







使用机器学习对图像进行压缩、搜索、插值和聚类
如何使用图像嵌入进行压缩、搜索、插值和聚类
机器学习中的嵌入提供了一种创建复杂、非结构化数据的简明、低维表示的方法。自然语言处理中通常使用嵌入来将单词或句子表示为数字。
在之前的一篇文章中,我展示了如何创建一个 1059x1799 HRRR 图像的简洁表示(50 个数字)。在本文中,我将向您展示嵌入有一些很好的属性,您可以利用这些属性来实现用例,如压缩、图像搜索、插值和大型图像数据集的聚类。
压缩
首先,嵌入是否捕捉到了图像中的重要信息?我们能把嵌入的图像解码成原始图像吗?
嗯,我们将无法恢复原始图像,因为我们获取了 200 万像素的值,并将它们放入一个长度=50 的向量中。尽管如此,嵌入是否捕捉到了天气预报图像中的重要信息?
以下是世界协调时 2019 年 9 月 20 日 05:00 HRRR 的原始预报:

2019 年 9 月 20 日天气
我们可以获得时间戳的嵌入并如下解码(完整代码在 GitHub 上)。首先,我们通过加载 SavedModel、找到嵌入层并重建所有后续层来创建解码器:
import tensorflow as tf
def create_decoder(model_dir):
model = tf.keras.models.load_model(model_dir)
decoder_input = tf.keras.Input([50], name='embed_input')
embed_seen = False
x = decoder_input
for layer in model.layers:
if embed_seen:
x = layer(x)
elif layer.name == 'refc_embedding':
embed_seen = True
decoder = tf.keras.Model(decoder_input, x, name='decoder')
print(decoder.summary())
return decoderdecoder = create_decoder('gs://ai-analytics-solutions-kfpdemo/wxsearch/trained/savedmodel')
一旦我们有了解码器,我们就可以从 BigQuery 中提取时间戳的嵌入:
SELECT *
FROM advdata.wxembed
这给了我们一个这样的表格:

然后,我们可以将上表中的“ref”值传递给解码器:
import tensorflow as tf
import numpy as np
embed = tf.reshape( tf.convert_to_tensor(df['ref'].values[0],
dtype=tf.float32), [-1, 50])
outimg = decoder.predict(embed).squeeze() * 60
plt.imshow(outimg, origin='lower');
请注意,TensorFlow 希望看到一批输入,因为我们只传入一个,所以我必须将其重新整形为[1,50]。类似地,TensorFlow 返回一批图像。我在显示它之前挤压它(删除虚拟尺寸)。结果呢?

如你所见,解码图像是原始 HRRR 的模糊版本。嵌入确实保留了密钥信息。它起到压缩算法的作用。
搜索
如果嵌入是一个压缩的表示,嵌入空间的分离程度会转化为实际预测图像的分离程度吗?
如果是这种情况,搜索过去与现在的一些情况“相似”的天气情况就变得容易了。在 200 万像素的图像上寻找相似物可能会很困难,因为风暴可能会略有不同,或者大小有所不同。
由于我们在 BigQuery 中有嵌入,所以让我们使用 SQL 来搜索类似于 2019 年 9 月 20 日 05:00 UTC:
WITH ref1 AS (
SELECT time AS ref1_time, ref1_value, ref1_offset
FROM `ai-analytics-solutions.advdata.wxembed`,
UNNEST(ref) AS ref1_value WITH OFFSET AS ref1_offset
WHERE time = '2019-09-20 05:00:00 UTC'
)SELECT
time,
**SUM( (ref1_value - ref[OFFSET(ref1_offset)]) * (ref1_value - ref[OFFSET(ref1_offset)]) ) AS sqdist**
FROM ref1, `ai-analytics-solutions.advdata.wxembed`
GROUP BY 1
ORDER By sqdist ASC
LIMIT 5
基本上,我们计算在指定时间戳(refl1)的嵌入和每隔一个嵌入之间的欧几里德距离,并显示最接近的匹配。结果是:

这很有道理。前一小时/后一小时的图像最相似。然后,从+/- 2 小时开始的图像等等。
如果我们想找到不在+/- 1 天内的最相似的图像呢?由于我们只有 1 年的数据,我们不打算进行大的类比,但让我们看看我们得到了什么:
WITH ref1 AS (
SELECT time AS ref1_time, ref1_value, ref1_offset
FROM `ai-analytics-solutions.advdata.wxembed`,
UNNEST(ref) AS ref1_value WITH OFFSET AS ref1_offset
WHERE time = '2019-09-20 05:00:00 UTC'
)SELECT
time,
SUM( (ref1_value - ref[OFFSET(ref1_offset)]) * (ref1_value - ref[OFFSET(ref1_offset)]) ) AS sqdist
FROM ref1, `ai-analytics-solutions.advdata.wxembed`
**WHERE time NOT BETWEEN '2019-09-19' AND '2019-09-21'**
GROUP BY 1
ORDER By sqdist ASC
LIMIT 5
结果有点出人意料:1 月 2 日和 7 月 1 日是天气最相似的日子;

好吧,让我们来看看这两个时间戳:


我们看到 9 月 20 日的图像确实落在这两张图像之间。两张图片中都有墨西哥湾沿岸和中西部北部的天气情况。就像 9 月 20 日的照片一样。
如果我们有(a)不止一年的数据,( b)在多个时间步加载 HRRR 预报图像,而不仅仅是分析场,以及©使用更小的切片来捕捉中尺度现象,我们可能会得到更有意义的搜索。这是留给感兴趣的气象学学生的练习
插入文字
回想一下,当我们寻找与 05:00 的图像最相似的图像时,我们得到了 06:00 和 04:00 的图像,然后是 07:00 和 03:00 的图像。在嵌入空间中,到下一个小时的距离大约为 sqrt(0.5)。
给定搜索用例中的这种行为,一个自然的问题是我们是否可以使用嵌入在天气预报之间进行插值。我们能对 t-1 和 t+1 的嵌入进行平均以得到 t=0 的嵌入吗?有什么错误?
WITH refl1 AS (
SELECT ref1_value, idx
FROM `ai-analytics-solutions.advdata.wxembed`,
UNNEST(ref) AS ref1_value WITH OFFSET AS idx
WHERE time = '2019-09-20 05:00:00 UTC'
),...SELECT SUM( (ref2_value - (ref1_value + ref3_value)/2) * (ref2_value - (ref1_value + ref3_value)/2) ) AS sqdist
FROM refl1
JOIN refl2 USING (idx)
JOIN refl3 USING (idx)
结果呢?sqrt(0.1),比 sqrt(0.5)少很多。换句话说,嵌入确实起到了方便的插值算法的作用。
为了将嵌入作为一种有用的插值算法,我们需要用远远超过 50 个像素的像素来表示图像。丢失的信息不可能这么高。同样,这是留给感兴趣的气象学家的练习。
使聚集
鉴于嵌入在可交换性和可加性方面看起来工作得非常好,我们应该期望能够对嵌入进行聚类。
让我们使用 K-Means 算法,要求五个聚类:
CREATE OR REPLACE MODEL advdata.hrrr_clusters
OPTIONS(model_type='kmeans', num_clusters=5, KMEANS_INIT_METHOD='KMEANS++')
ASSELECT arr_to_input(ref) AS ref
FROM `ai-analytics-solutions.advdata.wxembed`
生成的质心形成一个 50 元素的数组:

我们可以继续绘制五个质心的解码版本:
for cid in range(1,6):
**embed = df[df['centroid_id']==cid].sort_values(by='feature')['numerical_value'].values**
embed = tf.reshape( tf.convert_to_tensor(embed, dtype=tf.float32), [-1, 50])
outimg = decoder.predict(embed).squeeze() * 60
axarr[ (cid-1)//2, (cid-1)%2].imshow(outimg, origin='lower');
12.15992
以下是 5 个群集的结果形心:

当嵌入被聚类成 5 个簇时,这些是质心
第一个好像是你们班中西部风暴。第二个是芝加哥-克利夫兰走廊和东南部的大范围天气。第三个是第二个的强大变体。第四个是穿越阿巴拉契亚山脉的飑线。第五是内陆晴朗的天空,但是沿海的天气。
为了将聚类用作有用的预测辅助工具,您可能想要对更小的切片进行聚类,可能是 500 公里 x 500km 公里的切片,而不是整个美国。
在所有五个集群中,西雅图下雨,加利福尼亚阳光明媚。

后续步骤:
- 仔细阅读 GitHub 上的完整代码
- 阅读前两篇文章。一个是关于如何将 HRRR 文件转换成张量流记录,另一个是关于如何使用自动编码器来创建 HRRR 分析图像的嵌入。
- 我在华盛顿大学的科学研究所做了一个关于这个话题的演讲。看 YouTube 上的演讲:
compression vae——t-SNE 和 UMAP 的强大和多功能替代产品
介绍一种快速、易用、基于深度学习的降维工具

使用 CompressionVAE 的 MNIST 嵌入的风格化可视化,由Qosmo的程序员罗宾·荣格斯创建。
【TL;dr: CompressionVAE 是一个基于可变自动编码器思想的降维工具。它可以通过pip install cvae安装,使用方式与 scikit-learn 的 t-SNE 或 UMAP-learn 非常相似。完整的代码和文档可以在这里找到:https://github.com/maxfrenzel/CompressionVAE
降维是许多机器学习应用的核心。即使像 MNIST 这样简单的 28x28 像素黑白图像也要占据 784 维空间,而对于大多数感兴趣的真实数据来说,这可以轻松达到数万甚至更多。为了能够处理这种数据,第一步通常包括降低数据的维度。
这背后的一般思想是,不同的维度通常是高度相关和冗余的,并且不是所有的维度都包含等量的有用信息。降维算法的挑战是保留尽可能多的信息,同时用较少的特征描述数据,将数据从高维数据空间映射到低得多的维度潜在空间(也称为嵌入空间)。本质上是压缩的问题。一般来说,压缩算法越好,我们在这个过程中丢失的信息就越少(有一个小警告,根据应用程序的不同,并非所有信息都同样重要,因此最无损的方法不一定总是最好的)。
良好的降维技术允许我们创建更适合下游任务的数据,允许我们建立更紧凑的模型,并防止我们遭受维数灾难。它还使我们能够在二维或三维空间中可视化和分析数据。它可以发现大数据集中隐藏的潜在结构。
长期以来t-分布式随机邻居嵌入(t-SNE) ,特别是它作为 scikit-learn 的一部分的实现,一直是降维的主力(与 PCA 一起)。它很容易使用,有很多好的属性,特别是可视化。但是它有几个缺点。找到正确的参数并解释结果可能有点挑战性,并且它不能很好地扩展到高维空间(在输入和潜在维度中都是如此)。它的特性也使它不太适合非可视化的目的。
最近,均匀流形近似和投影(UMAP) 变得流行起来,并开始在许多应用中补充甚至取代 t-SNE,这要归功于它提供的几个优点。UMAP 要快得多,并且能更好地适应高维数据。它还更好地保留了全局结构,使其更适合可视化之外的许多应用。
在本文中,我想介绍这两种方法的替代方法:CompressionVAE(或简称为 CVAE)。CVAE 建立在 t-SNE 和 UMAP 实现的易用性基础上,但提供了几个非常可取的属性(以及一些缺点——它不是银弹)。
在其核心,CVAE 是一个变分自动编码器(VAE) 的 TensorFlow 实现,包装在一个易于使用的 API 中。我决定将其命名为 CompressionVAE,以赋予该工具一个独特的名称,但从根本上来说,它只是一个 VAE(可选地添加了反向自回归流层,以使学习到的分布更具表现力)。
因此,它基于与 VAE 相同的强大理论基础,并且可以很容易地扩展以考虑该领域中许多正在进行的发展。如果你想了解更多关于 VAEs 的一般知识,我写了一个关于这个主题的深入的三部分系列,从一个双人游戏的独特角度解释它们。
我们将在下面的示例中更深入地探讨 CVAE 的一些优点(和缺点),但这里只是一个总体概述:
- CVAE 比 SNE 霸王龙和 UMAP 都快
- CVAE 倾向于学习一个非常平滑的嵌入空间
- 学习到的表征非常适合作为下游任务的中间表征
- CVAE 学会了从数据到嵌入空间的确定性和可逆的映射(注意:UMAP 的最新版本也提供了一些可逆性)
- 该工具可以集成到实时系统中,无需重新培训即可处理以前未见过的示例
- 经过训练的系统是完整的生成模型,可用于从任意潜在变量生成新数据
- CVAE 很好地扩展到高维输入和潜在空间
- 原则上,它可以扩展到任意大的数据集。它既可以像 t-SNE 和 UMAP 实现那样获得全部训练数据,也可以一次只将一批训练数据加载到内存中。
- CVAE 是高度可定制的,即使在其当前的实现中,也提供了许多可控制的参数(同时也为缺乏经验的用户提供了相当健壮的默认设置)
- 除了当前的实现,它是高度可扩展的,并且将来的版本可以提供例如卷积或递归编码器/解码器,以允许除简单向量之外的更多问题/数据特定的高质量嵌入。
- VAEs 有一个非常强大和研究良好的理论基础
- 由于优化的目标,CVAE 往往不会得到一个非常强的集群之间的分离。非常手动地,在拥有平滑的潜在空间和获得强的团簇分离之间有一个权衡,VAE 更加平滑并且保留了全局结构。这可能是一个问题,也可能是一个优势,取决于具体的应用。
- 最大的缺点:和几乎任何深度学习工具一样,它需要大量的数据来训练。t-SNE 和 UMAP 在小数据集上工作得更好(当 CVAE 变得适用时没有硬性规定,但是通常通过运行
pip install cvae(或克隆库并从那里安装), CVAE 就可以使用了。在自述文件中可以找到更广泛的代码示例,但在其最基本的用例中,我们可以使用以下几行代码在数据阵列 X 上训练 CVAE 模型:
默认情况下,初始化 CompressionVAE 对象会创建一个具有二维潜在空间的模型,将数据 X 随机分为 90%的训练数据和 10%的验证数据,应用特征规范化,并尝试将模型架构与输入和潜在特征维度相匹配。它还将模型保存在一个临时目录中,下次在那里创建新的 CVAE 对象时,该目录将被覆盖。所有这些都可以定制,但我建议您参考自述文件了解详细信息。
训练方法应用基于验证数据丢失的自动学习率调度,并且在模型收敛时(由某些可调整的标准确定)或者在 50k 训练步骤之后停止。我们也可以通过键盘中断(ctrl-c 或 Jupyter notebook 中的‘中断内核’)来提前停止训练过程。此时模型将被保存。也可以停止训练,然后使用不同的参数重新开始(更多详细信息,请参见自述文件)。
一旦我们有了一个训练好的模型,我们就可以使用工具的 embed 方法来嵌入数据。例如,为了嵌入整个数据集 X,我们可以运行
# Import CVAE
from cvae import cvae# Initialise the tool, assuming we already have an array X containing the data
embedder = cvae.CompressionVAE(X)# Train the model
embedder.train()
在这种情况下,我们嵌入了模型在训练期间已经看到的数据,但是我们也可以向 embed 方法传递新的示例。
可视化嵌入
对于二维潜在空间,CVAE 自带可视化的内置方法。让我们假设我们在 MNIST 数据上训练我们的模型,并且最初以如下方式定义 X:
z = embedder.embed(X)
然后,我们可以通过以下方式绘制上面创建的嵌入
下面是一个这样的例子。
我们也可以扫描潜在空间,并使用 VAE 的生成器部分来可视化学习空间。
from sklearn.datasets import fetch_openml
mnist = fetch_openml('mnist_784', version=1, cache=True)
X = mnist.data
同样,您可以在自述文件中找到更多的详细信息和选项。
embedder.visualize(z, labels=[int(label) for label in mnist.target])
速度比较

CVAE 的好处之一是训练速度快。下面是在两个不同规模的流行数据集上与 UMAP 和 t-SNE 的一些比较:MNIST (70,000 个样本)和 Kuzushiji-49 (270,912 个样本)。
embedder.visualize_latent_grid()

为了进行比较,我使用了 scikit-learn 提供的 t-SNE 的基本版本,而不是任何多核版本。使用 UMAP 时,我收到一个“NumbaPerformanceWarning”,通知我不能使用并行化。所以这两种方法都有可能被加速,但是下面仍然是大多数用户会遇到的最普通的用例的一个很好的比较。所有测试都是在我的 MacBook Pro 上进行的,没有使用任何 GPU。
MNIST:
t-SNE: 5735 秒(单次)
UMAP:611±1 秒(10 次运行的平均值和标准偏差)
CVAE:121±39 秒(10 次运行的平均值和标准偏差)
- Kuzushiji-49:
- t-SNE:甚至没有尝试
- UMAP: 4099 秒(单次)
CVAE:235±70 秒(10 次运行的平均值和标准偏差)
- 我们看到,在这些数据集规模上,CVAE 在收敛时间方面明显更胜一筹,而且这种优势只会在更大的数据集上增强。请注意,CVAE 持续时间是由默认学习率计划和停止标准确定的收敛时间。
- 更详细的外观
- 下面的动画展示了一个在 MNIST 进行训练的例子。我们可以看到,CVAE 很快就接近了它的最终解,然后花了大部分时间来完善它。这表明,如果训练速度是一个关键问题,早期停止可能仍然会提供足够的结果,这取决于用例。自从我禁用了学习率衰减,这个特殊的模型实际上从未完全收敛。]
我们还在上面的速度数字中看到,由于当前版本对模型的初始化相当敏感,CVAE 在收敛时间上有相当大的差异。这种灵敏度既影响收敛速度,也影响最终结果。尝试几种模型并比较结果可能是值得的。作为一个例子,下面的潜在空间的三个不同的实例训练相同的 MNIST 数据。
然而,在所有情况下,我们看到 CVAE 倾向于实现一个非常平滑的潜在空间,并很好地保存全球结构。与此形成对比的是,例如,UMAP 的强聚类将相似的数字非常明显地分开,而对 CVAE 来说,它们平滑地流入彼此。
MNIST 嵌入和 UMAP 潜在空间的可视化,摘自 UMAP 文件。
上面的图也显示了 UMAP 逆变换的结果。与上面的 CVAE 版本相比,我们再次看到 CVAE 的潜在空间更加平滑。要明确的是,我在这里提出的“平滑”论点是非常定性的。如果你对更具体的东西感兴趣,我不久前给写了一篇关于这个主题的论文,但是我没有在这里的任何测试中应用这些更精确的指标。

关于用 CVAE 解码数据的一个注意事项:如果解码是主要的兴趣,我们可能应该有一个更专业的解码器。现在,解码器完全不受约束,例如,MNIST 模型可以输出值< 0 and > 255,即使它们作为像素值没有意义。我希望 CVAE 尽可能的通用和数据不可知。然而,在未来的版本中提供更多的选项来更加专门化这一点可能是值得的。例如,在 MNIST,通常的做法是通过 sigmoid 函数和适当的损耗将值限制在适当的范围内。

