







使用自制软件在 Mac 上安装 Python
原文:https://www.pythoncentral.io/installing-python-on-mac-using-homebrew/
Python 是一种广受欢迎的高级编程语言,因其可读性、简单性和灵活性而备受赞誉。世界各地的开发人员使用它来构建各种各样的应用程序,包括 web 应用程序、数据分析工具、科学模拟等等。
如果你是 Mac 用户,想要开始学习或使用 Python,你需要在你的电脑上安装它。在 Mac 上安装 Python 有几种不同的方法,但是使用自制软件是最简单和最方便的选择之一。
在本文中,我们将解释什么是家酿,如何在 Mac 上安装它,以及如何使用它来安装 Python。我们开始吧!
什么是自制?
家酿是一个命令行实用程序,允许您在 macOS 上安装和管理开源软件。它类似于 apt-get(用于 Ubuntu)或 yum(用于 CentOS)这样的包管理器。有了 Homebrew,你可以轻松地在 Mac 上安装包括 Python 在内的各种开源软件。
使用自制软件的一个好处是,它可以很容易地安装和管理同一软件的多个版本。例如,如果您正在处理一个需要旧版本 Python 的项目,您可以使用 Homebrew 安装该特定版本,而不会影响系统上默认安装的 Python 版本。
自制软件的另一个优点是它将软件安装在与系统其他部分分开的位置,这有助于避免冲突,保持系统整洁。
如何用自制软件在 Mac 上安装 Python?
在使用 Homebrew 安装 Python 之前,您需要安装 Homebrew 本身。以下是如何做到这一点:
第一步进入发射台>其他>终端启动终端 app。
第 2 步在终端窗口中运行以下命令,并按下 return 按钮,在 Mac 上安装 Homebrew:
/bin/bash-c " $(curl-fsSL https://raw . githubusercontent . com/home brew/install/HEAD/install . sh)"
第 3 步完成家酿安装,你将被提示输入您的管理员密码。要继续,只需输入并再次按下 return 即可。
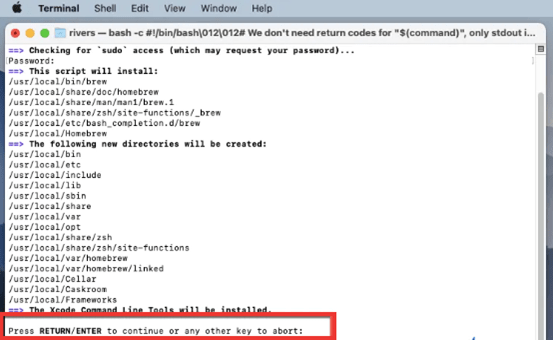
步骤 4:推迟直到安装完成。程序的实时更新将显示在终端窗口中。
安装家酿后,最好对其进行更新,以确保您拥有最新版本。要更新 Homebrew,请在终端中运行以下命令:
brew 更新
就是这样!您现在已经成功地在 Mac 上安装了 Homebrew。你可以用自制软件在你的 Mac 上安装 Python。
步骤 5 在终端窗口运行 brew install pyenv 命令,在 Mac 上安装 pyenv。借助这个 PyEnv 实用程序,您可以在不同的 Python 版本之间切换。
步骤 6 设置 pyenv 后,使用 pyenv install 3.11.1 命令在 Mac 设备上安装 Python 3。(这里 3.11.1 是 Python 目前拥有的版本号。您可以用需要的版本号替换版本号。)
如何检查 Python 是否成功安装在 Mac 上?
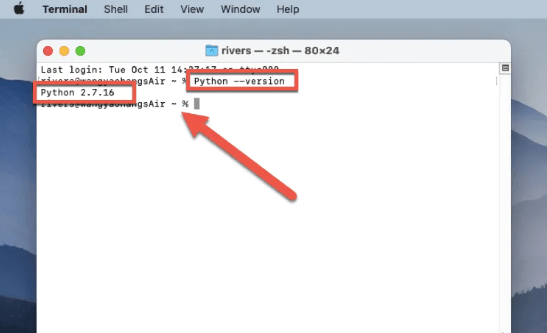
有几种不同的方法可以检查 Python 是否成功安装在 Mac 上。一种方法是打开终端窗口,输入命令“ Python - version ”。这将显示您的系统上当前安装的 Python 版本。
检查 Mac 上是否安装了 Python 的另一种方法是使用 Finder 应用程序来搜索 Python 可执行文件。您可以打开 Finder,从菜单栏中选择“转到”,然后选择“转到文件夹”在“转到文件夹窗口中,输入“ /usr/local/bin/python ”,按下“转到”按钮。如果您的系统上安装了 Python,这将打开包含 Python 可执行文件的文件夹。如果文件夹不存在或收到错误消息,这意味着您的系统上没有安装 Python。
还可以通过在终端窗口中使用“python”命令启动交互式 Python 会话来检查您的 Mac 上是否安装了 Python。如果安装了 Python,这将打开一个 Python 提示符,您可以在其中输入 Python 命令。如果未安装 Python,您将会收到一条错误消息,指出找不到该命令。
结束语
使用 Homebrew 在 Mac 上安装 Python 是在您的系统上设置 Python 开发环境的一个简单过程。无论您是刚刚开始使用 Python,还是经验丰富的程序员,这种方法都可以帮助您快速入门并使用 Python。
通过使用 Homebrew 安装 Python,您可以利用其强大的包管理功能,轻松安装和管理多个版本的 Python,以及其他开源软件包。如果你打算在你的 Mac 上使用 Python,通过 Homebrew 安装它绝对值得考虑。
PySide/PyQt 简介:基本部件和 Hello,World!
原文:https://www.pythoncentral.io/intro-to-pysidepyqt-basic-widgets-and-hello-world/
这一部分介绍了 PySide 和 PyQt 的最基本的要点。我们将谈一谈它们使用的对象种类,并通过几个非常简单的例子向您介绍 Python/Qt 应用程序是如何构造的。
首先,Qt 对象的基本概述。Qt 提供了许多类来处理各种各样的事情:XML、多媒体、数据库集成、网络等等,但是我们现在最关心的是可见的元素——窗口、对话框和控件。Qt 的所有可见元素都被称为小部件,是一个公共父类QWidget的后代。在本教程中,我们将使用“widget”作为 Qt 应用程序中任何可见元素的通称。
Qt widgets are themable. They look more-or-less native on Windows and most Linux setups, though Mac OS X theming is still a work in progress; right now, Python/Qt applications on Mac OS X look like they do on Linux. You can also specify custom themes to give your application a unique look and feel.
第一个 Python/Qt 应用程序:Hello,World
我们将从一个非常简单的应用程序开始,它显示一个带有标签的窗口,标签上写着“Hello,world!”这是以一种容易掌握的风格编写的,但不可模仿——我们稍后会解决这个问题。
# Allow access to command-line arguments
import sys
#从 PySide 导入 Qt
的核心和 GUI 元素。来自 PySide 的 QtCore import *
。QtGui 导入*
#每个 Qt 应用程序必须有且只有一个 Qt application 对象;
#它接收传递给脚本的命令行参数,因为它们
#可用于定制应用程序的外观和行为
Qt _ app = QA application(sys . argv)
#用我们的文本
label = QLabel('Hello,world!')
#将其显示为独立的小部件
label.show()
#运行应用程序的事件循环
qt_app.exec_()
# Allow access to command-line arguments
import sys
# SIP 允许我们选择希望使用的 API
导入 SIP
#使用更现代的 PyQt API(Python 2 . x 中默认不启用);
#必须在导入任何提供指定 API 的模块之前
sip.setapi('QDate ',2)
sip.setapi('QDateTime ',2)
sip.setapi('QString ',2)
sip.setapi('QTextStream ',2)
sip.setapi('QTime ',2)
sip.setapi('QUrl ',2)
sip.setapi('QVariant ',2)
#从 PyQt4 导入所有 Qt
。Qt 导入*
#每个 Qt 应用程序必须有且只有一个 Qt application 对象;
#它接收传递给脚本的命令行参数,因为它们
#可用于定制应用程序的外观和行为
Qt _ app = QA application(sys . argv)
#用我们的文本
label = QLabel('Hello,world!')
#将其显示为独立的小部件
label.show()
#运行应用程序的事件循环
qt_app.exec_()
对我们所做工作的高度概括:
- 创建 Qt 应用程序
- 创建小部件
- 将其显示为一个窗口
- 运行应用程序的事件循环
这是任何 Qt 应用程序的基本轮廓。无论打开多少个窗口,每个应用程序都必须有且只有一个QApplication对象,它初始化应用程序,处理控制流、事件调度和应用程序级设置,并在应用程序关闭时进行清理。
创建的小部件没有父部件,这意味着它显示为一个窗口;这是应用程序的启动窗口。如图所示,然后调用QApplication对象的exec_方法,这将启动应用程序的主事件循环。
关于这个例子的一些细节:
- 注意,
QApplication的构造函数接收sys.argv作为参数;这允许用户使用命令行参数来控制 Python/Qt 应用程序的外观、感觉和行为。 - 我们的主要小部件是一个
QLabel,它仅仅显示文本;任何小部件——也就是继承自QWidget的任何东西——都可以显示为一个窗口。3.
A note on the PyQt version: there’s a fair amount of boilerplate code preceding the creation of the QApplication object. That selects the API 2 version of each object’s behavior instead of the obsolescent API 1, which is the default for Python 2.x. In the future, our examples for both PySide and PyQt will omit the import section for space and clarity. But don’t forget that it needs to be there. (Actually, all of the sip lines could have been omitted from this example without any effect, as could the PySide.QtCore import, as it doesn’t use any of those objects directly; I’ve included them as an example for the future.)
两个基本部件
让我们来看两个最基本的 Python/Qt 小部件。首先,我们将回顾它们所有的父代,QWidget;然后,我们将看一个继承自它的最简单的小部件。
QWidget
QWidget 的构造函数有两个参数,parent QWidget和flags QWindowFlags,这两个参数由它的所有后代共享。小部件的父部件拥有该小部件,当父部件被销毁时,子部件在其父部件被销毁时被销毁,并且其几何形状通常受到其父部件的几何形状的限制。如果父控件是None或者没有提供父控件,则小部件归应用程序的QApplication对象所有,并且是一个顶级小部件,即一个窗口。如果窗口显示,参数flags控制部件的各种属性;通常,默认值 0 是正确的选择。
通常,您会像这样构造一个QWidget:
widget = QWidget()
或者
widget = QWidget(some_parent)
一个QWidget经常被用来创建一个顶层窗口,因此:
qt_app = QApplication(sys.argv)
#创建一个小部件
widget = QWidget()
#将其显示为独立的 widget
widget.show()
#运行应用程序的事件循环
qt_app.exec_()
QWidget类有许多方法,但大多数方法在另一个小部件的上下文中讨论更有用。然而,我们很快就会用到的一个方法是setMinimumSize方法,它接受一个QtCore.QSize作为它的参数;一个QSize代表一个小部件的二维(宽×高)像素度量。
widget.setMinimumSize(QSize(800, 600))
另外一个可以被所有 widgets 使用的QWidget方法是setWindowTitle;如果小部件显示为顶层窗口,这将设置其标题:
widget.setWindowTitle('I Am A Window!')
QLabel
我们已经在“你好,世界!”中使用了一个QLabel应用程序,但我们将仔细研究它。它主要用于显示纯文本或富文本、静态图像或视频,通常是非交互式的。
它有两个类似的构造函数,一个与QWidget相同,另一个采用一个text unicode 字符串来指定显示的文本:
label = QLabel(parent_widget)
或者
label = QLabel('Hello, world!', parent_widget)
默认情况下,标签的内容靠左对齐,但是可以使用QLabel的setAlignment方法将其更改为任意的PySide.QtCore.Qt.Alignment,如下所示:
label.setAlignment(Qt.AlignCenter)
您也可以使用QLabel的setIndent方法设置缩进;缩进是从内容对齐的一侧以像素为单位指定的;例如,如果对准是Qt.AlignRight,缩进将从右边开始。
要在QLabel中换行,请使用QLabel.setWordWrap(True);称之为“T2”式的文字转换。
A QLabel有更多的方法,但这是一些最基本的。
更高级的“你好,世界!”
