







用 5 行代码将文本转换成语音
了解文本到语音转换可以发挥作用的领域

照片由 Pexels 的赖爷 Subiyanto 拍摄
在这篇文章中,我将向你展示如何使用 Python 将文本转换成语音。这将是一个简单的机器学习项目,我们将了解一些基础的语音库称为 pyttsx3。如果你想知道在现实生活中我们可以在哪里使用文本到语音的转换,不要担心,你并不孤单。我在学习几乎任何东西之前都会问同样的问题,我会问自己这些信息会对我有什么帮助,在现实生活中哪里可以用到。这种思维方式帮助我更快地学习新事物,并激励我在个人生活中使用这些信息。
我将列举几个以非常好的方式使用文本到语音转换的行业。其中之一是在教室环境中,学生们还不知道如何阅读,但当你对他们说话时,他们可以理解。如今,技术在课堂上经常使用,一些文本到语音转换软件可以给老师们很大的帮助。一个简单的文本到语音转换会很有帮助,而不是老师花时间和每个孩子在一起,为他们朗读。这是一个很好的视频,展示了如何在课堂上使用文本到语音转换:
另一个文本到语音转换的好例子是在 Chromebooks 上。他们有一个辅助功能,称为“选择说话”,你可以选择/突出显示文本,计算机将大声朗读给使用该功能的人。
最后一个文本到语音转换的例子,我想和你分享的是有声读物。使用以前音频文件中的一些训练数据,可以让机器使用受过训练的人的声音阅读一本书。是的,人工智能越来越成为我们日常生活的一部分。此外,教一台机器比教一个人容易得多。这使得该领域的发展要快得多。让我们回到项目上来。
我们将建立一个机器程序,将我们的文本转换成语音。文本可以是不同的语言,这就是为什么在选择我们的语音模型时,我们必须确保语言匹配。让我们从导入库开始。
步骤 1 —图书馆
首先,我们将安装模块,这样我们就可以在我们的程序中使用它。我们将在这个项目中使用的唯一模块是 Pyttsx3。这是文本到语音模块,这个模块的一个好处是,它可以在你安装后离线工作。下面是安装该模块的代码:
pip install pyttsx3
如果你想进一步了解这个模块,这里有文档。现在让我们将模块作为库导入到我们的程序中。
import pyttsx3
第 2 步—文本
这一步是最容易的。您应该定义一个变量,并为其分配一个文本值。你的文字可长可短,这取决于你想要什么。下面,你可以看到我创建的文本变量,它被称为测试。
test = "Once upon a time, a person was trying to convert text to speech using python"
步骤 3 —语音引擎
在下面几行中,我们定义一个变量来分配我们的语音引擎。这很简单。
engine = pyttsx3.init()
现在,我们必须定义我们希望机器说的语言。如前所述,它必须与我们在文本中使用的语言相匹配。若要查看可用的语言,请运行以下代码:
voices = engine.getProperty('voices')for voice in voices:
print("Voice:")
print(" - ID: %s" % voice.id)
print(" - Name: %s" % voice.name)
print(" - Languages: %s" % voice.languages)
print(" - Gender: %s" % voice.gender)
print(" - Age: %s" % voice.age)
您将在终端中看到类似这样的内容:

声音
复制您想要使用的语言的“id ”,并将其粘贴到我们的程序中。我们使用 setProperty 方法来定义口语。
en_voice_id = "com.apple.speech.synthesis.voice.Alex"engine.setProperty('voice', en_voice_id)
最后一步
我们差不多完成了,下面的代码将告诉我们的语音引擎大声说出我们之前定义的文本。基本上电脑会给你读出来。确保您的扬声器已打开,可以听到声音。
engine.say(test)engine.runAndWait()
恭喜你,你已经创建了一个将文本转换成语音的程序。现在,您已经了解了这些软件是如何在幕后工作的。希望你喜欢这篇教程,并在今天学到一些新东西。伟大的提示:当你觉得太懒的时候,你可以用这个和你的朋友交流🙂
另一个你可能会感兴趣的机器学习项目
使用麦克风将您的语音实时转换为文本
towardsdatascience.com](/convert-your-speech-to-text-using-python-1cf3eccfa922)
转换到新的火花 3.0 UDF 风格
提示和技巧

伊恩·巴塔格利亚在 Unsplash 上拍摄的照片
Apache Spark 2.3 版本在 2017 年引入了熊猫 UDF。自从 Apache Arrow 取代 Py4J 来加速 JVM 和 Python 之间的数据传输以来,这个新特性显著提高了 Python UDFs 的性能。通过 Spark 与 Pandas 的接口,用户可以通过将 Python 库(例如sklearn、scipy)中编写的方法封装在 Pandas UDFs 中来轻松扩展它们。
除了原有的 Python UDF ( pyspark.sql.functions.udf在 1.3 版本引入),Spark 2.3+还有 3 种熊猫 UDF,包括PandasUDFType.SCALAR、PandasUDFType.GROUPED_MAP(均在 2.3.0 版本引入),以及PandasUDFType.GROUPED_AGG(2.4 版本引入,也可作为窗口函数)。2020 年 6 月,Spark 3.0 的发布为熊猫 UDF 引入了一套新的接口。在本文中,我将简要地探讨两个如何将旧样式(Pandas)UDF 转换成新样式的例子。
数据准备
我模拟了一个包含以下 4 列的数据框架
name:5 到 10 个字符之间的随机字符串名称email:随机假冒邮箱地址secret:长度为 4096 的十六进制字符串n:重复次数。我将重复一个更小的数据帧 1000 次
首先,为模拟定义一些函数
在熊猫身上模拟 10000 个样本
这将得到如下所示的数据帧

示例模拟数据
然后,重复这个数据帧 1000 次
对于 Spark 来说,这是一个很好的数据量
和最终模式
从 UDF 到熊猫 UDF 迭代器
最初的spark.sql.functions.udf将一个定制函数应用于列中的每一项,将另一列的值作为输入。在这个例子中,我们使用withColumn来存储udf应用程序的结果。
结果如下所示

应用 udf 的输出示例
在 Spark 3.0 中,我们可以使用迭代器熊猫 UDF 来代替
迭代器使用 Python 类型作为提示,让函数知道它正在迭代一对作为输入的pandas.series,并返回另一个pandas.series。上面的pandas_udf装饰器指定了系列元素将被返回的数据类型。请注意,输入序列的长度需要与输出序列的长度相同。嵌套函数apply_custom_mapper将两列作为熊猫系列,用户需要迭代该系列的每个元素来应用函数(例如custom_mapper)。然后接下来,用户需要构造迭代器来yield函数应用的结果。这看起来像一个双 for 循环,但它实际上是分离输入和输出的迭代,即首先迭代输入以应用初等函数custom_mapper来获得结果的迭代器,然后将结果逐步映射回输出序列。
具有分组和应用功能的熊猫 UDF
groupby.apply(pandas_udf)模式通常用于通过迭代数据帧的每个子组来应用自定义函数。自定义pandas_udf将每个组的数据作为 Pandas Dataframe(我们称之为pdf_in)作为输入,并返回另一个 Pandas Dataframe 作为输出(我们称之为pdf_out)。pdf_out的模式不需要与pdf_in的模式相同。在下面的例子中,我们将用组中列n的累积和(转换为字符串)替换secret列。然后我们将删除列n。我们需要在panads_udf装饰器中指定从df.drop("n").schema获得的输出模式。
对于在模式中添加新列,我们可以这样做
上述代码的输出如下所示

应用熊猫 UDF 的输出,后降一列
UDF 返回的行数不必与输入的行数相同。在下面的例子中,我们修改了上面的脚本,这样我们只返回每隔一行。
新界面改用groupby.applyInPandas(python_func, schema)。
第一个示例随后更改为
第二个示例更改为
注意,apply采用了一个pandas_udf函数,其中模式是在装饰器中指定的。另一方面,applyInPandas采用 Python 函数,其中模式在applyInPandas参数中指定。
熊猫 UDF 的记忆使用
最后要注意的是这些函数的内存使用情况。Spark 的熊猫 UDF 文档表明整组数据将被加载到内存中。在我们的groupby示例中,我们将pdf作为一个 10000 行的数据帧,因此我们期望每个执行器内核有大约 43 MB 的数据。如果每个执行器有 5 个内核。那么在内存中就变成了 215 MB 的数据。此外,我们的 UDF 的内存堆栈也增加了内存使用。假设我们将长度为 4096 的十六进制字符串转换为长度为 16384 的二进制numpy 布尔数组,每个数组将消耗大约 16kB 的内存,其中 10000 个数组将额外消耗 165 MB。5 个内核总共会额外增加 825 MB,也就是总共超过 1GB 的内存。因此,在涉及熊猫 UDF 的情况下调优 Spark 时,除了作为熊猫数据帧的公开数据组的大小之外,还需要注意 UDF 使用的内存量。
将 Python 代码转换成 Windows 应用程序(。exe 文件)
无限制共享的快速技巧

塔达斯·萨尔在 Unsplash 上拍摄的照片
您编写了一个令人惊叹的 Python 应用程序,并提交给了您的老板。他对此印象深刻,并希望在自己的系统中使用它。他既没有在自己的系统上安装 Python,也没有使用过它。你被卡住了!!!
如果以上听起来很熟悉,那么本教程将解决你的问题。在这里,我们将学习将 Python 代码转换成 Windows 可执行文件的过程。从现在开始,每当您想要与更广泛的社区共享您的优秀成果时,您不必担心在他们的系统上设置 Python 环境。只需创建一个可执行文件并发送给他们。他们将能够使用该应用程序,就像您在您的系统上一样。
你需要什么?
1。要转换的脚本
对于本教程,我们已经编写了一个小的 Python 代码来读取。csv '文件从窗口的文件夹中取出。这个文件有两列,每列包含一组随机数。该代码创建一个新列,其中包含两个输入列的数字之和。修改后的文件保存在与旧文件相同的文件夹位置。
**#### Importing the required library**
import pandas as pd**#### Reading csv file**
df = pd.read_csv("C:\\Ujjwal\\New_File_V1.csv")**#### Adding 2 columns**
df["Third_Column"] = df["Randome Numbers 1"] + df["Random Numbers 2"]**#### Exporting the data to same location**
df.to_csv("C:\\Ujjwal\\New_File_V2.csv",index = False)
输入 CSV 文件的示例列如下:

输入 CSV 文件(图片由作者提供)
代码执行后的输出文件如下所示:

输出 CSV 文件(图片由作者提供)
2。Pyinstaller 包
为了将 Python 代码转换成可执行文件,我们将使用 Pyinstaller 包。使用标准的“pip install”命令来安装此软件包。
**#### Install Command**
pip install pyinstaller
实际任务
让我们一步一步地将 Python 文件转换成一个 Windows 可执行文件:
- 打开命令提示符— 使用命令行将 Python 脚本转换为 Windows 可执行文件。为此,我们必须转到命令提示符。在你的窗口搜索框中键入“cmd”并打开命令提示符
- 更改文件夹位置 —使用以下命令,将命令提示符指向 Python 代码的位置:
**#### Change Folder Location**
cd folder_location
- 转换 —使用以下命令将 Python 文件转换成一个 Windows 可执行文件:
**#### Command for conversion**
pyinstaller --onefile filename
上述代码将创建一个与 python 代码功能相同的可执行文件。该可执行文件将在一个新文件夹 **dist,**中提供,该文件夹与您的 Python 脚本位于同一位置。
- 执行— 要执行文件,只需双击可执行文件,它将产生与您的 Python 脚本相同的结果。
常见问题解答
使用 pyinstaller 时,人们会面临一些常见的问题/挑战。本节将回答其中的大部分问题:
附加文件
除了包含可执行文件的 dist 文件夹之外,其他文件和文件夹正在被创建。你不需要它们。您可以在没有这些附加文件的情况下共享您的可执行文件。即使您将删除额外的文件和文件夹,您的可执行文件也不会失去其功能。
完成时间
可执行文件的创建和可执行文件的执行都是耗时的任务。对于像我们这样的短脚本,创建可执行文件需要将近 5 分钟,执行需要将近 30 秒。
可执行文件的大小
因为我们在 Python 脚本中导入包,为了使可执行文件自给自足,完整的包被合并到可执行文件中。这增加了可执行文件的大小。对于我们的例子,它超过了 300 MB
可执行文件失败,错误为
在执行可执行文件时,最容易遇到的错误是“**ModuleNotFoundError:没有名为的模块,模块名 ”。此错误和实际错误提示的示例屏幕截图如下:
**#### Error Prompt Message**
ModuleNotFoundError: No module named 'pandas._libs.tslibs.nattypes'
如果您遇到这样的错误(模块名称可能不同),请采取以下步骤:
- 转到安装 pyinstaller 包的 Windows 位置。因为我使用的是 Anaconda 发行版,所以下面是我系统上的位置:
**#### Package Location**
C:\Users\Ujjwal\Anaconda3\Lib\site-packages
- 在 pyinstaller 包文件夹中,搜索名为 hooks 的文件夹。这个文件夹里有大多数常用 Python 包的钩子文件。搜索引发错误的 Python 包的钩子文件。在我们的例子中,是熊猫。示例钩子文件及其内容如下:

原始钩子文件(图片由作者提供)
- 错误背后的原因是初始化’ hiddenimports’ ‘的命令出现故障。注释此语句并添加一个新的,其中’ hiddenimports '用引发错误的相同模块名初始化。对我们来说,是“熊猫。_libs.tslibs.nattype '。要添加的代码行如下:
**#### Code line for hook file**
hiddenimports = 'pandas._libs.tslibs.nattype'
- 一旦钩子文件被修改,保存它并重新创建新的可执行文件。在重新创建之前,请**确保删除旧的可执行文件和相关文件夹。**如果错误仍然存在,继续在钩子文件中添加其他缺失的模块。请注意,多个模块应该作为一个列表结构添加。
**#### Code line after adding multiple modules**
hiddenimports = ['pandas._libs.tslibs.np_datetime','pandas._libs.tslibs.nattype','pandas._libs.skiplist']
我们在示例中使用的最终钩子文件如下所示:

最终挂钩文件(图片由作者提供)
一旦添加了所有模块,错误就会得到解决。
结束语
在上面的教程中,我们已经尝试解决了一个小问题,这个问题是我们大多数人在工作中遇到的。
我希望这篇教程是有启发性的,并且你学到了一些新的东西。
会在以后的教程中尝试并带来更多有趣的话题。在此之前:
快乐学习!!!!
使用 Python 将您的语音转换为文本
使用麦克风将您的语音实时转换为文本

汤米·洛佩兹从派克斯拍摄的照片
在这篇文章中,我将向您展示如何使用 Python 将您的演讲转换成文本文档。在编程的话,这个过程基本上叫做语音识别。这是我们日常生活中常用的东西。例如,当你用声音给朋友发信息时。语音到文本的另一个很好的例子是添加一个正在说话的人的字幕。你在网飞节目或 YouTube 视频上看到的大多数字幕都是由使用人工智能的机器制作的。你能想象一群人整天工作只是为了给你最喜欢的节目添加字幕吗?我知道这很难想象。电脑编程的力量来了。我仍然记得我学习 for loops 的那一天,感觉我找到了一种在现实世界中达到无穷大的方法。不管怎样,介绍够了,让我们开始工作吧。
正如你从标题中可以理解的,在这篇文章中,我们将创建一个 python 程序,将我们的演讲转换成文本,并导出为文本文档。如果你是一个喜欢记笔记的人,这个程序将帮助你通过记录你自己来节省时间,并且也有你记录的打印版本。这就像在一场比赛中赢得两个奖杯🙂
让我们开始编码吧!
导入库
我们将使用 SpeechRecognition 模块,如果您还没有,让我们快速安装它。不用担心,在 Python 中安装一个模块是超级容易的。
pip install SpeechRecognition
是的,就是它。SpeechRecognition 模块支持多种识别 API,Google Speech API 就是其中之一。你可以从这里了解更多关于这个模块的信息。我们将在代码中使用 Google 的识别器。现在,在安装模块完成后,我们可以将它导入到我们的程序中。
import speech_recognition as sr
创建识别器
在这一步中,我们将创建一个识别器实例。
r = sr.Recognizer()
定义您的麦克风
在定义麦克风实例之前,我们将选择输入设备。可能有多个输入设备插入您的计算机,我们需要选择我们打算使用哪一个。你知道机器是假人,你必须准确地告诉他们该做什么!使用下面的代码,你将能够看到你的输入设备。
print(sr.Microphone.list_microphone_names())

