







你需要的只是关注
解释机器翻译的变压器架构

动机
假设我们想把英语翻译成德语。

(图片由作者提供)
我们可以清楚地看到,我们不能通过单独翻译每个单词来翻译这个句子。例如,英语单词“the”可以翻译成“der”或“die ”,这取决于与其相关的名词的性别。同样,单词“to”根本没有被翻译成德语,因为在德语句子中没有不定式。还有更多例子可以说明一个单词的上下文是如何影响其翻译的。
我们需要将整个输入句子的信息输入到我们的机器翻译模型中,这样它才能理解单词的上下文。
由于大多数机器翻译模型一次输出一个单词,我们也要给模型关于它已经翻译了哪些部分的信息。
过去,机器翻译主要是通过使用 LSTM 或 GRU 这样的递归神经网络来完成的。然而,他们很难学习单词之间的依赖关系,因为单词之间的计算步骤数随着距离的增加而增加,所以单词在句子中距离很远。
为了解决这个问题,引入了变形金刚,它消除了重复现象,代之以注意机制。我将介绍著名论文“你所需要的只是注意力”中提出的架构的内部运作。
编码器解码器
transformer 模型可以一次预测一个单词/单词。它将我们想要翻译的源句子和它已经翻译的句子部分作为输入。然后,变压器输出下一个字。
变压器有两个不同的部分,称为“编码器”和“解码器”。输入的句子被输入编码器,而已经翻译的部分被输入解码器,解码器也产生输出。

注意机制
注意力机制是 Transformer 架构的核心,其灵感来自于人脑中的注意力。想象你在一个聚会上。即使你的名字被淹没在其他的噪音中,你也能听出在房间的另一边有人在喊你的名字。你的大脑可以专注于它认为重要的事情,过滤掉所有不必要的信息。
在查询、键和值的帮助下,变压器中的注意力变得更加容易。
**Key:**Key 是一个单词的标签,用来区分不同的单词。
**查询:**检查所有可用的键,并选择最匹配的一个。所以它代表了对特定信息的主动请求。
**值:**键和值总是成对出现。当查询匹配一个键时,不是键本身,而是单词的值被进一步传播。值是一个单词包含的信息。
在 Transformer 架构中有三种不同的注意机制。一个是编码器和解码器之间的 T2。这种类型的关注被称为交叉关注,因为键和值是由不同于查询的序列生成的。

(图片作者
如果键、值和查询是从相同的序列中生成的,那么我们称之为自关注。在编码器和解码器中各有一种自我关注机制。
自我注意在下图中用紫色表示,交叉注意用红色表示。

(图片由作者提供)
“那么,在数字上是如何做到的呢?”,你可能会问。一种方法是使用成比例的点积注意力。
比例点产品关注度
首先,我们必须注意,我们通过使用嵌入层将单词表示为向量。这个向量的维数可以变化。例如,小型的 GPT-2 记号赋予器使用每个单词/记号 768 的嵌入大小。

(图片由作者提供)
从这些单词向量中,查询( q )、键( k )和值( v )向量通过矩阵乘以学习矩阵来计算。我们把这些矩阵叫做 M 。
在以下示例中,矩阵的形状为(3,2)。3 是单词向量的长度,2 是一个查询、键或值向量的长度。

(图片由作者提供)
我们将查询放在矩阵 Q 中,将键放在矩阵 K 中,将值放在矩阵 V 中。
注意力是这样计算的:

(图片由作者提供)
为了简化,我们考虑 3 个键、3 个值和 1 个查询。当在 Q 和转置的 **K,**之间取点积时,这与在每个键和查询之间取标量积是一样的。标量积越大,键和查询之间的角度越小。

(图片由作者提供)
然后,softmax 函数缩放分数向量,使其总和等于 1。然后分数向量乘以值向量。

(图片由作者提供)
使用这个过程,我们从值中选择更多的信息,其中键和查询更相似。
为了提高变压器的性能,我们可以引入多头关注。
多头注意力
多头注意力意味着我们有多个并行运行的点积注意力机制。这有助于网络同时处理多条信息。

摘自论文“注意力是你所需要的一切”
线性层是简单的学习权重矩阵。对于每个头部,我们通过不同的学习权重矩阵 W 来缩放 V 、 K 和 Q 。并且对于整个多头也有一个输出权重矩阵。

(图片由作者提供)
位置编码
因为转换器没有循环元素,所以当我们输入一个完整的句子时,转换器没有办法知道哪个单词在哪个位置。因此,我们必须对位置进行编码。一种方法是将不同频率的正弦波和余弦波附加到字向量上。

(图片由作者提供)
由于每个位置都有唯一的值组合,因此变压器能够准确地学习位置。

(图片由作者提供)
假设通过使用正弦波和余弦波作为位置编码,变换器应该能够知道超出训练样本大小的位置。
剩余连接和图层标准化
我们还在我们的架构中引入了剩余连接。这是通过在图层之后将输入添加到输出来完成的。

(图片由作者提供)
它们用于允许梯度直接流经网络,因此也被称为跳过连接。
执行层标准化以保持每个训练样本的平均值接近 0,标准偏差接近 1 。这有助于稳定训练,从而减少训练时间。

(图片由作者提供)
整体架构
下图是变压器的整体架构。编码器和解码器可以重复 N 次。

(图片由作者提供)
我们还没有提到架构的前馈部分。这是一个点式前馈网络。它是一个简单的神经网络,具有相同的输入和输出维度。

(图片由作者提供)
摘要
Transformer architecture 去掉了递归,代之以一种关注机制,这种机制使用查询来选择它需要的信息(值),基于键提供的标签。如果键、值和查询是从同一个序列中生成的,就叫自注意。在交叉注意中,查询是由不同于键值对的序列生成的。多头注意力有助于变形金刚同时处理多件事情。
关于源文本的信息被提供给编码器,关于目标句子的已翻译部分的信息被提供给解码器,解码器还输出下一个单词/单词。网络从以不同频率的正弦波和余弦波的形式提供的位置编码中学习句子中单词的顺序。
作者相关文章
作者撰写的其他文章
想联系支持我?
领英
https://www.linkedin.com/in/vincent-m%C3%BCller-6b3542214/
脸书
https://www.facebook.com/profile.php?id=100072095823739
推特
https://twitter.com/Vincent02770108
中等
https://medium.com/@Vincent.Mueller
成为中等会员并支持我(你的部分会员费直接归我)
https://medium.com/@Vincent.Mueller/membership
参考
Yannik Kilchers 关于“关注是你所需要的一切”的视频
K 纪元层归一化
Python 中吸引人的、有效的和描述性的图像可视化
添加比例尺、可视化图像分布、纠正异常值等。

作者图片
Seaborn-image 是一个基于 matplotlib 的开源 Python 可视化图像库。它旨在提供一个高级 API 来可视化图像数据,类似于 seaborn 提供高级 API 来可视化表格数据。顾名思义,seaborn-image很大程度上受到了seaborn库的启发。
装置
让我们从安装seaborn-image开始
$ pip install --upgrade seaborn-image
然后将seaborn-image导入为isns。
*import* seaborn_image *as* isns*# set context* isns.set_context("notebook")*# set global image settings* isns.set_image(*cmap*="deep", *origin*="lower")*# load sample dataset* polymer = isns.load_image("polymer")
seaborn-image中的所有函数都在一个平面名称空间中可用。
isns.set_context()帮助我们全局改变显示上下文(类似于seaborn.set_context())。
除了上下文,我们还使用isns.set_image()全局设置绘制图像的属性。稍后,我们还将看看如何使用isns.set_scalebar()来全局设置图像比例尺属性。
这些功能使用 matplotlib rcParams 定制显示。关于seaborn-image中设置的更多细节,您可以参考文档。
最后,我们从seaborn-image加载一个样本聚合物数据集。
在这篇文章中,我们将使用这个聚合物图像数据集进行可视化。
二维图像
可视化图像就像用我们的聚合物图像数据调用imgplot()函数一样简单。imgplot()在幕后使用 matplotlib imshow ,但是提供了对许多定制的简单访问。我们将在这篇博文中看看一些定制。
默认情况下,它会添加一个colorbar并关闭轴记号。然而,这仅仅是开始触及表面!
我们可以通过设置describe=True得到一些关于我们图像数据的基本描述性统计。
ax = isns.imgplot(polymer, *describe*=True) *# default is False*No. of Obs. : 65536
Min. Value : -8.2457214
Max. Value : 43.714034999999996
Mean : 7.456410761947062
Variance : 92.02680396572863
Skewness : 0.47745180538933696

作者图片
也可以使用
*imshow**,*的别名*imgplot*
画一个比例尺
虽然我们知道一些关于我们的聚合物图像数据的基本信息,但是我们仍然没有关于图像中特征的物理尺寸的任何信息。我们可以画一个比例尺来校正它。
要添加比例尺,我们可以指定单个像素的大小dx和物理的units。这里,单个像素的物理尺寸是 15 纳米。所以,我们设置dx=15和units="nm"。
ax = isns.imgplot(
polymer,
*dx*=15, *# physical size of the pixel
units*="nm", *# units
cbar_label*="Height (nm)" *# add colorbar label to our image* )

作者图片
注意:我们仅指定了单个像素的大小和单位,并绘制了适当大小的比例尺。
提示:您可以更改比例尺属性,如比例尺位置、标签位置、颜色等。全局使用
[*isns.set_scalebar()*](https://seaborn-image.readthedocs.io/en/latest/api/_context.html#seaborn_image.set_scalebar)。
异常值校正
真实的数据从来都不是完美的。它通常充满了异常值,这些异常值会影响图像显示。
# sample data with outliers
pol_outliers = isns.load_image("polymer outliers")ax = isns.imgplot(pol_outliers, cbar_label= "Height (nm)")

作者图片
上述示例数据集有一个影响图像显示的异常像素。我们可以使用所有seaborn-image 函数中的robust参数来校正异常值。
ax = isns.imgplot(
pol_outliers,
*robust*=True, *# set robust plotting
perc*=(0.5, 99.5), *# set the percentile of the data to view
cbar_label*="Height (nm)"
)

作者图片
这里,我们设置robust=True并绘制 0.5 到 99.5%的数据(使用perc参数指定)。这样做可以根据指定的健壮百分比适当地缩放色彩映射表,还可以在没有任何附加代码的情况下绘制色彩条扩展。
注意:您可以指定
*vmin*和*vmax*参数来覆盖*robust*参数。详见*imgplot*文档示例
图像数据分发
图像可视化的一个最重要的方面是知道底层图像数据的分布。在这里,我们使用imghist绘制一个直方图以及我们的聚合物图像。
*fig = isns.imghist(polymer, *dx*=15, *units*="nm", *cbar_label*="Height (nm)")*

作者图片
注意:不需要新的参数。
使用直方图和适当的色彩映射表提供了关于图像数据的附加信息。例如,从上面的直方图中,我们可以看到大部分数据的值小于 30 纳米,只有极少数值接近 40 纳米,如果我们不看直方图,这一点可能不明显。
提示:您可以使用
*bins*参数更改条柱的数量,使用*orientation*参数更改彩条和直方图的方向。详见*imghist*文档示例 。
重要的是,生成完整的图形,包括与颜色条级别匹配的直方图、描述图像中要素物理大小的比例尺、颜色条标签、隐藏轴刻度等。—只用了一行代码。本质上,这就是seaborn-image的目标——为 吸引人的、描述性的和有效的图像可视化 提供一个高级 API。
最后,这篇文章只介绍了seaborn-image为图像可视化提供的一些高级 API。更多细节可以查看详细的文档和教程以及 GitHub 上的项目。
感谢阅读!
原载于 2021 年 2 月 26 日https://sarthakjariwala . github . io*。*
音频深度学习变得简单:自动语音识别(ASR),它是如何工作的
动手教程,直观音频深度学习系列
语音到文本的算法和架构,包括 Mel 频谱图,MFCCs,CTC 损失和解码器,在平原英语

在过去的几年里,随着 Google Home、Amazon Echo、Siri、Cortana 等的流行,语音助手变得无处不在。这些是自动语音识别(ASR)最著名的例子。这类应用程序从某种语言的语音片段开始,并提取所说的单词作为文本。因此,它们也被称为语音转文本算法。
当然,像 Siri 和上面提到的其他应用程序走得更远。他们不仅提取文本,而且还解释和理解所说内容的语义,以便他们可以根据用户的命令做出响应或采取行动。
在这篇文章中,我将重点关注使用深度学习的语音到文本的核心功能。我的目标是不仅要理解事物是如何工作的,还要理解它为什么会这样工作。
我的音频深度学习系列中还有几篇文章,你可能会觉得有用。他们探索了这一领域的其他有趣主题,包括我们如何为深度学习准备音频数据,为什么我们将 Mel 光谱图用于深度学习模型,以及它们是如何生成和优化的。
- 最先进的技术 (什么是声音,它是如何数字化的。音频深度学习在解决我们日常生活中的哪些问题。什么是光谱图,为什么它们都很重要。)
- 为什么 Mel Spectrograms 表现更好 (用 Python 处理音频数据。什么是 Mel 光谱图以及如何生成它们)
- 数据准备和扩充 (通过超参数调整和数据扩充增强光谱图特征以获得最佳性能)
- 声音分类 (端到端的例子和架构对普通声音进行分类。一系列场景的基础应用。)
- 波束搜索 (语音到文本和 NLP 应用程序常用的增强预测的算法)
语音转文本
我们可以想象,人类的语音是我们日常个人和商业生活的基础,语音到文本的功能有大量的应用。人们可以用它来记录面向语音的聊天机器人的客户支持或销售电话的内容,或者记录会议和其他讨论的内容。
基本音频数据由声音和噪声组成。人类语言是一个特例。因此,我在文章中谈到的概念,如我们如何将声音数字化,以及为什么我们要将音频转换成频谱图,也适用于理解语音。然而,语音更复杂,因为它对语言进行编码。
像音频分类这样的问题从一个声音片段开始,并从一组给定的类别中预测该声音属于哪个类别。对于语音转文本问题,您的训练数据包括:
- 输入特征( X ):口语的音频剪辑
- 目标标签( y ):所说内容的文本副本

自动语音识别使用音频波作为输入特征,使用文本抄本作为目标标签(图片由作者提供)
该模型的目标是学习如何获取输入音频并预测说出的单词和句子的文本内容。
数据预处理
在声音分类文章中,我一步一步地解释了用于处理深度学习模型的音频数据的转换。对于人类语言,我们也遵循类似的方法。有几个 Python 库提供了这样的功能,librosa 是最流行的一个。

