







对学习机器人学和计算机视觉的高中生玛丽亚·罗斯沃尔德和什利亚·纳马的采访
https://www.youtube.com/embed/3q6gOlVzGDo?feature=oembed
采访保罗·李——医生、心脏病专家和深度学习研究员

在今天的博文中,我采访了 Paul Lee 博士,他是 PyImageSearch 的读者和纽约西奈山医学院附属的介入心脏病专家。
李博士最近在宾夕法尼亚州费城著名的美国心脏协会科学会议上展示了他的研究,他在会上演示了卷积神经网络如何能够:
- 自动分析和解释冠状动脉造影照片
- 检测患者动脉中的堵塞
- 并最终帮助减少和预防心脏病
此外,**李博士已经证明了自动血管造影分析可以部署到智能手机上,**使医生和技术人员比以往任何时候都更容易分析、解释和理解心脏病发作的风险因素。
李博士的工作确实非常出色,为计算机视觉和深度学习算法铺平了道路,以帮助减少和预防心脏病发作。
让我们热烈欢迎李博士分享他的研究。
采访保罗·李——医生、心脏病专家和深度学习研究员
阿德里安:嗨,保罗!谢谢你接受这次采访。很高兴您能来到 PyImageSearch 博客。
保罗:谢谢你邀请我。

Figure 1: Dr. Paul Lee, an interventional cardiologist affiliated with NY Mount Sinai School of Medicine, along with his family.
阿德里安:介绍一下你自己,你在哪里工作,你的工作是什么?
Paul: 我是纽约西奈山医学院的介入心脏病专家。我在布鲁克林有一家私人诊所。

Figure 2: Radiologists may one day be replaced by Computer Vision, Deep Learning, and Artificial Intelligence.
Adrian: 你最初是如何对计算机视觉和深度学习产生兴趣的?
Paul: 在《纽约客》杂志 2017 年一篇题为 人工智能对医学博士的文章中,当诊断自动化时会发生什么? ,乔治·辛顿评论说“他们现在应该停止培训放射科医生”。我意识到总有一天人工智能会取代我。我想成为控制人工智能的人,而不是被取代的人。
阿德里安:你最近在美国心脏协会上展示了你的作品《自动心脏冠状动脉造影分析》。你能给我们讲讲吗?
保罗:两年前开始上你的课程后,我开始熟悉计算机视觉技术。我决定把你教的东西应用到心脏病学上。
作为一名心脏病专家,我进行冠状动脉造影,以诊断我的病人是否有可能导致心脏病发作的心脏动脉堵塞。我想知道我是否可以应用人工智能来解释冠状动脉造影照片。
尽管困难重重,但由于你的持续支持,神经网络学会了可靠地解释这些图像。
我被邀请在今年费城的美国心脏协会科学会议上展示我的研究。这是心脏病专家最重要的研究会议。我的海报题为卷积神经网络用于冠状动脉造影的解释(CathNet) 。
(流通。2019;140:a 12950;https://ahajournals.org/doi/10.1161/circ.140.suppl_1.12950);海报如下:【https://github.com/AICardiologist/Poster-for-AHA-2019

Figure 3: Normal coronary angiogram (left) and stenotic coronary artery (right). Interpretation of angiograms can be subjectives and difficult. Computer vision algorithms can be used to make analyzations more accurate.
阿德里安:你能告诉我们更多关于心脏冠状动脉造影的信息吗?这些图像是如何捕捉的,计算机视觉/深度学习算法如何更好/更有效地分析这些图像(与人类相比)?
Paul: 为了明确诊断和治疗冠状动脉疾病(例如,在心脏病发作期间),心脏病专家进行冠状动脉血管造影,以确定解剖结构和狭窄程度。在手术过程中,心脏病专家从手腕或腿部插入一根狭窄的导管。通过导管,我们将造影剂注入冠状动脉,图像由 x 光捕捉。然而,血管造影照片的解释有时很困难:计算机视觉有可能使这些决定更加客观和准确。
图 3 *(左)*显示正常的冠状动脉造影照片,而图 3 *(右)*显示狭窄的冠状动脉。
阿德里安:你的研究中最困难的方面是什么,为什么?
保罗:我只有大约 5000 张照片。
起初,我们不知道为什么在获得高精度方面会有这么多困难。我们认为我们的图像没有经过适当的预处理,或者有些图像很模糊。
后来,我们意识到我们的图像没有问题:问题是 ConvNets 需要大量数据来学习一些对我们人类来说简单的东西。
确定图像中的冠状动脉树中是否有狭窄在计算上是复杂的。因为样本大小取决于分类的复杂性,所以我们很努力。我们必须找到一种用非常有限的样本训练神经网络的方法。
阿德里安:你花了多长时间来训练你的模型和进行你的研究?
保罗:花了一年多的时间。一半时间用于收集和预处理数据,一半时间用于训练和调整模型。我会收集数据,训练和调整我的模型,收集更多的数据或以不同的方式处理数据,并改进我以前的模型,并不断重复这个循环。

Figure 4: Utilizing curriculum learning to improve model accuracy.
阿德里安:如果你必须选择你在研究过程中应用的最重要的技术,那会是什么?
Paul: 我搜遍了 PyImageSearch,寻找用小样本数训练 ConvNets 的技术技巧:迁移学习,图像增强,用 SGD 代替 Adam,学习率计划表,提前停止。
每项技术都有助于 F1 分数的小幅提高,但我只达到了大约 65%的准确率。
我查看了 Kaggle 竞赛解决方案,寻找技术技巧。最大的突破来自一种叫做“课程学习”的技术我首先训练 DenseNet 解释一些非常简单的事情:“在那一小段直的动脉中有狭窄吗?”那只需要大约一百个样本。
然后我用有更多分支的更长的动脉段来训练这个预先训练好的网络。课程逐渐建立复杂性,直到学会在复杂图形的背景下解释狭窄。**这种方法极大地提高了我们的测试准确率,达到 82%。**也许预训练步骤通过将信息输入神经网络降低了计算复杂性。
文献中的“课程学习”其实有所不同:它一般是指根据错误率拆分他们的训练样本,然后根据错误率递增对训练数据批次进行排序。相比之下,我实际上创建了学习材料供 ConvNet 学习,而不仅仅是根据错误率重新安排批次。我是从我学习外语的经历中得到这个想法的,而不是从计算机文献中。一开始,我很难理解用日语写的报纸文章。随着我从初级,然后到中级,最后到高级日语课程,我终于可以理解这些文章了。

Figure 5: Example screenshots from the CathNet iPhone app.
Adrian: 你的计算机视觉和深度学习工具、库和软件包的选择是什么?
Paul: 我用的是标准包:Keras,Tensorflow,OpenCV 4。
我用 Photoshop 清理图像并创建课程。
最初我使用云实例[用于培训],但我发现我的 RTX 2080 Ti x 4 工作站更具成本效益。来自 GPU 的“全球变暖”杀死了我妻子的植物,但它大大加快了模型迭代的速度。
我们使用 Core ML 将 Tensorflow 模型转换为 iPhone 应用程序,就像您为您的口袋妖怪识别应用程序所做的一样。
我们的应用演示视频在这里:
https://www.youtube.com/embed/CaHPezrpAY8?feature=oembed
首席数据科学家彼得·叶访谈
原文:https://pyimagesearch.com/2022/08/03/an-interview-with-peter-ip-chief-data-scientist/
https://www.youtube.com/embed/TUvySJ2CWB8?feature=oembed
博士研究生、计算机视觉企业家劳尔·加西亚·马丁访谈
在这篇博文中,我采访了劳尔·加西亚·马丁,他是卡洛斯三世大学生物识别专业的博士生。
劳尔的工作重点是通过生物特征识别个人。您可能已经熟悉最流行的生物识别方法:
- 人脸识别
- 指纹识别
- 视网膜扫描
…但是你知道吗,你身体里的 静脉 也可以用来进行人体识别?
这种生物识别被称为静脉或血管生物识别(VBR)。
它没有其他生物识别系统研究得那么深入,但研究表明,它可以与其他方法一样准确,如果不是更准确的话。
劳尔在他的研究生生涯中一直在研究 VBR。正如他的谷歌学术简介显示的,他已经在计算机视觉的这个子领域发表了许多文章。
我不得不承认,劳尔让我想起了我读研究生时的自己。
劳尔不仅在进行研究并完成他的博士学位,而且他还是一名企业家。他的公司开发了可用于红外和热成像的专用相机(以及相关软件)。
这些摄像机可用于:
- 火灾探测
- 行业检查
- 安全性
- 军事应用
- 新冠肺炎体温检测
- 更不用说静脉识别了!
要了解更多关于 Raul 在静脉/血管生物识别方面的工作,包括他的工作如何帮助他建立自己的公司, 请务必阅读完整的采访内容!
博士候选人、计算机视觉企业家劳尔·加西亚·马丁的访谈
阿德里安:嗨,劳尔!感谢您抽出时间接受采访。很高兴您能来到 PyImageSearch 博客。
劳尔:嗨,阿德里安!非常感谢你给我这个绝佳的机会:你无法想象来到这里对我意味着什么,能够为 PyImageSearch 博客做贡献是一种荣誉和快乐。我真诚地希望 PyImageSearchers 可以在这次采访中找到一些有趣的东西,激励他们,就像你和我一样,追随他们的梦想和成为计算机视觉和深度学习专家的道路。
阿德里安:在我们开始之前,你能简单介绍一下你自己吗?你是马德里卡洛斯三世大学的博士生,除此之外还从事其他项目,对吗?
劳尔:我是马德里卡洛斯三世大学生物识别专业的博士生,今年是我的第三年,这是我四年来的第三年。正如你提到的,与此同时,我正试图继续进行一个创业计算机视觉项目。
阿德里安:是什么让你对研究计算机视觉感兴趣?
**劳尔:**从小我就记得我想成为一名发明家。2002 年左右,计算机视觉和深度学习还没有现在这么先进。我对他们一无所知,但我的梦想很明确:设计和开发技术解决方案来改善人们的生活。
因此,带着这个明确但尚未定义的目标,并感谢技术为我们提供的无限知识领域,我攻读了工业电子和自动化工程学士学位。从这个意义上说,我感到非常幸运,因为我有机会上大学,而且我一直得到家人的支持。
在还没有找到方向的情况下,我开始攻读电子系统和应用的硕士学位。我将大学学习与我的第一份工作结合起来,在一家工业领域的小公司担任电子硬件和固件开发员,在一家铁路领域的跨国公司担任软件测试员。
但是直到我开始硕士论文的时候,我才爱上了计算机视觉。这发生在我第一次使用 Python 和 OpenCV 从网络摄像头获得实时视频流的时候。
Adrian: 根据你在谷歌学术的简介,你的大部分工作都涉及到使用计算机视觉进行静脉识别和血管生物特征分析。你能告诉我们更多关于这项研究的信息吗?
Raul: 我的博士学位主要研究静脉或血管生物识别(VBR)。这是一种不太为人所知的生物识别模式,它使用独特人类模式的提取和分类来验证或识别人,就像面部或指纹识别一样。
有四种主要的 VBR 变体:手指、手掌、手背和手腕。我正在研究手腕 VBR,因为已经有了手指和手掌静脉模式的专利和一些商业系统。此外,我认为手腕静脉模式更容易可视化和捕捉。
Adrian: 你最近在 IEEE Access 上发表了一篇论文, 智能手机上静脉生物识别的深度学习 ( 图 1 )。你能告诉我们更多关于这篇论文的信息吗?在柯维德/疫情的世界里,我们为什么要用智能手机来识别静脉呢?
Raul: 首先我要提一下,我非常感谢你,因为这篇文章中呈现的大部分深度学习知识都是基于你的优秀的 用 Python 进行计算机视觉的深度学习 这本书中提炼出来的教导。我之前对深度学习(卷积神经网络,这里是 CNN)没有任何概念,在创纪录的时间内,我获得了具有良好组织和结构化信息的坚实知识。
这项工作的主要目标是使静脉生物识别更接近我们的日常生活,将这种生物识别变体嵌入到小型但功能强大的计算机中,该计算机已经成为我们身体的延伸:智能手机。为此,深度学习模型已集成到智能手机中,用于实时视频流认证和识别。
PyImageSearch 的读者可以在这里找到一个很好的视频摘要和演示:
https://www.youtube.com/embed/_DvuN3-LTKc?feature=oembed
对 SenseHawk 首席技术官 Saideep Talari 的采访(他刚刚筹集了 510 万美元资金)