既然我们已经研究了QWidget类及其后代QLabel,我们可以对我们的“Hello,world!”更能说明 Python/Qt 编程的应用程序。
上次我们只是为小部件创建了全局变量,我们将把窗口的定义封装在一个继承自QLabel的新类中。在这种情况下,这似乎有点枯燥,但是我们将在后面的例子中扩展这个概念。
# Remember that we're omitting the import
# section from our examples for brevity
#创建 QA application 对象
Qt _ app = QA application(sys . argv)
class HelloWorldApp(QLabel):
' ' '一个显示文本“Hello,world!”' '
def __init__(self):
#将对象初始化为 QLabel
QLabel。__init__(self,“你好,世界!”)
#设置大小、对齐方式和标题
self . Set minimumsize(QSize(600,400))
self.setAlignment(Qt。
self.setWindowTitle('你好,世界!')
def run(self):
' ' '显示应用程序窗口并启动主事件循环' ' ' '
self.show()
qt_app.exec_()
#创建应用程序的实例并运行它
HelloWorldApp()。run()
到目前为止,我们已经准备好在下一期中进行一些真正的内容,在下一期中,我们将讨论更多的小部件、布局容器的基础以及信号和插槽,它们是 Qt 允许应用程序响应用户动作的方式。
Python GUI 开发概述(Hello World)
原文:https://www.pythoncentral.io/introduction-python-gui-development/
Python 非常适合各种跨平台应用程序的快速开发,包括桌面 GUI 应用程序。然而,在开始用 Python 开发 GUI 应用程序时,需要做出一些选择,本文提供了在正确的道路上出发所需的信息。我们将讨论 Python 有哪些重要的 GUI 工具包,它们的优点和缺点,并为每个工具包提供一个简单的演示应用程序。
演示“hello world”应用程序概述
这个演示应用程序很简单:一个包含组合框的窗口,显示“hello”、“goodbye”和“heyo”选项;可以在其中输入自由文本的文本框;以及一个按钮,当单击该按钮时,将打印由组合框和文本框的值组合而成的问候语,例如“Hello,world!”—到控制台。以下是示例应用程序的模型:

注意,这里讨论的所有工具包都适用于我们的简单应用程序的类似面向对象的方法;它是从顶级 GUI 对象(如应用程序、窗口或框架)继承的对象。应用程序窗口由一个垂直布局小部件填充,它管理控件小部件的排列。Python 的其他 GUI 工具包,如早已过时的 pyFLTK 或简单的 easygui,采用了不同的方法,但这里讨论的工具包代表了 Python GUI 库开发的主流。
我试图为每个工具包提供惯用的代码,但是我对其中的一些并不精通;如果我做了任何可能误导新开发人员的事情,请在评论中告诉我,我会尽最大努力更新示例。
选择 Python GUI 工具包
有几个工具包可用于 Python 中的 GUI 编程;有几个是好的,没有一个是完美的,它们是不等价的;有些情况下,一个或多个优秀的工具包并不合适。但是选择并不困难,对于许多应用程序来说,您选择的任何 GUI 工具包都可以工作。在下面的工具包部分中,我试图诚实地列出每种工具的缺点和优点,以帮助您做出明智的选择。
一个警告:网上可获得的许多信息——例如,在 Python wiki 的 GUI 文章或 Python 2.7 FAQ 中——都是过时的和误导的。这些页面上的许多工具包已经有五年或更长时间没有维护了,其他的则太不成熟或没有正式的使用记录。另外,不要使用我见过到处流传的选择你的 GUI 工具包页面;它的加权代码使得除了 wxPython 之外几乎不可能选择任何东西。
我们将看看四个最流行的 Python GUI 工具包:TkInter、wxPython、pyGTK/PyGobject 和 PyQt/PySide。
TkInter
TkInter 是 Python GUI 世界的元老,几乎从 Python 语言诞生之日起,它就与 Python 一起发布了。它是跨平台的,无处不在的,稳定可靠,易于学习,它有一个面向对象的,出色的 Pythonic API,它可以与所有 Python 版本一起工作,但它也有一些缺点:
对主题化的有限支持
在 Python 2.7/3.1 之前,TkInter 不支持主题化,所以在每个平台上,它的定制窗口小部件看起来都像 1985 年左右的 Motif。从那以后,ttk 模块引入了主题窗口小部件,这在一定程度上改善了外观,但保留了一些非正统的控件,如 OptionMenus。
小部件精选
Tkinter 缺少其他工具包提供的一些小部件,比如非文本列表框、真正的组合框、滚动窗口等等。一些额外的控制由第三方提供,例如 Tix 来弥补不足。如果您考虑使用 TkInter,请提前模拟您的应用程序,并确保它可以提供您需要的所有控件,否则您可能会在以后受到伤害。
Tkinter 中的演示应用程序/Hello World
import Tkinter as tk
类示例 App(tk。frame):
' ' ' TkInter 的一个应用实例。实例化
并调用 run 方法运行。'
def __init__(self,master):
#使用父级的构造函数
tk.Frame 初始化窗口. __init__(self,
master,
width=300,
height=200)
#设置标题
self.master.title('TkInter 示例')
#这允许大小规范生效
self.pack_propagate(0)
#我们将使用灵活的包装布局管理器
self.pack()
#问候语选择器
#使用 StringVar 访问选择器的值
self.greeting_var = tk。string var()
self . greeting = tk。OptionMenu(self,
self.greeting_var,
'你好',
'再见',
' heyo ')
self . greeting _ var . set('你好')
#收件人文本输入控件及其 string var
self . recipient _ var = tk。string var()
self . recipient = tk。Entry(self,
text variable = self . recipient _ var)
self . recipient _ var . set(' world ')
go 按钮
self.go_button = tk。按钮(self,
text='Go ',
command=self.print_out)
#将控件放在表单
self.go_button.pack(fill=tk。x,边=tk。BOTTOM)
self . greeting . pack(fill = tk。x,边=tk。TOP)
self . recipient . pack(fill = tk。x,边=tk。顶部)
def print_out(self):
' ' '打印从用户
的选择中构造的
的问候语'【T3]打印(' %s,%s!'% (self.greeting_var.get()。title(),
self . recipient _ var . get())
def Run(self):
' ' '运行应用' ' ' '
self.mainloop()
app = ExampleApp(tk。tk()
app . run()
wxPython
注意,在撰写本文时,wxPython 仅适用于 Python 2.x
Python 的创始人吉多·范·罗苏姆这样评价 wxPython:
wxPython 是最好、最成熟的跨平台 GUI 工具包,但有许多限制。wxPython 不是标准 Python GUI 工具包的唯一原因是 Tkinter 先出现了。
至少,他说过一次,很久以前;吉多·范·罗苏姆到底做了多少 GUI 编程呢?
无论如何,wxPython 确实有很多优点。它有大量的小部件,在 Windows、Linux 和 OS X 上的本地外观和感觉,以及足够大的用户群,至少那些明显的错误已经被发现了。它不包含在 Python 中,但是安装很容易,并且它适用于所有最新的 Python 2.x 版本;wxPython 可能是目前最流行的 Python GUI 库。
尽管它并不完美;它的文档非常糟糕,尽管这个示范性的演示应用程序本身就是无价的文档,但它却是你能得到的所有帮助。我个人觉得 API 不和谐,令人不快,但其他人不同意。尽管如此,你几乎不会在使用 wxPython 的项目中发现它不能做你需要的事情,这是对它的一个很大的推荐。
wxPython 中的演示应用程序/Hello World
[python]
import wx
class ExampleApp(wx。frame):
def _ _ init _ _(self):
#每个 wx 应用程序必须创建一个应用程序对象
#才能使用 wx 做任何其他事情。
self.app = wx。应用程序()
#设置主窗口
wx.Frame.init(self,
parent=None,
title='wxPython Example ',
size=(300,200))
#可用的问候语
self.greetings = [‘hello ‘,’ goodbye ‘,’ heyo’]
#布局面板和 hbox
self.panel = wx。Panel(self,size=(300,200))
self.box = wx。BoxSizer(wx。垂直)
Greeting 组合框
self.greeting = wx。ComboBox(parent=self.panel,
value='hello ',
size=(280,-1),
choices=self.greetings)
#将问候语组合添加到 hbox
self . box . Add(self . greeting,0,wx。TOP)
self.box.Add((-1,10))
#收件人条目
self.recipient = wx。TextCtrl(parent=self.panel,
size=(280,-1),
value='world ')
#将问候语组合添加到 hbox
self . box . Add(self . recipient,0,wx。顶部)
#添加填充以降低按钮位置
self.box.Add((-1,100))
go 按钮
self.go_button = wx。按钮(self.panel,10,'& Go ')
#为按钮
自身绑定一个事件。绑定(wx。EVT _ 按钮,自我.打印 _ 结果,自我.去 _ 按钮)
#使按钮成为表单
self.go_button 的默认动作。SetDefault()
#将按钮添加到 hbox
self . box . Add(self . go _ button,0,flag=wx。ALIGN_RIGHT|wx。底部)
#告诉小组使用 hbox
self . panel . set sizer(self . box)
def print_result(self,*args):
’ ’ ‘打印从
用户所做的选择中构造的问候语’
打印(’ %s,%s!'% (self.greeting.GetValue()。title(),
self.recipient.GetValue()))
def run(self):
’ ’ '运行 app ’ ’
self。Show()
self.app.MainLoop()
#实例化并运行
app = example app()
app . run()
[/python]
pyGTK/pyGobject
pyGTK 是一个基于 GTK+ 的跨平台小部件工具包,GTK+ 是一个广泛使用的 GUI 工具包,最初是为图像处理程序 GIMP 开发的。pyGobject 是 pyGTK 的新版本,它使用 Gobject 内省并支持 GTK3 的特性。这两个版本的 API 密切相关,它们的功能和缺点也相似,因此对于我们的目的来说,可以将它们视为一体。pyGTK 的开发者推荐使用 pyGobject 进行新的开发。
pyGTK 只在 Windows 和 Linux 上使用本地小部件。虽然 GTK+支持本地窗口部件和 OS X 窗口,但 pyGTK 仍在开发中;目前,它在 Mac 上的外观和感觉模仿了 Linux。然而,小部件是主题化的,有大量非常吸引人的主题。pyGTK 在 Python 2.x 上也是最成功的;新版本开始支持 Python 3,但并不完整,尤其是在 Windows 上。安装 Windows 以前需要从不同的来源下载多个软件包,但最近一体化的二进制安装程序已经可用。
从积极的一面来看,pyGTK 是稳定的,经过良好的测试,并有一个完整的小部件选择。它还有出色的文档,如果你喜欢这类东西,还有一个出色的可视化 GUI 生成器,叫做 Glade 。它的 API 简单明了,大部分都很简单,只有少数例外,并且有相当好的示例代码。pyGTK 的底线是:它是一个可靠且功能强大的 GUI 工具包,但存在跨平台不一致的问题,并且不如其他同样优秀的替代产品受欢迎。
关于选择 pyGTK 的一个特别注意事项:如果你的应用程序涉及各种简单的、基于文本的列表框,pyGTK 的设计将会引起问题。与其他工具包相比,它严格的关注点分离和模型-视图-控制器划分使得列表框的开发异常复杂。当我刚接触 Python GUI 开发时,没有注意到这一点使我在一个重要的项目上落后了很多。
pyGTK/pyGobject 中的演示应用程序/Hello World
import gtk
class ExampleApp(gtk。window):
' ' ' pyGTK 的一个示例应用。实例化
并调用 run 方法运行。'
def __init__(self):
#初始化窗口
GTK . window . _ _ init _ _(self)
self . set _ title(' pyGTK Example ')
self . set _ size _ request(300,200)
self.connect('destroy ',gtk.main_quit)
#垂直构造布局
self.vbox = gtk。VBox()
#问候语选择器-注意使用便利的
# type ComboBoxText 如果可用,否则便利的
# function combo_box_new_text,后者已被弃用
if (gtk.gtk_version[1] > 24 或
(gtk.gtk_version[1] == 24 和 GTK . GTK _ version[2]>10)):
self . greeting = GTK。combobox text()
else:
self . greeting = gtk . combo _ box _ new _ text()
#修复方法名以匹配 GTK。combobox text
self . greeting . append = self . greeting . append _ text
#添加问候语
地图(self.greeting.append,['hello ',' goodbye ',' heyo'])
#收件人文本输入控件
self.recipient = gtk。entry()
self . recipient . set _ text(' world ')
go 按钮
