







掌握熊猫的 30 个例子
学习熊猫的综合实践指南

Pandas 是一个广泛使用的 Python 数据分析和操作库。它提供了许多加快数据分析和预处理步骤的功能和方法。
由于它的流行,有许多关于熊猫的文章和教程。这一个将会是其中之一,但是非常注重实际的一面。我将在 Kaggle 上的客户流失数据集上做例子。
这些示例将涵盖您可能在典型的数据分析过程中使用的几乎所有函数和方法。
让我们从将 csv 文件读入熊猫数据帧开始。
import numpy as np
import pandas as pddf = pd.read_csv("/content/churn.csv")df.shape
(10000,14)df.columns
Index(['RowNumber', 'CustomerId', 'Surname', 'CreditScore', 'Geography', 'Gender', 'Age', 'Tenure', 'Balance', 'NumOfProducts', 'HasCrCard','IsActiveMember','EstimatedSalary', 'Exited'], dtype='object')
1。删除列
drop 函数用于删除列和行。我们传递要删除的行或列的标签。
df.drop(['RowNumber', 'CustomerId', 'Surname', 'CreditScore'], axis=1, inplace=True)df.shape
(10000,10)
axis 参数设置为 1 表示删除列,设置为 0 表示删除行。将 inplace 参数设置为 True 以保存更改。我们删除了 4 列,所以列数从 14 列减少到了 10 列。
2.阅读时选择特定的列
我们只能从 csv 文件中读取一些列。读取时,列的列表被传递给 usecols 参数。如果您事先知道列名,这比以后再删除要好。
df_spec = pd.read_csv("/content/churn.csv", usecols=['Gender', 'Age', 'Tenure', 'Balance'])df_spec.head()

(图片由作者提供)
3.读取数据帧的一部分
read_csv 函数允许按照行读取数据帧的一部分。有两个选择。第一个是读取前 n 行。
df_partial = pd.read_csv("/content/churn.csv", nrows=5000)df_partial.shape
(5000,14)
使用 nrows 参数,我们创建了一个包含 csv 文件前 5000 行的数据帧。
我们还可以使用 skiprows 参数从文件的末尾选择行。Skiprows=5000 意味着我们在读取 csv 文件时将跳过前 5000 行。
4.样品
创建数据帧后,我们可能想要绘制一个小样本来工作。我们可以使用 n 参数或 frac 参数来确定样本大小。
- n:样本中的行数
- frac:样本大小与整个数据框架大小的比率
df_sample = df.sample(n=1000)
df_sample.shape
(1000,10)df_sample2 = df.sample(frac=0.1)
df_sample2.shape
(1000,10)
5.检查缺少的值
isna 函数确定数据帧中缺失的值。通过将 isna 与 sum 函数结合使用,我们可以看到每一列中缺失值的数量。
df.isna().sum()

(图片由作者提供)
没有丢失的值。
6.使用 loc 和 iloc 添加缺失值
我做这个例子是为了练习“loc”和“iloc”。这些方法基于索引或标签选择行和列。
- loc:使用标签选择
- iloc:带索引选择
让我们首先创建 20 个随机指数来选择。
missing_index = np.random.randint(10000, size=20)
我们将使用这些索引将一些值更改为 np.nan(缺失值)。
df.loc[missing_index, ['Balance','Geography']] = np.nan
“余额”和“地理位置”列中缺少 20 个值。让我们用索引代替标签来做另一个例子。
df.iloc[missing_index, -1] = np.nan
“-1”是“已退出”的最后一列的索引。
尽管我们对 loc 和 iloc 使用了不同的列表示,但是行值没有改变。原因是我们正在使用数字索引标签。因此,行的标签和索引是相同的。
丢失值的数量已更改:

(图片由作者提供)
7.填充缺失值
fillna 函数用于填充缺失的值。它提供了许多选项。我们可以使用特定的值、聚合函数(例如平均值),或者前一个或下一个值。
对于 geography 列,我将使用最常见的值。

(图片由作者提供)
mode = df['Geography'].value_counts().index[0]
df['Geography'].fillna(value=mode, inplace=True)

(图片由作者提供)
同样,对于 balance 列,我将使用该列的平均值来替换缺失的值。
avg = df['Balance'].mean()
df['Balance'].fillna(value=avg, inplace=True)
fillna 函数的 method 参数可用于根据列中的上一个或下一个值填充缺失值(例如 method='ffill ')。这对于序列数据(例如时间序列)非常有用。
8.删除丢失的值
处理缺失值的另一种方法是删除它们。“已退出”列中仍有缺失值。下面的代码将删除任何缺少值的行。
df.dropna(axis=0, how='any', inplace=True)
轴=1 用于删除缺少值的列。我们还可以为一列或一行所需的非缺失值的数量设置一个阈值。例如,thresh=5 意味着一行必须至少有 5 个非缺失值才不会被删除。缺少 4 个或更少值的行将被删除。
dataframe 现在没有任何缺失值。
df.isna().sum().sum()
0
9.基于条件选择行
在某些情况下,我们需要符合某些条件的观察值(即行)。例如,下面的代码将选择居住在法国的客户。
france_churn = df[(df.Geography == 'France') & (df.Exited == 1)]france_churn.Geography.value_counts()
France 808
10.用查询描述条件
查询函数提供了一种更灵活的传递条件的方式。我们可以用字符串来描述它们。
df2 = df.query('80000 < Balance < 100000')
让我们通过绘制余额柱的直方图来确认结果。
df2['Balance'].plot(kind='hist', figsize=(8,5))

(图片由作者提供)
11.用 isin 描述条件
条件可能有几个值。在这种情况下,最好使用 isin 方法,而不是单独写入值。
我们只是传递一个所需值的列表。
df[df['Tenure'].isin([4,6,9,10])][:3]

(图片由作者提供)
12.groupby 函数
Pandas Groupby 函数是一个多功能且易于使用的函数,有助于获得数据的概览。这使得探索数据集和揭示变量之间的潜在关系变得更加容易。
我们将做几个 groupby 函数的例子。先说一个简单的。下面的代码将根据地理-性别组合对行进行分组,然后给出每组的平均流失率。
df[['Geography','Gender','Exited']].groupby(['Geography','Gender']).mean()

(图片由作者提供)
13.通过 groupby 应用多个聚合函数
agg 函数允许对组应用多个聚合函数。函数列表作为参数传递。
df[['Geography','Gender','Exited']].groupby(['Geography','Gender']).agg(['mean','count'])

(图片由作者提供)
我们可以看到每个组中的观察计数(行)和平均流失率。
14.对不同的组应用不同的聚合函数
我们不必对所有列应用相同的函数。例如,我们可能希望看到每个国家的平均余额和客户总数。
我们将传递一个字典,指示哪些函数将应用于哪些列。
df_summary = df[['Geography','Exited','Balance']].groupby('Geography')\
.agg({'Exited':'sum', 'Balance':'mean'})df_summary.rename(columns={'Exited':'# of churned customers', 'Balance':'Average Balance of Customers'},inplace=True)df_summary

(图片由作者提供)
我还重命名了这些列。
编辑 :感谢罗恩在评论区的提醒。NamedAgg 函数允许重命名聚合中的列。语法如下:
df_summary = df[['Geography','Exited','Balance']].groupby('Geography')\
.agg(
Number_of_churned_customers = pd.NamedAgg('Exited', 'Sum'),
Average_balance_of_customers = pd.NamedAgg('Balance', 'Mean')
)
15.重置索引
您可能已经注意到,groupby 返回的数据帧的索引由组名组成。我们可以通过重置索引来改变它。
df_new = df[['Geography','Exited','Balance']]\
.groupby(['Geography','Exited']).mean().reset_index()df_new

(图片由作者提供)
编辑 :感谢罗恩在评论区的提醒。如果我们将 groupby 函数的 as_index 参数设置为 False,那么组名将不会用作索引。
16.用 drop 重置索引
在某些情况下,我们需要重置索引,同时删除原始索引。考虑从数据帧中抽取样本的情况。该示例将保留原始数据帧的索引,因此我们希望重置它。
df[['Geography','Exited','Balance']].sample(n=6).reset_index()

(图片由作者提供)
索引被重置,但原始索引作为新列保留。我们可以在重置索引时删除它。
df[['Geography','Exited','Balance']]\
.sample(n=6).reset_index(drop=True)

(图片由作者提供)
17.将特定列设置为索引
我们可以将数据帧中的任何一列设置为索引。
df_new.set_index('Geography')

(图片由作者提供)
18.插入新列
我们可以向数据帧添加一个新列,如下所示:
group = np.random.randint(10, size=6)
df_new['Group'] = groupdf_new

(图片由作者提供)
但是新列被添加在末尾。如果想把新列放在特定的位置,可以使用 insert 函数。
df_new.insert(0, 'Group', group)df_new

(图片由作者提供)
第一个参数是位置的索引,第二个是列的名称,第三个是值。
19.where 函数
它用于根据条件替换行或列中的值。默认的替换值是 NaN,但是我们也可以指定替换值。
考虑上一步中的数据帧(df_new)。对于属于小于 6 的组的客户,我们希望将余额设置为 0。
df_new['Balance'] = df_new['Balance'].where(df_new['Group'] >= 6, 0)df_new

(图片由作者提供)
符合指定条件的值保持不变,其他值被指定的值替换。
20。排名函数
它给这些值分配一个等级。让我们创建一个根据客户余额对客户进行排名的列。
df_new['rank'] = df_new['Balance'].rank(method='first', ascending=False).astype('int')df_new

(图片由作者提供)
method 参数指定如何处理具有相同值的行。“第一个”意味着根据它们在数组(即列)中的顺序对它们进行排序。
21.列中唯一值的数量
在处理分类变量时,这很方便。我们可能需要检查唯一类别的数量。
我们可以检查由 value counts 函数返回的序列的大小,或者使用 nunique 函数。

(图片由作者提供)
22.内存使用
这是由 memory_usage 函数简单完成的。

(图片由作者提供)
这些值以字节为单位显示使用了多少内存。
23.类别数据类型
默认情况下,分类数据与对象数据类型一起存储。但是,这可能会导致不必要的内存使用,尤其是当分类变量的基数较低时。
低基数意味着与行数相比,一列只有很少的唯一值。例如,geography 列有 3 个唯一值和 10000 行。
我们可以通过将它的数据类型改为“类别”来节省内存。
df['Geography'] = df['Geography'].astype('category')

(图片由作者提供)
地理列的内存消耗减少了近 8 倍。
24.替换值
replace 函数可用于替换数据帧中的值。

(图片由作者提供)
第一个参数是要替换的值,第二个参数是新值。
我们可以用字典做多次替换。

(图片由作者提供)
25.绘制直方图
Pandas 不是一个数据可视化库,但它使创建基本绘图变得非常简单。
我发现用熊猫创建基本图比使用额外的数据可视化库更容易。
让我们创建一个余额柱状图。
df['Balance'].plot(kind='hist', figsize=(10,6),
title='Customer Balance')

(图片由作者提供)
由于 pandas 不是一个数据可视化库,所以我不想详细介绍绘图。然而,图函数能够创建许多不同的图,如折线图、条形图、kde 图、面积图、散点图等。
26.减少浮点数的小数点
熊猫可能会为浮动显示过多的小数点。我们可以使用 round 函数轻松调整它。
df_new.round(1) #number of desired decimal points

(图片由作者提供)
27.更改显示选项
我们可以更改各种参数的默认显示选项,而不是每次都手动调整显示选项。
- get_option:返回当前选项
- set_option:更改选项
让我们将小数点的显示选项改为 2。
pd.set_option("display.precision", 2)

