







期货延续:它是什么,挑战,方法和更多
通常,大多数交易活动都是在交易合同中进行的。期货延续合约是帮助期货合约延续到下个月的交易合约之一。如果你对期货延续还不熟悉,可以看一下之前关于期货交易的 。
这个博客将带你经历从基础到建立持续未来的所有事情。它包括:
什么是期货延续?
代表一系列连续到期的铅期货合约的合同,具有相关的间隔,在该间隔期间,铅期货在另一个接管之前结束。
例如,让我们看看一系列原油期货合约。使用以下合约,期货合约将如下所示:
公司 2022 年 1 月
公司 12 月
公司 11 月【202102】公司 10 月
公司 20210922
在上面的列表中,每个合同都以年/月/日的日期格式提及。例如,在合同“CO October’ 20210922”中,2021 是年份,09 是九月,22 是日期。
上面的列表是一个连续合同的例子,每个合同显示了前一个合同的提前结束日期。在结束日期,前一个合同不再是主要合同,另一个合同将接管主要合同。
因此,该合约将于 2021 年 9 月 22 日到期,10 月合约将成为主力合约。那么下一个到期日是 2021 年 10 月 20 日。
接下来,合同在 2021 年 11 月 25 日到期,最后一份合同在 2022 年 1 月。这就是我们没有选择 2022 年合同最后到期日的原因。
期货延续合约的挑战
一种资产的期货合同有不同的到期日(在很短的时间内发生),这使得它们的技术分析和信号生成很困难。
例如,瘦肉型猪期货将于 10 月和 12 月到期。10 月份的瘦肉猪期货合约在到期日之后将不再存在。因此,数据将在很短的时间内可用。
这里的短时间,我们指的是大约三到六个月。计算瘦肉猪价格交叉的简单任务是 50 天移动平均线和 200 天移动平均线的交叉,这非常困难,因为我们没有太多的数据点。
但是有办法增加数据点吗?
我们需要将不同的到期期货缝合在一起,并创建一个连续的期货合约来增加数据点。
延续是通过将多个单独的序列拼接在一起而获得的时间序列。期货延续是通过拼接多个单独的期货合约获得的时间序列。
一个非常简单的解决方案是,当当月期货到期时,添加下一个到期日的数据。
例如,当 10 月瘦肉猪期货在 10 月 27 日到期时,我们可以追加 11 月瘦肉猪期货合约的数据。不幸的是,这可能导致错误的结果,因为这两个是不同的合同。
10 月 27 日的 10 月瘦肉猪期货价格将不同于 11 月瘦肉猪期货价格。通过简单地添加数据,你会在你的时间序列中引入人为的间隔。
让我们想象一下这个人为的缺口会是什么样子,因为这个缺口会让价格看起来像是在一个特定的方向上(下跌或上涨),而实际上却不是。
为了形象化,我们将使用 Python。首先,我们将导入必要的库。这里我们将阅读两份期货合约。这两份合约是 2020 年 10 月和 2020 年 12 月到期的瘦肉型猪的期货数据。
阿尔法生成-控制日内风险状况
原文:https://blog.quantinsti.com/controlling-intraday-risk-profile-10-jan-2017/
https://www.youtube.com/embed/ZUzBAHKRmiE?rel=0
网上研讨会日期和时间
2017 年 1 月 10 日星期二
上午 8:30 是|上午 9:00 在科技委
阿尔法生成
基于低频价格(如日末报价)的资产回报仍主导着现代投资组合分析。为了使投资组合指标在当天更相关,并提高估计的精确度,需要探索新的数据频率。
在本次演讲中,我们展示了如何使用高频市场数据进行投资组合风险管理和优化,从而改善传统的方差偏差权衡,并为策略回溯测试带来新的见解。
由于高频价格需要特殊处理,我们讨论微观结构噪声、价格跳跃、异常值、厚尾和长期记忆的自动模型管道的关键组成部分。
我们以基于日内投资组合指标的高频投资组合优化的介绍来结束我们的演讲。例子将在 Python 中显示。
斯蒂芬妮·托珀

- PortfolioEffect 投资组合分析总监
Stephanie 在 Karya Capital、UBS 和 Societe Generale 担任了 8 年的定量开发人员,并且是 MF Global 的高级风险分析师。她在利率衍生品和量化库开发方面拥有丰富的经验。
她拥有哥伦比亚大学的金融数学硕士学位和法国 ENSIMAG 大学的应用数学和计算机科学硕士学位。
谁应该参加?
对于那些需要任何频率的日内风险指标、投资组合优化、投资组合回溯测试和指标预测的人来说,本次网络研讨会非常有益。示例将在 Python 中显示。该会议非常适合:
- 研究人员
- 定量分析师
- 股票、交易所交易基金和指数交易员
- 那些寻找回溯测试策略的人
- 对金融市场感兴趣的 Python 程序员
关于 组合效应
PortfolioEffect 服务通过 4 个 API 提供投资组合优化、投资组合回溯测试、指标预测和日内风险指标:Python、R、Matlab 和 Java。我们服务的独特之处在于,所有的计算都是使用高频市场数据完成的,这有利于低频和高频交易者。我们涵盖 8000 多种美国股票(股票、指数、交易所交易基金)。客户也可以上传他们自己的市场数据。PortfolioEffect 服务采用高频市场微观结构理论的最新进展,以分笔成交点级别的分辨率提供经典的投资组合风险和优化结果。它使用自动模型管道以流式方式处理高频价格回报。
什么是校正人工智能以及它如何改善您的投资决策[研讨会]
原文:https://blog.quantinsti.com/corrective-ai-improve-investment-decisions-20-september-2022/
https://www.youtube.com/embed/nAOjbL5bsjA?rel=0
欧内斯特·陈博士向您介绍了人工智能的概念及其在金融市场中的应用。
扬声器
陈博士(创始人& CEO,PredictNow.ai Inc)

陈博士是 PredictNow.ai Inc .的创始人兼首席执行官,也是 QTS 资本管理有限公司的管理成员。自 1997 年以来,他曾在多家投资银行(摩根士丹利、瑞士瑞信银行、Maple)和对冲基金(Mapleridge、Millennium Partners、MANE)工作。
陈博士从康奈尔大学获得物理学博士学位,在加入金融业之前,他是 IBM 人类语言技术小组的成员。他是总部位于芝加哥的投资公司 EXP Capital Management,LLC 的联合创始人和负责人。
陈博士还是《量化交易:如何建立自己的算法交易业务》(Wiley)、《算法交易:制胜策略及其基本原理》(T2)(T3)的作者,他的第三本书也是最新的一本书是《机器交易:部署计算机算法征服市场》(T4)(T5)。
关于 Algo 交易大会 2022
QuantInsti 举办的 2022 年算法交易大会对有抱负的算法交易者来说是一个很好的学习机会。这是您联系您最喜爱的专家并免费获得所有问题答案的机会。
该活动于美国东部时间 2022 年 9 月 20 日上午 11:45(IST 时间晚上 9:15)举行。
协方差和相关性:简介、公式、计算等等
何塞·卡洛斯·冈萨雷斯·田中
让我们多了解你一点。你认为你需要在拳击场上看一场“协方差 vs 相关性”的比赛,这样你才能在它们之间做出正确的选择吗?
- 你是金融市场的初学者吗,想知道基本概念以便开始交易吗?
- 你知道原油是如何与美元、欧元或日元一起波动的吗?
- 你知道当世界陷入衰退时,黄金价格和利率是如何变化的吗?
无论你在行业中的地位如何,或者你有什么疑问,这篇简单易懂的文章将带你了解这两个概念:从定义和公式到交易应用,你也将准备好正确分析重要金融变量之间的关系。
所以,坐在舒适的座位上,喝杯咖啡,享受这种学习体验吧!
什么是协方差?
协方差是一种统计测量,其定义如下:它测量两个变量之间线性关联的方向。
有了这个解释,你就开始想象我们是你的老师,你举手说:“老师,我不明白。
别担心!让我们简化一下:它测量两个变量之间的同步方向。换句话说,你有两个变量的数据,协方差衡量这两个变量是同向还是反向移动。
我们说正协方差,如果两个变量同向变动:如果一个股票价格上涨,那么另一个股票价格也会上涨。我们说负协方差,当一个股票价格上涨,另一个股票价格向相反的方向,意思是,下跌。
关于“线性联想”这几个字,后面你就明白重点了。所以,是的,协方差可以是正的,也可以是负的。
假设我们有四种股票价格的数据:
- 亚马逊,
- 苹果,
- 沃尔玛,还有
- 微软。
在顶部,你可以看到一个正的协方差图:当亚马逊的股价上涨时,苹果的股价也朝着同样的正方向上涨。在底部,你可以看到,当微软向下移动时,沃尔玛则相反,向上移动,这意味着它们之间存在负协方差。


