







两大云数据仓库概述:亚马逊红移和 Azure SQL DWH
了解云数据仓库相对于传统数据仓库的优势

简介
在云数据仓库出现之前,大多数公司采用传统的数据仓库。
传统的数据仓库系统允许从组织的各种外部或内部来源收集数据以支持分析操作,但存在各种困难。
一般来说,传统数据仓库的体系结构由三层组成:
- 底层由不同种类的支持工具和实用程序组成,它们从不同的来源提取数据,转换数据并将其加载到数据仓库中。
- 中间层,以 OLAP 服务器为特征,这些服务器执行业务数据的多维分析,以便将数据转换成允许进行复杂计算的格式。
- 顶层,我们可以在其中使用不同的查询和报告工具。因此,我们可以执行数据分析和数据挖掘。
无论如何,为了维持这种系统,公司花费了大量资金来维护硬件、服务器机房以及雇佣特定团队来运行它的成本。云数据仓库成为这些问题的解决方案。
在本文中,我将向您概述当今最常用的云数据仓库,即 Amazon Redshift 和 Azure 数据仓库。

第一部分:亚马逊红移
Amazon Redshift 是一个快速、可扩展的数据仓库,被世界上最大的公司所使用。它允许公司构建强大的应用程序并生成报告。
红移是组织成称为集群的组的节点的集合。每个集群都运行在 Amazon redshift 引擎上,并且包含一个或多个数据库。该群集有一个领导节点和一个或多个计算节点。
该机制非常直观,领导节点接收来自客户端应用程序的查询,并传递查询和开发合适的执行计划。在建立计划之后,划分为片的计算节点通过在节点之间传输数据来解决查询,从而开始处理计划。
因此,一旦执行完成,领导者节点聚集来自计算节点的结果,并将其发送回客户端应用程序。
每次启动集群时,我们都需要指定节点类型,可以是使用硬盘驱动器的密集存储节点(DS)或使用固态驱动器的密集计算节点。
决定使用哪种类型的节点是基于我们希望导入 Amazon Redshift 的数据量、我们希望运行的查询的复杂性以及依赖于我们的查询的下游系统的需求。
对于 Amazon Redshift 与传统数据仓库相比的优势,我们可以很容易地理解,使用 Redshift 可以通过调整集群大小来快速扩展。因此,您可以向上扩展并增加计算节点的数量,也可以向下扩展并减少计算节点的数量。或者,您可以使用单节点或多节点选项。
Amazon Redshift 的一个特殊方面是列数据存储,它允许按列存储数据,而不是像传统数据仓库那样按行存储。列存储允许更好的数据压缩,减少了输入/输出操作,并且通过将所有记录一起存储在一个字段中,数据库可以更快地对相似类型的数据进行查询和分析。
Amazon Redshift 的另一个特别优势是大规模并行处理,即不同的处理器一起计算。事实上,正如您所记得的,集群有一个领导节点和一个或多个划分为片的计算节点。因此,当领导者节点收到查询时,它会制定执行计划。计算节点和片一起或并行工作来执行该计划。之后,领导者节点将结果发送回客户端应用程序。
Redshift 是一个非常经济的数据仓库,因为与传统的数据仓库不同,我们不需要花费硬件、不动产、电力和员工成本。这一事实大大降低了公司的成本。还有一点很重要,Amazon Redshift 允许从 Data Lake 中查询数据,Data Lake 是一个存储库,可以保存原始格式的原始数据。
最后但并非最不重要的是,Redshift 中的数据安全可靠,这要归功于备份和恢复选项。当我们在 Amazon Redshift 中存储数据时,会在 S3 上制作数据的副本。红移还提供了加密数据的选项。
第二部分:Azure SQL 数据仓库
Azure SQL 数据仓库是一个大规模并行处理系统,允许我们实现关系型大数据存储。它是一个平台即服务(PaaS ),这意味着我们不必担心底层架构,包括操作系统、存储、服务器等。
Azure SQL DWH 由存储和两种类型的节点组成,如控制节点和多个计算节点。
在 Azure 中,数据存储在 Blob storage 中,这是一种将非结构化数据作为对象存储在云中的服务。Blob 存储可以存储任何类型的文本数据。
控制节点作为 Amazon Redshift 中的领导节点,协调运行并行查询所需的所有数据移动。因此,当 Azure SQL DWH 收到请求时,控制节点会将请求转换为在每个计算节点上并行运行的独立查询。
我们可以将计算节点定义为旨在存储数据和处理查询的数据库。处理之后,结果返回到控制节点,控制节点汇总结果并向用户提供最终结果。
重要的是要知道,当计算节点与数据交互时,节点直接从 blob 存储中写入和读取。
结论
感谢亚马逊红移和 Azure SQL DWH 的两个例子,我们可以确认,对于一个公司来说,无论其规模大小,今天的最佳选择是考虑云数据仓库,而不是传统的数据仓库。
事实上,云 DWH 速度更快,具有超弹性,这使得公司可以轻松扩展。此外,它还提供现收现付模式或固定资产购买模式。
云 DWH 消除了客户进行软件升级和硬件迁移项目的需要。
构建传统数据仓库需要可靠的硬件预算,但有了云,就不需要可靠的硬件预算。事实上,我们可以从小架构开始,随着数据量和用户数量的增长而不断发展。
除了我的简讯,还可以在我的电报群 数据科学初学者 中取得联系。
神经网络中各种优化器综述
理解各种优化器之间的关系以及它们的优缺点。

在 Unsplash 上由 Hitesh Choudhary 拍摄的照片
优化器是用于改变神经网络属性(如权重和学习速率)以减少损失的算法或方法。优化器用于通过最小化函数来解决优化问题。
优化人员是如何工作的?
你应该如何改变你的神经网络的权重或学习速率来减少损失是由你使用的优化器定义的。优化算法负责减少损失,并尽可能提供最准确的结果。
使用一些初始化策略来初始化权重,并且根据更新等式在每个时期更新权重。

上面的等式是更新等式,使用它来更新权重以达到最精确的结果。使用一些称为优化器的优化策略或算法可以获得最佳结果。
在过去的几年里,人们研究了各种各样的优化器,每一种都有其优缺点。阅读整篇文章,了解算法的工作原理、优点和缺点。
梯度下降(物品):
梯度下降是最基本的一阶优化算法,它依赖于损失函数的一阶导数。它计算权重应该以何种方式改变,以便函数可以达到最小值。通过反向传播,损耗从一层转移到另一层,并且模型的参数(也称为权重)根据损耗进行修改,以便损耗可以最小化。


图片 1
从上图(图 1)可以看出,权重被更新以收敛到最小值。
优点:
- 实现起来非常简单。
缺点:
- 该算法一次采用 n 个点的整个数据集来计算导数,以更新需要大量存储器的权重。
- 极小值是在很长一段时间后达到的,或者是永远达不到的。
- 该算法可能会卡在局部最小值或鞍点:

图片 2
在上图(图 2)中,梯度下降可能会卡在局部最小值或鞍点,永远不会收敛到最小值。为了找到最佳解决方案,算法必须达到全局最小值。
随机梯度下降(SGD):
SGD 算法是 GD 算法的扩展,它克服了 GD 算法的一些缺点。GD 算法有一个缺点,它需要大量的内存来一次加载 n 点的整个数据集到计算机导数。在 SGD 算法的情况下,每次取一个点来计算导数。

图 3
从上图(图 3)可以看出,与梯度下降相比,更新需要更多的迭代次数才能达到最小值。在图 3 的右边部分,GD 算法达到最小值需要较少的步骤,但是 SGD 算法噪声更大,迭代次数更多。
优势:
- 与 GD 算法相比,内存需求更少,因为每次只取一个点来计算导数。
缺点:
- 与 GD 算法相比,完成 1 个历元所需的时间很长。
- 需要很长时间才能收敛。
- 可能会陷入局部最小值。
小批量随机梯度下降(MB-SGD):
MB-SGD 算法是 SGD 算法的扩展,它克服了 SGD 算法时间复杂度大的问题。MB-SGD 算法从数据集中取出一批点或点的子集来计算导数。
可以观察到,MB-SGD 的损失函数的导数与 GD 的损失函数的导数在若干次迭代之后几乎相同。但是与 GD 相比,MB-SGD 实现最小值的迭代次数很大,并且计算成本也很高。
权重的更新取决于一批点的损失的导数。在 MB-SGD 的情况下,更新的噪声更大,因为导数并不总是朝向最小值。
优点:
- 与标准 SGD 算法相比,收敛的时间复杂度更低。
缺点:
- 与 GD 算法的更新相比,MB-SGD 的更新噪音更大。
- 比 GD 算法需要更长的时间来收敛。
- 可能会陷入局部最小值。
SGD 带动量:
MB-SGD 算法的一个主要缺点是权重的更新非常嘈杂。具有动量的 SGD 通过对梯度去噪克服了这个缺点。权重的更新依赖于有噪声的导数,并且如果我们以某种方式对导数去噪,那么收敛时间将会减少。
想法是使用指数加权平均来对导数进行去噪,即与先前更新相比,给予最近更新更多的权重。
SGD 更新公式:




使用所有先前的更新来计算时间“t”处的动量,与先前的更新相比,给予最近的更新更大的权重。这导致收敛速度加快。
动量如何加速收敛?

图 4
当通过仅减去具有先前权重的梯度项来计算新权重时,更新在方向 1 上移动,并且如果通过减去具有先前权重的动量项来计算新权重,则更新在方向 2 上移动(图 5)。
如果我们结合这两个方程,通过用动量和梯度项之和减去先前的权重来计算新的权重,那么更新将向方向 3 移动,这导致对更新去噪。

图 5
上图(图 5)总结了 SGD+动量降噪梯度,与 SGD 相比收敛更快。
优点:
- 具有 SGD 算法的所有优点。
- 比 GD 算法收敛得更快。
缺点:
- 我们需要为每次更新多计算一个变量。
内斯特罗夫加速梯度(NAG):
NAG 算法的思想非常类似于带有动量的 SGD,只是略有不同。在具有动量算法的 SGD 的情况下,动量和梯度是在先前更新的权重上计算的。




根据 NAG 算法,首先计算点 W_(t-1)的动量 V_t,并沿该方向移动以到达 W_dash,然后计算新的更新权重 W_dash 处的梯度,并再次向梯度移动(图 6)。净运动导致朝向最小值的方向。

图 6
NAG 和带动量算法的 SGD 工作得一样好,并且具有相同的优点和缺点。
自适应梯度(AdaGrad):
对于前面讨论的所有算法,学习率保持不变。因此,AdaGrad 的关键思想是为每个权重设定一个自适应的学习速率。权重的学习速率将随着迭代次数而降低。





因此,随着迭代次数(t)的增加,学习率α增加,这导致学习率自适应地降低。
优势:
- 无需手动更新学习率,因为它会随着迭代自适应地变化。
缺点:
- 当迭代次数变得非常大时,学习率降低到非常小的数值,这导致收敛缓慢。
阿达德尔塔:
以前的算法 AdaGrad 的问题是学习率随着大量迭代而变得非常小,这导致收敛缓慢。为了避免这种情况,AdaDelta 算法有一个取指数衰减平均值的想法。



亚当:
在 AdaDelta 算法的情况下,我们存储梯度平方的指数衰减平均值来修改学习速率。对于 Adam optimizer,想法是存储梯度的一阶矩(g_t)和二阶矩(g_t 的平方)。
一阶矩的 EDA:

二阶矩的 EDA:

偏差校正:


更新功能:


优化器的结论和比较:

来源:https://arxiv.org/pdf/1412.6980.pdf
上图是本文中讨论的算法的迭代次数与训练损失的关系图。
对于给定的迭代次数(假设 100),从图中可以观察到 adam 在所有其他算法中收敛最快。
什么时候选择哪种算法?

来源:https://ruder . io/content/images/2016/09/saddle _ point _ evaluation _ optimizer . gif
- 在上面的动画中,可以看到 SGD 算法(红色)停滞在一个鞍点上。所以 SGD 算法只能用于浅层网络。
- 除 SGD 之外的所有其他算法最终一个接一个地收敛,AdaDelta 是最快的,其次是动量算法。
- AdaGrad 和 AdaDelta 算法可用于稀疏数据。
- 动量和 NAG 在大多数情况下工作良好,但速度较慢。
- Adam 的动画不可用,但是从上面的图中可以看出,它是收敛到最小值的最快算法。
- Adam 被认为是上面讨论的所有算法中最好的算法。
感谢您的阅读!
用 Flask 和 Heroku 构建和部署推荐器
使用 Heroku 构建混合推荐器和部署基于内容的过滤组件时基于模型的观点

我的数据科学沉浸式计划的顶点演示幻灯片的首页
在这篇文章中,我用 Flask 和 Heroku 展示了一种构建混合推荐器和部署一个基于模型的内容过滤系统的方法。这是我在新加坡大会(GA)下的数据科学沉浸式项目中的顶点项目。更多详情可以在这些 GitHub 回购链接中找到: GA_Capstone ,GA _ Capstone _ Flask _ Heroku _ deployment。
对于这个项目,我选择了咖啡作为感兴趣的主题,因为我周围都是热爱咖啡的社会团体(尽管我不喝咖啡!)而且我很清楚,在寻找喝茶的好去处时,实际上存在着无穷无尽的选择。因此,我认为建立一个推荐器可以解决被选择淹没的问题,并且不需要根据过多的属性如位置、服务标准等来过滤选择。,在这里可能会派上用场。
待建推荐系统类型概述
基于模型的内容过滤
一种基于内容的过滤模式,在受监督的机器学习算法(由特征 X 和目标 y 定义)的背景下构建,其中项目(在这种情况下为咖啡店)的各种特征(特征矩阵, X )用于预测用户评级(目标 y )。预测的用户评级然后以降序排列,并且认为合适的前 5 个或任意数字 n 被呈现为前 5 个或前 n 个推荐,供用户检查。
基于模型的协同过滤
一种基于机器学习算法的协同过滤范例,该算法从现有数据中学习用户-项目交互,以预测用户的项目评级(或在我们的上下文中用户的咖啡出口评级), 通过考虑具有相似评级模式的其他用户的项目评级——这就是为什么协作过滤 RecSys 经常遇到冷启动问题的原因,在该问题中,不可能找到具有与未对任何项目进行评级的新用户相似的评级模式的用户——然后向感兴趣的用户推荐那些相似用户最喜欢的项目(因此本质上是协作的)。
混合 RecSys
混合 RecSys 结合了基于内容的过滤和协作过滤,试图减少其中任何一种的缺点,以产生更整体和更全面的系统(可以说是两全其美),例如,基于内容的过滤不能产生交叉推荐,即,它倾向于只推荐与用户曾经喜欢的项目类型相同的项目。协同过滤通过其协同特性解决了这一问题——可以潜在地推荐不属于用户曾经喜欢的项目类别的项目,只要那些项目是具有相似评级模式的其他用户最喜欢的。另一方面,对于只涉及显式反馈的数据集,如用户评级(如 Yelp 数据集),协同过滤只考虑用户-项目交互矩阵,该矩阵包括用户 id、评级和项目 id。在这种情况下,基于内容的过滤可以通过提供更细粒度的项目特征来丰富 RecSys 的项目特征数据集(即类别、 review_count 、 avg_store_rating 等)。从而使 RecSys 更加全面和强大。
数据
该数据集包括大约 987 家当地咖啡饮食店和相关功能,6,292 条用户评论和 7,076 条用户评级,这些都是使用 BeautifulSoup 和 Yelp 的 API 令牌的组合从 Yelp 搜集来的。
由于在收集的数据集中有很大比例的用户只对 1-2 家商店进行评级,因此在随后的模型评估阶段的 train_test_split() 和交叉验证阶段,当数据集被分成由 userids 分层的训练和验证集时(尤其是如果 test_size 小于 0.5 并且交叉验证折叠数大于 2),针对所有这些用户的模型训练将不可避免地遇到错误。因此,我只将对至少 10 个不同渠道进行评级的用户纳入基于内容的过滤模型(这导致 110 /2552 用户被纳入模型训练)。数字 10 是任意选择的,尽管这可能与用户应该如何提供 10 个评级以生成部署模型中的前 5 个建议有关,我们将在后面看到。
从训练数据来看,我们的目标 y (用户评分)明显不平衡:

不平衡的目标类别:在类别 1 和类别 2 中几乎没有任何评级,在类别 3 中最小,大多数属于类别 4 和类别 5,其中类别 4 占主导地位
由于目标类的不平衡性质,以及我们不希望推荐差的推荐(误报)也不希望错过好的推荐(误报),一个微平均 F1 分数,这实质上是一个定义为精度和召回之间的微平均平衡的指标,用于稍后评估各个模型的性能。
型号
基于内容的过滤
将被合并到基于内容的过滤模型中的项目(或咖啡店)方面的特征是:

基于内容的过滤功能:评论、类别、评论数量和平均商店评级
使用 naive Tf-idf 矢量器将评论分解为词项频率,该矢量器用于在模型训练之前显示每个评论词项的区分强度及其与各种咖啡店的关联。
我调整并试验了各种有监督的机器学习算法,如逻辑回归、决策树分类器,以及集成方法,如极端梯度提升分类器(XGB)。 XGB 表现最好(微观平均 F1 分:0.97 ),被选中部署。XGB 是一种极端的梯度推进回归树(GBRT)算法,它:
- 减少偏差、方差,并从过去弱学习器的错误中“学习”以产生强学习器,因为它从浅的低方差/高偏差基础估计器开始,并根据过去估计器的错误迭代拟合估计器,以纠正那些错误/错误分类
- 通过使用更规则的模型形式化来控制过拟合 ,从而比常规的梯度增强方法如梯度增强分类器执行得更好
- 能够很好地处理混合数据类型(回想一下:用于基于内容过滤的数据集混合了数字和分类数据类型,分别像 review_count 和 reviews )

XGB 的一个实例——感谢https://blog.quantinsti.com/xgboost-python/
协同过滤
使用交替最小二乘法(ALS)算法,并使用 Pyspark 的交叉验证器 ( 微平均 F1 分数:1.0 )进行调整。ALS 是一种矩阵分解技术,它将用户-项目交互矩阵(如具有显式反馈的数据集的用户-项目评级矩阵)分解为用户和项目潜在因素,其中它们的点积将预测用户的项目评级(或在此上下文中各种咖啡店的用户评级)。它在固定用户或项目潜在因素之间交替,以在最小化损失(实际和预测用户评级之间的误差)的过程中,通过每次迭代的梯度下降来求解另一个:

矩阵分解损失函数:解释潜在的用户和项目因素,这些因素将在使用 ALS 算法时通过梯度下降来学习
混合 RecSys
基于内容的过滤和协作过滤通过对来自两个过滤系统的评级预测进行加权求和而结合在一起。例如,如果基于内容的过滤的预测用户评级是 3,而协作过滤的预测用户评级是 4,则最终的预测用户评级将是:
(0.97/(0.97(XGB 的微平均 F1)+1.0(ALS 的微平均 F1))(基于 XGB 的微平均 F1 分配给基于内容的过滤的权重)x3+(1.0/(0.97(XGB 的微平均 F1)+1.0(ALS 的微平均 F1))(基于 ALS 的微平均 F1 分配给协同过滤的权重)x 4 = ~3.51 = 3.5(四舍五入到最接近的 0.5)
混合 RecSys 的微平均 F1 分数为 1.0 。
Flask 应用程序实现
使用 Flask python 脚本和一些 html 模板,在本地虚拟环境中成功实现了混合 RecSys。
基本上,用户应该选择并评价他们以前去过或熟悉的 10 个当地咖啡饮品店(最好每个评价等级有 2 个不同的店,以便允许在后端工作的机器学习模型更全面地了解用户的“偏好”,这反过来将产生更可靠的推荐),并点击“提交以产生前 5 个推荐供所述用户检查。

在本地虚拟环境中实现的 Flask 应用程序的首页:用户首先根据既定的准则提交一些商店的评级

Flask 应用程序的首页还提供了额外的 Yelp 链接,链接到喝咖啡的商店,供用户在给它们评分前参考

根据提交的 10 个评分,为用户生成的前 5 个推荐示例
然而,与大多数部署的机器学习模型不同,这些模型仅简单地基于作为用户输入提供的看不见的特征(即 X_test )来预测结果,这种混合 RecSys 依赖于一对手动组合的机器学习模型来训练新的看不见的评级(即目标、 y_train) 和已评级的咖啡店(即特征、 X_train )并预测用户对其他未评级的咖啡店的评级。因此,点击“提交”后,平均需要15–20 多分钟才能在 Flask app 上生成前 5 条建议……这种持续时间对于 Heroku 这样的正式部署平台来说是不可接受的,只要等待时间超过仅仅 30 秒 ,Heroku 就会终止任何 web 应用程序的进程,并在错误日志中输出一条“请求超时消息和一个 H12 错误……
使用 Heroku 部署基于内容的过滤
鉴于上述情况,我只能尝试部署 RecSys 的“一半”,特别是 XGB 组件:因为 ALS 只能从 Pyspark-py spark . ml . recommendation库导入,而且我还没有找到详细介绍使用 Heroku 部署 py spark 代码的在线资源。找到的大多数资源都是关于 Scala 和 Spark 应用程序的,这些应用程序需要用 Scala 构建工具 ( sbt )和 jar 汇编进行编译,这对于我使用最少 Pyspark 代码的 Flask 应用程序来说似乎有点太复杂了——甚至没有 SparkContext 或 spark-submit ,只有 SparkSession 和 ALS 组件。
随着 RecSys 被削减到只有 XGB 组件,“请求超时”仍然是一个问题。在用*% %的时间削减了代码的 XGB 组件并在 Jupyter Notebook 中记录了每个代码单元的运行时之后,*我能够充分缩短运行时,以便 XGB 组件可以通过 Heroku 正式部署,而不是通过这里的。