(图片由作者提供)
您可能希望更改的其他一些选项有:
- max_colwidth:列中显示的最大字符数
- max_columns:要显示的最大列数
- max_rows:要显示的最大行数
28.通过列计算百分比变化
pct_change 用于通过系列中的值计算百分比变化。它在计算时间序列或连续元素数组中的变化百分比时非常有用。

(图片由作者提供)
从第一个元素(4)到第二个元素(5)的变化是%25,因此第二个值是 0.25。
29.基于字符串的过滤
我们可能需要根据文本数据(如客户姓名)过滤观察结果(行)。我已经向 df_new 数据帧添加了虚构的名称。

(图片由作者提供)
让我们选择客户名称以“Mi”开头的行。
我们将使用 str 访问器的 startswith 方法。
df_new[df_new.Names.str.startswith('Mi')]

(图片由作者提供)
endswith 函数根据字符串末尾的字符进行同样的过滤。
熊猫可以用绳子做很多操作。如果你想进一步阅读,我有一篇关于这个主题的单独文章。
熊猫让字符串操作变得简单
towardsdatascience.com](/5-must-know-pandas-operations-on-strings-4f88ca6b8e25)
30.设计数据框架的样式
我们可以通过使用返回一个 styler 对象的 Style 属性来实现这一点,它为格式化和显示数据帧提供了许多选项。例如,我们可以突出显示最小值或最大值。
它还允许应用自定义样式功能。
df_new.style.highlight_max(axis=0, color='darkgreen')

(图片由作者提供)
如果你想进一步阅读的话,我有一篇关于设计熊猫数据框架的详细文章。
让我们创造出比简单数字更多的东西。
towardsdatascience.com](/style-your-pandas-dataframes-814e6a078c6d)
结论
我们已经介绍了大量的数据分析功能和方法。当然,熊猫提供的还有很多,但不可能在一篇文章中涵盖所有内容。
随着您继续使用 pandas 进行数据分析任务,您可能会发现新的功能和方法。如同任何其他科目一样,熟能生巧。
我想分享另外两个帖子,它们涵盖了与这篇帖子不同的操作。
感谢您的阅读。如果您有任何反馈,请告诉我。
编码前要问的 30 个问题
入门
在为我的下一个数据科学工程项目编码之前,我会问这些问题。

我是一名软件工程师和数据科学家,在笔记本和软件包中编写代码。编码时最难学的一课是"在写代码之前先停下来想一想。投入到编码中感觉很棒,但是你可能会错过更大的画面或者基于当前假设的项目的一个重要方面。软件工程和数据科学可以带来令人兴奋的项目组合,包括数据清理、自动化、开发运维、分析开发、工具等等。一些项目可以很容易地跨越几个不同的领域。从最初的工作中退一步,开始思考手头的问题,这是很有价值的。至此,我想向你介绍我在着手一个新项目之前考虑的 30 个常见问题。
用例:过去、现在和未来
我想考虑的第一个领域是用例。当我着手一个项目时,我可能只知道最初的用例,但是在与其他涉众、客户或团队成员交谈后,可能会有更多的用例。
1\. Sit down and think about your current use case. How would you design the code for this use case?
2\. If there are past use cases you can examine, would you design the code differently to accommodate those?
3\. Are there potential future use cases that may differ from your past and present cases? How would these change the way you develop your code?
4\. Thinking about your code structure, sit down, and discuss it with one or more other developers. Would they approach the problem differently? Why?
5\. As you develop your code, consider how it can expand in the future. Would that be an easy feat, or will it be hard to accomplish? How can you make it more reusable or repeatable?
数据采集和清理
在理解了项目可能的用例之后,下一个要考虑的领域是数据获取和清理。根据您使用的数据,您可能需要考虑如何在工作中吸收、清理和利用这些数据。
6\. What data is required for this project to be successful?
7\. Do you need more than one dataset that requires some aggregation, or will you utilize one dataset? Do you need to get this data yourself? If so, how will you get this data?
8\. Will your code handle the I/O in your Python package or within a separate notebook that runs the code?
9\. Will you interface with another team that already gives you access through a database or API?
10\. Are there any processes you need to develop around the acquisition or cleaning this data that will ease the process?
11\. What format is your data? Does this format matter to your code?
自动化、测试和 CI/CD 管道
在理解了我的项目的用例以及你需要什么数据之后,我想回答的下一个问题是关于过程的自动化。我喜欢尽我所能实现自动化,因为这可以让我专注于其他工作。考虑使用可以根据需要运行的快速脚本来自动化代码的不同部分,创建按计划运行的作业,或者利用 CI/CD 管道来执行部署等日常任务。
12\. Should the output of the work get created regularly? Will, you ever need to repeat your analysis or output generation?
13\. Does the output get used in a nightly job, a dashboard, or frequent report?
14\. How often should the output be produced? Daily? Weekly? Monthly?
15\. Would anyone else need to reproduce your results?
16\. Now that you know your code structure, does it live in a notebook, standalone script, or within a Python package?
17\. Does your code need to be unit tested for stability?
18\. If you need unit testing for your Python package, will you set up a CI/CD pipeline to run automated testing of the code?
19\. How can a CI/CD pipeline help ensure your work is stable and doing as expected?
20\. If you are creating an analytic, do you need to develop metrics around the analytics to prove they produce the expected results?
21\. Can any aspect of this work be automated?
可重用性和可读性
我关注的最后一组问题集中在代码的可重用性和可读性上。你的团队中会不会有新人捡起你的代码,学习它,并快速使用它?
我喜欢写文档,这意味着我的代码通常会被很好地注释,并附有如何运行它的例子。当引入新的开发者时,添加文档、例子和教程是非常有用的,因为他们可以很快加入进来,并感觉他们正在很快做出贡献。没有人喜欢花很长时间去理解事情,并感觉自己在为团队做贡献。
就可重用性而言,这是您的用例可以派上用场的地方。如何在你的用例中使用你的代码,但又足够一般化,让其他人从你停止的地方继续,并在他们的用例中使用它。
22\. You have looked at your use cases. Can you standardize the classes or methods to fit the code's expansion?
23\. Is it possible to create a standardized library for your work?
24\. Can you expand your work to provide a utility or tool to others related to this work?
25\. As you write code, is it clear to others what the code is doing?
26\. Are you providing enough documentation to quickly onboard a new data scientist or software developer?
代码审查
最后,还有代码审查。在开始编码之前考虑代码评审似乎有点奇怪,但是让我们后退一步。在你的评估或经常性的讨论中,你会遇到一些常见的问题吗?思考这些案例,并在开发代码时利用它们。从过去关于代码实现的评论中学习,并不断发展您的技能。
27\. Do you need to have a code review for your project?
28\. If so, what comments do you anticipate getting on your work?
29\. Who can you meet with before the code review to discuss architecture or design decisions?
30\. What comments are you required to address, and what comments can you use for later investigation?
摘要
总的来说,这听起来可能很多,但这 30 个问题是思考如何设计下一个数据科学工程项目的好方法。当你回顾过去时,你在开始一个新项目之前会考虑哪些事情?我关注五个方面:
- 确定此项目工作存在哪些用例。
- 了解所需的数据采集和清理。
- 研究在您的流程中添加自动化、测试和 CI/CD 管道的可能性。
- 努力使您的代码可读和可重用,以便快速加入新的团队成员,并使代码在以后的阶段易于扩展。
- 利用代码评审的优势,并从中学习。
产品分析数据治理的 31 个最佳实践

来源: 坎瓦
当您组织的分析能力成熟时,数据治理的实施至关重要。一个目的是用可信的数据促进更快的决策。这是我们在这篇文章中关注的目标。
这篇文章将分享你的产品分析数据的数据治理最佳实践。结构如下:
- 定义角色和职责
- 分享治理的最佳实践和指导原则
- 执行治理策略和流程
随着数据量的增加和访问规模的扩大,实现这一目标变得更加困难。因此,尽快建立您的治理策略非常重要。

在 Cornerstone 的产品分析工具中,有一款产品的参与度高于预期。这些增加的参与人数转化为成功。因此,他们在商业评论中被介绍给领导层。这些数字如此突然地上升,确实令人感到奇怪。所以我们深入调查了一下。
当我们映射事件触发器时,我们注意到有些事件会触发两次。我们了解到,两个独立的团队以两种方式测试了同一个事件。一个来自前端,另一个来自后端。
每个团队都有不同但有效的理由来衡量同一事件。前端仪器测量用户参与度。后端检测跟踪成功/失败的方法调用。
我们要求后端团队更改活动名称。我们还要求他们提供触发事件的描述,以及应该如何解释数据。
如您所见,该解决方案非常简单,与分类相关。但是,令人头痛的问题已经存在了——对更高参与度的错误警报和对现实的模糊理解。如果根据这些数据做出决策,就会产生相关成本。

角色和责任:数据治理的“谁是谁”
A 在你的组织中给个人分配角色可以防止分析的狂野西部。大多数分析平台指导如何分配角色。而且,如果你有一个客户成功经理,她将能够帮助你在你的组织中找到合适的人。

本·斯威特在 Unsplash 上的照片
管理员
根据策略,您可能有一个或多个系统管理员。管理员负责:
- 确保数据系统的连续运行
- 设置访问和权限
- 发布功能并传播新功能
- 传达系统状态,如维护窗口、停机或策略更改
数据架构师
数据架构师将设计如何创建、管理和使用产品数据。这个角色有点宽泛,但是对于组织中适当的数据管理非常重要。
建筑师处理:
- 管理数据结构
- 设定术语和报告标准
- 指导解决数据质量问题
- 指导如何使用可用数据。
- 负责变更管理,并就此类流程和结构的任何变更进行沟通
在某些情况下,架构师与管理员是同一个人。
理事
管理者是执行既定政策的个人。州长的主要职责是:
- 确保所有贡献或使用数据的个人都遵守法规
- 咨询数据架构师和经理,进行必要的策略更改
- 针对任何不合规或政策变更实施补救流程
需要做出一个组织决策。州长在执法中应该扮演积极还是消极的角色?拥有专用资源的管理者将从积极的执行中受益。在许多情况下,州长已经有了一大堆的职责。在这种情况下,他们可能想要一个更被动的角色。

在实现 Amplitude 时,我的团队以积极的治理姿态开始。当项目经理建立他们的分类法时,我们有一个咨询和批准过程。这发生在他们把他们的提议变成用户故事之前。在我的团队批准之前,没有事件被检测。这确保了更干净和可靠的数据。
不幸的是,我的团队(三个人)花了很多时间来咨询和批准 30 多个 pm 的仪器。我们转向了一种被动的方法,允许团队检测和发布。然后,当数据被捕获时,我们将定期(两周一次)审查分类法。代价是我们会不时地捕捉不符合规范的事件。每当发生这种情况,我们都会执行补救过程(也是治理文档的一部分)。