将原始音频波转换为频谱图图像,以输入到深度学习模型(图片由作者提供)
加载音频文件
- 从输入数据开始,输入数据由音频格式的口语语音的音频文件组成。wav”或“. mp3”。
- 从文件中读取音频数据,并将其加载到 2D Numpy 数组中。这个数组由一系列数字组成,每个数字代表特定时刻声音的强度或振幅。这种测量的次数由采样率决定。例如,如果采样速率为 44.1kHz,则 Numpy 数组对于 1 秒钟的音频将具有单行 44,100 个数字。
- 音频可以有一个或两个通道,俗称单声道或立体声。对于双声道音频,第二个声道会有另一个类似的幅度数字序列。换句话说,我们的 Numpy 数组将是 3D 的,深度为 2。
转换为统一维度:采样率、通道和持续时间
- 我们的音频数据项可能会有很多变化。片段可能以不同的速率采样,或者具有不同数量的通道。剪辑很可能具有不同的持续时间。如上所述,这意味着每个音频项的尺寸将是不同的。
- 由于我们的深度学习模型期望我们所有的输入项都具有相似的大小,因此我们现在执行一些数据清理步骤来标准化我们的音频数据的维度。我们对音频进行重新采样,以便每个项目都具有相同的采样率。我们将所有项目转换到相同数量的频道。所有项目也必须转换为相同的音频持续时间。这包括填充较短的序列或截断较长的序列。
- 如果音频质量很差,我们可以通过应用噪声去除算法来消除背景噪声,以便我们可以专注于语音音频。
原始音频的数据扩充
- 我们可以应用一些数据扩充技术来增加输入数据的多样性,并帮助模型学习概括更广泛的输入。我们可以随机地将音频向左或向右移动一个小的百分比,或者少量地改变音频的音高或速度。
梅尔光谱图
- 这个原始音频现在被转换成 Mel 光谱图。频谱图通过将音频分解为包含在其中的一组频率,将音频的本质捕捉为图像。
MFCC
- 特别是对于人类语音,有时采取一个额外的步骤并将梅尔频谱图转换成 MFCC(梅尔频率倒谱系数)会有所帮助。MFCCs 通过仅提取最基本的频率系数来产生 Mel 频谱图的压缩表示,这些频率系数对应于人类说话的频率范围。
光谱图的数据扩充
- 我们现在可以使用一种称为 SpecAugment 的技术,对 Mel 光谱图图像应用另一个数据扩充步骤。这包括随机屏蔽掉垂直(即时间掩模)或水平(即频率屏蔽)来自频谱图的信息频带。注:我不确定这是否也适用于 MFCCs,是否会产生好的结果。
经过数据清理和扩充,我们现在已经将原始音频文件转换为 Mel 声谱图(或 MFCC)图像。
我们还需要从抄本中准备目标标签。这只是由单词的句子组成的常规文本,所以我们从脚本中的每个字符构建一个词汇表,并将它们转换成字符 id。
这给了我们输入特征和目标标签。这些数据已经准备好输入到我们的深度学习模型中。
体系结构
ASR 的深度学习架构有很多变体。两种常用的方法是:
- 一种基于 CNN(卷积神经网络)和 RNN(递归神经网络)的架构,使用 CTC Loss 算法来区分语音中单词的每个字符。百度的深度语音模型。
- 基于 RNN 的序列到序列网络,将声谱图的每个“切片”视为序列中的一个元素,例如 Google 的 Listen Attend Spell (LAS)模型。
让我们选择上面的第一种方法,并更详细地探讨它是如何工作的。概括地说,该模型由以下模块组成:
- 由几个残余 CNN 层组成的常规卷积网络,处理输入频谱图图像并输出这些图像的特征图。

光谱图由卷积网络处理以生成特征图(图片由作者提供)
- 由几个双向 LSTM 层组成的规则循环网络,将特征地图作为一系列不同的时间步长或“帧”进行处理,这些时间步长或“帧”与我们所需的输出字符序列相对应。(LSTM 是一种非常常用的循环层,它的完整形式是长短期记忆)。换句话说,它采用连续表示音频的特征图,并将它们转换成离散表示。

递归网络处理来自特征图的帧(图片由作者提供)
- 带有 softmax 的线性图层,使用 LSTM 输出为输出的每个时间步长生成字符概率。

线性层为每个时间步长生成字符概率(图片由作者提供)
- 我们还有位于卷积和递归网络之间的线性层,有助于将一个网络的输出整形为另一个网络的输入。
因此,我们的模型获取频谱图图像,并输出该频谱图中每个时间步长或“帧”的特征概率。
对齐序列
如果你稍微思考一下这个问题,你会意识到我们的拼图中还缺少一个重要的部分。我们的最终目标是将这些时间步或“框架”映射到我们的目标脚本中的单个字符。

该模型解码字符概率以产生最终输出(作者的图像)
但是对于一个特定的声谱图,我们怎么知道应该有多少帧呢?我们如何确切地知道每一帧的边界在哪里?我们如何将音频与文本脚本中的每个字符对齐?

左边是我们需要的排列。但是我们如何得到它呢??(图片由作者提供)
音频和声谱图图像没有被预先分割以给我们这个信息。
- 在口语音频中,因此在声谱图中,每个字符的声音可以具有不同的持续时间。
- 这些字符之间可能会有间隔和停顿。
- 几个字符可以合并在一起。
- 有些字符可以重复。例如,在单词“apple”中,我们如何知道音频中的“p”实际上是否对应于文字记录中的一个或两个“p”?

事实上,口语对我们来说并不整齐一致(图片由作者提供)
这实际上是一个非常具有挑战性的问题,也是为什么 ASR 如此难以正确解决的原因。这是 ASR 区别于分类等其他音频应用的显著特征。
我们解决这个问题的方法是使用一种巧妙的算法,它有一个听起来很好听的名字,叫做连接主义时间分类,简称 CTC。由于我不是“喜欢幻想的人”,而且很难记住这个长名字,我就用反恐委员会这个名字来指代它😃。
CTC 算法——训练和推理
当输入是连续的而输出是离散的,并且没有清晰的元素边界可用于将输入映射到输出序列的元素时,CTC 用于对齐输入和输出序列。
它的特别之处在于它会自动执行这种对齐,而不需要您手动提供这种对齐作为标记的训练数据的一部分。这将使创建训练数据集变得极其昂贵。
如上所述,在我们的模型中,卷积网络输出的特征映射被分割成单独的帧,并输入到递归网络。每一帧对应于原始音频波的某个时间步长。但是,在设计模型时,帧数和每帧的持续时间是由您选择作为超参数的。对于每一帧,线性分类器后面的递归网络预测词汇表中每个字符的概率。

连续的音频被分割成离散的帧并输入到 RNN(图片由作者提供)
CTC 算法的工作就是获取这些字符概率并导出正确的字符序列。
为了帮助它处理我们刚刚讨论过的对齐和重复字符的挑战,它在词汇表中引入了“空白”伪字符(用“-”表示)的概念。因此,网络输出的字符概率也包括每帧空白字符的概率。
请注意,空白与“空格”不同。空格是一个真正的字符,而空白意味着没有任何字符,有点像大多数编程语言中的“null”。它仅用于划分两个字符之间的界限。
CTC 以两种模式工作:
- CTC 丢失(在训练期间):它有一个地面真实目标抄本,并试图训练网络以最大化输出那个正确抄本的概率。
- CTC 解码(推断中):这里我们没有目标抄本可以参考,必须预测最可能的字符序列。
让我们更深入地研究一下,以理解算法的作用。我们将从 CTC 解码开始,因为它稍微简单一些。
CTC 解码
- 使用字符概率为每一帧选择最可能的字符,包括空格。例如," -G-o-ood "

CTC 解码算法(图片作者提供)
- 合并任何重复的字符,并且不用空格分隔。例如,我们可以将“ oo ”合并成一个“ o ”,但是我们不能合并“ o-oo ”。这就是 CTC 能够区分有两个单独的“o”并产生由重复字符拼写的单词的方式。例如," -G-o-od "
- 最后,因为空格已经达到了它们的目的,所以它删除了所有的空格字符。例如“好的”。
CTC 损失
损失被计算为网络预测正确序列的概率。为此,该算法列出了网络可以预测的所有可能的序列,并从中选择与目标转录本匹配的子集。
为了从可能序列的全集中识别该子集,该算法如下缩小可能性:
- 只保留出现在目标脚本中的字符的概率,而丢弃其余的。它只保留“G”、“o”、“d”和“-”的概率。
- 使用过滤的字符子集,对于每一帧,只选择那些以与目标抄本相同的顺序出现的字符。尽管“G”和“o”都是有效字符,但“Go”的顺序是有效序列,而“oG”是无效序列。

CTC 丢失算法(图片由作者提供)
有了这些约束,算法现在有了一组有效的字符序列,所有这些都将产生正确的目标转录本。例如,使用推理过程中使用的相同步骤,“-G-o-ood”和“-Go-od-”都将导致“好”的最终输出。
然后,它使用每一帧的单个字符概率来计算生成所有这些有效序列的总概率。网络的目标是学习如何最大化该概率,并因此降低产生任何无效序列的概率。
严格地说,由于神经网络使损失最小化,所以 CTC 损失被计算为所有有效序列的负对数概率。由于网络在训练期间通过反向传播最小化了这种损失,所以它调整其所有的权重以产生正确的序列。
然而,实际做到这一点比我在这里描述的要复杂得多。挑战在于有大量可能的字符组合来产生一个序列。就我们这个简单的例子来说,每帧可以有 4 个字符。有 8 个帧,所以我们有 4 * 8 个组合(= 65536)。对于任何有更多角色和更多画面的真实剧本,这个数字会呈指数增长。这使得简单地穷尽列出有效组合并计算它们的概率在计算上是不切实际的。
高效地解决这个问题是 CTC 如此创新的原因。这是一个迷人的算法,非常值得理解它如何实现这一点的细微差别。这本身就值得一篇完整的文章,我打算很快就写出来。但是现在,我们已经把重点放在建立对 CTC 做什么的直觉上,而不是深入它是如何工作的。
指标—单词错误率(WER)
在训练我们的网络之后,我们必须评估它的表现如何。语音到文本问题的一个常用度量是单词错误率(和字符错误率)。它一个字一个字地(或一个字符一个字符地)比较预测的输出和目标抄本,以计算出它们之间的差异。
差异可以是存在于转录本中但在预测中缺失的单词(被计为删除)、不在转录本中但已被添加到预测中的单词(插入)、或者在预测和转录本之间改变的单词(替换)。

统计转录本和预测之间的插入、删除和替换(图片由作者提供)
度量公式相当简单。它是差异相对于总字数的百分比。

单词错误率计算(图片由作者提供)
语言模型
到目前为止,我们的算法只把语音当作某种语言的字符序列。但是当把这些字符组合成单词和句子时,它们真的有意义吗?
自然语言处理(NLP)中的一个常见应用是建立语言模型。它捕捉了在一种语言中如何使用单词来构建句子、段落和文档。它可以是关于语言(如英语或韩语)的通用模型,也可以是特定于特定领域(如医学或法律)的模型。
一旦有了语言模型,它就可以成为其他应用程序的基础。例如,它可以用来预测句子中的下一个单词,辨别一些文本的情绪(例如,这是一篇积极的书评吗),通过聊天机器人回答问题,等等。
因此,当然,它也可以用于通过引导模型生成更有可能符合语言模型的预测来选择性地提高我们的 ASR 输出的质量。
波束搜索
当在推理过程中描述 CTC 解码器时,我们隐含地假设它总是在每个时间步长选择一个概率最高的单个字符。这就是所谓的贪婪搜索。
然而,我们知道使用一种叫做波束搜索的替代方法可以得到更好的结果。
虽然波束搜索通常用于 NLP 问题,但它并不是特定于 ASR 的,所以我在这里提到它只是为了完整。如果你想知道更多,请看看我的文章,其中详细描述了波束搜索。
结论
希望这能让您对用于解决 ASR 问题的构建模块和技术有所了解。
在早期的深度学习之前,通过经典方法解决这类问题需要理解音素等概念,以及大量特定领域的数据准备和算法。
然而,正如我们刚刚看到的深度学习,我们几乎不需要任何涉及音频和语音知识的功能工程。然而,它能够产生出色的结果,不断给我们带来惊喜!
最后,如果你喜欢这篇文章,你可能也会喜欢我关于变形金刚、地理定位机器学习和图像字幕架构的其他系列。
让我们继续学习吧!
音频深度学习变得简单(第一部分):最新技术
直观音频深度学习系列
颠覆性深度学习音频应用和架构世界的温和指南。以及为什么我们都需要了解光谱图,用简单的英语。

杰森·罗斯韦尔在 Unsplash 上的照片
尽管计算机视觉和 NLP 应用获得了最多的关注,但也有许多突破性的音频数据深度学习用例正在改变我们的日常生活。在接下来的几篇文章中,我的目标是探索音频深度学习的迷人世界。
下面是我计划在这个系列中发表的文章的简要概述。我的目标是不仅要理解事物是如何工作的,还要理解它为什么会这样工作。
- 最先进的技术——本文 (什么是声音,它是如何数字化的。音频深度学习在解决我们日常生活中的哪些问题。什么是光谱图,为什么它们都很重要。)
- 为什么 Mel Spectrograms 表现更好 (用 Python 处理音频数据。什么是 Mel 光谱图以及如何生成它们)
- 特性优化和增强 (通过超参数调整和数据增强增强光谱图特性以获得最佳性能)
- 音频分类 (端到端例子和架构对普通声音进行分类。一系列场景的基础应用。)
- 自动语音识别 (语音转文本算法和架构,使用 CTC 丢失和解码进行序列对齐。)
- 波束搜索
在这第一篇文章中,由于这一领域可能不为人们所熟悉,我将介绍这个主题,并概述音频应用的深度学习前景。我们将了解什么是音频,以及它是如何以数字形式呈现的。我将讨论音频应用对我们日常生活的广泛影响,并探索它们使用的架构和建模技术。
什么是声音?
我们都记得在学校时,声音信号是由气压的变化产生的。我们可以测量压力变化的强度,并随时间绘制这些测量值。
声音信号经常以规则的间隔重复,因此每个波都具有相同的形状。高度表示声音的强度,称为振幅。

显示振幅对时间的简单重复信号(经马克·利伯曼教授许可)
信号完成一个完整波所用的时间就是周期。信号在一秒钟内产生的波数称为频率。频率是周期的倒数。频率的单位是赫兹。
我们遇到的大多数声音可能不遵循这样简单而有规律的周期模式。但是不同频率的信号可以被加在一起以创建具有更复杂重复模式的复合信号。我们听到的所有声音,包括我们人类的声音,都是由这样的波形组成的。例如,这可能是乐器的声音。

带有复杂重复信号的音乐波形(来源,经乔治·吉布森教授许可)
人耳能够根据声音的“质量”(也称为音色)来区分不同的声音。
我们如何用数字方式表现声音?
为了将声波数字化,我们必须将信号转换成一系列数字,这样我们就可以将它输入到我们的模型中。这是通过在固定的时间间隔测量声音的振幅来实现的。