回到 2017 年,我请当时是 PyImageSearch 大师课程毕业生的 Saideep Talari 来到博客上,分享他如何从安全分析师转变为机器学习工程师和计算机视觉从业者的故事。
今天,他是同一家公司 SenseHawk 的首席技术官,该公司刚刚筹集了 510 万美元的资金。
Saideep 的故事一直是我最感兴趣的。他来自印度低收入地区的一个非常卑微的地方,努力工作,找到了他的第一份工作,成为一名 CV/ML 工程师,现在他是首席技术官,管理着一个分布在两个大陆的人工智能团队。
这是一个令人难以置信的故事,老实说,这不是我/PyImageSearch 可以邀功的。我真的相信不管 Saideep 在哪里学习计算机视觉和深度学习,他都会成功-他是一股不可阻挡的力量,他有勇气和决心不仅要构建世界级的人工智能应用程序,还要为他和他的家人提供令人惊叹的生活。
Saideep 是一个不可思议的人,一个我有幸称之为朋友的人,我们都很幸运他今天回到了 PyImageSearch 博客。
如果你还没有阅读 2017 年 Saideep 的采访,我建议你现在就阅读。然后回到这里看故事的第二部分。
对 SenseHawk 首席技术官 Saideep Talari 的采访(他刚刚筹集了 510 万美元资金)
阿德里安:嗨,赛德普!上次我们在 PyImageSearch 博客上看到你是在 2017 年。感谢您回来告诉我们您职业生涯的最新进展!为了让读者跟上进度,你能告诉我们一些关于你自己的情况吗?
嘿,阿德里安!在我开始之前,我想感谢你,因为这是一个很荣幸的采访的一部分。
尽管我出生并成长在互联网出现之前的文化中,但从 15 岁起,我就对技术产生了兴趣。不久之后,我开始为小型企业构建网络基础设施解决方案。
早在我读大学的时候,我就在信息安全领域为几家公司提供咨询,构建数据中心安全软件、防火墙管理、渗透测试和恶意软件分析。我对编程的热爱让我开发了分布式和去中心化的 web 应用程序,并帮助了几家初创公司开发他们的产品。
我个人主张用新技术和升级现有技术来扩展我的知识和技能基础。在我的旅程中,我亲身体会到技术本身并不重要。重要的是技术如何赋予人们权力并使其受益。
我于 2017 年加入 SenseHawk,担任 ML 工程师,迅速成长为 CTO,领导开发团队。
Adrian: 在 2017 年,你是一名网络安全分析师。然后你在印度找到了一份计算机视觉工程师的工作。你能告诉我们更多关于那份工作的情况吗?你在那家公司是如何使用计算机视觉的?
说实话,我从没想过自己会在那里呆很长一段时间。虽然一开始我很想知道为一家公司工作是什么感觉,但我从不相信我会喜欢它。
当我面试这份工作时,他们向我介绍了他们正在努力解决的一个问题。他们有来自一个拥有 250 万个光伏组件的太阳能站点的热图像,他们的目标是使用计算机视觉来识别和分类这些组件中的缺陷。
虽然他们相信人工智能可以解决他们的问题,但我并不确定,因此,我反驳了他们,让他们想知道为什么传统的算法 CV 做不到这一点。
我的第一个项目如此巨大,同时满足了我的好奇心和自尊心。尽管这个项目很简单,但它让我在最初的几个月里忙得不可开交。
过了一会儿,我又遇到了第二个需要解决的挑战,那就是利用图像推断基于跟踪器的太阳能站点的等级和自动索引。随着一系列项目的到来,我决定在这里多花些时间。我在这里——还有很多事情要做,还有很长的路要走。我必须说,兴奋和好奇仍然处于顶峰。
阿德里安:看着你的职业生涯令人难以置信,迪普说。**你从安全分析师一路走到计算机视觉工程师,现在你是 SenseHawk 的首席技术官,这是一家为太阳能发电厂开发人工智能软件的公司!**你能告诉我们更多关于 SenseHawk 的工作和你的角色吗?
SenseHawk 一直致力于让太阳能的每一步都尽可能简单无缝。
太阳能行业一直在解决设计、财务建模、建设、运营优化等诸多问题。
这使得他们依赖 20 种不同的工具和大型复杂的企业软件。由于这些系统大多没有集成,因此大量的数据、知识和流程都是手工完成的也就不足为奇了。
SenseHawk 试图通过构建一个系统来解决这个问题,该系统可以将 Solar 中的所有数据和流程集成到一个具有多个应用模块的平台中。
我们的目标是创建一个每一个太阳系的数字双胞胎,它集成了从预先规划到生命终结的所有数据和过程信息。该系统可以进一步使用这些信息来帮助自动化和优化下一代。我们最终想让太阳能的生命周期成为一个流水线过程。
我的职责是定义架构并构建一个系统,该系统可以利用基于 GIS 的物理站点模型无缝集成来自技术和业务流程的各种数据类型,同时开发业务和技术应用模块,并确保系统高度安全和企业就绪!
阿德里安:这听起来比计算机视觉和深度学习要多得多?SenseHawk 依靠无人机收集太阳能信息,对吗?使用无人机的背后动机是什么?为什么不让“脚踏实地”的人来设计这些太阳能电站,并验证电池板是否优化并正常工作?
实际上,要走下数千公顷的太阳能发电厂去检测和解决持续存在的问题是不可能的。有鉴于此,我们早些时候认为无人机可以成为现场检查和维护的重要工具,收集数据的速度比人工方法快 50 倍以上,并通过避免危险的工时来提高安全性。
然而,我们很快意识到,虽然依靠无人机收集高质量的数据是合法的,但它不是绝对必要的。在下文中,我们将重点转移到构建生产力工具和其他业务工具,以对太阳能资产进行尽职调查。
在确保没有其他工具可以提高现场人员的工作效率,同时又不影响使用的简单性的情况下,我们继续在移动中升级我们的软件。有了我们,太阳能公司可以重新想象他们的所有业务,并大大提高生产力。
阿德里安:你的客户如何使用 SenseHawk?SenseHawk 如何帮助这些公司赚钱和/或省钱?
Saideep: 我们的客户以多种方式使用 SenseHawk。太阳能产业是建立在公司的分层模型上的,这些公司专门从事生命周期的一部分。有:
- 为项目寻找资源并进行初始阶段工作的开发人员
- 一旦项目可行,投资并拥有项目的资产所有者
- 建造工地的 EPC 公司
- 试运行后管理场地 20 年的 O&M 公司
- 承担资产财务管理的资产经理
- 认证资产的独立工程师
- 和提供资本的金融机构
我们有这些公司都可以使用并合作的产品。
开发人员使用我们的系统进行场地评估和初始地形。然后,他们将这些数据传递给购买项目的资产经理和建设网站的 EPC。然后,EPC 使用这些数据完成初始设计并开始施工。
在施工期间,EPC 可以使用我们的系统来管理地形、监控施工进度、向现场操作人员分配和完成任务、进行质量控制检查、与其他参与公司共享信息,并建立整个现场的数字存储库,包括组件序列号、性能数据、质量控制清单、协议等。
这个“数字双胞胎”可以交给资产所有者,他现在可以访问管理网站所需的所有信息。
此时,O&M 公司和资产管理公司可以“接管”网站,并使用数据和附带的工具来简化管理。特别是 O&M 公司,仅通过采用我们的票务系统和应用程序来分配和完成现场工作,就可以节省成本,这总是一个昂贵的提议,因为需要进行卡车滚动并派人到现场。
我们的解决方案提供了必要的工具,以最大限度地减少现场操作人员需要在现场花费的时间。这在现有的解决方案中是不可能的。
就交付的价值而言,由于我们平台上的业务流程工具与现场应用程序相结合所推动的自动化和工作简化,我们的系统可显著节省成本和时间。
阿德里安:你的日常工作是什么样的?你是在管理其他开发人员还是仍然自己写代码?
当然,我仍然写代码,但不一定每天都写了。每当公司着手处理一个复杂而又令人兴奋的问题时,我都会亲自动手,在委派给团队之前努力找到解决方案。
我的一天很早就开始了,因为早晨是我工作效率最高的时候。从审查代码和设计新的解决方案到提高现有应用程序的性能和安全性,每件事都在我一天的前半天完成。
我通常在下午与我的团队一起安排电话会议,帮助他们解决问题并清除存在的障碍(如果有的话)。我还与其他利益相关者建立了联系,但这些联系并不频繁。
我通常会提前下班,给自己的私人生活留出空间。
虽然工作很重要,但我们对事业成功的渴望永远不应该驱使我们放弃自己的幸福。我把个人生活看得和职业一样重要,甚至更重要。我认为,创造和谐的工作生活平衡不仅对改善我们的身心健康至关重要,而且对我们的职业生涯也很重要。
阿德里安: SenseHawk 在印度和美国都有分支机构。你能告诉我们更多关于这些地点的信息吗?为什么要跨洲拆分团队?
Saideep: 在美国是至关重要的,因为我们的大多数客户都在这里,尤其是早期采用者和测试版客户,他们愿意快速采用新的解决方案并进行尝试。因此,对于 SenseHawk 来说,美国是产品定义过程中的一个关键输入源。美国也贡献了我们 60%以上的收入。
印度的角度很简单。所有的核心团队都有印度血统,印度提供了大量的工程人才,而不会耗尽国库!印度也是一个巨大的太阳能市场。
我们现在也在向中东扩张,在阿布扎比设立了办事处!这又是一次接近该地区客户的努力,该地区的定位是推动可再生能源领域的重大投资。阿布扎比还提供了与世界大部分地区的单一航班连接,因此是经营全球业务的理想地点。
阿德里安: SenseHawk 刚刚结束了一轮融资, 筹集了令人难以置信的 510 万美元! 你能告诉我们更多关于资金的情况吗?你是如何抚养它的,体验如何?
最初的外联活动由 Swarup 和 Rahul(创始人)领导。他们在去年 12 月底和今年 1 月进行了几次谈话——在世界与新冠肺炎陷入混乱之前。
有趣的是,与 Falcon Edge 的对话发生在 SF 的 Swarup,孟买的 Rahul 和伦敦的 FE 团队!仿佛这是未来几个月世界走向的一个信号。
所有的谈判都是远程进行的,在情人节那天,我们达成了协议!
在此之后,我们需要完成所有的尽职调查活动,包括财务、法律和技术方面的。事实上,这不是我第一次参与技术尽职调查。我知道这是一个漫长的过程,并认为这将需要几个星期。然而,这很简单,我们可以毫不费力地快速完成。它所做的只是让我认真记录我们正在做的事情,所以如果我们再次这样做,我们将来需要的所有信息都可以很容易地获得。
财务 DD 和法律 DD 花费了更长时间,因为每个人都在不同的地理位置,而且我们在美国和印度都有运营。由于所有的 COVID 不确定性,这真是一个奇怪的时间-有时,我从来不相信它会到来。但最终,资金确实到位了,对此我非常高兴。
阿德里安:现在资金有了保障,SenseHawk 的下一步是什么?你和你的团队在开发什么?
Saideep: 对我来说,下一步是扩大我的团队,在管道中建立新的模块,同时改进我们现有的产品,包括计算机视觉模块。所有这些都需要改进,以便更好地处理我们正在处理的各种网站和数据集。
此外,我还想应用深度学习来解决太阳能电站布局设计优化挑战,这些挑战需要大量的努力和迭代才能实现。
阿德里安:你这么年轻就拥有令人难以置信的辉煌事业。对于想追随你脚步的 PyImageSearch 读者,你有什么建议?
阿德里安,谢谢你的美言。
我给所有有志于技术的人的建议是,除了追随你的激情之外,还要在自己身上投资时间/金钱。
其次,练习,练习,再练习。如果你想学点什么,练习不仅会有帮助,还会让你在这方面变得完美。制造例子并让它们发挥作用,因为仅仅阅读一些东西是不够的。
不要停止学习,但比起新的语言或框架,更要关注你现有的资产。永远不要放弃你已经获得的东西,无论是技能还是经验。
最后,要明白不是每个复杂的问题都需要复杂的解决方案。它可以被分解成一堆简单的问题,因此,我们会有简单的解决方案。毕竟,简单问题的组合可能会变得复杂,但简单解决方案的总和总是简单的。
阿德里安:谢谢你加入我们,赛德普!如果一个 PyImageSearch 的读者想聊天,在哪里和你联系最好?
我愿意通过我的 LinkedIn 与的人联系。
摘要
在今天的博文中,我们采访了 SenseHawk 的首席技术官 Saideep Talari,他刚刚筹集了 510 万美元的资金。
我最初在 2017 年的 PyImageSearch 博客上说过 deep。当时,他刚刚从 PyImageSearch Gurus 课程毕业,并利用课程中的知识,成功地从安全分析师转向了计算机视觉和机器学习工程师。
如今,他是 SenseHawk 的首席技术官,也是他作为 CV/ML 工程师加入的那家公司,并管理着一个横跨两大洲的团队。
如果你想追随塞迪普的脚步,我建议你看看我的书和课程。他们为 Saideep 工作,我毫不怀疑他们也会为你工作。
专访 123 所机器学习工程师 Yi Shern
在今天的博文中,我采访了知名图片网站 123RF.com 的图片搜索阅读器和机器学习工程师 Yi Shern。
如果你不熟悉这个术语,“库存照片”是由专业摄影师拍摄的照片,然后授权给其他个人或公司用于营销、广告、产品开发等。
123RF 从知名摄影师那里收集高质量的库存照片,使它们易于搜索和发现,然后允许用户以合理的价格购买/许可这些照片。
最近,Yi Shern 和 123RF R & D 团队的其他成员在网站上发布了一个视觉搜索功能,使用户能够通过以下方式搜索和发现图片:
- 精确定位/选择图像的特定部分
- 自动表征和量化这些区域
- 然后返回与原始查询图像在视觉上相似的股票照片
他们的工作使得【123RF 的用户更容易快速找到适合他们项目的完美库存照片,让他们的用户更开心,更有效率,最重要的是,回头客。
让我们热烈欢迎 Yi Shern 分享他的作品。
专访 123 所机器学习工程师 Yi Shern
阿德里安:嗨伊!谢谢你接受这次采访。很高兴您能来到 PyImageSearch 博客。
**易:**不客气!谢谢你邀请我。
阿德里安:你能介绍一下你自己吗?你在哪里工作,你的工作是什么?
易:我在 123RF 做机器学习工程师。作为一个研发团队,我们主要致力于解决与计算机视觉和自然语言处理相关的问题,以改善用户在搜索和发现内容方面的体验。
Adrian: 你能告诉我们你在 123RF 参与的新的计算机视觉和深度学习项目吗?
**易:**最近,在 123RF 的网站上发布了一个名为视觉搜索的新功能,它使我们的用户能够通过精确定位图像的各个部分来搜索和发现图像,并获得视觉上相似的结果。视觉搜索有两个主要计算机视觉/深度学习组件:
- 第一部分是从 123RF 的整个图像集合中导出关于输入图像的视觉特征并执行最近邻检索。
- 第二个组件是我们的对象检测组件,使视觉搜索更容易使用。我主要参与了这个组件从研究到生产的开发。
阿德里安:你通常使用什么工具和库?哪些是你的最爱?
易: Arxiv Sanity 和 Twitter 一直是我了解最新人工智能新闻和发展的非常有用的工具。
我真的很喜欢 Keras 作为 Tensorflow 的接口,因为它简单易用,可以用于研究和生产机器学习模型。
我也很高兴 Keras 现在是 Tensorflow 2.0 的核心 API,我相信这是让机器学习更容易被从业者或研究人员使用的一个伟大进步。
Adrian: 在加入 123RF 团队之前,你在计算机视觉和深度学习方面的背景如何?
**易:**我在马来西亚莫纳什大学攻读计算机科学本科学位时,对计算机视觉和深度学习的知识和接触是零。
当我在那里学习时,教学大纲没有随着当前的趋势和进步而更新,所以深度学习没有包括在教学大纲中。我确实报名参加了一个图像处理班,在深度学习时代之前,该班教授那些历史悠久的传统图像处理技术。
Adrian: 你最初是如何对计算机视觉和深度学习产生兴趣的?
Yi: 我最初是在本科最后一年的项目中开始深度学习的,该项目是建立一个心电图(ECG)节律分类系统。
当时,有很多关于神经网络的讨论,所以对我来说这是一个很好的机会来了解神经网络及其对我的项目和医疗保健的贡献。
我第一次接触深度学习是通过 Hugo Larochelle 的 MOOC 以及 TensorFlow 网站上的编码教程。从那以后,它成了我的主要爱好。
我通过各种免费的 MOOCs 继续学习更多关于计算机视觉和深度学习的知识,并获得了一个研究实习机会,在马来西亚国家应用研发中心 MIMOS 从事应用研究并开发计算机视觉应用。
当我接近完成本科学位时,我确定我想追求一个能让我进一步学习和理解深度学习和计算机视觉的职业,这就是我如何在 123RF 结束的。
Adrian:用 Python 进行计算机视觉的深度学习 (DL4CV)在 123RF 中是如何准备/帮助你的工作的?
易:我非常欣赏 DL4CV 对不同计算机视觉任务的广泛覆盖,如图像识别、物体检测、风格转换、超分辨率等。
该材料呈现了一个非常系统的流程,以非常清晰和直观的方式介绍概念,并以连贯的方式构建更高级的概念。
除此之外,DL4CV 超越了理论,传授了非常实用的技能和建议,例如使用大型数据集,以高效和科学的方式反复创建和评估实验。这份材料对我在 123RF 解决问题和进行实验的方式产生了强烈的影响。
Adrian: 您会向其他正在尝试学习计算机视觉和深度学习的开发者、学生和研究人员推荐使用 Python 的 计算机视觉深度学习吗?
**易:**肯定是的。我会向任何对计算机视觉和深度学习感兴趣的人推荐这本书,不管他们的经验水平如何。
这本书已经做了一个伟大的工作,带来了清晰和详细的解释与实际演练。
除此之外,这份材料充满了阿德里安在该领域的经验和智慧,这本身就是无价的。
Adrian: 对于想跟随你的脚步,学习计算机视觉,并在计算机视觉/深度学习领域获得一份工作的人,你还有什么其他的建议吗?
易:我认为在编码和研究计算机视觉/深度学习文献之间取得良好的平衡,对于在该领域工作的人来说,都是很有价值的技能。
令人欣慰的是,arXiv 上有许多开源实现和文献,让我们能够跟上快速发展的步伐。
**首先,我建议挑选一个你感兴趣的想法,围绕它开发一个项目,**这可以提高你对类似问题的现有解决方案的理解,并随着项目的进展提高你的开发技能。
Adrian: 如果一个 PyImageSearch 的读者想聊天,联系你的最佳地点是哪里?
易:在推特上给我发 DM!我的句柄是 @yishern 。
摘要
在这篇博文中,我们采访了 123 RF R&D 部门的机器学习工程师 Yi Shern。
最近,谢恩和 123RF R&D 团队的其他成员发布了一个视觉搜索功能,允许用户使用图像查询而不是文本查询来查找股票照片。
这个功能不仅让 123RF 用户更容易找到照片,还让他们更有效率——最终带来回头客。
如果你想追随 Yi Shern 的脚步,一定要拿起一本用 Python 编写的 计算机视觉深度学习。
使用本书,您可以:
- 成功地将深度学习和计算机视觉应用到您自己的工作项目中
- 转换职业,在一家受人尊敬的公司/组织获得一个简历/DL 职位
- 获得完成理学硕士或博士学位所需的知识
- 进行值得在著名期刊和会议上发表的研究
- 周末完成你的业余爱好 CV/DL 项目
我希望你能加入我、Yi Shern 以及成千上万的 PyImageSearch 读者的行列,他们不仅掌握了计算机视觉和深度学习,还利用这些知识改变了他们的生活。
我们在另一边见。
为了在 PyImageSearch 上发布未来的博客文章和采访时得到通知,只要在下面的表格中输入您的电子邮件地址,,我一定会让您了解最新情况。
Python 线性分类简介
原文:https://pyimagesearch.com/2016/08/22/an-intro-to-linear-classification-with-python/
我们之前学习了 k-NN 分类器——一个简单到根本不做任何实际“学习”的机器学习模型。我们只需将训练数据存储在模型中,然后在测试时通过将测试数据点与我们的训练数据进行比较来进行预测。
我们已经讨论了 k-NN 的许多利弊,但在大规模数据集和深度学习的背景下,k-NN 最令人望而却步的方面是数据本身。虽然训练可能很简单,但测试非常慢,瓶颈是向量之间的距离计算。计算训练点和测试点之间的距离与数据集中的点数成线性比例,当数据集变得非常大时,这种方法就不切实际了。虽然我们可以应用近似最近邻方法,如 ANN 、 FLANN 或airy,来加速搜索,但这仍然不能缓解 k-NN 在实例化中没有维护数据副本的情况下无法工作的问题(或者至少在磁盘上有一个指向训练集的指针,等等)。).
要了解为什么在模型中存储训练数据的精确副本是一个问题,请考虑训练一个 k-NN 模型,然后将其部署到拥有 100、1,000 甚至 1,000,000 个用户的客户群。如果你的训练集只有几兆字节,这可能不是问题——但如果你的训练集是以千兆字节到兆兆字节来衡量的(正如我们应用深度学习的许多数据集的情况一样),你就有一个真正的问题了。
考虑一下 ImageNet 数据集的训练集,它包括超过 120 万张图像。如果我们在这个数据集上训练一个 k-NN 模型,然后试图将其部署到一组用户,我们将需要这些用户下载 k-NN 模型,它在内部表示 120 万张图像的副本。根据您压缩和存储数据的方式,该模型的存储成本和网络开销可能高达数百千兆字节到数千兆字节。这不仅浪费资源,而且对于构建机器学习模型来说也不是最优的。
相反,更理想的方法是定义一个机器学习模型,该模型可以在训练期间从我们的输入数据中学习 模式(要求我们在训练过程中花费更多时间),但具有由少量参数定义的好处,这些参数可以容易地用于表示模型*,而不管训练规模*。这种类型的机器学习称为参数化学习,定义为:
用一组固定大小的参数(与训练样本的数量无关)来概括数据的学习模型称为参数模型。无论您向参数模型扔多少数据,它都不会改变它需要多少参数的想法。
我们将回顾参数化学习的概念,并讨论如何实现简单的线性分类器。正如我们稍后将看到的,参数化学习是现代机器学习和深度学习算法的基石。
备注: 这份材料的大部分灵感来自安德烈·卡帕西在斯坦福的 cs231n 班里面的优秀线性分类笔记。非常感谢 Karpathy 和 cs231n 的其他助教整理了这么容易理解的笔记。
Python 线性分类简介
我已经使用过“参数化”这个词几次了,但是它到底是什么意思呢?
简单来说: 参数化 **就是定义给定模型必要参数的过程。**在机器学习的任务中,参数化涉及根据四个关键部分定义问题:数据,一个评分函数,一个损失函数,以及权重和偏差。我们将在下面逐一回顾。
数据
这个组件是我们将要学习的输入数据。该数据包括和数据点(即图像的原始像素强度、提取的特征等。)及其相关的类标签。通常我们用多维 设计矩阵 来表示我们的数据。
设计矩阵中的每一行代表一个数据点,而矩阵的每一列(其本身可以是多维数组)对应于一个不同的特征。例如,考虑 RGB 颜色空间中 100 个图像的数据集,每个图像的大小为 32×32 像素。该数据集的设计矩阵将是 X ⊆ R ^(100×(32×32×3)) ,其中 X [i] 定义了 R 中的第 i 幅图像。使用此符号, X [1] 是第一个图像,X2 是第二个图像,依此类推。
除了设计矩阵,我们还定义了一个向量 y ,其中y**I为数据集中的第 i 个示例提供了类标签。
计分功能
评分函数接受我们的数据作为输入,并将数据映射到类标签。例如,给定我们的输入图像集,评分函数获取这些数据点,应用某个函数 f (我们的评分函数),然后返回预测的类别标签,类似于下面的伪代码:
INPUT_IMAGES => F(INPUT_IMAGES) => OUTPUT_CLASS_LABELS
损失函数
损失函数量化了我们的预测类别标签与我们的真实类别标签的吻合程度。这两组标签之间的一致程度越高,就会降低我们的损失(并且提高我们的分类精度,至少在训练集上是如此)。
我们在训练机器学习模型时的目标是最小化损失函数,从而提高我们的分类精度。
权重和偏差
通常表示为 W 的权重矩阵和偏置向量 b 被称为我们将实际优化的分类器的权重或参数。基于我们的得分函数和损失函数的输出,我们将调整和摆弄权重和偏差的值,以提高分类的准确性。
根据您的模型类型,可能存在更多的参数,但在最基本的层面上,这些是您通常会遇到的参数化学习的四个构件。一旦我们定义了这四个关键部分,我们就可以应用优化方法,这些方法允许我们找到一组参数和 b ,这些参数使我们的损失函数相对于我们的得分函数最小化(同时增加我们的数据的分类精度)。
**接下来,让我们看看这些组件如何一起工作来构建一个线性分类器,将输入数据转换为实际的预测。
线性分类:从图像到标签
在这一节中,我们将探讨机器学习的参数化模型方法的更多数学动机。
开始,我们需要我们的 数据 。让我们假设我们的训练数据集被表示为x[I],其中每个图像具有相关联的类别标签y[I]。我们将假设 i = 1,…,N 和 y [i] = 1,…,K ,这意味着我们有 N 个维度为 D 的数据点,被分成 K 个唯一的类别。**
为了使这个想法更加具体,考虑一下来自图像分类器课程的“动物”数据集。在这样的数据集中,我们可能有 N = 3,000 个图像。每幅图像都是 32×32 像素,在 RGB 颜色空间中表示(即每幅图像三个通道)。我们可以将每幅图像表示为 D = 32×32×3 = 3,072 个不同的值。最后,我们知道总共有 K = 3 类标签:一个分别用于狗、猫和熊猫类。
给定这些变量,我们现在必须定义一个评分函数 f ,它将图像映射到类标签分数。完成该评分的一种方法是通过简单的线性映射:
【①
**让我们假设每个 x [i] 被表示为具有形状[ D×1 ]的单个列向量(在这个示例中,我们将把 32×32×3 图像展平为 3072 个整数的列表)。我们的权重矩阵 W 将具有[ K×D ]的形状(类别标签的数量取决于输入图像的维度)。最后 b ,偏置向量的大小为[ K×1 ]。偏差向量允许我们在一个或另一个方向上移动和平移我们的得分函数,而不会实际影响我们的权重矩阵 W 。偏差参数通常对成功学习至关重要。
回到动物数据集示例,每个 x [i] 由 3072 个像素值的列表表示,因此 x [i] 具有形状3072×1。权重矩阵 W 将具有[3×3072]的形状,并且最终偏置向量 b 将具有[ 3×1 ]的大小。
图 1 跟随线性分类评分函数 f 的图示。在左侧,我们有我们的原始输入图像,表示为 32×32×3 图像。然后我们将这个图像展平成一个 3072 像素亮度的列表,方法是获取 3D 阵列并将其重新成形为 1D 列表。
我们的权重矩阵 W 包含三行(每个类别标签一行)和 3072 列(图像中的每个像素一列)。取 W 和 x [i] 之间的点积后,我们在偏差向量中加入——结果就是我们实际的得分函数**。我们的评分函数在右边的产生三个值:分别与狗、猫和熊猫标签相关的分数。**
**备注: 不熟悉取点积的读者,不妨看看这篇快速简洁的教程。对于有兴趣深入学习线性代数的读者,我强烈推荐通过 Philip N. Klein (2013) 的《应用于计算机科学的矩阵线性代数的编码。
看着图 1 和方程(1) ,你可以说服自己,输入x[I]和y[I]是固定的和不是我们可以修改的东西。当然,我们可以通过对输入图像应用各种变换来获得不同的x[I]——但是一旦我们将图像传递到评分函数中,这些值不会改变。事实上,我们唯一可以控制的参数(就参数化学习而言)是我们的权重矩阵 W 和我们的偏差向量 b 。因此,我们的目标是利用我们的得分函数和损失函数来优化(即,以系统的方式修改)权重和偏差向量,使得我们的分类准确度增加。**
确切地说,我们如何优化权重矩阵取决于我们的损失函数,但通常涉及某种形式的梯度下降。
参数化学习和线性分类的优势
利用参数化学习有两个主要优势:
- 一旦我们完成了对模型的训练,我们可以丢弃输入数据,只保留权重矩阵 W 和偏差向量b。这个大大地减少了我们模型的大小,因为我们需要存储两组向量(相对于整个训练集)。
- 分类新的测试数据是快。为了执行分类,我们需要做的就是取 W 和 x [i] 的点积,然后加上 biasb***(即应用我们的评分函数)。这样做比需要将每个测试点与 k-NN 算法中的每个训练样本进行比较要快得多(T20)。*
*### 用 Python 实现的简单线性分类器
现在我们已经回顾了参数化学习和线性分类的概念,让我们使用 Python 实现一个非常简单的线性分类器。
这个例子的目的是而不是展示我们如何从头到尾训练一个模型。这个例子的目的是展示我们如何初始化一个权重矩阵 W ,偏置向量 b ,然后使用这些参数通过一个简单的点积对图像进行分类。
让我们开始这个例子。我们在这里的目标是编写一个 Python 脚本,将图 2 正确分类为的“狗”
要了解我们如何完成这种分类,请打开一个新文件,将其命名为linear_example.py,并插入以下代码:
# import the necessary packages
import numpy as np
import cv2
# initialize the class labels and set the seed of the pseudorandom
# number generator so we can reproduce our results
labels = ["dog", "cat", "panda"]
np.random.seed(1)
第 2 行和第 3 行导入我们需要的 Python 包。我们将使用 NumPy 进行数值处理,并使用 OpenCV 从磁盘加载示例图像。
第 7 行初始化“Animals”数据集的目标类别标签列表,而第 8 行为 NumPy 设置伪随机数发生器,确保我们可以重现该实验的结果。
接下来,让我们初始化权重矩阵和偏差向量:
# randomly initialize our weight matrix and bias vector -- in a
# *real* training and classification task, these parameters would
# be *learned* by our model, but for the sake of this example,
# let's use random values
W = np.random.randn(3, 3072)
b = np.random.randn(3)
第 14 行用正态分布的随机值初始化权重矩阵W,均值和单位方差为零。神经网络内部的权重可以取负值、正值和零值。这个权重矩阵有3行(每个类别标签一行)和3072列(我们的 32×32×3 图像中的每个像素一行)。
然后我们初始化行 15 上的偏差向量——这个向量也随机填充了在标准正态分布上采样的值。我们的偏差向量有3行(对应于类别标签的数量)和一列。
如果我们从零开始训练这个线性分类器*,我们将需要通过优化过程学习W和b的值。然而,由于我们还没有达到训练模型的优化阶段,我已经用值1初始化了伪随机数发生器,以确保随机值给我们“正确”的分类(我提前测试了随机初始化值,以确定哪个值给我们正确的分类)。目前,简单地将权重矩阵W和偏置向量b视为以神奇的方式优化的“黑盒数组”——我们将拉开帷幕,揭示这些参数是如何在未来的课程中学习的。*
*既然我们的权重矩阵和偏差向量已经初始化,让我们从磁盘加载我们的示例图像:
# load our example image, resize it, and then flatten it into our
# "feature vector" representation
orig = cv2.imread("beagle.png")
image = cv2.resize(orig, (32, 32)).flatten()
第 19 行通过cv2.imread从磁盘加载我们的图像。然后,我们在第 20 行的上将图像调整为 32×32 像素(忽略纵横比)——我们的图像现在表示为一个(32, 32, 3) NumPy 数组,我们将其展平为一个 3072 维的向量。
下一步是通过应用我们的评分函数来计算输出类标签分数:
# compute the output scores by taking the dot product between the
# weight matrix and image pixels, followed by adding in the bias
scores = W.dot(image) + b
第 24 行是评分函数本身——它只是权重矩阵W和输入图像像素强度之间的点积,然后加上偏差b。
最后,我们的最后一个代码块处理将每个类标签的评分函数值写入我们的终端,然后将结果显示在我们的屏幕上:
# loop over the scores + labels and display them
for (label, score) in zip(labels, scores):
print("[INFO] {}: {:.2f}".format(label, score))
# draw the label with the highest score on the image as our
# prediction
cv2.putText(orig, "Label: {}".format(labels[np.argmax(scores)]),
(10, 30), cv2.FONT_HERSHEY_SIMPLEX, 0.9, (0, 255, 0), 2)
# display our input image
cv2.imshow("Image", orig)
cv2.waitKey(0)
要执行我们的示例,只需发出以下命令:
$ python linear_example.py
[INFO] dog: 7963.93
[INFO] cat: -2930.99
[INFO] panda: 3362.47
请注意狗类如何具有最大得分函数值,这意味着“狗”类将被我们的分类器选为预测。事实上,我们可以在图 3 中的图 2 上看到正确绘制的文本dog。
再次提醒,请记住这是一个的工作示例。我 特意 设置我们的 Python 脚本的随机状态,以生成将导致正确分类的W和b值(您可以更改行 8 上的伪随机种子值,亲自查看不同的随机初始化将如何产生不同的输出预测)。
实际上,你永远不会初始化你的W和b值,并且认为会在没有某种学习过程的情况下给你正确的分类。相反,当从头开始训练我们自己的机器学习模型时,我们需要优化和通过优化算法(如梯度下降)学习 W和b。
我们将在未来的课程中介绍优化和梯度下降,但同时,请花时间确保您理解了第 24 行的以及线性分类器如何通过获取权重矩阵和输入数据点之间的点积,然后添加偏差来进行分类。因此,我们的整个模型可以通过两个值来定义:权重矩阵和偏差向量。当我们从零开始训练机器学习模型时,这种表示不仅简洁,而且强大。
损失函数的作用
在上一节中,我们讨论了参数化学习的概念。这种类型的学习允许我们获取多组输入数据和类别标签,并通过定义一组参数并对其进行优化,实际学习一个将输入映射到输出预测的函数。
但是为了通过我们的评分函数实际“学习”从输入数据到类标签的映射,我们需要讨论两个重要的概念:
- 损失函数
- 优化方法
让我们探讨一下在构建神经网络和深度学习网络时会遇到的常见损失函数。
我们的探索是对损失函数及其在参数化学习中的作用的简要回顾。如果你希望用更严格的数学推导来补充这一课,我强烈推荐吴恩达的 Coursera 课程、威滕等人(2011) 、哈林顿(2012) 和马斯兰德(2009) 。
什么是损失函数?
在最基本的层面上,损失函数量化了给定预测器在对数据集中的输入数据点进行分类时的好坏程度。图 4 显示了在 CIFAR-10 数据集上训练的两个独立模型的损失函数随时间的变化情况。损失越小,分类器在对输入数据和输出类别标签之间的关系建模方面就越好(尽管有一点我们可以过度拟合我们的模型——通过对训练数据过于接近建模,我们的模型失去了概括的能力)。相反,我们的损失越大,就需要做更多的工作来提高分类精度。
为了提高我们的分类精度,我们需要调整我们的权重矩阵 W 或偏差向量 b 的参数。确切地说我们如何着手更新这些参数是一个优化 问题,我们将在以后的课程中讨论这个问题。目前,简单地理解一个损失函数可以用来量化我们的评分函数在分类输入数据点方面做得有多好。
理想情况下,随着我们调整模型参数,我们的损失应该会随着时间的推移而减少。如图 4 所示,模型#1 的损失开始略高于模型#2 ,但随后迅速下降,并在 CIFAR-10 数据集上训练时继续保持较低水平。相反,型号#2 的损失最初会降低,但很快会停滞。在此特定示例中,模型#1 实现了更低的总体损失,并且可能是用于对来自 CIFAR-10 数据集的其他图像进行分类的更理想的模型。我说“可能”是因为模型#1 有可能过度拟合训练数据。我们将在以后的课程中讨论过度拟合的概念以及如何发现它。
多级 SVM 损耗
多类 SVM 损失(顾名思义)的灵感来自于(线性)支持向量机(SVMs) ,它使用一个评分函数 f 将我们的数据点映射到每个类标签的数值分数。这个函数 f 是一个简单的学习映射:
② = W x_i +b")
现在我们有了评分函数,我们需要确定这个函数在进行预测时有多“好”或“坏”(给定权重矩阵*【W】*和偏差向量 b )。为了做出这个决定,我们需要一个损失函数。
回想一下,当创建机器学习模型时,我们有一个设计矩阵* X ,其中 X 中的每一行都包含一个我们希望分类的数据点。在图像分类的上下文中, X 中的每一行都是一个图像,我们寻求正确地标记这个图像。我们可以通过语法 x [i] 来访问 X 里面的第 i 个图像。
同样,我们也有一个向量***【y】,其中包含了我们对每个【X】的类标签。这些 y 值是我们的基础事实标签并且我们希望我们的评分函数能够正确预测。就像我们可以通过x[I]来访问给定的图像一样,我们可以通过y[I]来访问相关的类标签。***
*为了简单起见,让我们将我们的评分函数缩写为 s :
( 3 ) 
这意味着我们可以通过第 i 个数据点获得第 j 类的预测得分:
( 4 ) 
使用这种语法,我们可以把所有这些放在一起,得到 铰链损失函数 :
( 5 ) 
备注: 几乎所有的损失函数都包含一个正则项。我现在跳过这个想法,因为当我们更好地理解损失函数时,我们将在未来的课程中回顾正则化。
看着上面的铰链损耗公式,你可能会对它的实际作用感到困惑。本质上,铰链损失函数是对所有个不正确的类(I≦**j)求和,并比较我们为第 j 个类标签(不正确的类)和第 y [i] 个类(正确的类)返回的评分函数 s 的输出。我们应用max 操作将值箝位在零,这对于确保我们不累加负值很重要。
**当损失 L [i] = 0 时,给定的x[I]被正确分类(我将在下一节提供一个数值例子)。为了得到整个训练集的损失,我们简单地取每个个体的平均值:
(6) 
你可能遇到的另一个相关损失函数是 平方铰链损失 :
 (7)
(7)
**平方项通过对输出进行平方来更严重地惩罚我们的损失,这导致预测不正确时损失的二次增长(相对于线性增长)。
至于您应该使用哪个损失函数,这完全取决于您的数据集。标准铰链损失函数通常被更多地使用,但在某些数据集上,平方变化可能会获得更好的精度。总的来说,这是一个您应该考虑调整的超参数。
多级 SVM 损失示例
现在我们已经了解了铰链损耗背后的数学原理,让我们来看一个实际例子。我们将再次使用“动物”数据集,该数据集旨在将给定图像分类为包含一只猫、狗或熊猫。首先,请看图 5 中的**,这里我已经包含了来自“动物”数据集的三个类的三个训练示例。**
给定一些任意的权重矩阵 W 和偏置向量 b , f ( x,W)=W x+b的输出分数显示在矩阵体中。分数越大,越有信心我们的评分函数是关于预测的。
让我们从计算“狗”类的损失L[I]开始:
>>> max(0, 1.33 - 4.26 + 1) + max(0, -1.01 - 4.26 + 1)
0
请注意我们的等式是如何包含两项的——狗的预测得分与猫和熊猫的得分之差。此外,观察“狗”的损失如何为零——这意味着狗被正确预测。对来自图 5 的图片#1 的快速调查证明了这一结果是正确的:“狗”的得分高于“猫”和“熊猫”的得分。
类似地,我们可以计算出图像#2 的铰链损耗,其中包含一只猫:
>>> max(0, 3.76 - (-1.20) + 1) + max(0, -3.81 - (-1.20) + 1)
5.96
在这种情况下,我们的损失函数大于零,说明我们的预测不正确。查看我们的评分函数,我们看到我们的模型预测狗为建议的标签,评分为 3 。 76(因为这是得分最高的标签)。我们知道这个标签是不正确的,在未来的课程中,我们将学习如何自动调整我们的权重来纠正这些预测。
最后,让我们以熊猫为例计算铰链损耗:
>>> max(0, -2.37 - (-2.27) + 1) + max(0, 1.03 - (-2.27) + 1)
5.199999999999999
同样,我们的损失是非零的,所以我们知道我们有一个不正确的预测。查看我们的评分函数,我们的模型错误地将这张图像标记为“猫”,而它应该是“熊猫”
然后,我们可以通过取平均值来获得三个示例的总损失:
>>> (0.0 + 5.96 + 5.2) / 3.0
3.72
因此,给定我们的三个训练示例,我们的总铰链损耗为 3 。 72 为参数 W 和 b 。
还要注意,我们的损失只有三幅输入图像中的幅幅为零,这意味着我们预测的幅幅是不正确的。在未来的课程中,我们将学习如何优化 W 和 b 以使用损失函数做出更好的预测,帮助我们朝着正确的方向前进。
交叉熵损失和 Softmax 分类器
虽然铰链损失非常普遍,但在深度学习和卷积神经网络的背景下,你更有可能遇到交叉熵损失和 Softmax 分类器。
这是为什么呢?简单来说:
Softmax 分类器给你每个类标签的 概率 ,而铰链损耗给你 余量 。
对我们人类来说,解释概率比解释分数要容易得多。此外,对于像 ImageNet 这样的数据集,我们经常查看卷积神经网络的 5 级精度(其中我们检查地面实况标签是否在网络为给定输入图像返回的前 5 个预测标签中)。查看(1)真正的类别标签是否存在于前 5 个预测中,以及(2)与每个标签相关联的概率是否是一个很好的属性。
了解交叉熵损失
Softmax 分类器是二进制形式的逻辑回归的推广。就像在铰链损失或平方铰链损失中一样,我们的映射函数 f 被定义为,它获取一组输入数据x**I并通过数据 x [i] 和权重矩阵 W 的点积将它们映射到输出类别标签(为简洁起见省略了偏差项):
(8)  = W x_i")
然而,与铰链损失不同,我们可以将这些分数解释为每个类别标签的非标准化对数概率,这相当于用交叉熵损失替换铰链损失函数:
(9) 
那么,我是怎么来到这里的呢?让我们把功能拆开来看看。首先,我们的损失函数应该最小化正确类别的负对数可能性:
 ")(10)
**概率陈述可以解释为:
 = e^{s_{y_{i}}} / \sum\limits_{j} e^{s_{j}}")(11)
**我们使用标准的评分函数形式:
 (12)
(12)
**总的来说,这产生了一个单个数据点的最终损失函数,如上所示:
 (13)
(13)
**请注意,这里的对数实际上是以 e 为底的(自然对数),因为我们之前对 e 取了幂的倒数。通过指数之和的实际取幂和归一化是我们的 Softmax 函数。负对数产生我们实际的交叉熵损失。
正如铰链损失和平方铰链损失一样,计算整个数据集的交叉熵损失是通过取平均值来完成的:
 (14)
(14)
**再次,我故意从损失函数中省略正则项。我们将在未来的课程中回到正则化,解释它是什么,如何使用它,以及为什么它对神经网络和深度学习至关重要。如果上面的等式看起来很可怕,不要担心——我们将在下一节通过数字示例来确保您理解交叉熵损失是如何工作的。
一个工作过的 Softmax 例子
为了演示实际的交叉熵损失,考虑图 6 。我们的目标是分类上面的图像是否包含一只狗、猫或熊猫。很明显,我们可以看到图像是一只“熊猫”— 但是我们的 Softmax 分类器是怎么想的呢?为了找到答案,我们需要逐一查看图中的四个表格。
第一个表包括我们的评分函数 f 的输出,分别用于三个类中的每一个。这些值是我们的三个类别的非标准化对数概率。让我们对评分函数的输出( e ^(s) ,其中 s 是我们的评分函数值),产生我们的非规范化概率 ( 第二个表)。
下一步是取等式(11) 的分母,对指数求和,并除以和,从而产生与每个类标签 ( 第三表)相关联的实际概率。注意概率总和是多少。
最后,我们可以取负的自然对数,-ln(p),其中 p 是归一化的概率,产生我们的最终损失(第四个和最后一个表)。
在这种情况下,我们的 Softmax 分类器将以 93.93%的置信度正确地将图像报告为熊猫。然后,我们可以对训练集中的所有图像重复这一过程,取平均值,并获得训练集的总体交叉熵损失。这个过程允许我们量化一组参数在我们的训练集上表现的好坏。
备注: 我使用了一个随机数生成器来获得这个特定示例的得分函数值。这些值仅用于演示如何执行 Softmax 分类器/交叉熵损失函数的计算。实际上,这些值不是随机生成的,而是基于参数 W 和 b 的评分函数 f 的输出。
总结
在本课中,我们回顾了参数化学习的四个组成部分:
- 数据
- 评分功能
- 损失函数
- 权重和偏差
在图像分类的上下文中,我们的输入数据是我们的图像数据集。评分函数为给定的输入图像产生预测。然后损失函数量化一组预测对数据集的好坏程度。最后,权重矩阵和偏置向量使我们能够从输入数据中实际“学习”——这些参数将通过优化方法进行调整和调谐,以获得更高的分类精度。
然后我们回顾了两个流行的损失函数:铰链损失和交叉熵损失。虽然铰链损失在许多机器学习应用程序(例如,支持向量机)中使用,但我几乎可以绝对肯定地保证,你会看到更多频率的交叉熵损失,主要是因为 Softmax 分类器输出的是概率而不是余量。概率对于我们人类来说更容易解释,所以这个事实是交叉熵损失和 Softmax 分类器的一个特别好的特性。更多关于铰链损耗和交叉熵损耗的信息,请参考斯坦福大学的 CS231n 课程(http://cs231n.stanford.edu、https://cs231n.github.io/linear-classify)。
在未来的课程中,我们将回顾用于调整权重矩阵和偏差向量的优化方法。优化方法允许我们的算法通过基于我们的得分和损失函数的输出更新权重矩阵和偏差向量,实际上从我们的输入数据中学习。使用这些技术,我们可以对获得更低损耗和更高精度的参数值采取增量步骤。优化方法是现代神经网络和深度学习的基石,没有它们,我们将无法从输入数据中学习模式。**************************
带有 ZBar 的 OpenCV 条形码和 QR 码扫描仪
原文:https://pyimagesearch.com/2018/05/21/an-opencv-barcode-and-qr-code-scanner-with-zbar/