问题: 如果变量 A 和 B 有一个正的协方差,那么我们是否应该解释为每当变量 A 的值变高时,B 也“总是”变高?”
不总是。这种直接或反向的同步也可能是强的或弱的。如果正负协方差的绝对值很大,那么我们说同步性很强,如果很小,我们说同步性很弱。
什么是强同步或弱同步?
我们能说的是,一个大的正协方差,或者说一个强的正同步性,意味着,大多数时候,两个变量会朝着同一个正方向运动。
负协方差也是如此:如果我们有两个变量的大的负协方差值,就绝对值而言,这意味着我们期望看到,大多数时候,两个变量的运动方向相反。
现在有了更清晰的定义,你有了一个推论和两个问题来测试你的知识:
- 协方差衡量的是两个变量之间的强关系还是弱关系?
- 两个变量之间能有完美的正向或反向同步吗?
对于这些问题,让我们带你去我们的另一个重要概念叫做相关性。
什么是相关性?
你可能会停下来,喝一口咖啡,然后对自己说:“【to】哦,这里有另一个定义,它包含了大量的信息!
嘿!完全不用担心!实际上,相关性也有类似的定义。先正式放一放。相关性衡量两个变量之间的线性关联程度。
我们知道,你很惊讶,又问:“我们还有‘线性联想’这几个字吗?
嘿!别急,我们以后再谈这个。现在,我们可以说:当协方差度量同步运动的方向时,相关性不仅度量同步运动的方向,还度量这种关系方向的程度,或“强度”。
我们稍后会看到这种“力量”是什么样子的。现在,让我们在下面表达这两个概念之间的区别:
协方差和相关有什么区别?
| 协方差 | 相关性 |
| 衡量一件事 | 衡量两件事 |
| 无限范围 | 有限范围 |
| 它有测量单位 | 无测量单位 |
| 可扩展值 | 不可伸缩值 |
区别#1:协方差衡量一件事,而相关性衡量两件事。
如上所述,协方差只测量两个变量的同步运动的方向。相关性不仅衡量关系的方向,还衡量这种关系的强度。
那么,亚马逊和苹果的股价同向或反向移动的效果如何呢?
你现在有两个技术工具来回答这个问题:
- 要找出两个变量是同向还是反向运动,可以使用协方差函数或相关函数。
- 关于这种正向或反向关系“有多好”,你需要用后者来回答这个问题。
区别#2:协方差和相关值范围不同。
协方差可以有一个无穷大的正值或无穷大的负值,取值范围是整个实数范围。然而,相关值范围仅在-1 和+1 之间。
所以你关于完美同步的问题可以在这里得到回答:因为协方差可以有任何实值,我们不能用这个统计量来评价两个变量之间完美的线性关联。
处理这个问题的最好方法是相关性。如果变量 A 和 B 的相关值为+1,你可以毫无疑问地说两个变量“总是”朝同一个方向运动。值为-1 的相关性也是如此:你可以毫无疑问地说,两个变量“总是”向相反的方向移动。
在这里你可以理解第一个区别。当相关性在-1 和 1 之间时,同步分别不是完全负的或正的。最后但并非最不重要的是,关于这种差异,我们必须说,几乎不可能看到现实世界中的变量具有恰好等于+1 或-1 的相关性。
区别#3:协方差和相关性有不同的度量单位。
你以后会从数学上理解它。现在,我们可以说协方差的度量单位是两个变量度量单位的乘积。
例如,如果你有亚马逊和苹果的两种股票价格,它们都以美元为度量单位,那么协方差的度量单位就是:美元乘以美元,也就是美元的平方。
然而,相关性根本没有任何度量单位。还不赶紧着急!啜饮你的咖啡,再等一会儿,就能完全理解这一点。
差异#4:如果变量的比例不同,协方差的值可能会改变,相关性不受此影响。
让我们举个例子来理解这种区别。你有两个股票价格,亚马逊和苹果,然后你计算它们的协方差和相关性,结果分别是“a”和“b”。
接下来,您决定将两个股票价格乘以 1000,并再次计算它们的协方差和相关性,结果得到值“c”和“d”。你会发现一件有趣的事情:
- 协方差“a”不同于协方差“c ”,
- 相关性“b”等于相关性“d”。
当您缩放一个或两个变量时,协方差的值会相应地改变。然而,相关性不受标度变化的影响。
如何计算协方差和相关性?
到目前为止,我们已经向你们解释了所有关于它们的概念和性质。但是从现在开始,你会对数学公式有更好的掌握。
首先,你必须区分什么是总体和样本数据。一旦您熟悉了这两个概念,让我们从公式的演示开始:
我们从协方差开始。
人口协方差:
σ
X
,
Y
2
=
∑
i
=
1
N
(
X
i
−
X
‾
)
(
Y
i
−
Y
‾
)
N
\sigma_{X,Y}^{2} = \frac{\sum_{i=1}^{N}\Bigl(X_{i}-\overline{X}\Bigr)\Bigl(Y_{i}-\overline{Y}\Bigr)}{N}
σX,Y2=N∑i=1N(Xi−X)(Yi−Y)Where:
( \sigma_{X,Y}^{2} ): Population Covariance between variables (X) and (Y).
(X_{i}): The (i^{th}) observation of the (X) variable.
(\overline{X}): The mean value of variable (X).
(Y_{i}): The (i^{th}) observation of the (Y) variable.
(\overline{Y}): The mean value of variable (Y).
(N): Total number of observations for variable (X) o (Y).
样本协方差:
S
X
,
Y
2
=
∑
i
=
1
N
(
X
i
−
X
‾
)
(
Y
i
−
Y
‾
)
N
−
1
S_{X,Y}^{2} = \frac{\sum_{i=1}^{N}\Bigl(X_{i}-\overline{X}\Bigr)\Bigl(Y_{i}-\overline{Y}\Bigr)}{N-1}
SX,Y2=N−1∑i=1N(Xi−X)(Yi−Y)Where:
( S_{X,Y}^{2} ): Sample Covariance between variables (X) and (Y). The other variables are the same as for the Population Covariance
那么,简单地说,我们如何解释协方差公式呢?这么说吧:协方差是一种度量,我们将分别由(Xi-X)和(Yi-Y)给出的 X 和 Y 的均值的每个偏差相乘,然后我们将所有这些乘积求和并除以 n
类似于变量方差的公式吧?嗯,两个公式几乎是相似的,唯一的区别是,在方差公式中,你看到的是与均方的偏差,对于协方差,你看不到平方偏差。
但是方差公式也可以写成:
σ X , Y 2 = ∑ i = 1 N ( X i − X ‾ ) 2 N = ∑ i = 1 N ( X i − X ‾ ) ( X i − X ‾ ) N \sigma_{X,Y}^{2} = \frac{\sum_{i=1}^{N}\Bigl(X_{i}-\overline{X}\Bigr)^2}{N}=\frac{\sum_{i=1}^{N}\Bigl(X_{i}-\overline{X}\Bigr)\Bigl(X_{i}-\overline{X}\Bigr)}{N} σX,Y2=N∑i=1N(Xi−X)2=N∑i=1N(Xi−X)(Xi−X)
你明白了吗?方差和协方差公式实际上是相同的;不同之处在于第二个括号,它由第二个变量的偏差代替。方差指的是单个变量,协方差指的是两个变量,这就是为什么它被称为“协”方差。
样本协方差与总体方差相同,但我们用被除数除以 N-1,而不是 N。这种差异的解释可以在本博客的“样本数据的标准偏差——贝塞尔的修正”部分找到。
如你所料,X 用 X 单位表示,Y 用 Y 单位表示。因为协方差公式是这两个变量的乘积,所以它将采用 XY 测量单位。
现在让我们来看看相关公式:
( \rho_{X,Y} = \frac{\sum_{i=1}{N}\Bigl(X_{i}-\overline{X}\Bigr)\Bigl(Y_{i}-\overline{Y}\Bigr)}{\sqrt{\biggl(\sum_{i=1}{N}\Bigl(X_{i}-\overline{X}\Bigr)2\biggr)\biggl(\sum_{i=1}{N}\Bigl(Y_{i}-\overline{Y}\Bigr)^2\biggr)}} = \frac{\sum_{i=1}{N}\Bigl(X_{i}-\overline{X}\Bigr)\Bigl(Y_{i}-\overline{Y}\Bigr)}{\sqrt{\biggl(\sum_{i=1}{N}\Bigl(X_{i}-\overline{X}\Bigr)2\biggr)}\sqrt{\biggl(\sum_{i=1}{N}\Bigl(Y_{i}-\overline{Y}\Bigr)^2\biggr)}})
ρ
X
,
Y
=
C
o
v
(
X
,
Y
)
σ
X
σ
Y
\rho_{X,Y} = \frac{Cov(X,Y)}{\sigma_X\:\sigma_Y}
ρX,Y=σXσYCov(X,Y)Where:
( \rho_{X,Y} ): Correlation between variables (X) and (Y).
(Cov(X,Y)): Covariance between (X) and (Y).
(\sigma_X): Standard Deviation of variable (X).
(\sigma_Y): Standard Deviation of variable (Y).
那么,我们如何用简单的语言解释这个公式呢?你已经知道了被除数,关于除数,如果你能记住方差公式,你就能知道除数是两个变量 X 和 y 的标准差的乘积。
所以我们可以说相关性是协方差除以两个变量的标准差。你可能会认为协方差和标准差有除数“N”或“N-1”,所以你可能会认为我们写错了第一个公式。
别担心,让我们让你看看约数发生了什么:
( \rho_{X,y } =∞)
( \rho_{X,y } =∞)
( \rho_{X,y } = \frac{\sum_{i=1}{n}\bigl(x_{i}-\overline{x}\bigr)\bigl(y_{i}-\overline{y}\bigr)}{\sqrt{\biggl(\sum_{i=1}{n}\bigl(x_{i}-\overline{x}\bigr)2\biggr)}\sqrt{\biggl(\sum_{i=1}{n}\bigl(y_{i}-\overline{y}\bigr)^2\biggr)}} )
ρ X , Y = C o v ( X , Y ) σ X σ Y \rho_{X,Y} = \frac{Cov(X,Y)}{\sigma_X\:\sigma_Y} ρX,Y=σXσYCov(X,Y)
现在你明白了吗?协方差和标准偏差的除数相互抵消。此外,如前所述,被除数的度量单位是 X 和 y 两个度量单位的乘积。除数的度量单位也是 X 和 y 两个标准差的乘积。
因此,由于被除数和除数具有相同的 XY 测量单位,所以它们相互抵消,从而得到没有测量单位的相关值。现在你能理解之前解释的区别了吧?
此外,你现在可以理解区别#4 了。为什么?因为协方差以 XY 测量单位结束,所以无论何时改变两个变量中任何一个的比例,除数的测量单位也会随之改变。
同时,由于相关公式没有度量单位,所以您可以对这两个变量中的任何一个进行的标度更改都不会影响-1 和 1 之间的相关范围。
我们已经了解了所有这些解释,现在你可能会问:
协方差和相关性的重要性
好吧,你现在问这个重要的问题。答案在于经济学和金融学的本质。作为经济学的一个重要组成部分,金融是关于市场的,在这个市场中,经济主体从一个或多个市场中买卖资产。
在市场内部或市场之间,由于每天都有相同的代理人进行交易,资产可以与任何其他资产以相同或相反的方向移动。
资产价格根据代理人的行为、市场条件等而变化。如果有一个人买了 100 股苹果股票,或者有一群人因为银行挤兑而卖出他们的银行股票,那么每个人的交易不仅会对资产本身产生影响,还会对其他股票或其他市场产生影响。
市场是相互关联的,因此相关性和协方差是金融市场研究的重要组成部分。如果市场或金融资产不是相互关联的,我们就不需要考虑协同运动。
你现在不仅知道这两个概念的含义,而且知道它们为什么重要。我们达到了我们的主要目的。
所以,现在,你想交易,对吗?
*你已经准备好检查苹果和亚马逊股票价格的相关性,现在你准备好按下你的经纪人平台上的买入和卖出按钮开始投资。*你不是吗?
不要!等一下!在你做决定之前,让我们向你解释一下协方差和相关性在交易和投资中的实际应用。
协方差和相关性的交易应用
交易应用#1:投资组合波动性计算
当你开始投资多只股票时,你必须考虑你的投资组合的波动表现如何。只有当你完全理解了协方差和相关性是如何工作的,才可能计算出这个投资组合的波动性。
所以,请不要按购买键。你可以在 Quantra 上查看我们的投资组合管理课程,了解更多。再等一会儿,让我们向你解释更多。
交易应用#2:统计套利
每当你进入统计套利,你必须理解相关性和协整的定义。统计套利不利用相关性,但是理解这两个概念之间的区别非常重要。
我们关于统计套利交易的课程会解释这一切。*我们可以猜测,你现在想要开始按下买入和卖出按钮进行套利,对吗?*我们告诉过你,再等等!
交易应用#3:回归估计中的相关变量
在两个或多个变量之间进行回归的主要条件之一是拥有不相关的独立变量。所以,既然你已经知道了相关性的含义,现在你就能够在回归估计中出现违反这一条件的情况下纠正问题。你可以通过这门关于用机器学习进行交易:回归的课程来扩展你关于这个话题的知识。
交易应用#4:预测资产价格的相关性
你看,金融资产价格,与受控物理实验中的变量相反,往往会随着时间的推移而经历状态变化。因此,如果你使用 2021 年的数据计算美国 2 年期国债收益率与联邦基金利率的相关性,那么 2022 年的这个值不一定是相同的。
随着时间的推移,相关性可能会有很大变化,这通常发生在不利的经济冲击或经济或金融危机中。使用相关性来预测你的下一个交易信号时要小心!
交易应用#5:预测资产价格回报的 ARMA 模型
那么,你听说过自回归移动平均(ARMA)模型吗?该模型试图用通过回归模型计算的过去收益估计值来预测资产价格收益,其中回归误差的移动平均值也很重要。
在这里你会了解到什么是自协方差和自相关函数。所以为了理解这两个概念,你必须先理解这篇文章的两个概念。
自相关函数是什么样的?
请记住,相关函数是基于两个变量计算的,也请记住,ARMA 模型试图用以前的收益来预测资产价格收益。因此,如果你说这些回报可以称为 rt,那么,自相关函数可以表示为:
ρ r t , r ( t − 1 ) = C o v ( r t , r ( t − 1 ) ) σ r t σ r ( t − 1 ) \rho_{r_{t},r_{(t-1)}} = \frac{Cov(r_{t},r_{(t-1)})}{\sigma_{r_{t}}\:\sigma_{r_{(t-1)}}} ρrt,r(t−1)=σrtσr(t−1)Cov(rt,r(t−1))
你想知道更多吗?在 Quantra 中获取关于时间序列分析的精彩课程。
交易应用#6:因果关系和相关性不是一回事
这是更多的交易知识,所以要注意这一点。因果关系意味着苹果股价的变动会导致亚马逊股价的变动。但是,我们这里所说的“原因”是什么意思呢?嗯,因果关系甚至在经济学中被哲学地讨论。哲学讨论到现在还没有结束。让我给你举个例子,这样你能更好地理解它。
想象一下,我们有纽约市每月的雨水量,也有纽约市每月的 GDP。你计算它们之间的相关性,得到的值是 0.95。
你可以说:*“哦,真有趣!那么,我可以说,每当这个城市下大雨时,这将导致纽约的 GDP 增加。”*没有!你不能说大量的雨水‘导致’了 GDP 的增长;或者相反,GDP 的增长会导致城市雨水的增加。
相关性只是意味着你可以找到这两个变量之间的同步模式,但这并不意味着雨水和 GDP 之间存在经济因果关系。
所以,当你作为交易者谈论相关性时,你必须记住这个概念不一定等同于因果关系。换句话说:
因果关系总是意味着相关,但相关并不总是意味着因果关系。
交易应用#7:相关性程式化事实
这也是融入你的背景知识的重要信息。当你想交易一些金融资产时,考虑一些全球相关性是很重要的。
在这里,我们向您呈现一些程式化的事实,当您想用这些资产进行交易时,请记住这些事实:
- 原油和货币:每当原油价格下跌,俄罗斯、加拿大、委内瑞拉或沙特阿拉伯等原油净出口国的货币就会下跌。然而,每当原油价格下跌时,像日本这样的原油净进口国往往会看到自己的货币升值。
- **逃向优质资产:**每当世界某个重要国家或地区发生金融动荡时,比如 1997 年亚洲金融危机,投资者往往会将资金撤出这些高收益国家,购买美国国债。这一行动使得受影响国家的货币对美元大幅贬值,美国国债往往会大幅升值。因此,在亚洲危机中,亚洲国家的货币与美国债券价格之间存在负相关关系。
- 股票-债券负相关关系:例如,每当美国经济开始繁荣时,投资者就会重新配置他们的投资组合。他们大量投资风险更高的资产,减少对美国国债的投资。当经济进入衰退时,情况正好相反,固定收益投资增加,股票投资减少。股票和债券之间的这种负相关关系是世界各国的共同特征。
- **黄金时变相关性:**当世界投资者更倾向于投资风险资产时,黄金与美国股市的正相关性增加。当他们变得更加厌恶风险时,由于全球经济衰退,黄金与美国股市成反比。
- 黄金和通货膨胀:当全球通货膨胀上升时,投资者倾向于增加黄金的投资组合配置,这意味着黄金和通货膨胀之间的相关性是正的。黄金具有对冲通货膨胀的作用。当通货膨胀超过预期时,贵金属会维持你的购买力。
- **黄金和美国利率:**当美国看到其利率上升时,这意味着经济状况良好。这使得全球投资者将他们的资源分配给风险更高的资产。因此,黄金在这个时期开始贬值。我们可以说黄金和美国利率一直是负相关的。
- **地缘政治与黄金:**每当出现影响全球的不利地缘政治冲击时,金价往往会上涨,因为这种贵金属充当了“避风港”的角色。
- **收益-波动率相关性:**当股价下跌时,公司的负债权益比率会增加,进而使其股价收益波动率增加。股票价格收益与其波动性之间的这种负相关关系被称为“杠杆效应”。当你交易股票并想要模拟波动性时,你应该考虑这种对你的估计的影响,以便捕捉负相关。
协方差和相关性简单练习题
如何计算协方差?
你现在准备好了,对吗?好了,先说一个简单的例子。假设我们有两个资产价格,微软和特斯拉,我们有每只股票 5 天的数据。
下面我们将数据以表格的形式呈现如下:
| 日期\库存 | 微软 | 特斯拉 |
| 第一天 | Two hundred and forty | Eight hundred and fifty |
| 第二天 | Two hundred and sixty-five | eight hundred |
| 第三天 | Two hundred and fifty-five | Eight hundred and twenty |
| 第四天 | Two hundred and eighty | Eight hundred and seventy |
| 第五天 | Three hundred and one | Nine hundred |
由于我们有样本而不是总体数据,我们将使用样本协方差和相关函数。首先,我们知道我们有 5 个观测值,这就是为什么我们的 N 变量是 5。
然后,我们必须计算每只股票的平均值。我们会帮你的,这两个平均值分别是:微软 268.2,特斯拉 848。接下来,我们必须计算每个观察值与平均值的偏差,必须对每个股票进行计算:
| 日期\库存 | 微软 | 特斯拉 | 微软偏离平均值 | 特斯拉偏离平均值 |
| 第一天 | Two hundred and forty | Eight hundred and fifty | -28.2 | Two |
| 第二天 | Two hundred and sixty-five | eight hundred | -3.2 | -48 |
| 第三天 | Two hundred and fifty-five | Eight hundred and twenty | -13.2 | -28 |
| 第四天 | Two hundred and eighty | Eight hundred and seventy | Eleven point eight | Twenty-two |
| 第五天 | Three hundred and one | Nine hundred | Thirty-two point eight | fifty-two |
完成后,您可以将每个日期的两个偏差相乘,然后将所有乘法结果相加,得到协方差公式的被除数:
| 微软对平均值的偏离 | 特斯拉偏离均值 | 两个偏差的乘积 |
| -28.2 | Two | -56.2 |
| -3.2 | -48 | One hundred and fifty-three point six |
| -13.2 | -28 | Three hundred and sixty-nine point six |
| Eleven point eight | Twenty-two | Two hundred and fifty-nine point six |
| Thirty-two point eight | fifty-two | One thousand seven hundred and five point six |
| | 协方差红利 | Two thousand four hundred and thirty-two |
计算协方差缺少什么?
你差不多完成了。你有了被除数,却没有除数。除数就是观察总数减一。所以让我们用(N - 1)除协方差被除数:
( Cov(Microsoft,Tesla) = \frac{2432}{5-1} = \frac{2432}{4} )
( Cov(Microsoft,Tesla) = 608 )
还记得定义吗?协方差衡量的是微软和特斯拉之间的同步运动的方向。那么从这个值中我们可以得到什么样的解读呢?我们可以说,因为 608 是一个正数,我们得出结论,这两个股票价格之间存在正的同步性。
现在你问我,微软和特斯拉之间的这种同步有多“强”?这可以用相关系数来回答。
相关系数怎么算?
一旦我们有了协方差值,你可以从上面记住,我们只需要微软和特斯拉的标准差。我们会用这些价值观来帮助你。微软和特斯拉的标准差分别为 23.42 和 39.62。所以应用这个公式,我们得到:
( Cov(Microsoft,Tesla) = \frac{2432}{23.42*39.62} = \frac{2432}{928.15} )
( Cov(Microsoft,Tesla) = 0.66 )
如果我们选择 0.5 作为阈值来决定相关值是接近 1 还是接近 0,这取决于研究人员,因为 0.66 大于 0.5,我们可以说微软和特斯拉之间的同步是积极的,也是强有力的。
在相关性定义中,我们所说的“线性关联度”是什么意思?
之前,我们向你解释过,相关性衡量两个变量之间的线性关联程度。这个解释是统计学教科书中的正式定义。
你怎么能以一种简单的理解来面对这种解释?
现在就这么办。
我们知道相关性的取值范围在-1 到+1 之间。也可能是零,对吧?让我们将这两种极端情况和一种接近于零的情况绘制成散点图:



如您所见,当相关性完全为+1 或-1 时,散点图本身就像一条线。这意味着变量 A 和 B 都有线性关系或线性关联。
如果相关性接近 1,你可以说,如果你画一条贯穿这些值的线,你会得到这条斜率为正的线。如果相关性接近-1,并且如果您绘制一条贯穿这些值的直线,您将得到一条斜率为负的直线。随着该值从 1 减小到 0,这种线性关联变得不太明显,同样,该值从-1 增大到 0。
相关性等于零或非常接近零意味着两个变量之间完全没有相关性,您还会看到这个相关值几乎是一个随机散点图。
使用我们上面的相关性定义,正相关性的强度可以理解为公式值从零趋向于+1。负相关的强度可以理解为从零到-1 的公式值。
让我们用图表来看看弱相关性或强相关性是如何表现的:


你已经看到了完全负相关的样子。现在你可以从上面的图表中看到强相关和弱相关可能是什么样子。上图显示负相关为-0.83,下图显示相关等于-0.25。
正如你所看到的,当值接近-1 时,你可以说这种负相关性很强。但是当相关性趋近于零时,在图形中看不清楚线性关联,我们也说这种负相关性弱。


接下来,让我们看看正相关的例子。上图显示了 0.84 的正相关性,下图显示了等于 0.29 的相关性。正如你所看到的,当值接近 1 时,你可以说这种正相关性很强。
但是当相关性趋近于零时,在图形中看不清楚线性关联,我们也说这种正相关性弱。
我们在上面的图表中展示了零相关的情况。现在,你可能会问我们,难道没有其他形式的不相关吗?
让我们看看另一张图表:

正如你所看到的,X 和 Y 之间的相关性为零,它同时具有正负线性关联。因此,有两种类型的相关等于零的图形:
- 随机散点图,以及
- 非线性散点图。
什么是好的协方差和相关值?
看到上一张图或者之前的图,你可能会问自己这个问题。你一定知道答案,所以我们在这里解释一下。实际上,对于所有情况下的协方差和相关函数,没有“好的”或“完美的”值。
例如,对于投资组合管理,股票协方差为负是一个很好的值,因此你可以在资产之间进行更好的分散。对于回归估计中的独立变量,您认为它们的相关性接近零是一个好值。
对于 ARMA 模型,您会希望自相关函数不为零,以确认模型的构建适合股票价格回报。
正如你所看到的,我们的协方差或相关性公式的好值取决于你在寻找什么:它取决于交易者或研究人员,也取决于你谈论的话题。
Python 中的协方差和相关性计算示例
现在让我们利用真实世界的数据来计算我们的主要编程语言 Python 中的这两个重要概念:
Python 中如何计算协方差和相关性
让我们下载微软和特斯拉的股价,用它们来进行计算:
我们首先建立环境来完成工作。如果你没有“yfinance”库,不要忘记安装它:
使用机器学习的覆盖呼叫策略
原文:https://blog.quantinsti.com/covered-call-strategy-machine-learning/
投资者利用备兑买入期权在持有股票的同时赚取一些小利润。交易员想要创建备兑买入期权的主要原因是,交易员看好标的股票,并希望长期持有,但该股票不支付任何股息。该股预计将在未来 6 个月内上涨,与此同时,你可能希望将该股作为抵押品,卖出一些看涨期权,将溢价收入囊中。但这种策略有风险,即如果股票上涨,那么你的股票将在到期时被赎回。因此,你可以以较低的溢价买回期权,而不是等待期权到期。
利用机器学习进行交易的方法有很多种。在这篇博客中,我将尝试向你展示如何通过使用简单的决策树算法来预测期权溢价的短期变动,并在持有股票的同时赚取差价。
有关不同期权交易策略的更多详情,请访问 https://quantra.quantinsti.com/
让我给你看一个例子,用漂亮的期货。Nifty50 是一个印度指数,由来自不同行业的 50 只股票组成。
为了执行上面讨论的策略,我们假设我们持有期货合同,然后我们试图在相同的基础上卖出一个看涨期权。为了做到这一点,我们在由各种希腊文组成的过去数据上训练一个机器学习算法,比如选项的 IV、delta、gamma、vega、theta 作为输入。因变量或预测将在第二天的收益中进行。每当算法产生卖出信号时,我们就写调用。首先,让我们导入必要的库。
导入库
创建交易策略:实践在线研讨会
原文:https://blog.quantinsti.com/create-a-trading-strategy-hands-on-online-workshop/
以下是我们研讨会的摘要:
https://www.youtube.com/embed/B23sVOkzEjY?rel=0
2020 年 3 月 11 日星期三晚上 8:00-9:00 IST
概述
在这个实践研讨会中,学习创建和测试可用于交易外汇、股票、期权、商品、加密货币和其他工具的交易策略。除了实践培训,我们还将为您提供工具和知识,帮助您将这些知识应用到自己的交易经验中。
它将包括什么?
- 如何想出一个交易策略的点子?
- 如何使用数据分析来验证想法?
- 如何创建回测的交易系统?
- 如何分析结果?
- 如何为自己的交易做到这一点?
- 向专家提问
演讲者简介
伊山·沙阿(AVP,内容&在昆汀斯提研究)

