







理解逻辑回归
这种方法的数学详细解释

作者图片
什么是逻辑回归?逻辑回归只是将线性回归应用于只有 2 个输出的特殊情况:0 或 1。这个东西最常用于分类问题,其中 0 和 1 代表两个不同的类,我们想要区分它们。
线性回归输出一个范围从-∞到+∞的实数。我们甚至可以在 0/1 分类问题中使用它:如果我们得到一个> = 0.5 的值,将其报告为类标签 1,如果输出< 0.5,将其报告为 0。

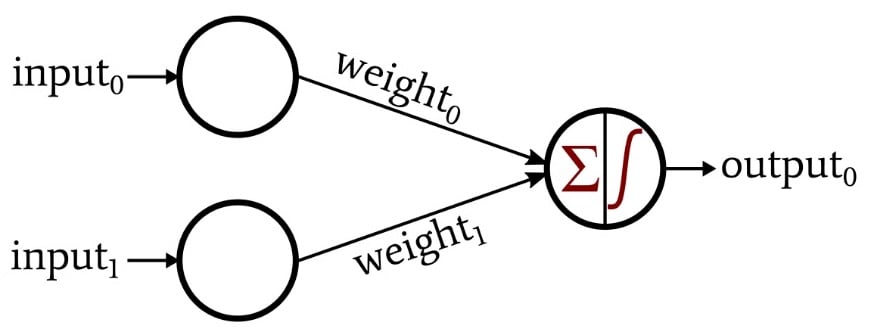
其中 x 是一个观察值的特征向量(加上偏差为常数 1 的分量), w 是权重向量。
但是,如果我们将回归线压缩成介于 0 和 1 之间的“S”形曲线,我们可以在准确性和可解释性方面获得稍好的结果。我们通过将 sigmoid 函数应用于线性回归模型的输出值来压缩回归线。
下面是 sigmoid 函数:

更确切地说,我们按如下方式计算输出:取输入的加权和,然后将这个结果数传递给 sigmoid 函数,并将 sigmoid 的输出报告为我们的逻辑回归模型的输出。
这一过程有助于我们获得稍好的准确性和输出的可解释性。如果我们的模型输出任何实数,如-5 或 7,这些数字实际上意味着什么?关于我们的两个类:0 和 1,我们能知道什么?
但是,当我们有介于 0 和 1 之间的输出时,我们可以把它们解释为概率。逻辑回归模型的输出是我们的输入属于标有 1 的类别的概率。我们模型输出的补充是我们输入属于标记为 0 的类别的概率。

其中 y 是输入 x 的真实类标签。
好的。至此,我们已经看到了给定输入,逻辑回归模型如何获得输出。但是它的重量呢?它应该有什么样的权重才能做出好的预测?
我们的模型需要学习这些权重,它学习的方式是给我们的模型一个目标函数,然后它找到最小化或最大化这个目标的权重。
有许多方法可以得到一个目标函数,特别是当我们考虑在目标中加入正则项的时候。
在本文中,我们将只探讨两个这样的目标函数。
首先,让我们将逻辑回归模型写成如下形式:

其中 X 是一个矩阵,以行的形式包含我们所有的观察结果,列代表特征。这是我们模型的输出,它是一个向量,包含对每个观察的预测。
让我们以下面的方式重写我们的逻辑回归方程:

最后一行右侧的操作是基于元素的。
你在上面最后一行观察到了什么?如果我们将最后一个等式右侧的函数应用于逻辑回归的标签,并将该函数应用的输出视为新标签,则我们获得线性回归。因此,我们可以使用误差平方和作为损失函数,并找出使其最小的权重。我们可以通过使用封闭形式的公式或 SGD(随机梯度下降)来找到权重,您可以在以下关于线性回归的文章中了解更多信息:
线性回归背后的数学详细解释
towardsdatascience.com](/understanding-linear-regression-eaaaed2d983e)
以下是线性回归的闭合解和损失梯度(我们可以在 SGD 算法中使用):


对于逻辑回归,我们只需将上述两个方程中的 y 替换为前一个方程的右侧:


当我们应用这些公式时,我们为 y hat 提供了真正的标签。
因此,我们可以将逻辑回归视为线性回归的一种形式,并使用线性回归的工具来解决逻辑回归。好的。除此之外我们还能做什么?
我们可以利用逻辑回归的特性来提出一个稍微好一点的方法。逻辑回归有什么类型的输出?一种可能性。
当涉及概率时,一种方便的方法是最大似然估计。我们将找到在给定输入的情况下使标签的可能性最大化的模型的权重。
我们从写似然函数开始。可能性只是给定输入的标签的联合概率,如果我们假设观察是独立的,则可以写成每个观察的概率的乘积。

其中 m 是观察次数。
似然性是一切的函数:输入 x、真实标签 y 和权重 w。但出于我们的目的(相对于 w 最大化它),我们将进一步将其视为 w 的函数。x 和 y 被视为我们无法更改的给定常数。

根据 yi 为 0 或 1,每个个体概率具有下列值之一:

更简洁的写法是:

现在,我们在似然函数中替换这个量,简化它的 argmax,并过渡到矩阵符号:

正如你在上面看到的,最大化权重的可能性和最小化最后一行的数量是一样的。这次找到一个封闭形式的解更加困难(如果可能的话),所以我们能做的最好的事情是计算这个量的梯度:

其中:上述部分中涉及的操作是基于元素的。X 前的点表示“将左边的列向量与矩阵 X 的每一列逐元素相乘”。上面的 1 是与 y 形状相同的列向量,用值 1 填充。
现在,上述梯度可以与基于梯度的优化算法(如 SGD)一起使用,以找到最佳权重。
在结束之前,让我们回顾一下我们在这篇文章中看到的一些东西:
- 什么时候可以用逻辑回归?答:当我们遇到二元分类问题时。
- 逻辑回归模型如何获得其输出?答:它计算其输入的加权和,然后将其传递给 sigmoid 函数。输出可以解释为概率。
- 我们如何找到模型的权重?答:我们可以摆弄标签,这样我们仍然可以使用线性回归,或者我们可以使用更适合它的东西,如 MLE。MLE 倾向于给出稍微好一点的结果。
这就是本文的全部内容。希望你觉得有用。
在接下来的两篇文章中,我将展示如何在 NumPy、TensorFlow 和 PyTorch 中实现逻辑回归。
学习逻辑回归的同时提高你的数字技能
towardsdatascience.com](/how-to-code-logistic-regression-from-scratch-with-numpy-d33c46d08b7f) [## 如何用 TensorFlow 实现 Logistic 回归
…没有你想象的那么难
medium.com](https://medium.com/nabla-squared/how-to-implement-logistic-regression-with-tensorflow-f5bf18416da1) [## 如何用 PyTorch 实现逻辑回归
了解逻辑回归并提高您的 PyTorch 技能
medium.com](https://medium.com/nabla-squared/how-to-implement-logistic-regression-with-pytorch-fe60ea3d7ad)
我希望这些信息对你有用,感谢你的阅读!
这篇文章也贴在我自己的网站这里。随便看看吧!
理解马尔可夫决策过程:强化学习背后的框架
了解强化学习中马尔可夫决策过程的概念

Alexander Schimmeck 在 Unsplash 上的照片
通过 AWS 和 Jakarta 机器学习,以有趣的方式继续我们了解强化学习的旅程。我们已经在第一篇文章中讨论了 AWS Deep Racer 和强化学习(RL)的基础知识。对于没有读过这篇文章或者想重读这篇文章的你,不要着急。您可以在这里再次找到它:
欢迎来到 AWS DeepRacer 之旅
towardsdatascience.com](/aws-deepracer-the-fun-way-of-learning-reinforcement-learning-c961cde9ce8b)
现在,在这篇文章中,我们将讨论如何制定 RL 问题。要做到这一点,我们需要理解马尔可夫决策过程或众所周知的 MDP。

典型的强化学习过程。作者图片
MDP 是一个框架,可以用来制定 RL 问题的数学。几乎所有的 RL 问题都可以建模为具有状态、动作、转移概率和回报函数的 MDP。
那么,我们为什么需要关心 MDP 呢?因为有了 MDP,一个代理人可以得到一个最优的策略,随着时间的推移得到最大的回报,我们将得到最优的结果。
好了,我们开始吧。为了更好地了解 MDP,我们需要先了解 MDP 的组成部分。
马尔可夫性质
未来只取决于现在而不是过去。
这句话概括了马尔可夫性质的原理。另一方面,术语“马尔可夫性质”是指概率论和统计学中随机(或随机确定)过程的无记忆性质。
举个例子,假设你拥有一家餐馆,管理原材料库存。您每周检查库存,并使用结果来订购下周的原材料。这个条件意味着你只考虑本周的库存来预测下周的需求,而不考虑上周的库存水平。
马尔可夫链
马尔可夫链由遵循马尔可夫性质的状态序列组成。这个马尔可夫链实际上是一个概率模型,它依赖于当前状态来预测下一个状态。
为了理解马尔可夫性质和马尔可夫链,我们将以天气预报为例。如果当前状态是多云,那么下一个状态可能是下雨或刮风。在第一个状态到下一个状态的中间,有一个概率我们称之为跃迁概率。

天气链。作者图片
从上图来看,当前状态是阴天的时候,下一个状态 70%会下雨,或者 30%会刮风。如果当前状态是多风的,那么下一个状态有 100%的可能性是多雨的。那么当状态是阴雨的时候,有 80%的概率下一个状态会保持阴雨,有 20%会变成多云。我们可以将这些状态和转移概率显示为如下表格或矩阵:

转移概率表和矩阵
作为总结,我们可以说马尔可夫链由一组状态及其转移概率组成。
马尔可夫奖励过程
马尔可夫奖励过程(MRP)是马尔可夫链的扩展,增加了一个奖励函数。所以,它由状态,转移概率和奖励函数组成。

杰里米·蔡在 Unsplash 上的照片
这个奖励函数给出了我们从每个状态得到的奖励。这个函数将告诉我们在阴天状态下我们获得的奖励,在刮风和下雨状态下我们获得的奖励。这种奖励也可以是正值或负值。
马尔可夫决策过程
至此,我们已经看到了关于马尔可夫性质、马尔可夫链和马尔可夫报酬过程。这些成为马尔可夫决策过程的基础(MDP)。在马尔可夫决策过程中,我们有行动作为马尔可夫奖励过程的补充。
让我们来描述一下这个 MDP,他是一个矿工,他想在格子迷宫中得到一颗钻石。在这种情况下,矿工可以在网格内移动以获取钻石。

钻石猎人迷宫。作者图片
在这种情况下,我们可以描述 MDP 包括:
- 一组状态 s ∈ S 。这些状态代表了世界上所有可能的构型。在这里,我们可以将状态定义为机器人可以移动到的网格。
- 一个转移函数 T(s,a,s’)。这代表了 MDP 的不确定性。给定当前位置,转移函数可以是向下移动 80%,向右移动 5%,向上移动 15%。
- 一个奖励函数 R(s,a,s’)。这个函数显示了每一步获得了多少奖励。代理人的目标是最大化奖励的总和。一般来说,在每一步都会有一个小的负面奖励来鼓励快速解决问题,而在实现目标时会有大的奖励,或者在终止状态或进入像僵尸和火这样的障碍时会有大的负面奖励。
- 一组动作 a ∈ A 。代理可以采取的所有可能操作的集合。在这个例子中,动作是向上、向下、向左和向右。
在 MDP,我们还需要理解几个术语。
行为空间
行动空间是一个行动者为达到目标可以采取的行动。在我们的 miner 示例中,动作空间向上、向下、向左和向右移动。这种行动空间可以分为两种类型。第一个是离散动作空间,第二个是连续动作空间。
政策
在 MDP,代理行为被定义为一种策略。该策略告诉代理在每种状态下要执行的操作。开始时,我们需要初始化一个随机策略。然后,代理将继续学习,最优策略从迭代中产生,其中代理在每个状态中执行良好的动作,这使得累积奖励最大化。
该策略可分为两种类型:
- 确定性策略。给定特定的状态和时间,策略告诉代理执行一个特定的操作。
- 随机政策。这并不直接针对某个特定的动作。相反,它将状态映射到动作空间上的概率分布。

确定性和随机性策略的例子。作者图片
插曲
一个情节是代理从初始状态到最终状态或终止状态所采取的动作。例如,从当前状态进入最终获得钻石的旅程。矿工运动是 D > A > B > C > F > I。

插曲插图。作者图片
返回
在强化学习中,我们的目标是最大化一集的累积回报。这个奖励是代理收到的奖励的总和,而不是代理从当前状态收到的奖励(即时奖励)。这种累积奖励也称为回报。
代理可以通过在每个状态下执行正确的动作来最大化回报。它将在最优策略的指导下实现这一正确的动作。
贴现因素
在奖励最大化的过程中,我们需要考虑当下和未来奖励的重要性。因此,贴现因子开始起作用。这个贴现因子决定了我们对未来奖励和眼前奖励的重视程度。
折扣因子的值范围从 0 到 1。较小的值(接近 0)更重视眼前的回报,而不是未来的回报。另一方面,高价值(接近 1)给予未来回报比眼前回报更大的重要性。
例如,在比赛中,我们的主要目标是完成一圈。那么我们需要给予未来的回报比眼前的回报更重要。所以,我们需要使用一个接近 1 的折现因子。
结论
恭喜你!!
至此,我们已经涵盖了什么是马尔可夫性质、马尔可夫链、马尔可夫报酬过程和马尔可夫决策过程。这包括 MDP 的重要术语,如行动空间、政策、情节、回报和折扣系数。
总之,强化学习可以被表示为具有状态、动作、转移概率和奖励函数的 MDP。
文献学
本课程将介绍智能计算机系统设计的基本思想和技术。一个…
inst.eecs.berkeley.edu](https://inst.eecs.berkeley.edu/~cs188/sp20/) [## 强化学习导论:马尔可夫决策过程
在一个典型的强化学习(RL)问题中,有一个学习者和一个被称为代理的决策者
towardsdatascience.com](/introduction-to-reinforcement-learning-markov-decision-process-44c533ebf8da) [## 马尔可夫性质
在概率论和统计学中,术语马尔可夫性是指随机变量的无记忆性。
en.wikipedia.org](https://en.wikipedia.org/wiki/Markov_property) [## 马尔可夫链
马尔可夫链是描述一系列可能事件的随机模型,其中每个事件的概率…
en.wikipedia.org。](https://en.wikipedia.org/wiki/Markov_chain) [## 马尔可夫决策过程
在数学中,马尔可夫决策过程(MDP)是离散时间随机控制过程。它提供了一个…
en.wikipedia.org](https://en.wikipedia.org/wiki/Markov_decision_process)
关于作者
Bima 是一名数据科学家,他总是渴望扩展自己的知识和技能。他毕业于万隆技术学院和新南威尔士大学,分别是采矿工程师。然后他通过 HardvardX、IBM、Udacity 等的各种在线课程开始了他的数据科学之旅。目前,他正与 DANA Indonesia 一起在印度尼西亚建立一个无现金社会。
如果您有任何疑问或需要讨论的话题,请通过 LinkedIn 联系 Bima。
用代码理解数学符号
当我们用我们最喜欢的语言来看时,求和、阶乘、矩阵等等都很简单