今天这篇关于用 OpenCV 读取条形码和二维码的博文是受到了我从 PyImageSearch 阅读器 Hewitt 那里收到的一个问题的启发:
嘿,阿德里安,我真的很喜欢图片搜索博客。我每周都期待你的邮件。继续做你正在做的事情。
我有个问题要问你:
OpenCV 有没有可以用来读取条形码或者二维码的模块?或者我需要使用一个完全独立的库吗?
谢谢艾利安。
好问题,休伊特。
简单的回答是没有,OpenCV 没有任何可以用来读取和解码条形码和二维码的专用模块。
然而,OpenCV 能做的是方便读取条形码和二维码的过程,包括从磁盘加载图像,从视频流中抓取新的一帧,并对其进行处理。
一旦我们有了图像或帧,我们就可以将它传递给专用的 Python 条形码解码库,比如 Zbar。
然后,ZBar 库将解码条形码或 QR 码。OpenCV 可以返回来执行任何进一步的处理并显示结果。
如果这听起来像一个复杂的过程,它实际上非常简单。ZBar 库及其各种分支和变体已经走过了漫长的道路。其中一套 ZBar 绑定,pyzbar,是我个人最喜欢的。
在今天的教程中,我将向您展示如何使用 OpenCV 和 ZBar 读取条形码和二维码。
另外,我还将演示如何将我们的条形码扫描仪部署到 Raspberry Pi 上!
要了解更多关于使用 OpenCV 和 ZBar 读取条形码和二维码的信息,请继续阅读。
带有 ZBar 的 OpenCV 条形码和 QR 码扫描仪
今天的博文分为四个部分。
在第一部分,我将向您展示如何安装 ZBar 库(使用 Python 绑定)。
ZBar 库将与 OpenCV 一起用于扫描和解码条形码和 QR 码。
一旦 ZBar 和 OpenCV 被正确配置,我将演示如何在单幅图像中扫描条形码和 QR 码。
从单幅图像开始会给我们提供为下一步做准备所需的练习:用 OpenCV 和 ZBar 实时读取条形码和二维码,
最后,我将演示如何将我们的实时条形码扫描器部署到 Raspberry Pi。
为条形码解码安装 ZBar(使用 Python 绑定)
几周前,来自 LearnOpenCV 博客的 Satya Mallick 发布了一篇关于使用 ZBar 库扫描条形码的非常棒的教程。
在今天的帖子中安装 ZBar 的说明主要是基于他的说明,但是有一些更新,最大的一个是关于我们如何安装 Python zbar绑定本身,确保我们可以:
- 使用 Python 3 (官方
zbarPython 绑定只支持 Python 2.7) - 检测并准确定位条形码在图像中的位置。
安装必要的软件是一个简单的三步过程。
**第一步:**从apt或brew库安装zbar
为 Ubuntu 或 Raspbian 安装 ZBar】
安装 ZBar for Ubuntu 可以通过以下命令完成:
$ sudo apt-get install libzbar0
为 macOS 安装 ZBar】
使用 brew 安装 ZBar for macOS 同样简单(假设您安装了 Homebrew):
$ brew install zbar
**步骤 2(可选)😗*创建一个虚拟环境并安装 OpenCV
您有两种选择:
- 使用一个已经准备好 OpenCV 的现有虚拟环境(跳过这一步,直接进入步骤 3 )。
- 或者创建一个新的、隔离的虚拟环境,包括安装 OpenCV。
虚拟环境是 Python 开发的最佳实践,我强烈建议您利用它们。
我选择创建一个新的、隔离的 Python 3 虚拟环境,并遵循链接在本页的 Ubuntu(或 macOS,取决于我使用的机器)OpenCV 安装说明。在遵循这些说明时,我所做的唯一改变是将我的环境命名为barcode:
$ mkvirtualenv barcode -p python3
***注意:*如果您的系统上已经安装了 OpenCV,您可以跳过 OpenCV 编译过程,只需将您的cv2.so绑定符号链接到新 Python 虚拟环境的site-packages目录中。
**第三步:**安装pyzbar
现在我的机器上有了一个名为barcode的 Python 3 虚拟环境,我激活了barcode环境(您的可能有不同的名称)并安装了pyzbar:
$ workon barcode
$ pip install pyzbar
如果您没有使用 Python 虚拟环境,您可以:
$ pip install pyzbar
如果你试图将pyzbar安装到 Python 的系统版本中,确保你也使用了sudo命令。
用 OpenCV 解码单幅图像中的条形码和 QR 码