伊桑·沙阿是 AVP,领导 QuantInsti 公司 Quantra 的内容和研究团队。在此之前,他曾在巴克莱全球市场团队和美国银行 Merill Lynch 工作。他在金融市场拥有丰富的经验,在不同的资产类别中担任不同的角色。
https://www.slideshare.net/slideshow/embed_code/key/72Qwt0tUgEN5xx
Create a Trading Strategy: Hands-on Online Workshop from QuantInsti
如何从头开始创建交易算法[网上研讨会]
原文:https://blog.quantinsti.com/create-trading-algorithm-webinar-22-july-2021/
网络研讨会录制
https://www.youtube.com/embed/tL5hpLIG3eo?rel=0
演示幻灯片
//www.slideshare.net/slideshow/embed_code/key/xfG2zGwjjPTJsW
How To Create A Trading Algorithm From Scratch from QuantInsti
关于会议
学习从零开始创建一个交易算法,并用真实的市场数据进行测试。了解创建交易算法的所有基本要素。本节将举例解释各种交易策略范例,如动量交易和均值回归。
会话大纲
- 一系列策略
- 基于动量的策略 vs 基于均值回复的策略
- 交易算法的组成部分
- 基于动量算法的一个例子
- 基于均值回复算法的一个例子
- 回溯测试和前瞻测试的重要性
- 互动问答
关于演讲者

Ashutosh Dave(高级助理,内容&在 QuantInsti 的研究)
Ashutosh 在金融衍生品交易和量化金融领域拥有十多年的经验。除了对 QuantInsti 的整体内容开发做出贡献之外,他还在我们的旗舰项目 EPAT 教授 Python。
在加入 QuantInsti 之前,他曾在伦敦的一家自营交易公司担任衍生品交易员,专门从事利率和大宗商品交易。他的主要兴趣领域包括将高级数据科学和机器学习技术应用于金融数据。
Ashutosh 拥有伦敦经济学院(LSE)的统计学硕士学位,并且是 GARP 的 FRM。他是《算法交易简易指南》(QuantInsti,2020)一书的合著者。
本次活动于: 2021 年 7 月 22 日星期四
美国东部时间上午 9:30 | IST 时间晚上 7:00 |新加坡时间晚上 9:30
对于那些正在寻找综合算法交易课程的人来说,QuantInsti 的 EPAT 课程是最好的选择。EPAT 提供业内最好的课程设置,在线课程由业内知名人士授课。您将获得专门的支持经理来解决您的所有疑问。完成认证课程后,你有资格获得终身职业援助。想知道更多关于 EPAT 的细节,今天就联系课程顾问吧。
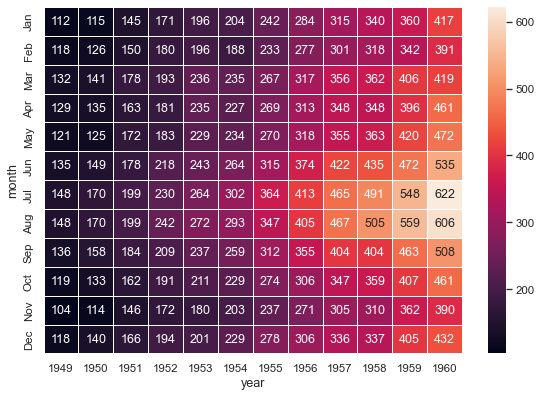
使用 Python Seaborn 创建热图
原文:https://blog.quantinsti.com/creating-heatmap-using-python-seaborn/
在这篇博客中,我们将学习使用 Seaborn Python 包来创建热图,交易者可以用它来跟踪市场。
我们的博客路线图是:
- 面向 Python 数据可视化的 Seaborn】
- 什么是热图?
- 金融领域热图的使用案例
- 创建热图的逐步 Python 代码
-显示股票单日价格变化百分比-显示股票价格变化之间的相关性 - 用于绘制热图的其他 Python 库
在我们之前的博客中,我们讨论了使用散景的 Python 中的数据可视化。现在我们把目光转向 Python 中另一个很酷的数据可视化包。
用于 Python 数据可视化的 Seaborn
Seaborn 是基于 Matplotlib 的数据可视化库。它为绘制有吸引力的统计图提供了一个高级接口。
Seaborn 构建在 Matplotlib 之上,其图形可以使用 Matplotlib 工具进一步调整,并使用任何 Matplotlib 后端进行渲染,以生成出版物质量的图形。
可以使用 Seaborn 创建的地块类型包括:
- 分布图
- 回归图
- 分类图
- 矩阵图
- 时间序列图
- 热图
绘图函数对包含整个数据集的 Python 数据框和数组进行操作,并在内部执行必要的聚合和统计模型拟合以生成信息图。一些例子可以在这里找到。

Source: Seaborn.pydata.org
什么是热图?
热图是数据的二维图形表示,矩阵中包含的各个值用颜色表示。
Seaborn 包允许创建带注释的热图,可以根据创建者的要求使用 Matplotlib 工具进行调整。

Annotated Heatmap: Source
金融业热图的使用案例
如前所述,热图是变量的矩阵表示,根据值的强度进行着色。因此,它为比较各种实体提供了一个极好的可视化工具。
它易于创建和定制,解释起来也很直观。因此,在处理金融中的多种资产时,它被广泛使用。
热图提供强大可视化功能的一些重要使用案例包括:
- 比较价格变化、回报等。各种资产
- 检查多只股票之间的相关性
由于热图为我们提供了一种简单的工具来理解两个实体之间的相关性,因此它们可以用于可视化机器学习模型的特征之间的相关性。这可以通过消除高度相关的特征来帮助特征选择。
创建热图的分步 Python 代码
现在让我们看看其中的几个用例,看看我们如何为它们创建 Python 代码。
显示股票单日价格变化百分比
我们将为在印度国家证券交易所(NSE)上市的 30 家制药公司的股票创建一个 Seaborn 热图。Seaborn 热图将显示股票代码及其单日价格变化百分比。
我们整理了医药股所需的市场数据,并构建了一个逗号分隔值(CSV)文件,该文件由股票代码及其在 CSV 文件前两列中各自的价格变化百分比组成。
由于我们的列表中有 30 家制药公司,我们将创建一个 6 行 5 列的热图矩阵。此外,我们希望 Seaborn 热图以降序显示股票的价格变化百分比。
为此,我们在 CSV 文件中按降序排列股票,并添加两列来表示热图中每只股票在 X & Y 轴上的位置。
步骤 1 -导入所需的 Python 包
我们导入以下 Python 包:
财务中的交叉验证:清除、禁运、组合
原文:https://blog.quantinsti.com/cross-validation-embargo-purging-combinatorial/
亚历克斯·里贝罗·卡斯特罗
交叉验证(CV)并不是一个新颖的话题,但是根据我作为数据科学家和前台从业者的经验,它是一个经常被低估和误用的统计工具。我相信,如果用适当的统计方法来处理,无数糟糕的交易想法本可以被抛弃。因此,这篇博客既是一个警示故事,也是对金融领域现代 CV 方法的快速参考。
我们将讨论以下主题:
机器学习中的交叉验证之前已经讨论过了,我想在这里把重点放在作为回溯测试工具的交叉验证上。我还会提到金融领域交叉验证(CV)的一些陷阱,特别是在数据泄露和数据偷窥方面。
概括地说,CV 是一个重采样工具,旨在分配精确度的测量值(例如:偏差、方差、置信区间、预测误差等)。)到样本估计(例如:模型性能、夏普值等)。CV 是统计学中的一个老概念,随着现代计算机和机器学习的出现,它的时代似乎又回来了。
在金融领域,CV 在处理高噪声对信号的影响,以及减轻策略过度拟合导致的虚假结果方面变得尤为重要。我还应该说,CV 不仅仅限于 ML 交易模型,还可以应用于通过数据挖掘创建的基于规则的策略。
封(港)
我将在 CV 的上下文中交替使用这两个术语(数据泄漏和数据峰值)。这里指的是信息有意无意跨褶皱泄露的情况。当您的模型或策略包含需要大量回顾历史数据的指标时,这一点非常重要。
让我们用一个具体的例子来说明。为了具体起见,假设
- 你的模型或策略取决于一个指标,比如 63 天(或 3 个营业月)后的实际波动率
- 你的折叠是按时间顺序排列的,以 1 年为单位
- 您当前的测试或样本外折叠是第 4 年
示意性地,褶皱看起来像这样:| - 1 - || - 2 - || - 3 - |(| - 4 - |)| - 5 - |
在第 4 年和第 5 年之间,第 5 年早期计算的波动性需要的信息只能在 OOS 折叠中获得。(折叠 3 和折叠 4 之间没有问题,因为折叠 4 中所需的信息已经可用。)
处理这种意外数据泄露的一种常见方法是使用 De Prado 所说的清除和禁止。用专业术语来说,这包括去除受影响褶皱边界附近的一些数据点,但这两个过程之间有细微的区别。
还有比我在这里提到的更多的东西,因为在德普拉多的术语中,每个标记的数据点都有两个时间:交易时间和事件时间。我在上面的例子中建议的特定类型的数据删除是禁运的一个例子。(它发生在吹扫之前。)在我们的具体示例中,我将从 fold (5)中删除前 63 天左右的时间。
寓意:要意识到你的特征的时间依赖性。
清洗
在我们讨论清除之前,我们需要谈谈金融中的事件时间。本质上,这意味着在一个金融时间序列中的任何标记数据点都有一个交易时间和一个事件时间。事件时间通常表示资产的未来市值达到某一水平的时间,如止损或获利价格。在实践中,这意味着标签变得依赖于路径,并且需要小心,以便在计算标签时我们不会偷窥样本外折叠。
举一个具体的例子,假设我们试图建立一个 ML 模型,根据各种数据源预测 IBM 价格在未来 5 个工作日内是否会上涨或下跌至少 50 个基点。这些波动的规模是根据 IBM 股票最近的实际波动水平估算的。一个常见的标记方案是:如果股价波动超过 50 个基点,则为+1;如果股价绝对值波动小于 50 个基点,则为 0;如果股价下跌超过 50 个基点,则为-1。
接下来,让我们假设我们典型的交易期限是 1 周。你今天进入一个头寸,一周后平仓。然而在实践中,大多数人会在交易中设置止损或止盈水平,这样如果达到这两个水平,他们就可以提前退出交易。关键是,要按市值计价交易,你需要观察未来 5 天或未来 5 个基点的价格路径(你可以提前退出)。
在标记过程中,我们必须注意删除测试文件夹中事件时间与交易时间重叠的数据。这个过程称为净化。
在实践中,首先禁止数据集,然后清除它。可以通过在训练折叠之前增加测试折叠的事件时间来实现禁运。(详见德普拉多。)
寓意 : 注意交易和事件之间的价格路径(如交易期限结束、止损、止盈等。)
关于金融领域标签建设的更多深入信息,我推荐 Quantra 的金融数据科学&特征工程介绍视频。
通过交叉验证进行回溯测试
一旦你制定了一个策略,不管是基于规则还是基于 ML,是时候对它进行回溯测试了。第一次,你获得了 0.5 的夏普比率(SR),并且对你的结果不满意,你决定调整你的策略。也许,你告诉自己应该对第一个指标使用不同的阈值水平,看看会发生什么,或者对另一个 ML 超参数使用更高的值。
也许我也应该尝试不同的进出时间。最终,在多次反复调整这个或那个参数之后,您最终得到了一个“完美的”参数组合和一个夏普比率为 2.0 的策略。
不可思议!现在你可以交易了。
然而,在现场交易中,你的表现发生了变化:你基本上失败了,亏损了。哪里出了问题?
我用这个虚构的例子来说明过度适应策略的概念,并说明 CV 在什么地方可以派上用场,来帮助你评估你的结果的统计意义。
您可以使用相同的过程将数据分割成多个折叠,或许可以重复上述相同的过程来校准 IS 折叠中的参数,并对 OOS 折叠中的策略进行回溯测试。
您选择的参数在 Is 折叠中是否稳健?
你在 OOS 弯的表现强劲吗?
如果是这样,你就有更多的统计数据证明你的策略是正确的。(否则,你就是在瞎猜,作为量化投资者,我们不应该给事后批评留有余地。)
这个练习也能让你抛弃一些不可靠的交易参数,因为它们在后验测试中的突出表现可能是由于过度拟合。
我们在机器交易领域的大多数人都熟悉 ML 策略的 CV,但是如上所述,它也可以用于基于规则的策略。CV 启发的回溯测试的一个积极结果是,你可以获得你所研究的整个市场历史的真实表现评估——不管是 5 年的时间窗(对于日交易者),还是高频交易者 1 周的数据。
寓意:回溯测试不是一种研究工具。避免多重回溯测试中的选择偏差,因为你会错误地从随机的历史模式中获利。(相当多的金融研究仍然是由回溯测试驱动的。)
例如,De Prado 在[AFML]中就如何防止回测过度拟合提出了各种建议:
1.为整个资产类别或投资领域开发模型,而不是特定的证券
2.应用集成技术作为既防止过度拟合又减少预测误差方差的手段(参见 Quantra 关于交易树的课程)
3.在你的研究完成之前不要进行回溯测试
4.用各种“假设”情景对你的策略进行压力测试
5.如果回溯测试没有发现一个有利可图的策略,从头开始。
这需要更多的纪律和适当的技能,但它可能会让你免受许多挫折和浪费金钱。
组合清除交叉验证
金融学中标准 CV 方法的一个主要缺点是 CV 只测试单一路径。在没有市场模拟器的情况下,一种替代方法是使用一些组合技巧来生成多个回溯测试路径。

对于博客的这一部分,我将提供一些 Python 代码,说明如何使用所谓的组合清除交叉验证从 1 条历史路径中构建 5 条回溯测试路径。(见上图。)我这里用一个具体的例子。
Python 中组合清除交叉验证的示例
我们将首先下载所需的库
机器学习交易模型中的交叉验证
原文:https://blog.quantinsti.com/cross-validation-machine-learning-trading-models/
由伊山沙阿
什么是机器学习中的交叉验证?
机器学习中的交叉验证是一种提供机器学习模型性能的精确测量的技术。当模型用于未来未知的数据集时,这种性能将更接近您的预期。
The application of the machine learning models is to learn from the existing data and use that knowledge to predict future unseen events. The cross validation in machine learning model needs to be thoroughly done to profitably trade in live trading.After reading this, you will be able to:
- 确定机器学习模型在预测买入信号和/或卖出信号方面是否良好
- 展示你的机器学习交易模型在不同压力情景下的表现
- 全面做机器学习交易模型的交叉验证
But before I explain how to do cross validation in machine learning model, I will first create a sample machine learning decision tree classifier model using price data of the Apple stock. Then, I’ll implement various cross validation measures on this model. To implement this in Python, I’ll follow the below steps
If you are already well versed with these steps and Python coding then you can skim through this part.
导入库
In [1]:
import quantrautil as q
import numpy as np
from sklearn import tree
 The libraries imported above will be used as follows:
The libraries imported above will be used as follows:
- quantrautil -这将用于从雅虎财经获取 AAPL 股票的价格数据。
- numpy -对 AAPL 股票价格进行数据操作,计算输入特征和输出。如果你想了解更多关于 numpy 的信息,你可以在这里找到。
- sklearn 有很多工具和机器学习模型的实现。“树”将用于创建决策树分类器模型。

获取数据
The next step is to import the price data of AAPL stock from quantrautil. The get_data function from quantrautil is used to get the AAPL data for 19 years from 1 Jan 2000 to 31 Dec 2018 as shown below. The data is stored in the dataframe aapl.In [2]:
aapl = q.get_data('aapl','2000-1-1','2019-1-1')
print(aapl.tail())
[*********************100%***********************] 1 of 1 downloaded
Open High Low Close Adj Close \
Date
2018-12-24 148.149994 151.550003 146.589996 146.830002 146.830002
2018-12-26 148.300003 157.229996 146.720001 157.169998 157.169998
2018-12-27 155.839996 156.770004 150.070007 156.149994 156.149994
2018-12-28 157.500000 158.520004 154.550003 156.229996 156.229996
2018-12-31 158.529999 159.360001 156.479996 157.740005 157.740005
Date Volume
2018-12-24 37169200
2018-12-26 58582500
2018-12-27 53117100
2018-12-28 42291400
2018-12-31 35003500