对于任何有兴趣从事机器学习和数据科学职业或研究的人来说,有一天将会到来,那就是超越 python 库,跟随好奇心进入这一切背后的数学。这通常会把你带到一个庞大的、公开的论文集,详细说明它是如何工作的。你对核心数学理解得越深,你可能就越接近创造新方法的灵光一现。在第一张纸上,一切似乎都很好,直到你遇到这样的事情:

对于任何研究数学多年或从事机器学习数学层面工作的人来说,这样的等式可以被仔细解析为含义和代码。然而,对许多其他人来说,这可能看起来像象形文字。事实是,古代数学领袖似乎选择了最有趣的符号来描述相当直观的方法。结果是:方程和变量看起来比实际复杂得多。
我发现代码不仅可以用来写程序,也是一种全球公认的解释复杂事物的语言。当我在学习一切数据科学背后的数学时,我总是发现获得对数学的普遍理解的最好方法是编写代码片段来描述方程。最终,这些符号变得可以理解,几乎可以作为普通报纸上的文本阅读。在这篇文章中,我希望分享一些用代码描述数学是多么简单的例子!
求和与乘积

求和符号是迭代数学中最有用和最常用的符号之一。尽管设计复杂,但实现非常简单,而且非常有用。
x = [1, 2, 3, 4, 5, 6]
result = 0for i in range(6):
result += x[i]Output of print(result) -> 21
如上所述,这个符号所代表的只是一个从底部数字开始,在顶部数字范围内的 for 循环。底部设置的变量成为索引变量,每个循环的任何结果都被添加到一个总值中。不太常见的是,可以使用以下方法:

这个符号通常被称为乘积运算符,其功能相同,但不是将每个结果相加,而是相乘。
x = [1, 2, 3, 4, 5, 1]
result = 1for i in range(6):
result *= x[i]Output of print(result) -> 120
阶乘
阶乘是“!”几乎存在于任何计算器上。对许多人来说,这一点可能更加明显,但编写一些代码来理解其中的机制仍然是值得的。
5!将表示为:
result = 1
for i in range(1,6):
result *= i
Output of print(result) -> 120
条件括号

条件括号用于根据一组条件转移方程式的流向。对于编码人员来说,这只是常见的“如果”语句。上述条件可以表示为:
i = 3
y = [-2, 3, 4, 1]
result = 0if i in y:
result = sum(y)
elif i > 0:
result = 1
else:
result = 0print(result) -> 6
如上所述,括号中每一行的正确符号指示了每条路径应该执行的内容。我在每个条件中添加了额外的“包含”符号,以增加更多的洞察力。如上所述,我们检查了 I 值是否在 y 列表中。认识到这一点后,我们返回了数组的和。如果 I 值不在数组中,我们将根据该值返回 0 或 1。
逐点和笛卡尔矩阵乘法
最后,我想快速介绍一些操作,这些操作通常是任何数据科学家通过他们最喜欢的语言库——矩阵乘法来完成的。最容易理解的形式是逐点操作。这简单地写成:

注意第一个要求是每个矩阵必须有相同的形状(即#行= & #列=)
其代码如下所示:
y = [[2,1],[4,3]]
z = [[1,2],[3,4]]
x = [[0,0],[0,0]]for i in range(len(y)):
for j in range(len(y[0])):
x[i][j] = y[i][j] * z[i][j]print(x) -> [[2, 2], [12, 12]]
最后,让我们看看一个典型的矩阵乘法过程,最常用于机器学习。用复杂的术语来说,这个操作寻找每个主要行与每个次要列的点积。主要是以下要求:假设[#rows,# columns]→矩阵 i x j 需要#columns(i) == #rows(j) →最终乘积的形状为[#rows(i),#columns(j)]
这可能看起来令人困惑,我最好的建议是看看 google images,看看这些需求的一些很好的可视化。

该等式的代码如下所示(使用 numpy 点方法):
y = [[1,2],[3,4]]
z = [[2], [1]]
# x has shape [2, 1]
x = [[0], [0]]for i in range(len(y))
for j in range(len(z):
x[i][j] = np.dot(y[i], z[:, j])
print(x) -> [[4],
[10]]
这只是几个例子,但是对这个简单代码的理解可以让任何一个程序员去了解最初不吉利的数学世界。当然,为了提高效率,这些方法都可以合并,并且通常都有现成的库方法。用简单的代码编写这些代码的目的是为了看看当它们以真实操作的形式写出来时有多大意义。
在https://www.mindbuilderai.com看看我目前在做什么
来源
[1]https://commons . wikimedia . org/wiki/File:Pure-mathematics-formula-blackboard . jpg
理解推荐系统的矩阵分解
了解如何实现 Google 在实现协作过滤模型时使用的矩阵分解算法

介绍
矩阵成了面试问题中必不可少的话题,不管你是开发人员还是数据工程师。作为一名数据工程师,操作和转换矩阵索引是一项非凡的能力。这个想法是在它下面学习数学。当你理解了算法,你需要做的就是玩指数来得到答案。
在这篇文章中,我将一步一步地分享实现矩阵分解函数的算法。代码片段应该在 R 中;但是,您可以用您喜欢的任何语言生成代码。
矩阵分解的现实应用是什么?
矩阵分解在许多应用中是一种重要的方法。有超级计算机可以进行矩阵分解。例如,跟踪航班的雷达利用一种叫做卡尔曼滤波的策略。卡尔曼滤波的核心是矩阵分解活动。当卡尔曼滤波器利用雷达跟踪你的飞行时,它们照亮了条件的直接框架。另一个很好的例子是 Google,它应用矩阵分解来开发一个协作过滤模型。
理解数学
矩阵分解算法的工作原理是将原始矩阵分解成两个矩阵,一个是上面的三角形(U ),另一个是下面的三角形(L)。在本教程中,我将坚持将方阵 A 因式分解为 LU,如下所示。
请注意:为了简单起见,我们不用担心 A 的置换行,可以假设 A 小于 5x5。最后,矩阵入口点(中枢)不等于零。本教程的目标是理解数学,并将其转化为代码。更复杂的版本将很快在另一篇文章中发布。

矩阵 A 是一个 I 乘 j 的正方形矩阵,分解成 L 和 U 矩阵。目标是在矩阵的右上角获得零— (L),在矩阵的左下角获得零— (U)。
U 矩阵

在这种情况下,我们需要找到一种方法来将提到的值降为零。重要的是要明白,我们必须在不交换行的情况下分解矩阵,我们需要保持行的顺序。在这种情况下,我们将使用线性代数中的行缩减方法。
为了更好的理解,我们来举个例子,假设我们有一个维数为 3×3 的方阵,如下图。

为了得到这个矩阵左下角的零,我们要做如下的事情:

我在这里做的是将 4 除以 2——这被称为乘数,然后用它乘以第一行。之后从第二排减去第一排。最后,将结果放在第二行。

对第三行重复这些步骤。注意,第一行应该保持不变。

现在,我们需要将 6 化为 0。我们可以通过实现以下内容来实现这一点:

请注意,我用 R2 而不是 R1,因为我不想失去我在第三行得到的零分。因此,我将该等式交替应用于第二行。

U 的最终形式
L 矩阵

L 矩阵是直接和简单的。这是一个梯队对角矩阵——对角线上是 1,右上角是 0。剩余值将是我们通过行缩减得到的乘数,其中 U 矩阵位于相同的索引中。
因此,L 矩阵的最终值将如下所示:

计算机算法
理解了数学之后,是时候构建一个通用的计算机程序来分解任何维数相对较大的矩阵了。

基本的算法思想
基本思想是遍历矩阵的列,然后遍历每一行来得到乘数。我们从 2 开始 j,因为我们需要保持第一行不变。我们设置了一个条件,只在行比列高的时候执行,因为我们想对角移动。我们一直想保留归约得到的零。
下面是用 R 语言实现的算法。您可以使用您喜欢的任何语言来实现相同的功能。
由于执行了两个嵌套的 for 循环— 引用,该算法的时间复杂度为 O(n2)。
结束语
试着继续解决矩阵挑战,学习数学技巧来战胜这类面试问题。一旦你发现问题,你就能抓住算法模式,这是很有帮助的。这样做会帮助你赢得面试,给面试官留下好印象。
最后,我希望这篇文章能让面试过程中的其他人受益。如果你能用不同的语言或使用不同的算法自己解决这个问题,我将不胜感激。感谢您的阅读,祝您求职顺利。
理解最大似然估计

马库斯·斯皮斯克在 Unsplash 上的照片
这是什么?它是用来做什么的?
我第一次学习 MLE 的时候,我记得我只是在想,“嗯?”这听起来更哲学和理想主义,而不是实际的。但事实证明,MLE 实际上非常实用,是一些广泛使用的数据科学工具(如逻辑回归)的关键组成部分。
让我们来看看 MLE 是如何工作的,以及如何用它来估计逻辑回归模型的贝塔系数。
MLE 是什么?
最简单地说,MLE 是一种估计参数的方法。每次我们拟合统计或机器学习模型时,我们都在估计参数。单变量线性回归有以下等式:
Y = B0 + B1*X
我们拟合该模型的目的是在给定 Y 和 x 的观测值的情况下估计参数 B0 和 B1。我们使用普通最小二乘法(OLS)而不是最大似然法来拟合线性回归模型并估计 B0 和 B1。但是类似于 OLS,MLE 是一种在给定我们观察到的情况下估计模型参数的方法。
MLE 提出问题,“给定我们观察到的数据(我们的样本),最大化观察到的数据发生的可能性的模型参数是什么?”
简单的例子
那是相当多的。让我们用一个简单的例子来说明我们的意思。假设我们有一个有盖的盒子,里面装着未知数量的红球和黑球。如果我们从有替换的盒子里随机选择 10 个球,最后我们得到了 9 个黑色的球和 1 个红色的球,这告诉我们盒子里的球是什么?
假设我们开始相信盒子里有相同数量的红色和黑色的球,观察到我们观察到的现象的概率是多少?
**Probability of drawing 9 black and 1 red (assuming 50% are black):**We can do this 10 possible ways (see picture below).Each of the 10 has probability = 0.5^10 = 0.097%Since there are 10 possible ways, we multiply by 10:Probability of 9 black and 1 red = 10 * 0.097% = **0.977%**

抽取 1 个红球和 9 个黑球的 10 种可能方法
我们也可以用一些代码来证实这一点(比起计算概率,我总是更喜欢模拟):
***In:***import numpy as np# Simulate drawing 10 balls 100000 times to see how frequently
# we get 9
trials = [np.random.binomial(10, 0.5) for i in range(1000000)]
print('Probability = ' + str(round(float(sum([1 for i\
in trials if i==9]))\
/len(trials),5)*100) + '%')***Out:***Probability = **0.972%**
模拟概率与我们计算的概率非常接近(它们并不完全匹配,因为模拟概率有方差)。
所以我们的结论是,假设盒子里有 50%的球是黑色的,那么像我们这样挑出尽可能多的黑球的可能性是非常低的。作为通情达理的人,我们会假设黑色球的百分比一定不是 50%,而是更高。那百分比是多少?
这就是 MLE 的用武之地。回想一下,MLE 是我们估计参数的一种方法。问题中的参数是盒子中黑色球的百分比。
MLE 问这个百分比应该是多少,才能最大化观察到我们观察到的现象的可能性(从盒子里抽出 9 个黑球和 1 个红球)。
我们可以使用蒙特卡罗模拟来探索这一点。下面的代码块遍历一个概率范围(盒子中黑色球的百分比)。对于每种概率,我们模拟抽取 10 个球 100,000 次,以查看我们最终得到 9 个黑色球和 1 个红色球的频率。
# For loop to simulate drawing 10 balls from box 100000 times where
# each loop we try a different value for the percentage of balls
# that are blacksims = 100000black_percent_list = [i/100 for i in range(100)]
prob_of_9 = []# For loop that cycles through different probabilities
for p in black_percent_list:
# Simulate drawing 10 balls 100000 times to see how frequently
# we get 9
trials = [np.random.binomial(10, p) for i in range(sims)]
prob_of_9.append(float(sum([1 for i in trials if i==9]))/len(trials))plt.subplots(figsize=(7,5))
plt.plot(prob_of_9)
plt.xlabel('Percentage Black')
plt.ylabel('Probability of Drawing 9 Black, 1 Red')
plt.tight_layout()
plt.show()
plt.savefig('prob_of_9', dpi=150)
我们以下面的情节结束:

抽取 9 个黑球和 1 个红球的概率
看到那座山峰了吗?这就是我们要找的。抽中 9 个黑球和 1 个红球的概率最大的黑球百分比值是其最大似然估计值— 我们的参数(黑球百分比)的估计值,最符合我们观察到的情况。
因此,MLE 有效地执行了以下操作:
- 写一个概率函数,将我们观察到的概率与我们试图估计的参数联系起来:我们可以将我们的概率写成 P(9 个黑色,1 个红色|黑色百分比= b)——假设盒子中黑色球的百分比等于 b,抽取 9 个黑色球和 1 个红色球的概率
- 然后我们找到使 P 最大化的 b 的值(9 黑 1 红|百分比黑=b) 。
从图片中很难看出,但是最大化观察我们所做的概率的黑色百分比值是 90%。似乎显而易见,对吗?虽然这个结果似乎明显是个错误,但支持 MLE 的潜在拟合方法实际上是非常强大和通用的。
最大似然估计和逻辑回归
现在我们知道了它是什么,让我们看看如何使用 MLE 来拟合一个逻辑回归( )如果你需要一个关于逻辑回归的复习,在这里查看我以前的帖子 ) 。
逻辑回归的输出是类别概率。在我之前关于它的博客中,输出是投篮的概率。但是我们的数据是以 1 和 0 的形式出现的,而不是概率。例如,如果我从不同的距离投篮 10 次,我的 Y 变量,即每次投篮的结果,看起来会像这样(1 代表投篮成功):
y = [0, 1, 0, 1, 1, 1, 0, 1, 1, 0]
而我的 X 变量,每次投篮离篮筐的距离(以英尺为单位),看起来就像:
X = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10]
我们如何从 1 和 0 到概率?我们可以把每一次击球看作是一个二项分布的随机变量的结果。关于二项分布的更多内容,请阅读我之前的文章。简单地说,这意味着每一次尝试都是它自己的尝试(就像扔硬币一样),有一些潜在的成功概率。只不过我们不仅仅是在估算一个单一的静态成功概率;相反,我们是根据我们投篮时离篮筐有多远来估计成功的概率。
所以我们可以把我们的问题重新架构成一个条件概率(y =投篮的结果):
P(y |离篮筐的距离)
为了使用 MLE,我们需要一些参数来拟合。在单变量逻辑回归中,这些参数是回归 beta:B0 和 B1。在下面的等式中,Z 是投篮命中率的对数(如果你不知道这是什么意思,这里解释一下)。
Z = B0 + B1*X
**你可以把 B0 和 B1 想象成描述距离和投篮概率之间关系的隐藏参数。**对于 B0 和 B1 的某些值,射击精度和距离之间可能存在强正相关关系。对其他人来说,它可能是微弱的积极的,甚至是消极的(斯蒂芬库里)。如果 B1 设置为等于 0,则根本没有关系:

不同 B0 和 B1 参数对概率的影响
对于每组 B0 和 B1,我们可以使用蒙特卡罗模拟来计算出观察到数据的概率。我们模拟的概率是对于一组猜测的 B0,B1 值,观察到我们的精确投篮序列(y=[0,1,0,1,1,1,0,1,1,0],给定离篮筐的距离=[1,2,3,4,5,6,7,8,9,10])的概率。
对于给定的 B0 和 B1,P(y=[0,1,0,1,1,1,0,1,0] | Dist=[1,2,3,4,5,6,7,8,9,10])
通过尝试一组不同的值,我们可以找到使 P(y=[0,1,0,1,1,1,0,1,1,0] | Dist=[1,2,3,4,5,6,7,8,9,10]) 最大化的 B0 和 B1 的值。这些将是 B0 和 B1 的最大似然估计。
显然,在逻辑回归和一般的 MLE 中,我们不会进行强力猜测。相反,我们创建了一个成本函数,它基本上是我们试图最大化的概率的倒置形式。这个代价函数与 P(y=[0,1,0,1,1,1,0,1,1,0] | Dist=[1,2,3,4,5,6,7,8,9,10]) 成反比,和它一样,代价函数的值随着我们的参数 B0 和 B1 而变化。我们可以通过使用梯度下降来最小化该成本函数,从而找到 B0 和 B1 的最佳值。
但在精神上,我们对 MLE 一如既往地做的是询问和回答以下问题:
给定我们观察到的数据,使观察到的数据发生的可能性最大化的模型参数是什么?
我在这篇文章中提到了以下文章:
通过一个游戏实例理解 MC 实验。

鸣谢:来自 Dota 2 的截图
我们经常会在项目中遇到不确定性,在这种情况下,我们需要对不同的成功机会进行评估。解决这种情况的一个非常好的方法是使用从潜在的不确定概率中得出的结果的重复模拟。这种技术被称为蒙特卡罗方法(或简称为 MC),它是以摩纳哥的蒙特卡洛赌场命名的,斯坦尼斯瓦夫·乌拉姆的叔叔在那里赌博。斯坦尼斯劳·乌兰和约翰·冯·努曼在秘密的曼哈顿计划中研究了这些方法。
这些方法的目的是为未知的确定性值找到一个数值近似值。这些方法强调在大规模试验中使用重复抽样,并使用 CLT 等工具逼近结果,这些工具将保证样本均值遵循正态分布,而不管随机过程的基本分布如何。
从观察者的角度来看,进行这样的实验大致需要以下步骤:
a.建立一个分布或概率向量,从中得出结果
b.多次重复得出结果的实验
c.如果结果是一个数字标量,则结果的平均值应按照 CLT 正态分布。
d.估计平均值、标准偏差,并构建预期结果的置信区间。
尽管通过阅读上面的内容看起来很简单,但问题的关键是编写适当的函数和代码来完成上面的步骤。如果潜在的随机变量是一个已知的常见分布,或者你需要使用一个随机发生器来选择一个结果,这个问题就简化了。
下面使用游戏 Dota 2 的例子来解释该方法,问题被定义如下:
“在 Dota 2 游戏中,玩家可以选择从宝藏中购买物品。这些物品通常是特定 Dota 2 英雄或另一个 NPC 的皮肤。在每个宝藏中,有两类物品,普通物品和稀有物品。玩家将购买宝藏的钥匙,然后旋转轮盘,轮盘将从常规物品或稀有物品中随机选择一个物品。每个物品的赔率是不相等的,稀有物品有不同的赔率,赔率随着每次旋转而减少,而普通物品的赔率是恒定的。
假设有 9 个常规物品和一个稀有物品,它们的赔率由赔率向量给出。每次旋转的费用是 175 英镑。在第 40 轮,获得稀有物品的几率是 1,这意味着它肯定会以 40 * 175 = 7000 的最高成本被选中。
odds _ to _ get _ rare _ item =[2000.0 583.0 187.0 88.0 51.0 33.0 23.0 17.0 13.1 10.4 8.5 7.1 6.0 5.2 4.5 4.0 3.6 3.2 2 2.9 2.6 2.4 2.2 1 1.9 1.8 1
我们如何估计收到稀有物品的预期成本?"
解决这个问题的方法如下:
a.定义一个模拟实验的函数,如下所示(用 Python 语言):
def simulate_cost_of_getting_rare_item(no_of_items,prob_to_get_rare_item,cost_of_each_round):
这个函数将接受。项目作为输入,赔率向量获得稀有项目,在我们的情况下是一个和每次旋转的成本。这个函数的输出将是所有旋转的总费用,直到找到稀有物品。
b.定义保存累积成本和计算旋转或迭代次数的变量。
cumulative_cost = 0
iteration = 1
然后我们有
c.在最初几次旋转中,必须至少选择一次常规物品,而不能得到一个重复的常规物品,直到所有常规物品都被选择。因此,您可以将模拟逻辑分为两部分,一部分用于初始回合,另一部分用于后续回合。
# for the first few picks; ensure that regular items are picked without repetition. This is achived by restricting the prob_items array with only availabe items subtracting the # already selected items in previous iterations from available items unless rare item is found
while iteration < no_of_items:
cumulative_cost += 175
prob_items = []
从概率向量中取出稀有物品的概率,将其从 1 中减去,并将剩余的概率平均分配给被遗漏的常规物品。根据计算的概率,使用随机方法(来自 random.choices())比较选择的项目。检查在物品概率向量中最后一个位置的是不是稀有物品。
left_out_prob = 1 - prob_to_get_rare_item[iteration-1]
prob_items = [left_out_prob/(no_of_items - iteration) for i in
range(no_of_items-iteration)]
prob_items.append(prob_to_get_rare_item[iteration-1])
item_chosen = choices([i for i in range(no_of_items-
iteration+1)],prob_items)
if item_chosen[0] == len(prob_items)-1:
return iteration, prob_items, item_chosen[0],
cumulative_cost
iteration += 1
d.一旦所有常规物品至少被选择一次,它们将在随后的回合中再次进入战斗(即,如果稀有物品在前 9 回合中没有被选择,则从第 10 回合开始),因此在随后的每次旋转中,要选择的物品数量将保持为 no_of_items。
# once all regular items are picked atleast once, then can repeat
# but since the decreasing odds of rare item, their probabilities
# for any of them getting selected over rare item is minimized
while True:
cumulative_cost += 175
prob_items = []
left_out_prob = 1 - prob_to_get_rare_item[iteration-1]
prob_items = [left_out_prob/(no_of_items - 1) for i in
range(no_of_items-1)]
prob_items.append(prob_to_get_rare_item[iteration-1])
item_chosen = choices([i for i in
range(no_of_items)],prob_items)
if item_chosen[0] == len(prob_items)-1:
return iteration, prob_items, item_chosen[0],
cumulative_cost
iteration += 1
e.函数定义完成后,在 100 * 1000 次试验中重复采样该函数,并计算预期成本
# now perform monte carlo simulations over 100 * 1000 trails
mean_cost = []
for outer_trials in range(100):
cost_vec = []
for inner_trials in range(1000):
iteration, prob_items, pick, cost =
simulate_cost_of_getting_rare_item
(no_of_items,prob_to_get_rare_item,cost_of_each_round)
cost_vec.append(cost)
mean_cost.append(sum(cost_vec)/len(cost_vec))
使用上面的技巧,我们可以估计得到一个稀有物品的预期成本大约是 2250。
azure 笔记本中提供了完整的代码:
[## 微软 Azure 笔记本电脑
提供对运行在微软 Azure 云上的 Jupyter 笔记本的免费在线访问。
notebooks.azure.com](https://notebooks.azure.com/spaturu/projects/dota-cost-of-rare-item)
我写了一个 python 模拟器来帮我玩彩票
我要多长时间才能赢得彩票?

介绍
我在纽约长大,彩票是我家庭文化的重要组成部分。对我来说,一个冰箱看起来是不完整的,除非有一些刮刮乐或百万彩票粘在上面。每个假期或生日,我都会(现在仍然如此)收到刮刮乐彩票,上面还半开玩笑半威胁地写着“如果你赢了大奖,我就能分到一份!”
不管是好是坏,我最终搬到了阿拉巴马州,在那里彩票是非法的。这对我来说有点震惊,但我最终还是习惯了。然而,每当我拜访纽约的家人时,当我看到发光的广告牌时,当我看到每个加油站的原色标志在我脸上炸开时,当我听到我的家人定期在谈话中提起它时,我都会想起它对人们的吸引力。
总而言之,我一直对幕后的实际数字很好奇。我最终决定全力以赴,模拟百万富翁,为我思考这个问题的方式增加一些视角。
目录
- 百万规则复习
- 模拟是如何工作的?
- 3 次模拟运行和可视化的结果
- 结论
百万富翁规则
让我们从基础开始。怎么玩 Mega Millions,有什么规则?(如果您已经知道这一点,请随意跳过)
他们的网站对此解释得很好。下面是一张图片,上面有说明和奖金细目以及相应的赔率。

【https://www.megamillions.com/
花点时间仔细检查一下。是的,在最后一行,赢得百万球的 1/37 的赔率是正确的。这也让我困惑了一分钟。之所以不是 1/25(由于只有 25 个巨型球,你最初会假设是 1/25 ),是因为该奖励是专门针对你只赢得巨型球而没有匹配任何白色球的情况。
模拟是如何工作的?
其核心是 2 个随机数生成器和一个“while-loop”。模拟器继续一次又一次地产生随机数(复制 5 个白球和一个大球),直到它们匹配,也就是赢得头奖。在每次运行期间,都有 if 语句将较小的奖金加起来,这样我们就可以跟踪总的利润/损失。
假设进入:
- 每次抽奖你只需购买一张票(每周 2 张),你总是得到标准的 2 美元的 megaball 票
- 如果你中了头奖,你可以选择一次性现金
- 所有的收益计算都是税前的(在这些情况下,我们也没有考虑货币的时间价值)
见解:
- 将结果与 Mega Millions 网站上的数学概率进行比较很有意思
- 让你有能力说你“中了彩票”
查看下面的代码,或者如果你想了解更多细节,请访问我的 Github
你可能已经注意到了,我把头奖设定为 197,000,000 美元。这不是武断的。我计算了过去 3 年的平均累积奖金。在模拟过程中,您可以随意尝试并改变头奖。
结果
数学上(如果你看了上一节的规则),你应该每 302,575,350 次就中一次头奖。我运行了 3 次模拟器。让我们将这些运行与统计平均值进行比较。
有用的类比:如果你掷骰子 6 次,理论上你应该掷出一个‘6’。然而,我们都知道你可以在第一次尝试中掷出 6 分。或者你可以在 20 次之后掷出 6。彩票中奖也一样。仅仅因为你玩了 3.02 亿次彩票,并不保证你会赢一次。你可能会赢上千次。或者你可能要尝试十亿次才能赢。这就是这些场景有趣之处。你永远不知道会有什么结果。
说了这么多,还是看结果吧!
场景 1 —幸运:2500 万次播放— 244,744 年
如果你每次抽奖(一周两次)买一张彩票,在这种情况下,你需要 244,744 年才能赢得头奖…而这是极其幸运的!请看下面的获奖数量分类:
播放数量:
下面显示了 2500 万次播放中获得的哑弹和奖品类型的分布。


原木检尺

线性标尺
利润/损失:
在你赢得头奖的前一天,你可能会损失 5000 万美元…但是,所有这些年都会有回报,因为一旦你赢了,你将立即领先 1.5 亿美元!(我排除了你在那段时间里从那 5000 万英镑中获得的利息收益…如果你认为你可能不会领先的话)
有趣的是,我们注意到彩票支付的中彩金额最少。


原木

线性的
此场景的中奖票(如果您想在真实场景中试试运气):

场景 2—平均:3.16 亿次播放—3,038,461 年
播放数量:
下面显示了 3.16 亿次播放中获得的哑弹和奖品类型的分布。这是你能得到的统计平均值。如果你每次抽奖(一周两次)都买一张彩票,那么你要花 3,038,461 年才能赢得头奖。这是最有可能的情况,也是你在玩彩票时应该期待的…


原木

线性的
利润/损失:
在你赢得头奖的前一天,你会损失 5.46 亿美元…不幸的是,即使你赢了 300 多万年,你仍然会损失 3.49 亿美元…


原木

线性的
场景 3——不吉利:4.51 亿次播放——434.19 万年
最后,我想我应该给你们展示一下这个不幸的场景,让你们看看这些数字。这些图表看起来与上面的场景几乎相同。
量

利润/损失:

结论
彩票中奖的可能性极小。如果你想要赌博的刺激而没有输钱的头痛,下载这个模拟器@ my GitHub 自己试试。如果你想在真实的事情上测试你的运气,你可以预计它需要大约 300 万年才能赢得头奖(假设你每周买 2 张票)。
但是!如果你决定长期玩下去,并且无论如何都坚持参与,那么在第一个一百万年里,你有大约 1/3 的机会赢得头奖(因此是有利可图的)。如果你在第一个 100 万年中了奖,累积奖金将会超过门票的花费…所以还是有希望的!
【https://andrewhershy.medium.com/membership】考虑通过我的推荐链接加入 Medium:
如果您觉得这很有帮助,请订阅。如果你喜欢我的内容,下面是我做过的一些项目:
使用地理空间数据了解微观移动模式
位置不是关于一个点,而是关于一条线!