self.go_button = gtk。按钮(' _Go')
#连接 Go 按钮的回调
self . Go _ button . Connect(' clicked ',self.print_out)
#将控件置于垂直布局
self . vbox . pack _ start(self . greeting,False)
self . vbox . pack _ start(self . recipient,False)
self . vbox . pack _ end(self . go _ button,False)
#将垂直布局添加到主窗口
self.add(self.vbox)
def print_out(self,*args):
' ' '打印从
用户所做的选择中构造的问候语'
打印(' %s,%s!'%(self . greeting . get _ active _ text()。title(),
self . recipient . get _ text())
def Run(self):
' ' '运行 app'
self.show_all()
gtk.main()
app = example app()
app . run()
PyQt/PySide
Qt 不仅仅是一个小部件工具包;它是一个跨平台的应用程序框架。PyQt,它的 Python 接口,已经存在好几年了,而且稳定成熟;随着 API 1 和 API 2 这两个可用 API 的出现,以及大量不推荐使用的特性,它在过去几年中已经有了一些改进。此外,即使 Qt 可以在 LGPL 下获得,PyQt 也是在 GNU GPL 版本 2 和 3 或相当昂贵的商业版本下获得许可的,这限制了您对代码的许可选择。
PySide 是对 PyQt 弊端的回应。它是在 LGPL 下发布的,省略了 PyQt 4.5 之前的所有不推荐使用的特性以及整个 API 1,但在其他方面几乎与 PyQt API 2 完全兼容。它比 PyQt 稍不成熟,但开发得更积极。
无论您选择哪种包装器,Python 和 Qt 都能完美地配合工作。更现代的 API 2 是相当 Pythonic 化和清晰的,有非常好的文档可用(尽管它的根源在 C++ Qt 文档中是显而易见的),并且产生的应用程序在最近的版本中看起来很棒,如果不是非常原生的话。这里有您可能想要的每一个 GUI 小部件,Qt 提供了更多——处理 XML、多媒体、数据库集成和网络的有趣类——尽管对于大多数额外的功能,您可能最好使用等效的 Python 库。
使用 Qt 包装器的最大缺点是底层 Qt 框架非常庞大。如果您的可分发包很小对您很重要,那么选择 TkInter,它不仅很小,而且已经是 Python 的一部分。此外,虽然 Qt 使用操作系统 API 来使其小部件适应您的环境,但并不是所有的部件都是严格的原生部件;如果原生外观是您的主要考虑因素,wxPython 将是更好的选择。但是 PyQt 有很多优点,当然值得考虑。
PyQt/PySide 的演示应用程序/Hello World
注意:对于 Qt,我用过 PySide 示例代码将使用 PyQt 运行,只有几行不同。
import sys
from PySide.QtCore import *
from PySide.QtGui import *
class ExampleApp(QDialog):
' ' '一个 PyQt 的示例应用。实例化
并调用 run 方法运行。'
def __init__(self):
#创建一个 Qt 应用程序——每个 PyQt 应用程序都需要一个
self . Qt _ app = QA application(sys . argv)
#可用的问候语
self.greetings = ['hello ',' goodbye ',' heyo']
#调用当前对象上的父构造函数
QDialog。__init__(自身,无)
#设置窗口
self.setWindowTitle('PyQt 示例')
self.setMinimumSize(300,200)
#添加垂直布局
self.vbox = QVBoxLayout()
#问候语组合框
self . greeting = QComboBox(self)
#添加问候语
列表(map(self.greeting.addItem,self.greetings))
#收件人文本框
self . recipient = QLineEdit(' world ',self)
# Go 按钮
self . Go _ button = q push button(&Go ')
#将 Go 按钮连接到其回调
self . Go _ button . clicked . Connect(self . print _ out)
#将控件添加到垂直布局中
self . vbox . Add widget(self . greeting)
self . vbox . Add widget(self . recipient)
#一个非常有弹性的间隔符,用于将按钮压到底部
self . vbox . Add stretch(100)
self . vbox . Add widget(self . go _ button)
#使用当前窗口的垂直布局
self.setLayout(self.vbox)
def print_out(self):
' ' '打印由用户选择的
构建的问候语'
打印(' %s,%s!'%(self . greetings[self . greeting . current index()]。title(),
self.recipient.displayText()))
def run(self):
' ' '运行应用程序并显示主窗体'
self . show()
self . Qt _ app . exec _()
app = example app()
app . run()
Python 类介绍(第 2 部分,共 2 部分)
原文:https://www.pythoncentral.io/introduction-to-python-classes-part-2-of-2/
在本系列的第一部分中,我们看了在 Python 中使用类的基础知识。现在我们来看看一些更高级的主题。
Python 类继承
Python 类支持继承,这让我们获得一个类定义并扩展它。让我们创建一个继承(或从第一部分中的例子派生出)的新类:
class Foo:
def __init__(self, val):
self.val = val
def printVal(self):
print(self.val)
类 derived Foo(Foo):
def negate val(self):
self . val =-self . val
这定义了一个名为DerivedFoo的类,它拥有Foo类所拥有的一切,还添加了一个名为negateVal的新方法。这就是它的作用:
>>> obj = DerivedFoo(42)
>>> obj.printVal()
42
>>> obj.negateVal()
>>> obj.printVal()
-42
当我们重新定义(或覆盖)一个已经在基类中定义的方法时,继承变得非常有用:
class DerivedFoo2(Foo):
def printVal(self):
print('My value is %s' % self.val)
我们可以按如下方式测试该类:
>>> obj2 = DerivedFoo2(42)
>>> obj2.printVal()
My value is 42
派生类重新定义了printVal方法来做一些不同的事情,每当调用printVal时都会使用这个新版本。这让我们可以改变类的行为,这通常是我们想要的(因为如果我们想要原始的行为,我们只需要使用原始的类)。注意,该方法的新版本调用旧版本,并且调用以基类的名称为前缀(否则 Python 会认为您调用的是新版本)。
Python 提供了几个函数来帮助您确定一个对象是什么类:
- 检查一个对象是否是指定类的一个实例,或者是一个派生类。
例如以下内容:
>>> print(isinstance(obj, Foo))
True
>>> print(isinstance(obj, DerivedFoo))
True
>>> print(isinstance(obj, DerivedFoo2))
False
- 检查一个类是否派生自另一个类
例如以下内容:
>>> print(issubclass(DerivedFoo, Foo))
True
>>> print(issubclass(int, Foo))
False
Python 类迭代器和生成器
Python 的for语句将循环遍历任何可迭代的,包括内置的数据类型,如数组和字典。例如:
>>> arr = [1,2,3]
>>> for x in arr:
... print(x)
1
2
3
当我们定义自己的类时,我们可以使它们可迭代,这将允许它们在 for 循环中工作。我们通过定义一个返回一个迭代器(一个跟踪我们在循环中的位置的对象)的__iter__方法和一个返回下一个可用值的__next__方法来实现这一点。请注意,Python 3.x 和 Python 2.x 的next方法的语法是不同的。对于 Python 3.x,您必须使用__next__方法,而对于 Python 2.x,您必须使用next方法。
这里有一个简单的例子,可以让你在一个数据结构上向后迭代。下面是类的定义:
[python]
class Backwards:
def init(self, val):
self.val = val
self.pos = len(val)
def iter(self):
回归自我
def next(self):
#如果 self.pos < = 0:
提升 StopIteration,我们就完成了
self.pos = self.pos - 1
return self.val[self.pos]
[/python]
[python]
class Backwards:
def init(self, val):
self.val = val
self.pos = len(val)
def iter(self):
回归自我
def next(self):
#我们完成了
如果 self.pos < = 0:
提高 StopIteration
self.pos = self.pos - 1
return self.val[self.pos]
[/python]
这是一个迭代类的例子:
>>> for x in Backwards([1,2,3]):
... print(x)
3
2
1
该类跟踪两件事,被迭代的数据结构和下一个要返回的值。__iter__方法只是返回对对象本身的引用,因为这是用来管理循环的。当 Python 遍历对象时,它会重复调用next方法来获取下一个值,直到没有剩余值时抛出StopIteration异常。
这是一个非常简单的例子,但是它的大部分是锅炉板代码(获取每一项并跟踪我们在循环中的进度),每次我们想要创建一个 iterable 类时都是一样的。然而,Python 又一次拯救了我们,它给我们提供了一种方法,使用生成器来消除所有这些重复的管理代码。
一个生成器是一种特殊的函数,它返回一个 iterable 对象,这个对象自动地记住它在一个循环中的位置。这是同一个例子,这次使用了一个发生器。
该功能可定义如下(注意:使用yield关键字):
def backwards(val):
for n in range(len(val), 0, -1):
yield val[n-1]
我们可以这样使用发电机:
>>> for x in backwards([1,2,3]):
... print(x)
3
2
1
如果你以前从未见过这种事情,你可能真的很难理解它,但是最简单的方法就是像这样阅读backwards函数:
- 在传入的值上向后循环。
- 在每一遍中,
yield下一个值,即暂时停止执行循环,并将下一个值返回给调用者。它做它想做的任何事情,然后当它再次调用我们时,我们从我们停止的地方继续循环。
作为对象的 Python 类
一个类描述了该类的实例看起来像什么,也就是说,它们将有什么方法和成员变量。在内部,Python 在自己的对象中跟踪每个类的定义,我们可以修改这个对象。这意味着我们可以动态地改变类的定义,甚至在运行时创建一个全新的类!
让我们从一个简单的类定义开始:
class Foo:
def __init__(self, val):
self.val = val
让我们来看看用法:
>>> obj = Foo(42)
>>> obj.printVal()
AttributeError: Foo instance has no attribute 'printVal'
哎呀!我们得到一个错误,因为这个类没有一个printVal方法。
好了,再加一个:-)。我们可以这样定义它:
def printVal(self):
print(self.val)
我们可以将函数添加到类中,如下所示:
>>> Foo.printVal = printVal
>>> obj.printVal()
42
我们定义了一个名为 printVal 的方法,它是独立的(也就是说,它是在类之外定义的),但是它看起来像一个类方法(也就是说,它有一个 self 参数)。然后,我们将它添加到类定义(Foo.printVal = printVal)中,这使得它变得可用,就好像它是原始类定义的一部分一样。
如果我们想删除它,我们可以使用普通的del语句:
>>> del Foo.printVal
>>> obj.printVal()
AttributeError: Foo instance has no attribute 'printVal'
为了在运行时创建一个全新的类,我们使用了type方法:
>>> obj = MyNewClass()
NameError: name 'MyNewClass' is not defined
>>> MyNewClass = type('MyNewClass', (object,), dict())
>>> obj = MyNewClass()
>>> print(obj)
<__main__.MyNewClass object at 0x01D79DCC>
type调用的第二个参数是我们想要从中派生的类的列表,而第三个参数是组成类定义的方法和成员变量的字典(您可以在这里定义它们,或者如上所述动态添加它们)。
要理解 Python 中的生成器和 yield 关键字,请查看文章 Python 生成器和 yield 关键字。
Python 类简介(第 1 部分,共 2 部分)
原文:https://www.pythoncentral.io/introduction-to-python-classes/
类是一种将相关信息组合成一个单元的方式(也称为对象,以及可以被调用来操作该对象的函数(也称为方法)。例如,如果您想跟踪一个人的信息,您可能想记录他们的姓名、地址和电话号码,并且能够将所有这些作为一个单元来操作。
Python 有一种稍微特殊的处理类的方式,所以即使你熟悉像 C++或 Java 这样的面向对象的语言,深入研究 Python 类仍然是值得的,因为有一些东西是不同的。
在我们开始之前,理解类和对象之间的区别是很重要的。一个类仅仅是对事物应该是什么样子,什么变量将被分组在一起,以及什么函数可以被调用来操纵这些变量的描述。使用这个描述,Python 可以创建这个类的许多实例(或对象),然后可以独立操作这些实例。把一个类想象成一个 cookie cutter——它本身并不是一个 cookie,但是它描述了一个 cookie 的样子,可以用来创建许多单独的 cookie,每个 cookie 都可以单独食用。好吃!