创建输入和输出数据集
In this step, I will create the input and output variable.
- 输入变量:我使用了’(开盘价-收盘价)/开盘价’,‘(高-低)/低’,最近 5 天回报率的标准差(std_5),以及最近 5 天回报率的平均值(ret_5)
- 输出变量:如果明天的收盘价高于今天的收盘价,则输出变量设置为 1,否则设置为-1。1 表示买入股票,-1 表示卖出股票。
The choice of these features as input and output is completely random. If you are interested to learn more about feature selection, then you can read here.In [3]:
# Features construction
aapl['Open-Close'] = (aapl.Open - aapl.Close)/aapl.Open
aapl['High-Low'] = (aapl.High - aapl.Low)/aapl.Low
aapl['percent_change'] = aapl['Adj Close'].pct_change()
aapl['std_5'] = aapl['percent_change'].rolling(5).std()
aapl['ret_5'] = aapl['percent_change'].rolling(5).mean()
aapl.dropna(inplace=True)
# X is the input variable
X = aapl[['Open-Close', 'High-Low', 'std_5', 'ret_5']]
# Y is the target or output variable
y = np.where(aapl['Adj Close'].shift(-1) > aapl['Adj Close'], 1, -1)

训练机器学习模型
All set with the data! Let’s train a decision tree classifier model. The DecisionTreeClassifier function from tree is stored in variable ‘clf’ and then a fit method is called on it with ‘X’ and ‘y’ dataset as the parameters so that the classifier model can learn the relationship between X and y.In [4]:
clf = tree.DecisionTreeClassifier(random_state=5)
model = clf.fit(X, y)
The model is ready. But how do we do cross validation of this model? Here’s how.
机器学习模型的交叉验证
If the cross validation is done on the same data from which the model learned then it is a no brainer that the performance of the model is bound to be spectacular.In [5]:
from sklearn.metrics import accuracy_score
print('Correct Prediction: ', accuracy_score(y, model.predict(X), normalize=False))
print('Total Prediction: ', X.shape[0])
Correct Prediction: 4775
Total Prediction: 4775
As you can see above, all the predictions are correct. But there is a lot of Python code here. Yes! accuracy_score is a function from sklearn.metrics package which tells you how many predictions are correct. It takes as input the actual output (y) and predicted output (model.predict(X)), compares both the inputs and tells us how many of them were correct. If you want to see the output in percentage then set the normalized parameter to True as done below.In [6]:
print(accuracy_score(y, model.predict(X), normalize=True)*100)
100.0
您如何克服使用相同数据进行训练和测试的问题?
One of the easiest and most widely used ways is to partition the data into two parts where one part of the data (training dataset) is used to train the model and the other part of the data (testing dataset) is used to test the model.  In [7]:
In [7]:
# Total dataset length
dataset_length = aapl.shape[0]
# Training dataset length
split = int(dataset_length * 0.75)
split
Out[7]:
3581
In [8]:
# Splittiing the X and y into train and test datasets
X_train, X_test = X[:split], X[split:]
y_train, y_test = y[:split], y[split:]
# Print the size of the train and test dataset
print(X_train.shape, X_test.shape)
print(y_train.shape, y_test.shape)
(3581, 4) (1194, 4)
(3581,) (1194,)
In the above code, the total dataset of 4775 points is divided into two parts; first 75% of dataset creates X_train and y_train which contains the dataset to train the model and the remaining 25% of dataset creates X_test and y_test which contains the dataset to test the model. The choice of 75% is random.In [9]:
# Create the model on train dataset
model = clf.fit(X_train, y_train)
In [10]:
# Calculate the accuracy
accuracy_score(y_test, model.predict(X_test), normalize=True)*100
Out[10]:
49.413735343383586
If you test the model on test dataset then a significant drop in accuracy is seen from 100% to 49.41%. The model performance in test dataset is closer to what you can expect if you take this model for live trading. However, there is still a major problem. The cross validation in the model is done on a single test dataset. In this example, on last 1194 data points. It could be by sheer luck that this model was able to predict with 49.41% in the test dataset. If I change the length of the train-test split from 75% to 80% or use different data points say first 1194 data points, then the accuracy of the model can vary a lot. Therefore, there is a need to test on multiple unseen datasets. But how do you achieve this?
K 重交叉验证技术
Don’t worry! K-fold cross validation technique, one of the most popular methods helps to overcome these problems. This method splits your dataset into K equal or close-to-equal parts. Each of these parts is called a “fold”. For example, you can divide your dataset into 4 equal parts namely P1, P2, P3, P4. The first model M1 is trained on P2, P3, and P4 and tested on P1. The second model is trained on P1, P3, and P4 and tested on P2 and so on. In other words, the model i is trained on the union of all subsets except the ith. The performance of the model i is tested on the ith part. When this process is completed, you will end up with four accuracy values, one for each model. Then you can compute the mean and standard deviation of all the accuracy scores and use it to get an idea of how accurate you can expect the model to be.  Some questions that you might have.
Some questions that you might have.
你如何选择折叠的数量?
The choice of the number of folds must allow the size of each validation partition to be large enough to provide a fair estimate of the model’s performance on it and shouldn’t be too small, say 2, such that we don’t have enough trained models to perform cross validation.
为什么这比原来的单次训练和试拆分的方法要好?
Well, as discussed above that by choosing a different length for the train and the test data split, the model performance can vary quite a bit, depending on the specific data points that happen to end up in the training or testing dataset. This method gives a more stable estimate of how the model is likely to perform on average, instead of relying completely on a single model trained using a single training dataset.
如何在用于训练模型的数据集之前的数据集上执行模型的交叉验证?是不是历史不准确?
If you train the model on a data from January 2010 to December 2018 and test on data from January 2008 to December 2009. Rightly so, the performance which we will obtain from the model will not be historically accurate. One of the limitations of this method. However, from the other side, this method can help to perform cross validation of how the model would have performed in the stress scenarios such as 2008. For example, when investors ask how the model would perform if stress scenarios such as the dot com bubble, housing bubble, or qe tapering occur again. Then, you can show the out-of-sample results of the model when such scenarios occurred. That should be likely performance when such scenarios occur again.
用 Python 编写 K-fold 代码
To code, KFold function from sklearn.model_selection package is used. You need to pass the number of splits required and whether to shuffle (True) the data points or not (False) to shuffle it and store it in a variable say kf. Then, call split function on kf and X as the input. The split function splits the index of the X and returns an iterator object. The iterator object is iterated using for loop and the integer index of train and test is printed.In [11]:
from sklearn.model_selection import KFold
kf = KFold(n_splits=4,shuffle=False)
In [12]:
kf.split(X)
Out[12]:
<generator object _BaseKFold.split at 0x0000000009936F68>
In [13]:
print("Train: ", "TEST:")
for train_index, test_index in kf.split(X):
print(train_index, test_index)
Train: TEST:
[1194 1195 1196 ... 4772 4773 4774] [ 0 1 2 ... 1191 1192 1193]
[ 0 1 2 ... 4772 4773 4774] [1194 1195 1196 ... 2385 2386 2387]
[ 0 1 2 ... 4772 4773 4774] [2388 2389 2390 ... 3579 3580 3581]
[ 0 1 2 ... 3579 3580 3581] [3582 3583 3584 ... 4772 4773 4774]
The total dataset of 4775 points is divided into four different ways. For the first fold, points 0 to 1193 are used as test dataset and the points 1194 to 4774 are used as train dataset and so on. I’ll create four different models for each of the fold shown above and determine the accuracy for each of the models. Again, this will be done through a for loop, by calling the fit method to train the model and by calling accuracy_score to determine the accuracy of the model.In [14]:
# Initialize the accuracy of the models to blank list. The accuracy of each model will be appended to this list
accuracy_model = []
# Iterate over each train-test split
for train_index, test_index in kf.split(X):
# Split train-test
X_train, X_test = X.iloc[train_index], X.iloc[test_index]
y_train, y_test = y[train_index], y[test_index] # Train the model
model = clf.fit(X_train, y_train)
# Append to accuracy_model the accuracy of the model
accuracy_model.append(accuracy_score(y_test, model.predict(X_test), normalize=True)*100)# Print the accuracy
print(accuracy_model)
[50.502512562814076, 49.413735343383586, 51.75879396984925, 49.79044425817267]
模型的稳定性
Let’s determine the variation and average accuracy of the model by calling the standard deviation and mean function from the numpy package.In [15]:
np.std(accuracy_model)
Out[15]:
0.8939494614206329
In [16]:
np.mean(accuracy_model)
Out[16]:
50.3663715335549
The accuracy of the model is 50.36% +/- 0.89%. This is more likely to be the behaviour of the model in live trading.
混淆矩阵
With the above accuracy, you got an idea about the accuracy of the model. But what is the model’s accuracy in predicting each label such as Buy and Sell? This can be determined by using the confusion matrix. In the above example, the confusion matrix will tell you the number of times the actual value was ‘buy’ and predicted was also ‘buy’, actual value was ‘buy’ but predicted was ‘sell’ and so on.In [18]:
# Import the pandas for creating a dataframe
import pandas as pd
# To calculate the confusion matrix
from sklearn.metrics import confusion_matrix
# To plot
%matplotlib inline
import matplotlib.pyplot as plt
import seaborn as sn
# Initialize the array to zero which will store the confusion matrix
array = [[0,0],[0,0]]
# For each train-test split: train, predict and compute the confusion matrix
for train_index, test_index in kf.split(X):
# Train test split
X_train, X_test = X.iloc[train_index], X.iloc[test_index]
y_train, y_test = y[train_index], y[test_index]
# Train the model
model = clf.fit(X_train, y_train)
# Calculate the confusion matrix
c = confusion_matrix(y_test, model.predict(X_test)) # Add the score to the previous confusion matrix of previous model
array = array + c
# Create a pandas dataframe that stores the output of confusion matrix
df = pd.DataFrame(array, index = ['Buy', 'Sell'], columns = ['Buy', 'Sell'])
# Plot the heatmap
sn.heatmap(df, annot=True, cmap='Greens', fmt='g')
plt.xlabel('Predicted')
plt.ylabel('Actual')
plt.show()
 From the above confusion matrix, if you focus on the darker green zone (1306), that is when actual value was sell and model also predicted sell. Then, out of 2509 (1306+1203) times, the model was right 1306 times when it predicted the sell signal. That is an accuracy of 52%. From this, we can infer that the model is better in predicting the sell signal compared to the buy signal. Time to say goodbye! I hope you enjoyed reading this blog. Do share your feedback, comments, and request for the blogs. Cross validation in machine learning is an important tool in the trader’s handbook as it helps the trader to know the effectiveness of their strategies. Now that you know the methodology of cross validation, you should check the course on Artificial Intelligence and test the effectiveness of the models.Disclaimer: All data and information provided in this article are for informational purposes only. QuantInsti® makes no representations as to accuracy, completeness, currentness, suitability, or validity of any information in this article and will not be liable for any errors, omissions, or delays in this information or any losses, injuries, or damages arising from its display or use. All information is provided on an as-is basis. **Suggested read: **Working Of Neural Networks For Stock Price Prediction
From the above confusion matrix, if you focus on the darker green zone (1306), that is when actual value was sell and model also predicted sell. Then, out of 2509 (1306+1203) times, the model was right 1306 times when it predicted the sell signal. That is an accuracy of 52%. From this, we can infer that the model is better in predicting the sell signal compared to the buy signal. Time to say goodbye! I hope you enjoyed reading this blog. Do share your feedback, comments, and request for the blogs. Cross validation in machine learning is an important tool in the trader’s handbook as it helps the trader to know the effectiveness of their strategies. Now that you know the methodology of cross validation, you should check the course on Artificial Intelligence and test the effectiveness of the models.Disclaimer: All data and information provided in this article are for informational purposes only. QuantInsti® makes no representations as to accuracy, completeness, currentness, suitability, or validity of any information in this article and will not be liable for any errors, omissions, or delays in this information or any losses, injuries, or damages arising from its display or use. All information is provided on an as-is basis. **Suggested read: **Working Of Neural Networks For Stock Price Prediction
众包情绪分析交易策略
原文:https://blog.quantinsti.com/crowdsourced-sentiment-analysis-strategy/

情绪分析交易策略在市场上并不新鲜。有许多资源可用于开发这种策略,捕捉市场情绪,并根据这些策略产生的信号进行交易。
我们也有一些金融新闻门户网站,它们使用情绪数据,建立情绪指标栏或进行民意调查,以衡量网站访问者的情绪。这个新闻网站可以测量各种话题和主题的情绪。
我遇到了一个这样的金融市场门户网站,它提供了所有股票的情绪指标栏,我想用情绪栏来创建一个策略。一般来说,基于情绪分析交易的策略涉及整理大量数据,并得出一个情绪分数,该分数可以给出有利可图的交易信号。在这种情况下,我直接使用情绪栏作为策略的输入。所以,这是我的简单策略。

我的第一步是找出我名单中每只股票的买入/卖出/持有值。我用 Python 写了一个简单的程序来帮助我实现这个目标。还需要 HTML 和 CSS 知识来找到情感栏的确切位置,并从 HTML 页面中获取相应的买入/卖出/持有值。我使用了相关的 Python 库,它们帮助我完成了所有繁重的工作。
下一步是以 Python 数据框或电子表格的形式存储这些值,以便进一步分析和验证这些值。

我能用这些值做什么?我如何知道网站上显示的情绪值是否公平地代表了股票的整体市场情绪?我做的一个实验是在开市前捕捉情绪得分,然后在市场交易结束时根据股票价格的变化进行验证。下表给出了股票样本的单日业绩。可以看出,结果并不令人鼓舞。然而,单日结果并不能告诉我们任何关于策略潜力的信息,因此,我们需要在一段时间内对其进行测试。

这是使用情感分数的一种方式。使用情感分数的其他方法有哪些?我在下面列出了一些可能的方法来处理情感分数和使用策略:
- 过滤分数,并在分数较高的股票中建仓。
- 将获得的情感分数与其他网站上显示的情感分数进行比较。
- 将这种策略与其他策略结合起来,产生强有力的交易信号。
我将继续致力于这个策略,观察一段时间后的结果,如果可能的话,尝试不同的方法来制定一个稳健的策略。我会在以后的博客里分享这个众包情绪策略的成果。所以,请关注我的下一篇关于情绪分析交易的博客。同时,你可以在我们的博客上阅读其他的情绪交易策略。
使用 R【工作模型】 进行交易情绪分析您可以报名参加 Quantra 上的情绪分析课程,该课程将帮助您利用 Twitter、新闻情绪数据设计新的交易策略。在本课程中,你将学习通过量化市场情绪来预测市场趋势。
下一步
如果你想学习算法交易的各个方面,那就去看看我们的算法交易(EPAT)执行项目(T2)。该课程涵盖了统计学&计量经济学、金融计算&技术和算法&定量交易等培训模块。EPAT 旨在让你具备成为成功交易者的正确技能。现在报名!
加密套利:概述,交易策略,机会,等等
苏莱曼·埃姆雷·耶希尔
加密货币套利是一个有趣的概念,具有有利的结果,但对于加密市场中的套利机会,交易者必须知道更多。在这个博客中找到一切。
我们涵盖:
- 什么是套利?
- 加密货币是如何交易的?
- 什么是加密货币套利?
- 市场上为什么会出现加密货币套利机会?
- 如何识别加密货币套利机会
- 加密货币市场的套利机会类型
- 如何开始加密货币套利交易?
- 加密货币套利的优势
- 加密货币套利的弊端
什么是套利?
套利意味着捕捉一种资产在不同市场之间的价格差异带来的利润机会。
假设一个资产 X 在两个市场交易,市场 A 和市场 B。如果它在市场 A 以 100 交易,在市场 B 以 105 交易,一个人可以享受无风险的 5%的利润机会,不包括交易成本。
在潜入加密货币套利之前,我们先来了解一下加密货币是如何交易的。
加密货币是如何交易的?
加密货币大多在集中交易所交易。用户可以出价或要求他们想要交易的加密货币,一旦特定的买卖订单匹配,买方和卖方之间就可以实现资产交换。
基于这一逻辑,加密货币在全球范围内全天候交易。相同的加密货币在数千家不同的交易所交易。
例如,您可以在下面看到 BTC 的一些交易市场:

Source: Coinmarketcap
什么是加密货币套利?
加密货币套利是通过同时从一个交易所购买加密货币并以略高的价格在另一个交易所出售来获利。
如果你在上面的比特币市场列表中查看价格一栏,不同交易所的价格会略有差异。尽管这些微小的差异无法吸收交易成本,但在高度波动时期,你可以体验净套利机会。
为什么市场上会出现加密货币套利机会?
如前所述,加密货币在全球数千家交易所进行交易。它们以不同的法定货币交易,也以主要的加密货币交易。
有几个原因导致不同市场之间的套利机会。
当地对法定货币转移的限制
一些国家限制资本流出该国,导致当地加密货币投资者被禁止进入该国以外的加密货币市场。这导致了当地加密货币交易所的供需失衡。
这种情况最著名的例子就是泡菜溢价。在韩国,加密货币投资者受到严格的资本管制,外国加密货币投资者不得在当地的加密货币交易所交易。因此,该国的加密货币价格偏离了其他加密货币市场。
下图显示了这种偏差。正如你所看到的,大多数时候,比特币在韩国的价格比其他市场更贵,这种情况在加密货币投资者中被称为“泡菜溢价”。