根据出行频率给路线涂上颜色。来源:Kepler.gl
我的用户如何在这个城市移动?他们去哪里了?这个城市的“流”是什么样子的?这在一天中是如何变化的?
这些是我们经常从用户(主要是微移动公司或按需公司)那里听到的问题。如果你是一家微型移动公司(拼车、打车、拼车),这些问题也在你的脑海中,这篇文章应该可以帮助你解决其中的一些问题。
什么是移动性分析?
到目前为止,我们已经讨论了主要以两种方式执行地理空间分析:
- **静态点:**分析关于不动的静态实体的指标或事件。例如,分析从一个车站出发的车次或这家餐厅的平均准备时间。
要了解更多信息,请查看:
对于一个公司来说,静态位置是他们的业务实体,不会移动久而久之。例如,对于一个…
blog.locale.ai](https://blog.locale.ai/optimizing-the-performance-of-static-locations-geospatially/)
- **聚合:**当我们在处理某个地点和时间发生的事件时,使用地理空间聚合系统,如 hexbin 或 geohash。例如,将一个城市的订单聚合到六边形网格上。
#旁注:如果你想了解更多关于网格的内容,请查看:
[## 空间建模花絮:Hexbins vs Geohashes?
如果你是一个像优步一样的两度市场,你会迎合数百万通过你的司机请求搭车的用户…
blog.locale.ai](https://blog.locale.ai/spatial-modelling-tidbits-honeycomb-or-fishnets/)
然而,为了理解行程中两个事件之间的度量*,运动分析非常有用。*
根据各种参数分析行程
在分析行程时,我们应该关注以下特征:
- **出发地:**行程从哪里出发?例如,在早上,当用户前往他们的工作地点时,行程的最后一英里很可能从住宅区或公交车站或地铁站附近开始。
- 目的地:旅程的终点是哪里?同样,在晚上,用户大多会回家。

此起点的目标点。来源:Kepler.gl
- **路径:**用户最常走的路线或路径是什么?最有价值的用户走哪些路径?如果有多种方式可以到达一个目的地,用户会选择哪种方式?例如,如果你是一家拼车或拼车公司,这也应该有助于你分析哪些是你最常去的路线,以获得最大数量的用户。
- **距离:**出行的平均距离是多少,它是如何随时间变化的?长途旅行从哪里始发?短途到哪里结束?例如,很多去海滩的旅行都是长途的,而且是在周末。此外,它们源自市中心。
- **所用时间:**行程的平均时间是多少,随着行程起点的不同,平均时间会有怎样的变化?短途旅行是否也会因为所经过的路线而花费大量的旅行时间?
- **重复性:**百分之多少的行程是重复行程?有多少用户是重复用户?
- 旅行可以有几个自己的特点。例如:你从旅行中获得多少收入?他们盈利吗?用户最不安全的路线有哪些?
通过分析运动数据获得的见解
你能从运动分析中获得什么额外的见解?
流动
流量分析(或网络分析)是为了了解城市在一天的不同时间甚至历史上是如何运动的。
例如,对于一家“最后一英里”配送公司,研究流程显示,配送合作伙伴开始向市中心移动,到了晚上,他们开始搬出去,因为他们大多数人住在郊区。但他们需要向内发展,因为这是他们获得订单最多的地区。
我们通常用弧线或线条来表示流动(并利用时间来理解其时间模式)。Arcs 图层有助于我们了解城市中最常去的出发地和目的地以及它们之间的距离。弧线不会显示两点之间的路径。下图显示了奥斯汀市的流量历史分析。

显示水流的 3d 弧线。来源:Kepler.gl
显示整体流程的另一种方式也可以使用线条,这些线条只是弧的视觉表示。

显示航线的线图层。来源:Kepler.gl
顶部 O-D 对
只是从上一点外推,当你研究流量的时候,你也可以识别出哪些是顶级的起止点。了解最常见的起点-目的地对使得重新分配变得很容易。你可以随时让你的车辆(或司机)在这些地点待命。这也应该有助于拼车公司鼓励在这些地点搭车。
闲置点
旅行中有哪些车辆或乘客空闲的地方?对于微移动公司来说,这是一个非常重要的分析。他们的自行车没有被利用的每一分钟都在损失金钱。他们中的大多数都是按每公里收费的。空闲点的一些分析点是:
- **何时:**出行中车辆闲置的时间是否有规律可循?例如,下午在热点旅游地点附近。
- **特点:**多少辆自行车一起经常出现在那个闲置地点?有多少独特的旅行?有多少独立用户?
- **持续时间:**车辆怠速多长时间?比如,在医院外面或者三个小时,直到电影结束。
- **频率:**车辆多久怠速一次?有时间或季节的模式吗?
- **到最近车站的距离:**如果自行车应该在一个车站,空闲点离那个位置有多远?
军团
出行次数最多的用户是哪些人?你的超级用户有什么共同点?他们平均花多少时间旅行?他们旅行了多远?他们去哪里了?
要了解什么样的人物角色对你的产品和什么样的用例有最大的效用,必须对你的超级用户有深入的了解。
极端值
异常值有助于您了解运动数据中的异常情况。有多少人去市郊?例如,在很多情况下,我们观察到人们跨越国界(这是非法的)。在这种情况下,对一个用户或一次旅行的透彻理解就变得相当有洞察力。
这个用户去了哪里?为什么?他总是走这些路线吗?在这些情况下,拥有一个特定用户或行程的详细视图是很重要的。

电网方面的供需。来源:Kepler.gl
需求-供给
供需分析是优化资产利用的关键(从而减少闲置时间)。
- 下一个需求时间:当旅行正在进行时,目的地的需求是什么样的?如果乘坐的目的地实际上是一个需求不足的地方,你的车辆可能会在那里闲置很长时间,或者乘坐者将不得不返回而没有乘坐。
- **兴趣点:**另一个非常有趣的分析是分析运动如何受到不同兴趣点的影响,如学校、大学、商场或旅游目的地。
- 外部事件:分析不同的外部事件,如下雨、大型音乐会、体育比赛、抗议活动如何影响你公司的需求和供应也是很有见地的。
现场运动分析
在场所,我们正在建立一个“运动”分析平台,使用用户、车辆或乘客的地理空间数据。供应和运营团队在微移动中监控现场情况,并做出更多战术决策。产品和分析团队可以使用它来进行历史分析,并做出更具战略性的决策。
为了帮助您更快更好地分析运动,我们已经建立了模型,可以根据您旅行中的 pings 自动创建路径。
我们的使命是为每一家收集位置数据的公司带来与优步和 Grab 相同水平的粒度分析。我们希望按需公司的业务团队能够在一分钟内获得运营洞察力,而不是几个小时或几周之后!
要了解我们的工作,请查看:
“我们在亚马逊的成功取决于我们每年、每月、每周、每天进行多少次实验。”——杰夫…
blog.locale.ai](https://blog.locale.ai/making-location-based-experimentation-a-part-of-our-dna/) [## 使用地理空间数据进行移动分析的产品
是什么让实时位置数据的分析与众不同?
towardsdatascience.com](/a-product-for-movement-analytics-using-geospatial-data-2aa95b18d693)
如果你想获得试玩,可以在 LinkedIn 或Twitter上与我取得联系或者访问我们的 网站 。
原贴 此处 。
理解机器学习中的运动分析
一篇关于运动分析基础知识以及如何利用机器学习来解决这一计算机视觉相关任务的简短文章。
介绍
运动分析是一项简单的任务,你和我每天都在做,不用花太多心思。我们的基本人类生理学已经从我们原始祖先的视觉能力进化到我们今天的感知检测和分析水平。

图片来自http://glenferriessc.com.au/how-good-is-your-posture/
短语“运动分析”是自我描述的;通俗地说,这是对物体如何在环境中移动的理解。
但是让我们用更专业的术语来描述运动分析
运动分析是对物体运动和轨迹的研究。
现在我们对什么是运动分析有了一个概述,但是它用在哪里呢?
运动分析可以应用于各种行业和学科。在医疗相关机构中,运动分析被用作观察行动障碍患者运动的非侵入性方法。
在视频监控中,运动分析用于视频跟踪和面部识别。

人类受试者的步态分析
运动分析是一项总体任务,可以分解为许多部分。
- 物体检测
- 物体定位
- 物体分割
- 跟踪
- 运动检测
- 姿态估计
提到的每一个组件都是一个值得注意的领域,需要另一篇介质文章。一些研究工作已经进入了有效解决每个部分的方法的探索。
我就不赘述了,只是对一些组件进行必要的说明:物体检测、运动检测、和姿态估计。本文将主要讨论它们与运动分析的关系,以及机器学习在其中的应用。
物体/人检测
这里的关键词是’检测’。为了能够理解和进行身体分析,我们首先必须在为分析提供的数字内容(图像序列)中检测身体。
我们来给物体检测下一个合适的定义:
作为计算机视觉任务的对象检测被定义为从图像或序列图像(视频)中的特定类别中识别感兴趣的对象的存在。
对象检测的任务通常包括在感兴趣的对象的实例周围示出边界框,并识别检测到的对象所属的类别。在特定的场景中,我们专注于识别图像中的一个对象;在其他一些情况下,我们对多个检测对象感兴趣。

图片来自 ImageNet 大规模视觉识别挑战赛(https://www . semantic scholar . org/paper/ImageNet-Large-Scale-Visual-Recognition-Challenge-Russakovsky-Deng/e 74 f 9 b 7 f 8 EEC 6 ba 4704 c 206 b 93 BC 8079 af 3d a4 BD)
有几个对象检测应用蓬勃发展的场景示例,例如视觉搜索引擎、人脸检测、动作检测、ariel 图像分析、行人检测和手势识别
通常,使用机器学习技术,有两种实现对象检测的主要方法,第一种是从头开始设计和训练网络架构,包括层的结构和权重参数值的初始化等。
第二种方法是利用 迁移学习 的概念,并在开始对定制数据集进行训练之前,利用在大型数据集上训练的预训练网络。

图片来自https://talentculture.com/
第二种方法消除了第一种方法所伴随的时间过长的缺点,第一种方法是从头开始训练网络所花费的时间要多得多,并且与采用预先训练的网络相比,需要付出更多的努力。
让我们退一步,观察作为计算机视觉任务的物体检测及其这些年的发展。在引入卷积神经网络来解决对象检测之前,传统的机器学习技术被用来识别图像中的对象。
诸如在 2005 年左右引入的【HOG】的方法使用组合 HOG/ SIFT(尺度不变特征变换)来基于图像梯度的归一化局部直方图识别图像内的兴趣点。
结果是生成仿射不变的 HOG 描述符,并在引入了【SVM(支持向量机)】 的检测链中使用,以基于 HOG 描述符检测感兴趣的对象。这项技术对于一般的检测场景(如行人检测)工作得相对较好,并且在与 MIT 行人数据库进行比较时产生了完美的结果。
应当注意,对象检测可以进一步分解为对象分割。对象分割算法和技术产生对象存在的高亮像素作为输出,而不是边界框;下面的链接提供了一个用于对象分割的方法示例:
[## 屏蔽 R-CNN
我们提出了一个概念上简单、灵活、通用的对象实例分割框架。我们的方法…
arxiv.org](https://arxiv.org/abs/1703.06870)
运动检测
关于运动检测的快速说明。
运动检测是对包含运动对象的图像进行图像处理的过程,该图像处理技术能够通过差分方法或背景分割来跟踪运动,其中通过丢弃图像的静止部分以隔离运动部分来提取图像内的运动特征。
这种技术主要依赖于对图像中像素强度的观察来确定该像素是否属于背景类别。通过识别帧或图片之间的像素强度的进展,可以在强度有显著变化的地方推断出运动。
运动检测是运动分析的一个基本方面,因为需要运动检测来确定对什么和在哪里进行分析。
更重要的是,计算机视觉和机器学习技术已经将运动检测的要求从受控环境中的硬件监控设备降低到仅需要摄像机来进行检测和进一步分析的最先进的算法。
姿态估计
姿态估计是从图像或图像序列中导出身体的重要身体部分和关节的位置和方向的过程。
姿态估计的输出是图像内身体姿态配置的 2D 或 3D 刚性表示。用于运动分析的基于姿态估计解决方案的应用的输出通常是由算法生成的图像,该图像以某种形式或方式描绘了原始图像内感兴趣对象的重要身体部位和关节的位置

来自https://github.com/CMU-Perceptual-Computing-Lab/openpose的 Gif
姿态估计已经在计算机视觉中得到发展,并成为一个独立的突出领域。姿态估计与计算机视觉和机器学习中的其他研究领域的关系,例如对象检测、跟踪和运动分析,鼓励了各种解决姿态估计的技术的发展。
我要谈一点技术问题。
为解决姿态估计而设计的早期方法提出了基于组件或实现模块化解决方案的技术。一些解决方案最初从具有静止背景的图像中分离出人的轮廓,然后估计关节和四肢的位置。
其他解决方案提出的技术也是基于阶段的解决方案,其涉及检测和提取视频序列或图像序列中代表人类的 2D 图形,然后基于 2D 图形和轨迹生成 3D 姿态估计。
在我看来,我仅仅触及了这个主题的表面,但至少如果你已经做到了这一步,你已经对运动分析及其子组件有了一些了解。
在以后的文章中,我将深入探讨所提到的运动分析的一些组件,并包括一些代码,说明如何在实际应用中实现它们。
如果你喜欢像这样的信息丰富的文章,请随时关注我,一旦我将来发布类似的文章,你会得到更新。
理解朴素贝叶斯算法
概率分类器

图片由 Riho Kroll 拍摄,Unsplash
朴素贝叶斯是一种分类算法,是基于贝叶斯定理的概率分类器。在进入朴素贝叶斯的复杂性之前,我们首先理解贝叶斯定理。
贝叶斯定理
贝叶斯定理说,如果事件 B 已经发生,那么我们可以求出事件 A 给定 B 的概率
数学上,贝叶斯定理表示为

其中 P(B)!= 0 (!=指不等于)
P(A|B) —事件 A 给定 B 的概率(称为后验)
P(B|A) —事件 B 给定 A 的概率(称为似然)
P(A) —事件 A 的概率(称为先验)
P(B) —事件 B 的概率(称为证据)
例如,如果我们有一个查询点 X (d 维布尔向量),我们必须预测它属于两个类中的哪一个(Y)。给定 X,如何计算 Y 的概率?

