







Meta:新的鼠标 Vs Python 时事通讯
原文:https://www.blog.pythonlibrary.org/2017/06/28/meta-the-new-mouse-vs-python-newsletter/
我最近决定给我的读者一个选择,让他们注册每周一次的我在这个博客上发表的文章的综述。我把它添加到了我的关注博客页面,但是如果你有兴趣每周收到一封包含上周所有文章链接的电子邮件,你也可以在下面注册:
订阅博客的每周电子邮件
- indicates requiredEmail Address *
First Name
Last Name
我要指出的是,这对我来说是一个小小的实验,我目前正在尝试将电子邮件正确格式化。我相信我终于有了一些看起来不错的东西,但在接下来的几周内,随着我对平台的了解,可能会发生一些小的变化。
迷你书评:MySQL for Python
原文:https://www.blog.pythonlibrary.org/2010/12/09/mini-book-review-mysql-for-python/
|  |
|
Python 的 MySQL
上个月,Packt Publishing 的市场部找到我,让我对他们的新书 Albert Lukaszewski 的《MySQL for Python》进行评论。这本书有 440 页,我应该很快读完。不幸的是,现实生活挡住了我的去路,我将对这本书的内容做一个小小的回顾(即 161 页+略读)。为什么?因为他们市场部一直烦我。将来,我打算只买我自己的书,这样我就不会有这些愚蠢的时间限制。
另一个原因是,我花了这么长时间来阅读这篇文章,因为我只有一本电子书,这使得阅读起来不太方便。我承认我更喜欢真书。它们不会像显示器那样让我的眼睛很快变干。我发现我对 MySQL 并不感兴趣…但你来我的博客不是为了看我的牢骚吧?让我们来看看这本书是否值得你辛苦赚来的钱!
继续复习!
这本书背后有一些相当重要的凭据。作者在 About 上撰写“关于 Python”专栏,评论者涵盖了所有作者、MySQL for Python 背后的主要程序员以及 Sun/Oracle 的 MySQL 支持团队成员。这本书的写作(正如所料)相当不错。我承认我觉得它有点干。然而,我还没有读过一本激动人心的数据库书籍。
无论如何,这本书的第一章是关于在你的机器上设置 MySQL 和 MySQL for Python 的。你可以从各个项目的网站上获得这些信息。第二章和第三章介绍了基本的 SQL 语法,到处都有一些 Python 例子。这让我有点困惑,因为我以为这本书是给那些已经了解 SQL,并且正在学习如何使用 Python 编程语言与 MySQL 接口的人看的。这些章节没有什么特别的问题,但是我希望更多的 Python,而不是 SQL。你的品味可能会不同。
我读的最后一章是第四章,是关于异常处理的。作者花了很多时间讨论警告和异常之间的区别,以及应该如何处理它们。本文还介绍了 MySQL for Python 包可以捕获的各种自定义错误。
我读了第五章的一半。它涵盖了如何使用 fetchone()和 fetchmany()方法以及循环和迭代器来逐个记录地检索结果。在这一章的最后我没有讲到电影数据库项目。
我还没有读到的章节涵盖了以下主题:插入多个条目、创建和删除(我猜是表);创建用户和授予访问权限(我认为是权限或安全性);日期和时间值、聚合函数和子句;选择替代品;字符串函数;显示 MySQL 元数据;最后,灾难恢复。
判决结果?
据我所知,我认为这本书很好地涵盖了这些主题。虽然我发现有很多内容需要复习(因此有点无聊),但我认为作为一个学习 SQL 和 Python 程序员新手,这本书会对我很有帮助。不过,我现在倾向于使用 SqlAlchemy 来处理我所有的数据库工作。尽管如此,如果你需要了解这个主题或者想学习如何用 Python 连接 MySQL 而不使用 SqlAlchemy 这样的 ORM,那么这本书就是为你准备的!否则,尝试在亚马逊网站或书店预览,以确保它符合您的需求。
2014 年 PyCon 小姐?看回放!
原文:https://www.blog.pythonlibrary.org/2014/04/14/miss-pycon-2014-watch-the-replay/
如果你和我一样,你错过了今年的 PyCon 北美 2014。这事发生在上周末。虽然主要会议已经结束,但代码冲刺仍在进行。无论如何,对于那些错过 PyCon 的人,他们已经在 pyvideo 上发布了一堆视频!每年,他们似乎都比上一年更快地发布视频。我自己也觉得这很棒。我期待着看一些这样的视频,这样我就可以看到我错过了什么。
PyPI 上发现更多域名抢注恶意软件
原文:https://www.blog.pythonlibrary.org/2018/10/31/more-typo-squatting-malware-found-on-pypi/
最近在针对 Windows 用户的 Python 打包索引上发现了恶意软件。该软件包被称为 colourama ,如果它被安装,最终会在你的电脑上安装恶意软件。基本上是希望你会拼错流行的coloramapackage。
你可以在媒体上阅读关于该恶意软件的更多信息,该媒体将该恶意软件描述为“加密货币剪贴板劫持者”。
实际上,去年当斯洛伐克国家安全局在 Python 打包索引中发现了几个恶意库时,我也写过这个问题。
本周,我注意到 Python 软件基金会正在考虑在 2019 年给 PyPI 增加安全性,他们在他们的博客上宣布了这一消息,尽管现在似乎还没有说会增加什么样的安全性。
关于 Python 的更多 Windows 系统信息
原文:https://www.blog.pythonlibrary.org/2010/02/06/more-windows-system-information-with-python/
上个月我写了一篇关于获取 Windows 系统信息的文章,我在我的一条评论中提到有另一个脚本可以做这些事情,但是我找不到它。嗯,今天我去挖掘了一下,找到了我想要的剧本。因此,我们要回到兔子洞去寻找更多的技巧和窍门,以便使用 Python 获得关于 Windows 奇妙世界的信息。
以下脚本摘自我在职时使用和维护的登录脚本。我们通常需要几种方法来识别特定用户的机器。幸运的是,大多数工作站都有几个唯一的标识符,比如 IP、MAC 地址和工作站名称(尽管这些都不一定是唯一的…例如,我们实际上有一个工作站,它的网卡与我们的一台服务器的 MAC 相同。不管怎样,让我们来看看代码吧!
如何获得您工作站的名称
在本节中,我们将使用平台模块来获取我们计算机的名称。在我之前的文章中,我们实际上提到了这个技巧,但是因为我们在下一个片段中需要这个信息,所以我将在这里重复这个技巧:
from platform import node
computer_name = node()
一点也不痛苦,对吧?只有两行代码,我们得到了我们需要的。但是实际上至少还有一种方法可以得到它:
import socket
computer_name = socket.gethostname()
这个片段也非常简单,尽管第一个片段稍微短一些。我们所要做的就是导入内置的 socket 模块,并调用它的 gethostname 方法。现在我们已经准备好获取我们电脑的 IP 地址了。
如何用 Python 获取你的 PC 的 IP 地址
我们可以使用上面收集的信息来获取我们电脑的 IP 地址:
import socket
ip_address = socket.gethostbyname(computer_name)
# or we could do this:
ip_address2 = socket.gethostbyname(socket.gethostname())
在这个例子中,我们再次使用了 socket 模块,但是这次我们使用了它的 gethostbyname 方法并传入了 PC 的名称。然后插座模块将返回 IP 地址。
也可以用蒂姆·戈登的T2 的【WMI】模块。下面的例子来自他精彩的 WMI 烹饪书:
import wmi
c = wmi.WMI ()
for interface in c.Win32_NetworkAdapterConfiguration (IPEnabled=1):
print interface.Description
for ip_address in interface.IPAddress:
print ip_address
print
它所做的只是遍历已安装的网络适配器,并打印出它们各自的描述和 IP 地址。
如何用 Python 获取 MAC 地址
现在我们可以将注意力转向获取 MAC 地址。我们将研究两种不同的方法来获得它,从 ActiveState 方法开始:
def get_macaddress(host='localhost'):
""" Returns the MAC address of a network host, requires >= WIN2K. """
# http://aspn.activestate.com/ASPN/Cookbook/Python/Recipe/347812
import ctypes
import socket
import struct
# Check for api availability
try:
SendARP = ctypes.windll.Iphlpapi.SendARP
except:
raise NotImplementedError('Usage only on Windows 2000 and above')
# Doesn't work with loopbacks, but let's try and help.
if host == '127.0.0.1' or host.lower() == 'localhost':
host = socket.gethostname()
# gethostbyname blocks, so use it wisely.
try:
inetaddr = ctypes.windll.wsock32.inet_addr(host)
if inetaddr in (0, -1):
raise Exception
except:
hostip = socket.gethostbyname(host)
inetaddr = ctypes.windll.wsock32.inet_addr(hostip)
buffer = ctypes.c_buffer(6)
addlen = ctypes.c_ulong(ctypes.sizeof(buffer))
if SendARP(inetaddr, 0, ctypes.byref(buffer), ctypes.byref(addlen)) != 0:
raise WindowsError('Retreival of mac address(%s) - failed' % host)
# Convert binary data into a string.
macaddr = ''
for intval in struct.unpack('BBBBBB', buffer):
if intval > 15:
replacestr = '0x'
else:
replacestr = 'x'
if macaddr != '':
macaddr = ':'.join([macaddr, hex(intval).replace(replacestr, '')])
else:
macaddr = ''.join([macaddr, hex(intval).replace(replacestr, '')])
return macaddr.upper()
由于上面的代码不是我写的,所以就不深入了。然而,我的理解是,这个脚本首先检查它是否可以执行 ARP 请求,这仅在 Windows 2000 和更高版本上可用。一旦得到确认,它就会尝试使用 ctypes 模块来获取 inet 地址。完成之后,它会通过一些我不太理解的东西来建立 MAC 地址。
当我第一次开始维护这段代码时,我认为一定有更好的方法来获取 MAC 地址。我想也许 Tim Golden 的 WMI 模块或者 PyWin32 包会是答案。我很确定他给了我下面的片段,或者我是在 Python 邮件列表档案中找到的:
def getMAC_wmi():
"""uses wmi interface to find MAC address"""
interfaces = []
import wmi
c = wmi.WMI ()
for interface in c.Win32_NetworkAdapterConfiguration (IPEnabled=1):
if interface.DNSDomain == 'www.myDomain.com':
return interface.MACAddress
不幸的是,虽然这种方法有效,但它明显降低了登录脚本的速度,所以我最终还是使用了原来的方法。我想 Golden 先生已经发布了一个较新版本的 wmi 模块,所以现在可能更快了。
如何获得用户名
用 Python 获取当前用户的登录名很简单。你所需要的就是 PyWin32 包。
from win32api import GetUserName
userid = GetUserName()
一次快速导入,我们就有了两行代码的用户名。
如何找到用户所在的组
我们可以使用上面获得的 userid 来找出它属于哪个组。
import os
from win32api import GetUserName
from win32com.client import GetObject
def _GetGroups(user):
"""Returns a list of the groups that 'user' belongs to."""
groups = []
for group in user.Groups ():
groups.append (group.Name)
return groups
userid = GetUserName()
pdcName = os.getenv('dcName', 'primaryDomainController')
try:
user = GetObject("WinNT://%s/%s,user" % (pdcName, userid))
fullName = user.FullName
myGroups = _GetGroups(user)
except Exception, e:
try:
from win32net import NetUserGetGroups,NetUserGetInfo
myGroups = []
groups = NetUserGetGroups(pdcName,userid)
userInfo = NetUserGetInfo(pdcName,userid,2)
fullName = userInfo['full_name']
for g in groups:
myGroups.append(g[0])
except Exception, e:
fullname = "Unknown"
myGroups = []
这比我们之前看到的任何一个脚本都要吓人,但实际上非常容易理解。首先,我们导入我们需要的模块或方法。接下来我们有一个简单的函数,它将一个用户对象作为唯一的参数。该函数将遍历该用户的组,并将它们添加到一个列表中,然后返回给调用者。难题的下一部分是获得主域控制器,我们使用 os 模块来完成。
我们将 pdcName 和 userid 传递给 GetObject(它是 win32com 模块的一部分)来获取我们的用户对象。如果工作正常,那么我们可以获得用户的全名和组。如果它失败了,那么我们捕获错误,并尝试从 win32net 模块中获取一些函数信息。如果这也失败了,那么我们就设置一些默认值。
包扎
希望你已经学到了一些有价值的技巧,可以用在你自己的代码中。我已经在 Python 2.4+中使用这些脚本好几年了,它们工作得非常好!
CodeEval.com 最流行的语言是什么?Python!
原文:https://www.blog.pythonlibrary.org/2014/02/05/most-popular-language-on-codeeval-com-python/
2013 年最流行的语言是什么?按照CodeEval.com的说法,是 Python!如果你把它和 TIOBE 比较,Python 只排在第 8 位,但至少它还在前十!希望 Python 在 2014 年继续壮大,并在许多新的地方得到应用。
您可能还会发现最新的 PYPL 编程语言流行指数也很有帮助,Python 将第三名列为教程中搜索最多的编程语言。
鼠标 vs Python 有松弛通道
原文:https://www.blog.pythonlibrary.org/2021/06/25/mouse-vs-python-has-a-slack-channel/
这个网站现在有一个松弛频道。加入是免费的。不需要订阅!
如果您想加入,请使用以下链接,该链接在未来 30 天内有效:
https://join . slack . com/t/mousevspython/shared _ invite/ZT-s 4 r 3 rwt 2-ookhegzp 1 cqoxebwioecaa
您可以与该网站的作者 Mike Driscoll 以及该网站的其他读者聊天。Mouse vs Python 致力于提供关于 Python 编程语言的优秀教程。只要你尊重别人,欢迎你加入 Slack!
我希望在那里见到你!
鼠标 Vs Python 成为 Python 开发者的 11 个必读博客
Code Condo 最近将这个博客 Mouse Vs Python 命名为“Python 开发者必读的 11 个博客”之一。这篇文章值得一读,因为它列出了许多其他非常好的网站,如 pydanny 和 Doug Hellman 的网站。当我学习 Python 的时候,我真的很喜欢 Effbot,但是我不认为 Lundh 先生会继续更新它,所以我不确定我对它的感觉。无论如何,如果你需要一些关于其他 Python 博客的想法,一定要看看这篇文章。
Mozilla 在浏览器中宣布 Pyodide - Python
原文:https://www.blog.pythonlibrary.org/2019/04/18/mozilla-announces-pyodide-python-in-the-browser/
本周早些时候,Mozilla 宣布了一个名为的新项目。Pyodide 的目标是将 Python 的科学堆栈引入浏览器。
Pyodide 项目将为您提供一个完整的、标准的 Python 解释器,它可以在您的浏览器中运行,还可以让您访问浏览器的 Web APIs。目前,Pyodide 不支持线程或网络套接字。Python 在浏览器中运行的速度也相当慢,尽管它可用于交互式探索。
文章还提到了其他项目,比如布莱森和斯库尔普特。这些项目是用 Javascript 重写 Python 的解释器。与 Pyodide 相比,它们的缺点是不能使用用 C 编写的 Python 扩展,比如 Numpy 或 Pandas。Pyodide 克服了这个问题。
无论如何,这听起来是一个非常有趣的项目。我一直认为我以前在浏览器中看到的 Python 在 Silverlight 中运行的演示很酷。这个项目现在基本上已经死了,但是 Pyodide 听起来是一个非常有趣的让 Python 进入浏览器的新技术。希望它会去某个地方。
我的 Python 职业生涯。init 面试
我最近在播客上接受了托拜厄斯·小萌( @TobiasMacey )的采访。_ _ init _ _(@ Podcast _ _ init _ _)关于我在 Python 程序员生涯中做过的一些事情。
您可以在这里收听:
如果你今年早些时候错过了,我也参加了 Talk Python to Me 播客谈论 Python 的历史,以及其他话题。
我的上下文管理器文章变成了截屏
上个月,我写了一篇关于上下文管理器的文章,一家名为 Webucator 的公司请求我允许将这篇文章改编成视频。最后看起来还不错。请查看以下内容:
https://www.youtube.com/embed/HTDtmk__weM?feature=oembed
Webucator 也有其他 Python 相关的培训。我不太了解他们,但如果这个视频是任何迹象,我认为他们值得一试。
我用 wxPython 书创建 GUI 应用程序的封面故事
我认为为我的新书《用 wxPython 创建 GUI 应用程序》写一点封面设计会很有趣。我本打算在实际的 Kickstarter 活动中发布这个消息。
我最初的封面想法是让老鼠指挥一只凤凰去攻击一条蛇。Phoenix 是 wxPython 4 发布前的代码名,您仍然可以在 wxPython 项目的文档和一些页面上看到对 Phoenix 的引用。
事实上,是我委托做的封面。这是它的草图:

原创封面概念艺术
正如你所看到的,艺术家很难记住这条蛇应该是一条蟒蛇。他继续在成品中犯懒惰的错误,我最终取消了那个封面。我不确定我是否会在未来的书中使用这个封面。我个人很喜欢老鼠和凤凰的样子,但是蟒蛇会一直困扰我。
所以我最终再次雇佣了 Varya Kolesnikova 来做这本书的封面。她是为我创作 Python 201 封面艺术的艺术家。你可以在 Behance 或 Instagram 上查看更多她的艺术作品。
这是她对我的新概念的原始草图,我的新概念是让老鼠骑着凤凰,背着蟒蛇:

实际封面概念艺术素描
我更喜欢她的方法,尽管她对凤凰的想法与我最初的想象大相径庭。
这是概念艺术的彩色版本:

色彩概念艺术素描
我喜欢 Varya 的艺术方法,她最终完成了你今天所知道的艺术品:

最终封面艺术
我正在努力完成这本书的最后几章。如果你有兴趣提前得到这本书,你可以现在就在 Leanpub 上预订。该书的最终版本将于 2019 年 5 月在发布。
我的第一次面试
原文:https://www.blog.pythonlibrary.org/2014/06/26/my-first-interview/
上周,DZone 联系我,问我是否愿意出现在他们的“本周发展”系列中。换句话说,他们想对我做一个简短的采访。采访是昨天开始的。如果你喜欢,你可以在这里阅读:
我不知道为什么链接在他们的 java 子域上,但不用说,我几乎所有的回答都谈到了 Python。如果与 Python 无关,我不会在我的博客上发布我的采访链接。不管怎样,如果你想多了解我一点,我想你可能会感兴趣。
我的第一个补丁被接受了!
原文:https://www.blog.pythonlibrary.org/2012/05/23/my-first-patch-was-accepted/
今天我有点兴奋,因为我的第一个补丁(甚至是第一张票!)已被接受。而且真的也没花多长时间。在我提交了第一个补丁后不到 24 小时,我的贡献就被添加了。虽然我的第一个版本不太好,但我不得不提交更多的版本。我想对 Brian Curtin 和 Eli Bendersky 表示感谢,他们帮助我解决了所有这些问题,并使我首次涉足核心 Python 开发取得了成功。就我个人而言,我认为即使这个补丁没有被接受,这也是一个成功,因为我在这个过程中仍然学到了很多东西。
从这次经历中学到的东西:
- 尽量不要跑题!实际上,我在 devguide 中修复的段落中发现了第二个问题,这可能应该放在一个单独的错误报告中。
- 给你的补丁编号!我不知道为什么我没有想到这一点,但伊莱告诉我,我应该在未来这样做,以减少提交者的困惑。那是一个巴掌大的瞬间。
我一直在阅读一些所谓的“简单错误”,并试图找出我还能在哪些方面提供帮助。我已经在 Python 本身包含的文档中发现了另一个错别字,我可能会尝试修复它。当然,我想实际上为代码做贡献,而不仅仅是文档,但是我可能更有可能找到我可以帮助解决的文档错误。希望有了更多的经验,我能更有效地做出贡献。祝黑我的蟒蛇伙伴们愉快!
网飞发布 Polynote -一种多语种 Jupyter 笔记本变体
网飞宣布他们将发布一款新的开源软件,他们称之为 Polynote 。Polynote 是一个受 IDE 启发的多语言笔记本,包括一流的 Scala 支持、Python 和 SQL。从网站上看,它似乎是建立在 Jupyter 笔记本之上的。
他们该项目的最高目标是再现性和可见性。您可以在媒体上阅读带有示例的完整公告。
这看起来是一个有趣的项目,我很好奇它如何影响 Jupyter 项目。我个人希望网飞的工作能够对 Python 社区有所帮助,或许还能增强 Jupyter Notebook 和 JupyterLab。
我喜欢它,这款笔记本允许每个电池运行不同的语言。你可以用 Jupyter Notebook 来做,但是这样做有点笨拙,而且不像使用 Polynote 正在使用的下拉控件那样用户友好。
有趣的是,Polynote 将其配置和依赖关系存储在笔记本的代码中。
Polynote 还使用 [Vega](http://reproducibility and visibility) 和 Matplotlib 支持健壮的数据可视化。
点击查看 Polynote 。
新的有效的书籍创作课程由马特哈里森
马特·哈里森(Matt Harrison)邀请我参加他的最新课程有效的书籍创作。这门课程将帮助你学习如何写一本技术书籍。马特采访了我,问我是如何写书的。(注:实际上我去年在我的文章中提到过这个问题)。
这门课最有趣的一点是马特教你如何写书。他还采访了像我这样的独立出版商以及有出版公司支持的知名作者。这样你就可以从出版游戏的两个方面来看待它。
我很高兴能花些时间亲自完成这个课程,看看我如何能提高自己的写作水平。Matt 给了我一个六折优惠码,你可以限时使用: MD40 。
如果你自己有兴趣成为一名作者,就去看看吧!
Python 中的新特性:格式化字符串文字
原文:https://www.blog.pythonlibrary.org/2017/02/08/new-in-python-formatted-string-literals/
Python 3.6 增加了另一种进行字符串替换的方法,他们称之为“格式化字符串文字”。你可以在 PEP 498 中读到关于这个概念的所有内容。这里我有点不高兴,因为 Python 的禅宗说应该有一种——最好只有一种——显而易见的方法来做这件事。现在 Python 有三种方式。在谈论最新的弦乐演奏方式之前,让我们回顾一下过去。
旧字符串替换
Python 刚开始的时候,他们按照 C++的方式使用 %s、%i 等进行字符串替换。这里有几个例子:
>>> The %s fox jumps the %s' % ('quick', 'crevice')
'The quick fox jumps the crevice'
>>> foo = 'The total of your purchase is %.2f' % 10
>>> foo
'The total of your purchase is 10.00'
上面的第二个示例演示了如何将一个数字格式化为精度设置为两位小数的浮点数。这种字符串替换方法也支持关键字参数:
>>> 'Hi, my name is %(name)s' % {'name': 'Mike'}
Out[21]: 'Hi, my name is Mike'
语法有点奇怪,我总是要查找它才能正确工作。
虽然这些字符串替换方法仍然受支持,但人们发明了一种新的方法,这种方法应该更清晰、功能更强。让我们看看这是什么样子:
>>> bar = 'You need to pay {}'.format(10.00)
>>> bar
'You need to pay 10.0'
>>> swede = 'The Swedish chef is know for saying {0}, {1}, {2}'.format('bork', 'cork', 'spork')
>>> swede
'The Swedish chef is know for saying bork, cork, spork'
我认为这是一个非常聪明的新添加。不过,还有一个额外的增强,那就是您实际上可以使用关键字参数来指定字符串替换中的内容:
>>> swede = 'The Swedish chef is know for saying {something}, {something}, {something}'
>>> swede.format(something='bork')
'The Swedish chef is know for saying bork, bork, bork'
>>> test = 'This is a {word} of your {something}'.format(word='Test', something='reflexes')
>>> test
'This is a Test of your reflexes'
这很酷,实际上也很有用。你会看到一些程序员会争论哪种方法更好。我看到一些人甚至声称,如果你做大量的字符串替换,原来的方法实际上比新的方法更快。不管怎样,这让你对旧的做事方式有了一个简要的了解。让我们看看有什么新的!
使用格式化字符串文字
从 Python 3.6 开始,我们得到格式化的字符串或 f 字符串。格式化字符串的语法与我们之前看到的稍有不同:
>>> name = 'Mike'
>>> f'My name is {name}'
'My name is Mike'
让我们把它分解一下。我们要做的第一件事是定义一个要插入字符串的变量。接下来我们想告诉 Python 我们想创建一个格式化的字符串文字。为此,我们在字符串前面加上字母“f”。这意味着字符串将被格式化。最后一部分与上一节的最后一个例子非常相似,我们只需要将变量名插入到字符串中,并用一对花括号括起来。然后 Python 变了一些魔术,我们打印出了一个新的字符串。这实际上非常类似于一些 Python 模板语言,比如 mako。
f-string 也支持某些类型的转换,比如 str() via !!s '和 repr() via '!r '这里有一个更新的例子:
>>> f'My name is {name!r}'
Out[11]: "My name is 'Mike'"
您会注意到输出中的变化非常微妙,因为添加的只是插入变量周围的一些单引号。让我们来看看更复杂一点的东西,即浮点数!
>>> import decimal
>>> gas_total = decimal.Decimal('20.345')
>>> width = 10
>>> precision = 4
>>> f'Your gas total is: {gas_total:{width}.{precision}}'
'Your gas total is: 20.34'
这里,我们导入 Python 的十进制模块,并创建一个表示气体总量的实例。然后我们设置字符串的宽度为 10 个字符,精度为 4。最后,我们告诉 f 字符串为我们格式化它。正如您所看到的,插入的文本在前端有一些填充,使其宽度为 10 个字符,精度基本上设置为 4,这截断了 5,而不是向上舍入。
包扎
新的格式化字符串文字或 f-string 并没有给格式化字符串增加任何新的东西。然而声称比以前的方法更灵活,更不容易出错。我强烈推荐阅读文档和 PEP 498 来帮助您了解这个新特性,这样您就可以确定这是否是您将来进行字符串替换的方式。
相关阅读
- Python 3.6 的新特性
- PEP 498 - 文字字符串插值
- Python 中的新特性:变量注释的语法
- Python 中的新特性:数字文字中的下划线
Python 中的新特性:变量注释的语法
原文:https://www.blog.pythonlibrary.org/2017/01/12/new-in-python-syntax-for-variable-annotations/
Python 3.6 增加了另一个有趣的新特性,被称为变量注释的语法。这个新特性在 PEP 526 中有所概述。这个 PEP 的基本前提是将类型提示( PEP 484 )的思想带到它的下一个逻辑步骤,基本上是将选项类型定义添加到 Python 变量中,包括类变量和实例变量。请注意,添加这些注释或定义不会突然使 Python 成为静态类型语言。解释器仍然不关心变量是什么类型。但是,Python IDE 或其他实用程序(如 pylint)可以添加一个注释检查器,当您使用一个已经注释为一种类型的变量,然后通过在函数中间更改其类型而被错误使用时,该检查器会突出显示。
让我们看一个简单的例子,这样我们就可以知道这是如何工作的:
# annotate.py
name: str = 'Mike'
这里我们有一个 Python 文件,我们将其命名为 annotate.py 。在其中,我们创建了一个变量, name ,并对其进行了注释,表明它是一个字符串。这是通过在变量名后添加一个冒号,然后指定它应该是什么类型来实现的。如果你不想的话,你不必给变量赋值。以下内容同样有效:
# annotate.py
name: str
当您注释一个变量时,它将被添加到模块或类的 annotations 属性中。让我们尝试导入注释模块的第一个版本,并访问该属性:
>>> import annotate
>>> annotate.__annotations__
{'name': }
>>> annotate.name
'Mike'
如您所见, annotations 属性返回一个 Python dict,其中变量名作为键,类型作为值。让我们给我们的模块添加一些其他的注释,看看 annotations 属性是如何更新的。
# annotate2.py
name: str = 'Mike'
ages: list = [12, 20, 32]
class Car:
variable: dict
在这段代码中,我们添加了一个带注释的列表变量和一个带注释的类变量的类。现在让我们导入新版本的 annotate 模块,并检查它的 annotations 属性:
>>> import annotate
>>> annotate.__annotations__
{'name': , 'ages': <class>}
>>> annotate.Car.__annotations__
{'variable': <class>}
>>> car = annotate.Car()
>>> car.__annotations__
{'variable': <class>}
这一次,我们看到注释字典包含两个条目。您会注意到模块级别的 annotations 属性不包含带注释的类变量。要访问它,我们需要直接访问 Car 类,或者创建一个 Car 实例,并以这种方式访问属性。
正如我的一个读者指出的,你可以通过使用类型模块使这个例子更符合 PEP 484。看一下下面的例子:
# annotate3.py
from typing import Dict, List
name: str = 'Mike'
ages: List[int] = [12, 20, 32]
class Car:
variable: Dict
让我们在解释器中运行这段代码,看看输出是如何变化的:
import annotate
In [2]: annotate.__annotations__
Out[2]: {'ages': typing.List[int], 'name': str}
In [3]: annotate.Car.__annotations__
Out[3]: {'variable': typing.Dict}
您会注意到,现在大多数类型都来自于类型模块。
包扎
我发现这个新功能非常有趣。虽然我喜欢 Python 的动态特性,但在过去几年使用 C++后,我也看到了知道变量应该是什么类型的价值。当然,由于 Python 出色的内省支持,弄清楚一个对象的类型是微不足道的。但是这个新特性可以让静态检查器更好,也可以让你的代码更明显,特别是当你不得不回去更新一个几个月或几年都没用过的软件的时候。
附加阅读
Python 中的新特性:数字文本中的下划线
原文:https://www.blog.pythonlibrary.org/2017/01/11/new-in-python-underscores-in-numeric-literals/
Python 3.6 增加了一些有趣的新特性。我们将在本文中看到的一个来自于 PEP 515:数字文字中的下划线。正如 PEP 的名字所暗示的那样,这基本上给了你在逗号通常所在的地方写长数字加下划线的能力。换句话说, 1000000 现在可以写成 1_000_000 。让我们来看一些简单的例子:
>>> 1_234_567
1234567
>>>'{:_}'.format(123456789)
'123_456_789'
>>> '{:_}'.format(1234567)
'1_234_567'
第一个例子展示了 Python 如何解释包含下划线的大数。第二个例子演示了我们现在可以给 Python 一个字符串格式化程序,即“_”(下划线),来代替逗号。结果不言自明。
计算时,包含下划线的数字文字的行为与普通数字文字相同:
>>> 120_000 + 30_000
150000
>>> 120_000 - 30_000
90000
Python 文档和 PEP 还提到可以在任何基本说明符后使用下划线。以下是摘自 PEP 和文档的几个示例:
>>> flags = 0b_0011_1111_0100_1110
>>> flags
16206
>>> 0x_FF_FF_FF_FF
4294967295
>>> flags = int('0b_1111_0000', 2)
>>> flags
240
有一些关于下划线的注意事项需要提及:
- 您只能使用一个连续的下划线,并且必须在数字之间和任何基本说明符之后
- 不允许使用前导下划线和尾随下划线
这是 Python 中一个有趣的新特性。虽然我个人在我目前的工作中没有这方面的任何用例,但希望你在自己的工作中会有一个。
发现针对 Linux 的新恶意 Python 库
原文:https://www.blog.pythonlibrary.org/2019/07/18/new-malicious-python-libraries-found-targeting-linux/
ZDNet 最近发表了一篇文章关于 Python 包索引(PyPI)上新发现的一组恶意软件相关的 Python 包。这些软件包包含一个后门,只有安装在 Linux 上才会激活。
这些软件包被命名为:
- libpeshnx
- libmesh
- 天秤座
它们是由一个名叫 ruri12 的用户编写的。PyPI 团队在 2019 年 7 月 9 日移除了这些包。然而,它们自 2017 年 11 月以来一直可用,并被定期下载。
详见原文。
像往常一样,当使用一个你不熟悉的软件包时,一定要自己做彻底的检查,以确保你不是无意中安装了恶意软件。
相关阅读
- ZDNet - 从 PyPI 中删除了针对 Linux 服务器的恶意 Python 库
- PyPI 上发现更多域名抢注恶意软件
- 在 Python 包索引(PyPI) 上发现恶意库
一个新的 Python Kickstarter 项目:高级 Web 开发,以 Django 1.6 为特色
昨晚,我收到了一封关于一个新的 Python 相关的 Kickstarter 的邮件。真正的 Python 团队增加了一个新的作者来写一本完全关于 Django 1.6 的书。这是一个我一直想研究的课题,但一直没有机会。希望通过支持这个项目,我能最终了解 Django。
我对他们之前项目的质量印象深刻,所以我觉得我可以放心地为这些作者背书。我相信这个项目会是高质量的,非常值得你花时间和金钱。另外,支持这些想分享知识的人也很有趣。如果你有兴趣支持这个项目,你可以去以下地址:
注意:他们在这一点上已经得到了充分的资助,并且一些支持级别已经满了,所以如果你想早点加入,现在正是时候!
新年 Python Meme - #2012pythonmeme
原文:https://www.blog.pythonlibrary.org/2011/12/21/new-years-python-meme-2012pythonmeme/
昨天我正在阅读 Python 博客,无意中发现了 Tarek Ziade 的 Python Meme 文章。我觉得这听起来是个有趣的想法,所以以下是我对他的问题的回答。
1。2011 年你发现的最酷的 Python 应用、框架或库是什么?
我想不出今年真正用过的新东西。然而,就在这一年,我开始广泛使用 wxPython 中的 ObjectListView 小部件。这是一个伟大的 wx 包装。这使得它非常容易使用。也是在这一年,我开始着手一个大的涡轮 2 项目,但是我还没有决定这是不是我最喜欢的项目。
2。2011 年你学到了什么新的编程技巧?
最近,我开始让我的代码比过去更有组织性和结构化,将我的组件分成不同的模块,进行更多的重构,尝试更多地遵循模型-视图-控制器模式,等等。今年我也开始更多地使用 Mercurial 源码控制和 BitBucket 。我仍然不是使用它们的专家,但是我知道足够的信息来保证我的消息来源的安全。
3。2011 年你贡献最大的开源项目叫什么?你做了什么?
wxPython 。我在我的 wiki 上为它写了很多文档,并在 wxPython 邮件列表和 StackOverflow 上帮助很多人理解它。
4。2011 年你看得最多的 Python 博客或网站是什么?
嗯,这是个难题。我读了很多蒂姆·戈尔登的《T1》,还有一些《T2》中的杰西·诺勒和《T4》中的道格·赫尔曼。我也喜欢大卫·比兹利,但是他写的不多。
5。2012 年你最想学的三件事是什么?
我需要更好地处理 Mercurial 分支和合并。学习更多的 TurboGears 和另一个 Python web 框架。测试(我知道一些,但还不够,尤其是与 GUI 相关的)。
6。你希望有人在 2012 年编写的顶级软件、应用或库是什么?
我希望有更好的易贝包装纸。我想写我自己的狙击手剧本。另一个不错的例子是某种一体化脚本,它可以为我的博客文章创建我的 bit.ly 链接,然后提交给各种主要的技术网站。
想自己列清单吗?方法如下:
- 将问题和答案复制粘贴到您的博客中
- 用标签# 2012 pythonme发推文
2011 年 10 月 Pyowa 总结
原文:https://www.blog.pythonlibrary.org/2011/10/07/october-2011-pyowa-wrap-up/
昨晚(2011 年 10 月 7 日)我们在美国路易斯安那州西得梅因的 IMT 集团大楼举行了十月派欧瓦会议。他们的一个程序员做了一个关于 python 开放文档 (pod)库的演讲,该库包含在 Appy 框架中。演讲的要点是,你可以使用 LibreOffice 或 OpenOffice 的“跟踪修改”功能或“字段”功能创建模板文件,然后使用 Appy 的 pod 合并你的数据,就像微软 Word 中的邮件合并一样。他继续展示更高级的东西,比如使用 LibreOffice 的评论功能创建循环来制作表格或插入图片。
演示结束后,提到了托管您自己的本地 PyPI,并讨论了 Git 与 Mercurial 的优缺点。也有一些关于 Pyowa 与当地 Ruby 集团合并的讨论。我们还讨论了召开一次会议,在会上我们可能会讨论 Mercurial、Git 和其他未来的源代码管理系统。还要注意,在这次会议上有免费的比萨饼和汽水。我们希望你能参加我们的下一次会议。
Jupyter 笔记本 101 只剩 2 天了
原文:https://www.blog.pythonlibrary.org/2018/08/13/only-2-days-left-for-jupyter-notebook-101/
还有两天就要加入我的新书的 Kickstarter 了,Jupyter Notebook 101 。这也是你帮助塑造这本书的最佳时机之一。我在写书时总是会考虑读者的反馈,并根据他们的要求在书中添加了很多额外的信息。