Source: CryptoQuant. Green-Red Line: Korea Premium Index, Black Line: BTC Price in USD
价格的突然变化
历史证明,加密货币容易出现高价格波动。价格可以在同一天内上下浮动 20%。有时,手动下单的交易员可能无法取消订单。
此外,由于加密货币交易所之间的流动性差异,一些加密交易所对这些价格波动的反应可能会稍慢或稍快。
例如,当加密货币价格开始下降时,非流动性交易所的市场订单将导致价格下跌更严重,这可能会产生套利机会。
交易和转移成本
有时候虽然没有限制,没有高波动的环境,但是因为交易成本的原因,还是可以看到价格的差异。
你可能会认为,虽然价格之间存在差异,但这并不意味着存在套利机会。然而,加密货币交易所中的每个人的交易成本并不相同。
对于产生高交易量的投资者来说,加密货币交易所的交易成本通常要低得多。因此,这些价格差异对他们来说是微小的套利机会。
如何识别加密货币套利机会
从广义上讲,你可以通过两种方式识别套利机会,人工计算和自动筛选。
考虑到交易所和加密货币对的数量,手动计算在这里似乎不是一个选项。
识别加密货币套利机会的最佳方法是创建一个加密货币套利机器人,因为这些套利机会出现的时间非常短。
然而,这不足以捕捉套利机会。你需要在你运营的交易所同时拥有法定货币和加密货币,因为你不知道在套利机会出现的情况下,你将是哪个交易所的买方或卖方。
加密货币市场最大的好处之一是市场数据是免费的,每个人都可以通过 API 访问交易所的实时数据。你甚至不需要从头开始创建算法来连接交易所的服务器并获取实时数据。
大多数加密货币交易所都有现成的客户端软件包,使您可以通过调用软件包中的函数来获取实时数据、发送订单和检查账户余额。
例如,你可以在这里找到币安的 python 包。为了能够使用这个软件包,首先,您需要通过在计算机的终端或命令行中写入以下命令来安装它:
“pip 安装币安-连接器”
现在,您可以获得实时和历史数据,并使用 python 下订单。例如,使用“klines”函数获取烛台数据:
基于数据抽取技术的加密货币交易策略
原文:https://blog.quantinsti.com/cryptocurrencies-data-strategy/
有许多来源可以获取网络上各种加密货币的数据。Quandl、Coinmarketcap、Poloniex 等来源。大多数都有 API 或。他们提供 csv 功能。您可以使用它来获取数据。今天,我们将看到如何使用 python 以一分钟的分辨率获取这些数据。
在这篇博客中,我使用 python 库 coinmarketcap 从网站这里获取数据

我还将讨论如何将数据保存在 dataframe 和 csv 中。最后,我解释了一个简单的策略来交易硬币。
首先,让我们导入必要的库

您可以 pip 安装上述所有库:
pip 安装熊猫
pip 安装日期时间
pip 安装 coinmarketcap
接下来,我们将使用上面的市场函数获取数据。然后我们会把各种加密货币的名称列出来,保存在一个名为 coins_list 的列表中。

让我们把这个列表打印出来,看看里面所有的名字。

我们在这个列表上总共有 1121 种货币。

接下来,我们将获取开始时间并保存它。这是我们将运行该脚本的时间。

接下来,我们创建两个名为 usd price 和 usd vol 的字典,它们将用于存储所有 1121 枚硬币的数据。

假设我想获得接下来 3 分钟的数据,那么让我们将这个时间保存为变量‘t’。

此后,我将每分钟 ping coinmarketcap 站点以获取数据,然后将其保存为 dataframe。我将在接下来的 t 分钟内继续这样做。

在这之后,我们创建两个字典,将硬币名称作为它们的键,美元价格和交易量作为它们的值。我们将这些值添加到相应的字典 usd price 和 usd vol 中,并将获取数据的时间作为它们的键。

之后,我们将计算循环遍历所有货币所用的时间。这一点很重要,当运行时间超过 1 分钟时,下一次数据获取将在下一分钟发生。因此,如果我们的数据处理需要更多的时间,我们可能需要删除一些不重要或不被我们跟踪的货币,以使数据连续。

我现在将详细解释这一点。如果您一直运行该代码,输出将如下所示。

您可以打印两个字典 usd vol 和 usd price 来查看数据的样子。
如果我们将这些数据转换成数据帧以便更好地查看:

现在,打印数据帧“a”

现在,观察左边的时间戳,它有 2 分钟的时间增量,这是因为当我们编写代码时,我们指定每当一分钟结束时都应该获取数据。因为,我们观察到循环时间超过一分钟,所以数据是在这之后的一分钟开始时获取的。因此,我们需要减少交易的货币。
完成后,我们可以将这些数据保存在 excel 中,以便进一步进行回溯测试。

一旦有了初始数据,就可以简单地将每分钟获取的数据追加到这个数据中。
加密货币交易策略:
在像比特币这样波动性很大的市场,顺势交易是明智的。但这并不意味着一些经过深思熟虑和平衡的均值回归策略,如多空投资组合、IndexArb(创建自己的指数)等,不能应用于比特币。要了解这些策略,你可以查看我们的课程,由 E. P. Chan 博士撰写的均值回复策略。
在这里,我使用了一个简单的“从众”策略。这种策略的基本前提是,当市场高度波动时,通过观察交易发生的方向来跟踪市场的现有趋势是有利可图的。我们之前保存在数据框“b”中的成交量数据将有助于从假突破中筛选出真正的突破。我们将一根蜡烛线的交易量与过去 n 根蜡烛线的平均值进行比较,以检查价格的突然上涨是否与交易量的增加有关。如果是这样,那么我们假设这是一个真正的突破,沿着运动的方向交易。相反,如果交易量小于平均交易量,但回报大于过去“n”回报的标准差,那么我们认为这是假突破,逆着运动方向交易。
现在来谈谈策略。首先,让我们导入必要的库。

接下来,我们导入之前存储的数据。

让我们从所有货币中选择一个符号进行交易,并将其保存为变量’ s’。(尝试一些流动性货币,如 BTC、瑞士法郎等,因为策略取决于交易量)

接下来,我们创建一个数据帧“data ”,它保存“s”的价格和数量信息。

接下来,我们决定时间段来计算回报和平均交易量的标准差。
在这种情况下,我假设这个窗口是 30。

为了应用这个策略,我们需要知道回报率,所以让我们先计算一下,然后计算回报率和平均交易量的标准差。

接下来,我们生成名为“Signal”的列,然后计算回报大于/小于观察到的标准偏差且成交量也高于观察到的平均成交量的信号。根据我们的基本假设,我们假设这是真实的信号。也就是说,市场是以成交量来支撑这一走势的。

接下来,我们创造反转信号,只要突破没有相应的交易量增加,我们就逆市场趋势而动。

在此之后,我们创建一个新的数据帧,只保存交替的信号,并丢弃其余的信号。我们这样做是为了减少交易噪音。本质上,我们持有一个位置,直到产生一个反信号。一旦我们准备好了新的信号,我们就可以计算策略的回报。

这里我们用不同于前面的方法计算回报,因为这个回报是我们根据过去的数据生成的信号执行头寸时得到的回报。这个回报会告诉你进场点之后的市场行为。
最后,我们将绘制策略回报的累计和,以直观显示策略的绩效。


这是一个简单的策略,不建议在没有适当的风险管理的情况下用于交易。在上图中,我们成功地捕捉到了一个突破。如果你想大幅减少交易次数,我们可以尝试增加时间周期或增加信号的标准差倍数。我在 ETH(以太坊)上尝试过同样的策略,结果很有希望。

这种策略只是为了向算法交易的新手演示,在没有适当的风险管理之前不应该交易。
下一步
在我们的后“9 大加密货币交易平台”中,详细介绍了国际市场交易商使用的一些最佳加密货币交易平台。
免责声明:股票市场的所有投资和交易都有风险。在金融市场进行交易的任何决定,包括股票或期权或其他金融工具的交易,都是个人决定,只能在彻底研究后做出,包括个人风险和财务评估以及在您认为必要的范围内寻求专业帮助。本文提到的交易策略或相关信息仅供参考。
下载 Python 代码
- 加密货币交易策略- Python 代码
印度的加密货币之旅
经历了十年的跌宕起伏、确定性和不确定性,印度最高法院似乎已经明确了加密货币在印度的前进方向。在这篇文章中,我们绘制了加密货币的完整旅程,谈论了它的兴衰以及与它相关的无数话题。
本文涵盖了事实知识,因此,我们将讨论以下内容:
什么是加密货币?
加密货币是一个创新的概念,作为在线购买商品和服务的交换媒介。加密货币的工作使用密码术。让我们简单了解一下加密货币的功能。对于每种加密货币,一个分布式账本技术(DLT) 用于保存所有交易的数据库。该数据库公开用于存储关于通过加密货币进行的金融交易的信息。此外,这个拥有完整交易记录列表(加密货币)的数据库被称为区块链。从技术上来说,这个列表或记录被称为块,它们在加密技术的帮助下连接在一起。
观看下面的视频,简单了解一些关于加密货币的有用信息:
https://www.youtube.com/embed/82LgksdhcvI?feature=oembed
那是在 2018 年,最高法院禁止在印度使用加密货币。但是,最近,最高法院解除了禁令。2019 年 4 月,印度储备银行发布了一份框架草案,用于监管沙箱。这将包括与金融技术相关的产品和服务,其中也包括区块链。
此外,这篇题为加密货币钱包-初学者指南的文章可能会帮助你,如果你希望更深入地研究加密货币的工作。另一篇名为9 大加密货币交易平台的文章将让你深入了解一些热门的加密货币交易平台。
接下来,我们将看看印度加密货币的现状。
印度加密货币的现状
最近,2020 年 3 月,印度央行实施的禁令被最高法院解除,自此加密货币交易变得合法。随着禁令的解除,你可以进行加密货币交易,但要有所有的预防措施。
提到取消禁令,NASSCOM 在推特上说,“我们欢迎最高法院取消 RBI 对加密货币交易的禁令。我们认为禁止技术不是解决办法,必须建立一个基于风险的框架来监管和监控加密货币和代币”。
根据 SEMrush 的通信主管 Fernando Angulo 发布的声明,“加密货币搜索在印度增长得太快了。因此,最近观察到该国的人们想要投资和购买加密货币。
可以看到,对加密货币的全面审查仍在进行。随着一切就绪和受监管的加密市场,毫无疑问,加密货币可以成为人们新的投资手段”。
尽管有些人反对加密货币,但在过去几年里,印度见证了比特币使用的增加。此外,根据研究论文非货币化对比特币的影响,政府也在考虑推出自己的加密货币,以使其成为印度卢比的替代货币。这样,任何价值下降都不会对经济造成太大影响。根据同一篇研究论文,印度中央政府已开始协商进程,以建立一个跨学科委员会,从而形成一个加密监管框架。
这些变化有望在资金的多样性方面对整个经济产生积极影响。
现在让我们来看看过去几年印度加密技术的兴衰。
印度加密技术的兴衰
自 2012 年至 2020 年,加密货币的价值经历了几次大起大落。从成为最受欢迎的支付方式,到随着禁令在 2018 年消失,我们将简要讨论这一切。
年份:2012 年
加密货币在 2012 年左右微妙地进入市场,当时小规模的比特币交易已经开始在全国范围内发生。
年份:2013 年
2013 年的某个时候,比特币开始在中国流行起来。
那是在 2013 年,当时名为 Kolonial(孟买沃利)的复古时代披萨店成为印度第一家接受比特币支付的餐厅服务。
2013 年后,这种平行货币的使用逐渐增多。
年份:2016 年
最后,当 2016 年实现去货币化时,更多的加密货币投资开始启动,以降低不确定性。人们开始大量购买比特币和其他加密货币,并在晚些时候出售。其他众所周知的加密货币类型有以太(ETH)、瑞波(XRP)和莱特币(LTC)。网上购物和股票投资的使用是从今年开始的。
年份:2017 年
自 2017 年比特币崩盘以来,围绕加密货币的使用一直存在一些担忧。2017 年的崩溃发生在政府发出警告反对使用相同的手段,并排除了被称为“庞氏骗局”的欺诈的可能性。政府仍然持有相同的观点,并可能继续下去,直到和除非密码市场得到监管。2017 年的加密崩溃还有另一个原因。由于中国警告不要投资加密货币的影响,加密市场受到了严重打击。中国人民银行反对虚拟货币投资,并提醒人们警惕洗钱、涉嫌操纵市场等负面影响。由于某些原因,这种情况在年底有所改善,例如:
- 日本于 2017 年 4 月宣布比特币为法定货币。
- 美国监管机构 CFTC(商品期货交易委员会)批准了加密货币交易。
- 在其他一些国家,人们对加密货币的使用越来越信任。
下图显示,比特币在 2017 年表现最低,但在年底有所上升:

来源:商业内幕
年份:2018 年
这一年,加密货币卷入了一场严肃的法律诉讼。此外,在 2018-19 年的预算讲话中,财政部长宣布政府不认为加密货币是法定货币。政府还提到,他们将采取一切必要措施,确保在所有活动中消除加密货币的使用。
然后,考虑到其不受监管的设置和风险,印度储备银行禁止使用相同的方法。
此外,根据 PRS 立法研究,法案草案于同年通过,该法案禁止在该国以任何形式开采(创造加密货币)、发行、购买、持有、出售或交易加密货币。然而,该法案允许将加密货币背后的技术或过程用于其他领域的任何实验、研究和教学。人们发现,crypto 使用的 DLT (分布式账本)可以用于支付、贸易融资、保险等等。
过去三年,加密货币经历了多次上下波动。
让我们来看看从 2014 年到 2020 年的过去七年中 BTC 价格变化的直观表示,以便对价格运动和 BTC 的表现有一个公平的想法。
以下 BTC 价格以美元为单位。