麦克风名称列表
这里你可以看到我检查输入设备的结果。我建议您在定义麦克风之前运行这个脚本,因为您可能会得到不同的结果。该脚本返回一个带有输入名称的数组列表,对我来说我想使用“内置麦克风”,所以数组列表的第一个元素。定义麦克风代码将如下所示:
mic = sr.Microphone(device_index=0)
识别语音
如前所述,我们将使用 recognize_google 方法,这是我们在 google 的朋友创建的语音识别模型。多亏了他们!
with mic as source:
audio = r.listen(source) result = r.recognize_google(audio)
如果您想在将结果导出到文本文档之前检查结果,可以在代码中添加下面一行。
print(result)
最后一步:导出结果
在这一步中,我们将创建一个文本文档并导出我们在上一步中得到的结果。您将看到“导出过程完成!”这个过程完成后,在终端窗口中添加一行。
with open('my_result.txt',mode ='w') as file:
file.write("Recognized text:")
file.write("\n")
file.write(result) print("Exporting process completed!")
最终代码
# import the module
import speech_recognition as sr # create the recognizer
r = sr.Recognizer() # define the microphone
mic = sr.Microphone(device_index=0) # record your speech
with mic as source:
audio = r.listen(source) # speech recognition
result = r.recognize_google(audio)# export the result
with open('my_result.txt',mode ='w') as file:
file.write("Recognized text:")
file.write("\n")
file.write(result) print("Exporting process completed!")
恭喜我的朋友!您已经创建了一个将您的演讲转换为文本并将其导出为文本文档的程序。希望你喜欢读这篇文章,并且今天学到了一些新的东西。从事像这样有趣的编程项目会帮助你提高编码技能。
您可能会感兴趣的另一个语音识别项目
使用谷歌云语音 API 将您的音频文件转换为文本
towardsdatascience.com](/building-a-speech-recognizer-in-python-2dad733949b4)
将深度学习研究论文转化为有用的代码
如果深度学习是一种超能力,那么将理论从纸上转化为可用的代码就是一种超能力

作者图片
为什么要学习实现机器学习研究论文?
正如我所说的,能够将一张纸转换成代码绝对是一种超能力,尤其是在机器学习这样一个每天发展越来越快的领域。
大多数研究论文来自大型科技公司或大学的人,他们可能是博士或从事尖端技术工作的人。
还有什么比能够复制这些顶尖专业人士的研究更酷的呢?另一件需要注意的事情是,那些能够将研究论文复制成代码的人需求量很大。
一旦你掌握了实施研究论文的诀窍,你将处于与这些研究者不相上下的状态。
这些研究人员也通过阅读和实施研究论文的实践获得了这些技能。
我如何阅读和实施论文?
你可能会说,“嗯,我对深度学习算法有一个大致的了解,如全连接网络,卷积神经网络,递归神经网络,但问题是,我想开发 SOTA(最先进的)语音克隆人工智能,但我对语音克隆一无所知:(”。
好的,这是你的答案(我的方法的某些部分摘自吴恩达关于阅读论文的建议)。
如果您想了解某个特定主题:
- 收集 5-6 篇与特定主题相关的论文(您可以简单地搜索 arxiv 或类似网站来获得与某个主题相关的论文)。
- 不要完全阅读一篇论文,而是浏览所有的论文,选择一篇你感兴趣的论文,或者如果你心中有一篇特定的论文,就去选择它,没有人能阻止你。
- 仔细阅读摘要,从高层次上理解文章的思想,看看你的兴趣是否仍然存在,如果是,继续浏览图片,看看你能否对文章的内容做出假设。
- 现在请一行一行地仔细阅读引言,因为论文中包含的大部分内容将在这里用最简单的方式和最少的数学来解释。
- 如果你愿意,你可以跳过第一遍的数学方程,如果希腊字母很熟悉就不要跳过数学。
- 在任何情况下,如果你被卡住了或者有些词令人困惑,不要犹豫去谷歌一下。没有人生来就是万物的主宰;)
- 完成第一遍后,你将处于这样一种状态,你理解这篇论文试图证明或改进的高层次观点。
- 在第二遍中,试着理解论文中的几乎所有内容,如果你遇到任何伪代码,试着把它转换成你选择的 python 库(PyTorch,TensorFlow…)
- 你可以通过阅读每篇论文的参考文献部分,获得更多的论文来阅读,并对该领域有更好的理解(与点连接相同)。
💡有效理解论文的一些技巧:
- 如果你是一个阅读研究论文的初学者,在阅读论文本身之前,阅读一些与该主题/研究论文相关的博客帖子和视频是很好的。这使你的工作更容易,你也不会因为那些希腊字母而气馁。
- 在为论文实现代码时,始终记笔记并突出研究论文中的要点,以便于参考。
- 如果您是实现研究论文的新手,并且在任何地方都遇到了困难,那么浏览开源实现并看看其他人是如何做到这一点的,这并不是一个坏主意。
注意:不要把第三点当成常规练习,因为你的学习曲线会下降,你会过度适应:)
你应该发展你自己的阅读和实施论文的方法,这只有通过开始才有可能,所以上面的步骤将帮助你开始。
根据吴恩达的说法,如果你能阅读关于一个主题的 5-10 篇论文(例如:声音克隆),你将处于实施声音克隆系统的良好状态,但是如果你能阅读关于那个主题的 50-100 篇论文,你将处于研究或开发该主题的尖端技术的状态。
让我们讨论一篇论文
- 高级概述
现在,你已经了解了如何阅读论文,让我们为自己阅读和实现一个。
我们将仔细阅读 Ian Goodfellow 的论文—(GAN)并用 PyTorch 实现同样的内容。
在论文摘要中清楚地讨论了论文内容的高级概述。
摘要告诉我们,研究人员正在提出一个包含两个神经网络的新框架,它们被称为生成器和鉴别器**。**
不要被名字搞混了,它们只是给两个神经网络取的名字。
但是在摘要部分要注意的要点是,上面提到的生成器和鉴别器相互竞争。
好吧,让我说清楚一点。
让我们以使用 GANs 生成不存在的新人脸为例。
生成器生成与真实图像具有相同尺寸(H×W×C)的新人脸,并将其显示给鉴别器,鉴别器判断该图像是生成器生成的假图像还是真实的人的图像。
现在你可能会有一个问题,“嗯,这个鉴别器是如何区分真假图像的?”,这是你的答案:
鉴别器的问题类型是图像分类,即鉴别器将不得不辨别图像是假的还是真的(0 或 1)。因此,我们可以像训练狗和猫分类器网络一样训练鉴别器,但我们将使用完全连接的网络,而不是卷积神经网络,因为这是论文所提出的。
💡DCGAN 是另一种类型的 GAN,它使用卷积神经网络而不是全连接网络,并且具有更好的结果。
所以我们以这样一种方式训练鉴别器,我们馈入一个图像,鉴别器输出 0 或 1,即假或真。
由于我们已经训练了鉴别器,我们将把生成器生成的图像传递给鉴别器,并分类它是真的还是假的。生成器调整其所有权重,直到它能够欺骗分类器来预测所生成的图像是真实的。
我们将为生成器提供一个随机概率分布(随机张量),生成器的职责是改变这个概率分布,以匹配真实图像的概率分布。
这些是我们在实施准则时应该遵循的步骤:
→加载包含真实图像的数据集。
→创建一个随机二维张量(虚假数据的概率分布)。
→创建鉴别器模型和发电机模型。
→训练鉴别器辨别真假图像
→现在将假图像的概率分布输入发生器,并测试鉴别器是否能够识别发生器产生的假图像。
→调整生成器(随机梯度下降)的权重,直到鉴别器无法识别伪图像。
你可能有几个疑问,但现在没关系,一旦我们将理论实现到代码中,你就会知道它是如何工作的。
2.损失函数
在实现代码之前,我们需要一个损失函数,以便优化我们的发生器网络和鉴别器网络。
鉴别器模型存在二进制分类问题,因此我们对鉴别器使用二进制交叉熵损失,或者您也可以使用本文中讨论的自定义损失函数。
来自论文的损失函数:【log D(x)】+【log(1-D(G(z)))】
x→实景
z→虚假数据或噪声(随机张量)
D→鉴别器型号
G→发电机型号
**G(z)→向发生器输入虚假数据或噪声(输出为虚假图像)
**D(x)→将真实图像送入鉴别器(输出为 0 或 1)
**D(G(z))→假数据被送到发生器,发生器输出图像,图像被送到鉴别器进行预测(输出为 0 或 1)
如果你想用纸上的损失函数,让我解释给你听:
根据该论文,对于鉴别器,我们需要最大化上述损失函数。
让我们看看等式的第一部分:
*— D(x) 输出 0 或 1,所以当我们最大化*log[D(x)】时,它使鉴别器在 x (实像)馈入时输出一个接近 1 的值,这就是我们所需要的。
现在,让我们来看看等式的第二部分:
— G(z) 输出一个与真实图像尺寸相同的图像,现在这个假图像被馈送到鉴别器( D(G(z) ),当我们最大化这个值时,鉴别器的输出将接近 1,因此当我们做[1d(G(z))]时,我们将得到一个接近于零的值,这正是我们将假图像传递到鉴别器时所需要的。
注:你可以在方程中加一个负号,把损失函数变成鉴别器的最小化问题,这比最大化容易。
对于发生器,我们需要最小化上述等式,但本文仅考虑等式【log(1D(G(z)))】的第二部分进行最小化。
—当我们最小化 D(G(z)) 时,鉴别器输出一个接近于 0 的值,方程的整体输出变得接近于 1,这就是我们的生成器想要实现的,在给定来自生成器的假图像时,忽悠鉴别器预测 1(真实)。
耶,让我们开始吧!
我已经在 google colab 中完成了代码实现,所以如果你尝试 google colab 或 jupyter notebook 中的代码将是最好的。
- 导入所需的库—
2.我们将使用单个图像作为真实图像,以便更快地训练和获得结果,因此生成器生成的图像将与此图像相似,您也可以使用图像的数据集,这完全取决于您。
我们将使用 PIL 库加载图像作为 PIL 图像,我们将使用 torchvision transforms 调整图像大小并将其转换为张量,然后为图像生成创建大小为(1×100)的假噪声。
3.创建一个鉴别器模型,它只不过是一个完全连接的神经网络,接收真实图像或虚假图像,输出 0 或 1。
4.创建一个生成器模型,它也是一个完全连接的网络,接收随机噪声并输出与真实图像大小相同的图像张量。
5.初始化模型、优化器和损失函数,然后将它们移动到所需的设备(cuda 或 cpu)。我们将对鉴别器使用二进制交叉熵损失,对发生器使用本文中讨论的损失函数(log(1D(G(z))))。
6.现在我们将训练该模型,整个 GAN 被训练五百个时期,鉴别器将被训练四个时期,并且对于五百个时期中的每个时期,发生器将被训练三个时期。
7.将生成图像的结果与真实图像进行比较。您可以调整学习率、动量、时期数以及生成器和鉴别器模型的层数,以获得更好的结果。

将我们的生成器图像与真实图像进行比较(图像由作者提供)
最后的想法
生成的图像可能没有很高的分辨率,因为这篇论文只是整个生成模型世界的开始。如果您的兴趣仍然存在,您可以继续阅读 DCGANs (深度卷积 GANs)或GANs 世界的任何其他论文,并实施它以查看惊人的结果,但请始终记住,本文是所有这些论文的基础。
链接到完整的代码可在这里。
凸和非凸损失函数下的价格优化

ML 问题的典型损失面([来源](https://www.cs.umd.edu/~tomg/projects/landscapes/ and arXiv:1712.09913)
优化用于许多日常活动,从使用谷歌地图找到到达目的地的最快路线,到通过在线应用程序点餐。在本帖中,我们将介绍两种主要损失函数的价格优化,即凸损失函数和非凸损失函数。我们还将介绍使用名为 scipy 的 python 库解决这些问题的最佳方法。在这个博客中使用的示例数据和代码的细节可以在这个笔记本中找到。
凸优化
凸优化问题是一个所有约束都是凸函数的问题,如果最小化,目标是凸函数,如果最大化,目标是凹函数。凸函数可以描述为具有单一全局最小值的光滑曲面。凸函数的示例如下:
*F(x,y) = x2 + xy + y2.*

凸函数(来源)
1.数据生成
为了了解优化是如何工作的,我正在生成一个玩具数据集,其中包括销售价格、数量和成本。让我们设定数据集的目标是找到一个使总利润最大化的价格。
销售价格(price): 这是一个在 1000 到 7000 之间产生的随机数。使用 numpy 随机函数生成数据。

价格直方图
**交易量:**交易量是销售价格的直线函数,其下降斜率如下所示:
*f(volume) = (-price/2)+4000*

体积直方图
销售价格和销售量之间的关系如下所示。正如预期的那样,随着价格的下降,我们看到了销售量的增加。

**成本:**成本变量代表产品的制造成本。这考虑了一些固定成本(即 300 英镑)和可变成本(即 0.25 英镑),可变成本是交易量的函数。
*f(cost) = 300+volume*0.25*
现在我们已经有了所有需要的变量,我们可以使用下面的简单公式来计算利润:
*f(profit) = (price — cost)*volume*
销售价格、交易量和利润的三维图如下所示。我们可以看到,这是一个钟形曲线,峰值利润在特定的数量和成本。一个企业的目标可能是利润最大化,在下一节中,我将展示我们如何使用 scipy 来实现这一目标。

3d 绘图:价格(x)、交易量(y)和利润(z)
2。根据观察数据估算成本和数量
在上面的部分中,我们已经生成了一个样本数据集。然而,在现实世界中,我们可能获得一小组观察数据,即产品的价格、数量和成本。此外,我们不知道支配因变量和自变量之间关系的基本函数。
为了模拟观察数据,让我们截取生成的数据,即价格为"<3000”. With this observational data we need to find the relationship between price vs cost and volume vs cost. We can do that by performing a simple linear regression on the observation data set. However for real world problem this may involve building complex non-linear models with a large number of independent variables.
**线性回归:**的所有点
- 价格 vs 成交量
我们把价格作为自变量‘X’,把成交量作为因变量‘y’。使用 python 中的 stats 模型库,我们可以确定一个线性回归模型来捕捉量价关系。
从下面的观察数据可以看出,我们的 R 平方为 1(即 100%),这意味着产品价格的变化可以很好地解释销量的变化。然而,这种完美的关系在现实生活的数据集中很难观察到。

此外,我们可以看到偏差为-3,999.67,价格系数为-0.5,近似于用于生成交易量数据的函数。
2。数量与成本
以类似的方式,以成本为因变量“y”和以数量为自变量“X”进行线性回归,如下所示。我们可以看到,成本模型的偏差和系数近似于用于生成成本数据的函数。因此,我们现在可以使用这些训练好的模型来确定凸优化的成本和体积。

