







使用 GridSearchCV
学习一种可靠的工具来减少机器学习中的歧义
作为一个仍处于数据科学职业生涯初期的人,无论我构建的模型是什么类型,使用的数据集有多大,或者我需要完成的交付成果是什么,都有一个与数据打交道的元素始终悬在我的头上:模糊性。事实上,数据只不过是存储在令人困惑的文件、文件夹、存储库等矩阵中的数字和字母。我们去哪里以及我们用这些数据做什么是完全没有脚本的(字面上…哈…哈)。然而,这也是数据的美妙之处。我们可以做任何我们想做的事情来帮助理解它!随着我的技能的进步和一些舒适的感觉,我已经意识到绝对总是有一个解决方案或路线来帮助减轻数据的混乱。
分类建模
分类机器学习是数据科学中一种非常强大的算法,也是我花了无数时间绞尽脑汁的一种算法。更新一下,分类是一种机器学习技术,它允许我们获取大量数据和数据特征,并输出某种分类。例如,如果我们有一个数据集,给出了过去一周的所有天气特征(温度、湿度、紫外线指数等。)我们可以使用分类模型来预测明天是雨天还是晴天。
有许多类型的分类模型,从逻辑回归到 boosting 方法,但每一种都包含大量的模糊性,因为它们不是一刀切的。它们包含元素、参数和超参数,需要根据您的数据需求进行调整。幸运的是,正如我们之前所说的,总有办法减轻歧义!朋友和陌生人,相约格子搜索。

阿曼德·库利在 Unsplash 上拍摄的照片
参数与超参数
在我们真正开始网格搜索之前,了解参数和超参数之间的区别非常重要。这两个词经常被互换使用,但实际上,它们是完全不同的。超参数是不能在模型中直接学习的模型元素。也就是说,它们是模型的用户输入,然后帮助确定模型的性能。参数更加通用,因为它们是超参数和其他与模型不直接相关的元素的组合。用更好的话来说,超参数是模型无法学习的,而参数是模型在训练阶段学习的。
from sklearn.tree import DecisionTreeClassifierX = pd.DataFrame(['Feat1'],['Feat2'],[...])
y = pd.Series('target')dt = DecisionTreeClassifier(
criterion = 'entropy',
max_depth = 6,
min_samples_split = 10,
random_state = 33
)dt.fit(X,y)
在上面的代码中,我们看到了一个决策树分类模型的实例。我们向决策树对象传递了几个参数。“Criterion”和“max_depth”都是超参数的实例,因为它们影响我们的模型学习的方式。
使用网格搜索
作为我们模型的输入,超参数现在变得极其重要。每个模型都有多个超参数可供使用,并且这些超参数都有多个输入可能性。如果我们允许上面的模型有太高的深度,或者太多的节点,我们的模型将会过拟合。但是,如果我们没有足够的,这将是欠适合。当我们增加 min_samples_split 时,max_depth 如何影响输出的精度?模型中的参数不是相互独立的。真正了解的唯一方法是尝试所有这些方法的组合!组合网格搜索是解决这些新问题的最佳方式,可以为我们的模型及其数据找到超参数和参数的最佳组合。
GridSearchCV 来自 sklearn 库,让我们能够网格搜索我们的参数。它通过将 K-Fold 交叉验证与参数(模型)的网格相结合来运行。我们将网格构造成一个字典(键=参数名,值=我们组合的不同可能性),然后将它传递给我们的估计器对象。
拟合多个倾向模型,并选择最佳表现的一个来实现利润优化
用 h2o 和 DALEX 评估购买金融产品可能性的案例研究

丹·梅耶斯在 Unsplash 上的照片
在当今时代,利用数据来理解客户行为驱动因素的企业拥有真正的竞争优势。通过有效地分析客户层面的数据,组织可以显著提高其在市场中的表现,并将精力集中在那些更有可能参与的客户身上。
从数据中梳理这种洞察力的一种经过试验和测试的方法是 倾向建模 ,它结合了以下信息:a 客户的人口统计数据(年龄、种族、宗教、性别、家庭规模、种族、收入、教育水平)心理图(社会阶层、生活方式和个性特征)参与度(打开的电子邮件、点击的电子邮件、移动应用程序上的搜索、网页停留时间等)。)、用户体验(客户服务电话和电子邮件等待时间、退款次数、平均运送时间)用户行为(不同时间尺度上的购买价值、最近一次购买后的天数、报价和转换之间的时间等)。)来估计某个客户档案执行某类行为(例如购买产品)的可能性。
一旦你了解了某个客户与某个品牌互动、购买某个产品或注册某项服务的可能性,你就可以利用这些信息来创造情景,比如最小化营销支出,最大化收购目标,以及优化电子邮件发送频率或折扣深度。
项目结构
在这个项目中,我正在分析一家银行向现有客户销售定期 a 存款的直接营销活动的结果,以确定哪种类型的特征更有可能让客户做出反应。营销活动基于电话,有时需要与同一个人进行多次联系。
首先,我将进行广泛的数据探索,并使用结果和见解为分析准备数据。
然后,我正在估算模型的数量,并使用模型不可知的方法评估它们的性能和对数据的拟合,这使得能够比较传统的“玻璃箱”模型和“黑箱”模型。
最后,我将拟合一个最终模型,该模型结合了探索性分析的结果和模型选择的洞察力,并使用该模型进行收入优化。
数据
library(tidyverse)
library(data.table)
library(skimr)
library(correlationfunnel)
library(GGally)
library(ggmosaic)
library(knitr)
library(h2o)
library(DALEX)
library(knitr)
library(tictoc)
数据是来自 UCI 机器学习库的 葡萄牙银行营销 集,描述了一家葡萄牙银行机构开展的旨在向其客户销售定期存款/存单的直接营销活动。营销活动基于 2008 年 5 月至 2010 年 11 月期间对潜在买家的电话访问。
我正在使用的数据(bank-direct-marketing . CSV)是bank-additional-full . CSV的修改版本,包含 41,188 个带有 21 个不同变量的示例(10 个连续变量,10 个分类变量加上目标变量)。具体来说,目标订阅是一个二进制响应变量,表示客户是否订阅(‘是’或数值 1)定期存款(‘否’或数值 0),这使得这成为一个 二进制分类问题 。
这些数据需要一些操作才能变成可用的格式,详情可以在我的网页上找到: 倾向建模——数据准备和探索性数据分析。在这里,我简单地在我的 GitHub repo 上为这个项目 加载我托管的预清理数据
data_clean <-
readRDS(file = "https://raw.githubusercontent.com/DiegoUsaiUK/Propensity_Modelling/master/01_data/data_clean.rds")
探索性数据分析
虽然是任何数据科学项目不可或缺的一部分,并且对分析的完全成功至关重要,但探索性数据分析(EDA) 可能是一个极其耗费人力和时间的过程。近年来,旨在加速这一过程的方法和库大量涌现,在这个项目中,我将对其中一个“街区上的新孩子”(correlation funnel)进行采样,并将其结果与更传统的 EDA 相结合。
相关通道
通过 3 个简单的步骤correlationfunnel可以生成一个图表,按照与目标变量绝对相关性的降序排列预测值。漏斗顶部的特征预计在模型中具有更强的预测能力。
这种方法提供了一种快速确定所有变量的预期预测能力等级的方法,并给出了任何模型中哪些预测因子应该具有强/弱特征的早期指示。
data_clean %>%
binarize(n_bins = 4, # bin number for converting features
thresh_infreq = 0.01 # thresh. for assign categ.
# features into "Other"
) %>% # correlate target variable to features
correlate(target = subscribed__1) %>% # correlation funnel visualisation
plot_correlation_funnel()

放大前 5 个特征,我们可以看到,在以下情况下,某些特征与目标变量(订购定期存款产品)的相关性更大:
- 与客户最后一次电话联系的时间是 319 秒或更长
- 客户最后一次联系后经过的
days数量大于 6 previous营销活动的结果是success- 就业人数为 509.9 万或更多
- 3 个月欧元银行同业拆放利率的值为 1.344 或更高

相反,漏斗底部的变量,如星期几**、住房和贷款。与目标变量相比,变化非常小(即:它们非常接近响应的零相关点)。因此,我不认为这些特性会影响响应。**

功能探索
在这种视觉相关性分析结果的指导下,我将在下一节中继续探索目标和每个预测因素之间的关系。为此,我将寻求优秀的 GGally 库的帮助,用Ggpairs可视化相关矩阵的修改版本,用 ggmosaic 包绘制mosaic charts,这是检查两个或更多分类变量之间关系的好方法。
目标变量
首先,目标变量 : subscribed显示出强烈的阶级不平衡**,在无类别中有近 89%到有类别中有 11%。**

我将在建模阶段通过在 h2o 中启用重新采样来解决类不平衡**。这将通过“收缩”主要类别(“否”或“0”)来重新平衡数据集,并确保模型充分检测哪些变量在驱动“是”和“否”响应。**
预言者
让我们继续看一些数字特征:

尽管关联漏斗分析显示持续时间具有最强的预期预测能力,但它在通话前是未知的(显然在通话后是已知的),并且几乎不提供可操作的洞察力或预测价值。因此,它应该从任何现实的预测模型中被丢弃,并且不会在这个分析中被使用。
****年龄的密度图与目标变量相比具有非常相似的方差,并且以相同的区域为中心。基于这些原因,应该不会对认购产生太大影响。
尽管本质上是连续的, pdays 和 previous 实际上是分类特征,并且都是强烈右偏的。由于这些原因,需要将它们离散成组。这两个变量也适度相关,表明它们可能捕捉到相同的行为。
接下来,我将银行客户数据与马赛克图表可视化:

根据相关渠道的调查结果,工作、教育、婚姻和默认都显示出与目标变量相比的良好变化水平,表明它们会影响响应。相比之下,住房和贷款位于漏斗的最底部,预计对目标几乎没有影响,因为按“已认购”响应划分时变化很小。
****默认只有 3 个“是”级别的观察值,这些观察值将被滚动到最不频繁的级别,因为它们不足以做出正确的推断。住房和贷款变量的“未知”级别有少量观察值,将被归入第二小类别。最后,工作、教育也将从最不常见水平的分组中受益。
继续讨论其他活动属性**😗*

虽然在原则上是连续的,战役在本质上是更明确的,并且是强烈右倾的,将需要被离散成组。然而,我们已经从早期的相关性分析中了解到,在任何模型中,这都不是一个强有力的变异驱动因素。
另一方面, poutcome 是期望具有强预测能力的属性之一。级别的不均匀分布表明将最不常见的级别(成功或scs)归入另一个类别。然而,联系以前购买过定期存款的客户是具有最高预测能力的特征之一,需要保留不分组。
然后,我在看最后一条联系信息**😗*

****联系和月份应影响响应变量,因为它们与目标相比都有较好的变化水平。月也将受益于最不常见级别的分组。
相比之下,星期几似乎不会影响响应,因为水平之间没有足够的变化。
最后但同样重要的是,社会和经济属性:

与目标变量相比,所有的社会和经济属性都显示出良好的变化水平,这表明它们都应该对响应产生影响。它们都显示出高度的多模态**,并且在密度图中不具有均匀的分布,并且将需要被分箱。**
同样值得注意的是,除了消费者信心指数之外,所有其他社会和经济属性彼此之间都有很强的相关性,这表明只有一个属性可以被包括在模型中,因为它们都在“拾取”相似的经济趋势。
探索性数据分析总结
- 使用相关通道进行的相关性分析有助于确定所有变量的预期预测能力等级
- ****期限与目标变量的相关性最强,而一些银行客户数据如住房和贷款的相关性最弱
- 但是,持续时间将而不是用于分析,因为它在调用前是未知的。因此,它提供的可操作的洞察力或预测价值非常少,应该从任何现实的预测模型中丢弃
- 目标变量 subscribed 显示了强烈的类别不平衡,其中近 89%的没有变动**,这需要在建模分析开始之前解决**
- 大多数预测者将受益于最不常见水平的分组
- 进一步的特征探索揭示了大多数社会和经济背景属性彼此之间有很强的相关性,这表明在最终模型中只能考虑其中的一部分
最终数据处理和转换
根据探索性数据分析的结果,我将最不常见的级别组合到“其他”类别中,将除age之外的所有变量设置为无序因子( h2o 不支持有序分类变量),并缩短一些分类变量的级别名称,以方便可视化。你可以在我的网页上找到所有细节和完整代码: 倾向建模——数据准备和探索性数据分析。
在这里,我简单地在我的 GitHub repo 上加载最终的数据集托管 :
data_final <-
readRDS(file = "https://raw.githubusercontent.com/DiegoUsaiUK/Propensity_Modelling/master/01_data/data_final.rds")
建模策略
为了坚持合理的项目运行时间,我选择了 h2o 作为我的建模平台,因为它提供了许多优势:
- 它非常容易使用,你可以立刻评估几个机器学习模型****
- 它不需要通过“二进制化”字符/因子变量来预处理它们**(这是在“内部”完成的),这进一步减少了数据格式化时间**
- 它有一个功能,即处理在数据探索阶段突出显示的类不平衡**——我只是在模型规范中设置了
balance_classes= TRUE,稍后会详细介绍** - 可以启用交叉验证,而不需要从训练集中“分割”出一个单独的
validation frame - 超参数微调(也称为网格搜索)可以与多种策略一起实施,以确保运行时间在不影响性能的情况下得到限制
使用 h2o 构建模型
我开始用rsample创建一个随机的训练和验证集,并将它们保存为train_tbl和test_tbl。
set.seed(seed = 1975) train_test_split <-
rsample::initial_split(
data = data_final,
prop = 0.80
) train_tbl <- train_test_split %>% rsample::training()
test_tbl <- train_test_split %>% rsample::testing()
然后,我启动一个 h2o 集群。我将内存集群的大小指定为“16G”,以帮助加快速度,并关闭进度条。
# initialize h2o session and switch off progress bar
h2o.no_progress()
h2o.init(max_mem_size = "16G")
接下来,我整理出响应和预测变量集。对于要执行的分类,我需要确保响应变量是因子**(否则 h2o 将执行回归)。这是在数据清理和格式化阶段解决的。**
# response variable
y <- "subscribed"# predictors set: remove response variable
x <- setdiff(names(train_tbl %>% as.h2o()), y)
拟合模型
对于这个项目,我正在估算一个广义线性模型**(又名弹性网)、一个随机森林(其中 h2o 指的是分布式随机森林)和一个梯度推进机(或 GBM)。**
为了实现对tree-based模型(DRF 和 GBM)的网格搜索,我需要建立一个随机网格来搜索h2o.grid()函数的最优超参数**。为此,我从定义要传递给hyper_params参数的搜索参数开始:**
sample_rate用于设置每棵树的行采样率col_sample_rate_per_tree定义了每棵树的列抽样max_depth指定最大树深min_rows确定每片叶子的最小观察次数mtries(仅 DRF)表示在树的每个节点上随机选择的列learn_rate(仅适用于 GBM)指定建立模型时模型学习的速率
# DRF hyperparameters
hyper_params_drf <-
list(
mtries = seq(2, 5, by = 1),
sample_rate = c(0.65, 0.8, 0.95),
col_sample_rate_per_tree = c(0.5, 0.9, 1.0),
max_depth = seq(1, 30, by = 3),
min_rows = c(1, 2, 5, 10)
)# GBM hyperparameters
hyper_params_gbm <-
list(
learn_rate = c(0.01, 0.1),
sample_rate = c(0.65, 0.8, 0.95),
col_sample_rate_per_tree = c(0.5, 0.9, 1.0),
max_depth = seq(1, 30, by = 3),
min_rows = c(1, 2, 5, 10)
)
我还为search_criteria参数设置了第二个列表,这有助于管理模型的估计运行时间:
- 将
strategy参数设置为 RandomDiscrete ,以便搜索从网格搜索参数中随机选择一个组合 - 将
stopping_metric设置为 AUC,作为提前停止的误差度量——当度量停止改善时,模型将停止构建新的树 - 使用
stopping_rounds,我将指定考虑提前停止前的训练轮数 - 我使用
stopping_tolerance来设置继续训练过程所需的最小改进 max_runtime_secs将每个型号的搜索时间限制为一小时****
search_criteria_all <-
list(
strategy = "RandomDiscrete",
stopping_metric = "AUC",
stopping_rounds = 10,
stopping_tolerance = 0.0001,
max_runtime_secs = 60 * 60
)
最后,我可以建立模型的公式。请注意,所有模型都有两个共同的参数:
nfolds参数,使交叉验证能够在不需要 validation_frame 的情况下执行——例如,如果设置为 5,它将执行 5 重交叉验证- 将
balance_classes参数设置为真,以解决探索性分析期间突出显示的目标变量的不平衡。启用后,h2o 将对多数类进行欠采样或对少数类进行过采样。
# elastic net model
glm_model <-
h2o.glm(
x = x,
y = y,
training_frame = train_tbl %>% as.h2o(),
balance_classes = TRUE,
nfolds = 10,
family = "binomial",
seed = 1975
)# random forest model
drf_model_grid <-
h2o.grid(
algorithm = "randomForest",
x = x,
y = y,
training_frame = train_tbl %>% as.h2o(),
balance_classes = TRUE,
nfolds = 10,
ntrees = 1000,
grid_id = "drf_grid",
hyper_params = hyper_params_drf,
search_criteria = search_criteria_all,
seed = 1975
)# gradient boosting machine model
gbm_model_grid <-
h2o.grid(
algorithm = "gbm",
x = x,
y = y,
training_frame = train_tbl %>% as.h2o(),
balance_classes = TRUE,
nfolds = 10,
ntrees = 1000,
grid_id = "gbm_grid",
hyper_params = hyper_params_gbm,
search_criteria = search_criteria_all,
seed = 1975
)
我通过 AUC 分数对基于树的模型进行排序,并从网格中检索主要模型
# Get the DRM grid results, sorted by AUC
drf_grid_perf <-
h2o.getGrid(grid_id = "drf_grid",
sort_by = "AUC",
decreasing = TRUE)# Fetch the top DRF model, chosen by validation AUC
drf_model <-
h2o.getModel(drf_grid_perf@model_ids[[1]])# Get the GBM grid results, sorted by AUC
gbm_grid_perf <-
h2o.getGrid(grid_id = "gbm_grid",
sort_by = "AUC",
decreasing = TRUE)# Fetch the top GBM model, chosen by validation AUC
gbm_model <-
h2o.getModel(gbm_grid_perf@model_ids[[1]])
性能评价
有许多库(比如 IML 、 PDP 、 VIP 和 DALEX 等等,但更受欢迎)帮助机器学习可解释性**、特性解释和一般性能评估,它们在最近几年都变得越来越受欢迎。**
有多种方法来解释机器学习结果(即局部可解释的模型不可知解释、部分依赖图、基于排列的变量重要性),但在这个项目中,我检查了DALEX包,该包侧重于模型不可知的可解释性**,并提供了一种跨具有不同结构的多个模型比较性能的便捷方式。**
DALEX使用的模型不可知方法的一个关键优势是可以在相同的尺度上比较传统“玻璃箱”模型和黑箱模型的贡献。然而,由于是基于排列的,它的主要缺点之一是不能很好地适应大量的预测变量和大型数据集。****
DALEX 程序
目前DALEX不支持一些更新的 ML 包,如 h2o 或 xgboost 。为了使它与这样的对象兼容,我遵循了 Bradley Boehmke 在他杰出的研究 中阐述的程序,用 DALEX 建模可解释性,从中我获得了很多灵感并借鉴了一些代码。
首先,数据集需要采用特定的格式:
# convert feature variables to a data frame
x_valid <-
test_tbl %>% select(-subscribed) %>% as_tibble()# change response variable to a numeric binary vector
y_valid <-
as.vector(as.numeric(as.character(test_tbl$subscribed)))
然后,我创建一个 predict 函数,返回一个数值向量,该向量提取二进制分类问题的响应概率。
# create custom predict function
pred <- function(model, newdata) {
results <- as.data.frame(h2o.predict(model,
newdata %>% as.h2o()))
return(results[[3L]])
}
现在,我可以用explain()函数将我的机器学习模型转换成 DALEK“解释器”,它充当参数的“容器”。
# generalised linear model explainer
explainer_glm <- explain(
model = glm_model,
type = "classification",
data = x_valid,
y = y_valid,
predict_function = pred,
label = "h2o_glm"
)# random forest model explainer
explainer_drf <- explain(
model = drf_model,
type = "classification",
data = x_valid,
y = y_valid,
predict_function = pred,
label = "h2o_drf"
)# gradient boosting machine explainer
explainer_gbm <- explain(
model = gbm_model,
type = "classification",
data = x_valid,
y = y_valid,
predict_function = pred,
label = "h2o_gbm"
)
评估模型
最后,我准备将解释器对象传递给几个 DALEX 函数,这些函数将帮助评估和比较不同模型的性能。考虑到性能指标可能反映模型预测性能的不同方面,在评估模型时评估和比较几个指标非常重要使用 DALEX 您可以做到这一点!
为了评估和比较我的模型的性能,我从 Przemyslaw Biecek 和 Tomasz Burzykowski 在他们的书 解释性模型分析 中使用的框架中获得了灵感,该框架是围绕关键问题构建的:
- 1 —模型是否合适?
- 2 —这些模型如何相互比较?
- 3-哪些变量在模型中很重要?
- 4 —单个变量如何影响平均预测?
1 —模型是否合适?
通用模型拟合
为了初步了解我的模型与数据的吻合程度,我可以使用简单明了的model_performance()函数,它计算选定的模型性能度量。
model_performance(explainer_glm)
## Measures for: classification
## recall : 0
## precision: NaN
## f1 : NaN
## accuracy : 0.8914653
## auc : 0.7500738
##
## Residuals:
## 0% 10% 20% 30% 40% 50%
## -0.48867133 -0.16735197 -0.09713539 -0.07193152 -0.06273300 -0.05418778
## 60% 70% 80% 90% 100%
## -0.04661088 -0.03971492 -0.03265955 0.63246516 0.98072521model_performance(explainer_drf)
## Measures for: classification
## recall : 0.1700224
## precision: 0.76
## f1 : 0.2778793
## accuracy : 0.9040913
## auc : 0.7993824
##
## Residuals:
## 0% 10% 20% 30% 40% 50%
## -0.87841486 -0.13473277 -0.07933048 -0.06305297 -0.05556507 -0.04869549
## 60% 70% 80% 90% 100%
## -0.04172427 -0.03453394 -0.02891645 0.33089059 0.98046626model_performance(explainer_gbm)
## Measures for: classification
## recall : 0.2192394
## precision: 0.7340824
## f1 : 0.33764
## accuracy : 0.9066408
## auc : 0.7988382
##
## Residuals:
## 0% 10% 20% 30% 40% 50%
## -0.83600975 -0.14609749 -0.08115376 -0.06542395 -0.05572322 -0.04789869
## 60% 70% 80% 90% 100%
## -0.04068165 -0.03371074 -0.02750033 0.29004942 0.98274727
基于所有模型可用的指标(准确性和 AUC ),我可以看到弹性网和梯度提升的表现大致相当,而随机森林紧随其后。AUC 的范围在. 78-.80 之间,而准确性的范围稍窄,为. 89-.90
残留诊断
如前一段所示,model_performance()还生成残差分位数,可以绘制这些分位数来比较模型间的绝对残差。
# compute and assign residuals to an object
resids_glm <- model_performance(explainer_glm)
resids_drf <- model_performance(explainer_drf)
resids_gbm <- model_performance(explainer_gbm)# compare residuals plots
p1 <- plot(resids_glm, resids_drf, resids_gbm) +
theme_minimal() +
theme(legend.position = 'bottom',
plot.title = element_text(hjust = 0.5)) +
labs(y = '')
p2 <- plot(resids_glm, resids_drf, resids_gbm, geom = "boxplot") +
theme_minimal() +
theme(legend.position = 'bottom',
plot.title = element_text(hjust = 0.5)) gridExtra::grid.arrange(p2, p1, nrow = 1)