上述表示中的问题
想想如果我们有上面的公式,可以有多少种组合。x 是 d 维布尔向量,2^d 向量 x 的可能组合,2 用于输出(2 类分类)。对于 P(X1,X2,…,Xd|Y),总的组合是 2^(d+1) ,这是巨大的,并且在真实世界的场景中是无效的。

图片由 Unsplash 的 Andrea Piacquadio 提供
朴素贝叶斯通过做一个假设来处理这个问题。
朴素贝叶斯
假设 — 输入向量中的每个特征有条件地独立于其他特征。
数学上。

它说明给定 c,A 有条件地独立于 B。
这有什么帮助?
分子,即 P(X1,X2,…,Xd|Y)*P(Y),等价于联合概率模型,可以表示为 P(X1,X2,…,Xd,Y)。然后我们可以用条件概率展开它。

在应用条件独立性的假设时,它可以写成

因此,使用条件独立的概率公式为

优点是,当假设条件独立时,我们只需找到 P(X1,X2,…,Xd|Y)的 (2d+2)值,(与 2^(d+2 相比明显较少) (2^(d+1)和 P(Y)的 2 个值。
如果我们有两个类,给定一个查询点(X),我们可以得到类 1 P(Y=1|X)和类 0 P(Y=0|X)的概率。基于 MAP 判定规则(最大后验概率)来决定分配给查询点的类别,即,给定 X (P(Y|X))时具有较高概率的类别。
例子
根据天气、温度和风力等特征,预测天气条件是否适合打网球。
x =[前景,温度,多风]
Y =[是,否]

作者图片
由于朴素贝叶斯遵循条件独立,我们将为 X 中的所有 I 和 y 中的 j 计算 P(Xi|Yj)
我们将计算可能性表。
表 1
Outlook P(Outlook|class)-其中 Outlook 可以是阴天、雨天和晴天,而 class 可以是是和否

表 2
温度 P(温度|等级)-其中温度可以是热、温和、冷,等级可以是是和否

表 3
Windy P(Windy | class)——其中 Windy 可以是强和弱而 class 可以是是和否

先验知识是:P(类=是)= 9/14
P(类=否)= 5/14
那么如果我们有一个查询点,如何计算它属于哪个类呢?
给定一个查询点 X’ =【晴、凉、强】
我们计算 P(class=Yes|X ')和 P(class=No|X ')

p(X’)是一个常数项,它等于

从可能性表中,我们得到公式中所需的值

由于类别’否’给定 X '的概率高于类别’是’给定 X ',查询点属于类别’否’。
优势
- 朴素贝叶斯算法还可以通过比较给定查询点的所有类的概率来执行多类分类。
- nave Bayes 算法在大数据集上是高效的,并且空间复杂度较小。
运行时间复杂度为 O(dc ),其中 d 是查询向量的维数,c 是类别总数。空间复杂度也是 O(dc ),因为我们只存储每个特征相对于类的可能性,即 P(Xd|Yc ),其中 d 是特征,c 是类。所以总的组合是(d*c)。 - 朴素贝叶斯在诸如垃圾邮件过滤和评论分类等文本分类问题上工作得相当好。
有不同类型的 NB,例如高斯朴素贝叶斯,它在处理连续数据时效果很好,多项式朴素贝叶斯,它通过使用文档中每个词的频率来进行文本分类。另一种类型是伯努利朴素贝叶斯,它只在特征采用两个值(0 和 1)时有效,类似于二进制单词袋模型中的值。
结论
朴素贝叶斯是一种分类算法,它基于贝叶斯定理和条件独立性假设。由于时间和空间复杂度较低,它在要求低延迟的实际应用中工作得很好。
感谢阅读!
理解朴素贝叶斯分类器
有多个例子

凯文·Ku 在 Unsplash 上的照片
在的监督学习(分类)的背景下,朴素贝叶斯或者更确切地说贝叶斯学习作为评估其他学习算法的黄金标准,同时作为一种强大的概率建模技术。
在这篇文章中,我们将从概念上讨论朴素贝叶斯分类器的工作原理,以便它以后可以应用于现实世界的数据集。
在许多应用中,属性集和类变量之间的关系是不确定的。换句话说,即使一个测试记录的属性集与一些训练样本相同,它的类标签也不能被确定地预测。这种情况可能是由于有噪声的数据或某些影响分类的混杂因素的存在而出现的。
例如,考虑根据一个人的饮食和锻炼频率来预测这个人是否有心脏病风险的任务。尽管大多数饮食健康、经常锻炼的人患心脏病的几率较小,但由于遗传、过度吸烟和酗酒等其他因素,他们仍有可能患心脏病。确定一个人的饮食是否健康或锻炼频率是否足够也需要解释,这反过来可能会给学习问题带来不确定性。
B 贝叶斯学习是一种为属性集和类变量之间的概率关系建模的方法。为了理解朴素贝叶斯分类器,首先需要理解的是贝叶斯定理。
贝叶斯定理是从贝叶斯定律中推导出来的,它规定:
给定证据 E,事件 H 的概率为:

在哪里,
P(E/H)是事件 E 发生的概率,假设 H 已经发生,
P(H)是事件 H 的先验概率,
P(E)是事件 E 的先验概率
上面的公式及其组成部分看起来非常专业,会让第一次学习它的人感到害怕。为了更好地理解,我们来看一些例子:
示例:电子邮件— 电子邮件总数:100,垃圾邮件:25,无垃圾邮件:75
a) 20 封垃圾邮件包含“购买”一词,5 封垃圾邮件不包含“购买”一词
**问】**如果一封电子邮件包含“购买”一词,那么它是垃圾邮件的概率有多大?
**解答:*问题要求我们确定 P(垃圾/购买)。按照上面提到的公式,事件 H 是邮件是‘spam’*,事件 E 是它包含了‘buy’这个词。给定示例中的数据,它可以在数学上/概率上写成:
p(垃圾邮件)= 25/100,
p(无垃圾邮件)= 75/100,
p(购买/垃圾邮件)= 20/25,
p(买入)= 25/100
使用贝叶斯定理,P(垃圾邮件/购买)可以计算为:
P(垃圾邮件/购买)= [P(购买/垃圾邮件)* P(垃圾邮件)] / P(购买)
p(垃圾邮件/购买)= [20/25 * 25/100] / 25/100
p(垃圾邮件/购买)= 20/25 = 0.8
b) 15 封垃圾邮件包含“便宜”一词,10 封垃圾邮件不包含“便宜”一词
**问】**如果一封邮件包含“廉价”一词,那么它是垃圾邮件的概率有多大?
**解答:*问题要求我们确定 P(垃圾/便宜)。按照上面提到的公式,事件 H 是邮件是‘spam’*,事件 E 是它包含了‘廉价’这个词。给定示例中的数据,它可以在数学上/概率上写成:
p(垃圾邮件)= 25/100,
p(无垃圾邮件)= 75/100,
p(便宜/垃圾)= 15/25,
p(便宜)= 25/100
使用贝叶斯定理,P(垃圾邮件/廉价邮件)可以计算为:
P(垃圾邮件/便宜)= [P(便宜/垃圾邮件)* P(垃圾邮件)] / P(便宜)
p(垃圾邮件/便宜)= [15/25 * 25/100] / 25/100
p(垃圾/便宜)= 15/25 = 0.6
c) 12 封垃圾邮件包含“购买&便宜的”字样,0 封垃圾邮件不包含“购买&便宜的”字样
如果一封电子邮件包含“买便宜的”字样,那么它是垃圾邮件的概率有多大?
**解答:*问题要求我们确定 P(垃圾/买&便宜)。按照上面提到的公式,事件 H 是邮件是‘垃圾邮件’*,事件 E 是包含‘便宜买&字样。给定示例中的数据,它可以在数学上/概率上写成:
p(垃圾邮件)= 25/100,
p(无垃圾邮件)= 75/100,
p(买&便宜/垃圾)= 12/25,
p(廉价购买)= 12/100
使用贝叶斯定理,P(垃圾邮件/购买&便宜)可以计算为:
P(垃圾邮件/廉价购买)= [P(廉价购买/垃圾邮件)* P(垃圾邮件)] / P(廉价购买)
p(垃圾邮件/廉价购买)= [12/25 * 25/100] / 12/100
p(垃圾邮件/廉价购买)= 1
它告诉了我们什么?
**解决方案:**我们得到的信息是,如果电子邮件包含单词“buy”,则该电子邮件是垃圾邮件的概率为 80%。
→这是标准的贝叶斯定理,但是天真因素在哪里呢?在概率中,两个事件 A 和 B 的条件概率写为:
P(A/B) = P(A 交点 B) / P(B)
当我们认为两个事件 A 和 B 是相互独立的时候,天真因素就出现了,这就把上面的符号修改为:
P(A/B) = P(A) * P(B)
如果我们把独立性的天真假设应用到例子的***【c)***部分,会有什么变化?让我们深入研究并确定。
垃圾邮件:25 封
20 包含“购买”— 20/25
15 包含“便宜”——15/25
→有多少包含“买便宜的”?
P(买&便宜/垃圾)= P(买)* P(便宜)
p(购买便宜的/垃圾邮件)= (20/25) * (15/25) = 12/25
如果是垃圾邮件,包含(计数)“购买便宜”的电子邮件是(12/25) * 25 = 12
无垃圾邮件:75 封邮件
5 包含“购买”— 5/75
10 包含“便宜”——10/75
→有多少包含“买便宜的”?
P(购买&便宜/没有垃圾邮件)= P(购买)* P(便宜)
p(买便宜的/没有垃圾邮件)= (5/75) * (10/75) = 2/225
包含“购买和便宜”的电子邮件是(2/225) * 75 = 2/3
P(买入&便宜)= (12 + (2/3)) / 100 的总概率
现在,电子邮件是垃圾邮件但同时包含“buy & cheap”的概率是多少?
P(垃圾邮件/廉价购买)= [P(廉价购买/垃圾邮件)* P(垃圾邮件)] / P(廉价购买)
p(垃圾邮件/购买和便宜)= [12/25 * 25/100] / (12 + (2/3)) / 100
p(垃圾邮件/购买和便宜)= 18/19 = 0.947
上面的例子在数学上可以写成:

现在,我们已经建立了贝叶斯定理和朴素假设的基础,让我们通过一个例子来看看如何在机器学习中使用它作为分类器:
以下是我们将使用的数据集:

威滕、弗兰克和霍尔的数据挖掘
在这个特定的数据集中,我们总共有 5 个属性。其中 4 个是自变量(天气、温度、湿度、风力),一个是我们将要预测的因变量(玩耍)。这是一个二元分类问题,因为因变量具有布尔性质,包含是或否。
由于这是非确定性的或者更确切地说是概率性的方法,因此该模型没有学习。
我们将对一个实例进行分类
x = <前景=晴朗,温度=凉爽,湿度=高,风=真>
为了计算这个,我们需要目标变量 Play 的先验概率
实例总数为 14,其中 9 个实例的值为 yes ,5 个实例的值为 no 。
p(是)= 9/14
p(否)= 5/14
按照目标变量,自变量的分布可以写成:

为了对实例 x,进行分类,我们需要计算播放=是和播放=否的最大可能性,如下所示:
播放的可能性=是
P(x/是)* P(是)= P(晴/是)* P(凉/是)* P(高/是)* P(真/是)* P(是)
活动的可能性=否
P(x/否)* P(否)= P(晴/否)* P(凉/否)* P(高/否)* P(真/否)* P(否)
由于天真的独立假设,各个属性的概率会成倍增加。
计算上述等式所需的值为:
p(晴天/是)= 2/9
p(酷/是)= 3/9
p(高/是)= 3/9
p(真/是)= 3/9
和
p(晴/否)= 3/5
p(冷/否)= 1/5
p(高/否)= 4/5
p(真/否)= 3/5
P(x/是)* P(是)=(2/9)(3/9)(3/9)(3/9)(9/14)= 0.0053
P(x/否)* P(否)=(3/5)(1/5)(4/5)(3/5)(5/14)= 0.0206
0.0206 > 0.0053
分类—无
朴素贝叶斯的利与弊
赞成者
- 预测一类测试数据集简单快捷。
- 朴素贝叶斯分类器与其他假设独立的模型相比表现更好。
- 与数值数据相比,它在分类数据的情况下表现良好。
- 它需要较少的训练数据。
缺点
- 如果测试数据集中的一个实例有一个在训练期间不存在的类别,那么它将赋予它“零”概率,并且不能进行预测。这就是所谓的零频率问题。
- 它也被认为是一个坏的估计。
- 它仅仅依赖于独立性预测假设。
我将免费赠送一本关于一致性的电子书。在这里获得你的免费电子书。
感谢您的阅读。我希望阅读这篇文章的人对朴素贝叶斯有所了解。
如果你喜欢阅读这样的故事,并想支持我成为一名作家,可以考虑报名成为一名媒体成员。每月 5 美元,你可以无限制地阅读媒体上的故事。如果你注册使用我的链接,我会赚一小笔佣金,不需要你额外付费。
作为一个媒体会员,你的会员费的一部分会给你阅读的作家,你可以完全接触到每一个故事…
tarun-gupta.medium.com](https://tarun-gupta.medium.com/membership)
你可以在这里阅读我的更多帖子:
[## 标记故事列表的快速链接—感谢您的访问
我也有一份以快节奏出版为目标的出版物。读书成为作家。
tarun-gupta.medium.com](https://tarun-gupta.medium.com/thank-you-for-visiting-my-profile-9f708062c75e)
理解神经网络
对神经网络架构的深入理解
在我之前的文章中,我简要讨论了深度学习以及如何开始使用它。如果你还没有看过那篇文章,请在这里阅读,对深度学习和机器学习有一个直观的认识。
如果你已经看过了,那就开始吧!

感知器
感知器?!你们中的一些人可能已经知道了。无论如何,感知器是神经网络的结构构建模块。就这么简单。通过形成层来组合许多感知机最终成为深度神经网络。感知器架构可能看起来像这样:

感知器模型。来源:关于电路的一切
这里,总共有两层:输入层和输出层。但是,在机器学习的世界中,开发人员不认为输入是一个层,因此他们会说,“这是一个单层感知器模型”。所以,当有人说,“我已经建立了一个 5 层的神经网络”,不要把输入算作一层。那么,这个感知机模型是做什么的呢?如上图所示,我们有 2 个输入和一个带有 sigma 和积分符号的单个节点,然后是输出。该节点计算两个数学表达式以给出输出。首先,它取输入加上一个偏差的加权和,然后该和通过一个非线性激活函数。稍后,激活函数产生预测输出。这整个过程在神经网络中称为前向传播。
请看这张图片:

感知器计算。
正向传播的灵感来自逻辑回归。如果你知道逻辑回归算法,这可能看起来很熟悉,但如果你不知道逻辑回归,这是没有必要的。权重(W)和偏差(b)是由神经网络“训练”的参数,所谓“训练”是指它们被设置为精确值,使得损失最小。
输出(上图中的“y”)是神经网络做出的预测。实际值和预测值之间的差异称为神经网络的损耗。但事情没那么简单。我们取预测值和实际值之间的差,而不是直接差。让我们明白我想说什么。
损失和成本函数
在继续之前,您应该知道的一件事是,预测值计算神经网络的损失,而神经网络是通过计算“Z”来计算的,Z 取决于“W”和“b”。最终,我们可以说损失取决于“W”和“b”。因此,“W”和“b”应设置为损耗最小的值。明确地说,神经网络总是最小化损失,而不是最大化精度。
当解决一个深度学习问题时,数据集是巨大的。例如,假设我们要构建一个图像分类器,对猫和狗的图像进行分类(你可以将其视为“Hello World!”计算机视觉的:)。所以为了训练神经网络,我们需要尽可能多的猫和狗的图像。在机器学习中,一只狗或一只猫的形象被认为是一个**“训练例子”。为了训练一个好的神经网络,我们需要大量的训练样本。损失函数是针对单个训练示例计算的损失。所以,实际上我们为神经网络的训练优化的是成本函数**。成本函数可以定义为针对每个训练示例单独计算的所有损失的平均值。
让我们假设有“m”个训练例子。那么成本函数就是:

我们把一个神经网络的损耗取为:
损耗(比方说,L) =预测值(比方说,yhat) —实际值(比方说,y)
由于神经网络的损失取决于“W”和“b ”,所以让我们仅针对“W”来绘制上述损失函数(为了简单起见,如果我们将“W”和“b”都考虑在内,我们必须绘制 3d 图,这将很难理解概念。此外,偏差“b”用于将激活函数向左或向右移动,就像公式中的截距线)
图可能看起来像这样:

这将是一条直线
这个损失函数的问题是,它是一条直线,不可能使用优化算法(如梯度下降)来优化损失函数(在下一节中告诉你)。现在,要明白损失函数应该是一条具有全局最小值的曲线。
后来研究人员又想出了另一个损失函数:

这称为“均方误差损失”,用于回归类问题。此外,对于一个训练示例,这似乎是一个公平的等式。它是一条抛物线。但是对于“m”个训练示例,即,对于成本函数,将是具有许多局部最小值的波状曲线。我们想要一个碗状曲线或凸状曲线来优化成本。

有许多局部极小值的波状曲线
所以,后来我们得到了一个公认的损失函数方程:

这个方程被称为“交叉熵损失,它被广泛用于深度学习中的分类问题。
上述等式的成本函数如下所示:

凸形曲线。
现在我们知道了如何计算神经网络的成本,让我们了解如何优化成本函数以获得更好的性能。
反向传播:训练神经网络
反向传播是神经网络构建中最重要的任务。这是对神经网络进行实际训练的过程。这是一项计算量很大的任务。事实上,它是神经网络中整个计算过程的三分之二。在前向传播中,我们看到了如何计算神经网络的成本。在反向传播中,我们使用这个成本来设置“W”和“b”的值,使得它可以最小化神经网络的成本。
一开始,我们将权重(W)和偏差(b)初始化为一些随机的小数字。随着模型的训练,权重和偏差会随着新值而更新。这种更新是在一种叫做梯度下降的优化算法的帮助下完成的。
在数学中,梯度意味着斜率或导数。下降意味着减少。所以通俗地说,梯度下降就是斜率递减。熟悉微积分有助于理解梯度下降。还记得我说过我们需要一个凸形代价函数来进行优化吗?原因是在下降过程中,我们不会陷入局部极小值。如果成本函数是波浪形的,它有机会停留在它的一个局部极小值,我们将永远不会有成本的全局最优值。

梯度下降算法的图形表示。
梯度下降算法的上述表示可以帮助你理解它。
在梯度下降算法中,我们分别计算计算成本相对于权重和偏差的导数。
让我们考虑一个简单的感知器模型,它有两个输入:

计算权重的梯度。
那么权重被更新为:

上式中的α称为神经网络的学习速率。这是一个超参数,稍后我会告诉你更多的超参数。现在,把它当作一个常数。
权重和偏差将被更新,直到成本函数达到其全局最优值。这样我们得到的预测输出误差会更小。
一次正向传播和一次反向传播一起被计为训练的 1 次迭代或时期。深度学习实践者必须在训练模型之前设置历元的数量(另一个超参数)。
深度神经网络
到目前为止,我们一直在研究感知器模型,处理感知器模型非常容易。但是当我们深入网络时,事情就变得很糟糕了。
现实世界中的问题有大量的输入特征,每个输入特征都有自己的权重和偏差,根据问题,模型中有许多隐藏层,每个隐藏层都有许多计算 Z 和 a 的节点。训练过程与我之前描述的相同,但它会重复神经网络中存在的节点数。

深度神经网络的训练。来源: Gfycat
在上面的 GIF 中,你可以猜到一个神经网络的复杂性和实现它的高计算要求。
让我们总结一下到目前为止我们学到的一切:
1。正向传播期间:
-初始化权重和偏差。
-计算每个节点的 Z 和 A。
-计算整个模型的成本。
2。反向传播期间:
-使用梯度下降优化成本。
-分别计算关于权重和偏差的成本梯度。
-更新参数(W & b)
3。重复步骤 1 和 2,直到成本函数达到其全局最优值。
我希望我在整篇文章中表达清楚了,并且你很好地理解了这些概念。如果没有,欢迎在评论中提问。还有,在评论里给你宝贵的建议,我好改进我的文章。
也可以建议你想学习深度学习领域的什么课题。
感谢大家抽出宝贵的时间阅读本文。
理解自然语言处理:人工智能如何理解我们的语言
让我们来一次自然语言处理的进化之旅…
“语言是文化的路线图。它告诉你它的人民来自哪里,他们将去哪里。”
—丽塔·梅·布朗
由 Google AI Research 提出,BI directionEN coderRpresentations fromTtransformers(BERT)是一个SstateofTheArt(SOTA)模型中的NnaturalGoogle 以其先进的算法为我们提供了许多方便而强大的工具。随着自然语言处理领域的前沿研究,谷歌搜索和谷歌翻译是几乎每天都在使用的两大服务,并且几乎成为我们思维的延伸。

机器人看书,图片来自莎士比亚牛津奖学金
在本文中,我们将了解 NLP 的发展以及它是如何变成今天这个样子的。我们将首先浏览机器学习之前的 NLP 简史。之后,我们将深入研究神经网络的进展及其在自然语言处理领域的应用,特别是神经网络中的Re currentNeuralN网络( RNN )。最后,我们将走进 SOTA 的模型,如HATN网络(韩 ) 和BI 方向E**N 编码器 R 代表从 T 变压器( BERT**
自然语言处理简史
“学习另一种语言不仅仅是学习相同事物的不同词汇,而是学习思考事物的另一种方式。”
——弗洛拉·刘易斯
NLP 领域的第一个想法可能早在 17 世纪就有了。笛卡尔和莱布尼茨提出了一种由通用数字代码创建的字典,用于在不同语言之间翻译文本。凯夫·贝克、阿塔纳斯·珂雪和乔安·约阿希姆·贝歇耳随后开发了一种基于逻辑和图像学的明确的通用语言。
1957 年,诺姆·乔姆斯基发表了《句法结构》。这部专著被认为是 20 世纪语言学中最重要的研究之一。该专著用短语结构规则和句法树构建了一个正式的语言结构来分析英语句子。"无色的绿色想法疯狂地沉睡."根据相结构规则构造的名句,语法正确但毫无意义。

“无色的绿色想法疯狂地沉睡”,图片来自 steemit
直到 20 世纪 80 年代,大多数 NLP 系统都是基于复杂的手写规则。直到后来,由于计算能力和可用训练数据的增加,机器学习算法开始发挥作用。最著名的机器学习算法之一是 RNN,一种基于神经网络的架构。随着用机器处理自然语言的需求不断增加,新的模型近年来一直在快速迭代。伯特是现在的 SOTA,也许几年后会被取代,谁知道呢?
我们刚刚复习了英语和西班牙语等拉丁词根语言的历史。其他语言如汉语、印地语和阿拉伯语则完全不同。英语可以用一套简单的规则来描述,而汉语不同,它的语法极其复杂,有时模糊得无法用逻辑元素来定义。

Example of Chinese Paragraphs, Image from 智经研究中心
汉语语法的复杂性和现代机器是基于逻辑电路的事实,也许是为什么流行的编程语言通常是英语的原因。过去曾有过几次用中文编写程序语言的尝试,如易和燕文。这些语言非常类似于我们日常使用的编程语言,如 Basic 和 c。这些尝试并不能证明中文是一种更好的编程语言。
不同词根的语言之间的翻译也更加困难。手语到我们日常语言的翻译也遇到了许多障碍。我猜这就是我们试图建造巴别塔所要付出的代价。为了惩罚试图建造这座塔的人类,据说上帝决定通过让我们说不同的语言来分裂人类。

巴别塔,图片来自 iCR
但随着时间的推移,我们克服了无数的障碍,走到了现在。随着技术的进步,语言障碍越来越不成问题。我们完全可以购买下面视频中的翻译棒,预订我们的日本之旅,而不需要事先了解任何日语。
NLP 算法也在许多其他领域帮助我们,例如自动字幕、用户体验研究、可访问性,甚至这篇文章的写作,因为如果没有语法的帮助,我的英语会很糟糕。现在,让我们深入那些令人敬畏的技术背后的计算机算法。
抽象语法树、上下文无关语法和编译器
“无色的绿色想法疯狂地沉睡.”
—诺姆·乔姆斯基
我们现代化的软件产业是建立在自然语言处理的基础上的。语法树的应用之一是我们的编译器。如果没有它,我们将不得不处理机器代码,而不是像 Python 和 JavaScript 这样简单易学的编程语言。想象一下用二进制机器指令来编码我们的机器学习算法,yuck…由诺姆·乔姆斯基发明,AbstractSyntaxTREE(AST和Context-FREEGrammar(CFG)被用来描述和分析我们用来编码的编程语言。
警告:下面的例子是出于教育目的而简化的。如果你真的想知道编译器到底是如何工作的,请参考更专业的文档。
抽象语法树
编译器使用 CFG 来解释以人类可读编程语言编写的代码。它将分解代码的逻辑,并从中解释出递归逻辑。为了理解代码是如何分解成递归逻辑的,最好将流程表示为 AST。下面是从代码中构造出的 AST 的图示。

抽象语法树解释一行代码
上下文无关语法
CFG 用于描述输入语言和输出标记之间的转换规则。在定义编译器的文件中,它通常以如下所示的方式编写:
if_stm : expr = left_bkt cond_stm right_bkt
cond_stm : expr = expr and_stm expr |
expr or_stm expr |
not_stm expr |
num less_than num |
num greater_than num
num : var | const
这些 CFG 基本上定义了 if 和 condition 语句的规则。例如,一个条件语句可以是多个条件语句(“expr”表示其本身,在本例中为“cond_stm”)与 and 语句(“and_stm”,在代码中表示为“&&”),或者是由“>”或“ Wikipedia 等比较器连接的简单数字,更多关于编译器的信息,如著名的另一个编译器(YACC)可以在这里找到。
自然语言处理的神经构建模块:单词嵌入、RNN 和 LSTM
“模仿人脑的复杂性,受神经启发的计算机将以类似于神经元和突触通信的方式工作。它可能会学习或发展记忆。”
—纳耶夫·阿尔·罗德汉
高级 NLP 算法是用各种神经网络构建的。我在我的 Alpha Go 文章中对神经网络有更详细的解释,包括与神经网络相关的历史。神经网络是有向无环图由人工神经元的连接层组成。输入图层中的值逐层传播到输出图层。这些基于神经科学家如何看待我们大脑工作的模型在最近几年显示出了一些竞争性的表现。

人工神经网络的前向传播
单词嵌入
神经网络以及其他机器学习模型通常以数字向量的形式接受输入。但是我们的英语单词不是数字。这就是为什么我们有单词嵌入。单词嵌入指的是将单词和短语从词汇表转换成数字向量的语言建模和特征学习技术。一个例子可能是用神经网络在数千个段落中运行,以收集哪些单词更经常与另一个单词一起出现,从而给它们更接近的值。
一个著名的单词嵌入模型集合可能是 Word2vect。该模型基于浅层神经网络,并假设段落中彼此接近的单词也共享相似的语义值。下面是解释它的视频。
理解 Word2Vec,视频来自 Youtube
递归神经网络(RNN)
RNN 是神经网络的一种变体,最擅长处理顺序数据。声波、股票历史和自然语言等数据被认为是连续的。RNN 是一种神经网络,在处理顺序数据的过程中,输出被反馈到网络中,允许它也考虑过去的状态。
在我们的自然语言中,句子的上下文并不总是由单词的上下文来表示。例如,“其他评论者认为食物很棒,但我认为不好”这句话有两个积极意义的词(棒极了)。人工神经网络对序列没有任何线索,只是总结一切,但 RNN 能够捕捉句子中的倒装句,如“但是”和“不是”,并根据它进行调整。

安正在处理一个句子

RNN 处理了一句话
长短期记忆(LSTM)
“如果不忘记,根本不可能活着。”
― 弗里德里希·尼采
在 RNN 句子处理的例子中,您可能想知道为什么大多数单词都是不相关的。这正是我们需要 LSTM 的原因。LSTM 引入了一个“忘记层”,它决定应该保留或忘记的信息,使模型在大量数据下更容易训练。LSTM 有三种单元状态,即遗忘状态、更新状态和输出状态,每种状态有不同的用途。
忘记状态
在遗忘状态期间,LSTM 将从输入和先前状态中检索信息。然后使用 sigmoid 函数σ来决定是否应该忘记之前的状态。sigmoid 函数将输出 0 到 1 之间的值。通过将它与前一状态的输出相乘,它将决定前一状态的多少应该被遗忘。

LSTM 忘记状态
更新状态
在更新状态期间,LSTM 将尝试更新状态值。一个超正切函数 tanh 将柔和地强制该值位于 0 和 1 之间,这样它就不会累积成一些疯狂的数字。另一个 sigmoid 函数用于确定有多少将被添加到单元状态中。

LSTM 更新状态
输出状态
最后,单元格状态将由另一个超正切函数处理。然后使用一个 sigmoid 函数来确定将有多少输入到输出中。

LSTM 输出状态
更多关于 LSTM 及其数学训练的详细解释可以在这里找到。
文本分类:与韩
恭喜你!我们终于走到了像韩和伯特这样的模式。我们先讨论韩,并不是因为一个模型优于另一个,只是因为韩更容易理解,可能有助于伯特的理解。由大学和微软研究院在 2016 年提出的,韩证明了它在文本分类方面的能力。能够对 Yelp 评论等文本进行分类有助于各种领域,如用户体验研究和支持票证管理。
我们先从说起,它是韩的基石。不要担心,它与我们在上一节中学习的 LSTM 非常相似。在此之后,我们将能够了解韩的建筑。
门控循环单元(GRU)

GRU,图片来自喧闹
“我开玩笑的!虽然是真的。反正过得好。”
— GRU
GRU 代表GateRe currentUnits。与 LSTM 相比,它们的功能较弱,但模型更简单。然而,在某些情况下,会比表现得更好,这一点我们在了解韩的时候会讲得更多。这就是为什么研究人员通常对这两种设备都进行实验,看哪一种效果最好。

GRU 解释道
GRU 通过 sigmoid 函数使用输入和先前状态来做出所有决定。总共有 2 个决定:
- 第一个决定是前一个状态是否将与输入状态合并。
- 第二个决定是这个混合状态(或普通输入状态)或前一个状态是否会进入下一个状态并作为输出。
更多关于 GRU 的变体及其详细的数学模型可以在这里找到。
分层注意网络
在由单词、句子、段落和故事组成的大军中,字母表中的每个字母都是坚定忠诚的战士。一个字母掉了,整个语言都变得含糊不清。”
——维拉·拿撒勒
传统的 RNN 和 LSTM 很难解释大量的文本,其中一些关键词彼此相距很远。这就是为什么 HAN 的注意机制从上下文向量 u 中生成重要性权重α的原因。这个重要性权重然后被用于选择性地过滤掉值得关注的输出。
韩运用两个主要层次对文本进行分类,即词层和句层。字向量首先被送入由双向 gru 组成的编码器。双向 GRU 就是方向相反的 gru 堆叠在一起。然后,输出用于计算注意力和上下文向量,输出将被输入到句子层的编码器中,以经历类似的过程。最终的输出向量将被相加并馈入 softmax 层。

分层注意网络(韩)解释说
关于韩的详细解释,其数学细节及其在 Yelp 评论上的表现,请参考原文。
语言理解:变压器和伯特
最后,我们做到了如题所示。为了充分理解这一节,我们可能必须理解广泛的数学推理。这些可以在变形金刚和伯特的原始论文中找到。在本文中,我们将只讨论基本架构。
编码器-解码器架构
首先,让我们看看编码器-解码器的架构。在机器翻译中,经常使用编码器-解码器结构,因为源文本和目标文本并不总是一一匹配。编码器首先用于从输入消息产生输出值,解码器将利用该输出值产生输出消息。