线性回归模型的结果——成本与数量。
使用 scipy 优化
我们将使用 scipy 优化库进行优化。该库有一个最小化功能,它接受以下参数,关于 scipy 最小化功能的更多细节可以在这里找到:
result = optimize.minimize(fun=objective,
x0=initial,
method=’SLSQP’,
constraints=cons,
options={‘maxiter’:100, ‘disp’: True})
- fun: 要最小化的目标函数。在我们的情况下,我们希望利润最大化。因此,这将意味着’-利润’最小化,其中利润被计算为:*利润=(价格-成本)数量
def cal_profit(price):
volume = mod_vol.predict([1, price])
cost = mod_cost.predict([1, volume])
profit = (price — cost)*volume
return profit###### The main objective function for the minimisation.
def objective(price):
return -cal_profit(price)
2。x0: 初步猜测,即在这种情况下,我们设定的初始价格为 2000 英镑。
initial = [2000]
**3。界限:**界限是优化中使用的下限和上限区间。它只能为某些支持有界输入的优化方法设置,如 L-BFGS-B、TNC、SLSQP、Powell 和 trust-const 方法。
#################### bounds ####################
bounds=([1000,10000])
**4。约束:**这里我们指定优化问题的约束。这种情况下的约束条件是可以生产的产品数量(即设置为 3,000 件)。这是一个不等式约束,即体积必须小于指定的单位数。也可以使用其他类型的约束,如等式约束。
# Left-sided inequality from the first constraint
def constraint1(price):
return 3000-mod_vol.predict([1, price])# Construct dictionaries
con1 = {'type':'ineq','fun':constraint1}# Put those dictionaries into a tuple
cons = (con1)
5 。方法:有多种方法可用于执行最小化操作,例如(见参考):
我们将使用 SLSQP 方法进行优化。序列二次规划 ( SQP 或 SLSQP )是一种约束非线性优化的迭代方法。
并非所有上述方法都支持使用边界和约束。因此我们使用 SLSQP,它支持使用优化的边界和约束。
凸优化的结果
优化总共运行了 3 次迭代。基于此,目标函数返回值为-6.6 密耳(即-6,587,215.16)。这导致价格为 4577 英镑,数量为 1710 英镑。我们得到一个负值,因为我们通过最小化负利润来最大化利润,这是一个凸函数。
Optimization terminated successfully. (Exit mode 0)
Current function value: -6587215.163007045
Iterations: 3
Function evaluations: 9
Gradient evaluations: 3
优化的结果与生成的数据集中看到的最大利润非常匹配。因此,我们知道优化已经如预期的那样工作。

最大利润值:价格(x)、数量(y)和利润(z)
非凸优化
在大多数机器学习问题中,我们会遇到本质上非凸的损失曲面。因此,它们将具有多个局部最小值。因此,在求解这种非凸问题时,如果我们“凸化”一个问题*(使其凸优化友好)*,然后使用非凸优化,可能会更简单且计算量更小。我将通过下面的例子演示我们如何实现这一点。
非凸数据集生成;
在这里,我们创造了另一种产品,其价格、数量和利润略有不同。假设该公司只能生产这些产品中的一种,并希望使用优化来找出它需要专注于哪些产品以及它需要以什么价格出售。

3d 绘图:产品 1 和产品 2 的非凸数据集
对非凸数据使用凸极小化
对于上述数据,如果我们使用与上面相同的凸优化,我们得到的解将是局部最小值,如下所示。对于5018的优化价格和 0 的产品类型,我们获得了686 万的最大利润。

凸优化的局部最小值
盆地跳跃算法
跳盆算法是一种结合了全局步进算法和每步局部最小化的算法。因此,这可用于寻找非凸损失表面可用的所有局部最小值选项中的最佳选项。下面的代码演示了这个算法的实现。

跳盆算法的全局最小值
如上所述,我们使用了与上例相同的方法,即 SLSQP,以及相同的边界和约束。然而,我们现在得到了一个稍微不同的结果。最大利润为980 万,优化价格为5957,产品类型为 1 。
结论:
总之,我们已经回顾了 scipy 中优化库在具有单一全局最小值的简单凸优化数据集上的使用,还回顾了在损失面具有多个局部最小值和一个全局最小值的情况下盆地跳跃算法的使用。希望你会发现上面的帖子很有用,并且提供了解决现实世界中优化问题的框架。
参考资料:
序列二次规划(SQP)是一种求解约束非线性优化的迭代方法。SQP 方法是…
en.wikipedia.org](https://en.wikipedia.org/wiki/Sequential_quadratic_programming) [## SciPy . optimize . basin hopping-SciPy v 1 . 5 . 2 参考指南
使用盆地跳跃算法寻找函数的全局最小值盆地跳跃是一种两阶段方法,它…
docs.scipy.org](https://docs.scipy.org/doc/scipy/reference/generated/scipy.optimize.basinhopping.html) [## SciPy . optimize . minimize-SciPy v 1 . 5 . 2 参考指南
一元或多元标量函数的最小化。参数要最小化的目标函数。在哪里……
docs.scipy.org](https://docs.scipy.org/doc/scipy/reference/generated/scipy.optimize.minimize.html#scipy.optimize.minimize) [## 为什么要研究理论机器学习的凸优化?
begingroup$机器学习算法一直在使用优化。我们最小化损失或错误,或最大化一些…
stats.stackexchange.com](https://stats.stackexchange.com/questions/324981/why-study-convex-optimization-for-theoretical-machine-learning)
凸包:包装数据的创新方法
如何利用包装算法实现数据可视化
什么是凸包?
假设我们有一组数据点。

检索自维基百科
想象一下,一根橡皮筋绕在这些钉子的周围。如果松开橡皮筋,它会在产生原始集合的紧密边界的点周围捕捉。
最终的形状是凸包,由接触橡皮筋创建的边界的点的子集描述。凸包是计算几何中普遍存在的结构。凸包在数据科学中有许多应用,例如:
- 分类:给定一组数据点,我们可以通过确定每一类的凸包将它们分成不同的类
- **避碰:**通过定义物体的凸包来避免与其他物体的碰撞。
- **图像处理和识别:**图像处理的要求是鲁棒性、高识别率和捕捉图像中物体形状的灵活性。这正是凸包发挥作用的地方。

从 Scikit 图像中检索

- **定义地图上的聚类:**地理信息系统,简称 GIS,存储地理数据,如国家的形状,山脉的高度。用凸包作为工具来定义不同区域的聚类,GIS 可以用来提取不同区域之间的信息和关系。
凸包还应用于其他领域,如数据挖掘、模式识别、人工智能、统计中异常值的检测等等。我希望凸包的应用能让你对这个工具感兴趣。更好的是。我们可以为我们的数据创建凸包!在开始写代码之前,让我们先了解一下凸包算法是如何工作的
格雷厄姆算法
格雷厄姆的扫描算法是一种计算平面中一组确定点的凸包的方法。

直觉:
- 对于每个点,首先确定从这些点之前的两个点行进是否构成左转或右转

从维基百科检索
- 如果是右转,倒数第二个点不是凸包的一部分,而是位于凸包内部。下图中,由于 D 相对于矢量 BC 做了一个右转, C 是而不是凸包的一部分。

检索自维基百科
- 然后我们将 D 与向量 BA 进行比较。由于 D 相对于矢量 BA 做了一个左转,D 被追加到凸包的栈中

检索自维基百科
伪代码:
代码使用ccw作为左转或右转的行列式。如果ccw > 0,那么新的点如果在前 2 点的左侧。ccw <0用于左侧,而ccw=0用于线性

检索自维基百科
你可以在这里更深入的了解算法。
为您的数据创建一个凸包
让我们看看如何利用 Python 的库来存储数据。用scipy.spatial.ConvexHull:使用凸包极其容易

或者用skimage把图像变成凸包
从 Scikit-image 中检索

从 Scikit-image 中检索
太好了!我们把数据包装得像礼物一样好。现在,它可以作为“礼物”送给你的朋友或同事了。用你的数据试试这个,观察它的神奇之处!
结论:
恭喜你!您刚刚学习了凸包,这是处理数据的额外工具。数据科学并不总是一条线性回归线。大多数时候,你会处理杂乱的数据。因此,知道有哪些工具将会给你带来灵活性和控制数据的能力。
如果你对如何用 Python 编写这个算法很好奇,可以在我的 Github 资源库中找到并分叉源代码。在我的笔记本中,我详细解释了每段代码,并提供了算法所需的函数(逆时针、点类、从点到向量、叉积等)。也许理解了这段代码会让你有信心尝试其他计算几何算法,并用 Python 创建自己的模块?
我喜欢写一些基本的数据科学概念,并尝试不同的算法和数据科学工具。你可以通过 LinkedIn 和 Twitter 与我联系。
如果你想查看我写的所有文章的代码,请点击这里。在 Medium 上关注我,了解我的最新数据科学文章,例如:
在 5 行简单的 Python 代码中利用您的数据分析
towardsdatascience.com](/how-to-create-interactive-and-elegant-plot-with-altair-8dd87a890f2a) [## 什么是卓越的图形以及如何创建它
作为一名数据科学家,了解如何制作重要的图表至关重要
towardsdatascience.com](/what-graphical-excellence-is-and-how-to-create-it-db02043e0b37) [## 用于机器学习的线性代数:求解线性方程组
代数是机器学习算法的底线机制
towardsdatascience.com](/linear-algebra-for-machine-learning-solve-a-system-of-linear-equations-3ec7e882e10f) [## 如何从头开始构建矩阵模块
如果您一直在为矩阵运算导入 Numpy,但不知道该模块是如何构建的,本文将展示…
towardsdatascience.com](/how-to-build-a-matrix-module-from-scratch-a4f35ec28b56) [## 高效 Python 代码的计时
如何比较列表、集合和其他方法的性能
towardsdatascience.com](/timing-the-performance-to-choose-the-right-python-object-for-your-data-science-project-670db6f11b8e)
参考
[1]哈桑·弗莱耶。图像处理中的凸包:范围审查。研究门。2016 年 5 月
[2]维基百科。格雷厄姆扫描
[3] Jayaram,M.A. *图像处理中的凸包:范围审查。*科学&学术出版。2016
高级卷积层概述
卷积层总结,以跟踪计算机视觉文献中的关键发展和先进概念
卷积层是计算机视觉体系结构的基本构件。采用卷积层的神经网络被广泛应用于分割、重建、场景理解、合成、对象检测等等
这篇文章的目的是提供一个摘要 和概述最近文献中出现的高级卷积层和技术。为了完整起见,我们从卷积的基础开始,然而,更严格的解释可以从。
**卷积:**从数学上来说,卷积是将两个信号合并成一个信号的“运算”,下面是维基百科中的一个插图,它突出了两个函数/信号 f(t)和 f(t-z)之间的卷积。卷积来获得(f*g)(t)

来自维基百科的卷积

深度学习中的主要卷积运算有
- 《2D》卷积:
形象地说,我们将一个核(绿色大小)卷积“滑动”到一个图像(蓝色)上,并学习这些核的权重。该内核的空间范围(F)是 3,并且过滤器,即内核的深度是 1,因此权重的数量是 331=9。我们可以通过“步幅”跳过像素并填充原始图像的区域,这里步幅是 0

的卷积块接受尺寸为 W1×H1×D1 的图像或特征图以及尺寸为(FFK)的核,并且典型地需要四个超参数:
- 过滤器数量 K: K
- 它们的空间范围 F: F
- 大步走
- 零填充的数量:P:如果我们对任何图像进行零填充
- 参数数量是(通道FF)*K
- 典型地,权重矩阵的形状是(F,F,通道,K)
这些操作组合起来提供了 W2H2D2 的最终输出特征图。工作细节见帖子
- w2 =(W1 F+2P)/S+1 w2 =(W1 F+2P)/S+1
- H2 =(H1 F+2P)/S+1 H2 =(H1 F+2P)/S+1
对于卷积,使用了两个额外的运算
- Max-pool :该操作减少了图像的数量维度:通常使用“Max”pool 操作中的 22 滤波器。过滤器用该块的最大值替换图像/特征图中的每个 22 块,这减小了下一层的特征图的大小。
- 非线性 (relu,tanh 等)在 max-pool 操作之前使用,以将非线性添加到操作中[ TODO: *未来工作:*添加关于各种非线性性能的注释]
滤波器(F)的空间范围是每个核的权重数量的主要贡献者。正如 CS231n 讲义中所解释的,当 F=3 和 F=7 时,砝码数量增加了三倍。通常,完整的深度网络由多层 CONV + RELU +池操作组成,以提取特征。因此,通常 F=3 被用作在每层学习特征向量的折衷,而不增加计算成本。
请参阅 C231n 课堂讲稿上的计算考虑部分作为额外参考

CS231n notes 中很好地总结了使用这三层的对象分类任务的关键架构,它们是 LeNet、AlexNet、ZFNet、GoogLeNet、VGGnet、Resnet。这些都是为了赢得 Imagenet 挑战赛而开发的。这些年来,有一种趋势是更大/更深的网络来提高性能。

图片来自 Resnet 文章
剩余/跳过连接
这些是微软团队在 2015 年推出的,目的是在更深的网络中保持准确性,作为 ImageNet 挑战赛的一部分。单个网络跳过的连接如下所示,其目的是学习剩余 R(x)。在更深的网络中,这允许在每一层学习“残留信息”。因此得名剩余连接。这项技术已经通过实验证明可以提高更深层网络的准确性。实现剩余/跳过的连接非常简单,如下所示。跳过连接也让我们克服了深层渐变消失的问题,并加快了训练速度。自从最初引入以来,这一实验结果已经在一系列计算机视觉算法中被广泛采用。resnets 的变体在此帖子中突出显示,其他细节和插图请参见博客。

*R(x)* = Output — Input = *H(x)* — *x***def** res_net_block(input_data, filters, conv_size): x = layers.Conv2D(filters, conv_size, activation='relu',
padding='same')(input_data)
x = layers.BatchNormalization()(x)
x = layers.Conv2D(filters, conv_size, activation=**None**,
padding='same')(x)
x = layers.BatchNormalization()(x)
x = layers.Add()([x, input_data])
x = layers.Activation('relu')(x)
**return** x
以上各层是用于计算机视觉任务的神经网络的关键组件,并且在广泛的领域和不同的体系结构中找到应用。现在我们转向更专业的层面。
卷积转置/步进卷积
具有步幅(≥2)和/或填充的卷积运算降低了所得特征图的维度。卷积转置是用来学习核的反向过程,将特征上采样映射到更大的维度。通常采用步幅> 1 来对图像进行上采样,这一过程在下面由 Thom Lane 撰写的文章中有很好的说明,其中 22 输入与填充和步幅卷积与 33 内核一起产生 5*5 特征图

图片来源 : Thom Lane 的博文
步长卷积在不同领域有着广泛的应用
- U-nets (医学图像分割)
- 生成模型 : 甘:生成器**:解码器,上采样层**
实现:所有主要的 DL 框架都跨越了卷积,然后需要使用适当的初始化,即随机或 Xavier 初始化。
屏蔽和门控卷积
屏蔽和门控卷积在 2016 年左右开始流行,在那里,Aaron van den Oord 等人的开创性工作引入了像素 RNN 和像素 CNN。这些是自回归方法,以先前像素为条件从概率分布中采样像素。

参考像素 RNN

由于每个像素都是通过对先前像素进行调节而生成的,因此在应用卷积运算时,为了确保对来自左侧和顶部行的像素进行调节,使用了掩码。两种类型的遮罩是:遮罩 A,用于第一通道和先前像素。蒙版:B,蒙版 B 所有通道和先前的像素,下面的层,都可用这里

图片来自像素 RNN 2016
注意:输入必须二进制化:2⁸,例如 256 位颜色,或者每个样本在 RGB 图像中介于 0-256 之间
引入屏蔽门控卷积以避免屏蔽卷积中的盲点。 Ord 等人,2016 提出隔离水平和垂直堆栈,即具有 1*1 卷积的门,水平堆栈中有剩余连接,如下所示。垂直堆栈中的剩余连接没有提供额外的性能改进,因此没有实现。

屏蔽门卷积的实现是可用的在这里。
****应用:主要用于解码器,例如用于 VAE 框架中的在先采样,以避免训练 GAN 的问题,例如模式崩溃,并生成高分辨率图像。
- ****像素 CNN 解码器:以先前值为条件的像素,导致更好的性能。需要在逐个像素的基础上进行更长的推断/采样。这些在 PixelCNN++ 中进行了优化,并在 Tensorflow Probability 上实现。
- 像素-VAE: 组合,每个维度是协方差矩阵的对角元素,这种高斯假设导致样本图像质量差,因此将传统解码器与 PixelCNN 组合,以帮助分布的“小尺度/相似”方面,这降低了对潜在学习更多全局信息的要求,通过改进 KL 项来证明,从而提高了性能。实现见此处
- VQ-VAE 和 VQ-瓦埃 2 :在 VAE 的潜在码图中使用 Pixel-CNN,避免了所有潜在变量的高斯假设,从而在更高维度中产生不同的图像。VQ-VAE 实现是由作者开源的,其他实现也是广泛可用的
可逆卷积
基于归一化流的可逆卷积目前被应用于生成模型中,以学习计算机视觉中图像的潜在概率分布 p(x)。维护动机是提供更好的损失函数,即负对数似然。
两个最常见的生成框架建模遭受近似推理时间问题,即 VAE 的损失函数函数(基于证据的下界,即 ELBO)是对数似然的下界的近似,因此推理/重建是近似。在 GAN 的方法中采用的对抗损失是基于“搜索”的方法,并且遭受采样多样性的问题,并且难以训练,即模式崩溃。
标准化流量的数学预备知识在斯坦福课堂笔记中有最好的概述,这里,我们使用那里的摘要。
在归一化流程中,随机变量 Z 和 X 之间的映射,由函数 f 给出,参数化θ,它是确定的和可逆的,使得
 ****
****
然后,使用变量公式的变化,可以获得 X 和 Z 的概率分布,在这种情况下,两个概率分布通过行列式项相关。不严格地说,决定因素是“比例”或标准化常数。

