
or bool(tweet.find('60 minute')):
return 1
取而代之的是正则表达式,我将我的 bool 转换计数减少到 1:
if bool(re.search('1|one|60 minute', tweet)): return 1
请注意,如果您只是检查一个字符串在另一个字符串中,您可以像这样使用基本 python 的in:
if 'one' in tweet:
正则表达式匹配多种方式来表达同一件事
完全披露,这需要一点点的试验和错误为我的情况。在识别出其中包含等待时间的推文后,我想对没有(延长)等待的推文进行适当的分类,并将它们与没有等待时间的推文(“埃德蒙兹码头等待时间标志停止服务”)和碰巧没有等待时间的推文(“金斯敦码头等待时间——一小时”)区分开来。没有 wsp 登机牌”)。
这里你需要在你的文本中寻找模式。我决定使用“no”后跟不确定数量的字符(在正则表达式句点(。)代表任何字符,星号(*)代表任何重复次数),后跟“等待”。
bool(re.search('no.*wait', text))
在评估等待时间之前,我确实切断了非常常见的“[不] wsp 登机牌”和华盛顿州渡轮更新网页的持续链接。这有助于简化文本搜索过程,减少意外匹配导致的错误机会。
额外提示:将多个 csv 加载到单个数据帧中。使用glob获取所有匹配正则表达式路径名的文件。在这种情况下,我需要数据文件夹中以 csv 结尾的所有文件。从那里,您可以读取它们中的每一个(这里有一个元组理解和pd.read_csv(),并使用pd.concat()将它们连接在一起
import globall_files = glob.glob("./data/*.csv")df_from_each_file = (pd.read_csv(f) for f in all_files)
df = pd.concat(df_from_each_file, ignore_index=True)
像往常一样,查看 GitHub repo 中的完整代码。编码快乐!

在 Unsplash 上由 Lidya Nada 拍摄的照片
从科学论文或图像中提取(数字化)数据

西印度群岛进出口图表(1700-1780)——w . play fair。来源: WikiCommons
我们经常看到感兴趣的图形,并希望将数据应用到我们自己的兴趣和设计中。这种情况经常发生在学术界,在学术界,研究需要与科学期刊和数据可视化中已经存在的研究进行比较,在数据可视化中,历史数据可以被建立和改进(通过添加新的数据/设计)。
我们如何提取数据
从图像中提取数据称为数字化。这是将模拟数字转换成量化的数字(数值)格式,用于操作和分析。
最简单的过程是定义一个图中的数据范围,并计算其中一条绘制线上的点的值。为此我们可以利用*【WPD】。*
webplot 数字化仪的使用案例
这可以与从 2D (X-Y)图到条形图,三元和极坐标图的绘图范围。WPD 基于网络的本质意味着它可以在一系列操作系统甚至在线界面上运行。您可以在以下网址获得此信息:
*[https://automeris.io/WebPlotDigitizer/](https://automeris.io/WebPlotDigitizer/)*
在这篇文章中,我们举了一个数字来说明在 1700 年到 1780 年间从西印度群岛的贸易中进口和出口的利润。这是 W. Playfair 手绘的可爱图形。在下面的部分中,我们描述了数字化图形的过程,然后用 python 提供了几个提取数据的快速绘图。
数字化过程
使用 WPD 软件,一般的数字化过程相对简单。算法功能隐藏在后台,用户只需在界面上更改少量“点击”参数。这一过程概述如下:
- 点击
file>Load Image>select the type of plot并上传您的图像。 - 对于
x-y图,选择您的边界。首先是最小已知 x 值*,然后是最大已知 x 值,接着是*最小和最大已知 y 值** - 输入已知点的值,并选择是否使用了
log秤(您可以在按下确认按钮后添加额外的配置点。) - 调整设置,如
mask(选择要探索的区域)、foreground(线条)和background颜色,以及pixel sampling间隔—注意,有时像素采样间隔内较大的平均区域会产生更好的结果(在示例中使用了 30 个像素)。 - 点击算法框内的
run。
这将产生如下所示的选择。

WebPlotDigitizer 在线界面的屏幕截图。
数据管理
最后,我们可以提取生成的逗号分隔文件(CSV)用于在另一个程序(如 JS、Python、R …)中绘图。python 中使用 pandas 的一个快速示例如下:



左:选择出口线。中间:进口和出口的折线图。右侧:显示两个值之间差异的堆积面积图。
结论
webplot 数字化仪是非常简单的使用程序,有许多实际应用。它的 HTML 和 javascript 特性使它既能在线运行,也能在大多数流行的操作系统上运行。最后,从出版物中提取数据的能力(尤其是原始数据丢失的出版物)使其成为现代科学家的无价工具。
从 Covid 的新闻中提取特征:时间序列文本数据建模的简单词袋方法|新冠肺炎文章 2
新冠肺炎文字分析
编者注: 走向数据科学 是一份以研究数据科学和机器学习为主的中型刊物。我们不是健康专家或流行病学家,本文的观点不应被解释为专业建议。想了解更多关于疫情冠状病毒的信息,可以点击 这里 。
这是我之前博客的续篇,在那里我探索了出现在印度媒体与新冠肺炎相关的新闻文章中的词汇。在本文中,我对文本进行了进一步的探索,并尝试使用词袋(BoW)方法在从文本中提取的特征之间建立显著的相关性。
关于数据源:
- **新闻文章数据:**新闻文章是用 NewsAPI 的 开发者计划刮出来的。日期范围为2020 年 3 月 10 日至 4 月 10 日对于本文,数据集每月增长。
- Covid 病例数据: 维基百科关于新冠肺炎·疫情在印度的文章
关于资料准备和基础探索:
在我之前的博客中记录了这个关于新冠肺炎数据的系列。它使用传统的记号化、词条化和清理过程,使用 nltk 和 Stanford CoreNLP 。
[## 探索印度媒体中关于新冠肺炎的新闻| NLP| Wordcloud |新冠肺炎文章 1
新冠肺炎改变了全球流行语。在本文中,我研究了我的印度新闻文章数据集,内容是关于…
towardsdatascience.com](/exploring-news-about-covid-19-in-indian-media-nlp-wordcloud-covid-19-article-1-2bcbb127dfb3)
背景:我到底想在这里实现什么?
这也是对所产生的时间序列数据的试验性研究,该数据仅由 30 个数据点组成。我的目标是提取诸如每日新闻量、与医疗保健、新冠肺炎和中央政府相关的每日令牌量等特征,并评估它们与 Covid 病例计数之间是否存在任何强相关性。
入门:
1.设置时间序列数据集:
我从维基百科的 excel 文件中提取了 covid 病例和死亡人数数据,并将其读入我的 Jupyter 笔记本。接下来,从我以前的博客中创建的数据集,我通过分组和统计每天发布的新闻数量来提取新闻量,并将它们合并。
代码:
**import** pandas **as** pd**# Read the data in**
df_covid_stats = pd.read_excel('covid_stats.xlsx')
df = pd.read_pickle(text_data_pickle_file_path)**# Group daily and count news volume**
df_news_vol=df[['published_at','title']].groupby(by='published_at')
.count().reset_index()
df_news_vol.columns = ['published_at', 'News Volume']# Merge Covid-19 stats with news volume data
df_merged = pd.merge(df_news_vol, df_covid_stats,
left_on='published_at', right_on='Date')
df_merged.head(5)
合并后的数据集如下所示:

合并数据的快照。
2.时间序列图:
然后,我绘制了这些点,以可视化和观察这三十天数据的模式。我不想拘泥于传统的折线图,所以下面是棒棒糖时间序列图的代码。看起来很整洁!!
代码:
**from** matplotlib.lines **import** Line2D
**import** matplotlib.pyplot **as** plt
**import** matplotlib **as** mpl
**import** seaborn **as** sns**# initializing configs**
columns = ['News Volume', 'Total Cases', 'Total Death']
colors = ['black', '#007acc', '#4db8ff']
custom_text = "Some Text"
plt.style.use('seaborn-darkgrid')
fig, ax = plt.subplots(figsize=(16,10), dpi= 80)**# Plot each column using the configs**
for i, column in enumerate(columns):
ax.vlines(x=df_merged.index, ymin=0, ymax=df_merged[column],
color='grey', linewidth=1, alpha=0.5)
ax.scatter(x=df_merged.index, y=df_merged[column], s=75,
color=colors[i])**# Setting up Title, Label, XTicks and Ylim**
ax.set_title('News Volume, Covid Cases and Deaths',
fontdict={'size':22})
ax.set_ylabel('News Volume')
ax.set_xticks(df_merged.index)
ax.set_xticklabels(df_merged.index.date, rotation=60,
fontdict={'horizontalalignment': 'right',
'size':12})
ax.set_ylim(bottom=0)**# Setting up Legends**
legend_elements = [Line2D([0], [0], marker='o', color='black',
label='News Volume', markersize=10),
Line2D([0], [0], marker='o', color='#007acc',
label='Total Cases', markersize=10),
Line2D([0], [0], marker='o', color='#4db8ff',
label='Total Death', markersize=10)]
ax.legend(handles=legend_elements, loc='upper left'plt.show()
时间序列图:

观察:
很明显,covid 病例数和死亡数在关注期内将呈指数级增长。但是,有趣和令人沮丧的是,新闻文章并没有显示出随着 covid 病例或死亡人数的变化。相反,如果你能发现,在新闻量数据中有三到五天的上升和下降周期模式。此外,在 covid 病例开始时,数量保持上升趋势,这也是一种预期行为。新闻数量随后保持一个均匀的水平,略有下降趋势,不再上升。所以,我们需要更多的数据!这有点道理,除了你可能已经注意到的异常值(我无法修复,因为我在开发计划中),但这个图表肯定会随着时间的推移而改善。
3.定义单词包特征和容量
因此,在这一步中,我直观地收集了一些与 covid、医疗保健和中央政府相关的令牌作为我的 BoW 特征,并循环浏览新闻标题,以获得每个 BoW 组的每篇新闻文章的这些令牌的计数。然后,我将每天的计数进一步分组,并将它们相加,得出我的时间序列特征。
代码:
**# Bag-of-Words**
covid_words_list = ['covid-19','corona', 'coronavirus']
central_government_list = ['government', 'modi', 'pm']
healthcare_list = ['doctor', 'healthcare', 'vaccine', 'cure',
'hospital', 'test', 'testing']**# Iteration Function**
def token_counts(x, words_list):
title_tokens = x[0]
if len(words_list) == 1:
return title_tokens.count(words_list[0])
elif len(words_list) >1 :
return sum([title_tokens
.count(each_word) for each_word in words_list])
else:
raise Exception("Recheck Wordlist")**# Applying lambda function to apply token_counts() on each row** df['Covid Count'] = df.title_cleaned.apply(lambda x: token_counts(x,
covid_words_list))
df['Central Gov Count'] = df.title_cleaned.apply(lambda x:
token_counts(x, central_government_list))
df['Healthcare Count'] = df.title_cleaned.apply(lambda x:
token_counts(x, healthcare_list))df_bow_extended = df[['Covid Count', 'Central Gov Count',
'Healthcare Count','published_at']]
.groupby(by='published_at')
.sum().reset_index()
df_bow_extended
分组数据:

顺便说一下…
我的弓看起来很简单,不是吗?查看下面的“后续步骤”部分。我将在接下来的博客中为我的弓做一些主题建模,这些博客将会有更多的数据点和标记来实验!

Ayo Ogunseinde 在 Unsplash 上拍摄的照片
4.连接完整的数据并绘制时间序列
接下来,我将这些特征与之前的我的时间序列数据集合并,生成了下面的时间序列图,以便直观地寻找模式。这一次,我使用普通的多线图表,以避免不必要的混乱,因为有六条线进行观察。
代码:
plt.close()**# Setting up Configs**
columns = ['News Volume','Total Cases', 'Total Death']
columns_bow = ['Covid Count', 'Healthcare Count',
'Central Gov Count']
colors = ['black', '#007acc', '#4db8ff']
colors_bow = ['#cc3300', '#0000e6', '#ff8533']plt.style.use('seaborn-darkgrid')
fig, ax = plt.subplots(figsize=(15, 10), dpi=100)**# Plotting the Time-Series**
for i, column in enumerate(columns):
ax.plot('published_at', column, '--', data=df_merged_extended,
color=colors[i], alpha=0.5)for i, column in enumerate(columns_bow):
ax.plot('published_at', column, data=df_merged_extended,
color=colors_bow[i], linewidth=2)**# Setting up Title, XTicks, Xlim, Ylim and Legend**
plt.title('Covid Cases and Deaths, News Volume and BOW Features from
10th March to 10th April, 2020')
plt.xticks(rotation=45)
plt.ylim(0, 900)
plt.xlim(min(df['published_at']), max(df['published_at']))
# print(ax.get_xlim())
# print(ax.get_ylim())
plt.text(737520.5, 310, 'News Volume', size='medium', color='black')
plt.legend()plt.show()
时间序列图:

观察:
在这一时期,医疗保健和政府话题的参与相当一致。这一趋势并没有显示出 covid 病例和死亡人数有任何特别的变化。Covid 主题和新闻文章量如预期的那样具有良好的相关性。因此,为了证明我们的观察,让我们在下一节中获得相关性。4 月 10 日,所有 BoW 功能均下降,显示 covid 案例数最高。同样,根据我们在数据集中看到的情况,这是意料之中的,因为这似乎是异常值的影响。
5.使用热图评估相关性
为了进行关联,我使用了熊猫的内置。corr()函数使用皮尔逊相关系数(ρ)来测量连续特征之间的线性关系,并返回一个 NxN 矩阵,其中 N =特征数量。您还可以使用我们在下一步中讨论的 Scipy。
。corr()自动跳过了我的 published_at 专栏。因此,在我得到相关矩阵后,我以完整的正方形格式绘制它,因为我喜欢完整正方形的热图,即使我意识到冗余信息的显示。
然而,我包括了其他两种格式的代码——下面的三角形包括和不包括对角线。你可以转置并在 mask_matrix 上得到上面的三角形。
代码:
**# Obtain Correlation**
corr = df_merged_extended.corr()**# Set up plt**
plt.style.use('default')
plt.figure(figsize=[10,10])**# Heat-map 1 : Full Square**sns.heatmap(corr, annot=True, vmin=-1, vmax=1, center=0,
square=True, cmap='Spectral', annot_kws={"size": 12},
linewidths=1, linecolor='white')**# Heat-map 2: Lower Triangle excluding diagonal**c=np.zeros_like(corr)
mask_matrix[np.triu_indices_from(mask_matrix)] = True
sns.heatmap(corr, annot=True, vmin=-1, vmax=1, center=0,
square=True, cmap='Spectral', mask = mask_matrix)**# Heat-map 3: Lower Triangle including diagonal**mask_matrix=np.zeros_like(corr)
mask_matrix[np.triu_indices_from(mask_matrix)] = True
mask_matrix = 1 - mask_matrix.T
sns.heatmap(corr, annot=True, vmin=-1, vmax=1, center=0,
square=True, cmap='Spectral', mask = mask_matrix)**# Set up Title and Text**
plt.title("Heatmap to Assess Correlation between Extracted
Features")
热图

