







用 python 训练神经网络来预测机器人动力学
了解如何处理真实的机器人数据。
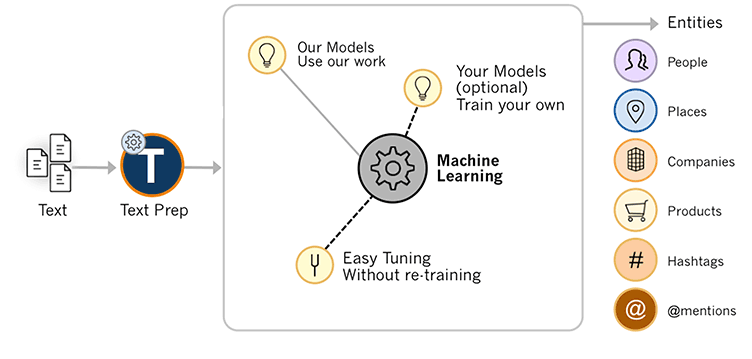
我作为机器人学习研究员的生活主要是数据科学(理解数据)和一点有趣的数学(强化学习)。这里有一个片段,你可以自己运行,并把经验带到你的项目(和职业生涯)中去!

一堆有趣的机器人平台,来自我的资格考试演讲。我们希望这些能飞起来!
深度学习和机器人技术
神经网络在多个数字领域,特别是计算机视觉和语言处理领域已经成为最先进的技术。神经网络是复杂的函数逼近(能够足够精确地拟合任何函数,从一个有趣的定理),那么为什么不将它们用于机器人呢?
在机器人中,我们想为两件事建立动力学模型:
- 计划采取行动。行动完成任务。这就制造出了有用的机器人。我们都想要有用的机器人。
- 了解系统。了解该系统可以为机器人开辟更多的未来行动和任务。

经典的神经网络图解。密集连接的非线性激活函数可以适合任何具有足够数量神经元的函数。
最优化问题
当用神经网络学习时,将预测系统动态中的离散步骤。动态系统采取如下所示的形式:
- s 是系统的状态(如物理位置)。
- 一个 是代理的动作(如电机电压)。
- f 是机器人的真实动力学。
- w 是扰动(随机性,或系统的未建模部分)。

动力系统的一般形式。
我们将用神经网络(有意地)建模的是底层函数, f ,我们隐式地捕捉数据中的扰动, w 。我们如何做到这一点?为了数据的“美观”,我们做了几件事。精确意味着数据接近均匀分布,平均值为 0,标准偏差为 1。



我们对学习到的动力学(用θ下标表示)进行建模,以预测状态的变化,而不是真实的状态。右边的 delta 状态是从上一个时间步到下一个时间步的简单变化。
在神经网络的环境中,这看起来像什么?具体来说,我们可以最小化状态变化和函数逼近之间的差的范数平方。这是一个均方差。在 PyTorch 这里实现。

最先进的技术是使用像 Adam 优化器、 Swish 激活函数(ReLU 的平滑版本)、学习率调度器等等。让神经网络工作的重要方法是数据标准化。如果你仔细看代码,我用一种非常模块化的方式处理它。没有它,将模型拟合到真实数据几乎是不可能的。

我玩的机器人——底部) Crazyflie 微型飞行器和顶部) Ionocraft 离子推进器。
代码(PyTorch)
这就是你如何运行代码。我包含了一个名为 ml 的 conda 环境(PyTorch,AI Gym,Mujoco 等等)。培训师代码可在学习目录中找到。参数存储在配置文件中。
(ml) user: dynamicslearn nato$ python learn/trainer.py robot=iono_sim
机器人
知识库中有经过预过滤的数据,这些数据来自通过强化学习学习控制的实验机器人的真实飞行。它是加州大学伯克利分校的一个活跃的研究资料库。
代码包括两个飞行机器人的模拟器,分别是 Crazyflie 和 Ionocraft 。这两个都允许你以 100 赫兹控制机器人,模拟器以 1000 赫兹计算动力学。你可以在这里找到动态模拟器。特定的机器人为不同的致动器定义力的转换。
丰富 NN 对象
当处理复杂任务时(弄清楚如何为机器人建模),拥有一个可配置的网络对象会有所帮助。你会在这里看到一系列的旗帜:
- 一个 prob 标志——它从 MSE 变成了一个高级损失函数,具有来自的更好的方差正则化。
- 一个历史参数——我们希望将过去的状态传递到预测器中(当状态进化得更快时,一些潜在的动态就会进化)。
- 一堆参数 — 隐藏宽度、深度、落差等。
- SciKitLearn 规范化标量——对于获得可行的优化表面非常重要(没有这个你可能会得到 NaN 的)。
注意,我用 X 表示状态,用 U 表示动作。
class GeneralNN(nn.Module):
def __init__(self, **nn_params):
super(GeneralNN, self).__init__()
# Store the parameters:
self.prob = nn_params['training']['probl']
self.hidden_w = nn_params['training']['hid_width']
self.depth = nn_params['training']['hid_depth'] self.hist = nn_params['history']
self.n_in_input = nn_params['du'] * (self.hist + 1)
self.n_in_state = nn_params['dx'] * (self.hist + 1)
self.n_in = self.n_in_input + self.n_in_state
self.n_out = nn_params['dt'] self.activation = Swish()
self.d = nn_params['training']['dropout']
self.E = 0 # clarify that these models are not ensemble self.scalarX = StandardScaler()
self.scalarU = MinMaxScaler(feature_range=(-1, 1))
self.scalardX = MinMaxScaler(feature_range=(-1, 1)) self.init_training = False
动态创建层
对于 PyTorch 新手来说,这可能是文章中最有用的部分。它让你创建一个不同深度和宽度的网络(另一种方法是对配置进行硬编码)。
layers = []
layers.append(('dynm_input_lin', nn.Linear(
self.n_in, self.hidden_w))) # input layer
layers.append(('dynm_input_act', self.activation))
for d in range(self.depth):
layers.append(
('d_l' + str(d), nn.Linear(self.hid_w, self.hid_w)))
layers.append(('dynm_act_' + str(d), self.activation))
layers.append(('d_o_l', nn.Linear(self.hid_w, self.n_out)))
self.features = nn.Sequential(OrderedDict([*layers]))
训练模型
省略公开可用的优化器代码,以及在许多教程中详述的,我们可以有一个很好的训练函数作为我们的顶级对象。让较低层次的抽象来处理细节。
def train_model(X, U, dX, model_cfg, logged=False):
if logged: log.info(f"Training Model on {np.shape(X)[0]} pts")
start = time.time()
train_log = dict() train_log['model_params'] = model_cfg.params
model = hydra.utils.instantiate(model_cfg) model.train_cust((X_t, U_t, dX_t), model_cfg.params) end = time.time()
if logged: log.info(f"Trained Model in {end-start} s")
return model, train_log
这个存储库还有更多的功能。我很乐意回答问题、提出请求和反馈。或者你可以在这里了解我的研究。
我在新型机器人的基于模型的强化学习方面的工作目录。最适合高考验的机器人…
github.com](https://github.com/natolambert/dynamicslearn) [## 自动化大众化
一个关于机器人和人工智能的博客,让它们对每个人都有益,以及即将到来的自动化浪潮…
robotic.substack.com](https://robotic.substack.com/)
使用决策树训练回归模型
对于复杂的非线性数据

作者图片
决策树是一种非参数监督学习方法,能够发现数据中复杂的非线性关系。他们可以执行分类和回归任务。但是在本文中,我们只关注带有回归任务的决策树。为此,等价的 Scikit-learn 类是DecisionTreeRegressor。
我们将从讨论如何用决策树训练、可视化和预测回归任务开始。我们还将讨论如何正则化决策树中的超参数。这样可以避免过拟合的问题。最后,我们将讨论决策树的一些优点和缺点。
代码约定
我们使用以下代码惯例来导入必要的库并设置打印样式。
目标受众
我假设您对决策树中使用的术语及其幕后工作原理有基本的了解。在本教程中,将重点介绍模型超参数调整技术,如k-折叠交叉验证。
问题陈述
我们打算在流行的加州住房数据集(Cali _ housing . CSV)中为非线性特征经度和 MedHouseVal (房屋中值)构建一个模型。
让我们看看数据集的前几行。

这个数据集有 20640 个观察值!
可视化数据
为了查看上述两个特征之间的关系,我们使用 seaborn 创建了以下散点图。

正如您在散点图中看到的,这两个特征之间存在复杂的非线性关系。决策树回归是一种强大的模型,能够在数据中发现这种复杂的非线性关系。
建立模型
让我们使用 sci kit-learn decision tree regressor 类来训练我们的模型。
让我们想象一下我们的模型。

我们可以使用 Graphviz 来可视化这个模型的树形图。

作者图片
我们的树中有 4 个叶节点。这是因为我们设置了 max_depth=2 。叶节点的数量相当于 2^max_depth 。超参数 max_depth 控制分支的复杂度。
在 max_depth=2 的这种情况下,模型不太符合训练数据。这就是所谓的 欠配 的问题。
让我们用 max_depth=15 创建一个不同的模型。通过重复相同的步骤,我们可以创建以下模型。

这里我们不能可视化树形图,因为它有 32768 (2 ⁵)个叶节点!在这种情况下,当 max_depth=15 时,模型非常适合训练数据,但是它不能推广到新的输入数据。这就是所谓的 过拟合 的问题。在这里,模型已经适应了数据的噪声,它试图记住数据,而不是学习任何类型的模式。
因此,当我们创建最佳模型时,我们应该避免欠拟合和过拟合的情况。
那么,超参数 max_depth 的最佳值是多少呢?找出 max_depth 的最佳值(不能太小也不能太大)称为 超参数调整 。
决策树回归的超参数调整
主要有两种方法。
- 使用 Scikit-learn**train _ test _ split()**函数
- 使用 k 折叠交叉验证
使用 Scikit-learn**train _ test _ split()**函数
这是一个实现起来非常简单的方法,但也是一个非常有效的方法。你需要做的就是将原始数据集拆分成两部分,分别叫做 训练集 和 测试集 。我们可以使用 sci kit-learntrain _ test _ split()函数轻松做到这一点。输入是特征矩阵— X 和目标向量— y** 。我们通常会保留大约 10%-30%的测试数据。超参数 random_state 接受整数。通过指定这一点,我们可以确保在不同的执行中有相同的分割。
然后我们用 X_train 、 y_train 训练模型,用 X_test 、 y_test 测试模型。这是针对从 1 到 20 范围内的 max_depth 超参数的不同值进行的,并绘制测试误差与训练误差。

在树深度= 7 的点上,测试误差开始增加,尽管训练误差持续减小。从该图中,我们可以确定 max_depth 超参数的最佳值为 7。
使用 k 倍交叉验证
一种更有前途的调整模型超参数的方法是使用 k 折叠交叉验证。通过使用这种方法,您可以同时调整多个超参数。这里,在训练集上进行训练,之后在验证集上进行评估,并且可以在测试集上进行最终评估。然而,将原始数据集划分为 3 个集合(训练、验证和测试)大大减少了训练过程的可用数据。
作为一个解决方案,我们使用一个叫做 k 的过程——折叠交叉验证其中 k 是折叠的次数(通常是 5 或 10)。在k-折叠交叉验证中,
- 我们首先使用 train_test_split() 函数将原始数据集分为训练集和测试集。
- 列车组进一步分为k-折叠数。
- 使用褶皱的k1训练模型,并在剩余的褶皱上进行验证。
- 该过程进行 k 次,并且在每次执行时报告性能测量。然后取平均值。
- 找到参数后,对测试集进行最终评估。
下图说明了 k -fold 交叉验证程序。

图片来自 Scikit-learn 官网
可以使用网格搜索方法和 k 折叠交叉验证来调整超参数。等效的 Scikit-learn 函数是 GridSearchCV 。它为指定的 k 折叠数找到所有超参数组合。
假设您想在 DecisionTreeRegressor 中为以下两个超参数从所有超参数组合中找出最佳组合。
- **最大深度:**1–10(10 个不同的值)
- min_samples_split: 10,20,30,40,50 (5 个不同的值)
下图显示了超参数空间。如果取一个点(一个组合), GridSearchCV 函数会搜索该组合,并使用这些值以及 k 折叠交叉验证来训练模型。同样,它搜索所有的组合(这里是 10 x 5= 50!).所以,它执行 50 x k 次!

作者图片

最佳值
现在,我们可以使用这些最佳值创建最佳模型。它避免了过拟合和欠拟合的情况。

决策树的优势
- 不需要特征缩放
- 可用于非线性数据
- 非参数:数据中很少的潜在假设
- 可用于回归和分类
- 易于想象
- 容易理解
决策树的缺点
- 决策树训练在计算上是昂贵的,尤其是当通过 k 折叠交叉验证调整模型超参数时。
- 数据的微小变化会导致决策树结构的巨大变化。
本教程由 鲁克山·普拉莫迪塔数据科学 365 博客作者设计创作。
本教程中使用的技术
- Python (高级编程语言)
- numPy (数字 Python 库)
- 熊猫 (Python 数据分析和操作库)
- matplotlib (Python 数据可视化库)
- seaborn (Python 高级数据可视化库)
- Scikit-learn (Python 机器学习库)
- Jupyter 笔记本(集成开发环境)
本教程中使用的机器学习
- 决策树回归
2020–10–26
在 Amazon SageMaker 中训练 TensorFlow 模型

数据集中的交通标志示例
介绍
Amazon SageMaker 是一个云机器学习平台,允许开发人员在云中创建、训练和部署机器学习模型。我之前用 TensorFlow 2 通过我的板载 CPU 对交通标志进行分类。今天我打算在亚马逊 SageMaker 上做。SageMaker 有几个优点:它为计算能力提供了更多的选择(并行计算的不同 CPU 和 GPU),我可以将模型部署为端点。
整个分析是在 SageMaker 的笔记本上完成的,而训练和预测是通过调用更强大的 GPU 实例来完成的。为了完整起见,本文将包括从预处理到端点部署的整个流程。
探索性分析和预处理
数据集可以从 Kaggle: GTSRB —德国交通标志识别基准下载。
以下是数据集的概述:
- 每个图像的大小略有不同
- 训练示例数= 39209
- 测试示例数量= 12630
- 班级数量= 43
这些图像的大小从 20x20 到 70x70 不等,都有 3 个通道:RGB。
所以我要做的第一件事是将所有图像的大小调整为 32x32x3,并将它们读入 numpy 数组作为训练特征。同时,我创建了另一个 numpy 数组,其中包含每个图像的标签,这些标签来自加载图像的文件夹名称。
我为一个类创建了一个调整大小和标记的函数。
对所有的类重复该过程。为了避免在笔记本断开连接的情况下再次进行预处理,我以 pickle 形式存储了数据。下次我想获得处理过的数据时,我可以简单地从 pickle 加载它们。
测试数据集也是如此。现在,我可以看到训练和测试数据集中的类分布。

训练和测试数据集的类分布
正如我们所看到的,在训练集中,样本的最大和最小数量分别为 2200 和 210 个。相差 10 倍。大约有 60%的课程只有< 1000 个例子。阶级分布不均衡。如果按原样使用,则存在一些示例数量较少的类别可能无法很好分类的风险。这将在后面的章节中详细讨论。
然后,我将训练数据分为训练集和验证集。
最后,我将数据标准化并转换成灰度。
以下是预处理后数据集的摘要。
- 训练示例数= 31367
- 验证示例数量= 7842
- 测试示例数量= 12630
- 图像数据形状= (32,32,1)
- 班级数量= 43
模型构建
我使用卷积神经网络(CNN)作为分类模型。总的来说,与传统的神经网络或其他传统的机器学习模型相比,CNN 在对大型数据集上的图像进行分类方面做得更好。
最大池层用于减少前一层输出的大小,从而使训练更快。脱落层也用于减少过度拟合。
网络架构类似于 LeNet,每层的详细信息如下:
培养
sagemaker.tensorflow.TensorFlow估算器处理定位脚本模式容器、上传脚本到 S3 位置和创建 SageMaker 培训任务。
为了让模型访问数据,我将它们保存为。npy 文件并上传到 s3 bucket。
训练脚本是一个独立的 python 文件。在培训作业期间,SageMaker 将在指定的实例上运行这个脚本。
现在,我可以定义训练作业并训练模型。我使用了一个ml.p2xlarge 实例。10 个历元后,验证精度为 0.979。完成这项工作花费了实例 158 秒。
端点部署和预测
模型已部署。我再次使用了一个ml.p2xlarge 实例。现在我们可以评估模型的性能了。一个度量是整个模型的准确性。
然而,更好的方法是查看每个类的准确性。由于某些类别的示例比其他类别少 10 倍,因此预计模型会偏向那些示例较多的类别。
从下图可以看出,大部分类的准确率> 90%。只有 5 个职业有 90%的准确率< 80%. Going back the class distribution plot, we can see all these 5 classes have no. of examples ~ 200. It is also noted that not all classes with ~ 200 examples has a lower accuracy.