定义一个 Python 类
让我们从定义一个简单的类开始:
class Foo:
def __init__(self, val):
self.val = val
def printVal(self):
print(self.val)
这个类被称为Foo,像往常一样,我们使用缩进来告诉 Python 类定义在哪里开始和结束。在这个例子中,类定义由两个函数定义(或者说方法)组成,一个叫做__init__,另一个叫做printVal。还有一个成员变量,没有明确定义,但我们将在下面解释它是如何创建的。

The diagram shows what the class definition looks like - 2 methods and 1 member variable. Using this definition, we can then create many instances of the class.
可以看到这两种方法都采用了一个名为self的参数。它没有有可以被称为self,但这是 Python 的惯例,虽然你可以称它为this或me或其他什么,但如果你称它为self之外的任何东西,你会惹恼其他 Python 程序员,他们将来可能会看你的代码。因为我们可以创建一个类的许多实例,当调用一个类方法时,它需要知道它正在处理哪个实例,这就是 Python 将通过self参数传入的内容。
__init__是一个特殊的方法,每当 Python 创建一个新的类实例(即使用 cookie cutter 创建一个新的 cookie)时,都会调用这个方法。在我们的例子中,它接受一个名为val的参数(而不是强制 self ),并在一个成员变量中复制一个参数,也称为val。与其他语言不同,在其他语言中,变量必须在使用前定义,Python 在第一次赋值时动态创建变量,类成员变量也不例外。为了区分作为参数传入的val变量和val类成员变量,我们给后者加上了 self 前缀。所以,在下面的语句中:
self.val = val
self.val指的是属于调用方法的类实例的 val 成员变量,而val指的是传递给方法的参数。
这有点令人困惑,所以让我们来看一个例子:
obj1 = Foo(1)
这将创建我们类的一个实例(即使用 cookie cutter 创建一个新的 cookie)。Python 自动为我们调用__init__方法,传入我们指定的值(1)。所以,我们得到了其中的一个:

我们再创建一个:
【python】
obj 2 = Foo(2)
除了将2传递给__init__方法之外,会发生完全相同的事情。
我们现在有两个独立的对象,val 成员变量有不同的值:
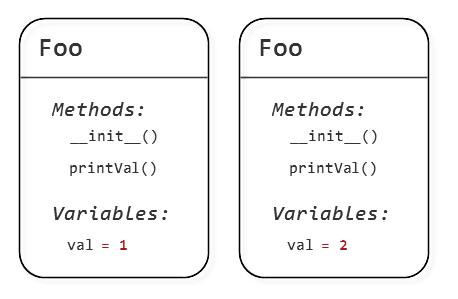
如果我们为第一个对象调用printVal,它将打印出其成员变量的值:
>>> obj1.printVal()
1
如果我们为第二个对象调用printVal,它将打印出的值,它的成员变量:
>>> obj2.printVal()
2
标准 Python 类方法
Python 类有许多标准方法,比如我们在上面看到的__init__,当类的一个新实例被创建时,它会被调用。以下是一些比较常用的方法:
__del__:当一个实例将要被销毁时调用,这允许你做任何清理工作,例如关闭文件句柄或数据库连接__repr__和__str__:都返回对象的字符串表示,但是__repr__应该返回一个 Python 表达式,可以用来重新创建对象。比较常用的是__str__,可以返回任何东西。__cmp__:调用比较对象与另一个对象。注意,这只在 Python 2.x 中使用,在 Python 3.x 中,只使用了丰富的比较方法。比如__lt__。__lt__、__le__、__eq__、__ne__、__gt__、__ge__:调用将一个对象与另一个对象进行比较。如果定义了这些函数,它们将被调用,否则 Python 将退回到使用__cmp__。__hash__:调用计算对象的散列,用于将对象放置在数据结构中,如集合和字典。__call__:让一个对象被“调用”,例如,你可以这样写:obj(arg1,arg2,...)。
Python 还允许你定义方法,让一个对象表现得像一个数组(所以你可以这样写:obj[2] = "foo"),或者像一个数字类型(所以你可以这样写:print(obj1 + 3*obj2))。
Python 类示例
下面是一个简单的实例,这个类模拟了一副扑克牌中的一张牌。
[python]
class Card:
Define the suits
DIAMONDS = 1
CLUBS = 2
HEARTS = 3
SPADES = 4
SUITS = {
CLUBS: ‘Clubs’,
HEARTS: ‘Hearts’,
DIAMONDS: ‘Diamonds’,
SPADES: ‘Spades’
}
#定义特殊牌的名称
值= {
1: 'Ace ',
11: 'Jack ',
12: 'Queen ',
13: ‘King’
}
def init(self,suit,value):
#保存花色和卡值
self.suit =花色
self.value =值
def lt(self,other):
#将该卡与另一张卡进行比较
#(如果我们较小,则返回 True;如果
较大,则返回 false;如果我们相同,则返回 0)
如果 self.suit < other.suit:
返回 True
elif self . suit>other . suit:
返回 False
if self.value < other.value:
返回 True
elif self . value>other . value:
返回 False
返回 0
def str(self):
#如果 self.value 在 self 中,则返回 self 的字符串描述
。值:
buf = self。VALUES[self . value]
else:
buf = str(self . value)
buf = buf+’ of '+self。套装
return buf
[/python]
[python]
class Card:
Define the suits
DIAMONDS = 1
CLUBS = 2
HEARTS = 3
SPADES = 4
SUITS = {
CLUBS: ‘Clubs’,
HEARTS: ‘Hearts’,
DIAMONDS: ‘Diamonds’,
SPADES: ‘Spades’
}
#定义特殊牌的名称
值= {
1: 'Ace ',
11: 'Jack ',
12: 'Queen ',
13: ‘King’
}
def init(self,suit,value):
#保存花色和卡值
self.suit =花色
self.value =值
def cmp(self,other):
#将该牌与另一张牌进行比较
#(如果我们较小则返回< 0,>如果
较大则返回> 0,如果我们相同则返回 0)
如果 self . suit<other . suit:
return-1
elif self . suit>other . suit:
return 1
elif self . value<other . value:
return-1
Eli
def str(self):
#如果 self.value 在 self 中,则返回 self 的字符串描述
。值:
buf = self。VALUES[self . value]
else:
buf = str(self . value)
buf = buf+’ of '+self。套装
return buf
[/python]
我们首先定义一些类常量来表示每种服装,并定义一个查找表,以便于将它们转换成每种服装的名称。我们还为特殊牌(a、j、q 和 k)的名称定义了一个查找表。
构造函数或__init__方法接受两个参数,suit 和 value,并将它们存储在成员变量中。
每当 Python 想要将一个Card对象与其他对象进行比较时,就会调用特殊的 cmp 方法。约定是,如果一个对象小于另一个对象,则该方法应该返回负值,如果大于另一个对象,则返回正值,如果两者相同,则返回零。注意,传入进行比较的另一个对象可以是任何类型,但是为了简单起见,我们假设它也是一个Card对象。
每当 Python 想要打印出一个Card对象时,就会调用特殊的__str__方法,因此我们返回一个人类可读的卡片表示。
下面是实际运行的类:
>>> card1 = Card(Card.SPADES, 2)
>>> print(card1)
2 of Spades
>>> card2 = Card(Card.CLUBS, 12)
>>> print(card2)
Queen of Clubs
>>> print(card1 > card2)
True
注意,如果我们没有定义一个自定义的__str__方法,Python 将会给出自己的对象表示,如下所示:
<__main__.Card instance at 0x017CD9B8>
所以,你可以明白为什么总是提供你自己的__str__方法是个好主意。🙂
私有 Python 类方法和成员变量
在 Python 中,方法和成员变量总是公共的,即任何人都可以访问它们。这对于封装来说不是很好(类方法应该是唯一可以改变成员变量的地方,以确保一切都保持正确和一致),所以 Python 有一个约定,以下划线开头的类方法或变量应该被认为是私有的。然而,这只是一个惯例,所以如果你真的想在课堂上胡闹,你可以,但是如果事情发生了,你只能怪你自己!
以两个下划线开头的类方法和变量名被认为是该类的私有*,即一个派生类可以定义一个相似命名的方法或变量,它不会干扰任何其他定义。同样,这仅仅是一个约定,所以如果你决定要查看另一个类的私有部分,你可以这样做,但是这样可以防止名字冲突。*
我们可以利用 Python 类的“一切都是公共的”特性来创建一个简单的数据结构,将几个变量组合在一起(类似于 C++ POD 或 Java POJO):
class Person
# An empty class definition
pass
>>> someone = Person()
>>> someone.name = 'John Doe'
>>> someone.address = '1 High Street'
>>> someone.phone = '555-1234'
我们创建一个空的类定义,然后利用 Python 会在首次分配成员变量时自动创建成员变量这一事实。
使用 Boto 在 AWS 上介绍 Python
原文:https://www.pythoncentral.io/introduction-to-python-on-aws-with-boto/
亚马逊网络服务为我们提供了廉价、便捷的云计算基础设施。那么我们如何在上面运行 Python 呢?
在 Amazon EC2 上设置 Python
EC2 是亚马逊的弹性计算云。它是用于在 AWS 上创建和操作虚拟机的服务。您可以使用 SSH 与这些机器进行交互,但是使用设置为 web 应用程序的 IPython HTML Notebook 要好得多。
您可以手动设置 IPython 笔记本服务器,但是有几个更简单的选项。
- NotebookCloud 是一个简单的 web 应用程序,使您能够从浏览器创建 IPython 笔记本服务器。它真的很容易使用,而且免费。
- 来自麻省理工学院的 StarCluster 是一个与亚马逊合作的更强大的库,它使用配置文件来简化创建、复制和共享云配置。它支持 IPython 开箱即用,并且在线提供了额外的配置文件。
两个选项都是开源的。
您不需要使用 IPython 或 Amazon EC2 来使用 AWS,但是这样做有很多好处。
无论您是在 EC2 上运行您的机器,还是只想使用普通机器上的一些服务,您通常都需要一种方法让您的程序与 AWS 服务器进行对话。
Python Boto 库
AWS 有一个广泛的 API,允许你编程访问每一个服务。有很多库可以使用这个 API,对于 Python,我们有 boto。
Boto 为几乎所有的亚马逊网络服务以及其他一些服务提供了一个 Python 接口,比如 Google Storage。Boto 是成熟的、有据可查的、易于使用的。
要使用 Boto,您需要提供您的 AWS 凭证,特别是您的访问密钥和秘密密钥。这些可以在每次连接时手动提供,但是将它们添加到 boto 配置文件更容易,这样 boto 就可以自动提供密钥。
如果您希望为您的 boto 设置使用一个配置,您需要在~/.boto 下创建一个文件。如果您希望在整个系统范围内使用这个配置,您应该在/etc/boto.cfg 下创建这个文件。ini 格式,至少应该包含一个凭据部分,如下所示:
[Credentials] aws_access_key_id = <your access key> aws_secret_access_key = <your secret key>
您可以通过创建连接对象来使用 boto,这些对象表示到服务的连接,然后与这些连接对象进行交互。
from boto.ec2 import EC2Connection
conn = EC2Connection()
注意,如果没有在配置文件中设置 AWS 键,您需要将它们传递给任何连接构造函数。
conn = EC2Connection(access_key, secret_key)
创建您的第一台 Amazon EC2 机器
现在,您有了一个连接,您可以使用它来创建一个新机器。您首先需要创建一个安全组,允许您访问您在该组中创建的任何机器。
group_name = 'python_central'
description = 'Python Central: Test Security Group.'