与 Heroku 一起部署的基于内容的过滤 RecSys:首页,用户在此提交 10 个出口评级

与 Heroku 一起部署的基于内容的过滤 RecSys:基于提交的 10 个评级的用户前 5 个建议的结果页面
模型限制
混合 RecSys 的一些局限性包括:
- 缺乏隐含数据
- RecSys 基于不更新的静态数据,因此将来可能会过时
- 可疑的数据质量(大多数用户只对 1-2 个网点进行评级,因此不可能对包含所有 2552 个用户的模型进行训练和交叉验证)
- 很难同时调整 Tf-idf 和训练具有单词术语和数字特征组合的模型——因此 Tf-idf 没有被调整,而是使用了一个简单的版本
- 均值归一化可作为 RecSys 根据每个网点的平均用户评级向开始时未提供任何评级的用户推荐网点的备用方案
未来计划
在线关注各种部署平台、 stackoverflow 和 Pyspark 部署的更新,看看 Pyspark ALS 组件是否可以整合到 Heroku 部署中,以便可以在线部署完整的混合 RecSys。
如果上述结果很好,可以潜在地结合用户设计/用户体验的概念,以更好地设计 html 用户界面,为 A/B 测试做准备,以衡量混合 RecSys 构建的有效性。
概述:每个学科和每个任务的最先进的机器学习算法
了解自然语言处理、计算机视觉、语音识别和推荐系统的最佳算法

CV =计算机视觉,NLP =自然语言处理,RS =推荐系统,SR =语音识别|来源:来自作者。
机器学习算法正在兴起。每年都有新的技术出现,超越了当前领先的算法。其中一些只是现有算法的微小进步或组合,而另一些是新创造的,并带来了惊人的进步。对于大多数技术,已经有很好的文章解释了其背后的理论,其中一些还提供了代码和教程实现。目前还没有人提供当前领先算法的概述,所以这个想法出现了,根据所取得的结果(使用性能分数)来呈现每个任务的最佳算法。当然,还有更多的任务,并不是所有的任务都可以呈现。我试图选择最受欢迎的领域和任务,并希望这可能有助于更好地理解。本文将重点讨论计算机视觉、自然语言处理和语音识别。
文中介绍了所有的领域、任务和一些算法。如果您只对某个子部分感兴趣,请跳到您想深入了解的部分。
计算机视觉
计算机视觉是机器学习中研究最多、最热门的领域之一。它用于解决许多日常问题,并连续涉及多种应用,其中最受欢迎的是自动驾驶汽车的愿景。我们将要研究的任务是语义分割、图像分类和目标检测。
语义分割
语义分割可以被视为在像素级别上理解图像的结构和组件。语义分割方法试图预测图像中的结构和对象。为了更好地理解,可以在下面看到街道场景的语义分段:

用 SegNet 进行语义分割【https://mi.eng.cam.ac.uk/projects/segnet/
目前领先的算法 HRNet-OCR 是由 Nvidia 的 Tao 等人在 2020 年提出的。它实现了 85.1%的平均交集/并集(平均 IOU)。HRNet-OCR 对图像进行缩放,并对每个缩放比例使用密集遮罩。然后,所有尺度的预测“通过在掩模之间执行逐像素乘法,然后在不同尺度之间进行逐像素求和,从而获得最终结果”[1]。
查看 Github 来的技术:
https://github.com/HRNet/HRNet-Semantic-Segmentation
其他顶层技术(方法—数据集):
- 高效网-L2+NAS-FPN —帕斯卡 VOC
- ResNeSt-269 — PASCAL 上下文
- VMVF —ScanNet
想看更多这样的故事?每天只需要 0.13 美元。
开始使用
图像分类
不同于语义分割,图像分类不关注图像上的区域,而是关注图像的整体。这个学科试图通过分配一个标签来对每个图像进行分类。

来源:图片由作者提供。
FixEfficientNet 已经于 2020 年 4 月 20 日与脸书人工智能研究团队的相应论文一起首次提交[2][3]。它目前是最先进的,在 ImageNet 数据集上具有最好的结果,480M 参数,前 1 名准确率为 88.5%,前 5 名准确率为 98.7%。FixRes 是 Fix Resolution 的简称,它试图为用于训练时间的 RoC(分类区域)或用于测试时间的 crop 保持固定的大小。EfficientNet 是 CNN 维度的复合缩放,提高了准确性和效率。
欲了解 FixEfficientNet 的更多信息,请阅读此。
其他顶层技术(方法—数据集):
- BiT-L — CIFAR-10
- Wide-ResNet-101—STL-10
- 分支/合并 CNN +均质过滤胶囊 — MNIST
目标检测
对象检测是识别图像中某一类对象的实例的任务。
目前领先的物体检测技术是谷歌大脑团队(Tan 等人)在 2020 年首次提出的Efficient-Det D7x[4]。它实现了 74.3 的 AP50 ( 了解 AP50 的更多信息:在 50 的固定 IoU 阈值下的平均精度)和 55.1 的 box AP。Efficient-Det 是 EfficientNets 与双向特征金字塔网络( BiFPNs )的组合。
正如上面简要解释的那样, EfficientNet 是 CNN 维度的复合缩放,它提高了准确性和效率。更多关于 EfficientNet 的信息,你可以点击这里。
在计算机视觉中,提高精确度的典型方法是创建具有不同分辨率的同一图像的多个副本。这导致了所谓的金字塔,因为最小的图像被布置为顶层,而最大的图像被布置为底层。要素金字塔网络代表了这样一个金字塔。双向意味着不仅有自上而下的方法,同时也有自下而上的方法。每个双向路径都被用作特征网络层,这导致了 bip pn。它有助于提高准确性和速度。有关 bip pn 的更多信息,点击此处。
其他顶层技术(方法—数据集):
自然语言处理
自然语言处理的常见定义如下:
NLP 是人工智能的一个子领域,它赋予机器阅读、理解和从人类语言中获取意义的能力。
NLP 任务的范围很广,正如定义所揭示的,它们都试图从我们的语言中推断出一些含义,并根据我们的语言及其组成部分进行计算。基于 NLP 的算法可以在各种应用和行业中找到。仅举几个你可能每天都会遇到的应用程序,如翻译器、社交媒体监控、聊天机器人、垃圾邮件过滤器、微软 word 或 messengers 中的语法检查和虚拟助手。
情感分析
情感分析是文本挖掘的一个领域,用于对文本数据中的情感进行解释和分类。目前领先的算法之一是 BERT ,它在 2019 年的 SST-5 细粒度分类数据集上实现了 55.5 的准确率。最初的论文由谷歌人工智能团队发布【5】。
BERT 代表来自变压器的双向编码器表示,并应用变压器技术的双向训练。Transformer 技术是一种用于语言建模的注意力模型,以前只应用于一个方向。从左到右或从右到左解析文本。更多细节,请阅读这篇伟大的文章。
其他顶层技术(方法—数据集):
- T5–3B—SST-2 二元分类
- NB-加权-BON+dv-余弦 — IMDb
语言建模
语言建模是基于现有文本/先前单词来预测文本中的下一个单词或字母的任务。GPT-2 模型被赋予了两个关于生活在安第斯山脉的一群独角兽的句子,它创造了一个惊人的故事。这里可以看。
在语言建模中,表现最好的算法之一可以在 Megatron-LM 中找到。这个模型和论文是英伟达团队在 2019 年首次提出的。一个类似 GPT-2 的模型在 83000 亿个参数上进行训练。它能够将当前最高水平的 15.8 分降低到只有 10.8 分的测试困惑度。使用的数据集是 WikiText103 [6]。
该模型利用了变压器网络。在他们的工作中,变形层由一个自我注意块和两层、多层感知机(MLP)组成。在每个块中,使用模型并行性。这有助于减少通信并保持 GPU 的计算能力。GPU 的计算被复制以提高模型的速度。
其他顶层技术(方法—数据集):
- GPT-3——宾州树木银行
- GPT-2——维基百科 2,文本 8,环境 8
机器翻译
机器翻译被用于谷歌翻译或 www.deepl.com 翻译等应用中。它用于使用算法将文本翻译成另一种语言。
这个领域最有前途的算法之一是 **Transformer Big +BT。**由谷歌大脑团队于 2018 年在本文中提出。一般来说,变压器是处理序列和机器翻译的最先进技术。转换器不使用循环连接,而是同时解析序列[7]。

输入以绿色表示,提供给模型(蓝色)并转换为输出(紫色)。 GIF 来源
正如你在上面的 gif 中看到的,输入和输出是不同的。这是由于两种不同的语言,例如输入是英语,而输出语言是德语。为了提高速度,并行化是该模型的一个关键方面。这个问题通过使用 CNN 和注意力模型来解决。自我关注有助于提高速度和对某些单词的关注,而 CNN 用于并行化[8]。更多关于变形金刚的信息,请阅读这篇伟大的文章。作者应用反向翻译(BT) 进行训练。在这种方法中,训练数据集被翻译成目标语言,并且算法将其翻译回原始语言。然后可以很好地观察表演[7]。
其他顶层技术(方法—数据集):
- 垫子+膝盖 — IWSLT2014 德语-英语
- MADL — WMT2016 英德
- 注意力编码器-解码器 +BPE — WMT2016 德语-英语
文本分类
文本分类的任务是给一个句子、一篇文章或一个单词分配一个特定的类别。目前在三个不同数据集(DBpedia、AG News 和 IMDb)上领先的算法是 XLNet。
谷歌人工智能团队在 2019 年首次展示了论文和技术 XLNet 。它在 20 个任务中改进了领先的算法 BERT。 XLNet 首创的方法叫做置换语言建模。它利用了单词的排列。假设你有三个单词,顺序如下[w1,w2,w3]。然后检索所有排列,这里是 321 = 6 个排列。显然,对于长句,这导致了无数的排列。位于预测字(例如 w2)之前的所有字用于预测[9]:
w3 w1 **w2**
w1 **w2** w3
w1 w3 **w2**
…
在行 1 中,w3 和 w 1 用于 w2 的预测。在行 2 中,只有 w1 用于预测,依此类推。为了更好地理解这项技术,你可以在这里阅读更多相关内容。
其他顶层技术(方法—数据集):
- 使用 _T + CNN — TREC-6
- SGC—20 条新闻
问题回答
问答是训练一个算法来回答问题的任务(通常基于阅读理解)。这项任务是迁移学习的一部分,因为要学习给定的文本数据库,并存储知识以在稍后的时间点回答问题。
通过 T5–11B,谷歌人工智能团队在四个不同的数据集上实现了最先进的基准测试:GLUE、SuperGLUE、SQuAD 和 CNN/Daily Mail。T5 代表文本到文本转换转换器中的五个 T,而 11B 代表用于训练算法的 110 亿个数据集。与 BERT 和其他优秀的算法相比,T5–11B 不输出输入句子的标签。相反,正如名称所示,输出也是一个文本字符串[10]。

来源:https://ai . Google blog . com/2020/02/exploring-transfer-learning-with-t5 . html
论文的作者已经严格评估和提炼了几十个现有的 NLP 任务,以将最好的想法应用到他们的模型中。这些包括对模型架构、预训练目标、未标记数据集、训练策略和规模的实验,如作者所述[10]:
模型架构 ,在这里我们发现编码器-解码器模型普遍优于“只有解码器”的语言模型;
预训练目标 ,我们确认填空式去噪目标(训练模型以恢复输入中缺失的单词)效果最佳,最重要的因素是计算成本;
未标记数据集 ,其中我们展示了对域内数据的训练可能是有益的,但是对较小数据集的预训练可能导致有害的过拟合;
和 缩放 ,其中我们比较模型大小、训练时间和集合模型的数量,以确定如何最好地利用固定的计算能力[11]
完整的 T5–11B 型号是现有 NLP 型号(如 BERT)的 30 多倍。
其他顶层技术(方法—数据集):
- T5–11B—1.1 班开发
- 阿尔伯特上的 SA-Net-squad 2.0
- 坦达-罗伯塔
推荐系统
你很可能已经见过并使用过各种各样的推荐系统。你最喜欢的网上商店或平台用它来推荐你可能感兴趣的类似产品。
该领域目前领先的算法之一是贝叶斯时间 SVD++。它是由谷歌团队在 2019 年提出的,并在 MovieLens100K 数据集上达到了 SOTA 基准。谷歌团队尝试了多种不同的方法和方法组合,直到他们找到贝叶斯矩阵分解和 timeSVD++的领先组合。使用吉布斯采样训练贝叶斯矩阵分解模型。更多关于这个模型和所有尝试过的方法,你可以在这里找到【12】。
其他顶层技术(方法—数据集):
- H+鞋面门控 —运动镜片 20M
- 缓解 —百万首歌曲数据集
- 贝叶斯 timeSVD++翻转 w/有序概率单位回归 — MovieLens 1M
语音识别
和推荐系统一样,语音识别也参与了我们的日常生活。越来越多的应用程序以虚拟助手的形式利用语音识别,如 Siri、Cortana、Bixby 或 Alexa。
该领域的领先算法之一是基于 ContextNet + SpecAugment 的带 Libri-Light 的嘈杂学生训练,由谷歌团队于 2019 年首次推出,论文【13】。
顾名思义,这种方法结合了语境和嘈杂的学生训练。上下文网络是一个 CNN-RNN 转换器。该模型由用于输入音频的音频编码器、用于产生输入标签的标签编码器和用于解码的两者的联合网络组成。对于标签编码器,使用 LSTM,音频编码器基于 CNN。嘈杂的学生训练是一种半监督学习,使用未标记的数据来提高准确性[13]。
在有噪声的学生训练中,连续训练一系列模型,使得对于每个模型,该系列中的前一个模型充当数据集的未标记部分上的教师模型。嘈杂的学生训练的显著特征是利用增强,其中教师通过读入干净的输入来产生高质量的标签,而学生被迫用大量增强的输入特征来复制这些标签。”[13]
Libri 光指的是未标记的音频数据集,模型在该数据集上被训练,并且该数据集是从音频书籍中导出的。
其他顶层技术(方法—数据集):
- ResNet + BiLSTMs 声学模型 —配电盘+ Hub500
- LiGRU+Dropout+batch norm+one phone Reg—TIMIT
- 大型-10h-LV-60k — Libri-Light 测试-清洁
结论
过去十年在多个学科和任务方面取得了突破。新的技术、算法和应用已经被发现和开发,而我们仍处于开始阶段。这主要是通过两项发展实现的:1)不断增长的数据库,这使得为算法提供足够的数据成为可能;2)处理器、RAM 和显卡的技术发展,使得训练需要更多计算能力的更复杂的算法成为可能。此外,随着数据科学投资的增加以及越来越多的人对数据科学和机器学习领域感兴趣,最先进的算法的半衰期也在缩短。连续,这篇文章可能已经过时一年。但是现在,这些领先的技术有助于创造越来越好的算法。
如果你知道其他应该添加的方法或学科,你可以评论或联系我。感谢您的反馈,希望您喜欢这篇文章!
** [## 通过我的推荐链接加入 Medium-Hucker Marius
作为一个媒体会员,你的会员费的一部分会给你阅读的作家,你可以完全接触到每一个故事…
medium.com](https://medium.com/@hucker.marius/membership)**
参考文献:
[1]陶,a .,萨普拉,k .,&卡坦扎罗,B. (2020)。语义切分的分层多尺度注意。ArXiv:2005.10821【Cs】。http://arxiv.org/abs/2005.10821
[2]h .图夫龙、a .韦达尔迪、m .杜泽和 h .杰古(2020 年 b)。修正训练-测试分辨率差异。ArXiv:2003.08237 [Cs] 。http://arxiv.org/abs/2003.08237
[3]h .图夫龙、a .韦达尔迪、m .杜泽和 h .杰古(2020 年 a)。修复列车测试分辨率差异。ArXiv:1906.06423【Cs】。http://arxiv.org/abs/1906.06423
【4】谭,m,庞,r,&乐,秦文伟(2020)。EfficientDet:可扩展且高效的对象检测。ArXiv:1911.09070【Cs,Eess】。http://arxiv.org/abs/1911.09070
**【5】Devlin,j .,Chang,m-w .,Lee,k .,& Toutanova,K. (2019)。BERT:用于语言理解的深度双向转换器的预训练。ArXiv:1810.04805【Cs】。【http://arxiv.org/abs/1810.04805 **
[6] Shoeybi,m .,Patwary,m .,Puri,r .,LeGresley,p .,Casper,j .,& Catanzaro,B. (2020 年)。威震天-LM:使用模型并行性训练数十亿参数语言模型。ArXiv:1909.08053【Cs】。http://arxiv.org/abs/1909.08053
[7]艾杜诺夫,s .,奥特,m .,奥利,m .,&格兰吉尔,D. (2018)。理解大规模回译。ArXiv:1808.09381【Cs】。http://arxiv.org/abs/1808.09381
[8] Vaswani,a .,Shazeer,n .,Parmar,n .,Uszkoreit,j .,Jones,l .,Gomez,A. N .,Kaiser,l .,& Polosukhin,I. (2017)。你需要的只是关注。ArXiv:1706.03762【Cs】。http://arxiv.org/abs/1706.03762
[9]h .图夫龙、a .韦达尔迪、m .杜泽和 h .杰古(2020 年 b)。修正训练-测试分辨率差异。ArXiv:2003.08237 [Cs] 。http://arxiv.org/abs/2003.08237
[10] Raffel,c .,Shazeer,n .,Roberts,a .,Lee,k .,Narang,s .,Matena,m .,周,y .,Li,w .,和刘,P. J. (2020)。用统一的文本到文本转换器探索迁移学习的局限性。 ArXiv:1910.10683 [Cs,Stat] 。http://arxiv.org/abs/1910.10683
【11】https://ai . Google blog . com/2020/02/exploring-transfer-learning-with-t5 . html
[12] Rendle,s .,Zhang,l .,& Koren,Y. (2019)。评估基线的困难:推荐系统的研究。ArXiv:1905.01395【Cs】。http://arxiv.org/abs/1905.01395
**[13] 朴德生、张、杨、贾、杨、韩、魏、邱、陈正忠、李、吴正荣、&乐、秦文武(2020)。改进自动语音识别的嘈杂学生训练。*ArXiv:2005.09629【Cs,Eess】【http://arxiv.org/abs/2005.09629 ***
我如何建立一个帮助我更有创造力的系统
“你的头脑是用来有想法的,而不是持有想法的。”—大卫·艾伦

来自 Pexels 的第三人拍摄的照片
T 数据空间中的信息和技术数量惊人——作为一名数据工程师,我亲身经历过。技术概念、数据库、云服务、开源框架以及用于数据科学、可视化和 ETL 过程的工具——似乎不可能跟上。如今我们消费了如此多的内容,我们不应该责怪自己没有能力管理这些信息过载。在本文中,我分享了几种技术和一个可行的模板,以组织我们消费的内容,并在我们作为数据专业人员的繁忙生活中为新的创意留出空间。
捕捉信息
在不断发展的技术世界中,很难跟上最新的发展。幸运的是,我们不必知道所有的事情,而是知道在哪里可以找到我们想要的信息。
我遇到过许多软件工程师,他们不写任何东西,仅仅依靠谷歌搜索(或者更确切地说是栈溢出搜索)来进行信息检索。不要误解我,我喜欢栈溢出,但是我讨厌解决同一个问题两次,仅仅因为我忘记了我以前是如何得到解决方案的。
因此,我开发了一个可以依赖的做事系统,它可以让我存储并在以后找到我需要的一切。基本原则是:
“你的头脑是用来有想法的,而不是用来持有想法的。”
大卫·艾伦[1]
如果你能把学过的东西捕捉到某个外部系统 ( 你的“第二大脑”)并依靠它快速找到相关信息,你就不需要把所有东西都储存在你的脑袋里。它给你更多的空间来思考新的想法,并把注意力放在最重要的事情上。
实现细节,比如你最后用哪个 app 做笔记(比如 idea,Evernote,Roam,RemNote,OneNote 等。),只要能让你捕捉、组织、检索一切,都无所谓。许多人仍然喜欢做物理笔记,如果这对你有用,那也没关系。
为什么获取信息如此重要?
以前我会看博文,看视频或者看一本关于某件事的书,它让我相信我抓住了它的要旨,我会记住它。但是当我几个月后不得不应用这些信息时,结果是我忘记了其中的大部分,并且我找不到我正在使用的资源。
我从中学到的是:
我们在技术工作中遇到的信息量是巨大的,我们不能依赖于记住所有的东西。
如今,事情变化得如此之快,以至于我们可能没有充分利用时间去了解事情的细节。很多时候,拥有一个宏观视角并在需要时更深入地研究我们捕捉到的笔记就足够了。
没有捕捉,我们仅仅依靠我们易错的记忆,这给我们自己很大的压力。如果我们没有抓住我们所学的东西,我们可能需要以后完全重新学习,因为几个月或几年后我们几乎忘记了一切。