经理和成员
经理和会员是产品分析数据的主要消费者。这些角色的需求围绕着报告和洞察生成。它们将是:
- 根据现有数据进行分析
- 从可用数据创建报告
- 在报告或仪表板上共享和协作
- 创建报告集合或组织数据
对于经理来说,关键的区别在于扩充分类法的能力。经理可以创建新事件或对分类进行更改。
在 Cornerstone,我们分配 PMs 经理角色。我们希望他们拥有各自产品的工具和分类法。UX/用户界面设计师是成员,因为他们可以创建洞察力,但不需要对数据结构进行更改。
观看者
视图通常是为仪表板和报告的纯粹消费者保留的。他们很少制作图表和进行分析。相反,他们在感兴趣的任何时候都会收到链接或读数。
在 Cornerstone,我们将观众权限分配给客户成功和营销等团队。在理想情况下,这些团队可以是成员。但是我们需要在允许他们分析能力之前,训练他们什么数据是可用的和正确的解释。
数据治理最佳实践
在构建治理策略时,有许多可能的领域需要关注。这些包括安全性、隐私、有效的存储/仓储等。提醒一下,我们这里的重点是用可信的数据帮助更快地做出决策。

根据经验,以下领域是组织治理文档的好方法:
1.访问和权限
以下最佳实践适用于上述角色定义。支持变更是指以任何方式改变数据分类或管理系统的能力。
- 将访问权限与一个人的工作和需求相匹配。
- 有一个请求更多权限的正当程序。
- 保守提供变更授权权限。
- 就正确管理培训变革授权角色。
- 首先从直属团队开始。
- 有一个常规的撤销和降级流程。
2.分类定义和管理
分类法是被度量的东西、如何被度量以及为什么被度量的官方记录。定义良好的分类法增加了分析和决策的信心。
- 标准化命名和语法
- 注重可读性和可报道性。
- 使字段和事件名称具有描述性。
- 需要一个清晰的定义——它是如何产生和解释的。
- 建立分类审核流程。
- 强制合规并执行补救措施。
- 建立变更管理流程。
- 定义负责沟通变更的人员。
3.质量和信任
在数据被捕获和报告的过程中,质量和信任关系到数据。质量被定义为完整性和与其目的(计划、决策等)的相关性。).信任围绕着准确性、精确性和整体一致性。
- 检查错误日志,确保数据质量和完整性。
- 定期审计数据的使用和生成
- 推荐数据完整性审计
- 定义数据完整性的流程/清单
- 定期审核“适当”分析报告
- 针对质量或信任问题制定沟通计划
- 注意盲点和重复计算
4.标准流程
治理关注使数据对组织有用的构造和契约。流程确保我们达到预期和标准。下面是您可能想要定义的一些流程。
- 审核流程以确保上述领域的合规性
- 促进遵守的补救程序
- 公告和变更的常规沟通流程
- 传福音节奏传播意识和用法
- 定期架构审查
- 业务影响审查
- 定额或预算评审
5.数据集成和导出
当产品分析数据与其他数据源(运营和经验)混合时,它最有价值。因此,与其他数据系统集成和导出以进行混合是组织的关键功能。
- 列出未来可能的整合需求
- 了解数据导出选项和限制
- 构建数据结构以简化集成
执行您的治理
政府政策和流程只有在可见、已知、可执行和最新的情况下才有价值。

调整政策和流程,使其有效运作。(来源:坎瓦)
传播
在易于访问的资源中编写治理策略和过程。无论是可共享的 PDF 还是全球可用的链接,请确保那些有权访问您的数据的人也有权访问文档。
一旦这些都写好了,就在所有适用的频道上大肆宣扬,以确保每个人都知道它们。
在 Cornerstone,我们将政策存储在一个集中的维基页面中。我们通过电子邮件和所有与分析相关的 Slack 渠道与产品和工程团队分享了这一点。
培养
在您共享文档之后,安排一个时间向接收者展示并讨论治理策略。治理文档是活的文档,应该随着组织的需求而变化。
将讨论作为测试策略和流程的一种方式。寻找机会使政策更加有效和简化。
更新
继续最后一段,不断寻找改进政策和简化流程的方法。随着组织的成熟,你也许可以放宽某些政策。
另一方面,您可能会发现您需要增加治理或者改变其他领域的行为。如有必要,接受调整。
结论
D 数据治理可能不是转型变革中最激动人心的部分。但是,确保您的所有其他投资(文化、数据系统、分析培训)都有回报是至关重要的。
正确的策略和流程可以确保数据可靠,并由正确的受众处理。编写这些治理文档不需要很多时间。但这确实需要开放的心态和灵活性,不断调整以使他们为一个组织工作。
如果您希望我详细说明或提供特定最佳实践的示例,请给我留言!
投资于你的战略技能。在这里注册订阅我的时事通讯。
面试准备的数据科学问题(机器学习概念)——第一部分
这两部分系列的这一部分包括模型评估技术、正则化技术、逻辑回归和偏差方差权衡。

我最近在 Youtube 上看完了这个机器学习播放列表(Josh Starmer 的 stat quest),并想到将每个概念总结成一个 Q/A。随着我为更多的数据科学面试做准备,我认为这将是一个很好的练习,以确保我在面试中清晰简洁地交流我的想法。如果我没有很好地解释任何概念,请在评论中告诉我。
注意:本文的目的不是向初学者教授一个概念。它假设读者在数据科学概念方面有足够的背景知识。如果你刚刚开始学习 ML,我强烈推荐你去 Youtube 上看看 StatQuest,这是我的最爱之一。
1.什么是交叉验证?什么时候用?我们可以使用交叉验证来调整模型参数吗?交叉验证有哪些类型?
交叉验证是一种模型评估技术,我们将给定的数据集分成不同的折叠,比如说 5 个,然后迭代地使用 4 个折叠进行训练,1 个折叠进行验证。使用这种技术的目的是检查模型对不同的训练集和测试集组合的稳健性。它还用于比较两个模型,看哪一个整体性能更好。
是的,我们可以使用交叉验证来调整模型参数。还有一种更常用的 N 重交叉验证,去掉一个交叉验证,取一个样本作为测试集,其余的作为训练集。
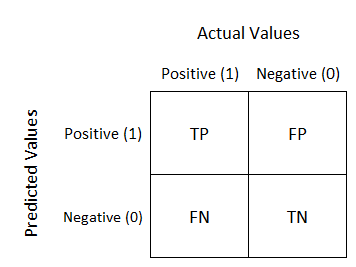
2.什么是混淆矩阵?
混淆矩阵是我们用于分类问题的另一种模型评估技术。在这种技术中,我们制作一个 NxN 矩阵,其中 N 是要预测的不同类别的数量,因此对于二进制分类问题,N=2。我们在 X 轴上有实际值,在 Y 轴上有预测值。模型评估是基于由此产生的一些指标完成的,如特异性、敏感性、精确度和召回率。

3.我们如何定义灵敏度、特异性和精确度?
灵敏度、回忆、功效或真阳性率是真阳性与阳性总数的比率。对于给定的分类问题,它告诉我们从所有阳性中正确分类的阳性的比例。

特异性或真阴性率是真阴性与总阴性的比率。它告诉我们正确分类的否定在所有否定中所占的比例。

精确度是真阳性与所有预测为阳性的病例的比例

4.什么是 F 分数?
f 分数是测试二元分类准确性的一种度量。这是精确和回忆的调和平均值。F 值取 0 到 1 之间的值,F 值越高,分类模型的能力越强。

5.我们什么时候用 ROC 和 AUC?它们代表什么?为什么我们要用 ROC 曲线?
ROC 曲线绘制了真阳性率(灵敏度)对假阳性率(1-特异性)。ROC 曲线用于参数调整。假设我们有一个逻辑回归模型,我们不知道使用什么阈值来分类真阳性和真阴性,那么在这种情况下,为每个阈值生成混淆矩阵可能是一个繁琐的过程,以决定使用哪个阈值。因此,我们制作 ROC 曲线,根据最适合我们的真阳性率和假阳性率来决定使用哪个阈值。我们用 AUC 来决定哪个模型更好。具有最大曲线下面积的模型是最佳模型。
6.偏差-方差权衡是什么?
在理解偏差和方差之间的权衡之前,让我们试着理解偏差和方差的含义:
偏差是指通过一个简单得多的模型[1] 来近似一个可能极其复杂的现实生活问题而引入的误差
另一方面,方差是如果我们使用不同的训练集对预测值 y-hat 进行估计,预测值 y-hat 将会改变的量[2]
偏差方差权衡有助于我们决定模型与训练集和测试集的匹配程度。完全符合训练集但在测试集上表现很差的模型被称为具有高方差,而符合测试集但不符合训练集的模型被称为具有高偏差。
7.赔率和概率有什么区别?各自是如何定义的?对数与逻辑回归有什么关系?
几率是某事发生与某事不发生的比率,而概率是某事发生与可能性总数的比率。
逻辑回归中的概率建模为

如果我们变换这个方程,使它在 X 轴上是线性的,我们会得到这样的结果

其中左边代表对数(赔率)
8.什么是逻辑回归?解释逻辑回归和线性回归的区别?
逻辑回归是一种机器学习技术,它根据一组观察到的 X 变量对响应 Y 属于特定类别的概率进行建模。概率由逻辑函数建模,其写作如下

线性回归用于预测持续反应,而逻辑回归用于分类。
9.比较线性回归和逻辑回归的系数。
简单线性回归的等式可以写成 Y = b0 + b1*X,其中 b1 表示 X 增加 1 个单位时 Y 的平均增加量,b0 是 Y 截距。
逻辑回归的方程式可以写成

这个方程表示一条 S 形曲线,为了将这个方程形象化为一条直线,我们可以对逻辑函数进行一些处理,得到

左边的函数表示对数(赔率),右边的方程现在是 x 的线性方程。因此,在逻辑回归的情况下,x 增加 1 个单位,对数(赔率)增加β1,或者相当于赔率乘以 e^β1.
然而,在线性回归和逻辑回归两种情况下,β1 的正值与 Y 的增加相关,在线性回归的情况下与 log(odds)相关,在逻辑回归的情况下与 Y 的增加相关。
10.解释最大似然法?为什么我们使用最大似然法而不是最小二乘法来计算逻辑回归的系数?
这是一种技术,用于估计最佳描述给定数据的分布的未知参数。可能性的等式是

其中θ是未知参数,x1,x2,…,xn 是数据点
逻辑函数是非线性函数,用 S 形曲线表示。现在,为了计算最小二乘,我们需要拟合一条线,使每个数据点到这条线的平方距离之和最小。因为计算 S 形曲线的残差更加复杂,所以最适合的方法是似然法,这是一种参数估计技术。
11.概率和似然的区别是什么?
概率和可能性虽然经常互换使用,但在某些情况下是不同的。在离散的情况下,它们代表相同的东西,但在连续分布的情况下,它们的意义完全不同。
在连续场景中,概率为**(数据|分布),读作数据给定分布**,而似然为(分布|数据),读作分布给定数据。
让我们从概率开始,每当我们被问到连续分布的概率时,它就是曲线下的面积。简而言之,给我们一个分布,曲线下的面积帮助我们找到在某个范围内观察到某个值的概率,即 P(数据|分布)。下图显示了代表篮球运动员身高的正态分布,平均值= 6.583,标准差= 0.3。曲线下的面积给出了 P(身高介于 6.7 & 6.9 |平均值= 6.583 &标准差= 0.3)

然而,在可能性的情况下,我们被给定一个数据集,我们的工作是找到最佳描述给定数据集的分布的参数,即 L(分布|数据)。我们通过对每个参数(平均值、标准偏差)取似然函数的导数来做到这一点,直到我们找到最大化似然函数的参数。在下图中,橙色分布底部的 x 表示我们要估计其平均值和标准差的给定样本集。因此,我们首先假设均值和标准差的值,并继续这一过程,直到我们找到一个分布,在这种情况下是橙色分布,它最大化了似然函数 **L(均值,标准差)**或最好地描述了数据。