group = conn . create _ security _ group(
group _ name,description
)
group.authorize('tcp ',8888,8888,'[0 . 0 . 0 . 0/0【T1 ')](http://0.0.0.0/0)
现在您有了一个组,您可以使用它创建一个虚拟机。为此,您需要一个 AMI,一个 Amazon 机器映像,这是一个基于云的软件发行版,您的机器将使用它作为操作系统和堆栈。我们将使用 NotebookCloud 的 AMI,因为它是可用的,并且已经用一些 Python 好东西进行了设置。
我们需要一些随机数据来为该服务器创建自签名证书,这样我们就可以使用 HTTPS 来访问它。
import random
from string import ascii_lowercase as letters
#以正确的格式创建随机数据
data = random.choice(('UK ',' US'))
对于范围(4)中的 a:
data+= ' | '
对于范围(8)中的 b:
data+= random . choice(letters)
我们还需要创建一个散列密码来登录服务器。
import hashlib
#您选择的密码放在这里
password = 'password '
h = hashlib . new(' sha1 ')
salt =(' % 0 '+str(12)+' x ')% random . getrandbits(48)
h . update(password+salt)
密码= ':'。join(('sha1 ',salt,h.hexdigest()))
现在,我们将散列密码添加到数据字符串的末尾。当我们创建一个新的虚拟机时,我们将把这个数据字符串传递给 AWS。机器将使用字符串中的数据创建一个自签名证书和一个包含您的散列密码的配置文件。
data += '|' + password
现在,您可以创建服务器了。
# NotebookCloud AMI
AMI = 'ami-affe51c6'
conn.run_instances(
AMI,
instance_type = 't1.micro ',
security _ groups =[' python _ central '],
user_data = data,
max_count = 1
)
要在线查找服务器,您需要一个 URL。你的服务器需要一两分钟的时间来启动,所以这是一个休息和烧水的好时机。
要获得 URL,我们只需轮询 AWS,看看服务器是否已经分配了公共 DNS 名称。以下代码假设您刚刚创建的实例是您的 AWS 帐户上的唯一实例。
import time
while True:
inst =[
I for r in conn . get _ all _ instances()
for I in r . instances
][0]
dns = inst。__dict__['公共域名']
如果 dns:
#我们希望这个实例 id 用于以后的
instance _ id = I . _ _ dict _ _[' id ']
中断
time.sleep(5)
现在,将 dns 名称转换成正确的 URL,并让浏览器指向它。
print('https://{}:8888'.format(dns))
现在,您应该自豪地拥有了一台全新的 IPython HTML 笔记本服务器。请记住,您需要上面提供的密码才能登录。
如果您想终止实例,您可以使用下面的代码行轻松完成。请注意,要做到这一点,您需要实例 id。如果遇到问题,您可以随时访问 AWS 控制台,并在那里控制您的所有实例。
conn.terminate_instances(instance_ids=[instance_id])
玩得开心!
Python 正则表达式简介
原文:https://www.pythoncentral.io/introduction-to-python-regular-expressions/
在 Python 中,在一个字符串中搜索另一个字符串相当容易:
>>> str = 'Hello, world'
>>> print(str.find('wor'))
7
如果我们确切地知道我们要找的是什么,这很好,但是如果我们要找的东西不是那么明确呢?例如,如果我们想搜索一年,那么我们知道这将是一个 4 位数的序列,但我们不知道这些数字将会是什么。这就是正则表达式的用武之地。它们允许我们基于我们所寻找的内容的一般描述来搜索子字符串,例如搜索 4 个连续数字的序列*。*
在下面的例子中,我们导入了包含 Python 正则表达式功能的re模块,然后用我们的正则表达式(\d\d\d\d)和我们想要搜索的字符串调用search函数:
>>> import re
>>> str = 'Today is 31 May 2012.'
>>> mo = re.search(r'\d\d\d\d', str)
>>> print(mo)
<_sre.SRE_Match object at 0x01D3A870>
>>> print(mo.group())
2012
>>> print('%s %s' % (mo.start(), mo.end())
16 20
在一个正则表达式中,\d表示任意位,所以\d\d\d\d表示任意位,任意位,任意位,或者说白了,连续 4 位。正则表达式大量使用反斜杠,反斜杠在 Python 中有特殊的含义,所以我们在字符串前面加了一个 r 使其成为一个原始字符串,它阻止 Python 以任何方式解释反斜杠。
如果re.search找到匹配我们正则表达式的东西,它返回一个匹配对象,其中保存了关于匹配内容的信息。在上面的例子中,我们打印出匹配的子字符串,以及它在被搜索的字符串中的开始和结束位置。
注意 Python 没有匹配日期(31)。它会匹配前两个字符,即与前两个\d匹配的 3 和 1 ,但是下一个字符(一个空格)不会匹配第三个\d,所以 Python 会放弃并继续搜索字符串的剩余部分。
匹配一组字符
让我们试试另一个例子:
>>> str = 'Today is 2012-MAY-31'
>>> mo = re.search(r'\d\d\d\d-[A-Z][A-Z][A-Z]-\d\d', str)
>>> print(mo.group())
2012-MAY-31
这一次,我们的正则表达式包含新元素[A-Z]。方括号表示与其中一个字符完全匹配。例如,[abc]表示 Python 将匹配一个 a 或 b 或 c ,但不匹配其他字母。由于我们想要匹配 A 和 Z 之间的任何字母,我们可以写出整个字母表([ABCDEFGHIJKLMNOPQRSTUVWXYZ]),但是谢天谢地,Python 允许我们使用连字符([A-Z])来缩短这个字母。所以,我们的正则表达式是\d\d\d\d-[A-Z][A-Z][A-Z]-\d\d,意思是:
- 寻找(或匹配)一个数字(4 次)。
- 匹配一个’-'字符。
- 匹配 A 和 Z 之间的一个字母(三次)。
- 匹配一个’-'字符。
- 匹配一个数字(2 次)。
如上例所示,Python 找到了嵌入在字符串中的日期。
不幸的是,我们的正则表达式目前只处理大写的月份名称:
# The month uses lower-case letters
>>> str = 'Today is 2012-May-31'
>>> mo = re.search(r'\d\d\d\d-[A-Z][A-Z][A-Z]-\d\d', str)
>>> print(mo)
None
有两种方法可以解决这个问题。我们可以传入一个标志,表示搜索应该不区分大小写:
>>> str = 'Today is 2012-May-31'
>>> mo = re.search(r'\d\d\d\d-[A-Z][A-Z][A-Z]-\d\d', str, re.IGNORECASE)
>>> print(mo.group())
2012-May-31
或者,我们可以扩展字符集来指定更多的字符:[A-Za-z]表示大写 A 到大写 Z,或者小写 A 到小写 Z 。
>>> str = 'Today is 2012-May-31'
>>> mo = re.search(r'\d\d\d\d-[A-Za-z][A-Za-z][A-Za-z]-\d\d', str)
>>> print(mo.group())
2012-May-31
正则表达式的重复
上一个例子中的正则表达式开始变得有点笨拙,所以让我们看看如何简化它。
在正则表达式中,{n}(其中 n 是数字)表示重复前面的元素 n 次。所以我们可以重写这个正则表达式:
\d\d\d\d-[A-Za-z][A-Za-z][A-Za-z]-\d\d
变成这样:
\d{4}-[A-Za-z]{3}-\d{2}
这意味着:
- 匹配任意数字(4 次)。
- 匹配一个’-'字符。
- 匹配字母 A-Z 或 a-z (3 次)。
- 匹配一个’-'字符。
- 匹配任意数字(2 次)。
这就是它的作用:
>>> str = 'Today is 2012-May-31'
>>> mo = re.search(r'\d{4}-[A-Za-z]{3}-\d{2}', str)
>>> print(mo.group())
2012-May-31
当指定应该匹配多少重复时,我们有很大的灵活性。
- 我们可以指定一个范围,例如
{2,4}表示匹配 2 - 4 次重复。
>>> str = 'abc12345def'
>>> mo = re.search(r'\d{2,4}', str)
>>> print(mo.group())
1234
- 我们可以忽略上限值,例如
{2,}表示“匹配 2 次或更多次重复”。
>>> str = "abc12345def"
>>> mo = re.search(r'\d{2,}', str)
>>> print(mo.group())
12345
常见重复的简写
有些类型的重复非常常见,它们有自己的语法。
{1,}表示匹配前一个元素一次或多次,但这也可以用特殊的+操作符来写(例如\d+)。
>>> str = 'abc12345def'
>>> mo = re.search(r'\d+', str)
>>> print(mo.group())
12345
{0,}表示匹配前一个元素零次或多次,但这也可以用*操作符来写(如\d*)。
>>> str = 'abc12345def'
>>> mo = re.search(r'\d*', str)
>>> print(mo.group())
呀,发生什么事了?!为什么这个什么都没打印出来?嗯,你必须小心操作符,因为它会匹配零或更多的重复。在这种情况下,Python 看着被搜索字符串的第一个字符,对自己说这是数字吗?没有。我匹配了零个或多个数字吗?是(零),所以正则表达式已经匹配了。*如果我们看看MatchObject告诉我们的:
>>> print('%s %s' % (mo.start(), mo.end()))
0 0
我们可以看到这正是所发生的,它在被搜索的字符串的最开始匹配了一个空的子字符串。让我们稍微改变一下我们的正则表达式:
>>> str = 'abc12345def'
>>> mo = re.search(r'c\d*', str)
>>> print(mo.group())
c12345
现在我们的正则表达式说匹配字母 c,然后零个或多个数字,这就是 Python 随后找到的。
{0,1}表示匹配前一个元素 0 或 1 次,但这也可以用?操作符来写(如\d?)。
>>> str = 'abc12345def'
>>> mo = re.search(r'c\d?', str)
# Note: the \d was matched 1 time
>>> print(mo.group())
c1
>>> mo = re.search(r'b\d?', str)
# Note: the \d was matched 0 times
>>> print(mo.group())
b
在下一篇文章中,我们将继续讨论正则表达式的更多高级用法。
Python 的 Django 简介
原文:https://www.pythoncentral.io/introduction-to-pythons-django/
什么是 Web 开发
Web 开发是一个宽泛的术语,指的是任何涉及到为互联网或内部网创建网站的工作。web 开发项目的最终产品各不相同,从由静态网页组成的简单站点到与数据库和用户交互的复杂应用程序。web 开发涉及的任务清单包括 web 设计、 web 内容开发、客户端-服务器脚本、 web 服务器和网络配置和电子商务开发。通常,web 开发意味着构建网站的非设计方面:编码。
大型企业通常有数百人在 IT / web 开发部门工作。例如,一所大学经常需要大量的 web 开发人员、图形设计人员、信息系统架构师来处理其庞大的基于 web 的基础设施,以便学生可以注册课程,教授可以上传考试分数等等。相比之下,较小的公司和个人通常需要一两个 web 开发人员和/或图形设计人员来为他们创建网站。
什么是 Web 框架
为了从事 web 开发项目,程序员需要利用众多 web 框架中的一个来编写代码,这些代码专用于作为高效且可伸缩的 web 服务器来管理内容并向最终用户提供服务。
web 框架是一个软件库,旨在帮助任何网站的开发。通过将常见的 web 功能打包到自身中,web 框架允许程序员使用开箱即用的代码和基础结构来创建网站,以便他们可以专注于构建面向业务逻辑的网站功能,而不是反复编写处理常见 web 编程任务的代码。例如,大多数 web 框架为数据库访问、模板引擎和 web 会话管理提供了库。如果没有 web 框架,无论何时开始一个新项目,人们都将被迫编写相同的模板代码来处理这些常见任务。
姜戈是什么
Django 是一个免费的开源 Python web 框架。在 2005 年首次发布后,它作为 web 开发的de-factor框架,越来越受 Python 程序员的欢迎。Django 强调组件的可重用性和可插拔性,这样不同的代码就可以即插即用,形成一个内聚的 web 系统。