时尚 MNIST 是另一个简单而有用的玩具数据集,用于探索该工具的功能和输出。首先,让我们在 UMAP 的观想中寻找对比。
时尚 MNIST 的嵌入和 UMAP 的潜在空间的可视化,摘自 UMAP 文献。
与此相比,这是一个经过训练的 CVAE 模型的结果。
我们再一次看到了与上面非常相似的结果,CVAE 的星团分离不那么明显,但是过渡更加平滑。

这个例子也很好地展示了 CVAE 是如何抓住本地和全球结构的。
在全球范围内,我们看到“踝靴”、“运动鞋”和“凉鞋”类别都聚集在一起,无缝地相互融合。我们观察到从“连衣裙”,到“衬衫”和“t 恤/上衣”(几乎完全重叠),到“套头衫”和“外套”的类似过渡。例如,我们在“裤子”和更大的鞋类集群之间看到了更强烈的区分(和不明确的重建)。有趣的是,包包几乎可以无缝地变成套头衫。

在局部我们也发现了很多结构,比如鞋子随着 y 的降低脚踝高度越来越高,随着 x 的增加脚踝高度越来越高。
所有这些都表明,模型已经清楚地学习/发现了数据集的一些底层潜在结构。
我们还可以玩数据插值。让我们随机挑选两个真实的例子,创建五个中介“假”数据点。
注意,这段代码假设embedder是一个 CVAE 实例,它是根据时尚 MNIST 数据X_fashion训练的。在做了一些整形和显示后,我们可以得到如下结果。
虽然这里讨论的所有示例都只是没有任何实际应用的玩具数据集,但 CVAE 可以应用于许多现实世界的问题,也可以用于生产环境。
在我现在的公司 Qosmo ,我们在几个项目中使用 CVAE 的变体,从纯粹的艺术到商业。我们开发的各种音乐推荐和播放列表生成解决方案就是一个例子。
import random
import numpy as np# Get two random data points
X1 = np.expand_dims(random.choice(X_fashion), axis=0)
X2 = np.expand_dims(random.choice(X_fashion), axis=0)# Embed both
z1 = embedder.embed(X1)
z2 = embedder.embed(X2)# Interpolate between embeddings in five steps
z_diff = (z2 - z1) / 6
z_list = [z1 + k*z_diff for k in range(7)]
z_interp = np.concatenate(z_list)# Decode
X_interp = embedder.decode(z_interp)
在其中的一些中,我们首先使用专有系统将歌曲转换为固定大小的非常高维的矢量表示,然后使用 CVAE 进一步压缩矢量,使它们更适合下游任务,最后使用另一个定制的系统,该系统使用创建的歌曲嵌入来生成有意义和自然的声音播放列表,可能还会考虑某些附加标准和实时数据(例如,当前天气或一天中的时间)。

如果您有兴趣使用这些系统中的一个,或者想根据您的特定需求与我们合作定制解决方案,请访问我们的网站并与我们联系。
压缩阀仍处于非常早期的阶段。但是我鼓励你试着把它应用到你自己的问题上。
如果当前的基本版本不能完全满足您的需求,您可以根据自己的需要随意扩展和修改它。如果你愿意分享你的定制,并让它成为 CVAE 主发行版的一部分,那就更好了。虽然肯定有很大的改进空间,但我希望当前的实现提供了一个很好的框架和起点,使这个过程尽可能简单。
我期待着看到每个人的用例和贡献(希望也能修复我草率的代码、潜在的错误和不稳定性)。
CompressionVAE 无法取代其他各种维度缩减工具,但我希望它能为现有的工具库提供有价值的补充。
快乐压缩!
I’m looking forward to see everyone’s use cases and contributions (and hopefully also fixes to my sloppy code, potential bugs, and instabilities).
CompressionVAE won’t be able to replace the various other dimensionally reductions tools, but I hope it provides a valuable addition to the existing arsenal of tools.
Happy compressing!
计算物理学
使用数据科学工具理解激发电影《到来》的物理定律

来自电影的图像到达。静止不动的原理启发了这本书的作者。
在看到电影到来的几天后,当我在写我之前的论文微分编程时,我发现 JAX 的作者,一个实现自动微分的库,推荐阅读结构和经典力学解释。我立刻被他们解释静止动作原理的巧妙方式所打动,这启发了我的到来。
这本书已经由麻省理工学院出版,并重新使用了同样的标题计算机程序的结构和解释,也是由麻省理工学院出版的。两者都可以在网上免费获得!
计算机程序的结构与解释,又称向导书是一本著名的计算机科学书籍。我强烈推荐它的阅读。当我读得非常开心的时候,我被这本关于经典力学的新书吸引住了,这本书似乎遵循了同样的模式。
作为一名机械领域的前研究人员,我没有对这本书失望;至于 SICP,我真的很喜欢阅读 SICM 的作品。这本书的整体思想是使用计算机科学提供的工具接近经典力学:数值分析,符号计算,自动微分,…
在本文中,我们将看到如何使用我们熟悉的数学和数值工具来计算刚体轨迹,使用激发电影降临的物理学原理:静止作用原理。
牛顿第二定律
我们所熟悉的物理学本质上是基于牛顿的设想。在他的设想中,基于微分方法,运动和力通过加速度联系起来:对物体施加力会改变其速度,即物体的加速度与力成正比。物体质量越大,力对其速度的影响越小:加速度与质量成反比。
这个关系通常被他著名的第二定律所包含:

牛顿第二物理定律。图片由作者提供。
使用这个公式,或者稍微复杂一点的版本,完全可以模拟刚性或可变形物体的运动。
静止作用原理
然而,在本文中,我们将重点介绍另一种方法,该方法由法国数学家牟培尔堆开发,由杰出的英国数学家汉密尔顿完善,由俄罗斯数学家奥斯特罗夫斯基进一步扩展,并由法国科学家拉格朗日推广:最小作用的原理,推广为静止作用的原理。
另外,请注意,这一原则是美国作家姜峯楠写的引人入胜的书《你生活的故事》的故事基础。这本书启发了同样著名的电影降临。但是文化上的离题已经够多了。让我们回到数学和物理。
我不会给你这个原理的陈述,在任何一本好的力学教科书中都可以找到。相反,就像在 SICM 中一样,我将强调我们如何利用这一原则,使用我们首选的编程语言:Python,在候选轨迹中选择物理上可接受的运动。
事实上,这个原则本质上是说,任何物理上可接受的路径都会最小化特定的功能。或者更准确地说,可接受路径周围的任何微小变化都必须保持函数不变,即路径是静止的。
因此,为了找到正确的路径,我们所要做的就是对目标进行一些最小化。再简单不过了,这是我们的日常工作。
编程物理学
为了计算这些可接受的路径,我们只需要:
- 一种创建候选轨迹的方法。为此,我们需要一个返回位置的时间函数。普通的 python 和一些多项式魔法就能胜任这项工作。
- 从轨迹中提取特征的方法:通常是它们的位置、速度、加速度和可能的高阶导数。我们可以用自动微分来解决这个问题。
- 一种在候选轨迹中识别物理上更合理的轨迹的方法。我们知道,由于静止动作的原理,这是通过最小化由先前步骤提取的候选轨迹特性特征相对于候选轨迹的函数来实现的。我们把这个函数称为动作,它是拉格朗日函数的两个时间戳之间的积分,另一个函数执行我们想要模拟的物理定律。
让我们具体一点,给这些概念加上一些代码。
创建轨迹
有各种选项来定义轨迹。例如,我们可以使用样条、贝塞尔曲线和伯恩斯坦多项式。但是当我们处理一个物理问题时,我们将使用拉格朗日多项式。
这些多项式非常方便:它们通过强制曲线通过预定义的控制点来控制曲线。为了做到这一点,拉格朗日设计了他的多项式,使得每个点 x_i 之前的系数对于不同于 t_i 的任何时间 t_k 都是 0.0,并且对于 t_i 等于 1.0。
这是一个有 3 个控制点的曲线的第一个控制点 x_0 的系数公式的例子。

拉格朗日多项式系数的一个例子。图片由作者提供。
用 Python 写的,给出了:
拉格朗日多项式代码
我们可以如下应用该代码,以获得示例轨迹:
用拉格朗日多项式定义简单曲线
生成的轨迹如下所示:

穿过 4 个控制点的轨迹
请注意,曲线正好穿过控制点。
提取特征特性
既然我们有了一种使用参数定义曲线的方法,就像控制点一样容易处理,我们需要一种工具来提取这些曲线上任何一点的特征。
因为我们需要的特征是位置、速度或加速度,即曲线相对于时间的各阶导数,所以我们可以使用自动微分。
我们定义了下面的函数, local_state ,它采用任何时间函数,使用 AD 库 JAX 计算其特性:
local_state 计算由时间函数 f. 定义的轨迹特征
我们可以在上面定义的曲线上应用这个函数。看曲线告诉我们,导数在 t=1.5 时一定为零。让我们用这几行代码来检查一下:
数组的第三个元素,时间导数为零,如 t=1.5 时所预期的
一切都像魔咒一样管用。
识别正确的轨迹
创建候选轨迹现在就像选择一组控制点一样简单。我们还有自动计算微分几何特征的工具。
我们现在需要的是一种在候选人中选择正确轨迹的方法,或者更好的是,收敛到正确的轨迹。
正如上面写的几行,以及牟培尔堆的陈述,几个世纪以来,我们知道一个物理上可接受的轨迹可以最小化所谓的动作。

通过对作者的候选轨迹 f. Image 的拉格朗日积分,在时间 t0 和 t1 之间计算动作。
这里 l 代表拉格朗日量,γ是我们的函数 *local_state,*负责特征提取。
为了执行集成,我们将使用标准的 scipy integrate 方法。
作为第一次尝试,我们将计算自由落体的轨迹。在这种情况下,物体只受到重力加速度的作用。当以零初始速度下落物体时,其在时间 t 的 y 坐标为:

y,坐标一时间 t .作者图片
在这种物理设置下,拉格朗日被定义为动能和重力势能之差,即:

拉格朗日当物体只受重力作用时。图片由作者提供。
将所有这些放在一起,我们得到:
相对于受扰动的曲线,真实轨迹的作用实际上是最小的。
自由落体示例
现在让我们检查从任何候选轨迹开始,当最小化动作时,我们可以收敛到正确的轨迹。为此,我们将使用scipy . optimize . minimize函数,使用几何 Nelder-Mead 最小化方法。
这导致下面的代码:
正如所料,我们收敛到右边的曲线,显示在时间 t 的 y 坐标:

初始曲线以蓝色显示。最小化动作后,我们收敛到正确的轨迹。图片由作者提供。
自由运动示例
我们再举一个例子,要被说服。在这种情况下,我们不仅要考虑 y ,还要考虑 x 。
我们不仅在 t0 时刻,而且在 t1 时刻加强我们身体的位置。因此我们有两个边界条件:
- t0: (0.0,0.0)
- t1: (0.0,4.0)
这一次,我们插值 2D 向量,而不仅仅是浮点。为了处理这个问题,我们将对每个维度使用一个拉格朗日多项式。另一种选择是使用单个多项式并使用 2D 点作为控制点。
参见下面的代码:
真实轨迹的方程式在real_trajectory函数中定义。它用于显示一些检查点,以确保我们收敛到正确的运动,如下所示:

蓝色曲线,即使离正确的轨迹相当远,也成功地收敛到正确的运动。图片由作者提供。
再来一次,一切都按预期工作。
结论:用编程来教物理(和数学)
通过这些基本的例子,我们已经表明,使用我们用于数据科学的相同工具,有可能简化对相当复杂的物理理论的理解。
我们已经能够用几行代码说明经典力学的变分方法,因此使理解这些理论原理背后的概念变得更容易。
在物理教学中引入像 python 这样的编程语言,以其强大的功能和灵活性,是帮助掌握复杂学科的一个非常好的方法。有了它们,实验物理定律并理解它们的真正含义就简单了。如今测试一个假设,建造一个玩具模型,展示曲线,…
没有比创建自己的模拟器更好的方法来理解一个复杂的现象。编程应该是任何物理课堂都会用到的工具。
计算无法计算的| SVI 和艾尔波是如何工作的
贝叶斯建模与真实世界数据一起工作的一个原因。随机海洋中的近似灯塔。

照片由威廉·布特在 Un spash上拍摄
当你想对你的数据获得更多的洞察力时,你依赖于编程框架,它允许你与概率进行交互。开始时你所拥有的只是数据点的集合。它只是对数据来源的底层分布的一瞥。然而,您最终不仅仅想要简单的数据点。您想要的是精细的、健谈的密度分布,您可以用它来执行测试。为此,您使用概率框架,如张量流概率、 Pyro 或 STAN 来计算概率的后验概率。
正如我们将看到的,这种计算并不总是可行的,我们依靠马尔可夫链蒙特卡罗(MCMC)方法或随机变分推断(SVI)来解决这些问题。特别是对于大型数据集,甚至是每天的中型数据集,我们必须执行神奇的采样和推理来计算值和拟合模型。如果这些方法不存在,我们将被我们想出来的一个整洁的模型所困,但是没有办法知道它实际上是否有意义。
我们使用 Pyro 构建了一个预测模型,该模型使用的正是——SVI:
将一段时间内的点连接起来,并满怀信心地进行预测(-区间)。
towardsdatascience.com](/pyro-top-down-forecasting-application-case-4781eb2c8485)
在这个故事中,我们将从 Pyro 的角度来看计算。
简而言之,Pyro 并没有强行计算后验概率,而是做出了一个我们可以改进的估计。但是为什么我们不能计算整个事情呢?很高兴你问了。
从无穷大到常数
假设我们有一个数据集 D ,我们想要拟合一个模型(θ)来准确描述我们的数据。为此,我们需要一组变量。这些变量对应于随机事件,我们称之为潜在随机变量,例如 z.
现在来看看我们的模型对后验概率分布 P 的依赖程度。这是一个很好的起点,现在我如何计算这个 P?为了让这个工作,我们必须做这样的推论:

(1) —给定我们数据中的观察值 x,计算潜在随机变量 z 的后验概率。
精通数学的读者已经看到上面等式的右边部分通常是不可计算的。我们面对未知事物上的全能积分的恐惧。现在把 z 作为连续变量,它可能是无限的。那相当大。
我们能做的是用一个变分分布;姑且称之为 Q 。在一个理想的世界中,这个近似的 Q 应该尽可能的接近我们正在计算的 P。那我们怎么去呢?
我们首先需要的是 P 和 Q 相似程度的度量。输入 Kullback Leibler 散度——你可以在数理统计年鉴中找到 Kullback 和 Leibler 的传奇论文[1]。
我们用来比较分布的工具,Kullback Leibler 散度被
定义为:

(2) —定义库尔贝克-莱布勒散度
这个度量告诉我们分布 P 和 Q 有多相似。如果它们相似,KL 就低,如果它们非常不同,差异就大。
现在,这个度量要求我们知道分布 P 和 q,但是我们还不知道 P。毕竟,这是我们正在计算的,到目前为止,我们的 Q 是一个野生猜测。
经过一些重新表述,我们最终得到了这个(参见[5]的分步解决方案):

(3) —从 KL 导出 ELBO,作为与常数 log§的和
第一部分(-E[log P(z,x)-log Q(z|x)])就是所谓的证据下界或 ELBO 。第二部分(log§)是一个常数。这对我们以后的计算更有利。我们现在要做的就是最大化 ELBO,使 P 和 q 之间的偏差最小。
Minimizing KL divergence corresponds to maximizing ELBO and vice versa.
用深度学习学习 Q
既然我们已经有了基本的理论,那么我们该如何处理我们的问题呢?我们可以通过使用某种形式的神经网络来估计 Q。我们已经有了 TensorFlow 或者 PyTorch 来处理 Pyro。与我们已经建立的模型相比,我们现在可以建立一些东西来描述我们的变分分布。一旦我们有了这个分布估计,我们就可以使用随机梯度下降来拟合我们的模型。所以让我们开始吧。
我们使用我们的数据作为模型和指南的输入。模型给了我们 P,而指南建议网络输出一个 Q。如果这是高斯分布,那么网络会给出平均值μ和标准差σ。如果我们用一个非常简单的形式来描绘这个过程,随着时间的推移,它看起来就像这样:

图 1 — 计算 n 个时间步上的后验概率时,用向导拟合模型的过程。
跟我说说 Pyro
让我们举一个简单的例子,给定潜在随机变量 z ,我们拟合一个模型函数 f 。该变量来自β分布(仅作为一个例子)。我们观察到的事件是伯努利随机发生的。这意味着事件要么发生,要么不发生。最后,事件是独立同分布的,我们写为烟火板符号。所以我们的模型是:
def model(self):
# sample `z` from the beta prior
f = pyro.sample("z", dist.Beta(10, 10))
# plate notion for conditionally independent events given f
with pyro.plate("data"):
# observe all datapoints using the bernoulli distribution
pyro.sample("obs", dist.Bernoulli(f), obs=self.data)
到目前为止,这是标准的烟火,你不必总是指定一个向导。Pyro 可以处理,但是会有一个向导在那里。通过指定向导,你可以完全控制你的建模过程。在这个例子中,向导的潜在 z 来自于此:
def guide(self):
# register the two variational parameters with pyro
alpha_q = pyro.param("alpha_q", torch.tensor(15),
constraint=constraints.positive)
beta_q = pyro.param("beta_q", torch.tensor(15),
constraint=constraints.positive)
pyro.sample("latent_z", NonreparameterizedBeta(alpha_q, beta_q))
最后,我们通过使用 SVI 对象来运行我们的推理。我们提供先前指定的模型和指定的指南。我们还依赖标准 PyTorch Adam optimizer 进行随机梯度下降。
def inference(self):
# clear everything that might still be around
pyro.clear_param_store()
# setup the optimizer and the inference algorithm
optimizer = optim.Adam({"lr": .0005, "betas": (0.93, 0.999)})
svi = SVI(self.model, self.guide, optimizer, loss=TraceGraph_ELBO())
你都准备好了。现在我们来看一些输出。
上面的例子只是伪代码,为了获得正确的输出,我使用了一个简单的贝叶斯回归任务,并计算了模型函数的后验概率(具体细节请参见我的github)。
我们使用 Pyro SVI 和 Markov Chain Monte Carlo 程序以及 NUTS 采样器。
丑陋的真相|比较 SVI 和 MCMC
到目前为止,一切听起来都很有希望——好得令人难以置信。对于生活中的每一件事,你应该经常检查你的结果。下面的例子(图 2-3)显示了前面提到的回归任务的拟合后验分布,并同时使用 SVI 和 MCMC。