OpenPyXL -使用 Python 处理 Microsoft Excel
原文:https://www.blog.pythonlibrary.org/2020/11/03/openpyxl-working-with-microsoft-excel-using-python/
商业世界使用微软 Office 。他们的电子表格软件解决方案微软 Excel 尤其受欢迎。Excel 用于存储表格数据、创建报告、绘制趋势图等等。在开始使用 Excel 和 Python 之前,让我们澄清一些特殊术语:
- 电子表格或工作簿-文件本身(。xls 或者。xlsx)。
- 工作表-工作簿中的一张内容表。电子表格可以包含多个工作表。
- 列-以字母标记的垂直数据行,以“A”开头。
- Row -用数字标记的水平数据行,从 1 开始。
- 单元格-列和行的组合,如“A1”。
在本文中,您将使用 Python 处理 Excel 电子表格。您将了解以下内容:
- Python Excel 包
- 从工作簿中获取工作表
- 读取单元格数据
- 遍历行和列
- 编写 Excel 电子表格
- 添加和移除工作表
- 添加和删除行和列
Excel 被大多数公司和大学使用。它可以以多种不同的方式使用,并使用 Visual Basic for Applications (VBA)进行增强。然而,VBA 有点笨拙——这就是为什么学习如何在 Python 中使用 Excel 是件好事。
现在让我们来看看如何使用 Python 编程语言处理 Microsoft Excel 电子表格!
Python Excel 包
您可以使用 Python 创建、读取和编写 Excel 电子表格。但是,Python 的标准库不支持使用 Excel 为此,您需要安装第三方软件包。最受欢迎的是 OpenPyXL 。您可以在此处阅读其文档:
OpenPyXL 不是你唯一的选择。还有其他几个支持 Microsoft Excel 的软件包:
- xlrd -用于读取旧的 Excel(。xls)文档
- xlwt -用于编写较老的 Excel(。xls)文档
- xlwings -可处理新的 Excel 格式,并具有宏功能
几年前,前两个库曾经是最流行的 Excel 文档库。然而,这些软件包的作者已经停止支持它们。xlwings 包很有前途,但是不能在所有平台上工作,并且需要安装 Microsoft Excel。
您将在本文中使用 OpenPyXL,因为它正在被积极开发和支持。OpenPyXL 不需要安装 Microsoft Excel,在所有平台上都可以使用。
您可以使用pip安装 OpenPyXL:
$ python -m pip install openpyxl
安装完成后,让我们看看如何使用 OpenPyXL 来读取 Excel 电子表格!
从工作簿中获取工作表
第一步是找到一个与 OpenPyXL 一起使用的 Excel 文件。这本书的 Github 资源库中有一个为您提供的books.xlsx文件。您可以通过以下网址下载:
请随意使用您自己的文件,尽管您自己的文件的输出不会与本书中的示例输出相匹配。
下一步是编写一些代码来打开电子表格。为此,创建一个名为open_workbook.py的新文件,并向其中添加以下代码:
# open_workbook.py
from openpyxl import load_workbook
def open_workbook(path):
workbook = load_workbook(filename=path)
print(f'Worksheet names: {workbook.sheetnames}')
sheet = workbook.active
print(sheet)
print(f'The title of the Worksheet is: {sheet.title}')
if __name__ == '__main__':
open_workbook('books.xlsx')
在这个例子中,您从openpyxl导入load_workbook(),然后创建open_workbook(),它接受 Excel 电子表格的路径。接下来,使用load_workbook()创建一个openpyxl.workbook.workbook.Workbook对象。该对象允许您访问电子表格中的工作表和单元格。是的,它的名字中确实有两个workbook。那不是错别字!
函数的其余部分演示了如何打印电子表格中所有当前定义的工作表,获取当前活动的工作表并打印出该工作表的标题。
当您运行此代码时,您将看到以下输出:
Worksheet names: ['Sheet 1 - Books']
<Worksheet "Sheet 1 - Books">
The title of the Worksheet is: Sheet 1 - Books
现在您已经知道了如何访问电子表格中的工作表,您已经准备好继续访问单元格数据了!
读取单元格数据
使用 Microsoft Excel 时,数据存储在单元格中。您需要一种从 Python 访问这些单元格的方法,以便能够提取这些数据。OpenPyXL 让这个过程变得简单明了。
创建一个名为workbook_cells.py的新文件,并将以下代码添加到其中:
# workbook_cells.py
from openpyxl import load_workbook
def get_cell_info(path):
workbook = load_workbook(filename=path)
sheet = workbook.active
print(sheet)
print(f'The title of the Worksheet is: {sheet.title}')
print(f'The value of {sheet["A2"].value=}')
print(f'The value of {sheet["A3"].value=}')
cell = sheet['B3']
print(f'{cell.value=}')
if __name__ == '__main__':
get_cell_info('books.xlsx')
这段代码将在 OpenPyXL 工作簿中加载 Excel 文件。您将获取活动工作表,然后打印出它的title和几个不同的单元格值。您可以通过使用 sheet 对象后跟方括号(其中包含列名和行号)来访问单元格。例如,sheet["A2"]将获取“A”列第 2 行的单元格。要获得该单元格的值,可以使用value属性。
**注意:**这段代码使用了 Python 3.8 中添加到 f 字符串的新特性。如果您使用早期版本运行此程序,将会收到一个错误。
当您运行这段代码时,您将得到以下输出:
<Worksheet "Sheet 1 - Books">
The title of the Worksheet is: Sheet 1 - Books
The value of sheet["A2"].value='Title'
The value of sheet["A3"].value='Python 101'
cell.value='Mike Driscoll'
您可以使用单元格的一些其他属性来获取有关单元格的附加信息。将以下函数添加到文件中,并更新末尾的条件语句以运行它:
def get_info_by_coord(path):
workbook = load_workbook(filename=path)
sheet = workbook.active
cell = sheet['A2']
print(f'Row {cell.row}, Col {cell.column} = {cell.value}')
print(f'{cell.value=} is at {cell.coordinate=}')
if __name__ == '__main__':
get_info_by_coord('books.xlsx')
在这个例子中,您使用cell对象的row和column属性来获取行和列信息。注意,列“A”映射到“1”,“B”映射到“2”,等等。如果要迭代 Excel 文档,可以使用coordinate属性获取单元格名称。
当您运行此代码时,输出将如下所示:
Row 2, Col 1 = Title
cell.value='Title' is at cell.coordinate='A2'
说到迭代,让我们看看下一步怎么做!
遍历行和列
有时,您需要迭代整个 Excel 电子表格或部分电子表格。OpenPyXL 允许您以几种不同的方式做到这一点。创建一个名为iterating_over_cells.py的新文件,并向其中添加以下代码:
# iterating_over_cells.py
from openpyxl import load_workbook
def iterating_range(path):
workbook = load_workbook(filename=path)
sheet = workbook.active
for cell in sheet['A']:
print(cell)
if __name__ == '__main__':
iterating_range('books.xlsx')
在这里,您加载电子表格,然后循环遍历“A”列中的所有单元格。对于每个单元格,打印出cell对象。如果您想更精细地格式化输出,可以使用在上一节中学习的一些单元格属性。
运行这段代码的结果如下:
<Cell 'Sheet 1 - Books'.A1>
<Cell 'Sheet 1 - Books'.A2>
<Cell 'Sheet 1 - Books'.A3>
<Cell 'Sheet 1 - Books'.A4>
<Cell 'Sheet 1 - Books'.A5>
<Cell 'Sheet 1 - Books'.A6>
<Cell 'Sheet 1 - Books'.A7>
<Cell 'Sheet 1 - Books'.A8>
<Cell 'Sheet 1 - Books'.A9>
<Cell 'Sheet 1 - Books'.A10>
# output truncated for brevity
默认情况下,输出会被截断,因为它会打印出相当多的单元格。OpenPyXL 通过使用iter_rows()和iter_cols()函数提供了其他方法来迭代行和列。这些方法接受几个参数:
min_rowmax_rowmin_colmax_col
您还可以添加一个values_only参数,告诉 OpenPyXL 返回单元格的值,而不是单元格对象的值。继续创建一个名为iterating_over_cell_values.py的新文件,并将以下代码添加到其中:
# iterating_over_cell_values.py
from openpyxl import load_workbook
def iterating_over_values(path):
workbook = load_workbook(filename=path)
sheet = workbook.active
for value in sheet.iter_rows(
min_row=1, max_row=3,
min_col=1, max_col=3,
values_only=True,
):
print(value)
if __name__ == '__main__':
iterating_over_values('books.xlsx')
这段代码演示了如何使用iter_rows()遍历 Excel 电子表格中的行,并打印出这些行的值。当您运行此代码时,您将获得以下输出:
('Books', None, None)
('Title', 'Author', 'Publisher')
('Python 101', 'Mike Driscoll', 'Mouse vs Python')
输出是一个 Python 元组,其中包含每一列中的数据。至此,您已经学会了如何打开电子表格和读取数据——既可以从特定的单元格读取,也可以通过迭代读取。现在您已经准备好学习如何使用 OpenPyXL 来创建 Excel 电子表格了!
编写 Excel 电子表格
使用 OpenPyXL 创建 Excel 电子表格并不需要很多代码。您可以使用Workbook()类创建一个电子表格。继续创建一个名为writing_hello.py的新文件,并将以下代码添加到其中:
# writing_hello.py
from openpyxl import Workbook
def create_workbook(path):
workbook = Workbook()
sheet = workbook.active
sheet['A1'] = 'Hello'
sheet['A2'] = 'from'
sheet['A3'] = 'OpenPyXL'
workbook.save(path)
if __name__ == '__main__':
create_workbook('hello.xlsx')
在这里实例化Workbook()并获得活动表。然后将“A”列的前三行设置为不同的字符串。最后,您调用save()并把保存新文档的path传递给它。恭喜你!您刚刚用 Python 创建了一个 Excel 电子表格。
接下来让我们看看如何在工作簿中添加和删除工作表!
添加和移除工作表
许多人喜欢在工作簿的多个工作表中组织他们的数据。OpenPyXL 支持通过其create_sheet()方法向Workbook()对象添加新工作表的能力。
创建一个名为creating_sheets.py的新文件,并将以下代码添加到其中:
# creating_sheets.py
import openpyxl
def create_worksheets(path):
workbook = openpyxl.Workbook()
print(workbook.sheetnames)
# Add a new worksheet
workbook.create_sheet()
print(workbook.sheetnames)
# Insert a worksheet
workbook.create_sheet(index=1,
title='Second sheet')
print(workbook.sheetnames)
workbook.save(path)
if __name__ == '__main__':
create_worksheets('sheets.xlsx')
这里您使用了两次create_sheet()来向工作簿添加两个新的工作表。第二个示例显示了如何设置工作表的标题以及在哪个索引处插入工作表。参数index=1意味着工作表将被添加到第一个现有工作表之后,因为它们的索引从0开始。
当您运行此代码时,您将看到以下输出:
['Sheet']
['Sheet', 'Sheet1']
['Sheet', 'Second sheet', 'Sheet1']
您可以看到新工作表已逐步添加到工作簿中。保存文件后,您可以通过打开 Excel 或其他与 Excel 兼容的应用程序来验证是否有多个工作表。
在这个自动创建工作表的过程之后,您突然得到了太多的工作表,所以让我们去掉一些。有两种方法可以移除板材。继续创建delete_sheets.py,看看如何使用 Python 的del关键字删除工作表:
# delete_sheets.py
import openpyxl
def create_worksheets(path):
workbook = openpyxl.Workbook()
workbook.create_sheet()
# Insert a worksheet
workbook.create_sheet(index=1,
title='Second sheet')
print(workbook.sheetnames)
del workbook['Second sheet']
print(workbook.sheetnames)
workbook.save(path)
if __name__ == '__main__':
create_worksheets('del_sheets.xlsx')
这段代码将创建一个新工作簿,然后向其中添加两个新工作表。然后它用 Python 的del关键字删除workbook['Second sheet']。您可以通过查看del命令前后的表单列表的打印结果来验证它是否按预期工作:
['Sheet', 'Second sheet', 'Sheet1']
['Sheet', 'Sheet1']
从工作簿中删除工作表的另一种方法是使用remove()方法。创建一个名为remove_sheets.py的新文件,并输入以下代码以了解其工作原理:
# remove_sheets.py
import openpyxl
def remove_worksheets(path):
workbook = openpyxl.Workbook()
sheet1 = workbook.create_sheet()
# Insert a worksheet
workbook.create_sheet(index=1,
title='Second sheet')
print(workbook.sheetnames)
workbook.remove(sheet1)
print(workbook.sheetnames)
workbook.save(path)
if __name__ == '__main__':
remove_worksheets('remove_sheets.xlsx')
这一次,通过将结果赋给sheet1,您保留了对您创建的第一个工作表的引用。然后在代码中删除它。或者,您也可以使用与前面相同的语法删除该工作表,如下所示:
workbook.remove(workbook['Sheet1'])
无论您选择哪种方法删除工作表,输出都是一样的:
['Sheet', 'Second sheet', 'Sheet1']
['Sheet', 'Second sheet']
现在让我们继续学习如何添加和删除行和列。
添加和删除行和列
OpenPyXL 有几个有用的方法,可以用来在电子表格中添加和删除行和列。以下是您将在本节中了解的四种方法的列表:
.insert_rows().delete_rows().insert_cols().delete_cols()
这些方法中的每一个都可以接受两个参数:
idx-插入行或列的索引amount-要添加的行数或列数
要了解这是如何工作的,创建一个名为insert_demo.py的文件,并向其中添加以下代码:
# insert_demo.py
from openpyxl import Workbook
def inserting_cols_rows(path):
workbook = Workbook()
sheet = workbook.active
sheet['A1'] = 'Hello'
sheet['A2'] = 'from'
sheet['A3'] = 'OpenPyXL'
# insert a column before A
sheet.insert_cols(idx=1)
# insert 2 rows starting on the second row
sheet.insert_rows(idx=2, amount=2)
workbook.save(path)
if __name__ == '__main__':
inserting_cols_rows('inserting.xlsx')
这里,您创建一个工作表,并在列“A”之前插入一个新列。列的索引从 1 开始,而相比之下,工作表从 0 开始。这实际上将 A 列中的所有单元格移动到 b 列,然后从第 2 行开始插入两个新行。
既然您已经知道了如何插入列和行,那么是时候了解如何删除它们了。
要了解如何删除列或行,创建一个名为delete_demo.py的新文件,并添加以下代码:
# delete_demo.py
from openpyxl import Workbook
def deleting_cols_rows(path):
workbook = Workbook()
sheet = workbook.active
sheet['A1'] = 'Hello'
sheet['B1'] = 'from'
sheet['C1'] = 'OpenPyXL'
sheet['A2'] = 'row 2'
sheet['A3'] = 'row 3'
sheet['A4'] = 'row 4'
# Delete column A
sheet.delete_cols(idx=1)
# delete 2 rows starting on the second row
sheet.delete_rows(idx=2, amount=2)
workbook.save(path)
if __name__ == '__main__':
deleting_cols_rows('deleting.xlsx')
这段代码在几个单元格中创建文本,然后使用delete_cols()删除 A 列。它还通过delete_rows()从第二行开始删除两行。在组织数据时,能够添加和删除列和行非常有用。
包扎
由于 Excel 在许多行业的广泛使用,能够使用 Python 与 Excel 文件进行交互是一项极其有用的技能。在本文中,您了解了以下内容:
- Python Excel 包
- 从工作簿中获取工作表
- 读取单元格数据
- 遍历行和列
- 编写 Excel 电子表格
- 添加和移除工作表
- 添加和删除行和列
OpenPyXL 可以做的甚至比这里介绍的更多。例如,您可以使用 OpenPyXL 向单元格添加公式、更改字体以及对单元格应用其他类型的样式。阅读文档并尝试在您自己的一些电子表格上使用 OpenPyXL,这样您就可以发现它的全部功能。
包装用于分发的 wxPyMail
原文:https://www.blog.pythonlibrary.org/2008/08/27/packaging-wxpymail-for-distribution/
在本文中,我将介绍打包我的程序 wxPyMail 所需的步骤,这样我就可以将它分发给其他 Windows 用户。我将使用 Andrea Gavana 的优秀的 GUI2Exe 实用程序来创建一个可执行文件,我将使用 Inno Setup 来创建一个安装程序。有人告诉我,Andrea 正在开发他的应用程序的新版本,所以当它发布时,我将针对该版本重新编写这篇文章并发布。
设置 GUI2Exe
用 GUI2Exe 创建可执行文件的过程非常简单。GUI2Exe 实际上是 py2exe 的一个 GUI 前端。我强烈推荐用 GUI2Exe 来创建你所有的可执行文件,因为它更容易使用。但是,如果您喜欢命令行,那么您可以单独使用 py2exe。它们甚至在 Samples 目录中包含 wxPython 应用程序的示例。反正下载完 GUI2Exe,安装好,加载程序。您现在应该会看到这样的内容:
现在进入文件 - > 新建项目,给你的项目起个名字。我要给我的起名叫 wxPyMail 。我准备加一个假的公司名,版权,给它一个节目名。一定要浏览您的主要 Python 脚本。这个项目是 wxPyMail.py,根据 Andrea 的网站,你应该把优化设置为 2,压缩设置为 2,捆绑文件设置为 1。这在大多数情况下似乎是可行的,但是我遇到过一些奇怪的错误,这些错误似乎是由于将最后一个设置为“1”而引起的。事实上,根据我在 py2exe 邮件列表上的一个联系人所说,“bundle”选项应该设置为 3,以尽量减少错误。将 bundle 设置为“1”的好处是,你最终只得到一个文件,但是因为我要用 Inno 把它卷起来,所以我要用选项“3”来确保我的程序运行良好。
还要注意,我已经包含了 XP 清单。这使得您的应用程序在 Windows 上看起来很“本地”,因此您的程序应该与当前有效的主题相匹配。
为了确保你能跟上,请看下面的截图:
一旦你得到了你想要的一切,点击右下角的编译按钮。这将在区文件夹中创建您想要分发的所有文件,除非您通过选中区复选框并编辑随后的文本框更改了名称。编译完成后,GUI2Exe 会询问您是否要测试您的可执行文件。继续并点击是。我第一次这样做时遇到了一个错误,当我查看日志时,它说找不到 smtplib 模块。要修复这个特定的错误,我们需要包含它。
要包含此模块,请在标有包含的框内单击,然后按 CTRL+A。您应该会看到一个图标和文字编辑我。只需点击这些单词并输入 smtplib 。现在试着编译它。我得到另一个奇怪的错误:
Traceback (most recent call last):
File "wxPyMail.py", line 20, in
import smtplib
File "smtplib.pyo", line 46, in
ImportError: No module named email.Utils
看起来我需要电子邮件模块。嗯,如果你包括电子邮件模块,那么你需要把它从排除列表中删除。然而,在做了所有这些之后,您仍然会得到一个关于不能导入“multipart”的错误。这花了我一分钟才弄明白,不过看起来邮件模块其实是一个包。因此,我将电子邮件包添加到包列表控件中。像以前一样从 Excludes 列表中删除 email 模块,也从 Includes listctrl 中删除 smtplib 模块,因为它本来就不是问题。要从这些控件中删除项目,您需要右键单击项目并选择“删除所选项目”。现在,您的屏幕应该看起来像这样:

请注意,这是大量的试验和错误。最终,您可以大致猜出哪些模块将被包含,哪些不会。好像 wmi.py 或者 BeautifulSoup 这样的小模块会被 py2exe 抢,但是 lxml 包这样的东西不会。随着练习,这个过程变得越来越容易,所以不要放弃!此外,如果您有问题,py2exe 组和 Andrea 都是很好的资源。
我们来做一个安装程序吧!
现在我们有了一个可执行文件和一堆依赖项,我们如何创建一个安装程序呢?有各种各样的实用程序,但是我将使用 Inno Setup。下载并安装后,运行程序。选择标记为“使用脚本向导创建新脚本文件”的选项。单击下一个的*,您应该会看到类似这样的内容:*
请随意填写,然后单击下一步。此屏幕允许您选择应用程序的默认安装位置。默认为程序文件即可。点击下一个。现在,您应该会看到以下屏幕:
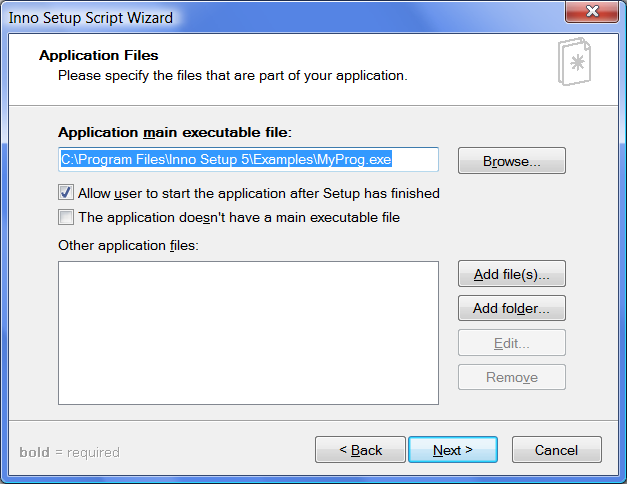
浏览到您创建的可执行文件以添加它。然后点击添加文件…按钮添加其余部分。你可以选择除 exe 文件之外的所有文件,然后点击 OK。然后点击下一个。确保开始菜单文件夹有正确的名称(在这种情况下,wxPyMail)并继续。如果您愿意,您可以忽略接下来的两个屏幕,或者尝试使用它们。不过,我没有使用许可证,也没有将信息文件显示给用户。完成前的最后一个屏幕允许您选择输出到的目录。我只是将它留空,因为它默认为可执行文件所在的位置,这对于本例来说很好。点击下一步和完成。
现在,您将拥有一个成熟的*。iss 文件。请阅读 Inno 的文档,了解您能做些什么,因为这超出了本文的范围。相反,只需点击构建菜单并选择编译。如果您没有收到任何错误消息,那么您已经成功地创建了一个安装程序!恭喜你!
然而,有一点需要注意。似乎有一些关于你是否能合法分发 MSVCR71.dll 文件的问题。有人说这个 dll 的发布需要 Visual Studio 2003 的许可,也有人说 python.org 团队以这样一种方式许可了 VS2003(即 VS7 ), Python 变成了“被许可软件”,而你变成了“发布者”。你可以在这个博客上读到所有血淋淋的细节,其中 Python 名人如 Phillip Eby(因 easy_install 而出名,是它的主要维护者)和 Fredrik Lundh 都参与其中。
我希望这有助于您成为一名优秀的 Python 应用程序开发人员。一如既往,如果您有任何问题或改进建议,请随时给我发电子邮件至 mike (at) pythonlibrary (dot) org。
Packt Publishing 支持 Pyowa
原文:https://www.blog.pythonlibrary.org/2009/04/18/packt-publishing-supports-pyowa/
Pycon 结束后,我联系了 python 组组织者邮件列表上的人,看看如何从出版商那里获得联系方式,希望为爱荷华 python 用户组(又名 Pyowa )会议收集联系方式并获得一些赠品。
我第一次接触是在 Packt Publishing 公司。他们给了我很大的帮助,甚至给了我一本关于姜戈的书让我复习。我希望能在接下来的几周内阅读和评论这本书。他们给了我一本贴在 Pyowa 主页上的书的样本。我也和奥莱利取得了联系,我希望这也能有好的结果。希望我能为未来的 Pyowa 会议带来一些像样的礼物。
下个月,Pyowa group 将接待一位来自 Mythbuntu 项目的核心开发人员,他将讲述他使用 Python 的经历。我们还计划了一个关于 SqlAlchemy 的演示,这是一个非常酷的 Python 对象关系映射器(ORM)。最后,我们将进行一次与 GIS 相关的代码审查。为此,我们将从我认为是 ArcGIS 的地方获取一些自动生成的代码,并尝试对其进行改进。所有这些活动将于 5 月 4 日(星期一)下午 7-9 点在马歇尔郡治安官办公室举行。还将提供小吃和饮料。方向在 Pyowa 网站上。
使用 Python 解析 MP3 中的 ID3 标签
原文:https://www.blog.pythonlibrary.org/2010/04/22/parsing-id3-tags-from-mp3s-using-python/
在开发我的 Python mp3 播放器时,我意识到我需要研究 Python 为解析 ID3 标签提供了什么。有大量的项目,但是大部分看起来不是死了,就是没有文档,或者两者都有。在这篇文章中,你将和我一起探索 Python 中 mp3 标签解析的广阔世界,我们将看看是否能找到一些我可以用来增强我的 MP3 播放器项目的东西。
在本练习中,我们将尝试从解析器中获取以下信息:
- 艺术家
- 相册标题
- 音轨标题
- 轨道长度
- 专辑发行日期
我们可能需要更多的元数据,但这是我在 mp3 播放体验中最关心的东西。我们将查看以下第三方库,看看它们的表现如何:
我们开始吧!
诱变剂能扭转乾坤吗?
在这次围捕中包括诱变剂的原因之一是因为除了 MP3 解析之外,它还支持 ASF,FLAC,M4A,Monkey’s Audio,Musepack,Ogg FLAC,Ogg Speex,Ogg Theora,Ogg Vorbis,True Audio,WavPack 和 OptimFROG。因此,我们可以潜在地扩展我们的 MP3 播放器。当我发现这个包裹时,我非常兴奋。然而,虽然该软件包似乎正在积极开发,但文档几乎不存在。如果你是一个新的 Python 程序员,你会发现这个库很难直接使用。
要安装诱变剂,你需要打开它,并使用命令行导航到它的文件夹。然后执行以下命令:
python setup.py install
你也可以使用 easy_install 或 pip ,尽管他们的网站上并没有具体说明。现在有趣的部分来了:试图弄清楚如何在没有文档的情况下使用这个模块!幸运的是,我找到了一篇的博文,给了我一些线索。从我收集的信息来看,诱变剂非常接近 ID3 规范,所以你实际上是在阅读 ID3 文本框架并使用它们的术语,而不是将其抽象化,这样你就有了类似 GetArtist 的功能。因此,TPE1 =艺术家(或主唱),TIT2 =标题,等等。让我们看一个例子:
>>> path = r'D:\mp3\12 Stones\2002 - 12 Stones\01 - Crash.mp3'
>>> from mutagen.id3 import ID3
>>> audio = ID3(path)
>>> audio
>>> audio['TPE1']
TPE1(encoding=0, text=[u'12 Stones'])
>>> audio['TPE1'].text
[u'12 Stones']
这里有一个更恰当的例子:
from mutagen.id3 import ID3
#----------------------------------------------------------------------
def getMutagenTags(path):
""""""
audio = ID3(path)
print "Artist: %s" % audio['TPE1'].text[0]
print "Track: %s" % audio["TIT2"].text[0]
print "Release Year: %s" % audio["TDRC"].text[0]
我个人觉得这很难阅读和使用,所以我不会在我的 mp3 播放器上使用这个模块,除非我需要添加额外的数字文件格式。还要注意的是,我不知道如何获取音轨的播放长度或专辑名称。让我们继续下一个 ID3 解析器,看看它的表现如何。
眼睛 3
如果你去 eyeD3 的网站,你会发现它似乎不支持 Windows。这是许多用户的一个问题,几乎让我放弃了这个综述。幸运的是,我发现了一个论坛,其中提到了一种使它工作的方法。我们的想法是将主文件夹中的“setup.py.in”文件重命名为“setup.py”,将“init.py.in”文件重命名为“init”。py”,您可以在“src\eyeD3”中找到它。然后就可以用常用的“python setup.py install”来安装了。一旦你安装了它,它真的很容易使用。检查以下功能:
import eyeD3
#----------------------------------------------------------------------
def getEyeD3Tags(path):
""""""
trackInfo = eyeD3.Mp3AudioFile(path)
tag = trackInfo.getTag()
tag.link(path)
print "Artist: %s" % tag.getArtist()
print "Album: %s" % tag.getAlbum()
print "Track: %s" % tag.getTitle()
print "Track Length: %s" % trackInfo.getPlayTimeString()
print "Release Year: %s" % tag.getYear()
这个包确实满足我们任意的要求。该软件包唯一令人遗憾的方面是它缺乏官方的 Windows 支持。我们将保留判断,直到我们尝试了我们的第三种可能性。
Ned Batchelder 的 id3reader.py
这个模块可能是三个模块中最容易安装的,因为它只是一个文件。你需要做的就是下载它,然后把文件放到站点包或者 Python 路径上的其他地方。这个解析器的主要问题是 Batchelder 不再支持它。让我们看看是否有一种简单的方法来获得我们需要的信息。
import id3reader
#----------------------------------------------------------------------
def getTags(path):
""""""
id3r = id3reader.Reader(path)
print "Artist: %s" % id3r.getValue('performer')
print "Album: %s" % id3r.getValue('album')
print "Track: %s" % id3r.getValue('title')
print "Release Year: %s" % id3r.getValue('year')
在不了解 ID3 规格的情况下,我看不出有什么明显的方法可以用这个模块获得走线长度。唉!虽然我喜欢这个模块的简单和强大,但缺乏支持和超级简单的 API 使我拒绝了它,而支持 eyeD3。目前,这将是我的 mp3 播放器的选择库。如果你知道一个很棒的 ID3 解析脚本,请在评论中给我留言。我在谷歌上也看到了其他人的名单,但其中有相当一部分人和巴彻尔德一样已经死了。
用 Python 解析 XML 和创建 PDF 发票
原文:https://www.blog.pythonlibrary.org/2012/07/18/parsing-xml-and-creating-a-pdf-invoice-with-python/
注:以下帖子最初发表在 Dzone 上。我更改了标题,因为我已经写了几篇 XML 解析文章,不希望我的读者将这篇文章与其他文章混淆。
我日常工作中的一项常见任务是获取一些数据格式输入,并对其进行解析以创建报告或其他文档。今天,我们将查看一些 XML 输入,用 Python 编程语言对其进行解析,然后使用 report lab(Python 的第三方包)创建一封 PDF 格式的信件。比方说,我的公司收到了一份三件商品的订单,我需要履行订单。这样的 XML 可以看起来像下面的代码:
<order_number>456789</order_number>
<customer_id>789654</customer_id>
<address1>John Doe</address1>
<address2>123 Dickens Road</address2>
<address3>Johnston, IA 55555</address3>
<order_items><item><id>11123</id>
<name>Expo Dry Erase Pen</name>
<price>1.99</price>
<quantity>5</quantity></item>
<item><id>22245</id>
<name>Cisco IP Phone 7942</name>
<price>300</price>
<quantity>1</quantity></item>
<item><id>33378</id>
<name>Waste Basket</name>
<price>9.99</price>
<quantity>1</quantity></item></order_items>
将上面的代码保存为 order.xml,现在我只需要用 Python 写一个解析器和 PDF 生成器脚本。您可以使用 Python 内置的 XML 解析库,其中包括 SAX、minidom 或 ElementTree,或者您可以出去下载许多用于 XML 解析的外部包中的一个。我最喜欢的是 lxml,它包括 ElementTree 的一个版本以及一段非常好的代码,他们称之为“objectify”。后一部分主要是将 XML 转换成点符号 Python 对象。我将用它来做我们的解析,因为它非常简单,易于实现和理解。如前所述,我将使用 Reportlab 来创建 PDF 文件。
下面是一个简单的脚本,它将完成我们需要的一切:
from decimal import Decimal
from lxml import etree, objectify
from reportlab.lib import colors
from reportlab.lib.pagesizes import letter
from reportlab.lib.styles import getSampleStyleSheet
from reportlab.lib.units import inch, mm
from reportlab.pdfgen import canvas
from reportlab.platypus import Paragraph, Table, TableStyle
########################################################################
class PDFOrder(object):
""""""
#----------------------------------------------------------------------
def __init__(self, xml_file, pdf_file):
"""Constructor"""
self.xml_file = xml_file
self.pdf_file = pdf_file
self.xml_obj = self.getXMLObject()
#----------------------------------------------------------------------
def coord(self, x, y, unit=1):
"""
# http://stackoverflow.com/questions/4726011/wrap-text-in-a-table-reportlab
Helper class to help position flowables in Canvas objects
"""
x, y = x * unit, self.height - y * unit
return x, y
#----------------------------------------------------------------------
def createPDF(self):
"""
Create a PDF based on the XML data
"""
self.canvas = canvas.Canvas(self.pdf_file, pagesize=letter)
width, self.height = letter
styles = getSampleStyleSheet()
xml = self.xml_obj
address = """ SHIP TO:
%s
%s
%s
%s
""" % (xml.address1, xml.address2, xml.address3, xml.address4)
p = Paragraph(address, styles["Normal"])
p.wrapOn(self.canvas, width, self.height)
p.drawOn(self.canvas, *self.coord(18, 40, mm))
order_number = '**Order #%s** ' % xml.order_number
p = Paragraph(order_number, styles["Normal"])
p.wrapOn(self.canvas, width, self.height)
p.drawOn(self.canvas, *self.coord(18, 50, mm))
data = []
data.append(["Item ID", "Name", "Price", "Quantity", "Total"])
grand_total = 0
for item in xml.order_items.iterchildren():
row = []
row.append(item.id)
row.append(item.name)
row.append(item.price)
row.append(item.quantity)
total = Decimal(str(item.price)) * Decimal(str(item.quantity))
row.append(str(total))
grand_total += total
data.append(row)
data.append(["", "", "", "Grand Total:", grand_total])
t = Table(data, 1.5 * inch)
t.setStyle(TableStyle([
('INNERGRID', (0,0), (-1,-1), 0.25, colors.black),
('BOX', (0,0), (-1,-1), 0.25, colors.black)
]))
t.wrapOn(self.canvas, width, self.height)
t.drawOn(self.canvas, *self.coord(18, 85, mm))
txt = "Thank you for your business!"
p = Paragraph(txt, styles["Normal"])
p.wrapOn(self.canvas, width, self.height)
p.drawOn(self.canvas, *self.coord(18, 95, mm))
#----------------------------------------------------------------------
def getXMLObject(self):
"""
Open the XML document and return an lxml XML document
"""
with open(self.xml_file) as f:
xml = f.read()
return objectify.fromstring(xml)
#----------------------------------------------------------------------
def savePDF(self):
"""
Save the PDF to disk
"""
self.canvas.save()
#----------------------------------------------------------------------
if __name__ == "__main__":
xml = "order.xml"
pdf = "letter.pdf"
doc = PDFOrder(xml, pdf)
doc.createPDF()
doc.savePDF()
下面是 PDF 输出:letter.pdf
让我们花几分钟来看一下这段代码。首先是一批进口货。这只是用来自 Reportlab 和 lxml 的所需内容设置了我们的环境。我还导入了十进制模块,因为我将添加数量,这对于浮点数学来说比仅仅使用普通的 Python 数学要精确得多。接下来,我们创建接受两个参数的 PDFOrder 类:一个 xml 文件和一个 pdf 文件路径。在我们的初始化方法中,我们创建两个类属性,读取 XML 文件并返回一个 XML 对象。coord 方法用于定位 Reportlab 流,这些流是动态对象,能够跨页面拆分并接受各种样式。
createPDF 方法是程序的核心。canvas 对象用于创建我们的 PDF 并在其上“绘图”。我将它设置为 letter 大小,还获取了一个默认样式表。接下来,我创建一个送货地址,并将其放置在页面顶部附近,距离左侧 18 毫米,距离顶部 40 毫米。之后,我创建并下订单编号。最后,我对订单中的项目进行迭代,并将它们放在一个嵌套列表中,然后将该列表放在 Reportlab 的表 flowable 中。最后,我定位表格并传递一些样式给它一个边框和内部网格。最后,我们将文件保存到磁盘。
文档已经创建好了,现在我已经有了一个很好的原型来展示给我的同事们。在这一点上,我需要做的就是通过为文本传递不同的样式(即粗体、斜体、字体大小)或稍微改变布局来调整文档的外观。这通常取决于管理层或客户,所以你必须等待,看看他们想要什么。
现在您知道了如何用 Python 解析 XML 文档并从解析的数据创建 PDF。
源代码
使用 lxml.objectify 用 Python 解析 XML
原文:https://www.blog.pythonlibrary.org/2012/06/06/parsing-xml-with-python-using-lxml-objectify/
几年前,我开始撰写一系列关于 XML 解析的文章。我介绍了 lxml 的 etree 和 Python 的 included minidom XML 解析库。不管出于什么原因,我没有注意到 lxml 的 objectify 子包,但我最近看到了它,并决定应该检查一下。在我看来,objectify 模块似乎比 etree 更“Pythonic 化”。让我们花点时间回顾一下我以前使用 objectify 的 XML 例子,看看它有什么不同!
让我们开始派对吧!
如果你还没有,出去下载 lxml ,否则你会跟不上。一旦你拿到了,我们可以继续。为了解析的方便,我们将使用下面这段 XML:
<appointment><begin>1181251680</begin>
<uid>040000008200E000</uid>
<alarmtime>1181572063</alarmtime>
<state><location><duration>1800</duration>
<subject>Bring pizza home</subject></location></state></appointment>
<appointment><begin>1234360800</begin>
<duration>1800</duration>
<subject>Check MS Office website for updates</subject>
<location><uid>604f4792-eb89-478b-a14f-dd34d3cc6c21-1234360800</uid>
<state>dismissed</state></location></appointment>
现在我们需要编写一些可以解析和修改 XML 的代码。让我们来看看这个小演示,它展示了 objectify 提供的一系列简洁的功能。
from lxml import etree, objectify
#----------------------------------------------------------------------
def parseXML(xmlFile):
""""""
with open(xmlFile) as f:
xml = f.read()
root = objectify.fromstring(xml)
# returns attributes in element node as dict
attrib = root.attrib
# how to extract element data
begin = root.appointment.begin
uid = root.appointment.uid
# loop over elements and print their tags and text
for appt in root.getchildren():
for e in appt.getchildren():
print "%s => %s" % (e.tag, e.text)
print
# how to change an element's text
root.appointment.begin = "something else"
print root.appointment.begin
# how to add a new element
root.appointment.new_element = "new data"
# print the xml
obj_xml = etree.tostring(root, pretty_print=True)
print obj_xml
# remove the py:pytype stuff
#objectify.deannotate(root)
etree.cleanup_namespaces(root)
obj_xml = etree.tostring(root, pretty_print=True)
print obj_xml
# save your xml
with open("new.xml", "w") as f:
f.write(obj_xml)
#----------------------------------------------------------------------
if __name__ == "__main__":
f = r'path\to\sample.xml'
parseXML(f)
代码被很好地注释了,但是我们还是会花一点时间来检查它。首先,我们将样本 XML 文件传递给它,将它对象化。如果你想访问一个标签的属性,使用 attrib 属性。它将返回标签属性的字典。要访问子标签元素,只需使用点符号。正如你所看到的,要得到 begin 标签的值,我们可以这样做:
begin = root.appointment.begin
如果需要迭代子元素,可以使用 iterchildren 。您可能必须使用嵌套的 for 循环结构来获取所有内容。改变一个元素的值就像给它分配一个新值一样简单。如果你需要创建一个新元素,只需添加一个句点和新元素的名称(如下所示):
root.appointment.new_element = "new data"
当我们使用 objectify 添加或更改项目时,它会给 XML 添加一些注释,比如xmlns:py = " http://code speak . net/lxml/objectify/pytype " py:py type = " str "。您可能不希望包含这些内容,所以您必须调用以下方法来删除这些内容:
etree.cleanup_namespaces(root)
您还可以使用“objectify.deannotate(root)”来做一些 deannotation 杂务,但是我无法让它在这个例子中工作。为了保存新的 XML,实际上似乎需要 lxml 的 etree 模块将它转换成一个字符串以便保存。
至此,您应该能够解析大多数 XML 文档,并使用 lxml 的 objectify 有效地编辑它们。我觉得很直观,很容易上手。希望你也会发现它对你的努力有用。
进一步阅读
抱枕:可预购 Python 图像处理
Pillow:用 Python 进行图像处理是我最新的一本关于 Python 的书。现在可以预订了。这意味着你可以购买这本书的早期版本,并在购买后免费获得所有更新,包括最终版本。最终版本将于 2021 年 4 月在完成。
你可以在 Leanpub 或 Gumroad 上预订这本书。