定期进行样本测量(来源
每个这样的测量称为一个样本,采样率是每秒的样本数。例如,常见的采样率大约是每秒 44,100 个样本。这意味着一个 10 秒钟的音乐片段将有 441,000 个样本!
为深度学习模型准备音频数据
直到几年前,在深度学习出现之前,计算机视觉的机器学习应用曾经依赖于传统的图像处理技术来进行特征工程。例如,我们会使用算法来检测角、边和面,从而生成手工制作的特征。对于 NLP 应用程序,我们也将依赖于诸如提取 N 元语法和计算词频之类的技术。
类似地,音频机器学习应用过去依赖于传统的数字信号处理技术来提取特征。例如,为了理解人类语音,可以使用语音学概念来分析音频信号,以提取像音素这样的元素。所有这些都需要大量特定领域的专业知识来解决这些问题,并调整系统以获得更好的性能。
然而,近年来,随着深度学习变得越来越普遍,它在处理音频方面也取得了巨大的成功。有了深度学习,不再需要传统的音频处理技术,我们可以依赖标准的数据准备,而不需要大量的手动和自定义生成特征。
更有趣的是,通过深度学习,我们实际上不会处理原始形式的音频数据。相反,常用的方法是将音频数据转换成图像,然后使用标准的 CNN 架构来处理这些图像!真的吗?把声音转换成图片?这听起来像科幻小说。😄
答案当然是相当普通和平凡的。这是通过从音频生成频谱图来完成的。首先让我们了解什么是光谱,并用它来理解光谱图。
范围
如前所述,不同频率的信号可以叠加在一起,形成复合信号,代表现实世界中出现的任何声音。这意味着任何信号都由许多不同的频率组成,可以表示为这些频率的总和。
频谱是组合在一起产生信号的一组频率。这幅图显示了一段音乐的频谱。
该频谱描绘了信号中存在的所有频率以及每个频率的强度或振幅。

频谱显示了构成声音信号的频率(来源,经 Barry Truax 教授许可)
信号中的最低频率称为基频。基频的整数倍频率称为谐波。
例如,如果基频为 200 赫兹,那么其谐波频率为 400 赫兹、600 赫兹等等。
时域与频域
我们之前看到的显示振幅与时间关系的波形是表示声音信号的一种方式。由于 x 轴显示了信号的时间值范围,因此我们是在时域中查看信号。
频谱是表示同一信号的另一种方式。它显示的是幅度与频率的关系,由于 x 轴显示的是信号的频率值范围,在时刻,我们看到的是频域中的信号。

时域和频域(来源
光谱图
由于信号随时间变化会产生不同的声音,因此其组成频率也随时间变化。换句话说,它的光谱随时间而变化。
信号的频谱图绘制了其随时间变化的频谱,就像信号的“照片”。它在 x 轴上绘制时间,在 y 轴上绘制频率。这就好像我们在不同的时间点一次又一次地获取光谱,然后将它们全部结合成一个单一的图。
它用不同的颜色来表示每个频率的幅度或强度。颜色越亮,信号的能量越高。频谱图的每个垂直“切片”实质上是该时刻信号的频谱,并显示了信号强度在该时刻信号中的每个频率上的分布。
在下面的例子中,第一张图片显示的是时域信号。幅度与时间的关系它让我们知道在任何时间点一个剪辑有多大声或安静,但它给我们提供的关于存在哪些频率的信息很少。

声音信号及其声谱图(图片由作者提供)
第二张图是频谱图,显示频域中的信号。
生成光谱图
频谱图是利用傅里叶变换将任何信号分解成其组成频率而产生的。如果这让你有点紧张,因为我们现在已经忘记了大学期间学过的傅立叶变换,不要担心😄!我们实际上不需要回忆所有的数学,有非常方便的 Python 库函数可以在一个步骤中为我们生成光谱图。我们将在下一篇文章中看到这些。
音频深度学习模型
现在我们知道了什么是频谱图,我们意识到它是音频信号的等效紧凑表示,有点像信号的“指纹”。这是一种将音频数据的基本特征捕捉为图像的优雅方式。

音频深度学习模型使用的典型管道(图片由作者提供)
所以大多数深度学习音频应用使用频谱图来表示音频。他们通常遵循这样的程序:
- 从波形文件形式的原始音频数据开始。
- 将音频数据转换成相应的声谱图。
- 可选地,使用简单的音频处理技术来扩充谱图数据。(在谱图转换之前,也可以对原始音频数据进行一些扩充或清理)
- 现在我们有了图像数据,我们可以使用标准的 CNN 架构来处理它们,并提取特征图,这些特征图是光谱图图像的编码表示。
下一步是根据您试图解决的问题,从这种编码表示中生成输出预测。
- 例如,对于一个音频分类问题,你可以通过一个通常由一些完全连接的线性层组成的分类器。
- 对于语音到文本的问题,你可以让它通过一些 RNN 层,从这个编码的表示中提取文本句子。
当然,我们跳过了许多细节,做了一些概括,但在这篇文章中,我们停留在一个相当高的水平。在接下来的文章中,我们将更详细地讨论所有这些步骤和所使用的架构。
音频深度学习解决了哪些问题?
日常生活中的音频数据可以以无数种形式出现,例如人类语音、音乐、动物声音和其他自然声音,以及来自人类活动(如汽车和机械)的人造声音。
鉴于声音在我们生活中的普遍存在和声音类型的多样性,有大量的使用场景需要我们处理和分析音频就不足为奇了。现在深度学习已经成熟,可以应用它来解决许多用例。
音频分类
这是最常见的用例之一,涉及到获取一个声音并将其分配给几个类中的一个。例如,任务可以是识别声音的类型或来源。这是汽车启动声,这是锤子声,哨声,还是狗叫声。

普通声音的分类(图片由作者提供)
显然,可能的应用是巨大的。这可以应用于根据机器或设备产生的声音来检测其故障,或者在监控系统中检测安全入侵。
音频分离和分段
音频分离包括从混合信号中分离出感兴趣的信号,以便可以用于进一步处理。例如,您可能想要从大量背景噪音中分离出个人的声音,或者从音乐表演的其余部分中分离出小提琴的声音。

从视频中分离单个发言人(来源,经 Ariel Ephrat 许可)
音频分段用于突出显示音频流中的相关部分。例如,它可以用于诊断目的,以检测人类心脏的不同声音和检测异常。
音乐流派分类和标记
随着音乐流媒体服务的流行,我们大多数人都熟悉的另一个常见应用是根据音频对音乐进行识别和分类。对音乐的内容进行分析,以找出它所属的流派。这是一个多标签分类问题,因为一首给定的音乐可能属于一个以上的流派。例如,摇滚、流行、爵士、萨尔萨、器乐以及其他方面,如“老歌”、“女歌手”、“快乐”、“派对音乐”等等。

音乐流派分类和标记(作者图片)
当然,除了音频本身,还有关于音乐的元数据,如歌手、发行日期、作曲家、歌词等,这些都可以用来为音乐添加丰富的标签。
这可以用于根据音乐收藏的音频特征对其进行索引,根据用户的偏好提供音乐推荐,或者用于搜索和检索与您正在收听的歌曲相似的歌曲。
音乐生成和音乐转录
这些天我们看到了很多关于深度学习被用于以编程方式生成看起来非常真实的人脸和其他场景的图片,以及能够编写语法正确和智能的信件或新闻文章的新闻。

音乐生成(作者图片)
类似地,我们现在能够生成与特定流派、乐器甚至特定作曲家风格相匹配的合成音乐。
在某种程度上,音乐改编反过来应用了这种能力。它需要一些声学效果并对其进行注释,以创建一个包含音乐中存在的音符的乐谱。
声音识别
从技术上讲,这也是一个分类问题,但处理的是语音识别。它可以用来识别说话者的性别,或者他们的名字(例如,这是比尔·盖茨还是汤姆·汉克斯,或者这是柯坦的声音还是入侵者的声音)

用于入侵检测的语音识别(图片由作者提供)
我们可能想检测人类的情绪,并从他们的语调中识别出这个人的情绪,例如,这个人是高兴、悲伤、生气还是有压力。
我们可以将此应用于动物的声音,以识别发出声音的动物的类型,或者潜在地识别这是一种温柔深情的咕噜声,一种威胁的吠叫,还是一种害怕的嚎叫。
语音到文本和文本到语音
在处理人类语言时,我们可以更进一步,不仅仅是识别说话者,而是理解他们在说什么。这包括从音频中提取单词,用说的语言,并转录成文本句子。
这是最具挑战性的应用之一,因为它不仅处理音频分析,还处理 NLP,并需要开发一些基本的语言能力来从发出的声音中破译不同的单词。

语音转文本(图片由作者提供)
相反,使用语音合成,人们可以走另一个方向,使用书面文本并从中生成语音,例如,使用人工语音作为会话代理。
显然,能够理解人类语言能够在我们的商业和个人生活中实现大量有用的应用,而我们只是刚刚开始触及表面。
已经实现广泛使用的最知名的例子是虚拟助手,如 Alexa、Siri、Cortana 和 Google Home,这些都是围绕这一功能构建的消费者友好型产品。
结论
在本文中,我们停留在一个相当高的水平,探索了音频应用的广度,并涵盖了用于解决这些问题的一般技术。
在下一篇文章中,我们将深入探讨预处理音频数据和生成频谱图的更多技术细节。我们将看看用于优化性能的超参数。
这将为我们更深入地研究几个端到端的例子做好准备,从普通声音的分类开始,到更具挑战性的自动语音识别,我们还将讨论有趣的 CTC 算法。
最后,如果你喜欢这篇文章,你可能也会喜欢我关于变形金刚、地理定位机器学习和图像字幕架构的其他系列。
让我们继续学习吧!
音频深度学习变得简单(第二部分):为什么 Mel 频谱图表现更好
直观音频深度学习系列
用 Python 处理音频的简明指南。什么是 Mel 光谱图以及如何用简单的英语生成它们。

这是我关于音频深度学习系列的第二篇文章。现在,我们知道了声音是如何以数字形式表示的,我们需要将其转换为声谱图以用于深度学习架构,让我们更详细地了解这是如何完成的,以及我们如何调整转换以获得更好的性能。
由于数据准备非常关键,尤其是在音频深度学习模型的情况下,这将是接下来两篇文章的重点。
下面是我计划在这个系列中发表的文章的简要总结。我的目标是不仅要理解事物是如何工作的,还要理解它为什么会这样工作。
- 最先进的技术 (什么是声音,它是如何数字化的。音频深度学习在解决我们日常生活中的哪些问题。什么是光谱图,为什么它们都很重要。)
- 为什么 Mel Spectrograms 性能更好—本文 (用 Python 处理音频数据。什么是 Mel 光谱图以及如何生成它们)
- 特性优化和增强 (通过超参数调整和数据增强增强光谱图特性以获得最佳性能)
- 声音分类 (端到端的例子和架构对普通声音进行分类。一系列场景的基础应用。)
- 自动语音识别 (语音转文本算法和架构,使用 CTC 丢失和解码进行序列对齐。)
- 波束搜索
音频文件格式和 Python 库
深度学习模型的音频数据通常会以数字音频文件的形式开始。通过听录音和音乐,我们都知道这些文件是根据声音的压缩方式以各种格式存储的。这些格式的例子有。wav、. mp3、。wma,。aac,。flac 等等。
Python 有一些很棒的音频处理库。Librosa 是最受欢迎的软件之一,拥有广泛的功能。scipy 也常用。如果您使用 Pytorch,它有一个名为 torchaudio 的配套库,与 Pytorch 紧密集成。它没有 Librosa 那么多的功能,但它是专门为深度学习而构建的。
它们都可以让你阅读不同格式的音频文件。第一步是加载文件。使用 librosa:
或者,您也可以使用 scipy 做同样的事情:
然后你可以想象声波:

将声波可视化(图片由作者提供)
听听吧。如果您使用的是 Jupyter 笔记本,您可以直接在单元格中播放音频。

在笔记本单元格中播放音频(图片由作者提供)
音频信号数据
正如我们在上一篇文章中看到的,音频数据是通过以固定的时间间隔对声波进行采样,并测量每个样本的声波强度或振幅而获得的。该音频的元数据告诉我们采样率,即每秒的样本数。
当音频以压缩格式保存在文件中时。当文件被加载时,它被解压缩并转换成一个 Numpy 数组。无论您从哪种文件格式开始,这个数组看起来都是一样的。
在内存中,音频以数字的时间序列表示,代表每个时间步长的幅度。例如,如果采样率是 16800,一秒钟的音频片段将有 16800 个数字。因为测量是以固定的时间间隔进行的,所以数据只包含振幅数字,而不包含时间值。给定采样速率,我们可以计算出每个幅度数测量是在哪个时刻进行的。

比特深度告诉我们每个样本的幅度测量可以取多少个可能值。例如,位深度为 16 意味着振幅数可以在 0 到 65535(2⁶-1)之间。位深度影响音频测量的分辨率,位深度越高,音频保真度越好。

位深度和采样率决定了音频分辨率(源)
光谱图
深度学习模型很少直接把这个原始音频作为输入。正如我们在第 1 部分中了解到的,通常的做法是将音频转换成声谱图。声谱图是声波的简明“快照”,因为它是图像,所以非常适合输入到为处理图像而开发的基于 CNN 的架构中。
频谱图是使用傅立叶变换从声音信号生成的。傅立叶变换将信号分解成其组成频率,并显示信号中每个频率的振幅。
声谱图将声音信号的持续时间分割成更小的时间片段,然后对每个片段进行傅立叶变换,以确定该片段中包含的频率。然后,它将所有这些部分的傅立叶变换组合成一个单一的图。
它绘制了频率(y 轴)与时间(x 轴)的关系,并使用不同的颜色来表示每个频率的幅度。颜色越亮,信号的能量越高。

简单的频谱图(图片由作者提供)
不幸的是,当我们展示这个光谱图时,没有太多的信息让我们看到。我们以前在科学课上看到的那些彩色光谱图都去哪了?
这是因为人类感知声音的方式。我们能够听到的大部分声音都集中在一个狭窄的频率和振幅范围内。让我们先探索一下,这样我们就能知道如何产生这些可爱的光谱图。
人类是如何听到频率的?
我们听到声音频率的方式被称为“音高”。这是对频率的主观印象。所以高音的频率比低音高。人类不会线性地感知频率。我们对低频之间的差异比对高频更敏感。
例如,如果你听不同的声音对,如下所示:
- 100 赫兹和 200 赫兹
- 1000 赫兹和 1100 赫兹
- 10000 赫兹和 10100 赫兹
你对每对声音之间的“距离”的感知是什么?你能区分每一对声音吗?
尽管在所有情况下,每对之间的实际频率差在 100 Hz 时完全相同,但 100Hz 和 200Hz 的那对听起来比 1000Hz 和 1100Hz 的那对更远。你很难区分 10000 赫兹和 10100 赫兹的频率对。
然而,如果我们认识到 200Hz 的频率实际上是 100Hz 的两倍,而 10100Hz 的频率只比 10000Hz 的频率高 1%,这似乎就不那么令人惊讶了。
这是人类感知频率的方式。我们听到的是对数标度,而不是线性标度。我们如何在数据中说明这一点?
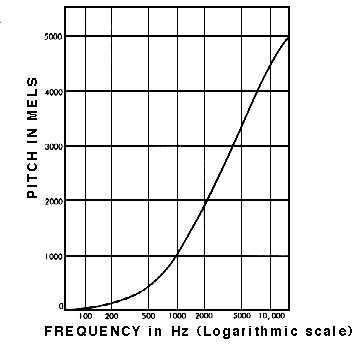
梅尔标度
Mel 量表是通过对大量听众进行实验来考虑这一点的。这是一种音高标准,听众可以据此判断每个单元与下一个单元的音高距离相等。