图 2——使用 SVI 和 MCMC 对具有两个变量的函数 f 进行贝叶斯回归。

图 3——模型拟合后,贝叶斯回归任务的密度分布与后验分布重叠的等高线图。两个模型变量 bF2 的相互作用和相互作用项 bF12。
先说好的一点:我们已经为 SVI 和麦克米伦安排了足够的后验概率。不太理想的是,它们明显不同。对马尔可夫方法和随机推理如何以及为什么不同的深入理解是各种研究的主题,深入的理解将是另一篇文章的主题。在这一点上,我们唯一能得出的结论是推理程序对我们最终的模型有明显的影响。
整洁——SVI 作品。关键点。
- 我们正视了一个看似不可行的问题,并研究了潜在过程的理论,以找出解决它的方法。
- 你可以使用深度学习框架,如 TF 和 PyTorch,通过近似另一个模型-分布来建立你的概率模型。
- 这一切的目标是最小化我们的两个近似后验之间的分歧(或最大化下界)。
- 我们应该总是看着我们的输出,问自己我们所看到的是否有意义。取样程序显然会影响我们的后验结果——所以我们应该小心。
总而言之,SVI 允许我们采用任何数据集,并用它进行贝叶斯建模。如果你问我,这是一个非常好的功能。
参考
- 南 Kullback 和 r . lei bler关于信息和充分性。1951 年在数理统计年鉴。
- D.温盖特和 t .韦伯。概率规划中的自动变分推理。2013 年月 arxiv 日。
- Pyro 文档— SVI 教程一
- 烟火文档— SVI 教程二
- 烟火文档— SVI 教程三
- 礼萨·巴巴纳扎德。随机变分推理。 UBC
- D.马德拉斯。 教程随机变分推理 。多伦多大学。2017.
完整的烟火例子
上面提到的例子只是作为一个关于如何建立一个 Pyro 类的粗略概述。功能代码可在 Pyro 文档中找到(参见[ 5 ])。
class BetaExample:
def __init__(self, data):
# ... specify your model needs here ...
# the dataset needs to be a torch vector
self.data = data def model(self):
# sample `z` from the beta prior
f = pyro.sample("z", dist.Beta(10, 10))
# plate notion for conditionally independent events given f
with pyro.plate("data"):
# observe all datapoints using the bernoulli likelihood
pyro.sample("obs", dist.Bernoulli(f), obs=self.data) def guide(self):
# register the two variational parameters with pyro
alpha_q = pyro.param("alpha_q", torch.tensor(15),
constraint=constraints.positive)
beta_q = pyro.param("beta_q", torch.tensor(15),
constraint=constraints.positive)
pyro.sample("latent_z", NonreparameterizedBeta(alpha_q, beta_q)) def inference(self):
# clear the param store
pyro.clear_param_store()
# setup the optimizer and the inference algorithm
optimizer = optim.Adam({"lr": .0005, "betas": (0.93, 0.999)})
svi = SVI(self.model, self.guide, optimizer, loss=TraceGra
用一行代码计算你收入的概率
你有没有问过自己,你达到既定财务目标的概率是多少?
如果你是一个自由职业者,一个零售商或者仅仅是一个活跃的媒体作家,你可以在下面找到一个简单的公式来更好地预测你的收入机会。
下面的讨论是基于这样一个想法,即任何业务都有一定程度的随机性。尤其是在日冕危机时期,任何预测都是不确定的。
然而,即使在如此困难的情况下,我相信一些应用数学永远不会有坏处。下面,您可以欣赏随机过程理论应用于简单业务场景的一些概念。
**必要前提:**我的目的是展示一些工作中的数学,而不是给出任何理财建议。请不要忘记,数学公式只有在工作假设得到满足时才是可靠的。
出乎意料
让我们从简单的开始,考虑在你的生意中你只以固定的价格销售一种类型的产品。这可能是一个具体的对象、数字内容或任何服务。
例如,假设你是一名业余画家,你以每幅 100 美元的价格出售你的作品。为了简洁起见,我们将用字母 a 来表示这个价格。所以,a= 100 $/艺术品,意思是每件艺术品一百美元。很好。
假设你知道,平均来说,你一个月卖出 r =10 件艺术品。你也有一些固定支出,如颜色、画笔等。你每月花在绘画材料上的钱正好是 50 美元。
一年能赚多少?你打开你信任的计算器应用程序和数字
a×r×t–c×t=(100×10×12-50×12)$ = 11400 $,
其中时间 t 设置为 12 个月。不过,这只是你的 期望 。你不能确定今年能卖出r×t =120 件艺术品。相反,每月售出的艺术品数量将围绕平均值随机波动。
下面的图有助于形象化随机性的影响。每条绿线都是一个独立的随机模拟,代表了未来可能的净收益轨迹。直到年底,波动会显著增加并偏离预期!

画家一年净收入的随机轨迹。每一个都是作为艺术品销售的齐次泊松过程产生的,并且由于画家的成本而不断向下漂移。黑线显示的是平均趋势。—图片由作者提供。
那么,如何主张不仅仅是期望值呢?
在假定卖出率 r 不随时间变化的情况下,结果是某段时间 t 卖出的艺术品数量 N(t) 按照一个均值等于 r × t 的 泊松分布 分布。不出意外的话,平均值r×t =120与预期的销售额是一致的,但是现在我们知道的更多了。精确分布的知识允许我们计算概率。
更准确地说,我们想知道在时间 t 时,净收益 E(t) 增长超过目标 g 的概率。用数学的话来说,这个概率可以简洁地写成 Prob( E(t) > g )。

蓝色区域代表净收入超过财务目标的概率。—图片由作者提供。
我们现在可以做一些数学计算并获得

超越财务目标概率的推导。—图片由作者提供。
这就是公式。我们已经表明,赚取超过目标 g 的概率与计算售出艺术品数量 N(t) 大于(g*+c×t)/a的可能性是完全相同的,这很容易通过泊松分布的累积分布函数的倒数获得。数字怎么弄?*
在 Julia 中,使用软件包发行版:
***using** Distributions
p = ccdf(Poisson(r*t),(g+c*t)/a)*
在 Python 中,使用包 scipy:
***import** scipy.stats **as** st
p = 1 - st.poisson.cdf((g+c*t)/a,r*t)*
首先,让我们做一个理智检查。在画家的例子中,获得超过预期的 11400 美元的概率是 47.6%。这是有道理的,因为卖出多于或少于 120 件艺术品的机会是相当对称的。(注:如果你在问自己为什么这个数字不是 50%,那只是因为 mean 和 median 不一样,一般来说)。
为了更好地了解赚钱的机会,可以将 Prob(E(t) > g) 绘制成目标值 g 的函数。例如,大约有 90%的机会超过净收益 1 万美元,但只有 0.9%的机会超过 1.4 万美元。

该曲线显示了超过给定财务目标的概率,使用 painter 示例中提供的公式进行计算。画家最好在梦想过高之前知道几率!—图片由作者提供。
更高的价格还是更多的销售?
在研究价格和平均销售额时,观察收入分布的行为很有趣。例如,通过调整价格 a 和平均销售额 r 同时保持他们的产品不变,人们很快就会意识到增加销售数字有一个稳定的效果:赚钱的概率集中在期望值附近。相反,以更高的价格卖出更少的商品会导致更不确定的结果。

预期销售额减少意味着收益的随机性增加。相反,由于大数定律,更多的销售是可以预测的。注意:使用的数字不反映价格和需求的规律。—图片由作者提供。
这个事实只不过是大数定律的一个结果:你加起来的随机事物越多,你就越能更好地描述它们的总和。实际上,我喜欢反过来思考这句话:
数字越小,机会越重要。
两个方向都是如此。你可能表现不佳,也可能中了大奖。这只是运气。
销售几种类型的产品
现在让我们考虑更常见的零售几种产品的情况,每种产品都有一个给定的价格。例如,再次以画家为例,我们可以想象我们出售三种不同类型的艺术品,取决于大小:小型、中型和大型画布,价格分别为 50 美元、100 美元和 200 美元。
我们再次假设平均每月卖出 r =10 件艺术品和来知道油画通常卖出的比例。比如 40%小,40%中,20%大。请注意,这些数字是这样的,期望是不变的,相对于一个产品的情况。但是赚的概率呢?现在会有显著的不同吗?
这种具体情况下,不会有太大变化。只需将 a 设置为项目价格的加权平均值( a =0.4×50 美元+0.4×100 美元+0.2×200 美元),就可以使用前面的公式安全地再次估算收入概率。
然而,只要每件商品“经常”售出,这种方法就能可靠地发挥作用,因此不存在过于接近小数量不确定区域的风险。如果项目价格彼此相差不大,该公式尤其准确,因为平均值更有代表性。
*如果情况不是这样,或者有些商品很少售出,那么为这种库存情况推导出一个特定的公式就很重要了。这可以通过泊松过程的 稀疏属性 来实现:以全局速率 r 和各个分数 f(i) 销售更多产品在数学上等价于以速率 *r(i)=r×f(i)独立销售每一个项目 i 。无论如何,最终公式在概念上与前面显示的公式相似,只是在计算净收益 E(t) 时,需要对所有项目的回报求和。
估计中等收入
最后,让我们探索一下 Medium 上最有趣的案例。如何计算你写作回报的概率?
主要的复杂之处在于,我们无法将媒体报道的收益建模为我们事先知道价格的项目。相反,我们也可以通过引入回报* 分布来以概率的方式描述它们。*
我们本质上想要将总的中等收入建模为在给定时间内将要出版的随机数量的故事的随机回报的总和。
回报分布可以被认为是前面提到的价格分数的连续版本。它描述了你发布的一个故事以何种概率获得一定的收益。显然,这种分布对于每个媒体作者来说是特定的,因为它强烈地依赖于媒体上的经验和受欢迎程度。
为了简单起见,我在这里用指数分布来描述 post 回报,原因有两个。首先,这适用于许多媒体作家:大多数帖子回报适中,少数稍好,但没有暴涨。其次,指数分布很简单,因为它只有一个参数,即每篇文章的平均回报。(还是那句话,姑且称之为a)**
在这些设置中,总中等收入由一个 复合泊松过程 描述,比率为 r×t ,被加数为指数分布。具体是什么意思?首先,让我们看看平均值。
对于所考虑的复合过程,平均总收益等于 a×r×t ,标准差为 a×sqrt(2×r×t) 。标准差给出了波动大小的概念:作为中心极限定理的结果,收益将在期望值上下一个标准差的区间内以 68%的概率下降。然而,为了让中心极限定理体面地工作,经验法则是考虑至少 20 个以上的总销售额(即,中等故事,在这种情况下)。
例如,如果你每周发布一篇文章,平均每篇文章赚 25 美元,那么一年后你将会得到(1300 255)美元(52 周)。
如果你对达到某个目标的概率特别感兴趣,画家的公式在这种情况下也很好,即使只是作为一个代理*。使用它仍然有效的原因是指数分布不太偏斜,就像画布价格的例子一样。*
但是,请注意,获得的概率值的可信度取决于这些建模假设的满足程度:
- 你对你的出版率有一个很好的估计
- 你的岗位收入是相互独立的,并以已知的平均值 a 呈指数分布
- 在时间跨度 t 内,上述任何一项都不会改变
你可能想试试这个公式。相反,如果您不喜欢近似,可以通过直接模拟直接计算 Prob(E(t) > g) 。这也只是一行代码。
在朱莉娅身上,
***using** Distributions
S = 10^6 # Number of simulations you want
p = length(findall([sum(rand(Exponential(a),rand(Poisson(r*t)))) for i=1:S] .> g)) / S*
或者用 Python
***import** numpy **as** np
S = 10**6 # Number of simulations you want
p = sum(map(lambda x : x > g, [sum(np.random.exponential(a,np.random.poisson(r*t))) for i in range(S)])) / S*
(附注:朱莉娅看起来好多了,而且速度快得惊人。我爱朱莉娅!)
上面的代码只是简单地将几次泊松分布的指数分布回报相加。然后,超过目标 g 的概率被简单地估计为总收益大于 g 的模拟的分数。
但是所有这些准确性真的有必要吗?但说实话,很可能不是。
应用于媒体的概率论的实际信息简单地证实了日常证据:确保你在媒体上成功的最强有力的方法是提高你的出版率和写出好东西。多一个多一个*,多一个多一个,并且两者的时间都更长 t 。总之,更多的艺术。*
即使我是一个学数学的人,我也相信生活有时会因为数字少而单词多而变得更加愉快。所以,写得好!
计算机辅助翻译系统与机器翻译
有什么区别,为什么重要?

照片由 Fotis Fotopoulos 在 Unsplash 上拍摄
我们都很熟悉谷歌翻译,可能在某个地方用过。但是我们真的知道其背后的原因吗?语言行业对自动化翻译工具有什么看法吗?如果你是个人或公司的利益相关者,考虑为你的文档或网站使用翻译服务,你尤其应该了解这些技术,以便做出明智的决定。作为一名德语到英语的翻译,我已经使用翻译技术二十年了,所以让我们来仔细看看吧!
什么是计算机辅助翻译工具,什么是翻译管理系统?
CAT(计算机辅助翻译)工具是支持译者准备翻译的软件。它转换要翻译的文本,对其进行分段,然后在自己的编辑器中对这些分段进行翻译。
CAT 工具由几个子系统组成。其核心是翻译记忆库™,它将各个翻译单元收集在一个数据库中。在翻译过程中,保存由一段源文本和目标语言中的对等译文组成的各个翻译单元。存储翻译单元可以确保翻译的一致性,以及在文本中使用相同的术语。这提高了输出文本的质量。
计算机辅助翻译工具将源文本分成句子、要点或标题等片段。然后在编辑器窗口中向翻译者显示各个片段。译者在源文本旁边或下面的相应部分输入他们的译文。这创建了存储在 TM 中的翻译单元,TM 是一个包含原始源内容和相应翻译的双语数据库。当翻译者将来翻译类似的文本时,程序会建议现有的、已保存的翻译。
因此,与机器翻译程序不同,CAT 工具或翻译记忆库不独立翻译,而是仅用于支持人工翻译并将创建的翻译存储在数据库中。事实上,研究表明,使用 CAT 工具时,翻译人员的工作速度提高了 28%。
计算机辅助翻译系统的优势
因此,卡特彼勒工具能够实现更快、更高质量的翻译,并确保翻译的一致性。此外,卡特彼勒工具可以准备和分割各种文件格式,如 Microsoft Word、Excel 和 PowerPoint 文件、Open Office 文件,甚至 XML 文件。这允许翻译人员处理某些文件类型,即使他们没有创建这些文件的原始软件,例如 InDesign。
如今,卡特彼勒工具已成为全球翻译公司和翻译人员使用的行业标准程序。
使用 CAT 工具和相关的翻译记忆库为将来的翻译打下基础,这将随着每次翻译的完成而增长。如果在 CAT 工具中打开一个新的源语言文件,并且使用了翻译记忆库,则在翻译该文件时会显示“新单词”、“100%匹配”(相同段)或“模糊匹配”(相似段)。然后,翻译员会对这些内容进行检查,如有必要,还会对其进行调整,以便能够接收目标片段。因此,轮子不必每次都重新发明。
此外,当一份文件的重复率很高时,翻译记忆系统的优势就很明显了。相应的片段只需翻译一次,然后可以通过工具自动插入文本中的所有其他实例。这使得翻译效率更高,并能为客户节省成本。
文本分析
CAT 工具通过将每个新文本与其翻译记忆库中存储的单位进行比较来分析每个新文本。然后,它评估有多少内容需要翻译,这些信息通常用于计算成本。分析通常分为以下几部分:
- **新单词:**以前从未被翻译过且不在翻译记忆库中的片段
- **模糊匹配:**与先前翻译过的内容相似的片段,这些片段存在于翻译记忆中,但需要译者进行编辑
- **100%匹配:**在翻译记忆库中找到的相同片段
- **上下文匹配:**出现在与翻译记忆库中完全相同的上下文中(即两次 100%匹配之间)的相同片段
- **重复:**在每个文件中出现不止一次的相同片段;翻译人员只需翻译一次,该工具会自动在整个文档中复制已翻译的片段

照片由 Miguelangel Miquelena 在 Unsplash 拍摄
每种类型的片段都需要译者付出不同程度的努力,从从头开始的全新翻译到不加修改的审阅。
当译者第一次使用 CAT 工具时,他们的 TM 仍然是空的,所有片段将作为“新单词”返回。但是一旦存储了更多的文本,杠杆作用就会开始增加。
除了翻译记忆库之外,卡特彼勒工具还有许多其他功能,包括:
- 术语管理
- 质量保证特征
- 搜索和替换功能
- 索引搜索
- 文本对齐功能
如今,卡特彼勒工具有桌面版、基于服务器或基于云的版本。基于服务器的版本通常由大型语言服务提供商使用,因为它们允许多个翻译人员同时为一个项目工作。
市场上最受欢迎的卡特彼勒工具包括:
- memoQ
- SDL Trados Studio
- 穿过
- OmegaT
- Wordfast
- 智能猫
重要的是,我们不要将 CAT 工具与机器翻译程序混淆。
什么是机器翻译?
机器翻译应用程序是一种将文本输入计算机算法的程序,计算机算法会自动将文本翻译成另一种语言。所以没有人参与翻译过程。
然而现在,许多 CAT 工具都提供了机器翻译插件。有趣的是,一些译者出于道德原因拒绝使用这些方法,或者因为他们认为这会导致较差的翻译质量,并冲淡了技巧。
我们区分了三种类型的机器翻译方法:
**1)基于规则的机器翻译:**这种方法依赖于语言专家开发的语法和语言规则,以及高度可定制的词典。
**2)统计机器翻译:**这种方法不依赖语言学规则和单词;相反,它通过分析大量现有的人工翻译来学习。
**3)神经机器翻译:**这种方法通过使用大型神经网络来自学如何翻译;它越来越受欢迎,因为它提供了比其他两种方法更好的结果。例如,谷歌 MT 和微软 Translator 依赖于神经网络。
一些流行的机器翻译程序有:
- DeepL
- 亚马逊山
- 谷歌山
- 全能技术
- 蒂尔德山
- 微软翻译器
- 希斯特兰
如今,许多语言服务提供商部署了某种机器翻译程序,并由人工翻译或编辑(称为“后期编辑”)对输出进行修改,以改善结果,这些结果通常是不合格的。
自然,这些自动化程序的成本比人工翻译要低,但代价总是较低的质量。语言是高度动态和复杂的,尽管机器翻译技术多年来有了很大的改进,但它永远无法准确识别每种语言的细微差别,并像人类翻译一样用另一种语言传达它们。
因此,无论它们听起来多么相似,CAT 工具和机器翻译程序的工作方式不同,用于不同的目的。简单来说,CAT 工具是专业翻译人员使用的,不适合外行用户。当然,人类的产出是有限且昂贵的。这就是机器翻译的用武之地。任何人都可以低价甚至免费使用机器翻译程序,但其可靠性要低得多。语言公司经常将它们与人工审核员一起部署。
如果您需要翻译服务,现在您可以权衡您的选择,做出符合您需求的明智决定。
计算机视觉 101:用 Python 处理彩色图像