从上图中我们可以看到,从 2014 年到 2017 年,价格大致保持不变,或者在一个特定的价格范围内(在 0 美元到 2500 美元之间)。此外,可以分析出,在 2018 年的某个时候,BTC 接近 2 万美元,然后一直保持在 2 万美元以下,直到现在,即 2020 年。它显示了其间的许多上升和下降趋势,以及接近 2019 年的价格大幅下降。
还有,你可以看下面的视频,了解一下算法交易在加密货币热潮中的作用。
https://www.youtube.com/embed/UYilw_AvC7E?feature=oembed
让我们继续前进,了解印度的规章制度。
印度关于加密货币的法规
加密货币的规则和法规尚未建立,这种监管机构的缺乏剥夺了投资者对几种风险的安全。我们列出了以下风险:
- 散户投资者的潜在损失。
- 波动对发展中国家的经济可能是危险的。
- 滥用技术可能导致资助从事恐怖主义、贩运等的有害或危险组织。
这种不受监管的加密货币市场不同于金融机构和市场,如第三方审计、财务报告和披露等。
由于最高法院已经取消了对使用加密货币的禁令,因此这些货币的使用必须受到监管框架的约束。据 2020 年 3 月 20 日的彭博报道,印度已经在计划监管加密货币,并且正在等待最高法院的判决。
之后,印度将对监管市场做出最终决定。即使在加密货币的监管到位后,在支付系统中使用它们的许可仍然是一个疑问。这是因为人们不习惯这种虚拟货币。
接下来,让我们看看使用加密货币时的注意事项。
加密货币的注意事项
由于存在一些与加密货币和加密市场的使用相关的担忧,因此必须了解该做什么和不该做什么,以便我们能够从投资中获得最大收益。
| Do 的 | 不要 |
| 了解加密货币的详细功能。 | 不彻底了解就投资,碰碰运气。 |
| 分析和预测市场。 | 假设价格变动,并在此基础上进行投资。 |
| 安全保存公共地址或密钥。 | 只把它们保存在你的记忆中,因为你可能会忘记并失去平衡。 |
| 了解一些加密货币投资背后的算法。 | 认为算法或技术诀窍是浪费时间,不要在上面投资。 |
| 如果你是加密货币的新手投资者,请与杠杆(贷款)保持距离。 | 当你不是加密货币的经验丰富的投资者时,要抓住杠杆的机会。 |
让我们看看为什么你应该注意上面提到的该做什么和不该做什么。
所以,基本上,这些是你不能放弃要点的原因:
非管制系统
这意味着加密货币具有非集中式或分散式控制。与中央银行系统不同,加密货币交易不受中央银行或任何授权实体的监管。正如我们之前读到的,所有加密货币交易都保存在一个公开可见的账本中。这表明任何人都可以过滤最大余额的帐户,并尝试入侵相同的帐户。
理解其功能有所帮助
在使用加密货币进行交易之前,正确理解其功能非常重要,否则,你可能会损失大量财富。你需要很好地意识到你的公钥和私钥,并小心保存它们,因为它们是访问钱包余额的唯一来源。丢失您的密钥或公共地址可能会让您失去所有加密货币,以防其他人得到它们。此外,如果没有关于如何预测市场涨跌的良好知识,你可能无法在最有利可图的时候交易。
砍
由于地址或密钥可在公共分类账中获得,因此有人有可能侵入您的账户并获取您的余额。因为它不是正规的,所以没有安全措施来保证你的账户信息的安全。这意味着你需要对加密货币背后的技术有一个正确的理解。
波动性
这个市场有很大的波动,因为金融杠杆(贷款)可以导致许多上升和下降趋势。这导致对所拥有的加密货币的数量进行正确统计的障碍。
在继续之前,让我们看一个关于加密货币框架下的电子钱包的短片。
https://www.youtube.com/embed/sCxNO5Inetk?feature=oembed
现在让我们来看看加密货币在印度的未来。
印度加密货币的未来
由于最高法院最近下令解除禁令,加密货币得到了推动,加密市场似乎有一个光明的未来。这项裁决支持比特币和以太坊等加密货币的交易。尽管如此,加密交易的全面使用可能需要一段时间,因为印度央行的正式通知正在等待中。
据新印度快报报道,查看过去一年比特币价值的数据,它从卢比。2019 年 3 月 27 万卢比。2019 年 7 月 84.6 万。但是,在 2019 年 12 月,它再次下降到卢比。46.9 万卢比。随着最高法院最近做出解除印度储备银行禁令的判决,比特币的价值上升到了 100 万卢比。2020 年 3 月 67.4 万。
现在看来,未来是光明的
最高法院已经解除了 RBI 在 2018 年对加密货币实施的禁令,称禁令是不相称的。这意味着印度储备银行没有保持与加密公司行为的平衡。
最高法院的这一支持及其判决让亚洲第三大国印度重拾了对加密货币的信心。
由于 crypto 的回归,所有数字货币或金融技术公司都在努力恢复其在印度的扩张计划。据《经济时报》报道,总部位于新加坡的加密公司 ZPX 将考虑扩大业务。密码交易所 WazirX 的联合创始人尼斯查尔·谢蒂(Nischal Shetty)补充说,对印度市场的投资将从今年开始,也就是 2020 年。
既然未来似乎一片光明,那就让我们看看新闻报道说了些什么,并增强我们对加密货币和市场的了解。
关于加密货币的最新消息
现在,我们有一个与加密货币相关的新闻列表,最近所有这些文章都给了我们一个关于该国加密现状的最新消息。继续读下去,丰富你的知识。让我们按照新闻的日期和年份降序排列。
根据上面的消息,印度开始看好对衍生品的投资。尽管,不仅仅是衍生品,对衍生品加密的投资也是这个国家正在见证的。
《反密码法》建议对交易加密货币处以 10 年监禁(2019)
据《今日商业》报道,在加密货币交易禁令实施一年后,据称任何从事加密货币交易的人都将被判处 10 年监禁。法律加强了措施来抑制密码的传播。
由于第一台比特币 ATM 机是在印度央行禁止加密货币后出现的,安装在孟加拉鲁鲁的那台被立即查封。
自从首次公开募股(ICO)成为初创企业最受欢迎的融资方式以来,这种方式一直在起起落落,本文将对此进行详细讨论。
结论
在本文中,我们涵盖了加密货币在印度的表现和地位。我们从加密货币的简要概述开始,然后讨论了与印度加密市场相关的一大块信息。
这篇文章旨在给你一个关于印度加密货币市场的新视角。我们还讨论了与加密货币相关的各种问题,以便我们对此保持谨慎,避免陷入困境。
如果你想学习算法交易,用量化策略升级你的加密货币交易,探索印度最好的算法交易课程quantin STI 的“EPAT”。
免责声明:本文中关于加密货币的任何信息仅用于传达一般信息。本文不提供投资、法律、税务等。建议。您不应将本文中的任何信息视为就加密货币使用、法律事务、投资、税收、加密货币开采、交易所使用、钱包使用等做出任何特定决定的呼吁。我们强烈建议向您自己的财务、投资、税务或法律顾问寻求建议。QuantInsti 和本文作者均不对因依赖本文发布或链接的信息而导致的任何损失、损害或不便承担责任。
加密货币钱包-初学者指南
原文:https://blog.quantinsti.com/cryptocurrency-wallets-beginners-guide/
作者:沙古塔·塔西尔达
这篇博客解释了什么是加密货币钱包以及如何使用它们。它涵盖了从加密钱包的功能到使用它们的风险,还列出了最流行的加密钱包及其功能。 话题覆盖 :
从物物交换体系开始到黄金,再到纸币,现在我们已经到了加密货币时代。随着超过 1300 种加密货币的出现,探索这个领域是绝对必要的。但是为什么加密货币会如此受欢迎呢?为了理解这一点,让我们首先了解加密货币实际上是什么!
什么是加密货币?
让我们把这个词分解一下来理解它。“Crypto”通常指加密技术,它涉及使用加密技术来保护不同实体之间的交易,而 currency 则指货币。因此,加密货币是一种通过加密进行保护的货币,可以在实体之间基于区块链技术进行数字或虚拟交易。就像我们有在线钱包来存储我们的数字货币一样,我们需要特殊的钱包来存储、发送或交易加密货币。
什么是加密货币钱包?
如果一个人希望存储、使用、出售或购买加密货币,加密货币钱包是必要的。我们知道,加密货币使用加密机制来保护交易。由于这个原因,它涉及到使用私钥和公钥。但是这些是什么?公钥充当个人的账户标识符,而私钥充当使用加密货币所需的密码,类似于 ATM pin。发送者将需要接收者的公钥来向他发送加密货币,并且接收者将能够通过使用私钥来访问和使用这些加密货币。必须保护私钥,以避免诸如黑客攻击、窃取加密货币等欺诈行为。加密货币钱包用于存储这些密钥,使用这些密钥进行加密货币交易。加密钱包显示钱包中加密货币的数量,从而使人们能够监控余额。
加密货币钱包是如何工作的?
与允许用真实货币或美元和欧元等货币买卖加密货币的加密货币交易所不同,加密钱包用于存储、发送和接收加密货币(一些加密钱包可能内置了加密货币与真实货币之间的转换交易所)。一旦你从交易所购买了加密货币,它就会存储在你在交易所的账户中。但是,不建议将加密货币存储在交易所提供的钱包中,因为在这种情况下,交易所将拥有您的私钥,而不是您。因此,您可以将它转移到您自己的加密钱包中,以获得对您所拥有的加密货币的控制权。为此,您需要首先在您的钱包上生成一个公钥和一个私钥,然后您可以使用这个公钥地址将您的加密货币从交易所转移到您的钱包。完成后,您就可以轻松地执行交易,使用其他帐户的公钥向其发送加密货币,并通过与发送者共享您的公钥向您的帐户接收加密货币。公钥的作用类似于电子邮件地址,它是特定帐户的标识符。另一方面,私钥就像一个密码,你可以用它来访问你的个人电子邮件帐户。私钥用于访问您的加密货币,这就是为什么绝对有必要保持它的安全和秘密,以避免黑客攻击,盗窃和其他攻击。
加密货币钱包的种类
密码可以大致分为两种类型,热钱包和冷钱包。这两种类型的主要区别在于,热钱包是连接到互联网或在线的,而数据是以离线模式存储在冷钱包中的。这些钱包又可以分为以下几类:
- 桌面钱包(热门钱包)
就像我们安装任何其他软件一样,这些软件被安装并存储在计算机和笔记本电脑上。然而,桌面钱包有受到计算机病毒或恶意软件影响的风险,因此总是推荐使用防病毒软件和强大的防火墙。一些例子是出埃及记,Jaxx,Electrum 等。
- 手机钱包(热门钱包)
这些钱包基本上是移动应用程序,可以在任何移动设备上轻松下载。这些软件比桌面软件更容易使用,也更轻便。一些移动应用程序可能也有其桌面或网络版本。移动钱包的几个例子是菌丝体,Coinomi,绿色地址等。
- 网络钱包(热门钱包)
这些钱包是作为加密货币交易的在线平台提供的,可以通过谷歌 Chrome、Mozilla Firefox 等网络浏览器访问。这些钱包风险更大,因为它们连接到互联网,在线存储你的私人密钥,很容易受到黑客攻击和在线攻击。一些可用的网络钱包有比特币基地、BitGo、Copay 等。
- 纸质钱包(冷钱包)
纸钱包指的是你的公钥和私钥的物理拷贝,它可能只是一张纸。这也指通过软件生成的私有和公共密钥的任何打印副本。它被认为是最安全的钱包之一,因为它不容易在网上丢失你的私人钥匙。它也可以由 QR 码组成,可以在执行任何交易时使用。
- 硬件钱包(冷钱包)
像 USB 这样的设备符合硬件钱包的条件。由于私钥和公钥物理上存储在一些硬件设备中,它们提供了更高的安全性,因为它们不太容易受到在线攻击,因此是最安全的选择。这些可以通过电脑连接,并与在线软件一起使用。
选择加密货币钱包前需要考虑的参数
- 支持的硬币
您可以根据钱包支持的硬币或加密货币以及您可能有兴趣交易的硬币来选择钱包。每个钱包都支持或验证某些类型的加密货币的交易,如比特币、以太坊、Ripple 等。一些钱包也可能只针对一种加密货币,并允许只涉及该加密货币的交易。
- 交易成本
这是选择加密货币钱包的最重要的决定因素之一。交易费用因钱包而异,因此在开始使用钱包之前必须了解交易费用。交易成本可以是固定的、动态的或用户定义的。固定成本可以直接以特定金额给出(例如:0.0005 BTC),也可以指定为百分比,具体取决于您的交易金额(例如:交易金额的 5%),动态成本可能取决于网络拥塞、矿工可用性等因素。并且将相应地变化。用户自定义交易费用由用户根据交易的紧急程度决定;用户设定的交易成本越低,完成交易所需的时间就越长,反之亦然。
- 匿名
使用加密货币的最大优势之一是其底层技术;区块链,为加密货币用户提供匿名性。但实际上是不可能追踪任何身份的吗?即使您的身份与您在区块链上的公开地址没有直接联系,有人也可以跟踪到您的公开地址的交易,并使用该地址识别您的 IP 地址,最终追踪到您的身份。因此,钱包可以提供为不同的交易生成多个公共地址的能力,使得很难使用不同的公共地址来跟踪那个人的身份。
- 备份功能
如果您丢失了私钥,您将面临丢失全部数据和存储的加密货币的风险,因为如果没有私钥,您将无法访问它们。有些钱包具有备份功能,以防万一你丢失了私人钥匙等数据。某些钱包提供使用密码恢复数据等功能。
- 分层确定性钱包
我们已经讨论了与在区块链上获得匿名相关的问题,并且还提到了一种解决方案,即生成用于交易的多个公共地址。分级确定性加密钱包或 HD 加密钱包是能够使用一系列计算来创建多个私有和公共地址的钱包,从而在区块链上保护您的隐私。它们还提供了一种功能,通过使用种子短语(将您的私钥转换为一系列单词)来帮助找回丢失的加密钱包。
使用加密货币钱包的风险
- 欺骗
欺骗是指恶意软件试图在发送者不知情的情况下更改发送者的地址,从而使一个人在加密钱包中将加密货币交易到错误的地址。由于缺乏安全协议,加密钱包可能容易受到这种攻击,这使得绝对有必要检查加密钱包提供的安全程度。
- 遗失加密钱包
丢失钱包会导致个人公钥和私钥的丢失,这反过来意味着丢失您存储的加密货币。在你的私钥被加密或保护的情况下,任何人都不可能破解你的私钥,因为它有 2^256 的可能性。然而,如果你的私钥被其他人知道,那么就有可能访问和使用你存储的加密货币。
- 集中式结构
由于所有公共地址都存储在区块链上,黑客跟踪公共地址上的交易变得更加容易,这使得黑客能够识别大量的地址,从而使这些公共地址成为易受攻击的目标。
- 交易费用
如前所述,交易成本在选择加密钱包时发挥着巨大的作用,因为一些钱包收取高达 50%的交易费。忽视这些细节可能会导致不可逆转的巨大损失。
- 冲销付款
由于这些支付是不可逆的,因此输入正确的收款人公共地址至关重要,因为支付一旦完成就无法撤销,并且在加密钱包中输入错误地址的情况下可能会导致损失。
流行的加密货币钱包
**支持的加密货币:**BTC ETC,ETH,LTC 等更多在此列出。
功能:——可在 Windows、Linux、Chrome、Firefox、Mac OSX、Android、iOS 等多个平台上使用。-允许通过 Shapeshift 在比特币、以太和 DAO 之间转换。-不在中央服务器上存储用户钱包的详细信息,从而提供更高的安全性。
支持的加密货币: BTC、LTC、ETH、DASH、XRP、更多。
特点: -内置兑换将 altcoins 转换为比特币-直观易用的界面-加密私钥,安全性更高。-可在 Windows、Mac OS 和 Linux 上使用。
支持的加密货币: BTC,ETH,XRP,XMR 还有很多更多。
功能: -称为原子交换的内置交换功能-由于加密的私钥,安全性更高-目前可在 Windows,Mac OS,Ubuntu,Debian,Fedora 上使用,并很快推出 Android 和 iOS 的移动钱包。-能够通过 Changelly 和 ShapeShift 购买美元和欧元加密货币。
支持的加密货币: BTC
特点: -极大的安全性,因为硬币存储在本地钱包中,第三方无法访问。-可以与 Trezor 或 Ledger 等冷存储选项集成-提供五种不同类型的帐户,如 HD、Bit ID、单地址、“仅观看”帐户和硬件帐户。你可以在这里阅读更多关于他们的信息。-提供一个名为“菌丝体本地交易者”的分散式面对面交易平台,实现买卖双方之间的交易,并根据交易计算信誉等级。-这是一款可在 Android 和 iOS 上使用的移动加密钱包。
****支持的加密货币:BCH BTC
功能: -多签名钱包,具有共享钱包的功能。-允许安全的应用内钱包生成和备份,因为它是一个分层确定性(HD)加密钱包。-安全存放多个不同的钱包。-在 Windows、Linux、Mac OS、Android 和 iOS 上可用
支持的加密货币: BTC
功能: -加密私钥-可用冷存储-可在 Windows、Mac OS、Linux、Android 上使用-支持第三方插件、Multisig 服务等。
支持的加密货币: BTC
特点: -它是一个 HD(分级确定性钱包)从而提供良好的安全性。-可在 Windows、Mac OS、Linux、Android、iOS 和 F-Droid 上使用。-即时交易确认。-双重认证带来更高的安全性。-允许创建纸质钱包备份。
支持的加密货币: BTC、BCH、ETH、LTC 和更多。
特点: - HD multisig 硬件加密钱包。-紧凑型 USB 加密钱包。-支持第三方应用程序-兼容 Windows、Linux 和 Mac OS。-使用 24 字恢复短语轻松备份和恢复
支持的加密货币: BTC、瑞士联邦理工学院、XRP、BCH 和更多。
特点: -允许离线存储的硬件钱包。-由于有 12-24 个单词的恢复短语,因此很容易访问。-能够生成许多公共地址。-兼容 Windows、Linux 和 Mac OS。