这里,
- ****“标准化”意味着变量的变化在应用可逆变换后给出了标准化的密度
- ****“流”表示可逆变换可以相互组合,以创建更复杂的可逆变换。
注:函数可以是单个函数,也可以是一系列序列函数,通常是从简单的(如潜在向量(Z ))到复杂分布(如(X)图像)的变换。这个公式允许我们“精确地”在两个分布之间进行变换,从而可以推导出负对数似然损失函数,推导见讲座。
标准化流量和神经网络:Dinh 等人,2014 年(NICE)和 Dinh 等人,2017 年(Real-NVP)的工作,开始提供神经网络架构,采用标准化流量进行密度估计。Kingma 等人的 Glow 是当前(2018 年)的技术水平,它建立在这些作品的基础上,其中引入了 1*1 可逆卷积来合成高分辨率图像。

发光关节参考

可逆卷积的 Glow 实现
对于 1*1 学习可逆卷积,关键的新颖之处在于减少了权重矩阵的行列式项的计算成本。这是通过对权重矩阵进行置换的 LU 分解,即 PLU 分解来实现的。随机排列被用来在每次迭代中保持“流动”。数学细节包含在论文的第 3.2 节中,它们还提供了一个使用 numpy 和 tensorflow 的实现,以便于查询。
这些由 Hoogeboom 等人进一步推广为 N*N 卷积,更多细节和实现(带优化)请见博文。我们的目的只是为了突出这些模型,更全面的细节我们请读者参考 CS236 讲座 7 和 8 以及 Glow 论文和 Lilian Weng 的博客文章。
****应用领域:图像合成与生成建模
用于图像处理的卷积神经网络——使用 Keras
Python 中使用 CNN 的综合指南

美国地质勘探局在 Unsplash 上拍摄的照片
什么是图像分类?
图像分类是根据图像的特征将图像分成不同类别的过程。特征可以是图像中的边缘、像素强度、像素值的变化等等。稍后,我们将尝试理解这些组件。现在让我们看看下面的图片(参见图 1)。这三幅图像属于同一个人,但是当在诸如图像颜色、面部位置、背景颜色、衬衫颜色等特征之间进行比较时,这三幅图像会有所不同。处理图像时最大的挑战是这些特征的不确定性。对于人眼来说,看起来都是一样的,但是,当转换为数据时,您可能不容易在这些图像中找到特定的模式。



图一。分别说明了作者在 2014 年和 2019 年拍摄的肖像。
图像由称为像素的最小的不可分割的片段组成,并且每个像素具有通常称为像素强度的强度。每当我们研究数字图像时,它通常带有三个颜色通道,即红绿蓝通道,俗称“RGB”值。为什么是 RGB?因为已经看到这三者的组合可以产生所有可能的调色板。每当我们处理彩色图像时,图像由多个像素组成,每个像素由 RGB 通道的三个不同值组成。让我们编码并理解我们正在谈论的内容。
import cv2
import seaborn as sns
import matplotlib.pyplot as plt
%matplotlib inline
sns.set(color_codes=True)# Read the image
image = cv2.imread('Portrait-Image.png') #--imread() helps in loading an image into jupyter including its pixel valuesplt.imshow(cv2.cvtColor(image, cv2.COLOR_BGR2RGB))
# as opencv loads in BGR format by default, we want to show it in RGB.
plt.show()image.shape
image.shape 的输出是(450,428,3)。图像的形状是 450 x 428 x 3,其中 450 代表高度,428 代表宽度,3 代表颜色通道的数量。当我们说 450 x 428 时,这意味着数据中有 192,600 个像素,每个像素都有一个 R-G-B 值,因此有 3 个颜色通道。
image[0][0]
image [0][0]为我们提供了第一个像素的 R-G-B 值,分别为 231、233 和 243。
# Convert image to grayscale. The second argument in the following step is cv2.COLOR_BGR2GRAY, which converts colour image to grayscale.
gray = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
print(“Original Image:”)plt.imshow(cv2.cvtColor(gray, cv2.COLOR_BGR2RGB))
# as opencv loads in BGR format by default, we want to show it in RGB.
plt.show()gray.shape
gray.shape 的输出为 450 x 428。我们现在看到的是一个由 192,600 多个像素组成的图像,但只包含一个通道。
当我们尝试将灰度图像中的像素值转换成表格形式时,我们观察到的就是这样的情况。
import numpy as np
data = np.array(gray)
flattened = data.flatten()flattened.shape
输出:(192600,)
我们有一个数组形式的所有 192,600 个像素的灰度值。
flattened
输出:数组([236,238,238,…,232,231,231],dtype=uint8)。注意灰度值可以在 0 到 255 之间,0 表示黑色,255 表示白色。
现在,如果我们拍摄多个这样的图像,并尝试将它们标记为不同的个体,我们可以通过分析像素值并在其中寻找模式来做到这一点。然而,这里的挑战是由于背景、色阶、服装等。图像之间各不相同,仅通过分析像素值很难找到模式。因此,我们可能需要一种更先进的技术,可以检测这些边缘或找到面部不同特征的潜在模式,使用这些模式可以对这些图像进行标记或分类。这就是像 CNN 这样更先进的技术发挥作用的地方。
CNN 是什么?
CNN 或卷积神经网络(CNN)是一类深度学习神经网络。简而言之,将 CNN 视为一种机器学习算法,它可以接受输入图像,为图像中的各个方面/对象分配重要性(可学习的权重和偏差),并能够区分它们。
CNN 的工作原理是从图像中提取特征。任何 CNN 都包含以下内容:
- 作为灰度图像的输入图层
- 输出层是一个二进制或多类标签
- 隐藏层由卷积层、ReLU(校正线性单位)层、汇集层和完全连接的神经网络组成
理解由多个神经元组成的 ANN 或人工神经网络不能从图像中提取特征是非常重要的。这就是卷积层和池层结合的地方。类似地,卷积和池层不能执行分类,因此我们需要一个完全连接的神经网络。
在我们深入了解这些概念之前,让我们试着分别理解这些单独的部分。

图二。说明了 CNN 从输入到输出数据的过程。图片摘自幻灯片 12《卷积神经网络简介》(斯坦福大学,2018 年)
假设我们可以访问不同车辆的多个图像,每个图像都被标记为卡车、轿车、货车、自行车等。现在的想法是利用这些预先标记/分类的图像,开发一种机器学习算法,该算法能够接受新的车辆图像,并将其分类到正确的类别或标签中。现在,在我们开始构建神经网络之前,我们需要了解大多数图像在处理之前都被转换为灰度形式。
5 编码嗅探如果你在数据科学行业工作,你必须知道
towardsdatascience.com](/are-your-coding-skills-good-enough-for-a-data-science-job-49af101457aa)
为什么是灰度而不是 RGB/彩色图像?

图 3。图像的 RGB 颜色通道。图像鸣谢—萨哈,S. (2018)
我们之前讨论过,任何彩色图像都有三个通道,即红色、绿色和蓝色,如图 3 所示。有几种这样的颜色空间,如灰度、CMYK、HSV,图像可以存在于其中。
具有多个颜色通道的图像面临的挑战是,我们有大量的数据要处理,这使得该过程计算量很大。在其他世界中,可以把它想象成一个复杂的过程,其中神经网络或任何机器学习算法必须处理三种不同的数据(在这种情况下是 R-G-B 值),以提取图像的特征并将它们分类到适当的类别中。
CNN 的作用是将图像简化为一种更容易处理的形式,而不会丢失对良好预测至关重要的特征。当我们需要将算法扩展到大规模数据集时,这一点非常重要。
什么是卷积?
图 4。说明了如何对输入图像进行卷积以提取特征。学分。GIF via GIPHY
我们知道训练数据由灰度图像组成,这些图像将作为卷积层的输入来提取特征。卷积层由一个或多个具有不同权重的核组成,用于从输入图像中提取特征。假设在上面的例子中,我们正在使用大小为 3 x 3 x 1 (x 1,因为我们在输入图像中有一个颜色通道)的内核(K),权重如下所示。
Kernel/Filter, K =
1 0 1
0 1 0
1 0 1
当我们基于核的权重在输入图像上滑动核(假设输入图像中的值是灰度强度)时,我们最终基于不同像素的周围/相邻像素值来计算不同像素的特征。例如,如下图 5 所示,当第一次对图像应用核时,我们在如下所示的卷积特征矩阵中得到等于 4 的特征值。

图 5。说明了当内核应用于输入图像时卷积特征的值。该图像是上面图 4 中使用的 GIF 的快照。
如果我们仔细观察图 4,我们会看到内核在图像上移动了 9 次。这个过程叫做**大步前进。**当我们使用步长值为 1 ( 非步长)的操作时,我们需要 9 次迭代来覆盖整个图像。CNN 自己学习这些核的权重。 该操作的结果是一个特征图,它基本上从图像中检测特征,而不是查看每一个像素值。
I 图像特征,如边缘和兴趣点,提供了图像内容的丰富信息。它们对应于图像中的局部区域,并且在图像分析的许多应用中是基本的:识别、匹配、重建等。图像特征产生两种不同类型的问题:图像中感兴趣区域的检测,通常是轮廓,以及图像中局部区域的描述,通常用于不同图像中的匹配(图像特征。(未注明)
让我们更深入地了解一下我们正在谈论的内容。
从图像中提取特征类似于检测图像中的边缘。我们可以使用 openCV 包来执行同样的操作。我们将声明一些矩阵,将它们应用于灰度图像,并尝试寻找边缘。你可以在这里找到关于功能的更多信息。
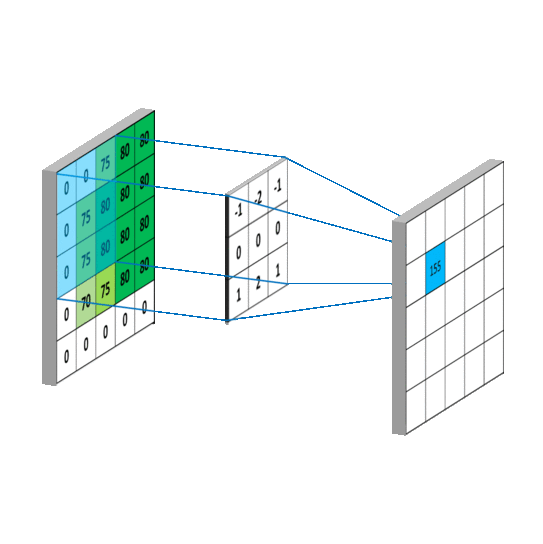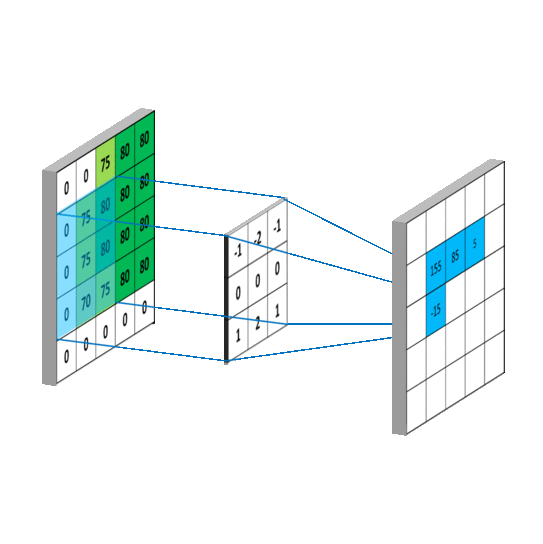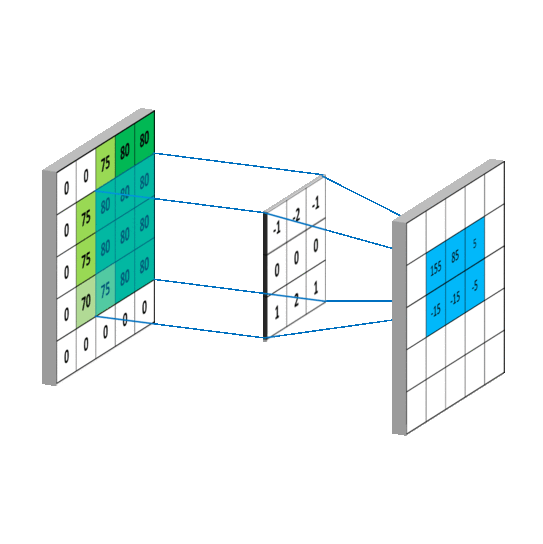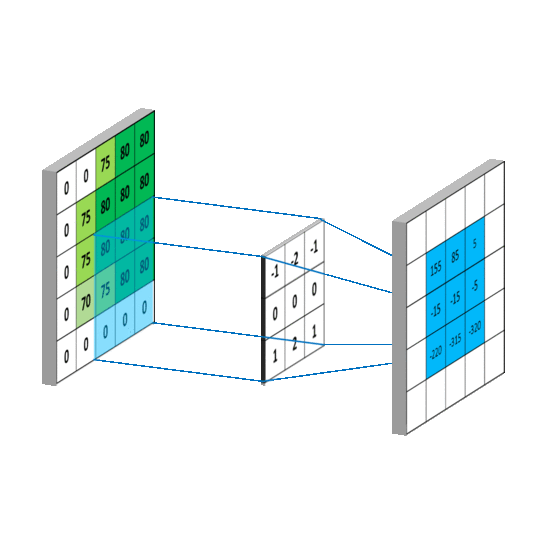
# 3x3 array for edge detection
mat_y = np.array([[ -1, -2, -1],
[ 0, 0, 0],
[ 1, 2, 1]])
mat_x = np.array([[ -1, 0, 1],
[ 0, 0, 0],
[ 1, 2, 1]])
filtered_image = cv2.filter2D(gray, -1, mat_y)
plt.imshow(filtered_image, cmap='gray')filtered_image = cv2.filter2D(gray, -1, mat_x)
plt.imshow(filtered_image, cmap='gray')


图 6。对数据应用 filter2D 变换时,显示带有边缘的图像。请注意,这两个图像明显不同。当我们谈论卷积层和内核时,我们主要是想识别图像中的边缘。使用 CNN 时,matrix_x 和 matrix_y 值由网络自动确定。图片取自作者开发的 Jupyter 笔记本。
import torch
import torch.nn as nn
import torch.nn.functional as fn
如果您使用的是 windows,请安装以下软件—# conda install pytorch torch vision cudatoolkit = 10.2-c py torch 以使用 py torch。
import numpy as np
filter_vals = np.array([[-1, -1, 1, 2], [-1, -1, 1, 0], [-1, -1, 1, 1], [-1, -1, 1, 1]])
print(‘Filter shape: ‘, filter_vals.shape)# Neural network with one convolutional layer and four filters
class Net(nn.Module):
def __init__(self, weight): #Declaring a constructor to initialize the class variables
super(Net, self).__init__()
# Initializes the weights of the convolutional layer to be the weights of the 4 defined filters
k_height, k_width = weight.shape[2:]
# Assumes there are 4 grayscale filters; We declare the CNN layer here. Size of the kernel equals size of the filter
# Usually the Kernels are smaller in size
self.conv = nn.Conv2d(1, 4, kernel_size=(k_height, k_width), bias=False)
self.conv.weight = torch.nn.Parameter(weight)
def forward(self, x):
# Calculates the output of a convolutional layer pre- and post-activation
conv_x = self.conv(x)
activated_x = fn.relu(conv_x)# Returns both layers
return conv_x, activated_x# Instantiate the model and set the weights
weight = torch.from_numpy(filters).unsqueeze(1).type(torch.FloatTensor)
model = Net(weight)# Print out the layer in the network
print(model)
我们创建可视化层,调用类对象,并在图像上显示四个内核的卷积的输出(Bonner,2019)。
def visualization_layer(layer, n_filters= 4):
fig = plt.figure(figsize=(20, 20))
for i in range(n_filters):
ax = fig.add_subplot(1, n_filters, i+1, xticks=[], yticks=[])
# Grab layer outputs
ax.imshow(np.squeeze(layer[0,i].data.numpy()), cmap='gray')
ax.set_title('Output %s' % str(i+1))
卷积运算。
#-----------------Display the Original Image-------------------
plt.imshow(gray, cmap='gray')#-----------------Visualize all of the filters------------------
fig = plt.figure(figsize=(12, 6))
fig.subplots_adjust(left=0, right=1.5, bottom=0.8, top=1, hspace=0.05, wspace=0.05)for i in range(4):
ax = fig.add_subplot(1, 4, i+1, xticks=[], yticks=[])
ax.imshow(filters[i], cmap='gray')
ax.set_title('Filter %s' % str(i+1))
# Convert the image into an input tensor
gray_img_tensor = torch.from_numpy(gray).unsqueeze(0).unsqueeze(1)
# print(type(gray_img_tensor))# print(gray_img_tensor)# Get the convolutional layer (pre and post activation)
conv_layer, activated_layer = model.forward(gray_img_tensor.float())# Visualize the output of a convolutional layer
visualization_layer(conv_layer)
输出:



图 7。说明了原始灰度图像上不同过滤器的输出。快照是使用 Jupyter Notebook 和上述代码生成的。
**注意:**根据与过滤器相关联的权重,从图像中检测特征。请注意,当图像通过卷积层时,它会尝试通过分析相邻像素强度的变化来识别特征。例如,图像的右上角始终具有相似的像素强度,因此没有检测到边缘。只有当像素改变强度时,边缘才可见。
为什么是 ReLU?
ReLU 或整流线性单元是应用激活函数来增加网络的非线性而不影响卷积层的感受野的过程。ReLU 允许更快地训练数据,而 Leaky ReLU 可以用来处理消失梯度的问题。其他一些激活函数包括泄漏 ReLU、随机化泄漏 ReLU、参数化 ReLU 指数线性单位(eLU)、缩放指数线性单位 Tanh、hardtanh、softtanh、softsign、softmax 和 softplus。
图 8。说明了 ReLU 的影响,以及它如何通过将负值转换为零来消除非线性。图片来源:GIF via Gfycat。
visualization_layer(activated_layer)

图 9。说明了 ReLU 激活后卷积层的输出。图片取自作者开发的 Jupyter 笔记本。

图 10。阐释了内核如何处理具有 R-G-B 通道的图像。图像鸣谢—萨哈,S. (2018)

图 11。在 5 x 5 图像上应用 3 x 3 内核。图片致谢(Visin,2016)
卷积运算的一般目标是从图像中提取高级特征。在构建神经网络时,我们总是可以添加多个卷积层,其中第一个卷积层负责捕获梯度,而第二个卷积层捕获边缘。图层的添加取决于图像的复杂程度,因此添加多少图层没有什么神奇的数字。注意,应用 3 x 3 滤波器会在原始图像中产生 3 x 3 卷积特征,因此为了保持原始尺寸,通常会在图像两端填充值。
池层的作用
池层对通常被称为激活图的卷积特征应用非线性下采样。这主要是为了降低处理与图像相关的大量数据所需的计算复杂度。合用不是强制性的,通常是避免的。通常,有两种类型的池,最大池,返回池内核覆盖的图像部分的最大值,以及平均池平均池内核覆盖的值。下面的图 12 提供了一个不同的池技术如何工作的工作示例。

图 12。说明了如何在激活图上执行最大和平均池。图片摘自幻灯片 18《卷积神经网络简介》(斯坦福大学,2018 年)
图像展平
一旦汇集完成,输出需要被转换成表格结构,人工神经网络可以使用该表格结构来执行分类。注意密集层的数量以及神经元的数量可以根据问题陈述而变化。此外,通常还会添加一个删除层,以防止算法过拟合。退出者在训练数据时会忽略一些激活图,但是在测试阶段会使用所有的激活图。它通过减少神经元之间的相关性来防止过度拟合。

图 13。展示了一个完整的 CNN,由输入图像、卷积层、汇集层、展平层、带有神经元的隐藏层和二进制输出层组成。这张图片是作者使用清晰图表制作的,可以在这里找到。
使用 CIFAR-10 数据集
下面的链接提供了一个使用 Keras 与 CNN 合作的端到端示例。
permalink dissolve GitHub 是超过 5000 万开发人员的家园,他们一起工作来托管和审查代码,管理…
github.com](https://github.com/angeleastbengal/ML-Projects/blob/master/Understanding%20Image%20Processing%20%2B%20CNN.ipynb) [## 使用 Python 实现决策树分类器和成本计算剪枝
使用成本计算修剪构建、可视化和微调决策树的完整实践指南…
towardsdatascience.com](/decision-tree-classifier-and-cost-computation-pruning-using-python-b93a0985ea77) [## ML 行业实际使用的图像处理技术有哪些?- neptune.ai
处理可用于提高图像质量,或帮助您从中提取有用的信息。这是…
海王星. ai](https://neptune.ai/blog/what-image-processing-techniques-are-actually-used-in-the-ml-industry)
参考
- 萨哈,S. (2018)。卷积神经网络综合指南 ELI5 方式。[在线]走向数据科学。可在:https://towardsdatascience . com/a-comprehensive-guide-to-convolutionary-neural-networks-the-Eli 5-way-3bd 2 b 1164 a 53 获取。
- Image 特色。(未注明)。【在线】可在:http://morpheo . inrialpes . fr/~ Boyer/Teaching/Mosig/feature . pdf .
- Stanford 大学(2018 年)。卷积神经网络介绍。[在线]可从以下网址获取:https://web . Stanford . edu/class/cs 231 a/lections/intro _ CNN . pdf
- 弗兰切斯科·visin(2016)。英语:卷积运算的一种变体的动画。蓝色贴图是输入,青色贴图是输出。【在线】维基共享。可从以下网址获取:https://commons . wikimedia . org/wiki/File:Convolution _ algorithm - Same _ padding _ no _ strides . gif【2020 年 8 月 20 日获取】。
- Bonner 大学(2019 年)。深度学习完全初学者指南:卷积神经网络。【在线】中等。可从:https://towardsdatascience . com/wtf-is-image-class ification-8e 78 a 8235 ACB 获取。
关于作者:高级分析专家和管理顾问,帮助公司通过对组织数据的商业、技术和数学的组合找到各种问题的解决方案。一个数据科学爱好者,在这里分享、学习、贡献;你可以和我在 上联系 和 上推特;
卷积神经网络数学直觉
我花了很长时间才明白 CNN 是如何运作的。相信我,这上面的内容少得令人难以置信,真的很少。无论在哪里,他们都会告诉你在 CNN 中前向传播是如何工作的,但从来没有开始向后传播。不了解全貌,一个人的理解总是半吊子。
先决条件
- 应熟悉 CNN 的基础知识——卷积层、最大池、全连接层。做一个基本的谷歌搜索,理解这些概念。应该需要一个小时左右才能开始。
- 微分学——应该知道链式法则是如何工作的,以及微分的基本规则。
- 应该知道反向传播数学在人工神经网络中的实际工作原理。如果你不知道的话,我强烈推荐你阅读我之前关于这个的文章。
本文性质
所以,我对其余文章的主要问题是——它们没有提到整体流程。每一层和概念都得到了很好的解释,但是反向传播是如何跨层工作的——这方面的信息缺失了。所以,对我来说,很难想象错误是如何从整体上回流的。因此,这篇文章将采取 CNN 的几个场景,并试图让你了解整个流程。
目的不是覆盖深度,而是覆盖广度和整体流程。至于深度,我会在需要的地方给你指出相关的文章,以帮助你有更深的直觉。把这篇文章当作 CNN 数学的索引。只是为了清楚地设定期望,这不会是一个 5 分钟的阅读。但是,我会要求你在需要的时候阅读相关的文章。
场景 1: 1 个卷积层+ 1 个全连接层

作者图片
前进传球
x 是输入图像,比如说(33 矩阵),滤波器是 a (22 矩阵)。两者都将被卷积以给出输出 XX (2*2 矩阵)。
现在,XX 将被拉平,并馈入一个以 w (1*4 矩阵)为权重的全连通网络,该网络将给出一个—输出。
最后,我们将通过计算 Y(预期)和输出(实际)之间的均方误差来计算误差。

作者图片
我强烈建议你自己计算 XX。这会给你一个卷积层的直觉。
领先的技术、音乐和电影节将于 2020 年 3 月 13 日至 22 日举行。它将以前沿的谈话为特色…
www.datadriveninvestor.com](https://www.datadriveninvestor.com/2020/01/13/the-future-of-humanity-is-genetic-engineering-and-neural-implants/)
偶数道次
向后传递的目标是选择 滤镜w这样我们就可以减少* E 了。基本上,我们的目标是如何改变 w 和滤波器,使 E 降低。*

作者图片
让我们从第一个学期开始。

作者图片
猜猜怎么回事?!
第 1 行:使用链式法则。
第二行:运用微分学。花一分钟在这上面。应该很容易理解。如果不是查我以前的文章(前提中提到的)。或者检查这个一个。
在下一步之前,一定要确保你自己做了这些计算。如果这不容易理解,请评论。
移到第二学期。

作者图片
不在办公室/假面骑士…这里有太多奇怪的逻辑吗?跟着我,会帮助你理解这一点。
第 1 行:基本链规则
第 2 行:第一项和第三项位于上述计算本身的线上。再次花一分钟或在纸上做它来理解这一点。
现在,这个转 w 到底是什么鬼!?我花了很长时间才明白这是怎么计算出来的。为此,您只需按照提到的顺序浏览这些概念。
- 转置卷积—输出为[11 矩阵],XX 为[14 矩阵(因为这里被扁平化)],对。所以,当我们反向传播时,我们增加了矩阵的大小。转置卷积有助于此。快进视频,看看他们进行转置卷积的逻辑。
- 现在深呼吸,通读和。这是理解计算输出如何随过滤器和 x 变化的直觉的最重要的一个粘贴上面文章的结论。JFYI,不要被全卷积弄糊涂了,它只不过是转置卷积(你刚刚在上面理解的)。

最后,我们可以像这样减小滤波器和 w 值。

作者图片
场景 2–2 个卷积层+ 1 个全连接层

作者图片
现在,添加尽可能多的卷积层,我们的方法将保持不变。像往常一样,目标是:

作者图片
前面两项我们已经计算过了。让我们看看最后一个学期的公式是什么。

作者图片
以防你需要深入研究这个。我推荐这篇文章。并相应地计算新的 F1、F2 和 w。
场景 3—最大池层如何??
最大池是 CNN 的一个重要概念,反向传播是如何实现的?

作者图片
仔细想想,max pooling layer 中没有像 filters 这样的变量。所以,我们不需要在这里调整任何值。
但是,它影响了我以前的层,对不对?!它通过将矩阵中的几个元素合并成一个数字来减小矩阵的大小。基本上,它确实会影响反向传播。它说有非最大值的值不会有任何梯度。
所以,我们在这里说的是,所有没有最大值的值都是 0。更有深度。

作者图片
已经尝试把所有好的相关文章放在一个地方,并帮助你看到卷积的全貌。请仔细阅读以上内容,如果在整个流程中仍然缺少一些东西,请告诉我——我很乐意编辑它以适应相同的内容。
卷积神经网络
理解层背后的直觉
1950 年,艾伦·图灵提交了一篇名为 的论文图灵测试, 其中他为机器被称为智能机器奠定了基础。尽管在人工智能领域取得了突破,但即使在今天,机器也不能被视为智能的。神经网络是人工智能的一个领域,旨在模仿人体的大脑结构。人工神经网络(ANN)是神经网络的一种基本类型,它能有效地发现数据中的隐藏模式并给出结果。
注意:本文假设读者对神经网络有基本的了解
一个问题仍然存在,即使机器可以处理和理解给它们的数据,但它们有能力像人类一样看东西吗?
是的!为机器提供视觉似乎是一件荒谬的事情,但一种叫做 卷积神经网络 的神经网络赋予了机器部分视觉。
既然一个图像只是数值像素值的集合,ANN 的就不能处理吗?这个问题的答案是**不!**虽然人工神经网络对数值数据分类很好,但在处理图像时缺乏对空间关系的考虑。我来简化一下。在处理图像列表时,如果 ANN 发现一只猫出现在一幅图像的右上角,那么它将假设它将一直出现在那里。因此,无论你的猫在图像的哪个位置,如果它不能在右上角找到它,那么它将给出一个否定的结果。
另一方面,卷积神经网络,也称为 ConvNet 在图像中的任何地方寻找物体时表现都异常出色。还有,如果你的猫脾气暴躁也不用担心,它还是会识别的。

图片来源:Adesh desh pande viaGitHub(麻省理工)
上图展示了 ConvNet 的基本架构,其中包含池化、FC 层、卷积等术语,乍一看似乎令人不知所措。本文旨在揭开这些术语的神秘面纱,并获得使用它们背后的直觉。
入门,先来了解一下我们在给网络喂什么!

安德烈·迈克在 Unsplash 上的照片
我们看到的图像看起来很迷人。但机器不是这么看的。它将其视为代表颜色通道强度值的数字像素值的集合。这张图片的尺寸是 5999 x 4000 x 3;其中 3 表示颜色通道的数量,即 RGB。其他颜色通道可以是 HSV、灰度等等。
机器如何从像素值中提取特征?
在数学中,一个称为卷积的概念将两个函数考虑在内,并产生第三个函数来表达一个函数的形状如何受另一个函数的影响。想象一下将滤镜应用到照片上。这里发生的是,它采取你的照片,并应用过滤器的功能,这可能是为了突出阴影。滤镜激活图像的某些功能,并生成输出图像。
那么问题来了,这些滤镜是什么? 滤镜只不过是具有特定值的 3D 矩阵,当它们在附近看到想要的图案时会变得兴奋。它们比在图像的宽度和高度上滑动的输入图像小得多。

用 3×3 滤波器对 5×5 图像进行卷积运算。摄影:Rob Robinson on MLNoteBook
当滤镜滑过图像时,它会聚焦在图像的某个邻域。它执行过滤器和图像部分的算术运算,并将结果存储在单个单元格中。在技术术语中,细胞被视为神经元。多个这样的神经元,当组合在一起时,形成了一个 2D 矩阵,称为激活图/特征图,或者更确切地说,我会说是来自图像的过滤器的喜好的集合。单个神经元指向的邻域称为局部感受野。

算术运算和局部感受野。Rob Robinson 在 MLNoteBook 上拍摄的照片
这个特征图是一个过滤器提取特征的结果。对于卷积图层,会使用多个要素,进而生成多个要素地图。要素地图堆叠在一起,作为输入传递给下一个图层。
过滤器的数量越多,特征图的数量就越多,特征的提取就越深入。
输出图像的大小会发生什么变化?

