







R 中的自举抽样
探索公立和私立学校的学费差异
Bootstrapping 使用带替换的随机抽样来估计样本的统计数据。通过对此样本进行重采样,我们可以生成能够代表总体的新数据。这大致基于大数定律。我们可以对统计数据进行多次估计,而不是对一个小样本的统计数据进行一次估计。因此,如果我们用替换重新采样 10 次,我们将计算 10 次期望统计的估计。
引导过程如下:
- 用替换 n 次重新采样数据
- 计算期望的统计数据 n 次,以生成估计统计数据的分布
- 从自举分布中确定自举统计量的标准误差/置信区间
在本文中,我将演示如何使用 TidyTuesday 的历史学费数据集执行 bootstrap 重采样来估计私立和公立大学的学费成本之间的关系。
首先,我们从 GitHub 加载数据。
library(tidyverse)
library(tidymodels)historical_tuition <- readr::read_csv('[https://raw.githubusercontent.com/rfordatascience/tidytuesday/master/data/2020/2020-03-10/historical_tuition.csv'](https://raw.githubusercontent.com/rfordatascience/tidytuesday/master/data/2020/2020-03-10/historical_tuition.csv'))# A tibble: 6 x 4
type year tuition_type tuition_cost
<chr> <chr> <chr> <dbl>
1 All Institutions 1985-86 All Constant 10893
2 All Institutions 1985-86 4 Year Constant 12274
3 All Institutions 1985-86 2 Year Constant 7508
4 All Institutions 1985-86 All Current 4885
5 All Institutions 1985-86 4 Year Current 5504
6 All Institutions 1985-86 2 Year Current 3367
目前,数据是长格式的,每行代表一个观察值。每年都有多个观察值,代表每种机构类型的数据:公立、私立、所有机构。为了利用数据进行重采样,我们需要将数据转换为宽格式,其中一列包含私立学校的学费,另一列包含公立学校的学费。这种宽格式中的每一行代表特定年份的历史学费。下面是将长格式数据转换为更宽格式的代码。我们将对建模感兴趣的列是public和private,它们代表由列year给出的特定学年公立和私立学校的学费。
tuition_df <- historical_tuition %>%
pivot_wider(names_from = type,
values_from = tuition_cost
) %>%
na.omit() %>%
janitor::clean_names()# A tibble: 25 x 5
year tuition_type all_institutions public private
<chr> <chr> <dbl> <dbl> <dbl>
1 1985-86 All Constant 10893 7964 19812
2 1985-86 4 Year Constant 12274 8604 20578
3 1985-86 2 Year Constant 7508 6647 14521
4 1985-86 All Current 4885 3571 8885
5 1985-86 4 Year Current 5504 3859 9228
6 1985-86 2 Year Current 3367 2981 6512
7 1995-96 All Constant 13822 9825 27027
8 1995-96 4 Year Constant 16224 11016 27661
9 1995-96 2 Year Constant 7421 6623 18161
10 1995-96 All Current 8800 6256 17208
有了这种更宽格式的数据,我们可以很快直观地了解私立和公立学校学费之间的关系。
tuition_df %>%
ggplot(aes(public, private))+
geom_point()+
scale_y_continuous(labels=scales::dollar_format())+
scale_x_continuous(labels=scales::dollar_format())+
ggtitle("Private vs Public School Tuition")+
xlab("Public School Tuition")+
ylab("Private School Tuition")+
theme_linedraw()+
theme(axis.title=element_text(size=14,face="bold"),
plot.title = element_text(size = 20, face = "bold"))
私立学校和公立学校的学费之间似乎存在直接的正相关关系。一般来说,私立学校比公立学校花费更多。我们现在将从数量上来看。

作者图片
我们可以对数据进行线性拟合,以确定私立学校和公立学校学费之间的关系。我们可以通过 r 中的lm函数来实现这一点。我们可以看到斜率估计为 2.38。公立学校每花费 1 美元的学费,私立学校预计要多支付 2.38 倍。
tuition_fit <- lm(private ~ 0 + public,
data = tuition_df)# We tidy the results of the fit
tidy(tuition_fit)# A tibble: 1 x 5
term estimate std.error statistic p.value
<chr> <dbl> <dbl> <dbl> <dbl>
1 public 2.38 0.0346 68.7 1.05e-66
现在,我们将使用重采样来尝试更好地估计公立和私立学校学费之间的关系。使用自举,我们将随机绘制替换以从原始数据集创建与原始数据集大小相同的新数据集。这实质上模拟了从原始数据集生成新的数据集。我们将对数据重新采样 1000 次。
# Set set.seed a starting number to generate a sequence of random numbers so that we can get reproducible results
set.seed(123)
tution_boot <- bootstraps(tuition_df,
times = 1e3,
apparent = TRUE)
接下来,我们将对 1000 次重新采样拟合一个线性模型。这些结果将存储在一个名为model的新列中,统计数据将存储在一个名为conf_inf的列中。然后,我们将对结果进行去嵌套,以提取估计的统计数据(直线的斜率)、误差和 p 值。
tuition_models <- tution_boot %>%
mutate(model = map(splits, ~lm(private ~ 0 + public,
data = .) ),
coef_inf = map(model, tidy))tuition_coefs <- tuition_models %>%
unnest(coef_inf)splits id model term estimate std.error statistic p.value
<list> <chr> <list> <chr> <dbl> <dbl> <dbl> <dbl>
1 <split [72/25]> Bootstrap0001 <lm> public 2.37 0.0354 66.7 8.41e-66
2 <split [72/28]> Bootstrap0002 <lm> public 2.38 0.0353 67.4 4.30e-66
3 <split [72/23]> Bootstrap0003 <lm> public 2.36 0.0365 64.9 6.19e-65
4 <split [72/25]> Bootstrap0004 <lm> public 2.30 0.0328 70.1 2.67e-67
5 <split [72/25]> Bootstrap0005 <lm> public 2.35 0.0364 64.7 7.15e-65
6 <split [72/26]> Bootstrap0006 <lm> public 2.36 0.0344 68.5 1.31e-66
7 <split [72/25]> Bootstrap0007 <lm> public 2.33 0.0299 77.9 1.61e-70
8 <split [72/23]> Bootstrap0008 <lm> public 2.34 0.0368 63.5 2.60e-64
9 <split [72/21]> Bootstrap0009 <lm> public 2.41 0.0349 68.9 8.70e-67
10 <split [72/26]> Bootstrap0010 <lm> public 2.39 0.0334 71.6 6.00e-68
# … with 991 more rows
我们现在有 1000 个估计值,这些估计值是通过重新采样获得的,存储在estimate列中的是私立学校和公立学校的学费之间的关系。现在的问题是,私立和公立学校学费之间的估计斜率的分布是什么?
tuition_coefs %>%
ggplot(aes(estimate))+
geom_histogram(alpha = .7)+
ggtitle("Distribution of Estimated Slope")+
xlab("Estimate")+
ylab("Frequency")+
theme_linedraw()+
theme(axis.title=element_text(size=14,face="bold"),
plot.title = element_text(size = 20, face = "bold"))
我们可以看到分布呈正态分布,我们可以感受到它有多宽。从数字上看,我们可以把这种分布的描述列表如下。

作者图片
int_pctl(tuition_models,
coef_inf)# A tibble: 1 x 6
term .lower .estimate .upper .alpha .method
<chr> <dbl> <dbl> <dbl> <dbl> <chr>
1 public 2.31 2.38 2.46 0.05 percentile
我们可以看到,通过 bootstrapping,描述私立和公立学校学费之间关系的估计斜率约为 2.38,与我们在没有 bootstrapping 的情况下获得的结果相似。这可能是因为公立和私立学校之间的潜在关系是线性的,并且线性模型的潜在假设适用于该数据集。线性回归的基本假设是:
- 变量之间的基本关系是线性的
- 误差通常是分布的
- 最佳拟合线周围有相等的方差(误差的同方差)
- 观察是独立的
此外,通过 bootstrapping,我们还可以获得关系的上下限,这是我们在未采样数据上仅使用线性模型时所没有的。
最后,我们可以可视化从自举样本中计算出的各种估计值。
tuition_aug <- tuition_models %>%
# Sample only 200 bootstraps for visualization
sample_n(200) %>%
mutate(augmented = map(model, augment)) %>%
unnest(augmented)tuition_aug %>%
ggplot(aes(public, private))+
geom_line(aes(y = .fitted, group = id), alpha = .1, color = 'grey')+
geom_point()+
scale_y_continuous(labels=scales::dollar_format())+
scale_x_continuous(labels=scales::dollar_format())+
ggtitle("200 of 1000 Slope Estimations from Bootstrap Resampling")+
xlab("Public School Tuition")+
ylab("Private School Tuition")+
theme_linedraw()+
theme(axis.title=element_text(size=14,face="bold"),
plot.title = element_text(size = 20, face = "bold"))

作者图片
总之,这篇博客演示了如何使用 R 中的 bootstrap 重采样来确定私立学校和公立学校学费之间的关系。这种技术使用随机抽样来估计几乎任何统计数据的抽样分布。
自助统计——如何解决简单统计测试的局限性
入门
你有一个数据样本。由此,您需要计算总体平均值的置信区间。你首先想到的是什么?通常是 t 检验。
但是 t 检验有几个要求,其中之一是均值的抽样分布接近正态(要么总体是正态的,要么样本相当大)。在实践中,这并不总是正确的,因此 t 检验可能并不总是提供最佳结果。
要解决这种限制,请使用 bootstrap 方法。它只有一个重要的要求:样本足够接近总体。常态不是必须的。
我们先来试试 t 检验,然后再和 bootstrap 法对比。
均值置信区间的单样本检验
让我们首先加载我们需要的所有库:
from sklearn.utils import resample
import pandas as pd
from matplotlib import pyplot as plt
import pingouin as pg
import numpy as np
import seaborn as snsnp.random.seed(42)
plt.rcParams["figure.figsize"] = (16, 9)
注意:我们在这里使用 Pingouin 库进行一些统计测试。这很棒,因为许多重要的技术都在同一个屋檐下,有统一的接口和语法。试试看:
【https://pingouin-stats.org/
现在回到主题,这是一个例子:
spl = [117, 203, 243, 197, 217, 224, 279, 301, 317, 307, 324, 357, 364, 382, 413, 427, 490, 742, 873, 1361]
plt.hist(spl, bins=20);

你可以假装这看起来很正常,但它有几个大的异常值,这是 t 检验不能容忍的。尽管如此,让我们对总体均值的 95%置信区间进行 t 检验:
pgtt = pg.ttest(spl, 0)
print(pgtt['CI95%'][0])[272.34 541.46]
这是一个非常宽的区间,反映了样本中值的分布。我们能做得更好吗?答案是肯定的,用自举法。
引导程序
如果样本更大,或者可以从同一人群中提取多个样本,结果会更好。但这在这里是不可能的——这是我们仅有的样本。
然而,如果我们假设样本非常接近总体,我们可以假装从总体中生成多个伪样本:我们真正做的是获取这个样本并对其进行重采样——使用相同的值生成相同大小的多个样本。然后我们处理生成的样本集。
你制作的伪样本数量需要很大,通常是数千个。
由于我们从原始样本生成的样本与原始样本的大小相同,因此一些值将在每个伪样本中重复。那很好。
平均值的 CI
让我们从原始样本中生成一万个重采样数据块:
B = 10000
rs = np.zeros((B, len(spl)), dtype=np.int)
for i in range(B):
rs[i,] = resample(spl, replace = True)
print(rs)[[ 279 1361 413 ... 357 357 490]
[ 307 427 413 ... 317 203 1361]
[ 413 279 357 ... 357 203 307]
...
[ 217 243 224 ... 279 490 1361]
[ 301 324 224 ... 224 317 317]
[ 324 301 364 ... 873 364 203]]
数组中的每一行都是重新采样的块,与原始样本大小相同。总共有 10k 线。
现在,让我们构建 bootstrap 分布:对于每条线,计算平均值:
bd = np.mean(rs, axis=1)
print(bd)[376.35 515.15 342.75 ... 507.8 426.15 377.05]
bootstrap 分布包含每个重新采样的数据块的平均值。从这里很容易得到均值的 95%置信区间:只需对 bootstrap 分布数组(均值)进行排序,截掉顶部和底部的 2.5%,读取剩余的极值:
bootci = np.percentile(bd, (2.5, 97.5))
print(bootci)[300.0975 541.705]
这就是平均值的 bootstrap 95%置信区间。它与 t 检验置信区间相比如何?
y, x, _ = plt.hist(bd, bins=100)
ymax = y.max()
plt.vlines(pgtt['CI95%'][0], 0, ymax, colors = 'red')
plt.vlines(bootci, 0, ymax, colors = 'chartreuse')
plt.vlines(np.mean(spl), 0, ymax, colors = 'black')
plt.show();

bootstrap CI(绿色)比 t-test CI(红色)更窄一些。
中值 CI
您也可以使用 bootstrap 为中值生成 CI:只需使用 np.median()而不是 np.mean()构建 bootstrap 分布:
bd = np.median(rs, axis = 1)
bootci = np.percentile(bd, (5, 95))
print(bootci)[279\. 382.]
差异 CI
让我们从已知方差(var=100)的正态总体中抽取一个样本:
sp = np.random.normal(loc=20, scale=10, size=50)
sns.violinplot(x=sp);

我们样本的方差确实接近 100:
print(np.var(sp))112.88909322502681
让我们使用 bootstrap 从现有样本中提取总体方差的置信区间。同样的想法:对数据进行多次重采样,计算每个重采样块的方差,得到方差列表的百分比区间。
rs = np.zeros((B, len(sp)), dtype=np.float)
for i in range(B):
rs[i,] = resample(sp, replace=True)
bd = np.var(rs, axis=1)
bootci = np.percentile(bd, (2.5, 97.5))
print(bootci)[74.91889462 151.31601521]
还不错;间隔足够窄,并且它包括总体方差的真值(100)。这是来自 bootstrap 分布的方差直方图:
y, x, _ = plt.hist(bd, bins=100)
ymax = y.max()
plt.vlines(bootci, 0, ymax, colors = 'chartreuse')
plt.vlines(np.var(sp), 0, ymax, colors = 'black')
plt.show();

两样本均值差,不成对
以下是两个李子样品的重量,按颜色分组:
https://raw . githubusercontent . com/FlorinAndrei/misc/master/plum data . CSV
plumdata = pd.read_csv('plumdata.csv', index_col=0)
sns.violinplot(x='color', y='weight', data=plumdata);

这两种颜色的平均重量不同吗?换句话说,平均权重差异的置信区间是多少?我们先来试试经典的 t 检验:
plum_red = plumdata['weight'][plumdata['color'] == 'red'].values
plum_yel = plumdata['weight'][plumdata['color'] == 'yellow'].values
plumtt = pg.ttest(plum_red, plum_yel)
print(plumtt['CI95%'][0])[8.67 27.2]
t 检验说—是的,在 95%的置信度下,红色李子的平均重量不同于黄色李子的平均重量(CI 不包括 0)。
对于 bootstrap,我们将对两个样本进行 10k 次重采样,计算每个重采样块的平均值,进行 10k 次平均值的差值,并查看平均值分布差值的 2.5 / 97.5 个百分点。
这是重新采样的数据:
plzip = np.array(list(zip(plum_red, plum_yel)), dtype=np.int)
rs = np.zeros((B, plzip.shape[0], plzip.shape[1]), dtype=np.int)
for i in range(B):
rs[i,] = resample(plzip, replace = True)
print(rs.shape)(10000, 15, 2)
10000 是重采样的次数,15 是每个重采样的长度,每种情况下我们比较 2 个样本。
让我们计算每个重采样块的平均值:
bd_init = np.mean(rs, axis=1)
print(bd_init.shape)(10000, 2)
bootstrap 分布是 10000 个重采样案例中每一个案例的平均值的差(红色平均值减去黄色平均值):
bd = bd_init[:, 0] - bd_init[:, 1]
print(bd.shape)(10000,)print(bd)[12.33333333 21\. 10.33333333 ... 21.46666667 11.66666667
17.06666667]
现在我们可以从 bootstrap 分布中获得均值差异的 CI:
bootci = np.percentile(bd, (2.5, 97.5))
print(bootci)[9.33333333 26.06666667]
bootstrap 再次提供了比 t-test 更紧密的间隔:
y, x, _ = plt.hist(bd, bins=100)
ymax = y.max()
plt.vlines(plumtt['CI95%'][0], 0, ymax, colors = 'red')
plt.vlines(bootci, 0, ymax, colors = 'chartreuse')
plt.show();

两样本差异均值,成对
以下是配对数据——几种品牌的绳索在潮湿或干燥条件下的强度:
https://raw . githubusercontent . com/FlorinAndrei/misc/master/strength . CSV
strength = pd.read_csv('strength.csv', index_col=0)
sns.violinplot(data=strength);

这些数据是否足以得出结论,干湿条件会影响绳索的强度?让我们计算一个 95%置信区间的平均强度差异,湿与干。首先,t 检验:
s_wet = strength['wet']
s_dry = strength['dry']
s_diff = s_wet.values - s_dry.values
strengthtt = pg.ttest(s_wet, s_dry, paired=True)
print(strengthtt['CI95%'][0])[0.4 8.77]
t 检验表明,在 95%的置信度下,潮湿/干燥条件确实产生了统计上的显著差异——但几乎没有。CI 的一端接近 0。
现在,让我们为同一个配置项进行引导。我们可以简单地取 s_diff(每根绳子的强度差异),然后回到单样本自举程序:
rs = np.zeros((B, len(s_diff)), dtype=np.int)
for i in range(B):
rs[i,] = resample(s_diff, replace = True)
bd = np.mean(rs, axis=1)
bootci = np.percentile(bd, (2.5, 97.5))
print(bootci)[1.33333333 8.5]
t 检验和 bootstrap 都同意,当条件不同时,强度不同,这在统计上有显著差异(95%的置信度)。自举自信一点(区间更窄,离 0 更远)。
y, x, _ = plt.hist(bd, bins=100)
ymax = y.max()
plt.vlines(strengthtt['CI95%'][0], 0, ymax, colors = 'red')
plt.vlines(bootci, 0, ymax, colors = 'chartreuse')
plt.show();