来源:佩克斯。com
了解处理 RGB 和实验室图像的基础知识,以促进您的计算机视觉项目!
每一个计算机视觉项目——无论是猫/狗分类器还是给旧图像/电影添加颜色——都涉及到图像处理。而最终,模型只能和底层数据一样好——垃圾入,垃圾出。这就是为什么在这篇文章中,我重点解释在 Python 中处理彩色图像的基础知识,它们是如何表示的,以及如何将图像从一种颜色表示转换成另一种颜色表示。
设置
在本节中,我们将设置 Python 环境。首先,我们导入所有需要的库:
import numpy as npfrom skimage.color import rgb2lab, rgb2gray, lab2rgb
from skimage.io import imread, imshowimport matplotlib.pyplot as plt
我们使用 scikit-image ,这是来自scikit-learn家族的一个库,专注于处理图像。有许多可供选择的方法,一些库包括matplotlib、numpy、 OpenCV 、 Pillow 等。
在第二步中,我们定义一个 helper 函数,用于打印出关于图像的信息摘要——它的形状和每一层中的值的范围。
该函数的逻辑非常简单,一旦我们描述了图像是如何存储的,维度切片就有意义了。
灰度等级
我们从最基本的情况开始,灰度图像。这些图像完全是由灰色阴影构成的。极端情况是黑色(对比度的最弱强度)和白色(最强强度)。
在遮光罩下,图像被存储为整数矩阵,其中一个像素的值对应于给定的灰度。灰度图像的数值范围从 0(黑色)到 255(白色)。下图直观地概述了这一概念。

在这篇文章中,我们将使用你已经看到的缩略图,彩色蜡笔的圆圈。选了这么一张有色彩的图不是偶然的:)
我们首先将灰度图像加载到 Python 中并打印出来。
image_gs = imread('crayons.jpg', as_gray=True)fig, ax = plt.subplots(figsize=(9, 16))
imshow(image_gs, ax=ax)
ax.set_title('Grayscale image')
ax.axis('off');

由于原始图像是彩色的,我们使用as_gray=True将其加载为灰度图像。或者,我们可以使用默认设置imread加载图像(这将加载一个 RGB 图像——在下一节介绍),并使用rgb2gray功能将其转换为灰度。
接下来,我们运行 helper 函数来打印图像摘要。
print_image_summary(image_gs, ['G'])
运行代码会产生以下输出:
--------------
Image Details:
--------------
Image dimensions: (1280, 1920)
Channels:
G : min=0.0123, max=1.0000
图像存储为 1280 行×1920 列的 2D 矩阵(高清晰度分辨率)。通过查看最小值和最大值,我们可以看到它们在[0,1]范围内。这是因为它们被自动除以 255,这是处理图像的常见预处理步骤。
RGB
现在是使用颜色的时候了。我们从 RGB 模型 开始。简而言之,这是一个加法模型,其中红色、绿色和蓝色(因此得名)的阴影以各种比例添加在一起,以再现广泛的颜色光谱。
在scikit-image中,这是使用imread加载图像的默认模式:
image_rgb = imread('crayons.jpg')
在打印图像之前,让我们检查一下摘要,以了解图像在 Python 中的存储方式。
print_image_summary(image_rgb, ['R', 'G', 'B'])
运行代码会生成以下摘要:
--------------
Image Details:
--------------
Image dimensions: (1280, 1920, 3)
Channels:
R : min=0.0000, max=255.0000
G : min=0.0000, max=255.0000
B : min=0.0000, max=255.0000
与灰度图像相比,这次图像存储为 3D np.ndarray。额外的维度表示 3 个颜色通道中的每一个。和以前一样,颜色的强度在 0-255 的范围内显示。它经常被重新调整到[0,1]范围。然后,任何层中的像素值为 0 表示该像素的特定通道中没有颜色。
一个有用的提示:当使用 OpenCV 的imread函数时,图像被加载为 BGR 而不是 RGB。为了使它与其他库兼容,我们需要改变通道的顺序。
是时候打印图像和不同的颜色通道了:
fig, ax = plt.subplots(1, 4, figsize = (18, 30))ax[0].imshow(image_rgb/255.0)
ax[0].axis('off')
ax[0].set_title('original RGB')for i, lab in enumerate(['R','G','B'], 1):
temp = np.zeros(image_rgb.shape)
temp[:,:,i - 1] = image_rgb[:,:,i - 1]
ax[i].imshow(temp/255.0)
ax[i].axis("off")
ax[i].set_title(lab)plt.show()
在下图中,我们可以分别看到原始图像和 3 个颜色通道。我喜欢这幅图像的原因是,通过关注单个蜡笔,我们可以看到 RGB 通道中的哪些颜色以及哪些比例构成了原始图像中的最终颜色。

或者,我们可以绘制单独的颜色通道,如下所示:
fig, ax = plt.subplots(1, 4, figsize = (18, 30))ax[0].imshow(image_rgb)
ax[0].axis('off')
ax[0].set_title('original RGB')for i, cmap in enumerate(['Reds','Greens','Blues']):
ax[i+1].imshow(image_rgb[:,:,i], cmap=cmap)
ax[i+1].axis('off')
ax[i+1].set_title(cmap[0])plt.show()
什么会生成以下输出:

我更喜欢这种绘制 RGB 通道的变体,因为我发现它更容易区分不同的颜色(由于其他颜色更亮和透明,它们更突出)及其强度。
在处理图像分类任务时,我们经常会遇到 RGB 图像。当将卷积神经网络(CNN)应用于该任务时,我们需要将所有操作应用于所有 3 个颜色通道。在这篇文章中,我展示了如何使用 CNN 来处理二值图像分类问题。
工党
除了 RGB,另一种流行的表示彩色图像的方式是使用 Lab 色彩空间(也称为 CIELAB)。
在进入更多细节之前,指出颜色模型和颜色空间之间的区别是有意义的。颜色模型是描述颜色的数学方法。颜色空间是将真实的、可观察的颜色映射到颜色模型的离散值的方法。更多详情请参考本答案。
Lab 颜色空间将颜色表示为三个值:
- L :从 0(黑色)到 100(白色)范围内的亮度,实际上是灰度图像
- a :绿-红色谱,数值范围为-128(绿色)~ 127(红色)
- b :蓝黄色光谱,数值范围为-128(蓝色)~ 127(黄色)
换句话说,Lab 将图像编码为灰度层,并将三个颜色层减少为两个。
我们首先将图像从 RGB 转换到 Lab,并打印图像摘要:
image_lab = rgb2lab(image_rgb / 255)
rgb2lab函数假设 RGB 被标准化为 0 到 1 之间的值,这就是为什么所有值都除以 255 的原因。从下面的总结中,我们看到实验室值的范围在上面规定的范围内。
--------------
Image Details:
--------------
Image dimensions: (1280, 1920, 3)
Channels:
L : min=0.8618, max=100.0000
a : min=-73.6517, max=82.9795
b : min=-94.7288, max=91.2710
下一步,我们将图像可视化——实验室一号和每个单独的通道。
fig, ax = plt.subplots(1, 4, figsize = (18, 30))ax[0].imshow(image_lab)
ax[0].axis('off')
ax[0].set_title('Lab')for i, col in enumerate(['L', 'a', 'b'], 1):
imshow(image_lab[:, :, i-1], ax=ax[i])
ax[i].axis('off')
ax[i].set_title(col)fig.show()

第一次尝试绘制实验室图像
嗯,第一次可视化 Lab 色彩空间的尝试远远没有成功。第一张图像几乎无法辨认,L 层不是灰度。根据本答案中的见解,为了正确打印,实验室值必须重新调整到【0,1】范围。这一次,第一个图层的重定比例与后两个不同。
#scale the lab image
image_lab_scaled = (image_lab + [0, 128, 128]) / [100, 255, 255]fig, ax = plt.subplots(1, 4, figsize = (18, 30))ax[0].imshow(image_lab_scaled)
ax[0].axis('off')
ax[0].set_title('Lab scaled')for i, col in enumerate(['L', 'a', 'b'], 1):
imshow(image_lab_scaled[:, :, i-1], ax=ax[i])
ax[i].axis('off')
ax[i].set_title(col)
fig.show()
第二次尝试要好得多。在第一幅图像中,我们看到了彩色图像的 Lab 表示。这一次, L 层是实际的灰度图像。仍然可以改进的是最后两层,因为它们也是灰度的。

第二次尝试绘制实验室图像
在最后一次尝试中,我们将彩色贴图应用到实验室图像的 a 和 b 层。
fig, ax = plt.subplots(1, 4, figsize = (18, 30))ax[0].imshow(image_lab_scaled)
ax[0].axis('off')
ax[0].set_title('Lab scaled')imshow(image_lab_scaled[:,:,0], ax=ax[1])
ax[1].axis('off')
ax[1].set_title('L')ax[2].imshow(image_lab_scaled[:,:,1], cmap='RdYlGn_r')
ax[2].axis('off')
ax[2].set_title('a')ax[3].imshow(image_lab_scaled[:,:,2], cmap='YlGnBu_r')
ax[3].axis('off')
ax[3].set_title('b')
plt.show()
这一次结果令人满意。我们可以清楚的分辨出 a 和 b 图层中不同的颜色。仍然可以改进的是色彩映射表本身。为了简单起见,我使用了预定义的颜色贴图,它包含一种介于两种极端颜色之间的颜色(黄色代表图层 a ,绿色代表图层 b )。一个潜在的解决方案是手动编码彩色地图。

第三次尝试绘制实验室图像
在处理图像着色问题时,经常会遇到 Lab 图像,例如著名的去模糊。
结论
在本文中,我回顾了使用 Python 处理彩色图像的基础知识。使用所介绍的技术,你可以开始自己解决计算机视觉问题。我认为理解图像是如何存储的以及如何将它们转换成不同的表示是很重要的,这样你就不会在训练深度神经网络时遇到意想不到的问题。
另一个流行的色彩空间是 XYZ。scikit-image还包含将 RGB 或 Lab 图像转换成 XYZ 的功能。
您可以在我的 GitHub 上找到本文使用的代码。一如既往,我们欢迎任何建设性的反馈。你可以在推特上或者评论里联系我。
我最近出版了一本关于使用 Python 解决金融领域实际任务的书。如果你有兴趣,我贴了一篇文章介绍这本书的内容。你可以在亚马逊或者 T21 的网站上买到这本书。
参考
[1]https://ai.stanford.edu/~syyeung/cvweb/tutorial1.html
https://github.com/scikit-image/scikit-image/issues/1185
计算机视觉——当计算机能够看见和感知的时候!!!
电脑能够看、听和学习。欢迎来到未来”——戴夫·沃尔特斯

众所周知,计算机的计算能力远远超过人类。因此,自 20 世纪中期以来,已经尝试通过利用计算机来逐渐自动化计算繁重的活动。随着机器学习(ML)应用的出现和日益熟练,预测模型已经占据了优先地位。ML 接管的一些例子如下
- 通过主动识别可能终止订阅的客户来留住客户
- 销售、需求、收入等的预测。对于任何行业
- 识别任何行业中交叉销售的客户
- 识别可能拖欠按揭付款的客户
- 通过识别可能发生故障的机器进行预防性维护
然而,历史上需要人类感知来解决的问题超出了经典(静态)ML 算法的范围。好消息是,随着 2010 年代初以来深度学习(DL)的大规模突破,在解决传统上需要人类直觉的问题时,可以观察到接近人类的表现。前面提到的感知问题需要处理声音和图像的技能。因此,通过听觉和视觉进行感知和处理的能力似乎是促进解决此类问题的主要技能。这些技能对人类来说是自然而直观的,但对机器来说却是难以捉摸的。下面给出了一些通过应用 DL 解决感知问题的例子
- 接近人体水平的图像分类和目标检测
- 接近人类水平的语音识别
- 接近人类水平的笔迹转录
- 改进的机器翻译
- 改进的文本到语音转换
- Google Now、亚马逊 Alexa 等数字助手
- 接近人类水平的自动驾驶
- 回答自然语言问题的能力
然而,必须指出的是,这仅仅是一个开始,我们仅仅触及到所能取得的成就的表面。也有正在进行的对形式推理领域的研究。如果成功,这可能在科学、心理学、软件开发等领域帮助人类。
我想到的问题是,机器如何做到这一点,即获得感知能力来解决需要人类直觉的问题。数字处理,解决处理数字和/或类别的问题,应用监督学习(或无监督学习)属于具有巨大计算能力的机器领域。能够看到和识别图像的组成部分是一项新技能,本文的重点是关注现在赋予计算机像人类一样解决图像问题的能力的过程。本文的内容包括以下内容
- 人工智能(AI)和深度学习(DL)简介
- 通过应用全连接层(FCN)即多层感知器(MLP)进行图像识别
- 卷积神经网络介绍(CNN)
- 为什么 CNN 在解决图像相关问题时比 MLPs 更常用
- CNN 的工作
- MLP 和 CNN 的表现对比
人工智能和 DL 简介
人工智能是一个通过应用逻辑、if-then 规则、决策树和 ML(包括 DL)使计算机能够模仿人类智能的领域。人工神经网络是人工智能的一个分支。以下图示将进一步阐明 AI 的子集,即 ML 和 DL。数据科学跨越了人工智能的所有层面。

图 1:人工智能子集(图片由作者提供)
任何人工神经网络架构的基础都始于这样一个前提,即模型需要经历多次迭代,考虑到错误,从错误中学习,并在学习足够多的时候实现拯救或饱和,从而产生等于或类似于现实的结果。下图向我们简要介绍了人工神经网络,并介绍了 DL 神经网络。

图 2:浅层网络与 DLNN 的比较(图片来自作者的早期文章
人工神经网络本质上是一种由多层处理单元(即神经元)组成的结构,这些处理单元获取输入数据,并通过连续的层对其进行处理,以获得有意义的表示。深度学习中的 deep 这个词代表了这种连续层表示的思想。有多少层对一个数据模型有贡献,称为模型的深度。上图更好地说明了结构,因为我们有一个只有一个隐藏层的简单 ANN 和一个有多个隐藏层的 DL 神经网络(DNN)。因此,DL 或 DLNN 是具有多个隐藏层的 ANN。
本文假设读者熟悉构成监督学习基础的概念,以及 DL 如何利用它来学习数据中的模式(在这种情况下是图像中的模式)以获得准确的结果。为了更好地理解本文的其余部分,需要对以下项目有概念性的理解
- 监督学习
- 深度学习
- 损失函数
- 梯度下降
- 向前和向后传播
为了复习,读者可以在互联网上探索关于这些主题的免费资料,或者浏览我发表的文章,深度学习的基础。深入研究上述每个概念超出了本文的范围。
通过应用完全连接的层,即多层感知器的图像识别
现在让我们深入研究一个实例,说明如何利用人工神经网络来查看图像并将它们分类到适当的类别。我们将从在真实世界数据集上应用 FCN 开始,并衡量所实现的效率。假设读者对什么是 FCN 及其操作方式有更深的理解。在非常高的层次上,FCN 或 MLP 是一个人工神经网络,其中每一层的每个元素都与下一层的每个元素相连接。下面的图 3 展示了 FCN 的样子。更多细节请参考我发表的文章,深度学习的基础。
我们试图解决的问题包括从街道拍摄的门牌号图像中识别数字。数据集名为街景门牌号(SVHN)。SVHN 是一个真实世界的图像数据集,用于开发机器学习和对象识别算法,对数据格式的要求最低,但来自一个明显更难、未解决的真实世界问题(识别自然场景图像中的数字和数字)。SVHN 是从谷歌街景图片中的门牌号获得的。
我们要实现的目标是从 SVHN 数据集获取一个图像,并确定该数字是什么。这是一个多类分类问题,有 10 个可能的类,每个类对应一个数字 0-9。数字“1”的标签为 1,“9”的标签为 9,“0”的标签为 10。虽然,在这个数据集中有接近 6,000,000 幅图像,但我们已经提取了 60,000 幅图像(42000 幅训练图像和 18000 幅测试图像)来做这个项目。这些数据是以一个数字为中心的 32 乘 32 的 RGB 图像的类似 MNIST 的格式(许多图像在边上确实包含一些干扰物)。
我们将使用原始像素值作为网络的输入。这些图像是大小为 32×32 的矩阵。因此,我们将图像矩阵整形为一个大小为 1024 ( 32*32)的数组,并将该数组提供给如下所示的人工神经网络。

图 3: FCN 建筑(图片由作者提供)
链接到数据集的是这里的。
下面是加载数据和可视化一些图像的代码。

图 Jupyter 笔记本的截图,显示了一些图片及其标签
用不同数量的隐藏层和每层中不同数量的神经元构建多个 MLPs。对每个模型的结果进行比较,三个隐藏层的结果最好。模型架构如下所示。它达到了大约 80%的准确率。
下面描述了损失如何逐渐减少和精确度如何迭代增加的可视化

图 Jupyter 笔记本截图
预测了测试数据(未暴露于训练过程)中的一些图像。相同的可视化和与其原始标签的比较如下所示。

图 Jupyter 笔记本截图
我们测试了来自可视化测试集的 3 幅图像,并且看到分类是准确的,这可以给我们成就感和舒适感。如前所述,在整个测试集上达到的准确度为 80%。由于测试集由 18000 幅图像组成,80%的准确率是相当可接受的性能。然而,这是最好的方法吗?这是能达到的最好结果吗?或者有比这更好的方法吗?带着这些问题,让我们进入下一部分。
端到端项目的完整代码可以在我的 github 帐户中找到。代码的链接也可以在这里找到。
卷积神经网络介绍(CNN)
虽然上面解释的全连接网络(FCN)达到了可接受的精度,但它还可以进一步改进。除了 FCN,还有另一类神经网络称为卷积神经网络(CNN),其内部操作更符合视觉图像的处理要求。已经发现 CNN 在涉及图像的用例中给出更好的性能。
CNN 比 FCN 好得多,因为基于它们的共享权重架构和平移不变性特征,它们是平移不变或空间不变的人工神经网络。我们将在下一节中深入探讨这个问题。
在我们详细了解 CNN 如何工作以及为什么它们比 fcn 更好之前,让我们先了解一下 CNN 的基本操作。理解 CNN 最重要的概念是卷积运算。
卷积是一种简单的数学运算,是许多常见图像处理运算符的基础。卷积提供了一种将通常大小不同但维数相同的两个数列“相乘”的方法,以产生维数相同的第三个数列。这可以用在图像处理中,以实现其输出像素值是某些输入像素值的简单线性组合的算子。
在图像处理环境中,输入数组之一通常只是图像的像素表示。第二个数组通常小得多,并且通常是二维的(尽管它可能只有单个像素厚),并且被称为内核。下面是图像和可用于卷积的内核的图形表示。