Django 宣扬的另一个原则是干(不要重复自己)。 DRY 旨在减少软件开发中各种重复的信息。例如,我们应该将服务器的静态文件夹的地址赋给应用程序的设置文件中定义的一个常量,这样我们就可以在将来轻松地更改它,而不是在代码的任何地方将服务器的静态文件夹写成一个原始字符串。
除了为常见的 web 任务(如数据库交互和会话管理)提供库之外,Django 还提供了一个内置的admin站点,允许网站的程序员和管理员通过 GUI 界面轻松地创建、读取、更新和删除数据库记录。
由 Django 支持的网站
以下是由 Django 支持的网站的非独家列表:
- pinterest.com:图钉板风格的照片分享网站。
- bitbucket.org:代码分享网站。
- instagram.com:照片分享网站。
- addons.mozilla.com:火狐浏览器的插件管理网站。
- disqus.com:社区博客评论托管网站。
如你所见,Django 完全有能力托管一些最受欢迎的社交分享网站,如 Pinterest 和 Instagram,以及一些最关键的网站,如 Bitbucket。由于 Django 推广和维护的最佳软件实践,大公司也开始采用新技术,并慢慢地从 J2EE 转移出去。
Django 与其他 Python Web 框架的比较
当然,Django 并不是唯一的 Python web 框架。其他流行的 Python web 框架有:
- Flask :开源的微型 web 框架,只提供 web 开发的核心库。它不提供数据库抽象、表单验证或任何其他可由第三方组件提供的组件。与 Django 不同,Flask 提供的开箱即用组件的数量保持在最低限度,这就是它被称为微型 web 框架的原因。
- 金字塔:一个受 Zope、Pylons 和 Django 启发的开源极简网络框架。它严格遵循 MVC (模型-视图-控制器)模式和持久性不可知。与 Django 相比,Pyramid 提供了一个额外的 URL 映射机制,称为 URL 遍历,它通过预定义的字典数据结构将 URL 映射到视图。
- Web2py:受 Ruby-on-Rails 启发的开源宏 Web 框架。它遵循 Ruby-on-Rails 关于配置方法的约定,并为各种组件和库提供了合理的缺省值。与 Django 相比,web2py 是不同的,因为它为程序员处理几乎所有的事情,同时提供更少的配置选项。
请注意,这些框架之间没有排名。无论你选择哪种 web 框架,最终最重要的问题是由你自己或你的团队来回答:我喜欢使用这个框架吗?一个易于使用的 web 框架能让任何程序员发挥出最高的效率。因此,选择一个你喜欢的框架,用它来创建优雅的网站。
摘要
在本文中,web 开发和 Django 的前景以鸟瞰图的形式呈现。除了学习 web 开发和 Django 的一般基础知识,我们还将 Django 与其他 Python web 框架进行了比较,得出的结论是,无论你选择哪个框架,都应该选择一个你爱用的框架。
Python 的 TkInter 介绍
原文:https://www.pythoncentral.io/introduction-to-pythons-tkinter/
在 Python 体验的某个阶段,您可能想要创建一个具有图形用户界面或 GUI(大多数人发音为“gooey”)的程序。有许多针对 Python 的工具包可以实现这一点,包括 Python 自己的原生 GUI 库 TkInter。在 Tkinter 中设置 GUI 并不复杂,尽管最终取决于您自己设计的复杂性。在这里,我们将通过一些简单的 GUI 示例来看看 Tkinter 模块的常用部分。在进入示例之前,让我们简要介绍一下 Tkinter 库必须提供的常用小部件(GUI 的构建块)。
简而言之,Tkinter 的所有小部件要么向 GUI 提供简单的输入(用户输入),要么从 GUI 输出(信息的图形显示),或者两者兼而有之。下面是最常用的输入和输出小部件的两个表格,并附有简要描述。
常用于输入的 Tkinter 小部件:
| 小工具 | 描述 |
| 进入 | 入口小部件是最基本的文本框,通常是一个单行高的字段,用户可以在其中键入文本;不允许太多格式 |
| 文本 | 让用户输入多行文本,并存储文本;提供格式选项(样式和属性) |
| 纽扣 | 用户告诉 GUI 执行命令的基本方法,例如对话框中的“确定”或“取消” |
| 单选按钮 | 让用户从列表中选择一个选项 |
| 复选按钮 | 允许用户从列表中选择多个选项 |
常用于输出的 Tkinter 小部件:
| 小工具 | 描述 |
| 标签 | 通过文本或图像显示信息的最基本方式 |
| 照片图像/位图图像 | 这些更像是类对象,而不是真正的小部件,因为它们必须与标签或其他显示小部件结合使用;它们分别显示图像和位图 |
| 列表框 | 显示文本项列表,用户可以从中突出显示一个(或多个,具体取决于配置) |
| 菜单 | 为用户提供菜单 |
尽管上面的小部件被分为“输入”和“输出”两类,但实际上它们都是双重的输入和输出,尤其是当回调(或事件绑定)开始起作用的时候。我们稍后将进一步研究回调和事件绑定,现在我们将看看上面应用程序中列出的一些小部件的例子。
要使用 Tkinter 模块,我们必须将其导入到我们的全局名称空间中。这通常是通过这样的语句来实现的:
[python]from tkinter import *[/python]
[python]from Tkinter import *[/python]
但是,为了保持名称空间的整洁,最好不要这样做。相反,我们将使用这种形式:
[python]import tkinter as tk[/python]
[python]import Tkinter as tk[/python]
这使我们能够访问模块,而不必每次都键入完整的模块名。当我们引用它时,你可以看到这一点:
>>> tk
<module 'Tkinter' from 'C:\Python27\lib\lib-tk\Tkinter.pyc'>
好了,我们现在准备好制作我们的 GUI 了——但是在此之前,让我们简单地想象一下我们希望它是什么样子,并检查一下内部 GUI 结构。现在我们将保持我们的设计简单,一个输出部件和一个输入部件——一个Label部件和一个Entry部件。
每个 Tkinter 小部件都由另一个被称为“父”的小部件管理或属于另一个小部件(属于另一个小部件的小部件被称为该小部件的“子部件”)。GUI 中唯一没有父窗口的小部件是主(或根)窗口。所有其他小部件都应该是根窗口的子窗口。此外,小部件通常物理上位于其父部件内部。这是基本结构。现在让我们开始建立我们的。第一步是创建我们的根窗口:
root1 = tk.Tk()
Tkinter Tk 对象是我们的根窗口,我们可以用子窗口填充它。首先是我们的标签。
label = tk.Label(root1, text='our label widget')
很快,我们有了一个标签。我们使用的第一个参数是父节点的名称(root1)。第二个参数是标签的标准关键字选项,用于设置它将显示的文本(如果有的话)。
接下来,我们初始化我们的输入小部件,条目:
entry = tk.Entry(root1)
初始化标签和条目小部件并设置好我们想要的选项后,剩下的就是告诉 Tkinter 将它们放在屏幕上它们的父窗口中。尽管我们设置了父类和选项,但是除非我们明确地告诉 Tkinter 显示它们,否则我们的小部件不会显示。
为了顺利处理这个过程,Tkinter 提供了一些内置的图形组织者,称为几何管理器。下表描述了每个可用的几何管理器。
| 几何图形管理器 | 描述 |
| 包装 | 用于用小部件填充父级空间 |
| 格子 | 将它管理的小部件放在父网格中。每个小部件在网格中都有自己的盒子或单元格(T0 )( T1 ),尽管它们可以通过一些选项覆盖多个 T2 单元格(T3) |
| 地方 | 允许明确设置窗口的大小和位置;主要用于实现自定义窗口布局,而不是普通布局 |
正如我们从第三个管理器的描述中看到的,pack 和 grid 管理器是用于常规公共布局的管理器,我们将在这个 GUI 中使用 pack。我们希望我们的标签在条目的顶部,所以我们将首先打包它,并使用一个选项将其设置在顶部,然后再打包条目(它将自动显示在标签下方):
label.pack(side=tk.TOP)
entry.pack()
搞定了。现在可以看到我们的小部件了。然而,您会注意到,如果您处于 Python 2.7 空闲状态,还没有 GUI 出现。就像任何其他小部件一样,必须告诉 Tkinter 显示根窗口,但是对于根窗口而不是几何管理器,必须调用主 Tk 循环,如下所示:
root1.mainloop()
现在我们应该可以看到一个新窗口,看起来像这样…

这可能会因您的设置/环境而有所不同,但不会相差太多。有了输入框,我们可以在窗口中键入我们想要的任意多的文本,尽管它不会做任何事情,只是呆在那里,因为我们没有让它做任何其他事情(即使我们点击“Enter”,标签也是一样)。
让我们关闭这个窗口,看一个有更多小部件的例子。我们还将快速了解一下事件绑定和网格管理器。请注意,在我们关闭 GUI 后,我们的根窗口及其所有子窗口将变得不可用,如果您尝试再次启动 root1 的主循环,或者尝试更改 label 的配置,您会发现这一点。
对于我们的第二个 GUI,我们将有一个标签和 3 个单选按钮。我们将像以前一样从根窗口开始,然后初始化标签:
root2 = tk.Tk()
label2 = tk.Label(root2, text='Choose a button')
我们现在有了根窗口和标签,但是在初始化 Radiobutton 之前,我们将创建一个 Tkinter 变量对象来跟踪每个 radio button 保存的值:
# Object of the Tkinter StringVar class
buttonstr = tk.StringVar()
现在我们将创建三个单选按钮,并将它们的值连接到我们的 buttonstr 变量:
buttonA = tk.Radiobutton(root2, text='Button A', variable=buttonstr, value='ButtonA string')
buttonB = tk.Radiobutton(root2, text='Button B', variable=buttonstr, value='ButtonB string')
buttonC = tk.Radiobutton(root2, text='Button C', variable=buttonstr, value='ButtonC string')
创建了 Radiobuttons 后,我们现在将检查当我们使用回调将方法连接到每个 Radiobuttons 时会发生什么。回调用于告诉 GUI 在小部件激活时执行一些命令或动作。我们将使用回调来打印每个单选按钮被选中时的值:
def showstr(event=None):
print(buttonstr.get())
我们刚刚定义的这个函数只不过是打印使用 get()方法访问的 StringVar 的值。我们现在可以通过使用command选项在 Radiobuttons 中引用这个函数作为回调:
buttonA.config(command=showstr)
buttonB.config(command=showstr)
buttonC.config(command=showstr)
好了,现在我们所有的小部件都初始化了,我们将设置它们在网格管理器中显示:
label2.grid(column=0, row=0)
buttonA.grid(column=0, row=1)
buttonB.grid(column=0, row=2)
buttonC.grid(column=0, row=3)
我们使用选项column和row告诉 grid 小部件的确切位置,但是如果我们不这样做,grid 会以默认顺序显示它们(列是零)。事不宜迟,我们现在将运行我们的 GUI。
root2.mainloop()
它应该是这样的:

**注意:**在我们选择一个单选按钮之前,似乎所有的单选按钮都被选择了——这仅仅是因为我们没有用 select()方法选择一个默认的单选按钮。如果我们在第一个按钮上使用这个方法,它将显示如下:
buttonA.select()
root2.mainloop()

现在,如果我们选择任何一个单选按钮(例如,A然后C然后B,那么我们应该会看到每个按钮的回调结果:
>>> root2.mainloop()
ButtonA string
ButtonC string
ButtonB string
除了用于将功能链接到窗口小部件的命令选项的回调之外,事件绑定可用于将某些用户“事件”(例如击键和鼠标点击)链接到缺少命令选项的窗口小部件。让我们用我们的第一个 GUI 例子来尝试一下。在所有其他设置都相同的情况下,就在打包输入框之后和启动 root1 主循环之前,我们将为“Enter”键设置一个事件绑定,这样如果按下它,输入框中的文本将被打印到空闲窗口。我们首先需要一种方法来完成这项工作:
# Prints the entry text
def showentry(event):
print(entry.get())
现在我们有了显示条目文本的方法,我们必须绑定事件(当用户点击“Enter”键且输入框处于焦点时):
>>> entry.bind('<Return>', showentry)
'29748480showentry'
在这一行中,我们使用了bind方法(每个小部件都可以使用)来连接我们的键盘事件(第一个参数)和我们的方法(第二个参数)。还要注意,对于return键,我们的事件名称是,而不是,因为这标志着 Tkinter 中完全不同类型的事件。我们可以忽略返回的函数名后面的短数字串,这对我们来说没有任何特殊意义。
如果我们现在运行根窗口的主循环,在我们的输入框中键入一些文本,并点击Enter键,Python 将显示我们键入的内容(试试看!).同样的功能可以用于 Tkinter GUI 中的任何小部件,并且可以用bind_all和bind_class方法同时绑定多个小部件。以同样的方式不受unbind、unbind_all和unbind_class方法的约束。
这就结束了我们对 Python Tkinter 库的介绍——它提供的工具与其他可用的第三方包相比是基本的,但是不要害怕使用它来发挥创造力!