观察:
有两个不同集群——
- 总病例和总死亡
- 船头特写和新闻卷
这些单独的特征组之间确实具有正相关性。这些集群彼此负相关。所以,我想,现在我们需要衡量相关性的可靠程度。此时,我们将我们的零假设公式化为——所有特征都是相互独立的。让我们看看下一步结果如何。
6.p 值和显著性评估
为了评估我们零假设的准确性,我使用了 Scipy 的 pearsonr 函数,该函数返回 Pearson 的相关系数(ρ)以及 p 值。下面是我用来评估的代码。我使用了三个级别的统计显著性评估— .01、. 02 和. 05。让我们看看下面的结果:
**from** scipy.stats **import** pearsonrdef assess_corr(col1, col2):
r, p = pearsonr(col1, col2)
return r, pdf_merged_extended.fillna(value=0, inplace=True)
df_merged_extended.set_index('published_at', inplace=True)df_stat_sig = pd.DataFrame(columns=df_merged_extended.columns,
index=df_merged_extended.columns)for col1 in df_merged_extended.columns:
for col2 in df_merged_extended.columns:
#print("{} and {}".format(col1, col2))
r, p = assess_corr(df_merged_extended[col1],
df_merged_extended[col2])
if p < 0.01:
df_stat_sig[col1][col2] = "{:.3f}".format(p) + "***"
elif p < 0.02:
df_stat_sig[col1][col2] = "{:.3f}".format(p) + "**"
elif p < 0.05:
df_stat_sig[col1][col2] = "{:.3f}".format(p) + "*"
else:
df_stat_sig[col1][col2] = "{:.3f}".format(p)df_stat_sig
输出:

观察:
所有弓形特征都与新闻量 e 强相关,具有小于 0.01 的统计显著性。同总例数和总死亡数。所以我们可以拒绝——
- 新闻计数独立于 Covid 计数、中央政府计数和医疗保健计数
- 总病例数独立于总死亡数
- Covid 计数独立于中央政府和医疗保健计数。
我们几乎可以拒绝医疗保健独立于中央政府的观点,尽管风险只有 5%多一点。我希望在下一篇关于这个数据集的时间序列分析的博客中,当我遍历大量数据点时,这一点会被最小化。
下一篇:
万岁!我有一些积极的结果,对这个实验的进展有积极的感觉。但是你有没有注意到在弓的特征定义中真正缺乏思考?如果我做了所有的思考,那么我的代码会做什么呢?

Sherise 拍摄的照片。 on Unsplash
因此,在下一篇博客中,我将研究一些从爱尔兰新闻上收集的数据,并检查一些令牌与印度令牌有何不同。请记住,这些国家在许多方面彼此不同,这将是一项有趣的研究,以了解媒体在第一世界国家和发展中经济体中的相似或不同之处。
我还把数据集扩展到了下个月,所以我有更多的数据可以处理。耶!!!
此外,在即将到来的博客中,我将评估新闻的主题,并将使用这些主题中出现的术语来丰富我的博客。此外,如果代码从同一个数据集创建字典,我就不必担心匹配标记。所以,敬请期待!
关于新冠肺炎文章系列:
这是我用我的新冠肺炎新闻媒体数据集写的第二篇博客,将会写更多关于我的操作和实验的文章。数据集也将增长更多。如果您有兴趣了解这个数据集是如何形成的,请跟我来!这是我以前的博客。
Github 链接到这个博客的笔记本:
[## royn5618/Medium_Blog_Codes
permalink dissolve GitHub 是超过 5000 万开发人员的家园,他们一起工作来托管和审查代码,管理…
github.com](https://github.com/royn5618/Medium_Blog_Codes/blob/master/Covid-Blog-Codes/Covid-Time-Series-Analysis-Prelim.ipynb)
Github 链接到该数据集上的所有笔记本:
[## royn5618/Medium_Blog_Codes
此时您不能执行该操作。您已使用另一个标签页或窗口登录。您已在另一个选项卡中注销,或者…
github.com](https://github.com/royn5618/Medium_Blog_Codes/tree/master/Covid-Blog-Codes)
感谢光临。我希望你喜欢阅读这篇博客。
从日期中提取特征
了解如何从熊猫的数据中获取有用的特征。

布鲁克·拉克在 Unsplash 拍摄的照片
一旦你开始使用熊猫,你会注意到日期有它们自己的数据类型。这是非常方便的,你可以用它来排序细胞根据日期和重要的时间序列分析和寻找趋势的数据。日期本身实际上传达了更多的信息,你只要看看简单的时间戳就能想到。
在本文中,您将学习如何从 pandas 的数据对象中提取所有可能的特征。每个特征类型的提取都将通过示例代码详细讨论。阅读完本文后,您将能够提取以下信息:
- 年
- 月
- 天
- 小时
- 分钟
- 一年中的某一天
- 一年中的第几周
- 星期几
- 四分之一
padas 中的日期类型
让我们开始在 pandas 中创建一些数据时间对象。我们可以通过下面的方式使用 pandas date_range 函数来实现。
import datetime
import numpy as np
import pandas as pd
dates = pd.Series(pd.date_range('2019-12-01 1:17', freq='31H15min', periods=5))
df = pd.DataFrame(dict(date=dates))
df.head()

如您所见,我们创建了一个数据帧,其中有一列名为 date ,我们用五个不同的时间戳填充它。第一个时间戳是 2019 年 1 月 12 日凌晨 1: 17,随后的时间戳使用 freq 参数增加 31 小时 15 分钟。
这足以演示一些简单的特征提取,所以让我们开始吧。
获取年份功能
我们将从获得年份特性开始。这很简单,我们只需在日期列调用日期.年份。请注意,我将把结果保存为数据框中的新列。
df['year'] = df.date.dt.year
df.head()

您可以看到,所有年份功能都保存在“年份”列中,对于所有行,它都等于 2019 年。
获取月份特征
以类似的方式,我们现在将为每一行得到一个月。
df['month'] = df.date.dt.month
df.head()

获取日功能
现在让我们得到这个月中的某一天。
df['day'] = df.date.dt.day
df.head()

获取小时功能
现在让我们从日期开始算一个小时。
df['hour'] = df.date.dt.hour
df.head()

获取细微特征
让我们来看一分钟特写。
df['minutes'] = df.date.dt.minute
df.head()

获取一年中的某一天功能
现在让我们来看看一年中的某一天。请注意,这是一年中的第几天,不同于我们之前提取的一个月中的第几天。
df['day_of_year'] = df.date.dt.dayofyear
df.head()

获取一年中的星期功能
我们可以提取的另一个重要特征是一年中的星期。
df['day_of_year'] = df.date.dt.dayofyear
df.head()

获取星期几功能
获取星期几功能可能是我最喜欢的从数据中提取的功能,因为它允许您进行每周分析,并且许多数据都有每周模式。
df['day_of_week'] = df.date.dt.dayofweek
df['day_of_week_name'] = df.date.dt.weekday_name
df.head()

我们创建了两个列星期几,其中星期几用数字表示(星期一=0,星期日=6 ),以及星期几名称列,其中星期几用字符串形式的星期几名称表示。我喜欢两种形式都有,因为数字形式使数据为机器学习建模做好准备,当我们分析数据时,字符串形式在图形上看起来很好。
另外,请注意,当在 date 上调用 dt.weekday_name 时,它用下划线拼写,这与我们提取的其他特征不同。
获取四分之一特征
我们将提取的最后一个特征是一年中的一个季度。
df['quarter'] = df.date.dt.quarter
df.head()