照片由 bongkarn thanyakij 从 Pexels
系统思维
作为一个雄心勃勃的人,你可能正在为自己设定目标。但是当你实现了目标,接下来呢?目标似乎有助于指明方向。然而,围绕它们来组织我们的工作可能会适得其反,因为目标关注的是目的地而不是过程。写下可实现的、可衡量的里程碑的愿景和计划可能会有所帮助,但最终:
“你没有达到你的目标。你会下降到你的系统的水平。”——詹姆斯·克利尔[2]
系统给了我们一个框架,将我们雄心勃勃的目标分解成小的可管理的步骤,并随着时间的推移看到更大的画面。一个健壮的系统允许捕获、组织、审查,并最终找到和应用相关信息。
查看和组织信息
在我们将任何信息捕获到一个可靠的系统中之后,我们应该能够很容易地将其组织成组。工作项目、个人项目,甚至是关于如何与朋友和家人共度时光的想法)并根据什么是最重要的,对所有事情进行优先排序。这种分类有很多好处:
- 我们可以看到更大的图景
- 我们可以区分什么是真正重要的,什么只是紧急的
- 我们可以开始处理我们最重要的事情
- 我们可以跟踪我们的进展,看看小任务是如何完成的。每天坚持阅读一本书的一章会让我们有所成就。
最后,我们可以睡得更好,因为我们知道一切(或至少一部分)都在我们的控制之下,因为所有的“生活类别”都在我们的系统中得到照顾。
实施一个完成任务的系统
建立任何可靠的系统都具有挑战性。例如,你可以使用概念来记录项目、工作任务以及任何你正在学习的东西。实际的工具比它的使用方式更重要。
完成任务系统的组成部分
理想的完成任务系统将让您:
- 跟踪你的项目,例如使用看板,
- 快速捕捉新信息——例如。通过使用某种收件箱
- 轻松对信息进行分类和组织以便于访问,例如,将待办事项或看板中的笔记分类到笔记本、页面、类别中,或者用标签进行标记(上图所示的知识库部分
- 通过创建模板使捕捉过程更容易
- 存储代码片段
- 轻松检索任何东西——例如。在概念中,你可以使用快捷键 Cmd + P ( 或者 Windows 上的 Ctrl + P)来搜索任何关键词——它甚至可以搜索你的代码片段
- 对你的任务进行优先排序
- 以对你有意义的方式组织信息。
最后一点很关键:如果你总结和构建任何捕捉到的信息让它对你有意义,你会让你的“未来自我”更容易理解你的意思。最重要的是,它将使扩展和与他人共享变得更容易管理。
在实践中运用知识
我们都是人,我们喜欢做简单的事情:看网飞,吃冰淇淋,或者仅仅是通过观看 YouTube 视频或浏览 Reddit 来获取信息。但是,纯粹的内容被动消费就不坚持了。例如,让我们想象两种场景:
- 被动学习:你正在看一段视频,视频中有人在解释如何编写程序。
- **主动学习:**你试图自己编写一些东西,你必须搜索特定的信息来解决你的问题,通过试错找到解决方案,并从你的错误中学习。
你也许能从第二个场景中回忆起更多。一个简单的积极参与内容的行为会使任何信息停留更长时间。例如,回到学校和大学,我经常用纸和笔做笔记,因为这让我不会对讲座感到厌烦。与此同时,记笔记时,我总是能够在以后更容易地回忆起这些信息。
主动学习和被动学习之间的区别可能是为什么我们通过做而不是仅仅看着别人做某事而学得更好的原因。
没有应用的知识就像知道一门外语的全部词汇,但仍然不能说。没有应用,这些知识在我们的大脑中就没有长期记忆的联系。我发现,即使编写最短的代码示例,也能更容易理解和记住任何编程概念。这同样适用于学习外语的过程——用我们刚学过的新单词造一个简单句,把它放在如何使用它的语境中,这样更容易记住它。
结论
在这篇文章中,我们讨论了完成任务系统的组件,这些组件可以通过捕捉我们学习到的信息到我们的“第二大脑”来帮助我们更积极地消费内容,第二大脑是一个外部系统,允许我们存储和组织我们工作的事情。如果使用得当,这样的系统将降低我们的压力水平,释放我们的精神资源,因为我们不再需要将所有东西都存储在我们的精神“RAM”中,而是可以将其中的一部分移动到一些“外部驱动器”中。
我鼓励你试一试。创建一个系统来组织项目,捕捉你所学的东西,并定期更新你的知识库,这在未来很可能会有指数级的回报。这将使工作和学习变得更加愉快,因为你将有一个系统来释放你的精神资源,专注于重要的事情。最后,我们永远不会停止学习,尤其是在技术领域,所以最好用系统来接近它。
感谢您的阅读!
参考文献
[1]“把事情做好”——作者:大卫·艾伦和大卫·凯尔文·艾伦
[2]“原子习惯:建立好习惯、改掉坏习惯的简单而有效的方法”——詹姆斯·克利尔的书
被 R 压倒?慢慢开始
面向非程序员的 R 命令的第一课

由 minkewink 在 Pixabay 上拍摄的照片
如果你没有做过大量的编程工作,学习 R 可能会相当令人生畏。
但如果你专注于基础,并通过实践慢慢积累技能,那就更容易了。在这里,我将给出一个简短的教训,告诉你在 r 中可以做的最基本的事情。
这篇文章改编自我的在线课程 ,所以你需要学习 R 。它假设你已经安装了一个r studio的副本,对个人来说是免费的。
让我们从如何在 R 中输入命令的基础开始,告诉 R 我们想要做什么。这叫做给 R 一个表达式。
做一些数学
如果您打开一个 RStudio 会话,您将看到一个控制台,其中有一些介绍性文本和一个提示(小的 > 符号):

RStudio。图片作者。
您可以在提示符后键入命令,在您按下 Return 或 Enter 键后,R 将会对它们进行评估;这意味着它将解释它们的含义,并试图计算出某种结果。
首先,让我们把 R 作为一个美化了的科学计算器。输入这些命令并按 Enter 键以获得一些输出:
1 + 2
3 - 1
所以 R 理解数字和常见的数学运算符。这包括带星号*的乘法和带正斜杠/的除法。
2 * 6
6 / 3
您可以使用插入符号^ (shift-6)来计算幂,例如计算四的平方。你也可以做负数。
4 ^ 2
4 ^ -2
数字
r 理解十进制记数法(是 a .还是 a,取决于你的国家;r 在这方面通常很聪明)。但是我们不在大数字中使用逗号或其他千位分隔符:那会给我们一个错误。
1.2345 + 1
12,345 + 1
圆括号
r 也理解并尊重*操作顺序。*乘方先于乘法,乘法先于加法,依此类推。是的,你必须重温高中数学的记忆。对于同一级别内的操作,R 从左到右工作。
1 + 2 * 3
4 / 2 / 8
您可以用括号修改这个顺序,就像您在任何其他
数学上下文中一样。如果你想让一加二先求值,你把它放在括号里,得到一个完全不同的答案:
(1 + 2) * 3
4 / (2 / 8)
我们也可以用括号来定义分数。这在某些情况下真的很重要。例如,如果你想求一个数的根呢?根实际上是分数幂。所以不要…
4 ^ 2
我们想反过来,这样我们从 16 开始,然后求平方根。
16 ^ 1 / 2
但是我们实际上做错了:上面的命令不会按照我们想要的顺序进行计算,因为 R 会先取插入符号——意思是先取幂——这意味着这实际上是 16 的 1 次方,然后除以 2。
但是我们想求平方根。我们需要把分数放在括号里。然后我们得到 16 的正确根是 4(不是 8)。
16 ^ (1 / 2)
还要注意,在我的例子中,我在 r 中留出了符号。这两个命令产生相同的结果:
3^4/2+(1/2)
3 ^ 4 / 2 + (1 / 2)
但是第二种可能更容易阅读。
一个例子
让我们用一个稍微更实用的例子来结束这一部分。我们可以做一道几何题,比如求球体的体积。公式是圆周率的三分之四乘以半径的立方:
v = 4/3⨉π⨉r
使用近似圆周率和半径 100,我们可以在 R 中输入如下内容:
4 / 3 * 3.14 * 100 ^ 3
r 也碰巧将单词 pi 理解为一个特殊符号,所以我们可以用它来代替,得到一个更准确的答案:
pi
4/3 * pi * 100 ^ 3
现在,给你一个小练习,反向计算:从体积 100 开始,确定半径是多少。
这并不难,是吗?现在你明白 R 是如何解释简单语句的了。接下来,您可以开始考虑在变量中存储值,以及如何使用它们。
Jasper McChesney 是一名高级数据分析师,拥有生物科学和数据可视化方面的背景。他曾在非营利组织、人力资源和高等教育部门工作过。他在马萨诸塞大学教授 R 课程,并在 Udemy 网上授课。
所以你需要学习 r,但你不是程序员。不要惊慌。在本课程中,我将带您参观…
www.udemy.com](https://www.udemy.com/course/so-you-need-to-learn-r/?couponCode=E01B6507F68E1467FCF4)
覆盖现实
为引人注目的 AR 内容整合已有经验
增强现实(AR)体验的一个关键部分是数字内容的质量和丰富程度。在之前的一篇文章中,我们探索了构建以对象为中心的通用 3d 模型,使用了传统的基于运动的结构( SfM )技术以及用于深度推断和姿态估计的已有架构。这里的重点是采用更好的方法来使用深度学习推断场景深度,以解决难以绘制地图的区域。
在本文中,我们考虑了从真实世界捕获构建高质量模型的一些其他挑战。例如,考虑从以下视频构建表示的任务:

目标;建立一个精确的,视觉上吸引人的日产探路者模型
这里的目标显然是从一个短视频中创建一个吸引人的 3d 车辆模型。传统的流水线相对简单:
- 估计摄像机的轨迹和它的内在参数
- 在多视图立体管道中使用该估计轨迹来提供密集的点云
- 从估计的立体点构建平滑的网格,并使用视频数据对其进行纹理处理
然而,闪亮的金属表面往往对多视图立体方法反应不佳(尽管我们可以利用更复杂的深度恢复方法,如前所述)。我们还遇到了另一个更难解决的问题:重建只能和场景覆盖一样好。下图说明了这一点:

从上面的视频轨迹恢复的场景结构。注意车辆后面未被观察到的大片区域。
从上面的重建中可以清楚地看到,相机没有完全探索场景,因此场景是不完整的——几个大区域丢失了。这是我们寻求补救的典型问题;即使没有一个完全探索过的场景,我们也应该能够对目标的几何形状和外观做出有根据的猜测。
这篇文章的核心论点是,我们对正在讨论的对象的内在属性有一个很好的想法,一辆 2000 年初的日产探路者。如果我们有一个现有的 3d 模型,我们可以直接用我们的先验模型替换推断的模型,只要定位、比例和纹理与视频紧密匹配。
我们的第一个任务是将场景分成前景/背景;使用现代全景分割方法,这是微不足道的:

场景的每帧实例遮罩。
给定上面的密集(每像素)每帧分割,我们可以轻松地将场景几何和纹理划分为前景和背景组件,如下所示:

稀疏的相机点云,与重建的网格形成对比。(为清晰起见,省略了部分网格)
上面的模型被渲染为背景网格和前景点云。虽然立体点不够密集,无法完全恢复汽车本身,但它们对于提供关于汽车的汇总统计数据很有用:位置、方向、比例。
给定背景分割和要插入的新内容的类别、位置和比例,我们如何着手生成实际的 3d 输入?一种方法是利用部分重建的网格并执行形状完成(例如,[ 1 ,[ 2 ,[ 3 )。或者,我们可以从图像中合成完整的 3d 形状,例如[ 1 、[ 2 、[ 3 、[ 4 以获得清晰的概览]。在本文中,我们将探讨后者。
在这种情况下,形状合成是从 2d 图像推断完全 3d 结构。作为一个例子, IM-NET 是一种用于生成形状建模的学习隐式场方法,其对于单视图 3d 重建特别有用。下面的动画展示了形状生成模块 IM-GAN 的示例:

IM-GAN 的样车模型。注意多样性和质量。
通过将估计的比例、平移和旋转应用于来自网络的采样 3d 输出,我们可以将合成的内容直接插入到场景中,如上所示。
使用来自单视图重建(SVR)模块对来自我们数据集的分割图像的预测输出,我们可以产生精确平滑的合成模型(合成模型与估计位置和比例的融合),这是我们对象的近似。然后使用原始视频中的图像进行纹理处理:

IM-SVR 的预测输出,使用原始视频图像进行纹理处理。未观察到/观察不到的组件以灰色呈现。
尽管上面有一些可见的伪像(车辆的车轮与估计的模型不完全匹配,并且由于可见性问题,一些区域没有纹理),但结果是令人信服的——我们不需要为我们(先验地)非常了解的对象建立繁重的数据收集例程。对于以可扩展的方式为已知对象生成准确、相关的模型,这是一种很有前途的方法。
2020 年牛津(真实)农业会议
NLP:3,8K tweets 的情感分析、单词嵌入和主题建模

介绍
上周,1 月 7 日至 9 日,牛津主办了历史悠久、传统而又务实的 牛津农业会议【OFC】及其解药 牛津真正的农业会议【ORFC】。两者都旨在将农业和食品部门的参与者联系起来,以应对当今农业的挑战。
过去三个月,我在世界可持续发展工商理事会为即将发表的论文“蛋白质途径:通过商业创新加速可持续食品体系转型”工作,该论文将在 2020 年达沃斯世界经济论坛上发布,我发现有必要看看该领域的最新讨论。
OFC 和 ORFC 为我提供了一个独特的机会。这些会议讨论了英国以及世界在农业方面面临的诸多挑战:应对粮食安全的必要性、保护自然生态系统的责任以及减少温室气体排放的必要性。
本文的目的是总结在 OFC 和 ORFC 期间发生的讨论,并获得英国农业食品部门最突出的参与者的概况。

粮农组织拍摄的图片
数据和方法
这篇博文的数据是使用 Twitter API 收集的。OFC 于 1 月 7 日至 9 日举行,ORFC 于 1 月 8 日至 9 日举行。我提前 5 天(2 日)开始收集推文,并在会议结束后一天(10 日)停止收集。总共记录了 3671 条推文,使用的标签是#OFC20、#OFC2020、#ORFC2020。
一旦收集了推文,我就使用自然语言处理(NLP)技术,即情感分析、词语嵌入和主题建模。
推文分析
以下图表说明了为更好地理解牛津(Real)农业会议的讨论而进行的分析。
菜单如下所示:
- **探索性数据分析:**每日和每小时的推文频率,按推文数量排名前 10 的推文,按点赞、转发和回复数量排名前 10 的推文。
- **情绪分析:**每日情绪得分,前 5 条最正面推文,前 5 条最负面推文
- **语义分析:**前 10 个单词,前 10 个标签,与“耕作”、“农业”和“食品”最接近的单词,推文中的主题
探索性数据分析
下面的线形图显示了从 OFC 和 ORFC 2020 开始前一周到两场会议结束后一天每天的推文数量和每小时的平均推文数量。最活跃的一天是 1 月 8 日,ORFC 的第一天和 OFC 的第二天,累积到近 2k 条推文。推文的每小时频率显示两个峰值,第一个在早上,上午 11 点,第二个在下午 3 点。这突出了会议与会者使用 Twitter 直接分享和评论正在进行的会谈。

左边的线形图显示了两次会议之前、期间和之后每天的推文数量,右边的线形图显示了每小时的平均推文数量。
看看以#OFC20 和#OFC2020 或#ORFC20 和#ORFC2020 为标签的十个最受欢迎的推特账户,就可以了解事件的主要参与者。下图显示了 OFC 和 ORFC 推特数量最多的十个推特账户。

左边的条形图显示了牛津农业会议的推文数量排名靠前的推文,右边的条形图显示了牛津真实农业会议的推文数量排名靠前的推文。推文的时间线是从 2020 年 1 月 2 日到 10 日。
在 OFC,最高职位大多由发人深省的演讲者占据,这与 ORFC 形成鲜明对比,后者由知名慈善机构和农民协会走在前面。
一些最活跃的 OFC 和 ORFC 参与者的快速事实!
莎拉·贝尔(Sarah Bell)是农业数字领导主题的一位有影响力的演讲者,罗布·约克(Rob Yorke)是农业主题的著名评论员,并促进了讨论:“如何资助“农业生态农业”?菲奥娜·史密斯教授是国际贸易教授,并在英国退出欧盟会议后讨论了英国农业食品贸易,马特·奈洛尔是 2017 年至 2020 年 OFC 的主任,也是“agrespect”的创始人,在农村促进和支持多样性、包容性和赋能。
土壤协会、农业生态学、可持续食品信托、创新农民、盖亚基金会(英国和爱尔兰种子主权)或可持续土壤与许多农民合作,并为可持续食品和耕作系统开展活动。食品伦理委员会的现任主任丹·克罗斯利毫无争议地赢得了推特发布数量的冠军。

图片来自土壤协会
下表显示了十条最受欢迎的推文,包括赞和转发。特别看看这些推文,可以深入了解最受欢迎的对话。气候变化、工业化植物汉堡的营养价值、英国农业食品贸易、泥炭地燃烧、种族主义、农林、农业生态以及牲畜对土壤肥力是热门推文中的主要话题。

该表显示了当时最受欢迎的推文(按点赞数、转发数)。请点击此链接进行交互式可视化。
同样有趣的是查看回复最多的推文。与上面的相比,这些推文显示了哪些话题引起了主要的讨论和辩论。
仔细看看内容,可以发现严肃的问题和有趣的评论很好地结合在一起!你想知道“如何开始一个农业会议”的答案是什么吗?!"?如果有,那就在这里看一下!

下表显示了当时最受欢迎的推文(根据回复数量)。请点击此链接进行交互式可视化。
情感分析
这种技术用于发现文本中表达的潜在情绪(积极、中性、消极)。已经为这项任务开发了几种工具。在这里,我使用了 VADER 图书馆,它是专门为理解社交媒体上表达的情绪而开发的。 Parul Pandey 文章或 GitHub 资源库是更好地了解 VADER 的绝佳资源。
下面的线形图显示了 OFC 和 ORFC 的平均情绪,其中+1 表示非常积极,-1 表示非常消极。

左边的线形图显示了 OFC 每天的平均情绪,右边的线形图显示了 ORFC 每天的平均情绪。
在会议开始的前一天,人们对会议的看法相对积极,但在会议开始后,这种看法略有下降。虽然 OFC 情绪在会议结束时再次上升,但 ORFC 情绪继续下降。
看起来 OFC 最终比 ORFC 发出了更加积极的信号!
如果你想知道这两次会议上最积极和最消极的推文是什么,看看下表吧!

这些表格显示了 OFC 和 ORFC 2020 年最积极和最消极的五条推文。
语义分析
为了从 tweets 中获得更细粒度的文本理解,我使用来自 gensim 库的 Word2Vec 模型创建了单词嵌入。这种技术可以很方便地找出哪些单词彼此关系更密切。对于 Word2Vec 模型背后的数学原理,请看一下托马斯·米科洛夫团队的原始研究论文。或者你可能更喜欢卡维塔·加内桑的更简化的文章或者维沙尔·库马尔的精彩应用。
但首先,让我们来看看最流行的词和标签在推文中的出现频率。

左边的线形图显示了 OFC 每天的平均情绪,右边的线形图显示了 ORFC 每天的平均情绪。
有趣的词是*未来、变化和战略,*指出农业系统需要规划和适应明天的气候。有趣的标签有“*农业生态学”、“土壤健康”和“农林学”,以及“农场化”、“农村包容”和“精神健康”。*第一组代表促进可持续农业的耕作方法,例如保护自然资源和确保粮食安全。第二组确定了当今农业系统中人们面临的主要挑战:精神压力和排斥。
词语嵌入
下面的四个散点图显示了与“*牲畜”、“土壤”、“气候”和“生物多样性”*实体更密切相关的词。

这四张图显示了与关键词牲畜、土壤、气候和生物多样性相关的最近的词(最近的邻居)。
牲畜
有意思的是“养畜”被收为“助养”、“减养”、“影响”、、、可持续”,即指“重要的*”、*、讨论“围绕着养畜、生产的部门。更具体地说,对于这个问题:**有哪些可能的可持续措施可以用来帮助畜牧业减少排放?**毫不奇怪,饲料质量、饲料添加剂、动物健康、厌氧消化器或放牧管理等词也与家畜相近,因为这些实体说明了农业食品专家提到的缓解选项。
树也接近于*“牲畜】、*并指向在 ORFC 讨论森林的会议。这种耕作方式将树木和牧场整合成一个单一的畜牧系统,有利于减缓气候变化、动物福利和饲料供应。
土壤
“土”显示与“畜”有一些相似的词语。这里重要的是“碳一词,即可能指 土壤固碳 。这个想法是通过更好的 T42 土地管理措施,可以显著提高土壤质量和土壤吸收有机碳的能力。
气候
看着密切相关的实体为“气候”、“必须”、“政策”、“人人”和“工作”有趣地指出。也许你正在思考格里塔·图恩伯格在 2019 年 9 月美国国会呼吁采取行动应对气候变化时所说的话:“你必须采取行动。你必须做不可能的事。”。或者是关于***【每个人*【行动**、协作工作“应对气候变化的需要”政策、企业领导的需要、可持续发展的农民和负责任的消费者**。
生物多样性
重要的是,与“生物多样性”接近的词有“农业生态学”、“实践”、“有机、消费者”。这说明了对有助于保护自然栖息地而不是破坏自然栖息地的农业实践的需求,也说明了消费者需要采用健康、均衡和可持续的饮食。

粮农组织提供的图片
结论
给你!虽然我错过了会议、鼓舞人心的演讲和人们,但我还是能瞥见辩论!当然,仍然有巨大的潜力来进一步挖掘推文,但这不会是今天。
你可以在这里找到交互式仪表盘可视化!
感谢阅读!
奥德
Ps:我有兴趣做社交网络分析!如果你碰到了什么好的文章或者 python 教程,请告诉我!
我是 数据和植物学家 在 垂直未来 ,以前在WBC SD。理学硕士。在城市分析和智能城市方面,来自 UCL 的 Bartlett 伦敦的 CASA 和 BSc。在食品科学方面来自 苏黎世联邦理工学院 。对城市、美食、健康充满热情通过Twitter或LinkedIn取得联系。
测试的 p 值和功效
解释 p 值
我们在统计类中都用过这个:如果 p <0.05. This short blog is about an explanation of p-value, and how it is connected to the confidence interval and power of a test.
p 值定义(来自统计 101/维基百科) ,则零假设被拒绝
p 值是在假设零假设正确的情况下,获得至少与实际观察到的结果一样极端的测试结果的概率。(难以轻易理解)
尝试另一种方法
零假设是我们想要检验的世界的描述(给一张优惠券是否会增加销售)。在这个世界上,我们相信赠送优惠券不会增加销售额。我们收集数据样本(希望它能代表总体)并获得我们的统计数据(均值、方差、中值等)。p 值是我们想要检查的世界丢弃我们从样本集合中获得的数字的概率。更多解释见下图。

图一。解释 p 值
p 值只是告诉我们,我们的零假设是否为真,以便我们可以拒绝它,或者我们不能拒绝它。但是,我们不应该满足于 p 值的局限性
p 值没有给出零假设真实程度的概率。它只是给出一个二元决策,决定是否可以拒绝
- p 值不考虑效果的精确程度(因为它假设我们知道样本大小,并不能说明太多关于样本大小的信息)
- 第一类错误会导致机会成本,但第二类错误可能更有害。考虑医学发展。拒绝一种可能有效的药物会让公司在投资上赔钱。然而,接受一种不起作用的药物会使人们的生命处于危险之中。我记得第一类和第二类错误是生产者的风险和消费者的风险。因此,检验的功效也很重要(检验的功效= 1-类型 II 错误=当零假设为假时拒绝零假设的概率)。更多关于测试能力的信息,请参见图 2。
图二。检验的势