卷积运算。图片作者: GitHub 上的 vdumoulin (麻省理工学院)
卷积运算后,输出图像的尺寸必然会减小。控制输出音量大小的参数是步幅、滤波器大小和填充。
- 步幅:步幅是我们滑动滤镜时移动的像素数。当步幅为 2 时,我们将过滤器移动 2 个像素。步幅越高,输出音量越小。通常,我们将步幅设置为 1 或 2。
- 过滤器大小:当我们增加过滤器大小时,我们间接增加了单个神经元中存储的信息量。在这种情况下,滤镜在图像上移动的次数会减少。这将最终导致输出体积的空间尺寸的减小。

填充 1
3.填充:顾名思义,它在原始图像周围添加一个无关紧要的覆盖物,以保持输出图像的大小不变。使用公式 *计算要添加的层数 P=(((O-1)S)+F-W)/2 其中 O 是输出图像的大小,W 是输入图像的大小,F 是滤波器大小,P 是要作为填充添加的层像素的数量,S 是跨距。例如,如果输入图像的大小是 5×5,过滤器的大小是 3×3,步幅是 1,并且我们希望输出图像的大小与输入图像的大小相同,则有效填充将是 1。
现在我们已经完成了图片的大部分工作,是时候考虑下一步了。
我们渴望让我们的神经网络变得灵活,也就是说,无论数据是什么,它都应该足够有效地从数据中进行识别。由于我们拥有的特征地图可以用一些线性函数来表示,不确定性因素似乎消失了。我们需要函数将不确定性,或者我应该说是非线性引入我们的神经网络。
有许多函数能够执行此任务,但这两个函数被广泛使用。
Sigmoid :它使用 g(z)=1/1+e⁻ᶻ函数引入非线性,该函数将数字转换为 0-1 之间的范围。Sigmoid 函数的主要问题之一是 消失梯度问题 。如果你不熟悉这个术语,不要担心。由奇-汪锋撰写的这篇文章解释了渐变消失的现象。

Sigmoid 函数图
ReLU: ReLU 代表整流线性单元。它使用函数 ***g(w)=max(0,w)将输入阈值设为 0。***ReLU 的性能也优于 Sigmoid 函数,它部分解决了消失梯度问题。虽然 ReLU 所遭受的一个问题是 垂死的 ReLU问题,但它的变体 泄漏的 ReLU 解决了这个问题。

ReLU 函数的一个图
既然我们已经使我们的网络强大到足以适应变化,我们可以把注意力集中在计算时间的另一个问题上。如果你还记得,我们的图像的尺寸是 5999 x 4000 x 3,对于一个单独的图像来说有 71,988,000 个像素值,我们有很多这样的图像。虽然机器的速度非常快,但处理这些数量庞大的像素值需要相当长的时间。
一个基本的本能是在群体中选择一个主导价值。这是通过机器使用称为池的操作来实现的。

图像的缩减采样。图片来自 Github (麻省理工学院)
我们定义一个池窗口,比如说 2 x 2。类似于过滤器,该窗口在图像上滑动,并从窗口中选择一个主导值。主导的定义随着方法而变化。
其中一种方法是 Max Pooling ,这是一种广泛流行的方法,从窗口内的图像中选择最大值。这将尺寸减小到 25%。其他汇集方法包括平均汇集、矩形邻域的 L2 范数,其不同之处在于选取主导值的方法。

最大池化。图片来自 Github (麻省理工学院)
因此,拥有 池层 的主要动机是为了降维。虽然,已经有关于移除池层并用卷积层代替它的讨论。力求简单:全卷积网提出了一个这样的架构,他们建议偶尔使用更大的步幅来减少初始表示的维数。
人工神经网络和 CNN 之间的关键区别是 CNN 处理图像中空间关系的能力,除此之外,两者的计算能力是相同的。既然我们已经提供了一个使用卷积、激活和汇集来处理空间关系的平台,我们现在可以利用 ANN 的能力。
全连接层 是常规神经网络或多层 Perceptron (MLP)的代表。

多层感知器
使用这些层的主要思想是通过卷积层和池层提取的高级特征的非线性组合进行学习。在训练网络时,神经元之间的权重作为一个参数,在训练时进行调整。由于这一层接受 1D 矢量形式的输入,我们需要 展平 来自先前层的输出,以馈送到 FC 层。
在分类多个类别的情况下,该层的输出是每个类别的真实值。为了从这些值中获得一些洞察力,使用了 Softmax 函数 。更多关于 Softmax 功能的信息可以在这里找到。它将这些真实值转换成类别概率。然后提取概率最高的类别作为预测类别。
虽然这些不是构建 CNN 时使用的唯一层,但它们是它的基本构件。根据问题的性质,可以添加多种其他类型的图层,例如缺失图层和归一化图层。
有许多 CNN 架构已经被证明在图像分类上表现得非常好。其中几个是:
- AlexNet
- VGGNet
- 雷斯内特
- 开始
- DenseNet
* [## AlexNet、VGGNet、ResNet、Inception、DenseNet 的架构比较
ILSVRC 挑战结果中具有超参数和准确性的图层描述
towardsdatascience.com](/architecture-comparison-of-alexnet-vggnet-resnet-inception-densenet-beb8b116866d)
虽然这些架构已经可以使用了,但是我强烈建议您尝试一下这些架构,并构建一个您自己的架构。*
感谢阅读!希望这篇文章有助于获得关于卷积神经网络的基本直觉。如有任何反馈或建议,可通过我的 邮箱LinkedIn联系我。我很想听听!**
下一篇文章将关注 CNN 的一个端到端例子!
快乐学习!
卷积神经网络冠军第 1 部分:LeNet-5 (TensorFlow 2.x)
关于最流行的卷积神经网络(CNN)架构的多部分系列的第 1 部分,包含可复制的 Python 笔记本。

查尔斯·德鲁维奥在 Unsplash 上拍摄的照片
卷积神经网络是一种特殊类型的神经网络,用于对具有强空间相关性的数据进行建模,例如图像、多元时间序列、地球科学研究(地震分类和回归)以及许多其他应用。自 1998 年以来,卷积网络经历了重大变化,在这一系列文章中,我旨在再现著名的模型架构冠军,即 LeNet、AlexNet、Resnet。我的目标是与更广泛的受众分享我的发现和研究,并提供可复制的 Python 笔记本。
**第二部分:**ImageNet 和 Tensorflow 上的 AlexNet 分类:
[## 卷积神经网络冠军第 2 部分:AlexNet (TensorFlow 2.x)
关于最流行的卷积神经网络(CNN)架构的多部分系列的第 2 部分…
towardsdatascience.com](/convolutional-neural-network-champions-part-2-alexnet-tensorflow-2-x-de7e0076f3ff)
第三部分:ImageNet 和 Tensorflow 上的 VGGnet 分类:
[## 卷积神经网络冠军第 3 部分:VGGNet (TensorFlow 2.x)
这个多部分系列的第 3 部分介绍了最流行的卷积神经网络(CNN)架构,包括…
towardsdatascience.com](/convolutional-neural-network-champions-part-3-vggnet-tensorflow-2-x-ddad77492d96)
用于这项研究的 Python 笔记本位于我的Github页面。
本研究使用的 Tensorflow 版本为 1.15.0。
本研究中使用的机器采用英特尔酷睿 I7 处理器,1.8 GHZ,16 GB 内存。
对图像应用卷积层(也称为“ConvNet”)并提取图像的关键特征进行分析是 conv net 的主要前提。每次将“Conv 层”应用于图像并将该图像分成称为感受野的小片,从而从图像中提取重要特征并忽略不太重要的特征。内核通过将其元素与感受野的相应元素相乘,使用一组特定的权重与图像进行卷积。通常将“合并图层”与 Conv 图层结合使用,以对卷积后的要素进行缩减采样,并降低模型对输入中要素位置的敏感度。
最后,向模型中添加密集块并公式化问题(分类和/或回归),可以使用典型的梯度下降算法(如 SGD、ADAM 和 RMSprop)来训练这种模型。
当然,在 1998 年之前,卷积神经网络的使用是有限的,通常支持向量机是图像分类领域的首选方法。然而,当乐纯等人[98]发表了他们关于使用基于梯度的学习进行手写数字识别的工作后,这种说法发生了变化。
数据
LeNet 模型是基于 MNIST 数据开发的。该数据集由手写数字 0-9 组成;六万幅图像用于模型的训练/验证,然后一千幅图像用于测试模型。该数据集中的图像大小为 28×28 像素。下图中可以看到一个例子。使用 MNIST 数据集的挑战在于,数字在形状和外观上经常会有细微的变化(例如,数字 7 的写法不同)。

MNIST 数据示例
查看 MNIST 数据集中的标签,我们可以看到标签的数量是平衡的,这意味着没有太大的差异。

MNIST 数据集中的标签计数
网络结构

LeCun 等人[98],LeNet5 网络的建议结构
LeNet-5 的建议模型结构有 7 层,不包括输入层。如数据部分所述,该模型中使用的图像是 MNIST 手写图像。提议的结构可以在上面的图片中看到,取自乐纯等人[98]的论文。每层的详细信息如下:
- 图层 C1 是第一个 Conv 图层,有 6 个特征地图,跨度为 1。使用附录中给出的公式,可以用 156 个可训练参数计算该层 28×28 的输出尺寸(详情请参考附录 1)。该层的激活功能为
tanh(详见附录 2)。 - 层 S2 是一个平均汇集层。该图层将上一个 Conv 图层的平均值映射到下一个 Conv 图层。汇集层用于降低模型对要素位置的依赖性,而不是对要素形状的依赖性。LeNet 模型中的池层大小为 2,跨度为 2。
- 层 C3 是第二组卷积层,有 16 个特征图。该层的输出维数是 10,有 2416 个参数。这一层的激活功能是
tanh。 - 层 S4 是另一个平均池层,维度为 2,步长为 2。
- 下一层负责将前一层的输出展平为一维数组。该层的输出尺寸为 400 (5×5×16)。
- 层 C5 是一个密集块(全连通层),有 120 个连接,48120 个参数(400×120)。这一层的激活功能是
tanh。 - 层 F6 是另一个 84 参数,10164 参数(84×120+84)的致密区块。这一层的激活功能是
tanh。 - 输出层有 10 个维度(等于数据库中的类别数),850 个参数(10×84+10)。输出层的激活函数是
sigmoid(详见附录 2)。
以下代码片段演示了如何使用 Tensorflow/Keras 库在 Python 中构建 LeNet 模型。Keras sequential 模型是层的线性堆叠。然后,我们需要定义每一层,如下所示。最后,需要编译模型,并且需要明确定义优化器、损失函数和指标的选择。这项工作中使用的优化器是sgd 或随机梯度下降。损失函数被优化以训练机器学习模型。这里使用的损失函数是交叉熵或对数损失,用于测量分类模型的性能,其输出是 0 到 1 之间的概率值。准确性度量用于评估培训的表现。损失函数是一个连续的概率函数,而准确度是正确预测的标签数除以预测总数的离散函数(参见附录 3)。
LeNet-5 层结构
请注意,在上面的代码片段中,我们没有指定任何关于如何初始化神经网络权重的内容。默认情况下,Keras 使用一个glorot_uniform初始化器。权重值是随机选择的,以确保通过网络传递的信息可以被处理和提取。如果权重太小,信息会因此缩小。如果权重太大,信息就会增长,变得太大而无法处理。Glorot 统一算法(也称为 Xavier 算法)从多元随机正态分布中选择适当的随机权重值,该随机正态分布根据神经网络的大小进行缩放[参见 Glorot 2010]。
用 Tensorflow 构建的 LeNet-5 网络总结如下(使用model.summary()):
Model: "sequential"
_________________________________________________________________
**Layer (type) Output Shape Param #**
=================================================================
conv2d (Conv2D) (None, 28, 28, 6) 156
_________________________________________________________________
average_pooling2d (AveragePo (None, 14, 14, 6) 0
_________________________________________________________________
conv2d_1 (Conv2D) (None, 10, 10, 16) 2416
_________________________________________________________________
average_pooling2d_1 (Average (None, 5, 5, 16) 0
_________________________________________________________________
flatten (Flatten) (None, 400) 0
_________________________________________________________________
dense (Dense) (None, 120) 48120
_________________________________________________________________
dense_1 (Dense) (None, 84) 10164
_________________________________________________________________
dense_2 (Dense) (None, 10) 850
=================================================================
Total params: 61,706
Trainable params: 61,706
Non-trainable params: 0
_________________________________________________________________
现在我们已经使用 Tensorflow 和 Keras 构建了 LeNet 模型,我们需要训练该模型。使用model.fit()和 feeding 训练和验证集,对模型进行训练。训练所需的附加参数是时期数、批量大小和详细信息:
- 一个时期是训练数据的一个完整呈现。从训练数据集中随机选择样本,并呈现给模型进行学习。因此,一个时期代表整个训练数据集的一个周期。
- 如前所述,一个时期指的是将数据完整地呈现给模型。训练数据是随机选择的,并输入到模型中。随机选择的数据中样本的数量称为批量。与较大的批量相比,较小的批量会产生噪声,但它们可能会很好地概括。较大的批处理大小用于避免内存限制问题,尤其是在使用图形处理单元(GPU)时。
- Verbose 指定输出日志记录的频率。如果设置为 1,将打印每个迭代模型损失。
培训代码片段。注意**to_categorical** 命令用于将一个类向量转换成二进制类矩阵。
一旦模型被训练,我们就可以使用我们已经准备好的测试集,通过使用model.evaluate()命令来评估模型训练的性能:
测试代码片段
下图显示了 10 个时期的模型训练结果。最初,随机选择神经网络的权重,但是在向模型呈现 48,000 张图片的 2 个时期之后,模型损失从 0.38 减少到 0.1。经过 10 个周期的模型训练,模型在测试集上的准确率超过了 95%。与当时以前的模型(主要是支持向量机)相比,这是一个大幅提高的准确性,因此 LeNet-5 巩固了其作为计算机视觉最早冠军之一的遗产。

LeNet-5 训练结果(10 个时期)
使用model.optimizer.get_config(),我们可以询问优化器参数。注意,我们只指定了优化器的类型、损失函数和准确性指标。从下面的代码片段可以看出,用于训练 LeNet 模型的优化器是一个随机梯度下降(SGD)优化器。learning rate默认设置为 0.01。学习率响应于由损失函数测量的观测误差来控制模型参数的变化。想象模型训练过程是从一座山到一座谷,学习率定义步长。步长越大,遍历解的速度越快,但可能导致跳过解。另一方面,步长越小,收敛时间越长。在比较复杂的问题中,步长常用decay。然而,在这个问题中,没有衰变足以得到好的结果。使用 SGD 的另一个参数是momentum。动量不是只使用当前步骤的梯度来引导搜索,而是累积过去步骤的梯度来确定前进的方向。因此,动量可以用来提高 SGD 的收敛速度。另一个参数是nesterov。如果设置为 true(布尔值),SGD 将启用内斯特罗夫加速梯度(NAG)算法。NAG 也是一种与动量密切相关的算法,其中步长使用学习率变化的速度进行修改(参见内斯特罗夫[1983])。
model.optimizer.get_config():
{'name': 'SGD',
'learning_rate': 0.01,
'decay': 0.0,
'momentum': 0.0,
'nesterov': False}
模型询问
有多种方法可以评估分类器的性能。从任何模型开发任务中获得的测试数据集的准确性性能是显而易见的选择。然而,混淆矩阵可以提供分类器的详细报告,并更好地评估分类性能。此外,如果每个类别中存在不相等数量的观察值,分类精度可能会产生误导。
混淆矩阵是正确/错误分类的样本数量的详细报告。沿着混淆矩阵对角线的样本数是正确预测的样本。所有其他样本都被误分类了。对角线上的样本数量越多,模型精度越高。从 MNIST 数据集上 LeNet-5 的混淆矩阵可以看出,大部分类别被正确分类。然而,在少数情况下,分类器很难正确地对标签进行分类,例如标签 5、4 和 8。例如,在 16 种情况下,分类器错误地将数字 2 分类为数字 7。下图描述了上述情况。

LeNet-5 混淆矩阵

误分类标签示例
优化器的选择
在前面的部分中,提到了 SGD 优化器用于这个优化的神经网络模型。然而,由于 SGD 的收敛速度慢和陷入局部极小值的问题,这种方法并不流行。自推出以来,自适应矩估计 aka Adam(有关更多详细信息,请参考 Kingma 等人[2014])在深度学习领域非常受欢迎。Adam 优化算法是随机梯度下降的扩展,其中动量默认应用于梯度计算,并为每个参数提供单独的学习速率。使用 Adam optimizer 并从头开始重新训练 LeNet-5,模型准确性可以提高到 98%,如以下学习曲线所示:

使用 Adam 优化器的 LeNet-5 训练结果(10 个时期)。
批量大小的影响
批量是神经网络训练中最重要的超参数之一。如前一节所述,神经网络优化器在每个训练时期随机选择数据并将其提供给优化器。所选数据的大小称为批量大小。将批量大小设置为训练数据的整个大小可能会导致模型无法对之前没有见过的数据进行很好的概括(参考 Takase 等人[2018])。另一方面,将批处理大小设置为 1 会导致更长的计算训练时间。批量大小的正确选择特别重要,因为它导致模型的稳定性和准确性的提高。以下两个条形图展示了从 4 到 2,048 的各种批量的测试精度和训练时间。该模型对批量 4-512 的测试准确率在 98%以上。然而,批量大小 4 的训练时间是批量大小 512 的训练时间的四倍以上。对于具有大量类和大量训练样本的更复杂的问题,这种影响可能更严重。