利用编码器-解码器架构进行翻译
变压器
“你需要的只是关注”
—变压器原始论文的标题
2017 年,来自谷歌的研究人员提出了一种完全基于自我关注的架构。自我关注意味着模型通过解释输入来自行决定关注,而不是从外部获取关注分数。
有 3 种不同类型的向量,查询向量 Q、密钥向量 K 和值向量 v。这些向量可以被理解为数据搜索机制。
- 查询(Q)是我们寻找的那种信息。
- Key (K)是查询的相关性。
- 值(V)是实际输入。

缩放的点积注意&多头注意,图片来自变形金刚原纸
缩放的点积注意力首先将 Q 和 K 相乘,然后在图中所示的一些转换之后将其与 V 相乘。多头注意力将从缩放的点积注意力中检索到的头连接起来。Mask 用于过滤掉一些值。这个机制解释起来有点复杂,这里的是一篇对注意力机制提供更详细解释的文章。
转换器是基于多头注意力的编码器-解码器架构。由于转换器使用简化的模型,不再考虑像 RNN 这样的位置信息,因此输入嵌入和位置嵌入都应用于输入,以确保模型也捕捉位置信息。添加& Norm 是剩余连接和批量规格化。前馈只是简单的前馈神经网络重塑向量。

变形金刚模型架构,图片来自变形金刚的原文
变压器的双向编码器表示(BERT)
2018 年,来自谷歌的研究人员推出了一种名为 BERT 的语言表示模型。BERT 模型架构是一个多层双向变压器编码器。构建框架有两个步骤——预训练和微调。
- 预训练:在预训练期间,模型在不同的预训练任务中根据未标记的数据进行训练。
- 微调:在微调过程中,首先用预先训练的参数初始化 BERT 模型,然后使用来自下游任务的标记数据微调所有参数。

BERT 预训练和微调程序,图片来自 BERT 的原文
模型在微调后提前了 11 个 NLP 任务的 SOTA。有关 BERT 的模式详情,请参考原始文件。
话说到最后…
我计划写关于自然语言处理和计算机视觉的文章。因为我已经在我的上一篇文章中写了关于卷积神经网络的内容,所以我决定先写一些关于递归神经网络的内容。还有更多关于卷积神经网络的内容,我已经在我的计算机视觉文章中阐述过了。我还打算写关于生成模型和自动化机器学习的文章。人工智能领域有无数的奇迹,跟随我在遥远的未来看到更多!
理解自然语言处理技术
我给有抱负的数据科学家的简单教程
快速理解基本文本分析和 ML 的方法

NLP 源简介 Unsplash
“从一个人和什么样的人交往,你就可以知道他是什么样的人。”——约翰·弗斯
什么是自然语言处理?
自然语言处理(NLP) 通过模拟人类理解文本的方式,帮助计算机理解文本。
由于近年来的数据增长,NLP 发展迅速。尤其是随着 Twitter、脸书和谷歌在搜索引擎或个人人工智能助理中处理非结构化数据的兴起。越来越多的自然语言处理的应用获得了巨大的普及。
自然语言处理的应用和问题
谷歌搜索图片

我对“猫”这个词的搜索
考虑一下谷歌搜索猫的图片。你指的是什么猫?
有这么多猫。在“猫”戏剧表演中有变异猫。你有卡通猫。你说的是哪一个?
- 当我说“一只可爱的猫”时。显然我想要那些小猫。
- 当我说“猫秀”的时候。显然我想要的是变异猫。
“可爱”和“秀”这样的相邻词进一步说明了我想要的。这是评估 NLP 性能的上下文。
谷歌助手
想想 Google Home Mini,你只需花 50 美元就能买到。它理解查询上下文吗?
想象一下,你的小女儿在她的作业项目“好的,谷歌,定义一闪一闪的小星星”上问谷歌 Home Mini。
Google Home 不应该聪明到知道这是一首歌的歌名吗?
情感分析
想象一下,你想预测唐纳德·特朗普(Donald Trump)在上次总统选举中击败希拉里·克林顿(Hillary Clinton)。
你能从推特上的普遍情绪预测一下吗?每位总统候选人的满意度如何以及如何?
[## 2019 年印度尼西亚大选的推特故事(Pemilu)
在印尼总统选举中,佐科维和普拉博沃成为最受关注的候选人,他们代表着…
towardsdatascience.com](/the-twitter-tale-of-indonesian-election-2019-pemilu-fb75cd084a32)
话题分析
想象一下你的硕士/学士班论坛:很难从所有这些信息中提取出什么是重要的。
你能建立一个模型,潜在地提取所有的关键主题,并基于此过滤帖子吗?
[## 使用 Python Dash、文本分析和 Reddit API 自动生成常见问题
问题陈述
towardsdatascience.com](/auto-generated-faq-with-python-dash-text-analysis-and-reddit-api-90fb66a86633)
自然语言处理变得越来越普遍和重要。潜力是巨大的,现在世界各地都在使用。
NLP 为什么难——歧义和上下文?
NLP 最大的敌人是歧义,而 NLP 最大的朋友是上下文——文森特·塔坦
想想我们在日常生活中是如何使用词汇的。
“你为什么这么沮丧?玩得开心拉!
“怎么了?
对我们来说,这些话的意思似乎非常清楚。“r u”代表“are you”,“what’s up”是一种常见的美国非正式问候语。
然而,这些句子中有歧义。“What’s up”字面回答应该是“The sun is up”而不是“I am good, thank you”。隐藏的上下文使我们很难向计算机解释这些句子的确切意思。
大多数时候,我们假设听者会根据我们对世界的了解和共同的背景来填补很多空白。
我们在哪里?
我们在做什么?
我们对彼此了解多少?
有趣的是,我们不知道意义是如何从我们大脑中的单词中产生的。但这一切对我们来说都很容易。
这就是为什么我们需要机器学习和 NLP 技术来让计算机从文本语料库中识别这些规则和上下文。
科拉布
在这节课中,我们将使用 Colab 来完成整个教程。随意打开这个直接跑。这个 colab 展示了 NLP 的一个简单应用。
编辑描述
colab.research.google.com](https://colab.research.google.com/drive/1nEumwX8cxppopls-73LbAxOf7j1u7Odr?usp=sharing)
如何理解“我爱冰淇淋?”

来源 Unsplash
想象你问你的女儿们喜欢吃什么。其中一个孩子回答说:“我喜欢冰淇淋!”你能猜出他们是兴奋地微笑还是皱眉吗?
如果我给你看“我的冰淇淋”这个词,你能做到吗?你怎么知道这孩子是不是皱着眉头?
为了回答这个情感分析问题,让我们将 NLP 分解为以下基本原则:
- 记号化:把每个单词分解编码成一个句子。
- 序列:按照特定的顺序映射记号,形成句子/序列。
- 嵌入:在多维图中表示记号,提供向量聚合,提供商业洞察(情感分析)。
标记化
记号化将文本分解成计算机可以理解的记号和索引。
我们将讨论如何通过标记来理解单词。考虑一下FRIED这个词。我们可以用 ASCII 数字来表示这些字母。但是FIRED 也有相同的字母,但是由于顺序不同,单词也不同。
好吧,那我们就用单词来代替。在文本“I love my dog”中,我们可以对每个单词→ 1[I], 2[love], 3[my], 4[dog]进行编码。我们将看一下实现令牌化的代码
Tokenizer API 已经删除了所有感叹号和标点符号,以便快速获得单词标记。
首先,我们需要标记来自 Keras 的 API。然后我们可以创造句子。Num_words 此处参数表示要保留的字数。在这种情况下,我们将保留在语料库中出现的 100 个最频繁的单词。
如果分词器在 word_index 中找到不存在的单词怎么办?然后我们需要指定词汇(OOV)标记中的**,它将单词标识为索引 1 。**

词的标记化和索引化
恭喜你。您刚刚将这些令牌编入了训练索引!
排序
排序表示单词序列中的句子及其各自的索引。我们使用tokenizer.texts_to_sequence 将语料库翻译成序列中的标记。
顺序很重要,因为单词的顺序很重要。“我爱鱼”和“鱼爱我”有不同的语义和语法错误。句子的顺序决定了哪个词是这个意思的宾语或主语。
这将对标记进行排序,并填充剩余的标记空间,以匹配最长序列的维度。这些对于在嵌入/情感分析期间运行数学运算非常重要。

测序的结果
注意,我们可以从这里提取几个索引:
- 0 → 在较短的句子上填充以匹配较长的句子
- 1 → OOV(不在词汇表中)。这些是 word_index 标记中没有的词汇
- > 1 → 在标记化 word_index 中找到的单词的索引
填充允许我们标准化每个语料库的长度。这使得使用 numpy 运行多个操作并为神经网络(NN)训练做准备变得更加容易。
把…嵌入
嵌入将输入投影到多维表示空间。例如,我们可以将下列单词投射到极性子空间。

嵌入:在维度空间中绘制单词
让我们在多维空间里画出每个单词。然后当我们想要有组合的意思时。我们可以将这些向量组合在一起,生成统一向量。
例如,good 被认为是正面情绪,而bad 被认为是负面情绪。但是如果你在同一个句子中使用good …和bad …的话(例如:我认为你的文章是good,但是你的笔迹是bad,那么情感是中性的。
通过 Tensorflow 和 Keras 的实验,我们可以用嵌入作为输入来训练神经网络。有了这个 colab 笔记本,你可以实验做卡格尔问题并运行代码。
额外收获:NLP 的进一步挑战
这在自然语言处理中有更多的应用。我希望这个简单的教程能激起你探索如何处理单词和语言的兴趣。
语法和词汇很复杂。我们需要更多的技术来衍生我们的特征和更好地标记。
- Lemma :应该表示的唯一单词。例如,在英语中我们有不同的时态。Run、ran 和 running 指的都是同一个词,即 run。汉语有不同意思的单词组合。如魏(危)纪(机)→危机
- 词性标注:单词记号是独立的意义单位。这可以是动词、词缀、前缀、名词等。例如
run是动词,但running可以是形容词(如running竞赛) - 分块:从词性标注中识别实体的提及。它将单词/标记分组为块
- 共指:链接一节中提到同一实体的词。奥巴马和罗姆尼谈到了他的童年。这里的
his指的是什么?
最后的想法
总之,我相信这些基本的自然语言处理在你的第一次探索中很容易实现。我们了解到:
- 记号化:把每个单词分解编码成一个句子。
- 序列:按照特定的顺序映射记号,形成句子/序列。
- 嵌入:在多维图中表示记号,提供向量聚合,提供商业洞察(情感分析)。
请随意看看您是如何在 DNN 框架(如 Tensorflow 和 Keras)中实现它的。
一如既往,如果你有任何问题,请通过 Linkedin 联系我。如果时间允许,我很乐意回答你的问题。
索利·德奥·格洛丽亚
参考
- 斯坦福大学的自然语言理解(NLU)
- 劳伦斯·莫罗尼的《NLP 零到英雄》
关于作者
文森特用 ML @ Google 对抗网络滥用。文森特使用高级数据分析、机器学习和软件工程来保护 Chrome 和 Gmail 用户。
除了在谷歌的工作,Vincent 还是《走向数据科学媒体》的特约撰稿人,为全球 50 万以上的观众提供有抱负的 ML 和数据从业者的指导。
在空闲时间,文森特在佐治亚理工学院攻读硕士学位,并为铁人三项/自行车旅行进行训练。
最后,请通过 LinkedIn , Medium 或 Youtube 频道 联系文森特
了解目标检测和 R-CNN。
让我们看看什么是目标检测,并详细了解基于 CNN 的区域提议。

使用 Canva 设计
最近,我们看到机场和火车站试图通过摄像头检测人们是否保持社交距离,戴上口罩。这些是由摄像机捕捉的实时视频,其中存在持续的运动。我们还看到了开发自动驾驶汽车的研究,这种汽车需要检测道路上的障碍,并相应地驾驶。这一切是如何发生的?
这就是物体检测发挥作用的地方。让我们了解对象检测是如何工作的,我们还将学习 R-CNN 的概念。 R-CNN 是目前已有的和最流行的架构如更快的 RCNN 和掩码 RCNN 的前身。去年, FAIR (脸书人工智能研究)开发了一个全功能框架,名为 Detectron2 ,它建立在这些最先进的架构、**更快的 R-CNN、**和 Mask R-CNN 之上。
在深入这个概念之前,我希望您熟悉一些概念,如卷积神经网络和标准架构。阅读此处了解更多。
分类

使用 Canva 设计
分类只是将图像标记到其各自的类别,而定位指的是围绕主题的边界框。目标检测指的是单个图像中的许多这样的实例(分类+定位)。在进入 R-CNN 之前,让我们先来看看地区提案的概念是如何被处理的,以及如何引导他们进入 R-CNN 的。
分类管道

使用 Canva 设计
在任何标准 CNN 架构中,如 VGG 网或亚历克斯网,卷积层和池层共同充当特征提取器。下面的全连接层和 softmax 层充当分类器。SVM 也可以用来代替这种完全连接的层+ Softmax。特征地图被拉伸成一维向量,并被馈送到完全连接的层。
本地化
现在,对于本地化部分,考虑每个图像只有一个对象。这里,我们还需要一个模型来预测边界框的坐标。为此,我们需要一个带有 L2 损失的回归模型(大多数情况下是 L2,但在一些异常情况下也会用到 L1)。因此,除了目前的分类管道,我们需要附加一个回归模型来预测边界框。可以将相同的特征映射馈送到该回归模型,并且在分类器的情况下,代替单个 softmax 输出层,我们现在需要四个结果。四个结果是表示边界框的坐标。

使用 Canva 设计
目标检测
现在,谈到对象检测,这里的情况是,在单个图像中可能有多个对象,并且这随图像而变化。我们事先不知道确切的人数。唯一的选择是扫描图像的所有可能位置。现在,想想在这样的图像上检测的想法。
我们可以考虑在这里使用滑动窗口技术,就是这样工作的。

使用 Canva 设计
使用这种技术,我们可以得到图像的所有可能的部分,然后把它输入到上面显示的网络中。然后,网络会查看图像的每个部分,如果识别出其中的任何潜在特征,就会决定作物中是否有物体。如果是,它给出边界框。这样,通过使用相同的网络,我们将能够检测图像中的对象。
但是对于标准架构,如 AlexNet 和 VGG Net,输入的大小是有限制的。裁剪后的图像不能直接输入网络。裁剪后的图像必须按网络接受的输入尺寸进行缩放。这整个过程被认为是预处理阶段(滑动窗口+裁剪+调整大小)。
如果你观察敏锐,你可能会注意到图像中的所有对象不需要有固定的大小来适应我们的滑动窗口。因此,固定大小的窗口不能解决这个问题。要么必须采用不同尺寸的窗口,要么必须在保持窗口尺寸固定的情况下将图像缩放成不同的尺寸。实验发现,使用图像的六个不同尺度足以定位图像中的大多数对象。因此,后者通常比前者更受青睐。在较小尺度的图像中检测到较大的物体,而在较大尺度的图像中检测到较小的物体。这个概念被称为形象金字塔。