图 7:图像和内核(作者提供的图像)
卷积是通过在图像上滑动内核来执行的,通常从左上角开始,以便将内核移动通过所有位置,其中内核完全适合图像的边界。(请注意,实现的不同之处在于它们在图像边缘做了什么,如下所述。)每个内核位置对应于单个输出像素,其值通过将内核值和内核中每个单元的底层图像像素值相乘,然后将所有这些数字相加来计算。
因此,在我们的示例中,输出图像中右下角像素的值将由下式给出:
o33 = I33 * W11+I34 * W12+I43 * W21+I44 * W22
由 CNN 完成的图像分类,通过获取输入图像、处理它并将其分类到某些类别下(例如,在我们的 use SVHN 用例中从 0 到 9)来工作。计算机将输入图像视为像素阵列。基于图像分辨率,它会看到 h x w x d( h =高度,w =宽度,d =尺寸)。

计算机视觉:计算机如何看到图像(来源:维基百科
卷积是从输入图像中提取特征的第一层。卷积通过使用输入数据的小方块学习图像特征来保持像素之间的关系。它是一种数学运算,需要两个输入,如图像矩阵和滤波器或内核。
下图说明了卷积(或相关)运算是如何执行的。这里,I 表示图像,W 表示将对输入图像进行卷积的核。

图 8:卷积运算
上面的描述可以通过一个核的实际例子来进一步简化,该核在由像素表示的图像上充当过滤器。上面的公式用于图像输入和内核权重,以得到内核或滤波器输出。

图 9:滤波器输出的计算
因此,当我们有一个更大的图像和一个典型的更小的内核时,内核将在图像上滑动,如下图所示,并通过卷积运算计算每次迭代的输出。滑过绿色方块的黄色方块就是内核。绿色方块是通过像素值表示的图像。卷积输出由右边的粉色方块表示,这实际上是学习到的特征。
图 10(来源:GIPHY 链接此处为。)
为什么 CNN 比 MLPs 更能解决图像相关问题
既然解决了卷积运算,让我们试着回答上面的问题。主要原因是
- 一个简单的 FCN 需要大量的参数来训练模型
- 在图像中,空间相关性是局部的
- 通常可用的图像数量有限
- 平移不变性是处理图像的关键要素
一个简单的 FCN 需要大量的参数来训练模型
FCNs(或 MLPs)对每个输入(例如,图像中的像素)使用一个感知器,并且对于大图像,权重的数量很快变得难以管理。它包含太多参数,因为它是完全连接的。每个节点都与上下一层中的所有其他节点相连,形成一个非常密集的网络。为了便于讨论,如果我们有一个如图 3 所示的人工神经网络,只有两个隐藏层的参数数量超过 2 亿个。这是一个尺寸只有 3232 的图像。对于尺寸为 200200 像素的中等大小的图像,需要训练的参数的数量将会达到顶点。因此,从(计算机的)计算能力的角度来看,使用 FCN(或 MLPs)来解决复杂的图像相关问题不是最佳方法。此外,如果可用图像的数量较少,用如此大量的参数进行训练将导致过度拟合。
在图像中,空间相关性是局部的。CNN 帮助实现平移不变性
另一个常见的问题是 MLP 对输入(图像)及其平移版本的反应不同,它们不是平移不变的。例如,如果一个航天飞机的图片出现在一个图片的图像的左上角,而在另一个图片的右下角,MLP 将试图纠正自己,并假设航天飞机将总是出现在图像的这一部分。请参考下面的图 11 进行说明。因此,MLP 不是图像处理的最佳选择。一个主要问题是,当图像被展平(矩阵到矢量)成 MLP 时,空间信息丢失。在 FCN 中,像素之间的相关性不是局部的,即航天飞机的组件与背景或图像中存在的任何其他对象相关(例如图 11 第一部分中的汽车)。因此,如果画面移动,模型中的学习就会受到影响。这是在 CNN 中解决的,因为它们依赖于卷积运算,并且即使图像移动,激活也将保持不变。当内核在图像上滑动以在每次迭代中提供激活时,激活被定位。重量是共享的。

图 11:CNN 中空间不变性的图示(图片由作者提供)
CNN 的工作
下图是一个 3232 大小的输入图像的 CNN 表示。我们有 20 个维数为 55 的核,它们执行前面解释的卷积运算。对图像进行第一次卷积运算后得到的特征图像的尺寸为 2828。下图中的 CONV 图层表示相同的图像,即 20 幅尺寸为 2828 的特征图像。计算任何卷积运算的结果维数的数学公式将在本节后面给出。

图 11:用于分类的 CNN 的端到端表示
这里引入的新概念是上图中的池层所表示的池操作,这个概念之前没有讨论过。
汇集操作包括在特征图的每个通道上滑动二维过滤器,并总结位于过滤器覆盖的区域内的特征。池层的数学计算与卷积运算非常相似。卷积层有助于学习图像的特征,并产生与使用的核的数量一样多的特征图。汇集层执行下采样操作,并汇总由卷积层生成的多个要素地图所产生的要素。这有助于巩固网络中的感受领域。典型的 CNN 架构通常具有一个接一个堆叠的多个卷积层和池层。
CNN 中的卷积层系统地将学习的滤波器应用于输入图像,以便创建概括输入中那些特征的存在的特征图。
卷积层被证明是非常有效的,并且在深度模型中堆叠卷积层允许靠近输入的层学习低级特征(例如,线),而在模型中更深的层学习高阶或更抽象的特征,如形状或特定对象。
卷积图层的要素地图输出的局限性在于,它们记录了输入中要素的精确位置。这意味着输入图像中特征位置的微小移动将导致不同的特征地图。这可以通过引入池层来解决。汇集图层汇总了由卷积图层生成的要素地图区域中的要素。因此,将对汇总的要素而不是由卷积层生成的精确定位的要素执行进一步的操作。这使得模型对于输入图像中特征位置的变化更加鲁棒。下面给出了两种主要的汇集方法
- 平均池:计算特征图上每个面片的平均值。

图 13:平均池操作的图示(来源
- 最大池(或最大池):计算特征图每个面片的最大值。

图 14:最大池操作的图示(来源)
在开始运行案例研究之前,我想解释的最后一件事是,当卷积图层应用于输入图像时,列出用于计算特征图维度的公式。相同的公式仍然适用于卷积和池的后续层。
输出图像尺寸= (W - F +2P)/S +1
其中 W =图像尺寸
F =过滤器的尺寸
P =填充
S =步幅
步幅表示我们在卷积中的每一步移动了多少步。默认情况下是一个。与步距 1 卷积。我们可以观察到输出的大小小于输入。为了保持输入中输出的维度,我们使用填充。填充是对输入矩阵对称加零的过程。对这两者更详细的解释可以在互联网上更多的免费内容中找到。
MLP 和 CNN 的表现对比
让我们继续我们试图在 SVHN 数据集上解决的数字识别问题。我们之前使用 FCNs(或 MLPs)达到了 80%的准确率。我们现在将在用于训练的数据集上试验 CNN 的应用。
下面提供了加载数据和预处理数据(标准化输入和一个热编码标签)的代码
第一个 CNN 尝试的模型架构如下
然后编译该模型,并通过它解析数据以进行训练。该模型在验证数据上给出了 90%的准确度,这已经比 MLP 实现的性能提高了 10%。下面给出了编译、训练和评估验证数据性能的代码
上面打印语句的输出是 90%。
模型如何迭代地学习特征并逐渐提高性能的可视化表示如下。我们看到了一种趋势,即每一个时期的损耗都在减少,而精度却在提高。

Jupyter Notebook 中模型精度随时期增加的图形表示
在用不同的模型架构进行了几次实验之后,从构建的 7 个 CNN 的集合中获得了最好的结果。准确率达到了 95%。模型中的混淆矩阵如下所示。整个代码的链接是 github 中的这里的。

Jupyter 笔记本的模型输出
结论
在这篇文章中,我们介绍了两种不同的方法来解决图像分类问题,即 FCNs 和 CNN。我们目睹了两种方法的性能差异,这是由于 CNN 优越的操作方式造成的。到目前为止,我们在 CNN 中看到的图像分类的优势进一步建立在解决更复杂的问题上,如对象检测和语义分割。它们都是复杂解决方案的关键组件,如自动驾驶汽车,机器必须识别汽车前方的不同物体及其结构,以便能够以适当的方向和角度驾驶汽车。本文开头的图片是我书房的桌子,后面是桌子上所有物品的标识。所有这些成就都建立在 CNN 潜在的和确定的概念之上。在接下来的几篇文章中,我们将探索一个称为迁移学习的新概念,它可以帮助我们处理训练图像数量不足的情况。敬请期待!!!
计算机视觉和终极乒乓人工智能
应用计算机视觉
使用 Python 和 OpenCV 在线玩 pong

人工智能在行动(右桨)
我最喜欢的一个 YouTuber,CodeBullet,曾经试图创造一个 pong AI 来统治他们。可悲的是,他遇到了麻烦,不是因为他没有能力,而是我不认为他当时的经验在计算机视觉方面有什么作用。他非常搞笑,我强烈推荐你观看他(建议家长咨询),如果你正在考虑阅读这篇文章的其余部分。此外,他是他所做的天才。爱你伙计。看他的视频这里。
这似乎是一个非常有趣和简单的任务,所以我必须尝试一下。在这篇文章中,我将概述我的一些考虑,如果你希望从事任何类似的项目,这可能会有所帮助,我想我会尝试更多的这些,所以如果你喜欢这种类型的事情,请考虑跟随我。
使用计算机视觉的好处是我可以使用一个已经构建好的游戏来处理图像。话虽如此,我们将使用与 CodeBullet 使用的来自 ponggame.org的游戏版本相同的游戏版本。它也有一个 2 人模式,所以我可以对我自己的人工智能玩;我做到了,这很难…
捕捉屏幕
最重要的事情是,得到屏幕。我想确保我的帧速率尽可能快,为此我发现 MSS 是一个很棒的 python 包。有了这个,我很容易达到 60 fps,相比之下,PIL 只有 20 fps。它以 numpy 数组的形式返回,所以我的生命是完整的。
挡板检测
为了简单起见,我们需要定义桨的位置。这可以用几种不同的方法来完成,但我认为最明显的方法是为每个桨屏蔽区域,并运行连接的组件来找到桨对象。下面是这段代码的一部分:
def get_objects_in_masked_region(img, vertices, connectivity = 8):
*'''****:return*** *connected components with stats in masked region
[0] retval number of total labels 0 is background
[1] labels image
[2] stats[0] leftmostx, [1] topmosty, [2] horizontal size, [3] vertical size, [4] area
[3] centroids
'''* mask = np.zeros_like(img)
# fill the mask
cv2.fillPoly(mask, [vertices], 255)
# now only show the area that is the mask
mask = cv2.bitwise_and(img, mask)
conn = cv2.connectedComponentsWithStats(mask, connectivity, cv2.CV_16U)
return conn
在上面,“顶点”只是一个定义遮罩区域的坐标列表。一旦我有了每个区域内的对象,我就可以得到它们的质心位置或边界框。需要注意的一点是,OpenCV 将背景作为第 0 个对象包含在任何连接的组件列表中,所以在这种情况下,我总是抓取第二大的对象。结果如下——右边绿色质心的桨是玩家/即将成为 AI 控制的桨。

挡板检测结果
移动船桨
现在我们有了输出,我们需要一个输入。为此,我求助于一个有用的软件包和其他人的代码——谢谢 StackOverflow。它使用 ctypes 来模拟键盘按键,在这种情况下,游戏是使用“k”和“m”键来玩的。我在这里得到了扫描码。在通过随机上下移动进行测试后,我们可以开始跟踪了。
乒乓检测
N ext up 用于识别和跟踪 pong。同样,这可以通过多种方式处理,其中一种方式是使用模板进行对象检测,但我还是使用了连接的组件和对象属性,即 pong 的面积,因为它是唯一具有其尺寸的对象。我知道每当乒乓球穿过或接触任何其他白色物体时,我都会遇到问题,但我也认为这没什么,只要我能在大多数时间里跟踪它。毕竟它是直线运动的。如果你看下面的视频,你会看到标记乒乓的红圈是如何闪烁的。这是因为它每 2 帧才发现 1 次。在 60 fps 时,这真的无关紧要。

乒乓检测显示为红色
用于反弹预测的光线投射
在这一点上,我们已经有了一个可以工作的人工智能。如果我们只是移动球员的球拍,使它和乒乓球在同一个 y 轴位置,它做得相当好。然而,当乒乓球反弹时,它确实会遇到问题。球拍太慢了,跟不上,需要预测乒乓球的位置,而不是移动到它现在的位置。这已经在上面的剪辑中实现了,但下面是两种方法的比较。

并排的两个 AI 选项。左为简单跟随,右为光线投射反弹预测
差别不是很大,但在正确的人工智能下,这绝对是一场更稳定的胜利。为此,我首先为 pong 创建了一个位置列表。为了平均起见,我将这个列表的长度保持在 5,但或多或少都可以。可能不想要更多,否则它需要更长的时间来发现它已经改变了方向。得到位置列表后,我使用简单的矢量平均来平滑并获得方向矢量——如绿色箭头所示。这也被标准化为一个单位向量,然后乘以一个长度,以便可视化。
投射光线只是这种方法的一种延伸——使正向投影变得更长。然后我检查未来的头寸是否在顶部和底部区域的边界之外。如果是这样,它只是将位置投射回游戏区域。对于左侧和右侧,它会计算与踏板 x 位置的交点,并将 x 和 y 位置固定到该点。这可以确保桨对准正确的位置。没有这一点,它往往会走得太远。下面是定义预测乒乓未来位置的光线的代码:
def pong_ray(pong_pos, dir_vec, l_paddle, r_paddle, boundaries, steps = 250):
future_pts_list = []
for i in range(steps):
x_tmp = int(i * dir_vect[0] + pong_pos[0])
y_tmp = int(i * dir_vect[1] + pong_pos[1])
if y_tmp > boundaries[3]: #bottom
y_end = int(2*boundaries[3] - y_tmp)
x_end = x_tmp
elif y_tmp < boundaries[2]: #top
y_end = int(-1*y_tmp)
x_end = x_tmp
else:
y_end = y_tmp
##stop where paddle can reach
if x_tmp > r_paddle[0]: #right
x_end = int(boundaries[1])
y_end = int(pong_pos[1] + ((boundaries[1] - pong_pos[0])/dir_vec[0])*dir_vec[1])
elif x_tmp < boundaries[0]: #left
x_end = int(boundaries[0])
y_end = int(pong_pos[1] + ((boundaries[0] - pong_pos[0]) / dir_vec[0]) * dir_vec[1])
else:
x_end = x_tmp
end_pos = (x_end, y_end)
future_pts_list.append(end_pos)
return future_pts_list
在上面的计算中,可能不太明显的是确定桨片到达目标的左右位置的截距。我们基本上是通过下图所示的相似三角形和等式来实现的。我们知道在边界中给出的桨的 x 位置的截距。然后,我们可以计算 pong 将移动多远,并将其添加到当前的 y 位置。

桨式瞄准拦截位置的计算示意图
这些桨虽然看起来是直的,但实际上有一个弯曲的反弹面。也就是说,如果你用球拍向两端击球,球会反弹,就好像球拍是倾斜的一样。因此,我允许球拍打在边缘,这增加了人工智能的攻击性,导致乒乓球飞来飞去。
结论
答虽然是为 pong 的特定实现而设计的,但相同的概念和代码可以用于任何版本——它只是改变了一些预处理步骤。当然,另一种方法是通过强化学习或只是简单的 conv 网来使用机器学习,但我喜欢这种经典的方法;至少在这种情况下,我不需要强大的通用性或困难的图像处理步骤。正如我提到的,这个版本的 pong 是双人的,老实说,我不能打败我自己的 AI…

如果你在这篇文章的任何部分提供了一些有用的信息或一点灵感,请关注我。
你可以在我的 github 上找到源代码。
链接到我的其他帖子:
- 《我的世界》测绘仪 —计算机视觉和光学字符识别从截图和绘图中抓取位置
Dask 和 PyTorch 的计算机视觉
免责声明:我是 Saturn Cloud 的高级数据科学家,Saturn Cloud 是一个使用 Dask 实现 Python 易于使用的并行化和扩展的平台。
将深度学习策略应用于计算机视觉问题,为数据科学家打开了一个可能性的世界。然而,要大规模使用这些技术来创造商业价值,需要大量的计算资源可用——而这正是土星云要解决的挑战!
在本教程中,您将看到使用流行的 Resnet50 深度学习模型在土星云上使用 GPU 集群进行大规模图像分类推理的步骤。使用 Saturn Cloud 提供的资源,我们运行任务的速度比非并行方法快 40 倍!