鉴于中值绝对残差,DRF 和 GBM 模型的表现似乎不相上下。查看右侧的残差分布,您可以看到这两个模型的中值残差最低,GLM 的尾部残差数量较多。这也反映在左侧的箱线图中,其中基于树的模型都实现了最低的中值绝对残差值。
2 —这些模型如何相互比较?
ROC 和 AUC
接收器工作特性(ROC) 曲线是一种图形化方法,允许可视化针对随机猜测的分类模型性能,这由图上的条纹线表示。该曲线在 y 轴上绘制了真阳性率(TPR ),在 x 轴上绘制了假阳性率(FPR)。
eva_glm <- DALEX::model_performance(explainer_glm)
eva_dfr <- DALEX::model_performance(explainer_drf)
eva_gbm <- DALEX::model_performance(explainer_gbm)plot(eva_glm, eva_dfr, eva_gbm, geom = "roc") +
ggtitle("ROC Curves - All Models",
"AUC_glm = 0.750 AUC_drf = 0.799 AUC_gbm = 0.798") +
theme_minimal() +
theme(plot.title = element_text(hjust = 0.5))

从 ROC 曲线可以看出两个方面:
- 直接阅读:所有模型的表现都比随机猜测要好
- 比较读数:AUC(曲线下面积) 总结了 ROC 曲线,可用于直接比较模型性能——完美的分类器 AUC = 1。
所有模型的表现都比随机猜测好得多,AUC 达到 0.75-. 80,其中 DRF 的得分最高,为 0.799。
3-哪些变量在模型中很重要?
可变重要性图
每种 ML 算法都有自己的方式来评估每个变量的重要性:例如,线性模型参考它们的系数,而基于树的模型则考虑杂质,这使得很难跨模型比较变量的重要性。
DALEX 通过置换计算可变重要性度量,这是模型不可知论,并允许在不同结构的模型之间进行直接比较。然而,当可变重要性分数基于排列时,我们应该记住,当特征数量增加时计算速度会变慢**。**
我再次将每个模型的“解释器”传递给feature_importance()函数,并将n_sample设置为 8000,以使用几乎所有可用的观察值。尽管不算过分,总执行时间是将近 30 分钟**,但这是基于相对较小的数据集和变量数量。不要忘记,计算速度可以通过减少n_sample来提高,这对较大的数据集尤其重要。**
# measure execution time
tictoc::tic()# compute permutation-based variable importance
vip_glm <-
feature_importance(explainer_glm,
n_sample = 8000,
loss_function = loss_root_mean_square) vip_drf <-
feature_importance(explainer_drf,
n_sample = 8000,
loss_function = loss_root_mean_square)vip_gbm <-
feature_importance(explainer_gbm,
n_sample = 8000,
loss_function = loss_root_mean_square) # show total execution time
tictoc::toc()## 1803.65 sec elapsed
现在,我只需将 vip 对象传递给一个绘图函数:正如自动生成的 x 轴标签( Drop-out loss )所暗示的,变量重要性如何计算背后的主要直觉在于,如果移除所选解释变量的贡献,模型拟合度会降低多少。分段越大,从模型中删除该变量时的损失就越大。
# plotting top 10 feature only for clarity of reading
plot(vip_glm, vip_drf, vip_gbm, max_vars = 10) +
ggtitle("Permutation variable importance",
"Average variable importance based on 8,000
permutations") +
theme_minimal() +
theme(plot.title = element_text(hjust = 0.5))

我喜欢这个情节,因为它汇集了丰富的信息。
首先,你可以注意到,尽管相对权重略有不同,但前 5 个特征对每个模型来说都是共同的,其中nr_employed(经济中使用的)是所有这些特征中唯一最重要的预测因素。这种一致性令人放心,因为它告诉我们,所有模型都在数据中选取相同的结构和交互,并向我们保证这些特征具有强大的预测能力。****
您还可以注意到 x 轴左边缘的不同起点,这反映了三个模型之间 RMSE 损失的差异:在这种情况下,弹性网模型具有最高的 RMSE,这表明在残差诊断中较早看到的较高数量的尾部残差可能不利于 RMSE 评分。
4 —单个变量如何影响平均预测?
部分依赖曲线
在我们确定了每个变量的相对预测能力后,我们可能想要调查它们与所有三个模型的预测反应之间的关系有何不同。部分相关(PD)图,有时也称为 PD 曲线,提供了一种很好的方法来检查每个模型如何响应特定的预测值。
我们可以从最重要的特性nr_employed开始:
**# compute PDP for a given variable
pdp_glm <- model_profile(explainer_glm,
variable = "nr_employed",
type = "partial")
pdp_drf <- model_profile(explainer_drf,
variable = "nr_employed",
type = "partial")
pdp_gbm <- model_profile(explainer_gbm,
variable = "nr_employed",
type = "partial")plot(pdp_glm$agr_profiles,
pdp_drf$agr_profiles,
pdp_gbm$agr_profiles) +
ggtitle("Contrastive Partial Dependence Profiles", "") +
theme_minimal() +
theme(plot.title = element_text(hjust = 0.5))**

尽管平均预测权重不同,但所有三个模型都发现,当经济中的就业水平达到 509.9 万(nInf_5099.1)时,银行客户更有可能签署定期存款。弹性网和随机森林都在我们在correlationfunnel分析中观察到的nr_employed(对随机森林不太明显)的 3 个不同级别中发现了完全相同的预测能力层级,其中 GBM 稍微有点失调。
现在让我们来看看age,一个预测器,如果你还记得 EDA,它预计不会对目标变量产生影响:

我们注意到的一件事是,平均预测(x 轴)的变化范围在年龄谱(y 轴)上相对较浅,证实了探索性分析的发现,即该变量的预测能力较低。此外, GBM 和随机森林都以非线性方式使用age,而弹性网模型无法捕捉这种非线性动态。
部分依赖图也可以作为一种诊断工具:查看poutcome(previous营销活动的结果)可以发现 GBM 和 random forest 在前一个活动的结果成功(scs)时正确地获得了更高的签约概率。

然而,弹性网模型未能做到这一点,这可能是一个严重的缺陷,因为在以前的活动中,成功与目标变量有非常强的正相关性。
我将以month特性结束,因为它提供了一个很好的例子,在这种情况下,您可能希望用行业知识和一些常识来覆盖模型的结果。具体来说, GBM 模型似乎表明3 月、10 月和12 月是成功几率更大的时期。

根据我以前对类似金融产品的分析经验,我不建议银行机构在圣诞节前几周增加直接营销活动,因为这是一年中消费者注意力从这类购买转移的时期。
最终模型
总而言之,随机森林是我最终选择的模型:它看起来是三个中更平衡的,并且没有显示出像month和poutcome这样的变量所看到的一些“奇怪之处”。
现在,我可以通过结合探索性分析的结果、模型评估的洞察力以及大量行业特定/常识考虑因素,进一步完善我的模型并降低其复杂性。
特别是我的最终型号:
- 排除了许多预测能力较低的特征(
age、housing、loan、campaign、cons_price_idx) - 删除了
previous,它在 PD 图中显示其 2 个级别之间的差异很小——它也与pdays适度相关,表明它们可能捕捉到相同的行为 - 也下降了
emp_var_rate,因为它与nr_employed有很强的相关性,也因为从概念上讲,它们控制着非常相似的经济行为
**# response variable remains unaltered
y <- "subscribed"# predictors set: remove response variable and 7 predictors
x_final <-
setdiff(names(train_tbl %>%
select(-c(age, housing, loan,
campaign, previous,
cons_price_idx, emp_var_rate)) %>%
as.h2o()), y)**
对于最终的模型,我使用了与原始随机森林相同的规范
**# random forest model
drf_final <-
h2o.grid(
algorithm = "randomForest",
x = x_final,
y = y,
training_frame = train_tbl %>% as.h2o(),
balance_classes = TRUE,
nfolds = 10,
ntrees = 1000,
grid_id = "drf_grid_final",
hyper_params = hyper_params_drf,
search_criteria = search_criteria_all,
seed = 1975
)**
同样,我们通过 AUC 分数对模型进行排序,并检索先导模型
**# Get the grid results, sorted by AUC
drf_grid_perf_final <-
h2o.getGrid(grid_id = "drf_grid_final",
sort_by = "AUC",
decreasing = TRUE)# Fetch the top DRF model, chosen by validation AUC
drf_final <-
h2o.getModel(drf_grid_perf_final@model_ids[[1]])**
最终模型评估
为了简单起见,我用同名包中的vip()函数可视化变量重要性图,该函数返回每个变量的排名贡献。
**vip::vip(drf_final, num_features = 12) +
ggtitle("Variable Importance", "") +
theme_minimal() +
theme(plot.title = element_text(hjust = 0.5))**

移除emp_var_rate使得education进入了前 10 名。可以理解的是,变量层次和相对预测能力有所调整和变化,但令人欣慰的是,看到其他 9 个变量在前一个模型的前 10 名中。
最后,我将该模型的性能与原始的随机森林模型进行比较。
**drf_final %>%
h2o.performance(newdata = test_tbl %>% as.h2o()) %>% h2o.auc()## [1] 0.7926509drf_model %>%
h2o.performance(newdata = test_tbl %>% as.h2o()) %>% h2o.auc()## [1] 0.7993973**
AUC 只变化了百分之几,这告诉我这个模型保持了它的预测能力。
关于部分相关图的一个重要观察
由于已经熟悉逻辑回归中的优势比,我开始了解同样的直觉是否可以扩展到黑盒分类模型。在我的研究过程中,一个关于 交叉验证 的非常有趣的帖子脱颖而出,它在来自决策树的 比值比和随机森林的 之间画出了一条平行线。
基本上,这告诉我们,部分依赖图可以以类似于优势比的方式来定义客户档案的哪些特征影响他/她执行某种类型行为的倾向。
例如,job、month和contact等特征将提供关于谁、何时和如何瞄准的上下文:
- 查看
job会告诉我们,担任管理员角色的客户比担任个体户角色的客户订阅的可能性大约高 25%。**** - 在 10 月日
month和 10 月日month与潜在客户取得联系,会比在 5 月日取得积极成果的几率增加一倍以上。**** contacting与通过电话通话相比,您的客户通过手机进行订购的机会增加了近四分之一。****
请注意,所有最终模型预测值的部分相关图可以在我的网页上找到:在我的网页上: 倾向建模——估计几个模型,并使用模型不可知方法比较它们的性能。
有了这样的洞察力,你就可以帮助制定整体营销和沟通计划,把重点放在更有可能订阅定期存款的客户身上。
然而,这些都是基于模型级别的解释器,它们反映了一个整体的、聚合的视图。如果您有兴趣了解模型如何对单次观察做出预测(即哪些因素会影响在单个客户级别参与的可能性),您可以求助于利用“本地模型”概念的 本地可解释模型不可知解释(LIME) 方法。我将在以后的文章中探讨 LIME 方法。
模型估计和评估综述
对于这个项目的分析部分,我选择 h2o 作为我的建模平台。h2o 不仅非常易于使用,而且具有许多内置功能,有助于加快数据准备:它处理类不平衡而不需要预先建模重采样,自动 __“二进制化”字符/因子 __ 变量,并实现交叉验证而不需要从训练集中“分割”出单独的validation frame。
在建立了一个随机网格来让搜索最佳超参数之后,我估计了模型的数量(一个逻辑回归、一个随机森林和一个梯度提升机器),并使用 DALEX 库通过一系列指标来评估和比较它们的性能**。该库采用了模型不可知的方法,使得能够在相同的规模上比较传统的“玻璃盒子”模型和“黑盒”模型。**
我最终选择的模型是随机森林**,我通过结合探索性分析的结果、从模型评估中收集的洞察力以及大量行业特定/常识考虑因素,进一步完善了该模型。这确保了降低模型的复杂性,而不影响预测能力。**
优化预期利润
现在我有了我的最终模型,拼图的最后一块是最终的“那又怎样?”这个问题让所有人都有了正确的认识。对客户签署定期存款的概率的估计可用于创建许多优化的场景,从最小化您的营销支出**,最大化您的总体收购目标,到推动一定数量的交叉销售机会。**
在我这样做之前,有几个内务任务需要“设置工作场景”和几个重要的概念要介绍:
- 阈值和 F1 分数
- 精确度和召回率
阈值和 F1 分数
该模型试图回答的问题是"该客户是否在直接营销活动后注册了定期存款?”而截止值(也称为阈值)是将预测分为Yes和No的值。
为了说明这一点,我首先通过将test_tbl数据集传递给h2o.performance函数来计算一些预测。
perf_drf_final <-
h2o.performance(drf_final, newdata = test_tbl %>% as.h2o()) perf_drf_final@metrics$max_criteria_and_metric_scores## Maximum Metrics: Maximum metrics at their respective thresholds
## metric threshold value idx
## 1 max f1 0.189521 0.508408 216
## 2 max f2 0.108236 0.560213 263
## 3 max f0point5 0.342855 0.507884 143
## 4 max accuracy 0.483760 0.903848 87
## 5 max precision 0.770798 0.854167 22
## 6 max recall 0.006315 1.000000 399
## 7 max specificity 0.930294 0.999864 0
## 8 max absolute_mcc 0.189521 0.444547 216
## 9 max min_per_class_accuracy 0.071639 0.721231 300
## 10 max mean_per_class_accuracy 0.108236 0.755047 263
## 11 max tns 0.930294 7342.000000 0
## 12 max fns 0.930294 894.000000 0
## 13 max fps 0.006315 7343.000000 399
## 14 max tps 0.006315 894.000000 399
## 15 max tnr 0.930294 0.999864 0
## 16 max fnr 0.930294 1.000000 0
## 17 max fpr 0.006315 1.000000 399
## 18 max tpr 0.006315 1.000000 399
与许多其他机器学习建模平台一样, h2o 使用与最大 F1 分数相关联的阈值,它只不过是精确度和召回率之间的加权平均值。在这种情况下,阈值@ Max F1 为 0.190 。
现在,我使用h2o.predict函数通过测试集进行预测。预测输出有三列:实际模型预测(predict),以及与该预测相关联的概率(p0和p1,分别对应于No和Yes)。如您所见,与当前截止相关的p1概率大约为 0.0646 。
drf_predict <-
h2o.predict(drf_final,
newdata = test_tbl %>% as.h2o())# I converte to a tibble for ease of use
as_tibble(drf_predict) %>%
arrange(p0) %>%
slice(3088:3093) %>%
kable() predict p0 p1
1 0.9352865 0.0647135
1 0.9352865 0.0647135
1 0.9352865 0.0647135
0 0.9354453 0.0645547
0 0.9354453 0.0645547
0 0.9354453 0.0645547
然而, F1 分数只是识别截止值的一种方式。根据我们的目标,我们也可以决定使用一个阈值,例如,最大化精度或召回率。
在商业设置中,预先选择的阈值@ Max F1 不一定是最佳选择:输入精度并调用**!**
精确度和召回率
Precision 显示模型对误报的敏感程度(即预测客户在订购而他/她实际上没有),而 Recall 查看模型对误报的敏感程度(即预测客户在没有订购而他/她实际上打算这样做)。**
这些指标与商业环境**非常相关,因为组织对准确预测哪些客户真正有可能subscribe **(高精度)**特别感兴趣,以便他们可以针对这些客户制定广告策略和其他激励措施。与此同时,他们希望尽量减少对被错误归类为subscribing **(高召回)的客户的努力,这些客户反而不太可能注册。
然而,从下面的图表中可以看出,当精度变高时,召回率变低,反之亦然。这通常被称为精确-召回权衡**。**