使用 Canva 设计
在这里,自行车和人的大小是不同的。你可以看到这个人不完全适合滑动窗口。为此,通过使用图像金字塔的概念,我们可以将图像调整到不同的尺度,在第三个尺度上,我们可以找到窗口内的人。然后,通过使用边界框回归器,我们可以将窗口的大小与地面实况相匹配。由于自行车与人相比是一个较小的物体,所以它可能在第一个或第二个位置被检测到。此外,请注意,该人也可能在其他尺度下被部分检测到,但置信度得分通常会更低,边界框也不会那么准确。
因此,这些是在输入端执行对象检测所需的额外预处理步骤。虽然我们已经使用滑动窗口和图像金字塔以及定位网络解决了对象检测的问题,但是这仍然将我们引向另一个问题。由于我们是在图像的所有位置以不同的比例裁剪图像补丁,所以我们最终会有大量的建议只针对单个图像。由于 CNN 的处理非常密集,这将是一个昂贵的操作。那么,我们如何解决这个问题呢?
我们可以使用一些区域提议算法来避免对网络的不必要的输入,而不是使用作为强力技术的滑动窗口方法。一些流行的区域提议技术包括颜色对比、边缘框、超像素跨越、选择性搜索等。在所有这些中,选择性搜索和边缘框被发现更加有效。选择性搜索也称为类别不可知检测器。
类别不可知检测器通常用作预处理器,产生一系列有趣的包围盒,这些包围盒很有可能包含猫、狗、汽车等。
显然,我们需要在类别不可知的检测器之后有一个专门的分类器来真正知道每个包围盒包含什么类别。虽然 R-CNN 不知道特定的区域提议方法,但我们使用选择性搜索来实现与先前检测工作的受控比较。
选择性搜索
选择性搜索使用层次聚类来获得各种区域建议。

目标识别的选择性搜索 J. R. R. Uijlings,K. E. A. van de Sande,T. Gevers,a . w . m . smulders
首先,它将像素非常紧密地分组,然后像素根据相似的颜色、纹理和成分合并成一个像素。在更高的层次上,我们通过裁剪出不同的小块从图像中得到一组区域建议,如最后一栏所示。
R-CNN

使用 Canva 设计
由于我们将地区提案与 CNN 合并,因此被称为 R-CNN 。由于诸如 VGG 网/亚历克斯网之类的本地化网络仅接受固定大小的输入,并且所有的区域提议可能都不是该大小,所以裁剪后的图像必须被扭曲成网络可接受的大小。
一开始 R-CNN 给出的准确率是 44%,有点低。但几经变化,提高到 66%。让我们看看精确度是如何提高的。
第一个架构不包括 BBox 回归器,因为他们认为这是不必要的,因为输入已经是裁剪后的图像。

使用 Canva 设计
使用上述架构,我们将获得 44%的精确度。使用的 AlexNet 是在 ImageNet 数据集上预先训练的,该数据集包含大约 1400 万张图像和 1000 个类别。但是为什么即使是在如此庞大的数据集上训练,我们得到的准确率也是如此之低?
这是因为 ImageNet 数据集中的图像具有特定的纵横比,而网络从选择性搜索中接收到的裁剪和扭曲图像具有不同的纵横比。这意味着,在一般情况下,网络会认为一个人的形象会是又高又瘦。但是,当我们将区域方案扭曲到所需的尺寸时,图像会被拉伸,其纵横比会受到干扰。这说明了准确性的一些损失。

使用 Canva 设计
如前所述,您可以查看两幅图像的纵横比。扭曲的图像看起来被拉伸了。这样,扭曲的图像看起来很不自然,扭曲了图像的纵横比。因此,为了解决这个问题,提出了用区域建议对网络进行微调。但是,该训练阶段包括 softmax 分类器而不是 SVM,并且损失函数将是交叉熵损失。要把握交叉熵背后的核心直觉,可以在这里阅读我之前的文章。为一个类分配一个 SVM,并且使用存储的特征映射离线训练 SVM。每个 SVM 都通过为该类提供正确和错误的建议来接受训练。

使用 Canva 设计
因此,当我们微调网络时,我们会更新卷积层和全连接层中的权重。这导致精度提高了 10%,导致 54.2% 。之后,还通过实验发现,包括边界框回归器导致了更好的准确性,因为它比以前更准确地收紧了边界框。它只包括一个完全连接的层,而不是两个。这导致精度进一步提高,达到 58.5% 。使用 VGG 网代替更深的 AlexNet 导致了 R-CNN 的最佳性能模型,其准确度为 66% 。

使用 Canva 设计
这是一个 R-CNN 的高层图表。此外,许多改进和实验是通过包括和移除完全连接的层来完成的,包括和不包括微调。观察到当微调时,更多数量的权重在完全连接的层中而不是卷积层中被改变,这是一个有趣的观察。

使用 Canva 设计
请注意,所有这些观察都是在 PASCAL VOC 2007 数据集上进行的,用于实验的架构是 Alex Net。
如果没有微调,即使我们添加完全连接的层,精度也不会有太大差异。这表明大部分精度是在卷积层本身中实现的,而完全连接的层几乎没有增加任何价值。需要考虑这一点,因为卷积层的模型大小大约为 3.7 MB ,而完全连接的层大约需要 192 MB 。我们可以想象排除 FC 层可以节省多少内存。然而,当我们根据地区提案对网络进行微调时,情况发生了变化。FC 层中的大多数权重都发生了变化,因此,我们可以看到准确性有了显著提高。此外,如果我们排除 FC7 层,我们会得到 53.1%的精度,仅比添加 FC7 层的精度低 1.1%。我们可以考虑去掉它,因为它占总模型尺寸的 29% 。但这不是强制性的,因为人们可以在时间、大小和准确性之间进行权衡。如果我们需要一个更精确的模型,并且我们有时间和空间,我们可以考虑将其用于关键应用,例如准确性更重要的医疗领域。
通过这个 R-CNN,我们避免了滑动窗口技术和图像金字塔的使用,但是我们得到了不同大小的区域建议。我们已经设法在不使用图像金字塔的情况下找到区域提议,但是每幅图像 2000 个提议太大,并且涉及巨大的计算。R-CNN 并不完美。它有一些缺点。
- 它在测试时很慢,因为它需要为每个地区的提议运行一个完整的 CNN 转发过程。事实上,它比之前性能最好的型号over feet慢了 9 倍,该型号主要使用卷积运算代替 FC 层,并有效地使用了滑动窗口概念。
- 它有一个复杂的多阶段训练管道(用于训练区域提议、训练 SVM 和 BBox 回归器的交叉熵)。
结论
我希望你已经理解了物体检测和 R- CNN 架构背后的原理。为了解决 R-CNN 的缺点,一年后快速 R-CNN 被提出,它比 RCNN 快 146 倍。更多关于快、更快、和遮罩区域的内容将在我接下来的文章中讨论。
编辑:你可以在这里 阅读这篇文章的下一部分,其中包括快速 RCNN 和更快的 RCNN 。
如果你想联系,在 LinkedIn 上联系我。
参考
对 ARELU 的理解
卷积神经网络的聚焦良好、面向任务的激活

汉斯-彼得·高斯特在 Unsplash 上拍摄的照片
激活函数是神经网络的组成部分之一,对训练过程有着至关重要的影响。当开发大多数类型的神经网络时,校正的线性激活函数(即,RELU)已经迅速成为默认的激活函数,这是因为校正函数实现起来很简单,具有代表性的稀疏性,以及通过具有 1 的梯度斜率几乎完全避免了消失梯度的问题。
本文旨在通过将可学习的激活功能公式化为基于元素的注意机制,展示一个全新的视角。由此产生的激活函数 ARELU 促进了小学习速率下的快速网络训练,这非常适合于迁移学习,并且使网络训练更能抵抗梯度消失。
ARELU 的配方

图 1:左图:用不同粒度的注意力地图说明了注意力机制。右图:在手写数字数据集 MNIST 的测试图像上使用 ReLU 和 AReLU 获得的激活前和激活后特征图的可视化。 [图像来源]
神经网络被认为是以一种简化的方式模仿人脑活动的一种努力。注意机制也是在深度神经网络中,试图实现选择性地专注于少数相关事物,而忽略其他事物的相同动作。
注意力可以说是当今深度学习领域最强大的概念之一,因为它指导网络学习输入的哪一部分对输出的贡献更大。具有不同粒度的注意力地图的一些注意力机制如下:

图 2:注意机制的类型
在所有的注意机制中,元素方面的注意是最细粒度的,因为特征量中的每个元素接收不同量的注意。因此,ARELU 被设计成使得对于网络的每一层,获得基于元素的注意力模块学习符号的注意力图,该注意力图基于其符号来缩放元素,从而导致正元素的放大和负元素的抑制。
对 ARELU 机理公式的理解
整个机制可以建立如下:

图 ARELU 激活的构建模块
元素式注意机制
等式(ii)中的调制器函数执行输入向量与注意力图的逐元素乘法。为了满足维度要求,如等式(I)所示,注意力图被扩展到输入向量的全维。

等式表 1:基于元素的注意机制
基于元素符号的注意
为了放大积极因素,抑制消极因素,注意力地图根据其在 ELSA 中的符号进行缩放。注意力由两个参数α和β决定,导致具有两个可学习参数的符号式注意力机制。

等式表 2:基于符号的基于元素的注意机制
基于注意力的校正线性单位

图 ARELU 可学习激活功能的解释
从等式(v)可以明显地证明,ARELU 放大了正元素,而相反,减小了负元素。

图 ARELU 阿海鲁激活后的初始状态
优化 ARELU 激活
优化包括误差函数的最小化。应用链式法则来最小化误差函数,对于等式(v)中的相应参数获得的梯度如下:

等式表 3:用于优化的 ARELU 可学习激活的导数
ARELU 激活能够在激活的输入上增加梯度,这使得避免梯度消失导致加速模型的训练收敛是合适的。对各种激活函数的比较研究表明,ARELU 在只有两个可学习参数的情况下表现最佳,并且对于不同的网络架构也是通用的。

图 6:在第一个时期之后,使用不同的优化器和学习速率,在 MNIST 上对 MNIST-Conv 进行五次训练的平均测试准确度(%)。我们将 AReLU 与 13 个不可学习的和 5 个可学习的激活函数进行比较。每个激活单元的参数数量列在可学习激活功能的名称旁边。对于不可学习的方法,最好的数字用蓝色粗体显示,对于可学习的方法,用红色显示。在表格的底部,我们用蓝色和红色分别报告了 AReLU 相对于其他不可学习和可学习方法的最佳改进。[ 图像来源
结论
通过添加注意力和 RELU 模块来获得 ARELU,已经清楚地表明,通过引入每层不超过两个额外的可学习参数,显著地提高了大多数主流网络架构的性能。ARELU 不仅使网络训练不受梯度消失的影响,而且能够以较小的学习速率进行快速学习,使其特别适合迁移学习。
参考
陈,邓生,。“基于注意力的校正线性单元.” arXiv 预印本 arXiv:2006.13858 (2020)。
理解光流和 RAFT
如何以迭代方式使用多尺度相关性求解光流

(来源)
计算机视觉中最重要的问题是对应学习。即给定一个物体的两幅图像,如何从两幅图像中找到该物体对应的像素?
主要针对视频的对应学习在目标检测和跟踪中有着广泛的应用。尤其是当视频中的对象被遮挡、变色、变形时。
什么是光流?

两幅图像的光流场
光流是两幅图像之间的矢量场,显示了如何移动第一幅图像中的对象的像素以在第二幅图像中形成相同的对象。它是一种对应学习,因为如果知道一个物体对应的像素,就可以计算出光流场。
光流方程和传统方法

两幅图像 H 和 I 之间的一点流
让我们采取最简洁的形式:两个图像之间的一点流。假设 H 中(x,y)处的像素流向 I 中的(x+u,y+v),则光流矢量为(u,v)。
如何求解(u,v)?我们建立一些方程有什么约束吗?
首先,当 H(x,y) = I(x+u,y+v)时,让我们用泰勒级数分解 I(x+u,y+v):

I(x+u,y+v)的泰勒级数逼近
然后,舍弃高阶项,结合 H(x,y) = I(x+u,y+v):

光流方程的推导过程
最后,在极限情况下,当 u 和 v 变为零时,我们得到的光流方程为:

光流方程
然而,在实际应用中,u 和 v 可能大或小,跨越几个到几十个像素,而不是零限制。因此,我们只能得到真实光流的近似。然而,如果 u 和 v 更接近于零,流场会更精确。
在上面的等式中,未知数是 u 和 v,因为其他变量可以从 x,y 和时间维度的差异中计算出来。因此,一个方程中有两个未知数,无法求解。因此,在过去的 40 年里,许多研究者试图提供 u,v 的其他方程组,使其可解。其中,最著名的方法是卢卡斯-卡纳德法。
深度学习时代,能否用深度神经网络求解光流?如果可以,网络设计的意义何在?
答案是肯定的,这几年也有这方面的工作,效果越来越好。我将介绍一个代表作品叫做 RAFT,它获得了 ECCV 2020 最佳论文奖。
大量
RAFT,又称递归全对场变换,是一种迭代求解光流的深度学习方法。

筏子的网络结构(来源
如上所述,给定两幅图像,找到它们之间相同对象的对应像素对是核心。在深度学习中,一切都是基于潜在特征图,这带来了效率和准确性。因此,可以通过相关场提取相应的像素对。

两幅图像的多尺度相关性
相关性显示两幅图像中两个像素之间的关系。对于大小为(H,W)的两幅图像,它们的相关场的大小将为(H,W,H,W),这称为 C1。如果我们把最后两个维度结合起来,我们会得到 C2 和 C3 等。对于图像 1 的像素,C1 示出了像素相关,C2 示出了与图像 2 的 2×2 像素相关,C3 示出了 4×4 像素相关,等等。这种多尺度方式可以帮助找到从小到大的位移,这对于具有大时间步长的视频中的光流估计是重要的。
对于图像 1 的每个像素,将其光流初始化为零,并在多尺度相关图中查找其周围区域,以搜索其在图像 2 中的对应像素。然后,估计图像 1 中的像素与其在图像 2 中搜索到的对应像素之间的光流。最后,根据估计的光流将图像 1 中的像素移动到新的位置,并且重复该过程直到收敛。在这种迭代方式下,每次只估计一个步骤的流量,最终的流量就是它们的总和。

损失和估计光流的收敛
关于 RAFT 的实现

(来源)
RAFT 模型可以分为两部分:编码器和迭代器。编码器部分类似于编解码网络中的编码器,用于提取输入图像的潜在特征图。迭代器实现为 ConvGRU 模块,这是一种 RNN 结构,可以预测一系列流程步骤,并通过共享参数进行迭代优化。
此外,规范和激活层仅用于编码器。
RAFT 的预测结果

预测光流图
我测试了作者提供的源,结果看起来不错。我用了一个 10 帧的视频剪辑。如上图,第一行是帧 0,第二行是帧 1~9,第三行分别是帧 0 和帧 1~9 之间的预测光流。结果表明,对于小时间间隔和大时间间隔的两个视频帧之间的光流可以平滑地预测。
参考
阅读陈数·杜(以及媒体上成千上万的其他作家)的每一个故事。您的会员费直接支持…
dushuchen.medium.com](https://dushuchen.medium.com/membership)


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言










{kind=link}
{kind=link}