12.我们为什么要使用正则化?
正则化技术用于减少模型过拟合。有两种常用的正则化方法,L1 正则化或套索和 L2 或岭回归。我们通过引入少量的偏差(或惩罚项)来做到这一点,使模型对训练数据不太敏感,从而避免过度拟合并减少测试数据的差异。正则化技术的目标是最小化下列山脊方程

接着是套索

λ决定斜率的惩罚,ε项是残差,β项是斜率。λ越高,惩罚越高。
13.套索和山脊有什么区别?我们如何选择调谐参数λ?
Lasso 和 Ridge 的最大区别在于,Ridge 回归可以将斜率渐近收缩到接近 0,而 Lasso 回归可以将斜率一直收缩到 0。当有许多无用的变量时,套索是有用的,而当大多数变量都有用时,山脊是有用的。
Lambda 可以取从 0 到无穷大的任何值。如果λ= 0,我们有最小二乘直线。我们可以通过交叉验证来选择 lambda 的值。λ越大,模型系数的变化越大。
14.拟合最小二乘回归线时,变量个数和样本个数之间的关系是什么?
n 应该总是至少等于 p,其中 n 是样本大小,p 是变量的数量。假设 n = 1,p = 2,不拟合任何线,我们至少需要 2 个数据点,对于一个数据点,我们可以有无限多条线通过该点。
15.有哪些方法可以替换丢失的数据?
有很多方法可以处理这种情况。
- 如果丢失值的实例数量只占整个数据集的一小部分,那么它们可以被安全地删除。
- 用平均值、中值或众数估算缺失值。这项技术的唯一警告是,如果数据有偏差,估算可能会导致错误的表示。例如,假设我们的数据集有两列,一列是个人的年龄,另一列是衡量个人健康状况的指数。现在,如果我们的数据集有健康指数的缺失值,并且如果数据偏向年轻人群,那么如果有老年人的缺失值,我们可能会用代表年轻人群的健康指数来替代它。
- 第三种方法是,我们可以找到与缺失值的变量高度相关的变量,并进行回归拟合。
16.解释朴素贝叶斯算法
“朴素贝叶斯”是一种分类算法,它使用贝叶斯定理将实例分类到特定类别。它假设预测值之间是独立的,这是一个主要的假设,因为一组预测值几乎不可能完全独立。当预测器是明确的时,它工作得很好。


这应该是一个停下来的好地方。在第二部分中,我们将讨论一些最常见的关于不同 ML 算法的面试问题。
参考:
[1]统计学习介绍— Gareth James,Daniela Witten,Trevor Hastie,Robert Tibshirani
[2]《统计学习导论》——加雷斯·詹姆斯、丹妮拉·威滕、特雷弗·哈斯蒂、罗伯特·蒂布拉尼
2020 年在 Twitter 上关注的顶级数据科学家

freestocks.org在 Unsplash 上拍照
数据科学|推特
这里有一份你应该关注的杰出数据科学家的名单。
用一句话来说就是——“世界上正在发生什么,人们在谈论什么。”这是 21 世纪媒体最热门的技术和领先的社交媒体平台之一。凭借高达 3 . 35 亿的月活跃用户,它也是模因病毒式传播和全世界分享人们观点的地方。
与其把 Twitter 作为一种娱乐机制,分散你对深层工作的注意力,让你被这个吸引你注意力的精心设计的产品所淹没,为什么不把它转变成一个学习和探索新想法的平台呢?
数据科学将在未来发挥至关重要的作用,甚至将帮助拯救世界免受气候变化。随着人工智能的激增,从年轻人到人工智能专家,每个人都必须了解关于人工智能的最新消息。还有比推特更好的地方吗?
在这篇文章中,我整理了一份 Twitter 上著名数据科学家的名单,我认为他们对数据科学领域做出了重大贡献,带来了这场伟大的革命。
没有他们,今天的四大科技公司——谷歌、亚马逊、脸书、苹果(GAFA)——就不会取得今天在人工智能和人工智能方面的进展。
为什么要在 twitter 上关注他们?
学习一个新话题的最好方法之一是通过从专家那里挑选。如果你想进入这个领域,为什么不跟随这些数据科学家,一窥在这个领域工作是什么样子。通过关注他们,你可以在你的 feed 中分享他们的经验、他们使用的工具、他们发现的有见地的帖子和文章、聚会、会议等。
事不宜迟,下面是在 Twitter 上关注的 33 位数据科学家的名单。它们没有任何特定的顺序。在 Twitter 上了解数据科学领域的顶尖人物,如果你还没有,现在就关注他们。
1.韦斯·麦金尼
Pandas 创始人,数据分析 Python 作者
韦斯·麦金尼的最新推文(@韦斯·麦金尼)。OSS 的非盈利主管 https://t.co/YVn0VFqgj0 专注于…
twitter.com](https://twitter.com/wesmckinn?s=20)
2. Yann LeCun
NYU 教授,脸书首席人工智能科学家
Yann LeCun (@ylecun)的最新推文。NYU 大学教授。脸书首席人工智能科学家。人工智能研究员…
twitter.com](https://twitter.com/ylecun?s=20)
3.院长阿博特
smarter HQ 联合创始人兼首席数据科学家
院长阿博特的最新推文(@deanabb)。联合创始人+首席数据科学家/ SmarterHQ,@smarterhq,作者…
www.twitter.com](http://www.twitter.com/deanabb)
4.柯克通天
博思艾伦首席数据科学家
Kirk Borne 的最新推文(@KirkDBorne)。首席数据科学家@BoozAllen。全球发言人。Top #BigData…
twitter.com](https://twitter.com/KirkDBorne?s=20)
5.迈克·塔米尔博士
首席 ML 科学家&SIG 机器学习/AI 主管,伯克利数据科学学院
Mike Tamir 博士的最新推文(@MikeTamir)。#UberATG &加州大学伯克利分校#DataScience 的负责人(推文是…
twitter.com](https://twitter.com/MikeTamir?ref_src=twsrc%5Egoogle%7Ctwcamp%5Eserp%7Ctwgr%5Eauthor)
6.道格切割
cloud era 首席架构师
Doug Cutting 的最新推文(@cutting)。Lucene,Nutch,Hadoop & Avro 的创始人。美国加州
twitter.com](https://twitter.com/cutting?lang=en)
7.彼得·斯科莫洛赫
机器学习、人工智能、数据科学执行官&投资人
彼得·斯科莫罗奇的最新推文(@peteskomoroch)。机器学习、人工智能、数据科学高管和投资者。过去…
twitter.com](https://twitter.com/peteskomoroch?s=20)
8.莫妮卡·罗加蒂
数据科学&人工智能顾问
莫妮卡·罗加蒂的最新推文(@mrogati)。数据科学和人工智能顾问;分数 CDO。前数据副总裁@Jawbone…
twitter.com](https://twitter.com/mrogati?lang=en)
9. DJ 帕蒂尔
前美国首席数据科学家
DJ Patil 的最新推文(@dpatil)。前美国首席数据科学家。我建造东西。美国加州
twitter.com](https://twitter.com/dpatil)
10.卢卡斯·比沃德
Weights and bias 的创始人/首席执行官
Lukas Biewald 的最新推文(@l2k)。Weights and bias(@ Weights _ bias)的创始人/CEO。前情提要…
twitter.com](https://twitter.com/l2k)
11.阿龙·哈勒维
艾,董事,前谷歌人,教授。
AlonHalevy 的最新推文(@AlonHalevy)。计算机科学家和咖啡栽培学家。脸书艾导演…
twitter.com](https://twitter.com/alonhalevy?lang=en)
12.肯尼斯·库基尔
*高级编辑,*经济学家
肯尼斯·库基尔的最新推文(@kncukier)。《经济学人》的高级编辑。NYT 畅销书《大…
www.twitter.com](http://www.twitter.com/kncukier)
13.南多·德弗雷塔斯
谷歌 DeepMind 机器学习团队的科学家领导
南多·德·弗雷塔斯的最新推文(@NandoDF)。我研究智能来理解我们是什么,并利用…
www.twitter.com](http://www.twitter.com/NandoDF)
14.约翰·艾尔德
艾尔德研究公司创始人
约翰·埃尔德的最新推文(@johnelder4)。艾尔德研究的创始人,最大最有经验的数据…
www.twitter.com](http://www.twitter.com/johnelder4)
15.费-李非
斯坦福大学计算机科学教授
飞的最新推文(@drfeifei)。斯坦福大学以人为中心的人工智能研究所副主任
www.twitter.com](http://www.twitter.com/drfeifei)
16.伯纳德·马尔
Bernard Marr&Co创始人兼首席执行官
Bernard Marr 的最新推文(@BernardMarr)。国际畅销作家;主旨发言人;未来学家…
www.twitter.com](http://www.twitter.com/BernardMarr)
17.希拉里·梅森
前机器学习总经理 Clouder
希拉里·梅森的最新推文(@hmason)。做一些新的东西。我♥数据和芝士汉堡。纽约市
www.twitter.com](http://www.twitter.com/hmason)
18.吴恩达
创始人兼 CEO,落地 AI
来自吴恩达的最新推文(@AndrewYNg)。Coursera 联合创始人;斯坦福计算机学院兼职教授。…的前任负责人
twitter.com](https://twitter.com/AndrewYNg)
19.伊利亚·苏茨基弗
OpenAI 的首席科学家
Ilya Sutskever 的最新推文(@ilyasut)。@openai
twitter.com](https://twitter.com/ilyasut)
20. Ben Lorica 罗瑞卡
奥莱利媒体公司首席数据科学家
The latest Tweets from Ben Lorica 罗瑞卡 (@bigdata). Data scientist starting anew in 2020; Past: Program Chair of…
twitter.com](https://twitter.com/bigdata)
21.杰克·波威
数据王创始人兼执行董事
杰克·波威的最新推文(@杰克·波威)。首席执行官@DataKind ||非常乐观||主要谈论民主…
twitter.com](https://twitter.com/jakeporway)
22.莉莲·皮尔森,体育专家
Data-Mania LLC 商业和数据策略师
莉莲皮尔森的最新推文,PE (@Strategy_Gal)。🇺🇸 3x 首席执行官在#科技⤸ ✮ B2B 首席执行官→#数据战略家+…
twitter.com](https://twitter.com/Strategy_Gal)
23.哈德利·韦翰
R for Data Science 的作者
哈德利·威克姆的最新推文(@哈德利·威克姆)。r,数据,可视化,🐕,🍸,🌈。他/她。德克萨斯州休斯顿
twitter.com](https://twitter.com/hadleywickham?s=20)
24.基拉·雷丁斯基
诊断机器人董事长兼首席技术官
Kira Radinsky 的最新推文(@KiraRadinsky)。诊断机器人董事长兼首席技术官(前易贝首席科学家…
www.twitter.com](http://www.twitter.com/KiraRadinsky)
25.理查德·索切尔
首席科学家,销售团队
理查德·索彻的最新推文(@RichardSocher)。Salesforce 的首席科学家。热爱人工智能研究和…
www.twitter.com](http://www.twitter.com/RichardSocher)
26.克里斯·苏尔达克
高德纳公司执行合伙人
克里斯·苏尔达克的最新推文(@CSurdak)。作家,火箭科学家,#rpa 和#bigdata 的家伙。专栏作家@TEBReview…
www.twitter.com](http://www.twitter.com/CSurdak)
27.巴斯蒂安·特龙
uda city 创始人兼总裁
来自巴斯蒂安·特龙的最新推文。创始人,乌达城总裁。加利福尼亚州山景城
www.twitter.com](http://www.twitter.com/SebastianThrun)
28.约翰·迈尔斯·怀特
脸书数据科学家
约翰·迈尔斯·怀特的最新推文(@johnmyleswhite)。纽约脸书数据基础设施团队的工程经理。前…
www.twitter.com](http://www.twitter.com/johnmyleswhite)
29.瑞安·罗萨里奥
Riot Games 的数据科学家/研究工程师
Ryan R. Rosario 的最新推文(@DataJunkie)。加州大学洛杉矶分校统计学博士:数据科学家@谷歌,讲师@加州大学洛杉矶分校…
twitter.com](http://twitter.com/DataJunkie)
30.奥利维尔·格里塞尔
Inria 的软件工程师
Olivier Grisel 的最新推文(@ogrisel)。@Inria 的工程师,sci-kit-learn 开发人员,由…
twitter.com](http://twitter.com/ogrisel)
31.格雷戈里·皮亚泰茨基
KD nuggets 总裁,LinkedIn 数据科学最高权威& Analytics
KDnuggets 的最新推文(@kdnuggets)。涵盖#人工智能、#分析、#大数据、#数据挖掘、#数据科学…
twitter.com](http://twitter.com/kdnuggets)
32.大卫·史密斯
虚拟城市的数据科学家
大卫·史密斯的最新推文(@revodavid)。微软的云倡导者。关于人工智能、数据科学、R #rstats 的推文…
twitter.com](http://twitter.com/revodavid)
33.德鲁·康威
冲积层的首席执行官和创始人
德鲁·康威的最新推文(@drewconway)。1994 年 CT 布里奇波特的大片电玩商店冠军。新…
twitter.com](http://twitter.com/drewconway)
一个行动计划