Accuracy per class
Conclusion and Future Improvement
I used the latest TensorFlow framework to train a model for traffic sign classification. The pipeline includes pre-processing, model construction, training, prediction and endpoint deployment. The validation accuracy is 0.979 and testing accuracy is 0.924. Most of the classes have accuracy >而只有 5 个职业有准确率< 80%. The root cause is likely to be the small training size for these classes. Future improvement for this model could include image augmentation.
你可以从 这里 访问笔记本和训练脚本。
用尼莫和闪电用 3 行代码训练对话式人工智能
实践教程
使用 NeMo 和 Lightning 大规模训练最先进的语音识别、NLP 和 TTS 模型

作者图片
NeMo (神经模块)是英伟达的一个强大框架,旨在轻松训练、构建和操纵最先进的对话式人工智能模型。NeMo 模型可以在多 GPU 和多节点上训练,有或没有混合精度,只需 3 行代码。继续阅读,了解如何使用 NeMo 和 Lightning 在多个 GPU 上训练端到端语音识别模型,以及如何根据自己的使用情况扩展 NeMo 模型,如在西班牙语音频数据上微调预训练的强大 ASR 模型。
在本文中,我们将重点介绍 NeMo 中的一些优秀特性,在 [LibriSpeech](http://In this article we covered some of the great out of the box features within NeMo, steps to build your own ASR model on LibriSpeech and fine-tuning to your own datasets across different languages.) 上构建自己的 ASR 模型的步骤,以及如何跨不同语言在自己的数据集上微调模型。
构建 SOTA 对话式人工智能
NeMo 提供了一个轻量级的包装器来开发跨不同领域的模型,特别是 ASR(自动语音识别)、TTS(文本到语音)和 NLP。NeMo 开箱即用,提供从头开始训练流行模型的示例,如谷歌研究所发布的臭名昭著的语音合成 Tactotron2 模型,以及微调预训练变压器模型(如 Megatron-LM )的能力,用于下游 NLP 任务,如文本分类和问题回答。
NeMo 还对各种语音识别模型提供现成的支持,提供预训练的模型以便于部署和微调,或者提供从零开始训练的能力,并且易于修改配置,我们将在下面详细讨论。
它使研究人员能够扩展他们的实验规模,并在模型、数据集和训练程序的现有实现基础上进行构建,而不必担心缩放、模板代码或不必要的工程。
NeMo 建立在 PyTorch 、 PyTorch Lightning 和许多其他开源库的基础上,提供了许多其他突出的功能,例如:
- 使用 ONNX 或 PyTorch TorchScript 导出模型
- 通过tensort进行优化,并使用 NVIDIA Jarvis 进行部署
- 在 NGC 有大量 SOTA 预培训车型
由闪电驱动
NeMo 团队没有从头开始构建对多个 GPU 和多个节点的支持,而是决定使用 PyTorch Lightning 来处理所有的工程细节。每个 NeMo 模型实际上都是一个照明模块。这使得 NeMo 团队可以专注于建立人工智能模型,并允许 NeMo 用户使用闪电训练器,它包括许多加快训练速度的功能。通过与 PyTorch Lightning 的紧密集成,NeMo 保证可以在许多研究环境中运行,并允许研究人员专注于重要的事情。
大规模培训端到端 ASR 模型
为了展示使用 NeMo 和 Lightning 来训练对话式人工智能是多么容易,我们将建立一个可以用来转录语音命令的 end 2 end 语音识别模型。我们将使用 QuartzNet 模型,这是一种用于 E2E(端到端)语音识别的完全卷积架构,它带有预先训练的模型,在大约 3300 小时的音频上训练,在使用更少参数的同时超越了以前的卷积架构。在大规模部署模型时,模型参数的数量成为准确性的关键权衡因素,尤其是在流式语音识别至关重要的在线设置中,如语音助理命令。

NVIDIA 的 QuartzNet BxR 架构
我们使用 LibriSpeech 作为我们的训练数据,这是一本流行的有声读物,标签为 dataset。NeMo 带有许多预设的数据集脚本,用于下载和格式化数据,以进行训练、验证和测试,可以在这里看到。
我们使用预设的 QuartzNet 配置文件定义模型配置,修改我们的数据输入以指向我们的数据集。
训练我们的模型只需要 3 行代码:定义模型配置,初始化闪电训练器,然后训练!
为了提高速度,您可以增加 GPU 的数量,并启用原生混合精度。两者都非常容易使用闪电训练器。
你可以利用所有的 Lightning 特性,比如检查点和实验管理以及更多的!关于 NeMo 中的 ASR 功能的互动视图,请查看 Google Colab。
定制您的模型
NeMo 使得训练技术或模型改变的实验变得极其容易。假设我们想用 Adam 替换我们的优化器,并更新我们的学习率计划以使用预热退火。这两者都可以通过配置文件来完成,而不需要使用预先构建的 NeMo 模块来修改代码。
利用低资源语言的迁移学习
我们已经看到 NVIDIA 在最近的论文中展示的在语音识别中应用迁移学习的令人印象深刻的结果。与从头开始训练相比,微调一个强大的预训练模型在收敛性和准确性方面显示出优势。

NVIDIA从零开始比较训练和微调预训练模型
NeMo 使获得迁移学习的好处变得简单。下面我们使用我们预先训练的英语 QuartzNet 模型,并在普通语音西班牙语数据集上进行微调。我们更新了训练数据输入、词汇表和一些优化配置。我们让教练处理剩下的事情。
从尼莫开始
在本文中,我们介绍了 NeMo 的一些现成特性,在 LibriSpeech 上构建自己的 ASR 模型的步骤,以及跨不同语言对自己的数据集进行微调的步骤。
这里有大量的 Google Colab 教程可供选择,涵盖了 NLP、语音识别和语音合成。你也可以在 PyTorch Lightning docs 这里找到更多信息。
用您自己的语言培训 GPT-2
一步一步的指导,训练你自己的 GPT-2 文本生成模型在你选择的语言从零开始

Jr Korpa 在 Unsplash 上拍摄的照片
我们都知道,随着注意力网络和《变形金刚》的发展,现代自然语言处理(NLP)在过去几年里取得了突飞猛进的进步。它为大量的新算法铺平了道路,为 NLP 的不同任务实现了最先进的(SOTA)。
OpenAI 一直是提供自己的语言模型(现已发布 GPT-3)的领导者之一,该模型是在巨大的互联网数据语料库上训练的。因为,GPT-3 是最近的现象,目前是英语,只能通过 OpenAI 提供的 API 访问,我们将注意力转移到它的早期版本,即 GPT-2 。要了解 GPT-2 的内部螺母和螺栓,我建议你通过这个链接。关于注意力和变形金刚的更多深度,这里有一些很好的链接:
- 杰伊·阿拉玛的《变形金刚》
- 哈佛 NLP 的注释变压器
GPT-2 也发布了英语版本,这使得人们很难用不同的语言生成文本。
那么,为什么不在你最喜欢的文本生成语言上训练你自己的 GPT-2 模型呢?这正是我们要做的。所以,事不宜迟,让我们开始吧。
对于演示,我已经考虑了非拉丁字母脚本(孟加拉语在这里),因为为什么不!!我已经为模型使用了 Huggingface 的实现。
1.收集数据。
所有数据科学家都同意,收集高质量的数据是最重要的阶段之一。因此,我们假设您已经有了一个包含。txt 文件,清除并存储所有数据。为方便起见,您可以使用 Wikipedia 文章数据,它是可用的,可以通过以下代码下载。
python wikipedia_download.py --lang bn
这将创建一个包含所有维基百科文件的文件夹,如下所示:

文件列表截图
2.标记化
现在,第二步是将数据标记化。为此,我们使用下面的类。
关于标记化的一些注释:
- 我们使用 BPE (字节对编码),这是一种子字编码,这通常不会将不同形式的字视为不同。(例如,最大将被视为两个标记:“大”和“est”,这是有利的,因为它保留了大和最大之间的相似性,而“最大”添加了另一个标记“est”,使其不同)。此外,它不像字符级编码那样低级,字符级编码不保留特定单词的任何值。
- 另一个小而微妙的地方是第 13 行代码中的 NFKC (规范化形式兼容性组合)。它是标准的 Unicode 兼容格式之一。如果语言是英语,这没有多大关系,但是因为我们使用孟加拉语,它包含一种不同的字符形式,所以我们使用这种特殊的语言。更多信息请点击链接
因此,我们在这里做的是将我们的数据标记化,并将其保存在一个文件夹中。将在指定目录下创建两个文件( merges.txt 和 vocab.json )。要运行该文件,请使用以下代码:
from tokenise import BPE_token
from pathlib import Path
import os# the folder 'text' contains all the files
paths = [str(x) for x in Path("./text/").glob("**/*.txt")]tokenizer = BPE_token()# train the tokenizer model
tokenizer.bpe_train(paths)# saving the tokenized data in our specified folder
save_path = 'tokenized_data'
tokenizer.save_tokenizer(save_path)
3.模型初始化
在真正的魔法开始之前,我们需要确保炮兵准备好了。让我们从一些初始化开始。
import tensorflow as tf
from transformers import GPT2Config, TFGPT2LMHeadModel, GPT2Tokenizer# loading tokenizer from the saved model path
tokenizer = GPT2Tokenizer.from_pretrained(save_path)tokenizer.add_special_tokens({
"eos_token": "</s>",
"bos_token": "<s>",
"unk_token": "<unk>",
"pad_token": "<pad>",
"mask_token": "<mask>"
})# creating the configurations from which the model can be made
config = GPT2Config(
vocab_size=tokenizer.vocab_size,
bos_token_id=tokenizer.bos_token_id,
eos_token_id=tokenizer.eos_token_id
)# creating the model
model = TFGPT2LMHeadModel(config)
我们还从所有文档中创建一个字符串,并对其进行标记。
single_string = ''
for filename in paths:
with open(filename, "r", encoding='utf-8') as f:
x = f.read() single_string += x + tokenizer.eos_tokenstring_tokenized = tokenizer.encode(single_string)
在我们对整个字符串进行编码后,我们现在继续制作 TensorFlow 数据集,将数据分割成相等的间隔,以便我们的模型可以学习。这里我们使用的块大小为 100(每个示例中的令牌长度),批量大小为 16。这是保持低,否则我们可以在 RTX 2060 GPU 上轻松运行它。
examples = []
block_size = 100
BATCH_SIZE = 12
BUFFER_SIZE = 1000for i in range(0, len(string_tokenized) - block_size + 1, block_size):
examples.append(string_tokenized[i:i + block_size])
inputs, labels = [], []for ex in examples:
inputs.append(ex[:-1])
labels.append(ex[1:])dataset = tf.data.Dataset.from_tensor_slices((inputs, labels))
dataset = dataset.shuffle(BUFFER_SIZE).batch(BATCH_SIZE, drop_remainder=True)
4.模特培训
现在是我们期待已久的部分,制作模型和训练。因此,我们定义了优化器、损失函数和指标,并开始训练。
# defining our optimizer
optimizer = tf.keras.optimizers.Adam(learning_rate=3e-5, epsilon=1e-08, clipnorm=1.0)# definining our loss function
loss = tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True)# defining our metric which we want to observe
metric = tf.keras.metrics.SparseCategoricalAccuracy('accuracy')# compiling the model
model.compile(optimizer=optimizer, loss=[loss, *[None] * model.config.n_layer], metrics=[metric])
现在,让我们训练模型
num_epoch = 10
history = model.fit(dataset, epochs=num_epoch)
5.预言;预测;预告
为了进行预测,我们只需要简单地对输入文本进行编码,并将其传递给模型
text = "লালমোহনবাবু "# encoding the input text
input_ids = tokenizer.encode(text, return_tensors='tf')# getting out output
beam_output = model.generate(
input_ids,
max_length = 50,
num_beams = 5,
temperature = 0.7,
no_repeat_ngram_size=2,
num_return_sequences=5
)

输出的屏幕截图
现在,如果你是一个孟加拉人,那么你可以指出,虽然句子的语法是正确的,但它看起来不连贯。没错,但是对于这个演示,我已经尽可能地简化了这个演示。
6.保存模型
好吧,在长时间的训练之后,如果我们结束了我们的训练,所有我们训练过的模型都丢失了,我们又需要从头开始训练它,这有什么好处呢?因此,让我们保存模型和记号化器,以便我们可以从我们停止的地方重新训练
from transformers import WEIGHTS_NAME, CONFIG_NAME
import osoutput_dir = './model_bn_custom/'# creating directory if it is not present
if not os.path.exists(output_dir):
os.mkdir(output_dir)model_to_save = model.module if hasattr(model, 'module') else model
output_model_file = os.path.join(output_dir, WEIGHTS_NAME)
output_config_file = os.path.join(output_dir, CONFIG_NAME)# save model and model configs
model.save_pretrained(output_dir)
model_to_save.config.to_json_file(output_config_file)# save tokenizer
tokenizer.save_pretrained(output_dir)
奖金
我们已经完成了所有的艰苦工作,所以要加载保存的模型和标记器,我们只需要执行两行代码,一切都准备好了。
tokenizer = GPT2Tokenizer.from_pretrained(output_dir)
model = TFGPT2LMHeadModel.from_pretrained(output_dir)
瞧啊。现在你可以用你自己的语言训练你自己的模型。创造出可以与任何语言的最佳文学作品相媲美的内容。
未来范围:
这个博客给出了如何用任何语言训练 GPT-2 模型的框架。这与现有的一些预训练模型不相上下,但要达到这种状态,我们需要大量的训练数据和计算能力。
参考资料:
[## 如何使用转换器和记号赋予器从零开始训练一个新的语言模型
在过去的几个月里,我们对我们的 transformers 和 tokenizers 库做了一些改进,目标是…
huggingface.co](https://huggingface.co/blog/how-to-train) [## 如何生成文本:使用不同的解码方法通过转换器生成语言
近年来,由于大规模语言生成的兴起,人们对开放式语言生成越来越感兴趣。
huggingface.co](https://huggingface.co/blog/how-to-generate)
培训定制 NER
本文解释了如何使用 spacy 和 python 从训练数据中训练和获取自定义命名的实体。
文章解释了什么是 spacy,spacy 的优点,以及如何使用 spacy 进行命名实体识别。现在,所有的就是训练你的训练数据从文本中识别自定义实体。

spaCy 是什么?
S paCy 是一个用于高级自然语言处理的开源软件库,用编程语言 Python 和 Cython 编写。该库在麻省理工学院的许可下发布,其主要开发者是软件公司 Explosion 的创始人 Matthew Honnibal 和 Ines Montani。
与广泛用于教学和科研的NLTK不同,spaCy 专注于提供生产使用的软件。从 1.0 版本开始,spaCy 还支持 深度学习 工作流,允许连接由流行的 机器学习 库训练的统计模型,如 张量流 ,py torch或MXNet
为什么不是 NLTK?
虽然 NLTK 提供了对许多算法的访问来完成一些事情,但是 spaCy 提供了最好的方法。它提供了迄今为止发布的任何 NLP 库的最快和最准确的语法分析。它还提供了对更大的词向量的访问,这些词向量更容易定制。
自定义-NER