梅尔标度测量人对音高的感知(来源,经 Barry Truax 教授许可)
人类是如何听到振幅的?
人类对声音振幅的感知是声音的响度。类似于频率,我们听到的响度是对数的,而不是线性的。我们用分贝标度来说明这一点。
分贝标度
在这个范围内,0 dB 代表完全静音。从那里开始,测量单位呈指数增长。10 dB 比 0 dB 大 10 倍,20 dB 大 100 倍,30 dB 大 1000 倍。在这个范围内,超过 100 分贝的声音开始变得难以忍受。

常见声音的分贝水平(改编自来源
我们可以看到,为了以现实的方式处理声音,在处理数据中的频率和振幅时,通过 Mel 标度和分贝标度使用对数标度是很重要的。
这正是 Mel 光谱图的目的。
梅尔光谱图
Mel 频谱图相对于绘制频率与时间关系的常规频谱图有两个重要变化。
- 它使用 Mel 标度,而不是 y 轴上的频率。
- 它使用分贝标度而不是振幅来表示颜色。
对于深度学习模型,我们通常使用这个而不是简单的声谱图。
让我们修改上面的谱图代码,用 Mel 标度代替频率。

使用 Mel 标度的光谱图(图片由作者提供)
这比以前好,但大多数光谱图仍然是暗的,没有携带足够的有用信息。所以我们修改一下,用分贝标度代替振幅。

梅尔光谱图(图片由作者提供)
终于!这是我们真正在寻找的东西😃。
结论
我们现在已经了解了如何预处理音频数据和准备 Mel 光谱图。但是在我们可以将它们输入深度学习模型之前,我们必须优化它们以获得最佳性能。
在下一篇文章中,我们将看看如何通过调整 Mel 光谱图来增强模型的数据,以及增加我们的音频数据来帮助我们的模型推广到更广泛的输入。
最后,如果你喜欢这篇文章,你可能也会喜欢我关于变形金刚、地理定位机器学习和图像字幕架构的其他系列。
让我们继续学习吧!
音频深度学习变得简单(第三部分):数据准备和增强
直观音频深度学习系列
增强声谱图特性以获得最佳性能的简明指南。还有数据扩充,用简单的英语说

由维达尔·诺德里-马西森在 Unsplash 上拍摄的照片
这是我关于音频深度学习系列的第三篇文章。到目前为止,我们已经了解了声音是如何数字化表示的,深度学习架构通常使用声音的声谱图。我们还看到了如何在 Python 中预处理音频数据以生成 Mel 光谱图。
在本文中,我们将更进一步,通过调整其超参数来增强我们的 Mel 谱图。我们还将研究音频数据的增强技术。这两者都是数据准备的重要方面,以便从我们的音频深度学习模型中获得更好的性能。
下面是我计划在这个系列中发表的文章的简要概述。我的目标是不仅要理解事物是如何工作的,还要理解它为什么会这样工作。
- 最先进的技术 (什么是声音,它是如何数字化的。音频深度学习在解决我们日常生活中的哪些问题。什么是光谱图,为什么它们都很重要。)
- 为什么 Mel Spectrograms 表现更好 (用 Python 处理音频数据。什么是 Mel 光谱图以及如何生成它们)
- 数据准备和扩充——本文 (通过超参数调整和数据扩充增强光谱图特性以获得最佳性能)
- 声音分类 (端到端的例子和架构来分类普通的声音。一系列场景的基础应用。)
- 自动语音识别 (语音转文本算法和架构,使用 CTC 丢失和解码进行序列对齐。)
- 波束搜索 (语音到文本和 NLP 应用程序常用的增强预测的算法)
超参数调谐光谱图优化
在第 2 部分中,我们学习了什么是 Mel 光谱图,以及如何使用一些方便的库函数来创建一个。但是为了真正获得我们深度学习模型的最佳性能,我们应该针对我们试图解决的问题优化 Mel 光谱图。
我们可以使用许多超参数来调整声谱图的生成方式。为此,我们需要理解一些关于光谱图是如何构建的概念。(我会尽量保持简单直观!)
快速傅立叶变换
计算傅立叶变换的一种方法是使用一种称为 DFT(离散傅立叶变换)的技术。DFT 的计算非常昂贵,因此在实践中,使用 FFT(快速傅立叶变换)算法,这是实现 DFT 的有效方式。
然而,FFT 将给出音频信号整个时间序列的整体频率分量。它不会告诉您音频信号中的这些频率成分是如何随时间变化的。例如,您将看不到音频的第一部分具有高频率,而第二部分具有低频率,等等。
短时傅立叶变换(STFT)
为了获得更精细的视图并查看频率随时间的变化,我们使用 STFT 算法(短时傅立叶变换)。STFT 是傅立叶变换的另一种变体,它通过使用滑动时间窗口将音频信号分解成更小的部分。它对每个部分进行 FFT,然后将它们合并。因此,它能够捕捉频率随时间的变化。

STFT 沿着信号滑动一个重叠窗口,并对每个片段进行傅立叶变换(源
这将沿着时间轴将信号分成多个部分。其次,它还将信号沿频率轴分成几个部分。它获取整个频率范围,并将其划分为等间距的频段(在 Mel 音阶中)。然后,对于每个时间段,它计算每个频带的振幅或能量。
让我们用一个例子来说明这一点。我们有一个 1 分钟的音频剪辑,包含 0Hz 到 10000 Hz 之间的频率(在 Mel 范围内)。假设梅尔谱图算法:
- 选择窗口,以便将我们的音频信号分成 20 个时间段。
- 决定将我们的频率范围分成 10 个频段(即 0–1000 赫兹、1000–2000 赫兹、…9000–10000 赫兹)。
该算法的最终输出是形状为(10,20)的 2D Numpy 数组,其中:
- 20 列中的每一列代表一个时间段的 FFT。
- 10 行中的每一行代表一个频带的幅度值。
我们来看第一列,这是第一时间段的 FFT。它有 10 行。
- 第一行是 0–1000Hz 之间第一个频带的振幅。
- 第二行是 1000–2000Hz 之间第二频带的振幅。
- …等等。
阵列中的每一列都成为 Mel 光谱图图像中的一个“列”。
Mel 光谱图超参数
这为我们调谐 Mel 谱图提供了超参数。我们将使用 Librosa 使用的参数名。(其他库将具有等效的参数)
频段
- fmin —最小频率
- fmax —显示的最大频率
- n_mels —频带的数量(即梅尔箱柜)。这是声谱图的高度
时间段
- n_fft —每个时间段的窗口长度
- hop_length —每步滑动窗口的样本数。因此,声谱图的宽度=样本总数/跳跃长度
您可以根据您拥有的音频数据类型和您正在解决的问题来调整这些超参数。
MFCC(人类语言)
Mel Spectrograms 对于大多数音频深度学习应用来说效果很好。然而,对于处理人类语音的问题,如自动语音识别,您可能会发现 MFCC(梅尔频率倒谱系数)有时工作得更好。
这些基本上采用 Mel 光谱图并应用几个进一步的处理步骤。这从 Mel 频谱图中选择对应于人类说话的最常见频率的频带的压缩表示。

由音频生成的 MFCC(图片由作者提供)
上面,我们已经看到相同音频的梅尔频谱图具有形状(128,134),而 MFCC 具有形状(20,134)。MFCC 从音频中提取与捕捉声音的基本质量最相关的小得多的特征集。
数据扩充
增加数据集多样性的一种常用方法是人工增加数据,尤其是在数据不足的情况下。我们通过小幅修改现有的数据样本来做到这一点。
例如,对于图像,我们可能会做一些事情,如稍微旋转图像,裁剪或缩放图像,修改颜色或光照,或者给图像添加一些噪声。由于图像的语义没有发生实质性的变化,因此来自原始样本的相同目标标签仍然适用于增强样本。例如,如果图像被标记为“猫”,则增强图像也将是“猫”。
但是,从模型的角度来看,这感觉像是一个新的数据样本。这有助于您的模型推广到更大范围的图像输入。
就像图像一样,也有几种技术来增强音频数据。这种增强既可以在产生声谱图之前对原始音频进行,也可以在生成的声谱图上进行。扩充频谱图通常会产生更好的结果。
光谱图增强
用于图像的常规变换不适用于光谱图。例如,水平翻转或旋转会显著改变声谱图及其代表的声音。
相反,我们使用一种称为 SpecAugment 的方法,在这种方法中,我们将声谱图的某些部分分离出来。有两种口味:
- 频率屏蔽—通过在谱图上添加水平条,随机屏蔽一系列连续频率。
- 时间掩码—类似于频率掩码,不同之处在于我们使用竖条随机从谱图中划出时间范围。

(图片由作者提供)
原始音频增强
有几个选项:
时移—将音频向左或向右移动一个随机量。
- 对于没有特定顺序的声音,如交通或海浪,音频可以环绕。

通过时移增强(图片由作者提供)
- 另一方面,对于像人类说话这种顺序很重要的声音,间隙可以用沉默来填充。
音高移位—随机修改声音各部分的频率。

通过音高变换增强(图片由作者提供)
时间延伸—随机减慢或加快声音。

通过时间拉伸增强(图片由作者提供)
添加噪声—向声音添加一些随机值。

通过添加噪声进行增强(图片由作者提供)
结论
我们现在已经看到了我们如何预处理和准备音频数据以输入到深度学习模型。这些方法通常应用于大多数音频应用。
我们现在准备探索一些真正的深度学习应用,并将在下一篇文章中涵盖一个音频分类示例,在那里我们将看到这些技术的实际应用。
最后,如果你喜欢这篇文章,你可能也会喜欢我关于变形金刚、地理定位机器学习和图像字幕架构的其他系列。
让我们继续学习吧!
音频深度学习变得简单:声音分类,循序渐进
动手教程,直观音频深度学习系列
音频深度学习基础应用场景的端到端示例和架构,用简单的英语讲述。

声音分类是音频深度学习中使用最广泛的应用之一。它包括学习对声音进行分类和预测声音的类别。这种类型的问题可以应用于许多实际场景,例如对音乐剪辑进行分类以识别音乐的流派,或者对一组说话者的简短话语进行分类以基于语音识别说话者。
在本文中,我们将通过一个简单的演示应用程序来理解用于解决此类音频分类问题的方法。我的目标是不仅要理解事物是如何工作的,还要理解它为什么会这样工作。
我的音频深度学习系列中还有几篇文章,你可能会觉得有用。他们探索了这一领域的其他有趣主题,包括我们如何为深度学习准备音频数据,为什么我们将 Mel 光谱图用于深度学习模型,以及它们是如何生成和优化的。
- 最先进的技术 (什么是声音,它是如何数字化的。音频深度学习在解决我们日常生活中的哪些问题。什么是光谱图,为什么它们都很重要。)
- 为什么 Mel Spectrograms 表现更好 (用 Python 处理音频数据。什么是 Mel 光谱图以及如何生成它们)
- 数据准备和扩充 (通过超参数调整和数据扩充增强光谱图特征以获得最佳性能)
- 自动语音识别 (语音转文本算法和架构,使用 CTC 丢失和解码进行序列对齐。)
- 波束搜索 (语音到文本和 NLP 应用程序常用的增强预测的算法)
音频分类
就像使用 MNIST 数据集对手写数字进行分类被认为是计算机视觉的“Hello World”类型的问题一样,我们可以将这一应用视为音频深度学习的入门问题。
我们将从声音文件开始,将它们转换成频谱图,将它们输入到 CNN plus 线性分类器模型中,并对声音所属的类别进行预测。

音频分类应用程序(图片由作者提供)
有许多合适的数据集可用于不同类型的声音。这些数据集包含大量音频样本,每个样本都有一个类别标签,根据您要解决的问题来识别声音的类型。
这些类别标签通常可以从音频样本的文件名的某个部分或者从文件所在的子文件夹名称中获得。或者,类标签在单独的元数据文件中指定,通常是 TXT、JSON 或 CSV 格式。
示例问题—对普通城市声音进行分类
在我们的演示中,我们将使用城市声音 8K 数据集,它包含了从日常城市生活中记录的普通声音的语料库。这些声音取自 10 个类别,如钻井、狗叫和警笛声。每个声音样本都标有其所属的类别。
下载数据集后,我们看到它由两部分组成:
- “ audio 文件夹中的音频文件:它有 10 个子文件夹,分别命名为“ fold1 ”到“ fold10 ”。每个子文件夹包含多个’。wav '音频样本等’fold 1/103074–7–1–0 . wav
- “元数据”文件夹中的元数据:它有一个文件“ UrbanSound8K.csv ”,该文件包含关于数据集中每个音频样本的信息,例如其文件名、其类别标签、“文件夹”子文件夹位置等等。对于这 10 个类别中的每一个,类别标签是一个从 0 到 9 的数字类别 ID。数字 0 代表空调,1 代表汽车喇叭,等等。
样本长度约为 4 秒。这是一个样本的样子:

演习的音频样本(图片由作者提供)

采样速率、通道数量、位数和音频编码
数据集创建者的建议是使用折叠进行 10 重交叉验证,以报告指标并评估模型的性能。然而,由于本文中我们的目标主要是作为音频深度学习示例的演示,而不是获得最佳指标,因此我们将忽略折叠,并将所有样本简单地视为一个大型数据集。
准备培训数据
至于大多数深度学习问题,我们会按照以下步骤:

深度学习工作流程(图片由作者提供)
这个问题的训练数据相当简单:
- 特征(X)是音频文件路径
- 目标标签(y)是类名
因为数据集有一个包含这些信息的元数据文件,所以我们可以直接使用它。元数据包含关于每个音频文件的信息。

既然是 CSV 文件,我们可以用熊猫来读。我们可以从元数据中准备要素和标签数据。
这为我们提供了训练数据所需的信息。

带有音频文件路径和类别 id 的训练数据
元数据不可用时扫描音频文件目录
拥有元数据文件对我们来说很容易。我们如何为不包含元数据文件的数据集准备数据?
许多数据集仅由排列在文件夹结构中的音频文件组成,从该文件夹结构中可以导出类别标签。为了以这种格式准备我们的训练数据,我们将执行以下操作:

元数据不可用时准备训练数据(图片由作者提供)
- 扫描目录并准备好所有音频文件路径的列表。
- 从每个文件名或父子文件夹的名称中提取类别标签
- 将每个类名从文本映射到数字类 ID
不管有没有元数据,结果都是一样的——特征由一列音频文件名组成,目标标签由类 id 组成。
音频预处理:定义变换
这种带有音频文件路径的训练数据不能直接输入到模型中。我们必须从文件中加载音频数据,并对其进行处理,以便它是模型所期望的格式。
当我们读取和加载音频文件时,这种音频预处理将在运行时动态完成。这种方法类似于我们对图像文件所做的。由于音频数据和图像数据一样,可能相当大且占用大量内存,所以我们不想提前一次将整个数据集读入内存。因此,我们在训练数据中只保留音频文件名(或图像文件名)。
然后,在运行时,当我们一次训练一批模型时,我们将加载该批的音频数据,并通过对音频应用一系列转换来处理它。这样,我们一次只能在内存中保存一批音频数据。
对于图像数据,我们可能有一个转换管道,首先将图像文件作为像素读取并加载。然后,我们可能会应用一些图像处理步骤来调整数据的形状和大小,将它们裁剪为固定的大小,并将它们从 RGB 转换为灰度。我们可能还会应用一些图像增强步骤,如旋转、翻转等。
音频数据的处理非常相似。现在我们只是在定义函数,稍后当我们在训练期间向模型提供数据时,它们将会运行。