置信区间也是根据α计算的。置信区间被解释为:(1)如果我们收集了 100 个样本(并为每个样本的统计量创建了一个置信区间),这些包含统计量真实值(如总体平均值)的置信区间的频率趋向于 1-α。(2)当我们计算一个置信区间时,我们说在未来的实验中,真实的统计值将位于该置信区间内(这相当于现在在(1)中讨论的进行多次重复)。
The confidence interval is also calculated from alpha. The confidence interval is interpreted as: (1)if we collect 100 samples (and create a confidence interval for a statistic for each of the sample), the frequency of these confidence intervals which will contain the true value of the statistic (e.g. population mean) tends to be 1-alpha. (2)When we calculate one confidence interval, we say that in future experiments, the true statistic value will lie within that confidence interval (which is equivalent to doing multiple replications now a discussed in (1)).
Python 代码的 p 值基础

阿奇·范顿在 Unsplash 上拍摄的照片
什么是 p 值?它是在给定实际分布的情况下,你获得测试结果的概率。或者在 A/B 测试设置中,在给定初始假设的情况下,例如“我们认为平均订单价值为 170 美元”,这是我们衡量某些东西的概率,例如平均订单价值。
p 值是以一定的置信度回答问题。你经常听到人们说,“我有 90%的信心得到那份工作”或者“我有 99.99%的信心我唱不出佛莱迪·摩克瑞的水平”或者类似的涉及自信程度的话。这是一样的,除了它是一个实际的数量。
我们在中心极限定理文章中看到,如果我们抽取足够多的样本,这些样本均值的分布将是正态分布,该正态分布的均值接近总体均值。那么一个自然的问题是,我们观察到某个样本均值的可能性有多大。
让我们看一个例子。
我们假设,和之前的一样,我们公司客户的平均订单价值是 170 美元。也就是说,我们的总体均值是 170 美元(标准差是 5 美元)。 所以我们的假设是,我们整个客户群的平均订单价值为 170 美元。
现在我们想验证我们的假设。总的来说,我们不能测试整个人口,所以我们求助于测试许多较小的人口样本。现在,如果我们抽取 10,000 个样本,那么这些样本平均值的分布将如下所示:

整个客户群(数百万人)的平均订单价值为 170 美元。如果你一次选取较小的人群样本,将这个样本重复 10,000 次,并绘制样本均值,它将看起来是这样的分布。样本均值将在 150 美元和 190 美元之间变化。
因此,您可以看到,任何给定样本的平均值都可能从 150 美元到 190 美元不等。
然后,假设我们对一组人进行抽样,得到他们的平均订单价值,结果是 183 美元。我们想知道这种情况发生的概率。但是在统计学中,我们会问,假设总体平均值为 170 美元,样本平均值为 183 美元或以上的概率是多少。
这可以通过计算上图中所有大于 183 的数字,并除以抽样总数 10000 来计算。将和中的代码用于:
pvalue_101(170.0, 5.0, 10000, 183.0)
大于 183.0 的数字百分比为 0.35%。这是一个很小的百分比,但不是零。如果你拒绝总体均值为 170 美元的假设,那将是错误的,因为我们清楚地从总体分布中得出这个样本均值。
同样,如果你想问,样本均值与总体均值 170 美元相差超过 13 美元的概率是多少?也就是说,得到小于 157 美元或大于 183 美元的样本均值的概率是多少?
超过人口平均数 170.0+/-13.0 的人数百分比为 0.77%。你可以看到,这个百分比是样本平均值的两倍,可能仅仅大于 183 美元。这是因为正态分布是围绕平均值对称的。
理解这个微小但非零的概率是很重要的。即使从完全相同的总体中抽取样本,样本平均值与总体平均值相差很大的可能性也不是零。因此,如果我们只运行 A/B 测试一天,这相当于抽取一个样本,我们就不能对总体均值做出决定。我们能做的是,估计在给定总体的情况下,我们得到样本均值的概率。
现在,假设你想知道相反的情况——95%的样本均值离总体均值有多远?这时68–95–99.7 规则就派上用场了。

图片鸣谢http://www . muela ner . com/WP-content/uploads/2013/07/Standard _ deviation _ diagram . png
上面写着:
- 我们有 68.2%的信心,如果我们抽取许多随机样本,样本均值将在μ+/- σ之间。在我们的例子中,170 +/- 5,即 68.2%的时间样本均值将在$165 和$175 之间
- 95.4%的时间我们的样本均值将在μ+/- 2σ之间。也就是说,95.4%的情况下,我们的样本均值将介于 160 美元和 180 美元之间。
在商界,人们经常谈论 p 值。p 值与上述规则密切相关。p 值衡量在给定总体平均值和标准差的情况下,样本平均值为某个值或更大值的概率。
结论
p 值给出了我们观察到我们所观察到的东西的概率,假设假设是真的。它没有告诉我们零假设为真的概率。
在我们的例子中,
- 假设总体均值为 170 美元,p 值为 0.35%将给出样本均值超过 183 美元的概率。
- 假设总体均值为 170 美元,p 值为 0.77%将给出样本均值大于 183 美元或小于 157 美元的概率。
- 它没有给我们假设为真的概率。 事实上拒绝总体均值为 170 美元的假设是危险的,因为我们显然是从总体均值 170 美元中得到样本均值的。
错误结论
人们通常会在开始一个实验时说他们想要 95%的置信度,这意味着他们期望 p 值为 5%(来自 100%-95%)。然后他们会取上述样本均值 183 美元,取其 p 值 0.35%,并说:“由于 0.35%<0.5%,我们的样本均值比我们允许的 5%更靠近尾部。因此,我们拒绝人口平均数为 170 美元的假设”。我们知道这是一个错误的结论,因为我们使用了 170 美元的总体均值来生成一些高于 183 美元的样本均值,尽管数量很少(见上图)。
你不能说假设是真是假。事实上,你甚至不能仅凭这一个数据点就否定这个假设。
开车回家是一个很难的教训。但总的来说,在生活中,我们无法说出任何假设为真的概率——我们所能说的只是根据某人的假设进行观察的概率。
Python 代码再现情节
您可以使用以下 Python 代码生成本文中的图和 p 值。
**def** pvalue_101(mu, sigma, samp_size, samp_mean=0, deltam=0):
np.random.seed(1234)
s1 = np.random.normal(mu, sigma, samp_size)
**if** samp_mean > 0:
print(len(s1[s1>samp_mean]))
outliers = float(len(s1[s1>samp_mean])*100)/float(len(s1))
print(**'Percentage of numbers larger than {} is {}%'**.format(samp_mean, outliers))
**if** deltam == 0:
deltam = abs(mu-samp_mean)
**if** deltam > 0 :
outliers = (float(len(s1[s1>(mu+deltam)]))
+float(len(s1[s1<(mu-deltam)])))*100.0/float(len(s1))
print(**'Percentage of numbers further than the population mean of {} by +/-{} is {}%'**.format(mu, deltam, outliers))
fig, ax = plt.subplots(figsize=(8,8))
fig.suptitle(**'Normal Distribution: population_mean={}'**.format(mu) )
plt.hist(s1)
plt.axvline(x=mu+deltam, color=**'red'**)
plt.axvline(x=mu-deltam, color=**'green'**)
plt.show()
p 值—已解释
它的含义和使用方法。用一个用例解释。

迈克尔·泽兹奇在 Unsplash 上的照片
p 值是推断统计学中的一个基本概念,用于根据统计检验的结果得出结论。简而言之,p 值是极端或不太可能的度量。事件发生的可能性帮助我们做出明智的决定,而不是随机的选择。
为了理解 p 值的重要性,我们应该熟悉两个关键术语:总体和样本。
- 人口是一个群体中的所有元素。例如,美国的大学生是指包括美国所有大学生的人口。欧洲的 25 岁人群包括了所有符合描述的人。
对人口进行分析并不总是可行或可能的,因为我们无法收集人口的所有数据。因此,我们使用样本。
- 样本是总体的子集。例如,美国 1000 名大学生是“美国大学生”人口的一个子集。
p 值提供的是基于样本统计评估或比较总体的能力。因此,P 值可以被认为是群体和样本之间的桥梁。
我更喜欢用现实生活中的例子来解释这种概念,我认为这样更容易理解这个主题。
假设你和你的朋友创建了一个网站。你对目前的设计不满意,想做些改变。你告诉你的朋友,如果你在设计上做一些改变,更多的人会点击网站,你会通过广告赚更多的钱。然而,你的朋友认为这是浪费时间,改变设计不会增加点击率(CTR)。

当前设计
- 你的朋友:改变设计不会提高点击率(零假设)。
- 你:改变设计会提高点击率(替代假设)。

新型设计
既然你们不能达成一致,你想做一个测试。顺便说一下,这种测试叫做假设测试,比较无效假设和可选假设。
测试设置
- 一半访问网站的人看到当前的设计,另一半看到新的设计
- 你记录两种设计的每日点击率
但是,您需要运行测试多长时间?在这种情况下,人口是从你开始测试之日到永远访问你的网站的所有人。这个数据是不可能收集的。因此,您收集了代表总体的样本。您运行测试 30 天,并分别记录每天的 CTR。现在,两个种群都有 30 个样本。为什么是 30?我们稍后会谈到这一点。

30 天的测试结果
每天都是一个样本。每天的数值是当天的平均 CTR(即样本平均值)。
取 30 天的平均值,可以看到新设计的 30 天平均 CTR 高于当前设计。你要求你的朋友立即改变网站的设计,因为新的设计增加了流量。你的朋友回答道:
- “坚持住!没有一致和大的差异,所以结果可能是由于随机的机会。如果我们再进行 30 天的测试,目前的设计可能会有更高的点击率。”
你的朋友建议做一个统计显著性检验并检查 p 值以了解结果是否具有统计显著性。
统计显著性测试测量样本的测试结果是否适用于整个人群。
是时候引入一些新概念了。
- 概率分布:显示事件或实验结果概率的函数。
- 正态(高斯)分布:一种看起来像钟的概率分布;

描述正态分布的两个术语是均值和标准差。Mean 是被观察到的概率最高的平均值。标准偏差是对数值分布程度的测量。随着标准差的增加,正态分布曲线变宽。y 轴表示要观察的值的概率。
中心极限定理
正态分布用于表示分布未知的随机变量。因此,它被广泛应用于包括自然科学和社会科学在内的许多领域。证明为什么它可以用来表示未知分布的随机变量的理由是中心极限定理(CLT) 。
根据 CLT ,当我们从一个分布中抽取更多样本时,样本平均值将趋向于一个正态分布,而不管总体分布如何。通常,如果我们有 30 个或更多的样本,我们可以假设我们的数据是正态分布的。这就是我们进行 30 天测试的原因。
假设数据呈正态分布,因此当前版本样本均值的分布函数如下:

注:要绘制正态分布,只需要知道均值和标准差。您可以使用收集的 30 个样本平均值来计算这些值。
样本平均值似乎是 10,因此更有可能观察到 10 左右的值。例如,CTR 为 11 并不奇怪,因为这种可能性很高。然而,获得 16.5 的值将是一个极端的结果,因为根据我们的分布函数,它具有非常低的概率。
如果根据当前设计的分布,新设计的样本均值被观察到的概率非常低,我们可以得出结论,新设计的结果不是随机出现的。如果结果不太可能被随机观察到,我们说这些结果在统计上是显著的。为了确定统计显著性,我们使用 p 值。 P 值是获得我们的观察值或有相同或较少机会被观察的值的概率。

假设新设计的样本平均值为 12.5。因为它是一个连续函数,所以区间的概率就是函数曲线下的面积。因此,12.5 的 p 值是上图中的绿色区域。绿色区域表示获得 12.5 或更极端值(在我们的例子中高于 12.5)的概率。
假设 p 值是 0.11,但是我们如何解释它呢?p 值为 0.11 意味着我们对结果有 89%的把握。换句话说,有 11%的概率结果是随机的。类似地,p 值为 0.5 意味着有 5%的概率结果是随机的。
p 值越低,结果越确定。
为了根据 p 值做出决定,我们需要设置一个置信水平,它表示我们对结果的确信程度。如果我们将置信度设为 95%,则显著性值为 0.05。在这种情况下,要使检验具有统计显著性,p 值必须低于 0.05。
如果你和你的朋友将置信水平设为 95%,发现 p 值为 0.11,那么你的结果在统计上不显著。你的结论是,由于随机因素,新设计的平均值更高。因此,您不需要更改设计。
如果新设计的样本平均值是 15,这是一个更极端的值,p 值将低于 0.11。

如果新版本的 CTR 高于当前版本,结果为 15.0,则为 p 值
我们可以看到,p 值比前一个小很多。假设 p 值现在是 0.02。因此,根据 95%的置信水平,该 p 值表明结果具有统计学意义。
值得一提的重要一点是,我们正在测试新设计的结果是否比当前设计的结果高。因此,在计算更多极值的概率时,我们只考虑右侧的值。如果我们检验结果是否不同,我们需要考虑分布函数的两边。

如果新版本的 CTR 与当前版本不同,结果为 15.0,则为 p 值
感谢您的阅读。如果您有任何反馈,请告诉我。
p 值、假设检验和统计显著性
如何理解差异是否真的重要?
你可能听说过双陆棋。虽然是最古老的棋盘游戏之一,但它抵制了数字时代,在许多东方文化中仍然非常普遍。双陆棋是一种双人游戏,每位玩家有 15 颗棋子。目标是将棋子移动到棋盘的角落并收集它们。玩家掷出一对骰子,并相应地移动棋子。因此,这是一个需要策略和运气同步才能获胜的游戏,我认为这是它存在了很长时间的主要原因。在这篇文章中,我们对双陆棋的“运气”部分感兴趣。

Backgommon ( 图源)
骰子有六种结果,从 1 到 6。当你掷两个骰子时,结果数增加到 36 (6x6)。为了简单起见,我假设这个游戏只有一个骰子。你能移动的次数取决于骰子的结果。所以,如果你掷出更高的数字,你可以快速移动,增加你赢的机会。如果你一直掷出所有的六,你的对手会在掷出几个后开始叫你“幸运”。例如,连续三次掷出 6 是极不可能的。现在是时候引入 p 值了。
P 值是一个事件发生可能性的量度。该定义可能会导致将 p 值理解为事件的概率。它与事件的概率有关,但它们不是一回事。
P 值是获得我们的观察值或有相同或更少机会被观察的值的概率。
考虑掷骰子的例子。让我们将事件 A 定义为“连续三次掷出 6”。那么,事件 A 的概率:

这个小数字是事件 a 的概率。事件 a 的 P 值是多少。P 值有三个组成部分:
- 事件 A 的概率
- 与事件 A 有同等机会发生的事件的概率
- 比事件 A 发生几率小的事件的概率
我们已经知道了事件 a 的概率,我们来计算其他部分。与事件 A 有同等机会发生的事件连续三次掷出不同的数字。比如三次滚动一个 1。由于骰子上有 6 个数字,这些事件的概率(排除 6 个,因为已经计算过了):

注意:为了简单起见,顺序被忽略。如果考虑顺序,5–6–6 或 6–5–6 与 6–6–6 的概率相同。我们认为情况 5–6–6 和 6–5–6 是相同的(一次 5 和两次 6)。
在我们的案例中,不存在发生几率更低的事件,因此发生几率更低的事件的概率为零。因此,连续三次滚动 6 的 p 值:

p 值很低,因此我们可以说这是一个不太可能发生的事件。
p 值多用于**假设检验。**考虑我们有一个网站,并计划在其设计上做一些改变,以增加流量。我们想测试“新设计”是否会吸引更多的注意力,从而增加网站的流量。我们应该定义两个假设:
- 零假设:新设计不会增加流量
- 替代假设:新设计增加了交通流量
我们通过点击率(CTR)来衡量流量。当不可能或不可行比较两个总体时,我们抽取样本并代表总体比较样本。在我们的例子中,人口是我们网站存在期间的所有流量,在它消亡之前是不可能知道的。所以我们取样本。我们向一半的观众展示当前的设计,向另一半的观众展示“新设计”。然后我们测量 50 天的点击率(即收集 50 个样本)。我们计算了所有样品的 CTR,发现“新设计”的平均 CTR 高于当前设计。我们是否仅仅通过比较手段就永久地改变了设计?绝对不行。
我们可能通过随机机会获得更高的点击率。我们需要检查 p 值。在进入这一步之前,我将提到一个被称为中心极限定理的最新定理:
根据中心极限定理,当我们从一个数据分布中取更多的平均值时,平均值将趋向于一个正态分布,而不管总体分布如何。如果样本量很大,样本数超过 30,中心极限定理就更加确定。
因此,当前版本的样本均值分布如下:

这是概率分布。如图所示,当前设计最有可能的 CTR 似乎是 10。我们可以说它可能观察到 12.5 和 7.5 之间的值。但是,随着值不断增加或减少,概率会显著降低。尾部的值非常极端,很难观察到。如果从新设计中获得的平均 CTR 约为 12.5,那么我们可以得出结论,这个结果可能是随机的,因为它也可能从当前设计中获得。回想一下,p 值是获得我们的结果或同样可能或更极端结果的概率。因此,这种情况下的 p 值是下图中的绿色区域。

从新版本中获得 12.5 的 p 值
假设新设计的平均 CTR 为 15.0,这是当前设计的极限值。使用当前设计观察 15.0 的 p 值可以在下图中看到。由于使用当前设计得到 15.0 的可能性极小,我们可以得出结论,新设计和当前设计的结果之间的差异是而不是由于随机机会。因此,新的设计实际上提高了网站的点击率。

从新版本中获得 15.0 的 p 值
p 值告诉我们这种差异是否真的重要。
注:我们正在测试新设计的结果是否比当前设计的高。如果我们要测试新设计的结果是否与当前设计的不同,我们将需要包括左边尾部的值,其概率等于或低于我们的结果。在这种情况下,p 值变为:

如果新版本不同于当前版本,则 p 值为 15.0
p 值越低,结果越确定。
如果 p 值是 0.05,那么我们对结果有 95%的把握。换句话说,有 5%的可能性结果是随机的。代表总体比较两个样本的过程称为统计显著性检验。
统计显著性检验测量样本的检验结果是否可能适用于整个人群。
在进行统计显著性测试之前,我们设置了一个置信水平,它表明我们对结果的确信程度。如果我们将置信度设为 95%,则显著性值为 0.05。在这种情况下,要使测试具有统计显著性,p 值必须低于显著性值。假设我们将测试的置信水平设为 95%,发现 p 值为 0.02,则:
- 我们 98%确定新设计的 CTR 高于当前设计。
- 有 2%的几率由于随机机会而获得结果。
- 根据我们的置信水平,结果具有统计学意义。
我们现在可以将样本结果应用于整个人口。在假设检验方面,这一结果建议拒绝零假设,并根据替代假设采取行动。回想一下两个假设:
- 零假设:新设计不会增加流量
- 替代假设:新设计增加了交通流量
我们可以采用新的设计。
置信度取决于任务。95%是一个常用值。对于像化学反应这样的敏感任务,置信度可以设置为高达 99.9%。在 99.9%置信水平的情况下,我们寻找 0.001 或更小的 p 值。
感谢您的阅读。如果你有任何问题,请让我知道。
p 值,以及何时不使用它们
如果你在涉及数据分析的领域(如今基本上是每个领域)查看已发表的研究论文,你会经常看到数字旁边有一个小星号*,并有一个脚注说“统计显著”。统计显著性本质上是一种检查,我们可以用来验证我们的结果不是由于偶然,它们涉及到计算一种叫做 p 值(概率值)的东西。虽然统计显著性星号通常被解释为对研究有效性的认可,但我们盲目使用 p 值会遇到一些问题。但是在我解释什么是 p 值以及与之相关的问题是什么之前,理解这类研究使用的一般框架——假设检验是很重要的。
假设检验
假设检验框架包括比较“零假设”和“替代假设”。通常,空值是现状,替代值是你的假设——你想要测试的假设。例如,假设你有一枚幸运硬币,你认为它偏向正面,你想收集数据来验证(或否定)你的想法。在这种情况下,无效假设或现状是硬币是而不是偏向的——正面的概率是 0.5。
零假设:P(头数)= 0.5
另一个是你想要测试的假设,硬币偏向正面。换句话说:
替代假设:P(头数)> 0.5
我们可以根据你想要测试的确切想法,用不同的措辞来表达。例如,如果你认为硬币是有偏向的,但是不确定偏向哪个方向,你可以选择概率(正面)!= 0.5.
现在,关于假设检验,有一件重要的事情需要注意——我们并不试图明确地说另一个假设是否正确。我们对这个框架所能做的就是,比如说,在一定程度上,我们收集的数据是否能让我们拒绝零假设。因此,我们正在收集证据反对无效,而不是数据支持备用。在这个框架中,您可能会犯两种错误:第一类错误,当 null 实际上为真时,您拒绝它;第二类错误,当 null 为假时,您保留它。这里还有一点很重要——I 类错误通常比 II 类错误更糟糕。当现状实际上是真的时,我们想要避免拒绝现状,所以我们通常会在拒绝空值时格外“保守”。你会看到一个常见的类比是刑事审判——零假设是被告是无辜的,只有当你收集的证据压倒性地否定零假设时,你才会得出相反的结论。在被证明有罪之前是无辜的。
最后要注意的是一个叫做“测试统计”的数字。这通常只是一些聚集你的数据的量,比如你所有观察的平均值。在我们掷硬币的例子中,检验统计量可以是我们看到的人头的比例。我们最终决定是否拒绝空值取决于这个检验统计量的值。如果它非常“极端”或不太可能给定零假设(假设我们看到 10 个头,如果硬币是无偏的,这是不太可能的),那么我们可以拒绝零。但是我们如何准确地测量检验统计量的极端程度呢?这就是 p 值的来源。
你如何计算 p 值?
我将重点介绍 p 值的解释,在实践中,p 值通常用于实际计算。p 值是在零假设下我们观察到一个测试统计量至少和我们实际看到的一样极端的概率。这个概率越低,我们观察到的数据就越极端。如果空值为真,数据越极端,越有证据表明空值不是真。
在我们抛硬币的例子中,假设我们将硬币抛了 10 次,看到了 7 次人头。获得这种极端或更高结果的概率包括获得正面 7、8、9 或 10 次。假设硬币真的是无偏的,这个概率是 0.172。这是我们的 p 值。
所以 p 值只是一个数字,代表有多少证据反对你的零假设。根据测试和测试统计的确切性质,我们会做出不同的假设和近似来获得该概率的值,但其核心是,这就是计算 p 值的全部内容。我们将根据预先确定的显著性水平选择拒绝或保留空值,这取决于 p 值是低于还是高于该水平。这种阈值最常用的显著性水平是 0.05,如果 p 值低于 0.05,我们拒绝空值,否则,我们保留它。我们称这种低 p 值的情况为“统计显著”结果。在掷硬币的例子中,由于我们的 p 值是 0.172,我们保留了硬币是无偏的零假设。换句话说,我们收集的数据不足以让我们拒绝零假设。
现在,快速说明一下什么是 p 值*不是。*不是 null 为真的概率!这样解释很容易,因为当 p 值很小时,我们拒绝空值,但这不是 p 值。事实上,假设检验框架根本没有给假设分配概率。它只查看在特定假设下看到数据的概率,如果概率很低,则拒绝该假设。给一个为真的假设分配一个概率完全是另外一回事,由贝叶斯推理解决(远远超出了这篇博文的范围)。
现在,让我们继续讨论为什么 p 值本身会产生误导。
统计意义与科学意义
反对 p 值的第一种情况需要理解统计显著性和科学显著性的区别。为了说明这一点,考虑一个例子。假设我们正试图测试一种用于治疗潜在致命疾病的新药的疗效。我们要测量的量是预期寿命。我们的无效假设是该药物不会影响预期寿命,我们的替代假设是该药物提高了预期寿命。假设我们运行一个实验,收集数据,计算我们的 p 值,结果是 0.03。那还不到 0.05,太棒了!我们已经证明了这种药物的有效性,对吗?
但是等等,我们真的知道预期寿命提高了多少吗?p 值表明,有足够的证据反对药物没有效果的假设,但它没有告诉我们预期寿命是增加了一周还是一年,这当然是该研究的一个重要方面。这是 p 值的一个核心问题——我们收集的数据越多,我们能够识别的影响就越小。虽然这通常是一件好事,但在大多数情况下,我们的零假设并不完全正确,因为现实世界如此复杂。即使在我们掷硬币的例子中,由于硬币的设计和我们投掷的方式,正面的实际概率也可能是 0.5001。给定足够多的掷硬币,我们可以潜在地检测到这一点并拒绝空值——但这并不意味着它实际上是一个重要的结果。所以单单一个很小的 p 值只能说明我们可以剔除零(统计显著性),而不能说明影响有多大(科学显著性)。
已发表研究中的选择偏差
这似乎是一个显而易见的观点,但对科学研究的有效性有着深远的影响——通常,只有积极的结果才会被发表。你很难找到试图测试一种药物疗效的公开研究,这种药物显示出高 p 值,因此无法证明该药物的有效性。这看起来很自然,对吗?为什么我们要公布一堆负面的结果,显示什么不起作用?当然,我们应该把重点放在实际显示积极结果的研究上。
然而,当我们考虑这种只在 p 值和统计显著性的确切含义的背景下发布积极结果的倾向时,我们开始遇到一些问题。要理解为什么会这样,假设一堆人决定要测试我的幸运币。1000 个人每人拿着硬币,翻转 10 次,计算 p 值。现在,如果我的硬币实际上是无偏的,我们会看到这样的分布:

1000 次抛硬币实验的结果
所以大多数人会像我们预期的那样得到 4、5 或 6 个头。对这些人来说,p 值很高,他们认为硬币是无偏的。但是很可能会有一些人最终连续翻转 10 个头像。在这组特定的实验中,有 3 个人翻转 10 个头。现在这些翻转并没有什么特别的,只是当你重复实验很多次时,你所期望发生的。但是在这种情况下 p 值是多少呢?0.00098!太好了,小于 0.05,所以他们继续发表他们的发现,第二天一篇文章出来了——“科学家明确证明幸运硬币是有偏见的”。
显然,这是一个极端的例子,但你可以看到这里的问题。根据定义,p 值允许有很小的假阳性机会。当类似的研究由多个小组进行,但只在结果为阳性时才发表时,很有可能许多已发表的研究正是如此——假阳性。这就是再现性如此重要的原因。如果有人重复一个已发表的实验,他们也应该能够实现低 p 值。这一问题以及其他相关问题导致了大约 15 年前的一场巨大的可重复性危机,引发这场危机的是约翰·约安尼迪斯的一篇著名论文,题为为什么大多数发表的研究结果是错误的。报纸上的一段引文:
p 值并不能最恰当地代表和概括研究,但是,不幸的是,有一种普遍的观念认为医学研究文章只能根据 p 值来解释。研究发现在这里被定义为任何达到正式统计学意义的关系,例如,有效的干预、信息预测、风险因素或关联。“负面”研究也很有用。“否定”实际上是一个用词不当的词,曲解的现象普遍存在。
XKCD 甚至有一个关于这个问题的相关漫画:

来源: XKCD
这个问题没有简单的解决方法。总会有一些遇到 1 型错误的机会,我们不能期望每一个负面的结果都被公布,以获得所进行研究的完整全球视图。一种可能性是降低我们认为显著的 p 值。几年前,一群科学家(包括约安尼迪斯)提出了一个提案,就是为了做到这一点,将 p 值阈值降低到 0.005。
即使这成为常态,这也只是权宜之计。解决根本问题的最佳办法是为负面研究提供发表的途径(如 Arxiv ),确保发表的正面结果研究包含所有需要由其他团队复制的信息,并以健康的怀疑态度解释即使很低的 p 值。
多重比较问题
关于 p 值和统计显著性的第三个问题与前一个问题非常相似,但考虑到它与大多数科技公司都采用的 A/B 测试框架的相关性,我认为值得一提。在技术领域,进行随机实验来测试各种变化的影响是很常见的。例如,如果您想测试更改首页字体的颜色会如何影响用户参与度,通常您会将一定比例的用户分配到现有的颜色(控制),将一定比例的用户分配到新的颜色(处理),并测量这两组用户参与度的差异。
现代的 A/B 测试框架已经变得非常复杂,以至于你可以查看大量的指标来试图理解你的治疗到底做了什么。由于样本量较大,它们通常还允许您测量非常小的差异(效应大小)。自然,它们也包含了 p 值计算和统计显著性。虽然这使我们能够全面分析我们运行的任何实验,但重要的是要注意,如果我们只是简单地查看所有可用的指标,我们最终会遇到与上一个案例相同的问题。不存在的差异仅仅因为噪音而显示出统计学意义的可能性总是很小,当我们查看大量指标时,很可能最终会遇到一些假阳性。
这只是统计学意义的本质,并不能真正避免。唯一的解决方案是记住这一点,并在运行实验之前定义您期望影响的指标。当您确实产生了您不期望改变的度量差异时,重要的是进一步挖掘并理解您的处理是否真正导致了差异,或者它只是碰巧是噪声。然而,除了 p 值之外,我们还可以采用和其他方法。
置信区间
在结束之前,我将快速讨论置信区间,它通常比 p 值更能提供信息。基于您收集的数据,您可以构建一个对应于 95%置信区间的参数值范围。如果你重复你的实验很多次,你会期望你构建的置信区间在 95%的时间里“捕获”真实的参数值。置信区间的好处是它们更容易解释,因为它们实际上显示了一系列的值!这意味着你可以看到效果的实际大小,以及结果是否有统计学意义。例如,考虑以下情况:

x 轴是你的效果的大小,或者你的治疗组和对照组之间的差异。0 代表零假设,虚线表示您认为“临床上”或“科学上”显著的差异水平,例如,您的药物将预期寿命延长了一年(这可能因实际研究而异)。
水平线显示了不同的置信区间,以及你可以从中推断出什么。当您的 95%置信区间不包含 0 时,这就相当于说您的 p 值小于 0.05,您的结果具有统计学意义。虽然知道这一点很有用,但你可以看到置信区间如何包含这一点,以及更多信息。如果您的置信区间高于您的临床显著性阈值,则结果最强。在图中,您可以看到统计和临床显著性的不同组合。然而,你只能通过查看置信区间来得到这个。如果你只看左边显示的 p 值,它们不能提供同样丰富的信息。所以从这个意义上说,置信区间比 p 值更有用。
结论
因此,我们已经看到了假设检验框架背后的动机和 p 值的直观含义。但除此之外,我们已经看到单独使用 p 值常常会导致误导性结果,尤其是在研究发表过程的背景下。鉴于这些问题,重要的是采取严格的实验过程,并尽可能促进负面结果的公布。这与置信区间的使用一起,通常有助于提供更可靠和信息更丰富的结果。
参考
[3] 一场关于 p 值的无聊辩论展示了科学——以及如何解决它
[5] 重新定义统计显著性
[6] 对假设检验和 P 值的直观解释
Python 中的打包:工具和格式
9 个问题的 16 种解决方案——你知道哪些?

由作者创建
虚拟环境是一个隔离的 Python 环境。它有自己安装的site-packages,可以不同于系统site-packages。别担心,我们稍后会更详细地讨论。
看完这篇文章,你就明白下面这些工具是什么了,它们解决了哪些问题:pip,pyenv,venv,virtualenv,pipx,pipenv,pip-tools,setup.py,requirements.txt,requirementst.in,Pipfile,Pipfile.lock,twine,poem,flint,hatch。
包装类型
对于本文,您需要区分两种类型的(打包)代码:
- 库由其他库或应用程序导入。库不会自己运行;它们总是由应用程序运行。Python 中库的例子有 Numpy,SciPy,Pandas,Flask,Django,点击,
- 应用被执行。Python 应用的例子有 awscli 、 Jupyter (笔记本)、任何用 Flask 或 Django 创建的网站。
你可以进一步区分它们,例如库和框架。或者命令行应用程序、具有图形用户界面的应用程序、服务等等。但是对于本文,我们只需要区分库和应用程序。
请注意,有些应用程序还包含可以导入的代码,或者有些库具有作为应用程序提供的部分功能。在这些情况下,您可以将它们用作库(包括项目中的代码)或应用程序(只是执行它们)。你是指挥官。
基础知识:pip、站点包和提示符
Python 将pip作为默认的包管理器。你像这样使用它:
pip install mpu
当您运行它时,您应该会看到以下消息:
Collecting mpu
Using cached [https://files.pythonhosted.org/packages/a6/3a/c4c04201c9cd8c5845f85915d644cb14b16200680e5fa424af01c411e140/mpu-0.23.1-py3-none-any.whl](https://files.pythonhosted.org/packages/a6/3a/c4c04201c9cd8c5845f85915d644cb14b16200680e5fa424af01c411e140/mpu-0.23.1-py3-none-any.whl)
Installing collected packages: mpu
Successfully installed mpu-0.23.1
为了能够向您展示输出和我插入的内容,我开始了包含我用$输入的命令的行:
$ pip install mpu
Collecting mpu
Using cached [https://files.pythonhosted.org/packages/a6/3a/c4c04201c9cd8c5845f85915d644cb14b16200680e5fa424af01c411e140/mpu-0.23.1-py3-none-any.whl](https://files.pythonhosted.org/packages/a6/3a/c4c04201c9cd8c5845f85915d644cb14b16200680e5fa424af01c411e140/mpu-0.23.1-py3-none-any.whl)
Installing collected packages: mpu
Successfully installed mpu-0.23.1
这个$叫做提示。在 Python 内部,提示是>>>:
$ python
>>> import mpu
>>> mpu.__file__
'/home/moose/venv/lib/python3.7/site-packages/mpu/__init__.py'
这个命令显示了软件包mpu的安装位置。默认情况下,这是系统的 Python 位置。这意味着所有 Python 包共享同一套已安装的库。
问题 1:需要不同的 Python 版本
我们安装了 Python 3.6,但是应用程序需要 Python 3.8。我们无法升级我们的系统 Python 版本,例如,因为我们缺少管理员权限,或者因为其他东西会损坏。
解决方案:pyenv
Pyenv 允许你安装任何你想要的 Python 版本。您还可以使用pyenv在 Python 环境之间轻松切换:
$ python --version
Python 3.6.0$ pyenv global 3.8.6$ python --version
Python 3.8.6$ pip --version
pip 20.2.1 from /home/math/.pyenv/versions/3.8.6/lib/python3.8/site-packages/pip (python 3.8)
更多信息,请阅读我的文章Python 开发初学者指南。详细安装说明,直接去【pyenv 官方网站。
问题 2:包装和配送大楼
你通常不仅仅使用裸 Python。作为开发者,我们站在巨人的肩膀上——整个免费软件生态系统。在 Python 的初期,人们只是复制文件。Python 文件在导入时也称为模块。如果我们在一个带有__init__.py的文件夹中有多个 Python 文件,它们可以互相导入。这个文件夹被称为包。包可以包含其他包——也有__init__.py的子文件夹,然后被称为子包。
复制文件和文件夹不方便。如果该代码的作者进行了更新,我可能需要更新几十个文件。我需要在第一时间知道是否有更新。我可能还需要安装数百个依赖项。通过复制粘贴来做这件事将是地狱。
我们需要一种更方便的方式来分发这些包。
解决方案:来源分配
包装系统需要三个核心组件:
- 包格式:Python 中最简单的格式叫做源码分发。它本质上是一个具有特定结构的 ZIP 文件。该文件的一个重要部分是可以指定包的依赖关系。它还应该包含其他元数据,比如包的名称、作者和许可信息。
- 软件包管理器:安装软件包的程序。pip 在 Python 中安装包。
- 软件仓库:包管理者可以寻找包的中心位置。在 Python 生态系统中,pypi.org是公共的。我甚至不知道还有其他公开的。当然,您可以创建私有的。
如前所述,我们需要一种方法来指定元数据和依赖关系。这是通过setup.py文件完成的。它通常看起来像这样:
from setuptools import setupsetup(
name="my_awesome_package",
version="0.1.0",
install_requires=["requests", "click"]
)
您可以使用更多的版本说明符,例如:
numpy>3.0.0 # 3.0.1 is acceptable, but not 3.0.0
numpy~=3.1 # 3.1 or later, but not version 4.0 or later.
numpy~=3.1.2 # 3.1.2 or later, but not version 3.2.0 or later.
为了创建源分布,我们运行
$ python setup.py sdist
我不太喜欢setup.py文件,因为它是代码。对于元数据,我更喜欢使用配置文件。Setuptools 允许使用一个setup.cfg文件。您仍然需要一个 setup.py,但它可以简化为:
from setuptools import setupsetup()
然后你就有了如下的setup.cfg文件。有关于 setup.cfg 格式的文档。
[metadata]
name = my_awesome_packageauthor = Martin Thoma
author_email = [info@martin-thoma.de](mailto:info@martin-thoma.de)
maintainer = Martin Thoma
maintainer_email = [info@martin-thoma.de](mailto:info@martin-thoma.de)# keep in sync with my_awesome_package/__init__.py
version = 0.23.1description = Martins Python Utilities
long_description = file: README.md
long_description_content_type = text/markdown
keywords = utility,platforms = Linuxurl = [https://github.com/MartinThoma/mpu](https://github.com/MartinThoma/mpu)
download_url = [https://github.com/MartinThoma/mpu](https://github.com/MartinThoma/mpu)license = MIT# [https://pypi.org/pypi?%3Aaction=list_classifiers](https://pypi.org/pypi?%3Aaction=list_classifiers)
classifiers =
Development Status :: 3 - Alpha
Environment :: Console
Intended Audience :: Developers
Intended Audience :: Information Technology
License :: OSI Approved :: MIT License
Natural Language :: English
Operating System :: OS Independent
Programming Language :: Python :: 3.7
Programming Language :: Python :: 3.8
Programming Language :: Python :: 3.9
Topic :: Software Development
Topic :: Utilities[options]
packages = find:
python_requires = >=3.7
install_requires =
requests
click[tool:pytest]
addopts = --doctest-modules --ignore=docs/ --durations=3 --timeout=30
doctest_encoding = utf-8[pydocstyle]
match_dir = mpu
ignore = D105, D413, D107, D416, D212, D203, D417[flake8]
max-complexity=10
max_line_length = 88
exclude = tests/*,.tox/*,.nox/*,docs/*
ignore = H301,H306,H404,H405,W503,D105,D413,D103[mutmut]
backup = False
runner = python -m pytest
tests_dir = tests/[mypy]
ignore_missing_imports = True
问题 3:安全上传
您希望将包安全地上传到 PyPI。你需要认证,你想确定没有人篡改你的包。
解决方案:缠绕
通过pip install twine安装绳,您可以上传您的分发文件:
twine upload dist/*
问题 4:依赖冲突
你想在版本1.2.3中安装需要库requests的youtube-downloader,在版本3.2.1中安装需要库requests的vimeo-downloader。因此库requests是两个应用程序的依赖项。这两个应用程序都需要用 Python 3.8 来执行。这是一个问题,因为两个应用程序都将requests存储在同一个site-packages目录中。一旦你安装了一个版本,另一个就没了。您需要两个不同的环境来运行这两个应用程序。
python 环境是 Python 可执行文件、pip 和一组已安装的软件包。不同的环境是相互隔离的,因此不会相互影响。
我们通过创建虚拟环境来解决这种依赖性冲突。我们称之为虚拟,因为它们实际上共享 Python 可执行文件和其他东西,比如 shells 的环境变量。
解决方案:venv
Python 有 venv 模块,碰巧也是可执行的。您可以创建和使用一个全新的虚拟环境,如下所示:
$ python -m venv my-fresh-venv
$ source my-fresh-venv/bin/activate(my-fresh-venv)$ pip --version
pip 20.1.1 from /home/moose/my-fresh-venv/lib/python3.8/site-packages/pip (python 3.8)
环境之所以被称为“新鲜”,是因为里面什么都没有。在source-调用activate脚本后安装的所有东西都将被安装在这个本地目录中。这意味着当你在一个这样的虚拟环境中安装youtube-downloader而在另一个虚拟环境中安装vimeo-downloader时,你可以同时拥有两者。你可以通过执行deactivate走出虚拟环境。
如果你想了解更多细节,我推荐你阅读 Python 虚拟环境:初级读本。
问题 5:不方便
您仍然需要一直在虚拟环境之间切换,这很不方便。
解决方案:pipx
pipx 自动将软件包安装到它们自己的虚拟环境中。它还会自动执行该环境中的应用程序😍
注意:这只对应用有意义!您需要在与应用程序相同的环境中使用库。所以永远不要用 pipx 安装库。用 pipx 安装应用程序(间接安装库)。
问题 6:更改第三方代码
作为一名应用程序开发人员,我想确保我的应用程序能够正常工作。我想独立于我使用的第三方软件的潜在突破性变化。
比如,想想 1.2.3 版本中需要requests的youtube-downloader。在某些时候,可能是在开发期间,那个版本的请求可能是最新的版本。然后youtube-downloader的开发就停止了,但是requests一直在改。
解决方案:依赖固定
给出您想要安装的确切版本:
numpy==3.2.1
scipy==1.2.3
pandas==4.5.6
然而,如果你在setup.py中这样做,这本身就有一个问题。您将在相同环境中的其他软件包上强制使用这个版本。Python 在这里相当混乱:一旦另一个包在同一环境的另一个版本中安装了您的一个依赖项,它就会被简单地覆盖。您的依赖项可能仍然有效,但是您没有得到预期的版本。
对于应用程序,您可以像这样将依赖项固定在setup.py中,并告诉您的用户使用pipx来安装它们。这样你和你的用户都会很开心💕
对于库,您不能这样做。根据定义,库包含在其他代码中。可能包含大量库的代码。如果它们都固定了它们的依赖关系,那么很可能会出现依赖冲突。如果开发的库本身有几个依赖项,这会使库开发变得困难。
通常的做法是不在setup.py文件中固定依赖关系,而是创建一个带有固定依赖关系的平面文本文件。 PEP 440 在 2013 年定义了格式或要求文件。它通常被称为requirements.txt或requirements-dev.txt,通常看起来像这样:
numpy==3.2.1
scipy==1.2.3
pandas==4.5.6
您还可以根据 PEP 440 指定下载包的位置(例如,不仅是名称,还有 git 存储库)。
requirements.txt 中的包(包括它们的依赖项)可以与
$ pip install -r requirements.txt
问题 7:改变传递依赖关系
想象你写的代码依赖于包foo和bar。这两个包本身也可能有依赖关系。这些依赖被称为代码的传递依赖。它们是间接依赖关系。你需要关心的原因如下。
假设发布了多个版本的foo和bar。foo和bar恰好都有一个依赖关系:fizz
情况是这样的:
foo 1.0.0 requires fizz==1.0.0
foo 1.2.0 requires fizz>=1.5.0, fizz<2.0.0
foo 2.0.0 requires fizz>=1.5.0, fizz<3.0.0bar 1.0.0 requires fizz>2.0.0
bar 1.0.1 requires fizz==3.0.0fizz 1.0.0 is available
fizz 1.2.0 is available
fizz 1.5.0 is available
fizz 2.0.0 is available
fizz 2.0.1 is available
fizz 3.0.0 is available
你可能想说“我需要foo==2.0.0和bar==1.0.0。有两个问题:
- 依赖满足可能很难:客户需要弄清楚这两个需求只能由
fizz==2.0.0或fizz==2.0.1来满足。这可能很耗时,因为 Python 源代码发行版没有很好地设计,也没有很好地公开这些信息(示例讨论)。依赖关系解析器实际上需要下载包来找到依赖关系。 - 中断传递性变更:包 foo 和 bar 无法声明它们的依赖关系。你安装了它们,事情就正常了,因为你碰巧有
foo==2.0.0、bar==1.0.0、fizz==2.0.1。但是过了一会儿,fizz==3.0.0就放出来了。不用告诉pip要安装什么,它就会安装最新版本的fizz。之前没有人测试过,因为它不存在。你的用户是第一个,这对他们来说是坏消息😢
解决方案:固定传递依赖关系
您还需要找出可传递的依赖关系,并准确地告诉 pip 要安装什么。为此,我从一个setup.py或requirements.in文件开始。requirements.in文件包含了我所知道的必须实现的内容——它与 setup.py 文件非常相似。与setup.py文件不同,它是一个平面文本文件。
然后我使用 pip-tools 中的pip-compile来寻找传递依赖关系。它将生成如下所示的requirements.txt文件:
#
# This file is autogenerated by pip-compile
# To update, run:
#
# pip-compile setup.py
#
foo==2.0.0 # via setup.py
bar==1.0.0 # via setup.py
fizz==2.0.1 # via foo, bar
通常情况下,我有以下内容:
- setup.py :定义抽象依赖和已知的最低版本/最高版本。
- requirements.txt :我知道的一个版本组合在我的机器上工作。对于我控制安装的 web 服务,这也用于通过
pip install -r requirements.txt安装依赖项 - 需求-开发在中:我使用的开发工具。pytest、flake8、flake8 插件、mypy、black 之类的东西……看我的静态代码分析贴。
- requirements-dev.txt :我使用的工具的确切版本+它们的传递依赖。这些也安装在 CI 管道中。对于应用程序,我还在这里包含了
requirements.txt文件。请注意,我创建了一个包含了requirements.txt的组合requirements-dev.txt。如果我在安装requirements-dev.txt之前安装requirements.txt,它可能会改变版本。这意味着我不会对完全相同的包版本进行测试。如果我在requirements-dev.txt之后安装requirements.txt,我可以为开发工具破坏一些东西。因此我通过
pip-compile --output-file requirements-dev.txt requirements.txt创建了一个组合文件
如果你想确定完全一样,你也可以加上--generate-hashes。
问题 8:非 Python 代码
像 cryptography 这样的包都有用 c 写的代码,如果你安装了 cryptography 的源代码发行版,你需要能够编译那些代码。您可能没有安装像 gcc 这样的编译器,编译需要相当多的时间。
解决方案:构建的发行版(轮子)
软件包创建者也可以上传构建的发行版,例如作为 wheels 文件。这可以防止你自己编译东西。事情是这样做的:
$ pip install wheels
$ python setup.py bdist_wheel
例如, NumPy 这样做:

pypi.org 的截图是作者拍摄的。
问题 9:构建系统的规范
Python 生态系统非常依赖 setuptools。不管 setuptools 有多好,总会有人们遗漏的功能。但是我们有一段时间不能改变构建系统。
解决方案:pyproject.toml
人教版 517 和人教版 518 规定了pyproject.toml文件格式。看起来是这样的:
[build-system]
requires = ["poetry-core>=1.0.0"]
build-backend = "poetry.core.masonry.api"
是的,不多。它告诉 pip 构建您的包需要什么。但这是迈向更大灵活性的良好一步。
其他工具,像 poem 和 black,使用这个文件为他们的pyproject.toml配置,类似于flake8、pytest、pylint和更多允许你添加配置到setup.cfg。