Python 图像库允许您使用 Python 编辑照片。Pillow 包是 Python 图像库的最新版本。您可以使用 Python 通过 Pillow 批量处理您的照片。
在本书中,您将了解以下内容:
- 打开和保存图像
- 提取图像元数据
- 使用颜色
- 应用图像滤镜
- 裁剪、旋转和调整大小
- 增强图像
- 组合图像
- 用枕头画画
- 图像印章
- 与 GUI 工具包集成
在这本书里,你会学到所有这些东西,甚至更多。很快你就能像专业人士一样使用 Python 编程语言编辑照片了!
Pillow:用 Python 进行图像处理的书籍示例
原文:https://www.blog.pythonlibrary.org/2021/01/05/pillow-image-processing-with-python-book-sample/
我的新书Pillow:Image Processing with Python的 Kickstarter 昨天获得了全额资助。我知道不看一本书很难决定是否要买,所以我免费发布这本书的前三章。你可以用这个 Dropbox 链接下载它们。这一小部分书还是 70 页的内容!

这本书进展顺利。如果你想在一本 Python 书中寻找一些新的和不同的东西,我希望你能抓住这个机会。
枕头:现在可以用 Python 进行图像处理了!
原文:https://www.blog.pythonlibrary.org/2021/04/06/pillow-image-processing-with-python-now-available/
Pillow:用 Python 进行图像处理是我最新的一本关于 Python 编程语言的书。平装本和 Kindle 版本现在可以在亚马逊上买到。
这本书的平装本是全彩色的。这就是为什么它比我买的其他书都贵的原因。我做了一个小视频,在这里我简单介绍了一下这本书:
https://www.youtube.com/embed/NwMPvmVtfxQ?feature=oembed
你可以在 Leanpub 或 Gumroad 上订购电子书版本。当您通过这些网站购买时,您将收到该书的 PDF、epub 和 mobi 版本。

Python 图像库允许您使用 Python 编辑照片。Pillow 包是 Python 图像库的最新版本。您可以使用 Python 通过 Pillow 批量处理您的照片。
在本书中,您将了解以下内容:
- 打开和保存图像
- 提取图像元数据
- 使用颜色
- 应用图像滤镜
- 裁剪、旋转和调整大小
- 增强图像
- 组合图像
- 用枕头画画
- 图像印章
- 与 GUI 工具包集成
在这本书里,你会学到所有这些东西,甚至更多。很快你就能像专业人士一样使用 Python 编程语言编辑照片了!
通过 Plotly 和 Python 在线绘制数据
原文:https://www.blog.pythonlibrary.org/2014/10/27/plotting-data-online-via-plotly-and-python/
我在工作中不怎么绘图,但我最近听说了一个名为plottly的网站,它为任何人的数据提供绘图服务。他们甚至有一个 Python 的 plotly 包(还有其他的)!因此,在这篇文章中,我们将学习如何与他们的包情节。让我们来做一些有趣的图表吧!
入门指南
您将需要 plotly 包来阅读本文。您可以使用 pip 获取软件包并安装它:
pip install plotly
现在你已经安装好了,你需要去 Plotly 网站创建一个免费账户。一旦完成,您将获得一个 API 密钥。为了使事情变得非常简单,您可以使用您的用户名和 API 密匙来创建一个凭证文件。下面是如何做到这一点:
import plotly.tools as tls
tls.set_credentials_file(
username="your_username",
api_key="your_api_key")
# to get your credentials
credentials = tls.get_credentials_file()
如果您不想保存凭据,也可以通过执行以下操作来登录他们的服务:
import plotly.plotly as py
py.sign_in('your_username','your_api_key')
出于本文的目的,我假设您已经创建了凭证文件。我发现这使得与他们的服务交互变得更容易使用。
创建图表
Plotly 似乎默认为散点图,所以我们就从这里开始。我决定从一个人口普查网站获取一些数据。您可以下载美国任何一个州的人口数据以及其他数据。在本例中,我下载了一个 CSV 文件,其中包含爱荷华州每个县的人口。让我们来看看:
import csv
import plotly.plotly as py
#----------------------------------------------------------------------
def plot_counties(csv_path):
"""
http://census.ire.org/data/bulkdata.html
"""
counties = {}
county = []
pop = []
counter = 0
with open(csv_path) as csv_handler:
reader = csv.reader(csv_handler)
for row in reader:
if counter == 0:
counter += 1
continue
county.append(row[8])
pop.append(row[9])
trace = dict(x=county, y=pop)
data = [trace]
py.plot(data, filename='ia_county_populations')
if __name__ == '__main__':
csv_path = 'ia_county_pop.csv'
plot_counties(csv_path)
如果您运行这段代码,您应该会看到如下所示的图形:
https://plot.ly/~driscollis/0.embed?width=640&height=480
转换为条形图
现在让我们看看能否将散点图转换成条形图。首先,我们将摆弄一下绘图数据。以下是通过 Python 解释器完成的:
>>> scatter = py.get_figure('driscollis', '0')
>>> print scatter.to_string()
Figure(
data=Data([
Scatter(
x=[u'Adair County', u'Adams County', u'Allamakee County', u'..', ],
y=[u'7682', u'4029', u'14330', u'12887', u'6119', u'26076', '..' ]
)
])
)
这显示了我们如何使用用户名和图的唯一编号来获取数字。然后我们打印出数据结构。您会注意到它没有打印出整个数据结构。现在,让我们进行条形图的实际转换:
from plotly.graph_objs import Data, Figure, Layout
scatter_data = scatter.get_data()
trace_bar = Bar(scatter_data[0])
data = Data([trace_bar])
layout = Layout(title="IA County Populations")
fig = Figure(data=data, layout=layout)
py.plot(fig, filename='bar_ia_county_pop')
这将在以下 URL 创建一个条形图:https://plot.ly/~driscollis/1。这是图表的图像:
https://plot.ly/~driscollis/1.embed?width=640&height=480
这段代码与我们最初使用的代码略有不同。在这种情况下,我们显式地创建了一个条对象,并将散点图的数据传递给它。然后我们将这些数据放入一个数据对象中。接下来,我们创建了一个布局对象,并给我们的图表加了一个标题。然后,我们使用数据和布局对象创建了一个图形对象。最后我们绘制了条形图。
将图形保存到磁盘
Plotly 还允许您将图形保存到硬盘上。您可以将其保存为以下格式:png、svg、jpeg 和 pdf。假设您手头还有上一个示例中的 Figure 对象,您可以执行以下操作:
py.image.save_as(fig, filename='graph.png')
如果您想使用其他格式保存,那么只需在文件名中使用该格式的扩展名。
包扎
至此,您应该能够很好地使用 plotly 包了。还有许多其他可用的图形类型,所以请务必通读 Plotly 的文档。它们还支持流式图形。据我了解,Plotly 允许你免费创建 10 个图表。在那之后,你要么删除一些图片,要么支付月费。
附加阅读
将 wxPyMail 移植到 Linux
原文:https://www.blog.pythonlibrary.org/2008/09/26/porting-wxpymail-to-linux/
将应用程序从一个操作系统移植到另一个操作系统是一个非常耗时的过程。幸运的是,wxPython 消除了这个过程中的痛苦。这只是我第二次把我的代码移植到 Linux 上。我平时上班都是在 Windows XP 上为 Windows XP 写。当我最初为工作编写 wxPyMail 时,我使用 Mark Hammond 的 PyWin32 库来获取用户的全名和用户名,以帮助构建他们的回信地址。以下是我当时使用的代码:
try:
userid = win32api.GetUserName()
info = win32net.NetUserGetInfo('server', userid, 2)
full_name = str(info['full_name'].lower())
name_parts = full_name.split(' ')
self.emailuser = name_parts[0][:1] + name_parts[-1]
email = self.emailuser + '@companyEmail'
except:
email = ''
如果我保留了那个代码,我将需要使用 wx。平台模块并测试“WXMSW”标志,如下所示:
if wx.Platform == '__WXMSW__':
try:
userid = win32api.GetUserName()
# rest of my win32 code
except:
# do something
pass
else:
# put some Linux or Mac specific stuff here
pass
这可能是移植代码最简单的方法,尤其是当您只有几个特定于操作系统的代码时。如果你有很多,那么你可能想把它们放入它们自己的模块中,并把它们导入到你的平台上。我相信还有其他方法可以实现这一点。
无论如何,我已经拿出了所有的 win32 的东西,因为它与我的组织。因此,wxPyMail 的新代码实际上在 Linux 上运行得很好。我在 Ubuntu Hardy Heron 上测试过。然而,我注意到一些美学问题。首先,这个框架似乎得到了关注,所以我不能在 wx 中输入电子邮件地址,甚至我的用户名。弹出的对话框。其次,我登录对话框中的标签和文本框在 Ubuntu 中太短了。它们在 Windows 上看起来很好,但在 Ubuntu 上标签被夹住了,当我完整输入用户名时,我看不到它。
因此,我更改了代码,使标签和文本框的大小更长。我还对主应用程序中的到字段和登录对话框中的用户名文本字段调用了 SetFocus()。除此之外,我做了一点重构,将 SMTP 服务器放在 init 中,这样更容易找到和设置。我还更改了我的各种控件实例,以便它们显式地反映它们的参数。
还要注意文件开头的“shebang”行:“#!/usr/bin/env python”。这告诉 Linux 这个文件可以使用 Python 执行,也告诉 Linux Python 安装文件夹在哪里。只要 python 在您的路径中的某个地方,您就应该能够使用这种方法。要检查路径上是否有 python,请打开命令提示符并键入“python”。如果您获得了 python shell,那么您就可以开始了。
你可能认为我们已经完成了,但是我们忘记了一个重要的部分。我们仍然需要告诉 Linux 使用 wxPyMail 作为 mailto 链接的默认电子邮件程序。我在 howtogeek 找到了一篇关于这个话题的操作文章。我们需要对它进行一些修改来使它工作,但是一旦你知道怎么做,它实际上是非常容易的。对于这个例子,我使用了 Ubuntu Hardy Heron (8.04)和 wxPython 2.8.9.1 以及 Python 2.5.2。
无论如何,首先你需要下载我的代码。当我第一次编写这个应用程序时,它是在 Windows 上。wxPython 邮件列表上的好心人向我指出我的代码有行尾问题,所以请确保您不会意外地将其转换回 Windows 格式。感谢罗宾·邓恩、克里斯托弗·巴克、科迪·普雷科德、弗兰克·米尔曼和一个叫基思的人。
其次,您需要告诉 Linux 在用户点击 mailto 链接时执行 python 脚本。在 Ubuntu 中,你可以通过进入系统,首选项,首选应用程序。将“邮件阅读器”更改为“自定义”,并在“命令”字段中添加以下内容:
/home/USERNAME/path/to/wxPyMail.py %s
用您的用户名替换 USERNAME,并根据需要调整路径。确保包含“%s ”,它表示传递给我们脚本的“mailto”字符串。现在,打开命令提示符,将目录更改为放置 python 脚本的位置。您将需要更改它的执行权限,所以应该这样做:
chmod +x wxPyMail.py
现在浏览到一个带有 mailto 链接的网站,并尝试一下吧!和往常一样,如果有任何问题或意见,欢迎发邮件给我,邮箱是 mike [at] pythonlibrary [dot] org。
下载源码
补充阅读
使用 Python 自动预订 Excel
原文:https://www.blog.pythonlibrary.org/2021/07/30/pre-order-automating-excel-with-python/
我的第十本 Python 书籍叫做用 Python 自动化 Excel:用 OpenPyXL 处理电子表格。还有 11 天就可以在 Kickstarter 上获得一件专属 t 恤了!
我也有电子书可以在 Gumroad 上预订。无论你是在 Kickstarter 还是 Gumroad 上购买,你都会得到这本书的早期版本,以及我对这本书的所有更新。
你可以在这里得到一些章节的样本,这样你就可以在决定购买之前试用这本书了!

在本书中,您将学习如何使用 Python 来完成以下任务:
- 创建 Excel 电子表格
- 阅读 Excel 电子表格
- 创建不同的细胞类型
- 添加和移除工作表
- 将 Excel 电子表格转换为其他文件类型
- 单元格样式(更改字体、插入图像、背景颜色等)
- 条件格式
- 添加图表
- 还有更多!
预购 Python 201 平装本
原文:https://www.blog.pythonlibrary.org/2016/04/11/pre-order-python-201-paperback/
我已经决定为我的下一本书提供平装本的预购。您将可以预订该书的签名版,该书将于 2016 年 9 月日发货。我将预购数量限制在 100 个。如果你有兴趣得到这本书,你可以这样做在这里

预购 Python 访谈
原文:https://www.blog.pythonlibrary.org/2018/02/07/pre-order-python-interviews/
我很高兴地宣布我正在写的另一本书,名为《Python 访谈》,由 Packt 出版社出版。这是他们网站的简介:

Python 访谈包含了 Mike Driscoll 和 Python 社区中各种领军人物之间的一系列一对一访谈。Mike 是 Python 社区的终身成员,多年来一直在他的博客 Mouse vs. Python 中对 Python 社区的精英进行“PyDev of the Week”采访。
在本书中,Mike 与 Python 社区的核心成员讨论了 Python,例如 Steve Holden(Python 软件基金会的前主席)、Mike Bayer(SQLAlchemy 的创建者)、Brett Cannon(Python 核心开发人员)、Glyph Lefkowitz(Twisted 的创建者)、Massimo DiPierro(web 2 py 的创建者)、Oliver schoen born(PyPubSub 的创建者)等等。采访中充满了对成功程序员的思想、Python 语言的内部运作、Python 的历史以及来自蓬勃发展的 Python 社区的幽默轶事的洞察。
Python 访谈目前可以预购,应该会在 2018 年 2 月下旬或者 2018 年 3 月出版。
注意:这些是全新的采访,并非摘自我的“本周 PyDev”系列。然而,这本书对这些采访有一些交叉,因为涉及了一些相同的主题。
产品评论:Python 闪存卡
原文:https://www.blog.pythonlibrary.org/2019/04/02/product-review-python-flash-cards/
没有哪家淀粉出版社以出版计算机编程书籍而闻名。然而,他们最近发布了一款名为 Python 闪存卡的新产品,作者是 Python 速成班的作者 Eric Matthes。我认为这是一个独特的产品,并决定要求审查副本。

这些卡片和它们的盒子是高质量的。我很喜欢他们用的卡片。卡本身针对 Python 3.7 。
每张卡的顶部都标有与其类别相匹配的颜色:

卡片也有编号。这在卡片引用其部分中的其他卡片或完全引用其他部分的时候很有用。这使得引用不同的卡片变得简单明了。
当然,抽认卡就其本质而言,短小精悍。所以卡片的测试和包装部分对我来说太简单了。另一方面,它们是闪存卡,所以介质不允许它们以我希望的方式被充实。如果你需要更多的细节,谷歌从未远离。
虽然我肯定不是这些卡片的目标市场,但我认为它们对想学习的高中生,甚至可能是大学新生很有用。它们对于刷新您的 Python 基础当然是有用的。如果你有学生,这一套可能会证明对他们很有用。