我们已经在这个博客中介绍了与加密钱包相关的主要概念。然而,围绕加密货币的话题有很多误解。这门课程解释了一切,从加密货币的基础知识和加密钱包的工作原理到开发和回溯测试加密货币交易策略,如 Ichimoku 云策略。
免责声明:本文中关于加密货币的任何信息仅用于传达一般信息。本文不提供投资、法律、税务等。建议。您不应将本文中的任何信息视为就加密货币使用、法律事务、投资、税收、加密货币开采、交易所使用、钱包使用等做出任何特定决定的呼吁。我们强烈建议向您自己的财务、投资、税务或法律顾问寻求建议。QuantInsti 和本文作者均不对因依赖本文发布或链接的信息而导致的任何损失、损害或不便承担责任。
关于暗池的一切
这篇文章带你从暗池的含义,一直到它激动人心的历史和现状。如果你想探索这个话题或者了解暗池交易,这篇文章会给你一个很好的视角。
让我们继续前进,在本文中找到更多关于暗池的信息,因为它涵盖了:
- 什么是交易中的暗池?
- 简史:为什么会有暗池?
- 暗池现状
- 暗池列表或类型
- 有趣的事实
- 利与弊&暗池
什么是交易中的暗池?
“暗池”是一个非常有创意的名字,指的是银行等大型机构中的私人股票市场。它们是合法的私人证券市场,也被称为另类交易系统(ATS)。
基本上,这是纽约证券交易所和道琼斯等证券交易所的替代交易。因此,这些被称为场外交易行为。此外,通过暗池投资的交易者仍然远远领先于市场上的其他交易者。多年来,人们认为股票在暗池中的交易多于在证券交易所交易。
交易中暗池的实际目的是让投资者/交易者能够根据全国最佳买价和卖价(NBBO) 完成订单。NBBO 被美国证券交易委员会监管 (SEC) 。该规则为交易者提供了最佳(高)买入价(在出售证券的情况下)和最佳(低)卖出价(在购买证券的情况下)。
根据 NBBO 的说法,让他们的订单得到执行,对于在交易中投入大量资金的机构交易者来说尤其重要。
尽管这种交易降低了交易成本,但其对市场的影响(积极或消极的)(因为所有信息都是“私人的”)仍有待理解。
例如,如果一家投资银行购买一家公司价值 100 万美元的股票以分散其投资组合,这必然会对该公司的市场价格产生影响。然而,如果它私下交易,市场将不会有任何波动或影响。
渐渐地,暗池受到了美国当局的监管。监管是一个缓慢的过程,因为它们在 1979 年或 20 世纪 80 年代初首次出现,但 SEC 直到 1998 年才监管它们。
为了收集更多关于暗池的知识,让我们了解一下前方暗池的历史。我们将讨论暗池何时出现,以及它们这些年来的发展。
让我们向前看,回头看看为什么会有暗池存在?
简史:为什么会有暗池?
暗池的出现是因为机构投资者希望在没有交易所参与的情况下私下进行投资。之所以如此,是因为暗池提供了交易的机会,而不会让投资面临市场上潜在的不利价格波动风险。此外,所有交易都是匿名的,除非某些法律要求要求交易者分享任何细节。
这是一个关于它们如何形成的简介,我们现在将从头开始讨论暗池的历史,它是这样的:
- 暗池的起源可以追溯到 1979 年。1979 年 4 月 26 日之后,任何在特定交易所上市的证券都被允许私下交易。
- 上世纪 80 年代,他们加快了步伐,一些投资者开始投资暗池。一开始,暗池交易被称为“楼上交易”。在全部交易活动中,有一部分投资者在暗池中交易。
- 1986 年,暗池变得更加流行,投资者在白天输入订单。在美国东部标准时间 6:30 收盘时,一种交易算法会根据该证券的收盘价撮合买卖双方。这将意味着交易商的结算。
- 到 1998 年,SEC 对暗池进行了监管,而在此之前暗池一直不受监管。
- 2017 年,据彭博称,据观察,在美国所有执行的交易中,有 40%是在暗池中完成的
在探索了暗池的历史之后,简单来说,让我们了解一下暗池的现状是怎样的。
暗池的现状
目前,暗池比以往任何时候都更加普遍。暗池的出现是因为大型机构投资者或交易员的需要。这些年来,这成了一种管理个人资金或投资的好方法。尤其是经纪人和银行正在利用它们,在自己的暗池中匹配客户的订单。
这里需要注意的是,暗资金池不仅对投资者,而且对中间实体来说都是有利可图的业务。这些实体让他们的客户对使用他们的暗池足够乐观,因为同样的,他们可以进行交易,而无需向证券交易所支付任何费用。
此外,实体还可以进行自我交易(买卖证券),以便从交易中获得更多利润。因此,暗池现在遍布全球。
现在,2018 年 2 月,据华尔街大游行报道,当道指暴跌 1000 点时,像摩根大通这样的各种银行都在交易自己的股票。加上摩根大通的两笔暗池交易,摩根大通单周投资自己股票的次数是 2521 次。
此外,根据《华尔街日报》的一份报告,根据 SmartAsset 的数据,2019 年 4 月,暗池和其他场外交易工具执行的美国股票交易份额接近 39%。
如今,暗池更加普遍,在美国,暗池已经成为市场不可或缺的一部分。因此,似乎没有人能逃脱暗池,它们在美国比其他任何国家都要普遍。
接下来,我们将看一下暗池的列表或类型。
暗池列表或类型
暗池主要有三种类型,它们是:
- 自主的
- 基于经纪交易商
- 基于交换
独立
顾名思义,这些暗池提供商由独立或单一公司运营。这些供应商为客户提供了低交易费用,也降低了因流动性不足而产生的成本。例如,美国的独立提供商是 Instinet 和 ITG。
基于经纪交易商的
这些供应商基本上是投资银行,他们在 NBBO 的帮助下为客户提供价格改进。此外,这些供应商是与其他银行或“买方”参与者进行贸易的专家。例如,经纪自营商是摩根大通和巴克莱资本。
基于交换的
基于交易所的提供商为对场外交易感兴趣的散户交易者提供了机会。这些通常为市场参与者提供更高水平的流动性。例如,这些供应商是纽约泛欧交易所和国际证券交易所。
在下一部分,我们将了解一些与暗池交易相关的有趣事实。
有趣的事实
暗池本身是一个非常有趣的概念。它给参与者带来了不同的体验,因为暗池交易不是通过交易所完成的。暗池有几个方面,探索起来相当有趣。让我们一个一个来看看。
对于暗池,你可能不确定价格
这是事实,你可能不确定暗池的价格,因为有可能你最终支付太多或太少。然而,这可以通过密切关注市场上可用的数据来解决。这样,你就可以计算出你的交易价格。然而,投资于暗池的交易者,在市场之前交易。这使得你今天买卖的股票很快就会改变价格。
暗池不被认为是透明的
暗池,顾名思义,是黑暗的,不可见的。相反,当你通过证券交易所进行交易并发出一个待执行的指令时,该指令会显示在交易所的交易簿中。该订单(您希望交易的股票的价格和数量)可供公众查看。
暗池已经遍布全球
如今,暗池遍布全球,交易总量的很大一部分是在暗中或私下进行的。在美国,正如我们上面提到的,几乎一半的股票是在暗池中交易的。此外,它们在美国是最常见的,因为美国的市场主要是关于股票交易的,它们在任何股票交易增长的国家都会更常见。
暗池和股票市场
在暗池中,交易者通常根据股票市场中最佳买价和最佳卖价的平均价格进行操作。在这里,最佳出价是买方愿意支付的最高价格,而最佳报价是卖方愿意出售其股票的最低价格。交易者从市场的最佳买价和最佳卖价中取出一个平均价格,这样暗池帮助他们得到一个比市场价格更好的价格。
HFT 帮助暗池成长
值得注意的是,HFT 或高频交易已经帮助暗池发展到可以通过它进行几笔交易的程度。高频交易意味着交易发生的最高速度。由于它允许在尽可能短的时间内进行大量交易,更多的交易者希望私下利用大订单。
暗池不违法
这种私下交易是合法的,也受到美国当局的监管。自暗池开始增长以来,监管机构一直在密切关注这种情况。在有暗池交易的国家,国家金融当局一直在监控和监管他们开展业务的各个方面。
你可以在这里阅读研究论文中的规定。
前面提到了一些关于暗池的有趣事实。讨论它们旨在增强你对私人交易的了解。这种交易有它自己的优点和缺点,我们将在“暗池的优点和缺点”一节中讨论。
暗池的利弊
毫无疑问,暗池的存在,是因为它为通过这一渠道买卖证券的交易者提供了多种优势。但是,并不是所有的事情都是美好的。私人投资有好处,但肯定也有一些坏处或坏处。
意识到这两点有助于避免这种投资可能导致的损失或不利影响。
好了,现在让我们讨论一下暗池交易的双方。
优点
- 暗池的主要优势之一是,交易者或投资者在执行交易时占据上风。之所以如此,是因为通过私人渠道进行的交易领先于市场或在交易所进行的交易。
- 使用暗池,您还可以获得定价数据保持私密的优势。这意味着在私人交易的情况下,由于数据对公众不可见,与基于交易所的交易不同,交易量不会突然激增。这防止了波动性,因此,交易者的订单要么以这个价格成交,要么不成交。
- 交易者在暗池交易中保持匿名有助于他们,因为竞争的投资者或交易者无法针对他们制定策略。在这种情况下,由于未完成的市场订单对其他交易者来说是不可见的,他们不能计划任何不利于私人交易者的事情来从他们前面的交易中获取利益。
缺点
- 自从暗池出现以来,人们一直在争论它们对交易所交易行为的影响。人们认为,这种交易做法通过使这一领域的交易具有竞争性而对基于交易所的交易产生不利影响。
- 另一点是,私人交易正在导致参与交易所交易的公司的流动性流失。由于暗池不断增长,越来越多的交易者开始从事私人交易。
- 此外,由于流动性低,出现的另一个问题是买卖差价。它不可避免地增长,并导致交易所市场参与者的交易成本上升。因此,它导致市场效率下降。
- 私人交易最常见的缺点是交易活动中潜在的欺诈,因为所有的细节都是隐藏的。由于缺乏透明度,出现了不道德地使用高频交易的案例。正如我们上面讨论的 HFT,交易者可以在私下交易中不道德地利用 HFT。这就造成了一个“不均衡”的交易场。
好吧!我们已经到了文章的结尾,并且已经了解了暗池交易的几个重要方面。让我们看看我们都涵盖了什么。
结论
在本文中,我们讨论了暗池的基本方面,并涵盖了一些关于暗池的重要事实。有许多关于它给交易者带来的好处和投资是否安全的讨论和困惑。因此,我们简要地讨论了所有这些,以便使围绕它的各个方面更加清楚。虽然我们的一些读者发现历史和这个主题的清晰定义很有吸引力,但其他人希望更深入地研究同样的问题。本文介绍了暗池的相关主题,并简要概述了暗池投资。
免责声明:本文中提供的所有数据和信息仅供参考。QuantInsti 对本文中任何信息的准确性、完整性、现时性、适用性或有效性不做任何陈述,也不对这些信息中的任何错误、遗漏或延迟或因其显示或使用而导致的任何损失、伤害或损害承担任何责任。所有信息均按原样提供。
一名数据分析师,一名数据库系统专家,现在是一名算法交易员——阿克谢的旅程
原文:https://blog.quantinsti.com/data-analyst-database-system-expert-algo-trader-story-akshay/
站起来面对你的恐惧需要很大的勇气,我们有时会遇到一些有才华的人,他们的故事激发了我们潜在的能量。我们不是在传授一些圣经比例的神话故事,我们向你展示一个人的旅程,他勇敢地前进,学习和成长,以获得实现他的愿望的优势,并在算法交易领域建立自己。
这是阿克谢·派的故事。我们与阿克谢取得了联系,了解了他的全部情况。
对话是这样进行的:
嗨,阿克谢!你能给我们介绍一下你自己吗?
嗨,我是阿克谢·派。我是一名“自我激励”的数据分析师,拥有出色的组织能力、高效率和对细节的敏锐眼光。我学东西也很快。
我在协助开发和升级数据库系统和分析技术以及为有效的数据管理制作方法和文件方面有丰富的经验。我还管理过复杂的内部和外部数据分析职责。
我以前没有交易过,现在也没有。但我渴望尽快开始。我对研究、打卡、建模和编码更感兴趣。
我喜欢处理数据,我喜欢处理数字,我喜欢动物——这些也是我的爱好。我不是一个户外人士,但给我数据,我会真的很高兴致力于此!我和妻子照顾流浪动物。我仍然关心很多动物。现在我在家里照顾 9 只猫,在外面照顾超过 15 只流浪狗。
在你职业生涯的开始阶段,你有相当多的经验。你想谈谈吗?
在学生时代,我是一个非常聪明的学生。在我第 12 次性病期间。,CET 考试第一次推出——我为之出场,过关,考上了工科计算机专业。不幸的是,由于糟糕的公司,以及一些个人原因,我不得不在第二年辍学。我的职业生涯就这样开始了。
毕业后,我开始在一家制造公司工作,工作了 2 年后,我每月只有 3000 印度卢比的薪水。我当时很纠结。所以我加入了一个组织,成为一名支持工程师,理论上,这是我的第一份工作。我为之工作的客户来自马萨诸塞州,当我加入时,不到 4 个月,那个客户就离开了,因为马萨诸塞州有不外包工作的政策。
所以,我是这个大公司的一员,没有毕业就回到了街上。但是公司注意到了这一点,把我重新安排到了一个职能部门——一个我负责招聘、人力资源相关活动以及其他类似活动的职能部门。我是一个技术人员,来自技术背景,我也非常擅长校对,我的逻辑非常强。
当我为所有这些组织工作时,我了解到他们所做的工作没有一项是电子维护的。一切都是手动的。除了添加和删除数据,没有人知道如何正确使用 excel。没有人会使用 vlookup,给数据加边,提取信息,什么都不做。我不知道如何使用这些东西。手工任务对我来说也是压倒性的。
在那个特定的角色中,我是第一个开始自动化大部分数据相关工作的人。最终,我学会了如何大声说话,并开始做演讲。我是第一个在 8 个月内开始制作数据的人,也是在 PRM,在 CEO 面前的会议上。
这就是我喜欢数据的原因。我是生活和呼吸数据。我会处理数字,整理来自其他供应商的数据,混合和呈现数据,有时甚至会处理数据。
我在那里工作了 4 年半,没有得到任何形式的提升,甚至大一新生也得到了两次提升。原因是我还没有毕业。我从来没有试图完成我的毕业,被压倒性的工作所掩盖。
2014 年,我决定我需要下定决心,完成我的毕业——这是我需要做的事情。我无法安排两者兼顾,所以我辞职了。因为我想从经济学或统计学专业毕业,又因为我负担不起比我拥有的资本还要昂贵的统计学课程,我报名参加了一个经济学学士课程。
为了继续我的生计,我和我的父亲开了一家家族企业“SM consultants”——在浦那经营 CMC 机器、立式机器、卧式机器等特许经营业务。利用我的机械知识和行业背景。它失败了。为什么?我们没有计划。我从那次“如何不做生意”的经历中学到了很多。所以,我们关闭了这项业务。
这是一个糟糕的阶段,但我完成了毕业。
不过,你对数据科学有很好的体验。这对你的职业生涯有什么影响?
2017 年,我决定要进入数据科学领域。我想回到数据分析领域,但当我开始寻找与数据分析相关的工作时,我意识到数据分析的下一步是数据科学。
因为我擅长数学,所以我有两个选择——全日制金融工程课程或数据科学课程,然后先找份工作,看看进展如何。最终,我会拿到硕士和博士学位。
当我开始在数据科学市场找工作时,我意识到公司不愿意给没有功能知识的人提供工作。
如果你想成为一名工程领域的数据科学家,你需要在物理方面有很强的实力,并拥有理学学士和理学硕士等资格证书。对于销售数据,需要有非常强的统计学毕业。金融、CAs、经济学学士等。-我有后者。因此,我决定尝试一下金融市场。
在这之前,我不知道市场和交易。我知道市场如何运作,但不知道交易所,尽管我知道微观经济学和宏观经济学。在做数据科学的时候,偶然发现了算法交易,想给它一个机会。一旦我开始阅读书籍,浏览网站,学习一些课程。
我妻子在 Syntel 工作。我们是通过她的一个朋友了解到 QuantInsti 的。当我加入 QuantInsti 后,我学到了很多自己都没有意识到的术语。许多学生很容易理解,但我却很难理解大部分内容。
我记得先联系了 QuantInsti 的 Rashmi,他与我分享了阅读的小册子和计划书——这给我留下了非常深刻的印象。我注册了这门课程。我刚从第一家公司取出全部积蓄,支付了 QuantInsti 的费用。
我生命中的每一个决定对我来说都是重大的决定。我从来没有打过安全牌。
你需要从某个地方开始,我意识到这是我的机会。我的妻子非常支持我,在经济上、情感上、各方面都与我同甘共苦。只是因为她和她的经济支持,我才能自由地做出这样的决定。
我被录取了。这个介绍让我大吃一惊,并深深地激励我去尝试它。老实说,前三堂课的统计部分下降得很可怕。我在家里苦苦挣扎。毫无疑问,我有太多的时间学习和掩盖一切,我觉得我是幸运的。
有人不能 24 小时直上学习,你就努力学习。对我来说这是一场斗争,但最终,如果你真的想学这个,你需要付出很多努力。起初,由于课堂教育的心态,我犹豫着是否要寻求帮助或问问题,因为我认为老师会帮助你。
有一次我跟不上了,我从后援队里找来了拉克西米。她帮了很大的忙。不管是什么样的疑问,我总是能收到他们的回答;无论我去找什么样的老师,他们总是引导我,用恰当的答案回答我的问题,从来没有拒绝过我。
当你与 Nitesh Khandelwal 先生交谈时,动机是在不同的层面上。我真的很钦佩他,他是一个非常优秀的人。我只和他说过两次话,而且是在我上课期间。
我经历了一段艰难的日子,我被登革热感染,我爸爸得了心脏病,我妻子得了风湿性关节炎,我妈妈生病了,我的宠物狗和猫死了…太可怕了。
在学习方面,由于这一切,我错过了我的 EPAT 批次。所以,我联系了拉克西米。尽管参加了前一批,但我很高兴 QuantInsti 理解了我的情况,并为我参加了后一批。所以,我别无选择,只能重新开始我的课程。第二次对我来说容易多了。我做了调查,开始了解更多。
在我的课程重新开始的时候,我又一次和尼泰什先生交谈,是的,这对我来说是鼓舞人心的。我也仍然有一些家庭事务,但是我继续前进。
你不断前行的雄心,创业,意想不到的波折。继续前进,继续。
我来自浦那,那里有很多数据科学的研究所,我探索过,也去过很多,但我没有从 QuantInsti 得到的那种感觉。
当我第一次翻阅宣传册,与 Rashmi 和其他人交谈时,我非常确定这就是我想要做的。准确地说,我在任何其他学院支付的费用几乎是我在 QuantInsti 支付费用的一半。它得到了肯定——这就是我想在我的职业生涯中做的事情。
我开始知道与量化相关的工作可以在孟买找到,而不是在浦那,我想我不能在家附近找到任何地方,这让我有点失望。但就在那时,拉克西米再次拯救了我,他建议我们的定位单元也有远程选项可用——这就是我如何继续进行的。
我现在的角色是一份远程工作,整个公司都远程在线连接。
在你的简介中,你提到了很多关于数据分析和数据管理的内容。你如何在你的职业生涯中运用这一点?
在我目前的职位上,我几乎没有使用过任何与数据科学相关的活动,甚至没有制作图表。目前,我仍在学习我的工作场所 ie 的工具和工作模式。了解流程。我目前只研究技术指标。
在我之前的角色中,即使是数据科学的基本模型,例如,即使是帕累托图也可以帮助你了解和识别客户、员工、组织内的困难领域、收入流失等等。当你带着数据去见你的老板并提供见解时,他将无法了解他的公司中存在的批判性本质。
当时,我在关注全球流动性,根据他们的技能组合、他们为之工作的客户等,在全球的哪些地区分配了多少资源。在大多数公司,人们只是被雇来分析数据。在我的公司,没有人能做到这一点,所以自从我开始分析,他们开始依赖我的数据。
老实说,我想要成功,赚比我妻子更多的钱,让她嫉妒,好像我的远程工作还不够。她在我的旅程中给了我很多支持,有一天我想为她做同样的事情。
既然你有咨询背景,并且从事纯技术工作,与有交易背景的人打交道,你有什么想法:
数据科学
人们并没有完全意识到他们应该在数据科学中扮演的角色。他们有这样的感觉,他们有一个特定的软件,他们需要产生洞察力,就是这样。他们所说的被公司当作事实接受。
只有当你想出新的东西时,他们才意识到他们错过了某些东西,而这些东西可能非常有用。因此,除非你提出新的数据点,否则你将会陷入困境。
数据管理
数据管理的范围在印度非常少。我在国外有很多朋友,但即使是他们,使用的自动化程度也比我们想象的要低。人们在数据管理领域有很大的发展空间。复苏只是时间问题。
我所看到的是,数据科学领域的人非常擅长使用工具,但他们不太擅长处理数据——这就成了一个问题。最终发生的是,你感到厌倦,你放弃了。
获得和提高数据科学技能
学习。学习很容易。学习工具——Python,Excel,学习它不需要时间,但是练习它需要时间。当原始数据来到你面前,你需要体验它,理解它,呼吸它。只有到那时,你才能正确地使用这个工具来展现你的洞察力。
只有你一次又一次地坚持下去,它才会来到你身边。
数据在未来交易中的作用
我不是说它将是一个重要的角色,
我是说它将是唯一的角色。
公司正在尽可能地消除人为干预。即使是在金融领域,当你做决定时,情绪也是一个非常大的缺点,人类的偏见是一个“不不!”对于这个领域。未来,数据驱动的决策将成为行业中最准确的决策。它现在正在发生,并没有完全接管,但它可能发生在今天或明天
人工智能或人工智能等新兴技术在算法和量化交易中的作用
他们将发挥巨大的作用。印度的大多数小型零售交易商不使用这些技术。我父亲仍然不知道如何使用 iPhone,他不信任电子商务平台,认为他的凭据可能会被盗,他的帐户可能会被黑客攻击。
老一代人仍然不信任技术,原因是没有人能够说服他们正确使用这些技术,向他们展示它在市场上的真正潜力。到目前为止,它在市场上有很大的市场空间。所以,没有多少人在做。
你对自己的职业有什么计划?
在做 EPAT 的时候,我想在完成后,我会在家人和朋友的支持下成为一名独立的散户交易者,然后我会出去寻找投资者——这就是我的计划。在 EPAT 的结尾,我意识到这不会发生。为什么?只做这个课程就能为你指明道路。你还是要自己在上面走。
所以,目前,我的目标是学习任何关于市场的东西,试图教会自己像交易者一样思考,用金融语言“说话”。因此,将来如果我与我的客户交流,我应该能够立即理解他们。我之前的计划暂时搁置。但我希望有一天它会成功。
你有什么想对想成为算法交易员的人说的话吗?
***努力!*T3】
就是这样!全身心地投入。相信我,产出和回报将是惊人的。
阿克谢,我们感谢你与我们分享你的经验。还有很多事情要做,还有很多山要爬,我们祝你一切顺利。
任何希望进入算法交易和量化交易领域的人都可以用在这个领域出类拔萃的必要技能和知识来装备自己。EPAT 通过其全面的课程和实践培训,帮助您做到这一点。
免责声明:为了帮助正在考虑从事算法和量化交易的个人,本案例研究是根据 QuantInsti 的 EPAT 项目的学生或校友的个人经历整理的。案例研究仅用于说明目的,并不意味着用于投资目的。EPAT**方案完成后取得的成果对所有个人而言可能不一致。T15】
为什么数据清理很重要,如何以正确的方式进行?
数据清理非常耗时,但却是数据分析过程中最重要、最有价值的部分。没有清理数据,数据分析的过程是不完整的。
但是如果我们跳过这一步会发生什么呢?
假设我们的价格数据中有一些错误的数据。不正确的数据在我们的数据集中形成了异常值。而我们的机器学习模型假设这部分数据集(也许特斯拉的价格确实在一天内从 50 美元跃升至 500 美元)。你现在知道分析的最终结果是什么了。
机器学习模型给出了错误的结果,没有人希望这样!由于预测相差甚远,您必须再次从头开始分析!因此,数据清理是分析的一个重要部分,不应该被忽略。
本博客将带您了解数据清理的整个过程,并为该过程中面临的一些挑战提供解决方案。
- 什么是数据?
- 各种数据来源
- 原始数据和经过处理的数据是什么样的?
- 数据清理的好处
- 高质量数据的特征
- 数据清理中使用的术语
- 清理数据的步骤
- 了解你的数据
- 清理数据时要解决的基本问题
- 交易数据清理
- 预先存在的软件
- 学习数据清洗的资源
- 常见问题解答
什么是数据?
数据科学是当今最受欢迎的职业之一。所以让我从回答这个古老的问题开始——什么是数据?嗯,根据维基百科,“数据是通过观察收集的一组关于一个或多个人或物体的定性或定量变量的值。”
考虑一个数据集,其中包含关于一批不同种类水果的信息。