Python 中的 SQLite 简介
原文:https://www.pythoncentral.io/introduction-to-sqlite-in-python/
SQLite3 是一个非常容易使用的数据库引擎。它是独立的、无服务器的、零配置的和事务性的。它非常快速和轻量级,并且整个数据库存储在单个磁盘文件中。它在许多应用中被用作内部数据存储。Python 标准库包括一个名为“sqlite3”的模块,用于处理该数据库。这个模块是一个符合 DB-API 2.0 规范的 SQL 接口。
使用 Python 的 SQLite 模块
要使用 SQLite3 模块,我们需要在 python 脚本中添加一条 import 语句:
import sqlite3
将 SQLite 连接到数据库
我们使用函数sqlite3.connect来连接数据库。我们可以使用参数“:memory:”在 RAM 中创建一个临时 DB,或者传递一个文件名来打开或创建它。
# Create a database in RAM
db = sqlite3.connect(':memory:')
# Creates or opens a file called mydb with a SQLite3 DB
db = sqlite3.connect('data/mydb')
当我们使用完数据库后,我们需要关闭连接:
db.close()
创建(CREATE)和删除(DROP)表格
为了对数据库进行任何操作,我们需要获得一个游标对象,并将 SQL 语句传递给游标对象来执行它们。最后,提交变更是必要的。我们将创建一个包含姓名、电话、电子邮件和密码列的用户表。
# Get a cursor object
cursor = db.cursor()
cursor.execute('''
CREATE TABLE users(id INTEGER PRIMARY KEY, name TEXT,
phone TEXT, email TEXT unique, password TEXT)
''')
db.commit()
要删除表格:
# Get a cursor object
cursor = db.cursor()
cursor.execute('''DROP TABLE users''')
db.commit()
请注意,提交函数是在 db 对象上调用的,而不是在游标对象上。如果我们输入cursor.commit,我们将得到AttributeError: 'sqlite3.Cursor' object has no attribute 'commit'
将数据插入数据库
为了插入数据,我们使用光标来执行查询。如果需要 Python 变量的值,建议使用“?”占位符。不要使用字符串操作或连接来进行查询,因为非常不安全。在本例中,我们将在数据库中插入两个用户,他们的信息存储在 python 变量中。
cursor = db.cursor()
name1 = 'Andres'
phone1 = '3366858'
email1 = 'user@example.com'
# A very secure password
password1 = '12345'
name 2 = ' John '
phone 2 = ' 5557241 '
email 2 = ' John doe @ example . com '
password 2 = ' abcdef '
# Insert user 1
cursor . execute(' ' ' Insert INTO users(name,phone,email,password)
VALUES(?,?,?,?)“”,(姓名 1,电话 1,电子邮件 1,密码 1))
打印('插入第一个用户')
# Insert user 2
cursor . execute(' ' ' Insert INTO users(name,phone,email,password)
VALUES(?,?,?,?)“”,(姓名 2,电话 2,电子邮件 2,密码 2))
打印('插入第二个用户')
db.commit()
Python 变量的值在元组内部传递。另一种方法是使用“:keyname”占位符传递字典:
cursor.execute('''INSERT INTO users(name, phone, email, password)
VALUES(:name,:phone, :email, :password)''',
{'name':name1, 'phone':phone1, 'email':email1, 'password':password1})
如果需要插入几个用户使用executemany和一个带有元组的列表:
users = [(name1,phone1, email1, password1),
(name2,phone2, email2, password2),
(name3,phone3, email3, password3)]
cursor.executemany(''' INSERT INTO users(name, phone, email, password) VALUES(?,?,?,?)''', users)
db.commit()
如果您需要获得刚刚插入的行的 id,请使用lastrowid:
id = cursor.lastrowid
print('Last row id: %d' % id)
用 SQLite 检索数据(选择)
要检索数据,对 cursor 对象执行查询,然后使用fetchone()检索单个行,或者使用fetchall()检索所有行。
cursor.execute('''SELECT name, email, phone FROM users''')
user1 = cursor.fetchone() #retrieve the first row
print(user1[0]) #Print the first column retrieved(user's name)
all_rows = cursor.fetchall()
for row in all_rows:
# row[0] returns the first column in the query (name), row[1] returns email column.
print('{0} : {1}, {2}'.format(row[0], row[1], row[2]))
光标对象作为迭代器工作,自动调用fetchall():
cursor.execute('''SELECT name, email, phone FROM users''')
for row in cursor:
# row[0] returns the first column in the query (name), row[1] returns email column.
print('{0} : {1}, {2}'.format(row[0], row[1], row[2]))
要使用条件检索数据,请再次使用“?”占位符:
user_id = 3
cursor.execute('''SELECT name, email, phone FROM users WHERE id=?''', (user_id,))
user = cursor.fetchone()
更新(UPDATE)和删除(DELETE)数据
更新或删除数据的过程与插入数据的过程相同:
# Update user with id 1
newphone = '3113093164'
userid = 1
cursor.execute('''UPDATE users SET phone = ? WHERE id = ? ''',
(newphone, userid))
#删除 id 为 2
Delete _ userid = 2
cursor . execute(' ' '从 id =?'的用户中删除'',(删除用户标识,))
db.commit()
使用 SQLite 交易
事务是数据库系统的一个有用属性。它确保了数据库的原子性。使用commit保存更改:
cursor.execute('''UPDATE users SET phone = ? WHERE id = ? ''',
(newphone, userid))
db.commit() #Commit the change
或者rollback回滚自上次调用commit以来对数据库的任何更改:
cursor.execute('''UPDATE users SET phone = ? WHERE id = ? ''',
(newphone, userid))
# The user's phone is not updated
db.rollback()
请记住总是调用commit来保存更改。如果您使用close关闭连接或者与文件的连接丢失(可能程序意外结束),未提交的更改将会丢失。
SQLite 数据库异常
最佳实践是始终用 try 子句或上下文管理器围绕数据库操作:
import sqlite3 #Import the SQLite3 module
try:
# Creates or opens a file called mydb with a SQLite3 DB
db = sqlite3.connect('data/mydb')
# Get a cursor object
cursor = db.cursor()
# Check if table users does not exist and create it
cursor.execute('''CREATE TABLE IF NOT EXISTS
users(id INTEGER PRIMARY KEY, name TEXT, phone TEXT, email TEXT unique, password TEXT)''')
# Commit the change
db.commit()
# Catch the exception
except Exception as e:
# Roll back any change if something goes wrong
db.rollback()
raise e
finally:
# Close the db connection
db.close()
在这个例子中,我们使用了 try/except/finally 子句来捕捉代码中的任何异常。finally关键字非常重要,因为它总是正确地关闭数据库连接。请参考这篇文章,了解更多关于例外的信息。请查看:
# Catch the exception
except Exception as e:
raise e
这被称为一个无所不包的子句,这里只是作为一个例子,在实际应用中你应该捕捉一个特定的异常,如IntegrityError或DatabaseError,更多信息请参考 DB-API 2.0 异常。
我们可以使用连接对象作为上下文管理器来自动提交或回滚事务:
name1 = 'Andres'
phone1 = '3366858'
email1 = 'user@example.com'
# A very secure password
password1 = '12345'
try:
with db:
db . execute(' ' ' INSERT INTO users(name,phone,email,password)
VALUES(?,?,?,?)“”,(姓名 1,电话 1,电子邮件 1,密码 1))
除了 sqlite3。IntegrityError:
打印('记录已经存在')
最后:
db.close()
在上面的例子中,如果 insert 语句引发了一个异常,事务将被回滚并打印消息;否则事务将被提交。请注意,我们在db对象上调用execute,而不是cursor对象。
SQLite 行工厂和数据类型
下表显示了 SQLite 数据类型和 Python 数据类型之间的关系:
None类型转换为NULLint类型转换为INTEGERfloat类型转换为REALstr类型转换为TEXTbytes类型转换为BLOB
行工厂类sqlite3.Row用于通过名称而不是索引来访问查询的列:
【python】
db = sqlite3 . connect(’ data/mydb ‘)
db . row _ factory = sqlite3。row
cursor = db . cursor()
cursor . execute(’ ’ ‘从用户中选择姓名、电子邮件、电话’ ')
对于游标中的行:
row[‘name’]返回查询中的姓名列,row[‘email’]返回电子邮件列。
打印(’ {0} : {1},{2} '。格式(行[‘姓名’],行[‘电子邮件’],行[‘电话’])
db . close()
Tweepy 简介,用于 Python 的 Twitter
原文:https://www.pythoncentral.io/introduction-to-tweepy-twitter-for-python/
Python 对于各种事物来说都是很棒的语言。非常活跃的开发人员社区创建了许多库,这些库扩展了语言并使使用各种服务变得更加容易。其中一个图书馆是 tweepy。Tweepy 是开源的,托管在 GitHub 上,支持 Python 与 Twitter 平台通信并使用其 API。关于库 Twython - 的介绍,请查看本文。
在撰写本文时,tweepy 的当前版本是 1.13。它于 1 月 17 日发布,与前一版本相比,提供了各种错误修复和新功能。2.x 版本正在开发中,但是目前还不稳定,所以大多数用户应该使用普通版本。
安装 tweepy 很简单,可以从 Github 库克隆:
git clone https://github.com/tweepy/tweepy.git
python setup.py install
或者使用简易安装:
pip install tweepy
这两种方式都为您提供了最新的版本。
使用 Tweepy
Tweepy 支持通过基本认证和更新的方法 OAuth 访问 Twitter。Twitter 已经停止接受基本认证,所以 OAuth 现在是使用 Twitter API 的唯一方式。
下面是如何使用 tweepy 和 OAuth 访问 Twitter API 的示例:
import tweepy
#消费密钥和访问令牌,用于 OAuth
Consumer _ key = ' 7 eyztcakinvs 3 T2 Pb 165 '
Consumer _ secret = ' a 44 r 7 wvbmw7 l 8 I 656y 4 l '
access _ token = ' z 00 xy 9 akhwp 8 vstj 04 l 0 '
access _ token _ secret = ' a1ck 98 w 2 nxxacmqmw 6 p '
# OAuth 进程,使用密钥和令牌
auth = tweepy。OAuthHandler(消费者密钥,消费者秘密)
auth.set_access_token(访问令牌,访问令牌 _ 秘密)
#使用认证创建实际接口
api = tweepy。API(授权)
# Sample 方法,用于更新状态
API . update _ status(' Hello Python Central!')
这段代码的结果如下:

基本身份验证和 OAuth 身份验证的主要区别在于消费者和访问密钥。使用基本认证,可以提供用户名和密码并访问 API,但自从 2010 年 Twitter 开始要求 OAuth 以来,这个过程变得有点复杂。必须在developer.twitter.com创建一个应用程序。
最初,OAuth 比基本 Auth 要复杂一些,因为它需要更多的努力,但是它提供的好处是非常有利可图的:
- Tweets 可以被定制为一个字符串来标识所使用的应用程序。
- 它不会泄露用户密码,使其更加安全。
- 管理权限更容易,例如,可以生成一组令牌和密钥,只允许从时间线读取,因此,如果有人获得这些凭据,他/她将无法编写或发送直接消息,从而将风险降至最低。
- 应用程序不回复密码,所以即使用户更改了密码,应用程序仍然可以工作。
登录到门户网站后,转到“应用程序”,可以创建一个新的应用程序,它将提供与 Twitter API 通信所需的数据。

这是一个拥有与 Twitter 网络对话所需的所有数据的屏幕。需要注意的是,默认情况下,应用程序没有访问直接消息的权限,因此,通过进入设置,将适当的选项更改为“读取、写入和直接消息”,您可以使您的应用程序能够访问每一个 Twitter 功能。
Twitter API
Tweepy 提供了对记录良好的 Twitter API 的访问。使用 tweepy,可以获得任何对象并使用官方 Twitter API 提供的任何方法。例如,User对象有自己的文档,遵循这些指导方针,tweepy 可以获得适当的信息。
Twitter API 中的类有Tweets、Users、Entities和Places。访问每一个都会返回一个 JSON 格式的响应,在 Python 中遍历信息非常容易。