获得更多功能
上面我们已经介绍了可以从熊猫日期对象中提取的基本特征。我已经把重点放在了最常见的特性上,但是还有更多的特性可以根据您的需要提取出来。
您可以查看 pandas 文档以了解更多信息,但一些附加功能包括:
- 这一天是工作日还是周末,
- 今年是不是闰年,
- 秒、微秒和纳秒
- 还有更多。
总结
在本文中,您已经学习了如何从 pandas 中的 date 对象获取基本特性,您可以使用这些特性进行探索性的数据分析和建模。现在是时候用在真实数据集上了,所以编码快乐!
最初发表于 aboutdatablog.com: 从熊猫,的日期中提取特征,2020 年 3 月 16 日。
PS:我正在 Medium 和上撰写深入浅出地解释基本数据科学概念的文章。你可以订阅我的 邮件列表 每次我写新文章都会收到通知。如果你还不是中等会员,你可以在这里加入。**
下面还有一些你可能喜欢的帖子:
** [## python 中的 lambda 函数是什么,为什么你现在就应该开始使用它们
初学者在 python 和 pandas 中开始使用 lambda 函数的快速指南。
towardsdatascience.com](/what-are-lambda-functions-in-python-and-why-you-should-start-using-them-right-now-75ab85655dc6) [## Jupyter 笔记本自动完成
数据科学家的最佳生产力工具,如果您还没有使用它,您应该使用它…
towardsdatascience.com](/jupyter-notebook-autocompletion-f291008c66c) [## 当你开始与图书馆合作时,7 个实用的熊猫提示
解释一些乍一看不那么明显的东西…
towardsdatascience.com](/7-practical-pandas-tips-when-you-start-working-with-the-library-e4a9205eb443)**
使用 PyMuPDF 从 pdf 中提取标题和段落

一种从 pdf 文档中解析标题和段落的简单方法
这是完全不同的东西:解析 pdf 文档并提取标题和段落!有各种各样的软件包可以从 pdf 文档中提取文本并将其转换成 HTML,但是我发现这些软件包对于手头的任务来说要么过于复杂,要么过于复杂。根据我的经验,一般的 pdf 解析器对所有文档进行一般化处理,但是对于结构相似的文档的特定用例,我们可以用自己的代码来提高性能!
方法学
由于 pdf 文件由非结构化的文本组成,我们需要在不同的文档中找到一些关于标题和段落如何分隔的相似之处。使用一个关于保险公司的荷兰保单条款的大型 pdf 文件(每个 50-150 页)的小样本,我发现有些一致的是标题和段落通常由文本的字体大小和字体粗细分隔,并且最常用的字体可以被认为是段落。现在,这是我们创造方法论的一个很好的起点。
- 使用 PyMuPDF 将段落标识为文档中使用最多的字体的文本,将标题标识为比段落样式更大的字体,将下标标识为比段落样式更小的字体。
- 为标题、段落和下标创建一个带有 HTML 样式元素标签的字典,比如
<h1>、<p>和<s0>。 - 用这些元素
<tags>注释文本片段。
识别段落、标题和下标
我们使用 PyMuPDF 包来读取 PDF 文件。该软件包逐页打开 pdf 文档,将其所有内容保存在一个block中,并识别文本size、font、colour和flags。我发现一些 pdf 文档只通过font和size来区分标题和段落,但是其他的使用所有四个属性。为了说明这一点,我们将添加一个granularity标志,这样我们就可以决定在区分文档中不同的文本部分时包含哪些属性。
在这个阶段,我们将创建一个包含所有不同样式和属性的dictionary和一个包含所有这些样式的[(font_size, count), ..]列表。
我们迭代文档的pages和blocks,由PyMuPDF包(导入为fitz)解析,并根据我们的granularity标志识别所有的样式和属性。
我们的一个文档的输出如下所示:
font_counts, styles = fonts(doc, granularity=False)[('9.5', 1079), ('10.0', 190), ('8.5', 28), ('10.5', 24), ...]{'12.0': {'size': 12.0, 'font': 'ArialMT'}, '9.0': {'size': 9.0, 'font': 'XKZKVH+VAGRoundedStd-Light'}, ...}
我们可以看到最常用的字体大小是9.5,有1079个这样大小的文本。很可能这个字体大小代表了我们文档中的段落。
元素标签字典
接下来,我们将为每种字体大小创建一个包含元素标签的字典。注意,这里我们只考虑字体大小,但是如果你在fonts()函数中使用granularity=True标志,通过几行额外的代码,你可以找到一种方法来合并其他属性!
line 12-13首先,我们确定段落的大小,以区分标签的类型<header>、<paragraph>或<subscript>。line 16-19我们将大小从高到低排序,以便我们可以向每个元素标签添加正确的整数。注意,我们使用1作为最大的标签,这个数字随着标题和下标的字体大小的减小而减小!我们这样做是因为它与 HTLM 标签的排序方式相同。line 22-32用标签填充字典,如下所示。
{60.0: '<h1>', 59.69924545288086: '<h2>', 36.0: '<h3>', 30.0: '<h4>', 24.0: '<h5>', 20.0: '<h6>', 16.0: '<h7>', 14.0: '<h8>', 13.0: '<h9>', 10.5: '<h10>', 10.0: '<h11>', 9.5: '<p>', 9.452380180358887: '<s1>', 9.404520988464355: '<s2>', 8.5: '<s3>', 8.0: '<s4>', 7.5: '<s5>', 7.0: '<s6>'}
提取标题和段落
我们再次迭代文档的页面和块。对于第一个块,我们用element tag和来自 span s['text']的实际文本初始化block_string。对于接下来的每个区间,我们检查字体size是否与前一个区间的字体size匹配,或者是否有新的文本大小。相应地,如果字符串大小相同,我们就将它们连接起来。blocks是由PyMuPDF包分隔和识别的文本部分,但我发现它们有时包含句子的一部分。因此,为什么我用一个'|'将它们连接起来,以表明一个新的块已经开始。在后处理步骤中,我们可以决定如何处理这些由管道分隔的部分(连接它们或分离它们)。
我们返回一个包含管道的字符串列表,然后能够识别哪些文本部分是标题、段落或下标,如下所示。
['<h4>Als onderdeel van het | ZekerheidsPakket Particulieren |', '', '<h1>Informatie over uw|', '<h2>Inboedelverzekering|', '<h1>Basis|', '', '<h6>Inhoud|', '', '<p>pagina| Leeswijzer, Uw verzekering in het kort | 3 | Polisvoorwaarden Inboedelverzekering Basis | 7 |', '', '<s3>3|', '', '<h7>Uw verzekering in het kort|',
正如您所看到的,我们仍然需要执行几个后处理步骤来清理数据,并可能以不同的方式对其进行排序,但这至少是一个起点。我希望你在这里学到了一些东西,并快乐编码!完整的脚本和示例 pdf 文档可以在这里找到。
从文本中提取关键短语:Python 中的 RAKE 和 Gensim
使用 Python 从大型文本段落中获取关键短语
《华盛顿邮报》称,它平均每天发布 1200 篇故事、图片和视频**(不过,这一数字还包括有线故事)。内容真多啊!谁有时间浏览所有的新闻?如果我们能从每篇新闻文章中提取相关的短语,这不是很棒吗?**

Romain Vignes 在 Unsplash 上拍摄的照片
关键短语是总结段落要点的一组单词(或词组)。这并不是对文本的总结,它只是文章中讨论的相关概念的列表。
关键短语提取是如何工作的?
- 当像“写作”、“书面的”、“写了的”这样的词表示相同的意思:“写”时,将每一个词包括在文章的词汇中是没有意义的。因此,我们对文本进行词汇化,也就是说,首先将每个单词转换成其词根形式。
- ****选择潜在短语:文本段落包含许多单词,但并非所有单词都相关。其中大多数可能是经常使用的词,如“a”、“that”、“then”等。这种词称为停用词,必须过滤掉,否则会污染输出。具有上下文相似性的连续单词必须组合在一起。
- ****给每个短语打分:一旦你有了一个可能的短语列表,你需要对它们进行排序,以确定哪一个是最重要的。
我们将讨论什么?
在这篇博客中,我们将探索以下关键短语提取算法的 python 实现:
- 耙子
- RAKE-NLTK
- 根西姆
让我们来看一段示例文本,这样我们就可以比较所有算法的输出:
AI Platform Pipelines has two major parts: (1) the infrastructure for deploying and running structured AI workflows that are integrated with [Google Cloud Platform](https://venturebeat.com/2020/03/09/google-launches-machine-images-to-simplify-data-science-workflows/) services and (2) the pipeline tools for building, debugging, and sharing pipelines and components. The service runs on a Google Kubernetes cluster that’s automatically created as a part of the installation process, and it’s accessible via the Cloud AI Platform dashboard. With AI Platform Pipelines, developers specify a pipeline using the Kubeflow Pipelines software development kit (SDK), or by customizing the TensorFlow Extended (TFX) Pipeline template with the TFX SDK. This SDK compiles the pipeline and submits it to the Pipelines REST API server, which stores and schedules the pipeline for execution.
耙子
RAKE 代表快速自动关键词提取**。算法本身在 Michael W. Berry 的 文本挖掘应用和理论 一书中有描述。我们在这里只是浏览一下实现,如果你想了解幕后发生了什么,我推荐这个站点。**
安装:

进口:

停用词:
从这里下载这个停用词列表,并将路径保存在一个名为 stop_dir 的变量中。
从文本创建一个耙子对象:

现在,是时候提取关键词了!RAKE 最初并不按照分数的顺序打印关键字。但是它返回分数和提取的关键短语。让我们编写一个快速函数来对这些提取的关键短语和分数进行排序。

将文本段落存储在一个变量中,并将其传递给 rake_object。我们将变量命名为字幕。第一行末尾的 10 意味着我们只提取前 10 个关键字。

答对了。我们完了!分数越高,关键词就越重要。
keywords: [(‘installation process’, 4.0), (‘tensorflow extended’, 4.0), (‘sharing pipelines’, 5.4), (‘google kubernetes cluster’, 9.5), (‘ai platform pipelines’, 10.4), (‘google cloud platform services’, 15.0), (‘cloud ai platform dashboard’, 15.0), (‘pipelines rest api server’, 15.4), (‘running structured ai workflows’, 15.5), (‘kubeflow pipelines software development kit’, 23.4)]
RAKE-NLTK
RAKE-NLTK 是的修改版本,它使用自然语言处理工具包 NLTK 进行一些计算。
安装:

导入,声明一个 RAKE-NLTK 对象并提取! 我们再次提取前 10 个关键词。

下面是使用 RAKE-NLTK 对同一段文本的输出。对于所选择的通道,RAKE 和 RAKE-NLTK 给出相同的输出。但情况并非总是如此。在其他段落中自己尝试一下吧!
[‘kubeflow pipelines software development kit’, ‘running structured ai workflows’, ‘pipelines rest api server’, ‘cloud ai platform dashboard’, ‘google cloud platform services’, ‘ai platform pipelines’, ‘google kubernetes cluster’, ‘two major parts’, ‘sharing pipelines’, ‘tensorflow extended’]
根西姆
在 Gensim Python 和 Cython 中实现,Gensim 是一个用于自然语言处理的开源库,使用现代统计机器学习。
安装:

导入和函数调用:

输出:
pipelines pipeline platform developers development sdk tfx kubernetes
Gensim 中简单的关键字函数调用似乎不执行内置的预处理。
结论
我们学习了如何编写 Python 代码来从文本段落中提取关键字。
以下是一些其他很酷的关键短语提取实现。看看他们!
您可以在所有这些算法上尝试示例文本段落,看看什么最适合您的用例!
发现了不同的关键词提取算法。放在评论里吧!
从 Scikit-Learn 管道中提取和绘制功能名称和重要性
如何解释您的渠道、模式及其特点

https://unsplash.com/photos/L0oJ4Dlfyuo
如果您曾经承担过生产机器学习模型的任务,您可能知道 Scikit-Learn 库提供了创建生产质量的机器学习工作流的最佳方式之一——如果不是最佳方式的话。生态系统的管道、列转换器、预处理程序、估算器、&、特征选择类是将原始数据转换为模型就绪特征的强大工具。
然而,在任何人让您部署到生产环境之前,您都需要对新模型的工作原理有一些基本的了解。解释黑盒模型如何工作的最常见方式是绘制要素名称和重要性值。如果您曾经尝试过从 ColumnTransformer 处理的异构数据集中提取特性名称,您就会知道这不是一件容易的事情。详尽的互联网搜索只让我注意到其他人问了同样的 问题或提供了部分答案,而不是产生一个全面和令人满意的解决方案。
为了补救这种情况,我开发了一个名为FeatureImportance的类,它将从管道实例中提取特性名称和重要性值。然后,它使用 Plotly 库,仅用几行代码来绘制特性的重要性。在这篇文章中,我将加载一个合适的管道,演示如何使用我的类,然后概述它是如何工作的。完整的代码可以在这里或者这篇博文的末尾找到。
注意:从 scikit-learn 1.0 中的变化开始,我的类可能无法工作。
在继续之前,我应该注意两件事:
- 我相信 Joey Gao 在这个帖子中的代码展示了解决这个问题的方法。
- 我的帖子假设您以前使用过 Scikit-Learn 和 Pandas,并且熟悉 ColumnTransformer、Pipeline 和预处理类如何促进可再现的特征工程过程。如果您需要复习,请查看这个 Scikit-Learn 示例。
创建管道
出于演示的目的,我编写了一个名为 fit_pipeline_ames.py 的脚本。它从 Kaggle 加载 Ames housing 训练数据,并适合中等复杂的管道。我在下面画出了它的视觉表现。
from sklearn import set_config
from sklearn.utils import estimator_html_repr
from IPython.core.display import display, HTML
from fit_pipeline_ames import pipe # create & fit pipeline
set_config(display='diagram')
display(HTML(estimator_html_repr(pipe)))

这个pipe实例包含以下 4 个步骤:
- ColumnTransformer 实例由 3 条管道组成,共包含 4 个 Transformer 实例,包括 category_encoders 包中的 SimpleImputer 、OneHotEncoder&GLMMEncoder。关于我如何动态构造这个特殊的 ColumnTransformer 的完整解释,请参见我以前的博客文章。
- VarianceThreshold 使用默认阈值 0,这将删除任何仅包含单一值的特征。如果一个特征没有变化,一些模型将会失败。
- 选择百分位数使用百分位数阈值为 90 的 f_regression 评分函数。这些设置保留了前 90%的功能,而丢弃了后 10%的功能。
- 使用前面步骤中创建和选择的特征,将 CatBoostRegressor 模型拟合到
SalesPrice因变量。
绘图功能重要性
在FeatureImportance的帮助下,我们可以提取特性名称和重要性值,并用 3 行代码绘制出来。
from feature_importance import FeatureImportance
feature_importance = FeatureImportance(pipe)
feature_importance.plot(top_n_features=25)