带代码的笔记本:
https://github . com/FlorinAndrei/misc/blob/master/bootstrap _ plain . ipynb
最后的想法
这只是基本的自举技术。它不执行偏差校正等。
没有解决小样本问题的方法。Bootstrap 功能强大,但并不神奇——它只能处理原始样本中的可用信息。
如果样本不能代表全部人口,那么 bootstrap 就不太准确。
使用 AWS Fargate 在 1000 个内核上引导 Dask
利用云的力量来供应和部署 1000 个内核,以处理大量数据并完成工作

美国宇航局在 Unsplash 拍摄的照片
作为一名数据工程师,我发现自己多次需要一个系统,在这个系统中,我可以构建繁重的大数据任务的原型。我的团队传统上使用 EMR 和 Apache Spark 来完成此类任务,但是随着关于 Apache 淘汰 hadoop 项目的消息以及 python 是数据分析的首选工具这一常见范例的出现,我开始追求一个更现代的 python 原生框架。
我的目标是实现 1000 核集群的一键式部署,可以运行约 1TB 数据的原型处理,然后拆除。另一个条件是,这些资源不需要干扰我团队的其他资源。因此一键 eks-fargate-dask 工具诞生了!
AWS Fargate
AWS Fargate 是一个用于容器的无服务器计算引擎,它与亚马逊弹性容器服务(ECS) 和亚马逊弹性库本内特服务(EKS) 一起工作。
简而言之,Fargate 使开发人员能够根据 pods 指定的需求来分配 CPU 和内存,而不是预先分配节点。
eksctl
eksctl 是一个用于管理 EKS 集群的 cli 工具。它允许通过 EC2(计算节点)或 Fargate(无服务器)后端使用一个命令来配置和部署 EKS 集群。截至本文撰写之时,它还不支持指定 Fargate spot 实例,这太糟糕了。
eksctl alsl 提供了实用程序命令,用于提供对 kubernetes 服务帐户的 IAM 访问。
达斯克
Dask 是一个库,它支持在远程或本地集群上通过并行计算来处理大于内存的数据结构。它为数组(numpy)和数据帧(pandas)等数据结构提供了熟悉的 python APIs。建立基于本地流程的集群非常简单,但依我个人之见,Dask 的亮点在于其令人惊叹的生态系统,允许在 Kubernetes、YARN 和许多其他多处理集群上建立集群。
把所有的放在一起
首先,我使用这个脚本部署一个 EKS Fargate 集群。该脚本需要在 IAM 角色的上下文中运行,该角色拥有许多 AWS 部署操作的权限(主要是部署 Cloudformation 堆栈)。用于 dask workers 的 IAM 角色并没有提供对 S3 服务的完全访问权限,因为我是从 S3 的 parquet 文件中加载数据的。
运行这个命令后,您应该有一个名为 dask 的 EKS 集群启动并运行。在接下来的部分,我们将部署一个 dask 头盔版本。可以通过设置值来定制舵释放。这些是我在 dask 集群中使用的值:
然后安装舵释放装置:
就是这样!您已经安装了 dask 集群!您可以在 s3 上运行这个使用开放的 ookla 数据集的示例笔记本,看看扩展集群如何提高性能。
Dask 数据框 API 与 pandas 并不是 100%兼容(可以说是设计上的)。Dask 的文档网站上有一堆有用的资源。
使用完集群后,记得缩小规模!
结论
我一直在寻找一种快速的方法,不依赖于 python 原生框架的原型大数据处理。这绝不适合生产使用,并且可能也没有进行成本优化,但是它完成了工作,在几分钟内我就能够处理超过 300GB 的 parquet 文件(数据帧中可以膨胀到 1TB)
自举标准差
许多人知道但很少讲述的基于 python 的故事

Bootstrapping 是一种重采样方法,它允许我们从样本中推断出总体的统计数据。它也很容易执行和理解,这使得它如此织补酷。使用 bootstrap 或完全了解其潜力的从业者知道,他们可以用它来估计各种人口统计数据,但我在网上找到的几乎所有例子都只使用 bootstrap 来估计人口的平均值。我想是时候改变这种状况了。
在这篇短文中,我将回顾 bootstrap 方法以及如何在 python 中执行它。然后,我们将使用这种方法来估计总体标准差的置信区间,以减轻关于如何引导总体统计数据而不是样本均值的任何困惑。我们将做一些可视化的工作,以便更好地理解我们所学的内容,并尝试抽取更多的样本,看看这会如何影响结果。
让我们开始吧。
设置
如果你愿意,你可以在 Jupyter 笔记本这里跟随。
从导入我们需要的所有包开始。
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
%matplotlib inline
import seaborn as sns
import scipy.stats as st
现在,让我们生成一个虚构的“人口”我编造了均值和标准差。如果你愿意,你可以自己编。
# generate a ficticious population with 1 million values
pop_mean = 53.21
pop_std = 4.23
population = np.random.normal(pop_mean, pop_std, 10**6)# plot the population
sns.distplot(population)
plt.title('Population Distribution')

作者图片
我们现在已经创建了一个“总体”,它有一百万个值,平均值为 52.21,标准差为 4.23。
抽取样本
我们希望从总体中抽取一个小样本,用于引导总体参数的近似值。实际上,我们只有样品。
# Draw 30 random values from the population
sample = np.random.choice(population, size=30, replace=False)
变量sample现在包含从总体中随机抽取的 30 个值。

作者图片
bootstrap——综述
我会很快地讲到这里。如果你想更深入地了解 bootstrap 方法,可以看看我以前的文章估计未来音乐人和非营利组织的在线活动捐赠收入——用 python 对置信区间进行 Bootstrap 估计。
自举的所有神奇之处都是通过替换采样实现的。替换意味着当我们抽取一个样本时,我们记录下这个数字,然后将这个数字返回给源,这样它就有同样的机会被再次选中。这就是我们正在分析的产生变异的原因,以便对总体做出推断。
我们可以认为这是从一顶帽子(或者一只靴子,如果你喜欢的话)中抽取数字。
- 数一数你帽子里的记录数
- 从你的帽子里随机抽取一张记录
- 记录该记录的值,并将记录放回帽子中
- 重复上述步骤,直到记录的数值数量与帽子中记录的数值数量相同
- 计算样本度量,如平均值或标准偏差,并记录下来
- 重复这个过程 1000 次左右
- 计算分位数以获得您的置信区间
让我们用numpy来做这个,它比从帽子里抽数字要快得多。
bs = np.random.choice(sample, (len(sample), 1000), replace=True)
现在我们有一个 30x1000 numpy的数组,每 1000 行代表一个新的样本。
为了推断总体平均值,我们可以取所有行的平均值,然后取这些平均值的平均值。
bs_means = bs.mean(axis=0)
bs_means_mean = bs_means.mean()
bs_means_mean
54.072626327248315
那还不错。记得人口平均数是53.21。
但这不是有用的部分。如果我们取样本的平均值,我们会得到相似的结果。
sample.mean()
54.12110644012915
真正的价值在于我们可以通过自举生成的置信区间。我们将返回并使用我们的bs_means变量,它包含 1000 个重采样样本的平均值。为了计算 95%的置信区间,我们可以取这些平均值的 0.025 和 0.975 分位数。95%的重采样样本的平均值在这两个分位数之间,这给出了我们的置信区间。
lower_ci = np.quantile(bs_means, 0.025)
upper_ci = np.quantile(bs_means, 0.975)lower_ci, upper_ci
(52.41754898532445, 55.602661654526315)
很神奇,对吧?如果从大量不同的可能人群中抽取相同的样本,这些人群中的 95/100 将具有介于 52.54 和 55.77 之间的平均值。
标准偏差
这是大多数 bootstrap 示例的终点,但我们想看看我们能在多大程度上重建我们的总体,所以我们还需要计算标准差。
好消息是,过程是相同的,除了我们采用每个重采样样本的标准差,而不是平均值。同样在我们以前取平均值的时候,我们现在可以计算标准差的平均值。
bs_stds = bs.std(axis=0)
bs_std_mean = bs_stds.mean()
bs_std_mean
4.398626063763372
我们可以像以前一样通过寻找分位数来计算总体标准差的置信区间。
lower_ci = np.quantile(bs_stds, 0.025)
upper_ci = np.quantile(bs_stds, 0.975)lower_ci, upper_ci
(3.3352503395296598, 5.387739215237817)
总体标准差的 95%置信区间为 3.34 至 5.39。
让我们把它画出来,以便更好地理解它的意思。
# plot the distributions with std at the confidence intervals
dist_low = st.norm(loc=bs_means_mean, scale=std_qtl_025)
y_low = dist_low.pdf(x)dist_high = st.norm(loc=bs_means_mean, scale=std_qtl_975)
y_high = dist_high.pdf(x)#plot
fig, (ax1, ax2) = plt.subplots(1, 2, figsize=(12, 5))plt.sca(ax1)
sns.distplot(population, ax=ax1)
plt.plot(x,y_low, color='red')
plt.plot(x,y_high, color='red')
plt.title('Variation in std at Confidence Intervals')# plot the distributions with mean at the confidence intervals
dist_low = st.norm(loc=means_qtl_025, scale=bs_std_mean)
y_low = dist_low.pdf(x)dist_high = st.norm(loc=means_qtl_975, scale=bs_std_mean)
y_high = dist_high.pdf(x)#plot
plt.sca(ax2)
sns.distplot(population)
plt.plot(x,y_low, color='red')
plt.plot(x,y_high, color='red')plt.title('Variation in mean at Confidence Intervals')

作者图片
第一个图显示 95/100 倍的人口分布将落在两个红色分布之间,代表标准差的上下置信区间。第二个图显示 95/100 倍的人口分布将落在两个红色分布之间,代表平均值的上下置信区间。现在我们对给定样本时可能的总体参数范围有了一个概念。
重采样次数
你可能还有另一个问题:如果我们重新采样 1000 次以上,我们会得到更精确的结果吗?
让我们通过重新采样 1000 万次而不是 1000 次来找出答案
bs_big = np.random.choice(sample, (len(sample), 10**7), replace=True)
计算平均值。
bs_means = bs_big.mean(axis=0)
bs_means_mean = bs_means.mean()
bs_means_mean
54.12096064254814
之前的平均值是 54.125363863656 那也差不了多少,离 53.21 的地面真相还远一点。
means_qtl_025 = np.quantile(bs_means, 0.025)
means_qtl_975 = np.quantile(bs_means, 0.975)means_qtl_025, means_qtl_975
(52.535753878990164, 55.76684250100114)
先前的值为(52.41754898532445,55.5555353651
bs_stds = bs_big.std(axis=0)
bs_std_mean = bs_stds.mean()
bs_std_mean
4.414164449356725
先前的值是 4.3986263372
std_qtl_025 = np.quantile(bs_stds, 0.025)
std_qtl_975 = np.quantile(bs_stds, 0.975)std_qtl_025, std_qtl_975
(3.3352503395296598, 5.387739215237817)
以前的值为(3.356752806683829,5.4663411850985)
似乎没有太大的区别。我们再把它画出来。
x = np.linspace(30, 80, 1000)# plot the distributions with std at the confidence intervals
dist_low = st.norm(loc=bs_means_mean, scale=std_qtl_025)
y_low = dist_low.pdf(x)dist_high = st.norm(loc=bs_means_mean, scale=std_qtl_975)
y_high = dist_high.pdf(x)#plot
fig, (ax1, ax2) = plt.subplots(1, 2, figsize=(12, 5))plt.sca(ax1)
sns.distplot(population, ax=ax1)
plt.plot(x,y_low, color='red')
plt.plot(x,y_high, color='red')
plt.title('Variation in std at Confidence Intervals\n10 million re-samples')# plot the distributions with mean at the confidence intervals
dist_low = st.norm(loc=means_qtl_025, scale=bs_std_mean)
y_low = dist_low.pdf(x)dist_high = st.norm(loc=means_qtl_975, scale=bs_std_mean)
y_high = dist_high.pdf(x)#plot
plt.sca(ax2)
sns.distplot(population)
plt.plot(x,y_low, color='red')
plt.plot(x,y_high, color='red')plt.title('Variation in mean at Confidence Intervals\n10 million re-samples')

作者图片
先前的绘图重采样 1000 次:

作者图片
我要说的是,这些结果基本上是听不出来的,当然,在我们的情况下,重采样 1000 次以上没有任何好处。
所以,这就是那个鲜为人知但却广为人知的故事:用均值和标准差来估计总体参数。
使用 Python 和 R
使用重复抽样估计抽样分布

来源:照片由来自 Pixabay 的 krzysztof-m 拍摄
确定一个总体特征的尝试常常受到这样一个事实的限制,即我们必须依靠一个样本来确定该总体的特征。
在分析数据时,我们希望能够估计抽样分布,以便进行假设检验和计算置信区间。
试图解决这个问题的一种方法是一种叫做自举的方法,通过重复采样来推断更广泛人群的结果。
例如,为了确定同一人群的不同样本是否会产生相似的结果,理想的方法是获取新的数据样本。然而,鉴于这可能是不可能的,一种替代方法是从现有数据中随机取样。
对于这个示例,我们将查看一系列酒店客户的平均每日房价(ADR)的分布。具体而言,ADR 数据的子集与 bootstrapping 技术结合使用,以分析在给定较大样本量的情况下,预期的分布情况。
当使用自举产生样本时,这通过替换来完成**。这意味着可以从样品中多次选择相同的元素。**
使用 Python 引导
使用从 Antonio、Almeida 和 Nunes 提供的数据集中随机抽取的 300 个酒店客户 ADR 值样本,我们将生成 5000 个大小为 300 的 bootstrap 样本。
具体来说,numpy 如下用于生成 300 个替换样本,而循环的用于一次生成 300 个样本的 5000 次迭代。
my_samples = []
for _ in range(5000):
x = np.random.choice(sample, size=300, replace=True)
my_samples.append(x.mean())
以下是引导样本的直方图:

来源:Jupyter 笔记本输出
这是随机选取的 300 个原始样本的直方图:

来源:Jupyter 笔记本输出
我们可以看到原始样本是显著正偏的。但是,自举样本的直方图近似于正态分布,这符合中心极限定理的假设,即随着样本大小的增加,无论原始分布的形状如何,基本数据分布都可以近似为正态分布。
bootstrapping 的主要用途是估计总体均值的置信区间。例如,95%的置信区间意味着我们有 95%的把握均值位于特定范围内。
引导样本的置信区间如下:
>>> import statsmodels.stats.api as sms
>>> sms.DescrStatsW(my_samples).tconfint_mean()(94.28205060553655, 94.4777529411301)
根据以上所述,我们可以 95%确信真实的人口平均数在 94.28 和 94.47 之间。
使用 R 自举
使用 R 中的 boot 库,可以进行类似形式的分析。
再次假设只有 300 个样本可用:
adr<-sample(adr, 300)
使用带有替换的随机取样,产生这 300 个样本的 5,000 个重复。
x<-sample(adr, 300, replace = TRUE, prob = NULL)> mean_results <- boot(x, boot_mean, R = 5000)
ORDINARY NONPARAMETRIC BOOTSTRAPCall:
boot(data = x, statistic = boot_mean, R = 5000)Bootstrap Statistics :
original bias std. error
t1* 93.00084 -0.02135855 2.030718
此外,以下是置信区间的计算:
> boot.ci(mean_results)
BOOTSTRAP CONFIDENCE INTERVAL CALCULATIONS
Based on 5000 bootstrap replicatesCALL :
boot.ci(boot.out = mean_results)Intervals :
Level Normal Basic
95% (89.04, 97.00 ) (88.98, 96.82 )Level Percentile BCa
95% (89.18, 97.02 ) (89.36, 97.32 )
Calculations and Intervals on Original Scale
生成自举样本的直方图:

来源:RStudio 输出
当在 R 中运行时,我们可以看到置信区间比使用 Python 运行时获得的置信区间更宽。虽然原因尚不清楚,但分析仍然表明,所获得的样本平均值代表了总体水平,不可能是偶然获得的。
限制
虽然自举是从样本推断总体特征的非常有用的工具,但一个常见的错误是假设自举是解决小样本问题的方法。
正如在交叉验证中所解释的,小样本量可能更不稳定,更容易与更广泛的人群产生重大偏差。因此,人们应该确保被分析的样本足够大,以便充分捕捉群体特征。
此外,小样本量的另一个问题是,bootstrap 分布本身可能会变得更窄,这反过来会导致更窄的置信区间,从而显著偏离真实值。
结论
在本文中,您已经看到:
- bootstrapping 如何允许我们使用重复抽样来估计抽样分布
- 随机抽样时替换的重要性
- 如何使用 Python 和 R 生成引导示例
- 自举的局限性以及为什么更大的样本量更好
非常感谢您的宝贵时间,非常感谢您的任何问题或反馈。你可以在 michael-grogan.com 的找到更多我的数据科学内容。
参考
- 安东尼奥,阿尔梅达,努内斯(2019)。酒店预订需求数据集
- 交叉验证:bootstrap 能被视为小样本的“治疗方法”吗?
- docs . scipy . org:scipy . stats . bootstrap
- 朱利安·比留:抽样分布
- 吉姆的《统计学:统计学中的自举法介绍及实例
- 多伦多大学编码器-R:Bootstrapping 和置换测试中的重采样技术
免责声明:本文是在“原样”的基础上编写的,没有任何担保。它旨在提供数据科学概念的概述,不应被解释为专业建议。本文中的发现和解释是作者的发现和解释,不被本文中提到的任何第三方认可或隶属于任何第三方。作者与本文提及的任何第三方无任何关系。
基于深度学习和 OpenCV 的无边界表格检测
构建您自己的对象检测器并将图像中的半结构化数据块转换为机器可读文本的方法