步骤:1 安装说明
点
安装后,您需要下载一个语言模型
康达
第二步:模型训练
完成第一步后,您就可以开始培训了。
→首先,导入定制创建过程所需的必要包。
→现在,主要部分是为输入文本创建您的自定义实体数据,其中命名实体将在测试期间由模型识别。
→定义要处理的训练模型所需的变量。
→接下来,加载流程的空白模型以执行 NER 动作,并使用 create_pipe 功能设置只有 NER 的管道。
→这里,我们想通过禁用除 NER 之外的不必要的流水线来训练识别器。 nlp_update 函数可用于训练识别器。
产出:培训损失
*100%|██████████| 3/3 [00:00<00:00, 32.00it/s]{'ner': 10.165919601917267}100%|██████████| 3/3 [00:00<00:00, 30.38it/s]{'ner': 8.44960543513298}100%|██████████| 3/3 [00:00<00:00, 28.11it/s]{'ner': 7.798196479678154}100%|██████████| 3/3 [00:00<00:00, 33.42it/s]{'ner': 6.569828731939197}100%|██████████| 3/3 [00:00<00:00, 29.20it/s]{'ner': 6.784278305480257}*
→为了测试训练好的模型,
→最后,将模型保存到保存在 output_dir 变量中的路径。
一旦保存了训练好的模型,就可以使用
在 GitHub 上可以找到完整的源代码。
结论
我希望你现在已经明白了如何在斯帕西 NER 模型的基础上训练你自己的 NER 模型。感谢阅读!
培训、验证和测试—成功比较模型性能
虽然建立模型本身就是一项具有挑战性的任务,但是比较它们的性能也是一项同样重要的工作。如果表现好得令人难以置信,那很可能是真的,原因如下。
如果您已经使用了机器学习算法,您可能会遇到像 train_test_split()这样的函数或类似的声音函数,这些函数在 scikit-learn、TensorFlow 或其他库中都可用。训练一个模型是做出好的预测的第一步,然而识别预测能力有多好是一个不同的问题。拆分数据对于建立训练、比较和测试模型的坚实基础是必要的。
我会把这个给你,模型选择据称不是最有趣或最令人兴奋的任务,但它对每个与数据打交道的人来说是必不可少的。
抛出模型和机器学习算法很容易,几乎任何人都可以做到——挑战在于正确地进行分析。
让我们从我们为什么要做这个开始:每个数据集都包含被称为真实以及随机效果的模式。让我们假设我们正在查看某个随机数据集。如果我们创建了一个允许我们预测值的模型,那么这个模型就会暴露于真实的和随机效应。我们不知道的是,哪些数据点是随机的,因此在这个特定的数据集中显示出完全独特的模式,哪些数据点是“典型的”(真实的效果),因此在其他新数据中看起来相似。
让我们反过来说,如果我们有一个只有完美“真实”数据的数据集,我们的模型将很好地拟合,并且在新数据上也表现得同样好,假设真实的影响也存在于任何其他数据集中。
但说真的,这只是假设。数据包含随机模式,我们的模型将适合随机和真实数据——这正是为什么我们需要测量所有模型的准确性。
真实世界的数据集将包含随机和真实的影响,因此不太可能有 100%准确的模型-即使如此,也很可能过度拟合模型训练的数据。此外,新的数据点还将包含(全新的)随机效应,我们的模型不太可能很好地捕捉到这些效应。
我们要回答的问题很简单,“我的模型准确吗”****“我的模型有多准确?”。基本上有两个切入点来回答这个问题,我有一个
- 单一模式或有
- 几种型号
必须对它们进行训练、评估和相互比较。为什么知道我们看的是单一模型还是不同模型很重要?因为根据这个假设,我们需要稍微不同地拆分我们的数据。
一般而言,交叉验证是评估模型性能和/或调整超参数的首选方式,然而,在处理各种模型时,应用不同的(子)数据集并查看模型性能通常非常方便。
如果你对交叉验证**(或蒙特卡洛交叉验证)更感兴趣,请点击以下链接:**
交叉验证是最先进的。它不是一个有趣的任务,但对每个处理数据的人来说是至关重要的…
towardsdatascience.com](/cross-validation-7c0163460ea0)
数据分割
**单一模型案例:**为了测试我们的模型的预测准确性,将数据分成训练部分和测试部分似乎是非常直观的,这样模型可以在一个数据集上训练,但在不同的新数据部分上测试。
这个测试的原因很简单,假设我们使用完整的数据集来训练模型,然后使用相同的数据来预测模型的准确性。自然,我们期望模型表现良好,因为所有的数据点都是“已知的”。这正是过度拟合这个术语所指的。我们感兴趣的是,该模型是否也能够处理刚刚介绍的数据——测试数据。
训练单个模型非常简单。我们将数据分成两个数据集:
- 模型拟合的训练数据
- 评估模型准确性的测试数据
简单看一下 R 文档会发现一个将数据分成训练和测试的示例代码——如果我们只测试一个模型,这是正确的做法。如果我们有几个模型要测试,数据应该被分成三部分——但是我稍后会讲到。
# 0.8 is the size of the training data
train_index <- sample(1:nrow(adult), 0.8 * nrow(adult))
test_index <- setdiff(1:nrow(adult), train_index)# Build X_train, y_train, X_test, y_test
X_train <- adult[train_index, -15] # income = column 15
y_train <- adult[train_index, "income"] # income = column 15X_test <- adult[test_index, -15] # income = column 15
y_test <- adult[test_index, "income"] # income = column 15
为了断定我们的训练模型是否具有良好的预测能力,我们简单地使用训练模型并预测对测试数据的响应。这些预测可以用来与真实的响应变量进行比较。以下演示代码说明了我们如何在简单的单模型情况下测量准确性(类似伪代码):
model <- classifier( y_train ~ X_train ) # y explained by X
predictions <- predict( model, X_test )RMSE( pred=predictions, obs=y_test ) # predictions vs. Obs
多模型案例。现在它变得不那么直观了。如果我们创建了几个模型——让我们假设我们改变了一个特定的超参数几次,以查看对模型的影响,或者我们使用了不同的分类模型,如 SVM 和 KNN——这些例子中的每一个都将被视为不同的模型。

坚实模型的关键,拆分你的数据[1]
让我们更具体地假设有 10 个模型,与所有其他模型相比,每个模型的特征在于具有不同的超参数。例如,模型可能在较大的 XYZ 值、较小的λ值等方面有所不同。—你明白我的意思了。
此时,我们在相同的训练数据上训练了 10 个模型。每个模型都有自己的精确度,有些会做得更好,有些会做得更差。现在的问题是,我们如何选择最佳模型,以及我们如何估计模型的“真实”准确性?
第一步:在每种型号中选择合适的型号
由于我们目前看到的 10 个模型只向**介绍了训练数据,**因此我们需要一个我们的模型以前没有见过的数据部分——验证数据。
我们可以使用验证数据来计算每个模型的准确性指标(每个模型都有不同的 hyper/参数)。这使我们能够按类型和它们的最佳得分对模型进行排序,并选择最佳的 k 个模型,以便稍后测试整体性能。我通常定义 k=2 或 3。
例如,如果我们有 10 个模型,它们有 3 个不同的基础类型(例如 3 个 KNN 模型、4 个购物车模型和 3 个支持向量机模型),我们只需从每个类别中选择最佳模型。
培训和验证到此结束。
第二步:测量你的模型的真实精度
手头有三个模型,我们必须不要假设验证数据上的性能是每个模型的“真实”性能。在这一点上,我们介绍最后一步,伴随着测试数据集。对于 k 个最佳(前 3 名)模型中的每一个,我们使用该模型对测试数据进行分类,并计算测试误差指标。
这听起来像是我们在重新做同样的事情,只是针对三个模型并使用测试集— 但是为什么呢?回忆一下我关于随机和真实效果的简短独白。验证后的最佳模型(就最高精度而言)可能是好的,但也有可能一个模型可能受益于更适合验证数据中的随机模式——随机效应——而这只是偶然。
这不是我们想要衡量我们的模型,我们不想选择一个模型,假设它是更好的,但在现实中,该模型只是由于运气优于。出于这个原因,测试集引入了另一层,将模型受益于纯粹随机性的机会降至最低。
第三步,即最终评估,到此结束。我们只是从三个模型中选出最好的。该模型是拟合的(训练数据),在验证数据上执行前 3 名,并且证明在测试数据上具有最好的准确性。**
如果现在观察到的精度比验证集上的精度低很多,我们该怎么办?
简单的回答是,没什么。坚持模型。我们通过合法的步骤来评估和比较我们所有的模型。如果结果最终显示较低的分数,那么这就是模型在新的和看不见的数据上的表现。不要再次运行此过程,例如使用不同的数据分割,直到您的最终模型做得更好—为什么?在相同的设置下重新应用这个过程来寻找更好的模型,仅仅意味着,您可能找到了一个过度拟合数据的模型,但是在将来的新数据上可能再次表现不佳。****
为了让这个从几个型号中选择最佳型号的过程更加有形,我们用更多的结构和术语来描述这些步骤:
- 训练数据集:训练数据集用于训练模型。该数据集应该是数据集的最大部分。当针对训练数据集进行测试时,模型通常表现良好,这仅仅是因为错误被低估(“向下偏差”)。
- 验证数据集:比较多个模型时需要。验证数据集用于验证模型并从中挑选最佳模型。
- 测试数据集:最终确定所选车型的真实性能**。测试误差可能会高于在前面步骤中观察到的误差。这一步让我们在所有的模型中选择**一个最终模型。****

模型选择过程
如前所述,我们不知道哪些数据点是随机效应,哪些不是。分割数据的方法有很多种,但一般来说,选择随机数据点是一个好主意——R 的 sample 或 Python 的 random.sample 函数可能非常方便。
这篇文章通过大量模型下的挑战模型选择提供了简短的指导。尽管这个主题肯定不会出现在最令人兴奋的机器学习讲座中,但遵循既定的程序来挑选和验证数据模型是至关重要的。
{下次见}
通过关系推理使用自我监督学习进行无标记数据训练
这个故事的目的是介绍使用表示学习在深度学习中训练未标记数据的新方法

背景和挑战📋
在现代深度学习算法中,对未标记数据的人工标注的依赖是主要限制之一。为了训练一个好的模型,通常我们需要准备大量的标注数据。在只有少量类和数据的情况下,我们可以使用来自标注公共数据集的预训练模型,并使用您的数据微调最后几个图层。然而,在现实生活中,当您的数据相当大时(商店中的产品或人脸,…)并且对于仅具有几个可训练层的模型来说学习将是困难的。此外,未标记的数据(例如,文档文本、互联网上的图像)的数量是不可计数的。将它们全部标记出来几乎是不可能的,但是不利用它们绝对是一种浪费。
在这种情况下,使用新的数据集从头开始再次训练深度模型将是一种选择,但这需要花费大量的时间和精力来标记数据,而使用预训练的深度模型似乎不再有帮助。这就是自我监督学习诞生的原因。这背后的想法很简单,它服务于两个主要任务:
- **代理任务:**深度模型将从没有注释的未标记数据中学习可概括的表示,然后将能够利用隐含信息自生成监控信号。
- **下游任务:**表示将针对监督学习任务进行微调,例如使用较少数量的标记数据进行分类和图像检索(标记数据的数量取决于基于您需求的模型的性能)
提出了许多不同的训练方法来学习这样的表示:相对位置[1]:模型需要理解对象的空间上下文,以告知部件之间的相对位置;拼图[2]: 模型需要将 9 个洗牌后的小块放回原来的位置;彩色化[3]: 该模型已经被训练为对灰度输入图像进行彩色化;准确地说,任务是将该图像映射到量化颜色值输出上的分布;**计数特征【4】😗*该模型通过缩放 和平铺,利用输入图像的特征计数关系学习特征编码器; SimCLR [5]: 该模型通过潜在空间中的对比损失,最大化同一样本的不同增强视图之间的一致性,来学习视觉输入的表示。
然而,我想介绍一种有趣的方法,它能够像人一样识别事物。人类学习的关键因素是通过比较相关和不同的实体来获取新知识。因此,如果我们可以通过关系推理方法[6]在自我监督的机器学习中应用类似的机制,这将是一个重要的解决方案。****
关系推理范式基于一个关键的设计原则:使用关系网络作为无标签数据集上的可学习函数,以量化同一对象的视图之间的关系(内部推理)和不同场景中不同对象之间的关系(内部推理)。通过在标准数据集(CIFAR-10、CIFAR-100、CIFAR-100–20、STL-10、tiny-ImageNet、SlimageNet)、学习时间表和主干网(浅层和深层)上的性能,评估了通过关系推理在自我监督机器学习中利用类似机制的可能性。结果表明关系推理方法在所有条件下都大大超过了最好的竞争对手,平均准确率为 14%,比最新的最先进方法高出 3%,如本文【6】所示。****
技术亮点📄

关系定义示例(图片由作者提供)
最简单的解释,关系推理只是一种方法论,试图帮助学习者理解不同对象(思想)之间的关系,而不是单独学习对象。这可以帮助学习者根据他们的差异轻松区分和记忆对象。关系推理系统[6]有两个主要组成部分:主干 结构和关系头。关系头用于托词任务阶段,用于支持底层神经网络主干学习未标记数据集中的有用表示,然后它将被丢弃。主干结构在托词任务中训练后用于下游任务,如分类或图像检索。
- 前期工作:关注场景内关系,意思是
同一物体中的所有元素都属于同一个场景(比如一个篮子里的球);标签数据集上的训练,主要目标是关系头[7]。 - ****新方法:关注同一对象不同视角之间的关系(内推理)和不同场景不同对象之间的关系(间推理);在未标记的数据和关系头上使用关系推理是在底层主干中学习有用表示的借口任务。
让我们讨论一下关系推理系统中某个部分的重点:
- 小批量增加:
如前所述,本系统引入了内推理和间推理?那么我们为什么需要它们呢?当没有给出标签时,不可能创建相似和不相似的对象对。为了解决这个问题,应用了自举技术,形成了内推理和间推理,其中 :
- 内部推理包括对同一对象的随机增强进行采样{ A1A2 }(积极的一对)(例如,对同一篮球的不同看法)
- 交互推理包括耦合两个随机对象{ A1B1}(负对)(如随机球篮球)
此外,随机增强函数(例如几何变换、颜色失真)的使用也被认为使场景间的推理更加复杂。这些增强功能的好处迫使学习者(骨干)注意更广泛的一组特征(例如,颜色、大小、纹理等)之间的相关性。).例如,在{脚球,篮球}对中,颜色本身就是该类别的一个强有力的预测因素。然而,随着颜色以及形状大小的随机变化,学习者现在很难区分这对之间的差异。学习者必须看一看另一个特征,因此,它导致更好的表示。
2。度量学习
**度量学习的目的是使用距离度量来拉近相似输入(肯定)的表示,同时移开不同输入(否定)的表示。然而,在**关系推理中,度量学习有着根本的不同:

度量学习和关系推理的比较

学习指标—对比损失(图片由作者提供)

学习指标—关系得分(作者图片)
3。损失函数
学习的目标是呈现对上的二元分类问题。因此,我们可以使用二元交叉熵损失来最大化伯努利对数似然,其中关系分数 y 表示通过 sigmoid 激活函数诱导的表示成员的概率估计。

损失函数
最后,本文[6]还提供了在标准数据集(CIFAR-10,CIFAR-100,CIFAR-100–20,STL-10,tiny-ImageNet,SlimageNet),不同主干(浅层和深层),相同学习时间表(epochs)上的关系推理结果。结果如下,要了解更多信息,你可以看看他的论文。
实验评估📊
在本文中,我想在公共图像数据集 STL-10 上重现关系推理系统。该数据集包括 10 个类(飞机、鸟、汽车、猫、鹿、狗、马、猴子、船、卡车),颜色为 96x96 像素。
首先,我们需要导入一些重要的库
STL-10 数据集由 1300 个标记图像组成(500 个用于训练,800 个用于测试)。然而,它还包括 100000 张未标记的图片,这些图片来自类似但更广泛的图片分布。例如,它包含其他类型的动物(熊、兔子等。)和交通工具(火车、公共汽车等。)除了标记集中的那些

STL-10 数据集
然后我们将根据作者的建议创建关系推理类
为了比较关系推理方法在浅层和深层模型上的性能,我们将创建一个浅层模型(Conv4)并使用深层模型的结构(Resnet34)。
**backbone = Conv4() *# shallow model*
backbone = models.resnet34(pretrained = False) *# deep model***
根据作者的建议,设置了一些超参数和增强策略。我们将在未标记的 STL-10 数据集上用关系头训练我们的主干。