Figure 1: Both QR and 1D barcodes can be read with our Python app using ZBar + OpenCV.
在我们实现实时条形码和二维码读取之前,让我们先从一台单图像扫描仪开始,先试一试。
打开一个新文件,将其命名为barcode_scanner_image.py,并插入以下代码:
# import the necessary packages
from pyzbar import pyzbar
import argparse
import cv2
# construct the argument parser and parse the arguments
ap = argparse.ArgumentParser()
ap.add_argument("-i", "--image", required=True,
help="path to input image")
args = vars(ap.parse_args())
在第 2-4 行上,我们导入我们需要的包。
pyzbar和cv2 (OpenCV)都需要按照上一节中的说明进行安装。
相比之下,argparse包含在 Python 安装中,它负责解析命令行参数。
这个脚本(--image)有一个必需的命令行参数,它在第 7-10 行被解析。
在本节的最后,您将看到如何在传递包含输入图像路径的命令行参数的同时运行脚本。
现在,让我们使用输入图像并让pyzbar工作:
# load the input image
image = cv2.imread(args["image"])
# find the barcodes in the image and decode each of the barcodes
barcodes = pyzbar.decode(image)
在的第 13 行,我们通过路径加载输入image(包含在我们方便的args字典中)。
从那里,我们调用pyzbar.decode找到并解码image ( 行 16 )中的barcodes。这就是泽巴所有神奇的地方。
我们还没有完成——现在我们需要解析包含在barcodes变量中的信息:
# loop over the detected barcodes
for barcode in barcodes:
# extract the bounding box location of the barcode and draw the
# bounding box surrounding the barcode on the image
(x, y, w, h) = barcode.rect
cv2.rectangle(image, (x, y), (x + w, y + h), (0, 0, 255), 2)
# the barcode data is a bytes object so if we want to draw it on
# our output image we need to convert it to a string first
barcodeData = barcode.data.decode("utf-8")
barcodeType = barcode.type
# draw the barcode data and barcode type on the image
text = "{} ({})".format(barcodeData, barcodeType)
cv2.putText(image, text, (x, y - 10), cv2.FONT_HERSHEY_SIMPLEX,
0.5, (0, 0, 255), 2)
# print the barcode type and data to the terminal
print("[INFO] Found {} barcode: {}".format(barcodeType, barcodeData))
# show the output image
cv2.imshow("Image", image)
cv2.waitKey(0)
从第 19 行的开始,我们循环检测到的barcodes。
在这个循环中,我们继续:
- 从
barcode.rect对象(第 22 行)中提取包围盒【T1(x,y)- 坐标,使我们能够定位并确定当前条码在输入图像中的位置。 - 在检测到的
barcode( 线 23 )周围的image上绘制一个包围盒矩形。 - 将
barcode解码成"utf-8"字符串,并提取条形码的类型(第 27 行和第 28 行)。在对象上调用.decode("utf-8")函数将字节数组转换成字符串是很关键的。您可以通过删除/注释它来进行试验,看看会发生什么——我将把这作为一个试验留给您来尝试。 - 格式化并在图像上绘制
barcodeData和barcodeType(第 31-33 行)。 - 最后,输出相同的数据和类型信息到终端用于调试目的(行 36 )。
让我们测试我们的 OpenCV 条形码扫描仪。你应该使用这篇博文底部的 【下载】 部分下载代码和示例图片。
从那里,打开您的终端并执行以下命令:
$ python barcode_scanner_image.py --image barcode_example.png
[INFO] Found QRCODE barcode: {"author": "Adrian", "site": "PyImageSearch"}
[INFO] Found QRCODE barcode: https://pyimagesearch.com/
[INFO] Found QRCODE barcode: PyImageSearch
[INFO] Found CODE128 barcode: AdrianRosebrock
正如您在终端中看到的,所有四个条形码都被找到并被正确解码!
参考图 1 获取处理后的图像,该图像覆盖了我们的软件找到的每个条形码的红色矩形和文本。
利用 OpenCV 实时读取条形码和二维码
在上一节中,我们学习了如何为单幅图像创建一个 Python + OpenCV 条形码扫描仪。
我们的条形码和二维码扫描仪工作得很好,但它提出了一个问题,我们能实时检测和解码条形码+二维码吗?
要找到答案,打开一个新文件,将其命名为barcode_scanner_video.py,并插入以下代码:
# import the necessary packages
from imutils.video import VideoStream
from pyzbar import pyzbar
import argparse
import datetime
import imutils
import time
import cv2
# construct the argument parser and parse the arguments
ap = argparse.ArgumentParser()
ap.add_argument("-o", "--output", type=str, default="barcodes.csv",
help="path to output CSV file containing barcodes")
args = vars(ap.parse_args())
在第 2-8 行上,我们导入我们需要的包。
此时,回想上面的解释,你应该认得出pyzbar、argparse、cv2。
我们还将使用VideoStream以高效、线程化的方式处理视频帧的捕获。你可以在这里了解更多关于视频流课程的信息。如果您的系统上没有安装imutils,只需使用以下命令:
$ pip install imutils
我们将解析一个可选的命令行参数--output,它包含输出逗号分隔值(CSV)文件的路径。该文件将包含从我们的视频流中检测和解码的每个条形码的时间戳和有效载荷。如果没有指定这个参数,CSV 文件将被放在我们当前的工作目录中,文件名为"barcodes.csv" ( 第 11-14 行)。
从那里,让我们初始化我们的视频流,并打开我们的 CSV 文件:
# initialize the video stream and allow the camera sensor to warm up
print("[INFO] starting video stream...")
# vs = VideoStream(src=0).start()
vs = VideoStream(usePiCamera=True).start()
time.sleep(2.0)
# open the output CSV file for writing and initialize the set of
# barcodes found thus far
csv = open(args["output"], "w")
found = set()
在第 18 和 19 行上,我们初始化并开始我们的VideoStream。您可以:
- 使用你的 USB 摄像头(取消注释第 18 行和注释第 19 行
- 或者,如果你正在使用树莓 Pi(像我一样),你可以使用 PiCamera(取消注释行 19 和注释行 18 )。
我选择使用我的 Raspberry Pi PiCamera,如下一节所示。
然后我们暂停两秒钟,让摄像机预热( Line 20 )。
我们会将找到的所有条形码写入磁盘的 CSV 文件中(但要确保不会写入重复的条形码)。这是一个(微不足道的)记录条形码的例子。当然,一旦条形码被检测和读取,您可以做任何您想做的事情,例如:
- 将其保存在 SQL 数据库中
- 将其发送到服务器
- 上传到云端
- 发送电子邮件或短信
实际操作是任意的 —我们只是用 CSV 文件作为例子。
请随意更新代码,以包含您希望的任何通知。
我们打开csv文件在行 24 上写。如果您正在修改代码以追加到文件中,您可以简单地将第二个参数从"w"更改为"a"(但是您必须以不同的方式搜索文件中的重复项)。
我们还为found条形码初始化了一个set。该集合将包含唯一的条形码,同时防止重复。
让我们开始捕捉+处理帧:
# loop over the frames from the video stream
while True:
# grab the frame from the threaded video stream and resize it to
# have a maximum width of 400 pixels
frame = vs.read()
frame = imutils.resize(frame, width=400)
# find the barcodes in the frame and decode each of the barcodes
barcodes = pyzbar.decode(frame)
在第 28 行的上,我们开始循环,从我们的视频流中抓取并调整一个frame(第 31 行和第 32 行)的大小。
从那里,我们调用pyzbar.decode来检测和解码frame中的任何 QR +条形码。
让我们继续循环检测到的barcodes:
# loop over the detected barcodes
for barcode in barcodes:
# extract the bounding box location of the barcode and draw
# the bounding box surrounding the barcode on the image
(x, y, w, h) = barcode.rect
cv2.rectangle(frame, (x, y), (x + w, y + h), (0, 0, 255), 2)
# the barcode data is a bytes object so if we want to draw it
# on our output image we need to convert it to a string first
barcodeData = barcode.data.decode("utf-8")
barcodeType = barcode.type
# draw the barcode data and barcode type on the image
text = "{} ({})".format(barcodeData, barcodeType)
cv2.putText(frame, text, (x, y - 10),
cv2.FONT_HERSHEY_SIMPLEX, 0.5, (0, 0, 255), 2)
# if the barcode text is currently not in our CSV file, write
# the timestamp + barcode to disk and update the set
if barcodeData not in found:
csv.write("{},{}\n".format(datetime.datetime.now(),
barcodeData))
csv.flush()
found.add(barcodeData)
如果您阅读了前面的部分,这个循环应该看起来非常熟悉。
事实上,第 38-52 行与那些单一形象剧本的相同。有关该代码块的详细介绍,请参考“单图像条形码检测和扫描”部分。
第 56-60 行是新的。在这些行中,我们检查是否发现了一个唯一的(以前没有发现的)条形码(行 56 )。
如果是这种情况,我们将时间戳和数据写入csv文件(第 57-59 行)。我们还将barcodeData添加到found集合中,作为处理重复的简单方法。
在实时条形码扫描器脚本的其余行中,我们显示帧,检查是否按下了退出键,并执行清理:
# show the output frame
cv2.imshow("Barcode Scanner", frame)
key = cv2.waitKey(1) & 0xFF
# if the `q` key was pressed, break from the loop
if key == ord("q"):
break
# close the output CSV file do a bit of cleanup
print("[INFO] cleaning up...")
csv.close()
cv2.destroyAllWindows()
vs.stop()
在行 63 上,我们显示输出frame。
然后在第 64-68 行,我们检查按键,如果"q"被按下,我们break退出主执行循环。
最后,我们在第 72-74 行上执行清理。
在 Raspberry Pi 上构建条形码和 QR 码扫描仪

Figure 2: My Raspberry Pi barcode scanner project consists of a Raspberry Pi, PiCamera, 7-inch touchscreen, and battery pack.
如果我被限制在办公桌前,条形码扫描仪还有什么意思?
我决定带上我的条形码扫描仪,使用我的 Pi、触摸屏和电池组。
图 2 中显示的是我的设置——正是我最近用于我的移动 Pokedex 深度学习项目的设置。如果您想用所示的外围设备构建自己的产品,我列出了产品和链接:
构建这个系统真的很容易,我已经在这篇博文中做了一步一步的说明。
一旦你的移动 ZBar 条形码扫描仪准备好了,使用这篇博文的 【下载】 部分下载这篇博文的相关代码。
从那里,在您的 Pi 上打开一个终端,使用以下命令启动应用程序(这一步您需要一个键盘/鼠标,但之后您可以断开连接并让应用程序运行):
$ python barcode_scanner_video.py
[INFO] starting video stream...
现在,您可以向摄像机展示条形码,完成后,您可以打开barcodes.csv文件(或者,如果您愿意,您可以在单独的终端中执行tail -f barcodes.csv,以便在数据进入 CSV 文件时实时查看数据)。
我尝试的第一个二维码显示在黑色背景上,ZBar 很容易发现:
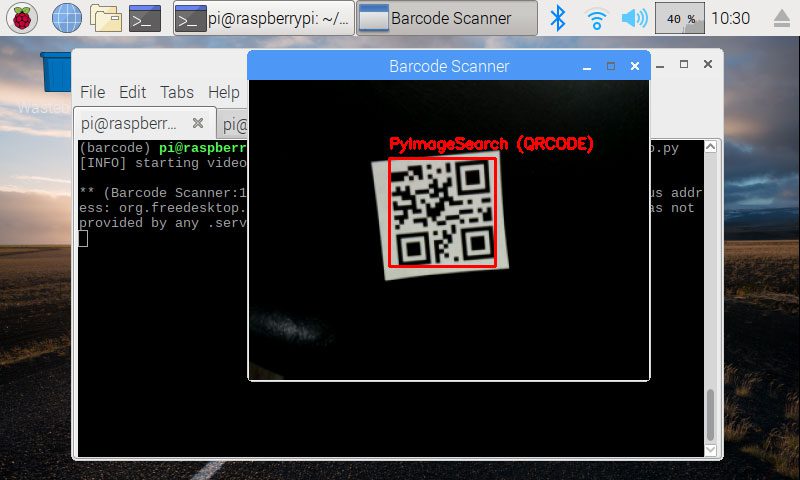
Figure 3: A QR code with the code “PyImageSearch” is recognized with our Python + ZBar application
然后我走向我的厨房,手里拿着 Pi、屏幕和电池组,找到了另一个二维码:
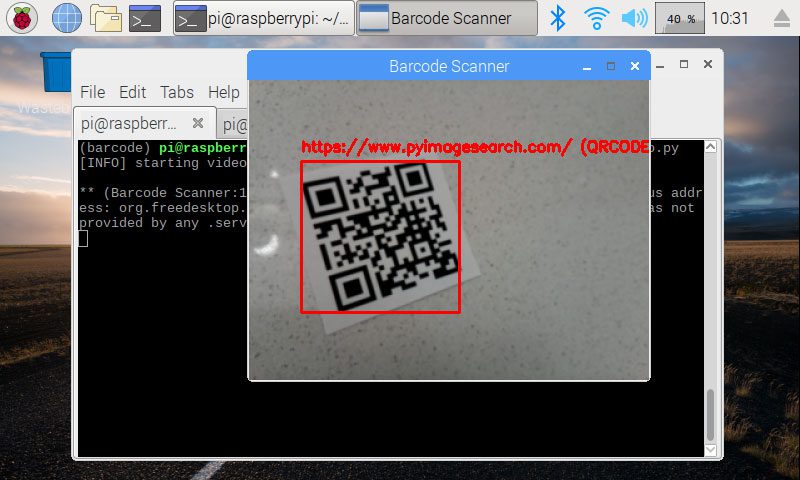
Figure 4: My website, “https://pyimagesearch.com/” is encoded in a QR code and recognized with ZBar and Python on my Raspberry Pi.
成功!它甚至可以在多个角度工作。
现在让我们尝试一个包含 JSON-blob 数据的二维码:
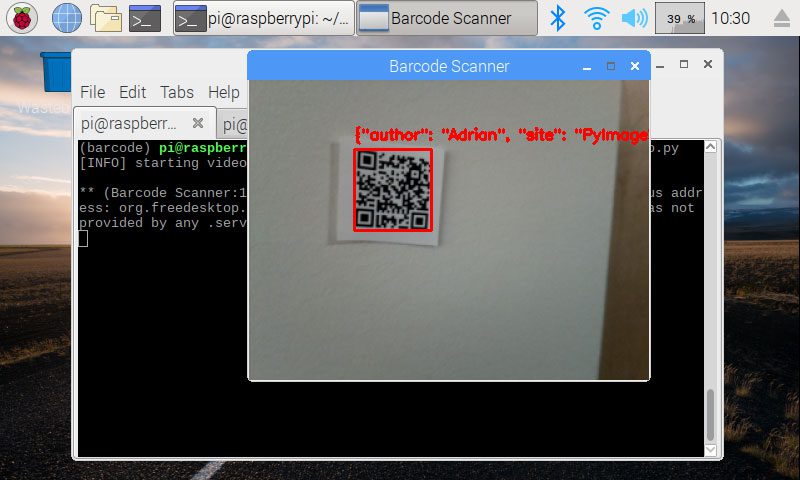
Figure 5: An OpenCV barcode and QR scanner with ZBar decodes an image of a QR with ease. I deployed the project to my Raspberry Pi so I can take it on the go.
不是我 OpenCV + ZBar + Python 条码扫描器项目的对手!
最后,我尝试了传统的一维条形码:
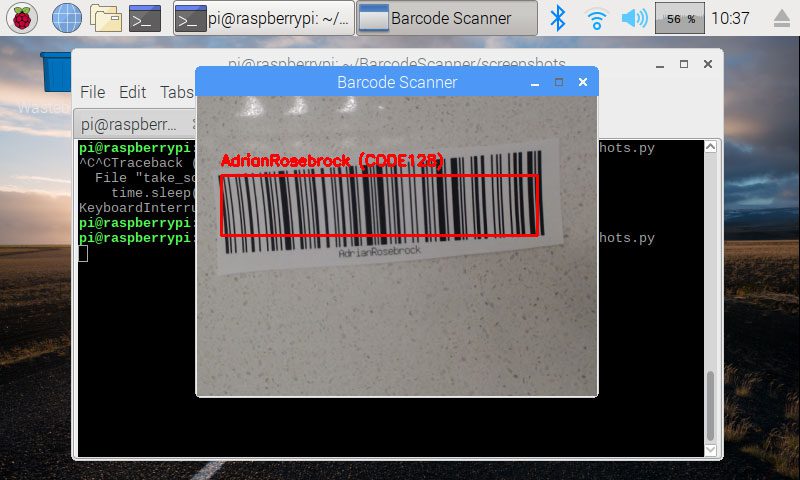
Figure 6: ZBar coupled with OpenCV and Python makes for a great Raspberry Pi barcode project. My name, “AdrianRosebrock” is encoded in this CODE128 barcode.
一维条形码对系统来说更具挑战性,尤其是在 PiCamera 不支持自动对焦的情况下。也就是说,我也成功地检测和解码了这个条形码。
你可能有最好的运气与 USB 网络摄像头,如罗技 C920 有很大的自动对焦。或者,你可以使用 Jeff Geerling 在他的博客中描述的方法来改变你的 PiCamera 的工厂焦点。
这是一个总结!
如果你有兴趣在我的网站上阅读额外的条形码博客帖子,请查看带有“条形码”标签的帖子。
摘要
在今天的博文中,您学习了如何构建 OpenCV 条形码和 QR 码扫描仪。
为此,我们使用了 ZBar 库。
一旦 ZBar 库安装到我们的系统上,我们就创建了两个 Python 脚本:
- 第一个在单一图像中扫描条形码和 QR 码的
- 以及实时读取条形码和 QR 码的第二脚本
在这两种情况下,我们都使用 OpenCV 来简化构建条形码/QR 码扫描仪的过程。
最后,我们通过将条形码阅读器部署到 Raspberry Pi 来结束今天的博文。
条形码扫描仪足够快,可以在 Raspberry Pi 上实时运行,没有任何问题。
您可以在自己的项目中随意使用这种条形码和 QR 码扫描仪功能!
如果你用它做了一些有趣的事情,一定要在评论中分享你的项目。
我希望你喜欢今天的帖子。下周见。
为了在 PyImageSearch 上发布博客文章时得到通知,请务必在下表中输入您的电子邮件地址!
分析 91 年《时代》杂志封面的视觉趋势
原文:https://pyimagesearch.com/2015/10/19/analyzing-91-years-of-time-magazine-covers-for-visual-trends/