在今天的例子中,我们将对狗的照片进行分类!
你将在这里学到:
- 如何在 Saturn Cloud 上设置和管理用于深度学习推理任务的 GPU 集群
- 如何在 GPU 集群上使用 Pytorch 运行推理任务
- 如何在 GPU 集群上使用 Pytorch 使用批处理来加速您的推理任务
设置
首先,我们需要确保我们的图像数据集可用,并且我们的 GPU 集群正在运行。
在我们的例子中,我们已经将数据存储在 S3 上,并使用[s3fs](https://s3fs.readthedocs.io/en/latest/)库来处理它,如下所示。如果你想使用同样的数据集,这是斯坦福狗的数据集,可以在这里找到:http://vision.stanford.edu/aditya86/ImageNetDogs/
要设置我们的 Saturn GPU 集群,过程非常简单。
【2020–10–15 18:52:56】信息— dask-saturn |星团准备就绪
我们没有明确说明,但是我们在集群节点上使用了 32 个线程,总共有 128 个线程。
**提示:**单个用户可能会发现您想要调整线程的数量,如果您的文件非常大,则减少线程数量——同时运行大型任务的太多线程可能需要比您的工作人员一次可用的内存更多的内存。
这一步可能需要一段时间才能完成,因为我们请求的所有 AWS 实例都需要启动。在最后调用client会监控旋转过程,并让你知道什么时候一切准备就绪!
GPU 能力
此时,我们可以确认我们的集群具有 GPU 功能,并确保我们已经正确设置了一切。
首先,检查 Jupyter 实例是否具有 GPU 功能。
torch.cuda.is_available()
真实
太棒了——现在让我们也检查一下我们的四个工人。
client.run(lambda: torch.cuda.is_available())
在这里,我们将“设备”设置为 cuda,这样我们就可以使用这些 GPU。
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
注意:如果你需要一些帮助来建立如何运行单个图像分类,我在 github 上有一个 扩展代码笔记本,可以给你那些说明以及其余的内容。
推理
现在,我们准备开始做一些分类!我们将使用一些定制的函数来高效地完成这项工作,并确保我们的工作能够充分利用 GPU 集群的并行性。
预处理
单一图像处理
这个函数允许我们处理一个图像,但是当然我们有很多图像要处理!我们将使用一些列表理解策略来创建我们的批次,并为我们的推断做好准备。
首先,我们将 S3 文件路径中的图像列表分成定义批处理的块。
s3fpath = 's3://dask-datasets/dogs/Images/*/*.jpg'batch_breaks = [list(batch) for batch in toolz.partition_all(60, s3.glob(s3fpath))]
然后我们将每个文件处理成嵌套列表。然后我们将稍微重新格式化这个列表设置,我们就可以开始了!
image_batches = [[preprocess(x, fs=s3) for x in y] for y in batch_breaks]
注意,我们已经在所有这些上使用了 Dask delayed装饰器——我们还不想让它实际运行,而是等到我们在 GPU 集群上并行工作的时候!
格式化批次
这一小步只是确保图像批次按照模型期望的方式组织。
运行模型
现在我们准备做推理任务了!这将有几个步骤,所有这些步骤都包含在下面描述的函数中,但是我们将通过它们进行讨论,以便一切都很清楚。
我们在这一点上的工作单位是一次 60 个图像的批次,这是我们在上一节中创建的。它们都整齐地排列在列表中,以便我们可以有效地使用它们。
我们需要对列表做的一件事是“堆叠”张量。我们可以在过程的早期这样做,但是因为我们在预处理中使用了 Dask delayed decorator,我们的函数实际上直到过程的后期才知道它们正在接收张量。因此,我们也通过把它放在预处理之后的函数中来延迟“堆栈”。
现在我们把张量堆叠起来,这样就可以把批次传递给模型了。我们将使用非常简单的语法来检索我们的模型:
方便的是,我们加载库torchvision,它包含几个有用的预训练模型和数据集。我们就是从那里拿到 Resnet50 的。调用方法.to(device)允许我们将模型对象分配给集群上的 GPU 资源。
现在我们准备运行推理!它在同一个函数中,风格如下:
我们将图像堆栈(只是我们正在处理的批处理)分配给 GPU 资源,然后运行推理,返回该批处理的预测。
结果评估
然而,到目前为止,我们得到的预测和事实并不是人类真正可读或可比的,所以我们将使用下面的函数来修正它们并得到可解释的结果。
这将从模型中获取我们的结果,以及一些其他元素,以返回好的可读预测和模型分配的概率。
preds, labslist = evaluate_pred_batch(pred_batch, truelabels, classes)
从这里开始,我们就快完成了!我们希望以一种整洁的、人类可读的方式将我们的结果传递回 S3,所以函数的其余部分会处理这一点。它将迭代每个图像,因为这些功能不是批处理。is_match是我们的自定义功能之一,您可以在下面查看。
把它们放在一起
现在,我们不打算手工将所有这些函数拼凑在一起,而是将它们组装在一个单独的延迟函数中,它将为我们完成这项工作。重要的是,我们可以将它映射到集群中的所有映像批次!
在群集上
我们真的已经完成了所有的艰苦工作,现在可以让我们的功能接手了。我们将使用.map方法来有效地分配我们的任务。
通过map,我们确保我们所有的批次都能应用该功能。使用gather,我们可以同时收集所有结果,而不是一个接一个地收集。用compute(sync=False)我们返回所有的期货,准备在我们需要的时候被计算。这可能看起来很艰巨,但是这些步骤是允许我们迭代未来所必需的。
现在我们实际上运行任务,我们也有一个简单的错误处理系统,以防我们的任何文件被搞乱或出现任何问题。
评价
当然,我们希望确保从这个模型中获得高质量的结果!首先,我们可以看到一个结果。
{‘name’: 'n02086240_1082 ',
’ ground _ truth ‘:’ Shih-zi ',
‘prediction’: [(b"203:‘西高地白梗’,",3.0289587812148966e-05)],
‘evaluation’: False}
虽然我们在这里有一个错误的预测,但我们有我们期望的那种结果!为了做更彻底的检查,我们将下载所有的结果文件,然后检查有多少有evaluation:True。
检查的狗狗照片数量:20580
分类正确的狗狗数量:13806
分类正确的狗狗比例:67.085%
不完美,但整体效果不错!
比较性能
因此,我们在大约 5 分钟内成功地对超过 20,000 张图片进行了分类。这听起来不错,但有什么选择呢?

技术/运行时间
- 无集群批处理/ 3 小时 21 分 13 秒
- 带批处理的 GPU 集群/ 5 分 15 秒
添加一个 GPU 集群会带来巨大的不同!
结论
正如这表明的那样,你当然能够在单节点计算中进行深度学习推理,比如在笔记本电脑上,但当你这样做时,你会等待很长时间。GPU 集群为您提供了一种大幅加速工作流的方式,使您能够更快地迭代并改进业务或学术实践。试想:如果您想每小时对您的图像进行推理,该怎么办?在这种情况下,单个节点根本无法工作,因为作业甚至无法在一小时内完成!
GPU 通常被视为机器学习任务的一个极端选择,但在现实中,在 GPU 可能的加速下,您通常可以降低人力时间和美元的总体成本。AWS 的一个 CPU 实例不是免费的,在那个实例上三个小时的计算成本会增加。在许多情况下,为了获得相同的结果,这可能比您在 GPU 集群上花五分钟的时间还要多。
在土星云,我们希望为数据科学社区提供最优质的计算资源,我们希望帮助每个人成为更有效的机器学习实践者。您可以了解更多关于我们和上述工具的信息(并免费试用我们的平台!)在我们的网站。
计算机视觉——使用卷积、池化和张量流创建分类器
计算机如何识别图像,以及如何在分类中使用它

本文旨在解释扁平化、卷积和汇集思想背后的直觉,以及在创建图像分类器时如何在 TensorFlow 中使用这些概念。
使用的技术有 python,TensorFlow 和 Keras API。
使用的数据集:
时尚 MNIST——【https://www.kaggle.com/zalando-research/fashionmnist
关于将用于说明关键概念的数据集的一些信息:
名称:时尚 MNIST
观察次数: 70000
类别数量: 10
类别的标签和名称:
0 - T 恤/上衣
一条裤子
两件套衫
3 -连衣裙
四层涂层
5 -凉鞋
6 件衬衫
7 -运动鞋
8 袋
9 -踝靴
随机样本:

集合中图像的随机样本
让我们从检查来自时尚 MNIST 数据集的图像开始:

28 x 28 t 恤图片
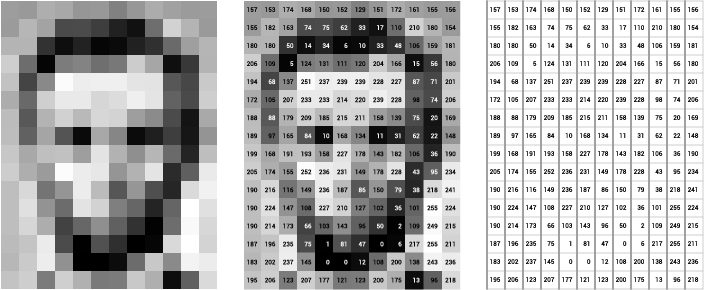
这是一个灰度(意味着它只有一个像素通道)图像,宽 28 像素,高 28 像素。我们只能看到图片的渲染形式,但图像本身是以数字矩阵的形式存储在计算机内存中的:

图片的矩阵表示
典型的像素值从 0 到 255,其中 0 为白色,255 为黑色。
计算机“看到”图像的方式仅仅是通过上面表示的像素值。即使是最先进的图像识别算法也只是将像素转换成数字数组。
基本上,当我们谈论计算机视觉时,我们谈论的是计算机学习数字矩阵和标签之间的关系。
当试图构造图像分类器时,最基本的方法是使用图像中的每个像素作为单独的特征。这个过程叫做展平。

拉平像素
在上面的图片中,我画了一个假想的笑脸图片,总共有 36 个像素。白色像素等于 0,黑色像素等于 1。
扁平化的过程只不过是将二维图片(或者更高维,如果图片有颜色的话)转换成一维向量。我假设数组从 0 开始,所以第 7 个坐标等于 1(代表[2][2]像素),第 10 个坐标等于 1(代表[2][5]像素),依此类推。展平的最终输出是一个 36 维向量。
一般规则是,如果输入是 n×m 像素化的图像,那么输出将是 n×m 长度的向量。
如果每张图片都有一个相关联的标签,比如“快乐”(=1)和“不快乐”(=0),那么模型的矩阵 X 和 Y 的构造就很简单:

从图片中创建矩阵
这个过程是将每张图片展平,并将每个矢量一个叠一个地堆叠起来。所以现在,我们可以开始建立模型,因为我们已经创建了代表图片的数字矩阵,各种优化算法可以开始工作了。
在上面画的例子中,如果我们有 100 张图片,那么 X 矩阵将有 100 行和 36 列(特征),Y 向量的长度将是 100。对于这样的小图片,像逻辑回归这样的技术在预测未来的图像标签时可以做得很好。然而,在本文中,我将只使用深度学习模型。
让我们使用时尚 MNIST 数据集和一个非常简单的深度学习模型,并为此使用 flatten()层:

模型拟合和测试
该模型在训练集和测试集中的准确率分别达到了 91.5% 和 88.3% 。
虽然仅使用展平层作为像素的主要预处理器工作良好,但它有其缺点。
首先,当图片从 28 x 28 像素增长到更真实的尺寸时,如 256 x 256、512 x 512 等等,每张图片的特征矩阵迅速扩展:

X 矩阵的指数增长
因此,即使对于现代机器来说,训练一个具有数百万特征的前馈网络也是非常昂贵的。
第二,当我们使用单个像素作为特征时,图片的轻微变化,如人脸不在中心,各种相机旋转,背景的变化都可能以戏剧性的方式扭曲特征矩阵。这将导致创建在测试集上推广良好的分类器非常困难。
第三,在大多数图片中,有大量的背景噪声,这不会以任何方式提高分类器的决策。例如,在时尚 MNIST 数据集中,背景中有许多白色像素,这只是扩展了特征矩阵,而没有向神经模型添加太多信息。
所有这三个问题都可以通过在神经网络中增加两层来解决——卷积和池化。
TensorFlow 官方文档中的卷积层可以在这里找到:https://www . tensor flow . org/API _ docs/python/TF/keras/layers/Conv2D/。
卷积是一种简单的数学运算,是许多常见图像处理运算符的基础。卷积提供了一种将两个数字数组“相乘”的方法,这两个数组通常大小不同,但维数相同,从而产生第三个维数相同的数字数组。这可以用在图像处理中,以实现其输出像素值是某些输入像素值的简单线性组合的算子。
下面的动画很好地理解了卷积运算:

回旋在行动
左边的块代表具有特定像素值的图像,中间的小 3x3 块通常被称为滤镜。
最终值是通过一个简单的公式计算出来的——滤镜在图像上滑动,滤镜中的值乘以适当的像素值并求和。例如,结果块中的第一个值由以下公式计算:
**7 * 1+0 * 2±1 * 3+1 * 4+5 * 0+3 -1+3 * 1+3 * 0+2 -1 = 6
不同的滤镜会突出显示图像中的不同属性。一些过滤器强调水平线,另一些强调垂直线和其间的任何东西。
比如一个滤镜:
【0 1 0】
【1-4 1】
【0 1 0】
会突出照片的边缘。python 中的一个例子:

原图

应用滤镜后的图片
张量流卷积层创建固定大小的随机滤波器,然后在训练阶段,算法决定如何改变滤波器值以尽可能优化损失函数。
在获得上一节描述的卷积特征后,我们决定区域的大小,比如说𝑚𝑥𝑛来汇集卷积特征。然后,我们将我们的卷积特征分成不相交的𝑚𝑥𝑛区域,并在这些区域上取平均(或最大)特征激活以获得汇集的卷积特征。然后,这些汇集的特征可用于分类。

联营业务
这种技术很有用,因为至少在某种程度上,它消除了图像中小像素变化的影响。例如,一只鸟的头可以在图像的中间,或者稍微偏左或偏右。
TensorFlow 官方文档:https://www.tensorflow.org/api_docs/python/tf/nn/pool
让我们将两个新层添加到我们的神经网络中:
model.summary() 输出:

模型概述
您可能会注意到,第一个卷积层的输出形状是 26 x 26 x 16,而图片的原始形状是 28 x 28。像素的损失是由于过滤的性质。回想一下第一部分的动画。图片边缘的像素仅用于计算滤波器值和丢弃值。
max-pooling 层输出的形状为 13 x 13 x 16,这是因为我们使用了(2,2)正方形,将原始图片大小缩小到原始图片的四分之一(回想一下动画)。展平层输出大小可以通过公式 13 * 13 * 16 来计算。
数字 16 等于 tf.keras.layers.Conv2D 层中定义的滤镜数。这意味着创建了 16 个独特的过滤器。因此,在网络的中心,从每一张输入图片中,有 16 张新图片被创造出来。
该模型的结果具有与更简单模型中相同的历元数:

模型的训练
池化和卷积层的加入提高了模型的训练和测试精度:训练集中的 96.08% ,测试集中的 91.4% 。
为了更好地理解计算机如何看待图像以及图像中的哪些特征最重要,我们可以直观地检查模型中第一层(即卷积层)的输出。
为此,我将使用以下代码:
对于 t 恤衫:


t 恤的卷积层
对于鞋子:


鞋子的回旋层
对于 t 恤,我们可以看到 t 恤边缘的直线被照亮,这意味着这些像素有助于确定类别。此外,前面的标志也是一个明显的特征。
对于鞋子,完全不同的像素被点亮。在这种情况下,鞋子顶部轮廓的水平线被照亮。
现在卷积的图像与最大池层一起滑动,变平并馈送到简单的前馈网络。
总的来说,最先进的图像分类器是使用数百万张图片训练的,在这些网络的核心,有各种池和卷积层的组合。
在获奖车型中,如
【https://keras.io/api/applications/resnet/#resnet50-function
或者
实例化异常架构。参考可选择加载 ImageNet 上预先训练的重量。请注意,数据…
keras.io](https://keras.io/api/applications/xception/)
有数百万个参数和数百个层,但是基本的构建块是卷积和池。
我希望对于基本的图像分类任务,读者可以使用我提供的代码。
编码快乐!
用于自动道路损伤检测的计算机视觉

城市道路鸟瞰图(来源)
注:本项目由 尼古拉斯·斯特恩 , 克莱尔·斯托尔兹 , 内森·爱因斯坦 , 安卡·德勒古列斯库 合著。
介绍
日益恶化的道路困扰着气候多变、预算紧张的地区。市政府在对热点地区进行分类和定位以解决问题时,如何保持领先是一个持续的挑战。在美国,大多数州仅采用半自动方法来跟踪道路损坏情况,而在世界其他地区,该过程完全是手动的,或者完全被放弃。收集这些数据的过程既昂贵又耗时,而且必须以相对较高的频率进行以确保数据是最新的。这就引出了一个问题:计算机视觉有帮助吗?
对于我们哈佛大学数据科学硕士项目的顶点项目,我们旨在与我们的行业合作伙伴 Lab1886 一起深入研究这个问题。特别是,我们寻求以下问题的答案:
我们能否通过利用汽车仪表盘上智能手机拍摄的原始视频片段,自动检测道路损坏的严重程度并进行分类?这样做需要克服哪些技术挑战?
这篇文章介绍了我们解决这个任务的方法,强调了我们在这个过程中遇到的意外问题。我们希望与更广泛的数据科学社区分享这些信息,以便为那些致力于类似目标的人提供信息并做好准备。
目前的技术水平

图 1:现有道路损坏检测论文的示例图像。
在深入我们自己的实现之前,我们调查了当前的技术水平,以了解其他人已经完成了什么。根据我们的文献综述,我们发现大多数方法可以分为以下几类:
- **3D 分析:**使用立体图像分析或激光雷达点云检测路面异常情况。
- **基于振动的分析:**利用车载加速度计或陀螺仪。
- **基于视觉的模型:**从边缘检测等传统技术&光谱 segmentation⁴到通过卷积神经网络(CNN)进行表示学习和分割。⁵
由于我们的主要任务是固有的视觉,并且无法访问激光雷达或振动数据,我们选择专注于基于视觉的算法,特别是监督学习方法。
我们早期注意到的一个问题是,相关研究主要依赖于特写图像或垂直于路面拍摄的图像。这是有问题的,因为这些图像看起来与从安装在仪表板上的摄像机流出的图像明显不同,所以不能用于训练或校准旨在摄取后者的模型。
我们的数据
我们可以访问从安装在汽车上的照相手机收集的数据集。整个数据集包括大约 27,000 张德国的道路图像,拍摄于 40 多次不同的旅行中,通常是在阳光充足和干燥的条件下。我们图像中的道路类型变化很大:一些是多车道的城市道路,周围有建筑,另一些是没有路标或建筑的乡村道路。路面也各不相同,从混凝土到沥青再到鹅卵石。以大约每秒 1 幅图像的速度连续拍摄图像。下面的图 2 中包含了一些例子。

图 2:来自 Lab1886 提供的数据集的样本图像。
数据注释困境
由于我们的数据集缺少标签,我们需要一种方法来解析每幅图像,并分割出每种道路损坏类型的相关像素,以及某种严重程度标签。手动,这是一个可怕的任务,所以我们的目标是以几种方式简化我们的生活。
首先,由于有许多不同形式的道路损坏(即鳄鱼裂缝、纵向裂缝、坑洼、补丁、油漆),我们选择缩小工作范围,仅查看油漆损坏。我们希望这不仅能使注释数据更容易处理,还能为我们以后识别其他类型的道路损坏提供信息。
其次,我们尝试使用预先训练的分类模型筛选出没有油漆损坏的图像。特别是,我们从前田等人的 al.⁶公司提取了两个预训练模型——在 10,000 多张图像上训练的分类器,以识别 8 种不同类型的道路损坏(包括磨损的油漆线)和边界框。这些模型很难推广到我们的数据集。看看图 3 中的小提琴图,我们可以看到,无论是否存在油漆损坏,模型预测的分布几乎是相同的。

图 3:来自 Maeda 等人、 MobileNet-SSD 和 Inception-SSD 的模型的小提琴图。这些图表明,再多的参数调整也无法帮助模型区分油漆损坏的存在与否。
第三,我们尝试通过 Mechanical Turk (MTurk)众包注释,这是亚马逊提供的一项服务,参与者可以执行简单的任务,以换取金钱补偿。我们的任务是:通过突出显示该区域并从下拉菜单中选择相应的严重性标签来注释图像中的油漆损坏。我们选择了以下简单的严重性等级:
- 1 —轻度损坏
- 2 —中度/中度损坏
- 3 —严重损坏
图 4 提供了一个 MTurk 注释接口的例子。我们用 200 幅图像的样本进行了几次试点实验,每次都修改指令,以纠正我们在之前的实验中观察到的不必要的行为。我们至少有三名工人为每张图片贴标签,以衡量贴标机的一致性。