我希望你喜欢这篇文章,并且我成功说服你清理了你的 Twitter。社交媒体正在吞噬我们的生活,如果你不找到一种方法将它转变成一个学习的地方,你很快就会被它吞噬。所以,开始过滤噪音,让高质量的信息进入你的生活,观察你的变化,一次一条。
如果一个一个地点击它们很辛苦,而且你是个大忙人,那就去我的个人资料,在这个推特 列表 上找到它们!
查看我关于数据科学最佳 TED 演讲的文章
这里列出了最精彩的 TED 演讲,这些演讲启发了你,并向你展示了数据的力量。
towardsdatascience.com](/best-ted-talks-for-data-science-11b699544f)
联系人
如果你想了解我的最新文章,请关注我的媒体。
其他联系方式:
快乐发微博,快乐学习,快乐编码。
35 个问题来测试你的 Python 集知识
如何通过掌握集合基础来碾压算法题

来自 Pexels 的 Andrea Piacquadio 的照片
在我追求精通采访算法的过程中,我发现钻研 Python 的基本数据结构很有用。
这是我写的个人问题列表,用来评估我对 Python 集合的了解。
你对 python 集合了解多少?
1.将一个对象转换成一个集合会保持对象的顺序吗?
不。集合不是有序的数据结构,所以不保持顺序。
看看当我们将列表[3,2,1]转换为集合时会发生什么。就变成了{1,2,3}。
a = set([3,2,1])
a
#=> {1, 2, 3}
2.检查一个集合是否是另一个集合的子集
这可以用issubset()方法来完成。
a = {4,5}
b = {1,2,3,4,5}a.issubset(b)
#=> Trueb.issubset(a)
#=> False
3.使用比较运算符检查集合是否是子集
如果s1的所有元素都在s2中,那么集合s1就是s2的子集。
如果第一个集合中的所有元素都存在于第二个集合中,那么操作符<=将返回True。是子集)。
a = {'a','b'}
b = {'a','b','c'}a <= b
#=> True
b <= a
#=> False
4.集合是自身的子集吗?
是的。
因为集合包含了自身的所有元素,所以它确实是自身的子集。当我们稍后对比“子集”和“真子集”时,理解这一点很重要。
a = {10,20}a.issubset(a)
#=> True
5.检查集合中是否存在特定值
像其他类型的 iterables 一样,我们可以用in操作符检查一个值是否存在于一个集合中。
s = {5,7,9}5 in s
#=> True6 in s
#=> False
6.检查值是否不在集合中
我们可以再次使用in操作符,但这次是以not开头。
s = {'x','y''z'}'w' not in s
#=> True'x' not in s
#=> False
7.什么是集合?
集合是唯一对象的无序集合。
当任何对象转换为集合时,重复值将被删除。
set([1,1,1,3,5])
#=> {1, 3, 5}
以我个人的经验来看,我使用集合是因为它们使得寻找交集、并集和差这样的运算变得容易。
8.子集和真子集有什么区别?
真子集是集合的子集,不等于自身。
比如:
{1,2,3}是{1,2,3,4}的真子集。
{1,2,3}不是{1,2,3}的真子集,但它是子集。
9.检查一个集合是否是真子集
我们可以使用<操作符检查一个集合是否是另一个集合的真子集。
{1,2,3} < {1,2,3,4}
#=> True{1,2,3} < {1,2,3}
#=> False
10.向集合中添加元素
与列表不同,我们不能使用+操作符向集合中添加元素。
{1,2,3} + {4}
#=> TypeError: unsupported operand type(s) for +: 'set' and 'set'
使用add方法添加元素。
s = {'a','b','c'}
s.add('d')
s
#=> {'a', 'b', 'c', 'd'}

11.复制一套
copy()方法对集合进行浅层复制。
s1 = {'a','b','c'}s2 = s1.copy()
s2
#=> {'c', 'b', 'a'}
12.检查一个集合是否是另一个集合的超集
一个集合s1是另一个集合s2的超集,如果s2中的所有值都能在s1中找到。
您可以使用issuperset()方法检查一个集合是否是另一个集合的超集。
a = {10,20,30}
b = {10,20}a.issuperset(b) #=> True
b.issuperset(a) #=> False
13.用比较运算符检查一个集合是否是超集
除了issuperset(),我们还可以使用>=比较操作符来检查一个集合是否是一个超集。
a = {10,20,30}
b = {10,20}a >= b #=> True
b >= a #=> False
14.集合是自身的超集吗?
因为集合s1中的所有值都在s1中,所以它是自身的超集。尽管它不是一个合适的超集。
a = {10,20,30}a.issuperset(a)
#=> True
15.检查一个集合是否是另一个集合的适当超集
如果s2中的所有值都在s1和s1 != s2中,则集合s1是另一个集合s2的真超集。
这可以用>操作器进行检查。
a = {10,20,30}
b = {10,20}
c = {10,20}a > b #=> True
b > c #=> False
16.将集合转换为列表
在集合上调用列表构造函数list(),将集合转换为列表。但是注意,不保证顺序。
a = {4,2,3}
list(a)
#=> [2, 3, 4]
17.如何迭代集合中的值?
一个集合可以像其他迭代器一样通过循环进行迭代。但是再次注意,顺序不保证。
s = {'a','b','c','d','e'}for i in s:
print(i)
#=> b
#=> c
#=> e
#=> d
#=> a
18.返回集合的长度
集合中元素的数量可以通过len()函数返回。
s = {'a','b','c','d','e'}len(s)
#=> 5
19.创建集合
可以使用带花括号的集合符号创建集合,例如,{…},示例:
{1,2,3}
#=> {1, 2, 3}
或使用 set 构造函数,示例:
# set(1,2,3)
=> TypeError: set expected at most 1 arguments, got 3set([1,2,3])
#=> {1, 2, 3}
但是请注意,后者需要传入另一个 iterable 对象,比如 list。
20.求两个集合的并集。
使用union()方法可以找到两个集合的并集。
s1 = {1,2,3,4,5}
s2 = {4,5,6,7,8}s1.union(s2)
#=> {1, 2, 3, 4, 5, 6, 7, 8}
也可以用|操作符找到。
s1 = {1,2,3,4,5}
s2 = {4,5,6,7,8}s1 | s2
#=> {1, 2, 3, 4, 5, 6, 7, 8}

21.求两个集合的交集
两个集合的交集可以用intersection()方法获得。
s1 = {1,2,3,4,5}
s2 = {4,5,6,7,8}s1.intersection(s2)
# => {4, 5}
也可以用&操作器拍摄。
s1 = {1,2,3,4,5}
s2 = {4,5,6,7,8}s1 & s2
# => {4, 5}
22.找出 s1 中不在 s2 中的元素
这可以用difference()方法找到。
s1 = {1,2,3,4,5}
s2 = {4,5,6,7,8}s1.difference(s2)
{1, 2, 3}
也可以用-操作符找到它。
s1 = {1,2,3,4,5}
s2 = {4,5,6,7,8}s1 - s2
{1, 2, 3}
23.从集合中移除元素
remove()按值从集合中删除元素。
s = {'x','y','z'}
s.remove('x')
s
#=> {'y', 'z'}
24.从集合中移除并返回未指定的元素
从集合中移除并返回一个元素,将集合视为一个无序队列。
s = {'z','y','x'}
s.pop()
s
#=> {'y', 'z'}
25.检查 2 个集合是否不相交
如果集合、s1和s2没有公共元素,则它们是不相交的。
a = {1,2,3}
b = {4,5,6}
c = {3}a.isdisjoint(b) #=> True
a.isdisjoint(c) #=> False
26.将另一个集合中的所有元素添加到现有集合中
方法从另一个集合中添加元素。
a = {1,2,3}
b = {3,4,5}a.update(b)
a
#=> {1, 2, 3, 4, 5}
这也可以通过|=操作器来完成。
a = {1,2,3}
b = {3,4,5}a |= b
a
#=> {1, 2, 3, 4, 5}
注意这与union不同。union()返回新集合,而不是更新现有集合。
27.从集合中移除所有元素
clear()从集合中删除所有元素。然后,该集合可用于将来的操作并存储其他值。
a = {1,2,3}
a.clear()
a
#=> set()
28.从集合中移除元素(如果存在)
discard()如果某个元素存在,则删除该元素,否则不执行任何操作。
a = {1,2,3}
a.discard(1)
a
#=> {2, 3}a = {1,2,3}
a.discard(5)
a
#=> {1, 2, 3}
与此形成对比的是remove(),如果您试图删除一个不存在的元素,它会抛出一个错误。
a = {1,2,3}
a.remove(5)
a
#=> KeyError: 5
29.将字典传递给 set 构造函数的结果是什么?
只有字典的键会存在于返回的集合中。
d = {'dog': 1, 'cat':2, 'fish':3}
set(d)
#=> {'cat', 'dog', 'fish'}
30.你能把两套拉链拉上吗?
是的。但是每个集合中的值可能不会按顺序连接。
请注意整数集中的第一个值是如何与字母集中的第三个值组合在一起的,(1, 'c')。
z = zip(
{1,2,3},
{'a','b','c'}
)
list(z)
#=> [(1, 'c'), (2, 'b'), (3, 'a')]