Giorgio Trovato 在 Unsplash 上拍摄的照片
荣誉奖
本节中的工具相对广泛,但是到今天为止,它们并没有真正解决上面的工具没有解决的任何问题。它们可能比其他的更方便使用。
virtualenv 和 virtualenvwrapper
第三方工具 virtualenv 存在于核心模块 venv 之前。它们并不完全相同,但对我来说,venv已经足够好了。如果有人能告诉我一个问题的解决方案是 virtualenv(而不是 venv ),我会很高兴🙂
virtualenvwrapper 扩展 virtualenv。
pipenv
Pipenv 是一个依赖管理和打包的工具。它介绍了两个新文件:
- Pipfile :一个 TOML 文件。它的内容在思想上类似于
requirements.in的内容:抽象依赖。 - Pipfile.lock :一个 TOML 文件。它的内容在思想上类似于
requirements.txt的内容:固定的具体依赖,包括可传递的依赖。
本质上,它包装了 venv。
诗意
诗歌是一个依赖管理和打包的工具。它结合了许多工具,但其核心功能与 pipenv 相同。主要区别在于它使用了pyproject.toml和poetry.lock而不是Pipfile和Pipfile.lock。霜明写了一篇诗与 pipenv 的详细比较。
诗歌包装或替换的项目有:
- 脚手架 :
poetry new project-namevs 千篇一律 - 建筑分布 :
poetry buildvspython setup.py build sdist_build - 依赖管理 :
poetry add foobarvs 手动编辑 setup.py / requirements.txt 文件。然后,poems 将创建一个虚拟环境,一个与Pipfile.lock概念相同的poetry.lock文件,并更新pyproject.toml。你可以在下面看到一个例子。它们使用自己的依赖部分,这与其他任何部分都不兼容。我希望他们搬到 PEP 631(更新见期)。 - 上传到 PyPI :
poetry publishvstwine upload dist/* - 凹凸版 :
poetry version minorvs 手动编辑setup.py/setup.cfg或使用凹凸版。⚠️尽管诗歌在包含一个版本的脚手架中生成了一个__init__.py,但poetry version并没有改变这一点!
它背离了指定依赖关系的事实上的标准setup.py / setup.cfg。相反,诗歌期望依赖关系在它的配置中:
[tool.poetry]
name = "mpu"
version = "0.1.0"
description = ""
authors = ["Martin Thoma <[info@martin-thoma.de](mailto:info@martin-thoma.de)>"]
license = "MIT"[tool.poetry.dependencies]
python = "^3.8"
awscli = "^1.18.172"
pydantic = "^1.7.2"
click = "^7.1.2"[tool.poetry.dev-dependencies]
我希望他们也能实现 PEP 621 和 PEP 631 ,在[project]部分给元数据和依赖项一个正式的位置。让我们看看,也许他们改变了那个。
有些人喜欢有一个什么都做的工具。我宁愿选择 Unix 哲学:
让每个程序做好一件事。要做一项新的工作,就要重新构建,而不是通过添加新的“特性”使旧的程序变得复杂。
由于诗歌结合了很多工具,它没有做什么也很重要:
- 包管理:你还需要 pip。并且 pip 支持 pyproject.toml 。
- 脚手架 : Cookiecutter 有很多模板。我自己创建了两个:一个用于典型的 Python 项目,一个用于 Flake8 插件。
- Setup.py :你可能不需要自己创建一个,但是 poems 会为你创建一个 Setup.py 文件。看看发行版文件就知道了。
我还应该指出,诗歌有一个超级好的命令行界面和视觉愉悦的网站。
舱口
孵化也旨在替代相当多的工具:
- 脚手架 :
hatch new project-namevs 千篇一律 - 凹凸版 :
hatch grow minorvs 手动编辑setup.py/setup.cfg或使用凹凸版 - 运行 pytest :
hatch testvspytest - 创建虚拟环境 :
hatch env my-venvvspython -m venv my-venv - 安装包 :
hatch install packagevspip install package
我在尝试孵化时犯了几个错误。
菲丽
Flit 是一种将 Python 包和模块放在 PyPI 上的方法。它是 setuptools 的第三方替代品。在这个意义上,它类似于 setuptools + twine 或诗歌的一部分。
康达
Conda 是 Anaconda 的包管理器。它比 pip 更强大,可以构建/安装任意语言的代码。有了pyproject.toml,我想知道康达在未来是否有必要🤔
红鲱鱼
- 这是在 Python 中安装东西的最古老的方法。它类似于
pip,但是你不能(轻易)卸载用easy_install安装的东西 distutils:虽然是核心 Python,但是已经不用了。setuptools更强大,到处安装。- 我不确定那是否曾经发生过?
pyvenv:弃用,支持venv。
摘要
pip是蟒蛇的包经理。它转到 Python 包索引PyPI.org 来安装你的包和它们的依赖项。- 抽象依赖可以用 setup.py、requirements.in、Pipfile 或者 pyproject.toml 来表示,你只需要一个。
- 具体的依赖关系可以用 requirements.txt,Pipfile.lock,或者 poetry.lock 来表示,你只需要一个。
- 构建包是用 setuptools 或者诗歌完成的。
- 上传包是用麻线或者诗歌完成的。
- 虚拟环境由 venv 或 poem/pipenv/hatch/conda 创建
- pipx 如果要安装应用的话很酷。不要用在图书馆。
付费搜索增量
重新思考你的目标并找到最佳投标水平——一份商业解释和一份操作指南。
许多广告商和数字营销专业人士通常致力于实现每笔销售的目标成本,同时最大化他们为企业带来的客户数量或销售额。今天,我们将挑战在付费搜索领域实现这些目标的最佳方式,引入增量概念。为此,我们不仅要解释背后的商业理性和理论,还要提出在渐进框架中操作的实际步骤,并提供代码样本,以高效的方式应对挑战。
让我们首先将增量定义为一个特定行为对总产出(即成本、销售、收入、利润或其他)变化的影响。为了理解增量,我们必须意识到总有一个基线情况,你想要对照它来衡量任何给定行为的影响:
- 场景 1 — 一个行动是完全递增的 —最终,如果基线场景是几乎什么都没有的状态,那么所有行动都是 100%递增的。例如,拥有一个电子商务公司的网站是 100%的增量。没有它就没有销售或收入。
- 场景 2 — 一项行动是部分递增的 —并非所有行动都像上面的行动一样重要。例如,考虑一家公司在谷歌上购买关于他们自己品牌的广告空间,如果他们不这样做,那么一些潜在客户会点击他们竞争对手的付费广告链接;然而,他们不能说点击自己广告的人带来的收入是 100%递增的,因为有些人可能会通过自己品牌的 SEO 有机链接来访问他们的网站,跳过竞争对手的付费广告。(注意:我并不主张不对你的品牌竞价,许多公司这样做是因为它们通常是廉价的点击,他们害怕竞争会吓跑一些自然客户)
- 场景 3 — 一个动作是部分递增的,你想知道做这个动作有多少是最佳的 —例如,想象一家餐馆,试图计算他们的菜单上应该有多少选项。当然,答案往往不止一个或两个,以增加选择和满足不同的客户群,然而,在这一点上,一个额外的菜单项增加变化的好处被不得不管理额外的食物库存,培训他们的厨师制作这样的食谱和增加厨房协调的难度的成本所超过,以在一个给定的服务中在不同的菜肴之间跳跃?可能许多餐馆都希望有一个工具来帮助他们解决这个优化问题。
- 场景 4 — 一个行动根本不是增量 —一个简单的例子是给你的员工发白色笔记本而不是黑色笔记本:这个行动在任何给定的时间点都不会增加员工的生产力。然而,有时非增量行动更难识别。例如,你向现有客户展示一些脸书广告,他们最终会在某个时候再次购买你的产品(这是有关联的)。虽然,他们可能会在任何情况下购买你的商品(相关性并不意味着因果关系),甚至他们中的一些人最终会再次从你那里购买,但他们对你公司的过度沟通感到不安,最终不会再回到你的网站或商店(在这种情况下,你的行动将是负增量)。
在继续之前,有一个小提示:关于付费搜索增量的含义,一个合理的预期可能是追求理解作为一个整体的渠道的增量价值(即,如果我们完全关闭了 ppc,会发生什么?一些潜在客户还会通过其他营销渠道找到我们吗?).尽管对于一些公司来说,这可能是一个非常有见地的研究,但这不是本文今天要探讨的内容。相反,本文将关注我们在场景 3 中描述的内容及其在付费搜索领域的应用。希望这能有助于你思考你的 PPC 目标,以及如何衡量实现这些目标的最佳出价。
因此,就像在餐馆优化他们应该拥有的菜单项目数量的例子中一样,一些谷歌广告广告可能会对你的业务有益和有利可图,而太多的谷歌广告广告开始对你的公司造成轻微的损失。这篇文章提出了一个框架,用于寻找谷歌广告的最佳数量,同时保持一种递增的心态,并远离一种平均的思维方式。这意味着在优化成熟度 2 和 3 之间进行如下所述的过渡(这可能与优化成熟度 1 和 2 之间的过渡一样重要和基本):
- 优化成熟度 1 — *公司目标—*SEM 渠道经理确保客户大致达到每次转化的总体目标,并且广告支出的回报符合高层管理人员或客户的期望。活动的多样性要么是有限的,要么是跨活动的每次转换的实际成本跨度非常大。
- 优化成熟度 2 — *平均值—*SEM 经理仍然确保客户的广告支出回报符合预期,但同时确保其拥有一个稳健的客户结构,其中大量活动在所有活动中实现相似的每次转化成本。其背后的基本原理是,首先,平均每次转化成本高于目标的活动对公司来说是无利可图的,其次,当所有活动都达到目标时,转化量最大化,而一些活动低于目标,另一些活动高于目标(即使在一天结束时,这两种情况都导致总体账户达到目标)。在确保上述内容后的第二步,SEM 经理通常还会确保除活动级别之外的其他“分割”客户的方式在每次转换的平均成本方面也是相同的(例如设备类型、主要位置、在许多活动中重复出现的广告组类型等)。).大多数公司都是在这种 ppc 优化成熟度水平上运营的。
- 优化成熟度 3 — 增量— 在此框架下运营的公司明白,他们的平均目标和指标只是冰山一角。关键的思维转变是,他们从“重新定义了这个问题:我每次转换的平均成本是多少?“转换”我愿意在任何特定转换上花费的最大金额是多少?”。他们还了解收益递减,并且收益递减取决于许多因素:他们知道每次转化的平均成本相同的两个活动的每次转化的增量成本可能非常不同,如果他们多花一英镑或一美元,他们不会在这两个活动中平均分配,而是将它应用于每次转化的增量成本较低的一个活动。然而,要将这样的框架付诸实践,他们首先要做的不同的事情是生成他们自己的数据集,因为增量指标并不容易获得,这通常涉及到许多跨团队的合作(并且他们决不会低估所有相关团队之间沟通、协调和购买的重要性)。没有这样的努力,这个框架将永远只是一个理论上的练习。最后,一旦解锁,他们通过使用他们的新指标、报告和营销业务目标,从理论到实践,从平均值到增量。
但是,我们所说的平均值相同但增量经济学不同的运动是什么意思呢?让我们考虑下面的例子:对于 ABC 和 XYZ 的活动,你已经设置了 6 的目标 cpa(这里假设智能竞价,但是如果你运行关键字级别手动竞价,应该没有什么不同),并且谷歌能够为你的每个活动以该平均成本获得 100 次转换。如果不考虑增量,你可能没有理由在优化每个活动时采取不同的行动。然而,在后台可能发生的情况是,活动 ABC 能够以平均价格 5.8 获得 80 次转化,并以平均价格 6.8 获得额外的 20 次转化(总 100 次转化的平均 cpa 仍然是 6/次转化) 然而,XYZ 战役可以让你以平均 4 英镑的价格获得 80 次转换,然后找些空闲时间让你以平均 14 英镑的价格获得额外的 20 次转换(总转换的平均 cpa 仍然是 6 英镑——是的,这种情况可能发生,而且确实在很多场合一直在发生! ).基本上,在一种情况下,你以合理的价格获得了额外的 20 次转换,而在另一种情况下,价格可能会让你赔钱,这总结了为什么平均值往往隐藏了一半的情况。我们用一个图表来说明这个观点,以此来结束这一部分:

每次转换的边际成本与平均成本
在这个阶段,我们已经奠定了理论框架,关于为什么 PPC 增量是重要的,但我们还没有提出一个实际的方法来操作在这个优化成熟度水平下,这可能是本文的主要观点。尽管这比在平均框架下操作要困难,因此很少有公司采用它。使用平均值的好处是,数据通常很容易使用,并且不需要额外的步骤来生成数据。Google ads 将为您提供详细的花费和转化数据,您可以根据这些数据轻松计算出您在账户本身或账户的几乎任何*【片段】*(每个活动、广告组、设备、设备和活动的组合、位置、受众等)上的平均每次转化成本。).如果你想在一个增量框架上操作,你必须弄清楚你想生成哪些数据,生成它,并确保其质量和准确性。
那么,你如何对你的 ppc 账户进行增量测试呢?是的,我说测试是因为一方面,对于许多人来说,ppc 增量可能还没有实现,另一方面,ppc 增量本身确实需要测试。当我们早些时候给出一个例子,在你的 100 次转换中,总成本为 600,你可能会以 4 的成本获得 80 次,以 14 的成本获得额外的 20 次,我们没有提到实际上有一种方法可以确定(或不确定)(至少从统计上来说)。这个载体很可能就是你所知道的谷歌广告的草稿和实验。该工具将允许您 A/B 测试您帐户中的任何活动,将搜索流量平均分配给对照和变体(或 google ads 行话中的原始和草稿活动),并查看如果您有草稿而不是原始活动,您的指标(花费和转化率)会发生什么。您的草案和原始活动之间的差异将为您提供增量支出和增量转换。不过要小心,如果我们不把统计显著性等同于我们的测试,它会像什么都不做一样提供信息。此外,您可能很难在活动级别获得统计显著性,并且您必须在测试中降低粒度(即,考虑从客户/活动组/组合级别开始)。
因此,它最终归结为以下步骤(现在我们进入文章的实际应用):
- 情况分析
- 大规模创建多个草稿和实验
- 监控测试的完整性
- 以适当的方式收集数据,并准备好进行测量。
- 评估测试
- 探索性分析
- 总结并准备未来的内分泌测试。
1)情景分析
这是计划、玩弄数字和预测阶段。像任何好的实验一样,你应该从一个假设开始,这个假设应该是可操作的(即,它的确认与否应该使你采取行动 A 或行动 B),并且可以以良好的准确度进行测量(即,你必须能够生成足够的数据来得出具有统计意义的结论,并且不应该存在任何技术、商业或业务障碍来阻止你生成这样的数据)。让我们回到我们的例子,我们有一个点击付费帐户,产生了 100 个转换,平均每次点击费为 6。在这种情况下,一个好的假设的例子可能是:
- 你想知道你的增量转换成本是否超过 15 英镑(例如,因为你在 15 英镑盈亏平衡,或者因为你想要至少 2 倍的边际 ROAS 来补偿你所有的其他成本)。
- 如果你证实了你的假设(每 conv 的递增转换率> 15),你将采取的行动是把你的出价降低到你在这个实验中测试的相同出价水平。
- 如果你否定了你的假设(增量转换< 15 每 conv),你将采取的行动是保持你的出价水平。
考虑到这一点,现在您将运行一些场景来处理测试的变量:
- 测试的潜在指标:漏斗下端的转换可能会提供您最感兴趣的答案,但是漏斗上端的转换更频繁,因此意味着测试持续时间更短。你越怀疑不同的出价对你的 ppc 帐户吸引的访问者类型的影响,你就越有理由努力将漏斗下端的转化作为你的测试指标,否则漏斗上端的转化可能就能做到;
- 出价水平的变化:测试彼此更接近的出价水平更有意思,比如 10%的变化,但你可能没有足够的数据来准确验证这样小的差异;
- 假设当你的出价按照上面定义的水平改变时,花费和转化率会发生什么:如果你降低出价,你的花费水平自然也会降低,但是会降低多少呢?你应该提前提出一些假设,并检查“如果你在测试结束时观察到这种差异”,这些假设会对你的估计和信心水平产生什么影响。您希望事先确保测试的设计足够稳健,能够承受不同的结果,并且仍然能够为您提供最初问题的答案:我的每次转换的增量成本是高于还是低于 15?为此,你会希望你的置信区间不重叠 15。
- 运行测试的时间:时间越长,您收集的数据越多,您的置信区间变得越小,但是运行测试总是有相关的成本,至少是牺牲的转换数量或不运行其他测试的机会成本。你的问题的答案越重要,你就越愿意延长测试时间。
你为上述 4 个变量考虑的选项越多,你最终得到的情景就越多,所以我们希望在综合的情景组合和不被它们淹没之间取得平衡。回到我们的例子,我们自己也创建了一些场景。我们考虑了两个指标:投标级别的两种变化;当改变每个投标级别时,对花费和转换会发生什么的两种不同假设;和两个测试持续时间。根据下表,所有这些组合导致了总共 16 种情况:

情况分析
首先需要解释的是,您将生成比“转换”数据多得多的“花费”数据,因此您的花费置信区间通常非常接近其点估计值,这意味着您的测试准确性将主要取决于您的转换数据。
其次,置信区间的计算不仅取决于您的假设,还取决于您将生成多少数据(您应该查看您的帐户历史记录,以了解在您的情况下有多少)。在“评估测试”部分,我们深入研究了置信区间计算,您也可以在场景分析中计算预期 ci 时应用这些计算。
因此,一旦我们有了所有这些,就该对我们实验的最终设计做出决定了,看一下示例中的场景,以下情况似乎是不可能的:
- 出价 10%的变动似乎不是一个选项。即使我们运行它 2 个月,并使用销售线索作为测试指标,在我们假设花费减少 15%和转化率减少 7%的场景中,置信区间将重叠 15。在测试结束时,我们可能会处于这样一种情况,我们既不能确认也不能反驳我们的假设,因此不确定是采取行动 A 还是行动 b。
- 基于 1 个月的购买量运行测试似乎也不在考虑范围之内(在我们的支出下降 50%和转化率下降 25%的场景中,置信区间与 15 重叠很多—[8.8;18.8];并且使用其他假设,置信区间刚好接近 15)
因此,我们的选择是:
- 运行测试 1 个月,并对潜在客户进行评估(两个花费/转换假设最终都在没有重叠的置信区间 15 内)
- 将测试持续时间延长至两个月,并将购买量转化为您的衡量指标(再次消除重叠 15)
你最终选择哪一个取决于在测试持续时间和低漏斗转化率的权衡中什么对你更重要。
2)按比例创建多个草稿和实验
此时,您已经选择了测试的设计,这是我们需要更多技术的地方,因为我们将引入代码示例来处理这一步。Python 作为选举的数据语言将会被使用,而且我们将会与 adwords API 交互。因此,首先你需要连接到你的帐户的 AdWords API。如果你之前没有用过 API,你首先要做的是获取一个开发者令牌;一个谷歌客户端 ID(这不同于客户端客户 ID——你实际上在谷歌广告用户界面上看到的一个类似于这个的数字:562–425–3085);谷歌客户端机密;和谷歌刷新令牌。在这里有关于如何开始使用 adwords API 并生成上述所有内容的非常有用的文档。
如果您成功完成了上述操作,那么下面的脚本应该会将您连接到 adwords API:
Google Adwords —连接到 API
接下来你可能要做的事情与预算有关。如果您的帐户中没有使用任何共享预算,您可以忽略这一点,但我敢打赌,至少您的一些活动是共享预算的。如果这确实是你的帐户的情况,那么下一位设置来解决使用草案和实验的缺点之一:你不能为使用共享预算的活动创建草案。这意味着您必须创建单独的预算,并将它们分配到您的活动中。幸运的是,您也可以通过编程来实现这一点,这将为您在您的客户中提议进入增量测试的所有活动节省大量时间。一旦您决定了每个活动的合理预算金额,以下脚本将帮助您创建这些预算:
Google Adwords API —为活动创建和分配预算
现在是介绍为什么 google 可能将这个特性命名为 Drafts 和 Experiments,而不是 juts Drafts 或只是 Experiments 的好时机,因为创建草稿是列表中的下一个。简而言之,草稿在创建时是现有活动的副本,它将始终与其原始活动保持链接(即不能独立运行),并将看到它的某些组件相对于原始活动发生变化(理论上你不必这样做,但这似乎毫无意义);而实验是将确定在何种情况下以及在多长时间内在草案和原始活动之间进行测试的设置(流量的分割是什么,如果分割是基于 cookie 或搜索,开始日期是什么,等等。).草稿是一场战役,实验是背景。
因此,列表中的下一步是创建草稿,这可以通过运行下面的脚本来完成:
Google Adwords API —创建草稿
当然,最需要注意的是这个create_draft()函数返回的信息,因为我们以后需要它来修改征兵活动和创建实验。这正是我们接下来要做的:改变征兵活动。
正如在前面的例子中,我们将认为你正在操作一个 target_cpa 智能投标策略,并且你想知道当你把你的目标降低 30%时会发生什么。下面的代码将帮助您做到这一点。
Google Adwords API —更改目标 CPA
上面的代码做了两件事,首先,它创建了一个目标 cpa 投资组合,其目标比分配给原始活动的投资组合少 30%,其次,它将新创建的投资组合分配给我们在上一步中创建的草稿活动。不过,我们还应该记住其他一些事情:
- 如果您的多个活动被分配到同一个投资组合,那么您不会希望为每个草稿活动创建一个投资组合。相反,更明智的方法是为共享相同目标 cpa 的每组草稿活动创建一个组合,并将该组合分配给具有相同目标的所有草稿。具体的代码会略有不同,但会遵循类似的逻辑。
- 在一些活动中,您可能有广告组,它们有自己的单独目标。如果是这种情况,你必须确保相应的广告组的草案活动将有他们的目标下降 30%(在这个例子中)。否则,你将不会有一个公平的测试,因为一些广告组不会像其他广告组一样被丢弃。您需要一个额外的脚本来完成这个操作。
一旦完成以上工作,我们就进入了使用草稿和实验进行实验的最后一步。这并不复杂,您只需要获取由create_draft()函数返回的 draft_id 和 campaign_id,然后选择一个实验名称(理想情况下,类似于标识原始活动的一个位和标识作为该测试一部分的整组实验的一个位,例如后缀:campaign _ 123-decrease _ 30 _ test)、一个分割百分比(推荐 50%)和一个分割类型(推荐 Cookie)。下面的代码将处理这一部分的最后操作:
Google Adwords API——创建实验
3)监控测试的完整性
当你运行一个测试时,没有什么比看到它被无效更糟糕的了,尤其是因为完全不可避免的原因。这一部分是关于如果我们不小心就会出错的事情的观察点,这些事情最终会使这个测试的数据(这些增量数据集)无效,而这些数据对于我们的最终目标是如此珍贵。问题的关键在于,你的原始广告和草稿广告之间唯一不同的地方是出价水平。所以:
- 如果您有任何团队成员或工具在整个客户范围内以系统的方式更新广告文案,请确保将相同的更改应用于原稿和草稿。
- 如果您的登录页面由于任何原因发生变化,请确保当天结束时原始和草稿具有相同的登录页面。
- 如果您要将出价修改量添加到您的活动中,您也需要将它们添加到草稿中。
- 如前所述,如果你的广告活动有广告组目标,他们将不得不减少/增加相同比例的主要活动目标,你需要确保他们在整个测试中保持不变。我添加了一些示例代码,说明如何快速进行这种比较,特别是利用 adwords API:
Google Adwords API —比较广告组
- 我想你已经明白了这一点,但为了全面起见,这里有一些其他的设置你可能要记住:预算,定位,受众,网络,广告轮换,转换,新的广告组或关键词,负面关键词,扩展。
最终,这是一个平衡,要么努力避免对你已经起草和试验的活动做很多改变;或者建立一个强大的系统,确保应用于原件的更改也应用于草稿。
最后,结束这一部分的一个额外的注意:你在选秀活动中的作品集在最初几天进入学习模式并表现得滑稽吗?如果是,请考虑将这些天从您的增量数据集中排除。
4)以适当的方式收集数据,并为测量做好准备
您已经启动了您的测试,并确保它在公平的条件下运行,接下来您要做的事情是以适合分析和评估的方式收集和准备测试数据。根据我们到目前为止所做的,我们也将借助 adwords api 来处理流程的这一步。
但首先让我问你,你听说过 fivetran 吗?如果没有,请帮你自己一个忙,直接去实现它!假设您目前正在使用 fivetran,或者您继续实现它并回到本文,我们将使用 google ads fivetran 连接器来获取我们需要的数据。另一种方法是直接使用 AdWords 查询语言(AWQL ),但是 fivetran 只需点击几下鼠标就能为我们处理所有的事情。
*因此,使用 fivetran,我们需要做的是创建一个新的 google ads 连接器,并将竞选业绩报告同步到您的选举数据库中( psst… 雪花 *是最好的一个)根据下图选择以下字段:
- AccountDescriptiveName
- CampaignId
- 活动名称
- AdNetworkType2 (测试分析不需要,但对深潜有用)
- 日期
- 装置(测试分析不需要,但对深潜有用)**
- 点击(测试分析不需要,但对深潜有用)**
- 转换策略
- 转换值
- 费用
- 印象(测试分析不需要,但对深潜有用)**
- 搜索印象分享(测试分析不需要,但对深潜有用)**

Fivetran 谷歌广告连接器
最后,一旦这些数据进入您的数据库,下面的查询将以适合测试评估的方式对其进行组织(这样的查询将作为测试评估的基础):
查询 Fivetran Google Ads 数据—用于评估的控制和测试数据
5)评估测试
在这个阶段,你的测试即将结束或者已经完成。你已经以适合分析的方式收集和准备了数据,这正是你现在要做的。但是怎么做呢?没有一种方法是正确的,但我们建议使用一种叫做 bootstrap 重采样的统计技术(这实际上与谷歌自己用来报告他们的置信区间的方法没有太大区别——尽管他们使用刀切重采样)。我们之所以需要这样做,是因为谷歌只报告单个活动实验的置信区间,所以如果你在多个活动上进行实验,你必须自己计算这些置信区间,就好像它们是一个大的活动一样,因为它们实际上都是同一个实验的一部分。
这一阶段的最终目标不仅是找出测试组和对照组之间的花费和转化率的差异(因为这相对容易,我们只需要查看两组实验的总花费和转化率),而且还要找出该差异的置信区间,从而进行重新采样。通过重新采样,我们将采用一个样本(传递冗余)替换不同日期不同活动表现的 n 个观察值,并比较测试和控制之间的差异(n 是第 4 节中提供的查询产生的总行数,即活动/日期的总组合)。我们将多次重复这一过程(通常在 1,000 到 10,000 次之间),并对每个过程比较测试和控制之间的差异。有了这组样本,我们现在可以计算这组样本的点估计值(重采样平均值的平均值)和性能方差,从而计算出我们的统计标准偏差:
***σ**x **= ( ∑ ( (xi -x) ^ 2 ) / j) ^ (½)**xi, being the mean of each resample
x, being the point estimator (the mean of all resamples' means)
j, being the number of resamples*
现在有了对照和试验之间的方差和观察到的差异,我们就能够计算出如此需要的置信区间:
***CI = x ± 1.64 * ( σ**x **/ n ^ (1/2) )**x, being the point estimator (the mean of all resamples' means)
**σ**x, the standard deviation of the samples' means
n, the size of the sample (i.e. combinations of campaigns/days)
1.64, Zα for a 90% Confidence Interval*
最后,我们可以以 90%的置信度说,在我们的 ppc 账户中,不同竞价级别的真实性能差异位于置信区间的下限和上限之间,并相应地做出商业决策——回到我们在场景分析部分的示例,这意味着如果置信区间低于 15,我们将保持我们的竞价级别,但是,如果置信区间高于 15,我们将降低我们的竞价 30%(因为边际转换的边际成本将高于我们的盈利阈值)
使用 python 和模拟根据步骤 4 中提出的方法准备的数据集的虚拟数据集进行此类计算的实际代码如下:
转化率差异的置信区间—评估试验
如果你有兴趣了解更多关于这种重采样技术及其背后的理论,我真的推荐这篇文章。
6)探索性分析。
这可能是整个旅程中最有趣、最快乐的阶段之一。你已经成功地确定了从投标级别 x 到投标级别 y 的增量价值,并为你的企业提供了关键信息,使其能够根据你的增量支出的增量价值来决定是保持还是改变投标级别。如果您是第一次这样做,或者如果您没有生成大量的转换数据,您可能已经为整个客户这样做了;或者你更进一步,对多个投资组合、活动组或其他进行了测试(这意味着你的测试实际上是一组测试,并且你相应地对它们中的每一个采取了行动)——然而,为了简单起见,在这一部分中,我们将假设你进行了总体账户测试。
然而,有一个明确的假设,我们想回答的是这个风险的主要目标,一个 ppc 增量测试也应该创造许多副产品,你不会想忽视。副产品可能需要计划(例如,如果你有目的地将你的活动细分为目标位置,即此刻下雨的位置和不下雨的位置——在大多数情况下很牵强,但例如,如果你有挡风玻璃业务或销售防滑链,这可能对你很重要),但通常它们会出现在一个或多个 adwords 报告类型中,在许多情况下,它们甚至是无意的,只有在仔细的测试后分析后才能发现。让我们更深入地了解第二个选项:我将更深入地给出几个示例,此外还会建议一个可能对您客户的不同增量级别产生有趣影响的因素列表,您的工作是查看所有这些因素,并找出哪些因素对您的业务更具决定性。
例 1:印象分享在增量中起着关键作用。想象你在你的网站上卖两种 t 恤——一种蓝色的和一种红色的(每种都有一个 ppc 活动)。它们的售价相同,但蓝色 t 恤的转换率是 40%,红色是 10%,因此你愿意为蓝色 t 恤的点击付费比红色 t 恤的点击多支付 4 倍。在这种情况下,两个活动的每次转化成本相同,但蓝色活动的印象份额可能更高(因为每次点击你支付的费用更多)。重要的是,通常情况下,当你拥有 80%的印象份额时,很难去追求你没有展示广告的额外的潜在客户,而当你的印象份额为 20%时,很难去追求更多的潜在客户,因此(经验法则)印象份额越高,你的每次转化的边际成本就越高,这在印象份额的两个极端都特别明显。下面是一个基于真实生活的例子,展示了印象份额在每次转化的边际成本中的作用:

边际成本和搜索印象份额
例子 2:你的主要竞争对手通过网络和应用程序提供服务,为了吸引客户,他们同时使用谷歌搜索广告和通用应用程序活动。这意味着你的竞争对手在移动设备上比在电脑上争夺相同搜索关键词的可能性更大,概率更高。电脑设备的竞争格局将更加有利,在所有条件相同的情况下,你会预计移动设备的每次转换边际成本将高于电脑。

边际成本和设备类型
潜在对内分泌起重要作用的因素列表:
- 印象份额(以及竞争力的其他衡量标准,如平均位置、页面绝对顶部等。)
- 设备
- 位置
- 受众(与您的网站有过互动的人与没有向您注册过任何活动的人;性别;人口统计;等等。)
- 活动类型/广告组类型
- 关键字匹配类型
- 一天中的时间和一周中的日期
- 网络
- 年龄和性别等人口统计因素
- 其他人喜欢天气(在上面的例子中提到);重大事件的发生(对于报纸业务);等等。你的创造力能让你得到多少就有多少
最后,关于这些分析最重要的是,它们应该并且很可能会告知您接下来将运行哪些测试。让我们再说一遍,这是您运行的第一个测试,您对哪些因素最有助于客户的增量没有先入为主的想法。在你运行这样的探索性分析后,你将能够制定一个更强有力的假设,并确保你设计一个测试来统计证明(或不证明)这一点。例如,您可以将活动分为四组,因为您观察到一种模式并设计了一个测试,该测试将确保您精确地找到它们的增量水平,并根据测试结果在它们之间转移支出;或者,您可以设计一个测试,以确认(或不确认)印象份额较高的活动/广告组/或设备的增量较小,从而将预算转移到信息系统级别较低的活动/广告组/设备。
7)总结并准备未来的内分泌测试。
如果你已经做到了这一步,那么恭喜你,你做到了——你已经在一个增量框架中优化了你的付费搜索账户。然而,现在也是思考未来的时候了,你将如何在一个渐进的世界中继续运作。下面列出了您在总结阶段需要考虑的 3 件最重要的事情:
- 我们希望测试结果是决定性的,并导致你采取这样或那样的行动,但即使是这样,这些发现也可能不会持续很久:拍卖的竞争格局是不断演变的,因此每次转换的边际成本将不断变化。你需要做好计划,以便在你的账户中保持一个合理的、恒定的测试水平,这样你就可以有准确的、最新的答案来指导你的优化目标。
- 您需要决定您将运行的下一组测试是否将在与第一组测试相同的维度上进行(即,按给定逻辑分组的客户/投资组合/活动等)。).如果是这种情况,您仍然需要检查测试设置是否有任何需要更改的地方(您能否在更短的时间内运行它?根据您现在所知道的,您应该改变测试指标吗?等等。).或者,您可能已经在探索性分析中发现了一些有趣的东西,现在想要确认(从统计学角度来说)。例如,在下一个测试中,您可以将您的活动分组为低/中/高印象份额,并测试增加/减少不同组的不同竞价级别;或者,您可能想测试不同的手机/平板电脑/电脑设备乘数,而不是改变活动的出价。
- 最后,在某些时候,您还会想要考虑在实现和测量这些测试方面的某种自动化。
结论
这篇文章讲述了付费搜索增量背后的原因,为什么你应该在你的营销优化程序中实现它,以及一个实际实现它的方法;但是我不会用这一节来强调任何一点,我会把它留到最后来讨论真正重要的影响。希望这将是额外的动力,你需要实际去做,并在你的付费搜索帐户上实现它。所以,让我以一家我们实施了这种方法的初创公司来结束我的演讲,以及它对公司的意义:
- 背景:这是一家处于高增长阶段的公司,因此从历史上看,他们愿意在每次转换的成本和每次转换的收入(平均)上达到收支平衡。在某个特定时期,该公司开始感到有必要展示盈利的迹象,这样谷歌广告就不能再以盈亏平衡的成本(平均)运营了。因此,挑战被定义为:从平均收支平衡走向边际收支平衡。
- 该方法是从投标级别 x 到 y 到 z 进行一系列测试(每个测试都遵循上述 7 个实际步骤),以找到投标级别曲线中每次转换的边际成本与到目前为止的平均成本相同的点。
- 结果是:1)我们在付费搜索中每节省 10%的总支出,我们只牺牲了付费搜索产生的总转化率的 4.2%。2) 从付费搜索的收支平衡到广告支出的回报率达到 233% 。3)没有单笔转股给公司带来亏损。
其他想法
留下一张便条,说明除了草稿和实验路线之外,解决这一挑战的潜在替代方法。第一个是使用谷歌广告竞价排名——这基本上是谷歌对支出、转换和转换价值的估计,如果你有不同的目标 cpas 或目标 road。您可以在 google ads UI 中一次性使用这些功能,或者通过 API 以编程方式使用这些功能:主要缺点是这些功能只能在广告组级别上使用,可能无法很好地概括您的用例,此外,广告组需要满足某些标准。如果这可以通过活动或组合级别的 API 实现,这将变得非常强大。第二种选择是使用traffic estimator API——我自己还没有使用过,因为我一直在使用智能竞价,但如果你使用手动竞价,这个工具应该可以帮助你计算出不同竞价级别(在这种情况下是最大 cpcs)下你会产生多少点击,如果你假设从点击到转化的转换率相同,你就可以计算出从竞价级别 x 到竞价级别 y 的每次转化的边际成本。
使用(Py)Stan 的应用贝叶斯推理的简单介绍
贝叶斯回归在 PyStan 中的应用
我们鼓励你在阅读这篇文章之前先看看这个概念背景。
设置
Stan【1】是一个用于贝叶斯推理和模型拟合的计算引擎。它依赖于哈密尔顿蒙特卡罗(HMC) [2]的变体,从大量分布和模型的后验分布中进行采样。
下面是设置 Stan 的详细安装步骤:https://pystan . readthedocs . io/en/latest/installation _ beginner . html
对于 MacOS:
- 安装
miniconda/anaconda - 安装
xcode - 更新你的 C 编译器:
conda install clang_osx-64 clangxx_osx-64 -c anaconda - 创造环境
stan或pystan - 键入
conda install numpy安装 numpy 或用您需要安装的包替换 numpy - 安装 pystan:
conda install -c conda-forge pystan - 或者:
pip install pystan - 还要安装:
arviz、matplotlib、pandas、scipy、seaborn、statsmodels、pickle、scikit-learn、nb_conda和nb_conda_kernels
设置完成后,我们可以打开(Jupyter)笔记本,开始工作。首先,让我们用以下代码导入我们的库:
import pystan
import pickle
import numpy as np
import arviz as az
import pandas as pd
import seaborn as sns
import statsmodels.api as statmod
import matplotlib.pyplot as plt
from IPython.display import Image
from IPython.core.display import HTML
掷硬币推理
回想一下在概念背景中,我是如何谈到在地上找到一枚硬币,并把它扔 K 次以获得公平感的。
我们满足于以下模型:

Y 的概率质量函数(PMF)如下:

首先,通过使用 NumPy 的random功能进行仿真,我们可以了解参数 a=b=5 的先验的行为:
sns.distplot(np.random.beta(5,5, size=10000),kde=False)

正如在概念背景中提到的,这个先验似乎是合理的:它在 0.5 左右是对称的,但在两个方向都有可能出现偏差。然后我们可以用下面的语法在pystan中定义我们的模型:
data对应我们模型的数据。在这种情况下,整数N对应于投掷硬币的次数,而y对应于长度为N的整数向量,它将包含我们实验的观察结果。parameters对应于我们模型的参数,在本例中为theta,或者获得“人头”的概率。model对应于我们的先验(beta)和似然(bernoulli)的定义。
# bernoulli model
model_code = """
data {
int<lower=0> N;
int<lower=0,upper=1> y[N];
}
parameters {
real<lower=0,upper=1> theta;
}
model {
theta ~ beta(5, 5);
for (n in 1:N)
y[n] ~ bernoulli(theta);
}
"""data = dict(N=4, y=[0, 0, 0, 0])
model = pystan.StanModel(model_code=model_code)
fit = model.sampling(data=data,iter=4000, chains=4, warmup=1000)la = fit.extract(permuted=True) # return a dictionary of arraysprint(fit.stansummary())
注意model.sampling的默认参数是iter=1000、chains=4和warmup=500。我们根据我们的时间和可用的计算资源来调整这些。
iter≥ 1 对应于我们每个 MCMC 链的运行次数(对于大多数应用来说,不应少于 1000 次)warmup或“老化”≥ 0 对应于我们采样开始时的初始运行次数。考虑到这些链在开始运行时非常不稳定和幼稚,实际上我们通常定义这个量来丢弃第一个 B=warmup数量的样本。如果我们不丢弃 B,那么我们就在估计中引入了不必要的噪声。chains≥ 1 对应于我们采样中的 MCMC 链数。
下面是上述模型的输出:
Inference for Stan model: anon_model_d3835c4370ff5e66f1e88bd3eac647ff.
4 chains, each with iter=4000; warmup=1000; thin=1;
post-warmup draws per chain=3000, total post-warmup draws=12000. mean se_mean sd 2.5% 25% 50% 75% 97.5%
theta 0.36 1.8e-3 0.12 0.14 0.27 0.35 0.44 0.61
lp__ -9.63 9.3e-3 0.71 -11.63 -9.81 -9.36 -9.18 -9.13
- 我们的
theta的后验均值大约是0.36< 0.5。尽管如此,95%的后验可信区间还是相当宽的:(0.14,0.61)。因此,我们可以说这个结果在统计学上不是结论性的,但是它指向偏见,而没有偶然跳到 0。
应用回归:汽车和每加仑英里数(MPG)

让我们构建一个贝叶斯线性回归模型来解释和预测不同规格和品牌的汽车数据集中的每加仑英里数(MPG)。尽管我的方法是一种“经典的”基于可能性的方法,或者更确切地说,是一种以分布为中心的方法,但是我们可以(并且应该!)使用原始的 ML 训练测试分割来评估我们预测的质量。
该数据集来自 UCI ML 知识库,包含以下信息:
1\. mpg: continuous
2\. cylinders: integers
3\. displacement: continuous
4\. horsepower: continuous
5\. weight: continuous
6\. acceleration: continuous
7\. model year: integers
8\. origin: categorical
9\. car name: string (index for each instance)
为什么我们不坚持我们的基本原则,使用标准线性回归?[3]回忆其功能形式如下:

- y 对应于我们的因变量,或感兴趣的结果—这里是
mpg。 - x 是具有 P 个特征或独立变量的 N 个样本的 N×P 矩阵。
- α是一个 N x 1 向量,表示模型截距,根据您的编码方案,可能有不同的解释。
- β是回归量/特征系数的 P×1 向量。
- ε是一个 N×1 随机向量,它遵循一个多变量正态分布,N×N协方差矩阵表示为σ。标准的线性回归情况要求该σ是沿对角线σ >为 0 的对角矩阵,即观测值之间的独立性。
现在,对于贝叶斯公式:

虽然前两条线看起来完全一样,但我们现在需要建立α、β和σ的先验分布。
在执行 EDA 时,我们应该始终考虑以下几点:
- 我的可能性有多大?
- 我的模型应该是什么?互动 vs 无互动?多项式?
- 我的参数(和超参数)是什么,我应该选择什么样的先验?
- 我是否应该考虑任何聚类、时间或空间相关性?
电子设计自动化(Electronic Design Automation)
与任何类型的数据分析一样,至关重要的是首先了解我们感兴趣的变量/特征,以及它们之间以及与我们的 y /结果之间的关系。
让我们从加载数据集开始:
cars_data = pd.read_csv("[~/cars.csv](https://raw.githubusercontent.com/sergiosonline/sergiosonline.github.io/master/files/cars.csv)").set_index("name")
print(cars_data.shape)
cars_data.head()