今天的博文将建立在我们上周所学的内容之上:如何使用 Python + Scrapy 构建一个图像刮刀来刮取~ 4000 张时代杂志封面图像。
现在我们有了这个数据集,我们要用它做什么呢?
问得好。
当检查这些类型的同质数据集时,我最喜欢应用的视觉分析技术之一是简单地在给定的时间窗口 (即时间帧)内对图像进行平均 。这个平均是一个简单的操作。我们所需要做的就是循环遍历我们的数据集(或子集)中的每一幅图像,并为每个 (x,y) 【坐标】保持 的平均像素亮度值。**
通过计算这个平均值,我们可以获得图像数据(即时间杂志封面)在给定时间范围内的外观的单一表示。在探索数据集中的可视化趋势时,这是一种简单而高效的方法。
在这篇博文的剩余部分,我们将把我们的时代杂志封面数据集分成 10 组——每一组代表已经出版的 10 十年 时代杂志。然后,对于这些组中的每一组,我们将计算该组中所有图像的平均值,给我们一个关于时间封面图像看起来如何的单个 视觉表示。该平均图像将允许我们识别封面图像中的视觉趋势;具体来说,在给定的十年中时间所使用的营销和广告技术。
分析 91 年《时代》杂志封面的视觉趋势
在我们深入这篇文章之前,通读一下我们之前关于刮时间杂志封面图片的课程可能会有所帮助——阅读之前的文章当然不是必须的,但确实有助于给出一些背景。
也就是说,让我们开始吧。打开一个新文件,命名为analyze_covers.py,让我们开始编码:
# import the necessary packages
from __future__ import print_function
import numpy as np
import argparse
import json
import cv2
def filter_by_decade(decade, data):
# initialize the list of filtered rows
filtered = []
# loop over the rows in the data list
for row in data:
# grab the publication date of the magazine
pub = int(row["pubDate"].split("-")[0])
# if the publication date falls within the current decade,
# then update the filtered list of data
if pub >= decade and pub < decade + 10:
filtered.append(row)
# return the filtered list of data
return filtered
第 2-6 行简单地导入我们必需的包——这里没有什么太令人兴奋的。
然后我们在第 8 行的上定义一个效用函数filter_by_decade。顾名思义,这种方法将遍历我们收集的封面图像,并找出所有在指定十年内的封面。我们的filter_by_decade函数需要两个参数:我们想要获取封面图片的decade,以及data,T3 只是来自我们前一篇文章的output.json数据。
现在我们的方法已经定义好了,让我们继续看函数体。我们将初始化filtered,这是data中符合十年标准的行列表(第 10 行)。
然后我们循环遍历data ( 第 13 行)中的每个row,提取发布日期(第 15 行),然后更新我们的filtered列表,前提是发布日期在我们指定的decade ( 第 19 行和第 20 行)内。
最后,过滤后的行列表在第 23 行上返回给调用者。
既然我们的助手函数已经定义好了,让我们继续解析命令行参数并加载我们的output.json文件:
# construct the argument parse and parse the arguments
ap = argparse.ArgumentParser()
ap.add_argument("-o", "--output", required=True,
help="path to output visualizations directory")
args = vars(ap.parse_args())
# load the JSON data file
data = json.loads(open("output.json").read())
同样,这里的代码非常简单。第 26-29 行处理解析命令行参数。这里我们只需要一个开关,--visualizations,它是到目录的路径,我们将在这个目录中存储 1920 年到 2010 年之间每十年的平均封面图像。
然后我们在第 32 行的处加载output.json文件(同样,这是从我们之前关于用 Python + Scrapy 抓取图像的文章中生成的)。
我们现在准备对时间杂志封面数据集进行实际分析:
# loop over each individual decade Time magazine has been published
for decade in np.arange(1920, 2020, 10):
# initialize the magazine covers list
print("[INFO] processing years: {}-{}".format(decade, decade + 9))
covers = []
# loop over the magazine issues belonging to the current decade
for row in filter_by_decade(decade, data):
# load the image
cover = cv2.imread("output/{}".format(row["files"][0]["path"]))
# if the image is None, then there was an issue loading it
# (this happens for ~3 images in the dataset, likely due to
# a download problem during the scraping process)
if cover is not None:
# resize the magazine cover, flatten it into a single
# list, and update the list of covers
cover = cv2.resize(cover, (400, 527)).flatten()
covers.append(cover)
# compute the average image of the covers then write the average
# image to disk
avg = np.average(covers, axis=0).reshape((527, 400, 3)).astype("uint8")
p = "{}/{}.png".format(args["output"], decade)
cv2.imwrite(p, avg)
我们首先在第 35 行的上循环 1920 年和 2010 年之间的每个decade,并初始化一个列表covers,以存储当前decade的实际封面图像。
对于每一个十年,我们需要从output.json中取出属于十年范围内的所有行。幸运的是,这很容易,因为我们有上面定义的filter_by_decade方法。
下一步是在线 43 上从磁盘加载当前封面图像。如果图像是None,那么我们知道从磁盘加载封面时出现了问题——数据集中大约有 3 张图像会出现这种情况,这可能是由于下载问题或抓取过程中的网络问题。
假设cover不是None,我们需要将它调整到一个规范的已知大小,这样我们就可以计算每个像素位置 ( 第 51 行)的 的平均值。这里我们将图像的大小调整为固定的 400 x 527 像素,忽略长宽比——调整后的图像随后被展平为一系列 400 x 527 x 3= 632,400 像素(其中 3 来自图像的红色、绿色和蓝色通道)。如果我们不将封面大小调整为固定大小,那么我们的行将不会对齐,我们将无法计算十年范围内的平均图像。
展平后的cover然后被累积到行 52 上的covers列表中。
使用np.average功能在第 56 行对十年的封面图片进行真正的“分析”。每个时间的杂志封面图像都由covers列表中一个展平的行表示。因此,要计算十年间所有封面的平均值,我们需要做的就是取每个列的平均像素值。这将给我们留下一个单个列表(同样是 632,400 -dim ),表示每个(x,y)坐标处的每个红色、绿色和蓝色像素的平均值。
然而,由于avg图像被表示为浮点值的 1D 列表,我们无法将其可视化。首先,我们需要对avg图像进行整形,使其宽度为 400 像素,高度为 527 像素,深度为 3(分别用于红色、绿色和蓝色通道)。最后,由于 OpenCV 期望 8 位无符号整数,我们将从np.average返回的float数据类型转换为uint8。
最后,行 57 和 58 获取我们的avg封面图像并将其写入磁盘。
要运行我们的脚本,只需执行以下命令:
$ python analyze_covers.py --output visualizations
几秒钟后,您应该会在您的visualizations目录中看到以下图像:
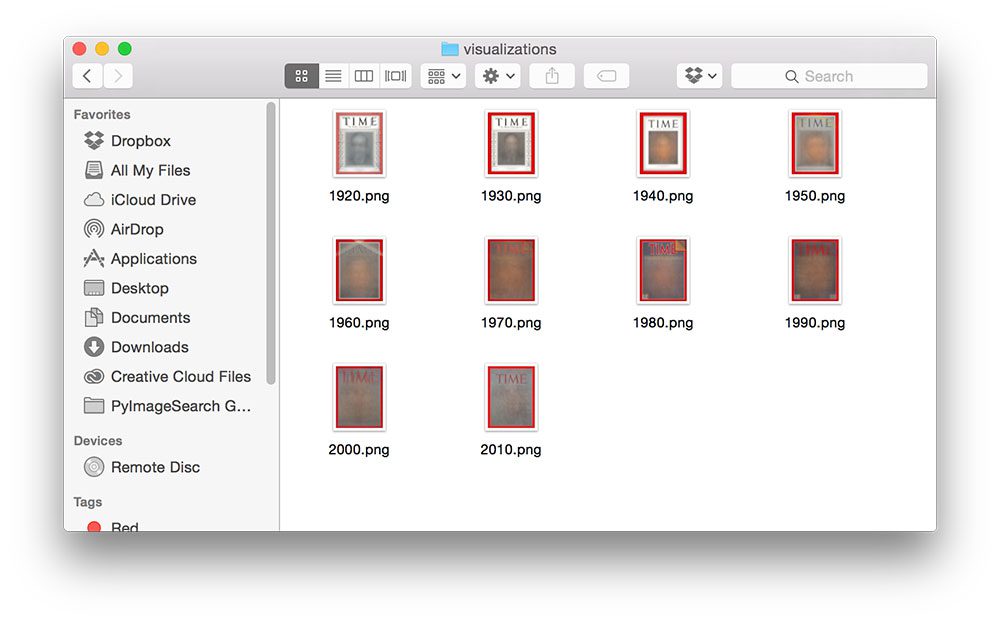
Figure 1: The output of our analyze_covers.py script for image averaging.
结果
Figure 2: Visualizing ten decades’ worth of Time magazine covers.
我们现在在我们的visualizations目录中有 10 张图片,平均每张对应于已经出版的**时间杂志的 10 个十年。
*但是这些可视化实际上意味着什么呢?通过研究它们,我们能获得什么样的洞见?
事实证明, 相当多——尤其是关于时代如何在过去 90 多年里用他们的封面进行营销和广告:

Figure 3: Average of Time magazine covers from 1920-1929.
- 原来时代杂志的封面是 全 黑白。但在 20 世纪 20 年代末,我们可以看到他们开始转移到现在标志性的红色边界。然而,封面的其他部分(包括肖像)仍然是黑白的。
- 时间标志总是出现在封面的顶部。
- 华丽的设计将封面肖像框在左边和右边。

Figure 4: Average of Time magazine covers from 1930-1939.
- Time 现在完全投入到他们的红色边框中,实际上边框的厚度已经略有增加。
- 总的来说,从 20 世纪 20 年代到 30 年代的设计变化不大。

Figure 5: Average of Time magazine covers from 1940-1949.
- 我们注意到的第一个变化是**红色边框不是唯一的颜色!*封面人物的肖像开始彩色打印。鉴于肖像区域似乎有相当多的颜色,这种变化可能发生在 20 世纪 40 年代早期的
** 另一个微妙的变化是“每周新闻杂志”版式的变化,直接在“时代”文本的下面。 同样值得注意的是,*“TIME”文本本身与前几十年相比更加固定(即位置变化非常小)。
*
Figure 6: Average of Time magazine covers from 1950-1959.
- 20 世纪 50 年代的封面图片展示了时代杂志的巨变,无论是从 封面版式 还是 营销和广告 。
** 首先,曾经被白色边框/华丽设计框住的肖像现在被扩展到覆盖整个封面——这一趋势一直延续到现代。* 元信息(如期刊名称和出版日期)总是刊登在杂志封面上;然而,我们现在开始在杂志的四个角落里看到这个元信息的一个非常固定和高度格式化的版本。* 最值得注意的是营销和广告方面的变化,用斜黄条来突出这期杂志的封面故事。*
*
Figure 7: Average of Time magazine covers from 1960-1969.
- 关于 20 世纪 60 年代的时代封面,你首先会注意到的是*“时代”文字的变化。虽然文本看起来是紫色的,但它实际上是从黑色到红色的过渡(平均起来是紫色)。之前的几十年时间*都使用黑色文字作为他们的标志,但是在 20 世纪 60 年代我们可以看到他们转换成了现在现代的红色。
- 其次,您会看到*“TIME”*文本以白色边框突出显示,用于在徽标和中心部分之间形成对比。
- 《时代周刊》仍在使用对角线条进行营销,让他们能够突出封面故事——但这些条现在更多的是“白色”而不是黄色。酒吧的宽度也减少了 1/3。

Figure 8: Average of Time magazine covers from 1970-1979.
- 在这里,我们看到营销和广告策略的另一个重大变化——*——*开始使用的人工折页(右上角),让我们可以“先睹为快”这期杂志的内容。
- 还要注意问题左下角开始出现的条形码。
- *“时间”*文本周围的白色边框已被移除。

Figure 9: Average of Time magazine covers from 1980-1989.
- 20 世纪 80 年代的《时间》杂志似乎延续了 20 世纪 70 年代的人工折页营销策略。
- 他们还重新插入了包围*“TIME”*文本的白色边框。
- 条形码现在主要用在左下角。
- 还要注意,条形码也开始出现在右下角。

Figure 10: Average of Time magazine covers from 1990-1999.
- 围绕*【TIME】*的白色边框又一次消失了——这让我很好奇这些年他们在进行什么类型的对比测试,以确定白色边框是否有助于杂志的更多销售。
- 条形码现在始终出现在杂志的左下角和右下角,条形码位置的选择高度依赖于美学。
- 还要注意,存在了近 20 年的人工折页现在已经不存在了。
- 最后,请注意*“TIME”*徽标的大小变化很大。

Figure 11: Average of Time magazine covers from 2000-2009.
- 可变标志尺寸在 2000 年代变得更加明显。
- 我们还可以看到条形码完全消失了。