plot方法接受许多控制绘图显示的参数。最重要的如下:
top_n_features:控制将要绘制的特征数量。默认值为 100。该图的标题将显示该值以及总共有多少个特征。要绘制所有特征,只需将top_n_features设置为大于总特征的数字。rank_features:该参数控制是否在特征名称前显示整数等级。默认为True。我发现这有助于解释,尤其是在比较来自多个模型的特性重要性时。max_scale:决定重要性值是否按最大值&乘以 100 进行缩放。默认为True。我发现这提供了一种直观的方式来比较其他特性和最重要的特性的重要性。例如,在上面的图中,我们可以说GrLivArea对模型的重要性是顶部特性OverallQty的 81%。
它是如何工作的
应该使用合适的管道实例来实例化FeatureImportance类。(如果您想将所有诊断打印到您的控制台,您也可以将verbose参数更改为True。)我的类验证这个管道以一个ColumnTransformer实例开始,以一个具有feature_importance_属性的回归或分类模型结束。作为中间步骤,流水线可以有任意数量的或没有来自sk learn . feature _ selection的类实例。
FeatureImportance类由 4 个方法组成。
- 是最难设计的方法。它遍历
ColumnTransformer转换器,使用hasattr函数来辨别我们正在处理的类的类型,并相应地提取特性名称。(特别注意:如果 ColumnTransformer 包含管道,并且管道中的某个转换器正在添加全新的列,则它必须位于管道的最后。例如,OneHotEncoder,MissingIndicator&simple imputr(add _ indicator = True)将之前不存在的列添加到数据集,因此它们应该在管道中排在最后。) get_selected_features通话get_feature_names。然后,基于get_support方法的存在,它测试主管道是否包含来自 sklearn.feature_selection 的任何类。如果是,此方法将仅返回选择器类保留的要素名称。它存储未在discarded_features属性中选择的特征。以下是我的管道中的选择器删除的 24 个特性:
feature_importance.discarded_features['BsmtFinSF2','BsmtHalfBath','Alley_Pave','LandContour_Lvl','Utilities_AllPub','Utilities_NoSeWa','LotConfig_Corner','LotConfig_FR2','Condition1_RRNe','Condition2_RRAe','Condition2_RRAn','HouseStyle_SLvl','RoofStyle_Mansard','RoofMatl_ClyTile','RoofMatl_Metal','RoofMatl_Roll','RoofMatl_Tar&Grv','ExterCond_Ex','Foundation_Stone','Foundation_Wood','BsmtFinType2_GLQ','Electrical_missing_value','FireplaceQu_Fa','GarageCond_Gd','MiscFeature_Gar2','SaleType_ConLI']
3.get_feature_importance调用get_selected_features然后创建一个熊猫系列,其中值是来自模型的特征重要性值,其索引是由前两种方法创建的特征名称。然后,该系列被存储在feature_importance属性中。
4.plot调用get_feature_importance并根据规格绘制输出。
密码
这篇博文的原始笔记本可以在这里找到。FeatureImportance的完整代码如下所示,可以在这里找到。
如果你创建了一个你认为应该被支持的管道,但是没有,请提供一个可重复的例子,我会考虑做必要的修改。
请继续关注关于使用 Scikit-Learn ColumnTransformers 和 Pipelines 训练和调整模型的更多帖子。如果你觉得这篇文章有帮助或者有任何改进的想法,请告诉我。谢谢!
在医院环境中从纸质表格中提取交接班数据

图片作者。
背景
在大多数医院的交接班时,会填写一份纸质表格来总结上一次交接班,并强调即将到来的交接班的关键方面。例如,一个完整的表单可能如下所示。

填好的表格样本。图片作者。
这些完成的表格在以后被收集在一起,一个人将仔细检查每一个表格并在计算机上手动输入数据。然后,记录的数据可以输入到分析系统中,以生成见解。
项目的目标
该项目的主要目标是通过构建一个工具来简化数据收集流程,
- 用户可以使用他们的智能手机给完成的表格拍照,
- 然后,该工具自动提取数据并预填充表单,并且
- 用户可以查看和保存数据。
用户可以选择在完成表单后立即拍照并上传,或者在稍后拍摄多个完成的表单。
其他一些功能包括:
- 提供表格的数字版本,用户可以直接在他们的电话/平板电脑上填写,
- 保存原始图像和提取的数据,
- 链接数据,如单位、用户等。到系统中的现有实体。
演示
在里贝里,我们建立了一个平台,用于在医院环境中收集数据和生成见解,以及提供临床改进计划。本文只关注使用 OCR 从纸质表单中提取数据——这是数据收集方面的一个特性。
下面是如何从纸质表格中提取数据并输入系统的演示。

OCR 演示。图片作者。
架构概述
我们使用微软的表单识别器服务从表单中提取数据。更具体地说,我们已经训练了一个定制模型,而不是使用预先构建的模型,来更好地处理我们的客户使用的表单的结构。
在非常高的水平上,我们将首先训练一个模型。然后,用户可以通过前端(又名 Riberry)将填写好的表格的照片上传到名为 Rumble 的 API。然后,Rumble 使用经过训练的模型从表单中提取数据,并在将提取的数据发送回用户之前对其进行转换和清理。下图对此过程有更详细的解释。

架构概述。图片作者。
训练模型
注意:本文的重点是展示最终产品,并反思在添加 OCR 支持方面学到的经验,而不是如何使用 Azure Form Recognizer 服务的分步指南。写指南也没有意义;你不可能真的打败他们的文档和例子。
如果您想学习如何使用表单识别器服务,我强烈推荐您通读他们的文档—这确实是最有效的方法。
表单识别器服务的核心是一组REST API,允许您通过使用监督/非监督机器学习来训练模型,管理(例如,列出、删除、复制)模型,以及使用定制/预构建的模型提取数据。
此外,它还提供了一个开源工具(OCR-Form-Tools) ,它可以与这些 REST APIs 进行交互,并提供一个直观的 UI 来标记您的数据,训练模型并通过预测测试文档来验证模型。
提示:在他们关于设置样品贴标工具的指南中,他们谈到了通过 Docker 运行该工具。
比起使用 Docker,我发现从 GitHub 中取出一份工具并从源代码中构建/运行它要容易得多。
在工具启动并运行之后,我能够轻松地标记我们的样本数据、训练模型和测试模型。

标记训练数据。图片作者。

训练一个模特。图片作者。

验证训练好的模型。图片作者。
杂项反思
现在项目已经部署到生产中,这是一个很好的时间来回顾它,反思我从做这件事中学到的各种事情/教训。
1.培训过程
使用监督学习方法预测表单内容应该有三个主要阶段,
- 检测表单上的文本元素(打印的或手写的)并计算它们的预期大小和位置,
- 从每个元素中提取实际的文本内容,
- 使用步骤 1 中获得的元素大小和位置信息,将元素分类到指定的不同标签中。
提示:通过监督学习,我们正在拟合一个模型,根据页面上元素的位置信息将页面上的元素分类到不同的标签中。
我们 不是 训练任何 NLP 模型从页面上识别的元素中提取文本。这一部分由表单识别器服务在内部处理。
每个文本元素的位置和大小由其由 8 个数字组成的边界框来表示。并且这 8 个数字应该是每个训练实例即每个文本元素的主要特征。
还可能有许多数据论证和特征操作技术应用于训练数据,以人工扩展数据集,从而提高模型的准确性。例如,他们可能会使用一些保留标签的变换技术,如去噪/锐化、弹性变形、仿射变换、降维等。
但总的来说,成本函数应该相对简单,只有几个变量。对于只需要 5 个文档就可以开始使用,我并不感到惊讶。
2.添加对复选框/单选问题的支持
表单识别器服务并不正式支持复选框或单选按钮,但是我已经能够很容易地绕过它,
- 为复选框或单选问题中的每个选项应用标签,以及
- 在预测时,将这些带有值的标签视为用户选择的选项。
例如,医院使用的表单包含一个带有两个选项的复选框问题— AM 或 PM。在训练过程中,我分别为 AM 和 PM 选项设置了标签_Shift.9:00和_Shift.17:00(见下文)。