# Creates the user object. The me() method returns the user whose authentication keys were used.
user = api.me()
print(' Name:'+user . Name)
print(' Location:'+user . Location)
print(' Friends:'+str(user . Friends _ count))
为我们提供了以下输出:
Name: Ahmet Novalic
Location: Gradacac,Bih
Friends: 59
这里记录了所有的 API 方法:https://docs.tweepy.org/en/stable/
Tweepy StreamingAPI
tweepy 的一个主要使用案例是监控 tweepy 并在事件发生时采取行动。其中的关键组件是StreamListener对象,它实时监控并捕捉推文。
StreamListener有几种方法,其中on_data()和on_status()是最有用的。下面是一个实现此行为的示例程序:
class StdOutListener(StreamListener):
''' Handles data received from the stream. '''
def on_status(self,status):
#打印推文的文本
print('推文文本:'+ status.text)
#状态对象中有许多选项,
#标签可以非常容易地访问。
对于 status . entries[' hash tags ']:
print(hash tag[' text '])
返回 true
def on_error(self,status _ code):
print(' get a error with status code:'+str(status _ code))
返回 True #继续监听
def on_timeout(self):
打印(' timeout ... ')
返回 True #继续收听
if _ _ name _ _ = = ' _ _ main _ _ ':
listener = StdOutListener()
auth = tweepy。OAuthHandler(消费者密钥,消费者秘密)
auth.set_access_token(访问令牌,访问令牌 _ 秘密)
stream = Stream(auth,listener)
Stream . filter(follow =[38744894],track=['#pythoncentral'])
因此,这个程序实现了一个StreamListener,代码被设置为使用 OAuth。创建了Stream对象,它使用该侦听器作为输出。作为 tweepy 中的另一个重要对象,Stream 也有许多方法,在本例中,filter()通过传递参数来使用。“follow”是其推文被监控的关注者列表,“track”是触发StreamListener的标签列表。
在这个例子中,我们使用我的用户 ID follow 和#pythoncentral hashtag 作为条件。运行程序并发布此状态后:

程序几乎立即捕捉到 tweet,并调用on_status()方法,该方法在控制台中产生以下输出:
Tweet text: Hello Again! #pythoncentral
pythoncentral
除了打印 tweet 之外,在on_status()方法中,还有一些额外的事情说明了 tweet 数据可以实现的可能性:
# There are many options in the status object,
# hashtags can be very easily accessed.
for hashtag in status.entities['hashtags']:
print(hashtag['text'])
这段代码遍历实体,选择“标签”,对于 tweet 包含的每个标签,它打印其值。这只是一个样本;tweet 实体的完整列表位于此处:https://developer . Twitter . com/en/docs/Twitter-API/data-dictionary/object-model/tweet。
结论
总而言之,tweepy 是一个很棒的开源库,它提供了对 Python 的 Twitter API 的访问。虽然 tweepy 的文档有点缺乏,也没有很多例子,但它严重依赖 Twitter API 的事实使它可能是 Python 最好的 Twitter 库,特别是考虑到对Streaming API 的支持,这是 tweepy 擅长的地方。像 python-twitter 这样的其他库也提供了许多功能,但是 tweepy 拥有最活跃的社区,并且在过去的一年中提交了最多的代码。
用于 tweepy 的额外资源可以在这里获得:
- 推特开发者
- 官方 tweepy 文档
- tweepy github 页面
- 邮件列表
- IRC, Freenode.net #tweepy.
Python 的 SQLAlchemy 入门教程
原文:https://www.pythoncentral.io/introductory-tutorial-python-sqlalchemy/
Python 的 SQLAlchemy 和对象关系映射
在编写任何 web 服务时,一个常见的任务是构建一个可靠的数据库后端。过去,程序员会编写原始的 SQL 语句,将它们传递给数据库引擎,并将返回的结果解析为普通的记录数组。如今,程序员可以编写对象关系映射 ( ORM )程序,以消除编写单调乏味、容易出错、不灵活且难以维护的原始 SQL 语句的必要性。
ORM 是一种编程技术,用于在面向对象编程语言的不兼容类型系统之间转换数据。通常,Python 等 OO 语言中使用的类型系统包含非标量类型,也就是说,这些类型不能表示为整数和字符串等基本类型。例如,一个Person对象可能有一个Address对象列表和一个与之相关的PhoneNumber对象列表。反过来,Address对象可以有一个PostCode对象、一个StreetName对象和一个StreetNumber对象与之相关联。虽然简单对象如PostCode s 和StreetName s 可以表示为字符串,但复杂对象如Address和Person不能仅用字符串或整数表示。此外,这些复杂对象还可能包含根本无法使用类型表达的实例或类方法。
为了处理管理对象的复杂性,人们开发了一类新的系统,称为 ORM 。我们之前的例子可以表示为一个带有一个Person类、Address类和PhoneNumber类的 ORM 系统,其中每个类映射到底层数据库中的一个表。一个 ORM 会为您处理这些问题,而您可以专注于系统逻辑的编程,而不是自己编写繁琐的数据库接口代码。
用 Python 编写数据库代码的老方法
我们将使用库 sqlite3 来创建一个简单的数据库,在下面的设计中有两个表Person和Address:

注意:如果您想了解如何使用 SQLite for Python,您可能想看看 Python 系列中的 SQLite。
在这个设计中,我们有两个表person和address,address.person_id是person表的外键。现在我们在一个文件sqlite_ex.py中编写相应的数据库初始化代码。
import sqlite3
conn = sqlite3.connect('example.db')
c = conn . cursor()
c . execute(' '
创建表 person
(id 整数主键 ASC,name varchar(250)NOT NULL)
' ' ')
c . execute(' '
创建表地址
(id 整数主键 ASC,street_name varchar(250),street_number varchar(250),
post _ code varchar(250)NOT NULL,person_id 整数 NOT NULL,
外键(person_id
c . execute(' '
INSERT INTO person VALUES(1,' python central ')
' ' ')
c . execute(' '
INSERT INTO address VALUES(1,' python road ',' 1 ',' 00000 ',1)
' ' ')
conn . commit()
conn . close()
请注意,我们在每个表中插入了一条记录。在您的 shell 中运行以下命令。
$ python sqlite_ex.py
现在我们可以查询数据库example.db来获取记录。在文件sqlite_q.py中编写以下代码。
import sqlite3
conn = sqlite3.connect('example.db')
c = conn . cursor()
c . execute(' SELECT * FROM person ')
print c . fetchall()
c . execute(' SELECT * FROM address ')
print c . fetchall()
conn . close()
并在您的 shell 中运行以下语句。
$ python sqlite_q.py
[(1, u'pythoncentral')]
[(1, u'python road', u'1', u'00000', 1)]
在前面的示例中,我们使用 sqlite3 连接提交对数据库的更改,使用 sqlite3 游标执行对数据库中的 CRUD (创建、读取、更新和删除)数据的原始 SQL 语句。尽管原始 SQL 确实完成了工作,但是维护这些语句并不容易。在下一节中,我们将使用 SQLAlchemy 的声明将Person和Address表映射到 Python 类中。
Python 的 SQLAlchemy 和声明性
编写 SQLAlchemy 代码有三个最重要的组成部分:
- 一个代表数据库中一个表的
Table。 - 将 Python 类映射到数据库中的表的
mapper。 - 一个定义数据库记录如何映射到普通 Python 对象的类对象。
SQLAlchemy 的声明允许在一个类定义中同时定义一个Table、mapper和一个类对象,而不必在不同的地方为Table、mapper和类对象编写代码。
以下声明性定义指定了sqlite_ex.py中定义的相同表格:
import os
import sys
from sqlalchemy import Column, ForeignKey, Integer, String
from sqlalchemy.ext.declarative import declarative_base
from sqlalchemy.orm import relationship
from sqlalchemy import create_engine
Base = declarative_base()
类 Person(Base):
_ _ tablename _ _ = ' Person '
#这里我们为表 person
定义列#注意,每个列也是一个普通的 Python 实例属性。
id = Column(Integer,primary _ key = True)
name = Column(String(250),nullable=False)
class Address(Base):
_ _ tablename _ _ = ' Address '
#这里我们为表地址定义列。
#注意,每一列也是一个普通的 Python 实例属性。
id = Column(Integer,primary _ key = True)
street _ name = Column(String(250))
street _ number = Column(String(250))
post _ code = Column(String(250),nullable = False)
Person _ id = Column(Integer,foreign key(' Person . id ')
Person = relationship(Person)
#创建一个引擎,将数据存储在本地目录的
# sqlalchemy_example.db 文件中。
engine = create _ engine(' SQLite:///sqlalchemy _ example . db ')
#在引擎中创建所有表。这相当于原始 SQL 中的“Create Table”
#语句。
Base.metadata.create_all(引擎)
将前面的代码保存到文件sqlalchemy_declarative.py中,并在 shell 中运行以下命令:
$ python sqlalchemy_declarative.py
现在,应该在当前目录中创建一个名为“sqlalchemy_example.db”的新 sqlite3 db 文件。因为 sqlalchemy 数据库现在是空的,所以让我们编写一些代码将记录插入数据库:
from sqlalchemy import create_engine
from sqlalchemy.orm import sessionmaker
from sqlalchemy _ 声明性导入地址、基、人
engine = create _ engine(' SQLite:///sqlalchemy _ example . db ')
#将引擎绑定到基类的元数据,以便可以通过 DBSession 实例
Base.metadata.bind = engine 访问
#声明
DBSession = session maker(bind = engine)
# DBSession()实例建立与数据库
#的所有对话,并代表加载到
#数据库会话对象中的所有对象的“暂存区”。在调用
# session.commit()之前,对
#会话中的对象所做的任何更改都不会持久化到数据库中。如果您对这些更改不满意,您可以通过调用
# session . roll back()
session = DBSession()来
#将它们全部恢复到上次提交时的状态
#在人员表中插入人员
新人员=人员(姓名= '新人员')
会话.添加(新人员)
会话.提交()
#在地址表中插入地址
new _ Address = Address(post _ code = ' 00000 ',person = new _ person)
session . add(new _ Address)
session . commit()
将前面的代码保存到本地文件sqlalchemy_insert.py中,并在您的 shell 中运行命令python sqlalchemy_insert.py。现在我们在数据库中存储了一个Person对象和一个Address对象。让我们使用sqlalchemy_declarative.py中定义的类来查询数据库:
>>> from sqlalchemy_declarative import Person, Base, Address
>>> from sqlalchemy import create_engine
>>> engine = create_engine('sqlite:///sqlalchemy_example.db')
>>> Base.metadata.bind = engine
>>> from sqlalchemy.orm import sessionmaker
>>> DBSession = sessionmaker()
>>> DBSession.bind = engine
>>> session = DBSession()
>>> # Make a query to find all Persons in the database
>>> session.query(Person).all()
[<sqlalchemy_declarative.Person object at 0x2ee3a10>]
>>>
>>> # Return the first Person from all Persons in the database
>>> person = session.query(Person).first()
>>> person.name
u'new person'
>>>
>>> # Find all Address whose person field is pointing to the person object
>>> session.query(Address).filter(Address.person == person).all()
[<sqlalchemy_declarative.Address object at 0x2ee3cd0>]
>>>
>>> # Retrieve one Address whose person field is point to the person object
>>> session.query(Address).filter(Address.person == person).one()
<sqlalchemy_declarative.Address object at 0x2ee3cd0>
>>> address = session.query(Address).filter(Address.person == person).one()
>>> address.post_code
u'00000'
Python 的 SQLAlchemy 概述
在本文中,我们学习了如何使用 SQLAlchemy 的声明编写数据库代码。与使用 sqlite3 编写传统的原始 SQL 语句相比,SQLAlchemy 的代码更加面向对象,更易于阅读和维护。此外,我们可以轻松地创建、读取、更新和删除 SQLAlchemy 对象,就像它们是普通的 Python 对象一样。
您可能想知道,如果 SQLAlchemy 只是原始 SQL 语句之上的一个抽象薄层,那么它不会给人留下深刻印象,您可能更喜欢编写原始 SQL 语句。在本系列的后续文章中,我们将研究 SQLAlchemy 的各个方面,并将其与原始 SQL 语句进行比较,当它们都用于实现相同的功能时。我相信在本系列的最后,您会确信 SQLAlchemy 优于编写原始 SQL 语句。

















 1037
1037

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