每批图像样本(K =16)
到目前为止,我们已经创建了训练模型所需的一切。现在,我们将在 10 个时期和 16 个增强图像(K)中训练主干和关系头部模型,通过 1 个 GPU Tesla P100-PCIE-16GB,浅层模型(Conv4)花费了 4 个小时,深层模型(Resnet34)花费了 6 个小时(您可以自由更改时期的数量以及另一个超参数以获得更好的结果)
**device = torch.device("cuda:0") if torch.cuda.is_available() else torch.device("cpu")backbone.to(device)
model = RelationalReasoning(backbone, feature_size)
model.train(tot_epochs=tot_epochs, train_loader=train_loader)
torch.save(model.backbone.state_dict(), 'model.tar')**
在训练我们的主干模型之后,我们丢弃关系头,并且仅将主干用于下游任务。我们需要用 STL-10 (500 张图片)中的标记数据来微调我们的主干,并在测试集中测试最终的模型(800 张图片)。训练和测试数据集将在没有扩充的情况下加载到 Dataloader 中。
我们将加载预训练的主干模型,并使用简单的线性模型将输出要素与数据集中的多个类连接起来。
***# linear model*
linear_layer = torch.nn.Linear(64, 10) # if backbone is Conv4
linear_layer = torch.nn.Linear(1000, 10) # if backbone is Resnet34*# defining a raw backbone model*
backbone_lineval = Conv4() *# Conv4* backbone_lineval = models.resnet34(pretrained = False) *# Resnet34*# load model
checkpoint = torch.load('model.tar') # name of pretrain weight
backbone_lineval.load_state_dict(checkpoint)**
此时,只有线性模型将被训练,主干模型将被冻结。首先,我们将看到微调 Conv4 的结果
然后在测试集上检查
Conv4 在测试集上获得了 49.98%的准确率,这意味着主干模型可以在未标记的数据集中学习有用的特征,我们只需要用很少的时期进行微调就可以获得很好的结果。现在让我们检查深度模型的性能。
然后在测试数据集上进行评估
在测试集上,我们可以获得 55.38%的准确率。在本文中,主要目标是再现和评估关系推理方法,以教导模型在没有标签的情况下区分对象,因此,这些结果是非常有希望的。如果你觉得不满意,你可以通过改变超参数如增强数、历元数或模型结构来自由地做实验。
最后的想法📕
自监督关系推理在定量和定性方式上都是有效的,并且具有从浅到深结构的不同大小的主干。通过比较学习的表征可以很容易地从一个领域转移到另一个领域,它们是细粒度的和紧凑的,这可能是由于准确性和增强数量之间的相关性。根据作者的实验[4],在关系推理中,扩充的数量在影响对象群的质量方面起着主要作用。自监督学习在许多方面具有成为机器学习的未来的强大潜力。
如果你想进一步讨论,可以联系我。这是我的 Linkedin
尽情享受吧!!!👦🏻
参考
[1]卡尔·多施等人。al,通过上下文预测的无监督视觉表征学习,2015。
[2]迈赫迪·诺鲁齐等人。al,通过解决拼图游戏实现视觉表征的无监督学习,2017。
[3]张等。al,彩色图像彩色化,2016。
[4]迈赫迪·诺鲁齐等人。al,通过学习计数进行表征学习,2017。
[5]陈婷等人视觉表征对比学习的简单框架,2020。
6 马西米利亚诺·帕塔基奥拉等人。al,
表征学习的自监督关系推理,2020。
7 亚当·桑托罗等人。al,关系递归神经网络,2018。
使用 cuML 训练机器学习模型的速度提高 150 倍
显卡的三倍内存将训练速度提高了 10 倍!
动机
Sklearn 是一个很棒的库,有各种各样的机器学习模型,可以用来训练数据。但是,如果您的数据很大,可能需要很长时间来训练您的数据,尤其是当您尝试不同的超参数以找到最佳模型时。
有没有一种方法可以让你训练机器学习模型的速度比用 Sklearn 快 150 倍,而且改动最小?是的,你可以用 cuML。
下面是对比使用 Sklearn 的RandomForestClassifier和 cuML 的RandomForestClassifier.训练同一个模型所需时间的图表

cuML 是一套快速、GPU 加速的机器学习算法,专为数据科学和分析任务而设计。它的 API 和 Sklearn 的差不多。这意味着您可以使用您用来训练 Sklearn 模型的相同代码来训练 cuML 的模型。
在本文中,我将使用不同的模型来比较这两个库的性能。我还将展示如何增加显卡的内存来提高 10 倍的速度。
安装累计
要安装 cuML,请按照第页的说明进行安装。确保在安装库之前检查先决条件。你可以安装所有的软件包,也可以只安装 cuML。如果电脑空间有限,我推荐安装 cuDF 和 cuML。
虽然在很多情况下,你不需要安装 cuDF 来使用 cuML,但是 cuDF 是 cuML 的一个很好的补充,因为它是一个 GPU 数据框架。

确保选择适合您电脑的选项。
创建数据
由于当有大量数据时,cuML 通常比 Sklearn 工作得更好,我们将使用sklearn.datasets.创建一个有 40000 行数据的数据集
from sklearn import datasets
X, y = datasets.make_classification(n_samples=40000)
将数据类型转换为np.float32,因为一些 cuML 模型要求输入为np.float32.
X = X.astype(np.float32)
y = y.astype(np.float32)
支持向量机
我们将创建函数来训练模型。使用该功能将使我们更容易比较不同的模型。
def train_data(model, X=X, y=y):
clf = model
clf.fit(X, y)
我们使用 iPython 的神奇命令%timeit将每个函数运行 7 次,然后取所有实验的平均值。
Average time of sklearn's SVC 48.56009825014287 s
Average time of cuml's SVC 19.611496431714304 s
Ratio between sklearn and cuml is 2.476103668030909
cuML 的 SVC 比 sklearn 的 SVC 快 2.5 倍!
我们通过剧情来形象化一下吧。我们创建一个函数来绘制模型的速度。我使用 cutecharts 是因为它让条形图更可爱。

更好的显卡
由于 cuML 的模型在运行大数据时比 Sklearn 的模型更快,因为它们是使用 GPU 训练的,如果我们将 GPU 的内存增加两倍会发生什么?
我使用的是外星人 M15 笔记本电脑,配有 NVIDIA GeForce 2060 和 6.3 GB 的显卡内存,用于之前的比较。
现在我将使用一台配备 NVIDIA Quadro RTX 5000 和 17 GB 显卡内存的 Dell Precision 7740 来测试 GPU 内存增加时的速度。
Average time of sklearn's SVC 35.791008955999914 s
Average time of cuml's SVC 1.9953700327142931 s
Ratio between sklearn and cuml is 17.93702840535976

哇!cuML 的 SVM 在显卡内存 17 GB 的机器上训练时比 Sklearn 的 SVM 快 18 倍!而且比在显卡内存 6.3 GB 的笔记本电脑上训练的速度还要快 10 倍。
这就是为什么如果我们使用像 cuML 这样的 GPU 加速库,我们的机器中最好有一个好的 GPU。
随机森林分类器
Average time of sklearn's RandomForestClassifier 29.824075075857113 s
Average time of cuml's RandomForestClassifier 0.49404465585715635 s
Ratio between sklearn and cuml is 60.3671646323408

cuML 的 RandomForestClassifier 比 Sklearn 的 RandomForestClassifier 快 60 倍!如果训练一只 Sklearn 的 RandomForestClassifier 需要 30 秒,那么训练一只 cuML 的 RandomForestClassifier 只需要不到半秒。多疯狂啊。
更好的显卡
Average time of Sklearn's RandomForestClassifier 24.006061030143037 s
Average time of cuML's RandomForestClassifier 0.15141178591425808 s.
The ratio between Sklearn’s and cuML is 158.54816641379068

在我的 Dell Precision 7740 笔记本电脑上训练时,cuML 的 RandomForestClassifier 比 Sklearn 的 RandomForestClassifier 快 158 倍!
最近邻分类器
Average time of sklearn's KNeighborsClassifier 0.07836367340000508 s
Average time of cuml's KNeighborsClassifier 0.004251259535714585 s
Ratio between sklearn and cuml is 18.43304854518441

注意:y 轴上的 20m 表示 20ms。
cuML 的 KNeighborsClassifier 比 Sklearn 的 KNeighborsClassifier 快 18 倍。
更好的显卡
sklearn 的 KNeighborsClassifier 的平均时间为 0.075111903228545 秒
cuml 的 KNeighborsClassifier 的平均时间为 0.000151379921

在我的 Dell Precision 7740 笔记本电脑上进行训练时,cuML 的 KNeighborsClassifier 比 Sklearn 的 KNeighborsClassifier 快 50 倍。
总结
你可以在 这里找到 其余比较的代码。****
下面是两个表格,总结了上两个库之间不同型号的速度:
-
外星人 M15 — GeForce 2060 和 6.3 GB 的显卡内存
-
Dell Precision 7740-Quadro RTX 5000 和 17 GB 的显卡内存
令人印象深刻,不是吗?
结论
恭喜你!您刚刚了解到,与 Sklearn 相比,在 cuML 上训练不同模型的速度有多快。如果使用 Sklearn 训练你的模型需要很长时间,我强烈建议尝试一下 cuML,考虑到与 Sklearn 的 API 相比,代码几乎没有任何变化。
当然,如果有一个像 cuML 这样使用 GPU 来执行代码的库,你的显卡越好,平均来说训练就越快。
查看 cuML 的文档,了解其他机器学习模型的详细信息。
本文的源代码可以在这里找到。
此时您不能执行该操作。您已使用另一个标签页或窗口登录。您已在另一个选项卡中注销,或者…
github.com](https://github.com/khuyentran1401/Data-science/tree/master/machine-learning/cuml)
我喜欢写一些基本的数据科学概念,并尝试不同的算法和数据科学工具。你可以在 LinkedIn 和 Twitter 上和我联系。
星这个回购如果你想检查我写的所有文章的代码。在 Medium 上关注我,了解我的最新数据科学文章,例如:
[## Yellowbrick 简介:可视化机器学习预测的 Python 库…
您将 f1 分数提高到了 98%!但这是否意味着你的模型表现更好呢?
towardsdatascience.com](/introduction-to-yellowbrick-a-python-library-to-explain-the-prediction-of-your-machine-learning-d63ecee10ecc) [## PyTorch 是什么?
想想 Numpy,但是有强大的 GPU 加速
towardsdatascience.com](/what-is-pytorch-a84e4559f0e3) [## 使用 Python 和情感分析探索和可视化您的 LinkedIn 网络
希望优化您的 LinkedIn 个人资料?为什么不让数据为你服务呢?
towardsdatascience.com](/sentiment-analysis-of-linkedin-messages-3bb152307f84) [## 如何用支持向量机学习非线性数据集
支持向量机简介及其在非线性数据集上的应用
towardsdatascience.com](/how-to-learn-non-linear-separable-dataset-with-support-vector-machines-a7da21c6d987)
训练你的思维,用 5 个步骤进行递归思考
如何轻松解决递归问题?

在您的编程之旅中,有几个里程碑是您需要克服的。例如,熟悉类,理解指针,掌握代码函数化的艺术,等等。对于新手来说,最难学的编程概念之一是递归,对于已经编程一段时间的人来说,这是需要掌握的。
当我第一次开始编码的时候——大约十年前——我很难理解递归。虽然有些人可以自然地递归思考,但其他人——包括我自己——却不能。
但是,
递归思维是你可以训练你的大脑去做和掌握的事情,即使你天生没有这种能力。
回到 2012 年,我看到一本非常酷的书,叫做《像程序员一样思考》。这本书教会我开发一个思维过程,帮助我解决多年来的各种编程问题。它给了我一个程序员在职业生涯中取得成功所需的正确思维过程的基础。
这些年来,我扩展了书中提出的那些技术,以便熟悉各种编程概念。
在本文中,我将向您介绍我用来解决任何递归问题的不同步骤。虽然我将使用 Python 来演示这些步骤,但是这些步骤可以应用于任何编程语言。他们的逻辑不是特定于语言的。
让我们—让我们,让我们,让我们—开始吧!
训练你递归思考的步骤
为了演示这个过程,我们来看一个简单的问题。假设我们需要对任何给定数字的位数求和。例如,123 的和是 6,for 57190 是 22,以此类推。
所以,我需要写一个代码,用递归来解决这个问题。在你说之前,我知道有其他方法可以解决这个问题——可以说是更好更容易的递归方法。但是,为了这篇文章,让我们考虑递归解决方案。
1-首先使用 iterable 方法。
这一步对大多数人来说相对简单。我们有一个数字,想用循环对它的数字求和。基本上,我们需要知道如何计算数字中有多少位数,然后逐一求和。
一种方法是将包含数字的变量转换为 str,这样更容易迭代。
num = 123 #The variable containing the number we want to sum its digits
num = str(num) #Casting the number to a str
s = 0 #Initialize a varible to accumulate the sum
#Loop over the digits and add them up
for i in range(len(num)):
s += int(num[i])
2-提取函数的参数。
使用循环解决问题将有助于我们理解答案,并找出它的所有非递归方面。现在我们有了答案,我们可以剖析它,提取我们需要继续前进的信息。
此时,我们需要问自己一个问题,如果我把它写成一个函数形式,函数参数会是什么?
这个问题的答案取决于你使用的编程语言。对于 Python,我们可以说只需要一个参数,就是变量num。
def sumOfDigitsIter(num):
num = str(num)
s = 0
for i in range(len(num)):
s += int(num[i])
return s
3-扣除最小的问题实例。
一旦我们得到了函数参数,我们将对它们进行更深入的研究。在我们的例子中,我们只有一个参数 num。
我们现在需要做的是根据参数找到最小的问题实例。回想一下,我们的目的是对一个给定数字的位数求和。这个问题最简单的例子是如果数字只有一个数字。
例如,如果num = 3,那么答案将等于变量本身,因为没有更多的数字相加。
4-将解决方案添加到最小问题实例中。
让我们再来看看我们刚刚写的函数:
def sumOfDigitsIter(num):
num = str(num)
s = 0
for i in range(len(num)):
s += int(num[i])
return s
按照这个函数的逻辑,如果参数 num 只有一个数字,那么仍然会执行循环。为了避免这种情况,我们可以添加一个条件语句,该语句只在输入数字的位数为 1 时执行。
def SumOfDigitsIter(num):
num = str(num)
if len(num) == 1:
return num
else:
s = 0
for i in range(len(num)):
s += int(num[i])
return s
5-扩展你的功能。
这是递归发生的步骤。到目前为止,我们并不太关心递归;我们在合乎逻辑地解决这个问题。这是从递归开始,从逻辑上考虑,然后转化为递归解决方案的最佳方法。
现在,让我们考虑一下函数的else部分。
else:
s = 0
for i in range(len(num)):
s += int(num[i])
return s
你可以把递归想象成展开一个问题实例,然后再次滚动它。我们可以从另一个角度来看这个问题,我们可以说 123 的和是 1+23 的和,23 的和是 2 +和 3——也就是 3。
因此,回滚到 123 = 1 +2 +3 =6。
让我们把它转换成代码。我们已经写好了最后一部分,它处理一位数。我们需要做的是将 num 个变量分解成一位数。
这就是递归。
def SumOfDigits2(num):
num = str(num)
if len(num) == 1:
return num
else:
return num[0] + sumOfDigits(num[1:])
所以,每次,我都调用相同的函数,但是输入更少。一旦到了最后一位数,我最终会得到 1 + 2 + 3 这样的数,最终加起来就是 6。
瞧,我得到了一个递归函数。
另一个例子
让我们考虑另一个例子,假设我们想要得到两个相同长度的整数列表的绝对差的和。例如,如果我们有[15,-4,56,10,-23]和[14,-9,56,14,-23],答案将是 10。
第一步:用循环求解
assert len(arr1) == len(arr2)
diffSum = 0
for i in range(len(arr1)):
diffSum += abs(arr1[i]-arr2[i])
第二步:提取参数
参数表= [arr1,arr2]。
第三步:扣除最小实例
这个问题的最小实例是当两个列表为空时;在这种情况下,没有区别,所以答案是 0。
第四步:求解最小实例。
if len(arr1) == 0:
return 0
现在你可能会说,为什么不确保 len(arr2) == 0 呢?assert 语句已经确保了两个列表具有相同的长度,这意味着如果我想检查它们是否为空,我只需要检查其中一个的长度。
第五步:递归
就像 digits sum 示例一样,如果我想对两个列表之间的绝对差求和,我可以得到前两个元素之间的差,然后是第二个,然后是第三个,依此类推,直到我用完所有的元素。
def recDiff(arr1,arr2):
assert len(arr1) == len(arr2)
if len(arr1) == 0:
return 0
else:
return abs(arr1[0]-arr2[0]) + recDiff(arr1[1:],arr2[1:])
外卖食品
递归被认为是程序员在成为“优秀程序员”的过程中需要经历的高级技术之一然而,一开始把一个人的脑袋包起来是相当棘手的,许多人发现很难掌握。
遵循简单明了的五个步骤,你可以轻松解决任何递归问题:
- 首先使用循环解决问题。
- 从中提取可能的输入,如果你想把它变成一个函数的话。
- 演绎问题最简单的版本。
- 写一个函数来解决这个问题的最简单的例子。
- 使用该函数编写一个新的递归函数。
虽然我提出了 5 个步骤,但是你不需要明确地经历所有的 5 个步骤,因为你会更加精确。随着时间的推移和练习,你将能够在头脑中执行这些步骤,而不用明确地写下来。
我把这个留给你,递归是一个需要掌握的具有挑战性的编程概念。所以,只要坚持下去,有耐心,多多练习;这是你真正掌握诀窍的唯一方法。
训练 GAN 从正态分布中采样
可视化生成性对抗网络的基础
在最初的生成对抗网络论文中,Ian Goodfellow 描述了一个简单的 GAN,当经过训练时,它能够生成与从正态分布中采样的样本不可区分的样本。此过程如下所示:

图 1:GAN 论文中发表的第一张图,展示了 GAN 如何将均匀噪声映射到正态分布。黑点是真实的数据点,绿色曲线是 GAN 产生的分布,蓝色曲线是鉴别器对该区域中的样本是否真实的置信度。这里 x 表示样本空间, z 表示潜在空间。(来源: Goodfellow 2014 )
此任务最简单的解决方案是让 GAN 逼近正态分布的逆 CDF 、x=φ⁻(z)。这是对 GANs 的直观而吸引人的看法:它们是在给定一组样本的情况下从未知分布中随机抽样的工具。在上面的例子中,这是正态分布。其他包括所有手写数字的分布和所有人脸的分布。描述人脸的累积分布函数已被证明是一项艰巨的任务,这就是为什么 GANs 及其生成照片级人脸图像的能力(以及其他许多令人兴奋的结果)成为如此热门的话题。
不幸的是,人们很容易陷入狂热,一头扎进复杂的 GAN 应用;大多数人从 MNIST 数据集、开始他们的 GAN 之旅,尽管其样本空间为 784 维。我以前探索过将 GANS 应用于二维问题,但发现即使这样也太复杂了,无法恰当地形象化近似分布。因此,我决定用《甘正典》中发表的第一幅图来说明这个问题。
问题是
我们将训练 GAN 从标准正态分布 N(0,1)中抽取样本。因此,样本 x 位于从 -∞ 到+∞的一维样本空间中。作为随机性的来源,GAN 将被赋予从均匀分布 U(-1,1)中提取的值。因此,值 z 位于范围从-1 到 1 的一维潜在空间中。因此,GAN 应该接近g(z)=φ⁻(f(z)),使得 f(z) 具有 U(0,1)分布。 f 的可能实现包括:

图 2:保持一致性的[-1,1]到[0,1]的可能映射
这些映射中的一个显然是“最佳”的,因为它简单且可解释。将逆 CDF 应用于这三个函数会产生以下结果:

图 3:图 2 中描述的三个函数的 x =φ⁻(f(z))
所有这三种映射都将 z~U(-1,1) 转换为 x~N(0,1) ,但是蓝色曲线是迄今为止最简单和最容易解释的。不幸的是,众所周知,神经网络不关心这些有价值的特征。
解决方案
一个简单的、完全连接的 GAN 被训练 600 个训练步骤(代码如下)。在每一步之后,发生器和鉴别器的测量结果都是可视化的,如下所示:

图 4:GAN 学习从 600 个时期的标准正态分布采样的动画。(左上)发生器和鉴别器的精度和损耗(右上)GAN 的观测概率密度和真实 N(0,1)密度(左下)潜在空间到样本空间的 GAN 映射和真实映射*φ⁻((z+1)/2)(右下)*鉴别器对样本空间的该区域中的值为真实值的置信度
左上角:指标
生成器和鉴别器都使用二进制交叉熵损失(或对数损失),这在这里与精度一起显示。在步骤 200 之后,两个网络在剩余的训练中基本上保持同步。众所周知,发电机损耗与 GAN 输出质量无关,但它仍然是一个有用的跟踪指标;如果发生器或鉴别器明显优于另一个,那么 GAN 将可能无法收敛。
右上角:概率密度
右上面板显示 GAN 的观测概率密度与标准正态分布的真实概率密度。理想情况下,当训练结束时,这两个人会准确地排成一行。正如你所看到的,有一个强烈的波动行为,因为甘反复过校正。
左下方:已学习的映射
左下方的面板显示了本实验中使用的真实映射,以及 GAN 学习到的映射。正如你所看到的,GAN 正在逼近非直观映射φ⁻((1-z)/2),并取得了成功。
右下角:鉴别器置信度
此面板显示了鉴别器对样本空间中该点的值为实数的置信度(即,从实数分布中提取,而不是 GAN)。从动画中可以立即看出两个观点。首先,鉴别器在识别整个样本空间中真实样本和虚假样本的相对频率方面相当有效;当真实样本多于虚假样本时,可信度增加,反之亦然。第二个观察是样本空间的极端,真实样本很少,显示出巨大的信心波动。这反映在右上图中,在该图中,极端区域中置信度的增加实际上促进了该区域中的样品生成(因此产生了波动行为)。
结果:
GAN 总共被训练了 30000 步,并学会产生以下功能:

图 5:30000 步训练后的 GAN
粗略地看一下 GAN 的输出,它确实呈现正态分布。然而,通过应用核密度估计(图 5,右上方),我们看到该分布只是一个粗略的近似值。这个缺点在 1 维设置中是明显的,在 1 维设置中,分布可以容易地可视化,但是识别“真实的”面部生成函数和由 GAN 学习的面部生成函数之间的偏差是一个困难得多的问题;事实上,在评估生成图像的 GANs 时,我们经常看到它们生成各种各样的真实样本,并认为这就足够了。确保 GAN 输出和鉴频器的中间激活具有与真实样本相似的统计特性是一个活跃的研究领域。
左下角的面板显示 GAN 已经学习了从潜在空间到样本空间的非直觉映射,这是在更高维度问题中呈指数增长的问题。这是不幸的,原因有二:首先,理想的 GAN 的输入应该与有用的、人类可理解的特征相关联。在这种情况下,这将是“增加潜在价值增加样本价值”,而在实践中,我们发现相反的情况发生。在生成人脸的情况下,可能是“增加这个潜在特征增加鼻子尺寸”或者“增加那个潜在特征增加头发亮度”。相反,典型地,潜在特征被映射到不止一个样本特征,例如鼻子尺寸和头发颜色,或者一个样本特征被映射到多个潜在特征。这使得将 GANs 应用于创造性任务变得困难。
另一个问题是,GAN 可以学习将潜在空间中的两个附近的点,比如说 z=0.49 和 z=0.51 ,映射到样本空间中非常远的点(如图 3 中分段函数的情况)。这使得训练变得复杂,因为中间值 z=0.50 ,将可能被映射到样本空间中的某个非常不现实的中间点。这在我以前关于同一主题的文章中已经观察到,并将在下一篇文章中进一步探讨。
所以你有它;甘的训练从来都不简单,即使是一维问题。作为结束语,我想重申我最喜欢的一条数据科学建议:将一切可视化,不管你认为自己了解多少。毕竟,科学上最激动人心的发现并不是来自“发现了!”而是“嗯,这太奇怪了…”
代码可从以下 github repo 获得:
可视化 GAN 训练,因为它学习将 U(-1,1)映射到 N(0,1)
github.com](https://github.com/ConorLazarou/medium/blob/master/12020/visualizing_gan_uni2norm/1_uniform_to_normal_1D.py)
在谷歌的人工智能平台上训练一个模型

尼古拉·塔拉先科在 Unsplash 上的照片
谷歌 ML 教程
如何使用谷歌云服务在 Python 中训练模型
欢迎阅读本系列关于在 Google 云平台上进行机器学习的第一篇文章!
我们将看看人工智能平台。它是与机器学习严格相关的工具的子集,其中包括:
- AI 平台训练,用于在云上训练/调优模型
- AI 平台预测,在云上托管训练好的模型
- 人工智能管道,使用 Kubernetes 和 Docker 图像创建一步一步的流程
和许多其他人。
免责声明:我与谷歌没有任何关系,我只是决定
写这些文章来分享我在日常工作中使用这些工具获得的知识。
对于这第一篇文章,我将重点关注 AI 平台培训,这是一个使用定制代码和可定制机器在云上运行
培训任务的产品。我认为使用人工智能平台训练你的模型的主要优点是:
- 你可以使用更强大的资源(比如多个内核或者一个 GPU)而没有很多麻烦去实例化它们
- 你可以与你的团队共享代码,然后使用一个通用的云基础设施复制相同的结果
在本教程中,我们将使用训练的定义编写实际的 Python 应用,运行本地测试,并在云平台上执行训练作业。
对于本教程,您需要
- 一个活跃的谷歌云平台账户(你可以访问主页建立一个新账户)和一个 GCP 项目
- 安装在工作站上的 Python 3、 gcloud 和 gsutil
- 用于教程的数据集,UCI 的 银行营销数据集 。在这里
你可以找到关于数据集的文档。我们将使用完整版本。
第一步:将数据存储在谷歌存储器上
在本地机器上下载数据集之后,转到 GCP 项目的 Google 存储控制台。创建一个新的 bucket(我称之为bank-marketing-model)并在其中加载数据集。现在,您的桶应该看起来像这样:

作者图片
或者,以一种更古怪的方式,您可以从命令行使用gsutil。进入包含数据集的本地目录并运行
gsutil mb gs://bank-marketing-model
gsutil cp ./bank-additional-full.csv gs://bank-marketing-model
gsutil mb创造了水桶gsutil cp将文件从本地路径复制到 GCS 存储桶
步骤 2:编写 Python 培训应用程序
如果你正在阅读这篇文章,很可能你已经知道如何编写一个端到端的 Python 程序来训练一个机器学习模型。无论如何,因为我们计划在云上训练模型,有一些步骤在某种程度上不同于通常的 Kaggle-ish 代码。
首先要记住的是,你只能使用 scikit-learn、XGBoost 或
Tensorflow 来训练你的模型(Pytorch 处于测试阶段,有一种方法可以使用定制的 Python 环境,但我们会在另一篇文章中看到)。
因此,Python 应用程序的基础是:
- 从存储中下载数据集
subprocess.call([
'gsutil', 'cp',
# Storage path
os.path.join('gs://', STORAGE_BUCKET, DATA_PATH),
# Local path
os.path.join(LOCAL_PATH, 'dataset.csv')
])df = pd.read_csv(os.path.join(LOCAL_PATH, 'dataset.csv'), sep=';')
- 做一些数据准备(分割训练测试、缺失插补等)并创建管道
train, test = train_test_split(df, test_size=args.test_size,
random_state=42)...pipeline = Pipeline([
# The ColumnTransformer divide the preprocessing process between
# categorical and numerical data
('data_prep',
ColumnTransformer([
('num_prep', StandardScaler(), num_features),
('cat_prep', OneHotEncoder(), cat_features)
])),
# ML model
('model',
RandomForestClassifier(
random_state=42,
n_jobs=args.n_jobs,
n_estimators=args.n_estimators,
max_depth=args.max_depth,
max_features=args.max_features if args.max_features is not
None else 'sqrt',
min_samples_split=args.min_samples_split,
class_weight='balanced',
max_samples=args.max_samples
))
])
- 训练模型
pipeline.fit(train, y_train)
- 获取一些性能指标
results = pd.DataFrame(
{'accuracy': [accuracy_score(y_train, pred_train),
accuracy_score(y_test, pred_test)],
'precision': [precision_score(y_train, pred_train, pos_label='yes'),
precision_score(y_test, pred_test, pos_label='yes')],
'recall': [recall_score(y_train, pred_train, pos_label='yes'),
recall_score(y_test, pred_test, pos_label='yes')],
'f1': [f1_score(y_train, pred_train, pos_label='yes'),
f1_score(y_test, pred_test, pos_label='yes')]},
index=['train', 'test']
)
- 将训练好的模型和结果存储在存储器上
subprocess.call([
'gsutil', 'cp',
# Local path of the model
os.path.join(LOCAL_PATH, 'model.joblib'),
os.path.join(args.storage_path, 'model.joblib')
])
subprocess.call([
'gsutil', 'cp',
# Local path of results
os.path.join(LOCAL_PATH, 'results.csv'),
os.path.join(args.storage_path, 'results.csv')
])
你可以在 Github 上找到完整的代码。
注意:在代码的顶部有一些你可以调整的参数。
步骤 3:在本地测试代码
在云平台上提交训练过程之前,最好在本地测试代码。无论是本地培训还是云端培训,我们都会使用gcloud;要运行的命令非常相似,但也有一些不同。
首先,用 AI 平台在本地训练模型,我们可以写一个命令“还原”这个逻辑:gcloud ai-platform(用 AI 平台)local(本地)train(训练模型)。我们添加了一些参数,其中一些特定于训练过程,另一些在我们的定制 Python 应用程序中定义。
进入主目录和src目录后,完整的命令如下:
gcloud ai-platform local train \
--module-name=src.train \
--package-path=./src \
-- \
--storage-path=gs://bank-marketing-model/test \
--n-estimators=25
让我们来看看参数:
module-name是要运行的 Python 模块的名称,以directory.python_file的形式package-path是模块目录的路径—-告诉我们开始发送自定义参数
由于这是一次测试,我们为随机森林指定了少量的树。
请记住,即使这是一个本地测试运行,它也会创建所有的工件,并将它们保存到您的存储桶中。如果一切运行无误,我们就可以切换到云上的实际训练了!
第四步:在人工智能平台上训练
现在我们已经编写了应用程序并对其进行了测试,我们终于可以在平台上训练我们的模型了。例如,我们可以实例化一个多核机器类型,并将森林的训练并行化。
如前所述,bash 代码非常相似,但是我们必须调用另一组命令。我们用jobs submit training代替local train:
gcloud ai-platform jobs submit training $JOB_NAME \
--module-name=src.train \
--package-path=./src \
--staging-bucket=gs://bank-marketing-model \
--region=$REGION \
--scale-tier=CUSTOM \
--master-machine-type=n1-standard-8 \
--python-version=3.7 \
--runtime-version=2.2 \
-- \
--storage-path=gs://bank-marketing-model/$JOB_NAME \
--n-estimators=500 \
--n-jobs=8
让我们再一次看看新的参数:
module-name和package-path与之前相同staging-bucket指向存储训练工件的 Google 存储桶region是谷歌云地区(此处为完整列表)。由于为这些作业实例化的机器位于世界各地,您可能希望指定在哪里实例化机器。如果您不确定如何设置该参数,只需设置离您最近的区域即可!scale-tier指定用于培训的机器类型。这是一个
高级参数,您可以将其设置为默认配置(如BASIC或STANDARD_1),或者将其设置为CUSTOM并使用master-machine-type参数来使用机器的低级定义。在我们的示例中,我们使用一台带有 8 内核的标准机器。我们也可以指定highmem(更多内存)或highcpu(更多虚拟 CPU)来代替standard``。这里的[是scale-tier`和可用机器的完整列表](https://cloud.google.com/ai-platform/training/docs/machine-types#compare-machine-types)。python-version和runtime-version参数指定安装在机器上的软件包的主干。对于每个运行时 ( 这里是完整列表)我们都有一个或多个可以使用的 Python 版本,以及一个已经安装的 Python 包列表。
额外提示:如果你想安装一个运行时列表中没有的包,在你的应用程序顶部添加一个“pip”命令,比如
subprocess.call(["pip “,” install ",包名)
- 对于我们的自定义参数,我们设置了更多的估计器,并指定并行运行 8 个作业。
注意:上面代码中的$JOB_NAME不是一个有效的名称,但是它是对之前定义的 bash 变量的引用。每次指定一个
不同的工作名称是非常重要的。例如,在 cloud_train 和
脚本中可以看到,我们可以指定
JOB_NAME=bank_marketing_$(date +%Y%m%d_%H%M%S)
所以后缀每次都会随着实际的日期和时间而改变。
如果你是第一次使用这个工具,它可能会要求你启用一个特定的 Google API(像ml.googleapis.com):接受启用它并继续。如果一切正常,该命令应该返回如下内容