添加对复选框/单选问题的支持。图片作者。
假设,如果我们将上面的表单输入到训练好的模型中,将为_Shift.9:00和_Shift.17:00提取一个字符串‘x’。如果这是一个复选框问题,我会认为两个选项都被选中,如果这是一个单选问题,我会认为第一个选项被选中。
3.异步提取数据,并在结果就绪时通知用户
在向其端点发送表单并从中提取数据之后,您将获得一个Operation-Location、,这是一个包含、[resultId](https://westus2.dev.cognitive.microsoft.com/docs/services/form-recognizer-api-v2/operations/AnalyzeWithCustomForm)、的 URL,用于跟踪进度并获得分析操作的结果。我们要反复检查这个结果数据的 URL。
提示:我将检查结果的频率设置为每秒一次。这似乎与他们的 OCR 工具用于检查结果的频率相同。
提示:如果您的用户必须等待结果才能采取下一步行动,请在发布图像进行分析之前对其进行压缩,以缩短等待时间。
如今智能手机上拍摄的图像相当大,我将它们压缩到 4.1 背景
纸质表单上的字段与数字表单上的字段并不完全匹配——纸质表单上的一些数据被忽略,而网络表单上有一些额外的字段。此外,虽然纸质表格很少改变,但我们会通过添加/删除问题或围绕现有问题移动来稍微更新数字表格。
4.2 我们如何设计它
web 表单上的问题及其布局是使用 JSON 文件定义的。不涉及细节,在下面的截图中,JSON 结构(右)定义了表单的团队部分(左)。
在 JSON 中定义问题。图片作者。
但是,我们也使用 JSON 文件中问题的名称来自动构造该问题的标签(在 OCR 中使用)。例如,在下面的截图中,标签— 团队…护士简写——“护士简写”问题是通过用一个点连接其所有祖先和自身的名字而创建的。
来自问题名称的标签。图片作者。
4.3 设计问题

这意味着,每当我们更改表格的数字版本时(例如,添加/删除问题或重新排列表格上的字段),都会生成一组新的标签。我们必须重新命名表单识别器中使用的标签,重新训练模型,将其复制到生产环境中等等。这是一个非常耗时的过程。
4.4 我们应该做什么而不是做什么

我们应该将标签生成从 form.gggg 的 JSON 定义中分离出来
假设纸质表单很少改变,我们应该硬编码一组标签用于表单识别器服务。然后,我们可以扩展 JSON 定义以包含一个label属性,该属性指定每个问题所使用的标签(如果适用的话)。
这不仅简化了绑定数据的代码(即,将提取的数据转换为域对象),还意味着我们可以自由地重新排列表单上的问题,而不必在表单识别器中重新训练模型。
参考
设置样品标签工具
- Form Recognizer API (v2.0)
- Form Recognizer documentation
- OCR-Form-Tools
- Set up the sample labelling tool
使用 Python 从视频中提取语音
使用 Google 语音识别 API 的简单实用项目

雅各布·欧文斯在 Unsplash 上的照片
在这篇文章中,我将向你展示如何从视频文件中提取演讲。在识别演讲之后,我们将把它们转换成文本文档。这将是一个简单的机器学习项目,这将有助于你理解谷歌语音识别库的一些基础知识。语音识别是机器学习概念下的一个热门话题。语音识别越来越多地用于许多领域。例如,我们在网飞节目或 YouTube 视频中看到的字幕大多是由使用人工智能的机器创建的。其他语音识别器的伟大例子是个人语音助手,如谷歌的 Home Mini,亚马逊 Alexa,苹果的 Siri。
目录:
- 入门
- 第一步:导入库
- 第二步:视频转音频
- 第三步:语音识别
- 最后一步:导出结果

入门指南
正如你可以理解的标题,我们将需要这个项目的视频记录。它甚至可以是你对着镜头说话的录音。使用名为 *MoviePy,*的库,我们将从视频记录中提取音频。下一步,我们将使用谷歌的语音识别库将音频文件转换成文本。如果您准备好了,让我们从安装库开始吧!
图书馆
我们将为这个项目使用两个库:
- 语音识别
- 电影
在将它们导入到我们的项目文件之前,我们必须安装它们。在 python 中安装模块库非常容易。您甚至可以在一行代码中安装几个库。在您的终端窗口中写下下面一行:
pip install SpeechRecognition moviepy
是的,就是它。 SpeechRecognition 模块支持多种识别 API,Google Speech API 就是其中之一。你可以从这里了解更多关于这个模块的信息。
MoviePy 是一个可以读写所有最常见的音频和视频格式的库,包括 GIF。如果您在安装 moviepy 库时遇到问题,请尝试安装 ffmpeg。Ffmpeg 是一个领先的多媒体框架,能够解码、编码、转码、复用、解复用、流式传输、过滤和播放人类和机器创造的几乎任何东西。
现在,我们应该开始在代码编辑器中编写代码了。我们将从导入库开始。
步骤 1-导入库
import speech_recognition as sr import moviepy.editor as mp
是的,这就是我们完成任务所需要的。抓紧时间,让我们进入下一步。
步骤 2 —视频到音频转换
在这一步,我们将做一些很酷的事情,将我们的视频记录转换成音频文件。视频格式有很多种,其中一些可以列举如下:
- MP4 (mp4、m4a、m4v、f4v、f4a、m4b、m4r、f4b、mov)
- 3GP (3gp、3gpp2、3g2、3gpp、3gpp 2)
- OGG (ogg、oga、ogv、ogx)
- WMV (wmv、wma、asf*)
我们应该知道我们的视频格式做转换没有任何问题。除了视频格式,了解一些音频格式也是一个很好的练习。以下是其中的一些:
- MP3 文件
- 加气混凝土
- WMA
- AC3(杜比数字)
现在,我们对这两种格式都有了一些了解。是时候使用 MoviePy 库进行转换了。你不会相信这有多容易。
clip = mp.VideoFileClip(r”video_recording.mov”)
clip.audio.write_audiofile(r”converted.wav”)
我建议转换成 wav 格式。它与语音识别库配合得很好,这将在下一步中介绍。
使用谷歌云语音 API 将您的音频文件转换为文本
towardsdatascience.com](/building-a-speech-recognizer-in-python-2dad733949b4)
步骤 3 —语音识别
首先,让我们定义识别器。
r = sr.Recognizer()
现在让我们导入在上一步(步骤 2)中创建的音频文件。
audio = sr.AudioFile("converted.wav")
完美!最棒的部分来了,就是识别音频文件中的语音。识别器将尝试理解语音并将其转换为文本格式。
with audio as source:
audio_file = r.record(source)result = r.recognize_google(audio_file)
最后一步—导出结果
干得好!艰苦的工作完成了。在这一步中,我们将把识别的语音导出到一个文本文档中。这将有助于你储存你的作品。我还添加了一个*打印(“准备!”)*结束代码。以便我们知道文件何时准备好,工作何时完成。
# exporting the result
with open('recognized.txt',mode ='w') as file:
file.write("Recognized Speech:")
file.write("\n")
file.write(result)
print("ready!")
视频演示
刚刚开始我在 YouTube 上的旅程,我将为您演示机器学习、数据科学、人工智能和更多项目。尽情享受吧!
作为一个媒体会员,你的会员费的一部分会给你阅读的作家,你可以完全接触到每一个故事…
lifexplorer.medium.com](https://lifexplorer.medium.com/membership)
恭喜你。你已经创建了一个程序,将视频转换成音频文件,然后从该音频中提取语音。最后,将识别的语音导出到文本文档中。希望你喜欢阅读这篇文章并参与这个项目。如果你今天学到了新东西,我很高兴。从事像这样的动手编程项目是提高编码技能的最好方式。
如果您在执行代码时有任何问题,请随时联系我。
相关内容:
了解文本到语音转换可以发挥作用的领域
towardsdatascience.com](/convert-text-to-speech-in-5-lines-of-code-1c67b12f4729) [## Python 中的简单人脸检测
如何使用 OpenCV 库检测图像中的人脸
towardsdatascience.com](/simple-face-detection-in-python-1fcda0ea648e)
Camelot 让从 pdf 中提取表格数据变得简单。
从 pdf 中提取表格并不困难。

丹尼·米勒在 Unsplash 上的照片
从 pdf 中提取表格数据很难。但更大的问题是,许多公开数据都是 PDF 文件。这些公开数据对于分析和获得重要见解至关重要。然而,访问这样的数据成为一个挑战。例如,让我们看看由[国家农业统计局(NASS)](http://by the National Agricultural Statistics Service (NASS),) 发布的一份重要报告,它涉及美国种植的主要农作物:

报告来源:https://www . NASS . USDA . gov/Publications/Todays _ Reports/Reports/pspl 0320 . pdf
对于任何分析,起点都应该是获取包含详细信息的表格,并将其转换为大多数可用工具都能接受的格式。正如你在上面看到的,在这种情况下,简单的复制粘贴是行不通的。大多数情况下,标题不在正确的位置,一些数字会丢失。这使得 pdf 处理起来有些棘手,显然,这是有原因的。我们将讨论这个问题,但首先让我们试着理解 PDF 文件的概念。
这篇文章是寻找合适数据集的完整系列文章的一部分。以下是该系列中包含的所有文章:
第 1 部分 : 为数据分析任务获取数据集—高级谷歌搜索
第 2 部分 : 为数据分析任务寻找数据集的有用站点
第三部分 : 为深度学习项目创建定制图像数据集
第 4 部分 : 毫不费力地将 HTML 表格导入 Google Sheets
第 5 部分 : 用 Camelot 从 pdf 中提取表格数据变得很容易。
第六部分 : 从 XML 文件中提取信息到熊猫数据帧
第 7 部分 : 5 个真实世界数据集,用于磨练您的探索性数据分析技能
可移植文档格式,又名 pdf

来源: [Adobe PDF 文件图标](http://Adobe Systems CMetalCore)
PDF 代表可移植文档格式。这是 Adobe 在 90 年代早期创建的一种文件格式。它基于 PostScript 语言,通常用于呈现和共享文档。开发 PDF 背后的想法是要有一种格式,使得在任何现代打印机上查看、显示和打印文档成为可能。
每个 PDF 文件都封装了一个固定布局平面文档的完整描述,包括文本、字体、矢量图形、光栅图像以及其他显示*维基百科 所需的信息。*
基本 PDF 文件包含以下元素。

来源:GUILLAUME ENDIGNOUX 的 PDF 语法简介
为什么从 PDF 中提取表格很难?
如果你看上面的 PDF 布局,你会发现其中没有表格的概念。PDF 包含将字符放置在二维平面的 x,y 坐标上的指令,不保留单词、句子或表格的知识。

来源:https://www . PDF scripting . com/public/PDF-Page-coordinates . cfm
那么 PDF 如何区分单词和句子呢?通过将字符放在一起来模拟单词,而通过将单词放在相对更远的位置来模拟句子。下图将更具体地巩固这一概念:

来源:http://www.unixuser.org/~euske/python/pdfminer/index.html
m 表示上图中两个字之间的距离, W 表示两个字之间的间距。任何带有空格的文本块被组合成一个。表格是通过在没有任何行或列信息的电子表格中输入单词来模拟的。因此,这使得从 pdf 中提取数据用于分析变得非常困难。然而,政府报告、文档等形式的大量公开数据。,以 pdf 格式发布。一种能够提取信息而不影响其质量的工具是当前需要的。这一点将我们带到了一个名为 Camelot 的多功能库,它被创建来从 pdf 中提取表格信息。
卡米洛特:人类 PDF 表格提取

来源:https://camelot-py.readthedocs.io/en/master/
Camelot 的名字来源于著名的 Camelot 项目,它是一个开源的 Python 库,可以帮助您轻松地从 pdf 中提取表格。它建立在另一个用于 PDF 文档的文本提取工具 pdfminer 之上。
它附带了许多有用的功能,例如:
- 可配置性— 适用于大多数情况,但也可以进行配置
- 使用 Matplotlib 库进行可视化调试
- 输出有多种格式,包括 CSV、JSON、Excel、HTML,甚至 Pandas dataframe。
- 开源 -麻省理工学院许可
- 详细的文档
装置
您可以通过 conda、pip 或直接从源代码安装 Camelot。如果您使用 pip,不要忘记安装以下依赖项: Tkinter 和 Ghostscript 。
*#conda (easiest way)
$ conda install -c conda-forge camelot-py#pip after [installing the tk and ghostscript dependencies](https://camelot-py.readthedocs.io/en/master/user/install-deps.html#install-deps)
$ pip install "camelot-py[cv]"*
工作
在我们开始工作之前,最好先了解一下到底发生了什么。通常,Camelot 使用两种解析方法来提取表:
你可以在文档中读到更多关于卡梅洛特的工作。
使用
现在让我们进入激动人心的部分——从 pdf 中提取表格。在这里,我使用了一个 PDF 文件,其中包含了印度 2015-16 年成人教育项目受益人数的信息。PDF 看起来像这样:

来源:https://www . mhrd . gov . in/sites/upload _ files/mhrd/files/statistics-new/ESAG-2018 . pdf
我们将从导入库和读入 PDF 文件开始,如下所示:
*import camelot
tables = camelot.read_pdf('schools.pdf')*
我们得到一个TableList对象,这是一个由[**Table**](https://camelot-py.readthedocs.io/en/master/api.html#camelot.core.Table)对象组成的列表。
*tables
--------------
<TableList n=2>*
我们可以看到已经检测到两个表,通过它的索引可以很容易地访问这两个表。让我们访问第二个表,即包含更多信息的表,并查看其形状:
*tables[1] #indexing starts from 0<Table shape=(28, 4)>*
接下来,让我们打印解析报告,它是表的提取质量的指示:
*tables[1].parsing_report{'accuracy': 100.0, 'whitespace': 44.64, 'order': 2, 'page': 1}*
它显示了高达 100%的准确性,这意味着提取是完美的。我们也可以如下访问表格的数据框架:
*tables[1].df.head()*

作者将 PDF 提取到 Dataframe |图像中
整个表格也可以提取为 CSV 文件,如下所示:
*tables.export('table.csv')*

作者导出为 CSV |图像的 PDF 表格
可视化调试
此外,您还可以根据指定的种类绘制 PDF 页面上的元素,如‘text’, ‘grid’, ‘contour’, ‘line’, ‘joint’等。这些对于调试和使用不同的参数来获得最佳输出非常有用。
*camelot.plot(tables[1],kind=<specify the kind>)*

在 PDF 页面上找到的绘图元素|作者图片
高级用法和 CLI
Camelot 也有一个命令行界面。它还配备了一系列高级功能,如:
- 读取加密的 pdf
- 阅读旋转的 pdf
- 当默认结果不完美时调整参数。指定精确的表格边界,指定列分隔符,等等。你可以在这里阅读更多关于这些功能的信息。
缺点
Camelot 只能处理基于文本的 pdf,不能处理扫描的文档。因此,如果你有扫描文件,你必须看看其他一些替代品。
⚔️神剑——网络界面:蛋糕上的糖衣
Camelot 的另一个有趣的特性是,它也有一个名为 Excalibur 的 web 界面,供那些不想编码但仍想使用该库特性的人使用。让我们快速看看如何使用它。
装置
安装 Ghostscript 后,使用 pip 安装 Excalibur:
*$ pip install excalibur-py*
然后使用以下命令启动 web 服务器:
*$ excalibur webserver*
然后,您可以导航到本地主机来访问该界面。下面的视频演示了整个过程:
Excalibur 演示|作者视频
结论
在上面的文章中,我们研究了 Camelot——这是一个开源 python 库,对于从 pdf 中提取表格数据非常有帮助。事实上,它有许多可以调整的参数,这使得它具有很好的可伸缩性,并适用于许多情况。Web 界面为寻找无代码环境的人们提供了一个极好的选择。总的来说,它似乎是一个有用的工具,可以帮助减少通常用于数据提取的时间。
参考
这篇文章的灵感来自 Vinayak Mehta 的演讲,vinay AKMehta 是 2019 印度 PyCon 上卡米洛特项目的创建者和维护者。一些资源摘自活动结束后公开分享的幻灯片。强烈建议观看演示以获得更清晰的内容。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言










{kind=link}
{kind=link}