预处理输入到我们模型的训练数据(图片由作者提供)
从文件中读取音频
我们需要做的第一件事是读取并加载音频文件。wav”格式。因为我们在这个例子中使用 Pytorch,下面的实现使用 torchaudio 进行音频处理,但是 librosa 也可以。

从文件加载的音频波(图片由作者提供)
转换到两个频道
一些声音文件是单声道的(即 1 个音频通道),而它们中的大多数是立体声的(即 2 个音频通道)。由于我们的模型期望所有项目具有相同的尺寸,我们将通过将第一个通道复制到第二个通道来将单声道文件转换为立体声。
标准化采样率
一些声音文件以 48000Hz 的采样率进行采样,而大多数以 44100Hz 的采样率进行采样。这意味着对于一些声音文件,1 秒钟的音频将具有 48000 的数组大小,而对于其他声音文件,它将具有 44100 的较小数组大小。同样,我们必须将所有音频标准化并转换为相同的采样速率,以便所有阵列具有相同的维度。
调整到相同的长度
然后,我们调整所有音频样本的大小,使其具有相同的长度,方法是通过用静音填充来延长其持续时间,或者将其截断。我们将该方法添加到我们的 AudioUtil 类中。
数据扩充:时移
接下来,我们可以对原始音频信号进行数据扩充,方法是应用时移,将音频向左或向右移动一个随机量。在这篇文章中,我将更详细地介绍这种和其他数据增强技术。

声波的时移(图片由作者提供)
梅尔光谱图
然后,我们将增强的音频转换为 Mel 声谱图。它们捕捉音频的基本特征,通常是将音频数据输入深度学习模型的最合适的方式。为了获得更多关于这方面的背景知识,你可能想阅读我的文章(这里和这里),这些文章用简单的语言解释了什么是 Mel 频谱图,为什么它们对音频深度学习至关重要,以及它们是如何生成的,以及如何调整它们以从你的模型中获得最佳性能。

一个声波的 Mel 声谱图(图片由作者提供)
数据扩充:时间和频率屏蔽
现在,我们可以进行另一轮增强,这次是在 Mel 声谱图上,而不是在原始音频上。我们将使用一种称为 SpecAugment 的技术,它使用这两种方法:
- 频率屏蔽—通过在谱图上添加水平条,随机屏蔽一系列连续频率。
- 时间掩码—类似于频率掩码,不同之处在于我们使用竖条随机从谱图中划出时间范围。

光谱增强后的 Mel 光谱图。请注意水平和垂直蒙版带(图片由作者提供)
定义自定义数据加载器
既然我们已经定义了所有预处理转换函数,我们将定义一个自定义 Pytorch 数据集对象。
要使用 Pytorch 将数据提供给模型,我们需要两个对象:
- 使用所有音频转换来预处理音频文件并一次准备一个数据项的自定数据集对象。
- 一个内置的 DataLoader 对象,它使用 Dataset 对象提取单个数据项并将它们打包成一批数据。
使用数据加载器准备批量数据
我们需要将数据输入到模型中的所有函数现在都已经定义好了。
我们使用自定义数据集从 Pandas 数据框架中加载要素和标签,并以 80:20 的比例将该数据随机分为训练集和验证集。然后,我们使用它们来创建我们的训练和验证数据加载器。

分割我们的数据用于训练和验证(图片由作者提供)
当我们开始训练时,数据加载器将随机获取一批包含音频文件名列表的输入特征,并对每个音频文件运行预处理音频转换。它还将获取一批包含类 id 的相应目标标签。因此,它将一次输出一批训练数据,这些数据可以直接作为输入输入到我们的深度学习模型中。

数据加载器应用转换并一次准备一批数据(图片由作者提供)
让我们从一个音频文件开始,逐步了解数据转换的步骤:
- 文件中的音频被加载到 shape 的 Numpy 数组中(num_channels,num_samples)。大多数音频以 44.1kHz 采样,持续时间约为 4 秒,结果是 44,100 * 4 = 176,400 个样本。如果音频有一个声道,数组的形状将是(1,176,400)。类似地,持续时间为 4 秒、具有 2 个声道并以 48kHz 采样的音频将具有 192,000 个样本和(2,192,000)的形状。
- 由于每个音频的通道和采样速率不同,接下来的两个转换会将音频重新采样为标准的 44.1kHz 和标准的 2 通道。
- 由于一些音频剪辑可能多于或少于 4 秒,我们也将音频持续时间标准化为 4 秒的固定长度。现在,所有项目的数组都具有相同的形状(2,176,400)
- 时移数据扩充现在随机地向前或向后移动每个音频样本。形状没有改变。
- 增强的音频现在被转换成 Mel 频谱图,产生(num_channels,Mel freq _ bands,time_steps) = (2,64,344)的形状
- SpecAugment 数据增强现在可以将时间和频率遮罩随机应用于 Mel 光谱图。形状没有改变。
因此,每个批次将有两个张量,一个用于包含 Mel 光谱图的 X 特征数据,另一个用于包含数字类 id 的 y 目标标签。这些批次是从每个训练时期的训练数据中随机选取的。
每个批次都有一个形状(批次 _sz,数量 _ 通道,Mel 频率 _ 波段,时间 _ 步骤)

一批(X,y)数据
我们可以看到一批中的一个项目。我们看到带有垂直和水平条纹的 Mel 谱图,显示了频率和时间掩蔽数据增强。

数据现在可以输入到模型中了。
创建模型
我们刚刚完成的数据处理步骤是我们的音频分类问题中最独特的方面。从这里开始,模型和训练过程与标准图像分类问题中通常使用的非常相似,并且不特定于音频深度学习。
由于我们的数据现在由光谱图图像组成,我们构建了一个 CNN 分类架构来处理它们。它有四个卷积块来生成特征图。然后,这些数据被重新调整为我们需要的格式,以便可以输入到线性分类器层,最终输出 10 个类别的预测。

该模型采用一批预处理数据并输出类别预测(图片由作者提供)
关于模型如何处理一批数据的更多细节:
- 将一批图像输入到具有 shape (batch_sz,num_channels,Mel freq_bands,time_steps) ie 的模型中。(16, 2, 64, 344).
- 每个 CNN 层应用其过滤器来增加图像深度。频道数量。随着内核和步长的应用,图像的宽度和高度会减小。最后,经过四个 CNN 层,我们得到输出的特征地图 ie。(16, 64, 4, 22).
- 这将汇集并展平为(16,64)的形状,然后输入到线性层。
- 线性层为每个类别 ie 输出一个预测分数。(16, 10)
培养
我们现在准备创建训练循环来训练模型。
我们为优化器、损失和调度器定义函数,以随着训练的进行动态地改变我们的学习率,这通常允许训练在更少的时期内收敛。
我们为几个时期训练模型,在每次迭代中处理一批数据。我们跟踪一个简单的准确性度量,它测量正确预测的百分比。
推理
通常,作为训练循环的一部分,我们还会评估验证数据的度量。然后,我们将对看不见的数据进行推断,也许是通过从原始数据中保留一个测试数据集。但是,出于本演示的目的,我们将使用验证数据。
我们运行一个推理循环,小心禁用梯度更新。通过模型执行正向传递来获得预测,但是我们不需要反向传递或运行优化器。
结论
我们现在已经看到了声音分类的端到端示例,这是音频深度学习中最基础的问题之一。这不仅在广泛的应用中使用,而且我们在这里讨论的许多概念和技术将与更复杂的音频问题相关,例如自动语音识别,我们从人类语音开始,理解人们在说什么,并将其转换为文本。
最后,如果你喜欢这篇文章,你可能也会喜欢我关于变形金刚、地理定位机器学习和图像字幕架构的其他系列。
让我们继续学习吧!
用雪花增强您的数据湖分析

凯利·西克玛在 Unsplash 上的照片
对雪花供电的数据湖的建议
M 如今,现代企业需要处理各种大规模、快速移动的数据源,这给数据团队带来了巨大的压力,他们需要持续提取、转换和加载数据以获得有意义的见解。除非出于分析目的对数据和信息进行战略性管理,否则它们不会提供切实的价值。
什么是数据湖?
虽然这是一个众所周知的概念,但对于门外汉来说,“数据湖”最简单的形式就是存储所有原始数据的仓库。
让我们更进一步;对于现代分析需求,数据湖是一个中央存储库,用于存储结构化数据(如本地或云数据库)、半结构化数据(如 json、avro、parquet、xml 和其他原始文件)以及非结构化数据(如从几个(甚至数百万个)批处理或连续数据流中获取的音频、视频和二进制文件)。

数据湖,作者图片
为什么是数据湖?
每个组织都以这样或那样的方式处理 SaaS(软件即服务)数据,因为 SaaS 应用程序易于配置和使用。因此,每秒钟都会产生指数级的数据量,这使得实时保护和存储数据变得非常困难。此外,如果不处理这些指数数据,就有可能失去从中获得的价值。
这就是数据湖出现的原因。数据湖平台强健、灵活且易于扩展,可为各种使用情形下的用户提供海量数据集的快速分析,包括维护单一真实来源。
让我们看看理想的数据湖需要解决的一些挑战:

挑战,作者图片
具有数据湖工作负载的雪花云数据平台

雪花——理想的数据湖,作者图片
雪花通过原生 SQL 支持实现快速数据访问、查询性能和复杂转换。它内置了数据访问控制和基于角色的访问控制(RBAC)来管理和监控数据访问安全性。
雪花为数据湖工作负载提供了灵活、弹性、健壮的大规模并行处理(MPP)架构,能够在单个 SQL 查询中加入各种数据格式(结构化和半结构化)。
*(注:对非结构化数据的支持目前在 数据湖工作量 处于私下预览)
- 用例: 增强现有云数据湖功能
企业在构建、设计和实现基于 S3、Blob 或 GCP 存储的数据湖方面花费了大量精力。为了实现简单性并利用雪花数据湖工作负载的高性能,企业应该扩大现有的数据湖。
如何?

外部表和简单的 SELECT 语句,按作者分类的图像
“雪花存储集成”功能将 AWS S3、Azure BLOB 或 GCP 存储上的云存储作为外部表(本质上是雪花生态系统之外的数据文件中的表)集成到雪花数据湖。
通过创建一个存储集成和一种文件格式(可以把它想象成一个决定文件格式配置的雪花对象),来自雪花的查询可以使用简单和标准的 ANSI SQL(如 select 语句)直接选择数据。这并不需要先将数据从它的云位置文件加载到雪花中。此外,这有助于确定相关数据是否是分析所必需的,以及是否应该存储在数据湖中。
另一方面,为了提高查询性能,可以在外部表之上使用带有“部分”选项的物化视图。物化视图中的这些数据可以在“云通知服务”的基础上自动刷新,该服务在外部“阶段”创建新数据文件时通知雪花。
优点?

实体化视图和外部表,按作者排序的图像
以下优势直接取自雪花——此处:
- 雪花支持对数据湖执行并发查询,而不会影响性能。
- 使用外部表直接查询数据湖中的数据,而不必移动数据。
- 通过对外部表使用物化视图来提高查询性能。
- 将外部表与 Apache Hive metastore 同步。
- 使用分区自动刷新功能,从您的数据湖中自动注册新文件。
- 借助 Snowsight(雪花的内置可视化用户界面)加速数据探索。
2.用例: 雪花表(原始数据湖+数据管道上的自动化)

雪花和数据管道,作者图片
使用雪花作为数据湖工作负载,从所有来源将所有数据按原样接收到雪花数据湖表中。轻松地同时对结构化和半结构化数据执行 SQL 操作。
矢量化拼花扫描仪的最新 GA 功能将拼花文件的性能提高了 8 倍。
利用雪花作为数据湖有助于使数据存储更便宜、压缩和高度安全。
使用外部表格的自动化数据管道

使用外部表格的自动化数据管道,按作者分类的图像
“流”、“数据共享”的可用性以及半结构化数据文件(如 parquet、avro 等)的增强性能。,您可以为云存储中的外部数据构建自动化的数据管道。
如何自动化?
当一个新文件进入云存储时,一个通知会在外部表上触发一个流。流和“任务”执行加载(通过转换)到雪花表格中。最后,通过外部(现在可能)和内部表的数据共享可以用来共享数据。或者我们可以简单地将内部表中的数据(丰富的数据)卸载到云存储中。这里的亮点是,加载- >转换- >卸载过程不需要人工干预。
优点?
以下优势直接取自雪花— 此处:
- 我们应该用雪花来扩充现有的数据湖,以提供免维护的自动化。
- 通过使用云通知和“Snowpipe”的连续数据管道,自动接收数据并支持变更数据捕获(CDC)。
- 我们使用标准的 ANSI SQL 高效地转换数据,并通过利用雪花的自动扩展、缩小、内扩或外扩计算将丰富的数据加载到雪花中。
- 我们使用针对“变体”数据类型和不同摄取风格的流和任务来构建和编排数据管道。
- 使用 RBAC 模型实现粒度访问控制。
- 轻松实现数据屏蔽、行列级过滤访问,增强数据安全性。
- 使用扩展功能,如数据共享和市场。
- 利用雪花压缩数据存储来减少数据量并最终降低成本。
- 使用单一云数据平台满足您的所有数据需求,加快数据接收、转换和消费。
- 向所有数据用户提供您的数据的一个副本—真实的单一来源。
- 通过将所有数据放入雪花中,最大限度地减少外部数据湖管理、调优和优化的任务。
总而言之,考虑使用雪花数据湖工作负载进行高效的数据接收、转换和编排。
如果您想要更多信息或帮助扩充或迁移您现有的数据湖,或者完全在雪花上构建一个新的数据湖,请随时联系我们。
或者发送电子邮件至hello@indigochart.com并在 LinkedIn 上关注我们:
https://www.linkedin.com/company/indigochart/
参考文献:
[1] 雪花文件,雪花公司。
[2] 雪花为数据湖,雪花公司。
[3] 自动化数据管道,雪花公司。
[4] 雪花数据湖,雪花公司。
使用情感分析的转换器和同义词替换来扩充您的小型数据集(第 1 部分)
如何增加数据集的大小,以便稍后用于 NLP 分类任务。