作者图片
在你的谷歌人工智能平台作业控制台中,你应该会看到新的作业正在运行

作者图片
现在,您可以通过两种方式监控培训作业:
- 使用建议的命令
gcloud ai-platform jobs stream-logs $JOB_NAME - 点击作业控制台上的查看日志

作者图片
万岁!作业正确结束。让我们来看看我们的储物桶:

作者图片
我们有了model.joblib对象、具有模型性能的results.csv文件以及由作业自动创建的用于存储 Python 应用程序的文件夹。
让我们来看看模型的性能…我们可以下载结果文件,或者键入命令
gsutil cat gs://your-bucket/your/path/to/results.csv
直接在命令行上查看文件。
对于我的训练模型,我得到了以下结果:
Measure | Train | Test
------------|----------|----------
Accuracy | 81.53% | 81.01%
Precision | 37.00% | 36.40%
Recall | 91.42% | 90.05%
F1 | 52.68% | 51.85%
这些是相当好的结果,但是我们可以通过 调整模型的超参数 来做得更好。在下一篇文章中,我们将看到如何稍微改变训练应用程序,使 AI 平台使用贝叶斯优化过程搜索最佳超参数!
感谢阅读,我希望你会发现这是有用的!
使用 BigQuery ML 为 Google Analytics 数据训练推荐模型
协同过滤推荐报纸文章
这篇文章演示了如何实现一个 WALS(矩阵分解)模型来进行协同过滤。对于协同过滤,我们不需要知道任何关于用户或内容的信息。本质上,我们需要知道的只是 userId、itemId 和特定用户对特定项目的评价。

图片由 geralt (cc0)提供
使用花费在页面上的时间作为评级
在这种情况下,我们正在处理报纸文章。该公司不会要求用户给文章打分。然而,我们可以用花在网页上的时间来代替评分。
以下是获取每个用户在每篇报纸文章上花费的持续时间的查询(通常,我们还会添加一个时间过滤器(“最近 7 天”),但我们的数据集本身仅限于几天。):
WITH CTE_visitor_page_content AS (
SELECT
# Schema: [https://support.google.com/analytics/answer/3437719?hl=en](https://support.google.com/analytics/answer/3437719?hl=en)
# For a completely unique visit-session ID, we combine combination of fullVisitorId and visitNumber:
CONCAT(fullVisitorID,'-',CAST(visitNumber AS STRING)) AS visitorId,
(SELECT MAX(IF(index=10, value, NULL)) FROM UNNEST(hits.customDimensions)) AS latestContentId,
(LEAD(hits.time, 1) OVER (PARTITION BY fullVisitorId ORDER BY hits.time ASC) - hits.time) AS session_duration
FROM
`cloud-training-demos.GA360_test.ga_sessions_sample`,
UNNEST(hits) AS hits
WHERE
# only include hits on pages
hits.type = "PAGE"
GROUP BY
fullVisitorId,
visitNumber,
latestContentId,
hits.time )
-- Aggregate web stats
SELECT
visitorId,
latestContentId as contentId,
SUM(session_duration) AS session_duration
FROM
CTE_visitor_page_content
WHERE
latestContentId IS NOT NULL
GROUP BY
visitorId,
latestContentId
HAVING
session_duration > 0
LIMIT 10
结果看起来像这样:

将评级字段缩放至[0,1]
我们希望花更多时间看一篇文章的访问者会更喜欢它。然而,会话持续时间可能有点可笑。注意第 3 行显示的 55440 秒(15 小时)。我们可以绘制数据集中会话持续时间的直方图:

因此,让我们按会话持续时间的中位数(平均持续时间将受到异常值的显著影响)来缩放和裁剪它的值:
...normalized_session_duration AS (
SELECT APPROX_QUANTILES(session_duration,100)[OFFSET(50)] AS median_duration
FROM aggregate_web_stats
)
SELECT
* EXCEPT(session_duration, median_duration),
CLIP(0.3 * session_duration / median_duration, 0, 1.0) AS normalized_session_duration
FROM
aggregate_web_stats, normalized_session_duration
其中剪辑定义如下:
CREATE TEMPORARY FUNCTION CLIP_LESS(x FLOAT64, a FLOAT64) AS (
IF (x < a, a, x)
);
CREATE TEMPORARY FUNCTION CLIP_GT(x FLOAT64, b FLOAT64) AS (
IF (x > b, b, x)
);
CREATE TEMPORARY FUNCTION CLIP(x FLOAT64, a FLOAT64, b FLOAT64) AS (
CLIP_GT(CLIP_LESS(x, a), b)
);
现在,会话持续时间已调整,并在正确的范围内:

将所有东西放在一起,并将其具体化为表格:
CREATE TEMPORARY FUNCTION CLIP_LESS(x FLOAT64, a FLOAT64) AS (
IF (x < a, a, x)
);
CREATE TEMPORARY FUNCTION CLIP_GT(x FLOAT64, b FLOAT64) AS (
IF (x > b, b, x)
);
CREATE TEMPORARY FUNCTION CLIP(x FLOAT64, a FLOAT64, b FLOAT64) AS (
CLIP_GT(CLIP_LESS(x, a), b)
);
CREATE OR REPLACE TABLE advdata.ga360_recommendations_data
AS
WITH CTE_visitor_page_content AS (
SELECT
# Schema: [https://support.google.com/analytics/answer/3437719?hl=en](https://support.google.com/analytics/answer/3437719?hl=en)
# For a completely unique visit-session ID, we combine combination of fullVisitorId and visitNumber:
CONCAT(fullVisitorID,'-',CAST(visitNumber AS STRING)) AS visitorId,
(SELECT MAX(IF(index=10, value, NULL)) FROM UNNEST(hits.customDimensions)) AS latestContentId,
(LEAD(hits.time, 1) OVER (PARTITION BY fullVisitorId ORDER BY hits.time ASC) - hits.time) AS session_duration
FROM
`cloud-training-demos.GA360_test.ga_sessions_sample`,
UNNEST(hits) AS hits
WHERE
# only include hits on pages
hits.type = "PAGE"
GROUP BY
fullVisitorId,
visitNumber,
latestContentId,
hits.time ),
aggregate_web_stats AS (
-- Aggregate web stats
SELECT
visitorId,
latestContentId as contentId,
SUM(session_duration) AS session_duration
FROM
CTE_visitor_page_content
WHERE
latestContentId IS NOT NULL
GROUP BY
visitorId,
latestContentId
HAVING
session_duration > 0
),
normalized_session_duration AS (
SELECT APPROX_QUANTILES(session_duration,100)[OFFSET(50)] AS median_duration
FROM aggregate_web_stats
)
SELECT
* EXCEPT(session_duration, median_duration),
CLIP(0.3 * session_duration / median_duration, 0, 1.0) AS normalized_session_duration
FROM
aggregate_web_stats, normalized_session_duration
培训推荐模型
表格数据现在看起来像这样:

我们可以按如下方式训练模型:
CREATE OR REPLACE MODEL advdata.ga360_recommendations_model
OPTIONS(model_type='matrix_factorization',
user_col='visitorId', item_col='contentId',
rating_col='normalized_session_duration',
l2_reg=10)
AS
SELECT * from advdata.ga360_recommendations_data
注意:如果您正在使用按需定价计划,您将会收到一条错误消息“训练矩阵分解模型不可用于按需使用。Totrain,请根据 BigQuery 公共文档中的说明设置预订(弹性或常规)。”。这是因为当基于数据定价时,矩阵分解往往变得昂贵。灵活插槽基于计算进行定价,而且便宜得多。所以, 设置 flex 槽位——你可以使用它们少至 60 秒。
您将使用 l2_reg 的值,它会为您的数据集产生合理的误差。你怎么知道合理?检查评估选项卡:

您希望平均值和中位数绝对误差相似,并且比 0.5 小得多(随机概率将是 0.5)。
做预测
以下是如何为每个用户找到前 3 条建议:
SELECT
visitorId,
ARRAY_AGG(STRUCT(contentId, predicted_normalized_session_duration)
ORDER BY predicted_normalized_session_duration DESC
LIMIT 3)
FROM ML.RECOMMEND(MODEL advdata.ga360_recommendations_model)
WHERE predicted_normalized_session_duration < 1
GROUP BY visitorId
这会产生:

尽情享受吧!
非常感谢卢卡·塞姆普雷和伊万·琼斯帮助弄清楚谷歌分析数据。
用对比学习训练一个初步的说话人确认模型
深入分析
说话人确认,深度学习,对比学习

我们的 Android 应用
对于我在大学的 Android 开发课程的小组项目组件,我们的团队构建并部署了一个身份验证系统,该系统通过说话者的语音档案进行身份验证。
继我描述语音认证系统的高级架构的上一篇文章(见下一段)之后,本文试图深入研究所使用的深度学习模型的开发过程。
我之前的文章可以在这里找到(一个带有移动部署的初级语音认证系统)。

不要害怕使用你的声音(照片由杰森·罗斯韦尔在 Unsplash 上拍摄)
在这篇短文中,我将描述开发语音认证模型的不同阶段,并讨论在此过程中收集到的一些个人学习经历。
下面是这篇文章的概述:
- 问题陈述
- 高级模型设计
- 数据预处理
- 通过对比学习的语音编码器
- 用于认证的二元分类器
- 模型性能
问题陈述
在我们开始之前,我们需要明确我们是如何尝试构建语音认证问题的。
语音认证主要有两种方式(广义而言):说话人识别和说话人确认。虽然这两种方法非常相关,但是当比较两个系统的相关安全风险时,它们将导致两个系统具有非常不同的特征。
问题定义:
- 说话人识别 : n 分类任务:给定一个输入话语,从 n 个已知说话人(类)中识别出正确的说话人。
- 说话人确认:二进制分类任务:给定说话人具有声明身份的输入话语,确定该声明身份是否正确。
我们可以看到,在说话人识别中,我们假设给定的输入话语属于我们已经知道的说话人(也许是办公室环境),并且我们正试图从 n 个已知的类别/说话人中挑选出最接近的匹配。
相反,在说话人验证中,我们假设我们不知道给定的输入话语属于谁(事实上我们不需要知道)。我们关心的是给定的一对输入话语是否来自同一个人。
准确地说,从整个说话人验证系统的角度来看,系统“知道”说话人自称是某个“已知”的人,而从模型的角度来看,模型只接收一对语音样本,并确定它们是否来自同一个人/来源。
想象一下使用常规的用户名和密码认证系统。系统知道你自称是谁(用户名),并检索参考密码的存储副本。然而,密码检查器只是检查参考密码是否与输入密码匹配,并将认证结果返回给验证系统。
在这个项目中,语音认证问题被框定为说话人确认问题。
旁白:
【* *在这一点上,值得注意的是,还有另一类语音分析问题叫做说话人日记化,它寻求分离出多人同时说话的源信号。
发言者日记涉及多人同时发言的场景(想象将麦克风放在两个坐满谈话者的桌子中间),我们试图隔离每个独特发言者的语音音频波形。这可能需要多个话筒从不同角度捕捉同一场景,或者只需要一个话筒(最困难的问题)。
我们可以看到这很容易变得非常复杂。一个例子是在给定对话的音频记录中识别谁在说话。在试图说出说话者的名字(说话者识别)之前,必须分离出对话中每个人的语音信号(说话者日记化)。当然,混合方法是存在的,这是一个活跃的研究领域。**]
高级模型设计
为迁移学习转换数据 —对于这项任务,我想尽可能地利用迁移学习,以避免独自构建复杂且高性能的模型。
为了实现这个目标,语音音频信号被转换成类似某种图像的频谱图(更准确地说,是 melspectrograms)。将音频转换成 melspectrograms 后,我可以使用 PyTorch 中任何流行的图像模型,如 MobileNetV2、DenseNet 等。

来自其中一个扬声器的 melspectrogram 的样本/切片
事后看来,我意识到我可以使用基于小波变换(WT)的方法,而不是基于傅立叶变换(FT)的 melspectrogram,来获得“更清晰”的光谱图图像。Youtube 视频中的一个演示比较了心脏 ECG 信号的小波变换和傅立叶变换之间的“图像质量”差异,结果是小波变换得到的频谱图在视觉上比傅立叶变换得到的频谱图更加“清晰”。
利用对比学习 —每个人都熟悉的对比学习的经典例子是使用三连音损失的设置。该设置每次编码 3 个样本:参考样本、阳性样本和阴性样本(2 个候选样本)。目标是减小参考样本和正样本之间的编码向量的距离,同时增加参考样本和负样本之间的编码向量的距离。
在我的方法中,我不想将候选样本的数量限制在 2 个。相反,我使用了一种类似于 SimCLR 的方法。艾尔。2020),其中使用多个候选样本,其中一个是阳性样本。然后“对比分类器”被迫从一堆候选样本中挑选出阳性样本。在后面的部分中有更多的细节。
两阶段迁移学习方法——为了解决说话人确认问题,我们将分两个阶段训练模型。
首先,将通过对比学习来训练说话人语音编码器。如上所述,对比学习将涉及多个候选样本,而不是通常的三重损失设置的正负对。
第二,然后在预训练的语音编码器之上训练二进制分类器。这将允许语音编码器在用于该转移学习任务(二进制分类器)之前被单独训练。
数据预处理
vox Cele 1 数据集——为了训练一个模型来识别一个说话者的声音轮廓(不管那意味着什么),我选择了使用vox Cele 1公共数据集。
VoxCeleb1 数据集包含野外多个说话者的音频片段,即说话者在“自然”或“常规”设置中说话。正在采访数据集中的讲话者,并且管理数据集中的音频片段,使得每个片段包含讲话者正在讲话的采访片段。该数据集包含在不同采访环境下对每个说话者的多次采访,并使用各种类型的设备,为我提供了我希望我的语音认证系统能够处理的可变性。
对于这个项目,只使用了音频数据(视频数据可用)。还有其他认证系统试图整合多种模式的数据(例如视频结合音频来检测语音是否是现场制作的),但我认为这超出了我的项目范围。
音频波形到声谱图 —为了能够利用流行的图像模型架构,语音音频信号被转换成类似于某种图像的声谱图。
首先,来自同一说话者的多个短音频样本被组合成一个长音频样本。由于 melspectrogram 基于短时傅立叶变换(STFT),因此可以将整个长音频样本一次性转换成 melspectrogram,并且可以从长频谱图中获得更小的频谱图切片。由于长音频样本是由来自单个唯一说话者的较小音频样本组成的,因此从长样本中提取切片应该会迫使模型专注于挑选出每个单独说话者的语音简档的独特特征。

来自一个扬声器的串联音频样本
接下来,使用 LibROSA (Librosa)库将长音频样本转换成 melspectrograms。以下是使用的关键参数:
- 目标采样率:22050
- STFT 之窗:2048
- STFT 跳长度:512
- 梅尔斯:128
功率谱然后被转换成对数标度的分贝数。因为我们是用图像网络进行分析,所以我们希望谱图中的“图像”特征在某种程度上均匀分布。

一个扬声器的 melspectrogram
创建“图像” —通过从长光谱图中截取较小的光谱图来进行采样。
光谱图“图像”以 RGB 图像格式创建为 128 x 128 x 3 阵列。在长光谱图上选择一个随机起始点,并通过将窗口滑动半步(128/2=64)获得三个 128×128 光谱图切片。然后通过[-1,1]之间的最大绝对值对“图像”进行归一化。
最初,我将同一个光谱切片复制了 3 次,将“灰度”图像转换为“RGB”图像。然而,我决定通过为每个“RGB”图像放置 3 个略有不同的切片,将更多信息打包到每个光谱图“图像”中,因为 3 个通道不具有普通 RGB 图像所具有的通常意义。使用这种滑动技术后,性能似乎略有提高。
通过对比学习的语音编码器
数据采样 —以下是用于语音编码器对比学习的数据采样的一些细节。[* *频谱图切片将被称为“图像”]
对于每个时期,将 200 个(总共 1000 个)随机全长光谱图载入存储器(“子样本”)(由于资源限制,不是所有的 1000 个全长光谱图都可以一次载入)。
对于每一行,使用 1 个参考和 5 个候选。候选图像包含 4 幅负图像和 1 幅正图像(随机混洗),并且图像是从子样本中随机生成的。
每个 epoch 有 2,000 行,批处理大小为 15 (MobileNetV2)和 6 (DenseNet121)。