图 MTurk 注释接口的例子。
即使在我们第三次迭代说明之后,工人们在注释什么和如何注释上仍有分歧。我们使用联合交集(IoU)“一致性”分数来量化同一图像的不同贴标机之间的一致性,如图 5 所示。根据协议分布,大多数标注者在他们的注释中根本没有重叠*。这是一个重要的迹象,表明对非专业人员来说,始终如一地标注油漆损坏是一项意想不到的困难任务。*
因此,我们最终选择自己标记数据。总的来说,我们注释了 1,357 幅图像,包括每个严重性级别的至少 300 个实例。

图 5:通过 MTurk 标记的图像的贴标机一致性分数的分布(通过对每个单独图像的不同注释取并集的交集来计算)。这显示了任务的高度主观性,以及众包它很难的原因。
建模
我们的核心任务是回答两个问题:
- 损伤在哪里?
- 有多糟糕?
不确定从建模的角度来看哪个问题更难回答,我们采用了两种方法。我们最初的方法是一个多阶段的方法,用两个不同的模型分别解决每个问题。
我们首先需要一种分割算法来识别输入图像中存在油漆损坏的区域。为了激励深度学习的使用,我们尝试了一些传统的计算机视觉技术,看看它们是否能够充分掩盖绘画。我们探索了阈值处理、分水岭分割和简单线性交互聚类(SLIC ),所有这些都需要大量的手动超参数调整,并且无法在多个图像之间进行推广。图 6 显示了这些方法在一个示例图像上的结果。

图 6:三种图像分割算法在我们的数据集中的单个图像上运行的结果。
因此,我们转向流行的卷积编码器-解码器网络,U-Net⁷,来执行单通道语义分割。模型的输出是每个像素的预测概率,即它是否代表油漆损坏。
理论上,我们将对预测进行阈值处理,以生成从输入图像中提取受损区域的掩模,然后将其输入分类器,以预测严重性标签。在实践中,我们使用基础事实注释来准备严重性分类模型的输入,认识到分段模型可能表现不佳的可能性。这样,我们能够分别评估分段和严重性分类的难度。我们使用的分类器是基于 ResNet18 架构的 CNN。

图 7:左图:原始图像。中/右:传递到我们的分类器模型中的相应屏蔽输入。
我们在总图像的 15%的测试集上评估了我们的每个模型。单类语义分割模型的输出示例如图 7 所示。与传统的计算机视觉方法相比,一个巨大的改进是该模型学会了分割油漆线(见图 8)。然而,该模型倾向于过度预测油漆损坏的存在,正如图 9 中显示的像素级精度和召回曲线所揭示的那样。

图 8:左图:原图。中间:地面真相面具。右图:单通道分段模型的阈值输出。
严重性分类器的结果显示,网络能够在一定程度上区分低和高严重性油漆损坏,但难以区分低和中等严重性损坏(见图 10)。这是一个危险信号,可能标记的低度和中度损害的实例彼此过于相似,因为模型对两者做出了相似的预测。考虑到我们自己在区分轻度和中度损伤时的困难程度,这个结果并不令人惊讶。

图 9:作为概率阈值函数的单通道分割模型的像素级精度和召回率。该模型预测,随着阈值的提高,损害会减少。

图 10:严重性分类网络的混淆矩阵。每一类的预测准确率如下:1–74.5%,2–5.9%,3–54.2%,总体:45%。
作为建模的第二种方法,我们调整了我们的 U-Net 以执行多类分割,现在除了包含所有无损坏像素的“背景”遮罩之外,还为每个严重性级别生成一个遮罩。一些预测的例子如图 11 所示。

图 11:多类分割模型的示例输出。从左至右:严重性等级 1、2 和 3 的输入、目标和像素级预测。
多级分割模型的性能与多级方法的分类器非常相似,因为它能够部分地将低严重性油漆损坏与高严重性油漆损坏区分开来,但对低严重性和中等严重性级别做出了相似的预测。这在图 12 中表现得最为明显。

图 12:作为概率阈值函数的多类分割模型的交集/并集。
多类模型的性能对预测阈值非常敏感,即在我们将该像素指定为“受损”之前,该模型在其逐像素预测中必须具有的确定性鉴于该模型在低和中等损害等级之间的不确定性,它倾向于给这两个等级分配非常低的概率。高于 20%的确定性阈值时,我们的多类分割模型仅预测高严重性损害。然而,较低的阈值导致了对受损区域的过度预测。这样,区分严重程度的困难就与识别损伤存在的困难混为一谈了。这支持了我们的假设,即从建模的角度来看,多阶段方法可能更有利于阐明任务的哪些方面最具挑战性。
关键要点
1.普遍性
理想情况下,我们的模型对于在新地点、从不同角度、在不同光照条件或天气下获取的新数据保持准确。我们发现,对于道路损坏检测,概化是一个真正的挑战。特别是,Maeda 等人的模型根本不能推广到我们的数据集。虽然日本的道路和德国的道路确实有细微的系统差异(德国的道路通常更宽,颜色更浅),但我们的工作表明,任何现有的模型都需要大量的再培训和调整,才能处理新的数据。此外,我们已经证明了用复杂的神经网络进行表征学习是必要的,因为简单的计算机视觉方法无法做到这一点。
在你说“咄”之前,事实上,当你考虑到已经注释道路损坏的公开可用数据的缺乏时,这是一个大问题。上面带有严重性标签的数据是不存在的。由于数据收集和注释的艰巨性,对于没有资源获取自己的数据或雇佣受过培训并具有专业知识的人员来构建复杂模型的地方政府来说,拥有预先训练的可概括模型将是一笔巨大的资产。
2.嘈杂的注释
我们的注释目标看似简单明了:识别受损的油漆,并给它分配 1、2 或 3 的严重性分数。然而,当我们开始回顾 MTurk 的结果时,我们发现事情并不那么简单。
即使贴标签机提供了极其详细的说明和大量的例子,工人之间也很少有一致意见。出现的一些意想不到的问题是:
- 应该突出显示整条油漆线,还是只突出显示虚线部分?
- 这里应该有油漆吗?
- 我们应该标记多远的距离?
- 损伤周围的“缓冲”区域有多少应该被注释以提供建模的背景?
即使在讨论了这些要点并自己标注了数据之后,我们还是目睹了几个矛盾的例子,说明什么构成了低与中等严重程度损害的实例。因此,我们建议研究人员将他们的严重程度分成满足他们要求的尽可能少的类别。我们怀疑这是我们的模型学会区分极端情况,但无法区分低度和中度严重程度的关键原因。为了减少这种错误,我们需要更一致的标签(也许由专家),更多的数据,或者更少的严重性等级。
3.模型评估
分割模型的定量评估是微妙的。首先,任何与地面真实遮罩的比较都会受到两个噪声源的影响:
- 来自不一致注释的非故意噪音(对我们来说是一个真正的问题)。
- 在注释过程中,围绕绘画高亮显示的场景上下文的数量。
为了说明第二点,考虑 IoU 指标。假设我们有一个完美的模型,只分割绘画线条,在突出场景上下文中的注释越自由,IoU 分数就越低。
另一种评估选择涉及以像素或图像为单位计算精度和召回率(即,可以对每个像素进行预测或对每个图像进行预测)。为了将像素级预测映射到图像,我们认为图像中任何正像素预测的存在都是该图像的正预测。哪个信息量更大?此外,任何精度和召回率的计算必须由最终用户希望模型有多保守来限定。
请注意,我们用于评估模型的指标并不构成一个详尽的列表。我们的建议是使用一套以像素和图像为单位的指标来了解模型在不同特异性水平上的表现。
结束语
深度学习模型在精选数据集上表现非常好,但在非结构化数据上还有改进的空间。当应用计算机视觉模型来执行自动道路损坏检测时,必须考虑的一些重要因素包括:
- 如何正确地对不同类型的损害进行分层。
- 如何保证标注一致?
- 几百万参数的深度学习模型需要多少标注才能有效学习:(1)哪里有损伤,和 (2)有多坏。
- 如何有效地评估一个细分模型,考虑注释是如何制作的以及最终用户是谁。
我们的贡献是概述这些挑战,并证明即使只有有限的数据和嘈杂的标签,我们的模型也能够学习分割油漆线,并开始分离严重程度的极端例子。建模能力是存在的;瓶颈是数据。
确认
我们要感谢我们的行业合作伙伴 Lab1886 给我们这个机会。此外,我们要感谢我们的导师,帕夫洛斯·普罗托帕帕斯博士和克里斯·坦纳博士,以及顶点课程的学生和教师在注释我们的图像方面给予的帮助。有关哈佛数据科学峰会的更多信息,请访问:capstone.iacs.seas.harvard.edu。
参考
[1] R. Fan,M. Liu,(2019)【IEEE 智能交通系统汇刊】
[2] S. Chen 等, 3D 激光雷达扫描桥梁损伤评估 (2012),法医工程 2012:通向更安全的明天
[3] S. Sattar 等人,使用智能手机传感器进行路面监控:综述 (2018),传感器(瑞士巴塞尔)
[4] E. Buza 等,基于图像处理和谱聚类的坑洞检测 (2013),第二届信息技术与计算机网络国际会议论文集
[5] J. Singh,S. Shekhar,使用 Mask 的智能手机捕获图像中的道路损坏检测和分类 R-CNN (2018), arXiv 预印本 arXiv:1811.04535
[6] H. Maeda,et al., 利用智能手机捕获的图像使用深度神经网络进行道路损伤检测 (2018), Comput。辅助民用基础设施。英语。
[7] O. Ronneberger 等, U-net:卷积网络用于生物医学图像分割 (2015),医学图像计算和计算机辅助介入国际会议
计算机视觉:全景拼接背后的直觉

田纳西州了望山顶的景色(1864 年)来源:https://en.wikipedia.org/wiki/Panoramic_photography
全景拼接的工作原理有 4 个主要部分。在这篇文章中,我将给出一个非常简短的概述,能够充分(希望)建立图像拼接工作背后的直觉。这也意味着我很可能会跳过任何数学概念和计算。
- 探测兴趣点
- 描述这些兴趣点
- 匹配我们兴趣点的这些描述符
- 执行单应完成拼接
1.检测兴趣点
当我们在图像中寻找兴趣点时,有几个特征。它们是:
a)可重复的兴趣点
我们希望能够找到图像中的特征,这些特征最终可以告诉我们同一场景的不同图像之间的匹配位置(从附近的视点)。
b)兴趣点的独特性
我们希望能够可靠地确定一幅图像中的哪个兴趣点与另一幅图像中的相应兴趣点相匹配。
c)缩放和旋转不变性
我们希望能够找到相同的兴趣点,即使图像被旋转、缩放或平移。
d)地点
局部特征将使我们对感兴趣点的检测对杂乱和遮挡更加鲁棒。


图一。我的 mac 默认背景截图。
想象上面的两张图片(图 1),很容易看出,如果我们选择海洋作为兴趣点,很难将左侧图像中的海洋与右侧图像中的海洋特别匹配(因为海洋在大范围的空间中看起来是相同的)。我们还注意到,选择诸如小石峰(橙色圆圈)的区域能够为我们以后的匹配提供更有价值的信息。
事实证明,角实际上是一个非常好的特征,可以作为兴趣点!有一种叫做 Harris 角点检测器的算法,可以帮助我们在图像中找到这样的角点作为兴趣点。

哈里斯角探测器
注意,哈里斯角点检测器只是帮助我们找到这些兴趣点的众多算法之一。还有其他方法,例如 SIFT,它使用高斯差分(DoG)来检测不同尺度的兴趣点。我个人认为这篇文章很值得一读。在后面的部分中理解 SIFT 很重要,因为我们将使用 SIFT 描述符来描述我们发现的兴趣点。
本质上,在取局部最大值(非最大值抑制)的点之前,Harris 角点算法从图像的梯度计算角点分数(使用二阶矩 H 矩阵)并将高于设定阈值的值标记为角点。哈里斯角对于旋转(因为 H 矩阵的特征值即使在旋转之后也保持不变)、平移和强度的附加变化是不变的。然而,它对于强度的缩放和比例不是不变的。为了使 Harris 角点在尺度上保持不变,我们需要一个额外的自动尺度选择步骤来找到一个给出我们的角点分数的局部最大值的尺度。
总结一下从图像中检测兴趣点的第一部分,角是兴趣点的良好表示,可以使用 Harris 角检测器找到。
2.描述我们的兴趣点
描述符基本上是以数学方式描述图像中某个区域的矢量表示。描述符也应该对旋转、缩放和平移不变。我将直接进入 SIFT 描述符,我们可以在我们的 Harris 角点检测器发现的兴趣点上使用它。
尺度不变特征变换 (SIFT) 由 David Lowe 于 2004 年发表。如果他的论文太难阅读,你可以参考这里的快速阅读 SIFT。SIFT 实际上是一种检测兴趣点并描述它们算法。然而,在这种情况下,我将只关注描述符本身。

图 2(显示了缩小的版本)。鸣谢:理查德·塞利斯基
SIFT 描述符的基本功能是在检测到的兴趣点周围提取一个 16x16 的窗口(图 2),然后将其划分为一个 4x4 的单元网格。在由高斯函数加权的窗口中的每个像素处计算梯度方向和幅度。然后,在每个单元中计算具有 8 个面元的加权梯度方向直方图(方向由其幅度加权)。最后,我们将这些直方图折叠成一个 128(16×8)维的向量(每个向量有 16 个 4×4 的单元,每个单元有 8 个面元)。
单元的划分给描述符一种空间知识的感觉,而主方向对直方图宁滨的移动使得描述符旋转不变。我们可以将最终向量归一化为单位长度,基于阈值箝位值,并再次重新归一化,以使其对光照变化相对更鲁棒。
总而言之,SIFT 对于一个描述符来说是非常健壮的。它对比例和旋转是不变的,可以处理视点的变化(高达 60 度的平面外旋转)并且可以处理照明的显著变化。
现在,我们已经通过 Harris 角点找到了我们的兴趣点,并使用 SIFT 描述符将这些兴趣点描述为一个区域。现在剩下的是形成不同点之间的匹配,并执行单应性以将不同的图像缝合在一起以形成全景图!
3.匹配我们兴趣点的描述符
为了在两幅图像的描述符之间形成匹配,我们使用最佳匹配的距离/第二最佳匹配的距离的比率距离方法。


图 3。图片来自 Unsplash。作者:伊山·瓦扎尔瓦
在图 3 中,如果我们只使用目标和最佳匹配的绝对距离(这里的距离指的是描述符的相似性——如果它们非常相似,那么距离就很小,反之亦然),很容易看到有多个模糊匹配可用(这里有许多类似的栅栏作为图像中的兴趣点,因此,我们不能确定最佳匹配是要匹配的正确特征)。
为了拒绝这些不明确的匹配,我们使用比率方法—接近 1 的高值表明匹配是不明确的,因为到最佳匹配的距离非常接近到第二最佳匹配的距离。然后,我们设置一个阈值(通常在 0.5-0.7 左右),并接受低于该阈值的匹配。换句话说,我们拒绝包含高度不确定性的匹配——在图 3 的情况下,不确定性很高,因为许多木质尖端靠近目标。
4.执行单应
一旦我们能够想象当我们试图把不同的图像拼接在一起时,我们试图做什么,就很容易理解单应性。想象两个场景。
(1)-每次拍摄照片时向左移动一步,同时保持相机不动。
(2)-站在固定的位置,手持相机旋转身体,并在旋转的同时拍摄不同的照片。
如果我们想将(1)中的图像拼接在一起,我们可以简单地将一张照片叠加在序列中的另一张照片上,并获得良好的效果。然而,在(2)中,如果我们想要通过简单地将图像依次叠加在另一个的顶部来将图像拼接在一起,我们将意识到拼接的结果是不好的(由于所捕获的图像的不同平面,区域将被遗漏)。因此,我们需要单应映射将一幅图像投影到另一幅图像的同一平面上,然后将它们拼接在一起。
接下来,您可以将单应性基本上视为一个矩阵——一个将点从一个图像转换到同一平面的另一个图像的矩阵。那么下一个问题是我们如何求解单应矩阵 H?
我们使用直接线性变换(DLT) 并通过计算奇异值分解(SVD) 来求解 H,该计算最少需要 4 次对应。我将跳过数学,但如果你感兴趣的话,可以随意查阅。
然而,DLT 可以在噪声环境中产生坏的结果,因为 DLT 是线性最小二乘估计,其考虑了我们的匹配中的坏的离群值。(注意,即使我们在前面的步骤中在匹配描述符时设置了阈值,仍然有可能出现不正确的匹配)。然后,我们可以使用随机样本一致性(RANSAC)产生更稳健的结果,其中我们在 H 矩阵的计算中仅包括内联体(近似正确的匹配)。然后,我们利用 DLT 和 RANSAC 给我们更好的结果。
一旦我们解决了单应矩阵,我们就可以使用矩阵计算从图像 A 到图像 B 的点,并很好地扭曲它以完成我们的全景拼接!
结论
在这里,我简要介绍了全景拼接的工作原理。具体来说,我谈到了使用 Harris 角点来检测作为兴趣点的角点,使用 SIFT 描述符来描述我们的兴趣点周围的区域,我们如何匹配这些描述符,以及我们如何计算单应性来形成不同图像的拼接。请注意,由于这是一个简短的概述,我有意省略了数学细节,并试图不要深入每个特定的算法/概念,因为我的目标是建立整个概念背后的直觉!
还有,这其实是我第一篇关于 medium 的文章!我希望你喜欢这篇文章,并从这篇文章中学到了一些东西。谢谢!
参考
- https://aishack.in/tutorials/harris-corner-detector/
- https://ai shack . in/tutorials/sift-scale-invariant-feature-transform-introduction/
- https://www.cs.ubc.ca/~lowe/papers/ijcv04.pdf
- 【https://en.wikipedia.org/wiki/Direct_linear_transformation
- https://en.wikipedia.org/wiki/Singular_value_decomposition
感谢阅读!我希望你喜欢它,这篇文章对你有帮助!
计算机视觉——通过人工智能自我学习进行物体定位
我希望我有一个机器人可以扫描我的房子,找到我丢失的钥匙
随着像脸书这样的公司在增强现实上花费数百万美元,在不久的将来,简单的眼镜将取代世界上几乎每一个屏幕,包括电视、手机,并将我们所有的环境转换成现实和屏幕的混合物。
我相信我的房子里有一个喜欢每天早上吃掉所有钥匙的洞,这是每次我上班迟到时它们从地球上消失的唯一原因。
但我仍然会等待有一天,我可以让我的眼镜或机器人扫描我的房间,找到我每天早上都在努力寻找的钥匙或我在房子某个地方丢失的耳机。
尽管每天都在不停地挣扎,但我决定为未来可能的机器人创建一个小小的后端项目,机器人/人工智能可以扫描房子的周围,为我找到东西。尽管:
- 问题的第一部分是告诉计算机一个物体看起来像什么,所以计算机知道实际上要找什么,所以我选择了最明显的方法,我们都做的检查一个物体看起来像什么,即通过在谷歌上搜索,所以当我告诉机器人在房间里找到我的钥匙或 AirPods 时,首先 Ai 会进行谷歌搜索,看看钥匙或 AirPods 实际上看起来像什么。
- 问题的第二部分是让人工智能意识到物体在图像中的位置,人工智能可以自动学习并决定物体的实际形状和大小,并可以在图像中定位物体。为了解决这个问题,我实现了**最小生成树聚类的研究工作——**你可以在这里找到研究论文——>http://cs.brown.edu/people/pfelzens/segment/
- 问题的第三部分是教 Ai,如何定制训练一个**物体检测 YOLO 模型,——**所以不管我要求什么,不管是钥匙,AirPods,还是我丢失的 u 盘 AI 将自动—
1 谷歌搜索对象的图像
2 从这些图像中生成训练数据
3 标记/标注图像中的对象
4 写下 YOLO 模型所需的所有适当的注释和文本文件
5 编辑具有适当配置的 YOLO·YAML 文件
6 训练图像,生成推理图,然后机器人将最终知道“钥匙”是什么,因此它可以打开摄像机并开始寻找它