作家创造的形象。
现在是 2021 年 1 月,一场风暴正在 Reddit 上酝酿。一群个人投资者,即 sub Reddit 'wall street bets的成员,开始谈论一家公司,行业专业人士和机构投资者认为这家公司正在走下坡路。而且理由很充分——他们的业务正在被在线零售商侵蚀。
但这些“流氓”个人投资者并不认同业内专业人士的观点。许多人用有意义的分析支持的金融术语来表达他们的观点。散户投资者对机构投资者前所未有的异议,以及 Reddit 用户的集体交易行为,导致 GameStop 股票暴涨。短短几天内,股价从 17.25 美元飙升至 500 多美元,创造了历史上最大的“空头挤压”之一。
为什么个人投资者战胜了大机构,为什么没有人预见到这一天的到来?
因为没人在听。
输入情感分析:
情感分析是自然语言处理(*)的一种形式。它识别和量化文本数据、情感状态以及其中的主题、人物和实体的主观信息。情感分析使用 NLP 方法和算法,这些方法和算法或者是基于规则的,或者是混合的,或者是依靠机器学习技术从**数据集中学习数据。*因此,it 最具挑战性的一个方面是在大规模范围内寻找并标记有意义的数据。
回到我们最初的案子。如果机构将人气作为分析指标,GameStop 的反弹不会让任何人感到意外。但是,要实现这一目标,还需要克服一些挑战。
魔鬼就在数据中:
首先,存在金融术语独特的问题。这个行业充满了术语,大多数情绪分析工具训练的数据不一定能够理解。然后是它的领域限制的本质和整体缺乏可用的结构化数据(分类)的问题。让我们现实一点,用 IMDb 电影评论或推特数据集的公共数据来训练 NLP 模型是不会成功的。综上所述,这些挑战导致大多数用于金融的现成 NLP 工具表现参差不齐。
我们需要的是来自声誉良好的金融领域来源的标记数据。尽管有大量的非结构化数据,但没有足够多的标记源来训练一个监督模型,以解决植根于金融情绪分析的内在挑战。
传统上,解决这一需求意味着手动通读成千上万的文档,对它们进行分类并相应地进行标记。这将是一个漫长而痛苦的过程,并不能保证很快给我们想要的结果。
幸运的是变形金刚及其通过迁移学习执行数据扩充和分类的能力可以改变这一切。
在这篇文章中,我们将基于我从网上收集和标记的金融文章的小样本建立一个大型数据集,我们随后将使用它来建立一个情感分析模型,该模型可以测量金融数据的情感。

什么是变形金刚和迁移学习?
简而言之 Transformers 是预先训练好的机器学习模型,主要用于文本数据。谷歌在 2017 年的论文’中首次介绍了注意力是你所需要的’,它们已经取代了 NLP 任务中的其他神经网络框架。
变形金刚的性能远远超过其他型号,这正是我们手头任务所需要的。在这个练习中,我们将使用 HuggingFace (一个提供用于下载预训练模型的 API 的包)。
迁移学习是一种监督学习,将为特定任务训练的现有模型应用于一组不同的类别,这些类别中的数据要少得多。理论上,原始模型已经从原始数据中学到了足够的东西,通过重新训练它的一部分,它可以应用于我们的新任务。迁移学习是通过用与我们的任务相关的新数据训练所述模型的最终层来完成的,从而使模型适应新的领域。
挑战:
对金融新闻等领域进行情感分析面临多重挑战。在金融领域可能有负面含义的词在其他领域不一定被认为是不好的。
处理财务数据时需要注意的另一个因素是在一个句子中处理多个身份。例如,常见的句子有‘在该机构的历史性裁决中,X 机构对 Y 公司罚款数百万美元’。这使得任何对情绪进行分类的尝试都变得困难,因为这取决于我们关注的是哪个实体。**
这个问题有很多有趣的解决方法;然而,在这篇文章中,我已经精心挑选了数据来避免这个问题,所以我们不会涉及它。如果你想了解更多如何处理这个问题,可以在这里找到一个方法。
在这个练习中,我使用了手动标记的 352 条财经新闻,我将它加载到一个熊猫数据框架中,删除了所有数字字符,单词被压缩(“s to is”),每篇文章的情绪要么被标记为积极,要么被标记为消极。

数据视图
我们写点代码吧!
数据扩充是一种创建新数据的方法,方法是对原始源进行多处小的更改,从而扩展可用于训练模型的数据。它广泛应用于图像分类任务,也已经成功地应用于文本分类任务。
在我们能够扩充数据之前,我们需要解决使用转换器的分类任务的一个主要瓶颈,它对可以训练的文本大小的限制,一些文章和金融文档可能有多页长,试图对它们训练模型可能会导致内存问题。为了解决这个问题,我们将使用名为 T5 的 transformer 模型来总结我们的文本数据。T5 是在非监督和监督任务的多任务混合上预先训练的编码器-解码器模型,并且对于该模型,每个任务被转换成文本到文本格式。T5 是开箱即用的总结任务的最佳表现者之一(无需对我们的数据进行训练),因此我们将在这里使用它。
函数’summary _ article’将我们的文章编码、汇总并解码回比源材料小得多的人类可读文本,超参数’ min_length ‘和’ max_length '将确保摘要的大小在标准阈值之间,同时保持其信息完整。一旦完成,输出将被传递到我们的增强管道的下一个步骤。
****Before Summarization:***
*len(data_source['text'].max().lower().split()) =* ***520***
***After Summarization:***
*len(data_source['text'].max().lower().split()) =* ***60****
有多种方法来为 NLP 执行数据扩充。有些技术比其他技术更复杂,而且都有优缺点。NLP 绝不是一门精确的科学,当涉及到扩充数据时,理解你的领域和任务是至关重要的。
“简约是极致世故*——老子:***
我发现关于数据增强的一篇论文很有趣,是的 Jason Wei 的【EDA:提高文本分类任务性能的简单数据增强技术】 。
在这篇文章中,Jason 和 Kai 探讨了同义词替换 (SR) 、随机插入 (RI) 、随机交换 (RS) 和随机删除 (RD) 如何成为轻量级且高效的数据扩充方式,何时以及如何实现,以及与其他方法相比,它们在 NLP 任务中的表现如何。

来自 Jason Wei 论文的子集。
飞马座的飞行;
**“用提取的间隙句进行抽象概括的预训练”,又名 飞马 。它的独特性在于它的“自我监督”,预训练目标架构。与其他通过提取句子的小部分来推断句子意思的模型不同,Pegasus 完全“屏蔽”了句子,并试图通过阅读句子前后的文本来找到它。
Pegasus 确实擅长数据总结,但也非常擅长转述句子。该模型非常易于使用,不需要很多依赖关系,只需几行代码,我们就可以为训练准备好我们的扩充数据集。
任务:
为了能够有效地利用我们的小数据集,我们将执行文本释义和同义词替换,以获得足够大和唯一的数据集来训练我们的情感分析模型。
型号名称为’ pegasus_paraphrase ',更多信息请点击此处。首先,我们将获得我们的依赖项,并下载模型和‘tokenizer’。记号赋予器将句子分解成更小的块,这些块的大小和形状取决于任务和模型。
我们需要做的就是编写一个方法,使用我们的记号化器将我们的文本转换为一个序列,它将截断长句,填充小句,并返回一个张量结构,模型将使用它来生成释义的句子。
每个句子都将通过模型,超参数值是通过试错法选择的。这里看到的超参数是:
- 【num _ beam】,模型将在一个序列中搜索最优后续词的次数
- ****‘num _ return _ sequences’**模型将生成的句子数量(我们将超过 50)
- 【温度】 调节高概率词出现的机会,减少低概率词在世代中出现的机会。
Pegasus 将生成新的句子,这些句子将作为新的系列返回到我们的数据帧中,其中每一行都是生成的文本列表。然后,我们将通过使用 Pandas 的“explode”功能将列表中的每个元素变成一行来使它们变平。
在模型遍历了每个句子之后,我们最终得到了一个比源材料大 11 倍的新数据集。然而,这个数据有一个问题。每一行中大约有一半(见下图)以非常相似的文本开始,忽略这一点可能会导致我们稍后付出代价,因为我们可能会过度拟合模型,破坏我们的努力。

项目中间输出:大多数作品都以非常相似的措辞开始
因此,我们将执行数据扩充任务的第二部分。同义词替换。这个过程将扩展文本,并进一步推广它。
首先,扩充的数据通过一个名为’ find_synonym 的方法传递,在这个方法中,在前半部分文本中找到的任何停用词和数值都被过滤掉。
然后把剩下的单词一分为二地分组。每一个新句子将会把每一组中的两个单词替换成它们各自的同义词。为了找到同义词,我们将利用一个名为自然语言工具包的包,更好的说法是’【nltk ',* 一套用于符号和统计自然语言处理的库和程序。具体来说它的语料库阅读器’ wordnet '包含了浩如烟海的词汇信息和同义词。*
最后,在函数遍历了数据集的每一行之后,我们将确保没有任何重复或空值,新的语料库将被保存以备后用。
在模型遍历了每个句子并且数据被正确格式化之后,我们最终得到了一个比源材料大 50 多倍的新数据集,它仍然保留了原始数据的含义、风格和上下文。

项目最终产出
结论:
在本文中,我们介绍了如何使用转换器和同义词替换技术来执行数据扩充,使用少量数据带来的挑战以及如何克服这些挑战,以及如何创建一个由足够大的带标签的金融文章组成的数据集来执行有意义的分析。
如果你好奇如何使用这些数据进行情感分析,点击这里跳转到本系列的第二部分: 如何使用变形金刚进行情感分析&迁移学习
来源:
- 本项目回购:https://github.com/cmazzoni87/ComputerVisionRegression
- 【EDA:提升文本分类任务性能的简易数据增强技术】 贾森·魏,。
- 飞马变形金刚文档:https://huggingface.co/transformers/model_doc/pegasus.html
- T5 变压器文档:https://huggingface.co/transformers/model_doc/t5.html
使用白蛋白和 PyTorch 的扩增方法
增强管道
讨论最新的增强研究和使用所讨论的方法的新颖实现

作者图片
自从深度神经网络在 20 世纪 90 年代末成名以来,有限的数据一直是一块绊脚石。缺少数据会导致*过拟合,*尤其是对于具有大量参数的架构。幸运的是,增强对于数据有限的机器学习任务来说是一个启示。它提供了两个主要优势。
首先,您可以通过创建原始数据集的多个扩充副本来增加数据量,这些副本也可用于平衡倾斜的数据集。
第二,它迫使模型对于样本中的不相关特征是不变的,例如,人脸检测任务中的背景。这有助于模型更好地概括。
在本帖中,我们将探索最新的数据扩充方法,以及使用所讨论方法的新颖实现。我们将主要讨论两种方法,自动增强和随机增强。所以,让我们从简单介绍这两种方法开始,然后继续讨论实现。
自动增强
在“ 中介绍的自动增强:从数据中学习增强策略 ”试图自动选择应用于样本的变换的类型和幅度。他们提出了一种强化学习方法,通过离散化搜索问题来找到有效的数据扩充策略。所提出的方法找到增强策略 S ,其具有关于变换、变换的幅度以及使用这些变换的概率的信息。
让我们看看算法的一些细节。
搜索空间
策略 S 包含五个子策略,每个子策略有两个变换,每个变换有一个幅度和一个概率参数。
注意这里的子策略对转换的顺序很敏感,如果应用程序的顺序颠倒了,则被视为不同的子策略。
有 16 种增强转换可供控制器选择(将在实现部分讨论)。每个变换的幅度和应用概率的范围分别被离散成 10 和 11 个均匀间隔的值。
搜索算法
搜索算法有两个组成部分:一个控制器,这是一个递归神经网络(RNN),和训练算法,这是最接近的政策优化算法。

来源:自动增强纸
控制器(RNN)从搜索空间预测增强策略 S ,然后预测的策略用于训练小得多的子模型。子模型在通过对训练集应用 5 个预测子策略而生成的扩充数据上被训练。对于小批量中的每个示例,随机选择 5 个子策略中的一个来扩充图像。然后,子模型在一个单独的保留验证集上进行评估,以测量精确度 R ,它被用作训练 RNN 控制器的奖励信号。
你可以在这里阅读全文了解所有细节。
AutoAugment 是第一批有效实现数据扩充自动化方法的论文之一,并显示出比以前的自动化方法好得多的结果。然而,单独的优化过程和非常大的搜索空间具有很高的计算成本。此外,该方法作出了一个强有力的假设,即来自一个较小网络的结果可以转移到一个大得多的网络。事实证明,这一假设并不完全正确,RandAugment 论文中指出,该论文提出了一种更快且在某些情况下性能更好的数据扩充方法,我们将在接下来讨论该方法。
随机扩增
像 AutoAugment 这样的大多数已学习的增强算法创建一个代理任务,该代理任务在较小的网络上为最佳增强策略进行优化,如前一部分所述。这种方法有一些需要解决的基本缺陷。在“ RandAugment:具有减少的搜索空间的实用自动数据扩充 ”中介绍的 RandAugment 试图绕过这种代理任务,并且还极大地减少了搜索空间,以减轻训练过程的计算负荷。该方法将参数的数量减少到两个, N 和 M (将在随后的小节中详细讨论),并在训练过程中将它们视为超参数。
搜索空间
RandAugment 不是学习策略,而是以 1/ K 的统一概率从一组 K 转换中随机挑选一个转换。要挑选的转换数量由超参数 N 给出,这将搜索空间中的总策略减少到 K pow N 。学习增强方法的主要好处来自增加样本的多样性,RandAugment 采用的均匀概率方法保持了样本的多样性,但搜索空间显著减小。