作者图片
文档解析
文档解析是将信息转换成有价值的业务数据的第一步。这些信息通常以表格形式存储在商业文档中,或者存储在没有明显图形边界的数据块中。一个无边界的表格可能有助于简化我们人类对半结构化数据的视觉感知。从机器阅读的角度来看,这种在页面上呈现信息的方式有很多缺点,使得很难将属于假定的表格结构的数据与周围的文本上下文分开。
表格数据提取作为一项业务挑战,可能有几个特别的或启发式的基于规则的解决方案,对于布局或风格稍有不同的表,这些解决方案肯定会失败。在大规模上,应该使用更通用的方法来识别图像中的表格状结构,更具体地说,应该使用基于深度学习的对象检测方法。
本教程的范围:
- 基于深度学习的物体检测
- 安装和设置 TF2 对象检测 API
- 数据准备
- 模型配置
- 模型训练和保存
- 现实生活图像中的表格检测和细胞识别
基于深度学习的物体检测
著名的 CV 研究员 Adrian Rosebrock 在他的“[深度学习对象检测温和指南](http://gentle guide to deep learning object detection)”中指出:“对象检测,无论是通过深度学习还是其他计算机视觉技术来执行,都建立在图像分类的基础上,并寻求精确定位对象出现的区域”。正如他所建议的,建立自定义对象检测器的一种方法是选择任何分类器,并在此之前使用一种算法来选择和提供图像中可能包含对象的区域。在这种方法中,您可以自由决定是否使用传统的 ML 算法进行图像分类(是否使用 CNN 作为特征提取器)或者训练一个简单的神经网络来处理任意的大型数据集。尽管其效率已被证明,但这种被称为 R-CNN 的两阶段对象检测范式仍然依赖于繁重的计算,不适合实时应用。
上述帖子中还进一步说,“另一种方法是将预先训练好的分类网络作为多组件深度学习对象检测框架中的基础(骨干)网络(如更快的 R-CNN 、 SSD ,或 YOLO )。因此,您将受益于其完整的端到端可培训架构。
无论选择是什么,它都会让你进一步了解重叠边界框的问题。在下文中,我们将触及为此目的执行的非最大抑制。
同时,请参考任意新类别的对象检测器的迁移学习流程图(参见交互视图):

作者图片
由于第二种方法速度更快、更简单且更准确,它已经被广泛用于商业和科学论文中的表格结构识别。例如,您可以很容易地找到使用【YOLO】、 RetinaNet 、 Cascade R-CNN 和其他框架从 PDF 文档中提取表格数据的实现。
继续学习本教程,您将了解如何使用像 TensorFlow (TF2)对象检测 API 这样的工具,使用预先训练的最先进的模型轻松构建您的自定义对象检测器。
开始之前
请注意,这不会是对深度学习对象检测的详尽介绍,而是对如何在特定开发环境( Anaconda/Win10 )中与 TF2 对象检测 API (和其他工具)交互以解决明显的业务问题(如无边界表格检测)的分阶段描述。在这篇文章的其余部分,我们将会比其他人更详细地介绍建模过程的一些方面和结果。尽管如此,在我们的实验之后,您将会找到基本的代码示例。要继续,你应该安装好 Anaconda 和宇宙魔方,下载 protobuf 并添加到 PATH。
TF2 对象检测 API 的安装和设置
在您选择的路径下创建一个新文件夹,我们在下文中称之为*‘项目的根文件夹’*。从您的终端窗口逐一运行以下命令:
*# from <project’s root folder>
conda create -n <new environment name> \
python=3.7 \
tensorflow=2.3 \
numpy=1.17.4 \
tf_slim \
cython \
git**conda activate <new environment name>**git clone* [*https://github.com/tensorflow/models.git*](https://github.com/tensorflow/models.git)*pip install git+https://github.com/philferriere/cocoapi.git#subdirectory=PythonAPI**cd models\research* *# from <project’s root folder>\models\researchprotoc object_detection\protos\*.proto — python_out=.**copy object_detection\packages\tf2\setup.py .**python setup.py install**python object_detection\builders\model_builder_tf2_test.py**conda install imutils pdf2image beautifulsoup4 typeguard**pip install tf-image**copy object_detection\model_main_tf2.py ..\..\workspace\.**copy object_detection\exporter_main_v2.py ..\..\workspace\.**cd ..\..*
它将在您的本地环境中安装使用 TF2 对象检测 API 所需的核心和一些助手库,并负责您的训练数据集。从这一步开始,你应该能够从 TF2 模型园下载一个预训练模型,并且从它得到相应预训练类的推论。
数据准备
我希望到目前为止你已经成功了!请记住,我们的最终目标是使用预训练模型来执行迁移学习,以检测单个“无边界”类,而该模型在初始训练时对此一无所知。如果你研究过我们的迁移学习流程图,你应该已经注意到我们整个过程的起点是一个数据集,不管有没有注释。如果你需要注释,有吨的解决方案可用。选择一个能给你 XML 注释的,与我们的例子兼容的。
我们拥有的注释数据越多越好(重要:这篇文章的所有表格图片都选自开放的数据源,如this,并由作者注释/重新注释)。但是一旦你尝试手工标注数据,你就会明白这项工作有多乏味。不幸的是,没有一个流行的用于图像增强的 python 库能够处理选定的边界框。在没有收集和注释新数据的高成本的情况下,增加初始数据集符合我们的利益。这就是一个 tf-image 包将变得方便的情况。
上述脚本将随机转换原始图像和对象的边界框,并将新图像和相应的 XML 文件保存到磁盘。这就是我们的数据集经过三倍扩展后的样子:

作者图片
接下来的步骤将包括将数据分成训练集和测试集。基于 TF2 对象检测 API 的模型需要一种特殊的格式用于所有输入数据,称为 TFRecord 。你会在 Github 库中找到相应的脚本来拆分和转换你的数据。
模型配置
在这一步,我们将创建一个标签映射文件()。pbtxt )将我们的类标签(‘无边界’)链接到某个整数值。 TF2 对象检测 API 需要此文件用于训练和检测目的:
*item {
id: 1
name: ‘borderless’
}*
实际的模型配置发生在相应的 pipeline.config 文件中。你可以阅读对模型配置的介绍,并决定是手动配置文件还是通过运行 Github 库中的脚本来配置文件。
到目前为止,您的项目的根文件夹可能如下所示:
📦borderless_tbls_detection
┣ 📂images
┃ ┣ 📂processed
┃ ┃ ┣ 📂all_annots
┃ ┃ ┃ ┗ 📜…XML
┃ ┃ ┗ 📂all_images
┃ ┃ ┃ ┗ 📜…jpg
┃ ┣ 📂splitted
┃ ┃ ┣ 📂test_set
┃ ┃ ┃ ┣ 📜…jpg
┃ ┃ ┃ ┗ 📜…XML
┃ ┃ ┣ 📂train_set
┃ ┃ ┃ ┣ 📜…jpg
┃ ┃ ┃ ┗ 📜…XML
┃ ┃ ┗ 📂val_set
┃ ┗ 📜xml_style.XML
┣ 📂models
┃ ┗ 📂…
┣ 📂scripts
┃ ┣ 📜…py
┣ 📂train_logs
┣ 📂workspace
┃ ┣ 📂data
┃ ┃ ┣ 📜label_map.pbtxt
┃ ┃ ┣ 📜test.csv
┃ ┃ ┣ 📜test.record
┃ ┃ ┣ 📜train.csv
┃ ┃ ┣ 📜train.record
┃ ┃ ┣ 📜val.csv
┃ ┃ ┗ 📜val.record
┃ ┣ 📂models
┃ ┃ ┗ 📂efficientdet_d1_coco17_tpu-32
┃ ┃ ┃ ┗ 📂v1
┃ ┃ ┃ ┃ ┗ 📜pipeline.config
┃ ┣ 📂pretrained_models
┃ ┃ ┗ 📂datasets
┃ ┃ ┃ ┣ 📂efficientdet_d1_coco17_tpu-32
┃ ┃ ┃ ┃ ┣ 📂checkpoint
┃ ┃ ┃ ┃ ┃ ┣ 📜checkpoint
┃ ┃ ┃ ┃ ┃ ┣ 📜ckpt-0.data-00000-of-00001
┃ ┃ ┃ ┃ ┃ ┗ 📜ckpt-0.index
┃ ┃ ┃ ┃ ┣ 📂saved_model
┃ ┃ ┃ ┃ ┃ ┣ 📂assets
┃ ┃ ┃ ┃ ┃ ┣ 📂variables
┃ ┃ ┃ ┃ ┃ ┃ ┣ 📜variables.data-00000-of-00001
┃ ┃ ┃ ┃ ┃ ┃ ┗ 📜variables.index
┃ ┃ ┃ ┃ ┃ ┗ 📜saved_model.pb
┃ ┃ ┃ ┃ ┗ 📜pipeline.config
┃ ┃ ┃ ┗ 📜efficientdet_d1_coco17_tpu-32.tar.gz
┃ ┣ 📜exporter_main_v2.py
┃ ┗ 📜model_main_tf2.py
┣ 📜config.py
┗ 📜setup.py
模型训练和保存
我们做了很多工作才来到这里,并为开始训练做好了一切准备。下面是如何做到这一点:
*# from <project’s root folder>
tensorboard — logdir=<logs folder>**set NUM_TRAIN_STEPS=1000**set CHECKPOINT_EVERY_N=1000**set PIPELINE_CONFIG_PATH=<path to model’s pipeline.config>**set MODEL_DIR=<logs folder>**set SAMPLE_1_OF_N_EVAL_EXAMPLES=1**set NUM_WORKERS=1**python workspace\model_main_tf2.py \
— pipeline_config_path=%PIPELINE_CONFIG_PATH% \
— model_dir=%MODEL_DIR% \
— checkpoint_every_n=%CHECKPOINT_EVERY_N% \
— num_workers=%NUM_WORKERS% \
— num_train_steps=%NUM_TRAIN_STEPS% \
— sample_1_of_n_eval_examples=%SAMPLE_1_OF_N_EVAL_EXAMPLES% \
— alsologtostderr**# (optionally in parallel terminal window)
python workspace\model_main_tf2.py \
— pipeline_config_path=%PIPELINE_CONFIG_PATH% \
— model_dir=%MODEL_DIR% \
— checkpoint_dir=%MODEL_DIR%*
现在,您可以在浏览器中监控培训过程,网址为 http://localhost:6006 :

作者图片
要在训练完成后导出您的模型,只需运行以下命令:
*# from <project’s root folder>
python workspace\exporter_main_v2.py \
— input_type=image_tensor \
— pipeline_config_path=%PIPELINE_CONFIG_PATH% \
— trained_checkpoint_dir=%MODEL_DIR% \
— output_directory=saved_models\efficientdet_d1_coco17_tpu-32*
图像中的表格检测和细胞识别
NMS 和欠条
由于我们已经保存了新的微调模型,我们可以开始检测文档中的表格。前面我们提到了一个物体检测系统不可避免的问题——重叠包围盒。考虑到我们正在处理的无边界表格的过度分段性质,我们的模型偶尔会为单个对象输出比您预期的更多的边界框。毕竟,这是我们的目标探测器正在正确发射的标志。为了处理重叠边界框(指同一对象)的移除,我们可以使用非最大抑制。
неre 是我们的检测器在执行非最大值抑制前后的推断结果:

看起来我们已经成功地解决了预测重叠矩形包围物体的问题,但是我们的检测仍然达不到真实边界框。这是必然的,因为没有完美的模型。我们可以用交并比(IoU)来测量检波器的精度。作为分子,我们计算预测边界框和实际边界框之间的重叠面积。作为分母,我们计算由预测边界框和实际边界框包围的区域。IoU 得分> 0.5 通常被认为是“好”的预测[ Rosenbrock,2016 ]。
对于我们测试集中的一些图像,我们有以下指标:

细胞识别和 OCR
这将是我们的三部分算法的最后步骤:在(1)表格被检测到之后,我们将(2)用 OpenCV 识别它的单元格(因为表格是无边界的)并将它们彻底分配到适当的行和列,以进一步进行(3)用pytesserac通过光学字符识别(OCR)从每个分配的单元格中提取文本。
大多数细胞识别算法都是基于表格的行结构。清晰和可检测的线条对于正确识别细胞是必要的。由于我们的表格没有空白,我们将手动重建表格网格,在经过阈值处理和调整大小的图像上搜索白色垂直和水平间隙。这种方法有点类似于这里使用的。
完成这一步后,我们可以用 OpenCV 找到轮廓(即我们的单元格边界),将它们分类并分配到一个类似表格的结构中:
图表上显示了整个工作流程:

作者图片
至此,我们已经将所有的盒子和它们的值按正确的顺序排序了。剩下的工作就是获取每个基于图像的盒子,通过膨胀和腐蚀为 OCR 做准备,并让pytesserac识别包含的字符串:

最后的想法
啊,走了很长一段路!我们的自定义对象检测器可以识别文档中的半结构化信息块(也称为无边界表格),进一步将它们转换为机器可读的文本。尽管这个模型没有我们预期的那么精确。因此,我们有很大的改进空间:
- 在我们模型的配置文件中进行更改
- 与来自模型园的其他模型玩耍
- 执行更保守的数据扩充
- 尝试重新使用模型,之前在表格数据上训练过(虽然不可用于 TF2 对象检测 API)
厌倦了使用条形图?
利用条形图获得创意的 5 种方法
条形图是我在工作中展示数据见解时最常用的图表形式之一。但是我经常觉得这有点单调和重复,尤其是当你需要在同一个仪表板上显示很多 KPI 的时候。

普里西拉·杜·普里兹在 Unsplash 上的照片
这里有五种不同的变化,您可以使用条形图来显示数据。
1.使用圆形条
我在我最近的一部即关于 F.R.I.E.N.D.S .的电视连续剧中使用了这个技巧。它的工作方式基本上是你给 tableau 提供两个度量名,然后用它们画一条线。这和画彗星图很像。
a.首先绘制一个普通的条形图,方法是将维拖到列架,将度量拖到行架。

Tableau 中的普通条形图(图片由作者提供)
b.接下来,在行架上添加另一个度量值作为 min(0)。它基本上是 0 处的一个点,将作为绘制直线的第二个点。
c.现在我们需要将图表类型改为折线图。

步骤 1c。作者图片
d.将测量名称添加到路径架,将测量值添加到行架,并将两个测量都移动到测量值架,如下所示。
e.现在,只需调整线条的大小,使其稍微粗一点。如果需要,调整轴。
你完了!

圆形条形图(图片由作者提供)
2.带底座的圆棒
这种图表在我之前的 F.R.I.E.N.D.S .中也使用过。它对分类维度非常有效。您也可以使用相同的技术构建堆积条形图。

底部有甘特条形图的圆形条形图(图片由作者提供)
它与上一节的图表完全相似。得到圆形条形图后,按照以下步骤操作。
a.只需向 rows shelf 添加另一个度量值— min(0)。
b.右键单击计算并选择双轴。

作者图片
c.接下来右键单击 Y 轴,然后单击同步轴。

作者图片
d.现在,将第二个度量的图表类型更改为甘特图。
e.缩小条形的尺寸,你会得到带底的圆形条形图。

作者图片
调整轴就行了!
3.显示百分比份额或评级的条形图—类型 1
这种条形图在传达整体情况时非常有效。我最近在我的 viz — 我的几周生活中使用了它。您可以通过三个简单的步骤来构建它。
a.将连续尺寸添加到柱架中。
b.将图表类型更改为圆形。
c.根据需要增加颜色的尺寸,并增加条形的大小。
你完了!

来源:我的 Viz(作者图片)
4.显示百分比份额或评级的条形图—类型 2
如上所述,这种类型的条形图有助于快速显示评级或百分比。它很容易建立,并遵循类似的技术。它看起来超级好,可以用在工具提示中,就像我一样。我们将使用这种技术构建一个水平条形图。

来源:我的 Viz
a.您需要创建一个 min(10)的计算字段,并将其放在列架上。
b.接下来,在列架上添加评级度量值,并选择双轴。同步轴。
c.将最小(10)测量的图表类型更改为条形,并选择一种浅色填充。
d.将“评分”测量的图表类型更改为圆形,并选择较暗的颜色。
e.相应地调整尺寸。
你有它!

来源:我的 Viz
5.重叠条形图
当您想要显示不同时间段之间的比较时,这些图表非常有用。例如,您的管理层希望了解不同业务部门的季度业绩。
为了构建这个,我使用了 Tableau 中的样本超市数据集。
a.选择要用来分割结果的维度。我在这个例子中使用了 segment。
b.为该特定时间范围创建两个具有度量值的计算字段。例如,我正在比较 2019 年和 2020 年的销售额。所以,我创造了 2019 年和 2020 年的销量。


每年的销售额(图片由作者提供)
c.将这些销售字段拖到行架上,然后选择双轴。同步轴。
d.将日期字段拖到颜色卡上。在我的例子中,是年份字段。
现在,有趣的部分。
e.调整两个条形的大小。我一般会把旧的时间段的线条做得粗一点,半透明一点,把最新的时间段的线条做得粗一点,薄一点。
这是结果。

重叠条形图(图片由作者提供)
今天到此为止,各位!
我希望这些技巧和提示能像帮助我一样帮助你提高你的 viz。
感谢阅读!
下次见……
用于宏基因组样本分型的借用文本分析
如何使用 TF-IDF、XGBoost 和 SHAP 对元基因组进行分类和解释
这篇文章显示:
1.使用 GridSearchCV 为宏基因组样本分型构建 TF-IDF 和 XGBoost 管道。
2.使用 TF-IDF 对分类轮廓进行矢量化以进行建模。
3.建立一个 F1 分数高的 XGBoost 模型。
4.使用 SHAP 查看特征贡献并识别每个样本类型的不同分类群
介绍
自从安东尼·范·列文虎克第一次看到微生物世界,我们人类就被它迷住了。在不到 400 年的时间里,我们从无知到认识到它们在我们的健康和全球生化循环中的关键作用。据估计,在我们的身体上,微生物的数量是人类细胞的十倍。从生物燃料到塑料降解、生物修复和医药,我们的未来越来越依赖于它们。
即使我们仍然使用显微镜和生物化学测试来观察微生物,但仅根据它们的外观和生物化学反应,很难区分谁是谁。DNA 测序来拯救。如今,我们不仅测序单个基因组,还测序整个微生物群落,也称为宏基因组。

顾名思义,宏基因组是样本或栖息地内所有基因组的总和,无论是病毒、细菌还是真核生物。我们通过对宏基因组进行整体测序或者通过靶向 16S 区域来确定宏基因组的内容。不同类型的样本包含不同的生物体,因此它们的元基因组也应该不同。相反,这意味着可以通过单独检查它们的分类特征来区分不同的样本类型。例如,现在可以通过分析患者的宏基因组来进行快速临床诊断(皮安塔多西等人)。2018 。事实上,元基因组也已经被用于监测藻华的不同阶段。2012 ,估算作物生产力(常等)。2017 )、土壤质量(维斯特加德等)。2017 、加斯陶等人。2019 、水质(毕比等)。2019 )等众多。
已经有一些机器学习方法用于宏基因组样本分型。一方面是来自阿斯加里等人的微音器。在从 16S rRNA 基因序列的浅层子采样获得的 k-mer 上使用深度神经网络(DNN)、随机森林(RF)和线性 SVM(as gari等)。2018 )。另一方面,Dhugnel 等人。开发了 MegaR 软件包,该软件包从全宏基因组测序或 16S rRNA 测序数据中选择关于宏基因组分类概况的广义线性模型(GLM)、SVM 或 RF(Dhungel等)。2021 )。
在本文中,我展示了我解决这个问题的方法。我把它变成一个多类文本分类问题。如 Dhungel 等人。,我使用宏基因组分类轮廓数据。我将简介视为文本,并使用词频-逆文档频率(TF-IDF)来突出重要的分类群,淡化那些过于世界性或过于罕见的分类群。然后 XGBoost 基于 TF-IDF 值构建模型。参数将首先通过网格搜索交叉验证进行优化。一旦模型被建立和测试,我使用 SHAP 来检查特征的重要性,这样我就可以知道哪个分类群代表哪个样本类型。这个项目的代码存放在我的 Github 仓库中:
https://github.com/dgg32/mgnify_sentiment
而 Jupyter 笔记本可以用 nbviewer 渲染。
1.从 MGnify 下载分类简介
MGnify 是一个研究网站,托管了全球科学家提交的大量元基因组。它还处理序列,并为我们提供下载的 API。首先,用我的脚本下载各种栖息地的分类资料,也就是样本类型。在这个演示中,我从以下类型下载了 JSON 数据:“生物反应器”、“淡水”、“宿主”、“海洋”、“沉积物”和“土壤”。在每个 JSON 中,都有一个分类单元列表(Woeseia、Geobacter 等),包括它们的分类等级(门、纲、科、属等)以及它们在样本中的出现次数。在这个项目中,我使用属作为词汇表。
之后,我将 JSON 文件扩展成“文本”,通过重复出现的每个分类单元,例如“埃希氏菌”。少于 20 个不同属的样品被排除在分析之外。这一过程在“沉积物”类型中产生了 462 个样本,在“宿主”类型中产生了 57,741 个样本(图 2。).