|  |
|
Python 闪存卡
书评
- 书评- 任务 Python:编写一个太空冒险游戏!肖恩·麦克马纳斯
- Julien Danjou 的《严肃的 Python:关于部署、可伸缩性、测试等的黑带建议》
- Brian Okken 的 pytestPython 测试
- Erik Westra 的 Python 模块编程
- Python Playground——好奇的程序员的极客项目Mahesh Venkitachalam 著
- L. Felipe Martins 著
有利可图的 Python 插曲:把家庭放在第一位
原文:https://www.blog.pythonlibrary.org/2019/08/26/profitable-python-episode-put-your-family-first/
本周,我是盈利的 Python 播客的嘉宾。你可以在这里查看:
https://www.youtube.com/embed/qdPvZUzPNA0?feature=oembed
在面试中,有人问我希望 Python 在浏览器中运行,我想不起有哪个产品的名字能让这种事情成为可能。我想到的产品是 Anvil ,虽然浏览器中还没有 Python,但已经很接近了。
我想到的另一个产品是微软的 Silverlight 浏览器插件,你可以在其中使用 IronPython。或者至少你曾经可以。我有段时间没查这个了。
以下是本集提到的其他内容的一些链接:
- 谈谈 Python 和我在那里的一集:第 156 集:Python 的历史和观点
- Pyowa: 爱荷华 Python 用户组
- 我在 Leanpub 和亚马逊的书籍
- 一拳侠漫画
- Python 网站中的测试驱动开发
参加这个节目太棒了。我总是喜欢谈论 Python。关于播客中提到的任何事情或播客本身,请随时问我任何问题。
印地出版的利与弊
原文:https://www.blog.pythonlibrary.org/2019/02/27/pros-and-cons-of-indy-publishing/
我个人是真的爱自助出版还是印第出版,所以有点偏颇。在这篇文章中,我将回顾一下我认为印第出版公司与“真正的”出版商相比的优缺点。
赞成的意见
以下是我最喜欢印第出版公司的部分:
- 我控制发布日期
- 我控制内容
- 电子书可以在几分钟内更新
- 你的版税税率是 70-90%
- 价格可以在几秒钟内改变
- 闪购很容易
- 在简历上看起来不错
我将对其中的一些观点进行一些扩展。我曾作为作者与两家出版社合作过: Packt Publishing 和press。Packt 有非常积极的完成工作的时间表。章节必须根据时间表来完成。当你接近尾声时,出版商也会给你出难题。当你自助出版时,你控制了所有这些。
当我想修改书中的错误、修改例子或添加章节时,我只需这样做并发送更新即可。
如果我想把我的书免费送给学生或任何我想送给的人,我也可以这样做。我也给当地的 python 用户组捐过书。如果你想为你的小组要些礼物,请随时联系我。如果你住得很远,我可能会收取运费。
Leanpub、亚马逊和 Gumroad 都有报告,你可以看看你的书卖得怎么样。这些都很有用。
最后,我想指出的是,雇主似乎并不关心这本书是自己出版还是通过出版商出版。不管怎样,他们通常会感兴趣和/或留下深刻印象。
骗局
以下是我从印第出版社了解到的一些弊端:
- 你没有编辑
- 没有技术审查人员
- 没有市场部
- 没有艺术系
在与几家出版商合作后,我注意到我没有从编辑那里得到任何有用的反馈。作为一名技术评审,我曾与 No Starch Press 合作过,我认为他们给了作者更好的反馈,但我只看到了一点,所以我真的不知道他们实际收到了多少。
我的书《wxPython 食谱》确实有几个技术评论家。这很有帮助,尽管没有我想象的那么大。正如我在之前的帖子中提到的,我通常在发布我的书之前使用我的博客和 Kickstarter 来获得关于我的书的反馈,这很好,甚至更好。
让别人来做营销是很好的。帕克特甚至给我指派了一个公关。Apress 给了我一些关于章节风格更加一致的想法。
从某种意义上来说,最大的缺点是你必须为所有的东西付钱。艺术品很贵。广告也很贵。你必须关注所有这些,弄清楚你想花什么,以及你想怎么花。
谈判合同
当你自己出版或者只是写很多博客时,出版商可能会找上门来,让你为他们写作。或者他们可能会要求购买你的书的版权,并以他们的品牌重印。虽然我没有很多谈判合同的经验,但我还是要提几点。
如果你在任何你想销售的社区都不出名,那会在谈判桌上对你不利。在你决定最终要价之前,确保你有出版商的时间表。
写一本书是一个耗时且通常孤独的过程。除非你已经写了很多,否则它很可能会比你预期的花费更多的时间。如果出版商想让你做一个约定,一定要让你的报酬涨上去。他们可能不会支付所有费用,但通常会增加一些。
我想提到的另一件事是,你得到的预付款可能是你为这本书得到的全部报酬。事实上,最好只是认为这是将要发生的事情,这样你就不会失望。让我们处理一些数字。大多数出版商支付大约 10%的版税。现在假设你得到了 4000 美元的预付款。当版税达到 4000 美元时,你不会开始得到版税。相反,当你的版税金额超过 4000 美元时,你就会得到报酬。
如果这本书的售价是 25 美元,你的版税大概是 1.25 美元。你需要卖出 3000 多本书才能开始获得版税。遗憾的是,你可能永远也到不了那里。
你可以在这里阅读更多关于这个话题和写作的书籍。
我认为与出版商合作的最大好处是,我的一本书得到了一个小小的包裹。作为印第出版商,我不能进入这些。我能从中赚到钱吗?我不知道。捆绑包的版税很少,最多只能按季度了解你的书卖得有多好。
包扎
我真的很喜欢出版自己的书。我喜欢它给我的内容自由,以及以我认为合适的方式分享内容的能力。不过,我从与出版商的合作中学到了很多。他们当然有他们的位置。但是我认为如果你愿意投入工作,没有他们你也能做得一样好。
组装 wxPython 应用程序
原文:https://www.blog.pythonlibrary.org/2008/06/09/putting-together-a-wxpython-application/
大约一周前,我写道,我正在开发一个示例应用程序,我将在这里发布。当我在做的时候,我意识到我需要找到一种简单、有条理和通用的方法来分解它。因此,我决定就我的应用程序创建一系列“如何做”的文章,并将它们发布在这里。然后,我将发布另一篇文章,将所有的片段放在一起。
该应用程序包括以下部分:
- wx。箱式筛分机
- wx。对话类
- wx。菜单,wx。StatusBar 和 wx。工具栏
- wx。AboutBox
注意:我已经有一个 BoxSizer 教程完成。
我认为这涵盖了 wxPython 的主要部分。我还将使用标准 Python 2.5 库的 email、urllib 和 smtplib 模块以及一些特定于 win32 的模块。我想你会发现这套文章很有教育意义。请务必让我知道你的想法。
PyBites 播客:第 043 集——成为一个多产的 Python 内容提供商
本周,Mike Driscoll(本网站的作者)做客 PyBites 播客。标题是第 043 集——成为一个多产的 Python 内容提供商
你可以在 PyBites 上收听播客。
在播客中,主持人和我讨论了:
- Mike 是如何进入编程和 Python 的(以及社区的重要性),
- Mike 如何在自动化测试框架中使用 Python(测试 C++ GUI 应用程序),
- Mike 是如何通过写博客和后来写 9(!)书籍,
- 如何跟上新技术,
- 如何在制作内容时保持一致性和积极性,
- 如今作为 Python 开发人员的基本技能,
- 应对冒名顶替综合症(意识到你可能比你想象的要多得多!)
- 学习新的库,结对编程的好处(初级和高级工程师都适用),
- 更多…
PyChecker: Python 代码分析
原文:https://www.blog.pythonlibrary.org/2011/01/26/pychecker-python-code-analysis/
PyChecker 是一个很酷的工具,用于检查 Python 脚本中的错误。它适用于 Python 2.0 - 2.7。在本文中,我们将编写一些蹩脚的代码,看看 PyChecker 能从中发现什么。然后,我们将根据我们的发现改进代码,直到代码通过检查。根据 PyChecker 的网站,它可以检测到以下问题:
- 找不到全局(例如,使用模块而不导入它)
- 向函数/方法/构造函数传递了错误数量的参数
- 向内置函数和方法传递错误数量的参数
- 使用与参数不匹配的格式字符串
- 使用不存在的类方法和属性
- 重写方法时更改签名
- 在相同的范围内重新定义函数/类/方法
- 在设置变量之前使用它
- self 不是为方法定义的第一个参数
- 未使用的全局变量和局部变量(模块或变量)
- 未使用的函数/方法参数(可以忽略自身)
- 模块、类、函数和方法中没有文档字符串
入门指南
我们不会测试它能检测到的所有东西,但是我们可以编写一些非常混乱的代码供 PyChecker 检查。开始编码吧!
import sys
########################################################################
class CarClass:
""""""
#----------------------------------------------------------------------
def __init__(self, color, make, model, year):
"""Constructor"""
self.color = color
self.make = make
self.model = model
self.year = year
if "Windows" in platform.platform():
print "You're using Windows!"
self.weight = self.getWeight(1, 2, 3)
#----------------------------------------------------------------------
def getWeight(this):
""""""
return "2000 lbs"
这段代码实际上并没有做太多的事情,只是为了举例说明。根据 PyChecker 的说法,这段代码有四个问题。你能看到问题吗?如果没有,那么让我们来看看如何使用 PyChecker 来揭露它们!一旦您安装了 PyChecker 并将其放在您的路径中(参见 PyChecker 的文档),您应该能够执行以下命令:
C:\Users\Mike\Documents\My Dropbox\Scripts\code analysis>pychecker bad.py
注意:只有当你在 Windows 系统路径上有 pychecker 时,以上才有效。从技术上讲,在 Windows 上你将使用 pychecker.bat
如果您这样做,您将得到如下结果:
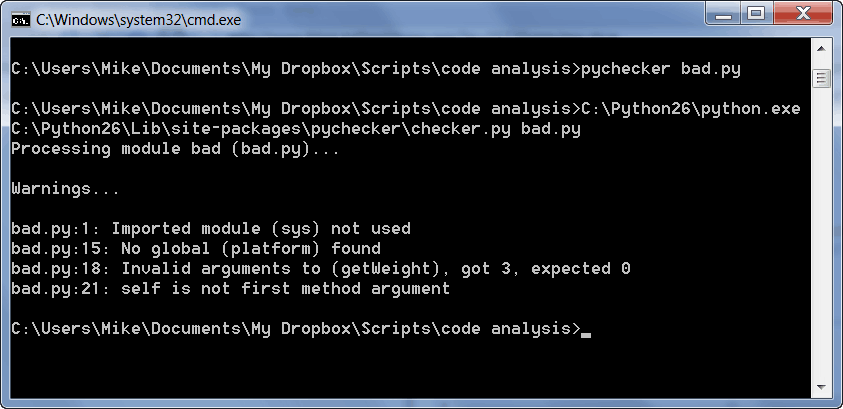
希望你能告诉我们这一切意味着什么,但我们会把它分解,以防你不知道。它发现了四个问题。它发现的第一个问题是我们导入了 sys 模块,但是我们没有使用它。第二个问题与第一个相反。我们指的是平台模块,但实际上不是进口的!第三,我们调用我们的 getWeight 方法,它报告我们给它传递了太多的参数。我认为 PyChecker 可能有一个错误,因为我们的方法应该接受一个方法,而不是零个。“this”参数肯定会让 PyChecker 感到困惑。幸运的是,它发现的最后一个问题是 getWeight 没有将 self 作为第一个参数。这就纠正了我提到的错误。虽然第一个方法不要求我们将其命名为“self ”,但这是类方法中第一个参数的常规命名约定。
其他提示
PyChecker 不只是在命令行上工作。也可以直接在代码中使用!您只需在模块顶部导入 PyChecker,如下所示:
import pychecker.checker
这将使 PyChecker 检查下面所有导入的模块,尽管它不会检查主模块。那是什么意思?这意味着,如果您在我们使用的示例中坚持这一行,您将不会看到任何与该代码相关的错误。PyChecker 文档说您还可以通过 os.environ 设置 PyChecker 的选项。
os.environ['PYCHECKER'] = 'command line options here'
说到这里,下面是常见的命令行选项:
[表 id=2 /]
如果您想要完整的命令列表,请键入以下命令:pychecker -h
注意:PyChecker 的文档字符串检查在默认情况下是关闭的,所以如果你想要的话,你需要传递"-m -f "命令。这只找到了类模块的空 docstring。“-f”似乎有一个小错误,它认为空文档字符串是可以的。我已经提醒过 PyChecker 小组了。
包扎
我认为 PyChecker 非常酷,看起来它可能是一个方便的工具。试试看,看你怎么想!
附加阅读
PyCon 2008(芝加哥)-第一天(第一部分)
原文:https://www.blog.pythonlibrary.org/2008/03/16/pycon-2008-chicago-day-1-part-one/
PyCon 的第一天(不包括辅导日)发生在 2008 年 3 月 14 日。我终于见到了 BDFL(仁慈的终身独裁者),吉多·范·罗苏姆。虽然我知道他来自荷兰,但我真的没有想到他有瑞士口音。太酷了!他最有趣的地方在于他描述了 Python 的下一次迭代;即同时发布 2.6 和 3.0。他希望他们能在 2008 年 8 月获释。
不过在 Guido 之前,有一个叫 Chris Hagner 的人在 White Oak Technologies 发表了“为什么 Python 很烂(但对我们有用)”之类的演讲。无论如何,他指出了 Python 的弱点,然后展示了如何利用它们的优势。哈格纳的缺点是:
- Python 开发人员数量少
- 很少有组织拥有 Python 解决方案(这使得他们在尝试新事物时有些紧张)
- Python“古怪”
- Python 很慢
他谈到了这些,但我的笔记不完整,所以我只谈重点。Python 开发人员相对较少的事实并没有阻止他的公司,因为与他交谈过的 Python 程序员通常比其他语言的程序员质量高得多。他用 Python 解决方案的“稀有性”作为卖点:“嘿!我们有一些不同的东西。”这在某种程度上也适用于“怪异”因素。最后,Python 的慢部分对他们大多数时间做的事情来说不是问题,这使他们更加注意测试和优化或为那些“慢”部分编写 C/C++扩展。
我下次再写我参加的讲座。
PyCon 2008(芝加哥)-第一天(第二部分)
原文:https://www.blog.pythonlibrary.org/2008/03/20/pycon-2008-chicago-day-1-part-two/
我参加的第一个讲座名为“用 Repoze 开发 2”。克里斯·P·麦克多诺的《佐普》。这是一个非常有趣的关于中间件的演示,它可以以允许 Zope2 在 Apache + mod_wsgi 中运行的方式重新实现 ZPublisher。Repoze 依赖于 Python 粘贴和 setuptools。如果我没记错的话,他给 Trac 演示了一个类似 Plone 的接口,但没有做任何修改。
在那之后,我去看了布雷特·坎农关于“进口是如何起作用的”的演讲。这是一个非常复杂的话题,我无法完全理解。它的要点是这样的:
- 有一个函数调用要导入
- 签发进口锁
- 名字是决心是坚决的
- 它检查 sys.modules 如果找到了,就停在这里。如果不是,那么