批量大小对模型准确性(上图)和训练时间(下图)的影响
汇集层的影响
如前所述,需要池层对要素地图中的要素检测进行下采样。有两个最常用的池操作符:平均池和最大池层。平均池层通过计算要素图中所选修补的平均值来运行,而最大池层计算要素图的最大值。
最大池操作如下图所示,通过从特征映射中选择最大特征值来工作。最大池化图层会歧视激活函数不太重要的要素,并且仅选择最高值。这样,只有最重要的功能才通过池层提供。最大池化的主要缺点是池化算子在具有高量值特征的区域中,仅选择最高值特征,而忽略其余特征;执行最大池化操作后,明显的特征消失,导致信息丢失(下图中的紫色区域)。

最大池操作
另一方面,平均池的工作方式是计算要素地图所选区域中要素的平均值。特征图中所选区域的所有部分都使用平均池来馈通。如果所有激活的幅度都很低,则计算出的平均值也会很低,并且由于对比度降低而上升。当池区域中的大多数激活都带有零值时,情况会变得更糟。在这种情况下,特征映射特征将大量减少。

平均联营业务
如前所述,最初的 LeNet-5 模型使用平均池策略。将平均池策略改为最大池策略在 MNIST 数据集上产生了大致相同的测试准确度。人们可以争论不同的池层的观点。但是,应该注意的是,与其他复杂的数据集(如 CIFAR-10 或 Imagenet)相比,MNIST 数据集相当简单,因此最大池化在此类数据集中的性能优势要大得多。

平均池策略和最大池策略的比较
特征旋转和翻转的效果
到目前为止,我们已经探索了 LeNet-5 模型的不同方面,包括优化器的选择、批量大小的影响和池层的选择。LeNet-5 模型是根据 MNIST 数据设计的。正如我们到目前为止所看到的,数字在每个图像中居中。然而,在现实生活中,数字在图像中的位置经常会发生移动、旋转,有时还会发生翻转。在接下来的几节中,我们将探讨 LeNet-5 模型对图像翻转、旋转和移动的图像增强和灵敏度的影响。图像增强是在 Tensorflow 图像处理模块[tf.keras.preprocessing](https://keras.io/api/preprocessing/image/).的帮助下完成的
翻动的效果
在本练习中,使用ImageDataGenerator (horizontal_flip=True)沿水平轴翻转图像。应用ImageDataGenerator测试新数据集中的图像结果,图像水平翻转,如下图所示。可以看出,预期该模型在翻转图像数据集上具有低精度。从测试准确率表可以看出,LeNet-5 模型的准确率从 98%下降到 70%。


测试翻转图像的准确性
仔细观察翻转图像数据集的混淆矩阵,可以发现一些有趣的东西。最高精度的标签是 0、1、8 和 4。前三个标签是对称的(0,1,8 ),因此模型对此类具有良好的预测准确性。但有趣的是,LeNet-5 模型在标签 4 上有很好的分类精度。这项测试的另一个有趣的方面是模型如何识别数字。例如,在翻转的数据集中,模型遭受准确性的标签之一是 3。该模型几乎有一半的时间将它误归类为数字 8。理解模型如何识别每个数字对于建立一个健壮的分类器是非常有用的。像 SHAP 这样的包可以提供理解任何深度神经网络模型的输入输出映射的手段(在 SHAP 库中找 DeepExplainer 模块)。

翻转图像预测的混淆矩阵
图像旋转
图像旋转是现实生活中另一个可能的场景。数字可以以相对于图像边界的角度书写。使用 Tensorflow 图像增强模块,可以使用下面的代码行生成随机旋转的图像:ImageDataGenerator(rotation_range=angle)。下图是 LeNet-5 模型在各种随机旋转图像下的测试结果。旋转越多,模型的预测越差。有趣的是,模型预测对于高达 20 度的旋转是相当令人满意的,然后预测迅速退化。

LeNet-5 在随机旋转图像上的预测
换挡的效果
一个最终的图像增强效果是沿着图像内的水平或垂直轴移动手指。使用ImageDataGenerator(width_shift_range=shift),这种效果可以很容易地应用于 MNIST 测试数据集。请注意,在本节中,我将演示width_shift 生成器的结果。LeNet-5 网络对宽度偏移的敏感度远高于图像翻转和图像旋转。从下图中可以看出,精度下降的速度比其他讨论过的图像增强过程要快得多。仅仅 10 度的宽度偏移就导致准确度从超过 95%下降到大约 48%。这种影响可能归因于模型的过滤器大小和核维数。

LeNet-5 在随机移位图像上的预测
在 CIFAR-10 数据集上的性能
正如我们从前面所有章节中看到的,LeNet-5 模型在手写数字识别中实现了一个重要的里程碑。由于其在分类问题上的优越性能,LeNet-5 模型在 20 世纪 90 年代中期被用于银行和 ATM 机的自动数字分类。然而,该模型的下一个前沿是解决图像识别问题,以识别图像中的各种对象。
在这最后一部分,我们的目标是在 CIFAR-10 数据集上训练 LeNet-5。CIFAR-10(加拿大高级研究所)是一个已建立的计算机视觉数据集,包含 60,000 幅彩色图像,大小为 32×32,包含 10 个对象类,如下图所示。这 10 个不同的类别代表飞机、汽车、鸟、猫、鹿、狗、青蛙、马、船和卡车。从下面的图片可以看出,图片的复杂程度远远高于 MNIST。

CIFAR-10 数据集
将 LeNet-5 结构应用于该数据集并训练该模型 10 个时期,得到 73%的准确度。该模型的测试准确率为 66%。考虑到人类在该数据集上的准确率约为 94%(根据 Ho-Phuoc [2018]),LeNet-5 类型结构的效率不足以实现高识别能力。

LeNet-5 结构在 CIFAR-10 数据集上的性能
摘要
LeNet-5 为训练和分类手写数字提供了重要的框架。正如我们在前面的章节中所看到的,LeNet-5 结构尽管在光学字符识别任务中取得了许多成功的里程碑,但在图像识别任务中表现不佳。然而,**Yann andréle Cun和许多同时代的人为更复杂的神经网络模型结构和优化技术铺平了道路。在下一篇文章中,我将探讨和讨论另一个卷积神经网络结构冠军, ALexNet。**
感谢阅读!我叫 阿米尔·内贾德博士。 我是一名数据科学家和QuantJam的编辑,我喜欢分享我的想法并与其他数据科学家合作。可以在GithubTwitter和LinkedIn上和我联系。**
QuantJam:
Quantjam 是一个媒体发布平台,提供金融、算法交易和…
medium.com](https://medium.com/quantjam)
你可以在以下网址看到我的其他作品:
Python 在金融数据集中的多部分时间序列分析时间序列是一系列数据…
amirnejad.medium.com](http://amirnejad.medium.com/)
附录(1)层尺寸
计算卷积神经网络输出维数的公式:


计算参数数量的公式:


使用上面的两个公式,可以计算 LeNet5 模型的输出维数和参数数目如下:

LeNet 尺寸和参数
附录(2)激活功能

tanh 激活函数

sigmoid 激活函数
附录(3)损失和精度函数
损失函数:

交叉熵函数
精度函数:

准确度函数
参考
- 勒昆,y .,博图,l .,本吉奥,y .,哈夫纳,P. (1998d)。基于梯度的学习在文档识别中的应用。IEEE 会议录,86(11),2278–2324。
- 神经网络的历史:https://dataconomy.com/2017/04/history-neural-networks/
- Khan,Asifullah,等人“深度卷积神经网络的最新架构综述”arXiv 预印本 arXiv:1901.06032 (2019)。
优化器:
- S. J. Reddi,S. Kale 和 S. Kumar。亚当和超越的融合。在 2018 年国际学习代表大会上。
- 随机梯度下降:https://blog . paper space . com/intro-to-optimization-momentum-rms prop-Adam/
- 金玛,迪德里克 P 和巴,吉米雷。亚当:一种随机优化方法。arXiv 预印本 arXiv:1412.6980,2014。
- 损失函数:https://ml-cheat sheet . readthedocs . io/en/latest/Loss _ functions . html
- 纽约州内斯特罗夫市(1983 年)。收敛速度为 o(1/k2)的无约束凸极小化问题的一种方法。Doklady ANSSSR(翻译为 Soviet.Math.Docl .),第 269 卷,第 543–547 页。
批量大小:
- T. TAKASE、S. OYAMA 和 M. KURIHARA。“为什么大批量训练会导致泛化能力差?一个全面的解释和一个更好的策略。载于:神经计算 30.7 (2018),第 2005–2023 页
联营策略:
- 夏尔马、沙鲁和拉杰什·梅赫拉。"卷积神经网络中汇集策略的含义:深刻的见解."计算与决策科学基础 44.3(2019):303–330。
- 布鲁,Y-Lan,等人《问本地人:图像识别的多向本地汇集》2011 计算机视觉国际会议。IEEE,2011 年。
初始化:
- https://andyljones . Tumblr . com/post/110998971763/an-explain-of-Xavier-initial ization
- http://proceedings.mlr.press/v9/glorot10a/glorot10a.pdf
混淆矩阵:
MNIST:
西法尔-10:
- https://www.cs.toronto.edu/~kriz/cifar.html
- 克里日夫斯基、亚历克斯和杰弗里·辛顿。“从微小的图像中学习多层特征.”(2009): 7.
- 和珅,天。“CIFAR10 比较深度神经网络和人类之间的视觉识别性能。”arXiv 预印本 arXiv:1811.07270 (2018)。
张量流图像增强:
SHAP
卷积神经网络冠军第 2 部分:AlexNet (TensorFlow 2.x)
关于最流行的卷积神经网络(CNN)架构的多部分系列的第 2 部分,包含可复制的 Python 笔记本
卷积神经网络是一种特殊类型的神经网络,用于对具有强空间相关性的数据进行建模,例如图像、多元时间序列、地球科学研究(地震分类和回归)以及许多其他应用。自 1998 年以来,卷积网络经历了重大变化,在这一系列文章中,我的目标是再现著名的模型架构冠军,如 LeNet、AlexNet、ResNet 等。我的目标是与更广泛的受众分享我的发现和研究,并提供可复制的 Python 笔记本。

信用:https://unsplash.com/@cbarbalis
**第一部分:**tensor flow 中的 Lenet-5 和 MNIST 分类:
关于最流行的卷积神经网络(CNN)架构的多部分系列,具有可再现的 Python…
towardsdatascience.com](/convolutional-neural-network-champions-part-1-lenet-5-7a8d6eb98df6)
第三部分:ImageNet 和 Tensorflow 上的 VGGnet 分类;
[## 卷积神经网络冠军第 3 部分:VGGNet (TensorFlow 2.x)
这个多部分系列的第 3 部分介绍了最流行的卷积神经网络(CNN)架构,包括…
towardsdatascience.com](/convolutional-neural-network-champions-part-3-vggnet-tensorflow-2-x-ddad77492d96)
用于这项研究的 Python 笔记本位于我的 Github 页面中。
本研究中使用的 Tensorflow 版本为 2.3。
LeNet-5 模型展示了阅读和分类手写数字的卓越能力。尽管 LeNet-5 网络结构在 MNIST 数据集上表现良好,但对 CIFAR-10 等更复杂图像进行分类的实际测试表明,该模型学习如此复杂模式的能力太低。因此,更强大的架构的开发进入了休眠状态,直到 2012 年 AlexNet 诞生。AlexNet 被认为是第一个深度 CNN 模型,由 Krizhevesky 等人提出。在此期间,有几项发展抑制了神经网络分类准确性的提高,即:
- Max pooling : Pooling 层用于降低神经网络模型对图像中特征位置的敏感性。在最初的 LeNet-5 模型中,使用了平均池层。然而,Ranzato 等人[2007]通过使用最大池层学习不变特征展示了良好的结果。最大池化图层会歧视激活函数不太重要的要素,并且仅选择最高值。这样,只有最重要的特性才会通过池层提供。更多信息请参考本系列的第 1 部分(链接)。
- GPU/CUDA 编程:在神经网络的早期发展中,模型训练过程中的一个主要瓶颈是计算机的计算能力,因为它们主要使用 CPU 来训练模型。2007 年,NVIDIA 公司推出了 CUDA(计算统一设备架构)编程平台,以促进 GPU(图形处理单元)上的并行处理。CUDA 支持在 GPU 上进行模型训练,与 CPU 相比,训练时间要短得多。因此,培训更大的网络成为可能。
- ReLU 激活函数 : Nair 和 hint on【2010】展示了修正线性单元(ReLU)提高受限玻尔兹曼机器分类精度的能力。ReLU 单元只是让任何大于零的值通过过滤器,并抑制任何小于零的值。ReLU 函数是不饱和的,这意味着当输入增加时函数的极限接近无穷大,因此它可以缓解消失梯度问题。
- ImageNet:深度学习领域取得成功的另一个催化剂是费-李非教授的团队在斯坦福大学建立的 ImageNet 数据库。ImageNet 包含来自数千个类别的数百万张带注释的图像。一年一度的 ImageNet 大规模视觉识别挑战赛(ILSVRC)见证了包括 AlexNet 在内的卷积神经网络结构的许多进步。训练数据是 2012 年发布的 ImageNet 的子集,具有属于 1,000 个类的 120 万个图像。验证数据集由属于 1,000 个类的 50,000 个图像组成(每个类 50 个图像)。在下面的示例中可以看到 ImageNet 图像的示例:

ImageNet 图片示例(l .飞飞,《ImageNet:众包、基准和其他很酷的东西》, CMU·VASC 研讨会,2010 年 3 月)
下载资料注意事项:ImageNet 官网( 链接 )可向个人提供图片。但是,提交请求后,我没有收到任何下载链接。下载图像最简单的方法是通过 ImageNet 对象本地化挑战( 链接 )。
AlexNet 模型结构

克里日夫斯基、亚历克斯、伊利亚·苏茨基弗和杰弗里·e·辛顿。"使用深度卷积神经网络的图像网络分类."神经信息处理系统进展。2012.
AlexNet 在 ILSVRC-2012 比赛中取得了 15.3%的前 5 名测试错误率(之前的模型错误率为 26%)的胜利。网络架构类似于 LeNet-5 模型(阅读更多关于 LeNet-5: Link 的内容),但具有更多卷积层,因此模型更深入。
模型中使用的主要激活函数是非饱和整流线性单元(ReLU)函数。该模型主要由 8 层组成:5 个卷积层和 3 个密集层。内核大小从 11×11 减小到 3×3。每个卷积层后面都有一个最大池层。该模型在前两个完全连接的层中使用 dropout 以避免过度拟合。下面给出了 AlexNet 在 Tensorflow 中的实现。
使用随机梯度下降(SGD)优化算法训练该模型。学习率初始化为 0.01,动量为 0.9,权重衰减为 0.0005。在 Tensorflow 中构建 AlexNet 模型的代码片段如下所示:
注意,模型中使用的优化器是带动量的梯度下降。这个优化器位于一个名为tensorflow_addons的独立包中(更多信息可以在这里看到)。
2 节课的 AlexNet 演示
在整个 ImageNet 数据集上训练 AlexNet 非常耗时,并且需要 GPU 计算能力。因此,在本节中,我将在 ImageNet 数据集上演示 AlexNet 类型结构的训练,该数据集由两个类组成:
- 类别
*n03792782*:山地车、全地形车、越野车 *n03095699*级:集装箱船,集装箱船
训练数据集由属于两类的 2,600 幅图像组成。调用AlexNet 函数会产生一个超过 6200 万可训练参数的网络,如下图所示:
Model: "AlexNet"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
conv2d (Conv2D) (None, 55, 55, 96) 34944
_________________________________________________________________
max_pooling2d (MaxPooling2D) (None, 27, 27, 96) 0
_________________________________________________________________
conv2d_1 (Conv2D) (None, 27, 27, 256) 614656
_________________________________________________________________
max_pooling2d_1 (MaxPooling2 (None, 13, 13, 256) 0
_________________________________________________________________
conv2d_2 (Conv2D) (None, 13, 13, 384) 885120
_________________________________________________________________
conv2d_3 (Conv2D) (None, 13, 13, 384) 1327488
_________________________________________________________________
conv2d_4 (Conv2D) (None, 13, 13, 256) 884992
_________________________________________________________________
max_pooling2d_2 (MaxPooling2 (None, 6, 6, 256) 0
_________________________________________________________________
flatten (Flatten) (None, 9216) 0
_________________________________________________________________
dense (Dense) (None, 4096) 37752832
_________________________________________________________________
dropout (Dropout) (None, 4096) 0
_________________________________________________________________
dense_1 (Dense) (None, 4096) 16781312
_________________________________________________________________
dropout_1 (Dropout) (None, 4096) 0
_________________________________________________________________
dense_2 (Dense) (None, 1000) 4097000
_________________________________________________________________
dense_3 (Dense) (None, 2) 2002
=================================================================
Total params: 62,380,346
Trainable params: 62,380,346
Non-trainable params: 0
_________________________________________________________________
模型训练和评估
AlexNet 模型在整个训练数据上训练 90 个时期,并在来自验证数据集的 50K 个图像上验证。CPU 上的训练模型示例如下所示(要在 GPU 上训练,使用tf.distribute.MirroredStrategy):
经过充分训练的 AlexNet 模型在 2 个类上可以达到 95%的准确率。下图显示了学习曲线以及训练集和验证集的损失。可以看出,验证集上的训练损失在 20 个时期后保持不变,并且模型学习不能被改进。