语音编码器对比学习设置
多连体编码器网络 —对于编码器网络,使用的基本型号为 MobileNetV2 和 DenseNet121。编码器层大小为 128(替换基本模型中的 Imagenet 分类器)。
为了便于对比学习,构建了多连体编码器模型包装器作为 torch 模块。包装器对每个图像使用相同的编码器,并且便于参考图像和候选图像之间的余弦相似性计算。
对比损失+类内方差减少 —对比损失和方差减少这两个目标被连续最小化(由于资源限制,理想情况下,这两个目标的损失应该相加并最小化)。计算每批的对比损失,同时每 2 批进行方差减少(类内 MSE)。
对于【对比损失】的争夺,继陈等人之后。艾尔。(2020)中,该问题被公式化为 n 分类问题,其中该模型试图从所有候选中识别正面图像。针对参考编码计算所有候选编码的余弦相似性,并且针对余弦相似性计算 softmax,从而产生概率。按照正常的 n 分类问题,交叉熵损失被最小化。
对于类内方差减少,目标是在编码空间将来自同一类的图像推得更近。对来自相同类别/说话者的图像进行采样,并计算平均编码向量。针对平均值(类内方差)计算编码的 MSE 损失,并且在反向传播之前将 MSE 损失缩放 0.20。
用于认证的二元分类器
数据采样 —以下是说话人确认二进制分类器使用的数据采样的一些细节。
对于每个时期,将 200 个(总共 1000 个)随机全长光谱图载入存储器(“子样本”)(由于资源限制,不是所有的 1000 个全长光谱图都可以一次载入)。
对于每个参考图像,生成 2 个测试图像,1 个正图像和 1 个负图像。这为每个参考图像产生 2 对/行,真实对(正)和视点替用图像对(负)。
图像是从子样本中随机生成的。每个 epoch 有 4,000 行,批处理大小为 320 (MobileNetV2 和 DenseNet121)。

说话人确认二进制分类器设置
验证二元分类器网络 —底层编码器网络是来自对比学习步骤的预训练编码器网络,其中权重在训练期间被冻结。
二进制分类器被设置为一个连体网络,其中计算来自输入对的编码向量的绝对差。然后在绝对差值层的顶部建立二元分类器。
模型培训(其他详细信息)
学习速率循环 —循环学习速率提高了对比学习步骤和二元分类器步骤中的模型准确性。
torch.optim.lr_scheduler。使用 CyclicLR(),步长(默认)为 2000,循环模式(默认)为“三角形”,没有动量循环(Adam 优化器)。
用于循环的学习率范围如下:
- 带对比学习的语音编码器: 0.0001 到 0.001
- B 二进制分类器: 0.0001 到 0.01
模型性能
正如预期的那样,模型性能不如最先进的模型。我认为促成因素是:
- melspectrogram 不是我能使用的最好的信号转换。基于小波变换的方法可能产生更高质量的频谱图“图像”。
- 使用的基本图像模型不是最先进的模型,因为我不能在我的中等大小的 GPU (3GB VRAM)上使用非常大的模型。也许像 ResNet 或 ResNeXt 这样更强大的模型可能会产生更好的结果。
- 只使用了一个语音数据集(VoxCeleb1)。更大数量和种类的数据肯定是可以使用的(但是,唉,最后期限越来越近了)。
以下是可比模型的等误差率(EER ):
- 我最好的模特 EER 19.74% (VoxCeleb)
- 乐和奥多比(2018),从零开始的最佳模型 EER 10.31% (VoxCeleb)
- 荣格等人。艾尔。(2017 年), EER 7.61% (RSR2015 数据集)
其他发现
基础模型大小 —使用更大的基础模型提高了分类性能(不足为奇)(MobileNetV2 vs DenseNet121)。
类内方差减少的效果 —类内方差减少提高了两个基础模型的分类性能。事实上,方差减少后的 MobileNetV2 的性能提高到了与 DenseNet121 相当的水平。

ROC(左)和 DET(右)曲线
下面是使用 MobileNetV2 和 DenseNet121 的二元分类分数分布[P(is_genuine)],有方差减少和无方差减少。

MobileNetV2 基本型号—不含/含方差减少(左/右)

DenseNet121 基本型号—无/有方差减少(左/右)
参考
陈,t .,科恩布利思,s .,m .和辛顿,g .,2020。视觉表征对比学习的简单框架。arXiv 预印本 arXiv:2002.05709
Jung,j .,Heo,h .,Yang,I .,Yoon,s .,Shim,h .和 Yu,h .,2017 年 12 月。基于 d 矢量的说话人确认系统。在 2017 人工智能、网络与信息技术国际研讨会(ANIT 2017) 。亚特兰蒂斯出版社。
n . le 和 j . m . Odobez,2018 年 9 月。基于类内距离方差正则化的鲁棒区分性说话人嵌入。在散置(第 2257–2261 页)。
在您自己的数据集上训练 TensorFlow 快速 R-CNN 对象检测模型
遵循本教程,您只需更改两行代码,就可以将对象检测模型训练到您自己的数据集。

寻找红血球、白血球和血小板!
计算机视觉正在彻底改变医学成像。算法正在帮助医生识别他们可能漏掉的十分之一的癌症患者。甚至有早期迹象胸部扫描可以帮助鉴别新冠肺炎,这可能有助于确定哪些病人需要实验室检测。
为此,在本例中,我们将使用 TensorFlow 对象检测 API 训练一个对象检测模型。虽然本教程描述了在医学成像数据上训练模型,但它可以很容易地适应任何数据集,只需很少的调整。
不耐烦?直接跳到 Colab 笔记本这里。
我们示例的各个部分如下:
- 介绍我们的数据集
- 准备我们的图像和注释
- 创建 TFRecords 和标签映射
- 训练我们的模型
- 模型推理
在整个教程中,我们将利用 Roboflow ,这是一个大大简化我们的数据准备和训练过程的工具。Roboflow 对于小数据集是免费的,所以我们将为这个例子做好准备!
我们的示例数据集:血细胞计数和检测(BCCD)
我们的示例数据集是 364 幅细胞群图像和 4888 个标识红细胞、白细胞和血小板的标签。最初由 comicad 和 akshaymaba 于两年前开源,可在https://public . robo flow . ai获得。(请注意,Roboflow 上的版本与最初版本相比,包含了微小的标签改进。)

截图 via Roboflow 公众。
幸运的是,这个数据集是预先标记的,所以我们可以直接为我们的模型准备图像和注释。
了解患者红细胞、白细胞和血小板的存在及其比例是识别潜在疾病的关键。使医生能够提高识别上述血细胞计数的准确性和处理量,可以大大改善数百万人的医疗保健!
*对于你的定制数据,*考虑以自动化的方式从谷歌图片搜索中收集图片,并使用像 LabelImg 这样的免费工具给它们加标签。
准备我们的图像和注释
直接从数据收集到模型训练会导致次优的结果。数据可能有问题。即使没有,应用图像增强也会扩展数据集并减少过度拟合。
为对象检测准备图像包括但不限于:
- 验证您的注释是否正确(例如,图像中没有任何注释超出框架)
- 确保图像的 EXIF 方向正确(即图像在磁盘上的存储方式不同于在应用程序中的查看方式,请参阅更多)
- 调整图像大小并更新图像注释以匹配新调整的图像大小
- 检查数据集的健康状况,如其类别平衡、图像大小和纵横比,并确定这些如何影响我们想要执行的预处理和增强
- 各种可以提高模型性能的颜色校正,如灰度和对比度调整
与表格数据类似,清理和扩充图像数据比模型中的架构更改更能提高最终模型的性能。
让我们看看数据集的“健康检查”:

可用此处。
我们可以清楚地看到,我们的数据集中存在很大的类别不平衡。在我们的数据集中,红细胞明显多于白细胞或血小板,这可能会给我们的模型训练带来问题。根据我们的问题环境,我们可能希望将一个类的识别优先于另一个类。
此外,我们的图像都是相同的大小,这使得我们的调整的决定更加容易。

可用此处。
当检查我们的对象(细胞和血小板)如何分布在我们的图像中时,我们看到我们的红细胞到处都是,我们的血小板有点向边缘分散,我们的白细胞聚集在我们图像的中间。考虑到这一点,当检测红细胞和血小板时,我们可能会厌倦裁剪图像的边缘,但如果我们只是检测白细胞,边缘就显得不那么重要了。我们还想检查我们的训练数据集是否代表样本外图像。例如,我们能否期望白细胞通常集中在新收集的数据中?
*对于您的自定义数据集,*按照这个简单的逐步指南将您的图像及其注释上传到 Roboflow。
创建 TFRecords 和标签映射
我们将使用速度更快的 R-CNN 的 TensorFlow 实现(稍后将详细介绍),这意味着我们需要为 TensorFlow 生成 TFRecords,以便能够读取我们的图像及其标签。TFRecord 是一种包含图像及其注释的文件格式。它在数据集级别序列化,这意味着我们为训练集、验证集和测试集创建一组记录。我们还需要创建一个 label_map,它将我们的标签名称(RBC、WBC 和血小板)映射为字典格式的数字。
坦白说,TFRecords 有点繁琐。作为开发人员,您的时间应该集中在微调您的模型或使用您的模型的业务逻辑上,而不是编写冗余代码来生成文件格式。因此,我们将使用 Roboflow 通过几次点击来为我们生成 TFRecords 和 label_map 文件。
首先,访问我们将在这里使用的数据集:https://public.roboflow.ai/object-detection/bccd/1(注意,我们使用的是数据集的特定版本。图像尺寸已调整为 416x416。)
接下来,点击“下载”系统可能会提示您使用 email 或 GitHub 创建一个免费帐户。
下载时,您可以下载各种格式的文件,下载到您的机器上,或者生成一个代码片段。出于我们的目的,我们希望生成 TFRecord 文件并创建一个下载代码片段(不是本地下载文件)。

导出我们的数据集。
会给你一段代码来复制。该代码片段包含一个到源图像、它们的标签以及一个划分为训练集、验证集和测试集的标签映射的链接。抓紧了!
*对于您的自定义数据集,*如果您按照的分步指南上传图像,系统会提示您创建训练、有效、测试分割。您还可以将数据集导出为您需要的任何格式。
训练我们的模特
我们将训练一个更快的 R-CNN 神经网络。更快的 R-CNN 是一个两级对象检测器:首先它识别感兴趣的区域,然后将这些区域传递给卷积神经网络。输出的特征图被传递到支持向量机(VSM)用于分类。计算预测边界框和基本事实边界框之间的回归。更快的 R-CNN,尽管它的名字,被认为是一个比其他推理选择(如 YOLOv3 或 MobileNet)更慢的模型,但稍微更准确。为了更深入的探究,请考虑这篇文章中的更多内容!
更快的 R-CNN 是 TensorFlow 对象检测 API 默认提供的许多模型架构之一,包括预训练的权重。这意味着我们将能够启动一个在 COCO(上下文中的公共对象)上训练的模型,并使它适应我们的用例。

利用 TensorFlow 模型动物园。(来源)
TensorFlow 甚至在 COCO 数据集上提供了几十个预先训练好的模型架构。
我们还将利用 Google Colab 进行计算,这是一种提供免费 GPU 的资源。我们将利用 Google Colab 进行免费的 GPU 计算(最多 12 小时)。
我们的 Colab 笔记本就是这里的。这个所基于的 GitHub 库就是这里的**。******
您需要确保使用您自己的 Roboflow 导出数据更新单元格调用的代码片段。除此之外,笔记本按原样训练!
关于这款笔记本,有几点需要注意:
- 为了运行初始模型,训练步骤的数量被限制为 10,000。增加这个值可以改善你的结果,但是要注意过度拟合!
- 具有更快 R-CNN 的模型配置文件包括在训练时的两种类型的数据扩充:随机裁剪,以及随机水平和垂直翻转。
- 模型配置文件的默认批量大小为 12,学习率为 0.0004。根据你的训练结果调整这些。
- 该笔记本包括一个可选的 TensorBoard 实现,使我们能够实时监控模型的训练性能。
在我们使用 BCCD 的例子中,经过 10,000 步的训练后,我们在 TensorBoard 中看到如下输出:

总的来说,我们的损失在 10,000 个纪元后继续下降。

我们正在寻找合适的盒子,但我们有过度适应的风险。

回忆可能表明一个类似的过度拟合的故事。
在这个例子中,我们应该考虑收集或生成更多的训练数据,并利用更大的数据扩充。
对于您的自定义数据集,只要您将 Roboflow 导出链接更新为特定于您的数据集,这些步骤基本相同。留意你的冲浪板输出是否过度配合!
模型推断
当我们训练我们的模型时,它的拟合度存储在一个名为./fine_tuned_model的目录中。我们的笔记本中有保存模型拟合的步骤——要么本地下载到我们的机器上,要么通过连接到我们的 Google Drive 并将模型拟合保存在那里。保存我们模型的拟合不仅允许我们在以后的生产中使用它,而且我们甚至可以通过加载最新的模型权重从我们停止的地方恢复训练!
在这个特定的笔记本中,我们需要将原始图像添加到/data/test 目录中。它包含 TFRecord 文件,但是我们希望我们的模型使用原始(未标记的)图像来进行预测。
我们应该上传我们的模型没有见过的测试图像。为此,我们可以将原始测试图像从 Roboflow 下载到我们的本地机器上,并将这些图像添加到我们的 Colab 笔记本中。
重新访问我们的数据集下载页面:https://public.roboflow.ai/object-detection/bccd/1
点击下载。对于格式,选择 COCO JSON 并下载到您自己的计算机上。(实际上,您可以下载除 TFRecord 之外的任何格式,以获得独立于注释格式的原始图像!)
在本地解压缩该文件后,您将看到测试目录的原始图像:

现在,在 Colab 笔记本中,展开左侧面板以显示测试文件夹:

右键单击“测试”文件夹并选择“上传”现在,您可以从本地机器上选择您刚刚下载的所有图像!
在笔记本中,其余的单元将介绍如何加载我们创建的已保存、已训练的模型,并在您刚刚上传的图像上运行它们。
对于 BCCD,我们的输出如下所示:

我们的模型在 10,000 个纪元后表现得相当好!
对于您的自定义数据集,这个过程看起来非常相似。你不用从 BCCD 下载图像,而是从你自己的数据集中下载图像,然后相应地重新上传。
下一步是什么
你做到了!您已经为自定义数据集训练了对象检测模型。
现在,在生产中使用这个模型回避了识别您的生产环境将会是什么的问题。例如,您会在移动应用程序中、通过远程服务器、甚至在 Raspberry Pi 上运行模型吗?如何使用模型决定了保存和转换其格式的最佳方式。
根据你的问题考虑这些资源作为下一步:转换到 TFLite (针对 Android 和 iPhone),转换到 CoreML (针对 iPhone 应用),转换到远程服务器上使用,或者部署到 Raspberry Pi 。
另外,订阅 Roboflow 更新当我们发布更多类似的内容时,第一个知道。
使用自定义数据集训练 YOLOv3 对象检测模型
遵循此指南,您只需更改一行代码,就可以将对象检测模型训练到您自己的数据集。 故事在这里发表过 。

在我们的引导式示例中,我们将训练一个模型来识别棋子。(完整视频)
不耐烦? 跳到 Colab 笔记本。
物体检测模型非常强大——从在照片中寻找狗到改善医疗保健,训练计算机识别哪些像素构成物品释放了近乎无限的潜力。然而,阻止构建新应用程序的最大障碍之一是采用最先进的、开源的和免费的资源来解决定制问题。
在本帖中,我们将介绍如何使用简化图像管理、架构和培训的工具为对象检测准备自定义数据集。在每一节中,我们将首先遵循我为一个特定示例所做的工作,然后详细说明您需要对自定义数据集进行哪些修改。我的建议是,在将这些步骤应用于您的问题之前,您应该一步一步地重复我的过程。
让我们从清楚地描述我们的过程开始。
任何给定的机器学习问题都是从一个格式良好的问题陈述、数据收集和准备、模型训练和改进以及推理开始的。通常,我们的过程不是严格线性的。例如,我们可能会发现我们的模型在一种类型的图像标签上表现很差,我们需要重新收集该示例的更多数据。