- 它检查 sys.meta _ path 如果找到了,就停在这里。如果不是,那么
- 它检查父 path 或 sys.path
你可以在这里下载他的幻灯片:http://us.pycon.org/2008/conference/schedule/
它有很多流程图,可能比我的总结更有意义。只需将鼠标放在上面,就会弹出一个窗口让你下载 PDF 文件。接下来,我看了杰夫·拉什关于创建一个本地 Python 用户组的演讲。他说话很快,但我得到了很多关于培养一只好哈巴狗的信息,希望我能为爱荷华州找到一只。他的幻灯片也可以在上面的链接中找到。
接下来我参加的两个讲座是针对系统管理员的。一篇是关于使用 Optparse 的,名为“使用 Optparse、子流程和 Doctest 来制作敏捷 Unix 实用程序”。这是诺亚·吉夫给的。我没有得到太多的好处,因为 PyCon 无线系统坏了,所以我不能使用代码。然而,它表现得很好,他的材料也可以在 PyCon schedule 网站上找到,所以我建议下载下来看看。
由于技术困难,Gift 之后的演示没有任何幻灯片,几乎与 Python 没有任何关系。它是由芝加哥用户组的一个成员 Sean Reifschneider 给出的,他称之为:“系统管理中的 Python:一个系统管理员如何、何时以及为什么使用 Python”。不幸的是,他大部分时间都在谈论他有多喜欢 Nagios 这个网络监控工具和 rsync 这个备份工具。他无法展示的幻灯片应该在这里:http://dev.tummy.com/~jafo/pycon2008/
“使用谷歌电子表格 API 在云中创建一个数据库”和杰弗里·斯卡德尔(谷歌)是下一个,它震撼了!他展示了如何使用 Python 实时修改谷歌电子表格。你可以在 http://rurl.com/kp7 的 观看幻灯片,但需要 Gmail 账户。无论如何,我认为把数据放在云端有很多好处,可以同时进行编辑,还可以把数据保存到硬盘上。他还展示了如何在 Atom 提要上进行 CRUD。python 绑定可以在 code.google.com的找到
斯卡德尔也是我在 PyCon 遇到的最好的人之一。
对我来说,这一天的最后一个话题是保罗·温克勒的《剩下的就容易了》。老实说,我也没从这本书里得到什么。主要原因是他在展示任何代码之前看了 23 张幻灯片。即便如此,代码也是乏味无趣的。也可以从 PyCon Schedule 网站上获得。希望温克勒会随着经验的增加而提高。主题很吸引人,但演讲的执行却不吸引人。
我会尽快把我在会议上的其他经历讲出来。抱歉耽搁了!
PyCon 2008(芝加哥)-第二天
原文:https://www.blog.pythonlibrary.org/2008/03/21/pycon-2008-chicago-day-2/
3 月 15 日,星期六,我终于找到了 PyCon 的窍门。我四处逛了逛,门一开,我就进了会议室。这是我住过的最大的房间之一。它让我想起了一个竞技场,只是没有高高的天花板。开场演讲是关于 Twisted,以及它如何获得某种支持,使他们成为一个真正的实体。有很多人在用麦克风玩烫手山芋,我很快就发现自己被弄糊涂了。话又说回来,我从一开始就对扭曲不感兴趣。
下一次全体会议由谷歌的 Brian Fitzpatick 主持。他的讲话是我见过的最圆滑、最有趣的。我也几乎什么都没学到。很奇怪这是怎么回事。
Van Lindberg 在最后一次全体会议上做了关于知识产权的发言。这是我第一次也是唯一一次真正有意识地走神的全体会议。我不反对知识产权。如果你想保护你的工作并获得报酬,这是非常重要的,但我发现这个谈话非常枯燥,坦率地说,很无聊。
接下来,有一个休息,然后是 6 个以上的会谈。列表如下:
使用 PyGame 和 PySight 创建一个交互式万圣节活动
Crunchy:Crunching on Python Documentation
不要给我们打电话,我们会给你打电话:Python 中的回调模式和习惯用法
使用 pyglet 的视觉和声音
Python 应用程序开发的案例研究——人性化的 Enso
Python 在您的浏览器中使用 IronPython & Silverlight
我真的很喜欢 PyGame 的万圣节演讲。约翰·哈里森是一个傻瓜,很高兴看到 Python 以一种有趣和创造性的方式被使用,吸引了社区的关注。观众也很喜欢。他有手工制作的激光枪、改装的《星球大战》激光枪、红外眼镜和一个运动跟踪装置。他的一些作品在 YouTube 上。我强烈建议你去看看。
嘎吱嘎吱是一个很好的想法,但是我仍然不知道如何将它应用到我正在做的或者可能会做的任何事情上。不过,你可以在这里仔细阅读:http://aroberge . blogspot . com/2007/01/crunchy-08-is-out . html
回拨习语的演讲者是亚历克斯·马尔泰利,我非常尊敬他。他是《果壳中的 Python》一书的作者,也是《Python 食谱》的编辑之一。不幸的是,亚历克斯浓重的口音加上深刻的主题让我很难理解。我认为你可以从这个家伙身上学到很多东西,所以如果你在下一次 PyCon 上看到他的名字,不要错过。请记住,你必须比平时更加注意。
皮格莱特吸引了很多人。那是一堂非常满的课。我之前喜欢 PyGame,但是这个也很有趣。幻灯片以 html 格式放在 PyCon 时间表网站上。去看看吧,因为我对此没什么可说的。
人性化的厄尔尼诺/南方涛动项目也没有为我做任何事情。不过,这里有一个获得更多信息的好地方:http://www.humanized.com/
迈克尔·福德谈到了 IronPython & Silverlight。他很酷,正在 Silverlight 上写一本关于 IronPython 的书。第二天还有一个关于 IronPython 的未来的演讲,也有一个令人印象深刻的 Silverlight 演示。但是我想得太多了。事实上,你可以在 Foord 的博客上看到他谈论的很多内容。
下次见。
PyCon 2008(芝加哥)-第三天
原文:https://www.blog.pythonlibrary.org/2008/03/22/pycon-2008-chicago-day-3/
我在 PyCon 的最后一天是 2008 年 3 月 16 日,星期天。我是第二天早上还要工作的不幸者之一。这一天对我来说似乎太匆忙了,这可能是我学到最少的原因。
第一次全体会议是用阿萨·拉斯金让客户端 Python 变得不那么糟糕。在某种程度上,这是关于 Mozilla 的,但拉斯金更关注于将 Python 变成一个易于更新的程序。这是一个让“冻结”你的 Python 应用程序变得更容易,让上述程序的整体更新和可插入性变得更容易的战斗号令。他的主要思想可以用这句名言“Python 需要成为一个平台”来概括。不过,他并没有给出如何实现这一目标的任何想法。你可以在这里了解更多:【http://www.toolness.com/wp/】T2
我非常期待哈蒙德关于 Python 和 Firefox 的演讲,他没有让我失望。我没意识到哈蒙德是澳大利亚人。他非常详细地介绍了自己多年来如何使用 Python、XPCOM 和 Mozilla,并讲述了 XPCOM / Mozilla 多年来的历史。
- XPCOM 绑定的问题:
- 文档不足
- 对麦克太苛刻了
- 没有二进制发行版(但这正在改变)
- 被认为是实验性的(但事实并非如此,只是缺乏社区)
- DOM 工作的性能问题
- 为什么没有社区(针对 XPCOM 绑定)?
- 高准入门槛
- 由非常大的项目使用
- Mozilla 社区认为它属于 Python,反之亦然
- 即使是 Mozilla 也在挣扎
最后,OLPC 代表伊万·克尔斯蒂奇站起来发言。他应该在哈蒙德之前,但伊万的笔记本电脑前一天晚上坏了,他疯狂地工作在他的幻灯片上,直到他的演讲。看到 OLPC 倡议的进展情况是令人感兴趣的。除了泛泛而谈之外,我对它了解得不多。我仍然对这个项目持“等等看”的态度,因为美国多年来一直在教育上砸钱,而且大部分都停滞不前。希望 OLPC 能真正帮助孩子们学习。伊万的谈话肯定是积极的。
休息之后,我参加了我的最后三场演讲:【Zope 做错了什么(以及它是如何被修复的),nose:对懒惰的程序员的测试,和 IronPython:前方的路。
Zope 讲座由 Lennart Regebro 主持。正如我参加的其他 Zope / Plone 讲座一样,Regebro 强调了迁移到 Zope3 和 Plone 3 以获得最新和最棒的产品的必要性。虽然利用新技术很好,但我的公司目前还做不到。所以我有点走神了。抱歉,伦纳特!欢迎你来看看他的博客:http://regebro.wordpress.com/
鼻子的演讲很受欢迎。事实上,这可能比前一天晚上的皮格莱特谈话更好。它是由《鼻子》的作者杰森·佩勒林给出的。然而,它与测试驱动开发(TDD)以及 nose 如何适应这种思维模式有更多的关系,而不仅仅是泛泛地谈论 nose。TDD 背后的想法非常好,也是我自己想要采纳的,所以这个演示是令人鼓舞的。希望我能在自己的作品中使用一些或全部 Pellerin 所说的内容。
最后,我们来到了 IronPython 展会。它由两名微软员工主持。主要发言人是吉姆·胡古宁和一个叫迪诺的程序员(我想)。我也看到迈克尔·福德在后面。他们展示了一个用 Python 和 Silverlight 设计的奇特的投票网站。它有小视频,每个问题都会在后台运行;当鼠标经过时,问题列表中的每一项都会稍微放大;在问题之间有一个简洁的过渡效果。还有一个很好的图表可以显示民意调查的进展情况。谈话非常圆滑,但我不得不在他们结束之前离开,以避免回家路上的交通堵塞。
他们还展示了如何在 IronPython 中运行 Django。这很酷,尽管我不确定这给了开发者什么额外的功能…除了能够将 Silverlight pizazz 添加到 Django 站点之外。
我本来希望他们会发布他们的代码,但我仍然没有在 PyCon 网站上看到任何东西。
这就是我在 PyCon 上的亮点——我会贴出更多关于我的观察和我所看到的其他东西的一般评论。
PyCon 2008(芝加哥)-在路上
原文:https://www.blog.pythonlibrary.org/2008/03/14/pycon-2008-chicago-on-the-road/
这是我的第一篇文章。我想我应该开始写我的 Python 经历,巧合的是, PyCon 正准备开始。所以我决定等等,这样我就可以写一些真正酷的东西了。这也将是我第一次参加 PyCon,也是我第一次来芝加哥。我的公司支付了这次旅行的费用,到目前为止,这是一次有趣的经历。
据谷歌地图显示,我住在爱荷华州的中部,所以这次旅行花了大约 5 个半小时或 299 英里。为了到达这里,我决定使用一个 Garmin Nuvi 350 GPS 装置。它完美地工作,除了它带我上了一些收费公路。我还没想出解决的办法。
到达目的地逸林酒店后,我很快办理了入住手续,晚餐后,我去看看能不能帮 ChiPy (芝加哥当地的用户群)打包行李。他们实际上似乎有太多的帮助,但我遇到了一些有趣的人。
我很快会写另一篇关于辅导日的文章。到时候见!
PyCon 2008(芝加哥)赞助利弊
原文:https://www.blog.pythonlibrary.org/2008/03/25/pycon-2008-chicago-sponsorship-pros-cons/
今年去 PyCon 的时候,我根本就没想过赞助商。然而,我在每样东西上都看到了他们的名字,直到会议的第一天,我才感到困扰。虽然我认为主持人 Goodger 先生是一个很好的人,但我认为赞助公告有时放错了地方。当圭多站起来做他的报告时,他不得不等到古德杰跑到房间的后面去找一些纸。每个人都在想“怎么回事!?"当古德杰回来读到“圭多的演讲是由……”我有点震惊。我是说,这是什么?
我也从未听说过“闪电谈话”。事实上,当我听说他们的时候,我认为他们听起来像一个蹩脚的主意。所以第一天就跳过了。第二天我决定去看看,因为我很无聊。在我看到的四个中,有两个是赞助的演讲,一个只是一些家伙咆哮着为什么他认为 Python 很烂。所有这些似乎都有点不合时宜。
在 c.l.py 上还可以听到更多:
我同意赞助商有助于降低会议成本,我完全支持这一点,支持免费赠品以及与他们交流的机会。但在某些情况下,它们可能有些过头,如果你读了上面的帖子,你会注意到闪电谈话是受损最严重的。我希望明年能参加,我希望组织者将来能学会如何更好地处理这个问题。
PyCon 2008(芝加哥)-辅导日
原文:https://www.blog.pythonlibrary.org/2008/03/15/pycon-2008-chicago-tutorial-day/
教程日,顾名思义,是 PyCon 参与者参加各种 Python 主题的教程的日子,包括 Django、Plone、wxPython、Python 101、SQLAlchemy、Python Eggs、Python 和 OLPC 等等。根据第二天的主题演讲,参加辅导日的人数超过了过去几年参加 PyCon 的人数。
我自己参加了 3 个:Python 中的 Eggs 和 Buildout 部署(Jeff Rush)、高级 SQLAlchemy (Michael Bayer、Jason Kirtland 和 Jonathan Ellis)和 Tail Wags Fangs:Python 开发人员应该了解的 Plone (Rob Lineberger)。
鸡蛋教程是我参加过的最好的一个。拉什先生知识渊博,善于交流这些知识。虽然它非常快,但我认为我在那一次学到了最多。
高级 SQLAlchemy 让模块的作者(Michael Bayer)做了演示。虽然显然非常聪明,但他有语速过快的倾向。无论如何我都不是 SQL 专家,所以我也不总是能理解。不过,我可能也会做同样的事情。他和杰森·科特兰搭档,听起来很酷,即使我不能总是跟上每件事。
最后一节课可能是最让我失望的。除了关于原型的部分,Plone 教程似乎更多的是针对用户和设计者,而不是开发者。我对 ZPT 的期望比什么都高。此外,尽管演示者看起来知识渊博,但他不断地犯小错误,或者告诉我们一件事,只是告诉我们不要理会他几分钟后说的话,从而改变了我的想法。这使得记笔记几乎不可能。
到那个教程结束的时候,是时候去酒店睡觉了。PyCon 的“真正”开始将在明天开始。不要换那个频道!我很快就会谈到这一点…
PyCon 2009 第 1 天-全体会议和早晨闪电
原文:https://www.blog.pythonlibrary.org/2009/03/27/pycon-2009-day-1-plenary-and-morning-lightning/
2009 年 3 月 27 日,芝加哥 PyCon 真正开始了。有些人可能会把前两天的教程称为 PyCon 前,但“真正的”会议直到今天才开始。今天早上,组织者已经安排了一个开幕全体会议和一些上午的闪电谈话。闪电过后,我们休息一会儿,然后开始更具体的讨论。 大卫·古德杰仍然是会议主席,并做了很好的介绍。巴里·哈肯斯接着就空地问题发表了讲话。闪电谈话涵盖了 DCVS (Brett Cannon),PyCon 本身(Doug Napoleone),Cassandra 数据库(Jonathan Ellis),Python 和 wiiMote (John Harris),ChiPy / PyCon Networking 的 Shawn 的某种数据库谈话,等等。在大多数情况下,他们相当不错,虽然肖恩让我的心思恍惚。他有一个艰难的工作来保持他的 PyCon 网络正常运行,所以我很欣赏他所做的。霍金斯和坎农似乎在人群中得到最多的回应,那不勒斯和哈里斯紧随其后。
目前就这些。回来拿我参加的会谈的报告,当我参加的时候(当 flakey 网络允许的时候)。