Figure 12: Average of Time magazine covers from 2010-Present.
- 我们现在来到现代时间杂志封面。
- 总的来说,2010 年和 2000 年没有太大区别。
- 然而,时间标志本身的大小似乎实质上变化不大,只沿 y 轴波动。
摘要
在这篇博文中,我们探索了在上一课中收集的时间杂志封面数据集。
为了对数据集进行可视化分析,并确定杂志封面的趋势和变化,我们对几十年来的封面进行了平均。鉴于《T2 时间》已经出版了十年,这给我们留下了十种不同的视觉表现。
总的来说,封面的变化可能看起来很微妙,但它们实际上对杂志的发展很有洞察力,特别是在营销和广告方面。
以下方面的变化:
- 标志颜色和白色镶边
- 突出封面故事的横幅
- 和人工折页
清楚地表明 Time 杂志正试图确定哪些策略足够“吸引眼球”,让读者从当地的报摊上买一份。
此外,他们在白边和无白边之间的转换向我表明,他们正在进行一系列的对比测试,积累了几十年的数据,最终形成了他们现在的现代标志。***
有 WGAN 和 WGAN-GP 的动漫脸
原文:https://pyimagesearch.com/2022/02/07/anime-faces-with-wgan-and-wgan-gp/
在这篇文章中,我们实现了两种 GAN 变体:Wasserstein GAN (WGAN)和 wasser stein GAN with Gradient Penalty(WGAN-GP),以解决我在上一篇文章 GAN 训练挑战:彩色图像的 DCGAN】中讨论的训练不稳定性。我们将训练 WGAN 和 WGAN-GP 模型,生成丰富多彩的64×64动漫脸。
这是我们 GAN 教程系列的第四篇文章:
- 生成对抗网络简介
- 入门:DCGAN for Fashion-MNIST
- GAN 训练挑战:DCGAN 换彩色图像
- 有 WGAN 和 WGAN-GP 的动漫脸(本教程)
我们将首先一步一步地浏览 WGAN 教程,重点介绍 WGAN 论文中介绍的新概念。然后我们讨论如何通过一些改变来改进 WGAN,使之成为 WGAN-GP。
瓦瑟斯坦甘
论文中介绍了 Wasserstein GAN 。其主要贡献是利用 Wasserstein 损失解决 GAN 训练不稳定性问题,这是 GAN 训练的一个重大突破。
回想一下在 DCGAN 中,当鉴别器太弱或太强时,它不会给生成器提供有用的反馈来进行改进。训练时间更长并不一定让 DCGAN 模型更好。
有了 WGAN,这些训练问题可以用新的 Wasserstein loss 来解决:我们不再需要在鉴别器和生成器的训练中进行仔细的平衡,也不再需要仔细设计网络架构。WGAN 具有几乎在任何地方都连续且可微的线性梯度(图 1 )。这解决了常规 GAN 训练的消失梯度问题,
以下是 WGAN 白皮书中介绍的一些新概念或主要变化:
- Wasserstein distance (或推土机的距离):测量将一种分布转换成另一种分布所需的努力。
- **瓦瑟斯坦损失:**一个新的损失函数,衡量瓦瑟斯坦距离。
- 在 WGAN 中,这个鉴别器现在被称为评论家。我们训练一个输出数字的评论家,而不是训练一个鉴别器(二进制分类器)来辨别一个图像是真是假(生成的)。
- 批评家必须满足 李普希兹约束 才能对瓦瑟斯坦的损失起作用。
- WGAN 使用权重剪辑来执行 1-Lipschitz 约束。
在我们实施每个新的 GAN 架构时,我将重点介绍与以前的 GAN 版本相比的变化,以帮助您了解新概念。以下是 WGAN 与 DCGAN 相比的主要变化:
表 1 总结了将 DCGAN 更新为 WGAN 所需的更改:
现在让我们浏览代码,用 TensorFlow 2 / Keras 在 WGAN 中实现这些更改。在遵循下面的教程时,请参考 WGAN Colab 笔记本这里的完整代码。
设置
首先,我们确保将 Colab 硬件加速器的运行时设置为 GPU。然后我们导入所有需要的库(例如 TensorFlow 2、Keras 和 Matplotlib 等。).
准备数据
我们将使用来自 Kaggle 的一个名为动漫人脸数据集的数据集来训练 DCGAN,该数据集是从www.getchu.com刮来的动漫人脸集合。有 63,565 个小彩色图像要调整大小到64×64进行训练。
要从 Kaggle 下载数据,您需要提供您的 Kaggle 凭据。你可以上传卡格尔。或者把你的 Kaggle 用户名和密钥放在笔记本里。我们选择了后者。
os.environ['KAGGLE_USERNAME']="enter-your-own-user-name"
os.environ['KAGGLE_KEY']="enter-your-own-user-name"
将数据下载并解压缩到名为dataset的目录中。
!kaggle datasets download -d splcher/animefacedataset -p dataset
!unzip datasets/animefacedataset.zip -d datasets/
下载并解压缩数据后,我们设置图像所在的目录。
anime_data_dir = "/content/datasets/images"
然后,我们使用image_dataset_from_directory的 Keras utils 函数从目录中的图像创建一个tf.data.Dataset,它将用于稍后训练模型。我们指定了64×64的图像大小和256的批量大小。
train_images = tf.keras.utils.image_dataset_from_directory(
anime_data_dir, label_mode=None, image_size=(64, 64), batch_size=256)
让我们想象一个随机的训练图像。
image_batch = next(iter(train_images))
random_index = np.random.choice(image_batch.shape[0])
random_image = image_batch[random_index].numpy().astype("int32")
plt.axis("off")
plt.imshow(random_image)
plt.show()
下面是这个随机训练图像在图 2 中的样子:
和以前一样,我们将图像归一化到[-1, 1]的范围,因为生成器的最终层激活使用了tanh。最后,我们通过使用带有lambda函数的tf.dataset的map函数来应用规范化。
train_images = train_images.map(lambda x: (x - 127.5) / 127.5)
发电机
WGAN 发生器架构没有变化,与 DCGAN 相同。我们在build_generator函数中使用 Keras Sequential API 创建生成器架构。参考我之前两篇 DCGAN 帖子中关于如何创建生成器架构的细节: DCGAN 用于时尚-MNIST 和 DCGAN 用于彩色图像。
在build_generator()函数中定义了生成器架构之后,我们用generator = build_generator()构建生成器模型,并调用generator.summary()来可视化模型架构。
评论家
在 WGAN 中,我们有一个批评家指定一个衡量 Wasserstein 距离的分数,而不是真假图像二进制分类的鉴别器。请注意,评论家的输出现在是一个分数,而不是一个概率。批评家被 1-Lipschitz 连续性条件所约束。
这里有相当多的变化:
- 将
discriminator重命名为critic - 使用权重剪裁在批评家上实施 1-Lipschitz 连续性
- 将评论家的激活功能从
sigmoid更改为linear
将discriminator更名为critic
如果您从 DCGAN 代码开始,您需要将discriminator重命名为critic。您可以使用 Colab 中的“查找和替换”功能进行所有更新。
所以现在我们有一个函数叫做build_critic而不是build_discriminator。
重量削减
WGAN 通过使用权重裁剪来实施 1-Lipschitz 约束,我们通过子类化keras.constraints.Constraint来实现权重裁剪。详细文件参考 Keras 层重量约束。下面是我们如何创建WeightClipping类:
class WeightClipping(tf.keras.constraints.Constraint):
def __init__(self, clip_value):
self.clip_value = clip_value
def __call__(self, weights):
return tf.clip_by_value(weights, -self.clip_value, self.clip_value)
def get_config(self):
return {'clip_value': self.clip_value}
然后在build_critic函数中,我们用WeightClipping类创建了一个[-0.01, 0.01]的constraint。
constraint = WeightClipping(0.01)
现在我们将kernel_constraint = constraint添加到评论家的所有CONV2D层中。例如:
model.add(layers.Conv2D(64, (4, 4),
padding="same", strides=(2, 2),
kernel_constraint = constraint,
input_shape=input_shape))
线性激活
在 critic 的最后一层,我们将激活从sigmoid更新为linear。
model.add(layers.Dense(1, activation="linear"))
请注意,在 Keras 中,Dense层默认有linear激活,所以我们可以省略activation="linear"部分,编写如下代码:
model.add(layers.Dense(1))
我把activation = "linear"留在这里是为了说明,在将 DCGAN 更新为 WGAN 时,我们将从sigmoid变为linear激活。
现在我们已经在build_critic函数中定义了模型架构,让我们用critic = build_critic(64, 64, 3)构建 critic 模型,并调用critic.summary()来可视化 critic 模型架构。
WGAN 模型
我们通过子类keras.Model定义 WGAN 模型架构,并覆盖train_step来定义定制的训练循环。
WGAN 的这一部分有一些变化:
- 更新批评家比更新生成器更频繁
- 评论家不再有形象标签
- 使用 Wasserstein 损失代替二元交叉熵(BCE)损失
更新评论家比更新生成器更频繁
根据论文建议,我们更新评论家的频率是生成器的 5 倍。为了实现这一点,我们向WGAN类的critic_extra_steps到__init__传递了一个额外的参数。
def __init__(self, critic, generator, latent_dim, critic_extra_steps):
...
self.c_extra_steps = critic_extra_steps
...
然后在train_step()中,我们使用一个for循环来应用额外的训练步骤。
for i in range(self.c_extra_steps):
# Step 1\. Train the critic
...
# Step 2\. Train the generator
图像标签
根据我们如何编写 Wasserstein 损失函数,我们可以 1)将 1 作为真实图像的标签,将负的作为伪图像的标签,或者 2)不分配任何标签。
下面是对这两个选项的简要说明。使用标签时,Wasserstein 损失计算为tf.reduce mean(y_true * y_pred)。如果我们有真实图像上的损耗+虚假图像上的损耗和仅虚假图像上的发生器损耗的评论家损耗,那么它导致评论家损耗的tf.reduce_mean (1 * pred_real - 1 * pred_fake)和发生器损耗的-tf.reduce_mean(pred_fake)。
请注意,评论家的目标并不是试图给自己贴上1或-1的标签;相反,它试图最大化其对真实图像的预测和对虚假图像的预测之间的差异。因此,在沃瑟斯坦损失的案例中,标签并不重要。
所以我们选择后一种不分配标签的选择,你会看到所有真假标签的代码都被去掉了。
瓦瑟斯坦损失
批评家和创造者的损失通过model.compile传递:
def compile(self, d_optimizer, g_optimizer, d_loss_fn, g_loss_fn):
super(WGAN, self).compile()
...
self.d_loss_fn = d_loss_fn
self.g_loss_fn = g_loss_fn
然后在train_step中,我们使用这些函数分别计算训练期间的临界损耗和发电机损耗。
def train_step(self, real_images):
for i in range(self.c_extra_steps):
# Step 1\. Train the critic
...
d_loss = self.d_loss_fn(pred_real, pred_fake) # critic loss
# Step 2\. Train the generator
...
g_loss = self.g_loss_fn(pred_fake) # generator loss
用于训练监控的KerasCallback
与 DCGAN 相同的代码,没有变化—覆盖 Keras Callback以在训练期间监控和可视化生成的图像。
class GANMonitor(keras.callbacks.Callback):
def __init__():
...
def on_epoch_end():
...
def on_train_end():
...
编译并训练 WGAN
组装 WGAN 模型
我们将wgan模型与上面定义的 WGAN 类放在一起。请注意,根据 WGAN 文件,我们需要将评论家的额外培训步骤设置为5。
wgan = WGAN(critic=critic,
generator=generator,
latent_dim=LATENT_DIM,
critic_extra_steps=5) # UPDATE for WGAN
瓦瑟斯坦损失函数
如前所述,WGAN 的主要变化是 Wasserstein loss 的用法。以下是如何计算评论家和发电机的 Wasserstein 损失——通过在 Keras 中定义自定义损失函数。
# Wasserstein loss for the critic
def d_wasserstein_loss(pred_real, pred_fake):
real_loss = tf.reduce_mean(pred_real)
fake_loss = tf.reduce_mean(pred_fake)
return fake_loss - real_loss
# Wasserstein loss for the generator
def g_wasserstein_loss(pred_fake):
return -tf.reduce_mean(pred_fake)
编译 WGAN
现在我们用 RMSProp 优化器编译wgan模型,按照 WGAN 论文,学习率为 0.00005。
LR = 0.00005 # UPDATE for WGAN: learning rate per WGAN paper
wgan.compile(
d_optimizer = keras.optimizers.RMSprop(learning_rate=LR, clipvalue=1.0, decay=1e-8), # UPDATE for WGAN: use RMSProp instead of Adam
g_optimizer = keras.optimizers.RMSprop(learning_rate=LR, clipvalue=1.0, decay=1e-8), # UPDATE for WGAN: use RMSProp instead of Adam
d_loss_fn = d_wasserstein_loss,
g_loss_fn = g_wasserstein_loss
)
注意在 DCGAN 中,我们使用keras.losses.BinaryCrossentropy()而对于 WGAN,我们使用上面定义的自定义wasserstein_loss函数。这两个wasserstein_loss函数通过model.compile()传入。它们将用于自定义训练循环,如上面的覆盖_step部分所述。
训练 WGAN 模型
现在我们干脆调用model.fit()来训练wgan模型!
NUM_EPOCHS = 50 # number of epochs
wgan.fit(train_images, epochs=NUM_EPOCHS, callbacks=[GANMonitor(num_img=16, latent_dim=LATENT_DIM)])
Wasserstein GAN 用梯度罚
虽然 WGAN 通过 Wasserstein 的损失提高了训练的稳定性,但即使是论文本身也承认“重量削减显然是一种实施 Lipschitz 约束的可怕方式。”大的削波参数会导致训练缓慢,并阻止评论家达到最佳状态。与此同时,过小的剪裁很容易导致渐变消失,这正是 WGAN 提出要解决的问题。
本文介绍了 Wasserstein 梯度罚函数(WGAN-GP),改进了 Wasserstein GANs 的训练。它进一步改进了 WGAN,通过使用梯度惩罚而不是权重剪裁来加强评论家的 1-Lipschitz 约束。
我们只需要做一些更改就可以将 WGAN 更新为 WGAN-WP:
- 从评论家的建筑中删除批量规范。
- 使用梯度惩罚而不是权重剪裁来加强 Lipschitz 约束。
- 用亚当优化器 (α = 0.0002,β [1] = 0.5,β [2] = 0.9)代替 RMSProp。
请参考 WGAN-GP Colab 笔记本此处获取完整的代码示例。在本教程中,我们只讨论将 WGAN 更新为 WGAN-WP 的增量更改。
添加梯度惩罚
梯度惩罚意味着惩罚具有大范数值的梯度,下面是我们在 Keras 中如何计算它:
def gradient_penalty(self, batch_size, real_images, fake_images):
""" Calculates the gradient penalty.
Gradient penalty is calculated on an interpolated image
and added to the discriminator loss.
"""
alpha = tf.random.normal([batch_size, 1, 1, 1], 0.0, 1.0)
diff = fake_images - real_images
# 1\. Create the interpolated image
interpolated = real_images + alpha * diff
with tf.GradientTape() as gp_tape:
gp_tape.watch(interpolated)
# 2\. Get the Critic's output for the interpolated image
pred = self.critic(interpolated, training=True)
# 3\. Calculate the gradients w.r.t to the interpolated image
grads = gp_tape.gradient(pred, [interpolated])[0]
# 4\. Calculate the norm of the gradients.
norm = tf.sqrt(tf.reduce_sum(tf.square(grads), axis=[1, 2, 3]))
# 5\. Calculate gradient penalty
gradient_penalty = tf.reduce_mean((norm - 1.0) ** 2)
return gradient_penalty
然后在train_step中,我们计算梯度惩罚,并将其添加到原始评论家损失中。注意惩罚权重(或系数λƛ)控制惩罚的大小,它被设置为每张 WGAN 纸 10。
gp = self.gradient_penalty(batch_size, real_images, fake_images)
d_loss = self.d_loss_fn(pred_real, pred_fake) + gp * self.gp_weight
移除批次号
虽然批归一化有助于稳定 GAN 训练中的训练,但它对梯度惩罚不起作用,因为使用梯度惩罚,我们会单独惩罚每个输入的 critic 梯度的范数,而不是整个批。所以我们需要从批评家的模型架构中移除批量规范代码。
Adam Optimizer 而不是 RMSProp
DCGAN 使用 Adam 优化器,对于 WGAN,我们切换到 RMSProp 优化器。现在对于 WGAN-GP,我们切换回 Adam 优化器,按照 WGAN-GP 论文建议,学习率为 0.0002。
LR = 0.0002 # WGAN-GP paper recommends lr of 0.0002
d_optimizer = keras.optimizers.Adam(learning_rate=LR, beta_1=0.5, beta_2=0.9) g_optimizer = keras.optimizers.Adam(learning_rate=LR, beta_1=0.5, beta_2=0.9)
我们编译和训练 WGAN-GP 模型 50 个时期,并且我们观察到由该模型生成的更稳定的训练和更好的图像质量。
图 3 分别比较了真实(训练)图像和 WGAN 和 WGAN-GP 生成的图像。
WGAN 和 WGAN-GP 都提高了训练稳定性。权衡就是他们的训练收敛速度比 DCGAN 慢,图像质量可能会稍差;然而,随着训练稳定性的提高,我们可以使用更复杂的生成器网络架构,从而提高图像质量。许多后来的 GAN 变体采用 Wasserstein 损失和梯度惩罚作为缺省值,例如 ProGAN 和 StyleGAN。甚至 TF-GAN 库默认使用 Wasserstein 损失。
总结
在这篇文章中,你学习了如何使用 WGAN 和 WGAN-GP 来提高 GAN 训练的稳定性。您了解了使用 TensorFlow 2 / Keras 从 DCGAN 迁移到 WGAN,然后从 WGAN 迁移到 WGAN-GP 的增量变化。你学会了如何用 WGAN 和 WGAN-GP 生成动漫脸。
引用信息
梅纳德-里德,M. 《有 WGAN 和 WGAN-GP 的动漫脸》, PyImageSearch ,2022,【https://pyimg.co/9avys】T4
@article{Maynard-Reid_2022_Anime_Faces,
author = {Margaret Maynard-Reid},
title = {Anime Faces with {WGAN} and {WGAN-GP}},
journal = {PyImageSearch},
year = {2022},
note = {https://pyimg.co/9avys},
}
要下载这篇文章的源代码(并在未来教程在 PyImageSearch 上发布时得到通知),只需在下面的表格中输入您的电子邮件地址!
宣布“案例研究:用计算机视觉解决现实世界的问题”

今天我有一些重大消息要宣布…
除了写一大堆关于计算机视觉、图像处理和图像搜索引擎的博客帖子,我一直在幕后, 在写第二本书 。
而且你可能在想,哎,你不是刚做完 实用 Python 和 OpenCV 吗?
没错。我做到了。
别误会我的意思。实用 Python 和 OpenCV 的反馈令人惊讶。它完成了我所想的——在一个周末 教授开发者、程序员和像你一样的学生计算机视觉的基础知识 。
但是现在你已经知道了计算机视觉的基础,并且有了一个坚实的起点,是时候继续学习一些更有趣的东西了…
让我们用你的计算机视觉知识来解决一些 实际的、真实世界的问题 。
什么类型的问题?
我很高兴你问了。继续读下去,我会告诉你的。
这本书包括什么?
这本书涵盖了现实世界中与计算机视觉相关的五个主要主题。看看下面的每一个,以及每一个的截图。
#1.照片和视频中的人脸检测
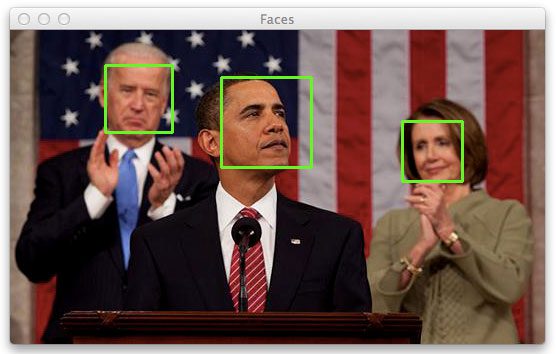
Figure 1: Learn how to use OpenCV and Python to detect faces in images.
到目前为止,这个博客上最受欢迎的教程一直是 “我如何在图像中找到人脸?” 如果你对人脸检测以及在图像和视频中寻找人脸感兴趣,那么这本书正适合你。
#2.视频中的目标跟踪
![]()
Figure 2: My Case Studies book will show you how to track objects in video as they move along the screen.
另一个我经常被问到的问题是 “我如何在视频中追踪物体?” 在这一章中,我将讨论如何使用一个物体的颜色来跟踪它在视频中移动时的轨迹。
#3.基于梯度方向直方图的手写识别

Figure 3: Learn how to use HOG and a Linear Support Vector Machine to recognize handwritten text.
这可能是整本案例研究书中我最喜欢的一章,因为它是如此实用和有用。
想象一下,你和一群朋友在酒吧或酒馆,突然一个漂亮的陌生人向你走来,递给你写在餐巾上的电话号码。
你会把餐巾塞在口袋里,希望不要弄丢吗?你会拿出手机手动创建一个新的联系人吗?
你可以。或者。你可以拍下电话号码的照片,让它被自动识别并安全存储。
在我的案例研究一书中的这一章,你将学习如何使用梯度方向直方图(HOG)描述符和线性支持向量机到对图像中的数字进行分类。
#4.基于颜色直方图和机器学习的植物分类
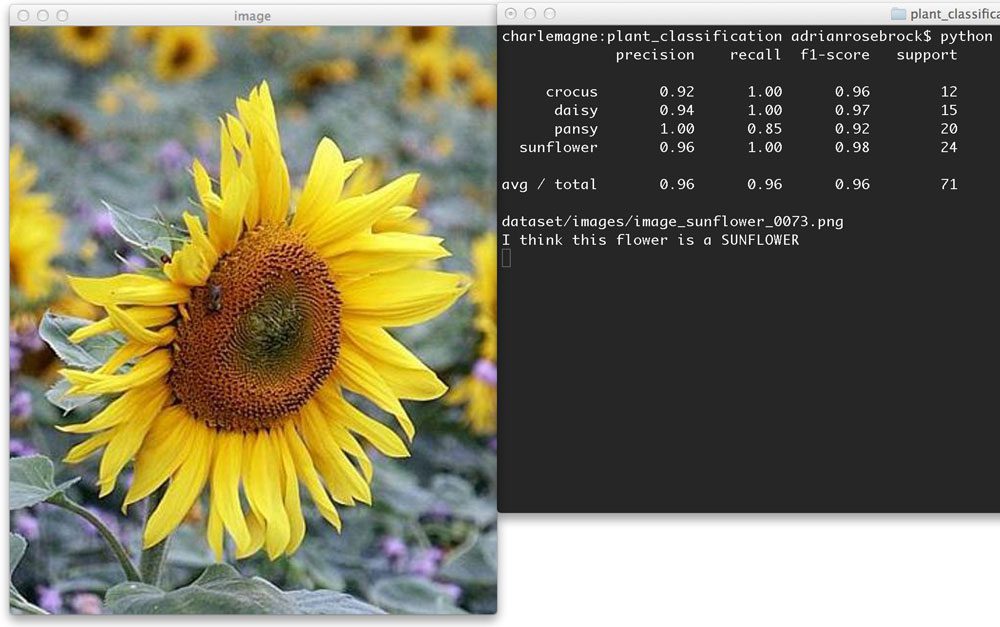
Figure 4: Learn how to apply machine learning techniques to classify the species of flowers.
计算机视觉的一个常见用途是对图像内容进行分类。为了做到这一点,你需要利用机器学习。这一章探索了如何使用 OpenCV 提取颜色直方图,然后使用 scikit-learn 训练一个随机森林分类器对一种花进行分类。
#5.构建 Amazon.com 图书封面搜索
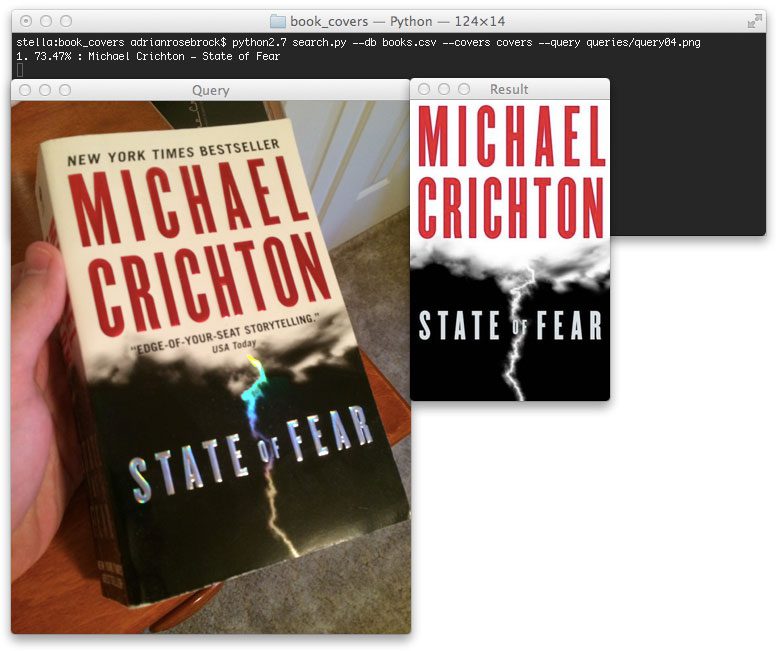
Figure 5: Applying keypoint detection and SIFT descriptors to recognize and identify book covers.
三周前,我和我的朋友格雷戈里出去喝了几杯啤酒,格雷戈里是旧金山一位炙手可热的企业家,他一直在开发一款软件,只使用一张图像就能立即识别和识别图书封面。使用这款软件,用户可以拍下他们感兴趣的书籍的照片,然后将它们自动添加到他们的购物车并运送到他们的家门口——比你的标准Barnes&Noble 便宜得多!
总之,我猜格雷戈里喝了太多啤酒,因为你猜怎么着?
他向我透露了他的秘密。
格雷戈里求我不要说出来…但我无法抗拒。
在本章中,你将学习如何利用关键点提取和 SIFT 描述符来执行关键点匹配。
最终的结果是一个系统,可以识别和识别一本书的封面在一瞬间…你的智能手机!
所有这些例子都有详细的介绍,从前面到后面,有很多代码。
当你读完我的案例研究书后,你将成为解决现实世界计算机视觉问题的专家。
那么这本书是给谁看的呢?
这本书是为像你一样有扎实的计算机视觉和图像处理基础的人准备的。理想情况下,你已经通读了实用 Python 和 OpenCV 并且对基础知识有了很强的掌握(如果你还没有机会阅读实用 Python 和 OpenCV ,绝对拿起一本)。
我认为我的新案例研究书是你学习计算机视觉旅程的下一步。
你看,这本书侧重于计算机视觉的基础知识,然后将它们应用于 解决实际现实世界的问题 。
因此,如果你对应用计算机视觉解决现实世界的问题感兴趣,你肯定会想买一本。
请排队预留您的位置,以便提前入场
如果你注册了我的时事通讯,我会发送每一章的预览,这样你就可以直接看到如何使用计算机视觉技术来解决现实世界的问题。
但是,如果你只是等不及并且想要锁定你的位置来排队接收 提前访问 到我的新案例研究电子书,只需点击这里。
听起来不错吧?
宣布 PyImageJobs:计算机视觉和深度学习工作委员会