自学模式的结果
这是完整自动化过程的算法-
1 Google 通过 AI 搜索物体的图片 -
在 Colab 环境中安装 Google chrome 和 Selenium
制作一个数据框,从谷歌获取前 200 个图像结果。
这里计算机/机器人会问你想看什么,我用了键,然后得到 200 个图像
最小生成树聚类 通过这种聚类分割,Ai 将理解对象在图像中的位置,并通过在它周围制作一个方框来标记它,以创建一个训练数据,实现自研究论文http://cs.brown.edu/people/pfelzens/segment/


人工智能标记的对象
现在物体被标记了,是时候找到 Ai 在物体周围创建的黄色轮廓的“框”值了。我们需要找到 xmin,xmax,ymin,ymax,这样就可以为 YOLO 对象模型编写注释了
Ai 自/自动 Yolo 模型训练和注释编写
为了得到物体周围盒子的 xmin、xmax、ymin 和 ymax,我们需要找到物体周围所有黄色的像素点,然后从所有这些点,我们可以很容易地得到我们的坐标。
按照下面我创建的代码,Ai 将首先在我们的训练数据中寻找每个图像中对象周围的所有黄色点,然后用坐标创建一个熊猫数据框

要编写 YOLO 注释,人工智能必须遵循一定的格式,人工智能需要在包含图像的同一文件夹中创建每个图像的文本文件,然后人工智能必须创建一个包含所有图像路径的 train.txt 文件。
image text file formula and fromat
<class_number> (<absolute_x> / <image_width>) (<absolute_y> / <image_height>) (<absolute_width> / <image_width>) (<absolute_height> / <image_height>)
上面的代码将会给 Ai 训练一个定制的 YOLO 物体检测模型所需的所有文本文件
Ai 将在 YOLO 上训练数据集
现在,人工智能将从图像和标记的注释中学习,一把钥匙或任何其他物体看起来是什么样子,
使用下面的代码,Ai 正在做三件事
1 安装 Yolo API
2 将 train.txt 拆分成训练和测试数据
3 打开 Yolo 模型的 YAML 文件并编辑所有必要的东西,如类的数量、训练的链接、测试数据和类名——在这种情况下,类名是键
训练数据和保存重量
打开网络摄像头并检测物体
现在,人工智能已经学会了什么是钥匙,现在我们可以将这个人工智能放入机器人或我们的增强眼镜中,然后它可以为我们扫描房间并找到钥匙。虽然眼镜或机器人还需要一些时间才能进入市场。所以现在我只是用我的笔记本电脑摄像头测试。

结论
看到 Ai 学习自己并检测物体是非常令人兴奋的,但整个笔记本需要 3 分钟来完成学习过程,这对于实际使用来说太长了。但随着量子计算的发展和并行处理的更好编码,实时自我训练和学习过程可能在未来几年内完成。虽然这个项目确保了让一个机器人去寻找你家丢失的东西不再是科幻幻想
对于,完整的 jupyter 笔记本和代码,可以通过github.com——https://github . com/Alexa Mann/Computer-Vision-Object-Location-through-Ai-Self-Learning查看我的知识库
边缘的计算机视觉
克服将 CV 应用引入生产的挑战

比尔·牛津在 Unsplash 上的照片
开发计算机视觉(CV)应用程序并将其投入生产需要集成几个硬件和软件。我们如何确保各部分无缝协作?使用正确的方法,我们可以加快 CV 应用程序的开发和部署。有必要找到一个平台,其目标是帮助开发人员使用一套集成的免费工具快速、轻松地从头开始创建计算机视觉应用程序。本文描述了开发和部署 CV 应用程序的一些挑战,以及如何减轻这些挑战。如果您想了解更多信息,可以观看关于计算机视觉部署挑战的免费网络研讨会。
世界上的计算机视觉
首先,一些背景。术语“计算机视觉”是指计算机能够像人类一样分析视觉数据,并对数据包含的内容做出推断的过程。当集成到应用程序中时,这些推理可以转化为可操作的响应。例如,以自动驾驶汽车为例:计算机视觉可以用来分析实时视频数据,以检测道路上的物体,然后运行计算机视觉模型的软件可以对这种检测做出反应,以停止汽车或改变其路径来避开物体。
CV 越来越多地被用来解决各种现实世界的问题,从安全和医疗保健到制造业、智能城市和机器人。CV 可用于检测放射报告中的癌细胞,帮助分析身体运动,如正确的步态和姿势,或跟踪生产线上的生产。
在本文的其余部分,我们将探讨构建和部署安全摄像机 CV 应用程序的挑战。您可以找到已经构建在 GitHub 上的这种应用程序的实现。当一个新人进入一个画面时,这个应用程序会注意到并记录下这个人的图像。在这篇博客中,我们将讨论构建这样一个应用程序的挑战,以及那些涉及部署它的人,可能使用多个摄像头,但是如果你想了解更多关于应用程序本身的代码逻辑,你可以阅读这个博客。
原型设计和开发 CV 应用程序
CV 应用程序包含许多组件,开发起来非常复杂。除了将执行处理的硬件与应用软件本身集成之外,开发生产就绪的计算机视觉应用程序的过程还包括许多步骤:数据收集和注释、训练计算机视觉模型、将使用不同框架制作的现有模型集成到您的应用程序中、将现有计算机视觉库集成到应用程序中,等等。考虑到开发计算机视觉解决方案的潜在成本和工作量,理想情况下,您还希望确保您的应用程序是灵活的,以便您的应用程序可以随着您的问题空间的发展而发展。这意味着确保您可以使用额外的模型类型,转移到不同的模型框架,或者在不中断应用程序的情况下更改硬件。
考虑到安全应用,假设您只想检测人。如果你想要一个能保证在一天的不同时间、不同天气等条件下工作的模型。对于生产质量的应用程序,您很可能需要收集和注释从您将使用的相机的角度以及在不同环境中拍摄的图像,并训练您自己的模型,反复几次此工作流以实现所需的性能。然而,假设你只是想要一个原型应用程序,在这种情况下,你可能会使用一个现有的检测人的模型,如 mobilenet_ssd 或 yolo_v2_tiny 。理想情况下,您可以尝试不同的模型,看看哪一个(哪些)效果最好,也许您的应用程序将受益于同时使用两个模型,以检测不同距离或不同条件下的人。一旦有了对象检测模型,就可以构建应用程序了。您将需要使用软件包,使您能够访问来自摄像机的视频流,并且您需要知道如何访问从您训练的模型返回的预测,以便您可以查看该人是否是新加入该帧的,并保存图像中与检测到的人的边界框相对应的部分。
部署计算机视觉应用
开发计算机视觉应用的另一个挑战是部署。一旦你有了一个计算机视觉应用的工作原型,你如何让它在世界上产生影响?虽然云通常被视为机器学习应用程序的一种非常灵活的解决方案,但它可能非常昂贵,具有更高的延迟,并且数据传输会带来安全风险。另一个越来越受欢迎的选择是将你的简历应用到边缘。
边缘上的简历
什么是边缘?一般而言,边缘设备是小型、轻量级的设备,计算机视觉应用可以在其上部署和运行。今天,许多边缘设备甚至具有图形处理单元(GPU)或视觉处理单元(VPU),这使得能够使用更大范围的模型和应用程序复杂性。在本文的上下文中,边缘设备是指诸如 Raspberry Pi、NVIDIA Jetson 设备(如 Jetson Nano 或 TX2)或各种物联网(Iot)设备之类的设备,这些边缘设备能够感知或评估其使用环境,并可能与其进行交互。
虽然可以使用互联网连接来部署应用程序,但是一旦应用程序位于边缘设备上,就不需要使用云连接来运行。这意味着应用程序所做的任何推理都是在边缘设备本身上进行的,而不是在云中,从而大大减少了应用程序将这些推理转化为行动的时间。对于某些用例,如自动驾驶车辆或安全摄像头,这是必不可少的。除了数据可能在发送到云或从云接收时丢失的风险之外,使用云方法所需的额外时间可能意味着无法及时响应任务,这对自动驾驶等任务来说可能是灾难性的。
除了边缘设备,还有专门的外围设备,特别是摄像机,它们本身没有互联网连接,边缘设备使用它们来提高性能或扩展应用功能。有了这样的设备,这种边缘处理的概念就更进一步了。虽然边缘设备通常连接到 USB 或带状摄像机,将图像数据传递到设备进行处理,但这些设备将处理器集成到摄像机本身中,进一步减少了推断时间。
此外,由于数据不需要通过边缘部署传输到云,所有数据都可以留在设备本身的封闭电路中,这更加安全,并且不需要云处理,成本也更低。

在边缘和云中部署 CV 应用程序的比较。创作于卢西德哈特(www.lucidchart.com)。
边缘部署面临的挑战
在边缘上部署生产质量的计算机视觉应用程序会带来一系列挑战。使用云计算,当计算需求增加时,您可以扩展实例,但是使用边缘设备,您会受到单个设备能力的限制。此外,通过边缘部署,如果不集成其他包,您可能无法访问设备状态。
让一切运转起来
我们已经讨论了开发和部署计算机视觉应用程序的复杂性;我们如何缓解这些挑战,尽快将 CV 应用投入生产?如果你看看 alwaysAI 这样的平台,有几个关键的方法可以用来降低工作流的复杂性:容器化和应用程序编程接口(API)抽象。
容器化是指将软件和依赖项捆绑在一个单元中的过程,可以在不同的环境中执行。AlwaysAI 利用使用 Docker 映像的容器化来实现在不同设备上的部署,包括 Raspberry Pi 和 Jetson Nano。它还整合了开源计算机视觉工具,如计算机视觉注释工具 (CVAT),这些工具依赖于直接打包到我们的包中,以简化这些工具的安装和使用。
alwaysAI 还开发了一个 API 来进一步加速开发。通过这个 API,用户可以与计算机视觉相关的对象进行交互并对其进行操作,例如关键点、边界框、标签等。从模型推断返回的,以及硬件特征如照相机,和外部实体如文件(图像、视频等)。)而不必知道这些请求背后的所有细节。这是如何工作的?API 充当复杂后端和最终用户之间的某种协商者。它定义了用户可以发出什么样的请求以及如何返回数据。通过隐藏这些调用中涉及的一些复杂性,这简化了用户的使用,并有助于确保只能发出适当的请求。
alwaysAI API 包装了其他 API,有助于进一步促进应用程序开发。OpenCV-Python API 是一个流行的计算机视觉库;alwaysAI 已经将一些最常见的 OpenCV-Python API 调用合并到其库中,以便简化这些函数的使用,并确保它们与其库的其他方面一起工作。此外,任何 alwaysAI 应用程序都可以直接导入 cv2,即 OpenCV 库,而无需安装库或添加任何依赖项。这样,依赖于 cv2 的遗留代码仍然可以工作,如果需要,用户可以默认使用 OpenCV-Python API,但是为了简单起见,可以使用一个库进行开发。
API 还可以帮助开发人员更好地访问硬件。一些专业相机,如 RealSense 和 OpenNCC Knight 相机,有自己的软件开发工具包(SDK)来促进应用程序的创建。这些 SDK 还包括 API,可能足以将这些相机与现有应用程序集成。虽然可以通过使用这些 API 直接访问硬件功能,但也可以将特定于相机的 API 合并到另一个已经用于应用程序开发的库中,这就是我们对 API 所做的。这意味着最终用户可以使用他们的应用程序已经使用的相同库来访问这些相机功能,并且可以保证正常工作。
API 和容器化也有助于克服上述与部署相关的挑战。使用基于容器的部署服务,您可以部署多个边缘设备并监控它们的状态。Kubernetes 和 T2 Docker Swarm 都支持监控和管理多个 Docker 容器,T4 balena 和 T5 也是如此,balena 是一项免费的商业服务。这两种方法都利用 API,第三方应用程序如开源的 Prometheus 或商业的 Datadog 可以使用 API 来获得对原始指标的更多洞察。虽然这种方法确实依赖于一些云连接,但实际的计算机视觉数据并不通过网络传输,因此您仍然可以保持在边缘部署的速度和低成本特性,并且安全性得到了提高,因为连接到边缘设备需要身份验证,并且应用程序数据仍保留在边缘上。
让我们最后一次回到我们的安全摄像头应用。您已经构建了自己的应用程序,可以轻松地更换不同的摄像机,并且可以在检测到物体时存储图像。现在,您可以使用我们上面提到的容器化技术来协调跨多个边缘设备的应用程序部署,如下图所示。使用正确的方法,平台、库和硬件可以无缝集成,使 CV 应用程序更容易开发和部署,并可扩展用于生产。

已部署的 CV 应用程序概述。创建于卢西德哈特(www.lucidchart.com)。
如果您想了解更多关于克服计算机视觉部署挑战的信息,您可以观看 YouTube 上的网络研讨会。
Eric VanBuhler 和 Stephanie Casola 对本文的贡献
计算机视觉深度学习导论
图像数据处理和特征提取背后的直觉是什么?
“计算机视觉”是机器学习的一个领域,处理图像识别和分类。可以开发计算机视觉模型来完成诸如面部识别、识别狗属于哪个品种,甚至从 CT 扫描中识别肿瘤等任务:可能性是无限的。
在关于这个主题的一系列文章中,我将探讨一些围绕计算机视觉的关键概念。在这篇文章中,我将提供一些关于计算机如何处理图像以及如何识别物体的直觉。
后续文章将处理深度学习模型的实际实现,该模型将学习将图像分类到几个类别中的一个——所有这些都在不到一百行代码中。
计算机是如何“看见”图像的?
计算机看图像的方式与人类不同——它们只能理解数字。因此,任何计算机视觉问题的第一步都是将图像包含的信息转换成机器可读的形式。幸运的是,一旦我们把一幅图像分解成它的组成部分,这是非常容易做到的。
图像由像素网格组成,每个像素就像一个小盒子,覆盖了图像的很小一部分,如下所示:

来自像素的原始图像
每个像素可以被看作是单一颜色的“点”。像素越多,就越能精细地表现图像的各个部分(分辨率越高的图像像素越多)。
现在我们知道了每个图像的构建模块是什么,但我们仍然需要弄清楚如何将它转换成一系列准确描述图像的数字。让我们来看一张 1920 * 1080 像素的高清图像。我们已经确定这个图像可以被分解成小盒子。在这种情况下,我们将有 2,073,600 个这样的小盒子,每个盒子可以用它的颜色来表示。因此,我们实际上有大约 200 万条信息——每条信息都描述了图像特定部分的颜色。
幸运的是,有一种用数字形式描述颜色的方法。每种可能的颜色都由一个独特的 3 位数字代码描述——这是 RGB 坐标(你可以在这里看到任何颜色的 RGB 代码)。所以我们现在可以用数字来表示任何图像,把它分解成像素,用一组 3 个数字来表示每个像素。我们现在已经把高清图像分解成大约 600 万个我们的计算机可以理解的数字。唷!
我们如何识别物体?
想想人类是如何识别物体的:即使我们只看到它们的轮廓,我们也能区分猫和狗,也就是说,我们不必进行彻底的视觉检查,也不必处理它们形状的每个细节,就能区分它们。这是因为我们的大脑会将一些关键的“特征”(比如大小和形状)与每个物体联系起来。然后,我们可以只关注这些特征,我们的大脑仍然能够识别它是什么。
显而易见,计算机视觉模型应该做同样的事情——从图像中提取特征,并将每个特征与特定类别的对象相关联。然后,当给它一张新的图像时,它会尝试通过将其特征与正确的类别进行匹配来识别它。但是我们如何训练计算机从一系列数字中提取这些特征呢?我们通过一个叫做“卷积”的过程来做到这一点。
卷积和特征提取
让我们通过一个简单例子来理解卷积是如何工作的:

卷积:作者图片
要将原始网格转换为“卷积”网格,我们需要一个卷积矩阵。该矩阵的目的是指定要提取的“特征”。然后,我们将该矩阵应用于原始数字网格,方法是将其值乘以原始网格的相应值,然后将结果相加。
在上面的例子中,我们有一个 99 的网格,我们希望与我们的 33 卷积矩阵卷积。我们将原始网格分成 9 个更小的 3*3 网格(以匹配卷积矩阵的大小)。然后,我们将前 9 个单元格(灰色)乘以卷积矩阵。在这个简化的例子中,除了 14 之外,所有的单元格都将变成 0,加上所有这些数字,我们得到:14。这就成为我们“转换”网格的第一个单元。我们对原始网格中的所有其他单元都遵循这一过程来填充我们的卷积网格。实际上,这个过程还需要考虑其他参数,例如“步长”,即每次运算后卷积矩阵向右“移动”多少位置,以及“填充”边缘,但核心原则保持不变。
那么我们在这里做了什么?我们将 99 的网格缩减为 33 的网格。如果我们认为这个操作是在图像中每个像素的 RGB 坐标上执行的,那么我们已经有效地从原始图像中“提取”了一些特征。这个非常简单的过程可以产生强大的效果,并且是每个图像过滤器的底层机制!
不服气?我们可以在下面的例子中看到这一点:

卷积特征提取:“轮廓”:作者图片
(你可以通过下载GIMP GUI 并遵循这里的说明来尝试应用你自己的卷积。)
我们现在可以从以下几个方面来理解卷积是多么强大。减少数据的维度(我们的 99 网格变成了 33 网格)
2。从我们的图像中提取特征,然后我们的模型可以学习将这些特征与不同的物体联系起来,从而学习识别它们。
在实践中,我们也可以“汇集”卷积的结果,进一步降低图像的维度。事实上,这是我们在开发深度学习模型以学习识别本系列后面的对象时将遵循的方法。
把所有的放在一起
在一个非常高的层面上,为了开发一个计算机视觉模型,我们将遵循的步骤是:
1。将图像转换成机器可读的数据(数字)
2。设置一些卷积,可以从图像中提取“特征”3。将这些信息输入神经网络,然后神经网络学习哪些特征与哪类物体相关(比如“狗”和“猫”)
4。拟合和评估这个模型


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言










{kind=link}
{kind=link}