31.集合可以通过索引访问吗?
不可以。试图通过索引访问集合将会引发错误。
s = {1,2,3}
s[0]
#=> TypeError: 'set' object is not subscriptable
32.集合和元组有什么区别?
元组是不可变的。集合是可变的。
元组中的值可以通过索引来访问。集合中的值只能通过值来访问。
元组有顺序。集合没有顺序。
集合实现了集合论,所以它们有很多有趣的功能,如并、交、差等。
33.set 和 frozenset 有什么区别?
冷冻集的行为就像集合一样,只是它们是不可变的。
s = set([1,2,3])
fs = frozenset([1,2,3])s #=> {1, 2, 3}
fs #=> frozenset({1, 2, 3})s.add(4)
s #=> {1, 2, 3, 4}fs.add(4)
fs #=> AttributeError: 'frozenset' object has no attribute 'add'
34.更新一个集合使其等于另一个集合的交集
intersection_update()将第一个集合更新为等于交集。
s1 = {1,2,3,4,5}
s2 = {4,5,6,7,8}s1.intersection_update(s2)
s1
#=> {4, 5}
这也可以用&=操作符来完成。
s1 = {1,2,3,4,5}
s2 = {4,5,6,7,8}s1 &= s2
s1
#=> {4, 5}
35.从第一个集合中移除第二个集合的交集
difference_update()从第一个集合中删除交集。
s1 = {1,2,3,4,5}
s2 = {4,5,6,7,8}s1.difference_update(s2)
s1
#=> {1, 2, 3}
操作员-=也工作。
s1 = {1,2,3,4,5}
s2 = {4,5,6,7,8}s1 -= s2
s1
#=> {1, 2, 3}
结论
你做得怎么样?
我们在日常编程中不经常使用集合,我们大多数人在编写 SQL 连接时只接触过集合论。也就是说,熟悉基础知识并没有坏处。
如果你觉得这很有趣,你可能也会喜欢我的 python 面试问题。
向前向上。
3D 深度学习变得更简单——脸书 PyTorch3D 框架简介

脸书发布了支持 3D 环境中深度学习的 PyTorch3D 框架。找出它是什么。
介绍
作为一个开源的机器学习库,PyTorch 越来越受到人工智能(AI)研究人员的欢迎,用于各种应用,包括计算机视觉和自然语言处理。作为其主要开发者,脸书人工智能研究中心(FAIR)已经注意到 PyTorch 和其他可用工具包中处理 3D(即 3 维)数据的有限功能,因此他们开发了 PyTorch3D 框架,旨在促进 3D 深度学习领域的创新研究。
该框架有三个关键特性,包括使用网格的数据结构、这些网格的操作和可区分的渲染器。下面介绍这些功能。
使用三角形网格的数据结构
对于 2D 图像输入,批处理很简单,包括生成一个形状为N X 3 X H X W的四维张量,如下所示。然而,3D 图像输入不是平坦的(即 2D),并且这种对 2D 图像输入的批处理将不起作用。

图像批处理 2D vs. 3D(来源: PyTorch3D
为了解决 PyTorch3D 中的这个问题,FAIR team 使用网格作为数据结构来处理 3D 图像输入。具体来说,3D 图像输入将被处理为多个顶点和面,从这些顶点和面可以形成三角形网格。如下面的动画图像所示,要批处理异构网格,网格数据结构可以是张量列表、打包张量和填充张量。更多细节可以参考这个链接。

PyTorch3D 中作为数据结构的网格(来源:脸书)
三角形网格上的操作
除了上面提到的对异构批处理输入的支持之外,PyTorch3D 还优化了几种常见运算符和损失函数的实现,如 Chamfer 和 Lapacian,前者是一种比较两组 3D 数据点云的方法。这些内置操作允许研究人员训练他们的模型,而不需要自己实现这些操作。

三角形网格上的操作(来源:脸书)
可微分网格渲染器
PyTorch3D 提供了一个高效的模块化可区分渲染器,允许研究人员将他们的 3D 模型转换为 2D 图像。这种模块化的可区分渲染器是创新的,因为传统的渲染引擎由于不可区分而无法融入深度学习。下面的动画图像显示了渲染器如何作为相机扫描工作。

可微分网格渲染器(来源:脸书
外卖和后续步骤
感谢 FAIR 开发这一强大工具包的工作以及作为开源项目的慷慨共享,这使得 3D 深度学习对许多人工智能研究人员来说更容易。如果你想探索这个工具包,在它的 GitHub 上有几个入门教程。

PyTorch3D 教程
参考
使用高岭土和 Colab 的 6 步 3D 对象检测分类器
一步一步的实际操作的 3D 对象检测分类器,没有 Linux 机器或 GPU 的先决条件

三维物体检测分类器
在本文中,您将学习开发 3D 对象检测分类器,而无需预先准备 Linux 机器或手中的 GPU。
3D 对象检测是解决诸如自动驾驶汽车、机器人和 AR/VR 应用等现实世界应用的一个重要方面。3D 数据提供可靠的深度信息,可用于精确定位物体/车辆。
3D 表示
以下是 3D 表示的一些类型

3D 表示
点云是 3D 空间中的点的集合,每个点由一个(XYZ)坐标指定,可选地还有其他属性(如 RGB 颜色)。点云被称为从诸如激光雷达的传感器获得的原始数据。在进一步处理之前,这些被转换成其他表示,例如多边形网格、体素网格。
点云(PC)表示更为可取,因为 PC 到其他格式的转换很容易,反之亦然。点表示保留了 3D 空间中原始的几何信息,没有任何离散化。
多边形网格由组多边形面组成,这些多边形面具有近似几何表面的共享顶点。
体积表示规则间隔的 3D 网格上的单个样本或数据点,体素网格是 3D 网格,其中每个单元或“体素”具有固定的大小和离散的坐标。
投影视图 RGB(D) 将 3D 对象投影到多个视图中,并提取相应的视图特征,然后融合这些特征以进行精确的对象检测。
Google Colab -简介
Google colaboratory 又名 colab,是一款免费使用 GPU 的 jupyter 笔记本电脑。当您在 colaboratory 上训练您的模型时,您可以使用基于 GPU 的虚拟机,每次最多给你 12 个小时。之后失去对该特定虚拟机实例的访问,并在 12 小时后连接到不同的虚拟机实例。所以请定期保存数据或检查点。可乐是完全免费的。

选择 GPU
要选择用于训练的 GPU,请选择运行时 > 更改运行时类型选择硬件加速器(无更改为 GPU)。
colab 预装了各大库(NumPy,matplotlib)和框架(TensorFlow,PyTorch)并进行定制安装尝试(!pip 安装。
探索谷歌实验室这里
高岭土- 3D 深度学习研究框架
Kaolin 是由 NVIDIA 的一个团队开发的开源 PyTorch 库,旨在加速 3D 深度学习研究。高岭土框架用几行代码将 3D 模型转换成深度学习数据集。高岭土为加载和预处理流行的 3D 数据集提供了便捷的途径。
Kaolin 框架将复杂的 3D 算法归结为简单的步骤,如点云数据到体素网格的转换,三角形网格表示。
高岭土框架使机器人、自动驾驶汽车、增强和虚拟现实等领域的研究人员受益。
现在,对于 3D 对象检测分类器,我们将使用高岭土框架。git 回购可以在这里找到
总之,这是我们一直在寻找的高岭土特性。

高岭土特征
资料组
该数据集可从普林斯顿模型网获得。model net 10 . ZIPZIP 文件包含来自 10 个类别的 CAD 模型,用于在我们的 3D 对象检测分类器中训练深度网络。培训和测试分割包含在文件中。CAD 模型在内部被完全清理,模型的方向(非比例)由我们自己手动调整。
MODELNET 10 有下面提到的 10 个类别:
浴缸,床,椅子,书桌,梳妆台,显示器,床头柜,沙发,桌子,卫生间
让我们开始吧…
3D 对象检测分类器
第一步:打开 google colab 这里,将运行时间改为 GPU(大约 4-5 分钟)
安装软件包
安装软件包
步骤 2:下载 MODELNET10 数据集
通过 X、Y、Z 移动可视化 3D 模型
步骤 3:数据加载
Kaolin 提供了方便的功能来加载流行的 3D 数据集(ModelNet10)。首先,我们将定义几个重要参数:
model_path该变量将保存 ModelNet10 数据集的路径。categories变量来指定我们要学习分类哪些类。num_points是我们将网格转换为点云时从网格中采样的点数。
最后,如果我们使用 CUDA 进行转换操作,我们将禁用多处理和内存锁定。
该命令定义了一个transform,它首先将一个网格表示转换为一个点云,然后将标准化为以原点为中心,标准偏差为 1。与图像非常相似,点云等 3D 数据需要进行归一化处理,以获得更好的分类性能。
split='train'参数表明我们正在装载“火车”拆分。rep='pointcloud'加载网格并转换成点云。transform=norm对每个点云应用标准化变换。
步骤 4:建立我们的模型、优化器和损失标准
步骤 5:训练点云分类器(大约 15-20 分钟)
以下代码行将训练和验证一个 PointNet 分类器

划时代训练
万岁!!!,就这样,你已经用高岭土训练了你的第一个 3D 物体检测分类器!!
步骤 6:在测试数据上评估训练的 3D 对象检测模型
我们将创建一个新的数据加载器,它将加载与我们以前的 val_loader 相同的数据,但是会进行混排,并获取一个样本批次。
接下来,我们使用一个小的可视化函数设置一个图形来可视化点云、地面实况标签和我们的预测。
对结果进行颜色编码,绿色表示正确,红色表示不正确。****
可视化结果
地面真相,Pred 预测。

拍拍背,完成 3D 对象检测分类器。
感谢阅读…
Jupyter 笔记本可以在这里找到
文章更新:2021 年 10 月 31 日
引用 URL
- Krishna mur thy Jatavallabhula等《高岭土:加速 3D 深度学习研究的 PyTorch 库》arXiv:1911.05063 v2论文
- https://github.com/NVIDIAGameWorks/kaolin
- 普林斯顿模型网
4.Google colab 指南
用人工智能探索艺术。
新模型的用法,有例子和 Colab 笔记本。

达芬奇《最后的晚餐》。通过 Merzmensch 的 3D 照片修复进行转换
我们生活在一个实验的大时代。嗯,科学、社会和文化一直在经历新的故事。想想文艺复兴或达达主义运动。但是数据科学,在计算边缘的当前状态下,允许我们做一些超出我们想象的事情。机器学习是通往未知的新旅程的最初起点。深度(无监督)学习则更进一步。
经过特定数据集的训练,人工智能可以可视化其对现实的感知——或增强现有的概念。当然,这取决于培训来源和能力。但我们人类也是如此——我们了解我们所知道的。我们知道我们所理解的。
艺术品背后的一瞥。
我一直想知道人工智能在特定情况下解释现实和艺术的能力。还有:用机器探索“幻觉”难道不是一件令人兴奋的事情吗?
就像我们的大脑用**补充了一个盲点(又见:盲点)中的信息缺失,用它“假设”的东西去补全缺失区域应该有的东西。**
有时它会朝着令人惊讶的方向发展。一个基于 StyleGAN 的网络应用程序以一种意想不到的方式“纠正”了我上传的图片:
NVIDIA AI 的 AI 实验图像修复给了我一些令人毛骨悚然的结果:
这是另一个奇妙的修复故障,由乔纳森·弗莱观察到:
西蒙·尼克劳斯(Simon Niklaus)等人的 3D 本·伯恩斯效应 为我们提供了一个全新的激动人心的维度——使用单一图像,分析整体的遮挡、深度和几何形状,使我们能够“进入”照片。
您可以将历史照片变得栩栩如生:
或者你甚至可以更进一步,在图片后面:
3D 本·伯恩斯效果非常适合透视清晰的照片或图像。当深度不容易确定时,情况就变得复杂了:
3D 摄影修复
凭借他们的论文“使用上下文感知分层深度修复的 3D 摄影”( PDF )有一个来自弗吉尼亚理工、国立清华大学、脸书的团队将图像的探索带到了另一个层次。**
****3D Photography using Context-aware Layered Depth Inpainting:**
[Project Website](https://shihmengli.github.io/3D-Photo-Inpainting/) / [Paper](https://drive.google.com/file/d/17ki_YAL1k5CaHHP3pIBFWvw-ztF4CCPP/view?usp=sharing) / [GitHub](https://github.com/vt-vl-lab/3d-photo-inpainting.git) / [Colab Notebook](https://colab.research.google.com/drive/1706ToQrkIZshRSJSHvZ1RuCiM__YX3Bz)Team: [Meng-Li Shih](https://shihmengli.github.io/) (1,2)
[Shih-Yang Su](https://lemonatsu.github.io/) (1)
[Johannes Kopf](https://johanneskopf.de/) (3)
[Jia-Bin Huang](https://filebox.ece.vt.edu/~jbhuang/) (1)1) Virginia Tech
2) National Tsing Hua University
3) Facebook**
在他们的项目网站上,可以看到各种各样的演示视频。
这里是各种现有模型之间的视频比较:
多层次深度的新方法给游戏带来了更多的维度。可移动对象后面的背景仍然是用修补填充的,但结果的三维效果令人惊叹。
使用基于 CNN 的深度估计和图像预处理,该模型以连接的方式延续不可见的区域:线条和图案的上下文感知延续非常令人信服。
将我制作的马格里特的图片与新模型进行比较:
或者偷偷溜进萨瓦尔多·达利和弗雷德里科·加西亚·洛卡的肖像照:
用 3D 照片修复探索艺术
如你所见,机器对隐藏层的解释令人着迷。
演示视频中的结果非常令人信服,但毕加索修改后的肖像最吸引我的是:

来自 3D 摄影 Inpaiting 演示视频(来源),摄影师:Herbert List / Magnum Photos
这里使用的照片描绘了毕加索在他的大奥古斯丁街工作室的《美食》(1948)前。而艺术家背后的绘画区域则由 AI 填充。
那么在机器的大脑里发生了什么呢?我做了一些实验,不知所措。
达芬奇《最后的晚餐》中耶稣背后的风景清晰而独特:
另一个马格里特——感受超现实梦境中的空间:
勒内·马格里特以他的幻觉和玩弄现实层面而闻名。在他的作品“L’Heureux donateur ”中,观者无法辨认,这是一个戴着帽子的男人的轮廓,上面画着夜景——还是一个男人形状的剪影,引导我们看到更远处的风景。
3D 照片修复带来了它的解释:
安德鲁·怀斯荒凉的世界变得更加生动:
皮拉内西乌托邦式的后城市结构有了深度:
在这些例子中,你可以清楚地看到深度层,由 CNN 以一种非常复杂和精确的方式生成。几何学和内容感知图像绘画展示了图像探索的未来。
该方法还包括图像的 3D 图,其可以在其他实现中使用。
目前 Twitter 上充斥着 3D 照片修复的实验。这里由runner 01(btw。一个精彩的必关注推特,最新人工智能模型和实验的来源):
此外,使用这种方法,历史摄影变得更有表现力。彩色的老爱尔兰实验用去彩色化(基于人工智能的彩色化)和 3D 本·伯恩斯效果对历史上的爱尔兰摄影。3D 照片修复在这里得到了完美的运用:
艺术家和数字探险家 马里奥·克林格曼 在博世**的尘世快乐花园中探索:****
作为上周的总结(随着《3D 照片在绘画中》的出版),他写道:
的确,是时候进行人工智能解读艺术的探索和实验了。
更新。Manuel Romero的这款 Colab 专为将图像转换成视频而设计,无需耗时的 3D 元数据。多文件上传和下载也是可用的。如果你想转换一堆照片,这款 Colab 适合你。
亲爱的读者们,你们会发现什么?
4.5 年的恋爱关系,在脸书活动
分析脸书与我女朋友的互动和信息数据
我最近下载了脸书所有关于我的数据。我发现了许多有趣的事情,但我特别想研究的一个领域是这些数据如何反映了我和我女朋友关系的进展。
在这篇文章中,我将(再次)通过数据科学与世界分享我们 21 世纪的爱情故事。在真正的千禧年时尚中,我将把我们的浪漫减少到我们在社交媒体上互动的总和,然而,看到相似之处将是有趣的——既与现实生活相似,也与我们在其他社交媒体上出现的关系相似。
正如我在本系列中的所有博客文章一样,分析和可视化都是使用 R 创建的。查看 my Github 中使用的代码以及帮助分析您自己的脸书数据的 R 包。
这可能是一个新的开始
2015 年 12 月 7 日星期一,晚上 7 点 30 分 11 秒整,我和我女朋友成为了脸书的朋友。那时我们已经认识了几个月,在同一个友谊小组,但是以前没有太多的交流。三天后,第一条信息被发送出去,剩下的,正如他们所说,就成为历史了…直到它在一篇博客文章中被分析。
数据集的性质意味着我没有我们在脸书关系的全貌,我只有从我这边看得见的东西。就信息而言,这不是问题,因为我可以看到所有的信息,但就喜欢、反应、评论和帖子而言,我只能看到我对我的女朋友采取了什么行动,而不是相反。
所以让我快速的分解一下:
- 正如我所说的,2015 年 12 月 7 日是开始日期,这是近 5 年的活动。作为参考,我们从 2016 年 3 月 31 日开始约会。
- 我在评论中提到她 213 次,在状态中提到她 4 次(我不经常发布状态)。
- 我对她的一些东西(帖子、评论、照片等)做出了“反应”。)209 次。
- 我们已经相互发送了 8598 条信息。虽然没有 Whatsapp 上的多,但还是远远超过了我的预期。和以前一样,我惊讶地发现我发的消息(4539 条)比她发的多(4092 条)。
- 还是像以前一样,我使用的独特词汇(3193 个)比我的女朋友(3049 个)多。
- 我还可以看到,我们使用 messenger 进行通话或视频聊天的时间达到了 125.1 分钟。
脸书调情
要显示上面的数字:

自从我们第一次互动以来的每 28 天内,我和我女朋友之间的脸书互动次数。

从我们第一条信息开始的 28 天内,我和女朋友之间发送的脸书信息的数量。
第一张图显示,随着时间的推移,我对脸书的使用越来越少,我们的互动在评论和反应之间平分秋色。
你可以看到我们的信息大多是在我们正式开始约会前的一个半月。我想在这之后,我们只是转移到 Whatsapp/text。由此得出一个有争议的结论: Messenger 是用来调情的,Whatsapp 是用来谈恋爱的?
这两个图表显示了我在 2017 年 9 月开始工作后活动增加的相同模式(我希望我的老板没有看到这一点)。对此的解释是,在这之前的几个月,我们住在一起,每天大部分时间都在一起,所以我们的大部分互动都是面对面的,而当我开始工作时,我大部分时间都在办公室,不得不出差,所以我们的社交媒体交流增加了。或者,你可以暗示我在应该工作的时候使用社交媒体。我不知道你怎么想,但我认为前者比后者更有说服力…
我喜欢“喜欢”你
除了观察一段时间内的反应,我们还可以根据类型和目标来分解反应。

我在女朋友的帖子、评论、照片或视频上使用了多少次每个反应。
毫不奇怪,喜欢比其他任何东西都要普遍得多。其余的,爱和哈哈是下一个最常用的。我很高兴不是‘愤怒’和‘抱歉’。
上图考虑了我对我女朋友在脸书上发布的每一类内容的所有反应。然而,如果我们考虑到(就像我们现实生活中的关系一样)我们在脸书的关系在过去 5 年里并没有保持不变,就会发现一些有趣的模式。这反映了对的喜欢。

随着时间的推移,我在脸书上对我女朋友的内容类型做出了反应。
众所周知,21 世纪的调情通常包括喜欢社交媒体上的照片。看看 2016 年上半年,我会觉得我也有这种感觉。
然而,在 2017 年年中之后,所有的照片反应都是在我们一起度假之后直接出现的。现在看来,这是我们俩唯一一次在脸书的个人资料上贴照片了。
我不想引起更多的关注,但在我 2017 年底开始工作后,活动也(再次)激增。你还可以看到前面提到的使用减少的模式,在 2020 年封锁期间,社交媒体互动几乎不存在。
为了与我之前关于 Whatsapp 聊天的文章进行更多的比较,我现在将快速浏览一下我们在脸书互相发送的消息内容…
嗯,你看怎么样?
下图显示了我们在 Facebook Messenger 上最常用的词——与所有文本分析一样,常见的停用词(“The”、“and”等)。)已被删除。

我女朋友和我在 Facebook Messenger 上最常用的词。
首先,我向你保证我们不会用第三人称称呼自己…这只是显示我们在 Facebook Messenger 上玩游戏的时间(例如,“Chris 开始了一个游戏。马上回复!”).
可笑的是,我们俩有了和在 Whatsapp 上一样的最常用词。上次我有一些评论,问我们是否已经解决了关于 yeah/yeh 拼写的分歧。这似乎只是火上浇油…
不出所料,所有“哈哈”的变体也很常见——我们都经常发这种消息,即使我们实际上并没有笑(我们不都是这样吗)。也许在“哈哈”和“哈哈哈”和“哈哈哈”的比较背后有一些有趣的心理学意义,但我会让你去想象。
我也认为我欠我的女朋友一个道歉,oi 出现在我最常用的 10 个词中对我来说并不是一种恭维…但是在我的辩护中,我没有辩护。
深呼吸
好了,差不多够了。希望你喜欢在社交媒体上看到对一段关系的现实描述,而不仅仅是我们在大多数人的时间线上看到的亮点。尽管一个“有影响力的人”社交媒体账户看起来和你在这里看到的很不一样,但在现实生活中,他们可能会说“哈哈”,尽管听起来很不酷。
我也希望你能借此反思你在社交媒体上的人际关系,以及这与现实世界有何不同。
如果你喜欢读这篇文章,那么请考虑分享并给我或我的出版物数据片一个关注,以便将来有更多的关注!
动机
本文是两件事的续篇/后续:
1)我之前的一篇文章《 3.5 年的一段感情,在 Whatsapp 留言 》,这是我写作时看得最多的故事。
我最近的系列作品“脸书到底了解我多少?”在那里,我用数据科学分析了脸书收集的 7500 份关于我的资料。请看 第一部分第一眼 , 第二部分位置数据可视化 , 第三部分了解我的好恶 和 第四部分了解我在脸书以外的活动。
您尚未充分使用的 4 个高级 SQL 特性