通用的机器学习工作流程。
问题陈述
国际象棋是一种充满智慧和策略的有趣游戏。提高你的游戏能力需要了解你以前在哪里犯了明显的错误,以及在同样的情况下一个比你强的玩家可能做出了什么举动。
因此,拥有一个能够识别游戏状态并记录下每一步棋的系统是很有价值的。这不仅需要确定给定的棋子是什么,还需要确定该棋子在棋盘上的位置——这是从图像识别到物体检测的一次飞跃。出于本文的目的,我们将把问题限制在对象检测部分:我们能否训练一个模型来识别哪个棋子是哪个棋子以及这些棋子属于哪个玩家(黑人或白人),以及一个模型在推理中找到至少一半的棋子。

图像处理问题,改编自斯坦福的cs 231n 课程
对于你的非象棋问题陈述,考虑将问题空间限制在一个特定的棋子上。此外,考虑模型性能的最低可接受标准。(在这个例子中,我们被限制为仅仅识别正确的边界框,并且为可接受的标准设置相对较低的标准。更严格地说,我们可能想要识别我们模型的 IOU 或mAP——但那是另一篇文章。)
数据收集
为了识别棋子,我们需要收集和注释棋子图像。
我在收集数据时做了一些假设。首先,我所有的图像都是从同一个角度拍摄的。我在棋盘旁边的桌子上架起了一个三脚架。作为推论,这将要求我的相机处于捕捉训练数据的同一角度——并不是所有的棋手都可能在比赛前架起三脚架。其次,我创建了 12 个不同的类:六个棋子乘以两种颜色各一个。

来自我们数据集的(未标记的)图像示例。
最终,我收集了 292 张照片。我标记了这些图片中的所有部分,总共有 2894 个注释。该数据集在此公开。对于标签,有许多高质量、免费和开源的工具可用,如 LabelImg 。我正好用了 RectLabel ,3 美元/月。

我在 RectLabel 中标记的示例图像。
对于你的非象棋问题,考虑收集与你的模型在生产中的表现相关的图像。这意味着确保你有一个相似的角度,光线,质量和框架中的物体。定型集考虑的模型在生产中可能遇到的情况越多,其性能就越好。添加标签时,最好绘制包含整个对象的边界框,即使对象和边界框之间有少量空间。简而言之,不要用你的边界框剪切掉任何底层对象。如果一个物体挡住了另一个物体的视线,贴上标签,就好像你可以看到整个物体一样(见上面的白主教和白鲁克的例子)。
如果你正在寻找已经带注释的图像,考虑像 Roboflow 或 Kaggle 这样的网站上的物体检测数据集。
数据准备
直接从数据收集到模型训练会导致次优的结果。数据可能有问题。即使没有,应用图像增强也会扩展数据集并减少过度拟合。
为对象检测准备图像包括但不限于:
- 验证您的注释是否正确(例如,图像中没有任何注释超出框架)
- 确保图像的 EXIF 方向正确(即,图像在磁盘上的存储方式不同于在应用程序中查看的方式,查看更多信息
- 调整图像大小并更新图像注释以匹配新调整的图像大小
- 各种可以提高模型性能的颜色校正,如灰度和对比度调整
- 格式化注释以匹配模型输入的需求(例如,为 TensorFlow 生成 TFRecords,或者为 YOLO 的某些实现生成一个平面文本文件)。
与表格数据类似,清理和扩充图像数据比模型中的架构更改更能提高最终模型的性能。
Roboflow Organize 专为无缝解决这些挑战而构建。事实上,Roboflow Organize 将您需要编写的代码减少了一半,同时为您提供了更多的预处理和增强选项。
让我们学习加载 MNIST 以外的影像数据集!( 来源 )
对于我们的特定国际象棋问题,我们已经预处理的国际象棋数据是可用的这里。
我们将使用名为“416 x416-自动定向”的下载版本
在我们的教程中,我们使用 416x416 的图像,因为(1)我们想要比最初捕获的 2284 × 1529 尺寸更小的图像,以便更快地训练,(2)对于 YOLOv3,32 的倍数对于其架构来说是最有性能的。

注意在这个导出中,我们的预处理包括“自动定向”和“调整大小”
我们的图像还应用了“自动定向”,这是一个 Roboflow 预处理步骤,可以去除非直观方向的 EXIF 数据。自动定向很重要,因为图像有时存储在磁盘上的方向与我们用来查看它们的应用程序不同。如果不加以纠正,这可能会导致我们的模型出现无声的故障(参见黑客新闻上的讨论)。我建议默认打开这个选项。
要下载此数据集,请选择“416 x416-自动定向”在右上角,选择“下载”系统会提示您创建一个免费帐户,并重定向回 chess 公共数据集页面。
现在,Roboflow 允许你下载各种格式的图片和注释。您还可以将它们本地下载到您的计算机上,或者生成一个代码片段,用于将它们直接下载到 Jupyter 笔记本(包括 Colab)或 Python 脚本中。
对于我们的问题,我们将使用一个 Keras YOLOv3 实现,它调用一个注释的平面文本文件。我们还将利用 Google Colab 进行培训,因此在导出选项中选择“显示下载代码”。

这些是您将为下载格式选择的选项。

Roboflow 生成一个代码片段,你可以直接放入 Jupyter 笔记本,包括 Colab。一定不要公开分享你的钥匙!
对于你的非象棋问题,你可以创建一个免费的 Roboflow 账户,上传图像,预处理,增强,并导出到你的模型可能需要的任何注释格式。为此,请遵循快速启动。
模特培训
我们将使用的模型架构被称为 YOLOv3,或者你只看一次,作者是 Joseph Redmon 。这种特定的模型是一次性学习器,这意味着每幅图像只通过网络一次来进行预测,这使得该架构的性能非常高,在预测视频馈送时每秒可查看高达 60 帧。从根本上说,YOLO 把一幅图像分成几个子部分,并对每个子部分进行卷积,然后汇集起来进行预测。这里有一个关于 YOLO 的深度潜水推荐。
现在,即使我们在自定义数据集上训练我们的模型,使用另一个已经训练好的模型的权重作为起点仍然是有利的。想象一下,我们想要尽可能快地爬上一座山,而不是完全从零开始创建我们自己的路径,我们将从假设别人的路径比我们随机尝试猜测曲折路径更快开始。
为了给我们的模型计算提供动力,我们将使用 Google Colab,它提供免费的 GPU 计算资源(在浏览器打开的情况下长达 24 小时)。

随着验证损失的下降,我们的模型正在改进。
在我们的笔记本中,我们主要做六件事:
- 选择我们的环境、模型架构和预适应权重(其他人的“线索”)
- 通过上面分享的 Roboflow 代码片段加载我们的数据
- 确定我们的模型配置,比如训练多少个时期,训练批量大小,我们的训练与测试集的大小,以及我们的学习率
- 开始训练(…等待!)
- 使用我们训练好的模型进行推理(预测!)
- (可选奖励)将我们新训练的重量保存到我们的 Google Drive 中,这样我们就可以在未来做出预测,而不必等待训练完成
现在,复制一份这个 Colab 笔记本,然后在那边继续我们的教程。
对于您的非象棋问题,为了训练这个相同的架构,**您只需要更改一个 URL,就可以在您的自定义数据集上训练一个 YOLOv3 模型。**该 URL 是 Roboflow 下载 URL,我们通过它将数据集加载到笔记本中。此外,你也可以调整训练参数,比如设置一个较低的学习率或者训练更多/更少的时期。
推理
一旦我们的模型完成训练,我们将使用它来进行预测。进行预测需要(1)设置 YOLOv3 模型架构(2)使用我们在该架构下训练的自定义权重。
在我们的笔记本中,这一步发生在我们调用 yolo_video.py 脚本时。该脚本接受视频文件或图像的路径、自定义权重、自定义锚点(在本例中我们没有训练任何内容)、自定义类、要使用的 GPU 数量、描述我们是否预测图像而不是视频的标志,以及预测的视频/图像的输出路径。
在我们的例子中,我们将使用自定义权重和自定义类名来调用脚本。该脚本编译一个模型,等待图像文件的输入,并为找到的任何对象提供边界框坐标和类名。边界框坐标以左下角像素(mix_x,min_y)和右上角像素(max_x,max_y)的格式提供。
作为一个重要的标注,我们在这个例子中加载的自定义权重实际上并不是 YOLOv3 架构的最佳值。我们将加载“初始重量”而不是最终的训练重量。由于 Colab 计算的限制,我们的模型无法训练最终的权重。这意味着我们的模型没有达到应有的性能(因为只有 YOLO 的主干架构适应了我们的问题)。从好的方面来看,这是免费计算!
请注意,您可以在左侧的 Colab 笔记本中看到可用的文件(如果您已经有注释,请通过找到“+Code”和“+Text”下方的小右箭头来展开面板)。在 keras-yolo-3 文件夹中,你可以看到我们可用的所有图像。
我建议在运行您的预测脚本时尝试这些图像,以了解我们模型的性能:
- 00a7a49c47d51fd16a4cbb17e2d2cf86.jpg 白王作品!+骑士
- 015d0d7ff365f0b7492ff079c8c7d56c.jpg 黑皇后搞混了
- 176b28b5c417f39a9e5d37545fca5b4c.jpg 只找到五个
- 4673f994f60a2ea7afdddc1b752947c0.jpg 白车(国王认为)
- 5ca7f0cb1c500554e65ad031190f8e9f.jpg 白棋(错过白王)
- fbf15139f38a46e02b5f4061c0c9b08f.jpg 黑王成功了!
再翻回上面你抄的笔记本,我们来试试这个剧本。
对于你的非象棋题,这一步会大体相同。如果您想将此模型应用于视频馈送或尝试不同的权重,请确保遵循笔记本中详细说明的参数。如果你在一个非 Colab 的环境中训练,这个环境也可以处理产生模型的最终权重,确保提供这些权重的路径,而不是我们的“initial_weights”你可以考虑在笔记本或谷歌硬盘上创建一个名为“预测”的目录,并将模型的预测结果写在那里。
下一步是什么
你做到了!您已经为象棋和/或自定义数据集训练了对象检测模型。
现在,在生产中使用这个模型回避了识别您的生产环境将会是什么的问题。例如,您会在移动应用程序中、通过远程服务器、甚至在 Raspberry Pi 上运行模型吗?如何使用模型决定了保存和转换其格式的最佳方式。
根据你的问题考虑这些资源作为下一步:转换到 TFLite (用于 Android 和 iPhone),转换到 CoreML (用于 iPhone 应用),转换到远程服务器上使用,或者部署到 Raspberry Pi 。
想要更多?

加入 Roboflow 社区进行物体检测讨论!
订阅 Roboflow 更新当我们发布更多这样的内容时,第一个知道。
用 CGI 训练 AI
我们仅使用合成数据来训练计算机视觉模型,以识别 raspberry pi 板上的组件。

树莓 Pi 组件使用 100%合成数据。
在本文中,我们介绍了如何训练计算机视觉模型(AI)仅使用合成数据(CGI)来检测树莓派的子成分。
利用合成数据进行训练是一种越来越受欢迎的方式,可以满足渴望数据的深度学习模型的需求。这个项目使用的数据集可以在 app.zumolabs.ai [1]免费获得。我们希望让每个人都能轻松使用合成数据,并计划在未来发布更多数据集。
问题
树莓派是一款非常受爱好者欢迎的单板电脑。我们的目标是检测板上的一些子组件:引脚连接器、音频插孔和以太网端口。虽然这是一个玩具问题,但它与你在现实世界中看到的并不遥远——在现实世界中,使用计算机视觉自动检测组件和缺陷可以提高制造的速度和可靠性。
数据
为了生成合成数据,我们首先需要对象的 3D 模型。幸运的是,在当今世界,大多数物体已经存在于虚拟世界。SketchFab、TurboSquid 或 Thangs 等资产聚合网站已经将 3D 模型商品化[2]。给聪明人的建议:如果你在网上找不到模型,试着直接联系制造商,或者自己扫描并制作模型。

(上)合成图像和(下)分割蒙版。
然后,我们使用游戏引擎(如 Unity 或 Unreal Engine)从各种摄像机角度和各种照明条件下拍摄我们的 3D 模型的数千张图像。每幅图像都有一个相应的分割蒙版,用于分割图像中的不同部分。在以后的文章中,我们将更深入地研究创建合成图像的过程(敬请关注!).
所以现在我们有成千上万的合成图像,我们应该很好,对不对?不要!在真实数据上测试综合训练的模型以了解模型是否成功地推广到真实数据是非常重要的。模拟产生的数据和真实数据之间存在差距,称为模拟真实差距。一种思考方式是,深度学习模型会在最小的细节上过度拟合,如果我们不小心,许多这些细节可能只存在于合成数据中。
对于这个问题,我们手动注释了一个由十几幅真实图像组成的小型测试数据集。手动注释既耗时又昂贵。重要的是要注意,如果我们使用真实的图像进行训练,我们将不得不手动注释成千上万的图像,而不是仅仅一小部分用于测试!不幸的是,这是目前的做事方式,是我们试图改变的现状。摆脱这种手动注释过程是构建更好的人工智能的关键一步。
我们可以开始缩小 sim2real 差距的一种方法是通过一种被称为域随机化 [3][4】的技术。这种策略包括虚拟角色扮演的随机化特性,尤其是背景和角色扮演本身的视觉外观。这具有下游效应,使得我们基于该数据训练的模型对于颜色和光照的变化更加鲁棒。这也被称为网络的概括能力。

领域随机化图像。

领域随机化:增加合成数据分布的方差。
模特与培训
现在我们来看看模型。有许多不同类型的计算机视觉模型可供选择。利用深度学习的模型是目前最受欢迎的。它们非常适合探测任务,比如这个项目。我们使用了 PyTorch 的 torchvision 库中基于 ResNet 架构的模型[5]。合成数据将与任何模型架构一起工作,因此请随意试验并找到最适合您的用例的模型。
我们用四个不同的合成数据集训练我们的模型,以显示域随机化和数据集大小如何影响我们的真实测试数据集的性能:
- 数据集 A —一万五千张逼真的合成图像。
- 数据集 B —一万五千域随机合成图像。
- 数据集 C — 6 千张逼真的合成图像。
- 数据集 D — 6 千域随机合成图像。

与真实数据相比,合成数据的平均精度。
我们使用 mAP(平均精度)来衡量我们的计算机视觉模型的性能。需要注意的是,性能指标可能非常随意,因此请务必查看模型预测,以确保您的模型能够发挥应有的性能。正如我们预测的那样,模型的性能随着我们使用的合成数据越多而提高。深度学习模型几乎总是会随着更大的数据集而改进,但是,更有趣的是,用域随机合成数据集进行训练会导致我们的真实测试数据集的性能显著提升。
结论
TLDR:在这篇文章中,我们训练了一个计算机视觉模型,使用完全合成的数据来检测树莓派的子成分。我们使用了域随机化技术来提高我们的模型在真实图像上的性能。然后,哒哒!我们训练过的模型处理真实数据**,尽管它从未见过一张真实图像**。
感谢您的阅读,请务必亲自在 app.zumolabs.ai 查看数据集!如果您有任何问题或对合成数据感到好奇,请发送电子邮件至 info@zumolabs.ai ,我们喜欢聊天。
参考文献
[1] Zumo 实验室数据门户。(app.zumolabs.ai)
[2]3D assets sites:sketch fab(sketch fab . com),TurboSquid (turbosquid.com),Thangs (thangs.com)。
[3]莉莲翁。“Sim2Real 传输的域随机化”。(https://lilian Weng . github . io/lil-log/2019/05/05/domain-randomization . html)。
[4] Josh Tobin 等人,“将深度神经网络从模拟转移到现实世界的领域随机化”IROS,2017。(https://arxiv . org/ABS/1703.06907)。
[5]GitHub 上的火炬视觉。(https://github . com/py torch/vision)。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言










{kind=link}