PyCon 2009-GUI 应用程序的功能测试(周五演讲)
上周五(3 月 27 日)去 PyCon 的最后一个讲座,我去了 Michael Foord 的、、桌面应用、的功能测试。他在演示中使用了他的书 中的 IronPython 示例。他的主要话题是关于测试图形用户界面及其固有的问题。Foord 给出了很多测试 GUI 的好理由,比如确保新代码不会破坏功能,它在重构时非常有用,单个测试充当应用程序的规范,它让你知道一个功能何时完成,测试可以推动开发。
使用 GUI 框架的一个大问题是,当你测试它们时,你不能阻塞主循环。这可能是一种痛苦。Foord 的解决方案是使用工具包的定时器对象来拉进并运行测试。他还提到在您的应用程序中创建钩子,允许您自己检测它。他的幻灯片列出了可以帮助 GUI 测试的各种包,比如 WATSUP 和 guitest,以及其他几个包。我不确定他的网站上是否有完整的列表,但是给他写封短信,他可能会给你。
最后,我发现这是我周五参加的内容更丰富的讲座之一。它给了我一些如何在我自己的应用程序中实现测试的想法。希望这些会有结果。

PyCon 2009-Python 是如何开发的(演讲)
原文:https://www.blog.pythonlibrary.org/2009/03/27/pycon-2009-how-python-is-developed-talk/
Python 核心开发人员 Brett Cannon 发表了关于如何开发 Pycon 的演讲。Brett 谈到了如何开始帮助编写 Python Core。首先,他建议学习错误跟踪系统以及如何使用它,然后开始修复错误。首先,请访问新闻-bugs-公告或 python-bugs-列表。在那里你可以提交 bug 并了解当前的 bug。随着你越来越出名(通过修复 bug),开发人员会给你额外的特权,最高的是提交特权。要修正一个 bug,一定要看 PEP 7 和 8。如果你遵守规则并正确提交你的补丁,它可能会被接受。提交 bug 时要有耐心,因为 Brett 提到过,目前只有 26 个开发人员真正在做核心的事情,并且要花很多时间来检查所有的 bug。
他还谈到了在内核中添加新特性或功能的过程。主要的想法是将你的想法提交到 python-ideas 列表。你也可以向 comp.lang.python 上的人反映。如果他们认为这是一个好主意,就写一个 PEP 并提交给 python-dev。准备好捍卫你的概念。还是那句话,做病人。这就是他真正谈论的一切。我认为这是一个非常好的演讲。

PyCon 2009 - IronPython:数据、方向和演示(演讲)
原文:https://www.blog.pythonlibrary.org/2009/03/27/pycon-2009-ironpython-data-directions-and-demos-talk/
Jim Hugunin 开始了他的演讲,他提到了他在微软的同事。他接着谈到了 IronPython 的最新版本,它是 2.6 Alpha,实际上尽可能地匹配 Python 2.6 版本。听起来最近版本的 IronPython 2.0 Final 也有很多很酷的东西,比如关闭了 500 个 bug,更多的内置功能和编译成 dll 的能力。
接下来,他介绍了 IronPython 在 Silverlight 中的使用。他展示了几个演示,其中一个看起来像 flash 游戏。他指出 Python 在 DLR 中运行时是沙箱化的,这很酷。说到这里,Huginin 快速浏览了一遍 DLR,然后继续深入讨论 C# 4.0。我想他说的是这个新版本允许在 C#程序中使用 Python 代码,但我不是很确定,因为这很令人困惑。如果你使用。NET 和 Python,您可能会发现这要有趣得多。等视频,看懂了再告诉我。

PyCon 2009 要来了,我要去!
原文:https://www.blog.pythonlibrary.org/2009/01/31/pycon-2009-is-coming-and-im-going/

PyCon 2009 将于 3 月 27 日星期五再次在伊利诺伊州芝加哥举行。去年有 1000 多人参加,我知道今年有希望再次打破去年的出席记录。今年是我第二次去。
我将参加两个辅导日(3 月 25 日和 26 日)。第一天我将参加马克·拉姆的涡轮齿轮教程。第二天,我打算去 Py。上午考,下午考 Chun 的互联网编程用 Python 课。希望春的课能像他的书一样好。
我希望在主会议期间也能看到 Christopher Barker 在 wxPython 和 web 上的演讲。除此之外,我没有任何其他具体的计划,所以我很乐意接受建议。如果你有任何建议,请告诉我。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