萨法尔·萨法罗夫在 Unsplash 上拍摄的照片
数据科学
从分层查询的能力到 SQL 中过程结构的范围
SQL 是一种强大的语言。SQL 是你将要使用的大部分技术的一部分。对于开发人员来说,SQL 的使用可能仅限于在数据库中插入和检索数据,但对于数据分析师、数据科学家和数据工程师来说,它通常远不止于此。SQL 让您可以直接访问数据库——有大量的分析可以在那里完成——而无需从数据库中获取数据并将其加载到 pandas 或 PySpark 中。显然,由于资源的原因,您在数据库中所能做的事情是有限的。
根据我多年来的观察,使用 R、Julia 或 Python 等统计编程语言的人倾向于用这种语言做几乎所有的事情,而有些事情实际上用 SQL 有时会更有效。除了基本的选择、插入、更新、连接和子查询之外,SQL 还有许多高级特性可用于数据分析,但我们并没有充分利用这些特性。
在 KDNuggets 上有一个帖子说这是你进行数据分析需要的最后一个指南。虽然这是一份写得很好的指南,但我认为它绝对是而不是你进行数据分析所需的最后一份指南。你需要知道更多。我要说的是,你现在正在阅读的 Medium 帖子也不是你成为 SQL 高手所需的最后指南。这里只讨论了 SQL 的一些被忽视、未被充分利用但却很强大的特性。让我们继续讨论其中的一些。
分层查询
像 Oracle 这样的企业关系数据库很久以前就开始支持分层数据的存储和检索。在 MySQL 8 发布之前,MySQL 可能是少数几个不支持直接查询分层数据的数据库之一。在过去的几年里,当我在 MySQL 中实现分层存储时,我不得不多次参考 Mike Hillyer 的这篇文章。这是一本很棒的读物。
想想看,分层数据无处不在——产品的类别和子类别以及进一步的子类别、组织结构、动物和植物物种、家谱等等。普通的 SQL 特性不足以高效地查询分层数据,因为这会导致大量的子查询(和混乱)。在 MySQL 5.7 或更早的版本中,您会使用一种叫做会话变量的东西来进行分层查询,而在 MySQL 8 或更高版本以及其他数据库中,您会使用递归公共表表达式。
分层数据无处不在——产品类别和子类别、组织结构、家谱等等。
我会给你一些这方面的背景。一天,一位前同事打电话给我,问我如何在 MySQL 5.7 上运行分层查询——直到这个版本的 MySQL 不支持公共表表达式。所以,下面是这个查询的样子。现在让我们来谈谈 cte😄
MySQL 8.0 之前的 MySQL 中的分层查询示例
递归公用表表达式
被亲切地称为 CTE,这是一个非常强大的构造,所有主要的关系数据库(包括大多数关系数据仓库)都支持它。它本质上减少了在一个查询中编写另一个查询的需要,即嵌套子查询。CTE 本质上是在查询范围内定义的视图。CTE 不以数据库对象的形式存在,而是作为查询的一部分存在。cte 对于可读性也非常好(如果做得好的话)。
CTE 本质上是在查询范围内定义的视图。
不久前,我写了一篇关于使用 SQL 生成随机数据的文章,并在一些查询中使用了 cte。你可以在这里快速浏览一下。同样,递归 CTE 就像一个调用自身的递归函数或方法。想象一个树形数据结构,开始解析并一直解析到一个叶子节点。也就是使用递归 cte 查询的数据的递归性。
在 MariaDB 中使用递归 cte
窗口功能
SQL 中最常用的分析函数是聚合函数。SQL 中的聚合函数与GROUP BY子句一起作用于整个数据集或数据集的一部分,而窗口函数扩展了聚合函数的功能,不仅仅是计算基本的聚合。窗口函数提供了对数据集和部分数据集进行二级聚合&汇总操作的能力,可选地具有移动窗口和其他有趣的功能。这给了我们计算的机会,比如
- 过去七个工作日的销售移动平均值
- 月收入累计
这给了我们在 SQL 中分析数据的强大能力,而不需要将数据带到外面的 pandas 或 PySpark 中进行处理。
在没有定义任何窗口的情况下,这里有一些可以加窗的基本分析函数。
表定义可以在 dataset 中找到— NASA 喷气推进实验室 编译成 GitHub 项目 由devstrology。
这里有一篇关于 SQL 中窗口函数的很有深度的文章。如果你感兴趣的话,一定要读一读。
从这里开始?本课是使用 SQL 进行数据分析的完整教程的一部分。看看开头…
mode.com](https://mode.com/sql-tutorial/sql-window-functions/)
过程语言
在之前的一篇文章中,我写了关于 SQL 的多种风格
衡量您的 SQL 风格有多强大的一个方法是,浏览数据库提供的全部特性集,并找出您的 SQL 风格是否完全符合 。但是,即使是图灵完整的 SQL 也不能保证处理查询 DSL 允许但架构不允许的特定用例。由于这个原因,存在如此多种风格的数据库/SQL。
一些主要的关系数据库提供的对 SQL 的过程语言扩展使它们变成了完整的语言。一些扩展是 PL/SQL、T-SQL 和 plgsql。过程语言允许您访问成熟编程语言中可用的大量结构,这些结构本身就在数据库中。例如,在 SQL 的过程版本中,您将能够编写循环结构,您将能够使用函数和过程编写结构化程序,您将能够访问许多数据类型和数据结构,您将能够进行面向对象的编程。
您可以想象,使用完整的编程语言的特性,直接在 SQL 中访问数据,而不用将数据推送到外部系统,可以完成很多工作。这样做不仅去除了额外的一层,还节省了移动数据所花费的大量网络时间。
结论
我们可以谈论 SQL 的更多强大功能,但是根据我的经验,我觉得我所观察和共事的许多人(和团队)都没有充分利用其中的一些功能,其中也包括数据库工程师!
4 个银行分析用例以及您需要哪些数据
商业
数据团队早期采用阶段的示例用例

安娜斯塔西娅·奥斯塔波维奇在 Unsplash 上的照片
用例是任何概念的可靠证明。通过预定义的成功指标,您可以轻松认识到这一概念的好处。当数字上升或下降时,您可以将其与传统数字进行比较。在整个数字中,每个人都相信它的价值,这是如此容易和舒适。
在我的工作生涯中,当管理团队必须投资或花钱做任何事情时,他们会请求一个称为 POC(概念验证)的流程。这就像你需要实现小业务领域的任务,并证明它是真正的工作之前,扩大概念。在决定采取任何重大行动之前,管理团队总是希望先看到 POC 的结果。
然而,如果您从未在该领域有过经验,就很难想到要用的用例。怎么知道哪种分析会带来大量的收益或者转化率?我可以提出哪些最佳实践分析用例来最大限度地提高实施成功率?这就是我们今天要看的。
域

在银行业,几个部门贡献了公司的总收入。例如,创造性地创造出具有许多有趣特性的新产品的产品团队。营销团队进行有吸引力的促销,以获得新客户或提高基线收入。渴望与客户达成交易的一线和销售团队。
分析可以帮助这些团队实现更好的绩效,如以下使用案例所示。
销售团队

马库斯·斯皮斯克在 Unsplash 上拍摄的照片
倾向模型
销售团队的首选数据科学模型是倾向模型。
倾向模型是试图预测有意向或可能购买特定产品的客户的模型。任何产品包括投资基金、保险产品、贷款和任何产品。
它的好处是缩小了要接触的客户规模。假设我们有一个 1000 万左右的基础客户。如果销售团队需要在 1 个月的活动期内联系所有客户,由于资源有限,他们无法实现。
分析有助于选择有很大潜力购买产品的目标客户,这样销售团队就可以花时间和精力说服那些感兴趣的人。此外,如果您需要更有效的目标客户,该模型可以从倾向模型升级为提升模型。
这节省了大量的时间,并大大增加了活动的收入和转化率。我在一家银行公司工作时,有机会开发几个倾向模型。当您在公司中没有任何已实施的分析用例时,这是一个首选方法。
it 的好处可以通过进行 A/B 测试并比较各组之间产生的收入或转换率来衡量。根据我的经验,当我们用传统的基于规则的方法测试模型性能时。事实证明,该模型几乎总是能击败传统的基于规则的模型。
**数据:**可以根据买/卖交易做一个倾向模型。您可以进行二进制分类,并将目标值设为 1,表示购买产品,设为 0,表示不购买产品。
消费能力预测
在我们从倾向模型中获得目标客户后,我们可以通过添加有用的维度(如每个客户的消费能力)来提高销售线索的质量。
购买力是指消费者会接受多少产品。例如,如果客户想购买人寿保险,销售人员应该向他们提供什么样的合适机票。这里模型的目标是每个顾客在产品上花费的钱数。这些特征可以是你拥有的任何东西,但最重要的是金融行为特征。
这种分析用例的好处是,通过只选择那些有机会在我们的产品上花大钱的人,你可以直接提高收入指标。通常,我会首先尝试开发倾向模型,然后我会说服他们通过添加消费能力预测来不断提高线索的质量。
销售团队会对这个模型结果更加满意,因为他们有销售金额的激励。如果我们向他们提供高消费能力的线索,他们也会得到更高的激励。对于数据和销售团队来说,这似乎是一个双赢的局面。
**数据:**你需要有你为每个客户销售的产品的大小,并把它作为一个目标变量。你可以使用任何回归模型来预测目标金额的消费能力。
产品推荐
接触客户的机会有限。在银行业务中,如果在特定月份有任何活动接触到客户。该客户将被列入排除名单 6 个月。这是为了保持顾客的新鲜感。你自己知道,你不希望销售人员一周给你打 3 次电话,推销同样的产品。这就是为什么我们必须限制顾客接触的数量。
鉴于上述原因,销售一种以上的产品对销售人员来说可能是个好主意,因为这增加了提供产品的可能性。
分析可以帮助对每个客户的首选产品进行排名,并将它们列给销售团队,以便主动为几种产品制定流畅的销售脚本。这里可以使用的技术是多类分类模型或排序模型。这要看你有什么数据,你是只有交易数据还是排名数据。
这些用例的范围也可以用于集客营销。当客户来到分行进行任何金融交易时,分行官员可以向客户建议排名产品,以增加产品提供的机会。
这些分析用例的优势可以通过比较推荐的产品排名和受欢迎的产品或基于政策的产品来衡量。我们可以测量每个组的占用率和收入。
这里需要注意的一点是,模型预测了客户购买产品的概率。但是没有考虑到客户将在建议的时间服用该产品。它只给出了客户可能购买的前 3 种产品。
**数据:**产品推荐是倾向模型的升级,基于所有目标产品而不是每个产品的 1/0 进行多类分类。
营销团队

分割
细分是商业智能的基本分析用例。它使客户的视野更加清晰。营销团队可以从每个客户群的深入行为中受益。此外,他们可以跟踪时间流逝后客户的行为变化。
分割可以从几种方法和数据维度的许多视图中导出。基本维度可以是人口统计、使用活动、地理位置、心理等。我们可以将细分的每个维度结合起来,进行复杂的多维度细分。例如,您可以从人口统计中导出第一个批发商细分,并从使用活动维度与高使用率客户相结合。
在实现方面,您可以基于启发式方法进行细分,例如基于探索性数据分析和一些基本统计的规则。
另一方面,您可以基于建模技术(如 K 均值、分层分割等)进行分割。建模有很多选择。您需要仔细检查并选择合适的方法。了解每种技术的利弊,以便分析结果在决策时更加可靠。
结果可能是一个带有其角色命名的客户列表,或者您可以将它放在仪表板中,以便营销团队在一段时间内掌握其客户角色,并将其附加到绩效指标的数量上。营销团队可以考虑他们必须向客户提供的下一个行动,以保持或提高绩效指标。
对于这些用例,很难衡量分析用例的成功,因为没有衡量这是否是一个好的客户群的指标。这取决于分析团队和终端用户之间的共识。但是,如果您可以获得具有一些收入相关特征的细分市场,您可以进行 AB 测试来比较每组之间的销售收入和增长,并查看细分的有效性。
**数据:**你在客户/会员层面的任何数据,都可以根据每个维度和特征进行细分。这里的想法是无限的。
结论
根据我在这里的经验,我列出了成功率最高的分析用例。这些使用案例可以应用到其他行业,因为我们有相同的业务运营基础,即创造收入。
这里还有很多我没有提到的分析用例。请随意分享你的方法。我们分享得越多,我们就越能相互学习,并将我们的最佳实践提高到一个新的水平。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言










{kind=link}