图二。本项目中每种样品的数量。图片作者。
2.读取、训练-测试-分割和 GridSearchCV
我用一个 Jupyter 笔记本开始。下面是数据导入、80:20 训练-测试-分割、Sklearn 管道和网格搜索交叉验证的代码。
在这种情况下,我从“土壤”、“沉积物”、“海洋”和“淡水”中导入数据。每种类型下都有相当数量的数据。此外,我认为它们是一个很好的挑战,因为这些栖息地在生理化学上相互重叠。例如,淡水和海水都含有水,沉积物和土壤都是固体基质。因此,可能有属可以存在于四种类型中的一种以上。该模型将学习属的组成,以便将四个分开。
TF-IDF 是一种在一组文档中选择和量化特征词的方法。在许多文档中出现频率过高的单词,如“the”、“a”和“an”等停用词,会被过滤掉,因为它们不会区分文档。对于生僻字也是如此。它有效地减少了词汇量。在文本分析中,这是一种简单而有效的方法。我“借用”TF-IDF 来过滤属。通过网格搜索,我确定 min_df 为 2,max_df 为 0.7,这意味着管道将忽略出现在少于两个样本中的所有属,但也会忽略出现在超过 70%的样本中的属。
网格搜索交叉验证可能需要很长时间才能完成,因为它需要交叉验证每个超参数组合五次。参数之间的差异有时并不显著。因此,明智地使用 GridSearchCV,并密切关注手表。在我的尝试中,我得到了一组参数作为回报。最佳模型的 CV 值为 0.98。
3.根据测试数据运行最佳模型
是时候使用测试数据上的最佳参数运行管道并评估结果了。
我的渠道返回非常高的 F1 分数。比较预测值和实际值,似乎“沉积物”类型的召回率相对较低(0.77),这可能是由于“沉积物”中的样本量低(总共只有 462 个),并且模型不能完全捕捉其特征。
4.用 SHAP 解释特性的重要性
模型建立后,我使用 SHAP 软件包来检查模型,以便了解哪些属代表哪些栖息地类型。本质上,SHAP 展示了 XGBoost 模型中特征的重要性。但是 SHAP 值比 XGBoost 中的“feature_importances”有几个优势,包括全局和局部的可解释性、一致性和准确性(在这里阅读更多)。但是 SHAP 确实需要一些繁重的计算。一个背景数据集为 300 的 SHAP 计算需要 5 秒多的时间。因此在这个项目中,我使用了 SHAP 自己的“kmeans”方法将训练数据总结为 300 个项目。我只生成了测试数据中前 100 个样本的 SHAP 值。
计算出 SHAP 值后,让我们快速浏览一下每个属对每个样本类型的贡献(图 3。和图 4。).

图 3。每个属对每个样本类型的平均 SHAP 值。作者图片。
图 3。显示出苔藓菌、白假丝酵母 Udaeobacter】、“白假丝酵母 Solibacter”和Chthoniobacter(Chthonius:生于希腊语中的土壤,也是卡德摩斯神话中一个斯巴达的名字)是对决策贡献最大的前四个属。为了了解它们到底是如何贡献的,我生成了蜂群图来显示它们在“土壤”和“海洋”类型中的 SHAP 值分布。

图 4。“土壤”和“海洋”分类中每个属的 SHAP 值分布。图片作者。
图 4。揭示了每个属的细节。每个点代表前 100 个测试样本中的一个,颜色表示该样本中行亏格的 TF-IDF 值。比如第一行是关于br iobacter。标尺高端的红点表明苔藓菌中的高 TF-IDF 值更有可能进行“土壤”分类。前四名中的其他三名也是如此。但是在硫磺单胞菌和 Hyphomonas丰富的地方,样本不太可能来自土壤,而更有可能来自海洋。奇怪的是盐囊菌似乎是土壤的指示,因为前两个菌株是嗜盐的,并且是从海洋沿海地区分离出来的( Iizuka 等人)。1998 年。
我们可以用一些“局部”案例来进一步证实这些“全局”观察。例如,下图显示了为什么模型将测试样本 19 输入为“土壤”。

图 5。测试样品 19 的决策。图片作者。
图 5。就是所谓的武力阴谋。它显示了每个属如何增加或减少每个类型的概率。例如,“ Candidatus Udaeobacter”的存在增加了“土壤”分类的概率,同时降低了所有其他类型的概率。
很明显,所有前四个属都存在于测试样品 19 中。它们的存在使该模型对“土壤”分类有 100%的置信度,而对其他三种分类则没有。同样明显的是,硫磺单胞菌和 Hyphomonas 的缺失使得“海洋”分类不太可能。
让我们验证“ Candidatus Udaeobacter”确实更有可能出现在测试样品的土壤中:

图 6。测试样本中四种生境类型中“念珠菌属 Udaeobacter”的 TF-IDF 分布。作者图片。
图 6。显示了“白念珠菌 Udaeobacter”的 TF-IDF 值在四种生境类型中的分布。该图表明,这种微生物在土壤中可达到高达 0.7 的 TF-IDF 值,而在其它土壤中低于 0.1。事实上,已知“白假丝酵母 Udaeobacter”是一种丰富且普遍存在的土壤细菌( Brewer et al )。2017 。
结论
上面这个简短的教程展示了我的宏基因组样本分型的文本分析方法。TF-IDF 简单而强大。它的价值有一个很容易理解的意义。与 MegaR 中许多令人困惑的数字规范化不同,TF-IDF 不仅量化,而且消除了世界性和稀有属,以便于以后的 XGBoost 建模。总的来说,TF-IDF 是一种很好的方法,可以让分类数据为建模做好准备。
XGBoost 是一个很棒的模型构建工具。它速度快,性能好。我的模型达到了 0.98 的加权平均精度。但是,本教程并不局限于 XGBoost。事实上,我鼓励你尝试 Lightgbm、Catboost 甚至神经网络。
SHAP 软件包是迈向可解释人工智能的一大步。它可以分解一个模型的决策,并突出每个栖息地类型的属指示。我们可以从文献中证实它的观察结果。在 Haliangium 的例子中,我们甚至可能发现一些属的新栖息地。
虽然这篇文章使用了 16S 的分类模式,但它也适用于从整个宏基因组或其他方式产生的模式。然而,这种对分类法的依赖也有其缺点。来自未知生物的序列不在此范围内,因为它们还没有分类学。此外,在某些情况下,为词汇表选择正确的分类级别也很棘手。当一些样本类型非常相似时,样本分型可能仅在物种甚至菌株的水平上起作用。例如,2011 年在德国爆发的 EHEC 是由一种 E 引起的。大肠杆菌菌株而大多数其他大肠杆菌。大肠杆菌是无害的,常见于我们的下肠道。在这种情况下,我们应该将词汇更改为应变级别,以便抓住差异。
现在,请尝试我的管道为您自己的宏基因组样本分型,并告诉我你对这个问题的看法。
https://dgg32.medium.com/membership
博鲁塔和 SHAP 为更好的功能选择
不同特征选择技术的比较及其选择

克里斯汀·塔博瑞在 Unsplash 上的照片
当我们执行监督任务时,我们面临的问题是在我们的机器学习管道中加入适当的特征选择。简单地在网上搜索,我们可以访问各种各样的关于特征选择过程的资源和内容。
总之,有不同的方法来执行特征选择。文献中最著名的是基于过滤器的和基于包装器的技术。在基于过滤器的程序中,非监督算法或统计用于查询最重要的预测值。在基于包装器的方法中,监督学习算法被迭代拟合以排除不太重要的特征。
通常,基于包装器的方法是最有效的,因为它们可以提取特征之间的相关性和依赖性。另一方面,他们显示更容易过度适应。为了避免这种缺乏并利用基于包装器的技术的优点,我们需要做的就是采用一些简单而强大的技巧。我们可以通过一点数据理解和一个秘密成分来实现更好的特征选择。别担心,我们不用黑魔法而是用 SHAP 的力量。
为了在特性选择过程中更好地利用 SHAP 的能力,我们发布了shap-hype tune:*一个 python 包,用于同时进行超参数调整和特性选择。*它允许在为梯度推进模型定制的单个管道中组合特征选择和参数调整。它支持网格搜索或随机搜索,并提供基于包装器的特征选择算法,如**递归特征消除(RFE)、递归特征添加(RFA)、**或 Boruta 。进一步的添加包括使用 SHAP 重要性进行特征选择,而不是传统的基于原生树的特征重要性。
在本帖中,我们将展示正确执行功能选择的实用程序。如果我们高估了梯度增强的解释能力,或者仅仅是我们没有一个总体的数据理解,这就揭示了事情并不像预期的那么简单。我们的范围是检测各种特征选择技术的表现如何,以及为什么 SHAP 的使用会有所帮助。
博鲁塔是什么?
每个人都知道(或者很容易理解)一个递归特征消除是如何工作的。它递归地适合考虑较小特征集的监督算法。其中被排除的特征是根据一些权重的大小(例如,线性模型的系数或基于树的模型的特征重要性)被认为不太重要的特征。
Boruta 和 RFE 一样,是一种基于包装器的特征选择技术。它不太为人所知,但同样强大。Boruta 背后的想法真的很简单。给定一个表格数据集,我们迭代地将监督算法(通常是基于树的模型)应用于数据的扩展版本。在每次迭代中,扩展版本由原始数据和水平附加的混洗列的副本组成。我们只维护每个迭代中的特性:
- 比最好的混洗特征具有更高的重要性;
- 比随机机会(使用二项式分布)更好。
RFE 和博鲁塔都使用监督学习算法来提供特征重要性排名。这个模型是这两种技术的核心,因为它判断每个特征的好坏。这里可能会出现问题。决策树的标准特征重要性方法倾向于高估高频或高基数变量的重要性。对于博鲁塔和 RFE 来说,这可能导致错误的特征选择。
实验
我们从 Kaggle 收集数据集。我们选择一个银行客户数据集,试图预测客户是否很快会流失。在开始之前,我们向数据集添加一些由简单噪声产生的随机列。我们这样做是为了理解我们的模型是如何计算特征重要性的。我们开始拟合和调整我们的梯度推进(LGBM)。我们用不同的分裂种子重复这个过程不同的时间,以克服数据选择的随机性。平均特征重要性如下所示。

各种分裂试验的平均特征重要性[图片由作者提供]
令人惊讶的是,随机特征对我们的模型非常重要。另一个错误的假设是认为 CustomerId 是一个有用的预测器。这是客户的唯一标识符,被梯度推进错误地认为是重要的。
鉴于这些前提,让我们在数据上尝试一些特征选择技术。我们从 RFE 开始。我们将参数调整与特征选择过程相结合。如前所述,我们对不同的分裂种子重复整个过程,以减轻数据选择的随机性。对于每个试验,我们考虑标准的基于树的特征重要性和 SHAP 重要性来存储所选择的特征。通过这种方式,我们可以画出在试验结束时一个特征被选择了多少次。

用 RFE(左)选择一个特征的次数;用 RFE + SHAP(右)选了多少次特写[图片由作者提供]
在我们的案例中,具有标准重要性的 RFE 显得不准确。它通常选择与 CustomerId 相关的随机预测值。 SHAP + RFE 最好不要选择无用的功能,但同时也要承认一些错误的选择。
作为最后一步,我们重复相同的程序,但是使用 Boruta。

用 Boruta 选择一个特征的次数(左);用博鲁塔+ SHAP(右)选了多少次特征[图片由作者提供]
标准的 Boruta 在不考虑随机变量和 CustomerId 方面做得很好。SHAP +博鲁塔似乎也做得更好,减少了选择过程中的差异。
摘要
在这篇文章中,我们介绍了 RFE 和博鲁塔(来自 shap-hypetune )这两个有价值的特性选择包装器方法。此外,我们用 SHAP 代替了特征重要性的计算。 SHAP 帮助减轻了选择高频或高基数变量的影响。总之,当我们有一个完整的数据理解时,RFE 可以单独使用。博鲁塔和 SHAP 可以消除对经过适当验证的选拔过程的任何疑虑。
如果你对题目感兴趣,我建议:
保持联系: Linkedin
波士顿 Airbnb 业务分析和挂牌价格预测
简介
答 irbnb 是一个在线市场,它安排并提供人们可以临时居住的房间或房屋。该公司只是一个连接租户和业主的经纪人,然后从每笔预订中获得佣金。无论你是主人还是客人,对业务有一个知情的决定是很重要的,并决定何时将你的房产挂牌出租,或以可承受的价格参观城市。我在这里分析了波士顿的业务是如何增长的,并提出了一个模型来预测给定上市的价格。完整的笔记本和代码可以在我的 GitHub 上找到。

https://unsplash.com/photos/iRKv_XiN-M
我的分析将集中在 2008 年至 2016 年收集的 Airbnb 数据。该数据集有 3585 个列表,95 个特征描述了业务的不同方面。原始数据集可以从 Kaggle 下载。
下面描述的分析只是基于我的观察,并不是真正的专家对如何开展业务的观点。我将尝试回答以下问题:
1-波士顿的 Airbnb 业务发展如何?
2-最受欢迎的社区是什么?是什么让他们受欢迎?
3-公司最忙的时候是什么时候?
4-影响波士顿 Airbnb 价格的特征是什么?我们可以根据预测模型预测新房源的租赁价格吗?
第一部分:波士顿的 Airbnb 业务发展如何?