让我们检查一下目标变量和预测变量之间的关系(如果有的话)。这里origin表示汽车的产地——它有三个等级:“美国”、“日本”和“欧洲”
sns.distplot(cars_data[cars_data['origin']=='American']['mpg'],color="skyblue", label="American",kde=False)
sns.distplot(cars_data[cars_data['origin']=='Japanese']['mpg'],color="red", label="Japanese",kde=False)
sns.distplot(cars_data[cars_data['origin']=='European']['mpg'],color="yellow", label="European",kde=False)
plt.legend()

美国汽车和日本汽车似乎有一些有趣的区别。
现在让我们检查一下数字变量和mpg之间的关系:
- 我更喜欢将这些可视化,而不是简单地计算相关性,因为这给了我它们之间关系的视觉和数学感觉,超越了简单的标量。
f, axes = plt.subplots(2, 3, figsize=(7, 7), sharex=False)sns.relplot(x="cylinders", y="mpg", data=cars_data, ax=axes[0, 0]);
sns.relplot(x="displacement", y="mpg", data=cars_data, ax=axes[0, 1]);
sns.relplot(x="horsepower", y="mpg", data=cars_data, ax=axes[0, 2]);
sns.relplot(x="acceleration", y="mpg", data=cars_data, ax=axes[1, 0]);
sns.relplot(x="year", y="mpg", data=cars_data, ax=axes[1, 1]);
sns.relplot(x="weight", y="mpg", data=cars_data, ax=axes[1, 2]);# close pesky empty plots
for num in range(2,8):
plt.close(num)
plt.show()

除了年份和加速度之外,其他年份都与 mpg 负相关,即排量每增加 1 个单位,mpg 就会减少。
培训/安装
让我们为拟合和测试准备数据集:
from numpy import random
from sklearn import preprocessing, metrics, linear_model
from sklearn.model_selection import train_test_split
from sklearn.metrics import mean_squared_errorrandom.seed(12345)cars_data = cars_data.set_index('name')
y = cars_data['mpg']
X = cars_data.loc[:, cars_data.columns != 'mpg']
X = X.loc[:, X.columns != 'name']
X = pd.get_dummies(X, prefix_sep='_', drop_first=False)
X = X.drop(columns=["origin_European"]) # This is our reference categoryX_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.15, random_state=0)X_train.head()

现在,转到我们的模型规范,它基本上没有偏离上面的抛硬币问题,除了我使用矩阵符号来尽可能简化模型表达式的事实:
# Succinct matrix notationcars_code = """
data {
int<lower=1> N; // number of training samples
int<lower=0> K; // number of predictors - 1 (intercept)
matrix[N, K] x; // matrix of predictors
vector[N] y_obs; // observed/training mpg
int<lower=1> N_new;
matrix[N_new, K] x_new;
}
parameters {
real alpha;
vector[K] beta;
real<lower=0> sigma;
vector[N_new] y_new;
}
transformed parameters {
vector[N] theta;
theta = alpha + x * beta;
}
model {
sigma ~ exponential(1);
alpha ~ normal(0, 6);
beta ~ multi_normal(rep_vector(0, K), diag_matrix(rep_vector(1, K)));
y_obs ~ normal(theta, sigma);
y_new ~ normal(alpha + x_new * beta, sigma); // prediction model
}
"""
data对应于我们模型的数据,如上面掷硬币的例子。parameters对应我们模型的参数。transformed parameters这里允许我将theta定义为我们的模型在训练集上的拟合值model对应于我们对sigma、alpha、beta的先验的定义,以及我们对 P(Y|X,α,β,σ) (normal)的似然。
上述先验是在初始数据检查后选择的:
- 为什么σ是指数先验?嗯,σ ≥ 0(根据定义)。为什么不是制服或者伽玛? PC 框架!【4】——我的目标是最节俭的模式。
- α 和β呢?这里最简单的事情是,给定一个正态概率,为这些参数选择正态先验是很方便的。您可能希望为这两个参数中的每一个选择不同的超参数。
- 为什么β是一个
multi_normal()?数理统计中有一个众所周知的结果,即长度为< ∞且具有单位对角协方差矩阵和向量均值μ < ∞的多正态随机变量(向量 W)等价于一个服从 N(μ,1)分布的独立正态随机变量 W 的向量。
关于 stan 有趣的是,我们可以请求在测试集上进行预测而无需重新拟合——更确切地说,它们可以在第一次调用中被请求。
- 我们通过在上面的调用中定义
y_new来实现这一点。 theta是我们对训练集的拟合预测。
我们指定要摄取的数据集,并继续从模型中取样,同时保存它以供将来参考:
cars_dat = {'N': X_train.shape[0],
'N_new': X_test.shape[0],
'K': X_train.shape[1],
'y_obs': y_train.values.tolist(),
'x': np.array(X_train),
'x_new': np.array(X_test)}sm = pystan.StanModel(model_code=cars_code)
fit = sm.sampling(data=cars_dat, iter=6000, chains=8)# Save fitted model!
with open('bayes-cars.pkl', 'wb') as f:
pickle.dump(sm, f, protocol=pickle.HIGHEST_PROTOCOL)# Extract and print the output of our model
la = fit.extract(permuted=True)
print(fit.stansummary())
以下是我打印的输出(出于本教程的目的,我去掉了Rhat和n_eff):
Inference for Stan model: anon_model_3112a6cce1c41eead6e39aa4b53ccc8b.
8 chains, each with iter=6000; warmup=3000; thin=1;
post-warmup draws per chain=3000, total post-warmup draws=24000.mean se_mean sd 2.5% 25% 50% 75% 97.5%
alpha -8.35 0.02 3.81 -15.79 -10.93 -8.37 -5.74 -0.97
beta[1] -0.48 1.9e-3 0.33 -1.12 -0.7 -0.48 -0.26 0.17
beta[2] 0.02 4.6e-5 7.9e-3 6.1e-3 0.02 0.02 0.03 0.04
beta[3] -0.02 8.7e-5 0.01 -0.04 -0.03 -0.02-6.9e-3 0.01
beta[4] -7.0e-3 4.0e-6 7.0e-4-8.3e-3-7.4e-3-7.0e-3-6.5e-3-5.6e-3
beta[5] 0.1 5.9e-4 0.1 -0.1 0.03 0.1 0.17 0.3
beta[6] 0.69 2.7e-4 0.05 0.6 0.65 0.69 0.72 0.78
beta[7] -1.75 2.9e-3 0.51 -2.73 -2.09 -1.75 -1.41 -0.73
beta[8] 0.36 2.7e-3 0.51 -0.64 0.02 0.36 0.71 1.38
sigma 3.33 7.6e-4 0.13 3.09 3.24 3.32 3.41 3.59
y_new[1] 26.13 0.02 3.37 19.59 23.85 26.11 28.39 32.75
y_new[2] 25.38 0.02 3.36 18.83 23.12 25.37 27.65 31.95
...
...
theta[1] 24.75 2.7e-3 0.47 23.83 24.44 24.75 25.07 25.68
theta[2] 19.59 2.6e-3 0.43 18.76 19.3 19.59 19.88 20.43
...
...
fit.stansummary()是一个像表格一样排列的字符串,它给出了拟合过程中估计的每个参数的后验均值、标准差和几个百分点。当alpha对应于截距时,我们有 8 个beta回归量,一个复杂性或观察误差sigma,我们在训练集theta上的拟合值,以及我们在测试集y_new上的预测值。
诊断
在引擎盖下运行 MCMC,我们以图表的形式检查基本诊断是至关重要的。对于这些图,我依靠优秀的arviz库进行贝叶斯可视化(和PyMC3一起工作也一样)。
- 链式混合 —轨迹图。这些系列图应显示出**“厚毛**”链在真实直线的“合理尺寸”区间内振荡,以指示良好的混合。“稀疏”链意味着 MCMC 没有有效地探索,并且可能在某些异常处停滞不前。
ax = az.plot_trace(fit, var_names=["alpha","beta","sigma"])

粗毛铁链!由于图像大小,我省略了 alpha 和 beta[1:2]。
- 我们参数的后验可信区间 —森林样地。这些应该作为我们的模型参数(和超参数)的比例和位置的可视化指南!).例如,σ(这里是 PC 框架[4]下的一个复杂度参数)不应该达到< 0。与此同时,如果ϐ预测值的可信区间不包含 0,或者如果 0 几乎不在其中,我们就可以获得“统计显著性”的意义
axes = az.plot_forest(
post_data,
kind="forestplot",
var_names= ["beta","sigma"],
combined=True,
ridgeplot_overlap=1.5,
colors="blue",
figsize=(9, 4),
)

看起来不错。**alpha**这里可以看作是代表我们引用类别的“collector”(我用的是引用编码)。我们当然可以规范化我们的变量,以实现更友好的缩放——我鼓励你尝试一下。
预言;预测;预告
贝叶斯推理具有预测能力,我们可以通过从预测后验分布中取样来产生预测能力:

这些(以及整个贝叶斯框架)的伟大之处在于,我们可以使用**(预测)可信区间**来给我们估计的方差/波动性的感觉。毕竟,如果一个预测模型的预测 50 次中有 1 次“足够接近”目标,那么它有什么用呢?
让我们看看我们的预测值与测试集中的观察值相比如何:
dff = pd.DataFrame({'y_pred':la['y_new'].mean(0), 'y_obs':y_test})
grid = sns.JointGrid(dff.y_pred, dff.y_obs, space=0, height=6, ratio=50,
xlim=(0,50), ylim=(0,50))
grid.plot_joint(plt.scatter, color="b")
x0, x1 = grid.ax_joint.get_xlim()
y0, y1 = grid.ax_joint.get_ylim()
lims = [max(x0, y0), min(x1, y1)]
grid.ax_joint.plot(lims, lims, ':k')plt.subplots_adjust(top=0.9)
grid.fig.suptitle('Bayes Test Predicted vs Obs',fontsize=20)
plt.show()

直虚线表示完美的预测。我们离它不远了。
然后,我们可以对这些预测进行 ML 标准度量(MSE ),以评估它们相对于保留测试集中的实际值的质量。
bay_test_mse = metrics.mean_squared_error(y_test, la['y_new'].mean(0))
print('Bayes Test MSE:', bay_test_mse)##### Bayes Test MSE: 10.968931376358526
当我们改变一些模型输入时,我们还可以可视化我们预测的值(以及它们相应的 95%可信区间):
az.style.use("arviz-darkgrid")sns.relplot(x="weight", y="mpg")
data=pd.DataFrame({'weight':X_test['weight'],'mpg':y_test}))
az.plot_hpd(X_test['weight'], la['y_new'], color="k", plot_kwargs={"ls": "--"})

sns.relplot(x="acceleration", y="mpg",
data=pd.DataFrame({'acceleration':X_test['acceleration'],'mpg':y_test}))
az.plot_hpd(X_test['acceleration'], la['y_new'], color="k", plot_kwargs={"ls": "--"})

在下文中,我使用statsmodels比较了我的贝叶斯模型和普通最大似然线性回归模型的性能:

他们表现得非常接近(为了这颗特殊的种子)。
**最佳实践:**为了获得模型性能的“更好”想法,您应该通过运行 K ≥ 30 训练测试分割的实现,在测试 MSE 上引导 95% 置信度区间(CLT)。
这是整个笔记本。py 导出格式:
https://gist . github . com/sergiosonline/6 a3 E0 b 1345 c8 f 002d 0e 7 b 11 AAF 252d 44
考虑
- 请注意,回归分析是一个现代数据科学问题大家族的一个非常容易的起点。在本教程之后,我希望你开始思考它的两种风格:ML(基于损失)和 classical(基于模型/可能性)。
- 贝叶斯推理并不难结合到您的 DS 实践中。采用基于损失的方法作为贝叶斯方法是可能的,但这是我将在后面讨论的主题。
- 只要你知道自己在做什么就有用!事先说明难。但是当你没有有限数量的数据(昂贵的数据收集/标记、罕见事件等)或者你确切知道你想要测试或避免什么时,它特别有用。
- 贝叶斯框架很少在 ML 任务(预测、分类等)中胜过它的(频繁主义者)ML 对应物,特别是当数据集的规模增长时。当处理大型数据集(大数据)时,您的先验知识很容易被数据淹没。
- 正确指定的贝叶斯模型是一个生成模型,因此您应该能够轻松地生成数据,以检查您的模型与正在讨论的数据集/数据生成过程的一致性。
- EDA 和 plots 在模型构建和检查过程之前、之中和之后都是至关重要的。[5]是一篇关于贝叶斯工作流中可视化重要性的精彩论文。
进一步的方向
我鼓励你批判性地思考改进这种预测的方法,不仅从贝叶斯的角度,而且从 ML 的角度。
数据集是否足够大或丰富,可以从严格的 ML 方法中受益?有哪些方法可以改进这个贝叶斯模型?在什么情况下,这个模型一定会优于 MLE 模型?如果观察值以某种方式相关(聚集的、自相关的、空间相关的等等)会怎样?当可解释性是建模优先考虑的问题时,该怎么做?
如果你想知道如何将贝叶斯方法扩展到深度学习,你也可以研究一下变分推理 [6]方法,作为纯贝叶斯治疗的可扩展替代方案。这里的是“简单”的概述,这里的是技术回顾。
参考文献
[1] B. Carpenter 等人 Stan:一种概率编程语言 (2017)。统计软件杂志 76 卷 1 期。DOI 10.18637/jss.v076.i01。
[2]贝当古先生。哈密顿蒙特卡罗概念介绍 (2017)。arXiv:1701.02434
[3] J .韦克菲尔德。贝叶斯和频率主义回归方法 (2013)。统计学中的斯普林格级数。斯普林格纽约。doi:10.1007/978–1–4419–0925–1。
[4] D. Simpson 等人惩罚模型组件复杂性:构建先验的原则性实用方法 (2017)。摘自:统计科学 32.1,第 1-28 页。doi: 10.1214/16-STS576。
[5] J. Gabry 等贝叶斯工作流中的可视化 (2019)。J. R. Stat。社会主义者答:182:389–402。doi:10.1111/rssa.12378
[6] D.M. Blei et al. 变分推断:统计学家综述 (2016)。美国统计协会杂志,第 112 卷,Iss。518,2017 年 DOI:10.1080/01621459 . 5565656567


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言










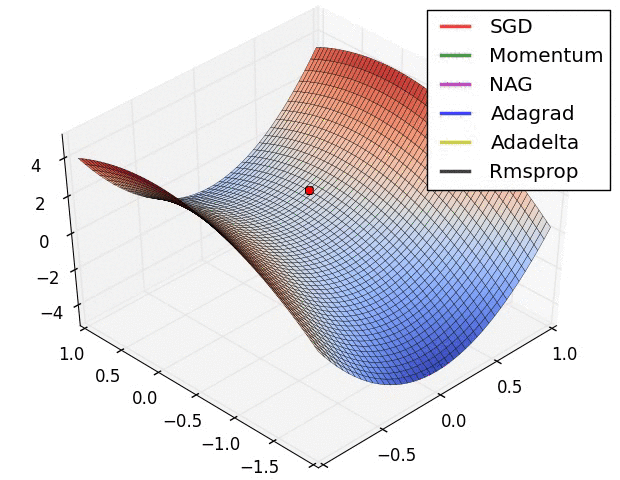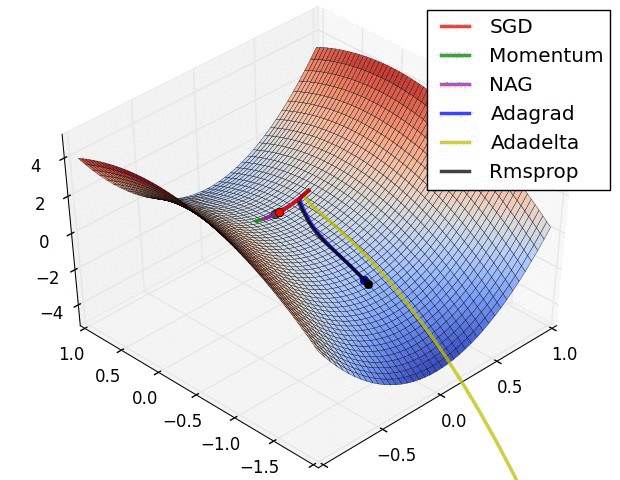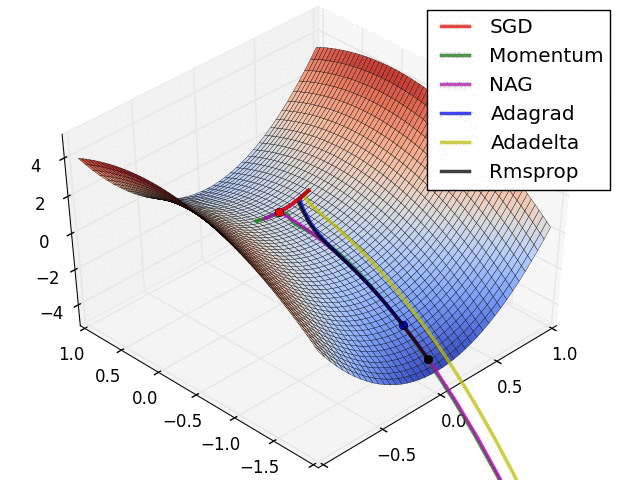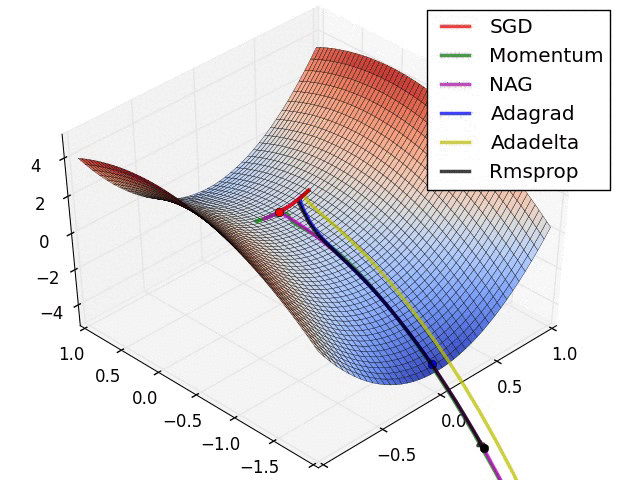{kind=link}
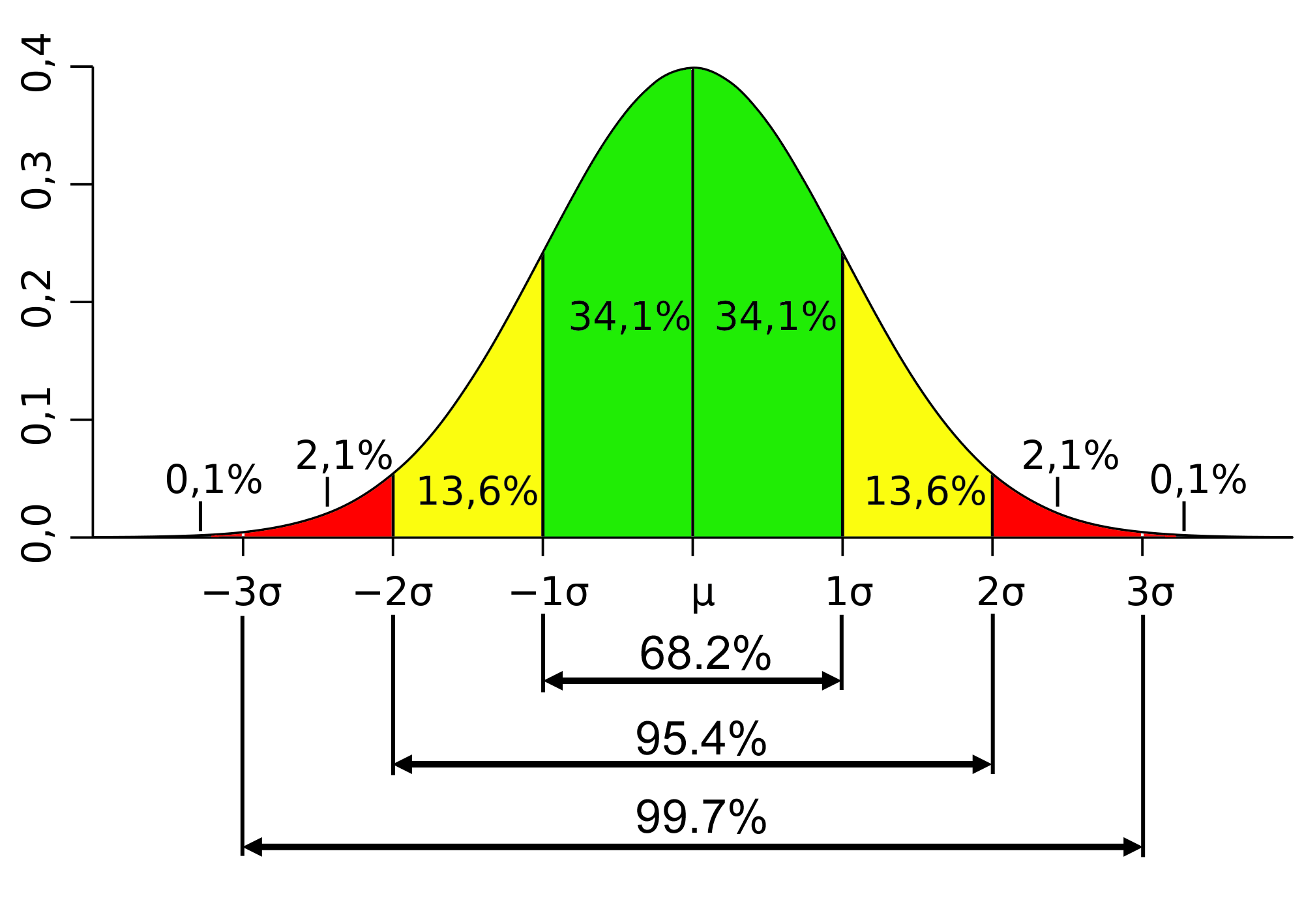{kind=link}
{kind=link}