今天,我很高兴地宣布 PyImageJobs 已经 正式推出 。
无论你是(1)期待 在计算机视觉、OpenCV 或深度学习领域找到一份工作 ,还是(2)试图 为你的公司、组织或项目填补一个计算机视觉职位——我都有你。
尽管 PyImageJobs 刚刚推出,庞大的 PyImageSearch 网络和社区已经使其成为 最大的计算机视觉就业在线平台 **,**将数千名有才华的计算机视觉、图像处理和深度学习开发人员与渴望聘用他们的公司联系起来。
在 PyImageJobs 中,您可以找到以下职位:
- 全职工作
- 兼职职位
- 承包和咨询
- 博士后职位
- 实习
- 小型项目
- …还有更多!
不管你是在找工作还是准备好下一次雇佣,PyImageJobs 都是适合你的工具。
为什么选择 PyImageJobs?
PyImageJobs 是出于需要而发展起来的。为了使 PyImageSearch 社区能够:
- 查找计算机视觉开发人员和工程师的工作职位、承包工作或项目。
- 将潜在的计算机视觉员工与渴望雇用他们的公司、组织和个人联系起来。
你看,每个月我都会收到近 100 份合同/咨询邀请,对我来说太多了,即使我围绕计算机视觉咨询建立了一个完整的公司。
我没有简单地拒绝这些提议,而是决定创建 PyImageJobs,帮助有才华的计算机视觉、图像处理和深度学习开发人员与准备招聘的公司和个人联系。
PyImageJobs 不仅仅是一个工作平台。无论你是在寻找全职员工、兼职员工,还是只是一个小项目的承包商/顾问——请放心,这就是 正是我创建 PyImageJobs 的原因。
由于 PyImageJobs 是由 PyImageSearch.com 社区提供支持的,你可以放心,因为有成千上万的读者准备申请你的职位。
如何在 PyImageJobs 上发布工作或项目?

Figure 1: You can post part-time positions, freelance/contract work, internships, post-doc positions, remote work, and simple projects on PyImageJobs.
我之前提到过,PyImageJobs 并不局限于全职工作。您还可以发布:
- 兼职职位
- 自由职业者/合同工
- 实习
- 博士后职位
- 远程工作
- 简单的项目
无论你是需要在你的公司雇用一名全职计算机视觉工程师,还是仅仅需要一名计算机视觉开发人员来帮助你当前的项目,试试 PyImageJobs 吧——我非常有信心你能找到一名符合你需求的开发人员。
要在 PyImageJobs 上发布您的下一份工作/项目:
- 前往 PyImageJobs 网站。
- 点击定价链接并选择一个计划。
- 填写职位描述。
一旦提交,您的工作将在 24 小时内发布,使您能够接触到成千上万活跃的计算机视觉、深度学习和 OpenCV 求职者。
**## 礼宾职位描述撰写服务(仅限限时)
在过去的一周里,我非常愉快地和一些雇主一起测试了 PyImageJobs 网站。
在几乎所有情况下我都注意到在雇主发布工作和他们找到下一个计算机视觉雇员之间的主要障碍是起草工作描述本身。
*招聘费用不是问题。这也不是信任问题——他们知道 PyImageJobs 和相关的 PyImageSearch 社区可以提供合格的应用程序。
相反,最主要的问题是,写一份工作描述可能是一个耗时且乏味的过程,尤其是如果你几乎没有写工作清单的经验。
毫无疑问——写一份完美的工作描述具有挑战性。幸运的是,我有多年的经验,不仅是与计算机视觉工程师一起工作,也有雇佣他们的经验。
对于一个 限时 ,我提供一个 礼宾职位说明书撰写服务 。在未来,我将为这项服务向收费,所以如果你想让我为你写你的工作/项目描述,确保你现在利用这个机会。
简单地告诉我你的工作,我会帮你起草一份工作描述,保证得到申请人。
很难达成这样的交易。
要注册礼宾写作服务,只需使用以下链接并给我发消息:
https://pyimagesearch.com/contact/
我如何获得 PyImageJobs 上的工作或项目?
为了得到一份工作或一个项目,我建议你做两件事。
首先,前往 PyImageJobs 网站并注册即时电子邮件通知:

Figure 2: Sign up for instant notifications to receive an email whenever a new job is posted on PyImageJobs. Don’t miss out on a great opportunity because you found out too late!
这将确保您在发布新职位的第一时间收到电子邮件通知。**你不想因为发现得太晚而错过一个绝佳的工作机会吧!**注册即时职位发布通知还将确保您每周收到 PyImageJobs 上发布的热门/新职位的精选摘要。
其次,准备好你的简历或者履历。确保它是最新的,并且包含您最近的项目。
当您准备申请工作时,点击工作列表,然后滚动到*“申请该工作”*按钮:

Figure 3: Applying for a job/position on PyImageJobs is as simple as filling out four quick fields.
点击此按钮将打开一个表格,您可以用它来申请该职位。您的信息将直接发送给雇主。
在未来的 PyImageSearch 博客帖子中,我将分享更多关于如何在申请 PyImageJobs 职位时让自己从人群中脱颖而出的信息。
摘要
今天,我很高兴地宣布 PyImageJobs 正式上线 。
无论你是(1)期待 在计算机视觉、OpenCV 或深度学习领域找到一份工作 ,还是(2)试图 为你的公司、组织或项目填补一个计算机视觉职位——我都有你。
如果你有兴趣提交你的工作或项目,请联系我,我会帮你发布你的工作。在有限的时间里,我甚至提供礼宾写作服务来帮你起草完美的工作/项目描述。
如果你想开始申请计算机视觉的工作,去 PyImageJobs 网站注册即时电子邮件通知列表(这样你就不会错过一个很好的工作机会)。
享受就业委员会,如果你有任何问题,请让我知道!***
宣布 PyImageSearch Web API
原文:https://pyimagesearch.com/2015/05/18/announcing-the-pyimagesearch-web-api/

今天我超级兴奋地正式宣布PyImageSearch web API。
我已经计划构建这个 API 有一段时间了,最后,上周关于构建一个人脸检测 Web API 的博客帖子正是我完成这个项目并将其发布到网上所需要的动力。
PyImageSearch Web API 是一个教学工具,用于进一步促进 PyImageSearch 博客上的高质量计算机视觉教程。
目前唯一的终点是图像中的人脸检测,但随着我在 PyImageSearch 博客上发布更多文章,终点的列表将继续增长。
例如,想象一下能够与我们构建的图像搜索引擎进行交互,以通过度假照片 进行 搜索。
一个 API 端点来处理 移动文档扫描 怎么样?
或者也许我们可以包装一个 深度学习分类器来识别手写数字 ?
正如你所看到的,有相当多的可能性——我认为我们会从这个 API 中获得很多乐趣。
因此,请留意新的 PyImageSearch 博客帖子的发布。在适当的时候,我会加入新的 API 端点。
在哪里可以访问 PyImageSearch Web API?
PyImageSearch Web API 可以在 http://api.pyimagesearch.com 的找到,其中也包括每个端点的文档。
PyImageSearch Web API 是免费的吗?
你打赌!PyImageSearch Web API100%免费。健康地使用它来帮助你的计算机视觉教育。
我可以在自己的应用程序中使用 PyImageSearch Web API 吗?
我会建议反对这样做。PyImageSearch web API 本来是一个教学工具,所以如果你滥用 API,我将不得不开始发布 API 密钥——这是我、真的不想做的事情。
PyImageSearch Web API 有商业版吗?
也许将来会有 PyImageSearch Web API 的商业版本,您可以在自己的应用程序中使用它,但不是现在。如果随着 API 的发展,人们对它有足够的兴趣,我当然可以想象创建一个商业的、生产级别的 API 版本,并授权给开发者。
我可以贡献 PyImageSearch Web API 吗?
如果你已经开发了一个你认为会成为一个伟大的端点的计算机视觉应用,请给我发消息。我还会建议你使用我的样板 Django 视图模板(可以在页面中间找到)来包装你的应用程序,以构建基于计算机视觉的 web APIs。
如何支持 PyImageSearch Web API?
我个人为运行 PyImageSearch Web API 的服务器和主机支付现金。如果你喜欢它,觉得它有用,或者从中学习到什么,你可以拿起我的书 实用 Python 和 OpenCV 的副本来支持我自己和 PyImageSearch 博客。否则,请欣赏 API!
请求一个 API 端点?
你认为之前在 PyImageSearch 博客上的一篇文章会成为一个好的 API 端点吗?或者对包含 API 端点的计算机视觉教程有什么建议?在下面评论这篇文章让我知道或者给我发消息。
使用 Keras、TensorFlow 和深度学习进行异常检测
原文:https://pyimagesearch.com/2020/03/02/anomaly-detection-with-keras-tensorflow-and-deep-learning/
在本教程中,您将学习如何使用自动编码器、Keras 和 TensorFlow 执行异常和异常值检测。
早在一月份,我就向您展示了如何使用标准的机器学习模型来执行图像数据集中的异常检测和异常值检测。
我们的方法非常有效,但它回避了一个问题:
深度学习可以用来提高我们异常检测器的准确性吗?
要回答这样一个问题,我们需要深入兔子洞,回答如下问题:
- 我们应该使用什么模型架构?
- 对于异常/异常值检测,某些深度神经网络架构是否优于其他架构?
- 我们如何处理阶级不平衡的问题?
- 如果我们想训练一个无人监管的异常检测器会怎么样?
本教程解决了所有这些问题,在它结束时,您将能够使用深度学习在自己的图像数据集中执行异常检测。
要了解如何使用 Keras、TensorFlow 和深度学习执行异常检测,继续阅读!
使用 Keras、TensorFlow 和深度学习进行异常检测
在本教程的第一部分,我们将讨论异常检测,包括:
- 是什么让异常检测如此具有挑战性
- 为什么传统的深度学习方法不足以检测异常/异常值
- 自动编码器如何用于异常检测
在此基础上,我们将实现一个自动编码器架构,该架构可用于使用 Keras 和 TensorFlow 进行异常检测。然后,我们将以一种无人监管的方式训练我们的自动编码器模型。
一旦训练了自动编码器,我将向您展示如何使用自动编码器来识别您的训练/测试集和不属于数据集分割的新图像中的异常值/异常。
什么是异常检测?
引用我的介绍异常检测教程:
异常被定义为偏离标准、很少发生、不遵循“模式”其余部分的事件
异常情况的例子包括:
- 由世界事件引起的股票市场的大幅下跌和上涨
- 工厂里/传送带上的次品
- 实验室中被污染的样本
根据您的具体使用案例和应用,异常通常只发生 0.001-1%的时间——这是一个令人难以置信的小部分时间。
这个问题只是因为我们的阶级标签中存在巨大的不平衡而变得更加复杂。
根据定义,异常将*很少发生,*所以我们的大多数数据点将是有效事件。
为了检测异常,机器学习研究人员创建了隔离森林、一类支持向量机、椭圆包络和局部离群因子等算法来帮助检测此类事件;然而,所有这些方法都植根于传统的机器学习。
深度学习呢?
深度学习是否也可以用于异常检测?
答案是肯定的——但是你需要正确地描述这个问题。
深度学习和自动编码器如何用于异常检测?
正如我在我的自动编码器简介教程中所讨论的,自动编码器是一种无监督的神经网络,它可以:
- 接受一组输入数据
- 在内部将数据压缩成潜在空间表示
- 从潜在表示中重建输入数据
为了完成这项任务,自动编码器使用两个组件:一个编码器和一个解码器。
编码器接受输入数据并将其压缩成潜在空间表示。解码器然后试图从潜在空间重建输入数据。
当以端到端的方式训练时,网络的隐藏层学习鲁棒的滤波器,甚至能够对输入数据进行去噪。
然而,从异常检测的角度来看,使自动编码器如此特殊的是重建损失。当我们训练自动编码器时,我们通常测量以下各项之间的均方误差 (MSE):
- 输入图像
- 来自自动编码器的重建图像
损失越低,自动编码器在重建图像方面做得越好。
现在让我们假设我们在整个 MNIST 数据集上训练了一个自动编码器:
然后,我们向自动编码器提供一个数字,并告诉它重建它:
我们希望自动编码器在重建数字方面做得非常好,因为这正是自动编码器被训练做的事情,如果我们观察输入图像和重建图像之间的 MSE,我们会发现它非常低。
现在让我们假设我们向自动编码器展示了一张大象的照片,并要求它重建它:
由于自动编码器在之前从未见过大象,更重要的是,从未被训练来重建大象, **我们的 MSE 将非常高。****
如果重建的 MSE 很高,那么我们可能有一个异常值。
Alon Agmon 在这篇文章中更详细地解释了这个概念。
配置您的开发环境
为了跟随今天的异常检测教程,我推荐您使用 TensorFlow 2.0。
要配置您的系统并安装 TensorFlow 2.0,您可以遵循 my Ubuntu 或 macOS 指南:
- 如何在 UbuntuT3 上安装 tensor flow 2.0【Ubuntu 18.04 OS;CPU 和可选的 NVIDIA GPU)
- 如何在 macOS 上安装 tensor flow 2.0(Catalina 和 Mojave OSes)
请注意: PyImageSearch 不支持 Windows — 参考我们的 FAQ 。
项目结构
继续从这篇文章的 “下载” 部分抓取代码。一旦你解压了这个项目,你会看到下面的结构:
$ tree --dirsfirst
.
├── output
│ ├── autoencoder.model
│ └── images.pickle
├── pyimagesearch
│ ├── __init__.py
│ └── convautoencoder.py
├── find_anomalies.py
├── plot.png
├── recon_vis.png
└── train_unsupervised_autoencoder.py
2 directories, 8 files
我们的convautoencoder.py文件包含负责构建 Keras/TensorFlow 自动编码器实现的ConvAutoencoder类。
我们将使用train_unsupervised_autoencoder.py中未标记的数据训练一个自动编码器,产生以下输出:
autoencoder.model:序列化、训练好的 autoencoder 模型。- 一系列未标记的图像,我们可以从中发现异常。
- 由我们的训练损失曲线组成的图。
recon_vis.png:将地面实况数字图像的样本与每个重建图像进行比较的可视化图形。
从那里,我们将在find_anomalies.py内部开发一个异常检测器,并应用我们的自动编码器来重建数据并发现异常。
使用 Keras 和 TensorFlow 实现我们的异常检测自动编码器
深度学习异常检测的第一步是实现我们的 autoencoder 脚本。
我们的卷积自动编码器实现与我们的自动编码器介绍文章以及我们的去噪自动编码器教程中的实现完全相同;然而,为了完整起见,我们将在这里回顾一下——如果你想了解关于自动编码器的更多细节,请务必参考那些帖子。
打开convautoencoder.py并检查:
# import the necessary packages
from tensorflow.keras.layers import BatchNormalization
from tensorflow.keras.layers import Conv2D
from tensorflow.keras.layers import Conv2DTranspose
from tensorflow.keras.layers import LeakyReLU
from tensorflow.keras.layers import Activation
from tensorflow.keras.layers import Flatten
from tensorflow.keras.layers import Dense
from tensorflow.keras.layers import Reshape
from tensorflow.keras.layers import Input
from tensorflow.keras.models import Model
from tensorflow.keras import backend as K
import numpy as np
class ConvAutoencoder:
@staticmethod
def build(width, height, depth, filters=(32, 64), latentDim=16):
# initialize the input shape to be "channels last" along with
# the channels dimension itself
# channels dimension itself
inputShape = (height, width, depth)
chanDim = -1
# define the input to the encoder
inputs = Input(shape=inputShape)
x = inputs
# loop over the number of filters
for f in filters:
# apply a CONV => RELU => BN operation
x = Conv2D(f, (3, 3), strides=2, padding="same")(x)
x = LeakyReLU(alpha=0.2)(x)
x = BatchNormalization(axis=chanDim)(x)
# flatten the network and then construct our latent vector
volumeSize = K.int_shape(x)
x = Flatten()(x)
latent = Dense(latentDim)(x)
# build the encoder model
encoder = Model(inputs, latent, name="encoder")
进口包括tf.keras和 NumPy。
我们的ConvAutoencoder类包含一个静态方法build,它接受五个参数:
width:输入图像的宽度。height:输入图像的高度。depth:图像中的通道数。filters:编码器和解码器将分别学习的滤波器数量latentDim:潜在空间表示的维度。
然后为编码器定义了Input,此时我们使用 Keras 的函数 API 循环遍历我们的filters,并添加我们的CONV => LeakyReLU => BN层集合。
然后我们拉平网络,构建我们的潜在向量。潜在空间表示是我们数据的压缩形式。
在上面的代码块中,我们使用自动编码器的encoder部分来构建我们的潜在空间表示——这个相同的表示现在将用于重建原始输入图像:
# start building the decoder model which will accept the
# output of the encoder as its inputs
latentInputs = Input(shape=(latentDim,))
x = Dense(np.prod(volumeSize[1:]))(latentInputs)
x = Reshape((volumeSize[1], volumeSize[2], volumeSize[3]))(x)
# loop over our number of filters again, but this time in
# reverse order
for f in filters[::-1]:
# apply a CONV_TRANSPOSE => RELU => BN operation
x = Conv2DTranspose(f, (3, 3), strides=2,
padding="same")(x)
x = LeakyReLU(alpha=0.2)(x)
x = BatchNormalization(axis=chanDim)(x)
# apply a single CONV_TRANSPOSE layer used to recover the
# original depth of the image
x = Conv2DTranspose(depth, (3, 3), padding="same")(x)
outputs = Activation("sigmoid")(x)
# build the decoder model
decoder = Model(latentInputs, outputs, name="decoder")
# our autoencoder is the encoder + decoder
autoencoder = Model(inputs, decoder(encoder(inputs)),
name="autoencoder")
# return a 3-tuple of the encoder, decoder, and autoencoder
return (encoder, decoder, autoencoder)
这里,我们采用潜在的输入,并使用完全连接的层将其重塑为 3D 体积(即,图像数据)。
我们再次循环我们的过滤器,但是以相反的顺序,应用一系列的CONV_TRANSPOSE => RELU => BN层。CONV_TRANSPOSE层的目的是将体积大小增加回原始图像的空间尺寸。
最后,我们建立了解码器模型并构建了自动编码器。回想一下,自动编码器由编码器和解码器组件组成。然后,我们返回编码器、解码器和自动编码器的三元组。
同样,如果您需要关于我们的 autoencoder 实现的更多细节,请务必查看前面提到的教程。
实施异常检测培训脚本
随着我们的 autoencoder 的实现,我们现在准备继续我们的训练脚本。
打开项目目录中的train_unsupervised_autoencoder.py文件,并插入以下代码:
# set the matplotlib backend so figures can be saved in the background
import matplotlib
matplotlib.use("Agg")
# import the necessary packages
from pyimagesearch.convautoencoder import ConvAutoencoder
from tensorflow.keras.optimizers import Adam
from tensorflow.keras.datasets import mnist
from sklearn.model_selection import train_test_split
import matplotlib.pyplot as plt
import numpy as np
import argparse
import random
import pickle
import cv2
导入包括我们的ConvAutoencoder、数据集mnist的实现,以及一些来自 TensorFlow、scikit-learn 和 OpenCV 的导入。
假设我们正在执行*无监督学习,*接下来我们将定义一个函数来构建一个无监督数据集:
def build_unsupervised_dataset(data, labels, validLabel=1,
anomalyLabel=3, contam=0.01, seed=42):
# grab all indexes of the supplied class label that are *truly*
# that particular label, then grab the indexes of the image
# labels that will serve as our "anomalies"
validIdxs = np.where(labels == validLabel)[0]
anomalyIdxs = np.where(labels == anomalyLabel)[0]
# randomly shuffle both sets of indexes
random.shuffle(validIdxs)
random.shuffle(anomalyIdxs)
# compute the total number of anomaly data points to select
i = int(len(validIdxs) * contam)
anomalyIdxs = anomalyIdxs[:i]
# use NumPy array indexing to extract both the valid images and
# "anomlay" images
validImages = data[validIdxs]
anomalyImages = data[anomalyIdxs]
# stack the valid images and anomaly images together to form a
# single data matrix and then shuffle the rows
images = np.vstack([validImages, anomalyImages])
np.random.seed(seed)
np.random.shuffle(images)
# return the set of images
return images
我们的build_supervised_dataset函数接受一个带标签的数据集(即用于监督学习)并把它变成一个无标签的数据集(即用于非监督学习)。
该函数接受一组输入data和labels,包括有效标签和异常标签。
鉴于我们的validLabel=1默认只有 MNIST 数字的被选中;然而,我们也会用一组数字三个图像(validLabel=3)污染我们的数据集。
contam百分比用于帮助我们采样和选择异常数据点。
从我们的一组labels(并使用有效标签),我们生成一个列表validIdxs ( 第 22 行)。完全相同的过程适用于抓取anomalyIdxs ( 线 23 )。然后,我们继续随机shuffle索引(第 26 行和第 27 行)。
考虑到我们的异常污染百分比,我们减少了我们的anomalyIdxs ( 行 30 和 31 )。
第 35 行和第 36 行然后构建两组图像:(1)有效图像和(2)异常图像。
这些列表中的每一个被堆叠以形成单个数据矩阵,然后被混洗并返回(行 40-45 )。注意到标签被有意丢弃,有效地使我们的数据集为无监督学习做好准备。
我们的下一个功能将帮助我们可视化无监督自动编码器做出的预测:
def visualize_predictions(decoded, gt, samples=10):
# initialize our list of output images
outputs = None
# loop over our number of output samples
for i in range(0, samples):
# grab the original image and reconstructed image
original = (gt[i] * 255).astype("uint8")
recon = (decoded[i] * 255).astype("uint8")
# stack the original and reconstructed image side-by-side
output = np.hstack([original, recon])
# if the outputs array is empty, initialize it as the current
# side-by-side image display
if outputs is None:
outputs = output
# otherwise, vertically stack the outputs
else:
outputs = np.vstack([outputs, output])
# return the output images
return outputs
visualize_predictions函数是一个助手方法,用于可视化自动编码器的输入图像及其相应的输出重建。original和重建(recon)图像将根据samples参数的数量并排排列并垂直堆叠。如果你读过我的自动编码器简介指南或者去噪自动编码器教程,这段代码应该看起来很熟悉。
既然我们已经定义了导入和必要的函数,我们将继续解析我们的命令行参数:
# construct the argument parse and parse the arguments
ap = argparse.ArgumentParser()
ap.add_argument("-d", "--dataset", type=str, required=True,
help="path to output dataset file")
ap.add_argument("-m", "--model", type=str, required=True,
help="path to output trained autoencoder")
ap.add_argument("-v", "--vis", type=str, default="recon_vis.png",
help="path to output reconstruction visualization file")
ap.add_argument("-p", "--plot", type=str, default="plot.png",
help="path to output plot file")
args = vars(ap.parse_args())
我们的函数接受四个命令行参数,它们都是输出文件路径:
--dataset:定义输出数据集文件的路径--model:指定输出训练自动编码器的路径--vis:指定输出可视化文件路径的可选参数。默认情况下,我将这个文件命名为recon_vis.png;但是,欢迎您用不同的路径和文件名覆盖它--plot: 可选的表示输出训练历史图的路径。默认情况下,该图将在当前工作目录中被命名为plot.png
现在,我们准备好了用于训练的数据:
# initialize the number of epochs to train for, initial learning rate,
# and batch size
EPOCHS = 20
INIT_LR = 1e-3
BS = 32
# load the MNIST dataset
print("[INFO] loading MNIST dataset...")
((trainX, trainY), (testX, testY)) = mnist.load_data()
# build our unsupervised dataset of images with a small amount of
# contamination (i.e., anomalies) added into it
print("[INFO] creating unsupervised dataset...")
images = build_unsupervised_dataset(trainX, trainY, validLabel=1,
anomalyLabel=3, contam=0.01)
# add a channel dimension to every image in the dataset, then scale
# the pixel intensities to the range [0, 1]
images = np.expand_dims(images, axis=-1)
images = images.astype("float32") / 255.0
# construct the training and testing split
(trainX, testX) = train_test_split(images, test_size=0.2,
random_state=42)
首先,我们初始化三个超参数:(1)训练时期的数量,(2)初始学习率,以及(3)我们的批量大小(第 86-88 行)。
行 92 加载 MNIST,而行 97 和 98 构建我们的无监督数据集,其中添加了 1%的污染(即异常)。
从这里开始,我们的数据集没有标签,我们的自动编码器将尝试学习模式,而无需事先了解数据是什么。
现在我们已经建立了无监督数据集,它由 99%的数字 1 和 1%的数字 3(即异常/异常值)组成。
从那里,我们通过添加通道维度和缩放像素强度到范围*【0,1】*(行 102 和 103 )来预处理我们的数据集。
使用 scikit-learn 的便利功能,我们将数据分成 80%的训练集和 20%的测试集(行 106 和 107 )。
我们的数据已经准备好了,所以让我们构建我们的自动编码器并训练它:
# construct our convolutional autoencoder
print("[INFO] building autoencoder...")
(encoder, decoder, autoencoder) = ConvAutoencoder.build(28, 28, 1)
opt = Adam(lr=INIT_LR, decay=INIT_LR / EPOCHS)
autoencoder.compile(loss="mse", optimizer=opt)
# train the convolutional autoencoder
H = autoencoder.fit(
trainX, trainX,
validation_data=(testX, testX),
epochs=EPOCHS,
batch_size=BS)
# use the convolutional autoencoder to make predictions on the
# testing images, construct the visualization, and then save it
# to disk
print("[INFO] making predictions...")
decoded = autoencoder.predict(testX)
vis = visualize_predictions(decoded, testX)
cv2.imwrite(args["vis"], vis)
我们用Adam优化器构建我们的autoencoder,用均方差loss ( 第 111-113 行)构建compile。
第 116-120 行使用 TensorFlow/Keras 启动培训程序。我们的自动编码器将尝试学习如何重建原始输入图像。不容易重建的图像将具有大的损失值。
一旦训练完成,我们将需要一种方法来评估和直观检查我们的结果。幸运的是,我们的后口袋里有我们的visualize_predictions便利功能。第 126-128 行对测试集进行预测,根据结果构建可视化图像,并将输出图像写入磁盘。
从这里开始,我们将总结:
# construct a plot that plots and saves the training history
N = np.arange(0, EPOCHS)
plt.style.use("ggplot")
plt.figure()
plt.plot(N, H.history["loss"], label="train_loss")
plt.plot(N, H.history["val_loss"], label="val_loss")
plt.title("Training Loss")
plt.xlabel("Epoch #")
plt.ylabel("Loss")
plt.legend(loc="lower left")
plt.savefig(args["plot"])
# serialize the image data to disk
print("[INFO] saving image data...")
f = open(args["dataset"], "wb")
f.write(pickle.dumps(images))
f.close()
# serialize the autoencoder model to disk
print("[INFO] saving autoencoder...")
autoencoder.save(args["model"], save_format="h5")
最后,我们:
- 绘制我们的训练历史损失曲线,并将结果图导出到磁盘(行 131-140 )
- 将我们无监督的采样 MNIST 数据集序列化为 Python pickle 文件存储到磁盘,这样我们就可以用它来发现
find_anomalies.py脚本中的异常(第 144-146 行 - 救救我们训练有素的
autoencoder( 第 150 行)
开发无监督的自动编码器训练脚本的精彩工作。
使用 Keras 和 TensorFlow 训练我们的异常探测器
为了训练我们的异常检测器,请确保使用本教程的 “下载” 部分下载源代码。
从那里,启动一个终端并执行以下命令:
$ python train_unsupervised_autoencoder.py \
--dataset output/images.pickle \
--model output/autoencoder.model
[INFO] loading MNIST dataset...
[INFO] creating unsupervised dataset...
[INFO] building autoencoder...
Train on 5447 samples, validate on 1362 samples
Epoch 1/20
5447/5447 [==============================] - 7s 1ms/sample - loss: 0.0421 - val_loss: 0.0405
Epoch 2/20
5447/5447 [==============================] - 6s 1ms/sample - loss: 0.0129 - val_loss: 0.0306
Epoch 3/20
5447/5447 [==============================] - 6s 1ms/sample - loss: 0.0045 - val_loss: 0.0088
Epoch 4/20
5447/5447 [==============================] - 6s 1ms/sample - loss: 0.0033 - val_loss: 0.0037
Epoch 5/20
5447/5447 [==============================] - 6s 1ms/sample - loss: 0.0029 - val_loss: 0.0027
...
Epoch 16/20
5447/5447 [==============================] - 6s 1ms/sample - loss: 0.0018 - val_loss: 0.0020
Epoch 17/20
5447/5447 [==============================] - 6s 1ms/sample - loss: 0.0018 - val_loss: 0.0020
Epoch 18/20
5447/5447 [==============================] - 6s 1ms/sample - loss: 0.0017 - val_loss: 0.0021
Epoch 19/20
5447/5447 [==============================] - 6s 1ms/sample - loss: 0.0018 - val_loss: 0.0021
Epoch 20/20
5447/5447 [==============================] - 6s 1ms/sample - loss: 0.0016 - val_loss: 0.0019
[INFO] making predictions...
[INFO] saving image data...
[INFO] saving autoencoder...
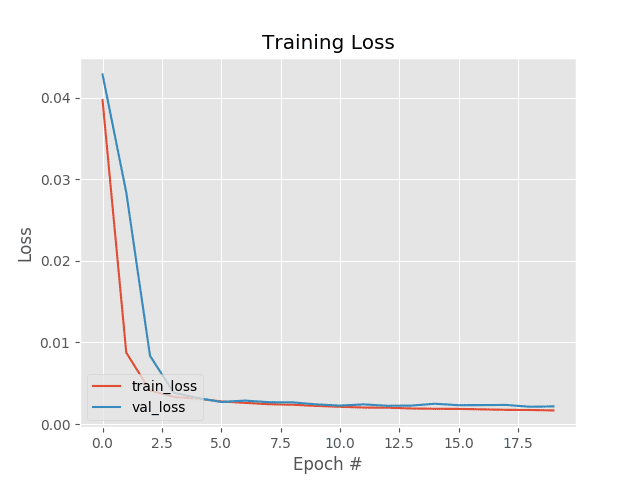
Figure 5: In this plot we have our loss curves from training an autoencoder with Keras, TensorFlow, and deep learning.
在我的 3Ghz 英特尔至强处理器上训练整个模型花费了 ~2 分钟,正如我们在图 5 中的训练历史图所示,我们的训练相当稳定。
此外,我们可以查看我们的输出recon_vis.png可视化文件,以了解我们的自动编码器已经学会从 MNIST 数据集正确地重建1数字:

Figure 6: Reconstructing a handwritten digit using a deep learning autoencoder trained with Keras and TensorFlow.
在继续下一部分之前,您应该确认autoencoder.model和images.pickle文件已经正确保存到您的output目录中:
$ ls output/
autoencoder.model images.pickle
在下一节中,您将需要这些文件。
使用 autoencoder 实现我们的脚本来发现异常/异常值
我们现在的目标是:
- 以我们预先训练的自动编码器为例
- 使用它进行预测(即,重建数据集中的数字)
- 测量原始输入图像和重建图像之间的 MSE
- 计算 MSE 的分位数,并使用这些分位数来识别异常值和异常值
打开find_anomalies.py文件,让我们开始吧:
# import the necessary packages
from tensorflow.keras.models import load_model
import numpy as np
import argparse
import pickle
import cv2
# construct the argument parse and parse the arguments
ap = argparse.ArgumentParser()
ap.add_argument("-d", "--dataset", type=str, required=True,
help="path to input image dataset file")
ap.add_argument("-m", "--model", type=str, required=True,
help="path to trained autoencoder")
ap.add_argument("-q", "--quantile", type=float, default=0.999,
help="q-th quantile used to identify outliers")
args = vars(ap.parse_args())
我们将从导入和命令行参数开始。从tf.keras导入的load_model使我们能够从磁盘加载序列化的 autoencoder 模型。命令行参数包括:
--dataset:我们的输入数据集 pickle 文件的路径,该文件作为我们的无监督训练脚本的结果被导出到磁盘--model:我们训练有素的自动编码器路径--quantile:识别异常值的第 q 个分位数
从这里,我们将(1)加载我们的自动编码器和数据,以及(2)进行预测:
# load the model and image data from disk
print("[INFO] loading autoencoder and image data...")
autoencoder = load_model(args["model"])
images = pickle.loads(open(args["dataset"], "rb").read())
# make predictions on our image data and initialize our list of
# reconstruction errors
decoded = autoencoder.predict(images)
errors = []
# loop over all original images and their corresponding
# reconstructions
for (image, recon) in zip(images, decoded):
# compute the mean squared error between the ground-truth image
# and the reconstructed image, then add it to our list of errors
mse = np.mean((image - recon) ** 2)
errors.append(mse)
第 20 行和第 21 行从磁盘加载autoencoder和images数据。
然后,我们通过我们的autoencoder传递images的集合,以进行预测并尝试重建输入(第 25 行)。
在原始和重建图像上循环,行 30-34 计算地面实况和重建图像之间的均方误差,建立errors的列表。
从这里,我们会发现异常:
# compute the q-th quantile of the errors which serves as our
# threshold to identify anomalies -- any data point that our model
# reconstructed with > threshold error will be marked as an outlier
thresh = np.quantile(errors, args["quantile"])
idxs = np.where(np.array(errors) >= thresh)[0]
print("[INFO] mse threshold: {}".format(thresh))
print("[INFO] {} outliers found".format(len(idxs)))
第 39 行计算误差的 q 分位数——这个值将作为我们检测异常值的阈值。
对照thresh、线 40 测量每个误差,确定数据中所有异常的指数。因此,任何具有值>= thresh的 MSE 都被认为是异常值。
接下来,我们将遍历数据集中的异常指数:
# initialize the outputs array
outputs = None
# loop over the indexes of images with a high mean squared error term
for i in idxs:
# grab the original image and reconstructed image
original = (images[i] * 255).astype("uint8")
recon = (decoded[i] * 255).astype("uint8")
# stack the original and reconstructed image side-by-side
output = np.hstack([original, recon])
# if the outputs array is empty, initialize it as the current
# side-by-side image display
if outputs is None:
outputs = output
# otherwise, vertically stack the outputs
else:
outputs = np.vstack([outputs, output])
# show the output visualization
cv2.imshow("Output", outputs)
cv2.waitKey(0)
在循环内部,我们并排排列每个original和recon图像,将所有结果垂直堆叠为一个outputs图像。第 66 和 67 行显示结果图像。
具有深度学习结果的异常检测
我们现在准备使用深度学习和我们训练的 Keras/TensorFlow 模型来检测我们数据集中的异常。
首先,确保您已经使用本教程的 “下载” 部分下载了源代码——从这里,您可以执行以下命令来检测我们数据集中的异常:
$ python find_anomalies.py --dataset output/images.pickle \
--model output/autoencoder.model
[INFO] loading autoencoder and image data...
[INFO] mse threshold: 0.02863757349550724
[INFO] 7 outliers found
MSE 阈值约为 0.0286,对应于 99.9%的分位数,我们的自动编码器能够找到七个异常值,其中五个被正确标记为:
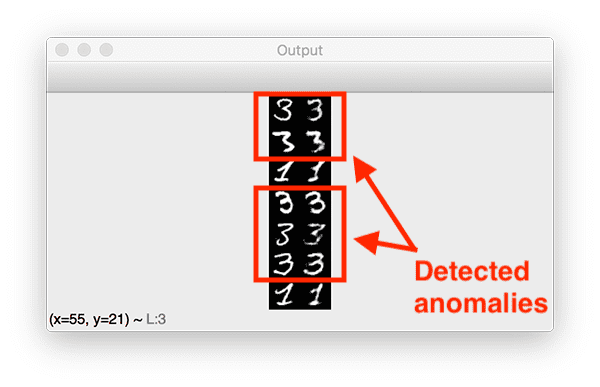
Figure 7: Shown are anomalies that have been detected from reconstructing data with a Keras-based autoencoder.
尽管自动编码器仅在 MNIST 数据集(总共 67 个样本)的所有3数字中的 1%上被训练,但在给定有限数据的情况下,自动编码器在重建它们方面做得非常好— ,但我们可以看到这些重建的 MSE 高于其他重建。
此外,被错误标记为异常值的1数字也可能被认为是可疑的。
深度学习实践者可以使用自动编码器来发现他们数据集中的异常值,即使图像被正确标记为!
正确标记但表明深度神经网络架构存在问题的图像应该表示值得进一步探索的图像子类——自动编码器可以帮助您发现这些异常子类。
我的自动编码器异常检测精度不够好。我该怎么办?
Figure 8: Anomaly detection with unsupervised deep learning models is an active area of research and is far from solved. (image source: Figure 4 of Deep Learning for Anomaly Detection: A Survey by Chalapathy and Chawla)
无监督学习,特别是异常/异常值检测,距离机器学习、深度学习和计算机视觉的解决领域很远—没有现成的异常检测解决方案是 100%正确的。
我建议你阅读 2019 年的调查论文, 深度学习异常检测:一项调查 ,由 Chalapathy 和 Chawla 撰写,以了解更多关于当前基于深度学习的异常检测的最新信息。
虽然很有希望,但请记住,该领域正在快速发展,但异常/异常值检测距离解决问题还很远。
摘要
在本教程中,您学习了如何使用 Keras、TensorFlow 和深度学习来执行异常和异常值检测。
传统的分类架构不足以进行异常检测,因为:
- 它们不能在无人监督的情况下使用
- 他们努力处理严重的阶级不平衡
- 因此,他们很难正确地回忆起异常值
另一方面,自动编码器:
- 自然适用于无人监督的问题
- 学会对输入图像进行编码和重构
- 可以通过测量编码图像和重建图像之间的误差来检测异常值
我们以一种无监督的方式在 MNIST 数据集上训练我们的自动编码器,通过移除类别标签,抓取所有具有值1的标签,然后使用 1%的3标签。
正如我们的结果所显示的,我们的自动编码器能够挑出许多用来“污染”我们的1的3数字。
如果你喜欢这个基于深度学习的异常检测教程,请在评论中告诉我!你的反馈有助于指导我将来写什么教程。
要下载这篇博文的源代码(并在未来教程在 PyImageSearch 上发布时得到通知),只需在下面的表格中输入您的电子邮件地址!


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