资料来源:RandAugment Paper
最后,类似于自动增强的每个变换的幅度范围被离散成由 M 给出的 10 个均匀间隔的值,然而,与已知的方法相反,所有的变换都遵循用于 M 的相同的时间表,这将幅度的搜索空间减少到仅仅一个。这是因为增强的最佳幅度取决于模型和训练集的大小,更大的网络需要更大的数据失真(请参考上图),这在直觉上是有意义的。该论文还指出,更大的数据集需要更大的数据失真,这似乎很奇怪,作者提出的一个假设是,小数据集的激进增强可能会导致低信噪比。在任何情况下,基于模型大小和训练集大小,所有变换都遵循最佳幅度的明确模式,这暴露了使用较小网络来估计所有任务的变换幅度的已有增强方法中的基本缺陷。
搜索算法
RandAugment 使用简单的网格搜索来寻找 N 和 M 的最优值,这是通过为两个超参数选择一组值并在单独的验证集上测试这些组的所有排列来完成的。最后,选择对验证集有最佳改进的组合。可以对每个样品、每个批次或每个时期执行该程序。
现在,我们已经对算法有了相当好的理解,让我们向实现前进。如前所述,RandAugment 是一种更好的算法,但是,AutoAugment 论文中的一些关键发现可以与 RandAugment 结合使用,以进一步降低计算成本。
你可以从这里下载这篇文章的笔记本,笔记本上有所有必要的代码来设置增强算法,并在 fastai 提供的一小部分 Imagenet 数据集上用 Resnet50 进行测试。然而,在这篇文章中,我们将只关注笔记本中与增强相关的部分。
履行
让我们从笔记本上的自定义 RandAugment 函数开始,然后对其进行分解。
def randAugment(N, M, p, mode="all", cut_out = False): **# Magnitude(M) search space** shift_x = np.linspace(0,150,10)
shift_y = np.linspace(0,150,10)
rot = np.linspace(0,30,10)
shear = np.linspace(0,10,10)
sola = np.linspace(0,256,10)
post = [4,4,5,5,6,6,7,7,8,8]
cont = [np.linspace(-0.8,-0.1,10),np.linspace(0.1,2,10)]
bright = np.linspace(0.1,0.7,10)
shar = np.linspace(0.1,0.9,10)
cut = np.linspace(0,60,10) **# Transformation search space** Aug =[#0 - geometrical
A.ShiftScaleRotate(shift_limit_x=shift_x[M], rotate_limit=0, shift_limit_y=0, shift_limit=shift_x[M], p=p),
A.ShiftScaleRotate(shift_limit_y=shift_y[M], rotate_limit=0, shift_limit_x=0, shift_limit=shift_y[M], p=p),
A.IAAAffine(rotate=rot[M], p=p),
A.IAAAffine(shear=shear[M], p=p),
A.InvertImg(p=p),
#5 - Color Based
A.Equalize(p=p),
A.Solarize(threshold=sola[M], p=p),
A.Posterize(num_bits=post[M], p=p),
A.RandomContrast(limit=[cont[0][M], cont[1][M]], p=p),
A.RandomBrightness(limit=bright[M], p=p),
A.IAASharpen(alpha=shar[M], lightness=shar[M], p=p)] **# Sampling from the Transformation search space** if mode == "geo":
ops = np.random.choice(Aug[0:5], N)
elif mode == "color":
ops = np.random.choice(Aug[5:], N)
else:
ops = np.random.choice(Aug, N)
if cut_out:
ops.append(A.Cutout(num_holes=8, max_h_size=int(cut[M]), max_w_size=int(cut[M]), p=p)) transforms = A.Compose(ops)
return transforms, ops
该功能大致可分为以下两部分。
量值搜索空间
本节将星等范围离散为 10 个均匀分布的值。
变换搜索空间
" Aug "是变换搜索空间,算法可以从中以均匀的概率挑选出 N 个变换。请花点时间看看这些单独的转换做了什么,以便更好地创建这个搜索空间。
注意该功能有三种模式“地理”、颜色、全部”。“地理”模式适用于基于颜色的特征定义图像中感兴趣对象的任务,例如火灾探测。类似地,“颜色”模式适用于形状定义感兴趣对象的任务,例如人脸检测、汽车检测等。然而,“全部”模式使用所有的转换。
AutoAugment 论文中的作者表明,不同的数据集对正向和负向的不同变换都很敏感。因此,“没有免费的午餐”定理也适用于数据扩充,你需要为每个项目调整算法。

来源:自动增强纸
注意上表中给出的幅度范围是针对 PIL 库中的函数,然而,我们在 randAugment()函数中使用白蛋白,主要是因为白蛋白库使用的 open cv 比 PIL 快。您必须进行实验,并为您喜欢使用的库计算出每个变换的幅度范围。
现在让我们来看看训练期间的转变幅度的时间表。
def train_model(model, criterion, optimizer, scheduler, **aug_mode="all"**, **cut_out=False**, **max_M=9**, num_epochs=25): best_model_wts = copy.deepcopy(model.state_dict())
best_acc = 0.0 **N=2;M=0;p=0.5** for epoch in range(num_epochs):
print('Epoch {}/{}'.format(epoch, num_epochs - 1))
print('-' * 10)
**transforms, ops = randAugment(N=N, M=M, p=p, mode=aug_mode, cut_out=cut_out)**
dataloaders, dataset_sizes = create_dataloaders(root, train_df, valid_df, label_dict, bs=32, **transforms=transforms**) # Each epoch has a training and validation phase
for phase in ['train', 'val']:
if phase == 'train':
model.train() # Set model to training mode
else:
model.eval() # Set model to evaluate mode running_loss = 0.0
running_corrects = 0 # Iterate over data.
for inputs, labels in dataloaders[phase]:
inputs = inputs.to(device)
labels = labels.to(device) # zero the parameter gradients
optimizer.zero_grad() # forward
# track history if only in train
with torch.set_grad_enabled(phase == 'train'):
outputs = model(inputs)
preds = torch.argmax(input = outputs, dim = 1)
loss = criterion(outputs, labels) # backward + optimize only if in training phase
if phase == 'train':
loss.backward()
optimizer.step() # statistics
running_loss += loss.item() * inputs.size(0)
running_corrects += torch.sum(preds == torch.argmax(input = labels, dim = 1))
if phase == 'train':
scheduler.step() epoch_loss = running_loss / dataset_sizes[phase]
epoch_acc = running_corrects.double() / dataset_sizes[phase] print('{} Loss: {:.4f} Acc: {:.4f}'.format(
phase, epoch_loss, epoch_acc)) # deep copy the model
if phase == 'val' and epoch_acc > best_acc:
best_acc = epoch_acc
best_model_wts = copy.deepcopy(model.state_dict())
**elif phase == 'val' and epoch_acc < best_acc:
stp = int((9-M)*((best_acc-epoch_acc)/best_acc))
M += max(1,stp)
M = min(M, max_M)
if M < max_M:
print("Augmentaion Magnitude Changed To : {}\n".format(M))** print('Best val Acc: {:4f}'.format(best_acc)) # load best model weights
model.load_state_dict(best_model_wts)
return model
在上面的代码块中,与时间表相关的代码行被加粗。
在这个示例中,我为 M 使用了预定的时间表,每当历元精度低于验证集上的最佳精度时, M 就递增。根据最大可能值(9)和当前值 M 之间的差值计算出 M 将增加的数量,当前值由两个精度和最佳精度之间的差值的比率缩放。
注意该时间表不会产生额外成本,但是非常严格,RandAugment paper 在每批之后对 N 和 M 进行网格搜索,以找到它们的最佳值。然而,即使与自动增强相比计算成本大幅降低,对于大多数机器学习项目来说,网格搜索对于具有适度设置和单个 gpu 的人来说仍然是不可行的。
此实现中使用的时间表不是唯一可用的时间表,您可以试验每个子策略的转换数量 N 以及这些转换的概率 p. 增强不是一门精确的科学,每个锁都有不同的密钥,您需要通过试验和创造性思维来找到匹配的密钥。
参考
自动增强纸:https://arxiv.org/abs/1805.09501
RandAugment 论文:https://arxiv.org/abs/1909.13719
Python 中的增广赋值表达式 Walrus 运算符:=及其他
不仅仅是关于海象算子,还有很多相关的概念

汤米·克兰巴赫在 Unsplash 上拍摄的照片
从 3.8 版本开始,Python 中就包含了新的特征增强赋值表达式。特别是,结果出现了一个新的操作符——内联赋值操作符:=。因为它的外观,这个操作符通常被称为海象操作符。在本文中,我将讨论这个操作符的关键方面,以帮助您理解这项技术。
事不宜迟,让我们开始吧。
表达式和语句的区别
在 Python 或一般的编程语言中,有两个密切相关的概念:表达式和语句。让我们看两行简单的代码,如下所示。
>>> 5 + 3 #A
8
>>> a = 5 + 3 #B
#A 是一个表达式,因为它的计算结果是一个整数。相比之下,#B 是一个语句,确切地说是一个赋值语句。更一般地说,表达式是计算值或 Python 中的对象的代码(Python 中的值都是对象)。例如,当你调用一个函数时(如abs(-5)),它是一个表达式。
语句是不计算任何值的代码。简而言之,他们执行一个动作,或者做一些事情。例如,赋值语句创建一个变量。with语句建立了一个上下文管理器。if…else…语句创建逻辑分支。
如您所见,表达式和语句的最大区别在于代码是否计算为对象。
你可能想知道为什么我们在这里关心这种区别。我们继续吧。
扩充赋值是一个语句
许多人熟悉的最常见的扩充任务形式是+=。下面的代码向您展示了一个示例。
>>> num = 5
>>> num += 4
判断一行代码是否是表达式的一个简单方法是简单地将它发送给内置的print函数,该函数应该接受任何对象。当您发送一个要打印的语句时,它会引发一个SyntaxError。让我们来试试:
>>> print(num += 4)
File "<input>", line 1
print(num += 4)
^
SyntaxError: invalid syntax
事实上,我们不能在print函数中使用增强赋值。或者,为了确定某些代码是否是表达式,有另一个内置函数eval,它计算一个表达式。当代码不能被求值时,比如一个语句,就会发生错误,如下所示。
>>> eval("num += 4")
Traceback (most recent call last):
File "<input>", line 1, in <module>
File "<string>", line 1
num += 4
^
SyntaxError: invalid syntax
事实上,x += y 是语句x = x + y的简写,这是一个设计好的赋值。因为产生的变量与用于增量(y)的变量同名(即 x),所以它也被称为就地加法运算。
同样的就地分配也适用于其他的扩充分配,例如-=、*=和/=。
扩充赋值表达式是一个表达式
与这些扩充赋值语句不同,新的扩充赋值表达式是一个表达式。让我们从一个简单的例子开始。
>>> (another_num := 15)
15
如上图,因为我们使用的是交互式 Python 控制台,所以如果该行代码的求值结果是任何对象(除了None,控制台在输出时会忽略它),那么求值结果会自动显示。因此,上面的扩充赋值表达式确实是一个表达式。请注意,这里使用的一对括号是出于语法原因,因为这样一个增强的赋值表达式本身没有任何实际用途,因此不推荐使用。
我们可以证明扩充赋值表达式的本质是一个带有print和eval函数的表达式,如下所示。
>>> print(another_num := 15)
15
>>> eval("(another_num := 15)")
15
实际用例是什么?
扩充赋值表达式也称为内联扩充赋值。正如它的行所示,这是一个内联操作,因此我们在刚刚求值的地方定义一个变量——本质上,我们将求值和赋值合并到一个步骤中。
也许这有点太专业,难以理解,但让我给出一个看似合理的用例。在一个典型的 if…else…语句中,if 或 else 子句只能接受表达式,这样子句就可以对运算的表达式求值为 true 或 falsy。显然,在从句中,你不能使用陈述句。考虑下面这个看似合理的用例。
def withdraw_money(account_number):
if account := locate_account(account_number):
take_money_from(account)
else:
found_no_account()
如上所示,locate_account函数返回使用account_number找到的账户。如果找到,从赋值表达式中创建的变量account将进一步用于if子句的主体中。否则,使用顺序方式,这里有一个可能的解决方案:
def withdraw_money(account_number):
account = locate_account(account_number)
if account:
take_money_from(account)
else:
found_no_account()
这两种实现之间的差异可能微不足道。然而,实际的用例可能更复杂,涉及更多的分支,这证明了使用赋值表达式技术的合理性。考虑以下使用案例:
def withdraw_money(account_number):
if account := locate_account_in_saving(account_number):
take_money_from_saving(account)
elif account := locate_account_in_checking(account_number):
take_money_from_checking(account)
elif account := locate_account_in_retirement(account_number):
take_money_from_retirement(account)
else:
pass
正如你所看到的,有了更多的分支,如果你选择分成两个独立的步骤:函数调用,然后赋值,上面的代码会变得复杂得多。不信的话,请自行尝试:)
结论
在本文中,我们回顾了 Python 3.8 中增加的扩充赋值表达式技术。我们不仅研究了这项技术本身,还回顾了与这项技术相关的关键概念。我希望您对这种技术及其正确的用例有更好的理解。
感谢阅读这篇文章。通过注册我的简讯保持联系。还不是中等会员?通过使用我的会员链接支持我的写作(对你没有额外的费用,但是你的一部分会费作为奖励由 Medium 重新分配给我)。
Python 中的扩充赋值
理解增强赋值表达式在 Python 中是如何工作的,以及为什么在可变对象中使用它们时要小心

介绍
Python 从 C 语言中借用的一个概念是扩充赋值,本质上是标准赋值的简称。
在今天的简短指南中,我们将讨论什么是扩充赋值,以及为什么在对可变数据类型使用它们时要格外小心。
Python 中的扩充赋值
扩充赋值创建了一种速记法,将二进制表达式合并到实际的赋值中。例如,以下两个语句是等效的:
a = a + b
a += b # augmented assignment
在下面的代码片段中,我们展示了 Python 语言中允许的所有扩充赋值
a += b
a -= b
a *= b
a /= b
a //= ba &= b
a |= b
a ^= ba >>= b
a <<= b
a %= b
a **= b
扩充赋值适用于任何支持隐含二进制表达式的数据类型。
>>> a = 1
>>> a = a + 2
>>> a
3
>>> a += 1
>>> a
4>>> s = 'Hello'
>>> s = s + ' '
>>> s
'Hello '
>>> s += 'World'
>>> s
'Hello World'
扩充赋值如何处理可变对象
当使用扩充赋值表达式时,将自动选取最佳操作。这意味着对于支持就地修改的特定对象类型,将应用就地操作,因为它比先创建副本再进行分配要快。如果你想添加一个条目到一个列表中,通常使用append()方法比使用连接更快:
>>> my_lst = [1, 2, 3]
>>> my_lst.append(4) # This is faster
>>> my_lst = my_lst + [4] # This is slower
由于就地操作速度更快,它们将被自动选择用于扩充任务。为了弄清楚这些表达式是如何处理可变对象类型的,让我们考虑下面的例子。
如果我们使用串联,那么将会创建一个新的列表对象。这意味着,如果另一个名称共享同一引用,它将不受新对象列表中任何未来更新的影响:
>>> lst_1 = [1, 2, 3]
>>> lst_2 = lst_1
>>> lst_1 = lst_1 + [4, 5]
>>> lst_1
[1, 2, 3, 4, 5]
>>> lst_2
[1, 2, 3]
现在,如果我们使用增强赋值表达式,这意味着表达式将使用extend()方法来执行更新,而不是连接,那么我们也将影响所有其他拥有共享引用的名称:
>>> lst_1 = [1, 2, 3]
>>> lst_2 = lst_1
>>> lst2 += [4, 5]
>>> lst_1
[1, 2, 3, 4, 5]
>>> lst_2
[1, 2, 3, 4, 5]
扩充赋值的三个优点
总而言之,扩充赋值表达式提供了以下三个优点:
- 它们需要更少的击键,而且更干净
- 它们速度更快,因为表达式的左边只需要计算一次。在大多数情况下,这可能不是一个巨大的优势,但当左侧是一个复杂的表达式时,它肯定是。
x += y # x is evaluated only once
x = x + y # x is evaluated twice
3.将选择最佳操作,这意味着如果对象支持就地更改,则就地操作将应用于串联。但是,您应该非常小心,因为有时这可能不是您想要的,因为在应用就地操作区域时,名称共享引用可能会相互影响。
最后的想法
在今天的文章中,我们讨论了 Python 中的增强赋值表达式,以及它们如何帮助您编写更 Python 化、更清晰甚至更快的代码。
此外,我们强调了这种类型的表达式如何应用于可变数据类型,这可能会给我们带来共享引用的麻烦。
成为会员 阅读介质上的每一个故事。你的会员费直接支持我和你看的其他作家。你也可以在媒体上看到所有的故事。
https://gmyrianthous.medium.com/membership
你可能也会喜欢
https://codecrunch.org/what-does-if-name-main-do-e357dd61be1a
使用 AugLy 扩充数据
使用 AugLy 增强文本、图像、音频和视频