作者的情节
正如我们在上面的图 1 中看到的,这项业务始于 2008 年,几乎没有上市,但多年来持续增长,仅在 2015 年就达到 1000 多家上市公司。2016 年的下降只是因为数据是在年底前收集的。
我们还提供了 2016 年和 2017 年的上市信息。我们看到,从 2016 年到 2017 年,可供预订的房源数量翻了一番,如下图图 2 所示。

作者的情节
第二部分:什么是最受欢迎的社区?是什么让他们受欢迎?
数据集中有 25 个不同的社区,下面是社区的列表数量和平均价格的分布。

邻域排名-由作者绘制
就上市数量而言,我们看到牙买加平原、南端、后湾、芬威、多切斯特、奥尔斯顿是最受欢迎的,每个城市都有超过 250 个上市项目。南波士顿海滨、海湾村、皮革区、后湾、市中心、唐人街挂牌均价较高。房源较少的小区,挂牌均价似乎较高。

作者的情节
正如我们在*图 5 中看到的。*如上图,这些年来,所有社区的收入都在增长。我们还注意到,列表数量越多的社区收入越多。
第三部分:生意最忙的时候是什么时候?
对于计划游览这座城市的人来说,了解什么时候是最忙的季节,什么时候是最忙的日子,以便做出相应的计划是很重要的。

图 7:按季节和星期列出可用性分布——按作者绘图
正如我们在上面的图 7 中看到的,最繁忙的季节是春季和夏季。我们看到,一周中的所有日子都有几乎相同的趋势,但周三的预订略有增加。毫无疑问,冬季是活动最少的最慢季节,因为波士顿会变得非常寒冷并下雪。有趣的是,在秋季,周三和周四似乎比一周中的其他日子更繁忙。秋天周末其实活动比较少。
第三部分:波士顿 Airbnb 中影响价格的特性有哪些?我们可以根据预测模型预测新房源的租赁价格吗?
在进入建模部分之前,我们将调查价格分布,然后检查可能影响价格的缺失值和异常值的存在。

作者的情节
上图 8 显示了按物业类型和房间类型划分的价格分布。与私人房间和共享房间相比,整个房间/公寓的平均价格在所有类型的房产中都较高。
然而,我们注意到异常值的存在,这些异常值是矩形以外的点。为了保持预测的一致性,我们将去掉这些极值。准确地说,我们将删除所有大于平均值 2 个标准偏差的数据点和小于平均值 2 个标准偏差的值。去除异常值后,图 9 显示了不同房间类型的整体价格范围。

作者的情节
我们可以看到有少量价值低于 200 美元的共享房间。包房和整个家/公寓代表了生意的核心,价格在不同的区间。
影响价格的前 15 个数字列
以下是对标价影响较大的前 15 列:
['accommodates', 'cleaning_fee', 'bedrooms', 'beds',
'host_listings_count', 'host_total_listings_count',
'calculated_host_listings_count', 'guests_included',
'review_scores_location', 'availability_30', 'host_acceptance_rate',
'bathrooms', 'availability_60', 'availability_90',
'review_scores_cleanliness']
影响价格的顶级分类列
['neighbourhood_cleansed',
'property_type',
'room_type',
'bed_type',
'cancellation_policy',
'host_is_superhost',
'instant_bookable',
'is_location_exact',
'require_guest_phone_verification',
'require_guest_profile_picture']

作者的情节
除了上面的数字特征和分类特征之外,我们还处理了市容列,这将在一次性编码后向我们的数据集添加 45 列。最后,我们将用来预测价格的最终数据集有 3494 行和 89 列。
上图(图 10 和图 11 )显示了预测价格和实际价格之间的相关性。我们看到预测价格和真实价格之间有很好的相关性。
预测后,R _ sqauared(这是数据与拟合回归线接近程度的统计度量。它也被称为决定系数,或多元回归的多重决定系数。)在训练数据上是 0.69,在测试数据上是 0.701。这表明我们可以很有把握地预测上市价格。
评估结果
我们仅通过挑选与价格密切相关的前 15 个数值变量、前 20 个分类变量就取得了上述结果。
为了改善我们的结果,我们设置了一个网格,并运行我们的算法来搜索导致最佳结果的特征集。我们发现,使用 23 个数值变量,45 个分类变量,我们在测试数据上获得了 0.704 的*R_sqauared*,与我们的原始结果相比,这并不是一个很大的改进。
我们已经使用上面找到的最佳特征尝试了随机森林回归器,并且在训练数据上获得了*R_sqauared* 0.95,在测试数据上获得了 0.73,这并不是比较两个分数之间方差的更好分数。
结论
在这篇博客中,我们分析了波士顿市的 Airbnb 数据,并回答了一些商业问题,这些问题可以让主人和客人就何时发布房源或何时游览这座城市做出明智的决定。
我们使用了一些功能来预测给定列表的标价。尽管我们的结果相当显著,但仍有改进的空间,可以处理一些栏目,如评论(来自客人的评论)、帖子的摘要、d 描述、邻居概述、房屋规则。
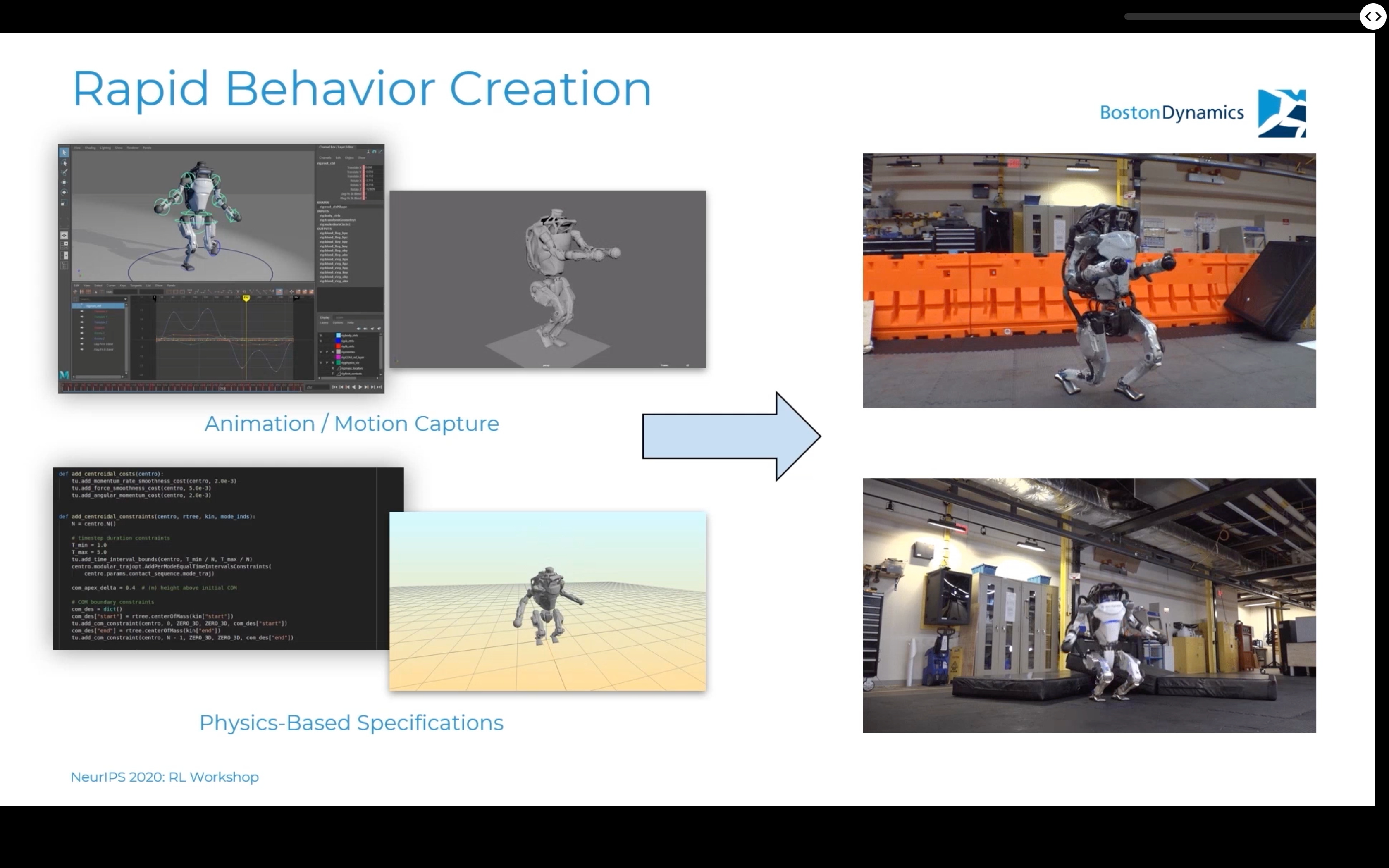
波士顿动力学:研究运动智能
杂技舞蹈视频华而不实,但有哪些实际的技术突破?韩国机器人产业正在发生什么?
这家机器人公司擅长制作病毒式技术视频,展示机器人能做的件小事、跑酷、欺凌、机器人,以及更多。波士顿动力公司的一个核心原则是运动智能的理念——强健、灵活,甚至可能是人类的运动模式。这些视频和技术已经到了最受欢迎的技术艺人得到一份拷贝并评论它的地步,它们是待售的,并且是可访问的。最近的视频试图展示一种新的人类运动方式(下图)。
他们对运动智能的关注真的帮助我了解了这家公司,它在哪里适合他们的视频,以及为什么老板不留下来。波士顿动力公司使用机器学习和人工智能作为工程堆栈中的工具,而不是将其扔向他们遇到的每个子问题。
在本帖中,我们:
- 理清波士顿动力公司的历史(它不是政府承包商),
- 展示他们所谓的突破 竞技智能 ,
- 和讨论现代子公司的下一步计划。
什么是波士顿动力
Boston Dynamics 在 2014 年放弃了所有 DARPA 的合同(它们是由 DARPA 种子基金启动的,但我们使用的大量 技术是!)他们有着有点复杂的买家和卖家历史,包括谷歌、软银和现在的现代——我认为这主要是他们的长期目标和市场的短期价值之间的脱节。波士顿动力公司的长期目标是创建一个运动智能的演示,并将其出售给能够解决其他认知问题(规划、后勤、互动)的人。
运动智能的目标是使机器人学中鲁棒性和速度的结合成为可能。如果这对你来说没有什么印象,看看一些历史上最好的机器人团队参赛的例子。

来源——波士顿动力博客。
我经常听到(我也延续了这种想法的一部分)他们的技术部分是由军事应用资助的,完全是为军事应用设计的。虽然他们的机器人在自己的环境中似乎很健壮,但他们并没有满足 21 世纪相反战争的许多趋势:远程、隐形和受损时的健壮(他们的机器人很吵——那些大型液压致动器不会偷偷靠近你!).要了解完整的历史,请查看维基百科、他们的关于页面,另一篇更长的历史文章,或者波士顿报纸 Raibert 的更多个人评论。
总而言之,他们一直专注于通过联合开发硬件和软件能力来推动腿式运动极限的目标。他们一直在纠结如何将这种进步货币化。
运动智能与机器智能
在这一部分,我将重点介绍他们的神奇是如何发生的。他们所做的硬件开发是一流的,但是机器智能中的 部分有可能扩展到更多的平台,所以我关注它。简而言之,与机器人研究的状态相比,他们的学习和控制基础设施不是革命性的,但它是发达的和高度功能化的。让我们期待波士顿动力公司的未来,他们的控制方法不要太依赖于他们的硬件平台,他们可以重复控制工程。
广义而言,运动智能首先需要发展低水平的控制能力和运动灵活性。这种灵活的机器人运动是公司价值的核心。他们研究如何优化液压等机械部件,以提高控制性能。他们精确集成所需的传感器(激光雷达、电机编码器、IMU 等。)来解决任务和许多不同的计算。
在 NeurIPs 2020 真实世界 RL 研讨会上,他们展示了他们的高水平方法(视频此处)。关于控制方法的幻灯片总结了他们的工具集:基于模型、预计算和细致的工程设计(这是研究实验室所缺少的)。
[ 将链接到我正在引用的幻灯片]
基于模型的
所有的模型都是错的,但有些是有用的【乔治盒子这里是他们幻灯片的主旨。
事实上,这是一种有趣的相互作用,因为他们可以非常详细地模拟他们机器人的某些方面(例如,一种类型的液压致动器),但当他们开始将碎片放在一起时,累积的模型有缺口——并且不可能知道确切的位置。
模型也是一个很好的工具,人类将参与其中(可以解释结果),但没有法律说基于模型的方法更有效。他们将它与幻灯片上的第二点紧密结合。
导航预行计算
基于模型的是配对、预计算,它们共同构成了模拟的工具。模拟是机器人技术的未来(比运行硬件实验要便宜得多,尤其是在流行病中),他们似乎已经充分利用了这一点。
现实世界 RL 研讨会上的对话强调了他们利用模型预测控制(MPC)的程度,这是目前已知的计算量最大的控制方法之一。不过,最近的工作已经转向离线求解 MPC,然后在线运行一个更简单的版本(他们没有证实这一点,但答案至少指向概念上类似的东西)。在实践中,这变成了:从真实的机器人试验中收集大量状态,然后离线求解每个可能状态下的最优动作,并运行读取这些动作的控制器(非常快)。
严格记录
他们在这里用数据驱动来表示一种不同的东西,“数据不会说谎”,这其实在 EE 和 ME 圈子里要常见得多(深度学习前的炒作,啾啾)。
我认为 RL 的许多领域可以从分析每一次试验中到底发生了什么中学到更多。知道代理是错的是一回事,但是弄清楚为什么它是错的以及错误如何随着时间传播是非常重要的。波士顿动力首先不是一家机器学习公司,这与他们的方法相匹配。
让新的机器人跳舞
值得说明的是,他们如何使用动作捕捉、模仿学习和丰富的模拟来制作他们最近的视频。为了更详细地阐述下图中的内容,他们让人类演员在录制环境中创建运动原语(或在物理模拟器中指定运动,这看起来不是很运动),使用模仿学习的技术来生成与运动匹配的策略,然后正确设置模拟器,以便新策略可以轻松地转移到机器人。
[行为生成幻灯片
最终,我们能够利用这个工具链在一天之内,也就是我们拍摄的前一天,创作出 Atlas 的一个芭蕾动作,并且成功了。所以这不是手写脚本或手写代码,而是有一个管道,让你可以采取一系列不同的运动,你可以通过各种不同的输入来描述,并推动它们通过机器人。
对于更大的图景,我只有一个想法:针对特定的行业约定,客户想要的预编程动作。你希望你的机器人能够拾取特定尺寸的包裹——让我们看看我们能否验证这个动作并更新你的机器人。有一个框架,设计者对输出足够有信心,他们可以通过软件更新来发布它,这听起来很像为什么这么多人喜欢他们的 Teslas(硬件上的软件更新实际上并不存在)。
他们在这些运动上投入了大量的工程时间。更值得思考的是更大的图片动机是什么(它不可能只是视频)。如果他们试图以任何人机交互的形式销售机器人,一套更丰富的动作可能非常有价值,但迄今为止没有任何迹象表明这一点。人类风格的舞蹈很可能会推动一个包的极限,也许是他们在 2 月 2 日宣布的新包。
艺术重点和恐怖谷
让机器人看起来像人类是一件值得警惕的事情。当然,人类的运动是动态的、优雅的、非常高效的,但这并不意味着它在不同的致动器下总是最优的。人类风格也会带来巨大的文化包袱和意想不到的影响。
这并不是说我反对具有人类功能的机器人——社会是围绕具有我们的腿和身高的生物构建的,这些生物可以轻松地在建筑物中导航并解决日常任务。我建议并希望机器人能够模仿人类的运动模式(比如使用两条腿,或者拥有带手和腕关节的手臂),但不以完全模仿为目标。
如果你对此感到好奇,请阅读我在恐怖谷的文章。

照片由 Unsplash 提供。
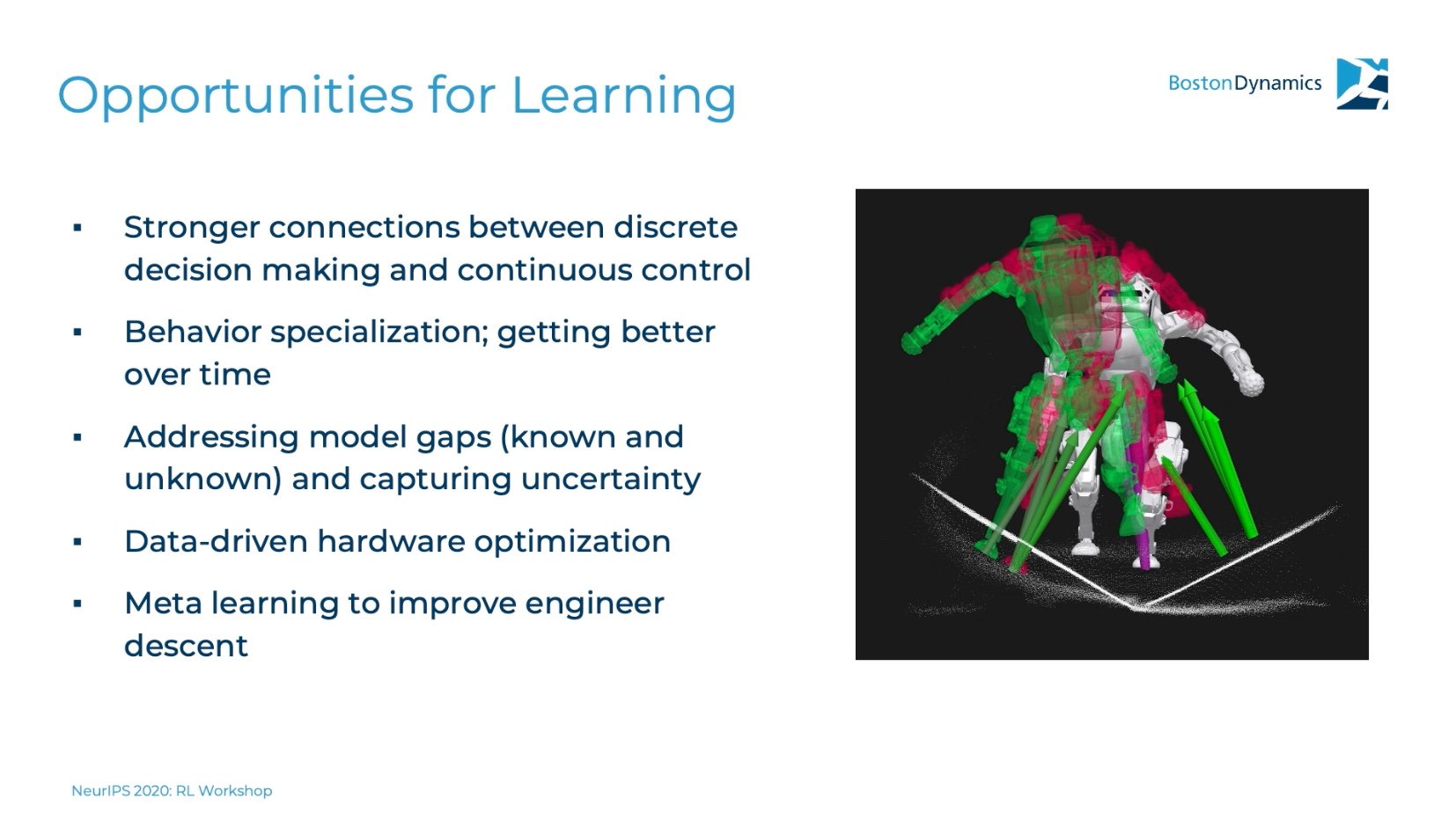
利用更多的学习
有学习机会的 滑梯 正在点上。持续学习、模型精度改进、基于学习的硬件优化和工程协助都是当今学习可以帮助解决的问题。
- 持续学习非常适合无模型学习——这是一个旨在从稀疏回报中学习的系统,没有转移到其他任务的目标。
- 现实世界中的模型精度归结为将数据拟合到扰动,或者他们已经优化以获得初始敏捷性的动力学模型与来自机载传感器的观测值之间的差异。模拟和物理来获得初始模型、数据,以及机器学习来更新它以匹配最近的现实。
- 用 ML 进行硬件优化:人类真的不擅长拟合多目标函数。当你在制造物理设备时,成本会随着材料和时间的增加而增加,让机器为你做这件事(我正在做的事情)。
- 工科出身。我喜欢他们的术语,我认为这只是填补裂缝的可以这么说,也是对学习可以有用的认可,即使对一家如此注重实际交付成果的公司来说。
波士顿(现代)动力公司的下一步是什么?
南韩有一套 文化价值观使得机器人代理在社会多个领域的扩散时机成熟。一份对来自国际机器人联合会的报告(我知道,双重引用,令人痛苦,但做机器人行业研究也是如此——这都是隐藏的)的分析得出结论:
韩国是世界上自动化程度最高的国家。
韩国精神&机器人
更有趣的是,正如一位韩国工程师声称 s:
任何一种非人类都可能有超越人类能力的精神或超能力。
这只是一种观点,但历史指向一套对其他存在更开放、更乐观的价值观。这种感觉肯定是基于动物的,但一小部分转化为机器人可以实质性地重构社会。
现代韩国的第一位国王丹根(Dangun)的故事,以及韩国对动物和潜在的非人类灵性生物的喜爱是奇妙的:
一只老虎和一只熊向万隆祈祷,希望他们能变成人类。听到他们的祈祷,万隆给了他们二十瓣大蒜和一捆艾蒿,命令他们只吃这种神圣的食物,并且在 100 天内不要晒太阳。大约二十天后,老虎放弃了,离开了山洞。然而,熊坚持下来了,被变成了一个女人。据说熊和老虎代表了两个寻求天帝恩宠的部落。
The bear-woman (Ungnyeo; 웅녀/ Hanja: 熊女) was grateful and made offerings to Hwanung. However, she lacked a husband, and soon became sad and prayed beneath a “divine birch” tree (Korean: 신단수; Hanja: 神檀樹; RR: shindansu) to be blessed with a child. Hwanung, moved by her prayers, took her for his wife and soon she gave birth to a son named Dangun Wanggeom.
由此,韩国对非人类生物以及它们所能带来的价值有了更多的开放。这是一个多么伟大的变化——美国人无法摆脱社交媒体监管的泥潭,并认为他们的发言者在听。
韩国实用性和机器人
Hyuandai 最近收购了 Boston Dynamics (来自《The Verge】)和《彭博》显示该公司并未持续盈利。重复销售和低盈利对一个公司来说不是一个好兆头(也许加入软银的基金对公司来说是一个坏兆头),那么下一步是什么呢?
那么现代为什么要买它们呢?使用机器人进行生产。这是一个大转变,我认为大多数人都没有预见到(浮华、敏捷的机器人乍一看最适合高端消费者和利基产品)。现代重型机械在 2020 年进入市场销售多种机器人,他们自称韩国头号机器人制造商。一个重要的背景是,韩国已经拥有了高密度的工业机器人(见关于韩国机器人产业的背景)。
波士顿动力公司在 Spot 和 Atlas 中创造的运动原型真的是人们可以建立的东西。制造业中的运动智能转化为强壮,这是非常有价值的。它只是没有敏捷性那么令人兴奋。
新产品
2 月 2 日有一个新的产品线公告扩展 Spot 的产品。我预计这将是硬件的变体(想想不同的手臂附件,而不仅仅是视频中展示的单臂)和不同的软件包,可以解决探索或更复杂的运动挑战等任务。
在采访和产品中,波士顿动力公司看起来更像是一个研究实验室,在推动腿式运动的软硬件协同设计的极限。我喜欢他们为这个领域所做的工作,但实际上,我希望在几年内有更多的盈利,也许随着他们成为一个行业研究实验室,宣传会更少。