为了充分理解这种动态及其含义,让我们先来看看截止零点和截止一点点,然后看看当您开始在两个位置之间移动阈值时会发生什么:
- 在阈值为零** ( 最低精度,最高召回)时,模型将每个客户分类为
subscribed = Yes。在这种情况下,你会通过直接营销活动联系每一个客户,但是浪费了宝贵的资源,因为还包括了那些不太可能订阅的客户。很明显,这不是一个最佳策略,因为你会招致更高的总体采购成本。** - 相反,在阈值一** ( 最高精度,最低召回)模型告诉你没有人可能订阅,所以你应该不联系任何人。这将为你节省大量的营销成本,但如果你通过直接营销将定期存款通知了那些已经订阅的客户,你将错过他们带来的额外收入。再说一次,这不是最优策略。**
当移动到一个更高的阈值时,该模型在将谁归类为subscribed = Yes时变得更加“挑剔”。因此,你在联系谁的问题上变得更加保守(精确度更高)并降低了你的采购成本,但同时你也增加了无法接触到潜在订户的机会(召回率更低),错失了潜在的收入。
这里的关键问题是你停在哪里?有没有“甜蜜点”,如果有,你如何找到它?嗯,那完全取决于你想达到的目标。在下一部分,我将运行一个迷你优化,目标是最大化利润**。**
寻找最佳阈值
对于这个小优化,我实施了一个简单的利润最大化**,基于与获得新客户相关的一般成本和从所述获得中获得的利益。这可以发展到包括更复杂的场景,但这超出了本练习的范围。**
为了理解使用哪个临界值是最佳的,我们需要模拟与每个临界点相关的成本效益。这是一个源自期望值框架的概念,参见 商业数据科学
为此,我需要两件东西:
- 每个阈值的预期比率 —这些可以从混淆矩阵中检索
- 每个客户的成本/收益 —我需要根据假设来模拟这些
预期利率
使用h2o.metric可以方便地检索所有分界点的预期比率。
# Get expected rates by cutoff
expected_rates <-
h2o.metric(perf_drf_final) %>%
as.tibble() %>%
select(threshold, tpr, fpr, fnr, tnr)
成本/收益信息
****成本效益矩阵是对四种潜在结果的成本和效益的商业评估。为了创建这样一个矩阵,我必须对一个组织在开展广告主导的采购活动时应该考虑的费用和优势做出一些假设。
让我们假设出售定期存款的成本为每位客户 30 英镑。这包括执行直接营销活动(培训呼叫中心代表,为主动呼叫留出时间,等等。)和激励措施,如为另一种金融产品提供折扣,或加入提供福利和津贴的会员计划。银行组织在两种情况下会产生这种类型的成本:当他们正确预测客户将会订阅时(真肯定,TP),以及当他们错误预测客户将会订阅时(假肯定,FP)。
我们还假设向现有客户出售定期存款的收入为每位客户 80 美元。当模型预测客户会订阅并且他们确实订阅时,组织将保证这一收入流(真正,TP)。
最后,还有真否定** (TN)场景,我们正确预测客户不会订阅。在这种情况下,我们不会花任何钱,但也不会获得任何收入。**
以下是成本情景的简要回顾:
- 真正 (TP) — predict 会订阅,他们确实这么做了:COST:-30;第 80 版
- 误报 (FP) — predict 会订阅,而实际不会:COST:-30;版本 0
- 真负 (TN) — predict 不会订阅,他们实际上也没有:COST:0;版本 0
- 假阴性 (FN) — predict 不会订阅,但他们确实订阅了:COST:0;版本 0
我创建了一个函数,使用阳性案例 (p1)的概率以及与真阳性 (cb_tp)和假阳性 (cb_fp)相关联的成本/收益来计算预期成本。这里不需要包括真阴性或假阴性,因为它们都是零。
我还包括之前创建的 expected_rates 数据帧,其中包含每个阈值的预期速率(400 个阈值,范围从 0 到 1)。
# Function to calculate expected profit
expected_profit_func <- function(p1, cb_tp, cb_fp) {
tibble(
p1 = p1,
cb_tp = cb_tp,
cb_fp = cb_fp
) %>%
# add expected rates
mutate(expected_rates = list(expected_rates)) %>%
unnest() %>%
# calculate the expected profit
mutate(
expected_profit = p1 * (tpr * cb_tp) +
(1 - p1) * (fpr * cb_fp)
) %>%
select(threshold, expected_profit)
}
多客户优化
现在为了理解多客户动态是如何工作的,我创建了一个假设的 10 个客户群来测试我的功能。这是一个简化的视图,因为我将相同的成本和收入结构应用于所有客户**,但是成本/收益框架可以针对单个客户进行定制,以反映他们单独的产品和服务水平设置,并且可以轻松调整流程,以针对不同的 KPI 进行优化(如净利润、 CLV 、订阅数量等)。)**
# Ten Hypothetical Customers
ten_cust <- tribble(
~"cust", ~"p1", ~"cb_tp", ~"cb_fp",
'ID1001', 0.1, 80 - 30, -30,
'ID1002', 0.2, 80 - 30, -30,
'ID1003', 0.3, 80 - 30, -30,
'ID1004', 0.4, 80 - 30, -30,
'ID1005', 0.5, 80 - 30, -30,
'ID1006', 0.6, 80 - 30, -30,
'ID1007', 0.7, 80 - 30, -30,
'ID1008', 0.8, 80 - 30, -30,
'ID1009', 0.9, 80 - 30, -30,
'ID1010', 1.0, 80 - 30, -30
)
我使用purrr将expected_profit_func()映射到每个客户,返回一个按阈值计算的每个客户预期成本的数据框架。这个操作创建了一个嵌套 tibble,我必须通过unnest()将数据帧扩展到一个级别。
# calculate expected cost for each at each threshold
expected_profit_ten_cust <-
ten_cust %>%
# pmap to map expected_profit_func() to each item
mutate(expected_profit = pmap(.l = list(p1, cb_tp, cb_fp),
.f = expected_profit_func)) %>%
unnest() %>%
select(cust, p1, threshold, expected_profit)
然后,我可以想象每个客户的预期成本曲线。
# Visualising Expected Cost
expected_profit_ten_cust %>%
ggplot(aes(threshold, expected_profit,
colour = factor(cust)),
group = cust) +
geom_line(size = 1) +
theme_minimal() +
tidyquant::scale_color_tq() +
labs(title = "Expected Profit Curves",
colour = "Customer No." ) +
theme(plot.title = element_text(hjust = 0.5))

最后,我可以合计预期成本,可视化最终曲线,并突出显示最佳阈值。
# Aggregate expected cost by threshold
total_expected_profit_ten_cust <- expected_profit_ten_cust %>%
group_by(threshold) %>%
summarise(expected_profit_total = sum(expected_profit)) # Get maximum optimal threshold
max_expected_profit <- total_expected_profit_ten_cust %>%
filter(expected_profit_total == max(expected_profit_total))# Visualize the total expected profit curve
total_expected_profit_ten_cust %>%
ggplot(aes(threshold, expected_profit_total)) +
geom_line(size = 1) +
geom_vline(xintercept = max_expected_profit$threshold) +
theme_minimal() +
labs(title = "Expected Profit Curve - Total Expected Profit",
caption = paste0('threshold @ max = ',
max_expected_profit$threshold %>% round(3))) +
theme(plot.title = element_text(hjust = 0.5))

这有一些重要的商业含义。根据我们的假设的 10 个客户群,选择优化的阈值0.092将产生近 164 的总利润,相比之下,与自动选择的0.190截止点相关的总利润近 147 。
这将导致的额外预期利润,接近每位客户1.7 英镑。假设我们有大约 500,000 的客户群,转换到优化型号可以产生额外的850,000的预期利润!
total_expected_profit_ten_cust %>%
slice(184, 121) %>%
round(3) %>%
mutate(diff = expected_profit_total - lag(expected_profit_total)) %>%
kable()threshold expected_profit_total diff
0.190 146.821 NA
0.092 163.753 16.932
显而易见,根据企业的规模,潜在利润增长的幅度可能是显著的。
结束语
在这个项目中,我使用了一个公开可用的数据集来估计银行现有客户在直接营销活动后购买金融产品的可能性。
在对数据进行彻底的探索和清理之后,我估计了几个模型和使用 DALEX 库比较了它们的性能和对数据的拟合**,该库侧重于模型不可知的可解释性。其关键优势之一是能够在相同的尺度上比较传统“玻璃箱”模型和黑箱模型的贡献。然而,由于是基于排列的,它的一个主要缺点是它不能很好地扩展到大量的预测器和更大的数据集。**
最后,我用我的最终模型实现了一个多客户利润优化**,它揭示了一个潜在的额外预期利润每个客户近 1.7(或者 85 万如果你有 50 万客户群)。此外,我还讨论了关键概念,如阈值和 F1 分数以及精确-召回权衡,并解释了为什么决定采用哪个截止值非常重要。**
在探索和清理数据、拟合和比较多个模型并选择最佳模型之后,坚持使用默认阈值@ Max F1 将达不到最终的“那又怎样?”这使得所有的艰苦工作都有了前景。
最后一件事:完成后不要忘记关闭 h2o 实例!
h2o.shutdown(prompt = FALSE)## [1] TRUE
代码库
完整的 R 代码和所有相关文件可以在我的 GitHub profile @ 倾向建模 中找到
参考
- 关于使用数据集的原始论文,请参见: 一种预测银行电话营销成功的数据驱动方法。决策支持系统 ,s .莫罗,p .科尔特斯和 p .丽塔。
- 加快探索性数据分析参见: correlationfunnel 包晕影
- 对于技术上严格但实用的机器学习可解释性请参见布拉德利·伯姆克的 模型可解释性与 DALEX****
- 要深入了解用于检查完全训练的机器学习模型并在模型不可知的框架中比较其性能的工具和技术,请参见:P. Biecek,T. Burzykowski
- 关于销售预测和产品延期交货优化的高级教程,请参见马特·丹乔的 预测销售分析:使用机器学习来预测和优化产品延期交货
- ****期望值框架见: 商业数据科学
原载于 2020 年 5 月 1 日https://diegousai . io。**
使用沙漏网络理解人类姿势
一个简单易懂的深入研究沙漏网络背后的人类姿态估计理论

人体姿态估计(来源
一个男人拿着一把刀向你跑来。你是做什么的?嗯,大多数人心里只会有一个想法:**跑。**嗯,你为什么要跑?因为观察这个男人咄咄逼人的姿态后,你可以断定他是想害你。既然你想活着看到明天,你决定尽可能跑得快。
你怎么能在几秒钟内完成所有这些复杂的分析呢?嗯,你的大脑刚刚做了一件叫做的人体姿态估计的事情。幸运的是,由于人类的姿势估计是通过眼睛和大脑的结合来完成的,这是我们可以在计算机视觉中复制的东西。
为了执行人体姿态估计,我们使用一种特殊类型的全卷积网络,称为沙漏网络。该网络的编码器-解码器结构使其看起来像一个沙漏,因此得名“沙漏网络”。

沙漏网络图(来源)。
但是,在我们深入研究网络的本质组件之前,让我们看看这个网络所基于的其他一些深层神经网络。
后退一步
在研究沙漏网络之前,您应该熟悉以下网络架构:
卷积神经网络(CNN)
- **重要性:**自动学习与特定对象最对应的特征,从而提高分类精度。
剩余网络
- 重要性:通过减缓网络梯度在反向传播中的收敛,允许更深的网络。
全卷积网络(FCN)
- **重要性:**用 1x1 卷积代替密集层,允许网络接受不同维度的输入。
编码器-解码器网络
- **重要性:**允许我们通过提取输入的特征并尝试重新创建它来操纵输入(例如。图像分割、文本翻译)
我们将更多地讨论编码器-解码器,因为这基本上就是沙漏网络,但如果你想要一些其他很酷的资源,这里有一些:视频, quora 线程,文章, GitHub 。
高层的网络
因此,希望您在学习所有这些网络架构时获得了一些乐趣,但是现在是时候将它们结合起来了。

沙漏网络架构(来源)
沙漏网络是一种卷积编码器-解码器网络(意味着它使用卷积层来分解和重建输入)。他们接受一个输入(在我们的例子中,是一个图像),并通过将图像解构为一个特征矩阵来从这个输入中提取特征。
然后,它采用这个特征矩阵并且将其与具有比特征矩阵更高的空间理解能力(比特征矩阵更好地感知对象在图像中的位置)的早期层组合。
- 注意:特征矩阵具有低空间理解,意味着我 t 并不真正知道物体在图像中的位置。这是因为,为了能够提取对象的特征,我们必须丢弃所有不是对象特征的像素。这意味着丢弃所有的背景像素,通过这样做,它删除了图像中对象位置的所有知识。
- 通过将特征矩阵与网络中具有更高空间理解能力的早期图层相结合,我们可以更好地了解输入内容(输入内容+输入内容在影像中的位置)。

我在 Canva 制作的快速图表。希望有帮助:)
将网络中的早期层传输到后面的层难道没有引起人们的注意吗?**resnet。**残差在整个网络中大量使用。它们用于将空间信息与特征信息结合起来,不仅如此,每个绿色块代表我们称之为 瓶颈块 的东西。
瓶颈是一种新型的残差。我们有 1 个 1X1 卷积、1 个 3X3 卷积和 1 个 1X1 卷积,而不是 2 个 3X3 卷积。这使得计算机上的计算变得容易得多(3×3 卷积比 1×1 卷积更难实现),这意味着我们可以节省大量内存。

左:剩余层右:瓶颈块(来源
所以总而言之,
- 输入:人物图像
- 编码:通过将输入分解成特征矩阵来提取特征
- 解码:结合特征信息+空间信息,深入理解图像
- **输出:**取决于应用程序,在我们的例子中,是关节位置的热图。
逐步了解流程
如果我们真的想能够编码,我们需要理解每一层发生了什么,为什么。因此,在这里,我们将分解整个过程,一步一步地进行,以便我们对网络有一个深入的了解(我们只是要回顾沙漏网络的架构,而不是整个培训过程)。
在这个网络中,我们将使用:
- **卷积层:**从图像中提取特征
- **最大池层:**消除图像中对特征提取不必要的部分
- **剩余层:**将层推进网络更深处
- **瓶颈层:**通过包含更多不太密集的卷积来释放内存
- 上采样层 : 增加输入的大小(在我们的例子中,使用最近邻技术——观看视频了解更多)
好了,在深入研究之前,让我们来看看沙漏网络的另一张图。

沙漏网络图(来源)
这里我们可以看到一些东西:
- 有两个部分:编码和解码
- 每个部分有 4 个立方体。
- 左边的立方体被传递到右边,形成右边的立方体
所以如果我们展开每个立方体,它看起来像这样:

瓶颈层(来源)
所以在网络全网图中,每个立方体都是一个瓶颈层(如上图)。在每个池层之后,我们会添加一个瓶颈层。
然而,第一层有点不同,因为它有一个 7X7 卷积(这是架构中唯一大于 3X3 的卷积)。以下是第一层的外观:

第一层的可视化
这是第一个立方体的样子。首先,输入被传递到与 BatchNormalization 和 ReLu 层结合的 7X7 卷积中。接下来,它被传递到一个瓶颈层,该层复制:一个通过最大池并执行特征提取,另一个仅在稍后的上采样(解码)部分连接回网络。
接下来的立方体(立方体 2、3 和 4)具有彼此相似的结构,但是与立方体 1 的结构不同。下面是其他多维数据集(在编码部分)的样子:

第二、第三和第四层的可视化
这些层要简单得多。先前的输出层被传递到瓶颈层,然后复制到残差层和用于特征提取的层。
我们将重复这个过程 3 次(在立方体 2、3 和 4 中),然后我们将生成特征地图。
以下是创建要素地图所涉及的图层(此部分是您在整个网络图中看到的三个非常小的立方体):

底层的可视化
这是网络中最深的层次。它也是要素信息最高的部分和空间信息最低的部分。在这里,我们的图像被压缩成一个矩阵(实际上是一个张量 T1),它代表了我们图像的特征。
为此,它通过了所有 4 个编码立方体和底部的 3 个瓶颈层。我们现在准备向上采样。以下是上采样层的外观:

放大图层的可视化
因此,在这里,传入的残差层将通过瓶颈层,然后在其自身(残差层)和上采样特征层(来自主网络)之间执行元素加法。
我们将重复这个过程 4 次,然后将最后一层(解码部分的第 4 个立方体)传递到最后一部分,在那里我们确定每个预测的准确度。
- 注:这叫**直接监督。**就是你*计算每个阶段末端的损耗而不是整个网络末端的损耗。*在我们的例子中,我们在每个沙漏网络的末端计算损失,而不是在所有网络组合的末端计算损失(因为对于人体姿势估计,我们使用堆叠在一起的多个沙漏网络)。
以下是最终图层的外观:

最终网络预测的可视化
这是网络的终点。我们通过卷积层传递最终网络的输出,然后复制该层以产生一组热图。最后,我们在网络的输入、热图和网络的两个输出(一个是预测,另一个是到达下一个网络末端的输出)之间执行元素相加。
然后,重复!
对,就是这样。你刚刚走过了整个沙漏网络。在实践中,我们将一起使用许多这样的网络,这就是标题为并重复为的原因。希望这个看似吓人的话题现在可以消化了。在我的下一篇文章中,我们将编写网络代码。
就像我之前提到的,我们将把这个应用到人体姿态估计中。然而,沙漏网络可以用于很多事情,比如语义分割、3d 重建等等。我读了一些关于沙漏网 3D 重建的很酷的论文,我会把它们链接到下面,这样你也可以读读。
总的来说,我希望你喜欢阅读这篇文章,如果你在理解这个概念上有任何困难,请随时通过电子邮件、linkedin 甚至 Instagram (insta:@nushaine)与我联系,我会尽力帮助你理解。除此之外,祝您愉快,编码愉快:)
资源
非常酷的论文
牛逼 GitHub Repos
在数据科学中使用内存访问
基于磁盘的数据库和内存访问之间的简单性能比较

图片来源:vectorgraphit.com。知识共享署名许可证。
在金融市场数据分析中,要分析的数据量和吞吐量可能令人望而生畏。这绝不是金融界特有的,因为它也发生在许多其他数据分析领域。这个特定行业的独特之处在于数据是高度结构化的(这在其他领域并不常见)。构成金融市场数据的是大量大小不一且大多互不相关的数据消息:最终很容易收到、存储、解码、解析和关联数亿条小消息。
分析如此大量的数据需要许多次迭代,并且在随机数据访问中节省时间的需要变得相关。
数据库与内存
在数据科学和数据工程中,我们面临许多次如前所述的处理数据集的需要。这可能是因为我们想要以大吞吐量注入数据——模拟环境——或者因为我们只是需要迭代大型数据集以进行统计分析或蒙特卡罗模拟——并非数据科学中的一切都可以简化为 ML 模型。
当存在这样的需求时,第一反应是使用数据库(可以是任何数据库)中的数据,并使用查询/访问策略来提取和使用数据。有时,这种方法根本无法避免,因为数据集太大,即使拆分也无法放入内存,或者因为使用数据的预期方式复杂多样。
但是在许多其他情况下,数据可以成功地简单地存储在 RAM 中,以便以后立即分配,或者在大块数据中,使用原始 I/O 直接从磁盘传输到内存。
后一种方法尽管简单,但通常不被采用(通过将数据访问减少到仅仅从磁盘进行内存复制,然后通过数组进行内存请求,从而减少了一层复杂性)。它肯定不适合所有的场景,但是它非常适合模拟、分析和回溯测试,正如在定量研究和分析中发现的那样。数据通常可以按年份或任何其他标准进行划分。
拆分可能被视为一个问题,但根据我的经验,它实际上简化了数据处理管道的后续阶段,即使使用数据库,也经常需要拆分。
在内存中存储要分配的数据的方式和将数据存储为可以查询的存储库的方式存在差异。如果您计划将所有内容都移入 RAM,那么理想情况下,您会希望存储一个将在编程语言中使用的结构的字节内存副本,而如果您计划使用数据库或存储库,那么它将是底层解决方案,即规定如何准备和存储数据的解决方案。
虽然您会发现许多人认为第一种方法违反了一些最佳实践(数据的字节顺序会引起可移植性问题,编译器不保证语言结构的一致性,等等),但事实是它在受控环境中工作得非常好,在受控环境中,您可以定义平台、操作系统、编译器和分析的源代码。
这些反对意见/建议可能对打算发布的商业软件有效,或者可能是从理论角度进行讨论的基础,但是在现实生活的研究和分析任务中,它们的有效性可能会受到质疑,在这种情况下,平台和环境都是及时受控和稳定的。
此外,我们已经到达了一个点,在平台和编译器架构方面没有太多的选择,所以关于字节序和编译器差异的讨论更多的是学术而不是实践。对我来说,这些是 80 年代和 90 年代的回忆,那时我们在平台方面更加多样化(SPARC、PowerPC、英特尔、Alpha)。这同样适用于许多不同 UNIX 供应商的操作系统。这种多样性很久以前就消失了。
RAM 比基于磁盘的数据库快多少?
为了回答这个问题,我们将测试两个场景。一个将模拟使用内存映射文件访问基于磁盘的存储系统(这被认为是大文件的快速访问方法),另一个将模拟针对内存阵列的直接内存访问。
在这两种情况下,文件和内存数组都填充了随机数据,我们在整个数据集(512Mb)上迭代 10 次,进行简单的计算(以避免编译器在其优化功能中跳过指令),我们将测量每种方法花费的时间。
用于测试基于磁盘的存储访问与内存访问的源代码
结果
在低端 FreeBSD 机器上运行的模拟结果清楚地显示了 RAM 如何显著提高访问性能:
durationTestFile
20318
durationTestArray
7312
即使我们用操作(每个检索字节的累积和与位屏蔽操作)来偏置测试,当比较内存和磁盘时,我们仍然得到 3:1 的速度性能比。可能内存与磁盘的隔离效应比这个比率还要高得多。
任何数据库或存储解决方案的性能都不可能超过内存映射文件的性能,因此我们可以得出结论,在内存上迭代可以大大减少计算时间。这不会让任何人感到惊讶,但是你仍然会发现有人声称两者是平等的,或者干脆否认直接内存访问方法是可行的,这是一个错误的假设。
作为对这个非正式基准的合理反对,有人可能会说我们没有考虑初始化数组的时间和将数据放入数组的时间。这些都是合理的反对意见,但是在对数据进行大量后续迭代(可能会持续几十分钟、几小时甚至几天)的情况下,使用内存而不是磁盘仍然有很大的好处,因为它将大大减少运行分析的时间。
处理时间越长,使用的内存就越多。
这种方法没有被广泛使用,因为它通常意味着能够压缩数据并处理底层语言的实际内存表示,而且它远远超出了在 JSON 和 *Jupyter 笔记本中处理数据的舒适区。*它可能更适合使用 C/C++ Java 或 Go 的低延迟开发环境。
还值得一提的是,整个方法只对高度结构化的数据有效,金融市场也是如此。处理非结构化数据或明确呈现关系依赖的数据需要不同的方法。
免责声明:此处表达的所有观点和信息均为我个人观点,并不代表我曾经、现在或将隶属或关联的任何实体的观点。
使用 joblib 加速 Python 管道

Marc-Olivier Jodoin 在 Unsplash 上拍摄的照片
让您的 Python 工作得更快!

动机:
随着多个预处理步骤和计算密集型流水线的增加,在某些点上有必要使流程高效。这可以通过删除一些冗余步骤或获得更多内核/CPU/GPU 来提高速度来实现。很多时候,我们专注于获得最终结果,而不考虑效率。我们很少努力优化管道或进行改进,直到耗尽内存或计算机挂起。最终,我们会觉得…
幸运的是,已经有了一个被称为 joblib 的框架,它提供了一组工具,使得 Python 中的管道在很大程度上变得轻量级。
为什么是 joblib?
将 joblib 工具集成为 ML 管道的一部分有几个原因。在他们的网站上提到了使用它的两个主要原因。然而,我想重新表述一下:
- 能够使用缓存,避免重新计算某些步骤
- 执行并行化,充分利用 CPU/GPU 的所有内核。
除此之外,我推荐 joblib 还有其他几个原因:
- 可以轻松集成
- 没有特定的依赖关系
- 节省成本和时间
- 简单易学
还有其他一些功能也很丰富,如果包含在日常工作中会很有帮助。
1.使用缓存的结果
在测试或创建模型时,我们经常需要多次重新运行我们的管道。有些函数可能会被调用多次,使用相同的输入数据,然后再次进行计算。Joblib 提供了一种更好的方法来避免重复计算相同的函数,从而节省了大量的时间和计算成本。比如下面我们举个简单的例子:

如上所述,该函数只是计算一个给定范围内的数字的平方。大约需要 20 秒才能得到结果。现在,让我们使用 joblib 的内存函数,定义一个位置来存储缓存,如下所示:

在第一次计算时,结果与之前的大约 20 秒非常相似,因为结果是第一次计算,然后存储到一个位置。让我们再试一次:

瞧啊。提供结果花了 0.01 秒。时间缩短了近 2000 倍。这主要是因为结果已经被计算并存储在计算机的缓存中。*所有功能的效率并不相同!*它可能因所请求的计算类型而有很大不同。但是你肯定会有这种通过缓存来加速管道的超能力!
要清除缓存结果,可以使用一个直接命令:
但是在使用这段代码之前要小心。你可能会毁掉你几周的计算工作。
2.并行化
顾名思义,我们可以使用“ *joblib 并行计算任何具有多个参数的指定函数。平行”。*在后台,当使用多个作业(如果指定)时,每个计算不会等待前一个完成,可以使用不同的处理器来完成任务。为了更好地理解,我展示了如何在缓存中运行并行作业。
考虑以下生成的随机数据集:
下面是我们正常顺序处理的运行,其中新的计算仅在先前的计算完成后开始。

对于并行处理,我们设置作业数= 2。作业的数量受限于 CPU 拥有或可用(空闲)的核心数量。

这里我们可以看到使用并行方法处理的时间减少了 2x 。
注意 :如果用于计算量较小的函数,使用此方法可能会降低性能。
3.倾卸和装载
我们经常需要存储和加载数据集、模型、计算结果等。在电脑上的某个位置来回移动。Joblib 提供了可用于轻松转储和加载的函数:
将数据转储到某个位置的代码
从某个位置加载数据的代码
4.压缩方法
当处理较大的数据集时,这些文件占用的空间非常大。使用特征工程,当我们添加更多的列时,文件会变得更大。幸运的是,如今,随着存储变得如此便宜,这不再是一个问题。然而,为了提高效率, joblib 提供的一些压缩方法使用起来非常简单:
a .简单压缩:
非常简单的就是上面显示的那个。它不提供任何压缩,但却是存储任何文件的最快方法


b .使用 Zlib 压缩:
这是一个很好的 3 级压缩方法,实现如下:


c .使用 lz4 压缩:
这是另一个很棒的压缩方法,也是已知最快的压缩方法之一,但压缩率略低于 Zlib。我个人认为这是最好的方法,因为它是压缩大小和压缩率之间的一个很好的平衡。下面是实现它的方法:


将所有内容放在一个表格中,如下所示:

作者创造的形象
结束语:
我发现 joblib 是一个非常有用的库。我已经开始将它们集成到我的许多机器学习管道中,并且肯定看到了许多改进。
感谢您抽出时间阅读这篇文章。任何意见/反馈总是很感谢!
使用 Jupyter 笔记本管理您的 BigQuery 分析
如何利用 Jupyter Notebook 更好地管理您的 SQL 查询?

图片来源:我们都去过那里…
如果你有打开和不断在一万个 BigQuery 标签页之间切换的困扰,你并不孤单。作为一名数据专业人员,使用 SQL 查询是一项日常任务,如果你没有条理,你会很快淹没在 Chrome 标签中。
幸运的是,您可以使用带有几个软件包的 Jupyter 笔记本,在处理 SQL 查询时会有更加愉快的体验。在这篇文章中,我将详细介绍设置环境的步骤,并将您的工作流程迁移到 Jupyter 笔记本上。无论您是数据分析师、数据工程师还是数据科学家,拥有一个有组织的工作流程将有助于显著提高您的工作效率。
环境设置
下载并安装 Anaconda
安装 Python 和 Jupyter Notebook 的最快最简单的方法是使用 Anaconda 发行版。你可以按照这里的指示找到在你的操作系统上安装 Anaconda 的指南。

确保将 Anaconda 添加到 PATH 环境变量中。
安装谷歌云 Python SDK 并认证
按照谷歌的指南为你的特定操作系统安装云 SDK。安装并初始化 SDK 后,您应该通过执行以下操作来设置应用程序默认身份验证:
打开终端/Anaconda 提示符/命令行,键入以下内容
gcloud auth application-default login
会弹出一个浏览器,要求你用谷歌账户登录。登录并选择Allow对云 SDK 进行认证。
安装 GCP python 库和 pandas_gbq
我们鼓励您为每个项目建立一个单独的环境来安装 python 包。为了简单起见,我将跳过在这里创建不同环境的步骤。
安装以下 Python 包:
pip install --user --upgrade google-api-python-client
pip install --user pandas-gbq -U
Jupyter 笔记本中的 SQL 查询
打开 Jupyter 笔记本或 Jupyter 实验室
您可以使用以下任一方法从命令行快速启动 Jupyter 笔记本或 Jupyter 实验室实例:
jupyter notebook
jupyter lab
创建一个 Python 3 笔记本,并确保您选择了之前安装软件包的环境。

导入库
import pandas as pd
import pandas_gbqfrom google.cloud import bigquery
%load_ext google.cloud.bigquery# Set your default project here
pandas_gbq.context.project = 'bigquery-public-data'
pandas_gbq.context.dialect = 'standard'
导入所需的库,就大功告成了!不再有无尽的 Chrome 标签,现在你可以在笔记本上组织你的查询,比默认编辑器有更多的优势。让我们复习一些例子。
在单元格查询中
借助%%bigquery的魔力,您可以编写如下多行单元格内查询:

您也可以使用%%bigquery df_name将结果存储到熊猫数据框中

可以使用— params标志在查询中传递参数:

但是,为了提高性能,一定要限制返回行。IPython Magics for BigQuery 的详细文档可以在这里找到。
使用 pandas_gbq 库
除了使用 IPython Magics,您还可以使用 pandas_gbq 与 BigQuery 进行交互。

将数据写回 BigQuery 也很简单。您可以运行以下代码:
df.to_gbq(df, table_id, project_id = project_id)
pandas_gbq的文件可以在这里找到。
使用 Python BigQuery 客户端
client = bigquery.Client(project = project_id)
query = '''
SELECT name, SUM(number) as count
FROM `bigquery-public-data.usa_names.usa_1910_current`
GROUP BY name
ORDER BY count DESC
LIMIT 5
'''
client.query(query).result().to_dataframe()
这段代码产生的结果与上述方法相同。但是,您可以使用 Python 客户端与 BigQuery 进行更高级的交互。诸如创建表、定义模式、定义自定义函数等。BigQuery Python 客户端的完整文档可以在这里找到。
结论
在这篇文章中,我介绍了使用 Jupyter Notebook 与 BigQuery 进行更程序化交互的步骤。以下是使用 Jupyter Notebook 查询数据时可以做的一些高级事情:
- 用 Jupyter 笔记本上的 markdown 单元格记录您的代码
- 以 HTML 或 PDF 格式分享您的分析
- 参数化您的查询
- 为您的查询编写单元测试
- 使用 BigQuery Python 客户端将基础设施实现为代码
- 构建一个 ETL 管道。
快乐学习!
使用一行代码写入关系数据库
PYTHON 和 SQL
这将使添加到数据库变得更加容易。

由 Instagram @softie__art 制作的艺术作品
当将数据从 Pandas 数据帧写入 SQL 数据库时,我们将使用DataFrame.to_sql方法。虽然您可以执行一个INSERT INTO类型的 SQL 查询,但是原生的 Pandas 方法使得这个过程更加容易。
下面是从熊猫文档中摘录的DataFrame.to_sql的完整参数列表:
**DataFrame.to_sql** ( self ,name:str, con , schema=None ,if _ exists:str= ’ fail ',index:bool
为了向您展示这种方法是如何工作的,我们将通过几个例子向费用记录的数据库添加交易。在本文中,我们将使用 SQLite 数据库。DataFrame.to_sql与 SQLite 和 SQLAlchemy 支持的其他数据库一起工作。
请随意创建您自己的数据库,以便您可以跟进。如果您对创建数据库不熟悉,下面快速介绍一下如何免费设置一个简单的 SQLite 数据库:
介绍如何使用 SQLite 浏览器来管理自己的数据库。
towardsdatascience.com](/an-easy-way-to-get-started-with-databases-on-your-own-computer-46f01709561)
在开始之前,不要忘记导入 Pandas 和 SQLite:
import sqlite3
import pandas as pd
用熊猫写数据库
在本练习中,我将在数据库的“Expense”表中插入新行:

示例 SQLite 数据库表
我用以下代码生成了一个示例事务数据框架:
data = {'Person': ['Byron'], 'Amount': [20], 'Category': ['Groceries'], 'Date':['27-08-20']}
df = pd.DataFrame.from_dict(data)
我们将插入到费用表中的数据帧如下所示:

准备输入新记录时,请确保数据框架中的列名与数据库表中的列名相匹配。
此外,所有操作都需要一个连接参数,您可以将它作为参数提供给con。要为 SQLite 数据库这样做,只需准备好这个变量供重用,其中db是本地 SQLite 数据库的文件路径。
conn = sqlite3.connect(db)
现在我们准备好开始了!
基本插入(和警告)
对于第一个例子,正如我们承诺的,我们使用下面一行代码:
df.to_sql(‘Expenses’, con=conn, if_exists=’append’, index=False)
这里,我们将"Expenses"作为我们想要写入的 SQLite 数据库中的表名。如前所述,我们还包含了con=conn,这样我们就可以连接到相关的 SQL 数据库。
默认情况下,如果一个表不存在,并且您尝试了上面的代码,一个新的表将在您的数据库中以您指定的名称创建。如果您想用现有的数据框架创建一个表,这是一种可行的方法。
对于我们的例子,表已经存在,所以我们需要指定应该发生什么。因为我们希望向表中添加新行并保留表中已有的行,所以我们传递if_exists='append',以便将数据帧中的新值插入到数据库表中。确保包括这一点,因为默认行为是if_exists='fail',这意味着代码将而不是执行。
我们还传递了index=False,因为index=True的默认行为是将数据帧的索引作为一列写入数据库表。但是,我们不需要这些信息,因为当我们添加新行时,SQLite 数据库中的“ID”列会自动增加。
自己摆弄这些参数,然后用 DB Browser for SQLite 检查更改,或者打印如下表格:
conn.execute("SELECT * FROM Expenses").fetchall()

用于检查结果的 SQL 查询的部分输出
写入大型数据帧—块大小
在前面的例子中,我们所做的只是将一个包含一行的数据帧插入到数据库表中。然而,对于更大的操作,如果您想写一个有几千行的数据帧,您可能会遇到一些问题。

从堆栈溢出发出样本
这可能是因为不同数据库的数据包大小限制。如果您的数据帧超过最大数据包大小(即一次发送的数据太多),将会发生错误,因为默认情况下,所有行都是一次写入的。
您可以通过指定一个chunksize来避免这种错误,T8 是您想要一次插入到数据库表中的数据帧中的行数。
例如,如果您有一个包含 2,000 行的表,并且您使用的数据库的最大数据包大小一次只允许 1,000 行,那么您可以将 chunksize 设置为 1,000 来满足该要求。
df.to_sql(‘Expenses’, con=conn, index=False, chunksize=1000)
我希望这个快速概述对您有用!Pandas 库提供了丰富的功能,可以进行各种各样的数据相关操作,您可以充分利用这些功能。如果您总是使用 SQL 查询或其他 Python 方法向数据库写入数据,那么单行的DataFrame.to_sql方法应该会为您提供一种快速而简单的替代方法。
如果您正在寻找一种简单的方法来探索和理解您的数据,Pandas 还提供了不同的排序功能来实现这一点:
正确探索、理解和组织您的数据。
towardsdatascience.com](/4-different-ways-to-efficiently-sort-a-pandas-dataframe-9aba423f12db)
要了解 Pandas MultiIndex 功能,它可用于各种高级数据分析任务,请查看以下内容:
[## 如何在 Pandas 中使用 MultiIndex 来提升您的分析
复杂数据分析中数据帧的层次索引介绍
towardsdatascience.com](/how-to-use-multiindex-in-pandas-to-level-up-your-analysis-aeac7f451fce)*
利用 K-均值聚类进行图像分离
使用 CNN 和 KMeans 来分离图像。
KMeans 聚类是最常用的无监督机器学习算法之一。顾名思义,它可以用来创建数据集群,本质上是隔离它们。
让我们开始吧。这里我将举一个简单的例子,从一个既有猫和狗的图像的文件夹中分离图像到它们自己的簇中。这将创建两个独立的文件夹(集群)。我们还将介绍如何自动确定 k 的最佳值。
我已经生成了一个猫和狗的图像数据集。

猫和狗的图像。
首先,我们将从导入所需的库开始。
import numpy as np
import tensorflow as tf
import matplotlib.pyplot as plt
from sklearn.cluster import KMeans
from sklearn.metrics import silhouette_score
import cv2
import os, glob, shutil
然后,我们将从图像文件夹中读取所有图像,并对它们进行处理以提取特征。我们将图像的大小调整为 224x224,以匹配我们的模型的输入层的大小,用于特征提取。
input_dir = 'pets'
glob_dir = input_dir + '/*.jpg'images = [cv2.resize(cv2.imread(file), (224, 224)) for file in glob.glob(glob_dir)]paths = [file for file in glob.glob(glob_dir)]
images = np.array(np.float32(images).reshape(len(images), -1)/255)
现在我们将在 MobileNetV2(迁移学习)的帮助下进行特征提取。为什么选择 MobileNetV2?你可能会问。我们可以用 ResNet50,InceptionV3 等。但是 MobileNetV2 速度快,资源也不多,所以这是我的选择。
model = tf.keras.applications.MobileNetV2(*include_top*=False,
*weights*=’imagenet’, *input_shape*=(224, 224, 3))predictions = model.predict(images.reshape(-1, 224, 224, 3))
pred_images = predictions.reshape(images.shape[0], -1)
既然我们已经提取了特征,现在我们可以使用 KMeans 进行聚类。因为我们已经知道我们正在分离猫和狗的图像
k = 2
kmodel = KMeans(*n_clusters* = k, *n_jobs*=-1, *random_state*=728)
kmodel.fit(pred_images)
kpredictions = kmodel.predict(pred_images)
shutil.rmtree(‘output’)for i in range(k):
os.makedirs(“output\cluster” + str(i))for i in range(len(paths)):
shutil.copy2(paths[i], “output\cluster”+str(kpredictions[i]))
这是输出,成功了!它把图像分离出来:
狗:

猫:

还有一件事,我们如何确定一个数据集的 K 值,对于这个数据集,你不知道类的数量。我们可以用侧影法或肘法来确定。这里我们将使用剪影法。这两种方法都应该用来获得最有把握的结果。我们将直接确定 k。
更多关于确定 K 的值:https://medium . com/analytics-vid hya/how-to-determine-the-optimal-K-for-K-means-708505d 204 EB
让我们将马的图像添加到原始数据集中。我们现在将确定 k 的值。
sil = []
kl = []
kmax = 10for k in range(2, kmax+1):
kmeans2 = KMeans(*n_clusters* = k).fit(pred_images)
labels = kmeans2.labels_
sil.append(silhouette_score(pred_images, labels, *metric* = ‘euclidean’))
kl.append(k)
我们现在将绘制这些值:
plt.plot(kl, sil)
plt.ylabel(‘Silhoutte Score’)
plt.ylabel(‘K’)
plt.show()

如您所见,K 的最佳值是 3。我们还成功创建了第三个集群:

结论
如您所见,KMeans 聚类是一种很好的图像分离算法。有时,我们使用的方法可能不会给出准确的结果,我们可以尝试通过使用不同的卷积神经网络来修复它,或者尝试将我们的图像从 BGR 转换为 RGB。
GitHub 资源库:https://GitHub . com/hris 1999/Image-Segregation-with-k means/
感谢阅读!希望你有美好的一天:)
使用 K-均值聚类创建支持和阻力:

迈克尔·泽兹奇在 Unsplash 上的照片
来自《走向数据科学》编辑的提示: 虽然我们允许独立作者根据我们的 规则和指导方针 发表文章,但我们并不认可每个作者的贡献。你不应该在没有寻求专业建议的情况下依赖一个作者的作品。详见我们的 读者术语 。
说到技术分析,支撑和阻力是人们谈论最多的概念。支撑位和阻力位被用作价格壁垒,价格在其中“反弹”。在本文中,我将使用 K-means 聚类算法来找到这些不同的支持和阻力通道,并根据这些见解进行交易。
支撑和阻力:
为了理解如何最好地实现某事,我们应该首先理解我们想要实现的事情。

自画支撑位和阻力位。作者图片
支撑位和阻力位,是画在图上的两条线,形成一个通道,价格就在这个通道里。
支持和阻力是由于来自卖方或买方的压力,证券不能再减少或增加的结果。一个很好的经验法则是,价格偏离支撑线或阻力线的次数越多,它再次起作用的可能性就越小。
支撑线和阻力线能很好地洞察进场点和卖点,因为支撑线和阻力线理论上是这段有限时间内的最低点和最高点。
支持和抵制策略的缺点是,它在一段未知的时间内有效,而且线条是主观的,因此容易出现人为错误。
计划概念:
K-means 聚类算法查找时间序列数据的不同部分,并将它们分组到定义数量的组中。这个数字(K)可以被优化。然后,每组的最高值和最低值被定义为该组的支持值和阻抗值。
现在我们知道了程序的意图,让我们试着用 Python 重新创建它!
代码:
import yfinance
df = yfinance.download('AAPL','2013-1-1','2020-1-1')
X = np.array(df['Close'])
这个脚本用来访问苹果股票价格的数据。对于这个例子,我们只在收盘价上实现支撑和阻力。
from sklearn.cluster import KMeans
import numpy as np
from kneed import DataGenerator, KneeLocator
sum_of_squared_distances = []
K = range(1,15)
for k in K:
km = KMeans(n_clusters=k)
km = km.fit(X.reshape(-1,1))
sum_of_squared_distances.append(km.inertia_)
kn = KneeLocator(K, sum_of_squared_distances,S=1.0, curve="convex", direction="decreasing")
kn.plot_knee()
# plt.plot(sum_of_squared_distances)
这个脚本测试不同的 K 值以找到最佳值:

2 的 K 值产生了很长一段时间都不会达到的支撑线和阻力线。

K 值为 9 会产生太常见的支撑和阻力,因此很难做出预测。
因此,我们必须找到 K 的最佳值,在比较 K 值之间的方差时通过肘点来计算。肘点是最大的进步,给定一定的动作。

基于 kneed 库,肘点在 4。这意味着最佳 K 值是 4。
kmeans = KMeans(n_clusters= kn.knee).fit(X.reshape(-1,1))
c = kmeans.predict(X.reshape(-1,1))
minmax = []
for i in range(kn.knee):
minmax.append([-np.inf,np.inf])
for i in range(len(X)):
cluster = c[i]
if X[i] > minmax[cluster][0]:
minmax[cluster][0] = X[i]
if X[i] < minmax[cluster][1]:
minmax[cluster][1] = X[i]
该脚本查找每个聚类中的点的最小值和最大值。当绘制时,这些线成为支撑线和阻力线。
from matplotlib import pyplot as plt
for i in range(len(X)):
colors = ['b','g','r','c','m','y','k','w']
c = kmeans.predict(X[i].reshape(-1,1))[0]
color = colors[c]
plt.scatter(i,X[i],c = color,s = 1)for i in range(len(minmax)):
plt.hlines(minmax[i][0],xmin = 0,xmax = len(X),colors = 'g')
plt.hlines(minmax[i][1],xmin = 0,xmax = len(X),colors = 'r')
这个脚本绘制了支撑位和阻力位,以及实际的价格图,这些价格图基于分类进行了颜色编码。不幸的是,我认为颜色是有限的,这意味着可以对数据进行颜色编码的 K 值有限。

这是程序的结果,一组支撑线和阻力线。请记住,当值回落到通道中时,线条是最准确的。此外,最终阻力线将是最不准确的,因为它考虑了最后一个值,而没有考虑任何其他值。
我的链接:
如果你想看更多我的内容,点击这个 链接 。
使用 K-Means 检测零售店中的变化

迈克·彼得鲁奇在 Unsplash 上的照片
识别消费者行为变化的无监督技术
U 当识别特定时期之间的变化时,受监督的机器学习算法会非常有用。
我将为批发商看一家零售商店。作为一家商店,你可能会期望或可能会瞄准你的客户群中的一些规律性。考虑到这一点,我将解释如何识别在一定时期内购买行为发生变化的客户。这种类型的分析可用于不同的领域。例如,它可以用来瞄准那些购买量较少的客户。在这种情况下,商店可以通过向他们提供折扣来留住他们。
我就不为了岗位而去走一遍整个数据科学的流程了。为了简明扼要,我将跳过这些步骤。如果你想了解更多关于解决业务问题的数据科学过程,看看这篇关于 CRISP-DM 方法论的帖子。
数据
它是一个管状数据集,包含英国零售商店中不同客户的交易。这里是公开的。
它包含材料采购的发票。来自 38 个国家 4372 个不同客户的 541909 张不同发票。

交易时间从 2011 年 12 月到 2012 年 12 月不等。
问题
乍一看,该数据集没有给出任何有关客户购买行为发生变化的提示。缺乏标签使得不可能应用监督技术,因为没有任何东西明确他们是哪种类型的顾客。这在一个层面上增加了问题的难度,其中有许多细微差别和未决问题。
在所有的机器学习问题中,对问题有很好的理解对于给出量身定制的解决方案至关重要。根据业务问题的不同,会有许多不同的方法。
考虑
我们将根据客户的行为对他们进行分组。为此,我们将使用两个变量,即每月采购频率和货币价值。
在 13 个月的购买活动中,我会比较两个时期的活动。第一个创建行为的基线,第二个评估它。对于前者,我们将使用 8 个月,对于后者,我们将使用 5 个月。它将分别占 60%和 40%的时间。
谈到技术细节,K-Means 是在数据中寻找相似性的好算法。将数据分成 5 组将足够大,但不会大到对微小的变化敏感。
由于商店的目标是增加购买频率或消费金额,因此可以用以下名称对这些群体进行分类:
- 休眠——很少访问,很少花钱。他们可能需要大的刺激来重新激活它们。
- 潜在客户——与最后一组相似,区别在于使他们成为更好的客户的刺激较小。
- 中—普通用户。
- 不定期——他们很少去,但去的时候往往会花很多钱。
- 忠诚——他们经常光顾商店,但不会花很多钱。
根据公司的战略,名称和组号可能会有所不同。数据科学和利益相关者之间的良好沟通和理解对于将业务需求正确转化为模型非常重要。
K-Means 快速介绍
这是最著名和最常用的无监督算法。它允许对数据进行分组或分类,这是您自己从未想到过的。此外,K-Means 属于硬聚类算法组,其原因是因为一旦分类完成,数据点就属于一个且仅属于一个组。另一方面,软聚类算法同时将数据分配给不同的组。
K-Means 的工作方式是,给定聚类的数量,它将根据到数据点的距离自动调整所有组的中心,直到算法收敛。一面之词,有不同类型的距离!K-Means 使用欧几里得距离(它是两个数据点之间的几何距离)。
使用 K-Means 的主要问题是算法不能自动计算最佳的聚类数。所以集群的数量取决于要解决的业务问题和屏幕后面的用户。然而,一些技术可以帮助用户估计最适合的聚类数。这被称为肘方法,但它不包括在这篇文章中。
K-Means 如何有助于检测变化?
在执行一些数据预处理操作后,这就是数据的样子。
tx.describe()

值得注意的是,两个变量(频率和货币值)都有一些异常值:
- 在价格上,中位数是 136 英镑,平均数是 390 英镑(与 1887 年的标准偏差相当大)。接下来,我将不包括花费超过 20,000 英镑的客户。
- 关于每月的总发票,中位数是每月 1 次访问,平均数是 0.8 次访问(标准偏差为 1.2)。在此之后,每月访问次数超过 15 次的客户将不会包括在分析中。
请注意,根据分析的性质,选择要移除的异常值可能会有所不同。
分割数据集
现在,是时候在基线期(8 个月)和评估期(5 个月)之间划分数据集了。这是两个时期的样子:

除了非常相似之外,我们从他们身上没有什么可以得到的。让我们开始分组吧。
k-表示动手!
如前所述,K-Means 使用欧几里得距离工作,这使得它在变量的尺度不同时很敏感。这是两个变量的情况。我将应用 0 到 1 之间的范围。
from sklearn.preprocessing import MinMaxScaler
scaler = MinMaxScaler(feature_range = (0, 1))baseline_norm = pd.DataFrame(scaler.**fit_transform(baseline)**,
index = baseline.index, columns = [‘PriceInvoices’,’TotalInvoices’])evaluation = pd.DataFrame(**scaler.transform(evaluation)**,
index = evaluation.index, columns = ['PriceInvoices','TotalInvoices'])
现在我们准备应用 K-Means 并看到一些结果:
from sklearn.cluster import KMeans**kmeans = KMeans(n_clusters = 5, init = ‘k-means++’, random_state = 1)**
y_kmeans_train = kmeans.**fit_predict(baseline_norm)**
关于 K-均值函数参数的几个解释?
- 如前所述,簇的数量被设置为 5。
- 我们使用的初始化方法是 k-means++,它灵活地选择聚类中心,从而加快收敛速度。
- 随机状态用于使算法具有确定性,换句话说,总是返回相同的结果。
下面是应用 K-Means 后两个周期的样子。注意,首先,我用基线数据集运行算法,以创建组。以便以后查看评估数据集中每个数据点的最接近组。
y_kmeans_test = kmeans.**predict**(evaluation.values)

在计算了从一个群集移动到另一个群集的客户端数量后,有 785 个不同的客户端。这是评估数据集中 40%的客户端。但是,检查集群变化的差异,我们可以看到许多客户端的变化非常小。这是因为许多客户端从一个集群的边缘移动到另一个集群的边缘。我们可以在下一个直方图中看到距离的分布。

为了减少标记的客户端数量,我们可以设置一个阈值,并挑选所有高于该级别的客户端。在我们的例子中,我选择了 0.25,所以它们在图表中是可见的。
最后,这些变化看起来是这样的。黄线是客户端的移动,而 X 标记是第一个位置,dop 是它们结束的位置。