数据集中的一些变量可能是定性的,如水果的名称、颜色、目的地和原产国、客户反馈(失望、满意、满意)或定量的,如水果的成本、运输成本、货物重量、运输成本和货物中的水果数量。
其中一些变量可能来自其他较低层次的变量。在这个例子中,运输成本来自水果成本和运输成本变量。

这些数量变量也可以分为两类,连续变量和离散变量。连续变量顾名思义在数轴上是连续的,可以取任何实值。离散变量可能只有特定的值,通常是整数。货物的重量将是一个连续变量,而如果我计算每批货物中水果的数量,它将是一个离散变量。
定性变量可以分为名义变量和序数变量。名义变量或无序变量是一种标签变量,这些标签没有量化值。例如,水果的颜色或货物的目的地可以是名义变量。序数或有序变量是那些标签有数量值的变量,也就是说,它们的顺序很重要。在水果的数据库中,顾客反馈将是一个有序变量。
大多数人认为数据科学是传达非常准确和精确信息的美丽图形和图表。然而,大多数人没有意识到的是产生这种数字的必要过程。
数据分析管道由 5 个步骤组成。
原始数据 - > 处理脚本->-整理数据->-数据分析 - > 数据通信
通常,管道的前三个步骤会被忽略。新手直接跳到数据分析这一步。任何企业或学术研究都将致力于获取他们的数据,并在内部对其进行预处理。所以你会想知道如何获取原始数据,并自己清理和预处理它。
这个博客将涵盖所有关于清理和获取数据进行分析的内容。
各种数据来源
首先,让我们谈谈你可以从哪里获得数据的各种来源。最常见的来源可能包括来自数据提供网站的表格和电子表格,如 Kaggle 或加州大学欧文分校机器学习库或从抓取网页或使用 API 获得的原始 JSON 和文本文件。的。xls 或者。来自 Kaggle 的 csv 文件可能经过预处理,但是原始的 JSON 和。txt 文件将需要工作,以获得一些可读格式的信息。详细的数据提取方法可以在这里找到。
原始数据和经过处理的数据是什么样的?
理想情况下,这是您希望干净数据的样子:

每列只有一个变量。在每一行中,您只有一个观察值。它被整齐地组织成一个矩阵形式,可以很容易地导入 Python 或 R 来执行复杂的分析。但通常情况下,原始数据并不是这样的。它看起来像这样-

让你头晕是吗?
这是使用 Twitter API 获得乔·拜登过去 20 条推文的查询结果。您还不能对这些数据进行任何形式的分析。
我们将在后面详细讨论原始和整洁数据的组成部分。
数据清理的好处

如上所述,要产生合理的结果,干净的数据集是必要的。即使您想要在数据集上构建模型,检查和清理数据也可以成倍地改善结果。向模型提供不必要的或错误的数据会降低模型的准确性。一个更干净的数据集会比任何花哨的模型给你更好的分数。一个干净的数据集也将使您组织中的其他人将来更容易处理它。
高质量数据的特征
在执行数据清理之后,您至少应该有以下这些东西-
- 你的原始数据
- 干净的数据集
- 描述数据集中所有变量的码本
- 包含对原始数据执行的产生干净数据的所有步骤的指令列表
当数据满足以下要求时,我们可以说它处于原始状态
- 自从交给它以来,没有任何软件应用于它
- 没有对数据执行任何操作。
- 没有执行任何汇总
- 没有从数据集中删除任何数据点
处理完数据后,它应该满足这些要求-
- 每行应该只有一个观察值
- 每列应该只有一个变量
- 如果数据存储在多个表中,请确保这些表之间至少有一列是公共的。如果需要,这将帮助您一次从多个表中提取信息。
- 在包含变量名称的每列顶部添加一行。
- 尽量使变量名易于阅读。例如,使用 Project_status 而不是 pro_stat
- 加工中使用的所有步骤都应记录下来,以便从头开始再现整个过程
对于第一次查看你的数据的人来说,密码本是必要的。这将帮助他们理解数据集的基本形式和结构。它应该包含-
- 关于变量及其单位的信息。例如,如果数据集包含一家公司的收入,一定要提到它是以百万还是以十亿美元为单位。
- 关于汇总方法的信息。例如,如果年收入是变量之一,说明你用什么方法得出这个数字,是收入的平均值还是中值。
- 提及你的数据来源,无论是你自己通过调查收集的还是从网上获得的。在这种情况下,也要提到网站。
- 常见的格式是. doc。txt 或降价文件(。md)。
说明列表是为了确保你的数据和研究是可重复的。使用指令列表,数据社区中的其他数据科学家可以验证您的结果。这增加了你研究的可信度。确保包括-
- 电脑脚本
- 这个脚本的输入应该是原始数据文件
- 输出应该是经过处理的数据
- 脚本中不应有用户控制的参数
数据清理中使用的术语
- 汇总 -使用多个观察值提供变量的某种形式的汇总。常用的聚合函数有。sum(),。均值()等。Python 提供了。aggregate() 可以同时执行多种功能的函数。
- Append - Append 意味着垂直连接或堆叠两个或多个数据帧、列表、序列等。使用。append() 函数追加数据帧。
- 估算 -一般来说,统计学家将估算定义为填补缺失值的过程。我们将在博客后面更详细地讨论插补。
- 删除重复数据 -删除重复数据是从数据集中删除重复观察值的过程。在本博客的后面会有更详细的讨论。
- 合并——合并和追加是数据清理中最容易混淆的术语。合并两个数据帧也包括将它们连接在一起。这里唯一的区别是我们将它们水平连接起来。例如,如果我们有两个数据集,一个包含用户的脸书数据,另一个包含用户的 Instagram 数据。我们可以根据用户使用的电子邮件 id(两个数据集中的公共列)合并这两个数据集,因为这对某个用户来说很可能是公共的。
- 缩放 -缩放或标准化是缩小特征范围并使其介于 0 和 1 之间的过程。这是用来为在上面建立机器学习模型准备数据的。ML 算法为高值分配较高的权重,为低值分配较低的权重。缩放将处理这种数值上的巨大变化。
- 解析 -解析是将数据从一种形式转换成另一种形式的过程。在博客的前面,我们查看了来自 Twitter API 的原始数据。原始形式的数据没有任何用处,因此我们需要对其进行解析。我们可以将每条推文作为观察,将推文的每个特征作为专栏。这将使数据以表格的形式呈现和可读。
清理数据的步骤
有几个步骤,如果遵循得当,将确保干净的数据集。
- 好好看看你的数据,了解数据中出现的基本问题
- 列出所有的基本问题,单独分析每个问题。试着估计问题的根源
- 清理数据集并再次执行探索性分析
- 检查清洗后的问题
了解您的数据
当你收到数据时,首先要做的一件事就是了解你收到了什么。了解数据集包含的内容——其中的变量、它们的类型、缺失值的数量等等。在这篇博客中,我们将使用一家银行的综合客户交易数据。数据集在这里可用。
首先,读取 excel 文件并使用。头()和。info()方法来获取数据帧的摘要。
数据工程及其在金融市场中的应用!
近年来,大数据的重要性迅速增长,随着时间的推移,数据工程师的任务变得更加重要。我们将在本文中讨论金融市场中数据工程师的一些事实和责任。
本文涵盖:
- 什么是数据工程?
- [数据工程领域的职责](#responsibilities-in-the-field-of-data- engineering)
- 金融市场中的数据工程
- 数据科学家 vs 数据工程师
- 数据工程的未来
什么是数据工程?
数据工程是一个为企业中的分析进行数据准备的领域。在这里,数据准备意味着构建和测试数据的个人。这个过程产生这样的数据,这些数据可以有效地用于实现特定企业所需的分析。这些现成的数据构建了数据架构。
数据工程师在开发和管理大量数据方面经验丰富。此外,数据工程师的主要职责之一是帮助数据科学家将原始数据转换为干净可用的数据。
这里的原始数据是指直接从源中提取的数据,可能包含多个问题,如重复、非平稳性等。干净和可用的数据是指准备好用于交易中各种目的的数据,例如回溯测试、分析和预测未来的交易。
接下来,我们将了解数据工程领域的职责。
数据工程领域的职责
数据工程通常是为了给企业提供准确的数据,需要精通 Python、Java 等编程语言。
同时,数据工程师具有以下特征:
- 支持数据科学家/分析师
- 管理数据
- 作为通才,以管道和数据库为中心
- 它们不断进化
支持数据科学家/分析师
数据工程师支持数据科学家/分析师根据优化的数据执行操作。数据工程师主要负责创建和维护数据基础设施。
管理数据
基本上也需要数据工程师来管理数据。他们的职责不仅仅是为专业用途创建优化的数据。他们还需要进一步管理数据,这意味着确保不会再出现错误、易于访问且可靠。
作为通才,以管道和数据库为中心
通常有三种类型的数据工程师,即:
- 通才
- 以管道为中心
- 以数据库为中心
多面手
有些数据工程师负责创建数据管道的所有工作,例如从数据源检索数据,对其进行处理并进行最终分析。这个过程也占用了数据科学家的全部技能。这是小公司或团队所需要的,他们没有足够的专业人员。
以管道为中心
中型公司需要他们,他们有复杂的数据需求,需要数据团队进行大量需要分布式系统和计算机科学背景的工作。
以数据库为中心
这些数据工程师通常在大公司工作,他们的数据分布在数据库中。这些公司中有各种数据分析师,数据工程师需要将信息从数据库的主应用程序中提取到分析数据库中。
它们不断进化
数据工程师随着技术进步和各种模型的引入而不断发展。在物联网(IOT)、人工智能和机器学习模型的推动下,数据工程领域正在快速发展。因此,数据工程师也需要不断发展和学习该领域的新实践。
展望未来,我们将了解金融市场中的数据工程。
金融市场中的数据工程
在金融市场中,数据工程师需要做收集数据、清理数据的常规工作,这意味着剔除重复数据等错误。最后一步是在清理数据的帮助下实现交易自动化。
- 风险管理
- 预测分析
- 欺诈检测
- 算法交易
风险管理
由于管理风险是任何金融机构的一个极其重要的方面,数据工程师扮演着重要的角色。在干净的数据集的帮助下,交易预测中的错误不会发生。这很重要,因为如果机器学习模型得到错误的数据,这将导致投资者持续亏损。
预测分析
在预测分析的帮助下,投资者可以预见数据模式,并采取正确的行动。数据工程师帮助公司/个人等以这种方式在金融市场投资时做出正确的决策。例如,如果机器学习模型被馈入具有重复或不规则的数据,它将导致错误的输入。这种错误的输入反过来会导致交易中的错误预测,从而减少收益。
欺诈检测
展望未来,数据工程还有助于欺诈检测。由于检测黑客是否已侵入系统以使数据恶意/不适合输入预测模型极其重要,因此必须由数据工程师检查和清理这些数据。
算法交易
在算法交易领域,数据工程师帮助清理数据,这些数据将被输入机器学习或深度学习模型,以预测交易。算法交易系统在预编程指令的帮助下执行指令。这样做时,历史回溯测试需要这些数据,这有助于了解所创建的策略对过去的数据是否有效。在这样做的时候,如果用于回溯测试的数据没有得到正确的研究,它可能会导致未来错误的交易决策。
现在让我们来看看数据科学家和数据工程师之间的区别。
数据科学家 Vs 数据工程师
数据科学家
- 与构建数据基础架构的数据工程师保持持续互动
- 通过使数据投入使用来对其采取行动
- 利用复杂的机器来处理数据或使数据投入使用
- 有一个数据管道,基本上是由数据工程师创建的优化数据
- 进行研究以确定他们提供数据的企业的趋势和需求
- 使用高级分析工具,如 R、Hadoop 和高级统计建模
数据工程师
- 提供可用于企业特定目的的数据基础设施。例如,用于交易、商业决策等。
- 需要构建高性能的数据,这些数据对于企业的特定目的而言是可靠的
- 使用 SQL、MySQL 等工具,这些工具支持数据科学家使用的工具
- 创建数据管道,为数据科学家提供优化的数据以便使用
- 通过维护数据科学家采取实际行动所需的数据基础设施来帮助他们。例如,将数据输入机器学习模型进行交易等。
这里的要点是,您将需要一名数据科学家和一名数据工程师来使数据集正常工作。对于任何使用数据集做出重要决策的企业来说,这两者都是至关重要的。
没有数据科学家,数据工程师不会有多大帮助,因为数据科学家使数据进入实际或实际使用。
同样,在数据工程师的帮助下,数据的建立不会出现诸如错误输入、重复数据等错误。
现在让我们进一步看看数据工程的未来。
数据工程的未来
随着技术的快速变化和进步,数据工程也在彻底转变。自从物联网(IOT)、人工智能、混合云计算等等。在进入金融市场等领域后,数据工程师也应该转型,并学会利用这些领域更好地发挥作用。
据 research 预计,到 2023 年,数据工程服务市场有望从 2017 年的 295.0 亿美元增长到 773.7 亿美元。
这是意料之中的,因为过去几年大数据被广泛采用。未来,随着技术的不断进步,大数据需求预计将会增长并主导市场。
结论
本文主要讨论了数据工程的基础知识。数据工程师在任何企业或交易中都起着至关重要的作用,因为数据集在决策时是最重要的。此外,随着更多的技术进步和对大数据使用的需求,数据工程的未来足够光明。
免责声明:本文中提供的所有数据和信息仅供参考。QuantInsti 对本文中任何信息的准确性、完整性、现时性、适用性或有效性不做任何陈述,也不对这些信息中的任何错误、遗漏或延迟或因其显示或使用而导致的任何损失、伤害或损害承担任何责任。所有信息均按原样提供。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言










{kind=link}