斑点在这种冰里会怎么样?来源—作者。
包装
波士顿动力公司是一家推动机器人领域发展和投资的重要公司。不过,我不会投资它们,这没关系。作为一名运动员,我被他们关于运动智能的理想所吸引,但作为一名研究人员,我真的对实用智能更感兴趣。如果机器人不能捡起一个新的物体或制作咖啡,那么它是否能跑酷就无关紧要了。希望现代公司为他们闪亮的新研究机构增加一个翻译部门。
我也在考虑把这个博客重新命名为更时髦的东西。主题不会改变,但它可能有助于增长。如果你有任何意见,请告诉我。
这个原本出现在我的自由子栈 民主化自动化 。请查看或关注我的 推特 !
用于浓缩咖啡的无底 vs 喷动移动式过滤器
咖啡数据科学
一个好的理由去无底的高峰
几年前我去了一家无底 portafilter ,从此一去不返。我把所有的机器都换成了无底的 portafilter,只有一台除外;La Peppina 脱衣服更有挑战性。深不见底的 portafilter 非常需要能够实时看到浓缩咖啡的发展,所以我想给出两个镜头的比较,以显示味道和提取的差异。
这是底部的样子。


左:原金 Expresso Portafilter,右:无底与 Pesado 精密篮子。所有图片由作者提供。
每一个镜头都是在 Kim Express 上用一个 Pesado 精密过滤器篮拍摄的。咖啡是同样的烘焙,而且是在同样的韩国研磨机上研磨的。
喷动移动式过滤器






无底移动式过滤器






从冰球投篮的角度来看,差异很小:


左:喷出,右:无底
绩效指标
我使用两个指标来评估技术之间的差异:最终得分和咖啡萃取。
最终得分 是评分卡上 7 个指标(辛辣、浓郁、糖浆、甜味、酸味、苦味和回味)的平均值。当然,这些分数是主观的,但它们符合我的口味,帮助我提高了我的拍摄水平。分数有一些变化。我的目标是保持每个指标的一致性,但有时粒度很难确定。
使用折射仪测量总溶解固体量(TDS),该数字结合咖啡的输出重量和输入重量,用于确定提取到杯中的咖啡的百分比,称为提取率(EY)** 。**
表演
对于口味来说,无底的 portafilter 是一个明显的赢家,对于任何想改善他们的浓缩咖啡的人来说,这是一个真正的游戏改变者。这是因为镜头的一些部分停留在移动式过滤器上,我还怀疑一个喷动的移动式过滤器可能会导致流动的一些变化。用玻璃或透明塑料过滤器来检验这种效果是很有趣的。最大的改进是甜味、酸味、苦味和回味。
 ****
****
就 EY 而言,它们非常相似,所以我很好奇是什么机制导致了味道的差异。
时差更难看出。所以我把时间量到 1g,时间量到 10ml。这些在无底的地方发生得更快,可能是因为在总时间相同的情况下,液体的移动距离更短。

无底移动式过滤器的两个优点是:
- 人们可以在拍摄过程中看到结果并进行调整。
- 移动式过滤器影响味道。
我强烈推荐那些对提升他们的咖啡体验感兴趣的人去无底咖啡吧。
如果你愿意,可以在 Twitter 和 YouTube 上关注我,我会在那里发布不同机器上的浓缩咖啡视频和浓缩咖啡相关的东西。你也可以在 LinkedIn 上找到我。也可以关注我中和订阅。
我的进一步阅读:
限制机器学习算法的样本大小
限制机器学习算法的样本大小非常有帮助。请继续阅读,找出方法。

米卡·鲍梅斯特在 Unsplash 上的照片
机器学习算法的一个常见问题是,我们不知道我们需要多少训练数据。解决这个问题的一个常见方法是经常使用的策略:保持训练,直到训练误差停止减小。然而,这仍然存在问题。我们怎么知道我们没有陷入局部最小值?如果训练误差有奇怪的行为,有时在训练迭代中保持平稳,但有时急剧下降,该怎么办?底线是,如果没有一种精确的方法来知道我们需要多少训练数据,那么我们是否完成了训练总是有一些不确定性。
然而,在某些问题中,实际上有可能从数学上确定我们需要多少训练数据。想法是这样的:我们有两个参数ε和 1 — δ。这些参数分别代表我们期望的测试集误差和我们期望的达到该测试集误差的概率。有了这两个参数,我们的目标是找到 m,达到这两个参数所需的最小样本数(训练数据)。例如,假设我们有ε = 0.05,δ = 0.1(所以 1 — δ = 0.9)。然后,我们的目标是找到最小数量的样本 m,这样我们的学习算法有 90%的机会在测试集上实现小于 5%的误差。
让我们来看一个具体的问题,看看这种方法是如何使用的。我们的两个自变量是 SAT 成绩和 GPA。我们的目标是用这两个变量来预测一个人是否是普通学生。我们把普通学生定义为 SAT 成绩和 GPA 都在中等水平的人。图形上,我们可以把 SAT 成绩放在 x 轴上,GPA 放在 y 轴上。所以下图中的矩形代表的是一个“一般学生”。长方形里面的每个人都是普通学生,外面的每个人都不是。我们学习算法的目标是计算出这个矩形的大小和位置。

蓝点是一般学生。黑点不是。蓝色矩形代表平均水平学生的界限。图片作者。
接下来的事情是定义我们的学习算法。我们得到了一个样本(SAT 分数,GPA)对,以及每一对是否是一个普通学生。我们的算法是这样工作的:取所有被标记为平均值的配对,然后画出适合这些配对的最小矩形。这个算法更容易用图片来表示:

绿点是我们的样本。我们的算法在样本中平均的点周围画出最小的矩形。图片作者。
现在让我们考虑一下这个算法是如何依赖于样本大小的。样本量越大,样本中代表的蓝色矩形(真实的平均学生临界值)就越多。因此,绿色矩形将覆盖更多的蓝色矩形。换句话说,样本量越大,误差越小,这是意料之中的。我们的目标是根据ε和δ明确定义这种关系。
首先,我们确定一个ε。回想一下,ε是我们希望达到的误差——我们希望误差不超过ε(更低也是可以接受的)。接下来,我们将构建一个ε可以实现的场景,并找出该场景的概率。考虑从蓝色矩形的四个边“生长”矩形。这四个新矩形的概率质量为ε/4。我们可以在图表上用 A、B、C 和 d 来表示它们。

每个红色矩形的概率质量为ε/4。图片作者。
首先,请注意,如果误差>ε,样本在至少一个矩形中一定没有点。这是因为如果样本在所有矩形中都有一个点,误差最多为ε,因为我们构建了四个矩形,使其最大组合概率质量为ε。

四个红色矩形中都有点的样本。因此,最大可能误差小于ε。图片作者。
所以 p(误差>ε) < P(sample has no point in at least 1 rectangle). There are 4 rectangles, so we have P(sample has no point in at least 1 rectangle) < P(sample has no point in A) + P(sample has no point in B) + P(sample has no point in C) + P(sample has no point in D) = 4* P(sample has no point in A) by symmetry, as we set all rectangles to have the same probability mass ε/4. Because our sample size is m, P(sample has no point in A) = (1 — ε/4)^m. Putting it all together, we have P(Error > ε) < 4(1 — ε/4)^m. Thus, given an arbitrary error ε, if we want to upper bound the probability of that error occurring with δ, we set δ > 4(1 — ε/4)^m.剩下的就是求解 m 得到 m > ln(δ/4) / ln(1 — ε/4)。我们可以用不等式(1 — x) < e^(-x) to simplify the expression to m > (4/ε)ln(4/δ) 。我们已经实现了根据ε和δ限制样本大小 m 的目标。
像这样的绑定非常有用。我们可以直接计算出要达到某个误差的某个概率需要多少样本。例如,如果我们希望有 99%的概率得到 1%的更好的误差,我们需要(4/0.01)ln(4/0.01) = 2397 个训练样本。如果我们能够为所有机器学习算法计算出这样的界限,生活将会变得容易得多。不幸的是,其他机器学习算法比我们的矩形算法更复杂,因此数学分析可能很难处理。其他时候,可能会找到一个界限,但这个界限可能太高,以至于在功能上没有用。然而,我相信机器学习理论的进步最终将为大多数机器学习算法提供有用的界限。
在本文中,我们根据ε和δ推导了一个简单学习问题的样本大小界限。如果你对这个分析机器学习算法的通用框架感兴趣,可以去看看我写的关于 PAC 学习的文章。如果你有任何问题/评论,请告诉我,感谢你的阅读!
Box-Cox 变换是我们需要的魔法
选择正确型号的聪明绝招

马修·施瓦茨在 Unsplash 上的照片
在进行统计分析时,我们通常希望得到正态分布的数据。这是因为事实上绝大多数的统计检验只有当我们在正态分布的数据点上使用它们时才是可解释的。
但是,如果我们的数据是非正态的,我们可能希望调查原因并执行相关的转换,以获得大致的正态分布。实现这一点的最流行的方法之一是 Box-Cox 变换。
什么是数据转换?
转换数据意味着对数据集的每个部分执行相同的数据操作。我们可以区分两组主要的变换:线性和非线性。
当我们的数据简单地除以或乘以某个常数,或者从我们的数据集中添加这样的常数或底物时,就会发生线性变换。因此,线性变换后,我们无法观察到数据分布的变化,我们的数据看起来不会比以前更正常。

线性模型。图片来自 https://en.wikipedia.org/wiki/Linear_regression
非线性变换可能更复杂。我们希望改变数据分布的形状,而不是基本的数学运算。它通常涉及对数、指数等的使用。其中一个例子是对数线性模型,它可以解释为简单线性模型变量的对数:

您可以在我之前的文章中找到关于这个模型的更多细节:
博克斯-考克斯方法
这种转变背后的故事被视为一个神话。据说,统计学家乔治·博克斯和大卫·考克斯爵士在威斯康辛州见过一次面,他们得出结论说,他们必须一起写一篇科学论文,因为他们的名字很相似,而且他们都是英国人。不管这个故事的真实性如何,最终,他们合作并在 1964 年发表的一篇论文中提出了他们的转变,并签上了他们的名字。

乔治·博克斯。图片来自https://en.wikipedia.org/wiki/George_E._P._Box
Box-Cox 变换是一种非线性变换,允许我们在线性和对数线性模型之间进行选择。通过这个操作,我们可以概括我们的模型,并在必要时选择一个变量。转换公式定义如下:

λ参数通常在-5 到 5 之间变化。考虑整个范围的值,并选择最适合我们数据集的值。
例如,当我们用 1 代替λ时,我们得到:

另一方面,当我们用-1 代替λ时,我们得到:

当 lambda 等于 0 时,最困难的部分是计算,因为我们剩下一个不确定的值。函数极限看起来像这样:

我们得到不定形式。在这种情况下,采用德累斯顿法则并用λ来区分是可行的:


大卫·考克斯爵士。图片来自https://en . Wikipedia . org/wiki/David _ Cox _(统计师)
我们什么时候可以使用它?
所描述的变换经常用于因变量和单个自变量的建模。在这种情况下,我们得到了 Box-Cox 模型:

“所有的模型都是错的,但有些是有用的。”—乔治·博克斯
同样,对于等于 1 的λ,该模型可以被解释为简单的线性模型:


对于等于-1 的λ,我们获得变量倒数的线性模型:


最后,对于等于 0 的λ,我们有一个对数线性模型:

正如你可能看到的,当我们用λ参数估计 Box-Cox 模型时,我们可以假设哪种函数形式最适合我们的数据。如果我们的λ参数接近 0,我们应该使用对数线性模型。当λ接近 1 时,我们应该使用简单的线性模型,而当λ接近-1 时,最合适的模型将是处理变量反演的模型。
我们必须记住,即使 Box-Cox 模型的个别情况是线性的,一般模型也有非线性的性质。因此,在大多数统计软件中,它通常是用数字来估计的。
参考
[1]麦切尔斯基,耶日。 *Ekonometria。*2009 年,UW WNE
[2]https://en.m.wikipedia.org/wiki/L%27H%C3%B4pital%27s_rule
[3]https://www.statisticshowto.com/box-cox-transformation/
https://en.wikipedia.org/wiki/Power_transform
男孩还是女孩?一个机器学习的网络应用程序从名字中检测性别
在 Tensorflow、Plotly Dash 和 Heroku 中使用自然语言处理找出一个名字的可能性别。

作为初为人父者,给孩子取名字是你必须做出的最有压力的决定之一。特别是对于像我这样一个数据驱动的人来说,在没有任何关于我孩子性格和偏好的数据的情况下,就必须决定一个名字,这简直是一场噩梦!
由于我的名字以“玛丽”开头,我经历了无数次人们通过电子邮件和短信称呼我为“小姐”的经历,但当我们最终见面或交谈时,才失望地意识到我实际上是一个男人😜。所以,当我和妻子为我们的小女儿取名时,我们问自己一个重要的问题:
人们能够识别出这个名字指的是一个女孩而不是一个男孩吗?****
事实证明,我们可以使用机器学习来帮助我们检查潜在的名字是否会更多地与男孩或女孩联系在一起!要查看我为此开发的应用程序,请前往https://www . boyorgirl . XYZ。

“boyorgirl”应用的 Gif 视频。作者图片
这篇文章的其余部分将讨论技术细节,包括
- 获得性别训练数据集的名称
- 预处理名称,使其与机器学习(ML)模型兼容
- 开发一个自然语言处理(NLP) ML 模型,读入一个名字并输出是男孩还是女孩的名字
- 构建一个简单的 web 应用程序,供人们与模型进行交互
- 在互联网上发布应用程序
解决方案的架构

应用程序架构。作者图片
获取性别培训数据集的名称
为了训练任何机器学习模型,我们需要大量的标记数据。在这种情况下,我们需要大量的姓名以及该姓名的相关性别。幸运的是,谷歌云的 Bigquery 有一个名为USA_NAMES [ Link 的免费开放数据集,它“包含了在美国出生的所有社会保障卡申请人的姓名。”数据集包含大约 35000 个名字和相关的性别,这对于我们的模型来说非常好。

数据集片段。作者图片
数据预处理
人名是文本数据,而 ML 模型只能处理数字数据。为了将我们的文本转换成数字表示,我们将执行以下步骤。

名称编码。作者图片
- 小写的名字,因为每个字符的大小写不传达任何关于一个人的性别的信息。
- 拆分每个字符:我们正在构建的 ML 模型的基本思想是读取名称中的字符,以识别可能表明男性或女性特征的模式。因此,我们把名字分成每个字符。
- 用空格填充名称,直到最多 50 个字符,以确保 ML 模型看到所有名称的长度相同。
- 将每个字符编码成一个唯一的数字,因为 ML 模型只能处理数字。在这种情况下,我们将’ ‘(空格)编码为 0,’ a ‘编码为 1,’ b '编码为 2,依此类推。
- 将每个性别编码成一个唯一的数字,因为 ML 模型只能处理数字。在这种情况下,我们将‘F’编码为 0,将‘M’编码为 1。