马库斯·斯皮斯克在 Unsplash 上的照片
当我们使用的数据集不包含太多信息时,数据扩充是一个重要的部分,因此我们不能单独使用这些数据来建立模型,因为模型不会因训练数据中缺乏信息而被一般化。让我们试着通过一个例子来理解这一点。
假设我们正在尝试建立一个图像分类模型。我们使用的数据集包含 10 个类和每个类的 100 幅图像。现在我们可以构建模型了,但问题是它是否能被泛化和优化到足以用于新数据集的预测。这个问题可能会出现,因为一个类中仅有 100 个图像可能无法捕获该类的所有信息。所以,我们能做的就是克服这一点,我们需要每一个类有更多的图像。
数据扩充通过处理图像来帮助生成数据。现在我们可以在训练本身中使用这些数据,或者用它来检查模型的稳健性。数据扩充通过稍微修改数据集影像的副本来创建更多影像。
AugLy 是由脸书研究团队创建的开源 python 库,它有助于数据扩充,并支持不同类型的数据,如音频、视频、图像和文本。它包含 100 多种可以相应使用的增强功能。
在本文中,我们将使用 AugLy 探索一些数据扩充技术。
安装所需的库
我们将从使用 pip 安装 AugLy 开始。下面给出的命令可以做到这一点。
!pip install augly
!sudo apt-get install python3-magic
导入所需的库
在这一步中,我们将导入加载图像和执行数据扩充所需的库。
import augly.image as imaugs
import augly.utils as utils
from IPython.display import display
导入库后,下一步是加载映像。
正在加载图像
对于本文,我们可以采用任何图像或图像数据集。我拍了自己的照片来进行数据扩充。为了使图像看起来更清晰而不覆盖所有屏幕,我们将使用 AugLy Scaler 缩放它。
input_img_path = "/content/img1.jpg"
input_img = imaugs.scale(input_img_path, factor=0.2)
执行增强
现在,我们将开始放大过程,并应用不同的图像放大。
- 模因格式
display(
imaugs.meme_format(
input_img,
text="LOL",
caption_height=70,
meme_bg_color=(0, 0, 0),
text_color=(250, 200, 150),
)
)

迷因(来源:作者)
在这里,您可以使用不同类型的文本并设置它们的颜色,您选择的文本将显示在您正在使用的图像上。
2。饱和度
display(
imaugs.saturation(
input_img,
factor=1.5
)
)

饱和度(来源:作者)
这里你可以看到饱和度是如何使图像变亮的,因子变量是可以改变的,你可以使用不同的饱和度值。
3。透视变换
aug = imaugs.PerspectiveTransform(sigma=200.0)
display(aug(input_img, metadata=meta))

观点(来源:作者)
西格玛值决定标准差的值,西格玛值越大,转换越剧烈。
类似地,AugLy 中提供了大量不同的增强功能,您可以使用下面的命令查看所有这些功能,并阅读它们,然后在您的图像中使用它们。
help(imaugs)

转换(来源:作者)
继续尝试不同的图像/图像数据集。如果您发现任何困难,请在回复部分告诉我。
本文是与 Piyush Ingale 合作完成的。
在你走之前
感谢 的阅读!如果你想与我取得联系,请随时联系我在 hmix13@gmail.com 或我的 LinkedIn 简介 。可以查看我的Github简介针对不同的数据科学项目和包教程。还有,随意探索 我的简介 ,阅读我写过的与数据科学相关的不同文章。
八月版:走向货币化
月刊
探索数据科学领域以创造财务价值

数据科学是一个快速发展的领域。新的工具、技术和经验正在各种平台上被开发、应用、收获和分享,包括本出版物。由于飞速的进步、不断增长的应用和简化的协作机制,信息过载很容易成为一种自然的结果。非常坦率地说(也是矛盾地说),关于我们提议简化的科学的数据的激增可能是压倒性的。
在许多行业中,数据科学的主要资助目的是产生商业价值。例如,即使数据项目的最初目的可能是更好地了解人口的社会方面,其结果通常会导致一个或多个价值驱动的货币化机会。不幸的是,其中一些好处最终实现了,而另一些根本没有实现。以浓缩的方式提取这些机会可能有助于我们从树木中看到森林,并激发更多关于从个人和组织的角度创造价值的想法。
在本月的新闻简报中,我们认为突出强调一些作者的工作重点是货币化的重要观点可能会有所帮助。我们希望您喜欢浏览该系列,这样做可能会激发您探索更多,点燃火花,并与 TDS 社区分享您自己的贡献。我们迫不及待地想看看你想出了什么!
TDS 志愿编辑助理 John Jagtiani 博士
产品分析推动免费增值转化——在移动游戏及其他领域
细分和查询客户数据将照亮增加货币化的道路
杰里米·利维 — 6 分钟
数据科学家的商业战略
在开始机器学习之前,先学习商业策略的基础知识
到饶彤彤 — 11 分钟
数据科学……没有任何数据?!
为什么尽早聘用数据工程师很重要
由凯西·科济尔科夫 — 6 分钟
建模:教授机器学习算法以交付商业价值
如何训练、调整和验证机器学习模型
到威尔·科尔森 — 9 分钟
insta cart 如何利用数据科学解决复杂的商业问题
买杂货从来没有这么复杂
安德烈·叶 — 11 分钟
企业难以采用深度学习的 5 个原因
当巨大的潜力不能转化为商业利益时
由 Ganes Kesari — 6 分钟
通过机器学习为您的企业创造价值的 6 个步骤
企业高管实现机器学习操作化和货币化的战略路线图
由毗瑟摩德—5 分钟
嘎吱嘎吱的数字。建立模型。预测未来。现在怎么办?
菜鸟数据科学家,还是顶级美元价值创造者?你想成为谁?
尼克·卡拉斯——4 分钟
数据科学家的业务基础知识
使用你的机器学习能力来影响基本的商业方程式。
简·扎瓦日基 — 7 分钟
数据驱动还没死
问题不在于术语;而是我们不是真心的。
由法布里吉奥·范蒂尼 —6 分钟
新播客专题节目
- 彼得·高— 自动驾驶汽车:过去、现在和未来
- 丹尼尔·菲兰— 探究人工智能安全的神经网络
- 2021 年:人工智能的一年(迄今为止)——与我们的朋友一起在《让我们谈谈人工智能》播客上回顾 2021 年最大的人工智能故事
- Divya Siddarth — 我们对人工智能的看法是错误的吗?
我们还要感谢最近加入我们的所有伟大的新作家:贾姆沙伊德·沙希尔,加尔·沈,布拉克·阿克布卢特,普哈·帕沙克,罗伯特·戴尔,巴维克·帕特尔,若昂·莫拉,杰米·温格,阿雷巴·梅里亚姆 米亚·罗姆、丹尼尔·梅尔乔尔、蒂亚戈·马丁斯、罗霍拉·赞迪、辛迪·霍西亚、阿比奥顿·奥劳耶、马里奥·迈克尔·克雷尔博士、乔尔·施瓦茨曼、拉斯·罗姆霍尔德、特万 埃里克·格林,洛夫库什·阿加瓦尔,阿比德·阿里·阿万,阿希什·比斯瓦斯,普拉纳夫·塔恩拉杰,卡西索,萨拉·加莱比克萨比,弗拉基米尔·布拉戈耶维奇, https://medium.com/u/c5e721e0bfda?source=post_page-----7ae1c8f72876-------------------------------- 迈克尔·甘斯梅尔、阿贾伊·埃德、西楚·张、阿克希尔·普拉卡什、艾丹·佩平、胡安·路易斯·鲁伊斯-塔格尔、莱安德罗·g·阿尔梅达、凯特·加洛等众多。 我们邀请你看看他们的简介,看看他们的工作。
AUK——AUC 的简单替代品
对于不平衡数据,比 AUC 更好的性能指标

由 Javier Quesada 在 Unsplash 上拍摄的照片
二进制分类和评价指标
分类问题在数据科学中普遍存在。通过分类,模型被训练来标注来自固定标签集的输入数据。当这个固定集合的长度为二时,那么这个问题就叫做二元分类。
通常,经过训练的二元分类模型为每个输入返回一个实数值 r 。如果实数值高于设定的阈值 t ,则为输入分配一个正标签,否则,将为输入分配一个负标签。
为二元分类问题计算的评估指标通常基于混淆矩阵。
为了评估分类模型的性能或对不同的模型进行排序,可以选择选取一个阈值 t 并基于它计算精度、召回率、F(1)分数和精度。此外,可以通过关注所有阈值(测试集中唯一的 r 分数的数量)来评估模型的性能,而不是选择一个阈值。基于后一种方法的一个常用图表是 ROC 曲线,它描绘了真实正比率(TP / TP + FN)与真实负比率(TN / TN + FP)的关系。然后,该曲线下的面积(AUC,0 到 1 之间的值)用于评估模型的质量,并将其与其他模型进行比较。
联合自卫军的缺点
AUC 是用于对模型性能进行排名的最常用的标量之一。然而,AUC 的缺点鲜为人知;Hand (2009)已经表明 AUC 对不同的分类器使用不同的分类成本分布(在这种情况下;对于不同的阈值 t ),并且它不考虑数据中的类偏度。然而,误分类损失应该取决于属于每个类别的对象的相对比例;AUC 不考虑这些前科。这相当于说,使用一个分类器,错误分类类别 1 是错误分类类别 0 的倍。但是,使用另一个分类器,误分类类 1 是 P 倍严重,其中P≦P*。这是无意义的,因为单个点的不同种类的错误分类的相对严重性是问题的属性,而不是碰巧被选择的分类器。*
海雀
为了克服这些缺点,Kaymak、Ben-David 和 Potharst (2012)提出了一个相关但不同的指标;Kappa 曲线下的面积(AUK),这是基于被称为 Cohen 的 Kappa 的公认指标。它测量绘制 Kappa 对假阳性率的图形下的面积。就像 AUC 可以被视为整体性能的指标一样,海雀也可以。然而,Kappa 由于偶然性而导致正确的分类。因此,它固有地解释了类偏度。
在本文中,作者展示了海雀的一些特征和优点:
- Kappa 是真阳性率和假阳性率之差的非线性变换。
- 凸 Kappa 曲线具有唯一的最大值,可用于选择最佳模型。
此外,如果数据集是平衡的:
- 科恩的 Kappa 提供了与 ROC 曲线完全相同的信息。
- AUK = AUC — 0.5 (AUK 和 AUC 仅相差一个常数)。
- AUK = 0.5 基尼(当数据集中没有偏斜时,AUK 等于基尼系数的一半)
- 当 ROC 曲线的梯度等于 1 时,Kappa 值最大。因此,通过 Kappa 找到最优模型没有任何附加价值。
结论
也就是说,如果数据集是平衡的。然而,AUC 和 AUK 可能对不平衡数据集有不同的模型排名(请阅读论文中的示例),这在投入生产时会产生巨大的影响。由于 AUK 解释了类偏度,而 AUC 没有,AUK 似乎是更好的选择,应该成为任何数据科学家工具箱的一部分。
代码
假设您有:
- *概率:*你的分类模型的输出;一个长度为 k 的实数列表。
- *标签:*分类模型的实际标签;一个由 0 和 1 组成的 k 长度列表。
然后,可以调用下面的类来计算 AUK 和/或得到 Kappa 曲线。
class AUK:
def __init__(self, probabilities, labels, integral='trapezoid'):
self.probabilities = probabilities
self.labels = labels
self.integral = integral
if integral not in ['trapezoid','max','min']:
raise ValueError('"'+str(integral)+'"'+ ' is not a valid integral value. Choose between "trapezoid", "min" or "max"')
self.probabilities_set = sorted(list(set(probabilities)))
#make predictions based on the threshold value and self.probabilities
def _make_predictions(self, threshold):
predictions = []
for prob in self.probabilities:
if prob >= threshold:
predictions.append(1)
else:
predictions.append(0)
return predictions
#make list with kappa scores for each threshold
def kappa_curve(self):
kappa_list = []
for thres in self.probabilities_set:
preds = self._make_predictions(thres)
tp, tn, fp, fn = self.confusion_matrix(preds)
k = self.calculate_kappa(tp, tn, fp, fn)
kappa_list.append(k)
return self._add_zero_to_curve(kappa_list)
#make list with fpr scores for each threshold
def fpr_curve(self):
fpr_list = []
for thres in self.probabilities_set:
preds = self._make_predictions(thres)
tp, tn, fp, fn = self.confusion_matrix(preds)
fpr = self.calculate_fpr(fp, tn)
fpr_list.append(fpr)
return self._add_zero_to_curve(fpr_list)
#calculate confusion matrix
def confusion_matrix(self, predictions):
tp = 0
tn = 0
fp = 0
fn = 0
for i, pred in enumerate(predictions):
if pred == self.labels[i]:
if pred == 1:
tp += 1
else:
tn += 1
elif pred == 1:
fp += 1
else: fn += 1
tot = tp + tn + fp + fn
return tp/tot, tn/tot, fp/tot, fn/tot
#Calculate AUK
def calculate_auk(self):
auk=0
fpr_list = self.fpr_curve()
for i, prob in enumerate(self.probabilities_set[:-1]):
x_dist = abs(fpr_list[i+1] - fpr_list[i])
preds = self._make_predictions(prob)
tp, tn, fp, fn = self.confusion_matrix(preds)
kapp1 = self.calculate_kappa(tp, tn, fp, fn)
preds = self._make_predictions(self.probabilities_set[i+1])
tp, tn, fp, fn = self.confusion_matrix(preds)
kapp2 = self.calculate_kappa(tp, tn, fp, fn)
y_dist = abs(kapp2-kapp1)
bottom = min(kapp1, kapp2)*x_dist
auk += bottom
if self.integral == 'trapezoid':
top = (y_dist * x_dist)/2
auk += top
elif self.integral == 'max':
top = (y_dist * x_dist)
auk += top
else:
continue
return auk
#Calculate the false-positive rate
def calculate_fpr(self, fp, tn):
return fp/(fp+tn)
#Calculate kappa score
def calculate_kappa(self, tp, tn, fp, fn):
acc = tp + tn
p = tp + fn
p_hat = tp + fp
n = fp + tn
n_hat = fn + tn
p_c = p * p_hat + n * n_hat
return (acc - p_c) / (1 - p_c)
#Add zero to appropriate position in list
def _add_zero_to_curve(self, curve):
min_index = curve.index(min(curve))
if min_index> 0:
curve.append(0)
else: curve.insert(0,0)
return curve #Add zero to appropriate position in list
def _add_zero_to_curve(self, curve):
min_index = curve.index(min(curve))
if min_index> 0:
curve.append(0)
else: curve.insert(0,0)
return curve
要计算 AUK,请使用以下步骤:
auk_class = AUK(probabilities, labels)auk_score = auk_class.calculate_auk()kappa_curve = auk_class.kappa_curve()
最后,我强烈建议只在计算积分时使用梯形,因为这也是 sklearn 计算 AUC 积分的方式。
参考
Hand,D. J. (2009)。测量分类器性能:ROC 曲线下面积的一致替代方法。机器学习, 77 (1),103–123。
凯马克,u .,本大卫,a .,,波塔斯特,R. (2012)。海雀:AUC 的简单替代。人工智能的工程应用, 25 (5),1082–1089。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}