学习曲线(作者图片)
评估模型性能的另一种方法是使用一种叫做混淆矩阵的方法。混淆矩阵是表格布局,由数据类别和使用训练好的分类器得到的预测组成。这里可以看到一个混淆矩阵的例子。这个混淆矩阵是通过在 100 个验证图像(每个类别 50 个图像)上运行训练好的神经网络分类器而获得的。可以看出,该模型在 bikes 类别中只错误分类了 1 个图像(用 0 表示)。然而,该模型将 3 幅图像错误分类到船只类别(用 1 表示)。

困惑矩阵(图片由作者提供)
4 个错误分类的图像如下图所示。在以下情况下,模型似乎无法完全识别图像中的对象:
- 图像中的对象被裁剪(部分可见的对象)
- 对象在背景中或被周围环境覆盖




错误分类的图片(作者图片,修改后的 ImageNet)
查看上面的图像并将它们与训练图像进行比较,很难看出这些图像分类错误背后的原因。使 CNN 模型更加透明的一种方法是可视化对预测“重要”的输入区域。有许多方法可以完成这项任务,如GradCAM、GradCAM++、ScoreCAM等。我使用 tf-keras-vis库中的GradCAM(更多信息:https://pypi.org/project/tf-keras-vis/)来检查错误分类图像上的模型行为。结果可以在下面看到。可以看出,模型很难聚焦于导入区域(用红色表示)。




分类错误的例子(作者图片,修改后的 ImageNet)
以下图像展示了正确分类的图像示例。可以看出,该模型关注图像中的重要特征,并且正确地预测图像的类别。有趣的是,经过训练的模型似乎能够识别自行车和骑自行车的人。一种不仅检测物体而且检测物体在图像中的位置的物体识别模型可以适当地解决这个问题。AlexNet 只能检测对象,但不能识别图像中的对象。物体识别的主题将在本系列的后续章节中讨论。


正确分类的图片示例(作者图片,修改后的 ImageNet)
摘要
AlexNet 开启了计算机视觉和深度学习的新时代。AlexNet 引入(或在某些情况下推广)了许多今天使用的相关计算机视觉方法,如 conv+池设计、dropout、GPU、并行计算和 ReLU。因此,作为这些发明的结果,AlexNet 能够减少 ImageNet 数据集上的分类错误。然而,AlexNet 模型需要提高分类精度。因此,许多模型都建立在 AlexNet 的成功之上,比如 VGGNet、,我将在下一篇文章中探讨和讨论这些模型。敬请关注,并在下面告诉我你的看法。
感谢阅读!我叫 阿米尔·内贾德博士。 我是一名数据科学家,也是QuantJam的编辑,我喜欢分享我的想法,并与其他数据科学家合作。可以在GithubTwitter和LinkedIn上和我联系。
QuantJam:
Quantjam 是一个媒体发布平台,提供金融、算法交易和…
medium.com](https://medium.com/quantjam)
你可以在以下网址看到我的其他作品:
Python 在金融数据集中的多部分时间序列分析时间序列是一系列数据…
amirnejad.medium.com](http://amirnejad.medium.com/)
所有图片均由作者制作,除非另有说明。
附录
Relu 激活功能:

Relu 激活功能(图片由作者提供)
参考
- 克里日夫斯基、亚历克斯、伊利亚·苏茨基弗和杰弗里·e·辛顿。"使用深度卷积神经网络的图像网络分类."神经信息处理系统进展。2012.
- 第九讲,CNN 建筑,费-李非&杨小琳,2017 ( Youtube )
最大池:
- 不变特征层次的无监督学习及其在物体识别中的应用。2007 年 IEEE 计算机视觉和模式识别会议。IEEE,2007 年。
ReLU:
- 奈尔、维诺德和杰弗里·e·辛顿。"校正的线性单位改进了受限的玻尔兹曼机器."ICML。2010.
CUDA:
- E. Lindholm、J. Nickolls、s .奥伯曼和 J. Montrym,“NVIDIA Tesla:统一的图形和计算架构”,IEEE Micro,第 28 卷,第 2 期,第 39–55 页,2008 年 3 月。
ImageNet:
- Russakovsky,Olga 等,“Imagenet 大规模视觉识别挑战”国际计算机视觉杂志 115.3(2015):211–252。
- https://www . learnopencv . com/keras-tutorial-using-pre-trained-imagenet-models/**
卷积神经网络:特征映射和滤波器可视化
了解卷积神经网络如何理解图像。

在本文中,我们将可视化不同 CNN 层的中间特征表示,以了解 CNN 内部发生了什么来对图像进行分类。
先决条件:
CNN 的快速概览
有监督的深度学习和机器学习在训练期间将数据和结果作为输入,以生成规则或数据模式。理解模型生成的数据模式或规则有助于我们理解结果是如何从输入数据中得出的。

**训练:**卷积神经网络以一幅二维图像和该图像的类别,如猫或狗作为输入。作为训练的结果,我们得到训练的权重,这是从图像中提取的数据模式或规则。
**推理或预测:**图像将是传递给训练好的模型的唯一输入,训练好的模型将输出图像的类别。图像的类别将基于训练期间学习的数据模式。
CNN 架构

将过滤器或特征检测器应用于输入图像以使用 Relu 激活功能生成**特征图或激活图。**特征检测器或过滤器有助于识别图像中的不同特征,如边缘、垂直线、水平线、弯曲等。
然后,为了平移不变性,在特征图上应用池化。汇集是基于这样一个概念:当我们少量改变输入时,汇集的输出不会改变。我们可以使用最小池、平均池或最大池。与最小或平均池相比,最大池提供了更好的性能。
展平所有输入,并将这些展平的输入传递给深度神经网络,该网络输出对象的类别
图像的类别可以是二进制的,如猫或狗,或者可以是多类别的分类,如识别数字或对不同的服装项目进行分类。
神经网络就像一个黑匣子,神经网络中学习到的特征是不可解释的。您传递一个输入图像,模型返回结果。
如果你得到了一个不正确的预测,并想弄清楚为什么 CNN 会做出这样的决定,该怎么办?
如果您能在 CNN 中可视化应用于不同卷积层的中间表示,以了解模型如何学习,那该多好。了解模型的工作将有助于了解错误预测的原因,从而更好地微调模型并解释决策
这里使用的例子是一个深度 CNN 模型,用于对猫狗进行分类。在开始学习可视化 CNN 生成的过滤器和要素地图之前,您需要了解卷积层和应用于它们的过滤器的一些关键点。
关于卷积层和过滤器的要点
- CNN 中滤镜的深度必须与输入图像的深度相匹配。滤镜中颜色通道的数量必须与输入图像保持一致。
- 为彩色图像的三个通道创建不同的 Conv2D 滤镜。
- 基于正态或高斯分布随机初始化每层的过滤器。
- **卷积网络的初始层从图像中提取高级特征,因此使用较少的滤波器。**随着我们构建更深的层,我们将过滤器的数量增加到前一层过滤器大小的两倍或三倍。
- 更深层的过滤器学习更多的特征,但是计算非常密集。
构建卷积神经网络
我们建立一个 CNN 来对狗和猫进行分类,然后将特征图或激活图以及用于在输入图像上生成它们的过滤器可视化
导入所需的库
**import tensorflow as tf
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense, Conv2D, Flatten, Dropout, MaxPooling2D
from tensorflow.keras.preprocessing.image import ImageDataGenerator, img_to_array, load_img****import os
import numpy as np
import matplotlib.pyplot as plt**
为图像处理创建数据
数据集可以从这里下载
我们将解压文件并创建如下所示的文件夹,然后将数据分成包含 10,000 只猫和 10,000 只狗图像的训练数据集以及包含 2500 只猫和 2500 只狗图像的验证数据集

设置关键参数
**batch_size = 64
epochs = 50
IMG_HEIGHT = 150
IMG_WIDTH = 150**
重新缩放并对训练图像应用不同的增强
**train_image_generator = ImageDataGenerator( rescale=1./255, rotation_range=45, width_shift_range=.15, height_shift_range=.15, horizontal_flip=True, zoom_range=0.3)**
重新调整验证数据
**validation_image_generator = ImageDataGenerator(rescale=1./255)**
为训练和验证数据集生成批量归一化数据
您的数据存储在目录中,因此使用 flow_from_directory() 方法。flow_from_directory()将从指定的路径获取数据,并生成批量的扩充规范化数据。
**train_data_gen = train_image_generator.flow_from_directory(batch_size=batch_size, directory=TRAIN_PATH, shuffle=True, target_size=(IMG_HEIGHT, IMG_WIDTH), class_mode='binary')****val_data_gen = validation_image_generator.flow_from_directory(batch_size=batch_size, directory=VAL_PATH, target_size=(IMG_HEIGHT, IMG_WIDTH), class_mode='binary')**

创建深度卷积神经网络模型
*#Build the model***model = Sequential([
Conv2D(16, 3, padding='same', activation='relu',
input_shape=(IMG_HEIGHT, IMG_WIDTH ,3)),
MaxPooling2D(),
Dropout(0.2),
Conv2D(32, 3, padding='same', activation='relu'),
MaxPooling2D(),
Conv2D(64, 3, padding='same', activation='relu'),
MaxPooling2D(),
Dropout(0.2),
Flatten(),
Dense(512, activation='relu'),
Dense(1)
])***# Compile the model*
**model.compile(optimizer='adam', loss=tf.keras.losses.BinaryCrossentropy(from_logits=True), metrics=['accuracy'])***# print the model architecture*
**model.summary(*)***

训练模特
我们训练模型 50 个时期
***history = model.fit_generator(
train_data_gen,
steps_per_epoch=1000,
epochs=epochs,
validation_data=val_data_gen,
validation_steps=1000
)***
特征可视化
特征可视化将图像中存在的内部特征转化为视觉上可感知或可识别的图像模式。特征可视化将帮助我们明确地理解所学的特征。
首先,您将可视化应用于输入图像的不同过滤器或特征检测器,并在下一步中可视化生成的特征映射或激活映射。
CNN 中的可视化过滤器或特征检测器
CNN 使用学习过的过滤器来卷积来自前一层的特征地图。过滤器是二维权重,并且这些权重彼此具有空间关系。
可视化过滤器的步骤。
- 使用 model.layers 遍历模型的所有层
- 如果该层是卷积层,则使用***get _ weights()***提取该层的权重和偏差值。
- 将过滤器的权重归一化到 0 和 1 之间
- 画出每个卷积层和所有通道的滤波器。对于彩色图像,RGB 有三个通道。对于灰度图像,通道数为 1
*#Iterate thru all the layers of the model*
**for layer in model.layers:
if 'conv' in layer.name:
weights, bias= layer.get_weights()
print(layer.name, filters.shape)**
*#normalize filter values between 0 and 1 for visualization*
**f_min, f_max = weights.min(), weights.max()
filters = (weights - f_min) / (f_max - f_min)
print(filters.shape[3])
filter_cnt=1**
* #plotting all the filters*
** for i in range(filters.shape[3]):**
*#get the filters*
** filt=filters[:,:,:, i]**
*#plotting each of the channel, color image RGB channels*
**for j in range(filters.shape[0]):
ax= plt.subplot(filters.shape[3], filters.shape[0], filter_cnt )
ax.set_xticks([])
ax.set_yticks([])
plt.imshow(filt[:,:, j])
filter_cnt+=1
plt.show()**

应用于猫和狗的 CNN 模型的过滤器。
可视化 CNN 中生成的特征图或激活图
通过将过滤器或特征检测器应用于输入图像或先前层的特征图输出来生成特征图。要素图可视化将提供对模型中每个卷积层的特定输入的内部表示的深入了解。
可视化特征地图的步骤。
- 定义一个新的模型,visualization _ model,该模型将图像作为输入。模型的输出将是要素地图,它是第一个图层之后所有图层的中间表示。这是基于我们用于培训的模型。
- 加载我们想要查看其特征地图的输入图像,以了解哪些特征对于图像分类是显著的。
- 将图像转换为 NumPy 数组
- 通过重新调整数组的大小来规范化数组
- 通过可视化模型运行输入图像,以获得输入图像的所有
中间表示。 - 为所有卷积层和最大池层创建图,但不为全连接层创建图。要打印要素地图,请检索模型中每个图层的图层名称。
**img_path='\\dogs-vs-cats\\test1\\137.jpg' #dog**
*# Define a new Model, Input= image
# Output= intermediate representations for all layers in the
# previous model after the first.*
**successive_outputs = [layer.output for layer in model.layers[1:]]***#visualization_model = Model(img_input, successive_outputs)*
**visualization_model = tf.keras.models.Model(inputs = model.input, outputs = successive_outputs)***#Load the input image*
**img = load_img(img_path, target_size=(150, 150))***# Convert ht image to Array of dimension (150,150,3)* **x = img_to_array(img)
x = x.reshape((1,) + x.shape)***# Rescale by 1/255*
**x /= 255.0**# Let's run input image through our vislauization network
# to obtain all intermediate representations for the image.
**successive_feature_maps = visualization_model.predict(x)**# Retrieve are the names of the layers, so can have them as part of our plot
**layer_names = [layer.name for layer in model.layers]
for layer_name, feature_map in zip(layer_names, successive_feature_maps):
print(feature_map.shape)
if len(feature_map.shape) == 4:**
*# Plot Feature maps for the conv / maxpool layers, not the fully-connected layers*
**n_features = feature_map.shape[-1]** *# number of features in the feature map*
**size = feature_map.shape[ 1]** *# feature map shape (1, size, size, n_features)*
*# We will tile our images in this matrix*
**display_grid = np.zeros((size, size * n_features))**
# Postprocess the feature to be visually palatable
**for i in range(n_features):
x = feature_map[0, :, :, i]
x -= x.mean()
x /= x.std ()
x *= 64
x += 128
x = np.clip(x, 0, 255).astype('uint8')** # Tile each filter into a horizontal grid
**display_grid[:, i * size : (i + 1) * size] = x***# Display the grid*
**scale = 20\. / n_features
plt.figure( figsize=(scale * n_features, scale) )
plt.title ( layer_name )
plt.grid ( False )
plt.imshow( display_grid, aspect='auto', cmap='viridis' )**

狗图像的特征图

猫图像的特征图
我们可以看到,对于狗的图像,鼻子和舌头是非常突出的特征,而对于猫的图像,耳朵和尾巴在特征图中非常突出。
代码可用此处
结论:
可视化 CNN 如何学习识别图像中存在的不同特征的内部故事,提供了对该模型如何工作的更深入的了解。这也将有助于理解为什么模型可能无法正确地对一些图像进行分类,从而微调模型以获得更好的准确性和精确度。
参考资料:
层是 Keras 中神经网络的基本构建块。一个层包括一个张量输入张量输出…
keras.io](https://keras.io/api/layers/) [## 卷积滤波器可视化— Keras 文档
从 future import print_function 导入时间将 numpy 作为 np 从 PIL 导入图像作为 pil_image 从…
keras.io](https://keras.io/examples/conv_filter_visualization/)


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}