预处理后的数据集片段。作者图片
NLP ML 模型
当我们读一个名字时,我们通过这个名字中出现的字符的顺序来识别这个名字的可能性别。例如,“斯蒂芬”很可能是一个男孩的名字,但“斯蒂芬妮”很可能是一个女孩的名字。为了模仿人类识别姓名性别的方式,我们使用tensorflow.keras API 构建了一个简单的双向 LSTM 模型。
模型架构
- 嵌入层:将每个输入字符的编码数字“嵌入”到一个密集的 256 维向量中。选择
embedding_dim是一个超参数,可以调整以获得所需的精度。 - 双向 LSTM 层:从上一步中读取字符嵌入序列,并输出一个表示该序列的向量。
units和dropouts的值也是超参数。 - 最终的密集层:输出一个接近 0 的 F 值或接近 1 的 M 值,因为这是我们在预处理步骤中使用的编码。
训练模型
我们将使用标准的tensorflow.keras培训渠道,如下所示
- 使用我们在模型架构步骤中编写的函数实例化模型。
- 将数据分成 80%的训练和 20%的验证。
- 一旦模型开始过度拟合,使用
EarlyStopping回调调用model.fit停止训练。 - 保存训练好的模型,以便在服务 web 应用程序时重复使用。
- 绘制训练和验证精度图,以直观检查模型性能。

训练精度。作者图片
Web 应用程序
既然我们已经有了训练有素的模型,我们可以创建一个 Plotly Dash [ Link ] web 应用程序[https://www . boyorgirl . XYZ]来从用户那里获取输入姓名,加载模型(在应用程序启动期间只加载一次),使用模型来预测输入姓名的性别,并在 web 应用程序上可视化结果。下面的代码片段只显示了 web 应用程序的模型推理部分。完整的 Plotly Dash web 应用程序代码,包括模型加载、文本框输入、表格输出和交互式条形图输出,可在我的 GitHub 存储库上获得。

样本推断结果。作者图片
在互联网上发布
最后一步是在互联网上发布我们的新应用程序,让世界各地的每个人都可以与之互动。经过一点点的研究,我决定使用 Heroku 来部署应用程序,原因如下。
- 免费!!!
- 简单的部署流程
- 最大 500MB 内存对于我的小型定制型号来说已经足够了。
部署单一回购
Heroku 网站[ 链接 ]详细记录了将应用部署到 Heroku 的步骤。我做了一些定制的修改来支持我的 mono-repo 格式,我在我的 Github repo [ 链接 ]中记录了这些修改。支持单一回购的主要变化有
- 添加以下构建包
heroku buildpacks:add -a <app> https://github.com/lstoll/heroku-buildpack-monorepo -i 1
- 添加以下配置
heroku config:set -a <app> PROCFILE=relative/path/to/app/Procfile
heroku config:set -a <app> APP_BASE=relative/path/to/app
指定工作人员的数量
重要!我花了一些时间才发现的一个主要问题是 Heroku 默认启动两个工人。因此,如果你的应用程序的大小超过 250MB,两个工人加起来将超过 Heroku 为免费应用程序设置的 500MB 限制。由于我不希望我的应用程序的流量大到需要两个工人,所以我通过使用 Procfile 中的-w 1标志只指定一个工人,轻松地解决了这个问题。
web: gunicorn -w 1 serve:server
设置 ping 服务
免费层 Heroku 应用程序在 30 分钟不活动后进入睡眠状态。因此,我使用了一个名为 Kaffeine [ Link ]的免费 ping 服务,每 10 分钟 ping 我的应用一次。这将确保应用程序零停机时间。
随后,我从免费层升级到爱好层(主要用于我的自定义域上的免费 SSL),确保应用程序永不休眠,因此 ping 服务不再与我的应用程序相关。
添加自定义域
最后,我从 name price[Link]购买了一个便宜的域名,并按照这里[ Link 的指示将该域名指向我的 Heroku 应用。
关于潜在偏见的免责声明
严肃地说,在使用这种方法时,我们需要记住一些限制和偏见。
- 这个模特对现实世界中的性别概念有零的理解!它只是根据属于不同性别的名字的历史数据,对一个特定的名字可能属于哪个性别做出一个有根据的猜测。例如,我的名字以“Marie”开头,模型检测出这是一个女性名字(置信度约为 90%!)虽然我其实是个男的。因此,这种方法延续了我们名字中固有的偏见,解决这些偏见超出了本研究的范围。
- 训练数据仅由二元性别(M 和 F)组成。因此,非二元性别没有得到代表。
总之,请不要使用这个应用程序对任何人的性别身份做出假设!
就是这样!我们很酷的 ML 应用程序可以根据名字预测性别,现在互联网上的任何人都可以与之互动!从我的测试来看,这款应用对英文名字的表现似乎非常好,对印度名字的表现也相当好,因为这些名字存在于训练数据集中。像中文名字这样的非英文名字表现很差。请你看一下,让我知道你的名字是否正确?感谢阅读!
所有代码都可以在我的 Github repo 上找到:[ 链接 ]
你可以访问“男孩还是女孩?”at:https://www . boyorgirl . XYZ
脑机接口将想象的笔迹解码成实时文本
你想知道 BCI 如何利用深度学习恢复失去行动或说话能力的人的交流吗?

通过手写进行大脑到文本的交流——作者根据[1]提供的照片
我们已经看到许多领域,如自然语言处理、计算机视觉、预测性维护、推荐系统,正在以这样或那样的方式通过深度学习进行革命。本文将讨论最近的研究,这些研究显示了深度学习在脑机接口(BCIs) 中的潜力。BCI 不仅仅是我们通常在科幻电影中看到的未来派界面;它可以恢复失去行动或说话能力的人的交流。
BCI 研究的主要焦点是恢复粗大运动技能,如伸手、抓握或用 2D 电脑光标点击打字[2]。然而,在最近的研究工作中,[1]的作者正在使用递归神经网络(RNN)将想象的手写运动解码为实时文本,以实现更快的通信速率。
利用这种新的大脑皮层内 BCI 解码想象笔迹的方法,研究参与者通过通用自动更正功能,实现了每分钟 90 个字符的打字速度和 99%的准确率>。尽管该研究参与者患有高度脊髓损伤,颈部以下瘫痪,但他的打字速度与健全的智能手机打字速度相当。
对想象的笔迹进行编码
首先,我们需要确定即使瘫痪多年后,运动皮层的神经活动可能足够强,对 BCI 有用。如果不是这样,那么我们就无法从想象的笔迹中解码出实时文本。因此,作为第一步,我们必须检验我们是否能通过想象笔迹从神经活动中对字符进行分类。

图 1:尝试手写的稳健神经活动编码[1]
如图 1A 所示,受试者按照电脑屏幕上的指示想象手写每个字符,就好像他的手没有瘫痪一样;参与者被要求尝试每个字符 27 次。因此,总共 31 个字符中的每一个都有 27 条轨迹。
图 1B 显示了三个示例字母的神经活动的前 3 个主成分(PCs)。基于图 1B,很明显,神经活动看起来是稳定的和可重复的,但是存在一些时间可变性(可能是由于书写速度)。图 1C 示出了在使用时间校准技术去除时间可变性之后得到的神经活动 PCs。
为了查看神经活动是否编码了笔的运动,作者们试图通过线性解码笔尖速度来重建每个字符。字母形状的可识别重建(图 1D)证实了笔尖速度在神经活动中被稳健地编码。此外,神经活动的 t-SNE 可视化(图 1E)显示,类似书写的字符具有或多或少类似的表示。
最后,使用简单的 k-最近邻分类器,[1]的作者能够以 94.1%的准确度从神经活动中分类字符。因此,上述所有研究都证明,与笔迹相对应的神经活动足够强,对 BCI 有用。
实时解码想象的笔迹

图 2:试图实时手写的神经解码[1]
现在令人兴奋的部分来了,使瘫痪的人能够通过想象手写他们想要的信息来交流。[1]的作者训练了一个 RNN,将神经活动转换成描述字符在每个时刻被书写的可能性的概率。RNN 还预测了任何新角色开始的可能性。RNN 的神经活动输入在时间上被分箱(20 毫秒箱)并且在每个电极处被平滑。如图 2A 所示,预测的概率既可以简单地设定阈值,也可以用自动更正功能广泛地处理。
为了收集 RNN 的训练数据,作者记录了参与者按照计算机显示器的指示想象完整手写句子时的神经活动。使用三天内收集的 242 个句子来训练初始模型。为了克服以下挑战,作者在自动语音识别中采用了深度学习方法[3–5]。
- 训练数据中每个字母的确切时间是未知的,这使得很难应用监督学习技术。
- 与典型的 RNN 数据集相比,该数据集的大小有限,因此很难防止过度拟合。
RNN 的表现在五天内进行评估,每天包含 7-10 个句子(不用于培训)。在解码器评估的每一天之后,当天的数据被累积添加到第二天的训练数据集中。图 2B 显示了两个示例评估轨迹,展示了 RNN 解码句子的能力(错误用红色突出显示,空格用“>”表示)。在图 2C 中显示了五天的错误率和打字速度。有了自动更正后处理,错误率大大降低了。[1]的作者还通过允许研究参与者回答开放式问题,在一个不太受限制的环境中评估了模型的性能。
用 2D 电脑光标点击打字(每分钟 40 个字符)[2]是脑皮质内 BCI 表现最好的方法。然而,[1]的作者已经表明,手写运动的解码速度可以快两倍以上,准确性水平相当。性能更好的原因是因为点对点可能比手写字母更难区分。
有趣的是看到时变的复杂运动模式,如手写字母,从根本上比简单的点对点运动更容易解码。看到自动语音识别深度学习方法[3–5]如何适用于这个 BCI 用例也非常鼓舞人心。
我希望这篇文章内容丰富,发人深省。谢谢:)
参考
[1] Francis R. Willett、Donald T. Avansino、Leigh R. Hochberg、Jaimie M. Henderson 和 Krishna V. Shenoy,通过手写进行高性能的大脑到文本的通信 (2021)
[2] Chethan Pandarinath,Paul Nuyujukian,Christine H Blabe 等人,瘫痪患者使用皮质内脑机接口进行高性能通信 (2017)
[3] Geoffrey Hinton 等人,用于语音识别中声学建模的深度神经网络:四个研究小组的共同观点 (2012)
[4] Graves A .、Mohamed A .、Hinton G .,深度递归神经网络语音识别 (2013)
[5]熊伟等,微软 2017 对话式语音识别系统 (2017)
广度与深度
意见
数据科学家应该是专家还是通才?
关于数据科学家是专攻还是通才更好,我已经看到了相当矛盾的建议。
紧张在于:为了脱颖而出,公司希望你成为他们需要的特定技能的专家。但是专注于一个利基市场意味着你有资格获得更少的工作,而很多(大多数?)雇主想要的是灵活的人,而不是只会一招的小马。那么一个数据科学家应该怎么做呢?专业化还是多元化?数据科学职业什么比较好?

专业化是什么意思
首先,我们先明确一下我说的专精是什么意思。专业化可能意味着成为特定类型数据的专家,如医疗索赔数据、金融欺诈数据、电子商务交易等。或者这可能意味着成为某个行业的专家——医疗保健、金融、电子商务等。或者这可能意味着建立特定工具的专业知识——深度学习、图像处理、因果建模等。
关键是,专家对可能出现在招聘启事中的东西有特定的经验。
另一方面,多面手拥有更广泛的技能或经验,但并不特别精通其中任何一项。也许他们已经涉足了许多不同行业的项目,或者使用了许多不同的工具,有点像“万金油”。
一个人是成为专家还是多面手在很大程度上取决于他的性格和背景。专业化会带来极大的满足感,因为你会成为某方面的深度专家,并感觉自己非常胜任自己的工作。概括对于那些喜欢学习和探索的人,或者那些容易厌倦的人(我属于这一阵营)来说是非常好的。
但是假设你对这两者不感兴趣,并且认为专攻和通才一样快乐,那么什么对你的职业最有利呢?
专业化或多元化建议的主要区别是:资历

我怀疑,之所以在专业化和多元化哪个更好的问题上有如此不同的信息,是因为这取决于你的资历。对于初级(或有抱负的)数据科学家和中级或高级数据科学家来说,成为专家或多面手意味着非常不同的事情。让我们看几个场景:
找工作
对于入门级或小众职位,专精是必由之路。
从招聘经理或招聘人员的角度考虑一下,从数百份简历中筛选——所有初级人员的简历看起来都非常相似。他们列出了非常相似的技能(标准数据科学堆栈)。他们有一些明显是为了学习的投资组合项目(尽管好的项目可能有一些更好的项目)。
一份简历脱颖而出的最简单的方法之一就是拥有一个与该职位主要从事的工作类型直接相关的项目或一些经验。
拥有处理医疗保健数据的经验对医疗保健公司来说会很好——他们认为你已经具备了做好工作所需的一些领域专业知识,并且能够更快地投入工作。如果你申请的是一份 NLP 繁重的工作,拥有自然语言处理的特定专业知识会比一般的数据科学概述看起来更好。在初级阶段,这些因素通常是简历能给出的最强信号。
中级及中级以上

在 Unsplash 上 Deva Darshan 拍摄的照片
在初级水平之外,我认为专业化的理由变得越来越弱。肯定有更专业化的高级职位。在极端的情况下,在他们的领域中处于领先地位的人几乎肯定会得到不错的报酬,而且找工作也不会有困难。
但对于普通的数据科学家来说,随着资历的增加,拥有丰富的经验变得更加重要。部分原因是职责的变化——初级人员通常被期望从事少量相关项目,而高级人员则被期望能够灵活地从事更广泛的项目。更广泛的技能组合通常比更深入的技能组合更适合更高级职位的需求。除了大型科技公司,大多数公司都没有超级专业化的数据科学团队,所以他们最终需要能够承担一系列工作。
除此之外,随着资历的增加,就业市场也发生了逆转——竞争减弱,更多的是求职者的市场。你不需要从一大群人中脱颖而出,但是有一些相关的工作经验是很好的。如果你已经涉猎了很多东西,那就更容易确保你对任何给定的工作都至少有一些经验。这扩大了你竞争的工作范围。
管理和领导通常需要多面手
如果你想走上领导岗位,成为多面手无疑是更容易的途径(同样,假设你不在拥有超专业数据科学团队的大型科技公司)。对于管理者来说,尤其是管理一个大团队的管理者,管理使用各种技能处理各种问题的员工是很常见的。在这些领域拥有一些基本的能力和理解对于领导这些工作是很重要的。再说一次,拥有更广泛的经验会让你申请更多的潜在职位。
结论
在数据科学领域,是专攻好还是通才好,这个问题没有放之四海而皆准的答案。然而,我认为总的建议应该是:专业化直到你达到中等水平,然后开始拓宽自己。当然,一个擅长网络的多面手可能会发现不需要专业知识就可以轻松进入这个领域,而一个专家可能会找到一个他们能够在整个职业生涯中占据的位置。每个人都有自己的兴趣,做你感兴趣的事情会让你成为一名更好的员工,这可能比试图过度优化你所学的东西产生更大的影响。但总的来说,为了工作的竞争力和安全感,我认为这个建议是一个不错的经验法则。
相关文章
将一个大的气流 DAG 分解成多个文件
模块化你的大气流 DAG 的大块,以便于使用和维护

丹尼尔·林肯在 Unsplash 上的照片
我正在处理一个长达数百行的气流 DAG 文件。进行更改需要在文件中来回移动,在便笺簿上做笔记以确保一切正确。一旦我开始在 IDE 中打开 DAG 文件的多个视图,我知道这是一个停下来并找到一种方法将 DAG 分成更小的片段的好时机。
随着 Airflow 2 中 TaskGroups 的出现,将一个大 DAG 分成几个部分在概念上和实践上都更容易了。这些部分可以重用,当然,它们更容易更新和维护。
TaskGroups 只是相关任务的 UI 分组,但是分组往往是逻辑的。任务组中的任务可以被捆绑和抽象,以便更容易地从比单个任务更大的单元构建 DAG。也就是说,任务组并不是将任务分组并将其移出 DAG 文件的唯一方式。你也可以有一个不在任务组中的逻辑任务块。后一种方法的缺点是,您失去了在 DAG 运行的 web UI 图形视图中将任务折叠到单个节点中的好处。
分解 DAG 的技巧是将 DAG 放在一个文件中,例如modularized_dag.py,将任务或任务组的逻辑块放在单独的文件中,每个文件一个逻辑任务块或任务组。每个文件都包含函数,每个函数都返回一个 operator 实例或一个 TaskGroup 实例。
为了快速说明,下面的modularized_dag.py从foo_bar_tasks.py引入了返回操作符的函数,从xyzzy_taskgroup.py引入了返回任务组的函数。在 DAG 上下文中,调用这些函数时将 DAG 对象dag作为参数传递,它们的返回值被分配给 task 或 TaskGroup 变量,这些变量可以被分配上下游依赖关系。
实运算符的简单示例
现在举一个真实的例子。让我们使用虚拟操作符和 Python 操作符来创建任务。
首先是 DAG 文件:dags/modularized_dag.py。它只是从plugins/includes/foo_bar_tasks.py导入分块任务函数,从plugins/includes/xyzzy_taskgroup.py导入任务组函数。它将使用 DAG 上下文创建的 DAG 传递给每个函数。
dags/modularized_dag.py:
from datetime import datetime, timedeltafrom airflow import DAG
from includes.foo_bar_tasks import build_foo_task, build_bar_task
from includes.xyzzy_taskgroup import build_xyzzy_taskgroup default_args = {
'owner': 'airflow',
'depends_on_past': False,
'email_on_retry': False,
'retries': 1,
'retry_delay': timedelta(minutes=5),
}with DAG(
dag_id="modularized_dag",
schedule_interval="[@once](http://twitter.com/once)",
start_date=datetime(2021, 1, 1),
default_args=default_args,
) as dag: # logical chunk of tasks
foo_task = build_foo_task(dag=dag)
bar_task = build_bar_task(dag=dag) # taskgroup
xyzzy_taskgroup = build_xyzzy_taskgroup(dag=dag) foo_task >> bar_task >> xyzzy_taskgroup
接下来是plugins/includes/foo_bar_tasks.py中逻辑分块的任务功能。我们的逻辑块中有几个函数,build_foo_task和build_bar_task。第一个返回伪运算符,第二个返回 Python 运算符。Python 操作符使用一个简单的导入日志记录函数log_info,它在下面的plugins/includes/log_info.py中定义。
plugins/includes/foo_bar_tasks.py:
from airflow import DAG
from airflow.operators.dummy import DummyOperator
from airflow.operators.python import PythonOperatorfrom includes.log_info import log_info def build_foo_task(dag: DAG) -> DummyOperator:
foo_task = DummyOperator(task_id="foo_task", dag=dag) return foo_task def build_bar_task(dag: DAG) -> PythonOperator:
bar_task = PythonOperator(
task_id="bar_task",
python_callable=log_info,
dag=dag,
) return bar_task
在逻辑块任务函数之后,我们在plugins/includes/xyzzy_taskgroup.py中有一个 TaskGroup 函数。这个任务组包括一对任务,baz_task用伪操作符实现,而qux_task用 Python 操作符实现。像上面的 chunked tasks 文件一样,这个文件也导入了日志功能log_info。
plugins/includes/xyzzy_taskgroup.py:
from airflow import DAG
from airflow.operators.dummy import DummyOperator
from airflow.operators.python import PythonOperator
from airflow.utils.task_group import TaskGroupfrom includes.log_info import log_info def build_xyzzy_taskgroup(dag: DAG) -> TaskGroup:
xyzzy_taskgroup = TaskGroup(group_id="xyzzy_taskgroup") baz_task = DummyOperator(
task_id="baz_task",
task_group=xyzzy_taskgroup,
dag=dag,
) qux_task = PythonOperator(
task_id="qux_task",
task_group=xyzzy_taskgroup,
python_callable=log_info,
dag=dag,
) baz_task >> qux_task return xyzzy_taskgroup
最后,这里是由foo_bar_tasks.py和xyzzy_taskgroup.py导入的简单日志功能。
plugins/includes/log_info.py:
import logging def log_info(**kwargs):
logging.info(kwargs)
一旦所有这些文件都准备好了,您就可以使用您的 Airflow web UI 来解包 DAG 并确保它正常工作。下面是modularized_dag.py的图形视图:

模块化的 DAG 非常好用!(作者供图)
我们可以检查 Python 操作符任务的日志(第一个来自逻辑分块的任务,第二个来自 xyzzy_taskgroup 内部):
bar_task用log_info功能输出高亮灰色:

从酒吧登录任务(作者提供照片)
xyzzy_taskgroup.qux_task用log_info功能输出高亮灰色:

xyzzy TaskGroup 中 qux 任务的日志(作者提供图片)
概观
我们已经介绍了如何通过将任务组或操作符返回函数放在独立的文件中,将一个大的 DAG 文件分解成模块化的块,现在模块化的 DAG 将从plugins/includes目录导入这些文件。使用 TaskGroup-returning 函数的优势在于:( 1)您可以将逻辑任务组抽象成 DAG 中的一个组件,以及(2)task group 中包含的任务将在 DAG 运行的 web UI 图形视图中折叠成单个节点。
2021 年进军数据科学:竞争越来越激烈了吗?
为什么现在成为数据科学家需要更多的准备

图片来源:韦斯·希克斯@ Unsplash
自从哈佛商业评论宣布数据科学是 21 世纪最性感的职业以来,已经有大约九年了。从那时起,许多有抱负的数据科学家开始提升自己的技能并进入就业市场,其中一些人成功地过渡到了数据科学工作。2021 年,数据科学就业市场仍在增长。尽管由于新冠肺炎疫情,2020 年的就业市场有所放缓,但对于年轻的专业人士来说,数据科学仍然是一个利润丰厚的职业。但是,许多有抱负的数据科学家面临的问题是,进入数据科学领域不像五年前那么容易了。
几年前,我开始在信息技术行业担任数据科学家。那时进入数据科学领域相对容易。数据科学领域仍然非常年轻,对公司来说是一个闪亮的新对象,所以他们会很容易地雇佣大量数据科学家。此外,公司对雇用数据科学家没有太多要求。拥有一些 Python 技能,学习一些 SQL,了解一些数据可视化和机器学习技术就足以获得初级数据科学工作。如今,人才找到初级数据科学工作变得越来越困难,因为更多的人才正在市场上寻找工作。
在这篇文章中,我解释了我认为进入数据科学的难度增加的一些原因。
1)在就业市场上,有抱负的数据科学家之间的竞争越来越激烈
数据科学在就业市场上的认知度仍然很高。来自不同领域的许多人才,从高度量化的领域(有时甚至来自心理学或生物学等领域),正在向数据科学过渡。与工作市场的需求相比,这导致初级数据科学家的人才供应增加。
如果我们从雇主的角度来看,大量人才在就业市场上积极寻找数据科学工作,会导致招聘流程中的开销。有时,对于数据科学领域的一个职位发布,公司必须查看数百份简历,并面试数十名候选人来填补职位空缺。例如,我在 Linkedin 上发布了一份自己公司的数据科学工作。虽然工作地点是德国法兰克福,但我们收到了全球近 500 名申请人。在申请人的人才库中,每个职位都有数十名相对合格的候选人,他们之间没有太大的差别。如果我们想筛选所有这些候选人并对他们进行面试,我们将面临严重的时间限制。这可能是许多公司寻找替代招聘方法的原因,比如雇佣招聘机构或依靠推荐,而不是亲自面试所有候选人。
总体而言,有抱负的数据科学家如今可能难以脱颖而出。此外,招聘经理为数据科学工作选择候选人变得更加困难和耗时。

单个数据科学职位发布的大量申请人(Linkedin 职位发布平台的快照)
2)工作需求膨胀
尽管初级人才供应充足,但对高级数据科学家的需求仍然高于就业市场的供应。对于有抱负的数据科学家来说,这可能是一个好消息,但这可能会给他们在职业生涯开始时进入该领域带来一些困难。为什么?
当就业市场对有经验的数据科学专业人员的需求高于人才供应时,高级数据科学家的工资就会上涨。这意味着支付更高价格雇佣有经验的数据科学家的公司期望更多,并希望专业人员带来更丰富的技能。比如现在,高级别的数据科学家需要了解软件工程、DevOps、大数据、云计算的很多技术,这是标准的做法。因此,人才可能会在他们需要完成的每个数据科学职位描述的要求部分找到一长串所需的技能和技术。虽然这可能只是高级数据科学人才的问题,但看看初级职位的工作描述就会发现,这种现象也正在转移到初级职位。公司知道,当他们雇用初级数据科学家时,他们还必须将他们培训到高级水平,找到一个已经知道大多数技术的候选人为他们节省了大量培训成本。因此,最终,有抱负的数据科学家必须付出更多努力才能进入这份工作。
3)新冠肺炎·疫情导致数据科学就业市场萎缩
由于新冠肺炎疫情和经济放缓,许多公司继续生存模式,这意味着他们削减所有不必要的和奢侈的开支,包括数据科学。这导致数据科学行业在 2020 年增长放缓。当就业市场上雇用数据科学家的公司越来越少时,也会在有抱负的数据科学家本身以及最近被解雇并积极寻找就业市场的高级候选人之间产生更多竞争。因此,竞争中的这种雪球效应使得有抱负的数据科学家更难进入这一领域。
4)来自数据工程和云等其他领域的竞争
是的,是真的!我们在数据领域有了新的竞争者,那就是数据工程。数据工程是一个在过去几年中大规模增长的领域,特别是随着更实惠的大数据和云工具的可用性以及机器学习管道的自动化。
随着大数据和机器学习管道的自动化趋势,公司正在将注意力转移到使用现成的基于云的机器学习模型,这比构建定制模型更容易部署。这导致公司希望雇用一些数据工程师、云和开发运维专家,而不是数据科学家。
还有,由于后大流行时代的经济环境不确定,许多公司暂时放弃了使用机器学习预测未来变量。相反,他们可能会利用时间和预算来开发大数据管道和数据基础设施。因此,在短期内,分析和机器学习专家的工作可能会减少,而数据工程师、云和开发运维专家的工作会增加。
尽管如此,我相信从长远来看,数据工程不会取代数据科学。大数据和云行业的增长实际上对数据科学家来说是个好消息,因为它让数据科学家和机器学习工程师的生活变得更加轻松,因为公司内部有了高性能的大数据管道,减少了数据科学团队在数据准备方面所需的手动工作。

谷歌搜索趋势搜索“数据科学工作”与“数据工程师工作”(谷歌趋势快照)
5)数据科学家的一些任务正在被云自动化
随着云计算平台中高级机器学习工具的出现,定制和现成机器学习模型之间的竞争变得更具挑战性。由于建立数据科学团队的成本很高,一些公司正在满足于现成的机器学习工具,至少在概念验证阶段,这些工具可能会解决他们的业务问题。使用这些工具可以减少数据科学家的数量,至少在疫情时代是这样。但是,在我看来,这种影响只是短期的,因为当涉及到机器学习模型的产业化并将其投入生产以推动有形的商业价值时,公司仍然需要定制的数据科学家来开发高性能的定制机器学习模型和分析工具。
展望:
2021 年,数据科学是一个不断增长的行业,也是一个仍然有利可图的职业,对许多年轻专业人士来说,进入门槛相对较低。但是,如今,要成为一名数据科学家,仅仅学习 Python 和一些机器学习工具是远远不够的。
有抱负的数据科学家需要用一套丰富的大数据和机器学习工具来装备自己,以便在就业市场上更具竞争力。此外,对于有抱负的数据科学家来说,使用有效的个人品牌和网络软技能脱颖而出变得更加重要。
更多文章来自作者:
</8-career-paths-for-junior-data-scientists-to-pursue-3e6041950e4e>
关于作者:
Pouyan R. Fard 是 Fard 咨询公司的首席执行官&首席数据科学家。Pouyan 在数据科学、人工智能和营销分析方面拥有多年的公司咨询经验,从初创公司到全球公司。他曾与医药、汽车、航空、运输、金融、保险、人力资源和销售&营销行业的财富 500 强公司合作。
Pouyan 还积极指导活跃在大数据行业的初创公司和求职者。他的热情是通过职业培训培养下一代数据科学家,并帮助他们找到数据科学领域的顶级工作机会。
Pouyan 已经完成了关于消费者决策预测建模的博士研究工作,并对开发机器学习和人工智能领域的最先进解决方案保持兴趣。
打破微软的垄断
人工智能|新闻
人工智能不应该掌握在少数人手中

费利克斯·米特迈尔在 Unsplash 上的照片
在他们的名人人工智能模型 GPT-3 当之无愧的受欢迎之后,OpenAI 已经成为一家极其知名的人工智能公司。GPT-3 拥有惊人的技能,它可以写诗、写文章或写代码,但如果没有微软的资金和计算能力的帮助,这些都不可能实现。
GPT-3 可以说是最先进的语言模型(至少在那些公开可用的模型中)。因此,将它用于大学和非营利机构的研究目的是合理的。取而代之的是,OpenAI 决定通过一个私有 API 来限制少数特权用户的访问。GPT-3 是他们的财产,所以他们可以决定谁可以品尝它,谁不可以——除了微软;他们可以为所欲为。
OpenAI 有使命。“我们的目标是以最有可能造福全人类的方式推进数字智能,不受产生财务回报需求的约束。”他们永远不会把他们的股东放在多数人之前,是吗?这在他们是非盈利的时候是真的,但现在不是了。现在,我们只能希望他们信守诺言。
目前,他们的大部分行动都指向相反的方向。获得他们的 API 的最佳方法是向他们描述你计划如何在创收机器上转换他们的 AI 模型。这并不是说他们无私地希望你赚钱——你要么赚钱,要么因为 OpenAI 设定的难以承受的成本而被迫关闭你的项目。TechTalks 创始人本·迪克森说“一些建立在 GPT-3 之上的非盈利、娱乐和科学项目已经宣布由于高昂的成本它们将被关闭。”
对于那些有门路并负担得起费用的人来说,还有最后一个障碍需要克服;OpenAI 的指导方针。如果他们认为你的项目不符合他们的政策,他们会不可逆转地关闭它——即使他们已经给了你上线的通行证。这就是发生在项目 12 月的创建者杰森·罗尔身上的事情。他建立了一个旨在让人们定制聊天机器人的网站,但当约书亚和杰西卡的聊天机器人(模拟他已故未婚妻的机器人)的故事在网上传播开来时,OpenAI 并不喜欢它。
这项技术应该掌握在少数人手中吗?
自从 GPT 3 发布后,OpenAI 坚决拒绝任何开源代码的可能性,全球的开发者和研究人员开始致力于创造一个复制品。他们希望允许那些被排除在 OpenAI 的朋友们的选择性小组之外的人研究和分析这个系统。
GPT-尼欧和 GPT-J 的创造者伊莱瑟雷就是这样一个倡议者——我最近谈到过他们。GPT-J 有 60 亿个参数,类似于第二好的 GPT-3 版本,称为居里(大约 67 亿个参数,据 EleutherAI 估计)。与 OpenAI 相反,EleutherAI 正在构建模型,以便与所有人分享。
让任何人不受控制地访问这些人工智能都有风险,但 EleutherAI 决定“利大于弊。”如果建造像 GPT-3 这样的模型是可能的——鉴于目前的艺术水平,这非常简单——允许人工智能安全和人工智能伦理的研究人员获得它们是确保所有人有一个更美好未来的最佳方法。可以肯定的是,基于获得财务利润的前景来选择用户听起来不像是有益于“整个人类”。
但像 GPT-j·伊柳瑟雷这样的模型缺乏一个关键方面。他开发了代码并分享了代码,但大多数受益者可能不具备充分利用人工智能所需的编程知识。一个类似 OpenAI 的 API 丢失了。一周前,当人工智能初创公司 NLP Cloud 宣布他们将在其 API 上支持 GPT J-以及其他模型,以更适中的价格为其客户提供“生产就绪解决方案”时,这种情况发生了变化。
民主化大型语言模型
像 GPT-3 和 GPT-J 这样的语言模型提醒我们,“能力越大,责任越大。”与他们的成功相伴而来的是大量的风险和潜在的危害。关于大多数少数民族受到歧视性待遇的伦理问题,缺乏安全控制,传播错误信息的能力,以及产生不可用内容都是最相关的问题。
这就是为什么 NLP Cloud 认为“NLP 模型的唯一解决方案是保持开源,并由社区持续审核。”如果模型本身就有问题,最好的方法是让专家彻底检查它们——让普通大众买得起。
但是如何让他们买得起呢?这种大型模型的一个关键问题(也是 OpenAI 和微软如此成功地保持其霸权的原因)是,它们需要大量的计算能力来运行。即使只有 GPT-3 的一小部分,GPT-J 仍然需要 25GB 的 GPU VRAM 来运行——更不用说用它进行大规模推理了。市场上的大多数 GPU 都不符合这个模型。
NLP 云提供了一个有竞争力的解决方案。他们以 API 的形式提供对 GPT-J 的访问,以备生产,同时保持价格“尽可能地可承受,尽管在服务器端需要非常高的计算成本。”他们的服务远非免费,但这是一个进步,扩大了强大人工智能的使用范围,同时削弱了微软的垄断地位。
成本比较
我们来对比一下 open ai(GPT-3 的居里版本)和 NLP Cloud (GPT-J)的定价方案。Curie 的现收现付定价方案是每 1000 个代币(750 字左右)0.0060 美元。NLP 云为 GPT-J 提供了各种各样的计划,根据你的情况,这些计划可能非常有竞争力——在特定情况下,OpenAI 仍然有更好的价格。大多数情况下的最佳选择是固定费率的 GPU 计划(根据 API 请求的数量,从每月 99 美元到每月 699 美元不等)。
主要优势是 NLP 云不按令牌数收费,所以不管你想生成多少单词,价格都是一样的。尽管如此,在某些情况下,OpenAI 更经济实惠,因为用户可能只想向 API 发出一些请求——例如,测试 API playground。NLP Cloud 也有一个现收现付的计划,但每个令牌的价格比 OpenAI 高得多。
为了用一个具体的例子来说明成本的差异,我将使用文章生成的例子(一个文本生成的特殊例子,其中提示文本比完成文本短得多)。假设很多人使用你的应用程序,所以你每分钟收到 10 个请求。在论文生成中,平均请求的合理大小可以是 100 个标记的提示和 1000 个标记的完成——相当于输入一个段落并返回一整页。让我们计算一下:
- open ai/Curie:$ 0.0060/1000 token 1100 token/request(提示&完成)10 requests/min 43200min/月=$ 2851.2/月。
- NLP 云/GPT-J:10 个请求/分钟的固定费率,与令牌数量无关=$ 699/月。
另一个非常受欢迎的服务可能是生成推文(尽管 OpenAI 严格限制任何社交媒体应用)。让我们再算一次,但这次提示有 300 个令牌,完成有 50:
- open ai/Curie:$ 0.0060/1000 token 350 token/request(提示&完成)10 requests/min 43200min/月=$ 907.2/月。
- NLP 云/GPT-J:10 个请求/分钟的固定费率,与令牌数量无关=$ 699/月。
正如我们所看到的,因为 OpenAI 提供了一个随用随付的计划,所以你用得越少,它就越便宜。如果你想彻底分析这个系统或者把它用于商业目的,这种情况不太可能发生。正是在这些情况下,NLP 云大放异彩。
一家公司应该对一项最终可能彻底改变世界的技术拥有如此大的控制权吗?对我来说没什么意义。期望他们对服务收费是完全合理的,但是限制他们基于不透明的标准选择的人的访问——无论是直接的还是通过强加昂贵的价格——都不是非常“公开”
像 EleutherAI 这样的倡议和 NLP Cloud 这样的公司押注于一个非常不同的未来:像 GPT-3 和 GPT-J 这样的大型语言模型——以及其他有待发明的人工智能类型——应该是开源的,每个人都可以使用。与 EleutherAI 不同,NLP Cloud 是一家首先受利润驱动的公司,但目前,他们似乎坚持自己的价值观。如果他们最终决定改变他们的使命,那么他们会像 OpenAI 一样受到批评。
最后,让我们不要忘记,重点不仅仅是允许人们访问该模型,而是从 OpenAI 和微软这样的公司手中夺取垄断权。认为他们是唯一能够通过人工智能带领我们走向更美好未来的人听起来充其量是傲慢,最糟糕的是专制。
如果你喜欢这篇文章,可以考虑订阅我的免费周报https://mindsoftomorrow.ck.page!每周都有关于人工智能的新闻、研究和见解!
您也可以直接支持我的工作,使用我的推荐链接 这里 成为媒介会员,获得无限权限!😃


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言










{kind=link}
{kind=link}
{kind=link}
{kind=link}