结论:
我们已经看到了如何使用机器学习技术来为零售店中的购买行为建模,我们使用 K-Means 实现了这一点。获得的结果可以用于不同的目的,我在这里解释的一个将适合营销目的。它有助于识别转向活动较少的群体的客户(例如,忠诚于中等)。然而,它可以外推到另一种分析。
缺点和改进 该分析有一些缺点:
- 分析完成后,客户端可能已经丢失,并且很难重新激活它们。解决这个问题的一个方法是为他们最后一次交易的时间添加一个新的变量,即最近时间。例如,RFM 分析将解决这个问题,将交易的新近性作为一个新的变量添加到分类中。
- 大量的客户都放弃了。软聚类技术,如高斯混合模型(GMMs)将作为 K-均值的替代方法来缓解这一问题。GMMs 将给出数据点属于每个聚类的概率。例如,一个聚类边缘的数据点将有接近两个聚类的 50%-50%的概率。
为了提高模型捕捉变化的性能,K-Means 可以处理尽可能多的变量,并且 K-Means 将按照相同的标准进行分组。然而,增加更多的变量会使可视化更加困难。
继续学习
正如我上面刚刚写的几行,你可以探索 RFM 分析,这是一个在业界广泛使用的伟大分析。
您可能想尝试其他非监督技术,如层次聚类或高斯混合模型。它们解决了 K-Means 的主要问题,但是请记住,即使它们解决了 K-Means 的一些问题,它们也有自己的缺点!正如所说,“天下没有免费的午餐”!
使用 k 近邻预测 Spotify 曲目的类型

来源:约翰·泰克里迪斯。
Spotify 是世界上最受欢迎的音频流媒体平台,提供超过 5000 万首歌曲和超过 1.7 亿用户的访问[1]。我们可以找到更多关于数据的方法之一是通过检查歌曲的音频特征。在这篇文章中,我将向你展示如何利用 Spotify 的音频功能、python 和 K-nearest neighbors(一种受监督的机器学习算法)来预测我最喜欢的歌曲的风格。我们开始吧!
检索数据
为了分析这些数据,我在 Spotify 中创建了两个大型播放列表,一个是爵士乐,一个是嘻哈/RnB 音乐,使用的是 Spotify 上每个流派下嵌套的播放列表。每个播放列表都有超过 1800 首歌曲,因此应该提供一个相当好的样本量来应用我们的机器学习算法。以下是爵士乐播放列表的示例:

Spotify 上的自定义聚合爵士播放列表。来源:内森·托马斯。
为了检索数据,我在 Spotify 上设置了一个开发者账户,以获取所需的相关凭证 (client_id,client_secret)。为了找到如何做到这一点,Spotify 为他们的 web API 提供了很好的文档[2];我建议你去看看它的入门指南。因此,我设置了一个 API 请求来检索四个因素:歌曲名称、歌曲 ID、专辑和艺术家。
API 设置。
之后,我检索了每首歌的音频特征。Spotify 有许多音频功能,用于描述每首曲目:可跳舞性、能量、模式、音调、响度、语速、声音、乐器性、活跃度、效价、速度和持续时间 [3]。其中大多数都是不言自明的,除了模式和价,前者指示音轨是大调还是小调,后者指示音轨值越高听起来越积极。以下是我收集的专栏摘录;这段代码检索每首歌曲的专辑名称:
输出:

hip-hop 属性数据帧的提取。
我总共收集了约 3000 首歌曲进行分析,平均分为两种风格。
数据可视化
将每个属性的值调整到 0 到 1 之间后,我们可以使用雷达图来查看每个流派的属性分布。
这些图表是交互式的,所以你可以自己随意摆弄图表,看看你能从数据中找到什么关系!
爵士乐:
爵士属性雷达图。来源:内森·托马斯。
嘻哈:
嘻哈属性雷达图。来源:内森·托马斯。
检查这两个流派的特征的雷达图,似乎爵士音乐通常比嘻哈音乐具有更低的能量,而爵士音乐比嘻哈音乐更像 T2 音乐。嘻哈歌曲也比爵士歌曲更快乐、更乐观。从定性的角度来看,这是有意义的,因为布鲁斯和流畅的爵士乐可以非常柔和,乐器在音轨中占主导地位。
通过取其主要成分、或 PCA,这是另一种可视化每种体裁分布的方式。PCA 降低了数据的维度,旨在提取信号并从数据中去除噪声。在这里找到更多关于算法的实际应用,在这里我把它应用到收益率曲线【4】。为了绘制 Spotify 的统计数据,我使用了前两个主要成分,,它们一起解释了超过 99%的数据:

每个流派的第一和第二主成分散点图。来源:内森·托马斯。
这张图再次证实了我们的雷达图分析——在散点图上,嘻哈音乐似乎更加集中和聚集在一起,而爵士歌曲似乎分布更广。
使用 kNN 预测流派
但是首先:kNN 实际上是做什么的?
简而言之,K-nearest neighbors 是一种监督的机器学习技术【5】,它获取一个数据点,并计算 K 个标记的数据点之间的距离,根据它从 K-nearest 数据点获得的票数对该点进行分类。“受监督的”部分意味着我们在测试之前就已经知道这首歌是什么类型的,因此有了标签。
例如,如果 k=3 并且三个最近的邻居被分类为 1。爵士乐,2。爵士乐和 3。hip-hop,这导致 2 比 1 的投票支持 jazz,并且新的数据点将被分类为 jazz。使用欧几里得距离计算距离(参见毕达哥拉斯定理[6])。

欧几里德距离方程。克里斯·麦考密克。
选择 k 值可能是一个复杂的过程,有几种不同的方法可以找到最佳值。然而,对于这个数据集,我将 k 近似为 n 的平方根。
首先,为了准备我们的数据,我们需要合并每种风格的两个数据帧,随机化这些行,并标记每首歌曲的类别(风格)。对于这个项目,爵士= 0,嘻哈= 1 。

这是我们所有歌曲的完整标签样本。
标记数据很重要,因为这些标记稍后将用于评估模型的准确性。
接下来,我们需要在训练数据和测试数据之间拆分数据。虽然 KNN 模型在技术上不需要训练(因为算法携带所有数据),但比较训练和测试样本的准确性将是一种方便的感觉检查。
培训 KNN 模特
与你可能习惯看到的通常的训练和测试分割不同,最好是对训练数据使用 k 倍交叉验证来获得我们的初始预测。这是通过随机移动数据集,然后将其分成 k 个部分(折叠)来实现的。对于这个例子,我选择了 k = 10。因此,k-folds 算法分离出一个折叠,将其用作测试集。其他九个折叠构成了训练数据。然后,将 KNN 模型拟合在训练集上,并在测试集上进行评估,保存评估分数并丢弃模型[7]。这个过程然后重复十次,不同的折叠用作测试集。这导致每个折叠在训练数据中使用九(k-1)次,并且作为测试集使用一次。有关该过程的直观解释,请参见下图:

k 倍交叉验证示例。来源:丹·奥弗。
这种方法是优越的,因此将数据集一次分割成 80%训练 20%测试分割。这是因为这向我们展示了模型在看不见的数据上表现得有多好。在前一种情况下,存在过度拟合模型的风险。
我们可以使用流行的 python 模块 sci-kit learn 来拟合模型:
取交叉验证分数的平均值,我们的模型在训练集上的准确率为 90%。伟大的结果!
将 KNN 模型与测试集相匹配
有了测试数据,我们就用剩下的值(再来 721 首)。
性能
将模型拟合到我们的训练数据,**我们的模型在测试集上的准确率为 91%。**作为感觉检查,这类似于我们的训练集上的准确度分数。我们可以使用混淆矩阵来可视化模型的性能。
混淆矩阵描述了我们的 KNN 分类模型的性能[8]。一个真正的正数告诉我们算法预测的是 1,而实际的类是 1。假阳性告诉我们模型预测的是 1,而实际的类是 0。反过来适用于真否定和假否定。我们的混淆矩阵告诉我们,模型中的错误主要来自假阴性。


KNN 模型的混淆矩阵。来源:内森·托马斯。
所以,成功!我们已经成功创建了一个模型,利用机器学习的力量,以 91%的准确率预测歌曲的风格。
**感谢阅读!**如果您有任何见解,请随时发表评论。包含我用来做这个项目的源代码的完整 Jupyter 笔记本可以在我的 Github 库上找到。
参考资料:
[1]《每日电讯报》,2020 年。“最佳音乐流媒体服务:苹果音乐、Spotify、YouTube 音乐和亚马逊音乐对比”。可在:https://www . telegraph . co . uk/technology/0/best-music-streaming-services-apple-music-Spotify-Amazon-music/获取
[2] Spotify,2020 年。《Web API 教程》。可从以下网址获得:https://developer . Spotify . com/documentation/we b-API/quick-start/
[3] Spotify,2020 年。“获取音轨的音频特征”。可从以下网址获得:https://developer . Spotify . com/documentation/we b-API/reference/tracks/get-audio-features/
[4]托马斯·内森,《走向数据科学》,2020 年。“将主成分分析应用于收益率曲线——艰难之路”。可从https://towardsdatascience . com/applying-PCA-to-yield-curve-4d 2023 e 555 b 3获取
[5] GeeksforGeeks,2020。“K-最近邻”。可在:https://www.geeksforgeeks.org/k-nearest-neighbours/
[6]数学趣味,2017。“毕达哥拉斯定理”。可在:https://www.mathsisfun.com/pythagoras.html
[7]机器学习掌握,2019。“k 倍交叉验证的温和介绍”。可在:https://machinelearningmastery.com/k-fold-cross-validation/
[8] GeeksforGeeks,2020 年。《机器学习中的混淆矩阵》。可从以下网址获得:https://www . geeks forgeeks . org/confusion-matrix-machine-learning/
[9] S .罗森博格、戴维;彭博,2018。"机器学习基础,第一讲:黑盒机器学习."可在:https://bloomberg.github.io/foml/#lectures
免责声明:本文表达的所有观点均为本人观点,与先锋集团或任何其他金融实体无关。我不是一个交易者,也没有用本文中的方法赚钱。这不是财务建议。
使用 Kafka 作为数据湖中的临时数据存储和数据丢失预防工具

汤姆·盖诺尔在 Unsplash 上的照片
探索 Kafka 如何用于存储数据以及作为流媒体应用的数据丢失预防工具
介绍
Apache Kafka 是一个流媒体平台,允许创建实时数据处理管道和流媒体应用程序。Kafka 对于一系列用例来说是一个优秀的工具。如果您对 Kafka 如何用于 web 应用程序的度量收集的例子感兴趣,请阅读我的上一篇文章。
Kafka 是数据工程师工具箱中的一种强大技术。当您知道 Kafka 的使用方式和位置时,您就可以提高数据管道的质量,并更高效地处理数据。在本文中,我们将看一个例子,说明 Kafka 如何应用于更不寻常的情况,如在亚马逊 S3 存储数据和防止数据丢失。如您所知,数据存储的容错性和持久性是大多数数据工程项目的关键要求之一。所以,知道如何以满足这些需求的方式使用卡夫卡是很重要的。
这里我们将使用 Python 作为编程语言。要从 Python 中与 Kafka 进行交互,还需要有一个特殊的包。我们将使用 kafka-python 库。要安装它,您可以使用以下命令:
pip install kafka-python
作为数据仓库的卡夫卡
卡夫卡可以用来存储数据。您可能想知道 Kafka 是关系数据库还是 NoSQL 数据库。答案是,非此即彼。
Kafka 作为一个事件流平台,处理的是流数据。同时,Kafka 可以在删除数据之前存储一段时间。这意味着 Kafka 不同于传统的消息队列,传统的消息队列在消费者阅读完消息后会立即丢弃消息。Kafka 存储数据的时间称为保留时间。理论上,你可以把这个周期设置为永远。Kafka 还可以在持久存储上存储数据,并通过集群内的代理复制数据。这只是使卡夫卡看起来像一个数据库的另一个特征。
那么,为什么 Kafka 没有被广泛用作数据库,为什么我们没有提出这可能是一种数据存储解决方案的想法?最简单的原因是因为 Kafka 有一些特性,这些特性对于一般的数据库来说是不典型的。例如,Kafka 也不提供对数据的任意访问查找。这意味着没有查询 API 可用于获取列、过滤列、将列与其他表连接等等。其实还有一个卡夫卡 StreamsAPI,甚至还有一个 ksqlDB。它们支持查询,非常类似于传统的数据库。但它们就像卡夫卡身边的脚手架。他们充当消费者,在数据被消费后为您处理数据。所以,当我们谈论 Kafka 而不是它的扩展时,这是因为 Kafka 中没有像 SQL 这样的查询语言来帮助你访问数据。顺便说一下,现代的数据湖引擎,比如 Dremio T1,可以解决这个问题。Dremio 支持使用 SQL 与本身不支持 SQL 的数据源进行交互。例如,你可以在 AWS S3 保存 Kafka 流的数据,然后使用 Dremio AWS edition 访问它。
卡夫卡也专注于用流工作的范例。Kafka 旨在充当基于数据流的应用程序和解决方案的核心。简而言之,它可以被视为大脑,处理来自身体不同部位的信号,并通过解释这些信号让器官工作。Kafka 的目标不是取代更传统的数据库。卡夫卡生活在一个不同的领域,它可以与数据库交互,但它不是数据库的替代品。在 Dremio 的帮助下,Kafka 可以轻松地与数据库和云数据湖存储(如亚马逊 S3 和微软 ADLS)集成。
请记住,卡夫卡具有存储数据的能力,并且数据存储机制相当容易理解。Kafka 存储从第一条消息到现在的记录(消息)日志。使用者从该记录日志中指定的偏移量开始获取数据。这是它看起来的简化解释:

偏移可以在历史中向后移动,这将迫使消费者再次读取过去的数据。
因为 Kafka 不同于传统的数据库,所以它可以用作数据存储的情况也有些特殊。以下是其中的一些:
- 当处理逻辑改变时,从头开始重复数据处理;
- 当一个新系统包含在处理管道中,并且需要从头或从某个时间点开始处理所有以前的记录时。此功能有助于避免将一个数据库的完整转储复制到另一个数据库;
- 当消费者转换数据并将结果保存在某个地方,但出于某种原因,您需要存储数据随时间变化的日志。
在本文的后面,我们将看一个例子,说明 Kafka 如何在与上述第一个用例类似的用例中用作数据存储。
Kafka 作为防止数据丢失的工具
许多开发人员选择 Kafka 作为他们的项目,因为它提供了高水平的持久性和容错性。这些功能是通过在磁盘上保存记录和复制数据来实现的。复制意味着数据的相同副本位于集群中的几个服务器(Kafka 代理)上。因为数据保存在磁盘上,所以即使 Kafka 集群在一段时间内处于非活动状态,数据仍然存在。由于有了复制,即使代理中的一个或几个集群受损,数据也能得到保护。
数据被消费后,通常会被转换和/或保存在某个地方。有时,在数据处理过程中,数据可能会损坏或丢失。在这种情况下,Kafka 可以帮助恢复数据。如果需要,Kafka 可以提供一种从数据流的开头执行操作的方法。
您应该知道,用于控制数据丢失防护策略的两个主要参数是复制因子和保留期。复制因子显示在 Kafka 集群中为给定主题创建了多少冗余数据副本。为了支持容错,您应该将复制因子设置为大于 1 的值。一般来说,推荐值是三。复制因子越大,Kafka 集群越稳定。您还可以使用这个特性将 Kafka 代理放在离数据消费者更近的地方,同时在地理上远程的代理上拥有副本。
保留期是 Kafka 保存数据的时间。很明显,时间越长,保存的数据就越多,在发生不好的事情时(例如,用户因断电而停机,或者数据库因意外的错误数据库查询或黑客攻击而丢失所有数据等)能够恢复的数据也就越多。).
例子
这里有一个例子,说明当数据处理的业务逻辑突然发生变化时,Kafka 的存储能力会非常有帮助。
假设我们有一个收集温度、湿度和一氧化碳(CO)浓度等天气指标的物联网设备。该设备的计算能力有限,因此它所能做的就是将这些指标发送到某个地方。在我们的设置中,设备将向 Kafka 集群发送数据。我们将每秒发送一个数据点,每秒测量一天(换句话说,物联网设备每天收集信息)。下面的图表展示了这一流程:

消费者订阅生产者向其发送消息的主题。消费者然后以指定的方式聚集数据。它在一个月内积累数据,然后计算平均指标(平均温度、湿度和 CO 浓度)。每个月的信息都应该写入文件。该文件只包含一行,值用逗号分隔。以下是该文件的一个示例:

先从《卡夫卡制作人》的创作说起。生产者将位于 producer.py 文件中。在文件的开头,我们应该导入我们需要的所有库并创建 KafkaProducer 实例,它将与位于 localhost:9092 上的 Kafka 集群一起工作:
import random
import json
Import time
from kafka import KafkaProducer
producer = KafkaProducer(bootstrap_servers=[‘localhost:9092’])
下面您可以看到生成数据并将其发送到 Kafka 集群的代码。在顶部,我们定义了温度、湿度和 CO 浓度的初始值( prev_temp 、prev _ weather、 prev_co_concentration )。计数器 i 用于记录索引。对于这个模拟,我们希望生成的值是随机的,但我们也希望避免非常不一致的结果(如在一天内将温度改变 40 度)。所以我们不只是产生随机值。当生成第二天的值时,我们还需要考虑前一天的值。同样,在每次迭代中,我们检查生成的数字是否在可接受的区间内。
topic_name = ‘weather’
i = 0prev_temp = round(random.uniform(-10, 35), 1)prev_humidity = random.randint(1, 100)prev_co_concentration = random.randint(50, 1500)while True:i += 1lower_temp_bound = -10 if (prev_temp-5) < -10 else (prev_temp-5)upper_temp_bound = 35 if (prev_temp+5) > 35 else (prev_temp+5)temperature = round(random.uniform(lower_temp_bound, upper_temp_bound), 1)lower_humid_bound = 1 if (prev_humidity-20) < 1 else (prev_humidity-20)upper_humid_bound = 100 if (prev_humidity+20) > 100 else (prev_humidity+20)humidity = random.randint(lower_humid_bound, upper_humid_bound)lower_co_bound = 50 if (prev_co_concentration-100) < 50 else (prev_co_concentration-100)upper_co_bound = 1500 if (prev_co_concentration+100) > 1500 else (prev_co_concentration+100)co_concentration = random.randint(lower_co_bound, upper_co_bound)weather_dict = {“record_id”: i,“temperature”: temperature,“CO_concentration”: co_concentration,“humidity”: humidity}producer.send(topic_name, value=json.dumps(weather_dict).encode())producer.flush()prev_temp = temperatureprev_humidity = humidityprev_co_concentration = co_concentrationtime.sleep(1)
在生成当前时间戳所需的所有数据之后,脚本从包含数据的字典中创建了 weather_dict 变量。之后,生产者将 JSON 编码的 weather_dict 发送到 Kafka 集群的指定主题。我们将当前值赋给相应的变量,这些变量代表来自前一个时间戳的数据。最后,在执行循环的下一次迭代之前,我们等待一秒钟。
现在让我们来研究一下 consumer.py 文件。在文件的顶部,我们用几个参数定义了消费者。第一个和第二个参数是订阅主题的名称和 Kafka 服务器所在的 URL。 auto_offset_reset 参数定义了发生offset auto frange错误时的行为。*‘earliest’*值意味着偏移应该移动到最早的可用记录。因此,所有消息(记录)将在出错后被再次使用。 consumer_timeout_ms 参数负责在指定时间段内没有新消息时关闭消费者。 -1 值表示我们不想关掉消费者。
您可以在文档中阅读关于 KafkaConsumer 的这些和其他参数的更多信息。
import json
from kafka import KafkaConsumer
consumer = KafkaConsumer(‘weather’,bootstrap_servers=[‘localhost:9092’],auto_offset_reset=’earliest’,consumer_timeout_ms=-1)
让我们转到 consumer.py 文件中最重要的部分。开始时,我们定义计数器 i 和我们将在一个月中存储数据的列表。在每次迭代中,我们将解码消息(从中提取 weather_dict )并将当天的值附加到相应的列表中。如果 i 计数器等于 30,我们计算该月指标的平均值。
i = 0
month_temperatures = []
month_humidities = []
month_co = []
month_id = 1
for message in consumer:
i += 1
value = message.value.decode()
weather_dict = json.loads(value)
month_temperatures.append(weather_dict[‘temperature’])
month_humidities.append(weather_dict[‘humidity’])
month_co.append(weather_dict[‘CO_concentration’])
if i == 30:
month_aggregation = {‘month_id’: month_id,
‘avg_temp’: round(sum(month_temperatures)/len(month_temperatures), 1),
‘avg_co’: round(sum(month_co)/len(month_co)),
‘avg_humidity’: round(sum(month_humidities)/len(month_humidities))
}with open(‘weather_aggregation.txt’,’a’) as file:data = [str(month_aggregation[‘month_id’]), str(month_aggregation[‘avg_temp’]),str(month_aggregation[‘avg_co’]), str(month_aggregation[‘avg_humidity’])]
file.write(“,”.join(data))
file.write(“,”)i = 0
month_id += 1
month_temperatures = []
month_humidities = []
month_co = []
接下来,我们打开文件weather _ aggregation . txt并将数据写入其中。数据写在一行中,没有换行。因此,需要读取文件的程序应该知道每 5 个值就是新数据点的开始。
在运行生产者和消费者之前,您应该运行 Kafka 集群。您可以使用以下命令完成此操作(假设您已经安装了 Kafka):
sudo kafka-server-start.sh /etc/kafka.properties
以下是输出文件的样子:

假设现在时间飞逝,过了一段时间后,业务需求发生了变化。现在我们需要以不同的方式处理天气数据。
首先,按照前面的要求,聚合指标(平均值)应该按周计算,而不是按月计算。其次,我们需要将摄氏温度转换成华氏温度。最后,我们想改变存储逻辑。而不是创建一个*。txt* 文件并将所有数据写入一个文件,我们需要创建一个包含列和行的 CSV 文件。每行应代表一个数据点(一周的数据)。此外,我们希望将相同的数据保存到 AWS S3 存储桶中。
更改代码来实现这些更改不成问题。但是我们之前收集了很多数据,我们不想丢失它们。在理想情况下,我们希望从头开始重新计算所有指标。因此,在结果中,我们需要接收新格式的数据,但要确保它包括我们之前使用不同处理方法的那些时间段。卡夫卡的储存能力会帮助我们。
让我们探索一下我们需要对代码进行的修改(文件 consumer.py )。首先,我们需要导入 boto3 库,指定 AWS 凭证,并实例化资源(S3)。此外,我们用列表更改了变量的名称,使它们反映了这样一个事实,即它们累积的是每周数据,而不是每月数据。下一个变化是,我们现在查看每第 7 条记录,以便执行聚合(之前我们等待每第 30 条记录)。另外,我们实现了从摄氏温度到华氏温度的转换公式((c * 1.8) + 32)。
import boto3
ACCESS_KEY = “<AWS_ACCESS_KEY>”SECRET_KEY = “<AWS_SECRET_KEY>”s3 = boto3.resource(‘s3’, aws_access_key_id=ACCESS_KEY, aws_secret_access_key=SECRET_KEY)i = 0week_temperatures = []week_humidities = []week_co = []week_id = 1for message in consumer:i += 1value = message.value.decode()weather_dict = json.loads(value)week_temperatures.append(weather_dict[‘temperature’])week_humidities.append(weather_dict[‘humidity’])week_co.append(weather_dict[‘CO_concentration’])if i == 7:week_aggregation = {‘week_id’: week_id,‘avg_temp’: round((sum(week_temperatures)/len(week_temperatures) * 1.8), 1)+32,‘avg_co’: round(sum(week_co)/len(week_co)),‘avg_humidity’: round(sum(week_humidities)/len(week_humidities))}if week_id == 1:with open(‘weather_aggregation.csv’,’a’) as file:data = [‘week_id’, ‘avg_temp’, ‘avg_co’, ‘avg_humidity’]file.write(“,”.join(data))file.write(“\n”)with open(‘weather_aggregation.csv’,’a’) as file:data = [str(week_aggregation[‘week_id’]), str(week_aggregation[‘avg_temp’]),str(week_aggregation[‘avg_co’]), str(week_aggregation[‘avg_humidity’])]file.write(“,”.join(data))file.write(“\n”)s3.Object(‘s3-bucket_name’, ‘weather_aggregation.csv’).put(Body=open(‘weather_aggregation.csv’, ‘rb’))i = 0week_id += 1week_temperatures = []week_humidities = []week_co = []
ACCESS_KEY = “<AWS_ACCESS_KEY>”SECRET_KEY = “<AWS_SECRET_KEY>”s3 = boto3.resource(‘s3’, aws_access_key_id=ACCESS_KEY, aws_secret_access_key=SECRET_KEY)i = 0week_temperatures = []week_humidities = []week_co = []week_id = 1for message in consumer:i += 1value = message.value.decode()weather_dict = json.loads(value)week_temperatures.append(weather_dict[‘temperature’])week_humidities.append(weather_dict[‘humidity’])week_co.append(weather_dict[‘CO_concentration’])if i == 7:week_aggregation = {‘week_id’: week_id,‘avg_temp’: round((sum(week_temperatures)/len(week_temperatures) * 1.8), 1)+32,‘avg_co’: round(sum(week_co)/len(week_co)),‘avg_humidity’: round(sum(week_humidities)/len(week_humidities))}if week_id == 1:with open(‘weather_aggregation.csv’,’a’) as file:data = [‘week_id’, ‘avg_temp’, ‘avg_co’, ‘avg_humidity’]file.write(“,”.join(data))file.write(“\n”)with open(‘weather_aggregation.csv’,’a’) as file:data = [str(week_aggregation[‘week_id’]), str(week_aggregation[‘avg_temp’]),str(week_aggregation[‘avg_co’]), str(week_aggregation[‘avg_humidity’])]file.write(“,”.join(data))file.write(“\n”)s3.Object(‘s3-bucket_name’, ‘weather_aggregation.csv’).put(Body=open(‘weather_aggregation.csv’, ‘rb’))i = 0week_id += 1week_temperatures = []week_humidities = []week_co = []
其他变化与已处理数据的保存有关。现在我们处理 CSV 文件,如果是第一周,我们将列名写入文件。此外,该脚本在每个数据点后添加一个新的行字符,以便在新的一行中写入有关每周的信息。最后,我们还将 weather_aggregation.csv 文件插入到 AWS S3 存储中。桶S3-桶名创建较早。
为了从我们的物联网设备生命周期的开始(当它开始向 Kafka 发送数据时)重新计算聚合,我们需要将偏移量移动到消息队列的开始。在 kafka-python 中,使用消费者的*seek _ to _ begin()*方法非常简单:
consumer.seek_to_beginning()
换句话说,如果我们将调用方法放在上面描述的代码之前,我们将偏移量移动到消费者队列的开始。这将迫使它再次读取已经读取和处理过的消息。这证明了一个事实,即当 Kafka 存储消息时,它不会在消费者阅读一次之后删除数据。下面是更新后的消费者生成的 weather_aggregation.csv 文件:

这个例子表明,卡夫卡是一个有用的数据存储系统。Kafka 在防止数据丢失方面的优势显而易见。假设我们的消费者所在的服务器停机了一段时间。如果卡夫卡没有数据存储能力,制作者发送的所有信息都会丢失。但我们知道,当消费者再次活着时,它将能够获取 Kafka 集群在消费者停机期间积累的所有消息。使用此功能不需要其他操作。你不需要移动偏移量。它将位于消费者最后一次使用的消息上;它将从停止的地方开始消耗数据。
我们演示的例子很简单,但它让我们明白卡夫卡是多么有用。目前,我们有 CSV 文件,其中包含每周汇总的天气数据。我们可以用它来进行数据分析(例如,看看将 Tableau 与亚马逊 S3 教程集成),创建机器学习模型(使用 ADLS Gen2 数据创建回归机器学习模型),或者用于应用程序的内部目的。Dremio 还允许我们加入数据湖中的数据源,并使用 SQL 对其进行处理(即使原始数据源不支持 SQL——参见合并来自多个数据集的数据或使用 Dremio 和 Python 分析学生成绩数据的简单方法教程)。Dremio 是数据工程工具包中的一个有用工具。
结论
在本文中,我们探讨了 Kafka 如何用于存储数据,以及如何作为流媒体应用程序的数据丢失预防工具。我们提供了这些特性的概述,列出了它们有用的用例,并解释了为什么 Kafka 不是传统数据库的替代品。我们展示了一个实现了不同的数据处理和转换方法的案例。与此同时,利益相关者希望从一开始就根据我们处理的所有数据的新方法来计算数据处理的结果。有了卡夫卡,这个问题迎刃而解。
使用 Kafka 在云数据湖中收集 Web 应用程序指标

伊利亚·巴甫洛夫在 Unsplash 上的照片
本文演示了如何使用 Kafka 从 web 应用程序中收集数据湖存储(如亚马逊 S3)的指标。
度量收集
指标是反映流程或系统状态的指标(值)。当我们有一系列数值时,我们也可以对趋势或季节性做出结论。总之,度量是过程或系统如何发展的指示器。指标可以由应用程序、硬件组件(CPU、内存等)生成。),web 服务器,搜索引擎,物联网设备,数据库等等。度量可以反映系统的内部状态,甚至一些真实世界的过程。真实世界指标的示例包括电子商务网站,它可以生成关于任何给定时间段内新订单数量的信息,空气质量设备,它可以收集关于空气中不同化学物质浓度的数据,以及 CPU 负载,这是关于计算机系统内部状态的指标的示例。
可以实时分析收集的指标,也可以存储起来供以后进行批量分析。收集的指标也可以用来训练机器学习模型。
收集指标可能是一个复杂的过程,因为它取决于许多参数和条件。指标的来源产生值,然后这些值或者被传送到云数据湖存储,或者被实时使用。将指标从源交付到存储的方法以及存储的方式可能会因情况而异。
有助于收集指标的工具之一是 Apache Kafka。
卡夫卡概述
Apache Kafka 是一个用于构建实时数据处理管道和流应用程序的工具。Kafka 是一个分布式系统,这意味着它可以从几个源作为一个集群运行。Kafka 集群是不同的数据生成器(称为生产者)和数据消费者(称为消费者)使用的中心枢纽。应用程序(桌面、web、移动)、API、数据库、web 服务和物联网设备都是生产者的典型例子。生产者是向 Kafka 集群发送数据的实体。消费者是从 Kafka 集群接收数据的实体。Kafka 集群可以由一个或多个 Kafka 代理组成。
卡夫卡使用主题来组织数据。主题是数据流的类别。主题中的每个数据点都有自己唯一的时间戳、键和值。生产者可以将数据写入特定的主题,而消费者可以订阅所需的主题来接收特定的数据集。Kafka 支持数据复制,即在不同的代理上创建相同数据的副本。这可以防止其中一个代理由于某种原因损坏或中断时数据丢失。
Kafka 是最受欢迎的事件流平台和消息队列之一。许多大公司用它来管理他们的数据管道。以下是卡夫卡提供的几个最重要的优势:
- 可扩展性(由于支持分布式操作)
- 容错
- 持久性
- 快速操作
- 高流通量
- 实时模式以及以批处理模式工作的能力
让我们看看 Kafka 是如何用于收集指标的。
Kafka 如何用于收集指标
通常,收集指标是实时完成的。这意味着指标的来源不断地生成数据,并可以作为数据流发送。正如我们所知,Kafka 是一个处理数据流的好工具,这就是为什么它可以用于收集指标。
在这个例子中,我们将使用一个简单的 Flask web 应用程序作为生产者。它将向 Kafka 集群发送有关其活动的指标。消费者将是一个 python 脚本,它将从 Kafka 接收指标,并将数据写入 CSV 文件。该脚本将从 Kafka 接收指标,并将数据写入 CSV 文件。Python 应用程序本身可以丰富数据,并将指标发送到云存储。在这一阶段,数据可供一系列同类最佳的数据湖引擎(如 Dremio)查询和处理。
这里有个小技巧:如果你想进行度量监控,可以使用 Prometheus、Grafana、Kibana 等工具。管道是相同的:web 应用程序将数据发送到 Kafka 集群中,然后指标应该被交付到前面提到的平台,在那里进行可视化和分析。如果发生某些事件,还可以设置警报和通知。
例子
让我们看看卡夫卡帮助下的度量收集的例子。我们将使用 Flask web 应用程序作为度量的来源。使用该应用程序,人们可以创建订单和购买必需品。这是该网站的主页:

非常简单:当用户点击新订单按钮时,他们将进入下一页,在那里他们可以下订单。

当用户选中复选框字段时,这意味着他们想立即为订单付款。否则,货物将在信用条件下供应。用户点击下单按钮后,进入下一页:

在此页面上,用户可以查看已创建订单的详细信息。这里的新元素是总价,其计算方法是将 1 个单位的价格乘以订购数量。
现在让我们看看应用程序的代码。它有几个文件,包括表格,模板,配置,数据库(SQLite)等。但是我们将只演示在生成和发送指标到 Kafka 集群中起作用的文件。
需要注意的是,对于本文,我们将使用 kafka-python 包。它允许我们直接从 Python 代码中使用 Kafka。我们使用以下命令安装它:
pip install kafka-python
下面,你可以看到来自 models.py 文件的代码。这个文件描述了数据库的结构。我们那里只有一张桌子叫做订单。它由一个 Python 类表示,其中每个属性都是数据库中的列。但是这个文件最有趣的部分是*send _ order _ info _ to _ Kafka()*函数。
import jsonfrom app import dbfrom sqlalchemy import eventfrom kafka import KafkaProducerclass Order(db.Model):id = db.Column(db.Integer, primary_key=True)customer_email = db.Column(db.String(120),nullable=False, default=””)amount = db.Column(db.Integer)total_price = db.Column(db.Integer)is_prepaid = db.Column(db.Boolean, default=False)@event.listens_for(Order, ‘after_insert’)def send_order_info_to_kafka(mapper, connection, target):assert target.id is not Noneproducer = KafkaProducer(bootstrap_servers=[‘localhost:9092’])topic_name = ‘new_orders’order_dict = {“order_id”: target.id,“order_amount”: target.amount,“order_total_price”: target.total_price,“is_paid”: target.is_prepaid}producer.send(topic_name, value=json.dumps(order_dict).encode())producer.flush()
这个函数由*event . listens _ for()*decorator(从 sqlalchemy 库导入)增强。当关于新订单的记录被插入数据库时,这个装饰器监视事件。当这种情况发生时,该函数创建一个 KafkaProducer 实例(指向正在运行的 Kafka 集群所在的 URL)并指定 Kafka 主题的名称 — new_orders 。然后,该函数创建消息体。我们想将订单的统计数据发送给 Kafka。这就是为什么对于每个订单,我们都用订单金额、总价以及是否预付的信息来创建字典。然后我们把这个字典转换成 JSON 格式,编码,用生产者的方法 send() 和 flush() 发送给卡夫卡。因此,每当用户创建新订单时,都会触发该函数。该函数的目的是向 Kafka 集群发送有关已创建订单的信息。
我们希望再收集一组指标——特定时间段内的请求数量。这是监控任何 web 应用程序的一个常见指标。因此,每当有人访问我们网站上的页面时,我们都需要向我们的 Kafka 集群发送通知。下面是我们如何实现这种行为。在文件 utils.py 中我们定义了名为的函数 ping_kafka_when_request() 。这个函数的主体与我们之前看到的函数非常相似。它创建生产者的实例,定义生产者应该提交消息的主题名称( web_requests ),然后使用 send() 和 flush() 方法发送消息。这个函数稍微简单一点,因为我们不需要为消息创建复杂的主体。每当一个新的请求出现时,我们就发送 value=1 。
from kafka import KafkaProducerdef ping_kafka_when_request():producer = KafkaProducer(bootstrap_servers=[‘localhost:9092’])topic_name = ‘web_requests’producer.send(topic_name, value=”1".encode())producer.flush()
为了使这个函数工作,我们需要在每个页面的视图函数中调用它。这可以在 routes.py 文件中完成(参见下面的代码)。有三个函数:( index() 、 create_order() 、 order_complete() )。这些函数中的每一个都负责在网站上呈现页面时执行一些逻辑。最复杂的函数是 create_order() 函数,因为它应该处理表单提交和向数据库插入新记录。但是如果我们谈论与 Kafka 的交互,您应该注意到这样一个事实:我们从 utils 文件中导入了*ping _ Kafka _ when _ request()*函数,并在每个视图函数内部调用它(在执行该函数中所有剩余的代码之前)。
from app import app, dbfrom app.models import Orderfrom flask import render_template, redirect, sessionfrom app.forms import OrderFormfrom .utils import ping_kafka_when_request@app.route(‘/’)def index():ping_kafka_when_request()return render_template(‘index.html’)@app.route(‘/order-new’, methods=[‘GET’, ‘POST’])def create_order():ping_kafka_when_request()form = OrderForm()if form.validate_on_submit():price = 15customer_email = form.email.dataamount = form.amount.datais_prepaid = form.is_paid_now.datatotal_price = amount * priceorder = Order(customer_email=customer_email,amount=amount,total_price=total_price,is_prepaid=is_prepaid)db.session.add(order)db.session.commit()session[‘order’] = {“email”: customer_email,“amount”: amount,“total_price”: total_price,“is_paid”: is_prepaid}return redirect(‘/order-new-complete’)return render_template(‘new_order.html’,title=’Make a new order’, form=form)@app.route(‘/order-new-complete’)def order_complete():ping_kafka_when_request()return render_template(‘new_order_complete.html’,order=session[‘order’])
这些是我们建筑的生产者方面。我们解释说,代码需要位于 web 应用程序内部,以便向 Kafka 集群发送指标。现在让我们看看另一面——消费者。
第一个文件是 consumer_requests.py 。我们来分块考察一下。在文件的开头,我们导入我们需要的所有包,并创建 Kafka consumer 的实例。我们将应用几个参数,以便它能够按照预期的方式工作。你可以在文档中读到它们。最重要的参数是我们希望为消费者订阅的主题名称(web_requests)和指向 Kafka 集群所在服务器的 bootstrap_servers 参数。
import timeimport threadingimport datetimefrom kafka import KafkaConsumerconsumer = KafkaConsumer(‘web_requests’,bootstrap_servers=[‘localhost:9092’],auto_offset_reset=’earliest’,enable_auto_commit=True,auto_commit_interval_ms=1000,consumer_timeout_ms=-1)
接下来,我们需要创建一个函数,它将每分钟轮询 Kafka 集群一次,并处理 Kafka 将返回的消息。该函数的名称是fetch _ last _ min _ requests(),您可以在下面的代码示例中看到它。它需要两个参数作为输入。 next_call_in 参数显示该函数的下一次调用应该发生的时间(记住我们需要每 60 秒从 Kafka 获取新数据)。不需要 is_first_execution 参数。默认情况下,它等于 False。
在函数开始时,我们确定下一次调用该函数的时间(从现在起 60 秒)。此外,我们为请求初始化计数器。然后,如果是第一次执行,我们创建文件 requests.csv 并向其中写入一行标题。这个数据集的结构将会很简单。它应该有两列— 日期时间和请求数量。每一行在日期时间列中有时间戳,在请求数量列中有网站在给定时间内处理的请求数量。
def fetch_last_min_requests(next_call_in, is_first_execution=False):next_call_in += 60counter_requests = 0if is_first_execution:with open(‘requests.csv’,’a’) as file:headers = [“datetime”, “requests_num”]file.write(“,”.join(headers))file.write(‘\n’)else:batch = consumer.poll(timeout_ms=100)if len(batch) > 0:for message in list(batch.values())[0]:counter_requests += 1with open(‘requests.csv’,’a’) as file:data = [datetime.datetime.now().strftime(“%Y-%m-%d %H:%M:%S”), str(counter_requests)]file.write(“,”.join(data))file.write(‘\n’)threading.Timer(next_call_in — time.time(),fetch_last_minute_requests,[next_call_in]).start()
如果这不是函数的第一次执行,我们将强制消费者轮询 Kafka 集群。您应该将 poll() 方法的 timeout_ms 参数设置为一个大于零的数字,因为否则,您可能会错过一些消息。如果 poll() 方法返回非 void 对象( batch ),我们希望遍历所有获取的消息,并且在每次迭代中,将 count_requests 变量加 1。然后,我们打开 request.csv 文件,生成行(由逗号连接的当前日期时间和 counter_requests 值的字符串),并将该行追加到文件中。
给定函数中的最后一行是定时器设置。我们将三个参数插入到定时器对象中。第一个是触发函数(第二个参数)的时间段。这段时间是通过从存储在 next_call_in 变量中的时间减去当前时间戳来动态计算的,这是我们在函数开始时计算的。定时器对象的第三个参数是带有参数的列表,这些参数应该传递给我们想要执行的函数。我们立即使用其 start() 方法启动计时器。
为什么我们需要这样一种微妙的方式来定义下一次函数调用发生的时间呢?难道就不能用更流行的 time.sleep() 方法吗?答案是否定的。我们使用这种方法是因为位于函数内部的逻辑的执行需要一些时间。例如,Kafka 集群轮询至少需要 100 毫秒。此外,我们还需要对请求进行计数,并将结果写入文件。所有这些事情都很耗时,如果我们简单地使用 time.sleep() 暂停执行,分钟周期将在下一次迭代中漂移。这可能会破坏结果。使用穿线。Timer object 是一种稍微不同但更合适的方法。我们不是暂停 60 秒,而是通过减去在函数体内执行代码所花费的时间来计算函数应该被触发的时间。
现在我们可以使用定义的函数了。只需在当前时间前初始化 next_call_in 变量,并使用*fetch _ last _ minute _ requests()*函数,将该变量作为第一个参数,将 True 标志作为第二个参数(以标记这是第一次执行)。
next_call_in = time.time()fetch_last_minute_requests(next_call_in, True)
这就是 consumer_requests.py 文件的全部内容。但是在执行它之前,您应该运行 Kafka 集群。下面是如何从终端本地完成此操作(假设您已经安装了它):
sudo kafka-server-start.sh /etc/kafka.properties
现在您可以运行该文件了。然后在你的浏览器中进入网络应用程序(你可以使用命令 flask run 运行 Flask 应用程序)并尝试浏览它——访问它的页面。过一会儿,您应该在您的消费者文件所在的文件夹中有文件 requests.csv 。该文件可能如下所示(实际数据会有所不同,取决于您访问应用页面的次数):

我们所做的是构建管道,允许我们使用 Kafka 和 Python 收集 web 应用程序指标(请求数量)。
现在我们来看另一个消费者。我们将这个文件命名为 consumer_orders.py 。文件的第一部分与前一个文件非常相似。一个区别是我们导入了 json 库,因为我们需要处理 json 编码的消息。另一个区别是 Kafka 消费者订阅了新订单主题。
import jsonimport timeimport datetimeimport threadingfrom kafka import KafkaConsumerconsumer = KafkaConsumer(‘new_orders’,bootstrap_servers=[‘localhost:9092’],auto_offset_reset=’earliest’,enable_auto_commit=True,auto_commit_interval_ms=1000,consumer_timeout_ms==-1)
主要函数是fetch _ last _ minute _ orders()。与前一个消费者的函数不同的是,这个函数有六个计数器,而不是只有一个。我们希望统计一分钟内创建的订单总数、订购的商品总数、所有订单的总成本、预付订单的数量、预付订单中的商品数量以及所有预付订单的总价。这些指标可能对进一步的分析有用。
另一个区别是,在开始计算上述值之前,我们需要使用 json 库解码从 Kafka 获取的消息。所有其他逻辑都与处理请求的消费者相同。应该写入数据的这个文件叫做 orders.csv 。
def fetch_last_minute_orders(next_call_in, is_first_execution=False):next_call_in += 60count_orders = 0count_tot_amount = 0count_tot_price = 0count_orders_paid = 0count_tot_paid_amount = 0count_tot_paid_price = 0
if is_first_execution:with open(‘orders.csv’,’a’) as file:headers = [“datetime”, “total_orders_num”,“total_orders_amount”, “total_orders_price”,“total_paid_orders_num”,“total_paid_orders_amount”,“Total_paid_orders_price”]file.write(“,”.join(headers))file.write(‘\n’)else:batch = consumer.poll(timeout_ms=100)if len(batch) > 0:for message in list(batch.values())[0]:value = message.value.decode()order_dict = json.loads(value)# all orderscount_orders += 1count_tot_amount += order_dict[“order_amount”]count_tot_price += order_dict[“order_total_price”]if order_dict[“is_paid”]:# only paid orderscount_orders_paid += 1count_tot_paid_amount += order_dict[“order_amount”]count_tot_paid_price += order_dict[“order_total_price”]with open(‘orders.csv’,’a’) as file:data = [datetime.datetime.now().strftime(“%Y-%m-%d %H:%M:%S”),str(count_orders), str(count_tot_amount),str(count_tot_price), str(count_orders_paid),str(count_tot_paid_amount),str(count_tot_paid_price)]file.write(“,”.join(data))file.write(‘\n’)threading.Timer(next_call_in — time.time(),fetch_last_minute_orders,[next_call_in]).start()
文件的最后一部分是相同的:获取当前时间并触发上面定义的函数:
next_call_in = time.time()fetch_last_minute_orders(next_call_in, True)
假设您已经运行了 Kafka 集群,那么您可以执行 consumer_orders.py 文件。接下来,进入你的 Flask 应用程序,在几分钟内创建一些订单。生成的 orders.csv 文件将具有以下结构:

您可以看到我们的 Python 脚本(尤其是那些处理订单数据的脚本)执行了一些数据丰富。
数据工程师可以定制这个过程。例如,如果应用程序非常大并且负载很高,Kafka 集群应该水平扩展。对于不同的指标,您可以有许多主题,并且每个主题都可以用自己的方式进行处理。可以跟踪新用户注册、用户变动、反馈数量、调查结果等。
此外,您可以设置一些低级指标的集合,如 CPU 负载或内存消耗。基本的管道将是类似的。还值得一提的是,将数据写入 CSV 文件并不是唯一的选择,您还可以利用开放的数据格式,如 Parquet,并将所有这些数据直接放到您的数据湖中。
一旦您收集了指标,您就可以使用 Dremio 直接查询数据,以及创建和共享虚拟数据集,这些数据集将指标与数据湖中的其他来源相结合,所有这些都不需要任何副本。
结论
在本文中,我们为从 Flask web 应用程序收集指标构建了一个数据管道。Kafka 集群用作数据生产者(部署在 web 应用程序中)和数据消费者(Python 脚本)之间的层。Python 脚本充当从 Kafka 获取指标,然后处理和转换数据的应用程序。给出的示例是基本的,但是您可以根据自己的需要,使用它来构建更复杂、更多样的指标收集管道。然后,您可以使用 Dremio 的数据湖引擎来查询和处理结果数据集。
使用 Kafka 优化你的 Twitter 流的数据流
高效处理来自 Twitter 的大数据指南

萨法尔·萨法罗夫在 Unsplash 上拍摄的照片
我最近在做一个大数据分析项目,在这个项目中,我从 Twitter 上长时间收集了大约 50-60 个热门话题的实时流数据。这个项目严重依赖 Twitter API 进行数据收集,使用 Twitter API 进行数据收集的一个主要限制是,客户端机器必须始终跟上数据流,如果不能,数据流就会断开,相信我,这种情况会经常发生,尤其是在您实时处理大量数据的情况下!在本文中,我将向您展示我的解决方案,通过使用 Kafka 作为消息队列来克服这一限制。
到目前为止,卡夫卡主要有两种风格,一种是阿帕奇基金会的,另一种是合流派的。对于本文,我们将使用合流版本,因为它为我们提供了一个很好的 Python 客户端来与 Kafka 进行交互。
入门
由于网上有很多关于如何从 Twitter 流式传输数据的惊人资源,我不会讨论如何获得您的 Twitter 开发人员帐户并设置 Python 库来从 Twitter 流式传输数据。本文面向已经在使用 Twitter API 进行数据收集并希望优化其数据流的数据科学家/工程师。请注意,这不是一个突破 Twitter 流媒体 API 速率限制的解决方案。
以下是您开始工作所需的物品清单:
- Ubuntu 或 Mac OS 驱动的机器
- 中级 Python 知识,熟悉 JSON
- 熟悉 Twitter API 和 Tweepy Python 库
- 融合平台的自我管理版本
到底什么是卡夫卡和合流台?
Kafka 是一个分布式流媒体平台,允许您创建数据流管道,它位于融合平台的核心,该平台包括各种功能,使 Kafka 更易于使用。有关 Kafka 和合流平台的更多详细信息,请参见下面的链接:
[## 什么是合流平台?汇合平台
Confluent 提供了业内唯一的企业级事件流平台
文件汇合](https://docs.confluent.io/current/platform.html#cp-platform)
在 Twitter 上使用 Kafka 的好处
将 Kafka 与您的 Twitter 流一起使用的主要好处之一是容错,因此您将拥有两个模块,而不是拥有一个收集、处理和保存所有内容到 JSON 文件中的 Python 模块。一个称为“生产者”的模块从 twitter 流中收集数据,然后将其作为日志保存到队列中,不做任何处理,另一个称为“消费者”的模块读取日志,然后处理数据,本质上创建了一个解耦的流程。以下是您的数据流外观的高级概述:

图 1.0。卡夫卡如何使用 Twitter
汇合平台设置
首先,你需要去 https://www.confluent.io/download的合流平台网站,下载合流平台的自我管理版本,并将其保存到你选择的目录中。对于我的 mac,它将在用户目录中。
第一步。设置动物园管理员
下载完成后,您需要设置 Zookeeper 服务器,它本质上是一个协调器,维护 Kafka 集群中的节点以及其他关键功能。
在您的终端上运行以下命令(请确保使用您的文件目录更新命令):
cd file_directory_of_your_choice/confluent-5.5.0/etc/kafkanano zookeeper.properties

图 1.1。终端上的 Zookeeper 服务器属性
您可以在这里更改和调整 zookeeper 服务器与 Kafka 集群的交互方式。然而,对于本文,我们将把它保留为默认值。
第二步。建立卡夫卡
现在我们继续设置 Kafka 服务器。在您的终端上运行以下命令:
nano server.properties

图 1.2。终端上的 Kafka 服务器属性
由于我们使用 Kafka 进行优化,我们将把默认日志保留时间减少到 5 小时,并将日志保留和段字节减少到 507374182。向下滚动到服务器属性配置文件中的日志保留策略部分,并进行以下调整:
log.retention.hours=5
log.retention.bytes=507374182
log.segment.bytes=507374182
然后,通过确保 Zookeeper 部分中的端口号正确,确保您的 Kafka 服务器能够连接到 Zookeeper 服务器。我们将使用 Zookeeper 服务器的默认设置。
zookeeper.connect=localhost:2181
第三步。启动服务器
现在大部分设置已经完成,我们将开始运行服务器。
初始化动物园管理员服务器
sudo file_directory_of_your_choice/confluent-5.5.0/bin/zookeeper-server-start file_directory_of_your_choice/confluent-5.5.0/etc/kafka/zookeeper.properties
初始化 Kafka 服务器
sudo file_directory_of_your_choice/confluent-5.5.0/bin/kafka-server-start file_directory_of_your_choice/confluent-5.5.0/etc/kafka/server.properties
第四步。主题创建和分区配置
Kafka 中的主题本质上是在多个分区中发布日志的类别。所以在我们的例子中,为了让我们的 Python 代码与 Kafka 交互,我们需要分配一个主题名并为该主题配置分区。
运行以下命令来创建和配置 Kafka 主题。
sudo file_directory_of_your_choice/confluent-5.5.0/bin/kafka-topics --zookeeper localhost:2181 --create --replication-factor 1 --partitions 2 --topic twitterdata
分区和复制因子可以根据您的偏好和配置进行调整。
Python 代码
为 Python 安装 Kafka API
所以在我们开始使用 Python 中的 Kafka 之前,我们需要安装 Python 中的 Kafka 库。在您的终端上运行以下代码:
pip3 install kafka
生产商模块代码
在您的 IDE 上,创建一个名为 producer 的新 Python 模块。在这里,您可以将 Tweepy 的 on_data 函数与 KafkaProducer 一起使用,将原始 twitter 数据输入 Kafka 集群。
消费模块代码
创建另一个名为 Consumer 的 Python 模块。该模块将从您的 Kafka 集群中读取原始数据,您可以添加额外的功能,如语言检测、情感分类器,而不用担心流断开,因为现在我们已经基本上解耦了整个 Twitter 流。
结论
总之,我们已经创建了一个解耦的 twitter 流,我们本质上将这个流分成两个不同的模块。一个模块用于从 Twitter API 检索数据并将其提供给 Kafka 集群,另一个模块用于从 Kafka 集群读取数据并单独处理数据。这允许我们处理来自 twitter 的原始数据,而不用担心流被断开。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言










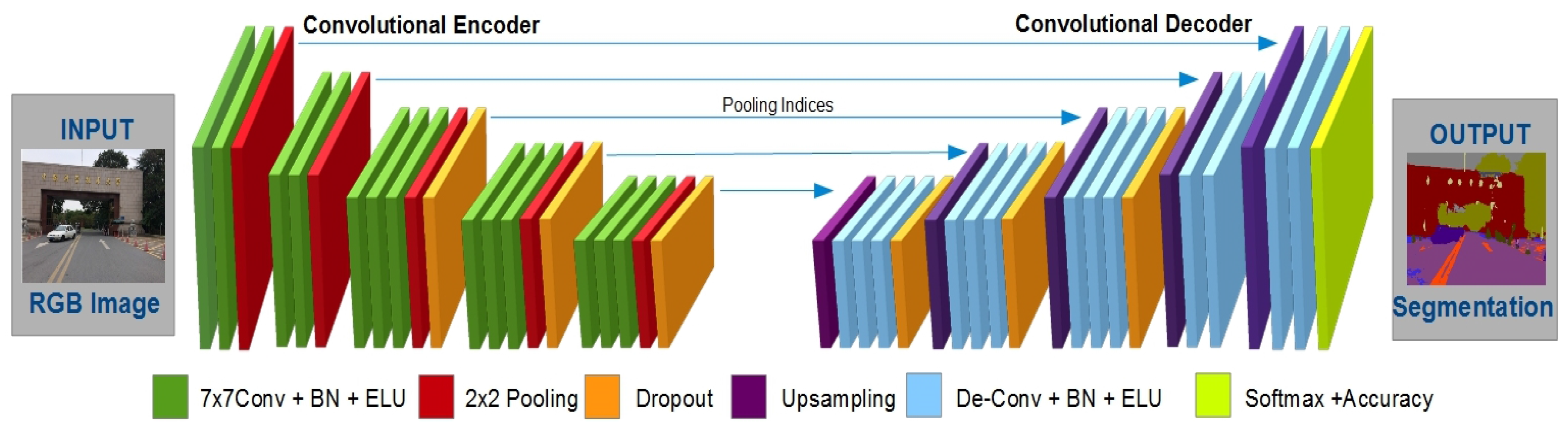{kind=link}
{kind=link}
{kind=link}
{kind=link}